
Liczby całkowite i rzeczywiste -...
30
Liczby całkowite i rzeczywiste Paulina Rogowiecka Klaudia Kamińska Adrianna Znyk Wykład 4(20 marzec 2014r.) 1
Transcript of Liczby całkowite i rzeczywiste -...

Liczby całkowite i rzeczywiste
Paulina Rogowiecka
Klaudia Kamińska
Adrianna Znyk
Wykład 4(20 marzec 2014r.)
1

Spis treści:
Czynniki pierwsze – metoda próbnych dzieleń
Pierwszość liczby naturalnej – algorytmy naiwne
Generowanie liczb pseudolosowych
Liczby Fibonacciego
Całkowity pierwiastek kwadratowy
2

Czynniki pierwsze – metoda próbnych
dzieleń
Problem i jego rozwiązanie
Podstawowy problem polega na znalezieniu rozkładu liczby p > 1 na iloczyn czynników pierwszych. Obecnie nie istnieje żaden szybki algorytm rozkładu dużej liczby naturalnej na czynniki pierwsze.
Zasadnicze twierdzenie arytmetyki mówi, iż każda liczba naturalna większa od 1 może być jednoznacznie zapisana jako iloczyn liczb
pierwszych.
3

Rozwiązanie
Pierwsze podejście do znalezienia rozkładu liczby p na jej czynniki pierwsze nazywa się ono bezpośrednim
poszukiwaniem rozkładu na czynniki pierwsze. Sprawdzimy podzielność liczby p przez kolejne liczby
naturalne od 2 do pierwiastka z p. Jeśli liczba p będzie podzielna przez daną liczbę, to liczbę wyprowadzimy na wyjście, a za nowe p przyjmiemy wynik dzielenia i
próbę dzielenia będziemy powtarzać dotąd, aż nie będzie to już możliwe. Wtedy przejdziemy do
następnego dzielnika.
4
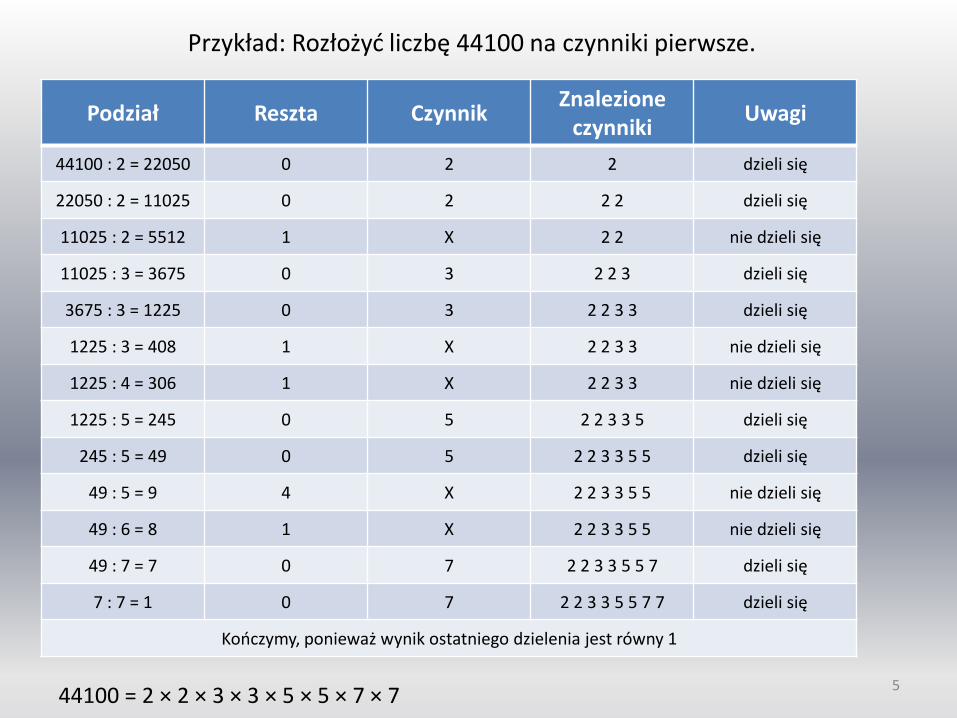
Przykład: Rozłożyć liczbę 44100 na czynniki pierwsze.
Podział Reszta Czynnik Znalezione
czynniki Uwagi
44100 : 2 = 22050 0 2 2 dzieli się
22050 : 2 = 11025 0 2 2 2 dzieli się
11025 : 2 = 5512 1 X 2 2 nie dzieli się
11025 : 3 = 3675 0 3 2 2 3 dzieli się
3675 : 3 = 1225 0 3 2 2 3 3 dzieli się
1225 : 3 = 408 1 X 2 2 3 3 nie dzieli się
1225 : 4 = 306 1 X 2 2 3 3 nie dzieli się
1225 : 5 = 245 0 5 2 2 3 3 5 dzieli się
245 : 5 = 49 0 5 2 2 3 3 5 5 dzieli się
49 : 5 = 9 4 X 2 2 3 3 5 5 nie dzieli się
49 : 6 = 8 1 X 2 2 3 3 5 5 nie dzieli się
49 : 7 = 7 0 7 2 2 3 3 5 5 7 dzieli się
7 : 7 = 1 0 7 2 2 3 3 5 5 7 7 dzieli się
Kończymy, ponieważ wynik ostatniego dzielenia jest równy 1
44100 = 2 × 2 × 3 × 3 × 5 × 5 × 7 × 7 5

