
Praca dyplomowa magisterska - dsp.agh.edu.pldydaktyka:praca_04-11-2014.pdf · AKADEMIA...
43
AKADEMIA GÓRNICZO-HUTNICZA IM.STANISLAWA STASZICA W KRAKOWIE WYDZIAL ELEKTROTECHNIKI, AUTOMATYKI, INFORMATYKI I IN ˙ ZYNIERII BIOMEDYCZNEJ KATEDRA INFORMATYKI STOSOWANEJ Praca dyplomowa magisterska Zastosowanie kart graficznych w obliczeniach geometrii d´ zwi ˛ eku Application of graphic cards for sound geometry calculations Autor: Krzysztof Gabis Kierunek studiów: Informatyka Opiekun pracy: dr in˙ z. Bartosz Ziólko Kraków, 2014
Transcript of Praca dyplomowa magisterska - dsp.agh.edu.pldydaktyka:praca_04-11-2014.pdf · AKADEMIA...

AKADEMIA GÓRNICZO-HUTNICZA IM. STANISŁAWA STASZICA W KRAKOWIE
WYDZIAŁ ELEKTROTECHNIKI, AUTOMATYKI,INFORMATYKI I INZYNIERII BIOMEDYCZNEJ
KATEDRA INFORMATYKI STOSOWANEJ
Praca dyplomowa magisterska
Zastosowanie kart graficznych w obliczeniach geometrii dzwiekuApplication of graphic cards for sound geometry calculations
Autor: Krzysztof GabisKierunek studiów: InformatykaOpiekun pracy: dr inz. Bartosz Ziółko
Kraków, 2014

Oswiadczam, swiadomy(-a) odpowiedzialnosci karnej za poswiadczenie nieprawdy, zeniniejsza prace dyplomowa wykonałem(-am) osobiscie i samodzielnie i nie korzystałem(-am)ze zródeł innych niz wymienione w pracy.

Serdecznie dziekuje rodzinie i przyjaciołom

Contents
1. Wstep............................................................................................................................................... 7
1.1. Symulacja dzwieku w grach.................................................................................................. 7
1.2. Rozwój i zastosowanie kart graficznych................................................................................ 9
1.3. Cel pracy................................................................................................................................ 11
1.4. Struktura pracy ...................................................................................................................... 11
2. Prowadzenie obliczen na kartach graficznych ............................................................................ 13
2.1. Model programowania Nvidia CUDA................................................................................... 13
2.2. Symulacja dzwieku w bibliotece RAYAV ............................................................................. 17
2.3. Wybór metody obliczen kolizji promien-trójkat ................................................................... 17
2.3.1. Metoda brute-force..................................................................................................... 18
2.3.2. Metody oparte na drzewach ....................................................................................... 18
2.3.3. Metody oparte na siatkach ......................................................................................... 19
3. Interfejs zewnetrzny biblioteki ..................................................................................................... 21
3.1. Funkcje zarzadzajace kontekstem ......................................................................................... 21
3.2. Funkcje zarzadzajace pamiecia ............................................................................................. 22
3.3. Funkcje uruchamiajace obliczenia ........................................................................................ 23
3.4. Funkcje sprawdzajace i finalizujace obliczenia..................................................................... 24
4. Projekt............................................................................................................................................. 25
4.1. Ogólny zarys metody............................................................................................................. 25
4.2. Tworzenie tablicy współrzednych barycentrycznych ............................................................ 25
4.3. Tworzenie siatki..................................................................................................................... 26
4.3.1. Obliczanie sredniego rozmiaru trójkata w scenie ...................................................... 27
4.3.2. Obliczanie prostopadłoscianu ograniczajacego scene ............................................... 27
4.3.3. Reprezentacja siatki w pamieci.................................................................................. 28
4.4. Tworzenie promieni ............................................................................................................... 29
4.4.1. Wiazka trójkatna ........................................................................................................ 29
4.4.2. Wiazka czworokatna .................................................................................................. 30
5

6 CONTENTS
4.4.3. Wiazka czworokatna o wspólnym zródle................................................................... 32
4.5. Testy przeciec promienia z geometria sceny ......................................................................... 32
4.5.1. Testy przeciec promienia z siatka .............................................................................. 33
4.5.2. Testy przeciec promienia z trójkatami w komórce siatki........................................... 33
5. Testy................................................................................................................................................. 35
5.1. Testy poprawnosci implementacji ......................................................................................... 35
5.2. Porównanie z metoda brute-force.......................................................................................... 35
5.3. Testy wydajnosci w bibliotece RAYAV................................................................................. 37
6. Wnioski ........................................................................................................................................... 41
K. Gabis Zastosowanie kart graficznych w obliczeniach geometrii dzwieku

1. Wstep
1.1. Symulacja dzwieku w grach
Gry komputerowe z kazdym kolejnym rokiem sa coraz bardziej realistyczne. Modele postaci i
otoczenia składaja sie z wiekszej liczby polygonów, symuluje sie takie zjawiska, jak cienie, swiatło
rozproszone czy półprzezroczyste materiały, a od około 10 lat bardzo duzy odsetek gier symuluje tez
fizyczne interakcje miedzy obiektami. Róznice w wygladzie miedzy wydana w 1996 roku gra Quake a
wydanym w 2014 roku Killzone: Shadow Fall mozna zobaczyc na rysunkach 1.1 i 1.2. Jak widac, na
przestrzeni ostatnich 18 lat gry stały sie fotorealistyczne i nie przypominaja prostych geometrycznych
kształtów, do których ograniczały sie w przeszłosci.
Niestety poza kilkoma wyjatkami symulacja dzwieku stoi w miejscu i ogranicza sie do kilku prostych
efektów nakładanych przez projektantów plansz, a nie symulacji propagacji dzwieku w czasie rzeczy-
wistym. Powodów takiego stanu rzeczy moze byc kilka. Jeszcze kilka lat temu realistyczna symulacja
dzwieku byłaby zbyt kosztowana obliczeniowo i jej zastosowanie mogłoby zmniejszyc jakosc obrazu
lub pogorszyc inne parametry rozgrywki. Jednak wraz ze wzrostem mocy obliczeniowej procesorów i
rozwojem kart graficznych, które od jakiegos czasu moga byc uzywane jako procesory ogólnego zas-
tosowania, powstała mozliwosc ulepszenia i tego aspektu elektronicznej rozrywki.
W grach komputerowych niezwykle wazne jest stworzenie poczucia, ze swiat w którym toczy sie
gra jest rzeczywisty. Nie da sie jednak tego osiagnac bez realistycznej symulacji dzwieku. Jak wiadomo
całkiem inaczej brzmi głos na otwartej przestrzeni, w umeblowanym pomieszczeniu, albo w hali mag-
azynowej. Trudno utrzymac iluzje obecnosci w danym miejscu, jesli jeden z naszych zmysłów mówi
nam cos całkiem przeciwnego. Innym waznym aspektem jest informowanie nas np. o wystepujacych w
grze zagrozeniach. W grach takich jak Counter Strike informacja o tym, gdzie znajduje sie przeciwnik
na podstawie odłgosu jego kroków, jest w stanie zmienic wynik rozgrywki i umozliwic nam wygrana,
nawet jak tylko o kilkadziesiat ms wyprzedza informacje wizualna.
Rozwiazaniem tego stanu rzeczy przez lata interesowało sie niewiele podmiotów. Pierwszym była w
latach 90 firma Aureal Semiconductor ze swoim silnikiem Aureal 3D, jednak firma ta zbankrutowała w
wyniku (wygranego) procesu z firma Creative Labs, i została przez własnie firme Creative Labs prze-
jeta w roku 2000, po czym zaniechano dalszych prac nad silnikiem Aureal 3D. Pózniej nad podob-
nymi rozwiazaniami pracowały jednostki akademickie, szczególnie zespół GAMMA na Uniwersytecie
Karoliny Północnej [10, 3]. Od roku 2012 nad biblioteka do realistycznej symulacji dzwieku w grach
7

8 1.1. Symulacja dzwieku w grach
Figure 1.1: Zrzut ekranu z gry Quake
Figure 1.2: Zrzut ekranu z gry Killzone: Shadow Fall
K. Gabis Zastosowanie kart graficznych w obliczeniach geometrii dzwieku

