
programowanie w SAS - zsk.ict.pwr.wroc.pl · • ACCESS pobieranie danych ze źródeł zewn. •...
21
1 Wprowadzenie do Systemu SAS i programowania w SAS 4GL Henryk Maciejewski [email protected] 2 Plan ♦ System SAS - wprowadzenie – SAS: moduly i aplikacje – Środowisko SAS – Organizacja danych w środowisku SAS ♦ Programowanie w SAS 4GL – język do przetwarzania danych
Transcript of programowanie w SAS - zsk.ict.pwr.wroc.pl · • ACCESS pobieranie danych ze źródeł zewn. •...

1
Wprowadzenie do Systemu SAS i programowania w SAS 4GL
Henryk Maciejewski
2
Plan
♦ System SAS - wprowadzenie– SAS: moduły i aplikacje
– Środowisko SAS
– Organizacja danych w środowisku SAS
♦ Programowanie w SAS 4GL – język do przetwarzania danych

3
System SAS - wprowadzenie
♦ Historycznie SAS = Statistical Analysis System♦ Obecnie, (a) system do budowania rozwiązań DSS (moduły do
pobierania danych, analiz, raportowania), (b) specjalizowane rozwiązania DSS
♦ Moduły – np.• Base SAS „core” (język, procedury) • STAT procedury analizy statystycznej• ACCESS pobieranie danych ze źródeł zewn.• GRAPH• AF, webAF budowa aplikacji• EIS• ...• OR, QC, ETS,... Procedury: „operations research”, „quality
control”, „time series forecasting”, itd. • Enterprise Miner• Data Warehouse Administrator
4
System SAS - wprowadzenie
♦ Rozwiązania biznesowe dla wspomagania decyzji (decision support) w środowiskach z duŜymi zasobami danych np. – Data warehousing– Data mining– IT resources management– Human resources management– Financial management – Web portal usage analysis– Data analysis in pharmaceutical industry– CRM, SRM (=Supplier RM), etc.

5
Środowisko programowania
♦ MVA (MultiVendor Architecture): programy przenośne: VMS, CMS, OS/390, Unix, Windows, OS/2
♦ Organizacja danych w środowisku SAS
– Pliki SAS (SAS files)Np. , SAS data sets, views, MDDBs
– Umieszczane w bibliotekach SAS (SAS libraries)referencja (LIBREF) do folderu, kartoteki itp. systemu operacyjnego np.
LIBNAME fhh ‘c:\data\fhh’;
6
Środowisko programowania -biblioteki♦ Biblioteki tworzone automatycznie
SASHELP -- SAS system files
SASUSER -- user profile files
WORK -- biblioteka tymczasowa – kasowana po zamkni ęciu systemu SAS, pozostałe s ą
permanentne
♦ Nazwy plików SAS – kwalifikowane: libraryname.filename, np.
fhh.abc -- plik w bibliotece fhh
abc -- plik w bibliotece WORK

7
Środowisko programowania – zbiory danych♦ Zbiory danych SAS - typy:
– DATA – tablica fizycznie przechowująca dane
– VIEW – nie zawiera fizycznie danych, a jedynie kod („query”)realizujący dostęp do danych. VIEW widziane jest przez identycznie jak DATA set (na ogół)
♦ Konwencja nazw– Wiersze to obserwacje
– Kolumny to zmienne (variables)
♦ Zbiory danych (data set) składają się z: – deskryptora - atrybuty zbioru i zmiennych
– danych
8
Środowisko programowania – zbiory danych♦ Wyświetlamy deskryptor DATA set:
PROC CONTENTS DATA=fhh.abc;
RUN;-----Alphabetic List of Variables and Attributes-----
# Variable Type Len Pos Format Informat Label
ƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒ
1 sex Char 2 16 $3. $3. sex
4 teach_duration Num 8 8 11. 11. teach_duration
2 teacher_Code Num 8 0 11. 11. teacher_Code
3 titel_code Char 12 18 $12. $12. titel_code
♦ Typy zmiennych w SAS– character – numeric
♦ Atrybuty zmiennych– Length - długości zmiennych: numeric: 3-8, character 1-32767 (MS Windows)– Format - jak drukować wartość zmiennej– Informat - jak konwertować „input string” do wartości zmiennej– Label - opis zmiennej

