

Warsaw University of Technology · Streszczenie Praca poświecona jest indukcji reguł gramatyki...
128
Transcript of Warsaw University of Technology · Streszczenie Praca poświecona jest indukcji reguł gramatyki...

Pamięci matki mojej

Streszczenie
Praca poświecona jest indukcji reguł gramatyki języka polskiego. Jest to problem łączą-cy w sobie zagadnienia gramatyk formalnych, przetwarzania języka naturalnego, uczeniamaszynowego i teorię wyuczalności.
Systemy informacyjne przetwarzające dokumenty języka naturalnego operują gramaty-kami zawierającymi setki lub tysiące reguł opisujących różne typy fraz. Pielęgnowanie takdużych zbiorów reguł wzajemnie na siebie wpływających jest praktycznie niewykonalne.Stąd duże zainteresowanie metodami umożliwiającymi ich automatyczne tworzenie.
Mając na uwadze powyższe, dokonano szczegółowego omówienia ewolucji idei związa-nych z indukcją gramatyki — począwszy od twierdzenia Golda o identyfikacji w granicy,które dało początek całej dziedzinie wiedzy, przez najprostsze formalizmy (jak uczenie au-tomatów skończonych) na uczeniu gramatyk bezkontekstowych z korpusów anotowanychstrukturalnie skończywszy.
Następnie przeprowadzono przegląd metod automatycznego anotowania strukturalne-go, ze szczególnym uwzględnieniem metod statystycznych. Wskazano słabe strony istnie-jących kryteriów i zidentyfikowano przyczyny tego stanu rzeczy.
W rozprawie zaproponowano nowe kryterium oceny wielopunktowych podziałów se-kwencji pozbawione wskazanych wad oraz na tej podstawie zbudowano nieobciążoną me-todę oceny jakości struktur szkieletowych. W celu zbadania zjawiska niedostatecznej gę-stości danych trenujących zaproponowano uniwersalną metodę odwzorowania informacjimorfologicznej.
Zaproponowane w rozprawie rozwiązania zostały zaimplementowane i przetestowanew eksperymentalnym systemie indukcji reguł gramatycznych. Przedstawiono wnioski bo-gato ilustrowane wynikami przeprowadzonych eksperymentów dla różnych parametryzacjialgorytmów i odwzorowań. Porównano także jakość automatycznej anotacji strukturalnejuzyskanej jako efekt działania proponowanych algorytmów oraz dwóch już istniejącychsystemów z efektami manualnego anotowania. Wyniki wskazują, że proponowane rozwią-zania prowadzą do poprawy jakości generowanej informacji strukturalnej w porównaniu zkonkurencyjnymi systemami.
Słowa kluczowe: indukcja gramatyk, przetwarzanie języka naturalnego, rozumienie ję-zyka naturalnego, techniki text-mining
Praca naukowa finansowana ze środków na naukę w roku 2006 jako projekt badawczypromotorski Ministerstwa Nauki i Szkolnictwa Wyższego numer T11C 007 29.

Indukcja reguł gramatyki języka polskiego
Spis treści
Od Autora 4
1 Wstęp 5
1.1 Potrzeba rozwoju systemów indukcji gramatyki języka . . . . . . . . . . . . 7
1.2 Aktualne obszary badań . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
1.3 Zakres pracy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
1.3.1 Motywacja do powstania pracy . . . . . . . . . . . . . . . . . . . . . 11
1.3.2 Tezy rozprawy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
1.4 Przegląd zawartości pracy . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
2 Pojęcia podstawowe 13
2.1 Język . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.2 Gramatyki . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.2.1 Formalizm gramatyk transformacyjnych Chomskiego . . . . . . . . . 14
2.2.2 Klasa gramatyk bezkontekstowych . . . . . . . . . . . . . . . . . . . 16
2.3 Problem indukcji gramatyk . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
2.3.1 Metoda prezentacji informacji . . . . . . . . . . . . . . . . . . . . . . 18
2.3.2 Relacja nazywania . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
2.3.3 Modele uczenia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
2.3.4 Przegląd metod uczenia gramatyk . . . . . . . . . . . . . . . . . . . 20
2.3.5 Uczenie z tekstu . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
2.3.6 Uczenie z ustrukturalizowanych danych . . . . . . . . . . . . . . . . 24
2.3.7 Uczenie podklas CFL . . . . . . . . . . . . . . . . . . . . . . . . . . 28
2.3.8 Alternatywne koncepcje CFL . . . . . . . . . . . . . . . . . . . . . . 30
2.4 Kryteria oceny . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
2.4.1 Ocena jakości struktur szkieletowych . . . . . . . . . . . . . . . . . . 31
2.4.2 Ocena jakości reguł gramatyki . . . . . . . . . . . . . . . . . . . . . 33
2.4.3 Ocena struktury związku wyrazowego . . . . . . . . . . . . . . . . . 34
2.5 Materiał tekstowy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
2.5.1 Analiza wstępna . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
2.5.2 Pojęcie tokenu . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
1

Spis treści Spis treści
2.5.3 Użyte dane . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
2.6 Automatyczne anotowanie syntaktyczne . . . . . . . . . . . . . . . . . . . . 40
2.6.1 Związki wyrazowe . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
2.6.2 Metody wykrywania struktury zdań . . . . . . . . . . . . . . . . . . 42
2.6.3 Informacja wzajemna (MI) . . . . . . . . . . . . . . . . . . . . . . . 43
2.6.4 Uogólniona informacja wzajemna (GMI) . . . . . . . . . . . . . . . 46
2.6.5 Zastosowanie GMI . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
3 Propozycje nowych metod indukcji gramatyk 48
3.1 Właściwości materiału tekstowego . . . . . . . . . . . . . . . . . . . . . . . 48
3.1.1 Dodatkowa informacja morfologiczna . . . . . . . . . . . . . . . . . . 48
3.1.2 Metoda odwzorowania informacji morfologicznej . . . . . . . . . . . 48
3.2 Propozycje nowych kryteriów oceny jakości podziałów . . . . . . . . . . . . 51
3.2.1 Kryterium GIMI . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
3.2.2 Kryterium GIMINorm . . . . . . . . . . . . . . . . . . . . . . . . . . 55
3.2.3 Kryterium SF . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
3.3 Struktura zdania . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
3.3.1 Algorytm wykrywania struktury zdania . . . . . . . . . . . . . . . . 58
3.3.2 Algorytm generowania podziałów . . . . . . . . . . . . . . . . . . . . 59
3.3.3 Konfiguracja badanych algorytmów . . . . . . . . . . . . . . . . . . 62
3.3.4 Indukowanie reguł gramatyki . . . . . . . . . . . . . . . . . . . . . . 63
4 Wyniki eksperymentów 64
4.1 Opis systemu . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
4.2 Estymowanie częstości występowania sekwencji . . . . . . . . . . . . . . . . 65
4.2.1 Drzewa przyrostków . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
4.2.2 Index tekstowy Lucene . . . . . . . . . . . . . . . . . . . . . . . . . . 66
4.3 Rozbiór przykładowego zdania . . . . . . . . . . . . . . . . . . . . . . . . . 66
4.4 Struktury szkieletowe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69
4.5 Reguły gramatyki . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72
4.5.1 Indukowanie reguł na zbiorze trenującym . . . . . . . . . . . . . . . 74
4.5.2 Pokrycie zbioru reguł na danych testowych . . . . . . . . . . . . . . 76
4.6 Wnioski . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 78
5 Propozycje zastosowań 80
5.1 Automatyczne anotowanie strukturalne . . . . . . . . . . . . . . . . . . . . 80
5.2 Grupowanie i kategoryzacja dokumentów . . . . . . . . . . . . . . . . . . . 80
5.2.1 Ocena przydatności γ–gramów . . . . . . . . . . . . . . . . . . . . . 81
5.2.2 Selekcja zdań o zadanej charakterystyce . . . . . . . . . . . . . . . . 82
5.2.3 Zastosowanie atrybutów strukturalnych . . . . . . . . . . . . . . . . 82
2

Spis treści Spis treści
5.3 Analiza stylu dokumentu tekstowego . . . . . . . . . . . . . . . . . . . . . . 82
5.3.1 Identyfikacja autora . . . . . . . . . . . . . . . . . . . . . . . . . . . 82
5.3.2 Wykrywanie błędów w korpusie . . . . . . . . . . . . . . . . . . . . . 82
5.3.3 Wykrywanie zjawisk w języku . . . . . . . . . . . . . . . . . . . . . . 83
5.4 Selekcja materiału tekstowego . . . . . . . . . . . . . . . . . . . . . . . . . . 83
5.5 Efektywne parsery . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
6 Podsumowanie 85
Bibliografia 88
Spis tabel 98
Spis rysunków 100
Aneksy 101
A.1 Spis oznaczeń i skrótów . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101
A.2 Przegląd literatury . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101
A.3 Budowa eksperymentalnego systemu indukcji reguł gramatycznych . . . . . 102
A.3.1 Struktura systemu . . . . . . . . . . . . . . . . . . . . . . . . . . . . 102
A.3.2 Sposób użycia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 104
A.3.3 Przykład działania . . . . . . . . . . . . . . . . . . . . . . . . . . . . 104
A.4 Zestawienie wyników eksperymentów . . . . . . . . . . . . . . . . . . . . . . 105
3

Indukcja reguł gramatyki języka polskiego
Od AutoraThe purpose of computing is insight,not numbers.R.W. Hamming
Gdy moc obliczeniowa komputerów wzrosła na tyle, że przestano uważać je za bardziejinteligentne kalkulatory lub maszyny do pisania, ludzie zapragnęli porozumiewać się z nimiza pomocą języka naturalnego. Rozumienie języka naturalnego to także dostęp do wiedzy,którą gromadzi ludzkość od zarania dziejów właśnie w postaci zapisów w języku natural-nym. Wprawdzie dopiero rozwój globalnej sieci Internet spowodował prawdziwą eksplozjęzarówno ilości, jak i dostępności dokumentów tekstowych, jednak szybko okazało się, żeproblemem jest nie sama dostępność szukanej informacji, ale wyszukanie relewantnychjej źródeł. Stąd duże zainteresowanie technikami automatycznego przetwarzania językanaturalnego.
Poszukując tematu rozprawy doktorskiej, skierowałem swoje myśli w stronę tej tema-tyki, dodatkowo zogniskowanej wokół problemów przetwarzania języka polskiego, gdyż tenjako język fleksyjny, dzięki mnogości form wyrazowych jest językiem niepokornym, trudnopoddającym się procesom automatycznej analizy. Interesującym tematem wydawało sięzbudowanie systemu automatycznego generowania streszczeń dla języka polskiego. Jed-nakże studia literaturowe szybko pokazały, że satysfakcjonujące mnie efekty możliwe sądo osiągnięcia tylko przy założeniu istnienia strukturalnego opisu języka — gramatyki.Inne rozwiązania, oparte na pewnych heurystykach zależnych od dziedziny problemu —choćby najbardziej wyrafinowane — mają skończoną przydatność, a systemy je imple-mentujące cierpią na zidentyfikowany przez Magermana [85] tzw. Toy Problem Syndrome,oznaczający, że stosowalność ich jest ograniczona do wąskiej dziedziny, nadając rozwiąza-niu charakter „zabawkowy”. Ja chciałem czegoś więcej, chciałem pokazać istnienie metodyrozwiązującej realne problemy.
Nie znalazłszy gotowych metod indukcji gramatyki przeznaczonych dla języka polskiegopostanowiłem, że właśnie znalezienie efektywnych metod indukcji reguł gramatyki językapolskiego będzie tematem mojej rozprawy — żywiąc nadzieje, że efekty mojej pracy będąprzydatne także dla dziedziny generowania streszczeń.
Podziękowania
Pragnę podziękować prof. Mieczysławowi Muraszkiewiczowi, bez którego pomocy pracanie powstałaby. Wyrazy wdzięczności składam także prof. Henrykowi Rybińskiemu, zacenne uwagi w momencie precyzowania przeze mnie tematyki rozprawy. Pragnę podzię-kować także dr. Adamowi Przepiórkowskiemu za udostępnienie źródłowej wersji KorpusuIPI PAN umożliwiającej dokonanie eksperymentów. Chciałbym podziękować dr. inż. An-drzejowi Pająkowi za cenne uwagi dotyczące tłumaczenia terminów nieistniejących dotądw języku polskim, a także dr. inż. Piotrowi Gawrysiakowi i mgr. inż. Damianowi Gajdzieza cenne uwagi warsztatowe, bez których niniejsza rozprawa nie mogłaby mieć dzisiejszegokształtu. Podziękowania pragnę także złożyć mgr Ninie Gierasimczuk za cenne dyskusjena temat teorii wyuczalności.
4

Indukcja reguł gramatyki języka polskiego
Rozdział 1
WstępThe first thing we do, let’skill all the language lawyers.Henryk VI, część II
Rozumienie języka naturalnego było i jest problemem trudnym, a potrzeba skuteczne-go wyszukiwania informacji ogromna. To właśnie dzięki językowi naturalnemu ludzkośćstanowi zbiorowość o potencjale intelektualnym znacznie większym niż suma inteligencjiposzczególnych jednostek. To medium umożliwiające gromadzenie wiedzy jaką zdobyliśmyw ciągu ostatnich kilku tysięcy lat. Zatem nie zdziwi fakt, że tematyka związana z języ-kiem naturalnym zawsze budziła duże zainteresowanie. Jednak aż do XIX wieku analizajęzyka naturalnego była domeną filozofii. Dopiero William Jones jako jeden z pierwszychzastosował metody analizy matematycznej i logiki do badania zjawiska języka naturalnego.W roku 1913 Markow [91] zaproponował po raz pierwszy statystyczne podejście do analizytekstów. Jednak — głównie dzięki krytyce Chomskiego [35], ale i z uwagi na brak możli-wości empirycznego sprawdzenia tez — podejście to aż do późnych lat osiemdziesiątychubiegłego stulecia uważane było za niezbyt obiecujące. Główny nurt badań skoncentrowałsię na analizie zależności pomiędzy składnią a semantyką języków, co w latach pięćdzie-siątych doprowadziło Zelliga Harrisa i Noama Chomskiego do sformułowania gramatykitransformacyjnej [33]. Zatem gramatyka sama w sobie nie jest celem. Jest prekursoremsemantyki. Jednak dość szybko okazało się, że nie istnieje jedna uniwersalna gramatykadanego języka. Co więcej, manualne stworzenie gramatyki jest niezwykle trudne i podatnena błędy.
W poszukiwaniu metod uczenia gramatyki podjęto próbę zbadania sposobu, w jakidzieci poznają gramatykę języka [93, 134]. Badacze są zgodni, że większość dzieci słabozna reguły gramatyki, natomiast ta część, która je zna, rzadko bierze je pod uwagę. Faktten może przemawiać za twierdzeniem, że możliwa jest nauka składni języka jedynie zpozytywnych przykładów, np. z tekstu. Jak pokazano w rozdziale 2.3.4, w ten sposóbzidentyfikować można jedynie najprostsze klasy języka (języki skończone). Dyskutuje sięproblem dostarczania dzieciom negatywnych przykładów — wtedy możemy założyć, żewykorzystują one model nauki z wyrocznią, co znacznie rozszerza klasę dostępnych tąmetodą języków. Istotna jest wiedza, jakie dodatkowe informacje otrzymuje dziecko (jakoograniczenie a priori nałożone na klasę reguł, które mogą pojawiać się w języku lub jakododatkowe informacje uzyskane z kolejności, w jakiej pojawiają się pozytywne przykłady).Przykłady prostsze pojawiają się na początku, dopóki dziecko nie osiągnie umiejętnościsprawnego operowania nimi. Środowisko, uzyskując odpowiednie pozytywne wzmocnienie,zmniejsza wysiłek w komunikacji z dzieckiem przez używanie coraz bardziej wyszukanychkonstrukcji gramatycznych. Dziecko analizuje nowe konstrukcje, używając wiedzy już zdo-bytej. Istnieją przykłady załamania procesu nauki języka u dzieci, u których zbyt wcześnierozpoczęto naukę drugiego języka. Może oznaczać to, że wcześniej nauczone proste regułyjęzyka nie pasują do nowych przykładów (pochodzących z nowego języka). Stąd załamanieprocesu.
5

1. Wstęp
Nieformalnie indukcja gramatyki (ang. grammar induction, grammatical inference, GI )jest problemem wnioskowania indukcyjnego, gdzie dziedziną jest klasa gramatyk. Problemuczenia zdefiniowany jest jako identyfikacja gramatyki nieznanego języka, z użyciem skoń-czonej liczby przykładów pochodzących z tego języka. Historia indukcji gramatyk jakodziedziny badań sięga roku 1967, kiedy to Mark Gold w swym przełomowym artykule[54] zaproponował model identyfikacji języka w granicy (ang. identification in the limit).Motywacją jego badań była chęć stworzenia formalnego modelu uczenia języka przez ludzi.Niestety wykazał także, że żadna klasa języków z hierarchii Chomskiego nie jest identyfiko-walna z użyciem wyłącznie pozytywnych przykładów (zdań należących do języka). Wynikten przez wiele lat był silnym inhibitorem rozwoju tej dziedziny wiedzy.
Początkowo pojawiły się prace dotyczące uczenia się automatów skończonych. Możnawymienić tu opracowania Trakhtenbrota i Barzdina [125], Wiehagena [133], Luzeaux [82],Yokomori [143]. Pojawiły się także pierwsze próby uczenia języków bezkontekstowych za-proponowanych przez Solomonoffa w [120], Knobe i Knobe w [72]. Odpowiedź na pytanie„Jak bardzo struktura jest potrzebna do opisu zdania?” stanowi seria artykułów Joshi’ego:[66, 67, 80, 70, 68, 65]. Jednak dopiero w latach osiemdziesiątych ubiegłego wieku praceAngluin [3], Shinohary [118] wskazały istnienie pewnych podklas języków (spełniającychpewne dodatkowe ograniczenia) identyfikowalnych z pozytywnych danych. Prace te po-zwoliły przełamać pesymizm. Równolegle trwały także badania nad identyfikacją języka zużyciem przykładów pozytywnych i negatywnych np. Tanatsugu w [122].
Prawdziwy przełom miał dopiero nadejść, za sprawą ustrukturalizowanej reprezentacjitekstu zaproponowanej w 1967 roku przez Ginsburga i Harrisona [53] i formalizmu grama-tyk nawiasowych zaproponowanych przez McNaughtona [92]. Konsekwencją tych prac byłypropozycje uczenia gramatyk z ustrukturalizowanego tekstu zaproponowane przez m.in.Levy i Joshi [79], Crespi-Reghizzi [42]. Jednak dopiero Sakakibara w roku 1992 pokazałw [107], że klasa gramatyk bezkontekstowych jest identyfikowalna z danych ustrukturali-zowanych. Zatem udało się sprowadzić problem indukcji gramatyki języka naturalnego doznalezienia odpowiedniej struktury dla danych tekstowych.
Równolegle trwały prace nad korpusami tekstów języka naturalnego (zob. roz. 2.4),a także nad sposobami ich wewnętrznej reprezentacji, tokenizacji i anotowania wydzielo-nych tokenów — co, jak się okazało, dla języków fleksyjnych nie jest zadaniem banalnym(por. [100]). Początkowo były to korpusy języka angielskiego, później dołączyły także innejęzyki narodowe, w tym język polski. Istnienie korpusów tekstów ujawniło kilka następ-nych problemów: zgodnie z prawem Zipfa (zob. roz. 2.5.3) nie jesteśmy w stanie zbudowaćtak wielkiego korpusu, który zapewni wystarczająco częste występowanie wszystkich wy-razów, w związku z czym zawsze będziemy odczuwać problem niedostatecznej gęstościdanych (ang. sparse data problem).
Dostępność wystarczająco dużych anotowanych korpusów zaowocowało szeregiem mniejlub bardziej udanych eksperymentów. Można tu wymienić system SPATTER opisany przezMagermana w [86], system AUTO opisany przez Shiha w [117], system EMILIE opisanyprzez Adriaans et al. w [1], system ABL van Zaanena opisany w [128]. Jednak, jak zauważyłMagerman w [85], istniejące systemy analizy języka naturalnego cierpią na tzw. Toy Pro-blem Syndrome, polegający na tym, że systemy przetwarzające język naturalny aspirują domiana rozwiązań ogólnych, w rzeczywistości zdając egzamin tylko dla jednej przykładowejklasy. Rezultatem jest częściowe, nieskalowalne i nieaplikowalne do całej klasy proble-mów rozwiązanie. Odpowiedzią na ten problem może być renesans metod statystycznych,możliwy właśnie dzięki istnieniu dużych korpusów tekstów ale także dzięki wzrostowi moż-liwości obliczeniowych komputerów, które wreszcie są w stanie podołać wyzwaniu, jakimjest analiza statystyczna dużych korpusów tekstu. Możliwe stało się estymowanie praw-dopodobieństw występowania sekwencji wyrazów, a co za tym idzie obliczania szeregustatystycznych miar: entropii, entropii krzyżowej, informacji wzajemnej i zaproponowanejprzez Magermana w [87] uogólnionej informacji wzajemnej. Miary te można zastosować
6

1.1. Potrzeba rozwoju systemów indukcji gramatyki języka 1. Wstęp
do wykrywania struktury w zdaniach języka naturalnego.
Jak pokazały wstępne eksperymenty, zastosowanie wspomnianych miar nie daje jednakzadowalających rezultatów — przynajmniej dla języka polskiego. Stanowiło to silną prze-słankę dla zbadania stosowalności metod statystycznych do wykrywania struktury zdańjęzyka polskiego. Rozważania na ten temat zawiera niniejsza praca.
1.1 Potrzeba rozwoju systemów indukcji gramatyki języka
Historycznie pierwszą metodą tworzenia gramatyki był opis języka tworzony manualnieprzez ekspertów. Formalizm gramatyk tworzonych przez lingwistów, choć wysoce pomoc-ny w badaniach nad zjawiskiem języka naturalnego, okazał się niewystarczający do au-tomatycznej analizy języka. Próba implementacji tychże gramatyk w systemach informa-tycznych zwana głęboką (ang. deep) analizą języka nie doczekała się sukcesów w prak-tycznym zastosowaniu. Podejściem skrajnie odmiennym jest analiza powierzchniowa (ang.shallow), dokonywana za pomocą formalizmu wzorców (będących pewnego rodzaju wyra-żeniami regularnymi). To uproszczone podejście zaowocowało powstaniem kilku udanychsystemów konwersacyjnych dających złudzenie rozmowy z drugim człowiekiem, np. sys-temy P.A.U.L.A, ELIZA, A.L.I.C.E [W14] i inne. Sam proces tworzenia gramatyki przezlingwistów oparty jest na intuicji, poprzednich doświadczeniach, metodzie prób i błędówi szeregu heurystyk. Proces ten jest bardzo trudny, podatny na błędy, a gramatyki w tensposób stworzone są na tyle skomplikowane, że praktycznie nie można ich pielęgnować anirozwijać. Oznacza to niestety także, że doświadczenia wyniesione z tej metody tworzeniagramatyk w znikomym stopniu można wykorzystać do zautomatyzowania tego procesu.
Kolejnym krokiem było tworzenie przez lingwistów reguł produkcji, za pomocą któ-rych można było dokonywać rozbioru zadanego korpusu tekstów. Jednakże stworzenie wtaki sposób użytecznej gramatyki, która pokryłaby cały (odpowiednio duży) korpus jestpraktycznie niemożliwe. Dodatkowym problemem jest to, że reguły gramatyki są tworzo-ne z założeniem, że analizowane zdania mają poprawną postać (czyli należą do języka).Warunek ten jest oczywiście niemożliwy do spełnienia w praktycznych zastosowaniach. Cowięcej, dodanie do korpusu nowych zdań pociąga za sobą potrzebę dodania nowych lubzmiany już istniejących reguł produkcji, czego rezultatem może być wprowadzenie błę-dów lub niepożądanych interakcji między regułami. Pewnym rozwiązaniem problemu jesttestowanie zmodyfikowanej gramatyki na odpowiednim korpusie. Nadal pozostaje jednakproblem wykrycia zdań tzw. „fałszywie pozytywnych” — gdyż zdania nienależące do ję-zyka nie występują w korpusie, zatem nadmierne uogólnienie reguł gramatyki nie możebyć wykryte tą drogą. Z drugiej strony przygotowanie odpowiedniej jakości przykładównegatywnych może być zbyt pracochłonne.
Podsumowując, tworzenie gramatyki przez ekspertów jest trudne i kosztowne. Procesten musi być przeprowadzony dla każdego języka osobno. W zastosowaniach praktycz-nych, dotyczących języka naturalnego, rzadko wymagane jest rozpoznawanie wszystkichmożliwych konstrukcji gramatycznych. Zwykle posługujemy się pewnym podzbiorem do-stępnych reguł — co za tym idzie, językiem będącym podzbiorem języka naturalnego.Dzięki temu spostrzeżeniu możemy obniżyć wymagania na ekspresywność użytego mo-delu1 i zastosować formalizm gramatyk bezkontekstowych, a co za tym idzie, umożliwićefektywne przetwarzanie języka naturalnego. To spostrzeżenie prowadzi do wniosku, żepo przyjęciu pewnych założeń możliwe jest wygenerowanie reguł gramatycznych dobrzeopisujących interesujący podzbiór języka, pozwalający na skuteczną analizę zdań języka.
Z tych powodów, systemy automatycznego generowania reguł gramatyki opisującejdany język stają się coraz bardziej atrakcyjne. Mają one niewątpliwe zalety — nawet nie-1W literaturze pojawiają się argumenty sugerujące, że język naturalny jest co najmniej kontekstowy
[44, 73, 116] jeśli nie rekurencyjnie przeliczalny.
7

1.1. Potrzeba rozwoju systemów indukcji gramatyki języka 1. Wstęp
wielka zmiana koncepcji algorytmu wpływa na wszystkie nowogenerowane reguły tak, żecały zbiór reguł od razu posiada pożądane cechy (czego nie można powiedzieć o regu-łach tworzonych manualnie). Trudności w budowie systemów indukcji reguł gramatyki sąspowodowane przez:
• duży rozmiar słownika wyrazów (redukowalny przez użycie informacji morfologicz-nej),
• skomplikowaną składnię (zwłaszcza języków fleksyjnych),
• niejednoznaczność zarówno na poziomie składniowym, jak i semantycznym,
• język naturalny stosuje się do dystrybucji Zipfa (zob. roz. 2.5.3), co oznacza, żeproblem niedostatecznej gęstości danych jest nierozwiązywalny,
• język naturalny nie jest zjawiskiem stacjonarnym — zmienia się w czasie,
• język ma tyle gramatyk, ilu użytkowników.
Znane podejścia do problemu indukcji reguł gramatyki to:
Metody symboliczne
Metody symboliczne stosują założenie Harrisa [59] wprost, tak jak opisane przez Solo-monoffa w [120], Knobe i Knobe w [72] lub wsparte algorytmami grupowania i innymiheurystykami jak w systemie EMILE opisanym przez Adriaans et al. w [1] i w systemieABL van Zaanena [128]. Mimo stosunkowo dobrych efektów, systemy te nie są skalowalne,głównie z uwagi na ilość przetwarzanych symboli i, co za tym idzie, wymagania pamięciowe.Metody symboliczne natomiast wyśmienicie nadają się do przekształcania (np. unifikacji)już istniejącego zbioru reguł — przykładem może tu być algorytm Sakakibary (zob. roz.3.3.4). Zawsze jednak należy pamiętać, że są one bardzo wrażliwe na zaszumienie danychtrenujących. Dlatego też powinno się stosować odpowiednie techniki, aby ten wpływ zmi-nimalizować.
Metody statystyczne
Wadą systemów statystycznych jest to, że nie można uczyć gramatyk iteracyjnie, dostar-czając w kolejnej iteracji bardziej skomplikowanych przykładów. Algorytm uczący się musiotrzymać wszystkie przykłady trenujące od razu.
Metody statystyczne — jak pokazał Magerman w [87, 84, 85] nadają się do wykrywa-nia związków wyrazowych (ang. constituent). Jednakże zaproponowane przez niego miarysą dalekie od doskonałości — szczególnie dla języka polskiego (por. roz. 2.6.3 i 2.6.4).Stąd potrzeba opracowania nowych rozwiązań, bardziej dopasowanych do charakterystykiprzetwarzanych danych.
Algorytmy genetyczne
Ciekawym podejściem zaprezentowanym np. w [47, 77] jest zastosowanie algorytmów gene-tycznych do indukcji reguł gramatyki. Populacje osobników stanowią gramatyki, z poszcze-gólnymi produkcjami jako chromosomami. Stosując odpowiednie operatory krzyżowania imutacji, a także odpowiednią funkcję oceny, algorytm genetyczny polepsza średnią jakośćosobników, doprowadzając w rezultacie do powstawania coraz lepszych rozwiązań. Proble-mem w tym podejściu może być jednak złożoność obliczeniowa funkcji oceniającej jakośćosobników, co może być czynnikiem dyskwalifikującym w przypadku dużych populacjiosobników testowanych na dużych korpusach tekstu.
8

1.2. Aktualne obszary badań 1. Wstęp
Sieci neuronowe
Porównanie sieci neuronowych z innymi technikami jest nadal trudne. Generalne zastoso-wania SN to predykcja symboli w badanej sekwencji i wykrywanie symboli nieterminalnychna podstawie wewnętrznego stanu sieci. Problematyczne jest także zagadnienie skalowal-ności, gdyż uczenie sieci neuronowej wymaga wielokrotnych iteracji po, z natury dużych,danych trenujących. Nieznane są także efektywne architektury SN. Również interpretacjaefektów uczenia, które powstają jako wynik klasteryzacji odpowiedzi sieci na pobudzeniebadaną sekwencją, pozostawia wiele do życzenia. Jednakże obiecujące pojęcie pamięci dłu-gotrwałej daje nadzieje na efektywną naukę rekursywnych pojęć. Przykład zastosowaniasieci neuronowych do parsowania tekstu możemy znaleźć np. w pracy Lyon et al. [83],Honkela [62] i Redingtona [103, str. 433].
1.2 Aktualne obszary badań
Indukcja gramatyk to wykrywanie wzorców, od najprostszych (automaty skończone) donajbardziej skomplikowanych, takich jak gramatyki rekurencyjnie przeliczalne. Zatem dzie-dzina ta znajduje zastosowanie wszędzie tam, gdzie mamy do czynienia z potrzebą wy-krycia struktury. Klasyczne zastosowania technik GI (ang. Grammar Induction) to: kla-syfikacja i analiza wzorców, klasyfikacja biologicznych sekwencji (RNA), rozpoznawanieznaków.
Dziedzina GI nie mogłaby się rozwijać, gdyby nie towarzyszyły jej prace nad meto-dami przygotowywania danych trenujących — znakowanie morfologiczne tekstu w językunaturalnym, udoskonalanie zbiorów znaczników morfologicznych, przygotowywanie corazto większych i doskonalszych korpusów anotowanych morfologicznie i strukturalnie. Opra-cowano także efektywne metody porównywania rozwiązań.
Zainteresowanie dziedziną indukcji gramatyk znalazło odzwierciedlenie w powstaniukonferencji poświęconej wyłącznie temu zagadnieniu. Jest to konferencja InternationalColloquium on Grammar Inference (ICGI) odbywająca się co cztery lata2. Zorganizowanoszereg konkursów („The OMPHALOS Context-free language learning competition”, „TheAbbadingo One Learning Competition”, „The Gowachin DFA Learning Benchmark”, „TheGECCO Learning DFA from Noisy Samples Competition”) znacznie przyspieszającychprzepływ idei. Następujące dziedziny związane są ściśle z badaniami GI:
Znakowanie morfosyntaktyczne
Znakowanie częściami mowy — zwane także znakowaniem morfosyntaktycznym — (ang.part-of-speech tagging) to wykrywanie informacji o formie gramatycznej słów na podstawieich morfologii. Ponieważ wyniki analizy przyrostków są w większości przypadków niejed-noznaczne, zatem konieczne jest zastosowanie metod wyznaczania relewantnego w danymkontekście znakowania. Większość badaczy wykazuje poprawność tego procesu na pozio-mie 95–99%, co jest uważane za ogromy postęp w stosunku do wcześniej stosowanychtechnik. Postęp ten uzyskano dzięki zastosowaniu metod programowania dynamicznegooraz ukrytych modeli Markowa3 (ang. hidden Markov models, HMM ).
2W roku 1993 odbyła się pierwsza (raczej nieformalna) konferencja International Colloquium on Gram-mar Inference (ICGI) w Wielkiej Brytanii — następne: Hiszpania (1994), USA (1998), Portugalia (2000),Grecja (październik 2004).3Ukryte modele Markowa nie znalazły zastosowania w zadaniach identyfikacji gramatyk języka natu-
ralnego, z uwagi na swą ograniczoną ekspresję. Szerszą dyskusję zastosowania HMM do analizy językanaturalnego można odnaleźć np. w [32].
9

1.2. Aktualne obszary badań 1. Wstęp
Zapytania do systemów baz danych w języku naturalnym
Systemy baz danych dysponują dedykowanymi językami zapytań pozwalającymi uzyskaćdostęp do danych. Są one jednak na tyle różne od języka naturalnego, że posługiwanie sięnimi dla osób niezajmujących się zawodowo informatyką stanowi duży problem. Z tegopowodu prowadzone są prace nad metodami pozwalającymi tłumaczyć język naturalnyna język zapytań. Bach w pracy [14] wskazuje, że wykonanie analizy morfologicznej, syn-taktycznej, semantycznej i pragmatycznej pozwala odwzorować zapytanie sformułowanew języku naturalnym na schemat ERD (ang. Entity Relationship Diagram) i dzięki temusformułować zapytanie w języku SQL.
Modelowanie związków organicznych
Szybki rozwój biologii molekularnej zaowocował potrzebą analizy, modelowania, i prze-widywania struktury skomplikowanych związków chemicznych. Naturalną konsekwencjątego faktu było połączenie biologii i informatyki w nową dziedzinę zwaną biologią oblicze-niową (ang. computational biology). W obszarze zainteresowań tej dziedziny znajduje sięwykrywanie wspólnych lub zgodnych wzorców wśród rodziny sekwencji, dopasowywaniewzorców, rozpoznawanie znanych członków rodziny sekwencji, a także wykrywanie nowychczłonków rodziny sekwencji. W modelowaniu RNA spotykamy także zastosowania w wy-różnianiu i przewidywaniu struktury drugorzędowej. Stosowane są tu formalizmy: HMM[76] i stochastyczne gramatyki bezkontekstowe [108].
Automatyczne tłumaczenie
Wykonywanie automatycznych tłumaczeń (ang. machine translation, MT )4 jest kolejnądziedziną w której informacja strukturalna znajduje zastosowanie. Na przykład, w sys-temach typu transfer–based tekst źródłowy jest przekształcany w reprezentację struktu-ralną. Następnie reprezentacja strukturalna zostaje przekształcona do postaci odpowia-dającej językowi docelowemu, po czym dopiero następuje generowanie wynikowego tekstutłumaczenia. Kaplan w artykule [71] pokazuje bardziej zaawansowaną metodę generowa-nia automatycznych tłumaczeń z użyciem informacji o wzajemnej odpowiedniości międzystrukturami języka źródłowego i docelowego.
Automatyczna generacja streszczeń
Streszczenia indykatywne można tworzyć za pomocą metody selekcji materiału tekstowe-go przedstawionego w rozdziale 5.4. Jednakże w przypadku streszczeń informatywnychpotrzebne jest bardziej zaawansowane podejście.
Jedno z nich traktuje rozbiór gramatyczny jako pierwszy krok ku automatycznemurozumieniu języka naturalnego. Nałożenie na zdanie struktury w sposób automatycznypoprzedza mapowanie tejże struktury w semantyczną reprezentację. Reprezentacja seman-tyczna może z kolei zostać poddana różnym przekształceniom — w tym uproszczeniom,przycięciu elementów nieinteresujących, usunięciu redundancji. Następnie z użyciem gra-matyki następuje wygenerowanie tekstu streszczenia w języku naturalnym. Należy zauwa-żyć, że takie podejście daje szanse na uzyskanie streszczenia maksymalnie zbliżonego dostworzonego przez człowieka.
4Doskonały wybór artykułów dotyczących automatycznych tłumaczeń znajduje się w [95].
10

1.3. Zakres pracy 1. Wstęp
1.3 Zakres pracy
1.3.1 Motywacja do powstania pracy
W ostatnich latach obserwujemy stały wzrost zainteresowania maszynowym uczeniem gra-matyk formalnych na podstawie tekstu w języku naturalnym i z ustrukturalizowanychdanych. Zagadnienia związane z indukcją reguł gramatyk regularnych (dających opisaćsię automatem skończonym) zostały dość dobrze przebadane. Nie dotyczy to jednak przy-padków bardziej ogólnych (o większej ekspresji) takich jak gramatyki bezkontekstowe.Oczekuje się, że prawdziwy przełom w praktycznym zastosowaniu gramatyk — jak rów-nież rozwój technik DM (ang. Data Mining) i TM (ang. Text Mining) — będzie związanyz badaniami nad indukcją reguł różnych podklas gramatyk bezkontekstowych.
Szczególnie interesująca wydaje się dziedzina przetwarzania języka naturalnego, z uży-ciem gramatyki wyindukowanej z przykładów pochodzących z tego języka. Osiągniętydzięki takiemu podejściu efekt wysokiego pokrycia zdań badanego języka przez reguły gra-matyki umożliwi znaczne zwiększenie efektywności i selektywności stosowanych dotychczasalgorytmów grupowania i klasyfikacji tekstu. Co więcej, automatycznie generowane gra-matyki, znacznie dokładniej opisujące język niż te tworzone przez ekspertów, umożliwiąbadania nad pragmatyką języka, związkami frazeologicznymi, właściwościami i wymaga-niami leksemów, i stworzonych na tej podstawie grup leksemów.
Język polski jako język należący do języków fleksyjnych (w przeciwieństwie do języ-ków pozycyjnych jakim jest np. język angielski) jest bardzo trudny do analizy właśnieza sprawą mnogości form fleksyjnych, homonimii (np. wyraz „kurzy” może być formą od„kura”, „kurzyć”, „kurz”, „kur”) — to ostanie zjawisko jest odpowiedzialne za niewielkąskuteczność analizy morfologicznej leksemów. Dopiero opracowanie skutecznego algorytmudezambiguacji morfosyntaktycznej (w Instytucie Podstaw Informatyki Polskiej AkademiiNauk w 2003 roku [48, 135]) otwiera nowe możliwości analizy. Badaniu niektórych z nichpoświęcona jest niniejsza praca.
1.3.2 Tezy rozprawy
Dostępne w literaturze wyniki eksperymentów oraz przeprowadzone badania wstępne po-zwoliły na postawienie następujących tez rozprawy:
Możliwe jest sformułowanie statystycznego kryterium oceny wielo-punktowych podziałów zdań, które nie preferuje konkretnej długościpodsekwencji.
Zastosowanie tego kryterium do oceny jakości struktur szkieletowychprzy budowie anotowanych strukturalnie korpusów języka naturalne-go pozwala na uzyskanie dobrej zgodności z korpusami anotowanymimanualnie.
Tak sformułowane tezy wymagają wytyczenia następujących celów pracy:
• stworzenie kryterium oceny struktur szkieletowych,
• zaanotowanie strukturalne przykładowego korpusu języka polskiego,
• analiza porównawcza korpusów anotowanych: przez człowieka, innymi dostępnymimetodami, a także z użyciem zaproponowanego kryterium,
• wyindukowanie gramatyki języka polskiego.
11

1.4. Przegląd zawartości pracy 1. Wstęp
1.4 Przegląd zawartości pracy
Struktura niniejszego dokumentu jest następująca:
• pracę rozpoczyna nota odautorska,
• rozdział pierwszy przedstawia tendencje rozwojowe technik indukcji gramatyk, wszczególności gramatyk języka naturalnego, wskazane zostały także możliwe kierunkibadań i zastosowania,
• rozdział drugi zawiera definicje podstawowych pojęć, które zostały wykorzystane wpracy. Opisano w nim także podstawowe modele uczenia gramatyk, algorytmy, atakże metody reprezentacji języków,
• rozdział trzeci opisuje nowe techniki indukcji gramatyki ze szczególnym uwzględnie-niem języka polskiego. Przedstawiono w nim metody budowania ustrukturalizowanejreprezentacji języka z anotowanego morfologicznie korpusu języka polskiego,
• rozdział czwarty zawiera wyniki eksperymentów oraz dyskusję wpływu wybranychdo analizy atrybutów gramatycznych na jakość gramatyki,
• rozdział piąty przedstawia możliwe zastosowania praktyczne przedstawionych metodindukcji gramatyki,
• pracę kończy podsumowanie, spis literatury, tabel i rysunków oraz aneksy zawiera-jące opis techniczny systemu indukcji reguł gramatycznych, krótka nota dotyczącazawartości najciekawszych pozycji bibliograficznych oraz wykresy szczegółowo pre-zentujące wyniki przeprowadzonych eksperymentów.
12

Indukcja reguł gramatyki języka polskiego
Rozdział 2
Pojęcia podstawoweGrammar is a piano I play by ear.All I know about grammar is its power.Joan Didion
2.1 Język
Języki naturalne są zbiorem wszystkich słów, zwrotów i zdań, które służą wzajemnemuporozumiewaniu ludzi. Jednakże rozumienie języka wymaga znajomości nie tylko znaczeniaposzczególnych słów, ale także możliwych związków między nimi. Co więcej, oba elementyprzenikają się wzajemnie, na co wskazuje fakt, że często jesteśmy w stanie zrozumieć senszdania błędnie zbudowanego (czyli nienależącego do języka), a także zdania poprawnegow sytuacji, gdy nie znamy znaczenia części wyrazów1. Formalna definicja języka wymagawprowadzenia następujących dwóch pojęć:
Definicja 1 Alfabetem Σ nazywamy dowolny, niepusty zbiór symboli zwanych literami.Jeżeli Σ jest skończonym zbiorem, to |Σ| oznacza liczność zbioru Σ.
Definicja 2 Słowami będziemy nazywać ciągi liter o dowolnej skończonej długości. Dłu-gość słowa x oznaczać będziemy przez |x|.
Zatem:
Definicja 3 Językiem L nad alfabetem Σ nazywamy dowolny podzbiór Σ∗ słów nad alfa-betem Σ.
Podana definicja języka jest bardzo prosta i elegancka zarazem. Jednak nastręcza ona wieluproblemów, np. z identyfikacją języka (w sensie jednoznacznego, niekoniecznie zwięzłego,opisu), określeniem przynależności wyrazu do języka, tworzenia poprawnych wyrazów zsymboli alfabetu, semantyki.
Ponieważ w dziedzinie języków formalnych i naturalnych te same pojęcia mają inneznaczenia, dlatego dla ustalenia uwagi tabela 2.1 wskazuje ich wzajemną odpowiedniość. Wdalszej części rozprawy stosowana będzie terminologia właściwa dziedzinie przetwarzaniajęzyka naturalnego.
Język opisywany jest przez gramatykę. W szczególnym (aczkolwiek mało interesują-cym przypadku) gramatykę języka może stanowić sam język (dla języków skończonych).Jednak we wszystkich interesujących przypadkach, w szczególności dotyczących języka1Zjawisko to w filozofii języka nazywa się kompozycyjnością.
13

2.2. Gramatyki 2. Pojęcia podstawowe
język naturalny przykład język formalny przykład
zdanie Duży pies goni małą dziewczynkę. słowo a b b asłowo „duży”, „pies”, . . . litera alfabetu „a”, „b”litera alfabetu „a”, „b”, „c”, . . . - -
Tabela 2.1: Odpowiadające sobie oznaczenia w opisie języków formalnych i naturalnych
naturalnego, który (jak pokazano np. w [101, str. 2]) jest nieskończony, takie podejściejest nieakceptowalne i bezużyteczne. Dlatego w wielu ośrodkach podjęte zostały próbystworzenia uniwersalnego formalizmu (gramatyki) umożliwiającego zwięzły opis języka.Interesujące, z praktycznego punktu widzenia, gramatyki posiadają cechy pozwalające nasprawdzenie przynależności jak i generowanie zdań. Problem semantyki pozostaje nadalproblemem trudnym, który nie doczekał się jeszcze rozwiązania. W języku naturalnym po-jęcie gramatyki i semantyki są ze sobą nierozerwalnie związane. Dlatego podejmując próbykonstruowania praktycznie użytecznych gramatyk opisujących język naturalny, niemożliwejest całkowite pominięcie informacji semantycznej.
Z drugiej strony nie wymaga się od kompilatorów sprawdzania semantycznej popraw-ności programów. Chociaż pewne cechy nowoczesnych kompilatorów wskazują na to, iżpodejmują one pewne próby analizy semantycznej np. badając czy istnieje taki scenariuszwykonania programu, który może doprowadzić do użycia wcześniej niezainicjalizowanejzmiennej.
2.2 Gramatyki
W niniejszym rozdziale przedstawiony zostanie szczegółowo formalizm gramatyk. Przeglą-dając słownik języka polskiego znaleźć można następującą definicję:
Gramatyka: nauka o zasadach budowy i odmiany wyrazów oraz o regułachskładni danego języka; zespół reguł, środków służących do tworzenia tekstu;także: kompletny opis jakiegoś języka.
Jednakże systemy przetwarzania języka naturalnego operujące gramatykami wymagająsformalizowanej definicji. Poniżej skoncentrujemy się na formalizmie gramatyk transfor-macyjnych Chomskiego, pomijając inne formalizmy takie jak gramatyki unifikacyjne (ang.constraint-based grammars).
2.2.1 Formalizm gramatyk transformacyjnych Chomskiego
Formalnie gramatykę transformacyjna można zdefiniować jako czwórkę:
(Σ, S, V, P )
gdzie Σ – alfabet, S – symbol początkowy, V – skończony zbiór symboli nieterminalnychtakich, że V ∩ Σ = φ, P ∈ (V ∪ Σ)∗ × (V ∪ Σ)∗ – zbiór reguł produkcji.
Noam Chomsky wprowadził podział gramatyk na cztery typy w zależności od postacireguł produkcji:
Typ 0 gramatyki bez ograniczeń. Zawiera wszystkie formalne gramatyki. Generują wszyst-kie języki rozpoznawane przez maszynę Turinga. Gramatyki tej klasy generują językirekurencyjne.
14

2.2. Gramatyki 2. Pojęcia podstawowe
Typ 1 gramatyki kontekstowe (ang. context-sensitive grammars). W produkcjach grama-tyk tej klasy po prawej stronie musi wystąpić co najmniej tyle samo symboli co polewej. Reguły przyjmują postać αAβ → αγβ, gdzie: A należy do symboli nieter-minalnych, natomiast α, β, γ są ciągami symboli terminalnych i nieterminalnych.γ musi być symbolem niepustym. Dopuszczalna jest także produkcja S → ε, jeśliS nie pojawia się po prawej stronie żadnej produkcji. Wszystkie języki generowaneprzez ten typ gramatyk mogą być rozpoznane przez niedeterministyczną maszynęTuringa, której długość taśmy jest ograniczona przez skończoną wielokrotność ciąguwejściowego. Gramatyki typu 1 nazywane są nieskracającymi lub kontekstowymi, ajęzyki generowane — kontekstowymi.
Typ 2 gramatyki bezkontekstowe (ang. context-free grammars, CFG), języki przez nie ge-nerowane nazywane są bezkontekstowymi. Wszystkie produkcje przybierają postać:A → γ, gdzie A jest symbolem nieterminalnym, γ jest łańcuchem symboli terminal-nych i nieterminalnych. Gramatyki bezkontekstowe stanowią podstawę teoretycznąwiększości języków programowania. Niedeterministyczny automat ze stosem (ang.pushdown automaton) akceptuje dokładnie klasę języków bezkontekstowych (ang.context-free languages, CFL).
Typ 3 gramatyki regularne (ang. regular grammars) (lub inaczej gramatyki lewostronnie li-niowe) generujące języki regularne. Wszystkie produkcje tej klasy muszą mieć jednąz następujących dwóch postaci: X → aY lub X → a, gdzie X, Y należą do symbo-li nieterminalnych, natomiast a należy do symboli terminalnych. Dopuszczalna jesttakże produkcja S → ε, jeśli S nie pojawia się po prawej stronie żadnej produk-cji. Automaty skończone (ang. finite state automata) akceptują dokładnie tę klasęjęzyków. Dodatkowo ta klasa języków może być opisana przez wyrażenia regularnestosowane szeroko do definiowania wzorców wyszukiwania i struktur leksykalnychjęzyków programowania.
Jeżeli klasy języków generowane przez gramatyki typu 0, 1, 2, 3 oznaczymy odpowiednioprzez K0,K1,K2,K3, to wiadomo, że K3 ⊂ K2 ⊂ K1 ⊂ K0. Oznacza to, że klasa o więk-szym indeksie zawiera jedynie podzbiór języków należących do klasy o indeksie mniejszym.
Gramatyka danego języka może być zapisana w wielu równoważnych postaciach. Wy-różniono kilka postaci, posiadających pewne cechy. Są to notacje m.in.:
BNF notacja Backusa-Naura (ang. Backus-Naur Form) — stosowana głównie do opisujęzyków programowania,
CNF postać normalna Chomskiego (ang. Chomsky Normal Form) — reguły mogą przyj-mować jedną z dwóch form: X → a lub X → Y Z, gdzie X, Y , Z należą do symbolinieterminalnych, natomiast a należy do symboli terminalnych.
GNF postać normalna Greibach (ang. Greibach Normal Form) — reguły mogą przyjmowaćjedynie postać X → aα, gdzie a należy do symboli terminalnych, α jest dowolnym(w tym pustym) ciągiem symboli terminalnych i nieterminalnych [45, 63].
Definicja 4 Drzewo wyprowadzenia (ang. derivation tree) gramatyki G = (Σ, S, V, P )jest drzewem o korzeniu etykietowanym symbolem S, każdemu węzłowi nie będącemu li-ściem przypisany jest symbol nieterminalny (należący do V ) taki, że wraz z bezpośrednimietykietowanymi następnikami odpowiada on pewnej regule produkcji należącej do P . Liściedrzewa mogą być etykietowane jedynie symbolami terminalnymi należącymi do Σ.
15

2.2. Gramatyki 2. Pojęcia podstawowe
a b b a b
A B
A B A B
AA
S
S → AAA → ABA → aB → b
Rysunek 2.1: Przykładowe drzewo wyprowadzenia wraz z odpowiadającą mu gramatyką
Definicja 5 Język L(G) generowany przez gramatykę transformacyjną to zbiór takichsłów, które mogą zostać wyprowadzone z symbolu początkowego S za pomocą dowolne-go drzewa wyprowadzenia powstałego z użyciem reguł produkcji należących do P . Relacjawyprowadzalności (ang. derivability) P ∗ jest przechodnim i zwrotnym domknięciem P .L(G) = {w|w ∈ Σ∗ i jest możliwe wyprowadzenie w z symbolu początkowego}.
Definicja 5 określa związek między językiem a gramatykami transformacyjnymi.
Język (typ gramatyki) Język akceptowany przez Problem x ∈ L
regularny automat skończony Rabina-Scotta rozstrzygalnybezkontekstowy automat ze stosem rozstrzygalnykontekstowy dwutaśmowa maszyna Turinga w
sposób liniowo ograniczonarozstrzygalny
rekurencyjny maszyna Turinga rozstrzygalnyrekurencyjnie przeliczalny dwutaśmowa maszyna Turinga półrozstrzygalny
Tabela 2.2: Zestawienie typów języków wraz z akceptującymi je automatami [75]
Przedstawione wyżej typy gramatyk cechuje różna ekspresja. Im większa ekspresjaformalizmu, tym większy zbiór zagadnień może być za jego pomocą opisany. Niestetyim większa ekspresja, tym większe problemy z przygotowaniem odpowiedniej gramatykii odpowiedzią na pytanie, czy dane zdanie należy do języka, czy nie. Zestawienie klasgramatyk znajduje się w tabeli 2.2. Wyjaśnienia wymagają jeszcze następujące pojęcia:
języki rekurencyjnie przeliczalne — dla których problem przynależności jest półroz-strzygalny (przy użyciu maszyny Turinga). Oznacza to, że jeżeli dany ciąg wejściowynależy do języka, to istnieje gwarancja, że maszyna Turinga zatrzyma się i będzieto stan terminalny. Jednak dopóki maszyna nie zatrzyma się, nie jesteśmy w sta-nie powiedzieć, czy w ogóle kiedykolwiek się zatrzyma, zatem nie jesteśmy w stanierozstrzygnąć, czy dany ciąg należy do języka,
języki rekurencyjne —dla których problem przynależności jest rozstrzygalny z użyciemmaszyny Turinga.
2.2.2 Klasa gramatyk bezkontekstowych
Spośród omawianych wyżej typów gramatyk na szczególną uwagę zasługuje formalizmgramatyk bezkontekstowych, ze względu na to, że znane są odpowiednio efektywne metodyparsowania z użyciem reguł bezkontekstowych. Nie można tego powiedzieć o gramatykachkontekstowych. Z drugiej strony ekspresja formalizmu bezkontekstowego jest na tyle duża,że pozwala na analizę wystarczająco dużego podzbioru zdań języka naturalnego2 — na co2Gramatyki bezkontekstowe są znacznie bardziej ogólne niż gramatyki regularne i mogą modelować
wiele sytuacji, które są poza zasięgiem wyrażeń regularnych np. stos, palindromy, struktury nawiasowe.
16

