
Wykorzystanie analizy asocjacyjnej w zarządzaniu serwisem ... fileCopyright © StatSoft Polska...
22
Copyright © StatSoft Polska 2014, [email protected] 101 WYKORZYSTANIE ANALIZY ASOCJACYJNEJ W ZARZĄDZANIU SERWISEM FLOTY POJAZDÓW Mateusz Marzec, Reliability Solutions Sp. z o.o.; Akademia Górniczo-Hutnicza, Katedra Robotyki i Mechatroniki Stale rosnące koszty utrzymania taboru autobusowego wymuszają potrzebę kształ to- wania odpowiedniej polityki serwisowej. Niezbędne do tego celu są tworzone przez eksploatatorów serwisowe bazy danych, które zawierają informację o zaistniałych awariach i wykonanych naprawach. Ze względu na obszerność baz danych oraz w wielu przypadkach ich nieustrukturyzowaną formę, „ręczna” analiza danych w poszukiwaniu odpowiednich zależności może być bardzo czasochłonna i nieefektywna. Rozwój metod KDD (ang. Knowledge Discovery in Databases) stwarza nowe możliwości rozwiązy- wania tego typu zadań. Niniejsze opracowanie proponuje zastosowanie podejścia z wykorzystaniem narzędzi text mining oraz data mining. Efektywność tych narzędzi została sprawdzona empirycznie na podstawie serwisowej bazy danych dużego pol- skiego przedsiębiorstwa transportowego. Baza ta zawiera informacje z 3 letniego okresu prowadzenia serwisu floty liczącej 300 autobusów. W pierwszej kolejności, z wyko- rzystaniem metod Text Mining, dokonano ekstrakcji atrybutów w celu ustruktury- zowania informacji zawartych w bazie danych. Następnie, z wykorzystaniem analizy asocjacyjnej, wskazano relację między uszkodzeniami poszczególnych podzespołów w badanych autobusach. W wielu przypadkach okazało się, że awarie nieistotne z punktu widzenia czasu ich napraw, kosztów oraz bezpieczeństwa mogą być przyczyną innych istotnych awarii (ang. downstream failure). Takie informacje poza zwiększeniem
Transcript of Wykorzystanie analizy asocjacyjnej w zarządzaniu serwisem ... fileCopyright © StatSoft Polska...

Copyright © StatSoft Polska 2014, [email protected]
101
WYKORZYSTANIE ANALIZY ASOCJACYJNEJ W ZARZĄDZANIU SERWISEM FLOTY POJAZDÓW
Mateusz Marzec, Reliability Solutions Sp. z o.o.;
Akademia Górniczo-Hutnicza, Katedra Robotyki i Mechatroniki
Stale rosnące koszty utrzymania taboru autobusowego wymuszają potrzebę kształto-
wania odpowiedniej polityki serwisowej. Niezbędne do tego celu są tworzone przez
eksploatatorów serwisowe bazy danych, które zawierają informację o zaistniałych
awariach i wykonanych naprawach. Ze względu na obszerność baz danych oraz w wielu
przypadkach ich nieustrukturyzowaną formę, „ręczna” analiza danych w poszukiwaniu
odpowiednich zależności może być bardzo czasochłonna i nieefektywna. Rozwój metod
KDD (ang. Knowledge Discovery in Databases) stwarza nowe możliwości rozwiązy-
wania tego typu zadań. Niniejsze opracowanie proponuje zastosowanie podejścia
z wykorzystaniem narzędzi text mining oraz data mining. Efektywność tych narzędzi
została sprawdzona empirycznie na podstawie serwisowej bazy danych dużego pol-
skiego przedsiębiorstwa transportowego. Baza ta zawiera informacje z 3 letniego okresu
prowadzenia serwisu floty liczącej 300 autobusów. W pierwszej kolejności, z wyko-
rzystaniem metod Text Mining, dokonano ekstrakcji atrybutów w celu ustruktury-
zowania informacji zawartych w bazie danych. Następnie, z wykorzystaniem analizy
asocjacyjnej, wskazano relację między uszkodzeniami poszczególnych podzespołów
w badanych autobusach. W wielu przypadkach okazało się, że awarie nieistotne
z punktu widzenia czasu ich napraw, kosztów oraz bezpieczeństwa mogą być przyczyną
innych istotnych awarii (ang. downstream failure). Takie informacje poza zwiększeniem

Copyright © StatSoft Polska 2014, [email protected]
102
bezpieczeństwa pasażerów mogą poprawić również dostępność floty pojazdów, poprzez
minimalizację czasu napraw oraz poprawę niezawodności, co przyniesie pozytywny
skutek ekonomiczny.
Problem gotowości technicznej środków transportu
Obecnie od eksploatowanych przez przewoźników środków transportu wymagany jest
bardzo wysoki poziom gotowości technicznej. Spowodowane jest to przede wszystkim
wymaganiami ekonomicznymi. W szczególności wysokie wymagania stawiane są
flotom autobusów miejskich, których przestoje generują poważne straty finansowe. Jak
wynika z badań przeprowadzonych przy współpracy z Miejskim Przedsiębiorstwem
Komunikacyjnym w Krakowie, straty te w przypadku autobusów klasy maxi sięgają
średnio 2500 zł/dobę, a w przypadku autobusów klasy mega 3000 zł/dobę [1]. Należy
wziąć pod uwagę również koszty napraw oraz innych działań serwisowych. W celu
zapewnienia realizacji zaplanowanych zadań przewozowych każdy przewoźnik utrzy-
muje rezerwowe środki transportu, aby wykorzystać je w przypadku awarii i koniecz-
nego przestoju. Mając na uwadze alternatywne metody zapewnienia gotowości floty,
można stwierdzić, że w wielu przypadkach polityka utrzymania zwiększonej rezerwy
jest nieuzasadniona ekonomicznie.
Dobrą alternatywą jest utrzymanie gotowości floty poprzez odpowiednie planowanie
serwisu. Do tego celu niezbędna jest analiza danych eksploatacyjno-serwisowych. Dane
tego typu zawierają informacje o sposobie eksploatacji maszyn (środowisko pracy, czas
eksploatacji, użytkownik itp.), jak również informacje o awariach i wykonanych napra-
wach. Analizując dane eksploatacyjno-serwisowe, jesteśmy w stanie wskazać m.in.
zależności między poszczególnymi awariami oraz zależności między awariami a czynni-
kami determinującymi sposób eksploatacji maszyn. Może okazać się przykładowo, że
awaria osuszacza klimatyzacji (wypuszczenie granulatu) powoduje awarię kompresora
(zatarcie), co skutkuje przestojem maszyny i poważnymi konsekwencjami finansowymi.
