
2017 01-27-titanic
22
In [ ]: %matplotlib inline import pandas as pd import numpy as np import pylab as plt # Customizations import seaborn as sns sns.set() # matplotlib defaults # Set the global default size of matplotlib figures plt.rc('figure', figsize=(9, 4)) # Size of matplotlib figures that contain subplots fizsize_with_subplots = (10, 10) # Size of matplotlib histogram bins bin_size = 10 План: 1. Описание задачи, данных 2. Как будем оценивать качество процент правильных ответов 3. Пробуем dummy метод: Нечисловые признаки пытаемся сделать числовыми: убираем все небуквы, если число ок. Иначе 0 Берем теперь все числовые признаки и подаем на вход advanced модели ML 4. Анализ данных 5. Построение финальной модели 6. Оценка результата Описание
-
Upload
iurii-zhidkov-frm -
Category
Data & Analytics
-
view
20 -
download
2
Transcript of 2017 01-27-titanic

In [ ]: %matplotlib inline import pandas as pd import numpy as np import pylab as plt # Customizations import seaborn as sns sns.set() # matplotlib defaults # Set the global default size of matplotlib figures plt.rc('figure', figsize=(9, 4)) # Size of matplotlib figures that contain subplots fizsize_with_subplots = (10, 10) # Size of matplotlib histogram bins bin_size = 10
План:
1. Описание задачи, данных2. Как будем оценивать качество процент правильных ответов3. Пробуем dummy метод: Нечисловые признаки пытаемся сделать числовыми: убираем все небуквы, если число ок. Иначе 0 Берем теперь всечисловые признаки и подаем на вход advanced модели ML
4. Анализ данных5. Построение финальной модели6. Оценка результата
Описание

«Гибель Титаника это одно из наиболее бесславных кораблекрушений в истории. 15 апреля 1912 года, во время своего первого рейса, Титаникзатонул после столкновения с айсбергом, погубив 1502 из 2224 человек пассажиров и команды. Эта сенсционная трагедия шокироваламеждународное сообщество и привела к улучшению требований правил техники безопасности на судах. Одной из причин того, что кораблекрушениеповлекло такие жертвы, стала нехватка спасательных шлюпок для пассажиров и команды. Также был элемент счастливой случайности, влияющий наспасение от утопления. Также, некоторые группы людей имели больше шансов выжить чем другие, такие как женщины, дети и высший класс. В этомсоревновании мы предложим вам завершить анализ того, какие типы людей скорее всего спасутся. В частности, мы попросим вас применить средствамашинного обучения для определения того, какие пассажиры спасутся в этой трагедии.»

ДанныеДанные делятся на 2 группы: обучающую (training set) и тестовую (test set). Для каждого пассажира из обучающей выборки известно, выжил он или нет,а для тестовой выборки нужно предсказать, выживет ли данный пассажир. То есть на выход нужно иметь список: id пассажира наш прогноз, выживетон или нет (0 или 1)
Подгрузим данные, посмотрим на них
In [ ]: df_train = pd.read_csv('2017‐01‐27‐train.csv') df_train_copy = df_train.copy() df_test = pd.read_csv('2017‐01‐27‐test.csv') df_train.head()
survival Выжил или нет (0 = No; 1 = Yes) pclass Класс пассажира (1 = 1st; 2 = 2nd; 3 = 3rd), 1‐лучший, 3‐худший) name Имя sex Пол age Возраст sibsp Число братьев/сестер, мужа или жены в сумме на борту (siblings) parch Число родителей/детей на борту (parent, child) ticket Номер билета fare Стоимость билета cabin Номер кабины embarked Порт посадки (C = Cherbourg; Q = Queenstown; S = Southampton)
Изучаем данные

Посмотрим на базовую информацию о датафрейме
In [ ]: df_train.info()
Отсюда видно, что поля Age, Embarked, Cabin имеют пропуски, особенно поле Cabin
Описательные статистики
In [ ]: df_train.describe()
Построение dummy модели
Давайте преобразуем строковые данные в числовые: из строки пробуем убрать все буквы таким образом: A12I3>123. Если не получается число,берем 0. Все пропуски заполняем нулями. Сразу все данные подаем на вход модели