9
Środowisko programowania – zbiory danych♦ Drukuj wartości zapisane w DATA set:
PROC PRINT DATA=fhh.abc;
RUN;
Obs sex teacher_Code titel_code teach_duration
1 M 1 006 1
2 M 2 502 1
3 M 3 .
4 M 4 1
5 M 5 022 1
6 M 6 006 1
7 W 7 1
8 M 8 006 1
♦ „Missing value”– Wskazuje Ŝe w danej obserwacji nie ma wartości zmiennej– „missing numeric values” reprezentowane przez . (kropka)– „missing character values” reprezentowane przez puste miejsce
10
Plan
♦ System SAS - wprowadzenie– SAS: moduły i aplikacje
– Środowisko SAS
– Organizacja danych w środowisku SAS
♦ Programowanie w SAS 4GL – język do przetwarzania danych

11
Programowanie w SAS
♦ SAS 4GL – język umoŜliwiający realizację:– Dostępu do danych („retrieval from external sources”)
– Przetwarzanie danych („cleaning, transforming, combining”)
– Analizę danych
– Raportowanie
♦ Inne języki programowania w środowisku SAS– SCL (object oriented SAS Component Lang.)
– SAS macro language
12
Przykład – pierwszy programDATA STEP
Utwórz data set abc
Utwórz zmienne w abc
Wykonaj „data step”
PROC STEP
Drukuj data set abc
data abc;
teachers= 283 ;
students= 853 ;
all=teachers+students;
s_per_t=students/teachers;
run ;
proc print data=abc;
run;
Data Set WORK.ABC
Obs teachers students all s_per_t
1 283 853 1136 3.01413
13
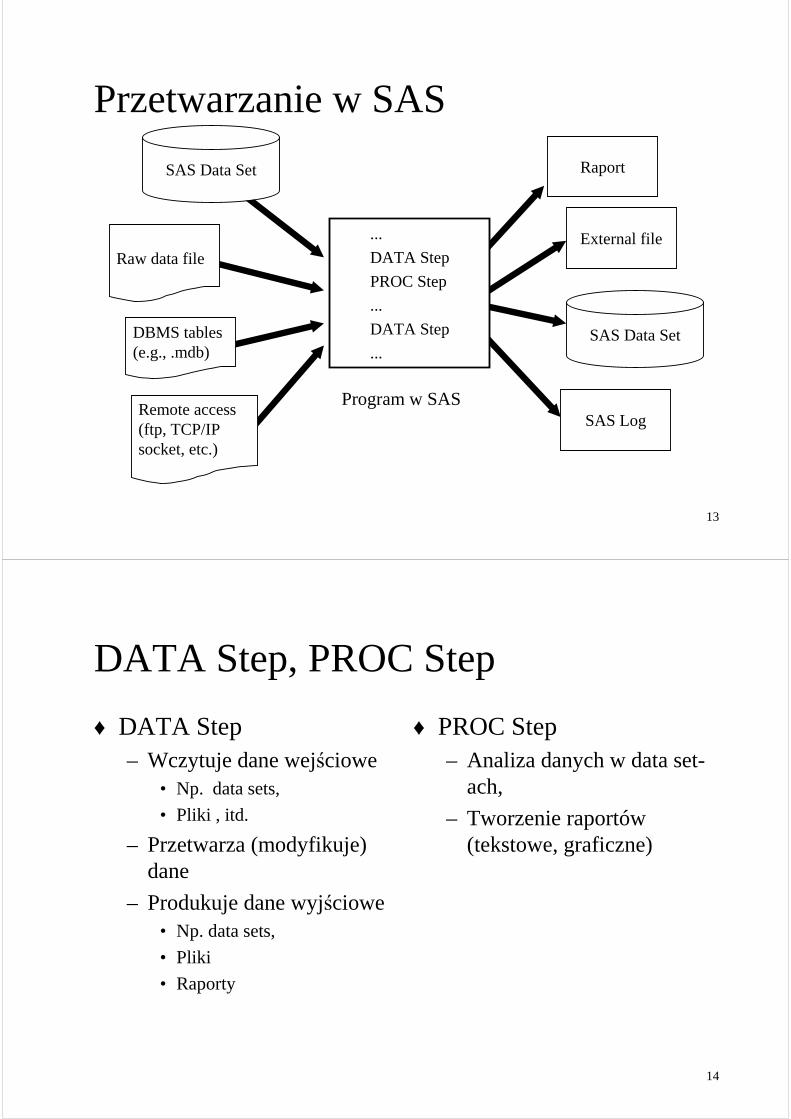
Przetwarzanie w SAS
