
Analizy statystyczne w pracach naukowych czego unikać, na...
23
Analizy statystyczne w pracach naukowych – czego unikać, na co zwracać uwagę. Statistics in academic papers, what to avoid and what to focus on. dr Dominik M. Marciniak Uniwersytet Medyczny im. Piastów Śląskich we Wrocławiu Wydział Farmaceutyczny Katedra i Zakład Technologii Postaci Leku
Transcript of Analizy statystyczne w pracach naukowych czego unikać, na...

Analizy statystyczne w pracach naukowych – czego unikać, na co
zwracać uwagę. Statistics in academic papers, what to avoid and what to focus on.
dr Dominik M. Marciniak
Uniwersytet Medyczny im. Piastów Śląskich we Wrocławiu
Wydział Farmaceutyczny
Katedra i Zakład Technologii Postaci Leku

Najczęściej wykonywane analizy
statystyczne w naukach medycznych
Jednowymiarowe analizy klasyczne:
– Wyznaczanie statystyk opisowych (średnia, odchylenie standardowe, wariancja, mediana, moda, współczynnik zmienności, błąd standardowy, skośność, kurtoza, przedziały ufności, kwartyle, percentyle, itp.), określanie niepewności pomiarowych.
– Porównywanie dwóch średnich – testy t
– Porównywanie wielu średnich – analiza wariancji ANOVA
– Testy Chi-kwadrat
– Regresja linowa i korelacja
– Testy nieparametryczne

Ogólne modele liniowe i nieliniowe:
–Regresja liniowa i wieloraka
–Regresja nieliniowa
–Regresja logistyczna
–Wieloczynnikowa i wielowymiarowa analiza wariancji – MANOVA.
–Analiza kowariancji
–Analiza reszt

Analizy wielowymiarowe i przemysłowe:
–Analiza kanoniczna
–Analiza dyskryminacyjna i analiza głównych składowych
–Analiza czynnikowa
–Analiza skupień
–Analiza log-linowa
–Analiza korespondencji
–Analiza przeżycia
–Estymacja nieliniowa

Obecnie wszyscy jesteśmy
statystykami
dzięki rozbudowanym
programom komputerowym,
które sprowadzają
przeprowadzenie analizy
statystycznej do jednego
kliknięcia myszką.

Podstawowe pojęcia statystyczne Niepewności pomiarowe, cyfry znaczące: Każdy, nawet najprostszy wynik pomiaru powinien być
przedstawiany w następującej formie:
x = xnp +/- δx.
wartość zmierzona = najlepsze przybliżenie +/- niepewność (błąd pomiaru)
Najczęściej popełniane błędy dotyczą zapisów:
Wartość zmierzona = 9,82 +/- 0,03385 - niepoprawnie
Niepewności eksperymentalne powinny być prawie zawsze zaokrąglane do jednej cyfry znaczącej. Jeżeli pierwszą cyfrą znaczącą niepewności δx jest 1 lub 2 to możemy podać dwie cyfry znaczące.
Wartość zmierzona = 9,82 +/- 0,03 – poprawnie
Wartość zmierzona = 6051,78 +/- 30 – niepoprawnie
Ostatnia cyfra znacząca w każdym wyniku powinna zwykle być tego samego rzędu co niepewność.
Wartość zmierzona = 6050 +/- 30 – poprawnie
Wynik 92,8 z niepewnością 0,3 to 92,8 +/- 0,3
Wynik 92,8 z niepewnością 3 to 93 +/- 3
Wynik 92,8 z niepewnością 30 to 90 +/- 30
Liczby używane w obliczeniach powinny mieć zwykle jedną cyfrę znaczącą więcej niż te podawane ostatecznie.

Brak należytego zrozumienia istoty problemu badawczego, przed przystąpieniem do analizy statystycznej:
– Na każde zjawisko działają dwa rodzaje przyczyn: Przyczyny główne – wynikają z istoty problemu, działają w sposób trwały i dobrze ukierunkowany, jednakowo na wszystkie elementy badanej zbiorowości, to one powodują powstanie prawidłowości (są składnikiem systematycznym).
Przyczyny uboczne – czyli losowe, oddziałują różnie na poszczególne elementy zbiorowości, działają różnokierunkowo i w sposób nietrwały. One powodują odchylenia od prawidłowości i są źródłem tzw. składnika losowego.
Dobre zrozumienie problemu to przede wszystkim poprawna identyfikacja przyczyn głównych i ubocznych.
Statystyka to nauka służebna wobec innych nauk. Ma służyć potwierdzaniu hipotez
badawczych, a nie ich kreowaniu.

