
PRACA DOKTORSKA - IITiSmkubanek/zal/praca.pdf · Praca Petajana wywołała spore poruszenie i...
170
POLITECHNIKA CZĘSTOCHOWSKA Wydział Inżynierii Mechanicznej i Informatyki Instytut Informatyki Teoretycznej i Stosowanej Mgr inż. Mariusz KUBANEK METODA ROZPOZNAWANIA AUDIO-WIDEO MOWY POLSKIEJ W OPARCIU O UKRYTE MODELE MARKOWA PRACA DOKTORSKA Promotor Prof. dr hab. inż. Leonid Kompanets Częstochowa, 2005
Transcript of PRACA DOKTORSKA - IITiSmkubanek/zal/praca.pdf · Praca Petajana wywołała spore poruszenie i...

POLITECHNIKA CZĘSTOCHOWSKA Wydział Inżynierii Mechanicznej i Informatyki Instytut Informatyki Teoretycznej i Stosowanej
Mgr inż. Mariusz KUBANEK
METODA ROZPOZNAWANIA AUDIO-WIDEO MOWY POLSKIEJ W OPARCIU O UKRYTE MODELE MARKOWA
PRACA DOKTORSKA
Promotor Prof. dr hab. inż. Leonid Kompanets
Częstochowa, 2005

2
SPIS TREŚCI
1. FORMUŁOWANIE PROBLEMU ROZPOZNAWANIA AUDIO-WIDEO MOWY POLSKIEJ........................................................................................................................... 4
1.1. Specyficzne cechy audio-wideo mowy jako obiekt do rozpoznawania ........................... 4
1.2. Przegląd analityczny metod rozpoznawania audio-wideo mowy ...................................... 7
1.3. Cel i teza pracy, bronione rozwiązania naukowe.................................................................. 21
2. SZKIC METODY AV_Mowa_PL..................................................................................... 23
2.1. Wymagania funkcjonalne do opracowania metody AV_Mowa_PL ................................ 23
2.2. Specyfika podstawowych informacyjnych procedur metody............................................ 24
2.3. Proponowane sposoby fuzji charakterystyk audio-wideo sygnałów............................... 30
3. TWORZENIE WEKTORÓW OBSERWACJI SYGNAŁU AUDIO MOWY................. 34
3.1. Zasady tworzenia wektorów obserwacji sygnału mowy..................................................... 34
3.2. Proponowane metody ES i CZS do definiowania słów izolowanych.............................. 40
3.3. Specyfika kodowania sygnału mowy w postaci cepstrum ................................................. 47
3.4. Kwantyzacja wektorowa cepstrum za pomocą algorytmu Lloyda................................... 55
4. OSOBLIWOŚCI STOSOWANIA UKRYTYCH MODELI MARKOWA W METODZIE
AV_Mowa_PL ................................................................................................................... 63
4.1. Wybór struktury i parametrów ukrytych modeli Markowa dla rozpoznawania audio-
wideo mowy polskiej .................................................................................................................... 63
4.2. Algorytm Viterbiego do inicjowania wstępnych parametrów modeli ............................ 72
4.3. Algorytm Bauma-Welcha do reestymacji parametrów modeli......................................... 76
4.4. Specyfika estymacji parametrów ukrytych modeli Markowa ........................................... 80
5. TWORZENIE WEKTORÓW OBSERWACJI SYGNAŁU AUDIO-WIDEO MOWY
POLSKIEJ......................................................................................................................... 87
5.1. Opracowanie metody detekcji twarzy na podstawie koloru skóry................................... 87
5.2. Metoda lokalizacji oczu do wyznaczenia obszaru ust ......................................................... 93
5.3. Proponowana metoda CSM wykrywania krawędzi ust z obrazu wideo ......................... 97

3
6. OPRACOWANIE SYSTEMU AVM_PL DO REALIZACJI METODY AV_Mowa_PL ................................................................................................................ 108
6.1. Struktura i charakterystyki techniczne systemu .................................................................. 108
6.2. Ekstrakcja charakterystyk sygnałów audio-wideo mowy................................................. 119
6.3. Fuzja charakterystyk audio-wideo mowy.............................................................................. 131
6.4. Budowa i nauczanie parametryczne ukrytych modeli Markowa.................................... 134
7. BADANIE POZIOMU BŁĘDÓW METODY AV_Mowa_PL ZA POMOCĄ SYSTEMU
AVM_PL .......................................................................................................................... 140
7.1. Charakterystyka stworzonej bazy audio-wideo komend .................................................. 140
7.2. Obiekty, cele i metodyki eksperymentów ............................................................................. 143
7.3. Analiza wyników eksperymentu.............................................................................................. 152
WNIOSKI KOŃCOWE ......................................................................................................... 156
WYKAZ DEFINICJI I SKRÓTÓW ...................................................................................... 158
SUMMARY ........................................................................................................................... 161
LITERATURA....................................................................................................................... 162

4
1. FORMUŁOWANIE PROBLEMU ROZPOZNAWANIA AUDIO-WIDEO MOWY POLSKIEJ
Sformułowano problem rozpoznawania audio-wideo mowy. Zaprezentowano podstawowe
cechy audio-wideo mowy polskiej. Przedstawiono przegląd analityczny istniejących metod
rozpoznawania audio-wideo mowy, wraz z porównaniem najbardziej popularnych w
literaturze metod trekingu ust oraz rozpoznawania audio-wideo mowy izolowanej i ciągłej.
Postawiono cel i tezę pracy oraz bronione rozwiązania naukowe.
1.1. Specyficzne cechy audio-wideo mowy jako obiekt do rozpoznawania
Rozpoznawanie audio mowy ma zastosowanie w wielu dziedzinach. Jednak w rzeczywistym
otoczeniu funkcjonowania systemów rozpoznawania audio mowy nie można zapewnić
warunków pracy uważanych w przybliżeniu za idealne, czyli takie, które nie powodują
jakiegokolwiek negatywnego wpływu na skuteczność rozpoznawania. Takie rzeczywiste
otoczenie to na przykład.: biuro, samochód, fabryka, gdzie zakłócający sygnał audio jest
bardzo intensywny i zróżnicowany.
Zakłócenia mowy można podzielić na hałas otaczającego środowiska, echo
spowodowane specyficznym otoczeniem, zmieniony sposób mówienia, a także echo, szumy i
zniekształcenia spowodowane przez niepoprawnie funkcjonujący mikrofon. Hałas
otaczającego środowiska może być ciągły (odgłos wentylatorów i silników), lub też
pojawiający się z przerwami (przejeżdżanie samochodów, dzwonienie telefonów, zakłócająca
mowa). Echo spowodowane specyficznym otoczeniem często pojawia się w pomieszczeniach,
w których występują wnęki oraz inne czynniki wywołujące pogłos. Zmieniony sposób
mówienia powodują czynniki związane ze stanem zdrowia mówcy (przeziębienie), a także
różne stany emocjonalne (stres, śmiech) i różnorodny sposób wypowiadania (wolno, szybko,
cicho, głośno). Zakłócenia wprowadzane przez zastosowane mikrofony uzależnione są od
różnorodności charakterystyk filtrów, czy też graniczne częstotliwości pasma przejścia
zmieniające sygnał mowy.
Percepcja ludzkiej mowy jest z natury wielo-modalnym procesem, w którym
wykorzystuje się analizę sygnału akustycznego, polegającą na analizie gramatycznej,
semantycznej i pragmatycznej. Dodatkowo wiadomo, że człowiek posiada zdolność czytania
mowy poprzez analizę ruchu ust mówcy, czyli tzw. zdolność czytania z ruchu warg. Do tej

5
pory wiele badań prowadzono na temat automatycznego rozpoznawania mowy (ang.
Automatic Speech Recognition, ASR). Obecnie główne wysiłki skierowane są na tworzenie
systemów odpornych na negatywnie wpływające czynniki zewnętrzne. Zaczęto poszukiwać
sposobów ograniczenia wpływu zakłócenia na właściwą pracę systemów. Jednym z takich
sposobów może być zastosowanie w niniejszej pracy dołączenia do rozpoznawanej audio
mowy, mowy wideo, będącej elementem ograniczającym wpływ negatywnych czynników
zewnętrznych na skuteczność rozpoznawania. Z uwagi na możliwość kojarzenia mowy na
podstawie ruchu warg zaproponowano połączenie informacji audio i wideo w podjęciu
decyzji o treściowym wyniku wypowiedzi, specjalnie w zakłóconym środowisku audio
mowy.
Zastosowanie rozpoznawania audio mowy w zakłóconym otoczeniu prowadzi często
do błędnych wyników, spowodowanych nieprawidłową interpretacją fonemów o bliskim
brzmieniu. Wideo mowa również może być błędnie interpretowana, co wyjaśnia przykład
nazwany efektem McGurk, gdzie wypowiedziany w języku angielskim fonem /ga/, w wideo
mowie przypomina fonem /ba/ [84], a wiele osób rozpoznaje w wypowiedzi fonem /da/
[84,98]. Wideo sygnał nie niesie wystarczającej informacji, zawiera jednak kilka
uzupełniających informacji do audio sygnału [78,84]. Na przykład, używając wskazówek
wideo do podjęcia decyzji, czy osoba wypowiedziała fonem /ba/, czy /ga/, może być
łatwiejsze niż podjęcie decyzji bazując wyłącznie na wskazówkach audio, które mogą być
nieco zmieszane. Z drugiej strony, podjęcie właściwej decyzji rozpatrując fonemy /ka/ i /ga/
jest bardziej realne z audio, niż z wideo sygnału. Dla przykładu w języku polskim, używając
wskazówek wideo do podjęcia decyzji, czy osoba wypowiedziała fonem /m/, czy /n/, może
być łatwiejsze niż podjęcie decyzji bazując wyłącznie na wskazówkach audio, jednakże
podjęcie właściwej decyzji rozpatrując fonemy /m/ i /p/ jest bardziej realne z audio, niż z
wideo sygnału.
Powyższe fakty wywarły duży wpływ na sfery rozpoznawania audio-wideo mowy
(ang. Audio-Visual Speech Recognition, AVSR), znane również jako automatyczne czytanie z
ruchu warg (ang. Autamatic Lip-Reading, ALR), czytanie mowy (ang. Speech Reading, SR)
[16,84]. Prace w tej dziedzinie prowadzone są w celu polepszenia zakresu rozpoznawania
automatycznej mowy poprzez ekstrakcję cech z obszaru ust mówcy i połączenie z tradycyjną
mową akustyczną. Takie osiągnięcie zysku jest szczególnie imponujące w hałaśliwym
środowisku, gdzie tradycyjna metoda rozpoznawania audio mowy wypada niezbyt korzystnie.
Zmniejszające się koszty uzyskania wysokiej jakości systemów nagrywających sekwencje
wideo oraz zwiększająca się moc obliczeniowa komputerów pozwalają przypuszczać, iż

6
zintegrowane systemy rozpoznawania audio wideo mowy mogą byś powszechnie stosowane,
mimo ogromnej ilości danych wideo przetwarzanych w czasie pracy takiego systemu [16,84].
Przy rozpoznawaniu audio-wideo mowy należy rozwiązać cztery podstawowe
zagadnienia:
• identyfikacji i ekstrakcji określonych charakterystyk audio,
• identyfikacji i ekstrakcji określonych charakterystyk wideo,
• racjonalnej integracji (fuzji) i synchronizacji audio-wideo sygnałów,
• wyboru i realizacji aparatu realizującego uczenie i rozpoznawanie sygnałów mowy.
W pracy zaproponowano metodę AV_Mowa_PL do rozpoznawanie słów izolowanych
audio-wideo mowy polskiej w oparciu o ukryte modele Markowa (UMM), polegające na
wykorzystaniu informacji dźwiękowych i wizyjnych. Metodę opracowano dla mowy polskiej,
gdyż jak do tej pory nie napotkano na specyficzne badania dotyczące mowy polskiej. Przy
ekstrakcji cech audio zastosowano analizę cepstralną mowy. Wykorzystano bank filtrów o
charakterystykach amplitudowo-częstotliwościowych zbliżonych do charakterystyk
przeciętnego ludzkiego ucha. Opracowano kilka rozwiązań mających uodpornić metodę na
negatywny wpływ zewnętrznych zakłóceń. Przy ekstrakcji cech wideo zastosowano szereg
metod niezbędnych do osiągnięcia potrzebnego poziomu funkcjonowania procedury trekingu
ust w czasie rzeczywistym w sekwencji wideo. Dla wymienionego celu wykorzystano
charakterystyki kącików i zewnętrznych krawędzi ust oraz wyraźnie pojawiający się, bądź też
nie, język podczas wypowiadania poszczególnych fonemów. Zaproponowano trzy metody
fuzji charakterystyk sygnałów audio i wideo mowy.
Na Rys.1.1 zilustrowano ideę rozpoznawania audio-wideo mowy, zastosowaną w
opracowanej metodzie AV_Mowa_PL.
Rys.1.1 Ilustracja idei rozpoznawania audio-wideo mowy

7
1.2. Przegląd analityczny metod rozpoznawania audio-wideo mowy
Automatyczne rozpoznawanie audio-wideo mowy wywołało wśród naukowców nowe i
ambitne zadania porównania i rywalizacji z automatycznym rozpoznawaniem samej audio
mowy. Dodanie do charakterystyk audio mowy, charakterystyk wideo, wymaga wydobycia
potrzebnych informacji o mowie z nagrania wideo zawierającego frontalną twarz mówcy.
Wymaga dokładnej detekcji twarzy, lokalizacji, trekingu ust mówcy i estymacji wizualnych
parametrów. W porównaniu z samą audio mową, rozpoznawanie audio-wideo mowy zawiera
dwa osobne strumienie informacji, każdego z sygnałów. Połączenie tych strumieni powinno
zapewnić lepsze osiągi w porównaniu z nowoczesnymi osiągami przy wykorzystaniu każdego
ze źródeł osobno. Oba zagadnienia, mianowicie ekstrakcja charakterystyk wideo i fuzja
charakterystyk audio i wideo stanowią trudne problemy, generując wiele prac badawczych w
środowiskach naukowych świata.
Istotnie, zaczynając już od lat osiemdziesiątych, powstało wiele artykułów na temat
AVSR, z czego większość ukazała się podczas ostatniej dekady. Pierwszy automatyczny
system czytania mowy wprowadził Petajan [86]. Mając nagranie wideo twarzy mówcy oraz
stosując proste progowanie, był on w stanie wyznaczyć binarny obraz ust, a następnie
wysokość, szerokość, obwód i powierzchnię ust, będących wizualnymi charakterystykami
mowy. W kolejnym kroku rozpoznawanie wideo mowy, bazującej na dynamicznej
zmienności ust w czasie [92], dołączył do rozpoznawania audio mowy. Jego metoda znacznie
poprawiła osiągnięcia ASR dla pojedynczego użytkownika. Praca Petajana wywołała spore
poruszenie i wkrótce powstało wiele rozmaitych ośrodków badawczych, zajmujących się
zagadnieniem AVSR. Wśród przodujących ośrodków znalazła się ośrodek badawczy
kierowany przez Christiana Benoit’a, mieszczący się w Grenoble. Dla przykładu, panowie
Adjoudani i Benoit w pracy [2] przedstawili problem fuzji charakterystyk sygnałów audio i
wideo, polegający na strategii końcowego połączenia osobnych dla każdego z sygnałów
wyników. Innym razem rozpatrywali niezawodność estymacji, bazując na rozproszonych
prawdopodobieństwach czterech najlepszych wypowiedzi audio mowy oraz wideo mowy.
Zaprezentowali opis zysku, jaki uzyskali dzięki zastosowaniu AVSR dla zbioru 54 różnych
komend, wypowiedzianych przez pojedynczego użytkownika w języku francuskim. Później
stworzyli multimedialną platformę dla procesu audio-wideo mowy, zawierającą kamerę
zamontowaną na głowie użytkownika, dla poprawienia dokładności wyznaczania regionu ust
użytkownika [1]. Ostatnio, prace naukowców ośrodka badawczego z Grenoble prowadzono
dla zagadnienia AVSR, wykorzystując bazę wypowiedzi komend w języku francuskim i

8
wypowiedzi liczb w języku angielskim, a także nowy system rozpoznawania audio-wideo
mowy opisany w pracy [50].
Systemy AVSR rozróżniają trzy główne aspekty [51]: ekstrakcja charakterystyk wideo
mowy, fuzja charakterystyk audio i wideo mowy, zastosowanie metody do rozpoznawania
mowy. Niestety różnorodne algorytmy zaproponowane w literaturze dla automatycznego
czytania mowy są bardzo trudne do porównania, ponieważ najczęściej są testowane na
własnych bazach wypowiedzi audio-wideo. Na dodatek, badania skuteczności AVSR
prowadzono z wykorzystaniem baz danych, zawierających krótkie wypowiedzi i w wielu
przypadkach dla bardzo małej liczby mówców oraz dla niewielkiej liczby wszystkich
wypowiedzi [19,20,51]. Takie typowe zadania to: pozbawione sensu słowa [2,102], słowa
izolowane [13,37,49,53,80,81,83,86], połączone litery [89], połączone cyfry [88,117], zdania
ograniczone do słownika [44], lub mowa ciągła ograniczona do niewielkiego słownika [22].
Bazy danych nagrywane są zwykle w języku angielskim, ale zdarzają się przykłady tworzenia
baz danych dla innych języków, jak np. dla języka francuskiego [2,3,4,37,106], języka
niemieckiego [11,67], języka japońskiego [82] oraz języka węgierskiego [29]. Jednakże,
skoro metody wykorzystujące rozpoznawanie mowy mają być wprowadzane do pracy w
rzeczywistym świecie, praca badawcza powinna być prowadzona na słownikach o
uniwersalnym przeznaczeniu. Pierwszą próbę w kierunku stworzenia rzeczywistego systemu
rozpoznawania audio-wideo mowy opisano w pracy [84], gdzie system niezależny od
użytkownika zastosowano do słownika (ang. Large Vocabulary Continuous Speech
Recognition, LVCSR), zawierającego nagrania wypowiedzi wielu użytkowników i na
różnorodne tematy, uzyskane w rzeczywistych warunkach pracy systemu. Zaprezentowano
znaczący zysk rozpoznawania audio-wideo mowy w porównaniu z rozpoznawaniem samej
audio mowy, dla zakłóconego środowiska audio, co potwierdziło założenia, że rozpoznawanie
audio-wideo mowy może być przydatne dla zadań rozpoznawania mowy z zakłóconym
sygnałem audio. Zaczęto prowadzić prace nad polepszaniem metod ekstrakcji charakterystyk
wideo mowy oraz fuzji charakterystyk sygnałów audio i wideo, prowadzącym do
uniwersalności systemów w rzeczywistym świecie.
Ekstrakcja charakterystyk wideo mowy
Jak już wcześniej wspomniano, największą trudnością w zagadnieniach AVSR jest ekstrakcja
wymaganych charakterystyk z sygnału wideo. Problem złożony jest z dwóch zasadniczych
kwestii: trekingu obrazu twarzy i ust oraz reprezentacji wideo mowy przy pomocy jak
najmniejszej liczby informacyjnych parametrów. Do rozwiązania tego problemu zastosowano

9
kilka metod, np.: treking ust uwzględniający ich wysokość i szerokość [2,13,89], czy też
parametryczny model ust [16,30,73]. Jednak tylko dokładna detekcja regionu ust jest
wystarczająca do uzyskania wszystkich wizualnych charakterystyk. Takie podejście pozwala
na sporą redukcję parametrów, poprzez odpowiednią transformację pikseli określających
region ust [10,36,80,90]. Zbyteczny dla głosu dokładnie wyznaczony region ust ma
największe znaczenie, wpływające na dobre osiągnięcia systemów SR [54].
Detekcja twarzy
Problem detekcji twarzy oraz detekcji specyficznych części twarzy zajmuje ważne i obszerne
miejsce w pozycjach literaturowych na świecie [48,70,95,97,103]. W połączeniu z systemami
SR, ma zastosowanie do takich zagadnień, jak: wizualne czytanie tekstu [18,24,28],
identyfikacja i weryfikacja osób [19,40,57,58,75,110,116], lokalizacja mówcy [12,109,118],
detekcja źródła mowy [31], poprawa i odzyskiwanie obrazu [104] oraz inne. Skuteczność
detekcji twarzy i ust jest zadaniem dość trudnym, szczególnie w sytuacjach zmienności tła,
pozycji twarzy oraz oświetlenia [55].
W literaturze dotyczącej AVSR, gdzie zagadnienia, takie jak ekstrakcja wideo
charakterystyk, lub algorytmy fuzji sygnałów audio-wideo, są typowymi dla badaczy
zadaniami, detekcja twarzy i ust jest często ignorowana, bądź też znaczenie uproszczona. Dla
przykładu, w niektórych bazach użytkownicy mają założone specjalnie oznakowane
charakterystycznymi punktami okulary, w innych usta mówców są odpowiednio
pomalowane, co prowadzi do trywialności w procesie trekingu ust [2,50]. W innych pracach,
gdzie sygnały audio i wideo mowy są podzielone (przykładowo bazy Tulips1, (X)M2VTS,
AMP/CMU), strefa ust wyznaczona jest od razu, w badaniach pominięty zostaje etap
lokalizacji strefy ust. Na dodatek, praktycznie we wszystkich bazach występują nagrania z
niezmienną pozycją twarzy mówców oraz z niezmiennym oświetleniem.
Generalnie, wszystkie systemy AVSR wymagają wyznaczenia strefy ust, dla
poprawnego funkcjonowania zastosowanych do ekstrakcji cech algorytmów. Istnieje wiele
metod wyznaczania strefy ust, bazujących na tradycyjnych technikach analizy obrazu, takich
jak segmentacja na podstawie koloru skóry, detekcja krawędzi, progowanie obrazu,
dopasowanie do szablonu lub informacja o ruchu [48], oraz bazujących na statystycznych
technikach modelowania i zagadnieniach sztucznej inteligencji, jak nm. zastosowanie sieci
neuronowych.
Typowy algorytm detekcji twarzy i lokalizacji części twarzy opisano w pracy [97]. W
algorytmie zastosowano technikę dopasowywania do szablonu. Taką technikę zastosowano w

10
pracach [84, 87] do ekstrakcji parametrów wideo mowy. Dla danej ramki wideo, na początku
wykonywana jest detekcja twarzy, poprzez zastosowanie połączonych metod, z których kilka
używanych jest później do określenia wymaganych charakterystyk twarzy. Na początku
określany jest rozmiar prostokątnego (m x n) modelu twarzy. Następnie poszukiwany jest
model twarzy, najbardziej pasujący do obszaru, wydzielonego z danej ramki wideo, spośród
wszystkich ułożonych w piramidę modeli, określonych przez dopuszczalne położenie i skalę.
W pracy [87] przyjęto, że modele twarzy powinny zawierać się pomiędzy 10 % a 75 %
szerokości ramki wideo. Przed porównaniem z kolejnymi modelami piramidy, badany obszar
jest proporcjonalnie zwiększany o 15 %. Opisana metoda wprowadza opóźnienia
spowodowane koniecznością przeszukiwania i porównywania z modelami.
W przypadku, gdy sygnał wideo jest sygnałem kolorowym, na podstawie segmentacji
można szybko i dokładnie określić obszar ramki wideo, przypominający kolorem w dużym
stopniu barwę ludzkiej skóry. Znormalizowane wartości RGB każdego z pikseli,
przetransformowane zostają na początku do przestrzeni HSV. W takiej przestrzeni kolor
skóry różnych ludzi i dla zmiennych warunków oświetlenia, podlega najmniejszym zmianom
[48,97]. W dokładnej implementacji wymagane jest, aby poszukiwany obszar twarzy zawierał
minimum 25 % pikseli, o zabarwieniu zbliżonym do koloru skóry, spośród wszystkich pikseli
danej ramki wideo. W ten sposób redukowana zostaje liczba porównywanych modeli (w
zależności oczywiście od tła ramki wideo), co prowadzi do znacznego przyspieszenia
obliczeń i redukcji fałszywych obszarów. Badany obszar ramki zostaje pomniejszony do
rozmiaru modelu i każdy z pikseli jest dodawany do wektora twarzy o długości m x n. Wektor
twarzy przydzielony jest do jednej z dwóch klas: twarzy i nie-twarzy. Dla wektorów twarzy
obliczana jest odległość (ang. Distance From Face Space, DFFS). Najbardziej zbliżony
obszar ramki, przedstawiony w postaci wektora, jest wynikiem algorytmu detekcji twarzy
[97].
Detekcja regionu krawędzi ust
Dla wyznaczonej już twarzy zastosowano zespół detektorów do zlokalizowania punktów
charakterystycznych twarzy. Położenie każdego z punktów charakterystycznych twarzy
określane jest przez wynik kombinacji statystycznego, początkowego położenia, liniowego
oszacowania i DFFS, bazując na zadanym rozmiarze punktów charakterystycznych modelu.
W celu określenia centrum ust, zastosowano cztery punkty charakterystyczne, wyznaczające
kąciki ust oraz położenie górnej i dolnej wargi, przyjmując wyznaczone centrum dla

11
wszystkich ramek wypowiedzi wideo. Centrum to określa region ust, który może zawierać
wyłącznie same usta, lub też może być zakłócony przez inne części twarzy [87].
Po wyznaczeniu regionu ust, kolejnym etapem jest zlokalizowanie konturów ust.
Istnieje kilka popularnych metod, m.in.: aktywnych konturów [60], szablonów [100,115],
aktywnych modeli kształtu i wyglądu [25,27]. W metodzie aktywnych konturów występuje
elastyczna krzywa, reprezentowana przez zadaną liczbę kontrolnych punktów. Położenie
kontrolnych punktów jest modyfikowane iteracyjnie, poprzez zbieżność w kierunku lokalnego
minimum energii funkcji, zdefiniowanej na bazie krzywej gładkości ograniczeń i
dopasowanego kryterium do wymaganych charakterystyk obrazu wideo [60]. Taki algorytm
zastosowano do estymacji konturów ust w systemie SR, opisanym w pracy [21].Inną znacznie
częściej używaną techniką trekingu ust jest metoda szablonów, zastosowana przykładowo w
systemie Chandramohana i Silsbee [15]. Szablony tworzą sparametryzowane krzywe w ten
sposób, że są one dopasowywane do wymaganego kształtu poprzez minimalizowanie energii
funkcji, zdefiniowanej tak samo, jak w metodzie aktywnych konturów. Metoda aktywnych
modeli kształtu i wyglądu bazuje na kształcie ust lub statystycznym modelu wyglądu. Modele
mogą być stosowane do trekingu ust w sposób zaproponowany w pracy [26]. Założenie jest
takie, że dla niewielkiego poruszenia w stosunku do aktualnego płożenia modelu do
wejściowego obrazu, istnieje liniowa relacja pomiędzy różnicą w projekcji modelu i
wejściowego obrazu oraz wymaganej modyfikacji parametrów modelu. Dla dopasowania
modelu do wejściowego obrazu zastosowano iteracyjny algorytm. Alternatywnie,
dopasowanie może być wykonane przez metodę simpleksowego spadku, tak jak w pracy [73].
W systemach SR zastosowano różne propozycje definiowania wideo charakterystyk.
Można je pogrupować w trzy zasadnicze kategorie: wyglądu ust; konturu lub kształtu ust;
połączenia wyglądu i kształtu [51].
Definiowanie wideo charakterystyk na podstawie wyglądu ust
Definiowanie wideo charakterystyk na podstawie wyglądu ust polega na rozpatrywaniu całej
części obrazu wideo, zawierającej region ust mówcy, który wnosi podstawowe informacje dla
czytania z ruchu warg. Taki region może być prostokątem, mieszczącym w sobie usta, ale
także spore części twarzy, np. szczęka i policzki [87], czy nawet całą twarz [79]. Czasami
może to być trójelementowy prostokąt, podzielony na przyległe prostokątne ramki podczas
próby wychwycenia dynamicznej informacji mowy, we wczesnej fazie przetwarzania [89].
Alternatywnie, region ust może odpowiadać liczbie pionowych profili konturu ust [37], lub
może być tylko okręgiem dookoła centrum ust [36]. Wektor charakterystyk jest otrzymywany

12
przez analizę pikseli monochromatycznego regionu ust [10,36,37,88], lub wartości
kolorowych [21]. Przykładowo, dla prostokątnego M x N regionu ust ze zlokalizowanym
centrum (mt, nt) ramki wideo Vt(m, n) w czasie t, wynikowy wektor charakterystyk o długości
d = MN, będzie wynosił:
{ }]2/[]2/[],2/[]2/[:),( NnnNnMmmMmnmVx tttttt +<≤−+<≤−← (1.1)
Powinien on zawierać jak najwięcej informacji wideo mowy. Typowy wymiar d wektora (1.1)
jest zbyt duży, aby uzyskać zadawalające statystycznie modelowanie mowy przez
zastosowanie modeli UMM [92]. Dlatego jako wizualne charakterystyki, stosuje się
odpowiednio przekształcone wartości pikseli regionu ust. W pracy [81] zastosowano filtrację
dolnoprzepustową poprzez odpowiednie próbkowanie obrazu i zróżnicowanie regionu ust,
natomiast w pracy [80] zaproponowano nieliniową dekompozycję obrazu poprzez „odsiew”.
Obie przytoczone metody zastosowano w celu redukcji wymiarowości i ekstrakcji
charakterystyk wideo. Jednak najlepsze osiągi dotyczące takiej redukcji uzyskano przez
zastosowanie tradycyjnych przekształceń obrazu [46], zapożyczonych z literatury dotyczącej
kompresji obrazu oczekując, że takie podejście zastosowane do czytania mowy, pozwoli na
zachowanie największej liczby znaczących informacji. Generalnie D x d wymiarowa macierz
liniowej transformacji P jest wyznaczana przez przekształcenie wektora danych yt = Pxt,
zawierającego najwięcej informacji spośród jego D << d elementów. Do uzyskania macierzy
P podawanych jest L uczących przykładów, oznaczanych przez xl, l = 1,…,L.
Najbardziej popularną metodą reprezentacji charakterystyk jest metoda PCA (ang.
Principal Components Analysis) znana także pod nazwą transformacji Karhunena-Loevea.
[10,11,21,36,37,70,73,88]. Metoda bazująca na tym przekształceniu pozwala na znaczną
redukcję rozmiarów przestrzeni cech, pozostawiając do identyfikacji obrazu tylko kilka,
mających znaczenie dla rozważanych klas obrazów danych [70]. PCA osiąga optymalną
kompresję informacji, w sensie minimalnego błędu kwadratowego pomiędzy oryginalnym
wektorem xt i rekonstruowanym na podstawie jego projekcji yt. Jednak zastosowanie
skalowania danych wprowadza problem w klasyfikacji wektora wynikowego [17]. W pracy
[88] przyjęto implementację PCA, w której dane skaluje się zgodnie z ich odwrotną wariancją
i wylicza się jej macierz korelacji R, poprzez złożenie AΛAT [91], gdzie A = [a1,…,ad] ma
jako kolumny wektory własne z R oraz Λ jest macierzą diagonalną zawierającą wartości
własne z R. Zakładając, że D największych takich wartości własnych jest umieszczonych na
j1,…,jD przekątnych pozycjach, macierz projekcji danych wynosi PPCA = [aj1,…,ajD]T. Dla
zadanego wektora xt, wektor charakterystyk wyznaczany jest jako yt = PPCAxt.

13
Alternatywą do metody PCA jest zastosowanie do wyznaczania charakterystyk wideo
mowy, metod DCT (ang. Discrete Cosine Transform) oraz DWT (ang. Discrete Wavelet
Transform). Przykładowo, DCT przyjęto w pracach [36,82,83,84,88], DWT w pracach
[87,89]. Wielu naukowców stosuje oddzielne przekształcenia [46], co pozwala na szybką
implementację [91], gdy parametry określające rozmiar ramki M i N przyjmują
wielokrotności potęgi liczby 2 (typowe rozpatrywane wartości to M, N = 16, 32, 64). Należy
zauważyć, że w każdym przypadku macierz P może mieć wiersze pochodzące od macierzy
transformacji obrazu o większej energii przekształconych danych niż dane uczące [88].
Innym stosowanym w procesie analizy wyglądu narzędziem jest LDA (ang. Linear
Discriminant Analysis), stosowane jako mapy charakterystyk w nowej przestrzeni, dla
poprawienia klasyfikacji. Metoda oparta o LDA redukuje rozmiar obrazu wejściowego
prowadząc w tym samym czasie także do lepszego grupowania obrazów w zredukowanej
przestrzeni cech [70]. LDA było pierwszy raz zaproponowane do SR w pracy [36],
zastosowane bezpośrednio do wektora (1.1). LDA również rozpatrywano kaskadowo, po
uprzedniej projekcji PCA pojedynczej ramki regionu ust oraz jako sprzężenie sąsiednich
wektorów projekcji PCA [79]. LDA zakłada, że zestaw klas C, takich jak stany UMM, został
wybrany a-priori oraz że zestaw wektorów danych uczących xl, l,…,L jest oznaczony jako
c(l)∈C. Następnie poszukiwana jest taka macierz PLDA, aby przykładowe próbki
uczące{PLDAxl, l,…,L} były dobrze separowane wewnątrz zadanych klas C, zgodnie z funkcją
próbek uczących wewnątrz rozproszonej klasy macierzy SW i pomiędzy rozproszoną klasą
macierzy SB [93]. Macierze te uzyskiwane są jako:
∑∑∈∈
−−=Σ=Cc
TccB
Cc
cW mmmmcSicS ))()(Pr(,)Pr( )()()( , (1.2)
gdzie: Pr(c) = Lc/L, c∈C, oznacza empiryczne prawdopodobieństwo funkcji masowej;
Lc = ΣLl-1 δc(l),c; δi,,j = 1, jeśli i = j, 0 w pozostałych przypadkach; m(c) i Σ(c) oznaczają
odpowiednio klasę uśrednionych próbek i kowariancję; m = Σc∈C Pr(c)m(c) jest całkowitą
średnią próbek. Wyznaczenie PLDA, czyli uogólnionych wartości własnych i stosownych
wektorów własnych pary macierzy (SB, SW), spełniających zależność SBF = SWFΛ, pierwszy
raz zastosowano w pracach [45,93]. Macierz F = [f1,…,fd] zawiera jako kolumny, uogólnione
wektory własne. Zakładając, że D największych takich wartości własnych jest umieszczonych
na j1,…,jD przekątnych pozycjach Λ, wówczas macierz wynosi PLDA = [fj1,…,fjD]T. Przyjmując
opisane założenia do zależności (1.2), należy zaznaczyć, że rząd macierzy SB nie może być
większy niż |C| - 1, gdzie |C| oznacza liczbę klas, stąd D ≤ |C| - 1. Na dodatek rząd d x d
wymiarowej macierzy SW nie może przekraczać L - |C|, dlatego mając niewystarczające dane

14
uczące, pojawia się potencjalny problem względem wymiaru d wejściowego wektora
charakterystyk.
W systemie SR zaprezentowanym w pracy [87] LDA połączono z MLLT (ang.
Maximum Likelihood Linear Transform). To przekształcenie poszukuje kwadratowej,
nieosobliwej macierzy rotacji danych PMLLT, która maksymalizuje prawdopodobieństwo
obserwacji danych w oryginalnej przestrzeni charakterystyk, przy założeniu diagonalnej
kowariancji danych w przekształcanej przestrzeni [47]. Taka rotacja danych jest korzystna,
odkąd w większości systemów ASR, diagonalne kowariancje są specjalnie przyjmowane,
podczas modelowania klas obserwacji warunkowego rozkładu prawdopodobieństwa z
mieszanymi gaussowskimi modelami. Macierz PMLLT otrzymywana jest z zależności [47]:
Σ= ∏∈
−
Cc
LTcL
PMLLT
c
PPdiagPP 2)( )))((det()det(maxarg (1.3)
Można to rozwiązać numerycznie, co pokazano w pracy [91]. Należy zaznaczyć, że LDA i
MLLT są przekształceniami danych, mającymi na celu poprawienie wydajności klasyfikacji
oraz maksymalizację prawdopodobieństwa modelowania danych.
Opisane metody popularniejsze zastosowanie znalazły w systemach rozpoznawania
obrazów, bo w rzeczywistości sprowadzają się do podobnej analizy obrazu ust każdej ramki z
sekwencji wideo. Wprowadzają zbyt duże utrudnienia w wychwyceniu najbardziej
informacyjnych cech sygnałów dynamicznej wideo mowy, których największe skupisko
zawierają krawędzie ust. Analiza wyglądu ust jest zbyt mało odporna na zmienności wyglądu,
powodując niepotrzebne zakłócenia.
Definiowanie wideo charakterystyk na podstawie kształtu ust
W zestawieniu z metodami bazującymi na charakterystykach wyglądu ust, metody bazujące
na ekstrakcji charakterystyk kształtu ust zakładają, że najwięcej informacji czytania mowy
zawartych jest w konturze ust mówcy [79], lub bardziej ogólnie, w konturze całej twarzy (tj.
oprócz ust bierze się pod uwagę szczękę, policzki, itd.). Dwa typy charakterystyk wchodzą w
skład opisywanej kategorii: typ geometryczny oraz model kształtu bazowych charakterystyk.
W obu przypadkach wymagany jest algorytm do lokalizacji wewnętrznej lub zewnętrznej
krawędzi ust oraz w przypadku całej twarzy, do lokalizacji punktów charakterystycznych
kształtu twarzy.
Jednym z takich algorytmów jest algorytm do ekstrakcji geometrycznych
charakterystyk. Mając kontur ust, określony przez wystarczającą i sensowną liczbę punktów

15
charakterystycznych, w łatwy sposób można wyznaczyć takie elementy jak wysokość,
szerokość, obwód i pole ust, zawierające znaczącą informację o wideo mowie. Nie
przypadkowo tak duża liczba systemów SR pracuje, używając wszystkich lub poszczególnych
elementów ust [2,3,4,13,44,49,50,53,58,86,106,117]. Z konturu ust mogą być uzyskane
dodatkowe wizualne charakterystyki, takie jak momenty obrazu ust, czy też Fourierowskie
deskryptory konturu ust, niezmienne podczas drobnych przekształceń obrazu. Istotnie, liczba
centralnych momentów wewnętrznego konturu binarnego obrazu, lub znormalizowanych
momentów, jak to zdefiniowano w pracy [34], może być rozpatrywana jako wizualne
charakterystyki [29]. Znormalizowany szereg Fourierowskich współczynników
parametryzacji konturu [34], może również być używany do uwydatnienia wspomnianych
wcześniej geometrycznych charakterystyk w niektórych systemach SR, w celu polepszenia
automatycznego czytania mowy [49,88].
Innym algorytmem do lokalizacji krawędzi ust jest algorytm charakterystyk modelu
ust. W pracy [6] opisano kilka parametrycznych modeli użytych do trekingu kształtu twarzy i
ust. Parametry tych modeli mogą być z łatwością użyte jako wizualne charakterystyki.
Przykładowo w pracy [21] zastosowano do estymacji konturu ust, algorytm bazujący na
elastycznej krzywej, używając jako wizualne charakterystyki, wektory zawierające punkty
charakterystyczne, opisujące te krzywe. W pracy [102], jak również w pracy [15] użyto
wzorzec parametrów ust.
Popularnym modelem ust jest ASM (ang. Active Shape Model). ASM jest elastycznym
modelem statystycznym, który reprezentuje dany obiekt przez zestaw określonych punktów
[27,73]. Takim obiektem może być wewnętrzny lub zewnętrzny kontur ust [72], lub
połączenie różnych konturów twarzy, jak w pracy [79]. Do wyznaczania ASM, na początku
oznaczane jest K punktów określających kontur ust w zadanych obrazach uczących, a
następnie współrzędne punktów umieszczane są w 2K wymiarowym wektorze: T
KKS yxyxyxx ],,...,,,,[ 2211
)( = . (1.4)
Mając dany zestaw wektorów (1.4) można użyć PCA do wyznaczenia optymalnego,
ortogonalnego liniowego przekształcenia P(S)PCA, co daje statystyczny model ust lub twarzy.
W celu wyznaczenia osi pierwotnej wariacji kształtu, każdy zestaw uczący musi być
wyrównany poprzez transformacje takie jak: przesunięcie, obrót i skalowanie [27,35]. Dla
zlokalizowanego konturu ust, charakterystyki wizualne wyznacza się z y(S) = P(S)PCA x(S).
Należy zauważyć, że wektory (1.4) mogą być uzyskane z algorytmu trekingu bazującego na
B-splajnach jak w [30].

16
Opisane metody bazujące na kształcie ust i twarzy mówcy, wykorzystuje się w
połączeniu z metodami porównywania z wzorcem. Wprowadza to konieczność ciągłego
skalowania i dopasowywania do szablonu każdej z ramek sekwencji wideo wypowiedzi.
Połączone charakterystyki wyglądu i kształtu
Cechy wizualne, bazujące na wyglądzie oraz kształcie są z natury dość różne, ponieważ
kodują informacje wysokiego i niskiego poziomu o ruchach twarzy i ust mówcy. Nie jest
więc zaskoczeniem, że złożenie obu kategorii charakterystyk zostało wykorzystane w wielu
systemach ASR. W większości przypadków charakterystyki obu kategorii po prostu
połączono. Przykładowo w pracy [14] połączono geometryczne charakterystyki ust z
projekcją PCA zbioru pikseli zawartych wewnątrz ust. W pracy [73], jak również [37]
połączono charakterystyki ASM z PCA uzyskanymi z regionu ust, składającego się z
fragmentów obrazu wokół konturu ust. W pracy [21] połączono wektory punktów
opisujących elastyczne krzywe konturu ust z charakterystykami PCA wartości koloru pikseli
prostokątnego regionu ust.
Innym podejściem do połączenia tych dwóch klas charakterystyk jest utworzenie
pojedynczego modelu kształtu i wyglądu twarzy. AAM (ang. Active Appearance Model) [26]
dostarcza strukturę do statystycznego ich połączenia. Budowa AAM wymaga trzech aplikacji
PCA:
• Obliczenia przestrzeni własnej kształtu, które modeluje deformację kształtu, dając w
wyniki macierz P(S)PCA, obliczoną tak jak w (1.4).
• Obliczenia przestrzeni własnej wyglądu, w celu zamodelowania zmian wyglądu, dając
w wyniku macierz P(A)PCA wektorów wyglądu regionu ust. Jeżeli rozważyć wartości
koloru pikseli regionu ust o wymiarach M x N, takie wektory wyznacza się z T
MNMNMNA bgrbgrbgrx ],,,...,,,,,,[ 222111
)( = , (1.5)
podobnie jak wektory (1.1).
• Obliczenia połączonych przestrzeni własnych kształtu i wyglądu. Wygląd jest
macierzą P(A,S)PCA, wektorów uczących
TTSTATTSPCA
TSTAPCA
TASA yWyPxWPxx ],[],[ )()()()()()(),( == , (1.6)
gdzie: W – jest odpowiednio przeskalowaną diagonalną macierzą [79].
Celem PCA jest usunięcie korelacji zbędnych ze względu na kształt i wygląd, a także
utworzenie pojedynczego modelu, opisującego zwięźle kształt i występującą deformację
wyglądu. Taki pojedynczy model użyto w do SR w pracach [79] i [84].

17
Połączenie obu metod analizujących kształt i wygląd pozwala na uzyskanie większej
liczby informacyjnych cech wideo mowy, ale skoro każda z metod osobno wymaga
skomplikowanej analizy, to w połączeniu, dodatkowo niepotrzebnie wydłuży proces
ekstrakcji cech wideo w systemach AVSR. Najwięcej informacji w wideo mowie wnoszą
zewnętrzne krawędzie ust oraz pojawiający się, bądź też nie, język między zębami, podczas
wypowiadania poszczególnych fonemów, stąd analiza właśnie tych elementów twarzy jest w
zupełności wystarczająca do poprawnego działania systemów AVSR [68].
Integracja sygnałów audio-wideo w procesie rozpoznawania mowy
W systemach rozpoznawania audio-wideo mowy, oprócz ekstrakcji wizualnych
charakterystyk, konieczna jest jeszcze ekstrakcja audio charakterystyk z akustycznego
nagrania wypowiedzi. Przykładowo charakterystykami audio mowy mogą być współczynniki
analizy cepstralnej w częstotliwościowej skali mel MFCC (ang. Mel Frequency Cepstral
Coefficients), lub liniowego kodowania predykcyjnego LPC (ang. Linear Prediction Coding),
zazwyczaj wydobywane z szybkością 100 Hz [32,92]. Dla kontrastu, wizualne
charakterystyki są generowane najczęściej z szybkością 25 klatek/s. Ważnym zadaniem jest
odpowiednie połączenie charakterystyk obu sygnałów.
Sporo miejsca w literaturze poświęcono zagadnieniom fuzji charakterystyk sygnałów
audio i wideo mowy, np w [2,10,37,51,84,88,106]. Zaproponowane techniki różnią się
między sobą przeznaczeniem i podstawowymi założeniami. Architektura kilku takich metod
[106] bazuje wyłącznie na akustycznych modelach percepcji mowy człowieka [78]. Jednak w
większości przypadków badania dotyczące rozpoznawania audio-wideo mowy prowadzone są
dla rozdzielonego układu obu sygnałów audio i wideo mowy.
Techniki integracji sygnałów audio i wideo mogą być zasadniczo podzielone na
metody fuzji charakterystyk, dając wspólny wektor charakterystyk, przeznaczony do
rozpoznawania [2,87,106] oraz fuzji poszczególnych wyników rozpoznawania każdego z
sygnałów z osobna [37,51,84,88].
Modelowanie audio-wideo mowy
Przy projektowaniu systemów ASR rozważa się dwa centralne aspekty: generowania
charakterystyk obserwacji oraz statystycznego modelowania tego procesu generowania.
Podstawową jednostką mowy jest fonem, generowany przez specyficzne ułożenie i ruch
elementów traktu głosowego. Nie wszystkie różne fonemy audio mają różne odpowiedniki w
postaci wideo mowy, stąd liczba rozróżnialnych fonemów wideo mowy jest znacznie

18
mniejsza od liczby fonemów audio. Charakterystykę rozróżnialnych odpowiedników
fonemów wideo mowy zaprezentowano w [30,78]. Takie wizualne odwzorowanie fonemów
wywodzi się z zagadnień dotyczących czytania z ruchu ust. Wspomniane odwzorowanie
może być generowane na podstawie statystycznych technik grupowania, zaproponowanych w
[44].
Najczęściej spotykanym podejściem realizującym rozpoznawanie mowy jest
zastosowanie do modelowania mowy, modeli UMM. Modele te jako sygnał wejściowy
przyjmują wektory będące sekwencją obserwacji, uzyskanych w procesie ekstrakcji cech
sygnału. W systemach rozpoznawania samej audio mowy jest to najczęściej spotykane
podejście [32,92,114]. Istnieje jednak kilka innych aparatów wykorzystywanych do
rozpoznawania mowy, takich jak: DTW (ang. Dynamic Time Warping), użyte przykładowo w
[86], sztuczne sieci neuronowe (ang. Artificial Neural Network, ANN), jak w [67], połączenie
ANN-DTW [10,36], oraz połączenie ANN-HMM [50]. W przypadku UMM najczęściej
stosuje się dwa zasadnicze typy modeli: dyskretne modele UMM [99], oraz ciągłe modele
UMM [102].
Techniki fuzji sygnałów audio i wideo
Fuzja charakterystyk używa pojedynczego klasyfikatora w celu zamodelowania sprzężonych
wektorów synchronicznych w czasie charakterystyk audio i wideo, lub ich odpowiednich
transformacji. Do takich metod zalicza się sprzęganie cech [2], ważenie cech [106], obie
znane również jako fuzja bezpośredniej identyfikacji [106] oraz ekstrakcja cech hierarchiczną
dyskryminacją liniową [87]. Modele rejestracji cech opisane w [106] również należą do tej
kategorii. Wzmocnienie cech audio na podstawie danych wizualnych [42] oraz sprzężone
charakterystyki audio-wideo [43], również zaliczają się do tego typu fuzji.
W metodzie sprzęgania cech AV-Concat, dane są wektory cech audio i wideo o(A)t i
o(V)t rzędu DA i DV, synchroniczne w czasie. Połączony, sprzężony wektor charakterystyk
audio-wideo w czasie t oznaczono: DTTV
tTA
tAV
t Rooo ∈= ],[ )()()( , (1.7)
gdzie D = DA + DV. Tak jak we wszystkich metodach fuzji charakterystyk, proces generacji
sekwencji charakterystyk (1.7) jest modelowany przez pojedynczy model UMM z emisją
prawdopodobieństwa
∑=
=cK
kckck
AVtDck
AVt smoNwco
1
)()( ),;(]|Pr[ , (1.8)

19
dla wszystkich klas c ∈ C [2]. Tego typu fuzja stanowi proste podejście do audio-wideo ASR,
implementowane z niewielkimi zmianami w większości istniejących systemów. Jednak rząd
(1.7) może być dosyć duży, powodując niewłaściwe określenie prawdopodobieństwa
sekwencji obserwacji.
Charakterystyki sygnału wideo zawierają przy rozpoznawaniu mowy mniej
informacji, niż charakterystyki audio, nawet w przypadku bardzo dużych zakłóceń kanału
audio. Należy się więc spodziewać, że odpowiednia reprezentacja małego rzędu (1.7)
powinna prowadzić do takiej samej lub nawet lepszej wydajności HMM. W pracy [90]
zaproponowano LDA do redukcji rzędu. Po LDA użyto rotacji danych bazującej na MLLT w
celu osiągnięcia największego prawdopodobieństwa modelowania danych. W systemie ASR
[90] zaproponowana metoda składa się z dwuetapowej aplikacji LDA i MLLT, analizującej
współczynniki MFCC sygnału audio oraz DWT sygnału wideo. Ostatecznie wektor fuzji
charakterystyk hierarchiczną dyskryminacją AV-HiLDA wynosi: )()()( AV
tAV
LDAAV
MLLTHiLDAt oPPo = . (1.9)
W celu poprawienia skuteczności rozpoznawania mowy w warunkach mocno
zakłóconego sygnału audio, można dołączyć sygnał wideo mowy AV-Enh, uzyskując
połączoną strukturę, zaproponowaną w [43]. W takiej metody wektor wzmocnionych
charakterystyk audio o(AEnh)t może być uzyskany jako liniowa transformacja sprzężonych
wektorów charakterystyk audio-wideo (1.7), dana wzorem: )()()( AV
tAV
EnhAEnh
t oPo = , (1.10)
gdzie macierz P(AV)Enh = [p(AV)
1, p(AV)2,…, p(AV)
DA] składa się z D-wymiarowych wektorów
wierszy p(AV)Ti, dla i = 1,…,DA i ma wymiar DA x D. Prostym sposobem oszacowania
macierzy P(AV)Enh może być aproksymacja o(AEnh)
t ≈ o(AClean)t w sensie odległości euklidesowej,
gdzie wektor o(AClean)t oznacza niezakłócone charakterystyki audio, dostępne dodatkowo,
oprócz charakterystyk i zakłóconych wektorów audio, dla wielu chwil czasowych t w
zestawie uczącym T.
Fuzja wyników rozpoznawania w ASR
Chociaż opisane metody fuzji charakterystyk posiadają udokumentowane wyniki poprawienia
rozpoznawania audio-wideo mowy w porównaniu z rozpoznawaniem samej audio mowy
[84], to nie mają uniwersalnych modeli, niezawodnych dla każdego z strumieni. Informacyjna
zawartość mowy oraz różnica mocy sygnałów audio i wideo, może być uzależniona od:
rodzaju danej wypowiedzi, zakłócenia sygnału audio w określonym środowisku, zakłócenia

20
sygnału wideo, niedokładności trekingu twarzy i ust oraz specyficznych charakterystyk
mówców. Odpowiednia fuzja wyników rozpoznawania, zapożyczona z literatury dotyczącej
kombinacji klasyfikatorów, pozwala na uzyskanie niezawodności dla każdego ze strumieni.
Rozpoznawanie mowy ciągłej wprowadza trudność dla zagadnień fuzji
klasyfikatorów, spowodowaną faktem, że sekwencje klas również mszą być estymowane.
Najwydajniejszą jak dotąd metodą jest wczesna integracja stanów modeli UMM każdego ze
strumieni AV-MS-Joint. W ogólnej postaci, klasa prawdopodobieństwa obserwacji
rozszerzonego modelu UMM, jest wynikiem prawdopodobieństwa obserwacji komponentów
pojedynczych strumieni. Taki model stosowano w systemach rozpoznawania audio mowy,
gdzie przykładowo oddzielnymi strumieniami były współczynniki energii sygnału i
współczynniki MFCC [114]. W dziedzinie rozpoznawania audio-wideo mowy, model UMM
zawiera dwa strumienie, pierwszy powiązany z sygnałem audio i drugi powiązany z sygnałem
wideo. Rozszerzony model UMM obszernie użyto w zadaniach rozpoznawania audio-wideo
mowy z mocno okrojonymi bazami słów [37,58,82,88].
Mając dany połączony wektor obserwacji o(AV)t, wynik emisji stanów rozszerzonego
modelu UMM uzyskiwany jest z:
∏ ∑∈ =
=AVs
K
kscksck
stDsck
AVt
scsct
ssmoNwco
1
)()( )],;([]|Pr[ λ . (1.11)
Należy zaznaczyć, że zależność (1.11) jest odpowiednikiem liniowej kombinacji w dziedzinie
logarytmu prawdopodobieństwa. λsct oznacza reprezentujące strumień wagi, przyjmujące
tylko dodatnie wartości i ogólnie, będące funkcjami s, dla stanów c ∈ C modeli UMM, ramki
wypowiedzi w chwili czasowej t. Parametry rozszerzonego modelu UMM opisuje zależność: TT
VCACTAVAV Ccaa }],],{[,[ ∈= λλ , (1.12)
gdzie aAV = [rT, bTA, bT
V]T zawiera prawdopodobieństwo przejścia r oraz parametry
prawdopodobieństwa emisji bA i bV komponentów pojedynczych strumieni. Podobne
rozwiązanie daje połączona estymacja parametrów aAV, w odniesieniu do narzuconej
synchronizacji stanów [92,114].
Jak już wcześniej wspomniano, metodę AV-MS-Joint stosowano jak do tej pory dla
niewielkich zadań rozpoznawania mocno ograniczonej ilości wypowiedzi. Metoda wymaga
utworzenia połączonego wektora, a co za tym idzie, synchronizacji wprowadzającej sztuczne
dodawanie obserwacji, dla zachowania zgodności wektorów obserwacji sygnałów audio i
wideo. Takie sztuczne zwiększanie wektora obserwacji wideo powoduje zakłócenia
rzeczywistej sekwencji obserwacji wideo mowy.