1.2. Rozwój i zastosowanie kart graficznych 9
pracuje Zespół Przetwarzania Sygnałów działajacy przy wydziale Informatyki, Elektroniki i Telekomu-
nikacji AGH w ramach projektu RAYAV (Raytracer Audio i Video).
Celem projektu RAYAV jest stworzenie i rozwój biblioteki słuzacej do realistycznej symulacji
dzwieku w grach komputerowych. Korzysta on z techniki beamtracingu1 i raytracingu2 w celu okresle-
nia, jak powinien brzmiec dzwiek pochodzacy od danego zródła w danym punkcie przestrzeni.
1.2. Rozwój i zastosowanie kart graficznych
W celu szybkiego wyswietlania obrazów na ekranach komputerów od lat 80-tych zaczeły powstawac
dedykowane temu celowi karty graficzne [12]. Na poczatku były to głównie układy przeznaczone do
celów specjalistycznych, takich jak stacje robocze czy symulatory lotu, ale w drugiej połowie lat 90-tych
rozpoczeto produkcje i sprzedaz kart przeznaczonych dla komputerów osobistych. Przodowały w tym
takie firmy jak 3dfx, Matrox, Rendition, ATI i Nvidia, jednak był to młody i dynamicznie zmieniajacy
sie rynek i po kilku latach zdominowała go rywalizacja pomiedzy ATI a Nvidia.
W roku 1999 firma Nvidia zaprezentowała karte GeForce 256. Po raz pierwszy uzyto wtedy sfor-
mułowania GPU 3 w odniesieniu do procesora graficznego NV10, na którym sie opierała. Składał sie
on z 23 milionów tranzystorów i był wykonany w technologii 220nm. Róznił sie on od wczesniejszych
układów tym, ze sam przeprowadzał kosztowne obliczeniowo transformacje trójwymiarowych obiektów
i scen do ich dwuwymiarowej reprezentacji. Wczesniej tego typu obliczenia były przeprowadzane przez
CPU4, a przeniesienie ich na GPU znacznie go odciazyło. GeForce 256 był tez pierwsza karta udostep-
niajaca tzw. programowalne pixel shadery, czyli małe programy, które były wykonywane równolegle
dla kazdego piksela obrazu. Przez nastepne lata mozliwosci kart stawały sie coraz wieksze i coraz lep-
iej radziły sobie z przeprowadzaniem duzej liczby złozonych obliczen. Dla porównania wydany w roku
2012 procesor graficzny GK110 Kepler składał sie z 7 miliardów tranzystorów i był wyprodukowany w
technologii 28 nm. Oznacza to 300-krotny wzrost liczby tranzystorów w ciagu 13 lat. Tak duzy wzrost
liczby tranzystorów przełozył sie bezposrednio na mozliwosci obliczeniowe procesorów graficznych,
które juz czesto przewyzszaja mozliwosci nowoczesnych CPU, co widac na rysunku 1.3. Jednak z uwagi
na charakterystyke obliczen potrzebnych do wyswietlania obrazów, nie sa to procesory ogólnego zas-
tosowania i nie nadaja sie do wszystkich typów obliczen. Bardzo dobrze radza sobie z obliczeniami,
które mozna zrównoleglic, natomiast gorzej z obliczeniami sekwencyjnymi. W roku 2007 firma Nvidia
wydała zestaw narzedzi słuzacych do programowania swoich kart w celach ogólnego zastosowania o
nazwie CUDA, a w roku 2009 stworzona standard OpenCL (Open Computing Language) słuzacy podob-
nym celom, ale z uwagi na otwartosc bedacy dostepny na kartach graficznych i procesorach wszystkich
wiekszych producentów.
1Beamtracing - sledzenie wiazek2Raytracing - sledzenie promieni3GPU (Graphics Processing Unit) - graficzna jednostka obliczeniowa4CPU (Central Processing Unit) - centralna jednostka obliczeniowa
K. Gabis Zastosowanie kart graficznych w obliczeniach geometrii dzwieku
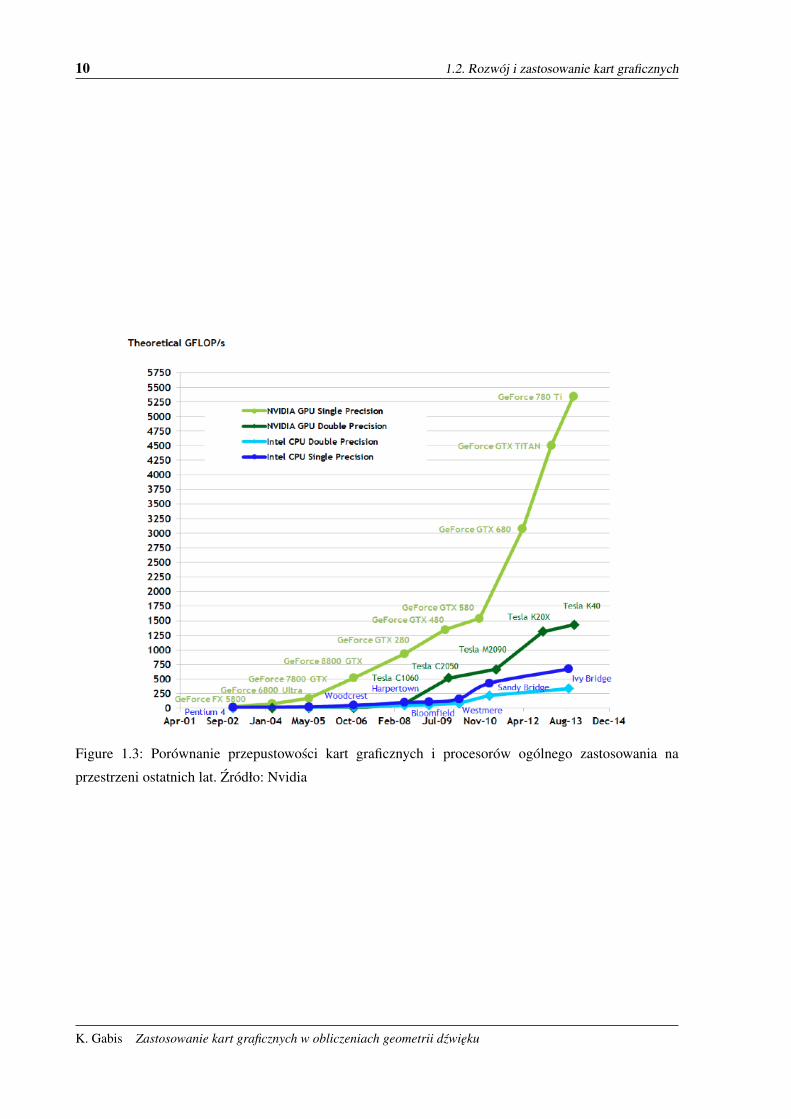
10 1.2. Rozwój i zastosowanie kart graficznych
Figure 1.3: Porównanie przepustowosci kart graficznych i procesorów ogólnego zastosowania na
przestrzeni ostatnich lat. Zródło: Nvidia
K. Gabis Zastosowanie kart graficznych w obliczeniach geometrii dzwieku

1.3. Cel pracy 11
W chwili obecnej karty graficzne znajduja szerokie zastosowanie w takich dziedzinach, jak biolo-
gia molekularna, medycyna, fizyka, symulacje finansowe, obliczenia kryptograficzne i wiele innych.
Mozna sie spodziewac, ze trend ten bedzie kontynuowany i GPGPU5 znajdzie wiele innych zastosowan
w dziedzinach, do których do tej pory były uzywane komputery oparte o CPU albo dedykowane układy
scalone.
1.3. Cel pracy
Celem pracy jest stworzenie biblioteki, która bedzie umozliwiała projektowi RAYAV przeniesienie
na karty graficzne czesci obliczen wykrywajacych kolizje wiazek z trójkatami sceny. Z uwagi na to, ze
obliczenia te mozna prowadzic równolegle, jest to zadanie bardzo dobrze nadajace sie do przeniesienia
na karty graficzne. Powinno to skrócic czas obliczen potrzebnych do okreslenia sciezek dzwieku miedzy
zródłami dzwieku a odbiornikiem, które sa niezbedne do poprawnej symulacji dzwieku. Poza tym, w
czasie, gdy obliczenia sa prowadzone na karcie graficznej, mozna uzyc CPU w innym celu, jak np.
filtrowanie dzwieku czy liczenie pogłosu. Do stworzenia biblioteki wybrano srodowisko CUDA, gdyz
istnieje na rynku dłuzej od konkurencyjnych rozwiazan, ma lepszej klasy narzedzia programistyczne i
zapewnia dokładniejsza kontrole nad karta graficzna.
1.4. Struktura pracy
Rozdział 2 wprowadza do prowadzenia obliczen na kartach graficznych z wykorzystaniem tech-
nologii Nvidia CUDA. W dalszej czesci przedstawia on ogólny zarys metody symulacji dzwieku uzy-
wanej przez biblioteke RAYAV i wybiera obszar, który bedzie mógł byc przeniesiony na karty graficzne.
Koncówka rozdziału przeznaczona jest na wybranie odpowiedniej metody, która zostanie zaimplemen-
towana.
Rozdział 3 opisuje interfejs zewnetrzny powstałej biblioteki. Składaja sie na niego funkcje zarzadza-
jace kontekstem obliczen, zarzadzajace pamiecia, uruchamiajace obliczenia, sprawdzajace stan obliczen
oraz funkcje je konczace.
Rozdział 4 poswiecony jest opisowi opracowanej metody. Przedstawia on algorytmy, które były
konieczne do zaimplementowania, takie jak obliczanie współrzednych barycentrycznych, tworzenie
siatki oraz przechodzenie przez nia.
Rozdział 5 przedstawia wyniki testów poprawnosci, testów porównawczych opracowanej metody w
zestawieniu z metoda brute-force oraz testów w zestawieniu z metoda wczesniej opracowana dla bib-
lioteki RAYAV oparta o CPU.
Rozdział 6 poswiecony jest wnioskom z wykonanej pracy.
5GPGPU (General-Purpose computing on Graphics Processing Units) - obliczenia ogólnego zastosowania na procesorach
graficznych
K. Gabis Zastosowanie kart graficznych w obliczeniach geometrii dzwieku

12 1.4. Struktura pracy
K. Gabis Zastosowanie kart graficznych w obliczeniach geometrii dzwieku

2. Prowadzenie obliczen na kartach graficznych
2.1. Model programowania Nvidia CUDA
Wydana w 2007 roku platforma CUDA ma na celu uproszczenie i zgeneralizowanie modelu pro-
gramowania kart graficznych firmy Nvidia. Przed jej wydaniem do programowania kart graficznych
stosowało sie shadery graficzne, ale było to podejscie opierajace sie na abstrakcjach scisle zwiazanych
z grafika komputerowa i mało nadajacych sie do programowania ogólnego zastosowania. Platforma
CUDA składa sie z bibliotek zapewniajacych niskopoziomowa kontrole na karta graficzna, kompilatorów
jezyków CUDA C/C++ i CUDA Fortran oraz zestawu narzedzi, takich jak profiler czy rozszerzenia zin-
tegrowanych srodowisk programistycznych (IDE). Od momentu wydania jest ona ciagle wzbogacana o
nowe funkcje i mozliwosci wraz z rozwojem procesorów graficznych.
Istnieje szereg róznic pomiedzy procesorami ogólnego zastosowania oraz procesorami graficznymi
[6]. Najwieksza to ilosc i typ uzywanych przez nich jednostek obliczeniowych. Na przykład wydany
w 2013 roku procesor Intel Core i5-4570T ma 2 rdzenie o taktowaniu 2,9 GHz mogace wykonywac
równoczesnie po 2 watki na rdzen. Z kolei wydana w 2014 roku karta Nvidia GeForce GTX 750 ma układ
GM107 posiadajacy 4 rdzenie (nazywane Streaming Multiprocessor) o taktowaniu 1020 Hz mogace
wykonywac równoczesnie po 128 watki na rdzen. Samo porównywanie mozliwosci obliczeniowych
rdzeni CPU i GPU jest trudne, gdyz ich zastosowanie jest inne. Jeden rdzen CPU moze wykonywac re-
latywnie mało watków równoczesnie, ale w celu zwiekszenia wydajnosci korzysta z takich technik, jak
potokowanie, branch prediction 1 i wykonywanie instrukcji poza kolejnoscia. W połaczeniu z wieksza
czestotliwoscia taktowania zegara sprawia to, ze jeden watek CPU wykonuje znacznie wiecej operacji na
sekunde od jednego watku GPU. Bardzo istotne jest to, ze watki na CPU sa niezalezne od siebie i moga w
danej chwili wykonywac rózne instrukcje. W przypadku GPU watki sa podzielone na grupy, zazwyczaj
po 32 watki, tzw. warpy, gdzie kazdy watek wykonuje w danej chwili ta sama instrukcje. W przypadku
instrukcji warunkowych prowadzi to do tego, ze nawet jak jeden watek przyjmie inne rozgałeznie, to
reszta wykonuje dokładnie te same instrukcje, przy czym ich wynik jest odrzucany. Zjawisko to nazywa
sie warp divergence. Z tego powodu trzeba zwracac uwage na to, by watki w obrebie tego samego warpa
1Branch prediction - przewidywanie rozgałezien, w przypadku instrukcji warunkowych procesor spekuluje na temat ich
wyniku i prowadzi zgodnie z ta spekulacja obliczenia. Jesli okaze sie, ze instrukcja warunkowa przyjeła inna wartosc, obliczenia
te sa odrzucane i sa przeprowadzane dla poprawnej wartosci.
13

