
PRACA DYPLOMOWA INŻYNIERSKA · Rok akademicki 2012 / 2013 Politechnika Warszawska Wydział...
46
Rok akademicki 2012 / 2013 Politechnika Warszawska Wydział Elektroniki i Technik Informacyjnych Instytut Informatyki PRACA DYPLOMOWA INŻYNIERSKA Dominik Olędzki Interfejs komputera wykorzystujący kamerę Opiekun pracy prof. nzw. dr hab. Przemysław Rokita Ocena: ..................................................... ................................................................ Podpis Przewodniczącego Komisji Egzaminu Dyplomowego
Transcript of PRACA DYPLOMOWA INŻYNIERSKA · Rok akademicki 2012 / 2013 Politechnika Warszawska Wydział...

Rok akademicki 2012 / 2013
Politechnika Warszawska
Wydział Elektroniki i Technik Informacyjnych
Instytut Informatyki
PRACA DYPLOMOWA INŻYNIERSKA
Dominik Olędzki
Interfejs komputera wykorzystujący kamerę
Opiekun pracy
prof. nzw. dr hab. Przemysław Rokita
Ocena: .....................................................
................................................................
Podpis Przewodniczącego
Komisji Egzaminu Dyplomowego

Specjalność: Inżynieria Systemów Informatycznych
Data urodzenia: 1990.03.19
Data rozpoczęcia studiów: 2009.10.01
Życiorys
Urodziłem się 19. marca 1990 roku w Łosicach gdzie ukończyłem szkołę podstawową i
gimnazjum. W latach 2006 – 2009 uczęszczałem do I Liceum Ogólnokształcącego
im. Bolesława Prusa w Siedlcach. W październiku 2009 roku rozpocząłem studia na Wydziale
Elektroniki i Technik Informacyjnych Politechniki Warszawskiej na kierunku Informatyka.
Od stycznia 2010 roku aktywnie działałem w ramach Koła Naukowego Twórców Gier
„Polygon”.
.......................................................
Podpis studenta
EGZAMIN DYPLOMOWY
Złożył egzamin dyplomowy w dniu .................................................................................. 2013 r
z wynikiem ..................................................................................................................................
Ogólny wynik studiów: ...............................................................................................................
Dodatkowe wnioski i uwagi Komisji: .........................................................................................
......................................................................................................................................................
......................................................................................................................................................

STRESZCZENIE
Celem pracy jest omówienie próby zaprojektowania i wykonania przez autora interfejsu
komputera wykorzystującego kamerę, realizowanego w systemie przetwarzania obrazu
stworzonym na potrzeby pracy dyplomowej. Praca zawiera opis dostępnych produktów i
technologii, przygotowanego systemu oraz trzech zaproponowanych rozwiązań opartych o
wykrywanie położenia i orientacji głowy i części twarzy, wraz z rezultatami i wnioskami.
System bazuje na czujniku ruchu wyposażonym w kamerę RGB oraz sensor głębi.
Słowa kluczowe: czujnik ruchu, interfejs komputera
COMPUTER INTERFACE USING VIDEO CAMERA
The purpose of this paper is to describe my attempt to design and develop human-computer
interface based on camera, implemented in image processing system, created for the thesis.
This paper contains a description of currently available products and technologies, created
processing system and the three proposed solutions based on detection of position and
orientation of human head and face features with results and conclusions. System uses a
motion sensor equipped with RGB video camera and depth sensor.
Keywords: motion sensor, computer interface

Pragnę złożyć serdeczne podziękowania
Panu prof. nzw. dr hab. Przemysławowi Rokicie za
wskazówki i pomoc merytoryczną w przygotowaniu
niniejszej pracy.

1
Spis treści
Spis treści 1
Wprowadzenie 3 1.
Rozwiązania dostępne na rynku 4 2.
Kontrolery gier 4
Systemy inwazyjne 5
Systemy nieinwazyjne 5
Technologia 6 3.
Sprzęt 6
Oprogramowanie 8
System przetwarzania obrazu 10 4.
Wymagania 10
Rozwiązanie 11
Metoda pierwsza 16 5.
Położenie gałek ocznych 16
Orientacja gałek ocznych 18
Wzajemne relacje położenia kamery i monitora 18
Program do generowania danych uczących sieci 19
Program do wyznaczania punktu skupienia wzroku 23
Wnioski z metody pierwszej 24
Metoda druga 26 6.
Metoda trzecia 34 7.

2
Plany rozwoju 37 8.
Podsumowanie 39 9.
Bibliografia 40 10.
Dodatek A. Zawartość płyty DVD. 41

3
Wprowadzenie 1.
Według raportu Gartnera, na świecie jest już ponad miliard
komputerów (1). Spotykamy je na co dzień, w domu, w pracy i w
szkole, ale warto zadać sobie pytanie, co jest powodem tak dużej
popularności urządzeń, które jeszcze 20 lat temu uchodziły za
narzędzia dla naukowców i specjalistów. Moim zdaniem jedną z
głównych przyczyn tego stanu rzeczy, jest dążenie producentów sprzętu
i oprogramowania do ułatwienia obsługi tych urządzeń.
Dzisiaj aby móc korzystać z komputera nie musimy już znać na
pamięć setek komend, powszechne są interfejsy graficzne, a powoli
wkraczają do naszych domów nowoczesne urządzenia takie jak czujniki
ruchu i kamery obserwujące wykonywane przez nas gesty. W mojej
pracy starałem się zaprojektować interfejs komputera nie wymagający
obsługi myszki ani klawiatury, bazujący na kamerze i czujniku ruchu.
Celem mojej pracy było zbadanie dostępnych technologii oraz
zaprojektowanie i implementacja interfejsu komputera
wykorzystującego kamerę. Cel ten można zrealizować na wiele
różnorodnych sposobów, ja chciałem oprzeć swoje rozwiązanie na
technikach śledzenia spojrzenia użytkownika. Rozwiązanie takie
umożliwiłoby korzystanie z komputera osobom o obniżonej sprawności
ruchowej, a moim zdaniem byłoby również wygodnym sposobem
obsługi komputera dla osób o pełnej sprawności.
W pracy tej opisałem trzy metody, które opracowałem: pierwsza
oparta o badanie położenia i orientacji gałek ocznych użytkownika,
druga o badanie położenia i orientacji głowy użytkownika oraz trzecia
oparta na śledzeniu dłoni. Ponadto, do testowania opracowanych
metod stworzyłem uniwersalny i łatwy w użyciu system przetwarzania
obrazu, który również opisałem w tej pracy.

4
Rozwiązania dostępne na rynku 2.
Produkty służące do obsługi komputera za pomocą gestów
rozpoznawanych dzięki obrazowi z kamer i sensorów można
zaklasyfikować do jednej z kategorii:
kontrolery gier,
inne systemy inwazyjne,
inne systemy nieinwazyjne.
Kontrolery gier
Konsole gier wideo przeżywają swój renesans dzięki zastosowaniu
nowoczesnych technologii bazujących na czujnikach ruchu i
kamerach. Trzy najbardziej popularne produkty to Microsoft Kinect,
Sony Playstation Move oraz Nintendo Wii.
Produkt firmy Microsoft charakteryzuje się brakiem
jakiegokolwiek kontrolera, sterowanie oparte jest o czujnik ruchu,
podobny do tego użytego w mojej pracy. Użytkownik wybiera funkcje
na ekranie wskazując je palcem, a ponadto może wykonywać różnego
rodzaju gesty, od prostego „kliknięcia” po figury taneczne w grach.
Playstation Move to zestaw z kamerą i kontrolerami trzymanymi w
dłoni. Kontroler jest w kształcie pałeczki z podświetlaną kulką
zmieniającą barwę w zależności od gracza i przebiegu rozgrywki.
Kamera znajduje kulkę w polu widzenia i określa jej położenie w
przestrzeni trójwymiarowej, a kontroler wyposażony w akcelerometr i
żyroskop, pozwala na ocenę orientacji w przestrzeni i prędkości ruchu.
Firma Nintendo stworzyła rozwiązanie podobne do Playstation
Move, ale kontroler jest kształtem bardziej zbliżony do pilota, a zamiast
kulki zastosowano sensor podczerwieni w kontrolerze, który rejestruje
położenie specjalnej podstawki z diodami LED umieszczanej pod
telewizorem. Ponadto kontroler wyposażono w akcelerometr, a
żyroskop umieszczono w dodatkowej części dołączanej do kontrolera
(Wii MotionPlus).

5
Systemy inwazyjne
Systemy inwazyjne charakteryzują się obecnością urządzeń zwykle
zakładanych na głowę użytkownika: okulary, kaski, kamery na
wysięgniku, często nie pozwalające na swobodne ruchy ciała. Punkt, w
którym skupia się wzrok użytkownika wyznaczany jest na podstawie z
góry założonego położenia głowy i analizy obrazu gałki ocznej
uzyskanego za pomocą bardzo blisko umieszczonej kamery. Jednym z
najbardziej popularnych jest EC8™ System firmy Eye-Com Corporation
Systemy nieinwazyjne
Systemy nieinwazyjne nie wymagają zakładania żadnego
dodatkowego sprzętu. Na przykład EyeTech TM4 firmy EyeTech Digital
Systems składa się z kamery oraz źródła światła podczerwonego, które
po odbiciu umożliwia wykrycie źrenicy oka. Rozwiązanie to daje dużą
dokładność (do około 1°), ale nie pozwala na swobodę ruchów ciała.
Ponadto, cena urządzenia zaczyna się od około 6500 dolarów.
Ciekawe rozwiązanie zaproponowała firma Tobii Technology, która
ma w swojej ofercie urządzenie o bardzo wysokiej dokładności, które do
estymacji kierunku spojrzenia używa metody bazującej na odbiciu
światła podczerwonego od rogówki (ang. Pupil-Center-Corneal Reflection)
(2). Cena modułu śledzenia wzroku wynosi 6900 dolarów.

