
Zarzadzanie˛ uzytkownikami˙ i wirtualnymi organizacjami w...
109
Akademia Górniczo - Hutnicza im. Stanislawa Staszica w Krakowie Wydzial Elektrotechniki, Automatyki, Informatyki i Elektroniki Katedra Informatyki Zarz ˛ adzanie u˙ zytkownikami i wirtualnymi organizacjami w centrum obliczeniowym Liwiusz Ociepa [email protected] Praca magisterska napisana pod kierunkiem dr in˙ z. Mariana Bubaka, konsultacje mgr in˙ z. Marcin Radecki Kraków, 2009
Transcript of Zarzadzanie˛ uzytkownikami˙ i wirtualnymi organizacjami w...

Akademia Górniczo - Hutnicza im. Stanisława Staszica w KrakowieWydział Elektrotechniki, Automatyki, Informatyki i Elektroniki
Katedra Informatyki
Zarzadzanie uzytkownikamii wirtualnymi organizacjami w centrum
obliczeniowym
Liwiusz [email protected]
Praca magisterskanapisana pod kierunkiemdr inz. Mariana Bubaka,konsultacjemgr inz. Marcin Radecki
Kraków, 2009

Serdeczne podziekowania składamPanu dr inz. Marianowi Bubakowi,bez pomocy Którego praca ta niezostałaby napisana.Goraco pragne podziekowac takzePanu mgr inz. Marcinowi Radeckiemu,opiekunowi mojej pracy, za cennewskazówki, dzieki którym praca tazyskała na wartosci oraz za mozliwosczapoznania sie z działaniem centrumobliczeniowego.
Praca została wykonana przy wsparciu projektu PL-Grid.numer umowy: POIG.02.03.00-00-007/08-00, strona WWW: www.plgrid.pl.
Projekt jest czesciowo finansowany ze srodków Europejskiego Funduszu Regionalnego,jako element Programu Operacyjnego Innowacyjna Gospodarka.

Streszczenie
Tematem pracy jest zarzadzanie uzytkownikami od strony systemu
operacyjnego. Z tego punktu widzenia wirtualne organizacje wystepuja
przede wszystkim jako jednostka grupujaca uzytkowników oraz maszyny
obliczeniowe. Tytułowy system jest oparty o baze danych PostgreSQL
zawierajaca dane systemu replikujaca, z zastosowaniem metody
push, dane do bazy LDAP i serwera haseł Kerberos5. System
ten został zaprojektowany jako system zarzadzania wykorzystywany
w srodowisku obliczen gridowych. Opracowanie zawiera opis konfiguracji
poszczególnych serwerów systemu - zarówno serwerów głównych jak
i serwerów obliczeniowych korzystajacych z usług Systemu Zarzadzania
Uzytkownikami i Wirtualnymi Organizacjami. Opisy te obejmuja
konfiguracje serwerów PostgreSQL, slapd (zarówno serwera master
jak i serwerów slave), krb5-kdc-ldap (serwer KDC MIT Kerberos5
z backendem w bazie LDAP), bibliotek systemowych pam_krb5, nss-
ldapd. Przedstawione zostały metody tunningu i partycjonowania
baz PostgreSQL (PL/Proxy) i OpenLDAP (chainning i referral).
Przedstawione zostały równiez mechanizmy zapewniajace wysoka
dostepnosc poszczególnych komponentów systemu - walmgr w przypadku
PostgreSQL, replikacja multimaster i master-slave w przypadku
OpenLDAP i zapewnienie wysokiej dostepnosci bazy haseł Kerberos
poprzez zastosowanie serwera LDAP jako backendu KDC. Praca
powstała w ramach projektu PL-Grid.
Słowa kluczowe: zarządzanie użytkownikami, zarządzanie wirtualnymiorganizacjami, PostgreSQL, OpenLDAP, MIT Kerberos 5, krb5-kdc-ldap,
replikacja multimaster, replikacja master-slave, replikacja push, polling,
zarządzanie certyfikatami, wysoka dostępność, systemy gridowe.

Spis treści
Wstep 6Cel pracy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7Struktura pracy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
1 Istniejace rozwiazania 91.1 Perun . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
1.1.1 Architektura systemu Perun . . . . . . . . . . . . . . . . . . . . 111.2 Virtual User System . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 141.3 Grid User Management System . . . . . . . . . . . . . . . . . . . . . . . 141.4 Podsumowanie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2 Analiza i projekt Systemu Zarzadzania Uzytkownikami i Wirtualnymi Orga-nizacjami 162.1 Metodologia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 162.2 Wstepna analiza zagadnienia . . . . . . . . . . . . . . . . . . . . . . . . 172.3 Zarzadzanie uzytkownikami a zarzadzanie wirtualnymi organizacjami . . 172.4 Wymagania funkcjonalne i niefunkcjonalne . . . . . . . . . . . . . . . . 18
2.4.1 Wymagania funkcjonalne . . . . . . . . . . . . . . . . . . . . . . 182.4.2 Wymagania niefunkcjonalne . . . . . . . . . . . . . . . . . . . . 25
2.5 Wymagania a istniejace rozwiazania . . . . . . . . . . . . . . . . . . . . 262.6 Diagramy przypadków uzycia . . . . . . . . . . . . . . . . . . . . . . . 262.7 Plan architektury systemu . . . . . . . . . . . . . . . . . . . . . . . . . . 262.8 Planowane technologie . . . . . . . . . . . . . . . . . . . . . . . . . . . 352.9 Diagram klas Systemu Zarzadzania Uzytkownikami i Wirtualnymi Orga-
nizacjami . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 362.9.1 Diagram klas zarzadzania maszynami obliczeniowymi . . . . . . 37
2.10 Diagramy sekwencji . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37

Spis treści 4
3 Prototypy aplikacji bazodanowej realizujacej stawiane wymagania 423.1 Zmiany technologii w stosunku do projektu . . . . . . . . . . . . . . . . 423.2 Architektura systemu . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
3.2.1 Pierwsza wersja architektury systemu zarzadzania . . . . . . . . 453.2.2 Druga wersja architektury systemu zarzadzania . . . . . . . . . . 453.2.3 Przyczyny zmian w architekturze . . . . . . . . . . . . . . . . . 47
3.3 Architektura bazy danych . . . . . . . . . . . . . . . . . . . . . . . . . . 473.3.1 Opisy tabel systemu zarzadzania . . . . . . . . . . . . . . . . . . 473.3.2 Tabele techniczne . . . . . . . . . . . . . . . . . . . . . . . . . . 503.3.3 Widoki uzywane do replikacji danych . . . . . . . . . . . . . . . 513.3.4 Procedury składowane uzywane do operacji na tabelach własciwych 513.3.5 Procedury uzywane w mechanizmach replikacji danych . . . . . 53
3.4 Architektura bazy LDAP . . . . . . . . . . . . . . . . . . . . . . . . . . 543.4.1 Dublowanie danych - wady i zalety . . . . . . . . . . . . . . . . 54
3.5 Replikacja danych z bazy SQL do LDAP i Kerberos . . . . . . . . . . . . 553.5.1 Replikacja danych z bazy SQL do LDAP . . . . . . . . . . . . . 563.5.2 Replikacja danych z bazy SQL do Kerberos . . . . . . . . . . . . 583.5.3 Dyskusja na temat technologii zastosowanej do replikacji z bazy
PostgreSQL do LDAP . . . . . . . . . . . . . . . . . . . . . . . 59
4 Przygotowanie serwerów do współpracy z Systemem Zarzadzania Uzytkowni-kami i Wirtualnymi Organizacjami 614.1 Konfiguracja serwera głównego bazy danych i instalacja aplikacji . . . . 61
4.1.1 OpenLDAP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 624.1.2 MIT Kerberos5 . . . . . . . . . . . . . . . . . . . . . . . . . . . 664.1.3 PostgreSQL . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 684.1.4 Konfiguracja replikacji z bazy SQL do LDAP i Kerberos . . . . . 70
4.2 Konfiguracja serwerów głównych dla projektów . . . . . . . . . . . . . . 714.3 Konfiguracja maszyn obliczeniowych . . . . . . . . . . . . . . . . . . . 72
4.3.1 Konfiguracja Name Service Switch . . . . . . . . . . . . . . . . 724.3.2 Konfiguracja Pluggable Authentication Modules . . . . . . . . . 73
4.4 Zmiana obejmujaca wszystkie serwery LDAP . . . . . . . . . . . . . . . 744.5 Podsumowanie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 75

Spis treści 5
5 Rozwiazania zwiekszajace niezawodnosc poszczególnych komponentów Sys-temu Zarzadzania Uzytkownikami i Wirtualnymi Organizacjami 765.1 Serwis www Systemu Zarzadzania Uzytkownikami i Wirtualnymi Organi-
zacjami . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 775.1.1 Zarzadzanie sesjami . . . . . . . . . . . . . . . . . . . . . . . . 805.1.2 Scenariusze awarii . . . . . . . . . . . . . . . . . . . . . . . . . 80
5.2 Serwer PostgreSQL . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 815.3 Serwer Kerberos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 825.4 Serwer OpenLDAP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 825.5 Podsumowanie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85
6 Optymalizacja i skalowalnosc usług wchodzacych w skład Systemu Zarzadza-nia Uzytkownikami i Wirtualnymi Organizacjami 866.1 Analiza systemowa . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 87
6.1.1 Wpływ zwiekszenia liczby uzytkowników na obciazenie poszcze-gólnych elementów systemu zarzadzania . . . . . . . . . . . . . 87
6.1.2 Wpływ zwiekszenia liczby maszyn czy projektów na obciazenieposzczególnych elementów systemu zarzadzania . . . . . . . . . 89
6.2 Poszukiwanie waskich gardeł systemu i analiza ich wpływu na działaniesystemów obliczeniowych . . . . . . . . . . . . . . . . . . . . . . . . . 89
6.3 Metody eliminacji waskich gardeł . . . . . . . . . . . . . . . . . . . . . 906.3.1 Serwer www . . . . . . . . . . . . . . . . . . . . . . . . . . . . 906.3.2 Baza danych PostgreSQL . . . . . . . . . . . . . . . . . . . . . 916.3.3 Baza danych LDAP . . . . . . . . . . . . . . . . . . . . . . . . . 93
6.4 Podsumowanie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 95
7 Podsumowanie i dalszy rozwój Systemu Zarzadzania Uzytkownikami i Wir-tualnymi Organizacjami 977.1 Dalszy rozwój systemu . . . . . . . . . . . . . . . . . . . . . . . . . . . 99
Bibliografia 102
Spis ilustracji 106
Spis akronimów 107

Wstęp
Wraz ze wzrostem popularnosci dziedzin w których zastosowanie maja obliczeniawielkiej skali rosnie zapotrzebowanie na moc obliczeniowa. Równoczesnie moznazaobserwowac tendencje zastepowania najmocniejszych maszyn starszego typu nienowymi ich modelami ale klastrami złozonymi z wielu urzadzen indywidualnie o duzomniejszej mocy obliczeniowej dostarczajacych w sumie duzo wieksza ilosc zasobów.Zmiany te sa pochodna rozwoju rozwiazan sieciowych - dzieki nim mozliwe jestzastapienie bardzo drogich maszyn SMP1 klastrami maszyn połaczonymi szybkimisieciami - gigabitowym ethernetem czy infiniband. Wraz z takimi zmianami rosnieznaczaco stopien skomplikowania prac wykonywanych przy zarzadzaniu centrumobliczeniowym - poczawszy od samego zarzadzania konfiguracja, na zarzadzaniuuzytkownikami konczac. Wieksza liczba uzytkowników oraz wieksza liczba urzadzen,którymi trzeba zarzadzac, znaczaco zwiekszaja czasochłonnosc codziennych czynnosciadministracyjnych. Dodatkowo w wypadku recznego wykonywania tego typu zadan rosnieprawdopodobienstwo popełnienia błedu czy pominiecia któregos z urzadzen (na przykładw wypadku jego chwilowej niedostepnosci). Pojawienie sie bardzo duzej liczby urzadzenposiadajacych bardzo liczna baze uzytkowników spowodowało koniecznosc zrewidowaniadotychczasowych procedur postepowania. Pojawiły sie nieznane do tej pory na takaskale problemy z zachowaniem spójnosci baz uzytkowników, z systemami zarzadzaniahasłami, wreszcie z centralizacja zarzadzania samymi maszynami. Do tej pory stosowanerozwiazania w tym zakresie (głównie NIS2) okazały sie byc zbyt mało elastycznea dodatkowo podatne na rozne ataki od zakłócajacych działanie po naruszenia ograniczendostepu do zasobów. Zaczeto wprowadzac mechanizmy centralnego zarzadzaniauzytkownikami nowego typu - przechowywanie haseł w serwerach Kerberos czyLDAP3. Jednak rozwiazania te nie sa same w zaden sposób zintegrowane z systemami
1Symmetric multiprocessing2Network Information Service3Lightweight Directory Access Protocol

Wstęp 7
obliczen gridowych. Nie mozemy przy tym zapomniec, ze systemy gridowe wprowadzajawłasne pojecia grupujace rózne byty funkcjonujace w ich ramach - uzytkowników czyklastry obliczeniowe. Sa one o tyle wazne, ze bardzo czesto nie bedziemy operowacna pojedynczych uzytkownikach czy klastrach - ale na całych ich grupach poprzez zmianyw ramach wirtualnych organizacji.
Cel pracy
Specyfika pracy uzytkowników gridowych jest szerokie stosowanie certyfikatów.Poczawszy od ich wygenerowania, podpisania, poprzez ich stosowanie do uwierzytelnianiaw systemach gridowych az do działan zwiazanych z ich odwoływaniem. Mechanizmy tesa w dalszym ciagu bardzo słabo zintegrowane z systemami zarzadzania uzytkownikami.Celem tej pracy jest stworzenie systemu, który przy uzyciu standardów przemysłowychw zarzadzaniu uzytkownikami i sprzetem zapewniałby podstawowa integracje z systemamigridowymi. Integracje obejmujaca w pierwszej kolejnosci zarzadzanie certyfikatami.Dodatkowym utrudnieniem jest to, ze bardzo czesto zamiast zarzadzac pojedynczymiuzytkownikami bedziemy operowac na całych ich grupach poprzez wirtualne organizacje.Celem pracy jest stworzenie projektu i implementacja prototypu czesci bazodanowej.Aplikacja bazodanowa obejmuje strukture bazy SQL4, system replikacji danych dobaz LDAP i bazy haseł Kerberos oraz logike aplikacji zlokalizowana w procedurachskładowanych w bazie danych. W skład tej czesci aplikacji wchodzi równiezprzygotowanie serwerów do współpracy z nia oraz opracowanie rozwiazan z zakresuwysokiej niezawodnosci. Sama praca stanowi tylko pierwszy krok do stworzeniakompleksowego rozwiazania. Dodatkowo opisana zostanie niezbedna konfiguracjaserwerów wchodzacych w skład klastrów obliczeniowych. Jednym z podstawowychproblemów, które system ma rozwiazywac jest skalowalnosc i wysoka niezawodnoscdostarczonego rozwiazania.
Struktura pracy
Pierwszy rozdział koncentruje sie nad analiza systemów juz istniejacych dla którychtworzone rozwiazanie jest alternatywa.
4Structured Query Language

Wstęp 8
Kolejny, drugi rozdział przedstawia analize i projekt systemu zarzadzania.Przedstawione w nim sa wymagania jakie spełniac musi aplikacja, do jakich zastosowanbedzie uzywany (analiza przypadków uzycia), jak bedzie wygladało przetwarzaniekazdego zadania (sekwencje wykonywanych operacji) czy plan architektury systemui zastosowanych technologii. Dodatkowo w rozdziale tym zostanie zaprezentowany projektstruktury bazy danych.
Nastepny rozdział - trzeci - zawiera opis prototypów aplikacji. Jego poczatek opisujezmiany w technologii bedace skutkiem zmiennych wymagan srodowiska. Przedstawionezostały opisy architektury - zarówno koncowej jak i wersji posrednich. Opisana zostałarówniez w całosci aplikacja bazodanowa - jej struktura jak i opis tego czym jest„tabela” przedstawiana na poszczególnych schematach. Rozdział ten zawiera równiezopis architektury bazy LDAP wraz z uzasadnieniem takiego a nie innego doborupodziału na poddrzewa. Oczywiscie w rozdziale opisujacym działajaca aplikacje nie mozezabraknac opisu zrealizowanego mechanizmu replikujacego dane z bazy SQL do bazyLDAP czy Kerberos.
W rozdziale czwartym opisany został sposób konfiguracji serwerów do współpracyz systemem zarzadzania. Opis ten dotyczy zarówno serwerów głównych jak i serwerówobliczeniowych.
Rozdział piaty opisuje w jaki sposób aplikacja spełnia wymagania wysokiejdostepnosci i jakie mechanizmy dodatkowe mozna zastosowac aby nie istniały w systemiezarzadzania pojedyncze punkty awarii (single points of failure).
Rozdział kolejny - szósty opisuje zagadnienia zwiazane z wydajnoscia, strojeniem(tunningiem) oraz skalowalnoscia tego rozwiazania.
Rozdział siódmy przedstawia spostrzezenia jakie pojawiły sie w trakcie prac nadsystemem oraz wnioski z jego realizacji wraz mozliwymi kierunkami dalszego jegorozwoju.

Rozdział1
Istniejące rozwiązania
Rozdział zawiera opisy konkurencyjnych rozwiazan działajacych w tym
samym oraz zblizonym obszarze zastosowan zarzadzania uzytkownikami
co System Zarzadzania Uzytkownikami i Wirtualnymi Organizacjami.
Przedstawiony został system Perun, jego architektura i sposób działania.
Poza Perunem zostały bardzo krótko opisane systemy VUS i GUMS,
które mimo działania w przestrzeni zarzadzania uzytkownikami, obejmuja
inny jej obszar (zarzadzanie uzytkownikami z punktu widzenia systemów
gridowych a nie systemu operacyjnego wykorzystywanego do współpracy
z systemami gridowymi). Przedstawione zostały braki tych systemów,
szczególnie w obszarze zarzadzania certyfikatami oraz wirtualnymi
organizacjami.
1.1 Perun
Jednym z pierwszych rozwiazan próbujacym sprostac opisanym we wstepieproblemom był Perun [3] - system powstał w ramach projektu czeskiego narodowegogridu. System ten miał dostarczac zunifikowane srodowisko dla pracownikówkorzystajacych z jego zasobów. Miał eliminowac biurokratyczne bariery dla uzytkownikówjednego centrum obliczeniowego chcacych wykonac obliczenia w innym centrum.
W trakcie jego tworzenia starano sie w pierwszej kolejnosci rozwiazac nastepujaceproblemy:
◦ Rosnaca liczba systemów obliczeniowych jest geograficznie rozproszona - zasoby sadostepne w trzech miastach - Praga, Brno i Pilzno. Kazde z centrów obliczeniowychuczestniczacych w projekcie ma własny, niezalezny zespół administratorów.

Rozdział 1. Istniejące rozwiązania 10
◦ System działa w srodowisku heterogenicznym - obejmujac swoim działaniemurzadzenia od komputerów klasy PC, poprzez superkomputery Silicon Graphics,Digital Equipment, Compaq czy Hawlett Packard, klastry linuksowe czy urzadzeniaprodukcji IBM. Daje to potrzebe obsługiwania wielu róznych architektursprzetowych (MIPS1, IA-322, IA-643, x86-64, Power i inne) oraz wielu róznychsystemów operacyjnych (Linux, IRIX, Digital Unix i inne).
◦ System działa w istniejacym srodowisku i jego wdrozenie nie mozedoprowadzic do zakłócen działania dla dotychczasowych uzytkowników -co wiecej systemy zarzadzajace musza uwzgledniac istnienie na maszynachobliczeniowych srodowiska pracy. Musza uwzgledniac istnienie kont uzytkownikównieobsługiwanych przez ten system.
◦ Ze wzgledu na duza liczbe róznych urzadzen rozproszonych geograficznie twórcysystemu musieli przyjac, ze nie istnieje taki moment, gdy wszystkie urzadzenia sawłaczone i sprawne.
Przy tak złozonych problemach zarzadzanie ad-hoc systemami okazało sie zbytskomplikowane i mało skalowalne. Analizujac potrzeby uzytkowników twórcy systemuopracowali liste podstawowych wymagan jakie musi spełniac system zarzadzaniazasobami:
◦ zarzadzanie uzytkownikami w srodowiskach heterogenicznych
◦ konfiguracja powiazanych z tym usług (Kerberos, AFS4, LDAP . . . )
◦ odpornosc na awarie systemów obliczeniowych
◦ nie moze wprowadzac nowych pojedynczych punktów awarii
◦ skalowalnosc i rozszerzalnosc
◦ rózne interfejsy dla róznych rodzajów uzytkowników i zadan - przykładowo interfejswebowy dla systemów rejestracji uzytkownika czy nieinteraktywny zestaw narzedzikonsolowych do celów administracyjnych.
1Microprocessor without Interlocked Pipeline Stages2Intel Architecture, 32-bit3Intel Itanium architecture, 64-bit4Andrew File System

Rozdział 1. Istniejące rozwiązania 11
W trakcie dalszych prac nad systemem musiano rozwazyc kilka sprzecznych podejsc:
◦ Rozproszone czy scentralizowane repozytorium konfiguracji.W wypadku centralnego zarzadzania konfiguracja duzo łatwiej mozna zapewnicwysokie wymagania odnosnie zachowania spójnosci danych. Zapewnienieich w architekturze rozproszonej jest zadaniem niezwykle skomplikowanym- czego przykładem sa istniejace do tej pory problemy i niedociagnieciaw stosowanych w bazach danych mechanizmach replikacji multimaster.Wprowadzenie rozproszonego modelu zarzadzania konfiguracja wymagałobyopracowania i wdrozenia efektywnych algorytmów takiej replikacji na poziomiesystemu zarzadzania. Z drugiej strony duzo wyzsza odpornosc na awarie moznauzyskac korzystajac z rozproszonych repozytoriów danych.
◦ Odpornosc na awarie czy scisłe przestrzeganie/wymuszanie ograniczen.Zmiany w konfiguracji moga dotyczyc wielu zasobów równoczesnie. Scisłeprzestrzeganie ograniczen wymagałoby zastosowania dwuetapowego zatwierdzania(2-phase commit). Z drugiej strony stosowanie takich rozwiazan bywa kłopotliwei nieskalowalne w systemach z duzym prawdopodobienstwem awarii zarzadzanychsystemów.
Projektujac system jako całosc jego twórcy musieli podjac kilka naprawde trudnychdecyzji i obnizyc niektóre wymagania aby móc spełnic inne. Skutkiem tego w systemiePerun istnieje centralna baza danych, w której mozna bardzo łatwo wymusic zastosowanieograniczen. Jednak zmiany te sa nastepnie propagowane do systemów docelowychprzy zastosowaniu metody push (centralny serwer „wypycha” zmiany do komputerówdocelowych, a nie jest odpytywany o nie). Maszyny obliczeniowe nigdy nie odpytujacentralnego serwera - dzieki czemu w razie jego awarii nie mozna co prawda prowadzicdziałan zmieniajacych parametry kont uzytkowników, zmieniajacych konfiguracje maszyni tym podobnych - lecz podstawowe zadania maszyn pozostaja niezakłócone.
1.1.1 Architektura systemu Perun
◦ Baza danych - baza danych składa sie z tabel systemowych i tabel zawierajacychdane uzytkowników (tabele aplikacji zawierajace dane systemu). W tabelachaplikacji sa przechowywane dane opisujace konfiguracje zarzadzanych zasobów.Tabele systemowe opisuja system Perun i sa bezposrednio uzywane i dostepne dla

Rozdział 1. Istniejące rozwiązania 12
usług zarzadzajacych. Podstawowa tabela jest „JOURNAL” do której zapisywanesa wszelkie zmiany w tabelach aplikacyjnych - zarówno w celach historycznych jaki w celu pobrania ich przez system propagujacy zmiany na maszynach docelowych.Pozostałe tabele systemowe opisuja konfiguracje systemu Perun oraz informacjeo stanie usług wchodzacych w jego skład.
◦ Interfejsy uzytkowników - na podstawie poziomu uprawnien rozrózniamy dwieklasy uzytkowników:
◦ administratorzy zasobów - maja mozliwosc zmieniac konfiguracje danegozasobu. Loguja sie do bazy jako nazwani uzytkownicy (kazdy ma imiennekonto w bazie danych)
◦ zwykli uzytkownicy - uzytkownicy zasobów. Maja minimalne mozliwosci zmiandanych w bazie - dokładniej tylko informacji osobistych ich dotyczacych.Z punktu widzenia bazy danych loguja sie korzystajac ze wspólnego kontabazodanowego o minimalnych uprawnieniach.
W systemie dostepne sa trzy rózne interfejsy dla uzytkowników:
◦ Interfejs webowy - uzywany przez zwykłych uzytkowników do zmian ichdanych osobowych, rejestracji czy zapytan o dodatkowe konta. Poza tym przezten interfejs sa dostepne dla administratorów informacje globalne na tematkonfiguracji zasobów czy ich stanu.
◦ CLI5 - interfejs linii komend - zbiór nieinteraktywnych komend uzywanychprzez administratorów zarówno bezposrednio jak i do konstrukcji skryptówautomatyzujacych bardziej złozone czynnosci.
◦ Bezposredni dostep do bazy - uzywany przez administratorów do wykonywaniarzadszych czynnosci do których budowa narzedzi konsolowych byłabyekonomicznie nieuzasadniona.
◦ Usługi - usługa w systemie Perun nazywamy jednostke konfiguracji zmienianatylko jako całosc przy uzyciu atomowych operacji. Dokładna definicja usługizalezy od konkretnej aplikacji - lecz powyzsza zasada dotyczy kazdej usługi.Przykładem jest „passwd” - jej zmiana powoduje zmiany we wszystkich plikach
5command-line interface

Rozdział 1. Istniejące rozwiązania 13
odpowiadajacych za informacje o uzytkownikach czyli: /etc/passwd, /etc/shadow,/etc/group czy /etc/aliases.
Zmiany w konfiguracji sa propagowane z zastosowaniem ponizszej procedury.
◦ Zmiany w bazie sa przechwytywane przez triggery na poziomie bazy danychi wstawiane do dziennika (tabela „JOURNAL”).
◦ Zmiany w dzienniku sa monitorowane przez inny trigger, którybudzi/powiadamia „service planner daemon”.
◦ Usługa planujaca, bazujac na nazwie zmienianej tabeli, filtruje zmianyz wykorzystaniem wtyczek (planning plugins). Wtyczki te posiadaja wiedzena temat struktury i semantyki przetwarzanych danych i przetwarzaja je w pary- usługa i zasób docelowy, które powinny byc zaktualizowane.
◦ Usługa planujaca (planner daemon) sortuje wyniki działan wtyczek, eliminujepowtarzajace sie dane i oznacza wynikowe usługi do aktualizacji. Opóznieniamiedzy zmiana danych w bazie a zmiana usługi sa konfigurowane w zaleznosciod usługi
◦ Kolejne kroki sa wykonywane przez aplikacje rozdzielajaca zadania (servicedispatcher):
◦ usługi, które powinny zostac zaktualizowane sa regularnie monitorowane
◦ zaleznosci miedzy usługami sa rozwiazywane (przetwarzane a nieznoszone)
◦ dla kazdej pary usługa, zasób uruchamiana jest wtyczka aktualizujaca(update plugin). Wtyczka posiada wiedze na temat struktury i semantykiprzetwarzanych danych
◦ wtyczka moze albo samodzielnie dokonac zmiany (dodanie konta do bazyKerberos) albo połaczyc sie ze zdalnym zarzadca zasobów i dostarczyc mudanych niezbednych do dokonania zmian
Wszelkie błedy sa przechwytywane przez aplikacje rozdzielajaca zadania.W zaleznosci od konfiguracji aktualizacja zmian moze byc ponawianakilkukrotnie zanim bład zostanie zgłoszony administratorom (zgłoszenie typu„permanent failure”).
◦ Akcje wykonywane recznie - mimo, ze tworzac Peruna starano sie zautomatyzowactak wiele działan jak tylko było to mozliwe i ekonomicznie uzasadnione, istnieja

Rozdział 1. Istniejące rozwiązania 14
przypadki gdy wymagane jest działanie administratora bezposrednio na serwerze.Przykładem jest wspomniane wczesniej zgłoszenie typu „permanent failure”.
1.2 Virtual User System
System VUS6 [4] został stworzony w odpowiedzi na potrzebe umozliwianiauzytkownikom wykorzystywania zasobów obliczeniowych centrum obliczeniowegobez koniecznosci zakładania im imiennych kont na serwerach. Wywodzi sieczesciowo z rozwiazania opartego o współdzielone konta. Podstawowym usprawnieniemwprowadzonym przez VUS jest zapisywanie historii mapowania miedzy kontem a jegouzytkownikiem wraz ze zliczaniem wykorzystania zasobów w trakcie pracy. Dziekitakiemu podejsciu mozliwe stało sie nie tylko monitorowanie działan w powiazaniuz rzeczywistym uzytkownikiem systemu, ale równiez wyliczanie rzeczywistych kosztówuzytkowania systemu przez poszczególnych uzytkowników, co jest bardzo istotnymzagadnieniem przy komercyjnym stosowaniu rozwiazan gridowych.
1.3 Grid User Management System
GUMS7 [11] jest systemem odwzorowujacym identyfikatory gridowe na kontasystemowe. Takie działania sa niezbedne, gdy systemy obliczeniowe nie uzywajawyłacznie gridowych systemów uwierzytelniania, lecz stosuja własne oparte o kontasystemu UNIX czy o hasła przechowywane w bazie Kerberos. W takiej sytuacji kazdezadanie przychodzace do wezła musi zostac zestawione z odpowiadajacym mu kontemlokalnym. GUMS nie zajmuje sie egzekwowaniem przestrzegania tych odwzorowan.Jedyne co robi to zwraca odpowiednie wartosci do gatekeepera, który jest odpowiedzialnyza samo przestrzeganie tych ograniczen.
1.4 Podsumowanie
Zaden z trzech opisywanych systemów nie odpowiada w pełni wymaganiom (Rozdział2.4) stawianym przed naszym systemem zarzadzania. Najblizszy mu funkcjonalniejest Perun, przed którym dodatkowo postawiono wymagania zmniejszenia ograniczen
6Virtual User System7Grid User Management System

Rozdział 1. Istniejące rozwiązania 15
natury organizacyjnej. Podstawowymi funkcjonalnosciami, których brakuje Perunowisa mechanizmy zarzadzania certyfikatami oraz operacje na wirtualnych organizacjach.Systemy VUS i GUMS, mimo działania w tym samym obszarze zarzadzaniauzytkownikami, obsługuja nieco inny krag zastosowan - mapowanie konta uzytkownikagridowego na rzeczywiste konto w systemie.

