
Program automatycznej lub półautomatycznej translacji z ...zskl.p.lodz.pl/~morawski/Dyplomy/praca...
82
Program automatycznej lub półautomatycznej translacji z języka Delphi do Ady’95 promotor: dr Michał Morawski autor: Marcin Buchwald Wydział Fizyki Technicznej, Informatyki i Matematyki Stosowanej (FTIMS), Politechnika Łódzka
-
Upload
hoangkhuong -
Category
Documents
-
view
215 -
download
1
Transcript of Program automatycznej lub półautomatycznej translacji z ...zskl.p.lodz.pl/~morawski/Dyplomy/praca...

Program automatycznej lub półautomatycznej translacji z
języka Delphi do Ady’95
promotor: dr Michał Morawski
autor: Marcin Buchwald
Wydział Fizyki Technicznej, Informatyki i Matematyki Stosowanej (FTIMS),
Politechnika Łódzka

Spis treści Bibliografia........................................................................................................3
Spis przykładów................................................................................................4
1. Wstęp..........................................................................................................6
2. Podstawy teoretyczne analizy składniowej i teorii kompilatorów........8
2.1 Definicja i struktura języka.........................................................................8
2.2 Analiza zdań..............................................................................................11
2.3 Konstrukcja diagramu składni...................................................................14
2.4 Konstrukcja analizatora składniowego dla zadanej gramatyki..................17
3. Analiza porównawcza języków Ada'95 i Delphi...................................23
3.1 Organizacja programu..........................................................................24
3.2 Podprogramy........................................................................................25
3.3 Instrukcje..............................................................................................26
3.4 Typy danych.........................................................................................31
3.4.1 Typy proste.............................................................................. 31
3.4.2 Typy strukturalne.....................................................................32
3.4.3 Typy wskaźnikowe..................................................................34
3.4.4 Typy proceduralne...................................................................34
3.5 Programowanie obiektowe (OOP) ......................................................35
3.6 Podsumowanie.....................................................................................36
4. Budowa i działanie programu D2A........................................................37
4.1 Struktura programu D2A.....................................................................37
4.2 Działanie programu D2A.....................................................................39
4.2.1 Translacja struktur obiektowych..............................................39
4.2.2 Enkapsulacja............................................................................40
4.2.3 Metody.....................................................................................40
4.2.4 Dziedziczenie...........................................................................42
4.2.5 Polimorfizm..............................................................................43
4.2.6 Konstruktor...............................................................................47
4.2.7 Destruktor.................................................................................48
4.2.8 Property.....................................................................................49
4.2.9 Typy zagnieżdżone...................................................................53
1

4.2.10 Instrukcja "with".......................................................................54
4.2.11 Rekord z wariantami.................................................................55
4.2.12 Funkcje i procedury..................................................................57
4.2.13 Dyrektywy kompilatora (pragma)............................................61
4.2.14 Komentarze..............................................................................64
4.2.15 Asembler..................................................................................65
4.2.16 Obsługa wyjątków...................................................................66
4.2.17 Zmienne typu obiect................................................................69
4.2.18 Procedury new i dispose..........................................................70
4.2.19 Inne konstrukcje nie wspierane przez D2A.............................70
5. Załączniki................................................................................................72
A. Notacje BNF, EBNF.......................................................................72
B. Składnia Object Pascala w EBNF..................................................73
2

Bibliografia:
1. Andrzej Pasławski, Programowanie w Delphi 5.0, Edition 2000, 2000
2. Niklaus Wirth, Algorytmy + struktury danych = programy, WNT, 2000
3. Niklaus Wirth, Wstęp do programowania systematycznego, WNT, 1987
4. Ada95 reference manual, dołączony do pakietu GNAT
5. Programing with Delphi, dołączony do pakietu Delphi 5.0
6. A Brief History of Pascal, http://www.oberon.ch/resources/component_pascal/history.html
7. Visual Studio .NET: C# introduction,
http://msdn.microsoft.com/vstudio/nextgen/technology/csharpintro.asp
8. Jerzy Grębosz, Symfonia C++, Oficyna Kallimach, 1996
3

Spis przykładów
1. Przykład 2.1 – definicja prostego języka .......................................................9
2. Przykład 2.2 – definicja prostego języka .......................................................9
3. Przykład 2.3 – definicja prostego języka .....................................................12
4. Przykład 2.4 – definicja prostego języka .....................................................13
5. Przykład 2.5 – definicja prostego języka .....................................................16
6. Przykład 2.6 – program analizatora prostego języka ...................................20
7. Przykład 3.1a – organizacja programu – Delphi ..........................................24
8. Przykład 3.1b – organizacja programu – Ada ..............................................25
9. Przykład 3.2 – instrukcja loop w Adzie .......................................................30
10. Przykład 3.3 – typy proste w Adzie .............................................................32
11. Przykład 3.4 – typy strukturalne – tablice ...................................................33
12. Przykład 3.5 – typy strukturalne – rekordy .................................................33
13. Przykład 3.6 – typy wskaźnikowe ...............................................................34
14. Przykład 3.7 – typy proceduralne ................................................................35
15. Przykład 4.2a – metody – Delphi ................................................................40
16. Przykład 4.2b – metody – Ada ....................................................................41
17. Przykład 4.3 – polimorfizm .........................................................................43
18. Przykład 4.4a – polimorfizm – Delphi .........................................................45
19. Przykład 4.4b – polimorfizm – Ada .............................................................46
20. Przykład 4.5a – konstruktor – Delphi ..........................................................47
21. Przykład 4.5b – konstruktor – Ada ..............................................................48
22. Przykład 4.6a – property – Delphi ...............................................................50
23. Przykład 4.6b – property – Ada ...................................................................51
24. Przykład 4.7a – typy zagnieżdżone – Delphi ...............................................53
25. Przykład 4.7b – typy zagnieżdżone – Ada ...................................................53
26. Przykład 4.8a – rekord z wariantami – Delphi .............................................56
27. Przykład 4.8b – rekord z wariantami – Ada .................................................56
28. Przykład 4.9a – przekazywanie parametrów do podprogramu – Delphi ....58
29. Przykład 4.9b – przekazywanie parametrów do podprogramu – Ada .........58
30. Przykład 4.10 – zwracanie wartości funkcji w Delphi.................................60
31. Przykład 4.11 – dyrektywy kompilatora w Delphi.......................................62
32. Przykład 4.12 – dyrektywy kompilatora w Delphi.......................................62
4

33. Przykład 4.13 – dyrektywy kompilatora w Delphi.......................................62
34. Przykład 4.14 – dyrektywy kompilatora w Delphi.......................................63
35. Przykład 4.15 – komentarze.........................................................................64
36. Przykład 4.16 – kod asemblera w Delphi.....................................................65
37. Przykład 4.17 – przetłumaczony kod asemblera..........................................66
38. Przykład 4.18 – obsługa wyjątków..............................................................67
39. Przykład 4.19 – blok finally.........................................................................68
40. Przykład 4.20 – typ object...........................................................................70
5

1. Wstęp
Celem tej pracy jest stworzenie narzędzia, za pomocą którego programista mógłby w szybki sposób
tłumaczyć kod napisany w języku Object Pascal (pakiet Delphi) do języka Ada ’95, nazywanego w
niniejszej pracy po prostu Adą. Język Delphi, następca popularnego Turbo Pascala firmy Borland,
w przeciągu ostatnich lat stał się jednym z najpopularniejszych środowisk programistycznych na
platformę systemu operacyjnego Microsoft Windows, a ostatnio także dla systemu Linux (Kylix).
Od tego czasu powstało dużo bibliotek napisanych dla tego języka. Zaistniała potrzeba
udostępnienia niektórych z nich dla potrzeb programistów innych języków, w tym Ady. Ada w
porównaniu z Delphi oferuje znacznie większą uniwersalność (można pisać w niej m. in.
sterowniki, gry, programy biznesowe a nawet systemy operacyjne), bezpieczeństwo, zgodność ze
standardami i lepsze kompilatory (np. GNAT) [4]. Korzystanie z bibliotek napisanych w Delphi
przez programy Ady nie zawsze jest możliwe. Często jedynym wyjściem jest przepisanie takich
bibliotek na nowo tym razem w Adzie. Pomocnym narzędziem w tej czynności jest program do
automatycznej lub półautomatycznej translacji z Delphi do Ady’95.
Oba te języki wywodzą się z języka Pascal. Powstał on w późnych latach sześćdziesiątych
ubiegłego wieku, w zastępstwie pierwszego języka wysokiego poziomu jakim był Algol (1960 r.)
[2], który pomimo czytelnej, strukturalnej i systematycznie zdefiniowanej składni nie oferował tak
podstawowych typów danych jak wskaźniki czy typ znakowy. Twórcą Pascala był prof. Niklaus
Wirth z instytutu ETH w Zurichu. Poza uproszczeniem lub też odrzuceniem niektórych zbędnych,
przestarzałych konstrukcji, Wirth dodał możliwość definiowania nowych typów danych na
podstawie innych, już istniejących [6]. Dodatkowo język Pascal zaopatrzono w tzw. dynamiczne
struktury danych, czyli takie struktury, które mogą zmieniać swój rozmiar w trakcie trwania
programu (np. możliwość implementacji kolejek, stosów oraz tablice dynamiczne). Przyczyną
sukcesu tego języka, oprócz wymieniowych wcześniej zalet, stała się budowa kompilatora Pascala,
który produkował prosty kod pośredni, niezależny od konkretnej architektury (P-code). Inny moduł
interpretował P-code i tłumaczył go na kod maszynowy dla danego procesora. To spowodowało, że
przenoszenie kompilatora stało się prostsze – trzeba było za każdym razem pisać jedynie interpreter
P-code, a nie cały kompilator. Na podobnej zasadzie działa między innymi język Java. Tu kod
pośredni tzw. bytecode jest interpretowany za pomocą maszyny wirtualnej javy (ang. java virtual
machine). Najbardziej popularnym kompilatorem stał się Turbo Pascal firmy Borland –
6

późniejszych twórców Delphi. Pascal miał potężny wpływ na inne języki, między innymi na Adę,
Delphi, Modulę-2, Simulę, Smalltalk, Cedar, Oberon, Component Pascal a nawet na Visual Basic.
W związku z tym, że języki Delphi i Ada’95 mają wspólne korzenie, istnieją znaczne podobieństwa
w podstawowych strukturach języka. Z założenia translator powinien wyręczyć programistę w
tłumaczeniu pewnych podstawowych konstrukcji, które stanowią znaczną część kodu programu.
Takie fragmenty języka jak pętle, instrukcje warunkowe, definicje podprogramów czy rekordów
mogą być łatwo przetłumaczone za pomocą programu translacyjnego. Inne z kolei konstrukcje są w
obu językach bardzo różne. Jest tak w przypadku programowania obiektowego (OOP), które nie
było częścią Pascala wzorcowego. Ada i Delphi implementują to zagadnienie w krańcowo różne
sposoby. Kwestia prawidłowego przetłumaczenia takich konstrukcji stanowi dla translatora
największe wyzwanie. Niektóre konstrukcje nie są tłumaczone (np. typy set of), inne zaś częściowo
(np. typy interface). Powodem tego jest zazwyczaj brak w Adzie odpowiednika danej konstrukcji z
Delphi. Dodatkowo Ada została zaprojektowana z myślą o minimalizacji błędów, które programista
popełnia pisząc kod programu. Stąd język ten jest bardzo restrykcyjny i wiele rzeczy (takich jak
przekazywanie do funkcji parametrów przez referencję) jest niedozwolona. W końcu Ada jest
językiem bardziej uniwersalnym od Delphi. Istnieje wiele implementacji Ady na wiele platform i
systemów operacyjnych, Delphi zaś zaprojektowano na platformę PC/Windows (od niedawna także
PC/Linux). Tam gdzie translator nie jest w stanie przetłumaczyć poprawnie danej konstrukcji,
powinien wstawić o tym informację dla użytkownika – programisty, tak by mógłby on zrobić to
samodzielnie.
Na koniec kilka uwag o formalnej stronie pracy. W pracy użyto czcionki Times New Roman. Dla
kodu w przykładach użyto czcionki Curier. Dla zwiększenia czytelności przykładów niektóre
elementy języka Ada i Delphi (w tym słowa kluczowe) zostały napisane tłustym drukiem.
Odniesienia do literatury zostały umieszczone w nawiasach kwadratowych.
7

2. Podstawy teoretyczne analizy składniowej i teorii kompilatorów [2]
Rozdział ten w sposób teoretyczny traktuje o tym, co wszyscy programiści doskonale znają -
interpretacji i kompilacji.
Narzędzia komputerowe służące do przetworzenia tekstu napisanego w języku programowania
(programu) to translatory. Translatory tłumaczą kod programu do postaci wykonywanej przez
komputer, lub nadającej się do przetworzenia przez inny program. Przykładem tych pierwszych są
translatory popularnych języków programowania, takich jak C, które tłumaczą kod w języku
programowania do kodu maszynowego, wykonywalnego przez procesor komputera. Przykładem
tych drugich mogą być translatory języków skryptowych, na przykład bash. Te z kolei, zamieniają
treść skryptu na sekwencję poleceń wykonywanych przez system operacyjny.
W tym rozdziale podane zostaną podstawowe definicje i reguły teorii kompilacji a w szczególności
analizy strukturalnej języka.
2.1 Definicja i struktura języka
Na wstępie należy zdefiniować samo pojęcie języka, jakie będzie używane w niniejszej pracy.
Podstawą każdego języka jest słownik. Elementy słownika są zazwyczaj nazywane słowami; w
świecie języków formalnych nazywa się je symbolami (podstawowymi). Cechą charakterystyczną
języków formalnych (formalizacja polega na dokładnym określeniu alfabetu języka, tj. znaków,
których można używać w tekstach pisanych w tym języku, określenia dopuszczanego łączenia tych
znaków - gramatyki języka) jest to, że pewne ciągi słów są rozpoznawane jako poprawne, dobrze
zbudowane zdania języka. O innych ciągach słów mówi się, że są niepoprawne lub źle zbudowane.
O tym, że ciąg słów jest zdaniem poprawnym lub nie, decyduje gramatyka, mówiąc inaczej –
składnia lub struktura języka. Składnia to zbiór reguł lub formuł (produkcji), określający zbiór
(formalnie poprawnych) zdań. Ważniejsze jest jednak to, że taki zbiór reguł nie tylko pozwala nam
decydować, czy dany ciąg słów jest zdaniem, ale także dla konkretnego zdania określa jego
strukturę, która jest pomocna w rozpoznaniu znaczenia zdania. Jasne jest więc, że składnia i
semantyka (znaczenie) są blisko ze sobą powiązane. Dlatego definicje strukturalne są traktowane
jako definicje pomocnicze dla innych celów.
8