Schemat krokowy Algorytm rozkładu liczby naturalnej na czynniki pierwsze
Wejście
p – liczba rozkładana na czynniki pierwsze, pϵ N, p > 1
Wyjście:
Czynniki pierwsze liczby p.
Elementy pomocnicze:
g – granica sprawdzania podzielności liczby p. gϵN
i –kolejne podzielniki, iϵN
Lista kroków:
01: g[√p] ; granica sprawdzania czynników pierwszych
02: Dla i=2,3,…g wykonuj kroki 03…06 ; w pętli sprawdzamy podzielność liczby p przez kolejne liczby
03: Dopóki p mod i=0 ; dopóki dzielnik dzieli p
04: Pisz i ; wyprowadzamy go i
05: pp div i ; dzielimy przez niego p
06: Jeśli p=1 ,to zakończ ; pętlę przerywamy, gdy stwierdzimy brak dalszych dzielników
07: Jeśli p>1 to pisz p ; p może posiadać ostatni czynnik większy od pierwiastka z p
08: Zakończ 6

Program-przykład #include <iostream>
#include <cmath>
using namespace std;
int main ()
{
unsigned int p,i,g;
cin >> p;
g = (unsigned int) sqrt (p);
for(i = 2; i <=g; i++)
{
while(!(p % i))
{
cout << i << ‘’ ‘’;
p/= i ;
}
if( p==1) break;
}
if(p > 1) cout << p;
cout << endl;
return 0;
}
Wynik 3971235724 2 2 431 2303501
Program w pierwszym wierszu czyta liczbę p i w następnym wierszu wypisuje kolejne czynniki pierwsze tej liczby.
7

Pierwszość liczby naturalnej – algorytmy naiwne
Problem i jego rozwiązanie Problem polega na sprawdzeniu, czy liczba naturalna p jest
pierwsza.
8

Rozwiązanie
Liczba jest pierwsza jeśli nie posiada dzielników innych poza 1 i sobą samą. Pierwsze rozwiązanie testu na pierwszość polega na próbnym dzieleniu liczby p przez liczby z przedziału od 2 do [√p] i badaniu reszty z dzielenia. Powód takiego postępowania jest prosty – jeśli liczba p posiada czynnik większy od pierwiastka z p, to drugi czynnik musi być mniejszy od pierwiastka, aby ich iloczyn był równy p. W przeciwnym razie iloczyn dwóch liczb większych od √p dawałby liczbę większą od p. Zatem wystarczy przebadać podzielność p przez liczby z przedziału <2,[√p]>, aby wykluczyć liczby złożone.
9

Schemat krokowy Algorytm sprawdzania pierwszości liczby naturalnej
Wejście: p – liczba badana na pierwszość, p ϵ N, p > 1
Wyjście: TAK, jeśli p jest pierwsze lub NIE w przypadku przeciwnym.
Elementy pomocnicze: g – granica sprawdzania podzielności p. g ϵ N
i –kolejne podzielniki liczby p, i ϵ N
Lista kroków: 01: g[√p] ; wyznaczamy granicę sprawdzania podzielności p
02: Dla i=2,3,…,g wykonuj krok 03 ; przebiegamy przez przedział <2,[√p]>
03: Jeśli p mod i=0, to pisz NIE i zakończ ; jeśli liczba z przedziału <2,[√p]> dzieli p, to p nie jest pierwsze
04: Pisz TAK ; jeśli żadna liczba z <2,[√p]> nie dzieli p, p jest pierwsze
05: Zakończ 10