Brak jednorodności i reprezentowalności badanej próby: Statystyka wykazuje dwupoziomowe działanie – w oparciu o wyliczone konkretne statystyki na podstawie wyników zebranych z części populacji zwanej próbą, wnioskujemy o całej populacji. Zarówno próba jak populacja powinny być jednorodne.
Zbiorowość jest jednorodna wtedy, gdy wszystkie jej elementy pozostają pod wpływem działania tych samych przyczyn głównych. Próba jest reprezentatywna, jeżeli jej
struktura jest identyczna lub bardzo zbliżona do zbiorowości ogólnej.
Brak losowego doboru próby: Próba jest dobrze wylosowana, jeżeli każdy element
zbiorowości ogólnej ma takie samo prawdopodobieństwo wejścia do próby.
Najczęściej w badaniach ankietowych dochodzi do nielosowego doboru próby.
Przekład błędu: wyników ankiet przeprowadzanych na studentach lub ankiet internetowych nie można uogólniać na całe społeczeństwo.

Cechy statystyczne Mylne określanie i wykorzystywanie skal pomiarowych: Zasadniczo rozróżniamy cztery rodzaje skal pomiarowych: nominalna, porządkowa, przedziałowa i ilorazowa. Od przyjętej skali zależy wybór odpowiedniej analizy statystycznej.
Najczęściej mylone są skale przedziałowa bądź ilorazowa (wykorzystywane w większości testów parametrycznych) ze skalą porządkową (na której oparte są z reguły testy nieparametryczne). Rangi, które są efektem pomiaru skali porządkowej, nie pozwalają na liczenie odległości (a więc również różnic) i średnich.
Przykład: Wykorzystując nieparametryczne odpowiedniki testu t takie jak: test U Manna-Whitneya, czy test serii Walda-Wolfowitza nie należy przedstawiać wykresów średnia-błąd_standardowy-1,96*błędu_standardowego tylko mediana-25%/75%-minimum/maksimum.:

Szeregi statystyczne Błędy w budowie szeregów rozdzielczych:
– Szeregi z dziurami:
Wiek: 0-4, 5-9, 10-14, 15-19 itd.
– Szeregi otwarte:
Wiek: (0,5), (5,10), (10,15), (15,20) itd.
Zgodnie z definicją dystrybuanty – poprawnie zdefiniowany szereg rozdzielczy powinien być lewostronnie domknięty, a prawostronnie otwarty:
Wiek: <0,5), <5,10), <10,15), <15,20) itd.

Prawdopodobieństwo
Definicja prawdopodobieństwa wprowadzona mówi, że jest to funkcja o wartościach z przedziału <0,1>.
Częsty błąd to traktowanie prawdopodobieństwa jako liczby z przedziału od 0 do 100.

Liczebność próby
Nie ma prostej i uniwersalnej odpowiedzi na pytanie jaka powinna być minimalna liczebność próby.
Liczebność próby zależy od wielu czynników i często trudno ją określić na początku badań (konieczne jest często przeprowadzanie wstępnych badań pilotażowych na małej grupie). Liczebność próby zależy między innymi od:
– Rodzaju analizy statystycznej
– Rodzaju analizowanego parametru
– Jaka jest zmienność analizowanego zjawiska
– Jak dużą różnicę chcemy wykazać
– Jaki przyjmiemy poziom ufności p