Uzasadniona ekonomicznie wydaje się więc wymiana osuszacza w oparciu o stałe

Copyright © StatSoft Polska 2014, [email protected]
103
interwały czasowe lub ocenę jego stanu technicznego. Mając na uwadze zależności
między awariami a sposobem eksploatacji maszyn, możemy również posłużyć się przy-
kładem kompresora. Kompresor układu klimatyzacji autobusu eksploatowanego w re-
gionach o wysokiej temperaturze może uleć zatarciu w wyniku braku wydajności wenty-
latora skraplacza, który zmniejsza ciśnienie oraz temperaturę czynnika w chłodnicy
klimatyzacji. Mając z kolei na uwadze te fakty, należy rozważyć montaż dwóch
wentylatorów, co pozwoli zwiększyć ich wydajność. Wskazując zestawy reguł postaci
„JEŚLI-TO”, jesteśmy w stanie nie tylko określić właściwą strategię serwisową maszyn,
ale również wskazać ich błędy konstrukcyjne, co znacznie zwiększa gotowość
operacyjną. Takie informacje są niezwykle istotne zarówno dla eksploatatorów, jak
i producentów maszyn.
Analiza danych eksploatacyjno-serwisowych
Niniejsza praca przedstawia przebieg oraz wyniki analizy danych przeprowadzonej dla
dużego przedsiębiorstwa komunikacyjnego w Polsce z wykorzystaniem oprogramo-
wania STATISTICA. Obiektem analizy była flota licząca 180 pojazdów autobusowych
klasy maxi oraz mega. Dane obejmowały trzyletni okres eksploatacji floty, a ich forma
została przedstawiona w tab. 1.
Tabela 1. Dane dotyczące zaistniałych awarii.
Nr Nr autobusu Przebieg Nr części Nazwa części Działanie serwisowe
1 AA001 80 000 AUX345672
Końcówka
ramienia
dolnego
niesprawna końcówka ramienia
dolnego drzwi - wymiana
2 AA002 10 000 BDI53455 Prowadnik akcja serwisowa wymiany sworzni
i prowadników drzwi
3 AA001 120 000 QWW673484 Przegub drzwi niesprawny potencjometr -
wymiana przegubu drzwi

Copyright © StatSoft Polska 2014, [email protected]
104
Jak można zauważyć, nie wszystkie pozycje w tabeli odnoszą się do awarii. Pozycja nr 2
jest związana z wymianą „prowadnika” w ramach akcji serwisowej producenta. Chcąc
wyszukać zależności między awariami, należy więc wyłączyć z bazy danych wszystkie
pozycje niezwiązane z awarią. Aby to zrobić, należy poddać analizie opisy działań
serwisu w kolumnie „działanie serwisowe”. Niestety opisy te mają formę nieustruktu-
ryzowanego tekstu, którego „ręczna” analiza może być bardzo czasochłonna, szczegól-
nie w przypadku dużych zbiorów danych. Aby wskazać, czy dany rekord w bazie
danych jest związany z awarią czy zaplanowanym działaniem serwisowym (np.
wymiana prewencyjna, kontrola, akcja serwisowa), wykorzystano narzędzia text mining.
Wykorzystanie narzędzi text mining do sklasyfikowania tekstu [2]
Text mining jest procesem wykorzystującym odpowiednie algorytmy obliczeniowe do
przetwarzania danych testowych w celu ekstrakcji interesującej nas wiedzy. Text mining
przebiega w sposób automatyczny, dając nam możliwość szybkiej i dogłębnej analizy
tekstu wg zadanych kryteriów.
Analiza text mining danych opisanych w poprzedniej sekcji pracy przebiegała w pięciu
etapach:
1. określenie celu i zakresu analizy,
2. przygotowanie danych źródłowych,
3. zdefiniowania analizy,
4. przetworzenie danych,
5. wykonanie obliczeń.
1. Określenie celu i zakresu analizy
W pierwszym etapie analizy text mining należało określić cel i zakres analizy. Jak
wcześniej wspomniano, obiektem analizy były dane dotyczące działań serwisowych

Copyright © StatSoft Polska 2014, [email protected]
105
przeprowadzonych w okresie trzech lat na flocie liczącej 180 autobusów. Baza danych
liczyła 200 000 rekordów, które zawierały następujące informacje:
ID pojazdu, na którym przeprowadzono działania serwisowe,
przebieg autobusu w dniu serwisu,
ID części bezpośrednio związanej z serwisem,
nazwa tej części,
opis podjętego działania serwisowego.
Celem analizy było zakwalifikowanie rekordów w bazie danych do jednej z dwóch
kategorii:
awaria,
wymiana prewencyjna.
W tym celu poddano analizie opisy przeprowadzonych działań serwisowych.
2. Przygotowanie danych źródłowych
W drugim etapie przekształcono dane do postaci, która dawała możliwość współpracy
z oprogramowaniem STATISTICA. Wiązało się to z wykonaniem następujących
czynności:
1. obróbka analizowanych danych opisowych,
2. „ręczne” zakwalifikowanie losowo wybranej próbki danych do jednej z dwóch kate-
gorii (awaria/prewencja),
3. podział danych na próbę uczącą i testującą klasyfikator.
Obróbka analizowanych danych opisowych polegała na sprawdzeniu pisowni (z wyko-
rzystaniem komercyjnego oprogramowania), usunięciu znaków formatujących oraz na

Copyright © StatSoft Polska 2014, [email protected]
106
ujednoliceniu sposobu kodowania znaków (jest to niezwykle istotne w przypadku
tekstów w języku polskim). W efekcie przykładowe zdanie:
„niesprawna końcówka ramienia dolnego drzwi – wymiana”
przybrało następującą formę:
„niesprawna koncowka ramienia dolnego drzwi wymiana”.
W wyniku wstępnej obróbki danych otrzymano tekst bez jakichkolwiek znaków forma-
tujących o ujednoliconym sposobie kodowania znaków.