Program w SAS
Raport
External file
SAS Log
SAS Data Set
SAS Data Set
Raw data file
DBMS tables(e.g., .mdb)
Remote access(ftp, TCP/IP socket, etc.)
...
DATA Step
PROC Step
...
DATA Step
...
14
DATA Step, PROC Step
♦ DATA Step– Wczytuje dane wejściowe
• Np. data sets,
• Pliki , itd.
– Przetwarza (modyfikuje) dane
– Produkuje dane wyjściowe• Np. data sets,
• Pliki
• Raporty
♦ PROC Step– Analiza danych w data set-
ach,
– Tworzenie raportów (tekstowe, graficzne)
15
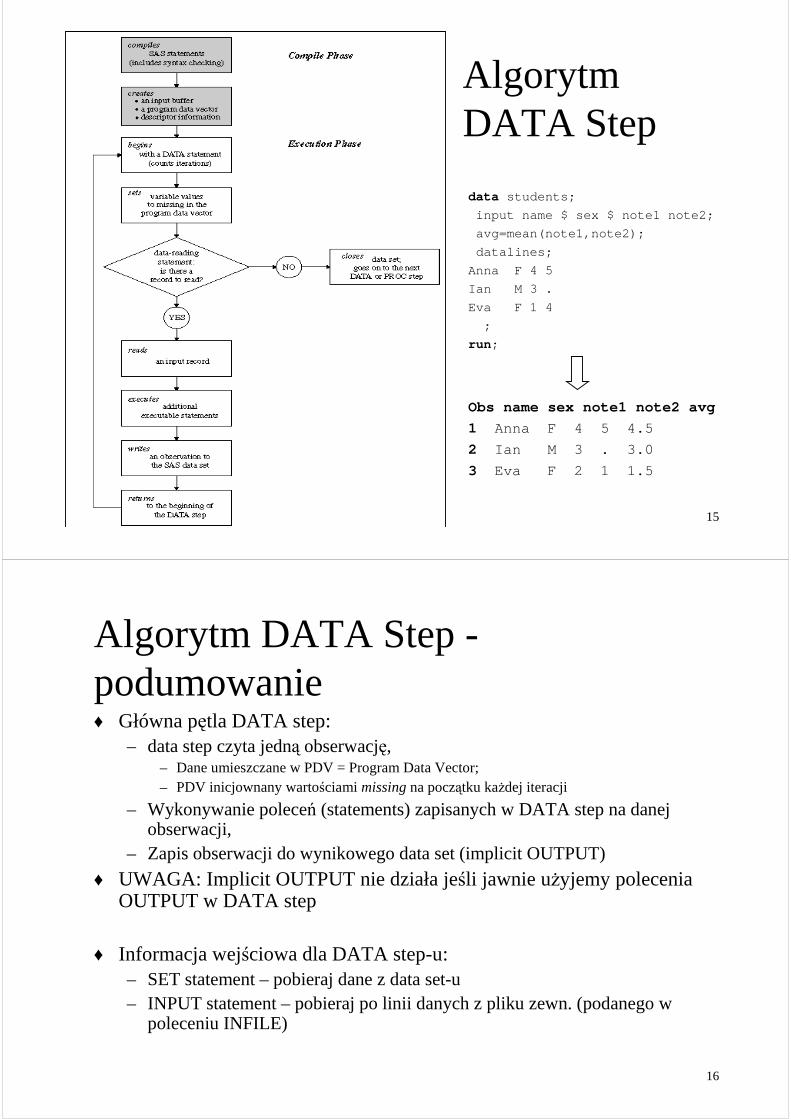
AlgorytmDATA Step
data students;
input name $ sex $ note1 note2;
avg=mean(note1,note2);
datalines;
Anna F 4 5
Ian M 3 .
Eva F 1 4
;
run ;
Obs name sex note1 note2 avg
1 Anna F 4 5 4.5
2 Ian M 3 . 3.0
3 Eva F 2 1 1.5
16
Algorytm DATA Step -podumowanie♦ Główna pętla DATA step:
– data step czyta jedną obserwację,– Dane umieszczane w PDV = Program Data Vector;– PDV inicjownany wartościami missingna początku kaŜdej iteracji
– Wykonywanie poleceń (statements) zapisanych w DATA step na danej obserwacji,
– Zapis obserwacji do wynikowego data set (implicit OUTPUT)
♦ UWAGA: Implicit OUTPUT nie działa jeśli jawnie uŜyjemy polecenia OUTPUT w DATA step
♦ Informacja wejściowa dla DATA step-u:– SET statement – pobieraj dane z data set-u– INPUT statement – pobieraj po linii danych z pliku zewn. (podanego w
poleceniu INFILE)

