

AI&SEO - jak sztuczna inteligencja może zmienić rynek wyszukiwarek
Upload
hoangquynhCategory
view
214download
0
Seminarium — Instytut Informatyki Politechniki Poznańskiej6 styczeń 2004
Dawid Weiss
Instytut InformatykiPolitechnika Poznańska
Grupowanie wyników zapytańdo wyszukiwarek internetowych
oraz propozycje usprawnień algorytmów przy pomocy fraz poprawnych językowo

Plan prezentacji
• Wprowadzenie i przedstawienie problemu
• Problemy szczegółowe i stan wiedzy• Analiza skupień w dokumentach tekstowych• Znalezienie czytelnego opisu dla grupy• Ocena jakości grupowania
• Badania własne i plany na przyszłość• Nowe algorytmy grupowania• Nowe metody wyboru opisu grup
• Uwzględnienie specyfiki języka polskiego
• Propozycje miar oceny jakości grupowania• System Carrot2
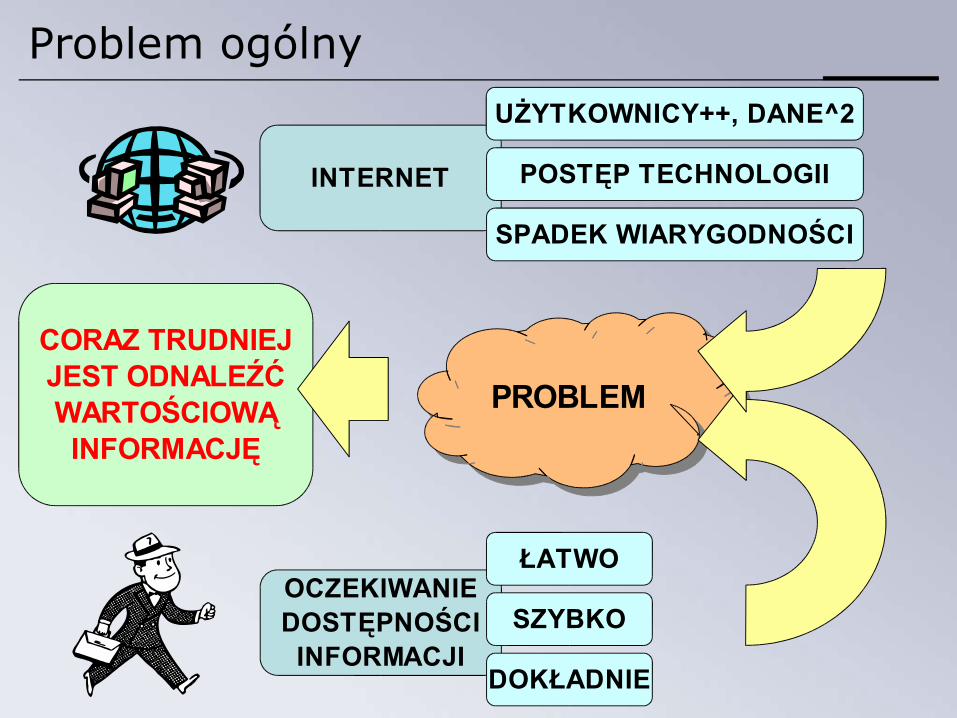
Problem ogólny
OCZEKIWANIEDOSTĘPNOŚCI
INFORMACJI
ŁATWO
SZYBKO
DOKŁADNIE
INTERNET
UŻYTKOWNICY++, DANE^2
POSTĘP TECHNOLOGII
SPADEK WIARYGODNOŚCI
PROBLEM
CORAZ TRUDNIEJJEST ODNALEŹĆWARTOŚCIOWĄ
INFORMACJĘ
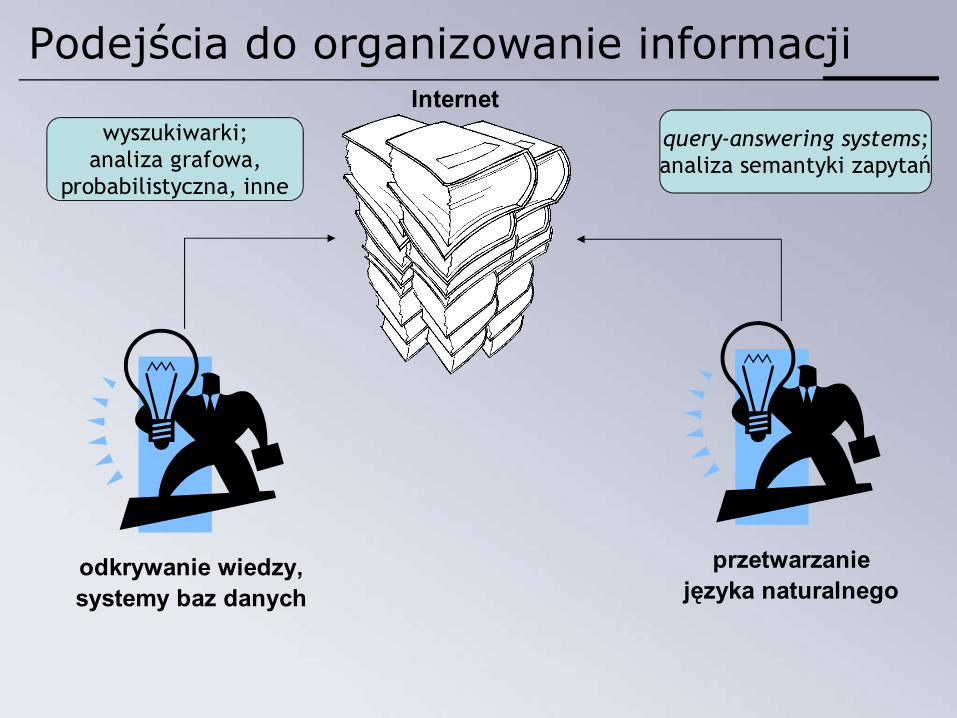
Podejścia do organizowanie informacjiInternet
query-answering systems;analiza semantyki zapytań
przetwarzaniejęzyka naturalnego
wyszukiwarki;analiza grafowa,
probabilistyczna, inne
odkrywanie wiedzy,systemy baz danych

Modele „inżynierskie” – wyszukiwarki
• Liniowy model „dopasowania” (ang. relevance)
• Pracują bez próby zrozumienia tekstu
• Poszukują pytań, a nie odpowiedzi
• Bardzo szybkie i efektywne
• Dobre dla precyzyjnie określonych celów

