

Analiza danych biznesowych - Strona Głównazsi.tech.us.edu.pl/~nowak/adb/w2.pdf · Tabele i...
69
Wykład 2
-
Upload
nguyendang -
Category
Documents
-
view
217 -
download
0
Transcript of Analiza danych biznesowych - Strona Głównazsi.tech.us.edu.pl/~nowak/adb/w2.pdf · Tabele i...

Wykład 2

Czasami nie ma potrzeby pamiętania wszystkichinformacji w systemie, zwłaszcza jeśli wiemy, żepewne zmienne są zależne od innych. Wtedy te któresą zależne można usunąć z systemu a pamiętaćjedynie zależności.
Czasami także pewne wartości mogą być po prostuobliczone z innych więc dla zmniejszenia zajętościpamięci lepiej się takich pozbywać.
Czasami jest też stosowana technika PCA.

Czasem (gdy danych jest bardzo dużo) lepiej wziąćdo analizy podzbiór danych zamiast całego zbioru odrazu.
Powstaje problem jak wybrać taki podzbiór by był onmożliwie najbardziej „reprezentatywny” ?
Jest wiele możliwości: wybór losowy, analiza skupieńi potem wybór po jednej obserwacji z każdej grupy,tzw. balanced sampling gdy przedmiotem analizyjest wykrywanie pewnych rzadkich zjawisk i ichweryfikacja (np. wykrywanie defraudacji).

Wtedy dobrze jest od razu podstawowymistatystykami porównać oba zbiory.
Potem dobrze jest przeprowadzić testowaniehipotez, np. t-test dla porównania średnich wartościw zbiorze wejściowych i próbie wybranej do analizyw celu weryfikacji czy nie uległa znacznej zmianieistotność zmiennych.
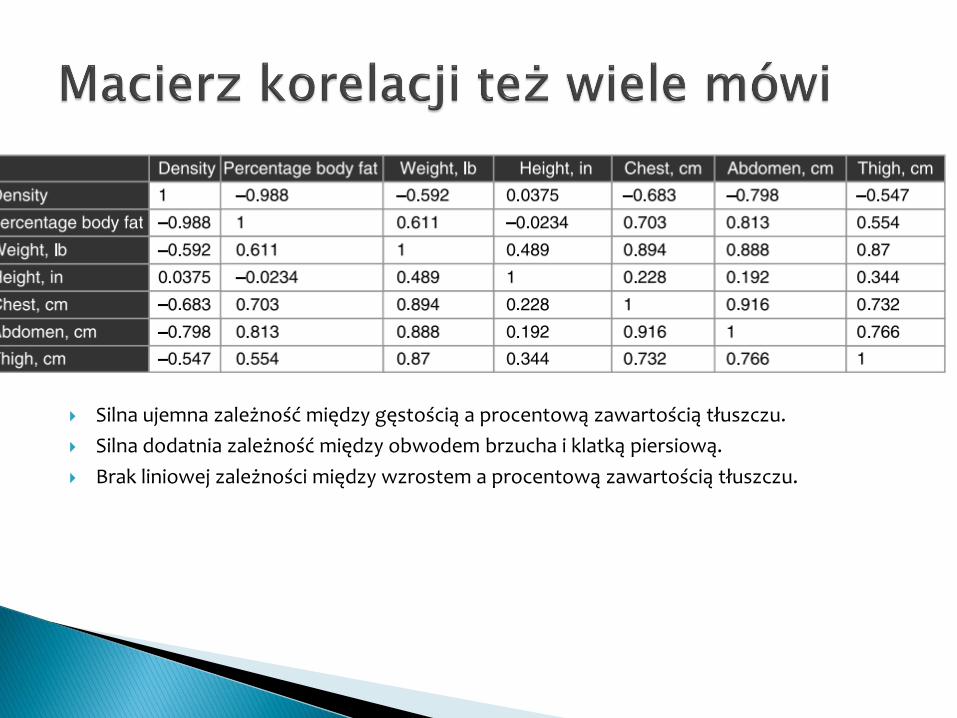
Silna ujemna zależność między gęstością a procentową zawartością tłuszczu.
Silna dodatnia zależność między obwodem brzucha i klatką piersiową.
Brak liniowej zależności między wzrostem a procentową zawartością tłuszczu.

Korelacja (współzależność cech) określa wzajemnepowiązania pomiędzy wybranymi zmiennymi.
Charakteryzując korelację dwóch cech podajemydwa czynniki: kierunek oraz siłę.
Wyrazem liczbowym korelacji jest współczynnikkorelacji (rlub R), zawierający się w przedziale [-1; 1].

korelacja dodatnia (wartość współczynnikakorelacja dodatnia (wartość współczynnika korelacjiod 0 do 1) –informuje, że wzrostowi wartości jednejcechy towarzyszy wzrost średnich wartości drugiejcechy,
korelacja ujemna (wartość współczynnika korelacjiod -1 do 0) -informuje, że wzrostowi wartości jednejcechy towarzyszy spadek średnich wartości drugiejcechy.

poniżej 0,2 - korelacja słaba (praktycznie brakzwiązku)
0,2 –0,4 - korelacja niska (zależność wyraźna)
0,4 – 0,6 - korelacja umiarkowana (zależność istotna)
0,6 –0,8 - korelacja wysoka (zależność znaczna)
0,8 –0,9 - korelacja bardzo wysoka (zależność bardzoduża)
0,9 –1,0 - zależność praktycznie pełna


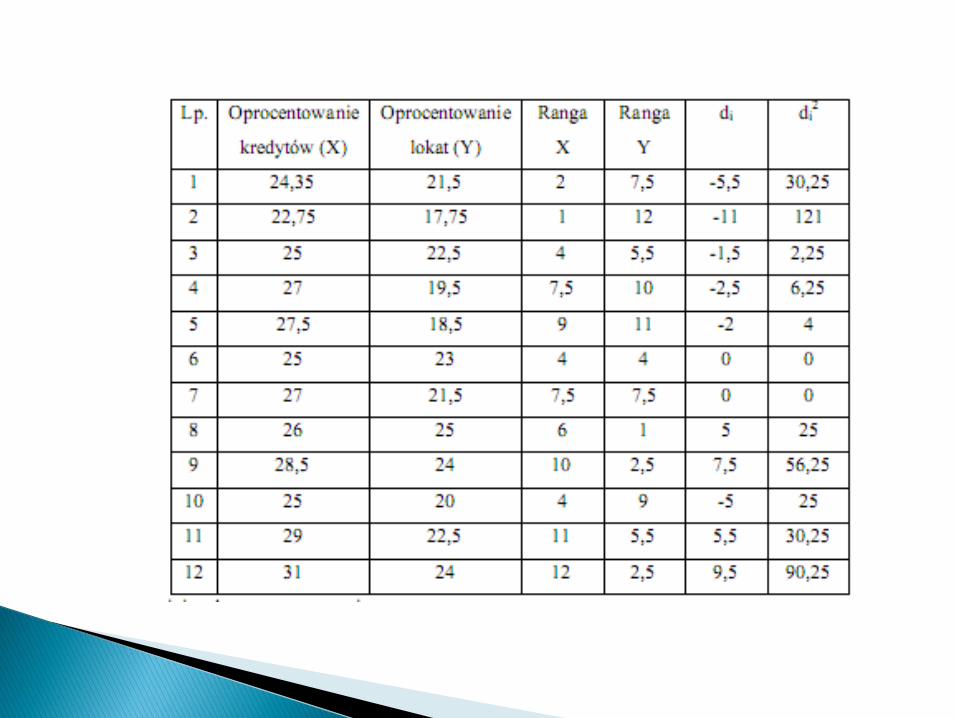
W lutym 1996 roku w 12 bankach działających na terenie Częstochowyzanotowano następujące oprocentowanie kredytów (w stosunkurocznym), oraz następujące oprocentowanie lokat złotówkowych 12miesięcznych: Tab. Oprocentowanie kredytów i lokat złotówkowych 12 miesięcznych w bankach częstochowskich na
dzień 15.II.1996.
Pytanie: czy istnieje zależność między oprocentowaniem
kredytów a oprocentowaniem lokat w wymienionych bankach?

gdzie:
di -oznaczają różnice między rangami odpowiadających sobie wartości cechy xi i cechy yi (i = 1,2,...,n)
n - liczba obserwacji.
1. Porządkujemy wyjściowe informacje według rosnących (lub malejących) wariantów jednej z cech.
2. Nadajemy numery (kolejne liczby naturalne) - rangowanie

Podstawiając do wzoru otrzymujemy:
Współczynnik korelacji rang dla badanych cech wynosi -0,37.