6
Technologia 3.
Sprzęt
Do zrealizowania celu swojej pracy inżynierskiej potrzebowałem
niestandardowej kamery, dosyć dużego monitora oraz wydajnego
układu graficznego. W tym podrozdziale opisałem te elementy systemu.
Czujnik ruchu
Urządzenie, którego używałem to ASUS Xtion Pro Live. Nie jest to
typowa kamera, powszechnie przyjęto określenie „czujnik ruchu”.
Urządzenie to zawiera kilka sensorów:
1. kamera wideo RGB o rozdzielczości 1280 x 1024 piksele
(około 10 kl/s, przy rozdzielczości 640 x 480 30 kl/s);
2. promiennik podczerwieni;
3. matryca CCD czuła na światło podczerwone o rozdzielczości
1600 x 1200 pikseli;
4. 2 mikrofony zlokalizowane na krańcach urządzenia.
Pełna specyfikacja urządzenia dostępna jest na stronie producenta
(3).
Promiennik podczerwieni oraz matryca czuła na podczerwień
pozwala na wyznaczenie odległości od czujnika dla każdego piksela
obrazu w postaci mapy głębi, co z kolei, po odpowiednim
przekształceniu, pozwala na wyznaczenie pozycji każdego piksela
obrazu w przestrzeni trójwymiarowej. Metoda skanowania przestrzeni,
którą zastosowano w tym urządzeniu nazywana jest „światłem
strukturyzowanym” (ang. structured light), metoda ta dokładniej
opisana jest w pozycji (4) bibliografii.
Ze względu na sposób przetwarzania informacji z matrycy czułej
na podczerwień, rozdzielczość wynikowa mapy głębi wynosi tylko
640 x 480 pikseli.

7
Monitor
Ze względu na niską dokładność urządzenia pomiarowego (mała
rozdzielczość wideo i mapy głębi), ważnym parametrem systemu jest
rozmiar monitora. Szerokość kątowa monitora na siatkówce oka jest
określona następującym wzorem:
Gdzie w – szerokość monitora, L – odległość obserwatora od
monitora. Im większy monitor, tym kąty wychylenia gałki będą większe,
a tym samym, błąd względny mniejszy. Zależność przedstawiono na
rysunku 1. W swojej pracy użyłem monitora o przekątnej 27 cali,
uznając ten rozmiar za wystarczająco duży do dokładnych pomiarów, a
jednocześnie dostępny w akceptowalnej cenie.
RYSUNEK 1
Układ graficzny
Operacje związane z przetwarzaniem obrazów są bardzo
wymagające obliczeniowo, dlatego używa się do nich specjalnych kart
graficznych. Firma NVIDIA Corporation stworzyła technologię CUDA
(ang. Compute Unified Device Architecture) służącą do wykonywania
własnych, niestandardowych programów przy użyciu kart graficznych.
𝛼
𝑤
𝐿

8
Najbardziej wymagające kroki moich algorytmów wykorzystują tę
technologię, dlatego wyposażyłem komputer w kartę graficzną firmy
NVIDIA współpracującą z technologią CUDA.
Oprogramowanie
W swojej pracy użyłem kilku produktów z kategorii
oprogramowania pośredniczącego, w tym: zestaw narzędzi
programistycznych do kamery ASUS Xtion Pro Live, biblioteki
przetwarzania obrazu OpenCV, platformy programistycznej Qt do
budowy interfejsu graficznego.
Oprogramowanie czujnika ruchu
W skład oprogramowania firmy PrimeSense dostarczonego wraz z
czujnikiem ruchu wchodzą:
1. Sterownik urządzenia dla systemów Windows i Linux.
2. Biblioteka OpenNI (Open Natural Interaction),
dostarczająca uniwersalny interfejs programistyczny dla
urządzeń naturalnego interfejsu użytkownika, takich jak
ASUS Xtion i Microsoft Kinect.
3. Oprogramowanie NITE stanowiące warstwę pośrednią
między urządzeniem, a biblioteką OpenNI. Jest to zestaw
algorytmów do wykrywania gestów oraz analizowania
sceny.
Przetwarzanie obrazu
Do implementacji opracowanych rozwiązań posłużyłem się
biblioteką OpenCV autorstwa firm Intel oraz Willow Garage. Wybrałem
tę bibliotekę ze względu na szeroki zakres zastosowania, wysoką
wydajność implementowanych algorytmów, a przede wszystkim ze
względu na silne wsparcie społeczności użytkowników na portalach
internetowych. Ponadto, OpenCV zawiera wiele implementacji
algorytmów korzystających z technologii CUDA oraz bardzo dobrze
współpracuje z używaną przeze mnie platformą programistyczną Qt.

9
Interfejs użytkownika
Do stworzenia interfejsu graficznego opisanych programów użyłem
zestawu bibliotek Qt firmy Qt Development Frameworks. Biblioteki te
umożliwiają łatwe i szybkie stworzenie aplikacji zdarzeniowych z
interfejsem graficznym, a w tym ułatwiają implementację np. widoków
trójwymiarowych z użyciem OpenGL, których używałem do testowania
metody drugiej.
Środowisko programistyczne i inne narzędzia
Jako środowisko programistyczne używałem Microsoft Visual
Studio 2010, w którym napisałem bibliotekę – system przetwarzania
obrazu oraz pięć innych programów, opisałem wszystkie w dalszej
części pracy. Biblioteka oraz pięć programów napisałem w języku C++,
jeden w języku C#. Poza opisanymi wyżej bibliotekami, w trakcie pracy
używałem jeszcze oprogramowania AForge.NET Framework 1 – do
uczenia sieci neuronowej, Accord.NET Framework2 – używałem modułu
Statistics do analizy głównych składowych, ARToolkit 3 – do
wyznaczania relacji kamera-monitor na podstawie markerów.
Poza tym, kod źródłowy projektu umieściłem na repozytorium
Subversion w serwisie Google Code. Jako klienta SVN używałem
oprogramowania TortoiseSVN dla systemu Windows.
1 http://www.aforgenet.com/ 2 http://code.google.com/p/accord/ 3 http://www.hitl.washington.edu/artoolkit/

10
System przetwarzania obrazu 4.
Wymagania
Do zrealizowania celu pracy inżynierskiej potrzebowałem
uniwersalnego narzędzia, które pozwoliłoby na testowanie różnych
podejść, metod przetwarzania i analizy obrazów oraz zapisywanie
wyników. Oprogramowanie, którego szukałem musiało obsługiwać
wiele strumieni danych wejściowych oraz pozwalać na wspólne
przetwarzanie odpowiadających sobie klatek w każdym ze strumieni.
Jednocześnie potrzebowałem oprogramowania, które obsługiwałoby
używany przeze mnie czujnik ruchu. Niestety nie znalazłem
odpowiedniego rozwiązania, co zmusiło mnie do stworzenia własnego,
uniwersalnego systemu przetwarzania obrazu. Projektując system
określiłem następujące wymagania funkcjonalne:
1. System musi obsługiwać czujnik ruchu ASUS Xtion Pro
Live.
2. Musi pozwalać na współbieżne przetwarzanie obrazu z wielu
źródeł, np. obrazu RGB i mapy głębi z czujnika.
3. Musi być łatwo rozszerzalny o nowe metody przetwarzania.
4. Powinien wspomagać wielokrotne używanie raz napisanego
kodu.
5. Powinien izolować poszczególne metody przetwarzania tak
aby ułatwić wymianę poszczególnych etapów i umożliwić
szybkie lokalizowanie błędów.
Ponadto, system powinien spełniać poniższe wymagania
pozafunkcjonalne:
1. System powinien działać na komputerze PC wyposażonym w
system operacyjny Microsoft Windows.
2. Powinien wykorzystywać możliwości procesorów
wielordzeniowych i kart graficznych współpracujących z
technologią CUDA.

11
3. Wydajność systemu powinna pozwalać na przetwarzanie co
najmniej 10 klatek na sekundę dla metod opisanych w
niniejszej pracy.
Rozwiązanie
System, który stworzyłem spełnia prawie wszystkie powyższe
wymagania, aktualnie nie wykorzystuje wielu rdzeni do równoległego
przetwarzania, ponieważ wydajność była satysfakcjonująca i nie było
takiej potrzeby, a ponadto, utrudniłoby to implementację wielu
używanych filtrów. Moje rozwiązanie jest biblioteką statyczną
dołączaną do pozostałych projektów, która dostarcza łatwego i
uniwersalnego interfejsu do implementacji niestandardowych metod
przetwarzania. Umożliwia przetwarzanie danych z wielu źródeł, w tym
nie tylko obrazu, ale również dźwięku czy innych dowolnych danych
liczbowych, które można zapisać w postaci macierzy. Kroki
przetwarzania mogą przyjmować dane z kilku strumieni oraz mogą
generować kilka strumieni nowych danych, mogą być dowolnie
łączone, przeplatane i zapętlane. System składa się z dwóch
kluczowych elementów: grafu przetwarzania oraz zestawu filtrów.
Graf przetwarzania
Graf przetwarzania obrazu jest strukturą, która definiuje
kolejność kroków przetwarzania oraz przepływ danych między nimi.
Odpowiada za wywołanie wszystkich potrzebnych filtrów w
odpowiedniej kolejności i na odpowiednich danych. Filtry po
stworzeniu są dodawane do listy filtrów grafu, który przed
uruchomieniem przetwarzania wyznacza kolejność w jakiej filtry
powinny być wywoływane, aby spełnione zostały określone między nimi
zależności przepływu danych. Graf przetwarzania decyduje również o
wyborze jednej z dwóch metod przetwarzania zawartych w każdym
filtrze: przetwarzanie danych poprawnych, przetwarzanie danych, w
których co najmniej jedna składowa jest niepoprawna.