2.3. Problem indukcji gramatyk 2. Pojęcia podstawowe
nie pozwalają gramatyki regularne.
W toku badań nad indukcją gramatyk, popularną taktyką ominięcia konsekwencjitwierdzenia Golda (zob. str. 20) było definiowanie podklasy CFG ograniczonej w takisposób, że nie zawierała ona wszystkich skończonych języków [78]. Stąd został zdefinio-wany szereg podklas, np.: simple deterministic grammar, even linear grammar, k-boundedgrammar, reversible grammar.
Tak jak ukryte modele Markowa są stochastycznym rozszerzeniem formalizmu auto-matów skończonych, tak istnieje stochastyczne roszerzenie formalizmu gramatyk bezkon-tekstowych zwane stochastycznymi gramatykami bezkontekstowymi (ang. stochastic contextfree grammar, SCFG). SCFG jest nadklasą HMM w hierarchii Chomskiego. Polega ono natym, iż każdej regule gramatyki przyporządkowuje się prawdopodobieństwo. GramatykaSCFG przypisuje prawdopodobieństwo do każdego wyprowadzonego zdania i tym samymdefiniuje funkcję gęstości. Prawdopodobieństwo to obliczane jest jako iloczyn prawdopo-dobieństw wszystkich reguł występujących w drzewie wywodu, zakładając, że użycie regułnie zależy od siebie nawzajem. Gdy istnieje więcej niż jedno drzewo wywodu dla danegozdania, prawdopodobieństwo wyprowadzenia obliczane jest jako suma prawdopodobieństwkażdego z drzew wywodu.
Problem uczenia SCFG zasadniczo dzieli się na dwa aspekty: znalezienie odpowiedniejtopologii gramatyki i określenie prawdopodobieństw3. Problem ten został szczegółowo opi-sany w pracy Sakakibary [108, str. 27-32].
Problemem z użyciem SCFG, jak zauważono w [84, str. 12], jest założenie o nieza-leżności występowania reguł gramatyki w danym drzewie wywodu. Założenie to jest zbytsilne, gdyż zgodnie z intuicją4 użycie reguły A determinuje w pewien sposób zbiór regułużytych w następnej kolejności. Zatem proste obliczenie prawdopodobieństwa wystąpieniadanego drzewa rozbioru jako multiplikacji prawdopodobieństw występujących w nim regułnie jest właściwym podejściem. Właściwym podejściem jest użycie iloczynu prawdopodo-bieństw warunkowych wystąpienia reguł. Nastręcza to jednak problemy z ich obliczeniem— z uwagi na ich dużą liczbę, jak i wymagania co do wielkości korpusu.
2.3 Problem indukcji gramatyk
Problem indukcji gramatyki sprowadza się (w szerokim tego słowa znaczeniu) do naukiopisu języka z danych pochodzących z języka, choć niekoniecznie będących zdaniami wtym języku. Proces indukcji gramatyki można podzielić na dwa etapy: identyfikacji klasyjęzyka i identyfikacji samego języka. Etap pierwszy jest istotny, gdyż od klasy języka zależyaparat formalny, którego należy użyć w drugim etapie (patrz tabela 2.2). Należy zauważyć,że identyfikowalność jest własnością klasy języków, a nie poszczególnych języków. Identy-fikacja klasy języka jest problemem trudnym, a w ogólnym przypadku, gdy mamy dostęptylko do pozytywnych przykładów, problemem nierozwiązywalnym [54]. Często w prak-tycznych problemach zakłada się a priori klasę gramatyki, której reguły będą rozważane.Choć formalnie niepoprawne, takie postępowanie często daje zadowalające efekty, gdyżzwykle rozpatrujemy tylko podzbiór całego języka, a generowane reguły mają prostsząpostać.
Gold w [54] zaproponował pojęcie modelu wyuczalności języka (ang. language learna-bility model) jako następującą trójkę:
1. definicja uczenia języka (ang. definition of learnability)5,3Do estymowania prawdopodobieństw w gramatykach SCFG służy algorytm „inside-outside”.4Na przykład zaimki znacznie częściej występują w zdaniu w roli podmiotu niż okolicznika.5Definicja uczenia języka identyfikuje kryteria pozwalające stwierdzić, że język został wyuczony (ziden-
tyfikowany).
17

2.3. Problem indukcji gramatyk 2. Pojęcia podstawowe
2. metoda prezentacji informacji,
3. definicja relacji nazywania (ang. naming relation).
2.3.1 Metoda prezentacji informacji
Metoda prezentacji informacji precyzuje sposób, w jaki nauczyciel (wyrocznia) będzieuczył ucznia, czyli prezentował dane trenujące. Mogą one składać się wyłącznie z przy-kładów pozytywnych (należących do języka) (def. 6) lub przykładów pozytywnych i nega-tywnych (def. 7).
Definicja 6 Pozytywną reprezentacją (ang. positive representation) nieznanej gramatykiG jest nieskończona sekwencja przykładów, która zawiera wszystkie i tylko elementy na-leżące do L(G). Pozytywna reprezentacja zwana jest także przykładami pozytywnymi lubtekstem.
Definicja 7 Kompletną reprezentacją nieznanej gramatyki G jest nieskończona sekwen-cja uporządkowanych par (w, l) ∈ Σ∗ × {0, 1}, gdzie l = 1 wtedy i tylko w tedy, gdy wjest wygenerowane przez G i taką, że każdy łańcuch z Σ∗ pojawi się przynajmniej raz ja-ko pierwszy element pary w sekwencji, gdzie Σ oznacza alfabet. Reprezentacja kompletnazwana też jest informantem.
2.3.2 Relacja nazywania
Relacja nazywania precyzuje sposób podejmowania decyzji o tym, czy dana nazwa —którą może być gramatyka — odpowiada poszukiwanemu językowi. Danemu językowi możeodpowiadać więcej niż jedna nazwa. Relacje nazywania dzielą się na:
generator — nazywanie polega na wygenerowaniu za pomocą maszyny Turinga (z uży-ciem wybranej gramatyki) zdań, a następnie porównaniu ich z docelowym językiem.W przypadku zgodności, badana gramatyka opisuje docelowy język, w przeciwnymprzypadku należy testować pozostałe gramatyki kandydujące;
tester — nazywanie zależy od tego, czy maszyna Turinga realizująca wybraną gramatykęakceptuje podany język. Jeżeli test wypadł pozytywnie, testowana gramatyka opi-suje docelowy język, w przeciwnym przypadku należy testować pozostałe gramatykikandydujące.
Należy zauważyć, że jeśli istnieje tester dla danego języka L, wtedy L jest rekurencyjny,natomiast jeżeli istnieje tylko generator dla danego języka L, wtedy L jest rekurencyj-nie przeliczalny [54]. Można efektywnie przekształcić tester w generator. Dlatego każdaklasa języków identyfikowalna za pomocą testera jest również identyfikowalna za pomocągeneratora. Dwie relacje nazywania są równoważne, gdy dla każdej metody prezentacjiinformacji, dwa modele uczenia otrzymane z ich wykorzystaniem są równoważne.
2.3.3 Modele uczenia
W teorii uczenia algorytmicznego (ang. Computational Learning Theory — COLT) wy-stępują trzy główne formalne modele uczenia z przykładów (wnioskowania indukcyjnego):
• identyfikacja w granicy (ang. identification in the limit) Golda [54],
• nauka poprzez zapytania (ang. query learning model) Angluin [7],
18

2.3. Problem indukcji gramatyk 2. Pojęcia podstawowe
• model uczenia PAC (ang. probably approximately correct) wprowadzony przez Va-lianta [126].
Identyfikacja języka w granicy
Model identyfikacji w granicy zakłada, że uczenie jest procesem nieskończonym i, że algo-rytm uczący M ma dostęp do nieskończonej sekwencji danych trenujących pochodzącychz nieznanej gramatyki G. Graniczna hipoteza postawiona przez algorytm jest uważanaza kryterium sukcesu. Identyfikacja języka w granicy (pierwszy raz opisana w pracy [54])polega na cyklicznym wykonywaniu następujących kroków:
1. przykłady zdań należących do języka it pojawiają się w sposób sekwencyjny,
2. dla każdego nowego przykładu uczący się algorytm tworzy hipotezę H(i1, . . . , it),
3. algorytm uczący się odnosi sukces wtedy, gdy po skończonym czasie stawiane hipo-tezy są takie same (sekwencja hipotez jest zbieżna) i poprawnie opisują język.
Algorytm uczący M przetwarza kolejne partie sekwencji kompletnej reprezentacji gra-matyki G i wysuwa kolejne hipotezy. Jeśli dla każdej kompletnej reprezentacji nieznanejgramatyki G, M jest w stanie ustalić poprawną gramatykę ekstensjonalnie równoważnągramatyce docelowej G po przetworzeniu skończonej ilości przykładów, i nigdy później niezmienić ustalonej hipotezy, wtedy mówimy, że M zidentyfikował G w granicy z użyciemkompletnej reprezentacji. Warto zauważyć, że uniwersalną metodą implementującą iden-tyfikację w granicy jest identyfikacja przez wyliczenie (ang. identification by enumeration).
Nauka poprzez zapytania
Angluin w artykule [7] zaproponowała model uczenia w obecności nauczyciela, który po-trafi udzielić odpowiedzi na specyficznego typu pytania dotyczące nieznanej gramatyki G.W modelu tym, zwanym uczeniem poprzez zapytania (ang. query learning model), nauczy-cielem jest wyrocznia, która potrafi odpowiadać na pewne rodzaje pytań, zadawane przezalgorytm uczący się nieznanej gramatyki G. Pytania mają jedną z dwóch postaci:
• pytania o przynależność. Danymi wejściowymi jest łańcuch w ∈ Σ∗, a nauczycielodpowiada „tak” jeśli w zostało wygenerowane przez G i „nie” w przeciwnym wy-padku,
• pytania o równoważność. Dane wejściowe to gramatyka G′, a odpowiedzią jest „tak”,gdy G′ jest równoważne G (tzn. G′ generuje ten sam język co G — koniec proce-su uczenia) i „nie” w przeciwnym przypadku. Gdy padnie odpowiedź negatywna,zwracany jest także łańcuch w należący do różnicy symetrycznej języka L(G) wy-generowanego przez gramatykę G i języka L(G′) wygenerowanego przez gramatykęG′. Ciąg w jest zwany kontrprzykładem.
Algorytm uczący się zadaje pytania wyroczni (nauczycielowi), aby poznać nieznaną gra-matykę G. Po pewnym skończonym czasie algorytm zwraca szukaną gramatykę. W tymschemacie uczenia nie występuje pojęcie granicy. Należy zauważyć, że odpowiedzi na py-tania o równoważność niosą więcej więcej informacji niż odpowiedzi na pytania o przy-należność. Jednak te drugie grają istotną rolę w procesie uczenia, np. klasa gramatykregularnych (akceptowanych przez DFA) jest identyfikowalna w czasie wielomianowym zjednoczesnym użyciem pytań o równoważność i pytań o przynależność, a nie może byćefektywnie zidentyfikowana z użyciem jedynie pytań o równoważność [8].
19

2.3. Problem indukcji gramatyk 2. Pojęcia podstawowe
Model uczenia PAC
Valiant [126] wprowadził niezależny od rozkładu, probabilistyczny model uczenia z loso-wych przykładów, który jest nazywany modelem uczenia PAC (ang. probably approximatelycorrect). Model ten zakłada, że próbki ze zbioru Σ∗ losowane są niezależnie. Rozkład pró-bek D jest arbitralnie ustalony i nieznany uczniowi. Algorytm uczący się pobiera próbkęprzykładów jako dane wejściowe i na tej podstawie określa gramatykę. Sukces procesumierzony jest dwoma parametrami: precyzja (ang. accuracy) ε i pewność (ang. confiden-ce) δ, które narzucone są z góry jako parametry procesu nauczania. Błąd gramatyki G′
w stosunku do nieznanej gramatyki G jest zdefiniowany jako suma prawdopodobieństwD(w) łańcuchów w w różnicy symetrycznej L(G) i L(G′) w stosunku do D. Algorytmuczący się z powodzeniem w modelu PAC to taki, który z wysokim prawdopodobieństwem(przynajmniej 1− δ) znajdzie gramatykę, której błąd jest dostatecznie mały (nie większyniż ε).
2.3.4 Przegląd metod uczenia gramatyk
Twierdzenie 1 (Gold [54]) Klasa gramatyk zawierająca wszystkie języki skończone i przy-najmniej jeden język nieskończony nie jest identyfikowalna wyłącznie z pozytywnych przy-kładów.
Twierdzenie 1 mówi, że nawet klasa języków regularnych nie może być zidentyfikowanaw granicy tylko z pozytywnych danych (a przecież język naturalny jest co najmniej bez-kontekstowy). Zgodnie z tym twierdzeniem, nie istnieje algorytm mogący identyfikowaćklasę języków bezkontekstowych (a nawet klasę języków regularnych) tylko z pozytywnychprzykładów6. Te fakty wskazują, że uczenie z pozytywnych przykładów jest zbyt słabe zpunktu widzenia praktycznych zastosowań. Jednakże prawdą jest, że uczenie z pozytyw-nych przykładów jest bardzo użyteczne i ważne z praktycznego punktu widzenia z uwagina łatwą dostępność danych trenujących (niezwykle trudnym problemem jest przygotowa-nie kompletnych przykładów, gdyż wymaga to pełnej wiedzy o — nieznanym przecież —poszukiwanym języku).
Zatem oczywiste podejście polegające na użyciu tekstu w języku naturalnym do naukigramatyki okazuje się niewykonalne. Jest to zresztą zjawisko powszechne w maszynowymuczeniu, gdyż dostęp do danych wyłącznie pozytywnych sprzyja zbytniej generalizacji hi-potez. Znane są jednak pewne metody pozwalające ominąć to ograniczenie dzięki zasto-sowaniu bogatszego źródła informacji np. użycie wyroczni odpowiadającej na pytania orównoważność gramatyk lub o przynależność; użycie danych niosących informacje o struk-turze gramatyki, etc. Angluin w artykule [3] podała warunki konieczne i wystarczające dlaklasy języków, która może być z sukcesem zidentyfikowana tylko z pozytywnych danych.Tabela 2.3 zawiera wymagania nałożone na dane trenujące, aby identyfikacja języka wgranicy mogła zakończyć się sukcesem.
Przegląd metod uczenia gramatyk rozpocznie uczenie gramatyk regularnych (determi-nistycznych automatów skończonych), stanowiące doskonały przykład ilustrujący general-ne problemy związane z tą tematyką.
6Szkic dowodu: rozważmy przykładowy algorytm uczący się. Algorytm musi zidentyfikować poprawniekażdy skończony język po przetworzeniu skończonej ilości przykładowego tekstu. To czyni możliwym skon-struowanie nieskończonej liczby takich przykładów należących do języka nieskończonego, które za każdymrazem doprowadzą do błędnej decyzji algorytmu. Można osiągnąć taki efekt poprzez sukcesywne powięk-szanie skończonego podzbioru nieskończonego języka. Na każdym etapie powtarzamy elementy aktualnegopodzbioru, aż algorytm popełni błąd.
20

2.3. Problem indukcji gramatyk 2. Pojęcia podstawowe
Model uczenia Klasa językapierwotnie rekurencyjny tekst z generatorem7
(ang. anomalous text)rekurencyjnie przeliczalnerekurencyjne
informantpierwotnie rekurencyjnekontekstowe
tekst ustrukturalizowanybezkontekstoweregularne
nadskończona7 (ang. superfinite)tekst
skończone
Tabela 2.3: Zakresy identyfikowalności języków z danych w granicy [54]. Klasą nadskończo-ną nazywamy każdą klasę języków, która zawiera wszystkie języki skończone i przynajmniejjeden nieskończony.
Uczenie automatów skończonych
Opracowaniami, które dają pełen obraz dotychczasowych osiągnięć w dziedzinie uczeniaautomatów skończonych, są prace Trakhtenbrota i Barzdina [125], praca Wiehagena [133],praca Luzeaux [82] i doskonała praca przeglądowa Pitta [97].
Definicja 8 Deterministycznym automatem skończonym (ang. deterministic finite sta-te automaton, DFA) nazywamy piątkę uporządkowaną A = (Q,Σ, δ, q0, F ), gdzie Q jestskończonym zbiorem stanów, Σ jest alfabetem symboli wejściowych, δ jest funkcją przejśćδ : Q × Σ → Q, q0 ∈ Q jest stanem początkowym i F ⊆ Q jest zbiorem stanów koń-cowych. Język akceptowany przez deterministyczny automat skończony A jest oznaczanyprzez L(A).
Uczenie z reprezentatywnych przykładów Próbka reprezentatywna języka L(A)to taki skończony podzbiór S zbioru L(A), który wymusza na automacie A badającymakceptowalność elementów z S użycie wszystkich przejść między stanami. Aby zidentyfiko-wać nieznany DFA A = (Q,Σ, δ, q0, F ) z przykładów, potrzebny jest zbiór będący próbkąreprezentatywną języka L(A). Weźmy pod uwagę zbiór R(S) wszystkich przedrostków łań-cuchów ze zbioru S. Dla każdego stanu q automatu A musi istnieć taki łańcuch u ∈ R(S)taki, że δ(q0, u) = q. Co więcej, dla każdego stanu q i każdego przejścia δ(q, a) ze stanuq, gdzie a ∈ Σ, istnieje łańcuch va ∈ R(S) taki, że δ(q0, v) = q i δ(q, a) = δ(q0, va) = q′.Zatem wszystkie przejścia i stany są reprezentowane przez łańcuchy należące do R(S).Pozostaje jeszcze problem rozróżnienia dwóch stanów qu i qv reprezentowanych przez dwałańcuchy u i v należące do R(S), takie że qu = δ(q0, u) i qv = δ(q0, v), gdy qu i qv sąróżnymi stanami A. Angluin w artykule [4] zaproponowała efektywny sposób rozwiązaniatego problemu z użyciem pytań o przynależność.
Twierdzenie 2 (Angluin [4]). Klasa deterministycznych automatów skończonych jest iden-tyfikowalna w czasie wielomianowym z reprezentatywnej próbki języka z użyciem pytań oprzynależność.
7Jest to tłumaczenie zaproponowane w [52].
21

2.3. Problem indukcji gramatyk 2. Pojęcia podstawowe
Uczenie z nauczycielem Angluin w artykule [6] rozważa uczenie z wykorzystaniem„minimalnie adekwatnego nauczyciela” (ang. minimally adequate teacher). Nauczyciel po-trafi odpowiedzieć tylko na dwa typy pytań zadawanych przez algorytm uczący się, a do-tyczących nieznanego DFA. Są to wspomniane na stronie 19 pytania o przynależność ipytania o równoważność. We wspomnianym artykule Angluin pokazała, że pytania o rów-noważność kompensują brak reprezentatywnych próbek języka i zaprezentowała efektywnyalgorytm identyfikujący DFA z użyciem pytań o równoważność i przynależność.
Twierdzenie 3 (Angluin [6]) Klasa deterministycznych automatów skończonych możebyć identyfikowalna w czasie wielomianowym z użyciem pytań o równoważność i przyna-leżność.
Yokomori w artykule [143] rozważa efektywną identyfikację niedeterministycznych auto-matów skończonych z użyciem pytań o przynależność i równoważność.
Podklasy DFA Gold [54] pokazał, że istnieje podstawowa różnica między klasami gra-matyk identyfikowalnych z pozytywnych reprezentacji, a kompletnych reprezentacji. Wska-zał także, że żadna nadskończona (ang. superfinite) klasa języków nie może być identy-fikowalna w granicy tylko z pozytywnych przykładów. Klasa języków regularnych jestnadskończona, zatem należałoby w pewien sposób ograniczyć DFA, aby umożliwić iden-tyfikację z pozytywnych przykładów.
Aby uniknąć problemu nadmiernej generalizacji8 (ang. overgeneralization), Anglu-in [5] wprowadziła szereg podklas DFA, nazwanych automatami k-reversible (dla k =0, 1, 2, . . . )9 i pokazała, że istnienie próbki charakterystycznej (ang. characteristic sample)jest wystarczające do identyfikacji klasy k-reversible DFA z pozytywnych danych. Próbkacharakterystyczna dla automatu k-reversible A jest skończonym zbiorem S ⊂ L(A), takim,że L(A) jest najmniejszym językiem k-reversible zawierającym S. Wynika z tego, że każdapróbka charakterystyczna jest próbką reprezentatywną dla k-reversible DFA.
Twierdzenie 4 (Angluin [5]) Klasa k-reversible automatów, dla k = 0, 1, 2, . . . jest iden-tyfikowalna w granicy z pozytywnych danych.
Angluin w artykule [5] przedstawiła rodzinę wydajnych algorytmów indukujących językik-reversible z pozytywnych danych.
Następną interesującą podklasą DFA jest klasa automatów ściśle deterministycznych(ang. strictly deterministic automata), którą zaproponował Yokomori w artykule [143].Automaty ściśle deterministyczne to takie DFA, których zbiór etykiet W na krawędziachprzejść jest ograniczony do skończonego podzbioru łańcuchów nad Σ, każda krawędź ozna-czona jest unikalną etykietą (żadne dwie krawędzie nie są etykietowane tak samo) i dlakażdego symbolu a ∈ Σ istnieje co najwyżej jedna etykieta w W zaczynająca się od a.
Twierdzenie 5 (Yokomori [143]) Klasa ściśle deterministycznych automatów jest iden-tyfikowalna w granicy z pozytywnych danych.
8Problem nadmiernej generalizacji w systemach GI objawia się tym, że algorytm uczący się zgadujejęzyk będący nadzbiorem właściwym języka poszukiwanego.9Przykładowo automat 0-reversible to taki DFA, który ma co najwyżej jeden stan końcowy i żadne
dwie krawędzie o takiej samej etykiecie nie zbiegają się w jednym stanie. Uczenie automatów 0-reversible zreprezentatywnej próbki S polega na skonstruowaniu automatu na drzewie (ang. tree automaton) A′, któryakceptuje dokładnie zbiór S, a następnie połączeniu stanów A′, tak, aby spełnić ograniczenia nałożone naautomat 0-reversible.
22

2.3. Problem indukcji gramatyk 2. Pojęcia podstawowe
Uczenie DFA z zaszumionych danych W praktyce, dane trenujące rzadko są wol-ne od szumu (błędnych łańcuchów). Istnieje zaledwie kilka prac poświęconych wpływowizaszumionych danych. Ich przegląd można znaleźć np. w pracy Sakakibary [108, str. 21].
Uczenie gramatyk bezkontekstowych
Jak pokazano w poprzednim punkcie, identyfikacja DFA z użyciem przykładów jest dośćdobrze zbadana. Jednak pytanie, czy istnieją analogiczne rozwiązania dla CFG, pozosta-wało przez długi czas otwarte.
W środowisku GI indukcja gramatyk bezkontekstowych uważana jest za problem trud-ny. Pierwsze wyniki badań nie napawały optymizmem. Angluin w artykule [8] pokazała,że cała klasa CFG nie jest identyfikowalna w czasie wielomianowym jedynie z użyciempytań o równoważność. Co więcej, udowodniono (Angluin i Kharitonov [10]), że problemidentyfikacji klasy CFG z użyciem pytań o przynależność i równoważność ma taką samązłożoność obliczeniową, jak problemy kryptograficzne, dla których nieznane są wielomia-nowe algorytmy (np. odwracanie kodowania RSA).
Mimo negatywnych rezultatów, prace nad tym zagadnieniem były nadal kontynuowane.Motywacją była tu większa ekspresywność CFG w porównaniu do DFA, a co za tymidzie, większe możliwości praktycznego zastosowania tego formalizmu. W rozdziale 2.3.6zaprezentowane zostały udane podejścia do indukcji całej klasy CFG z użyciem dodatkowejinformacji, a także metody efektywnej indukcji podklas CFG (rozdział 2.3.7).
Dalsza część rozprawy poświęcona jest głównie indukcji gramatyk bezkontekstowych,jako z jednej strony bardziej ekspresywnych niż DFA i bardziej efektywnych w przetwa-rzaniu w porównaniu do gramatyk kontekstowych, z drugiej strony.
2.3.5 Uczenie z tekstu
Jedną z pierwszych metod uczenia CFG z tekstu była metoda zaproponowana przez Solo-monoffa w [120]. Ponieważ była to metoda używająca tylko pozytywnych danych, wiemy,że nie mogła być kompletna (jak zauważył to Fu w [50], algorytm nie radził sobie z od-krywaniem produkcji postaci A → aAa|aAd), jednakże to podejście miało istotny wpływna późniejsze prace. Scenariusz uczenia wyglądał następująco: uczeń otrzymywał pewnąpróbkę pozytywnych danych S+ ⊂ L i dostęp do wyroczni, która potrafi odpowiedziećna pytanie, czy podany łańcuch należy do języka czy nie. Strategią zaproponowaną przezSolomonoffa jest znajdowanie powtarzających się wzorców: dla każdego łańcucha w ∈ S+,usuń pewną jego część i zapytaj wyroczni, czy nowy łańcuch należy do języka. Jeśli tak,należy wnioskować, że musi istnieć pewna reguła rekursywna. Istotnie, jeśli w języku ist-nieje dużo łańcuchów postaci anbn, zapewne produkcja postaci A → aAb znajduje sięw gramatyce. Podana metoda jest oczywiście nieefektywna i silnie zależna od łańcuchówzawartych w zbiorze S+. Jak wspomniano wcześniej, nie umożliwia wnioskowania całej kla-sy CFL. Podobne podejście zostało zaprezentowane przez Knobe i Knobe w [72] wspartejedynie kilkoma oczywistymi heurystykami. Zaprezentowany algorytm silnie zależy od ko-lejności prezentowanych danych i charakteryzuje się nieakceptowalną złożonością czasową.Natomiast Tanatsugu w [122] zaproponował rozszerzenie dostępnych danych o przykła-dy negatywne. Prezentowana technika polega na usuwaniu samozawierających struktur zeskończonego zbioru, tworząc liniową gramatykę. CFG powstawała w wyniku kompozycjiwyindukowanej liniowej gramatyki.
Powstaje następujące pytanie: jeżeli założyć, że informacja o języku prezentowana jestjako tekst, to dlaczego zatem nie zidentyfikować najprostszej gramatyki akceptującej po-daną próbkę? Taki sposób identyfikacji nazywany jest identyfikacją przez wyliczenie (ang.
23

2.3. Problem indukcji gramatyk 2. Pojęcia podstawowe
identification by enumeration). Jednak w większości ciekawych przypadków takie postę-powanie zawodzi. Jeżeli poszukiwany język jest bardziej skomplikowany, niż zakłada toalgorytm uczący, wtedy wszystkie próby identyfikacji języka będą skazane na niepowo-dzenie, ponieważ poszukiwany język będzie zawsze spójny z prezentowanymi próbkami,natomiast wyindukowane języki będą podzbiorami właściwymi poszukiwanego języka. Je-żeli algorytm uczący założy L, który jest zbyt skomplikowany, pozytywne dane tekstowenigdy nie zaprzeczą temu założeniu. (Analogia do zjawiska nadmiernego dopasowania walgorytmach genetycznych, gdy topologia sieci neuronowej jest zbyt skomplikowana).
2.3.6 Uczenie z ustrukturalizowanych danych
W poprzednim rozdziale wspomniano, że uczenie gramatyki bezkontekstowej jedynie zpozytywnych przykładów nie jest możliwe, gdyż takie dane trenujące niosą ze sobą zbytmało informacji. Powstała zatem potrzeba stworzenia nowej, odpowiednio silnej metodyreprezentacji materiału tekstowego. Praca Chomskiego [34] z roku 1965 wskazuje, że do-stępność opisu strukturalnego jest warunkiem wstępnym do opisu samego języka. Dwalata później Ginsburg i Harrison w artykule [53] zaproponowali ustrukturalizowaną repre-zentację tekstu, nazwaną bracketed languages, zawierającą pełną informację o strukturzegramatycznej zdania — symbole terminalne i użyte reguły produkcji. Taka reprezentacjawymagała jednak znajomości gramatyki, zatem nie była przydatna do indukcji grama-tyk. W tym samym roku McNaughton w artykule [92] zaproponował formalizm gramatyknawiasowych (ang. parenthesis grammars). Dla każdej gramatyki bezkontekstowej G od-powiadająca gramatyka nawiasowa10 (G) powstaje poprzez zastąpienie każdej produkcjipostaci A → α gramatyki G przez produkcję A → (α) (przy założeniu, że nawiasy nienależą do alfabetu).
Gramatyka nawiasowa generuje język (L), którego każde zdanie niesie ze sobą informa-cje dotyczące struktury gramatyki. Zatem język taki jest strukturalnym opisem gramatyki,każde zdanie zaś jest ustrukturalizowanym łańcuchem zwanym także strukturalnym opisem(ang. structured string, structural description), strukturą szkieletową lub krócej szkieletem(ang. skeleton, skeletal structure description). Wszystkie nawiasy są tego samego rodza-ju i nie są etykietowane, co jest równoważne z brakiem informacji, z którego symbolunieterminalnego, i z której reguły pochodzą.
Levy i Joshi w artykule [79] sugerują istnienie metody efektywnego uczenia gramatykiz ustrukturalizowanych danych. Natomiast w artykule [69] wskazują, że kategorie grama-tyczne (alfabet nieterminalny gramatyki) nie niosą żadnej informacji (z punktu widzeniaformalizmu), a ich liczba i wzajemne zawieranie jest kwestią efektywności i elegancji opisu— oznacza to także, że rozbiór zdania nie musi być unikalny. Jednakże z uwagi na łatwośćinterpretacji przez człowieka reguł produkcji pożądane jest, aby gramatyka była tak prostajak to tylko możliwe, a reguły, z których się składa, odpowiadały opisywanym strukturom.
Definicja 9 Bezetykietowym drzewem wyprowadzenia (ang. unlabeled derivation tree)gramatyki bezkontekstowej G nazywamy takie drzewo wyprowadzenia, w którym usuniętoetykiety wewnętrznych węzłów, pozostawiając jedynie etykiety liści.
Ustrukturalizowany łańcuch składa się z symboli terminalnych należących do Σ i znakównawiasów: „(”, „)” (nienależących do alfabetu) wskazujących jednoznacznie kształt beze-tykietowego drzewa wyprowadzenia (definicja 9). Taki opis kładzie nacisk na grupowaniewyrazów, co może być ważne z psycholingwistycznego punktu widzenia, gdyż intuicyjniestrukturę zdania rozpatrujemy w kategoriach grup wyrazów, a nie odpowiadających im
10Gramatyki nawiasowe okazały się wystarczająco informatywnym sposobem reprezentacji, aby problemrównoważności języków był rozwiązywalny dla tej klasy języków.
24

2.3. Problem indukcji gramatyk 2. Pojęcia podstawowe
kategorii składniowych. Przykład bezetykietowego drzewa wyprowadzenia z CFG wraz zodpowiadającym mu szkieletem znajduje się na rysunku 2.2. Jak widać, taka reprezentacjazachowuje strukturę gramatyki, natomiast zupełnie zaniedbuje informacje dotyczące regułprodukcji i symboli nieterminalnych.
< <Duży pies> <goni <małą dziewczynkę> > >
Rysunek 2.2: Przykład ustrukturalizowanej reprezentacji zdania
Jedną z pierwszych prac, w której pokazano możliwość wykorzystania szkieletów doindukcji gramatyk, była praca Crespi-Reghizzi [42]. Autor proponuje metodę identyfikacjiw granicy podklasy CFG nazwanej operator precedence grammars. W następnej pracy [43]proponuje metodę identyfikacji noncounting context-free languages, będącej także podkla-są CFG, wskazując, że ta podklasa jest niegorsza niż CFG do opisu języków naturalnych.W roku 1990 Sakakibara zaproponował algorytm11 identyfikujący S-automat (def. 11)w czasie wielomianowym (twierdzenie 6) z użyciem ustrukturalizowanych pytań o przy-należność i równoważność (ang. structural membership and equivalence queries). NiechD(G) oznacza zbiór drzew wywodu gramatyki bezkontekstowej G, a s(D(G)) oznaczazbiór bezetykietowych drzew wywodu (ustrukturalizowanych łańcuchów) gramatyki G.Pytanie o strukturalną przynależność jest pytaniem o to, czy ustrukturalizowany łańcuchjest wygenerowany przez nieznaną gramatykę G. Odpowiedzią na pytanie o strukturalnąrównoważność jest „prawda” jeśli gramatyka G′ jest strukturalnie równoważna szukanejgramatyce G, w przeciwnym przypadku odpowiedzią jest „fałsz” wraz z kontrprzykła-dem będącym ustrukturalizowanym łańcuchem stanowiącym różnicę symetryczną międzys(D(G)) i s(D(G′)). Pytanie o strukturalną równoważność jest pytaniem o równoważnośćgramatyk i dla gramatyk nawiasowych jest problemem rozstrzygalnym.
Twierdzenie 6 (Sakakibara [106]) Klasa gramatyk bezkontekstowych jest identyfikowalnaw czasie wielomianowym z użyciem ustrukturalizowanych pytań o równoważność i przyna-leżność.
Jednak metody indukcji CFG z zastosowaniem wyroczni mają niewielkie znaczenie wpraktycznych zastosowaniach. Pomocny tu okazał się formalizm automatów na drzewach(def. 10) rozważanych np. w [41].
Definicja 10 Automatem na drzewach (T–automatem) wstępującym (ang. frontier-to-root tree automaton) nazywamy czwórkę uporządkowaną A = (Q,Σ, F, δ), taką, że:
• Q jest skończonym zbiorem stanów,
• Σ jest skończonym alfabetem rangowym, z rangą symbolu wyznaczoną relacją czę-ściowego porządku a : Σ → N określającą liczbę argumentów symbolu,
• F ⊆ Q jest zbiorem stanów końcowych,
11Będący rozszerzeniem algorytmu Angluin [5] uczenia automatów skończonych (twierdzenie 3).
25

2.3. Problem indukcji gramatyk 2. Pojęcia podstawowe
• δ jest zbiorem funkcji przejść postaci:
f(q1, . . . , qn) → q
gdzie n = a(f), n ≥ 0, f ∈ F , q1, . . . , qn ∈ Q.
T–automat jest rozszerzeniem deterministycznego automatu skończonego polegającym natym, że DFA wyznacza następny stan na podstawie stanu poprzedniego i akceptowanegosymbolu, T–automat wyznacza stan następny za pomocą n–argumentowego konstruktorapobierającego n stanów. Zbiory drzew wyprowadzenia CFG zostały nazwane przez Tha-thera [123] zbiorami lokalnymi z uwagi na fakt, że przynależność każdego drzewa możebyć ustalona poprzez lokalne sprawdzenie etykietowanych węzłów i ich potomków. Zbiorydrzew akceptowane przez T-automat są zwane zbiorami rozpoznawalnymi (ang. recogni-zable sets). Związek między zbiorami lokalnymi i rozpoznawalnymi można określić na-stępująco: każdy zbiór rozpoznawalny jest homomorficznym obrazem zbioru lokalnego, wktórym za pomocą homomorfizmu usunięto informacje o pozycji potomków (Levy i Joshy[79]). Zatem zaistniała potrzeba wprowadzenia nowego pojęcia: S-automatu (def. 11). Nie-formalnie mówiąc różnica między T-automatem a S-automatem jest taka, że pierwszy wprzeciwieństwie do drugiego nie uwzględnia kolejności potomków rozpatrywanego węzła.Oznacza to, że T-automaty akceptują więcej niż zawierają zbiory lokalne. Problem ten niewystępuje w dziedzinie S-automatów.
Definicja 11 (Levy [79]) Automatem na szkieletach (S–automatem) wstępującym (ang.skeletal frontier-to-root tree automaton, SA) Ms nad alfabetem Σ nazywamy czwórkę upo-rządkowaną Ms = (Q,Σ, F, δ) taką, że:
• Q jest skończonym zbiorem stanów,
• Σ jest skończonym alfabetem,
• F ⊆ Q jest zbiorem stanów końcowych,
• δ ⊆ (Q ∪ Σ)∗ × Q jest funkcją przejść, która przypisuje stan do węzła na podsta-wie stanów jego bezpośrednich potomków czytanych od lewej do prawej strony jakołańcuch (Q ∪ Σ)∗.
Jeżeli stan każdego węzła jest wyznaczony jednoznacznie, wtedy Ms jest nazywany deter-ministycznym, w przeciwnym razie Ms nazywamy niedeterministycznym.
Kluczową własnością szkieletów (twierdzenie 7) jest to, że są one dokładnie zbiorem drzewwyprowadzenia akceptowanych przez S-automat (def. 11). Nieformalnie, gdy S–automatMs otrzyma nieetykietowane drzewo T jako dane wejściowe, po pierwsze przypisuje stanydo liści T , a następnie porusza się w górę drzewa, przypisując stany każdemu węzłowiwyłącznie na podstawie stanów dzieci danego węzła. Ms akceptuje T wtedy i tylko wtedy,gdy korzeniowi drzewa T zostanie przypisany stan końcowy. Dzięki takiemu podejściuproblem uczenia CFG można sprowadzić do problemu uczenia się S–automatu.
Twierdzenie 7 (Levy [79]) Niech G będzie gramatyką CFG. S(MG) = S(TG). (Zbiórszkieletów akceptowanych przez MG jest dokładnie zbiorem szkieletów zbioru drzew wypro-wadzeń TG gramatyki G).
Istotnym pytaniem jest to, jakie są dolne ograniczenia na rozmiar i liczbę drzew należącychdo zbioru trenującego. Częściową odpowiedzią jest twierdzenie 8.
26

2.3. Problem indukcji gramatyk 2. Pojęcia podstawowe
Twierdzenie 8 (Levy [79]) Niech S będzie zbiorem szkieletów rozpoznawanych przez de-terministyczny S-automat MS o co najwyżej k stanach. Zbiór wszystkich szkieletów o wy-sokości ≤ 2k akceptowalnych przez MS jednoznacznie identyfikuje S (a tym samym CFGktórej odpowiada S).
Oznacza to, że szkielety są odpowiednią reprezentacją do identyfikacji nieznanego językaspójnego ze zbiorem trenującym. Kategorie składniowe są produktem ubocznym procesuidentyfikacji języka.
W 1990 roku Sakakibara [106] rozważał problem uczenia CFG z użyciem opisu struk-turalnego. Jednak dopiero dwa lata później w [107] dowiódł, że informacja o strukturzegramatycznej nieznanej gramatyki umożliwia jej efektywną identyfikację. Pokazał, że ist-nieje podklasa CFG, zwana gramatyką reversible context-free, która jest identyfikowalnaw granicy z pozytywnej reprezentacji ustrukturalizowanych łańcuchów (bezetykietowychdrzew wyprowadzenia). Następnie dowiódł, że gramatyki reversible context-free są postaciąnormalną CFG.
Definicja 12 Gramatyka reversible context-free jest gramatyką bezkontekstową
G = (V,Σ, P, S)
taką, że:
1. A → α i B → α znajdują się w zbiorze produkcji P implikuje, że A = B,12
2. A → αBβ i A → αCβ znajdują się w zbiorze produkcji P implikuje, że B = C,13
gdzie A, B i C są symbolami nieterminalnymi, a α, β ∈ (N ∪ Σ)∗.
Twierdzenie 9 (Sakakibara [108]) Klasa gramatyk reversible context-free jest identyfi-kowalna w granicy z użyciem pozytywnej reprezentacji ustrukturalizowanych łańcuchów,takich, które zostałyby wygenerowane przez gramatykę reversible context-free nieznanegojęzyka bezkontekstowego.
Należy zauważyć, że twierdzenie 9 nie implikuje faktu, że cała klasa języków bezkon-tekstowych jest identyfikowalna z użyciem pozytywnej ustrukturalizowanej reprezentacji,gdyż dla pewnych języków należących do klasy CFG może nie istnieć strukturalna repre-zentacja pozwalająca na zidentyfikowanie gramatyki reversible context-free.
Poniżej zaprezentowany zostanie przykład ilustrujący działanie algorytmu identyfiku-jącego gramatykę reversible context-free z użyciem ustrukturalizowanych łańcuchów Sazaproponowanego w [108]. Początkowo algorytm tworzy gramatykę bezkontekstową G0,która generuje dokładnie Sa, to znaczy taką, że s(D(G0)) = Sa. Następnie algorytm łączysymbole nieterminalne w taki sposób aby powstała gramatyka reversible context-free Gtaka, że:
s(D(G)) = min{s(D(G′))|Sa ∈ s(D(G′))}
gdzie, G′ jest gramatyką reversible context-free. Załóżmy, że:
Sa = {<< ab >< c >>,<< a < ab > b >< c < c >>,<< ab >< c < c >>>}
12Jest to definicja gramatyki invertible.13Jest to definicja gramatyki reset-free.
27

2.3. Problem indukcji gramatyk 2. Pojęcia podstawowe
Pierwszym krokiem algorytmu jest skonstruowanie gramatyki G0, takiej, że s(D(G0)) =Sa:
S → ABA → abB → cS → CDC → aC ′bC ′ → abD → cD′
D′ → cS → EFE → abF → cF ′
F ′ → c
Aby spełnić warunek (1) definicji 12, symbole nieterminalne (A,C ′, E) i (B,D′, F ′) w G0
powinny zostać połączone, tworząc następujące reguły produkcji:
S → ABA → abB → cS → CDC → aAbD → cBS → AFF → cB
Aby spełnić warunek (1), symbole D,F powinny zostać połączone:
S → ABA → abB → cS → CDC → aABD → cBS → AD
Aby spełnić warunek (2), symbole nieterminalne (B,D), a także (A,C) powinny zostaćpołączone. Ostatecznie postać gramatyki reversible context-free jest następująca:
S → ABA → abA → aAbB → cB → cB
która generuje język {ambmcn|m,n ≥ 1}.
Makinen [88] udoskonalił algorytm indukcji gramatyki reversible CFG zaproponowanyprzez Sakakibarę, zwiększając jego efektywność. Zaproponował także podklasę gramatykireversible CFG, zwaną gramatyką type invertible, która jest identyfikowalna z pozytywnejstrukturalnej reprezentacji w liniowym czasie (w stosunku do rozmiaru zbioru trenującego).
2.3.7 Uczenie podklas CFL
Najpopularniejszą taktyką, stosowaną przez badaczy w celu uniknięcia konsekwencji twier-dzenia Golda, jest ograniczenie rozważanych języków do podklas CFL, w szczególności ta-kich, które nie zawierają wszystkich skończonych języków. Angluin pokazała, że k-bounded
28

2.3. Problem indukcji gramatyk 2. Pojęcia podstawowe
CFG jest identyfikowalna w czasie wielomianowym z użyciem pytań o równoważność inieterminalnych pytań o przynależność [6]14. Poniżej znajduje się podsumowanie wynikówinnych badaczy:
• Yokomori w pracy [141] rozważał klasę nazwaną simple deterministic grammars.Zaproponował wielomianowy algorytm identyfikacji w granicy z pozytywnej repre-zentacji. Był to pierwszy przykład klasy języków zawierających języki nieregularne,która jest identyfikowalna w granicy w czasie wielomianowym zgodnie z kryteriumzaproponowanym przez Pitta w [97] (tzn. czas uaktualniania hipotezy jest ograniczo-ny wielomianowo od rozmiaru szukanej gramatyki n i sumy długości prezentowanychprzykładów, liczba ukrytych błędów predykcji (ang. implicit errors of prediction) po-pełnianych przez algorytm uczący jest ograniczona wielomianowo od n.
Definicja 13 Very simple grammar to taka CFG G = (N,Σ, P, S), w której (wpostaci normalnej Greibach) dla każdego symbolu terminalnego a ∈ Σ istnieje jednai tylko jedna reguła produkcji rozpoczynająca się od a (tzn. dokładnie jedna regułapostaci A → aα, gdzie α ∈ (N ∪ Σ)∗).
Twierdzenie 10 (Yokomori [141]). Klasa very simple grammars jest identyfiko-walna w granicy z pozytywnych danych w czasie wielomianowym.
Wynika z tego, że klasa very simple grammars jest identyfikowalna w czasie wie-lomianowym z użyciem jedynie pytań o równoważność. Algorytm uczenia tej klasyprzedstawiony jest w [142].
• Szeroko znaną techniką stosowaną w uczeniu gramatyk jest redukcja problemu ucze-nia gramatyk do innego problemu wyuczalności, który jest rozstrzygalny. Takadaw [121] pokazał, że problem uczenia even linear languages może być rozwiązanyprzez zredukowanie go do uczenia DFA i pokazał algorytm redukcji o wielomianowejzłożoności.
Definicja 14 Even linear grammar jest gramatyką CFG o produkcjach postaci A →uBv lub A → w, gdzie u i v mają tą samą długość, A i B są symbolami nietermi-nalnymi, u, v, w są łańcuchami nad alfabetem Σ.
Twierdzenie 11 (Takada [121]) Problem uczenia klasy gramatyk even linear jestredukowalny do problemu uczenia klasy automatów skończonych.
• Burago w [27] zaprezentował algorytm uczenia structurally reversible languages,structurally reversible context-free grammars i pokazał, że ta klasa jest identyfiko-walna w czasie wielomianowym z użyciem pytań o równoważność i przynależność.
Definicja 15 Structurally reversible CFG to takie CFG, dla którego każdy nieter-minalny wyraz wygenerowany przez tę gramatykę nie stanowi rozszerzenia innegonieterminalnego wyrazu.
Structurally reversible CFG jest podklasą CFG i klasa structurally reversible CFLjest nadklasą właściwą VSL (very simple languages).
• Berman w [15] zaprezentował algorytm uczenia one–counter languages — językówakceptowanych przez deterministic one-counter automata.
• Feldman et al. w pracy [49] przedstawił algorytm uczenia pivot languages.14Nieterminalne pytanie o przynależność to pytanie, czy łańcuch w można wyprowadzić z symbolu nie-terminalnego A, zatem jest to „silne” pytanie o strukturę gramatyki, stąd stanowi znaczną pomoc dlaalgorytmu uczącego.
29

2.4. Kryteria oceny 2. Pojęcia podstawowe
2.3.8 Alternatywne koncepcje CFL
Jak wspomniano w rozdziale 2.3, problem identyfikacji języka to problem budowy jedno-znacznej i skończonej jego reprezentacji. Kilku badaczy zmierzyło się z tym zagadnieniem,proponując reprezentacje niewywodzące się z gramatyk transformacyjnych. Na uwagę za-sługują tu prace Yokomori [140] i Arikawa [13].
2.4 Kryteria oceny
Jednym z kryteriów oceny efektywności algorytmu uczącego się jest to, czy jego złożonośćczasowa (lub pamięciowa) jest ograniczona wielomianowo z uwzględnieniem odpowiednichparametrów [108]. Jednakże w przypadku indukcji reguł gramatyki języka naturalnegoistotniejszym problemem jest ocena jakości uzyskanych wyników, gdyż odpowiedź na py-tanie, czy dany rozbiór zdania jest poprawny, nie musi być jednoznaczna.
Należy być świadomym faktu, że istniejące korpusy tekstów języka naturalnego nie sąspójne ani w czasie, ani w materiale, ani nawet w użytych oznaczeniach, czy nałożonychna zdania strukturach (korpusy anotowane strukturalnie). Poziom wewnętrznej spójności(jak twierdzi Magerman w [85]) szacowany jest na około 70% — zatem notowany przezniektórych badaczy poziom zgodności rzędu 90% i więcej jest pewnym nadużyciem —oczywiście tłumaczonym tym, iż do doświadczeń dany korpus został przygotowany przeznp. usunięcie błędów anotacji lub usunięcie błędnych zdań. Oznacza to oczywisty błądbadawczy, gdyż wyniki osiągnięte w ten sposób są nieweryfikowalne, ponieważ sam korpusjest nieosiągalny szerszemu gronu badaczy.
W [19] Bod wskazuje, że ocena jakości parsowania nie jest trywialnym zadaniem —nawet dla człowieka. Anotator oceniający jakość przedstawionego mu parsowania (wykona-nego automatycznie, czy też przez innego anotatora) często przychyla się do zaproponowa-nej wersji. Gdyby jednak poproszono go o przygotowanie własnej propozycji, a następnieskonfrontowanie jej z ocenianym rozbiorem gramatycznym — z pewnością oceniłby ją jakonieprawidłową, gdyby różniła się od tej, którą sam zaproponował. Jest to spowodowanetym, iż przedstawiona wersja wpływa na postrzeganie anotatora.
Problemem jest także to, że nawet ten sam anotator dokonujący rozbioru gramatycz-nego tego samego zdania, może uzyskać inne wyniki, gdy tylko oba zdarzenia będą odpo-wiednio oddalone w czasie. Spowodowane jest to między innymi przez fakt, że anotatorwraz z rosnącym doświadczeniem przychylać się może do różnych wersji rozbioru grama-tycznego tego samego zdania. Sprawa jest jeszcze bardziej skomplikowana w przypadkuporównywania wyników uzyskanych przez dwóch anotatorów.
Z tych właśnie powodów istniejące korpusy anotowane strukturalnie są wewnętrznieniespójne, co jest związane zarówno z czasem przeprowadzenia anotowania danej częścijak i z osobą anotatora.
Przykładowe anotowane korpusy to:
• anotowane częściami mowy:
– Brown Corpus,
– British National Corpus,
– Lancaster/Oslo–Bergen Corpus of British English,
– Oxford Text Archive Corpus,
– Korpus Języka Polskiego IPI PAN,
• anotowane strukturalnie:
30