17
Programowanie w data step –„Idiomy programisty”♦ Wybór obserwacji z data set
♦ Wybór zmiennych
♦ Tworzenie nowych / modyfikacja zmiennych
♦ OUTPUT statement – tworzenie wielu zbiorów
♦ Łączenie data set-ów („stacking, merging”)
♦ „BY-group processing”
♦ Czytanie/pisanie plików zewnętrznych
18
Wybór obserwacjidata male;
set students;
if sex=‘F’ then delete;
run;
data male;
set students;
if sex=‘M’;
run;
lub:
data male;
set students;
where sex=‘M’;
run;
data male;
set students (where=(sex=‘M’));
run;
Wyślij na wyjście wybrane obserwacjeUŜywając subsetting IF:→ usuń obserwacje jest wyraŜenie if jest
prawdą;
→ przetwarzaj dalej obserwację jeśli warunek jest prawdą;
UŜywając WHERE (statement lub data set option)
→ WHERE statement
→ WHERE data set option

19
Wybór obserwacjidata male;
set students;
if sex=‘F’ then delete;
run;
data male;
set students;
if sex=‘M’;
run;
lub:
data male;
set students;
where sex=‘M’;
run;
data male;
set students (where=(sex=‘M’));
run;
Obs name sex note1 note2 avg
1 Anna F 4 5 4.5
2 Ian M 3 . 3.0
3 Eva F 2 1 1.5
Obs name sex note1 note2 avg
1 Ian M 3 . 3
20
Wybór zmiennychdata avg_only;
set students;
drop sex note1 note2;
run;
data avg_only;
set students;
keep name avg;
run;
lub:
data avg_only;
set students (drop= sex note1 note2);
run;
data avg_only;
set students (keep= name avg);
run;
Wyślij na wy tylko wybrane zmienne
UŜywając DROP, KEEP statements
→ DROP statement
→ KEEP statement
UŜywając DROP, KEEP data set options
→ DROP data set option
→ KEEP data set option

21
Wybór zmiennychdata avg_only;
set students;
drop sex note1 note2;
run;
data avg_only;
set students;
keep name avg;
run;
lub:
data avg_only;
set students (drop= sex note1 note2);
run;
data avg_only;
set students (keep= name avg);
run;
Obs name sex note1 note2 avg
1 Anna F 4 5 4.5
2 Ian M 3 . 3.0
3 Eva F 2 1 1.5
Obs name avg
1 Anna 4.5
2 Ian 3.0
3 Eva 1.5
22
Tworzenie nowych zmiennychdata pass (drop= sex note1 note2
avg);
set students;
if avg < 2 then result='passed';
else result='failed';
run ;
Obs name sex note1 note2 avg
1 Anna F 4 5 4.5
2 Ian M 3 . 3.0
3 Eva F 2 1 1.5
Obs name result
1 Anna failed
2 Ian failed
3 Eva passed