Rozdział2
Analiza i projekt SystemuZarządzania Użytkownikamii Wirtualnymi Organizacjami
Rozdział przedstawia projekt i analize Systemu Zarzadzania
Uzytkownikami i Wirtualnymi Organizacjami wykonany z zastosowaniem
notacji UML. Projekt i analiza obejmuja analize wymagan, diagramy
przypadków uzycia, diagramy sekwencji, projekt architektury, planowane
do wykorzystania technologie i diagramy klas.
2.1 Metodologia
W trakcie projektowania system zarzadzania uzytkownikami i wirtualnymiorganizacjami nie był do konca zdefiniowany zbiór funkcjonalnosci, który bedzierealizowany w ramach tej pracy. Z tego tez powodu została podjeta decyzja o zastosowaniumodelu przyrostowego tworzenia oprogramowania. Do opisu poszczególnych fazprojektu uzyty został jezyk UML1 - najpowszechniej stosowany jezyk formalny słuzacydo modelowania fragmentów rzeczywistosci, w tym do przedstawiania projektu systemówinformatycznych.
1Unified Modeling Language

Rozdział 2. Analiza i projekt Systemu Zarządzania Użytkownikami i Wirtualnymi Organizacjami 17
2.2 Wst¦pna analiza zagadnienia
Wstepna analiza zagadnienia pod katem przyszłych zastosowan oraz srodowiskaw którym system bedzie działał wykazały, ze bedzie miał trzy klasy uzytkowników.Zwykłego uzytkownika, administratora systemu oraz administratora systemuz uprawnieniami do zarzadzania certyfikatami.
◦ Zwykły uzytkownik jest osoba, która korzysta z mozliwosci jakie daje centrumobliczeniowe - wykorzystuje serwery do wykonywania obliczen czy przetwarzaniadanych.
◦ Administrator systemu jest osoba, która wykonuje zadania scisle zwiazanez funkcjonowaniem systemu - ma mozliwosc zakładania kont w systemie,przydzielania dostepu do serwerów czy zmian przyporzadkowywania do grupsystemowych. Jednym z podstawowych zadan administratora jest przydzielanieuzytkowników do wirtualnych organizacji i wiazanie wirtualnych organizacjiz projektami.
◦ Administrator systemu wraz z uprawnieniami do zarzadzania certyfikatamijest niespotykana zbyt powszechnie rola w tego typu systemach. Jego obecnosc jestzwiazana ze szczególna rola certyfikatów w procesie uzywania systemów gridowychoraz koniecznoscia wykonywania operacji zatwierdzajacych zapytania o podpisaniecertyfikatu uzytkownika centrum obliczeniowego. Jego podstawowym zadaniem jestweryfikacja i potwierdzanie zgłoszen podpisania certyfikatu wysyłanych do centrumcertyfikacji - CA2.
2.3 Zarz¡dzanie u»ytkownikami a zarz¡dzanie
wirtualnymi organizacjami
Z punktu widzenia projektowanego systemu wirtualne organizacje sa głównej mierzeobiektami grupujacymi. Z jednej strony grupuja uzytkowników ułatwiajac wykonywanieoperacji na wiekszej ich liczbie jednoczesnie. Z drugiej grupuja klastry obliczenioweco umozliwia wieksza automatyzacje działan dla pojedynczych uzytkowników - dodaniejednego uzytkownika do wirtualnej organizacji umozliwiac ma w prosty sposób dodanie
2Certification Authority

Rozdział 2. Analiza i projekt Systemu Zarządzania Użytkownikami i Wirtualnymi Organizacjami 18
go do wszystkich projektów / klastrów obliczeniowych z którymi wirtualna organizacjajest powiazana.
2.4 Wymagania funkcjonalne i niefunkcjonalne
2.4.1 Wymagania funkcjonalne
Wymagania funkcjonalne beda rozpatrywane z punktu widzenia kazdej z klasuzytkownika przedstawionej wczesniej. Zbiory wymagan funkcjonalnych zawieraja siew sobie. Oznacza to, ze wszystkie wymagania uzytkownika systemu sa równiezwymaganiami obu administratorów, a wymagania funkcjonalne administratora dotyczarówniez administratora z uprawieniami do zarzadzania certyfikatami. Analiza wymaganjest kluczowa dla zrozumienia zbioru funkcjonalnosci jakie ma realizowac system. Kazdaz funkcjonalnosci jest opisana nastepujacymi atrybutami: nazwa, zadanie jakie realizuje,parametry wejsciowe, wynik i ewentualne uwagi.
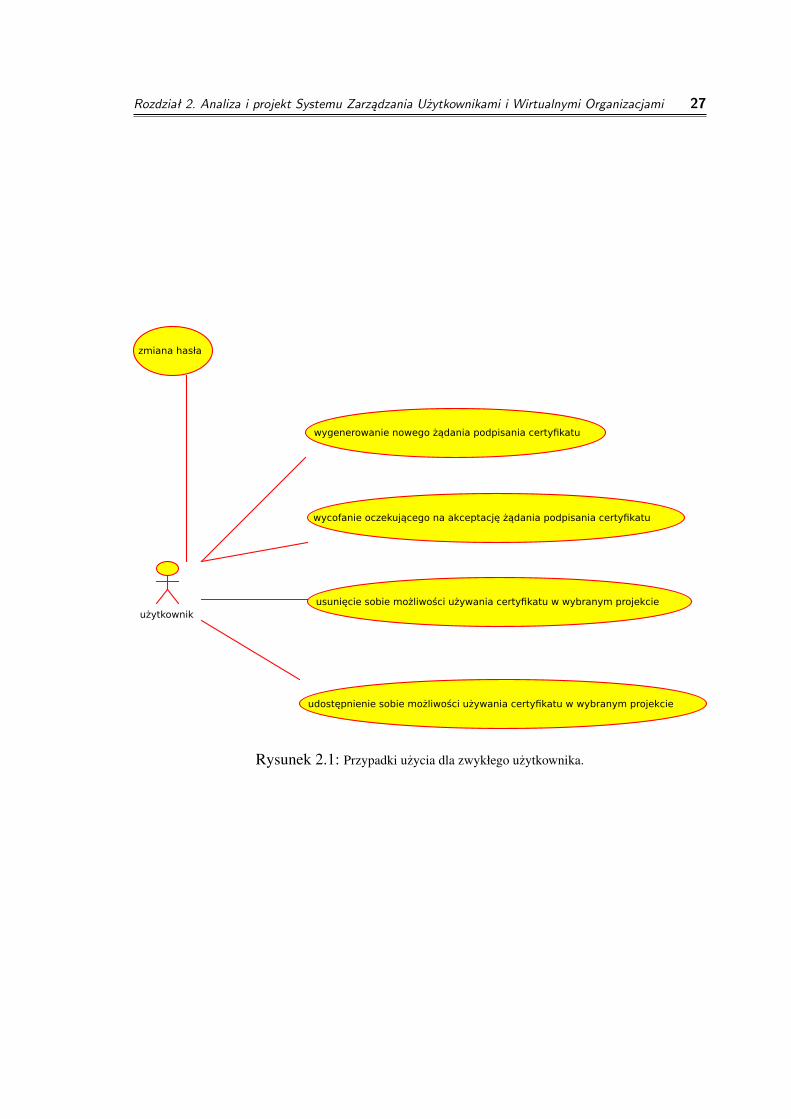
◦ Uzytkownik systemu
◦ zmiana hasła uzytkownika
cel: zmiana hasła uzywanego do uwierzytelniania w systemie zarzadzania orazw klastrach obliczeniowych
parametry wejsciowe: stare hasło, nowe hasło
zwracany wynik: sukces, porazka
◦ wygenerowanie nowego zadania podpisania certyfikatu
cel: uzyskanie nowego certyfikatu uzywanego w systemach gridowych
parametry wejsciowe: dane osobowe
zwracany wynik: sukces, porazka
uwagi: wygenerowanie zadania nowego certyfikatu nie powiedzie sie, gdyw kolejce czeka juz zadanie danego uzytkownika do tego samego CA
◦ wycofanie oczekujacego na akceptacje zadania podpisania certyfikatu
cel: wycofanie zadania podpisania certyfikatu
parametry wejsciowe: identyfikator zadania
zwracany wynik: sukces, porazka

Rozdział 2. Analiza i projekt Systemu Zarządzania Użytkownikami i Wirtualnymi Organizacjami 19
◦ udostepnienie sobie mozliwosci uzywania certyfikatu w wybranym projekcie
cel: umozliwienie sobie uzywania wybranego certyfikatu na wszystkichmaszynach wchodzacych w skład wybranego projektu
parametry wejsciowe: identyfikator projektu, identyfikator certyfikatu
zwracany wynik: sukces, porazka
◦ usuniecie sobie mozliwosci uzywania certyfikatu w wybranym projekcie
cel: zlikwidowanie mozliwosci podpisywania wybranym certyfikatem namaszynach nalezacych do danego projektu
parametry wejsciowe: identyfikator projektu, identyfikator certyfikatu
zwracany wynik: sukces, porazka
◦ Administrator
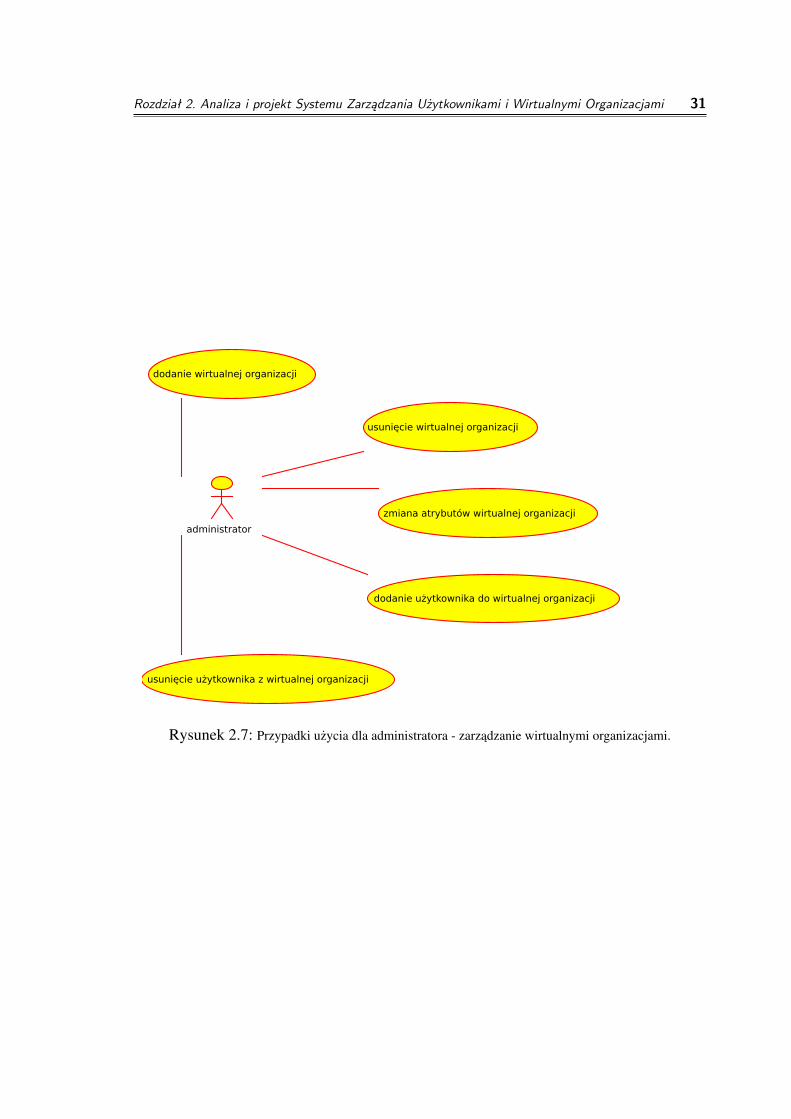
◦ zarzadzanie wirtualnymi organizacjami
◦ dodanie wirtualnej organizacji
cel: dodanie do systemu zarzadzania wirtualnej organizacji grupujacejuzytkownikówparametry wejsciowe: nazwa wirtualnej organizacji, rodzaj wirtualnejorganizacji, adres listy dyskusyjnej wirtualnej organizacjizwracany wynik: identyfikator wirtualnej organizacji
◦ usuniecie wirtualnej organizacji
cel: usuniecie niepotrzebnej wirtualnej organizacji z systemu zarzadzaniaparametry wejsciowe: identyfikator wirtualnej organizacjizwracany wynik: sukces, porazka
◦ zmiana atrybutów wirtualnej organizacji
cel: modyfikacja niektórych atrybutów wirtualnej organizacjiparametry wejsciowe: identyfikator wirtualnej organizacji, atrybuty dozmianyzwracany wynik: sukces, porazka
◦ dodanie uzytkownika do wirtualnej organizacji
cel: dodanie uzytkownika do wirtualnej organizacji oraz do wszystkichprojektów i list dyskusyjnych, do których wirtualna organizacja nalezyparametry wejsciowe: identyfikator uzytkownika, identyfikator wirtualnejorganizacji

Rozdział 2. Analiza i projekt Systemu Zarządzania Użytkownikami i Wirtualnymi Organizacjami 20
zwracany wynik: sukces, porazka
◦ usuniecie uzytkownika z wirtualnej organizacji
cel: usuniecie uzytkownika z wirtualnej organizacji oraz wszystkichprojektów i list dyskusyjnych do których nalezy wirtualna organizacja,chyba, ze przynaleznosc do nich jest zapewniana przez członkostwow innej wirtualnej organizacjiparametry wejsciowe: identyfikator uzytkownika, identyfikator wirtualnejorganizacjizwracany wynik: sukces, porazka
◦ dodanie wirtualnej organizacji do projektu
cel: dodanie wirtualnej organizacji oraz wszystkich jej członków doprojektu oraz do odpowiadajacych projektowi list dyskusyjnychparametry wejsciowe: identyfikator projektu, identyfikator wirtualnejorganizacjizwracany wynik: sukces, porazka
◦ usuniecie wirtualnej organizacji z projektu
cel: usuniecie wirtualnej organizacji oraz wszystkich jej członkówz projektu oraz odpowiadajacych projektowi list dyskusyjnych, o ileprzynaleznosc do projektu czy listy dyskusyjnej nie jest skutkiem innychczynnikówparametry wejsciowe: identyfikator projektu, identyfikator wirtualnejorganizacjizwracany wynik: sukces, porazka
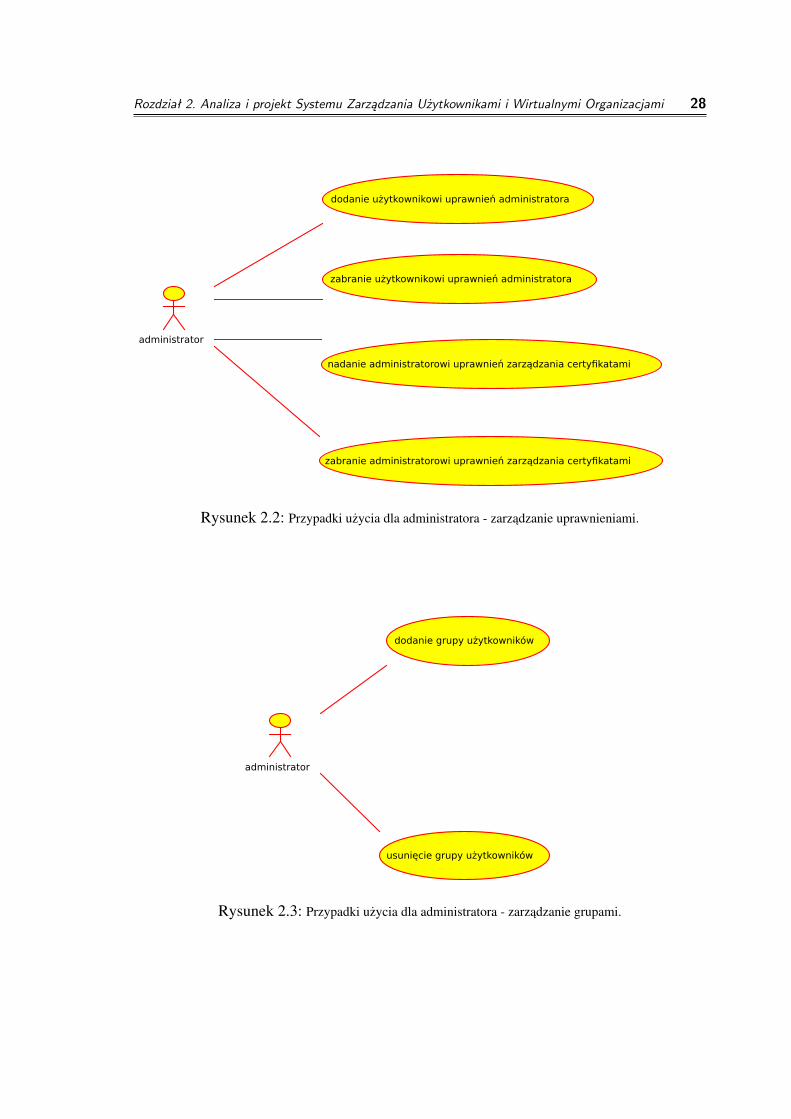
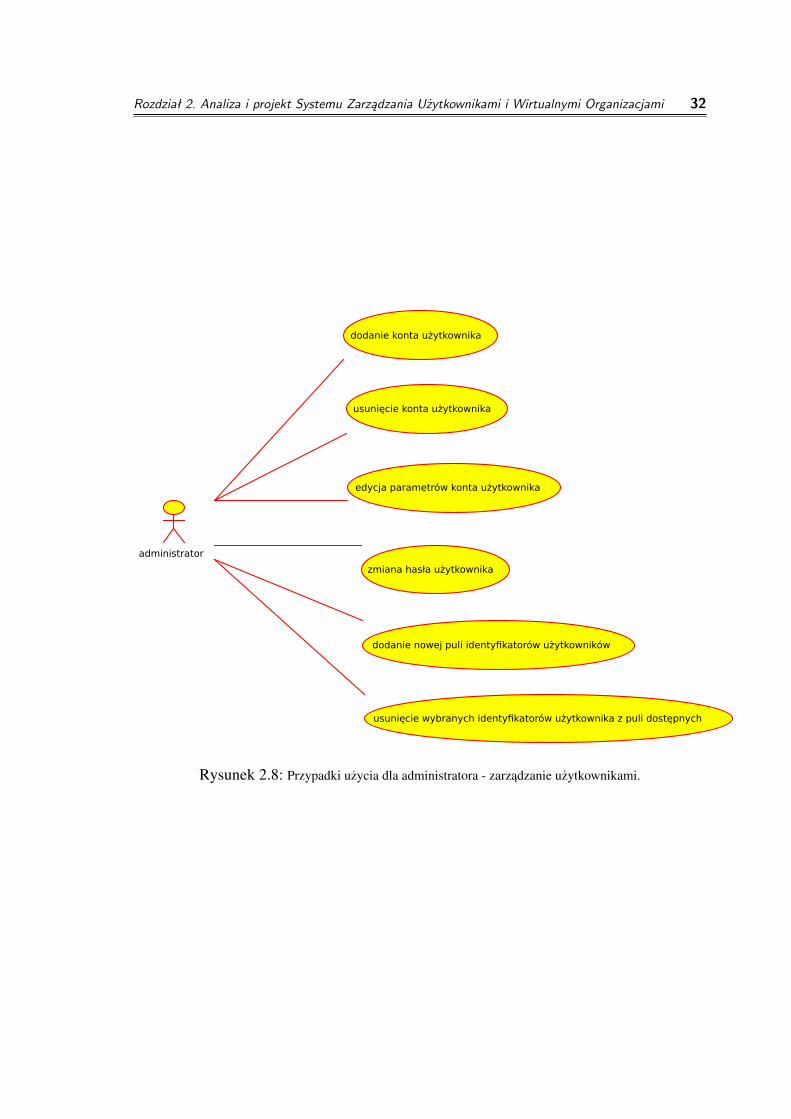
◦ zarzadzanie uzytkownikami i uprawnieniami
◦ dodanie konta uzytkownika
cel: załozenie nowemu uzytkownikowi konta umozliwiajacego pracew srodowisku klastrów obliczeniowychparametry wejsciowe: identyfikator uzytkownika, imie, nazwisko,instytucja z ramienia której uzytkownik bedzie pracował, dane adresowe,hasło (moze byc wygenerowane)zwracany wynik: sukces, porazka
◦ zmiana danych uzytkownika
cel: umozliwienie poprawienia błedów w kontach albo zmian pewnychparametrów

Rozdział 2. Analiza i projekt Systemu Zarządzania Użytkownikami i Wirtualnymi Organizacjami 21
parametry wejsciowe: dane do zmianyzwracany wynik: sukces, porazka
◦ dodanie administratora
cel: nadanie uzytkownikowi uprawnien administratoraparametry wejsciowe: identyfikator uzytkownikazwracany wynik: sukces, porazka
◦ usuniecie administratora
cel: odebranie uzytkownikowi uprawnien administratoraparametry wejsciowe: identyfikator uzytkownikazwracany wynik: sukces, porazka
◦ nadanie/zabranie administratorowi mozliwosci zarzadzania certyfikatami
cel: zdefiniowanie administratora jako lokalnego zarzadce certyfikatówalbo zabranie takiej mozliwosciparametry wejsciowe: identyfikator administratora, uprawnieniazwracany wynik: sukces, porazka
◦ dodanie do puli identyfikatorów uzytkowników nowego zakresu
cel: uzytkownicy dodawani przez system zarzadzania moga dostawacidentyfikatory systemowe tylko sposród zdefiniowanych przezadministratorówparametry wejsciowe: granice zakresówzwracany wynik: liczba dodanych identyfikatorów
◦ usuniecie z puli identyfikatorów systemowych wybranych, nieuzywanych
identyfikatorów lub dodanych przez pomyłke
cel: usuniecie z puli identyfikatorów systemowych identyfikatorówprzeznaczonych dla uzytkowników, którzy nie maja byc zarzadzani przezsystem zarzadzaniaparametry wejsciowe: zbiór identyfikatorówzwracany wynik: brak
◦ zarzadzanie grupami
◦ dodanie grupy
cel: dodanie grupy uzytkowników do systemuparametry wejsciowe: nazwa grupy, opis grupy, identyfikator grupy (gid)zwracany wynik: identyfikator grupy

Rozdział 2. Analiza i projekt Systemu Zarządzania Użytkownikami i Wirtualnymi Organizacjami 22
◦ usuniecie grupy
cel: usuniecie z systemu zarzadzania i wszystkich klastrówobliczeniowych grupyparametry wejsciowe: identyfikator grupyzwracany wynik: sukces, porazka
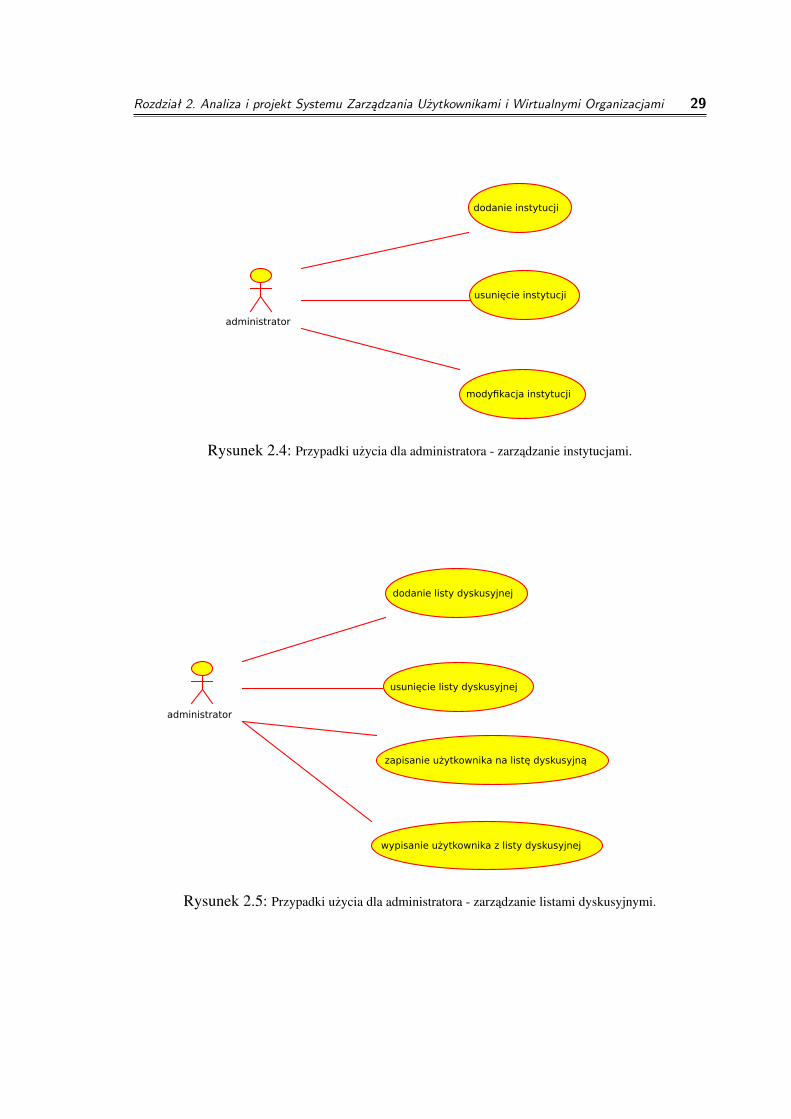
◦ zarzadzanie instytucjami
◦ dodanie instytucji
cel: dodanie informacji na temat instytucji do systemuparametry wejsciowe: nazwa i dane teleadresowe instytucjizwracany wynik: identyfikator instytucji
◦ usuniecie instytucji
cel: usuniecie z systemu instytucji, która juz nie współpracuje z systememzarzadzaniaparametry wejsciowe: identyfikator instytucjizwracany wynik: sukces, porazka
◦ modyfikacja instytucji
cel: zmiana parametrów instytucji (nazwy, danych teleadresowych)parametry wejsciowe: identyfikator instytucji, nazwa, dane teleadresowezwracany wynik: sukces, porazka
◦ zarzadzanie listami dyskusyjnymi
◦ dodanie listy
cel: dodanie listy dyskusyjnej do serwisu zarzadzania i serwera listdyskusyjnychparametry wejsciowe: adres listy, rodzaj listy (dyskusyjna, newsletter,moderowana lista dyskusyjna),zwracany wynik: identyfikator listy
◦ usuniecie listy
cel: usuniecie niepotrzebnej listy dyskusyjnejparametry wejsciowe: identyfikator listyzwracany wynik: sukces, porazka
◦ zapisanie uzytkownika na liste dyskusyjna
cel: dodanie uzytkownikowi mozliwosci zapisania sie na liste dyskusyjnadanego projektu, nawet jezeli nie nalezy do danego projektu i lista