2.4. Kryteria oceny 2. Pojęcia podstawowe
– The Penn Treebank Project (wersja druga poprawiona) [90],
– Prague Czech-English Dependency Treebank,
– Dutch OVIS Treebank.
Zatem, skoro ocena jakości uzyskanych wyników stanowi tak duży problem, zostanie onprzedstawiony szerzej, pozostawiając zagadnienie złożoności obliczeniowych do rozważeniaw przyszłości.
Proces indukcji gramatyki można podzielić na dwa etapy:
• przygotowanie struktur szkieletowych,
• wygenerowanie reguł gramatyki z użyciem struktur szkieletowych.
Dlatego wyniki każdego z nich mogą być oceniane osobno z zastosowaniem odpowiednichmiar wymienionych i opisanych poniżej.
2.4.1 Ocena jakości struktur szkieletowych
Ewaluacja wyników uzyskanych jako efekt działania algorytmów uczących się bez nadzo-ru jest trudna. Tak jest też w przypadku algorytmów wykrywających strukturę zdania.Jednym ze sposobów jest porównanie tak powstałych struktur z korpusem anotowanymstrukturalnie (ang. treebank), przy użyciu różnych metryk. Jedną z najbardziej popular-nych jest metryka PARSEVAL (użyta do oceny wyników m.in. w artykułach [130, 18]).Powyższa metryka przeznaczona jest do oceny metod uczenia z nadzorem, gdyż ocenianajest zgodność ze wzorcowym korpusem. Niewątpliwą zaletą metryki PARSEVAL jest ogól-na dostępność programu, który ją implementuje (pod adresem [W9]) i popularność, jakąsię cieszy. Dzięki temu istnieje przynajmniej teoretyczna możliwość porównania ze sobąalgorytmów proponowanych przez różnych autorów.
Problemem w porównywaniu algorytmów jest to, iż wykorzystują one pewne specyficz-ne cechy korpusów, na których badane są efekty ich działania (np. częściowo anotowanykorpus użyty w [96]) lub istniejące korpusy są specjalnie przygotowywane poprzez wy-kluczenie pewnych zdań lub poprawienie błędów w anotacji. Oddzielnym problemem jesttakże unifikacja sposobu prezentowania wyników działania algorytmów przez implemen-tujące je systemy. Przykładowo system ABL [W10][129, 131] prezentuje wyniki działaniajako anotowane strukturalnie zdania, natomiast system EMILE [W11][1] jako zbiór wy-indukowanych reguł, ale tylko tych, których wsparcie jest odpowiednio wysokie. Zatemporównanie wyników działania wspomnianych systemów nie jest proste, gdyż nawet użyciereguł gramatyki pochodzących z systemu EMILE do anotowania strukturalnego badanegokorpusu nie pozwoli na dokonanie rozbioru gramatycznego wszystkich zdań. Interpretacjatej asymetrii w wynikach nie jest oczywista (zob. [130]).
Porównywanie wyników dwóch algorytmów operujących na różnych korpusach, w szcze-gólności anotowanych innym zbiorem etykiet, ma niewielką praktyczną przydatność (pozaprzykładami skrajnymi). Dlatego nie należy się spodziewać, że taki sposób oceny spełnipokładane w nim nadzieje. Otrzymane w ten sposób wyniki można analizować jedyniejakościowo nie zaś ilościowo.
Poniższe miary zaczerpnięte z metryk PARSEVAL [18] implementowane w programieevalb dostępnym pod adresem [W9], użyte są między innymi w artykułach [129, 128].
NCBP Non-Crossing Brackets Precision — procent wykrytych związków wyrazowych(ang. constituent), które nie nakładają się (ang. overlap) z jakimkolwiek związkiemwyrazowym z korpusu trenującego.
31

2.4. Kryteria oceny 2. Pojęcia podstawowe
NCBR Non-Crossing Brackets Recall — procent związków wyrazowych w korpusie tre-nującym, które nie nakładają się z jakimkolwiek wykrytym związkiem wyrazowym.
ZCS Zero-Crossing Sentences — procent zdań, które nie mają nakładających się związkówwyrazowych.
BR zupełność (ang. Bracketing Recall) — zdefiniowana wzorem:
BR =liczba prawidłowo wykrytych związków wyrazowych
liczba związków wyrazowych w korpusie
BP precyzja (ang. Bracketing Precision) — zdefiniowana wzorem:
BP =liczba prawidłowo wykrytych związków wyrazowychliczba wszystkich wykrytych związków wyrazowych
CM Complete Match — procent zdań w których BR i BP mają wartość 100%.
CB Average Crossing Brackets — średnia liczba nakładających się związków wyrazowychw zdaniu.
≤ 2CB Two or Less Crossing Brackets — procent zdań z nakładającymi się co najwyżejdwoma związkami wyrazowymi.
Fscore — miara będąca wypadkową BR i BP zdefiniowana wzorem15:
F =2 BR BPBR+ BP
Wartość precyzji BP i zupełności BR dobrze nadaje się do porównania struktur nawiaso-wych z anotowanym strukturalnie korpusem. Jednakże nie można tych miar rozpatrywaćoddzielnie, gdyż np. wysoka wartość precyzji przy niskiej wartości zupełności świadczy otym, że testowany korpus został anotowany zbyt ubogą informacją strukturalną. W szcze-gólnym przypadku, gdy w testowanym korpusie istnieje informacja tylko o jednym związkuwyrazowym i związek ten występuje także w korpusie wzorcowym otrzymujemy znikomomałą wartość BR, natomiast wartość BP wynosi 100%. Przypadek odwrotny, gdy zupeł-ność ma wysoką wartość, a precyzja niską świadczy o tym, że testowany korpus zostałanotowany zbyt bogatą informacją strukturalną — w szczególnym przypadku, gdy bada-ny korpus zawiera informacje o wszystkich możliwych związkach wyrazowych16 wartośćBR wyniesie 100% natomiast wartość BP będzie niska. Należy zatem zdefiniować miaręuwzględniającą jednocześnie wartości BR i BP. W najprostszym przypadku może to byćśrednia arytmetyczna, geometryczna lub miara Fscore. Z uwagi na to, iż miara Fscorenajmniej faworyzuje przypadki skrajne17 (rys. 2.3a) dlatego właśnie ona najlepiej nadajesię do oceny jakości korpusów anotowanych strukturalnie. Charakterystykę miary Fscoreprzedstawia rys. 2.3b.
Pereira i Schabes w artykule [96] pokazali, że ocena zgodności uzyskanej struktury zkorpusem i ocena z użyciem entropii krzyżowej (ang. crossentropy) nie są ze sobą zgodne.Co więcej, model wytrenowany na ustrukturalizowanym korpusie zwykle wykazuje lep-sze wyniki z uwzględnieniem pierwszej miary, gorsze zaś w drugiej. Ponadto algorytmyoptymalizujące jedno kryterium zwykle notują złe wyniki w drugim.
Ponieważ podziały mają charakter hierarchiczny, wprowadźmy następującą definicjęzwiększającą precyzję opisu:15Miara jest przekształconym wskaźnikiem zaproponowanym przez Rijsbergena w pracy [127]:
Eα = 1 −1
α 1
BR+ (1 − α) 1
BP
zatem: Fscore = 1 − E0,5.16Których zbiór jest nadzbiorem związków wyrazowych występujących w korpusie testowym.17Gdy jeden z parametrów ma wartość wysoką a drugi niską.
32
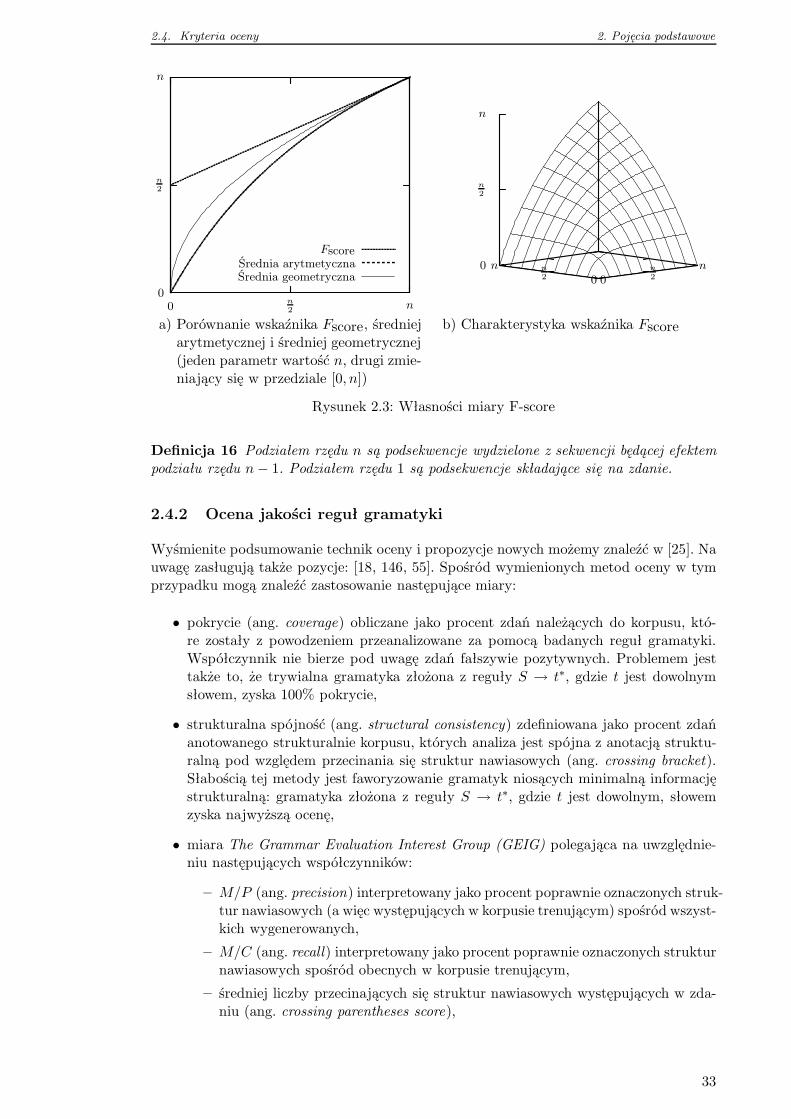
2.4. Kryteria oceny 2. Pojęcia podstawowe
n
n
2
0nn
20
FscoreŚrednia arytmetycznaŚrednia geometryczna
nn
20n n
2 0
n
n
2
0
a) Porównanie wskaźnika Fscore, średniejarytmetycznej i średniej geometrycznej(jeden parametr wartość n, drugi zmie-niający się w przedziale [0, n])
b) Charakterystyka wskaźnika Fscore
Rysunek 2.3: Własności miary F-score
Definicja 16 Podziałem rzędu n są podsekwencje wydzielone z sekwencji będącej efektempodziału rzędu n − 1. Podziałem rzędu 1 są podsekwencje składające się na zdanie.
2.4.2 Ocena jakości reguł gramatyki
Wyśmienite podsumowanie technik oceny i propozycje nowych możemy znaleźć w [25]. Nauwagę zasługują także pozycje: [18, 146, 55]. Spośród wymienionych metod oceny w tymprzypadku mogą znaleźć zastosowanie następujące miary:
• pokrycie (ang. coverage) obliczane jako procent zdań należących do korpusu, któ-re zostały z powodzeniem przeanalizowane za pomocą badanych reguł gramatyki.Współczynnik nie bierze pod uwagę zdań fałszywie pozytywnych. Problemem jesttakże to, że trywialna gramatyka złożona z reguły S → t∗, gdzie t jest dowolnymsłowem, zyska 100% pokrycie,
• strukturalna spójność (ang. structural consistency) zdefiniowana jako procent zdańanotowanego strukturalnie korpusu, których analiza jest spójna z anotacją struktu-ralną pod względem przecinania się struktur nawiasowych (ang. crossing bracket).Słabością tej metody jest faworyzowanie gramatyk niosących minimalną informacjęstrukturalną: gramatyka złożona z reguły S → t∗, gdzie t jest dowolnym, słowemzyska najwyższą ocenę,
• miara The Grammar Evaluation Interest Group (GEIG) polegająca na uwzględnie-niu następujących współczynników:
– M/P (ang. precision) interpretowany jako procent poprawnie oznaczonych struk-tur nawiasowych (a więc występujących w korpusie trenującym) spośród wszyst-kich wygenerowanych,
– M/C (ang. recall) interpretowany jako procent poprawnie oznaczonych strukturnawiasowych spośród obecnych w korpusie trenującym,
– średniej liczby przecinających się struktur nawiasowych występujących w zda-niu (ang. crossing parentheses score),
33

2.4. Kryteria oceny 2. Pojęcia podstawowe
gdzie: M – liczba struktur nawiasowych zgodnych z korpusem, P – liczba strukturnawiasowych zaproponowanych przez parser, C – liczba struktur nawiasowych wkorpusie.
Na potrzeby oceny istotności reguł indukowanych z użyciem korpusów anotowanych struk-turalnie zdefiniujmy pojęcie wsparcia strukturalnego reguły.
Definicja 17 Wsparciem strukturalnym S-sup reguły gramatyki na zadanym korpusie na-zywać będziemy liczbę struktur szkieletowych korpusu mogących zostać przeanalizowanychz jej użyciem.
Nasuwa się także pytanie, w jaki sposób wyznaczyć istotność pojedynczej reguły. Natu-ralne jest, iż reguła często używana przy rozbiorze zdań należących do danego korpusu(mająca większe S-sup) ma większe znaczenie, niż reguła używana rzadko. Z drugiej stro-ny, istotność każdej reguły można zbadać, znajdując odpowiedź na pytanie: „co stanie się,gdy usuniemy daną regułę?” [79]. Im bardziej gramatyka zubożona o daną regułę tracipokrycie korpusu, tym usuwana reguła ma większą wartość.
Ostatnim problemem jest ocena złożoności i jakości gramatyki. W tym przypadkumożna użyć następujących kryteriów:
• rozmiaru słownika kategorii syntaktycznych (symboli nieterminalnych). Zbyt małaliczba symboli nieterminalnych powoduje, że uzyskany rozbiór zdania niesie ze sobąniewystarczającą ilość informacji. Natomiast zbyt duża liczba symboli nieterminal-nych niesie ze sobą potrzebę ich późniejszej kategoryzacji celem ich odpowiedniegoodwzorowania,
• liczby reguł (po sprowadzeniu do jednej z postaci normalnych — por. roz. 2.2.1, wtym odpowiednio traktując proste reguły przepisujące symbol terminalny w nieter-minalny). Gramatyki ze zbyt małą liczbą reguł są ogólne, natomiast, gdy zawierajązbyt wiele reguł są za bardzo dopasowane do zbioru trenującego, a co za tym idzie,mają małą zdolność do generalizacji,
• ilości reguł w funkcji wsparcia S-sup — rozkład ten wskazuje, jak bardzo specjali-zowane reguły występują w wygenerowanej gramatyce,
• pokrycia korpusu przez zbiór reguł o wsparciu S-sup większym od zadanego —wskazuje, jak duży wpływ na pokrycie ma usunięcie reguł o najmniejszym wsparciu.Oczywiste jest, iż im lepszej jakości gramatyka (i zdania występujące w korpusie),tym ten wpływ będzie mniejszy.
2.4.3 Ocena struktury związku wyrazowego
Ponieważ związki wyrazowe mogą posiadać wewnętrzną strukturę, która w szczególnymprzypadku może być bardzo skomplikowana (jeśli związek wyrazowy będzie reprezentowałnp. zdanie podrzędne), autor niniejszej rozprawy proponuje zdefiniować kryterium ocenygłębokości struktury związku wyrazowego jako:
Definicja 18 Głębokość wewnętrznej struktury związku wyrazowego — to monotonicznafunkcja τ(w1, . . . , wn) posiadająca następujące właściwości:
• τ(w1) = τ(w2)
• τ(w1) ≤ τ(w1w2)
34

2.5. Materiał tekstowy 2. Pojęcia podstawowe
• τ(w1w2w3) ≤ τ(w4w5w6), gdy związek wyrazowy w4w5w6 ma bogatszą strukturę we-wnętrzną18, niż związek w1w2w3.
Głębokość wewnętrznej struktury τ możemy zdefiniować w najprostszym przypadku ja-ko: wysokość wewnętrznego drzewa rozbioru, liczbę węzłów drzewa rozbioru, maksymalnądługość sekwencji wyrazów w podziale pierwszego rzędu lub kombinację powyższych.
2.5 Materiał tekstowy
Tekst w języku naturalnym początkowo dla maszyny cyfrowej stanowił jedynie sekwencjekodów mających odpowiednią reprezentację graficzną, czytelną dla człowieka. Były to cza-sy, gdy elementy tekstowe były używane jako etykiety przetwarzanych danych numerycz-nych ułatwiające interpretację wyników. Jednak bardzo szybko okazało się, że komputerywyśmienicie zastępują maszyny do pisania, ułatwiając reedycję przygotowanych wcześniejdokumentów, czy nawet umożliwiając proste przeszukiwanie. Jednak wszystkie te operacjenie brały pod uwagę informacji lingwistycznej. Dopiero pojawienie się pierwszych proceso-rów tekstów spowodowało przełom — wykrywanie błędów ortograficznych czy literówek,a także przenoszenie wyrazów między wierszami wymagało dokonania analizy przetwa-rzanego tekstu. Opracowano odpowiednie algorytmy i sposoby efektywnej reprezentacjiinformacji. Przykładem może być tu program ISPELL czy pakiet LATEX, nie wspominająco popularnych pakietach biurowych. Jednak powyższe techniki są nadal niewystarczają-ce, gdy celem nie jest zwykła prezentacja, a interpretacja tekstu rozumiana jako próbazastąpienia człowieka, począwszy od czynności najprostszych, takich jak klasyfikacja czygrupowanie, na budowie reprezentacji wiedzy skończywszy.
Aby spełnić powyższe wymagania, zdefiniowano proces analizy i rozumienia językanaturalnego, wydzielając następujące etapy:
• analizę wstępną — opisaną szczegółowo w rozdziale 2.5.1,
• analizę syntaktyczną — której dotyczy niniejsza praca,
• analizę semantyczną — polegającą na badaniu znaczenia zdań. Dla tego procesuanaliza syntaktyczna jest co najmniej dużym ułatwieniem,
• analizę pragmatyczną — polegającą na badaniu zależności między wyrazami i zda-niami.
Przy opracowaniu proponowanych w niniejszej pracy metod indukcji reguł korzystanoz efektów pierwszego etapu analizy języka naturalnego. Dlatego poniżej przedstawionyzostanie szczegółowo pierwszy etap analizy języka polskiego, którym jest analiza wstępna.
2.5.1 Analiza wstępna
Analiza wstępna obejmuje wszystkie te czynności, które, dzięki analizie morfologicznejmateriału tekstowego i analizie statystycznej, pozwalają uzyskać zawarte w nim w sposóbniejawny informacje. Słowem, analiza wstępna to substytut szeregu procesów, którychprzeprowadzenie pozwala nam na interpretację analizowanego tekstu języka naturalnego.
Bogata fleksja języka polskiego stanowi olbrzymie wyzwanie dla wszystkich badaczyzajmujących się analizą tego języka. Metody polegające na prostym sprowadzaniu wyrazówdo form podstawowych (ang. stemming), a następnie badaniu tak przygotowanego tekstuokazały się mieć ograniczone zastosowanie.18Z punktu widzenia danego zastosowania.
35
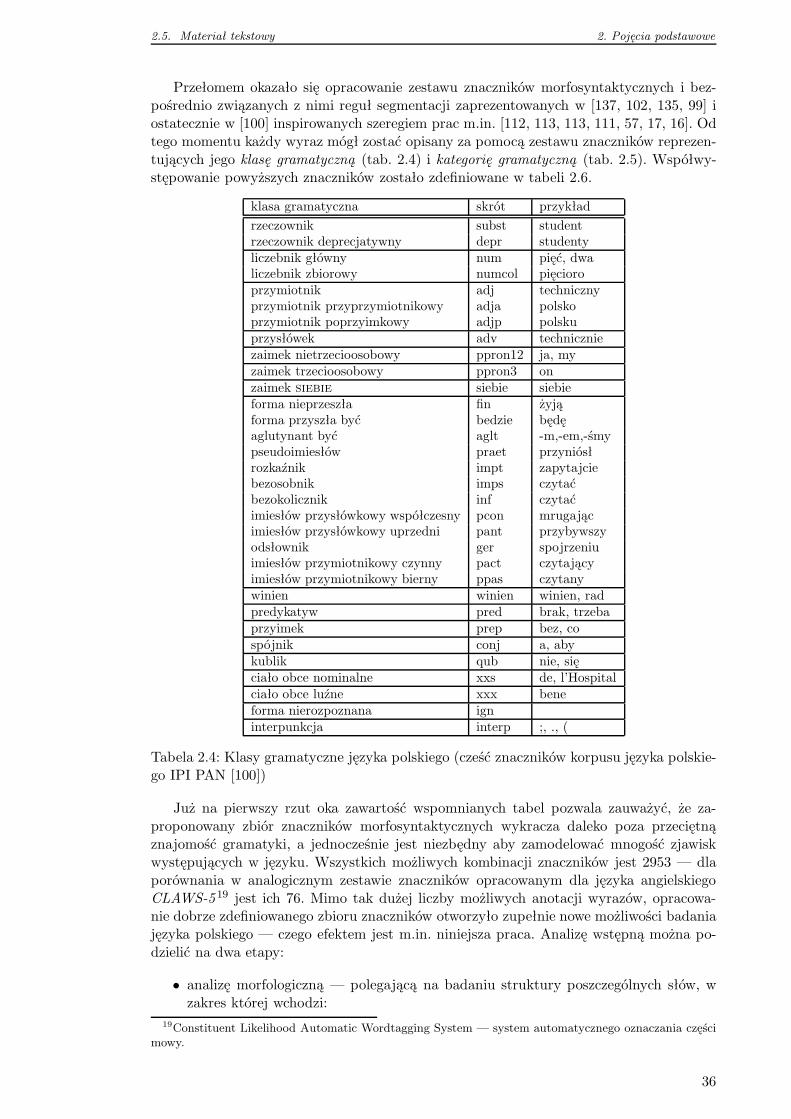
2.5. Materiał tekstowy 2. Pojęcia podstawowe
Przełomem okazało się opracowanie zestawu znaczników morfosyntaktycznych i bez-pośrednio związanych z nimi reguł segmentacji zaprezentowanych w [137, 102, 135, 99] iostatecznie w [100] inspirowanych szeregiem prac m.in. [112, 113, 113, 111, 57, 17, 16]. Odtego momentu każdy wyraz mógł zostać opisany za pomocą zestawu znaczników reprezen-tujących jego klasę gramatyczną (tab. 2.4) i kategorię gramatyczną (tab. 2.5). Współwy-stępowanie powyższych znaczników zostało zdefiniowane w tabeli 2.6.
klasa gramatyczna skrót przykładrzeczownik subst studentrzeczownik deprecjatywny depr studentyliczebnik główny num pięć, dwaliczebnik zbiorowy numcol pięcioroprzymiotnik adj technicznyprzymiotnik przyprzymiotnikowy adja polskoprzymiotnik poprzyimkowy adjp polskuprzysłówek adv techniczniezaimek nietrzecioosobowy ppron12 ja, myzaimek trzecioosobowy ppron3 onzaimek siebie siebie siebieforma nieprzeszła fin żyjąforma przyszła być bedzie będęaglutynant być aglt -m,-em,-śmypseudoimiesłów praet przyniósłrozkaźnik impt zapytajciebezosobnik imps czytaćbezokolicznik inf czytaćimiesłów przysłówkowy współczesny pcon mrugającimiesłów przysłówkowy uprzedni pant przybywszyodsłownik ger spojrzeniuimiesłów przymiotnikowy czynny pact czytającyimiesłów przymiotnikowy bierny ppas czytanywinien winien winien, radpredykatyw pred brak, trzebaprzyimek prep bez, cospójnik conj a, abykublik qub nie, sięciało obce nominalne xxs de, l’Hospitalciało obce luźne xxx beneforma nierozpoznana igninterpunkcja interp ;, ., (
Tabela 2.4: Klasy gramatyczne języka polskiego (cześć znaczników korpusu języka polskie-go IPI PAN [100])
Już na pierwszy rzut oka zawartość wspomnianych tabel pozwala zauważyć, że za-proponowany zbiór znaczników morfosyntaktycznych wykracza daleko poza przeciętnąznajomość gramatyki, a jednocześnie jest niezbędny aby zamodelować mnogość zjawiskwystępujących w języku. Wszystkich możliwych kombinacji znaczników jest 2953 — dlaporównania w analogicznym zestawie znaczników opracowanym dla języka angielskiegoCLAWS-5 19 jest ich 76. Mimo tak dużej liczby możliwych anotacji wyrazów, opracowa-nie dobrze zdefiniowanego zbioru znaczników otworzyło zupełnie nowe możliwości badaniajęzyka polskiego — czego efektem jest m.in. niniejsza praca. Analizę wstępną można po-dzielić na dwa etapy:
• analizę morfologiczną — polegającą na badaniu struktury poszczególnych słów, wzakres której wchodzi:
19Constituent Likelihood Automatic Wordtagging System — system automatycznego oznaczania częścimowy.
36

2.5. Materiał tekstowy 2. Pojęcia podstawowe
kategoria gramatyczna wartość skrót przykładliczba pojedyncza sg oko
mnoga pl oczyprzypadek mianownik nom woda
dopełniacz gen wodycelownik dat wodziebiernik acc wodęnarzędnik inst wodąmiejscownik loc wodziewołacz voc wodo
rodzaj męski osobowy m1 papież, kto, wujostwomęski zwierzęcy m2 baranek, walc, babsztylmęski rzeczowy m3 stółżeński f stułanijaki n dziecko, okno, co, skrzypce
osoba pierwsza pri bredzędruga sec bredzisztrzecia ter bredzi
stopień równy pos cudnywyższy comp cudniejszynajwyższy sup najcudniejszy
aspekt niedokonany inperf iśćdokonany perf zajść
zanegownie niezanegowana aff pisanie, czytanegozanegowana neg niepisanie, nieczytanego
akcentowość akcentowana ack jego, niego, tobienieakcentowana nack go, -ń, ci
poprzyimkowość poprzyimkowa preap niego, -ńnieporzyimkowa npraep jego, go
akomodacyjność uzgadniająca congr dwaj, pięciomarządząca rec dwóch, dwu, pięciorgiem
aglutynacyjność nieaglutynacyjna nagl nióśłaglutynacyjna agl niósł-
wokaliczność wokaliczna wok -emniewokaliczna nwok -m
Tabela 2.5: Kategorie gramatyczne języka polskiego (cześć znaczników korpusu językapolskiego IPI PAN [100])
– wydzielenie tokenów,
– sprowadzenie wyrazu do formy podstawowej dla danego fleksemu, znakowaniemorfosyntaktyczne. Ten proces może dać w efekcie więcej niż jedno możliweznakowanie, dlatego niezbędne jest ujednoznacznianie;
• ujednoznacznianie (dezambiguacja) — wybór jednego spośród możliwych znakowańmorfosyntaktycznych, właściwego w danym kontekście.
Automatyzacja procesu analizy wstępnej w przypadku języka polskiego jest możliwa dziękiistnieniu następującego oprogramowania20:
• analizator morfologiczny Morfeusz autorstwa Marcina Wolińskiego [136][W12],
• program ujednoznaczniający (ang. dezambiguator) autorstwa Łukasza Dębowskiego[48].
20Przygotowanego na potrzeby projektu budowy Anotowanego Korpusu Języka Polskiego w InstytuciePodstaw Informatyki Polskiej Akademii Nauk.
37

2.5. Materiał tekstowy 2. Pojęcia podstawowe
liczba
przypadek
rodzaj
osoba
stopień
aspekt
zanegowanie
akcentowość
poprzyimkowość
akomodatywność
aglutynacyjność
wokaliczność
rzeczownik + + orzeczownik deprecjatywny o + oliczebnik główny o + + +liczebnik zbiorowy o + o +przymiotnik + + + +przymiotnik przyprzym.przymiotnik poprzymim.przysłówek +zaimek nietrzecioosobowy o + + o +zaimek trzecioosobowy + + + o + +zaimiek siebie +forma nieprzeszła + + oforma przyszła być + + oaglutynant być + + o +przeudoimiesłów + + o +rozkaźnik + + obesosobnik obezokolicznik oim. przys. współczesny oim. przys. uprzedni oodsłownik + + o o +im. przym. czynny + + + o +in. przym. bierny + + + o +winien + + opredykatywprzyimek ospójnikkublikciało obce nominalne + + ociało obce luźneforma nierozpoznanainterpunkcja
Tabela 2.6: Charakterystyka morfosyntaktyczna klas gramatycznych języka polskiego[100]. Symbol „+” oznacza, że dla danej klasy fleksyjnej dana kategoria gramatycznajest morfologiczna — fleksemy należące do tej klasy zwykle „odmieniają się” przez tękategorię, symbol „o” oznacza, że dana kategoria jest słownikowa (dla każdego fleksemudanej klasy wszystkie formy tego fleksemu mają tę samą wartość tej kategorii, choć byćmoże są to potencjalnie różne wartości dla różnych fleksemów, jak w przypadku rodzajurzeczowników).
38

2.5. Materiał tekstowy 2. Pojęcia podstawowe
2.5.2 Pojęcie tokenu
Każde zdanie języka naturalnego składa się z wyrazów — i właśnie wyrazy uważane sąza najmniejszy niepodzielny element języka. Jednak bliższa analiza zjawisk występują-cych w językach fleksyjnych (przedstawiona np. w [100]) prowadzi do powstania bardziejprecyzyjnego pojęcia tokenu21, które możemy zdefiniowanego jako:
Definicja 19 Token — to sekwencja bezpośrednio następujących po sobie znaków, nale-żąca jednocześnie tylko do jednego wyrazu.
2.5.3 Użyte dane
Wniniejszej pracy wykorzystano postać źródłową fragmentu Anotowanego Korpusu JęzykaPolskiego IPI PAN 22 [100][W3] którą stanowi zestaw plików XML — oddzielnych dlakażdego utworu. Zdanie z rys. 2.2, gdyby znajdowało się w udostępnionej próbce, mogłobybyć przedstawione jak na rys. 2.5.
Na uwagę zasługuje fakt, że korpus podzielony jest na zdania (tagi <chunk>), co za-sadniczo ułatwia wykrywanie reguł gramatycznych, które przecież dotyczą budowy zdania.Zdania składają się z tokenów (tagi <tok>). Każdy token poddany jest szczegółowej anali-zie morfologicznej — zwykle niejednoznacznej — a jej efekty przedstawione są w sekwencjitagów <lex>. Parametr disamb="1" tagu <lex> oznacza, że dana analiza morfologicznaaktualnie przetwarzanego tokenu została uznana w toku procesu ujednoznaczniania zarelewantną w aktualnym kontekście. Reasumując, możemy stwierdzić, że każdy token cha-rakteryzowany jest przez następujące parametry:
orth — postać, pod jaką token występuje w tekście źródłowym,
base — forma podstawowa, do której token został sprowadzony podczas analizy morfolo-gicznej i ujednoznaczniania,
ctag — sekwencja etykiet odpowiadających formie gramatycznej tokenu. Interpretacja wtabelach: 2.4, 2.5 i 2.6.
Charakterystyka badanego tekstu
Badany fragment składa się z 4 784 484 tokenów podzielonych na 245 598 zdań.
Materiał tekstowy stosuje się do prawa Zipfa [147], które mówi, że częstość występowa-nia danego zjawiska23 jest odwrotnie proporcjonalna do jego pozycji w rankingu częstości.Formalnie dystrybucja Zipfa przybiera postać:
f =k
r
gdzie f – częstość występowania, r – numer kolejny na liście rankingowej uporządkowanejwedług wzrastającej częstości, k – parametr wyznaczony eksperymentalnie. W materialetekstowym możemy znaleźć szereg tego typu zależności:
• liczba sekwencji w funkcji długości sekwencji (rys. 2.6),
• wśród sekwencji o danych długościach, sekwencje uszeregowane według liczby wy-stąpień (rys. 2.4).
21Token zwany jest także w literaturze segmentem.22Anotowany Korpus Języka Polskiego (IPI PAN) jest pierwszym publicznie dostępnym korpusem (liczą-cym ponad 100mln pozycji) zbiorem tekstów literackich anotowanych lingwistycznie (morfosyntaktycznie)stworzony zgodnie ze współczesnymi standardami i praktykami tworzenia dużych korpusów.23tu: sekwencji odwzorowań
39
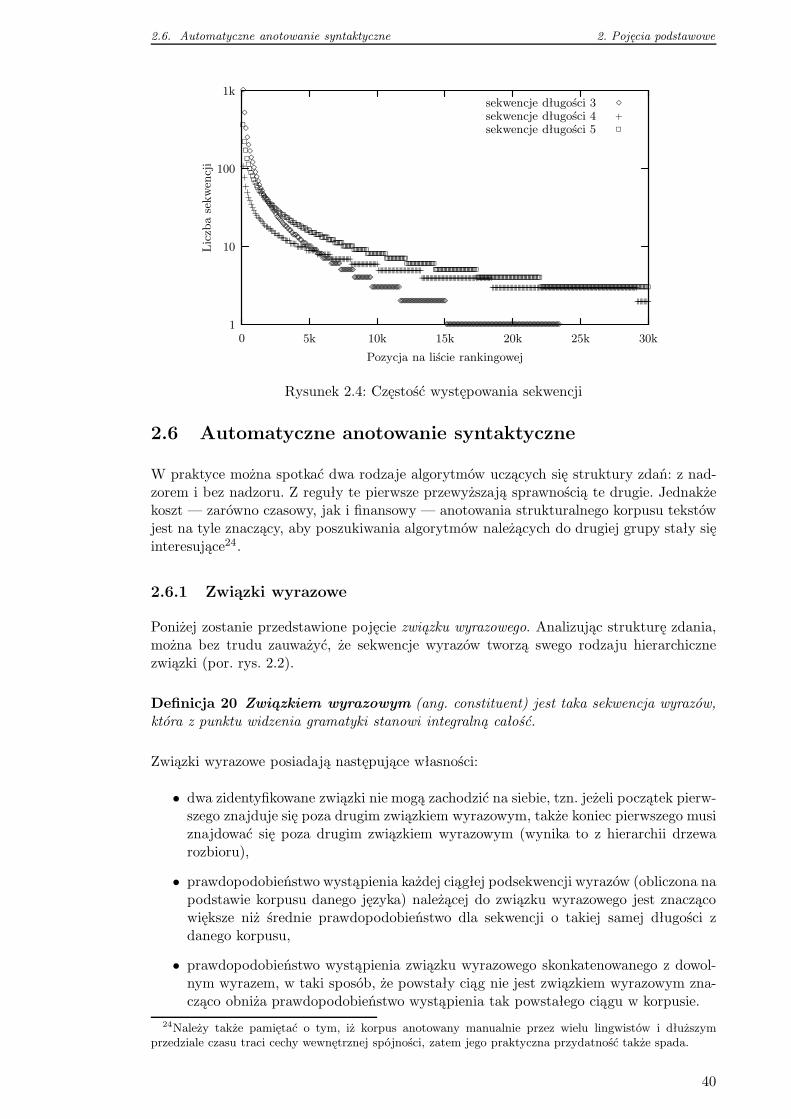
2.6. Automatyczne anotowanie syntaktyczne 2. Pojęcia podstawowe
1k
100
10
130k25k20k15k10k5k0
Liczbasekwencji
Pozycja na liście rankingowej
sekwencje długości 33
3
3
3
333333333333333333333
33333333333333333333333333
33333333
3333333333333
3333333333
3333333333333
333333333333333333333
3333333333333333333333333333333333
333333333333333333333333333333333333333333333333333333333333333333333333333333333333
3
sekwencje długości 4
+
+
+++++++++++++++++++++++++++++++++++++++++++++
++++++++++++++++++
+++++++++++++++++++++++++++++++++++
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
+++++++++
+
sekwencje długości 52
2
2
222222222222222222222222222222222222222222222222222222222222
22222222222
222222222222222222
22222222222222222222222222222
2222222222222222222222222222222222222222222222222222
22222222222222222222222222222222222222222222222
22222222222222222222222222222222222222222222222222222222222222222222222222222222
2
Rysunek 2.4: Częstość występowania sekwencji
2.6 Automatyczne anotowanie syntaktyczne
W praktyce można spotkać dwa rodzaje algorytmów uczących się struktury zdań: z nad-zorem i bez nadzoru. Z reguły te pierwsze przewyższają sprawnością te drugie. Jednakżekoszt — zarówno czasowy, jak i finansowy — anotowania strukturalnego korpusu tekstówjest na tyle znaczący, aby poszukiwania algorytmów należących do drugiej grupy stały sięinteresujące24.
2.6.1 Związki wyrazowe
Poniżej zostanie przedstawione pojęcie związku wyrazowego. Analizując strukturę zdania,można bez trudu zauważyć, że sekwencje wyrazów tworzą swego rodzaju hierarchicznezwiązki (por. rys. 2.2).
Definicja 20 Związkiem wyrazowym (ang. constituent) jest taka sekwencja wyrazów,która z punktu widzenia gramatyki stanowi integralną całość.
Związki wyrazowe posiadają następujące własności:
• dwa zidentyfikowane związki nie mogą zachodzić na siebie, tzn. jeżeli początek pierw-szego znajduje się poza drugim związkiem wyrazowym, także koniec pierwszego musiznajdować się poza drugim związkiem wyrazowym (wynika to z hierarchii drzewarozbioru),
• prawdopodobieństwo wystąpienia każdej ciągłej podsekwencji wyrazów (obliczona napodstawie korpusu danego języka) należącej do związku wyrazowego jest znaczącowiększe niż średnie prawdopodobieństwo dla sekwencji o takiej samej długości zdanego korpusu,
• prawdopodobieństwo wystąpienia związku wyrazowego skonkatenowanego z dowol-nym wyrazem, w taki sposób, że powstały ciąg nie jest związkiem wyrazowym zna-cząco obniża prawdopodobieństwo wystąpienia tak powstałego ciągu w korpusie.
24Należy także pamiętać o tym, iż korpus anotowany manualnie przez wielu lingwistów i dłuższymprzedziale czasu traci cechy wewnętrznej spójności, zatem jego praktyczna przydatność także spada.
40

2.6. Automatyczne anotowanie syntaktyczne 2. Pojęcia podstawowe
<chunk type="s">
<tok>
<orth>Duży</orth>
<lex>
<base>duży</base>
<ctag>adj:sg:nom:m1:pos</ctag>
</lex>
<lex>
<base>duży</base>
<ctag>adj:sg:nom:m2:pos</ctag>
</lex>
<lex>
<base>duży</base>
<ctag>adj:sg:nom:m3:pos</ctag>
</lex>
<lex disamb="1">
<base>duży</base>
<ctag>adj:sg:acc:m3:pos</ctag>
</lex>
<lex>
<base>duży</base>
<ctag>adj:pl:nom:m1:pos</ctag>
</lex>
</tok>
<tok>
<orth>pies</orth>
<lex disamb="1">
<base>pies</base>
<ctag>subst:sg:nom:m2</ctag>
</lex>
</tok>
<tok>
<orth>goni</orth>
<lex disamb="1">
<base>gonić</base>
<ctag>fin:sg:ter:imperf</ctag>
</lex>
</tok>
<tok>
<orth>małą</orth>
<lex>
<base>mały</base>
<ctag>adj:sg:inst:f:pos</ctag>
</lex>
<lex disamb="1">
<base>mały</base>
<ctag>adj:sg:acc:f:pos</ctag>
</lex>
</tok>
<tok>
<orth>dziewczynkę</orth>
<lex disamb="1">
<base>dziewczynka</base>
<ctag>subst:sg:acc:f</ctag>
</lex>
</tok>
</chunk>
Rysunek 2.5: Przykładowe zdanie anotowane zgodnie ze strukturą korpusu IPI PAN
41
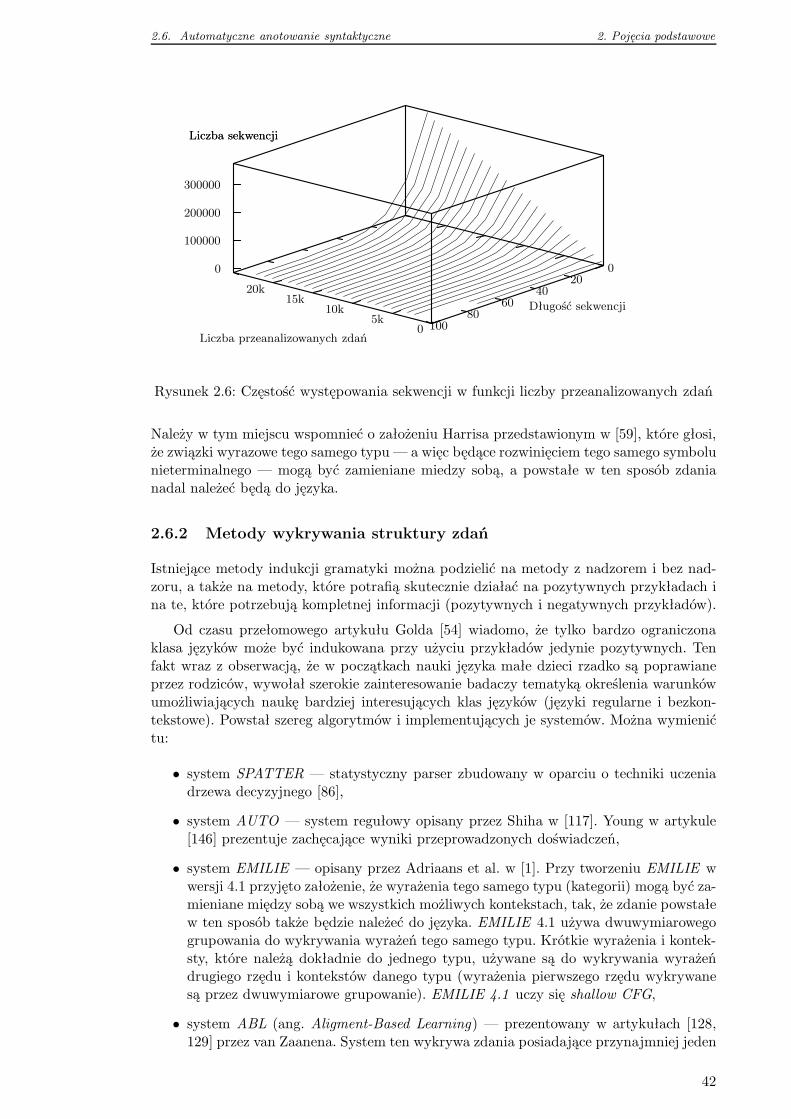
2.6. Automatyczne anotowanie syntaktyczne 2. Pojęcia podstawowe
20k15k
10k5k
0
020
4060
80100
0
100000
200000
300000
Liczba sekwencji
Liczba przeanalizowanych zdań
Długość sekwencji
Liczba sekwencji
Rysunek 2.6: Częstość występowania sekwencji w funkcji liczby przeanalizowanych zdań
Należy w tym miejscu wspomnieć o założeniu Harrisa przedstawionym w [59], które głosi,że związki wyrazowe tego samego typu — a więc będące rozwinięciem tego samego symbolunieterminalnego — mogą być zamieniane miedzy sobą, a powstałe w ten sposób zdanianadal należeć będą do języka.
2.6.2 Metody wykrywania struktury zdań
Istniejące metody indukcji gramatyki można podzielić na metody z nadzorem i bez nad-zoru, a także na metody, które potrafią skutecznie działać na pozytywnych przykładach ina te, które potrzebują kompletnej informacji (pozytywnych i negatywnych przykładów).
Od czasu przełomowego artykułu Golda [54] wiadomo, że tylko bardzo ograniczonaklasa języków może być indukowana przy użyciu przykładów jedynie pozytywnych. Tenfakt wraz z obserwacją, że w początkach nauki języka małe dzieci rzadko są poprawianeprzez rodziców, wywołał szerokie zainteresowanie badaczy tematyką określenia warunkówumożliwiających naukę bardziej interesujących klas języków (języki regularne i bezkon-tekstowe). Powstał szereg algorytmów i implementujących je systemów. Można wymienićtu:
• system SPATTER — statystyczny parser zbudowany w oparciu o techniki uczeniadrzewa decyzyjnego [86],
• system AUTO — system regułowy opisany przez Shiha w [117]. Young w artykule[146] prezentuje zachęcające wyniki przeprowadzonych doświadczeń,
• system EMILIE — opisany przez Adriaans et al. w [1]. Przy tworzeniu EMILIE wwersji 4.1 przyjęto założenie, że wyrażenia tego samego typu (kategorii) mogą być za-mieniane między sobą we wszystkich możliwych kontekstach, tak, że zdanie powstałew ten sposób także będzie należeć do języka. EMILIE 4.1 używa dwuwymiarowegogrupowania do wykrywania wyrażeń tego samego typu. Krótkie wyrażenia i kontek-sty, które należą dokładnie do jednego typu, używane są do wykrywania wyrażeńdrugiego rzędu i kontekstów danego typu (wyrażenia pierwszego rzędu wykrywanesą przez dwuwymiarowe grupowanie). EMILIE 4.1 uczy się shallow CFG,
• system ABL (ang. Aligment-Based Learning) — prezentowany w artykułach [128,129] przez van Zaanena. System ten wykrywa zdania posiadające przynajmniej jeden
42

2.6. Automatyczne anotowanie syntaktyczne 2. Pojęcia podstawowe
wyraz wspólny, a następnie tak dzieli zdania, aby części wspólne wyodrębniały gru-py wyrazowe, które razem tworzą wspólny typ (ponieważ występują w takim samymotoczeniu — wprost z założenia Harrisa — por. roz. 2.6.1). Autor nie wspomina oproblemach z regułami nieuzasadnionymi lingwistycznie, ani o skalowalności algo-rytmu — ale można wnioskować, że jest to co najmniej n2. Metoda należy do grupyoperującej na zwykłym tekście.
Inne interesujące algorytmy, które są dostępne jedynie w postaci opisujących je artykułówto:
• algorytm zaproponowany przez Pereire i Schabesa w [96] będący rozszerzeniem al-gorytmu inside-outisde; wykorzystuje on częściowo ustrukturalizowany korpus jakoźródło dodatkowych informacji,
• algorytm hybrydowy zaproponowany przez Brilla w [20, 21, 22] będący połącze-niem naiwnego parsera CFG z uczącym się systemem umożliwiającym transformacjeotrzymanej w kroku pierwszym struktury zdania za pomocą prostych reguł tak, abyzminimalizować błędy parsowania. Algorytm wymaga dostępności korpusu anotowa-nego strukturalnie,
• kolejnym podejściem zaproponowanym w [24] jest użycie miary nazwanej divergen-ce25 do identyfikacji reguł postaci A → CD (przez identyfikowanie par A,CD, dlaktórych funkcja gęstości prawdopodobieństwa w sąsiedztwie ma odpowiednio po-dobny przebieg, zaś przydatność każdej reguły opisana jest parametrem liczbowymjako funkcja miary podobieństw). Autorzy przedstawiają tylko metodę generowaniabinarnych drzew rozkładu. Wskazują na pewne wady metody i na pewne technikiredukcji ich wpływu (poprzez porównanie entropii bigramów i trigramów),
• algorytm używający korpusów równoległych26 do wykrywania struktury zdań zapro-ponowany przez Wu w [138],
• podejście zaproponowane przez Boda w pozycji [19], zwane metodą DOP (ang. DataOriented Parsing), polegające na użyciu anotowanego korpusu jako swoistego odpo-wiednika doświadczenia jednostki w używaniu języka. Autor przedstawia hipotezędotyczącą wpływu tychże doświadczeń na prawdopodobieństwo użycia danej frazyw przyszłości,
• algorytm bazujący na ograniczeniu zbioru symboli nieterminalnych, które mogą wy-stępować po prawej stronie reguł produkcji przy zadanej lewej stronie, zapropono-wany przez Carrolla i Charniaka w [31],
• algorytmy wykorzystujące kryterium minimum description length (MDL) do uzy-skania odpowiedniej postaci indukowanej gramatyki — użyte np. w [56, 39].
2.6.3 Informacja wzajemna (MI)
Pojęcie informacji wzajemnej (ang. mutual information) zostało użyte przez m.in. DavidaMagermana w artykule [87] i w dysertacji [85] oraz w pracy Brilla et al. [23] jako parametrumożliwiający wykrycie związków wyrazowych. Według hipotez stawianych przez autorówinformacja wzajemna jest pomocnym narzędziem przy odkrywaniu struktury badanychzdań.25Definicja sumy entropii względnej obu rozkładów znajduje się w artykule [24].26Rozumianych jako zbiór odpowiadających sobie tekstów w dwóch różnych językach.
43

2.6. Automatyczne anotowanie syntaktyczne 2. Pojęcia podstawowe
Informację wzajemną definiuje wzór 2.1. Jest to miara niezależności dwóch zmiennychlosowych. Innymi słowy, określa jak dobrze wartość zmiennej X pozwala przewidzieć war-tość zmiennej Y .
MI(x, y) = logPX,Y (x, y)
PX(x)PY (y)(2.1)
W przypadku, gdy zdarzeniami losowymi są sekwencje wyrazów (lub ich odpowiednioprzygotowanych odwzorowań), Magerman [87] proponuje użyć następującego wzoru:
MI(x, y) ≈ log
|xy||C2|
|x||C1|
|y||C1|
(2.2)
gdzie, |xy| – liczba wystąpień bigramów „xy” w korpusie, |x| – liczba wystąpień symbolu„x” w korpusie, |y| – liczba wystąpień symbolu „y” w korpusie, |C2| – całkowita liczbabigramów w korpusie, |C1| – całkowita liczba unigramów w korpusie.
Magerman nie wspomina jednakże, że wzór 2.2 stanowi dobre przybliżenie wartościMI jedynie w przypadku, gdy prawdopodobieństwo sekwencji odwrotnej — „yx” — bę-dzie znikomo małe — co nie zawsze jest prawdą. Dlatego wzór ten powinien przybraćnastępującą postać:
MI(x, y) ≈ log
|xy|+|yx||C2|
|x||C1|
|y||C1|
(2.3)
Jednak w tym przypadku tracimy właściwość asymetrii, a przecież dla sekwencji wyrazówkolejność ma kluczowe znaczenie. Zatem wprowadzenie do licznika drugiego składnika niejest korzystne. Także mianownik, będący iloczynem estymat dwóch prawdopodobieństwstwarza problemy, ponieważ jako iloczyn jest z definicji symetryczny. Zatem używającwzoru 2.2 musimy pamiętać o ograniczeniach w jego stosowalności.
Interpretacja MI w przypadku sekwencji wyrazów
Definicję miary wzajemnej zależności dwóch zmiennych losowych można wykorzystać dowyznaczenia miejsca podziału n-wyrazowej sekwencji stanowiącej zdanie. Poniższe rozu-mowanie zostało przytoczone za Davidem Magermanem [87]. Załóżmy, że zdanie składasię z sekwencji n wyrazów:
S = x1, x2, . . . , xm−1, xm, . . . , xn
które potraktujemy jak bigram dwóch ciągów S1 i S2 takich, że:
S = S1||S2
S1 = x1, . . . , xm−1
S2 = xm, . . . , xn
gdzie, || oznacza operację konkatenacji. Zatem informację wzajemną możemy obliczyćkorzystając ze wzoru:
MI(S1, S2) = logP(S)
P(S1)P(S2)(2.4)
Uwzględniając rozważania zawarte w rozdziale 2.6.1 możemy powiedzieć, że prawdopo-dobieństwo wystąpienia podsekwencji wyrazów należących do związku wyrazowego jeststosunkowo wysokie. Ten wysoki poziom powinien być utrzymany, gdy rozpatrujemy co-raz większe podsekwencje. Jednakże, gdy do maksymalnej podsekwencji dołączymy wyraz
44