Niczym nieuzasadniony jest strach badaczy przed małą próbą. Większość klasycznych analiz statystycznych można wykonać w oparciu o próby trzyelementowe. Lepiej wykonać analizę statystyczną na małej próbie niż nie wykonywać jej wcale !!!
Kluczem jest uświadomienie sobie jaki wpływ ma liczebność próby na wyniki wnioskowania statystycznego:
Przy małej próbie trudno udowodnić hipotezy badawcze (szczególnie w
przypadku dużej zmienności analizowanej zmiennej i skrajnie małej liczebności próby
– np. 3), natomiast przy bardzo dużej próbie można wykazać istotność
statystyczną dowolnie małej różnicy.
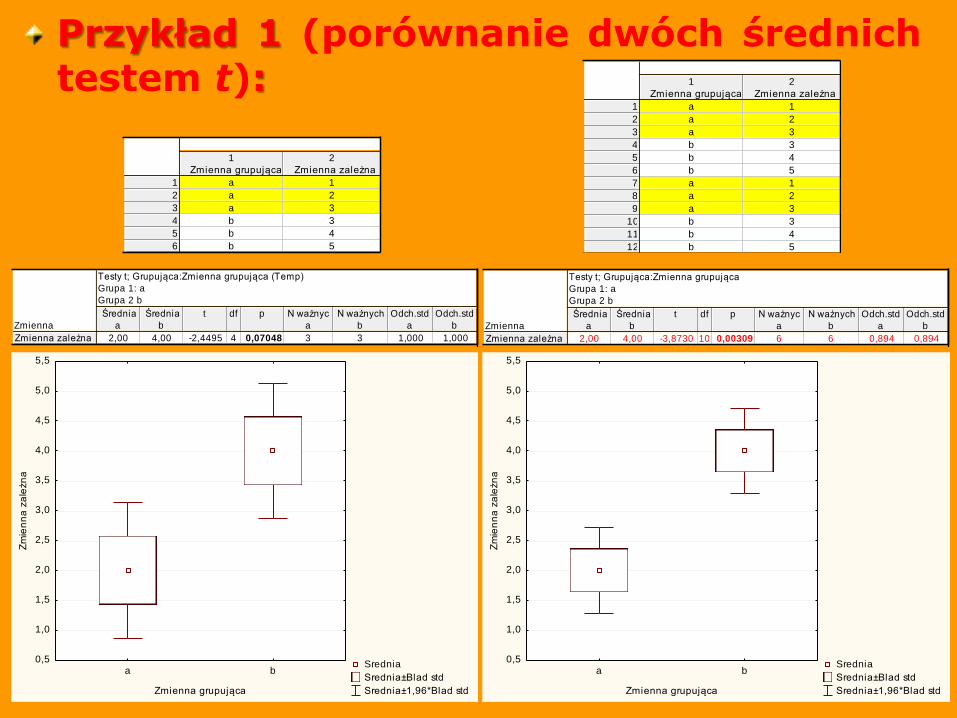
Przykład 1 (porównanie dwóch średnich testem t):
1
Zmienna grupująca
2
Zmienna zależna
1
2
3
4
5
6
a 1
a 2
a 3
b 3
b 4
b 5
Srednia
Srednia±Blad std
Srednia±1,96*Blad std
a b
Zmienna grupująca
0,5
1,0
1,5
2,0
2,5
3,0
3,5
4,0
4,5
5,0
5,5
Zm
ien
na
za
leżn
a
1
Zmienna grupująca
2
Zmienna zależna
1
2
3
4
5
6
7
8
9
10
11
12
a 1
a 2
a 3
b 3
b 4
b 5
a 1
a 2
a 3
b 3
b 4
b 5
Srednia
Srednia±Blad std
Srednia±1,96*Blad std
a b
Zmienna grupująca
0,5
1,0
1,5
2,0
2,5
3,0
3,5
4,0
4,5
5,0
5,5
Zm
ien
na
za
leżn
a
Testy t; Grupująca:Zmienna grupująca
Grupa 1: a
Grupa 2 b
Zmienna
Średnia
a
Średnia
b
t df p N ważnyc
a
N ważnych
b
Odch.std
a
Odch.std
b
Zmienna zależna 2,00 4,00 -3,8730 10 0,00309 6 6 0,894 0,894
Testy t; Grupująca:Zmienna grupująca (Temp)
Grupa 1: a
Grupa 2 b
Zmienna
Średnia
a
Średnia
b
t df p N ważnyc
a
N ważnych
b
Odch.std
a
Odch.std
b
Zmienna zależna 2,00 4,00 -2,4495 4 0,07048 3 3 1,000 1,000
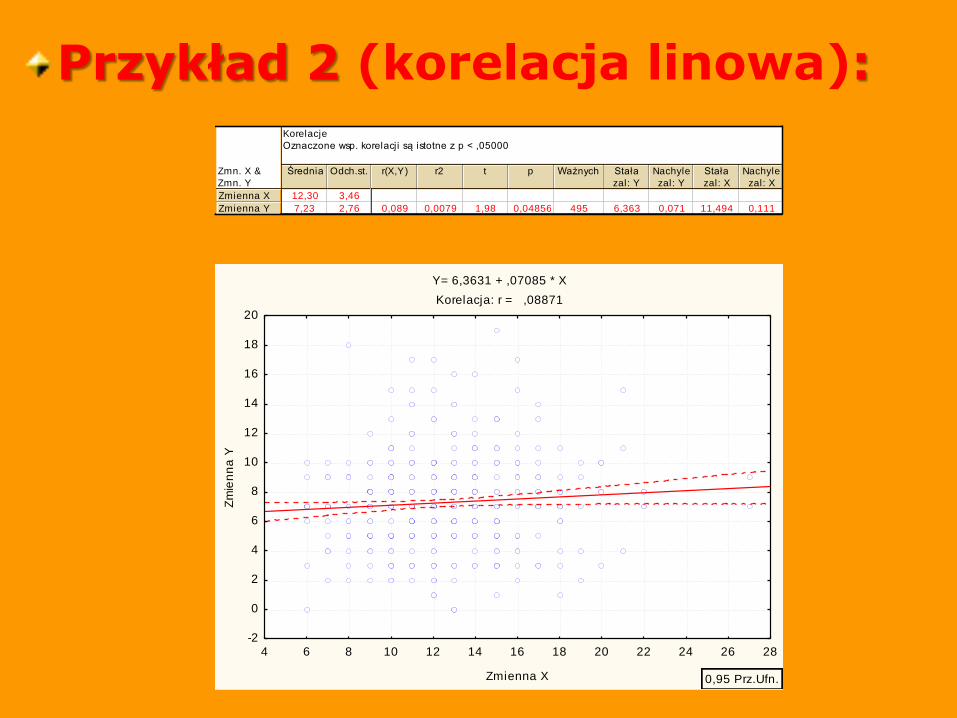
Przykład 2 (korelacja linowa): Korelacje
Oznaczone wsp. korelacji są istotne z p < ,05000
Zmn. X &
Zmn. Y
Średnia Odch.st. r(X,Y) r2 t p Ważnych Stała
zal: Y
Nachyle
zal: Y
Stała
zal: X
Nachyle
zal: X
Zmienna X
Zmienna Y
12,30 3,46
7,23 2,76 0,089 0,0079 1,98 0,04856 495 6,363 0,071 11,494 0,111
Y= 6,3631 + ,07085 * X
Korelacja: r = ,08871
4 6 8 10 12 14 16 18 20 22 24 26 28
Zmienna X
-2
0
2
4
6
8
10
12
14
16
18
20
Zm
ien
na
Y
0,95 Prz.Ufn.