Rozdział 2. Analiza i projekt Systemu Zarządzania Użytkownikami i Wirtualnymi Organizacjami 23
nie jest zamknieta, dodatkowo mozna zakładac listy niezwiazane scislez projektem czy wirtualna organizacja i do takich list mozna sie zapisacw taki sposóbparametry wejsciowe: identyfikator uzytkownika, identyfikator listyzwracany wynik: sukces, porazka
◦ wypisanie uzytkownika z listy dyskusyjnej
cel: uzytkownik moze nie chciec byc zapisanym na liste dyskusyjnadotyczaca danego klastra, wirtualnej organizacji do której nalezy, mozeuzywac innych metod komunikacji (archiwum dostepne przez www),w takim wypadku nalezy mu udostepnic mechanizm wypisania)parametry wejsciowe: identyfikator uzytkownika, identyfikator listyzwracany wynik: sukces, porazka
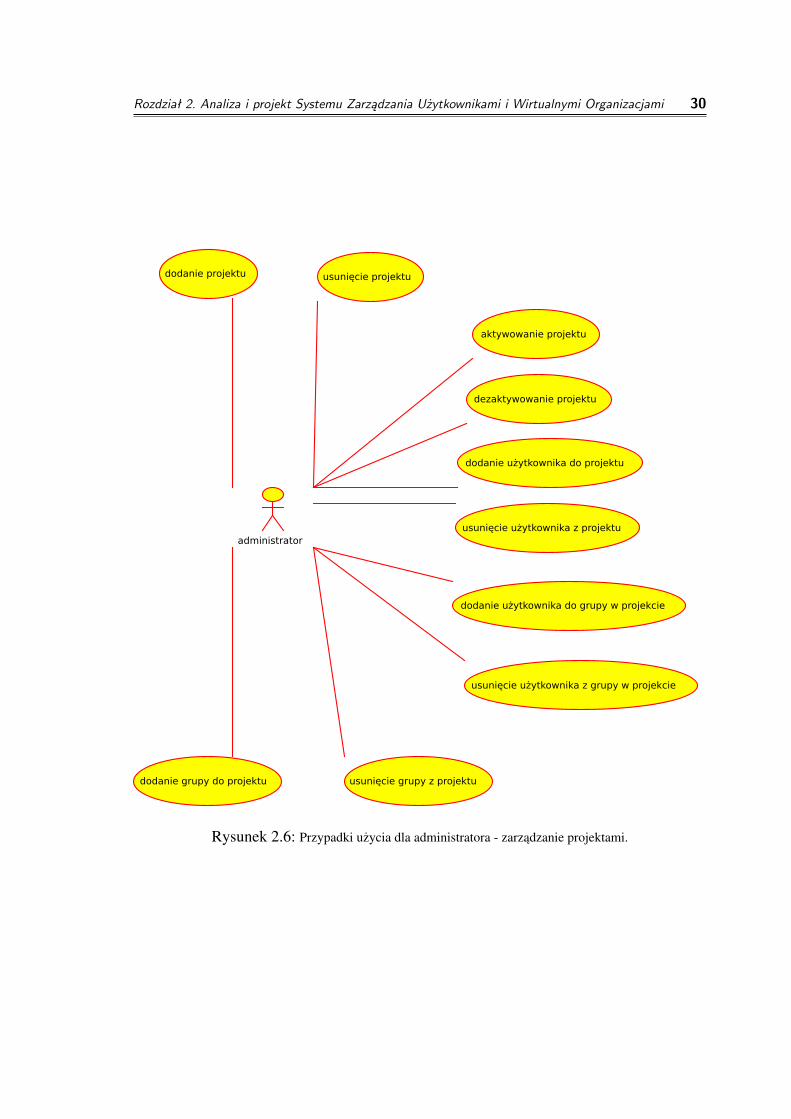
◦ zarzadzanie projektami
◦ dodanie projektu
cel: dodanie projektu - struktury grupujacej klastry obliczeniowe pracujacenad wspólnymi projektami i posiadajace wspólna baze uzytkownikówparametry wejsciowe: nazwa projektu, opis projektu, adres listydyskusyjnej projektuzwracany wynik: identyfikator projektu
◦ usuniecie projektu
cel: usuniecie projektu z działajacej kopii systemuparametry wejsciowe: identyfikator projektuzwracany wynik: sukces, porazka
◦ dezaktywowanie projektu
cel: tymczasowe wyłaczenie danego projektuparametry wejsciowe: identyfikator projektuzwracany wynik: sukces, porazka
◦ aktywowanie projektu
cel: aktywowanie uprzednio zdezaktywowanego projektuparametry wejsciowe: identyfikator projektuzwracany wynik: sukces, porazka
◦ dodanie uzytkownika do projektu
cel: dodanie uzytkownikowi mozliwosci skorzystania z klastrówobliczeniowych wchodzacych w skład projektu

Rozdział 2. Analiza i projekt Systemu Zarządzania Użytkownikami i Wirtualnymi Organizacjami 24
parametry wejsciowe: identyfikator uzytkownika, identyfikator projektu,data waznosci konta w projekcie, flaga okreslajaca czy dane kontow projekcie jest aktywnezwracany wynik: sukces, porazka
◦ usuniecie uzytkownika z projektu
cel: zablokowanie uzytkownikowi niepracujacemu nad danym projektemmozliwosci korzystania z jego zasobówparametry wejsciowe: identyfikator uzytkownika, identyfikator projektuzwracany wynik: sukces, porazka
◦ dodanie grupy do projektu
cel: umozliwienie zarzadzania wybrana grupa na serwerach nalezacych doprojektuparametry wejsciowe: identyfikator grupy, identyfikator projektuzwracany wynik: identyfikator grupy
◦ usuniecie grupy z projektu
cel: zablokowanie mozliwosci zarzadzania członkostwem w danej grupiew wybranym projekcieparametry wejsciowe: identyfikator grupy, identyfikator projektuzwracany wynik: sukces, porazka
◦ dodanie uzytkownika do grupy w projekcie
cel: dodanie uzytkownikowi uprawnien posiadanych przez grupeparametry wejsciowe: identyfikator grupy, identyfikator uzytkownika,identyfikator projektuzwracany wynik: sukces, porazka
◦ usuniecie uzytkownika z grupy w projekcie
cel: zabranie uzytkownikami uprawnien, jakie daje przynaleznosc dowybranej grupy w ramach projektuparametry wejsciowe: identyfikator grupy, identyfikator uzytkownika,identyfikator projektuzwracany wynik: sukces, porazka
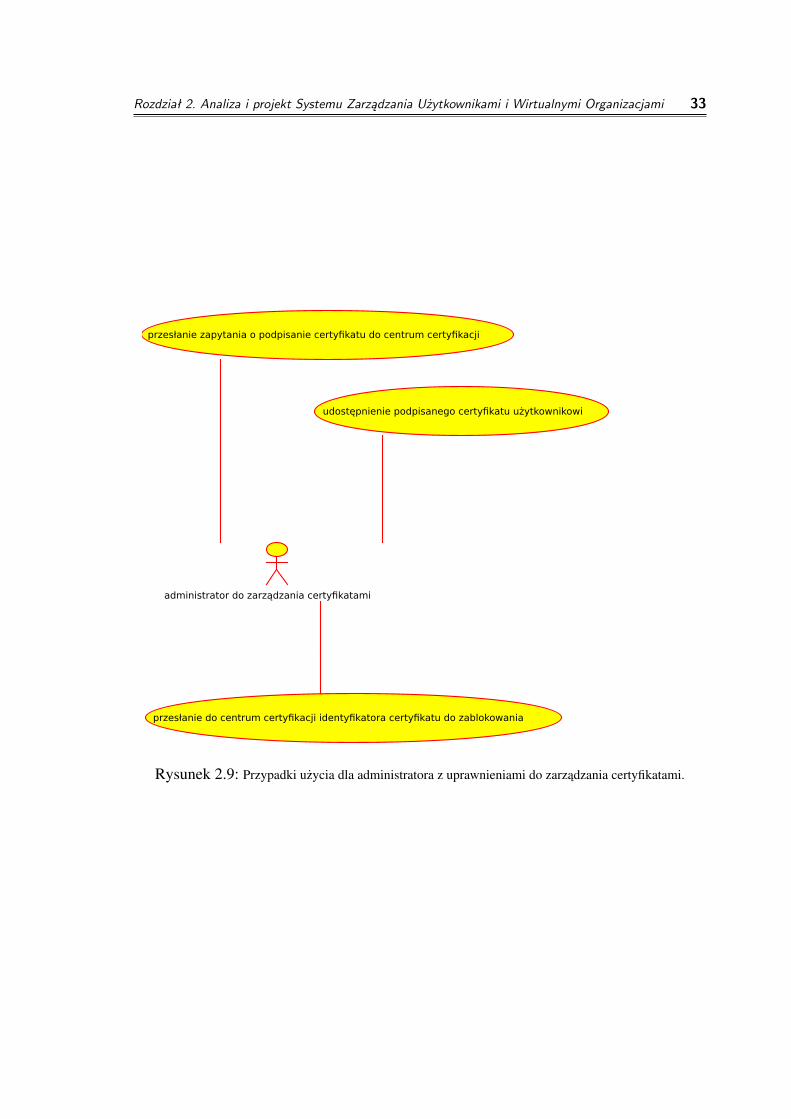
◦ Administrator z uprawieniami do zarzadzania certyfikatami
◦ przesłanie zapytania o podpisanie certyfikatu do centrum certyfikacji
cel: poswiadczenie autentycznosci zadania podpisania certyfikatu

Rozdział 2. Analiza i projekt Systemu Zarządzania Użytkownikami i Wirtualnymi Organizacjami 25
parametry wejsciowe: zadanie podpisania certyfikatu wygenerowane wczesniejprzez uzytkownika systemu
zwracany wynik: podpisany certyfikat
◦ udostepnienie podpisanego certyfikatu uzytkownikowi
cel: umozliwienie korzystania z podpisanego certyfikatu uzytkownikowisystemu
parametry wejsciowe: podpisany certyfikat, identyfikator uzytkownika
zwracany wynik: sukces, porazka
◦ przesłanie do centrum certyfikacji identyfikatora certyfikatu do zablokowania
cel: zablokowanie mozliwosci uzywania wybranego certyfikatu
parametry wejsciowe: odcisk certyfikatu
zwracany wynik: sukces, porazka
2.4.2 Wymagania niefunkcjonalne
◦ Komponenty poziomu systemu operacyjnego projektowanego systemu zarzadzanianie moga w mierzalny sposób spowalniac i opózniac funkcjonowania klastrówobliczeniowych.
◦ System musi zawierac mechanizmy wysokiej dostepnosci umozliwiajacefunkcjonowanie klastrów w przypadku awarii jednego badz kilku komponentówsystemu
◦ System musi byc skalowalny zarówno wzgledem liczby maszyn fizycznych jaki wzgledem liczby uzytkowników
◦ Listy maszyn, uzytkowników, projektów, wirtualnych organizacji, itd. musza miecmozliwosc dowolnego sortowania i filtrowania
◦ Listy maszyn, uzytkowników, projektów, wirtualnych organizacji, itd. musza miecmozliwosc wybrania wyswietlanych pól rekordów
◦ System ten ma umozliwiac działanie równoczesnie na kilkuset serwerach fizycznychi wirtualnych
◦ System musi byc łatwy w obsłudze

Rozdział 2. Analiza i projekt Systemu Zarządzania Użytkownikami i Wirtualnymi Organizacjami 26
2.5 Wymagania a istniej¡ce rozwi¡zania
Zaden z trzech opisywanych w rozdziale 1 systemów nie odpowiada wymaganiomstawianym przed naszym systemem zarzadzania uzytkownikami i wirtualnymiorganizacjami. Zaden z prezentowanych systemów nie oferuje mozliwosci operowaniana grupach urzadzen czy uzytkowników w ramach wirtualnych organizacji oraznie przewiduje zarzadzania cyklem zycia certyfikatów. Niestety, sa to z naszego punktuwidzenia mankamenty uniemozliwiajace zastosowanie ich do naszych potrzeb. Dodatkowosystemy te operuja na innych warstwach niz System Zarzadzania - nasz system operujeduzo blizej warstwy systemu operacyjnego - pozostałe systemy nastawione sa bardziejna operowanie pojeciami w ujeciu gridowym (chodzi przede wszystkim o uzytkownikówi wirtualne organizacje)
2.6 Diagramy przypadków u»ycia
Diagramy przypadków uzycia przedstawiaja wszystkie akcje jakie moze wykonywacdany uzytkownik w systemie. Diagramy przypadków uzycia administratora zostałypodzielone wzgledem przedmiotu wykonywanych działan (listy mailingowe, uprawnieniaczy grupy uzytkowników). Analiza i przedstawienie przypadków uzycia jest jednaz najpowszechniejszych metod inzynierii oprogramowania słuzaca do zdefiniowaniazamknietego zbioru funkcjonalnosci jakie ma dostarczac system informatyczny.
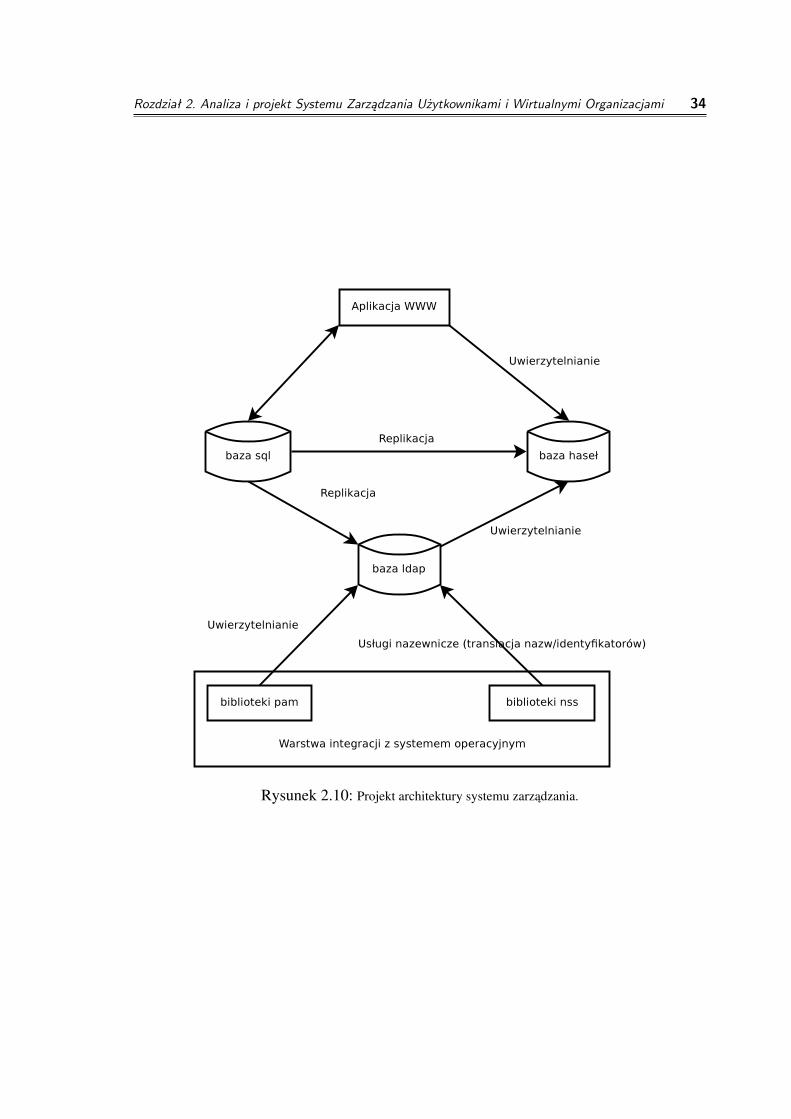
2.7 Plan architektury systemu
System zarzadzania składa sie z pieciu podstawowych komponentów: bazy danychSQL, bazy LDAP, bazy haseł Kerberos, aplikacji www oraz czesci systemowej działajacejna serwerach obliczeniowych. Czesc systemowa działajaca na serwerach obliczeniowych(na rysynku 2.10 opisanej jako Warstwa integracji z systemem operacyjnym) składa sie zdwóch elementów - bibliotek PAM3 i NSS4.
◦ Biblioteki NSS - biblioteki te udostepniaja systemowi operacyjnemu mechanizmyzamiany identyfikatorów tekstowych na identyfikatory numeryczne orazidentyfikatorów numerycznych na identyfikatory testowe. Przykładem jest zamiana
3Pluggable authentication modules4Name Service Switch
Rozdział 2. Analiza i projekt Systemu Zarządzania Użytkownikami i Wirtualnymi Organizacjami 27
Rysunek 2.1: Przypadki uzycia dla zwykłego uzytkownika.
Rozdział 2. Analiza i projekt Systemu Zarządzania Użytkownikami i Wirtualnymi Organizacjami 28
Rysunek 2.2: Przypadki uzycia dla administratora - zarzadzanie uprawnieniami.
Rysunek 2.3: Przypadki uzycia dla administratora - zarzadzanie grupami.
Rozdział 2. Analiza i projekt Systemu Zarządzania Użytkownikami i Wirtualnymi Organizacjami 29
Rysunek 2.4: Przypadki uzycia dla administratora - zarzadzanie instytucjami.
Rysunek 2.5: Przypadki uzycia dla administratora - zarzadzanie listami dyskusyjnymi.
Rozdział 2. Analiza i projekt Systemu Zarządzania Użytkownikami i Wirtualnymi Organizacjami 30
Rysunek 2.6: Przypadki uzycia dla administratora - zarzadzanie projektami.
Rozdział 2. Analiza i projekt Systemu Zarządzania Użytkownikami i Wirtualnymi Organizacjami 31
Rysunek 2.7: Przypadki uzycia dla administratora - zarzadzanie wirtualnymi organizacjami.
Rozdział 2. Analiza i projekt Systemu Zarządzania Użytkownikami i Wirtualnymi Organizacjami 32
Rysunek 2.8: Przypadki uzycia dla administratora - zarzadzanie uzytkownikami.
Rozdział 2. Analiza i projekt Systemu Zarządzania Użytkownikami i Wirtualnymi Organizacjami 33
Rysunek 2.9: Przypadki uzycia dla administratora z uprawnieniami do zarzadzania certyfikatami.
Rozdział 2. Analiza i projekt Systemu Zarządzania Użytkownikami i Wirtualnymi Organizacjami 34
Rysunek 2.10: Projekt architektury systemu zarzadzania.

Rozdział 2. Analiza i projekt Systemu Zarządzania Użytkownikami i Wirtualnymi Organizacjami 35
nazwy uzytkownika na numer UID5 w systemach unix. W wypadku naszegosystemu biblioteki te uzyskuja te informacje z serwera LDAP.
◦ Biblioteki PAM - biblioteki te udostepniaja systemowi operacyjnemu mechanizmyuwierzytelniania oraz przygotowania srodowiska pracy dla uzytkownika. Wwypadku naszego systemu beda sie głównie komunikowac z serwerem LDAP.
◦ Baza danych LDAP - główna baza uzywana z poziomu systemu operacyjnego.Zawiera dane o uzytkownikach, grupach i członkostwach uzytkowników w grupachw hierarchii bazujacej na projektach.
◦ Baza haseł Kerberos - z tego powodu, ze uzytkownik moze wystepowac w kilkuprojektach równoczesnie zdecydowalismy sie wydzielic jedyne dane zmienianez kilku róznych miejsc systemu (system operacyjny, aplikacja www) do oddzielnejbazy - bazy haseł Kerberos. Dzieki temu zmiana hasła w ramach jednego projektuzmieni je równiez w pozostałych.
◦ Baza danych SQL - główna baza systemu - zawiera wszystkie (poza hasłami) daneuzytkowników, projektów oraz wirtualnych organizacji wraz z powiazaniami miedzynimi. Na podstawie zawartosci tabel tej bazy generowane sa rekordy LDAP uzywaneprzez serwery obliczeniowe.
◦ Aplikacja www - w rzeczywistosci dwie oddzielne aplikacje www. Jedna tointerfejs do webserwisów - umozliwiajaca w prosty sposób wykonanie szereguoperacji poprzez dostarczenie strumienia danych w zdefiniowanym formacie, druganatomiast to panel administracyjny do zarzadzania danymi przy uzyciu przegladarkiinternetowej.
2.8 Planowane technologie
W wypadku komponentów systemowych (biblioteki PAM i NSS) wyboru wielkiegonie ma. Ze wzgledu na stosowane mechanizmy dystrybucji oprogramowania najlepiej zdacsie na to, co jest dostarczane wraz ze stosowana dystrybucja. Dzieki takiemu podejsciurozwiazana mamy kwestie poprawek bezpieczenstwa dla całosci systemu.
5User identifier

Rozdział 2. Analiza i projekt Systemu Zarządzania Użytkownikami i Wirtualnymi Organizacjami 36
◦ Baza SQL - na poczatku rozmów na temat projektu została podjeta decyzjaodnosnie kryteriów doboru bazy danych SQL. Baza musi byc relacyjna, zapewniacintegralnosc danych i byc baza darmowa o otwartym kodzie. Badajac dostepnerozwiazania doszlismy do listy trzech aplikacji: Firebird [27], MySQL [28]i PostgreSQL [15]. Z tej grupy wybralismy PostgreSQL. Przewazyła łatwoscprogramowania mechanizmów działajacych wewnatrz bazy w róznych jezykachprogramowania, brak problemów z integralnoscia danych oraz najwyzsza z tychtrzech skalowalnosc. Istotne znaczenie miała tez bardzo liberalna licencja [32].
◦ Baza LDAP - w wypadku tym do wyboru były tylko dwie opcje - Fedora DirectoryServer oraz OpenLDAP. Wybór padł na OpenLDAP. Czynnikiem decydujacymw tym wypadku była bardzo dobra dokumentacja róznych aspektów działania bazyLDAP oraz bardzo dobre opinie na temat stabilnosci jej działania.
◦ Baza haseł Kerberos - do wyboru były dwa rozwiazania - MIT6 Kerberos5i Heimdal. Obie implementacje dostarczaja zarówno serwery jak i czesc kliencka.Wybrana została implementacja MIT ze wzgledu na to, ze jest implementacjareferencyjna i testy współpracy uzywanych komponentów były prowadzone z jejuzyciem.
◦ Aplikacja www - planowanym jezykiem dla tej aplikacji był php - najpopularniejszyjezyk sstosowany do tworzenia aplikacji webowych. Najwazniejszym powodem byłaogromna baza gotowych bibliotek oraz łatwosc utrzymywania aplikacji na serwerachdocelowych.
2.9 Diagram klas Systemu Zarz¡dzania
U»ytkownikami i Wirtualnymi Organizacjami
Ze wzgledu na zwiekszenie czytelnosci diagram klas został podzielony na dwie czesci- czesc zwiazana z zarzadzaniem uzytkownikami oraz na czesc zwiazana z zarzadzaniemserwerami. Elementem wspólnym obu diagramów sa projekty. Celem tej pracy byłowykonanie czesci systemu do zarzadzania uzytkownikami, projektami i wirtualnymiorganizacjami. Jednak analizujac system jako całosc nie mozna pominac czesci drugiej
6Massachusetts Institute of Technology

Rozdział 2. Analiza i projekt Systemu Zarządzania Użytkownikami i Wirtualnymi Organizacjami 37
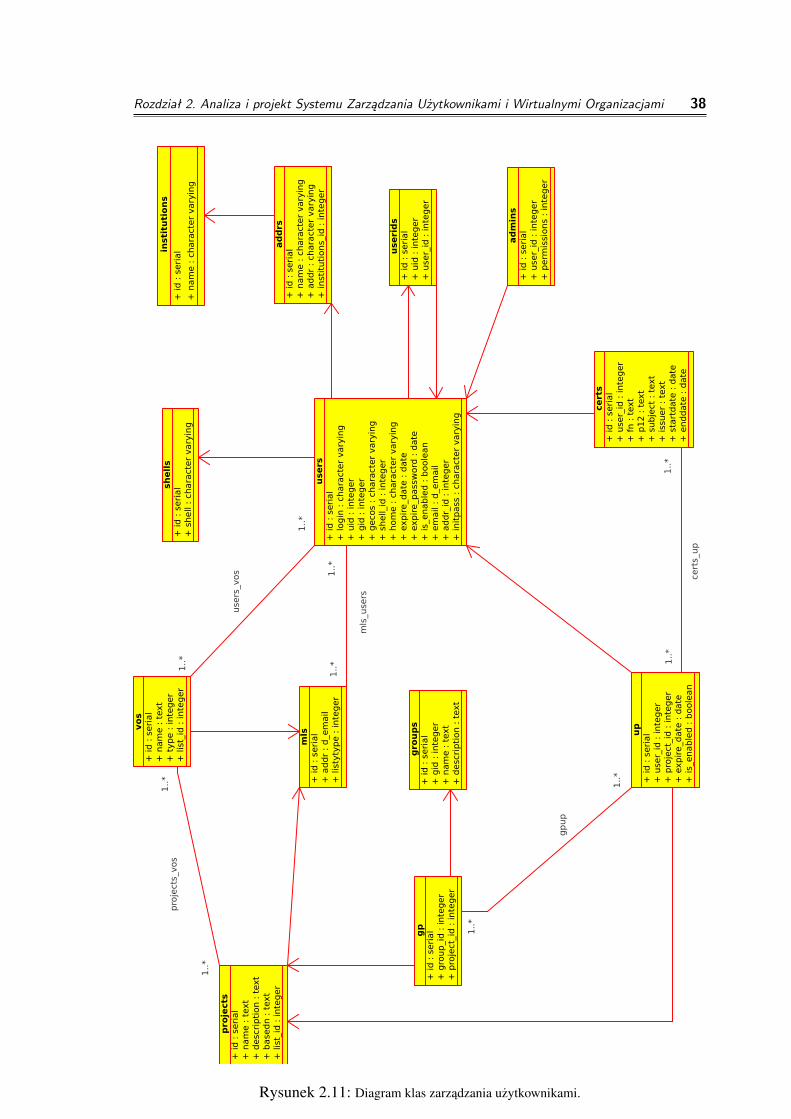
- zarzadzania maszynami obliczeniowymi. Nazwy tabel przedstawione tutaj sa nazwamifinalnymi po zmianach dokonanych w zwiazku ze zmianami technologii aplikacji www.
Opis tabel z diagramu klas zarzadzania uzytkownikami (Rysunek 2.11) znajduje siew Rozdziale 3 - opisujacym architekture bazy danych.
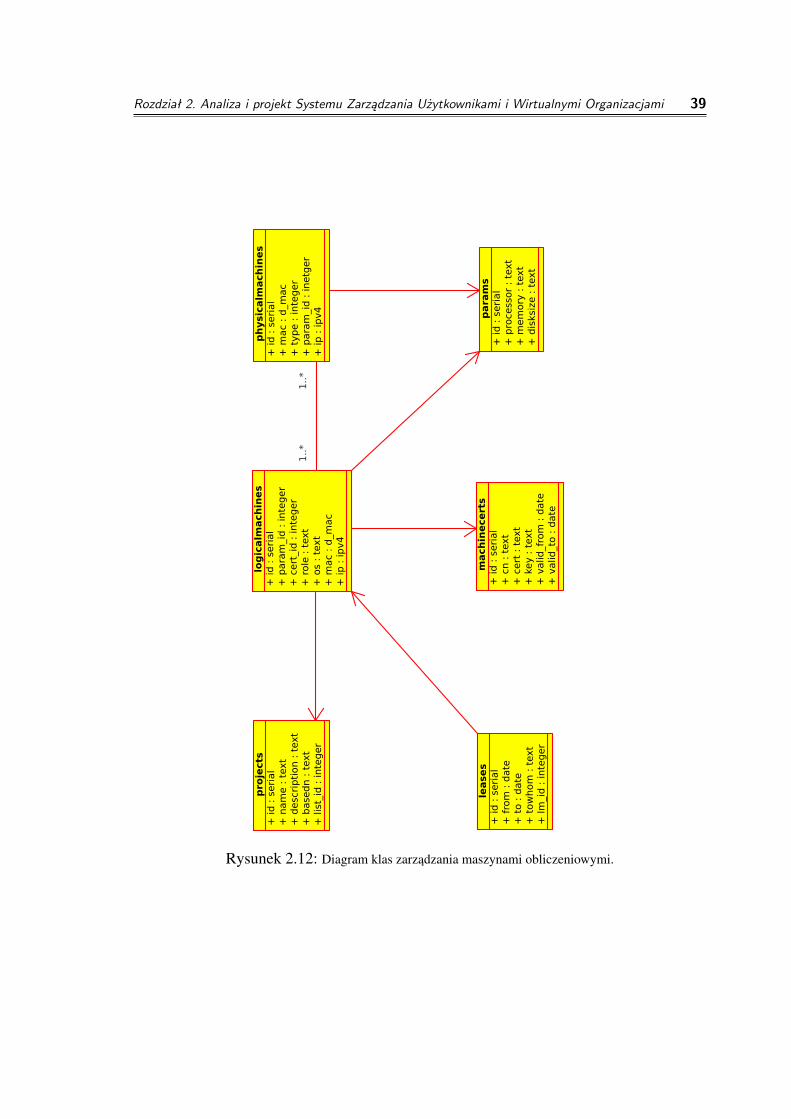
2.9.1 Diagram klas zarz¡dzania maszynami obliczeniowymi
Opis tabel do diagramu klas zarzadzania maszynami obliczeniowymi (Rysunek 2.12).
◦ Tabela physicalmachines zawiera informacja na temat maszyn fizycznychzarzadzanych przy uzyciu projektowanego systemu, w tym podstawowe parametry -adres mac, adres ip, rodzaj maszyny oraz wskaznik do tablicy opisujacej parametryserwera.
◦ Tabela machinecerts zawiera certyfikaty uzywane przez maszyny logiczne.
◦ Tabela params zawiera informacje o parametrach maszyn (zarówno logicznychjak i fizycznych). Informacje na temat rodzaju procesora, ilosci pamieci czypojemnosciach dysków.
◦ Tabela logicalmachines zawiera informacje na temat maszyn logicznych uzywanychw centrum obliczeniowym. Moga to byc zarówno systemy złozone z wielu maszynfizycznych uzywane jako jedna wielka jednostka obliczeniowa jak i małe maszynywirtualne, których wiele moze sie znajdowac na jednej maszynie fizycznej. Z tegopowodu powiazanie z maszynami fizycznymi opisuje relacja wiele do wielu.
◦ Tabela leases opisuje wypozyczenia maszyn obliczeniowych. Zawiera informacjekomu została maszyna wypozyczona i na jaki okres czasu.
2.10 Diagramy sekwencji
Diagramy sekwencji przedstawiaja kolejnosc wykonywanych operacji oraz przepływsterowania przy realizacji modelowanej operacji. Tworzenie tego typu diagramów pomagalepiej zrozumiec planowany przebieg danej operacji co przekłada sie na wczesniejszewykrycie ewentualnych błedów projektowych.
W wypadku sekwencji nie było potrzeby tworzyc diagramów opisujacych wszystkieoperacje bowiem wiekszosc operacji sprowadza sie do prostych operacji na bazie danych
Rozdział 2. Analiza i projekt Systemu Zarządzania Użytkownikami i Wirtualnymi Organizacjami 38
Rysunek 2.11: Diagram klas zarzadzania uzytkownikami.
Rozdział 2. Analiza i projekt Systemu Zarządzania Użytkownikami i Wirtualnymi Organizacjami 39
Rysunek 2.12: Diagram klas zarzadzania maszynami obliczeniowymi.