21
1.3. Cel i teza pracy, bronione rozwiązania naukowe
Jak wykazano w przeglądzie dotychczasowych rozwiązań, metody rozpoznawania audio-
wideo mowy są znacznie skuteczniejsze od metod rozpoznawania audio mowy. Jednak
sposoby ekstrakcji cech wideo mowy i fuzji charakterystyk obu sygnałów (audio i wideo) są
trudne do zaimplementowania w praktycznych systemach. Oprócz tego, metody
rozpoznawania audio-wideo mowy polskiej znajdują się na etapie początkowym.
Celem pracy jest opracowanie metody rozpoznawania słów izolowanych audio-wideo mowy
polskiej w oparciu o modele UMM, opierająca się na tezie:
Fuzja sygnału audio mowy i sygnału wizualnego ruchu ust, czyli wideo mowy,
jest przesłanką do opracowania efektywnej metody rozpoznawania audio-wideo
mowy polskiej, która posiada porównywalne właściwości z prezentowanymi
dotychczas rozwiązaniami rozpoznawania mowy, stosowanymi dla innych
języków; dodatkowym rozwiązanym problemem jest dopasowanie metody do
warunków pracy w środowisku z zakłóconym sygnałem audio.
Skuteczność opracowywanej metody AV_Mowa_PL ma być potwierdzona eksperymentalnie
w terminach osiągniętych poziomów błędów. Należy także przeprowadzić eksperymentalny
dobór racjonalnych (optymalnych) parametrów dla poszczególnych etapów metody.
Bronione rozwiązania naukowe
1. Metoda AV_Mowa_PL rozpoznawania słów izolowanych audio-wideo mowy polskiej.
Fuzja charakterystyk audio i wideo mowy zrealizowana poprzez wykorzystanie
wspólnych oraz oddzielnych modeli UMM. Charakterystyki metody są porównywalne z
charakterystykami osiągniętymi w zaprezentowanych metodach dla innych języków.
2. Metody ES i CZS, a także ich fuzja do definiowania początku i końca słów izolowanych
audio mowy.
3. Metoda śledzenia ruchu ust, w której wykorzystano automatyczne metody: detekcji
twarzy na podstawie koloru skóry; lokalizacji oczu; definiowania obszaru ust, a także
opracowaną metodę CSM do wykrywania kącików i zewnętrznych krawędzi ust, oraz

22
metodę EPdo ekstrakcji i kodowania wymaganych parametrów z ruchomego obrazu ust,
w procesie tworzenia wektorów obserwacji wideo mowy.
5. Metody Sr, ASr_I, ASr_II fuzji charakterystyk sygnałów audio i wideo mowy.
6. Słuszność wykorzystania metody AV_Mowa_PL do identyfikacji użytkownika na
podstawie audio-wideo mowy.
7. Eksperymentalne potwierdzenie faktu, że metoda AV_Mowa_PL jest efektywna w
warunkach podwyższonego zakłócenia sygnału audio.
Praca zawiera wyniki badań, uzyskane w ramach realizacji projektu badawczego
promotorskiego NR 4 T11C 003 25, finansowanego przez Ministerstwo Nauki i
Informatyzacji.

23
2. SZKIC METODY AV_Mowa_PL
Przedstawiono podstawowe założenia i wymagania dotyczące metody AV_Mowa_PL
rozpoznawania audio-wideo mowy polskiej w oparciu o modele UMM. Omówiono procedury
ekstrakcji charakterystyk audio i wideo, oraz sposoby ich fuzji.
2.1. Wymagania funkcjonalne do opracowania metody AV_Mowa_PL
Wymagania do opracowania metody AV_Mowa_PL można podzielić na wymagania
teoretyczne (niezbędne podczas opracowywania i analizy poszczególnych procedur metody),
wymagania sprzętowo-systemowe (pozwalające na swobodne zaimplementowanie systemu),
wymagania do procedur przeprowadzenia założonych badań i założenia wstępne (przyjęte dla
prawidłowego funkcjonowania metody).
Teoretyczne przygotowania z zakresu cyfrowego przetwarzania sygnałów, cyfrowego
przetwarzania obrazów, artykulacji i percepcji mowy, znajomości zagadnień technik
biometrycznych, sztucznej inteligencji, narzędzi ucząco-rozpoznających oraz programowania,
stanowiły założenia, jakie postawiono przed opracowaniem metody AV_Mowa_PL.
Wymagania sprzętowo-systemowe w zasadzie, oprócz sprzętu komputerowego z
systemem operacyjnym, pod którym działa środowisko Matlab, dotyczą tylko konieczności
posiadania mikrofonu i kamery internetowej o rozdzielczości nagrywania 640 x 480 pikseli
przy szybkości 15 klatek/s. Parametrów odnoszących się do procesora, pamięci i karty
graficznej nie określono, gdyż badania nie były prowadzone dla danych wejściowych
przetwarzanych w czasie rzeczywistym.
W celu sprawnego działania metody należy przyjąć pewne założenia wstępne.
Dotyczą one sposobu rejestrowania wypowiedzi audio i wideo mowy, środowiska pracy oraz
możliwości praktycznego zastosowania metody.
Do rozpoznawania audio-wideo mowy potrzebne jest nagranie wypowiedzi audio i
zarejestrowany obraz ruchu ust, podczas wypowiadania danego słowa. Dlatego oprócz
mikrofonu, konieczne jest użycie kamery ustawionej na wypowiadającego komendy
użytkownika tak, aby cała twarz znalazła się w kadrze kamery. Jako urządzenie do
przechwytywania obrazu można użyć kamerę internetową o rozdzielczości nagrywania 640 x
480 pikseli. Przy takiej rozdzielczości możliwe jest wychwycenie twarzy użytkownika oraz
rzeczywistego konturu ust podczas nagrywanej wypowiedzi. Stosując kamerę internetową o

24
maksymalnej rozdzielczości nagrywania 320 x 240 pikseli, należy tak ją ustawić, aby
wyłapywała tylko obszar samych ust, gdyż w innym przypadku nie uzyska się rzeczywistego
konturu ust. Użytkownik powinien wypowiadać poszczególne komendy prosto do obiektywu
kamery, starając się przy tym trzymać głowę w pozycji zbliżonej do pionowej.
Podczas rejestracji dźwięku, mikrofon powinien znajdować się w odległości około 20
cm tak, aby nie wychwytywał niezamierzonego dmuchania w mikrofon podczas
wypowiadania niektórych fonemów. Mikrofon nie powinien wchodzić w kadr kamery.
Wymagania dotyczące otoczenia nie są ściśle sprecyzowane względem akustyki, gdyż
założeniem metody AV_Mowa_PL jest rozpoznawanie mowy w środowisku ze szczególnie
zakłóconym sygnałem audio. Dla celów badawczych wykorzystano cichy pokój, a zakłócenia
sztucznie dodawano do sygnału audio mowy. Przyjęto natomiast wymagania dotyczące
rejestracji obrazu. Założono, że pomieszczenie powinno być dobrze oświetlone, światłem
jednolitym, nie powodującym zbyt dużych przekłamań w rejestrowanych kolorach. Źródło
światła powinno być skierowane na użytkownika systemu.
2.2. Specyfika podstawowych informacyjnych procedur metody
Metoda AV_Mowa_PL składa się z kilku podstawowych bloków funkcjonowania. Każdy z
tych bloków odpowiada za prawidłowe działanie całego systemu, dlatego aby osiągnąć
zadawalające wyniki, należy poszczególne etapy racjonalnie realizować. Konieczne jest
pójście na kompromis, wybierając pomiędzy prawidłowym funkcjonowaniem systemu, a
rzeczywistą szybkością reagowania na wprowadzane dane wejściowe.
Pierwszym etapem rozpoznawania audio-wideo mowy jest odpowiednie nagranie
wypowiedzi audio i wideo mowy użytkownika. Przyjęto częstotliwość próbkowania dźwięku
8 kHz, a częstotliwość nagrywania obrazu 15 klatek/s. Przy takich parametrach nagrywania
jedna klatka obrazu zawiera około 533 próbki sygnału. Sygnał audio zostaje oddzielony od
sygnału wideo, gdyż w dalszych etapach, ekstrakcja wymaganych charakterystyk realizowana
jest oddzielnie dla każdego z kanałów. Podczas nagrywania sygnału audio nie można
stosować kompresji, prowadzącej do bezpowrotnej utraty niektórych ważnych cech. Sygnał
wideo mowy można kompresować, używając jednego z kodeków zaimplementowanych w
Matlabie.

25
Analiza sygnału audio
W procesie analizy audio sygnału w pierwszym kroku należy przygotować książkę kodową,
będącą niezbędnym mechanizmem przy ekstrakcji wymaganych charakterystyk sygnału audio
i tworzeniu wektorów obserwacji. Proces tworzenia książki kodowej wykonuje się za każdym
razem, gdy do systemu dodawany jest nowy użytkownik. Książka kodowa odzwierciedla
przestrzeń akustyczną danego użytkownika. Po utworzeniu książki kodowej wejściowe
sygnały danego użytkownika poddawane są kwantyzacji wektorowej, przechodząc przez te
same bloki procesu tworzenia książki kodowej.
Na Rys.2.1 pokazano podstawowe informacyjne bloki analizy audio sygnału.
Rys. 2.1 Podstawowe bloki analizy sygnału audio
Analizę kanału audio należy rozpocząć od odfiltrowania sygnału, usuwając elementy
sygnału będące jego zakłóceniami. Filtracja sygnału pozwala na jego wygładzenie,
polepszenie stosunku sygnału do szumu, ograniczenie szerokości pasma przenoszenia oraz
wykrywanie zjawisk objawiających się zmianami widma. Dodatkowo wykonując filtrację
antyaliasingową, zapobiega się zniekształceniom oraz zjawisku nakładania się widm, często
powstającym w trakcie przetwarzania analogowo-cyfrowego (A/C), kiedy górne
częstotliwości sygnału są wyższe niż połowa wyższej częstotliwości próbkowania sygnału
[7]. W systemie pracującym w warunkach zbliżonych do idealnych można pominąć etap
wstępnej filtracji, w celu przyspieszenia działania. Jednak założeniem systemu rozpoznawania
audio-wideo mowy jest poprawne działanie w warunkach szczególnie zakłóconych, dlatego w
pracy zastosowano wstępną filtrację.

26
W systemach rozpoznawania słów izolowanych podczas nagrań konieczne jest
robienie krótkotrwałych, ale wyraźnych przerw w postaci ciszy, pomiędzy poszczególnymi
słowami. Ze względu na wspomniany rodzaj rozpoznawania, po wstępnym odfiltrowaniu
sygnału, kolejnym etapem jest wydzielenie czystego, właściwego sygnału audio, poprzez
usunięcie ciszy sprzed i spoza sygnału. Zastosowano dwie połączone metody usuwania
zbędnej ciszy. Pierwsza z nich bazująca na wyliczeniu energii sygnału i odrzuceniu
wszystkich próbek nie przekraczających przyjętego progu energii, druga zliczająca liczbę
zmian wartości próbek sygnału z mniejszej na większą i na odwrót, w określonym przedziale
czasowym. Zastosowanie tych dwóch metod pozwala na właściwe wydzielenie sygnału audio,
umożliwiając poprawne realizowanie pozostałych etapów systemu.
Ze względu na niestacjonarność sygnału, wynikającą z dynamicznych właściwości
ludzkiej mowy, kolejny etap polega na zastosowaniu podziału wejściowego sygnału na
stacjonarne ramki. Sygnał uważa się za stacjonarny w krótkich przedziałach czasowych (10 ÷
30 ms). Każdą taką stacjonarną ramkę w procesie tworzenia wektorów obserwacji zastąpiono
symbolem obserwacji. W tworzonym systemie przyjęto długość każdej ramki równą 30 ms,
co przy danym próbkowaniu sygnału odpowiada 240 próbkom. W celu zachowania
stacjonarności sygnału zastosowano metodę nakładania się kolejnych ramek. W metodzie tej
każda kolejna ramka nałożona jest na poprzednią z pewnym opóźnieniem. Przyjęto
opóźnienie 10 ms, czyli 80 ostatnich próbek sygnału poprzedniej ramki jest jednocześnie 80
próbkami następnej ramki. Zastosowanie metody nakładania się kolejnych ramek prowadzi
niekiedy do powstawania niepotrzebnych wysokich częstotliwości w widmie sygnału. W celu
usunięcia powstałej nieciągłości przetwarzanego sygnału zastosowano dla każdej wydzielonej
ramki specjalne zawężające okno, tłumiące wartości skrajnych próbek. Etap podziału sygnału
na stacjonarne ramki z zastosowanymi tłumiącymi oknami pozwala na dalszą analizę sygnału
uważanego za stacjonarny, zachowując jego ciągłość bez fałszywych prążków w widmie.
Wzorując się na biologicznych przesłankach nieliniowej w dziedzinie częstotliwości
analizy widma sygnału przez ludzkie ucho, w etapie analizy sygnału przez bank filtrów
zastosowano podobne nieliniowe przetwarzanie częstotliwości. W tym etapie widmo sygnału
uzyskanego przez szybką transformatę Fouriera (ang. Fast Fourier Transform, FFT) podlega
procesowi filtracji przez bank 21 filtrów o szerokości 300 meli, przesuniętych względem
siebie o 150 meli, pokrywających częstotliwości z przedziału od 0 do 4192 Hz. Dzięki takiej
filtracji uzyskuje się zbiór charakterystyk z wygładzonego widma sygnału. Uzyskane za
pomocą FFT prążki widma połączone są w mniejszą liczbę przedziałów częstotliwości.

27
Charakterystyki uzyskanych filtrów, zajmujących tylko połowę całkowitego widma, w
pewnym stopniu naśladują system słuchowy człowieka.
Kolejny etap analizy sygnału audio polega na zastosowaniu przekształcenia
cepstralnego uzyskanych wcześniej parametrów banków filtrów, uniezależniając sygnał
mowy od wpływu niezmiennego w czasie kanału transmisji. Współczynniki cepstrum
uzyskuje się poprzez zsumowanie parametrów banków każdego z filtrów, a następnie
zastosowanie dyskretnych przekształceń kosinusowych logarytmów tych parametrów.
Przyjmując liczbę współczynników cepstrum równą 20, uzyskuje się zakodowaną tymi
dwudziestoma współczynnikami pojedynczą ramkę o długości 240 próbek. Zarówno analizę
sygnału za pomocą banku filtrów oraz współczynników cepstrum, wykonuje się dla każdej
pojedynczej stacjonarnej ramki.
W procesie tworzenia książki kodowej, analizie cepstralnej należy poddać nagranie
zawierające zbiór wypowiedzi danego użytkownika, dobrany co do ilości i rodzaju słów w ten
sposób, aby w całości pokryć przestrzeń akustyczną dla tego użytkownika. Zbiór taki
powinien zawierać słowa obejmujące wszystkie fonemy języka polskiego wchodzące w skład
przyjętego zagadnienia systemu. W przypadku sterowania systemem odpowiednimi
komendami, można utworzyć zbiór wypowiedzi złożonych z wszystkich komend, jednak jeśli
jest to tylko wykonalne, można ograniczyć ten zbiór pomijając komendy, których
poszczególne fonemy występują już w innych, wziętych do zbioru komendach. Zbiór
współczynników cepstrum wyznaczonych dla wszystkich ramek sygnału wejściowego,
podlega procesowi kwantyzacji, czyli podziałowi na przyjętą liczbę obszarów. Podział ten
dokonuje się wykorzystując algorytm Lloyda. Każdemu wyróżnionemu obszarowi przypisana
zostaje wartość symbolu z ograniczonego przyjętą liczbą obszarów zbioru symboli. W ten
sposób wszystkie zakodowane przy pomocy współczynników cepstrum ramki zostają
sklasyfikowane do jednego z wydzielonych obszarów.
Podczas normalnej pracy systemu, gdzie dla danego użytkownika została już
utworzona książka kodowa, ostatni etap analizy sygnały audio polega na zakodowaniu każdej
ramki sygnału przy pomocy symboli książki kodowej. Jest to tzw. kwantyzacja wektorowa,
gdzie zbiór wektorów współczynników cepstrum zostaje zamieniony na ciąg symboli, w
pracy nazwany wektorem obserwacji. Dla każdej ramki oblicza się odległość wektora
współczynników cepstrum, od każdego z obszarów wydzielonych w książce kodowej.
Symbol obszaru, dla którego ta odległość jest najmniejsza zostaje przypisany badanej ramce.
Wynikiem analizy sygnału audio jest ekstrakcja wymaganych cech tego sygnału, co w
przyjętych założeniach odpowiada zakodowaniu pojedynczego sygnału wejściowego

28
złożonego z kilku tysięcy próbek, przy pomocy kilkudziesięciu symboli obserwacji. Każdy z
sygnałów wejściowych przedstawiony zostaje w postaci wektora obserwacji, co jest
niezbędne w systemach wykorzystujących modele UMM. Dodatkowo tak znaczne
ograniczenie liczby danych wejściowych w dużym stopniu upraszcza cały proces uczenia i
rozpoznawania.
Analiza sygnału wideo
Proces analizy wideo sygnału ma na celu wydzielenie potrzebnych charakterystyk ruchu ust z
wideo wypowiedzi.
Na Rys.2.2 pokazano podstawowe bloki analizy sygnału wideo.
Rys.2.2 Podstawowe bloki analizy sygnału wideo
W procesie analizy sygnału wideo pierwszy etap polega na zlokalizowaniu twarzy
użytkownika w nagranej wypowiedzi. Zakładając, że nagrana wypowiedz jest sekwencją
kolorowych obrazów, twarz człowieka można zlokalizować na podstawie jego koloru skóry
[70]. Oczywiście badania prowadzono tylko dla użytkowników o białym kolorze skóry. W
etapie tym sygnał wideo należy podzielić na poszczególne ramki i dla każdej ramki
zlokalizować obszar odpowiadający specyficznemu kolorowi skóry białego człowieka. Jeśli
oprócz ludzkiej twarzy w danej ramce zostaną zlokalizowane jeszcze inne elementy
przypominające taki kolor, wówczas konieczne jest użycie odpowiednich filtrów oraz
odpowiedniej maski, aby dokładnie wydzielić obszar samej twarzy.
Po wydzieleniu prostokątnego obszaru twarzy, w następnym etapie wykonuje się
lokalizację obszaru ust. Ponieważ zlokalizowanie obszaru ust jest dość trudnym zadaniem,
lepiej jest skorzystać z elementów twarzy, łatwiejszych do namierzenia. Takimi elementami
są oczy. Proces lokalizacji oczu wykonuje się na obszarze monochromatycznym. Najpierw

29
dla całego obrazu znajdowana jest pozioma linia oczu, a następnie tylko dla niewielkiego
fragmentu zawierającego obszar w otoczeniu poziomej linii oczu, znajdowane są pionowe
linie oczu. Pionową i poziome linie oczu wyznacza się na podstawie gradientów jasności
pikseli wzdłuż każdej kolumny oraz każdego wiersza obrazu wejściowego [70]. Na podstawie
wyznaczonych współrzędnych oczu, określany jest przybliżony obszar ust dla każdej ramki,
poprzez doświadczalne wyznaczenie wielkości tego obszaru i odległości jego centrum od
centrum współrzędnych oczu.
Kolejnym etapem w analizie sygnału wideo jest znalezienie współrzędnych kącików
ust i wyznaczenie zewnętrznych krawędzi ust. Dużym ułatwieniem jest ograniczenie
zarejestrowanej wypowiedzi, do obszaru samych ust użytkownika. Do znalezienia położenia
kącików ust można wykorzystać podobne podejście, jak w przypadku lokalizacji
współrzędnych oczu, jednak lepszym rozwiązaniem jest wykorzystanie specyficznego koloru
ust. Poprzez progowanie, dla każdej ramki wyznacza się wartości pikseli przypominających
kolor ust. Pozostałym pikselom przypisuje się wartość 0. Progowanie to realizuje się dla
obrazu kolorowego. Dla wyznaczonego obszaru zawierającego kolor samych ust, na
podstawie specyficznego kształtu ust określa się współrzędne kącików ust. Najczęściej są to
współrzędne niezerowych, najbardziej skrajnych w poziomie pikseli. Na podstawie
wyznaczonych kącików ust określa się zewnętrzne krawędzie ust, górną i dolną. Dokładne
wydzielenie tych krawędzi ma duży wpływ na właściwe zakodowanie ruchu ust w sekwencji
wypowiedzi.
Ostatnim etapem analizy sygnału wideo jest zakodowanie każdej ramki zawierającej
dany kształt ust, przy pomocy odpowiedniego symbolu obserwacji. Kształt ust opisywany jest
przy pomocy ustalonej liczby punktów, dobranych tak, aby w miarę dokładnie odzwierciedlić
rzeczywiste zewnętrzne granice ust. Na podstawie współrzędnych wszystkich punktów, dla
każdej ramki określany jest symbol obserwacji. Uzyskany w ten sposób wektor obserwacji
stanowi sygnał wejściowy w procesie uczenia i rozpoznawania za pomocą modeli UMM.
Cały proces analizy sygnału wideo pozwala na zakodowanie pojedynczej ramki, zawierającej
640 x 480 pikseli, każdy o współrzędnej x, y (614400 wartości), przy pomocy jednego
symbolu obserwacji. Należy zaznaczyć, że nie jest to kompresja obrazu, a jedynie sposób
zakodowania jego niewielkiej części.
Uczenie
W procesie uczenia zastosowano podejście stochastyczne bazujące na modelach UMM
wykorzystywanych do modelowania ciągów czasowych. Uczenie modeli UMM polega na jak

30
najlepszym dopasowaniu wartości jego parametrów. Poprzedzając proces uczenia, konieczne
jest ustalenie topologii modelu, czyli określenie liczby jego stanów, a co za tym idzie:
• rozmiaru macierzy A prawdopodobieństw przejść między stanami,
• rozmiaru wektora prawdopodobieństw początkowych π,
• rozmiaru wektora rozkładów wyjściowych B.
Odpowiedni dobór liczby stanów wpływa na dokładność i szybkość uczenia. Proces
uczenia ma na celu znalezienie wartości, czyli estymacji parametrów modelu λ = (π, A, B),
dla zadanej uczącej sekwencji obserwacji. Podawana sekwencja obserwacji składa się z kilku
powtórzeń tej samej wypowiedzi audio i wideo zakodowanej w postaci symboli obserwacji.
W systemie rozpoznawania słów izolowanych zastosowano dla każdego słowa
oddzielny model opisany odpowiednią transkrypcją gramatyczną. Liczba modeli odpowiada
liczbie słów zawartych w słowniku systemu. Dodanie nowego słowa do słownika wiąże się z
utworzeniem nowego modelu, przy czym w procesie uczenia estymuje się parametry tylko
tego nowego modelu, parametry pozostałych modeli nie zmienia się. Przyjęto dodatkowo, że
wszystkie modele są tych samych rozmiarów. Dla nowego użytkownika systemu konieczne
jest utworzenie nowego zbioru modeli dla każdej z wypowiedzi. Można od nowa uczyć
istniejące już modele, jednak wtedy utraci się ich wartość dla poprzedniego użytkownika.
Rozpoznawanie
W procesie rozpoznawania następuje wyznaczenie transkrypcji fonetycznej i gramatycznej
nieznanych, rozpoznawanych wypowiedzi. Rozpoznawane słowo reprezentowane przez
wektor obserwacji porównywane jest z wszystkimi modelami UMM w systemie. Ponieważ
każdy model UMM można traktować jako generator sekwencji obserwacji, dlatego
rozpoznawanie polega na określeniu prawdopodobieństwa wygenerowania wejściowej
sekwencji obserwacji przez dany model. Największe prawdopodobieństwo określa model,
który był uczony na danych najbardziej zbliżonych do rozpoznawanego słowa. Rezultatem
rozpoznania jest odpowiednik transkrypcji gramatycznej zwycięskiego modelu.
2.3. Proponowane sposoby fuzji charakterystyk audio-wideo sygnałów
W pracy zaproponowano trzy metody fuzji wektorów obserwacji sygnału audio i wideo:
synchroniczną Sr i dwie asynchroniczne ASr_I i ASr_II.

31
W metodzie synchronicznej Sr pokazanej na Rys.2.3 połączenie wektorów obserwacji
zastosowano przed etapem uczenia.
Rys.2.3 Schemat działania systemu opartego na synchronicznej fuzji charakterystyk Sr
Wektory obserwacji sygnałów audio i wideo różnią się przede wszystkim długością.
Po rozdzieleniu sygnałów, podczas analizy audio usunięto ciszę sprzed i spoza właściwego
nagrania. W sygnale wideo również usunięto klatki zawierające ciszę, na podstawie
kluczowych ramek oznaczających początek i koniec właściwego nagrania audio.
Dla nagrania o jednosekundowej długości wektor obserwacji audio ma długość około
45 ÷ 55 obserwacji, natomiast wektor obserwacji wideo zawiera 15 obserwacji. Czyli średnio
trzy, cztery ramki audio odpowiadają jednej ramce wideo. Fuzję charakterystyk audio i wideo
wykonano w ten sposób, że stworzono tablicę kodową zawierającą wszystkie możliwe
kombinacje symboli obserwacji obu wektorów. Następnie przydzielano w czasie
odpowiadającym ramce audio symbol obserwacji z tablicy kodów, będący symbolem
wypadkowym. W ten sposób utworzony wspólny wektor obserwacji zawierał symbole
obserwacji znacznie przekraczające rozmiary książki kodowej audio i wideo.
Ponieważ w wideo mowie często wypowiedz różnych fonemów audio ma zbliżoną
wypowiedź wideo, dlatego w metodzie tej ograniczono rozmiar słownika do 10 symboli. Przy
37 symbolach z książki kodowej audio stworzono tablicę kodową zawierającą 370 symboli
zsynchronizowanych sygnałów audio i wideo.
W pierwszej zaproponowanej metodzie asynchronicznej ASr_I, jako wektory uczące i
testujące wprowadzano sekwencje obserwacji sygnałów audio i wideo osobno, bez
jakiejkolwiek fuzji i synchronizacji Wektor obserwacji wideo, podobnie jak w poprzedniej

32
metodzie również pozbawiony jest klatek zawierających ciszę. Schemat działania systemu z
pierwszą asymetryczną metodą fuzji charakterystyk ASr_I pokazano na Rys.2.4.
Rys.2.4 Schemat działania systemu opartego na pierwszej metodzie asynchronicznej fuzji charakterystyk ASr_I
Asynchroniczność w tej metodzie polega na tym, że tylko pierwsze ramki sygnałów
audio i wideo są ze sobą zgodne. Nie jest tu ważna synchronizacja, a tylko sekwencja
obserwacji. Wektory obserwacji kilku różnych powtórzeń tej samej wypowiedzi w procesie
uczenia wprowadza się do modelu jako dane uczące na przemian, zaczynając od wektora
obserwacji audio, a następnie wprowadzając wektor obserwacji wideo. Uczony modeli nie
tylko musi rozpoznawać ciąg sekwencji sygnału audio, ale pamięta również odpowiadającą
tej sekwencji, sekwencję obserwacji wideo. W przypadku zakłóceń któregokolwiek z
sygnałów, model jest w stanie rozpoznać wypowiedź na podstawie sygnału prawidłowego.
W rzeczywistości większy wpływ na poprawność rozpoznawania ma sygnał audio,
jednak w pracy zakłada się, że to tylko sygnał audio może ulec zakłóceniu, a sygnał wideo ma
być elementem pomocnym w podjęciu decyzji. Dlatego przy w miarę racjonalnym zakłóceniu
sygnału audio, system działa poprawnie.
Druga z zaproponowanych metod asynchronicznych ASr_II polega na tym, że tworzy
się osobne modele dla sygnału audio i wideo. Schemat działania systemu z drugą
asymetryczną metodą fuzji charakterystyk ASr_II pokazano na Rys.2.5.
Na podstawie odpowiednich wektorów obserwacji uczy się modele sygnałów audio i
wideo osobno. Modele opisane są odpowiednią transkrypcją gramatyczną. Każdy z modeli na
podstawie swoich parametrów generuje sekwencję obserwacji, która jest porównywana z
sekwencją rozpoznawaną. Prawdopodobieństw wygenerowania sekwencji obserwacji audio
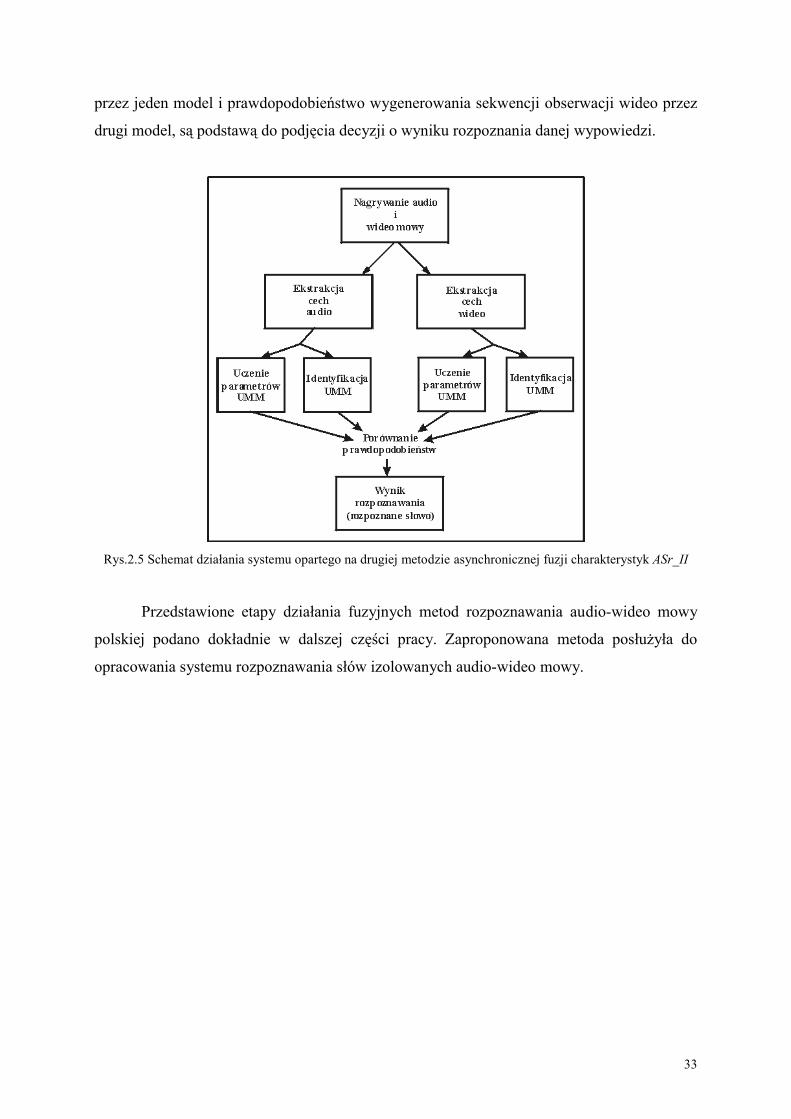
33
przez jeden model i prawdopodobieństwo wygenerowania sekwencji obserwacji wideo przez
drugi model, są podstawą do podjęcia decyzji o wyniku rozpoznania danej wypowiedzi.
Rys.2.5 Schemat działania systemu opartego na drugiej metodzie asynchronicznej fuzji charakterystyk ASr_II
Przedstawione etapy działania fuzyjnych metod rozpoznawania audio-wideo mowy
polskiej podano dokładnie w dalszej części pracy. Zaproponowana metoda posłużyła do
opracowania systemu rozpoznawania słów izolowanych audio-wideo mowy.

34
3. TWORZENIE WEKTORÓW OBSERWACJI SYGNAŁU AUDIO MOWY
Omówiono szczegółowo proces tworzenie wektorów obserwacji sygnałów mowy z
wykorzystaniem znanych algorytmów ekstrakcji sygnałów mowy i połączenia ich z
oryginalnymi autorskimi rozwiązaniami.
3.1. Zasady tworzenia wektorów obserwacji sygnału mowy
Podczas tworzenia systemu rozpoznawania mowy należy wykonać kilka podstawowych
etapów i zadań zawierających:
• odpowiednie przygotowanie danych wejściowych,
• wybór i utworzenie parametrów algorytmu realizującego rozpoznawanie mowy,
• opracowanie procedur rozpoznawania, oraz uczenie i testowanie systemu.
Istnieje także kilka podejść do projektowania systemów automatycznego
rozpoznawania mowy. Najważniejsze z nich to:
1. Podejście akustyczne, w którym głównie wykorzystywano parametry akustyczno-
fonetyczne służące do konstruowania obrazów i wzorców; najczęściej to jest w systemach
probabilistycznych.
2. Podejście oparte na znajomości wytwarzania mowy przez człowieka, które polega na
analizie głównych procesów artykulacji poszczególnych jednostek językowych.
3. Podejście oparte na bionicznej koncepcji rozpoznawania, czyli na modelowaniu procesu
rozpoznawania mowy przez człowieka.
4. Podejście uwypuklające proces rozumienia mowy na podstawie pewnych cech
prozodycznych, jak np. transjenty (przejścia międzyfonemowe formantów), dźwięczność
(bezdźwięczność) spółgłosek, zmiany intonacji [52,94].
W realnych systemach automatycznego rozpoznawania mowy najczęściej realizuje się
pewną kombinacją wymienionych podejść, z tym, że któreś z nich pełni zwykle funkcję
dominującą. W większości poprawnie działających systemów automatycznego
rozpoznawania mowy mają zastosowanie dwa pierwsze podejścia [52].
Podstawowym etapem jest analiza na poziomie akustycznym, w wyniku której
następuje ekstrakcja parametrów akustycznych. Drugim poziomem rozpoznawania jest
poziom ekstrakcji fonetycznych charakterystyk informacyjnych. Następuje równoległe
wydzielanie charakterystyk prozodycznych (intonacja, akcent, rytm), które pozwalają na

35
określenie głównych struktur lingwistycznych. Kolejnym poziomem jest segmentacja i
klasyfikacja fonetyczna pozwalająca na ustalenie określonych ciągów fonetycznych. Ciągi
fonetyczne pozwalają na realizację procedury porównania słów ze słownika. Hipotetyczne
słowa (lub inne jednostki językowe) kończą proces rozpoznawania [52,94].
W systemach rozpoznawania mowy wykorzystujących UMM podstawą
rozpoznawania są jednostki fonetyczne, dla których tworzone są oddzielne modele akustyczne
[111]. Jako jednostki fonetyczne stosowane są słowa, sylaby, trifony, diafony i fonemy. Pod
pojęciem „fonem” rozumieć należy zbiór alofonów, które mają jednakowe funkcje i nie
wywołają znaczeniowych rozróżnień w obrębie danej mowy. Pod pojęciem „diafon”
rozumieć należy taką jednostkę językową, która zawiera informację przejściową od środka
quasi-stacjonarnych odcinków pary samogłoska-spółgłoska lub spółgłoska-samogłoska.
Zarówno proces tworzenia modeli UMM oraz właściwy proces rozpoznawania należy
poprzedzić procesem ekstrakcji charakterystyk z sygnałów mowy; realizuje się to przez
przetworzenie plików audio za pomocą narzędzi programowych. Dla modeli UMM z
dyskretnymi rozkładami wyjściowymi należy dokonać kwantyzacji wektorowej uzyskanych
charakterystyk, które nazywają się wektorami obserwacji [112].
Jeżeli w stosunku do aplikacji zostanie przyjęte wymaganie, aby dowolne słowa
mogły być dodane do leksykonu systemu bez konieczności przeprowadzania dodatkowego
treningu, potrzebne są dane uczące z dobrym pokryciem akustycznym i fonetycznie
zrównoważone, czyli uwzględniające wszystkie i we właściwej ilości zjawiska akustyczne
występujące na granicy rozpoznawanych jednostek fonetycznych.
Udoskonalenie pracy systemu rozpoznawania mowy umożliwia zastosowanie
gramatyki języka (czyli wykorzystanie wiedzy lingwistycznej) w celu ograniczenia wyboru
słów w każdym miejscu rozpoznawanej wypowiedzi. Gramatyka w minimalnym stopniu
wpływa na postać tworzonych modeli UMM jednostek akustycznych [5,112].
Dla danych testowych transkrypcja gramatyczna (skrypty podpowiedzi) zostanie
wykorzystana do oceny pracy systemu. Wygodnym sposobem tworzenia skryptów
podpowiedzi jest zastosowanie gramatyki zadania jako generatora losowego.
Filtracja sygnału mowy
Podstawowym etapem w procesie rozpoznawania mowy jest ekstrakcja wymaganych
charakterystyk z nagranych sygnałów audio-mowy. W zależności od tego, czy realizowane
jest rozpoznawanie fonemowe, czy rozpoznawanie całych pojedynczych słów, należy
dokonać odpowiedniej analizy badanego sygnału mowy. Ekstrakcja charakterystyk

36
wykonywana jest zarówno w procesie uczenia jak i testowania, prowadząc do pewnego
rodzaju kompresji sygnału audio na potrzeby tworzonego systemu rozpoznawania.
Zasadniczy wpływ na wybór charakterystyk reprezentujących mowę ma proces wytwarzania i
percepcji mowy przez człowieka.
Często proces wytwarzania mowy jest reprezentowany przez model typu źródło-filtr.
Sygnał wymuszenia (źródło) modelowany jest za pomocą:
• pseudookresowego ciągu impulsów dla głosek dźwięcznych: samogłosek, spółgłosek
płynnych, spółgłosek nosowych, głoski niesylabicznej „j” oraz głoski drżącej „r”;
• szumu białego dla bezdźwięcznych głosek trących, zwartych i zwarto-trących;
• sumy powyższych wymuszeń dla dźwięcznych głosek trących, zwartych, zwarto-
trących.
Trakt głosowy (usta, język, krtań, nos), bezpośrednio kształtujący sygnał mowy,
zwykle modelowany jest za pomocą filtru o skończonej odpowiedzi impulsowej (SOI).
Sygnał mowy w tym modelu jest splotem wymuszenia i odpowiedzi impulsowej filtru
[105,111].
Filtracja sygnałów umożliwia realizację następujących celów obróbki sygnałów:
ograniczenie szerokości pasma; polepszenie stosunku sygnału do szumów; wygładzenie
sygnału; wykrywanie zjawisk objawiających się zmianami widma; filtrację antyaliasingową,
zapobiegającą zniekształceniom, które mogły powstać w trakcie przetwarzania A/C, gdy
górne częstotliwości sygnału są wyższe niż ½ częstotliwości próbkowania [7]. W celu
uniknięcia aliasing’u stosuje się filtrację dolnoprzepustową, odcinającą składowe sygnału
powyżej częstotliwości Nyquista [105].
Podstawowym parametrem wyznaczającym objętość wynikowego zbioru danych
wprowadzanych do systemu jest częstotliwość próbkowania sygnałów. Częstotliwość ta
powinna być jak najmniejsza, ale należy zwrócić uwagę na fakt, iż częstotliwość zmian
obwiedni sygnałów na wyjściach filtrów musi być mniejsza od połowy przyjętej
częstotliwości próbkowania. Stosując filtrację dolnoprzepustową wprowadzanego sygnału
można uzyskać dowolnie małą częstotliwość graniczną, gubiąc jednak bezpowrotnie
informacje o tych partiach sygnału mowy, w których widmo zmienia się w sposób szybki
[105]. Ponieważ szybkie zmiany widma sygnału odpowiadają szybkim ruchom
artykulacyjnym narządów mowy, na ogół niosą one znacznie więcej informacji o
wypowiadanych wyrazach niż długotrwałe nawet okresy, w których widmo się nie zmienia,
gdyż narządy mowy pozostają nieruchome i trwa artykulacja stanów quasi-ustalonych
samogłosek lub spółgłosek szumowych. Wynika z tego, że przy rozpoznawaniu mowy te

37
właśnie szybkie zmiany widma sygnału będą bardzo przydatne, a ich utraty w momencie
wprowadzania sygnału mowy do systemu rozpoznawania nie da się później w żaden sposób
zrekompensować [105].
Częstotliwość próbkowania musi być wystarczająca do przeniesienia
zarejestrowanych zmian w widmie. Typową częstotliwością próbkowania mowy, przyjętą
również w telefonii, jest 8000 próbek/s. Jeśli składowa sygnału o najwyższej częstotliwości
jest równa f0, to należy pobierać próbki sygnału częściej niż 2f0 razy na sekundę (reguła
Nyquista). Reguła Nyquista może być rozszerzona na sygnały, które mają tylko składowe o
częstotliwościach pomiędzy f1 i f2. Jeśli f1 i f2 spełniają odpowiednie kryteria, to aby
odtworzyć dokładnie sygnał, należy próbkować sygnał z częstotliwością przynajmniej 2(f2 –
f1) próbek na sekundę [96]. Dla okna czasowego o długości 10 ms częstotliwość próbkowania
sygnałów wyjściowych z filtrów powinna wynosić około 100 Hz, czyli maksymalna
częstotliwość zmian widma wiernie oddana we wprowadzonym sygnale będzie wynosić 50
Hz. Sygnał na wyjściach filtrów poddawany jest jedynie uśrednianiu i mogą w nim
występować tętnienia o częstotliwości odpowiadającej częstotliwości środkowej filtru,
dlatego trzeba bardzo starannie odfiltrować częstotliwości większe od przyjętej częstotliwości
Nyquista.
Procedura projektowania filtrów rozpoczyna się od określenia wymaganej funkcji
transmitancji (przepustowego okna), po czym następuje obliczenie współczynników filtru,
które dadzą taką funkcję transmitancji [74]. Filtry dolnoprzepustowe to filtry, które
przepuszczają składowe poniżej ustalonej częstotliwości odcięcia f0. Jednym ze sposobów
charakteryzacji filtrów jest funkcja przeniesienia modułu, czyli stosunek modułu wejścia i
wyjścia filtru jako funkcji częstotliwości. W idealnym przypadku wszystkie składowe sygnału
wejściowego o częstotliwości poniżej f0 pozostają niezmienione z wyjątkiem wzmocnienia o
stałą. Wszystkie częstotliwości powyżej f0 zostają zatrzymane dając ostre odcięcie. W
przypadku filtru rzeczywistego odcięcie jest bardziej stopniowe. Także wzmocnienie
składowych o częstotliwości mniejszej niż f0 nie jest stałe, a składowe powyżej f0 nie są
całkowicie tłumione. Powstaje tzw. pulsacja w paśmie przejścia i tłumienia [96].
Filtrowanie cyfrowe, to obliczenie ważonej sumy bieżącego i poprzednich wejść do
filtra, a w pewnych przypadkach także ostatnich wyjść filtra. Ogólna postać związku wejścia
z wyjściem filtra jest następująca [96]:
∑ ∑= =
−− +=N
i
M
iiniinin ybxay
0 1, (3.1)