Testowanie hipotez statystycznych
Problemy dotyczące właściwego zrozumienia pojęcia
hipoteza statystyczna.
Problemy dotyczące właściwego zrozumienia pojęcia
poziom istotności α.
Problemy dotyczące właściwego doboru testów
statystycznych.
Problemy dotyczące weryfikacji założeń testów
statystycznych.
Problemy dotyczące porównań wielokrotnych „każdy
z każdym”.
Problem związany z istotnością współczynnika
korelacji.

Hipoteza statystyczna i poziom istotności Hipoteza statystyczna to dowolny sąd o populacji sformułowany bez wykonywania pełnego badania całej populacji, tylko przeprowadzany na podstawie analizy danych z próby.
W statystyce formułujemy dwie hipotezy: hipotezą zerową H0 i hipotezę alternatywną H1.
Najczęściej hipoteza badawcza jest wyrażona jako hipoteza alternatywna H1, a nie jako hipoteza zerowa H0, która nie
pozostawia wyboru.
W toku testowania możemy podjąć dwie decyzje:
– Odrzucić hipotezę zerową H0 i przyjąć hipotezę alternatywną H1.
– Nie mamy podstaw do odrzucenia hipotezy zerowej H0.
W toku testowania możemy popełnić dwa błędy:
– Błąd pierwszego rodzaju: odrzucenie prawdziwej hipotezy zerowej H0.
– Błąd drugiego rodzaju: przyjęcie fałszywej hipotezy zerowej H0.
Hipoteza zerowa
Decyzje
Nie ma podstaw do odrzucenia H0
Odrzucić H0
Hipoteza zerowa
prawdziwa
Decyzja prawidłowa Błąd I rodzaju
Hipoteza zerowa
fałszywa
Błąd II rodzaju Decyzja prawidłowa
Poziom istotności α jest to
prawdopodobieństwo popełnienia
błędu pierwszego rodzaju. Zakłada
do sam badacz z góry. Zwykle jest
to 0,05 lub 0,01.