Query-answering systems
• Oparte na zastosowaniu NLP
• Zazwyczaj specyficzne dla języka (angielski)
• Kontrowersyjna skalowalność
• Mimo wad, ciekawe wyniki
• Odpowiadają na zapytania o szerokim kontekście
• Google również powoli dąży w tę stronę (define:)
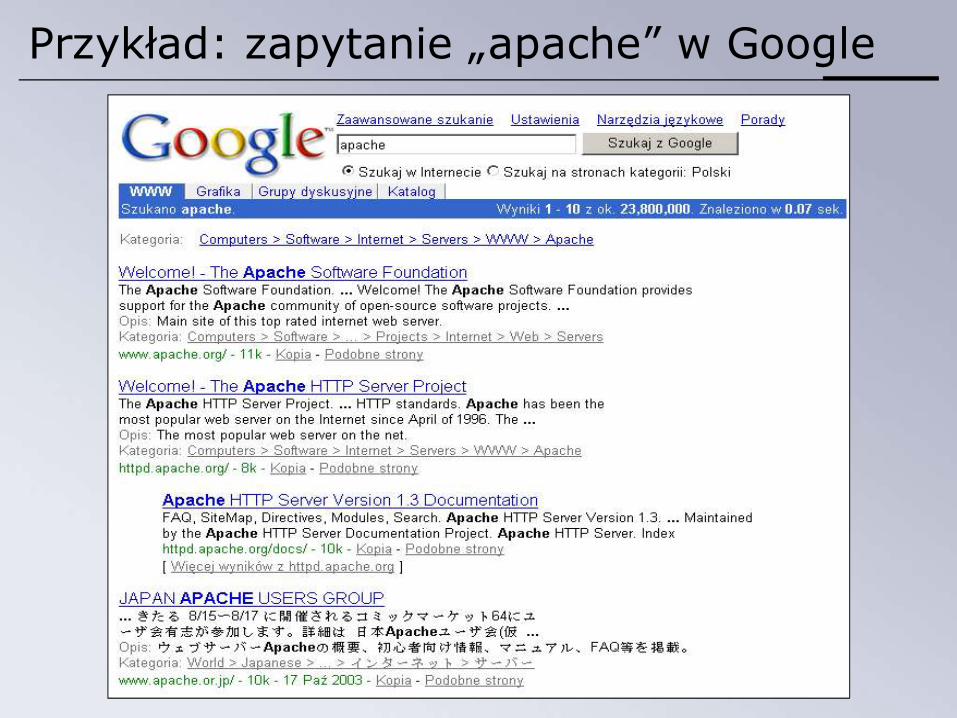
Przykład: zapytanie „apache” w Google
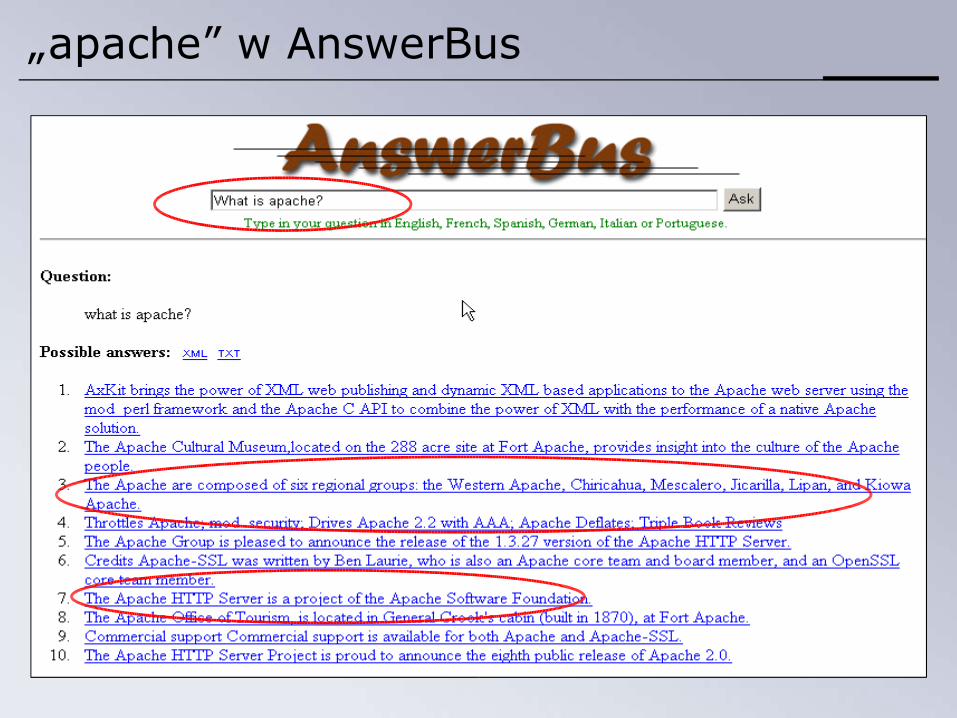
„apache” w AnswerBus
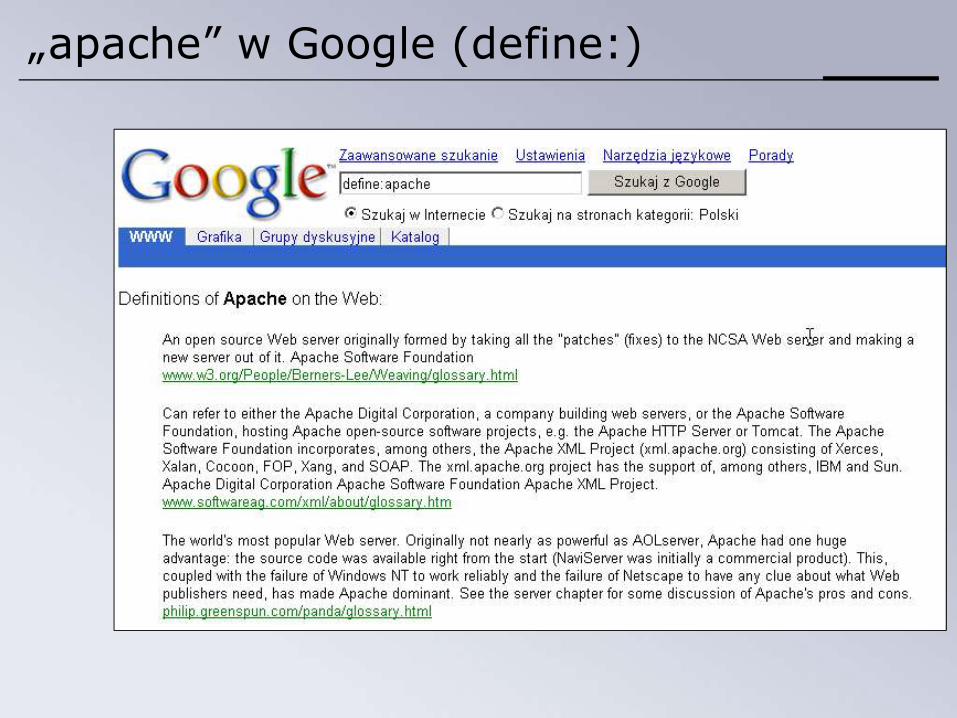
„apache” w Google (define:)
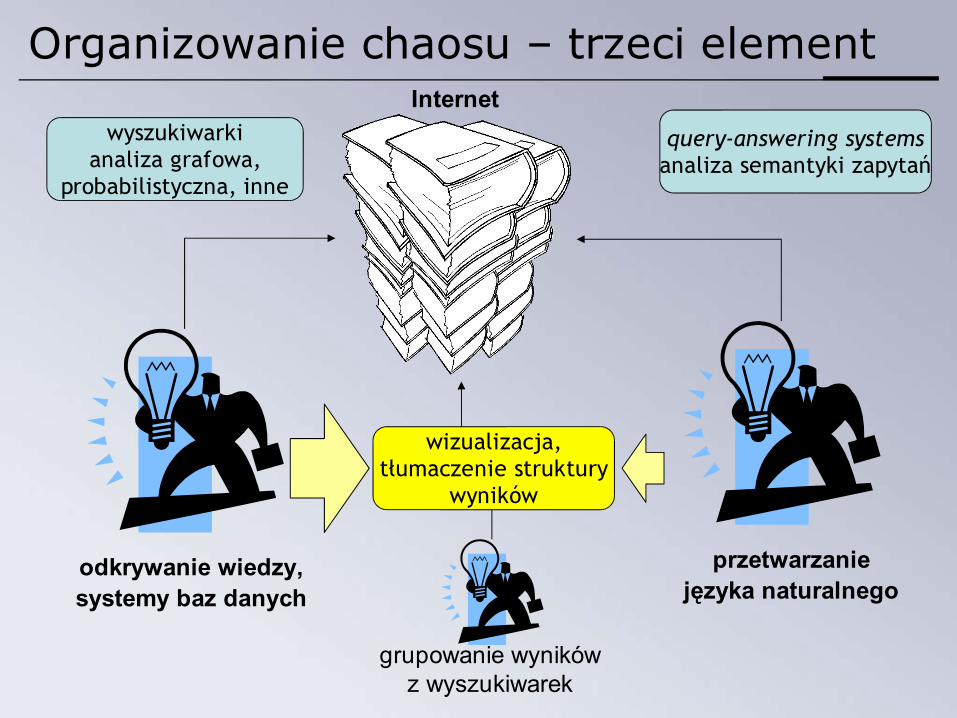
Organizowanie chaosu – trzeci elementInternet
query-answering systemsanaliza semantyki zapytań
przetwarzaniejęzyka naturalnego
wyszukiwarkianaliza grafowa,
probabilistyczna, inne
odkrywanie wiedzy,systemy baz danych
grupowanie wynikówz wyszukiwarek
wizualizacja,tłumaczenie struktury
wyników
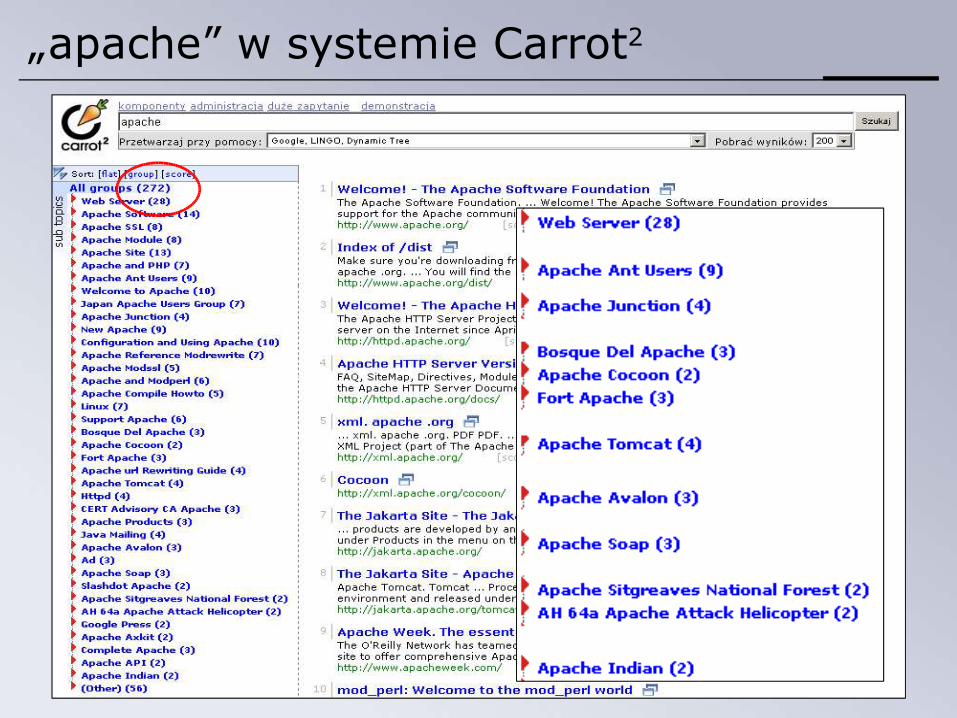
„apache” w systemie Carrot2
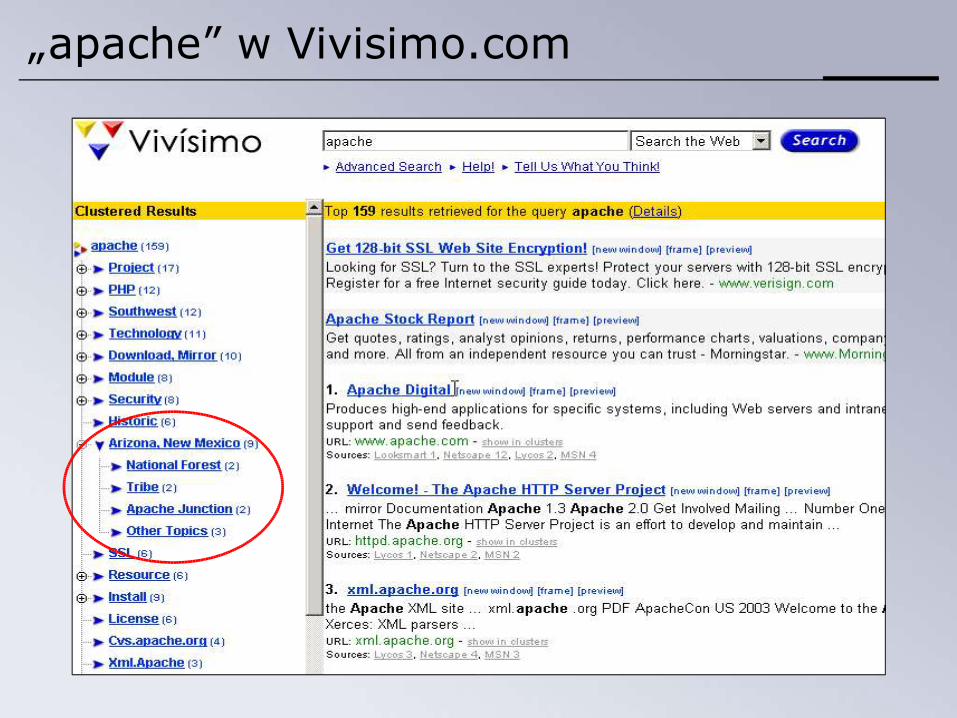
„apache” w Vivisimo.com
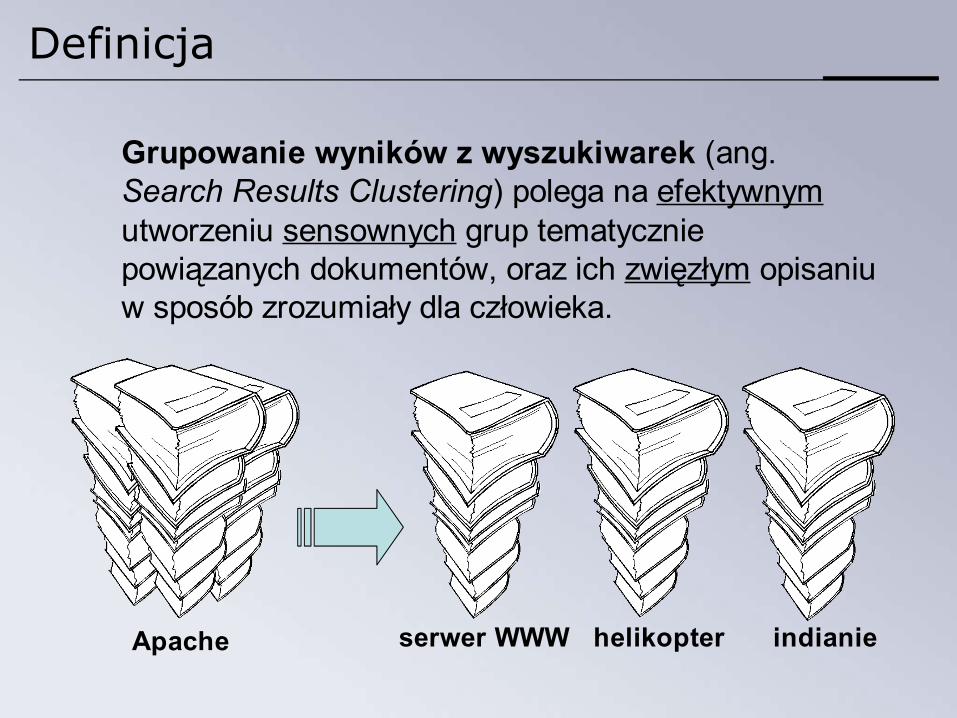
Definicja
serwer WWW helikopter indianie
Grupowanie wyników z wyszukiwarek (ang. Search Results Clustering) polega na efektywnym utworzeniu sensownych grup tematycznie powiązanych dokumentów, oraz ich zwięzłym opisaniu w sposób zrozumiały dla człowieka.
Apache