2.6. Automatyczne anotowanie syntaktyczne 2. Pojęcia podstawowe
−3,2−3
−2,8−2,6−2,4−2,2−2
−1,8−1,6−1,4−1,2
654321
MI
Punkt podziału
−20
2
4
6
8
10
10987654321
MI
Punkt podziału
Dwa dni temu był tu Zbyszko . - To mistrz ujmie się za nami i będzie wojna .
−20
2
4
6
8
10
121110987654321
MI
Punkt podziału
−202468
101214
1413121110987654321
MI
Punkt podziałuTak też uczynię , jak radzisz , żeby m tak zdrów
był !
Cała jego postawa zdradzała człowieka dumnego ,
przywykłego do rozkazywania i ufnego w siebie .
Rysunek 2.7: WartościMI dla wybranych zdań
spoza danego związku wyrazowego, spowoduje to znaczące obniżenie prawdopodobień-stwa wystąpienia takiej sekwencji wyrazów. Zakładając, że S1 stanowi związek wyrazowy,formalnie można to zapisać następująco:
P(S1) = P(x1, xm−1) ≈ P(x1, xm−2)
P(S1) = P(x1, xm−1) ≫ P(x1, xm)
Ponieważ we wzorze 2.4 licznik jest stały dla danego zdania, natomiast zmienia się tylkomianownik, zatem na wartość informacji wzajemnej podziału na dwie podsekwencje S1
i S2 ma wpływ jedynie prawdopodobieństwo wystąpienia w korpusie tychże sekwencji.Zatem w miejscu podziału dwóch związków wyrazowych stanowiących zdanie (wartościP(S1) i P(S2) przyjmą wartości maksymalne) informacja wzajemna będzie przyjmowaławartość minimalną.
W praktyce wartości informacji wzajemnej nawet dla krótkich zdań nie umożliwia-ją wyznaczenia punktu podziału. Przykładowe wartości MI przedstawione na rys. 2.7wskazują, że minimalne wartości parametruMI najczęściej wskazują skrajne punkty po-działów.
Ciekawe zastosowanie dla MI do indukcji SCFG zaproponował Clark w [38, 39]. Wtej metodzie MI stanowi kryterium odrzucenia związków wyrazowych wygenerowanychz użyciem context distribution clustering (CDC)27. Metoda ta polega na obliczeniu MIdla symboli bezpośrednio sąsiadujących z lewej i prawej strony proponowanego związkuwyrazowego28. Jeśli tak obliczony wskaźnik jest poniżej progu29, proponowany związekwyrazowy jest eliminowany jako nieuzasadniony lingwistycznie. Oznacza to, że nie stano-wi rozwinięcia żadnego symbolu nieterminalnego. Metoda zasadza się na spostrzeżeniu, żezwiązki wyrazowe z reguły pojawiają się w specyficznym kontekście. Dzięki temu metodama charakter czysto statystyczny — nie wymaga żadnej dodatkowej informacji lingwistycz-nej. Warto zauważyć, że autor zaproponował także interesującą metodę przezwyciężenia
27Metoda polegająca na grupowaniu najczęściej występujących w korpusie sekwencji z użyciem informacjio rozkładzie prawdopodobieństwa symboli otaczających badane sekwencje.28Który będzie później zamieniony na symbol nieterminalny.29Wartość progu jest zależna od długości badanego związku wyrazowego.
45
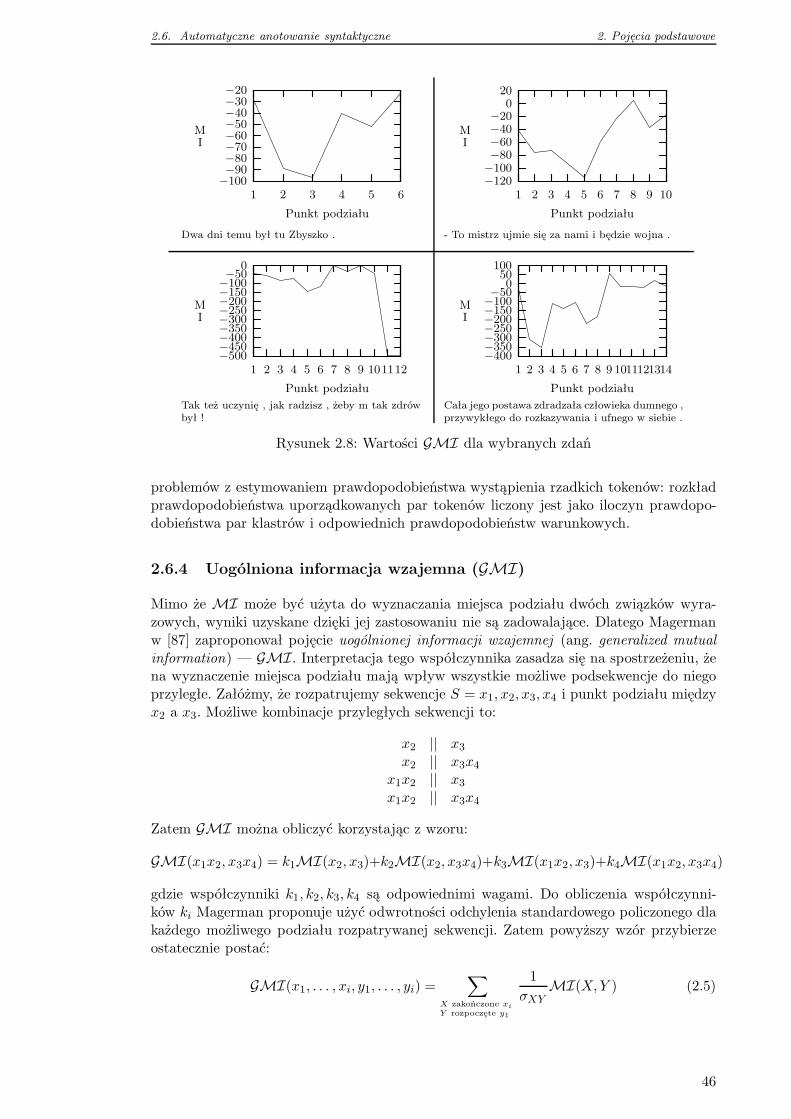
2.6. Automatyczne anotowanie syntaktyczne 2. Pojęcia podstawowe
−100−90−80−70−60−50−40−30−20
654321
MI
Punkt podziału
−120−100−80−60−40−20
020
10987654321
MI
Punkt podziału
Dwa dni temu był tu Zbyszko . - To mistrz ujmie się za nami i będzie wojna .
−500−450−400−350−300−250−200−150−100−50
0
121110987654321
MI
Punkt podziału
−400−350−300−250−200−150−100−50
050
100
1413121110987654321
MI
Punkt podziałuTak też uczynię , jak radzisz , żeby m tak zdrów
był !
Cała jego postawa zdradzała człowieka dumnego ,
przywykłego do rozkazywania i ufnego w siebie .
Rysunek 2.8: Wartości GMI dla wybranych zdań
problemów z estymowaniem prawdopodobieństwa wystąpienia rzadkich tokenów: rozkładprawdopodobieństwa uporządkowanych par tokenów liczony jest jako iloczyn prawdopo-dobieństwa par klastrów i odpowiednich prawdopodobieństw warunkowych.
2.6.4 Uogólniona informacja wzajemna (GMI)
Mimo że MI może być użyta do wyznaczania miejsca podziału dwóch związków wyra-zowych, wyniki uzyskane dzięki jej zastosowaniu nie są zadowalające. Dlatego Magermanw [87] zaproponował pojęcie uogólnionej informacji wzajemnej (ang. generalized mutualinformation) — GMI. Interpretacja tego współczynnika zasadza się na spostrzeżeniu, żena wyznaczenie miejsca podziału mają wpływ wszystkie możliwe podsekwencje do niegoprzyległe. Załóżmy, że rozpatrujemy sekwencje S = x1, x2, x3, x4 i punkt podziału międzyx2 a x3. Możliwe kombinacje przyległych sekwencji to:
x2 || x3
x2 || x3x4
x1x2 || x3
x1x2 || x3x4
Zatem GMI można obliczyć korzystając z wzoru:
GMI(x1x2, x3x4) = k1MI(x2, x3)+k2MI(x2, x3x4)+k3MI(x1x2, x3)+k4MI(x1x2, x3x4)
gdzie współczynniki k1, k2, k3, k4 są odpowiednimi wagami. Do obliczenia współczynni-ków ki Magerman proponuje użyć odwrotności odchylenia standardowego policzonego dlakażdego możliwego podziału rozpatrywanej sekwencji. Zatem powyższy wzór przybierzeostatecznie postać:
GMI(x1, . . . , xi, y1, . . . , yi) =∑
X zakończone xi
Y rozpoczęte y1
1
σXY
MI(X,Y ) (2.5)
46

2.6. Automatyczne anotowanie syntaktyczne 2. Pojęcia podstawowe
2.6.5 Zastosowanie GMI
Jak pokazano w artykule [87] zastosowanie GMI do wyznaczania krańców związków wyra-zowych daje obiecujące rezultaty. Na wykresach przedstawionych na rysunku 2.8 znajdująsię wartości GMI dla wybranych zdań — tych samych zdań, dla których na rysunku 2.7przedstawiono wykresy MI. Porównanie odpowiednich części powyższych wykresów po-zwala stwierdzić, że parametr GMI charakteryzuje się większym zróżnicowaniem wartości,a co za tym idzie, wzrasta szansa wykrycia za jego pomocą związków wyrazowych.
Algorytm zaproponowany przez Magermana rozpoczyna od pojedynczych wyrazów,wykrywając związki najniżej w hierarchii. Następnie próbuje łączyć związki wyrazoweniższego rzędu, tworząc drzewo rozbioru (szczegóły w [87]).
Na uwagę zasługują pewne niepożądane cechy algorytmu:
• aby wyeliminować błędne konstrukcje gramatyczne zastosowano antygramatykę (ang.distituent grammar) — algorytm ignorował propozycje związków wyrazowych, któreodnalazł w tej przedefiniowanej gramatyce,
• zaprezentowana interpretacja minimów GMI wskazujących krańce związków wyra-zowych nie została jasno sprecyzowana i ma charakter uznaniowy.
Zatem, mimo dużego skoku jakościowego uzyskanego dzięki zaprezentowanej metodzie, nienadaje się ona do bezpośredniego zastosowania dla języka polskiego.
47

Indukcja reguł gramatyki języka polskiego
Rozdział 3
Propozycje nowych metodindukcji gramatyk
Keep it simple:as simple as possible,but no simpler.A. Einstein
3.1 Właściwości materiału tekstowego
W lingwistyce, techniki zwane immediate constituent analysis, IC — opisane późnej przezChomskiego w formalizmie gramatyk struktur frazowych (ang. phrase structure grammars,PSG) — powstały pierwotnie do rekursywnego łączenia wyrazów stanowiących zdanie wzwiązki wyrazowe, nie kładąc nacisku na nazywanie kategorii syntaktycznych [132, 59, 98].Stąd też tradycyjne metody przedstawiania zdań za pomocą diagramów polegają główniena reprezentowaniu segmentacji zdania.
3.1.1 Dodatkowa informacja morfologiczna
Anotacja morfologiczna występująca w Korpusie IPI (tabele 2.5, 2.6) dla pewnych klasgramatycznych nie niesie dostatecznie dużo informacji użytecznej w procesie indukcji gra-matyki. Świadczą o tym liczne błędy w anotacji fleksemów: interpunkcja (etykieta interp)i kublik (etykieta qub) jakie zaobserwowano w toku eksperymentów.
Wszystkie nieodmienne formy niemieszczące się w innych kategoriach zostały oznaczo-ne w Korpusie etykietą qub. Znajdują się tu m.in. fleksemy „nie” i „się”. Tak samo jedna-kowe traktowanie wszystkich znaków przestankowych nie jest z punktu widzenia indukcjigramatyki odpowiednie. Dlatego też sposób znakowania morfologicznego w zbudowanymsystemie został wzbogacony przez autora niniejszej rozprawy o etykiety przedstawione wtabeli 3.1.
3.1.2 Metoda odwzorowania informacji morfologicznej
Jak pokazano na rys. 2.5 każdy leksem anotowany jest informacją morfologiczną składającąsię z etykiet wymienionych w tabelach: 2.5, 2.6.
W literaturze dotyczącej tematyki GI pojawiają się wzmianki, że statystyczne podejściedo przetwarzania języka naturalnego jest narażone na problem niedostatecznej ilości da-nych trenujących (ang. sparse data) potrzebnych do wyestymowania odpowiednich praw-dopodobieństw. Zgodnie z tabelą 2.6 nie wszystkie tokeny charakteryzowane są przez ten
48
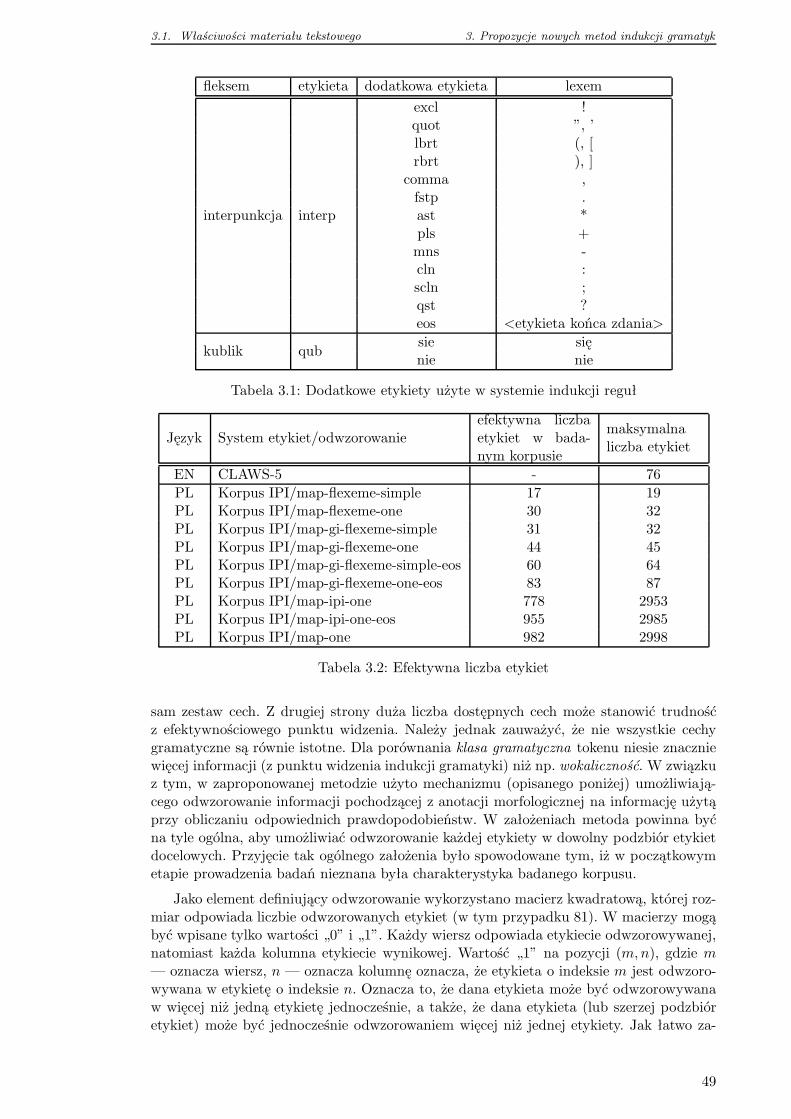
3.1. Właściwości materiału tekstowego 3. Propozycje nowych metod indukcji gramatyk
fleksem etykieta dodatkowa etykieta lexem
interpunkcja interp
excl !quot ”, ’lbrt (, [rbrt ), ]comma ,fstp .ast *pls +mns -cln :scln ;qst ?eos <etykieta końca zdania>
kublik qubsie sięnie nie
Tabela 3.1: Dodatkowe etykiety użyte w systemie indukcji reguł
Język System etykiet/odwzorowanieefektywna liczbaetykiet w bada-nym korpusie
maksymalnaliczba etykiet
EN CLAWS-5 - 76PL Korpus IPI/map-flexeme-simple 17 19PL Korpus IPI/map-flexeme-one 30 32PL Korpus IPI/map-gi-flexeme-simple 31 32PL Korpus IPI/map-gi-flexeme-one 44 45PL Korpus IPI/map-gi-flexeme-simple-eos 60 64PL Korpus IPI/map-gi-flexeme-one-eos 83 87PL Korpus IPI/map-ipi-one 778 2953PL Korpus IPI/map-ipi-one-eos 955 2985PL Korpus IPI/map-one 982 2998
Tabela 3.2: Efektywna liczba etykiet
sam zestaw cech. Z drugiej strony duża liczba dostępnych cech może stanowić trudnośćz efektywnościowego punktu widzenia. Należy jednak zauważyć, że nie wszystkie cechygramatyczne są równie istotne. Dla porównania klasa gramatyczna tokenu niesie znaczniewięcej informacji (z punktu widzenia indukcji gramatyki) niż np. wokaliczność. W związkuz tym, w zaproponowanej metodzie użyto mechanizmu (opisanego poniżej) umożliwiają-cego odwzorowanie informacji pochodzącej z anotacji morfologicznej na informację użytąprzy obliczaniu odpowiednich prawdopodobieństw. W założeniach metoda powinna byćna tyle ogólna, aby umożliwiać odwzorowanie każdej etykiety w dowolny podzbiór etykietdocelowych. Przyjęcie tak ogólnego założenia było spowodowane tym, iż w początkowymetapie prowadzenia badań nieznana była charakterystyka badanego korpusu.
Jako element definiujący odwzorowanie wykorzystano macierz kwadratową, której roz-miar odpowiada liczbie odwzorowanych etykiet (w tym przypadku 81). W macierzy mogąbyć wpisane tylko wartości „0” i „1”. Każdy wiersz odpowiada etykiecie odwzorowywanej,natomiast każda kolumna etykiecie wynikowej. Wartość „1” na pozycji (m,n), gdzie m— oznacza wiersz, n — oznacza kolumnę oznacza, że etykieta o indeksie m jest odwzoro-wywana w etykietę o indeksie n. Oznacza to, że dana etykieta może być odwzorowywanaw więcej niż jedną etykietę jednocześnie, a także, że dana etykieta (lub szerzej podzbióretykiet) może być jednocześnie odwzorowaniem więcej niż jednej etykiety. Jak łatwo za-
49
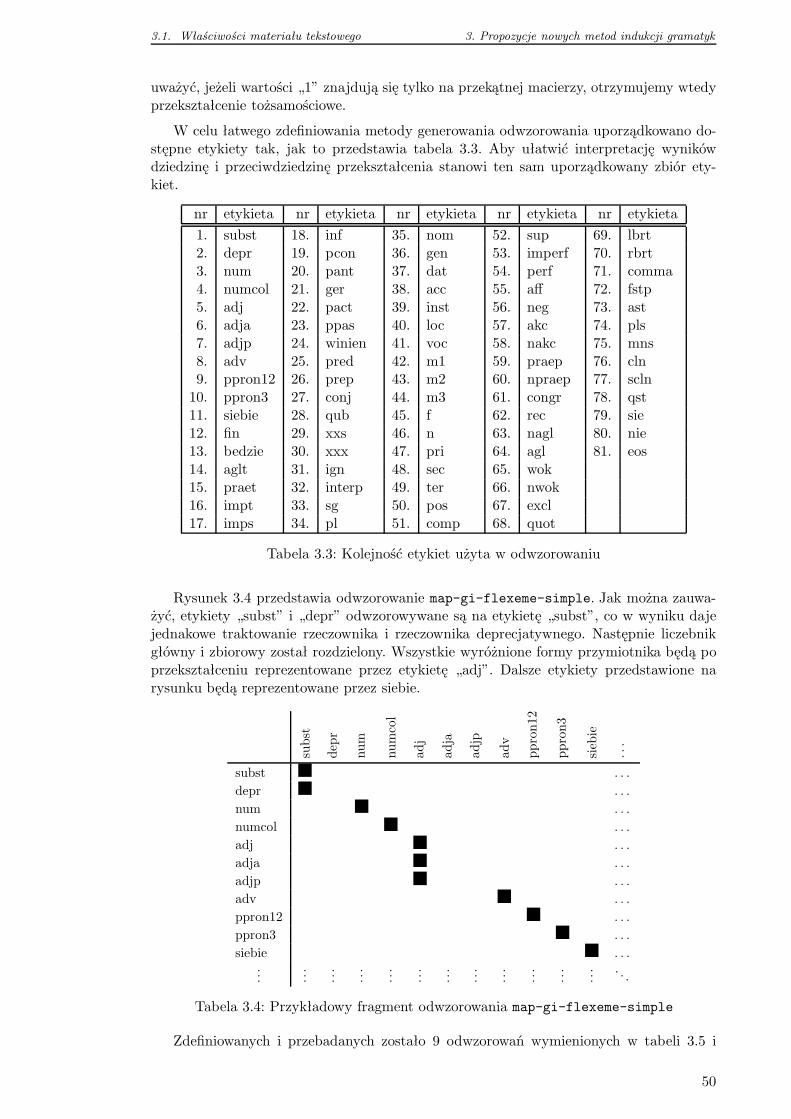
3.1. Właściwości materiału tekstowego 3. Propozycje nowych metod indukcji gramatyk
uważyć, jeżeli wartości „1” znajdują się tylko na przekątnej macierzy, otrzymujemy wtedyprzekształcenie tożsamościowe.
W celu łatwego zdefiniowania metody generowania odwzorowania uporządkowano do-stępne etykiety tak, jak to przedstawia tabela 3.3. Aby ułatwić interpretację wynikówdziedzinę i przeciwdziedzinę przekształcenia stanowi ten sam uporządkowany zbiór ety-kiet.
nr etykieta nr etykieta nr etykieta nr etykieta nr etykieta
1. subst 18. inf 35. nom 52. sup 69. lbrt2. depr 19. pcon 36. gen 53. imperf 70. rbrt3. num 20. pant 37. dat 54. perf 71. comma4. numcol 21. ger 38. acc 55. aff 72. fstp5. adj 22. pact 39. inst 56. neg 73. ast6. adja 23. ppas 40. loc 57. akc 74. pls7. adjp 24. winien 41. voc 58. nakc 75. mns8. adv 25. pred 42. m1 59. praep 76. cln9. ppron12 26. prep 43. m2 60. npraep 77. scln10. ppron3 27. conj 44. m3 61. congr 78. qst11. siebie 28. qub 45. f 62. rec 79. sie12. fin 29. xxs 46. n 63. nagl 80. nie13. bedzie 30. xxx 47. pri 64. agl 81. eos14. aglt 31. ign 48. sec 65. wok15. praet 32. interp 49. ter 66. nwok16. impt 33. sg 50. pos 67. excl17. imps 34. pl 51. comp 68. quot
Tabela 3.3: Kolejność etykiet użyta w odwzorowaniu
Rysunek 3.4 przedstawia odwzorowanie map-gi-flexeme-simple. Jak można zauwa-żyć, etykiety „subst” i „depr” odwzorowywane są na etykietę „subst”, co w wyniku dajejednakowe traktowanie rzeczownika i rzeczownika deprecjatywnego. Następnie liczebnikgłówny i zbiorowy został rozdzielony. Wszystkie wyróżnione formy przymiotnika będą poprzekształceniu reprezentowane przez etykietę „adj”. Dalsze etykiety przedstawione narysunku będą reprezentowane przez siebie.
subst
depr
num
numcol
adj
adja
adjp
adv
ppron12
ppron3
siebie
...
subst . . .depr . . .num . . .numcol . . .adj . . .adja . . .adjp . . .adv . . .ppron12 . . .ppron3 . . .siebie . . ....
.................................. . .
Tabela 3.4: Przykładowy fragment odwzorowania map-gi-flexeme-simple
Zdefiniowanych i przebadanych zostało 9 odwzorowań wymienionych w tabeli 3.5 i
50

3.2. Propozycje nowych kryteriów oceny jakości podziałów3. Propozycje nowych metod indukcji gramatyk
przedstawionych graficznie na rys. 3.1 i 3.2.
nazwa odwzorowania opis
map-flexeme-one odwzorowanie tożsamościowe etykiet oznaczających klasęgramatyczną (etykiety 1-32). Pozostałe etykiety są ignoro-wane
map-flexeme-simple odwzorowane są tylko klasy gramatyczne pogrupowane wkategorie: rzeczowinik, czasownik, etc.
map-gi-flexeme-one odwzorowanie map-gi-flexem-one rozszerzone o etykiety za-warte w tabeli 3.1
map-gi-flexeme-one-eos jak powyżej, wyróżniony etykietą ostatni token zdaniamap-gi-flexem-simple odwzorowanie map-gi-flexem-simple rozszerzone o etykiety
zawarte w tabeli 3.1map-gi-flexeme-simple-eos jak powyżej, wyróżniony etykietą ostatni token zdaniamap-ipi-one odwzorowanie tożsamościowe dla etykiet 1-66map-ipi-one-eos jak powyżej, wyróżniony etykietą ostatni token zdaniamap-one odwzorowanie tożsamościowe
Tabela 3.5: Zdefiniowane odwzorowania
Interpretacja poszczególnych członów nazw odwzorowań jest następująca:
one — oznacza występowanie symboli „1” tylko na głównej przekątnej macierzy,
flexeme-one — oznacza, że część odwzorowania dotyczącego etykiet określających klasęgramatyczną jest tożsamościowa (etykiety 1-32, tab. 3.3),
flexeme-simple — oznaczają, że odwzorowanie przekształca etykiety określające kla-sę gramatyczną tak, że grupy klas gramatycznych będą reprezentowane jako jednaetykieta,
ipi-one — symbole „1” występują tylko w obrębie etykiet występujących w Korpusie IPIna głównej przekątnej macierzy (etykiety 1-66, tab. 3.3),
gi — dołączono dodatkowe etykiety niewystępujące w Korpusie IPI (etykiety 67-80, tab.3.3),
eos — dołączono odwzorowanie etykiety 81 (tab. 3.3) oznaczającej koniec zdania.
3.2 Propozycje nowych kryteriów oceny jakości podziałów
Założeniem przyjętym podczas badań było sformułowanie takiego kryterium, które w spo-sób jednoznaczny pozwalałoby ocenić strukturę zdania. Oznacza to usunięcie uznaniowości
nazwa odwzorowania wynik odwzorowaniamap-flexeme-one :adj :subst :fin :adj :subst
map-flexeme-simple :adj :subst :fin :adj :subst
map-gi-flexeme-one-eos :adj :subst :fin :adj :eos:subst
map-gi-flexeme-one :adj :subst :fin :adj :subst
map-gi-flexeme-simple-eos :adj :subst :fin :adj :eos:subst
map-gi-flexem-simple :adj :subst :fin :adj :subst
map-ipi-one-eos :acc:adj:m3:pos:sg :m2:nom:sg:subst :fin:imperf:sg:ter :acc:adj:f:pos:sg :acc:eos:f:sg:subst
map-ipi-one :acc:adj:m3:pos:sg :m2:nom:sg:subst :fin:imperf:sg:ter :acc:adj:f:pos:sg :acc:f:sg:subst
map-one :acc:adj:m3:pos:sg :m2:nom:sg:subst :fin:imperf:sg:ter :acc:adj:f:pos:sg :acc:eos:f:sg:subst
Tabela 3.6: Odwzorowania przykładowego zdania
51

3.2. Propozycje nowych kryteriów oceny jakości podziałów3. Propozycje nowych metod indukcji gramatyk
map-flexem-simple map-flexeme-one
map-gi-flexeme-one-eos map-gi-flexeme-one
map-gi-flexeme-simple-eos map-gi-flexem-simple
map-ipi-one-eos map-ipi-one
Rysunek 3.1: Odwzorowania opisów lexemów ctag.
52

3.2. Propozycje nowych kryteriów oceny jakości podziałów3. Propozycje nowych metod indukcji gramatyk
map-one
Rysunek 3.2: Odwzorowania opisów ctag (cd.)
w ocenie i uniezależnienie od dodatkowej informacji lingwistycznej (takich jak antygrama-tyka wspomniana w rozdziale 2.6.5).
Ponieważ wyniki badań nad kryterium MI i GMI (zobacz rozdział 2.6.3 i 2.6.5)okazały się bardzo zachęcające, dalsze prace skierowane zostały ku zbadaniu własnościpowyższych kryteriów i zaproponowaniu nowego kryterium o cechach spełniających po-wyższe założenia.
Definicja miaryMI (wzór 2.1) używa pojęcia dwóch zmiennych losowych i ich wzajem-nej zależności. Ich odpowiednikiem w zdaniu są dwa związki wyrazowe (def. 20) tworzącezdanie. Jednakże należy zauważyć, że generalnie zdanie może składać się z wielu związkówwyrazowych, a cecha ta jest zależna od charakteru każdego zdania. Zatem dopuszczaniejedynie podziałów binarnych wydaje się zbyt ostrym ograniczeniem. Rozwiązaniem tegoproblemu może być nowe, wolne od tego ograniczenia kryterium, nazwane przez autoraniniejszej rozprawy, GIMI.
3.2.1 Kryterium GIMI
Modyfikując kryteriumMI tak, aby mogło uwzględniać dowolną liczbę podziałów zdania,otrzymujemy poniższe kryterium:
GIMI(x, . . . , y) = logPX...Y (x, . . . , y)
PX(x) . . .PY (y)(3.1)
Należy zauważyć, że od tego momentu zrywamy z pojęciem informacji wzajemnej i zaj-mujemy się tworzeniem kryterium, które będzie miało interpretacje jedynie przy struktu-ralizowaniu zdań.
Zaproponowane wzorem 3.1 kryterium posiada istotne zalety w porównaniu z kryte-riumMI, gdyż obliczając jego wartość dla wszystkich możliwych podziałów danego zda-nia jesteśmy w stanie wprost ocenić jakość tych podziałów. Opierając się na interpretacjizwiązku wyrazowego (roz. 2.6.1) możemy stwierdzić, że prawdopodobieństwo wystąpieniadanej sekwencji tokenów znacząco wzrasta, gdy stanowi ona związek wyrazowy (cały lubjego element). Gdy każdy z czynników mianownika równania 2.5 osiągnie wartość mak-symalną, możemy zakładać, że podział sekwencji tokenów stanowiących zdanie odbył siędokładnie w miejscach podziałów związków wyrazowych. W przeciwnym przypadku jedenz elementów nie byłby związkiem wyrazowym, zatem prawdopodobieństwo jego wystąpie-nia byłoby znacznie niższe, co spowodowałoby również odpowiednie zmniejszenie wartościcałego wyrażenia stanowiącego mianownik. Ponieważ licznik równania dla danego zdaniapozostaje bez zmian, zatem maksymalizując mianownik, minimalizujemy wartość całego
53

3.2. Propozycje nowych kryteriów oceny jakości podziałów3. Propozycje nowych metod indukcji gramatyk
wyrażenia. Stąd prosty wniosek, że prawdopodobne miejsca podziału zdania na związkiwyrazowe, to te, dla których kryterium GIMI przyjmuje wartości minimalne.
Jak pokazały eksperymenty, wskaźnik GIMI jest obciążony — preferuje podział nakrótkie podsekwencje. Przeprowadzone doświadczenia dały odpowiedź na pytanie, czymto jest spowodowane. Otóż, jak pokazuje rys. 3.3, średnia wartość wskaźnika MI (czyliuproszczonego do jednego punktu podziału wskaźnika GIMI) w funkcji długości sekwencjii pozycji punktu podziału ma bardzo specyficzny przebieg. Jak łatwo zauważyć, wartośćśrednia GIMI rośnie wraz z długością badanego zdania i odległością punktu podziałuod krańców zdania. Jednocześnie wariancja (przedstawiona na rys. 3.4) zachowuje sięodwrotnie — ma duże wartości przy małych długościach zdań lub gdy punkt podziałuznajduje się na skrajnej pozycji. W innych miejscach przyjmuje wartości minimalne. Tozjawisko jest szczególnie niepokojące, gdyż oznacza, że obszary niskiej wartości wariancjinie mogą służyć jako kryterium podziału.
Należy podkreślić, że przytoczone tu wykresy są zgodne z przykładowymi przebiegamiwartości MI pokazanymi na rys. 2.7, gdzie wartości MI rosły, gdy punkt podziału byłusytuowany centralnie, a malały w przeciwnym przypadku. Rysunek 3.5 rzuca pewne
0 1020 30
40 5060 70
80
0102030405060700
2
4
6
8
10
12
14
wartość średniaMI
długość sekwencjipunkt podziału
wartość średniaMI
Rysunek 3.3: Wartość średniaMI dla podsekwencji z testowanego korpusu
światło na naturę tego współczynnika. Przedstawione tam wartości średnie odpowiednichprawdopodobieństw PX , PY , PXY wskazują, że:
• średnia wartość prawdopodobieństwa jest obciążona i rośnie wraz z długością se-kwencji,
• jednocześnie wariancja spada, co oznacza, że przydatność prawdopodobieństwa jakowskaźnika miejsca podziału spada wraz z długością sekwencji.
Przyczyn występowania tego zjawiska należy dopatrywać się w tym, że:
• długie zdania (a zatem i długie sekwencje) są stosunkowo rzadkie w korpusie językanaturalnego (por. rys. 3.6),
• jednocześnie wraz z długością zdania rośnie liczba możliwych kombinacji tokenów1,zatem rośnie także liczba takich sekwencji, które występują tylko raz w korpusie
1Jednak w języku naturalnym, a zatem i w korpusach nie występują wszystkie możliwe kombinacje(por. rys. 3.6).
54

3.2. Propozycje nowych kryteriów oceny jakości podziałów3. Propozycje nowych metod indukcji gramatyk
0 1020 30
40 5060 70
80
010203040506070-0.500.511.522.533.544.55
wartość wariancji MI
długość sekwencjipunkt podziału
wartość wariancji MI
Rysunek 3.4: WariancjaMI dla podsekwencji z testowanego korpusu
(wielkość korpusu nie ma znaczenia, gdyż mogą to być zarówno wyszukane kon-strukcje gramatyczne charakterystyczne dla konkretnego autora lub błędy czy to wanotacji korpusu, czy w materiale źródłowym),
• jak pokazuje rys. 2.6 liczba sekwencji o zadanej długości rośnie liniowo wraz z liczbąprzeanalizowanych zdań. Szybkość wzrostu jest jednak silnie zależna od długościsekwencji — dla dłuższych sekwencji przyrost jest znacznie wolniejszy w porównaniuz sekwencjami krótszymi (porównaj rys. 3.7). To zjawisko jest spowodowane przezniską zawartość długich zdań w języku naturalnym oraz przez fakt, że sekwencjadzieli się na większą liczbę podsekwencji krótkich niż długich (por. wzór 3.5),
• dwa powyższe zjawiska: duża różnorodność długich sekwencji i stosunkowo małaich liczba prowadzi do sytuacji, gdy prawdopodobieństwo wystąpienia dostateczniedługiej sekwencji jest stosunkowo wysokie (w porównaniu ze średnim prawdopodo-bieństwem wystąpienia sekwencji krótkich), gdyż w krańcowym przypadku stanowi:
1
liczba wszystkich wystąpień sekwencji o długości n
Także wartość średnia przyjmuje wartości wysokie, natomiast wariancja niskie. Stąd,dla długich sekwencji tokenów używanie prawdopodobieństwa daje złe rezultaty. Dla-tego też używanie wskaźnikaMI, mimo teoretycznie słusznych założeń praktycznienie spełniło pokładanych w nim nadziei.
3.2.2 Kryterium GIMINorm
Uwzględniając powyższą analizę, można zaproponować kryterium podziału zdania nazwiązki wyrazowe uwzględniające własności danych tekstowych:
GIMINorm(x, . . . , y) = log
PX...Y (x,...,y)N|X...Y |
PX(x)N|X|
· · · PY (y)N|Y |
(3.2)
gdzie Nl oznacza współczynnik normalizacji zależny jedynie od długości sekwencji, dlaktórej obliczane jest prawdopodobieństwo. Dzięki niemu kryterium GIMINorm jest wraż-liwe jedynie na odstępstwa wartości prawdopodobieństwa podsekwencji od odpowiednich
55
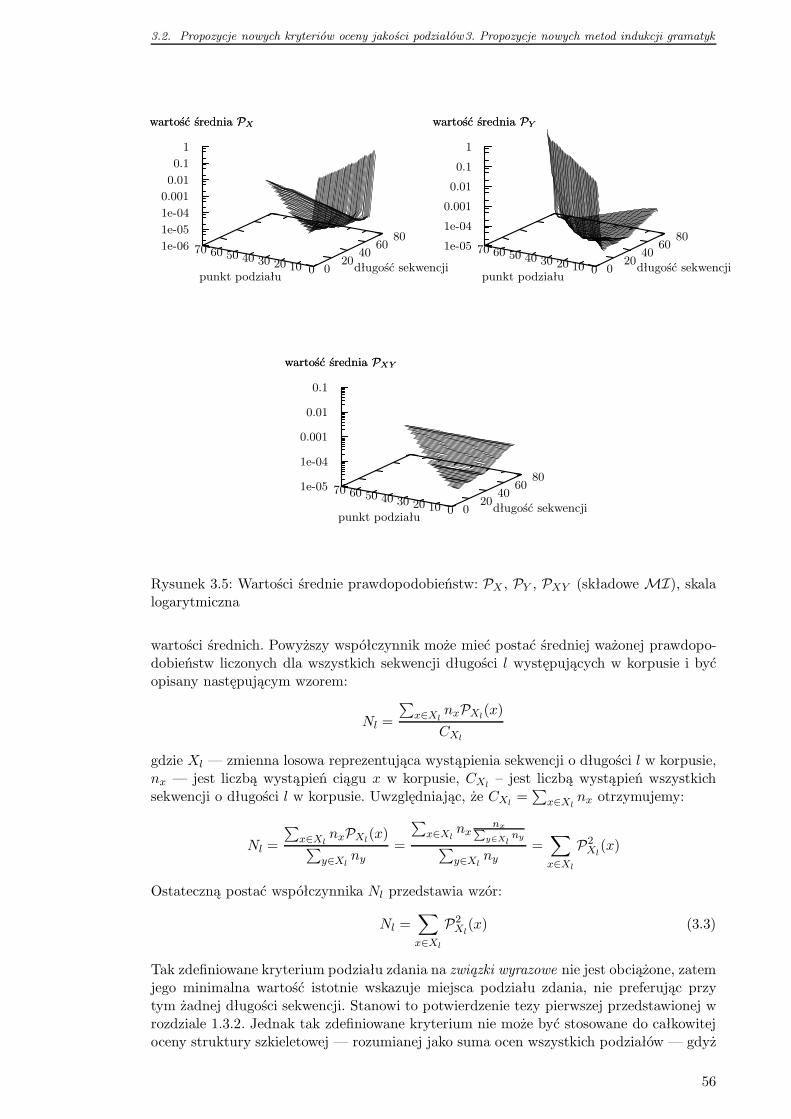
3.2. Propozycje nowych kryteriów oceny jakości podziałów3. Propozycje nowych metod indukcji gramatyk
020406080
0102030405060701e-061e-051e-040.0010.010.11
wartość średnia PX
długość sekwencjipunkt podziału
wartość średnia PX
020406080
0102030405060701e-05
1e-04
0.001
0.01
0.1
1
wartość średnia PY
długość sekwencjipunkt podziału
wartość średnia PY
020406080
0102030405060701e-05
1e-04
0.001
0.01
0.1
wartość średnia PXY
długość sekwencjipunkt podziału
wartość średnia PXY
Rysunek 3.5: Wartości średnie prawdopodobieństw: PX , PY , PXY (składoweMI), skalalogarytmiczna
wartości średnich. Powyższy współczynnik może mieć postać średniej ważonej prawdopo-dobieństw liczonych dla wszystkich sekwencji długości l występujących w korpusie i byćopisany następującym wzorem:
Nl =
∑x∈Xl
nxPXl(x)
CXl
gdzie Xl — zmienna losowa reprezentująca wystąpienia sekwencji o długości l w korpusie,nx — jest liczbą wystąpień ciągu x w korpusie, CXl
– jest liczbą wystąpień wszystkichsekwencji o długości l w korpusie. Uwzględniając, że CXl
=∑
x∈Xlnx otrzymujemy:
Nl =
∑x∈Xl
nxPXl(x)
∑y∈Xl
ny
=
∑x∈Xl
nxnx
P
y∈Xlny∑
y∈Xlny
=∑
x∈Xl
P2Xl
(x)
Ostateczną postać współczynnika Nl przedstawia wzór:
Nl =∑
x∈Xl
P2Xl
(x) (3.3)
Tak zdefiniowane kryterium podziału zdania na związki wyrazowe nie jest obciążone, zatemjego minimalna wartość istotnie wskazuje miejsca podziału zdania, nie preferując przytym żadnej długości sekwencji. Stanowi to potwierdzenie tezy pierwszej przedstawionej wrozdziale 1.3.2. Jednak tak zdefiniowane kryterium nie może być stosowane do całkowitejoceny struktury szkieletowej — rozumianej jako suma ocen wszystkich podziałów — gdyż
56
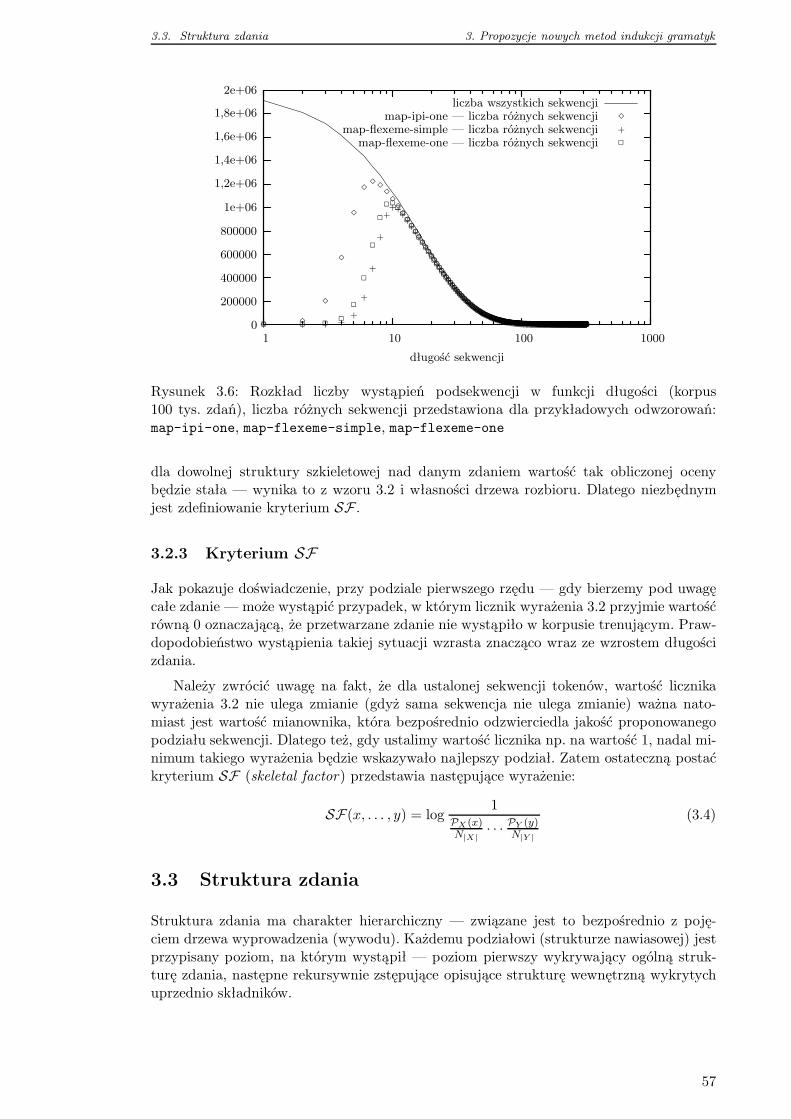
3.3. Struktura zdania 3. Propozycje nowych metod indukcji gramatyk
0
200000
400000
600000
800000
1e+06
1,2e+06
1,4e+06
1,6e+06
1,8e+06
2e+06
1 10 100 1000
długość sekwencji
liczba wszystkich sekwencjimap-ipi-one — liczba różnych sekwencji
33
3
3
3
33
33
3
3
33333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333
3
map-flexeme-simple — liczba różnych sekwencji
+ + + ++
+
+
+
+++
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
+
map-flexeme-one — liczba różnych sekwencji
2 2 22
2
2
2
2
22222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222
2
Rysunek 3.6: Rozkład liczby wystąpień podsekwencji w funkcji długości (korpus100 tys. zdań), liczba różnych sekwencji przedstawiona dla przykładowych odwzorowań:map-ipi-one, map-flexeme-simple, map-flexeme-one
dla dowolnej struktury szkieletowej nad danym zdaniem wartość tak obliczonej ocenybędzie stała — wynika to z wzoru 3.2 i własności drzewa rozbioru. Dlatego niezbędnymjest zdefiniowanie kryterium SF .
3.2.3 Kryterium SF
Jak pokazuje doświadczenie, przy podziale pierwszego rzędu — gdy bierzemy pod uwagęcałe zdanie — może wystąpić przypadek, w którym licznik wyrażenia 3.2 przyjmie wartośćrówną 0 oznaczającą, że przetwarzane zdanie nie wystąpiło w korpusie trenującym. Praw-dopodobieństwo wystąpienia takiej sytuacji wzrasta znacząco wraz ze wzrostem długościzdania.
Należy zwrócić uwagę na fakt, że dla ustalonej sekwencji tokenów, wartość licznikawyrażenia 3.2 nie ulega zmianie (gdyż sama sekwencja nie ulega zmianie) ważna nato-miast jest wartość mianownika, która bezpośrednio odzwierciedla jakość proponowanegopodziału sekwencji. Dlatego też, gdy ustalimy wartość licznika np. na wartość 1, nadal mi-nimum takiego wyrażenia będzie wskazywało najlepszy podział. Zatem ostateczną postaćkryterium SF (skeletal factor) przedstawia następujące wyrażenie:
SF(x, . . . , y) = log1
PX (x)N|X|
· · · PY (y)N|Y |
(3.4)
3.3 Struktura zdania
Struktura zdania ma charakter hierarchiczny — związane jest to bezpośrednio z poję-ciem drzewa wyprowadzenia (wywodu). Każdemu podziałowi (strukturze nawiasowej) jestprzypisany poziom, na którym wystąpił — poziom pierwszy wykrywający ogólną struk-turę zdania, następne rekursywnie zstępujące opisujące strukturę wewnętrzną wykrytychuprzednio składników.
57
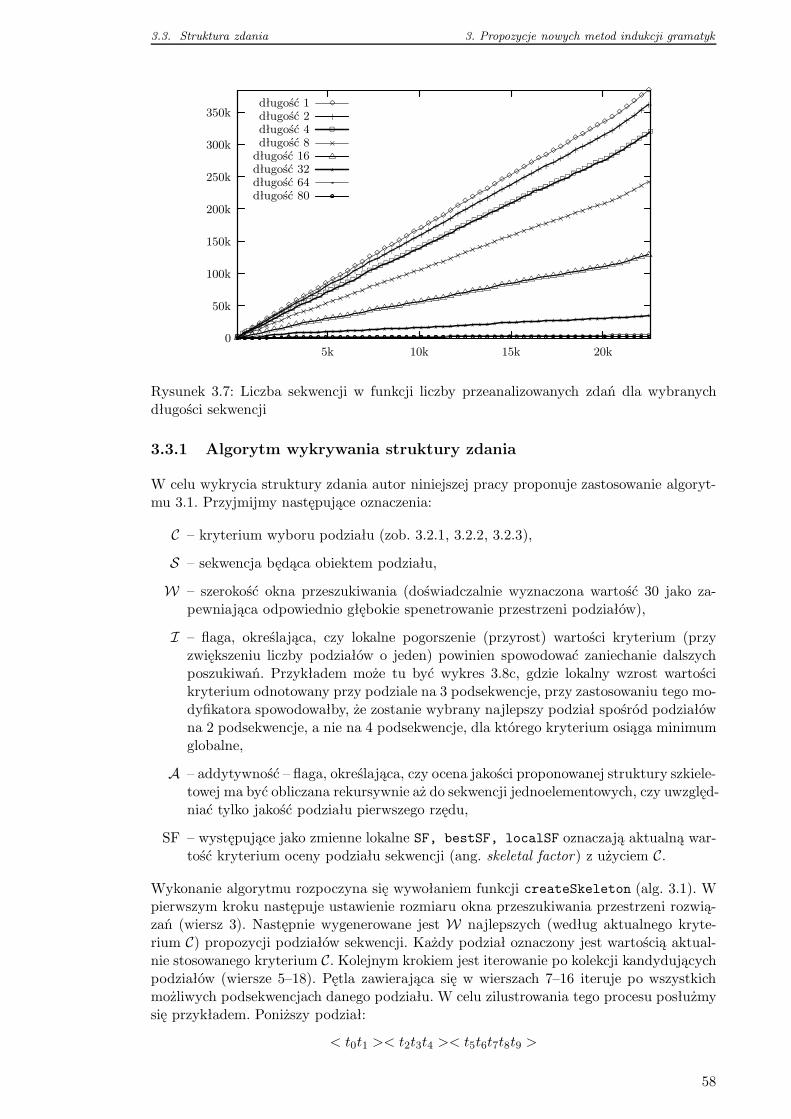
3.3. Struktura zdania 3. Propozycje nowych metod indukcji gramatyk
350k
300k
250k
200k
150k
100k
50k
020k15k10k5k
długość 1
33
33
33
33
33
33
33
33
33
33
33
33
33
33
33
33
33
33
33
33
33
33
33
33
33
33
33
33
3
3
długość 2
++
++
++
++
++
++
++
++
++
++
++
++
++
++
++
++
++
++
++
++
+++
++
++
++
++
++
++
++
+
długość 4
22
22222
222
2222
2222222
22
222222
222
222
222
22
22
222222
22222
22222
222222
2222
22
22
22
222
długość 8
×××××××××××××××××××××××××××××××××××××××××××××××××××××××××
×
długość 16
△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△
△
długość 32
⋆ ⋆ ⋆ ⋆ ⋆ ⋆ ⋆ ⋆ ⋆ ⋆ ⋆ ⋆ ⋆ ⋆ ⋆ ⋆ ⋆ ⋆ ⋆ ⋆ ⋆ ⋆ ⋆ ⋆ ⋆ ⋆ ⋆ ⋆ ⋆ ⋆ ⋆ ⋆ ⋆ ⋆ ⋆ ⋆ ⋆ ⋆ ⋆ ⋆ ⋆ ⋆ ⋆ ⋆ ⋆ ⋆ ⋆ ⋆ ⋆ ⋆ ⋆ ⋆ ⋆ ⋆ ⋆ ⋆ ⋆
⋆
długość 64długość 80
Rysunek 3.7: Liczba sekwencji w funkcji liczby przeanalizowanych zdań dla wybranychdługości sekwencji
3.3.1 Algorytm wykrywania struktury zdania
W celu wykrycia struktury zdania autor niniejszej pracy proponuje zastosowanie algoryt-mu 3.1. Przyjmijmy następujące oznaczenia:
C – kryterium wyboru podziału (zob. 3.2.1, 3.2.2, 3.2.3),
S – sekwencja będąca obiektem podziału,
W – szerokość okna przeszukiwania (doświadczalnie wyznaczona wartość 30 jako za-pewniająca odpowiednio głębokie spenetrowanie przestrzeni podziałów),
I – flaga, określająca, czy lokalne pogorszenie (przyrost) wartości kryterium (przyzwiększeniu liczby podziałów o jeden) powinien spowodować zaniechanie dalszychposzukiwań. Przykładem może tu być wykres 3.8c, gdzie lokalny wzrost wartościkryterium odnotowany przy podziale na 3 podsekwencje, przy zastosowaniu tego mo-dyfikatora spowodowałby, że zostanie wybrany najlepszy podział spośród podziałówna 2 podsekwencje, a nie na 4 podsekwencje, dla którego kryterium osiąga minimumglobalne,
A – addytywność – flaga, określająca, czy ocena jakości proponowanej struktury szkiele-towej ma być obliczana rekursywnie aż do sekwencji jednoelementowych, czy uwzględ-niać tylko jakość podziału pierwszego rzędu,
SF – występujące jako zmienne lokalne SF, bestSF, localSF oznaczają aktualną war-tość kryterium oceny podziału sekwencji (ang. skeletal factor) z użyciem C.
Wykonanie algorytmu rozpoczyna się wywołaniem funkcji createSkeleton (alg. 3.1). Wpierwszym kroku następuje ustawienie rozmiaru okna przeszukiwania przestrzeni rozwią-zań (wiersz 3). Następnie wygenerowane jest W najlepszych (według aktualnego kryte-rium C) propozycji podziałów sekwencji. Każdy podział oznaczony jest wartością aktual-nie stosowanego kryterium C. Kolejnym krokiem jest iterowanie po kolekcji kandydującychpodziałów (wiersze 5–18). Pętla zawierająca się w wierszach 7–16 iteruje po wszystkichmożliwych podsekwencjach danego podziału. W celu zilustrowania tego procesu posłużmysię przykładem. Poniższy podział:
< t0t1 >< t2t3t4 >< t5t6t7t8t9 >
58