Rozważmy np. zdanie „Ala ma kota”. Słowo „Ala” jest tu podmiotem, „ma” – orzeczeniem, zaś
„kota” - dopełnieniem. Można zdefiniować język za pomocą składni:
PRZYKŁAD 2.1
<zdanie> ::= <podmiot><orzeczenie><dopełnienie>
<podmiot> ::= Ala | Zuzia
<orzeczenie> ::= ma | karmi
<dopełnienie> ::= psa | kota
Trzy powyższe wiersze pozwalają stwierdzić, że
(1) Zdanie składa się z następujących po sobie podmiotu, orzeczenia i dopełnienia.
(2) Podmiot jest albo pojedynczym słowem „Ala”, albo słowem „Zuzia”
(3) Orzeczenie jest albo pojedynczym słowem „ma”, albo słowem „karmi”
(4) Dopełnienie jest albo pojedynczym słowem „kota”, albo słowem „psa”
Zatem zdanie „Ala ma kota” należy do języka zdefiniowanego w przykładzie 2.1. Inne poprawne
zdania tego języka to np. „Zuzia karmi psa”, „Ala karmi kota”, „Zuzia ma psa”.
Podstawowa koncepcja jest wiec następująca: zdanie języka można wyprowadzić z początkowego
symbolu <zdanie> stosując kolejno reguły zastępowania.
Formalizm, za pomocą którego zdefiniowano język z przykładu 2.1, zwany jest notacją BNF
(Backus-Naur-Form) [zał. A], po raz pierwszy użytą do zdefiniowania Algolu 60. Konstrukcje
zdaniowe <zdanie>, <podmiot>, <orzeczenie>, <dopełnienie> zwane są symbolami pomocniczymi
(nieterminalnymi), słowa koty, psy, śpią, jedzą nazywają się symbolami końcowymi (terminalnymi),
reguły zaś są nazywane produkcjami. Symbole ::= i / nazywa się metasymbolami notacji BNF. Jeśli
w celu skrócenia zapisu użyjemy pojedynczych dużych liter do oznaczania symboli końcowych, to
przykładowa definicja języka przyjmie następującą postać:
PRZYKŁAD 2.2
S::=AB
A::=x|y
B::=z|w
9

Język zdefiniowany przez składnię zawiera cztery zdania xz, yz, xw, yw.
W celu uściślenia omawianych pojęć wprowadzimy następujące definicje matematyczne:
(1) Język L=L(T, N, P, S) jest określony przez
(a) słownik symboli końcowych – T;
(b) zbiór symboli pomocniczych (kategorii gramatycznych) – N;
(c) zbiór produkcji (reguł syntaktycznych) – P;
(d) symbol S (należący do N), zwany symbolem początkowym.
(2) Język L=L(T, N, P, S) jest zbiorem ciągów symboli końcowych ξ, które mogą być
wyprowadzone z S zgodnie z podana poniżej regułą 3.
L={ξ | S →* ξ i ξ∈T*}
(liter greckich używamy dla oznaczenia ciągów symboli).
T* oznacza zbiór wszystkich ciągów symboli z T.
(3) Ciąg δn może być wyprowadzony z ciągu δ0 wtedy i tylko wtedy, jeśli istnieją ciągi δ1, δ2, ..., δn
takie, że każdy δi może być bezpośrednio wyprowadzony z δi-1 zgodnie z podaną poniżej regułą
4:
(δ0 →* δn) ↔ ((δi-1→δi) dla i=1,...,n)
(4) Ciąg η może być bezpośrednio wyprowadzony z ciągu ξ wtedy i tylko wtedy, jeśli istnieją ciągi
α, β, ξ’, η’ takie, że
(a) ξ=αξ’ β
(b) η=αη’ β
(c) P zawiera produkcję ξ’::= η’
Uwaga: notacji α::=β1 | β2 | ... | βn używamy jako skróconego zapisu zbioru produkcji α::=β1,
α::=β2, ... , α::=βn.
Język nazywamy bezkontekstowym wtedy i tylko wtedy, gdy można go zdefiniować za pomocą
zbioru produkcji bezkontekstowych. Produkcja jest bezkontekstowa wtedy i tylko wtedy, gdy jest
postaci:
A::=ξ ( A∈N, ξ∈(N ∪T)* )
tj. jeśli jej lewa strona składa się z pojedynczego symbolu pomocniczego i może być zastąpiona
przez ξ, niezależnie od kontekstu, w jakim pojawia się A. Jeśli produkcja jest postaci
αAβ::=αξβ
10

to zwana jest kontekstową, ponieważ zastąpienie A przez ξ może się zdarzyć tylko w kontekście α i
β.
2.2 Analiza zdań
Podstawowy zadaniem translatora jest nie generowanie, lecz rozbiór zdań i struktur zdaniowych.
Opracowanie algorytmów rozbioru zdań jest zadaniem teorii analizy składniowej.
Pożądanym założeniem jest by koszt liczenia związany z analizą zdania był funkcją liniową jego
długości, a co najwyżej nie przekraczał n*ln(n) gdzie n jest długością zdania. Pierwszą
konsekwencją tego założenia jest fakt, że określenie kolejnego kroku analizy musi zależeć tylko od
obecnego stanu obliczeń oraz pojedynczego, aktualnie wczytanego symbolu. Drugą konsekwencją
jest to, że żadnego z kolejnych kroków analizy nie można cofnąć. Metoda rozbioru spełniająca oba
warunki nazywa się analizą bez powrotów z wyprzedzeniem o jeden symbol (ang. one-symbol-
lookahead without backtracking). Taką analizą jest rozbiór generacyjny (zstępujący, ang. top-
down). Polega ona na odtworzeniu kroków generujących zdanie od symbolu początkowego.
Np. dla zdania „psy jedzą” trzeba określić czy należy ono do języka zdefiniowanego w przykładzie
1. Zdanie tego języka można wyprowadzić tylko z symbolu początkowego <zdanie>. Z definicji
zdanie poprawne jest tylko wtedy, gdy składa się z podmiotu i następującego po nim orzeczenia.
Teraz trzeba określić czy pierwszą cześć zdania można wyprowadzić z symbolu nieterminalnego
<podmiot>. Jest to prawda, gdyż słowo (symbol) „psy” jest jednym z alternatywnych symboli
terminalnych definiujących <podmiot>. Następnie zajmujemy się (wczytujemy) drugi symbol:
„jedzą”. Analogicznie postępujemy w dalszym ciągu sprawdzając, czy to słowo jest
<orzeczeniem>. Poniższa tabela ilustruje tę metodę.
<zdanie> Ala ma kota
<podmiot> <orzeczenie><dopełnienie> Ala ma kota
Ala <orzeczenie><dopełnienie> Ala ma kota
<orzeczenie><dopełnienie> ma kota
ma <dopełnienie> ma kota
<dopełnienie> kota
11
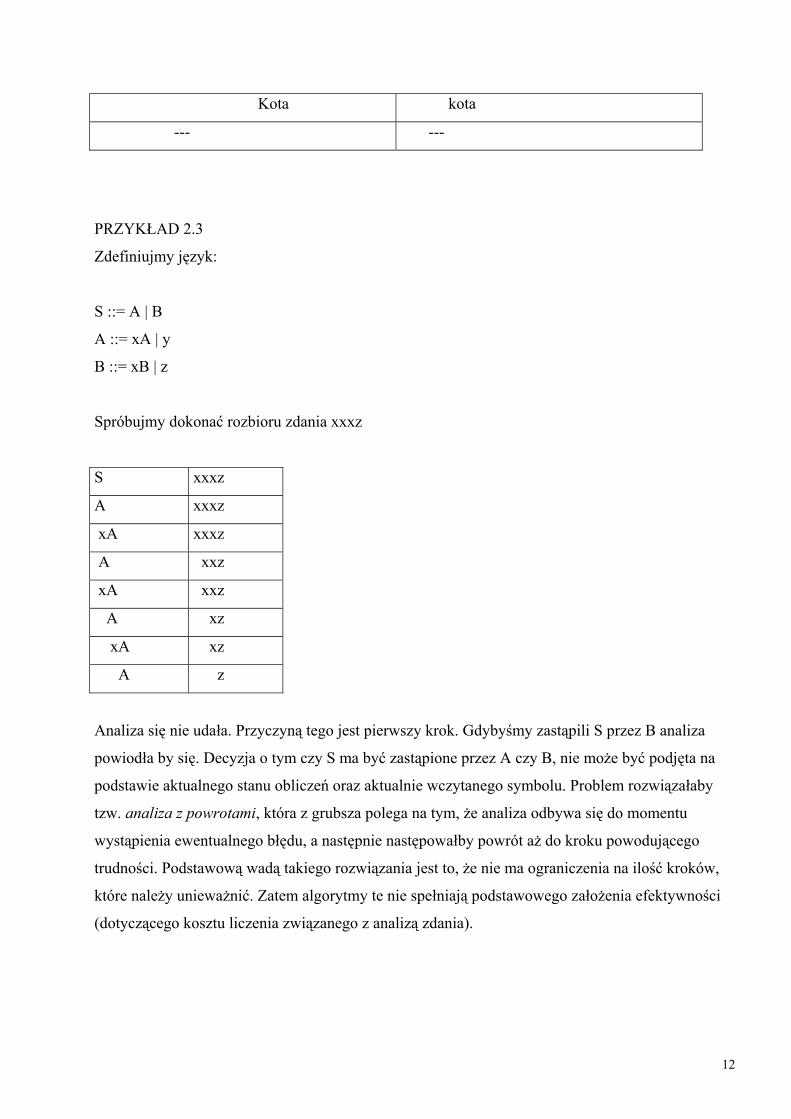
Kota kota
--- ---
PRZYKŁAD 2.3
Zdefiniujmy język:
S ::= A | B
A ::= xA | y
B ::= xB | z
Spróbujmy dokonać rozbioru zdania xxxz
S xxxz
A xxxz
xA xxxz
A xxz
xA xxz
A xz
xA xz
A z
Analiza się nie udała. Przyczyną tego jest pierwszy krok. Gdybyśmy zastąpili S przez B analiza
powiodła by się. Decyzja o tym czy S ma być zastąpione przez A czy B, nie może być podjęta na
podstawie aktualnego stanu obliczeń oraz aktualnie wczytanego symbolu. Problem rozwiązałaby
tzw. analiza z powrotami, która z grubsza polega na tym, że analiza odbywa się do momentu
wystąpienia ewentualnego błędu, a następnie następowałby powrót aż do kroku powodującego
trudności. Podstawową wadą takiego rozwiązania jest to, że nie ma ograniczenia na ilość kroków,
które należy unieważnić. Zatem algorytmy te nie spełniają podstawowego założenia efektywności
(dotyczącego kosztu liczenia związanego z analizą zdania).
12

S Xxxz
B Xxxz
xB Xxxz
B Xxz
xB Xxz
B Xz
xB Xz
B z
z z
--- ---
W związku z tym podstawową konsekwencją analizy bez powrotów z wyprzedzeniem o jeden
symbol jest następująca reguła:
REGUŁA 2.1
Dla zadanej produkcji
A ::= ξ1 | ξ2 | ... | ξn
zbiory pierwszych symboli w zdaniach, które mogą być wyprowadzone z ξi muszą być rozłączone,
tzn.
pierw(ξi) ∩ pierw(ξj) = ∅, dla wszystkich i≠j
Zbiór pierw(ξ) jest zbiorem wszystkich symboli końcowych, które mogą wystąpić na pierwszej
pozycji w zdaniach wyprowadzonych z ξ. Zbiór ten można wyznaczyć wg następujących zasad:
(1) jeśli pierwszy symbol argumentu jest symbolem końcowym, to pierw(aξ)={a}
(2) jeśli pierwszy symbol jest symbolem pomocniczym i istnieje produkcja
A ::= α1 | α2 | ... | αn
to
pierw(Aξ) = pierw(α1) ∪ pierw(α2) ∪ ... ∪ pierw(αn)
PRZYKŁAD 2.4
S ::= Ax
A ::= x | ε
13

gdzie ε oznacza pusty ciąg symboli.
Dokonajmy rozbioru zdania x.
S x
Ax x
xx x
x ---
Sytuacja ta jest zwana problemem pustego słowa. Wynikła ona z zastosowania produkcji A ::= x
zamiast A ::= ε. Jak uniknąć tej pułapki mówi drugą reguła:
REGUŁA 2.2
Dla każdego symbolu A∈N, z którego można wyprowadzić pusty ciąg symboli (A→*ε), zbiór
pierwszych symboli musi być rozłączny ze zbiorem symboli, które mogą następować po dowolnym
ciągu wyprowadzonym z A, tzn.
pierw(A) ∪ nast(A) = ∅
Zbiór nast(A) wyznacza się następująco: dla każdej produkcji Pi postaci
X ::= ξAη
przez Si oznaczmy pierw(ηi). Suma wszystkich takich zbiorów Si tworzy zbiór nast(A). Jeśli z co
najmniej jednego ηi możena utworzyć pusty ciąg symboli, to zbiór nast(X) należy włączyć do
nast(A).
W przykładzie mamy:
pierw(A) = nast(A) ={x}
2.3 Konstrukcja diagramu składni
REGUŁY KONSTRUKCJI DIAGRAMU
A1. Każdy symbol pomocniczy A, dla którego istnieje produkcja
14
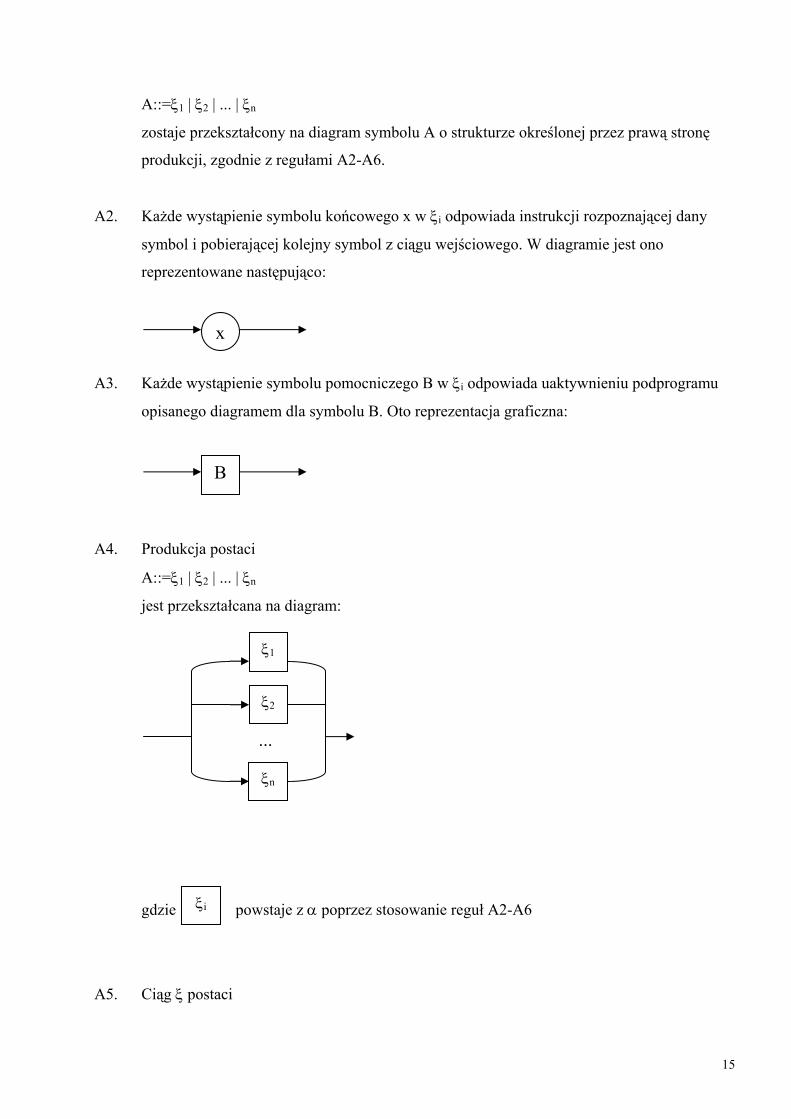
A::=ξ1 | ξ2 | ... | ξn
zostaje przekształcony na diagram symbolu A o strukturze określonej przez prawą stronę
produkcji, zgodnie z regułami A2-A6.
A2. Każde wystąpienie symbolu końcowego x w ξi odpowiada instrukcji rozpoznającej dany
symbol i pobierającej kolejny symbol z ciągu wejściowego. W diagramie jest ono
reprezentowane następująco:
x
A3. Każde wystąpienie symbolu pomocniczego B w ξi odpowiada uaktywnieniu podprogramu
opisanego diagramem dla symbolu B. Oto reprezentacja graficzna:
A4. Produkcja postaci
A::=ξ1 | ξ2 | ... | ξn
jest przekształcana na diagram:
.
ξ2
ξ1
B
gdzie poξi
A5. Ciąg ξ postaci
..
ξn
wstaje z α poprzez stosowanie reguł A2-A6
15