14 2.1. Model programowania Nvidia CUDA
jak najczesciej korzystały z tych samych rozgałezien. Model programowania uzywany przy programowa-
niu kart graficznych firmy Nvidia nazywa sie SIMT 2 [1].
Karty graficzne najlepiej nadaja sie do obliczen na duzych zbiorach danych, gdzie nie ma znaczenia
kolejnosc prowadzonych obliczen [4]. Taka operacja jest np. mapowanie, gdzie na kazdym elemencie we-
jsciowym tablicy jest wykonywana taka sama operacja (np. podniesienie do kwadratu). W tradycyjnym
podejsciu z zastosowaniem CPU stosuje sie do tego petle for, która po kolei wykonuje dana operacje
na kazdym elemencie i zapisuje wynik w tablicy wyjsciowej, co pokazano we fragmencie kodu 2.1 w
postaci funkcji podnoszacej kazdy element tablicy do kwadratu. Chcac wykonac te same obliczenia przy
pomocy funkcji mapujacej na GPU uzywa sie tak zwanego kernela, który jest wykonywany równolegle
na kazdym elemencie tablicy wejsciowej. Przykładowy kernel i jego wywołanie pokazano w algorytmie
2.2. Z uwagi na to, ze karta graficzna korzysta z osobnej pamieci, nalezy najpierw zaalokowac na niej
odpowiednia ilosc miejsca i skopiowac dane wejsciowe. Po przeprowadzeniu obliczen nalezy z kolei
skopiowac dane wyjsciowe z pamieci karty. W przypadku srodowiska CUDA uzywa sie nazwy device
odnoszac sie do GPU oraz host odnoszac sie do CPU.
void square(const float *input, int len, float *output)
{
for (int i = 0; i < len; i++) {
output[i] = input[i] * input[i];
}
}
Fragment Kodu 2.1: Podniesienie elementów tablicy do kwadratu przy pomocy petli for na
CPU.
2SIMT (Single Instruction, Multiple Threads) - Jedna instrukcja jest wykonywana przez wiele watków równoczesnie
K. Gabis Zastosowanie kart graficznych w obliczeniach geometrii dzwieku

2.1. Model programowania Nvidia CUDA 15
__global__ void square_kernel(const float *input, float *output)
{
int i = threadIdx.x;
output[i] = input[i] * input[i];
}
void square(const float *h_input, int len, float *h_output)
{
float *d_input = NULL;
float *d_output = NULL;
size_t size = len * sizeof(float);
cudaMalloc((void**)&d_input, size);
cudaMalloc((void**)&d_input, size);
cudaMemcpy(d_input, h_input, size, cudaMemcpyHostToDevice);
square_kernel<<< 1, len >>> (d_input, d_output);
cudaMemcpy(h_output, d_output, size, cudaMemcpyDeviceToHost);
cudaFree(d_input);
cudaFree(d_output);
}
Fragment Kodu 2.2: Podniesienie elementów tablicy do kwadratu przy pomocy Nvidia CUDA
na GPU.
Aby przeprowadzic obliczenia na kartach graficznych nalezy przeprowadzic nastepujace kroki:
1. Zaalokowac na GPU pamiec potrzebna na tablice wejsciowa i wyjsciowa.
2. Skopiowac dane wejsciowe do tablicy zaalokowanej na karcie graficznej.
3. Wywołac kernel dla wszystkich elementów tablicy.
4. Skopiowac dane wyjsciowe do pamieci hosta.
Podczas wywołania kernela okresla sie liczbe watków, jaka ma byc utworzona. Z uwagi na
ograniczenia sprzetowe watki sa dzielone na bloki. W kartach z CUDA Compute Capability 5.0 zaden
blok nie moze miec wiecej niz 1024 watki. Z uwagi na charakterystyke niektórych problemów, które
operuja na dwuwymiarowych lub trójwymiarowych zbiorach danych, przy wywołaniu kernela mozna
okreslic jego wymiary w trójwymiarowej przestrzeni. Kazda instancja kernela ma przypisany trójwymi-
arowy indeks w obrebie bloku oraz w obrebie siatki tworzonej przez bloki. Na podstawie tych indeksów
i wymiarów bloku mozna obliczyc indeks globalny. Indeks najczesciej mówi o tym, do których danych
powinien sie odwołac kernel przy prowadzeniu obliczen, jest odpowiednikiem indeksu przy prowadzeniu
obliczen z uzyciem petli.
Karty graficzne korzystaja z kilku rodzajów pamieci, które róznia sie wielkoscia, szybkoscia, typem
dostepu oraz widocznoscia [7]. Przedstawiono je w tabeli 2.1.
K. Gabis Zastosowanie kart graficznych w obliczeniach geometrii dzwieku
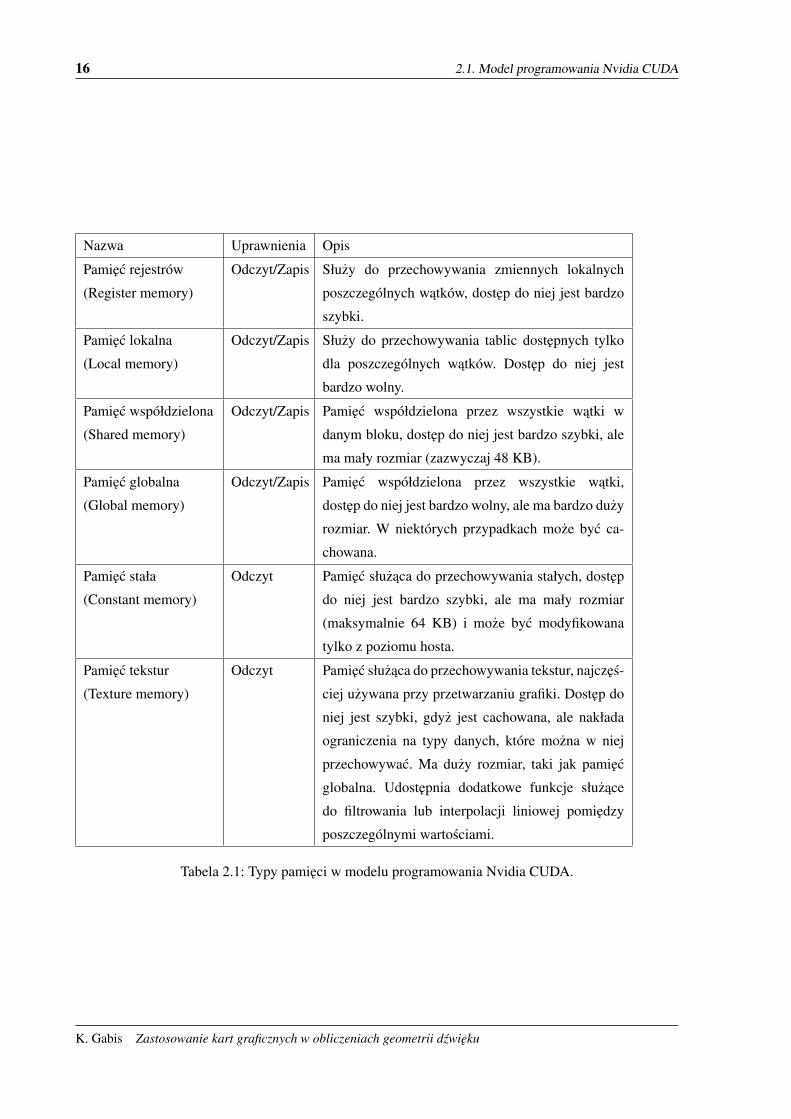
16 2.1. Model programowania Nvidia CUDA
Nazwa Uprawnienia Opis
Pamiec rejestrów
(Register memory)
Odczyt/Zapis Słuzy do przechowywania zmiennych lokalnych
poszczególnych watków, dostep do niej jest bardzo
szybki.
Pamiec lokalna
(Local memory)
Odczyt/Zapis Słuzy do przechowywania tablic dostepnych tylko
dla poszczególnych watków. Dostep do niej jest
bardzo wolny.
Pamiec współdzielona
(Shared memory)
Odczyt/Zapis Pamiec współdzielona przez wszystkie watki w
danym bloku, dostep do niej jest bardzo szybki, ale
ma mały rozmiar (zazwyczaj 48 KB).
Pamiec globalna
(Global memory)
Odczyt/Zapis Pamiec współdzielona przez wszystkie watki,
dostep do niej jest bardzo wolny, ale ma bardzo duzy
rozmiar. W niektórych przypadkach moze byc ca-
chowana.
Pamiec stała
(Constant memory)
Odczyt Pamiec słuzaca do przechowywania stałych, dostep
do niej jest bardzo szybki, ale ma mały rozmiar
(maksymalnie 64 KB) i moze byc modyfikowana
tylko z poziomu hosta.
Pamiec tekstur
(Texture memory)
Odczyt Pamiec słuzaca do przechowywania tekstur, najczes-
ciej uzywana przy przetwarzaniu grafiki. Dostep do
niej jest szybki, gdyz jest cachowana, ale nakłada
ograniczenia na typy danych, które mozna w niej
przechowywac. Ma duzy rozmiar, taki jak pamiec
globalna. Udostepnia dodatkowe funkcje słuzace
do filtrowania lub interpolacji liniowej pomiedzy
poszczególnymi wartosciami.
Tabela 2.1: Typy pamieci w modelu programowania Nvidia CUDA.
K. Gabis Zastosowanie kart graficznych w obliczeniach geometrii dzwieku

2.2. Symulacja dzwieku w bibliotece RAYAV 17
2.2. Symulacja dzwieku w bibliotece RAYAV
Biblioteka RAYAV uzywa sledzenia wiazek [13] do obliczen interakcji dzwieku z trójkatami
reprezentujacymi geometrie sceny oraz filtrów akustycznych do obliczen pogłosu. W pierwszym etapie
tworzone sa sciezki dzwieku, na podstawie których dzwiek dochodzi ze zródła do odbiornika. Na pod-
stawie utworzonych sciezek w pózniejszym etapie jest syntezowany dzwiek, który uwzglednia charak-
terystyke akustyczna materiałów, które uczestniczyły w tworzeniu sciezek. Sciezki dzwieku sa tworzona
na podstawie odbic, dyfrakcji oraz transmisji. Do obliczen odbic sa uzywane wiazki bedace ostrosłu-
pami scietymi o podstawie czworokatnej lub trójkatnej. Na ich podstawie tworzone sa promienie, które
sa uzywane do testów przeciec z trójkatami sceny. Wiecej o wiazkach i tworzeniu na ich podstawie
promieni napisano w podrozdziale 4.4. Oprócz testów przeciec sprawdzane jest takze, czy w obrebie
wiazki nie znajduje sie zródło dzwieku. Jesli takie zródło znajduje sie w obrebie wiazki, tworzona jest
sciezka dzwieku miedzi zródłem a odbiornikiem na podstawie której syntezowany bedzie w dalszym
etapie dzwiek. Dzieki testom przeciec mozna sprawdzic, z którymi trójkatami przecina sie wiazka i na
tej podstawie tworzone sa kolejne wiazki. Z uwagi na to, ze liczba wiazek rosnie w sposób geome-
tryczny, czesc wiazek jest łaczona oraz symulacje ogranicza sie do maksymalnie 2 odbic. Reszta odbic
jest symulowana na etapie syntezy. Poniewaz biblioteka musi działac w czasie rzeczywistym, obliczenia
jednej klatki dzwieku nie moga zajac dłuzej niz 30ms.
Etapem najlepiej nadajacym sie do przeniesienia na karty graficzne jest detekcja kolizji wiazek z
trójkatami sceny, gdyz po pierwsze etap ten jest jednym z najbardziej kosztownych obliczeniowio, a po
drugie obliczenia dla poszczególnych wiazek mozna prowadzic równoczesnie. Zdecydowano sie wiec na
stworzenie biblioteki, która bedzie udostepniała funkcje wywołujace testy przeciec na karcie graficznej
na podstawie przekazanych wiazek i zwracała identyfikatory trójkatów, z którymi sie te wiazki przecieły.
Podejscie polegajace na stworzeniu osobnej biblioteki uprosciło prace, gdyz wprowadzane przez autora
zmiany nie kolidowały ze stale rozwijajaca sie biblioteka RAYAV. Przez charakterystyke problemu sto-
suje sie 3 typy wiazek: wiazki poczatkowe, wiazki odbite oraz wiazki dyfrakcyjne. Wiazki te róznia sie
typem podstawy oraz sposobem reprezentacji w bibliotece. Nowe wiazki sa obliczane w obrebie bib-
lioteki RAYAV, przez co interfejs jest bardzo prosty i elastyczny. Interfejs biblioteki został szczegółowo
opisany w rozdziale 3.
2.3. Wybór metody obliczen kolizji promien-trójkat
Z uwagi na koniecznosc zachowania zgodnosci z metoda uzywana w bibliotece RAYAV
postanowiono wykrywac kolizje wiazki z trójkatami sceny przez tworzenie na bazie wiazki promieni.
Promien jest to półprosta skierowana z wyznaczonym zwrotem. Jest on reprezentowany w pamieci
przez punkt poczatkowy oraz jednostkowy wektor kierunkowy. Testy kolizji promieni z trójkatami
sa powszechnie stosowane do generowania realistycznej grafiki komputerowej [14, 5] oraz do de-
tekcji kolizji obiektów fizycznych w grach komputerowych [11], przez co istnieje wiele metod ich
K. Gabis Zastosowanie kart graficznych w obliczeniach geometrii dzwieku