3.3. Struktura zdania 3. Propozycje nowych metod indukcji gramatyk
1 Bes tSke l e tons c r e a t eSk e l e t on (C,S,W , I )2 {3 bes tSke l e tons . setMaxCapacity (W ) ;4 bestCandidates = f i n dD i v i s i o n s (C,S,W , I ) ;5 for ( d iv i s i onCand ida te : bes tCandidates )6 {7 for ( d i v i s i o n : d iv i s i onCand ida te )8 {9 subDivCandidates = c r e a t eSk e l e t on (C,d i v i s i o n . sequence ( ) ,W , I ) ;10 bestSubDiv i s ion = chooseBest ( subDivCandidates ) ;11 merge ( d iv i s i onCand ida te . b ra cke t s ( ) , bes tSubDiv i s ion . b ra cke t s ( ) ) ;12 i f (A)13 {14 d iv i s i onCand ida te . SF += bestSubDiv i s ion . SF ;15 }16 }17 bes tSke l e tons . add ( d iv i s ionCandidate , d iv i s i onCand idate . SF ) ;18 }19 return bes tSke l e tons ;20 }
Algorytm 3.1: Algorytm wykrywania struktury zdania
generuje następujące podsekwencje:
< t0t1 >,< t2t3t4 >,< t5t6t7t8t9 >
Dla każdej z podsekwencji wykonywana jest rekursywnie funkcja createSkeleton (wiersz9), a następnie spośród kandydujących podziałów danej podsekwencji wybierany jestnajlepszy podział (wiersz 10) i następuje połączenie reprezentacji struktur nawiasowych(wiersz 11). Jeżeli flaga A jest ustawiona na wartość prawda, następuje kumulowaniewspółczynnika SF. Gdy wszystkie podsekwencje zostaną już podzielone i połączone z kan-dydującym podziałem pierwszego rzędu, podział ten zostaje dodany do uporządkowanegozbioru kandydujących rozwiązań bestSkeletons. Gdy kandydujące podziały zostaną prze-tworzone, dysponujemy uporządkowanym zbiorem W podziałów, w kolejności malejącejoceny jakości podziału.
Na osobne wyjaśnienie zasługuje znaczenie flagi A (addytywność kryterium oceny po-działu z uwzględnieniem ocen podpodziałów). Gdy jest ona ustawiona na wartość:
fałsz — wtedy na wartość oceny danej struktury szkieletowej ma wpływ tylko ocenapodziału pierwszego rzędu, natomiast jakość podziałów podsekwencji nie jest branapod uwagę,
prawda —wartość oceny struktury szkieletowej jest obliczona na podstawie oceny struktu-ry wszystkich podsekwencji. Dzięki temu rozwiązanie, którego struktura szkieletowapierwszego poziomu była oceniona najwyżej, może zostać przesłonięte przez innąpropozycję, o lepszych właściwościach ze względu na podpodziały.
3.3.2 Algorytm generowania podziałów
Algorytm 3.2 przedstawia metodę wyznaczania W najlepszych podziałów sekwencji S —podziałów kandydujących. Wykonanie algorytmu sprowadza się do przeszukania przestrze-ni dostępnych podziałów, począwszy od 1. punktu podziału, na spełnieniu warunku stopuskończywszy. Przeszukiwanie przestrzeni podziałów powinno zatrzymać się, gdy jeden zponiższych warunków zostanie spełniony:
59

3.3. Struktura zdania 3. Propozycje nowych metod indukcji gramatyk
• liczba punktów podziału osiągnie wartość maksymalną dla danej sekwencji i wynie-sie: |S| − 1,
• najlepszy podział przy n punktach podziału jest gorszy niż najlepszy podział przyn− 1 punktach podziału (wiersz 8). Jest to warunek opcjonalny używany, gdy flagaI jest prawdziwa.
1 Bes tDiv i s i ons f i n dD i v i s i o n s (C,S,W , I )2 {3 be s tD iv i s i o n s . setMaxCapacity (W ) ;4 bestSF = MAXVALUE;5 SF = MAXVALUE;6 for ( divNo=1; divNo<|S| ; divNo++)7 {8 i f (I && bestSF < SF)9 {10 return be s tD iv i s i o n s ;11 }12 bestSF = min(SF , bestSF ) ;13 SF = MAXVALUE;14 d i v i s i o n s = prepa r eDiv i s i ons ( divNo ,S ) ;15 for ( d i v i s i o n : d i v i s i o n s )16 {17 l o ca lSF = eva l ua t eD iv i s i o n (C,S, d i v i s i o n ) ;18 SF = min ( loca lSF , SF ) ;19 be s tD iv i s i o n s . add ( d i v i s i o n , loca lSF ) ;20 }21 }22 return be s tD iv i s i o n s ;23 }
Algorytm 3.2: Algorytm generowania najlepszych podziałów
Scenariusz wykonania algorytmu 3.2 przedstawia się następująco:
1. spośród jednopunktowych podziałów wybieranych jest W najlepszych, (przeszuki-wana jest cała przestrzeń podziałów, oceniany jest każdy podział),
2. spośród kandydatów wygenerowanych w poprzednim kroku generowani są kandydacinastępnego rzędu poprzez zbadanie wpływu dodania kolejnego punktu podziału nawartość kryterium oceny. Zostało dowiedzione eksperymentalnie, że najlepsze po-działy następnego rzędu są rozwinięciem najlepszego podziału kroku poprzedniego.Dodatkowo, aby wykluczyć możliwość pominięcia podziału, którego rozwinięcie mo-że w następnym kroku okazać się najlepsze, w każdej iteracji rozpatrywane jest oknoW najlepszych podziałów.
Rysunek 3.8 przedstawia wartości kryterium SF dla najlepszych podziałów przy zadanejliczbie punktów podziału. Przedstawiono wyniki dla różnych odwzorowań (tab. 3.5). Zgod-nie z oczekiwaniami wartość kryterium początkowo maleje wraz ze zwiększaniem liczbypodziałów, osiąga minimum, a następnie rośnie. Należy zauważyć, że optymalna liczbapodziałów zależy silnie od przyjętego odwzorowania. Rysunek c) stanowi doskonały przy-kład, w którym ustawienie flagi I zmienia liczbę podziałów z 4 na 2 dzięki uwzględnieniupierwszego minimum lokalnego wartości kryterium oceny.
60

3.3. Struktura zdania 3. Propozycje nowych metod indukcji gramatyk
a)
map-ipi-one
map-ipi-one-eos
map-one
map-gi-flexeme-one-eos
map-flexeme-one
map-gi-flexeme-one
map-gi-flexeme-simple-eos
map-gi-flexeme-simple
map-flexeme-simple
05
1015
2025
liczba punktów podziału
-10-5051015202530
wartość SF
b) c)
-6
-5
-4
-3
-2
-1
0
2 4 6 8 10 12 14 16 18 20 22
wartość
SF
liczba punktów podziału
map-flexeme-simple
-5
0
5
10
15
20
25
30
2 4 6 8 10 12 14 16 18 20 22
wartość
SF
liczba punktów podziału
map-ipi-one
Rysunek 3.8: Wartość współczynnika SF dla najlepszego n–punktowego podziału zdania39455 dla różnych odwzorowań
Przeszukiwanie przestrzeni podziałów
Na uwagę zasługuje funkcja prepareDivisions która generuje podziały kandydujące.Ponieważ liczba możliwych podziałów rośnie wykładniczo wraz z długością sekwencji(rys. 3.9a), to sprawdzenie współczynnika SF dla każdego z możliwych podziałów oka-zuje się nieefektywne. Dla sekwencji 31–elementowej liczba możliwych podziałów sięga ok.109. Jak pokazuje rys. 3.9b, liczba możliwych podziałów wzrasta znacząco, także wraz zliczbą punktów podziału.
Z powodu eksplozji liczby podziałów opracowano i zastosowano heurystyki ogranicza-jące znacznie tę liczbę. Są to:
• wykrycie, że podziały kandydujące wyższych rzędów są rozwinięciem kandydatówniższych rzędów — zatem wystarczające jest zbadanie tylko dodatkowego punktupodziału,
• jeżeli została wykryta podsekwencja, która nie występuje w korpusie, należy ominąć
61
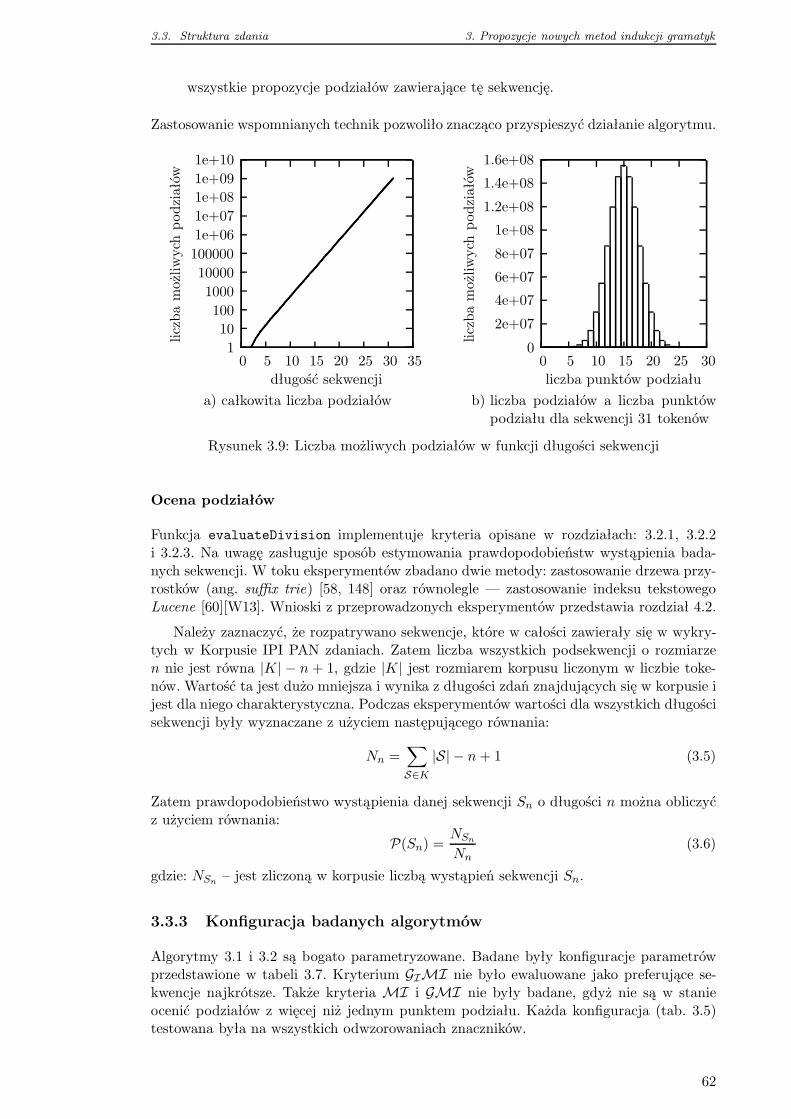
3.3. Struktura zdania 3. Propozycje nowych metod indukcji gramatyk
wszystkie propozycje podziałów zawierające tę sekwencję.
Zastosowanie wspomnianych technik pozwoliło znacząco przyspieszyć działanie algorytmu.
1101001000100001000001e+061e+071e+081e+091e+10
0 5 10 15 20 25 30 35
liczbamożliwychpodziałów
długość sekwencji
0
2e+07
4e+07
6e+07
8e+07
1e+08
1.2e+08
1.4e+08
1.6e+08
0 5 10 15 20 25 30
liczbamożliwychpodziałów
liczba punktów podziału
a) całkowita liczba podziałów b) liczba podziałów a liczba punktówpodziału dla sekwencji 31 tokenów
Rysunek 3.9: Liczba możliwych podziałów w funkcji długości sekwencji
Ocena podziałów
Funkcja evaluateDivision implementuje kryteria opisane w rozdziałach: 3.2.1, 3.2.2i 3.2.3. Na uwagę zasługuje sposób estymowania prawdopodobieństw wystąpienia bada-nych sekwencji. W toku eksperymentów zbadano dwie metody: zastosowanie drzewa przy-rostków (ang. suffix trie) [58, 148] oraz równolegle — zastosowanie indeksu tekstowegoLucene [60][W13]. Wnioski z przeprowadzonych eksperymentów przedstawia rozdział 4.2.
Należy zaznaczyć, że rozpatrywano sekwencje, które w całości zawierały się w wykry-tych w Korpusie IPI PAN zdaniach. Zatem liczba wszystkich podsekwencji o rozmiarzen nie jest równa |K| − n + 1, gdzie |K| jest rozmiarem korpusu liczonym w liczbie toke-nów. Wartość ta jest dużo mniejsza i wynika z długości zdań znajdujących się w korpusie ijest dla niego charakterystyczna. Podczas eksperymentów wartości dla wszystkich długościsekwencji były wyznaczane z użyciem następującego równania:
Nn =∑
S∈K
|S| − n + 1 (3.5)
Zatem prawdopodobieństwo wystąpienia danej sekwencji Sn o długości n można obliczyćz użyciem równania:
P(Sn) =NSn
Nn
(3.6)
gdzie: NSn – jest zliczoną w korpusie liczbą wystąpień sekwencji Sn.
3.3.3 Konfiguracja badanych algorytmów
Algorytmy 3.1 i 3.2 są bogato parametryzowane. Badane były konfiguracje parametrówprzedstawione w tabeli 3.7. Kryterium GIMI nie było ewaluowane jako preferujące se-kwencje najkrótsze. Także kryteria MI i GMI nie były badane, gdyż nie są w stanieocenić podziałów z więcej niż jednym punktem podziału. Każda konfiguracja (tab. 3.5)testowana była na wszystkich odwzorowaniach znaczników.
62

3.3. Struktura zdania 3. Propozycje nowych metod indukcji gramatyk
nazwa konfiguracji C A I W
SF SF prawda fałsz 30SF BEST FIRST SF fałsz fałsz 1SF NOINC SF prawda prawda 30SF BEST FIRST NOINC SF prawda prawda 1
Tabela 3.7: Zestawienie parametrów używanych algorytmów
3.3.4 Indukowanie reguł gramatyki
Do indukcji reguł gramatyki z użyciem struktur szkieletowych użyto metody zapropono-wanej przez Sakakibarę (przedstawionej w rozdziale 2.3.6). Ponieważ powyższa metodazakłada, że dane trenujące nie zawierają błędnie skonstruowanych struktur szkieletowych,nie nadaje się ona bezpośrednio do zastosowania praktycznego. Wyniki wstępnych ekspe-rymentów potwierdziły te obawy. Proces unifikacji symboli nieterminalnych powodowałsprowadzenie wszystkich symboli nieterminalnych do jednego symbolu. Oczywistym jest,że gramatyka, w której występuje tylko jeden symbol nieterminalny, ma znikomą wartość.
Definicja 12 wymienia dwa etapy unifikacji symboli nieterminalnych. W toku badańokazało się, że drugi z nich jest odpowiedzialny za nadmierną unifikację symboli nieter-minalnych. Wprowadzono zatem modyfikację polegającą na tym, iż można go zastosowaćjedynie dla reguł o wsparciu S-sup większym od zadanego — parametr ten zwany będziedalej RCFG2sup. Takie rozwiązanie pozwoliło wyeliminować zjawisko nadmiernej unifika-cji symboli nieterminalnych.
63

Indukcja reguł gramatyki języka polskiego
Rozdział 4
Wyniki eksperymentówThe biggest difference between time and spaceis that you can’t reuse time.Merrick Furst
Niniejszy rozdział przedstawia eksperymentalną weryfikację propozycji przestawionych wrozdziale 3. Głównym celem było sprawdzenie przydatności zaproponowanych metod wprocesie indukcji reguł gramatyki w praktycznie interesujących zastosowaniach — z uży-ciem korpusu tekstów ogólnie dostępnych, a zatem nieprzygotowanych specjalnie do tegocelu. Wykonano analizę porównawczą z systemami EMILIE i ABL (por. roz. 2.6.2). Doło-żono też wszelkich starań, stosując dobre praktyki programistyczne (m.in. wzorce projek-towe, szereg optymalizacji, testy podzespołów (ang. unit test) pokrywające prawie w 100%krytyczne fragmenty kodu), aby powstały system eksperymentalny był jak najwyższej ja-kości i mógł być wykorzystany w całości lub w części w zastosowaniach praktycznych.
4.1 Opis systemu
Zbudowany system GImoże dokonywać indukcji reguł gramatyki bezkontekstowej, jak rów-nież anotować strukturalnie zdania korpusu języka polskiego anotowanego morfologiczniew postaci zgodnej ze strukturą Korpusu IPI PAN (opisaną w rozdziale 2.5)1.
Zaimplementowano znane z literatury kryteria oceny struktur szkieletowych takie jak:MI, GMI, a także nowe, będące propozycją autora niniejszej rozprawy: SF , GIMI,GIMINorm (roz. 3.2), metody odwzorowania informacji morfologicznej (roz. 3.1.2) i al-gorytmy generowania struktury zdania (roz. 3.3), a także udoskonalony algorytm genero-wania reguł gramatycznych Sakakibary (roz. 2.3.6 i 3.3.4). System został wyposażony wmoduł algorytmu genetycznego (z szeregiem strategii operatorów mutacji i krzyżowaniaoptymalizowanych do operowania na tablicach użytych w metodzie odwzorowania infor-macji morfologicznej) — wstępne wyniki tych doświadczeń nie zostały ujęte w niniejszejrozprawie, nie mniej były pomocne w ukierunkowaniu dalszych poszukiwań.
Dostępny jest także moduł oceny jakości struktur szkieletowych2 i moduł oceny przy-datności wyindukowanych reguł gramatyki — będący częścią modułu parsera, który po-siada także możliwość wyznaczania zbioru zdań wspierających zadany zbiór reguł.
Opis techniczny systemu zawiera dodatek A.3.
1Zastosowanie danych wejściowych innej postaci wymaga jedynie zaimplementowania odpowiednichfiltrów.2Niezależny od PARSEVAL.
64

4.2. Estymowanie częstości występowania sekwencji 4. Wyniki eksperymentów
4.2 Estymowanie częstości występowania sekwencji
Kryteria oceny jakości struktur szkieletowych zaproponowane w rozdziale 3.2 wyliczane sąna podstawie prawdopodobieństw wystąpienia sekwencji. Prawdopodobieństwa te możnaestymować z użyciem dostatecznie dużego korpusu języka naturalnego. Zwykle tego ty-pu dane trenujące są zaszumione i wymagają odfiltrowania zdań nienależących do języka.Przeprowadzenie takiego procesu w sposób manualny zwykle jest bardzo kłopotliwe z uwa-gi na ilość materiału tekstowego. Dlatego w eksperymentalnym systemie zaproponowanometodę, która nie wymaga tego typu przygotowania. Dzięki temu proces indukcji grama-tyki może przebiegać w pełni automatycznie, gdyż budowa anotowanego korpusu językapolskiego także przebiega w sposób automatyczny.
Przetworzenie korpusu polegało na pobraniu kolejnych zdań i sprowadzeniu ich dopostaci sekwencji etykiet3 (przykłady znajdują się w tab. 3.6), a następnie przygotowaniutakiej reprezentacji, która umożliwi efektywne obliczanie częstości występowania zadanychsekwencji.
4.2.1 Drzewa przyrostków
Przygotowane sekwencje posłużyły do budowy drzewa przyrostków (ang. suffix trie) [58,148]. Eksperyment pokazał, że mimo bardzo ekonomicznej implementacji węzłów, rozmiardrzewa szybko przekraczał pojemność dostępnej pamięci operacyjnej (4GB) po czym efek-tywność procesu budowy drzewa gwałtownie spadała (poniżej 1% pierwotnej) z uwagi naciągłą wymianę stron pamięci z plikiem wymiany (szamotanie się systemu). Aby przeciw-działać temu zjawisku, wprowadzono procedurę przycinania najmniej obiecujących gałęzireprezentujących rzadkie sekwencje — a zatem te, które są głównie efektem błędu (lite-rówka, sekwencja nietypowa, błąd w analizie morfologicznej). Przycinanie drzewa zostałopodzielone na dwa etapy:
• przycinanie w trakcie budowy drzewa, polegające na usunięciu tych węzłów, dlaktórych długość ścieżki od korzenia drzewa jest większa od zadanej i jednocześnieilość podsekwencji reprezentowanych przez dany węzeł jest mniejsza od zadanej (weksperymencie były to wartości odpowiednio 20 i 2),
• ostateczne przycinanie, przeprowadzone na koniec procesu budowy drzewa, usuwa-jące wszystkie węzły, które reprezentują mniej podsekwencji niż zadana wartość (weksperymencie usuwano węzły, które reprezentowały pojedynczą podsekwencję).
Należy zauważyć, że przycinanie drzewa przyrostków w zaproponowanej postaci praktycz-nie nie wpływa na wynik eksperymentu. Jest to spowodowane w tym, że dla poprawnościuzyskanych wyników każda podsekwencja, dla której liczone były prawdopodobieństwawystąpienia, musiała wystąpić w korpusie co najmniej 5 razy, zatem usunięcie informacjio sekwencjach występujących tylko jednokrotnie nie ma wpływu na wyniki.
Wnioski z przeprowadzonych eksperymentów są następujące:
• użycie drzewa przyrostkowego jest efektywne przy estymowaniu prawdopodobieństw.Natomiast jego budowa wymagała opracowania szeregu mechanizmów i heurystykpozwalających w odpowiednich momentach przycinać budowane drzewo,
• materiał tekstowy zawiera dużo niepowtarzalnych sekwencji, które można usunąćbez wpływu na estymowane prawdopodobieństwa wystąpienia sekwencji.
3Informacja morfologiczna każdego tokenu przetwarzana była z użyciem aktualnego odwzorowania (od-wzorowania omówione są w rozdziale 3.1.2).
65

4.3. Rozbiór przykładowego zdania 4. Wyniki eksperymentów
Problemy z niedostateczną pojemnością pamięci operacyjnej mogą zostać rozwiązane zapomocą suffix arrays, których opis znajduje się np. w artykule [89], jednakże nie było toprzedmiotem eksperymentów.
4.2.2 Index tekstowy Lucene
Jako alternatywny sposób estymowania prawdopodobieństwa wystąpienia danej sekwencjiużyto także indeksu tekstowego Lucene. Jego niewątpliwą zaletą jest praktycznie nie-ograniczony rozmiar przetwarzanego korpusu. Przy indeksowaniu jako dokumenty trak-towano pojedyncze zdania. Wykorzystano tu zapytanie typu SpanTermQuery4 do zlicza-nia wystąpień sekwencji w korpusie. Niestety testy wydajnościowe wykazały, że użycieSpanTermQuery jest nieefektywne, gdy zapytanie dotyczy długich sekwencji i w zapropo-nowanej wersji nie nadaje się do praktycznego zastosowania. Problemem była tu specyfikasamego indeksu ujawniająca się w przypadku poszukiwania wzorców, które mogą na siebienachodzić (tzn. początek i koniec wzorca są identyczne) lub gdy dany wzorzec występowałwielokrotnie w jednym zdaniu. Wykrycie takiej sytuacji wymagało wykonania serii dodat-kowych zapytań, co dodatkowo spowalniało proces estymowania prawdopodobieństw.
4.3 Rozbiór przykładowego zdania
Poniżej przedstawione zostanie użycie algorytmu 3.1 w celu uzyskania rozbioru przykłado-wego zdania (rys. 2.2). W tym przykładzie zostało wybrane odwzorowanie map-flexeme-simple (por. rys. 3.1 i 3.2) przekształcające zdanie w następującą sekwencję:
:adj :subst :fin :adj :subst
Użyto konfiguracji SF5 algorytmu (tab. 3.7). Minimalne wsparcie sekwencji ustawiono nawartość 5.
Nr Ocena Podział1. −0,95123 <Duży pies><goni><małą dziewczynkę>2. −0,95036 <Duży pies><goni małą dziewczynkę>3. −0,89915 <Duży pies goni><małą dziewczynkę>4. −0,35687 <Duży><pies><goni><małą dziewczynkę>5. −0,35687 <Duży pies><goni><małą><dziewczynkę>6. −0,35600 <Duży><pies><goni małą dziewczynkę>7. −0,30478 <Duży pies goni><małą><dziewczynkę>8. −0,21231 <Duży pies><goni małą><dziewczynkę>9. −0,20576 <Duży><pies goni><małą dziewczynkę>10. −0,01849 <Duży pies goni małą><dziewczynkę>11. 0,02321 <Duży><pies goni małą dziewczynkę>12. 0,23749 <Duży><pies><goni><małą><dziewczynkę>13. 0,38204 <Duży><pies><goni małą><dziewczynkę>14. 0,38859 <Duży><pies goni><małą><dziewczynkę>15. 0,57894 <Duży><pies goni małą><dziewczynkę>
Tabela 4.1: Przykładowe zdanie — podział pierwszego rzędu
Pierwszym krokiem jest wygenerowanie wszystkich podziałów pierwszego rzędu i oce-nienie każdego z nich według zdefiniowanego kryterium6. Tabela 4.1 prezentuje wyniki4SpanTermQuery jest elastyczną implementacją zapytań w indeksie tekstowym Lucene pozwalającą na
określenie liczby wystąpień zadanej sekwencji w zaindeksowanym korpusie.5Dla zademonstrowania różnic użyto także nieaddytywnej wersji algorytmu o nazwie SF BEST FIRST.6W tym przypadku kryterium SF omówione w rozdziale 3.2.3.
66

4.3. Rozbiór przykładowego zdania 4. Wyniki eksperymentów
obliczeń. Następujący podział kandydujący pierwszego rzędu został uznany za najlepszy:
<Duży pies><goni><małą dziewczynkę>
Drugim krokiem jest rekursywne dokonanie analogicznych obliczeń dla każdej z wydzielo-nych podsekwencji (tab. 4.2)7.
Nr Ocena Podział
a-1. 0,52537 <Duży>a-2. 0,04854 <Duży><pies>a-3. 0,34004 <Duży><pies goni>a-4. −0,40541 <Duży pies><goni>a-5. 0,18894 <Duży><pies><goni>a-6. 1,05576 <Duży><pies goni><małą>a-7. 0,85887 <Duży><pies><goni małą>a-8. 0,71431 <Duży><pies><goni><małą>a-9. 0,26451 <Duży pies><goni małą>a-10. 0,86542 <Duży pies><goni><małą>a-11. 0,17204 <<Duży pies><goni>><małą>a-12. 0,86542 <Duży><pies goni><małą>a-13. −0,47682 <dziewczynkę>a-14. 0,14039 <goni>a-15. 0,66577 <goni><małą>a-16. −0,40541 <goni><małą dziewczynkę>a-17. 0,33350 <goni małą><dziewczynkę>a-18. 0,18894 <goni><małą><dziewczynkę>a-19. 0,52537 <małą>a-20. 0,04854 <małą><dziewczynkę>a-21. −0,47682 <pies>a-22. −0,33642 <pies><goni>a-23. 0,33350 <pies goni><małą>a-24. −0,40541 <pies><goni małą>a-25. 0,18894 <pies><goni><małą>a-26. −0,88137 <pies><<goni><małą dziewczynkę>>a-27. −0,88224 <pies><goni><małą dziewczynkę>a-28. −0,28788 <pies><goni><małą><dziewczynkę>a-29. −0,73114 <pies goni><małą dziewczynkę>a-30. −0,13677 <pies goni><małą><dziewczynkę>a-31. 0,05356 <<pies goni><małą>><dziewczynkę>a-32. −0,14332 <pies><goni małą><dziewczynkę>
Tabela 4.2: Przykładowe zdanie — podziały kolejnych rzędów
W przypadku nieaddytywnej wersji algorytmu wybrany zostanie najlepszy kandydują-cy podział pierwszego rzędu podzielony rekursywnie z użyciem najlepszych kandydującychpodziałów dla wyznaczonych podsekwencji. Otrzymamy zatem szkielet przedstawiony narys. 4.2b. Oceną szkieletu w tym przypadku pozostaje ocena podziału pierwszego rzę-du. Taki sposób podziału jest efektywny czasowo, jednakże nie uwzględnia sytuacji, gdywybrany podział poprzedniego rzędu nie pozwala na znalezienie dobrego podziału rzęduwyższego. Z taką sytuacją mamy do czynienia w rozpatrywanym przypadku. Najlepszypodział kandydujący pierwszego rzędu rozdziela grupę orzeczenia na dwie części.
7Oczywiście w wersji nieaddytywnej wystarczy rozpatrywać tylko najlepszy podział kandydujący pierw-szego rzędu, w wersji addytywnej należy rozpatrzeć wszystkie przypadki.
67
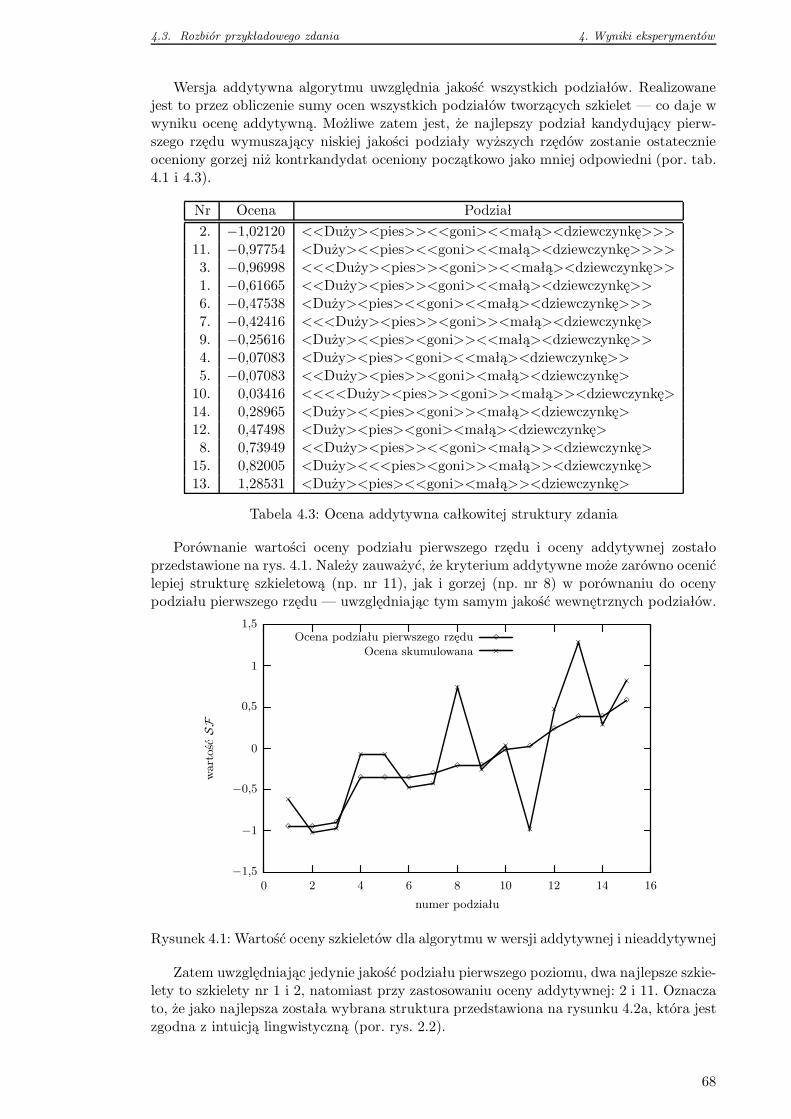
4.3. Rozbiór przykładowego zdania 4. Wyniki eksperymentów
Wersja addytywna algorytmu uwzględnia jakość wszystkich podziałów. Realizowanejest to przez obliczenie sumy ocen wszystkich podziałów tworzących szkielet — co daje wwyniku ocenę addytywną. Możliwe zatem jest, że najlepszy podział kandydujący pierw-szego rzędu wymuszający niskiej jakości podziały wyższych rzędów zostanie ostatecznieoceniony gorzej niż kontrkandydat oceniony początkowo jako mniej odpowiedni (por. tab.4.1 i 4.3).
Nr Ocena Podział2. −1,02120 <<Duży><pies>><<goni><<małą><dziewczynkę>>>11. −0,97754 <Duży><<pies><<goni><<małą><dziewczynkę>>>>3. −0,96998 <<<Duży><pies>><goni>><<małą><dziewczynkę>>1. −0,61665 <<Duży><pies>><goni><<małą><dziewczynkę>>6. −0,47538 <Duży><pies><<goni><<małą><dziewczynkę>>>7. −0,42416 <<<Duży><pies>><goni>><małą><dziewczynkę>9. −0,25616 <Duży><<pies><goni>><<małą><dziewczynkę>>4. −0,07083 <Duży><pies><goni><<małą><dziewczynkę>>5. −0,07083 <<Duży><pies>><goni><małą><dziewczynkę>10. 0,03416 <<<<Duży><pies>><goni>><małą>><dziewczynkę>14. 0,28965 <Duży><<pies><goni>><małą><dziewczynkę>12. 0,47498 <Duży><pies><goni><małą><dziewczynkę>8. 0,73949 <<Duży><pies>><<goni><małą>><dziewczynkę>15. 0,82005 <Duży><<<pies><goni>><małą>><dziewczynkę>13. 1,28531 <Duży><pies><<goni><małą>><dziewczynkę>
Tabela 4.3: Ocena addytywna całkowitej struktury zdania
Porównanie wartości oceny podziału pierwszego rzędu i oceny addytywnej zostałoprzedstawione na rys. 4.1. Należy zauważyć, że kryterium addytywne może zarówno ocenićlepiej strukturę szkieletową (np. nr 11), jak i gorzej (np. nr 8) w porównaniu do ocenypodziału pierwszego rzędu — uwzględniając tym samym jakość wewnętrznych podziałów.
−1,5
−1
−0,5
0
0,5
1
1,5
0 2 4 6 8 10 12 14 16
wartość
SF
numer podziału
Ocena podziału pierwszego rzędu
3 33
3 3 33
3 3
33
3
3 3
3
3
Ocena skumulowana
×
××
× ×
××
×
×
×
×
×
×
×
×
×
Rysunek 4.1: Wartość oceny szkieletów dla algorytmu w wersji addytywnej i nieaddytywnej
Zatem uwzględniając jedynie jakość podziału pierwszego poziomu, dwa najlepsze szkie-lety to szkielety nr 1 i 2, natomiast przy zastosowaniu oceny addytywnej: 2 i 11. Oznaczato, że jako najlepsza została wybrana struktura przedstawiona na rysunku 4.2a, która jestzgodna z intuicją lingwistyczną (por. rys. 2.2).
68

4.4. Struktury szkieletowe 4. Wyniki eksperymentów
<Duży pies> <goni<małą dziewczynkę>> <Duży pies> <goni> <małą dziewczynkę>
a) struktura szkieletowa wygenerowanaaddytywnie
b) struktura szkieletowa wygenerowanienieaddytywnie
Rysunek 4.2: Wygenerowane struktury szkieletowe
4.4 Struktury szkieletowe
Aby ocenić jakość generowanych automatycznie struktur szkieletowych, należy porównaćje ze strukturami szkieletowymi stworzonymi manualnie, przy czym porównywalne są je-dynie struktury szkieletowe zbudowane nad tym samym zdaniem. Wskaźniki służące doporównania zostały omówione w rozdziale 2.4.1. Jako punkt odniesienia dla uzyskanychwyników należy wziąć wyniki uzyskiwane przez inne algorytmy na tych samych danychtestowych.
Korpus manualnie stworzonych struktur szkieletowych (zwanych dalej korpusem te-stowym) składał się z 254 zdań wybranych spośród 57 817 zdań korpusu anotowanegomorfologicznie i strukturalnie. Wybrano zdania, których ocena struktur szkieletowychstworzonych automatycznie była najlepsza — oznacza to zdania, w których występujązwiązki wyrazowe, do których wydzielenia były silne przesłanki statystyczne, a co za tymidzie, jakość wygenerowanych struktur szkieletowych była wysoka. Ten sposób wyborupozwolił także wyeliminować w sposób automatyczny zdania o niskiej jakości, takie jaknp.:
Jan Kowalski ( IV LO ) - 33 . 41 ; 50 m st . motylkowym - 1 .
Wybrane zdania, niezależnie od anotacji strukturalnej automatycznej, zostały anotowanestrukturalnie w sposób manualny.
Eksperymenty przeprowadzone były dla wszystkich odwzorowań (tab. 3.5). Zapropono-wane w niniejszej rozprawie algorytmy były testowane w konfiguracjach: SF, SF NOINC,SF BEST FIRST, SF BEST FIRST NOINC (por. tab. 3.7). Jako danych trenujących uży-to 249 598 odwzorowanych zdań.
Porównano otrzymane wyniki z wynikami uzyskanymi z użyciem systemów ABL i EMI-LE (opisanych w rozdziale 2.6.2). Jednakże okazało się, że korpus trenujący 249 598 zdańjest poza możliwościami obu systemów — z uwagi na czas działania i na zajętość pamięcioperacyjnej. Akceptowane czasy (do 3 godzin dla jednej iteracji) uzyskano zmniejszająckorpus trenujący do 10 000 zdań.
Ostatecznie każdy z systemów wygenerował struktury szkieletowe na zdaniach z kor-pusu testowego. Porównanie wyników działania wszystkich systemów z uwzględnieniemwszystkich odwzorowań znajdują się w tabeli 4.4. Wartości zostały obliczone za pomocąprogramu evalb będącego implementacją miary PARSEVAL.8
Analizując wspomnianą tabelę, możemy zauważyć, że pokrycie dla proponowanychw niniejszej rozprawie algorytmów oscyluje w granicach 23%–44%, co oznacza, że będącalgorytmami bez nadzoru potrafią wykryć do 44% struktur nawiasowych zaproponowanychprzez człowieka i to przy precyzji 40%. Należy uważać to za wynik dobry, zwłaszcza, że8Ponieważ postać struktur szkieletowych generowanych przez oba systemy jest różna od tej, jakiej
oczekuje program evalb, dokonano stosownych konwersji.
69
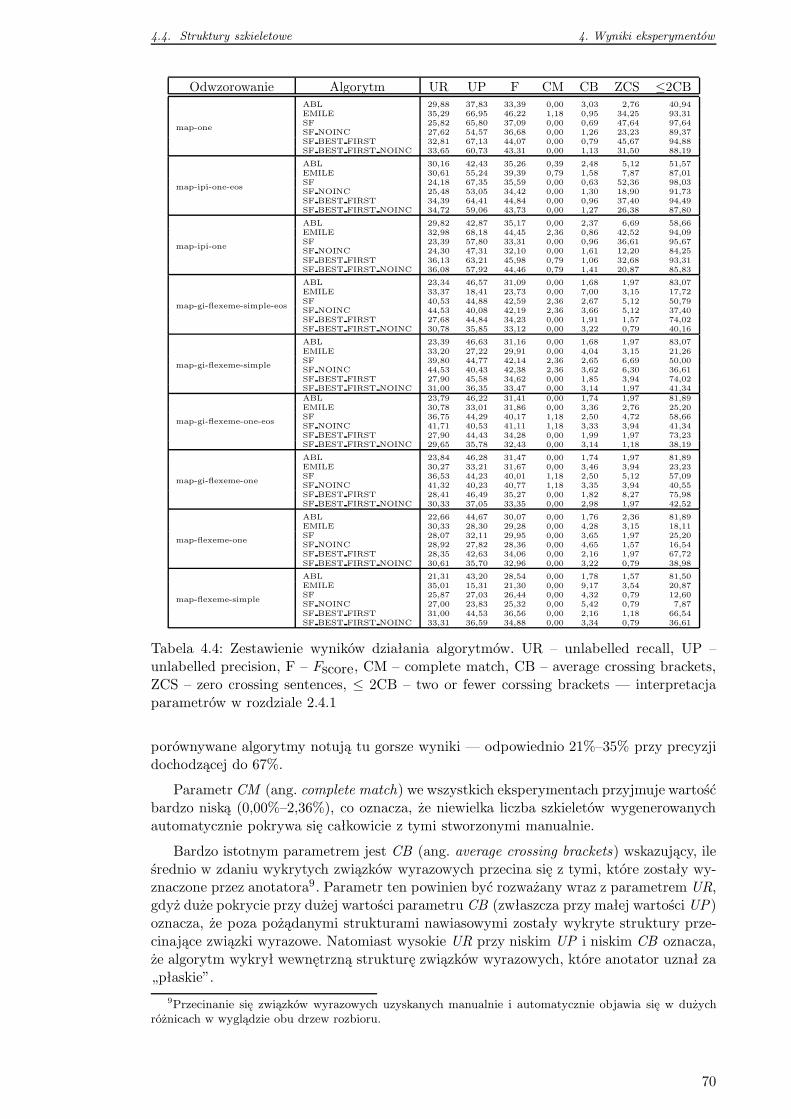
4.4. Struktury szkieletowe 4. Wyniki eksperymentów
Odwzorowanie Algorytm UR UP F CM CB ZCS ≤2CB
map-one
ABL 29,88 37,83 33,39 0,00 3,03 2,76 40,94EMILE 35,29 66,95 46,22 1,18 0,95 34,25 93,31SF 25,82 65,80 37,09 0,00 0,69 47,64 97,64SF NOINC 27,62 54,57 36,68 0,00 1,26 23,23 89,37SF BEST FIRST 32,81 67,13 44,07 0,00 0,79 45,67 94,88SF BEST FIRST NOINC 33,65 60,73 43,31 0,00 1,13 31,50 88,19
map-ipi-one-eos
ABL 30,16 42,43 35,26 0,39 2,48 5,12 51,57EMILE 30,61 55,24 39,39 0,79 1,58 7,87 87,01SF 24,18 67,35 35,59 0,00 0,63 52,36 98,03SF NOINC 25,48 53,05 34,42 0,00 1,30 18,90 91,73SF BEST FIRST 34,39 64,41 44,84 0,00 0,96 37,40 94,49SF BEST FIRST NOINC 34,72 59,06 43,73 0,00 1,27 26,38 87,80
map-ipi-one
ABL 29,82 42,87 35,17 0,00 2,37 6,69 58,66EMILE 32,98 68,18 44,45 2,36 0,86 42,52 94,09SF 23,39 57,80 33,31 0,00 0,96 36,61 95,67SF NOINC 24,30 47,31 32,10 0,00 1,61 12,20 84,25
SF BEST FIRST 36,13 63,21 45,98 0,79 1,06 32,68 93,31SF BEST FIRST NOINC 36,08 57,92 44,46 0,79 1,41 20,87 85,83
map-gi-flexeme-simple-eos
ABL 23,34 46,57 31,09 0,00 1,68 1,97 83,07EMILE 33,37 18,41 23,73 0,00 7,00 3,15 17,72
SF 40,53 44,88 42,59 2,36 2,67 5,12 50,79SF NOINC 44,53 40,08 42,19 2,36 3,66 5,12 37,40SF BEST FIRST 27,68 44,84 34,23 0,00 1,91 1,57 74,02SF BEST FIRST NOINC 30,78 35,85 33,12 0,00 3,22 0,79 40,16
map-gi-flexeme-simple
ABL 23,39 46,63 31,16 0,00 1,68 1,97 83,07
EMILE 33,20 27,22 29,91 0,00 4,04 3,15 21,26SF 39,80 44,77 42,14 2,36 2,65 6,69 50,00SF NOINC 44,53 40,43 42,38 2,36 3,62 6,30 36,61SF BEST FIRST 27,90 45,58 34,62 0,00 1,85 3,94 74,02SF BEST FIRST NOINC 31,00 36,35 33,47 0,00 3,14 1,97 41,34
map-gi-flexeme-one-eos
ABL 23,79 46,22 31,41 0,00 1,74 1,97 81,89EMILE 30,78 33,01 31,86 0,00 3,36 2,76 25,20SF 36,75 44,29 40,17 1,18 2,50 4,72 58,66SF NOINC 41,71 40,53 41,11 1,18 3,33 3,94 41,34SF BEST FIRST 27,90 44,43 34,28 0,00 1,99 1,97 73,23SF BEST FIRST NOINC 29,65 35,78 32,43 0,00 3,14 1,18 38,19
map-gi-flexeme-one
ABL 23,84 46,28 31,47 0,00 1,74 1,97 81,89EMILE 30,27 33,21 31,67 0,00 3,46 3,94 23,23SF 36,53 44,23 40,01 1,18 2,50 5,12 57,09SF NOINC 41,32 40,23 40,77 1,18 3,35 3,94 40,55SF BEST FIRST 28,41 46,49 35,27 0,00 1,82 8,27 75,98SF BEST FIRST NOINC 30,33 37,05 33,35 0,00 2,98 1,97 42,52
map-flexeme-one
ABL 22,66 44,67 30,07 0,00 1,76 2,36 81,89EMILE 30,33 28,30 29,28 0,00 4,28 3,15 18,11SF 28,07 32,11 29,95 0,00 3,65 1,97 25,20SF NOINC 28,92 27,82 28,36 0,00 4,65 1,57 16,54SF BEST FIRST 28,35 42,63 34,06 0,00 2,16 1,97 67,72
SF BEST FIRST NOINC 30,61 35,70 32,96 0,00 3,22 0,79 38,98
map-flexeme-simple
ABL 21,31 43,20 28,54 0,00 1,78 1,57 81,50EMILE 35,01 15,31 21,30 0,00 9,17 3,54 20,87SF 25,87 27,03 26,44 0,00 4,32 0,79 12,60SF NOINC 27,00 23,83 25,32 0,00 5,42 0,79 7,87
SF BEST FIRST 31,00 44,53 36,56 0,00 2,16 1,18 66,54SF BEST FIRST NOINC 33,31 36,59 34,88 0,00 3,34 0,79 36,61
Tabela 4.4: Zestawienie wyników działania algorytmów. UR – unlabelled recall, UP –unlabelled precision, F – Fscore, CM – complete match, CB – average crossing brackets,ZCS – zero crossing sentences, ≤ 2CB – two or fewer corssing brackets — interpretacjaparametrów w rozdziale 2.4.1
porównywane algorytmy notują tu gorsze wyniki — odpowiednio 21%–35% przy precyzjidochodzącej do 67%.
Parametr CM (ang. complete match) we wszystkich eksperymentach przyjmuje wartośćbardzo niską (0,00%–2,36%), co oznacza, że niewielka liczba szkieletów wygenerowanychautomatycznie pokrywa się całkowicie z tymi stworzonymi manualnie.
Bardzo istotnym parametrem jest CB (ang. average crossing brackets) wskazujący, ileśrednio w zdaniu wykrytych związków wyrazowych przecina się z tymi, które zostały wy-znaczone przez anotatora9. Parametr ten powinien być rozważany wraz z parametrem UR,gdyż duże pokrycie przy dużej wartości parametru CB (zwłaszcza przy małej wartości UP)oznacza, że poza pożądanymi strukturami nawiasowymi zostały wykryte struktury prze-cinające związki wyrazowe. Natomiast wysokie UR przy niskim UP i niskim CB oznacza,że algorytm wykrył wewnętrzną strukturę związków wyrazowych, które anotator uznał za„płaskie”.
9Przecinanie się związków wyrazowych uzyskanych manualnie i automatycznie objawia się w dużychróżnicach w wyglądzie obu drzew rozbioru.
70
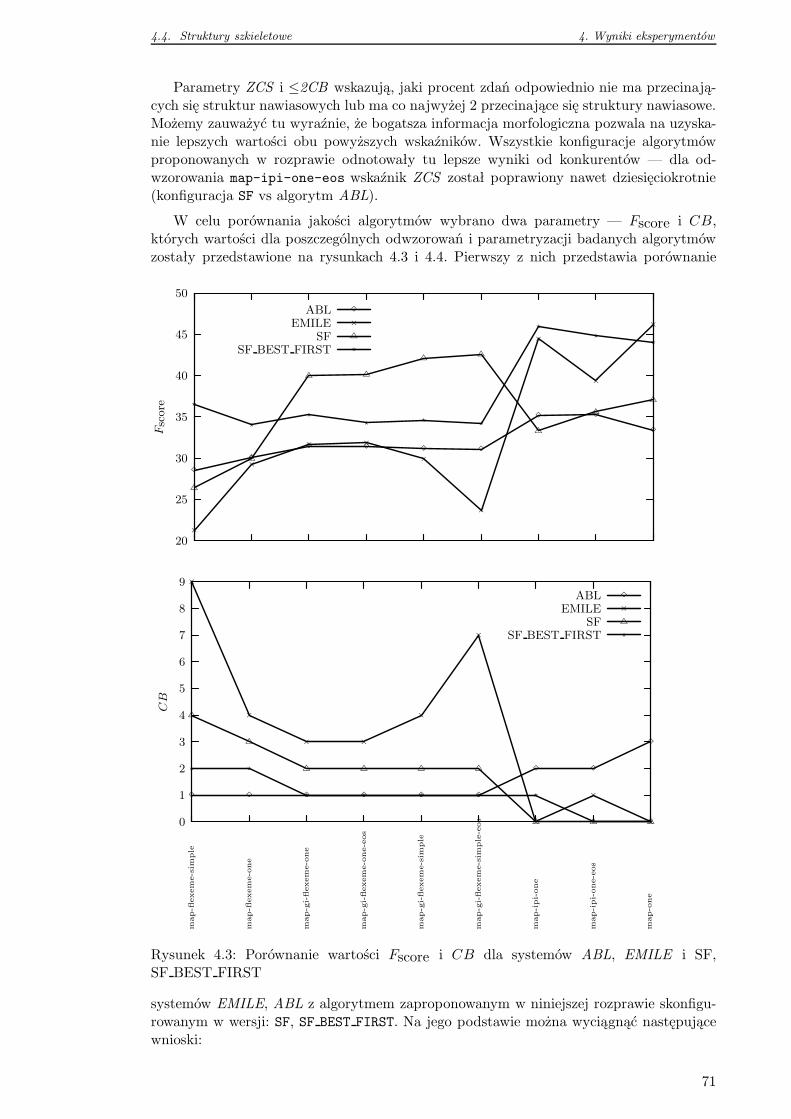
4.4. Struktury szkieletowe 4. Wyniki eksperymentów
Parametry ZCS i ≤2CB wskazują, jaki procent zdań odpowiednio nie ma przecinają-cych się struktur nawiasowych lub ma co najwyżej 2 przecinające się struktury nawiasowe.Możemy zauważyć tu wyraźnie, że bogatsza informacja morfologiczna pozwala na uzyska-nie lepszych wartości obu powyższych wskaźników. Wszystkie konfiguracje algorytmówproponowanych w rozprawie odnotowały tu lepsze wyniki od konkurentów — dla od-wzorowania map-ipi-one-eos wskaźnik ZCS został poprawiony nawet dziesięciokrotnie(konfiguracja SF vs algorytm ABL).
W celu porównania jakości algorytmów wybrano dwa parametry — Fscore i CB,których wartości dla poszczególnych odwzorowań i parametryzacji badanych algorytmówzostały przedstawione na rysunkach 4.3 i 4.4. Pierwszy z nich przedstawia porównanie
20
25
30
35
40
45
50
Fscore
ABL
3
3
3 3 3 3
3 3
3
3
EMILE
×
×
× ×
×
×
×
×
××
SF
△
△
△ △
△ △
△
△
△
△
SF BEST FIRST
⋆
⋆
⋆⋆ ⋆ ⋆
⋆
⋆⋆
⋆
0
1
2
3
4
5
6
7
8
9
map-one
map-ipi-one-eos
map-ipi-one
map-gi-flexeme-simple-eos
map-gi-flexeme-simple
map-gi-flexeme-one-eos
map-gi-flexeme-one
map-flexeme-one
map-flexeme-simple
CB
ABL
3 3 3 3 3 3
3 3
3
3
EMILE
×
×
× ×
×
×
×
×
×
×
SF
△
△
△ △ △ △
△ △ △
△
SF BEST FIRST
⋆ ⋆
⋆ ⋆ ⋆ ⋆ ⋆
⋆ ⋆
⋆
Rysunek 4.3: Porównanie wartości Fscore i CB dla systemów ABL, EMILE i SF,SF BEST FIRST
systemów EMILE, ABL z algorytmem zaproponowanym w niniejszej rozprawie skonfigu-rowanym w wersji: SF, SF BEST FIRST. Na jego podstawie można wyciągnąć następującewnioski:
71