23
Tworzenie nowych zmiennych
Uwaga – nie rób tak:
data pass;
set students (drop= sex note1 note2 avg);
if avg < 2 then result='passed';
else result='failed';
run ;
UWAGA: w tym przykładzie sex, note1,2 iavg nie są wczytywane ze zbioru we, stąd wartość avg jest niezainicjowana (czyli missing)
Obs name sex note1 note2 avg
1 Anna F 4 5 4.5
2 Ian M 3 . 3.0
3 Eva F 2 1 1.5
Obs name avg result
1 Anna . passed
2 Ian . passed
3 Eva . passed
24
OUTPUT Statementdata males females;
set students;
if sex='F' then output females ;
if sex='M' then output males ;
drop sex;
run ;
Zapisuje bieŜącą obserwację do wyjściowego data set
UŜyteczna przy tworzeniu kilku zbiorów z jednego data set-u
UWAGA: je śli OUTPUT jest jawnie uŜyty w DATA step, „ implicit OUTPUT” nie działa (p. algorytm DATA step)
Obs name sex note1 note2 avg
1 Anna F 4 5 4.5
2 Ian M 3 . 3.0
3 Eva F 2 1 1.5
females males
1 Anna 1 Ian
2 Eva

25
OUTPUT– Generacja danychdata generator;
do x= 1 to 100 ;
y=rannor(- 1);
output;
end;
run ;
UWAGA: nie ma instrukcji specyfikuj ącej dane wejściowe (np. SET albo INPUT), więc będzie wykonana tylko jedna iteracja głównej pętli DATA steo-u(DATA step main loop)
Wynik: 100 wartości losowych z rozkładu N(0,1)
Obs x y
1 1 0.52813
2 2 0.51177
...
...
99 99 -0.23971
100 100 0.92665
26
Łączenie data set-ów (instrukcja SET)data all;
set males females;
run ;
data all2;
set males(in=m) females(in=f);
if m then sex=‘M’;
if f then sex=‘F’;
run ;
Łącznie data set-ów (stacking): przetwarzaj obserwacje z pierwszego data set, potem drugiego itd..
Z którego zbioru we pochodzi dana obserwacja? – zrób tak:– males(in=m) tworzy automatic
variablem(m=1 dla obserwacji ze zbioru males ; m=0 poza tym)
– UWAGA: zmienne automatyczne (tu: m i f) nie są zapisywane do wyjściowego zbioru danych
Obs name note1 note2 avg sex
1 Ian 3 . 3.0 M
2 Anna 4 5 4.5 F
3 Eva 2 1 1.5 F

27
Łączenie data set-ów (MERGE)data lib;
input name $ @ 8 date yymmdd10. title $20. ;
datalines;
Anna 2000/12/14 Hamlet
Anna 2000/12/14 SAS Programming
Witek 2001/07/12 XML
;
run ;
proc sort data=students out=students_sort;
by name;
run ;
data st_books;
merge students_sort lib;
by name;
keep name sex title;
run ;
Operacja „match-merging” data set-ów:
Data set STUDENTS:
Obs name sex note1 note2 avg
1 Anna F 4 5 4.5 2 Ian M 3 . 3.0 3 Eva F 2 1 1.5
Data set LIB:
Obs name date title
1 Anna 2000-12-14 Hamlet 2 Anna 2000-12-14 SAS Programming 3 Witek 2001-07-12 XML
Wynikowy data set:
Obs name sex title
1 Anna F Hamlet2 Anna F SAS Programming3 Eva F4 Ian M5 Witek XML
28
„BY-group Processing” w DATA Stepdata best_note worst_note;
set exam;
by st_code;
if first.st_code then
output best_note;
if last.st_code then
output worst_note;
keep st_code sem note;
run ;
„BY-group” jest podzbiorem obserwacji z ustaloną wartością zmiennej podanej w poleceniu BY (zbioór musi byćposortowany po tej zmiennej)
UŜycie polecenia BY w DATA step tworzy zmienne automatyczne, np.
FIRST.st_codeLAST.st_code
ustawione przez DATA step na 1 tylko dla pierwszej (ostatniej) obserwacji w grupie „BY-group”
Data set EXAM:
st_code sem note
1 WS96/97 11 WS96/97 41 WS95/96 6
2 WS99/00 12 WS00/01 33 WS99/00 13 WS99/00 1...
BY-group
BY-group