Program-przykład
#include <iostream> #include <cmath> using namespace std; int main () { unsigned long long g,i,p; bool t; cin >> p; g = (unsigned long long) sqrt (p); t=true; for(i = 2; i <=g; i++) { if (p % i == 0) { t=false; break; } } if( t ) cout << ‘’TAK’’; else cout << ‘’NIE’’; cout << endl; return 0; }
Wynik 10000000000037
TAK
Program odczytuje w pierwszym wierszu liczbę p, a w drugim wierszu wypisuje słowo TAK, jeśli liczba p jest pierwsza lub NIE w przypadku przeciwnym. W programie zastosowano zmienne 64-bitowe, zatem zakres p jest dosyć duży. Jednakże dla wielkich liczb naturalnych test na pierwszość może zająć wiele czasu.
11

Generowanie liczb pseudolosowych
Mieszanie pseudolosowe Zadanie mieszania, tasowania zawartości tablicy sprowadza
się do wykonywania w pętli zamiany miejscami dwóch elementów tablicy o wylosowanych indeksach. Pętla musi
być wykonana tyle razy, aby tasowanie objęło wszystkie elementy – w praktyce wystarcza ilość wykonań równa 3n,
gdzie n jest ilością elementów.
Problem 1: Dany, skończony zbiór liczb całkowitych pomieszać pseudolosowo.
12

Schemat krokowy: Algorytm mieszania pseudolosowego
Wejście n – liczba elementów w tablicy, n ϵ N Z –tablica elementów, indeksy
rozpoczynają się od 0 Wyjście: Tablica Z z potasowaną zawartością
Zmienne pomocnicze i – licznik obiegów pętli i ϵ N
x –przechowuje element tablicy Z przy zamianie zawartości. Typ ten sam, co elementy tablicy Z.
losowa(x) –funkcja zwracająca liczbę pseudolosową z zakresu od 0 do x - 1 Lista kroków:
01: Dla i=1,2,…,3n: wykonuj 02…07 ; tasowanie wykonujemy w pętli
02: i1 losowa (n) ; losujemy pierwszy indeks
03: i2 losowa (n) ; losujemy drugi indeks
04: x Z[i1] ; zamieniamy miejscami Z[i1] i Z[i2]
05: Z[i1] Z[i2]
06: Z[i2] x
07: Zakończ 13
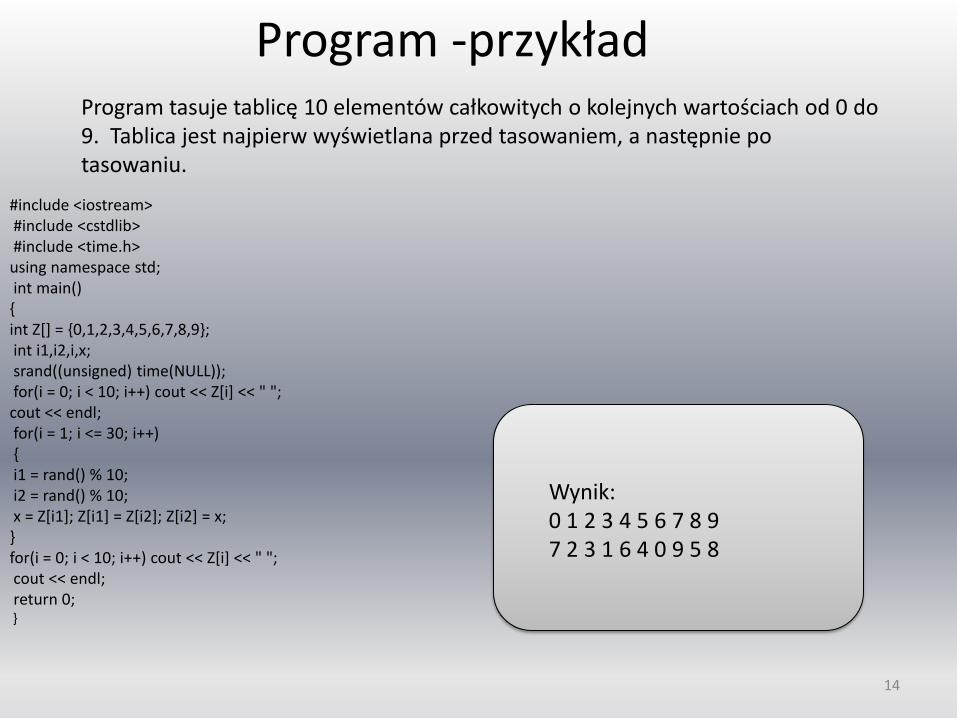
Program -przykład
#include <iostream> #include <cstdlib> #include <time.h> using namespace std; int main() { int Z[] = {0,1,2,3,4,5,6,7,8,9}; int i1,i2,i,x; srand((unsigned) time(NULL)); for(i = 0; i < 10; i++) cout << Z[i] << " "; cout << endl; for(i = 1; i <= 30; i++) { i1 = rand() % 10; i2 = rand() % 10; x = Z[i1]; Z[i1] = Z[i2]; Z[i2] = x; } for(i = 0; i < 10; i++) cout << Z[i] << " "; cout << endl; return 0; }
Wynik: 0 1 2 3 4 5 6 7 8 9 7 2 3 1 6 4 0 9 5 8
Program tasuje tablicę 10 elementów całkowitych o kolejnych wartościach od 0 do 9. Tablica jest najpierw wyświetlana przed tasowaniem, a następnie po tasowaniu.
14