Predykcja – zdolność do wykorzystania wiedzyzgromadzonej w systemie do przewidywaniawartości dla nowych danych, wcześniejniesklasyfikowanych.
Opis danych - zdolność do identyfikacjiinteresujących faktów, wzorców, zależności, relacjilub nieprawidłowości w danych, wiedza taka ma byćpotem wykorzystana w odpowiednim celu, np.wykrywanie fałszywych roszczeńubezpieczeniowych.

Asocjacje – wykrywanie pewnych zależności międzydanymi, które wielokrotnie występują wspólnie np.produktów kupowanych razem przez klientów.
Grupowanie – wykrywanie profili klientów, dlaukierunkowanych kampanii marketingowych.
Wykrywanie odchyleń (outliers) – defraudacje.

Klasyfikacja - model może przewidzieć, czy klientkupi, czy nie dany produkt (metody takie jak regresjalogistyczna, analiza dyskryminacyjna, naiwnyklasyfikator Bayesa)
Przewidywanie – związane z estymacją,prognozowaniem i odnoszące się do generowaniaoceny lub prognozy nazmiennej ciągłej. Np. Model, który przewidujesprzedaż za dany kwartał (najczęściej za pomocąregresji).

Oprogramowanie Traceis pozwala na:
Przygotowanie danych do analizy,
Generowanie statystyk,
Wizualizacja zmiennych, grupowanie obserwacji, predykcję.
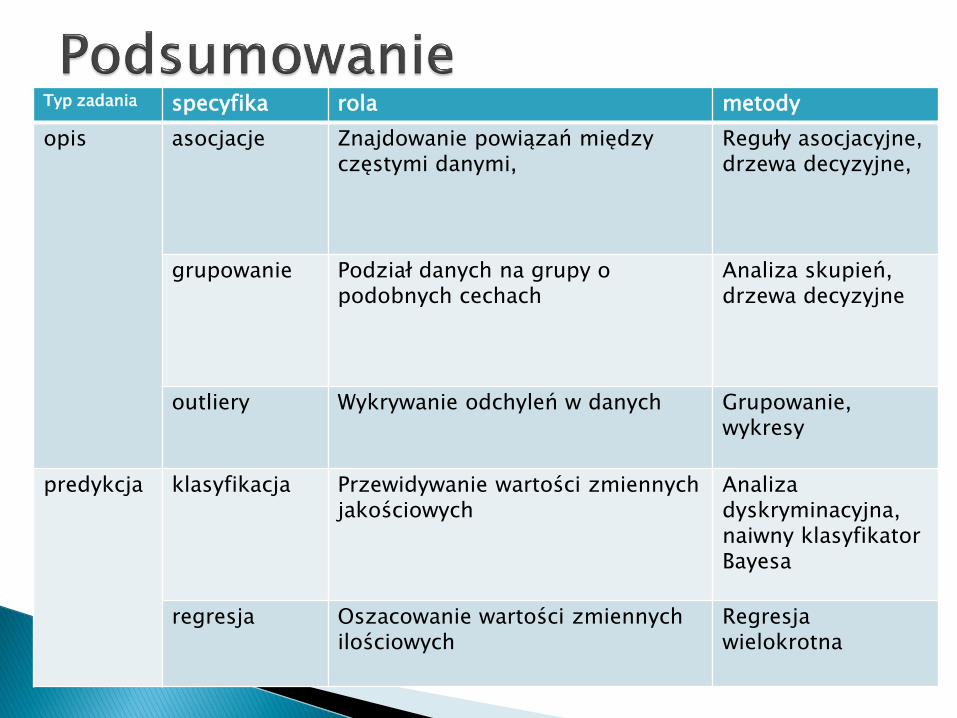
Typ zadania specyfika rola metody
opis asocjacje Znajdowanie powiązań między częstymi danymi,
Reguły asocjacyjne, drzewa decyzyjne,
grupowanie Podział danych na grupy o podobnych cechach
Analiza skupień, drzewa decyzyjne
outliery Wykrywanie odchyleń w danych Grupowanie, wykresy
predykcja klasyfikacja Przewidywanie wartości zmiennych jakościowych
Analiza dyskryminacyjna,naiwny klasyfikator Bayesa
regresja Oszacowanie wartości zmiennych ilościowych
Regresjawielokrotna

