
Metoda list inwersyjnych - Strona Głównazsi.tech.us.edu.pl/~nowak/swibio/MLI.pdf · pytania w...
42
Metoda list inwersyjnych Wykład III
Transcript of Metoda list inwersyjnych - Strona Głównazsi.tech.us.edu.pl/~nowak/swibio/MLI.pdf · pytania w...

Metoda list inwersyjnych
Wykład III

Plan wykładu
• Cele metody
• Tworzenie kartoteki wyszukiwawczej
• Redundancja i zajętość pamięci
• Wyszukiwanie informacji
• Czasy wyszukiwania
• Ocena metody: wady i zalety
• Modyfikacje
• aktualizacja

Cel metody
• Skrócenie czasu wyszukiwania na pytania szczegółowe – pamiętając o tym jak długi był czas wyszukiwania odpowiedzi na tego typu pytania w metodzie list prostych !

Lista inwersyjna
• To lista adresów obiektów, które w swoim opisie zawierają deskryptor di (di tx), gdzie
di =(aj,vij).
• Oznaczamy je jako L(di)={n1,n2,…,nz} pod warunkiem, że elementy: n1,n2,…,nz będą adresami obiektów x1,x2,…,xz .
• Tworzymy tyle list inwersyjnych ile jest w systemie deskryptorów di.

Tworzenie kartoteki wyszukiwawczej

Przykładowy system informacyjny
• Wszystkie obiekty mają unikalne opisy a więc
funkcja adresująca przydzieli każdemu
obiektowi inny adres
C B A
X1 C1 B1 A1
X2 C1 B2 A1
X3 C2 B1 A1
X4 C2 B2 A1
X5 C3 B2 A2
X6 C3 B2 A1
X7 C4 B1 A2
x8 C4 B2 a2

C B A
1 X1 C1 B1 A1
2 X2 C1 B2 A1
3 X3 C2 B1 A1
4 X4 C2 B2 A1
5 X5 C3 B2 A2
6 X6 C3 B2 A1
7 X7 C4 B1 A2
8 x8 C4 B2 a2
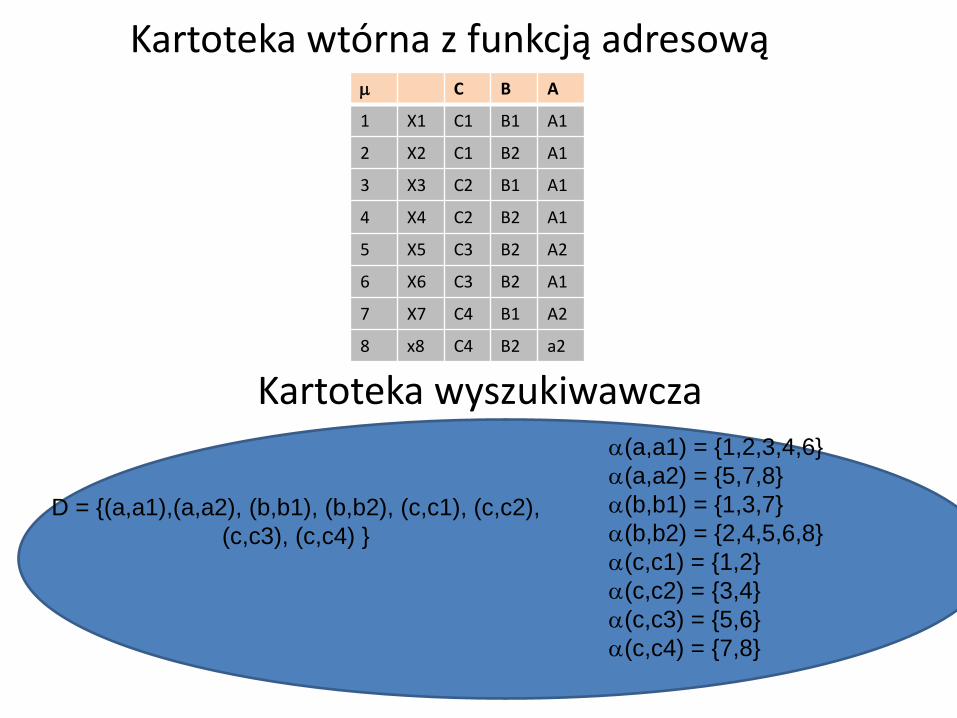
Kartoteka wyszukiwawcza
Kartoteka wtórna z funkcją adresową C B A
1 X1 C1 B1 A1
2 X2 C1 B2 A1
3 X3 C2 B1 A1
4 X4 C2 B2 A1
5 X5 C3 B2 A2
6 X6 C3 B2 A1
7 X7 C4 B1 A2
8 x8 C4 B2 a2
(a,a1) = {1,2,3,4,6}
(a,a2) = {5,7,8}
(b,b1) = {1,3,7}
(b,b2) = {2,4,5,6,8}
(c,c1) = {1,2}
(c,c2) = {3,4}
(c,c3) = {5,6}
(c,c4) = {7,8}
D = {(a,a1),(a,a2), (b,b1), (b,b2), (c,c1), (c,c2),
(c,c3), (c,c4) }