12
Poza samym procesem przetwarzania, graf filtrów odpowiada
również za stworzenie interfejsu umożliwiającego wyświetlanie wyników
oraz kontrolę parametrów w trakcie przetwarzania. W tym celu tworzy
widżet ekranowy agregujący widżety udostępniane przez filtry.
Architekturę typowej aplikacji wykorzystującej mój system
przetwarzania przedstawia rysunek 2, graf przetwarzania jest zawarty
w aplikacji.
RYSUNEK 2
Filtry
Filtr można utożsamiać z funkcją:
Gdzie:
– liczba wejść filtra;
– liczba wyjść filtra;
- macierze wejściowe określonego o określonej liczbie
wymiarów i w pełni lub częściowo określonych wymiarach – np. obraz
RGB o rozdzielczości 640 x 480 pikseli lub zestaw punktów w
przestrzeni trójwymiarowej zapisanych w postaci wektorów poziomych
tak, że każdy wiersz macierzy określa inny punkt;
- macierze wejściowe określone na tych samych zasadach
co macierze wejściowe;
Aplikacja Graf przetwarzania
Filtr Filtr

13
- dodatkowe wartości logiczne określające czy dane wejściowe w
macierzy są poprawne;
- dodatkowe wartości logiczne określające czy dane wyjściowe
w macierzy są poprawne;
– funkcja przetwarzania danych, dzięki dodatkowym flagom
poprawności danych może w wyjątkowy sposób obsługiwać sytuacje
błędne lub częściowy brak danych.
Filtry można podzielić na trzy kategorie:
1. filtry wejściowe,
2. filtry wyjściowe,
3. filtry przetwarzające.
Filtry wejściowe to takie, które dostarczają danych z określonego
źródła. Charakteryzują się brakiem wejść i (zwykle) jednym wyjściem,
w moim systemie do tej grupy należą filtry takie jak:
RGBInput – pobiera obraz RGB z czujnika ruchu ASUS Xtion
Pro Live;
DepthInput – pobiera mapę głębokości z czujnika ruchu;
IRInput – pobiera obraz z matrycy czułej na podczerwień z
czujnika ruchu;
ConstInput – generuje stałą, wcześniej ustaloną macierz;
FileInput – odczytuje dane z pliku;
StreamInput – generuje ciąg wcześniej ustalonych macierzy;
ParameterInput – generuje wartości parametryzowane za
pomocą suwaków na widżecie wyświetlanym w oknie grafu
przetwarzania.
Filtry wyjściowe to takie, które wyświetlają lub zapisują wyniki
przetwarzania, zwykle mają jedno wejście i nie mają żadnych wyjść. Do
tej grupy należą takie filtry:
ImageOutput – wyświetla obraz we własnym widżecie;
FileOutput – zapisuje obrazy do kolejnych plików w
formacie ddd.png, gdzie ddd zastępuje kolejnymi liczbami;

14
ConsoleOutput – wyświetla wartość w konsoli, przydatne w
przypadku małych macierzy zawierających np. współrzędne
jednego punktu lub macierz transformacji, używane do
testowania;
CSVOutput – zapisuje kolejne macierze wyjściowe w postaci
rozciągniętej do jednego wiersza do pliku w formacie CSV,
obsługuje wiele strumieni wejściowych, ale trzeba pamiętać
ich kolejność i wymiary;
OpenGLOutput – wyświetla trzy rodzaje danych: punkty w
przestrzeni trójwymiarowej, wektory w przestrzeni
trójwymiarowej oraz macierze transformacji, tło widoku
stanowi siatkę na płaszczyźnie XZ przestrzeni
trójwymiarowej, punkty rysowane są jako koła określonym
kolorze i średnicy, wektory jako strzałki, a macierze
transformacji jako trzy wektory jednostkowe równoległe do
osi układu współrzędnych, przekształcone za pomocą
macierzy transformacji, w każdym z widoków widoczne są
trzy półprzezroczyste wektory OX, OY i OZ przydatne jako
punkt odniesienia;
PointOnScreenOutput – wyświetla koło o określonym kolorze
i promieniu na widoku pełnoekranowym w punkcie w
przestrzeni dwuwymiarowej, przekazanym za pomocą
wejścia.
Do filtrów przetwarzających należą takie, które przetwarzają dane
wejściowe, a wyniki tego przetwarzania udostępniają za pośrednictwem
swoich wyjść. W trakcie pisania pracy zaimplementowałem wiele filtrów
tego rodzaju, nie ma potrzeby wypisywania ich, a wiele z nich
opakowuje funkcje OpenCV.
Dane z wejść i wyjść filtrów przekazywane są w postaci macierzy,
obiektu klasy Mat biblioteki OpenCV. Dzięki temu rozwiązaniu filtry
mogą przekazywać między sobą niemal dowolne dane numeryczne,
macierze mają dowolną liczbę wymiarów, dowolne rozmiary oraz
dowolny typ danych. Poza standardowymi połączeniami wyjść i wejść
15
filtrów, w systemie występują również asocjacje między filtrami, które
są wymagane przez niektóre zastosowania np. do wywoływania metod
udostępnianych przez API czujnika ruchu. W swoich zastosowaniach
starałem się konsekwentnie używać kilku typów danych: obrazy 3-
kanałowe RGB, obrazy 1-kanałowe – w skali szarości (liczby całkowite)
i mapa głębi (liczby zmiennoprzecinkowe), punkty i wektory w
przestrzeni dwu- i trójwymiarowej, macierze transformacji. Ponieważ
system udostępnia wspólny dla wszystkich filtrów interfejs, do
opisywania projektowanych grafów przetwarzania zaproponowałem
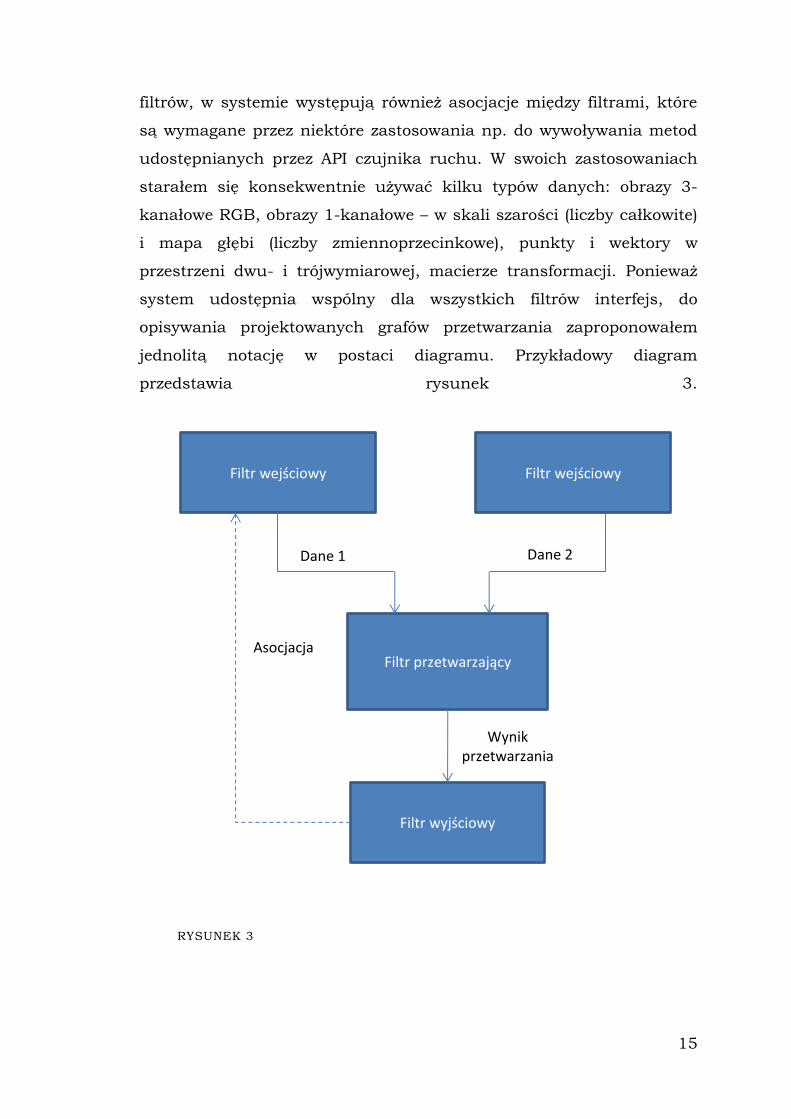
jednolitą notację w postaci diagramu. Przykładowy diagram
przedstawia rysunek 3.
RYSUNEK 3
Filtr wejściowy
Filtr przetwarzający
Filtr wyjściowy
Filtr wejściowy
Dane 1 Dane 2
Asocjacja
Wynik przetwarzania

16
Metoda pierwsza 5.
Pierwsza próba budowy interfejsu komputera zakładała obsługę
bez użycia myszy. Głównym założeniem było wykrycie punktu na
ekranie monitora, na którym użytkownika skupia wzrok i przesunięcie
tam kursora. Do osiągnięcia tego celu potrzebne były następujące
dane:
1. położenie gałek ocznych względem czujnika;
2. kąty obrotu gałek ocznych w osi pionowej i osi poziomej
prostopadłej do kierunku spojrzenia;
3. położenie kamery względem monitora;
4. wymiary i rozdzielczość monitora.
W dalszej części rozdziału przedstawiłem diagram programów
zbudowanych na bazie opisanego wcześniej systemu przetwarzania,
realizujących metodę pierwszą.
Położenie gałek ocznych
Czujnik ruchu udostępnia mapę głębi widzianej sceny, dzięki tym
danym oraz obrazowi z matrycy RGB możemy określić położenie
punktów sceny w przestrzeni trójwymiarowej w układzie związanym z
czujnikiem ruchu. W tym celu najpierw musimy wyznaczyć położenie
gałek ocznych na obrazie RGB w układzie dwuwymiarowym obrazu.
Dokonywane jest to za pomocą klasyfikatora cech Haaro-podobnych,
którego implementację dostarcza biblioteka OpenCV. Ponieważ
wykrywanie oczu w każdej klatce znacząco obniżyłoby wydajność
rozwiązania, wykrywanie następuje etapowo. Pierwszym krokiem jest
znalezienie twarzy na obrazie przy użyciu klasyfikatora cech Haaro-
podobnych, jeśli nie znaleziono twarzy we wcześniejszej klatce
wyszukiwanie przeprowadzane jest w obrębie całej klatki, w innym
wypadku wyszukiwanie przeprowadzane jest w obszarze, w którym
istnieje wysokie prawdopodobieństwo znalezienia twarzy, jest to obszar
o szerokości i wysokości 25% większej niż prostokąt, w którym ostatnio