Ważne podproblemy SRC
I. Wyodrębnić podobne dokumenty
III. Opisać utworzone grupy
V. Zweryfikować jakość wyników
All the real knowledge which we possess, depends on methods by which we distinguish the similar from the dissimilar.
— Genera plantarum, Linnaeus
A good cluster—or document grouping—is one,which possesses a good, readable description.
— Vivisimo
It is quality rather than quantity that matters.— Seneca (5 BC - 65 AD), Epistles
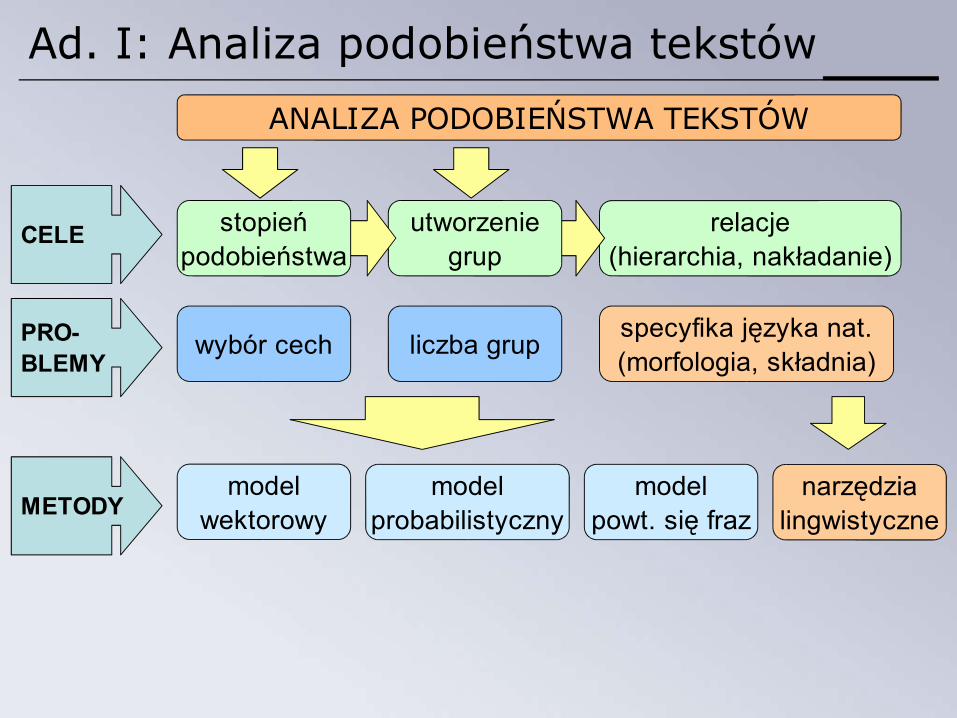
Ad. I: Analiza podobieństwa tekstów
ANALIZA PODOBIEŃSTWA TEKSTÓW
relacje(hierarchia, nakładanie)
utworzeniegrup
stopieńpodobieństwa
CELE
PRO-BLEMY
wybór cech liczba grup specyfika języka nat.(morfologia, składnia)
METODYmodel
wektorowymodel
probabilistycznymodel
powt. się fraznarzędzia
lingwistyczne

Definicje podstawowe
• Przez frazę będziemy rozumieli uporządkowany ciąg słów zaczerpnięty z tekstu• W specyficznych przypadkach dopuszcza się również
frazy o długości jednego słowa• „an expression whose meanings cannot be inferred from
the meanings of the words that make it up” [źródło: WordNet]
• Przez słowo kluczowe będziemy rozumieli słowo reprezentujące znaczenie pewnej dłuższej sekwencji słów, w szczególności całego dokumentu