4.5. Reguły gramatyki 4. Wyniki eksperymentów
• bogatsza informacja morfologiczna pozwala poprawić jakość struktur szkieletowych— widać to zwłaszcza w przypadku systemu EMILE, który znacząco poprawia jakośćswego działania dla odwzorowań map-ipi-one, map-ipi-one-eos, map-one,
• prawie dla wszystkich odwzorowań algorytmy proponowane w rozprawie notują lep-sze rezultaty w porównaniu z badanymi konkurentami. Możemy zauważyć, że dlabogatej informacji morfologicznej lepsze rezultaty dają algorytmy z nieaddytywnaoceną szkieletów (np. SF BEST FIRST), natomiast w przypadku wystąpienia uboższejinformacji morfologicznej lepsze są algorytmy z addytywną oceną szkieletów (np. SF).Jest to istotna cecha, gdyż nie zawsze możemy zastosować pełną informacje morfo-logiczną — wymaga ona dostępności odpowiednio dużego korpusu trenującego, ta-kiego, w którym wszystkie sekwencje odwzorowań wyrazów będą dostatecznie częstowystępowały. W przypadkach, gdy taki korpus nie jest dostępny, możemy zmniej-szyć wymagania na jego rozmiar, stosując uboższe odwzorowanie — które zapewninam nadal odpowiednio gęstą reprezentację. Aby nie nastąpiła znaczna utrata ja-kości generowanych szkieletów, należy wtedy zastosować addytywną ocenę strukturszkieletowych,
• można zauważyć korelację między współczynnikami Fscore i CB. Wzrost wartościFscore oznacza także obniżenie średniej wartości CB — jest to zgodne z intuicją,gdyż jednoczesny wzrost precyzji i pokrycia powinien powodować obniżenie liczbyprzecinających się struktur szkieletowych.
Aby porównać wpływ parametru I (por. roz. 3.3.1) na rys. 4.4 porównano wartości Fscorei CB uzyskane przez algorytm zaproponowany w niniejszej rozprawie dla następującychparametryzacji: SF, SF NOINC, SF BEST FIRST, SF BEST FIRST NOINC. Należy zauważyć,że ustawienie parametru I generalnie powoduje nieznaczne pogorszenie jakości tworzo-nych struktur szkieletowych — zarówno Fscore i CB. Jedynie w przypadku odwzoro-wań map-gi-flexeme-one, map-gi-flexeme-one-eos, map-gi-flexeme-simple nastąpi-ła nieznaczna poprawa, jednakże tylko dla parametryzacji SF i SF NOINC. Zatem należywnioskować, że dla nieaddytywnej oceny szkieletów ustawienie parametru I powodujepogorszenie wyników, natomiast dla oceny addytywnej wynik jest zależny od odwzorowa-nia. Należy zauważyć, że ustawiony parametr I powoduje, że algorytm ma tendencje dowykrywania dłuższych związków wyrazowych, co może powodować pogorszenie wyników.
4.5 Reguły gramatyki
Aby ocenić jakość reguł gramatyki wykonano szereg eksperymentów, w których zbadanonastępujące zależności:
• liczbę reguł w funkcji RCFG2sup,10
• rozkład liczby reguł w funkcji S-sup11 i RCFG2sup,
• pokrycie wyindukowanego zbioru reguł na zbiorze trenującym w funkcji RCFG2sup,
• pokrycie wyindukowanego zbioru reguł na zbiorze testowym w funkcji RCFG2sup.
Wszystkie eksperymenty przeprowadzono dla parametryzacji przedstawionych w tabeli3.7, odwzorowań przedstawionych w tabeli 3.5 i następujących wartości RCFG2sup: 50,100, 200, 400, 800, 1600, 3200, 6400, 12800, 25600, 51200. Poniżej zamieszczono wybranewykresy będące ich efektem. Wszystkie wykresy stanowią treść dodatku A.4. Rozmiarkorpusu anotowanego strukturalnie użytego do eksperymentów to 58 000 zdań i około1 000 000 struktur nawiasowych.10Interpretacja parametru w rozdziale 3.3.4.11Definicja 17 na stronie 34.
72
4.5. Reguły gramatyki 4. Wyniki eksperymentów
25
30
35
40
45
50
Fscore
SF
△
△
△ △
△△
△
△
△
△
SF NOINC
3
3
33
3 3
3
3
3
3
SF BEST FIRST
⋆
⋆
⋆
⋆ ⋆⋆
⋆
⋆⋆
⋆
SF BEST FIRST NOINC
0
1
2
3
4
5
map-one
map-ipi-one-eos
map-ipi-one
map-gi-flexeme-simple-eos
map-gi-flexeme-simple
map-gi-flexeme-one-eos
map-gi-flexeme-one
map-flexeme-one
map-flexeme-simple
CB
SF
△
△
△ △ △ △
△ △ △
△
SF NOINC
3
3
3 3 3 3
3 3 3
3
SF BEST FIRST
⋆ ⋆
⋆ ⋆ ⋆ ⋆ ⋆
⋆ ⋆
⋆
SF BEST FIRST NOINC
Rysunek 4.4: Porównanie wartości Fscore i CB dla SF, SF NOINC, SF BEST FIRST,SF BEST FIRST NOINC
73
4.5. Reguły gramatyki 4. Wyniki eksperymentów
4.5.1 Indukowanie reguł na zbiorze trenującym
Na rysunku 4.5 przedstawiono zależność liczby reguł i symboli nieterminalnych od para-metru RCFG2sup. Analizując ich przebieg możemy wyciągnąć następujące wnioski:
liczba reguł liczba symboli nieterminalnych
80k70k60k50k40k30k20k10k010 100 1000 10000
RCFG2sup
map-gi-flexeme-one-eos
△ △
△
△
△ △ △ △ △ △
22
2
2
2
22 2 2 2
33
3
3
3
3
3 3 3 3
30k
25k
20k
15k
10k
5k
1k10 100 1000 10000
RCFG2sup
map-gi-flexeme-one-eos
△ △ △△
△ △ △ △ △ △
2 22
2
2
22
2 2 2
3 3
3
3
3
3 3 3 3
SF
SF BEST FIRST △
SF BEST FIRST NOINC 2
SF NOINC 3
SF
SF BEST FIRST △
SF BEST FIRST NOINC 2
SF NOINC 3
Rysunek 4.5: Liczba reguł i symboli nieterminalnych w funkcji RCFG2sup dla odwzoro-wania map-gi-flexeme-one-eos
• liczba reguł i liczba symboli nieterminalnych mają parami podobny przebieg —choć odpowiednie wartości bezwzględne różnią się między sobą. Związane jest toz procesem unifikacji reguł — unifikacja symboli nieterminalnych pociąga za sobąunifikację reguł,
• RCFG2sup steruje efektywnością drugiej fazy unifikacji reguł (por. roz. 3.3.4). Zmia-na jego wartości pozwala zunifikować inicjalny zbiór do kilkudziesięciu reguł (dlaniektórych odwzorowań, por. rys. A.3) — przy niskich wartościach parametru lubteż zupełnie wyłączyć tę fazę unifikacji — dla wartości wysokich (zależnych od od-wzorowania, por. rys. A.3, A.4, A.2). Należy zauważyć, że dla pewnych wartościRCFG2sup (specyficznych dla danego odwzorowania) zwiększanie wartości tego pa-rametru nie zmienia już ilości reguł i symboli terminalnych. Oznacza to, że drugafaza unifikacji została praktycznie wyłączona. Dlatego użyteczny zakres wartościRCFG2sup znajduje się w przedziale, w którym przebieg wykresu jest stromy —tam należy szukać odpowiedniej wartości właściwej dla konkretnego zastosowania.W miejscach wypłaszczeń zmiana wartości nie przyniesie żadnych rezultatów,
• wersje algorytmów z ustawionym parametrem I notują większe wartości liczby reguł isymboli nieterminalnych od odpowiedników bez ustawionego parametru, co oznacza,że te wersje algorytmu generują bardziej różnorodne reguły, trudniej poddające sięprocesowi unifikacji, a zatem mniej ogólne,
• odwzorowania upraszczające (map-flexeme-simple, map-flexeme-one) powodują,że proces unifikacji przebiega z większą intensywnością w porównaniu z innymi od-wzorowaniami, co daje w efekcie niewielką liczbę reguł i symboli nieterminalnych.Zatem dla tych odwzorowań parametr RCFG2sup powinien być ustawiany na war-tość wysoką (np. 10000),
• maksymalna liczba reguł i symboli nieterminalnych zależy od rodzaju użytego algo-rytmu. Rodzaj odwzorowania ma tu drugorzędne znaczenie.
74

4.5. Reguły gramatyki 4. Wyniki eksperymentów
110
1001000 10
1001000
10000100000
1
10
100
1000
10000
100000
map-gi-flexeme-one
S-supRCFG2sup
110
1001000 10
1001000
10000100000
1
10
100
1000
10000
100000
map-gi-flexeme-one-eos
S-supRCFG2sup
Rysunek 4.6: Liczba reguł w funkcji S-sup i RCFG2sup dla parametryzacji SF NOINC
Kolejną ważną zależnością jest rozkład liczby reguł w funkcji wsparcia reguły S-sup dlaróżnych wartości parametru RCFG2sup (rys. 4.6). Zwraca uwagę fakt, że znaczna licz-ba spośród ogólnej liczby reguł ma wsparcie równe 1 — odsetek ten wynosi od 60% do95%, co doskonale pokazuje rysunek 4.7. Manipulowanie parametrem RCFG2sup pozwa-la wpływać na rozkład ilości reguł w funkcji wsparcia S-sup. Reguły o niskim wsparciusą efektem szumu w danych trenujących. Przeprowadzono zatem następny eksperyment,który pokazał, jaki wpływ ma usunięcie reguł o najniższym wsparciu na pokrycie zbiorutrenującego. Jak pokazano na rysunku 4.8, mimo usunięcia reguł o najmniejszym wspar-ciu, pokrycie zbioru trenującego pozostaje nadal wysokie — zwłaszcza dla odwzorowaniamap-gi-flexeme-one. Należy to tłumaczyć faktem, że około 10% reguł o najwyższymwsparciu zapewnia 90% pokrycia zbioru testowego. Wnikliwy przegląd reguł o wyższymwsparciu ujawnił istnienie reguł o wsparciu powyżej 10 000. Na rysunku 4.6 uwidocznionesą one w miejscu wypłaszczenia wykresu dla wartości S-sup większych od 1 000.
Na podstawie rys. 4.8 możemy wyciągnąć następujące wnioski:
• zwiększanie parametru RCFG2sup zmniejsza ogólność indukowanych reguł, co ob-jawia się zwiększonym wpływem S-sup na pokrycie,
• istnieje taka wartość S-sup, dla której pokrycie gwałtownie spada — na prezentowa-
75
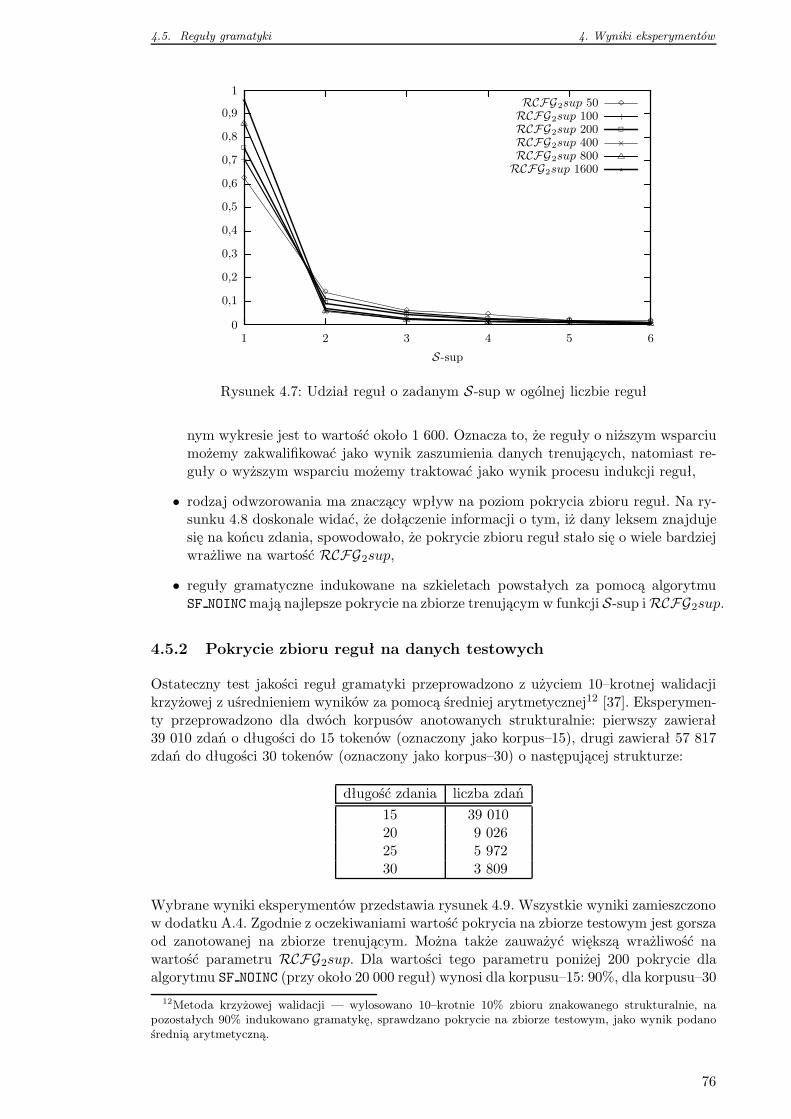
4.5. Reguły gramatyki 4. Wyniki eksperymentów
0
0,1
0,2
0,3
0,4
0,5
0,6
0,7
0,8
0,9
1
1 2 3 4 5 6
S-sup
RCFG2sup 50
3
3
33
3 3
3
RCFG2sup 100
+
+
++ + +
+
RCFG2sup 200
2
2
22 2 2
2
RCFG2sup 400
×
×× × × ×
×
RCFG2sup 800
△
△△ △ △ △
△
RCFG2sup 1600
⋆
⋆
⋆ ⋆ ⋆ ⋆
⋆
Rysunek 4.7: Udział reguł o zadanym S-sup w ogólnej liczbie reguł
nym wykresie jest to wartość około 1 600. Oznacza to, że reguły o niższym wsparciumożemy zakwalifikować jako wynik zaszumienia danych trenujących, natomiast re-guły o wyższym wsparciu możemy traktować jako wynik procesu indukcji reguł,
• rodzaj odwzorowania ma znaczący wpływ na poziom pokrycia zbioru reguł. Na ry-sunku 4.8 doskonale widać, że dołączenie informacji o tym, iż dany leksem znajdujesię na końcu zdania, spowodowało, że pokrycie zbioru reguł stało się o wiele bardziejwrażliwe na wartość RCFG2sup,
• reguły gramatyczne indukowane na szkieletach powstałych za pomocą algorytmuSF NOINCmają najlepsze pokrycie na zbiorze trenującym w funkcji S-sup iRCFG2sup.
4.5.2 Pokrycie zbioru reguł na danych testowych
Ostateczny test jakości reguł gramatyki przeprowadzono z użyciem 10–krotnej walidacjikrzyżowej z uśrednieniem wyników za pomocą średniej arytmetycznej12 [37]. Eksperymen-ty przeprowadzono dla dwóch korpusów anotowanych strukturalnie: pierwszy zawierał39 010 zdań o długości do 15 tokenów (oznaczony jako korpus–15), drugi zawierał 57 817zdań do długości 30 tokenów (oznaczony jako korpus–30) o następującej strukturze:
długość zdania liczba zdań
15 39 01020 9 02625 5 97230 3 809
Wybrane wyniki eksperymentów przedstawia rysunek 4.9. Wszystkie wyniki zamieszczonow dodatku A.4. Zgodnie z oczekiwaniami wartość pokrycia na zbiorze testowym jest gorszaod zanotowanej na zbiorze trenującym. Można także zauważyć większą wrażliwość nawartość parametru RCFG2sup. Dla wartości tego parametru poniżej 200 pokrycie dlaalgorytmu SF NOINC (przy około 20 000 reguł) wynosi dla korpusu–15: 90%, dla korpusu–30
12Metoda krzyżowej walidacji — wylosowano 10–krotnie 10% zbioru znakowanego strukturalnie, napozostałych 90% indukowano gramatykę, sprawdzano pokrycie na zbiorze testowym, jako wynik podanośrednią arytmetyczną.
76

4.5. Reguły gramatyki 4. Wyniki eksperymentów
map-gi-flexeme-one
SF BEST FIRST-400
SF BEST FIRST-200
SF BEST FIRST-100
SF BEST FIRST-50
SF BEST FIRST NOINC-400
SF BEST FIRST NOINC-200
SF BEST FIRST NOINC-100
SF BEST FIRST NOINC-50
SF NOINC-400
SF NOINC-200
SF NOINC-100
SF NOINC-50
SF-400
SF-200
SF-100SF-50
algorytm-RCFG2sup
1 10 100 1000 10000 100000S-sup
00, 10, 20, 30, 40, 50, 60, 70, 80, 9
1
map-gi-flexeme-one-eos
SF BEST FIRST-400
SF BEST FIRST-200
SF BEST FIRST-100
SF BEST FIRST-50
SF BEST FIRST NOINC-400
SF BEST FIRST NOINC-200
SF BEST FIRST NOINC-100
SF BEST FIRST NOINC-50
SF NOINC-400
SF NOINC-200
SF NOINC-100
SF NOINC-50
SF-400
SF-200
SF-100SF-50
algorytm-RCFG2sup
1 10 100 1000 10000 100000S-sup
0
0, 2
0, 4
0, 6
0, 8
1
Rysunek 4.8: Pokrycie zbioru reguł dla różnych konfiguracji algorytmów, RCFG2sup iminimalnego wsparcia reguł S-sup
77
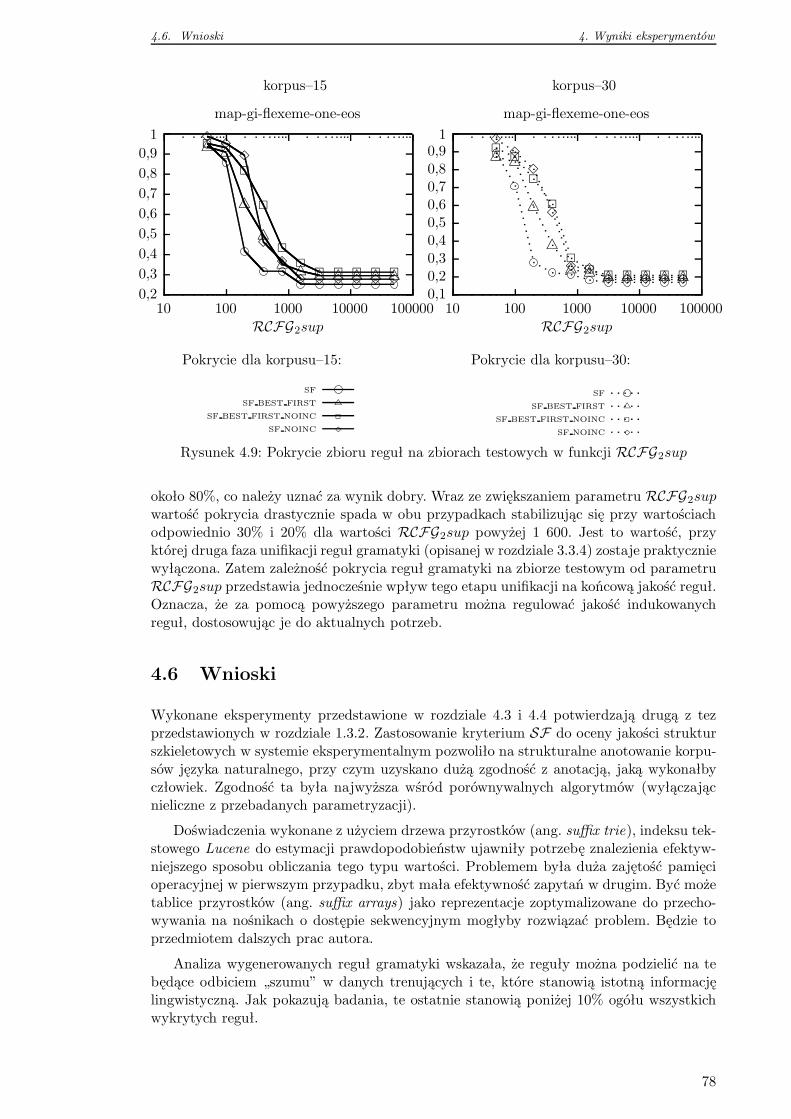
4.6. Wnioski 4. Wyniki eksperymentów
korpus–15 korpus–30
0,2
0,3
0,4
0,5
0,6
0,7
0,8
0,9
1
10 100 1000 10000 100000
RCFG2sup
map-gi-flexeme-one-eos
33
3
3
3
3 3 3 3 3 3
2 2
2
2
2
22 2 2 2 2
△ △
△
△
△ △ △ △ △ △ △
0,10,20,30,40,50,60,70,80,9
1
10 100 1000 10000 100000
RCFG2sup
map-gi-flexeme-one-eos
3
3
3
3
3 33 3 3 3 3
22
2
2
22
2 2 2 2 2
△ △
△
△
△ △ △ △ △ △ △
Pokrycie dla korpusu–15:
SF
SF BEST FIRST △
SF BEST FIRST NOINC 2
SF NOINC 3
Pokrycie dla korpusu–30:
SF
SF BEST FIRST △
SF BEST FIRST NOINC 2
SF NOINC 3
Rysunek 4.9: Pokrycie zbioru reguł na zbiorach testowych w funkcji RCFG2sup
około 80%, co należy uznać za wynik dobry. Wraz ze zwiększaniem parametru RCFG2supwartość pokrycia drastycznie spada w obu przypadkach stabilizując się przy wartościachodpowiednio 30% i 20% dla wartości RCFG2sup powyżej 1 600. Jest to wartość, przyktórej druga faza unifikacji reguł gramatyki (opisanej w rozdziale 3.3.4) zostaje praktyczniewyłączona. Zatem zależność pokrycia reguł gramatyki na zbiorze testowym od parametruRCFG2sup przedstawia jednocześnie wpływ tego etapu unifikacji na końcową jakość reguł.Oznacza, że za pomocą powyższego parametru można regulować jakość indukowanychreguł, dostosowując je do aktualnych potrzeb.
4.6 Wnioski
Wykonane eksperymenty przedstawione w rozdziale 4.3 i 4.4 potwierdzają drugą z tezprzedstawionych w rozdziale 1.3.2. Zastosowanie kryterium SF do oceny jakości strukturszkieletowych w systemie eksperymentalnym pozwoliło na strukturalne anotowanie korpu-sów języka naturalnego, przy czym uzyskano dużą zgodność z anotacją, jaką wykonałbyczłowiek. Zgodność ta była najwyższa wśród porównywalnych algorytmów (wyłączającnieliczne z przebadanych parametryzacji).
Doświadczenia wykonane z użyciem drzewa przyrostków (ang. suffix trie), indeksu tek-stowego Lucene do estymacji prawdopodobieństw ujawniły potrzebę znalezienia efektyw-niejszego sposobu obliczania tego typu wartości. Problemem była duża zajętość pamięcioperacyjnej w pierwszym przypadku, zbyt mała efektywność zapytań w drugim. Być możetablice przyrostków (ang. suffix arrays) jako reprezentacje zoptymalizowane do przecho-wywania na nośnikach o dostępie sekwencyjnym mogłyby rozwiązać problem. Będzie toprzedmiotem dalszych prac autora.
Analiza wygenerowanych reguł gramatyki wskazała, że reguły można podzielić na tebędące odbiciem „szumu” w danych trenujących i te, które stanowią istotną informacjęlingwistyczną. Jak pokazują badania, te ostatnie stanowią poniżej 10% ogółu wszystkichwykrytych reguł.
78

4.6. Wnioski 4. Wyniki eksperymentów
Przebadano wiele odwzorowań — od silnie upraszczających do wzbogacających infor-mację morfologiczną. Wskazano różnice w zachowaniu się proponowanego kryterium dlakażdego z nich. Pokazano także wpływ współczynnika RCFG2sup na ilość i jakość reguł.Szczegółowe wykresy znajdują się w dodatku A.4.
Przeprowadzone eksperymenty wskazały, że brak gazetteera powodował pojawieniesię błędów w rozbiorze nazw geograficznych, nazw towarzystw, etc. — w prezentowanejwersji algorytm dokonywał podziałów, mimo że powinny stanowić całość i tak też byćtraktowane przy liczeniu odpowiednich prawdopodobieństw. Także sposób anotowania,który w badanej wersji nie wykrywał takich tokenów jak wielokropek (traktując go jakosekwencje trzech osobnych tokenów), powodował, że podejmowane były próby nałożeniastruktury na tę sekwencje — w większości przypadków nałożona struktura łączyła je wjeden symbol nieterminalny. Mimo wspomnianych usterek w korpusie trenującym uzyskanewyniki należy ocenić jako dobre.
79

Indukcja reguł gramatyki języka polskiego
Rozdział 5
Propozycje zastosowańNo rule is so general,which admits not some exception.Robert Burton
5.1 Automatyczne anotowanie strukturalne
Podstawowym zastosowaniem przedstawionych w niniejszej rozprawie technik jest auto-matyczne anotowanie strukturalne tekstu w języku naturalnym. W zależności od wartościparametrów procesu strukturalizowania otrzymamy struktury szkieletowe o różnych wła-ściwościach przydatnych w określonych szczegółowych zastosowaniach. Dlatego parametryte powinny być dobierane z uwzględnieniem specyfiki przetwarzanego materiału tekstowe-go (np. tak, aby uniknąć problemu niedostatecznej ilości danych trenujących), a takżespecyfiki zastosowania wynikowych struktur szkieletowych. Proces doboru parametrówmożna zautomatyzować używając algorytmów genetycznych [12] (szczególnie odwzorowa-nia opisane w rozdziale 3.1.2 były projektowane z myślą o tej metodzie) lub metod uczeniaze wzmocnieniem (ang. reinforcement learning) [37].
5.2 Grupowanie i kategoryzacja dokumentów
Systemy automatycznej kategoryzacji i grupowania dokumentów wykorzystują algorytmy,które możemy podzielić na:
1. specjalizowane — przygotowane specjalnie do przetwarzania danych tekstowych.Przykładem może tu być np. algorytm STC prezentowany w [148],
2. ogólnego zastosowania, np. support vector machines (SVM) [28], k–nearest neighbor(kNN), naiwny klasyfikator bayesowski [37].
Zaletą drugiego podejścia jest mnogość dostępnych algorytmów, wadą konieczność przy-gotowania akceptowalnej przez algorytmy reprezentacji dokumentów. Klasycznym podej-ściem jest przedstawienie dokumentu jako wektora (macierzy, czy hiperkostki) liczb od-powiadających częstości występowania odpowiednio wyselekcjonowanych słów (lub odpo-wiednio bigramów, czy n–gramów). Podejście to zostało dokładnie opisane przez Gawry-siaka w [51]. Zauważa on, że reprezentacja n–gramowa jest niezwykle kłopotliwa w prze-twarzaniu z uwagi na jej rozmiary1, a także na fakt, że jest to reprezentacja rzadka —stosunkowo niewielka liczba n–gramów spośród wszystkich możliwych występuje w każdym
1dla 2000 słów reprezentacja trigramowa ma 8 109 elementów
80

5.2. Grupowanie i kategoryzacja dokumentów 5. Propozycje zastosowań
dokumencie, co jest generalnie niekorzystne przy obliczaniu odległości lub podobieństwamiędzy reprezentacjami. Dlatego proponuje on w swej pracy wprowadzenie reprezentacjiγ–gramowej o zmiennej liczbie słów. Przydatność każdego γ–gramu proponuje on oce-nić za pomocą pewnej monotonicznej funkcji oceny γ(w1, . . . , wn), gdzie w1, . . . , wn jestsekwencją słów. Funkcja w najprostszym przypadku może być obliczana jako częstość wy-stępowania n–gramu w korpusie lub być pokrewną funkcją do miary TF-IDF (ang. termfrequency–inverse document frequency) [114].
Zastosowanie informacji strukturalnej w procesie grupowania i kategoryzacji możemypodzielić na następujące zagadnienia:
• ocenę przydatności γ–gramów,
• selekcję zdań o zadanej charakterystyce,
• zastosowanie atrybutów strukturalnych.
5.2.1 Ocena przydatności γ–gramów
Korzystając z informacji o strukturze szkieletowej zdania możemy polepszyć właściwo-ści funkcji oceniającej γ(w1, . . . , wn). Wystarczy zauważyć, że γ–gramy reprezentującedokument powinny tworzyć związki wyrazowe, gdyż w przeciwnym wypadku, ich wystę-powanie będzie miało charakter przypadkowy — wynikający ze współwystępowania oboksiebie dwóch związków wyrazowych. Zatem informacja o strukturze szkieletowej znajdziezastosowanie przy:
• wyznaczaniu γ–gramów, z użyciem których będziemy tworzyć reprezentacje doku-mentów — uwzględnione będą tylko tylko te sekwencje kandydujące, które występująw związkach wyrazowych, nie przecinając ich. Dodatkowo możemy nałożyć ograni-czenia na głębokość wewnętrznej struktury rozpatrywanych związków wyrazowychużywając współczynnika τ (definicja 18 na str. 34). Jest to ograniczenie znacznie bar-dziej elastyczne niż ograniczanie z góry dopuszczalnej ilości wyrazów w γ–gramie.Oznacza to, że do reprezentacji dokumentów mogą być dopuszczone nawet długie cią-gi wyrazów pod warunkiem, że ich wewnętrzna struktura jest wystarczająco płaska, iże spełnią inne warunki wymienione we wspomnianej pracy Gawrysiaka. Dodatkowo,współczynnik τ może stanowić jeden ze składników funkcji oceniającej γ(w1, . . . , wn)— odzwierciedlając stopień skomplikowania wewnętrznej struktury — im większy,tym przydatność danego γ–gramu mniejsza.
• wyznaczaniu reprezentacji każdego dokumentu — przy zliczaniu wystąpień γ–gramumożemy uwzględniać, czy:
– w całości zawiera się w jednym związku wyrazowym,– zawierający związek wyrazowy występuje w sąsiedztwie określonych symbolinieterminalnych,– występuje w określonym miejscu drzewa rozbioru lub jest parsowany przez okre-ślony podzbiór reguł gramatyki,– wyrazy tworzące γ–gram współwystępują w związkach wyrazowych o zada-nym τ niekoniecznie w kolejności, w jakiej zostały przedstawione w γ–gramie.Ponieważ w danym związku wyrazowym kolejność wyrazów ma drugorzędneznaczenie2, możemy potraktować go jako elementarny worek słów (ang. bag ofwords), co w niektórych zastosowaniach może mieć kluczowe znaczenie, redu-kując rozmiar rozpatrywanej przestrzeni rozwiązań.
2Semantyka związku wyrazowego jest określona przez formy fleksyjne wyrazów ją tworzących np.: „chło-piec kupił cukierki”, „cukierki kupił chłopiec”, „kupił chłopiec cukierki” mimo różnej kolejności mają takiesamo znaczenie.
81

5.3. Analiza stylu dokumentu tekstowego 5. Propozycje zastosowań
5.2.2 Selekcja zdań o zadanej charakterystyce
Dużym problemem przy grupowaniu dokumentów tekstowych oprócz wyboru odpowiednioreprezentatywnych γ–gramów jest wybór podzbioru zdań każdego dokumentu, na pod-stawie którego będzie obliczona reprezentacja. Należy się spodziewać, że przygotowaniewspomnianej reprezentacji na podstawie wybranych reprezentatywnych dla danego do-kumentu zdań będzie miało lepsze właściwości, niż zbudowanie reprezentacji z użyciemwszystkich dostępnych zdań. Metodę wyboru zdań reprezentatywnych z użyciem regułgramatyki bezkontekstowej przedstawia rozdział 5.4.
5.2.3 Zastosowanie atrybutów strukturalnych
Zupełnie nowym podejściem jest użycie metaopisu, jakim jest wyindukowana gramatykado grupowania i kategoryzacji. Możliwe tu jest podejście czysto gramatyczne — z użyciemjedynie gramatyk. Podobieństwo dwóch dokumentów mogłoby być opisane za pomocą mia-ry PARSEVAL [W9][18]. Drugim podejściem jest system hybrydowy, łączący reprezentacjeγ–gramowe z dodatkowymi informacjami o strukturze gramatycznej. Możliwe są tu miaryuwzględniające charakterystykę zbioru reguł użytych do parsowania danego dokumentu.
5.3 Analiza stylu dokumentu tekstowego
5.3.1 Identyfikacja autora
Jak pokazano w [1] analiza gramatyki dokumentu, może służyć do wykrywania zmianystylu dzieła — np. analiza Biblii wykazała, że 19 księga prezentuje odmienny styl odpoprzedzających ją ksiąg. Każdy autor ma swój własny charakteryzujący go styl. Znaj-duje to odbicie w wykrytych związkach wyrazowych i wyindukowanych za ich pomocąregułach gramatyki. Zatem traktując korpus prac danego autora jako zbiór trenujący,można wyindukować charakterystyczną dla niego gramatykę. W ten sam sposób otrzymaćmożna gramatyki wyindukowane na badanych dziełach literackich (lub ich fragmentach).Porównanie otrzymanych w ten sposób gramatyk (np. za pomocą technik pokazanych wrozdziale 2.4.2) pozwala wykryć w sposób automatyczny prawdopodobnego autora dzie-ła. Także analizując gramatyki wyindukowane na poszczególnych fragmentach większegodzieła, można wykryć ewentualne zapożyczenia.
5.3.2 Wykrywanie błędów w korpusie
Reguły stanowią syntetyczny opis korpusu, na którym zostały wyindukowane. Dzięki te-mu ułatwiają analizę zjawisk w nim zachodzących. Korpusy języka liczą ponad 100 mln.wyrazów podzielonych na kilkanaście milionów zdań. Zatem przejrzenie ręczne tak obszer-nego materiału celem wychwycenia nieprawidłowości — zwłaszcza tych nieznanych — jestpraktycznie niemożliwe. Inaczej jest w przypadku reguł gramatyki wyindukowanych nakorpusie. Reguł jest znacznie mniej, około kilkunastu tysięcy. Od razu możemy podzielićreguły według wsparcia. Reguły o dużym wsparciu to reguły modelujące zjawiska języko-we, a także reprezentujące błędy systematyczne. Tych ostatnich powinno być bardzo mało— a są tym cenniejsze, że dzięki nim możliwe jest wykrycie i usunięcie ewentualnych uste-rek w metodzie analizy morfologicznej korpusu. Reguły o małym wsparciu dotyczą błędówróżnorakiej postaci: m.in. zwyczajnych literówek w tekstach źródłowych, niedoskonałościanalizatora morfologicznego i dezambiguatora ujawniających się tylko w określonych przy-padkach, czy złego podziału na zdania (problem haplologii kropki). Ilustracją może tu byćwyindukowanie m.in. reguły postaci S → . które wskazują, że w korpusie znajdują sięzdania składające się jedynie z samego znaku przestankowego.
82

5.4. Selekcja materiału tekstowego 5. Propozycje zastosowań
Kolejnym zastosowaniem może być wykrywanie błędów w korpusach anotowanych syn-taktycznie przez ekspertów. Można sobie wyobrazić modyfikację algorytmu umożliwiającąśledzenie spójności takiego korpusu (poprzez porównanie zdań anotowanych przez lingwi-stów ze sposobem anotowania wygenerowanym za pomocą algorytmu — metody porów-nania omówione zostały w rozdziale 2.4 — przy założeniu, że parametry algorymów zosta-ną dobrane tak, aby minimalizować różnice między anotacją strukturalną automatycznąi wzorcową anotacją manualną). Istnienie takiego kryterium może ułatwić podniesieniespójności anotacji strukturalnej korpusu tekstów języka naturalnego.
5.3.3 Wykrywanie zjawisk w języku
Język naturalny nie jest zjawiskiem stacjonarnym— podlega ciągłym zmianom związanymz dostosowaniem do potrzeb używającego go społeczeństwa. Gramatyki indukowane nakorpusach grupujących dzieła z określonych okresów mogą rzucać nowe światło na zjawiskai trendy zachodzące w języku na przestrzeni lat.
Zatem interesującym zagadnieniem może być poszukiwanie zależności w wyindukowa-nych regułach za pomocą algorytmów eksploracji danych. Rozważanymi zagadnieniamimogą być tu:
• poszukiwanie podobieństw między regułami,
• sposoby unifikacji reguł (podobne reguły ale dla różnych przypadków, rodzajów,czasów).
Badając współwystępowanie danego wyrazu wraz z symbolami nieterminalnymi może-my określić czy np. czasownik wymaga dopełnienia, czy można użyć dopełnienia bliższegoi dalszego. Z drugiej strony z rozkładu symboli terminalnych będących w grupie podmiotumożemy wnioskować o semantyce danego czasownika, a przynajmniej o kontekstach, wktórych może być zastosowany.
Jak pokazano w [36, str. 21], gdy dostępny jest sparsowany korpus, można za pomo-cą odpowiednich statystyk, np. informacji wzajemnej określić wzajemne związki międzywyrazami, np. z jakimi czasownikami łączy się dany rzeczownik.
5.4 Selekcja materiału tekstowego
Ciekawym problemem jest wydzielenie z dokumentu tych zdań, które mają pewną zadanącharakterystykę. Można tego dokonać za pomocą wielu technik. Klasycznym podejściemjest wyznaczenie zbioru słów o dużej wartości semantycznej (będącej swego rodzaju prze-ciwieństwem stopword list) i zdefiniowanie kryterium wyboru zdań w oparciu o obecnośćpodzbioru wspomnianych wyrazów w zdaniu. Technikę tę stosuje się w niektórych pakie-tach biurowych w celu wygenerowania podsumowania indykatywnego.
Bardziej zaawansowane metody wyboru interesujących zdań mogą wykorzystywać in-formację strukturalną. W szczególnym przypadku, wybór interesujących zdań mógłbyprzebiegać następująco:
1. indukowanie gramatyki z użyciem przygotowanego korpusu,
2. przygotowanie podzbioru reguł definiującego właściwości interesującego nas tekstu,możliwe są tu dwa podejścia:
• wybór manualny interesujących nas reguł. Ponieważ ilość wyindukowanych re-guł jest zwykle dość znaczna (sięgająca kilkudziesięciu tysięcy), takie podejściemoże być mało atrakcyjne,
83

5.5. Efektywne parsery 5. Propozycje zastosowań
• wybór reguł, które są wspierane przez korpus zawierający zdania trenujące. Wten sposób możemy wybrać z dużego korpusu zdania podobne do tych prezen-towanych w korpusie trenującym,
3. wybór tych zdań, które są parsowane w całości lub w części (w zależności od podej-ścia) przez wygenerowane w poprzednim kroku reguły.
Należy zauważyć, że taka metoda wyboru zdań jest bardziej elastyczna, gdyż pozwala nadowolne manipulowanie zbiorem reguł akceptujących zdania włączane do podsumowania,z drugiej strony pozwala na precyzyjne określenie kryteriów jakie akceptowane zdaniamuszą spełniać.
5.5 Efektywne parsery
Złożoność obliczeniowa procesu parsowania nadal pozostaje dużym problemem. Przykła-dowa złożoność czasowa algorytmów parsowania gramatyki bezkontekstowej to:
• algorytm CYK — O(n3),
• algorytm Earley — O(n3),
• algorytm Valiant — O(n2,81).
Zatem parsowanie długich zdań stanowi problem. Możliwe są dwie metody przyspieszeniaprocesu parsowania. Pierwsza z nich polega na wykryciu pełnej struktury szkieletowej(np. za pomocą przedstawionego w niniejszej pracy algorytmu), a następnie wybraniuodpowiednich reguł odpowiadających wyznaczonemu szkieletowi3.
Drugie podejście ma charakter hybrydowy: ponieważ czas parsowania rośnie z sześcia-nem długości zdania, zatem szybkie znalezienie podziału pierwszego rzędu (przy podejściuzstępującym) lub najbardziej elementarnych związków wyrazowych (przy podejściu wstę-pującym) redukuje efektywną długość zdania, umożliwiając dokonanie dalszej analizy jużza pomocą zwykłych algorytmów parsowania.
Aby wykluczyć sytuację, w której zaproponowane błędnie związki wyrazowe uniemoż-liwią dokonanie rozbioru, należy zaproponować n kandydatów w kolejności malejącej przy-datności wyznaczonej za pomocą jednego z zaproponowanych kryteriów. Parametr n po-winien być tak dobrany, aby zapewnić zakładaną efektywność procesu parsowania.
Wyznaczenie podziałów kandydujących pierwszego rzędu jest trywialne — algorytm3.2 jest skonfigurowany tak, aby uzyskiwać podziały pierwszego rzędu.
Natomiast w celu znalezienia elementarnych związków wyrazowych4 należy zmodyfi-kować algorytm 3.2, stosując dodatkowe kryterium oceniające wewnętrzną strukturę kan-dydującego związku wyrazowego. W najprostszym przypadku kryterium może brać poduwagę jedynie długość związku wyrazowego.
3Proces ten jest równoważny przyporządkowaniu każdemu węzłowi drzewa wywodu symbolu nietermi-nalnego, w taki sposób, że korzeń drzewa będzie miał przyporządkowany symbol startowy S.4Związków, które nie mają wewnętrznej struktury.
84

Indukcja reguł gramatyki języka polskiego
Rozdział 6
PodsumowaniePerfection is achievedonly on the point of collapse.C. N. Parkinson
Niniejsza rozprawa poświęcona została metodom indukcji reguł gramatyki języka natural-nego z użyciem korpusu tekstów tego języka. Zostały w niej przedstawione podstawowezagadnienia związane z formalizmem gramatyk, metody uczenia gramatyk regularnych ibezkontekstowych. Szczególny nacisk położono na aspekt możliwości praktycznego zastoso-wania proponowanych rozwiązań. Stąd badania zogniskowane zostały wokół zagadnieniagramatyk bezkontekstowych indukowanych z użyciem jedynie pozytywnych przykładów— zawartych w stosunkowo łatwo dostępnych korpusach języka naturalnego. Odrzuco-no a priori rozwiązania wymagające dodatkowej wiedzy zarówno w postaci wyroczni czyprzykładów negatywnych (zdań nienależących do języka) — jako trudno dostępne, a zatemniepraktyczne. Wybrano podejście statystyczne — stojące w opozycji do metod symbo-licznych, jednakże zapewniające możliwość przetwarzania dużych korpusów tekstów językanaturalnego, co z kolei pozwala na uzyskanie dobrych rezultatów na danych testowych.
Praca zawiera przegląd aktualnego stanu wiedzy w dziedzinie indukcji reguł grama-tyki, poczynając od przedstawienia formalizmu gramatyki, przez modele uczenia, metodyuczenia gramatyk regularnych, na metodach uczenia gramatyk bezkontekstowych kończąc.Szczególnie dużo miejsca poświęcono dotychczasowym osiągnięciom w uczeniu gramatykbezkontekstowych z korpusu tekstów języka naturalnego, z uwagi na ich wagę dla dalszychrozważań. Praca zawiera przegląd metod oceny struktur szkieletowych i reguł gramatyki.Omówiono także postać badanego korpusu języka naturalnego wraz z metodą anotacji.Przegląd literatury zamyka krytyczna analiza własności kryteriów używanych dotąd dowykrywania związków wyrazowych: informacji wzajemnej i uogólnionej informacji wza-jemnej, poprzedzona listą algorytmów indukcji gramatyk.
Przegląd literatury, a także powtórzenie najistotniejszych opisanych tam eksperymen-tów pozwoliło zidentyfikować zjawiska niedostatecznie zbadane, mające kluczowe znaczeniedla rozważanego tematu. Osobistym wkładem autora jest tu:
• wykrycie zjawiska zaniku różnorodności i gwałtownego spadku ogólnej liczby sekwen-cji wraz ze wzrostem ich długości, co umożliwiło
• wskazanie przyczyn niepowodzenia zastosowań informacji wzajemnej i uogólnionejinformacji wzajemnej w wykrywaniu związków wyrazowych, umożliwionej przez
• przedstawienie wartości średniej informacji wzajemnej i wartości średniej będącychjej czynnikami prawdopodobieństw w zależności od długości sekwencji umożliwiającezidentyfikowanie niekorzystnych zjawisk.
Wyciągnięte wnioski pozwoliły na znalezienie rozwiązań pozbawionych wad dotychczaso-wych metod. Osobistym wkładem autora jest tu:
85

6. Podsumowanie
• zdefiniowanie niewrażliwego na długość sekwencji kryterium oceny SF podziałówwielopunktowych. Za pomocą tego kryterium można ocenić podział sekwencji niena-leżącej do zbioru trenującego (której estymowane prawdopodobieństwo wystąpieniawynosi zero), a także porównać jakość podziałów wielopunktowych o różnej licz-bie punktów podziału. Należy zauważyć, że dotychczas w literaturze można spotkaćjedynie kryteria oceny podziałów jednopunktowych wrażliwych na długość wydzie-lonych podsekwencji,
• zdefiniowanie metod oceny struktury szkieletowej na podstawie oceny podziałów tęstrukturę definiujących,
• uniwersalna metoda zawężania i poszerzania informacji morfologicznej, umożliwia-jąca zbadanie wpływu szczegółowości informacji morfologicznej na jakość genero-wanych struktur szkieletowych i gramatyk, jak i na zjawisko niedostatecznej ilościdanych trenujących (ang. sparse data),
• algorytm wykrywania struktury zdania,
• algorytm generowania podziałów,
• udoskonalenie metody generowania reguł gramatyki RCFG ze struktur szkieletowychSakakibary polegająca na zdefiniowaniu nowego parametru RCFG2sup sterującegotym procesem,
• wskazanie metod rozdzielenia reguł będących efektem niedoskonałości w danych tre-nujących od reguł niosących istotną informację strukturalną.
Wykonane eksperymenty pokazują, iż zastosowanie zaproponowanych metod pozwala nauzyskanie:
• korpusów anotowanych strukturalnie o jakości większej od notowanych przez badanekonkurencyjne algorytmy,
• reguł gramatyk bezkontekstowych o pokryciu na zbiorze testowym w granicach 20%–90% w zależności od wartości parametru RCFG2sup,
co świadczy o skuteczności przyjętych rozwiązań.
Podstawowym zastosowaniem przedstawionych w niniejszej rozprawie metod jest wy-krywanie struktur hierarchicznych w danych tekstowych. Jak pokazano, wykryte strukturymogą posłużyć do indukowania reguł gramatyki RCFG. Rozdział piąty niniejszej rozprawypodaje kilka przykładowych zastosowań, możemy tu wymienić:
• grupowanie i kategoryzację dokumentów,
• analizę stylu dokumentu tekstowego,
• selekcję materiału tekstowego,
• poprawienie wydajności parserów gramatyk bezkontekstowych.
Przeprowadzone badania wskazują, że podejście statystyczne do indukowania reguł gra-matyki języka naturalnego daje obiecujące rezultaty. Pojawiły się także nowe zagadnienia,których zbadanie może rzucić nowe światło na tę dziedzinę. Są to:
• efektywne estymowanie prawdopodobieństw występowania sekwencji w korpusie,
86

6. Podsumowanie
• koncepcja traktowania podsekwencji jako mikroworków słów (ang. bag of words),a nie jako sekwencji. Opracowanie odpowiednich metod estymowania prawdopodo-bieństw,
• opracowanie metod automatycznego doboru parametrów zaproponowanego w niniej-szej pracy algorytmu, maksymalizujących podobieństwo wygenerowanych szkieletówdo tych, które stworzyłby człowiek. Oznacza to stworzenie wersji systemu uczącegosię z nadzorem,
• opracowanie metod automatycznego doboru optymalnej tablicy odwzorowania do-stosowanej do konkretnego zastosowania. Możliwe tu są następujące metody: użyciealgorytmów genetycznych, traktując pojedyncze tablice odwzorowań jako osobniki,a wiersze/kolumny jako chromosomy, użycie metod grupowania symboli nietermi-nalnych wygenerowanej gramatyki celem znalezienia symboli podobnych i takie do-branie tablic odwzorowań, aby odpowiednie termy po przekształceniu trafiły do tychsamych symboli nieterminalnych. Możliwe jest połączenie obu metod,
• sposób wyboru cech minimalnie charakterystycznych spośród informacji morfologicz-nej,
• metoda dynamicznego doboru odwzorowania w zależności od rzędu przetwarzanegopodziału lub długości przetwarzanej sekwencji,
• poszukiwanie zależności w wyindukowanych regułach za pomocą algorytmów eksplo-racji danych,
• automatyczne wykrywanie progu odcięcia reguł „szumu” od reguł „wiedzy”,
• opracowanie metody automatycznego nazywania wykrytych kategorii syntaktycz-nych uwzględniającej postać reguł zawierających daną kategorię syntaktyczną (sym-bol nieterminalny) po prawej stronie,
• zbudowanie systemu hybrydowego — metoda zaproponowana w niniejszej pracy słu-żyłaby do wykrywania związków wyrazowych o małej długości (2–3 tokeny), podzia-ły niższych rzędów wykrywane byłyby drogą łączenia już wykrytych związków zapomocą metod symbolicznych,
• opracowanie nowych metod oceny struktur szkieletowych uwzględniających dodat-kowe informacje np. ilość podziałów.
Wymienione zagadnienia będą przedmiotem dalszych prac autora.
87

Indukcja reguł gramatyki języka polskiego
Bibliografia
[1] P. W. Adriaans, M. Trautwein, M. Vervoort. Towards high speed grammar inductionon large text corpora. SOFSEM ’00: Proceedings of the 27th Conference on CurrentTrends in Theory and Practice of Informatics, strony 173–186, London, UK, 2000.Springer-Verlag.
[2] D. Angluin. Finding patterns common to a set of strings. J. Comput. System Sci.,strony 46–62, 1980.
[3] D. Angluin. Inductive inference of formal languages from positive data. Informationand Control, 45:117–135, 1980.
[4] D. Angluin. A note on the number of queries needed to identify regular languages.Information and Control, 51:76–87, 1981.
[5] D. Angluin. Inference of reversible languages. Journal of the Association for Com-puting Machinery, 29(3):741–765, 1982.
[6] D. Angluin. Learning k-bounded context-free grammars. Raport instytutowyYALEU DCS TR-557, Yale University, New Haven, CT, 1987.
[7] D. Angluin. Queries and concept learning. Machine Learning, 2(4):319–342, 1988.
[8] D. Angluin. Negative results for equivalence queries. Machine Learning, 5(2):121–150, 1990.
[9] D. Angluin. Computational learning theory: survey and selected bibliography. Proce-edings of the twenty-fourth annual ACM symposium on Theory of computing, strony351–369. ACM Press, 1992.
[10] D. Angluin, M. Kharitonov. When won’t membership queries help? Selected papers ofthe 23rd annual ACM symposium on Theory of computing, strony 336–355. AcademicPress, Inc., 1995.
[11] D. Angluin, C. H. Smith. Inductive inference: Theory and methods. ACM Comput.Surv., 15(3):237–269, 1983.
[12] J. Arabas. Wykłady z algorytmów ewolucyjnych. Wydawnictwa Naukowo–Techniczne, Warszawa, 2001.
[13] S. Arikawa, T. Shinohara, A. Yamamoto. Learning elementary formal systems. The-or. Comput. Sci., 95(1):97–113, 1992.
[14] M. Bach, S. Kozielski. Translacja zapytań do baz danych sformułowanych w językunaturalnym na zapytania w języku SQL. I Krajowa Konferencja Naukowa Techno-logie Przetwarzania Danych, 2005.
[15] P. Berman, R. Roos. Learning one-counter languages in polynomial time (extendedabstract). In 28th Annual Symposium on Foundations of Computer Science, strony61–67, Los Angeles, California, 12-14 October 1987. IEEE.
88