W kolejnym kroku, przy pomocy doświadczonych pracowników działu serwisu, zakwa-
lifikowano 5% losowo wybranych opisów napraw jako naprawy poawaryjne lub pre-
wencyjne. Ta próbka danych posłuży programowi STATISTICA do zbudowania modelu
klasyfikatora, za pomocą którego program automatycznie zakwalifikuje pozostałe 95%
danych.
W ostatnim kroku próbkę danych podzielono w stosunku 50/50 na grupę uczącą i testu-
jącą. Taki podział pozwoli „wytrenować” klasyfikator oraz sprawdzić jego dokładność.
W efekcie tych działań dane wejściowe do analizy text mining miały formę
przedstawioną w tabeli 2.

Copyright © StatSoft Polska 2014, [email protected]
107
Tabela 2. Dane wejściowe do analizy.
Nr Opis Awaria? Podział
1 awaria modulatora wymiana modulatora EBS TAK Testing
2 pekniety wspornik Wymiana wspornika katowego mocowania
oponczy TAK Training
3 Obsluga techniczna P1 NIE Training
4 Akumulator - nie utrzymuje pojemnosci wymiana akumulatora TAK Training
5 Akcja serwisowa wymiany uchwytow paskowych NIE Testing
6 uzupelnienie brakujacej instalacji elektrycznej NIE Testing
7 Wymiana klocków hamulcowych NIE Training
... ... ... ...
3. Zdefiniowanie analizy
Zdefiniowanie analizy polegało na wskazaniu programowi STATISTICA danych będą-
cych przedmiotem analizy. Po wybraniu narzędzia Text Mining wyświetliło się okno
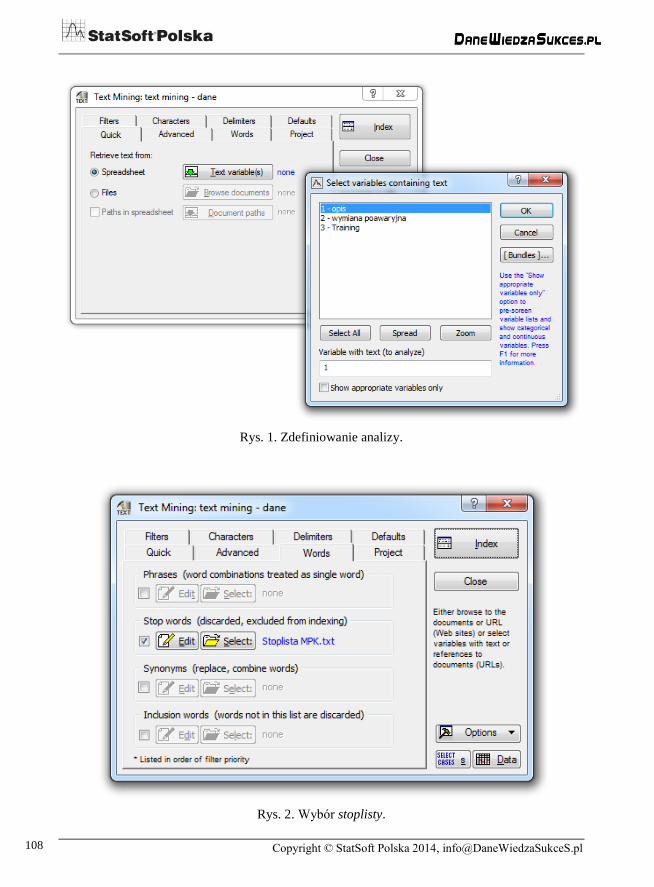
dialogowe, gdzie wskazano dane tekstowe (rys. 1).
Aby zoptymalizować analizę, w zakładce Words wybrano przygotowaną wcześniej stop-
listę. Wykorzystanie stoplisty pozwoliło wyeliminować wyrazy, które nie miały żadnego
znaczenia dla analizy (np. „Kraków”, „autobus”, „kierowca” itp.).
Copyright © StatSoft Polska 2014, [email protected]
108
Rys. 1. Zdefiniowanie analizy.
Rys. 2. Wybór stoplisty.

Copyright © StatSoft Polska 2014, [email protected]
109
Pozostałe opcje pozostawiono przy wartościach domyślnych, po czym wybrano przycisk
Index.
4. Przetworzenie danych
Po wybraniu przycisku Index program przystąpił do przetwarzania danych. W tym celu
oprogramowanie wykonało następujące czynności:
1. usunięcie znaków interpunkcyjnych,
2. przekształcenie opisów na listy wyrazów,
3. usunięcie wyrazów nieistotnych (wskazanych przez stoplistę),
4. redukcja wyrazów do rdzenia.
W pierwszej kolejności program usunął z tekstu znaki interpunkcyjne, a następnie
utworzył dla opisów listy ich wyrazów. W efekcie opisy:
opis 1: „niesprawna koncowka ramienia dolnego drzwi wymiana”
opis 2: „akcja serwisowa wymiany sworzni i prowadnikow drzwi”
opis 3: „niesprawny potencjometr wymiana przegubu drzwi”
przybrały formę list przedstawionych w tabeli 3.

Copyright © StatSoft Polska 2014, [email protected]
110
Tabela 3. Opisy awarii w formie list wyrazów.