38
gdzie ciąg xn jest sygnałem wejściowym filtra, ciąg yn - wyjściowym, a wartości ai i bi -
współczynniki filtra.
Jeśli ciąg wejściowy składa się z jedynki, po której następują same zera, to ciąg
wyjściowy jest impulsową reakcją filtru. W przypadku, gdy wszystkie bi są równe 0, to
impulsowa reakcja zaniknie po N próbkach. Takie filtry są nazywane filtrami SOI. Filtry SOI
są zawsze stabilne (dopóki wejście jest ograniczone, wyjście także jest ograniczone), gdyż
dają w wyniku średnie ważone.
Do zaprojektowania filtru dolnoprzepustowego SOI można użyć poniższych funkcji
transmitancji (okna) [74]:
• okno prostokątne:
1,...,2,1,0,1)( −== Nndlanw (3.2)
• okno trójkątne:
2/22/,...,2,1,0,
2/)(
NnnorazNndla
Nnnw −=== (3.3)
• okno Hanninga:
1,...,2,1,0)/2cos(5,05,0)( −=−= NndlaNnnw π (3.4)
• okno Hamminga:
1,...,2,1,0)/2cos(46,054,0)( −=−= NndlaNnnw π (3.5)
• okno Blackmana:
1,...,2,1,0)4cos(08,0)2cos(5,042,0)( −=+−= NndlaN
nN
nnw ππ (3.6)
• okno Czebyszewa:
))(coshcosh[
)]cos([coscos()( 1
1
α
πα
−
−
⋅
⋅⋅
−=N
NmN
DFTodwrotnapunktowaNnw
1,...,2,1,0,))10(cosh1cosh( 1 −== − NnmiN
agdzie γ (3.7)
• okno Kaisera:
211,...,2,1,0
)(
])(1[)(
0
20 −=−=
−−= NpiNndla
Ip
pnInw
β
β (3.8)
Projektowanie filtrów metodą okna polega na zredukowaniu nieciągłości w(n) z
użyciem funkcji okien innych niż okno prostokątne [74].
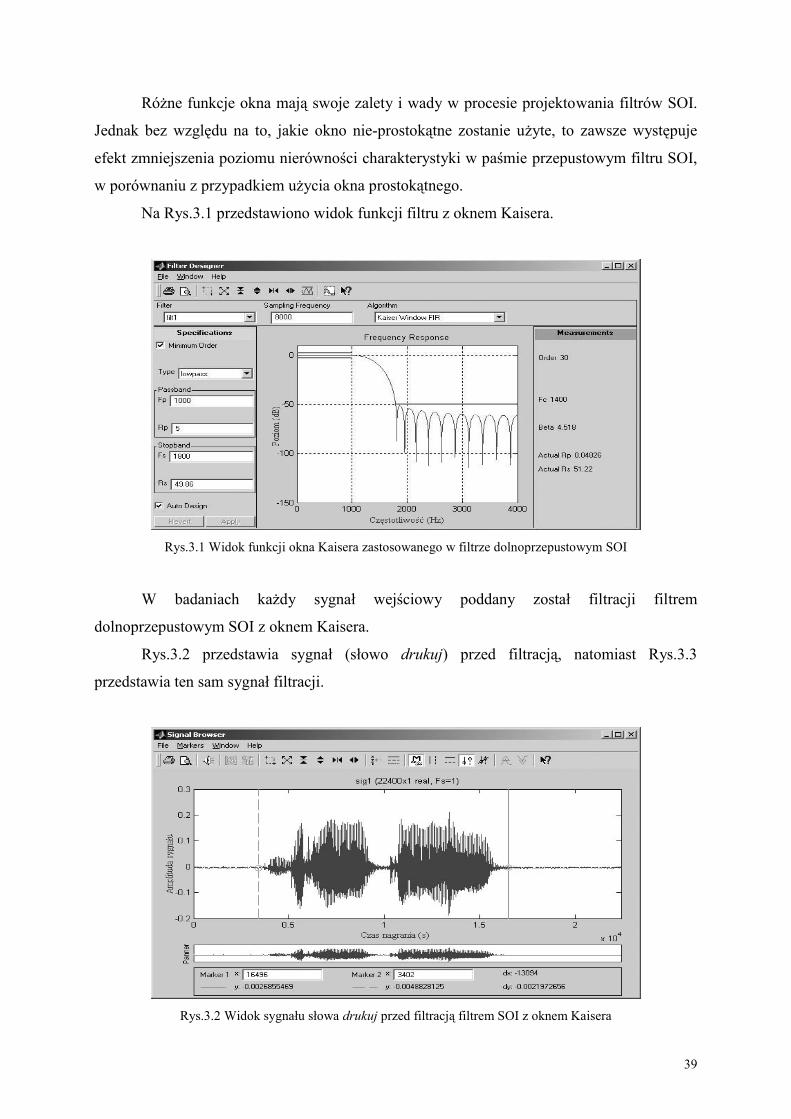
39
Różne funkcje okna mają swoje zalety i wady w procesie projektowania filtrów SOI.
Jednak bez względu na to, jakie okno nie-prostokątne zostanie użyte, to zawsze występuje
efekt zmniejszenia poziomu nierówności charakterystyki w paśmie przepustowym filtru SOI,
w porównaniu z przypadkiem użycia okna prostokątnego.
Na Rys.3.1 przedstawiono widok funkcji filtru z oknem Kaisera.
Rys.3.1 Widok funkcji okna Kaisera zastosowanego w filtrze dolnoprzepustowym SOI
W badaniach każdy sygnał wejściowy poddany został filtracji filtrem
dolnoprzepustowym SOI z oknem Kaisera.
Rys.3.2 przedstawia sygnał (słowo drukuj) przed filtracją, natomiast Rys.3.3
przedstawia ten sam sygnał filtracji.
Rys.3.2 Widok sygnału słowa drukuj przed filtracją filtrem SOI z oknem Kaisera
40
Rys.3.3 Widok sygnału słowa drukuj po filtracji filtrem SOI z oknem Kaisera
3.2. Proponowane metody ES i CZS do definiowania słów izolowanych
Po poddaniu sygnału wejściowego filtracji, kolejnym etapem jest wydzielenie czystego słowa
z nagranej wypowiedzi. Należy usunąć ciszę sprzed i spoza właściwego sygnału. Znajomość
charakterystyk ludzkiej mowy pozwala na wyznaczenie granic rozpoczynającej i kończącej
dane słowo. Wyróżnić należy w tym procesie trzy zasadnicze części nagrania: ciszę, różnego
rodzaju zakłócenia, właściwy sygnał mowy. Zarówno w procesie rozpoznawania słów
izolowanych jak i rozpoznawania mowy ciągłej właściwy podział nagranego sygnału ma
znaczący wpływ na skuteczność rozpoznawania.
W pracy przedstawiono metodę wykrywania początku i końca słowa bazującą na
energii sygnału (algorytm energii sygnału – ES) oraz na częstości zmian stanów sygnału dla
określonego odcinka czasowego i częstotliwości próbkowania (algorytm częstości zmian
sygnału – CZS).
W metodzie ES sygnał wejściowy dzielony jest na ramki o rozmiarze 256 próbek.
Wartości rozmiarów ramek uzależnione są od częstotliwości próbkowania. Zastosowano
częstotliwość próbkowania 8000 Hz. Następnie dla każdej ramki obliczona zostaje jej
energia:
,..11
2,∑
=
==N
iijj MjdlaXweE (3.9)
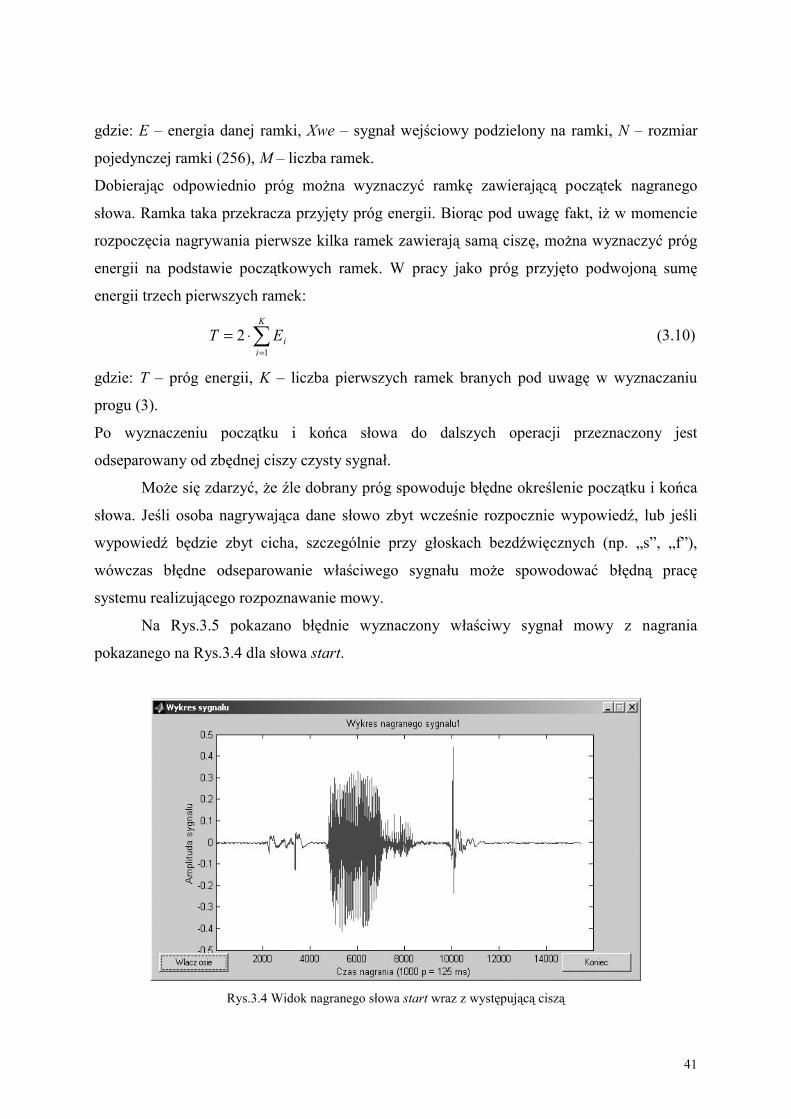
41
gdzie: E – energia danej ramki, Xwe – sygnał wejściowy podzielony na ramki, N – rozmiar
pojedynczej ramki (256), M – liczba ramek.
Dobierając odpowiednio próg można wyznaczyć ramkę zawierającą początek nagranego
słowa. Ramka taka przekracza przyjęty próg energii. Biorąc pod uwagę fakt, iż w momencie
rozpoczęcia nagrywania pierwsze kilka ramek zawierają samą ciszę, można wyznaczyć próg
energii na podstawie początkowych ramek. W pracy jako próg przyjęto podwojoną sumę
energii trzech pierwszych ramek:
∑=
⋅=K
iiET
12 (3.10)
gdzie: T – próg energii, K – liczba pierwszych ramek branych pod uwagę w wyznaczaniu
progu (3).
Po wyznaczeniu początku i końca słowa do dalszych operacji przeznaczony jest
odseparowany od zbędnej ciszy czysty sygnał.
Może się zdarzyć, że źle dobrany próg spowoduje błędne określenie początku i końca
słowa. Jeśli osoba nagrywająca dane słowo zbyt wcześnie rozpocznie wypowiedź, lub jeśli
wypowiedź będzie zbyt cicha, szczególnie przy głoskach bezdźwięcznych (np. „s”, „f”),
wówczas błędne odseparowanie właściwego sygnału może spowodować błędną pracę
systemu realizującego rozpoznawanie mowy.
Na Rys.3.5 pokazano błędnie wyznaczony właściwy sygnał mowy z nagrania
pokazanego na Rys.3.4 dla słowa start.
Rys.3.4 Widok nagranego słowa start wraz z występującą ciszą
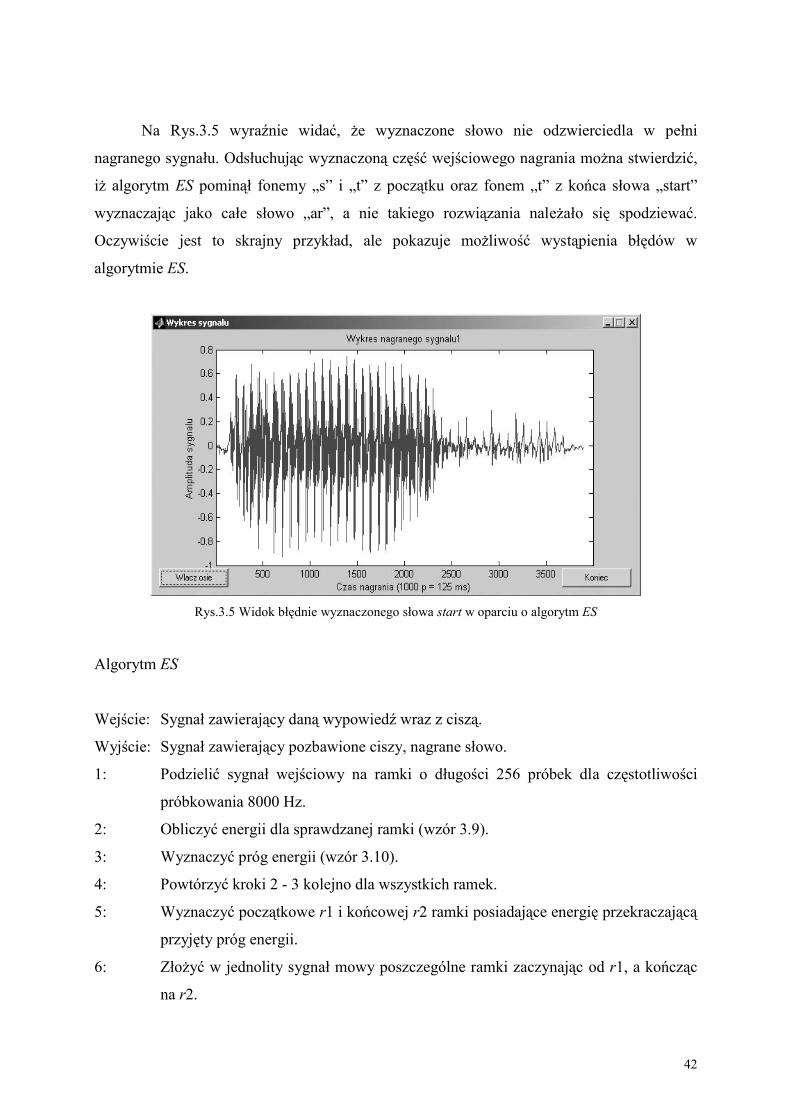
42
Na Rys.3.5 wyraźnie widać, że wyznaczone słowo nie odzwierciedla w pełni
nagranego sygnału. Odsłuchując wyznaczoną część wejściowego nagrania można stwierdzić,
iż algorytm ES pominął fonemy „s” i „t” z początku oraz fonem „t” z końca słowa „start”
wyznaczając jako całe słowo „ar”, a nie takiego rozwiązania należało się spodziewać.
Oczywiście jest to skrajny przykład, ale pokazuje możliwość wystąpienia błędów w
algorytmie ES.
Rys.3.5 Widok błędnie wyznaczonego słowa start w oparciu o algorytm ES
Algorytm ES
Wejście: Sygnał zawierający daną wypowiedź wraz z ciszą.
Wyjście: Sygnał zawierający pozbawione ciszy, nagrane słowo.
1: Podzielić sygnał wejściowy na ramki o długości 256 próbek dla częstotliwości
próbkowania 8000 Hz.
2: Obliczyć energii dla sprawdzanej ramki (wzór 3.9).
3: Wyznaczyć próg energii (wzór 3.10).
4: Powtórzyć kroki 2 - 3 kolejno dla wszystkich ramek.
5: Wyznaczyć początkowe r1 i końcowej r2 ramki posiadające energię przekraczającą
przyjęty próg energii.
6: Złożyć w jednolity sygnał mowy poszczególne ramki zaczynając od r1, a kończąc
na r2.
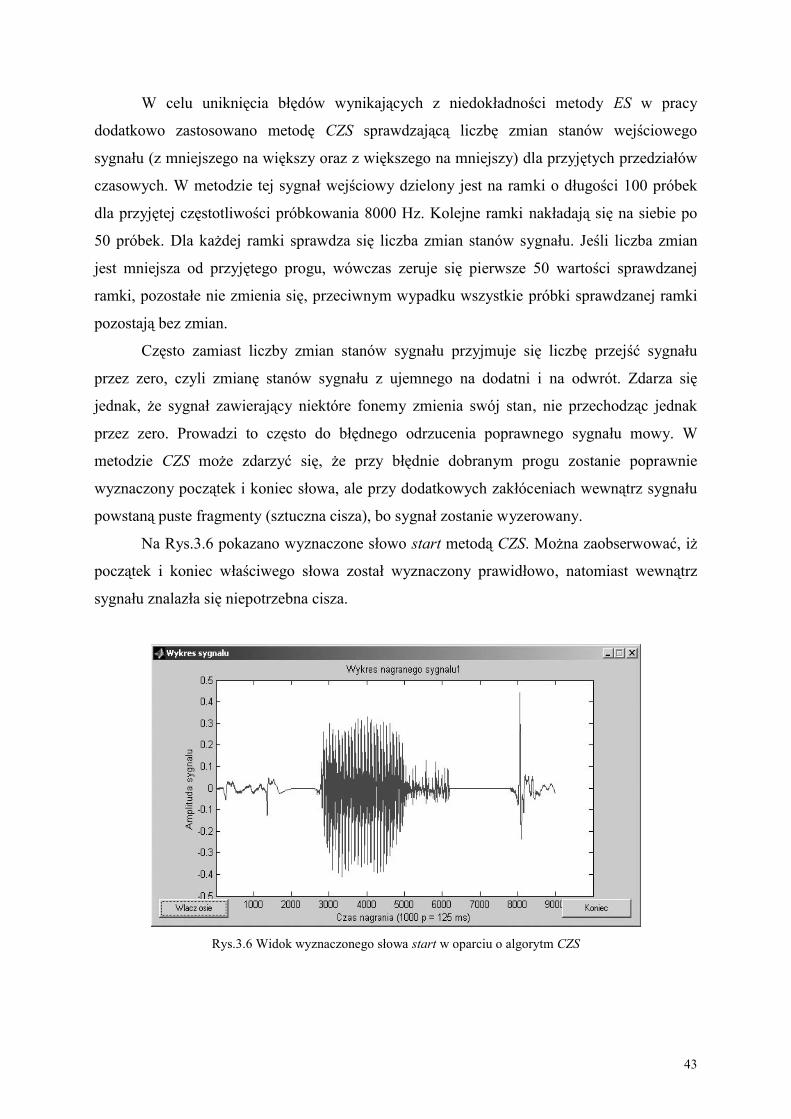
43
W celu uniknięcia błędów wynikających z niedokładności metody ES w pracy
dodatkowo zastosowano metodę CZS sprawdzającą liczbę zmian stanów wejściowego
sygnału (z mniejszego na większy oraz z większego na mniejszy) dla przyjętych przedziałów
czasowych. W metodzie tej sygnał wejściowy dzielony jest na ramki o długości 100 próbek
dla przyjętej częstotliwości próbkowania 8000 Hz. Kolejne ramki nakładają się na siebie po
50 próbek. Dla każdej ramki sprawdza się liczba zmian stanów sygnału. Jeśli liczba zmian
jest mniejsza od przyjętego progu, wówczas zeruje się pierwsze 50 wartości sprawdzanej
ramki, pozostałe nie zmienia się, przeciwnym wypadku wszystkie próbki sprawdzanej ramki
pozostają bez zmian.
Często zamiast liczby zmian stanów sygnału przyjmuje się liczbę przejść sygnału
przez zero, czyli zmianę stanów sygnału z ujemnego na dodatni i na odwrót. Zdarza się
jednak, że sygnał zawierający niektóre fonemy zmienia swój stan, nie przechodząc jednak
przez zero. Prowadzi to często do błędnego odrzucenia poprawnego sygnału mowy. W
metodzie CZS może zdarzyć się, że przy błędnie dobranym progu zostanie poprawnie
wyznaczony początek i koniec słowa, ale przy dodatkowych zakłóceniach wewnątrz sygnału
powstaną puste fragmenty (sztuczna cisza), bo sygnał zostanie wyzerowany.
Na Rys.3.6 pokazano wyznaczone słowo start metodą CZS. Można zaobserwować, iż
początek i koniec właściwego słowa został wyznaczony prawidłowo, natomiast wewnątrz
sygnału znalazła się niepotrzebna cisza.
Rys.3.6 Widok wyznaczonego słowa start w oparciu o algorytm CZS
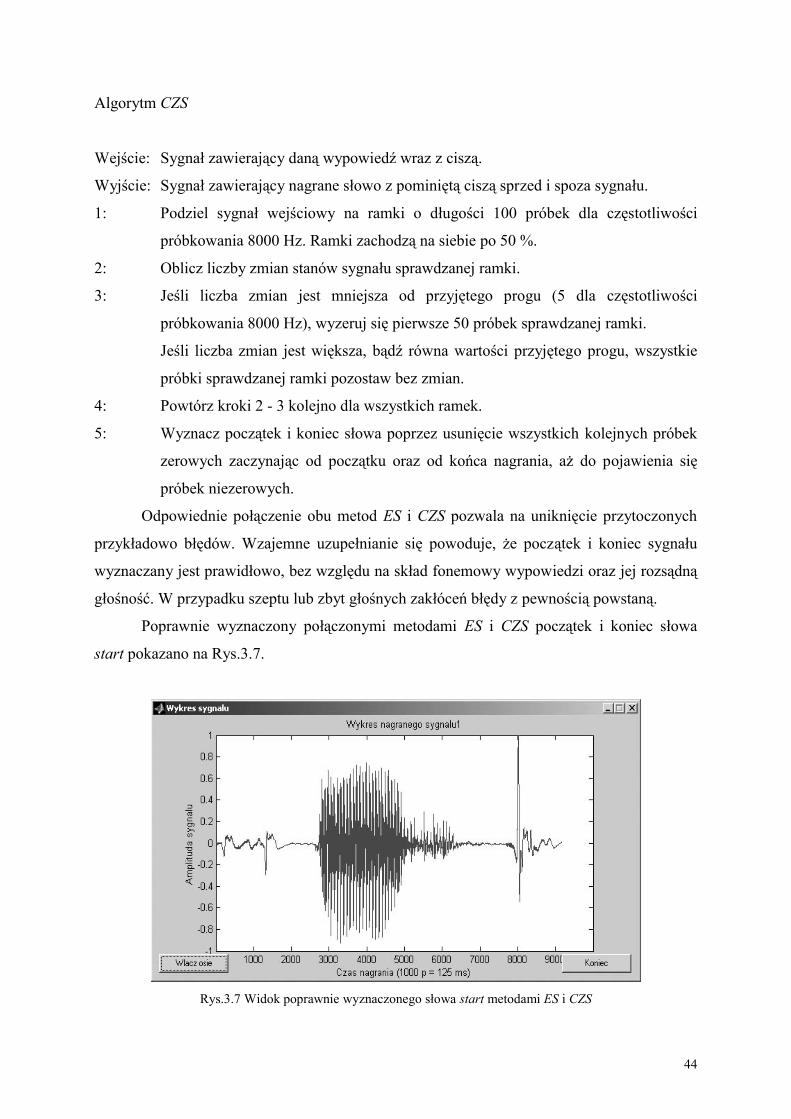
44
Algorytm CZS
Wejście: Sygnał zawierający daną wypowiedź wraz z ciszą.
Wyjście: Sygnał zawierający nagrane słowo z pominiętą ciszą sprzed i spoza sygnału.
1: Podziel sygnał wejściowy na ramki o długości 100 próbek dla częstotliwości
próbkowania 8000 Hz. Ramki zachodzą na siebie po 50 %.
2: Oblicz liczby zmian stanów sygnału sprawdzanej ramki.
3: Jeśli liczba zmian jest mniejsza od przyjętego progu (5 dla częstotliwości
próbkowania 8000 Hz), wyzeruj się pierwsze 50 próbek sprawdzanej ramki.
Jeśli liczba zmian jest większa, bądź równa wartości przyjętego progu, wszystkie
próbki sprawdzanej ramki pozostaw bez zmian.
4: Powtórz kroki 2 - 3 kolejno dla wszystkich ramek.
5: Wyznacz początek i koniec słowa poprzez usunięcie wszystkich kolejnych próbek
zerowych zaczynając od początku oraz od końca nagrania, aż do pojawienia się
próbek niezerowych.
Odpowiednie połączenie obu metod ES i CZS pozwala na uniknięcie przytoczonych
przykładowo błędów. Wzajemne uzupełnianie się powoduje, że początek i koniec sygnału
wyznaczany jest prawidłowo, bez względu na skład fonemowy wypowiedzi oraz jej rozsądną
głośność. W przypadku szeptu lub zbyt głośnych zakłóceń błędy z pewnością powstaną.
Poprawnie wyznaczony połączonymi metodami ES i CZS początek i koniec słowa
start pokazano na Rys.3.7.
Rys.3.7 Widok poprawnie wyznaczonego słowa start metodami ES i CZS
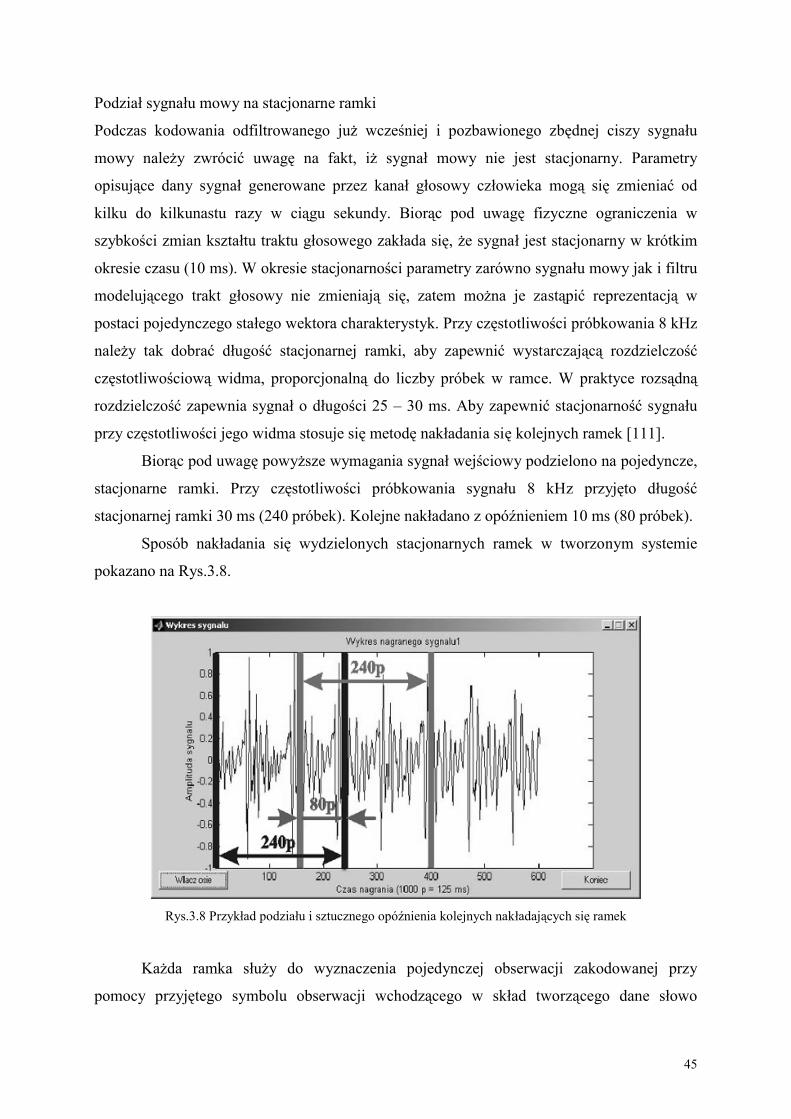
45
Podział sygnału mowy na stacjonarne ramki
Podczas kodowania odfiltrowanego już wcześniej i pozbawionego zbędnej ciszy sygnału
mowy należy zwrócić uwagę na fakt, iż sygnał mowy nie jest stacjonarny. Parametry
opisujące dany sygnał generowane przez kanał głosowy człowieka mogą się zmieniać od
kilku do kilkunastu razy w ciągu sekundy. Biorąc pod uwagę fizyczne ograniczenia w
szybkości zmian kształtu traktu głosowego zakłada się, że sygnał jest stacjonarny w krótkim
okresie czasu (10 ms). W okresie stacjonarności parametry zarówno sygnału mowy jak i filtru
modelującego trakt głosowy nie zmieniają się, zatem można je zastąpić reprezentacją w
postaci pojedynczego stałego wektora charakterystyk. Przy częstotliwości próbkowania 8 kHz
należy tak dobrać długość stacjonarnej ramki, aby zapewnić wystarczającą rozdzielczość
częstotliwościową widma, proporcjonalną do liczby próbek w ramce. W praktyce rozsądną
rozdzielczość zapewnia sygnał o długości 25 – 30 ms. Aby zapewnić stacjonarność sygnału
przy częstotliwości jego widma stosuje się metodę nakładania się kolejnych ramek [111].
Biorąc pod uwagę powyższe wymagania sygnał wejściowy podzielono na pojedyncze,
stacjonarne ramki. Przy częstotliwości próbkowania sygnału 8 kHz przyjęto długość
stacjonarnej ramki 30 ms (240 próbek). Kolejne nakładano z opóźnieniem 10 ms (80 próbek).
Sposób nakładania się wydzielonych stacjonarnych ramek w tworzonym systemie
pokazano na Rys.3.8.
Rys.3.8 Przykład podziału i sztucznego opóźnienia kolejnych nakładających się ramek
Każda ramka służy do wyznaczenia pojedynczej obserwacji zakodowanej przy
pomocy przyjętego symbolu obserwacji wchodzącego w skład tworzącego dane słowo
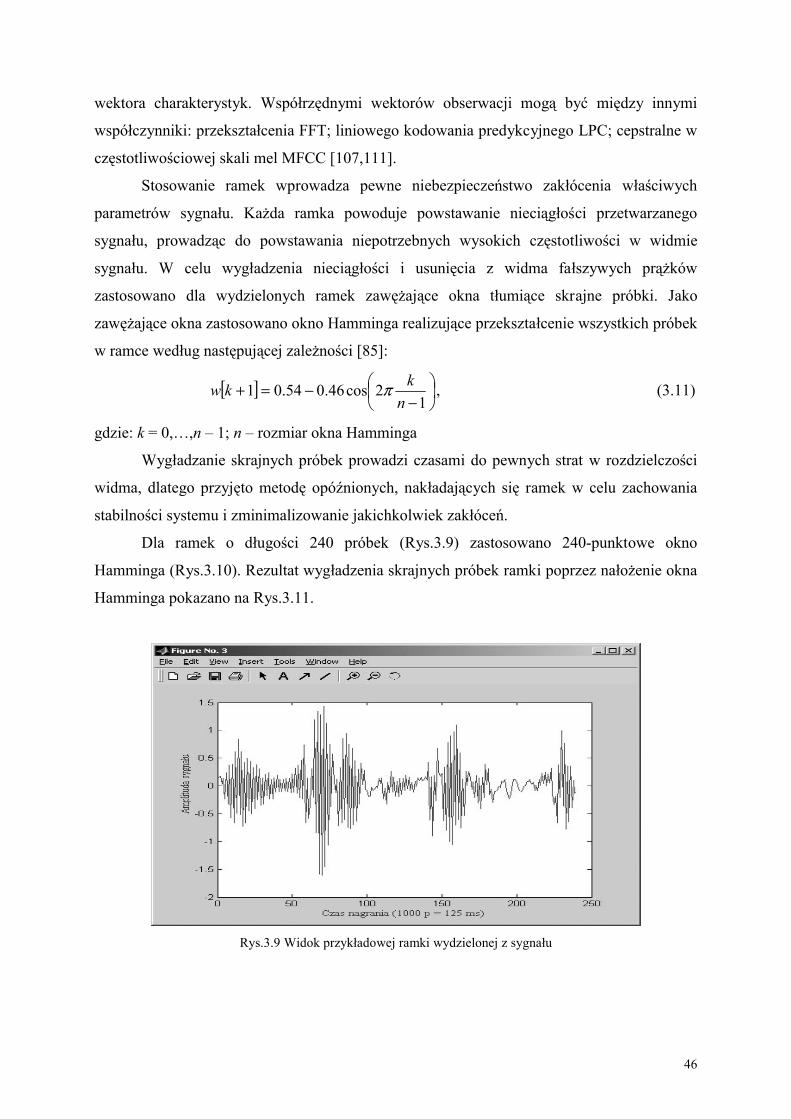
46
wektora charakterystyk. Współrzędnymi wektorów obserwacji mogą być między innymi
współczynniki: przekształcenia FFT; liniowego kodowania predykcyjnego LPC; cepstralne w
częstotliwościowej skali mel MFCC [107,111].
Stosowanie ramek wprowadza pewne niebezpieczeństwo zakłócenia właściwych
parametrów sygnału. Każda ramka powoduje powstawanie nieciągłości przetwarzanego
sygnału, prowadząc do powstawania niepotrzebnych wysokich częstotliwości w widmie
sygnału. W celu wygładzenia nieciągłości i usunięcia z widma fałszywych prążków
zastosowano dla wydzielonych ramek zawężające okna tłumiące skrajne próbki. Jako
zawężające okna zastosowano okno Hamminga realizujące przekształcenie wszystkich próbek
w ramce według następującej zależności [85]:
[ ]
−−=+
12cos46.054.01
nkkw π , (3.11)
gdzie: k = 0,…,n – 1; n – rozmiar okna Hamminga
Wygładzanie skrajnych próbek prowadzi czasami do pewnych strat w rozdzielczości
widma, dlatego przyjęto metodę opóźnionych, nakładających się ramek w celu zachowania
stabilności systemu i zminimalizowanie jakichkolwiek zakłóceń.
Dla ramek o długości 240 próbek (Rys.3.9) zastosowano 240-punktowe okno
Hamminga (Rys.3.10). Rezultat wygładzenia skrajnych próbek ramki poprzez nałożenie okna
Hamminga pokazano na Rys.3.11.
Rys.3.9 Widok przykładowej ramki wydzielonej z sygnału
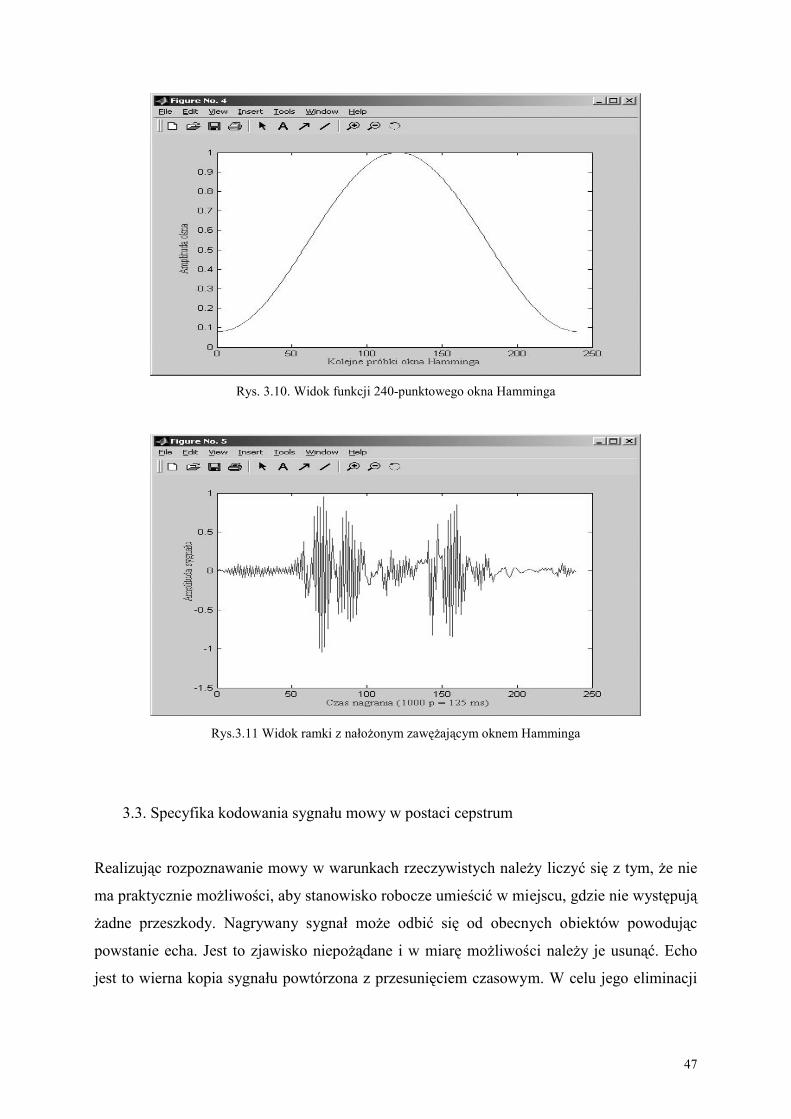
47
Rys. 3.10. Widok funkcji 240-punktowego okna Hamminga
Rys.3.11 Widok ramki z nałożonym zawężającym oknem Hamminga
3.3. Specyfika kodowania sygnału mowy w postaci cepstrum
Realizując rozpoznawanie mowy w warunkach rzeczywistych należy liczyć się z tym, że nie
ma praktycznie możliwości, aby stanowisko robocze umieścić w miejscu, gdzie nie występują
żadne przeszkody. Nagrywany sygnał może odbić się od obecnych obiektów powodując
powstanie echa. Jest to zjawisko niepożądane i w miarę możliwości należy je usunąć. Echo
jest to wierna kopia sygnału powtórzona z przesunięciem czasowym. W celu jego eliminacji

48
należy zastosować narzędzia pozwalające na porównanie przesuniętych sygnałów. Taką
możliwość daje cepstrum sygnału.
Termin cepstrum został wprowadzony przez Bogerta i współautorów w pracy [9].
Zaobserwowali oni, że logarytm spektrum mocy sygnału zawierającego echo ma dodatkowy
okresowy składnik powodujący echo. Generalnie, dźwięczna mowa x(t) może być
postrzegana jako reakcja odpowiedniego filtru artykulacji traktu głosowego napędzanego
przez pseudo okresowe źródło g(t). Sygnał x(t) można otrzymać jako splot g(t) oraz impulsu
odpowiedzi traktu głosowego h(t) jako [41,107]:
∫ −=t
dthgtx0
)()()( τττ , (3.12)
który jest równoważny do
)()()( ωωω HGX ⋅= , (3.13)
gdzie X(ω), G(ω) i H(ω) są wyznaczone jako FFT odpowiednio z x(t), g(t) i h(t).
Jeśli x(t) jest funkcją okresową, |X(ω)| jest reprezentowany przez widma liniowe, czyli
przedziały częstotliwości będące odwrotnością podstawowego okresu g(t). Dlatego, kiedy
|X(ω)| jest wyznaczane przez FFT z kolejnych w czasie próbek dla krótkiego okresu sygnału
mowy, wówczas są to wyraźnie ostre przedziały z równymi odstępami wzdłuż osi
częstotliwości [41,107]. Logarytm X(ω) wynosi:
)(log)(log)(log ωωω HGX += (3.14)
Pierwszy i drugi składnik prawej strony równania (3.14) opisuje odpowiednio właściwe
widmo oraz widmo obwiedni [76,107]. Początkowo był to model okresowy, później globalny
model wzdłuż osi częstotliwości.
Istnieje duża różnica pomiędzy odwrotną szybką transformatą Fouriera IFFT z obu
elementów:
)(log)(log)(log)( 111 ωωωτ HGXc −−− ℑ+ℑ=ℑ= , (3.15)
co w terminologii [9] zapisuje się jako:
)))))((((log( 10 samplevoiceFFTabsIFFTrealCepstrum = (3.16)
Dokonując operacji logarytmowania widma sygnału mnożenie zamieniane zostaje w
sumę. Następuje przejście z dziedziny częstotliwości w dziedzinę czasu. Na początku
cepstrum zgromadzona jest energia sygnału właściwego, echo uwidacznia się w dalszych
momentach czasowych. Jest ono reprezentowane przez pojedyncze prążki przesunięte na osi
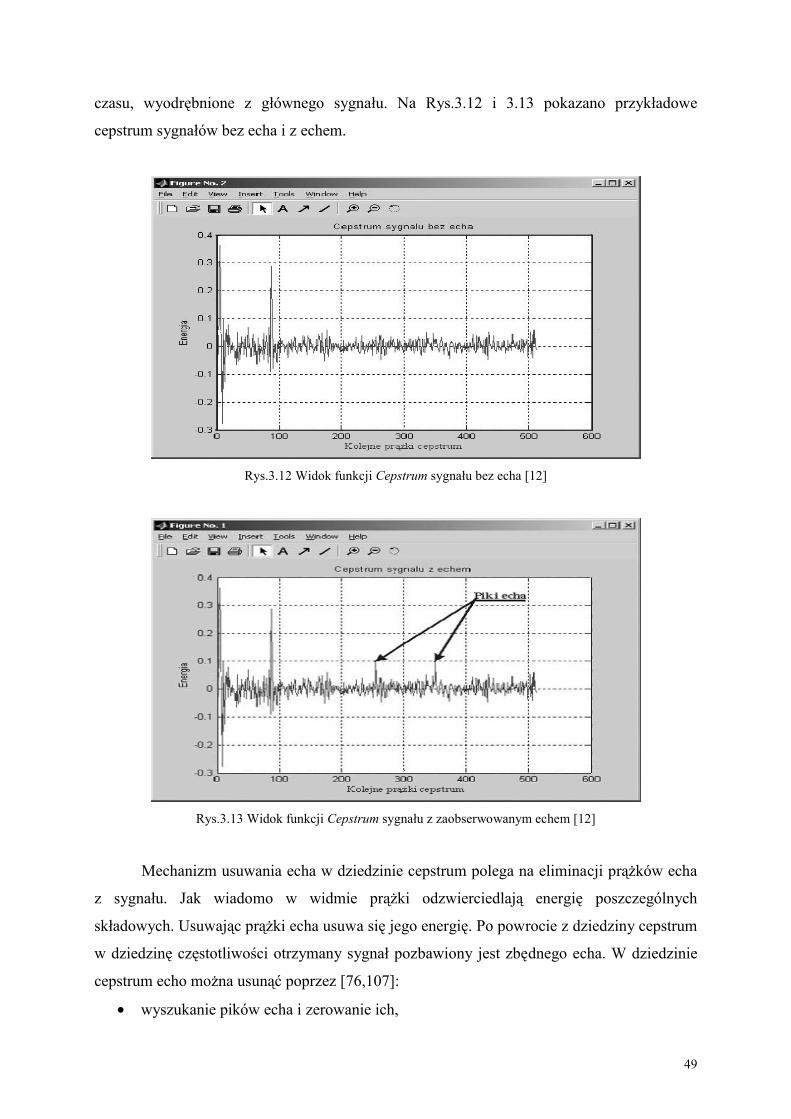
49
czasu, wyodrębnione z głównego sygnału. Na Rys.3.12 i 3.13 pokazano przykładowe
cepstrum sygnałów bez echa i z echem.
Rys.3.12 Widok funkcji Cepstrum sygnału bez echa [12]
Rys.3.13 Widok funkcji Cepstrum sygnału z zaobserwowanym echem [12]
Mechanizm usuwania echa w dziedzinie cepstrum polega na eliminacji prążków echa
z sygnału. Jak wiadomo w widmie prążki odzwierciedlają energię poszczególnych
składowych. Usuwając prążki echa usuwa się jego energię. Po powrocie z dziedziny cepstrum
w dziedzinę częstotliwości otrzymany sygnał pozbawiony jest zbędnego echa. W dziedzinie
cepstrum echo można usunąć poprzez [76,107]:
• wyszukanie pików echa i zerowanie ich,
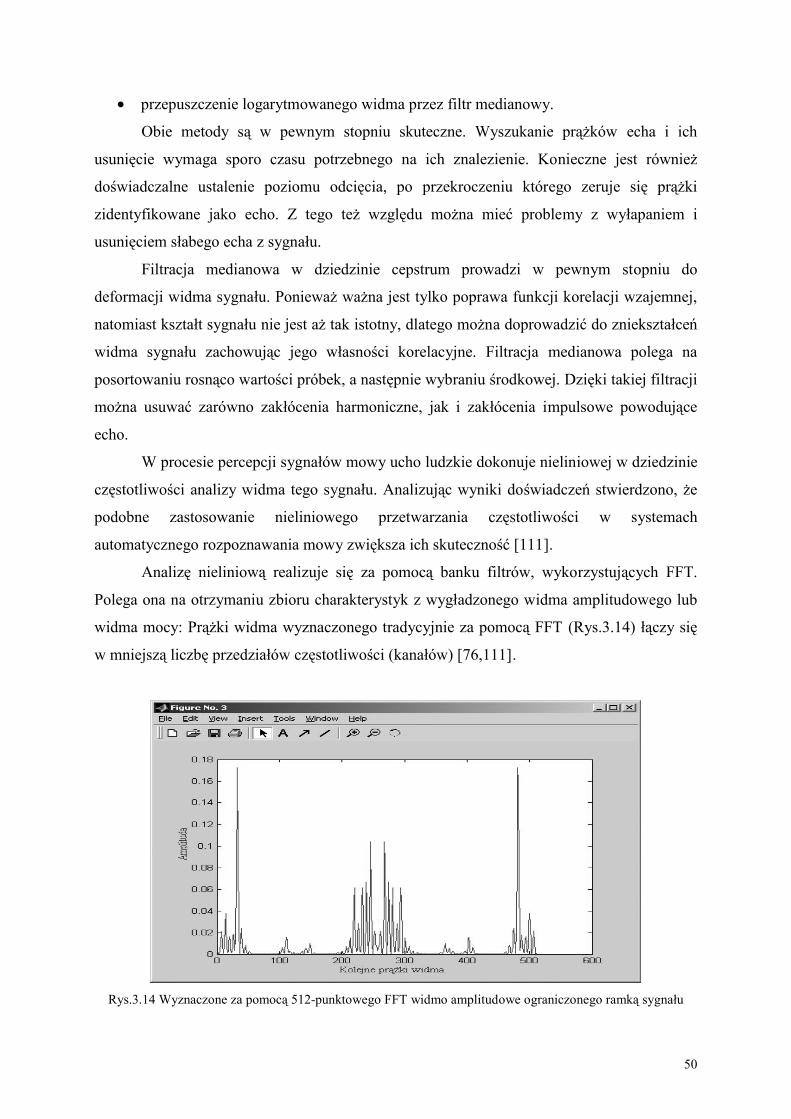
50
• przepuszczenie logarytmowanego widma przez filtr medianowy.
Obie metody są w pewnym stopniu skuteczne. Wyszukanie prążków echa i ich
usunięcie wymaga sporo czasu potrzebnego na ich znalezienie. Konieczne jest również
doświadczalne ustalenie poziomu odcięcia, po przekroczeniu którego zeruje się prążki
zidentyfikowane jako echo. Z tego też względu można mieć problemy z wyłapaniem i
usunięciem słabego echa z sygnału.
Filtracja medianowa w dziedzinie cepstrum prowadzi w pewnym stopniu do
deformacji widma sygnału. Ponieważ ważna jest tylko poprawa funkcji korelacji wzajemnej,
natomiast kształt sygnału nie jest aż tak istotny, dlatego można doprowadzić do zniekształceń
widma sygnału zachowując jego własności korelacyjne. Filtracja medianowa polega na
posortowaniu rosnąco wartości próbek, a następnie wybraniu środkowej. Dzięki takiej filtracji
można usuwać zarówno zakłócenia harmoniczne, jak i zakłócenia impulsowe powodujące
echo.
W procesie percepcji sygnałów mowy ucho ludzkie dokonuje nieliniowej w dziedzinie
częstotliwości analizy widma tego sygnału. Analizując wyniki doświadczeń stwierdzono, że
podobne zastosowanie nieliniowego przetwarzania częstotliwości w systemach
automatycznego rozpoznawania mowy zwiększa ich skuteczność [111].
Analizę nieliniową realizuje się za pomocą banku filtrów, wykorzystujących FFT.
Polega ona na otrzymaniu zbioru charakterystyk z wygładzonego widma amplitudowego lub
widma mocy: Prążki widma wyznaczonego tradycyjnie za pomocą FFT (Rys.3.14) łączy się
w mniejszą liczbę przedziałów częstotliwości (kanałów) [76,111].
Rys.3.14 Wyznaczone za pomocą 512-punktowego FFT widmo amplitudowe ograniczonego ramką sygnału
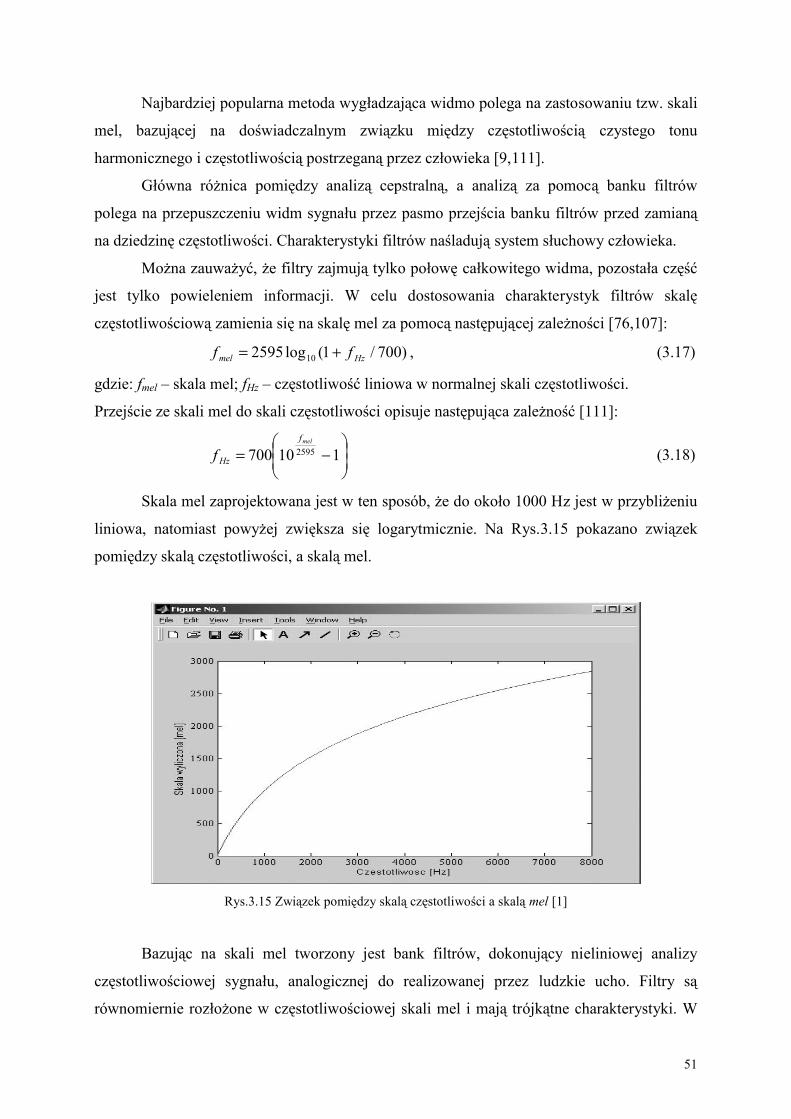
51
Najbardziej popularna metoda wygładzająca widmo polega na zastosowaniu tzw. skali
mel, bazującej na doświadczalnym związku między częstotliwością czystego tonu
harmonicznego i częstotliwością postrzeganą przez człowieka [9,111].
Główna różnica pomiędzy analizą cepstralną, a analizą za pomocą banku filtrów
polega na przepuszczeniu widm sygnału przez pasmo przejścia banku filtrów przed zamianą
na dziedzinę częstotliwości. Charakterystyki filtrów naśladują system słuchowy człowieka.
Można zauważyć, że filtry zajmują tylko połowę całkowitego widma, pozostała część
jest tylko powieleniem informacji. W celu dostosowania charakterystyk filtrów skalę
częstotliwościową zamienia się na skalę mel za pomocą następującej zależności [76,107]:
)700/1(log2595 10 Hzmel ff += , (3.17)
gdzie: fmel – skala mel; fHz – częstotliwość liniowa w normalnej skali częstotliwości.
Przejście ze skali mel do skali częstotliwości opisuje następująca zależność [111]:
−= 110700 2595
melf
Hzf (3.18)
Skala mel zaprojektowana jest w ten sposób, że do około 1000 Hz jest w przybliżeniu
liniowa, natomiast powyżej zwiększa się logarytmicznie. Na Rys.3.15 pokazano związek
pomiędzy skalą częstotliwości, a skalą mel.
Rys.3.15 Związek pomiędzy skalą częstotliwości a skalą mel [1]
Bazując na skali mel tworzony jest bank filtrów, dokonujący nieliniowej analizy
częstotliwościowej sygnału, analogicznej do realizowanej przez ludzkie ucho. Filtry są
równomiernie rozłożone w częstotliwościowej skali mel i mają trójkątne charakterystyki. W
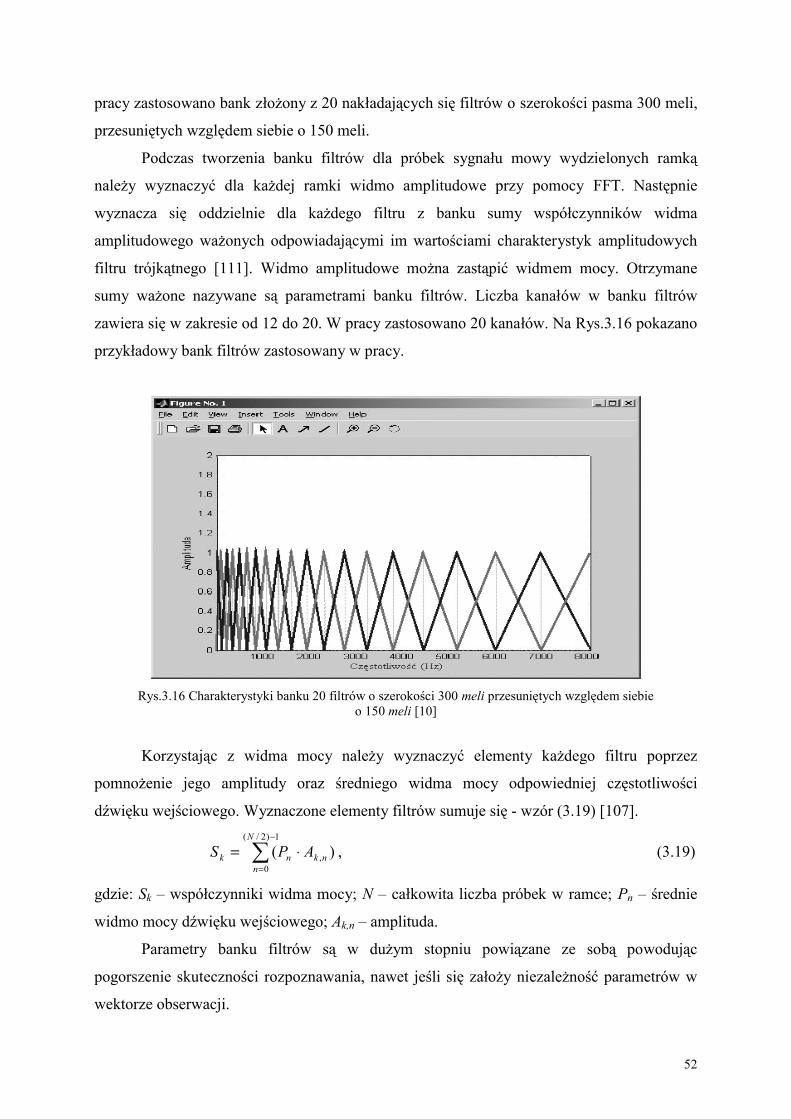
52
pracy zastosowano bank złożony z 20 nakładających się filtrów o szerokości pasma 300 meli,
przesuniętych względem siebie o 150 meli.
Podczas tworzenia banku filtrów dla próbek sygnału mowy wydzielonych ramką
należy wyznaczyć dla każdej ramki widmo amplitudowe przy pomocy FFT. Następnie
wyznacza się oddzielnie dla każdego filtru z banku sumy współczynników widma
amplitudowego ważonych odpowiadającymi im wartościami charakterystyk amplitudowych
filtru trójkątnego [111]. Widmo amplitudowe można zastąpić widmem mocy. Otrzymane
sumy ważone nazywane są parametrami banku filtrów. Liczba kanałów w banku filtrów
zawiera się w zakresie od 12 do 20. W pracy zastosowano 20 kanałów. Na Rys.3.16 pokazano
przykładowy bank filtrów zastosowany w pracy.
Rys.3.16 Charakterystyki banku 20 filtrów o szerokości 300 meli przesuniętych względem siebie
o 150 meli [10]
Korzystając z widma mocy należy wyznaczyć elementy każdego filtru poprzez
pomnożenie jego amplitudy oraz średniego widma mocy odpowiedniej częstotliwości
dźwięku wejściowego. Wyznaczone elementy filtrów sumuje się - wzór (3.19) [107].
∑−
=
⋅=1)2/(
0, )(
N
nnknk APS , (3.19)
gdzie: Sk – współczynniki widma mocy; N – całkowita liczba próbek w ramce; Pn – średnie
widmo mocy dźwięku wejściowego; Ak,n – amplituda.
Parametry banku filtrów są w dużym stopniu powiązane ze sobą powodując
pogorszenie skuteczności rozpoznawania, nawet jeśli się założy niezależność parametrów w
wektorze obserwacji.