29
Zmienne automatyczneNp. kontrola błędów na wejściu:
data results err_log;
infile ‘C:\temp\results.txt’;
input name $ jump date yymmdd8.;
if _error_ then output err_log;
else output results;
run ;
Tworzone przez DATA step; nie sączęścią Program Data Vector; nie sązapisywane do wyjściowych data setów, np.:
_N_ - numer iteracji DATA step-u
_ERROR_ - ustawiany na 1 jeśli wystąpiłbłąd w przetwarzaniu dancych(input data error, math error, itd. )
FIRST.by_variable
LAST. by_variable – zobacz BY-groupprocessing
30
Czytanie plików zewnętrznychdata results err_log;
infile ‘C:\temp\results.txt’;
input name $ 1-10 jump @24 dateyymmdd8.;
if _error_ then output err_log;
else output results;
run ;
Polecenie INFILE – podaj plik, z którego będą czytane dane (podajemy w postaci fizycznej ścieŜki lub FILEREF utworzony przez polecenie FILENAME, np. FILENAME fileref ‘path’;
Polecenie INPUT– Czyta (co najmniej jedną) lini ę z
pliku– Konwertuj lini ę do wartości
zmiennych wg:• Specyfikacji zmiennych, np.
– name $ - character variable– jump, date – numeric variables
• Specyfikacji kolumn, np. – name $ 1-10 – zakres kolumny
• Informat-ów, np. – date yymmdd. – informat dla
zmiennej date

31
Czytanie plików zewnętrznychdata xy;
input x y;
datalines;
1 2 3
4
5 6 7 8
;
run ;
data xy_ok;
input x y @@;
datalines;
1 2 3
4
5 6 7 8
;
run ;
Modyfikujemy zachowanie INPUT:
INPUT var1 var2 var3 @@;
Ten INPUT nie zaczyna czytać nowej linii dopóki ma dane w buforze wejściowym, które moŜe konwertować na zmienne
UWAGA: polecenie INFILE moŜe miećopcje:
INFILE spec_pliku <opcje>;np.
DML=‘,’; separator tokenów w liniiFIRSTOBS=3; zacznij czytać plik od 3 l.
i wiele innych...
Obs x y1 1 2 2 4 5
Obs x y1 1 2 2 3 43 5 64 7 8
32
Zapis do plików zewnętrznychdata _null_; *no data set;
set fhh.exam;
file 'c:\temp\exam.txt';
put student_code 1- 4 ', ' sem@24 note 3.1 ;
run;
Polecenie FILE – podaj plik do którego będzie zapis danych
Polecenie PUT– zapisz jedną lini ę do pliku wyj ściowego, uŜywając atrybutów FORMAT przypisanych zmiennym lub podanych w poleceniu PUT
data _null_ - data step nie będzie tworzył wyj ściowego data set-u

33
Jawne konwersja – funkcje PUT i INPUTdata a;
t=1234.56;
n=PUT(t,8.1);
n2=PUT(t, comma8.1);
t2=INPUT(n2,comma8.2);
run;
proc print;
run;
Obs t n n2 t2
1 1234.56 1234.6 1,234.6 1234.6
Zmienna_znakowa = PUT(zmienna, format);
Zmienna numeryczna lub znakowa = INPUT(zmienna, informat);
34
Instrukcja RETAINdata wzrosty_miesieczne;
set gielda; *data kurs mies;
BY mies;
RETAIN pocz;
IF FIRST.mies then pocz =kurs;
IF LAST.mies then DO;
Wzrost=kurs-pocz;Output;
end;
run;
Składnia polecenia RETAIN:
RETAIN var initial_val;
Zmienna var nie będzie inicjowana na ‘missing’ na początku kolejnych iteracji DATA step (warto ść będzie zachowana z poprzedniej iteracji)
RównieŜ:
var+expression;
Co jest równowaŜne:
RETAIN var 0;var=SUM(var,expression);