Cechy kartoteki wyszukiwawczej
• Kolejność list inwersyjnych jest dowolna ale dla szybkości wyszukiwania stosuje się: porządek leksykograficzny dla nazw (kodów) deskryptorów.

Redundancja
• Informacja o każdym obiekcie pamiętana jest w wielu miejscach – dokładnie tylu ile jest atrybutów opisujących każdy obiekt.
3 razy pamiętamy informację o adresie {1}
3 atrybuty w systemie: {a,b,c}
(a,a1) = {1,2,3,4,6}
(a,a2) = {5,7,8}
(b,b1) = {1,3,7}
(b,b2) = {2,4,5,6,8}
(c,c1) = {1,2}
(c,c2) = {3,4}
(c,c3) = {5,6}
(c,c4) = {7,8}

Wzór na redundancję
(a,a1) = {1,2,3,4,6}
(a,a2) = {5,7,8}
(b,b1) = {1,3,7}
(b,b2) = {2,4,5,6,8}
(c,c1) = {1,2}
(c,c2) = {3,4}
(c,c3) = {5,6}
(c,c4) = {7,8}
Dla r=8
2),(
2),(
2),(
2),(
5),(
3),(
3),(
5),(
4
3
2
1
2
1
2
1
cc
cc
cc
cc
bb
bb
aa
aa
28
8)22225335(
R

Zajętość pamięci
• Zajętość pamięci zależy od liczby deskryptorów opisujących obiekty w systemie bo to dla nich budowane są listy inwersyjne.
Zajętość pamięci potrzebna na zapamiętanie jednej listy
inwersyjnej.
R – liczba deskryptorów

Wyszukiwanie
• Mając zadane pytanie odnajdujemy listy inwersyjne a następnie adresy tych obiektów, które mają w swoim opisie deskryptory zawarte w pytaniu.
• Dla niezaprzeczonych deskryptorów pytania obliczamy część wspólną (iloczyn mnogościowy) odpowiadających im list inwersyjnych.

Wyszukiwanie – pytanie ogólne

przykład (a,a1) = {1,2,3,4,6}
(a,a2) = {5,7,8}
(b,b1) = {1,3,7}
(b,b2) = {2,4,5,6,8}
(c,c1) = {1,2}
(c,c2) = {3,4}
(c,c3) = {5,6}
(c,c4) = {7,8}
Wyszukiwanie odpowiedzi:
1. Szukamy wśród list inwersyjnych tej właściwej a
więc zawierającej deskryptor z pytania t:
Czy t (a,a1) ? NIE
Czy t (a,a2) ? NIE
Czy t (b,b1) ? NIE
Czy t (b,b2) ? NIE
Czy t (c,c1) ? NIE
Czy t (c,c2) ? NIE
Czy t (c,c3) ? TAK
2. Wygenerowanie listy inwersyjnej (c,c3) =
{5,6}={x5,x6}
3. Znaczenie termu t: (t) = (c,c3) = {5,6}={x5,x6}