Ładowanie danych: zbiory danych mogą zawieraćnawet 20 tyś. Wierszy i 30 tyś. kolumn
Przygotowanie danych
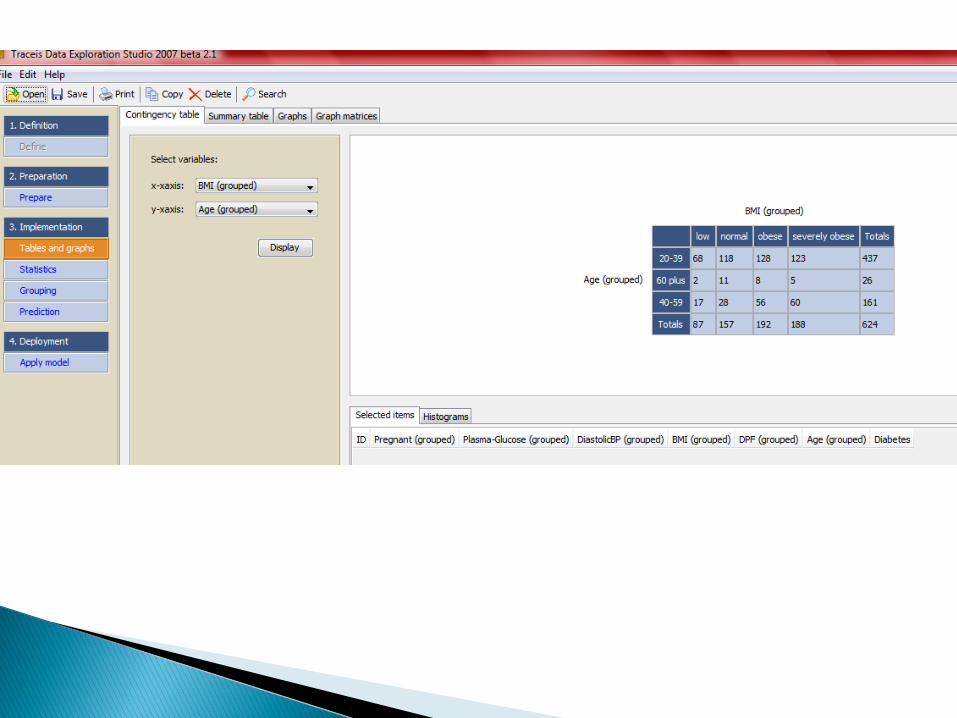
Tabele i wykresy: tablice kontyngencji, wykresyczęstości, histogram, wykresy pudełkowe
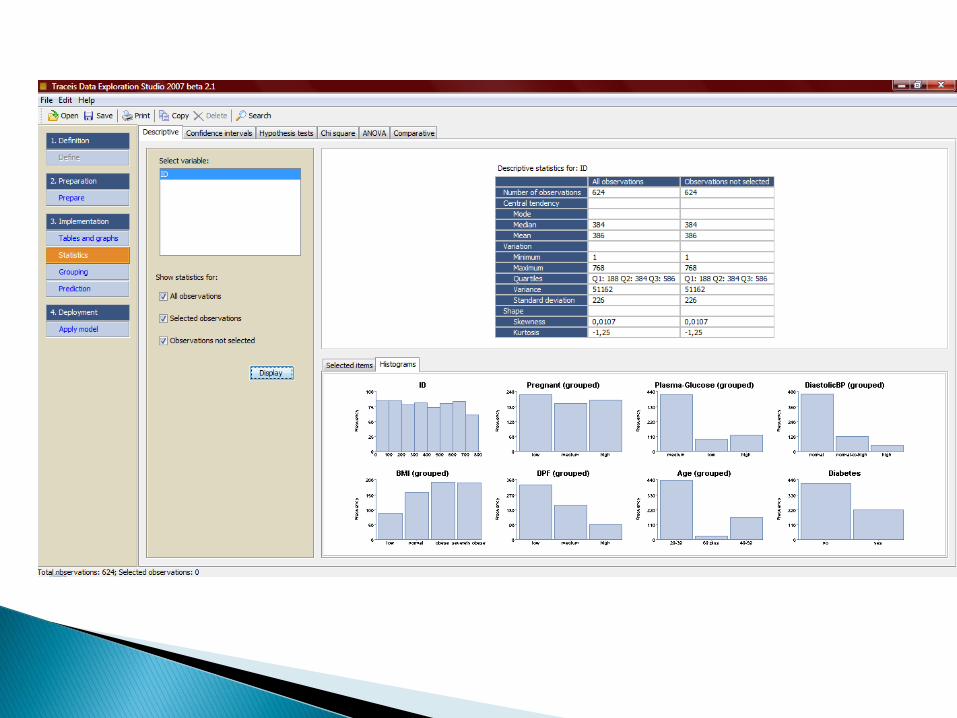
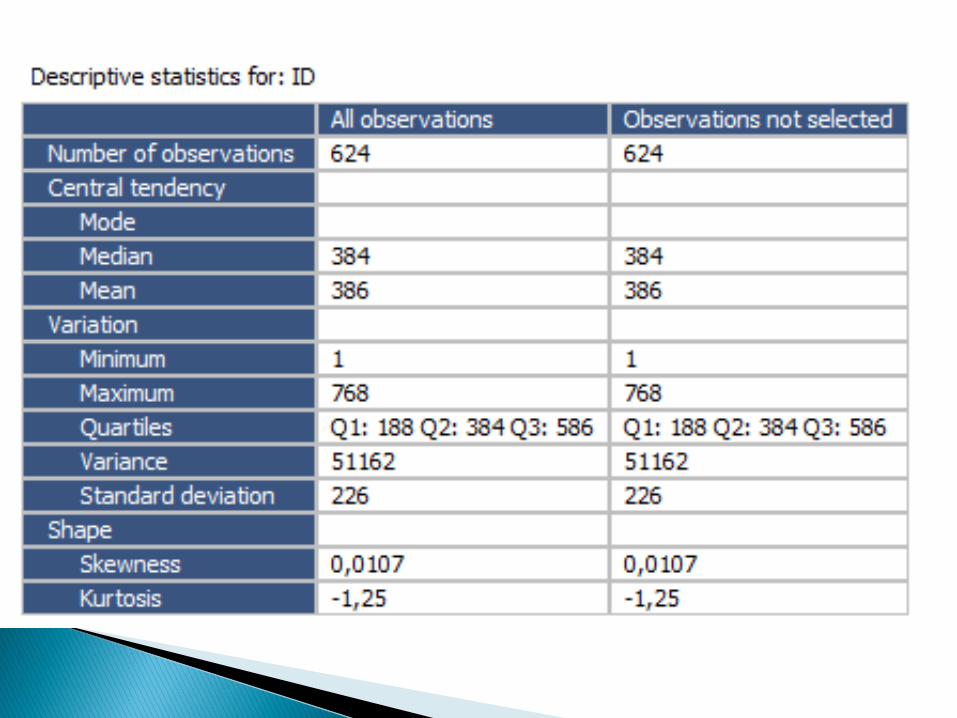
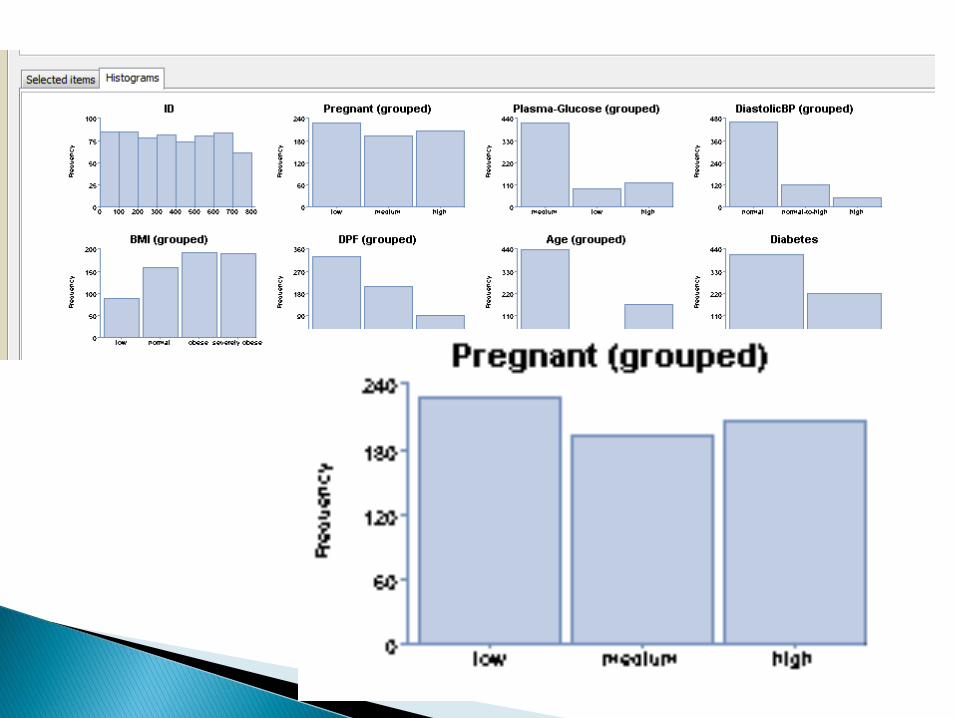
Statystyki: statystyka opisowa, przedziałyufności, rozkład chi-kwadrat, testowanie hipotezstatystycznych, analiza wariancji
Grupowanie:analiza skupień, reguły asocjacyjne,drzewa klasyfikacyjne
Predykcja: k-NN, naiwny klasyfikator Bayesa,sieci neuronowe
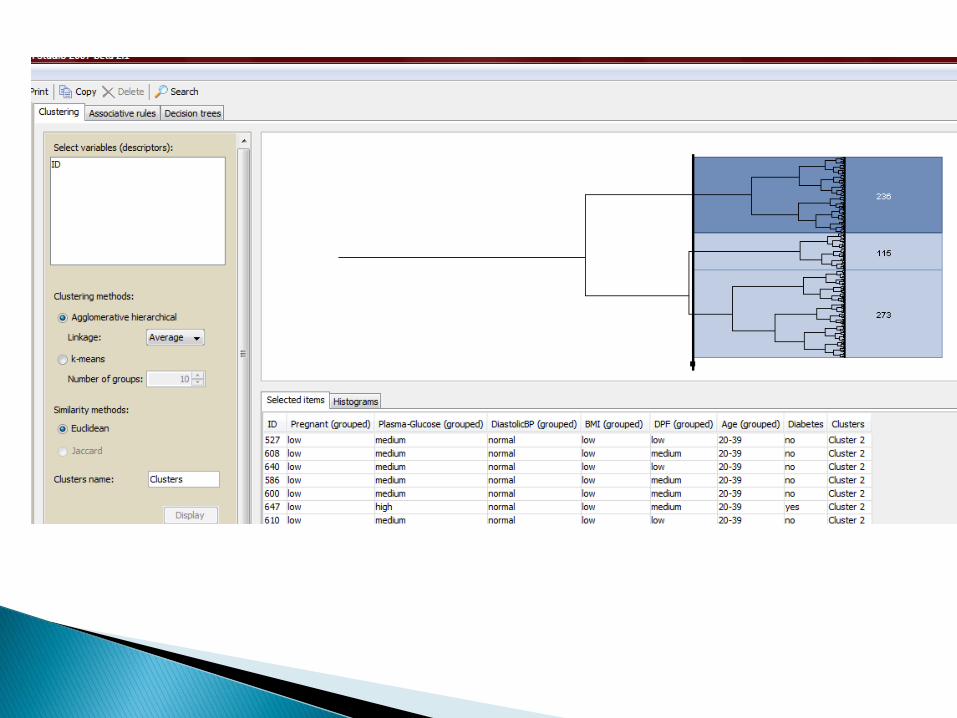
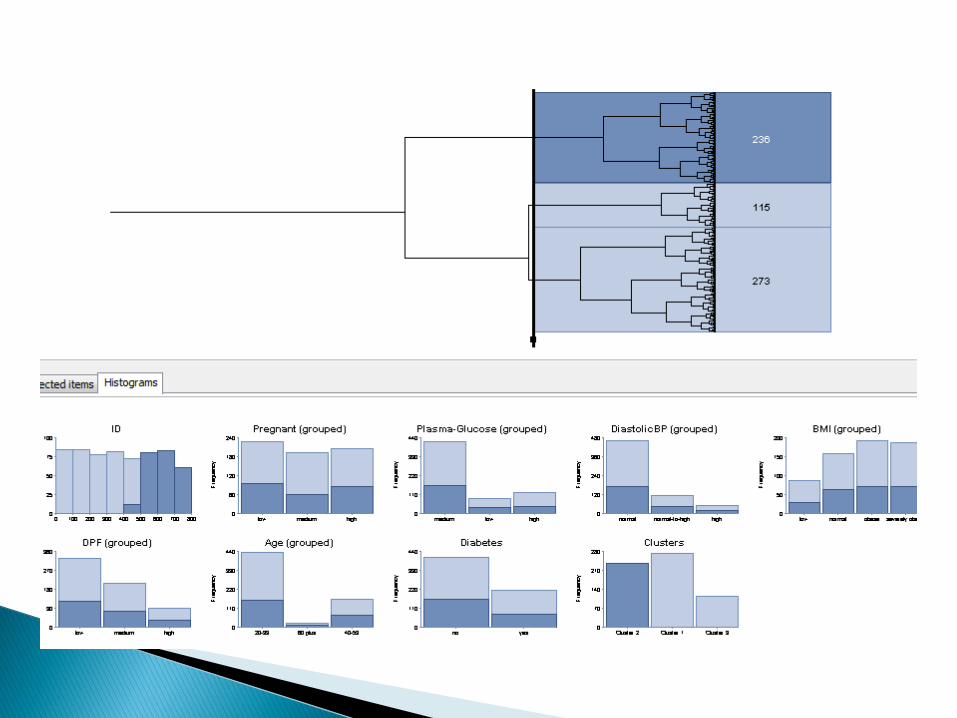