Bibliografia Bibliografia
[16] J. S. Bień. Koncepcja słownikowej informacji morfologicznej i jej komputerowejweryfikacji. Wydawnictwa Uniwersytetu Warszawskiego, Warszawa, 1991.
[17] J. S. Bień, Z. Saloni. Pojęcie wyrazu morfologicznego i jego zastosowanie do opisufleksji polskiej (wersja wstępna). Prace Filologiczne XXXI, 1982.
[18] E. Black, S. Abney, S. Flickenger, C. Gdaniec, C. Grishman, P. Harrison, D. Hindle,R. Ingria, F. Jelinek, J. Klavans, M. Liberman, M. Marcus, S. Roukos, B. Santorini,T. Strzalkowski. Procedure for quantitatively comparing the syntactic coverage ofenglish grammars. Proceedings of a workshop on Speech and natural language, strony306–311, San Francisco, CA, USA, 1991. Morgan Kaufmann Publishers Inc.
[19] R. Bod. Beyond Grammar:An Experiencer-Based Theory of Language. CSLI Publi-cations, Stanford, USA, 1998.
[20] E. Brill. Automatic grammar induction and parsing free text: a transformation-basedapproach. HLT ’93: Proceedings of the workshop on Human Language Technology,strony 237–242, Morristown, NJ, USA, 1993. Association for Computational Lingu-istics.
[21] E. Brill. Transformation-based error-driven parsing, 1993.
[22] E. Brill. Transformation-based error-driven learning and natural language proces-sing: a case study in part-of-speech tagging. Comput. Linguist., 21(4):543–565, 1995.
[23] E. Brill, D. Magerman, M. Marcus, B. Santorini. Deducing linguistic structure fromthe statistics of large corpora. JCIT: Proceedings of the fifth Jerusalem conferenceon Information technology, strony 380–389, Los Alamitos, CA, USA, 1990. IEEEComputer Society Press.
[24] E. Brill, M. Marcus. Automatically acquiring phrase structure using distributionalanalysis. HLT ’91: Proceedings of the workshop on Speech and Natural Language,strony 155–159, Morristown, NJ, USA, 1992. Association for Computational Lingu-istics.
[25] T. Briscoe, J. Carroll, A. Sanlippo. Parser evaluation : A survey and a new proposal,1993.
[26] H. Bunke, A. Sanfeliu, redaktorzy. Syntactic and Structural Pattern Recognition— Theory and Application, wolumen 7 serii World Scientific Series in ComputerScience. World Scientific, 1990.
[27] A. Burago. Learning structurally reversible context-free grammars from queries andcounterexamples in polynomial time. Proceedings of the seventh annual conferenceon Computational learning theory, strony 140–146. ACM Press, 1994.
[28] C. J. C. Burges. A tutorial on support vector machines for pattern recognition. DataMin. Knowl. Discov., 2(2):121–167, 1998.
[29] R. Carrasco, J. Oncina. Learning stochastic regular grammars by means of a statemerging method. Grammatical Inference and Applications, ICGI’94, number 862serii Lecture Notes in Artificial Intelligence, strony 139–150. Springer Verlag, 1994.
[30] R. C. Carrasco, J. Oncina, redaktorzy. Grammatical Inference and Applications,wolumen 862 of LNCS/LNAI. Springer Verlag, 1994.
[31] G. Carroll, E. Charniak. Two experiments on learning probabilistic dependencygrammars from corpora. Raport instytutowy CS-92-16, 1992.
89

Bibliografia Bibliografia
[32] E. Charniak. Statistical Language Learning. MIT - Press, Cambridge, MA, 1993.
[33] N. Chomsky. Syntactic structures. The Hague: Mouton, 1957.
[34] N. Chomsky. Aspects of the theory of syntax. MIT Press, 1965.
[35] N. Chomsky. Knowledge of language: its nature, origins, and use. Praeger, NewYork, 1986.
[36] K. Church, W. Gale, P. Hanks, D. Hindle. Using statistics in lexical analysis. U. Ze-rnik, redaktor, Lexical Acquisition: Exploiting On-line Resources to Build a Lexicon,strony pp. 116–164. Erlbaum, 1991.
[37] P. Cichosz. Systemy uczące się. Wydawnictwa Naukowo-Techniczne, Warszawa,2000.
[38] A. Clark. Inducing syntactic categories by context distribution clustering. C. Cardie,W. Daelemans, C. Nedellec, E. T. K. Sang, redaktorzy, Proceedings of the FourthConference on Computational Natural Language Learning and of the Second Le-arning Language in Logic Workshop, Lisbon, 2000, strony 91–94. Association forComputational Linguistics, Somerset, New Jersey, 2000.
[39] A. Clark. Unsupervised induction of stochastic context-free grammars using distri-butional clustering. ConLL ’01: Proceedings of the 2001 workshop on ComputationalNatural Language Learning, strony 1–8, Morristown, NJ, USA, 2001. Association forComputational Linguistics.
[40] R. A. Cole, J. Mariani, H. Uszkoreit, A. Zaenen, V. Zue. Survey of the state of theart in human language technology, 1995.
[41] H. Comon, M. Dauchet, R. Gilleron, F. Jacquemard, D. Lugiez,S. Tison, M. Tommasi. Tree automata techniques and applications.http://www.grappa.univ-lille3.fr/tata, 1997.
[42] S. Crespi-Reghizzi. An effective model for grammar inference. Information Proces-sing 71, strony 524–529. Elsevier North-Holland, 1972.
[43] S. Crespi-Reghizzi, G. Guida, D. Mandrioli. Noncounting context-free languages. J.ACM, 25(4):571–580, 1978.
[44] C. Culy. The complexity of the vocabulary of bambara. W. J. Savitch, E. Bach,W. Marsh, G. Safran-Naveh, redaktorzy, The Formal Complexity of Natural Langu-age, strony 349–357. Reidel, Dordrecht, 1987.
[45] E. Dobryjanowicz. Podstawy Przetwarzania języka naturalnego. Wybrane metodyanalizy składniowej. Akademicka Oficyna Wydawnicza RM, Warszawa 1992.
[46] F. Drewes. Introduction to tree languages. 2004.
[47] G. Dąbrowski. Zastosowanie systemów klasyfikujących do przetwarzania języka na-turalnego. Praca magisterska, Politechnika Wrocławska, Instytut Cybernetyki Tech-nicznej, 2001.
[48] Ł. Dębowski. Trigram morphosyntactic tagger for polish. M. Kłopotek, S. Wierz-choń, K. Trojanowski, redaktorzy, Intelligent Information Processing and Web Mi-ning, Proceedings of the International IIS:IIPWM’04, strony 409–413. Springer,2004.
[49] J. A. Feldman, J. Gips, J. J. Horning, S. Reder. Grammatical complexity andinference. Raport instytutowy CS-125, Comput. Sci. Dept., Stanford, 1969.
90

Bibliografia Bibliografia
[50] K. S. Fu, T. L. Booth. Grammatical inference: introduction and survey. IEEETranscations on Systems, Man, and Cybernetics, SMC-5:95–111, 409–423, 1975.
[51] P. Gawrysiak. Automatyczna kategoryzacja dokumentów. Praca doktorska, Politech-nika Warszawska, 2001.
[52] N. Gierasimczuk. Algorytmiczne podejście do problemu uczenia się języka. Pracamagisterska, Uniwersytet Warszawski, Wydział Filozofii i Socjologii, 2005.
[53] S. Ginsburg, M. A. Harrison. Bracketed context-free languages. Journal of Computerand System Sciences, 1(1):1–23, 1967.
[54] E. M. Gold. Language identification in the limit. Information and Control,10(5):447–474, 1967.
[55] J. Goodman. Parsing algorithms and metrics. A. Joshi, M. Palmer, redaktorzy, Pro-ceedings of the Thirty-Fourth Annual Meeting of the Association for ComputationalLinguistics, strony 177–183, San Francisco, 1996. Morgan Kaufmann Publishers.
[56] P. Grunwald. A minimum description length approach to grammar inference. Con-nectionist, Statistical, and Symbolic Approaches to Learning for Natural LanguageProcessing, strony 203–216, London, UK, 1996. Springer-Verlag.
[57] W. Gruszczyński, Z. Saloni. Składnia grup liczebnikowych we współczesnym językupolskim. Studia Gramatyczne II, 1978.
[58] D. Gusfield. Algorithms on strings, trees, and sequences: computer science and com-putational biology. Cambridge University Press, New York, NY, USA, 1997.
[59] Z. S. Harris. Methods in Structural Linguistics. 1951.
[60] E. Hatcher, O. Gospodnetic. Lucene in Action. Manning Publications Co., 2005.
[61] C. D. L. Higuera. Current trends in grammatical inference. Proceedings of the JointIAPR International Workshops on Advances in Pattern Recognition, strony 28–31.Springer-Verlag, 2000.
[62] T. Honkela, V. Pulkki, T. Kohonen. Contextual relations of words in Grimm tales,analyzed by self-organizing map. F. Fogelman-Soulie, P. Gallinari, redaktorzy, Proc.ICANN’95, International Conference on Artificial Neural Networks, wolumen II,strony 3–7, Nanterre, France, 1995. EC2.
[63] J. E. Hopcroft, J. D. Ullman. Wprowadzenie do teorii automatów, języków i obliczeń.Wydawnictwo Naukowe WNT, 2003.
[64] H. Ishizaka. Polynomial time learnability of simple deterministic languages. MachineLearning, 5(2):151–164, 1990.
[65] A. K. Joshi. From strings to trees to strings to trees ... Proceedings of the 32ndconference on Association for Computational Linguistics, strony 33–33. Associationfor Computational Linguistics, 1994.
[66] A. K. Joshi, S. R. Kosaraju, H. M. Yamada. String adjunct grammars: I. Local anddistributed adjunction. 21(2):93–116, Wrze. 1972.
[67] A. K. Joshi, S. R. Kosaraju, H. M. Yamada. String adjunct grammars: II. Equationalrepresentation, null symbols, and linguistic relevance. Information and Control,21:235–260, 1972.
91

Bibliografia Bibliografia
[68] A. K. Joshi, L. S. Levy. Constraints on structural descriptions: Local transforma-tions. SIAM Journal on Computing, 6(2):272–284, 1977.
[69] A. K. Joshi, L. S. Levy. Phrase structure trees bear more fruit than you would havethought. Comput. Linguist., 8(1):1–11, 1982.
[70] A. K. Joshi, L. S. Levy, M. Takahashi. Tree adjunct grammars. J. Comput. Syst.Sci., 10(1):136–163, 1975.
[71] R. M. Kaplan, K. Netter, J. Wedekind, A. Zaenen. Translation by structural corre-spondendes. S. Nirenburg, H. Somers, Y. Wilks, redaktorzy, Readings in MachineTranslation, strony 263–271. MIT Press, jun 2003.
[72] B. Knobe, K. Knobe. A method for inferring context-free grammars. Informationand Control, 31:129–146, 1977.
[73] A. Kornai. Natural languages and the Chomsky hierarchy. Proceedings of the secondconference on European chapter of the Association for Computational Linguistics,strony 1–7. Association for Computational Linguistics, 1985.
[74] T. Koshiba. Typed pattern languages and their learnability. Proceedings of theSecond European Conference on Computational Learning Theory, strony 367–379.Springer-Verlag, 1995.
[75] S. Kowalski, A. W. Mostowski. Teoria automatów i lingwistyka matematyczna. Pań-stwowe Wydawnictwo Naukowe, Warszawa, 1979.
[76] A. Krogh, M. Brown, I. S. Mian, K. Sjolander, D. Haussler. Hidden markov modelsin computational biology: Applications to protein modeling. Raport instytutowy,1993.
[77] M. Lankhorst. Breeding grammars: Grammatical inference with a genetic algorithm,1994.
[78] L. Lee. Learning of context-free languages: A survey of the literature. Raportinstytutowy TR-12-96, Harvard University, 1996.
[79] L. Levy, A. Joshi. Skeletal structural descriptions. Information and Control, 39:192–211, List. 1978.
[80] L. S. Levy. Structural aspects of local adjunct languages. Information and Control,23(3):260–287, Paz. 1973.
[81] M. Li, P. M. B. Vitanyi. Inductive reasoning and Kolmogorov complexity. Journalof Computer and System Sciences, 44(2):343–384, 1992.
[82] D. Luzeaux. Towards a unifying paradigm of positive regular grammar inference.15th IMACS World Congress, Berlin, Allemagne, Sier. 1997.
[83] C. Lyon, B. Dickerson. A fast partial parse of natural language sentences using aconnectionist method. Proceedings of the seventh conference on European chapter ofthe Association for Computational Linguistics, strony 215–222, San Francisco, CA,USA, 1995. Morgan Kaufmann Publishers Inc.
[84] D. M. Magerman. Everything you always wanted to know about probability theorybut were afraid to ask, 1992.
[85] D. M. Magerman. Natural Language Parsing as Statistical Pattern Recogintion.Praca doktorska, Stanford University, Luty 1994.
92

Bibliografia Bibliografia
[86] D. M. Magerman. Statistical decision-tree models for parsing. Meeting of the Asso-ciation for Computational Linguistics, strony 276–283, 1995.
[87] D. M. Magerman, M. P. Marcus. Parsing a naural language using mutual informationstatistics. Eight National Conference on Artificial Intelligence, Sier. 1990.
[88] E. Makinen. On the structural grammatical interference problem for some classesof context-free grammars. Inf. Process. Lett., 42(1):1–5, 1992.
[89] U. Manber, G. Myers. Suffix arrays: a new method for on-line string searches. SODA’90: Proceedings of the first annual ACM-SIAM symposium on Discrete algorithms,strony 319–327, Philadelphia, PA, USA, 1990. Society for Industrial and AppliedMathematics.
[90] M. P. Marcus, M. A. Marcinkiewicz, B. Santorini. Building a large annotated corpusof english: The penn treebank. Comput. Linguist., 19(2):313–330, 1993.
[91] A. A. Markov. An example of statistical investigation in the text of ‘Eugene Onegin’illustrating coupling of texts in chains. Proc. Acad. of Sciences, St. Petersberg, 1913.
[92] R. McNaughton. Parenthesis grammars. J. ACM, 14(3):490–500, 1967.
[93] D. McNeill. Handbook of Social Psychology, rozdział Developmental psycholinguistic.1966.
[94] L. Miclet. Syntactic and Structural Pattern Recognition — Theory and Application,wolumen 7 serii World Scientific Series in Computer Science, rozdział GrammaticalInference. World Scientific, 1990.
[95] S. Nirenburg, H. Somers, Y. Wilks, redaktorzy. Readings in Machine Translation.MIT Press, Czerw. 2003.
[96] F. Pereira, Y. Schabes. Inside-outside reestimation from partially bracketed corpora.Proceedings of the 30 th annual meeting on Association for Computational Lingu-istics, strony 128–135, Morristown, NJ, USA, 1992. Association for ComputationalLinguistics.
[97] L. Pitt. Inductive Inference, DFAs, and Computational Complexity. Proceedingsof the International Workshop on Analogical and Inductive Inference, strony 18–44.Springer-Verlag, 1989.
[98] P. Postal. Constituent Structure: A Study of Ccontemporary Mmodelsl of SyntacticDescription. Indiana Univ. Press, Bloomington, 1967.
[99] A. Przepiórkowski. Składniowe uwarunkowania znakowania morfosyntaktycznego wkorusie IPI PAN. Polonica XXII-XXIII, 2003.
[100] A. Przepiórkowski. Korpus IPI PAN. Wersja wstępna / The IPI PAN Corpus:Preliminary version. IPI PAN, Warszawa, 2004.
[101] A. Przepiórkowski, A. Kupść, M. Marciniak, A. Mykowiecka. Formaly opis językapolskiego. Teoria i implementacja. Akademicka Oficyna Wydawnicza EXIT, 2002.
[102] A. Przepiórkowski, M. Woliński. A flexemic tagset for Polish. Proceedings of Mor-phological Processing of Slavic Languages, strony 33–40, 2003.
[103] M. Redington, N. Chater, S. Finch. Distributional information: A powerful cue foracquiring syntactic categories. Cognitive Science, 22(4):425–469, 1998.
93

Bibliografia Bibliografia
[104] H. Rybiński. On first-order-logic databases. ACM Trans. Database Syst., 12(3):325–349, 1987.
[105] H. Rybiński, D. Gajda, P. Gawrysiak, M. Gołębski. Extending Open Source SoftwareSolutions for CRM Text Mining. International Conference e-Society. InternationalAssotiation for Development of the Information Society, 2004.
[106] Y. Sakakibara. Learning context-free grammars from structural data in polynomialtime. Theoretical Computer Science, 76(2-3):223–242, 1990.
[107] Y. Sakakibara. Efficient learning of context-free grammars from positive structuralexamples. Information and Computation, 97(1):23–60, 1992.
[108] Y. Sakakibara. Recent advances of grammatical inference. Theoretical ComputerScience, 185(1):15–45, 1997.
[109] Y. Sakakibara, M. Brown, R. Hughey, I. S. Mian, K. Sjolander, R. C. Underwood,D. Haussler. The application of stochastic context-free grammars to folding, ali-gning and modeling homologous RNA sequences. Submitted to Journal of MolecularBiology, List. 1993.
[110] Y. Sakakibara, H. Muramatsu. Learning context-free grammars from partially struc-tured examples. A. L. Oliveira, redaktor, Grammatical Inference: Algorithms andApplications. 5th International Colloquium, ICGI 2000, wolumen 1891 serii LectureNotes In Artificial Inteligence, strony 229–240. Springer, 2000.
[111] Z. Saloni. O tzw. formach nieosobowych [rzeczowników] męskoosobowych we współ-czesnej polszczyźnie. Biuletyn Polskiego Towarzystwa Językoznawczego XLI.
[112] Z. Saloni. Kategorie gramatyczne grup imiennych we współczesnym języku polskim,rozdział Kategoria rodzaju we współczesnym języku polskim, strony 41–75. Ossoli-neum, 1976.
[113] Z. Saloni. Kategorie gramatyczne liczebników we współczesnym języku polskim.Studia Gramatyczne I, 1977.
[114] G. Salton, M. J. McGill. Introduction to Modern Information Retrieval. McGraw-Hill, Inc., New York, NY, USA, 1986.
[115] Y. Seginer. Learning context free grammars in the limit aided by the sample di-stribution. M. van Zaanen, C. de la Higuera, P. Adriaans, J. Oncina, redaktorzy,Proceedings of the Workshop and Tutorial on Learning Context Free grammars ECM-L/PKDD 2003, 2003.
[116] S. M. Shieber. Evidence against the context-freeness of natural language. W. J.Savitch, E. Bach, W. Marsh, G. Safran-Naveh, redaktorzy, The Formal Complexityof Natural Language, strony 320–334. Reidel, Dordrecht, 1987.
[117] H.-H. Shih, S. J. Young. A system for computer assisted grammar construction. Ra-port instytutowy TR.170, Engineering Department, Cambridge University, England,Czerw. 1994.
[118] T. Shinohara. Inductive inference from positive data is powerful. The 1990 Workshopon Computational Learning Theory, strony 339–351, San Mateo, California, 1990.Morgan Kaufmann.
[119] T. Shinohara. Rich classes inferable from positive data. Inf. Comput., 108(2):175–186, 1994.
94

Bibliografia Bibliografia
[120] R. Solomonoff. A new method for discovering the grammars of phrase structurelanguages. Proceedings of the International Conference on Information Processing,1959.
[121] Y. Takada. Grammatical inference for even linear languages based on control sets.Information Processing Letters, 28(4):193–199, 1988.
[122] K. Tanatsugu. A grammatical inference for context-free languages based on self-embedding”. Bulletin of Informatics and Cybernetics, 2 (3-4):149–163, 1987.
[123] J. Thatcher. Currents in the theory of computing, rozdział Tree automata: an infor-mal survey, strony 143–178. Prentice Hall, 1973.
[124] J. Tokarski. Fleksja polska. Klasyka Językoznawstwa Polskiego. Wydawnictwo Na-ukowe PWN, wydanie III, 2001.
[125] B. Trakhtenbrot, Y. Barzdin. Finite Automata: Behavior and Synthesis. NorthHolland Pub. Comp., Amsterdam, 1973.
[126] L. Valiant. A theory of the learnable. Communications of the Association for Com-puting Machinery, 27(11):1134–1142, 1984.
[127] C. J. van Rijsbergen. Information retrieval. Butterworths, London, 1979.http://www.dcs.gla.ac.uk/Keith/Preface.html.
[128] M. van Zaanen. Bootstrapping structure using similarity. P. Monachesi, redaktor,Computational Linguistics in the Netherlands 1999, strony 235–245, 1999.
[129] M. van Zaanen. ABL: Alignment-based learning. COLING 2000 - Proceedings ofthe 18th International Conference on Computational Linguistics, strony 961–967,Morristown, NJ, USA, 2000. Association for Computational Linguistics.
[130] M. van Zaanen, P. Adriaans. Comparing two unsupervised grammar induction sys-tems: Alignment-based learning vs. EMILE. Raport instytutowy, University of Le-eds, School of Computing, 2001.
[131] M. van Zaanen, J. Geetzen. ABL: Alignment–based Learner, version 1.0, 2006.Available on: http://www.ics.mq.edu.au/~menno/research/software/abl/.
[132] R. S. Wells. Immediate constituents. Language, 23:81–117, 1947.
[133] R. Wiehagen. From inductive inference to algorithmic learning theory. Proceedings ofthe Third Workshop on Algorithmic Learning Theory, strony 13–24. Springer-Verlag,1993.
[134] J. G. Wolff. Language acquisition, data compression and generalization. Language& Communication, 2:57–89, 1982.
[135] M. Woliński. System znaczników morfosyntaktycznych w korpusie IPI PAN. PolonicaXXII-XXIII, 2003.
[136] M. Woliński. Morfeusz — a practical tool for the morphological analysis of polish.M. Kłopotek, S. Wierzchoń, K. Trojanowski, redaktorzy, Intelligent InformationProcessing and Web Mining, IIS:IIPWM’06 Proceedings, strony 503–512. Springer,2006.
[137] M. Woliński, A. Przepiórkowski. Projekt anotacji mofrosyntaktycznej korpusu językapolskiego. Prace IPI PAN 938, 2001.
95

Bibliografia Bibliografia
[138] D. Wu. An algorithm for simultaneously bracketing parallel texts by aligning words.Proceedings of the 33rd annual meeting on Association for Computational Lingu-istics, strony 244–251, Morristown, NJ, USA, 1995. Association for ComputationalLinguistics.
[139] Z. B. Wu, L. S. Hsu, C. L. Tan. A survey of statistical approaches to natural languageprocessing. Raport instytutowy TRA4/92, Singapore, 1992.
[140] T. Yokomori. Inductive inference of context-free langauges based on context-freeexpressions. Int. J. Computer Math., 24:115–140, 1988.
[141] T. Yokomori. Polynomial-time identification of very simple grammars from positivedata. Raport instytutowy CSIM 90-15, University of Electro-Communications, De-partment of Computer Science and Information Mathematics, Chofu, Tokyo, Japan,1990.
[142] T. Yokomori. Polynomial-time learning of very simple grammars from positive data.Proceedings of the fourth annual workshop on Computational learning theory, strony213–227. Morgan Kaufmann Publishers Inc., 1991.
[143] T. Yokomori. Learning non-deterministic finite automata from queries and counte-rexamples. Machine Intelligence, 13:169–189, 1994.
[144] T. Yokomori. On polynomial-time learnability in the limit of strictly deterministicautomata. Machine Learning, 19:153–179, 1995.
[145] T. Yokomori. Polynomial-time identification of very simple grammars from positivedata. Theor. Comput. Sci., 298(1):179–206, 2003.
[146] S. J. Young, H.-H. Shih. Computer assisted grammar construction. R. C. Carrsco,J. Oncina, redaktorzy, Grammar Inference and Applications. Second InternationalColloquium, ICGI-94, wolumen 862 serii Lecture Notes In Artificial Inteligence, stro-ny 282–290. Springer-Verlag, 1994.
[147] G. K. Zipf. Human behavior and the principle of least effort. Addison-Wesley Press,Cambridge, MA, 1949.
[148] S. M. zu Eissen, B. Stein, M. Potthast. The suffix tree document model revisited.M. Tochtermann, redaktor, Proceedings of the I-KNOW ’05, Graz, strony 596–603,2005.
[W1] http://eurise.univ-st-etienne.fr/gi/ — Homepage of Grammatical Induc-tion Community,
[W2] http://www.info.ucl.ac.be/people/pdupont/pdupont/gram.html—GrammarInduction References Page,
[W3] http://www.korpus.pl/— Korpus IPI PAN,
[W4] http://gate.ac.uk/— GATE, A General Architecture fot Text Engineering Ho-mepage,
[W5] http://www.learningtheory.org/—COLT, Computational Learning Theory Ho-mepage,
[W6] http://simpleparse.sourceforge.net/— Simple Parser Generator,
[W7] http://www.cis.upenn.edu/~treebank/— The Penn Treebank Project,
[W8] http://ufal.mff.cuni.cz/pcedt/—Prague Czech-English Dependency Treebank,
96

Bibliografia Bibliografia
[W9] http://nlp.cs.nyu.edu/evalb/— evalb – implementacja metryki PARSEVAL,
[W10] http://www.ics.mq.edu.au/~menno/research/software/abl— oprogramowa-nie implementujące Alignment-Based Learning,
[W11] http://staff.science.uva.nl/~pietera/Emile/— oprogramowanie implemen-tujące algorytm EMILE,
[W12] http://nlp.ipipan.waw.pl/~wolinski/morfeusz/— analizator morfologiczny„Morfeusz”,
[W13] http://lucene.apache.org/java/docs/— pełnotekstowy index,
[W14] http://www.alicebot.org/— A.L.I.C.E Artificial Intelligence Foundation.
97

Indukcja reguł gramatyki języka polskiego
Spis tabel
2.1 Odpowiadające sobie oznaczenia w opisie języków formalnych i naturalnych 14
2.2 Zestawienie typów języków wraz z akceptującymi je automatami . . . . . . 16
2.3 Zakresy identyfikowalności języków z danych w granicy . . . . . . . . . . . . 21
2.4 Klasy gramatyczne języka polskiego . . . . . . . . . . . . . . . . . . . . . . 36
2.5 Kategorie gramatyczne języka polskiego . . . . . . . . . . . . . . . . . . . . 37
2.6 Charakterystyka morfosyntaktyczna klas gramatycznych języka polskiego . 38
3.1 Dodatkowe etykiety użyte w systemie indukcji reguł . . . . . . . . . . . . . 49
3.2 Efektywna liczba etykiet . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
3.3 Kolejność etykiet użyta w odwzorowaniu . . . . . . . . . . . . . . . . . . . . 50
3.4 Przykładowy fragment odwzorowania map-gi-flexeme-simple . . . . . . . 50
3.5 Zdefiniowane odwzorowania . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
3.6 Odwzorowania przykładowego zdania . . . . . . . . . . . . . . . . . . . . . . 51
3.7 Zestawienie parametrów używanych algorytmów . . . . . . . . . . . . . . . 63
4.1 Przykładowe zdanie — podział pierwszego rzędu . . . . . . . . . . . . . . . 66
4.2 Przykładowe zdanie — podziały kolejnych rzędów . . . . . . . . . . . . . . . 67
4.3 Ocena addytywna całkowitej struktury zdania . . . . . . . . . . . . . . . . . 68
4.4 Zestawienie wyników działania algorytmów . . . . . . . . . . . . . . . . . . 70
98

Indukcja reguł gramatyki języka polskiego
Spis rysunków
2.1 Przykładowe drzewo wyprowadzenia wraz z odpowiadającą mu gramatyką . 16
2.2 Przykład ustrukturalizowanej reprezentacji zdania . . . . . . . . . . . . . . 25
2.3 Własności miary F-score . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
2.4 Częstość występowania sekwencji . . . . . . . . . . . . . . . . . . . . . . . . 40
2.5 Przykładowe zdanie anotowane zgodnie ze strukturą korpusu IPI PAN . . . 41
2.6 Częstość występowania sekwencji w funkcji liczby przeanalizowanych zdań . 42
2.7 WartościMI dla wybranych zdań . . . . . . . . . . . . . . . . . . . . . . . 45
2.8 Wartości GMI dla wybranych zdań . . . . . . . . . . . . . . . . . . . . . . 46
3.1 Odwzorowania opisów lexemów ctag. . . . . . . . . . . . . . . . . . . . . . . 52
3.2 Odwzorowania opisów ctag (cd.) . . . . . . . . . . . . . . . . . . . . . . . . 53
3.3 Wartość średniaMI dla podsekwencji z testowanego korpusu . . . . . . . . 54
3.4 WariancjaMI dla podsekwencji z testowanego korpusu . . . . . . . . . . . 55
3.5 Wartości średnie prawdopodobieństw: PX , PY , PXY . . . . . . . . . . . . . 56
3.6 Rozkład liczby wystąpień podsekwencji w funkcji długości . . . . . . . . . . 57
3.7 Liczba sekwencji w funkcji liczby przeanalizowanych zdań . . . . . . . . . . 58
3.8 Wartość współczynnika SF dla najlepszego n–punktowego podziału . . . . 61
3.9 Liczba możliwych podziałów w funkcji długości sekwencji . . . . . . . . . . 62
4.1 Wartość oceny szkieletów dla algorytmu w wersji addytywnej i (. . . ) . . . . 68
4.2 Wygenerowane struktury szkieletowe . . . . . . . . . . . . . . . . . . . . . . 69
4.3 Porównanie wartości Fscore i CB dla systemów ABL, EMILE i (. . . ) . . . . 71
4.4 Porównanie wartości Fscore i CB dla SF, SF NOINC, SF BEST FIRST, (. . . ) . 73
4.5 Liczba reguł i symboli nieterminalnych . . . . . . . . . . . . . . . . . . . . . 74
4.6 Liczba reguł w funkcji S-sup i RCFG2sup dla parametryzacji SF NOINC . . 75
4.7 Udział reguł o zadanym S-sup w ogólnej liczbie reguł . . . . . . . . . . . . 76
4.8 Pokrycie zbioru reguł dla różnych konfiguracji algorytmów, RCFG2sup (. . . ) 77
4.9 Pokrycie zbioru reguł na zbiorach testowych w funkcji RCFG2sup . . . . . 78
A.1 Schemat eksperymentalnego systemu indukcji reguł gramatyki . . . . . . . . 103
A.2 Liczba reguł i symboli nieterminalnych (cz. 1) . . . . . . . . . . . . . . . . . 105
A.3 Liczba reguł i symboli nieterminalnych (cz. 2) . . . . . . . . . . . . . . . . . 106
99

Spis rysunków Spis rysunków
A.4 Liczba reguł i symboli nieterminalnych (cz. 3) . . . . . . . . . . . . . . . . . 107
A.5 Liczba reguł w funkcji S-sup i RCFG2sup (SF BEST FIRST cz. 1) . . . . . 108
A.6 Liczba reguł w funkcji S-sup i RCFG2sup (SF BEST FIRST cz. 2) . . . . . 109
A.7 Liczba reguł w funkcji S-sup i RCFG2sup (SF BEST FIRST cz. 3) . . . . . 110
A.8 Liczba reguł w funkcji S-sup i RCFG2sup (SF BEST FIRST NOINC cz. 1) 111
A.9 Liczba reguł w funkcji S-sup i RCFG2sup (SF BEST FIRST NOINC cz. 2) 112
A.10 Liczba reguł w funkcji S-sup i RCFG2sup (SF BEST FIRST NOINC cz. 3) 113
A.11 Liczba reguł w funkcji S-sup i RCFG2sup (SF cz. 1) . . . . . . . . . . . . . 114
A.12 Liczba reguł w funkcji S-sup i RCFG2sup (SF cz. 2) . . . . . . . . . . . . . 115
A.13 Liczba reguł w funkcji S-sup i RCFG2sup (SF cz. 3) . . . . . . . . . . . . . 116
A.14 Liczba reguł w funkcji S-sup i RCFG2sup (SF NOINC cz. 1) . . . . . . . . 117
A.15 Liczba reguł w funkcji S-sup i RCFG2sup (SF NOINC cz. 2) . . . . . . . . 118
A.16 Liczba reguł w funkcji S-sup i RCFG2sup (SF NOINC cz. 3) . . . . . . . . 119
A.17 Pokrycie zbioru reguł dla różnych konfiguracji algorytmów (cz. 1) . . . . . . 120
A.18 Pokrycie zbioru reguł dla różnych konfiguracji algorytmów (cz. 2) . . . . . . 121
A.19 Pokrycie zbioru reguł dla różnych konfiguracji algorytmów (cz. 3) . . . . . . 122
A.20 Pokrycie zbioru reguł na korpusie testowym w funkcji RCFG2sup (cz. 1) . . 123
A.21 Pokrycie zbioru reguł na korpusie testowym w funkcji RCFG2sup (cz. 2) . . 124
A.22 Pokrycie zbioru reguł na korpusie testowym w funkcji RCFG2sup (cz. 3) . . 125
100

Indukcja reguł gramatyki języka polskiego
Aneksy
A.1 Spis oznaczeń i skrótów
CFG Context-free grammar
CFL Context-free languages
DM Data Mining
GBML Genetic-Based Machine Lerning
DFA Deterministic Finite Automata
GI Grammar Induction lub Grammatical Inference
HMM Hidden Markov Model
IC Immediate Constituent Analysis
ICGI International Colloquium on Grammatical Inference
IDF Inverterd Document Frequency
IG Information Gain
IR Information Retrieval
MT Machine Translation
NLP Natural Language Processing
NLU Natural Language Understaning
PAC Probably Approximately Correct (learning model)
TF Term Frequency
TM Text Mining
VMM Visible Markov Model
A.2 Przegląd literatury
Poniżej zamieszczono najbardziej istotne pozycje literaturowe podzielone tematycznie:
• wstęp do teorii automatów i języków: [63],
• prace przeglądowe: [40, 108, 94, 26, 78, 61, 139],
• automaty na drzewach: [123, 41, 46],
101

A.3. Budowa eksperymentalnego systemu indukcji reguł gramatycznych Aneksy
• inductive inference: [11, 81],
• computational learning theory: [9],
• algorytmy genetyczne w GI: [47, 77]
• podklasy CFG: noncounting CFL [42], parenthesis grammars [92], strictly deter-ministic automata [144], simple deterministic gramars [64], very simple grammars[141, 145], even linear languages [121], structuraly reversible CFG [27],
• indukcja DFA: [11, 97], z użyciem reprezentatywnej próbki i pytań o przynależność[4], z nauczycielem [6], k-reversible DFA [5],
• GI w NLP: [29, 30, 96],
• GI w biologii obliczeniowej (ang. computational biology): [109, 76, 109],
• modele uczenia: w granicy [54], poprzez zapytania [7], PAC [126],
• identyfikowalność z pozytywnych informacji: [3, 119, 141],
• pattern languages: [2, 74],
• strukturalna reprezentacja tekstu: [53, 92],
• immediate constituent analysis: [132, 98, 59],
• gramatyki stochastyczne (SCFG): [109, 108, 32],
• automatyczne wykrywanie struktur szkieletowych: [117, 146, 21, 24, 23, 87],
• fleksja polska: [112, 113, 113, 111, 57, 17, 16, 124],
• automatyczna analiza morfologiczna: [137, 102, 135, 99, 36, 136, 48].
A.3 Budowa eksperymentalnego systemu indukcji reguł gra-
matycznych
Eksperymenty, których wyniki przedstawiono w rozdziale 4 i w dodatku A.4, zostały prze-prowadzone przy wykorzystaniu, stworzonego przez autora niniejszej rozprawy, systemuindukcji reguł gramatyki o nazwie GI. Specjalnie na potrzeby budowy tego systemu zostałstworzony szkielet (ang. framework) uniwersalnego środowiska doświadczalnego o nazwieEE (ang. experimental environment), zapewniający niezbędną podstawową funkcjonalność.System EE powstał jako wersja rozwojowa oprogramowania będącego wynikiem prowadzo-nych projektów z zakresu tematyki Text Mining w Zakładzie Systemów InformacyjnychInstytutu Informatyki Politechniki Warszawskiej (wyniki doświadczeń dostępne są m.in.w [105]). System EE jest oprogramowaniem OpenSource i zostanie opublikowany z licencjaApache Licence.
A.3.1 Struktura systemu
Systemy GI i EE zostały zaimplementowane w języku JAVA. Zastosowano koncepcję bu-dowy komponentowej z wykorzystaniem kontenera komponentów i wzorca projektowegoconstructor dependency injection zapewniającego maksymalną elastyczność konfiguracji.Schemat systemu został przedstawiony na rys. A.1.
102
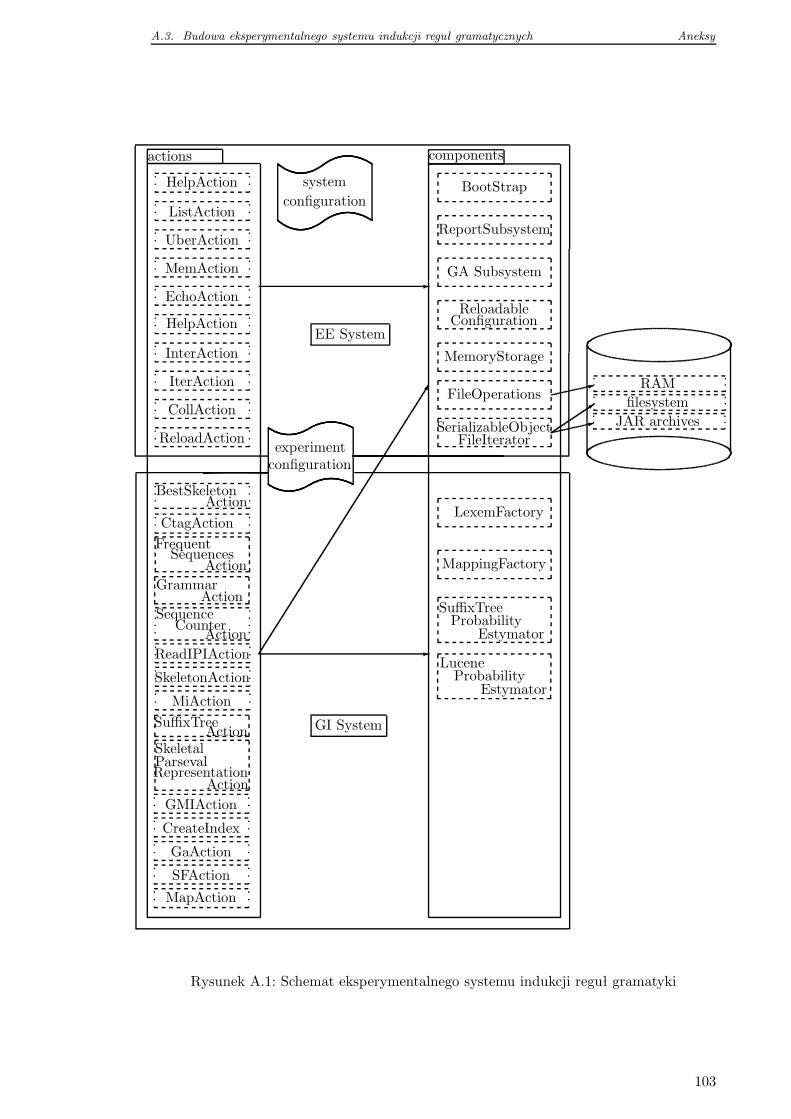
A.3. Budowa eksperymentalnego systemu indukcji reguł gramatycznych Aneksy
IterAction
UberAction
MemoryStorage
MemAction
ListAction
HelpAction
:
BootStrap
FileOperations3:
CollAction
CreateIndex
CtagAction
EchoAction
GaAction
GMIAction
HelpAction
InterAction
MapAction
MiAction
ReadIPIAction
ReloadAction
SFAction
SkeletonAction
LexemFactory
MappingFactory
GA Subsystem
ReportSubsystem
componentsactions
experimentconfiguration
systemconfiguration
-
-
�
SerializableObjectFileIterator
ReloadableConfiguration
EE System
GI System
RepresentationAction
Action
BestSkeletonAction
FrequentSequences
ActionSequenceCounter
SuffixTree
ProbabilityEstymator
EstymatorProbability
Lucene
RAMfilesystemJAR archives
SkeletalParseval
SuffixTreeAction
GrammarAction
Rysunek A.1: Schemat eksperymentalnego systemu indukcji reguł gramatyki
103

A.3. Budowa eksperymentalnego systemu indukcji reguł gramatycznych Aneksy
A.3.2 Sposób użycia
System może być używany zarówno w sposób interakcyjny (dzięki wywołaniu akcji Inte-rAction) jak i wsadowy. Sposób interakcyjny pozwala wykonywać zdefiniowane w systemieakcje wpływając na ich działanie za pomocą parametrów zgodnych z zasadami przyjętymiw powłoce bash. Zaimplementowano także funkcje ułatwiające interakcje użytkownika zsystemem, takie jak: historia wydanych komend, podpowiadanie nazw plików, akcji, pa-rametrów, obiektów MemoryStorage.
Wywołanie wsadowe także może zakończyć się interakcyjnie, zwłaszcza, gdy jego efek-ty pozostają w pamięci operacyjnej i operator chce zdecydować po zapoznaniu się z nimi odalszych działaniach. Także nieobsłużona sytuacja wyjątkowa, przy przetwarzaniu wsado-wym, skutkuje przejściem systemu w tryb interakcji z użytkownikiem, celem umożliwieniausunięcia problemu i kontynuacji procesu obliczeń.
A.3.3 Przykład działania
Poniżej przedstawiono przykładową konfigurację przetwarzania wsadowego (umożliwiającąznalezienie najczęściej występujących fraz w korpusie):
## Phrase counter con f i g## author : Marcin Go l ebsk i## date : 2007−01−04
UberAction . d e f au l t . execut ionSequence=\echo To count phrases use : ”uber −c phrase ” ;\echo To count phrases use ( sk e l e t on cons ide red ) : ”uber −c s k e l e t a l−phrase ” ;\In t e rAct ion
UberAction . s k e l e t a l−phrase . execut ionSequence=UberAction \−c process−a l l−c r i t e r i a −p l e n l i s t , min support , m i n l e n g t h o f f s e t \−− l e n l i s t 20 ,25 ,30 ,35 ,40 ,45 ,50 ,55 −−min support 5 −−min l e n g t h o f f s e t 5
UberAction . process−a l l−c r i t e r i a . execut ionSequence=I te rAct ion \− l SF NOINC, SF , SF BEST FIRST NOINC , SF BEST FIRST −c process−a l l−maps \−o opt ion −−map $map −p map, min support , m in l eng th o f f s e t , l e n l i s t \−−min support $min support −−min l e n g t h o f f s e t $m in l e n g t h o f f s e t \−− l e n l i s t $ l e n l i s t ;\
UberAction . process−a l l−maps . execut ionSequence=I te rAct ion \− l map−f lexeme−simple ,map−i p i−one ,map−one ,map−i p i−one−eos ,\map−gi−f lexeme−simple−eos ,map−gi−f lexeme−simple ,\map−gi−f lexeme−one−eos ,map−gi−f lexeme−one ,map−f lexeme−one \
−c s k e l e t a l−phrase−work −o map −p min support , max length ,\min l eng th o f f s e t , l e n l i s t , opt ion \
−−min support $min support −−max length $max length \−−min l e n g t h o f f s e t $m in l e n g t h o f f s e t −−opt ion $opt ion −− l e n l i s t $ l e n l i s t
UberAction . s k e l e t a l−phrase−work . execut ionSequence=UberAction \−c create−i t e r a t o r s −−max length 15 −−min l e n g t h o f f s e t 15 \−p min support , m in l eng th o f f s e t , option ,map \−−min support $min support −−opt ion $opt ion −−map $map ;\I t e rAct ion − l $ l e n l i s t −c create−i t e r a t o r s −o max length \−p min support , m in l eng th o f f s e t , option ,map −−min support $min support \−−min l e n g t h o f f s e t 5 −−opt ion $opt ion −−map $map ;\Skeleta lPhraseCounterAct ion −s sk e l−prop−i t e r −$map−$option−len−15 \−s sk e l−prop−i t e r −$map−$option−len−20 \−s sk e l−prop−i t e r −$map−$option−len−25 \−s sk e l−prop−i t e r −$map−$option−len −30;\UberAction −c remove−i t e r a t o r s −−max length 15 −−min l e n g t h o f f s e t 15 \
−p min support , m in l eng th o f f s e t , option ,map −−min support $min support \−−opt ion $opt ion −−map $map ;\
104
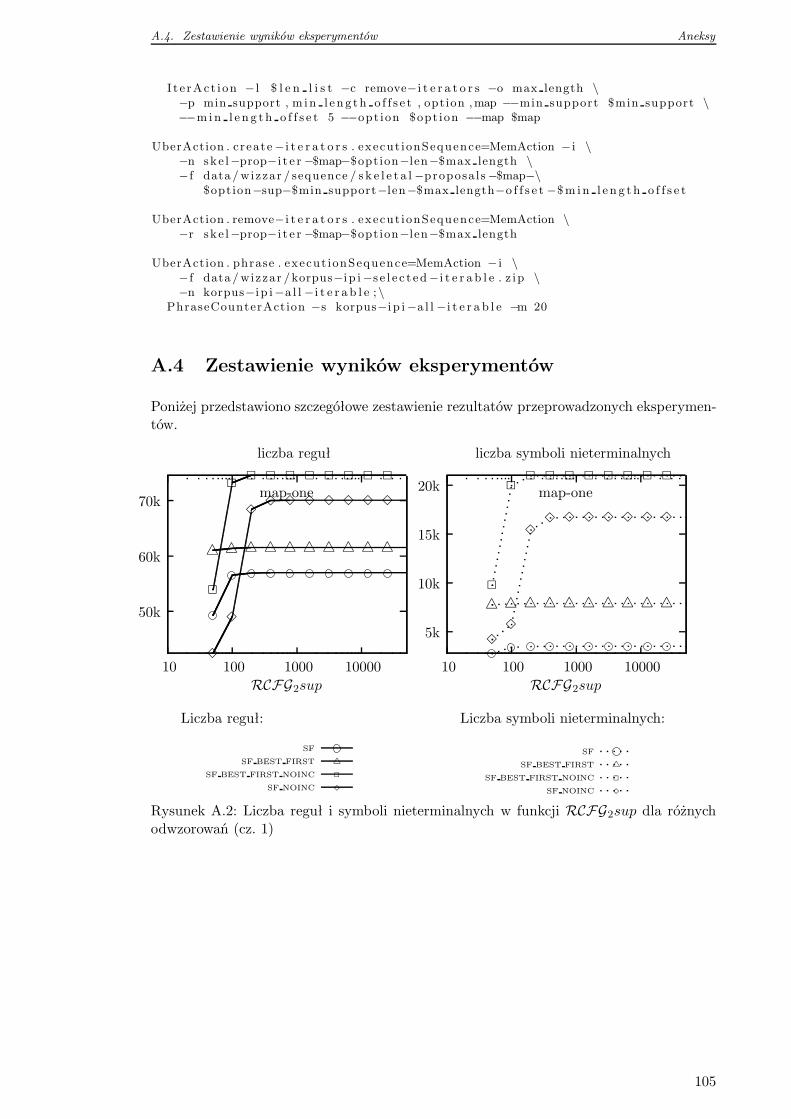
A.4. Zestawienie wyników eksperymentów Aneksy
I t e rAct ion − l $ l e n l i s t −c remove−i t e r a t o r s −o max length \−p min support , m in l eng th o f f s e t , option ,map −−min support $min support \−−min l e n g t h o f f s e t 5 −−opt ion $opt ion −−map $map
UberAction . create− i t e r a t o r s . execut ionSequence=MemAction − i \−n ske l−prop−i t e r −$map−$option−len−$max length \− f data /wizzar / sequence / s k e l e t a l−proposals−$map−\$option−sup−$min support−len−$max length−o f f s e t −$m in l e n g t h o f f s e t
UberAction . remove− i t e r a t o r s . execut ionSequence=MemAction \−r sk e l−prop−i t e r −$map−$option−len−$max length
UberAction . phrase . execut ionSequence=MemAction − i \− f data /wizzar /korpus−i p i−s e l e c t ed−i t e r a b l e . z ip \−n korpus−i p i−a l l−i t e r a b l e ;\PhraseCounterAction −s korpus−i p i−a l l−i t e r a b l e −m 20
A.4 Zestawienie wyników eksperymentów
Poniżej przedstawiono szczegółowe zestawienie rezultatów przeprowadzonych eksperymen-tów.
liczba reguł liczba symboli nieterminalnych
70k
60k
50k
10 100 1000 10000RCFG2sup
map-one
△ △ △ △ △ △ △ △ △ △
2
22 2 2 2 2 2 2 2
3
3
33 3 3 3 3 3 3
20k
15k
10k
5k
10 100 1000 10000RCFG2sup
map-one
△ △ △ △ △ △ △ △ △ △2
22 2 2 2 2 2 2 2
3
3
33 3 3 3 3 3 3
Liczba reguł:
SF
SF BEST FIRST △
SF BEST FIRST NOINC 2
SF NOINC 3
Liczba symboli nieterminalnych:
SF
SF BEST FIRST △
SF BEST FIRST NOINC 2
SF NOINC 3
Rysunek A.2: Liczba reguł i symboli nieterminalnych w funkcji RCFG2sup dla różnychodwzorowań (cz. 1)
105