53
Poprawienie jakości rozpoznawania można uzyskać poprzez zastosowanie
przekształcenia cepstralnego parametrów banku filtrów, polegającego na wyznaczeniu
współczynników cepstralnych w skali mel MFCC jako dyskretnych przekształceń
kosinusowych logarytmów parametrów banku filtrów według zależności [33,107]:
,...1,1
)5.0(cos)(log1
NndlaK
knSMFCCK
kkn =
+−=∑
=
π (3.20)
gdzie: Sk – współczynniki widma mocy; K – liczba wymaganych współczynników cepstrum;
N – liczba filtrów w banku filtrów.
W pracy przyjęto liczbę wymaganych współczynników cepstrum K równą 20, co
oznaczało zastosowanie 21 filtrów w banku filtrów pokrywających częstotliwość z przedziału
od 0 do 4192 Hz.
Dodatkową zaletą współczynników MFCC jest uniezależnienie sygnału mowy od
wpływu kanału transmisji. Przy założeniu, że kanał transmisji jest liniowym układem
dynamicznym, sygnał na jego wyjściu jest splotem sygnału mowy (wejściowego) i
odpowiedzi impulsowej tego układu. Zatem widmo zniekształconego sygnału mowy
(wyjściowego) jest iloczynem widma sygnału mowy i charakterystyki częstotliwościowej
kanału transmisji. W dziedzinie wartości cepstrum mnożenie staje się zwykłym dodawaniem,
i wpływ kanału transmisji może być zredukowany poprzez odjęcie wartości średniej
współczynników MFCC od wszystkich wektorów obserwacji (przyjmuje się, że kanał
transmisji nie zmienia się w czasie). W rzeczywistości wartość średnia jest estymowana dla
ograniczonej ilości danych a operacja odejmowania wartości średniej nie eliminuje wpływów
kanału transmisji na sygnał. Mimo tego ta prosta technika jest w praktyce bardzo efektywna,
kompensując długotrwałe wpływy na widmo sygnału, wywołane przez różne mikrofony i
kanały transmisji stosowane podczas rejestracji sygnałów mowy. Aby wykonać. cepstralną
normalizację wartością średnią, należy wyznaczyć wartość średnią każdego współczynnika
cepstrum dla wszystkich wypowiedzi uczących. Ze względu na sposób realizacji kompensacja
cepstralną wartością średnią nie ma zastosowania dla sygnału rejestrowanego na żywo [111].
Pasmo częstotliwości, w którym analizowany jest sygnał, może pokrywać cały zakres
częstotliwości, lub zostać ograniczone (np w celu odrzucenia zakresów częstotliwości). W
tym ostatnim przypadku należy zadać częstotliwość dolną i górną analizowanego pasma,
wówczas zadana liczba kanałów w banku filtrów zostanie rozłożona równomiernie w skali
mel wzdłuż całego zakresu w ten sposób, że dolna częstotliwość pasma pokrywać się będzie z
dolną częstotliwością odcięcia pierwszego filtru, a górna częstotliwość pasma będzie górną
częstotliwością docięcia ostatniego filtru [111].

54
Algorytm MFCC
Wejście: Kolejne ramki o długości 240 próbek podzielonego wejściowego sygnału mowy o
częstotliwości 8000 Hz.
Wyjście: Kolejne wyznaczone sekwencje dwudziestu współczynników cepstrum dla każdej z
wejściowych ramek.
1: Wyznacz bank k filtrów, każdy o szerokości 300 meli, przesuniętych względem
siebie o 150 meli.
2: Wyznacz 512-punktową FFT z badanej ramki.
3: Przefiltrj 256 wartości wyznaczonego widma sygnału przez bank filtrów.
4: Wyznacz parametry banku filtrów Sk (wzór 3.19).
5: Wyznacz współczynniki cepstralne w skali mel MFCCk (wzór 3.20).
6: Powtórz kroki2 – 5 kolejno dla wszystkich ramek.
Wykresy wyznaczonych współczynników cepstrum dla wszystkich ramek słowa
wyloguj na Rys.3.17. Widać podobieństwo wyznaczonych współczynników MFCC
szczególnie końcowych ramek odpowiadających fonemowi „j” badanego słowa wyloguj.
Wypowiedź została nagrana z akcentem na fonem „j” w celu pokazania możliwości
odróżnienia fonemów języka polskiego.
Rys.3.17 Widok 20 współczynników cepstrum wyznaczonych dla sekwencje ramek słowa wyloguj

55
3.4. Kwantyzacja wektorowa cepstrum za pomocą algorytmu Lloyda
W zastosowaniu kompresji bezstratnej dane generowane przez źródło muszą być
reprezentowane za pomocą jednego z niewielkiej liczby słów kodowych. Liczba możliwych
różnych danych jest generalnie dużo większa od liczby przeznaczonych do ich
reprezentowania słów kodowych. Proces reprezentowania dużego zbioru wartości za pomocą
zbioru znacznie mniejszego jest nazywany kwantyzacją [96]. W przypadku rozpoznawania
mowy polskiej z zastosowaniem UMM podstawie danych uczących dobranych tak, aby
pokryć w całości przestrzeń akustyczną danego zagadnienia, wszystkie poszczególne słowa
można kodować przy pomocy 37 symboli kodowych, odpowiadających liczbie fonemów
języka polskiego. Dane potrzebne do utworzenia książki kodowej poddawane są procesowi
kwantyzacji. Przykładowo słowo o sekundowej długości reprezentowane jest przez wektor
obserwacji o długości około 60 pojedynczych obserwacji, gdzie każda z obserwacji
zakodowana jest przez jeden z 37 symboli książki kodowej.
Kwantyzacja jest dość prostym procesem, jednakże projektowanie kwantyzatora ma
znaczący wpływ na uzyskany stopień kompresji oraz stratę poniesioną w algorytmach
kompresji stratnej. W praktyce kwantyzator składa się z dwóch odwzorowań: kodującego i
dekodującego. Koder dzieli zbiór wartości generowanych przez źródło na pewną liczbę
przedziałów. Każdy przedział jest reprezentowany przez inne słowo kodowe. Koder
reprezentuje wszystkie dane źródła, które należą do danego przedziału, za pomocą słowa
kodowego reprezentującego ten przedział. Ponieważ dla każdego przedziału może należeć
wiele wartości, przekształcenie kodujące jest nieodwracalne. Znajomość kodu realizuje
jedynie podział, do którego należy dana próbka. Nie mówi natomiast, która z wielu wartości
w tym przedziale jest faktyczną próbkowaną wartością [96].
Dla każdego generowanego przez koder słowa kodowego dekoder generuje
rekonstruowaną wartość. Ponieważ słowo kodowe reprezentuje cały przedział i nie ma
sposobu, aby dowiedzieć się, która liczba z tego przedziału była w rzeczywistości
wygenerowana przez źródło, dekoder wybiera wartość, która w pewnym sensie najlepiej
reprezentuje wszystkie wartości z tego przedziału.
Konstrukcja przedziałów może być traktowana jako część procesu projektowania
kodera. Wybór rekonstruowanych wartości jest częścią projektowania dekodera. Wierność
rekonstrukcji zależy zarówno od przedziałów, jak i rekonstruowanych wartości, dlatego
podczas projektowania koder i dekoder traktuje się jako parę.

56
Dobrą metodą tworzenia efektywnych algorytmów kompresji stratnej i bezstratnej jest
grupowanie danych źródłowych i kodowanie ich w postaci jednego bloku. Taki pojedynczy
blok można traktować jako wektor, dlatego taki typ kwantyzacji nazywa się kwantyzacją
wektorową [108]. W kwantyzacji wektorowej dane wejściowe grupowane są w bloki lub
wektory. N kolejnych próbek mowy można traktować jako element N–wymiarowej
przestrzeni. Taki wektor danych źródła stanowi element danych wejściowych do
kwantyzatora wektorowego. Zarówno w koderze, jak i dekoderze kwantyzatora wektorowego
znajduje się N – wymiarowych wektorów nazywanych książką kodową kwantyzatora
wektorowego [96]. Wektory kodowe z książki mają reprezentować te wektory, które
otrzymuje się z danych źródłowych. Każdemu wektorowi kodowemu przypisany jest
liczbowy indeks.
Kwantyzacja wektorowa Q o wymiarze przestrzeni M i wymiarze wektorów N jest
odwzorowaniem wektora x z M – wymiarowej przestrzeni Euklidesowej RM do skończonego
zbioru Y zawierającego NM – wymiarowe wyjścia lub punkty reprodukcji, nazywane słowami
kodowymi. A zatem [108]:
YRQ M →: , (3.21)
gdzie: x = [x1,x2,…,xM]T; (y1, y2, …,yN) ∈ Y; yi = [yi1,yi2,…,yiM]T, dla i = 1,…,N, Y jest
książką kodową kwantyzatora.
Działanie odwzorowania opisywane jest jako:
NidlayxQ i ,...,1,)( == . (3.22)
Podział za pomocą każdej z N–punktowej M–wymiarowej kwantyzacji wektorowej realizuje
się jako podział przestrzeni Euklidesowej RM w N obszarów lub komórek Ri, dla i = 1,…,N.
Komórkę oznaczoną jako i – tą definiuje się przez;
{ } )()(: 1ii
Mi yQyxQRxR −==∈= . (3.23)
Dla zadanej książki kodowej Y o rozmiarze N optymalny podział komórek „najbliższy sąsiad”
określa się jako:
)},(),(:{ jii yxdyxdxR ≤= , (3.24)
gdzie: i,j = 1,…,N; i ≠ j.
Stąd wynika, że Q(x) = yi tylko wtedy, gdy d(x,yi) ≤ d(x,yj). Tak więc w książce
kodowej Y, koder zawiera minimalną (minimalnie zakrzywioną drogę pomiędzy dwoma
punktami) odległość lub odwzorowanie „najbliższy sąsiad” z:
),(min))(,( jiyxdxQxd = . (3.25)

57
Aby można było dokonywać pomiaru odległości konieczne jest określenie środka
ciężkości elementów obszaru uznawanych za podobne. Środek ciężkości (ang. Centroid)
obszaru o podobnych składowych cent(R0) określa się jako wektor y0 (jeśli taki istnieje)
minimalizujący zakrzywienie drogi pomiędzy punktami X ∈ R0 i y0:
}},|),({}|),({:{)( 00000 RXyXdERXyXdEyRcent ∈≤∈= (3.26)
dla każdego y ∈ RM. Dla zadanego podziału {Ri; i = 1,…,N}, optymalne wektory kodowe
wynoszą:
)( ii Rcenty = . (3.27)
Obszar zawierający elementy o podobnych właściwościach oprócz środka ciężkości
musi posiadać także granicę. Dla podziału Ri, i = 1,…,N, granicę każdego z obszarów określa
się jako:
}),,(),(:{ jiyxdyxdxB ij ≠== (3.28)
Dla wszystkich i,j = 1,…,N. Zatem granica składa się z punktów równomiernie oddalonych
od yj i tak samo od innych yi.
Warunkiem koniecznym, aby książka kodowa była optymalna dla danego źródła
rozkładu jest:
φ=B . (3.29)
Stąd wynika, że wyznaczona kompletna granica musi być pusta, pozbawiona źródłowych
elementów obszarów. Alternatywnie można to zapisać jako prawdopodobieństwo P równe:
0}),,(),(:{ =≠= jiyxdyxdxP ji (3.30)
dla wszystkich i,j = 1,…,N.
Zakładając, że wyznaczona granica nie jest pusta, przynajmniej jeden x jest równo
odległy od wektorów kodowych yi oraz yj. Odwzorowanie x w yi lub yj będzie dawać dwa
kodujące schematy z takim samym średnim rozkładem.
Projektując książkę kodową Y o rozmiarze N, wymagane jest znalezienie wejściowego
podziału komórek Ri oraz słów kodowych takich, że średnia odległość (zakrzywienie) D =
E{d(X,Q(X))} jest minimalizowane. Wejściowy losowy wektor X jest wektorem z daną
funkcją gęstości prawdopodobieństwa (ang. Probability Density Function, PDF). Możliwe jest
poprawienie działania kwantyzatora poprzez wykonanie dwóch kroków iteracji Lloyda.
Iteracja Lloyda może być stosowana bezpośrednio do kwantyzacji wektorowej. W przypadku
wektorów, obliczenie środków ciężkości wymaga oszacowania wielokrotnie całości (zakłada
się ciągły rozkład wejściowy), co generalnie nie jest możliwe w sposób analityczny. W
praktyce wektor uczący składa się z Nt wektorów

58
1,...,1,0; −= tk Nkx (3.31)
używanych do optymalizacji kwantyzacji wektorowej. Wektory te są przykładowymi
wynikami wejściowego losowego wektora X. Należy założyć, że każdy przykładowy wektor
ma prawdopodobieństwo masowe 1/Nt. Jeśli wartość Nt jest wystarczająco duża, statystyczne
własności danych wejściowych zbliżają się do ciągłego rozkładu losowego wektora X.
Iteracja Lloyda z procesu uczenia realizowana jest w dwóch krokach [108].
Algorytm iteracji Lloyda
Wejście: Zadana książka kodowa Ym.
Wyjście: Ulepszona nowa książka kodowa Ym+1.
1: Dla zadanej książki kodowej Ym = {ym,i; i = 1,2,…,N} podziel dane wejściowe na
obszary zawierające podobne dane przy użyciu warunków metody „najbliższy
sąsiad”
)},(),(:{ ,,, jmkjmkkim yxdyxdxR ≤= (3.32)
Dla wszystkich i ≠ j, k = 0,…,Nt – 1.
Do zapewnienia warunku pustości granicy (3.30) użyj reguły „tie-breaking” [108].
Dla przykładu, jeśli d(xk,yi) = d(xk,yj), to losowe przyporządkowanie może być
rozplanowane, a xk przyporządkowuje się dowolnie do Ri lub Rj.
2: Stosując warunki wyznaczania środków ciężkości obszarów, na podstawie
znalezionych środków ciężkości komórek otrzymasz nową książkę kodową Ym+1.
Jeśli w kroku pierwszym została wygenerowana pusta komórka, wówczas wektor
kodowy jest przydzielony dla tej komórki.
Pusta komórka może się pojawić wtedy, kiedy wektor nie jest wyznaczony z danych
wejściowych. Taka sytuacja może się zdarzyć, jeśli szczególne słowo kodowe komórki jest
bardzo daleko oddalone od wektora danych wejściowych. Pusta komórka nie przyczynia się
do poprawy rezultatów, dlatego powinna być usunięta. Zróżnicowanie heurystycznych
rozwiązań podpowiada, aby zajmować się problemem pustych komórek. Jedno z
przykładowych rozwiązań jest takie, aby podzielić największą komórkę na dwie komórki
przez dodanie odpowiedniego słowa kodowego z losową liczbą mającą małą niezgodność,
generującą tą drogą dwie oddzielne wersje oryginalnego słowa kodowego.

59
Iteracja Lloyda może być użyta do poprawy początkowej kwantyzacji z wstępnej
książki kodowej. Jeśli wejściowa PDF nie jest traktowana matematycznie, przykładowy
rozkład bazuje na używanych w zamian empirycznych obserwacjach. Algorytm Lloyda do
kwantyzacji wektorowej zawiera się w trzech podstawowych krokach [108].
Algorytm Lloyda
Wejście: Dane wejściowe z zadaną książka kodowa Ym.
Wyjście: Podzielona na obszary dane wejściowe.
1: Rozpocznij z początkową książką kodową Y1 (m = 1).
2: Dla zadanej książki kodowej Ym wykonaj iteracje Lloyda do wygenerowania
poprawionej książki kodowej Ym+1.
3: Wylicz średnie zakrzywienie dla Ym+1 (Dm+1). Jeśli różnica w porównaniu z
poprzednią iteracją jest niewielka, zatrzymaj działania algorytmu. W innym
przypadku ustaw m +1 na m i przejdź do kroku 2.
Jednym z uzasadnionych kryteriów zatrzymania jest użycie ułamkowego spadku w
zakrzywieniu (Dm – Dm+1) / Dm. Algorytm zatrzymuje się, kiedy ten współczynnik jest
mniejszy od przyjętego progu.
Ponieważ w pracy zastosowano analizę sygnału za pomocą współczynników
cepstrum, dlatego na wejście algorytmu Lloyda podawane są wektory odpowiadających
poszczególnym ramkom wyznaczonych współczynników cepstrum.
Kwantyzacja wektorowa wykonywana jest w procesie tworzenia książki kodowej w
oparciu o zestaw nagrań wejściowych zbudowany tak, aby w całości pokryć przestrzeń dla
danego zagadnienia i danego użytkownika. W przypadku systemów dedykowanych, czyli
przeznaczonych wyłącznie dla danego użytkownika, biorąc pod uwagę fakt, iż w języku
polskim występuje 37 fonemów, można utworzyć zestaw nagrań przeznaczonych do
tworzenia książki kodowej złożony z kilkunastu słów zawierających wszystkie 37 fonemów.
W pracy zastosowano podział danych wejściowych na 37 obszarów teoretycznie
odpowiadających poszczególnym fonemom. Na Rys.3.18 pokazano utworzoną książkę
kodową z zestawu wejściowego zawierającego 20 współczynników cepstrum dla każdej ze
stacjonarnych ramek.
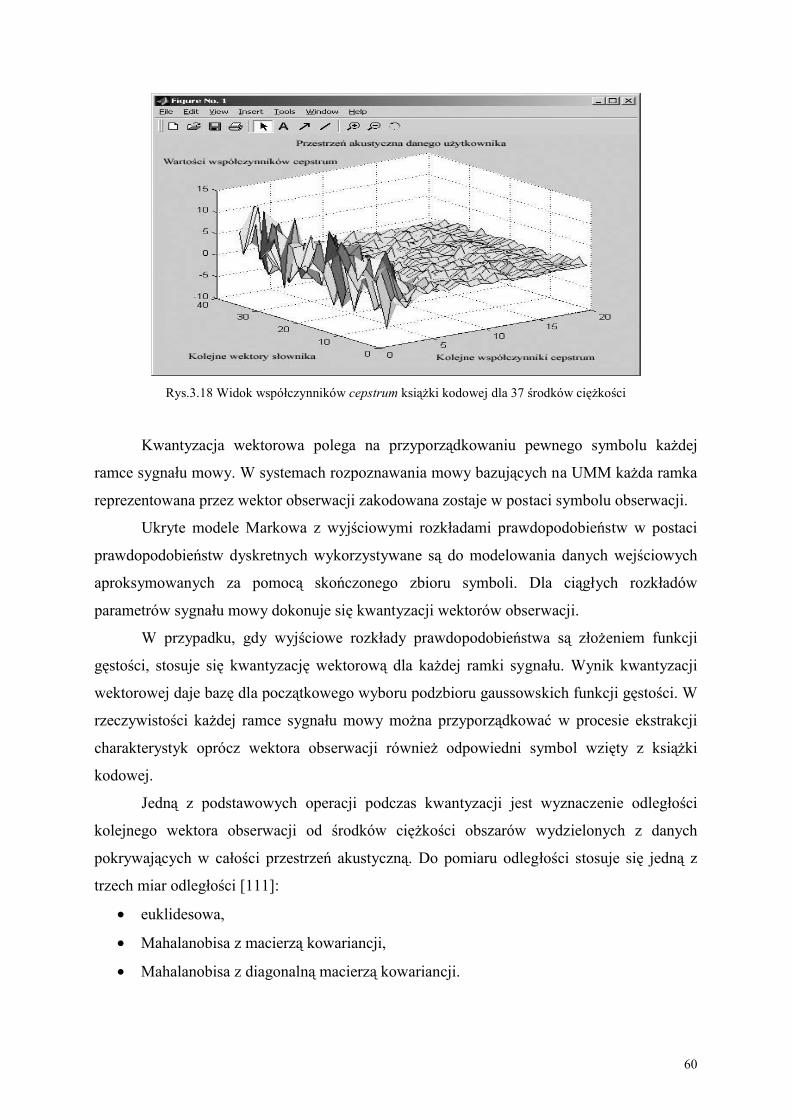
60
Rys.3.18 Widok współczynników cepstrum książki kodowej dla 37 środków ciężkości
Kwantyzacja wektorowa polega na przyporządkowaniu pewnego symbolu każdej
ramce sygnału mowy. W systemach rozpoznawania mowy bazujących na UMM każda ramka
reprezentowana przez wektor obserwacji zakodowana zostaje w postaci symbolu obserwacji.
Ukryte modele Markowa z wyjściowymi rozkładami prawdopodobieństw w postaci
prawdopodobieństw dyskretnych wykorzystywane są do modelowania danych wejściowych
aproksymowanych za pomocą skończonego zbioru symboli. Dla ciągłych rozkładów
parametrów sygnału mowy dokonuje się kwantyzacji wektorów obserwacji.
W przypadku, gdy wyjściowe rozkłady prawdopodobieństwa są złożeniem funkcji
gęstości, stosuje się kwantyzację wektorową dla każdej ramki sygnału. Wynik kwantyzacji
wektorowej daje bazę dla początkowego wyboru podzbioru gaussowskich funkcji gęstości. W
rzeczywistości każdej ramce sygnału mowy można przyporządkować w procesie ekstrakcji
charakterystyk oprócz wektora obserwacji również odpowiedni symbol wzięty z książki
kodowej.
Jedną z podstawowych operacji podczas kwantyzacji jest wyznaczenie odległości
kolejnego wektora obserwacji od środków ciężkości obszarów wydzielonych z danych
pokrywających w całości przestrzeń akustyczną. Do pomiaru odległości stosuje się jedną z
trzech miar odległości [111]:
• euklidesowa,
• Mahalanobisa z macierzą kowariancji,
• Mahalanobisa z diagonalną macierzą kowariancji.

61
Symbole książki kodowej reprezentujące środki ciężkości odrębnych obszarów mogą
być rozmieszczone w tablicy liniowej lub drzewie binarnym. W tablicy liniowej wektor
obserwacji porównywany jest z każdym środkiem ciężkości i przypisywany jest mu symbol
kwantyzacji wektorowej odpowiadający najbardziej podobnemu obszarowi. W drzewie
binarnym gdzie każdy symbol oprócz końcowych połączony jest z dwoma następnymi
symbolami, wektor obserwacji porównywany jest z każdym symbolem z tej samej hierarchii
drzewa, począwszy od symbolu startowego. Symbole w drzewie rozłożone są tak, aby
poszczególne gałęzie zawierały symbole o zbliżonych właściwościach. W ten sposób nie ma
konieczności przeszukiwania wszystkich symboli.
Euklidesowa miara odległości dij pomiędzy dwoma obiektami Xi = (x1i,x2
i,…,xSi) oraz
Xj = (x1j,x2
j,…,xSj) wyliczana jest przy zastosowaniu następującej metryki [105]:
∑=
−=S
k
jk
ikij xxd
1
2)( . (3.33)
Miara euklidesowa ma jednak taką wadę, że operacja podnoszenia do kwadratu i
następującego po niej wyciągania pierwiastka jest czasochłonna, a co za tym idzie niedogodna
obliczeniowo. Aby to zlikwidować, w pracy zastosowano inną metrykę zwaną metryką
„Manhattan” (odpowiada ona odległości, jaką należy pokonać poruszając się z punktu Xi do
Xj tylko po drodze prostopadłej lub równoległej, bez możliwości pójścia na skróty). W
metryce tej odległość punktów Xi oraz Xj wyraża się wzorem [105]:
∑=
−=S
k
jk
ikij xxd
1|| . (3.34)
Uciążliwe obliczeniowo operacje zostały w tej metryce niemal w całości
wyeliminowane i zastąpione prostymi i szybko wykonywanymi działaniami. Przyjęcie
metryki danej wzorem (3.34) powoduje, że kulę w przestrzeni cech zastępuje sześcian. Może
on niekiedy lepiej pasować do kształtów obszarów w przestrzeni cech.
Obie definicje odległości mają wspólną wadę. Jeśli zakres zmienności któregoś z
rozważanych parametrów okaże się większy niż dla innego parametru, to odpowiednie
składniki w sumie będą dominowały nad pozostałymi, co szczególnie dotkliwie może dać się
zauważyć we wzorze (3.33), ze względu na operację podnoszenia do kwadratu [105].
Algorytm kodowania wektorów obserwacji
Wejście: Wektory obserwacji kodowanego sygnału w postaci współczynników cepstrum
oraz utworzona przy pomocy algorytmu Lloyda książka kodowa.
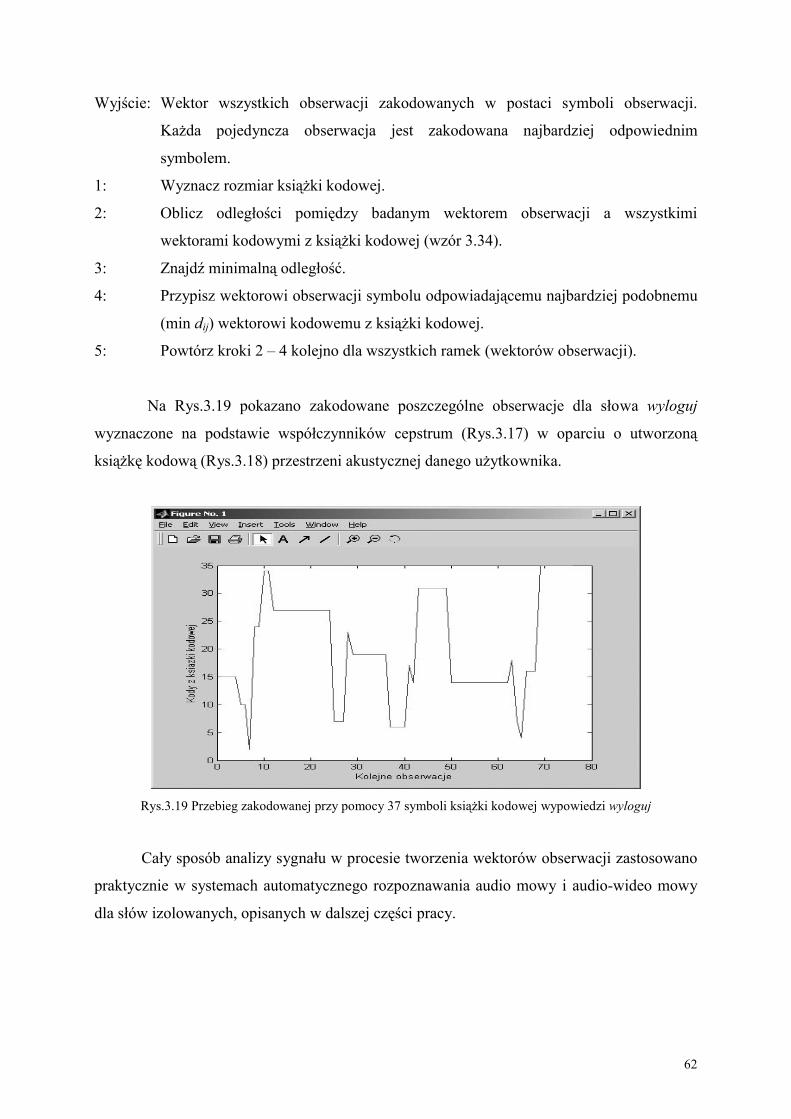
62
Wyjście: Wektor wszystkich obserwacji zakodowanych w postaci symboli obserwacji.
Każda pojedyncza obserwacja jest zakodowana najbardziej odpowiednim
symbolem.
1: Wyznacz rozmiar książki kodowej.
2: Oblicz odległości pomiędzy badanym wektorem obserwacji a wszystkimi
wektorami kodowymi z książki kodowej (wzór 3.34).
3: Znajdź minimalną odległość.
4: Przypisz wektorowi obserwacji symbolu odpowiadającemu najbardziej podobnemu
(min dij) wektorowi kodowemu z książki kodowej.
5: Powtórz kroki 2 – 4 kolejno dla wszystkich ramek (wektorów obserwacji).
Na Rys.3.19 pokazano zakodowane poszczególne obserwacje dla słowa wyloguj
wyznaczone na podstawie współczynników cepstrum (Rys.3.17) w oparciu o utworzoną
książkę kodową (Rys.3.18) przestrzeni akustycznej danego użytkownika.
Rys.3.19 Przebieg zakodowanej przy pomocy 37 symboli książki kodowej wypowiedzi wyloguj
Cały sposób analizy sygnału w procesie tworzenia wektorów obserwacji zastosowano
praktycznie w systemach automatycznego rozpoznawania audio mowy i audio-wideo mowy
dla słów izolowanych, opisanych w dalszej części pracy.

63
4. OSOBLIWOŚCI STOSOWANIA UKRYTYCH MODELI MARKOWA W METODZIE AV_Mowa_PL
Przedstawiono metodę rozpoznawania audio-wideo mowy polskiej na bazie ukrytych modeli
Markowa do klasyfikacji rozpoznawanych słów izolowanych. Podano informacyjne
szczegóły stosowania UMM, specyfikację topologii i sposoby estymacji parametrów UMM
wykorzystywanych do podjęcia decyzji metodą największego prawdopodobieństwa.
4.1. Wybór struktury i parametrów ukrytych modeli Markowa dla rozpoznawania audio-
wideo mowy polskiej
UMM to pojęcie doskonale znane w zastosowaniach inżynieryjnych już od pół wieku. Jak
dotąd najszerzej korzystano z nich do modelowania ciągów czasowych w rozpoznawaniu
mowy i właśnie tam znalazły swoje pierwotne zastosowanie, umożliwiając analizę i
przetwarzanie dźwięków mowy w systemach rozpoznawania mowy i identyfikacji mówcy.
Sporym problemem w zagadnieniach rozpoznawania mowy jest niestacjonarność
sygnału mowy. Ukształtowanie traktu głosowego generującego określony dźwięk mowy o
widmie zawierającym częstotliwości nawet do 4 kHz może się zmieniać około 10 razy na
sekundę. Rozwiązaniem tego problemu jest podział sygnału mowy na ramki o długości od 10
do 30 ms, zakładając stacjonarność sygnału w tak krótkich przedziałach czasowych.
Zarówno w procesie uczenia i testowania, dane wejściowe wprowadzane do modelu
przedstawione są w postaci wektora sekwencji obserwacji. Pojedyncza obserwacja
przedstawiająca własności krótkookresowe dźwięku odpowiada zakodowanej stacjonarnej
ramce poddanej kwantyzacji wektorowej. Czasowa sekwencja wszystkich obserwacji dla
danego sygnału mowy tworzy wektor obserwacji przedstawiający własności długookresowe
sekwencji dźwięków wchodzących w skład wypowiedzi.
Dla przedziału czasowego t = 1,…,T wektor sekwencji obserwacji O będzie złożony z
zaobserwowanych w chwilach czasowych t pojedynczych obserwacji ot, czyli O =
(o1,o2,…,oT).
Opierając się na faktach o niejednoznaczności i zmienności akustycznej sygnału
mowy zastosowano stochastyczne modelowanie mowy, łączące modelowanie własności
krótkookresowych pojedynczych dźwięków oraz modelowanie własności długookresowych
traktu głosowego, odpowiedzialnych za tworzenie sekwencji poszczególnych dźwięków.

64
Wprowadzając do systemu rozpoznającego uzyskaną z badanego sygnału mowy
sekwencję obserwacji O, należy wyznaczyć najbardziej prawdopodobną wypowiedź w w
zbiorze wszystkich wypowiedzi Wi zarejestrowanych dla danego zagadnienia. Najbardziej
prawdopodobną wypowiedź uzyskuje się rozwiązując zadanie wyboru maksymalnego
prawdopodobieństwa P(Wi|O) z wykorzystaniem reguły Bayesa
)()|()(
maxargOP
WOPWPw ii
i= , (4.1)
gdzie: P(Wi) – prawdopodobieństwo wystąpienia i–tej wypowiedzi, określone dla zadanej
bazy słów; P(O|Wi) – prawdopodobieństwo uzyskania sekwencji obserwacji O dla i–tej
wypowiedzi, określone dla modelu akustycznego mowy [111].
W procesie uczenia na podstawie zbioru sekwencji obserwacji wydobytych z kilku
różnych powtórzeń tej samej wypowiedzi w tworzy się oddzielny model M generujący
obserwacje, których podobieństwo do obserwacji przedstawiającej rozpoznawaną wypowiedź
stanowi podstawę rozpoznawania tej wypowiedzi.
Zadanie wyboru maksymalnego prawdopodobieństwa P(Wi|O) opisanego zależnością
(4.1) rozwiązuje się dla wszystkich utworzonych modeli Mi bazy wypowiedzi Wi, jako:
)|()|( ii MOPWOP = , (4.2)
gdzie: P(O|Mi) – prawdopodobieństwo wygenerowania sekwencji obserwacji O przez i–ty
model.
Stochastyczne modelowanie własności krótkookresowych pojedynczych dźwięków
oraz długookresowych zmian kolejnych dźwięków można realizować przy pomocy UMM.
Wówczas miarą podobieństwa pozyskanej sekwencji obserwacji do wypowiedzi jest
prawdopodobieństwo wygenerowania tej sekwencji przez odpowiedni model [111].
Obserwacje wykorzystywane przez UMM w procesie modelowania nie mają
bezpośredniego wpływu na wygenerowanie kolejnych obserwacji, a pośrednio zależność
kolejnych obserwacji w sekwencji obserwacji jest modelowana jako zależność pomiędzy
stanami w sekwencji stanów, generującymi te obserwacje. Każdorazowa zmiana stanów
modelu następuje w przyjętych krokach czasowych, powodując w tych samych krokach
czasowych generowanie przez model będący w odpowiednim stanie obserwację (Rys.4.1) z
określonym prawdopodobieństwem. Przejście ze stanu do stanu opisuje skończony łańcuch
Markowa działający w dyskretnym czasie.
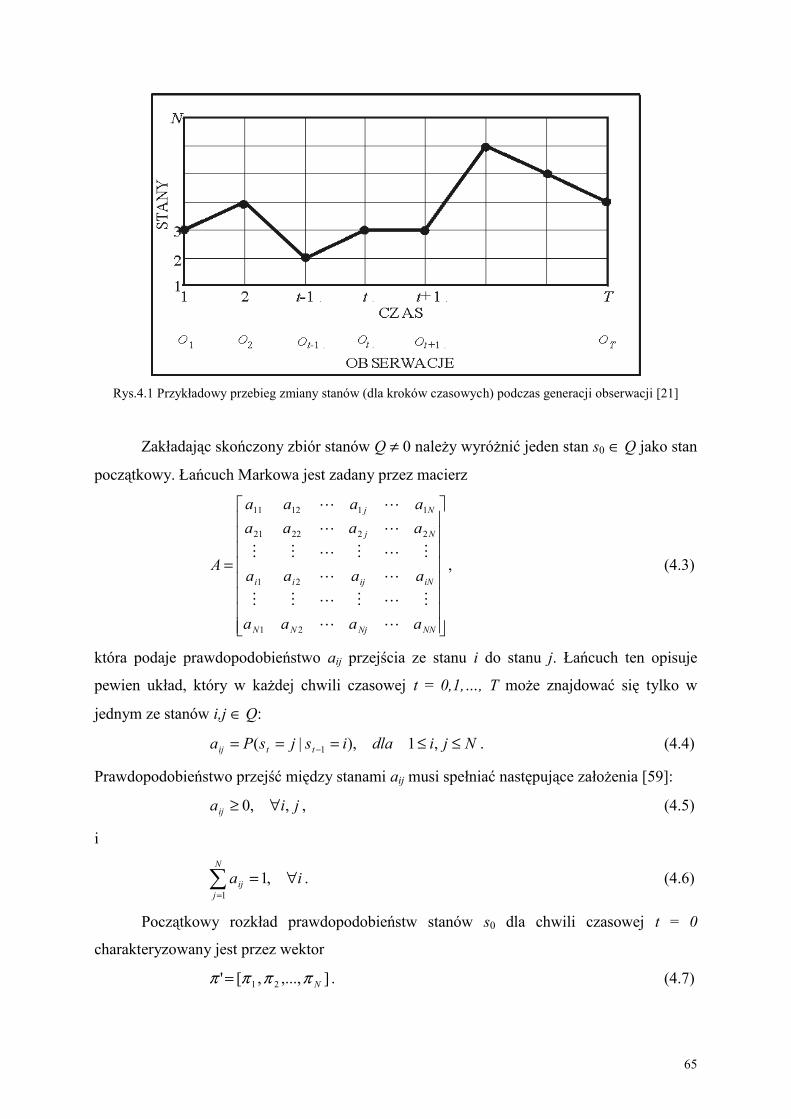
65
Rys.4.1 Przykładowy przebieg zmiany stanów (dla kroków czasowych) podczas generacji obserwacji [21]
Zakładając skończony zbiór stanów Q ≠ 0 należy wyróżnić jeden stan s0 ∈ Q jako stan
początkowy. Łańcuch Markowa jest zadany przez macierz
=
NNNjNN
iNijii
Nj
Nj
aaaa
aaaa
aaaaaaaa
A
LL
MLMLMM
LL
MLMLMM
LL
LL
21
21
222221
111211
, (4.3)
która podaje prawdopodobieństwo aij przejścia ze stanu i do stanu j. Łańcuch ten opisuje
pewien układ, który w każdej chwili czasowej t = 0,1,…, T może znajdować się tylko w
jednym ze stanów i,j ∈ Q:
NjidlaisjsPa ttij ≤≤=== − ,1),|( 1 . (4.4)
Prawdopodobieństwo przejść między stanami aij musi spełniać następujące założenia [59]:
jiaij ,,0 ∀≥ , (4.5)
i
∑=
∀=N
jij ia
1,1 . (4.6)
Początkowy rozkład prawdopodobieństw stanów s0 dla chwili czasowej t = 0
charakteryzowany jest przez wektor
],...,,[' 21 Nππππ = . (4.7)

66
Jeżeli prawdopodobieństwa przejść między stanami nie zależą od rozpatrywanego
okresu, wówczas łańcuch Markowa jest jednorodny w czasie [23]. Ważnym faktem jest, że
jednorodny łańcuch Markowa jest reprezentowany jednoznacznie poprzez macierz
prawdopodobieństw przejścia oraz rozkład początkowy.
Losowe generowanie obserwacji jest charakteryzowane przez poszczególne wektory
rozkładów prawdopodobieństwa obserwacji, umieszczone w macierzy B [59]:
=
======
======
======
======
NsMosMosMo
Nsososo
Nsososo
Nsososo
bbb
bbbbbbbbb
B
/2/1/
/32/31/3
/22/21/2
/12/11/1
L
MLMM
L
L
L
(4.8)
o następujących składowych:
NidlaisoPob ttti ,...,2,1),|()( === . (4.10)
Wyjściowe rozkłady prawdopodobieństwa najczęściej są dyskretnymi rozkładami dla
skończonego zbioru obserwacji wyjściowych reprezentowanych przez symbole obserwacji,
lub też n-wymiarowymi funkcjami gęstości prawdopodobieństwa. Zależność (4.10)
utożsamiana jest z prawdopodobieństwem wygenerowania obserwacji ot przez model będący
w i-tym stanie, jeśli oczywiście ot jest dowolnym wektorem w przestrzeni Euklidesowej En.
Na Rys.4.2 pokazano schemat generowania wyjść ot dla poszczególnych stanów.
Rys.4.2 Schemat generowania wyjść ot dla stanów z prawdopodobieństwem przejścia aij

67
Pojedynczy model UMM λ zbudowany jest z parametrów modelu π, A, B, tworząc
nierozłączną w sensie poprawności i założeń UMM trójkę specyficznych elementów.
Rozpatrując ewolucję stanu modelu, zakładając, że Qt jest prawdopodobieństwem znalezienia
się układu w danym stanie w chwili t, można wyznaczyć Qt+1:
'1 πtt AQ =+ , (4.11)
gdzie: π’ = Qt=0.
Generowana przez model określona obserwacja wyznaczana jest w oparciu o
zależność (4.11)
11 ++ = tt BQO . (4.12)
Podstawiając (4.11) do (4.12) uzyskamy sposób wygenerowania wyjścia w chwili t przez
model w pełni określony macierz zmian stanu, macierz obserwacji i stan początkowy [38]:
'1 πtt BAO =+ . (4.13)
W systemach realizujących automatyczne rozpoznawanie słów izolowanych, gdzie
wypowiedzi są pojedynczymi słowami, a zbiór wszystkich dopuszczalnych wypowiedzi
tworzy słownik, w fazie treningu dokonuje się ekstrakcji sekwencji obserwacji O =
(o1,o2,…,oT) dla każdej wypowiedzi ze zbioru uczącego, budując dla każdego słowa ze
słownika oddzielny model UMM. W fazie rozpoznawania wyznacza się prawdopodobieństwo
wygenerowania sekwencji obserwacji z badanej wypowiedzi przez wszystkie modele UMM
zbudowane wcześniej. Prawdopodobieństwo jest podstawą procesu rozpoznawania, poprzez
przyporządkowanie rozpoznawanej wypowiedzi określonemu modelowi.
W procesie uczenia uzyskuje się zbiór modeli dopasowanych do danych wejściowych,
zgodnie z przyjętym kryterium. Najczęściej przyjmowanym kryterium podczas estymacji
parametrów modelu UMM jest kryterium największego prawdopodobieństwa, ze względu na
istnienie prostych a zarazem efektywnych algorytmów rozwiązania zadania.
W najprostszym ciągłym modelu UMM rozkład wyjściowy dla i-tego stanu ma postać
wielowymiarowej gaussowskiej funkcji gęstości [111, 112]:
−∑−−
∑=∑= − )()'(
21exp
||)2(
1);;()( 1itiit
iniitti oooNob µµ
πµ , (4.14)
gdzie: n - wymiar wektora obserwacji ot.
W takim przypadku każdy stan we wszystkich modelach UMM charakteryzowany jest przez
wektorową wartość średnią µi oraz macierz kowariancji Σi.
Przyjęcie założenia, że macierz kowariancji jest diagonalna, nie prowadzi do dużego
wzrostu błędów modelowania, dając za to spore uproszczenie problemu, jeśli oczywiście

68
funkcje gęstości rozkładów parametrów są unimodalne. W przypadku rozkładów
multimodalnych, jako rozkłady wyjściowe stosuje się następujące kompozycje [111, 112]:
∑−
∑=iM
mimimtimti oNcob
1
),,()( µ , (4.15)
gdzie: cmi - waga m-tego składnika kompozycji; Mi - liczba wszystkich składników
kompozycji.
Również w zależności (4.15) można przyjąć macierz kowariancji w postaci macierzy
diagonalnej. Warunkiem, aby kompozycja rozkładów normalnych była rozkładem gęstości
prawdopodobieństwa jest spełnienie przez wagi cim następujących założeń:
∑=
=iM
mimc
1
1 , (4.16)
i
0≥mic . (4.17)
Jeśli wektor obserwacji ot zostanie podzielony na statystycznie niezależne strumienie
ots (s ∈ {1,2,…,S}), zakładając, że wektor obserwacji składa się z takich właśnie niezależnych
strumieni, wówczas prawdopodobieństwo wygenerowania wektora obserwacji ot przez model
M wynosi:
)|()...|()|()|( 21 MoPMoPMoPMoP tSttt = , (4.18)
Przy czym wyjściowe rozkłady estymowane są niezależnie dla każdego strumienia. Dla
każdego strumienia można ustawić różne wagi ks.
Okazuje się, że budowa ciągłych rozkładów jest utworzona z normalnych
wielowymiarowych rozkładów gęstości [111, 112]: s
iskS
s
M
mismismtsismti oNcob ∏ ∑
= =
∑=
1 1),,()( µ , (4.19)
gdzie: Mis – liczba składników kompozycji w s-tym strumieniu; cism –współczynniki wagowe
m-tego składnika w s-tym strumieniu.
W przypadku dyskretnych modeli UMM rozkłady wyjściowe są w postaci
dyskretnych rozkładów prawdopodobieństwa. Dla modelu będącego w i-tym stanie,
dyskretny rozkład wyjściowy dla obserwacji ot przyjmuje postać:
)]([)( titi ovPob = , (4.20)
gdzie: v(os) –symbol obserwacji ze zbioru v-elementowego, będący wynikiem kwantyzacji
wektorowej wektora obserwacji ot; Pi[v(ot)] –prawdopodobieństwo wygenerowania w i-tym
stanie symbolu v.

69
W pracy przyjęto, że symbol obserwacji jest elementem książki kodowej tworzonej w
procesie kwantyzacji wektorowej. Każdy symbol z książki kodowej odpowiada wektorowi
obserwacji, któremu jest najbliższy. Wektory obserwacji tworzące przestrzeń akustyczną
odpowiednią dla danego zagadnienia dobierane są tak, aby w całości i równomiernie pokryć
tę przestrzeń. Czasami dla jednego użytkownika wystarczy kilkanaście wypowiedzi do
utworzenia książki kodowej.
Dla obserwacji z wydzielonymi niezależnymi strumieniami ot = (ot1,ot2,…,otS),
dyskretny rozkład wyjściowy w i-tym stanie przyjmuje postać [112]:
∏−
=S
s
ktssisti
sovPob1
)]}([{)( , (4.21)
gdzie: ks –współczynnik wagowy przypisany s-temu strumieniowi.
Na Rys.4.3 pokazano zakodowane podczas fazy treningu jako wektory obserwacji pięć
powtórzeń słowa cofnij.
Rys.4.3 Widok w postaci wektorów obserwacji pięciu powtórzeń wypowiedzi cofnij
Łatwo zauważyć podobieństwo końcowych obserwacji (fonem „j”). Celowo podczas
nagrywania wypowiedzi zaakcentowano ten fonem przedłużając jego brzmienie. Kodowanie
zrealizowano na 37 symbolach obserwacji. Patrząc na Rys. 4.3. widać, że fonem „j”
odpowiada symbolowi 30. Oczywiście kolejność symboli reprezentujących poszczególne
fonemy zmienia się wraz z tworzeniem nowej książki kodowej na podstawie nowej sekwencji
wypowiedzi, charakterystycznej dla indywidualnego użytkownika.

70
Specyfikacja topologii ukrytych modeli Markowa
Opracowując system automatycznego rozpoznawania słów izolowanych należy zbudować
UMM dla wszystkich słów wchodzących w skład słownika. Dla każdego modelu należy
określić liczbę stanów, czyli rozmiar macierzy A prawdopodobieństw przejść między stanami
oraz elementy każdego wektora z macierzy B = [bi(ot)], przedstawiające rozkłady wyjściowe.
Na początku w procesie tworzenia UMM konieczne jest zdefiniowanie jednego lub
więcej modeli prototypowych, w których można zastosować dowolność wartości tych modeli,
gdyż wykorzystuje się je przede wszystkim do wyznaczenia topologii właściwych modeli
UMM. Dopiero te właściwe modele UMM wykorzystuje się dalej w procesie treningu.
Dla pojedynczego modelu UMM tworzy się odpowiednio nazwany plik, w którym
przechowywane będą wartości parametrów modelu UMM o określonym z góry typie ciągłym,
bądź dyskretnym. Wygodne jest nazywanie modelu odpowiednikiem tekstowym wypowiedzi,
dla której tworzony jest model.
Budując wektor obserwacji o określonym rozmiarze i przedstawionej w postaci kodów
zawartości należy pamiętać, aby dla wszystkich strumieni S o współczynnikach wagowych ks
(s = 1,2,…,S), suma rozmiarów wszystkich strumieni odpowiadała rozmiarowi wektora
obserwacji.
Ważnym elementem określania specyfikacji topologii UMM jest jak najlepsze
ustalenie liczby stanów. Zbyt mała liczba stanów może wprowadzać zbyt małą kombinację
wszystkich stanów dla różnych słów z utworzonego słownika. Może się wówczas okazać, że
różne słowa mogą mieć podobne przejścia między stanami w łańcuchu Markowa. Z drugiej
strony za duża liczba stanów przede wszystkim niepotrzebnie wydłuży wszystkie procesy
obliczeniowe. Dodatkowo przy zbyt dużej liczbie stanów, w procesie rozpoznawania,
prawdopodobieństwa wystąpienia sekwencji obserwacji dla badanego słowa mogą nie być
dostatecznie wysokie. Dla słów izolowanych przyjmuje się, że liczba stanów emisyjnych
powinna odpowiadać liczbie fonemów wchodzących w skład pojedynczej wypowiedzi [39].
Oczywiście poszczególne słowa ze słownika będą się różniły liczbą fonemów, dlatego należy
wybrać odpowiednio średnią wartość, ze wskazaniem na większą liczbę stanów. Przyjmuje
się, że pierwszy i ostatni stan nie są emisyjne.
Macierz przejść A wypełnia się niezerowymi, najczęściej losowymi wartościami
wszędzie tam, gdzie możliwe są przejścia między stanami. Pozostałe wartości elementów
macierzy powinny być zerowane. Całą macierz należy znormalizować tak, aby wszystkie
wiersze sumowały się do jedynki, za wyjątkiem ostatniego, który powinien być zerowany ze
względu na zastosowany sposób składania macierzy przejść.