35
Perspektywy (VIEW)data pracv bledy(keep=id)/ VIEW=pracv ;
INFILE ‘pracownicy.txt’ missover;
INPUT nr data yymmdd8. nazwisko $ kwota;
IF kwota=. then
OUTPUT bledy;
ELSE
OUTPUT stview;
run;
VIEW utworzone za pomocą DATA stepu
Nie zawiera danych a jedynie kod pozwalajścy na uzyskanie danych
Jest zbiorem tylko do odczytu
UWAGA!!!Zbiór bledy nie zostanie utworzony zaraz
po wykonaniu programu, ale dopiero po pierwszym odwołaniu do perspektywy pracv, np. przez:
proc print data=pracv;
run;
36
Tablice (polecenie ARRAY)data a;
INPUT skok1 skok2 skok3;
ARRAY s(3) skok1 skok2 skok3;
DO i=1 TO 6;
IF s(i)=0 then s(i)=.;
END;
run;
lub:
ARRAY x(*) _NUMERIC_:
Ale uwaga – ten wariant tworzyzmienne tymczasowe:
ARRAY y(100) _TEMPORARY_ (100*.);
Tablica jest referencją do istniejących zmiennych, zgrupowanych pod wspólną nazwą
Polecenie ARRAY nie tworzy nowych zmiennych)
Wszystkie zmienne numeryczne w data stepie
Zmienne te nie są zapisywane do zbioru wyjściowego
Są automatycznie ‘RETAINED’

37
Język makr – makrozmienne%LET swieta=’24dec2002'd;
%LET zbior=klasa;
TITLE „Raport dla zbioru &zbior ”;
Ile_dni = &swieta – today();
put ‘Do Swiat zostało ‘ ile_dni ‘ dni;
Makrozmienne:- przechowują jedynie teksty;- wartości makrozmiennych są
ustalane przed kompilacjąprogramu;
- wartości są rozwijane w „”, nie są w ‘’
- %LET w ‘open source’ (poza definicją makroprogramu) tworzy globalną makrozmienną
38
Język makr – makroprogramy%macro import(rawfile, ds);
data &ds;
infile &rawfile;
input t @;
%do i=1 %to &N;
input v&i %eval(&KOL+&i) @;
%end;
run;
%mend import;
%let rf=‘t.txt';
%import(&rf,t);
W makroprogramach moŜemy uŜywaćwyraŜeń i funkcji wykonywanych przez makroprocesor, np.
- %if %then %else ;- %do %to %end;- %eval()- %sysevalf()

39
Interfejs makr i DATA step ZauwaŜ, Ŝe w poniŜszym (błędnym) kodzie
makrozmienna foot nie chce zaleŜeć od wartości zmiennej w DATA stepie...
data a;
...
if full then do;
%let foot=’pe łne’;
end;
else do;
%let foot=’puste’;
end;
proc print;
footnote “&foot”; /*zawsze b ędzie napis ‘puste’ !!!*/
run;
Wartości makrozmiennych są ustawiane przed kompilacją programu – stąd kod obok jest błędny...
Wydrukuj ostatnio utworzony data set...
40
Interfejs makr i DATA step Teraz kod jest poprawny
data a;
...
if full then do;
call symput(‘foot’,’pe łne’);
end;
else do;
call symput(‘foot’,’puste’);
end;
proc print;
footnote “&foot”; /* napis zale Ŝy od full */
run;
SYMPUT / SYMGET – interfejs pomiędzy językiem makr a DATA stepem
SYMPUT – ustawia wartośćmakrozmiennej w czasie wykonywania DATA stepu
SYMGET – pobiera wartośćmakrozmiennej, ustawionej przez SYMPUT
CALL SYMPUT(‘total’, total); CALL SYMPUT(‘POS’||left(_N_),
pos);
pos=SYMGET(‘POS’||left(_N_));

41
Interfejs makr i DATA step
data _null_;
if 0 then set history nobs=count;
call symput('num',
left(put(count,8.)));
stop;
run;
data _null_;
put "Ilosc obserwacji w zbiorze history = &num";
run;
Przykład – podaj ile jest obserwacji w data set
Opcja nobs polecenia set ustawia w zmiennej count ilość obserwacji w zbiorze. Robi to w czasie kompilacjidata stepu.
Polecenie STOP w celu uniknięcia zapętlenia (jest polecenie SET, a nigdy nie będzie spełniony warunek końca danych)


















