NIE STRASZNY NAM KRYZYS, CZYLI JAK NIE DAĆ SIĘ … · Próby konkurowania przez proste...
44
Model ekonometryczny NIE STRASZNY NAM KRYZYS, CZYLI JAK NIE DAĆ SIĘ DEPRESJI Determinanty depresji w Polsce Michał Danilewski Paweł Klimaszewski UNIWERSYTET WARSZAWSKI WYDZIAŁ NAUK EKONOMICZNYCH WARSZAWA 2009
-
Upload
truongminh -
Category
Documents
-
view
213 -
download
0
Transcript of NIE STRASZNY NAM KRYZYS, CZYLI JAK NIE DAĆ SIĘ … · Próby konkurowania przez proste...

Model ekonometryczny
NIE STRASZNY NAM KRYZYS, CZYLI JAK NIE DAĆ SIĘ DEPRESJI
Determinanty depresji w Polsce
Michał Danilewski Paweł Klimaszewski
UNIWERSYTET WARSZAWSKI
WYDZIAŁ NAUK EKONOMICZNYCH WARSZAWA 2009

2
SPIS TREŚCI
1. Problem ekonometryczny......................................................................................3 1.1. Opis hipotez badawczych, podstawy teoretyczne oraz próba ekonomicznego uzasadnienia ..................................................................................................................4
1.1.1. Podstawy teoretyczne modelu.........................................................................4 1.1.2. Hipotezy badawcze .........................................................................................7
2. Opis zbioru danych oraz definicje zmiennych ......................................................8 3. Oszacowanie modelu ..........................................................................................16
3.1. Zastosowanie Liniowego Modelu Prawdopodobieństwa................................16 3.2. Estymacja modelu logit i probit ......................................................................19
3.2.1. Model logit - wybór zmiennych do modelu..................................................19 3.2.2. Diagnostyka i testy modelu logit...................................................................21 3.2.3. Analiza dopasowania ...................................................................................23 3.2.4. Wybór zmiennych do modelu probit.............................................................25 3.2.5. Diagnostyka i testy modelu probit ................................................................27 3.2.6. Analiza dopasowania ...................................................................................29
4. Wybór właściwego modelu.................................................................................31 5. Interpretacja wyników.........................................................................................34
5.1. Efekty cząstkowe ............................................................................................34 5.2. Ilorazy szans....................................................................................................35 5.3. Efekty cząstkowe i wnioski dla wybranej grupy respondentów .....................37
5.3.1. Oszacowanie i interpretacja efektów cząstkowych.......................................37 5.3.2. Wnioski z efektów cząstkowych...................................................................38
6. Wnioski końcowe................................................................................................40 7. Bibliografia .........................................................................................................42 8. Załączniki ............................................................................................................43
8.1. Skala Depresji Becka ......................................................................................43 8.2. Wykresy zależności ciągłych zmiennych objaśniających i prawdopodobieństwa bycia w depresji .......................................................................44

3
1. Problem ekonometryczny
Prognozy ekonomistów stały się faktem – kryzys ekonomiczny dotarł również
do Polski i raczej nie ominie nikogo z nas. Przede wszystkim odczuje go (o ile jeszcze
nie odczuła) zdecydowana większość firm i ich menedżerowie. Co zrobić, aby skutki
kryzysu dotknęły nas w jak najmniejszym stopniu? Jak podejmować decyzje, aby
pomimo trudności nie stracić zimnej krwi i, co za tym idzie, profitów osiągniętych w
czasie hossy?
W obliczu kryzysu nic nie jest pewne. Nie można liczyć na to, że firmy mające
dziś wielu kontrahentów, jutro bądź za miesiąc nadal będą ich miały. Z dnia na dzień
możemy być zaskoczeni wiadomościami, że przedsiębiorstwo będące naszym
partnerem upadło lub ma poważne problemy.
Dlatego do kryzysu trzeba się przygotować. Strategia rozwoju musi być dobrze
przemyślana i zaplanowana. Lepiej już teraz się zabezpieczyć, pozyskując skuteczne
narzędzia obniżające koszty i rozszerzając działalność o nowe kontrakty, które pomogą
zdywersyfikować dostawców i odbiorców. Przedsiębiorstwa powinny mieć gotowe
rozwiązania, kiedy kryzys już przyjdzie. Należałoby też pomyśleć o opcjach, które
byłyby lepsze i tańsze od obecnie używanych.
Próby konkurowania przez proste zwiększanie wielkości produkcji mogą okazać
się zbyt ryzykowne. Nie ma bowiem gwarancji, że świeżo wyprodukowane towary
znajdą nabywców. Wydatki włożone w rozbudowę linii produkcyjnych, magazynów
itp. mogą się po prostu nie zwrócić. W efekcie, nawet wzrost sprzedaży, przy
nieproporcjonalnie większym wzroście kosztów produkcji, będzie oznaczał ujemne
wyniki finansowe firmy.
Kluczowym czynnikiem (szczególnie w sektorze małych i średnich
przedsiębiorstw), który może zdecydować o przetrwaniu czasu kryzysu, jest postawa
menedżera. To on staje się odpowiedzialny za realizowanie strategii, podejmowanie
trudnych decyzji i wykonywanie ryzykownych działań. Sukces nie zależy jednak
wyłącznie od wiedzy i doświadczenia osób na stanowiskach kierowniczych. Równie
ważna jest sfera emocjonalna: kondycja psychiczna, pewność siebie i odporność na
stres.
Coraz więcej menedżerów, w związku z załamaniem na rynku, nie potrafi
poradzić sobie z trudnościami własnego przedsiębiorstwa. Ryzyko nietrafionych
decyzji, konieczność wzięcia odpowiedzialności za spadającą sprzedaż, typowanie

4
pracowników do zwolnienia wpływają na zwiększenie napięcia w miejscach pracy.
Stres, zdenerwowanie i przemęczenie prowadzą do spadku motywacji, przejawiającego
się rezygnacją, długotrwałym przygnębieniem i niechęcią do działania. Pojawiająca się
depresja1 powoduje, że zamiast dokonywać odpowiednich działań w celu ratowania
firmy, zarządzający podejmują błędne decyzje, które tylko pogarszają sytuację.
Depresja, choć dotyka coraz więcej osób, często aktywnych i pełnych życia, nie jest
wyrokiem i skutecznie można się przed nią zabezpieczyć. Im wcześniej pozna się jej
determinanty, tym szybciej będzie można podjąć kroki w celu ich wyeliminowania.
Celem naszej pracy jest zbadanie czynników wpływających na depresję wśród
Polaków, a następnie zbadanie wpływu tych czynników na osoby o charakterystyce
typowej dla menedżera.
Wśród czynników wpływających na depresję, ważną rolę odgrywają z
pewnością cechy wewnętrzne, które są niemierzalne i różne dla każdej jednostki.
Istnieje jednak szereg zmiennych mierzalnych, które wpływają na nasz dobrostan,
szczęście, odporność na stres, a co za tym idzie – skłonność do depresji. Takie zmienne
będą podlegały badaniu w modelu ekonometrycznym przedstawionym w niniejszej
pracy.
1.1. Opis hipotez badawczych, podstawy teoretyczne oraz
próba ekonomicznego uzasadnienia
W rozdziale tym przedstawione zostaną prace naukowców którzy zajmowali się
badaniem czynników determinujących depresję. Wnioski z prezentowanych artykułów
były nam pomocne przy formułowaniu hipotez, które zamieszczone są w dalszej części
pracy.
1.1.1. Podstawy teoretyczne modelu
V. Lorant, C. Croux, S. Weich, D. Deliege, J. Mackenbach i M. Ansseau w
artykule Depression and socio-economic risk factors2 opisali swoje badania na temat
1 Według prof. Antoniego Kępińskiego depresja to stan chorobowy charakteryzujący się nasileniem objawów i wydłużonym czasem ich utrzymywania się. Niepokój powinno wzbudzić nie samo przygnębienie, ale to, że trwa ono już długo i zmienia nasze funkcjonowanie, dezorganizuje codzienne życie. Smutek nie jest już tym, co pojawia się od czasu do czasu, ale czymś stale towarzyszącym. Antoni Kępiński (1918–1972) – wybitny lekarz psychiatra, autor znanych książek na temat depresji, m.in.: „Melancholia”. 2 V. Lorant, C. Croux, S. Weich, D. Deliege, J. Mackenbach, M. Ansseau, Depression and socio-economic risk factors: 7-year longitudinal population study, “The British Journal of Psychiatry” 2007, nr 190, s. 293-298.

5
czynników socjo-ekonomicznych determinujących depresję. W swojej pracy
wykorzystali dane pochodzące z siedmiu fal badania panelowego przeprowadzanych w
rocznych odstępach czasu. Dane gromadzono w oparciu o Belgijski Sondaż
Gospodarstw Domowych obejmujący osoby w wieku powyżej 16 lat w latach 1992 –
1999. Próba liczyła 11 909 respondentów, wśród których u 17,3% stwierdzono objawy
depresji. W oszacowanym przez autorów modelu logit prawdopodobieństwo
znalezienia się w stanie depresji zostało uzależnione od takich zmiennych niezależnych,
jak: własna ocena zamożności dokonywana przez respondenta, ubóstwo (jako zmienna
zero-jedynkowa), dochód gospodarstwa domowego, bezrobocie, działalność społeczna
oraz stan cywilny. Otrzymane rezultaty pozwoliły stwierdzić, iż powyższe czynniki
mają istotny wpływ na prawdopodobieństwo depresji wśród Belgów. Potwierdziły się
przypuszczenia naukowców, że pogarszający się stan materialny, związany ze spadkiem
dochodów respondenta lub byciem bezrobotnym, zwiększa prawdopodobieństwo
depresji. Ciekawym wnioskiem był fakt, iż osoby które deklarowały swoją społeczną
aktywność, rozumianą jako czynny udział w organizacjach non-profit, wolontariacie,
kampaniach społecznych itp., wykazywały się dużo mniejszą podatnością na depresję.
Badanie pokazało również, że kobiety mają większe prawdopodobieństwo wpadnięcia
w depresję niż mężczyźni. Okazało się natomiast, że posiadanie partnera skutecznie
zmniejsza ryzyko załamania depresyjnego.
R. M. Nesse i G. C. Williams w swojej pracy Why we get sick opublikowanej w
1994 r. w „New York Times Books” opisali wyniki swoich badań na temat depresji i jej
determinantów. W pięciu badaniach, obejmujących łącznie 39 tys. osób z różnych
krajów zachodnich, stwierdzono, że dzisiejsi młodzi ludzie mają znacznie wyższe
ryzyko doświadczenia co najmniej jednego epizodu depresyjnego w porównaniu ze
starszymi pokoleniami. Autorzy tłumaczą to m.in. procesami cywilizacyjnymi (ryzyko
depresji rośnie wraz ze wzrostem poziomu ekonomicznego rozwoju kraju), które
znacznie silniej odbijają się na psychice młodych pokoleń niż osób starszych,
dorastających w tzw. erze lęku po drugiej wojnie światowej. Nesse i Williams
zaproponowali następujące wyjaśnienie: „Komunikacja masowa, zwłaszcza telewizja i
filmy, czyni z nas wszystkich jeden wielki zespół rywali, współzawodniczących ze sobą
kosztem bliskich związków z ludźmi (...) Dawniej miałeś spore szanse wybić się w
czymś. Nawet jeśli nie byłeś najlepszy, twoje własne otoczenie doceniało twoje
zdolności. Dziś wszyscy rywalizujemy z tymi, którzy są najlepsi na świecie. Oglądając
ludzi sukcesu w telewizji, stajemy się zawistni. Zawiść przyczyniała się zapewne do

6
motywowania naszych przodków do osiągania tego, co osiągnęli inni. Dziś natomiast,
nieliczni z nas mogą zdobyć to, do czego skłania nas zazdrość i nikt z nas nie jest w
stanie mieć tak fantastycznego życia, jakie oglądamy w telewizji”3.
Do zupełnie odwrotnych wniosków doszedł jednak J. Czapiński w badaniach
przeprowadzonych w Polsce i opublikowanych w Diagnozie Społecznej w 2005 r.4 W
przeciwieństwie do społeczeństw zachodnich (USA, Kanada), zależność między
wiekiem i depresją w Polsce jest nie negatywna, lecz pozytywna. Jest ona również u nas
kilkakrotnie silniejsza. W Polsce to ludzie starsi częściej cierpią na depresję niż młodzi.
Nie wiemy, skąd bierze się polski fenomen odwrócenia zależności między wiekiem i
depresją. Czapiński sugeruje, że być może wynika on z pokoleniowo zróżnicowanych
zdolności adaptacyjnych: ludzie, którzy dorastali i żyli w czasach PRL, mają większe
trudności z odnalezieniem się w nowej rzeczywistości wolnej gospodarki5. Ludzie starsi
czują się więc bardziej zagubieni i niechciani (choćby na rynku pracy). Zgodnie z
badaniami, odwrócony i nadzwyczaj silny związek między wiekiem i depresją nie
słabnie jednak w miarę upływu czasu. Dzisiejsi 30-latkowie, którzy wchodzili w
dorosłość już po upadku komunizmu, są dużo bardziej skłonni do depresji od obecnych
20-latków. Takie zachowanie, niespotykane w krajach Europy Zachodniej, pozostaje
największą tajemnicą transformacji i Polaków.
Podsumowując poprzedni akapit, według badań Czapińskiego6, najważniejszym
czynnikiem wyjaśniającym stan psychiczny Polaków jest wiek. Drugim, równie
istotnym kryterium okazała się być liczba przyjaciół. W trudnych chwilach, zwłaszcza
w obliczu problemów osobistych, poczucie bezinteresownej życzliwości i pomocy ze
strony innych ludzi może być kluczowym czynnikiem chroniącym człowieka od
depresji. Jak mawia przysłowie, prawdziwych przyjaciół poznaje się w biedzie i tego
dowodzi badanie Czapińskiego.
Zgodnie z wynikami Diagnozy Społecznej7 kolejnym ważnym determinantem
okazał się dochód na osobę. Wraz ze spadkiem dochodu rośnie prawdopodobieństwo
depresji. Na osłabienie poczucia dobrostanu, a co za tym idzie, wzrost ryzyka depresji,
wpływa również bezrobocie i nadużywanie alkoholu. Badania dowiodły również istotną
3 R.M. Nesse, G. C. Williams, Why we get sick, “New York Times Books”, 1994 r., s. 220. 4 Badanie to zostało przeprowadzone na próbie 12 988 Polaków i zawiera kompleksowe dane na temat gospodarstw domowych oraz postaw, stanu ducha i zachowań osób tworzących te gospodarstwa. 5 J. Czapiński, T. Panek, Diagnoza Społeczna 2005, s. 116. 6 Ibidem, s 117-123. 7 Ibidem.

7
rolę małżeństwa, które staje się czynnikiem wzmacniającym kondycję psychiczną i ma
znaczny wpływ na ograniczenie prawdopodobieństwa wpadnięcia w depresję.
1.1.2. Hipotezy badawcze
Wyciągając wstępne wnioski z badań przywołanych w poprzednim
podrozdziale, można zauważyć, iż skłonności do depresji są uwarunkowane przez wiele
czynników. Nie ma zgody, co do kierunku wpływu niektórych z nich np. wieku
respondenta. Istnieje również wiele przeciwstawnych poglądów o istotności
poszczególnych kryteriów. Celem naszej pracy będzie weryfikacja części z tych
poglądów oraz analiza determinantów depresji wśród Polaków. Praca ta będzie
stanowiła odpowiedź na następujące pytania:
� Jak wiek osoby wpływa na prawdopodobieństwo bycia w depresji?
Opierając się na wynikach przedstawionych badań skłaniamy się do tezy,
że wśród Polaków takie prawdopodobieństwo rośnie wraz ze wzrostem
wieku. Im człowiek starszy, tym jego sytuacja materialna i zdrowotna
jest trudniejsza, co zwiększa podatność do depresji.
� Czy kobiety są bardziej podatne na depresję?
Przypuszczamy, że można zauważyć taką zależność, co wynika z
większej wrażliwości w porównaniu z mężczyznami.
� Czy dochód ma wpływ na prawdopodobieństwo bycia w depresji?
Sądzimy, że ludzie zamożniejsi mają mniejszą skłonność do wpadnięcia
w depresję8. Wynika to z tego, że mając zagwarantowany dobrobyt, nie
trzeba się nieustannie martwić o zaspokojenie podstawowych potrzeb.
� Czy fakt bycia bezrobotnym ma wpływ na depresję?
Można stwierdzić, że fakt utraty pracy może mieć znaczny wpływ
na prawdopodobieństwo bycia w depresji, co wynika z braku
regularnych dochodów – sytuacji nieustannego napięcia nerwowego.
8 Pomijamy tu pojedyncze przypadki milionerów (ze względu na ich znikomość w badanej próbie), u których faktycznie można byłoby zaobserwować dodatni wpływ dochodu na prawdopodobieństwo bycia w depresji.