Losowanie bez powtórzeń Zadanie losowania bez powtórzeń można rozwiązać na kilka
różnych sposobów. Jeśli przedział <a,b> jest mały, to możemy go odwzorować w tablicy, następnie zawartość tej tablicy potasować
poprzednio podanym algorytmem i jako wynik zwrócić pierwsze n elementów. Tasowanie nie dubluje elementów tablicy, zatem otrzymamy n liczb bez powtórzeń. Taki algorytm posiada
klasę złożoności obliczeniowej O(n). Jeśli przedział <a,b> jest bardzo duży, a n stosunkowo małe, to
postępujemy w sposób następujący. Przygotowujemy pustą tablicę o n elementach. Losujemy liczbę pseudolosową. Jeśli
wylosowana liczba jest już w tablicy, to losujemy ponownie dotąd, aż wylosowanej liczby nie będzie w tablicy. Liczbę dopisujemy do
tablicy. Jeśli tablica jest zapełniona, kończymy. W przeciwnym razie powtarzamy losowanie. Algorytm w takiej postaci posiada
optymistyczną klasę złożoności obliczeniowej O(n2).
Problem 2: Wylosować z przedziału całkowitego <a,b> n liczb pseudolosowych bez powtórzeń.
15

Schemat krokowy: Algorytm losowania bez powtórzeń
Wejście
n – liczba określająca, ile liczb pseudolosowych bez powtórzeń należy wylosować, n ϵ N a,b –liczby określające całkowity przedział losowania, b - a ≥ n, a,b ϵ C
Wyjście:
n różnych od siebie liczb pseudolosowych z przedziału <a,b>
Zmienne pomocnicze
T – tablica przechowująca wylosowane liczby pseudolosowe. Indeksy od 0 do n-1.
i – licznik wylosowanych liczb pseudolosowych. i ϵ N
j –wykorzystywane do przeszukiwania tablicy T. j ϵ N
x –wylosowana liczba pseudolosowa losowa(x) –funkcja zwracająca liczbę pseudolosową z zakresu od 0 do x - 1
Lista kroków:
01: Dla i = 0,1,...,n-1 wykonuj 02...06
02: x ← a + losowa(b - a + 1) ; losujemy liczbę pseudolosową
03: Dla j = 0,1,...,i - 1 wykonuj 04 ; sprawdzamy, czy wylosowana liczba jest w T
04: Jeśli T[j] = x, to idź do 02 ; jeśli tak, powtarzamy losowanie
05: T[i] ← x ; jeśli nie, zapamiętujemy w T wylosowaną liczbę
06: Wyprowadź x ; wyprowadzamy liczbę na wyjście