Rozdział 2. Analiza i projekt Systemu Zarządzania Użytkownikami i Wirtualnymi Organizacjami 40
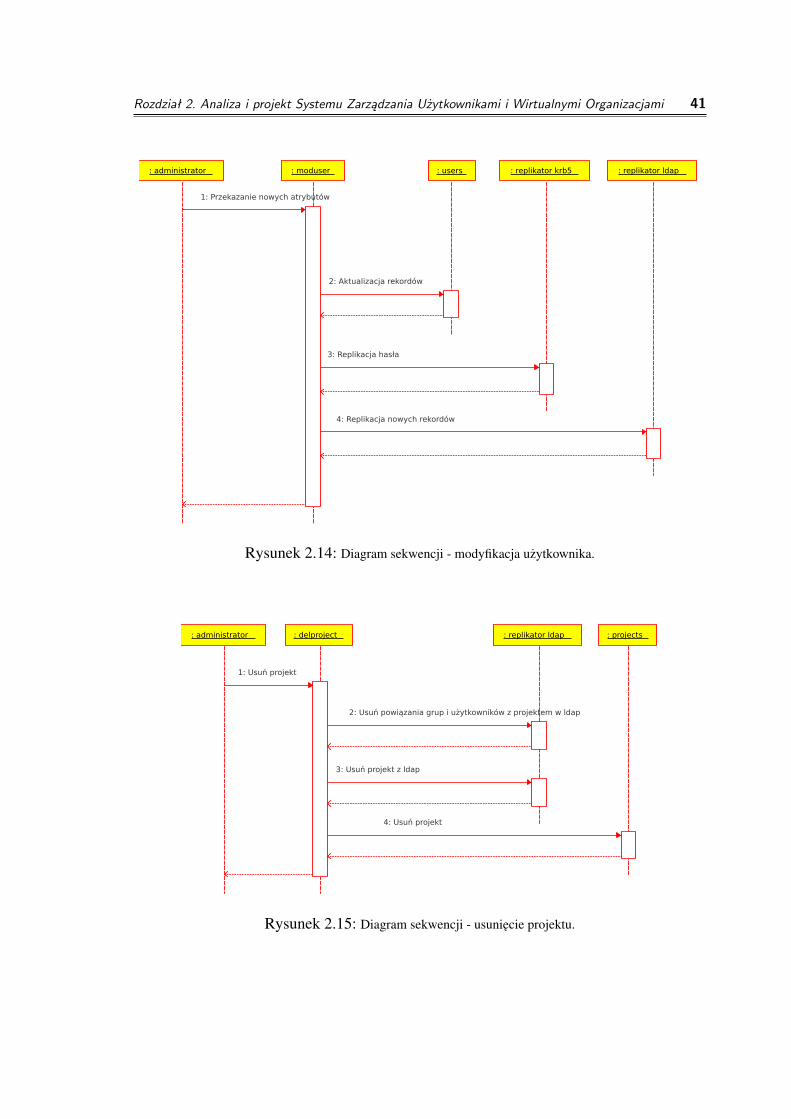
z ewentualna propagacja zmian w bazie LDAP badz w bazie haseł Kerberos. Trzybardziej skomplikowane sekwencje zostały przedstawione ponizej. Obiekty przedstawionena schematach nie beda obiektami z punktu widzenia programowania - moga bycto obiekty (administrator), tabele obiektów (userids) czy nawet procedury (adduser).Dodatkowa trudnosc na tym etapie sprawiaja mechanizmy propagacji zmian z relacyjnejbazy danych do bazy haseł czy do bazy LDAP - tutaj roboczo zostały one nazwanereplikator krb5 i replikator ldap.
Rysunek 2.13: Diagram sekwencji - dodanie uzytkownika.
Rozdział 2. Analiza i projekt Systemu Zarządzania Użytkownikami i Wirtualnymi Organizacjami 41
Rysunek 2.14: Diagram sekwencji - modyfikacja uzytkownika.
Rysunek 2.15: Diagram sekwencji - usuniecie projektu.

Rozdział3
Prototypy aplikacjibazodanowej realizującejstawiane wymagania
Rozdział przedstawia opisy działajacych prototypów aplikacji
bazodanowej wraz ze zmianami architektury. Zawiera równiez opis
replikacji typu push z bazy PostgreSQL do bazy LDAP i Kerberos.
Zawarte sa tez opisy tabel, widoków oraz procedur składowanych -
zarówno uzywanych do modyfikacji danych jak i do replikacji z bazy SQL
do LDAP i Kerberos.
3.1 Zmiany technologii w stosunku do projektu
W czasie prac nad systemem zaszły dwie podstawowe zmiany technologiczne majacewpływ na całosc aplikacji. Pierwsza z nich została wymuszona przez modyfikacje API1
serwera OpenLDAP. Zaszła koniecznosc rezygnacji z uzywania serwera OpenLDAP jakoposrednika miedzy systemem operacyjnym a serwerem Kerberos. Wtyczka umozliwiajacabezposrednia komunikacje z serwerem Kerberos została zdezaktywowana przez twórcówserwera OpenLDAP. Dalszy rozwój tego serwera spowodował, ze wtyczka ta (z powoduniedostosowywania jej do zmian zachodzacych w serwerze OpenLDAP) przestała bycz nim zgodna. Zmiana ta wymusiła zmiany w architekturze systemu zarzadzaniauzytkownikami (przedstawione na Rysunku 3.1). Druga zmiana była zwiazana z tempemtworzenia kodu aplikacji www. Według poczatkowych załozen aplikacja www miała zostac
1Application programming interface

Rozdział 3. Prototypy aplikacji bazodanowej realizującej stawiane wymagania 43
napisana w jezyku php. W trakcie prac okazało sie, ze lepszym wyborem bedzie tandem:Ruby on Rails [24], ActiveRecord [25] i ActiveScaffold [26]. Aby jednak wygodniekorzystac z ActiveRecorda trzeba było zmienic nazwy tabel, pól a czasami nawet typówdanych. Dzieki temu jednak mozna duzo bardziej zautomatyzowac tworzenie odwzorowanrekordów w tabelach na obiekty w aplikacji www. Aplikacja www bedzie uzywałado działania serwera mongrel [20] wraz z serwerem memcached [19] do przechowywaniainformacji o sesjach uzytkowników.
3.2 Architektura systemu
System składa sie z pieciu głównych elementów:
◦ Biblioteki NSS - ich celem jest zapewnienie mechanizmu tłumaczenia nazww systemie Linux na identyfikatory numeryczne oraz identyfikatorów numerycznychna nazwy (przykład: uzytkownik root ma UID 0, biblioteki NSS odpowiadajaza zamiane nazwy root na identyfikator 0 jak i identyfikatora 0 na nazweroot). Funkcje dostarczane przez te biblioteki moga byc wykorzystywanew dowolnym momencie działania systemu (uruchomienie polecenia ps czy ls mozespowodowac wywołanie funkcji zamieniajacych identyfikator numeryczny na nazweuzytkownika).
◦ Biblioteki PAM - ich celem jest dostarczenie mechanizmów uwierzytelnianiaoraz konfiguracji sesji uzytkownika. Funkcje dostarczane przez bibliotekiPAM sa wykorzystywane w trzech momentach zycia sesji uzytkownika.Podczas uwierzytelniania - nastepuje sprawdzenie poprawnosci danychuwierzytelniajacych, przygotowanie srodowiska uzytkownika (np. ustawieniezmiennych srodowiskowych odpowiedzialnych za lokalizacje skrzynki pocztowej,ustawienie limitów, tworzenie badz montowanie katalogów niezbednych dopracy uzytkownika, ustawienie dostepu do terminala z którego korzystauzytkownik). Drugim takim momentem jest zmiana hasła - funkcje bibliotekiweryfikuja poprawnosc starego hasła oraz moga wykonac testy sprawdzajacestopien skomplikowania nowego hasła oraz jego podobienstwa do poprzedniego.Zakonczenie pracy i zamkniecie sesji - w tym momencie zwykle nie sa wykonywanezadne akcje. W specyficznych przypadkach po zakonczeniu ostatniej sesjiuzytkownika moze zostac odmontowany jego katalog domowy. Moga zostac

Rozdział 3. Prototypy aplikacji bazodanowej realizującej stawiane wymagania 44
przeprowadzone działania majace na celu wyłaczenie pozostawionych przezuzytkownika procesów badz usuniecie plików tymczasowych.
◦ Bazy LDAP - główna baza uzytkowników z punktu widzenia systemu operacyjnego(nie zawiera haseł). Biblioteki NSS w niej sprawdzaja odwzorowania nazwi identyfikatorów numerycznych. Baza LDAP posiada strukture drzewiasta, w którejkazdy projekt znajduje sie w oddzielnym poddrzewie. Samo konto uzytkownikanie jest reprezentowane w bazie LDAP - dopiero powiazanie go z projektempowoduje dodanie uzytkownika do odpowiedniego poddrzewa odpowiedzialnegoza dany projekt. Powoduje to niestety pewna nadmiarowosc danych. Identyczneinformacje sa zawarte w wielu poddrzewach. Taka decyzja została podjeta abyuproscic zarzadzanie systemem. Dzieki temu, ze hasła zostały wydzielone dooddzielnej bazy (Kerberos) zaden rekord w LDAP nie jest zmieniany z poziomusystemu operacyjnego. Co za tym idzie jedynym zródłem zmian w bazie LDAP jestbaza uzytkowników PostgreSQL.
◦ Systemu zarzadzania hasłami Kerberos5 - baza zawierajaca hasła w systemie. Jestuzywana do uwierzytelniania z poziomu systemu operacyjnego (za posrednictwempam_krb5) oraz w aplikacji www. Ze wzgledu na mozliwosci replikacji orazskalowalnosc backendem serwera Kerberos jest serwer OpenLDAP. Hasła oraz innedane uzytkowników zostały od siebie oddzielone, aby umozliwic uzytkownikowiposiadanie jednego hasła we wszystkich projektach, a co za tym idzie we wszystkichklastrach obliczeniowych. Nalezy przy tym zauwazyc, ze baza haseł jest jedynymkomponentem systemu do którego operacje zapisu sa prowadzone z kazdego miejscasystemu. Przeniesienie tej funkcjonalnosci do bazy LDAP znaczaco utrudniłobyreplikacje danych. W chwili obecnej zawartosc bazy LDAP moze byc zmienianatylko z poziomu bazy danych SQL. Dodatkowo nie mozemy zapominac, ze stosujacoddzielna baze haseł w postaci Kerberosa, mozemy wykorzystac ja w przyszłoscirówniez do uwierzytelniania uzytkowników systemu Windows.
◦ Bazy danych PostgreSQL - główna baza systemu. Zawiera prawie wszystkie daneo projektach, uzytkownikach (wyjatkiem sa hasła) oraz powiazaniach miedzy nimi.Baza poza tabelami z modelu bazy zawiera bardzo duzo struktur pomocniczych.Aby odizolowac warstwe widoczna przez aplikacje www wszystkie operacjewykonywane sa za posrednictwem widoków, procedur wbudowanych oraz systemureguł wiazacych widoki, operacje i procedury. Dzieki takiemu podejsciu udało

Rozdział 3. Prototypy aplikacji bazodanowej realizującej stawiane wymagania 45
sie zdefiniowac niezmienny interfejs aplikacji bazodanowej, widoczny jednakzetak, jakby były to zwykłe tabele. Rozwiazanie takie zostało wymuszone przezzastosowany mechanizm translacji danych bazy relacyjnej na obiekty (Object-Relational Mapping) - ActiveRecord.
Miedzy poszczególnymi komponentami systemu komunikacja odbywa sie z uzyciemnastepujacych protokołów
◦ Aplikacja www - serwer PostgreSQL - protokół postgresqla
◦ Aplikacja www - serwer Kerberos - GSSAPI2
◦ PostgreSQL - Kerberos - protokół wewnetrzny MIT Kerberos5
◦ PostgreSQL - OpenLDAP - protokół LDAPS3
◦ OpenLDAP - serwer Kerberos - protokół krb5
◦ pam-ldap - OpenLDAP - protokół LDAPS
◦ nss-ldap - OpenLDAP - protokół LDAP
3.2.1 Pierwsza wersja architektury systemu zarz¡dzania
W przypadku samej architektury aplikacji nie zostały wprowadzone istotne zmianyw stosunku do projektu. Architektura systemu pozostała bez zmian - zmieniły sie jedynieuzyte rozwiazania.
3.2.2 Druga wersja architektury systemu zarz¡dzania
Podstawowa zmiana architektoniczna jest dodanie komunikacji bezposredniej miedzybibliotekami PAM a serwerem Kerberos. W tym wypadku jest uzywany protokół natywnyserwera MIT Kerberos5.
2Generic Security Services Application Program Interface3LDAP z szyfrowaniem

Rozdział 3. Prototypy aplikacji bazodanowej realizującej stawiane wymagania 46
(a) Pierwsza wersja architektury systemu zarzadzania.
(b) Druga wersja architektury systemu zarzadzania.
Rysunek 3.1: Porównanie architektur systemu zarzadzania.

Rozdział 3. Prototypy aplikacji bazodanowej realizującej stawiane wymagania 47
3.2.3 Przyczyny zmian w architekturze
Podstawowa przyczyna zmian w architekturze systemu były zmiany w kodzie serweraOpenLDAP, które spowodowały, ze wykorzystywane przez nas rozwiazanie przestałobyc wspierane. Rozwiazaniem tym był mechanizm kpasswd - mozliwosc zdefiniowaniahasła uzytkownika w postaci pozwalajacej serwerowi LDAP przetłumaczyc je na rekordKerberosa i nastepnie weryfikacja hasła w serwerze Kerberos. Sugerowana alternatywabyło uzycie Cyrus SASL4 [33] wraz w pam_krb5, co w praktyce oznacza dodaniekilku warstw komunikacyjnych. Z tego tez powodu zdecydowalismy sie zlikwidowacjedna warstwe posredniczaca w komunikacji i kontaktowac sie z serwerem Kerberosbezposrednio z pam_kbr5 z serwerów obliczeniowych.
3.3 Architektura bazy danych
3.3.1 Opisy tabel systemu zarz¡dzania
◦ Tabela users - podstawowa tabela systemu zarzadzania uzytkownikami - zawierawiekszosc informacji o koncie - login, UID, GID5 grupy głównej, GECOS6,wskazanie na rekord powłoki systemowej, katalog domowy, date waznosci konta,date waznosci hasła, znacznik czy konto jest aktywne, adres email oraz wskazaniena instytucje, do której dany uzytkownik nalezy. Tabela ta moze zawierac hasłodo konta w dwóch momentach działania systemu. Zaraz po załozeniu konta,zanim hasło zostanie zreplikowane do systemu Kerberos5 oraz po zmianie hasłaprzez administratora z panelu administracyjnego zanim hasło zostanie zreplikowanedo systemu Kerberos5.
◦ Tabela institutions zawiera liste wszystkich instytucji, które maja swoichuzytkowników w systemie
◦ Tabela addrs zawiera liste wszystkich adresów instytucji wymienionych w punkciepoprzednim
◦ Tabela userids zawiera liste wszystkich mozliwych do wykorzystaniaidentyfikatorów numerycznych w systemie operacyjnym zarezerwowanych dla
4Cyrus Simple Authentication and Security Layer5Group identifier6pole zawierajace imie, nazwisko, informacje kontaktowe

Rozdział 3. Prototypy aplikacji bazodanowej realizującej stawiane wymagania 48
Systemu Zarzadzania Uzytkownikami i Wirtualnymi Organizacjami. Dodawanienowej puli polega na uruchomieniu funkcji, której przekazywany jest kolejny zakresidentyfikatorów. Tabela ta zawiera tez odnosnik do rekordu uzytkownika, któremuzostał przydzielony dany identyfikator albo null w wypadku gdy nie jest on jeszczeuzywany.
◦ Tabela admins zawiera liste wskazan do tabeli uzytkowników oraz zestawuprawnien wskazywanego uzytkownika (w chwili obecnej wystepuja tylko dwiewartosci - zwykły administrator oraz administrator z uprawnieniami do zarzadzaniacertyfikatami - RA7).
◦ Tabela certs zawiera dane certyfikatów uzytkowników w formacie PKCS8#12 wrazz kopia niektórych danych z certyfikatu w postaci jawnej - subject, cn certyfikatu,wystawca, oraz obie daty ograniczajace waznosc certyfikatu - date poczatkowai koncowa.
◦ Tabela vos zawiera dane na temat wirtualnych organizacji - nazwe, rodzaj, orazwskazanie na liste dyskusyjna (mailingowa) danej organizacji
◦ Tabela projects zawiera dane na temat projektów - nazwe, opis, wskazaniena liste dyskusyjna projektu oraz basedn projektu. Basedn projektu jest to nazwaprojektu uzywana do celu identyfikacji projektu w systemie LDAP - po dołaczeniuglobalnego, wspólnego suffixu dla całego systemu okresla lokacjizacje poddrzewaprojektu w głównym serwerze LDAP.
◦ Tabela mls zawiera informacje o listach mailingowych, z ich typem oraz adresemlisty
◦ Tabela groups zawiera liste wszystkich grup pobocznych uzywanych przez system.Moze zawierac równiez grupy główne - jednak nie jest to konieczne - dodatkowogrupy takie moga byc równiez grupami pobocznymi uzytkowników.
Tabele łaczace w modelu bazy SQL - ze wzgledu na stosowany system mapowaniazawartosci bazy danych na obiekty aplikacji www ActiveRecord zastosowana zostałapolityka nazewnicza nadajaca tabeli łaczacej nazwe poprzez złaczenie nazw tabelłaczonych w kolejnosci alfabetycznej. Tabele zawierajace tylko informacje o powiazaniach
7Regional Authority8Public Key Cryptography Standards

Rozdział 3. Prototypy aplikacji bazodanowej realizującej stawiane wymagania 49
wiele do wielu rekordów z innych tabel to: users_vos, projects_vos, mls_users, certs_up,
gp, gpup. Jedna tabela łaczaca zawiera tych danych nieco wiecej - up - łaczy ona tabeleuzytkowników z tabela projektów. Zawiera ona dodatkowo dane na temat daty wygasnieciakonta uzytkownika w projekcie oraz informacje na temat tego, czy konto w danymprojekcie jest aktywowane.
Tabele opisywane powyzej sa nieco bardziej złozone - nie w rozumieniu stopniaskomplikowania tabeli relacyjnej bazy danych, lecz ze wzgledu na dodatkowe mechanizmyi poboczne struktury danych z nia powiazane. Na pojedynczy byt opisywany poprzednioskłada sie szereg dodatkowych struktur. Opisy ponizsze dotycza przypadku tabeli addrs(przykładowe komendy tworzace te struktury dla tabeli foo zostały przedstawionena rysunku 3.2).
◦ Tabela o nazwie t_addrs - tak zwana tabela własciwa
◦ Sekwencja zapewniajaca nam unikalnosc klucza głównego tabeli addrs_id_seq
◦ Procedury modyfikujace tabele - addaddr, deladdr i modaddr
◦ Widok uzywany przez aplikacje www - addrs
◦ Reguły przyporzadkowujace operacji na widoku dana procedure. INSERT - addaddr,DELETE - deladdr, UPDATE - modaddr.
Dzieki takiemu rozwiazaniu mozna przeprowadzic dodatkowa walidacje poprawnosciwprowadzonych danych niezaleznie od walidacji aplikacji www. Dodatkowo w ramachprocedur składowanych uruchamiane sa mechanizmy replikacji opisane w pózniejszychrozdziałach. Niektóre tabele nie powinny posiadac mozliwosci zmiany wartosci w nichzawartych - w takim wypadku wystarczy zdefiniowac aby w wypadku próby wykonaniaoperacji UPDATE wykonac akcje NOTHING - czyli nic nie rób. Dzieki takiemu podejsciuduzo łatwiej mozna ograniczyc uprawnienia do dokonywania zmian w bazie. Aplikacjawww jedynie moze operowac na widokach - nie ma dostepu do tabel własciwych.Jezeli doszłoby do naruszenia dostepu poprzez włamanie do aplikacji www, nadal niebyłyby mozliwe operacjie na danych docelowych - w tym nawet nie byłoby mozliwosciobejrzenia niezreplikowanych do serwera Kerberos5 haseł. Zamiast haseł w widoku jestpokazywanych szesc symboli X. Kolejna kwestia jest to, czemu została podjeta decyzjao oddzielnym definiowaniu sekwencji, zamiast zdac sie na typ SERIAL dostepny w baziedanych. Wyjasnienie jest dosc proste - wybrany mechanizm mapowania wierszy relacyjnej

Rozdział 3. Prototypy aplikacji bazodanowej realizującej stawiane wymagania 50
bazy danych na obiekty nie korzysta z dobrodziejstwa bazy danych, sam pobiera kolejnawartosc z tworzonej automatycznie przy zastosowaniu typu SERIAL sekwencji i wstawiaja w kolumnie id. Jako, ze działania odnosza sie do widoku a nie do tabeli nazwawymaganej sekwencji jest inna niz ta, która zostałaby automatycznie utworzona przyzastosowaniu typu SERIAL.
create table t_foo (id integer primary key default nextval(’public.foo_id_seq’) not null,....);
create sequence foo_id_seq;
create view foo as select * from t_foo;
create or replace rule r_foo_insertas on insertto foodo insteadselect addfoo(...);
create or replace rule r_foo_deleteas on deleteto foodo insteadselect delfoo(...);
create or replace rule r_foo_updateas on updateto foodo insteadselect modfoo(...);
create or replace function addfoo(...) as $$...$$ language plpgsql;
create or replace function delfoo(foo_id_arg int, OUT ret int) as $$...$$ language plpgsql;
create or replace function modfoo(...) as $$...$$ language plpgsql;
Rysunek 3.2: Sposób tworzenia tabeli na przykładzie "tabeli foo". Schemat przedstawia stopienskomplikowania pojedynczej tabeli.
3.3.2 Tabele techniczne
Tabele techniczne nie zawieraja mechanizmów podobnych do opisanych w poprzednimpunkcie - sa wykorzystywane i modyfikowane tylko przez aplikacje wewnetrznesystemu zarzadzania. Stad tez nie było konieczne definiowanie az tylu mechanizmówzabezpieczajacych co w wypadku tabel z danymi.

Rozdział 3. Prototypy aplikacji bazodanowej realizującej stawiane wymagania 51
◦ t_config - tabela zawierajaca globalne dane konfiguracyjne - przykładowo korzenstruktury w bazie LDAP, dane administratorów serwera LDAP oraz Kerberos5
◦ t_ldap - tabela z rekordami w formacie ldif do replikacji do serwera LDAP
◦ t_ldaparch - tabela z wynikami działania replikacji do bazy LDAP, zawiera zarównoudane zmiany jak i nieudane.
◦ t_krb5 - tabela z poleceniami aplikacji kadmin do replikacji zmian haseł z serweraPostgreSQL do serwera Kerberos5
◦ t_krb5arch - tabela z wynikami prób dokonania replikacji danych do serweraKerberos5
◦ ldaptemplate - tabela zawierajaca szablony uzywane do generowania rekordóww formacie ldif
◦ krb5template - tabela zawierajaca szablony komend uzywanych do propagacjizmian haseł z serwera PostgreSQL do systemu zarzadzania hasłami Kerberos5 przypomocy aplikacji kadmin
3.3.3 Widoki u»ywane do replikacji danych
◦ vpl_p - widok uzywany do operacji na tabeli projektów
◦ vpl_gp - widok uzywany do operacji na tabeli łaczacej grupy i projekty
◦ vpl_up - widok uzywany do operacji na tabeli łaczacej projekty z uzytkownikami
◦ vpl_cup - widok uzywany do operacji na tabeli łaczacej certyfikaty z instancjauzytkownika w ramach projektu
◦ vpl_gpup - widok uzywany przy zmianie przynaleznosci uzytkownika w projekciedo grupy w projekcie
3.3.4 Procedury skªadowane u»ywane do operacji na tabelach wªa±ciwych
Procedury składowane sa drobnymi aplikacjami napisanymi w jezyku obsługiwanymprzez baze danych oraz uruchamianymi w obrebie bazy danych. Ze wzgledu na fakt, izdziałaja tylko na danych zawartych w bazie oraz w niewielkim stopniu przetwarzaja danewprowadzone przez uzytkownika zostały napisane w jezyku plpgsql.

Rozdział 3. Prototypy aplikacji bazodanowej realizującej stawiane wymagania 52
◦ addadmin - dodanie uzytkownikowi uprawnien administratora wraz z ustawieniematrybutu bycia lub nie RA
◦ deladmin - skasowanie uzytkownikowi uprawnien administratora
◦ chadmin - zmiana statusu administratora (czy ma byc RA czy nie)
◦ adduserid - dodanie jednego UID do listy dostepnej dla systemu
◦ adduserids - dodanie zakresu UID do listy dostepnej dla systemu
◦ deluserid - skasowanie niewykorzystywanego UID z listy dostepnej dla systemu
◦ addinst - dodanie instytucji
◦ modinst - zmiana parametrów instytucji
◦ delinst - usuniecie instytucji z systemu
◦ addaddr - dodanie adresu instytucji do systemu
◦ modaddr - zmiana adresu instytucji w systemie
◦ deladdr - skasowanie adresu instytucji z systemu
◦ addshell - dodanie powłoki systemowej dostepnej dla uzytkowników
◦ modshell - zmiana sciezki do powłoki systemowej dostepnego dla uzytkowników
◦ delshell - skasowanie nieuzywanej przez uzytkowników powłoki systemowej
◦ adduser - dodanie uzytkownika do systemu
◦ moduser - zmiana parametrów uzytkownika w systemie
◦ enable - aktywowanie konta uzytkownika w systemie
◦ disable - dezaktywowanie konta uzytkownika w systemie - standardowo kontouzytkownika nie jest kasowane - moze byc za to wyłaczone. Operacja kasowaniauzytkownika z widoku users wywołuje w rzeczywistosci procedure dezaktywujacakonto
◦ addgroup - dodanie nowej grupy pobocznej do systemu

Rozdział 3. Prototypy aplikacji bazodanowej realizującej stawiane wymagania 53
◦ chpwd - zmiana hasła uzytkownika
◦ addproject - dodanie projektu do systemu
◦ delproject - skasowanie projektu z systemu
◦ adduserproject - dodanie uzytkownika do projektu wraz z ustawieniem parametrów- aktywny, do kiedy konto ma byc aktywne w ramach projektu
◦ deluserproject - usuniecie uzytkownika z projektu
◦ addcert - dodanie certyfikatu do systemu
◦ delcert - skasowanie certyfikatu z systemu
◦ addcup - dodanie powiazania miedzy certyfikatem a uzytkownikiem
◦ delcup - skasowanie powiazania uzytkownika z certyfikatem
◦ addgp - dodanie powiazania grupy pobocznej z projektem
◦ delgp - skasowanie powiazania grupy pobocznej z projektem
◦ addgpup - dodanie uzytkownika w projekcie (up) do grupy znajdujacej sie w tymsamym projekcie (gp)
◦ delgpup - usuniecie uzytkownika w projekcie z grupy w projekcie
◦ getuserstatus - zwrócenie informacji czy uzytkownik jest adminsitratorem
3.3.5 Procedury u»ywane w mechanizmach replikacji danych
◦ doldap_rec - procedura w jezyku plperlu (plperl untrusted) przygotowujaca rekordw formacie ldif na podstawie szablonu, widoku i otrzymanego identyfikatora
◦ dokrb5_com - procedura w jezyku plperlu przygotowujaca komende dla aplikacjikadmin na podstawie szablonu, widoku i otrzymanego identyfikatora
◦ doldap - procedura w jezyku plpgsql, która rekord otrzymany od doldap_recumieszcza w tabeli t_ldap
◦ dokrb5 - procedura w jezyku plpgsql, która komende otrzymana z procedurydokrb5_com umieszcza w tabeli t_krb5

Rozdział 3. Prototypy aplikacji bazodanowej realizującej stawiane wymagania 54
3.4 Architektura bazy LDAP
Struktura bazy LDAP jest oparta na podziale na projekty. Kazdy projektposiada oddzielne poddrzewo zawierajace wszystkie dane niezbedne do samodzielnegofunkcjonowania. Oznacza to, ze kazdy uzytkownik ma oddzielny rekord w bazie LDAPdla kazdego projektu, z którym został powiazany. W zaleznosci od liczby projektów,do której uzytkownicy sa przypisani, moze prowadzic do znacznej nadmiarowosci danych.Oczywiscie nalezy nadmienic, ze nadmiarowosc ta nie zmienia rzedu wielkosci bazydanych.
Strukture drzewa LDAP pokazuje rysunek 3.3.
dn: dc=example, dc=com
dn: ou=projekt2, dc=example, dc=comdn: ou=projekt1, dc=example, dc=com
dn: ou=users, ou=project1dc=example , dc=com
dn: ou=groups, ou=project1dc=example , dc=com
dn: cn=user1, ou=users, ou=project1dc=example , dc=com
dn: cn=user2, ou=users, ou=project1dc=example , dc=com
dn: cn=user3, ou=users, ou=project1dc=example , dc=com
dn: cn=group1, ou=groups, ou=project1dc=example , dc=com
dn: cn=group2, ou=groups, ou=project1dc=example , dc=com
Rysunek 3.3: Przykład struktury drzewa LDAP.
3.4.1 Dublowanie danych - wady i zalety
Z powodu przyjetej struktury drzewa w bazie LDAP wiele danych jest powielanychwielokrotnie. Dla kazdego powiazania uzytkownika z projektem istnieje oddzielny rekord