In [ ]: from sklearn import metrics from sklearn.cross_validation import train_test_split from sklearn.metrics import accuracy_score number_columns = ['Survived', 'Pclass', 'Age', 'SibSp', 'Parch', 'Fare', 'Cabin', 'Ticket', 'Name'] #number_columns = ['Survived', 'Pclass', 'Age'] tmp = df_train.copy() def to_number2(s): import re non_decimal = re.compile(r'[^\d.]+') try: return float(non_decimal.sub('', s)) except: return 0 def to_number(s): return abs(hash(s)) % (10 ** 8) tmp['Cabin'] = tmp['Cabin'].astype(str).apply(to_number) tmp['Ticket'] = tmp['Ticket'].apply(to_number) tmp['Name'] = tmp['Name'].apply(to_number) tmp = tmp[number_columns] X = tmp.drop(u'Survived', axis=1).fillna(0).values Y = tmp['Survived'].fillna(0).values train_x, test_x, train_y, test_y = train_test_split(X, Y, test_size=0.30, random_state=1) clf = clf.fit(train_x, train_y) predict_y = clf.predict(test_x) print (u"Точность = %.2f" % (accuracy_score(test_y, predict_y)))
Анализ данных

In [ ]: # Set up a grid of plots fig = plt.figure(figsize=fizsize_with_subplots) fig_dims = (3, 3) # Plot death and survival counts plt.subplot2grid(fig_dims, (0, 0)) df_train['Survived'].value_counts().plot(kind='bar', title=u'Число выживших') # Plot Pclass counts plt.subplot2grid(fig_dims, (0, 1)) df_train['Pclass'].value_counts().plot(kind='bar', title=u'Распределение по классам') # Plot Sex counts plt.subplot2grid(fig_dims, (1, 0)) df_train['Sex'].value_counts().plot(kind='bar', title=u'Распределение по полу') plt.xticks(rotation=0) # Plot Embarked countsplt.subplot2grid(fig_dims, (1, 1)) df_train['Embarked'].value_counts().plot(kind='bar', title=u'Распределение по портам') # Plot the Age histogram plt.subplot2grid(fig_dims, (0, 2)) df_train['Age'].hist() plt.title(u'Распределение возрастов')
Посмотрим как распределена выживание по классам. Предсказуемо: первый класс выживает чаще
In [ ]: pclass_xt = pd.crosstab(df_train['Pclass'], df_train['Survived']) pclass_xt
То же самое картинкой