71
Dla każdego i-tego stanu emisyjnego i każdego s-tego (s = 1,2,…,S) strumienia
danych, w przypadku rozkładów wyjściowych ciągłych, ustala się liczbę Mis składowych
kompozycji, a dla każdej m-tej (m = 1,2,…,Mis) składowej, ustala się współczynnik wagowy
cism oraz wektor wartości średnich µism i wektor wariancji σism lub macierz kowariancji Σism.
W przypadku rozkładów wyjściowych dyskretnych, ustala się prawdopodobieństwa
wystąpienia symboli, będących wynikiem kwantyzacji wektorowej strumienia danych [112].
Wyznaczając składniki kompozycji tworzących rozkład wyjściowy, można utworzyć
zbiór typowych składników w postaci gaussowskich funkcji gęstości, zamiast estymowania
składników kompozycji oddzielnie dla każdego stanu. Zbiór ten wykorzystywany jest później
przy tworzeniu rozkładów wyjściowych wszystkich stanów określonego modelu lub nawet
zbioru wszystkich modeli UMM. Powinien on pokrywać przestrzeń akustyczną, której
elementami są wektory obserwacji uzyskane z rozpoznawanych sygnałów mowy
wchodzących w skład słownika. Zbiór składników kompozycji tworzy książkę kodową dla
każdego strumienia, gdy wejściowe obserwacje podzielone są na niezależne strumienie
danych. Dla takiego założenia, rozkład wyjściowy w postaci:
∏ ∑= =
∑=
S
s
kM
msmsmtsismti
ss
Ofcob1 1
),,()( µ (4.22)
dla i-tego stanu polega na wyznaczeniu dla każdego strumienia danych, współczynników
wagowych cism (m = 1,2,…,Ms, s = 1,2,…,Ss), przypisanych składnikom kompozycji [112].
Należy zaznaczyć, że liczba składowych wchodzących w skład kompozycji, a także
parametry gaussowskich funkcji gęstości nie są powiązane z numerami stanów.
Stosowanie zbiorowych kompozycji daje możliwość prymityzowania algorytmów
uczenia. Jednak takie systemy charakteryzują się gorszą dokładnością modelowania sygnału
mowy. Zwykle liczba składowych w książce kodowej dla modelu o powiązanej kompozycji
waha się w granicach kilkuset elementów. Oprócz zdefiniowania książki kodowej konieczne
jest podanie dla każdego stanu wektora współczynników wagowych o wymiarze równym
liczbie składników książki kodowej.
Na etapie definiowania modelu prototypowego, jeśli nie ma żadnych informacji o
danych uczących zakłada się, że dopiero w procesie uczenia wyznaczone zostaną rzeczywiste
wartości prawdopodobieństw wszystkich dopuszczalnych przejść między stanami,
początkowo zaś prawdopodobieństwa aij są równe i oczywiście większe od zera. Natomiast
składowe funkcje gęstości tworzące rozkłady wyjściowe dla wszystkich stanów modelu

72
muszą być składowymi normalnymi o zerowych wartościach średnich i jednostkowych
wariancjach.
W przypadku, gdy sygnał mowy jest segmentowany na poziomie jednostek
fonetycznych oraz każdemu segmentowi przypisana jest nazwa jednostki fonetycznej, to
dostępne wypowiedzi indeksowane mogą być zastosowane w procesie uczenia metodą słów
izolowanych. Z wszystkich wypowiedzi uczących wydzielane są segmenty sygnału mowy
odpowiadające jednostce fonetycznej, dla której tworzony jest model UMM. Wydzielone
segmenty stanowią dane uczące w procesie estymacji wartości początkowych parametrów
UMM za pomocą iteracyjnej procedury segmentacyjnej.
Dla nieindeksowanych dostępnych wypowiedzi, modelom wszystkich jednostek
fonetycznych przypisuje się identyczne wartości średnie i wariancje równe wartości średniej i
wariancji wszystkich sygnałów mowy przeznaczonych do uczenia.
System automatycznego rozpoznawania mowy tworzony jest zwykle od najprostszego
do bardziej złożonego. W najprostszym systemie zależnym od mówcy, rozkłady wyjściowe są
dyskretne lub ciągłe w postaci normalnych wielowymiarowych funkcji gęstości, a jednostki
fonetyczne stanowią słowa, zaś modele jednostek fonetycznych nie zależą od kontekstu. W
bardziej złożonym systemie niezależnym od mówcy, dane są uogólniane w celu uzyskania
większej odporności estymowanych wspólnych parametrów, zwiększona zostaje liczba
składowych kompozycji w rozkładach wyjściowych, a jednostki fonetyczne zależne od
kontekstu przedstawione są w postaci składowych elementów słowa. Po każdej edycji modeli
UMM następuje reestymacja parametrów modeli za pomocą uczenia zintegrowanego.
Tworząc słownik systemu można celowo wypowiadać poszczególne słowa na różne
sposoby. Na początku w procesie uczenia wykorzystywana jest pierwsza odnaleziona w
słowniku wymowy wypowiedź. Gdy powstaną rozsądne modele UMM jednostek
fonetycznych, można przeprowadzić uczenie uzupełniające, uwzględniające różnorodną
wymowę danych uczących, co w skrajnych przypadkach może się wiązać z potrzebą
zastosowania nowej transkrypcji fonetycznej do końcowej reestymacji modeli UMM
jednostek fonetycznych.
4.2. Algorytm Viterbiego do inicjowania wstępnych parametrów modeli
Algorytm Viterbiego wykorzystuje się do rozwiązania problemu znalezienia optymalnej
sekwencji stanów q = (q1, q2,..., qT), dla podanego wektora obserwacji O = (o1, o2,..., oT) i

73
modelu λ. Optymalnym kryterium jest decyzja, a dokładniej wyznaczenie maksymalnego
prawdopodobieństwa wygenerowania podanej sekwencji stanów.
Rozwiązując przytoczony problem, należy w przybliżeniu określić najbardziej
prawdopodobną ścieżkę. Następnie określając ścieżkę (q1, q2,..., qT) z maksymalnym
prawdopodobieństwem
),|,...,,( 21 λOqqqP T , (4.23)
wyznacza się końcową ścieżkę δ(i) o najwyższym prawdopodobieństwie dla modelu
będącego w i-tym stanie:
( ) ( )λδ |,...,,,,...,,max 2121,...,, 121ttqqq
oooiqqqPit
==−
. (4.24)
Dokonując odpowiedniego podstawienia końcowa ścieżka wyznaczana jest następującą
zależnością [59]:
( ) ( )[ ] ( )1.
1 max ++ ⋅= tjijtii obaii δδ . (4.25)
Oznaczając zbiór powtórzeń określonej wypowiedzi, dla której zostanie utworzony N-
stanowy model HMM przez {Or} (r = 1,2,...,R), z każdej wypowiedzi Or wydziela się Tr
ramek o czasie trwania 30 ms, a następnie każdą ramkę przekształca się w obserwację za
pomocą analizy cepstralnej.
W pierwszej iteracji algorytmu, w celu zainicjowania nowego modelu HMM
sekwencja obserwacji każdego powtórzenia Or wypowiedzi jest dzielona na N równych
części. W kolejnych iteracjach obserwacje dla wszystkich powtórzeń wypowiedzi zostaną
przyporządkowane stanom modelu HMM za pomocą procedury dopasowania stanów
Viterbiego. Przyporządkowanie wykonywane jest niezależnie dla każdego powtórzenia (r =
1,2,...,R) i jest wynikiem procesu optymalizacji z następującym kryterium:
12)(max)( −≤≤= NidlaaTT iNriirN ϕϕ , (4.26)
gdzie:
[ ]12
12)()1(max)( .
−≤≤
−≤≤−=
Nioraz
Ttdlaobatt rrtjijiij ϕϕ
, (4.27)
∏ ∑= =
∑=
S
s
kM
mjsmjsm
rtsjsm
rtj
sjs
oNcob1 1
),,()( µ , (4.28)
z warunkami początkowymi w postaci:
1)1(1 =ϕ , (4.29)
)()1( 11r
jjj oba=ϕ , (4.30)

74
dla 2 ≤ j ≤ N – 1.
Dla Aij oznaczającego ogólną liczbę przejść z i-tego do j-tego stanu, jakie miały
miejsce dla wszystkich powtórzeń wypowiedzi w ostatniej iteracji procesu optymalizacji,
prawdopodobieństwa przejść między stanami estymowane są za pomocą następujących
częstości względnych:
∑=
= N
kik
ijij
A
Aa
2
ˆ . (4.31)
Nowe przyporządkowanie obserwacji do stanów wyznaczane jest przez
maksymalizującą ϕN(Tr) (dla r = 1,2,…,R) sekwencję stanów.
Dla rozkładów wyjściowych w postaci kompozycji rozkładów, dalsze przypisywanie
obserwacji do składowych kompozycji realizowane jest wewnątrz każdego i-tego stanu.
Proces ten opiera się na mechanizmie grupowania, w celu umieszczenia każdego strumienia
obserwacji orst w jednej z Msi grup, a także na mechanizmie przypisania każdego strumienia
obserwacji orst do składowej kompozycji generującej tę obserwację z największym
prawdopodobieństwem.
Funkcję φrism(t) przyjmującą wartość 1, gdy s-ty strumień obserwacji or
st został
przyporządkowany do m-tej składowej kompozycji i-tego stanu oraz przyjmującą wartość 0 w
pozostałych przypadkach, można zdefiniować dla każdej obserwacji orst, przydzielonej do
określonej składowej kompozycji.
Estymacja wartości średnich i wariancji odbywa się za pomocą zwykłych wartości
średnich:
( )
( )∑∑
∑∑
= =
= == R
r
T
t
rjsm
R
r
T
t
rst
rjsm
jsm r
r
t
ot
1 1
1 1ˆφ
φµ , (4.32)
( )( )( )
( )∑∑
∑∑
= =
= =
−−=Σ R
r
T
t
rjsm
R
r
T
tjsm
rstjsm
rst
rjsm
jsm r
r
t
oot
1 1
1 1
'ˆˆˆ
φ
µµφ. (4.33)
Na podstawie liczby obserwacji przyporządkowanych każdej składowej, estymowane są
współczynniki wagowe składowej kompozycji:
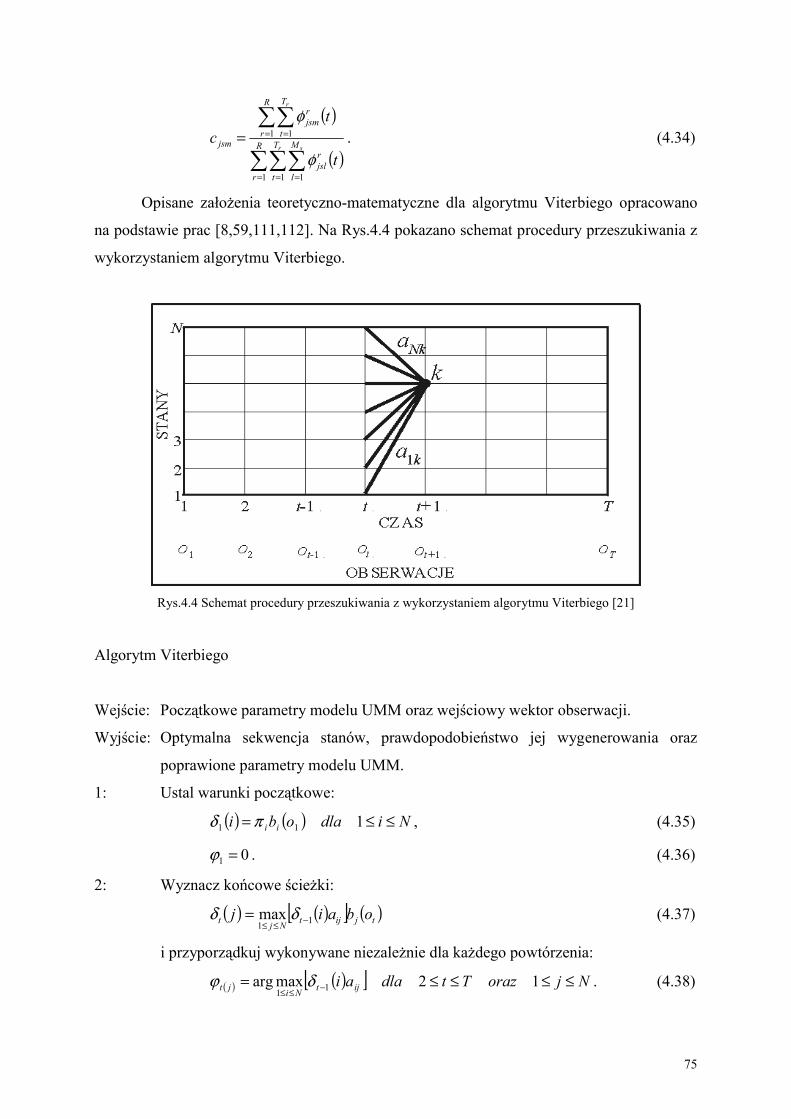
75
( )
( )∑∑∑
∑∑
= = =
= ==R
r
T
t
M
l
rjsl
R
r
T
t
rjsm
jsm r s
r
t
tc
1 1 1
1 1
φ
φ. (4.34)
Opisane założenia teoretyczno-matematyczne dla algorytmu Viterbiego opracowano
na podstawie prac [8,59,111,112]. Na Rys.4.4 pokazano schemat procedury przeszukiwania z
wykorzystaniem algorytmu Viterbiego.
Rys.4.4 Schemat procedury przeszukiwania z wykorzystaniem algorytmu Viterbiego [21]
Algorytm Viterbiego
Wejście: Początkowe parametry modelu UMM oraz wejściowy wektor obserwacji.
Wyjście: Optymalna sekwencja stanów, prawdopodobieństwo jej wygenerowania oraz
poprawione parametry modelu UMM.
1: Ustal warunki początkowe:
( ) ( ) Nidlaobi ii ≤≤= 111 πδ , (4.35)
01 =ϕ . (4.36)
2: Wyznacz końcowe ścieżki:
( ) ( )[ ] ( )tjijtNjt obaij 11max −≤≤
= δδ (4.37)
i przyporządkuj wykonywane niezależnie dla każdego powtórzenia:
( ) ( )[ ] NjorazTtdlaai ijtNijt ≤≤≤≤= −≤≤12maxarg 11
δϕ . (4.38)

76
3: Wyznacz prawdopodobieństwa wygenerowania końcowej ścieżki:
( )[ ]iP TNiδ
≤≤=
1
* max , (4.39)
i właściwą optymalną ścieżkę:
( )[ ]iq TNiT δ≤≤
=1
* maxarg . (4.40)
4: Wyznacz końcową sekwencje stanów wstecz:
( ) 1,...,2,1*11
* −−== ++ TTtdlaqq ttt ψ . (4.41)
4.3. Algorytm Bauma-Welcha do reestymacji parametrów modeli
Algorytm Bauma-Welcha wykorzystuje się do rozwiązania problemu takiej estymacji
parametrów modelu λ=(π,A,B), aby uzyskać maksimum P(O|λ), dla podanego wektora
obserwacji O = (o1,o2,...,oT). Rozpoznając daną wypowiedź zakłada się, że wypowiedź ta
składa się ze znaków ze znanego słownika z V słowami. Na podstawie kilku powtórzeń słowa,
algorytm buduje statystyczny model danego słowa w słowniku, który jest następnie używany
przy rozpoznawaniu. Każda wypowiedź generuje obserwację, którą rozważa się jako
realizację o długości T procesu losowego o skończonej przestrzeni stanów.
Z uwagi na to, że z powodu komplikacji rozwiązanie może się powtarzać, należy
rozwiązać przytoczony problem metodą nieanalityczną. Parametry modelu λ=(π,A,B)
estymowane są dla uzyskania maksymalnego P(O|λ) zakładając, że ξ(i,j) jest
prawdopodobieństwem przebywania modelu w stanie i dla czasu t i w stanie j dla czasu t + 1,
a δ(i) jest ścieżką końcową o najwyższym prawdopodobieństwie dla modelu będącego w
stanie i. Prawdopodobieństwo to wyznacza się z zależności:
( ) ( ) ( ) ( )( )
( ) ( ) ( )( ) ( ) ( )∑∑
= =++
++++ == N
i
N
jttjijt
ttjijttjij
jobai
jobaiOP
jobaiji
1 111
1111
|,
βα
βαλβα
ξ . (4.42)
Procedura Bauma-Welcha zbliżona jest do procedury Viterbiego. Różnica polega na
tym, że funkcja φ przyporządkowania obserwacji do konkretnego stanu, zastąpiona zostaje
funkcją określającą prawdopodobieństwo przyporządkowania obserwacji do dowolnego
stanu. Prawdopodobieństwo to wyznaczane jest za pomocą prawdopodobieństw „w przód” i
„w tył”.

77
Prawdopodobieństwo „w przód” αj(t) (dla 2 ≤ j ≤ N – 1 oraz 1 < t ≤ T) wyznaczane
jest dla wydzielonych jednostek fonetycznych za pomocą następującej zależności
rekurencyjnej:
( ) ( ) ( )rtj
N
jijij obatt
−= ∑
−
=
1
21αα , (4.43)
z warunkami początkowymi:
( ) 111 =α (4.44)
( ) ( ) 121 1 −≤≤= NjdlaOba rtjjjα (4.45)
i warunkami końcowymi:
( ) ( )∑−
=
=1
2
N
jiNrirN aTT αα . (4.46)
Prawdopodobieństwo „w tył” βi (dla 2 ≤ i ≤ N – 1 oraz 1 ≤ t < T) wyznaczane jest za
pomocą następującej zależności rekurencyjnej:
( ) ( ) ( )∑−
=+ +=
1
21 1
N
jj
rtjiji tobat ββ , (4.47)
z warunkami początkowymi:
( ) NidlaaT iNri ≤≤= 1β (4.48)
i warunkiem końcowym:
( ) ( ) ( )∑−
=
=1
2111 11
N
jj
rjj oba ββ . (4.49)
W momencie czasu t wartości prawdopodobieństw α i β odpowiadające stanowi
wejściowemu i stanom wyjściowym modelu UMM reprezentują prawdopodobieństwa „w
przód” i „w tył”. Prawdopodobieństwa te przyjmuje się w uczeniu zintegrowanym, w którym
model UMM jest złożeniem jednostek fonetycznych o numerach q = 1,2,…,Q. Dodatkowo
należy założyć, że prawdopodobieństwo „w przód” reprezentowane jest w czasie t - ∆t, a
prawdopodobieństwo „w tył” w czasie t + ∆t, przy stosunkowo niewielkiej wartości ∆t.
Dla t = 1, warunki początkowe dla prawdopodobieństwa „w przód” określone jak:
( ) ( )
≠=
=−
− 1111
1 )(1
)1(1
)(1
1qgdyaqgdy
qN
qαα , (4.50)
( ) ( )1)()(
1)( 1 oba q
jqj
qj =α , (4.51)
( ) ( )∑−
=
=1
2
)()()( 11q
N
j
qiN
qj
qN aαα , (4.52)

78
gdzie indeks górny oznacza numer modelu w złożeniu modeli. Oprócz przedstawionych
założeń, zeruje się wszystkie niewyspecyfikowane wartości prawdopodobieństwa α.
Dla czasu t > 1, warunki początkowe dla prawdopodobieństwa „w przód” są następujące:
( ) ( ) ( )
≠+−=
= −−−−−
1110
)1(1
)1(1
)1()(
111
qgdyattqgdy
t qN
qqN
q
qqααα , (4.53)
( ) ( ) ( ) ( )tq
j
N
i
qij
qi
qj
qqj obatatt
q)(
1
2
)()()(1
)(1
)( 1
−+= ∑
−
=
ααα , (4.54)
( ) ( )∑−
=
=1
2
)()()(q
N
i
qiN
qi
qN att αα . (4.55)
Dla t = T, warunki początkowe dla prawdopodobieństwa „w tył” określone jak:
( ) ( )
≠=
= ++++
QqgdyaTQqgdy
T qN
qN
qN
qqq )1(
11(
)(
11
1ββ , (4.56)
( ) ( )TaT qN
qiN
qi qq
)()()( ββ = , (4.57)
( ) ( ) ( )∑−
=
=1
2
)()()(1
)(1
qN
j
qjT
qj
qj
q TobaT ββ , (4.58)
gdzie zeruje się wszystkie niewyspecyfikowane wartości prawdopodobieństwa β.
Dla czasu t < T, warunki początkowe dla prawdopodobieństwa „w tył” są następujące:
( ) ( ) ( )
≠++=
= +++++
QqgdyattQqgdy
t qN
qN
Nqq
q )1(1
)1()1(1
)(
111
0βββ , (4.59)
( ) ( ) ( ) ( )∑−
=+ ++=
1
2
)(1
)()()()()( 1q
N
j
qjt
qj
qij
qN
qiN
qi tobatat βββ , (4.60)
( ) ( ) ( )∑−
=
=1
2
)()()(1
)(1
qN
j
qjt
qj
qj
q tobat ββ . (4.61)
Z przedstawionych zależności wynika, że prawdopodobieństwo P(O|λ) można
wyznaczyć zarówno z prawdopodobieństwa „w przód”, jak i prawdopodobieństwa „w tył” w
następujący sposób:
( ) ( ) ( )11βαλ == TOP N . (4.62)
Opisane założenia teoretyczno-matematyczne dla algorytmu Bauma-Welcha
opracowano na podstawie prac [8,59,111,112]. Na Rys.4.5 pokazano schemat procedury
estymacji z wykorzystaniem algorytmu Bauma-Welcha.
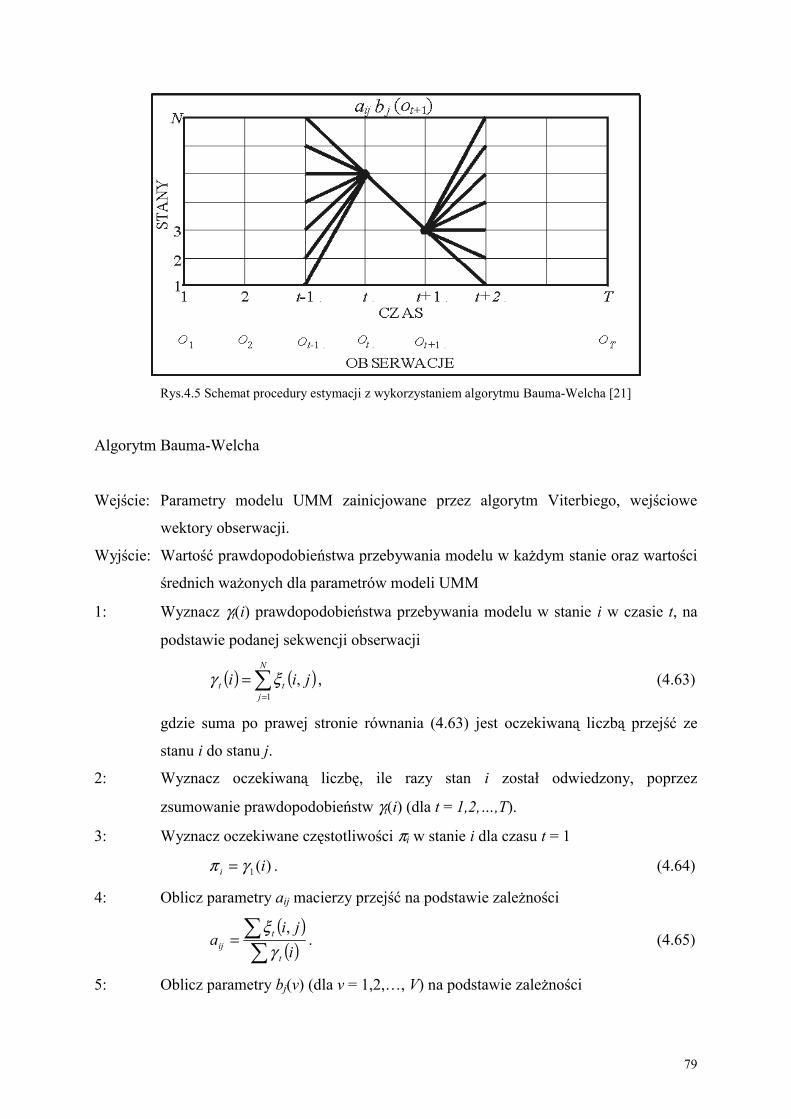
79
Rys.4.5 Schemat procedury estymacji z wykorzystaniem algorytmu Bauma-Welcha [21]
Algorytm Bauma-Welcha
Wejście: Parametry modelu UMM zainicjowane przez algorytm Viterbiego, wejściowe
wektory obserwacji.
Wyjście: Wartość prawdopodobieństwa przebywania modelu w każdym stanie oraz wartości
średnich ważonych dla parametrów modeli UMM
1: Wyznacz γt(i) prawdopodobieństwa przebywania modelu w stanie i w czasie t, na
podstawie podanej sekwencji obserwacji
( ) ( )∑=
=N
jtt jii
1
,ξγ , (4.63)
gdzie suma po prawej stronie równania (4.63) jest oczekiwaną liczbą przejść ze
stanu i do stanu j.
2: Wyznacz oczekiwaną liczbę, ile razy stan i został odwiedzony, poprzez
zsumowanie prawdopodobieństw γt(i) (dla t = 1,2,…,T).
3: Wyznacz oczekiwane częstotliwości πi w stanie i dla czasu t = 1
)(1 ii γπ = . (4.64)
4: Oblicz parametry aij macierzy przejść na podstawie zależności
( )( )∑
∑=iji
at
tij γ
ξ ,. (4.65)
5: Oblicz parametry bj(v) (dla v = 1,2,…, V) na podstawie zależności

80
( ) ( )( )∑
∑ ==i
ivb
tt
tvotj
t
γγ, . (4.66)
4.4. Specyfika estymacji parametrów ukrytych modeli Markowa
Estymacja parametrów UMM przebiega w kilku etapach w procesie zwanym uczeniem lub
treningiem. Polega ona na takim doborze parametrów modelu, aby jak najlepiej dopasować
model generujący później obserwacje, do sekwencji obserwacji podawanej na wejście.
Inaczej mówiąc estymacja parametrów polega na jak najlepszym doborze prawdopodobieństw
przejść i emisji w oparciu o zaobserwowany zbiór obserwacji uczących, wyemitowanych
przez dany model.
Dla wypowiedzi z transkrypcją fonetyczną stosuje się tzw. uczenie zintegrowane, w
którym dla każdej wypowiedzi uczącej łączy się w sekwencję odpowiednie modele UMM
jednostek fonetycznych zgodnie z jej transkrypcją fonetyczną. Dla każdego modelu w
sekwencji wyznacza się na podstawie wszystkich danych uczących, statystyki dotyczące
przebywania modelu w stanie, wartości średnich oraz wariancji.
Sekwencje wektorów obserwacji wprowadzane do systemu jako dane uczące,
najczęściej wyznaczane są na bieżąco, bezpośrednio z wejścia akustycznego lub też z
przechowywanych tymczasowo w pamięci zarejestrowanych wcześniej danych głosowych.
Można także dane głosowe odczytywać z utworzonych wcześniej plików oznaczonych
odpowiednią transkrypcją fonetyczną, przyspieszając w ten sposób proces uczenia oraz
unikając wielokrotnego przetwarzania tych samych danych głosowych.
Duży wpływ na metodę uczenia ma typ utworzonego modelu UMM, ze szczególnym
uwzględnieniem ciągłych, bądź dyskretnych rozkładów wyjściowych stanów modeli.
Dodatkowo na metodę uczenia wpływa postać danych uczących, przedstawionych w formie
wypowiedzi indeksowanych, zaopatrzonych tylko w transkrypcję fonetyczną lub w postaci
izolowanych jednostek fonetycznych (słowo).
Gdy jednostką fonetyczną jest słowo, oddzielny model UMM tworzony jest dla
każdego słowa ze słownika systemu. Najczęściej w procesie uczenia modelu określonego
słowa wykorzystywane są próbki kilku powtórzeń tego słowa, wymawiane w sposób
izolowany, tzn. z wyraźnie zaznaczoną ciszą przed i poza właściwą wypowiedzią. Jeżeli z
próbek usunięta zostanie cisza przed i po słowie, to mogą być one zastosowane do uczenia

81
bezpośrednio, bez potrzeby ich indeksowania. Zwykle tworzenie modeli UMM dla słów
izolowanych przebiega w dwóch etapach:
• wyznaczenie wartości początkowych parametrów modelu za pomocą procedury
segmentowej, która wykorzystuje algorytm Viterbiego,
• reestymacja parametrów modelu za pomocą procedury Bauma-Welcha [111].
Jeśli rozpoznawanie odbywa się w zakłóconym, niesprzyjającym środowisku, a
dodatkowo znacznie ograniczona jest ilość danych uczących, wówczas dobrym podejściem
jest zastosowanie modeli ze stałą wariancją, które mogą zapewnić większą odporność na
wpływy środowiska. W takich modelach rozkłady wyjściowe wszystkich stanów mają
wariancje identyczne, równe ogólnej wariancji sygnału mowy zastosowanego do uczenia, jak
również stałe, które nie podlegają reestymacji w procesie uczenia.
Gdy system automatycznego rozpoznawania mowy stosuje mniejszą jednostkę
fonetyczną od słowa, np. fonem, wówczas oddzielny model UMM jest konstruowany dla
każdego posłowa. Biorąc pod uwagę fakt, iż w języku polskim występuje 37 fonemów,
wystarczy utworzyć 37 modeli UMM, aby w całości pokryć przestrzeń akustyczną dla danego
użytkownika, dla wszystkich występujących w języku polskim słów. W przypadku słów
izolowanych, liczba dostępnych słów ograniczona będzie o wielkość słownika systemu.
Rozpoznawanie mowy ciągłej (dla podejścia fonemowego, bez przerw między wyrazami) jest
możliwe, dzięki możliwości łączenia modeli posłów w sekwencje odpowiadające słowom z
rozpoznawanego słownika.
Dla każdej wypowiedzi na podstawie transkrypcji fonetycznej tworzy się sekwencję
połączonych modeli UMM jednostek fonetycznych, będącej w zasadzie pojedynczym, choć
złożonym modelem, wykorzystywanym do gromadzenia niezbędnych dla reestymacji
statystyk w procesie uczenia. Przetwarzając w ten sposób wszystkie wypowiedzi uczące,
otrzymuje się zbiór zakumulowanych statystyk, wykorzystywany do reestymacji parametrów
wszystkich modeli UMM posłów. W przytoczonym procesie nie jest konieczna indeksacja
wypowiedzi, czyli informacja o czasowych granicach posłów, transkrypcje są potrzebne tylko
do identyfikacji sekwencji posłów w wypowiedzi.
W uczeniu zintegrowanym, wstępny zbiór modeli UMM otrzymuje się najczęściej
dwoma podstawowymi sposobami. Pierwszy ze sposobów polega na uzyskiwaniu zbioru
modeli poprzez inicjowanie każdego modelu UMM niezależnie, za pomocą wcześniej
opisanej procedury uczenia słów izolowanych, wykorzystując mały zbiór ręcznie
indeksowanych początkowych danych uczących, poprzez wydzielenie z wypowiedzi
uczących, segmentów sygnału mowy odpowiadających inicjowanemu modelowi. W drugim

82
ze wspomnianych sposobów, początkowy zbiór modeli uzyskuje się poprzez przypisanie
wyznaczonej na podstawie wszystkich wypowiedzi uczących wartości średniej i wariancji
wszystkim rozkładom normalnym we wszystkich inicjowanych modelach UMM. Założeniem
tej procedury jest równomierna segmentacja każdej wypowiedzi uczącej podczas pierwszego
cyklu zintegrowanej reestymacji.
Budując system automatycznego rozpoznawania mowy bazującego na modelach
UMM, należy uwzględnić fakt, iż ilość danych treningowych dla każdego modelu jest
zmienna oraz rzadko kiedy wystarczająca. Aby obejść wspomniane trudności, można tak
wzajemnie powiązać parametry modeli, aby dane uczące stały się wspólne, wówczas wynik
estymacji będzie bardziej odporny na wszelkiego rodzaju zakłócenia oraz zmiany.
Podstawową zasadą przy tworzeniu modeli UMM zarówno dla wydzielonej jednostki
fonetycznej, jak i dla wypowiedzi ciągłej jest traktowanie tych modeli jako generatora
wektorów obserwacji. Każda wykorzystywana w czasie uczenia sekwencja obserwacji
stanowi wyjście stanów modelu UMM, którego parametry mają być wyznaczone. Gdyby
znany był stan, który wygenerował każdy wektor obserwacji w danych uczących, wtedy
mogłyby być wyznaczone nieznane wartości średnie i wariancje rozkładu wyjściowego tego
stanu, poprzez wykorzystanie wszystkich wektorów skojarzonych z tym stanem, a także
macierz przejść, na podstawie liczby przejść między stanami [111].
W przypadku inicjowania parametrów modelu metodą wydzielonych jednostek
fonetycznych, w kolejnych iteracjach najpierw wykorzystuje się algorytm Viterbiego do
znalezienia najbardziej prawdopodobnej sekwencji stanów obserwacji, a następnie na
podstawie obserwacji przypisanych określonym stanom wyznacza się parametry modelu
UMM. Wyznaczanie uporządkowanej sekwencji stanów za pomocą algorytmu Viterbiego
powtarzane jest tak długo, aż logarytm prawdopodobieństwa wygenerowania danych
uczących przez model przestanie narastać w kolejnych iteracjach. Śledzenie procesu
estymacji możliwe jest dzięki wyświetlaniu informacji o kolejnym numerze iteracji, wartości
prawdopodobieństwa oraz jego zmianie w stosunku do poprzedniego kroku.
W utworzonym systemie automatycznego rozpoznawania słów izolowanych można na
bieżąco śledzić cały proces uczenia, kontrolując wspomniane parametry.
Reestymacja parametrów modelu jest bardzo podobna do inicjacji, z tą jednak różnicą,
że na wejście wprowadza się wyznaczony wcześniej początkowy model UMM, a do
estymacji parametrów wykorzystuje się algorytm Bauma-Welcha. Następnie przy
wyznaczaniu prawdopodobieństwa przebywania modelu w każdym stanie stosuje się
algorytm „w przód-w tył”, określając średnie ważone dla parametrów modeli UMM.

83
Różnica pomiędzy algorytmami wykorzystywanymi w procesach inicjacji oraz
estymacji polega na tym, że algorytm Viterbiego wyznacza ostrą decyzję o tym, który stan
generuje określony wektor obserwacji z wypowiedzi uczącej, natomiast algorytm Bauma-
Welcha wyznacza jedynie prawdopodobieństwo wygenerowania obserwacji przez dany stan.
Często zastosowanie tego drugiego algorytmu jest pomocne podczas estymacji modeli UMM
fonemów, ponieważ w naturalnej mowie trudno wskazać ostre granice między fonemami.
Jeśli tworzone są modele z dużą liczbą składowych kompozycji dla każdego stanu,
może wystąpić sytuacja, gdzie składowym kompozycjom przyporządkowano bardzo mało
wektorów obserwacji i w konsekwencji albo wariancje, albo odpowiadające tym składowym
wagi, mają bardzo małe wartości. W takim przypadku składowa kompozycji powinna być
usunięta, albo należy nadać minimalną dopuszczalną wartość wariancji lub współczynnikowi
wagowemu kompozycji.
Jeśli wypowiedzi uczące są za krótkie, często stosuje się praktykę ignorowania
wszystkich wypowiedzi, mających mniejszą liczbę ramek niż model stanów emisyjnych, bądź
też zmniejsza się liczbę stanów emisyjnych. Zakłada się, że modele mogą różnić się liczbą
stanów emisyjnych, jednak w pracy zastosowano jednakową liczbę stanów dla wszystkich
modeli, ze względu na spore uproszczenie programistyczne.
Przed rozpoczęciem procesu uczenia, konieczna jest znajomość wcześniej
zainicjowanego zbioru modeli UMM wszystkich jednostek fonetycznych wykorzystywanych
w systemie. Nazewnictwo modeli wchodzących w skład zbioru powinno odpowiadać
nazewnictwu symboli zastosowanych w transkrypcji fonetycznej oraz każdy symbol
transkrypcji fonetycznej musi posiadać odpowiedni model.
Procedura reestymacji parametrów wymaga w tworzonym systemie utworzenia pliku
(pliki.mat), zawierającego listę wszystkich modeli UMM. Na podstawie odczytanych nazw
modeli tworzone są oddzielne dla każdego modelu pliki o tych nazwach (*.mat),
przechowujące parametry modeli UMM. Każdemu takiemu modelowi odpowiada zbiór
nagrań przechowywanych w plikach typu *.wav.
Z matematycznego punktu widzenia proces estymacji prawdopodobieństw przejść
między stanami modelu wydzielonej jednostki fonetycznej, dla zbioru uczącego {Or}, gdzie r
= 1,2,…,R, przedstawia się następująco [38,111,112]:
∑ ∑
∑ ∑
= =
=
−
=+ +
=R
r
ir
T
t
ri
r
R
r
T
t
rj
rtjij
ri
rij r
r
tP
tobatPa
1 1
1
1
11
)(1
)1()()(1
ˆβα
βα, (4.67)

84
gdzie 1 ≤ i ≤ N oraz 1 < j < N, a Pr jest prawdopodobieństwem wygenerowania r-tej
obserwacji.
Każde przejście z wejściowego stanu nieemisyjnego reestymowane jest następująco:
∑=
=R
r
rj
rj
rj PR
a1
1 )1()1(11ˆ βα , (4.68)
gdzie 1 < j < N, natomiast przejścia ze stanów emisyjnych do końcowego stanu
nieemisyjnego reestymowane są zależnością:
∑ ∑
∑
= =
==R
r
T
t
ir
ri
r
R
r
rj
ri
rij r
tP
TTPa
1 1
1
)(1
)()(1
ˆβα
βα, (4.69)
gdzie 1 < i < N.
Wyznaczanie wartości przeciętnych, kowariancji i współczynników wagowych
kompozycji, dla modelu UMM z rozkładami wyjściowymi w postaci kompozycji o Ms
składowych w s-tym strumieniu, realizuje się w następujący sposób. Na początku obliczane
jest prawdopodobieństwo przebywania modelu w j-tym stanie, m-tej składowej kompozycji s-
tego strumienia dla obserwacji w t-tej chwili czasowej z r-tego powtórzenia wypowiedzi:
)()()()(1)( * rtjs
rj
rstjsmjsm
rj
r
rjsm obtobctU
PtL β= , (4.70)
gdzie:
≠−
== ∑
−
=
1)1(
1)( 1
2
1
tgdyat
tgdyatU N
iij
ri
jrj α , (4.71)
∏≠
=sk
rktjk
rtjs obob )()(* . (4.72)
Prawdopodobieństwo przypisania obserwacji m-tej składowej kompozycji dla pojedynczego
strumienia, równe jest prawdopodobieństwu przebywania w stanie:
)()(1)()( ttP
tLtL jjr
rj
rjsm βα== . (4.73)
Reestymację parametrów modeli dla sformułowanych wielkości wyznacza się następująco:
∑∑
∑∑
− −
= ==R
r
T
t
rism
R
r
T
t
rst
rism
ism r
r
tL
OtL
1 1
1 1
)(
)(µ̂ , (4.74)

85
∑∑
∑∑
= =
= =
−−=Σ
R
r
T
t
rism
R
r
T
tism
rstism
rst
rism
ism r
r
tL
OOtL
1 1
1 1
)(
)')()((ˆ
µµ (4.75)
a współczynniki wagowe składowych kompozycji:
∑∑
∑∑
− −
= ==R
r
T
t
ri
R
r
T
t
rism
ism r
r
tL
tLc
1 1
1 1
)(
)(. (4.76)
Dla modelu w uczeniu połączonych jednostek fonetycznych, ze względu na fakt, że
stany wejściowe mogą być osiągane w dowolnym momencie czasu jako wynik przejścia z
poprzedniego modelu, proces reestymacji został odpowiednio zmodyfikowany.
Prawdopodobieństwa przejść wyznacza się z następujących zależności [38,111,112]:
∑ ∑
∑ ∑
= =
=
−
=+ +
=R
r
rqi
T
t
rqi
r
R
r
T
t
rqj
rt
qj
qij
rqi
rqij
ttP
tobatPa
r
r
1
)(
1
)(
1
1
1
)(1
)()()(
)(
)()(1
)1()()(1
ˆβα
βα. (4.77)
Prawdopodobieństwo przejścia z nieemisyjnych stanów wejściowych do modelu UMM
wyraża się wzorem:
∑ ∑
∑ ∑
= =
+
=
−
=
+=
R
r
T
t
rqqN
rqrqrq
r
R
r
T
t
rqj
rt
qj
qj
rq
rqj r
q
r
tatttP
tobatPa
1 1
)1(1
)(1
)(1
)(1
)(1
1
1
1
)()()(1
)(1
)(1
)()()()(1
)()()(1
ˆβαβα
βα. (4.78)
Prawdopodobieństwo przejścia z modelu UMM do nieemisyjnych stanów wyjściowych
wyraża się wzorem:
∑ ∑
∑ ∑
= =
=
−
==R
r
T
t
rqi
rqi
r
R
r
T
t
rqN
qiN
rqi
rqiN r
r
q
ttP
tatPa
1 1
)()(
1
1
1
)()()(
)(
)()(1
)()(1
ˆβα
βα. (4.79)
Prawdopodobieństwo przejścia bezpośredniego z wejściowych stanów nieemisyjnych do
wyjściowych stanów nieemisyjnych jest reestymowane za pomocą następującej zależności:
∑ ∑
∑ ∑
= =
+
=
+−
=
+=
R
r
T
t
rqqN
rqrqrq
r
R
r
rqT
t
qN
rq
rqN r
q
r
q
q
tatttP
tatPa
1 1
)1(1
)(1
)(1
)(1
)(1
1
)1(1
1
1
)(1
)(1
)(1
)()()()(1
)()(1
ˆβαβα
βα. (4.80)

86
Proces reestymacji parametrów modelu połączonych jednostek fonetycznych dla
rozkładów wyjściowych realizuje się następująco. Na początku obliczane jest
prawdopodobieństwo przebywania q-tego modelu w j-tym stanie, m-tej składowej
kompozycji s-tego strumienia dla obserwacji w t-tej chwili czasowej z r-tego powtórzenia
wypowiedzi:
)()()()(1)( )*()()()()()( rt
qjs
rqj
rst
qjsm
qjsm
rqj
r
rqjsm obtobctU
PtL β= , (4.81)
gdzie:
≠−+
==
∑−
=
1)1()(
1)()( 1
2
)()()(1
)(1
)(1
)(1
)(
tgdyatat
tgdyattU qN
i
qij
rqi
qj
rq
qj
rq
rqj αα
α, (4.82)
∏≠
=sk
rkt
qjk
rt
qjs obob )()( )()*( . (4.83)
Reestymację parametrów q-tych modeli dla sformułowanych wielkości wyznacza się
następująco:
∑∑
∑∑
− −
= ==R
r
T
t
rqism
R
r
T
t
rqst
rqism
qism r
r
tL
OtL
1 1
)(
1 1
)()(
)(
)(
)(µ̂ , (4.74)
∑∑
∑∑
= =
= =
−−=Σ
R
r
T
t
rqism
R
r
T
t
qism
rqst
qism
rqst
rqism
qism r
r
tL
OOtL
1 1
)(
1 1
)()()()()(
)(
)(
)')()((ˆ
µµ (4.75)
a współczynniki wagowe składowych kompozycji:
∑∑
∑∑
− −
= ==R
r
T
t
rqi
R
r
T
t
rqism
qism r
r
tL
tLc
1 1
)(
1 1
)(
)(
)(
)(. (4.76)
Przedstawienie całego przeglądu struktury modeli UMM, opisanego w pracy [111],
matematycznych osobliwości, procesów estymacji parametrów na podstawie wejściowych
wektorów obserwacji, algorytmów Viterbiego i Bauma-Welcha, było z góry zamierzone.
Systemy automatycznego rozpoznawania audio mowy i audio-wideo mowy, zbudowano
bazując na topologii modeli UMM dla słów izolowanych. W dalszej części pracy
przedstawione zostanie praktyczne wykorzystanie modeli UMM.

87
5. TWORZENIE WEKTORÓW OBSERWACJI SYGNAŁU AUDIO-WIDEO MOWY POLSKIEJ
Przedstawiono metody ekstrakcji cech wideo mowy potrzebnych w systemie rozpoznawania
audio-wideo mowy. Podano metody lokalizacji twarzy, oczu i ust w obrazie kolorowym.
Zaproponowano własne metody wykrywania kącików i krawędzi ust, a także tworzenia
wektorów obserwacji wideo mowy.
5.1. Opracowanie metody detekcji twarzy na podstawie koloru skóry
W opracowanej metodzie AV_Mowa_PL zaproponowano sposób, wykorzystujący do podjęcia
decyzji o wyniku rozpoznania wypowiedzi zarówno informację audio mowy, jak również
wideo mowy. Przyjęto jako informację wideo mowy, wektor obserwacji tworzony w procesie
ekstrakcji cech wideo. Ekstrakcja cech wideo wiąże się z analizowaniem ruchu ust osoby
wypowiadającej dane słowo. Jest to tzw. czytanie z ruchu ust (ang. Lip-Reading) [77]. Aby
zrealizować proces czytania z ruchu ust, konieczne jest zaimplementowanie w systemie
procedury trekingu ust, czyli ciągłego śledzenia ruchu ust (ang. Lip-Tracking) [77].
Mając do dyspozycji zarejestrowaną przez kamerę sekwencję ramek,
odzwierciedlających wypowiedź wideo danego użytkownika, ciężko jest zrealizować treking
ust, bezpośrednio próbując zlokalizować usta na każdej z ramek, chyba że kamera ustawiona
jest tak, że wyłapuje podczas wypowiedzi tylko obszar samych ust. Takie podejście wymaga
dość ścisłego użytkowania systemu, gdyż z góry trzeba by było ustalić pozycję u odległość
użytkownika od kamery. W rzeczywistych warunkach kamera powinna wychwytywać całą
twarz użytkownika, wówczas przedział odległości, w jakiej użytkownik powinien znajdować
się przed kamerą, znacznie się zwiększy, a sposób pracy z systemem będzie o wiele
łatwiejszy. W takim rodzaju nagrań, gdzie wiadomo, że w kadrze znajduje się cała twarz
użytkownika systemu, konieczne jest przejście przez kilka znaczących etapów pozwalających
na w miarę dokładne wychwycenie konturu ust z każdej ramki nagrania.
Pierwszym etapem procesu tworzenia wektorów obserwacji wideo mowy jest
lokalizacja twarzy użytkownika w nagraniu wideo. Wyodrębnianie twarzy może być
realizowane na obrazach monochromatycznych, jednak ze względu na wymagania niektórych
metod zastosowanych w procesie ekstrakcji cech wideo, wykorzystano kolorowe sekwencje
ramek wypowiedzi.

88
Ponieważ z założenia system przeznaczony jest do pracy w danej chwili wyłącznie dla
jednego użytkownika, wiadomo, że kadr zawiera tylko twarz jednej osoby. W takim
przypadku realizuje się lokalizację twarzy (ang. Face Localization, FL) [70]. Wykonanie
lokalizacji twarzy wiąże się z koniecznością ograniczenia całego kadru, do obszaru
zawierającego tę twarz. Proces lokalizacji twarzy dla wszystkich ramek, czyli ciągłego
monitorowania jej pozycji określany jest mianem trekingu twarzy (ang. Face Tracking) [70,
113].
W pracy zastosowano metodę wyodrębniania twarzy z obrazu kolorowego, opierającą
się na specyficznym kolorze skóry (ang. Skin Color Detection) [70]. Metoda ta polega na
poszukiwaniu w obrazie będącym pojedynczą ramką sekwencji wideo, pikseli
odpowiadających barwie skóry.
Proces wyodrębniania twarzy zrealizowano na sekwencji wideo o modelu RGB i
jakości kolorów 24 bity. Dla każdej z ramek wyodrębniono składowe poszczególnych
kolorów RGB. Poszczególne składowe nie odzwierciedlają wyraźnie w mniejszym, bądź
większym stopniu obszaru twarzy, co pokazano na Rys.5.1.
Rys.5.1 Przykładowy obraz kolorowy RGB autora wraz z komponentami
Aby uzyskać obraz w znacznym stopniu wyodrębniający kolor skóry, zastosowano
różne operacje matematyczne na poszczególnych składowych RGB. Dobrym rozwiązaniem,
wystarczającym dla poprawnego działania systemu, jest wykonanie operacji odejmowania od
składowej R, składowej B. Różnica tych składowych określa obszar danej klatki, w dużym
stopniu przypominający kolor ludzkiej skóry. Niestety oprócz właściwego koloru skóry,
różnica wyróżnionych składowych wyodrębnia również elementy tła, wprowadzając
dodatkowe zakłócenie. Elementy o barwie zbliżonej do żółtej, pomarańczowej, brązowej,
przy zastosowaniu różnicy R – B, mają podobne właściwości, co ludzka skóra.
Na Rys.5.2 pokazano przykładowe operacje matematyczne na składowych RGB [70].