opis 1 opis 2 opis 3
niesprawna akcja niesprawny
koncowka serwisowa potencjometr
ramienia wymiany wymiana
dolnego sworzni przegubu
drzwi prowadnikow drzwi
wymiana drzwi
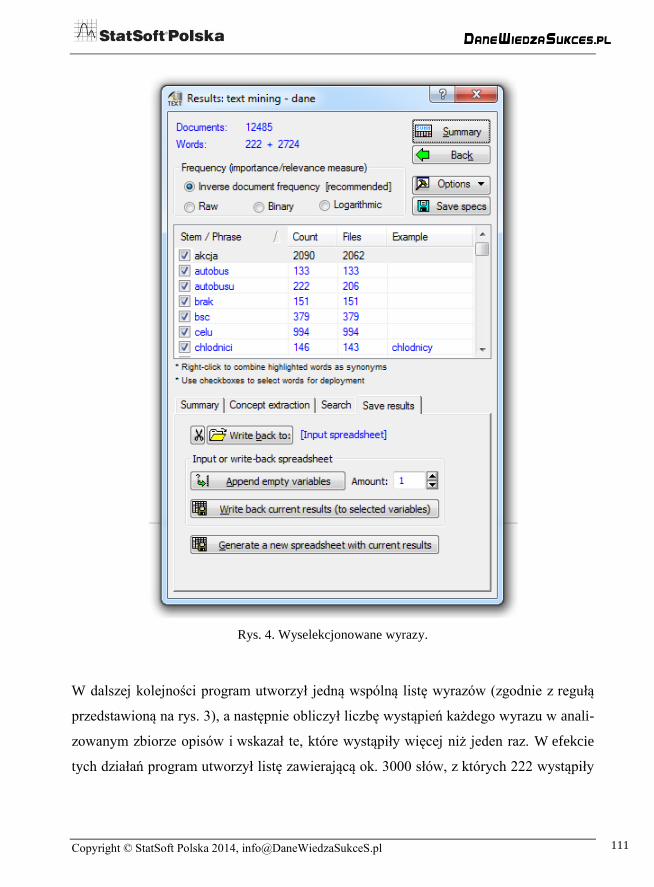
W kolejnych krokach program usunął z list wyrazy nieistotne (zgodnie z wybraną
wcześniej stoplistą), a pozostałe wyrazy na listach sprowadził do ich rdzenia, czyli do
formy podstawowej. Forma podstawowa oznacza, że wyrazy "chłodnica" i "chłodnicy"
będą miały swoją wspólną formę podstawową "chłodnic".
Rys. 3. Sposób tworzenia listy wyrazów.
Copyright © StatSoft Polska 2014, [email protected]
111
Rys. 4. Wyselekcjonowane wyrazy.
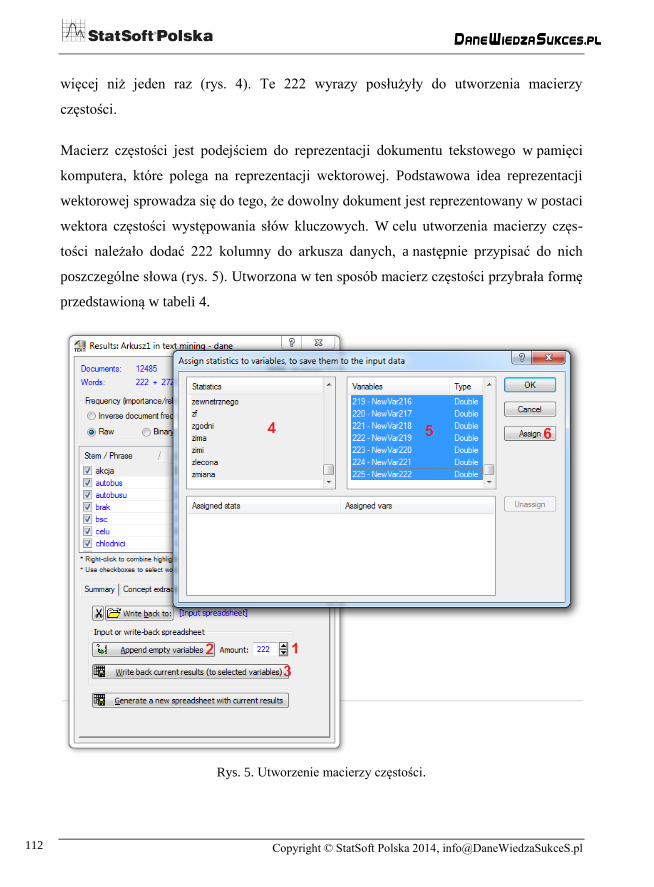
W dalszej kolejności program utworzył jedną wspólną listę wyrazów (zgodnie z regułą
przedstawioną na rys. 3), a następnie obliczył liczbę wystąpień każdego wyrazu w anali-
zowanym zbiorze opisów i wskazał te, które wystąpiły więcej niż jeden raz. W efekcie
tych działań program utworzył listę zawierającą ok. 3000 słów, z których 222 wystąpiły
Copyright © StatSoft Polska 2014, [email protected]
112
więcej niż jeden raz (rys. 4). Te 222 wyrazy posłużyły do utworzenia macierzy
częstości.
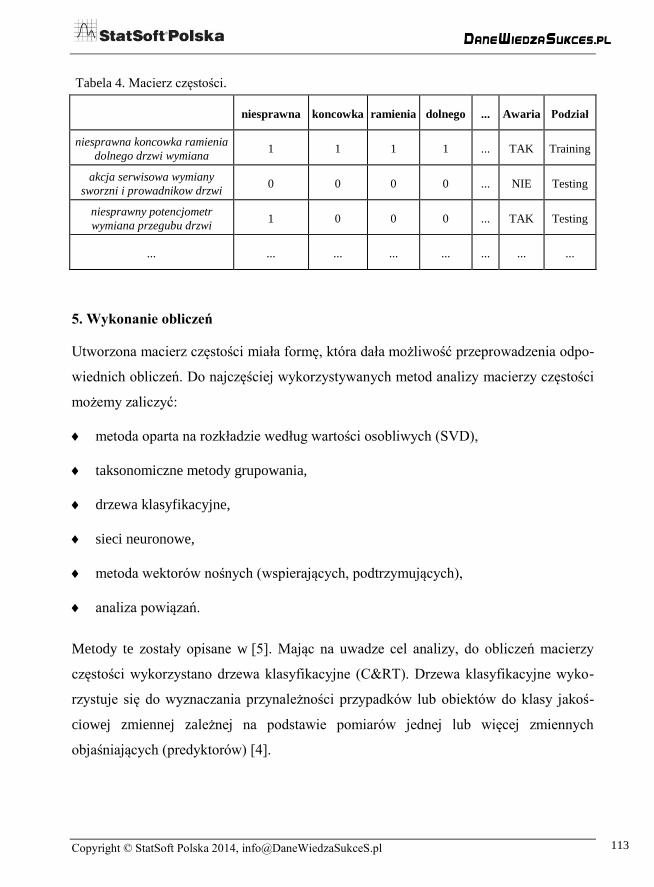
Macierz częstości jest podejściem do reprezentacji dokumentu tekstowego w pamięci
komputera, które polega na reprezentacji wektorowej. Podstawowa idea reprezentacji
wektorowej sprowadza się do tego, że dowolny dokument jest reprezentowany w postaci
wektora częstości występowania słów kluczowych. W celu utworzenia macierzy częs-
tości należało dodać 222 kolumny do arkusza danych, a następnie przypisać do nich
poszczególne słowa (rys. 5). Utworzona w ten sposób macierz częstości przybrała formę
przedstawioną w tabeli 4.