Abalone Database [ftp://ftp.ics.uci.edu/pub/machine-learning-databases/abalone/]
Adult Database[ftp://ftp.ics.uci.edu/pub/machine-learning-databases/adult/]
Auto-Mpg [ftp://ftp.ics.uci.edu/pub/machine-learning-databases/auto-mpg/]
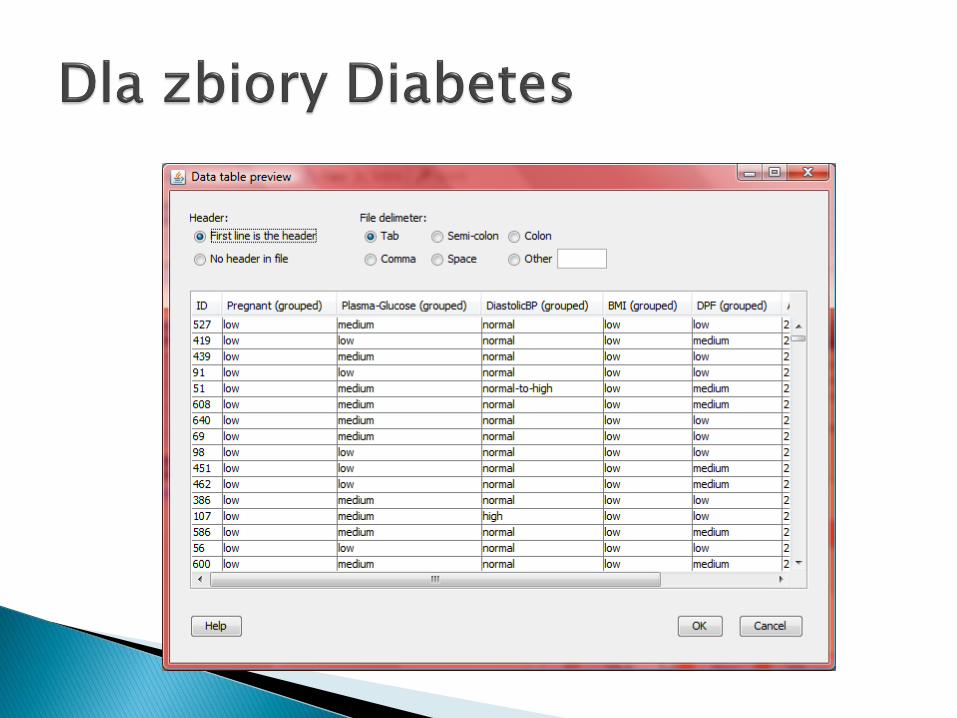
Pima Indians Diabetes Database [ftp://ftp.ics.uci.edu/pub/machine-learning-databases/pima-indians-diabetes/]
Dodatkowe źródła danych dostępne: Kdnuggets [http://www.kdnuggets.com/datasets/index.html] IEEE Neural Networks Council Standards Committee
[http://neural.cs.nthu.edu.tw/jang/benchmark/]
Frequent Itemset Mining Dataset Repository [http://fimi.cs.helsinki.fi/data/]
National Cancer Institute Data Sets [http://discover.nci.nih.gov/datasets.jsp]
KDDCUP [http://www.acm.org/sigs/sigkdd/kddcup/]
StatLib [http://lib.stat.cmu.edu/datasets/]
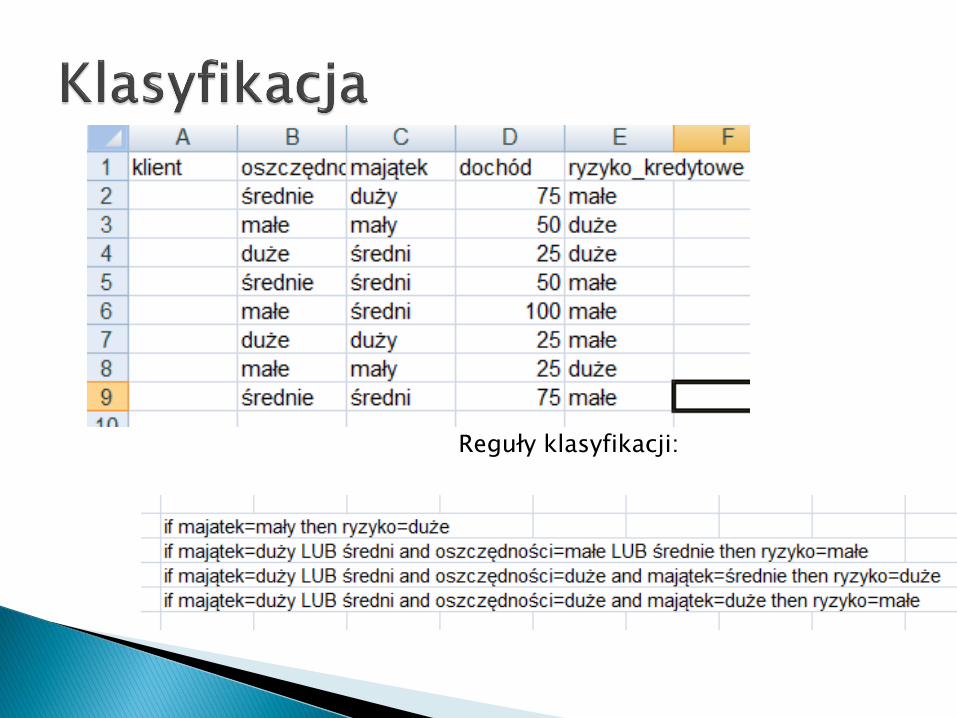
Reguły klasyfikacji:
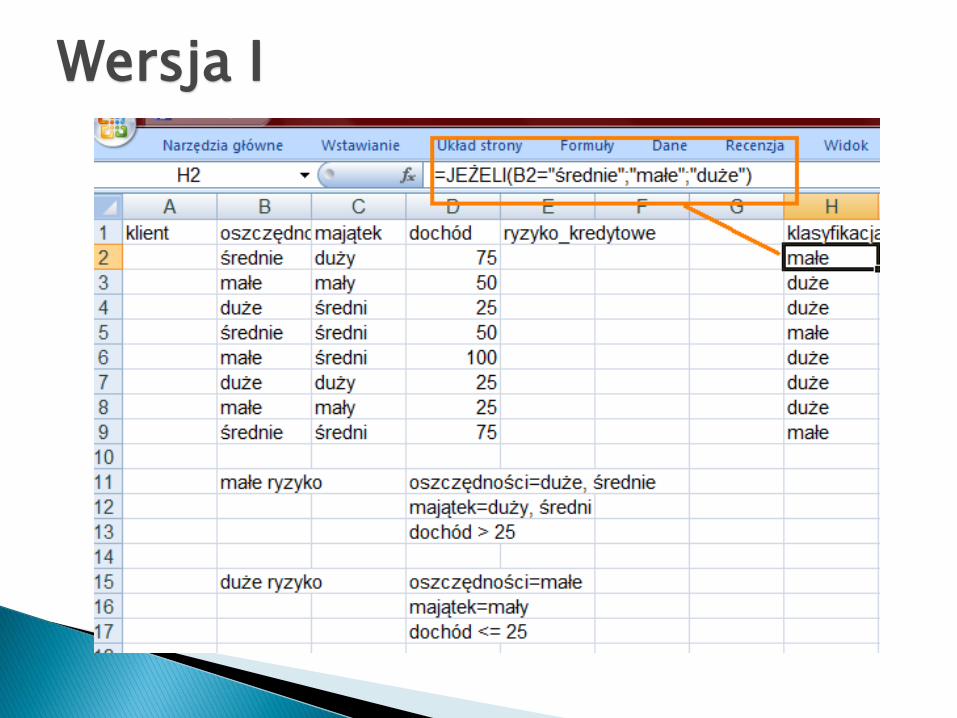
Wersja I
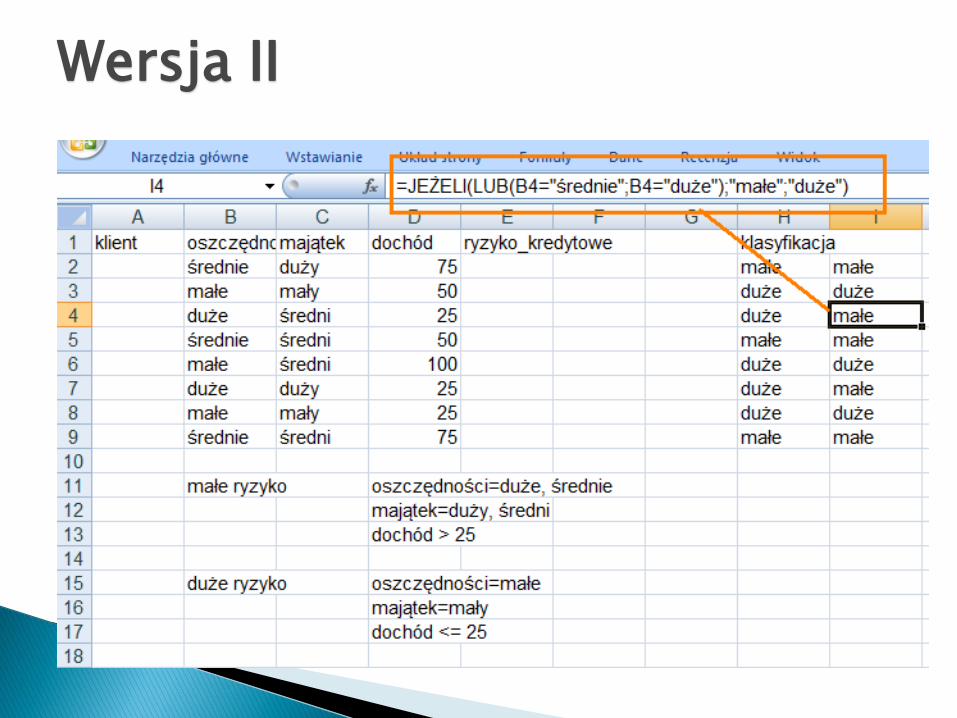
Wersja II