Rozdział 3. Prototypy aplikacji bazodanowej realizującej stawiane wymagania 55
uzytkownika w bazie LDAP. Dla kazdego powiazania grupy z projektem istnieje w bazieLDAP oddzielny rekord grupy. Podstawowymi zaletami takiego rozwiazania sa:
◦ wzrost elastycznosci zarzadzania replikacja
◦ ograniczenie dostepu dla administratora serwera do danych z innych projektów
◦ zmniejszenie rozmiarów baz LDAP na serwerach z lokalnymi replikami w ramachprojektów
Wzrost elastycznosci zarzadzania replikacja przejawia sie w tym, ze do serwerówLDAP w projektach mozemy replikowac tylko wybrane poddrzewo. Administratorzyna maszynach jednego projektu nie moga podejrzec listy uzytkowników innychprojektów. Dzieki takiemu podejsciu zwieksza sie stopien izolacji i bezpieczenstwoinformacji. Mozliwosc replikacji tylko wybranego poddrzewa zwieksza wydajnoscprocesu dystrybucji zmian w bazie relacyjnej do baz LDAP. Dzieki takiemu rozwiazaniuzmniejszaja sie równiez rozmiary indeksów na serwerach, które sa najbardziej obciazoneoraz upraszczaja zapytania do serwera LDAP. Dodatkowo nie mozna zapomniec, ze skorodo serwerów LDAP w projektach replikowane sa tylko pojedyncze poddrzewa, to zajetoscprzestrzeni dyskowej tam wykorzystywanej maleje. Jedyna wada jest wzrost zajetoscidysku na serwerach zawierajacych główne serwery LDAP. Nalezy przy tym nadmienic,ze wzrost ten nie zmienia rzedu wielkosci zajmowanej przestrzeni dyskowej.
3.5 Replikacja danych z bazy SQL do LDAP
i Kerberos
Nalezy pamietac, ze posiadanie danych rozmieszczonych w trzech róznych rodzajachbaz wymaga poswiecenia czasu na zapewnienie ich spójnosci. Zadanie to zostałopowierzone stworzonemu w ramach pracy mechanizmowi replikacji danych z bazy SQLdo baz LDAP i haseł Kerberos. Projektujac czy juz programujac mechanizmy replikacjitrzeba rozpoczac od przeanalizowania kierunków przepływu danych miedzy serwerami.Analizujac schemat architektury z zaznaczonymi kierunkami przepływu danych moznazauwazyc kilka prawidłowosci:
◦ dane w serwerze LDAP sa zmieniane tylko przez baze SQL
◦ zmian w bazie haseł mozna dokonywac z dowolnego punktu systemu

Rozdział 3. Prototypy aplikacji bazodanowej realizującej stawiane wymagania 56
Równoczesnie nalezy pamietac, ze baza LDAP zawiera podzbiór danych z bazy SQL,natomiast baza haseł Kerberos zawiera dane niezalezne od zawartosci bazy danych SQL.Z tego własnie powodu jedyne mechanizmy uzywane do zachowania spójnosci danych,jakie sa wykorzystywane, ograniczaja sie do replikacji danych z bazy SQL do bazy LDAPoraz z bazy SQL do bazy haseł Kerberos. Mozna by sie zastanawiac do czego potrzebnajest mozliwosc replikacji haseł z bazy SQL do bazy haseł. Ten przypadek jest potrzebnyw sytuacji wprowadzania duzej ilosci danych z poziomu interfejsu administratora -przykładowo zakładanie duzej liczby uzytkowników wraz z wiazaniem ich z odpowiednimiprojektami. Wykonujac takie działania tylko w bazie SQL mamy zapewniona integralnoscdanych i pewnosc, ze dane operacje zostana wykonane atomowo (albo sie wykonajaw całosci albo wcale). Dodawanie uzytkowników do bazy SQL, a nastepnie ustawianieim hasła w bazie Kerberos bezposrednio z poziomu aplikacji www wymagałoby zaszyciaw logice aplikacji www mechanizmów obsługujacych sytuacje awaryjne - dokładniejwycofywanie zmian w bazie Kerberos, gdy transakcja w bazie SQL zostanie wycofanaoraz wycofanie zmian w bazie SQL, gdy nie uda sie wprowadzic danych do bazy Kerberos.Ograniczenie mozliwosci zmian bezposrednio w bazie haseł do zmiany własnego hasłaznaczaco upraszcza scenariusze, które musi uwzgledniac aplikacja www.
3.5.1 Replikacja danych z bazy SQL do LDAP
◦ Pierwsza wersja mechanizmu replikacji danych z serwera PostgreSQLdo serwera LDAP była dosc skomplikowana. Kazda tabela w bazie, której danebyły replikowane posiadała specjalna kolumne o nazwie ldap i typie bitstring(3)- oznaczajacym napis składajacy sie z trzech cyfr ze zbioru {0, 1}. Kazde z póloznaczało rodzaj modyfikacji w bazie. Pierwsza pozycja oznaczała koniecznoscdodania rekordu, druga jego zmiane, natomiast trzecia jego usuniecie. Rozwiazanietakie powodowało szereg problemów. Podstawowym z nich była obsługa sytuacjiawarii badz niedostepnosci serwera LDAP w czasie kasowania rekordów. Przytakim rozwiazaniu rekordy w bazie nie były kasowane w momencie wydaniadecyzji o skasowaniu - tylko w momencie usuniecia ich z pozostałych baz.Drugim z problemów było działanie replikacji danych do serwera LDAP wewnatrzbazy PostgreSQL. Procesy replikujace działajace wewnatrz bazy musiały mieczwiekszone uprawnienia wzgledem wiekszosci kodu aplikacji bazodanowych (abymozna było komunikowac sie z serwerem LDAP oraz uzywac zewnetrznychmodułów perla) - program ten został napisany w jezyku plperl. Kazdy typ

Rozdział 3. Prototypy aplikacji bazodanowej realizującej stawiane wymagania 57
operacji dla kazdego rodzaju rekordu miał zdefiniowane oddzielne funkcje,które przygotowywały operacje w formacje LDIF9 (tekstowy format mogacyodwzorowywac zawartosc bazy LDAP oraz jej zmiany), a nastepnie wykonywałyoperacje replikacji (w sumie 10 dodatkowych funkcji zajmujacych sie wyłacznieprzygotowywaniem rekordów i replikacja danych). Jezeli nie udało sie wykonacreplikacji w ramach transakcji zmieniajacej dane w aplikacji bazodanowej byłustawiany odpowiedni znacznik (kolumna ldap), kolejna próba wykonania zmianbyła dokonywana poprzez analize zawartosci kolumny ldap dla wszystkichzdefiniowanych trójek: tabeli, wartosci niezerowego bitu kolumny ldap orazodpowiadajacej tej dwójce procedury.
◦ Druga wersja mechanizmu replikacji danych z serwera PostgreSQL do serweraLDAP została wykonana w podobny sposób do pierwszej - z tym, ze mechanizmsamej replikacji został przeniesiony do zewnetrznego procesu. Pobranie danychz tabeli oraz przygotowanie rekordu w formacje LDIF pozostało w niezmienionejformie w stosunku do pierwszej wersji. Zewnetrzny proces wykonujacy operacjereplikacji został napisany w jezyku interpretera sh i jest uruchamiany regularnie cominute przez program cron.
◦ Wersja trzecia replikacji z serwera PostgreSQL do LDAP oznaczała całkowitarewolucje. Został przygotowany mechanizm replikacji oparty na szablonach orazjednej procedurze w jezyku plperl przygotowujacej rekordy w formacie LDIF,oraz uproszczony został mechanizm samej replikacji. Zostały dodane trzy tabele:t_ldap, t_ldaparch oraz ldaptemplate. Do kazdej tabeli, w której zmiana powinnapowodowac replikacje danych dopisany został dodatkowy widok zawierajacywszystkie dane niezbedne do wypełnienia szablonu rekordu. W tabeli ldaptemplatezawarte sa szablony oraz dane niezbedne do ich identyfikacji (powiazaniaz własciwa tabela oraz rodzajem operacji), w tabeli t_ldap umieszczane sa rekordypo interpretacji przez procedure w jezyku plperl. Samo umieszczenie rekorduw tabeli jest dokonywane przez procedure w jezyku plpgsql działajaca w ramach tejsamej transakcji co zmiana w tabeli zródłowej. Cały czas tabele t_ldap przegladasekwencyjnie zewnetrzny proces, który dla kazdego znalezionego rekordu starasie umiescic go w serwerze LDAP. Niezaleznie od wyniku tej operacji do tabelit_ldaparch trafia zarówno ten rekord, jak i komunikat serwera LDAP zwrócony
9LDAP Data Interchange Format

Rozdział 3. Prototypy aplikacji bazodanowej realizującej stawiane wymagania 58
po próbie dokonania zmian, oraz wartosc prawda/fałsz oznaczajaca czy udało sierekord ten zreplikowac. Jezeli replikacja sie powiodła rekord jest kasowany z tabelit_ldap. Program w jezyku interpretera sh, dokonujacy własciwej replikacji danychw chwili obecnej został pozbawiony wszelkich informacji na temat struktury bazy,powiazan tabel, procedur i typów zmian.
3.5.2 Replikacja danych z bazy SQL do Kerberos
Replikacja danych z serwera PostgreSQL do serwera Kerberosa jest dosc szczególna.Dane zródłowe dla serwera haseł Kerberos5 sa kasowane natychmiast po dokonaniureplikacji. Co wiecej informacja o hasle nie moze trafic do logów aplikacji. Inaczej nizw wypadku serwera LDAP serwer PostgreSQL nie jest jedynym zródłem danych dlaserwera Kerberos5. Zmiana hasła z poziomu systemu operacyjnego (polecenie passwdi kpasswd) oraz z poziomu serwisu www dokonuje zmian bezposrednio w bazie Kerberosa.
◦ Pierwsza wersja mechanizmu replikacji danych z serwera PostgreSQLdo serwera MIT Kerberos5 była dosc skomplikowana. Tabela z uzytkownikamiw systemie posiadała specjalne pole krb5 o typie bitstring(3) - oznaczajacymnapis składajacy sie z trzech cyfr ze zbioru {0, 1}. Kazde z pól oznaczałorodzaj modyfikacji w bazie. Pierwsza pozycja oznaczała koniecznosc dodaniarekordu, druga jego zmiane, natomiast trzecia jego usuniecie. Rozwiazanie takiepowodowało szereg problemów. Podstawowym z nich była obsługa sytuacji awariibadz niedostepnosci serwera Kerberos5 w czasie kasowania rekordów. Przy takimrozwiazaniu rekordy w bazie nie były kasowane w momencie wydania decyzjio skasowaniu - tylko w momencie usuniecia ich z pozostałych baz. Drugimz problemów było działanie replikacji danych do serwera Kerberosa wewnatrzbazy PostgreSQL. Procesy replikujace działajace wewnatrz bazy musiały mieczwiekszone uprawnienia wzgledem wiekszosci kodu aplikacji bazodanowych (abymozna było komunikowac sie z serwerem Kerberosa oraz uzywac zewnetrznychmodułów perla).
◦ Druga wersja mechanizmu replikacji danych z serwera PostgreSQL do serweraKerberos5 została wykonana w podobny sposób do pierwszej - z tym, ze mechanizmsamej replikacji został przeniesiony do zewnetrznego procesu. Pobranie danychz tabeli oraz przygotowanie rekordu w formacie polecenia programu kadminpozostało w niezmienionej formie w stosunku do pierwszej wersji. Zewnetrzny

Rozdział 3. Prototypy aplikacji bazodanowej realizującej stawiane wymagania 59
proces wykonujacy operacje replikacji został napisany w jezyku interpretera sh i jesturuchamiany regularnie co minute przez program cron.
◦ Wersja trzecia replikacji z serwera PostgreSQL do Kerberos5 podobnie jakw wypadku poprzednio opisywanej komunikacji oznaczała całkowita rewolucje.Został przygotowany mechanizm replikacji oparty na szablonach oraz jednejprocedurze w jezyku plperl przygotowujacej rekordy w formacie polecen programukadmin, oraz uproszczony został mechanizm samej replikacji. Zostały dodane trzytabele: t_krb5, t_krb5arch oraz krb5template. W tabeli krb5template zawarte saszablony oraz dane niezbedne do ich identyfikacji (powiazania z rodzajem operacji),w tabeli t_krb5 umieszczane sa rekordy po interpretacji przez procedure w jezykuplperl. Samo umieszczenie rekordu w tabeli jest dokonywane przez procedurew jezyku plpgsql działajaca w ramach tej samej transakcji co zmiana w tabelizródłowej. Cały czas tabele t_krb5 przeglada sekwencyjnie zewnetrzny proces, którydla kazdego znalezionego rekordu stara sie wykonac polecenie programu kadmin.Niezaleznie od wyniku tej operacji do tabeli t_krb5arch trafia zarówno ten rekord, jaki komunikat serwera Kerberos5 zwrócony po próbie dokonania zmian, oraz wartoscprawda/fałsz oznaczajaca czy udało sie rekord ten zreplikowac. Jezeli replikacjasie powiodła rekord dodatkowo jest kasowany z tabeli t_krb5. Program w jezykuinterpretera sh, dokonujacy własciwej replikacji danych w chwili obecnej zostałpozbawiony wszelkich informacji na temat struktury bazy, powiazan tabel, proceduri typów zmian.
3.5.3 Dyskusja na temat technologii zastosowanej do replikacji z bazy
PostgreSQL do LDAP
Procedury w jezyku plperl w bazie danych PostgreSQL wymagaja instalacji tegojezyka w postaci niezaufanej (untrusted). Róznica miedzy sposobem instalacji zaufanyma niezaufanym jest zwiazana z zabezpieczeniami interpretera. Wersja zaufana (trusted)uniemozliwia wykonywanie jakichkolwiek działan na poziomie systemu operacyjnegooraz operowanie na wewnetrznych danych bazy danych. Instalacja funkcji jako niezaufanejlikwiduje te ograniczenia. Piszac w jezyku niezaufanym plperl (plperlu - plperluntrusted) nalezy pamietac o kilku faktach. Otwarte deskryptory nie zostana zamknietepo zakonczeniu działania interpretera perla, gdyz jest on uruchamiany w procesie bazydanych, który z załozenia moze działac wiele dni/miesiecy. Z tego tez powodu, inaczejniz w wypadku uzywania tego jezyka do celu automatyzacji prostych czynnosci (pisania

Rozdział 3. Prototypy aplikacji bazodanowej realizującej stawiane wymagania 60
prostych skryptów) nalezy duzo uwazniej podejsc do operacji wejscia/wyjscia. Jednymz problemów, który moze wystapic, jest buforowanie operacji zapisu. Niestety planujacdokonywanie skomplikowanych operacji na napisach, na danych zawartych w bazieoraz wykonywanie działan systemowych jestesmy skazani na plperl. Pozostałe jezykiproceduralne dostepne dla PostgreSQL posiadaja albo za mało mozliwosci (plpgsql jesttylko rozwinieciem jezyka SQL w kierunku strukturyzacji kodu i dostarczenia strukturkontrolnych - petli, operacji warunkowych), albo znajduja sie jeszcze w zbyt wczesnymetapie rozwoju aby mozna było bezpiecznie powierzyc im tak istotne zagadnieniajak replikacja danych (plpython, plruby, pljava). Mozna oczywiscie rozszerzac bazePostgreSQL o własne moduły w jezyku C. Niestety stopien skomplikowania bazy danychoraz liczba mozliwych do popełnienia błedów, nawet przy pisaniu niewielkiego modułu,pozostawiaja te alternatywe jako ostateczna - gdy wszelkie inne srodki zawioda badz niedostarczaja niezbednych do wykonania zadania mechanizmów.

Rozdział4
Przygotowanie serwerówdo współpracy z SystememZarządzania Użytkownikamii Wirtualnymi Organizacjami
Na wstepie trzeba zaznaczyc, ze lokalizacja plików konfiguracyjnych,
katalogów czy programów dotyczyc bedzie dystrybucji Debian
GNU/Linux. W wypadku uzywania w innych dystrybucjach nalezy te
sciezki dostosowac zgodnie z dokumentacja dystrybucji. Przedstawiona
została konfiguracja serwerów krb5-kdc-ldap, PostgreSQL na serwerze
głównym, serwera slapd na serwerze głównym oraz na serwerach
głównych projektów wraz z opisem replikacji master - slave. Zarówno
po stronie serwera master jak i serwerów slave. Przedstawiona
została konfiguracja bibliotek libldap i pam_krb5 oraz aplikacji
wchodzacych w skład nss-ldapd. Opisany został równiez sposób instalacji
oprogramowania - zarówno w czesci bazodanowej jak i systemowej.
4.1 Kon�guracja serwera gªównego bazy danych
i instalacja aplikacji
Do działania systemu zarzadzania na serwerze głównym wymagana jest obecnoscpakietów:
◦ postgresql-8.3 - Serwer PostgreSQL

Rozdział 4. Przygotowanie serwerów do współpracy z Systemem Zarządzania Użytkownikami
i Wirtualnymi Organizacjami 62
◦ postgresql-client-8.3 - Program kliencki psql serwera PostgreSQL
◦ postgresql-plperl-8.3 - Wsparcie dla aplikacji w jezyku perl uruchamianychwewnatrz bazy PostgreSQL
◦ slapd - Serwer OpenLDAP
◦ ldap-utils - Aplikacje uzywajace protokołu LDAP do współpracy z serweremOpenLDAP
◦ krb5-admin-server - Serwer administracyjny MIT Kerberos5
◦ krb5-config - Pliki konfiguracyjne serwera MIT Kerberos5
◦ krb5-kdc-ldap - Wtyczka do przechowywania danych serwera MIT Kerberos5w bazie LDAP
◦ krb5-kdc - Serwer kluczy MIT Kerberos5
◦ krb5-user - Podstawowe aplikacje uzywajace systemu MIT Kerberos5do uwierzytelniania
4.1.1 OpenLDAP
Konfiguracje serwera OpenLDAP (serwer ten ma nazwe własna slapd) nalezy zaczacod zdefiniowania domeny jaka bedzie uzywana, a co za tym idzie oznaczenia korzeniadrzewa LDAP. Do celów opisowych przyjeta została domena example.com i korzendrzewa „dc=example,dc=com”.
◦ Konfiguracja biblioteki libldap
Z ustawien tej biblioteki korzystaja narzedzia uzywane do replikacji zmianzachodzacych w bazie relacyjnej do bazy LDAP. Plikiem w którym dokonywanesa zmiany jest /etc/ldap/ldap.conf. Przyjmujac, ze serwer główny LDAP znajdujesie na tej samej maszynie co serwer PostgreSQL, plik ten powinien zawierac dwaprezentowane ponizej wpisy.
BASE dc=example , dc=comURI l d a p : / / 1 2 7 . 0 . 0 . 1

Rozdział 4. Przygotowanie serwerów do współpracy z Systemem Zarządzania Użytkownikami
i Wirtualnymi Organizacjami 63
W wypadku, gdy serwer główny LDAP bedzie znajdowac sie na innej maszynie,nalezy zadbac o szyfrowanie komunikacji. W takim wypadku trzeba bedziezadbac o to aby biblioteka libldap (albo raczej biblioteka SSL1 z której libldapkorzysta) miała dostep do certyfikatu CA, które podpisało certyfikat serwera LDAP.Przyjmujac, ze serwer LDAP jest dostepny pod adresem ldap.example.com oraz takisam adres wystepuje w polu cn certyfikatu zawartosc pliku /etc/ldap/ldap.conf bedziemiała przedstawiona ponizej postac.
BASE dc=example , dc=comURI l d a p s : / / l d a p . example . comTLS_CACERT / e t c / l d a p / ca . pem
◦ Konfiguracja serwera slapd
Konfiguracje serwera slapd dostosowuje sie poprzez edycje pliku/etc/ldap/slapd.conf. Konfiguracja automatycznie wygenerowana na etapie instalacjipakietu slapd jest w wiekszosci wystarczajaca. Podstawowe zmiany, jakie nalezywprowadzic odnosza sie głównie do szyfrowania (opcje dotyczace TLS2) orazreplikacji.
◦ Zmiany odnoszace sie do szyfrowania połaczen
Zmiany te musimy wprowadzic w sekcji globalnej pliku konfiguracyjnego(przed pierwszym wystapieniem dyrektywy backend). Ograniczaja siedo definicji lokalizacji plików zawierajacych certyfikaty i klucze SSL.
T L S C A C e r t i f i c a t e F i l e / e t c / l d a p / ldap−ca . pemT L S C e r t i f i c a t e F i l e / e t c / l d a p / ldap−c r t . pemT L S C e r t i f i c a t e K e y F i l e / e t c / l d a p / ldap−key . pem
◦ Zmiany definiujace lokalizacje serwerów LDAP
W pliku /etc/default/slapd nalezy zdefiniowac adresy pod którymi dostepny jestserwer slapd.
SLAPD_SERVICES=" l d a p : / / 1 2 7 . 0 . 0 . 1 : 3 8 9 / l d a p s : / / / "
◦ Zmiany dotyczace replikacji w sekcji globalnej
W sekcji globalnej nalezy dopisac ładowanie modułów niezbednychdo przeprowadzenia replikacji.
1Secure Socket Layer2Transport Layer Security

Rozdział 4. Przygotowanie serwerów do współpracy z Systemem Zarządzania Użytkownikami
i Wirtualnymi Organizacjami 64
module load a c c e s s l o gmodule load s y n c p r o v
Pierwszy z modułów (accesslog) słuzy do logowania w bazie wszelkichoperacji wykonywanych w innej bazie LDAP. Drugi (syncprov) dostarczamechanizmów niezbednych po stronie serwera master w protokolesynchronizacji baz LDAP (LDAP Content Synchronization - RFC4533).
◦ Zmiany dotyczace replikacji w replikowanej bazie
◦ Zaczynamy od załozenia indeksów na atrybuty wymagane do replikacji
i n d e x entryCSN eqi n d e x entryUUID eq
Po dodaniu takich wpisów nalezy pamietac o wygenerowaniu indeksów.Do tego celu trzeba wyłaczyc serwer slapd i uruchomic z kontauzytkownika openldap program slapindex.
◦ Kolejnym etapem jest właczenie funkcjonalnosci dostarczanej przez moduł
syncprov
o v e r l a y s y n c p r o vsyncprov−c h e c k p o i n t 1000 60
Dokładny opis opcji mozna znalezc w manualu slapo-syncprov(5)
◦ Rejestracja zmian w replikowanej bazie
o v e r l a y a c c e s s l o glogdb cn= a c c e s s l o gl o g o p s w r i t e sl o g s u c c e s s TRUEl o g p u r g e 07+00:00 01+00:00
W ten sposób definiuje sie, ze zmiany maja byc zapisywane w bazie„cn=accesslog”, której zawartosc ma byc codziennie czyszczona z wpisówstarszych niz siedmiodniowe.
◦ Wyłaczenie limitów dla uzytkownika, który bedzie uzywany do replikacji
Przyjmujac, ze uzytkownik uzywany do replikacji bedzie miał nazwe„cn=replicator,dc=example,dc=com” wpisy wyłaczajace ograniczeniana zwracana liczbe wyników wyszukiwania beda miały postacprezentowana ponizej.

Rozdział 4. Przygotowanie serwerów do współpracy z Systemem Zarządzania Użytkownikami
i Wirtualnymi Organizacjami 65
l i m i t s dn . e x a c t =" cn= r e p l i c a t o r , dc=example , dc=com"t ime . s o f t = u n l i m i t e dt ime . ha rd = u n l i m i t e ds i z e . s o f t = u n l i m i t e ds i z e . ha rd = u n l i m i t e d
◦ Zapewnienie dostepu dla uzytkownika uzywanego do replikacji
do wszystkich atrybutów wszystkich obiektów
Ponizej zaprezentowane zostały przykłady domyslnych list kontrolidostepu, uwzgledniajace modyfikacje wykonane pod katem replikacji.Domyslne uprawnienia zezwalały administratorowi na wszelkie operacjew bazie LDAP, kazdemu uzytkowikowi na przegladanie bazy z wyjatkiematrybutów odpowiadajacych za hasła oraz pozwalały na uwierzytelnianie(dostep auth do atrybutu userPassword). Po zmianach udostepniajacychdo odczytu wszystkie atrybuty listy kontroli dostepu (najbardziejpodstawowe) beda miały nastepujaca postac:
a c c e s s t o a t t r s = use rPassword , shadowLastChangeby dn =" cn=admin , dc=example , dc=com" w r i t eby dn =" cn= r e p l i c a t o r , dc=example , dc=com" r e a dby anonymous a u t hby s e l f w r i t eby ∗ none
a c c e s s t o a t t r s =userPKCS12by dn =" cn=admin , dc=example , dc=com" w r i t eby dn =" cn= r e p l i c a t o r , dc=example , dc=com" r e a dby anonymous a u t hby s e l f w r i t eby ∗ none
a c c e s s t o dn . base =""by ∗ r e a d
a c c e s s t o ∗by dn =" cn=admin , dc=example , dc=com" w r i t eby dn =" cn= r e p l i c a t o r , dc=example , dc=com" r e a dby ∗ r e a d
◦ Konfiguracja bazy replikacji

Rozdział 4. Przygotowanie serwerów do współpracy z Systemem Zarządzania Użytkownikami
i Wirtualnymi Organizacjami 66
d a t a b a s e hdbs u f f i x " cn= a c c e s s l o g "d i r e c t o r y / v a r / l i b / ldap− r e p l i c a t i o nr o o t d n " cn= a c c e s s l o g "i n d e x d e f a u l t eqi n d e x entryCSN , o b j e c t C l a s s , reqEnd , r e q R e s u l t , r e q S t a r to v e r l a y s y n c p r o vsyncprov−n o p r e s e n t TRUEsyncprov−r e l o a d h i n t TRUE
l i m i t s dn . e x a c t =" cn= r e p l i c a t o r , dc=example , dc=com"t ime . s o f t = u n l i m i t e dt ime . ha rd = u n l i m i t e ds i z e . s o f t = u n l i m i t e ds i z e . ha rd = u n l i m i t e d
a c c e s s t o ∗by dn =" cn=admin , dc=example , dc=com" w r i t eby dn =" cn= r e p l i c a t o r , dc=example , dc=com" w r i t eby ∗ r e a d
Trzeba przy tym pamietac aby przed uruchomieniem serwera slapd z takakonfiguracja utworzyc katalog /var/lib/ldap-replication bedacy własnosciauzytkownika openldap.
4.1.2 MIT Kerberos5
◦ Przygotowanie serwera slapd do przechowywania danych serwera haseł
◦ Dołaczenie schematu opisujacego typy danych do serwera OpenLDAP
Nalezy skopiowac plik Kerberos.schema z dystrybucji MIT Kerberos5do katalogu /etc/ldap/schema i dopisujemy do pliku /etc/ldap/slapd.confponizsza linijke
i n c l u d e / e t c / l d a p / schema / k e r b e r o s . schema
◦ Modyfikacja list kontroli dostepu
Dane serwera Kerberos bedziemy przechowywac w drzewie„cn=EXAMPLE.COM,dc=example,dc=com”. Do list kontroli dostepunalezy dopisac regułe umozliwiajaca operacje na poddrzewie uzywanym przez

Rozdział 4. Przygotowanie serwerów do współpracy z Systemem Zarządzania Użytkownikami
i Wirtualnymi Organizacjami 67
Kerberosa dla zdefiniowanych wczesniej uzytkowników i blokujaca dosteppozostałym.
a c c e s s t o dn . s u b t r e e =" cn=EXAMPLE.COM, dc=example , dc=com"by dn =" cn=admin , dc=example , dc=com" w r i t eby dn =" cn= r e p l i c a t o r , dc=example , dc=com" r e a dby ∗ none
◦ Dodanie indeksów do przyspieszenia wyszukiwania atrybutów uzywanych przez
Kerberosa
i n d e x k r b P r i n c i p a l N a m e eq
Po dodaniu nalezy uruchomic program slapindex z uprawnieniamiuzytkownika openldap, przy wyłaczonym serwerze slapd, w celuwygenerowania zdefiniowanych indeksów.
◦ Konfiguracja serwera MIT Kerberos 5
Na podstawie załozen przyjetych w poprzedzajacej czesci, fragmenty plikukonfiguracyjnego, na które musimy zwrócic szczególna uwage zostałyprzedstawione ponizej.
[ l i b d e f a u l t s ]d e f a u l t _ r e a l m = EXAMPLE.COM
[ r e a l m s ]EXAMPLE.COM = {
kdc = l o c a l h o s ta d m i n _ s e r v e r = l o c a l h o s td a t a b a s e _ m o d u l e = o p e n l d a p _ l d a p c o n f
}
[ d b d e f a u l t s ]l d a p _ k e r b e r o s _ c o n t a i n e r _ d n = dc=example , dc=com
[ dbmodules ]o p e n l d a p _ l d a p c o n f = {
d b _ l i b r a r y = k l d a pl d a p _ k e r b e r o s _ c o n t a i n e r _ d n = dc=example , dc=comldap_kdc_dn = cn=admin , dc=example , dc=comldap_kadmind_dn = cn=admin , dc=example , dc=coml d a p _ s e r v i c e _ p a s s w o r d _ f i l e = / e t c / k rb5 / s e r v i c e . k e y f i l e