17
znaleziono twarz. Jeśli użytkownik nie wykona szczególnie szybkiego
ruchu, skuteczność tego rozwiązania jest bardzo wysoka. Jeśli nie
udało się znaleźć twarzy w obszarze wysokiego prawdopodobieństwa,
wyszukiwanie następuje w obrębie całej klatki.
Wstępne wyszukiwanie twarzy przyspiesza proces detekcji oczu,
ponieważ oczy, jako mniejsze elementy obrazu, są trudniejsze do
znalezienia i wymagają więcej czasu. Po znalezieniu twarzy, można
przeprowadzić detekcję oczu tylko w ograniczonym obszarze obrazu.
Po znalezieniu położenia oczu na obrazie RGB z czujnika ruchu,
należy obliczyć ich położenie w przestrzeni trójwymiarowej względem
czujnika. Przypomnę, że obraz dwuwymiarowy powstaje na matrycy
kamery w sposób, który opisuje rzutowanie perspektywiczne, poniżej
podałem formułę pozwalającą na obliczenie położenia rzutu
perspektywicznego punktu na matrycę kamery w zależności od
położenia punktu w przestrzeni, we współrzędnych jednorodnych.
Wzory te nie uwzględniają transformacji współrzędnych z matrycy
kamery do współrzędnych obrazu w postaci cyfrowej oraz
zniekształcenia obiektywu kamery.
[
]
[
]
[
]
– punkt w przestrzeni trójwymiarowej,
– macierz projekcji,
- rzut punktu P na matrycę kamery,
– ogniskowa kamery.
Jak widać, podczas rzutowania perspektywicznego zatracana jest
informacja o odległości punktu P od kamery. Wartość tę można
odczytać z mapy głębi, którą tworzy czujnik ruchu. W efekcie
współrzędne pierwotnego punktu P możemy policzyć za pomocą wzoru:

18
W ten sposób z obrazu RGB i mapy głębi uzyskaliśmy współrzędne
położenia gałek ocznych w przestrzeni trójwymiarowej o początku
układu współrzędnych związanym z kamerą.
Orientacja gałek ocznych
Samo położenie gałek ocznych nie wystarczy do wyznaczenia
kierunku spojrzenia, do tego celu potrzebujemy jeszcze dwóch kątów
obrotu gałek ocznych. Początkowo założyłem, że kąty te można
wyznaczyć za pomocą odpowiednio nauczonej sieci neuronowej.
Warstwa wejściowa sieci posiadała 400 neuronów (20x20 pikseli),
warstwa wyjściowa 2 wartości w przedziale ⟨ ⟩, a warstwa ukryta 50
neuronów. Próba wynosiła 3000 obrazów dla 100 różnych punktów na
ekranie, 90% próby przeznaczyłem na zbiór uczący, a 10% na zbiór
testowy. Neurony w sieci aktywowane były bipolarną funkcją
sigmoidalną i uczone za pomocą algorytmu wstecznej propagacji błędu
(5) przez 10000 epok lub do momentu uzyskania średniego błędu
kwadratowego mniejszego niż 0,2 (wszystkie dane znormalizowano do
przedziału ⟨ ⟩ ). Niestety tak zaprojektowana sieć neuronowa nie
wykazała zadowalającej zdolności uczenia się. W trakcie uczenia średni
błąd kwadratowy zmalał od wartości początkowej 0,92 do wartości 0,02
(dla 10000 epok) oraz wartości 0,19 (dla drugiego warunku), ale w
żadnym z opisanych wypadków sieć nie uzyskała pożądanej własności
uogólniania wzorca, przez co praktyczne zastosowanie rozwiązania nie
daje satysfakcjonujących rezultatów.
Wzajemne relacje położenia kamery i monitora
Aby rzutować wektor spojrzenia na płaszczyznę monitora, musimy
znać jego położenie i orientację w zależności od kamery, ponieważ do
tej pory wszystkie operacje wykonywaliśmy w układzie współrzędnych
związanym z kamerą. W tym celu należy dokonać niezbędnych
pomiarów i skonstruować macierz transformacji, którą mnoży się z

19
każdym punktem obliczonym we współrzędnych kamery. Ciekawym
rozwiązaniem, które można wprowadzić do tego kroku w przyszłości
wydaje się być biblioteka ARToolkit udostępniająca narzędzia dla
twórców aplikacji związanych z ideą rozszerzonej rzeczywistości.
Kamerę i monitor należałoby oznaczyć odpowiednimi markerami, a
następnie wykonać kilka zdjęć pod różnymi kątami obejmujących oba
urządzenia i dokonać wyznaczenia macierzy transformacji między nimi
przy użyciu biblioteki ARToolkit. Niestety pierwsze próby tego typu
podejścia nie dawały oczekiwanych rezultatów, więc pozostawiam ten
temat jako potencjalny punkt rozwoju pracy w przyszłości.
Program do generowania danych uczących sieci
Sposób w jaki chciałem uzyskać kąty odchylenia gałek ocznych,
opisany w podrozdziale „Orientacja gałek ocznych” wymaga zebrania
zestawu uczącego i testowego. Do tego celu przygotowałem pierwszy
program. Tak jak pisałem w rozdziale 4., wszystkie programy bazujące
na moim systemie przetwarzania obrazu można przedstawić w formie
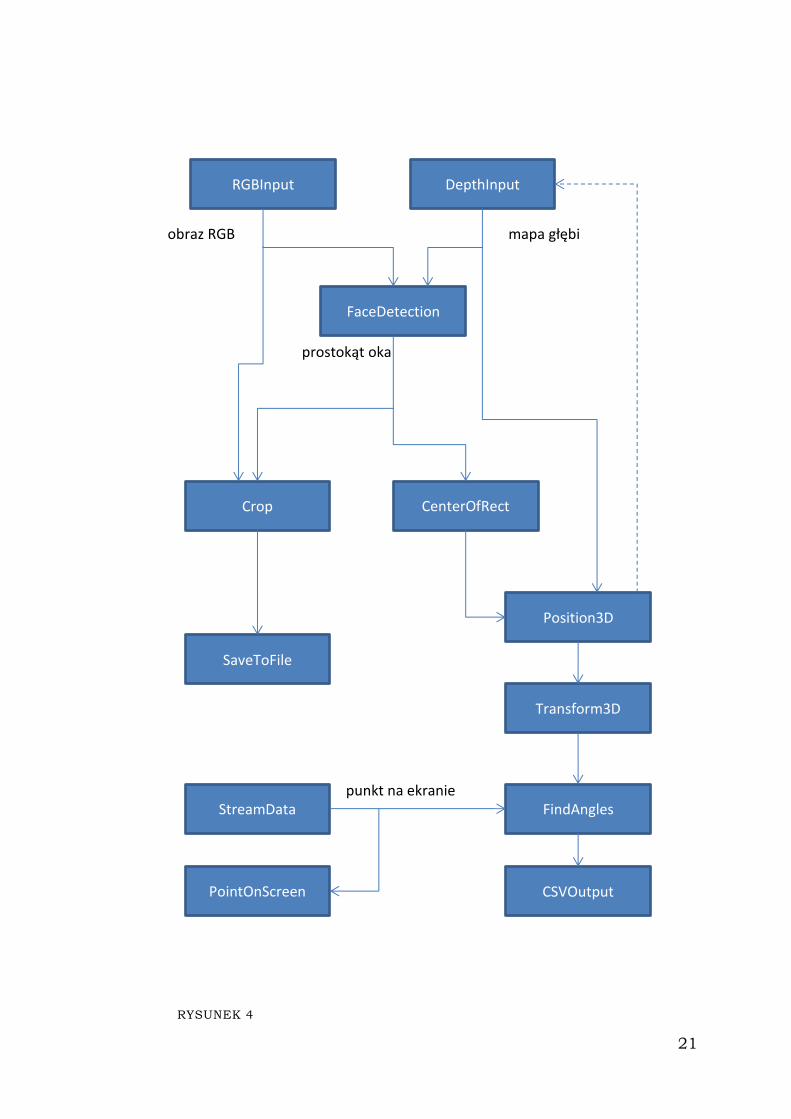
diagramu filtrów. Rysunek 4. przedstawia diagram dla pierwszego
programu. Diagram uwzględnia tylko jedno oko, aby zachować
czytelność, ponieważ obraz drugiego oka jest przetwarzany analogicznie
i nie ma potrzeby dublowania diagramu. W tabeli 1. przedstawiłem opis
filtrów występujących na diagramie.
Program po uruchomieniu generuje zestaw losowych punktów,
których współrzędne mieszczą się w zakresie rozdzielczości monitora, a
następnie zaczyna wyświetlać je na pełnoekranowym widżecie.
Użytkownik powinien zachowywać się naturalnie i śledzić oczami
pojawiający się punkt. W tym czasie czujnik ruchu rejestruje obraz
RGB i mapę głębi, a program oblicza o jaki kąt użytkownik powinien
odchylić każde z oczu, aby punkt skupienia wzroku trafiał w cel na
ekranie. Wszystkie dane liczbowe zapisywane są do arkusza CSV (jeden
wiersz na klatkę), a wszystkie obrazy oczu są wycinane i zapisywane do
plików PNG o nazwie zawierającej numer klatki. Tak zebrane dane
można poddać analizie.
20
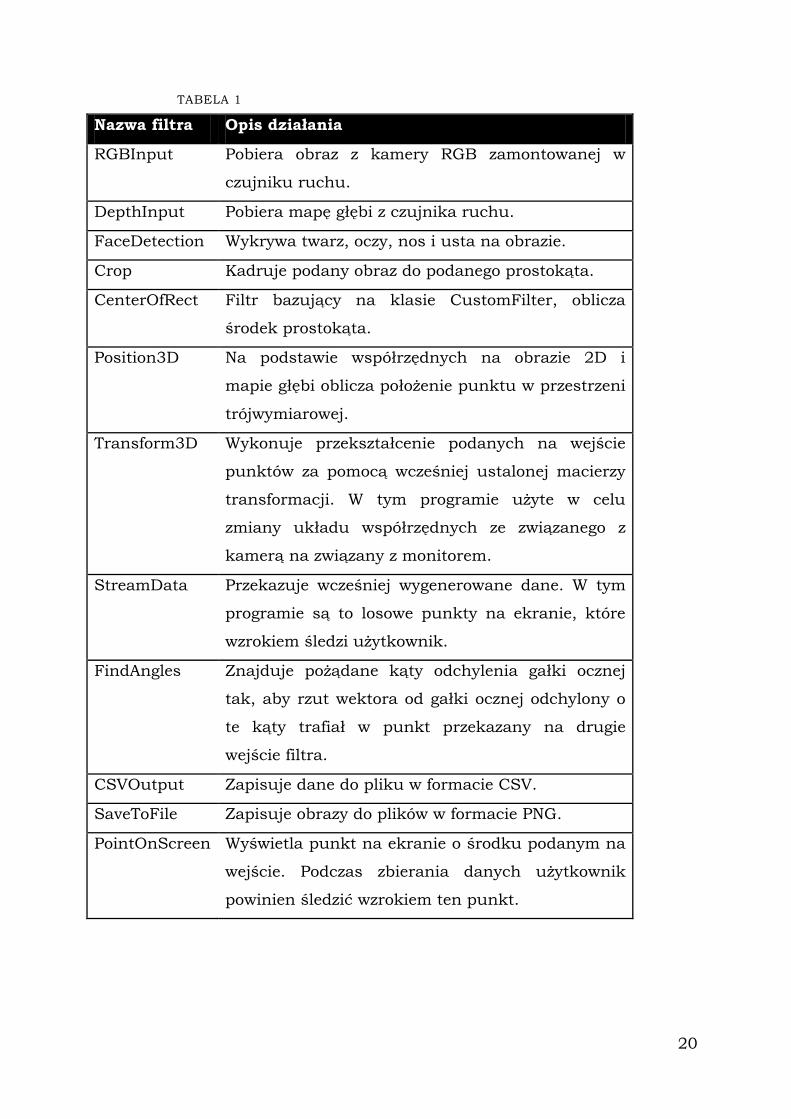
TABELA 1
Nazwa filtra Opis działania
RGBInput Pobiera obraz z kamery RGB zamontowanej w
czujniku ruchu.
DepthInput Pobiera mapę głębi z czujnika ruchu.
FaceDetection Wykrywa twarz, oczy, nos i usta na obrazie.
Crop Kadruje podany obraz do podanego prostokąta.
CenterOfRect Filtr bazujący na klasie CustomFilter, oblicza
środek prostokąta.
Position3D Na podstawie współrzędnych na obrazie 2D i
mapie głębi oblicza położenie punktu w przestrzeni
trójwymiarowej.
Transform3D Wykonuje przekształcenie podanych na wejście
punktów za pomocą wcześniej ustalonej macierzy
transformacji. W tym programie użyte w celu
zmiany układu współrzędnych ze związanego z
kamerą na związany z monitorem.
StreamData Przekazuje wcześniej wygenerowane dane. W tym
programie są to losowe punkty na ekranie, które
wzrokiem śledzi użytkownik.
FindAngles Znajduje pożądane kąty odchylenia gałki ocznej
tak, aby rzut wektora od gałki ocznej odchylony o
te kąty trafiał w punkt przekazany na drugie
wejście filtra.
CSVOutput Zapisuje dane do pliku w formacie CSV.
SaveToFile Zapisuje obrazy do plików w formacie PNG.
PointOnScreen Wyświetla punkt na ekranie o środku podanym na
wejście. Podczas zbierania danych użytkownik
powinien śledzić wzrokiem ten punkt.
21
RYSUNEK 4
RGBInput
FaceDetection
CenterOfRect
Position3D
DepthInput
StreamData FindAngles
CSVOutput
Crop
SaveToFile
PointOnScreen
Transform3D
obraz RGB mapa głębi
prostokąt oka
punkt na ekranie