ξ::=α1α2 ... αm
Przekształca się na diagram:
α1 α1 α1...
gdzie powstaje z α poprzez stosowanie reguł A2-A6 αi
A6. Jeśli ξ jest postaci
ξ::={α}
to konstruujemy następujący diagram:
α
gdzie powstaje z α poprzez stosowanie reguł A2-A6 α
PRZYKŁAD 2.5
A ::= x | (B)
B ::= AC
C ::= {+A}
W tej gramatyce symbole +, x, (, ) są symbolami końcowymi, podczas gdy nawiasy { i }, należące
do rozszerzonej notacji BNF są metasymbolami oznaczającymi iteracje. Przykładowe zdania tego
języka to:
x
(x)
(x+x)
((x))
W wyniku zastosowania reguł A1-A6 otrzymamy trzy diagramy:
16
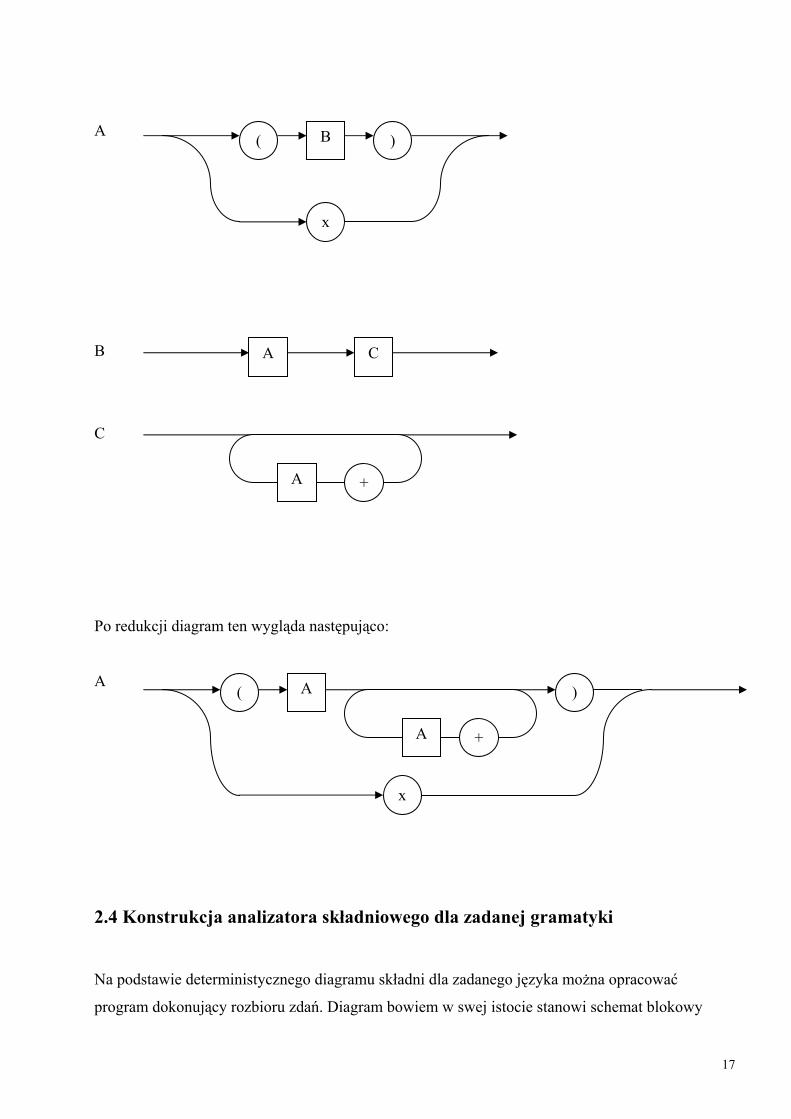
A ( B
x
)
B
C
A C
+A
Po redukcji diagram ten wygląda następująco:
A ( A )
x
+A
2.4 Konstrukcja analizatora składniowego dla zadanej gramatyki
Na podstawie deterministycznego diagramu składni dla zadanego języka można opracować
program dokonujący rozbioru zdań. Diagram bowiem w swej istocie stanowi schemat blokowy
17

takiego programu. Istnieją reguły, które w prosty sposób pozwalają konstruować program na
podstawie diagramów syntaktycznych, ew. zbioru notacji BNF.
REGUŁY PRZEJŚCIA OD DIAGRAMU DO PROGRAMU
Założenia przyjęte dla reguł B1-B6:
- Kod programu analizatora jest w tym wypadku zapisany w języku Ada’95,
- funkcją pobierającą symbole (tokeny) ze strumienia wejściowego jest nast_znak,
- zmienną przechowującą aktualny analizowany symbol jest znak,
- funkcję otrzymaną dla diagramu S będziemy oznaczać przez T(S).
B1. Każdy diagram należy zastąpić deklaracją procedury zgodnie z regułami B2-B6.
B2. Ciąg elementów postaci
S2 S1 Sn ...
należy zastąpić instrukcją
begin T(S1);
T(S2);
...
T(Sn);
end
B3. Diagram postaci
18

należy zastąpić ins
.
S2
S1
case znak do when L1 = when L1 = ...
when L1 =end case
gdzie { Li | i=1,2,.
B4. Diagram postaci
S
należy zastąpić ins
loop exit when T(S);
end loop
gdzie T(S) otrzym
B5. Element diagramu
wywołaniem proce
..
trukcją Sn
> T(S1);
> T(S2);
> T(Sn);
..,n } oznacza zbiór symboli poczatkowych.
trukcją
znak /= L;
ano zgodnie z regułami B2-B6, L=pierw(S).
oznaczający inny diagram A (symbol nieterminalny) należy zastąpić
dury implementującej diagram A.
19

B6. Element diagramu oznaczający symbol końcowy x należy zastąpić instrukcją:
if znak=x then x:=nast_znak;
else blad;
end if;
gdzie blad jest procedurą wywoływaną przy napotkaniu niepoprawnej konstrukcji.
PRZYKŁAD 2.6
Funkcje analizatora dla gramatyki zdefiniowanej w przykładzie 2.5. Założono, że istnieje funkcja
nast_znak, która podaje kolejne symbole końcowe, zmienna znak, która reprezentuje aktualnie
analizowany symbol. W razie napotkania błędu funkcja zwraca wartość logiczną fałsz (false), w
przypadku pomyślnej analizy zwracana jest wartość logiczna prawda (true).
function A return boolean; function B return boolean; function C return boolean; ...
function A return boolean is ok: boolean;
begin if znak = ‘x’ then znak := nast_znak;
elsif znak = ‘(’ then znak := nast_znak;
ok := B;
if not ok then return false; end if; else return false; end if;
20

return true; end A; function B return boolean is ok: boolean;
begin ok := A;
if not ok then return false; end if; ok := C;
if not ok then return false; end if; return true; end A;
function C return boolean is ok: boolean;
begin loop exit when znak /= ‘+’; znak := nast_znak;
ok := A;
if not ok then return false; end if; end loop; return true; end A; Po uproszczeniu diagramu mamy tylko jedną funkcję, działanie pozostaje identyczne.
function A return boolean is ok: boolean;
begin if znak = ‘x’ then znak := nast_znak;
elsif znak = ‘(’ then znak := nast_znak;
loop
21

exit when znak /= ‘+’; znak := nast_znak;
ok := A;
if not ok then return false; end if; end loop; else return false; end if; return true; end A;
A oto procedura główna programu analizatora:
procedure analizuj is begin znak := nast_znak;
if A then put_line(”zdanie poprawne”);
else put_line(”zdanie nie należy do języka”);
end if; end analizuj;
22

3. Analiza porównawcza języków Ada’95 i Delphi
Delphi to nazwa narzędzia programistycznego oraz dialektu języka Object Pascal produkowanego
przez firmę Borland. Object Pascal jest językiem wysokiego poziomu oferującym metody
programowania zarówno strukturalne jak i obiektowe. Jak zostało wspomniane na wstępie, fakt, że
oba języki mają wspólnego przodka (Pascal) implikuje duże podobieństwa w ich strukturach
podstawowych, takich jak instrukcje proste (np. instrukcja przypisania), warunkowe oraz deklaracje
rekordów. Delphi i Ada’95 należą do języków algorytmicznych, zorientowanych obiektowo i
modułowych.
Historia powstania i rozwoju obu języków jest odmienna. Ada jest dzieckiem programu Department
of Defense Common High Order Language, który został zainicjowany w roku 1975. Celem było
stworzenie języka programowania wysokiego poziomu (High Order Language) odpowiedniego dla
komputerowych systemów typu embeded, wykorzystywanych przez Departament Obrony USA
(Departament of Defence, DoD). Aby określić wymagania stawiane takim językom powstała grupa
High Order Language Working Group (HOLWG). Wypracowała ona dokument Directive 5000.29
opisujący te wymagania. Na tej podstawie sporządzono listę języków spełniających kryteria
przyjęte w Directive 5000.9. Były to COBOL, FORTRAN, TACPOL, CMS-2, SPL/1, oraz JOVIAL
J3 i J73. Analizy ekonomiczne dowiodły, że użycie jednego, uniwersalnego języka wyłoby bardziej
zyskowne, zarówno pod względem kosztów jak i niezawodności oprogramowania. Odpowiedzią na
to był język Ada [4].
Delphi to bezpośredni potomek pakietu Turbo Pascal – najpopularniejszego narzędzia
programistycznego na platformę MsDOS. Prostota budowania interfejsu użytkownika za pomocą
biblioteki VCL (Visual component Library), łatwy, zunifikowany dostęp do baz danych oraz
możliwość korzystania z najnowszych technologii (COM, CORBA [5]) spowodował, że pakiet ten
stał się idealnym narzędziem do budowy aplikacji biznesowych. Podstawową zaletą Delphi jest
możliwość prostego, intuicyjnego, a przede wszystkim szybkiego produkowania aplikacji, co w
dodatku nie wymaga dużego doświadczenia programistycznego.
Inne cele, które przyświecały powstaniu tych języków spowodowały, że pomimo wielu często
powierzchownych podobieństw bardzo się od siebie różnią.
23

3.1 Organizacja programu
Zacznę od organizacji programu. Oba języki oferują możliwość modularyzacji kodu. W Delphi
moduły mają nazwę Unit. Język nie oferuje możliwości zagnieżdżania modułów. Nazwa pliku z
tekstem modułu powinna pokrywać się z jego nazwą zadeklarowaną po słowie kluczowym unit
(oczywiście uzupełnioną o rozszerzenie pas). Każdy plik z modułem dzieli się na dwie części:
interface i implementation. Część interface składa się z deklaracji tych typów, zmiennych, stałych i
podprogramów, które będą widoczne poza modułem, zaś w części implementation znajduje się ich
definicja. Procedura główna programu definiowana jest w pliku o rozszerzeniu dpr (od Delphi
Project). Jeśli programista chce używać typów, zmiennych i in. zadeklarowanych w module X to
musi to zadeklarować za pomocą konstrukcji uses X. Np.
PRZYKŁAD 3.1a
unit A;
interface //początek części interface – deklaracje publiczne uses B, C; //deklaracja korzystania z modułów B i C ...
implementation //implementacja modułu uses D,E; //deklaracja korzystania z modułów D i E //nie są one widoczne w części interface
...
end.
W Adzie moduły noszą nazwę pakiety (package). Istnieje możliwość deklarowania pakietów
zagnieżdżonych (tj. definiowanie podpakietów). Odpowiednikiem części interface z Delphi jest
deklaracja modułu w pliku o rozszerzeniu ads. Implementacja jest umieszczona w pliku o
rozszerzeniu adb. Odpowiednikiem konstrukcji uses X jest with X; use X. With X sprawia, że
zawartość modułu jest widoczna a use X pozwala pominąć przedrostek „X.” przed dowolnym
typem, zmienną czy stałą z X.
24

PRZYKŁAD 3.1b
plik a.ads (interfejs modułu):
with B; use B; -- deklaracja korzystania z modułów B i C with C; use C;
package A is --początek odpowiednika części interface ...
end A.
plik a.adb:
with D; use D; -- deklaracja korzystania z modułów D i E with E; use E;
package body A is --początek odpowiednika części implementation ...
end A.
Podsumowując: Ada oferuje prezentuje bardziej zaawansowane możliwości organizacji kodu od
Delphi, pozwala na porządkowanie kodu w strukturze drzewiastej. Delphi zaś nie oferuje nic poza
prostą modularyzacją. Na szczęście na potrzeby translacji to wystarczy, w Adzie łatwo osiągnąć
podobną strukturę jak w Delphi.
3.2 Podprogramy
Object Pascal odziedziczył po Pascalu całą dziedzinę dotyczącą programowania strukturalnego.
Mamy więc podział podprogramów na funkcje – podprogramy zwracające wyniki swoich obliczeń
oraz procedury nie robiące tego. Definicja procedury składa się z jej nagłówka oraz bloku. Blok
zawiera część deklaracyjną (w której deklaruje się stałe, zmienne, typy i podprogramy lokalne dla
procedury) oraz właściwą treść procedury, pomiędzy słowami begin i end. W nagłówku procedury,
25

po jej nazwie, może wystąpić lista parametrów formalnych ujęta w nawiasy. Podobnie deklaruje się
funkcje. W nagłówku, po dwukropku, określany jest typ zwracanej przez funkcję wartości.
Deklaracje procedur i funkcji mogą być zagnieżdżane w przeciwieństwie do takich języków jak
C/C++ czy Java. W Adzie struktura podprogramów wygląda niemal identycznie, różnice są
głównie natury kosmetycznej. Tak więc na końcu procedury czy funkcji stoi słowo kluczowe end
uzupełnione przez nazwę podprogramu, typ wartości zwracanej przez funkcję podaje się po słowie
kluczowym return, a nie po dwukropku jak ma to miejsce w Delphi, itd. Istotne dla translatora
różnice w podejściu do podprogramów tkwią głównie w sposobie zwracania wartości przez funkcje
oraz nieco innej strukturze parametrów formalnych. Zostało to szczegółowo omówione w rozdziale
czwartym (par. 4.2.12).
3.3 Instrukcje
Instrukcje proste, do których zalicza się:
- instrukcje przypisania, np.
var_a := value;
- instrukcje wywołanie podprogramu
proc(2); //wywołanie procedury
wart:=fun(1,2,3); //wywołanie funkcji
- instrukcje skoku do etykiety goto etykieta;
w obu językach są identyczne.
Instrukcje strukturalne to instrukcje, które zawierają jedna lub więcej instrukcji prostych, oraz
ewentualne wyrażenia warunkowe decydujące o wykonaniu tych poleceń. W Delphi najprostszą z
nich jest instrukcja grupująca, tzn. sekwencja dowolnych instrukcji umieszczona pomiędzy słowami
kluczowymi begin i end, poprzedzielanych średnikiem. Może być to (w szczególności) instrukcja
pusta, tj. brak instrukcji. Ada oferuje instrukcje grupującą z możliwością definiowania lokalnych
zmiennych, stałych, typów i podprogramów. Jej składnia to:
declare <definicja lokalnych zmiennych, stałych, typów i podprogramów >
begin
26