Wersja III
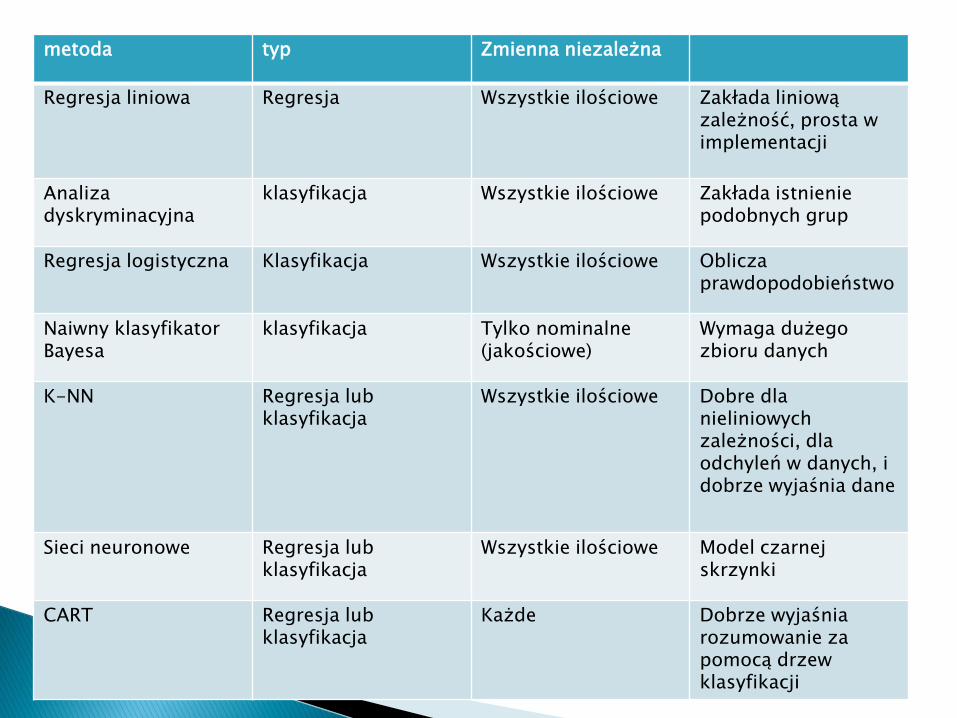
metoda typ Zmienna niezależna
Regresja liniowa Regresja Wszystkie ilościowe Zakłada liniową zależność, prosta w implementacji
Analiza dyskryminacyjna
klasyfikacja Wszystkie ilościowe Zakłada istnienie podobnych grup
Regresja logistyczna Klasyfikacja Wszystkie ilościowe Oblicza prawdopodobieństwo
Naiwny klasyfikator Bayesa
klasyfikacja Tylko nominalne (jakościowe)
Wymaga dużego zbioru danych
K-NN Regresja lub klasyfikacja
Wszystkie ilościowe Dobre dla nieliniowych zależności, dla odchyleń w danych, i dobrze wyjaśnia dane
Sieci neuronowe Regresja lub klasyfikacja
Wszystkie ilościowe Model czarnej skrzynki
CART Regresja lub klasyfikacja
Każde Dobrze wyjaśnia rozumowanie za pomocą drzew klasyfikacji

majątek
Duże ryzyko
Średni, duży
oszczędności
mały
duże
Małe, średnie
Małe ryzykomajątek
duży Średni
Małe ryzyko Duże ryzyko

Naiwny klasyfikator bayesowski jest prostym probabilistycznymklasyfikatorem.
Zakłada się wzajemną niezależność zmiennych niezależnych (tunaiwność)
Bardziej opisowe może być określenie- „model cech niezależnych”. Model prawdopodobieństwa można wyprowadzić korzystając z
twierdzenia Bayesa. W zależności od rodzaju dokładności modelu prawdopodobieństwa,
naiwne klasyfikatory bayesowskie można „uczyć” bardzo skuteczniew trybie uczenia z nadzorem.

Jeśli wiemy, że kulek czerwonych jest 2 razy mniej niż zielonych (bo czerwonych jest 20 a zielonych 40) to prawdopodobieństwo tego, że kolejna (nowa) kulka będzie koloru zielonego jest dwa razy większe niż tego, że kulka będzie czerwona.
Dlatego możemy napisać, że znane z góry prawdopodobieństwa:
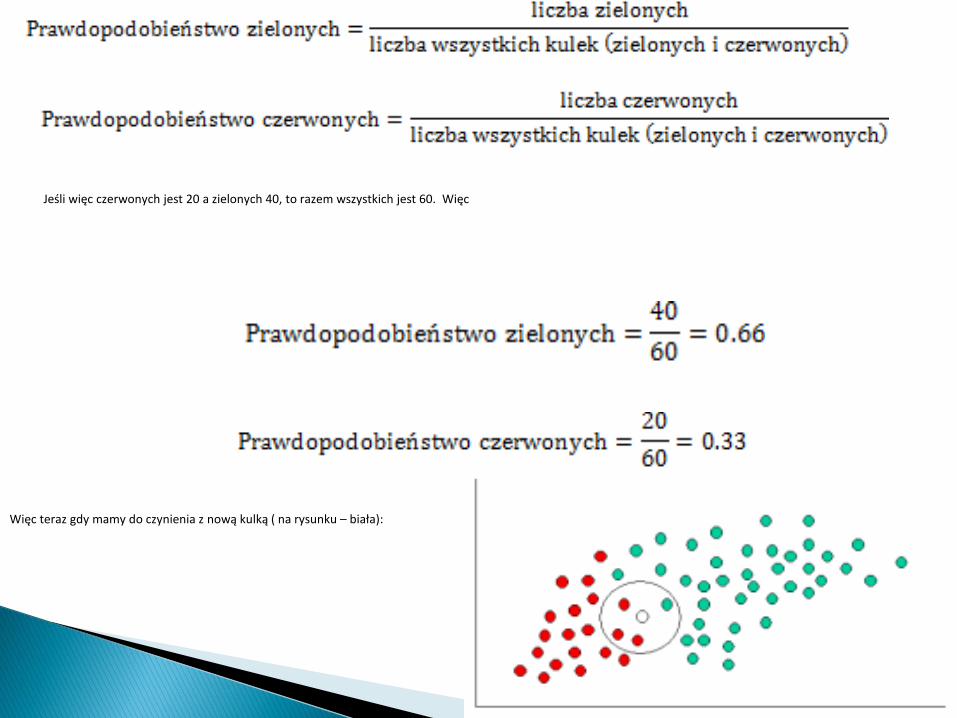
Jeśli więc czerwonych jest 20 a zielonych 40, to razem wszystkich jest 60. Więc
Więc teraz gdy mamy do czynienia z nową kulką ( na rysunku – biała):