Wyszukiwanie: pytanie szczegółowe

Przykład Wyszukiwanie odpowiedzi na pytanie t=(a,a1)(b,b1) + (c,c3)
1. T =t1 + t2
T1 = (a,a1)(b,b1)
T2=(c,c3)
2. Szukamy odpowiednich list inwersyjnych osobno dla każdego termu składowego (najpierw dla t1):
a) Szukamy deskryptora (a,a1)
Czy t (a,a1) ? Tak -> (a,a1) = {1,2,3,4,6}
b) Szukamy deskryptora (b,b1)
Czy t (a,a1) ? NIE
Czy t (a,a2) ? Nie
Czy t (b,b1) ? Tak -> (b,b1) = {1,3,7}
c) Wyznaczamy znaczenie termu t1, który jest iloczynem deskryptorów (a,a1) i (b,b1):
(t1) = {1,2,3,4,6} {1,3,7}={1,3} = {x1,x3}
3. Szukamy teraz znaczenia termu t2:
a) Szukamy list inwersyjnych dla wszystkich deskryptorów tego pytania, a wiec tylko (c,c3):
Czy t (a,a1) ? NIE
Czy t (a,a2) ? NIE
Czy t (b,b1) ? NIE
Czy t (b,b2) ? NIE
Czy t (c,c1) ? NIE
Czy t (c,c2) ? NIE
Czy t (c,c3) ? TAK -> (c,c3) = {5,6}
b) Wyznaczamy znaczenie termu t2: (t2) = {5,6} = {x5,x6}
4. Wyznaczamy znaczenie termu t:
(t) = {x1,x3} {x5,x6}={x1,x3,x5,x6}

W porównaniu z metodą list prostych…
• Nie jest tu konieczne przeglądanie wszystkich list inwersyjnych na dane pytanie. Należy wybrać tylko tyle list inwersyjnych, ile jest deskryptorów w pytaniu i wykonać na tych listach operacje mnogościowe.
• Jest to więc szybsza metoda, ale ma również swoje wady:
1. Metoda operuje na adresach (numerach), a nie na opisach obiektów. Nie możemy więc bezpośrednio przy wyszukiwaniu uwzględnić m.in. związków między deskryptorami w opisach dokumentów.
2. Deskryptory ogólne (powtarzające się w dużej liczbie opisów dokumentów) zwiększają redundancję i czas wyszukiwania.

Czas wyszukiwania
• Dla każdego deskryptora szukamy listy inwersyjnej i potem dokonujemy przecięcia (operacji mnogościowej).
• gi – czas generowania listy inwersyjnej dla deskryptora di
• p – czas przecięcia

Aktualizacja
• Dodanie nowego obiektu wymaga wstawienia adresu obiektu wszędzie tam (gdzie występują deskryptory opisujące ten obiekt).
• Usunięcie obiektu wiąże się z koniecznością usunięcia adresu obiektu z każdej listy inwersyjnej w której on występuje.
• Modyfikacja opisu obiektu wymaga usunięcia adresu obiektu z listy, która mu już nie odpowiada i dopisania do tej, która jest właściwa.

Wady i zalety
• Podstawowymi wadami metody list inwersyjnych są:
• nadmierna redundancja
• zajętość pamięci.
Aby zmniejszyć te dwa parametry, nie tracąc zbytnio na szybkości można zastosować wybrane modyfikacje.


MODYFIKACJE:
PORZĄDKOWANIE ADRESÓW OBIEKTÓW NA LISTACH
PORZĄDKOWANIE LIST
1.WG DŁUGOŚCI
2.LEKSYKOGRAFICZNIE
3.WG WYBRANEGO KRYTERIUM Z TABLICA ADRESOWĄ (INDEKSOWANIE)
4.WG CZĘSTOŚCI WYSTĘPOWANIA DANYCH DESKRYPTORÓW W PYTANIU
TWORZENIE LIST ZREDUKOWANYCH
•ZAZNACZANIE PRZEDZIAŁÓW ADRESÓW
•LISTY DLA PAR DESKRYPTORÓWZ ZAZNACZENIE CZĘSCI WSPÓLNEJ
•LISTY WIELODESKRYPTOROWE
•USUWANIE LIST DŁUGICH – LISTY ZANEGOWANE
•TWORZENIE LIST DLA PEWNEGO POZBIORU DESKRYPTORÓW
DEKOMPOZYCJE
•ATRYBUTOWA
•OBIEKTOWA
•OBIEKTOWO – ATRYBUTOWA