22
Opisany program został zawarty na dołączonej płycie DVD, w
katalogu o nazwie Metoda 1. Instrukcja kompilacji również znalazła się
na płycie, w katalogu Media. Po uruchomieniu programu użytkownik
zobaczy poniższy ekran.
RYSUNEK 5
Czarny punkt wskazuje miejsce, w którym należy skupić wzrok.
Punkt zmienia położenie co sekundę, a użytkownik powinien go śledzić
wzorkiem. Po każdej klatce w katalogu Output/eyes/ zapisywane są
obrazy oczu w rozmiarach w jakich zostały wykryte, a w katalogu
Output/eyes50/ obrazy o rozmiarze 50 x 50 pikseli o środku w tym
samym punkcie co oryginalne. Ponadto zapisywany jest arkusz
kalkulacyjny w pliku Output/output.csv, w którym pierwsze dwie
kolumny odnoszą się do lewego oka, a drugie dwie do prawego oka.
Pierwsza kolumna dla oka oznacza oczekiwany kąt odchylenia gałki
ocznej w poziomie, a druga w pionie, obie wartości podane są w
radianach. Ostatnie dwie kolumny arkusza to położenie punktu na
wyświetlaczu, ponieważ punkty generowane są losowo. Tak pozyskane
dane można wykorzystać do uczenia sieci neuronowej za pomocą
programu NetsTest, który znajduje się na płycie w katalogu Uczenie
sieci. Proces można obejrzeć na nagraniach:

23
metoda_1_zbieranie_probek.mp4 oraz
metoda_1_zbieranie_probek_ekran.wmv.
Program do wyznaczania punktu skupienia wzroku
Program do wyliczania punktu, na który spogląda użytkownik jest
bardzo podobny do programu do zbierania danych uczących. Dane
poddawane są analogicznym przekształceniom, a główna różnica
wynika z faktu konieczności wyliczenia innej niewiadomej – wcześniej
wyliczaliśmy kąty na podstawie danego punktu docelowego, teraz kąty
musimy estymować za pomocą sieci neuronowej, a wyliczać punkt
docelowy. Jeśli punkt wyliczony dla prawego oka jest inny niż ten
wyliczony dla lewego (prawie zawsze tak jest), punkty są uśredniane.
Rysunek 6. przedstawia diagram działania programu. W programie
pojawiły się nowe filtry, opisałem je w tabeli 2.
TABELA 2
Nazwa filtra Opis działania
NeuroNetwork Implementacja tego filtra nie powstała, ponieważ
tymczasowo zrezygnowałem z rozwijania tej metody
ze względu na niezadowalające wyniki uczenia sieci
neuronowej. Koncepcyjnie, filtr ten powinien
obliczać wartości kątów odchylenia gałki ocznej na
podstawie wyciętego obrazka. Wagi neuronów w
sieci byłyby ładowane na początku działania
programu.
Projection Ten filtr wykonuje rzutowanie punktu podanego na
wejście wzdłuż wektora o odchyleniu podanym za
pomocą dwóch kątów (drugie wejście) względem osi
OZ, na płaszczyznę monitora, czyli płaszczyznę XY.
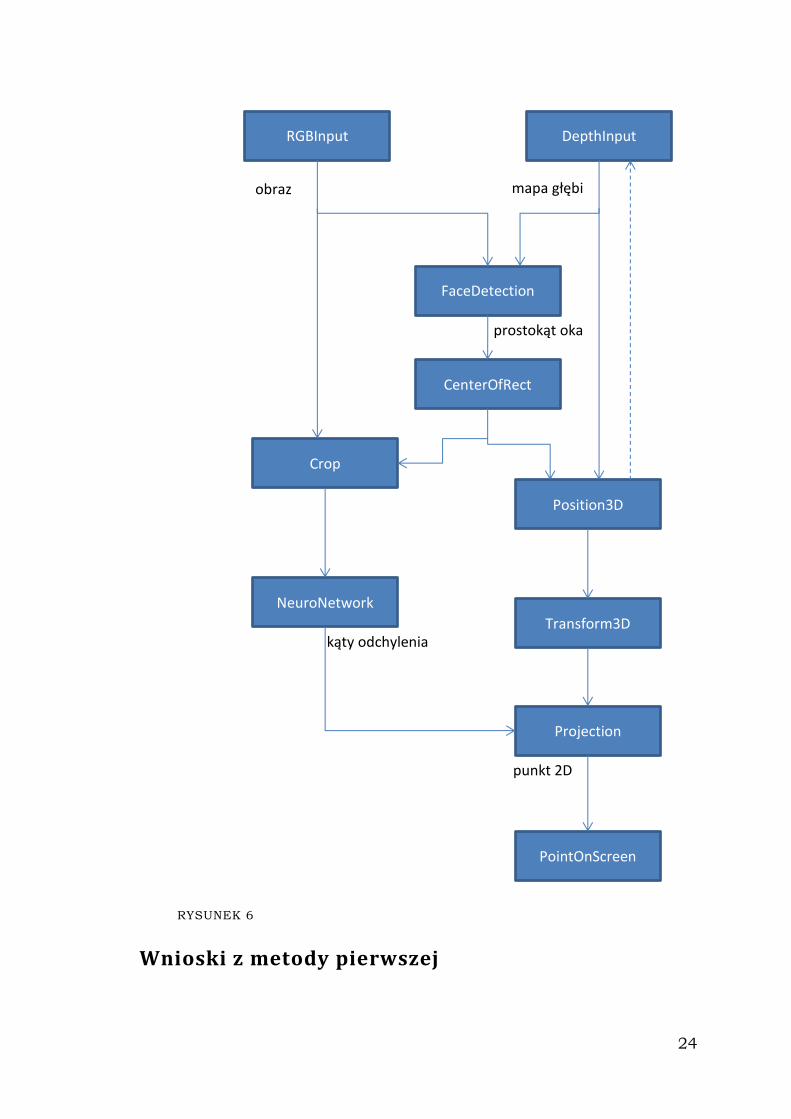
24
RYSUNEK 6
Wnioski z metody pierwszej
RGBInput DepthInput
FaceDetection
CenterOfRect
Crop
Position3D
NeuroNetwork
Transform3D
PointOnScreen
Projection
obraz mapa głębi
prostokąt oka
kąty odchylenia
punkt 2D