In [ ]: # Normalize the cross tab to sum to 1: pclass_xt_pct = pclass_xt.div(pclass_xt.sum(1).astype(float), axis=0) pclass_xt_pct.plot(kind='bar', stacked=True, title=u'Распределение выживания по классам') plt.xlabel(u'Класс пассажира') plt.ylabel(u'Доля выживания')
Пол
Посмотрим на пол. Для этого сначала преобразуем female>0, male>1
In [ ]: df_train['Sex_Val'] = df_train['Sex'].map({'female': 0, 'male': 1}).astype(int) df_train[['Sex_Val', 'Sex']].head()
Аналогично строим распределения выживания по полу. Видим, что большинство женщин спаслось, в то время как большинство мужчин нет
In [ ]: sex_val_xt = pd.crosstab(df_train['Sex_Val'], df_train['Survived']) sex_val_xt_pct = sex_val_xt.div(sex_val_xt.sum(1).astype(float), axis=0) sex_val_xt_pct.plot(kind='bar', stacked=True, title=u'Доля выживания по полу')
Давайте посмотрим, можно ли извлечь дополнительную информацию, если использовать одновременно пол и класс пассажира.
Для этого посчитаем число комбинаций, и построим распределение, как обычно
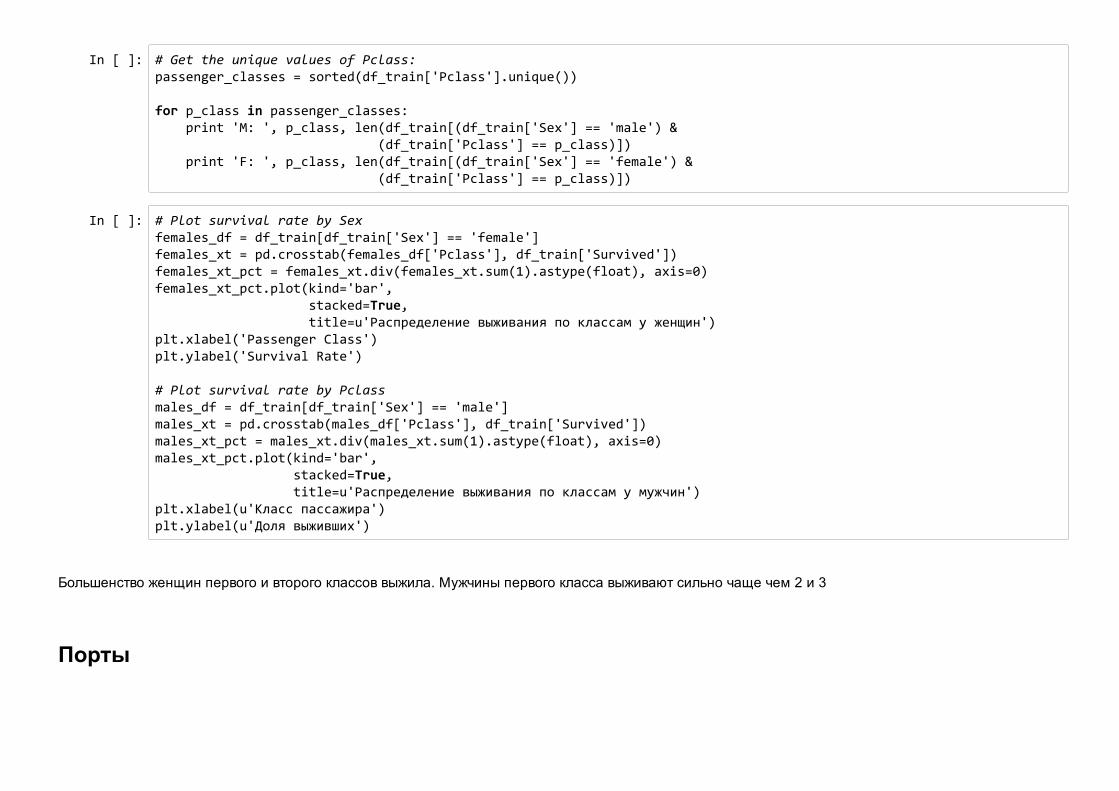
In [ ]: # Get the unique values of Pclass: passenger_classes = sorted(df_train['Pclass'].unique()) for p_class in passenger_classes: print 'M: ', p_class, len(df_train[(df_train['Sex'] == 'male') & (df_train['Pclass'] == p_class)]) print 'F: ', p_class, len(df_train[(df_train['Sex'] == 'female') & (df_train['Pclass'] == p_class)])
In [ ]: # Plot survival rate by Sex females_df = df_train[df_train['Sex'] == 'female'] females_xt = pd.crosstab(females_df['Pclass'], df_train['Survived']) females_xt_pct = females_xt.div(females_xt.sum(1).astype(float), axis=0) females_xt_pct.plot(kind='bar', stacked=True, title=u'Распределение выживания по классам у женщин') plt.xlabel('Passenger Class') plt.ylabel('Survival Rate') # Plot survival rate by Pclass males_df = df_train[df_train['Sex'] == 'male'] males_xt = pd.crosstab(males_df['Pclass'], df_train['Survived']) males_xt_pct = males_xt.div(males_xt.sum(1).astype(float), axis=0) males_xt_pct.plot(kind='bar', stacked=True, title=u'Распределение выживания по классам у мужчин') plt.xlabel(u'Класс пассажира') plt.ylabel(u'Доля выживших')
Большенство женщин первого и второго классов выжила. Мужчины первого класса выживают сильно чаще чем 2 и 3
Порты