Rys. 5. Utworzenie macierzy częstości.
Copyright © StatSoft Polska 2014, [email protected]
113
Tabela 4. Macierz częstości.
niesprawna koncowka ramienia dolnego ... Awaria Podział
niesprawna koncowka ramienia
dolnego drzwi wymiana 1 1 1 1 ... TAK Training
akcja serwisowa wymiany
sworzni i prowadnikow drzwi 0 0 0 0 ... NIE Testing
niesprawny potencjometr
wymiana przegubu drzwi 1 0 0 0 ... TAK Testing
... ... ... ... ... ... ... ...
5. Wykonanie obliczeń
Utworzona macierz częstości miała formę, która dała możliwość przeprowadzenia odpo-
wiednich obliczeń. Do najczęściej wykorzystywanych metod analizy macierzy częstości
możemy zaliczyć:
metoda oparta na rozkładzie według wartości osobliwych (SVD),
taksonomiczne metody grupowania,
drzewa klasyfikacyjne,
sieci neuronowe,
metoda wektorów nośnych (wspierających, podtrzymujących),
analiza powiązań.
Metody te zostały opisane w [5]. Mając na uwadze cel analizy, do obliczeń macierzy
częstości wykorzystano drzewa klasyfikacyjne (C&RT). Drzewa klasyfikacyjne wyko-
rzystuje się do wyznaczania przynależności przypadków lub obiektów do klasy jakoś-
ciowej zmiennej zależnej na podstawie pomiarów jednej lub więcej zmiennych
objaśniających (predyktorów) [4].
Copyright © StatSoft Polska 2014, [email protected]
114
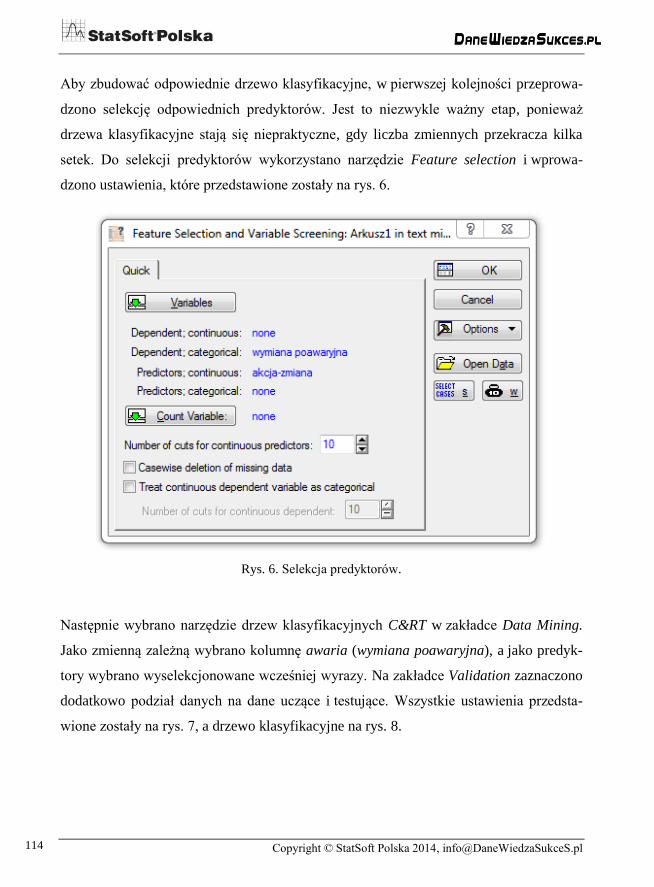
Aby zbudować odpowiednie drzewo klasyfikacyjne, w pierwszej kolejności przeprowa-
dzono selekcję odpowiednich predyktorów. Jest to niezwykle ważny etap, ponieważ
drzewa klasyfikacyjne stają się niepraktyczne, gdy liczba zmiennych przekracza kilka
setek. Do selekcji predyktorów wykorzystano narzędzie Feature selection i wprowa-
dzono ustawienia, które przedstawione zostały na rys. 6.
Rys. 6. Selekcja predyktorów.
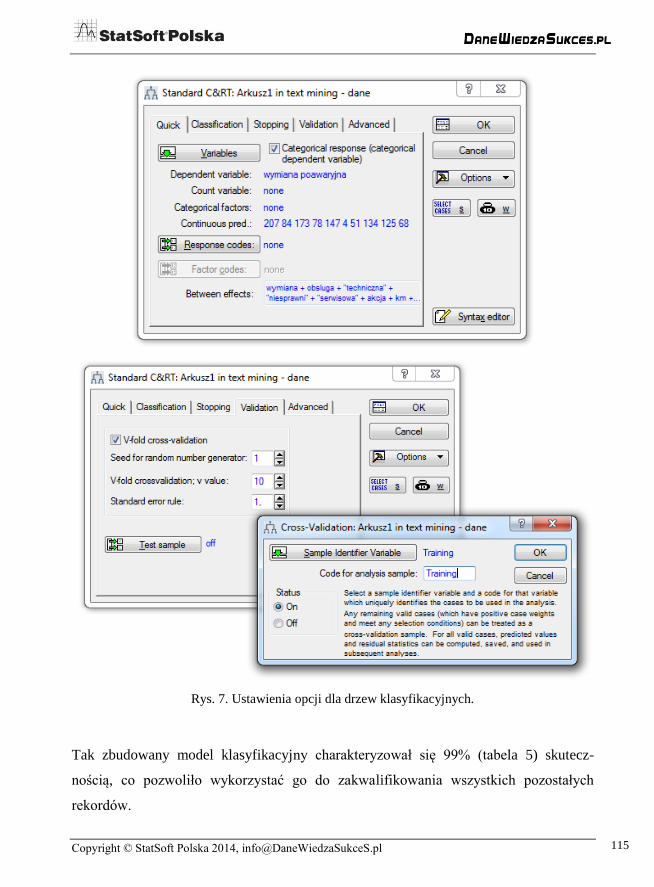
Następnie wybrano narzędzie drzew klasyfikacyjnych C&RT w zakładce Data Mining.