Określanie hipotez statystycznych po przeprowadzeniu doświadczeń. – Hipotezy statystyczne należy jasno określić przed badaniem, na
etapie jego projektowania. Niedopuszczalne jest formułowanie ich w oparciu o otrzymane wyniki.
Nieokreślenie czy hipoteza alternatywna H1 ma być jednostronna (kierunkowa) czy dwustronna (bezkierunkowa). – Dla przykładu porównując testem t dwie średnie hipoteza zerowa H0
brzmi dwie średnie są sobie równe, hipoteza alternatywna H1 może brzmieć jedna średnia jest większa od drugiej (kierunkowa), lub jedna średnia jest różna od drugiej (bezkierunkowa). Często wykonując tego typu testy nie zwraca się uwagi co tak naprawdę wykazano.
Częsty błąd, który można znaleźć w publikacjach naukowych to stwierdzenie, że przyjmujemy hipotezę zerową H0. – Hipotezy zerowej nie można przyjąć H0 (nie można udowodnić
równości średnich czy braku korelacji między zmiennymi), można nie mieć podstaw do jej odrzucenia co w praktyce oznacza tyle że nie udało nam się wykazać słuszności naszych założeń sformułowanych w hipotezie alternatywnej H1.

Właściwy dobór i weryfikacja założeń testów
statystycznych
Niewłaściwy dobór testu statystycznego to najczęściej popełniana grupa błędów przy przeprowadzaniu analiz statystycznych, a najważniejsze z nich to:
Stosowanie testów parametrycznych bez sprawdzenia założeń dotyczących wymaganego rozkładu, jednorodności wariancji itp. Testy parametryczne zawsze oparte są na założeniach o typie rozkładu zmiennej losowej, którą badamy (często i innych założeniach). Ich stosowanie narzuca nam konieczność weryfikacji czy badana zmienna losowa spełnia wszystkie wymagane założenia – co bardzo często nie jest robione lub ignorowane są wyniki testów sprawdzających założenia.
Stosowanie testów dla prób zależnych w sytuacji gdy mamy do czynienia z próbami niezależnymi i na odwrót. Określenie czy mamy do czynienia z próbami zależnymi czy niezależnymi często jest dość trudne. W celu stwierdzenia z jakim powiązaniem zmiennych mamy do czynienia można się kierować jedną bardzo pomocną zasadą: Jeżeli przeprowadzając doświadczenie, porównywane zmienne można teoretycznie pozyskać w jednym i tym samym czasie to zwykle mamy do czynienia ze zmiennymi niezależnymi. Jeżeli natomiast niezbędny jest odstęp czasowy pomiędzy zbieranymi wynikami będącymi następnie analizowanymi zmiennymi losowymi, to z reguły istnieje czynnik uzależniający zmienne od siebie.
Przykład:
Leki A i B podajemy dwóm niezależnym grupą osób – zmienne niezależne.
Leki A i B podajemy tej samej grupie osób – potrzebny jest czas wymycia jednego z leków – zmienne zależne.

Nieprzestrzeganie minimalnej liczebności próby wymaganej dla danego testu.
Wiele testów (test chi-kwadrat, niektóre rodzaje testów t, prawie wszystkie wyrafinowane analizy wielowymiarowe) wymaga minimalnej liczebności próby co, często jest ignorowane. Prawie wszystkie testy nie tolerują 0 i 1, a są bardzo mało precyzyjne dla prób o liczebnościach 2-5.
Przy różnego typu estymacjach parametrów często stosuje się zasadę minimum: liczebność próby musi być większa od ilości
estymowanych parametrów.
Nieodpowiednie dobranie testów do skali pomiarowej, z którą mamy do czynienia.
Częsty błąd dotyczący analizy regresji liniowej i korelacji to wyznaczanie współczynnik korelacji liniowej Pearsona dla zmiennych o charakterze porządkowym, lub odwrotnie, wyznaczanie korelacji Spearmana dla zmiennych w skali przedziałowej lub ilorazowej.