25
Najsłabszym punktem metody pierwszej okazała się sieć
neuronowa. Prawdopodobnie zbiór uczący sieci neuronowej był zbyt
mało różnorodny, ponieważ dla każdego punktu na ekranie
generowano aż 30 obrazów, co z 3000 próbek dawało 100 rzeczywiście
różnorodnych punktów. Sieć uzyskała pewną zdolność rozpoznawania
wartości odchylenia kąta dla punktów we zbioru uczącego, ale nie
zyskała cechy uogólniania wzorca przez co wyniki na innym zbiorze
testowym nie były satysfakcjonujące.
Myślę, że dalsza praca nad tą metodą musiałaby uwzględnić
przebudowanie i przetestowanie innych rodzajów sieci neuronowej oraz
próbę selekcji informacji z obrazów w celu zmniejszenia liczby
wymiarów wektora wejściowego.

26
Metoda druga 6.
Po nieudanej próbie wyznaczenia punktu, w którym skupia się
wzrok użytkownika, uprościłem założenia projektu. Druga metoda
zakłada, że użytkownik steruje kursorem za pomocą ruchów całą
głową. Program miał wyznaczać rzut czubka nosa wzdłuż wektora
skierowanego zgodnie z orientacją głowy, na płaszczyznę monitora,
czyli sterowanie kursorem miało odbywać się poprzez wskazywanie
położenia nosem.
Po uruchomieniu programy zakładamy, że głowa użytkownika
znajduje się mniej więcej naprzeciwko środka monitora i jest
skierowana w jego kierunku, w tym stanie wektor, po którym będziemy
rzutować ma współrzędne w układzie związanym z monitorem,
gdzie oś Z wskazuje głębokość i rośnie wraz z oddalaniem od monitora.
Ta metoda bazuje na obliczaniu transformacji, której poddane
zostały punkty charakterystyczne wykryte w obszarze głowy w okresie
czasu między poszczególnymi klatkami obrazu. Algorytm składa się z
pięciu ogólnych kroków, które opisałem w kolejnych podrozdziałach.
1. Wykrycie punktów charakterystycznych w obszarze twarzy.
2. Połączenie punktów w pary, z punktami odpowiadającymi z
poprzedniej klatki.
3. Znalezienie przekształcenia między punktami z kolejnych
klatek.
4. Nałożenie przekształcenia na wektor wzdłuż którego
rzutujemy.
5. Rzutowanie czubka nosa wzdłuż wektora na monitor.
Wykrycie punktów charakterystycznych
Tak jak w poprzednim przypadku, w celu skrócenia czasu
przetwarzania klatki, pierwszą operacją przeprowadzaną na obrazie
jest wykrycie twarzy. Tutaj również posłużyłem się znaną metodą
klasyfikatora cech Haaro-podobnych. Metoda ta działa bardzo szybko,
ponieważ nie zależy nam na znalezieniu dokładnego położenia i

27
rozmiaru twarzy, a tylko przybliżony obszar zainteresowania, co można
uzyskać dostosowując parametry wyszukiwania, a ponadto biblioteka
OpenCV dostarcza implementację klasyfikatora dla kart graficznych
wspierających technologię CUDA.
Po znalezieniu twarzy na obrazie, na podstawie prostokąta
tworzona jest maska bitowa, która później podawana jest jako
parametr do operacji znajdowania punktów charakterystycznych.
Aktualnie jednym z najlepszych algorytmów znajdowania cech
charakterystycznych w obrazie jest SURF (ang. Speeded Up Robust
Features) (6). Algorytm ten po raz pierwszy został zaprezentowany w
2006 roku przez Herberta Baya z Eidgenössische Technische
Hochschule Zürich. Opiera się on o sumy dwuwymiarowych falek
Haara, co pozwala na wydajne użycie sumacyjnych postaci obrazu
(ang. integral image, summed area table) (7). Ja użyłem implementacji z
biblioteki OpenCV w postaci klasy SurfFeatureDetector.
Ze względu na system przetwarzania, który przesyła między
filtrami macierze, cechy wykrytych punktów takie jak o położenie,
rozmiar czy orientacja muszą być zapisane do postaci wektora liczb
zmiennoprzecinkowych. Po zapisaniu wszystkich punktów w postaci
macierzy, są one przekazywane do bufora zapamiętującego dane na
jedną klatkę oraz do filtra znajdującego przekształcenie między
punktami z poszczególnych klatek.
Połączenie punktów
Odpowiadające sobie punkty charakterystyczne obrazu z
aktualnej i poprzedniej klatki muszą zostać połączone w pary. W tym
celu wykorzystuję metodę najbliższych sąsiadów, która została
zaimplementowana w OpenCV przy użyciu biblioteki FLANN (ang. Fast
Library for Nearest Neighbors).
Wyznaczanie przekształcenia (8)
Wyznaczenie przekształcenia między dwoma zestawami punktów
w przestrzeni trójwymiarowej należy do skomplikowanych problemów

28
optymalizacyjnych, szczególnie w przypadku gdy błędy pomiaru są
znaczne lub zbiór danych zawiera punkty fałszywe.
Pierwszym etapem wyznaczania przekształcenia między dwoma
zbiorami danych A i B zawierającymi po N odpowiadających sobie
punktów P jest obliczenie centroidów:
[ ]
∑
∑
Obliczanie centroidów ma na celu wyłuskanie z danych samego
przesunięcia, pozostawiając rotację bez zmian. Przesuwamy punkty z
obu zbiorów tak, aby centroidy znalazły się w środku układu
współrzędnych po czym możemy przystąpić do wyznaczania macierzy
rotacji. Jest wiele sposobów na znalezienie optymalnej macierzy rotacji
tak, aby odległości odpowiadających sobie punktów były jak
najmniejsze. Jednym z nich jest skorzystanie z metody rozkładu
macierzy według wartości osobliwych (SVD, ang. Singular Value
Decomposition). Metoda ta jest szeroko dostępna w różnych
bibliotekach programistycznych, również w OpenCV, którego używamy.
Każdą macierz rzeczywistą można przedstawić w postaci
rozkładu według wartości osobliwych.
Twierdzenie:
Dla każdej macierzy rzędu o wymiarach istnieją takie macierze
ortogonalne i ( i oraz taka macierz pseudodiagonalna , że:
gdzie macierz ma postać:
[
]
oznacza macierz diagonalną r-tego stopnia, gdzie:
oraz:

29
Przy czym liczby to niezerowe wartości osobliwe macierzy .
W celu znalezienia macierzy rotacji tworzymy akumulator, macierz
rozmiaru , sumując iloczyny wycentrowanych, odpowiadających
sobie punktów ze zbiorów i . Następnie dokonujemy rozkładu i
obliczamy macierz obrotu według wzorów:
∑
[ ]
Musimy jeszcze obsłużyć jedną wyjątkową sytuację. Gdy
wyznacznik macierzy jest mniejszy od 0, należy zmienić znak liczb w
trzeciej kolumnie macierzy.
Aby znaleźć wynikową macierz transformacji należy złożyć
wszystkie przekształcenia.
[
]
[
]
[
]
Nałożenie przekształcenia i rzutowanie punktu
Do przekształcania wektora orientacji głowy użyjemy filtra
Multiply, który na swoje wejścia przyjmuje dwie macierze, a na
wyjściu daje wynik mnożenia tych macierzy. Należy jeszcze wziąć pod
uwagę różnice w położeniu kamery względem monitora, co uzyskamy
za pomocą filtra Transform3D z odpowiednio ustawioną macierzą