Jako zmienną zależną wybrano kolumnę awaria (wymiana poawaryjna), a jako predyk-
tory wybrano wyselekcjonowane wcześniej wyrazy. Na zakładce Validation zaznaczono
dodatkowo podział danych na dane uczące i testujące. Wszystkie ustawienia przedsta-
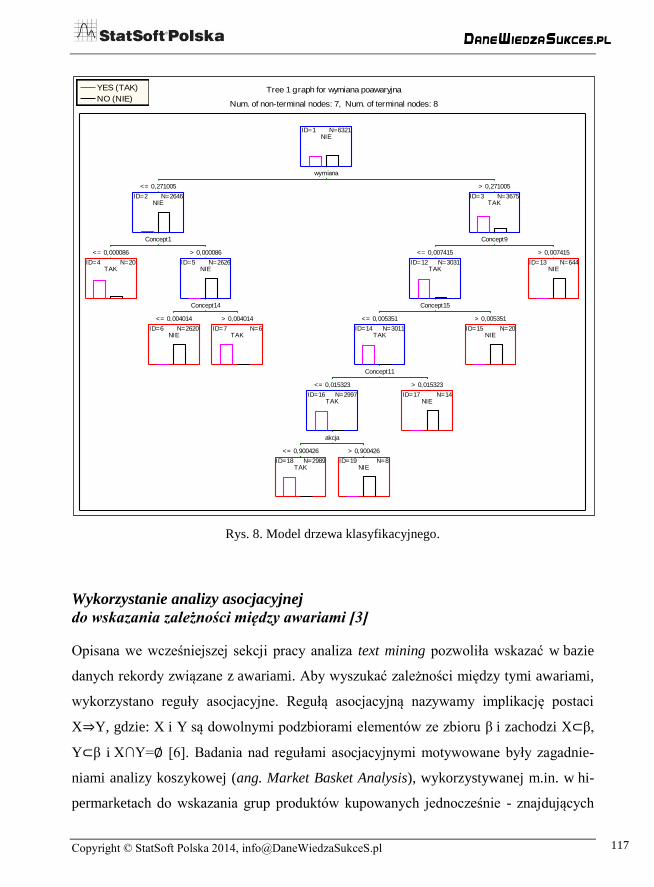
wione zostały na rys. 7, a drzewo klasyfikacyjne na rys. 8.
Copyright © StatSoft Polska 2014, [email protected]
115
Rys. 7. Ustawienia opcji dla drzew klasyfikacyjnych.
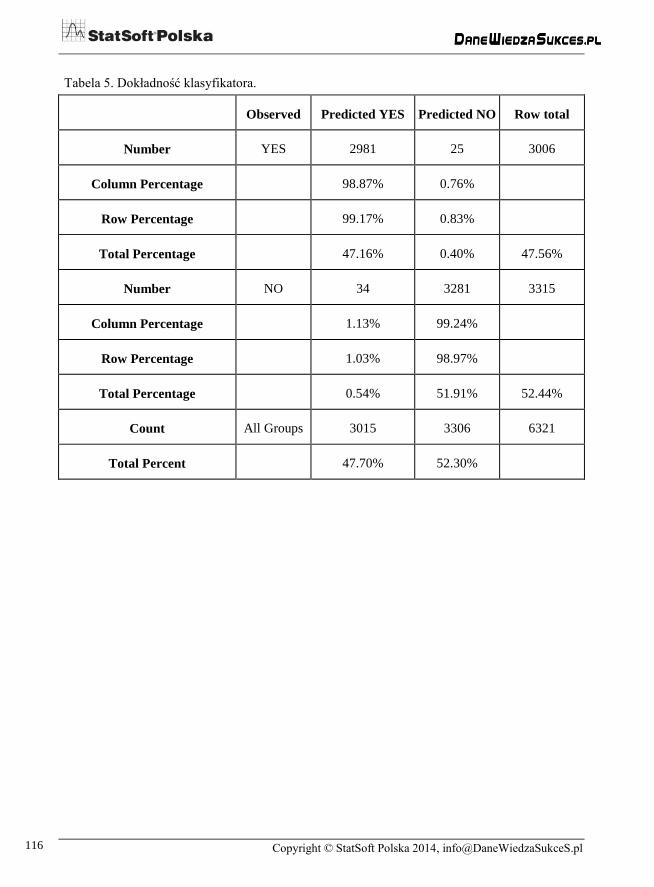
Tak zbudowany model klasyfikacyjny charakteryzował się 99% (tabela 5) skutecz-
nością, co pozwoliło wykorzystać go do zakwalifikowania wszystkich pozostałych
rekordów.
Copyright © StatSoft Polska 2014, [email protected]
116
Tabela 5. Dokładność klasyfikatora.
Observed Predicted YES Predicted NO Row total
Number YES 2981 25 3006
Column Percentage
98.87% 0.76%
Row Percentage
99.17% 0.83%
Total Percentage
47.16% 0.40% 47.56%
Number NO 34 3281 3315
Column Percentage
1.13% 99.24%
Row Percentage
1.03% 98.97%
Total Percentage
0.54% 51.91% 52.44%
Count All Groups 3015 3306 6321
Total Percent
47.70% 52.30%
Copyright © StatSoft Polska 2014, [email protected]
117
Rys. 8. Model drzewa klasyfikacyjnego.
Wykorzystanie analizy asocjacyjnej
do wskazania zależności między awariami [3]
Opisana we wcześniejszej sekcji pracy analiza text mining pozwoliła wskazać w bazie
danych rekordy związane z awariami. Aby wyszukać zależności między tymi awariami,
wykorzystano reguły asocjacyjne. Regułą asocjacyjną nazywamy implikację postaci
X⇒Y, gdzie: X i Y są dowolnymi podzbiorami elementów ze zbioru β i zachodzi X⊂β,
Y⊂β i X∩Y=∅ [6]. Badania nad regułami asocjacyjnymi motywowane były zagadnie-
niami analizy koszykowej (ang. Market Basket Analysis), wykorzystywanej m.in. w hi-
permarketach do wskazania grup produktów kupowanych jednocześnie - znajdujących
Tree 1 graph for wymiana poawaryjna
Num. of non-terminal nodes: 7, Num. of terminal nodes: 8
ID=1 N=6321NIE
ID=2 N=2646NIE
ID=5 N=2626NIE
ID=3 N=3675TAK
ID=12 N=3031TAK
ID=14 N=3011TAK
ID=16 N=2997TAK
ID=4 N=20TAK
ID=6 N=2620NIE
ID=7 N=6TAK
ID=18 N=2989TAK
ID=19 N=8NIE
ID=17 N=14NIE
ID=15 N=20NIE
ID=13 N=644NIE
wymiana
<= 0,271005 > 0,271005
Concept1
<= 0,000086 > 0,000086
Concept14
<= 0,004014 > 0,004014
Concept9
<= 0,007415 > 0,007415
Concept15
<= 0,005351 > 0,005351
Concept11
<= 0,015323 > 0,015323
akcja
<= 0,900426 > 0,900426
YES (TAK)
NO (NIE)

Copyright © StatSoft Polska 2014, [email protected]
118
sie w jednym „koszyku”. Tego typu informacje mogą być wykorzystane do odpowied-
niego rozmieszczenia towarów na półkach, co spowoduje większą sprzedaż.