18 2.3. Wybór metody obliczen kolizji promien-trójkat
przeprowadzania [2], które w głównej mierze słuza zminimalizowaniu ilosci testów promieni z trójka-
tami sceny. Trzy z nich opisano ponizej.
2.3.1. Metoda brute-force
Metoda brute-force polega na testowaniu przeciecia kazdego promienia z kazdym trójkatem sceny.
Jej złozonosc obliczeniowa rosnie liniowo proporcjonalnie do liczby trójkatów na scenie, przez co nie
nadaje sie ona do zastosowania w czasie rzeczywistym. Jest ona za to bardzo prosta w implementacji,
przez co uzywa sie jej do weryfikacji poprawnosci wyników uzyskanych innymi metodami. We fragmen-
cie kodu 2.3 znajduje sie przykładowa implementacja, która zwraca odległosc do najblizszego punktu
przeciecia promienia z trójatek z wektora trójkatów, lub +FLT_MAX w przypadku nie znalezienia punktu
przeciecia.
float testInteresection(const Ray &ray, const std::vector<Triangle> &
triangles) {
float closestIntersection = +FLT_MAX;
for (const Object &triangle : triangles) {
float currentIntersection = testIntersection(ray, triangle);
if (currentIntersection < closestIntersection) {
closestIntersection = currentIntersection;
}
}
return closestIntersection;
}
Fragment Kodu 2.3: Algorytm brute-force
2.3.2. Metody oparte na drzewach
W metodach opartach na drzewach geometria sceny jest przed samymi testami przetwarzana do al-
ternatywnej, hierarchicznej reprezentacji. Umozliwia to testowanie przeciecia tylko z czescia trójkatów
znajdujacych sie na scenie, z którymi to przeciecie moze wystapic. Złozonosc obliczeniowa rosnie wtedy
w sposób logarytmiczny wzgledem liczby trójkatów na scenie, co umozliwia jej praktyczne zastosowanie
w czasie rzeczywistym nawet na bardzo złozonych scenach. Jej minusem jest jednak to, ze zmiana ge-
ometrii sceny moze sie wiazac z przebudowa całego drzewa, co moze byc zbyt czasochłonne, by byc
przeprowadzone w czasie rzeczywistym. Problematyczna jest równiez implementacja tej metody na kar-
tach graficznych, gdyz przechodzenie przez drzewo wiaze sie z nieregularnymi wzorcami dostepu do
pamieci, co bardzo zle wpływa na szybkosc prowadzenia obliczen, gdyz wprowadza spore opóznienia,
gdy procesor graficzny czeka na dane z pamieci, nic w tym czasie nie obliczajac.
K. Gabis Zastosowanie kart graficznych w obliczeniach geometrii dzwieku
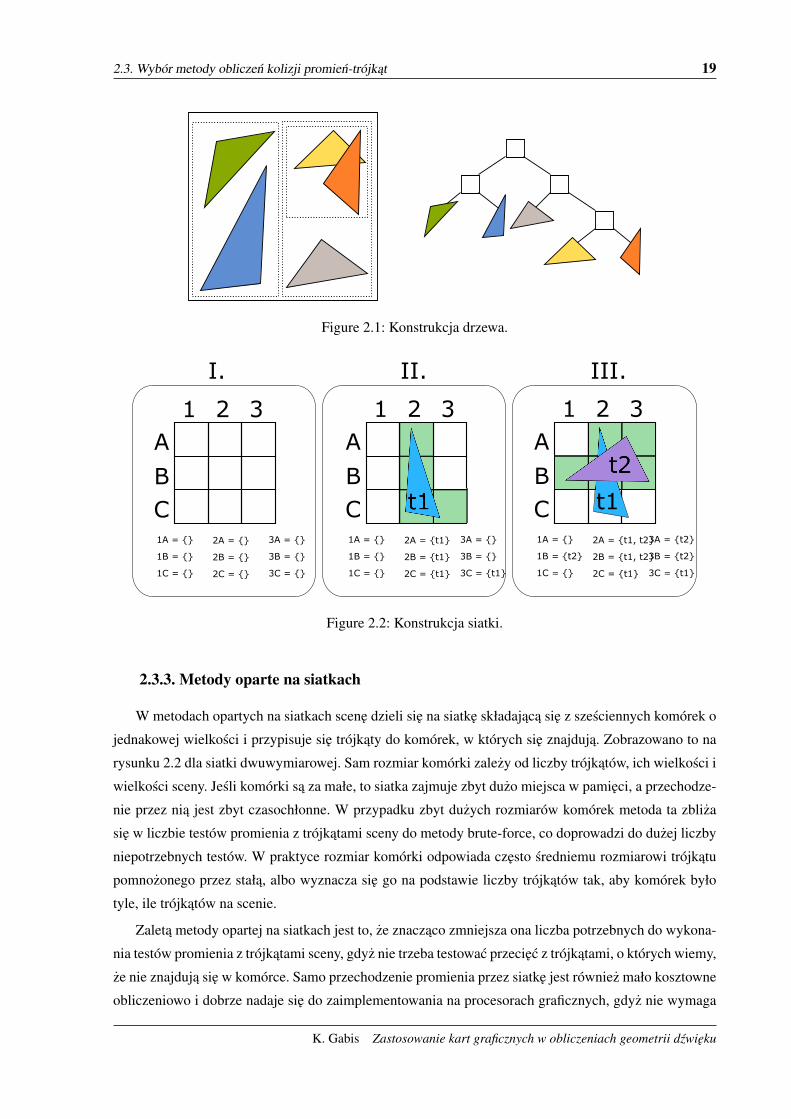
2.3. Wybór metody obliczen kolizji promien-trójkat 19
Figure 2.1: Konstrukcja drzewa.
A
B
C
1 2 3
1A = {}
1B = {}
1C = {}
2A = {}
2B = {}
2C = {}
3A = {}
3B = {}
3C = {}
A
B
C
1 2 3
1A = {}
1B = {}
1C = {}
2A = {t1}
2B = {t1}
2C = {t1}
3A = {}
3B = {}
3C = {t1}
A
B
C
1 2 3
1A = {}
t1
1B = {t2}
1C = {}
2A = {t1, t2}
2B = {t1, t2}
2C = {t1}
3A = {t2}
3B = {t2}
3C = {t1}
I. II. III.
Figure 2.2: Konstrukcja siatki.
2.3.3. Metody oparte na siatkach
W metodach opartych na siatkach scene dzieli sie na siatke składajaca sie z szesciennych komórek o
jednakowej wielkosci i przypisuje sie trójkaty do komórek, w których sie znajduja. Zobrazowano to na
rysunku 2.2 dla siatki dwuwymiarowej. Sam rozmiar komórki zalezy od liczby trójkatów, ich wielkosci i
wielkosci sceny. Jesli komórki sa za małe, to siatka zajmuje zbyt duzo miejsca w pamieci, a przechodze-
nie przez nia jest zbyt czasochłonne. W przypadku zbyt duzych rozmiarów komórek metoda ta zbliza
sie w liczbie testów promienia z trójkatami sceny do metody brute-force, co doprowadzi do duzej liczby
niepotrzebnych testów. W praktyce rozmiar komórki odpowiada czesto sredniemu rozmiarowi trójkatu
pomnozonego przez stała, albo wyznacza sie go na podstawie liczby trójkatów tak, aby komórek było
tyle, ile trójkatów na scenie.
Zaleta metody opartej na siatkach jest to, ze znaczaco zmniejsza ona liczba potrzebnych do wykona-
nia testów promienia z trójkatami sceny, gdyz nie trzeba testowac przeciec z trójkatami, o których wiemy,
ze nie znajduja sie w komórce. Samo przechodzenie promienia przez siatke jest równiez mało kosztowne
obliczeniowo i dobrze nadaje sie do zaimplementowania na procesorach graficznych, gdyz nie wymaga
K. Gabis Zastosowanie kart graficznych w obliczeniach geometrii dzwieku

20 2.3. Wybór metody obliczen kolizji promien-trójkat
wielu nieregularnych dostepów do pamieci. Własnie ta metoda została wybrana jako najlepiej nadajaca
sie do zastosowania w bibliotece.
K. Gabis Zastosowanie kart graficznych w obliczeniach geometrii dzwieku