MODYFIKACJE:
PORZĄDKOWANIE ADRESÓW OBIEKTÓW NA LISTACH
PORZĄDKOWANIE LIST
1.WG DŁUGOŚCI
2.LEKSYKOGRAFICZNIE
3.WG WYBRANEGO KRYTERIUM Z TABLICA ADRESOWĄ (INDEKSOWANIE)
4.WG CZĘSTOŚCI WYSTĘPOWANIA DANYCH DESKRYPTORÓW W PYTANIU
TWORZENIE LIST ZREDUKOWANYCH
•ZAZNACZANIE PRZEDZIAŁÓW ADRESÓW
•LISTY DLA PAR DESKRYPTORÓWZ ZAZNACZENIE CZĘSCI WSPÓLNEJ
•LISTY WIELODESKRYPTOROWE
•USUWANIE LIST DŁUGICH – LISTY ZANEGOWANE
•TWORZENIE LIST DLA PEWNEGO POZBIORU DESKRYPTORÓW
DEKOMPOZYCJE
•ATRYBUTOWA
•OBIEKTOWA
•OBIEKTOWO – ATRYBUTOWA

Tworzymy listy inwersyjne tylko dla wybranego podzbioru D’ deskryptorów, gdzie D’ D. Wybrany zbiór może być zbiorem deskryptorów najczęściej występujących w pytaniach do systemu S lub zbiorem deskryptorów pewnego atrybutu (pewnych atrybutów). Tworzymy listy inwersyjne
(di) = {n1,n2,…,nk} gdzie:
di D’
'Ddii
TWORZENIE LIST DLA PEWNEGO POZBIORU DESKRYPTORÓW

•Poprawa czasu wyszukiwania odpowiedzi •zmniejszenie zajętości pamięci
Cel modyfikacji:

Jeśli t = t1 + t2 + . . . + tm i ti=d1 * d2 * …* dk to należy rozpatrzyć 3
przypadki: 1. Wszystkie deskryptory termów składowych zawierają się w D’. Jest to
najlepszy możliwy przypadek. W tej sytuacji szybkość systemy jest maksymalna. Postępuje się jak w klasycznej metodzie list inwersyjnych.
(ti) = α(d1)α(d2) … α(dk) , djD’, 1≤ j ≤ k, gdzie k to liczba deskryptorów pytania ti 2. Jeśli nie wszystkie deskryptory pytania ti należą do zbioru D’ to budujemy
odpowiedź przybliżoną jako zbiór Xp, taki, że Xp = α(dj) dla każdego djD’. Wtedy Xti Xp . Taki zbiór Xp przeglądamy moetodą list prostych by znaleźć adresy tych obiektów, które w swoim opisie zawierają też pozostałe deskryptory pytania:
(ti) = X ti = {x Xp: (x,ai) = vi, (ai,vi)=di. di ti i di D’} 3. Jeśli żaden z deskryptorów nie zawiera się w D’ to należy dokonać
przeglądu zupełnego (czyli potraktować kartotekę wtórną jako wyszukiwawczą i wykorzystać klasyczną metodę list prostych).
Wyszukiwanie
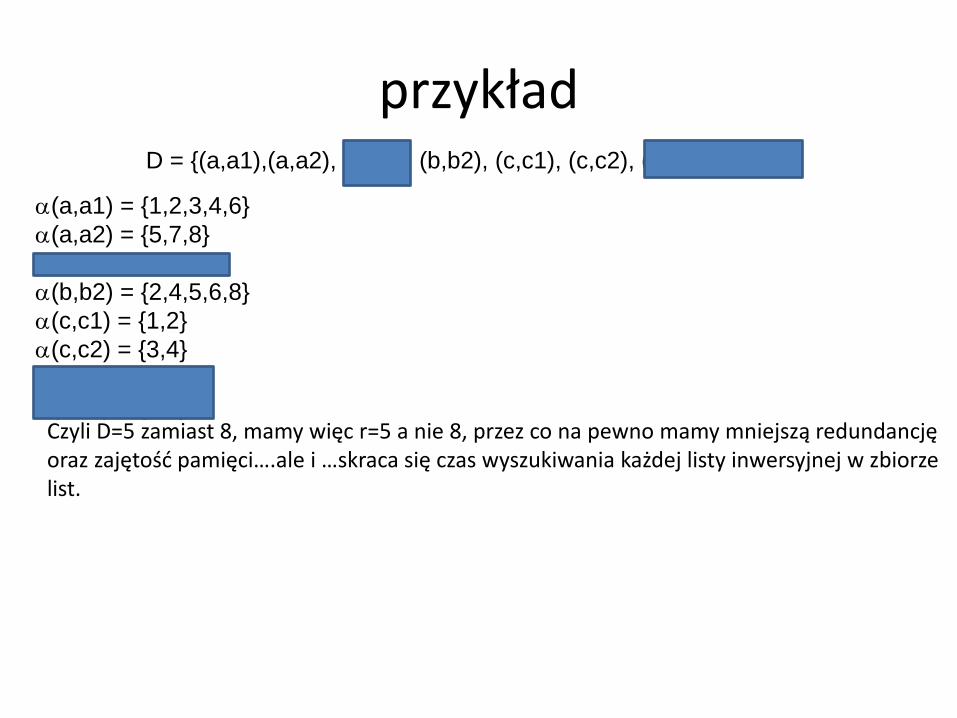
D = {(a,a1),(a,a2), (b,b1), (b,b2), (c,c1), (c,c2), (c,c3), (c,c4) }
(a,a1) = {1,2,3,4,6}
(a,a2) = {5,7,8}
(b,b1) = {1,3,7}
(b,b2) = {2,4,5,6,8}
(c,c1) = {1,2}
(c,c2) = {3,4}
(c,c3) = {5,6}
(c,c4) = {7,8}
przykład
Czyli D=5 zamiast 8, mamy więc r=5 a nie 8, przez co na pewno mamy mniejszą redundancję oraz zajętość pamięci….ale i …skraca się czas wyszukiwania każdej listy inwersyjnej w zbiorze list.