<sekwencja instrukcji>
end
Blok instrukcji pomiędzy słowami kluczowymi begin i end jest w sensie syntaktycznym jak i
semantycznym zbieżny z instrukcja grupującą w Delphi. W Adzie instrukcja pusta to null.
Równie ważną instrukcją strukturalną jest instrukcja warunkowa. W Object Pascalu ma ona postać:
if <warunek> then <instrukcja1>;
else <instrukcja2>;
Część else jest opcjonalna. Należy zauważyć, że <instrukcja1> i <instrukcja2> mogą być
instrukcjami strukturalnymi, w szczególności instrukcjami grupującymi. Jeśli w miejsce
<instrukcja2> wstawić inną instrukcję warunkową to otrzyma się instrukcję wyboru, np.
if <warunek1> then begin //początek instrukcji grupującej <sekwencja instrukcji>
end else if <warunek2> then //w bloku else mamy inna instrukcję warunkową
<instrukcja1>
else //blok else dla drugiej instrukcji warunkowej <instrukcja2>
end
A oto odpowiednik w Adzie:
if <warunek1> then <sekwencja instrukcji1>
elsif <warunek2> then <sekwencja instrukcji2>
27

else <sekwencja instrukcji3>
end if
Jak widać instrukcja warunkowa w Adzie potrafi samodzielnie grupować inne instrukcje, przez co
zbędny staje się blok begin..end. Dodatkowo dzięki słowu kluczowemu elsif można za pomocą
jednej instrukcji warunkowej zapisać to, co w Delphi wymagałoby kilku (zagnieżdżonych, po
słowie kluczowym else). Daje to nieco większą przejrzystość kodu.
Pokrewną instrukcją jest instrukcja wyboru (case). W zależności od selektora (typu porządkowego)
mogą być podejmowane różne akcje. Struktura tej instrukcji została pokazana na poniżej:
Delphi:
case <selektor> of <wartość1>: <instrukcja1>; <wartość2>: <instrukcja2>; ...
<wartość3>: <instrukcja3>; else: <instrukcjan>; end
Ada’95:
case <selektor> is when <wartość1> => <instrukcja1>; when <wartość2> => <instrukcja2>; ...
when <wartość3> => <instrukcja3>; when others => <instrukcjan>; end
W obu przypadkach wykonanie danej partii kodu (<instrukcja1>, <instrukcja2>, ...) zależy od
wartości selektora. Opcjonalny blok else (when others w Adzie) jest wykonywany gdy selektor jest
28

różny od wartości określonych explicite w poprzednich blokach. Różnice na poziomie
syntaktycznym są niewielkie, sprowadzają się do użycia nieco innych słów kluczowych i symboli
przy określaniu warunków. Struktura „<wartość>:” w Delphi odpowiada strukturze „when
<wartość> =>” w Adzie. I analogicznie „else:” jest równoważne „when others =>”. Na poziomie
semantycznym różnica jest jedna: w Delphi jeśli selektor nie pasuje do żadnej wartości oraz brak
jest bloku else to żadna partia instrukcji case nie zostanie wykonana, kompilator Ady nie pozwala
by tego typu sytuacja zaszła, traktuje to jako błąd. Translator radzi sobie z tym problemem dodając
automatycznie
when others => null;
jeśli w instrukcji case brak jest bloku else.
Ważnymi instrukcjami strukturalnymi są instrukcje pętli. I w tym przypadku Ada oferuje ich
bogatszy wachlarz. W Object Pascalu mamy do dyspozycji instrukcje while, repeat i for. Dwie
pierwsze różnią się tylko tym, że w instrukcji while najpierw sprawdza się warunek kontynuacji
pętli, potem zaś wykonuje instrukcje, w instrukcji repeat jest odwrotnie. Pętla for ma zastosowanie
wówczas, gdy ilość iteracji jest znana. Pętla zostanie wykonana dla każdej wartości zmiennej
sterującej (typu porządkowego) z określonego przedziału:
for <zmienna> := <wartość minimalna> to <wartość maksymalna> do <instrukcja>;
Lub dla zmiennej malejącej:
for <zmienna> := <wartość maksymalna > downto <wartość minimalna> do
<instrukcja>;
W Adzie pętla jest implementowana poprzez instrukcję loop. Istnieje kilka wariantów tej instrukcji.
Np. Odpowiednik while w Adzie jest następujący:
while <warunek> loop
29

<sekwencja instrukcji oddzielonych średnikami>
end loop;
Dla pętli for mamy:
for <zmienna> in <wartość minimalna> .. <wartość maksymalna> loop <sekwencja instrukcji oddzielonych średnikami>
end loop;
Dla zmiennej malejącej:
for <zmienna> in reverse <wartość minimalna> .. <wartość maksymalna> loop <sekwencja instrukcji oddzielonych średnikami>
end loop;
Dodatkowo instrukcja loop w Adzie może przyjąć bardzie ogólną i elastyczną postać:
loop <sekwencja instrukcji oddzielonych średnikami>
end loop;
wyjście w pętli gwarantuje tutaj użycie instrukcji exit, która może wystąpić wielokrotnie w bloku
loop. Na przykład:
PRZYKŁAD 3.2
loop b := fun1(x);
exit when b<6; --wyjście pod warunkiem b<6 c := b – fun2(x);
exit when c>2 or c<-1; --wyjście pod warunkiem (c>2 or c<-1) end loop;
30

Tutaj z pętli można wyjść w dwóch miejscach za każdym razem warunek wyjścia jest inny. Aby
osiągnąć podobną funkcjonalność w Delphi należy posłużyć się poleceniem break w połączeniu z
instrukcją warunkową.
3.4 Typy danych
Object Pascal jest (jak Ada) językiem w którym dane zawsze są określonego typu. Definiuje dość
surowe reguły konwersji danych, Ada pod tym względem jest jeszcze bardziej restrykcyjna. Zatem
oba języki należą do grupy tzw. strong typed languages. Typy w Object Pascalu dzieli się na:
- proste,
- łańcuchowe,
- strukturalne,
- wskaźnikowe,
- proceduralne
Pomimo, że Ada oferuje tu nieco odmienną hierarchię (niewątpliwie o wiele bardziej złożoną)
posłużę się tym podziałem do opisu porównawczego typów danych obu języków.
3.4.1 Typy proste
Do tej grupy zalicza się typy porządkowe i rzeczywiste. Typy porządkowe to: całkowitoliczbowe,
znakowe, logiczne, wyliczeniowe oraz okrojone. Do typów całkowitoliczbowych należą m. in.
Integer, Cardinal, Byte, Word , LongInt oraz Int64. Różnią się one od siebie ilością bitów (od 8 do
64) i znakiem.
Typy rzeczywiste to Single, Double, Extended, Double, Real i Currency. Ada ma
zaimplementowany mechanizm tworzenia typów całkowitoliczbowych i rzeczywistych poprzez
podanie dziedziny, liczby bitów, itd. Predefiniowane są dwa typy root_integer i root_real, które są
typami bazowymi dla wszystkich innych typów całkowitoliczbowych i rzeczywistych. Np.:
PRZYKŁAD 3.3
type My_Integer is range -20_000 .. +20_000;
31

MI: My_Integer;
MIB: My_Integer'Base;
type My_Float is digits 7; type Your_Float is digits 7 range -1.0E-20 .. +1.0E+20;
Mamy tu do czynienia z dwoma typami całkowitymi. Zmienne typu My_Integer mogą przyjmować
wartości z przedziału –20000 do 20000 zaś zmienne typu My_Integer’Base zajmują szesnaście
bitów, stąd ich dziedzina to –215 .. +215-1. Typy rzeczywiste to My_Float i Your_Float. Oba
przechowują liczby rzeczywiste z dokładnością do siedmiu cyfr po przecinku, różnią się tym, że
podczas kompilacji i później podczas działania programu sprawdzany jest zakres dla zmiennych
typu Your_Float.
Object Pascal dla Delphi 5.0 zawiera tylko jeden typ znakowy, Jest to Char. Zmienne typu Char
reprezentują jednobajtowe znaki ANSI. Ada oprócz typu Character (odpowiednik Char z Object
Pascala) oferuje typ Wide_Character, który reprezentuje znaki Unicode.
3.4.2 Typy strukturalne
Najprostszym typem złożonym w Object Pascalu jest zbiór (typ set of), który stanowi kolekcję
elementów określonego typu porządkowego. Liczba elementów zbioru nie może przekraczać 256.
Zdefiniowano operacje na zbiorach:
• +, -, * oznaczają odpowiednio sumę, różnicę i iloczyn zbiorów
• =, <>, >= i <= oznaczają równość i zawieranie się zbiorów
Typ ten jest reliktem, pozostałym po dawnych wersjach Pascala, tym niemniej wciąż znajduje
zastosowanie. Ada nie posiada konstrukcji set of. Istnieje co prawda odpowiednik – rozwiązanie
oparte na zastosowaniu wektorów typu boolean, związanych z danym typem porządkowym, ale jest
ono rzadko stosowane i nie zaimplementowane w translatorze D2A.
32

Kolejnym typem złożonym jest tablica. Tablica to uporządkowany zbiór elementów danego typu.
Konstruuje się ją za pomocą słowa kluczowego array. Implementacja tablic jest podobna w obu
językach. Np.:
PRZYKŁAD 3.4
Delphi:
type Int_Arr = array [1..100] of Integer; //wektor 100 liczb integer Int_Arr2 = array [1..100, 1..100] of Integer; //macierz
Ada’95:
type Int_Arr is array(1..100) of Integer; --wektor 100 liczb integer Int_Arr2 is array(1..100, 1..100) of Integer; -- macierz
Jeszcze jednym wspólnym dla obu języków typem strukturalnym jest rekord (record). Rekordy to
kolekcje elementów różnych typów, poszczególne elementy są nazywane polami. Pola rekordu
dostępne są poprzez odwołania kwalifikowane (nazwa zmiennej typu rekordowego, po niej kropka i
nazwa danego pola). Rekordy mogą mieć tzw. warianty. W zależności od selektora niektóre pola
mogą wystąpić w rekordzie lub nie. Oto przykład rekordu w Object Pascalu:
PRZYKŁAD 3.5
type rec = record pole1: Integer;
case selektor: Integer of //w tej części wybór wariantów 0: (pole1: Boolean;);
1: (pole2: String;);
33

end; Szczegółowe różnice pomiędzy implementacją tablic i rekordów w obu językach w kontekście
translacji z Delphi do Ady zostały ujęte w paragrafach 4.2.9 i 4.2.11.
3.4.3 Typy wskaźnikowe
Zmienna typu wskaźnikowego (wskaźnik) przechowuje adres innej zmiennej danego typu. Np.:
PRZYKŁAD 3.6
Delphi:
type PInteger = ^Integer;
var int: Integer = 3;
p_integer: PInteger = @int;
Ada’95:
type PInteger = access Integer;
int: aliased Integer := 3;
p_integer: PInteger := int’access;
Podstawowa różnica pomiędzy implementacją wskaźników w obu językach polega na dużo
większej restrykcyjności Ady. Na przykład zmienna, na którą wskazuje wskaźnik musi być
zadeklarowana ze słowem kluczowym aliased.
3.4.4 Typy proceduralne
34

Typem proceduralnym w Object Pascalu jest wskaźnik do podprogramu. Przyczyną, dla której
istnieje osobna klasyfikacja w Delphi dla tych typów jest zapewne nieco inny sposób definiowania
wskaźników do podprogramów. W Adzie typ proceduralny to inaczej access to subprogram.
PRZYKŁAD 3.7
Delphi:
var f: procedure(i :integer); procedure proc(i:integer); ...
f:=proc;
f(2); //równoważne z wywołaniem proc(2)
Ada’95:
type a_proc is access procedure(i :integer); f: a_proc;
procedure proc(i:integer); ...
f:=proc;
f(2); --równoważne z wywołaniem proc(2)
3.5 Programowanie obiektowe (OOP)
Ponieważ oryginalny Pascal nie dawał możliwości programowania obiektowego, jego następcy:
Object Pascal i Ada musiały wypracować własne konstrukcje służące temu. Stąd zupełnie
odmienne podejście do tego tematu. Twórcy Object Pascala zdecydowali się na stworzenie
architektury przypominającej C++ czy Javę. Ada’95 jest oparta bezpośrednio na strukturalnej
Adzie’83, co w pewnym sensie ograniczyło możliwości języka w sensie syntaktycznym, tym
niemniej udało się zachować funkcjonalność OOP. Wszystkie różnice pomiędzy oboma językami
na tym polu opisuje i objaśnia rozdział czwarty (paragrafy: 4.2.1-4.2.8).
35

3.6 Podsumowanie
Podsumowując, Ada jest językiem bardziej skomplikowanym, za to dającym programiście dużo
większe możliwości w konstruowaniu aplikacji niż Object Pascal. W powyższej analizie
pominąłem te aspekty języka Ada’95, które są właściwie nieobecne w Object Pascalu (między
innymi wbudowane w język konstrukcje służące do programowania współbieżnego). Większe
bogactwo języka Ada jest korzystne z punktu widzenia programu translacyjnego. Dla prawie każdej
konstrukcji w Delphi istnieje odpowiednik w Adzie.
36