Porównania wielokrotne
„każdy z każdym” Należy pamiętać, że zakładany poziom istotności α dotyczy
pojedynczego testowania, i jeżeli daną procedurę statystyczną wykorzystamy wielokrotnie to zakładane prawdopodobieństwo popełnienia błędu pierwszego rodzaju na poziomie 0,05 dla całej analizy będzie znacznie wyższe, co zwykle jest niedopuszczalne. Tego typu błędy najczęściej są popełniane przy wykonywaniu dwóch typów analiz statystycznych:
Porównywanie wielu średnich ze sobą i wykorzystywanie do tego testu t (porównując „każdy z każdym”) zamiast analizy wariancji ANOVA wraz z testami post-hoc.
Przykład:
Przy poziomie istotności α = 0,05 prawdopodobieństwo, że się nie pomylimy
dla jednego porównania wynosi 1 - 0,05 = 0,95.
Dla dwóch porównań 0,952 = 0,9025.
Dla czterech grup mamy sześć porównań, a wówczas wartość ta wynosi 0,956 = 0,7351.
Prawdopodobieństwo, że pomylimy się co najmniej jeden raz wynosi 1- 0,7351 = 0,265.
Określanie istotności statystycznej współczynników korelacji liniowej r w macierzach korelacji.
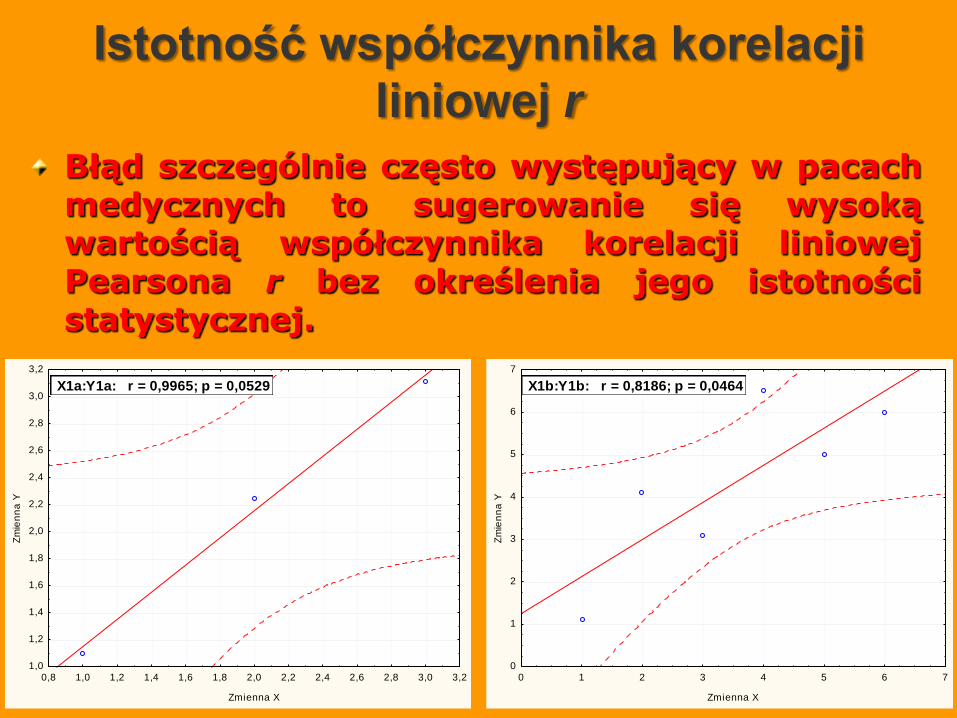
Istotność współczynnika korelacji
liniowej r
Błąd szczególnie często występujący w pacach medycznych to sugerowanie się wysoką wartością współczynnika korelacji liniowej Pearsona r bez określenia jego istotności statystycznej.
0,8 1,0 1,2 1,4 1,6 1,8 2,0 2,2 2,4 2,6 2,8 3,0 3,2
Zmienna X
1,0
1,2
1,4
1,6
1,8
2,0
2,2
2,4
2,6
2,8
3,0
3,2
Zm
ien
na
Y
X1a:Y1a: r = 0,9965; p = 0,0529
0 1 2 3 4 5 6 7
Zmienna X
0
1
2
3
4
5
6
7
Zm
ien
na
Y
X1b:Y1b: r = 0,8186; p = 0,0464

Wartość p Mylenie wartości p z poziomem istotności α.
Wartość p to najwyższy możliwy poziom istotności, przy którym możemy odrzucić testowaną hipotezę w oparciu o uzyskane dane empiryczne.
Jeżeli p < α to odrzucamy hipotezę zerową H0.
Mało eleganckie zapisy wartości p.
W publikacjach naukowych można znaleźć zapisy wartości p typu: p = 0,0000 co jest wynikiem bezmyślnego kopiowania tabel z wynikami analiz statystycznych – taki zapis jest nieelegancki i lepiej go zastąpić równoważnym zapisem p < 0,0001.


