=(5+3+5+2+2 – 8)/8 = 9/8 = 1.1
= 5 * …
=tg jest mniejsze bo szukamy na liscie 5 list inwersyjnych a nie 8

MODYFIKACJE poprawiające
czas wyszukiwania odpowiedzi

Porządkowanie adresów obiektów ww list inwersyjnych
• Skraca to czas przecięcia dwóch list inwersyjnych
L(a,a1) = {3,1,7,6}
L(b,b4)={2,1,5,6}
L((a,a1) (b,b4)) = {3,1,7,6} ∩{2,1,5,6}={1,6}
Ale by taką operację mnogościową wykonać
potrzebujemy następujących porównań:
3 z 2, 3 z 1, 3 z 5, 3 z 6 – brak wspólnego
elementu „3”
1 z 2, 1 z 1 – „1” jest wspólnym elementem
7 z 2, 7 z 1, 7 z 5, 7 z 6 – „7” nie jest wspólnym
elementem
6 z 2, 6 z 1, 6 z 5, 6 z 6 – „6” jest wspólnym
elementem
A wiec porównań jest 14 !!!
L(a,a1) = {1,3,6,7}
L(b,b4)={1, 2,5,6}
L((a,a1) (b,b4)) = {1,3,6,7} ∩{1, 2,5,6}}={1,6}
Ale by taką operację mnogościową wykonać
potrzebujemy następujących porównań:
1 z 1 – „1” jest wspólnym elementem
3 z 1, 3 z 2, 3 z 5 - brak wspólnego elementu
„3”
6 z 5, 6 z 6 – „6” jest wspólnym elementem
7 z 6, koniec listy – „7” nie jest wspólnym
elementem
A wiec porównań jest 7 !!!
Bez uporządkowania z uporządkowaniem

Porządkujemy listy w ten sposób, ze na początku są listy najkrótsze a na końcu najdłuższe !!!
q = d1q * d2
q * ...* dsk
gdzie d1q – pierwszy deskryptor pytania.
Zalety:
- wpływa to na czas przecięcia list inwersyjnych (bierze się
pierwszy deskryptor z listy i pyta się czy znajduje się w pytaniu, jeśli tak to zapamiętujemy daną listę)
Aktualizacja: jest skomplikowana, zmienia się bowiem długość list i należy jest od początku uporządkować !!!
PORZĄDKOWANIE LIST WG
DŁUGOŚCI