8
� Jakie znaczenie na badane zjawisko ma wykształcenie respondenta?
Uważamy, iż osoby posiadające wyższe wykształcenie znajdują się w
lepszej sytuacji życiowej, a także posiadają lepsze perspektywy na
przyszłość, zatem są mniej podatne na popadnięcie w depresję.
� Czy praktyki religijne, chodzenie do kościoła, wiara ma wpływ na bycie w
depresji?
Badanie przeprowadzone w Diagnozie Społecznej wykazało, że wiara
wpływa ujemnie na skłonności depresyjne. Biorąc pod uwagę
charakterystykę społeczeństwa polskiego, można twierdzić, iż praktyki
religijne powodują, że ludzie w trudnych chwilach znajdują oparcie w
wierze i rzadziej popadają w depresję, niż osoby czujące się
pozostawione samym sobie.
� Czy nadużywanie alkoholu ma wpływ na skłonności depresyjne?
Naszym zdaniem problemy z alkoholem mogą istotnie wpływać na
pojawienie się skłonności depresyjnych.
� Jak stan cywilny wpływa na prawdopodobieństwo wystąpienia badanego
zjawiska?
Naszym zdaniem osoby będące w związku małżeńskim powinny
cechować się mniejszym prawdopodobieństwem bycia w depresji, niż
osoby, które owdowiały, są w separacji lub po rozwodzie.
2. Opis zbioru danych oraz definicje zmiennych
Dane wykorzystane do budowy poniższego modelu pochodzą z badania
„Diagnoza Społeczna” przeprowadzonego w 2005 r. Wyniki kolejnych edycji badania,
wraz z bazami danych i metodologią są publikowane na stronie internetowej
www.diagnoza.com. Z udostępnionej bazy danych, w pierwszym kroku wybrano
zmienne zawarte w hipotezach przedstawionych w poprzednim rozdziale. Z tego zbioru
usunięto następnie obserwacje, dla których respondent nie udzielił odpowiedzi na
pytania dotyczące badanych przez nas zmiennych. W efekcie, ostateczną analizą objęto
6 156 osób.

9
Większość zmiennych została pozyskana za pomocą pojedynczych pytań.
Wyjątek stanowiła zmienna depr. Została ona uzyskana na podstawie skali depresji
psychicznej, złożonej z siedmiu pozycji – symptomów9, zapożyczonych ze znanego i
często stosowanego w badaniach psychologicznych Inwentarza Depresji autorstwa A.
T. Becka, na który składa się dwadzieścia jeden pytań10. Wybór siedmiu pozycji
spośród dwudziestu jeden symptomów został dokonany przez prof. Czapińskiego –
jednego z autorów Diagnozy Społecznej. Decyzję podyktowano względami
psychometrycznymi: w poprzednich badaniach zmienne wykazały najsilniejszy związek
z obiektywnymi wyznacznikami warunków życia. Wskaźnikiem depresji była więc
suma odpowiedzi na wszystkie siedem pytań. Wynik powyżej siedmiu świadczył o
stanie depresyjnym respondenta. Wskaźnik depresji traktować można jako miarę
stopnia nieprzystosowania psychicznego, odzwierciedlającą nieskuteczność radzenia
sobie z problemami czy stresem życiowym. Wskaźników opartych na tej skali nie
należy odczytywać jako diagnozy poziomu klinicznych zaburzeń depresyjnych w
wymiarze populacji. Poniżej zostały przedstawione zmienne użyte przez nas w modelu.
Zmienna objaśniana:
� depr - jest to zmienna binarna, przyjmująca wartości:
0 – gdy osoba nie ma depresji
1 – gdy osoba ma depresję
Tabela 1. Charakterystyka zmiennej zależnej depr
bycie w | depresji | Freq. Percent Cum. ------------+----------------------------------- 0 | 4,443 72.17 72.17 1 | 1,713 27.83 100.00 ------------+----------------------------------- Total | 6,156 100.00
Źródło: Opracowanie własne
Powyższe zestawienie pokazuje, że wśród badanych osób 27,83% było w trakcie badania w depresji. Osób, które nie były w depresji jest 4 443, co stanowi 72,17% liczebności próby.
9 Wykaz tych symptomów został zamieszczony w załącznikach. 10 A. T. Beck, C. H. Ward, M. Mendelson, J. Mock, J. Erbaugh, An inventory for measuring depression, “Archives of General Psychiatry”, 1961, nr 4,s. 561-571.
10
Zmienne objaśniające:
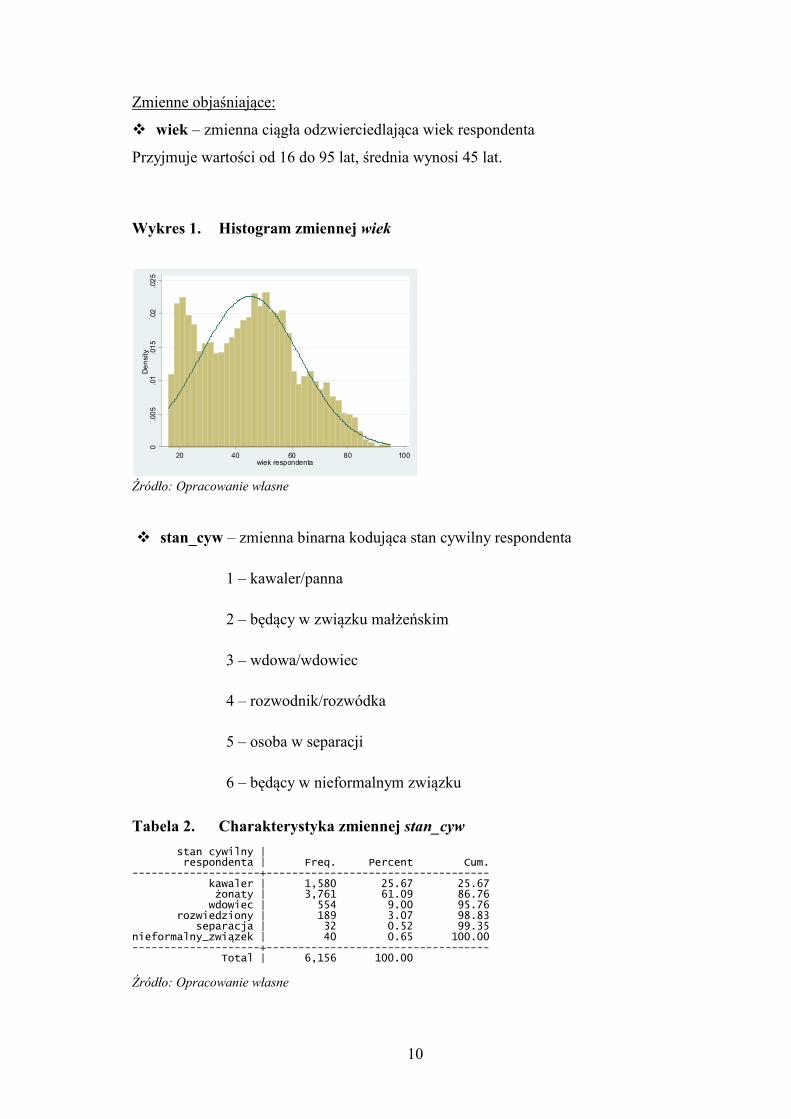
� wiek – zmienna ciągła odzwierciedlająca wiek respondenta
Przyjmuje wartości od 16 do 95 lat, średnia wynosi 45 lat.
Wykres 1. Histogram zmiennej wiek
0.0
05
.01
.01
5.0
2.0
25
De
nsity
20 40 60 80 100wiek respondenta
Źródło: Opracowanie własne
� stan_cyw – zmienna binarna kodująca stan cywilny respondenta
1 – kawaler/panna
2 – będący w związku małżeńskim
3 – wdowa/wdowiec
4 – rozwodnik/rozwódka
5 – osoba w separacji
6 – będący w nieformalnym związku
Tabela 2. Charakterystyka zmiennej stan_cyw
stan cywilny | respondenta | Freq. Percent Cum. --------------------+----------------------------------- kawaler | 1,580 25.67 25.67 Ŝonaty | 3,761 61.09 86.76 wdowiec | 554 9.00 95.76 rozwiedziony | 189 3.07 98.83 separacja | 32 0.52 99.35 nieformalny_związek | 40 0.65 100.00 --------------------+----------------------------------- Total | 6,156 100.00
Źródło: Opracowanie własne

11
Badana próba dobrze odzwierciedla przekrój polskiego społeczeństwa, w którym
większość stanowią małżeństwa, w naszej próbie jest ich 61,09%. Najmniejszy udział
mają osoby w separacji i będące w nieformalnym związku, odpowiednio 0,52% i
0,65%. Na potrzeby estymacji zmienna została podzielona na zmienne zerojedynkowe:
� stan_cyw_1
0 – gdy respondent jest stanu innego niż wolny
1 – gdy respondent jest stanu wolnego
� stan_cyw_2
0 – gdy respondent nie jest w związku małżeńskim
1 – gdy respondent jest w związku małżeńskim
� stan_cyw_3
0 – gdy respondent nie jest wdowcem lub wdową
1 – gdy respondent jest wdowcem lub wdową
� stan_cyw_4
0 – gdy respondent nie jest rozwiedziony
1 – gdy respondent jest rozwiedziony
� stan_cyw_5
0 – gdy respondent nie znajduje się w separacji
1 – gdy respondent jest w separacji
� stan_cyw_6
0 – gdy respondent nie znajduje się w nieformalnym związku
1 – gdy respondent jest w nieformalnym związku
12
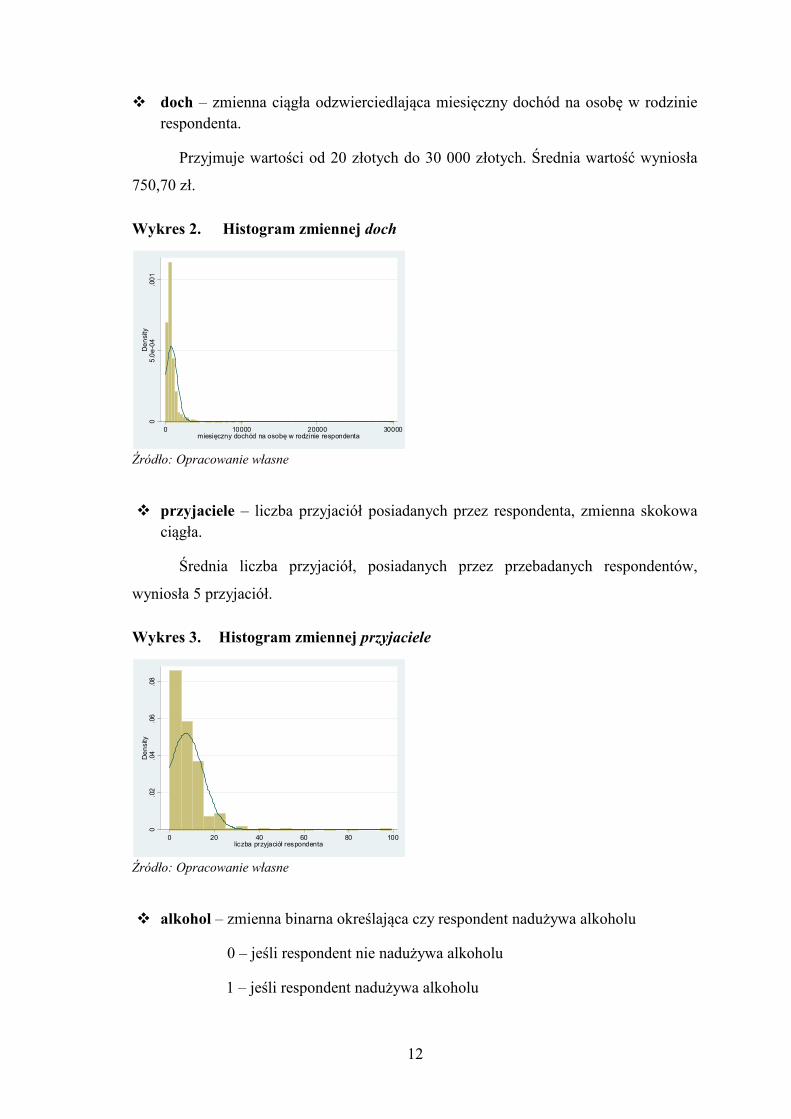
� doch – zmienna ciągła odzwierciedlająca miesięczny dochód na osobę w rodzinie respondenta.
Przyjmuje wartości od 20 złotych do 30 000 złotych. Średnia wartość wyniosła
750,70 zł.
Wykres 2. Histogram zmiennej doch
05
.0e
-04
.00
1D
en
sity
0 10000 20000 30000miesięczny dochód na osobę w rodzinie respondenta
Źródło: Opracowanie własne
� przyjaciele – liczba przyjaciół posiadanych przez respondenta, zmienna skokowa
ciągła.
Średnia liczba przyjaciół, posiadanych przez przebadanych respondentów,
wyniosła 5 przyjaciół.
Wykres 3. Histogram zmiennej przyjaciele
0.0
2.0
4.0
6.0
8D
en
sity
0 20 40 60 80 100liczba przyjaciół respondenta
Źródło: Opracowanie własne
� alkohol – zmienna binarna określająca czy respondent nadużywa alkoholu
0 – jeśli respondent nie nadużywa alkoholu
1 – jeśli respondent nadużywa alkoholu

13
Tabela 3. Charakterystyka zmiennej alkohol
naduŜywanie | alkoholu | Freq. Percent Cum. ------------+----------------------------------- nie | 5,776 93.83 93.83 tak | 380 6.17 100.00 ------------+----------------------------------- Total | 6,156 100.00
Źródło: Opracowanie własne
W badanej próbie 6,17% osób przyznało się, że zdarza się im nadużywać
alkoholu.
� bezrobocie – zm. binarna odzwierciedlająca fakt czy respondent jest bezrobotny
0 – jeśli respondent nie jest bezrobotny
1 – jeśli respondent jest bezrobotny
Tabela 4. Charakterystyka zmiennej bezrobocie
bycie na | bezrobociu | Freq. Percent Cum. ------------+----------------------------------- tak | 664 10.79 10.79 nie | 5,492 89.21 100.00 ------------+----------------------------------- Total | 6,156 100.00
Źródło: Opracowanie własne.
Wśród ankietowanych, blisko co dziesiąta osoba była bezrobotna.
� plec – zmienna binarna kodująca płeć respondenta, przyjmuje wartości:
0 – jeśli respondent jest mężczyzną
1 – jeśli respondent jest kobietą
Tabela 5. Charakterystyka zmiennej plec
płeć | respondenta | Freq. Percent Cum. ------------+----------------------------------- męŜczyzna | 2,882 46.82 46.82 kobieta | 3,274 53.18 100.00 ------------+----------------------------------- Total | 6,156 100.00
Źródło: Opracowanie własne.
47% badanej próby stanowili mężczyźni, kobiety – 53%.
� wyksz – zmienna binarna przedstawiająca poziom wykształcenia respondenta:

14
1 – podstawowe
2 – zawodowe
3 – średnie
4 – wyższe
Tabela 6. Charakterystyka zmiennej wyksz
wykształcen | ie | respondenta | Freq. Percent Cum. ------------+----------------------------------- podstawowe | 1,677 27.24 27.24 zawodowe | 1,651 26.82 54.06 średnie | 2,119 34.42 88.48 wyŜsze | 709 11.52 100.00 ------------+----------------------------------- Total | 6,156 100.00
Źródło: Opracowanie własne
Na potrzeby estymacji zmienna wyksz została podzielona na zmienne
zerojedynkowe:
� wyksz_1
0 – gdy respondent ma wykształcenie inne niż podstawowe
1 – gdy respondent ma wykształcenie podstawowe
� wyksz_2
0 – gdy respondent ma wykształcenie inne niż zawodowe
1 – gdy respondent ma wykształcenie zawodowe
� wyksz_3
0 – gdy respondent ma wykształcenie inne niż średnie
1 – gdy respondent ma wykształcenie średnie
� wyksz_4
0 – gdy respondent ma wykształcenie inne niż wyższe
1 – gdy respondent ma wyższe wykształcenie

15
� rel – zmienna binarna kodująca częstotliwość brania udziału w nabożeństwach lub innych spotkaniach o charakterze religijnym; przyjmowała następujące poziomy:
0 – 0 razy w miesiącu
1 – 1-3 razy w miesiącu
4 – 4 razy w miesiącu
5 – 5 i więcej razy w miesiącu
Tabela 7. Charakterystyka zmiennej rel
ile razy w | miesiącu | bierze | respondent | udział w | naboŜeństwa | ch lub | innych spot | Freq. Percent Cum. ------------+----------------------------------- 0 | 1,890 30.70 30.70 1 | 1,374 22.32 53.02 4 | 2,031 32.99 86.01 5 | 861 13.99 100.00 ------------+----------------------------------- Total | 6,156 100.00
Źródło: Opracowanie własne
Wśród przebadanych respondentów ok. 33% zadeklarowało, że 4 razy w
miesiącu uczestniczy w nabożeństwach lub innych spotkaniach o charakterze
religijnym. 30,7% osób odpowiedziało, że są niepraktykujący. W spotkaniach
religijnych i nabożeństwach sporadycznie (od 1 do 3 razy w miesiącu) bierze udział
22,32%, natomiast ok. 14% respondentów chodzi na nie częściej niż 4 razy w miesiącu.
Na potrzeby estymacji zmienna rel została podzielona na następujące zmienne
zerojedynkowe:
� rel_0
0 – gdy respondent bierze udział nabożeństwach lub innych spotkaniach
o charakterze religijnym
1 – gdy respondent nie bierze udziału w praktykach religijnych
� rel_1
0 – gdy respondent nie bierze udziału w nabożeństwach lub uczestniczy
w nich częściej niż 3 razy w miesiącu
1 – gdy respondent bierze udział w nabożeństwach 1-3 razy w miesiącu

16
� rel_4
0 – gdy respondent nie uczestniczy w nabożeństwach i innych
spotkaniach religijnych równo 4 razy w miesiącu
1 – gdy respondent bierze udział w nabożeństwach lub innych
spotkaniach religijnych 4 razy w miesiącu
� rel_5
0 – gdy respondent nie bierze udziału w nabożeństwach lub uczestniczy
w nich rzadziej niż 5 razy w miesiącu
1 – gdy respondent bierze udział w nabożeństwach lub innych spotkaniach religijnych częściej niż 4 razy w miesiącu
3. Oszacowanie modelu
3.1. Zastosowanie Liniowego Modelu Prawdopodobieństwa
W tym podrozdziale zostanie przedstawiony najprostszy model - Liniowy Model
Prawdopodobieństwa (LMP). Przy pomocy komendy „reg” wyestymowano na początku
następujący model MNK:
Wykres 4. Wynik regresji LMP
. xi: reg depr wiek i.stan_cyw doch przyjaciele i.alkohol i.bezrobocie i.plec i.wyksz i.rel Source | SS df MS Number of obs = 6156 -------------+------------------------------ F( 17, 6138) = 134.85 Model | 336.188156 17 19.7757739 Prob > F = 0.0000 Residual | 900.143715 6138 .14665098 R-squared = 0.2719 -------------+------------------------------ Adj R-squared = 0.2699 Total | 1236.33187 6155 .200866267 Root MSE = .38295 ------------------------------------------------------------------------------ depr | Coef. Std. Err. t P>|t| [95% Conf. Interval] -------------+---------------------------------------------------------------- wiek | .0116001 .0004017 28.88 0.000 .0108127 .0123875 _Istan_cyw_2 | -.0371383 .0150273 -2.47 0.013 -.066597 -.0076796 _Istan_cyw_3 | .0697246 .0250222 2.79 0.005 .0206724 .1187769 _Istan_cyw_4 | .0380776 .0313313 1.22 0.224 -.0233427 .0994979 _Istan_cyw_5 | .1686013 .0690574 2.44 0.015 .0332245 .303978 _Istan_cyw_6 | -.1095719 .0616679 -1.78 0.076 -.2304626 .0113189 doch | -.0000178 6.94e-06 -2.57 0.010 -.0000314 -4.24e-06 przyjaciele | -.0024106 .0006421 -3.75 0.000 -.0036693 -.0011519 _Ialkohol_2 | .0902827 .0209022 4.32 0.000 .0493071 .1312583 _Ibezroboc~2 | .0068198 .0161997 0.42 0.674 -.0249373 .0385769 _Iplec_2 | .1007329 .0104886 9.60 0.000 .0801717 .1212941 _Iwyksz_2 | -.1049716 .0140461 -7.47 0.000 -.1325068 -.0774364 _Iwyksz_3 | -.1417181 .0130964 -10.82 0.000 -.1673917 -.1160445 _Iwyksz_4 | -.1684441 .0179007 -9.41 0.000 -.2035358 -.1333524 _Irel_1 | -.0002943 .0136977 -0.02 0.983 -.0271465 .0265579 _Irel_4 | -.0293169 .0125883 -2.33 0.020 -.0539944 -.0046395 _Irel_5 | -.0185403 .0162158 -1.14 0.253 -.050329 .0132483 _cons | -.1549484 .0232224 -6.67 0.000 -.2004725 -.1094243 ------------------------------------------------------------------------------
Źródło: Opracowanie własne
17
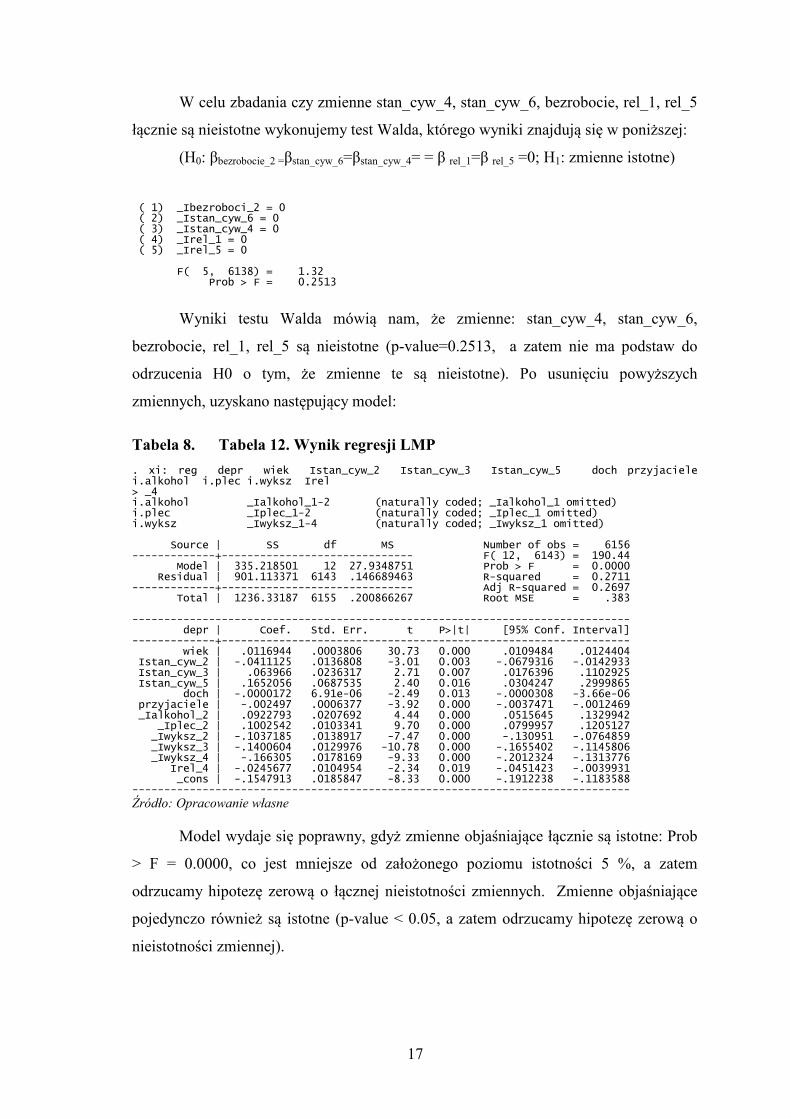
W celu zbadania czy zmienne stan_cyw_4, stan_cyw_6, bezrobocie, rel_1, rel_5
łącznie są nieistotne wykonujemy test Walda, którego wyniki znajdują się w poniższej:
(H0: βbezrobocie_2 =βstan_cyw_6=βstan_cyw_4= = β rel_1=β rel_5 =0; H1: zmienne istotne)
( 1) _Ibezroboci_2 = 0 ( 2) _Istan_cyw_6 = 0 ( 3) _Istan_cyw_4 = 0 ( 4) _Irel_1 = 0 ( 5) _Irel_5 = 0 F( 5, 6138) = 1.32 Prob > F = 0.2513
Wyniki testu Walda mówią nam, że zmienne: stan_cyw_4, stan_cyw_6,
bezrobocie, rel_1, rel_5 są nieistotne (p-value=0.2513, a zatem nie ma podstaw do
odrzucenia H0 o tym, że zmienne te są nieistotne). Po usunięciu powyższych
zmiennych, uzyskano następujący model:
Tabela 8. Tabela 12. Wynik regresji LMP
. xi: reg depr wiek Istan_cyw_2 Istan_cyw_3 Istan_cyw_5 doch przyjaciele i.alkohol i.plec i.wyksz Irel > _4 i.alkohol _Ialkohol_1-2 (naturally coded; _Ialkohol_1 omitted) i.plec _Iplec_1-2 (naturally coded; _Iplec_1 omitted) i.wyksz _Iwyksz_1-4 (naturally coded; _Iwyksz_1 omitted) Source | SS df MS Number of obs = 6156 -------------+------------------------------ F( 12, 6143) = 190.44 Model | 335.218501 12 27.9348751 Prob > F = 0.0000 Residual | 901.113371 6143 .146689463 R-squared = 0.2711 -------------+------------------------------ Adj R-squared = 0.2697 Total | 1236.33187 6155 .200866267 Root MSE = .383 ------------------------------------------------------------------------------ depr | Coef. Std. Err. t P>|t| [95% Conf. Interval] -------------+---------------------------------------------------------------- wiek | .0116944 .0003806 30.73 0.000 .0109484 .0124404 Istan_cyw_2 | -.0411125 .0136808 -3.01 0.003 -.0679316 -.0142933 Istan_cyw_3 | .063966 .0236317 2.71 0.007 .0176396 .1102925 Istan_cyw_5 | .1652056 .0687535 2.40 0.016 .0304247 .2999865 doch | -.0000172 6.91e-06 -2.49 0.013 -.0000308 -3.66e-06 przyjaciele | -.002497 .0006377 -3.92 0.000 -.0037471 -.0012469 _Ialkohol_2 | .0922793 .0207692 4.44 0.000 .0515645 .1329942 _Iplec_2 | .1002542 .0103341 9.70 0.000 .0799957 .1205127 _Iwyksz_2 | -.1037185 .0138917 -7.47 0.000 -.130951 -.0764859 _Iwyksz_3 | -.1400604 .0129976 -10.78 0.000 -.1655402 -.1145806 _Iwyksz_4 | -.166305 .0178169 -9.33 0.000 -.2012324 -.1313776 Irel_4 | -.0245677 .0104954 -2.34 0.019 -.0451423 -.0039931 _cons | -.1547913 .0185847 -8.33 0.000 -.1912238 -.1183588 ------------------------------------------------------------------------------
Źródło: Opracowanie własne
Model wydaje się poprawny, gdyż zmienne objaśniające łącznie są istotne: Prob
> F = 0.0000, co jest mniejsze od założonego poziomu istotności 5 %, a zatem
odrzucamy hipotezę zerową o łącznej nieistotności zmiennych. Zmienne objaśniające
pojedynczo również są istotne (p-value < 0.05, a zatem odrzucamy hipotezę zerową o
nieistotności zmiennej).

18
Jednak z LMP wiąże się występowanie dwóch wad: heteroskedastyczność
składnika losowego oraz brak gwarancji, że prawdopodobieństwo wystąpienia wartości
dopasowanych znajdzie się w przedziale [0,1].
Homoskedastyczność składnika losowego zbadano za pomocą testu Breuscha-
Pagana, którego wyniki zamieszczono poniżej.
H0: Var (εi) = σ2 (składnik losowy jest homoskedastyczny)
H1: Var (εi) = σ2 (składnik losowy jest heteroskedastyczny)
. hettest Breusch-Pagan / Cook-Weisberg test for heteroskedasticity Ho: Constant variance Variables: fitted values of depr chi2(1) = 373.63 Prob > chi2 = 0.0000
Ponieważ Prob > chi2 = 0.0000 więc jest mniejsze niż zadany poziom
istotności 5 %, a zatem odrzucamy hipotezę zerową o homoskedastyczności.
Przeprowadzona analiza potwierdziła występowanie w modelu heteroskedastyczności.
Drugą wadę sprawdzono poprzez użycie komendy „sum yhat”, gdzie yhat to
wartości dopasowane i otrzymano:
Tabela 9. Wartości dopasowane w LPM
sum yhat
Variable | Obs Mean Std. Dev. Min Max -------------+-------------------------------------------------------- yhat | 6156 .2782651 .2333727 -.2531153 1.080731
Źródło: Opracowanie własne
Dwie ostatnie wartości z powyższej tabeli wskazują na występowanie w LMP
również drugiej wady – prawdopodobieństwo wystąpienia wartości dopasowanych
należy do przedziału [-0,25;1,08]. W estymacji wystąpiło 14 przypadków, w których
wartość dopasowana była większa od 1 i 515 przypadków gdzie była mniejsza od 0.
Wartości dopasowanych spoza przedziału [0,1] nie da się zinterpretować, gdyż
prawdopodobieństwo nie może być mniejsze od 0 lub większe od 1.
Heteroskedastyczność składnika losowego, powoduje, iż otrzymane statystyki testowe
są nieprawidłowe i nie możliwe jest dokonanie wnioskowania statystycznego.
Otrzymane wyniki jednoznacznie wykluczają Liniowy Model Prawdopodobieństwa.