3. Interfejs zewnetrzny biblioteki
Aby nie wymuszac kazdorazowej kompilacji biblioteki RAYAV po zmianie kodu w tworzonej przez
autora bibliotece, zdecydowana sie na stworzenie biblioteki dynamicznie linkowanej. Interfejs został
udostepniony przez szereg opisanych w kolejnych podrozdziałach funkcji. Kazda funkcja przyjmuje
jako pierwszy parametr kontekst typu RAYA_GPU_CTXT_HANDLE (poza funkcja go inicjalizujaca), który
jest odpowiedzialny za przechowywanie stanu biblioteki i pozwala uniknac stosowania zmiennych glob-
alnych. Funkcje te dziela sie na 4 grupy:
– Funkcje zarzadzajace kontekstem
– Funkcje zarzadzajace pamiecia
– Funkcje uruchamiajace obliczenia
– Funkcje sprawdzajace i finalizujace obliczenia
3.1. Funkcje zarzadzajace kontekstem
RAYA_GPU_CTXT_HANDLE libraya_gpu_create_grid_context(uint_t platform, uint_t
device);
void libraya_gpu_delete_context(RAYA_GPU_CTXT_HANDLE ctxt);
void libraya_gpu_set_triangles(RAYA_GPU_CTXT_HANDLE ctxt, const Triangle*
triangles, uint_t numTriangles);
Fragment Kodu 3.1: Deklaracje funkcji zarzadzajacych kontekstem
Za zarzadzanie kontekstem odpowiadaja 3 funkcje, których deklaracje przedstawiono we fragmencie
kodu 3.1. Pierwsza z nich, libraya_gpu_create_context odpowiada za zaalokowanie i stworzenie
kontekstu. Przyjmuje ona 2 parametry, które decyduja o wyborze platformy i urzadzenia uzytego podczas
obliczen. W przypadku CUDY platforma ta jest zawsze taka sama, ale pozostawiono mozliwosc jej
wyboru ze wzgledu na zapewnienie zgodnosci z platforma OpenCL, które to moze wykorzystywac kilka
21

22 3.2. Funkcje zarzadzajace pamiecia
platform. Wybór urzadzenia ma znaczenie wtedy, gdy komputer ma wiecej niz jedna karte wspierajaca
platforme Nvidia CUDA. Funkcja zwraca uchwyt do utworzonego kontekstu.
Za usuwanie wczesniej utworzonego kontekstu odpowiada funckja libraya_gpu_delete_context,
której jedynym argumentem jest uchwyt do kontekstu.
Ostatnia z funkcji jest libraya_gpu_set_triangles, która przekazuje bibliotece trójkaty stanow-
iace geometrie sceny, które beda uzywane przy obliczeniach kolizji. Trójkaty te sa wczytywane do siatki
i kopiowane do pamieci karty graficznej. Argumentami tej funkcji jest uchwyt do kontekstu, wskaznik
na tablice trójkatów oraz ich liczba. Połozenie poszczególnych trójkatów w tablicy stanowi tez ich iden-
tyfikator, wiec informacja ta musi zostac zapisana przy zmianie reprezentacji.
3.2. Funkcje zarzadzajace pamiecia
void* cdecl* libraya_gpu_malloc(size_t size);
void libraya_gpu_free(void *ptr);
Fragment Kodu 3.2: Deklaracje funkcji zarzadzajacych pamiecia.
Deklaracje funkcji zarzadzajacych pamiecia znajduja sie we fragmencie kodu 3.2. Działaja one
analogicznie do znajdujacych sie w bibliotece standardowej C funkcji malloc i free. Ich obec-
nosc wynika z tego, ze niektóre bufory musza byc zaalokowane w niestronicowanej pamieci, aby
transfer z nich do pamieci karty graficznej i z powrotem przebiegał asynchronicznie. Funkcja
libraya_gpu_malloc zwraca wskaznik do niestronicowanego obszaru pamieci o rozmiarze równym
przekazanemu argumentowi, natomiast funkcja libraya_gpu_free zwalnia pamiec zaalokowana przy
pomocy libraya_gpu_malloc.
K. Gabis Zastosowanie kart graficznych w obliczeniach geometrii dzwieku

3.3. Funkcje uruchamiajace obliczenia 23
3.3. Funkcje uruchamiajace obliczenia
bool
libraya_gpu_beam_triangle_grid_start(RAYA_GPU_CTXT_HANDLE ctxt,
uint_t beams_count, const Frustum4* beams,
uint_t beam_subdiv, trngID_t* foundIDs);
bool
libraya_gpu_beam_triangle_grid_start3(RAYA_GPU_CTXT_HANDLE ctxt,
uint_t beams_count, const Frustum3* beams,
uint_t beam_subdiv, trngID_t* foundIDs);
bool
libraya_gpu_beam4x_triangle_grid_start(RAYA_GPU_CTXT_HANDLE ctxt,
uint_t beams_count, const Frustum4Ex* beams,
uint_t beam_subdiv, trngID_t* foundIDs);
bool
libraya_gpu_beam_triangle_grid_start3_and_diffraction(RAYA_GPU_CTXT_HANDLE
ctxt,
uint_t beams3_count, const Frustum3* beams3,
uint_t beamsDiffraction_count, const Frustum4Ex *beamsDiffraction,
uint_t beam_subdiv, trngID_t* foundIDs);
Fragment Kodu 3.3: Deklaracje funkcji uruchamiajacych obliczenia.
Do uruchamiania obliczen słuza 4 funkcje, których deklaracje znajduja sie we fragmen-
cie kodu 3.3. Pierwsze trzy z nich róznia sie jedynie typem stosowanych wiazek, natomiast
libraya_gpu_beam_triangle_grid_start3_and_diffraction słuzy do równoczesnego wywoływa-
nia testów dla Frustum3 i Frustum4Ex.
Funkcja libraya_gpu_beam_triangle_grid_start jako argument przyjmuje kontekst, liczba
wiazek, wskaznik do tablicy wiazek typu Frustum4, podział wiazki oraz wskaznik do tablicy wyników.
Przy n wiazkach i podpodziale s rozmiar tablicy wyników powinien wynosic n × 4s. Po za-
konczeniu obliczen do tablicy wyników kopiowane sa identyfikatory trójkatów które przecieły sie
z poszczególnymi promieniami w obrebie wiazki. Identyfikatory dla kazdej kolejnej wiazki o in-
deksie w zawsze maja po 4s elementów i sa przesuniete wzgledem poczatku tablicy o w × 4s el-
ementów. Po wywołaniu funkcji obliczenia sa uruchamiane asynchronicznie i wyniki sa dostepne
dopiero po wywołaniu libraya_gpu_beam_triangle_finish opisanego w podrozdziale 3.4. W przy-
padku powodzenia funkcja zwraca true, natomiast w przypadku niepowodzenia false. Funkcje
libraya_gpu_beam_triangle_grid_start3 oraz libraya_gpu_beam4x_triangle_grid_start dzi-
ałaja w identyczny sposób, ale odpowiednio dla Frustum4 oraz Frustum4Ex
Funkcja libraya_gpu_beam_triangle_grid_start3_and_diffraction rozpoczyna
K. Gabis Zastosowanie kart graficznych w obliczeniach geometrii dzwieku

24 3.4. Funkcje sprawdzajace i finalizujace obliczenia
równoczesnie obliczenia dla wiazek typu Frustum3 oraz Frustum, a w tablicy foundsIDs najpierw
znajduja sie wyniki dla wiazek typu Frustum3, a nastepnie dla Frustume4Ex.
3.4. Funkcje sprawdzajace i finalizujace obliczenia
bool libraya_gpu_beam_triangle_is_finished(RAYA_GPU_CTXT_HANDLE ctxt);
bool libraya_gpu_beam_triangle_finish(RAYA_GPU_CTXT_HANDLE ctxt);
Fragment Kodu 3.4: Deklaracje funkcji sprawdzajacych i finalizujacych obliczenia.
Z uwagi na to, ze obliczenia sa przeprowadzane asynchronicznie, konieczna jest funkcja do
sprawdzenia ich stanu oraz do zaczekania na ich zakonczenie.
Funkcja libraya_gpu_beam_triangle_is_finished przyjmuje jako argument kontekst
RAYA_GPU_CTXT_HANDLE i zwraca true, jesli obliczenia sie zakonczyły, natomiast false, jesli
ciagle trwaja.
Funkcja libraya_gpu_beamtriangle_finish równiez jako argument przyjmuje kontekst. Nieza-
leznie od stanu obliczen czeka ona na ich koniec i kopiuje wyniki do przekazanej w funkcjach je
uruchamiajacych tablicy foundsIDs. W przypadku powodzenia operacji zwraca true, w innym wypadku
zwraca false.
K. Gabis Zastosowanie kart graficznych w obliczeniach geometrii dzwieku

4. Projekt
W rozdziale tym opisano algorytmy, które zostały zastosowane do zaimplementowania metody
obliczajacej kolizje wiazek z trójkatami przy pomocy kart graficznych.
4.1. Ogólny zarys metody
Ponizej przedstawiono główne kroki, które sa stosowne w celu przeprowadzenia obliczen. Sa one
wywoływane przez uzytkowników biblioteki przy pomocy interfejsu przedstawionego w rozdziale 3.
Pominieto operacje kopiowania danych do i z pamieci karty graficznej.
1. Obliczenia po stronie CPU:
(a) Utworzenie tablicy współrzednych barycentrycznych dla wiazek trójkatnych.
(b) Zbudowanie siatki w oparciu o przekazana tablice trójkatów.
2. Obliczenia po stronie GPU:
(a) Obliczenia punktu poczatkowego i wektora kierunkowego promienia.
(b) Iterowanie przez poszczególne komórki siatki.
(c) Wykonywanie testów przeciecia promienia z trójkatami w poszczególnych komórkach.
(d) Zapisanie identyfikatora trójkata przecinajacego sie w najblizszym punkcie z testowanym
promieniem.
4.2. Tworzenie tablicy współrzednych barycentrycznych
Zauwazono, ze srodki trójkatów wynikajacych z podziału trójkata na 4 czesci zawsze maja takie
same współrzedne barycentryczne dla tego samego stopnia podziału. Zdecydowano sie wiec obliczac
je wczesniej, gdyz obliczenie punkta na trójkacie w oparciu o współrzedne barycentryczne jest bardzo
prosta i mało kosztowna obliczeniowo operacja. Tablice współrzednych tylko raz kopiuje sie do pamieci
globalnej karty, przy czym przy jej generowaniu zapewniono, zeby współrzedne dla wczesniejszego
podziału były przed współrzednymi dla kolejnego podziału. W ten sposób pierwsze 4 współrzedne
25

26 4.3. Tworzenie siatki
odpowiadaja podziałowi 1, pierwsze 16 podziałowi 2, pierwsze 64 podziałowi 3 itd. Tablica współrzed-
nych jest generowana w miare potrzeb, tzn. jesli wykonywane sa obliczenia dla podziału 4, a tablica
zawiera współrzedne tylko dla podziału 2 włacznie, to generowane sa i kopiowane na karte współrzedne
dla podziału 4. Przy nastepnym wywołaniu dla podziału 4 nie trzeba juz powtórnie generowac i kopiowac
współrzednych. Algorytm tworzacy tablice współrzednych barycentrycznych znajduje sie we fragmencie
kodu 4.1.
std::vector<float3> get_subdivision_coordinates(size_t subdiv)
{
int cords_count = (size_t)pow(4, subdiv);
Triangle start_triangle(make_float3(1, 0, 0), make_float3(0, 1, 0),
make_float3(0, 0, 1));
std::vector<float3> result;
std::queue<Triangle> queue;
queue.push(start_triangle);
result.push_back(start_triangle.get_center());
while (result.size() < cords_count) {
Triangle t = queue.front();
queue.pop();
float3 mid_ab = (t.a+t.b)/2.0f;
float3 mid_ac = (t.a+t.c)/2.0f;
float3 mid_bc = (t.b+t.c)/2.0f;
Triangle t1(mid_ab, mid_ac, mid_bc);
Triangle t2(t.a, mid_ab, mid_ac);
Triangle t3(t.b, mid_ab, mid_bc);
Triangle t4(t.c, mid_bc, mid_ac);
queue.push(t1);
queue.push(t2);
queue.push(t3);
queue.push(t4);
result.push_back(t2.get_center());
result.push_back(t3.get_center());
result.push_back(t4.get_center());
}
return result;
}
Fragment Kodu 4.1: Algorytm tworzacy tablice współrzednych barycentrycznych dla
przekazanego podziału.
4.3. Tworzenie siatki
Etapy tworzenia siatki:
1. Obliczenie sredniego rozmiaru trójkata.
K. Gabis Zastosowanie kart graficznych w obliczeniach geometrii dzwieku