Посмотрим на порты. У нас есть 2 осутствующих значения. Заполним их тем портом, которого у нас большинство: порт S. Также преобразуем именапортов
In [ ]: # Get the unique values of Embarked embarked_locs = sorted(df_train['Embarked'].unique()) embarked_locs_mapping = dict(zip(embarked_locs, range(0, len(embarked_locs) + 1))) embarked_locs_mapping
In [ ]: df_train['Embarked_Val'] = df_train['Embarked'] \ .map(embarked_locs_mapping) \ .astype(int) df_train[['Embarked_Val','Embarked']].head()
In [ ]: df_train['Embarked_Val'].hist(bins=len(embarked_locs), range=(0, 3)) plt.title(u'Распределение поров') plt.xlabel(u'Порт') plt.ylabel(u'Число') plt.show()
Заполняем миссинги
In [ ]: if df_train['Embarked'].isnull().sum() > 0: df_train.replace({'Embarked_Val' : { embarked_locs_mapping[np.NaN] : embarked_locs_mapping['S'] } }, inplace=True)
Проверяем, что теперь все хорошо
In [ ]: embarked_locs = sorted(df_train['Embarked_Val'].unique()) embarked_locs

Строим распределение по портам
In [ ]: embarked_val_xt = pd.crosstab(df_train['Embarked_Val'], df_train['Survived']) embarked_val_xt_pct = \ embarked_val_xt.div(embarked_val_xt.sum(1).astype(float), axis=0) embarked_val_xt_pct.plot(kind='bar', stacked=True) plt.title(u'Распределение выживания по портам') plt.xlabel(u'Порт') plt.ylabel(u'Доля выживания')
Видим, что с первого порта выжило больше людей
Посмотрим, связано ли это с классами/полами пассажиров (может просто на первом порту садятся больше пассажиров 1го класса, поэтому ивыживаемость больше)
In [ ]: # Set up a grid of plots fig = plt.figure(figsize=fizsize_with_subplots) rows = 2 cols = 3 col_names = ('Sex_Val', 'Pclass') for portIdx in embarked_locs: for colIdx in range(0, len(col_names)): plt.subplot2grid((rows, cols), (colIdx, portIdx ‐ 1)) df_train[df_train['Embarked_Val'] == portIdx][col_names[colIdx]] \ .value_counts().plot(kind='bar', title=u'Порт ' + unicode(portIdx))
Когда мы сделали порты целыми числами, мы упорядочили их. При анализе данных неправильно упорядочивать подобные вещи, в этом нет никакогосмысла. Для этого заменим 1 колонку с полем Порта на 3 колонки типа: является первым портом, является вторым портом и является 3 портом.Каждая такая колонка принимает 0 или 1. При таком подходе мы правильно исопльзуем принадлежность к тому или иному порту. Такая процедураназывается Onehot encoding

In [ ]: if 'Embarked_Val_1' not in df_train.columns: df_train = pd.concat([df_train, pd.get_dummies(df_train['Embarked_Val'], prefix='Embarked_Val')], axis=1) df_train[['Embarked', 'Embarked_Val_1', 'Embarked_Val_2', 'Embarked_Val_2']].head()
Возраст
Изучим возраст. Аналогично с колонкой Порта, в поле Age есть много пропусков.
In [ ]: df_train[df_train['Age'].isnull()][['Sex', 'Pclass', 'Age']].head()
Что сделаем? Давайте заполним пропуски медианой по группе ПолКласс пассажира
In [ ]: # To keep Age in tact, make a copy of it called AgeFill # that we will use to fill in the missing ages: df_train['AgeFill'] = df_train['Age'] # Populate AgeFill df_train['AgeFill'] = df_train['AgeFill'] \ .groupby([df_train['Sex_Val'], df_train['Pclass']]) \ .apply(lambda x: x.fillna(x.median()))
In [ ]: len(df_train[df_train['AgeFill'].isnull()])
Нарисуем что получилось