19
3.2. Estymacja modelu logit i probit
Decyzja związana z odrzuceniem Liniowego Modelu Prawdopodobieństwa
skłania do wybrania pomiędzy modelem logit a probit. Estymowaliśmy kilkakrotnie
modele logit, a następnie probit tak aby wyeliminować nieistotne zmienne objaśniające.
Następnie dokonaliśmy diagnostyki i interpretacji miar dopasowania. Przebieg naszej
pracy został przedstawiony w dalszej części tego rozdziału.
3.2.1. Model logit - wybór zmiennych do modelu
Na początku dokonaliśmy regresji modelu logit wykorzystując wszystkie
zaproponowane przez nas zmienne objaśniające. Model ten nazwaliśmy logit bez
ograniczeń.
Tabela 10. Regresja modelu logit bez ograniczeń
xi: logit depr wiek i.stan_cyw doch przyjaciele i.alkohol i.bezrobocie i.plec i.wyksz i.rel Logistic regression Number of obs = 6156 LR chi2(17) = 1786.57 Prob > chi2 = 0.0000 Log likelihood = -2746.8015 Pseudo R2 = 0.2454 ------------------------------------------------------------------------------ depr | Coef. Std. Err. z P>|z| [95% Conf. Interval] -------------+---------------------------------------------------------------- wiek | .0694981 .0029201 23.80 0.000 .0637747 .0752214 _Istan_cyw_2 | .1438785 .1201006 1.20 0.231 -.0915143 .3792713 _Istan_cyw_3 | .4985071 .1661469 3.00 0.003 .1728652 .8241489 _Istan_cyw_4 | .5177468 .1975176 2.62 0.009 .1306194 .9048743 _Istan_cyw_5 | 1.224789 .4126733 2.97 0.003 .4159638 2.033613 _Istan_cyw_6 | -.6266812 .563972 -1.11 0.266 -1.732046 .4786836 doch | -.0001048 .0000466 -2.25 0.025 -.0001962 -.0000135 przyjaciele | -.0200326 .0050499 -3.97 0.000 -.0299301 -.010135 _Ialkohol_2 | .6873934 .1361221 5.05 0.000 .420599 .9541879 _Ibezroboc~2 | -.0112905 .1178981 -0.10 0.924 -.2423665 .2197855 _Iplec_2 | .7381142 .0747627 9.87 0.000 .591582 .8846463 _Iwyksz_2 | -.4176098 .0928009 -4.50 0.000 -.5994963 -.2357233 _Iwyksz_3 | -.7679063 .0893872 -8.59 0.000 -.9431019 -.5927107 _Iwyksz_4 | -.9020616 .1268686 -7.11 0.000 -1.150719 -.6534038 _Irel_1 | -.0193804 .0955842 -0.20 0.839 -.206722 .1679611 _Irel_4 | -.2246684 .0876977 -2.56 0.010 -.3965527 -.0527842 _Irel_5 | -.1631553 .1110885 -1.47 0.142 -.3808848 .0545741 _cons | -4.19559 .1854769 -22.62 0.000 -4.559118 -3.832062 ------------------------------------------------------------------------------
Źródło: Opracowanie własne
Wśród estymowanych zmiennych uwagę zwróciły zmienne nieistotne:
stan_cyw_2, stan_cyw_6, bezrobocie, rel_1, rel_5. W celu zweryfikowania ich
istotności za pomocą odpowiednich testów, dokonaliśmy regresji modelu logit z
ograniczeniami - bez zmiennych stan_cyw_2, stan_cyw_6, bezrobocie, rel_1, rel_5.
20
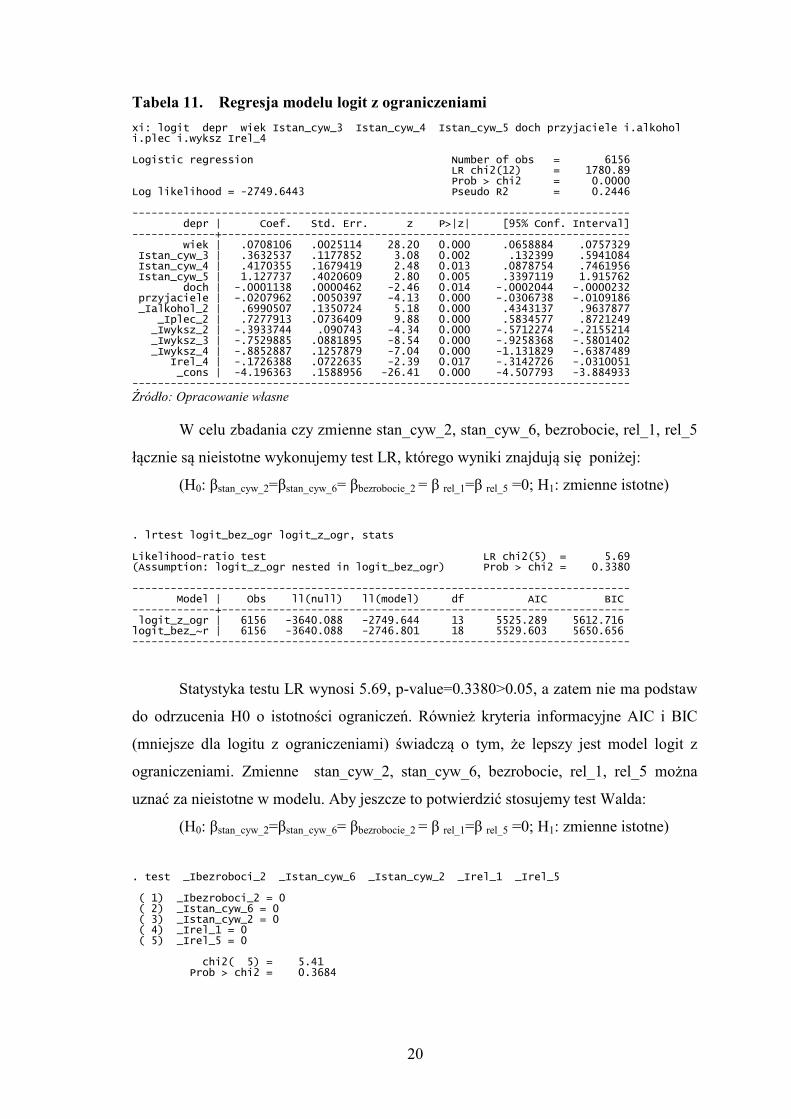
Tabela 11. Regresja modelu logit z ograniczeniami
xi: logit depr wiek Istan_cyw_3 Istan_cyw_4 Istan_cyw_5 doch przyjaciele i.alkohol i.plec i.wyksz Irel_4 Logistic regression Number of obs = 6156 LR chi2(12) = 1780.89 Prob > chi2 = 0.0000 Log likelihood = -2749.6443 Pseudo R2 = 0.2446 ------------------------------------------------------------------------------ depr | Coef. Std. Err. z P>|z| [95% Conf. Interval] -------------+---------------------------------------------------------------- wiek | .0708106 .0025114 28.20 0.000 .0658884 .0757329 Istan_cyw_3 | .3632537 .1177852 3.08 0.002 .132399 .5941084 Istan_cyw_4 | .4170355 .1679419 2.48 0.013 .0878754 .7461956 Istan_cyw_5 | 1.127737 .4020609 2.80 0.005 .3397119 1.915762 doch | -.0001138 .0000462 -2.46 0.014 -.0002044 -.0000232 przyjaciele | -.0207962 .0050397 -4.13 0.000 -.0306738 -.0109186 _Ialkohol_2 | .6990507 .1350724 5.18 0.000 .4343137 .9637877 _Iplec_2 | .7277913 .0736409 9.88 0.000 .5834577 .8721249 _Iwyksz_2 | -.3933744 .090743 -4.34 0.000 -.5712274 -.2155214 _Iwyksz_3 | -.7529885 .0881895 -8.54 0.000 -.9258368 -.5801402 _Iwyksz_4 | -.8852887 .1257879 -7.04 0.000 -1.131829 -.6387489 Irel_4 | -.1726388 .0722635 -2.39 0.017 -.3142726 -.0310051 _cons | -4.196363 .1588956 -26.41 0.000 -4.507793 -3.884933 ------------------------------------------------------------------------------
Źródło: Opracowanie własne
W celu zbadania czy zmienne stan_cyw_2, stan_cyw_6, bezrobocie, rel_1, rel_5
łącznie są nieistotne wykonujemy test LR, którego wyniki znajdują się poniżej:
(H0: βstan_cyw_2=βstan_cyw_6= βbezrobocie_2 = β rel_1=β rel_5 =0; H1: zmienne istotne)
. lrtest logit_bez_ogr logit_z_ogr, stats Likelihood-ratio test LR chi2(5) = 5.69 (Assumption: logit_z_ogr nested in logit_bez_ogr) Prob > chi2 = 0.3380 ------------------------------------------------------------------------------ Model | Obs ll(null) ll(model) df AIC BIC -------------+---------------------------------------------------------------- logit_z_ogr | 6156 -3640.088 -2749.644 13 5525.289 5612.716 logit_bez_~r | 6156 -3640.088 -2746.801 18 5529.603 5650.656 ------------------------------------------------------------------------------
Statystyka testu LR wynosi 5.69, p-value=0.3380>0.05, a zatem nie ma podstaw
do odrzucenia H0 o istotności ograniczeń. Również kryteria informacyjne AIC i BIC
(mniejsze dla logitu z ograniczeniami) świadczą o tym, że lepszy jest model logit z
ograniczeniami. Zmienne stan_cyw_2, stan_cyw_6, bezrobocie, rel_1, rel_5 można
uznać za nieistotne w modelu. Aby jeszcze to potwierdzić stosujemy test Walda:
(H0: βstan_cyw_2=βstan_cyw_6= βbezrobocie_2 = β rel_1=β rel_5 =0; H1: zmienne istotne)
. test _Ibezroboci_2 _Istan_cyw_6 _Istan_cyw_2 _Irel_1 _Irel_5 ( 1) _Ibezroboci_2 = 0 ( 2) _Istan_cyw_6 = 0 ( 3) _Istan_cyw_2 = 0 ( 4) _Irel_1 = 0 ( 5) _Irel_5 = 0 chi2( 5) = 5.41 Prob > chi2 = 0.3684

21
Również test Walda mówi, że zmienne stan_cyw_2, stan_cyw_6, bezrobocie,
rel_1, rel_5 są nieistotne (p-value=0.3684, a zatem nie ma podstaw do odrzucenia H0 o
tym, że zmienne te są nieistotne). Przyjmujemy więc do dalszej analizy model bez tych
zmiennych. W modelu tym łącznie wszystkie zmienne objaśniające są istotne
(statystyka LR chi2 = 1780.89, Prob > chi2 = 0.0000 jest mniejsze niż zadany poziom
istotności α = 0.05, a zatem odrzucamy H0 o łącznej nieistotności zm. objaśniających).
3.2.2. Diagnostyka i testy modelu logit
• Test typu związku (linktest)
Przed przystąpieniem do weryfikacji hipotez należy sprawdzić czy przyjęty
model jest prawidłowo wyspecyfikowany. W tym celu przeprowadzono test typu
związku, który jest uogólnieniem testu RESET. Wyniki prezentuje poniższa tabela:
Tabela 12. Test typu związku
. linktest Logistic regression Number of obs = 6156 LR chi2(2) = 1780.95 Prob > chi2 = 0.0000 Log likelihood = -2749.6116 Pseudo R2 = 0.2446 ------------------------------------------------------------------------------ depr | Coef. Std. Err. z P>|z| [95% Conf. Interval] -------------+---------------------------------------------------------------- _hat | .9934854 .0385394 25.78 0.000 .9179495 1.069021 _hatsq | -.0046166 .0180399 -0.26 0.798 -.0399741 .0307409 _cons | .0038601 .0427348 0.09 0.928 -.0798986 .0876187
Źródło: Opracowanie własne
Jak widać zmienna hatsq jest nieistotna (p-value=0.798>0.05, nie mamy
podstaw do odrzucenia H0 o nieistotności zmiennej hatsq). Wskazywało by to, iż dla
wartości dopasowanych ważne są ich pierwsze a nie wyższe potęgi, a zatem mamy do
czynienia z prawidłową postacią modelu.
Wykonano również, znajdujące się poniżej, testy Pearsona i Hosmera –
Lemeshow’a, na poprawność formy funkcyjnej, w których:
H0: zastosowana forma funkcyjna jest prawidłowa
H1: zastosowana forma funkcyjna nie jest prawidłowa

22
• Test jakości dopasowania Pearsona (goodness of fit test)
Tabela 13. Wynik testu Pearsona
. estat gof Logistic model for depr, goodness-of-fit test number of observations = 6156 number of covariate patterns = 6105 Pearson chi2(6092) = 6286.71 Prob > chi2 = 0.0399
Źródło: Opracowanie własne
• Test wersja Hosmera-Lemeshow'a - dzielimy na 10 podprób według decyli
wartości dopasowanych:
Tabela 14. Wynik testu Hosmera – Lemeshow’a.
. estat gof , group(10) table /*H0: poprawna forma funkcyjna*/ Logistic model for depr, goodness-of-fit test
(Table collapsed on quantiles of estimated probabilities) +--------------------------------------------------------+ | Group | Prob | Obs_1 | Exp_1 | Obs_0 | Exp_0 | Total | |-------+--------+-------+-------+-------+-------+-------| | 1 | 0.0449 | 24 | 20.4 | 592 | 595.6 | 616 | | 2 | 0.0678 | 40 | 34.2 | 576 | 581.8 | 616 | | 3 | 0.0968 | 52 | 50.4 | 563 | 564.6 | 615 | | 4 | 0.1458 | 57 | 74.2 | 559 | 541.8 | 616 | | 5 | 0.2034 | 98 | 107.0 | 517 | 508.0 | 615 | |-------+--------+-------+-------+-------+-------+-------| | 6 | 0.2688 | 140 | 145.0 | 476 | 471.0 | 616 | | 7 | 0.3557 | 200 | 191.8 | 416 | 424.2 | 616 | | 8 | 0.4764 | 260 | 252.2 | 355 | 362.8 | 615 | | 9 | 0.6672 | 353 | 346.0 | 263 | 270.0 | 616 | | 10 | 0.9659 | 489 | 491.8 | 126 | 123.2 | 615 | +--------------------------------------------------------+ number of observations = 6156 number of groups = 10 Hosmer-Lemeshow chi2(8) = 8.73 Prob > chi2 = 0.3660
Źródło: Opracowanie własne
W teście Pearsona chi2(6092) = 6286.71, p-value = 0.0399< 0.05, który jest
wartością zadanego poziomu istotności, zatem odrzucamy hipotezę zerową wskazującą
na poprawność formy funkcyjnej. Gdybyśmy jednak przyjęli istotność na poziomie 0.01
(p-value = 0.0399> 0.01) to nie mielibyśmy podstaw do odrzucenie H0 o poprawności
funkcyjnej modelu.