Rozdział 4. Przygotowanie serwerów do współpracy z Systemem Zarządzania Użytkownikami
i Wirtualnymi Organizacjami 68
l d a p _ s e r v e r s = l d a p : / / 1 2 7 . 0 . 0 . 1l d a p _ c o n n s _ p e r _ s e r v e r = 5
}
◦ Utworzenie domeny Kerberosa w bazie LDAP wraz z generowaniem pliku z hasłem
uzywanym do odkodowywania bazy (stashfile)
k d b 5 _ l d a p _ u t i l −D cn=admin , dc=example , dc=com c r e a t e \−r EXAMPLE.COM −s
◦ Utworzenie pliku z hasłem uzywanym do dostepu do bazy LDAP
k d b 5 _ l d a p _ u t i l −D cn=admin , dc=example , dc=com s t a s h s r v p w \−f / e t c / k rb5kdc / s e r v i c e . k e y f i l e \cn=admin , dc=example , dc=com
4.1.3 PostgreSQL
Aplikacja działajaca w bazie danych wymaga bazy PostgreSQL w wersji 8.3. Pracebyły prowadzone równiez w wersji 8.1 oraz 8.2 lecz koncowe testy zgodnosci zostałyprzeprowadzone tylko dla wersji 8.3 oraz wersji beta 8.4. Poczatkowe kroki instalacjiwymagaja uprawnien superuzytkownika bazy danych PostgreSQL. Ponizsze przykładywymagaja aby w systemie PostgreSQL był dostepny uzytkownik mgr z uprawnieniamisuperuzytkownika bazy oraz baza mgr bedaca jego własnoscia. Operacje przedstawioneponizej nalezy wykonywac z poziomu uruchomionej konsoli PostgreSQLa (psql)podłaczonej do bazy docelowej. Dodatkowym załozeniem jest to, ze pliki z aplikacjaznajduja sie w katalogu biezacym oraz to, ze uzytkownik z którego uprawnieniami bedadokonywane operacje na bazie przez aplikacje www bedzie miał nazwe mgrwww i bedzieposiadał minimalne uprawnienia.
◦ Instalacja jezyków pl/pgsql, pl/perl, pl/perlu (wymagane uprawnienia
superuzytkownika)
CREATE LANGUAGE p l p g s q l ;CREATE LANGUAGE p l p e r l ;CREATE LANGUAGE p l p e r l u ;
◦ Instalacja procedur systemu zarzadzania (wymaga uprawnien superuzytkownika)

Rozdział 4. Przygotowanie serwerów do współpracy z Systemem Zarządzania Użytkownikami
i Wirtualnymi Organizacjami 69
\ i l d a p k r b 5 . p l s q l\ i l d a p k r b 5 . p l\ i f u n k c j e . p l s q l
◦ Tworzenie tabel, widoków i reguł operacji na widokach systemu zarzadzania
(wymaga uprawnien zwykłego uzytkownika)
\ i t a b e l e . s q l\ i l d a p k r b 5 \ _ t a b l e . s q l\ i widok i . s q l\ i r e g u l y . s q l
◦ Tworzenie tabel do systemów replikacji oraz uzupełnianie danych w tabelach
z szablonami do replikacji
\ i t e m p l a t e . s q l
◦ Uzupełnienie tabel systemu zarzadzania przykładowymi danymi
W pliku dane.sql znalezc mozna przykładowe dane do systemu zarzadzania - przedzaładowaniem ich do bazy trzeba bezwzglednie dostosowac dane dodawane do tabelit_config. W szczególnosci jest to basedn, który okresla korzen drzewa, w którymbeda tworzone poddrzewa projektów.
\ i dane . s q l
Dostosowanie dostępu do bazy danych oraz konfiguracja zabezpieczeń dla serwera www
◦ Przestawienie adresu na którym nasłuchuje serwer PostgreSQL
Domyslnie serwer PostgreSQL w systemie Debian nasłuchuje tylko na interfejsieloopback (adres 127.0.0.1). Zmiana tego zachowania wymaga przestawienia opcjilisten_addresses i restartu serwera PostgreSQL. Zmiany dokonuje sie edytujacplik /etc/postgresql/8.3/main/postgresql.conf a nastepnie restartujac baze danych(/etc/init.d/postgresql-8.3 restart).
◦ Nadanie uprawnien do łaczenia do bazy dla aplikacji www
Dla kazdego ip, z którego łaczyc bedzie sie aplikacja www, nalezy dodac podobnydo ponizszego wpis do pliku /etc/postgresql/8.3/main/pg_hba.conf.

Rozdział 4. Przygotowanie serwerów do współpracy z Systemem Zarządzania Użytkownikami
i Wirtualnymi Organizacjami 70
h o s t mgr mgrwww 1 1 . 1 1 . 1 1 . 1 1 / 3 2 md5
Wpis ten oznacza, ze z komputera z adresem ip 11.11.11.11 moze do bazymgr podłaczyc sie uzytkownik mgrwww uzywajac hasła przesłanego w postaciszyfrowanej (opcja md5).
◦ Ustawienie uprawnien dostepu do procedur i widoków systemu zarzadzania
Dla kazdej procedury bazy danych nalezy odebrac uprawnienia do jej wywoływania.Przyczyna takiego stanu rzeczy jest definiowanie ich jako procedur, które sauruchamiane z uprawnieniami uzytkownika, który dodał je do bazy a nie tego,który je uruchamia (security definer). Przyjmujac ponownie nazwe konta uzywanegodo operacji z poziomu panelu www jako mgrwww musimy dla kazdej takiejprocedury wywołac sekwencje polecen:
GRANT EXECUTE ON FUNCTION nazwa f u n k c j i ( t ypy argumentów )TO mgrwww ;
Dla kazdego widoku, na którym operowac bedzie aplikacja www nalezyzdefiniowac mozliwosc czytania, pisania, kasowania i aktualizacji dla uzytkownikaz uprawnieniami którego bedzie aplikacja www korzystac z bazy (w naszymprzykładzie mgrwww)
GRANT SELECT , INSERT , DELETE , UPDATE ON nazwa widokuTO mgrwww ;
4.1.4 Kon�guracja replikacji z bazy SQL do LDAP i Kerberos
Konfiguracje replikacji z bazy SQL do serwera LDAP czy do bazy haseł Kerberosnalezy zaczac od wyboru katalogu w którym beda przechowywane skrypty orazpliki konfiguracyjne. W naszym wypadku bedzie to /usr/local/mgr. Nalezy skopiowaczawartosc katalogu sh aplikacji do katalogu /usr/local/mgr i nastepnie zmienic zawartoscplików krb5.conf i ldap.conf stosownie do zdefiniowanych wczesniej parametrów(dostep do bazy, dane do logowania i wykonywania operacji w bazie LDAP orazdane do logowania do bazy haseł Kerberos). W tej chwili mozna przetestowac, czyreplikacja została przeprowadzona, uruchamiajac recznie skrypty /usr/local/mgr/dokrb5.shi /usr/local/mgr/doldap.sh. Nastepnie musimy dopisac do crona uruchamianie co minuteskryptów /usr/local/mgr/dokrb5.sh i /usr/local/mgr/doldap.sh.

Rozdział 4. Przygotowanie serwerów do współpracy z Systemem Zarządzania Użytkownikami
i Wirtualnymi Organizacjami 71
∗ ∗ ∗ ∗ ∗ / u s r / l o c a l / mgr / dokrb5 . sh∗ ∗ ∗ ∗ ∗ / u s r / l o c a l / mgr / d o l da p . sh
4.2 Kon�guracja serwerów gªównych dla projektów
Serwery główne projektów posiadaja replike poddrzewa drzewa LDAP dla danegoprojektu. Konfiguracja serwerów głównych sprowadza sie ustawienia konsumenta (slave)replikacji. Jedynym pakietem, specyficznym dla systemu zarzadzania, jaki musi bycna tych serwerach zainstalowany jest slapd.
i n d e x o b j e c t c l a s s , entryCSN , entryUUID eq
r o o t d n " cn=admin , dc=example , dc=com"
s y n c r e p l r i d =000p r o v i d e r =" l d a p : / / ldap−m a s t e r . example . com"bindmethod = s i m p l eb inddn =" cn= r e p l i c a t o r , dc=example , dc=com"c r e d e n t i a l s =" h a s l o "s e a r c h b a s e =" ou= p r o j e k t 1 , dc=example , dc=com"l o g b a s e =" cn= a c c e s s l o g "l o g f i l t e r ="(&( o b j e c t C l a s s = a u d i t W r i t e O b j e c t ) ( r e q R e s u l t = 0 ) ) "t y p e = r e f r e s h A n d P e r s i s tr e t r y ="60 +"s y n c d a t a = a c c e s s l o gs t a r t t l s = c r i t i c a lt l s _ c a c e r t = / e t c / l d a p / ca . pem
u p d a t e r e f " l d a p : / / ldap−m a s t e r . example . com"
Powyzszy przykład opisuje konfiguracje, w której serwer master replikacji jestdostepny pod adresem ldap-master.example.com (nie mozna zapomniec o tym abycertyfikat był wystawiony z takim cn). Do pobierania danych z serwera jest uzywanyuzytkownik cn=replicator,dc=example,dc=com z hasłem „haslo”. Dane sa umieszczanena serwerze projektu z uzyciem konta cn=admin,dc=example,dc=com. Dyrektywylogbase, logfilter, syncdata w takiej postaci specyfikuja zastosowanie oszczedniejszejwersji replikacji - replikacji tylko zmieniajacych sie fragmentów rekordów (deltasyncrepl). Updateref definiuje lokalizacje serwera, w którym mozna dokonywac

Rozdział 4. Przygotowanie serwerów do współpracy z Systemem Zarządzania Użytkownikami
i Wirtualnymi Organizacjami 72
modyfikacji bazy LDAP, gdyby takie próby pojawiały sie przy połaczeniu do danej repliki(zwykle wskazuje na serwer master replikacji).
4.3 Kon�guracja maszyn obliczeniowych
Do współdziałania z systemem zarzadzania na maszynach obliczeniowych wymaganajest instalacja nastepujacych pakietów:
◦ libnss-ldapd
◦ libpam-krb5
◦ krb5-user
W wypadku wiekszosci współczesnych dystrybucji dostarczane sa narzedzia znaczacoupraszczajace przedstawiony sposób konfiguracji. W wypadku dystrybucji pochodzacychod RedHata jest to authconfig, w wypadku dystrybucji pochodzacych od Debiana jest topam-auth-update.
4.3.1 Kon�guracja Name Service Switch
Od wielu lat stosowanym standardem w wypadku współpracy bibliotek NSSz serwerami LDAP było libnss-ldap, jednak biblioteka ta posiadała pare powaznychograniczen i błedów. Podstawowym problemem było to, ze dla kazdego zapytaniabyło nawiazywane oddzielne połaczenie do serwera LDAP. Powodowało to, ze niemozna było wykorzystywac mozliwosci buforowania wyników zapytan na poziomieprotokołu LDAP oraz czasami doprowadzało do przeciazania serwera LDAP obsługazbednych połaczen. Dodatkowym problemem było to, ze kazdy proces dokonujacyoperacji z wykorzystaniem libnss-ldap musiał ładowac kopie biblioteki libldap. Z tegowłasnie powodu lepiej wykorzystac nowe rozwiazanie - libnss-ldapd. Podstawowa róznicaw porównaniu do libnss-ldap jest to, ze obsługa połaczen i zapytan do bazy LDAP zajmujesie dedykowana aplikacja uruchamiana na etapie startu systemu. Jedynie ta aplikacjawymaga do swojego działania biblioteki libldap.
◦ Konfiguracja libnss-ldapd
Konfiguracja libnss-ldapd wymaga dostosowania pliku /etc/nss-ldapd.confdo współpracy z serwerem głównym projektu. Przykładowa zawartosc zostałazaprezentowana ponizej.

Rozdział 4. Przygotowanie serwerów do współpracy z Systemem Zarządzania Użytkownikami
i Wirtualnymi Organizacjami 73
u r i l d a p : / / p r o j e k t 1 . example . com /base dc=example , dc=com# binddn cn=konto , dc=example , dc=com# bindpw h a s l ou i d n s l c dg i d n s l c d
Przy takiej konfiguracji serwer nslcd (czesc aplikacji libnss-ldapd, która jestodpowiedzialna za komunikacje z serwerem LDAP) bedzie uruchomionyz uprawnieniami uzytkownika nslcd i grupy nslcd. Bedzie sie łaczył z serweremLDAP dostepnym pod adresem projekt1.example.com i wyszukiwał uzytkownikóww drzewie dc=example,dc=com. Zawartosc przykładowego pliku zawierawykomentowane opcje binddn i bindpw. Sa one potrzebne, gdy replika serweraLDAP, w której dokonywane sa operacje, uniemozliwia anonimowe wyszukiwanie.
◦ Konfiguracja libnss
Drugim etapem konfiguracji Name Service Switch jest uaktywnienie uzywanialibnss-ldapd przez biblioteki systemowe. Taki wynik uzyskamy poprzezdostosowanie pliku /etc/nsswitch.conf do wykorzystywania danych z bazyLDAP.
passwd : compat l d a pgroup : compat l d a pshadow : compat l d a p
4.3.2 Kon�guracja Pluggable Authentication Modules
Konfiguracja PAM, podobnie jak w wypadku NSS, jest dwustopniowa. Pierwszymkrokiem jest dostosowanie plików konfiguracyjnych pam_krb5 do współpracyz uruchomionymi serwerami. Nastepnie nalezy skonfigurowac system PAM tak, abykorzystał z pam_krb5.
◦ Konfiguracja pam_krb5
Konfiguracja pam_krb5 wymaga wskazania serwera kluczy Kerberos (KDC3) orazserwera administracyjnego (kadmin) słuzacego do zmiany haseł. Zmiany te sawprowadzane w pliku /etc/krb5.conf
3Key Distribution Center

Rozdział 4. Przygotowanie serwerów do współpracy z Systemem Zarządzania Użytkownikami
i Wirtualnymi Organizacjami 74
[ l i b d e f a u l t s ]d e f a u l t _ r e a l m = EXAMPLE.COM
[ r e a l m s ]EXAMPLE.COM = {
kdc = l o c a l h o s ta d m i n _ s e r v e r = l o c a l h o s t
}
Poprawnosc zmian mozna sprawdzic, uzywajac programów kinit oraz klist.
◦ Konfiguracja uwierzytelniania
Konfiguracji uwierzytelniania dokonuje sie edytujac pliki /etc/pam.d/common-{auth|account|password|session}
Odpowiednie dodatkowe wpisy maja postac
a u t h s u f f i c i e n t pam_krb5 . sos e s s i o n r e q u i r e d pam_krb5 . soa c c o u n t r e q u i r e d pam_krb5 . sopassword s u f f i c i e n t pam_krb5 . so
W wypadku systemu zarzadzania niezbedne jest równiez utworzenie katalogudomowego na docelowym serwerze. Do tego celu wykorzystywany jest modułpam_mkhomedir.
s e s s i o n r e q u i r e d pam_mkhomedir . so s k e l = / e t c / s k e l
Wpis taki oznacza, ze jezeli logujacy sie uzytkownik nie posiada katalogudomowego to zostanie mu on utworzony na bazie katalogu /etc/skel (zawartosckatalogu /etc/skel zostanie skopiowana do katalogu domowego uzytkownika jakojego własnosc).
4.4 Zmiana obejmuj¡ca wszystkie serwery LDAP
Poza zmianami przedstawionymi wczesniej na kazdym serwerze nalezy umiescicw katalogu /etc/ldap/schema plik pkcs12.schema z katalogu db aplikacji i dopisac w sekcjiodpowiedzialnej za uzywane schematy uzywanie pliku pkcs12.schema
i n c l u d e / e t c / l d a p / schema / pkcs12 . schema

Rozdział 4. Przygotowanie serwerów do współpracy z Systemem Zarządzania Użytkownikami
i Wirtualnymi Organizacjami 75
4.5 Podsumowanie
Przedstawiona konfiguracja obejmuje najprostsze przypadki. Wraz z rozwojemi wzrostem skomplikowania systemu nastapi równiez wzrost stopnia skomplikowaniaplików konfiguracyjnych. Dodatkowo, szczególnie w przypadku konfiguracji PAM, mozepojawic sie potrzeba dostosowania konfiguracji do współpracy z wieksza liczba modułów.

Rozdział5
Rozwiązania zwiększająceniezawodnośćposzczególnychkomponentów SystemuZarządzania Użytkownikamii Wirtualnymi Organizacjami
W rozdziale tym zostały przedstawione rozwiazania zwiekszajace
niezawodnosc i dostepnosc Systemu Zarzadzania Uzytkownikami
i Wirtualnymi Organizacjami. W wypadku serwera www została
przedstawiona konfiguracja wraz ze scenariuszami awarii
z zastosowaniem serwerów haproxy i keepalived. W przypadku serwera
PostgreSQL została przedstawiona konfiguracja z wykorzystaniem
rozwiazania pracujacego w trybie warm-standby przy zastosowaniu
narzedzia walmgr. W wypadku serwera slapd zostało opisane
zastosowanie mechanizmów replikacji zarówno multi-master jak
i master-slave wraz z postepowaniem w scenariuszach awarii. Serwer
MIT Kerberos5 wykorzystuje w roli backendu serwer LDAP stad tez
korzysta z jego rozwiazan wysokiej dostepnosci.

Rozdział 5. Rozwiązania zwiększające niezawodność poszczególnych komponentów Systemu
Zarządzania Użytkownikami i Wirtualnymi Organizacjami 77
Wysoka dostepnosc jest okresleniem obejmujacym ogół rozwiazan od etapu projektowaniasystemów az do ich implementacji , wdrozenia i działania, które ograniczaja do minimumprzestoje w pracy. Przestoje te nalezy podzielic na przestoje planowane i przestojenieplanowane. Przestoje planowane sa zwiazane z pracami konserwacyjnymi. Przestojenieplanowane sa skutkiem sytuacji awaryjnych.
Ze wzgledu na stosowane rozwiazania w systemie nie sa konieczne dodatkowemechanizmy wspierajace wysoka niezawodnosc czy wysoka dostepnosc. Jednak zewzgledu na duza liczbe róznych serwisów wchodzacych w skład systemu konfiguracjacałosci tak, aby spełniała wymagania wysokiej dostepnosci oraz wysokiej niezawodnoscijest zadaniem nietrywialnym. Dzieki zastosowaniu powszechnie znanych protokołów(LDAP, krb5, protokół PostgreSQL, http) mozna stworzyc system pozbawionypojedynczych punktów awarii (single points of failure).
Kazdy z komponentów systemu zarzadzania moze byc punktem awarii, jezelinie zostanie zwielokrotniony w sposób umozliwiajacy szybkie przełaczenie połaczenw wypadku awarii jednego z wezłów. Kluczowym elementem jest tutaj jednak wpływniedostepnosci danego komponentu na prowadzone prace obliczeniowe. Analizujacschemat architektury systemu mozna dojsc do wniosku, ze najbardziej krytycznymelementem jest tutaj serwer LDAP oraz w nieco mniejszym stopniu serwer Kerberos5.Bez nich nie bedzie działac logowanie (w wypadku niedostepnosci jednego albo drugiego)albo nie bedzie działac zarówno logowanie jak i wiele operacji lokalnych na maszynach(w wypadku awarii serwera LDAP).
5.1 Serwis www Systemu Zarz¡dzania
U»ytkownikami i Wirtualnymi Organizacjami
Wymagania wysokiej dostepnosci/wysokiej niezawodnosci zapewnia mozliwoscuruchomienia aplikacji na wielu serwerach mongrel. Serwery te moga działac na kilkumaszynach równoczesnie. Dla uproszczenia na schemacie 5.2 zostały umieszczone tylkotrzy serwery mongrel (3, 4, 5). Maszyny z load-balancerem (1, 2) maja uruchomioneusługi:
◦ haproxy [29] - posredniczenie w połaczeniach do serwerów www, monitorowanieich stanu i w wypadku awarii serwera www wstrzymanie przekazywania połaczendo niego (odłaczenie od klastra)
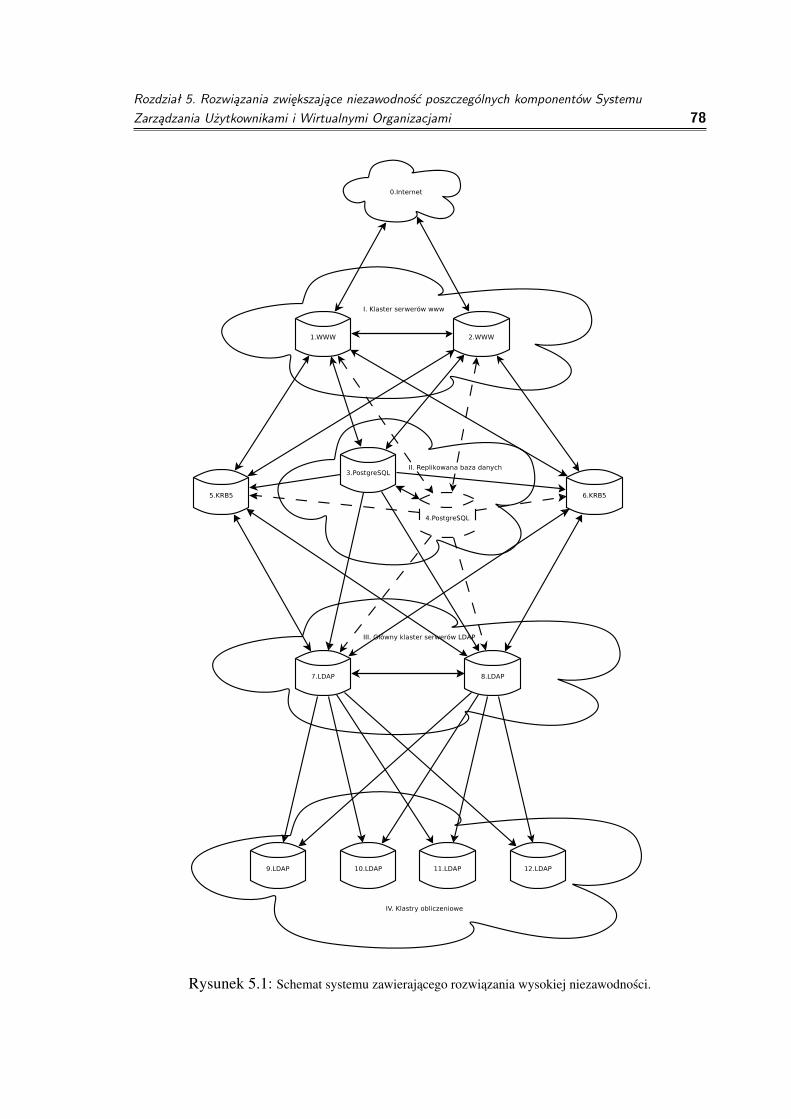
Rozdział 5. Rozwiązania zwiększające niezawodność poszczególnych komponentów Systemu
Zarządzania Użytkownikami i Wirtualnymi Organizacjami 78
Rysunek 5.1: Schemat systemu zawierajacego rozwiazania wysokiej niezawodnosci.
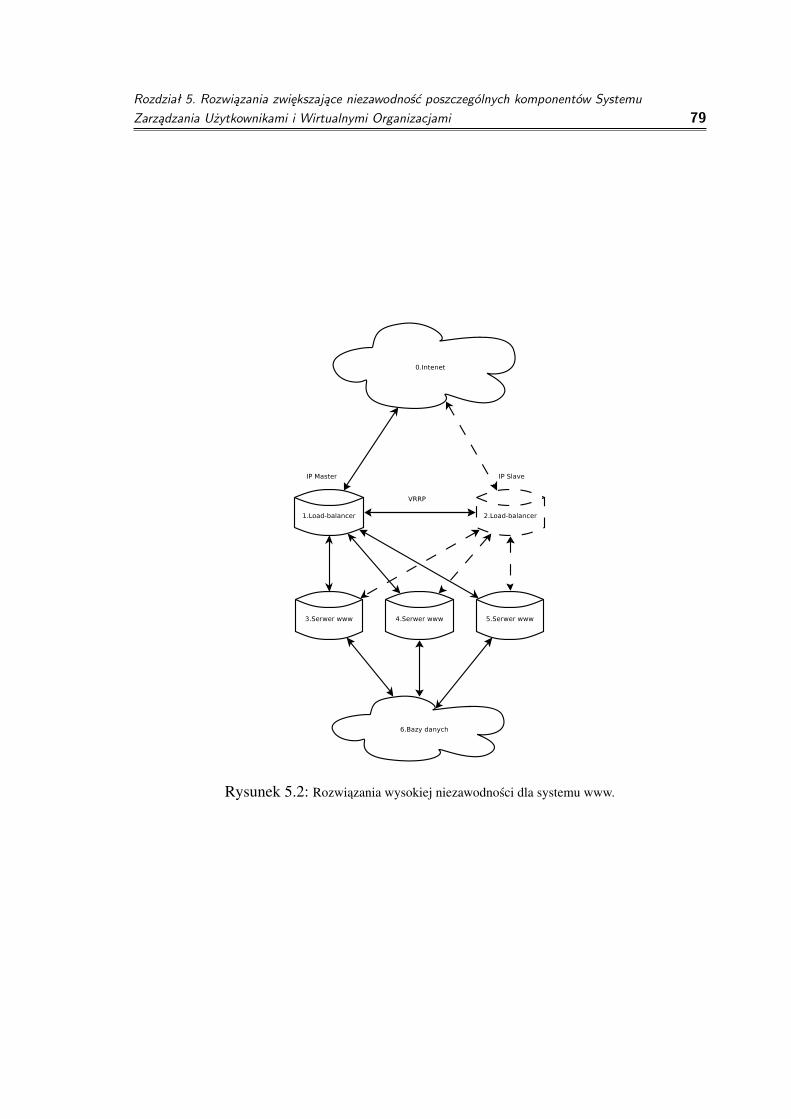
Rozdział 5. Rozwiązania zwiększające niezawodność poszczególnych komponentów Systemu
Zarządzania Użytkownikami i Wirtualnymi Organizacjami 79
Rysunek 5.2: Rozwiazania wysokiej niezawodnosci dla systemu www.

Rozdział 5. Rozwiązania zwiększające niezawodność poszczególnych komponentów Systemu
Zarządzania Użytkownikami i Wirtualnymi Organizacjami 80
◦ keepalived [30] - monitoring działania serwerów haproxy i przełaczanie aktywnegoip do drugiej maszyny w wypadku awarii
5.1.1 Zarz¡dzanie sesjami
System do zarzadzania uzytkownikami nie musi przechowywac informacji o sesjiprzez dłuzszy czas. Dlatego tez mozna załozyc, ze mechanizmem wystarczajacymdo przechowywania tych informacji bedzie serwer memcached działajacy na kazdejz maszyn z serwerem www (3, 4, 5). Aby zapobiec „wylogowaniu” z serwerapoprzez przekierowanie kolejnych pakietów http przez haproxy do róznych serwerówmongrel (kazdy ma swój własny serwer memcached), haproxy moze ustawiac ciasteczka,na podstawie których bedzie pózniej podejmował decyzje o kierowaniu kolejnych pakietówhttp.
5.1.2 Scenariusze awarii
◦ awaria wezła load-balancera
◦ awaria serwera slave
◦ oznaczenie wezła jako uszkodzonego
◦ odciecie wezła (fencing) - moze zostac przeprowadzone poprzezwyłaczenie portów w switchu, odłaczenie zasilania, albo wyłaczeniemaszyny wirtualnej, w której wezeł został uruchomiony
◦ poinformowanie administratora o awarii i/lub przeprowadzenie działaniamajacego na celu przywrócenie poprawnosci działania wezła
◦ awaria serwera master
◦ oznaczenie serwera master jako uszkodzonego
◦ elekcja nowego serwera master
◦ przejecie wirtualnego ip, na którym działaja usługi przez nowy serwermaster
◦ odciecie uszkodzonego wezła
◦ poinformowanie administratora o awarii i/lub przeprowadzenie działannaprawczych
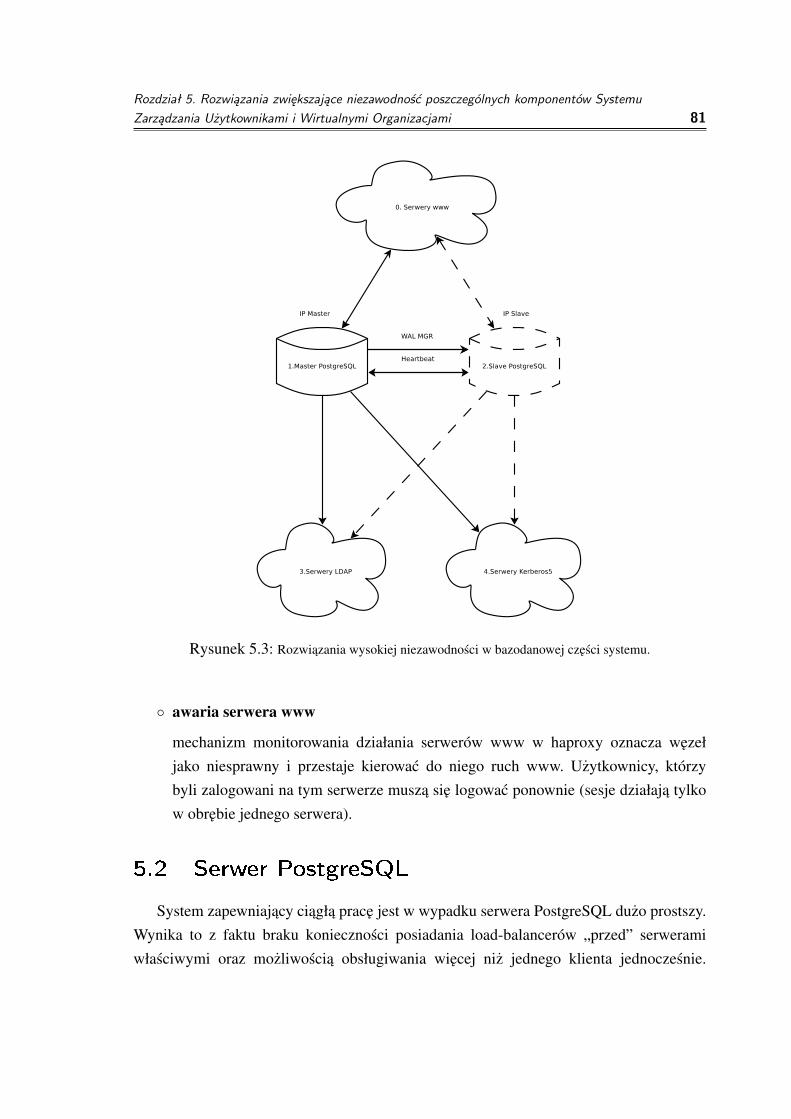
Rozdział 5. Rozwiązania zwiększające niezawodność poszczególnych komponentów Systemu
Zarządzania Użytkownikami i Wirtualnymi Organizacjami 81
Rysunek 5.3: Rozwiazania wysokiej niezawodnosci w bazodanowej czesci systemu.
◦ awaria serwera www
mechanizm monitorowania działania serwerów www w haproxy oznacza wezełjako niesprawny i przestaje kierowac do niego ruch www. Uzytkownicy, którzybyli zalogowani na tym serwerze musza sie logowac ponownie (sesje działaja tylkow obrebie jednego serwera).
5.2 Serwer PostgreSQL
System zapewniajacy ciagła prace jest w wypadku serwera PostgreSQL duzo prostszy.Wynika to z faktu braku koniecznosci posiadania load-balancerów „przed” serweramiwłasciwymi oraz mozliwoscia obsługiwania wiecej niz jednego klienta jednoczesnie.