To spróbujmy ustalić jaka ona będzie. Dokonujemy po prostu klasyfikacji kulki do jednej z dwóch klas: zielonych bądź czerwonych.
Jeśli weźmiemy pod uwagę sąsiedztwo białej kulki takie jak zaznaczono, a więc do 4 najbliższych sąsiadów, to widzimy, że wśród nich są 3 kulka czerwone i 1 zielona.
Obliczamy liczbę kulek w sąsiedztwie należących do danej klasy : zielonych bądź czerwonych z wzorów:
W naszym przypadku, jest dziwnie, bo akurat w sąsiedztwie kulki X jest więcej kulek czerwonych niż zielonych,mimo, iż kulek zielonych jest ogólnie 2 razy więcej niż czerwonych. Dlatego zapiszemy, że

Dlatego ostatecznie powiemy, żePrawdopodobieństwo że kulka X jest zielona = prawdopodobieństwo kulki
zielonej * prawdopodobieństwo, że kulka X jest zielona w swoim sąsiedztwie
=
Prawdopodobieństwo że kulka X jest czerwona = prawdopodobieństwo kulki czerwonej * prawdopodobieństwo, że kulka X jest czerwona w swoim sąsiedztwie =
Ostatecznie klasyfikujemy nową kulkę X do klasy kulek czerwonych, ponieważ ta klasa dostarcza namwiększego prawdopodobieostwa posteriori.

– jeden z algorytmów regresji nieparametrycznej używanych w statystyce do prognozowania wartości pewnej zmiennej losowej. Może również byd używany do klasyfikacji.
-

Dany jest zbiór uczący zawierający obserwacje z których każdama przypisany wektor zmiennych objaśniających oraz wartośdzmiennej objaśnianej Y.
Dana jest obserwacja C z przypisanym wektorem zmiennychobjaśniających dla której chcemy prognozowad wartośdzmiennej objaśnianej Y.

1. porównanie wartości zmiennych objaśniających dla obserwacji C z wartościami tych zmiennych dla każdej obserwacji w zbiorze uczącym.
2. wybór k (ustalona z góry liczba) najbliższych do C obserwacji ze zbioru uczącego.
3. Uśrednienie wartości zmiennej objaśnianej dla wybranych obserwacji, w wyniku czego uzyskujemy prognozę.
Przez "najbliższą obserwację" mamy na myśli, taką obserwację, której odległośd do analizowanej przez nas obserwacji jest możliwie najmniejsza.
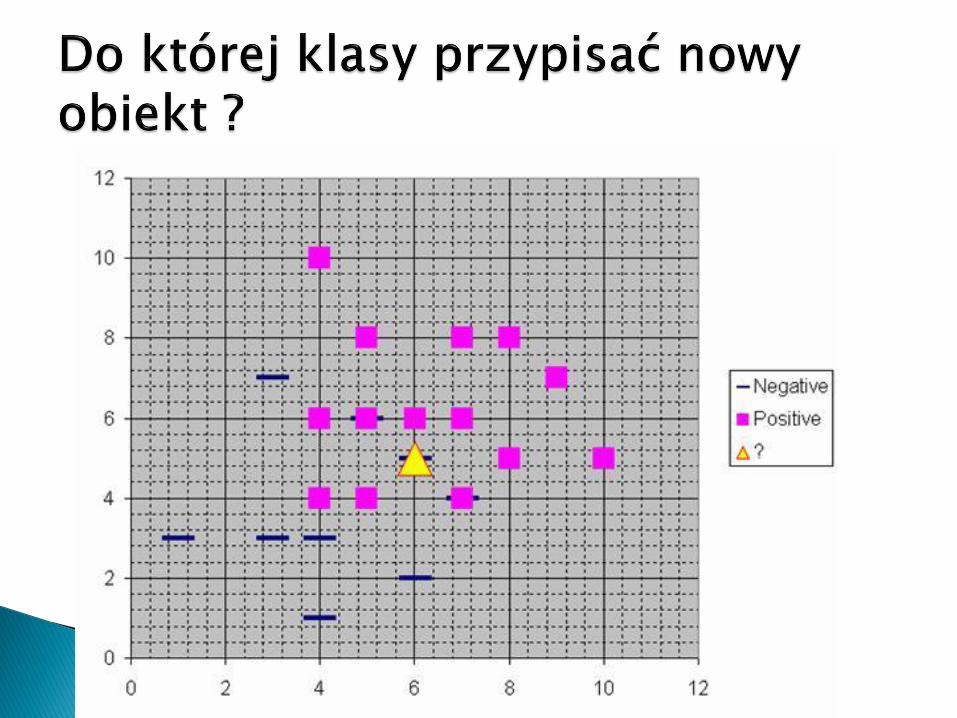


Najbliższy dla naszego obiektu „buźka” jest obiekt
Więc przypiszemy nowemu obiektowi klasę:

Mimo, że najbliższy dla naszego obiektu „buźka” jest obiekt
Metodą głosowania ustalimy, że skoro mamy wziąć pod uwagę 5 najbliższych sąsiadów tego obiektu, a widać, że 1 z nich ma klasę:
Zaś 4 pozostałe klasę:
To przypiszemy nowemu obiektowi klasę:

Schemat algorytmu:
Poszukaj obiektu najbliższego w stosunku do obiektu klasyfikowanego.
Określenie klasy decyzyjnej na podstawie obiektu najbliższego.
Cechy algorytmu:
Bardziej odporny na szumy - w poprzednim algorytmie obiekt najbliższyklasyfikowanemu może być zniekształcony - tak samo zostaniezaklasyfikowany nowy obiekt.
Konieczność ustalenia liczby najbliższych sąsiadów.
Wyznaczenie miary podobieństwa wśród obiektów (wiele miarpodobieństwa).
Dobór parametru k - liczby sąsiadów:
Jeśli k jest małe, algorytm nie jest odporny na szumy – jakość klasyfikacji jestniska. Jeśli k jest duże, czas działania algorytmu rośnie - większa złożonośćobliczeniowa. Należy wybrać k, które daje najwyższą wartość klasyfikacji.