Ważność reguł asocjacyjnych opisuje się z wykorzystaniem takich wskaźników jak:
wsparcie, zaufanie i przyrost. Wartości progowe tych zmiennych ustala użytkownik pod-
czas definiowania analizy. Pozwala to odrzucić reguły asocjacyjne o marginalnym
znaczeniu.
Wsparcie zestawu to frakcja rekordów zawierających ten zestaw. Innymi słowy, jest to
miara, jak często wystąpiła awaria jedno- lub k-elementowa. Duże wsparcie danej części
świadczy o jej dużej awaryjności.
Zaufanie jest to prawdopodobieństwo warunkowe, że zestawy zawierające część A będą
również zawierać część B. Innymi słowy, reguła ta pozwala ustalić, jakie jest prawdopo-
dobieństwo awarii części A, jeśli doszło do awarii części B. Reguły ze 100% wsparciem
posłużyły m.in. do ustalenia zestawów naprawczych, co usprawniło proces wydawania
części z magazynu.
Przyrost jest definiowany na podstawie zaufania i wsparcia. Jeśli występuje zestaw
„jeśli A, to C” ze 100% zaufaniem, tzn. zawsze, kiedy dochodzi do awarii części A,
dochodzi również do awarii części C i jednocześnie wsparcie awarii części C jest niskie
(tzn. awaria części C występuje rzadko), to taki zestaw będzie miał wysoki przyrost.
Innymi słowy, wysoki przyrost zestawu „jeśli A, to C” będzie świadczyć o tym, że
awaria części C jest spowodowana w głównej mierze awarią części A.
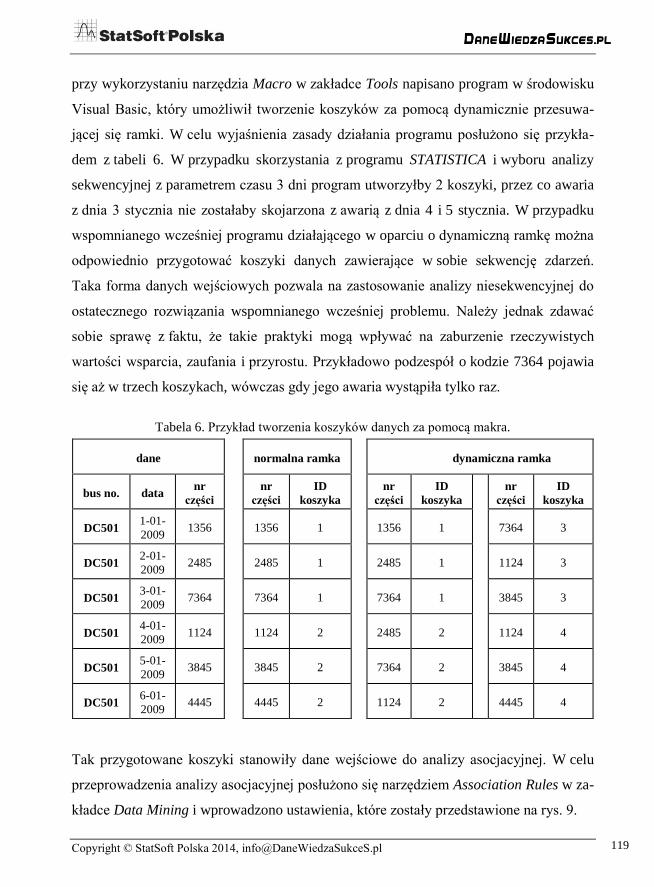
Aby przeprowadzić analizę, należało w pierwszej kolejności podzielić dane na „koszy-
ki”. Program STATISTICA daje możliwość tworzenia koszyków przy wykorzystaniu
parametru czasu. W przypadku bazy danych dotyczących awaryjności autobusów takie
rozwiązanie nie było jednak optymalne. Jeśli przykładowo za pomocą parametru czasu
program utworzyłby koszyki obejmujące okres 3 dni, to awaria dnia trzeciego koszyka
n nie zostałaby skojarzona z awarią w pierwszym dniu koszyka n+1. W związku z tym
Copyright © StatSoft Polska 2014, [email protected]
119
przy wykorzystaniu narzędzia Macro w zakładce Tools napisano program w środowisku
Visual Basic, który umożliwił tworzenie koszyków za pomocą dynamicznie przesuwa-
jącej się ramki. W celu wyjaśnienia zasady działania programu posłużono się przykła-
dem z tabeli 6. W przypadku skorzystania z programu STATISTICA i wyboru analizy
sekwencyjnej z parametrem czasu 3 dni program utworzyłby 2 koszyki, przez co awaria
z dnia 3 stycznia nie zostałaby skojarzona z awarią z dnia 4 i 5 stycznia. W przypadku
wspomnianego wcześniej programu działającego w oparciu o dynamiczną ramkę można
odpowiednio przygotować koszyki danych zawierające w sobie sekwencję zdarzeń.
Taka forma danych wejściowych pozwala na zastosowanie analizy niesekwencyjnej do
ostatecznego rozwiązania wspomnianego wcześniej problemu. Należy jednak zdawać
sobie sprawę z faktu, że takie praktyki mogą wpływać na zaburzenie rzeczywistych
wartości wsparcia, zaufania i przyrostu. Przykładowo podzespół o kodzie 7364 pojawia
się aż w trzech koszykach, wówczas gdy jego awaria wystąpiła tylko raz.