4. Budowa i działanie programu D2A
4.1 Struktura programu D2A
Podstawowym narzędziem translatora jest program D2A – dokonujący translacji pojedynczego
pliku zapisanego w języku Delphi na plik Ady’95.
Program składa się z:
- analizatora leksykalnego - modułu wczytującego tekst programu w języku źródłowym (Delphi)
oraz dzielącego ten tekst na podstawowe symbole terminalne (tokens).
- modułu translacyjnego – modułu dokonującego rozbioru ciągu wejściowych symboli i
tłumaczącego go na język docelowy (Ada’95).
- modułu drzewa syntaktycznego służącego jako struktura pomocnicza dla modułu
translacyjnego.
- modułu wyjściowego – pełniącego funkcje edytora składającego ciąg symboli wyjściowych i
komentarzy translatora oraz zapisujących je do pliku docelowego (Ada’95).
plik źródłowy
moduł translacyjny
drzewo syntaktyczne
bufor wyjściowy
plik docelowy
analizator leksykalny
Szkieletem programu D2A jest analizator gramatyki języka Object Pascal rozbudowywanego przez
firmę Borland pod nazwą Delphi. Analizator został oparty na definicji języka zawartej w
dokumentacji do pakietu Borland Delphi 5 przekształconej w notację EBNF [zał. B].
37

Każdą definicję symbolu nieterminalnego przekształcono na podprogram analizujący dany symbol
zgodnie z regułami B1-B6 par 4 roz. 1.
Drugim, pomocniczym narzędziem jest program D2Amake, który służy do translacji danego pliku
oraz innych plików, od których jest on zależny.
Uruchomienie programu odbywa się z linii poleceń. Jeśli wywołamy program bez parametrów, na
ekranie pojawi się następujący komunikat:
usage: d2a [<options>] <input_file> [<preproc_file>]
where options are:
-p preprocess only (do not translate)
-c include source as comment
-t NUM tab spacing
-mp PREFIX use PREFIX as method prefix
-tp PREFIX use PREFIX as temp name prefix
-cp PREFIX use PREFIX as constructor prefix
-ap PREFIX use PREFIX as access of class prefix
-ac PREFIX use PREFIX as access'class of class prefix
-ci PREFIX use PREFIX as translator comment prefix
-cn NAME use NAME as class parameter name
Program za podstawowy parametr przyjmuje nazwę pliku źródłowego zawierającego tekst w języku
Delphi (zwyczajowe rozszerzenia to pas i dpr). Wynikiem działania programu są trzy pliki: plik z
deklaracją modułu (rozszerzenie ads), plik z definicją modułu (rozszerzenie adb) – oba zawierające
tekst przetłumaczony oraz plik zawierający publiczne typy, zmienne i stałe zdefiniowane w części
interface pliku wejściowego (rozszerzenie ppc).
Znaczenie poszczególnych parametrów jest opisane w poniższej tabeli:
38

parametr znaczenie wart. domyślna
-p Program nie tłumaczy tekstu Delphi, generuje jedynie plik pcc z
typami, zmiennymi i stałymi zadeklarowanymi w części interface
pliku wejściowego.
-
-c Do plików wynikowych dołączany jest tekst programu Delphi w
formie komentarzy.
-
-t NUM Program formatuje tekst wyjściowy. Ta opcja określa ilość spacji
przypadających na jedno wcięcie.
4
-mp PREFIX Określa prefiks dla metod klas d2a_method
-tp PREFIX Określa prefiks dla nazw tymczasowych (dla zmiennych, czy typów
pomocniczych)
d2a_tmp
-cp PREFIX Określa prefiks dla konstruktora klasy d2a_constructor
-ap PREFIX D2A definiuje dla każdej klasy typ będący wskaźnikiem do niej.
Nazwa tego typu to konkatenacja prefiksu PREFIX i nazwy klasy
(łącznikiem jest znak podkreślenia).
d2a_access
-ac PREFIX Jw., wskaźnik typu access’class d2a_access_class
-ci PREFIX Prefiks definiuje łańcuch znaków jaki pojawia się na początku każdej
linii komentarza generowanego przez D2A (aby odróżnić od
komentarzy użytkownika)
++d2a++
-cn NAME Nazwa parametru klasy dla metod. d2a_object
4.2 Działanie programu D2A
4.2.1 Translacja struktur obiektowych
Podejście do programowania zorientowanego obiektowo (OOP) stanowi jedną z bardziej istotnych
różnic pomiędzy Delphi i Adą’95. Począwszy od różnic na poziomie składniowym, poprzez
odmienne podejście do enkapsulacji (hermatyzacji), polimorfizmu czy dziedziczenia a skończywszy
39

na takich elementach Delphi, które nie istnieją w Adzie, można uznać to zagadnienie za
najpoważniejszy problem postawiony przed translatorem.
Typy class z Delphi tłumaczony jest na typ tagged record. Tagged record ma zaimplementowane
dziedziczenie jednobazowe i polimorfizm.
4.2.2 Enkapsulacja
Enkapsulacja jest zbędna, gdyż jest ona w swej istocie jedynie zabezpieczeniem przed
niedozwolonym użyciem składowych danego typu klasowego (prywatnych pól i metod).
Wychodząc z założenia, że tekst wejściowy (w Delphi) jest poprawny, wiadomo, że reguły
enkapsulacji są w nim spełnione, a zatem będą także spełnione w tekście wyjściowym, pomimo że
nie pola zmiennej typu tagged record nie będą zabezpieczone przed niepowołanym dostępem.
Jedynym nasuwającym się zagrożeniem dla pominięcia dyrektyw określających widoczność
(public, private) jest fakt, że programista może zechcieć rozwijać kod już przetłumaczony przez
translator. Wtedy kompilator Ady nie będzie wstanie zweryfikować czy dane pole/metoda jest
prywatne czy też publiczne. Translator w miejsce dyrektyw określających widoczność wstawia
odpowiedni komentarz:
--d2a: public
--d2a: private
zatem programista jest wstanie określić widoczność składowych używanej klasy.
4.2.3 Metody
Specyfiką Ady’95 jest definiowanie metod (procedur lub funkcji) dla klasy (tagged record) poza jej
blokiem, w przeciwieństwie do innych języków obiektowych, takich jak C++, Java oraz Delphi,
gdzie metody definiowane (a przynajmniej deklarowane) są identycznie jak pola (zmienne).
Różnice podejścia oraz konsekwencje zeń wynikające zilustruję na poniższym przykładzie:
PRZYKŁAD 4.2a
Delphi:
type KLASA = class
40

a,b,c: integer;
procedure PROC(x,y,z: integer); end;
implementation
procedure KLASA.PROC(x,y,z: integer); begin a:=x;
b:=y;
c:=z;
end;
...
var KLASA_VAR: KLASA; ...
KLASA_VAR.PROC(1,2,3);
...
PRZYKŁAD 4.2b
Ada’95:
type KLASA is tagged record a,b,c: integer;
end record;
procedure PROC ( obj: KLASA’class; x,y,z:integer ) is begin obj.a:=x;
obj.b:=y;
obj.c:=z;
end PROC_KLASA;
41

...
KLASA_VAR: KLASA;
...
PROC(KLASA_VAR,1,2,3);
...
W przykładzie zdefiniowano klasę KLASA w Delphi oraz jej odpowiednik w Ada’95. Klasa ta
zawiera trzy pola typu integer (a,b,c) oraz jedną procedurę PROC, która przypisuje każdej z tych
zmiennych pewną wartość (określoną odp. przez jej parametry). Jest ona deklarowana wewnątrz
klasy, zaś jej definicja znajduje się w części implementacyjnej pliku Delphi. Procedura w
przykładzie 2b jest zadeklarowana i zdefiniowana poza ciałem klasy, jej pierwszym parametrem
jest zmienna reprezentująca daną klasę. Z takiego podejścia wynika kilka istotnych różnic w kodzie
wykorzystującym wywołanie metod klas.
• w Delphi w ciele procedury PROC pola klasy są traktowane jak zmienne lokalne, odwołuje się
do nich podając ich nazwy bez kwalifikatorów dostępu.
w Adzie dostęp do wszystkich pól zdefiniowanych dla danej klasy odbywa się za
pośrednictwem pierwszego parametru metody.
Zatem linia a:=x; zostaje przetłumaczone na obj.a:=x;
Analogiczne podejście obowiązuje dla wywoływania innych metod danej klasy.
• w Delphi odwołuje się do metod danej klasy z poza klasy tak jak do pól, czyli poprzedzając
nazwę metody nazwą zmiennej typu danej klasy i kropką, np.
KLASA_VAR.PROC(1,2,3);
W Adzie taki napis należy zmienić na
PROC(KLASA_VAR,1,2,3);
4.2.4 Dziedziczenie
42

Zarówno w Delphi jak i w Adzie’95 obowiązuje model dziedziczenia jednobazowego tzn. dla danej
klasy może istnieć tylko jeden przodek. Problem pojawia się gdy klasa Delphi implementuje jeden
lub więcej interfejsów [5] (deklaracja implementacji test technicznie identyczna do zadeklarowania
dziedziczenia). Ada nie obsługuje interfejsów w składni języka zatem nie istnieje możliwość
translacji. W przypadku, gdy translator natknie się na wielokrotne dziedziczenie/implementację
przyjmie, że klasą bazową jest pierwszy identyfikator z listy identyfikatorów w deklaracji
dziedziczenia/implementacji a następnie wstawi w kod odp. ostrzeżenie:
--d2a: warning: multiple inheritance not implemented
Każda klasa Delphi pochodzi (pośrednio bądź nie) od klasy TObject. Stworzono plik base.ads, w
którym zdefiniowano specjalną klasę o nazwie Object, która jest klasą bazową dla wszystkich klas
przetłumaczonych z Delphi. Pochodzi ona od klasy Controlled. Zawiera odpowiednie procedury
wywoływane przy tworzeniu i niszczeniu obiektów.
4.2.5 Polimorfizm
Podejście do polimorfizmu jest w obu językach odmienne. W Delphi przyjęto model zbliżony do
Javy, czyli każda zmienna reprezentująca klasę jest niejawnie referencją [8] bądź wskaźnikiem do
niej. Obiekty różnych klas mogą posiadać metody o identycznych nazwach, ale innym działaniu. Na
etapie kompilacji nie zawsze wiadomo, jaki typ (klasę) reprezentuje dany obiekt (pamiętajmy jest to
w istocie referencja do obiektu). Może to być typ wynikający z deklaracji tegoż obiektu, można
jednak przypisywać do niego inny obiekt, typu dowolnej klasy pochodnej względem klasy
zadeklarowanej. Metody, które podlegają mechanizmowi polimorfizmu – wirtualne deklarowane są
z dyrektywą virtual w klasie bazowej oraz override w klasach pochodnych (w tych, w których
chcemy skorzystać z polimorfizmu).
Zastosowanie polimorfizmu ilustruje poniższy przykład:
PRZYKŁAD 4.3
type T_X=class a:integer;
function fun:boolean; virtual;
43

constructor Create( x:integer ); end;
T_Y=class(T_X) //tu dziedziczenie po klasie T_X
b:integer;
function fun:boolean; override; constructor Create( x,y:integer ); end;
implementation
T_X.fun:boolean;
begin return false; end;
T_Y.fun:boolean;
begin return true; end;
...
var zmienna:T_X; bool:boolean;
...
zmienna:=T_X.Create(1); //zmienna ma typ T_X
bool:=zmienna.fun; //zmiennej bool zostanie przyp. wart. false
zmienna:=T_Y.Create(1,2); //zmienna ma typ T_Y
bool:=zmienna.fun; //zmiennej bool zostanie przyp. wart. true
44

W Adzie wszystkie zmienne traktuje się jednakowo, nie ma niejawnych odniesień do obiektów.
Model polimorfizmu jest także znacząco różny. Nie istnieje praktycznie analogia do techniki
zastosowanej w przykładzie 2. Ostatnia część kodu zostanie przetłumaczona na:
zmienna:=T_X_Create(1);
bool:=T_X_fun(zmienna);
zmienna:=T_Y_Create(1,2); //tu błąd
bool:=T_X_fun(zmienna);
w trzeciej linii kompilator Ady zgłosi wystąpienie błędu, ponieważ kreator T_Y_Create zwraca typ
T_Y nie T_X (patrz konstruktory/destruktory), czyli typ zmiennej zmienna. Powyższa sytuacja jest
niemożliwa do wykrycia przez translator, zatem użytkownik programista będzie zmuszony polegać
na komunikacie kompilatora Ady.
Inne możliwe wykorzystanie polimorfizmu prezentuje przykład 3:
PRZYKŁAD 4.4a
Delphi:
type T_X=class function fun: boolean; virtual; function st: boolean; end;
T_Y=class(T_X) function fun: boolean; virtual; end;
implementation ...
//definicja funkcji fun identyczna jak w przykładzie 2
function st:boolean; begin
45

return fun; end; ...
var obj_x:T_X; obj_y:T_Y;
bool:boolean;
...
bool:=obj_x.fun; //bool=false
bool:=obj_x.st; //bool=false
bool:=obj_y.fun; //bool=true
bool:=obj_y.st; //bool=true
Tutaj funkcja niewirtualna st wywołuje funkcję wirtualną fun, zdefiniowaną w X_T, bądź Y_T w
zależności od typu obiektu, który tę funkcję (st) wywołuje. Tego typu zachowanie można
zaimplementować w języku Ada’95. Odpowiednikiem kodu z Delphi w języku Ada’95 jest
następujący tekst:
PRZYKŁAD 4.4b
Ada’95
--definicje klas T_X, T_Y analog. do klas w Delphi
function fun (This : T_X) return boolean; function fun (This : T_Y) return boolean;
function st (This : X'Class) return boolean is begin return fun (This); end st;
...
46

obj_x:T_X;
obj_y:T_Y;
bool:boolean;
...
bool:=fun(obj_x); //bool=false
bool:=st(obj_x); //bool=false
bool:=fun(obj_y); //bool=true
bool:=st(obj_y); //bool=true
Zatem wynik wywołania funkcji st oraz fun jest analogiczny w obu językach. Wnioskiem z tego jest
następujący schemat translacyjny:
• dla klasy KLASA metody wirtualne Delphi, tłumaczone są na analogiczne metody Ady’95
parametr klasy jest typu KLASA
• dla klasy KLASA metody niewitrualne Delphi, tłumaczone są na analogiczne metody Ady’95
parametr klasy jest typu KLASA’class.
4.2.6 Konstruktor
W Delphi do utworzenia instancji klasy, czyli obiektu, potrzebne jest wywołanie konstruktora.
Każda klasa posiada bezparametrowy konstruktor domyślny Create odziedziczony po klasie
TObject, jest to konstruktor pusty. Konstruktor definiuje się poprzez użycie słowa kluczowego
constructor. Konstruktor wywołuje się względem klasy (w przeciwieństwie do innych metod
wywoływanych względem instancji klasy). W danej klasie można definiować dowolna ilość
konstruktorów.
Ten mechanizm nie jest zaimplementowany w Adzie’95. Każdą definicję i deklaracje konstruktora
translator zamienia na odpowiednia definicję (deklarację) funkcji o nazwie będącej połączeniem
przedrostka (domyślnie d2a_constructor), nazwy klasy i nazwy konstruktora (łącznikiem jest znak
podkreślenia) a zwracającej typ klasy, dla której ów konstruktor został zadeklarowany. Tak więc
np. napis: constructor KLASA.Create( i : integer); tłumaczony jest na:
47

function d2a_constructor_KLASA_Create( i : integer) return KLASA; Warto zwrócić uwagę, że funkcja d2a_constructor_KLASA_Create nie przyjmuje za pierwszy
parametr klasy, gdyż jej wywołanie ma charakter statyczny. W ten sposób użycie konstruktora w
obu językach jest identyczne:
PRZYKŁAD 4.5a
Delphi:
type KLASA=class zmienna: integer;
constructor Create(i:integer) end; ...
var klasa_var:KLASA; ...
klasa_var:=KLASA.Create(1);
PRZYKŁAD 4.5b
Ada’95:
type KLASA is tagged record zmienna: integer;
end record; function d2a_constructor_KLASA_Create( i : integer) return KLASA; ...
klasa_var:KLASA;
...
klasa_var:=d2a_constructor_KLASA_Create(1);
4.2.7 Destruktor
48