23
Wyniki testu Hausmana – Lemeshow’a, to: chi2(7) = 8.73, a p-value = 0.3660 >
0.05 (zadany poziom istotności), zatem w tym teście nie odrzucamy hipotezy zerowej,
wskazującej na poprawność formy funkcyjnej.
W związku z tym, że użyta tu wersja testu Pearsona charakteryzuje się małą
mocą (w szczególności, jeśli podpróby są mało liczne; tak jest w naszym przypadku)
możemy zaufać pozostałym testom - Hausmana – Lemeshow’a i uogólnionemu testowi
RESET, które potwierdziły, iż przyjęta forma funkcyjna jest prawidłowa i model został
odpowiednio wyspecyfikowany.
3.2.3. Analiza dopasowania
W tym miejscu należałoby przyjrzeć się bliżej wskaźnikom determinacji.
• Miary dopasowania
Tabela 15. Miary dopasowania modelu logit
. fitstat Measures of Fit for logit of depr Log-Lik Intercept Only: -3640.088 Log-Lik Full Model: -2749.644 D(6143): 5499.289 LR(12): 1780.887 Prob > LR: 0.000 McFadden's R2: 0.245 McFadden's Adj R2: 0.241 Maximum Likelihood R2: 1.000 Cragg & Uhler's R2: 1.000 McKelvey and Zavoina's R2: 0.384 Efron's R2: 0.286 Variance of y*: 5.337 Variance of error: 3.290 Count R2: 0.795 Adj Count R2: 0.264 AIC: 0.898 AIC*n: 5525.289 BIC: -48099.507 BIC': -1676.185
Źródło: Opracowanie własne
Uzyskany model dla zmiennej ukrytej yi* byłby wyjaśniany w 38,4%, gdyby zmienna ta
była bezpośrednio obserwowalna (pseudo R² McKelvey-Zavoina=0.384). Model
prawidłowo przewiduje sukcesy i porażki w 79,5% przypadków (R²
liczebnościowe=0.795). Dzięki użyciu w zmiennych objaśniających model prawidłowo
przewiduje sukcesy i porażki w 26,4% przypadków (skorygowane liczebnościowe
R²=0.264).
Kolejnym analizowanym elementem jest wrażliwość i specyficzność modelu.
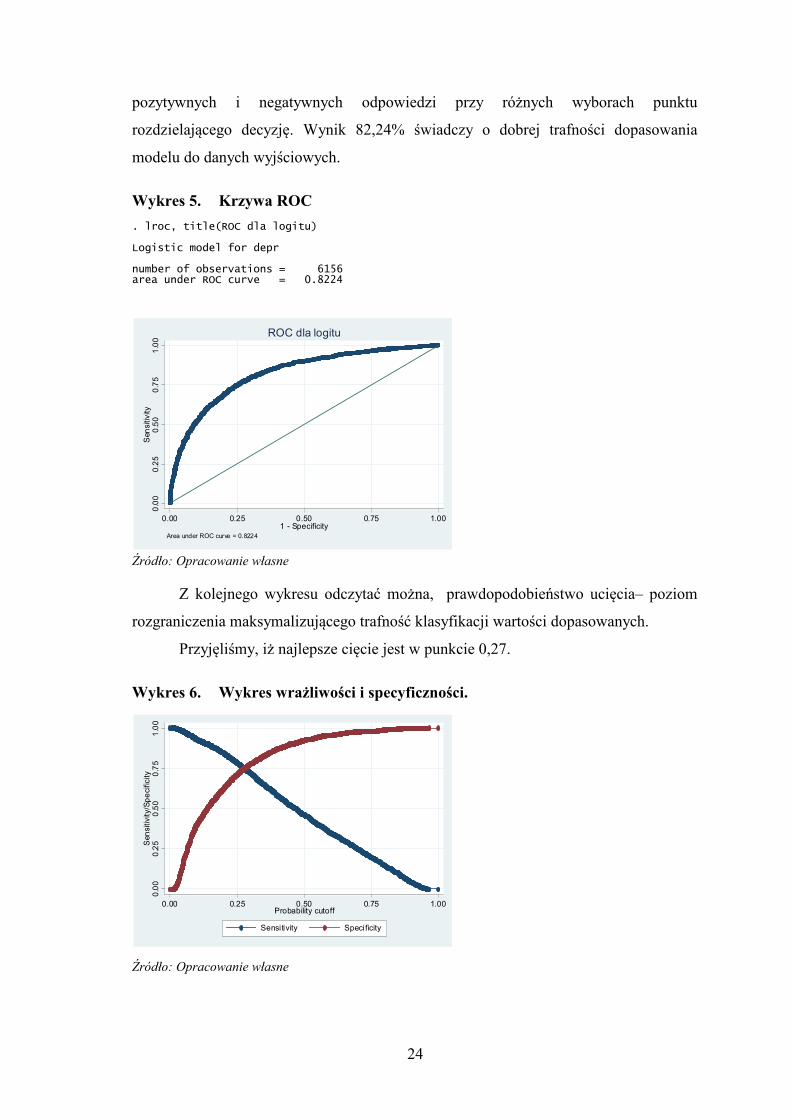
• Wrażliwość i specyficzność
Im lepiej model przewiduje, tym bardziej krzywa ROC odgięta jest w kierunku
górnego rogu rysunku. Pole pod krzywą używane jest jako miara jakości dopasowania
modelu. U nas wynosi ono 0,8224 (max 1). Jest to procent dobrze zakwalifikowanych
24
pozytywnych i negatywnych odpowiedzi przy różnych wyborach punktu
rozdzielającego decyzję. Wynik 82,24% świadczy o dobrej trafności dopasowania
modelu do danych wyjściowych.
Wykres 5. Krzywa ROC
. lroc, title(ROC dla logitu) Logistic model for depr number of observations = 6156 area under ROC curve = 0.8224
0.0
00
.25
0.5
00
.75
1.0
0S
en
sitiv
ity
0.00 0.25 0.50 0.75 1.001 - Specificity
Area under ROC curve = 0.8224
ROC dla logitu
Źródło: Opracowanie własne
Z kolejnego wykresu odczytać można, prawdopodobieństwo ucięcia– poziom
rozgraniczenia maksymalizującego trafność klasyfikacji wartości dopasowanych.
Przyjęliśmy, iż najlepsze cięcie jest w punkcie 0,27.
Wykres 6. Wykres wrażliwości i specyficzności.
0.0
00
.25
0.5
00
.75
1.0
0S
en
sitiv
ity/S
pe
cific
ity
0.00 0.25 0.50 0.75 1.00Probability cutoff
Sensitivity Specificity
Źródło: Opracowanie własne

25
Dla wyznaczonego prawdopodobieństwa cięcia wyznaczona zostały tabela
liczebności:
Tabela 16. Klasyfikacja modelu ( punkt odcięcia równy 0.27)
. lstat,cutoff(0.27) Logistic model for depr -------- True -------- Classified | D ~D | Total -----------+--------------------------+----------- + | 1300 1152 | 2452 - | 413 3291 | 3704 -----------+--------------------------+----------- Total | 1713 4443 | 6156 Classified + if predicted Pr(D) >= .27 True D defined as depr != 0 -------------------------------------------------- Sensitivity Pr( +| D) 75.89% Specificity Pr( -|~D) 74.07% Positive predictive value Pr( D| +) 53.02% Negative predictive value Pr(~D| -) 88.85% -------------------------------------------------- False + rate for true ~D Pr( +|~D) 25.93% False - rate for true D Pr( -| D) 24.11% False + rate for classified + Pr(~D| +) 46.98% False - rate for classified - Pr( D| -) 11.15% -------------------------------------------------- Correctly classified 74.58% --------------------------------------------------
Źródło: Opracowanie własne
Powyższa tabela pokazuje, że na 1713 obserwacji, w których u badanego
respondenta zaobserwowano objawy depresji, model prawidłowo przewidział 1300 z
nich, a tylko 413 osób (24,11 % liczebności grupy) zakwalifikował błędnie. Wrażliwość
wyniosła 75,89%, co znaczy że model prawidłowo przewidział 75,89% przypadków
depresji tam gdzie faktycznie była ona zaobserwowana. Specyficzność równa 74,07%
świadczy o tym, że wśród osób u których nie zaobserwowano depresji prawidłowo
zostało przewidziane 74,07% takich przypadków. Wśród 4443 ankietowanych, którzy
nie wykazywali depresji, 1152 osób (czyli 25,93%) zostało błędnie zdiagnozowanych.
Podsumowując, średnio 74,58 % wszystkich obserwacji zostało trafnie
zaklasyfikowanych.
3.2.4. Wybór zmiennych do modelu probit
Na początku dokonaliśmy regresji modelu probit wykorzystując wszystkie
zaproponowane przez nas zmienne objaśniające. Model ten nazwaliśmy probit bez
ograniczeń. Wyniki estymacji znajdują się w tabeli na następnej stronie.
26
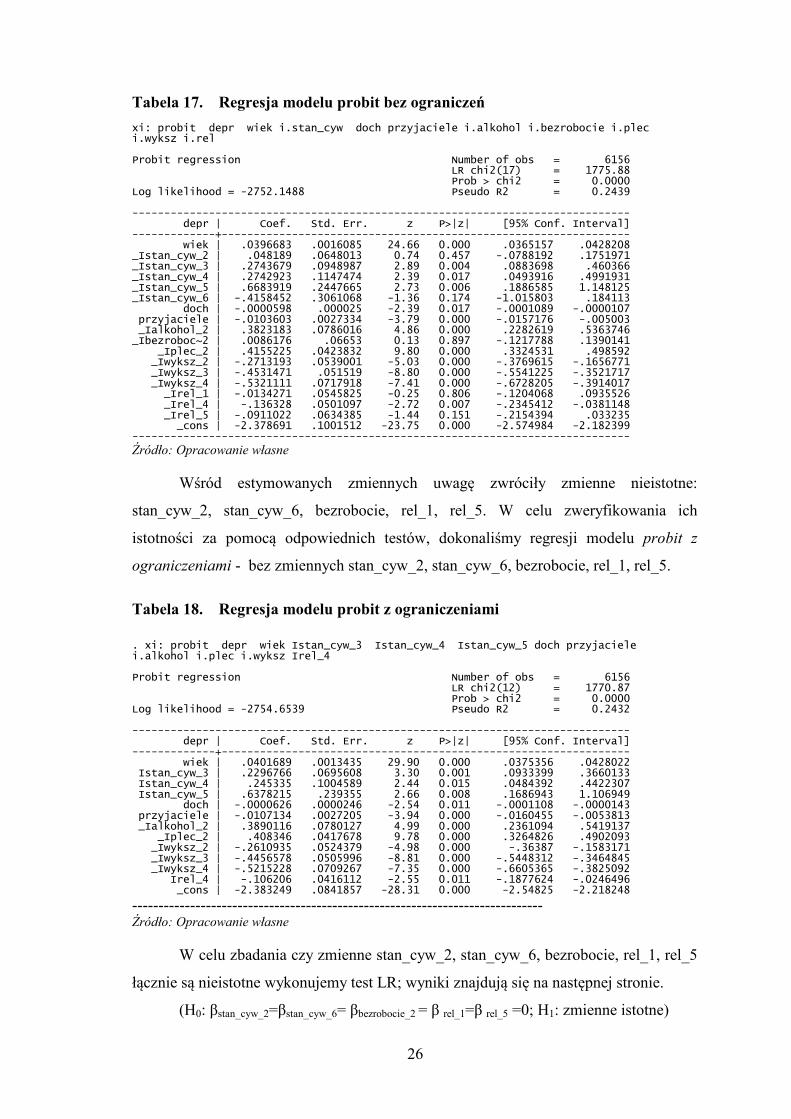
Tabela 17. Regresja modelu probit bez ograniczeń
xi: probit depr wiek i.stan_cyw doch przyjaciele i.alkohol i.bezrobocie i.plec i.wyksz i.rel Probit regression Number of obs = 6156 LR chi2(17) = 1775.88 Prob > chi2 = 0.0000 Log likelihood = -2752.1488 Pseudo R2 = 0.2439 ------------------------------------------------------------------------------ depr | Coef. Std. Err. z P>|z| [95% Conf. Interval] -------------+---------------------------------------------------------------- wiek | .0396683 .0016085 24.66 0.000 .0365157 .0428208 _Istan_cyw_2 | .048189 .0648013 0.74 0.457 -.0788192 .1751971 _Istan_cyw_3 | .2743679 .0948987 2.89 0.004 .0883698 .460366 _Istan_cyw_4 | .2742923 .1147474 2.39 0.017 .0493916 .4991931 _Istan_cyw_5 | .6683919 .2447665 2.73 0.006 .1886585 1.148125 _Istan_cyw_6 | -.4158452 .3061068 -1.36 0.174 -1.015803 .184113 doch | -.0000598 .000025 -2.39 0.017 -.0001089 -.0000107 przyjaciele | -.0103603 .0027334 -3.79 0.000 -.0157176 -.005003 _Ialkohol_2 | .3823183 .0786016 4.86 0.000 .2282619 .5363746 _Ibezroboc~2 | .0086176 .06653 0.13 0.897 -.1217788 .1390141 _Iplec_2 | .4155225 .0423832 9.80 0.000 .3324531 .498592 _Iwyksz_2 | -.2713193 .0539001 -5.03 0.000 -.3769615 -.1656771 _Iwyksz_3 | -.4531471 .051519 -8.80 0.000 -.5541225 -.3521717 _Iwyksz_4 | -.5321111 .0717918 -7.41 0.000 -.6728205 -.3914017 _Irel_1 | -.0134271 .0545825 -0.25 0.806 -.1204068 .0935526 _Irel_4 | -.136328 .0501097 -2.72 0.007 -.2345412 -.0381148 _Irel_5 | -.0911022 .0634385 -1.44 0.151 -.2154394 .033235 _cons | -2.378691 .1001512 -23.75 0.000 -2.574984 -2.182399 ------------------------------------------------------------------------------
Źródło: Opracowanie własne
Wśród estymowanych zmiennych uwagę zwróciły zmienne nieistotne:
stan_cyw_2, stan_cyw_6, bezrobocie, rel_1, rel_5. W celu zweryfikowania ich
istotności za pomocą odpowiednich testów, dokonaliśmy regresji modelu probit z
ograniczeniami - bez zmiennych stan_cyw_2, stan_cyw_6, bezrobocie, rel_1, rel_5.
Tabela 18. Regresja modelu probit z ograniczeniami
. xi: probit depr wiek Istan_cyw_3 Istan_cyw_4 Istan_cyw_5 doch przyjaciele i.alkohol i.plec i.wyksz Irel_4 Probit regression Number of obs = 6156 LR chi2(12) = 1770.87 Prob > chi2 = 0.0000 Log likelihood = -2754.6539 Pseudo R2 = 0.2432 ------------------------------------------------------------------------------ depr | Coef. Std. Err. z P>|z| [95% Conf. Interval] -------------+---------------------------------------------------------------- wiek | .0401689 .0013435 29.90 0.000 .0375356 .0428022 Istan_cyw_3 | .2296766 .0695608 3.30 0.001 .0933399 .3660133 Istan_cyw_4 | .245335 .1004589 2.44 0.015 .0484392 .4422307 Istan_cyw_5 | .6378215 .239355 2.66 0.008 .1686943 1.106949 doch | -.0000626 .0000246 -2.54 0.011 -.0001108 -.0000143 przyjaciele | -.0107134 .0027205 -3.94 0.000 -.0160455 -.0053813 _Ialkohol_2 | .3890116 .0780127 4.99 0.000 .2361094 .5419137 _Iplec_2 | .408346 .0417678 9.78 0.000 .3264826 .4902093 _Iwyksz_2 | -.2610935 .0524379 -4.98 0.000 -.36387 -.1583171 _Iwyksz_3 | -.4456578 .0505996 -8.81 0.000 -.5448312 -.3464845 _Iwyksz_4 | -.5215228 .0709267 -7.35 0.000 -.6605365 -.3825092 Irel_4 | -.106206 .0416112 -2.55 0.011 -.1877624 -.0246496 _cons | -2.383249 .0841857 -28.31 0.000 -2.54825 -2.218248
------------------------------------------------------------------------------ Źródło: Opracowanie własne
W celu zbadania czy zmienne stan_cyw_2, stan_cyw_6, bezrobocie, rel_1, rel_5
łącznie są nieistotne wykonujemy test LR; wyniki znajdują się na następnej stronie.
(H0: βstan_cyw_2=βstan_cyw_6= βbezrobocie_2 = β rel_1=β rel_5 =0; H1: zmienne istotne)