Model wektorowy
• Zbiór unikalnych słów T=t1, t2, … tn
• Dokumenty (D=d1, d2, … dm) reprezentowane jako n-wymiarowe wektory• di=[wi1, wi2, … win], gdzie wij jest wagą j-tego słowa w
dokumencie i
• Wagi słów — jak dane słowo jest charakterystyczne dla dokumentu?• Wiele różnych form:
• binarna — wij=1 lub wij=0
• częstość wystąpień - wij=tfij(tj)
• tfidf (Salton) – wij=tfij(tj)*log(N/dfij(tj))

Przykład — macierz term-document
0.000.000.000.710.710.000.000.000.001.000.000.000.000.580.000.710.000.000.000.710.580.000.710.000.000.000.710.581.000.000.000.710.710.000.00
A
The t=5 terms:T1: InformationT2: SingularT3: ValueT4: ComputationsT5: Retrieval
D1: Large Scale Singular Value ComputationsD2: Software for the Sparse Singular Value DecompositionD3: Introduction to Modern Information RetrievalD4: Linear Algebra for Intelligent Information RetrievalD5: Matrix ComputationsD6: Singular Value Analysis of CryptogramsD7: Automatic Information Organization
The d=7 documents:
Źródło: Prezentacja Carrot2 Milestone report, Stanisław Osiński

Algorytmy grupowania a VSM
• wykorzystanie informacji o bliskości dokumentów w macierzy A• metody analizy skupień dla danych numerycznych
• właściwości i ograniczenia• grupy zazwyczaj sferyczne• każde słowo jest traktowane oddzielnie• problemy ze znalezieniem opisu grup• trudności w parametryzacji
• brak naturalnego kryterium stopu
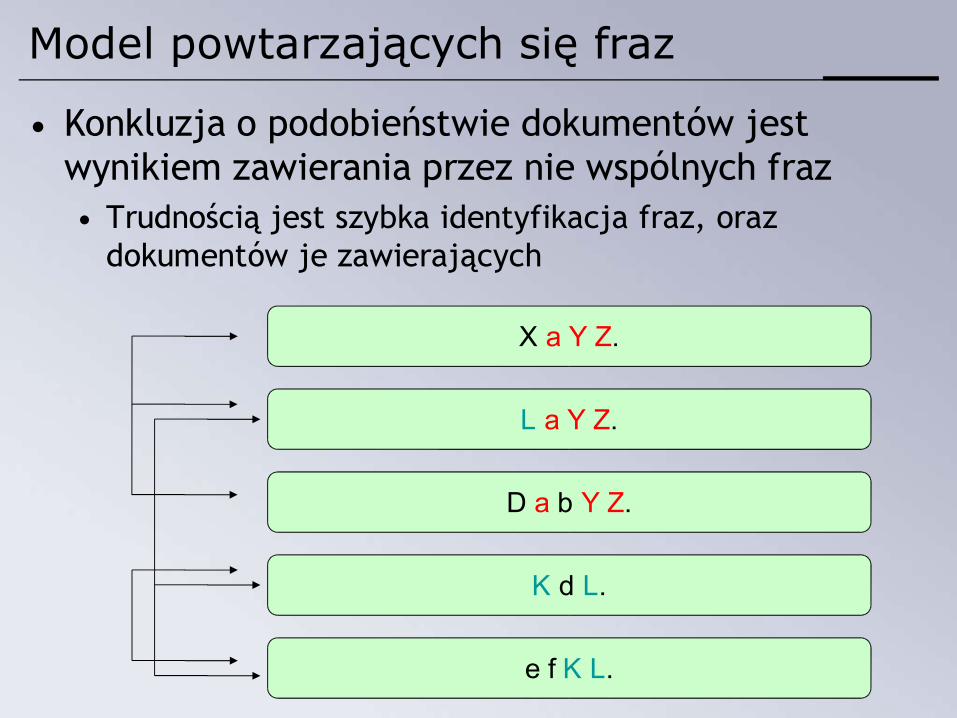
Model powtarzających się fraz
• Konkluzja o podobieństwie dokumentów jest wynikiem zawierania przez nie wspólnych fraz• Trudnością jest szybka identyfikacja fraz, oraz
dokumentów je zawierających
L a Y Z.
D a b Y Z.
K d L.
e f K L.
X a Y Z.
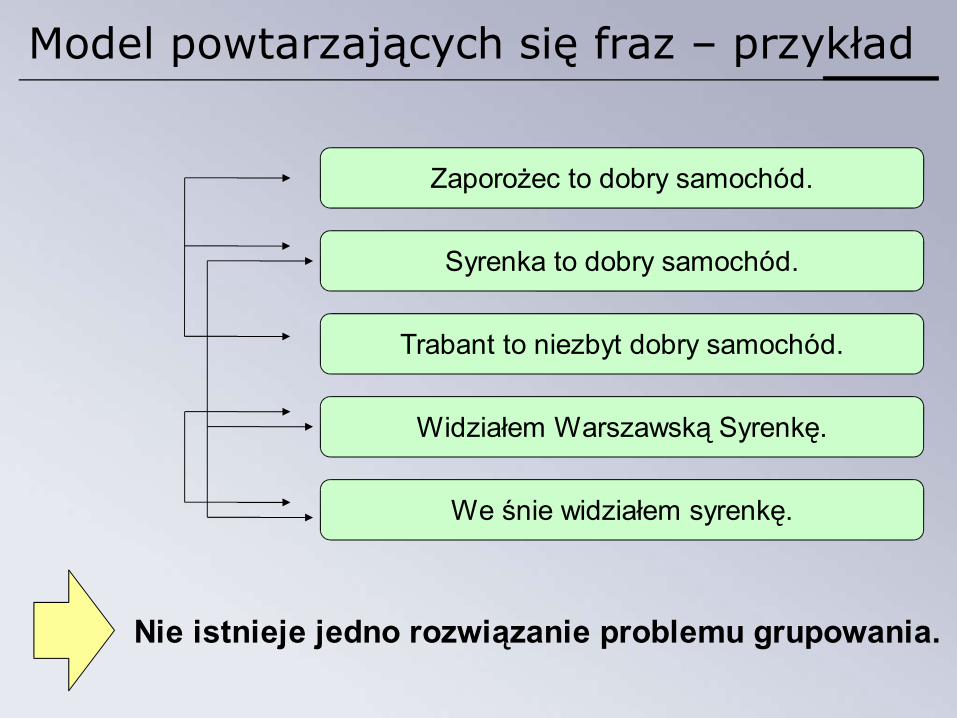
Model powtarzających się fraz – przykład
Syrenka to dobry samochód.
Trabant to niezbyt dobry samochód.
Widziałem Warszawską Syrenkę.
We śnie widziałem syrenkę.
Zaporożec to dobry samochód.
Nie istnieje jedno rozwiązanie problemu grupowania.

Model powtarzających się fraz
• zalety• brak numerycznej miary odległości• frazy stanowią zazwyczaj dobre opisy grup• (teoretycznie) liniowa złożoność — O(N)
• wady• słabo radzi sobie z szumem (noise words)• problemy z separacją mało licznych grup• wrażliwość na progi i język dokumentów
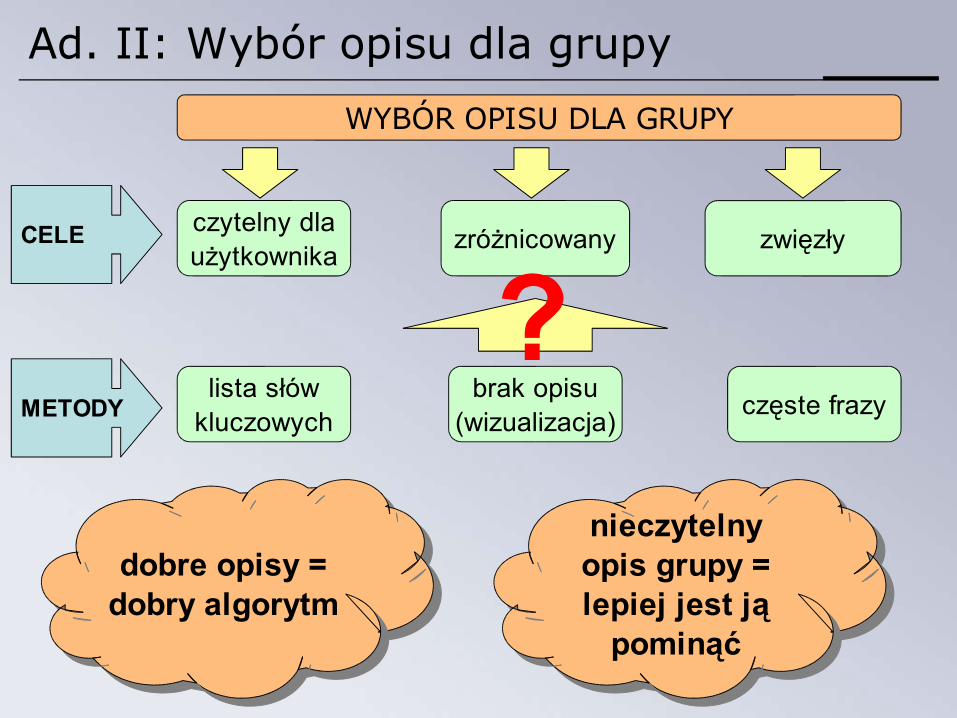
Ad. II: Wybór opisu dla grupy
WYBÓR OPISU DLA GRUPY
zwięzłyzróżnicowanyczytelny dlaużytkownika
CELE
dobre opisy =dobry algorytm
nieczytelny opis grupy = lepiej jest ją
pominąć
METODYlista słów
kluczowychbrak opisu
(wizualizacja) częste frazy
?