07: Zakończ 16
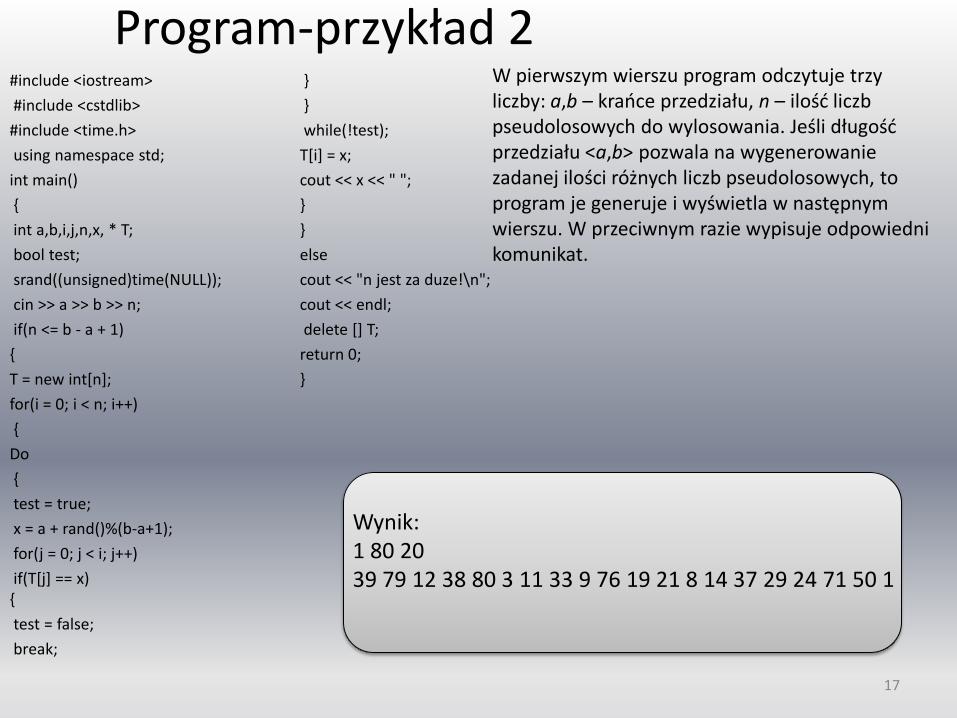
Program-przykład 2 #include <iostream>
#include <cstdlib>
#include <time.h>
using namespace std;
int main()
{
int a,b,i,j,n,x, * T;
bool test;
srand((unsigned)time(NULL));
cin >> a >> b >> n;
if(n <= b - a + 1)
{
T = new int[n];
for(i = 0; i < n; i++)
{
Do
{
test = true;
x = a + rand()%(b-a+1);
for(j = 0; j < i; j++)
if(T[j] == x) {
test = false;
break;
}
}
while(!test);
T[i] = x;
cout << x << " ";
}
}
else
cout << "n jest za duze!\n";
cout << endl;
delete [] T;
return 0;
}
Wynik: 1 80 20 39 79 12 38 80 3 11 33 9 76 19 21 8 14 37 29 24 71 50 1
W pierwszym wierszu program odczytuje trzy liczby: a,b – krańce przedziału, n – ilość liczb pseudolosowych do wylosowania. Jeśli długość przedziału <a,b> pozwala na wygenerowanie zadanej ilości różnych liczb pseudolosowych, to program je generuje i wyświetla w następnym wierszu. W przeciwnym razie wypisuje odpowiedni komunikat.
17

Liczby Fibonacciego Leonardo Fibonacci był włoskim matematykiem
żyjącym w latach od 1175 do 1250. Jest on autorem specyficznego ciągu liczbowego, który pojawia się w wielu zastosowaniach informatycznych (i nie tylko).
Wyrazy ciągu Fibonacciego definiujemy rekurencyjnie w sposób następujący:
F0 = 0 F1 = 1
Fi = Fi-2 + Fi-1, dla i > 1
Problem: Wyznaczyć n-ty wyraz ciągu Fibonacciego.
18

Rozwiązanie 1 Rozwiązanie opieramy bezpośrednio na definicji wykorzystując wywołania rekurencyjne. Jest
to bardzo złe rozwiązanie (podajemy je tylko ze względów dydaktycznych), ponieważ algorytm wielokrotnie oblicza wyrazy ciągu, co w efekcie prowadzi do wykładniczej klasy złożoności
obliczeniowej O(2n).
Schemat krokowy: Algorytm generacji liczb Fibonacciego metodą rekurencyjną
Wejście n – numer liczby ciągu Fibonacciego do wyliczenia, n ϵ N
Wyjście: n-ta liczba ciągu Fibonacciego
Lista kroków funkcji Fibo(n):
01: Jeśli n ≤ 1, to zwróć n i zakończ ; f0 lub f1
02: Zwróć Fibo(n - 2) + Fibo(n - 1) i zakończ ; dwa wywołania rekurencyjne
19