Wyznaczanie odległości obiektów: odległość euklidesowa

Obiekty są analizowane w ten sposób , że oblicza się odległości bądź podobieństwa międzynimi. Istnieją różne miary podobieństwa czy odległości. Powinny być one wybieranekonkretnie dla typu danych analizowanych: inne są bowiem miary typowo dla danychbinarnych, inne dla danych nominalnych a inne dla danych numerycznych.
Nazwa Wzór
odległośd euklidesowa
odległośd kątowa
współczynnik korelacji
liniowej Pearsona
Miara Gowera
gdzie: x,y - towektory wartościcechporównywanychobiektów wprzestrzeni p-wymiarowej, gdzieodpowiedniowektory wartościto: oraz .
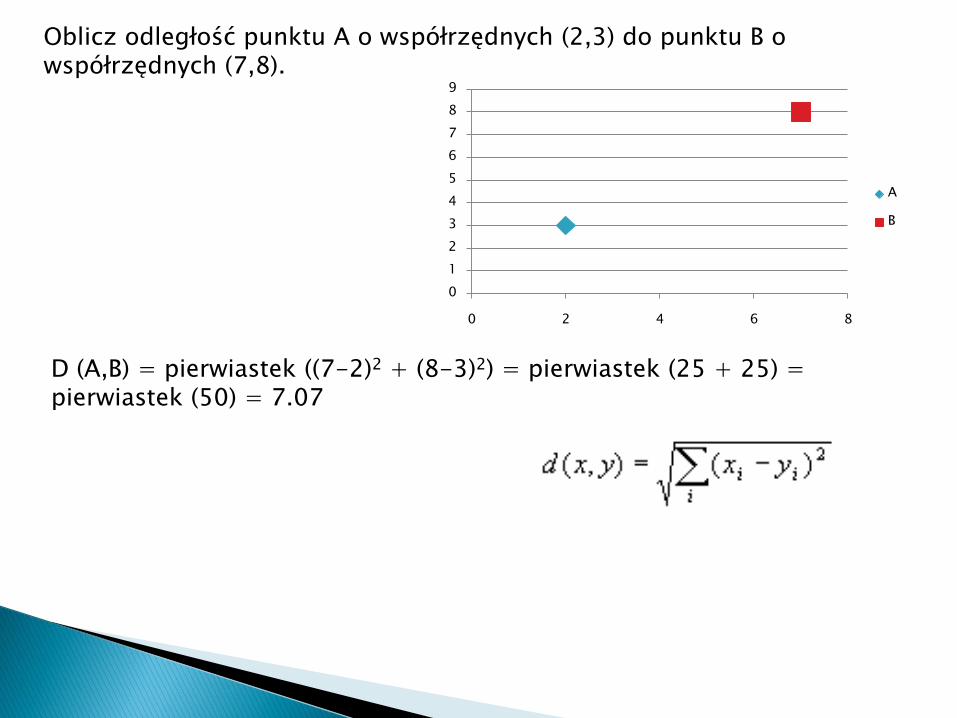
Oblicz odległość punktu A o współrzędnych (2,3) do punktu B o współrzędnych (7,8).
D (A,B) = pierwiastek ((7-2)2 + (8-3)2) = pierwiastek (25 + 25) = pierwiastek (50) = 7.07
0
1
2
3
4
5
6
7
8
9
0 2 4 6 8
A
B
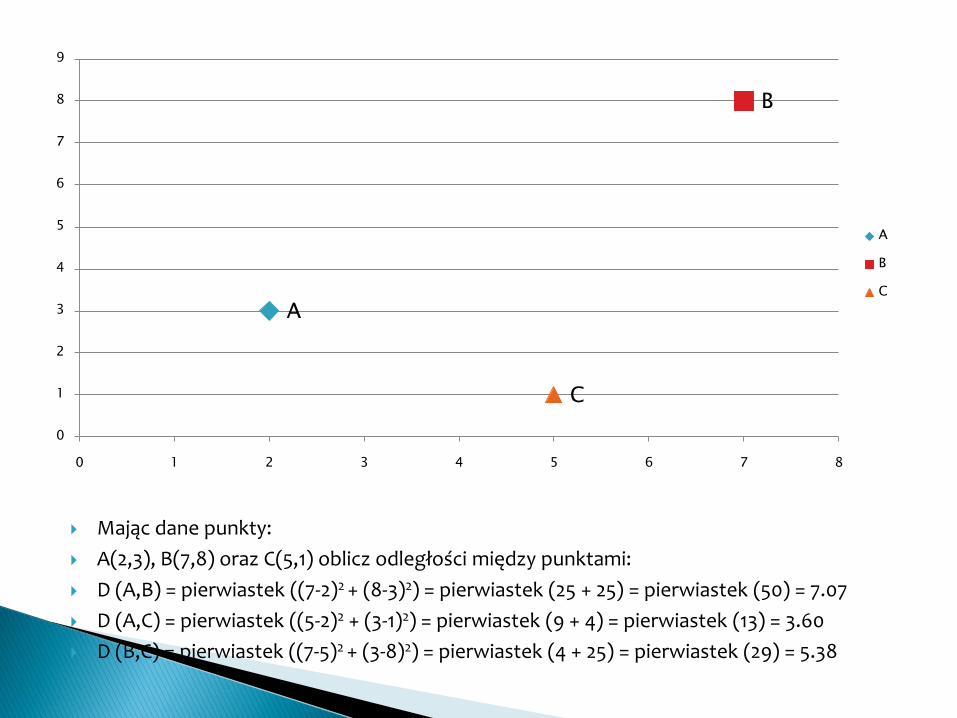
Mając dane punkty:
A(2,3), B(7,8) oraz C(5,1) oblicz odległości między punktami:
D (A,B) = pierwiastek ((7-2)2 + (8-3)2) = pierwiastek (25 + 25) = pierwiastek (50) = 7.07
D (A,C) = pierwiastek ((5-2)2 + (3-1)2) = pierwiastek (9 + 4) = pierwiastek (13) = 3.60
D (B,C) = pierwiastek ((7-5)2 + (3-8)2) = pierwiastek (4 + 25) = pierwiastek (29) = 5.38
A
B
C
0
1
2
3
4
5
6
7
8
9
0 1 2 3 4 5 6 7 8
A
B
C
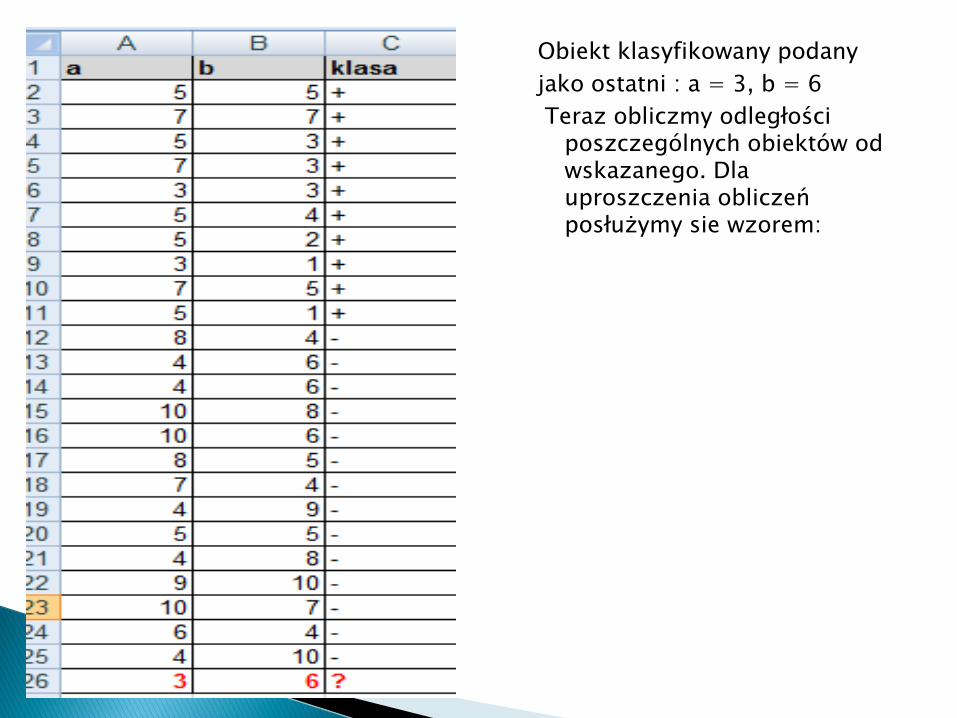
Obiekt klasyfikowany podany
jako ostatni : a = 3, b = 6
Teraz obliczmy odległości poszczególnych obiektów od wskazanego. Dla uproszczenia obliczeń posłużymy sie wzorem:
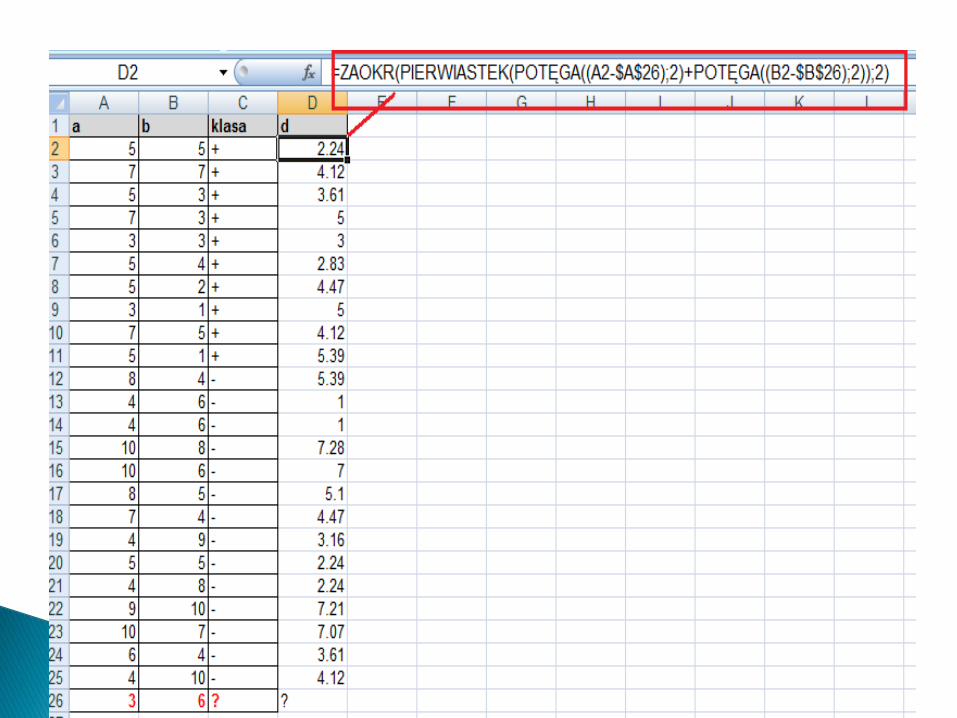