89
Rys.5.2 Odpowiednie różnice składowych RGB dla obrazu z Rys.5.1
W celu wyeliminowania podobieństwa koloru skóry do elementów tła, nie będących
ludzką skórą, zastosowano progowanie obrazu, będącego wynikiem różnicy składowych R –
B [70]. Wartość progu należy wyznaczyć doświadczalnie. Zastosowanie w systemie
możliwości korygowania tej wartości na bieżąco pozwala na optymalne skonfigurowanie
systemu dla danego użytkownika i warunków pracy. Jeśli jednak system nie będzie posiadał
takiej możliwości korygowania, wówczas konieczne jest ustalenie na sztywno tego progu.
Wartość progu powinna wahać się w granicach od 20 do 40. Dodatkowo, aby usunąć wszelkie
drobne zakłócenia z kadru, przypominające kolorem ludzką skórę, zastosowano filtrację
medianową.
Na Rys.5.3 pokazano zastosowanie operacji progowania i filtracji medianowej do
obrazu uzyskanego w sposób różnicy składowych R – B.
a)
b)
c) Rys.5.3 Zastosowanie operacji progowania i filtracji medianowej:, a) – progowanie z różnej wartością progu, b)
– filtracja z różną liczbą powtórzeń, c) – podwójna filtracja medianowa i progowanie

90
Kolejnym krokiem w lokalizacji twarzy jest znalezienie jej centrum. Centrum twarzy
potrzebne jest do wyznaczenia prostokątnej maski, po nałożeniu której zostanie
wyodrębniona twarz użytkownika.
W pracy zastosowano podejście polegające na znajomości specyficznego, owalnego
kształtu twarzy człowieka. W oparciu o te przesłanki, centrum twarzy wyznacza się w ten
sposób, że zlicza się wszystkie kolejne piksele o wartości większej od zera, wzdłuż
wszystkich wierszy i kolumn obrazu. W wierszu o maksymalnej liczbie kolejnych,
niezerowych pikseli, połowa takiego poziomego, niezerowego odcinka wyznacza oś pionową
twarzy, zaś w kolumnie o maksymalnej liczbie kolejnych, niezerowych pikseli, połowa
takiego pionowego, niezerowego odcinka wyznacza oś poziomą twarzy. Punkt przecięcia bu
osi wyznacza poszukiwane centrum twarzy. Jeśli wystąpi kilka wierszy lub kolumn o
maksymalnej liczbie kolejnych niezerowych wartości pikseli, wówczas jako dominujący
wiersz i kolumnę, przyjmuje się środkowe z tych jednakowych wierszy i kolumn.
Na Rys.5.4 pokazano sposób wyznaczania centrum twarzy.
Rys.5.4 Sposób wyznaczania centrum twarzy
Na podstawie znalezionego centrum zlokalizowanej twarzy, wyznacza się prostokątną
maskę zawierającą cały obszar twarzy. Prostokątna maska ma odpowiednio wysokość równą
maksymalnej liczbie kolejnych, niezerowych pikseli spośród wszystkich kolumn obrazu, zaś
szerokość równą maksymalnej liczbie kolejnych, niezerowych pikseli, spośród wszystkich
wierszy obrazu.
Może się zdarzyć, że wyznaczona maska nie będzie zawierała dokładnie całej twarzy
użytkownika. Nie ma to jednak wpływu na poprawność działania systemu, pod warunkiem,
że w zlokalizowanym obszarze znajdą się oczy i usta użytkownika. Brak części czoła, bądź

91
dodatkowo zlokalizowana szyja użytkownika, mająca również kolor skóry, nie będzie
wprowadzała błędów.
Przedstawiony sposób wyznaczania centrum twarzy nie jest wystarczający, jeśli w
kadrze znajdzie się element przypominający kolorem ludzką skórę, a będzie miał kształt
przypominający owal i będzie większy od twarzy znajdującej się w tym samym kadrze.
System zlokalizuje największy z tych elementów, gdyż założono, że głównym elementem
każdego kadru jest twarz użytkownika. Odrzuci natomiast elementy o kształcie znacznie
różniącym się od kształtu ludzkiej twarzy, co pokazano na Rys.5.5, gdzie jako element
zakłócający dodano rękę.
Rys.5.5 Przykład poprawnej lokalizacji twarzy w kadrze przy zakłóceniu w postaci ręki
Polepszenie sposobu działania zastosowanych do lokalizacji twarzy metod progowania
i filtracji medianowej można uzyskać poprzez celowe zmniejszenie rozmiaru obrazu przed
filtracją i progowaniem [70]. Zwiększając obraz do rozmiaru pierwotnego uzyska się
dokładniejszy kształt twarzy. W pracy zastosowano procedurę pomniejszania obrazu
roboczego w celu przyspieszenia działania systemu oraz polepszenia działania filtracji
medianowej. Z pierwotnego rozmiaru kadru 640 x 480 pikseli pomniejszono ośmiokrotnie
obraz przeznaczony do obróbki do rozmiaru 80 x 60.
Po wyznaczeniu współrzędnych wierzchołków prostokątnej maski, nową sekwencję
wypowiedzi wideo, zawierającą ograniczony obraz do obszaru samej twarzy użytkownika,
wygenerowano z sekwencji ramek o pierwotnym rozmiarze.
Ponieważ użytkownik systemu z reguły wypowiadając dane komendy trzyma głowę w
miarę nieruchomo, dla przyspieszenia wszelkich operacji, można by zastosować lokalizację
twarzy tylko dla pierwszej ramki, przyjmując, że twarz na pozostałych ramkach znajduje się
w tym samym miejscy. W pracy zastosowano jednak pełen treking twarzy, powtarzając

92
lokalizację twarzy dla wszystkich ramek. Jest to metoda nieco wolniejsza, jednak pozwalająca
na zachowanie stabilności systemu. Należy dodać, że rozmiar uzyskanej maski musi być
jednakowy dla wszystkich ramek. Przyjęto, że na wszystkie ramki nakłada się maskę
wyznaczoną dla pierwszej ramki. Różnią się tylko współrzędne wyznaczonych centrów
twarzy dla poszczególnych ramek.
Algorytm LT (Lokalizacja Twarzy)
Wejście: Kolorowa sekwencja wideo zarejestrowanej kamerą wypowiedzi danego
użytkownika systemu.
Wyjście: Kolorowa sekwencja wideo wypowiedzi danego użytkownika systemu,
ograniczona do wyznaczonego obszaru twarzy.
1: Podziel sekwencję wideo na pojedyncze ramki.
2: Redukuj rozmiar ramki.
3: Rozłóż ramki na składowe RGB zapisane w formie macierzowej.
4: Wyznacz obszar koloru skóry SK = R – B.
5: Zastosuj filtrację medianową.
6: Zastosuj progowanie.
7: Wyznacz centrum twarzy.
8: Nałóż prostokątną maskę na obszar SK > 0.
9: Powtórz kroki 2 – 8 dla wszystkich ramek.
10: Wyznacz z początkowej sekwencji wideo obszar twarzy mówcy, na podstawie
maski nałożonej na każdą ramkę.
Na Rys.5.6 pokazano przykładowy wynik automatycznej lokalizacji twarzy
użytkownika dla pojedynczej ramki, podczas działania systemu.
Rys.5.6 Widok przykładowej automatycznej lokalizacji twarzy dokonany przez system

93
5.2. Metoda lokalizacji oczu do wyznaczenia obszaru ust
Do wyznaczenia obszaru zawierającego obraz ust użytkownika posłużono się metodą
wyznaczenia współrzędnych oczu. Ponieważ przy prawidłowym zadziałaniu procedury
lokalizacji i wydzielenia twarzy wiadomo, że na sekwencji wypowiedzi wideo, poszczególne
ramki zawierają całą twarz użytkownika. W szczególnych przypadkach obszar opisujący
twarz może być zbyt duży, lub zbyt mały, ważne jest, aby w wyznaczonym obrazie
użytkownika znalazły się oczy i usta.
Do wyznaczenia pionowej i poziomych linii oczu zastosowano metodę obliczania
gradientów jasności pikseli wzdłuż kolumn i wierszy obrazu wejściowego, a następnie
integralną projekcję poziomą i pionową (ang. Gradient Method and Integral Projection,
GMIP) [70].
Pierwszym etapem wyznaczenia współrzędnych oczu jest zamiana obrazu kolorowego
o modelu barw RGB, na obraz monochromatyczny. Zastosowano tutaj proste przekształcenie
polegające na zsumowaniu poszczególnych składowych RGB, a następnie podzieleniu
wszystkich otrzymanych wartości przez liczbę składowych. Operację uzyskania obrazu
monochromatycznego opisuje poniższa następująca zależność:
xsizejoraz
ysizeidlaK
imcolorimgray
K
kkji
ji
_,...,2,1
_,...,2,1,_
_ 1,,
,
=
==∑= , (5.1)
gdzie: size_x – szerokość obrazka w pikselach; size_y – wysokość obrazka; K – iczba
składowych obrazu kolorowego.
Po zamianie obrazu kolorowego na obraz monochromatyczny, kolejnym etapem jest
wyznaczenie poziomej linii oczu. Założono, że wypowiadający komendy użytkownik trzyma
głowę pionowo, a co za tym idzie, oczy znajdują się na jednej poziomej linii. Wyznaczenie
poziomego położenia oczu należy rozpocząć od wyznaczenia gradientu sąsiednich wartości
pikseli, wzdłuż każdego z wierszy. Gradient uzyskuje się poprzez moduł różnicy wartości
piksela w bieżącej kolumnie i wartości piksela w następnej kolumnie. Następnie należy
zsumować uzyskane gradienty w każdej z kolumn, wzdłuż wszystkich wierszy, realizując
sumowanie za pomocą funkcji projekcji poziomej. Jako linię poziomą oczu przyjęto wiersz o
największej wartość sumy gradientów. Sposób wyznaczenia poziomej linii oczu przedstawia
zależność [70]:

94
1_,...,2,1
|__|_1_
11,,
−=
−= ∑
−
=+
ysizeidla
imgrayimgrayMAXlinehxsize
jjiji , (5.2)
gdzie: size_x –szerokość obrazka w pikselach; size_y – wysokość obrazka.
Na podstawie wyznaczonej poziomej linii oczu określa się obszar obliczania
gradientów w etapie określania pionowych linii oczu. Nie jest konieczne przeszukiwanie całej
wysokości obrazka, skoro jest już wyznaczona pozioma linia oczu. W pracy przyjęto
założenie, że obliczanie gradientów sąsiednich wartości pikseli odbywa się wzdłuż
ograniczonego obszaru każdej z kolumn. Również w tym przypadku należy zsumować
uzyskane gradienty w każdym z wierszy, wzdłuż każdej z ograniczonych kolumn. Założono,
że pionowa linia lewego oka wyznaczona jest poprzez kolumnę o największej wartości sumy
gradientów lewej części twarzy, a pionowa linia prawego oka wyznaczona jest poprzez
kolumnę o największej wartości sumy gradientów prawej części twarzy. Jeśli twarz została
zlokalizowana poprawnie, to zawsze dzieląc obraz twarzy na pół wzdłuż pionowej osi uzyska
się stan w którym oczy znajdą się po obu stronach osi. Poniższe wzory opisują sposób
wyliczenia poziomych linii oczu [70]:
2_,...,2,1
|__|__2
_,1,
xsizejdla
imgrayimgrayMAXllinevT
Tlinehijiji
=
−= ∑
−=+
, (5.3)
1_,...,22_,1
2_
|__|__2
_,1,
−++=
−= ∑
−=+
xsizexsizexsizejdla
imgrayimgrayMAXrlinevT
Tlinehijiji
, (5.4)
gdzie: size_x – szerokość obrazka w pikselach; size_y –wysokość obrazka; T –połowa
przedziału ograniczającego wyznaczanie gradientu.
Jeśli użytkownik systemu podczas wypowiedzi nie trzyma głowy w miarę pionowo,
można zastosować rozbudowaną procedurę wyznaczania współrzędnych oczu. A mianowicie
po wyznaczeniu poziomej linii oczu, która oczywiście nie jest dokładną linią obu oczu, należy
wyznaczyć pionowe linie oczu. A w kolejnym kroku, dla ograniczonych obszarów zawartych
w pobliżu poziomej i pionowych linii oczu, można jeszcze raz wyznaczyć poziomą linię oczu,
osobno dla lewego i prawego oka. W ten sposób uzyska się dokładne współrzędne środków
oczu, dla przechylonej twarzy. Oczywiście ten kąt pochyłu nie może być zbyt przesadny. Dla

95
prawidłowego wyznaczenia obszaru ust konieczny jest jeszcze w takim przypadku obrót
twarzy do pozycji pionowej.
Wyznaczone współrzędne pozycji oczu w pojedynczej ramce pokazano na Rys.5.7.
Rys.5.7 Ilustracja wyznaczonej pozycji oczu metodą GMIP
Patrząc na Rys.5.7 można zauważyć, że linie opisujące poziomą i pionowe projekcje
są bardzo poszarpane, co może być przyczyną niezbyt dokładnego wyznaczenia środków
oczu. Dokładne wyznaczenie środków oczu jest o tyle ważne, że zastosowano współrzędne
oczu do wyznaczenia regionu twarzy zawierającego same usta. Błędne wyznaczenie środków
oczu może spowodować, iż w wyznaczonym obszarze ust, część ust znajdzie się poza tym
obszarem. W celu wyeliminowania takich przypadków zastosowano wygładzenie linii
projekcji poprzez uśrednianie wyznaczonych gradientów sąsiednich kolumn i wierszy.
Zależności (5.5) i (5.6) opisują sposób wygładzenia linii projekcji:
1_,...,2,1
_,...,2,1_
_ 1,
,
−=
−==∑=
+
xsizejoraz
MysizeidlaM
imgradimgrad
M
mjmi
ji , (5.5)
Mxsizejoraz
TlinehTlinehidlaM
imgradimgrad
M
mmji
ji
−=
+−==∑=
+
_,...,2,1
_,...,__
_ 1,
, , (5.6)
gdzie: size_x – jszerokość obrazka; size_y – j wysokość obrazka; M – stopień wygładzenia
linii; T –połowa przedziału ograniczającego wyznaczanie gradientu.

96
Takie wygładzenie linii projekcji pozwala na jednoznaczne wyznaczenie
współrzędnych środków oczu, co można zaobserwować na Rys.5.8.
Rys.5.8 Wyznaczone pozycje oczu metodą GMIP z wygładzonymi liniami projekcji
Kolejnym etapem jest wyznaczenie obszaru twarzy, zawierającego całe usta
użytkownika. Wyznaczenie tego obszaru oparto o zlokalizowane wcześniej środki oczu.
Region ust wyznacza prostokątny obszar o wierzchołkach wyznaczonych w sposób
doświadczalny. Wykorzystując odległość pomiędzy środkami oczu, przesuwając się o tę
odległość od linii oczu w dół, można w przybliżeniu określić położenie w pionie ust na
twarzy. Szerokość i wysokość prostokąta należy dobrać tak, aby całe usta były w nim
zawarte. Z drugiej strony powinno się ograniczyć na tyle ten obszar, aby nie wykraczać poza
badaną twarz.
Na podstawie wyznaczonego regionu ust dla każdej ramki utworzono sekwencję
wypowiedzi wideo, ograniczoną do obszaru samych ust. Treking położenia regionu ust na
twarzy ściśle jest uzależniony od zlokalizowanych środków oczu. Lokalizację regionu ust
realizuje się dla każdej ramki, gdyż należy przewidzieć, że użytkownik nie jest w stanie
trzymać głowy nieruchomo podczas wypowiedzi. Rozmiar każdego z wyznaczonych
regionów ust jest proporcjonalnie identyczny, dlatego w łatwy sposób można utworzyć
ograniczoną sekwencję wideo.
Na Rys.5.9 pokazano wyznaczone regiony ust z pojedynczych ramek, na podstawie
algorytmu LU, dla różnych użytkowników.

97
Rys.5.9 Rezultaty wyznaczania strefy ust w oparciu o metodę LU
Algorytm LU (Lokalizacja Ust)
Wejście: Kolorowa sekwencja wideo wypowiedzi danego użytkownika systemu,
ograniczona do wyznaczonego obszaru twarzy.
Wyjście: Kolorowa sekwencja wideo wypowiedzi danego użytkownika systemu,
ograniczona do wyznaczonego regionu ust.
1: Podziel sekwencje wideo na pojedyncze ramki.
2: Konwertuj każdą ramkę RGB formatu macierzowego do skali szarości (5.1).
3: Wyznacz poziomą linię oczu h_line (5.2), z wygładzoną linią projekcji (5.5).
4: Wyznacz pionowe linie oczu v_line_l (5.3) i v_line_r (5.4), z wygładzonymi
liniami projekcji (5.6).
5: Wyznacz współrzędne oczu jako przecięcie poziomej i pionowych linii oczu.
6: Wyznacz przybliżony regionu ust na podstawie współrzędnych oczu.
7: Nałóż prostokątną maskę wielkości wyznaczonego regionu ust..
8: Powtórz kroki 2 – 7 dla wszystkich ramek.
9: Wyznacz z wejściowej sekwencji obszar ust mówcy na podstawie maski nałożonej
na każdą ramkę.
5.3. Proponowana metoda CSM wykrywania krawędzi ust z obrazu wideo
Kolejnym etapem w procesie ekstrakcji cech wideo, czyli tworzenia wektorów obserwacji
wideo mowy jest zlokalizowanie krawędzi ust użytkownika. Ponieważ podczas naturalnej

98
mowy usta poruszają się najczęściej w pionie, kąciki ust pozostają w miejscu lub ewentualnie
poruszają się w poziomie, zaś odległość pomiędzy wewnętrzną i zewnętrzną krawędzią dolnej
oraz górnej wargi pozostaje bez zmian, zastosowano tylko kąciki i zewnętrzne krawędzie ust
jako główne cechy procesu trekingu ust. Schemat poruszania się ust w naturalnej wideo
mowie, zastosowany w pracy pokazano na Rys.5.10.
Rys.5.10 Zastosowany schemat wizualizacji ruchu ust
Jak wynika z Rys.5.10 ważnym elementem ekstrakcji charakterystyk ust jest
zlokalizowanie kącików ust. Dokładne zlokalizowanie kącików ust jest o tyle istotne, że
później na podstawie ich położenia realizowane jest wykrywanie zewnętrznych krawędzi ust
oraz rozmieszczenie punktów charakterystycznych.
Jednym ze sposobów, jaki zastosowano do zlokalizowania kącików ust jest metoda
zastosowana już do wyznaczenia współrzędnych centrów oczu [70]. W identyczny sposób
wykonano wyznaczenie poziomej linii kącików ust opisanej wzorem (5.2). Pionowe linie
kącików ust wyznaczono na podstawie zależności (5.3) i (5.4), z tą jednak różnicą, że nie
brano pod uwagę maksymalnej wartości sumy gradientów dla każdej z połów ramki. Pionową
linię lewego kącika ust, wyznaczono jako pierwsze maksimum przekraczające określony
próg, poruszając się rosnąco od pierwszego indeksu. Pionową linię prawego kącika ust,
wyznaczono jako pierwsze maksimum przekraczające określony próg, poruszając się
malejąco od ostatniego indeksu [70]. Wartość progu, po przekroczeniu którego można uznać
maksimum, jako kolumnę wyznaczającą położenie kącików ust dobrano w sposób
doświadczalny.
Przed rozpoczęciem wyznaczania współrzędnych kącików ust należy również
przekonwertować kolorowy obraz ust do obrazu w skali szarości.
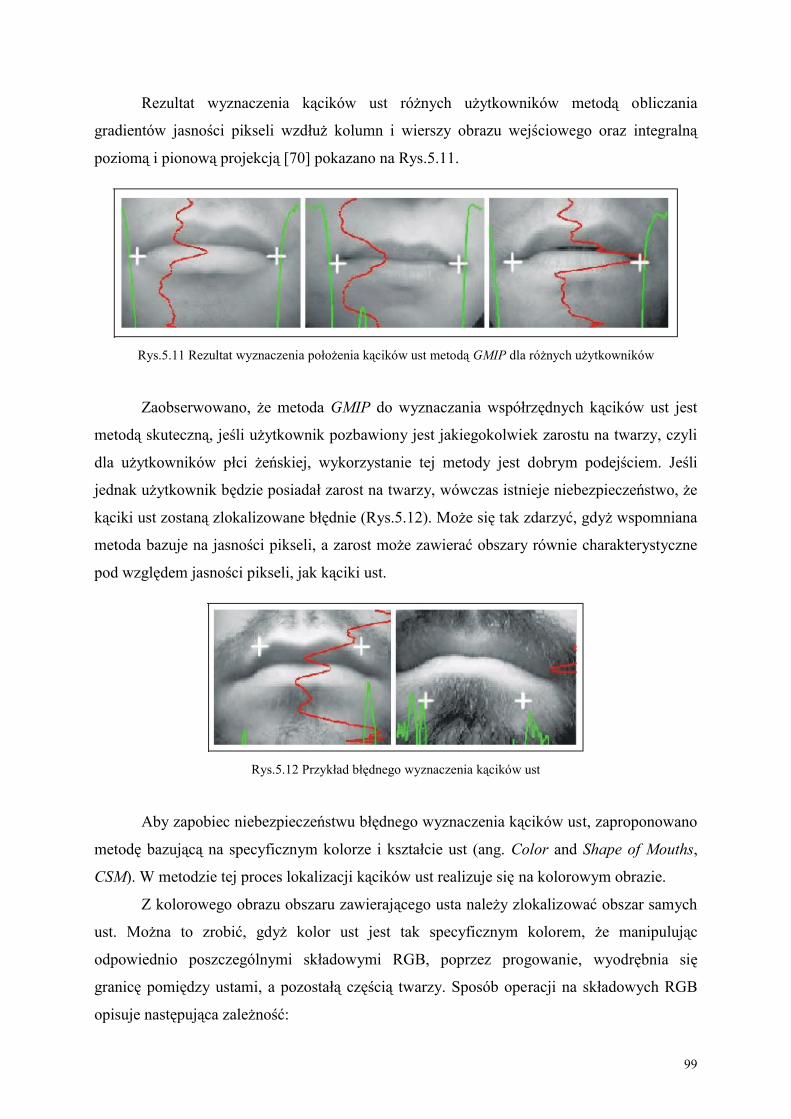
99
Rezultat wyznaczenia kącików ust różnych użytkowników metodą obliczania
gradientów jasności pikseli wzdłuż kolumn i wierszy obrazu wejściowego oraz integralną
poziomą i pionową projekcją [70] pokazano na Rys.5.11.
Rys.5.11 Rezultat wyznaczenia położenia kącików ust metodą GMIP dla różnych użytkowników
Zaobserwowano, że metoda GMIP do wyznaczania współrzędnych kącików ust jest
metodą skuteczną, jeśli użytkownik pozbawiony jest jakiegokolwiek zarostu na twarzy, czyli
dla użytkowników płci żeńskiej, wykorzystanie tej metody jest dobrym podejściem. Jeśli
jednak użytkownik będzie posiadał zarost na twarzy, wówczas istnieje niebezpieczeństwo, że
kąciki ust zostaną zlokalizowane błędnie (Rys.5.12). Może się tak zdarzyć, gdyż wspomniana
metoda bazuje na jasności pikseli, a zarost może zawierać obszary równie charakterystyczne
pod względem jasności pikseli, jak kąciki ust.
Rys.5.12 Przykład błędnego wyznaczenia kącików ust
Aby zapobiec niebezpieczeństwu błędnego wyznaczenia kącików ust, zaproponowano
metodę bazującą na specyficznym kolorze i kształcie ust (ang. Color and Shape of Mouths,
CSM). W metodzie tej proces lokalizacji kącików ust realizuje się na kolorowym obrazie.
Z kolorowego obrazu obszaru zawierającego usta należy zlokalizować obszar samych
ust. Można to zrobić, gdyż kolor ust jest tak specyficznym kolorem, że manipulując
odpowiednio poszczególnymi składowymi RGB, poprzez progowanie, wyodrębnia się
granicę pomiędzy ustami, a pozostałą częścią twarzy. Sposób operacji na składowych RGB
opisuje następująca zależność:

100
<−<−<−
=321
_TGRTBRTGB
ustreg , (5.7)
gdzie T1, T2, T3 są doświadczalnie dobranymi wartościami progowania. Na podstawie
doświadczeń ustalono, że najbardziej optymalne wartości progów wynoszą: T1 ≅ 20, T2 ≅ 40
i T3 ≅ 40. W ten sposób wyznacza się piksele o wartościach odpowiadających specyficznemu
kolorowi ust. Pozostałym pikselom przypisuje się wartość zerową.
W systemie zastosowano możliwość doboru wartości progowych dla indywidualnych
użytkowników, aby uzyskać optymalne warunki, co pokazano na Rys.5.13.
Rys. 5.13. Przykład poprawnego doboru wartości progowej
Największy wpływ na poprawne wyznaczenie obszaru ust mają wartości progowe T1 i
T3. Jest tak w większości przypadków, jednak podczas badać zdarzyło się kilka razy, że bez
wartości progowej T2 nie byłoby możliwe poprawne określenie obszaru ust, co jest wynikiem
indywidualnych cech ust oraz różnorodności oświetlenia.
Znając budowę kształtu ust można wyznaczyć kąciki ust jako skrajne w poziomie
niezerowe piksele. Poszukiwanie tych pikseli należy wykonać w ograniczonym obszarze ust,
w pobliżu poziomej osi ust. Schemat wyznaczania kącików ust pokazano na Rys.5.14.
Poszukiwanie kącików ust odbywa się tylko na zaciemnionym obszarze Rys.5.13 Szerokość
tego obszaru o poziomej osi odpowiadającej poziomej osi ust określonej jako połowa odcinka
max i – min i, dobrano doświadczalnie tak, aby było możliwe poprawne wyznaczenie
kącików. A nie ma sensu przeszukiwać całej ramki, skoro można ją znacznie ograniczyć i
przyspieszyć proces poszukiwań.
Dzięki tej metodzie uzyskano o wiele większą odporność, w porównaniu z metodą
GMIP, na zakłócenia w postaci zarostu na twarzy.
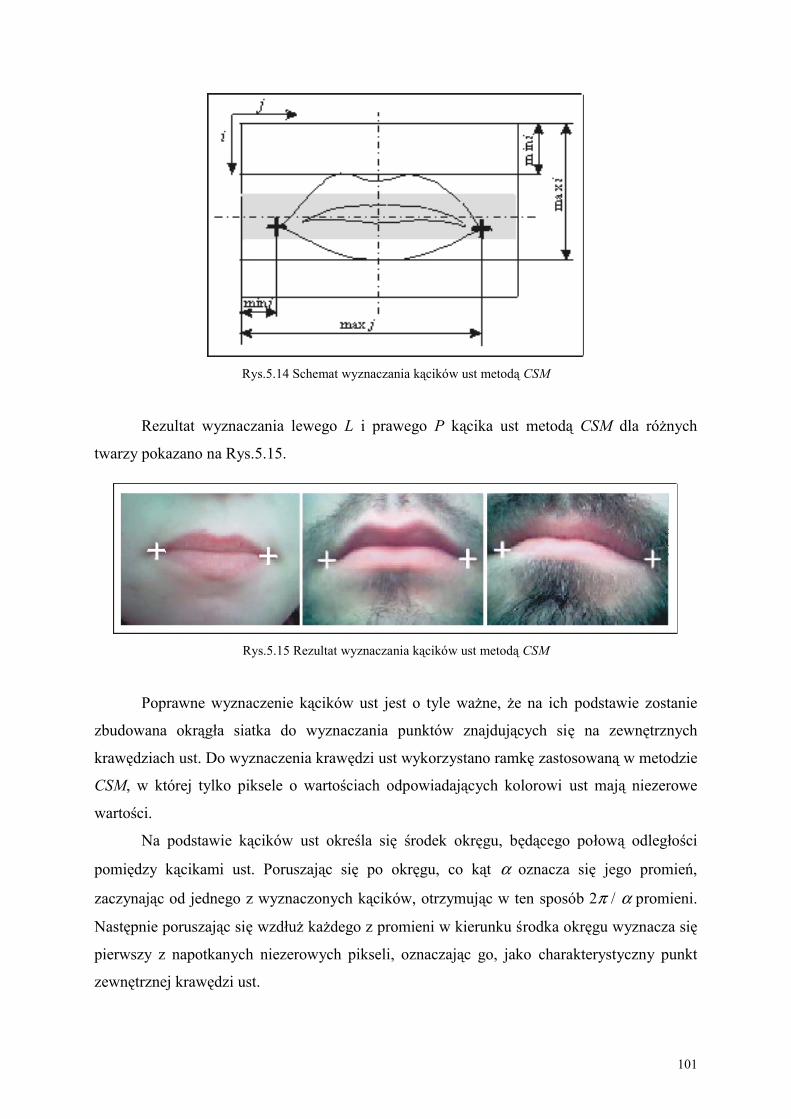
101
Rys.5.14 Schemat wyznaczania kącików ust metodą CSM
Rezultat wyznaczania lewego L i prawego P kącika ust metodą CSM dla różnych
twarzy pokazano na Rys.5.15.
Rys.5.15 Rezultat wyznaczania kącików ust metodą CSM
Poprawne wyznaczenie kącików ust jest o tyle ważne, że na ich podstawie zostanie
zbudowana okrągła siatka do wyznaczania punktów znajdujących się na zewnętrznych
krawędziach ust. Do wyznaczenia krawędzi ust wykorzystano ramkę zastosowaną w metodzie
CSM, w której tylko piksele o wartościach odpowiadających kolorowi ust mają niezerowe
wartości.
Na podstawie kącików ust określa się środek okręgu, będącego połową odległości
pomiędzy kącikami ust. Poruszając się po okręgu, co kąt α oznacza się jego promień,
zaczynając od jednego z wyznaczonych kącików, otrzymując w ten sposób 2π / α promieni.
Następnie poruszając się wzdłuż każdego z promieni w kierunku środka okręgu wyznacza się
pierwszy z napotkanych niezerowych pikseli, oznaczając go, jako charakterystyczny punkt
zewnętrznej krawędzi ust.

102
Wartość skoku promieni α dobiera się w zależności od tego, jak dokładnie chce się
odwzorować zewnętrzne krawędzie ust. W pracy przyjęto, że każdy z promieni oznacza się co
22,5 o, co daje 16 punktów charakterystycznych w tym dwa kąciki ust. Jest to wystarczająca
liczba punktów do odwzorowania w miarę rzeczywistego ruchu ust. Zwiększanie liczby
punktów charakterystycznych powoduje tylko niepotrzebny wzrost obliczeń, a należy wziąć
pod uwagę fakt, iż i tak mimo dużej liczby punktów nie uzyska się idealnie rzeczywistych
krawędzi ust, co spowodowane jest niezbyt ostrą granicą pomiędzy obszarem o kolorze ust, a
obszarem o kolorze skóry. Wszelkie naprężenia mięśni ust powodują zmianę barw w pobliżu
krawędzi ust, tak więc należy przyjąć, że krawędzie ust są krawędziami w pewnym sensie
ruchomymi.
Na Rys.5.16 pokazano schemat wyznaczania punktów charakterystycznych
zewnętrznych krawędzi ust.
Rys.5.16 Schemat wyznaczania punktów charakterystycznych zewnętrznych krawędzi ust
W procesie wyznaczania krawędzi ust może się zdarzyć, że pojawi się zakłócający
obszar nie będący obszarem ust, a mający podobny kolor, lub źle zostanie zidentyfikowany
obszar ust, przyjmując zerowe wartości pikseli. Spowoduje to błędne wyznaczenie punktów
określających zewnętrzne krawędzie ust. Dlatego zastosowano ciągłe monitorowanie
położenia każdego z tych punktów w porównaniu z położeniem punktów sąsiednich i jeśli
zajdzie taka potrzeba, określa się nowe współrzędne punktu, na podstawie punktów
sąsiednich.
Przykład korekcji błędnie wyznaczonego punktu pokazano na Rys.5.17.

103
Rys.5.17 Przykład korekcji błędnie wyznaczonego punktu
Na Rys.5.17 widać, że wyznaczony obszar ust jest poszarpany, szczególnie wzdłuż
zewnętrznej krawędzi. Ponieważ właśnie ruch ust wyznaczony zewnętrzną krawędzią podczas
wypowiedzi ma największy wpływ na utworzenie wektora obserwacji, dlatego konieczne jest
odpowiednie wygładzenie tej zewnętrznej krawędzi. Zastosowano filtrację medianową w celu
usunięcia drobnych zakłóceń z obrazu, a przy tym uzyskano znaczne wygładzenie
wyznaczonego obszaru ust. Przykład poprawienia działania systemu przez zastosowanie
wspomnianej filtracji pokazano na Rys.5.18, gdzie z lewej strony umieszczono ramkę z
wyznaczoną krawędzią i kącikami ust bez filtracji, z prawej ramkę z zastosowaną filtrację.
Rys.5.18 Przykład zastosowania filtracji medianowej podczas detekcji zewnętrznych krawędzi ust
O ile w audio mowie można rozróżnić wszystkie fonemy, o tyle w wideo mowie
często jest tak, że usta wypowiadające różne fonemy mają bardzo zbliżony wygląd i układ.
Niektóre fonemy można rozróżnić w wideo mowie poprzez zaobserwowanie, czy podczas
wypowiedzi pojawia się, bądź też nie, język bezpośrednio przy zębach. Tak na przykład usta
podczas wypowiadania fonemów „a” i „l” są bardzo podobnie ułożone, jednak dla fonemu „l”
można zaobserwować pojawiający się język. Podobnie bez widocznego języka wypowiada się

104
fonemy „i” i „j”, a z językiem „t” i „d”. Na tej podstawie w systemie wprowadzono
przydzielenie odpowiedniej wagi dla fonemów z zaobserwowanym językiem, w celu
poprawienia rozróżnialności poszczególnych wideo fonemów.
Algorytm LKU (Lokalizacja Krawędzi Ust):
Wejście: Kolorowa sekwencja wideo wypowiedzi danego użytkownika systemu,
ograniczona do wyznaczonego regionu ust.
Wyjście: Sekwencja wektorów współrzędnych punktów charakterystycznych ust
zlokalizowanych dla każdej ramki.
1: Podziel sekwencji wideo na pojedyncze ramki.
2: Wyznacz lewy L i prawy P kąciki ust metodą GMIP lub CSM.
3: Wyznacz region ust (5.7).
4: Odfiltruj medianowo w celu usunięcia zakłóceń i wygładzenia zewnętrznych
krawędzi ust.
5: Wyznacz siatki i = 2π/α promieni o środku okręgu S = (L + P)/2, długości di ≥ P –
S i skoku α, rozpoczynając od promienia wyznaczonego przez punkty S i P.
6: Wyznacz punkty określające zewnętrzne krawędzie ust pi = max d(S,di) ∈ reg_ust.
7: Skontroluj położenia każdego z wyznaczonych punktów pi na podstawie punktów
sąsiednich i w zależności od potrzeb modyfikuj ich położenia.
8: Sprawdź położenia języka mówcy i odpowiednie ustawienie wagi dla ramki.
9: Powtórz kroki 2 – 8 dla wszystkich ramek
10: Utwórz sekwencji wektorów współrzędnych wyznaczonych punktów
charakterystycznych.
Przykład lokalizacji kącików i zewnętrznych krawędzi ust oraz wyznaczania punktów
charakterystycznych dla różnych użytkowników pokazano na Rys.5.19 Cały proces odbywa
się automatycznie w zbudowanym systemie rozpoznawania audio-wideo słów izolowanych.
Zastosowano możliwość ciągłego monitorowania każdej z klatek w celu weryfikacji
poprawności lokalizacji krawędzi.
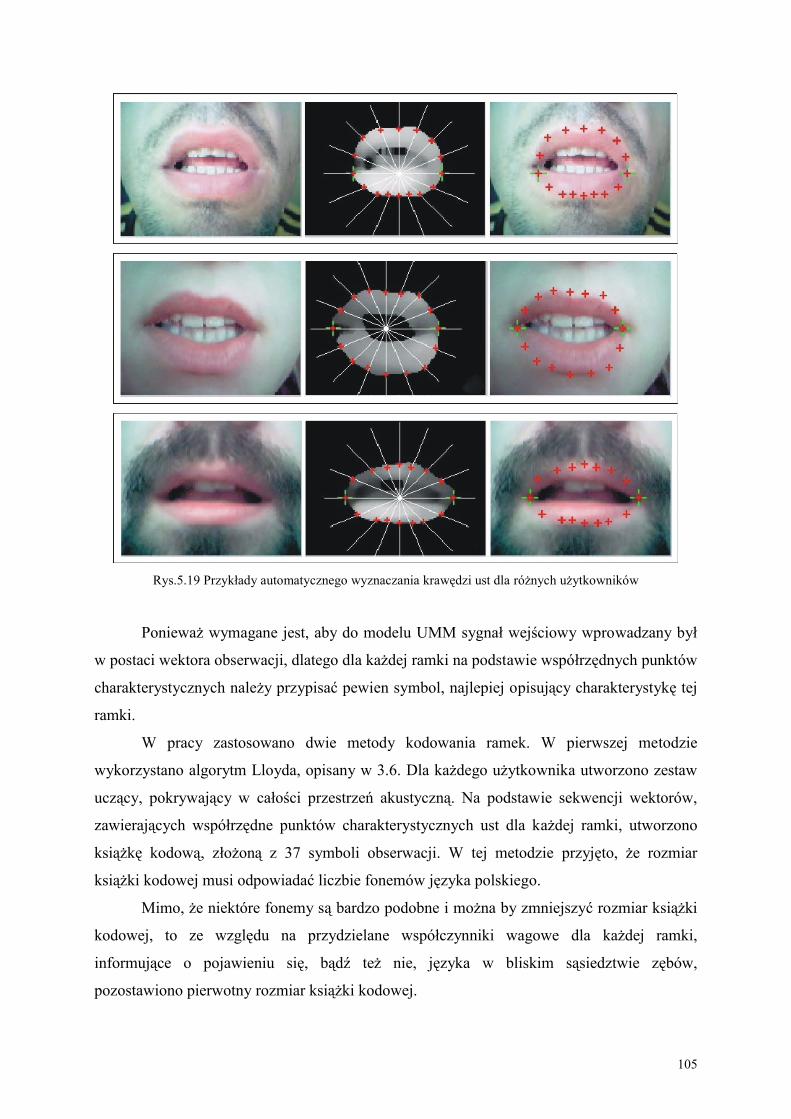
105
Rys.5.19 Przykłady automatycznego wyznaczania krawędzi ust dla różnych użytkowników
Ponieważ wymagane jest, aby do modelu UMM sygnał wejściowy wprowadzany był
w postaci wektora obserwacji, dlatego dla każdej ramki na podstawie współrzędnych punktów
charakterystycznych należy przypisać pewien symbol, najlepiej opisujący charakterystykę tej
ramki.
W pracy zastosowano dwie metody kodowania ramek. W pierwszej metodzie
wykorzystano algorytm Lloyda, opisany w 3.6. Dla każdego użytkownika utworzono zestaw
uczący, pokrywający w całości przestrzeń akustyczną. Na podstawie sekwencji wektorów,
zawierających współrzędne punktów charakterystycznych ust dla każdej ramki, utworzono
książkę kodową, złożoną z 37 symboli obserwacji. W tej metodzie przyjęto, że rozmiar
książki kodowej musi odpowiadać liczbie fonemów języka polskiego.
Mimo, że niektóre fonemy są bardzo podobne i można by zmniejszyć rozmiar książki
kodowej, to ze względu na przydzielane współczynniki wagowe dla każdej ramki,
informujące o pojawieniu się, bądź też nie, języka w bliskim sąsiedztwie zębów,
pozostawiono pierwotny rozmiar książki kodowej.

106
Książkę kodową należy utworzyć oddzielnie dla każdego użytkownika przed
procesem uczenia. Można jednak założyć, że wideo mowa jest bardziej elastyczna niż audio
mowa, bo jako wektory charakterystyk wprowadza się do algorytmu Lloyda stosunek
odległości każdego z punktów od prostej wyznaczonej przez kąciki ust, do odległości
pomiędzy kącikami. Przyjmując takie założenia utworzono tylko jedną książkę kodową,
wspólną dla wszystkich użytkowników.
W procesie uczenia wykonano kwantyzację wektorową opisaną w 3.7. Każdą
wypowiedź powtórzono po kilka razy, w celu uodpornienia systemu na różnorodność sposobu
wypowiadania danego użytkownika. Na podstawie książki kodowej, dla każdej ramki
przypisano symbol reprezentujący obszar w przestrzeni Euklidesowej najbardziej zbliżony do
wektora charakterystyk opisującego daną ramkę. W ten sposób otrzymano wektory
obserwacji będące zakodowanymi powtórzeniami tej samej wypowiedzi. Uzyskane wektory
obserwacji należy wprowadzać kolejno do modelu UMM, jako dane uczące.
Założono, że zbudowany system jest systemem dedykowanym i dlatego podczas
pracy, system działa poprawnie tylko dla użytkownika, dla którego został on nauczony.
Przyjęto, że można uczyć system na podstawie tej samej książki kodowej, danymi
pochodzącymi od różnych użytkowników.
W drugiej, zaproponowanej w pracy metodzie kodowania ramek EP zrezygnowano z
tworzenia książki kodowej. Zastosowano uproszczoną metodę kodowania wykorzystującą
położenie każdego z punktów charakterystycznych, względem prostej wyznaczonej przez
kąciki ust. W metodzie tej dla każdej ramki należy obliczyć sumę stosunku odległości
wszystkich punktów od prostej, wyznaczonej przez kąciki ust. Ponieważ przyjęto 16 punktów
charakterystycznych, dlatego każdy z wyliczonych stosunków podzielono przez 16. Wartość
uzyskanych w ten sposób sum, po pomnożeniu przez 100 waha się w granicach od 31 do 80,
oczywiście przy poprawnie zlokalizowanych punktach charakterystycznych na zewnętrznych
krawędziach ust. Przyjęto, że uzyskane symbole powinny zawierać się w przedziale od 1 do
50, dlatego dla każdego użytkownika należy określić minimalną wartość kodu i na tej
podstawie odpowiednio zredukować wartości kodów do założonego przedziału.
Z jednej strony można zwiększyć zakres kodów, przez co uzyska się szersze
przedziały kodów dla tych samych fonemów, z drugiej strony, skoro w języku polskim jest
tylko 37 fonemów, a dodatkowo niektóre z nich mają bardzo podobny układ ust, można
pomniejszyć liczbę kodów, w celu zmniejszenia rozmiarów modeli UMM. W pracy przyjęto
zarówno rozszerzony, jak i okrojony zakres kodów, co było wymogiem w procesie
doświadczenia efektywności różnych typów fuzji audio i wideo charakterystyk.
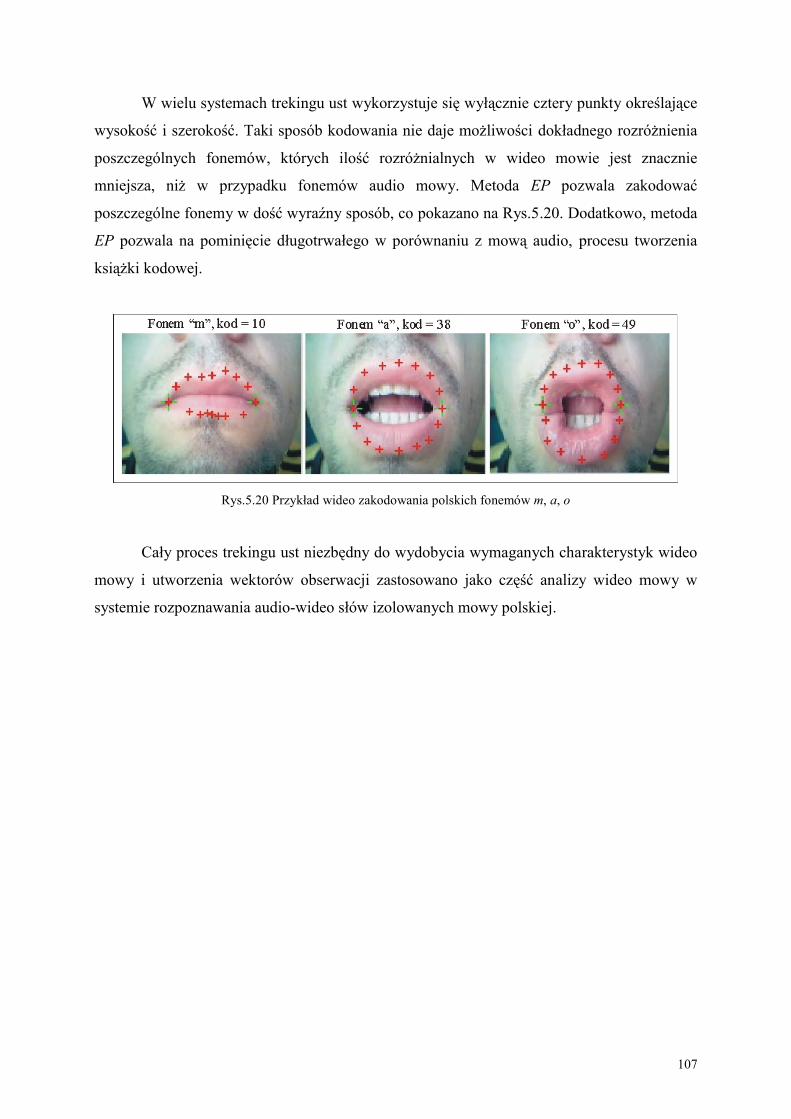
107
W wielu systemach trekingu ust wykorzystuje się wyłącznie cztery punkty określające
wysokość i szerokość. Taki sposób kodowania nie daje możliwości dokładnego rozróżnienia
poszczególnych fonemów, których ilość rozróżnialnych w wideo mowie jest znacznie
mniejsza, niż w przypadku fonemów audio mowy. Metoda EP pozwala zakodować
poszczególne fonemy w dość wyraźny sposób, co pokazano na Rys.5.20. Dodatkowo, metoda
EP pozwala na pominięcie długotrwałego w porównaniu z mową audio, procesu tworzenia
książki kodowej.
Rys.5.20 Przykład wideo zakodowania polskich fonemów m, a, o
Cały proces trekingu ust niezbędny do wydobycia wymaganych charakterystyk wideo
mowy i utworzenia wektorów obserwacji zastosowano jako część analizy wideo mowy w
systemie rozpoznawania audio-wideo słów izolowanych mowy polskiej.

108
6. OPRACOWANIE SYSTEMU AVM_PL DO REALIZACJI METODY AV_Mowa_PL
Podano szczegółowy opis budowy, charakterystyk technicznych i działania opracowanego
systemu do rozpoznawania audio-wideo słów izolowanych w języku polskim, nazwanego
AVM_PL. Przedstawiono poszczególne etapy działania systemu z przykładowymi danymi i
wynikami uzyskiwanymi w każdym z etapów.
6.1. Struktura i charakterystyki techniczne systemu
System rozpoznawania audio-wideo mowy polskiej, nazwany AVM_PL, zbudowano w
środowisku programistycznym Matlab 6.0. System realizuje rozpoznawanie słów
izolowanych. Wykonany został w ten sposób, że stanowi jeden z wielu komponentów
systemu Matlab, co wiąże się z tym, iż aby można było na nim pracować, konieczne jest
zainstalowanie pakietu Matlab i zarejestrowanie komponentu AVM_PL.
Do prawidłowego funkcjonowania systemu konieczne jest posiadanie mikrofonu
rejestrującego audio mowę, oraz kamery rejestrującej wideo mowę z rozdzielczością
nagrywania 640 x 480 pikseli. Taka rozdzielczość nagrywania jest konieczna przy
rzeczywistym funkcjonowaniu systemu, tzn. kamera rejestruje całą twarz użytkownika,
pozwalając na swobodny sposób wypowiedzi. System umożliwia również korzystanie z
wideo wypowiedzi o rozdzielczości 320 x 240 pikseli, lecz w takim przypadku wideo mowa
musi być ograniczona do obszaru zawierającego same usta użytkownika. Jest to o tyle
niewygodne, że użytkownik musi znajdować się bardzo blisko kamery i wypowiadać
poszczególne komendy w sposób bardzo stabilny.
Ponieważ sporo czasu zajmuje analiza wideo w systemie AVM_PL to, mimo iż
wymagania sprzętowe komputera są takie same jak wymagania sprzętowe dla prawidłowego
funkcjonowania środowiska Matlab, dobrze jest używać system na sprzęcie komputerowym z
procesorem powyżej 1GHz i pamięcią 256 MB. Przy niższych parametrach system działa,
lecz może się on stać nieatrakcyjnym dla użytkownika ze względu na zbyt długi czas analizy
wideo mowy. Uczenie i testowanie systemu wykonano na procesorze 2,6 GHz i pamięci 512
MB.
Sygnał audio można próbkować z jak najmniejszą częstotliwością. Przyjęto, że sygnał
audio jest sygnałem monofonicznym (jeden kanał), o częstotliwości próbkowania 8 KHz,
szybkości transmisji bitów 128 kb/s oraz o rozmiarze próbki audio 16 bitów. Można sygnał

109
próbkować z większą częstotliwością, lecz 8 kHz jest częstotliwością standardową, przyjętą
również w telefonii, wystarczającą do rzeczywistego opisu sygnału mowy. W przypadku
zastosowania sygnału stereo, system i tak analizuje tylko jeden, pierwszy kanał. Szybkość
transmisji bitów oraz rozmiar próbki audio również mogą być zwiększane. Dodatkowo należy
zaznaczyć, że dźwięk audio nie może być w jakikolwiek sposób skompresowany.
Wymagania dotyczące sygnału wideo są takie, że dla obrazu, rozmiar próbki wideo
powinien wynosić 24 bity. Przy 16 bitach system nie działa, ze względu na własności
środowiska Matlab. Sygnał wideo również nie może być skompresowany. Zakłada się, że
rzeczywisty obraz uzyskuje się przy szybkości 26 klatek/s. Jest to standard przyjęty w
telewizji i z taką szybkością również należy nagrywać wideo mowę. Dla skrócenia czasu
analizy wideo mowy można przyjąć szybkość nagrywania 15 klatek/s. Taka szybkość
wystarcza do prawidłowego przedstawienia wideo mowy, pod warunkiem, że użytkownik
będzie wypowiadał słowa niezbyt szybko. Jest to minimalna szybkość przyjęta w systemie
AVM_PL.
System AVM_PL składa się z trzech podstawowych programów, mogących pracować
zupełnie niezależnie. Pierwszy z nich odpowiada za analizę wideo mowy, a dokładniej, za
zlokalizowanie twarzy i regionu ust użytkownika na podstawie nagrania wideo. Po wczytaniu
pamięci systemu należy wprowadzić wideo z kamery. Ponieważ w systemie Matlab nie ma
możliwości nagrywania obrazu w trybie rzeczywistym, dlatego konieczne jest zarejestrowanie
wideo mowy wcześniej, a następnie otworzenie pliku wideo w systemie AVM_PL. Każda z
wypowiedzi wideo powinna być przechowywana w oddzielnym pliku, o nazwie
jednoznacznie określającej treść nagrania.
Po wczytaniu filmu wideo następuje proces lokalizacji twarzy dla każdej z klatek.
Można na bieżąco regulować wartością progu rozkładu R – B. W następnym kroku
wyświetlony zostaje film ograniczony do zlokalizowanego obszaru twarzy, złożony
oczywiście z wszystkich klatek. Na bieżąco można śledzić, czy twarz użytkownika została
poprawnie zlokalizowana.
Ostatnim z etapów tej części programu jest lokalizacja oczu i wyznaczenie regionu
ust. Wszystkie części programu realizowane są w sposób automatyczny. Dla kontroli
poprawności poszczególnych etapów, każdy etap wywołuje się przy pomocy odpowiedniego
przycisku. Można w ten sposób po kilka razy powtarzać każdy z etapów, dobierając
optymalne wyniki analizy wideo mowy dla danego użytkownika. Po wyznaczeniu regionu ust
następuje wywołanie programu odpowiedzialnego za treking ust.

110
Widok okna programu do lokalizacji twarzy i regionu ust użytkownika pokazano na
Rys.6.1.
Rys.6.1 Widok okna programu do lokalizacji twarzy i strefy ust
Drugi z programów odpowiada za prawidłowe zlokalizowanie zewnętrznych krawędzi
ust, wyznaczenie punktów charakterystycznych i utworzenie wektorów obserwacji. Po
wyznaczeniu regionu ust następuje kalibracja każdej z ramek w celu otrzymania dokładnego
obszaru zawierającego piksele o kolorze podobnym do specyficznego koloru ust. Możliwe
jest korygowanie na bieżąco wartości progowych dla rozkładów składowych kolorów B – G,
R – B oraz R – G.
Po odpowiednim skorygowaniu wartości progowych następuje właściwa realizacja
procesu trekingu ust. Proces ten realizowany jest przy pomocy metod GMIP oraz CSM. Jak
już wcześniej wyjaśniono, obie metody różnią się sposobem wyznaczania kącików ust. Na
bieżąco wyświetlane są klatki obrazu wejściowego, klatki roboczego obrazu w celu śledzenia
poprawności wyznaczania krawędzi i punktów charakterystycznych ust, oraz klatki obrazu
wyjściowego z umieszczonymi na zewnętrznych krawędziach punktami charakterystycznymi.
Podczas realizacji trekingu ust realizowane jest dodatkowo automatyczne kodowanie
każdej z klatek. Wyświetlany jest każdorazowo wyznaczony kod dla danej ramki.

111
Po przeanalizowaniu całej sekwencji ramek wideo wypowiedzi następuje przejście do
programu realizującego proces ekstrakcji audio cech, uczenia i modeli UMM i rozpoznawania
słów izolowanych. Oczywiście, jeśli w procesie uczenia na wejście podawane jest kilka
powtórzeń tej samej wypowiedzi, wówczas zanim nastąpi przejście do programu następnego
programu, konieczne jest przeanalizowanie wszystkich powtórzeń wypowiedzi wideo.
Jeśli zamiast całej twarzy użytkownika podczas wypowiedzi zostanie zarejestrowany
tylko region ust, wówczas pierwszy z programów realizujący lokalizację twarzy i regionu ust
należy pominąć, a cały proces rozpocząć od programu do trekingu ust. W programie do
rekinku ust dodano opcję otwierającą film wideo dla przypadków z ograniczoną wypowiedzią
do obszaru samych ust.
Widok okna programu do trekingu ust i wyznaczania wektorów obserwacji pokazano
na Rys.6.2.
Rys.6.2 Widok okna programu do trekingu ust i budowania wektorów obserwacji
Trzecim z podstawowych programów systemu AVM_PL realizuje procesy analizy
audio mowy, synchronizacji charakterystyk audio i wideo, uczenia i testowania. Program
umożliwia realizację rozpoznawania audio-wideo mowy, jak i samej audio mowy.
W przypadku samej audio mowy, bezpośrednio w tym programie następuje
nagrywanie wypowiedzi, zarówno w procesie uczenia oraz testowania. Istnieje możliwość

112
ustalenia częstotliwości próbkowania sygnału audio oraz długości nagrania, którą dobiera się
w zależności od długości wypowiadanego słowa, bądź słow. Oczywiście dla uczenia i
rozpoznawania samej audio mowy, pominięty zostaje proces analizy wideo mowy, wcześniej
opisany.
W przypadku rozpoznawania audio-wideo mowy, na podstawie wczytanych w
procesie ekstrakcji cech wideo plików, zawierających nagrania wideo wypowiedzi, wczytane
zostają odpowiednie wypowiedzi audio. Proces wczytywania odbywa się automatycznie,
poprzez oddzielenie sygnałów audio od analizowanych wcześniej sygnałów wideo. Każde z
nagrań należy opisać odpowiednią transkrypcją gramatyczną, potrzebną w dalszej części
programu, do nazewnictwa utworzonych modeli UMM.
Na Rys.6.3 pokazano widok okna programu realizującego wczytywanie oraz
nagrywanie sygnałów audio mowy.
Rys.6.3 Widok okna programu do wczytywania i nagrywania audio mowy
W tej części programu można jeszcze odtworzyć wczytane nagrania audio, można
również obejrzeć wykresy tych nagrań. Również nagrany sygnał audio można zapisać pod
odpowiednią nazwą pliku, podpowiadaną użytkownikowi w oparciu o wpisaną transkrypcję
gramatyczną.