Program- przykład:
#include <iostream>
using namespace std;
unsigned long fibo(int n)
{
if(n <= 1) return n;
else return fibo(n - 2) + fibo(n - 1);
}
int main()
{
int n;
cin >> n;
cout << fibo(n) << "\n\n";
return 0;
}
Wynik: 25 75025
W pierwszym wierszu program odczytuje n – numer liczby Fibonacciego do wyliczenia. W następnym wierszu program wypisuje wartość n-tej liczby Fibonacciego. Z uwagi na wykładniczą klasę złożoności obliczeniowej czas obliczeń szybko rośnie, zatem nie podawaj zbyt dużych n (<45), inaczej nie doczekasz się wyniku lub komputer zgłosi przepełnienie pamięci.
20

Rozwiązanie 2
Drugie rozwiązanie wykorzystuje zasadę programowania dynamicznego .Polega ona
na tym, iż rozwiązanie wyższego poziomu obliczamy z rozwiązań otrzymanych na poziomie niższym, które odpowiednio zapamiętujemy. Dzięki temu
podejściu program nie musi liczyć wszystkich składników od początku, wykorzystuje wyniki
poprzednich obliczeń. W efekcie klasa złożoności obliczeniowej algorytmu spadnie do O(n).
21

Schemat krokowy: Algorytm generacji liczb Fibonacciego metodą iteracyjną
Wejście
n – numer liczby ciągu Fibonacciego do wyliczenia, n ϵ N
Wyjście:
n-ta liczba ciągu Fibonacciego
Elementy pomocnicze:
f0,f1,f – kolejne trzy liczby Fibonacciego, f0,f1,f ϵ C
Lista kroków:
01: f0 ← 0 ; pierwsza lub fi-2 liczba Fibonacciego
02: f1 ← 1 ; druga lub fi-1 liczba Fibonacciego
03: Dla i = 0,1,...,n wykonuj 04...08
04: Jeśli i > 1, to idź do 06
05: f ← i i następny obieg pętli 03
06: f ← f0 + f1 ; obliczamy kolejną liczbę Fibonacciego
07: f0 ← f1 ; zapamiętujemy wyniki obliczeń pośrednich
08: f1 ← f ; dla następnego obiegu pętli
09: Pisz f
10: Zakończ 22
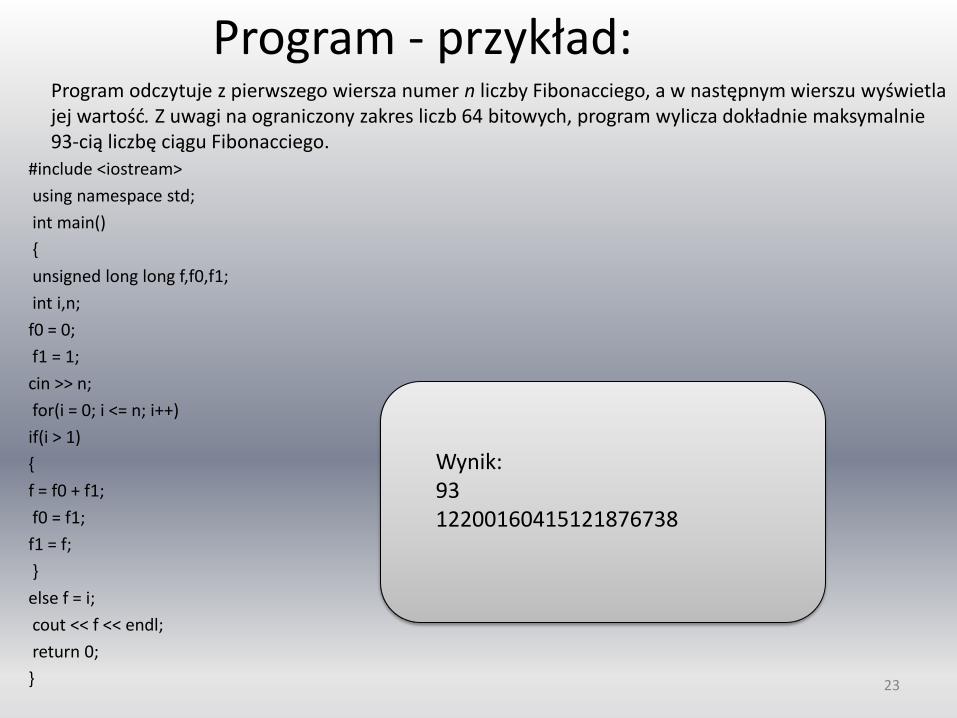
Program - przykład:
#include <iostream>
using namespace std;
int main()
{
unsigned long long f,f0,f1;
int i,n;
f0 = 0;
f1 = 1;
cin >> n;
for(i = 0; i <= n; i++)
if(i > 1)
{
f = f0 + f1;
f0 = f1;
f1 = f;
}
else f = i;
cout << f << endl;
return 0;
}
Wynik: 93 12200160415121876738
Program odczytuje z pierwszego wiersza numer n liczby Fibonacciego, a w następnym wierszu wyświetla jej wartość. Z uwagi na ograniczony zakres liczb 64 bitowych, program wylicza dokładnie maksymalnie 93-cią liczbę ciągu Fibonacciego.
23