4.3. Tworzenie siatki 27
2. Obliczenie prostopadłoscianu ograniczajacego scene.
3. Obliczenie rozmiaru komórki i rozmiaru siatki w 3 wymiarach (szerokosc, wysokosc, głebokosc).
4. Przypisanie kazdej poszczególnej komórce listy trójkatów, które z nia koliduja.
5. Przypisanie kazdej nie-pustej komórce offsetu1 do tablicy trójkatów oraz liczby trójkatów, z
którymi sie przecina.
4.3.1. Obliczanie sredniego rozmiaru trójkata w scenie
Do obliczenia sredniego rozmiaru trójkata w scenie wystarczy policzyc prostopadłoscian ogranicza-
jacy kazdy trójkat i zsumowac jego rozciagłosc w kazdym z wymiarów. Algorytm ten pokazano we
fragmencie kodu 4.2.
float computeAverageTriangleSize(const Triangle *triangles, size_t
trianglesCount)
{
float acc = 0.0f;
for (int i = 0; i < trianglesCount; i++) {
AABB tbox = computeTriangleAABB(triangles[i]);
float3 extent = tbox.max - tbox.min;
acc += extent.x + extent.y + extent.z;
}
return acc / ((float)trianglesCount * 3.0f);
}
Fragment Kodu 4.2: Algorytm obliczajacy sredni rozmiar trójkata.
4.3.2. Obliczanie prostopadłoscianu ograniczajacego scene
Obliczenie prostopadłoscianu ograniczajacego scene jest bardzo proste i polega na znalezieniu na-
jmniejszych i najwiekszych wartosci wsród wymiarów wierzchołków trójkatów sceny. Algorytm ten jest
przedstawiony we fragmencie kodu 4.3. Aby rozmiary komórek były takie same w kazdym wymiarze,
wymiary szescianu sa nastepnie zaokraglane w góre tak, by były bez reszty podzielne przez rozmiar
komórki.
1Offset - przesuniecie.
K. Gabis Zastosowanie kart graficznych w obliczeniach geometrii dzwieku

28 4.3. Tworzenie siatki
AABB computeTrianglesAABB(const Triangle *triangles, size_t trianglesCount)
{
float3 min = make_float3(FLT_MAX, FLT_MAX, FLT_MAX);
float3 max = make_float3(FLT_MIN, FLT_MIN, FLT_MIN);
for (int i = 0; i < trianglesCount; i++) {
Triangle t = triangles[i];
min.x = t.a.x < min.x ? t.a.x : min.x;
min.x = t.c.x < min.x ? t.c.x : min.x;
min.x = t.b.x < min.x ? t.b.x : min.x;
min.y = t.a.y < min.y ? t.a.y : min.y;
min.y = t.c.y < min.y ? t.c.y : min.y;
min.y = t.b.y < min.y ? t.b.y : min.y;
min.z = t.a.z < min.z ? t.a.z : min.z;
min.z = t.c.z < min.z ? t.c.z : min.z;
min.z = t.b.z < min.z ? t.b.z : min.z;
max.x = t.a.x > max.x ? t.a.x : max.x;
max.x = t.b.x > max.x ? t.b.x : max.x;
max.x = t.c.x > max.x ? t.c.x : max.x;
max.y = t.a.y > max.y ? t.a.y : max.y;
max.y = t.b.y > max.y ? t.b.y : max.y;
max.y = t.c.y > max.y ? t.c.y : max.y;
max.z = t.a.z > max.z ? t.a.z : max.z;
max.z = t.b.z > max.z ? t.b.z : max.z;
max.z = t.c.z > max.z ? t.c.z : max.z;
}
return AABB(min, max);
}
Fragment Kodu 4.3: Algorytm obliczajacy prostopadłoscian ograniczajacy scene.
4.3.3. Reprezentacja siatki w pamieci.
struct Cell {
int triangleOffset;
int triangleCount;
}
Fragment Kodu 4.4: Deklaracja struktury reprezentujacej komórke.
Aby ograniczyc zuzycie pamieci i nieregularne dostepy do pamieci postanowiono przechowywac
informacje o trójkatach przecinajacych sie z kazda komórka w postaci jednowymiarowej tablicy struktur
Cell, której deklaracja znajduje sie sie we fragmencie kodu 4.4. Same trójkaty sa przechowywane w
osobnej tablicy, wspólnej dla całej siatki. Aby uzyskac jednowymiarowy indeks na podstawie indeksu
K. Gabis Zastosowanie kart graficznych w obliczeniach geometrii dzwieku

4.4. Tworzenie promieni 29
trójwymiarowego uzyto algorytmu znajdujacego sie we fragmencie kodu 4.5.
int ComputeCellIndex(int x, int y, int z) const
{
return width*height*z + width*y + x;
}
Fragment Kodu 4.5: Algorytm obliczajacy indeks do tablicy komórek.
4.4. Tworzenie promieni
Aby zachowac prosty interfejs i ograniczyc transfer danych do pamieci karty graficznej promienie
sa liczone na podstawie przekazanych wiazek po stronie GPU. Biblioteka RAYAV korzysta z 3 typów
wiazek i obliczenia dla kazdego z nich musza byc równiez wspierane przez stworzona w tej pracy bib-
lioteke. Do okreslenia liczby promieni uzywane jest pojecie podziału wiazki. W przypadku podziału
s = 1, wiazka jest dzielona na 4 równe czesci i srodek kazdej z nich jest poczatkiem promienia. Dla
podziału s = 2 wiazka jest tak jak wczesniej dzielona na 4 równe czesci, a pózniej kazda z tych czesci
jest dzielona na 4 kolejne, co daje 16 promieni. Relacja liczby wiazek w od s wynosi wiec w = 4s.
Obliczenia dla kazdego promienia sa prowadzone przez osobne watki na karcie graficznej, a połozenie
promienia jest okreslane na podstawie identyfikatora watku. Dla kolejnych generacji wiazek stosuje sie
rózne stopnie podziału, np. podział 433 oznacza, ze dla pierwszej generacji wiazek stosuje sie podział 4,
dla drugiej podział 3 i dla trzeciej podział 3.
Po obliczeniu punktu poczatkowego i wektora kierunkowego promienia dalsze obliczenia sa juz takie
same dla kazdego typu wiazki.
4.4.1. Wiazka trójkatna
struct Frustum3 {
float3 origin;
float3 a, b, c;
}
Fragment Kodu 4.6: Deklaracja wiazki trójkatnej.
Wiazka trójkatna jest tworzona przy pomocy wczesniej obliczonej tablicy współrzednych barycen-
trycznych reprezentujacych srodki trójkatów powstałych w wyniku podziału trójkata tworzacego wiazke.
Algorytm ten opisano dokładnie w podrozdziale 4.2. W kazdym poszczególnym watku wystarczy nastep-
nie na podstawie identyfikatora promienia wczytac współrzedne barycentryczne z przekazanej do ker-
nela tablicy i na ich podstawie obliczyc współrzedne punktu bedacego poczatkiem promienia. Nastep-
nie wektor kierunkowy promienia jest tworzony przez odjecie punktu poczatkowego wiazki od punktu
K. Gabis Zastosowanie kart graficznych w obliczeniach geometrii dzwieku

30 4.4. Tworzenie promieni
Figure 4.1: Tworzenie promieni na podstawie wiazki trójkatnej o podziale 1.
poczatkowego promienia i jego znormalizowanie. Odpowiedzialny za to kod znajduje sie we fragmencie
kodu 4.7. Zobrazowano to równiez na rysunku 4.1.
int beamID = blockIdx.y;
int rayID = (blockIdx.x*blockDim.x) + threadIdx.x;
Frustum3 beam = beams[beamID];
float3 bc = barycentricCoordinates[rayID];
float3 direction = beam.a*bc.x + beam.b*bc.y + beam.c*bc.z;
float3 origin = beam.origin + direction;
Ray ray(origin, direction);
Fragment Kodu 4.7: Tworzenie promienia w oparciu o wiazke trójkatna, tablice współrzednych
barycentrycznych i identyfikator watku.
4.4.2. Wiazka czworokatna
struct Frustum4Ex {
float3 a, orig_b, orig_c, orig_d;
float3 dir_a, dir_b, dir_c, dir_d;
};
Fragment Kodu 4.8: Deklaracja wiazki czworokatnej.
Wiazka czworokatna jest reprezentowana przez 4 koplanarne punkty stanowiace podstawe wiazki i
4 wektory kierunku. Jako poczatki promieni sa uzywane srodki czworokatów powstałych przy podziale
wiazi, które uzyskuje sie przez interpolacje liniowa miedzy punktami podstawy wiazki. W identyczny
K. Gabis Zastosowanie kart graficznych w obliczeniach geometrii dzwieku

4.4. Tworzenie promieni 31
Figure 4.2: Tworzenie promieni na podstawie wiazki czworokatnej o podziale 1.
sposób obliczany jest wektor kierunkowy. Do interpolacji potrzebne sa dwie współrzedne, fx i fy, które
sa obliczane na podstawie identyfikatora watku. Kod odpowiedzialny za te obliczenia znajduje sie we
fragmencie kodu 4.11. Zobrazowano to równiez na rysunku 4.2.
int stepsCount = sqrt(blockDim.x);
int beamID = blockIdx.y;
int rayID = (blockIdx.x*blockDim.x) + threadIdx.x;
int x = rayID % stepsCount;
int y = rayID / stepsCount;
float3 direction, origin;
Frustum4Ex beam = beams[beamID];
float fx = ((float)(x)+0.5f)/(float)(stepsCount);
float fy = ((float)(y)+0.5f)/(float)(stepsCount);
direction = lerp(lerp(beam.dir_d, beam.dir_a, fx), lerp(beam.dir_c, beam.
dir_b, fx), fy);
origin = lerp(lerp(beam.orig_d, beam.orig_a, fx), lerp(beam.orig_c, beam.
orig_b, fx), fy);
Ray ray(origin, direction);
Fragment Kodu 4.9: Tworzenie promienia w oparciu o wiazke czworokatna oraz identyfikator
watku.
K. Gabis Zastosowanie kart graficznych w obliczeniach geometrii dzwieku