27
Likelihood-ratio test LR chi2(5) = 5.01 (Assumption: probit_z_ogr nested in probit_bez_ogr) Prob > chi2 = 0.4146 ------------------------------------------------------------------------------ Model | Obs ll(null) ll(model) df AIC BIC -------------+---------------------------------------------------------------- probit_z_ogr | 6156 -3640.088 -2754.654 13 5535.308 5622.735 probit_bez~r | 6156 -3640.088 -2752.149 18 5540.298 5661.351 ------------------------------------------------------------------------------
Statystyka testu LR wynosi 5.01, p-value=0.4146>0.05, a zatem nie ma podstaw
do odrzucenia H0 o istotności ograniczeń. Również kryteria informacyjne AIC i BIC
(mniejsze dla probitu z ograniczeniami) świadczą o tym, że lepszy jest model probit z
ograniczeniami. Zmienne stan_cyw_2, stan_cyw_6, bezrobocie, rel_1, rel_5 można
uznać za nieistotne w modelu. Aby jeszcze to potwierdzić stosujemy test Walda:
(H0: βstan_cyw_2=βstan_cyw_6= βbezrobocie_2 = β rel_1=β rel_5 =0; H1: zmienne istotne) . test _Ibezroboci_2 _Istan_cyw_6 _Istan_cyw_2 _Irel_1 _Irel_5 ( 1) _Ibezroboci_2 = 0 ( 2) _Istan_cyw_6 = 0 ( 3) _Istan_cyw_2 = 0 ( 4) _Irel_1 = 0 ( 5) _Irel_5 = 0 chi2( 5) = 4.78 Prob > chi2 = 0.4430
Również test Walda mówi, że zmienne stan_cyw_2, stan_cyw_6, bezrobocie,
rel_1, rel_5 są nieistotne (p-value=0.4430>0.05, a zatem nie ma podstaw do odrzucenia
H0 o tym, że zmienne te są nieistotne). Do dalszych rozważań przyjmujemy więc model
probit z ograniczeniami. W modelu tym łącznie wszystkie zmienne objaśniające są
istotne (stat. LR chi2 = 1770.87, Prob > chi2 = 0 i jest mniejsze niż zadany poziom
istotności α = 0.05, a zatem odrzucamy H0 o łącznej nieistotności zm. objaśniających).
3.2.5. Diagnostyka i testy modelu probit
• Test typu związku (linktest)
Przed przystąpieniem do weryfikacji hipotez należy sprawdzić czy przyjęty
model jest prawidłowo wyspecyfikowany. W tym celu przeprowadzono test typu
związku, który jest uogólnieniem testu RESET. Wyniki prezentuje poniższa tabela:
Tabela 19. Test typu związku
. linktest Probit regression Number of obs = 6156 LR chi2(2) = 1771.77 Prob > chi2 = 0.0000 Log likelihood = -2754.2031 Pseudo R2 = 0.2434 ------------------------------------------------------------------------------ depr | Coef. Std. Err. z P>|z| [95% Conf. Interval] -------------+---------------------------------------------------------------- _hat | 1.023556 .0367176 27.88 0.000 .9515909 1.095521 _hatsq | .0265228 .0279438 0.95 0.343 -.028246 .0812917 _cons | -.0086776 .0255013 -0.34 0.734 -.0586592 .0413041
Źródło: Opracowanie własne

28
Jak widać zmienna hatsq jest nieistotna (p-value=0.343>0.05, nie mamy
podstaw do odrzucenia H0 o nieistotności zmiennej hatsq ), Wskazywało by to, iż dla
wartości dopasowanych ważne są ich pierwsze a nie wyższe potęgi, a zatem mamy do
czynienia z prawidłową postacią modelu.
Wykonano również, znajdujące się poniżej, testy Pearsona i Hosmera –
Lemeshow’a, na poprawność formy funkcyjnej, w których:
H0: zastosowana forma funkcyjna jest prawidłowa
H1: zastosowana forma funkcyjna nie jest prawidłowa
• Test jakości dopasowania Pearsona (goodness of fit test)
Tabela 20. Wynik testu Pearsona
. estat gof Probit model for depr, goodness-of-fit test number of observations = 6156 number of covariate patterns = 6105 Pearson chi2(6092) = 6469.60 Prob > chi2 = 0.0004
Źródło: Opracowanie własne
• Test wersja Hosmera-Lemeshow'a - dzielimy na 10 podprób według decyli
wartości dopasowanych:
Tabela 21. Wynik testu Hosmera – Lemeshow’a
estat gof , group(10) table Probit model for depr, goodness-of-fit test (Table collapsed on quantiles of estimated probabilities) +--------------------------------------------------------+ | Group | Prob | Obs_1 | Exp_1 | Obs_0 | Exp_0 | Total | |-------+--------+-------+-------+-------+-------+-------| | 1 | 0.0402 | 24 | 16.9 | 592 | 599.1 | 616 | | 2 | 0.0662 | 40 | 32.1 | 576 | 583.9 | 616 | | 3 | 0.0993 | 49 | 50.7 | 566 | 564.3 | 615 | | 4 | 0.1515 | 62 | 76.9 | 554 | 539.1 | 616 | | 5 | 0.2123 | 95 | 111.8 | 520 | 503.2 | 615 | |-------+--------+-------+-------+-------+-------+-------| | 6 | 0.2779 | 143 | 150.6 | 473 | 465.4 | 616 | | 7 | 0.3610 | 203 | 196.2 | 413 | 419.8 | 616 | | 8 | 0.4738 | 255 | 253.0 | 360 | 362.0 | 615 | | 9 | 0.6492 | 351 | 340.3 | 265 | 275.7 | 616 | | 10 | 0.9726 | 491 | 485.0 | 124 | 130.0 | 615 | +--------------------------------------------------------+ number of observations = 6156 number of groups = 10 Hosmer-Lemeshow chi2(8) = 13.57 Prob > chi2 = 0.0938
Źródło: Opracowanie własne
W teście Pearsona chi2(6092) = 6469.6, p-value = 0.0004< 0.05, który jest
wartością zadanego poziomu istotności, zatem odrzucamy hipotezę zerową wskazującą
na poprawność formy funkcyjnej.

29
Wyniki testu Hausmana – Lemeshow’a, to: chi2(8) = 13.57, a p-value = 0.0938
> 0.05 (zadany poziom istotności), zatem w tym teście nie odrzucamy hipotezy zerowej,
wskazującej na poprawność formy funkcyjnej.
W związku z tym, że użyta tu wersja testu Pearsona charakteryzuje się małą
mocą (w szczególności, jeśli podpróby są mało liczne; tak jest w naszym przypadku)
możemy zaufać pozostałym testom - Hausmana – Lemeshow’a i uogólnionemu testowi
RESET, które potwierdziły, iż przyjęta forma funkcyjna jest prawidłowa i model został
odpowiednio wyspecyfikowany.
3.2.6. Analiza dopasowania
W tym miejscu należałoby przyjrzeć się bliżej wskaźnikom determinacji.
• Miary dopasowania
Tabela 22. Miary dopasowania modelu probit
. fitstat Measures of Fit for probit of depr Log-Lik Intercept Only: -3640.088 Log-Lik Full Model: -2754.654 D(6143): 5509.308 LR(12): 1770.868 Prob > LR: 0.000 McFadden's R2: 0.243 McFadden's Adj R2: 0.240 Maximum Likelihood R2: 1.000 Cragg & Uhler's R2: 1.000 McKelvey and Zavoina's R2: 0.400 Efron's R2: 0.285 Variance of y*: 1.667 Variance of error: 1.000 Count R2: 0.795 Adj Count R2: 0.263 AIC: 0.899 AIC*n: 5535.308 BIC: -48089.488 BIC': -1666.166
Źródło: Opracowanie własne
Uzyskany model dla zmiennej ukrytej yi
* byłby wyjaśniany w 40%, gdyby
zmienna ta była bezpośrednio obserwowalna (pseudo R² McKelvey-Zavoina=0.4).
Model prawidłowo przewiduje sukcesy i porażki w 79,5% przypadków (R²
liczebnościowe=0.795). Dzięki użyciu w zmiennych objaśniających model prawidłowo
przewiduje sukcesy i porażki w 26,3% przypadków (skorygowane liczebnościowe
R²=0.264).
Kolejnym analizowanym elementem jest wrażliwość i specyficzność modelu.
• Wrażliwość i specyficzność
Im lepiej model przewiduje, tym bardziej krzywa ROC odgięta jest w kierunku
górnego rogu rysunku. Pole pod krzywą używane jest jako miara jakości dopasowania
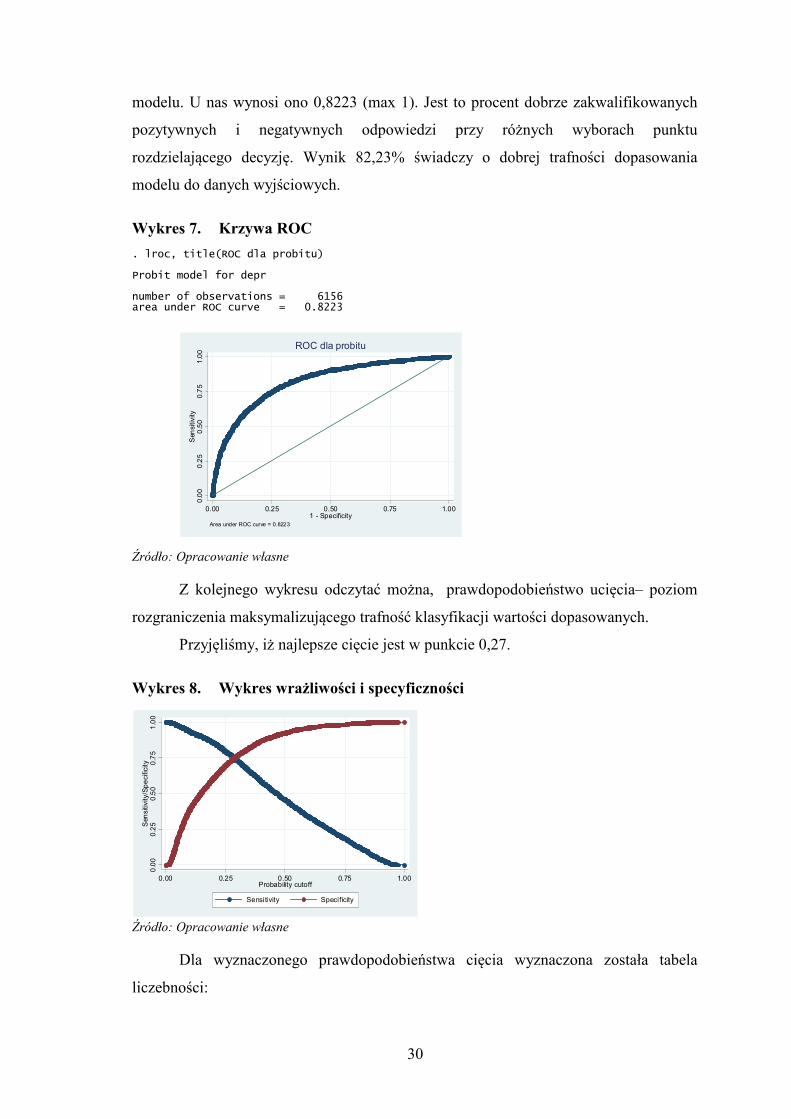
30
modelu. U nas wynosi ono 0,8223 (max 1). Jest to procent dobrze zakwalifikowanych
pozytywnych i negatywnych odpowiedzi przy różnych wyborach punktu
rozdzielającego decyzję. Wynik 82,23% świadczy o dobrej trafności dopasowania
modelu do danych wyjściowych.
Wykres 7. Krzywa ROC
. lroc, title(ROC dla probitu) Probit model for depr number of observations = 6156 area under ROC curve = 0.8223
0.0
00
.25
0.5
00
.75
1.0
0S
en
sitiv
ity
0.00 0.25 0.50 0.75 1.001 - Specificity
Area under ROC curve = 0.8223
ROC dla probitu
Źródło: Opracowanie własne
Z kolejnego wykresu odczytać można, prawdopodobieństwo ucięcia– poziom
rozgraniczenia maksymalizującego trafność klasyfikacji wartości dopasowanych.
Przyjęliśmy, iż najlepsze cięcie jest w punkcie 0,27.
Wykres 8. Wykres wrażliwości i specyficzności
0.0
00
.25
0.5
00
.75
1.0
0S
en
sitiv
ity/S
pe
cific
ity
0.00 0.25 0.50 0.75 1.00Probability cutoff
Sensitivity Specificity
Źródło: Opracowanie własne
Dla wyznaczonego prawdopodobieństwa cięcia wyznaczona została tabela
liczebności:

31
Tabela 23. Klasyfikacja modelu ( punkt odcięcia równy 0.27)
. lstat,cutoff(0.27) Probit model for depr -------- True -------- Classified | D ~D | Total -----------+--------------------------+----------- + | 1322 1219 | 2541 - | 391 3224 | 3615 -----------+--------------------------+----------- Total | 1713 4443 | 6156 Classified + if predicted Pr(D) >= .27 True D defined as depr != 0 -------------------------------------------------- Sensitivity Pr( +| D) 77.17% Specificity Pr( -|~D) 72.56% Positive predictive value Pr( D| +) 52.03% Negative predictive value Pr(~D| -) 89.18% -------------------------------------------------- False + rate for true ~D Pr( +|~D) 27.44% False - rate for true D Pr( -| D) 22.83% False + rate for classified + Pr(~D| +) 47.97% False - rate for classified - Pr( D| -) 10.82% -------------------------------------------------- Correctly classified 73.85% --------------------------------------------------
Źródło: Opracowanie własne
Powyższa tabela pokazuje, że na 1713 obserwacji, w których u badanego
respondenta zaobserwowano objawy depresji, model prawidłowo przewidział 1322 z
nich, a tylko 391 osób (22,83 % liczebności grupy) zakwalifikował błędnie. Wrażliwość
wyniosła 77,17%, co znaczy że model prawidłowo przewidział 77,17% przypadków
depresji tam gdzie faktycznie była ona zaobserwowana. Specyficzność równa 72,56%
świadczy o tym, że wśród osób u których nie zaobserwowano depresji prawidłowo
zostało przewidziane 72,56% takich przypadków. Wśród 4443 ankietowanych, którzy
nie wykazywali depresji, 1219 osób (czyli 27,83%) zostało błędnie zdiagnozowanych.
Podsumowując, średnio 73,85 % wszystkich obserwacji zostało trafnie
zaklasyfikowanych.
4. Wybór właściwego modelu
Czynnikami, które miał pomóc w wyborze odpowiedniego modelu były
współczynniki determinacji a także kryteria informacyjne AIC i BIC. Wyniki tych miar
w obu modelach były bardzo zbliżone. W modelu probit otrzymaliśmy:
R2liczebnościwe=0,795, R2 McKelvey Zavoina=0,4 oraz skorygowane R2
liczebnościowe=0,263. W modelu logit zaś: R2 liczebnościwe=0,795, R2 McKelvey
Zavoina=0,384, skorygowane R2 liczebnościowe=0,264. Podsumowując, skorygowane
R2 liczebnościowe jest większe w modelu logit w stosunku do modelu probit, R2

32
liczebnościowe jest równe, natomiast R2 McKelvey Zavoina jest niższe w modelu logit.
Kryteria informacyjne AIC i BIC świadczą na korzyść logitu11 (mniejsze dla logitu).
Biorąc pod uwagę powyższe wyniki a także zaprezentowaną wcześniej literaturę, w
której do estymacji tego problemu ekonometrycznego użyto modelu logit, będziemy
uznawać model logit za najlepiej opisujący omawiane przez nas zjawisko.
Wartości współczynników determinacji prezentują poniższe tabele:
Tabela 24. Współczynniki determinacji modelu probit
. fitstat Measures of Fit for probit of depr Log-Lik Intercept Only: -3640.088 Log-Lik Full Model: -2754.654 D(6143): 5509.308 LR(12): 1770.868 Prob > LR: 0.000 McFadden's R2: 0.243 McFadden's Adj R2: 0.240 Maximum Likelihood R2: 1.000 Cragg & Uhler's R2: 1.000 McKelvey and Zavoina's R2: 0.400 Efron's R2: 0.285 Variance of y*: 1.667 Variance of error: 1.000 Count R2: 0.795 Adj Count R2: 0.263 AIC: 0.899 AIC*n: 5535.308 BIC: -48089.488 BIC': -1666.166
Źródło: Opracowanie własne
Tabela 25. Współczynniki determinacji modelu logit
. fitstat Measures of Fit for logit of depr Log-Lik Intercept Only: -3640.088 Log-Lik Full Model: -2749.644 D(6143): 5499.289 LR(12): 1780.887 Prob > LR: 0.000 McFadden's R2: 0.245 McFadden's Adj R2: 0.241 Maximum Likelihood R2: 1.000 Cragg & Uhler's R2: 1.000 McKelvey and Zavoina's R2: 0.384 Efron's R2: 0.286 Variance of y*: 5.337 Variance of error: 3.290 Count R2: 0.795 Adj Count R2: 0.264 AIC: 0.898 AIC*n: 5525.289 BIC: -48099.507 BIC': -1676.185
Źródło: Opracowanie własne
Dodatkowo pomiędzy estymowanymi modelami występuje silna korelacja:
Tabela 26. Wynik korelacji pomiędzy modelem probit i logit
. pwcorr prlogit prprobit | prlogit prprobit -------------+------------------ prlogit | 1.0000 prprobit | 0.9994 1.0000
Źródło: Opracowanie własne
11 W modelu logit: AIC: 0.898, BIC: -48099.507; w modelu probit: AIC: 0.899,BIC: -48089.488.