W Delphi destruktory wywoływane są na ogół niejawnie (np. podczas usuwania obiektu ze stosu,
lub przy dealokacji za pomocą funkcji Free). Każda klasa ma jeden domyślny destruktor o nazwie
Destroy odziedziczony (tak jak Create) po klasie TObject. Program D2A zamienia każdą definicje i
deklarację destruktora na odp. funkcję o nazwie będącej konkatenacją przedrostka (domyślnie
d2a_destructor), nazwy klasy i nazwy destruktora (łącznikiem jest znak podkreślenia), dla której
ów konstruktor został zadeklarowany. Tak wiec np. napis: destructor KLASA.Destroy; tłumaczony jest na: procedure d2a_destructor_KLASA_Destroy(d2a_object: in out KLASA);
Ponieważ każda klasa Delphi pochodzi (pośrednio bądź nie) od klasy TObject stworzono w Adzie
specjalną klasę o nazwie Object (patrz: dziedziczenie), która jest klasą bazową dla wszystkich klas
przetłumaczonych z Delphi. Pochodzi ona od klasy Controlled, a co za tym idzie dziedziczy trzy
procedury: Initialize, Finalize oraz Adjust. Procedura Finalize jest wykonywana w momencie
niszczenia obiektu a więc wtedy, gdy wykonywane są destruktory w Delphi. Gdy dana klasa
(Delphi) ma zadeklarowany destruktor, wtedy translator oprócz odp. przetłumaczenia deklaracji i
definicji umieszcza wywołanie procedury destruktora w ciele procedury Finalize co daje pożądany
efekt, analogiczny do użycia destruktora w Delphi.
4.2.8 Property
Property to unikalna konstrukcja językowa obecna właściwie tylko w Delphi i nowym języku C#
[7]. Property tak jak pole definiuje atrybut obiektu, lecz w przeciwieństwie do pola (który jest
niczym więcej niż miejscem przechowywania danych, które mogą być sprawdzane bądź
zmieniane), z property powiązane są pewne akcje przy odczytywaniu lub modyfikowaniu jego
danych.
Deklaracja property zawiera nazwę i typ oraz co najmniej jeden tzw. specyfikator dostępu (ang.
access specifier). Oto składnia:
property propertyName[indexes]: type index integerConstant specifiers;
gdzie:
49

• propertyName to identyfikator
• [indexes] – to opcjonalny ciąg deklaracji parametrów przedzielanych przecinkiem (analogicznie
do deklaracji tablic)
• struktura index integerConstant jest opcjonalna
• specifiers to specyfikatory dostępu mogą być to: read, write, stored, default, nodefault i
implements. Każde property musi mieć co najmniej specyfikator read lub write.
Properties w przeciwieństwie do pól nie mogą być przekazywane jako parametry typu var (in out w
terminologii Ady), i ogólnie nie można tworzyć wskaźników czy referencji [8] do nich. Powodem
tego jest fakt, że property nie istnieje fizycznie w pamięci komputera, każde wystąpienie danego
property jest zamieniane przez kompilator Delphi na odpowiednie wywołanie metody bądź pola,
które jest do niego przypisane. Analogiczne zadanie wykonuje translator D2A. Należy podkreślić,
że w tekście przetłumaczonym przez D2A properties jako takie nie występują, są one tłumaczone
na odp. konstrukcje językowe tak jak czyni to kompilator Delphi. Demonstruje to poniższy
przykład:
PRZYKŁAD 4.6a
Delphi:
type Class0 = class i: integer;
end;
type Class1 = class c0Var:Class0;
c0Arr:array[1..3] of Class0;
function getClass0:Class0; function getC0Arr(index:integer):Class0; procedure setC0Arr(index:integer; c0_var:class0);
50

property c0Prop: Class0 write c0Var read getClass0; property c0ArrPr[i:integer]: Class0 read getC0Arr write setC0Arr;
property c0IndPr: Class0 index 1 read getC0Arr write setC0Arr; end;
implementation
//tu definicja odpowiednich metod klasy Class1
...
var c1:Class1; ...
c1.c0Prop:=c1.c0Prop;
c1.c0ArrProp[3]:=c1.c0ArrProp[1];
c1.c0Prop3:=c1.c0ArrProp[1];
...
Po translacji otrzymujemy następujący kod:
PRZYKŁAD 4.6b
Ada’95:
type Class0 is new Object with record i : integer ;
end record ; type d2a_access_Class0 is access all Class0 ; type d2a_access_class_Class0 is access all Class0 ' class ; function d2a_class_method_Class0_fun ( d2a_object : access Class0 ' class ; d2a_tmp_i : integer ) return boolean -- d2a: destructor ;
procedure Finalization ( d2a_object : in out Class0 ) ;
type d2a_temp_10001 is array ( 1 .. 3 ) of Class0 ;
51

type Class1 is new Object with record c0Var : Class0 ;
c0arr : d2a_temp_10001;
--++d2a++ : Property: c0Prop
--++d2a++ : Property: c0ArrPr
--++d2a++ : Property: c0IndPr
end record ; type d2a_access_Class1 is access all Class1 ; type d2a_access_class_Class1 is access all Class1 ' class ; function d2a_class_method_Class1_getClass0 ( d2a_object : access Class1 ' class ) return Class0 ; function d2a_class_method_Class1_getC0Arr ( d2a_object : access Class1 ' class ; d2a_tmp_index : integer ) return Class0 ; procedure d2a_class_method_Class1_setC0Arr ( d2a_object : access Class1 ' class ; d2a_tmp_index : integer ; d2a_tmp_c0_var : class0
) ;
procedure Finalization ( d2a_object : in out Class1 ) ;
W części implementacyjnej (package body) mamy następujący kod:
c1:Class1;
...
c1 . c0Var := d2a_class_method_Class1_getClass0 ( c1 '
unrestricted_access ) ;
d2a_class_method_Class1_setC0Arr ( c1 ' unrestricted_access , 3 ,
d2a_class_method_Class1_getC0Arr ( c1 ' unrestricted_access , 1 )
) ;
d2a_class_method_Class1_setC0Arr ( c1 ' unrestricted_access , 1 ,
d2a_class_method_Class1_getC0Arr ( c1 ' unrestricted_access , 1 )
) ;
52

Jak widać każde wystąpienie property zostało przetłumaczone na wywołanie odpowiednich funkcji
bądź procedur lub zastąpione przez pola.
Translator implementuje jedynie specyfikatory read i write, inne ze względu na specyfikę
oryginalnego środowiska uruchamiania programów Delphi – platformy MsWindows (jak stored),
czy też brak odpowiednich narzędzi w języku Ada’95 (jak implements) nie zostały
zaimplementowane, użytkownik może to zrobić na własną rękę – tak gdzie dany specyfikator
property nie został zaimplementowany translator umieści komunikat o tym. Praktycznie jednak
specyfikatory inne niż read i write są nieużywane.
4.2.9 Typy zagnieżdżone
Pod pojęciem typ zagnieżdżony rozumiem definicję rekordu (record) lub tablicy(array) w ciele
innego rekordu bądź klasy. Definicja taka jest anonimowa, tzn. tak zdefiniowany typ nie ma
własnej nazwy. Na przykład:
PRZYKŁAD 4.7a
type A = record B: record C:boolean;
end; D: array (1..256) of boolean; end;
Pole B rekordu A jest rekordem anonimowym, natomiast pole D jest tablicą anonimową. Żadna z
tych konstrukcji nie jest legalna w języku Ada. Prostym obejściem tego problemu jest
zdefiniowanie oddzielnych typów pomocniczych na zewnątrz ciała rekordu dla pól B oraz D. Typy
takie byłyby wykorzystane każdy tylko raz na potrzeby definicji odpowiednich pól w rekordzie A.
Tę technikę stosuje D2A. Za każdym razem, gdy napotka definicję typu zagnieżdżonego, definiuje
53

typ pomocniczy o unikalnej nazwie generowanej przez funkcje getVarName (patrz funkcja
getVarName). Oto wersja przetłumaczona kodu z przykładu 6a:
PRZYKŁAD 4.7b
type d2a_temp_10000 is record C:boolean;
end record;
type d2a_temp_10001 is array ( 1 .. 255 ) of boolean ;
type A is record B: d2a_temp_10000;
D: d2a_temp_10001;
end;
4.2.10 Instrukcja „with”
Znana z poprzednika Delphi – Pascala instrukcja „with” nastręcza kolejne trudności translacyjne.
Ta skądinąd przydatna konstrukcja nie występuje w rodzinie języków Ada. Powoduje ona, ze nazwę
rekordu (bądź obiektu klasy), do której się odwołujemy, podaje się tylko raz. Na przykład rekord:
type A = record p1:integer;
p2:boolean;
p3:string[1..256]
end;
var var_a:A;
54

Zmienną var_a można zainicjować na dwa sposoby:
var_a.p1:=0;
var_a.p2:=true;
var_a.p3:=’string’;
bądź przy wykorzystaniu instrukcji „with”:
with var_a do p1:=0;
p2:=true;
p3:=’string’;
end;
W tak prostych przypadkach translator radzi sobie bez problemu, dodatkowo informując
użytkownika, że tłumaczona jest instrukcja „with” za pomocą komunikatu:
--d2a : 'With' statement
Powyższy przykład D2A przetłumaczyłby w następujący sposób:
--++d2a++ : 'With' statement
declare d2a_temp_10000 : A renames var_a ; begin d2a_temp_1000.p1:=0;
d2a_temp_1000.p2:=true;
d2a_temp_1000.p3:=”string”;
end;
W przypadkach gdy translator nie może skorzystać z konstrukcji Ady: renames, tj. wtedy gdy w
instrukcji „with” obiektem jest wynik wywołania konstruktora lub funkcji lub w funkcjach jest
zmienną result, w kodzie pojawi się komunikat:
--d2a : Error: 'with statement' selector
a odpowiednie instrukcje których dotyczące odpowiedniego selektora nie zostaną zmienione.
55

4.2.11 Rekord z wariantami
W większości przypadków rekordy z wariantami są tłumaczone bez problemów, ponieważ istnieją
w obu językach odpowiadające sobie struktury. Jest jednak jeden wyjątek, jeśli po słowie
kluczowym case występuje nazwa typu bez identyfikatora zmiennej. Tego typu przypadek nie jest
możliwy w Adzie. Translator wtedy definiuje pomocniczą zmienną o unikalnej nazwie stworzonej
przez funkcje getVarName (patrz funkcja getVarName). Dodatkowo informuje o tym fakcie
użytkownika umieszczając w kodzie ostrzeżenie o tym zabiegu. Poniższy przykład ilustruje tę
metodę:
PRZYKŁAD 4.8a
Delphi:
type TShapeList = (Rectangle, Triangle, Circle, Ellipse, Other);
TFigure = record case TShapeList of Rectangle: (Height, Width: Real);
Triangle: (Side1, Side2, Angle: Real);
Circle: (Radius: Real);
Ellipse, Other: ();
end;
Co translator przetłumaczy na:
PRZYKŁAD 4.8b
Ada’95:
type TShapeList is (Rectangle, Triangle, Circle, Ellipse, Other);
var d2a_temp_10000: TShapeList;
56

type TFigure is record case TShapeList of when Rectangle => Height, Width: Real;
when Triangle => Side1, Side2, Angle: Real;
when Circle => Radius: Real;
when Ellipse, Other => null; end record;
4.2.12 Funkcje i procedury
Pierwszą narzucającą się różnicą pomiędzy podprogramami w Delphi i Adzie są parametry
formalne. Dotyczy to nie tylko procedur i funkcji, ale także destruktorów i konstruktorów klas. W
Delphi parametr formalny ma następującą składnie
<FormalParameters> ::= '(' <FormalParm>{';'<FormalParm>} ')'
<FormalParm> ::= [VAR | CONST | OUT] <Parameter>
<Parameter> ::= <Ident> ':' <SimpleType> '=' <ConstExpr>
(patrz dodatek B2)
Przykładowo nagłówek procedury może mieć postać: procedre DoSomething(const X: Real = 1.0; I: Integer = 0; var S: string);
Kluczową różnicą w podejściu obu języków do parametrów formalnych jest użycie modyfikatorów
parametrów. W Delphi są nimi var, const, out, zaś w Adzie in, out, in out. Relacje pomiędzy nimi
przedstawia poniższa tabela:
Delphi Ada Działanie
var in out Parametr przekazywany jest przez referencję, jego zawartość może być
57

zmieniana.
out out Parametr przekazywany jest przez referencję, brak wartości
początkowej, służy do wyprowadzenia danych z podprogramu.
const in Parametr przekazywany jest przez wartość, nie może być
modyfikowany w ciele podprogramu (typu read only)
brak - Parametr przekazywany jest przez wartość, może być modyfikowany w
ciele podprogramu
- brak Analogiczne jak użycie parametru in
Jak widać w pierwszych trzech przypadkach nie ma trudności z translacją odpowiednich
parametrów – następuje tu tylko prosta zamiana odpowiednich modyfikatorów var na in out, const
na in, modyfikator out pozostaje bez zmian. W przypadku czwartym tj. wtedy, gdy brak
modyfikatora dla parametru w Delphi brak odpowiednika w języku Ada. Rozwiązanie jest
następujące: translator tworzy pomocnicze parametry, po jednym dla każdego parametru nie
posiadającego modyfikatora. W Adzie te parametry są typu in (czyli read only). Dodatkowo w
części deklaracyjnej podprogramu tworzone są zmienne, w ilości odpowiadającej ilości nowo
utworzonych parametrów inicjowane ich wartościami. Np.
PRZYKŁAD 4.9a
Delphi:
procedre PROC(a,b,c: real = 1.0; x,y,z: integer = 0); ...
begin ...
end;
tłumaczone jest na
PRZYKŁAD 4.9b
Ada’95
procedre PROC(d2a_temp_a,d2a_tmp_b,d2a_tmp_c: real := 1.0; d2a_tmp_x, d2a_tmp_y, d2a_tmp_z: integer := 0);
58

a: real:=d2a_tmp_a;
b: real:=d2a_tmp_b;
c: real:=d2a_tmp_c;
x: integer:= d2a_tmp_x;
y: integer:= d2a_tmp_y;
z: integer:= d2a_tmp_z;
...
begin ...
end;
W ten sposób w ciele podprogramu można korzystać z wartości przekazywanych przez parametry i
jednocześnie modyfikować je, co zapewnia brak użycia modyfikatora w parametrach Delphi.
Inny problem w translacji podprogramów jest założenie twórców Ady dotyczące funkcji;
mianowicie funkcja nie ma prawa modyfikować swoich parametrów. Konsekwencją tego założenia
jest fakt, że nie można w prosty sposób tłumaczyć funkcji zawierających parametry typu var i out.
Zagadnienie to dotyczy także konstruktorów, gdyż są one tłumaczone na funkcje (patrz
Konstruktory). Rozwiązanie D2A polega na zastąpieniu typów parametrów typu var i out przez
wskaźniki do tych typów. Np.
function FUNC( var x: boolean ):integer;
zastąpione zostanie przez:
function FUNC( x: access boolean) return integer;
Oczywiście w wywołaniach funkcji do każdego parametru typu var lub out zostanie dodany
modyfikator unrestricted_access. Tak np. wywołanie funkcji:
var bool:boolean; i:integer;
...
i:=FUNC( bool );
59

zastąpione zostanie przez:
bool:boolean;
i:integer;
...
i:=FUNC(bool’unrestricted_access);
Różnica pomiędzy funkcjami w oby językach polega także na zwracaniu wyniku funkcji. W Adzie
robi to instrukcja return, która kończy działanie funkcji oraz przekazuje wynik (reprezentowany
przez identyfikator następujący po słowie kluczowym return). W Pascalu i pochodnym Delphi,
sprawa jest bardziej skomplikowana. W każdej funkcji są zdefiniowane domyślnie i niejawnie dwie
predefiniowane zmienne: jedna o nazwie Result, drugiej nazwa jest identyczna z nazwą funkcji.
Obie te zmienne maja typ taki jak typ zwracany przez funkcję. Można przypisywać wartość do
zmiennej Result lub nazwy funkcji wielokrotnie w bloku funkcji. Kiedy wykonanie podprogramu
dobiega końca zostaje zwracana ostatnia wartość przypisana do jednaj z tych zmiennych. Na
przykład:
PRZYKŁAD 4.10
function Power(X: Real; Y: Integer): Real; var I: Integer;
begin Result := 1.0;
I := Y;
while I > 0 do begin if Odd(I) then Result := Result * X; I := I div 2; X := Sqr(X);
end; end;
60