32 4.5. Testy przeciec promienia z geometria sceny
4.4.3. Wiazka czworokatna o wspólnym zródle
struct Frustum4 {
float4 origin;
float3 a, b, c, d;
};
Fragment Kodu 4.10: Deklaracja wiazki czworokatnej o wspólnym zródle.
Wiazka czworokatna o wspólnym poczatku jest reprezentowana przez 4 koplanarne punkty stanow-
iace podstawe wiazki oraz punkt zródłowy. Obliczenie promienia na jej podstawie jest bardzo podobne
do obliczen dla wiazki czworokatnej i równiez wiaze sie z interpolacja liniowa pomiedzy wierzchołkami
czworokata, co pokazano we fragmencie kodu 4.11 oraz zobrazowano na rysusnku 4.3. Zdecydowano
sie na taka reprezentacje z powodu zmniejszenia w ten sposób ilosci danych kopiowanych do pamieci
karty graficznej.
int stepsCount = sqrt(blockDim.x);
int beamID = blockIdx.y;
int rayID = (blockIdx.x*blockDim.x) + threadIdx.x;
int x = rayID % stepsCount;
int y = rayID / stepsCount;
float fx = ((float)(x)+0.5f)/(float)(stepsCount);
float fy = ((float)(y)+0.5f)/(float)(stepsCount);
Frustum4 beam = beams[beamID];
float3 direction = lerp(
lerp(beam.d, beam.a, fx),
lerp(beam.c, beam.b, fx), fy);
float3 origin = beam.origin + direction;
Ray ray(origin, direction);
Fragment Kodu 4.11: Tworzenie promienia w oparciu o wiazke czworokatna czworokatna oraz
identyfikator watku.
4.5. Testy przeciec promienia z geometria sceny
Na testy przeciec promienia z geometria sceny składaja sie 2 etapy:
1. Testy przeciec promienia z siatka.
2. Testy przeciec promienia z trójkatami w komórce siatki.
K. Gabis Zastosowanie kart graficznych w obliczeniach geometrii dzwieku

4.5. Testy przeciec promienia z geometria sceny 33
Figure 4.3: Tworzenie promieni na podstawie wiazki czworokatnej o wspólnym zródle o podziale 1.
Figure 4.4: Etapy przechodzenia promienia segmentami przez dwuwymiarowa siatke az do napotkania
trójkata. Komórki białe reprezentuja komórki nieodwiedzone, natomiast zielone komórki odwiedzone.
4.5.1. Testy przeciec promienia z siatka
Aby sprawdzic kolizje promienia z trójkatami znajdujacymi sie w poszczególnych komórkach siatki
konieczny jest algorytm sprawdzajacy wszystkie komórki znajdujace sie na drodze promienia. Na-
jbardziej odpowiedni i powszechnie stosowany do tego celu jest algorytm opisany przez Johna Ama-
natidesa i Andrew Woo [8] działajacy podobnie do algorytmu Bresenhama [15]. Jego działanie polega
na przechodzeniu przez siatke od punktu poczatkowego segmentami, komórka po komórce, az napotka
sie punkt koncowy albo natrafi na koniec siatki. Jego działanie zobrazowano na rysunku 4.4. Mozliwe
jest wygenerowanie tablicy wszystkich komórek przecinajacych sie z promieniem, ale bardziej efekty-
wne jest wykonywanie testów kolizji promienia z trójkatami w kazdej napotkanej komórce w trakcie
przechodzenia przez siatke, gdyz mozna w ten sposób uniknac niepotrzebnych obliczen. Działanie algo-
rytmu zostaje przerwane po napotkaniu kolizji z trójkatem w obrebie testowanej komórki.
4.5.2. Testy przeciec promienia z trójkatami w komórce siatki
Po natrafieniu promienia na komórke najpierw sprawdzane jest to, czy jest pusta. Jesli tak, to nie
moze zajsc kolizja. W innym wypadku nastepuje sprawdzanie po kolei kolizji promienia z kazdym
trójkatem komórki w celu znalezienia najblizszego poczatkowi promienia punktu kolizji. Jesli zostanie
K. Gabis Zastosowanie kart graficznych w obliczeniach geometrii dzwieku

34 4.5. Testy przeciec promienia z geometria sceny
znaleziony, sprawdzane jest równiez, czy znajduje sie on w obrebie testowanej komórki. Jesli nie, to jest
on odrzucany.
Same testy przeciec promien-trójkat uzywaja alternatywnej reprezentacji trójkata w postaci punktu
odnisienia i 2 krawedzi oraz algorytmu autorstwa Tomasa Möller’a i Bena Trumbore’a [9]. Algorytm ten
uzywa współrzednych barycentrycznych do sprawdzenia, czy punkt przeciecia promienia z płaszyczyzna
trójkata znajduje sie w jego srodku, czy na zewnatrz. Zaleta tego algorytmu jest to, ze posiada on mało
rozgałezien i jest prosty w implementacji.
K. Gabis Zastosowanie kart graficznych w obliczeniach geometrii dzwieku

5. Testy
Do testów zastosowano komputer z procesorem Intel Core2 Quad Q6600, 4GB pamieci RAM oraz
z karta graficzna Nvidia GeForce GTX 750. Do czesci testów uzyto scen Church oraz SpaceStation,
które sa uzywane jako sceny testowe przy testowaniu biblioteki RAYAV. Scena Church składa sie z 1147
trójkatów, przedstawia ja rysunek 5.1. Scena SpaceStation składa sie z 760 trójkatów, przedstawia ja
rysunek 5.2. Warto zaznaczyc, ze biblioteka RAYAV korzysta w trakcie obliczen tylko z jednego rdzenia
CPU, a uzyty procesor nie wspiera instrukcji wektorowych AVX.
5.1. Testy poprawnosci implementacji
W celu sprawdzenia poprawnosci implementacji zdecydowano sie stworzyc wizualizacje uzyskanych
wyników. Do tego celu uzyto modelu czajniczka z Utah składajacego sie z 6319 trójkatów. Zdecydowano
sie na ten model, poniewaz jest on jednym ze standardowych modeli referencyjnych uzywanych przy
generowaniu grafiki komputerowej. W celu wizualizacji utworzono czworokatna wiazke skierowana w
kierunku czajniczka, która posłuzyła za odpowiednik kamery. Uzyto podziału wiazki wynoszacego 9,
co dało rozdzielczosc 512x512 pikseli oraz utworzyło 262 144 promieni. Na podstawie uzyskanych
wyników uzyskano obraz png, gdzie kazdy piksel odpowiadał jednemu promieniowi. W przypadku
znalezienia kolizji piksel przyjmował kolor czerwony, w innym wypadku był biały. Uzyskane wyniki
przedstawiono na rysunkach 5.3a, 5.3b oraz 5.3c. W praktyce okazało sie to bardzo przydatne przy
tworzeniu prawidłowej implementacji, gdyz pozwalało na szybkie wykrywanie zaistaniałych w niej
błedów.
5.2. Porównanie z metoda brute-force
Celem tych testów było porównanie wydajnosci metody opartej na siatkach z metoda brute-force.
Testy przeprowadzono na wiazkach trójkatnych oraz czworokatnych. W celu najlepszego odwzorowa-
nia warunków, w jakich bedzie pracowała biblioteka, uzyto sceny Church oraz rzeczywistych danych
o wiazkach zrzuconych z biblioteki RAYAV. W przypadku wiazek trójkatnych uzyto 2008 wiazek o
podziale 3, natomiast w przypadku wiazek czworokatnych uzyto 2235 wiazek równiez o podziale 3.
Dla obu typów wiazek i metod przeprowadzono po 1000 nastepujacych po sobie testów, których czas
35

36 5.2. Porównanie z metoda brute-force
Figure 5.1: Scena Church.
Figure 5.2: Scena SpaceStation.
K. Gabis Zastosowanie kart graficznych w obliczeniach geometrii dzwieku