Całkowity pierwiastek kwadratowy Całkowity pierwiastek kwadratowy jest
największą liczbą całkowitą p, która spełnia nierówność:
p2 ≤ x
Problem:
Znaleźć kwadratowy pierwiastek całkowity nieujemnej liczby rzeczywistej x.
24

Rozwiązanie 1 Problem możemy rozwiązać następująco.
Tworzymy ciąg kwadratów kolejnych liczb całkowitych począwszy od 0:
02 12 22 32 ...i2
do momentu, gdy dla pewnego i otrzymamy spełnioną
nierówność i2 > x. Wtedy p = i - 1.
Pozostaje do rozwiązania efektywny sposób tworzenia kwadratów kolejnych liczb całkowitych. Wypiszmy kilkanaście początkowych
wyrazów tego ciągu: i 0 1 2 3 4 5 6 7 8 9 10 11 12 ...
i2 0 1 4 9 16 25 36 49 64 81 100 121 144 ...
Teraz policzmy ciąg różnic pierwszego rzędu: r1i = i2 - (i-1)2, dla i > 0.
25
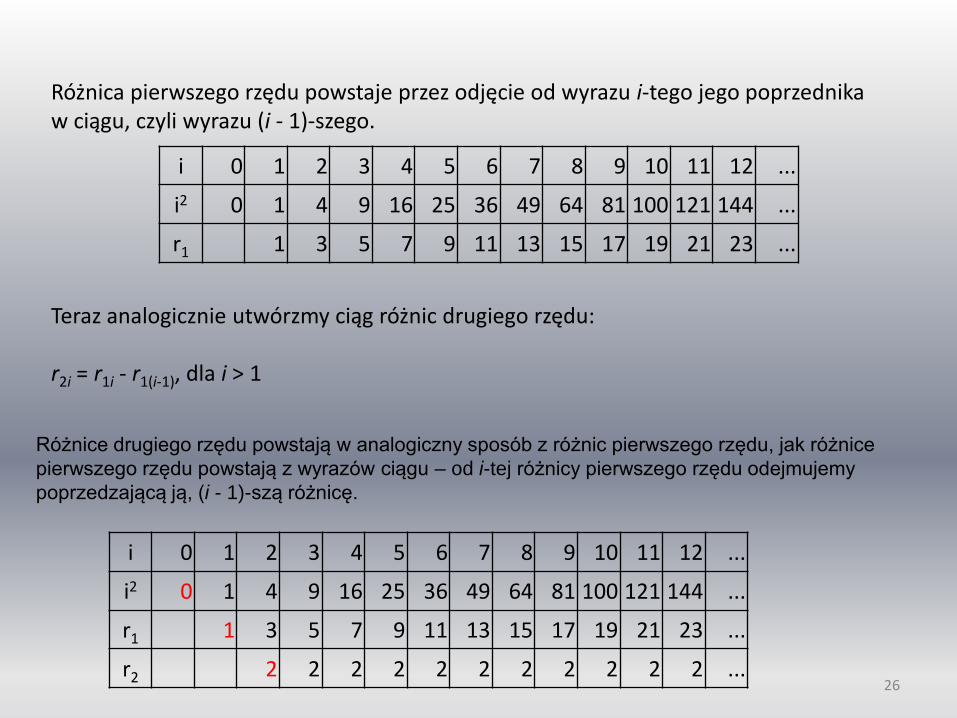
Różnica pierwszego rzędu powstaje przez odjęcie od wyrazu i-tego jego poprzednika w ciągu, czyli wyrazu (i - 1)-szego.
i 0 1 2 3 4 5 6 7 8 9 10 11 12 ...
i2 0 1 4 9 16 25 36 49 64 81 100 121 144 ...
r1 1 3 5 7 9 11 13 15 17 19 21 23 ...
Teraz analogicznie utwórzmy ciąg różnic drugiego rzędu: r2i = r1i - r1(i-1), dla i > 1
Różnice drugiego rzędu powstają w analogiczny sposób z różnic pierwszego rzędu, jak różnice
pierwszego rzędu powstają z wyrazów ciągu – od i-tej różnicy pierwszego rzędu odejmujemy
poprzedzającą ją, (i - 1)-szą różnicę.
i 0 1 2 3 4 5 6 7 8 9 10 11 12 ...
i2 0 1 4 9 16 25 36 49 64 81 100 121 144 ...
r1 1 3 5 7 9 11 13 15 17 19 21 23 ...
r2 2 2 2 2 2 2 2 2 2 2 2 ... 26