33
Badania wykazały, że ostatecznie wyestymowane parametry w modelu logit
przyjmują wyższe wartości, jednak znaki przy zmiennych pozostają niezmienione.
Prezentuje to poniższa tabela:
Tabela 27. Oszacowania parametrów przy zmiennych niezależnych w modelu
logit i probit
. est table logit_z_ogr probit_z_ogr ---------------------------------------- Variable | logit_z_~r probit_z~r -------------+-------------------------- wiek | .07081065 .0401689 Istan_cyw_3 | .36325369 .22967659 Istan_cyw_4 | .41703548 .24533495 Istan_cyw_5 | 1.1277368 .63782148 doch | -.00011383 -.00006258 przyjaciele | -.02079619 -.01071339 _Ialkohol_2 | .69905069 .38901157 _Iplec_2 | .72779127 .40834596 _Iwyksz_2 | -.39337442 -.26109352 _Iwyksz_3 | -.7529885 -.4456578 _Iwyksz_4 | -.88528874 -.52152284 Irel_4 | -.17263883 -.10620595 _cons | -4.196363 -2.3832487 ---------------------------------------- Źródło: Opracowanie własne
Interpretacja znaków przy parametrach jest w większości zgodna z naszymi
przypuszczeniami zawartymi w hipotezach na początku pracy:
− wraz ze wzrostem wieku rośnie prawdopodobieństwo doświadczenia
epizodu depresyjnego,
− będąc owdowiałym, rozwiedzionym lub w separacji prawdopodobieństwo
wpadnięcia w depresję jest większe niż będąc osobą w stanie wolnym lub
małżeństwie lub w związku nieformalnym,
− wraz ze wzrostem dochodu prawdopodobieństwo depresji maleje,
− wzrost liczby przyjaciół wpływa na zmniejszenie prawdopodobieństwa
wpadnięcia w depresję,
− nadużywanie alkoholu powoduje zwiększenie prawdopodobieństwa
wpadnięcie w depresję,
− kobiety są bardziej narażone na depresję niż mężczyźni,
− posiadanie innego wykształcenia niż podstawowe wpływa na mniejsze
prawdopodobieństwo, że będzie się cierpieć na depresję,
− regularne uczęszczanie na spotkania o charakterze religijnym zmniejsza
prawdopodobieństwo wpadnięcia w depresję.
34
5. Interpretacja wyników
5.1. Efekty cząstkowe
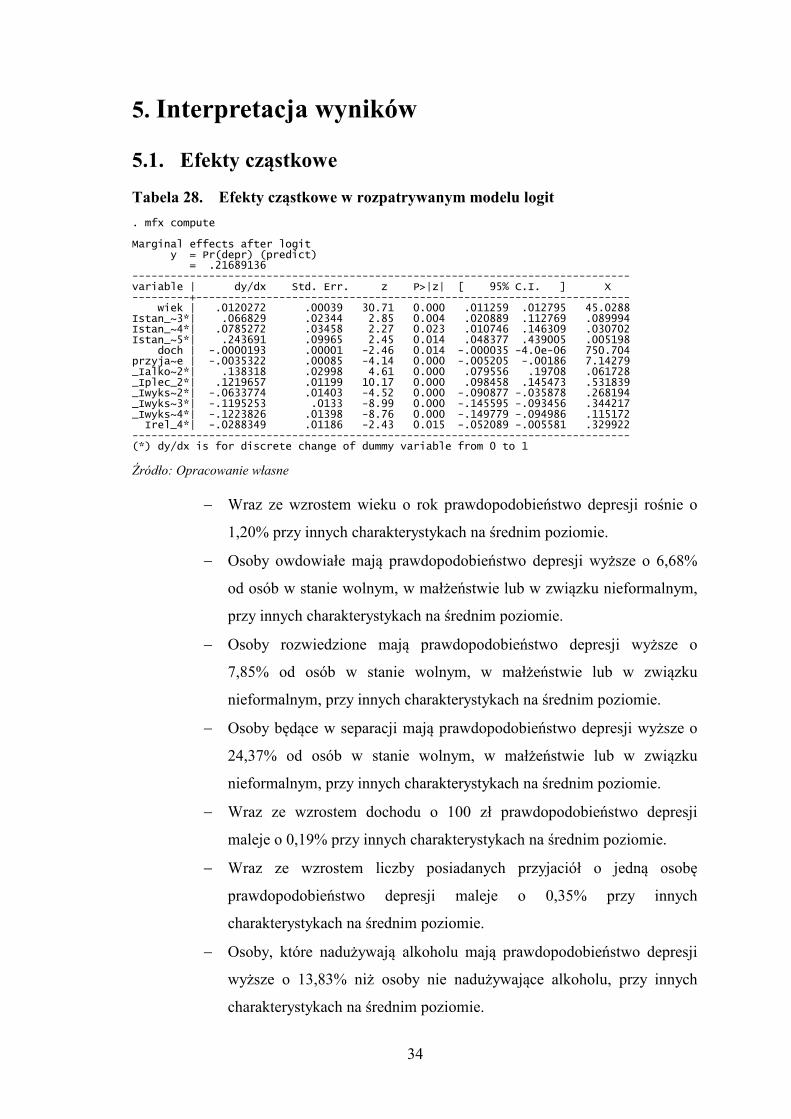
Tabela 28. Efekty cząstkowe w rozpatrywanym modelu logit
. mfx compute Marginal effects after logit y = Pr(depr) (predict) = .21689136 ------------------------------------------------------------------------------ variable | dy/dx Std. Err. z P>|z| [ 95% C.I. ] X ---------+-------------------------------------------------------------------- wiek | .0120272 .00039 30.71 0.000 .011259 .012795 45.0288 Istan_~3*| .066829 .02344 2.85 0.004 .020889 .112769 .089994 Istan_~4*| .0785272 .03458 2.27 0.023 .010746 .146309 .030702 Istan_~5*| .243691 .09965 2.45 0.014 .048377 .439005 .005198 doch | -.0000193 .00001 -2.46 0.014 -.000035 -4.0e-06 750.704 przyja~e | -.0035322 .00085 -4.14 0.000 -.005205 -.00186 7.14279 _Ialko~2*| .138318 .02998 4.61 0.000 .079556 .19708 .061728 _Iplec_2*| .1219657 .01199 10.17 0.000 .098458 .145473 .531839 _Iwyks~2*| -.0633774 .01403 -4.52 0.000 -.090877 -.035878 .268194 _Iwyks~3*| -.1195253 .0133 -8.99 0.000 -.145595 -.093456 .344217 _Iwyks~4*| -.1223826 .01398 -8.76 0.000 -.149779 -.094986 .115172 Irel_4*| -.0288349 .01186 -2.43 0.015 -.052089 -.005581 .329922 ------------------------------------------------------------------------------ (*) dy/dx is for discrete change of dummy variable from 0 to 1
Źródło: Opracowanie własne
− Wraz ze wzrostem wieku o rok prawdopodobieństwo depresji rośnie o
1,20% przy innych charakterystykach na średnim poziomie.
− Osoby owdowiałe mają prawdopodobieństwo depresji wyższe o 6,68%
od osób w stanie wolnym, w małżeństwie lub w związku nieformalnym,
przy innych charakterystykach na średnim poziomie.
− Osoby rozwiedzione mają prawdopodobieństwo depresji wyższe o
7,85% od osób w stanie wolnym, w małżeństwie lub w związku
nieformalnym, przy innych charakterystykach na średnim poziomie.
− Osoby będące w separacji mają prawdopodobieństwo depresji wyższe o
24,37% od osób w stanie wolnym, w małżeństwie lub w związku
nieformalnym, przy innych charakterystykach na średnim poziomie.
− Wraz ze wzrostem dochodu o 100 zł prawdopodobieństwo depresji
maleje o 0,19% przy innych charakterystykach na średnim poziomie.
− Wraz ze wzrostem liczby posiadanych przyjaciół o jedną osobę
prawdopodobieństwo depresji maleje o 0,35% przy innych
charakterystykach na średnim poziomie.
− Osoby, które nadużywają alkoholu mają prawdopodobieństwo depresji
wyższe o 13,83% niż osoby nie nadużywające alkoholu, przy innych
charakterystykach na średnim poziomie.

35
− Kobiety o charakterystykach średnich w próbie mają o 12,20% większe
prawdopodobieństwo depresji niż mężczyźni o charakterystykach
średnich w próbie.
− Osoby o wykształceniu zawodowym mają o 6,33% niższe
prawdopodobieństwo depresji niż osoby o wykształceniu podstawowym,
przy innych charakterystykach na średnim poziomie.
− Osoby o wykształceniu średnim mają o 11,95% niższe
prawdopodobieństwo depresji niż osoby o wykształceniu podstawowym,
przy innych charakterystykach na średnim poziomie.
− Osoby o wykształceniu wyższym mają o 12,24% niższe
prawdopodobieństwo depresji niż osoby o wykształceniu podstawowym,
przy innych charakterystykach na średnim poziomie.
− Osoby uczęszczające regularnie 4 razy w miesiącu na spotkania religijne
mają o 2,88% niższe prawdopodobieństwo depresji niż pozostałe osoby,
przy innych charakterystykach na średnim poziomie.
5.2. Ilorazy szans
Tabela 29. Ilorazy szans w rozpatrywanym modelu logit
. xi: logit depr wiek Istan_cyw_3 Istan_cyw_4 Istan_cyw_5 doch przyjaciele i.alkohol i.plec i.wyksz Irel_4,or Logistic regression Number of obs = 6156 LR chi2(12) = 1780.89 Prob > chi2 = 0.0000 Log likelihood = -2749.6443 Pseudo R2 = 0.2446 ------------------------------------------------------------------------------ depr | Odds Ratio Std. Err. z P>|z| [95% Conf. Interval] -------------+---------------------------------------------------------------- wiek | 1.073378 .0026957 28.20 0.000 1.068108 1.078674 Istan_cyw_3 | 1.438001 .1693752 3.08 0.002 1.141564 1.811415 Istan_cyw_4 | 1.517456 .2548445 2.48 0.013 1.091852 2.108961 Istan_cyw_5 | 3.088658 1.241829 2.80 0.005 1.404543 6.792111 doch | .9998862 .0000462 -2.46 0.014 .9997956 .9999768 przyjaciele | .9794186 .004936 -4.13 0.000 .9697919 .9891408 _Ialkohol_2 | 2.011842 .2717443 5.18 0.000 1.543903 2.621607 _Iplec_2 | 2.070502 .1524737 9.88 0.000 1.792225 2.391988 _Iwyksz_2 | .674776 .0612312 -4.34 0.000 .5648317 .806121 _Iwyksz_3 | .470957 .0415335 -8.54 0.000 .3961997 .5598199 _Iwyksz_4 | .412595 .0518995 -7.04 0.000 .3224431 .5279525 Irel_4 | .8414415 .0608055 -2.39 0.017 .7303199 .9694707 ------------------------------------------------------------------------------
Źródło: Opracowanie własne
− Szansa wpadnięcia w depresję dla osoby o wieku wyższym o 1 wynosi 1,07
szansy wpadnięcia w depresję dla osoby o rok młodszej.

36
− Szansa wpadnięcia w depresję dla osoby owdowiałej wynosi 1,44 szansy
wpadnięcia w depresję osoby w stanie wolnym, w małżeństwie lub w
związku nieformalnym.
− Szansa wpadnięcia w depresję dla osoby rozwiedzionej wynosi 1,52 szansy
wpadnięcia w depresję osoby w stanie wolnym, w małżeństwie lub w
związku nieformalnym.
− Szansa wpadnięcia w depresję dla osoby będącej w separacji wynosi 3,09
szansy wpadnięcia w depresję osoby w stanie wolnym, w małżeństwie lub w
związku nieformalnym.
− Szansa wpadnięcia w depresję dla osoby o dochodzie wyższym o jednostkę
wynosi 99,99% szansy wpadnięcia w depresję dla osoby o dochodzie
niższym o jednostkę.
− Szansa wpadnięcia w depresję dla osoby posiadającej o 1 przyjaciela więcej
wynosi 97,94% szansy wpadnięcia w depresję dla osoby o liczbie przyjaciół
mniejszej o 1.
− Szansa wpadnięcia w depresję dla osoby nadużywającej alkoholu wynosi
2,01 szansy wpadnięcia w depresję osoby, która nie nadużywa alkoholu.
− Szansa wpadnięcia w depresję dla kobiet wynosi 2,07 szansy wpadnięcia w
depresję dla mężczyzn.
− Szansa wpadnięcia w depresję dla osób z wykształceniem zawodowym jest
równa 67,48% szansy wpadnięcia w depresję dla osób z wykształceniem
podstawowym.
− Szansa wpadnięcia w depresję dla osób z wykształceniem średnim jest
równa 47,10% szansy wpadnięcia w depresję dla osób z wykształceniem
podstawowym.
− Szansa wpadnięcia w depresję dla osób z wykształceniem wyższym jest
równa 41,26% szansy wpadnięcia w depresję dla osób z wykształceniem
podstawowym.
− Szansa wpadnięcia w depresję dla osób uczęszczających regularnie 4 razy w
miesiącu na spotkania religijne jest równa 84,14% szansy wpadnięcia w
depresję dla pozostałych osób.

37
5.3. Efekty cząstkowe i wnioski dla wybranej grupy
respondentów
W celu uzyskania odpowiedzi na postawione przez nas we wstępie pytanie
dotyczące czynników wpływających na depresję u menedżerów, postanowiliśmy
stworzyć efekty cząstkowe dla respondenta: mężczyzna w wieku 40 lat z
wykształceniem wyższym (reszta zmiennych na poziomie średnim z próby) – czyli o
przykładowych charakterystykach potencjalnego menedżera.
5.3.1. Oszacowanie i interpretacja efektów cząstkowych
Tabela 30. Efekty cząstkowe dla mężczyzny w wieku 40 lat z wykształceniem
wyższym
. mfx, at(plec = 1 wiek = 40 wyksz=4) Marginal effects after logit y = Pr(depr) (predict) = .16246995 ------------------------------------------------------------------------------ variable | dy/dx Std. Err. z P>|z| [ 95% C.I. ] X ---------+-------------------------------------------------------------------- wiek | .0096355 .00027 35.72 0.000 .009107 .010164 40 Istan_~3*| .0545165 .01964 2.78 0.006 .016015 .093018 .089994 Istan_~4*| .0644445 .02911 2.21 0.027 .007395 .121494 .030702 Istan_~5*| .2116253 .09383 2.26 0.024 .027717 .395533 .005198 doch | -.0000155 .00001 -2.47 0.013 -.000028 -3.2e-06 750.704 przyja~e | -.0028298 .00068 -4.14 0.000 -.004169 -.001491 7.14279 _Ialko~2*| .1154026 .02602 4.44 0.000 .064413 .166392 .061728 _Iplec_2*| .097899 .00969 10.11 0.000 .078917 .116882 .531839 _Iwyks~2*| -.0503515 .0112 -4.50 0.000 -.072298 -.028405 .268194 _Iwyks~3*| -.0950265 .0108 -8.80 0.000 -.116199 -.073854 .344217 _Iwyks~4*| -.095412 .01092 -8.73 0.000 -.116824 -.074 .115172 Irel_4*| -.0230335 .00944 -2.44 0.015 -.041542 -.004526 .329922 ------------------------------------------------------------------------------ (*) dy/dx is for discrete change of dummy variable from 0 to 1
Źródło: Opracowanie własne
Następnie przeanalizowaliśmy zaprezentowane w powyższej tabeli wyniki.
Dokonując interpretacji należy pamiętać, że omawiamy skutki zmiany badanej
zmiennej przy pozostałych charakterystykach na poziomie średnim. Na podstawie
analiz zaobserwowano, że:
− prawdopodobieństwo doświadczenia depresji przez czterdziestoletniego
mężczyznę posiadającego wyższe wykształcenie wynosi 16,24%12,
− wraz ze wzrostem wieku o rok prawdopodobieństwo depresji wzrasta o
0,96%,
− badając stan cywilny respondenta, w przypadku wdowca,
prawdopodobieństwo depresji jest wyższe o 5,45% w porównaniu z osobą w
stanie wolnym, w małżeństwie lub w związku nieformalnym,
12 Wszystkie kolejne charakterystyki odnoszą się do grupy mężczyzn w wieku 40 lat posiadających wyższe wykształcenie.