Result i nazwa funkcji reprezentują zawsze tę samą wartość. Zatem funkcja
function MyFunction: Integer; begin MyFunction := 5;
Result := Result * 2;
MyFunction := Result + 1;
end;
zwraca zawsze wartość 11. Niestety obie zmienne nie są całkowicie zastępowalne. Nazwa funkcji
interpretowana jest jak Result tylko wtedy, gdy znajduje się po lewej stronie operatora przypisania,
w przeciwnym wypadku kompilator Delphi interpretuje ją jako wywołanie rekurencyjne. Na
zmienną Result nie nałożono żadnych ograniczeń dot. operacji, rzutowania i innych.
Translator deklaruje dla każdej funkcji zmienną o nazwie Result, będącą odpowiednikiem
predefiniowanej zmiennej o tej samej nazwie w Delphi. Dodatkowo na końcu bloku funkcji
dodawane są każdorazowo następująca linia:
return Result;
Zmienna będąca nazwą funkcji nie jest przez program zmieniana, nie pojawia się też żaden
komunikat o jej wystąpieniu. Nie jest to jednak potrzebne, gdyż kompilator Ady napotykając tę
zmienną po lewej stronie operatora przypisania (czyli tam gdzie jest jej jedyne dozwolone miejsce),
zakomunikuje o błędzie.
4.2.13 Dyrektywy kompilatora (pragma)
Pragmy są to polecenia dla kompilatora umieszczone bezpośrednio w kompilowanym kodzie
źródłowym. W Delphi (analogicznie do Turbo Pascala firmy Borland) dyrektywy przekazywane są
w komentarzach. Kompilator Delphi uzna dany komentarz za dyrektywę jeśli zawiera on znak
dolara ($) umieszczony bezpośrednio po znakach zaczynających komentarz ({ lub (*). Przykładem
jest dyrektywa {$warnings off}, która powoduje, że kompilator nie generuje żadnych
ostrzeżeń. Oczywiście dyrektywy są różne się dla różnych języków a nawet różnych kompilatorów
tego samego języka. Z tego względu nie są one tłumaczone. Translator umieszcza w miejscu
pragmy odpowiedni komentarz np.
61

--d2a: pragma: warnings off.
Użytkownik musi tłumaczyć odpowiednie pragmy na własną rękę. Wyjątkiem są {$IFDEF string},
{$ELSE}, {$ENDIF}. Bloki kodu pomiędzy tymi dyrektywami są parsowane pod warunkiem
spełnienia odpowiedniego warunku – zdefiniowania lub nie odpowiedniego symbolu za pomocą
pragmy {$DEFINE string} lub przełącznika /D string w linii poleceń kompilatora Delphi. Oto
przykład:
PRZYKŁAD 4.11
{$IFDEF MSWINDOWS} procedure RegisterNonActiveX(ComponentClasses: array of TComponentClass;
AxRegType: TActiveXRegType);
begin if not Assigned(RegisterNonActiveXProc) then raise EComponentError.CreateRes(@SRegisterError); RegisterNonActiveXProc(ComponentClasses, AxRegType)
end; {$ENDIF}
Ignorowanie przez translator tych dyrektyw mogło by być fatalne w skutkach z dwóch powodów:
• alternatywne części kodu mogłyby być przetłumaczone co powodowało by błędy w wykonaniu
programu spowodowane duplikacją kodu. Ponadto tłumaczone byłyby niepożądane części kodu.
Np.
PRZYKŁAD 4.12
{$IFDEF MSWINDOWS} procedure RegisterNonActiveX(ComponentClasses: array of TComponentClass;
AxRegType: TActiveXRegType);
{$ENDIF}
62

spowodowałoby przetłumaczenie deklaracji procedury RegisterNonActiveX, zbędnej np.
pod system Gnu/Linux (zdefiniowany symbol LINUX nie MSWINDOWS).
• tłumaczenie obu alternatywnych części kodu połączone i ignorowaniem dyrektyw mogłoby
sprawić, że translator uznałby dany kod za błędny. Np.:
PRZYKŁAD 4.13
{$IFDEF MSWINDOWS} uses Windows, Messages, SysUtils, Variants, TypInfo, ActiveX; {$ENDIF} {$IFDEF LINUX} uses Libc, SysUtils, Variants, TypInfo, Types; {$ENDIF}
D2A ignorując pragmy „widziałby” kod następująco:
uses Windows, Messages, SysUtils, Variants, TypInfo, ActiveX; uses Libc, SysUtils, Variants, TypInfo, Types;
Co jest oczywistym błędem składniowym.
Aby rozwiązać te problemy zdecydowałem się stworzyć prosty program narzędziowy ifdefproc,
który eliminuje niepożądane części kodu. Przyjmując za parametry symbole, które użytkownik
decyduje się zdefiniować program pozostawia w pliku źródłowym kod oznaczony przez te symbole.
Tak więc, gdy zdecydujemy się użyć ifdefproc i zdefiniować symbol LINUX to z kodu:
PRZYKŁAD 4.14
{$IFDEF MSWINDOWS} uses Windows, Messages, SysUtils, Variants, TypInfo, ActiveX; {$ENDIF} {$IFDEF LINUX} uses Libc, SysUtils, Variants, TypInfo, Types;
63

{$ENDIF}
pozostanie
uses Libc, SysUtils, Variants, TypInfo, Types;
4.2.14 Komentarze
W Delphi można umieszczać komentarze na kilka sposobów. Komentarz zaczynający się znakiem {
lub parą (* może mieć jedna lub więcej linii. Kończy się odp. znakiem } bądź parą *). Istnieje
możliwość zagnieżdżania komentarzy. Komentarz zaczynający się parą // zajmuje jedną linie (do
napotkania znaku końca linii). W Adzie możliwy jest tylko jeden rodzaj komentarzy – odpowiednik
komentarzy jednoliniowych z Delphi. Zaczyna się on parą – kończy zaś znakiem końca linii.
Wszystkie komentarze są tłumaczone na poziomie leksykalnym tj. przez analizator leksykalny. Oto
kilka przykładów komentarzy i ich tłumaczenia:
PRZYKŁAD 4.15
Delphi:
{ten komentarz ma
więcej niż
jedną linię
}
Ada:
--ten komentarz ma
--więcej niż
--jedną linię
--
Delphi:
(*komentarz { zagnieżdżony } *)
64

Ada:
--komentarz {zagnieżdżony}
Delphi:
//ten komentarz kończy się znakiem końca linii
Ada:
--ten komentarz kończy się znakiem końca linii
4.2.15 Asembler
Delphi oferuje możliwość łączenia kodu wysokiego poziomu z instrukcjami asemblera w sposób
łatwy i efektywny. Programista chcąc to zrobić powinien zdefiniować podprogram opatrując jego
deklarację dyrektywą assembler, a następnie zamiast bloku bagin..end użyć konstrukcji asm..end.
W tym bloku umieszcza się instrukcje asemblera:
PRZYKŁAD 4.16
function GetFieldClassTable(AClass: TClass): PFieldClassTable; assembler; asm MOV EAX,[EAX].vmtFieldTable
OR EAX,EAX
JE @@1
MOV EAX,[EAX+2].Integer
@@1:
end; Translator nie tłumaczy tych instrukcji, ponieważ nie istnieje w Adzie, która jest językiem bardziej
uniwersalnym i przeznaczonym także do tworzenia programów także na inne komputery niż PC,
jednolita metoda łączenia kodu asemblera z kodem wysokiego poziomu. Na przykład popularny
65

kompilator gnat wykorzystuje sposób znany z systemu gnu/gcc (którego częścią de facto jest), co
nie jest rzeczą oczywistą w przypadku innych kompilatorów (np. Aonix). Translator pomija
dyrektywę assembler (umieszczając w kodzie wynikowym odp. komentarz), blok asm..end
tłumaczy na blok begin..end, pomija instrukcje asemblera (przytacza je w odp. komentarzu) oraz
umieszcza ostrzeżenie:
--++d2a++ : F_Block: asm expression not implemented
Przykładowa funkcja przytoczona powyżej jest tłumaczona w następujący sposób:
PRZYKŁAD 4.17
function GetFieldClassTable ( d2a_tmp_AClass : TClass ) return PFieldClassTable --++d2a++ : F_ClassType: function directives not
supported:assembler
is result : PFieldClassTable ;
AClass : TClass := d2a_tmp_AClass ;
begin --++d2a++ : F_Block: asm expression not implemented
--
--MOV EAX,[EAX].vmtFieldTable
--OR EAX,EAX
--JE @@1
--MOV EAX,[EAX+2].Integer
--@@1:
--
end GetFieldClassTable ;
Jak widać na tym przykładzie funkcja ma puste ciało zatem kompilator Ady wygeneruje odpowiedni
komunikat o błędzie.
4.2.16 Obsługa wyjątków
Wszystkie nowoczesne języki programowania, takie jak Java, Delphi, Ada czy C++ oferują
mechanizm wyjątków. Jest to przejrzysty, ujednolicony i prosty sposób radzenia sobie z obsługą
66

błędów. Wszystkie błędy wykonania, to znaczy takie błędy, które ujawniają się dopiero w trakcie
trwania programu, sygnalizowane są przez wystąpienie tzw. wyjątku (ang. exception). Istnieją
odpowiednie konstrukcje służące do sygnalizowania (tj. rzucania, ang. throw, raise) wyjątków oraz
ich obsługi (w żargonie: łapania, ang. catch). Mechanizm jest prosty. W momencie powstania
błędu, może być to np. przekroczenie zakresu tablicy, dzielenie przez zero, brak wolnej pamięci
operacyjnej lub błąd wywołany explicite za pomocą instrukcji raise (throw), generowany jest
wyjątek. Technicznie jest to zmienna pewnego typu odpowiadającego napotkanemu błędowi,
składowe tej zmiennej zazwyczaj zawierają pewne dane na temat natury błędu. Kontrola programu
przenoszona jest do miejsca w którym zadeklarowano przechwycenie tego wyjątku. Na przykład:
PRZYKŁAD 4.18
Delphi:
try //w tym bloku kontrola wyjątków ...
float_var := strtofloat(string_var);
except //blok przechwytywania wyjątków on EConvertError do //instrukcje w razie wyst. wyj. EConvertError
float_var := 0;
else // instrukcje w razie wyst. innych wyjątków ...
end;
Ada’95:
begin ...
float_var := strtofloat(string_var);
exception when EConvertError => //instrukcje w razie wyst. wyj. EConvertError
67

float_var := 0;
when others => // instrukcje w razie wyst. innych wyjątków ...
end;
W powyższym przykładzie błąd może wystąpić podczas wykonania funkcji strtofloat, która
konwertuje zmienną łańcuchową do liczby zmiennoprzecinkowej. Jeśli wystąpi błąd podczas
wykonywania tej instrukcji kontrola programu zostanie przeniesiona do bloku except (lub exception
w Adzie). Tam zostaną wykonane instrukcje zdefiniowane dla danego wyjątku. Na wypadek gdy nie
można przewidzieć jaki wyjątek zostanie wywołany przewidziano blok else (w Adzie when others).
Jeżeli w danym podprogramie nie przewidziano obsługi wyjątku, a on wystąpi, to kontrola
przekazywana jest do miejsca, z którego ten podprogram został wywołany. Jeśli w żadnym
podprogramie w hierarchii programu nie ma obsługi wyjątku to program taki kończy działanie
komunikatem o wystąpieniu nie obsłużonego błędu. Niektóre języki (takie jak Java) wymuszają
wręcz na programiście obsługiwanie wyjątków, inne (na przykład Delphi, Ada) nie.
W Delphi blok try..except może być uzupełniony przez użyteczną konstrukcję finally. Instrukcje
znajdujące się w bloku finally zostaną wykonane niezależnie od tego czy w bloku try wystąpi błąd
czy nie. W Adzie blok finally symulowany jest poprzez zwykłą instrukcję grupującą, umieszczoną
po konstrukcji exception..end. Np.:
PRZYKŁAD 4.19
Delphi:
try RefreshTreeView;
finally AfterItemsModified;
end;
68

Ada’95:
--++d2a++ : try statement
begin
d2a_class_method_TRootSprig_RefreshTreeView ( d2a_object ) ;
--++d2a++ : finally statement
exception when others => null ; end ; begin d2a_class_method_TrootSprig_AfterItemsModified ( d2a_object ) ;
end ;
Translator tłumaczy poprawnie większość instrukcji związanych z obsługą wyjątków. Nie
obsługuje jedynie instrukcji raise at, która jest ściśle związana z asemblerem (par. 4.2.15).
4.2.17 Zmienne typu obiect
Są to typy alternatywne do typów class. Deklaracja ich jest identyczna za wyjątkiem tego, że
zamiast użycia słowa kluczowego class używamy słowo object, np.:
PRZYKŁAD 4.20
type objectTypeName = object (ancestorObjectType) procedure PROC; function FUN:boolean; p1:integer;
p2:boolean;
end;
69