Ad. III: Problem weryfikacji wyników
• Natura problemu grupowania jest nieprecyzyjna i opierająca się podziałowi na podproblemy
• Nie istnieje jedno obiektywnie dobre rozwiązanie
• Użytkownicy mają różne oczekiwania• Rozeznanie w tematyce• Poznanie struktury zbioru dokumentów• Zawężenie zakresu zapytania• …
• Ocena musi być więc wielokryterialna
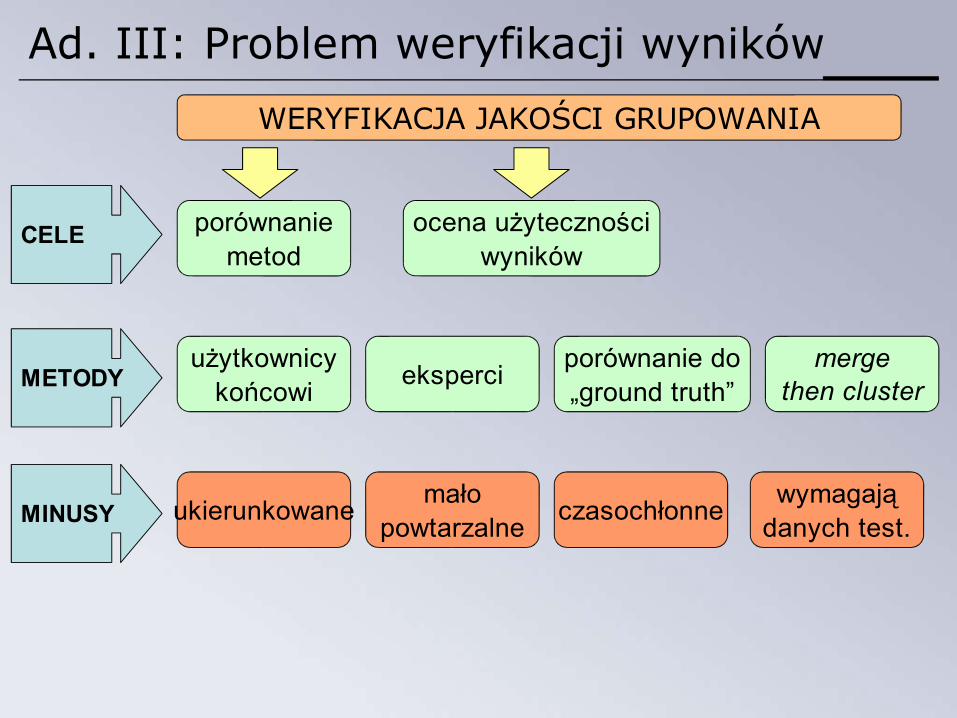
Ad. III: Problem weryfikacji wyników
WERYFIKACJA JAKOŚCI GRUPOWANIA
ocena użytecznościwyników
porównaniemetod
CELE
METODYużytkownicy
końcowi eksperci mergethen cluster
porównanie do„ground truth”
MINUSY ukierunkowane małopowtarzalne czasochłonne wymagają
danych test.

Plan prezentacji
• Wprowadzenie i przedstawienie problemu
• Problemy szczegółowe i stan wiedzy• Analiza skupień w dokumentach tekstowych• Znalezienie czytelnego opisu dla grupy• Ocena jakości grupowania
• Badania własne i plany na przyszłość• Nowe algorytmy grupowania• Nowe metody wyboru opisu grup
• Uwzględnienie specyfiki języka polskiego
• Propozycje miar oceny jakości grupowania• System Carrot2
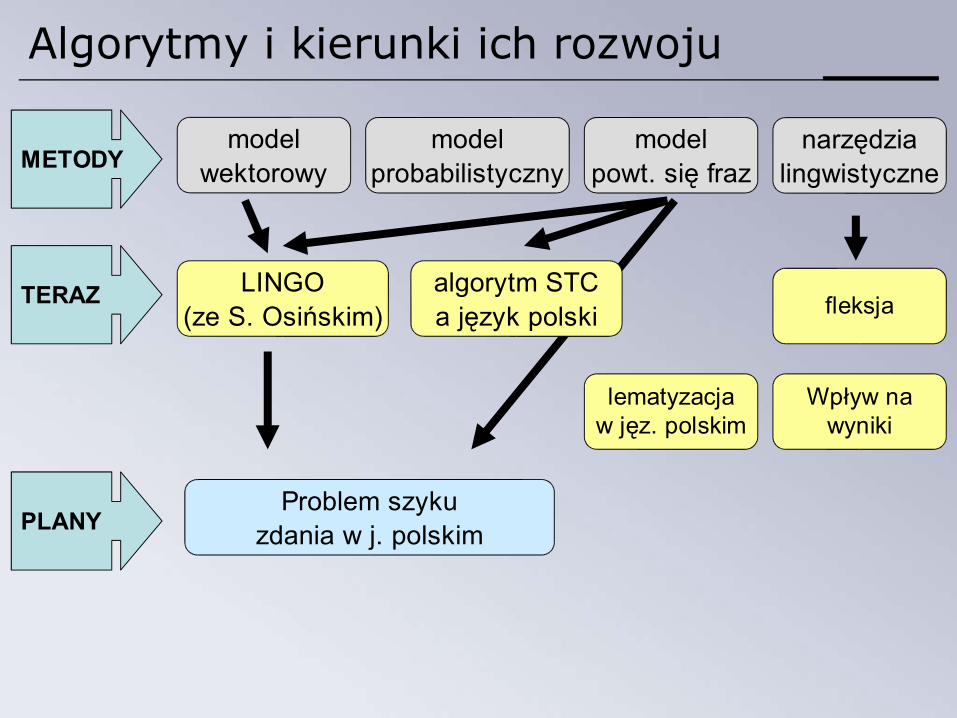
Algorytmy i kierunki ich rozwoju
METODYmodel
wektorowymodel
probabilistycznymodel
powt. się fraznarzędzia
lingwistyczne
PLANYProblem szyku
zdania w j. polskim
TERAZ LINGO(ze S. Osińskim) fleksja
Wpływ nawyniki
lematyzacjaw jęz. polskim
algorytm STCa język polski

Specyfika języka polskiego
• Bogata fleksja• Afiksy (pre, post i infiksy)• Alternacje tematyczne (oboczności)
• Szyk zdania w języku polskim jest „luźniejszy” dzięki wsparciu ze strony fleksji• Jan uderzył Pawła [John hit Paul]• Pawła uderzył Jan [Paul hit John]

Fleksja i lematyzacja
• Czym jest lematyzacja?• Sprowadzenie formy fleksyjnej do postaci słownikowej
(lematu)
• Lematyzacja w kontekście odkrywania wiedzy• Odróżnienie słów o innym semantycznym znaczeniu od
form jednego słowa, które przyjmuje inny zapis w zależności od funkcji w zdaniu
• Lematyzacja w IR nie musi być językowo poprawna

Lametyzator
• formy fleksyjne i podstawowe ze słownika i-spell-pl
• skompresowane do automatu skończonego
• zalety• bardzo szybki - O(n), n – długość słowa• spora liczba słów (1.4 miliona? ispell-pl)• darmowy (GPL)
• wady• rozpoznaje jedynie słowa ze słownika• nie wszystko zgodne jest z gramatyką języka polskiego• brak anotacji morfosyntaktycznych

Uzyskane wyniki – problem fleksji
• Quasi-stemmer
• Kiedy dwa wyrazy mogą być uznane za formy wspólnego leksemu?• wyrazy posiadają wspólny prefiks• po odrzuceniu prefiksu pozostała część znajduje się na
liście dopuszczalnych końcówek• odwrócony indeks często występujących końcówek
obliczony z dużego korpusu
• słabości metody• nie uwzględnia alternacji• relacja porównania nieprzechodnia

STC a fleksja polska
• Pierwsza publiczna implementacja algorytmu STC
• Postawiono pytanie: Jak STC będzie działał dla dokumentów w języku polskim?
• Pokazano, iż nawet prosty lematyzator wyraźnie wpływa na poprawę wyników grupowania w STC• szczególnie widoczne w przypadku j. polskiego, ale
również i w j. angielskim
• Inny wniosek z badań: frazy częste, jako sekwencje, są słabym elementem determinującym grupy dla języków fleksyjnych