38
− mężczyzna po rozwodzie ma prawdopodobieństwo depresji wyższe o 6,44%,
zaś u osób w separacji prawdopodobieństwo depresji wzrasta o 21,16% w
porównaniu z osobami w stanie wolnym, w małżeństwie lub w związku
nieformalnym,
− wraz ze wzrostem zarobków o 1000 zł prawdopodobieństwo depresji maleje
o 1,55%,
− mężczyźni, którzy nadużywają alkoholu mają prawdopodobieństwo depresji
wyższe o 11,54% niż osoby nie nadużywające alkoholu,
− wraz ze wzrostem liczby posiadanych przyjaciół o jedną osobę,
prawdopodobieństwo depresji maleje tylko o 0,28%,
− u mężczyzn, którzy zadeklarowali, że uczęszczają regularnie na spotkania o
charakterze religijnym, prawdopodobieństwo wpadnięcia w depresję było o
23,03% niższe od pozostałych.
5.3.2. Wnioski z efektów cząstkowych
Po przeanalizowaniu wyników badania, należy zauważyć istnienie kilku
kluczowych czynników, na które każdy menedżer powinien zwrócić uwagę, aby nie dać
się trudnościom i przetrwać obecny kryzys .
Zgodnie z badaniem, wraz ze wzrostem liczby posiadanych przyjaciół o jedną
osobę prawdopodobieństwo depresji maleje o 0,28%. Badania wykazały ponadto, że
osoby będące w separacji lub po rozwodzie mają wyższe prawdopodobieństwo
wpadnięcia w depresję, niż osoby w stanie wolnym, w małżeństwie lub w związku
nieformalnym (prawdopodobieństwo wyższe o odpowiednio: 21,16% i 6,44%).
Uważamy więc, że każdy menedżer, szczególnie w czasie kryzysu, powinien postawić
na przyjaciół i rodzinę. To właśnie najbliżsi w obliczu niepewnego jutra i stresu z tym
związanego, stanowią dla nas oparcie. Zgodnie z tezą prof. Czapińskiego13 poczucie
bezinteresownej życzliwości i pomocy ze strony innych ludzi może być kluczowym
czynnikiem chroniącym człowieka od depresji. A zatem każdy menedżer musi
pamiętać, że na jego sukces nie składa się tylko i wyłącznie praca. Ogromnie ważną
rolę odgrywa utrzymanie równowagi pomiędzy życiem prywatnym i zawodowym.
Oprócz czasu spędzanego w firmie, każdy zarządzający powinien mieć go również dla
swoich przyjaciół i bliskich.
13 J. Czapiński, T. Panek, Diagoza Społeczna 2005

39
Warto również nawiązywać nowe znajomości. Nie można unikać ludzi,
separować się, walczyć z trudnościami w pojedynkę. Wniosek ten można również
odnieść do naszych dotychczasowych partnerów czy kontrahentów. Być może warto
nawiązać z nimi lepszy kontakt, wypracowywać wspólne rozwiązania, postawić na
marketing relacyjny. Marketing relacyjny, jak pisze Philip Kotler,14 polega na tym, że
przedsiębiorstwo nieustannie współpracuje z klientem, tak by odkryć metody
umożliwiające klientowi zwiększenie oszczędności przy dokonywaniu zakupu oraz
optymalne wykorzystanie możliwości danego produktu15. Budowanie partnerskich
związków między firmą a jej kontrahentami prowadzi do obniżenia kosztów
transakcyjnych i oszczędza czas dzięki wspólnemu zaufaniu.
Innym ważnym czynnikiem, który może pokrzyżować plany wtedy, gdy należy
stawić czoła wyzwaniom, może być nadużywanie alkoholu. Menedżer odpowiedzialny
za realizowanie strategii, podejmowanie trudnych decyzji i wykonywanie ryzykownych
działań musi zdawać sobie sprawę, że nie może on łatwo uciekać w kierunku używek,
które na pewno nie rozwiążą pojawiających się problemów. Nasze badanie pokazało, że
mężczyźni o wybranych charakterystykach, którzy nadużywają alkoholu mają
prawdopodobieństwo depresji wyższe o 11,54% niż ci, którzy nie nadużywają alkoholu.
Od kondycji psychicznej menadżera, pewności siebie, odporności na stres może
zależeć, czy firmie uda się przetrwać na rynku, czy też popadnie w tarapaty finansowe i
zbankrutuje. Duży wpływ na pewność siebie ma to, czy osoba ma świadomość, że nie
jest pozostawiona samej sobie w pojawiających się trudnościach. Jak pokazuje
przeprowadzone badanie, uczęszczanie na spotkania o charakterze religijnym i
pozytywny stosunek do wiary mogą ograniczyć prawdopodobieństwo wpadnięcia w
depresję. Mężczyźni o wybranych charakterystykach, którzy zadeklarowali, że
uczęszczają regularnie na spotkania o charakterze religijnym, mieli niższe
prawdopodobieństwo wpadnięcia w depresję o 23,03%.
Kolejnym ciekawym spostrzeżeniem jest fakt, że wraz ze wzrostem dochodu
maleją skłonności do depresji. Wraz ze wzrostem dochodu o 1000 zł
prawdopodobieństwo depresji u badanych respondentów malało o 1,55%. W takim
razie, należałoby zastanowić się czy drastyczne obniżanie pensji menedżerom jest dobrą
receptą na wyjście z kryzysu. Jak pokazują badania, może się okazać, że pomimo
14 Philip Kotler (ur.1931 w Chicago), ekonomista amerykański, honorowy profesor Katedry Marketingu Międzynarodowego w Kellogg School of Management na Northwestern University, która jest jedną z najważniejszych uczelni biznesu na świecie, kształcących w zakresie marketingu. 15 P. Kotler, Marketing, Rebis, Warszawa 2005.

40
oszczędności finansowych, działanie to przyniesie odwrotny skutek dla
przedsiębiorstwa. Po obniżeniu zarobków, słabiej zmotywowany czy wręcz
zdemotywowany menedżer może uznać, że jego trud nie jest wystarczająco nagradzany
i może być przez to bardziej podatny na załamanie się.
6. Wnioski końcowe
Przeprowadzona estymacja miała na celu zbadać czynniki wpływające w Polsce
na prawdopodobieństwo wpadnięcia w depresję. Jej zadaniem było również
dostarczenie odpowiedzi na pytanie na co muszą zwracać uwagę menedżerowie, aby w
czasie kryzysu odpowiednio chronić się przed ryzykiem depresji, a co za tym idzie,
niemożności skutecznego prowadzenia działań zarządczych w firmie.
Analiza, której dokonano w niniejszej pracy, potwierdziła fakt
wieloczynnikowości determinowania depresji. Ryzyko skłonności depresyjnych wśród
dorosłych Polaków zależy od wieku, płci, dochodu na osobę w gospodarstwie
domowym, stanu cywilnego, wykształcenia, nadużywania alkoholu i stosunku do
praktyk religijnych.
Ciekawym zjawiskiem okazał się fakt, że zmienna zero-jedynkowa określająca
bezrobocie okazała się nieistotna statystycznie. Oznacza to, iż w polskim
społeczeństwie brak zatrudnienia nie musi oznaczać ryzyka depresji. Stoi to w opozycji
do przywoływanych w pierwszym rozdziale badań V. Loranta, C. Crouxa, S. Weicha,
D. Deliege’a, J. Mackenbacha i M. Ansseaua16, w których fakt bycia bezrobotnym
istotnie zwiększał prawdopodobieństwo doświadczenia depresji.
Zarówno nasze badanie jak i badanie przeprowadzone przez w/w autorów
potwierdziło hipotezę, że kobiety są bardziej podatne na ryzyko depresji w porównaniu
z mężczyznami. Sprawdziła się również teza, że wraz ze wzrostem dochodu,
prawdopodobieństwo wpadnięcia w depresję maleje. Mając dobre zarobki można
zagwarantować sobie lepsze warunki życia, nie musząc martwić się o zaspokojenie
swoich potrzeb w przyszłości. Będąc spokojnym o jutro, człowiek posiada psychiczny
komfort i jest dużo mniej podatny na depresję w porównaniu z życiem w nieustannej
niepewności.
W naszym badaniu okazało się również, że w kwestii prawdopodobieństwa
depresji, nie ma różnicy czy osoba jest w stanie wolnym, w związku małżeńskim lub
16 V. Lorant, C. Croux, S. Weich, D. Deliege, J. Mackenbach, M. Ansseau, op.cit., s. 293-298.

41
związku nieformalnym. Natomiast fakt rozpadu małżeństwa czy to przez rozwód,
separację lub owdowienie powoduje znaczne zwiększenie skłonności depresyjnych. A
zatem hipoteza przedstawiona w przywoływanym powyższej belgijskim badaniu, że
utrata „drugiej połowy” powoduje, iż ludzie są bardziej narażeni na załamanie, okazała
się prawdziwa.
Ciekawym spostrzeżeniem jest również potwierdzenie się w naszych badaniach
faktu sugerowanego przez J. Czapińskiego,17 że w przeciwieństwie do społeczeństw
zachodnich (USA, Kanada), wraz ze wzrostem wieku rośnie prawdopodobieństwo bycia
w depresji. W Polsce, inaczej niż wykazały badania R. M. Nessego i G. C. Williams’a18,
to ludzie starsi częściej cierpią na depresję niż młodsi. Naszym zdaniem może być to
związane z tym, że w społeczeństwach Europy Wschodniej sytuacja materialna i
zdrowotna osób starszych jest dużo gorsza niż tych z zachodniej części Europy i świata.
Niewielkie emerytury i renty, drożejące leki oraz ograniczony dostęp do świadczeń
medycznych powoduje, że polscy emeryci mogą być sfrustrowani, a przez to bardziej
podatni na załamania psychiczne.
Ze względu na specyfikę polskich realiów, uznaliśmy, że istotnym czynnikiem
determinującym depresję jest wykształcenie. Nasza praca potwierdziła te
przypuszczenia. Osoby z wyższym wykształceniem znacznie rzadziej cierpią na
depresję niż słabiej wykształcone. Wyższe kwalifikacje pomagają znaleźć lepszą pracę,
a co za tym idzie, zapewnić sobie i swojej rodzinie lepsze warunki bytu. Ponadto, biorąc
pod uwagę charakterystykę społeczeństwa polskiego, można było przypuszczać, że
osoby posiadające problemy z alkoholem mogą mieć skłonności depresyjne, co
potwierdziło się w naszym modelu. Ostatnią cechą typową dla polskich realiów jest
wysoki odsetek osób deklarujących się jako osoby wierzące. Respondenci, którzy
dodatkowo deklarowali regularne praktyki religijne, charakteryzowali się niższymi
skłonnościami depresyjnymi.
W odniesieniu do kadry zarządzającej, która stanowiła szczególną grupę
respondentów objętych zainteresowaniem autorów niniejszego modelu, okazało się, że
podstawowym czynnikiem obniżającym ryzyko depresji, jest równowaga życia
prywatnego i zawodowego. Podtrzymywanie relacji z przyjaciółmi, otwarcie na nowe
znajomości, zaangażowanie w życie rodzinne są w stanie pomóc menedżerom
17 J. Czapiński, T. Panek, Diagnoza Społeczna 2005, s. 116. 18 R.M. Nesse, G. C. Williams, Why we get sick, “New York Times Books”, 1994 r., s. 220.

42
właściwie zarządzać firmą w czasie kryzysu. Nie bez znaczenia pozostaje rola
motywacji do pracy i odpowiedniego wynagrodzenia.
Przeprowadzone przez nas badanie pozwoliło lepiej zrozumieć, co ma
największy wpływ na badane zjawisko depresji oraz na co należy zwrócić uwagę aby
odnieść sukces i wyjść na kryzysie zwycięsko. Nie straszny nam kryzys!
7. Bibliografia
Beck A. T., Ward, C. H., Mendelson M., Mock J., Erbaugh J., An inventory for measuring depression,”Archives of General Psychiatry”, 1961, nr 4.
Czapiński J., Panek T., Diagnoza Społeczna 2005.
Kaplan G. A., Roberts E., Camacho T., Psychosocial predictors of depression, “American Journal of Epidemiology”, 1987, nr 125.
Kotler P. Marketing, Rebis, Warszawa 2005.
Lorant V., Croux C., Weich S., Deliege D., Mackenbach J., Ansseau M., Depression and socio-economic risk factors: 7-year longitudinal population study, “The British Journal of Psychiatry”, 2007, nr 190.
Mycielski J., Skrypt do ekonometrii, Warszawa 2008.
Nesse R. M., Williams G. C., Why we get sick, “New York Times Books”, 1994.

43
8. Załączniki
8.1. Skala Depresji Becka
N. 0 - sądzę że wyglądam nie gorzej niż dawniej. 1 - martwię się tym że wyglądam staro i nieatrakcyjnie. 2 - czuję że wyglądam coraz gorzej. 3 - jestem przekonany że wyglądam okropnie i odpychająco. O. 0 - mogę pracować tak jak dawniej. 1 - z trudem rozpoczynam każdą czynność. 2 - z wielkim wysiłkiem zmuszam się do zrobienia czegokolwiek. 3 - nie jestem w stanie nic robić. P. 0 - sypiam dobrze jak zwykle. 1 - sypiam gorzej niż dawniej. 2 - rano budzę się 1 - 2 godziny za wcześnie i trudno jest mi ponownie usnąć. 3 - budzę się kilka godzin za wcześnie i nie mogę usnąć. Q. 0 - nie męczę się bardziej niż dawniej. 1 - meczę się znacznie łatwiej niż poprzednio. 2 - męczę się wszystkim co robię. 3 - jestem zbyt zmęczony aby cokolwiek robić. R. 0 - mam apetyt nie gorszy niż dawniej. 1 - mam trochę gorszy apetyt, 2 - apetyt mam wyraźnie gorszy. 3 - nie mam w ogóle apetytu. T. 0 - nie martwię się o swoje zdrowie bardziej niż zawsze. 1 - martwię się swoimi dolegliwościami, mam rozstrój żołądka, zaparcia, bóle. 2 - stan mego zdrowia bardzo mnie martwi często o tym myślę. 3 - tak bardzo martwię się o swoje zdrowie że nie mogę o niczym innym myśleć. U. 0 - moje zainteresowania seksualne nie uległy zmianom. 1 - jestem mniej zainteresowany sprawami płci (seksu) 2 - problemy płciowe wyraźnie mnie interesują. 3 - utraciłem wszelkie zainteresowania sprawami seksualnymi.
44
8.2. Wykresy zależności ciągłych zmiennych objaśniających i
prawdopodobieństwa bycia w depresji
Wykres 9. Wiek respondenta a prawdopodobieństwo bycia w depresji
0.2
.4.6
.81
Pra
wd
op
od
obie
ństw
o w
pa
dn
ięcia
w d
ep
resję
20 40 60 80 100wiek respondenta
Źródło: Opracowanie własne
Wykres 10. Dochód respondenta a prawdopodobieństwo bycia w depresji
0.2
.4.6
.81
Pra
wd
op
od
obie
ństw
o w
pa
dn
ięcia
w d
ep
resję
0 10000 20000 30000miesięczny dochód na osobę w rodzinie respondenta
Źródło: Opracowanie własne
Wykres 11. Liczba przyjaciół respondenta a prawdopodobieństwo bycia w
depresji
0.2
.4.6
.81
Pra
wd
op
od
obie
ństw
o w
pa
dn
ięcia
w d
ep
resję
0 20 40 60 80 100liczba przyjaciół respondenta
Źródło: Opracowanie własne