Różnice rzędu drugiego tworzą już ciąg stały o wyrazach równych 2. W tabelce na czerwono zaznaczyliśmy pierwsze wyrazy odpowiednio: ciągu kwadratów i2 → 0 ciągu różnic pierwszego rzędu r1i → 1 ciągu różnic drugiego rzędu r2i → 2 Mając te trzy wartości możemy rekurencyjnie konstruować ciąg kolejnych kwadratów: a = 0, r11 = 1, r2 = 2, gdzie a0 – pierwszy wyraz ciągu kwadratów Dla i > 0 mamy: r1i = r1(i-1) + r2 – kolejna różnica pierwszego rzędu powstaje z poprzedniej przez dodanie różnicy drugiego rzędu ai = ai-1 + r1i – kolejny kwadrat powstaje z poprzedniego przez dodanie wyliczonej różnicy pierwszego rzędu
27

Schemat krokowy: Algorytm obliczania całkowitego pierwiastka kwadratowego – wersja nr 1
Wejście
x – liczba, której pierwiastek obliczamy, x ≥ 0, x ϵ R
Wyjście:
całkowity pierwiastek kwadratowy z x
Elementy pomocnicze:
i – numery wyrazów ciągu kwadratów, i ϵ C
a –wyraz ciągu kwadratów, aϵ C
r1 –różnica pierwszego rzędu, r1ϵ N
r2 –różnica drugiego rzędu, r2 ϵ N
Lista kroków: 01: a ← 0 ; pierwszy kwadrat 02
02: r1 ← 1 ; początkowa wartość różnicy pierwszego rzędu
03: r2 ← 2 ; wartość różnic drugiego rzędu
04: i ← 0 ; numer pierwszego wyrazu
05: Dopóki a ≤ x wykonuj 06...08 ; szukamy pierwszego wyrazu a większego od x
06: a ← a + r1 ; następny kwadrat
07: r1 ← r1 + r2 ; wyliczamy nową różnicę pierwszego rzędu
08: i ← i + 1 ; następny numer
09: Zakończ z wynikiem i - 1 ; obliczamy pierwiastek całkowity 28

Program-przykład:
#include <iostream>
using namespace std;
int main()
{
double x;
unsigned int i,a,r1,r2;
cin >> x;
a = 0; r1 = 1; r2 = 2;
for(i = 0; a <= x; i++)
{
a += r1; r1 += r2;
}
i--;
cout << i << endl
<< i * i << endl
<< endl;
return 0;
}
Wynik: 135 11 121
W pierwszym wierszu program odczytuje liczbę x. Następnie wyznacza jej całkowity pierwiastek kwadratowy i wypisuje go w wierszu drugim. Dodatkowo w wierszu trzecim program wypisuje kwadrat znalezionego pierwiastka kwadratowego dla celów porównawczych.
29

Koniec !!
30


