Znajdujemy więc k najbliższych sąsiadów. Załóżmy, że szukamy 9 najbliższychsąsiadów. Wyróżnimy ich kolorem zielonym.Sprawdzamy, które z tych 9 najbliższych sąsiadów są z klasy „+” a które z klasy „-” ?By to zrobić musimy znaleźć k najbliższych sąsiadów (funkcja Excela o nazwie MIN.K)
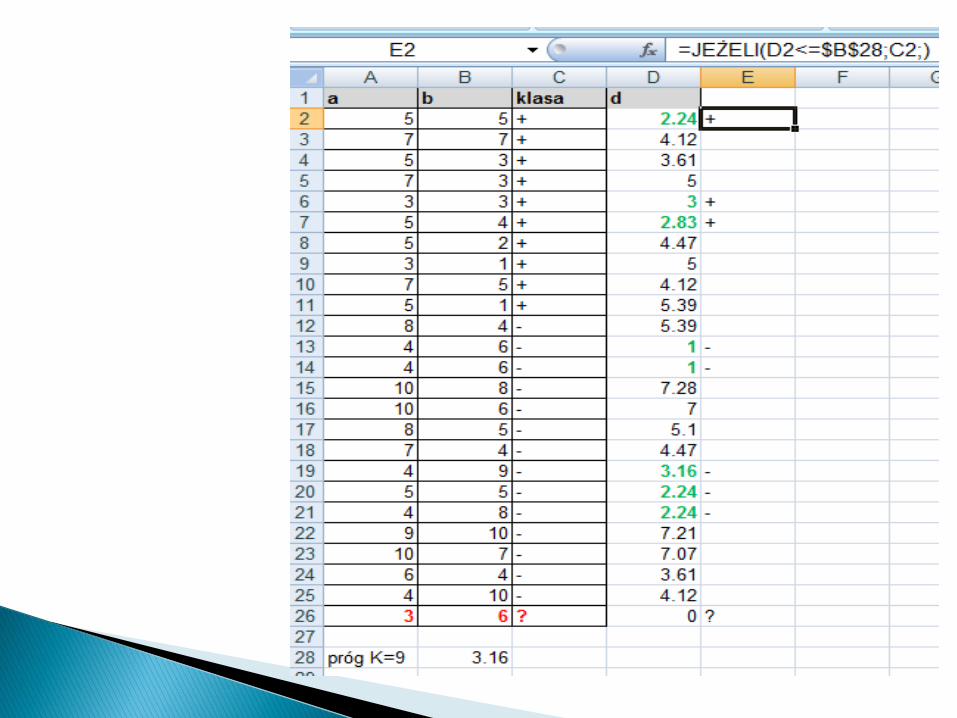
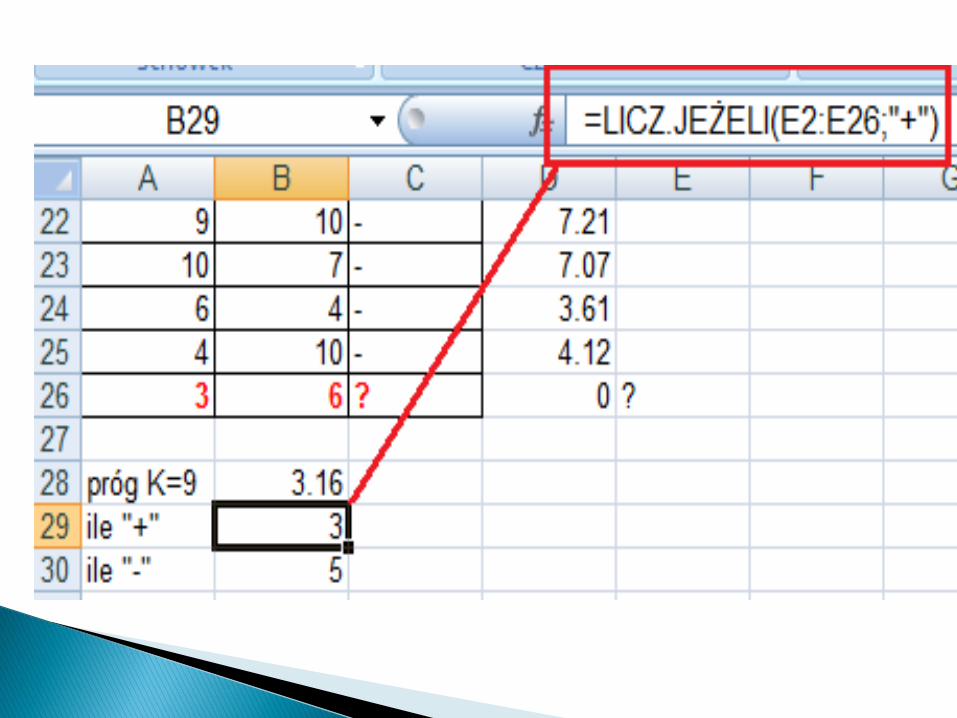

Teraz w komórce (kolumna C, wiersz 26) wreszcie możemy napisad formułę, która wstawi odpowiednią wartośd.
W ten sposób stwierdzimy, że obiekt a=3 i b=6 zaliczymy do klasy „-”
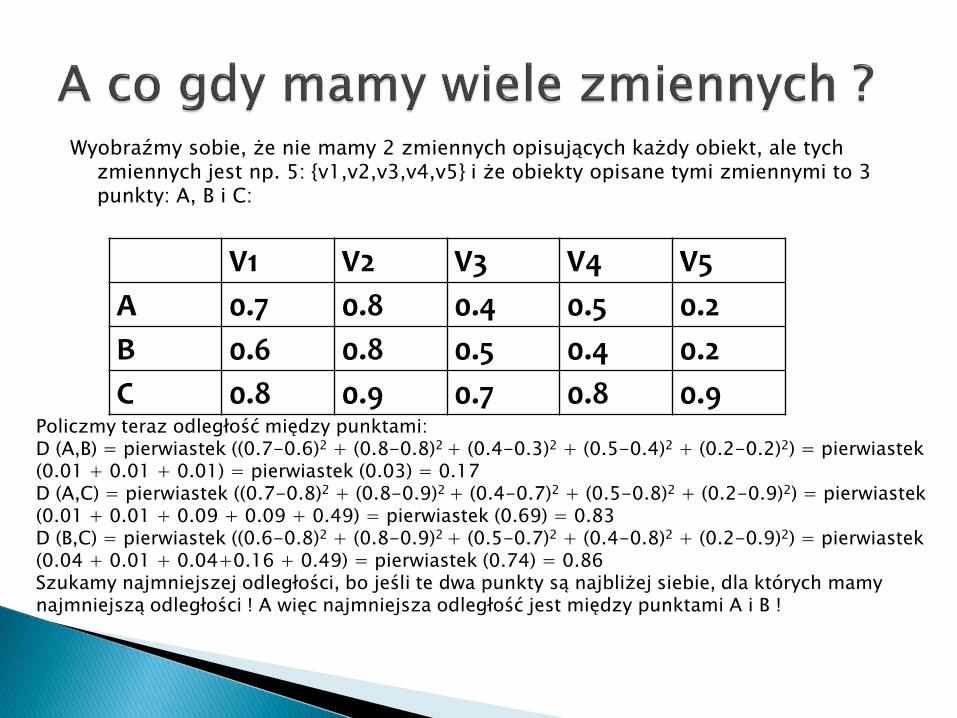
Wyobraźmy sobie, że nie mamy 2 zmiennych opisujących każdy obiekt, ale tych zmiennych jest np. 5: {v1,v2,v3,v4,v5} i że obiekty opisane tymi zmiennymi to 3 punkty: A, B i C:
V1 V2 V3 V4 V5
A 0.7 0.8 0.4 0.5 0.2
B 0.6 0.8 0.5 0.4 0.2
C 0.8 0.9 0.7 0.8 0.9Policzmy teraz odległość między punktami:D (A,B) = pierwiastek ((0.7-0.6)2 + (0.8-0.8)2 + (0.4-0.3)2 + (0.5-0.4)2 + (0.2-0.2)2) = pierwiastek (0.01 + 0.01 + 0.01) = pierwiastek (0.03) = 0.17D (A,C) = pierwiastek ((0.7-0.8)2 + (0.8-0.9)2 + (0.4-0.7)2 + (0.5-0.8)2 + (0.2-0.9)2) = pierwiastek (0.01 + 0.01 + 0.09 + 0.09 + 0.49) = pierwiastek (0.69) = 0.83D (B,C) = pierwiastek ((0.6-0.8)2 + (0.8-0.9)2 + (0.5-0.7)2 + (0.4-0.8)2 + (0.2-0.9)2) = pierwiastek (0.04 + 0.01 + 0.04+0.16 + 0.49) = pierwiastek (0.74) = 0.86Szukamy najmniejszej odległości, bo jeśli te dwa punkty są najbliżej siebie, dla których mamy najmniejszą odległości ! A więc najmniejsza odległość jest między punktami A i B !


Czym różni się predykcja od klasyfikacji?
Na czym polega algorytm K-NN ?
Na czym bazuje alg. Naiwnego klasyfikatora Bayesa ?
Co wiemy dzięki badaniu korelacji?



