In [ ]: # Set up a grid of plots fig, axes = plt.subplots(2, 1, figsize=fizsize_with_subplots) # Histogram of AgeFill segmented by Survived df1 = df_train[df_train['Survived'] == 0]['Age'] df2 = df_train[df_train['Survived'] == 1]['Age'] max_age = max(df_train['AgeFill']) axes[0].hist([df1, df2], bins=max_age / bin_size, range=(1, max_age), stacked=True) axes[0].legend((u'Умерли', u'Выжили'), loc='best') axes[0].set_title(u'Распределение по возрасту') axes[0].set_xlabel(u'Возраст') axes[0].set_ylabel(u'Число') # Scatter plot Survived and AgeFill axes[1].scatter(df_train['Survived'], df_train['AgeFill'])axes[1].set_title(u'Распределение возраста выживших') axes[1].set_xlabel(u'Выжили') axes[1].set_ylabel(u'Возраст')
Видно, что дети выживают чаще
Давайте посмотрим, как выглядит распределение возрастов в классах
In [ ]: for pclass in passenger_classes: df_train.AgeFill[df_train.Pclass == pclass].plot(kind='kde') plt.title('Age Density Plot by Passenger Class') plt.xlabel('Age') plt.legend(('1st Class', '2nd Class', '3rd Class'), loc='best')
Видим, что чем лучше класс тем больше в среднем возраст пассажиров. Оно и логично

Размер семьиВ машинном обучении есть такое важное понятие, как feature engineering, заключающееся в создании новых фич по уже имеющимся. Создании новыхданных на основе имеющихся позволяет вычленять более информативные признаки, которые могут улучшать модели
Построим признак: размер семьи, равный сумме братьев/сестер/родителей/детей. Это колонки parch и SibSp
In [ ]: df_train['FamilySize'] = df_train['SibSp'] + df_train['Parch'] df_train[['SibSp', 'Parch', 'FamilySize']].iloc[10:15].head()
In [ ]: df_train['FamilySize'].hist() plt.title(u'Распределение размера семьи у всех пассажиров')
Посмотрим, как размер семьи влияет на выживание
Как всегда, посмотрим как распределена смертность в зависимости от размера семьи
In [ ]: # Get the unique values of Embarked and its maximum family_sizes = sorted(df_train['FamilySize'].unique()) family_size_max = max(family_sizes) df1 = df_train[df_train['Survived'] == 0]['FamilySize'] df2 = df_train[df_train['Survived'] == 1]['FamilySize'] plt.hist([df1, df2], bins=family_size_max + 1, range=(0, family_size_max), stacked=True) plt.legend(('Died', 'Survived'), loc='best') plt.title(u'Выжившие по размеру семьи')
In [ ]: df_train.pivot_table('PassengerId', ['FamilySize'], u'Survived', 'count').plot(title=u'Абсолютное распределение выживания')

Видно, что семьи с 13 членами выживают чаще. Отсюда данный признак информативен и может улучшить модель
Подготовка финальных данных
Выкинем неинформативные колонки
In [ ]: df = df_train.copy() df = df.drop(['Name', 'Sex', 'Ticket', 'Cabin', 'Embarked'], axis=1)
Выкинем колонки, которые мы преобразовавыли в том или ином виде, и у которых есть копия, но с другим названием
In [ ]: df = df.drop(['Age', 'SibSp', 'Parch', 'PassengerId', 'Embarked_Val'], axis=1) df.dtypes
Соберем весь код, который мы писали выше воедино в одну функцию