Algorytm Lingo
• Label INduction Grouping Algorithm, autor: Stanisław Osiński
• Oparty o model wektorowy
• Odwrócony proces grupowania — najpierw opisy, później dokumenty
• Opiera się na metodzie rozkładu macierzy A przy pomocy metody SVD (Singular Value Decomposition)• redukcja szumów• ujawnia ukryte związki między dokumentami
• Wykorzystuje frazy częste aby opisać odnalezione grupy
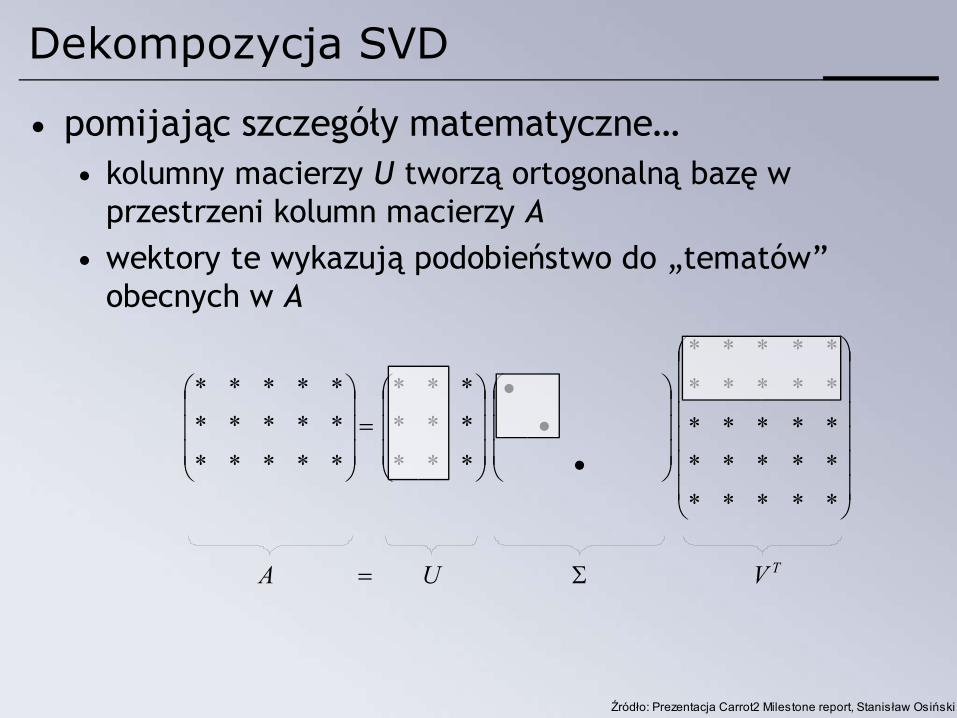
Dekompozycja SVD
• pomijając szczegóły matematyczne…• kolumny macierzy U tworzą ortogonalną bazę w
przestrzeni kolumn macierzy A • wektory te wykazują podobieństwo do „tematów”
obecnych w A
*************************
*********
***************
TVUA
Źródło: Prezentacja Carrot2 Milestone report, Stanisław Osiński
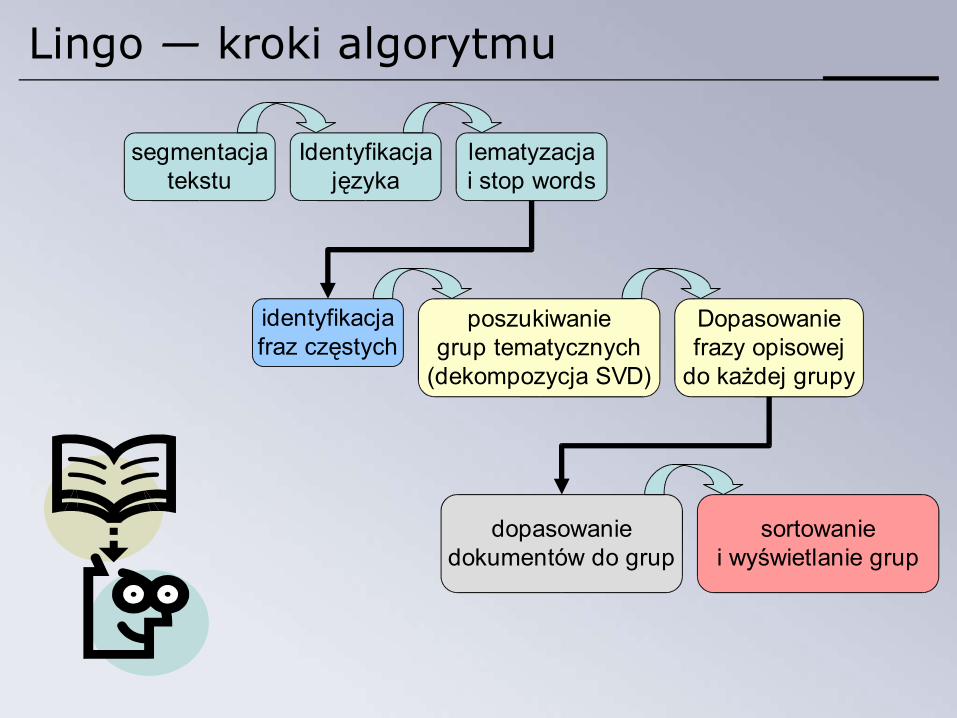
Lingo — kroki algorytmu
segmentacjatekstu
Identyfikacjajęzyka
lematyzacjai stop words
identyfikacjafraz częstych
poszukiwaniegrup tematycznych
(dekompozycja SVD)
Dopasowaniefrazy opisowej
do każdej grupy
dopasowaniedokumentów do grup
sortowaniei wyświetlanie grup

LINGO — podsumowanie
• zalety• zróżnicowane tematycznie grupy (dzięki użyciu SVD)• dokument może należeć do więcej niż jednej grupy• nie ma problemu znalezienia opisu grupy
• niedociągnięcia• płaska struktura grup• spore wymagania zasobowe (SVD)• brak możliwości obliczeń przyrostowych

O wpływie składni na wyniki…
• Obserwacja: frazy częste są nierzadko nieczytelne (eliptyczne lub bezsensowne)
• Istnieją jednak pewne reguły składniowe…• Jaś pilnuje Leszka i Marii albo Kubusia.• *Pilnuje Marii i albo Kubusia Leszka Jaś.
• … które nie są jednak jednoznaczne• Kogo pilnuje Jaś w zdaniu powyżej?

O wpływie składni na wyniki, c.d.
• Propozycja 1: Wybór opisów grup na podstawie reguł składniowych języka?
• Propozycja 2: Wyrzucenie nieczytelnych, lub wątpliwych opisów grup?

Przykłady i ograniczenia
• Eliminacja fraz (wypowiedzeń) eliptycznych• „[zbiory] biblioteki narodowej”
• „Correctness boost” przy wyborze opisu grupy• „biblioteki narodowej”• „biblioteka narodowa”
• Nie planuje się:• rozszyfrowywania znaczeń zaimków• ustalania jednoznacznego sensu leksemów• analizy skomplikowanych schematów składniowych

Składniowo poprawne opisy grup
• Wymagania• analizator morfologiczny
• Morfeusz [M. Woliński, IPI PAN], FormAn [TIP Sp. z o. o.]
• wybór reguł dla pobieżnej analizy składniowej• do zrobienia…
• źródła: parsery do rozkładu zdań w j. polskim [Vetulani, ??], Składnia współczesnego języka polskiego Z. Saloni, M. Świdziński
• Aplikacja• Do praktycznie dowolnej klasy algorytmów
• Lingo, STC, HSTC?
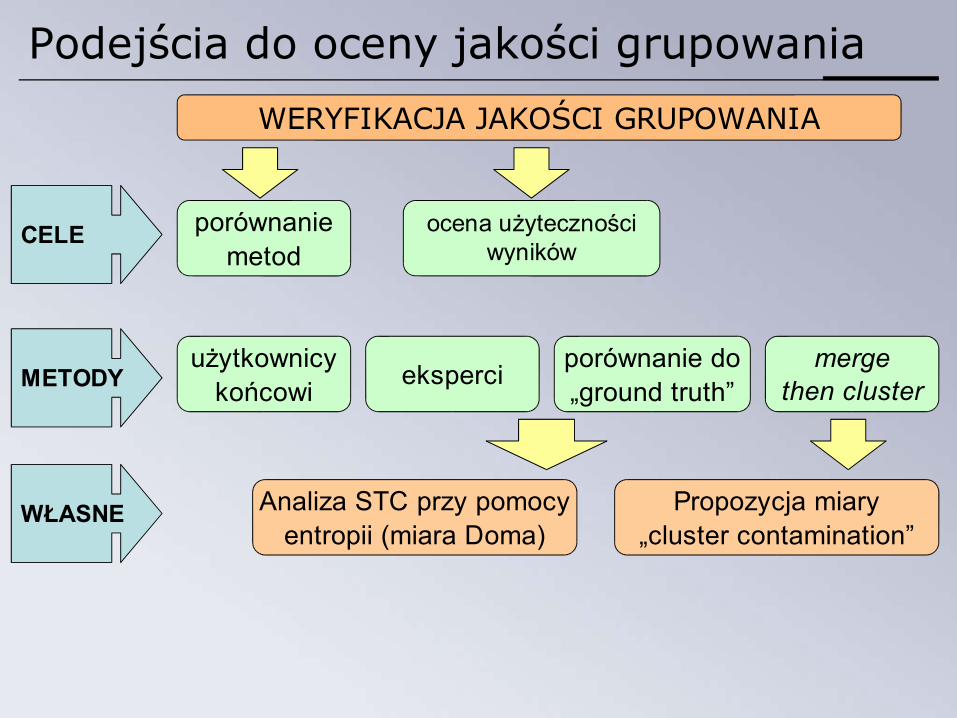
Podejścia do oceny jakości grupowania
WERYFIKACJA JAKOŚCI GRUPOWANIA
ocena użytecznościwyników
porównaniemetod
CELE
METODYużytkownicy
końcowi eksperci mergethen cluster
porównanie do„ground truth”
WŁASNE Analiza STC przy pomocyentropii (miara Doma)
Propozycja miary„cluster contamination”