A.4. Zestawienie wyników eksperymentów Aneksy
liczba reguł liczba symboli nieterminalnych
40k
30k
20k
10k
010 100 1000 10000
RCFG2sup
map-flexeme-simple
△ △ △ △ △ △ △ △
△△
2 2 2 2 22 2
2 2
2
3 3 3 3 3 3
33 3
3
10k
5k
1k
10 100 1000 10000RCFG2sup
map-flexeme-simple
△ △ △ △ △ △ △ △
△ △
2 2 2 2 2 2 2 2 2
2
3 3 3 3 3 3 3 3 3
3
50k
40k
30k
20k
10k
010 100 1000 10000
RCFG2sup
map-flexeme-one
△ △ △ △ △△
△
△
△△
2 2 2 2 2
22
2 2
2
3 3 3 33
3
3
3
3
3 15k
10k
5k
1k
10 100 1000 10000RCFG2sup
map-flexeme-one
△ △ △ △ △ △ △
△△ △
2 2 2 2 2 2 2
2 2
2
3 3 3 3 3 3 33
3
3
60k
50k
40k
30k
20k
10k
10 100 1000 10000RCFG2sup
map-gi-flexeme-one
△ △ △ △ △△
△ △
△ △
2 2 22 2
2
2
2
2 2
3 3 33
3
3
33 3
320k
15k
10k
5k
1k10 100 1000 10000
RCFG2sup
map-gi-flexeme-one
△ △ △ △ △ △
△ △
△ △
2 2 2 2 2 2
2
2
2 2
3 3 3 3 33
33 3
3
80k70k60k50k40k30k20k10k010 100 1000 10000
RCFG2sup
map-gi-flexeme-one-eos
△ △
△
△
△ △ △ △ △ △
22
2
2
2
22 2 2 2
33
3
3
3
3
3 3 3 3
30k
25k
20k
15k
10k
5k
1k10 100 1000 10000
RCFG2sup
map-gi-flexeme-one-eos
△ △ △△
△ △ △ △ △ △
2 22
2
2
22
2 2 2
3 3
3
3
3
3 3 3 3
Rysunek A.3: Liczba reguł i symboli nieterminalnych w funkcji RCFG2sup dla różnychodwzorowań (cz. 2)
106
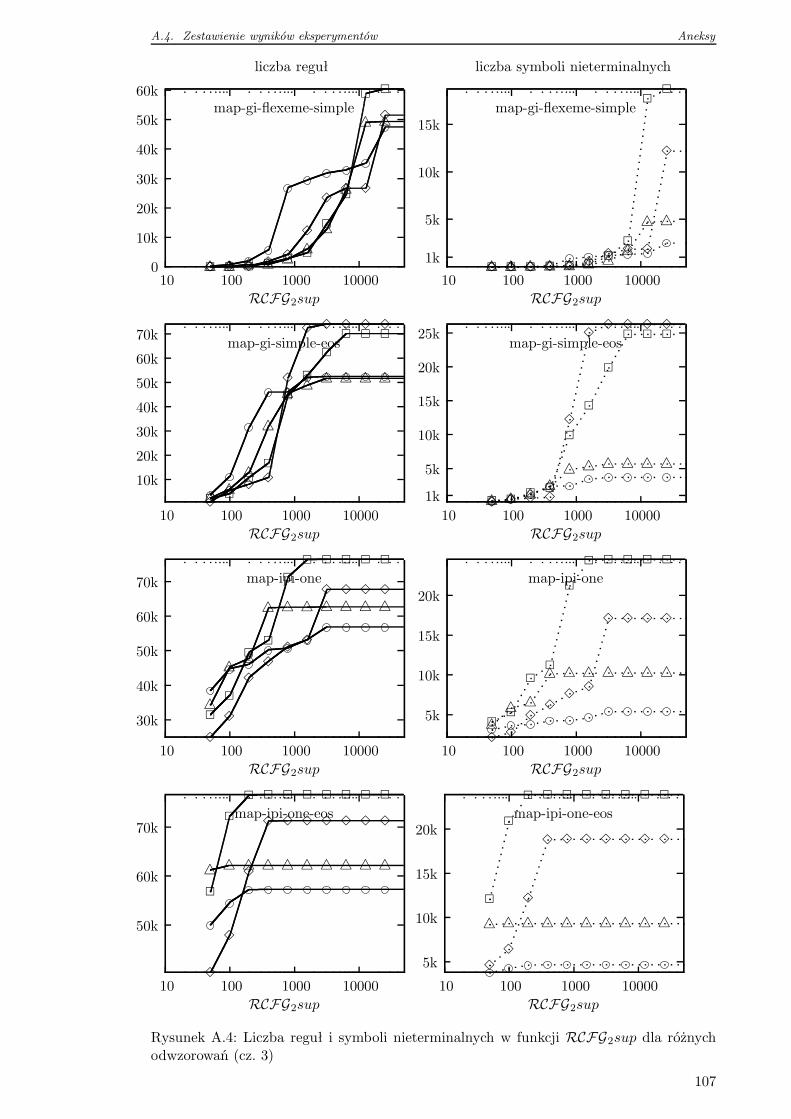
A.4. Zestawienie wyników eksperymentów Aneksy
liczba reguł liczba symboli nieterminalnych
60k
50k
40k
30k
20k
10k
010 100 1000 10000
RCFG2sup
map-gi-flexeme-simple
△ △ △ △ △△
△
△
△ △
2 2 2 2 22
2
2
2 2
3 3 3 33
3
33 3
315k
10k
5k
1k
10 100 1000 10000RCFG2sup
map-gi-flexeme-simple
△ △ △ △ △ △ △△
△ △
2 2 2 2 2 22
2
22
3 3 3 3 3 33 3 3
3
70k
60k
50k
40k
30k
20k
10k
10 100 1000 10000RCFG2sup
map-gi-simple-eos
△△
△
△
△△ △ △ △ △
2 2
2
2
2
2
2
2 2 2
33
33
3
3 3 3 3 325k
20k
15k
10k
5k
1k10 100 1000 10000
RCFG2sup
map-gi-simple-eos
△ △ △△
△ △ △ △ △ △
2 22 2
2
2
2
2 2 2
3 3 3 3
3
33 3 3 3
70k
60k
50k
40k
30k
10 100 1000 10000RCFG2sup
map-ipi-one
△
△△
△ △ △ △ △ △ △
2
2
22
2
2 2 2 2 2
3
3
3
3
33
3 3 3 3 20k
15k
10k
5k
10 100 1000 10000RCFG2sup
map-ipi-one
△△ △
△ △ △ △ △ △ △
22
2
2
2
2 2 2 2 2
33
33
33
3 3 3 3
70k
60k
50k
10 100 1000 10000RCFG2sup
map-ipi-one-eos
△ △ △ △ △ △ △ △ △ △
2
2
2 2 2 2 2 2 2 2
3
3
3
3 3 3 3 3 3 320k
15k
10k
5k
10 100 1000 10000RCFG2sup
map-ipi-one-eos
△ △ △ △ △ △ △ △ △ △
2
2
2 2 2 2 2 2 2 2
3
3
3
3 3 3 3 3 3 3
Rysunek A.4: Liczba reguł i symboli nieterminalnych w funkcji RCFG2sup dla różnychodwzorowań (cz. 3)
107
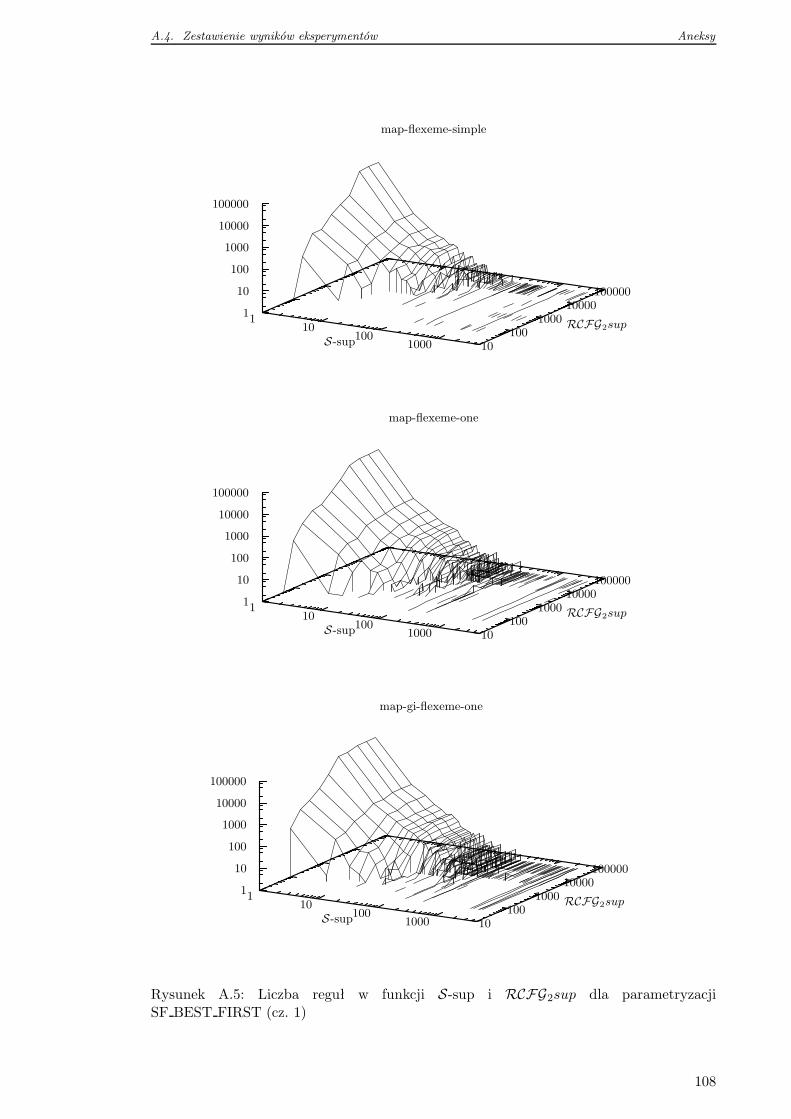
A.4. Zestawienie wyników eksperymentów Aneksy
110
1001000 10
1001000
10000100000
1
10
100
1000
10000
100000
map-flexeme-simple
S-supRCFG2sup
110
1001000 10
1001000
10000100000
1
10
100
1000
10000
100000
map-flexeme-one
S-supRCFG2sup
110
1001000 10
1001000
10000100000
1
10
100
1000
10000
100000
map-gi-flexeme-one
S-supRCFG2sup
Rysunek A.5: Liczba reguł w funkcji S-sup i RCFG2sup dla parametryzacjiSF BEST FIRST (cz. 1)
108
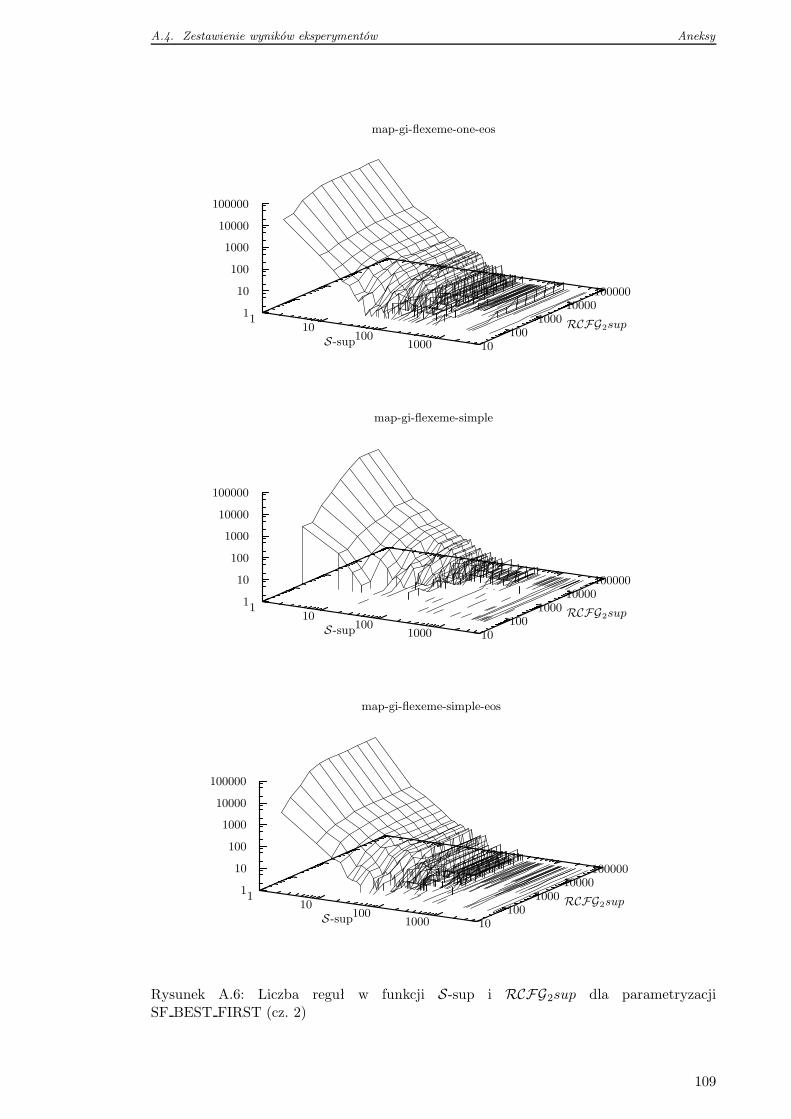
A.4. Zestawienie wyników eksperymentów Aneksy
110
1001000 10
1001000
10000100000
1
10
100
1000
10000
100000
map-gi-flexeme-one-eos
S-supRCFG2sup
110
1001000 10
1001000
10000100000
1
10
100
1000
10000
100000
map-gi-flexeme-simple
S-supRCFG2sup
110
1001000 10
1001000
10000100000
1
10
100
1000
10000
100000
map-gi-flexeme-simple-eos
S-supRCFG2sup
Rysunek A.6: Liczba reguł w funkcji S-sup i RCFG2sup dla parametryzacjiSF BEST FIRST (cz. 2)
109
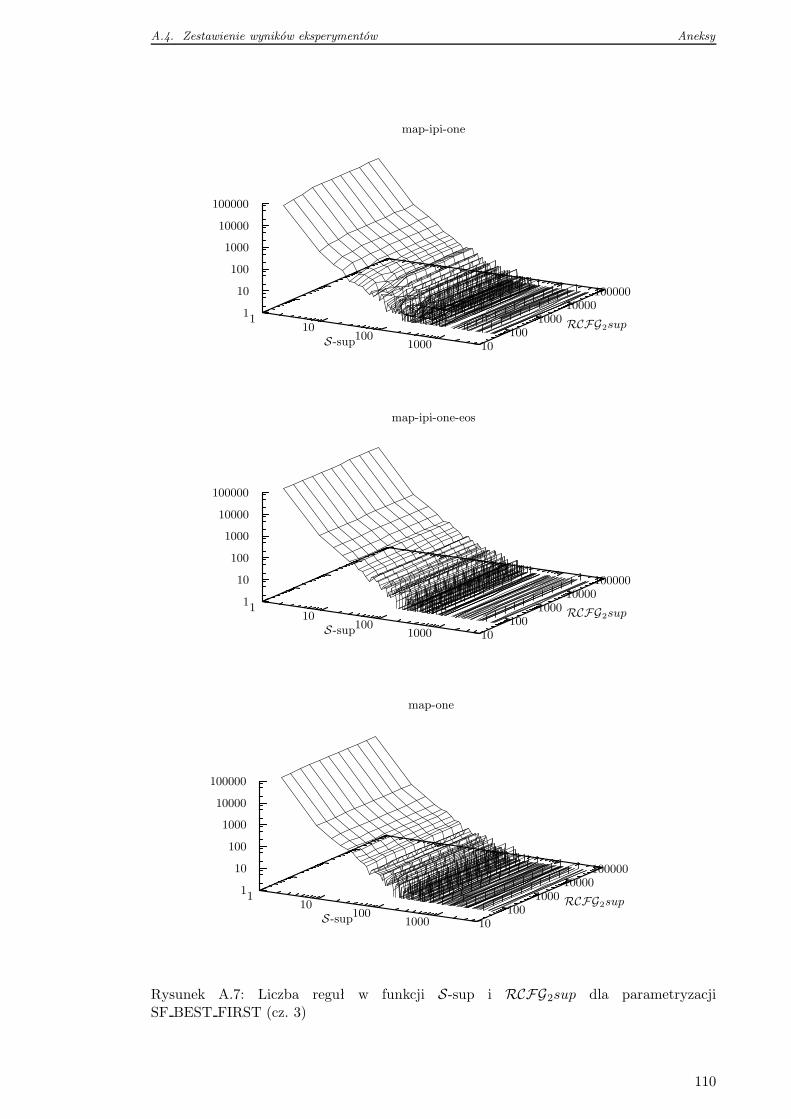
A.4. Zestawienie wyników eksperymentów Aneksy
110
1001000 10
1001000
10000100000
1
10
100
1000
10000
100000
map-ipi-one
S-supRCFG2sup
110
1001000 10
1001000
10000100000
1
10
100
1000
10000
100000
map-ipi-one-eos
S-supRCFG2sup
110
1001000 10
1001000
10000100000
1
10
100
1000
10000
100000
map-one
S-supRCFG2sup
Rysunek A.7: Liczba reguł w funkcji S-sup i RCFG2sup dla parametryzacjiSF BEST FIRST (cz. 3)
110
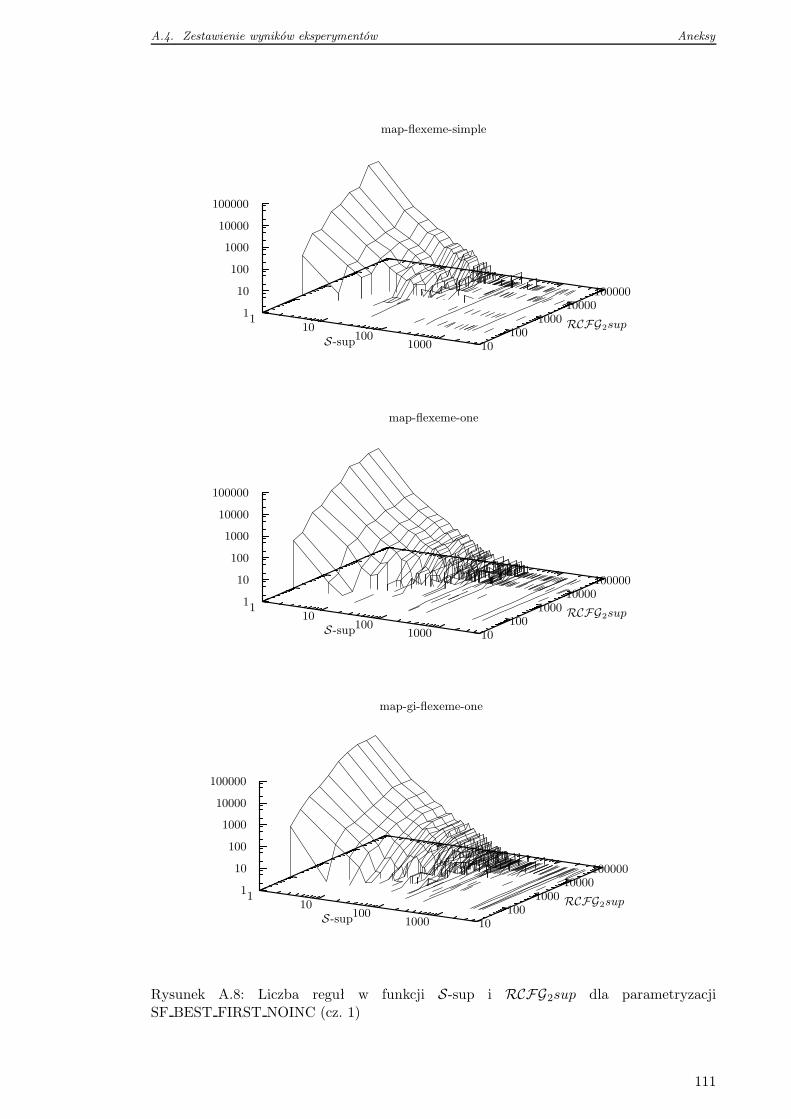
A.4. Zestawienie wyników eksperymentów Aneksy
110
1001000 10
1001000
10000100000
1
10
100
1000
10000
100000
map-flexeme-simple
S-supRCFG2sup
110
1001000 10
1001000
10000100000
1
10
100
1000
10000
100000
map-flexeme-one
S-supRCFG2sup
110
1001000 10
1001000
10000100000
1
10
100
1000
10000
100000
map-gi-flexeme-one
S-supRCFG2sup
Rysunek A.8: Liczba reguł w funkcji S-sup i RCFG2sup dla parametryzacjiSF BEST FIRST NOINC (cz. 1)
111
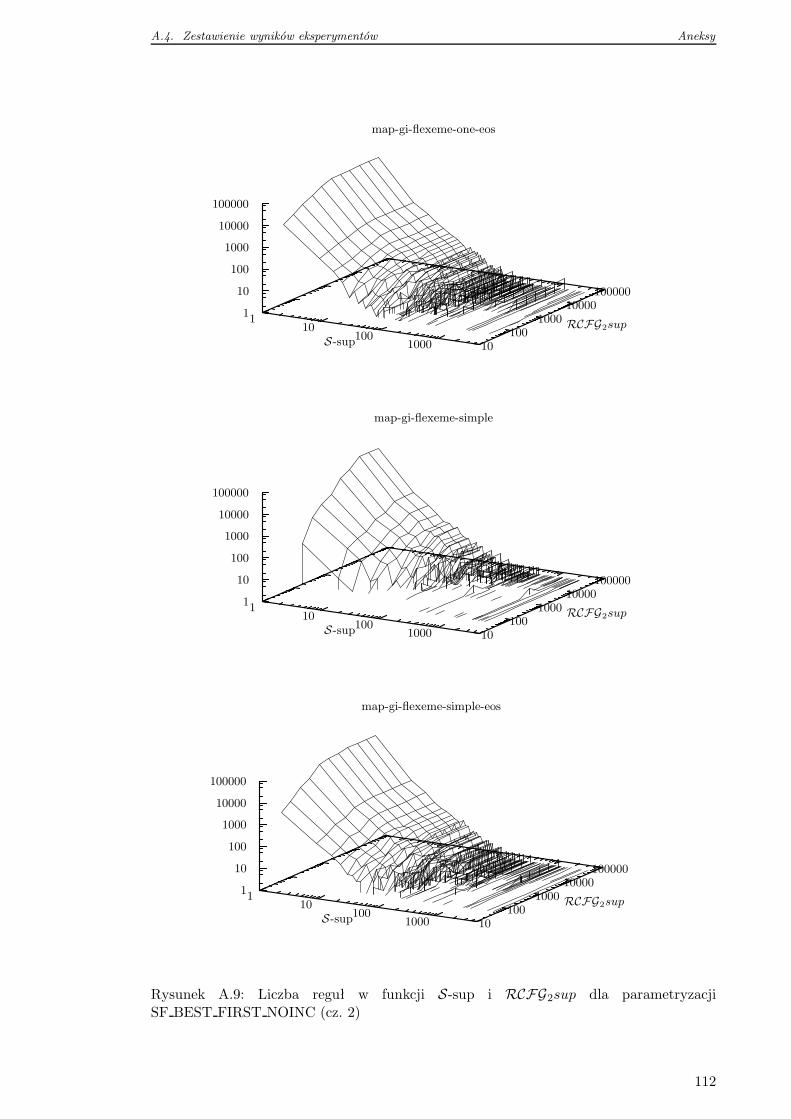
A.4. Zestawienie wyników eksperymentów Aneksy
110
1001000 10
1001000
10000100000
1
10
100
1000
10000
100000
map-gi-flexeme-one-eos
S-supRCFG2sup
110
1001000 10
1001000
10000100000
1
10
100
1000
10000
100000
map-gi-flexeme-simple
S-supRCFG2sup
110
1001000 10
1001000
10000100000
1
10
100
1000
10000
100000
map-gi-flexeme-simple-eos
S-supRCFG2sup
Rysunek A.9: Liczba reguł w funkcji S-sup i RCFG2sup dla parametryzacjiSF BEST FIRST NOINC (cz. 2)
112
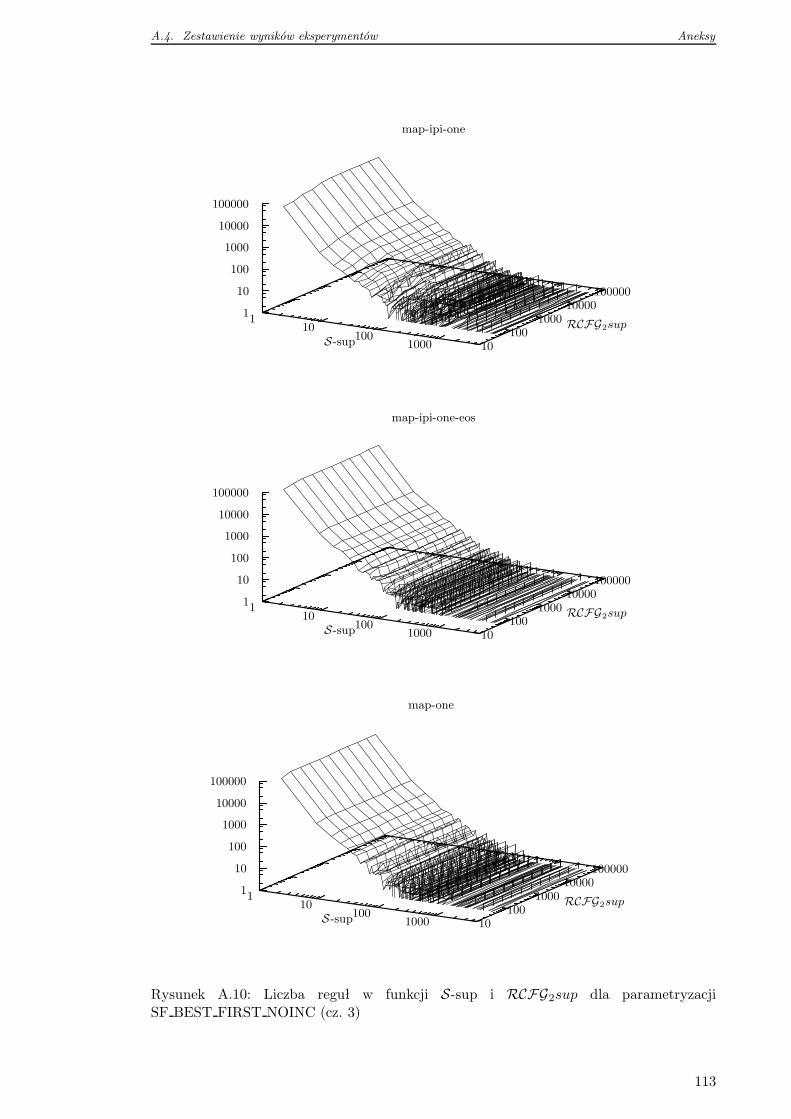
A.4. Zestawienie wyników eksperymentów Aneksy
110
1001000 10
1001000
10000100000
1
10
100
1000
10000
100000
map-ipi-one
S-supRCFG2sup
110
1001000 10
1001000
10000100000
1
10
100
1000
10000
100000
map-ipi-one-eos
S-supRCFG2sup
110
1001000 10
1001000
10000100000
1
10
100
1000
10000
100000
map-one
S-supRCFG2sup
Rysunek A.10: Liczba reguł w funkcji S-sup i RCFG2sup dla parametryzacjiSF BEST FIRST NOINC (cz. 3)
113
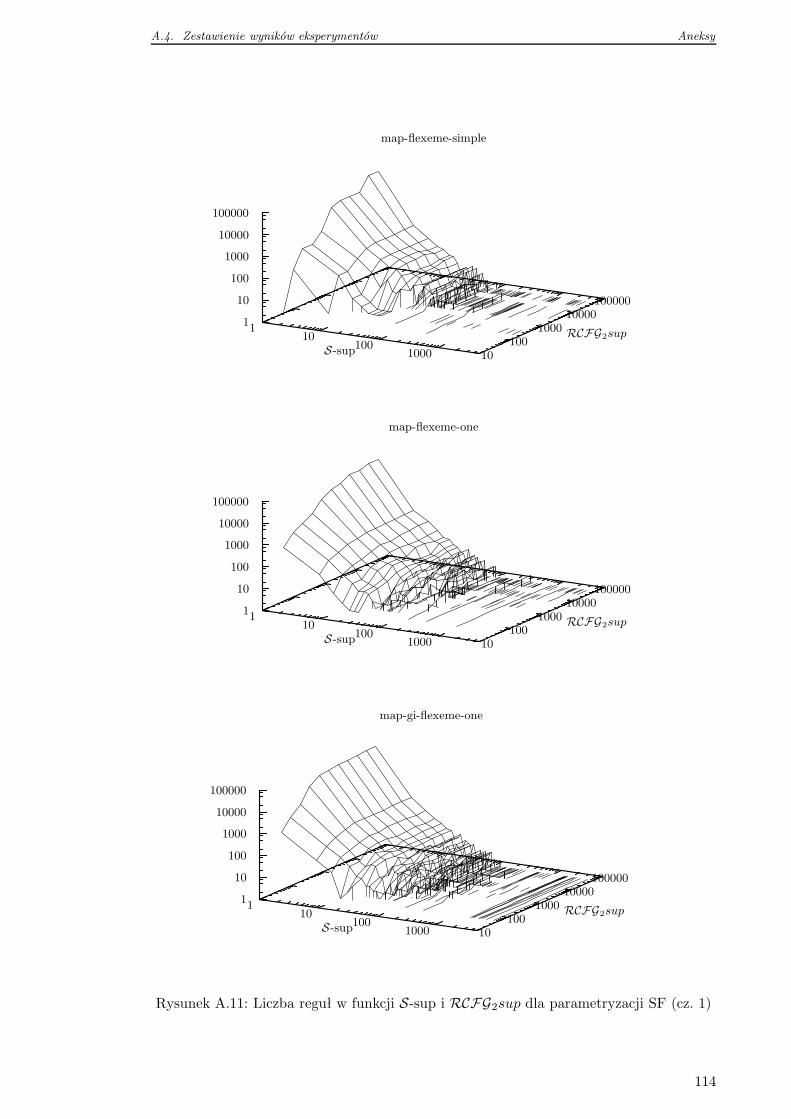
A.4. Zestawienie wyników eksperymentów Aneksy
110
1001000 10
1001000
10000100000
1
10
100
1000
10000
100000
map-flexeme-simple
S-supRCFG2sup
110
1001000 10
1001000
10000100000
1
10
100
1000
10000
100000
map-flexeme-one
S-supRCFG2sup
110
1001000 10
1001000
10000100000
1
10
100
1000
10000
100000
map-gi-flexeme-one
S-supRCFG2sup
Rysunek A.11: Liczba reguł w funkcji S-sup i RCFG2sup dla parametryzacji SF (cz. 1)
114
A.4. Zestawienie wyników eksperymentów Aneksy
110
1001000 10
1001000
10000100000
1
10
100
1000
10000
100000
map-gi-flexeme-one-eos
S-supRCFG2sup
110
1001000 10
1001000
10000100000
1
10
100
1000
10000
100000
map-gi-flexeme-simple
S-supRCFG2sup
110
1001000 10
1001000
10000100000
1
10
100
1000
10000
100000
map-gi-flexeme-simple-eos
S-supRCFG2sup
Rysunek A.12: Liczba reguł w funkcji S-sup i RCFG2sup dla parametryzacji SF (cz. 2)
115

A.4. Zestawienie wyników eksperymentów Aneksy
110
1001000 10
1001000
10000100000
1
10
100
1000
10000
100000
map-ipi-one
S-supRCFG2sup
110
1001000 10
1001000
10000100000
1
10
100
1000
10000
100000
map-ipi-one-eos
S-supRCFG2sup
110
1001000 10
1001000
10000100000
1
10
100
1000
10000
100000
map-one
S-supRCFG2sup
Rysunek A.13: Liczba reguł w funkcji S-sup i RCFG2sup dla parametryzacji SF (cz. 3)
116
A.4. Zestawienie wyników eksperymentów Aneksy
110
1001000 10
1001000
10000100000
1
10
100
1000
10000
100000
map-flexeme-simple
S-supRCFG2sup
110
1001000 10
1001000
10000100000
1
10
100
1000
10000
100000
map-flexeme-one
S-supRCFG2sup
110
1001000 10
1001000
10000100000
1
10
100
1000
10000
100000
map-gi-flexeme-one
S-supRCFG2sup
Rysunek A.14: Liczba reguł w funkcji S-sup i RCFG2sup dla parametryzacji SF NOINC(cz. 1)
117
A.4. Zestawienie wyników eksperymentów Aneksy
110
1001000 10
1001000
10000100000
1
10
100
1000
10000
100000
map-gi-flexeme-one-eos
S-supRCFG2sup
110
1001000 10
1001000
10000100000
1
10
100
1000
10000
100000
map-gi-flexeme-simple
S-supRCFG2sup
110
1001000 10
1001000
10000100000
1
10
100
1000
10000
100000
map-gi-flexeme-simple-eos
S-supRCFG2sup
Rysunek A.15: Liczba reguł w funkcji S-sup i RCFG2sup dla parametryzacji SF NOINC(cz. 2)
118

A.4. Zestawienie wyników eksperymentów Aneksy
110
1001000 10
1001000
10000100000
1
10
100
1000
10000
100000
map-ipi-one
S-supRCFG2sup
110
1001000 10
1001000
10000100000
1
10
100
1000
10000
100000
map-ipi-one-eos
S-supRCFG2sup
110
1001000 10
1001000
10000100000
1
10
100
1000
10000
100000
map-one
S-supRCFG2sup
Rysunek A.16: Liczba reguł w funkcji S-sup i RCFG2sup dla parametryzacji SF NOINC(cz. 3)
119
A.4. Zestawienie wyników eksperymentów Aneksy
map-flexeme-simple
SF BEST FIRST-400
SF BEST FIRST-200
SF BEST FIRST-100
SF BEST FIRST-50
SF BEST FIRST NOINC-400
SF BEST FIRST NOINC-200
SF BEST FIRST NOINC-100
SF BEST FIRST NOINC-50
SF NOINC-400
SF NOINC-200
SF NOINC-100
SF NOINC-50
SF-400
SF-200
SF-100SF-50
algorytm-RCFG2sup
1 10 100 1000 10000 100000S-sup
00, 10, 20, 30, 40, 50, 60, 70, 80, 9
1
map-flexeme-one
SF BEST FIRST-400
SF BEST FIRST-200
SF BEST FIRST-100
SF BEST FIRST-50
SF BEST FIRST NOINC-400
SF BEST FIRST NOINC-200
SF BEST FIRST NOINC-100
SF BEST FIRST NOINC-50
SF NOINC-400
SF NOINC-200
SF NOINC-100
SF NOINC-50
SF-400
SF-200
SF-100SF-50
algorytm-RCFG2sup
1 10 100 1000 10000 100000S-sup
00, 10, 20, 30, 40, 50, 60, 70, 80, 9
1
map-gi-flexeme-one
SF BEST FIRST-400
SF BEST FIRST-200
SF BEST FIRST-100
SF BEST FIRST-50
SF BEST FIRST NOINC-400
SF BEST FIRST NOINC-200
SF BEST FIRST NOINC-100
SF BEST FIRST NOINC-50
SF NOINC-400
SF NOINC-200
SF NOINC-100
SF NOINC-50
SF-400
SF-200
SF-100SF-50
algorytm-RCFG2sup
1 10 100 1000 10000 100000S-sup
00, 10, 20, 30, 40, 50, 60, 70, 80, 9
1
Rysunek A.17: Pokrycie zbioru reguł dla różnych konfiguracji algorytmów, RCFG2sup iminimalnego wsparcia reguł S-sup — korpus trenujący (cz. 1)
120

A.4. Zestawienie wyników eksperymentów Aneksy
map-gi-flexeme-one-eos
SF BEST FIRST-400
SF BEST FIRST-200
SF BEST FIRST-100
SF BEST FIRST-50
SF BEST FIRST NOINC-400
SF BEST FIRST NOINC-200
SF BEST FIRST NOINC-100
SF BEST FIRST NOINC-50
SF NOINC-400
SF NOINC-200
SF NOINC-100
SF NOINC-50
SF-400
SF-200
SF-100SF-50
algorytm-RCFG2sup
1 10 100 1000 10000 100000S-sup
0
0, 2
0, 4
0, 6
0, 8
1
map-gi-flexeme-simple
SF BEST FIRST-400
SF BEST FIRST-200
SF BEST FIRST-100
SF BEST FIRST-50
SF BEST FIRST NOINC-400
SF BEST FIRST NOINC-200
SF BEST FIRST NOINC-100
SF BEST FIRST NOINC-50
SF NOINC-400
SF NOINC-200
SF NOINC-100
SF NOINC-50
SF-400
SF-200
SF-100SF-50
algorytm-RCFG2sup
1 10 100 1000 10000 100000S-sup
00, 10, 20, 30, 40, 50, 60, 70, 80, 9
1
map-gi-flexeme-simple-eos
SF BEST FIRST-400
SF BEST FIRST-200
SF BEST FIRST-100
SF BEST FIRST-50
SF BEST FIRST NOINC-400
SF BEST FIRST NOINC-200
SF BEST FIRST NOINC-100
SF BEST FIRST NOINC-50
SF NOINC-400
SF NOINC-200
SF NOINC-100
SF NOINC-50
SF-400
SF-200
SF-100SF-50
algorytm-RCFG2sup
1 10 100 1000 10000 100000S-sup
0
0, 2
0, 4
0, 6
0, 8
1
Rysunek A.18: Pokrycie zbioru reguł dla różnych konfiguracji algorytmów, RCFG2sup iminimalnego wsparcia reguł S-sup — korpus trenujący (cz. 2)
121
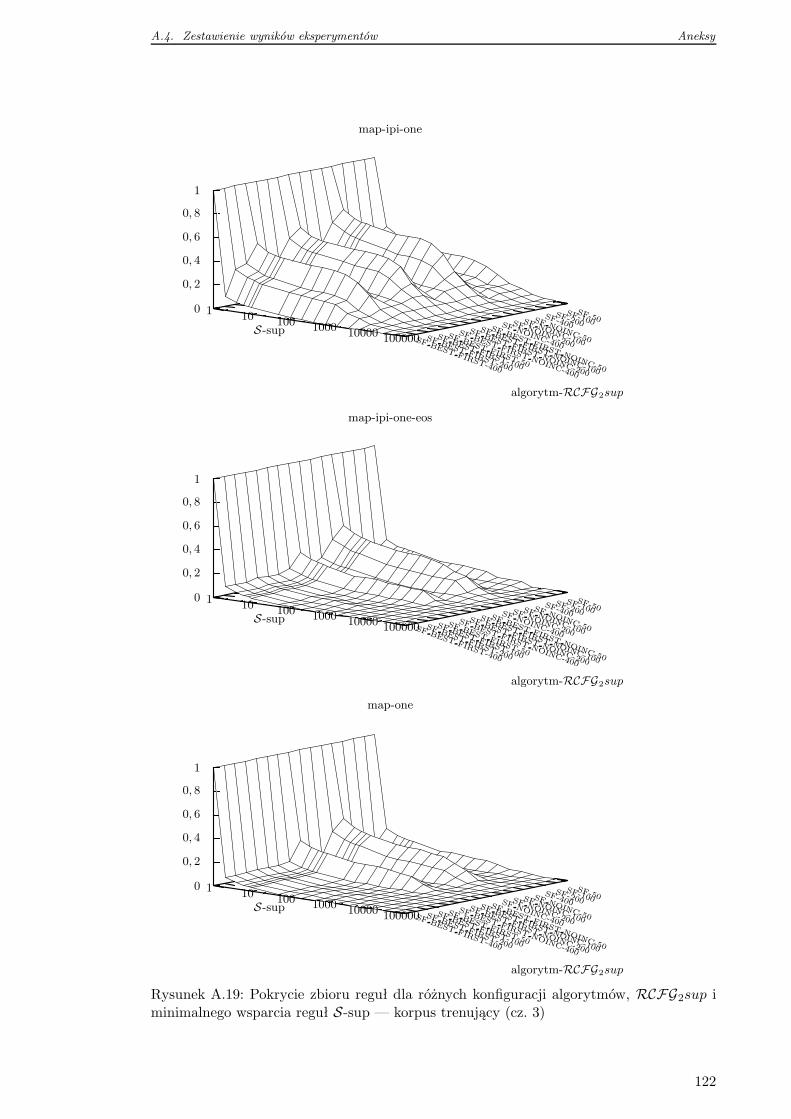
A.4. Zestawienie wyników eksperymentów Aneksy
map-ipi-one
SF BEST FIRST-400
SF BEST FIRST-200
SF BEST FIRST-100
SF BEST FIRST-50
SF BEST FIRST NOINC-400
SF BEST FIRST NOINC-200
SF BEST FIRST NOINC-100
SF BEST FIRST NOINC-50
SF NOINC-400
SF NOINC-200
SF NOINC-100
SF NOINC-50
SF-400
SF-200
SF-100SF-50
algorytm-RCFG2sup
1 10 100 1000 10000 100000S-sup
0
0, 2
0, 4
0, 6
0, 8
1
map-ipi-one-eos
SF BEST FIRST-400
SF BEST FIRST-200
SF BEST FIRST-100
SF BEST FIRST-50
SF BEST FIRST NOINC-400
SF BEST FIRST NOINC-200
SF BEST FIRST NOINC-100
SF BEST FIRST NOINC-50
SF NOINC-400
SF NOINC-200
SF NOINC-100
SF NOINC-50
SF-400
SF-200
SF-100SF-50
algorytm-RCFG2sup
1 10 100 1000 10000 100000S-sup
0
0, 2
0, 4
0, 6
0, 8
1
map-one
SF BEST FIRST-400
SF BEST FIRST-200
SF BEST FIRST-100
SF BEST FIRST-50
SF BEST FIRST NOINC-400
SF BEST FIRST NOINC-200
SF BEST FIRST NOINC-100
SF BEST FIRST NOINC-50
SF NOINC-400
SF NOINC-200
SF NOINC-100
SF NOINC-50
SF-400
SF-200
SF-100SF-50
algorytm-RCFG2sup
1 10 100 1000 10000 100000S-sup
0
0, 2
0, 4
0, 6
0, 8
1
Rysunek A.19: Pokrycie zbioru reguł dla różnych konfiguracji algorytmów, RCFG2sup iminimalnego wsparcia reguł S-sup — korpus trenujący (cz. 3)
122
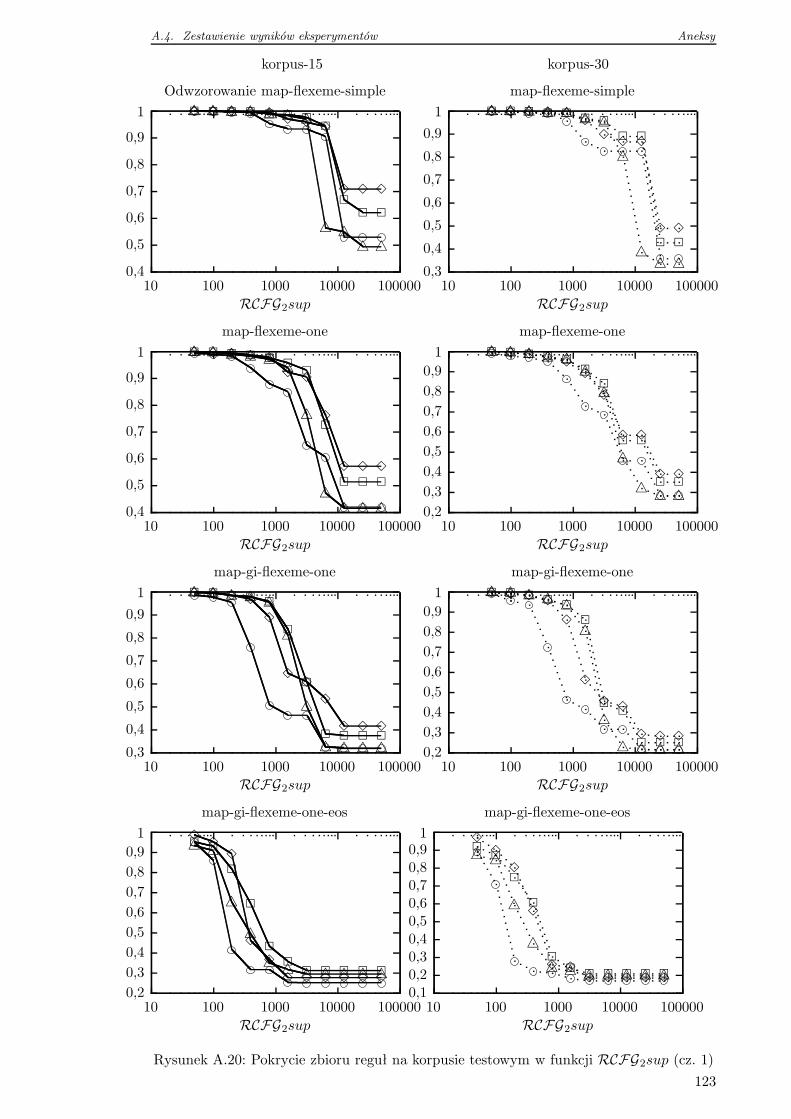
A.4. Zestawienie wyników eksperymentów Aneksy
korpus-15 korpus-30
0,4
0,5
0,6
0,7
0,8
0,9
1
10 100 1000 10000 100000
RCFG2sup
Odwzorowanie map-flexeme-simple3 3 3 3 3
3 3 3
3 3 3
2 2 2 2 2 2 22
2
2 2
△ △ △ △ △ △ △
△ △△ △
0,3
0,4
0,5
0,6
0,7
0,8
0,9
1
10 100 1000 10000 100000
RCFG2sup
map-flexeme-simple3 3 3 3 3
3
33 3
3 3
2 2 2 2 22 2
2 2
2 2
△ △ △ △ △ △ △
△
△△ △
0,4
0,5
0,6
0,7
0,8
0,9
1
10 100 1000 10000 100000
RCFG2sup
map-flexeme-one3 3 3 3 3
3 3
3
3 3 3
2 2 2 2 22
2
2
2 2 2
△ △ △ △ △△
△
△△ △ △ 0,2
0,3
0,4
0,5
0,6
0,7
0,8
0,9
1
10 100 1000 10000 100000
RCFG2sup
map-flexeme-one3 3 3 3
33
3
3 3
3 3
2 2 2 2 22
2
2 2
2 2
△ △ △ △ △△
△
△
△△ △
0,3
0,4
0,5
0,6
0,7
0,8
0,9
1
10 100 1000 10000 100000
RCFG2sup
map-gi-flexeme-one3 3 3 3
3
33
3
3 3 3
2 2 2 2 2
2
2
2 2 2 2
△ △ △ △ △
△
△
△ △ △ △ 0,2
0,3
0,4
0,5
0,6
0,7
0,8
0,9
1
10 100 1000 10000 100000
RCFG2sup
map-gi-flexeme-one3 3 3
3
3
3
33
3 3 3
2 2 2 22
2
22
2 2 2
△ △ △ △ △
△
△
△ △ △ △
0,2
0,3
0,4
0,5
0,6
0,7
0,8
0,9
1
10 100 1000 10000 100000
RCFG2sup
map-gi-flexeme-one-eos
33
3
3
3
3 3 3 3 3 3
2 2
2
2
2
22 2 2 2 2
△ △
△
△
△ △ △ △ △ △ △
0,10,20,30,40,50,60,70,80,9
1
10 100 1000 10000 100000
RCFG2sup
map-gi-flexeme-one-eos
3
3
3
3
3 33 3 3 3 3
22
2
2
22
2 2 2 2 2
△ △
△
△
△ △ △ △ △ △ △
Rysunek A.20: Pokrycie zbioru reguł na korpusie testowym w funkcji RCFG2sup (cz. 1)
123
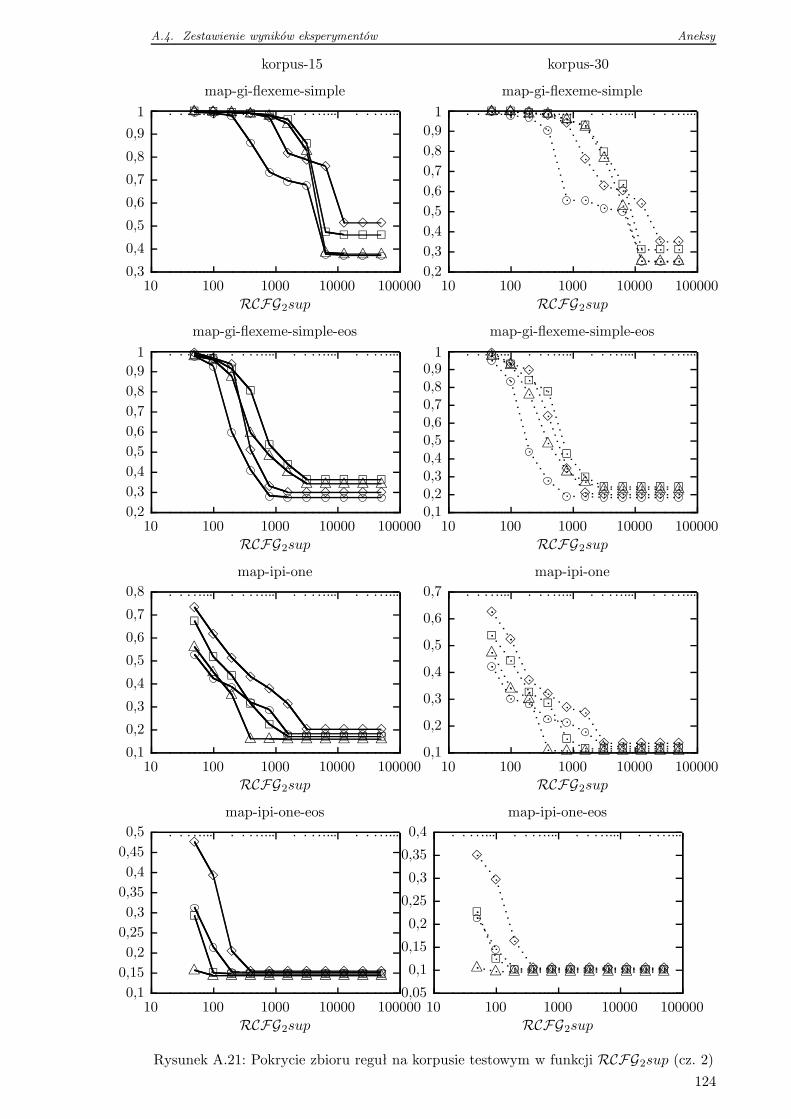
A.4. Zestawienie wyników eksperymentów Aneksy
korpus-15 korpus-30
0,3
0,4
0,5
0,6
0,7
0,8
0,9
1
10 100 1000 10000 100000
RCFG2sup
map-gi-flexeme-simple3 3 3 3 3
33
3
3 3 3
2 2 2 2 2 2
2
2 2 2 2
△ △ △ △ △△
△
△ △ △ △0,2
0,3
0,4
0,5
0,6
0,7
0,8
0,9
1
10 100 1000 10000 100000
RCFG2sup
map-gi-flexeme-simple3 3 3 3
3
3
3 3
3
3 3
2 2 2 22
2
2
2
2 2 2
△ △ △ △ △△
△
△
△ △ △
0,2
0,3
0,4
0,5
0,6
0,7
0,8
0,9
1
10 100 1000 10000 100000
RCFG2sup
map-gi-flexeme-simple-eos
33
3
3
33 3 3 3 3 3
2 22
2
2
2
2 2 2 2 2
△ △△
△
△△
△ △ △ △ △
0,10,20,30,40,50,60,70,80,9
1
10 100 1000 10000 100000
RCFG2sup
map-gi-flexeme-simple-eos
33
3
3
3
3 3 3 3 3 3
22
22
2
22 2 2 2 2
△△
△
△
△△ △ △ △ △ △
0,1
0,2
0,3
0,4
0,5
0,6
0,7
0,8
10 100 1000 10000 100000
RCFG2sup
map-ipi-one
3
3
3
33
3
3 3 3 3 3
2
2
2
2
22 2 2 2 2 2
△
△
△
△ △ △ △ △ △ △ △0,1
0,2
0,3
0,4
0,5
0,6
0,7
10 100 1000 10000 100000
RCFG2sup
map-ipi-one
3
3
3
3
33
3 3 3 3 3
2
2
22
22 2 2 2 2 2
△
△△
△ △ △ △ △ △ △ △
0,1
0,15
0,2
0,25
0,3
0,35
0,4
0,45
0,5
10 100 1000 10000 100000
RCFG2sup
map-ipi-one-eos
3
3
3
3 3 3 3 3 3 3 3
2
2 2 2 2 2 2 2 2 2 2△ △ △ △ △ △ △ △ △ △ △0,05
0,1
0,15
0,2
0,25
0,3
0,35
0,4
10 100 1000 10000 100000
RCFG2sup
map-ipi-one-eos
3
3
3
3 3 3 3 3 3 3 3
2
22 2 2 2 2 2 2 2 2△ △ △ △ △ △ △ △ △ △ △
Rysunek A.21: Pokrycie zbioru reguł na korpusie testowym w funkcji RCFG2sup (cz. 2)
124

A.4. Zestawienie wyników eksperymentów Aneksy
korpus–15 korpus–30
0,1
0,15
0,2
0,25
0,3
0,35
0,4
0,45
10 100 1000 10000 100000
RCFG2sup
map-one
3
3
3 3 3 3 3 3 3 3 3
2
2 2 2 2 2 2 2 2 2 2△ △ △ △ △ △ △ △ △ △ △
0,05
0,1
0,15
0,2
0,25
0,3
0,35
10 100 1000 10000 100000
RCFG2sup
map-one
3
3
3 3 3 3 3 3 3 3 3
2
2 2 2 2 2 2 2 2 2 2△ △ △ △ △ △ △ △ △ △ △
Pokrycie dla korpusu–15:
SF
SF BEST FIRST △
SF BEST FIRST NOINC 2
SF NOINC 3
Pokrycie dla korpusu–30:
SF
SF BEST FIRST △
SF BEST FIRST NOINC 2
SF NOINC 3
Rysunek A.22: Pokrycie zbioru reguł na korpusie testowym w funkcji RCFG2sup (cz. 3)
125


