113
W kolejnym etapie następuje ekstrakcja charakterystyk audio mowy i synchronizacja z
wideo mową. W procesie ekstrakcji charakterystyk istnieje możliwość wstępnej filtracji
sygnałów audio, dla wybranego rodzaju filtracji, poziomu filtracji oraz liczbie kolejnych
filtrów. Nałożone filtry można również usunąć z sygnału. Po rozpoczęciu analizy sygnału
audio następuje kolejno:
• wydzielenie właściwego sygnału mowy, poprzez usunięcie ciszy sprzed i spoza
sygnału,
• podział sygnału na zachodzące na siebie stacjonarne ramki,
• nałożenie filtru wygładzającego skrajne próbki każdej z ramek,
• zakodowanie każdej z ramek przy pomocy współczynników cepstrum,
• kwantyzacja wektorowa na podstawie wyznaczonych współczynników cepstrum.
W ten sposób każdy z wprowadzanych sygnałów audio zakodowany i przedstawiony
zastaje przy pomocy wektorów obserwacji. Ze względu na różną długość powtórzonej kilka
razy tej samej wypowiedzi, każdy z wektorów obserwacji również może mieć różną długość.
Wykres każdego z wydzielonych sygnałów, pozbawionych zbędnej ciszy znajdującej
się na początku i na końcu nagrania można obejrzeć w tej części systemu, zarówno przed, jak
i po wstępnej filtracji.
Jeśli pojedynczy sygnał audio zawiera kilka wypowiedzi, oddzielonych wyraźną ciszą,
co jest wymagane w systemie, wówczas każda z wypowiedzi zapisywana jest jako oddzielna
wypowiedź. Konieczne jest jeszcze odpowiednie opisanie tej wprowadzanej wypowiedzi
audio tak, aby wiadomo było, co oznaczają poszczególne słowa. Dotyczy to oczywiście tylko
etapu ekstrakcji cech audio w procesie uczenia. Dodatkowo, dla każdej z wydzielonych
wypowiedzi oznaczane są kluczowe ramki, będące początkiem i końcem właściwego
nagrania. Na podstawie tych kluczowych ramek następuje synchronizacja charakterystyk
audio i wideo mowy, czyli usunięcie symboli obserwacji odpowiadających ramkom wideo
mowy, zawierającym ciszę w wypowiedzi wideo. W ten sposób następuje wydzielenie
właściwego sygnału wideo mowy.
Po utworzeniu wektorów obserwacji audio mowy i zmodyfikowaniu zawartości
wektorów wideo mowy, system realizuje integrację charakterystyk obu sygnałów. W
zależności od wybranego rodzaju fuzji, budowany jest jeden wspólny wektor obserwacji dla
audio i wideo mowy, lub łączone są w parę oddzielne wektory obserwacji obu sygnałów.
Taka para wektorów opisująca tę samą wypowiedź wprowadzana jest w dalszej części pracy

114
systemu do modeli UMM, jako dane uczące, lub rozpoznawalne. Sposób fuzji należy ustalić
przed uruchomieniem systemu AVM_PL.
Widok okna programu do ekstrakcji cech audio, synchronizacji i fuzji z wideo mową
pokazano na Rys.6.4.
Rys.6.4 Widok okna programu do ekstrakcji cech audio, synchronizacji i fuzji z wideo mową
Po utworzeniu wektorów obserwacji audio mowy, synchronizacji i fuzji z wektorami
obserwacji wideo mowy, kolejny etap realizuje uczenie modeli UMM na podstawie danych
wejściowych.
Po wywołaniu aplikacji uczenia, w pierwszym kroku następuje wydzielenie
parametrów uczenia na podstawie danych wejściowych oraz zdefiniowanych w programie
danych dotyczących budowy UMM. Określone zostają takie parametry, jak:
• liczba stanów, jakie może przyjmować model, a co za tym idzie, rozmiar parametrów
modelu,
• liczba dyskretnych wyjść, jakie może generować model będący w danym stanie,
• długość wektorów obserwacji, która może być różna dla różnych powtórzeń tej samej
wypowiedzi,
• liczba kolejnych sekwencji obserwacji, czyli liczba wypowiedzi podawanych na
wejście.

115
Wszystkie te parametry potrzebne są do zdefiniowania całego środowiska uczenia
modeli UMM. Wartości parametrów modeli UMM początkowo generowane są losowo.
Liczba modeli w procesie uczenia odpowiada założeniom dotyczącym sposobu fuzji audio i
wideo charakterystyk. W zasadzie podczas pojedynczego uczenia tworzony jest jeden model
UMM dla danej wypowiedzi, uczony w oparciu o wektory obserwacji audio i wideo mowy,
kilku jej powtórzeń. Tylko w przypadku, gdy fuzja następuje po procesie uczenia, budowane i
uczone są dwa oddzielne modele dla sygnałów audio i wideo.
Przyjęto maksymalną liczbę iteracji równą 200, ale w zasadzie proces uczenia trwa o
wiele krócej. Jest wstrzymywany, jeśli różnica wyników logarytmów prawdopodobieństw
sekwencji obserwacji przez model w dwóch sąsiednich krokach jest mniejsza od przyjętego
progu zatrzymania. Zdarza się, że uczenie trwa zaledwie kilkanaście iteracji. Proces uczenia
na bieżąco można śledzić. Wyświetlana jest w wierszu pleceń każda iteracja z wynikiem
uzyskanego logarytmu prawdopodobieństwa. Proces uczenia można powtórzyć, jeśli
użytkownik stwierdzi, że uzyskany wynik nie jest wystarczający i mógłby wpłynąć
negatywnie na proces rozpoznawania.
Po zakończeniu uczenia następuje zapis do pliku nauczonych parametrów modelu
UMM. Każdy z utworzonych i nauczonych modeli przechowywany jest w osobnym pliku o
nazwie odpowiadającej treści wypowiedzi, na której parametry modelu UMM były uczone.
Widok okna programu do ekstrakcji parametrów, budowy i uczenia modeli UMM
pokazano na Rys.6.5.
Rys.6.5 Widok okna programu do ekstrakcji parametrów, budowy i uczenia modeli UMM

116
W przypadku, gdy po nauczeniu systemu wszystkich komend dla danego
użytkownika, któraś z wypowiedzi jest błędnie rozpoznawana, można powtórzyć uczenie dla
tej wypowiedzi. Cały proces uczenia polega na stopniowym rozbudowywaniu bazy
nauczonych słów, a co za tym idzie, bazy modeli. W systemie możliwe jest dodawanie oraz
odejmowanie nowych komend bez konieczności douczania lub modyfikacji parametrów
pozostałych modeli UMM.
W procesie rozpoznawania cały przebieg budowy wektorów obserwacji audio i wideo
mowy jest taki sam, jak w procesie uczenia. Oczywiście w przypadku rozpoznawania na
wejście podawane są wektory obserwacji tylko jednej wypowiedzi, bez jej powtórzeń.
Po wywołaniu aplikacji testowania, w pierwszym kroku następuje wydzielenie
parametrów testowania na podstawie danych wejściowych. Liczba stanów oraz liczba
dyskretnych wyjść musi odpowiadać wartościom ustalonym w procesie uczenia.
Testowanie polega na sprawdzeniu wszystkich utworzonych w procesie uczenia
modeli. Dla każdego modelu wyliczane jest prawdopodobieństwo wygenerowania podanej na
wejście sekwencji obserwacji przez ten model. Model o największym prawdopodobieństwie
przyjmuje się jako zwycięski.
Na podstawie transkrypcji gramatycznej zwycięskiego modelu następuje wypisanie
wartości tekstowej rozpoznawanej wypowiedzi. Jeśli na wejście podano ciąg różnych
wypowiedzi, wówczas analizowana jest oddzielnie każda z wypowiedzi, a wynikiem jest
wyświetlenie ciągu tekstowego rozpoznanych wypowiedzi.
W systemie zastosowano możliwość podglądu prawdopodobieństw wygenerowania
wejściowej sekwencji obserwacji przez wszystkie modele. Umożliwia to sprawdzenie
rozróżnialności danej wypowiedzi. Można zaobserwować zbliżone prawdopodobieństwo
wygenerowane przez modele uczone na wypowiedziach o podobnym brzmieniu do
rozpoznawanej wypowiedzi.
Jeśli na wejście poda się słowo, dla którego system nie został nauczony, wówczas
wynikiem rozpoznania będzie słowo o podobnym brzmieniu, na którym system był uczony.
Jest to oczywiście błędne rozpoznanie. Aby zapobiec takiej sytuacji wprowadzono wartość
progową określającą, kiedy prawdopodobieństwo wygenerowania sekwencji obserwacji
można uznać za właściwe. Wartość prawdopodobieństwa dla właściwego modelu jest
znacznie większa od wartości prawdopodobieństwa pozostałych modeli.
Na Rys.6.6 pokazano okno programu realizującego rozpoznawanie wejściowych
wypowiedzi audio i wideo mowy. Wynikiem rozpoznawania jest rozpoznane słowo.

117
Rys.6.6 Widok okna programu realizującego rozpoznawanie
System AVM_PL umożliwia także identyfikację użytkowników. Na podstawie słów w
całości pokrywających przestrzeń akustyczną każdego z nich budowana jest wspólna
sekwencja wypowiedzi, potrzebna do utworzenia książki kodowej. W procesie uczenia każdy
z użytkowników wypowiada po kilka powtórzeń tej samej wypowiedzi. Treść wypowiedzi dla
wszystkich użytkowników jest taka sama. Podczas nagrywania w transkrypcji gramatycznej
zamiast wartości tekstowej wypowiedzi podawany jest unikalny identyfikator użytkownika.
W procesie uczenia dla każdego użytkownika budowany jest oddzielny model UMM. W
procesie identyfikacji następuje wyznaczenie identyfikatora użytkownika o charakterystyce
mowy najbardziej zbliżonej do mowy podanej na wejście.
Budowa książki kodowej
Proces tworzenia książki kodowej realizowany jest każdorazowo, dla nowego użytkownika
systemu. Jest on częścią systemu AVM_PL, wywoływany z linii poleceń systemu Matlab.
Książkę kodową należy utworzyć przed rozpoczęciem pracy z systemem AVM_PL.
Poszczególne etapy tworzenia książki kodowej omówiono w rozdziale 3. Sposób analizy
sygnału audio mowy jest podobny do analizy w procesie tworzenia wektorów obserwacji
będących danymi wejściowymi podczas uczenia i rozpoznawania. Jedyna różnica polega na
tym, że przy tworzeniu książki kodowej podawany na wejście jest zestaw słów
pokrywających w całości przestrzeń akustyczną użytkownika dla określonego zadania. Do
badań zastosowany następujący zestaw słów: kropka, wyloguj, przecinek, wytnij, pięć, cofnij,
118
wyczyść, wyszukaj, drukuj, zamień, uruchom, pogrubienie, cudzysłów, kąt, drzwi, dźwig,
źrebak. Zestaw słów stanowi sekwencję tych wypowiedzi, oddzielonych wyraźną ciszą.
Zawiera on wszystkie 37 fonemów języka polskiego.
Na Rys.6.7 pokazano widok zestawu słów zastosowanych w procesie tworzenia
książki kodowej danego użytkownika, dla audio mowy.
Rys.6.7 Widok zestawu słów zastosowanych do budowy książki kodowej
Cały zestaw słów traktowany jest jak jedna wypowiedź. Nie stosuje się tutaj
wydzielania właściwych słów, poprzez usunięcie ciszy, gdyż również dla ciszy przydzielany
jest pewien symbol książki kodowej. Dla całego zestawu wypowiedzi tworzona jest książka
kodowa pokrywająca w całości przestrzeń akustyczną danego użytkownika. Wejście stanowi
sekwencja wektorów współczynników cepstrum, każdej z zakodowanych ramek.
Dla tego samego zestawy słów tworzona jest książka kodowa wideo mowy. W tym
przypadku wejście stanowi sekwencja wektorów zawierających stosunki odległości od
prostej, wyznaczonej przez kąciki ust, każdego z punktów charakterystycznych
wyznaczonych na zewnętrznych krawędziach ust, do odległości pomiędzy kącikami ust.
Każdy z wektorów charakteryzuje oddzielną ramkę wideo mowy.
Widok przestrzeni akustycznej audio mowy, utworzonej książki kodowej dla danego
użytkownika w oparciu o zestaw słów kodowych audio mowy pokazano na Rys.6.8, zaś
widok przestrzeni wideo mowy, utworzonej książki kodowej w oparciu o ten sam zestaw słów
kodowych wideo mowy pokazano na Rys.6.9.
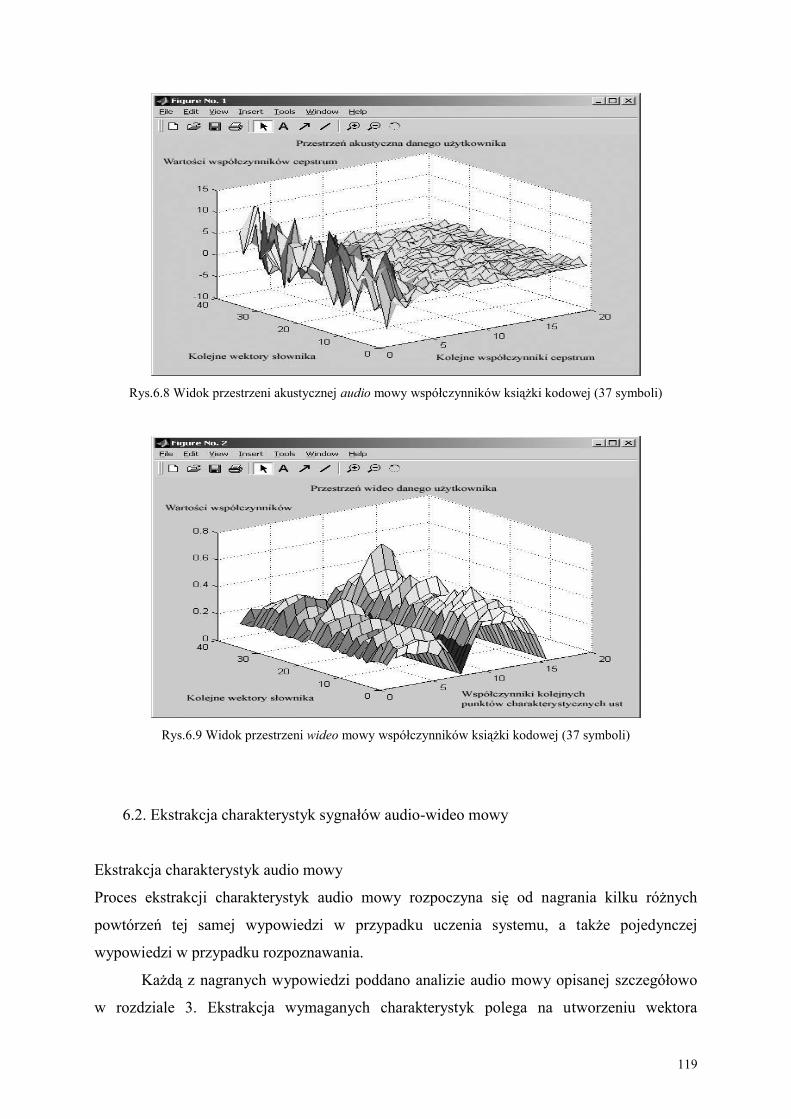
119
Rys.6.8 Widok przestrzeni akustycznej audio mowy współczynników książki kodowej (37 symboli)
Rys.6.9 Widok przestrzeni wideo mowy współczynników książki kodowej (37 symboli)
6.2. Ekstrakcja charakterystyk sygnałów audio-wideo mowy
Ekstrakcja charakterystyk audio mowy
Proces ekstrakcji charakterystyk audio mowy rozpoczyna się od nagrania kilku różnych
powtórzeń tej samej wypowiedzi w przypadku uczenia systemu, a także pojedynczej
wypowiedzi w przypadku rozpoznawania.
Każdą z nagranych wypowiedzi poddano analizie audio mowy opisanej szczegółowo
w rozdziale 3. Ekstrakcja wymaganych charakterystyk polega na utworzeniu wektora

120
obserwacji, będącego sekwencją obserwacji wygenerowanych w kolejnych chwilach
czasowych. Taki sposób zakodowania wejściowej wypowiedzi audio jest konieczny dla
zastosowanego aparatu stochastycznego, wykorzystującego modele UMM.
W celu dokładniejszego wytłumaczenia zasady działania analizy audio wykorzystanej
w zbudowanym systemie AVM_PL, budowę wektorów obserwacji zaprezentowano dla
przykładowych trzech różnych wypowiedzi: katalog, sześć i nagrywanie. Dodatkowo każdą
wypowiedź powtórzono po kilka razy.
W pierwszym kroku system dokonuje wstępnej filtracji dolnoprzepustowej, z
zastosowaniem odpowiedniej funkcji transmitancji. Jako funkcję transmitancji zastosowano
okno Kaisera z pasmem przejścia dla częstotliwości od 0 do 1000 Hz oraz pasmem
zaporowym dla częstotliwości powyżej 2000 Hz.
Po wstępnej filtracji zapobiegającej zjawisku nakładania się widm, wykonywane jest
wydzielanie właściwego sygnału, poprzez usunięcie ciszy sprzed i spoza nagrania. System
realizuje wydzielanie w oparciu o algorytmy bazujące na energii sygnału oraz na częstości
zmian stanów sygnału dla określonego odcinka czasowego i częstotliwości próbkowania.
Na Rys.6.10 – 6.12 pokazano wynik działania etapu wydzielania właściwego sygnału
dla przykładowych wypowiedzi.
Rys.6.10 Widok trzech różnych wypowiedzi słowa katalog przed i po wydzielaniu właściwego sygnału

121
Rys.6.11 Widok trzech różnych wypowiedzi słowa sześć przed i po wydzielaniu właściwego sygnału
Rys. 6.12. Widok trzech różnych wypowiedzi słowa nagrywanie przed i po wydzielaniu właściwego sygnału

122
W kolejnym etapie procesy analizy audio mowy system AVM_PL realizuje podział
wejściowego sygnału na stacjonarne ramki o długości 30 ms każda, co przy częstotliwości
próbkowania 8000 Hz daje długość ramki równą 240 próbek. Każda kolejna ramka nakładana
jest na poprzednią z opóźnieniem 10 ms (80 próbek). Takiej kwantyzacji sygnału dokonano w
celu zachowania stacjonarności i poprawnej ciągłości w procesie analizy dynamicznego
sygnału.
Każda ramka w dalszej części podlega filtracji z wykorzystaniem banku 21 filtrów o
szerokości 300 meli, przesuniętych względem siebie o 150 meli wzdłuż osi częstotliwości
zgonie ze skalą mel. Uzyskane współczynniki banku filtrów poddano procesowi analizy
cepstralnej. Każdą przefiltrowaną ramkę zakodowano przy pomocy 20 współczynników
cepstrum.
Widok wyznaczonych współczynników cepstrum dla każdej z ramek przykładowych
wypowiedzi pokazano na Rys.6.13 – 6.15.
Rys.6.13 Widok zakodowanej każdej ramki słowa katalog z uwzględnieniem 20 współczynników cepstrum

123
Rys.6.14 Widok zakodowanej każdej ramki słowa sześć z uwzględnieniem 20 współczynników cepstrum
Rys.6.15 Widok zakodowanej każdej ramki słowa nagrywanie z uwzględnieniem 20 współczynników cepstrum

124
Zakodowane przy pomocy współczynników cepstrum słowa w kolejnym kroku
poddano kwantyzacji wektorowej z wykorzystaniem utworzonej wcześniej książki kodowej,
dla danego użytkownika. Jako miarę odległości w systemie zastosowano metrykę „uliczną” –
wzór – 3.34. Dla każdej zakodowanej ramki przydzielono symbol obszaru najbliższego tej
ramce w przestrzeni akustycznej danego użytkownika. W ten sposób w procesie analizy audio
mowy utworzono wymagane w systemie wektory obserwacji.
Wyznaczone wektory obserwacji dla przykładowych nagrań pokazano w Tab.6.1.
Tab.6.1 Wektory obserwacji wyznaczone dla przykładowych nagrań audio mowy
Słowo Wektory obserwacji audio
Katalog 1 21 34 23 23 23 23 23 23 23 23 13 13 23 11 11 11 21 23 23 23 23 23 23 23 23 23 23 23 23 19 19 6 6 9 6 19 19 19 19 19 19 6 6 6 6 6 17 17 31 31 31 31 15 31 15 15 15 33 7 7 7 7 7 7 7 5
Katalog 2 21 21 23 23 23 23 23 23 23 23 23 23 23 13 13 13 11 21 23 23 23 23 23 23 23 23 23 23 23 23 17 17 7 9 19 19 19 19 19 6 6 6 6 6 17 31 14 31 31 15 31 31 9 5 5 7 5 5 5 2
Katalog 3 21 23 23 23 23 23 23 23 23 23 23 23 13 13 13 13 13 23 23 23 23 23 23 23 23 23 23 23 23 7 19 17 7 7 19 19 19 19 19 19 19 6 6 9 31 31 31 31 31 31 15 33 5 5 7 7 7 7 5 15
Katalog 4 34 23 23 23 23 23 23 23 23 23 13 13 13 23 13 21 23 23 23 23 23 23 23 23 23 23 23 23 23 23 17 17 7 19 19 19 19 19 19 6 6 6 17 31 31 31 31 31 31 15 31 33 5 5 7 7 7 7 7 5
Sześć 1 26 26 26 26 26 26 26 26 36 26 26 26 26 34 34 23 23 23 23 32 32 32 32 32 32 32 32 27 8 8 20 26 26 26 26 26 26 26 26 26 26 26 26 36 26 26 20 37 20 37 37 20 26 26 26 26 26 26 26 26 26 26 26
Sześć 2 26 26 26 26 26 26 26 26 26 26 26 26 20 34 34 23 23 23 23 23 32 32 32 32 32 32 32 32 27 8 8 36 26 26 26 26 26 26 26 26 26 26 26 26 26 26 20 37 37 37 37 20 26 26 26 26 26 26 26 26 26 26 36
Sześć 3 26 26 26 26 26 26 26 26 26 26 26 26 26 26 26 34 34 23 23 23 23 23 23 23 32 32 32 32 32 32 32 27 8 8 26 26 26 26 26 26 26 26 26 26 26 26 26 26 26 36 37 20 20 20 26 26 26 26 26 26 26 26 26 26 26
Sześć 4 26 26 26 26 26 26 26 26 26 26 26 26 26 26 34 34 23 23 32 23 23 32 32 32 32 32 32 32 32 27 8 36 26 26 26 26 26 26 26 26 26 26 26 26 26 26 20 36 37 37 26 26 26 26 26 26 26 26 26 26 26 26
Nagrywanie 1 15 5 5 5 5 5 5 23 23 23 23 23 23 23 32 34 33 33 5 31 27 27 27 34 27 27 27 27 27 27 27 7 7 5 18 15 24 19 23 23 23 23 23 23 23 23 23 23 32 17 33 33 33 18 30 30 35 35 8 8 8 8 32 32 32 32 32 32 34 25 25 25 25 25 25 29 29 25
Nagrywanie 2 15 5 5 5 18 18 18 23 23 23 23 23 23 23 23 23 32 34 17 33 33 27 27 27 34 7 27 27 27 27 27 27 27 34 34 18 18 3 10 24 19 23 23 23 23 23 23 23 23 23 23 23 23 34 33 33 18 33 18 30 30 22 22 22 8 8 32 32 32 32 32 32 32 34 25 25 25 25 28 25 28 29 29 29
Nagrywanie 3 5 5 5 7 5 5 7 23 23 23 23 23 23 23 23 23 32 34 33 5 5 7 27 27 7 34 27 27 27 27 27 27 27 34 7 33 5 5 15 5 24 24 19 23 23 23 23 23 23 23 23 23 23 23 32 33 33 33 33 33 30 30 30 30 35 22 8 8 8 32 32 32 8 32 32 32 25 25 25 25 25 12 12 12 12 28
Nagrywanie 4 15 5 5 5 7 5 34 23 23 23 23 23 23 23 23 32 32 33 5 5 33 7 27 27 34 34 34 27 27 27 27 27 27 27 27 34 7 33 5 5 5 18 5 24 19 23 23 23 23 23 23 23 23 23 23 32 32 33 33 5 18 18 30 30 30 30 35 35 8 8 8 32 32 32 32 32 32 32 25
Wektory obserwacji utworzono w oparciu o książkę kodową o rozmiarze 37 symboli
obserwacji. Mogłoby się wydawać, że taka liczba kodów dla audio mowy jest wystarczająca,
gdyż właśnie tyle jest fonemów w języku polskim. Jednak brakuje odpowiedników dla ramek
znajdujących się w chwili przejścia między dwoma sąsiednimi fonemami. Można zauważyć,

125
że dla wypowiedzi „sześć”, fonem „sz”, „ś” i „ć” mają kod 26. Podobnie jest z fonemami „a”
oraz „e” mającymi kod 23. Jest to spowodowane zbyt małą liczbą kodów. Dla dużej liczby
słów w słowniku systemu należy użyć większego rozmiaru książki kodowej, jednak w pracy
przebadano tylko 70 komend sterowania systemem operacyjnym, dlatego 37 kodów w książce
kodowej jest wystarczające do zakodowania i rozróżnienia poszczególnych słów.
Ekstrakcja charakterystyk wideo mowy
Proces ekstrakcji charakterystyk wideo mowy, podobnie jak w przypadku audio mowy
rozpoczyna się od nagrania kilku różnych powtórzeń tej samej wypowiedzi w przypadku
uczenia systemu, a także pojedynczej wypowiedzi w przypadku rozpoznawania.
Każdą z nagranych wypowiedzi poddano analizie wideo mowy opisanej szczegółowo
w rozdziale 5. Ekstrakcja wymaganych charakterystyk polega na utworzeniu wektora
obserwacji, będącego sekwencją obserwacji wygenerowanych w kolejnych chwilach
czasowych, w tym przypadku w kolejnych ramkach nagrania wideo.
Aby dokładniej wytłumaczyć zasadę działania analizy wideo mowy, wykorzystanej
zbudowanym systemie AVM_PL, budowę wektorów obserwacji zaprezentowano dla tych
samych, co w ekstrakcji charakterystyk audio, przykładowych trzech różnych wypowiedzi:
„katalog”, „nagrywanie” oraz „sześć”, tego samego użytkownika. Dodatkowo każdą
wypowiedź również powtórzono po kilka razy.
Proces analizy wideo mowy rozpoczyna się od zlokalizowania twarzy użytkownika,
jego oczu, a następnie wyznaczeniu regionu zawierającego usta, dla każdej ramki filmu
wideo. Właściwa analiza wideo mowy realizowana jest w na podstawie ciągłego śledzenia
położenia kącików ust, zewnętrznych krawędzi ust oraz ułożenia języka osoby w
zarejestrowanej wypowiedzi wideo.
W systemie AVM_PL proces trekingu ust można obserwować na bieżąco dla każdej
ramki. Jest to o tyle ważne, że skoro system ma działać poprawnie, to wymagane jest, aby
punkty charakterystyczne, określające zewnętrzne krawędzie ust, były zlokalizowane
prawidłowo. Etap lokalizacji krawędzi ust poprzedzony jest kalibracją, która modyfikowana
jest tylko przy rozpoczęciu pracy z systemem, później można ją pominąć, gdyż raz ustawione
wartości progowe wystarczają do dalszej pracy tego samego użytkownika z systemem.
Rezultat wyznaczenia metodą CSM punktów, określających kąciki i zewnętrzne
krawędzie ust dla przykładowych wypowiedzi tego samego użytkownika pokazano na
Rys.6.16 – 6.18. Ramki ułożone są w kolejności od lewej, do prawej strony w każdym
rzędzie.

126
Rys.6.16 Widok sekwencji kolejnych ramek wideo wypowiedzi katalog ze zlokalizowanymi krawędziami ust
Rys.6.17 Widok sekwencji kolejnych ramek wideo wypowiedzi sześć ze zlokalizowanymi krawędziami ust

127
Rys.6.18 Widok sekwencji ramek wideo wypowiedzi nagrywanie ze zlokalizowanymi krawędziami ust
Na podstawie zlokalizowanych kącików ust, oraz punktów charakterystycznych
wyznaczających zewnętrzne krawędzie ust, w kolejnym etapie procesu analizy wideo mowy,
dla każdej ramki tworzony jest wektor określający położenie każdego z punktów. W systemie
AVM_PL ust reprezentowane są przez 16 punktów.
W systemie możliwy jest dwojaki sposób kodowania każdej z ramek. Pierwszy polega
na przydzieleniu dla każdej ramki kodu, opisującego obszar, do którego najbardziej jest
podobny wektor opisujący. Uzyskany w ten sposób wektor sekwencji obserwacji zawiera
kody o wartościach odpowiadających rozmiarowi książki kodowej. W drugim ze sposobów
dla każdej ramki, na podstawie położenia wszystkich 16 punktów wyznacza się wypadkową
wartość kodu, bez konieczności korzystania z książki kodowej.
Na Rys.6.19 – 6.21 pokazano wektory położeń każdego z punktów charaktery-
stycznych ust dla wszystkich ramek wypowiedzi w procesie trekingu ust.
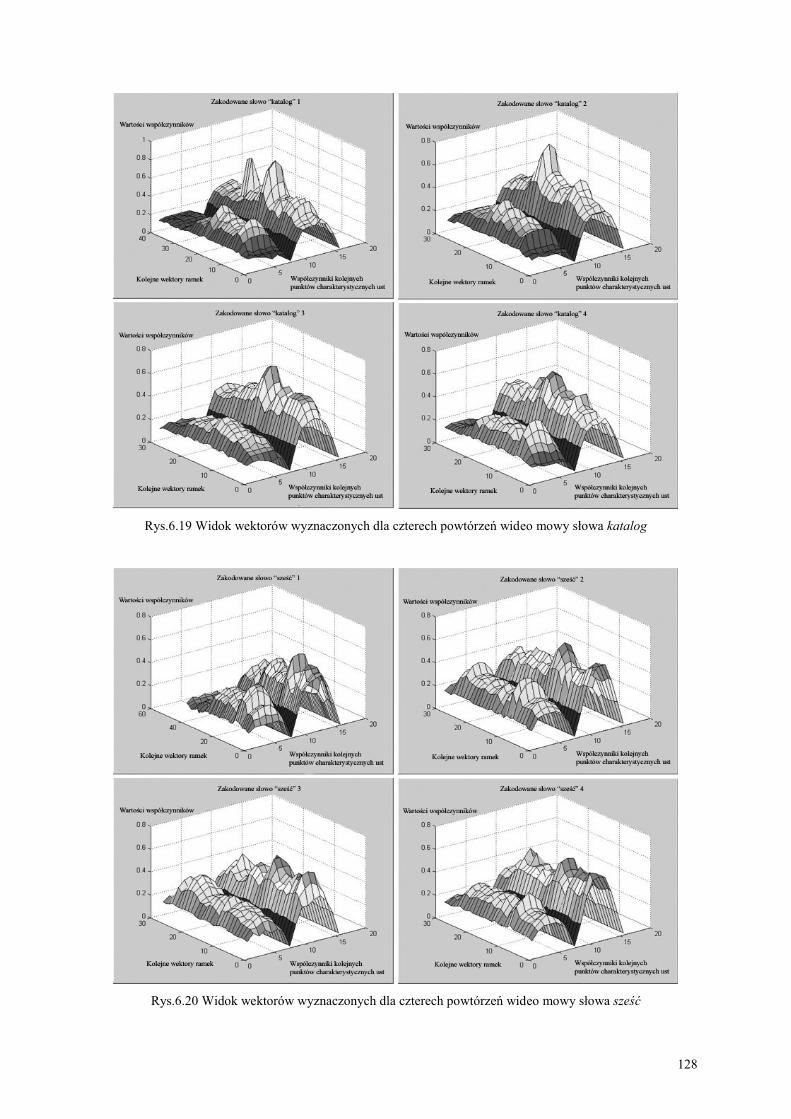
128
Rys.6.19 Widok wektorów wyznaczonych dla czterech powtórzeń wideo mowy słowa katalog
Rys.6.20 Widok wektorów wyznaczonych dla czterech powtórzeń wideo mowy słowa sześć

129
Rys.6.21 Widok wektorów wyznaczonych dla czterech powtórzeń wideo mowy słowa nagrywanie
Proces kodowania wideo mowy kończy się utworzeniem wektorów obserwacji. Dla
pojedynczej wypowiedzi tworzony jest jeden wektor obserwacji. Długość wektorów
obserwacji powtórzeń tej samej wypowiedzi w zasadzie zawsze jest różna. Spowodowane jest
to różnym sposobem wypowiadania przez użytkownika (wolno, szybko). Zasada działania
systemu AVM_PL jest taka, że ma on rozpoznawać wypowiedzi poprawnie, bez względu na
prędkość ich wypowiadania. W systemie zastosowano podejście polegające na celowo
zróżnicowanej szybkości wypowiadania komend w procesie uczenia. Takie podejście
pozwala na zachowanie większej elastyczności systemu dla danego użytkownika.
Ponieważ w celu ograniczenia czasu trwania operacji analizy wideo założono, że
wideo mowę powinno się nagrywać z częstotliwością minimalną, a jednocześnie pozwalającą
na rzeczywiste odzwierciedlenie ruchu ust użytkownika. Przyjęto, że taką wystarczającą
częstotliwością jest nagrywanie 15 klatek/s. Na podstawie Rys.6.12 – 6.14 oraz 6.18 - 6.20
można zauważyć, że liczba ramek wideo mowy jest znacznie mniejsza od liczby ramek audio
mowy, oczywiście dla tej samej wypowiedzi. Spowodowane jest to między innymi tym, że w
audio mowie zastosowano zjawisko nakładania się kolejnych ramek, zwiększając ten sposób
sztucznie ich liczba. Łatwo można policzyć różnicę w liczbie ramek audio i wideo mowy. Dla

130
nagrania o czasie trwania 1 s., w przypadku audio mowy z częstotliwością próbkowania 8000
Hz, w zbudowanym systemie uzyskuje się niepełne 34 nie nakładające się ramki oraz
niepełne 50 nakładających się ramek z opóźnieniem 10 s. Dla tego samego nagrania w
przypadku wideo mowy uzyskuje się 15 ramek, czyli ponad trzy razy mniej niż dla audio
mowy. Ponieważ jest to system w głównej mierze opierający się na sygnałach audio, dlatego
takie rozwiązanie można przyjąć jako właściwe. Jednak bardziej logiczne jest zwiększenie
częstotliwości nagrywania obrazu wideo do 25 klatek/s. Zbudowany system AVM_PL
automatycznie przestawia się na odpowiednią częstotliwość nagrywania obrazu wideo,
pozwalając na eksperymenty i dobór optymalnych parametrów wideo mowy dla określonego
użytkownika.
Na podstawie wyznaczonych wektorów współczynników położenia każdego z
punktów charakterystycznych ust system dokonuje kwantyzacji wektorowej. Początkowo
wektory utworzone w systemie zawierają obserwacje odpowiadające również ciszy, lub
ramkom ust nie wypowiadających żadnych fonemów, a wykonujących zbędne ruchy. Takie
wektory obserwacji wprowadzane są do etapu realizującego synchronizację oraz fuzję z
wektorami obserwacji audio mowy. Dopiero na podstawie kluczowych ramek audio mowy
następuje synchronizacja, a co za tym idzie, usunięcie zbędnych ramek wideo.
Jeśli system miałby dokonywać usunięcia zbędnych ramek na podstawie wideo mowy,
wówczas konieczne by było, aby użytkownik miał zamknięte usta przed oraz po właściwej
wypowiedzi. Problem pojawiłby się wtedy, gdy dana wypowiedź zaczynałaby się, bądź też
kończyła fonemem, dla którego układ ust przypominałby zamknięte usta. Wydaje się, że nie
jest możliwe takie rozwiązanie pozbycia się zbędnych ramek.
Wektory obserwacji uzyskane podczas kwantyzacji dla przykładowych wideo
wypowiedzi zamieszczono w Tab.6.2 oraz 6.3. Wektory te pozbawiono już zbędnych ramek.
Tab.6.2 Wektory obserwacji wyznaczone dla przykładowych nagrań wideo mowy z wykorzystaniem książki
kodowej Słowo Wektory obserwacji wideo
Katalog 1 25 29 29 25 17 21 25 25 25 25 29 37 33 33 29 17 21 21 21 21 17 17 13 Katalog 2 25 25 25 21 17 21 25 25 25 29 29 33 29 21 21 21 17 17 13 13 Katalog 3 25 29 25 21 21 21 25 25 25 25 25 29 25 21 21 17 21 21 13 13 Katalog 4 24 25 25 25 21 21 25 25 25 25 29 29 29 25 25 21 17 21 17 13 13 Sześć 1 23 21 21 25 29 29 25 25 21 25 25 25 21 21 21 21 21 21 21 21 21 Sześć 2 23 25 21 21 21 29 25 21 21 21 17 21 21 21 21 25 25 25 21 25 21 Sześć 3 25 21 21 25 21 25 29 29 29 25 25 21 25 21 21 21 25 17 21 21 21 21 Sześć 4 23 21 21 21 25 25 21 25 25 21 17 21 21 21 21 21 21 21 21 21 21 Nagrywanie 1 21 29 25 17 13 17 13 13 9 9 21 25 25 21 21 21 25 25 25 25 17 9 Nagrywanie 2 21 21 25 25 25 21 17 17 21 17 13 13 17 29 29 25 21 21 25 29 29 25 21 17 13 9 Nagrywanie 3 21 21 17 25 25 25 17 13 17 13 13 9 9 13 29 25 25 21 17 21 25 25 21 21 13 9 Nagrywanie 4 21 17 17 25 25 21 17 17 17 17 17 13 13 13 17 25 25 21 21 21 25 25 25 21 17 13 9

131
Tab.6.3 Wektory obserwacji wyznaczone dla przykładowych nagrań wideo mowy bez wykorzystania książki kodowej
Słowo Wektory obserwacji wideo Katalog 1 33 40 36 33 30 25 33 35 33 33 43 49 48 43 36 25 31 27 29 29 22 20 20 Katalog 2 34 32 34 30 28 29 33 35 33 39 43 43 39 31 24 26 25 21 21 20 Katalog 3 35 39 37 35 28 32 33 37 33 35 38 40 43 30 27 27 26 23 24 20 Katalog 4 33 34 34 33 30 28 35 33 33 33 35 40 43 34 31 25 28 24 29 23 21 Sześć 1 31 28 28 30 32 36 32 30 26 26 33 33 30 29 28 27 29 29 28 31 30 Sześć 2 31 33 29 33 28 31 31 30 26 26 26 27 29 30 30 32 32 32 32 31 29 29 Sześć 3 30 33 33 30 32 30 36 35 35 32 26 27 30 27 28 28 28 29 27 28 29 29 Sześć 4 31 30 28 30 33 33 32 31 34 27 26 30 29 29 28 26 29 29 30 30 28 Nagrywanie 1 27 32 29 23 20 20 21 17 15 15 29 33 32 23 27 30 33 34 33 32 20 18 Nagrywanie 2 27 26 31 34 32 27 21 21 26 21 18 18 23 37 36 34 27 28 32 37 38 34 28 22 18 Nagrywanie 3 26 26 23 35 35 32 24 19 22 20 18 15 15 18 34 35 33 27 25 29 33 33 30 27 18 Nagrywanie 4 27 23 35 34 26 22 23 22 23 21 17 16 16 24 34 33 31 26 28 31 34 33 30 24 16
6.3. Fuzja charakterystyk audio-wideo mowy
Sposób fuzji charakterystyk audio i wideo mowy, przedstawionych w postaci wektorów
obserwacji, zrealizowano na trzy różne sposoby. Każda z metod wymaga wcześniejszej
synchronizacji, polegającej na wyznaczeniu pierwszej i ostatniej ramki wypowiedzi wideo, na
podstawie pierwszej i ostatniej ramki wypowiedzi audio, wydzielających właściwy,
pozbawiony zbędnej ciszy sygnał.
W pierwszej zaproponowanej metodzie Sr fuzji charakterystyk wejściowych sygnałów
zastosowano podejście synchroniczne, polegające na wyznaczeniu wektora wypadkowych
obserwacji, z wektorów obserwacji obu wejściowych sygnałów danej wypowiedzi. Przyjęto,
że głównym sygnałem jest sygnał audio, dlatego rozmiar wypadkowego wektora obserwacji
odpowiadał rozmiarowi wektora audio obserwacji.
Sygnał audio o częstotliwości próbkowania 8000 Hz kodowano na postawie książki
kodowej złożonej z 37 symboli obserwacji. Sygnał wideo o częstotliwości nagrywania 25
klatek/s kodowano za pomocą 10 symboli, zakładając ograniczoną liczbę różnych fonemów
wideo mowy. Takie założenia przyjęto ze względu na konieczność ograniczenia rozmiaru
wypadkowego wektora obserwacji, gdyż na podstawie tegoż rozmiaru, definiowany jest
rozmiar parametru B modelu UMM, określającego prawdopodobieństwo wygenerowania
określonej obserwacji przez model będący w danym stanie.
Dla założonych parametrów nagrywania sygnałów przyjęto, że na dwie obserwacje
audio mowy przypada jedna obserwacja wideo mowy. Aby zachować synchronizację, wektor
obserwacji wideo mowy zwiększono dwukrotnie, tworząc dla każdej obserwacji jej kopię,
zachowując odpowiednią kolejność. W przypadku, gdy oba wektory obserwacji różniły się
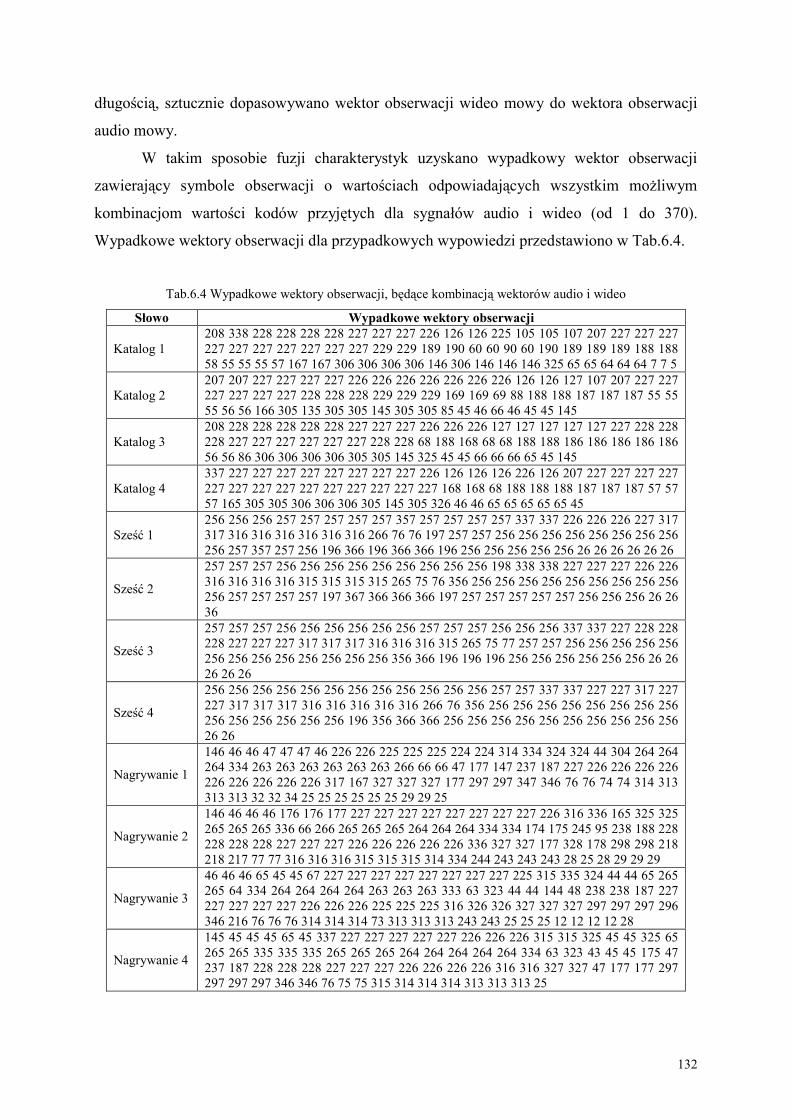
132
długością, sztucznie dopasowywano wektor obserwacji wideo mowy do wektora obserwacji
audio mowy.
W takim sposobie fuzji charakterystyk uzyskano wypadkowy wektor obserwacji
zawierający symbole obserwacji o wartościach odpowiadających wszystkim możliwym
kombinacjom wartości kodów przyjętych dla sygnałów audio i wideo (od 1 do 370).
Wypadkowe wektory obserwacji dla przypadkowych wypowiedzi przedstawiono w Tab.6.4.
Tab.6.4 Wypadkowe wektory obserwacji, będące kombinacją wektorów audio i wideo
Słowo Wypadkowe wektory obserwacji
Katalog 1 208 338 228 228 228 228 227 227 227 226 126 126 225 105 105 107 207 227 227 227 227 227 227 227 227 227 227 229 229 189 190 60 60 90 60 190 189 189 189 188 188 58 55 55 55 57 167 167 306 306 306 306 146 306 146 146 146 325 65 65 64 64 64 7 7 5
Katalog 2 207 207 227 227 227 227 226 226 226 226 226 226 226 126 126 127 107 207 227 227 227 227 227 227 228 228 228 229 229 229 169 169 69 88 188 188 187 187 187 55 55 55 56 56 166 305 135 305 305 145 305 305 85 45 46 66 46 45 45 145
Katalog 3 208 228 228 228 228 228 227 227 227 226 226 226 127 127 127 127 127 227 228 228 228 227 227 227 227 227 227 228 228 68 188 168 68 68 188 188 186 186 186 186 186 56 56 86 306 306 306 306 305 305 145 325 45 45 66 66 66 65 45 145
Katalog 4 337 227 227 227 227 227 227 227 227 226 126 126 126 226 126 207 227 227 227 227 227 227 227 227 227 227 227 227 227 227 168 168 68 188 188 188 187 187 187 57 57 57 165 305 305 306 306 306 305 145 305 326 46 46 65 65 65 65 65 45
Sześć 1 256 256 256 257 257 257 257 257 357 257 257 257 257 337 337 226 226 226 227 317 317 316 316 316 316 316 316 266 76 76 197 257 257 256 256 256 256 256 256 256 256 256 257 357 257 256 196 366 196 366 366 196 256 256 256 256 256 26 26 26 26 26 26
Sześć 2
257 257 257 256 256 256 256 256 256 256 256 256 198 338 338 227 227 227 226 226 316 316 316 316 315 315 315 315 265 75 76 356 256 256 256 256 256 256 256 256 256 256 257 257 257 257 197 367 366 366 366 197 257 257 257 257 257 256 256 256 26 26 36
Sześć 3
257 257 257 256 256 256 256 256 256 257 257 257 256 256 256 337 337 227 228 228 228 227 227 227 317 317 317 316 316 316 315 265 75 77 257 257 256 256 256 256 256 256 256 256 256 256 256 256 256 356 366 196 196 196 256 256 256 256 256 256 26 26 26 26 26
Sześć 4
256 256 256 256 256 256 256 256 256 256 256 256 257 257 337 337 227 227 317 227 227 317 317 317 316 316 316 316 316 266 76 356 256 256 256 256 256 256 256 256 256 256 256 256 256 256 196 356 366 366 256 256 256 256 256 256 256 256 256 256 26 26
Nagrywanie 1
146 46 46 47 47 47 46 226 226 225 225 225 224 224 314 334 324 324 44 304 264 264 264 334 263 263 263 263 263 263 266 66 66 47 177 147 237 187 227 226 226 226 226 226 226 226 226 226 317 167 327 327 327 177 297 297 347 346 76 76 74 74 314 313 313 313 32 32 34 25 25 25 25 25 25 29 29 25
Nagrywanie 2
146 46 46 46 176 176 177 227 227 227 227 227 227 227 227 226 316 336 165 325 325 265 265 265 336 66 266 265 265 265 264 264 264 334 334 174 175 245 95 238 188 228 228 228 228 227 227 227 226 226 226 226 226 336 327 327 177 328 178 298 298 218 218 217 77 77 316 316 316 315 315 315 314 334 244 243 243 243 28 25 28 29 29 29
Nagrywanie 3
46 46 46 65 45 45 67 227 227 227 227 227 227 227 227 225 315 335 324 44 44 65 265 265 64 334 264 264 264 264 263 263 263 333 63 323 44 44 144 48 238 238 187 227 227 227 227 227 226 226 226 225 225 225 316 326 326 327 327 327 297 297 297 296 346 216 76 76 76 314 314 314 73 313 313 313 243 243 25 25 25 12 12 12 12 28
Nagrywanie 4
145 45 45 45 65 45 337 227 227 227 227 227 226 226 226 315 315 325 45 45 325 65 265 265 335 335 335 265 265 265 264 264 264 264 264 334 63 323 43 45 45 175 47 237 187 228 228 228 227 227 227 226 226 226 226 316 316 327 327 47 177 177 297 297 297 297 346 346 76 75 75 315 314 314 314 313 313 313 25

133
W drugiej zaproponowanej metodzie ASr_I fuzji charakterystyk oba wektory audio i
wideo mowy podawano na wejście modelu UMM osobno, bez sztucznego zwiększania
wektora wideo mowy. Synchronizacja w tej metodzie ograniczono tylko do wyznaczenia
kluczowych ramek określających początek i koniec właściwej wypowiedzi. Ponieważ oba
wejściowe wektory obserwacji znacznie różniły się długością, dlatego w zasadzie ta metoda,
jest metodą asynchroniczną, gdyż nie ma synchronizacji wszystkich obserwacji obu
wektorów.
Specyfika tej metody odznacza się tym, iż wprowadzane osobno wektory obserwacji
audio i wideo mowy, stanowią dane uczące dla tego samego modelu UMM. Model
charakteryzujący daną wypowiedź zbudowano w ten sposób, aby był w stanie wygenerować
zarówno sekwencję audio, jak i wideo. Przykładowo, dla danej wypowiedzi, na wejście
jednego tego samego modelu UMM, podawano dwa wektory obserwacji na przemian: wektor
audio mowy i wektor wideo mowy.
W takim asynchronicznym sposobie fuzji charakterystyk audio i wideo mowy,
konieczne jest zachowanie zgodności, co do liczby symboli, na których kodowano oba
sygnały. Zarówno wektor obserwacji audio, jak i wideo muszą być kodowane na takiej samej
liczbie obserwacji, oraz tych samych wartości obserwacji, gdyż parametry modelu UMM
muszą zawierać wszystkie odpowiedniki obu sygnałów. Prawdopodobieństwo
wygenerowania sekwencji obserwacji dla danej wypowiedzi, stanowi sumę
prawdopodobieństw wygenerowania sekwencji obserwacji audio oraz wideo.
W Tab.6.5 pokazano sposób podawania sekwencji obserwacji audio i wideo mowy, na
wejście trzech różnych modeli UMM, reprezentujących przykładowe wypowiedzi.
Tab.6.5 Wektory obserwacji audio i wideo podawane na wejście modelu UMM danej wypowiedzi
Słowo Wektory obserwacji audio i wideo
Katalog 1
Audio: 21 34 23 23 23 23 23 23 23 23 13 13 23 11 11 11 21 23 23 23 23 23 23 23 23 23 23 23 23 19 19 6 6 9 6 19 19 19 19 19 19 6 6 6 6 6 17 17 31 31 31 31 15 31 15 15 15 33 7 7 7 7 7 7 7 5
Wideo: 25 29 29 25 17 21 25 25 25 25 29 37 33 33 29 17 21 21 21 21 17 17 13
Sześć 1
Audio: 26 26 26 26 26 26 26 26 36 26 26 26 26 34 34 23 23 23 23 32 32 32 32 32 32 32 32 27 8 8 20 26 26 26 26 26 26 26 26 26 26 26 26 36 26 26 20 37 20 37 37 20 26 26 26 26 26 26 26 26 26 26 26
Wideo: 31 28 28 30 32 36 32 30 26 26 33 33 30 29 28 27 29 29 28 31 30
Nagrywanie 1
Audio: 15 5 5 5 5 5 5 23 23 23 23 23 23 23 32 34 33 33 5 31 27 27 27 34 27 27 27 27 27 27 27 7 7 5 18 15 24 19 23 23 23 23 23 23 23 23 23 23 32 17 33 33 33 18 30 30 35 35 8 8 8 8 32 32 32 32 32 32 34 25 25 25 25 25 25 29 29 25
Wideo: 21 29 25 17 13 17 13 13 9 9 21 25 25 21 21 21 25 25 25 25 17 9