Rozdział 5. Rozwiązania zwiększające niezawodność poszczególnych komponentów Systemu
Zarządzania Użytkownikami i Wirtualnymi Organizacjami 82
Z tego tez powodu została podjeta decyzja o wyborze scenariusza z jednym serweremaktywnym i jednym w stanie warm-standby. Do tego celu mozna wykorzystac aplikacjewalmgr z pakietu skytools. Walmgr stosuje technike zwana log-shipping w celu utrzymaniaaktualnej kopii serwera głównego na serwerze zapasowym. Rozwiazanie to polega naumieszczaniu logów transakcyjnych bazy danych na serwerze zapasowym i uruchomieniuna nim serwera baz danych, który aktualizuje stan bazy na podstawie zawartosci logów.Aby zmiana bazy w wypadku awarii odbyła sie w sposób mozliwie niezauwazalny dlaserwera www, nowy serwer przejmuje równoczesnie adres ip, do którego kierowane sapołaczenia z serwerów www.
5.3 Serwer Kerberos
Systemu Kerberos uzywamy do zarzadzania hasłami zarówno z poziomu serwisuwww jak i z poziomu klastrów obliczeniowych. Z tego tez powodu wymaganejest, aby serwery te spełniały wyzsze wymagania dostepnosci/niezawodnosci nizpozostałe komponenty systemu. Niestety istniejace implementacje Kerberosa nie zawierajadziałajacych mechanizmów replikacji multimaster (mozliwosc pisania do kazdej maszynyi synchronizacja zmian miedzy nimi wraz z polityka rozwiazywania konfliktów). Istniejacerozwiazanie replikacyjne jest zdecydowanie niezadowalajace - polega na robieniu kopiibazy Kerberosa (dump bazy), a nastepnie wykonywaniu łaczenia kopii z działajaca replikana serwerze slave. Rozwiazanie to jest wysoce nieskalowalne (dump bazy przy duzejliczbie uzytkowników moze byc wykonywany dosc długo) i czas replikacji zmienia sieliniowo wzgledem liczby uzytkowników, a nie wzgledem dokonywanych zmian. W chwiliobecnej istnieje jednak mozliwosc zastosowania wtyczki do serwera MIT Kerberos5dodajacej mozliwosc posiadania bazy danych aplikacji w serwerze LDAP. Dzieki temumozna wykorzystac rozbudowane mozliwosci replikacyjne serwera LDAP (opisane wRozdziale 5.4) do zapewnienia wysokiej niezawodnosci bazy haseł Kerberos.
5.4 Serwer OpenLDAP
Uzywamy serwera OpenLDAP (slapd) posiadajacego mozliwosc replikacji zarównow modelu multimaster (zmian mozna dokonywac na kazdej maszynie replikowaneji zostana rozpropagowane do pozostałych) jak i master - multiple slaves (operacjezapisu mozna prowadzic tylko na jednej maszynie - pozostałe moga słuzyc tylko
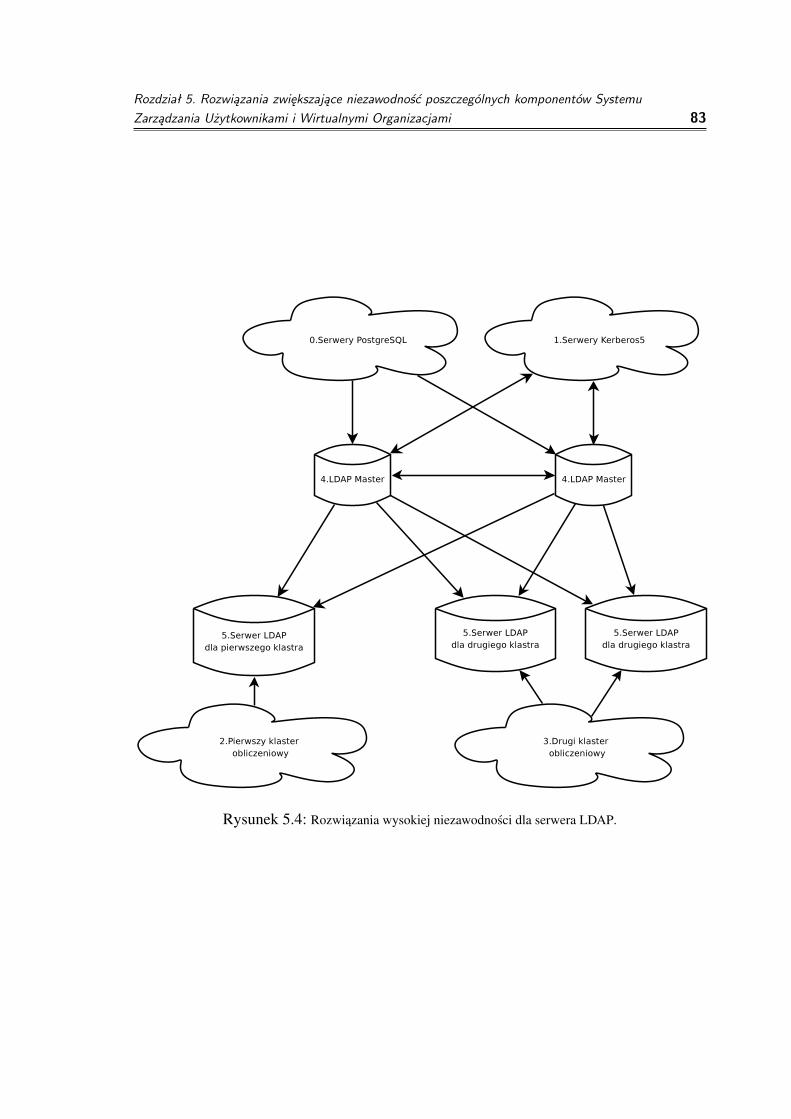
Rozdział 5. Rozwiązania zwiększające niezawodność poszczególnych komponentów Systemu
Zarządzania Użytkownikami i Wirtualnymi Organizacjami 83
Rysunek 5.4: Rozwiazania wysokiej niezawodnosci dla serwera LDAP.

Rozdział 5. Rozwiązania zwiększające niezawodność poszczególnych komponentów Systemu
Zarządzania Użytkownikami i Wirtualnymi Organizacjami 84
do operacji odczytu). Podczas analizy modelu wykorzystania systemu LDAP zostałwyciagniety wniosek, ze w wypadku systemu zarzadzania uzytkownikami najlepiejbedzie sie sprawdzał model hybrydowy powyzszych dwóch. Replikacja multimasterobejmowac powinna serwery główne, z którymi w sytuacji działania komunikuja sietylko serwery baz danych PostgreSQL, serwery Kerberos oraz repliki LDAP działajacew obrebie klastrów obliczeniowych. Nie jest przewidywana potrzeba zwiekszania liczbytych serwerów powyzej dwóch - dwa serwery LDAP wraz z zarzadzaniem ich adresamisieciowymi przez heartbeat wydaja sie rozwiazaniem wystarczajacym z punktu widzeniawymagan wysokiej niezawodnosci/dostepnosci. Jedynym problemem w wypadku awariiobu głównych serwerów LDAP byłby brak mozliwosci uwierzytelnienia sie, zarównow panelu na stronie www, jak i w klastrach obliczeniowych. Z tego tez powodu, abyzminimalizowac skutki ewentualnych awarii, nalezy wprowadzic nastepujace rozwiazanie:
◦ kazdy serwer Kerberos uzywa wszystkich serwerów LDAP do składowania danych
◦ serwerami LDAP dla Kerberosa sa serwery główne LDAP z replikacja multimaster(operacje zapisu mozna wykonywac na kazdym serwerze)
Zalety powyzszego rozwiazania:
◦ W razie potrzeby mozna zwiekszac niezaleznie zarówno liczbe serwerów LDAP, jaki Kerberos. Nie ma zwiazku miedzy tymi liczbami.
◦ W wypadku awarii system bedzie działał, póki bedzie sprawny przynajmniej jedenserwer Kerberos i jeden serwer główny LDAP
◦ Szybka propagacja zmian danych w serwerze Kerberos miedzy róznymi maszynami(w przeciwienstwie do replikacji master - slave wbudowanej w system MITKerberos).
Zupełnie oddzielna sprawa jest rozwiazywanie nazw w systemie, w klastrzeobliczeniowym. Kazdy klaster obliczeniowy posiada swoja własna replike poddrzewaserwera LDAP. Usługi tłumaczace nazwy na identyfikatory i identyfikatory na nazwyuzywaja, w pierwszej kolejnosci, serwerów lokalnych dla klastra obliczeniowego -a w wypadku braku mozliwosci połaczenia z nimi serwerów głównych.
Scenariusze awarii:
◦ awaria jednego z głównych serwerów LDAP

Rozdział 5. Rozwiązania zwiększające niezawodność poszczególnych komponentów Systemu
Zarządzania Użytkownikami i Wirtualnymi Organizacjami 85
◦ heartbeat drugiej maszyny przejmuje ip serwera
◦ wszystkie zapytania do pierwszej maszyny spoza klastra LDAP sa obsługiwaneprzez serwer drugi, zapytania do serwera drugiego sa obsługiwane bez zmian
◦ awaria jednego z serwerów Kerberos
Aplikacje klienckie nie mogac sie uwierzytelnic w jednym z serwerów, ponawiajapróbe na serwerze kolejnym z listy.
◦ awaria serwera LDAP w klastrze obliczeniowym
Aplikacje korzystaja z kolejnych serwerów LDAP zdefiniowanych w konfiguracji- sa to albo inne serwery LDAP, w obrebie klastra obliczeniowego, albo serwerygłówne LDAP.
5.5 Podsumowanie
Powyzsze rozwiazania bardzo skutecznie zabezpieczaja przed skutkaminieplanowanych przestojów. Nic nie stoi na przeszkodzie, aby te same rozwiazaniabyły stosowane w przypadku przestojów serwisowych. Jednak w tym wypadku trzebasie zastanowic, czy rekonfiguracja systemu zwiazana z przeniesieniem obsługi miedzyserwerami jest konieczna w czasie prac prowadzonych w trakcie okna serwisowego.Nalezy pamietac, ze najczesciej prace konserwacyjne nie trwaja wiecej niz kilka godzinw nocy. W najprostszej konfiguracji tylko serwer www oraz baza danych PostgreSQLnie sa zwielokrotnione. Co za tym idzie jedynie operacje na certyfikatach moga miec,zwiazana z planowanymi przestojami, przerwe w działaniu. W praktyce przerwaw działaniu serwera www czy bazy PostgreSQL nie powoduje przerw w działaniupodstawowych systemów centrum obliczeniowego. Z tego tez powodu mozna przyjac,ze system zarzadzania nie wprowadza mechanizmów, które wprowadzałyby mozliwoscpojawiania sie dodatkowych przestojów. Jedynym przypadkiem, który mógłby wywołactaki efekt jest uszkodzenie jednej z głównych baz LDAP, które zostałoby zreplikowanedo pozostałych wezłów. Z tego własnie powodu bardzo istotnym wymaganiem systemujest stosowanie pewnego i sprawdzonego systemu wykonywania kopii zapasowych.

Rozdział6
Optymalizacjai skalowalność usługwchodzących w składSystemu ZarządzaniaUżytkownikamii Wirtualnymi Organizacjami
W rozdziale tym przedstawione zostały metody poprawienia parametrów
wydajnosciowych poszczególnych komponentów Systemu Zarzadzania
Uzytkownikami i Wirtualnymi Organizacjami - zarówno w wersji
jednomaszynowej jak i rozkładanie obciazenia miedzy wiele urzadzen.
W przypadku bazy PostgreSQL poza konfiguracja indeksów, buforów
oraz umieszczaniem logów transakcyjnych oraz wybranych tabel
na dedykowanych, szybszych dyskach, zaproponowane zostało
wykorzystanie PL/Proxy do partycjonowania bazy danych. W przypadku
serwera slapd przedstawiona została analiza mozliwosci buforowania
zarówno wyników samych zapytan (na poziomie systemu operacyjnego
przy uzyciu nscd oraz przy zastosowaniu Proxy Cache Engine) jak
i buforowania danych przez serwer slapd (bufory BerkeleyDB, slapd
Entry Cache, IDL Cache). Zostały przedstawione równiez metody budowy

Rozdział 6. Optymalizacja i skalowalność usług wchodzących w skład Systemu Zarządzania
Użytkownikami i Wirtualnymi Organizacjami 87
rozproszonego katalogu - zarówno z zastosowaniem chainningu jak i
referrali.
Zastosowanie systemu zarzadzania w srodowiskach obliczeniowych wymaga bardzopowaznego podejscia do kwestii skalowalnosci rozwiazania. Podstawowym elementemjest tutaj identyfikacja waskich gardeł systemu, analiza stopnia ich zagrozenia dlaprac podstawowych prowadzonych w srodowisku obliczeniowym oraz przygotowanierozwiazan minimalizujacych negatywne oddziaływanie nowego systemu.
6.1 Analiza systemowa
Analizujac schemat systemu mozna łatwo dojsc do wniosku, ze najbardziejobciazonym elementem systemu zarzadzania jest serwer LDAP. Tylko ten element jestwykorzystywany cały czas przez klastry obliczeniowe, zarówno do translacji nazwi identyfikatorów jak i jako baza dla serwera Kerberos. Na drugim biegunie znajduje sieaplikacja www wraz z baza danych. Uzytkowników zmieniajacych hasło czy operujacychna certyfikacie w jednym momencie jest duzo mniej niz uzytkowników prowadzacychobliczenia.
6.1.1 Wpªyw zwi¦kszenia liczby u»ytkowników na obci¡»enie
poszczególnych elementów systemu zarz¡dzania
Nalezy na wstepie zauwazyc, ze samo zwiekszenie liczby uzytkowników niepowinno miec wpływu na prowadzone prace obliczeniowe. Co wiecej oczekiwanaliczba uzytkowników, oscylujaca w granicach rzedu tysiecy, nie stanowi problemuwydajnosciowego zarówno dla bazy LDAP jak i dla wybranej bazy SQL (PostgreSQL).Serwery te sa w stanie wydajnie pracowac na wiele wiekszych zbiorach danych. Jezelitylko wykorzystanie maszyn obliczeniowych nie uległo zmianie obciazenie generowaneprzez sam proces obliczeniowy nie powinno ulec zmianie. Inaczej ma sie sprawaw wypadku gdy wzrost liczby uzytkowników doprowadził do zwiekszenia wykorzystaniazasobów centrum obliczeniowego. Jednak ten przypadek bardziej odpowiada zwiekszeniuliczby maszyn w centrum. Jedynymi realnie zmieniajacymi sie parametrami, wraz zewzrostem liczby uzytkowników, sa rozmiar bazy i odpowiadajacy mu wzrost rozmiarówindeksów oraz zwiekszenie liczby operacji wykonywanych z poziomu panelu www.Jednak nawet bardzo duze centra obliczeniowe nie posiadaja wystarczajaco licznej
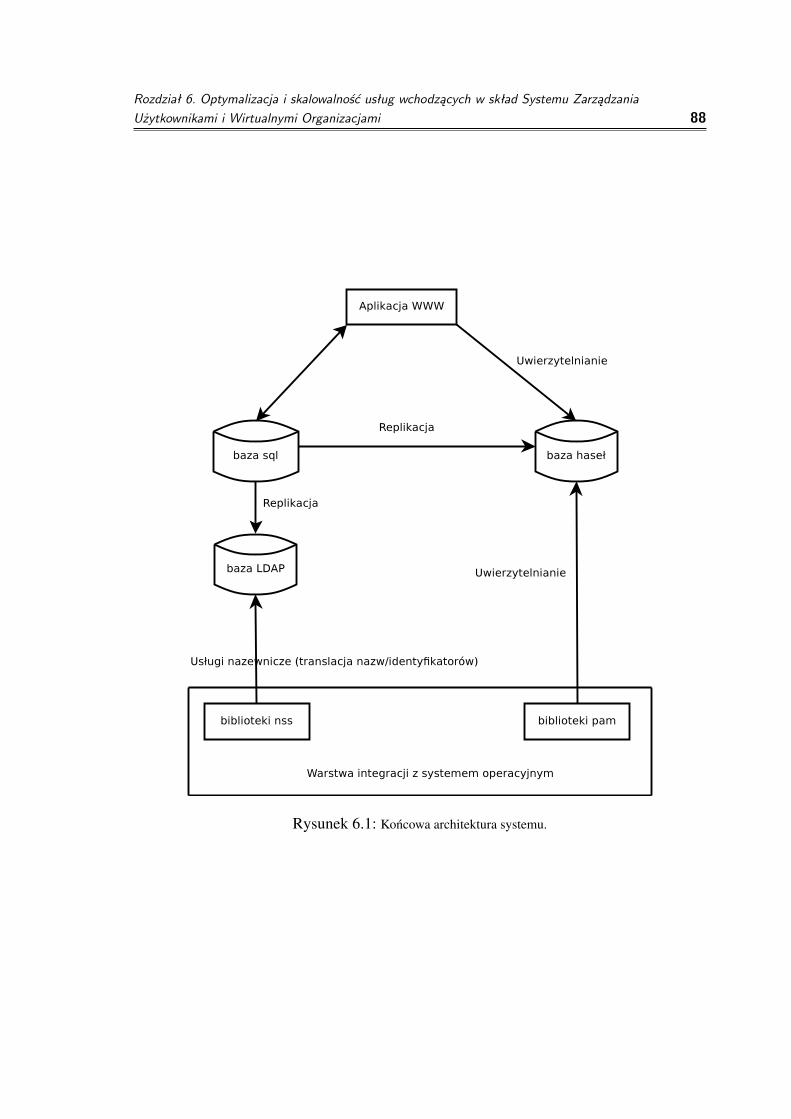
Rozdział 6. Optymalizacja i skalowalność usług wchodzących w skład Systemu Zarządzania
Użytkownikami i Wirtualnymi Organizacjami 88
Rysunek 6.1: Koncowa architektura systemu.

Rozdział 6. Optymalizacja i skalowalność usług wchodzących w skład Systemu Zarządzania
Użytkownikami i Wirtualnymi Organizacjami 89
grupy badaczy/uzytkowników, aby miało to istotny wpływ na działanie zarówno bazyPostgreSQL jak i bazy LDAP. Jedynym punktem, który moze odczuc wzrost obciazeniawynikajacy ze znacznego zwiekszenia liczby uzytkowników, jest aplikacja www.
6.1.2 Wpªyw zwi¦kszenia liczby maszyn czy projektów na obci¡»enie
poszczególnych elementów systemu zarz¡dzania
Zupełnie inaczej wyglada sprawa wzrostu liczby wykorzystywanych maszyn. W takimwypadku zwieksza sie obciazenie praktycznie kazdego elementu systemu zarzadzania.Jezeli liczba maszyn wzrosnie w ramach jednego klastra obliczeniowego, rosnie obciazenieserwera LDAP pracujacego w tym projekcie. Rosnie równoczesnie obciazenie serweraKerberos (a co za tym idzie dostarczajacego mu dane serwera LDAP), wynikajaceze wzrostu liczby logujacych sie uzytkowników (wzrost liczby dostepnych maszynpowoduje wzrost liczby logujacych sie uzytkowników, którzy chca prowadzic obliczeniaz wykorzystaniem nowych zasobów). Wzrost liczby maszyn nie powinien spowodowaczmiany obciazenia bazy danych - systemy działajace w ramach klastrów obliczeniowychnie kontaktuja sie bezposrednio z baza danych PostgreSQL.
Wzrost liczby projektów, a wraz z nim liczby maszyn powiazanych z projektem,powoduje przede wszystkim wzrost obciazenia centralnych serwerów LDAP orazw niewielkim stopniu wzrost obciazenia bazy danych, zwiazany ze zwiekszeniemliczby generowanych rekordów wraz z kazda zmiana w rekordzie uzytkownika. Wzrostobciazenia w centralnej bazie LDAP jest zwiazany z pojawieniem sie nowego poddrzewaw strukturze bazy oraz jego replikacja do klastrów pracujacych dla danego projektu.Podobny wzrost obciazenia pojawia sie równiez w wypadku serwerów Kerberos, a coza tym idzie równiez dostarczajacy mu danych serwer LDAP.
6.2 Poszukiwanie w¡skich gardeª systemu
i analiza ich wpªywu na dziaªanie systemów
obliczeniowych
Kluczowym elementem badania i poprawy skalowalnosci systemu jest znalezienietych jego punktów, które moga ograniczac wydajnosc pozostałych elementów. Mogato byc zarówno elementy strukturalne jak i zastosowane protokoły komunikacyjne.Na poczatku nalezy sie zastnowic, jaki wpływ maja poszczególne elementy systemu

Rozdział 6. Optymalizacja i skalowalność usług wchodzących w skład Systemu Zarządzania
Użytkownikami i Wirtualnymi Organizacjami 90
zarzadzania na działalnosc podstawowa centrum obliczeniowego. W trakcie obliczenwykonywanych na klastrach obliczeniowych jedynym elementem, z którym mozeodbywac sie komunikacja, jest serwer LDAP. Z poziomu systemów obliczeniowychna etapie logowania lub zmiany hasła wystepuje równiez komunikacja do serwera Kerberos- jednak wydajnosc tego elementu ma znaczenie marginalne - proces logowania do systemujest zdarzeniem o kilka rzedów wielkosci krótszym niz same operacje na serwerzeczy obliczenia. Zupełnie innym zagadnieniem jest wpływ pozostałych komponentówna obliczenia. Uzytkownik, z poziomu panelu administracyjnego, jedyne co moze zrobic,to zmienic sobie hasło albo wykonac operacje na certyfikacie (generowanie nowego,dodanie do projektu itd.). Administrator z poziomu panelu wykonuje duzo wiecej zadan- zarzadzanie uzytkownikami, projektami itd. Jednak w wypadku administratora bedziemozliwosc wykonywania tych zadan przy uzyciu skryptów korzystajacych z interfejsuXML-RPC1 i za jego posrednictwem automatyzowania bardziej złozonych operacji. Niema potrzeby aby działajace bez interakcji z uzytkownikiem skrypty powłoki miały krótkiczas odpowiedzi.
6.3 Metody eliminacji w¡skich gardeª
W tej czesci przedstawione zostały techniki, które mozna zastosowac w wypadkupojawienia sie problemów z wydajnoscia poszczególnych komponentów systemu. Sa onedwojakiego rodzaju - ogólna optymalizacja pojedynczej instancji serwera oraz rozwiazaniarozdzielajace obciazenie na wieksza liczbe maszyn.
6.3.1 Serwer www
Serwer www nie powinien byc bardzo mocno obciazony - podstawowymi operacjamiwykonywanymi za jego posrednictwem sa operacje na certyfikatach badz zmiana haseł.Operacje te wykonuje sie jednak stosunkowo rzadko, co przekłada sie na niewielkiewymagania wydajnosciowe w stosunku do pozostałych komponentów systemu. Istniejajednak centra obliczeniowe, w których liczba uzytkowników jest na tyle wysoka, ze mimostosunkowo niewielkiego obciazenia przypadajacego na serwer www jedna jego instancjamoze okazac sie niewystarczajaca. W takim wypadku nalezy zastosowac rozwiazania,które umozliwia działanie na wiecej niz jednej instancji serwera www. Najwazniejsza
1Protokół zdalnego wywoływania procedur (remote procedure calling) wykorzystujacy XML dokodowania komunikacji

Rozdział 6. Optymalizacja i skalowalność usług wchodzących w skład Systemu Zarządzania
Użytkownikami i Wirtualnymi Organizacjami 91
cecha ułatwiajaca zwielokrotnianie serwera www jest fakt, ze serwer ten nie tworzylokalnie plików. Jedynymi bytami z jakimi sie komunikuje (albo moze komunikowac) sa -serwer proxy/load-balancer haproxy, serwer baz danych PostgreSQL i opcjonalnie serwermemcached (buforowanie sesji oraz danych). Dzieki takiemu rozwiazaniu, jezeli dojdziedo sytuacji, gdy przetwarzanie kodu aplikacji przebiega za wolno, mozna bedzie dołaczyckolejne serwery mongrel z kopia aplikacji www do zarzadzania. Jedynym miejscemingerencji w działajacym systemie bedzie modyfikacja konfiguracji serwera proxy tak abyuwzgledniał przy przekazywaniu zapytan dodatkowy serwer mongrel.
6.3.2 Baza danych PostgreSQL
W wypadku bazy tej pierwszym problemem wydajnosciowym z jakim siemozemy zetknac to brak załozonych indeksów. Ten przypadek mozna bardzo łatwoprzeanalizowac, uzywajac w konsolowej aplikacji psql komendy „explain analyze”.W wyniku przedstawiony zostaje w drzewiastej strukturze sposób przetworzenia zapytaniana elementarne operacje. Obecnosc wsród nich skanowania sekwencyjnego (Seq Scan)moze swiadczyc o braku indeksu. Nie nalezy przy tym traktowac tego jako pewnik -w przypadku gdy planista serwera PostgreSQL zdecyduje, ze w wyniku zapytania zostaniezwróconych wiekszosc wierszy z tabeli, nie bedzie wyszukiwał ich przy uzyciu indeksów(nawet jezeli sa) tylko zastosuje skanowanie sekwencyjne.
Kolejnym krokiem poprawiajacym wydajnosc jest porozdzielanie róznych tabelna róznych dyskach - w zaleznosci od profilu uzytkowania systemu mozna czesciejuzywane tabele umiescic na szybkich dyskach (np. scsi), a mniej uzywane na wolniejszych(np. sata). Dobrym rozwiazaniem jest umieszczenie logów transakcyjnych na szybkim,dedykowanym medium. Warto pamietac równiez o tym, ze dla kazdej bazy danychkluczowym elementem jest pamiec operacyjna - im jej wiecej tym lepiej - dzieki temuwiecej danych z dysków jest buforowanych.
Jezeli osiagnieta zostanie granica rozszerzalnosci pojedynczej maszyny, czas bedziepomyslec o zastosowaniu rozwiazan klastrowych. Z dostepnych mechanizmów (replikacjamulti-master, replikacja master-slave oraz partycjonowanie danych) nalezy wybracrozwiazanie uwzgledniajac profil wykorzystania zasobów. Baza danych ma bardzoszczególny profil uzytkowania. Dominowac w niej beda operacje dodawania (INSERT),aktualizacji (UPDATE) i kasowania (DELETE). Z tego tez powodu nie ma sensu rozwazaczastosowania replikacji master-slave oraz multi-master. Replikacja sama w sobie nieprzyspiesza operacji zapisu w bazie danych, moze tylko je spowalniac. Dobór jednego