(c,c1) = {1,2}
(c,c2) = {3,4}
(c,c3) = {5,6}
(c,c4) = {7,8}
(a,a2) = {5,7,8}
(b,b1) = {1,3,7}
(a,a1) = {1,2,3,4,6}
(b,b2) = {2,4,5,6,8}
T= (c,c1)(b,b2) = {1,2}^{2,4,5,6,8} = {2}={x2}
(a,a1) = {1,2,3,4,6}
(a,a2) = {5,7,8}
(b,b1) = {1,3,7}
(b,b2) = {2,4,5,6,8}
(c,c1) = {1,2}
(c,c2) = {3,4}
(c,c3) = {5,6}
(c,c4) = {7,8}

(a,a1) = {1,2,3,4,6}
(a,a2) = {5,7,8}
(b,b1) = {1,3,7}
(b,b2) = {2,4,5,6,8}
(c,c1) = {1,2}
(c,c2) = {3,4}
(c,c3) = {5,6}
(c,c4) = {7,8}
Umożliwia zastosowanie
a). podziału połówkowego do wyszukiwania odpowiedniej listy inwersyjnej. Wówczas ilość porównań = log 2 k gdzie k – ilość list inwersyjnych
b). Przeszukiwania blokowego. Wówczas średnia liczba porównań = k
Zalety:
Czas szukania odpowiedniej listy znacznie się wtedy zmniejsza, natomiast czas przecięcia dwóch list nie !!!
Aktualizacja: nie wpływa, pod warunkiem pamiętania list pustych
PORZĄDKOWANIE LIST
LEKSYKOGRAFICZNIE
T=(c,c2) (c,c2) > (c,c1) (a,a1) = {1,2,3,4,6}
(a,a2) = {5,7,8}
(b,b1) = {1,3,7}
(b,b2) = {2,4,5,6,8}
(c,c1) = {1,2}
(c,c2) = {3,4}
(c,c3) = {5,6}
(c,c4) = {7,8}
(c,c1) = {1,2}
(c,c2) = {3,4}
(c,c3) = {5,6}
(c,c4) = {7,8}

Zalety:
Czas szukania odpowiedniej listy znacznie się wtedy zmniejsza, natomiast czas przecięcia dwóch list nie !!!
Wady:
Metoda nie zdaje egzaminu w przypadku zadania pytania spoza zbioru standardowych pytań !!! (tak samo jak przy odcedzaniu)
PORZĄDKOWANIE LIST WG CZĘSTOŚCI
WYSTĘPOWANIA DANYCH DESKRYPTORÓW W
PYTANIACH

MODYFIKACJE zmniejszające
zajętość pamięci

Jeżeli w jakiejś liście występuje ciąg kolejnych adresów można wtedy
zaznaczyć przedział – poprzez znacznik i wtedy nie wpisujemy adresów wszystkich obiektów, a tylko pierwszy i ostatni adres danego ciągu.
Np.:
L(d1)={1, 2, 3, 4, 5, 8, 12, 13, 14, 15, 16, 20}
L’(d1)={1 5, 8, 12 16, 20}
Zalety:
-Czas wyszukiwania jest krótszy
-zmniejszona zajętość pamięci
Aktualizacja: skomplikowana ze względu na konieczną zmianę przedziałów
ZAZNACZANIE PRZEDZIAŁÓW
ADRESÓW
(a,a1) = {14,6}
(a,a2) = {5,7,8}
(b,b1) = {1,3,7}
(b,b2) = {2,4 6,8}
(c,c1) = {1,2}
(c,c2) = {3,4}
(c,c3) = {5,6}
(c,c4) = {7,8}

Jeżeli mamy 2 listy L(di) i L(dj) i listy te mają pewne wspólne dla siebie adresy obiektów to:
Lw(di,dj)= L(di) L(dj)
Lr(di)= L(di) \ Lw(di,dj)
Lr(dj)= L(dj) \ Lw(di,dj)
L(di,dj)= { Lr(di) Lw(di,dj) Lr(dj) }
LISTY DLA PAR DESKRYPTORÓWZ
ZAZNACZENIE CZĘSCI WSPÓLNEJ
(a,a1) = {14,6}
(a,a2) = {5,7,8}
(b,b1) = {1,3,7}
(b,b2) = {2,4 6,8}
(c,c1) = {1,2}
(c,c2) = {3,4}
(c,c3) = {5,6}
(c,c4) = {7,8}
Zalety:
-Czas wyszukiwania jest krótszy
-zmniejszona zajętość pamięci
Aktualizacja: raczej prosta
(a,a1) = {14,6}
(b,b1) = {1,3,7}
(c,c1) = {1,2}
(c,c2) = {3,4}
(c,c3) = {5,6}
(c,c4) = {7,8}
w(a,a2)(b,b2) = {7#5,8#2,4,6}