In [ ]:

def clean_data(df): # Get the unique values of Sex sexes = sorted(df['Sex'].unique()) # Generate a mapping of Sex from a string to a number representation genders_mapping = dict(zip(sexes, range(0, len(sexes) + 1))) # Transform Sex from a string to a number representation df['Sex_Val'] = df['Sex'].map(genders_mapping).astype(int) # Get the unique values of Embarked embarked_locs = sorted(df['Embarked'].unique()) # Generate a mapping of Embarked from a string to a number representation embarked_locs_mapping = dict(zip(embarked_locs, range(0, len(embarked_locs) + 1))) # Transform Embarked from a string to dummy variables df = pd.concat([df, pd.get_dummies(df['Embarked'], prefix='Embarked_Val')], axis=1) # Fill in missing values of Embarked # Since the vast majority of passengers embarked in 'S': 3, # we assign the missing values in Embarked to 'S': if len(df[df['Embarked'].isnull()] > 0): df.replace({'Embarked_Val' : { embarked_locs_mapping[np.NaN] : embarked_locs_mapping['S'] } }, inplace=True) # Fill in missing values of Fare with the average Fare if len(df[df['Fare'].isnull()] > 0): avg_fare = df['Fare'].mean() df.replace({ None: avg_fare }, inplace=True) # To keep Age in tact, make a copy of it called AgeFill # that we will use to fill in the missing ages: df['AgeFill'] = df['Age'] # Determine the Age typical for each passenger class by Sex_Val. # We'll use the median instead of the mean because the Age

# histogram seems to be right skewed. df['AgeFill'] = df['AgeFill'] \ .groupby([df['Sex_Val'], df['Pclass']]) \ .apply(lambda x: x.fillna(x.median())) # Define a new feature FamilySize that is the sum of # Parch (number of parents or children on board) and # SibSp (number of siblings or spouses): df['FamilySize'] = df['SibSp'] + df['Parch'] return df def drop_columns(df, drop_passenger_id): # Drop the columns we won't use: df = df.drop(['Name', 'Sex', 'Ticket', 'Cabin', 'Embarked'], axis=1) # Drop the Age column since we will be using the AgeFill column instead. # Drop the SibSp and Parch columns since we will be using FamilySize. # Drop the PassengerId column since it won't be used as a feature. df = df.drop(['Age', 'SibSp', 'Parch'], axis=1) if drop_passenger_id: df = df.drop(['PassengerId'], axis=1) return df

Построение модели
Приступим к обучению модели. Берем все числовые признаки, которые уже были и котоыре мы преобразовали и подаем пачкой на вход в модельСлучайных деревьев (Random forest). Обучаем модель, смотрим, как она предсказывает выживание пассажиров
In [ ]: from sklearn.ensemble import RandomForestClassifier clf = RandomForestClassifier(n_estimators=100) train_data = df.values train_features = train_data[:, 1:] train_target = train_data[:, 0] clf = clf.fit(train_features, train_target) score = clf.score(train_features, train_target) "Mean accuracy of Random Forest: {0}".format(score)
На обучающей выборке получили 98% точности. Посмотрим, что на тестовой выборке
In [ ]: df_test = pd.read_csv('2017‐01‐27‐test.csv') # Data wrangle the test set and convert it to a numpy array df_test = clean_data(df_test) df_test = drop_columns(df_test, drop_passenger_id=False) test_data = df_test.values test_x = test_data[:, 1:] test_y = clf.predict(test_x)

Выгрузим данные для Kaggle
In [ ]: df_test['Survived'] = test_y df_test[['PassengerId', 'Survived']] \ .to_csv('2017‐02‐27‐results‐rf.csv', index=False)
Вот как выглядят ответы
In [ ]: df_test[['PassengerId', 'Survived']].head()
Оценка качества моделиМы можем оценить качество модели сами. Для этого разобьем нашу обучующую выборку на 2 части: новую обучающую и новую тестовую. На нихбудем обучаться и проверять качество модели
In [ ]: from sklearn import metrics from sklearn.cross_validation import train_test_split from sklearn.metrics import accuracy_score # Split 80‐20 train vs test data train_x, test_x, train_y, test_y = train_test_split(train_features, train_target, test_size=0.30, random_state=0) clf = clf.fit(train_x, train_y) predict_y = clf.predict(test_x) print (u"Точность = %.2f" % (accuracy_score(test_y, predict_y)))
Получили точность 81%.





