30
transformacji. Transformacji tej należy poddać punkt czubka nosa jak i
wyznaczony wektor orientacji głowy.
Diagram programu
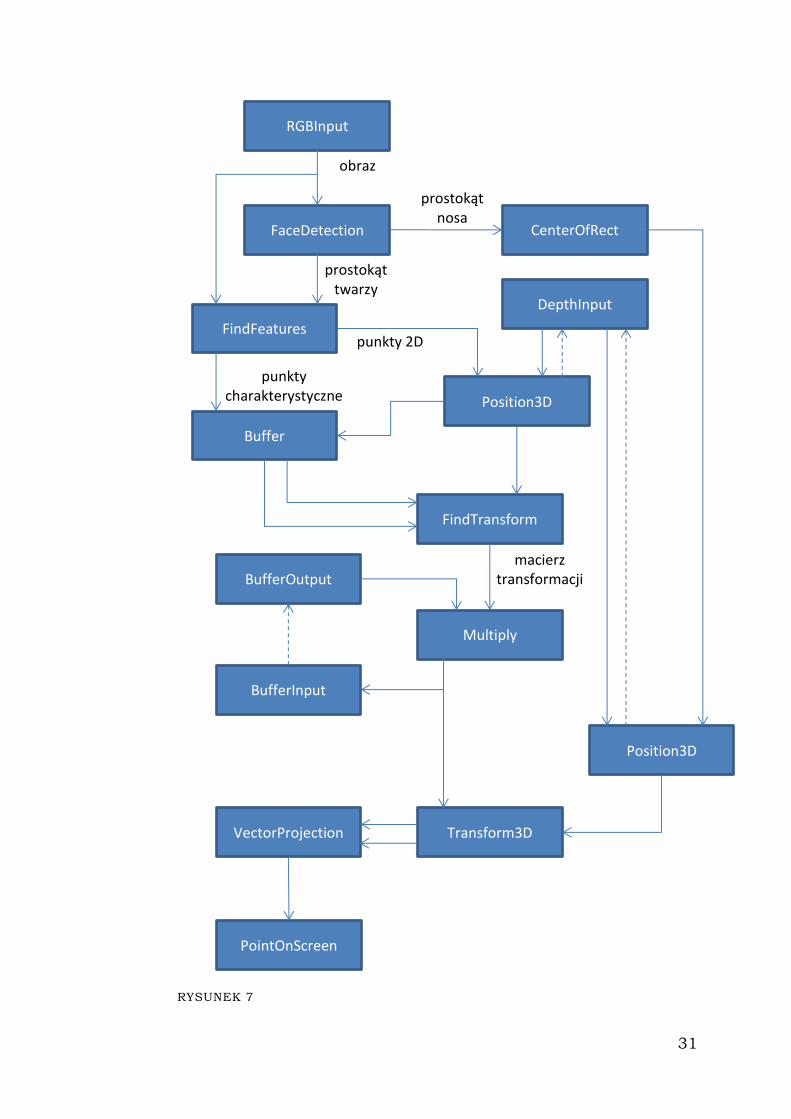
Poniżej, na rysunku 7. przedstawiłem diagram programu dla
systemu przetwarzania obrazu. Nowym elementem na tym diagramie
jest filtr cykliczny zrealizowany za pomocą dwóch filtrów: BufferInput i
BufferOutput. Takie rozwiązanie wymuszone jest przez założenie
projektowe grafu przetwarzania, że dla jednej klatki każdy filtr może
zostać wywołany tylko raz.
TABELA 3
Nazwa filtra Opis działania
FindFeatures Ten filtr znajduje punkty charakterystyczne na
obrazie za pomocą algorytmu SURF. Na wyjścia
wystawia macierz punktów 2D oraz macierz
odpowiadających im punktów
charakterystycznych.
Buffer Przechowuje dane przez jedną klatkę po czym
wystawia je na wyjście.
BufferOutput
BufferInput
Te dwa filtry współpracują ze sobą, aby możliwe
było stworzenie zależności cyklicznych. Na swoje
wyjścia BufferOutput wystawia macierze, które
podano na wejścia BufferInput.
Multiply Na wyjściu wynik mnożenia dwóch macierzy z
wejść.
VectorProjection Rzutowanie punktu wzdłuż wektora na
płaszczyznę monitora XY.
31
RYSUNEK 7
RGBInput
DepthInput
FaceDetection
FindFeatures
Buffer
Position3D
FindTransform
Multiply
BufferInput
BufferOutput
CenterOfRect
Position3D
Transform3D VectorProjection
PointOnScreen
obraz
prostokąt nosa
prostokąt twarzy
punkty 2D
punkty charakterystyczne
macierz transformacji
32
Opisany program znajduje się na dołączonej płycie w katalogu
Metoda 2. Konfiguracja i uruchomienie przebiega analogicznie do
pierwszego programu opisanego w poprzednim rozdziale. Po
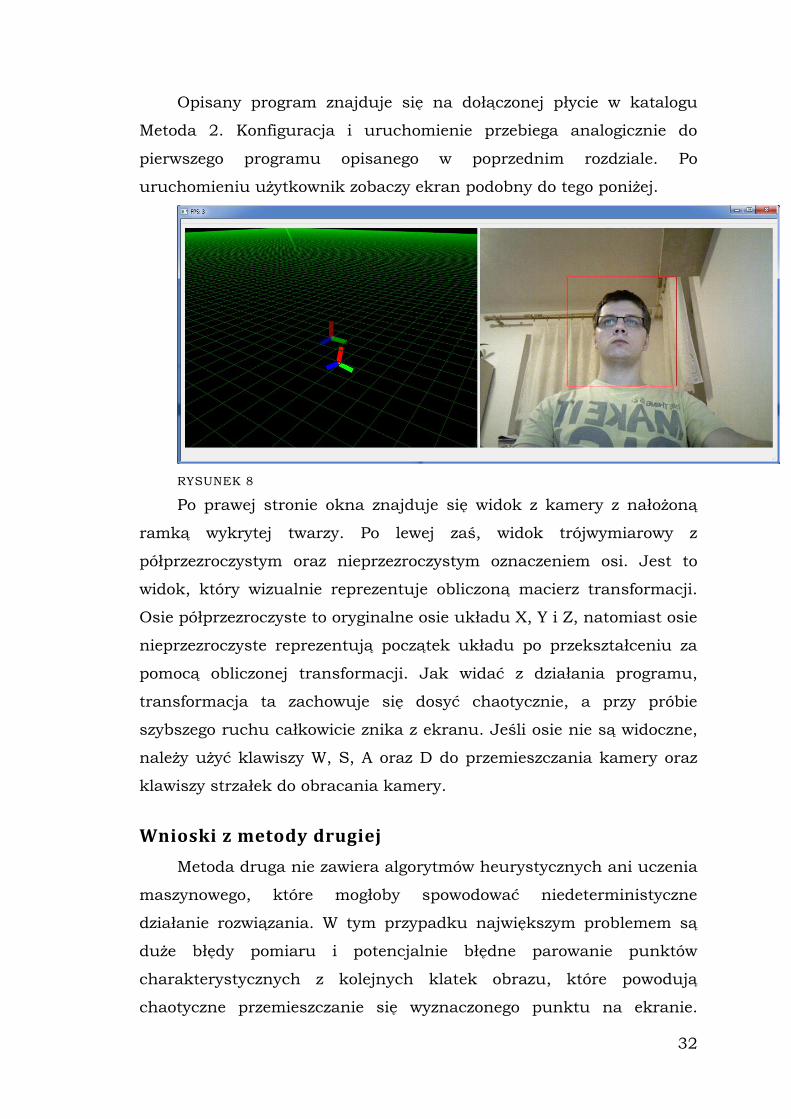
uruchomieniu użytkownik zobaczy ekran podobny do tego poniżej.
RYSUNEK 8
Po prawej stronie okna znajduje się widok z kamery z nałożoną
ramką wykrytej twarzy. Po lewej zaś, widok trójwymiarowy z
półprzezroczystym oraz nieprzezroczystym oznaczeniem osi. Jest to
widok, który wizualnie reprezentuje obliczoną macierz transformacji.
Osie półprzezroczyste to oryginalne osie układu X, Y i Z, natomiast osie
nieprzezroczyste reprezentują początek układu po przekształceniu za
pomocą obliczonej transformacji. Jak widać z działania programu,
transformacja ta zachowuje się dosyć chaotycznie, a przy próbie
szybszego ruchu całkowicie znika z ekranu. Jeśli osie nie są widoczne,
należy użyć klawiszy W, S, A oraz D do przemieszczania kamery oraz
klawiszy strzałek do obracania kamery.
Wnioski z metody drugiej
Metoda druga nie zawiera algorytmów heurystycznych ani uczenia
maszynowego, które mogłoby spowodować niedeterministyczne
działanie rozwiązania. W tym przypadku największym problemem są
duże błędy pomiaru i potencjalnie błędne parowanie punktów
charakterystycznych z kolejnych klatek obrazu, które powodują
chaotyczne przemieszczanie się wyznaczonego punktu na ekranie.

33
Kolejnym źródłem błędów są punkty charakterystyczne, które zmieściły
się w obszarze oznaczonym jako twarz, ale znajdują się np. na tle.
Rozwiązaniem tego typu problemów mogą być statystyczne metody
klasyfikacji punktów jako obserwacje odstające, np. RANSAC (ang.
RANdom SAmple Consensus). Ponadto, trudno jest poprawnie obsłużyć
sytuację, w której twarz użytkownika wychodzi poza obszar
widoczności kamery, a następnie znowu się pojawia. Resetowanie
wektora orientacji głowy w tej sytuacji może spowodować
rozkalibrowanie i stale wskazywać przesunięty punkt na ekranie.
Najlepszym sposobem obsługi takiego zdarzenia wydaje się być
ponowne kalibrowanie.