Tabela 6. Przykład tworzenia koszyków danych za pomocą makra.
dane normalna ramka dynamiczna ramka
bus no. data nr
części
nr
części
ID
koszyka
nr
części
ID
koszyka
nr
części
ID
koszyka
DC501 1-01-
2009 1356 1356 1 1356 1 7364 3
DC501 2-01-
2009 2485 2485 1 2485 1 1124 3
DC501 3-01-
2009 7364 7364 1 7364 1 3845 3
DC501 4-01-
2009 1124 1124 2 2485 2 1124 4
DC501 5-01-
2009 3845 3845 2 7364 2 3845 4
DC501 6-01-
2009 4445 4445 2 1124 2 4445 4
Tak przygotowane koszyki stanowiły dane wejściowe do analizy asocjacyjnej. W celu
przeprowadzenia analizy asocjacyjnej posłużono się narzędziem Association Rules w za-
kładce Data Mining i wprowadzono ustawienia, które zostały przedstawione na rys. 9.
Copyright © StatSoft Polska 2014, [email protected]
120
Rys. 9. Ustawienia analizy asocjacyjnej.
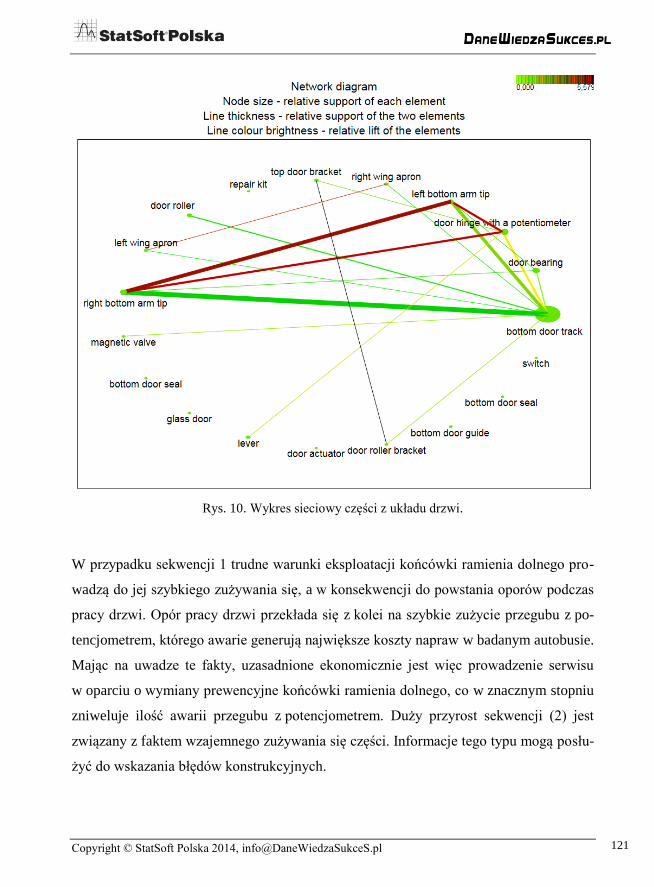
Wyniki analizy asocjacyjnej można przedstawić na wykresach sieciowych i wykresach
reguł, by na ich podstawie zinterpretować wyniki. Na rys. 10 przedstawiono przykła-
dowy wykres sieciowy dla awarii z układu drzwi.
Analizując wykres, można wyróżnić ważne relacje:
1. końcówka ramienia dolnego (bottom arm tip) ↔ przegub drzwi z potencjometrem
(door hinge with a potentiometer),
2. prowadnica dolna drzwi (bottom door track) ↔ prowadnik dolny (door bearing),
3. końcówka ramienia dolnego lewa (left bottom arm tip) ↔ końcówka ramienia
dolnego prawa (right bottom arm tip),
Copyright © StatSoft Polska 2014, [email protected]
121
Rys. 10. Wykres sieciowy części z układu drzwi.
W przypadku sekwencji 1 trudne warunki eksploatacji końcówki ramienia dolnego pro-
wadzą do jej szybkiego zużywania się, a w konsekwencji do powstania oporów podczas
pracy drzwi. Opór pracy drzwi przekłada się z kolei na szybkie zużycie przegubu z po-
tencjometrem, którego awarie generują największe koszty napraw w badanym autobusie.
Mając na uwadze te fakty, uzasadnione ekonomicznie jest więc prowadzenie serwisu
w oparciu o wymiany prewencyjne końcówki ramienia dolnego, co w znacznym stopniu
zniweluje ilość awarii przegubu z potencjometrem. Duży przyrost sekwencji (2) jest
związany z faktem wzajemnego zużywania się części. Informacje tego typu mogą posłu-
żyć do wskazania błędów konstrukcyjnych.

Copyright © StatSoft Polska 2014, [email protected]
122
Podsumowanie
W artykule przedstawiono przebieg oraz wyniki analizy data mining dla danych doty-
czących awaryjności autobusów. Przeprowadzona analiza text mining wykazała bardzo
wysoką dokładność klasyfikatora (99%) w automatycznej analizie tekstu. Narzędzia text
mining pozwoliły znacznie zmniejszyć nakład pracy w przygotowywaniu danych wej-
ściowych do analizy asocjacyjnej. Przeprowadzona w dalszym etapie analiza asocja-
cyjna wskazała wiele znaczących reguł, których znajomość dała możliwość opracowania
odpowiedniej strategii eksploatacji floty pojazdów, jak również wskazania cennych dla
konstruktorów informacji dotyczących wad konstrukcyjnych pojazdów.
Literatura
1. Marzec M.: Analiza dostępności obiektów mechatronicznych, Praca dyplomowa
magisterska, Akademia Górniczo-Hutnicza, 2012.
2. Marzec M., Uhl T., Michalak D.: Verification of text mining techniques accuracy
when dealing with urban buses maintenance data, w druku.
3. Marzec M., Uhl T.: „Using data mining tools to show correlations between failures
occurring in city buses” Diagnostyka, Vol. 4(64), 3-9, 2012.
4. StatSoft, Inc. (2011). STATISTICA (data analysis software system), version 10.
www.statsoft.com.
5. Lula P.: Text mining jako narzędzie pozyskiwania informacji z dokumentów teksto-
wych, Data Mining: poznaj siebie i swoich klientów, StatSoft Polska, 2005.
6. Klosgen W., Żytkow M.: Handbook of data mining and knowledge discovery,
Oxford University Press, 2002.


