Ocena przy pomocy miary Byrona E. Doma
• Wymaga zbioru grup „ground truth”, który określa „wzorcowe” rozwiązanie
• Analiza macierzy kontyngencji
• Wskazuje jak zbiór wynikowy grup różni się od wzorcowego (agregacja do jednej liczby)
A B C h(c)a 2 0 1 3b 0 0 3 3c 0 3 0 3
h(k) 2 3 4
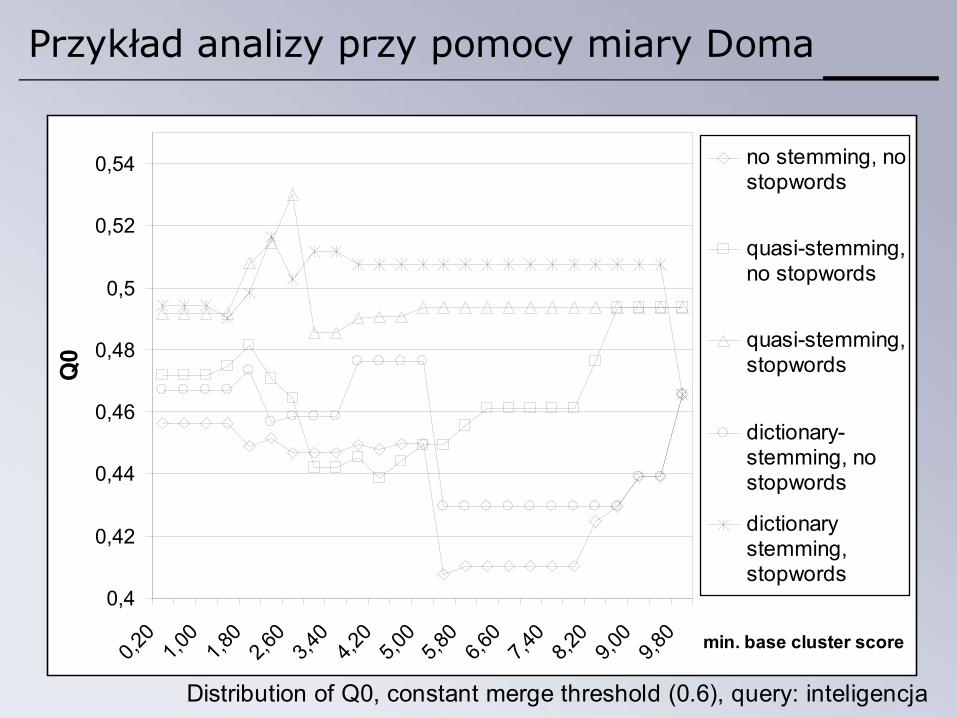
Przykład analizy przy pomocy miary Doma
0,4
0,42
0,44
0,46
0,48
0,5
0,52
0,54
0,20
1,00
1,80
2,60
3,40
4,20
5,00
5,80
6,60
7,40
8,20
9,00
9,80 min. base cluster score
Q0
no stemming, nostopwords
quasi-stemming,no stopwords
quasi-stemming,stopwords
dictionary-stemming, nostopwords
dictionarystemming,stopwords
Distribution of Q0, constant merge threshold (0.6), query: inteligencja

Miara Doma – podsumowanie
• Trudno pozyskać zbiór „ground truth” od ekspertów
• Liczbowa wartość miary jest kłopotliwa w interpretacji
• Wiele ograniczeń przyjętego modelu (partitioning, binary assignment, flat clusters)

Propozycja miary „cluster contamination”
• Wymaga danych wejściowych jak do „merge and cluster”• Jakikolwiek zbiory o spójnej strukturze, np. dokumenty z
kategorii ODP
• Nie mierzy podobieństwa do „idealnego” rozkładu grup
• Nie agreguje wyników wszystkich grup
• Można łatwo ocenić jak grupy utworzone algorytmicznie mają się do pierwotnych klas
• Intuicyjna w interpretacji
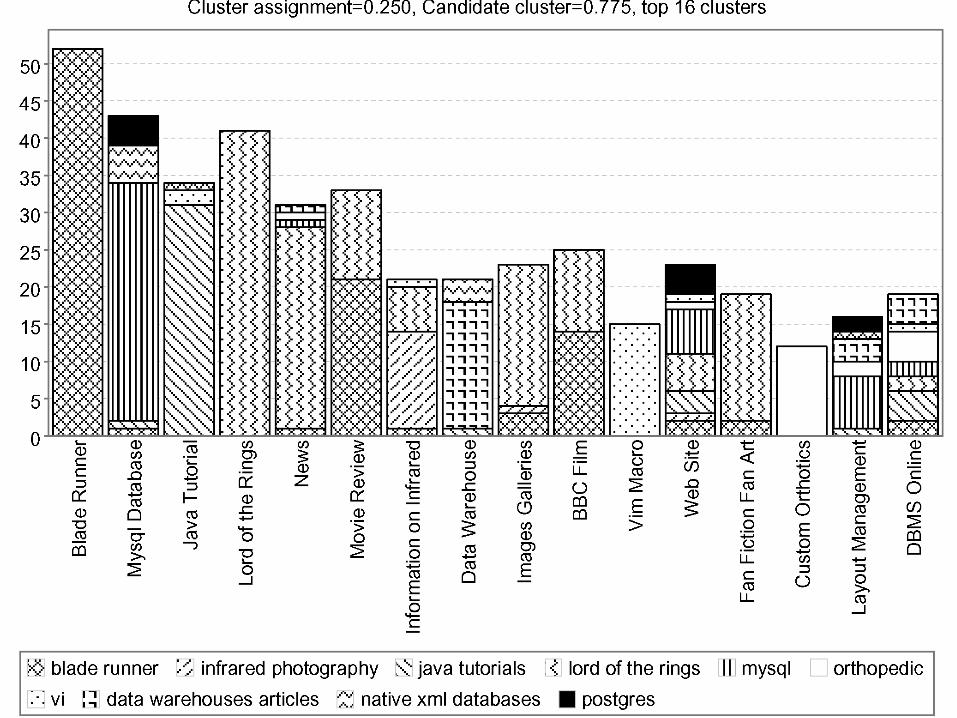

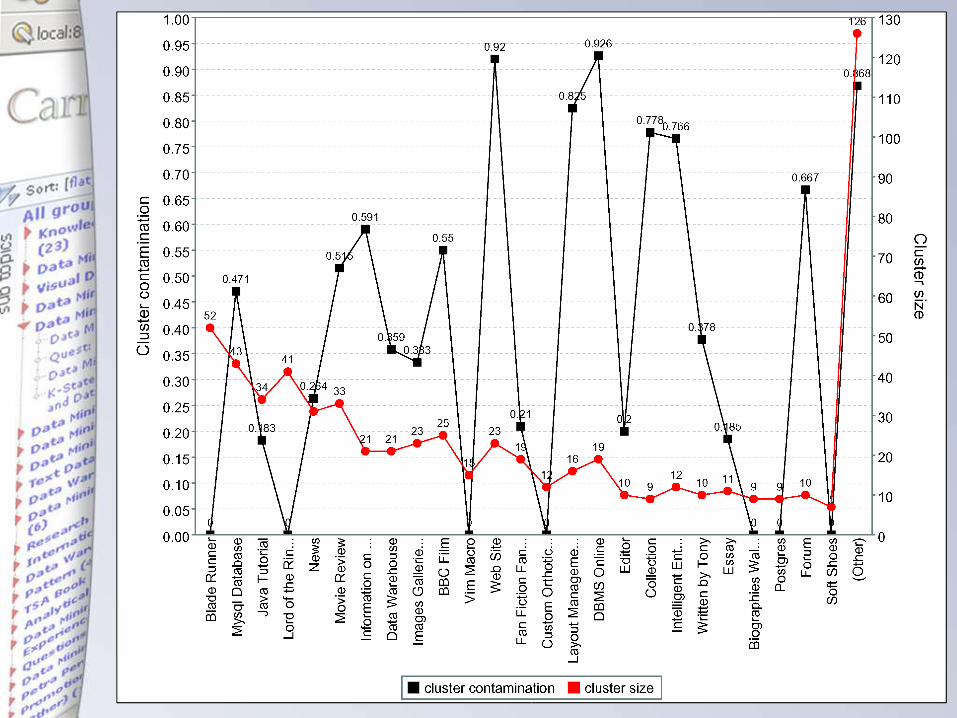
Cluster contamination measure
• Liczba par obiektów, które znalazły się w tej samej grupie k, a początkowo nie były ze sobą w żadnej partycji (błąd domieszki)
• Maksymalny błąd to