Technicznie różnią się tym, że w przeciwieństwie do klas (class) nie pochodzą od klasy TObject.
Stąd nie posiadają wbudowanych konstruktorów, destruktorów i innych metod. tworzy się je za
pomocą procedury New a niszczy procedurą Dispose. Poza tym można deklarować zmienne typów
obiektowych identycznie jak rekordy. Typ ten jest wspierany przez Delphi wyłącznie ze względu na
kompatybilność wsteczną ze starszymi wersjami języka. Ich używanie nie jest rekomendowane.
D2A traktuje oba typy class i object tak samo.
4.2.18 Procedury new i dispose.
Procedury te służą do odpowiednio umieszczania i destrukcji zmiennych na stercie. W przypadku
instancji klas ich użycie nie jest rekomendowane – do tego służą konstruktory i destruktory.
Procedury te nie są w żaden sposób tłumaczone, użytkownik powinien zamienić każde wystąpienie
procedury new na wywołanie operatora new w Adzie. Np.
new(X);
zastąpić przez
new X;
Wystąpienia procedury dispose powinna być usunięte (Ada posiada wbudowany mechanizm
dealokacji), ew. zastąpione przez operator unchecked_dealocation.
4.2.19 Inne konstrukcje nie wspierane przez D2A
Translator nie tłumaczy następujących konstrukcji Delphi:
• zbiory, typy zbiorów (set of) i operacji na nich.
• typ FILE, standardowe funkcje wejścia/wyjścia takie jak write, writeln, read i in. będące w
praktyce częścią języka (umieszczone w Delphi ze względu na kompatybilność ze starszymi
wersjami języka Pascal – w praktyce dziś nie używane)
• dyrektywy kompilatora (pragmy) za wyjątkiem IFDEF, ENDIF, ELSE.
• inne dyrektywy dotyczące funkcji takie jak assembler, stdcall, register, za wyjątkiem tych
dyrektyw które dotyczą programowania zorientowanego obiektowo (OOP) w szczególności
polimorfizmu czyli: virtual, override, reintroduce.
70

Załącznik A Notacje BNF, EBNF.
Notacja BNF, równania normalne Backusa, BNF (angielskie Backus-Naur Form), system
zapisywania produkcji gramatyki zaproponowany przez J. Backusa i P. Naura przy okazji prac
prowadzonych nad językiem Algol 60. Symbole metajęzykowe (alfabetu pomocniczego), służące
do nazywania jednostek składniowych definiowanego języka umieszcza się w nawiasach kątowych.
Symbol := , czytany “jest równe z definicji”, łączy strony produkcji. Pionowa kreska (|) oznacza w
produkcjach spójnik logiczny “albo” i pozwala na zmniejszenie ich liczby. Symbole alfabetu
końcowego pisze się w BNF bez żadnych zaznaczeń.
Notacja EBNF, EBNF (z angielskiego Extended Backus-Naur Form), notacja BNF rozszerzona o
następujące symbole:
1) nawiasy [a] oznaczające co najwyżej jednokrotne wystąpienie napisu a;
2) nawiasy {a} oznaczające, że napis a może wystąpić dowolnie wiele razy po sobie;
3) a+ – plus po symbolu a (lub po nawiasach [], {}) oznacza, że symbol lub napis może wystąpić
dowolną niepustą liczbę razy;
4) a* – gwiazdka po symbolu a (lub po nawiasach [], {}) oznacza, że symbol lub napis można
powtórzyć dowolną liczbę razy (w szczególności – zero).
Stosuje się też liczbowe oznaczenia dopuszczalnych krotności występowania symboli, pisane w
postaci dolnych i górnych indeksów na prawo od nawiasu.
Powyższe hasła opracowano na podstawie “Słownika Encyklopedycznego - Informatyka” Wydawnictwa Europa.
Autor - Zdzisław Płoski. ISBN 83-87977-16-0. Rok wydania 1999.
71

Załącznik B. Definicja języka Object Pascal w notacji EBNF [zał. A].
Wielkość liter w Object Pascal nie ma znaczenia, w poniższych definicjach przyjęto konwencje
pisania symboli końcowych wielkimi literami.
<Goal> ::= <Program> | <Package> | <Library> | <Unit>
<Program> ::= [PROGRAM <Ident> ['(' <IdentList> ')'] ';']
<ProgramBlock> '.'
<Unit> ::= UNIT <Ident> ';'
<InterfaceSection>
<ImplementationSection>
<InitSection> '.'
<Package> ::= PACKAGE <Ident> ';'
[<RequiresClause>]
[<ContainsClause>]
END '.'
<Library> ::= LIBRARY <Ident> ';'
<ProgramBlock> '.'
<ProgramBlock> ::= [<UsesClause>]
<Block>
72

<UsesClause> ::= USES IdentList ';'
<InterfaceSection> ::= INTERFACE <UsesClause>][<InterfaceDecl>]
...
<InterfaceDecl> ::= { <ConstSection> | <TypeSection> |
<VarSection> | <ExportedHeading> }
<ExportedHeading> ::= { <ProcedureHeading> ';' [<Directive>] |
<FunctionHeading> ';' [<Directive>] }
<ImplementationSection> ::= IMPLEMENTATION [<UsesClause>]
[<DeclSection>]...
<Block> ::= [<DeclSection>] <CompoundStmt>
<DeclSection> ::= { <LabelDeclSection> | <ConstSection>
<TypeSection> | <VarSection> |
<ProcedureDeclSection> }
<LabelDeclSection> ::= LABEL <LabelId>
<ConstSection> ::= CONST {<ConstantDecl> ';'}
<ConstantDecl> ::= (<Ident> '=' <ConstExpr>) |
(<Ident> ':' <TypeId> '=' <TypedConstant>)
<TypeSection> ::= TYPE {<TypeDecl> ';'}
<TypeDecl> ::= (<Ident> '=' <Type>) |
(<Ident> '=' <RestrictedType>)
<TypedConstant> ::= <ConstExpr> | <ArrayConstant> |
<RecordConstant>
73

<ArrayConstant> ::= '(' <TypedConstant>
{','<TypedConstant>} ')'
<RecordConstant> ::= '(' <RecordFieldConstant>
{';'<RecordFieldConstant>} ')'
<RecordFieldConstant> ::= <Ident> ':' <TypedConstant>
<Type> ::= <TypeId> | <SimpleType> | <StrucType>
<PointerType> | <StringType> | <ProcedureType>
<VariantType> | <ClassRefType>
<RestrictedType> ::= <ObjectType>|<ClassType>|<InterfaceType>
<ClassRefType> ::= CLASS OF <TypeId>
<SimpleType> ::= <OrdinalType>|<RealType>
<RealType> ::= REAL48 | REAL | SINGLE | DOUBLE | EXTENDED
CURRENCY | COMP
<OrdinalType> ::= <SubrangeType>|<EnumeratedType>|<OrdIdent>
<OrdIdent> ::= SHORTINT | SMALLINT | INTEGER | BYTE |
LONGINT | INT64 | WORD | BOOLEAN | CHAR | WIDECHAR |
LONGWORD | PCHAR
<VariantType> ::= VARIANT | OLEVARIANT
<SubrangeType> ::= <ConstExpr> '..' <ConstExpr>
<EnumeratedType> ::= '(' <IdentList> ')'
74

<StringType> ::= STRING | ANSISTRING | WIDESTRING |
( STRING '[' ConstExpr ']' )
<StrucType> ::= [PACKED] (<ArrayType> | <SetType> |
<FileType> | <RecType>)
<ArrayType> ::= ARRAY ['[' <OrdinalType>
{','<OrdinalType>}']'] OF Type
<RecType> ::= RECORD [<FieldList>] END
<FieldList> ::= <FieldDecl>{';'<FieldDecl>} [<VariantSection>]
[';']
<FieldDecl> ::= <IdentList> ':' <Type>
<VariantSection> ::= CASE [<Ident> ':'] <TypeId> OF
<RecVariant>{';'<RecVariant>}
<RecVariant> ::= <ConstExpr>{','< ConstExpr >} ':' '('
[<FieldList>] ')'
<SetType> ::= SET OF <OrdinalType>
<FileType> ::= FILE OF <TypeId>
<PointerType> ::= '^' <TypeId>
<ProcedureType> ::= (<ProcedureHeading> | <FunctionHeading>)
[OF OBJECT]
<VarSection> ::= VAR <VarDecl> {'; <VarDecl>}
<VarDecl> ::= <IdentList> ':' <Type> [(ABSOLUTE (<Ident> |
75

<ConstExpr>)) | '=' <ConstExpr>]
<Expression> ::= <SimpleExpression> {<RelOp><SimpleExpression>}
<SimpleExpression> ::= ['+' | '-'] <Term> {<AddOp> <Term>}
<Term> ::= <Factor> {<MulOp> <Factor>}
Factor ::= <Designator> ['(' <ExpressionList> ')'] |
'' <Designator> |
<Number> |
<String> |
NIL |
'(' <Expression> ')' |
NOT <Factor> |
<SetConstructor> |
<TypeId> '(' <Expression> ')'
<RelOp> ::= '>' | '<' | '<=' | '>=' | '<>' | IN | IS | AS
<AddOp> ::= '+' | '-' | OR | XOR
<MulOp> ::= '*' | '/' | DIV | MOD | AND | SHL | SHR
<Designator> ::= <QualId> {'.' <Ident> | '[' <ExpressionList>
']' | '^'}
<SetConstructor> ::= '[' [<SetElement> {',' <SetElement>}] ']'
<SetElement> ::= <Expression> ['..' <Expression>]
<ExpressionList> ::= <Expression>/','...
<Statement> ::= [<LabelId> ':'] [<SimpleStatement> |
76

<StructStmt>]
<StmtList> ::= <Statement>{';'<Statement>}
<SimpleStatement> ::= <Designator> ['(' <ExpressionList> ')'] |
<Designator> ':=' <Expression> |
INHERITED |
GOTO <LabelId>
<StructStmt> ::= <CompoundStmt> | <ConditionalStmt> |
<LoopStmt> | <WithStmt>
<CompoundStmt> ::= BEGIN <StmtList> END
<ConditionalStmt> ::= <IfStmt> | <CaseStmt>
<IfStmt> ::= IF <Expression> THEN <Statement>
[ELSE <Statement>]
<CaseStmt> ::= CASE <Expression> OF
<CaseSelector>{';'<CaseSelector>} [ELSE <Statement>]
[';'] END
<CaseSelector> ::= <CaseLabel>{','<CaseLabel>} ':' <Statement>
<CaseLabel> ::= <ConstExpr> ['..' <ConstExpr>]
<LoopStmt> ::= <RepeatStmt> | <WhileStmt> | <ForStmt>
<RepeatStmt> ::= REPEAT <Statement> UNTIL <Expression>
<WhileStmt> ::= WHILE <Expression> DO <Statement>
<ForStmt> ::= FOR <QualId> ':=' <Expression> (TO | DOWNTO)
77

<Expression> DO <Statement>
<WithStmt> ::= WITH <IdentList> DO <Statement>
<ProcedureDeclSection> ::= <ProcedureDecl> | <FunctionDecl>
<ProcedureDecl> ::= <ProcedureHeading> ';' [<Directive>]
<Block> ';'
<FunctionDecl> ::= FunctionHeading> ';' [<Directive>]
<Block> ';'
<FunctionHeading> ::= FUNCTION <Ident> [<FormalParameters>] ':'
(<SimpleType> | STRING)
<ProcedureHeading> ::= PROCEDURE <Ident> [<FormalParameters>]
<FormalParameters> ::= '(' <FormalParm>{';'<FormalParm>} ')'
<FormalParm> ::= [VAR | CONST | OUT] <Parameter>
<Parameter> ::= ( <IdentList> [':' ([ARRAY OF] <SimpleType> |
STRING | FILE)] ) |
(<Ident> ':' <SimpleType> '=' <ConstExpr> )
<Directive> ::= CDECL | REGISTER | DYNAMIC | VIRTUAL|
EXPORT | EXTERNAL | FAR | FORWARD| MESSAGE|
OVERRIDE | OVERLOAD | PASCAL | REINTRODUCE|
SAFECALL | STDCALL
<ObjectType> ::= OBJECT [<ObjHeritage>] [<ObjFieldList>]
[<MethodList>] END
<ObjHeritage> ::= '(' <QualId> ')'
78

<MethodList> ::= (<MethodHeading> [';' VIRTUAL])
{';'(<MethodHeading> [';' VIRTUAL])}
<MethodHeading> ::= <ProcedureHeading> | <FunctionHeading> |
<ConstructorHeading> | <DestructorHeading>
<ConstructorHeading> ::=CONSTRUCTOR <Ident>[<FormalParameters>]
<DestructorHeading> ::= DESTRUCTOR <Ident> [<FormalParameters>]
<ObjFieldList> ::= (<IdentList> ':' Type)/';'...
<InitSection> ::= ( INITIALIZATION <StmtList>
[FINALIZATION <StmtList>] END ) |
( BEGIN StmtList END ) |
END
<ClassType> ::= CLASS [<ClassHeritage>]
{[<ClassFieldList>] |
[<ClassMethodList>] |
[<ClassPropertyList>] }
END
<ClassHeritage> ::= '(' <IdentList> ')'
<ClassVisibility> ::= PUBLIC | PROTECTED | PRIVATE | PUBLISHED
<ClassFieldList> ::= {[<ClassVisibility>] <ObjFieldList>';'}
<ClassMethodList> ::= {[<ClassVisibility>] <MethodList>';’}
<ClassPropertyList> ::= {[<ClassVisibility>] <PropertyList>';'}
79

<PropertyList> ::= PROPERTY <Ident> [<PropertyInterface>]
<PropertySpecifiers>
<PropertyInterface> ::= [<PropertyParameterList>] ':' <Ident>
<PropertyParameterList> ::= '['{<IdentList> ':' <TypeId>)';'}]'
<PropertySpecifiers> ::= INDEX <ConstExpr> |
READ <Ident> |
WRITE <Ident> |
STORED (<Ident> | Constant) |
(DEFAULT <ConstExpr> | NODEFAULT]) |
IMPLEMENTS <TypeId>
<InterfaceType> ::= INTERFACE [<InterfaceHeritage>]
{[<ClassMethodList>] |
[<ClassPropertyList>] }
END
<InterfaceHeritage> ::= '(' <IdentList> ')'
<RequiresClause> ::= REQUIRES <IdentList>';'
<ContainsClause> ::= CONTAINS <IdentList>';'
<IdentList> ::= <Ident>{','<Ident>}
<QualId> ::= [<UnitId> '.'] <Ident>
<TypeId> ::= [UnitId '.'] <type-identifier>
<Ident> ::= <identifier>
<ConstExpr> ::= <constant-expression>
80

<UnitId> ::= <unit-identifier>
<LabelId> ::= <label-identifier>
<Number> ::= <number>
<String> ::= <string>
81




![(step mm3 [tryb zgodności]) - is.pw.edu.plpiotr_bartkiewicz/STEP/pliki/kursy/KLM3.pdf · sprawdzenie nastaw i strategii układu automatycznej regulacji, ... chłodzenia przy pomocy](https://static.fdocuments.pl/doc/165x107/5c783feb09d3f2cb498b9cc9/step-mm3-tryb-zgodnosci-ispwedupl-piotrbartkiewiczstepplikikursyklm3pdf.jpg)