Rozdział 6. Optymalizacja i skalowalność usług wchodzących w skład Systemu Zarządzania
Użytkownikami i Wirtualnymi Organizacjami 92
Rysunek 6.2: Rozwiazanie zwiekszajace skalowalnosc systemu bazy danych SQL.
z tych mechanizmów opiera sie na analizie statystycznej zapytan wraz z ich wagai decydowaniu czy operacje przyspieszane (odczyty) dominuja w stopniu wystarczajacymdo wprowadzenia tego mechanizmu. W wypadku systemu zarzadzania uzytkownikamii wirtualnymi organizacjami, gdzie wiekszosc zapytan czytajacych komunikuje siez serwerami LDAP a nie baza danych PostgreSQL nie ma powodu stosowac replikacji.
Inaczej ma sie sprawa z partycjonowaniem. Mozemy poszukac tabel czesto uzywanychi zdecydowac, ze dane w nich maja byc rozmieszczone na kilku róznych serwerach.Niestety taka zmiana wymaga juz modyfikacji aplikacji. Wszelkie operacje zapisudo tabel własciwych musza przechodzic przez warstwe posrednia stworzona przy pomocyPL/Proxy [18]. Pl/Proxy jest mechanizmem słuzacym do partycjonowania tabel i zdalnegowywoływania zapytan bazujacym na generowaniu skrótu z wartosci wybranych kolumni na tej podstawie rozkładaniu danych miedzy serwery bedace czescia klastra. Dziekitakiemu rozwiazaniu operacje zapisu sa kierowane tylko do docelowego serwera (jednegow klastrze), natomiast operacje wyszukiwania operuja na kazdym wezle na duzo mniejszej

Rozdział 6. Optymalizacja i skalowalność usług wchodzących w skład Systemu Zarządzania
Użytkownikami i Wirtualnymi Organizacjami 93
ilosci danych, co wpływa na rozmiar indeksów i ogólna szybkosc. Koncowe wyniki musijednak połaczyc warstwa posrednia w postaci PL/Proxy.
6.3.3 Baza danych LDAP
W wypadku bazy LDAP, zanim zostanie rozpoczeta optymalizacja, nalezy siezastanowic nad kwestiami buforowania wyników zapytan w systemach obliczeniowych.Nalezy zwrócic uwage na to, ze generalnie rzecz biorac poza hasłami (weryfikowanymiprzy logowaniu), reszta danych, nawet jezeli jest nieaktualna, nie przeszkadzaw poprawnym działaniu. Wazne jest jednak to, aby nowe dane były dostepne. Analizujacprzedstawione powyzej fakty mozna dojsc do wniosku, ze w tym wypadku bardzokorzystne byłoby przechowywanie w lokalnych buforach na maszynach obliczeniowychkopii danych tam wykorzystywanych. Do tego celu stosowany jest daemon nscd2 dostepnywraz biblioteka GNU libc.
Dodatkowo sam serwer OpenLDAP posiada mozliwosci buforowania wynikówzapytan. Słuzy temu Proxy Cache Engine. Definiowane sa w nim szablony zapytan, którychwyniki (jak równiez same zapytania) maja byc lokalnie buforowane. W wypadku zapytanrozbieznych ze zdefiniowanymi szablonami oraz tych, które pasuja do szablonu ale ichwyniku nie ma lokalnie zapamietanego, zapytanie trafia do własciwego serwera LDAP,a nastepnie jego wynik jest zwracany aplikacji klienckiej. W przypadku gdy zapytaniepasuje do szablonu, jego wynik jest równoczesnie zapisywany w lokalnym buforze.
Problemy z wydajnoscia bazy LDAP moga miec podobne przyczyny jak w wypadkubazy PostgreSQL - brak indeksów. Zakładanie indeksów w wypadku serwera OpenLDAPjest nieco trudniejsze. Po pierwsze trzeba znalezc atrybut, który bedziemy indeksowac.Jezeli w trakcie działania serwera LDAP znajdzie sie w logach komunikat: „<=bdb_equality_candidates: (foo) index_param failed (18)”, bedzie to oznaczało, zebrakuje indeksu na atrybucie foo. Zakładanie indeksów w wypadku OpenLDAP nie jestniestety az tak proste jak w wypadku PostgreSQL. Proces ten jest kilkufazowy.
◦ Konfiguracji serwera - w miejscu definicji indeksów w pliku konfiguracyjnym nalezydopisac
i n d e x foo eq
◦ Indeks ten trzeba jeszcze utworzyc. Do tego celu słuzy narzedzie slapindex.Uruchamiajac je nalezy pamietac, ze musi ono działac przy wyłaczonym serwerze
2Name Service Cache Daemon

Rozdział 6. Optymalizacja i skalowalność usług wchodzących w skład Systemu Zarządzania
Użytkownikami i Wirtualnymi Organizacjami 94
OpenLDAP oraz musi działac z uprawnieniami uzytkownika OpenLDAP. Powygenerowaniu indeksów mozna ponownie uruchomic serwer OpenLDAP.
Kolejna istotna kwestia jest optymalizacja wykorzystania pamieci na buforowaniedanych. W wypadku serwera OpenLDAP wystepuja trzy rodzaje buforów (pomijajacbuforowanie na poziomie systemu operacyjnego).
◦ Pierwszym rodzajem buforów sa bufory bazy BerkeleyDB (format organizacjidanych na dysku stosowany przez OpenLDAP). Ze wzgledu na rozmiar danychprzechowywanych w systemie LDAP mozna przyjac, ze bufor ten powinienspokojnie pomiescic całosc bazy. Jezeli tak nie bedzie, warto starac sie zmiescicw pamieci id2entry.bdb. Jezeli i to sie nie uda, trzeba dobrac rozmiar cache tak, abyw pamieci znajdowały sie wszystkie najczesciej uzywane dane.
◦ Drugim rodzajem buforów jest bufor na przetworzone rekordy (slapd Entry Cache).Rekordy znajdujace sie w tym cache beda serwowane bezposrednio z pamiecioperacyjnej - zostały wczesniej sparsowane i stad tez beda najszybciej dostepne.Warto przy tym pamietac, ze rozmiar rekordu w buforze na przetworzone rekordyjest około dwa razy wiekszy niz w buforze bazy BerkeleyDB.
◦ Trzecim rodzajem buforów majacym wpływ na wydajnosc serwera OpenLDAPjest IDL Cache. Jest to bufor przechowujacy wyniki najczestszych wyszukiwan.Rekomendowanymi wartosciami sa: w wypadku stosowania back-bdb rozmiarodpowiadajacy buforowi na przetworzone rekordy, w wypadku stosowania back-hdb rozmiar trzykrotnie przekraczajacy rozmiar bufora zawierajacego przetworzonerekordy.
Omówione wczesniej rozwiazania dotycza optymalizacji pojedynczej instancji serweraLDAP. Jezeli bedzie to niewystarczajace, mozna zajac sie optymalizacja strukturyserwerów. W profilu uzytkowania serwerów LDAP wiekszosc operacji bedzie operacjamiwyszukiwania i odczytu. Z tego tez powodu nalezy omówic rozwiazania przyspieszajacetego typu operacje.
Operacje odczytu mozna przyspieszyc rozkładajac je miedzy wieksza liczbe maszyn.Wystarczy w tym celu zwielokrotnic repliki działajace na rzecz poszczególnych klastrówobliczeniowych. Rozwiazanie to jednak nie pomaga w sytuacji gdy rozmiar bazy i liczbaklientów bedzie na tyle duza, ze pojawia sie nawet problemy z zapisami (liczbaoperacji zmiany hasła, dodawania uzytkownika, modyfikacji uzytkownika (czy ogólnie

Rozdział 6. Optymalizacja i skalowalność usług wchodzących w skład Systemu Zarządzania
Użytkownikami i Wirtualnymi Organizacjami 95
danych w bazie LDAP) bedzie przekraczac rzad tysiecy w ciagu sekundy). W takimwypadku jedynym rozwiazaniem bedzie partycjonowanie katalogu (w nomenklaturzeLDAP operacje te okresla sie mianem tworzenia rozproszonego katalogu). Cała operacjaopiera sie na specjalnym typie obiektu - referral. Obiekt taki wskazuje, ze całe poddrzewo,którego jest korzeniem znajduje sie w katalogu wskazywanym przez atrybut ref. Przykładzaczerpniety z dokumentacji OpenLDAP [14]:
dn : dc= s u b t r e e , dc=example , dc= n e to b j e c t C l a s s : r e f e r r a lo b j e c t C l a s s : e x t e n s i b l e O b j e c tdc : s u b t r e er e f : l d a p : / / b . example . n e t / dc= s u b t r e e , dc=example , dc= n e t
Innym rozwiazaniem jest tak zwany chaining - w wypadku tworzenia rozproszonegokatalogu z uzyciem typu obiektu referral potrzebne jest poprawnie działajace wsparcie zestrony aplikacji uzywajacych protokołu LDAP. W wypadku zastosowania chainingu całyproces przetwarzania rozproszonego jest dla aplikacji przezroczysty - serwer zajmuje sieoperacjami na obiektach zdalnych i zwraca wyniki bezposrednio aplikacji.
Najczesciej polecanym rozwiazaniem jest zastosowanie formy łaczacej rozwiazaniaopisywane powyzej. Definiowane sa poddrzewa lokalne i zdalne. Do baz lokalnychaplikacje odwołuja sie bezposrednio, natomiast wyniki zapytan z baz zdalnychprzechowywane sa w lokalnym buforze.
6.4 Podsumowanie
Majac obraz całosci prezentowanych rozwiazan z dziedziny skalowalnoscii optymalizacji warto zauwazyc, ze najbardziej obciazone normalna praca elementysystemu zarzadzania sa optymalizowane poprzez sama architekture systemu. Najczesciejwykonywane operacje nie wykorzystuja systemów centralnych (baza PostgreSQL,centralne serwery LDAP poza weryfikacja hasła czy serwer www) tylko lokalne w ramachklastrów obliczeniowych repliki poddrzew drzewa LDAP. Dodatkowo łatwo moznazauwazyc, ze wzrost obciazenia tych elementów moze zostac łatwo przezwyciezonypoprzez zwielokrotnienie instancji lokalnej repliki czy niewielka - umozliwiajacawprowadzenie kolejnego poziomu podziału poddrzewa - przebudowe struktury bazyLDAP.

Rozdział 6. Optymalizacja i skalowalność usług wchodzących w skład Systemu Zarządzania
Użytkownikami i Wirtualnymi Organizacjami 96
(a) Rozwiazanie zwiekszajace skalowalnosc bazy LDAP - referral.
(b) Rozwiazanie zwiekszajace skalowalnosc bazy LDAP - chaining.
Rysunek 6.3: Porównanie rozwiazan zwiekszajacych skalowalnosc bazy LDAP.

Rozdział7
Podsumowanie i dalszyrozwój Systemu ZarządzaniaUżytkownikamii Wirtualnymi Organizacjami
Aplikacja bazodanowa, której zbudowanie było celem tej pracy, działa i na jejpodstawie mozna dopisac kolejne komponenty całego systemu - aplikacje www orazrozszerzenie do zarzadzania cała infrastruktura serwerowa centrum obliczeniowego.Działanie tej aplikacji zostało przetestowane przy wypełnianiu bazy danymi testowymi.Niestety obserwowanie działania całosci, bez znajomosci jezyka SQL, jest mocnoutrudnione - całosc jest dobrze przygotowana pod katem współpracy z aplikacjawww i obserwacja działania wymaga dokonywania zmian w zawartosci bazy danychoraz obserwowania efektów tych zmian na serwerach obliczeniowych. Dotyczy tow szczególnosci operacji dotyczacych uzytkowników - zarówno bezposrednio jaki poprzez wirtualne organizacje.
Zbudowanie systemu wspomagajacego prace administratorów w centrumobliczeniowym w dziedzinie zarzadzania uzytkownikami i wirtualnymi organizacjamioraz konfiguracja jest zadaniem nietrywialnym. Widac to chocby po liczbie problemów,jakie trzeba rozwiazac przy samym zarzadzaniu uzytkownikami. Problemy z zachowaniemspójnosci danych miedzy róznymi systemami. Problemy z wydajnoscia czy skalowalnosciarozwiazan. Dodatkowym problemem przy wprowadzaniu nowosci jest badanie ichwpływu na zadania podstawowe - systemy obliczeniowe w centrum obliczeniowymnie powinny zuzywac wiekszosci swoich zasobów na operacje administracyjne, czy

Rozdział 7. Podsumowanie i dalszy rozwój Systemu Zarządzania Użytkownikami i Wirtualnymi
Organizacjami 98
wiekszosci czasu spedzac na oczekiwaniu na wyniki działan systemowych. Pamietacnalezy przy tym, ze system taki nie działa w prózni. Jego wdrozenie musi uwzgledniacistnienie srodowiska działania, oraz wymagania dotyczace oprogramowania z jakiegomoze korzystac. Własnie te czynniki spowodowały koniecznosc kilkukrotnych zmianw architekturze czy stosowanych rozwiazaniach. Wycofanie przez projekt OpenLDAPmozliwosci bezposredniego definiowania haseł jako identyfikatorów Kerberosa wymusiłowprowadzenie dosc istotnej zmiany w architekturze. Tworzac systemy stosowanew praktyce, ale uzywajace istniejacego oprogramowania, trzeba miec na wzgledziepotrzebe wprowadzania ciagłych zmian. Jakiekolwiek bardziej skomplikowaneoprogramowanie wymaga korekt, poprawek i zmian bedacych pochodnymi zmieniajacegosie swiata i zmian w wymaganiach uzytkowników. Nie wiadomo czy za rok albodwa zamiast systemów opartych o hasła nie bedzie trzeba wprowadzic rozwiazanwykorzystujacych sprzetowe klucze szyfrujace. Czy zamiast przechowywania certyfikatóww bazie LDAP nie beda one przechowywane w urzadzeniach podłaczonych do stacjiroboczej, które beda dostarczac je tylko systemowi uwierzytelniania w gridzie. Podobniejest z systemami zarzadzania konfiguracja. W momencie gdy rozpoczynane były prace nadSystemem Zarzadzania Uzytkownikami i Wirtualnymi Organizacjami nie był dostepnysystem o wystarczajaco zaawansowanym systemie zarzadzania konfiguracja maszyn,który nadawałby sie do wykorzystania w centrum obliczeniowym. W chwili obecnejistnieje tego typu system - puppet [22], który na dodatek jest dostepny na otwartej licencji.Oczywiscie jego zastosowanie wymaga wykonania sporej ilosci pracy przy przygotowaniuzarówno samego srodowiska, przygotowaniu konfiguracji aplikacji oraz przede wszystkimwprowadzeniu administratorów do nowego sposobu zarzadzania urzadzeniami.
Przygladajac sie po raz kolejny rozwiazaniom opracowanym w ramach innychprojektów - przede wszystkim Perunowi mozna znalezc bardzo wiele analogiiw działaniu i architekturze docelowego rozwiazania. W obu przypadkach zastosowanymmechanizmem uwierzytelniania jest Kerberos. W obu wypadkach w pewnym stopniu jeststosowana replikacja polegajaca na wypychaniu z głównej maszyny dalej (podstawowaróznica dotyczy tego jak daleko ona siega - w wypadku Peruna ten model działaniadotyczy propagowania zmian do maszyn docelowych, w przypadku Systemu ZarzadzaniaUzytkownikami i Wirtualnymi Organizacjami tego typu mechanizm stosowany jestjedynie do propagacji zmian miedzy technologiami - replikacja z bazy danych SQLdo bazy haseł Kerberos czy do bazy LDAP - replikacja zmian dalej jest prowadzonaz zastosowaniem mechanizmów odpytywania (pollingu)). Co ciekawe architektura samej

Rozdział 7. Podsumowanie i dalszy rozwój Systemu Zarządzania Użytkownikami i Wirtualnymi
Organizacjami 99
aplikacji bazodanowej wykazuje równiez pewne podobienstwa - przede wszystkimzastosowanie widoków jako mechanizmów ograniczajacych dostep do samych danychi uniemozliwienie aplikacji operowania na tabelach.
Wbrew oczekiwaniom zapewnienie aplikacji wysokiej niezawodnosci okazało sienie byc az tak trudnym zadaniem. Prawdopodobna przyczyna tego stanu rzeczy byłodpowiedni dobór technologii. Zastosowanie serwera LDAP oraz pluginu do serweraKerberos umozliwiajacego przechowywanie danych w serwerze LDAP umozliwiłozbudowanie systemu, który bedzie działał poprawnie nawet w wypadku awarii wiekszoscijego komponentów. Jedynym mechanizmem, który wymagał kilkukrotnych zmianzwiazanych z niezawodnoscia była replikacja danych z serwera SQL do bazy LDAP.Jednak wynik koncowy wydaje sie byc przynajmniej zadowalajacy - tym bardziej, zezaprojektowany i przetestowany mechanizm moze byc przy niewielkim nakładzie pracyzastosowany do replikacji danych z serwera PostgreSQL do dowolnego innego systemuprzechowywania danych (ten sam mechanizm jest stosowany do zarzadzania listamidyskusyjnymi oraz do propagacji danych z bazy SQL do systemu Kerberos).
7.1 Dalszy rozwój systemu
◦ Aplikacja www
Podstawowa kwestia wymagajaca pracy jest napisanie interfejsu www do systemuzarzadzania. Ze wzgledu na architekture aplikacji bazodanowej i wbudowaniew nia całej logiki wraz z mechanizmami replikacji aplikacja www bedzie prostympanelem operujacym na tabelach w bazie danych. Wraz z budowa interfejsu wwwz wykorzystaniem Ruby on Rails mozna bardzo łatwo dodac do aplikacji mozliwoscwykonywania działan a posrednictwem webservice.
Z punktu widzenia administratorów systemu przydatna opcja byłoby udostepnienieza posrednictwem RSS1 informacji zawartych w tabelach t_krb5arch, t_ldaparchi t_emlsarch. Tabele te zawieraja informacje na temat skutecznosci mechanizmówreplikacji danych z bazy PostrgeSQL do baz Kerberos5, LDAP oraz do systemu listmailingowych.
◦ Listy mailingowe oraz komunikacja z centrum podpisujacym certyfikaty1Really Simple Syndication

Rozdział 7. Podsumowanie i dalszy rozwój Systemu Zarządzania Użytkownikami i Wirtualnymi
Organizacjami 100
Jedyne bardziej skomplikowane mechanizmy jakie pozostały do napisaniato generowanie i przetwarzanie maili słuzacych do komunikacji z centrumpodpisujacym certyfikaty oraz prosta integracja oprogramowania do zarzadzanialistami dyskusyjnymi z Systemem Zarzadzania Uzytkownikami i WirtualnymiOrganizacjami (w tym wypadku wystarczy, bazujac na dokrb5.sh albo doldap.sh,napisac prosty skrypt, który bedzie pobierał dane z tabeli t_emls, zapisywał wynikido t_emlsarch i w wypadku sukcesu kasował zbedne rekordy z t_emls).
◦ Dostep do certyfikatów z poziomu aplikacji wchodzacych w skład Globus toolkit
Celem kluczowym systemu jest umozliwienie posiadania przez uzytkownika wiecejniz jednego certyfikatu w jednym projekcie. A dodatkowo mozliwosc łatwego nimizarzadzania. W chwili obecnej aplikacja bazodanowa umozliwia łatwe zarzadzaniecertyfikatami wraz z ich replikacja do odpowiednich poddrzew bazy ldap. Potrzebnaw tym miejscu zmiana jest modyfikacja proxy do pobierania certyfikatów takaby umozliwiało pobieranie ich z bazy ldap wraz z mozliwoscia wyboru, któryz certyfikatów ma zostac uzyty.
◦ Wdrozenie całosci i testowanie
Po zakonczeniu opisywanych prac nalezy wdrozyc aplikacje w srodowiskuprodukcyjnym i przeprowadzic jej testy wydajnosciowe wraz z testami awaryjnosci.
Dodatkowo wraz z powstawaniem aplikacji www powinny zostac do niejnapisane testy funkcjonalne i regresyjne - dzieki czemu bedzie mozna po kazdejzmianie wersji oprogramowania przeprowadzic zautomatyzowane testy poprawnoscidziałania całosci aplikacji w srodowisku testowym - zblizonym do produkcyjnego.
Do tego celu niezbedne jest zbudowanie srodowiska do testowania. Polecanymdo testowania aplikacji webowych rozwiazaniem jest Selenium [23]. Dziekijego zastosowaniu mozna bedzie po nagraniu testów przy uzyciu przegladarkifirefox wraz z rozszerzeniami dostarczanymi z selenium odtwarzac je przy uzyciupraktycznie dowolnej uzywanej przegladarki w srodowisku testowym.
◦ Dalszy kierunek rozwoju aplikacji
Aplikacja systemu zarzadzania winna byc rozwijana w kierunku kompleksowegozarzadzania serwerami w centrum obliczeniowym. Kolejnym etapem rozwojumogłoby byc zarzadzanie serwerami fizycznymi wraz z mechanizmamiautomatycznego dodawania ich do klastrów obliczeniowych oraz przygotowaniem

Rozdział 7. Podsumowanie i dalszy rozwój Systemu Zarządzania Użytkownikami i Wirtualnymi
Organizacjami 101
niezbednej konfiguracji. Sam mechanizm automatycznej instalacji systemunalezałoby oprzec o start serwerów z sieci i instalacje z zastosowaniem gotowychobrazów systemu (protokół bootp i pobieranie obrazów przy uzyciu udpcast [21] czyanalogicznie działajacej aplikacji) a nastepnie dostosowanie działajacego systemuprzy uzyciu scentralizowanego systemu zarzadzania konfiguracja (w tym wypadkupolecanym rozwiazaniem jest puppet).

Bibliografia
[1] I. Foster, C. Kesselman. The Grid: Blueprint for a New Computing Infrastructure.
Morgan Kaufmann Publishers, 1999.
[2] I. Foster, C. Kesselman, S. Tuecke. The Anatomy of the Grid: Enabling Scalable
Virtual Organizations. International J. Supercomputer Applications, 2001.
[3] A. Krenek, Z. Sebestianova. Perun - Fault-Tolerant Management of Grid Resources.
M. Bubak, M. Turała, K. Wiatr (eds). Cracow 04 Grid Workshop, WorkshopProceedings, strony 133-140, Kraków, 2004.
[4] M. Jankowski, P. Wolniewicz, N. Meyer. Virtual User System for Globus based
Grids. M. Bubak, M. Turała, K. Wiatr (eds). Cracow 04 Grid Workshop, WorkshopProceedings, strony 316-322, Kraków, 2004.
[5] F. Piedad, M. Hawkins. High availability: design, techniques, and processes. PrenticeHall, 2001.
[6] I. Foster, C. Kesselman, J. M. Nick, S. Tuecke. The Physiology of the Grid. An Open
Grid Services Architecture for Distributed Systems Integration. 6/22/2002.
[7] J. Denemark, M. Jankowski, A. Krenek, L. Matyska, N. Meyer, M. Ruda,P. Wolniewicz. Best Practices of User Account Management with Virtual
Organization Based Access to Grid. Parallel Processing and Applied Mathematics,strony 633-642, Springer Berlin / Heidelberg, 2006.
[8] M. Bubak. Wykład z Systemów Gridowych na kierunku Informatyka. AkademiaGórniczo - Hutnicza, 2004/2005.
[9] J. Kitowski. Wykład z Systemów Wysokiej Niezawodnosci na kierunku Informatyka.
Akademia Górniczo - Hutnicza, 2004/2005.

Bibliografia 103
[10] Strona domowa projektu PL-Grid,http://www.plgrid.pl/
[11] Przeglad systemu GUMS (Grid User Management System),https://www.racf.bnl.gov/Facility/GUMS/1.3/index.html, 15 grudnia 2008.
[12] Dokumentacja systemu OpenLDAP w wersji 2.2,http://www.openldap.org/doc/admin24/, 25 lutego 2004.
[13] Dokumentacja systemu OpenLDAP w wersji 2.3,http://www.openldap.org/doc/admin24/, 19 lutego 2008.
[14] Dokumentacja systemu OpenLDAP w wersji 2.4,http://www.openldap.org/doc/admin24/, 21 stycznia 2009.
[15] Dokumentacja systemu PostgreSQL w wersji 8.3.7,http://www.postgresql.org/docs/8.3/static/index.html
[16] Dokumentacja Berkeley DB,http://www.oracle.com/technology/documentation/berkeley-db/db/ref/toc.html
[17] Strona domowa projektu walmgr,http://skytools.projects.postgresql.org/doc/walmgr.html
[18] Strona domowa projektu PL/Proxy,https://developer.skype.com/SkypeGarage/DbProjects/PlProxy
[19] Strona domowa serwera memcached,http://www.danga.com/memcached/
[20] Strona domowa serwera mongrel,http://mongrel.rubyforge.org/
[21] Strona domowa programu udpcast,http://udpcast.linux.lu/
[22] Strona domowa programu puppet,http://reductivelabs.com/products/puppet/
[23] Strona domowa projektu selenium,http://seleniumhq.org/

Bibliografia 104
[24] Strona domowa projektu Ruby On Rails,http://rubyonrails.org/
[25] Strona domowa projektu ActiveRecord,http://ar.rubyonrails.org/
[26] Strona domowa projektu ActiveScaffold,http://activescaffold.com/
[27] Strona domowa serwera baz danych firebird,http://www.firebirdsql.org/
[28] Strona domowa serwera baz danych MySQL,http://www.mysql.com/
[29] Strona domowa serwera Haproxy,http://haproxy.1wt.eu/
[30] strona domowa serwera Keepalived,http://www.keepalived.org/
[31] Wikipedia,http://www.wikipedia.org/
[32] Licencja PostgreSQLa,http://www.postgresql.org/about/licence
[33] Strona domowa projektu Cyrus,http://cyrusimap.web.cmu.edu/

Spis ilustracji
2.1 Przypadki uzycia dla zwykłego uzytkownika. . . . . . . . . . . . . . . . 272.2 Przypadki uzycia dla administratora - zarzadzanie uprawnieniami. . . . . 282.3 Przypadki uzycia dla administratora - zarzadzanie grupami. . . . . . . . . 282.4 Przypadki uzycia dla administratora - zarzadzanie instytucjami. . . . . . . 292.5 Przypadki uzycia dla administratora - zarzadzanie listami dyskusyjnymi. . 292.6 Przypadki uzycia dla administratora - zarzadzanie projektami. . . . . . . 302.7 Przypadki uzycia dla administratora - zarzadzanie wirtualnymi organiza-
cjami. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 312.8 Przypadki uzycia dla administratora - zarzadzanie uzytkownikami. . . . . 322.9 Przypadki uzycia dla administratora z uprawnieniami do zarzadzania cer-
tyfikatami. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 332.10 Projekt architektury systemu zarzadzania. . . . . . . . . . . . . . . . . . 342.11 Diagram klas zarzadzania uzytkownikami. . . . . . . . . . . . . . . . . . 382.12 Diagram klas zarzadzania maszynami obliczeniowymi. . . . . . . . . . . 392.13 Diagram sekwencji - dodanie uzytkownika. . . . . . . . . . . . . . . . . 402.14 Diagram sekwencji - modyfikacja uzytkownika. . . . . . . . . . . . . . . 412.15 Diagram sekwencji - usuniecie projektu. . . . . . . . . . . . . . . . . . . 41
3.1 Porównanie architektur systemu zarzadzania. . . . . . . . . . . . . . . . 463.2 Sposób tworzenia tabeli na przykładzie "tabeli foo". Schemat przedstawia
stopien skomplikowania pojedynczej tabeli. . . . . . . . . . . . . . . . . 503.3 Przykład struktury drzewa LDAP. . . . . . . . . . . . . . . . . . . . . . 54
5.1 Schemat systemu zawierajacego rozwiazania wysokiej niezawodnosci. . . 785.2 Rozwiazania wysokiej niezawodnosci dla systemu www. . . . . . . . . . 795.3 Rozwiazania wysokiej niezawodnosci w bazodanowej czesci systemu. . . 815.4 Rozwiazania wysokiej niezawodnosci dla serwera LDAP. . . . . . . . . . 83

Rozdział 7. Spis ilustracji 106
6.1 Koncowa architektura systemu. . . . . . . . . . . . . . . . . . . . . . . . 886.2 Rozwiazanie zwiekszajace skalowalnosc systemu bazy danych SQL. . . . 926.3 Porównanie rozwiazan zwiekszajacych skalowalnosc bazy LDAP. . . . . 96

Spis akronimów
AFS Andrew File System
API Application programming interface
CA Certification Authority
CLI command-line interface
GECOS pole zawierajace imie, nazwisko, informacje kontaktowe
GID Group identifier
GSSAPI Generic Security Services Application Program Interface
GUMS Grid User Management System
IA-32 Intel Architecture, 32-bit
IA-64 Intel Itanium architecture, 64-bit
KDC Key Distribution Center
LDAPS LDAP z szyfrowaniem
LDAP Lightweight Directory Access Protocol
LDIF LDAP Data Interchange Format
MIPS Microprocessor without Interlocked Pipeline Stages
MIT Massachusetts Institute of Technology
NIS Network Information Service
NSS Name Service Switch

Rozdział 7. Spis akronimów 108
PAM Pluggable authentication modules
PC Personal Computer
PKCS Public Key Cryptography Standards
RA Regional Authority
RSS Really Simple Syndication
SMP Symmetric multiprocessing
SQL Structured Query Language
SSL Secure Socket Layer
TLS Transport Layer Security
UID User identifier
UML Unified Modeling Language
VUS Virtual User System
XML-RPC Protokół zdalnego wywoływania procedur (remote procedure calling)wykorzystujacy XML do kodowania komunikacji
Cyrus SASL Cyrus Simple Authentication and Security Layer
nscd Name Service Cache Daemon


