Cluster contamination measure, c.d.
O projekcie Carrot2
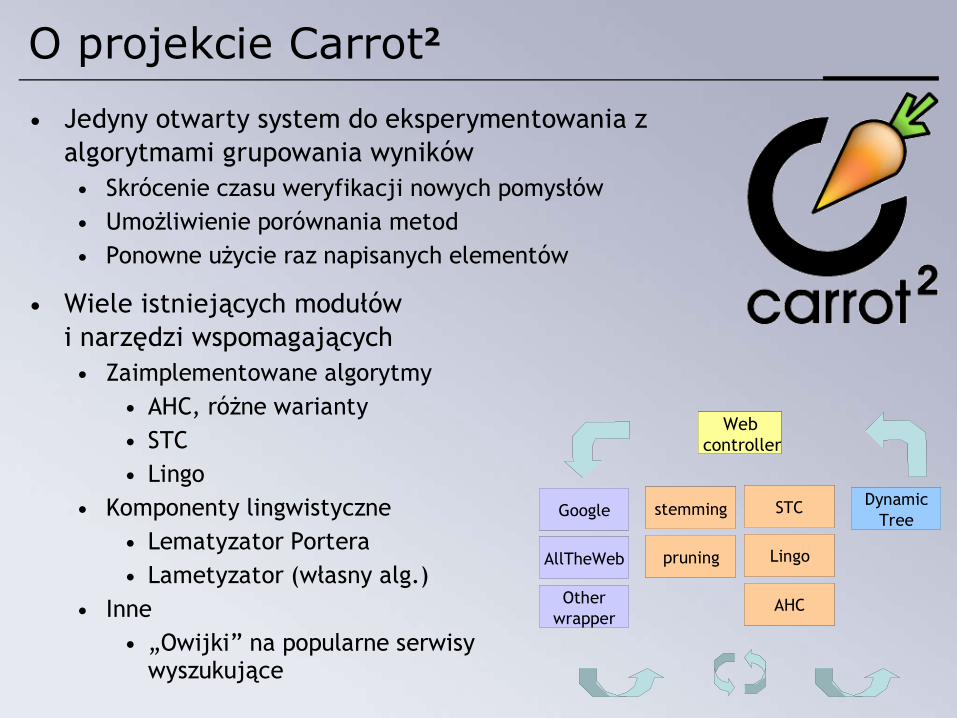
• Jedyny otwarty system do eksperymentowania z algorytmami grupowania wyników• Skrócenie czasu weryfikacji nowych pomysłów• Umożliwienie porównania metod• Ponowne użycie raz napisanych elementów
• Wiele istniejących modułówi narzędzi wspomagających• Zaimplementowane algorytmy
• AHC, różne warianty• STC• Lingo
• Komponenty lingwistyczne• Lematyzator Portera• Lametyzator (własny alg.)
• Inne• „Owijki” na popularne serwisy
wyszukujące
Webcontroller
AllTheWeb
Otherwrapper
STC
Lingo
AHC
stemming
pruning
DynamicTree
Webcontroller
AllTheWeb
Otherwrapper
STC
Lingo
AHC
stemming
pruning
DynamicTree
Webcontroller
AllTheWeb
Otherwrapper
STC
Lingo
AHC
stemming
pruning
DynamicTree

O projekcie (c.d.)
• 3 MSc (PP), 2 MSc (inne uczelnie), pozytywny odzew ze świata komercyjnego i naukowego
• Inżynieria oprogramowania w praktyce• continuous integration [M. Fowler]• środowisko projektu
• ANT, DocBook, strona WWW w XML, Bugzilla…
• projekt umieszczony na SourceForge, licencja BSD• Strona domowa:
http://www.cs.put.poznan.pl/dweiss/carrot
• Współpraca z projektem Egothor• Wyszukiwarka grupująca dla *.cs.put.poznan.pl!
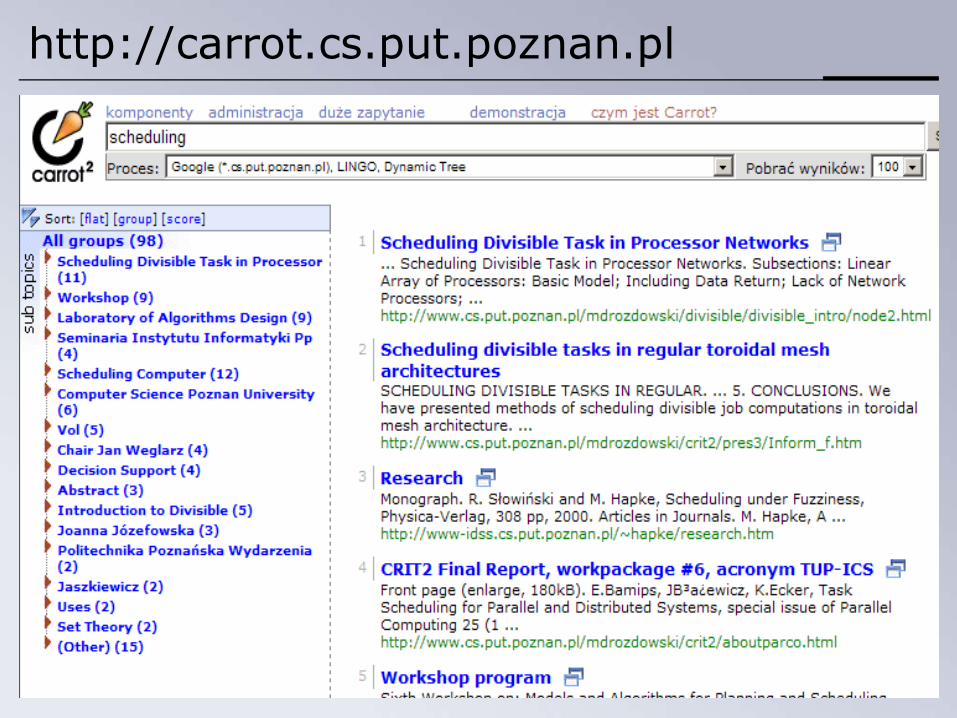
http://carrot.cs.put.poznan.pl
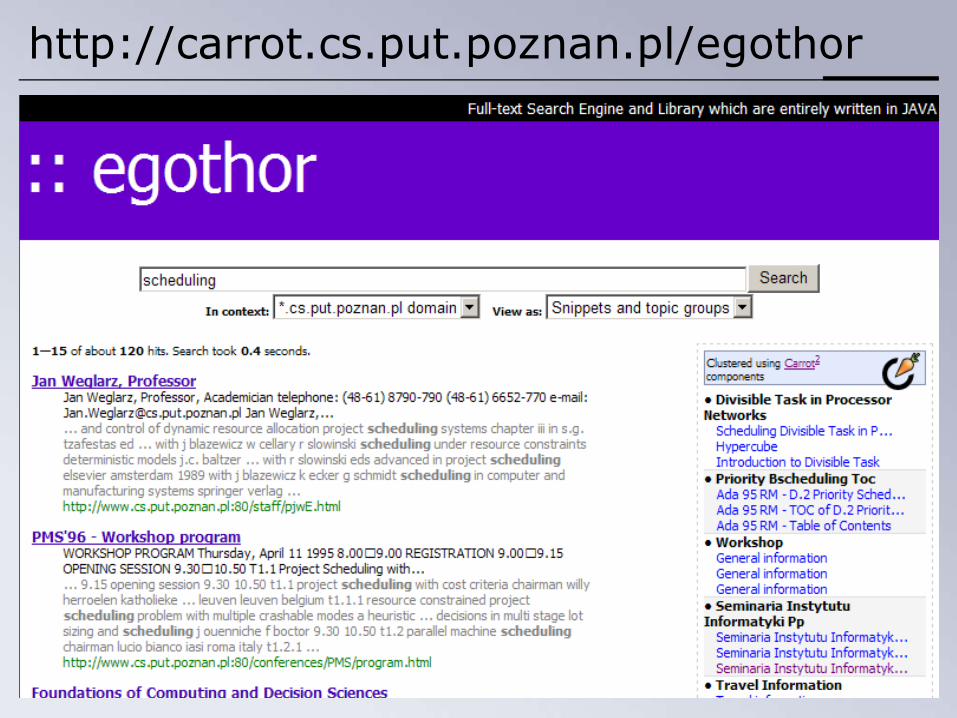
http://carrot.cs.put.poznan.pl/egothor


