5.3. Testy wydajnosci w bibliotece RAYAV 37
(a) (b) (c)
Figure 5.3: Wyniki uzyskane podczas testów poprawnosci implementacji w miare postepów prac. Na
rysunku 5.3a popełniono bład polegajacy nad nadpisaniu zmiennej, co doprawdziło do testowania kolizji
w nieprawidłowych komórkach. Na rysunku 5.3b popełniono bład polegajacy na złym warunku przejscia
do nastepnej komórki, przez co czesc komórek nie była brana pod uwage. Rysunek 5.3c przedstawia
finalna, prawidłowa implementacje.
usredniono. Wyniki przedstawiono na rysunku 5.4. Jak widac, metoda oparta na siatkach jest prawie
10-krotnie szybsza.
5.3. Testy wydajnosci w bibliotece RAYAV
Aby sprawdzic wydajnosc biblioteki w docelowym zastosowaniu przeprowadzono testy wydajnosci
w aplikacji testujacej biblioteke RAYAV. W testach tych porównano czas aktualizacji klatki przy stan-
dardowej metodzie obliczen geometrii dzwieku opartej na CPU oraz z zastosowaniem utworzonej w tej
pracy biblioteki korzystajacej z kart graficznych. Na czas aktualizacji klatki poza obliczeniami geometrii
składaja sie równiez inne obliczenia prowadzone przez biblioteke. Do testów posłuzyły sceny Church
oraz Spacestation. Scena Church uzywała podziału wiazki 433, natomiast scena SpaceStation podzi-
ału 444. Na scenach tych przez 15 sekund rejestrowano czas aktualizacji klatki dla GPU, a nastepnie
po ponownym uruchomieniu aplikacji rejestrowano czas aktualizacji klatki dla CPU. Odbiornik znaj-
dował sie w czasie rejestrowania w zblizonym punkcie sceny dla obu testów. Na rysunku 5.5 przedstaw-
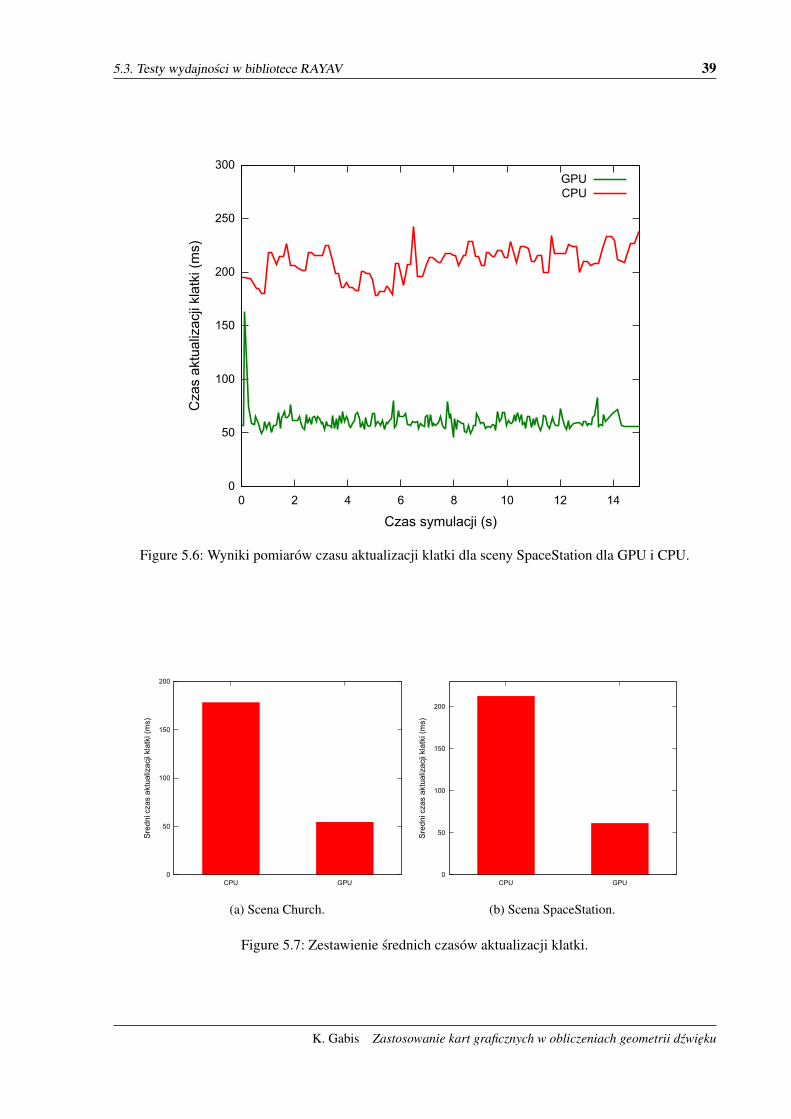
iono wyniki dla sceny Church, natomiast na rysunku 5.6 przedstawiono wyniki dla sceny SpaceStation.
Zestawienie srednich wyników znajduje sie na rysunku 5.7.
Przy obliczeniach geometrii dzwieku na GPU sredni czas aktualizacji klatki jest ponad 3-krotny,
niz przy obliczeniach na CPU. Jest to bardzo duzy skok wydajnosci, który jest odczuwalny w trakcie
działania aplikacji testowej. Z uwagi na to, ze jest to łaczny czas aktualizacji klatki, zawierajacy w sobie
m.in. obliczenia syntezy dzwieku, to same obliczenia kolizji mogły odnotowac wiekszy, niz 3-krotny
wzrost wydajnosci.
K. Gabis Zastosowanie kart graficznych w obliczeniach geometrii dzwieku
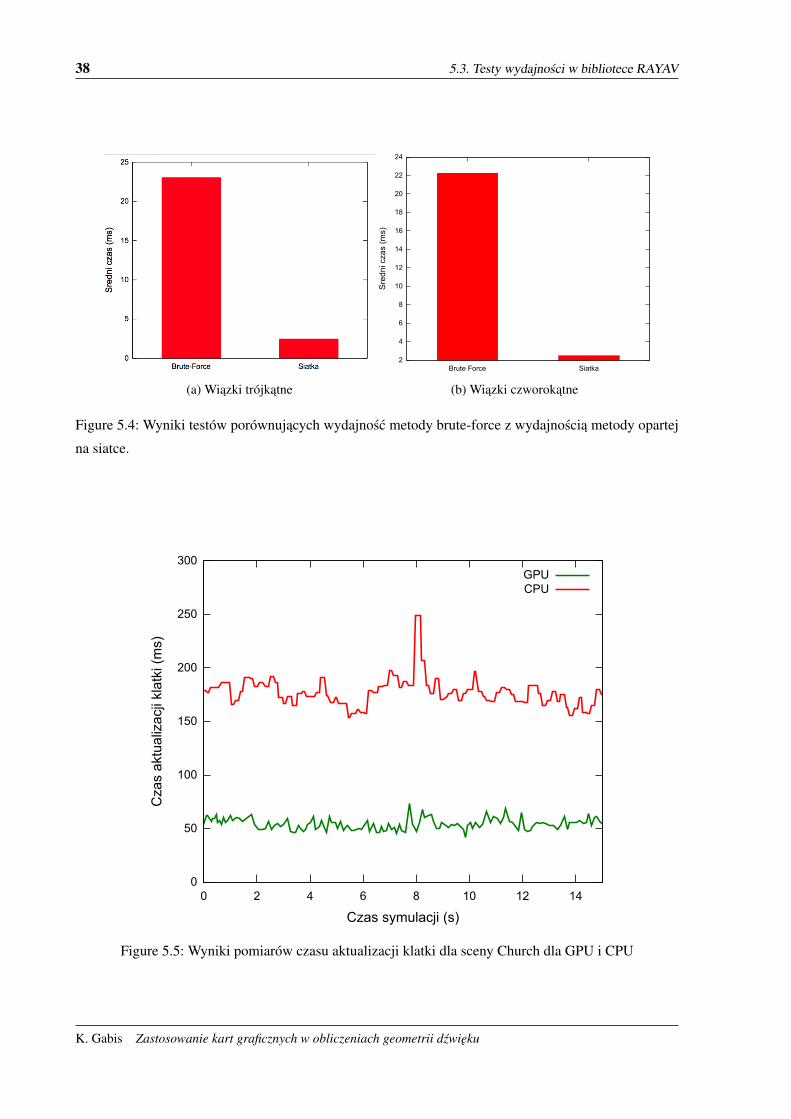
38 5.3. Testy wydajnosci w bibliotece RAYAV
(a) Wiazki trójkatne
2
4
6
8
10
12
14
16
18
20
22
24
Brute Force Siatka
Sre
dn
i cza
s (
ms)
(b) Wiazki czworokatne
Figure 5.4: Wyniki testów porównujacych wydajnosc metody brute-force z wydajnoscia metody opartej
na siatce.
0
50
100
150
200
250
300
0 2 4 6 8 10 12 14
Cza
s a
ktu
aliz
acji
kla
tki (m
s)
Czas symulacji (s)
GPU
CPU
Figure 5.5: Wyniki pomiarów czasu aktualizacji klatki dla sceny Church dla GPU i CPU
K. Gabis Zastosowanie kart graficznych w obliczeniach geometrii dzwieku
5.3. Testy wydajnosci w bibliotece RAYAV 39
0
50
100
150
200
250
300
0 2 4 6 8 10 12 14
Cza
s a
ktu
aliz
acji
kla
tki (m
s)
Czas symulacji (s)
GPU
CPU
Figure 5.6: Wyniki pomiarów czasu aktualizacji klatki dla sceny SpaceStation dla GPU i CPU.
0
50
100
150
200
CPU GPU
Sre
dni
cza
s ak
tual
iza
cji k
latk
i (m
s)
(a) Scena Church.
0
50
100
150
200
CPU GPU
Sre
dni
cza
s ak
tual
iza
cji k
latk
i (m
s)
(b) Scena SpaceStation.
Figure 5.7: Zestawienie srednich czasów aktualizacji klatki.
K. Gabis Zastosowanie kart graficznych w obliczeniach geometrii dzwieku

40 5.3. Testy wydajnosci w bibliotece RAYAV
K. Gabis Zastosowanie kart graficznych w obliczeniach geometrii dzwieku

6. Wnioski
W ramach pracy stworzono biblioteke, która słuzy do obliczen kolizji wiazek z trójkatami sceny z za-
stosowaniem kart graficznych. Opracowane przez autora rozwiazanie korzysta z platformy Nvidia CUDA
w celu prowadzenia obliczen ogólnego zastosowania na kartach graficznych firmy Nvidia. Po porówna-
niu istniejacych metod słuzacych do przeprowadzania testów kolizji promieni z trójkatami zdecydowano
sie zastosowac metode oparta na siatkach, gdyz przez regularne wzorce dostepu do pamieci najlepiej
nadawała sie ona do przeniesienia na karty graficzne. Zaimplementowana metoda okazała sie ponad
10-krotnie szybsza od naiwnej implementacji korzystajacej z metody brute-force. Stworzona biblioteke
zintegrowano z biblioteka RAYAV przy pomocy przedstawionego w rozdziale 3 interfejsowi. Podczas
testów na scenach testowych z zastosowaniem biblioteki RAYAV odnotowano ponad trzykrotny spadek
czasu potrzebnego na obliczenia klatki dzwieku, co miało znaczacy wpływ na płynnosc działania bib-
lioteki. Wyniki takie pokazuja, ze współczesne karty graficzne bardzo dobrze nadaja sie do prowadzenia
niektórych rodzajów obliczen ogólnego zastosowania i trend przenoszenia na nie czesci obliczen bedzie
sie w przyszłosci nasilał za sprawa ich coraz wiekszych mozliwosci obliczeniowych. Z tego tez powodu
powinno sie traktowac obecne komputery klasy PC jako jednostki heterogeniczne, posiadajace wiecej,
niz jeden typ procesora, aby uzyskac maksymalna wydajnosc tworzonych aplikacji. Jest to szczególnie
wazne w aplikacjach działajacych w czasie rzeczywistym, które przeprowadzaja intesywne obliczenia.
41

42
K. Gabis Zastosowanie kart graficznych w obliczeniach geometrii dzwieku

Bibliography
[1] Nvidia Corporation. Nvidia’s next generation cuda compute and graphics architecture: Fermi. 2009.
[2] Christer Ericson. Real-time Collision Detection. Elsevier, Amsterdam, 2005.
[3] Christian Lauterbach et al. Interactive sound rendering in complex and dynamic scenes using
frustum tracing. IEEE Transactions On Visualization And Computer Graphics, vol. 13, no. 6, 2007.
[4] Shuai Che et al. A performance study of general-purpose applications on graphics processors using
cuda. Journal of Parallel and Distributed Computing, vol. 68, no. 10, 2008.
[5] Steven Parker et al. Optix: A general purpose ray tracing engine. ACM Transactions on Graphics.
[6] Victor W. Lee et al. Debunking the 100x gpu vs. cpu myth: an evaluation of throughput computing
on cpu and gpu. Proceedings of the 37th annual international symposium on Computer architecture,
2010.
[7] Mike Giles. Different memory and variable types. https://people.maths.ox.ac.uk/
gilesm/cuda/lecs/lec2-2x2.pdf, 2014. [Online; Dostep 24.10.2014].
[8] John Amanatides i Andrew Woo. A fast voxel traversal algorithm for ray tracing. Proceedings of
Eurographics, 1987.
[9] Tomas Möller i Ben Trumbore. Fast, minimum storage ray/triangle intersection. Journal of Graph-
ics Tools, 1997.
[10] Carl Schissler i Dinesh Manocha. Gsound: Interactive sound propagation for games. AES Interna-
tional Conference on Audio for Games, 2011.
[11] François Lehericey. Iterative and predictive ray-traced collision detection for multi-gpu architec-
tures. 2013.
[12] Chris McClanahan. History and evolution of gpu architecture. 2011.
[13] Sz. Pałka, B. Głut i B. Ziółko. Visibility determination in beam tracing with application to real-time
sound simulation. Computer Science, AGH, vol. 15, no. 2, 2014.
43

44 BIBLIOGRAPHY
[14] Tomas Akenine-Möller, Eric Haines i Natty Hoffman. Real-Time Rendering 3rd Edition. A. K.
Peters, Ltd., Natick, MA, USA, 2008.
[15] Wikipedia. Bresenham’s line algorithm — Wikipedia, the free encyclopedia. http://en.
wikipedia.org/w/index.php?title=Bresenham’s%20line%20algorithm&
oldid=626419151, 2014. [Online; Dostep: 24.09.2014].
K. Gabis Zastosowanie kart graficznych w obliczeniach geometrii dzwieku


