LISTY DLA PAR DESKRYPTORÓWZ
ZAZNACZENIE CZĘSCI WSPÓLNEJ (a,a1) = {14,6}
(b,b1) = {1,3,7}
(c,c1) = {1,2}
(c,c2) = {3,4}
(c,c3) = {5,6}
(c,c4) = {7,8}
w(a,a2)(b,b2) = {7#5,8#2,4,6}
Wówczas gdy:
1) T = (a,a2)(b,b2) odpowiedź na pytanie mamy od razu jako…
2) T = (a,a2) odpowiedź na pytanie uzyskujemy poprzez złączenie
elementów listy: 7 oraz 5,8 = {5,7,8}
3) T = (b,b2) odpowiedź uzyskujemy jako połączenie elementów: {5,8} oraz
{2,4,6} = {2,4,5,6,8}

Jeżeli mamy 2 listy L(di) i L(dj) i listy te mają pewne wspólne dla siebie adresy obiektów to:
Np.:
L(d1)={1, 2, 5, 7, 8, 12, 17}
L(d2)={1, 4, 5, 9, 10, 17, 20} L(d1*d2) = {1, 5, 17}
Zalety:
-Czas wyszukiwania jest krótszy
-zmniejszona zajętość pamięci Aktualizacja: bardziej skomplikowana
W przypadku list łączonych należy określić współczynnik Q, który
wskazuje minimalną liczbę adresów wspólną dla dwóch list, dla
których efektywne jest stosowanie tej modyfikacji, a zdeterminowane jest minimalizacją kosztów , zlikwidowanie
redundancji oraz wszelkich działań niezbędnych do
wyselekcjonowania z listy wspólnej adresów dotyczących danego deskryptora. L(d1 * d2 * d3 * d4)={1, 8, 12}
LISTY WIELODESKRYPTOROWE – szczególne przypadek list dla par deskryptorów

Listy muszą pochodzić z jednego atrybutu wzajemnie dwudeskryptorowego o
wartościach wzajemnie się negujących – któraś z wartości musi występować w
opisie obiektów.
Zalety:
-Czas wyszukiwania – 2 sposoby: np. = a1 * a2
szukamy a1 i przecinamy z listą dla a2
szukamy obiekty z a2 – odjąć obiekty z a1
-zmniejszona zajętość pamięci
Aktualizacja: skomplikowana
Listy zanegowane
T = t1 * t2
L(A1,1) = {x2}
L(A1,2) = {x1,x3,x4,x5,x6,x7,x8}
L(A2,a) = {x1,x2,x4,x5,x6,x8}
L(A2,b) = {x3,x7}
T=(A1,1)*(A2,b)
T=d1*d2
d1 = (A1,1) = (A1, 2)
(d1)={x2}
d2 = (A2,b)
(d1)={x3,x7}
L(A1,1) = {x2}
L(A1,2) = {x1,x3,x4,x5,x6,x7,x8}
A więc: L(A1,2) = {x1,x3,x4,x5,x6,x7,x8}={x2}

Podsumowanie
• Aktualizacja bardziej skomplikowana niż dla metody list prostych
• Duża redundancja
• Szybsze wyszukiwanie niż w metodzie list prostych













![Lista zmian programu - GidexLista zmian w projekcie: List kolejowy Wygenerowano: 2020-06-10 08:39:09 List kolejowy 0006343 [Bazy danych] Zaktualizowano dane stacji na podstawie zmiany](https://static.fdocuments.pl/doc/165x107/5f826e82d5b33b255815c5e9/lista-zmian-programu-lista-zmian-w-projekcie-list-kolejowy-wygenerowano-2020-06-10.jpg)