34
Metoda trzecia 7.
Trzeci projekt interfejsu komputera, który przygotowałem
wyróżnia się z dwóch pozostałych, ponieważ do obsługi komputera
wykorzystuje dłonie, a poza tym, jest próbą wykorzystania pakietu
narzędzi programistycznych dostarczonych przez producenta razem z
czujnikiem ruchu.
Opis
Co prawda, narzędzia dla programistów dostarczone z kamerą
mają bardzo wygodny interfejs programistyczny, ale w celu zachowania
spójności pracy, ten projekt również zrobiłem na bazie własnego
systemu przetwarzania obrazu. Wymagało to napisania nowego filtra,
który opakowuje funkcje bibliotek producenta. Filtr HandDetector
posiada jedno wyjście i jest to macierz punktów w przestrzeni
trójwymiarowej określających pozycję dłoni na scenie. Kolejność
punktów jest zachowywana między klatkami.
Implementacja filtru HandDetector polega na zdefiniowaniu i
zarejestrowaniu funkcji obsługi odpowiednich zdarzeń w API kamery.
Śledzenie dłoni rozpoczyna się po wykryciu gestu machania, ukrycie
dłoni na chwilę spowoduje przerwanie śledzenia. I tak, filtr
implementuje procedury obsługi następujących zdarzeń:
1. Wykrycie gestu machania – powoduje rozpoczęcie śledzenia.
2. Wykrycie nowej dłoni – powoduje dodanie deskryptora do
tablicy dłoni.
3. Aktualizacja położenia dłoni – powoduje zaktualizowanie
deskryptora w tablicy.
4. Zniknięcie dłoni – powoduje usunięcie deskryptora z tablicy.
Oczywiście, funkcja Process filtra bada stan tablicy deskryptorów
i ustala na wyjściu położenie śledzonych dłoni w przestrzeni
trójwymiarowej.
Na podstawie tego filtra zrobiłem program demonstracyjny
pozwalający na odbijanie piłki rękami, znajduje się na płycie z

35
materiałami. Najpierw należy pomachać do urządzenia, aby program
zaczął śledzić dłoń (za pierwszym razem może się nie udać). Gdy dłoń
zostanie wykryta, z góry spada piłka, którą można odbijać. Oczywiście,
jeśli w tym czasie pomachamy drugą dłonią, ona również zostanie
wykryta.
Diagram tego projektu jest bardzo prosty i nie ma potrzeby
przedstawiania go tutaj. Natomiast jako ciekawostkę, pozwolę sobie
wspomnieć, że prosta gra została zaimplementowana w postaci filtra
przetwarzania obrazu. Filtr Game przyjmuje na wejściu obraz RGB,
którego używa jako tło oraz macierz z punktami na obrazie, w których
znajdują się wykryte dłonie. Sam filtr Game nie tworzy żadnego widżetu,
do wyświetlania używa innego, standardowego filtra – ImageOutput.
Poniżej przedstawiam zrzut ekranu z aplikacji demonstrującej
metodę trzecią. Program ten znajduje się na płycie, w katalogu Metoda
3. Sposób uruchomienia jest analogiczny do dwóch poprzednich
programów. W katalogu Media znajduje się nagranie wideo
prezentujące działanie programu.
RYSUNEK 9

36
Wnioski z metody trzeciej
W tym wypadku nie było problemów z dokładnością działania, do
tego zastosowania oferowana dokładność jest wystarczająca, choć
czasami widoczne są „przeskoki” punktów, w których wykryto dłonie.
Do tej metody zastosowałem zestaw narzędzi dostarczonych przez
producenta kamery, nie ma zastrzeżeń co do ich działania, ale nie
dostarczają one wystarczającej dokładności pomiarów do zrealizowania
dwóch poprzednich metod, którymi się zajmowałem.

37
Plany rozwoju 8.
W przyszłości chciałbym rozwinąć system przetwarzania do
postaci narzędzia dostępnego dla osób nie potrafiących programować,
ponieważ w tym momencie system jest biblioteką statyczną, a nie
znalazłem narzędzia, które pozwoliłoby mi na przetestowanie kilku
metod bez potrzeby pisania kodu. W tym celu chciałbym stworzyć
graficzny edytor diagramów przepływu danych i możliwość zapisywania
ich do plików. Ponadto, system wymaga stworzenia wielu filtrów, które
pomimo tego, że są podstawowe i często używane, nie zostały
zaimplementowane, ponieważ nie były potrzebne do moich projektów.
Kluczowym zagadnieniem jest zapewnienie kompatybilności z innymi
kamerami dostępnymi na rynku, a przede wszystkim ze standardowym
interfejsem obsługi kamery internetowej. Bardzo pożądana jest również
opcja nagrywania i odtwarzania plików audio-video na przykład do
testowania rozwiązań.
Najsłabszym ogniwem pierwszego rozwiązania jest sieć
neuronowa, dlatego w przyszłości chciałbym ją lepiej zaprojektować
oraz zdobyć więcej próbek, co pozwoliłoby na nauczenie sieci
wyznaczania kierunku wzroku użytkownika.
Co do drugiego rozwiązania, problem stanowią fałszywe punkty
charakterystyczne oraz zbyt mała dokładność wyznaczania
przekształceń. Dlatego też chciałbym zaimplementować jeden z
algorytmów statystycznych służący do eliminowania obserwacji
odstających od modelu, np. RANSAC. Myślę, że ten krok znacząco
poprawi dokładność obliczeń.
Problemem, który dotyka obu powyższych rozwiązań jest trudność
w ręcznym określeniu dokładnych relacji przestrzennych kamera-
monitor. Chciałbym opracować możliwie łatwą i dokładną metodę na
wyznaczanie tych relacji (macierzy transformacji z jednego układu
współrzędnych do drugiego). Możliwe, że udałoby się to osiągnąć dzięki
samemu czujnikowi głębi, który mógłby w jakiś sposób identyfikować

38
monitor, a następnie analizować zmiany zachodzące na scenie podczas
przenoszenia urządzenia w inne miejsce.

39
Podsumowanie 9.
Nie udało mi się zrealizować pierwotnie postawionego celu, ale
opracowałem trzy metody, których dokładność nie jest zadowalająca,
ale po poznaniu ich mocnych i słabych stron stwierdzam, że są one
dobrą bazą do rozwoju i dalszych badań w tym temacie, na przykład w
ramach pracowni dyplomowej magisterskiej.
Ponadto zapoznałem się z możliwościami urządzenia, którym
dysponowałem podczas tworzenia pracy oraz z oprogramowaniem
dostarczonym z czujnikiem ruchu i na tej podstawie przygotowałem
program demonstracyjny korzystający z tego oprogramowania, będący
implementacją pewnego interfejsu komputera dla prostej gry
zręcznościowej bazującą na wykrywaniu dłoni.
Bardzo pomocnym i wygodnym narzędziem okazał się stworzony
przeze mnie w ramach tej pracy system przetwarzania obrazu, który
również warto rozwijać podczas dalszych badań tematu.

40
Bibliografia 10.
1. Gartner, Inc. Gartner, Inc. Gartner. [Online] 23 6 2008.
http://www.gartner.com/newsroom/id/703807.
2. Tobii Technology. An introduction to eye tracking and Tobii Eye
Trackers. 27 1 2010.
3. ASUSTeK Computer Inc. ASUS Xtion Pro Live. [Online]
http://pl.asus.com/Multimedia/Motion_Sensor/Xtion_PRO_LIVE/#sp
ecifications.
4. Szeliski Richard. Computer Vision: Algorithms and
Applications. brak miejsca : Springer, 2010.
5. Tadeusiewicz Ryszard. Sieci neuronowe. Warszawa :
Akademicka Oficyna Wydaw. RM, 1993.
6. Khvedchenia Ievgen. Comparison of the OpenCV's feature
detection algorithms. Computer Vision Talks. [Online] 11 1 2011.
http://computer-vision-talks.com/2011/01/comparison-of-the-
opencvs-feature-detection-algorithms-2/.
7. SURF: Speeded Up Robust Features. Bay Herbert, Tuytelaars
Tinne i Van Gool Luc. Graz, Austria : Springer Berlin Heidelberg,
2006.
8. Ho Nghia. Finding optimal rotation and translation between
corresponding 3D points. Nghia Ho. [Online] 09 2011.
http://nghiaho.com/?page_id=671.

41
Dodatek A. Zawartość płyty DVD .
Poniżej przedstawiam hierarchię katalogów i plików utworzoną na
dołączonej płycie DVD.
Media
o konfiguracja_projektow.wmv – wideo prezentujące
ustawienia projektu.
o metoda_1_uczenie_sieci.jpg – zrzut ekranu z
programu do uczenia sieci na podstawie próbek.
o metoda_1_zbieranie_probek.mp4 – nagranie procesu
tworzenia próbek do metody pierwszej.
o metoda_1_zbieranie_probek_ekran.wmv –
przechwycenie obrazu monitora z procesu tworzenia
próbek do metody pierwszej.
o metoda_2.wmv – prezentacja programu opartego na
metodzie drugiej.
o metoda_3.wmv – prezentacja programu opartego na
metodzie trzeciej.
Metoda 1
o Projekt MS Visual Studio 2010 z programem 1
Metoda 2
o Projekt MS Visual Studio 2010 z programem 2
Metoda 3
o Projekt MS Visual Studio 2010 z programem 3
Potrzebne biblioteki
o Accord.NET Framework-2.7.1.exe – biblioteka do
przetwarzania obrazu, obliczeń statystycznych,
uczenia maszynowego, wykorzystana w programie
NetsTest do uczenia sieci neuronowej.
o cudatoolkit_4.2.9_win_32.msi – narzędzia firmy
NVidia do tworzenia programów używających
technologii CUDA, instalacja opcjonalna.

42
o OpenCV-2.4.3.exe – biblioteka do przetwarzania
obrazu, baza dla mojego systemu przetwarzania.
o qt-win-opensource-4.8.4-vs2010.exe – platforma
programistyczna dla programów o interfejsie
graficznym, bardzo bogaty zestaw bibliotek.
System przetwarzania
o Projekt MS Visual Studio 2010 z systemem
przetwarzania, tworzy bibliotekę statyczną, którą
podłączamy w poprzednich programach.
Uczenie sieci
o Projekt MS Visual Studio 2010 w języku C# z
programem do uczenia sieci neuronowej na podstawie
próbek i danych z programu „Metoda 1”.
Praca dyplomowa.pdf – tekst pracy dyplomowej.












![Praca dyplomowa - Zespół Przetwarzania Sygnałów [DSP AGH]dydaktyka:wersja_demonstracyjna... · Zaświadczam także, że niniejsza inżynierska praca dyplomowa nie była wcześniej](https://static.fdocuments.pl/doc/165x107/5c78f93a09d3f2c9458bba5a/praca-dyplomowa-zespol-przetwarzania-sygnalow-dsp-agh-dydaktykawersjademonstracyjna.jpg)