134
W trzeciej zaproponowanej metodzie ASr_II fuzji charakterystyk audio i wideo mowy
zastosowano podejście, polegające na utworzeniu osobnych modeli UMM dla obu wektorów
obserwacji. Każdy z modeli generował sekwencję obserwacji najbardziej prawdopodobną do
wejściowej, a fuzja charakterystyk realizowana była poprzez zsumowanie wyznaczonych
prawdopodobieństw.
W tej metodzie można stosować różne rozmiary słowników kodowych sygnałów
audio oraz wideo, a także różne wartości stosowanych kodów. Modele mogą również różnić
się liczbą przyjętych stanów. Podobnie jak poprzednia, również ta metoda jest metodą
asynchroniczną, gdyż oba wektory obserwacji danej wypowiedzi różnią się znacznie
długością i nie jest zachowana synchronizacja poszczególnych obserwacji. Konieczna jest
jedynie odpowiednia transkrypcja gramatyczna budowanych modeli UMM, w celu
zachowania poprawności sumowania prawdopodobieństw wygenerowanych dla
odpowiednich modeli.
6.4. Budowa i nauczanie parametryczne ukrytych modeli Markowa
Budowa ukrytych modeli Markowa
Etap budowy modeli UMM w systemie AVM_PL, realizowany jest automatycznie, na
podstawie zadanej liczby stanów, oraz rozmiaru słownika książki kodowej, na podstawie
której utworzono wejściowe wektory obserwacji.
Budowa modeli UMM odbywa się tyko podczas działania systemu w trybie uczenia i
polega na utworzeniu parametrów określających dany model λ = (π, A, B). W systemie
parametr π, określający początkowy rozkład stanów, charakteryzowany jest przez wektor o
rozmiarze odpowiadającym zadeklarowanej liczbie stanów q. Parametr A, określający
prawdopodobieństwo przejścia ze stanu do stanu, charakteryzowany jest przez macierz
kwadratową o liczbie wierszy i kolumn odpowiadającej zadeklarowanej liczbie stanów q.
Parametr B, określający prawdopodobieństwo, że model będący w danym stanie wygeneruje
określoną obserwację, charakteryzowany jest przez macierz o liczbie wierszy odpowiadającej
zadeklarowanej liczbie stanów q oraz o liczbie kolumn odpowiadającej rozmiarowi słownika
książki kodowej o.
W systemie założono, że dla każdej wypowiedzi budowany jest oddzielny model
UMM. Tak więc realizując rozpoznawanie słów izolowanych, uzyskuje się liczbę modeli
równą liczbie słów zawartych w bazie systemu. W przypadku rozpoznawania słów
izolowanych audio wideo mowy, gdzie zastosowano podejście polegające na budowie modeli
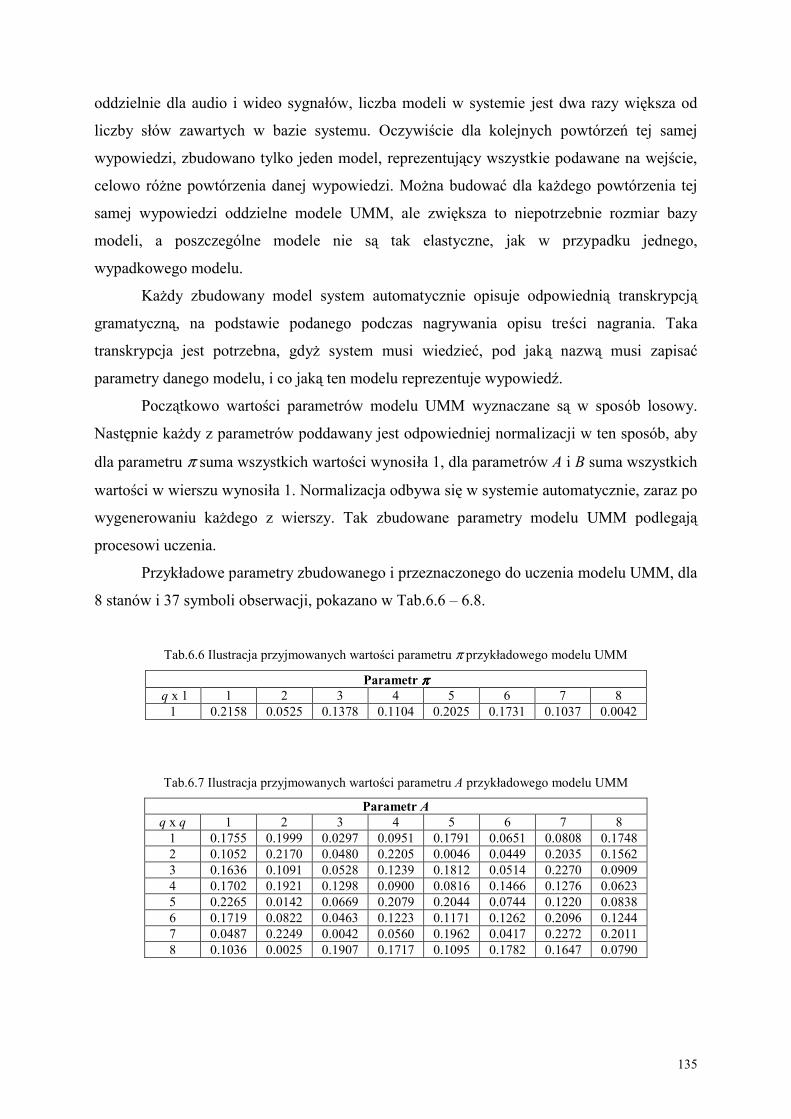
135
oddzielnie dla audio i wideo sygnałów, liczba modeli w systemie jest dwa razy większa od
liczby słów zawartych w bazie systemu. Oczywiście dla kolejnych powtórzeń tej samej
wypowiedzi, zbudowano tylko jeden model, reprezentujący wszystkie podawane na wejście,
celowo różne powtórzenia danej wypowiedzi. Można budować dla każdego powtórzenia tej
samej wypowiedzi oddzielne modele UMM, ale zwiększa to niepotrzebnie rozmiar bazy
modeli, a poszczególne modele nie są tak elastyczne, jak w przypadku jednego,
wypadkowego modelu.
Każdy zbudowany model system automatycznie opisuje odpowiednią transkrypcją
gramatyczną, na podstawie podanego podczas nagrywania opisu treści nagrania. Taka
transkrypcja jest potrzebna, gdyż system musi wiedzieć, pod jaką nazwą musi zapisać
parametry danego modelu, i co jaką ten modelu reprezentuje wypowiedź.
Początkowo wartości parametrów modelu UMM wyznaczane są w sposób losowy.
Następnie każdy z parametrów poddawany jest odpowiedniej normalizacji w ten sposób, aby
dla parametru π suma wszystkich wartości wynosiła 1, dla parametrów A i B suma wszystkich
wartości w wierszu wynosiła 1. Normalizacja odbywa się w systemie automatycznie, zaraz po
wygenerowaniu każdego z wierszy. Tak zbudowane parametry modelu UMM podlegają
procesowi uczenia.
Przykładowe parametry zbudowanego i przeznaczonego do uczenia modelu UMM, dla
8 stanów i 37 symboli obserwacji, pokazano w Tab.6.6 – 6.8.
Tab.6.6 Ilustracja przyjmowanych wartości parametru π przykładowego modelu UMM
Parametr ππππ q x 1 1 2 3 4 5 6 7 8
1 0.2158 0.0525 0.1378 0.1104 0.2025 0.1731 0.1037 0.0042
Tab.6.7 Ilustracja przyjmowanych wartości parametru A przykładowego modelu UMM
Parametr A q x q 1 2 3 4 5 6 7 8
1 0.1755 0.1999 0.0297 0.0951 0.1791 0.0651 0.0808 0.1748 2 0.1052 0.2170 0.0480 0.2205 0.0046 0.0449 0.2035 0.1562 3 0.1636 0.1091 0.0528 0.1239 0.1812 0.0514 0.2270 0.0909 4 0.1702 0.1921 0.1298 0.0900 0.0816 0.1466 0.1276 0.0623 5 0.2265 0.0142 0.0669 0.2079 0.2044 0.0744 0.1220 0.0838 6 0.1719 0.0822 0.0463 0.1223 0.1171 0.1262 0.2096 0.1244 7 0.0487 0.2249 0.0042 0.0560 0.1962 0.0417 0.2272 0.2011 8 0.1036 0.0025 0.1907 0.1717 0.1095 0.1782 0.1647 0.0790
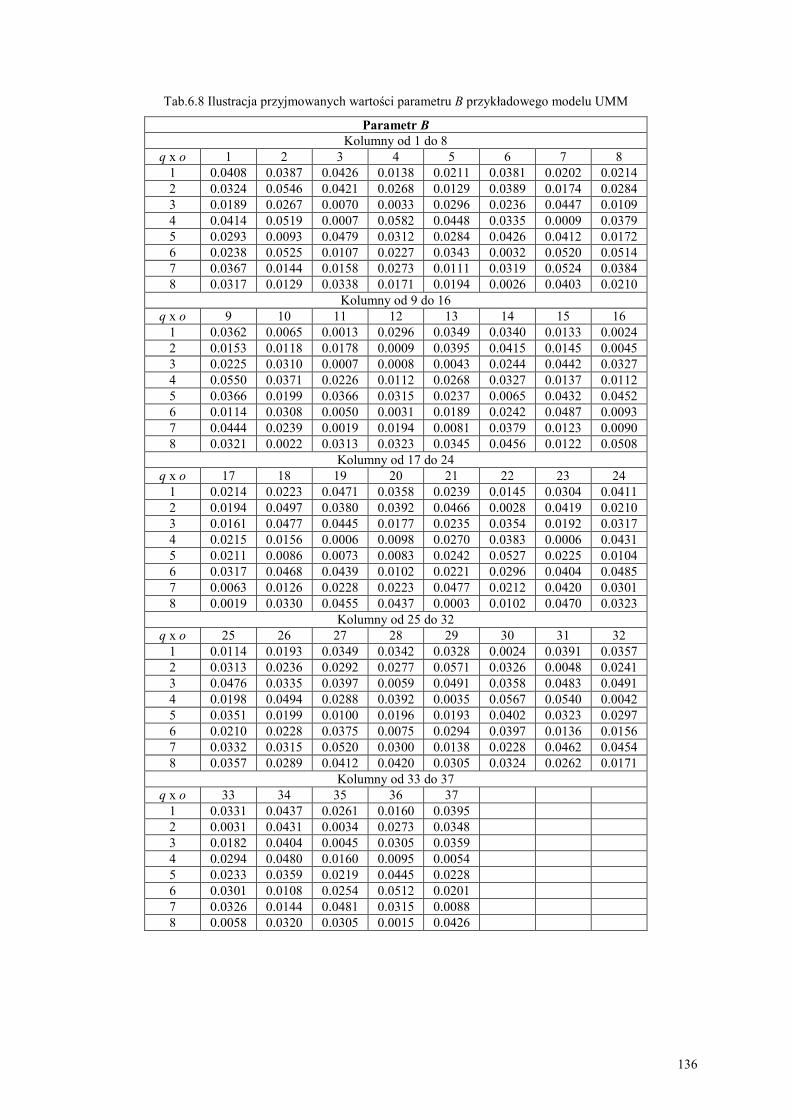
136
Tab.6.8 Ilustracja przyjmowanych wartości parametru B przykładowego modelu UMM Parametr B
Kolumny od 1 do 8 q x o 1 2 3 4 5 6 7 8
1 0.0408 0.0387 0.0426 0.0138 0.0211 0.0381 0.0202 0.0214 2 0.0324 0.0546 0.0421 0.0268 0.0129 0.0389 0.0174 0.0284 3 0.0189 0.0267 0.0070 0.0033 0.0296 0.0236 0.0447 0.0109 4 0.0414 0.0519 0.0007 0.0582 0.0448 0.0335 0.0009 0.0379 5 0.0293 0.0093 0.0479 0.0312 0.0284 0.0426 0.0412 0.0172 6 0.0238 0.0525 0.0107 0.0227 0.0343 0.0032 0.0520 0.0514 7 0.0367 0.0144 0.0158 0.0273 0.0111 0.0319 0.0524 0.0384 8 0.0317 0.0129 0.0338 0.0171 0.0194 0.0026 0.0403 0.0210
Kolumny od 9 do 16 q x o 9 10 11 12 13 14 15 16
1 0.0362 0.0065 0.0013 0.0296 0.0349 0.0340 0.0133 0.0024 2 0.0153 0.0118 0.0178 0.0009 0.0395 0.0415 0.0145 0.0045 3 0.0225 0.0310 0.0007 0.0008 0.0043 0.0244 0.0442 0.0327 4 0.0550 0.0371 0.0226 0.0112 0.0268 0.0327 0.0137 0.0112 5 0.0366 0.0199 0.0366 0.0315 0.0237 0.0065 0.0432 0.0452 6 0.0114 0.0308 0.0050 0.0031 0.0189 0.0242 0.0487 0.0093 7 0.0444 0.0239 0.0019 0.0194 0.0081 0.0379 0.0123 0.0090 8 0.0321 0.0022 0.0313 0.0323 0.0345 0.0456 0.0122 0.0508
Kolumny od 17 do 24 q x o 17 18 19 20 21 22 23 24
1 0.0214 0.0223 0.0471 0.0358 0.0239 0.0145 0.0304 0.0411 2 0.0194 0.0497 0.0380 0.0392 0.0466 0.0028 0.0419 0.0210 3 0.0161 0.0477 0.0445 0.0177 0.0235 0.0354 0.0192 0.0317 4 0.0215 0.0156 0.0006 0.0098 0.0270 0.0383 0.0006 0.0431 5 0.0211 0.0086 0.0073 0.0083 0.0242 0.0527 0.0225 0.0104 6 0.0317 0.0468 0.0439 0.0102 0.0221 0.0296 0.0404 0.0485 7 0.0063 0.0126 0.0228 0.0223 0.0477 0.0212 0.0420 0.0301 8 0.0019 0.0330 0.0455 0.0437 0.0003 0.0102 0.0470 0.0323
Kolumny od 25 do 32 q x o 25 26 27 28 29 30 31 32
1 0.0114 0.0193 0.0349 0.0342 0.0328 0.0024 0.0391 0.0357 2 0.0313 0.0236 0.0292 0.0277 0.0571 0.0326 0.0048 0.0241 3 0.0476 0.0335 0.0397 0.0059 0.0491 0.0358 0.0483 0.0491 4 0.0198 0.0494 0.0288 0.0392 0.0035 0.0567 0.0540 0.0042 5 0.0351 0.0199 0.0100 0.0196 0.0193 0.0402 0.0323 0.0297 6 0.0210 0.0228 0.0375 0.0075 0.0294 0.0397 0.0136 0.0156 7 0.0332 0.0315 0.0520 0.0300 0.0138 0.0228 0.0462 0.0454 8 0.0357 0.0289 0.0412 0.0420 0.0305 0.0324 0.0262 0.0171
Kolumny od 33 do 37 q x o 33 34 35 36 37
1 0.0331 0.0437 0.0261 0.0160 0.0395 2 0.0031 0.0431 0.0034 0.0273 0.0348 3 0.0182 0.0404 0.0045 0.0305 0.0359 4 0.0294 0.0480 0.0160 0.0095 0.0054 5 0.0233 0.0359 0.0219 0.0445 0.0228 6 0.0301 0.0108 0.0254 0.0512 0.0201 7 0.0326 0.0144 0.0481 0.0315 0.0088 8 0.0058 0.0320 0.0305 0.0015 0.0426
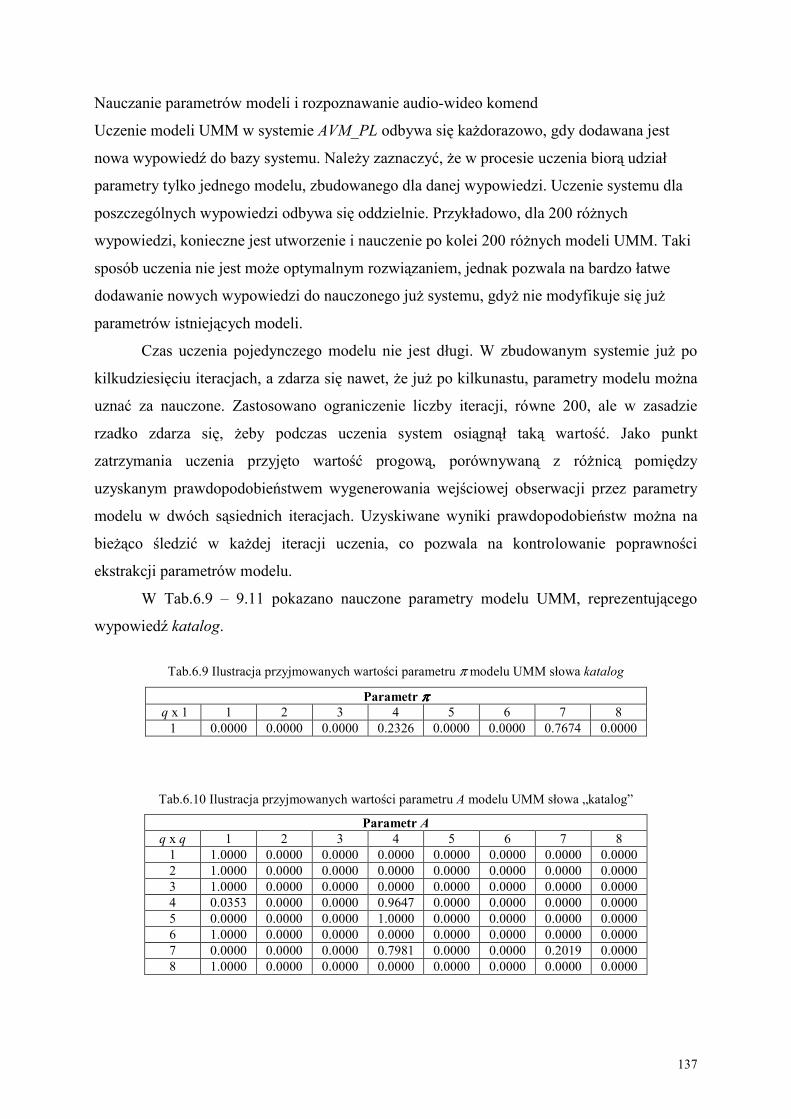
137
Nauczanie parametrów modeli i rozpoznawanie audio-wideo komend
Uczenie modeli UMM w systemie AVM_PL odbywa się każdorazowo, gdy dodawana jest
nowa wypowiedź do bazy systemu. Należy zaznaczyć, że w procesie uczenia biorą udział
parametry tylko jednego modelu, zbudowanego dla danej wypowiedzi. Uczenie systemu dla
poszczególnych wypowiedzi odbywa się oddzielnie. Przykładowo, dla 200 różnych
wypowiedzi, konieczne jest utworzenie i nauczenie po kolei 200 różnych modeli UMM. Taki
sposób uczenia nie jest może optymalnym rozwiązaniem, jednak pozwala na bardzo łatwe
dodawanie nowych wypowiedzi do nauczonego już systemu, gdyż nie modyfikuje się już
parametrów istniejących modeli.
Czas uczenia pojedynczego modelu nie jest długi. W zbudowanym systemie już po
kilkudziesięciu iteracjach, a zdarza się nawet, że już po kilkunastu, parametry modelu można
uznać za nauczone. Zastosowano ograniczenie liczby iteracji, równe 200, ale w zasadzie
rzadko zdarza się, żeby podczas uczenia system osiągnął taką wartość. Jako punkt
zatrzymania uczenia przyjęto wartość progową, porównywaną z różnicą pomiędzy
uzyskanym prawdopodobieństwem wygenerowania wejściowej obserwacji przez parametry
modelu w dwóch sąsiednich iteracjach. Uzyskiwane wyniki prawdopodobieństw można na
bieżąco śledzić w każdej iteracji uczenia, co pozwala na kontrolowanie poprawności
ekstrakcji parametrów modelu.
W Tab.6.9 – 9.11 pokazano nauczone parametry modelu UMM, reprezentującego
wypowiedź katalog.
Tab.6.9 Ilustracja przyjmowanych wartości parametru π modelu UMM słowa katalog
Parametr ππππ q x 1 1 2 3 4 5 6 7 8
1 0.0000 0.0000 0.0000 0.2326 0.0000 0.0000 0.7674 0.0000
Tab.6.10 Ilustracja przyjmowanych wartości parametru A modelu UMM słowa „katalog”
Parametr A q x q 1 2 3 4 5 6 7 8
1 1.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 2 1.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 3 1.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 4 0.0353 0.0000 0.0000 0.9647 0.0000 0.0000 0.0000 0.0000 5 0.0000 0.0000 0.0000 1.0000 0.0000 0.0000 0.0000 0.0000 6 1.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 7 0.0000 0.0000 0.0000 0.7981 0.0000 0.0000 0.2019 0.0000 8 1.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000
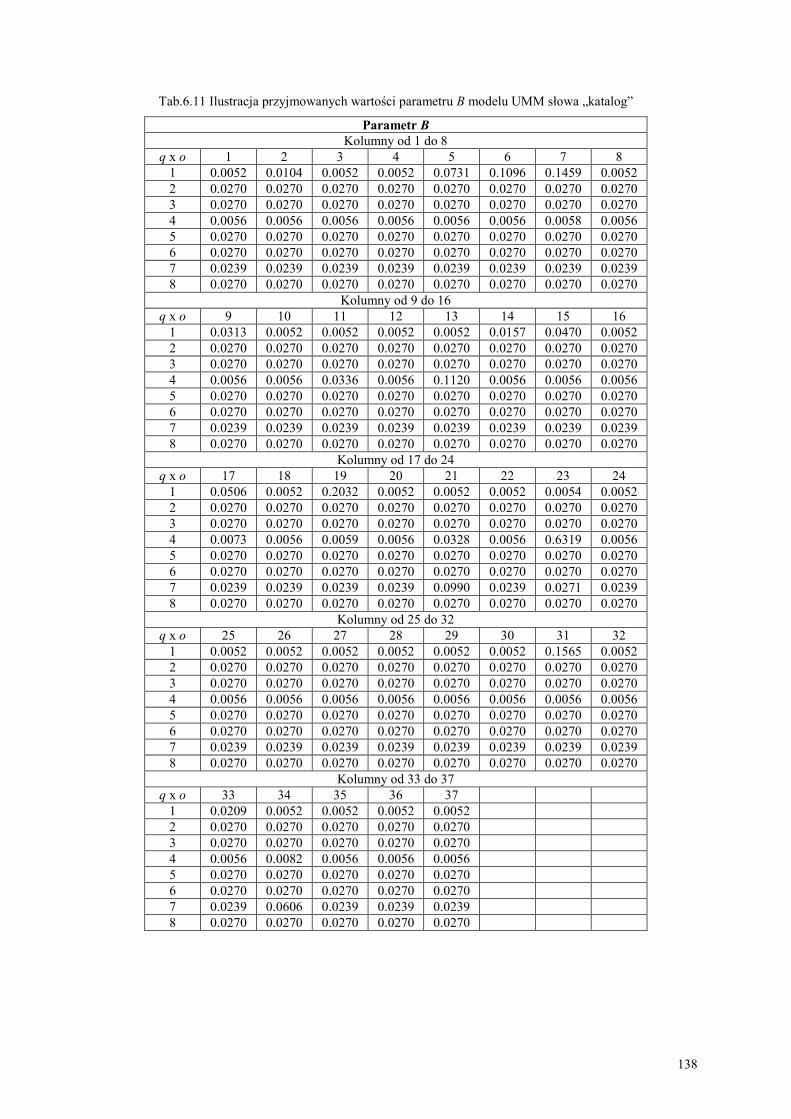
138
Tab.6.11 Ilustracja przyjmowanych wartości parametru B modelu UMM słowa „katalog” Parametr B
Kolumny od 1 do 8 q x o 1 2 3 4 5 6 7 8
1 0.0052 0.0104 0.0052 0.0052 0.0731 0.1096 0.1459 0.0052 2 0.0270 0.0270 0.0270 0.0270 0.0270 0.0270 0.0270 0.0270 3 0.0270 0.0270 0.0270 0.0270 0.0270 0.0270 0.0270 0.0270 4 0.0056 0.0056 0.0056 0.0056 0.0056 0.0056 0.0058 0.0056 5 0.0270 0.0270 0.0270 0.0270 0.0270 0.0270 0.0270 0.0270 6 0.0270 0.0270 0.0270 0.0270 0.0270 0.0270 0.0270 0.0270 7 0.0239 0.0239 0.0239 0.0239 0.0239 0.0239 0.0239 0.0239 8 0.0270 0.0270 0.0270 0.0270 0.0270 0.0270 0.0270 0.0270
Kolumny od 9 do 16 q x o 9 10 11 12 13 14 15 16
1 0.0313 0.0052 0.0052 0.0052 0.0052 0.0157 0.0470 0.0052 2 0.0270 0.0270 0.0270 0.0270 0.0270 0.0270 0.0270 0.0270 3 0.0270 0.0270 0.0270 0.0270 0.0270 0.0270 0.0270 0.0270 4 0.0056 0.0056 0.0336 0.0056 0.1120 0.0056 0.0056 0.0056 5 0.0270 0.0270 0.0270 0.0270 0.0270 0.0270 0.0270 0.0270 6 0.0270 0.0270 0.0270 0.0270 0.0270 0.0270 0.0270 0.0270 7 0.0239 0.0239 0.0239 0.0239 0.0239 0.0239 0.0239 0.0239 8 0.0270 0.0270 0.0270 0.0270 0.0270 0.0270 0.0270 0.0270
Kolumny od 17 do 24 q x o 17 18 19 20 21 22 23 24
1 0.0506 0.0052 0.2032 0.0052 0.0052 0.0052 0.0054 0.0052 2 0.0270 0.0270 0.0270 0.0270 0.0270 0.0270 0.0270 0.0270 3 0.0270 0.0270 0.0270 0.0270 0.0270 0.0270 0.0270 0.0270 4 0.0073 0.0056 0.0059 0.0056 0.0328 0.0056 0.6319 0.0056 5 0.0270 0.0270 0.0270 0.0270 0.0270 0.0270 0.0270 0.0270 6 0.0270 0.0270 0.0270 0.0270 0.0270 0.0270 0.0270 0.0270 7 0.0239 0.0239 0.0239 0.0239 0.0990 0.0239 0.0271 0.0239 8 0.0270 0.0270 0.0270 0.0270 0.0270 0.0270 0.0270 0.0270
Kolumny od 25 do 32 q x o 25 26 27 28 29 30 31 32
1 0.0052 0.0052 0.0052 0.0052 0.0052 0.0052 0.1565 0.0052 2 0.0270 0.0270 0.0270 0.0270 0.0270 0.0270 0.0270 0.0270 3 0.0270 0.0270 0.0270 0.0270 0.0270 0.0270 0.0270 0.0270 4 0.0056 0.0056 0.0056 0.0056 0.0056 0.0056 0.0056 0.0056 5 0.0270 0.0270 0.0270 0.0270 0.0270 0.0270 0.0270 0.0270 6 0.0270 0.0270 0.0270 0.0270 0.0270 0.0270 0.0270 0.0270 7 0.0239 0.0239 0.0239 0.0239 0.0239 0.0239 0.0239 0.0239 8 0.0270 0.0270 0.0270 0.0270 0.0270 0.0270 0.0270 0.0270
Kolumny od 33 do 37 q x o 33 34 35 36 37
1 0.0209 0.0052 0.0052 0.0052 0.0052 2 0.0270 0.0270 0.0270 0.0270 0.0270 3 0.0270 0.0270 0.0270 0.0270 0.0270 4 0.0056 0.0082 0.0056 0.0056 0.0056 5 0.0270 0.0270 0.0270 0.0270 0.0270 6 0.0270 0.0270 0.0270 0.0270 0.0270 7 0.0239 0.0606 0.0239 0.0239 0.0239 8 0.0270 0.0270 0.0270 0.0270 0.0270

139
Sposób modyfikacji wartości parametrów modelu UMM opisano szczegółowo w
rozdziale 4.
Po zakończeniu procesu uczenia, system zapisuje wartości nauczonych parametrów w
pliku, o nazwie odpowiadającej wypowiedzi, dla której utworzono dany model. Dodatkowo
dopisana zostaje dana wypowiedź, do bazy nauczonych wypowiedzi, w celu identyfikacji
rozmiaru i zawartości bazy. System umożliwia również przegląd oraz usuwanie wybranych
wypowiedzi z basy systemu.
Proces rozpoznawania poprzedzony jest identycznym sposobem ekstrakcji
charakterystyk i wyznaczenia wektora obserwacji, jaki zastosowano również w procesie
uczenia. O ile w procesie uczenia na wejście podawano od jednego, do kilku powtórzeń tej
samej wypowiedzi, o tyle w procesie rozpoznawania podawane jest tylko jedno powtórzenie.
Jest to logiczne, jednak system umożliwia również rozpoznawanie sekwencji powtórzeń tej
samej wypowiedzi, dając w wyniku sumę prawdopodobieństw wygenerowania
poszczególnych wektorów obserwacji przez model UMM. Takie rozpoznawanie zastosowano
tylko do przetestowania prawidłowego funkcjonowania systemu, w normalnej pracy systemu
opcja ta jest wyłączona.
Po wyznaczeniu wektora obserwacji dla danej wypowiedzi, system wylicza
prawdopodobieństwo wygenerowania tej sekwencji obserwacji przez wszystkie modele
zawarte w bazie systemu. Na podstawie pliku określającego rozmiar i zawartość bazy
następuje wczytywanie parametrów poszczególnych modeli. Możliwe jest śledzenie
uzyskanych wartości prawdopodobieństw przez wszystkie modele. Model, który uzyskał
największe prawdopodobieństwo wygenerowania wejściowej sekwencji obserwacji,
uznawany jest za zwycięski, a wynikiem rozpoznania jest wartość transkrypcji gramatycznej
opisującej ten model.
Jeśli do rozpoznawania użytkownik podałby wypowiedź, dla której system nie został
nauczony, wówczas wynikiem będzie wypowiedź, dla której system został nauczony, a która
jest najbardziej podobna fonetycznie do wypowiedzi wejściowej. Prawdopodobieństwo
wygenerowania takiej wypowiedzi jest na tyle małe, że można ograniczyć możliwość
rozpoznawania wypowiedzi spoza bazy. W systemie zastosowano wartość progową, po
przekroczeniu której, wyznaczone prawdopodobieństwo można uznać za wystarczające do
podjęcia decyzji o wyniku rozpoznania. Jeśli próg nie został przekroczony, wówczas system
identyfikuje wprowadzaną wypowiedź, jako rozpoznanie „nieokreślone”.

140
7. BADANIE POZIOMU BŁĘDÓW METODY AV_Mowa_PL ZA POMOCĄ SYSTEMU AVM_PL
Przedstawiono szczegółową charakterystykę utworzonej na potrzeby badawcze bazy
wypowiedzi audio-wideo. Opisano obiekty, cele i sposoby przeprowadzenia eksperymentów
sprawdzających funkcjonowanie stworzonego systemu oraz do rozpoznawania izolowanych
wypowiedzi audio-wideo mowy polskiej. Zamieszczono wyniki przeprowadzonych
eksperymentów z rozważaniami.
7.1. Charakterystyka stworzonej bazy audio-wideo komend
Dla celów testowo-badawczych było stworzono bazę AV_BM, zawierającą izolowane
wypowiedzi audio-wideo mowy polskiej. Samo badanie audio mowy w opracowanym
systemie AVM_PL nie wprowadza konieczności tworzenia jakiejkolwiek bazy, gdyż
środowisko programistyczne Matlab umożliwia rejestrowanie na bieżąco dźwięków,
pochodzących bezpośrednio z mikrofonu. Jednak nie ma możliwości rejestrowania obrazu
pochodzącego bezpośrednio z kamery, dlatego przy pracy z systemem, wymagane jest
wcześniejsze zarejestrowanie wideo mowy, a co się z tym wiąże, również audio mowy.
Dodatkowo, uwzględniając założenia dotyczące warunków pracy systemu, konieczne było
przebadanie tych samych wypowiedzi w różnym stopniu zakłócenia, co narzucało
wielokrotne korzystanie z zarejestrowanych wcześniej wypowiedzi audio-wideo mowy. Z
tych właśnie powodów utworzono bazę audio-wideo mowy.
Przyjęto następujące założenia dotyczące formatu nagrać:
dla sygnału audio:
• częstotliwość próbkowania – 8000 Hz,
• szybkość transmisji bitów – 128 kb/s,
• rozmiar próbki audio – 16 bitów, - format dźwięku – PCM,
dla sygnału wideo:
• rozmiar obrazu – 640 x 480 pikseli,
• szybkość klatek – 15 klatek/s, rozmiar próbki wideo – 24 bity,
• kompresja wideo – Indeo video 5.04.

141
Utworzona baza składa się z dwóch zasadniczych części: pierwsza - zdecydowanie
obszerniejsza, do badania skuteczności rozpoznawania audio-wideo mowy; druga - do
identyfikacji użytkowników w oparciu o wypowiedzi audio-wideo mowy.
Baza AV_BM zawiera wypowiedzi, będące przykładowymi komendami sterowania
systemem operacyjnym, co pozwala na praktyczne jej wykorzystanie. Wszystkie
wykorzystane komendy stanowią słownik złożony z 70 różnych wypowiedzi. Dodatkowo dla
każdej wypowiedzi nagrano po siedem różnych powtórzeń. W ten sposób uzyskano słownik
złożony z 490 wypowiedzi jednego użytkownika. Do tworzenia tej bazy wykorzystano
nagrania 10 użytkowników, co określiło całkowitą liczbę wszystkich wypowiedzi zawartych
w bazie, równą 4900 nagrań. Każdą z wypowiedzi zawarto w oddzielnym pliku .avi. Nazwa
każdego pliku odpowiada treści nagrania oraz numerowi powtórzenia danej wypowiedzi.
Przykładowo dla wypowiedzi „katalog” utworzono następujące pliki: katalog1.avi,
katalog2.avi, katalog3.avi, katalog4.avi, katalog5.avi, katalog6.avi, katalog7.avi. Pierwsze
cztery powtórzenia każdej wypowiedzi przeznaczono do uczenia systemu, natomiast
pozostałe trzy - do rozpoznawania.
W Tab.7.1 zamieszczono zbiór komend, nagranych dla jednego użytkownika.
Kolejność wypowiedzi odpowiada kolejności wprowadzania nagrań do systemu.
Tab.7.1 Zbiór komend dla jednego użytkownika zawartych w bazie AV_BM
Użytkownik 1 L.p. Wypowiedź L.p. Wypowiedź L.p. Wypowiedź L.p. Wypowiedź L.p. Wypowiedź
1 Katalog 15 wyloguj 29 trzy 43 poprzedni 57 dwukropek 2 Kopiuj 16 nowy 30 cztery 44 menu 58 klamra 3 Uruchom 17 wyszukaj 31 pięć 45 plik 59 nawias 4 Usuń 18 pomoc 32 sześć 46 start 60 apostrof 5 Wytnij 19 drukuj 33 siedem 47 stop 61 cudzysłów 6 Zamknij 20 zamień 34 osiem 48 wstecz 62 pytajnik 7 Zakończ 21 wyczyść 35 dziewięć 49 edycja 63 wielkie 8 Wklej 22 dalej 36 plus 50 shift 64 małe 9 na dół 23 tabulator 37 minus 51 control 65 widok
10 do góry 24 kropka 38 cofnij 52 alt 66 kursywa 11 Enter 25 przecinek 39 w lewo 53 slash 67 pogrubienie 12 Spacja 26 zero 40 w prawo 54 backslash 68 podkreślenie 13 Otwórz 27 jeden 41 mysz 55 wykrzyknik 69 właściwości 14 Zapisz 28 dwa 42 następny 56 średnik 70 nagrywanie
W bazie znalazły się wypowiedzi w języku angielskim, do których właśnie w takiej
postaci jest przyzwyczajona większość użytkowników komputerów. Aby zbytnio nie
zmieniać tych przyzwyczajeń, wspomniane wypowiedzi pozostawiono w angielskiej postaci.
Oczywiście podczas nagrań wypowiadano te komendy zgodnie z wymową. Ponieważ system

142
ma realizować rozpoznawanie audio-wideo mowy polskiej, dlatego zdecydowana większość
komend pochodzi z języka polskiego.
W celu utworzenia książki kodowej, w bazie umieszczono zestawy wypowiedzi,
dobrane tak, aby w całości pokryć przestrzeń akustyczną danego użytkownika, dla
określonego zadania. Dla każdego użytkownika nagrano oddzielny zestaw wypowiedzi,
złożony z następujących słów: kropka, wyloguj, przecinek, wytnij, pięć, cofnij, wyczyść,
wyszukaj, drukuj, zamień, uruchom, pogrubienie, cudzysłów, kąt, drzwi, dźwig, źrebak.
Baza przeznaczona do identyfikacji użytkowników w oparciu o wypowiedzi audio-
wideo mowy AV_BI zawiera wypowiedzi, będące przykładowymi hasłami zabezpieczającymi
system przed włamaniem niepożądanych osób. Wszystkie wykorzystane hasła stanowią
słownik złożony z 5 różnych wypowiedzi. Dodatkowo dla każdej wypowiedzi nagrano po
dwa różne powtórzenia. W ten sposób uzyskano słownik złożony z 10 wypowiedzi jednego
użytkownika. Do tworzenia tej bazy wykorzystano nagrania 30 użytkowników, co określiło
całkowitą liczbę wszystkich wypowiedzi zawartych w bazie, równą 300 nagrań. W
porównaniu do poprzedniej bazy, gdzie każde z nagrań powtórzono siedem razy, tutaj
ograniczono liczbę powtórzeń ze względu na konieczność uniknięcia elastyczności
wypowiedzi, która mogłaby doprowadzić do akceptacji niewłaściwego użytkownika.
Założono, że system jest uczony tylko na jednej wypowiedzi, dlatego aby zaakceptować
identyfikowanego użytkownika, konieczne jest niemal identyczne powtórzenie tej
wypowiedzi.
Również w tej bazie każdą z wypowiedzi zawarto w oddzielnym pliku .avi. Nazwa
każdego pliku odpowiada treści nagrania oraz numerowi powtórzenia danej wypowiedzi.
Pierwsze powtórzenie stanowi wejście uczące systemu, drugie, wejście identyfikujące
użytkownika. Nagrano wypowiedzi, hasła przedstawiające imię i nazwisko użytkownika oraz
słowa nagrywanie, zaloguj i identyfikacja. Hasła dobrano w ten sposób, aby identyfikować
użytkowników na podstawie tych samych i różnych treściowo różnych wypowiedzi.
Zestaw wypowiedzi do tworzenia książki kodowej, jaki również umieszczono w bazie,
zawiera ciąg różnych wypowiedzi wszystkich użytkowników. Założono, że w procesie
identyfikacji użytkownika, należy wykorzystać jedną, wspólną książkę kodową. Takie
założenie pozwala na uniknięcie identycznego zakodowania różnych fonemów.
Wszystkie wypowiedzi nagrywano w cichym pokoju, starając się jak najmniej
zakłócać sygnał audio. SNR wyniósł w przybliżeniu 20dB. Wszelkie modyfikacje potrzebne
do przeprowadzenia poszczególnych eksperymentów dokonywane są bezpośrednio w
systemie na podstawie tych niezakłóconych nagrań.

143
7.2. Obiekty, cele i metodyki eksperymentów
Obiektem badań jest system AVM_PL realizujący rozpoznawanie słów izolowanych oraz
identyfikację użytkownika w oparciu o metodę AV_Mowa_PL, wykorzystującą fuzję
charakterystyk izolowanych słów audio-wideo.
Celem eksperymentu było zbadanie poprawności i poziomu błędów za pomocą systemu
AVM_PL dla kilku proponowanych wariantów, a także porównanie uzyskanych wyników z
rozpoznawaniem samej audio mowy w warunkach szczególnie zakłóconych.
Badania wstępne
Przed przeprowadzeniem eksperymentu wykonano badania wstępne, polegające na
eksperymentalnym doborze rozmiaru książki kodowej oraz liczby stanów UMM. Założono,
że odpowiedni dobór tych parametrów pozwoli na właściwe przeprowadzenie głównego
eksperymentu. Badania przeprowadzono dla samej audio mowy w warunkach
niezakłóconych, wykorzystując bazę słów ograniczoną do 50 różnych wypowiedzi. Każdą
wypowiedź w procesie uczenia powtórzono 5 razy.
Dobierając liczbę kodów w książce kodowej, zwrócono uwagę na fakt, iż w języku
polskim jest 37 fonemów, więc przyjęto liczbę 37 jako wyjściowy rozmiar książki kodowej.
Oprócz samych fonemów w procesie artykulacji mowy występuje zjawisko przejść
międzyfonemowych, dla których również należałoby przypisać odpowiednie kody. Biorąc
pod uwagę wszystkie możliwe kombinacje, konieczne by było zastosowanie 1332 kodów
odpowiadających przejściom międzyfonemowym oraz dodatkowo 37 kodów
odpowiadających samym fonemom. Po przeprowadzeniu wstępnych badań stwierdzono, że
liczba 1369 to zdecydowanie za duży rozmiar słownika. Przeprowadzono badanie
skuteczności rozpoznawania dla rozmiaru słownika wynoszącego odpowiednio 256, 128, 64,
37 i 32. Przy rozmiarach większych niż 37 pojawiło się zjawisko kodowania tego samego
fonemu przy pomocy kilku zupełnie różnych kodów, co wprowadziło możliwość błędnego
rozpoznawania danego słowa przedstawionego w postaci wektora obserwacji, gdzie każda
obserwacja odpowiadała pojedynczemu kodowi z książki kodowej. Przy rozmiarze 32
pojawiła się sytuacja, w której różne fonemy zostały zakodowane przy pomocy tego samego
kodu. Obserwując wyniki rozpoznawania dla różnych rozmiarów książki kodowej
stwierdzono, że najlepsze rezultaty dało zakodowanie sygnałów przy pomocy 37 kodów.
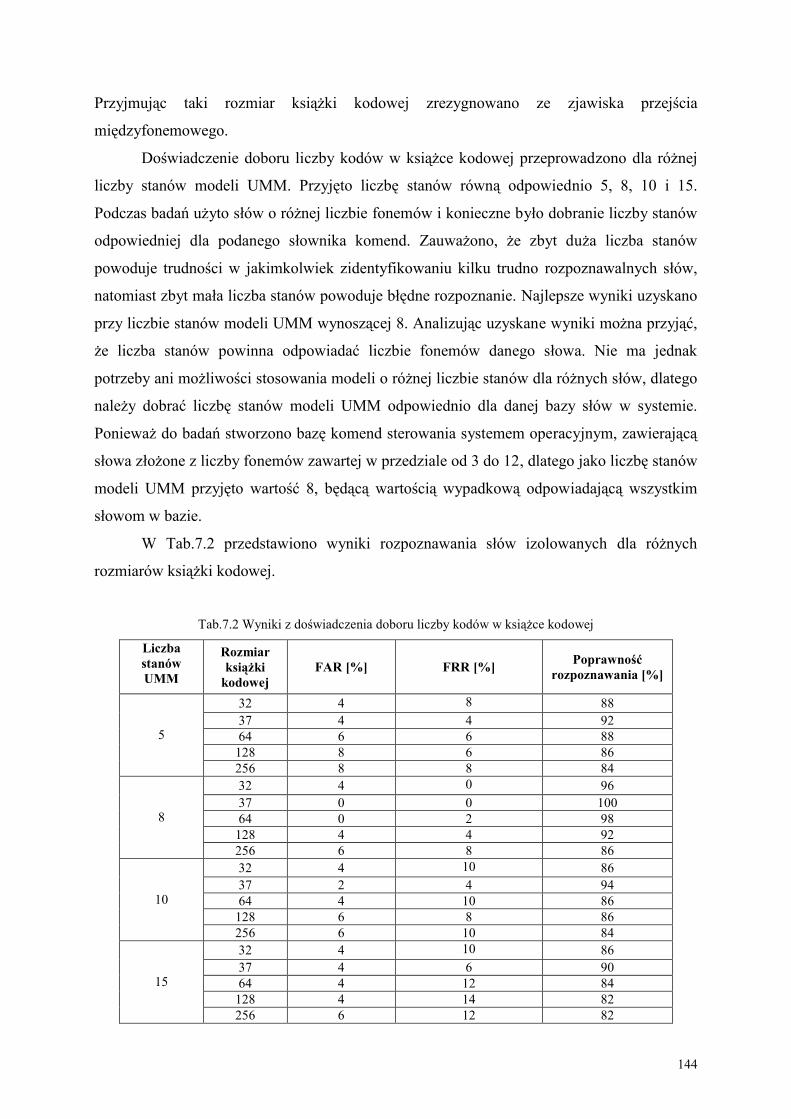
144
Przyjmując taki rozmiar książki kodowej zrezygnowano ze zjawiska przejścia
międzyfonemowego.
Doświadczenie doboru liczby kodów w książce kodowej przeprowadzono dla różnej
liczby stanów modeli UMM. Przyjęto liczbę stanów równą odpowiednio 5, 8, 10 i 15.
Podczas badań użyto słów o różnej liczbie fonemów i konieczne było dobranie liczby stanów
odpowiedniej dla podanego słownika komend. Zauważono, że zbyt duża liczba stanów
powoduje trudności w jakimkolwiek zidentyfikowaniu kilku trudno rozpoznawalnych słów,
natomiast zbyt mała liczba stanów powoduje błędne rozpoznanie. Najlepsze wyniki uzyskano
przy liczbie stanów modeli UMM wynoszącej 8. Analizując uzyskane wyniki można przyjąć,
że liczba stanów powinna odpowiadać liczbie fonemów danego słowa. Nie ma jednak
potrzeby ani możliwości stosowania modeli o różnej liczbie stanów dla różnych słów, dlatego
należy dobrać liczbę stanów modeli UMM odpowiednio dla danej bazy słów w systemie.
Ponieważ do badań stworzono bazę komend sterowania systemem operacyjnym, zawierającą
słowa złożone z liczby fonemów zawartej w przedziale od 3 do 12, dlatego jako liczbę stanów
modeli UMM przyjęto wartość 8, będącą wartością wypadkową odpowiadającą wszystkim
słowom w bazie.
W Tab.7.2 przedstawiono wyniki rozpoznawania słów izolowanych dla różnych
rozmiarów książki kodowej.
Tab.7.2 Wyniki z doświadczenia doboru liczby kodów w książce kodowej
Liczba stanów UMM
Rozmiar książki
kodowej FAR [%] FRR [%] Poprawność
rozpoznawania [%]
32 4 8 88 37 4 4 92 64 6 6 88
128 8 6 86 5
256 8 8 84 32 4 0 96 37 0 0 100 64 0 2 98
128 4 4 92 8
256 6 8 86 32 4 10 86 37 2 4 94 64 4 10 86
128 6 8 86 10
256 6 10 84 32 4 10 86 37 4 6 90 64 4 12 84
128 4 14 82 15
256 6 12 82

145
Do badań poprawności funkcjonowania metody AV_Mowa_PL wybrano rozmiar
książki kodowej wynoszący 37 i liczbę stanów modelu UMM wynoszącą 8, gdyż tylko przy
takich parametrach uzyskano 100 % skuteczności rozpoznawania przykładowych 50 komend
w warunkach niezakłóconych.
Badania poziomu błędów metody AV_Mowa_PL
W celu udowodnienia poprawności metody i zbadania jej poziomu błędów przeprowadzono
szereg eksperymentów dotyczących działania trekingu ust, rozpoznawania audio i audio-
wideo mowy, a także identyfikacji użytkowników dla różnego poziomu zakłócenia (przy SNR
wynoszącym 20, 15, 10, 5, i 0 dB) i różnych metod fuzji sygnałów audio i wideo. Do badań
wykorzystano bazy AV_BM i AV_BI.
Etapy eksperymentu
Etap 1: Badanie poprawności definiowania sygnału audio mowy, za pomocą metod ES i
CZS.
2: Badanie poziomu błędów trekingu kącików i krawędzi ust metodami GMIP i CSM.
3: Badanie poziomu błędów rozpoznawania audio mowy przy różnym SNR.
4: Badanie poziomu błędów rozpoznawania audio-wideo mowy przy różnym SNR, z
wykorzystaniem zaproponowanej synchronicznej metody Sr fuzji charakterystyk
sygnałów audio i wideo.
5: Badanie poziomu błędów rozpoznawania audio-wideo mowy przy różnym SNR, z
wykorzystaniem zaproponowanej metody ASr_I fuzji charakterystyk sygnałów audio
i wideo.
6: Badanie poziomu błędów rozpoznawania audio-wideo mowy przy różnym SNR, z
wykorzystaniem zaproponowanej metody ASr_II fuzji charakterystyk sygnałów
audio i wideo.
7: Badanie poziomu błędów identyfikacji użytkowników na podstawie audio mowy
przy różnym SNR.
8: Badanie poziomu błędów identyfikacji użytkowników na podstawie audio-wideo
mowy przy różnym SNR, z wykorzystaniem pierwszej metody ASr_I fuzji
charakterystyk sygnałów audio i wideo.
9: Zestawienie wyników poziomu błędów rozpoznawania z istniejącymi metodami
(AV-Concat, AV-HiLDA, AV-Enhanced, AV-MS-Joint).
10: Analiza wyników eksperymentu.

146
W etapach 3-6 wykorzystano utworzoną bazę audio-wideo mowy AV_BM. W etapach
2,6,7 wykorzystano utworzoną bazę do identyfikacji użytkowników AV_BI.
W etapie 1 zbadani poprawność definiowania sygnału audio mowy, poprzez usuwanie
ciszy z nagrania. Wykorzystano dwie metody ES i CZS w układzie połączonym. Opis
algorytmów, przeprowadzenie badań i obserwacje wyników omówiono w paragrafie 3.2, 6.2.
Etap 2
W pierwszym doświadczeniu wykonano dwa testy. Doświadczenie polegało na zbadaniu
poziomu błędów trekingu kącików ust z wykorzystaniem metod GMIP [70] i CSM. Poprawne
określenie kącików ust ma duże znaczenie w systemie AVM_PL, gdyż na podstawie
zlokalizowanych kącików ust określane są zewnętrzne krawędzie ust. Podczas eksperymentu
przetestowano mowę dwadzieścia różnych osób wypowiadających pojedyncze słowa. Każde
nagranie zawierało około 50 ramek/s, więc przetestowano blisko 1000 ramek wideo. Dla
każdej ramki ręcznie oznaczano kąciki ust i następnie porównywano z kącikami
wyznaczonymi przy pomocy metod GMIP i CSM. Opis procedur wchodzących w skład
trekingu ust, poszczególnych wyników lokalizacji twarzy, oczu, kącików i krawędzi ust
przedstawiono w rozdziale 5, w paragrafach 5.1 – 5.3.
W Tab.7.3 pokazano średnie błędy popełniane przy pomocy obu testowanych metod
dla każdej z badanych ramek o rozdzielczości 320 x 240 pikseli.
Tab.7.3 Średnie błędy lokalizacji kącików ust dla metod GMIP [70] i CSM
Metoda Liczba ramek
Błąd współrzędnej x
[pixel]
Błąd współrzędnej y
[pixel] GMIP 1000 16,7 18,9 CSM 1000 4,8 5,7
W drugim doświadczeniu również wykorzystano metody GMIP i CSM. Przetestowano
dwadzieścia osób wypowiadających pojedyncze słowa z wyraźnym podziałem na fonemy.
Dla każdej ramki wyznaczono krawędzie ust. Punkty określające te krawędzie porównywano
z punktami określającymi przykładowo zdefiniowane modele ust, oznaczając rozpoznany
obiekt, jako obiekt usta oraz obiekt inny niż usta (+) i (-). Obiekt inny niż usta (+) oznaczał,
że kąciki ust zostały wyznaczone poprawnie, natomiast krawędzie ust zostały wyznaczone
błędnie. Obiekt (-) oznaczał, że ani kąciki ust, ani krawędzie nie zostały poprawnie
wyznaczone.
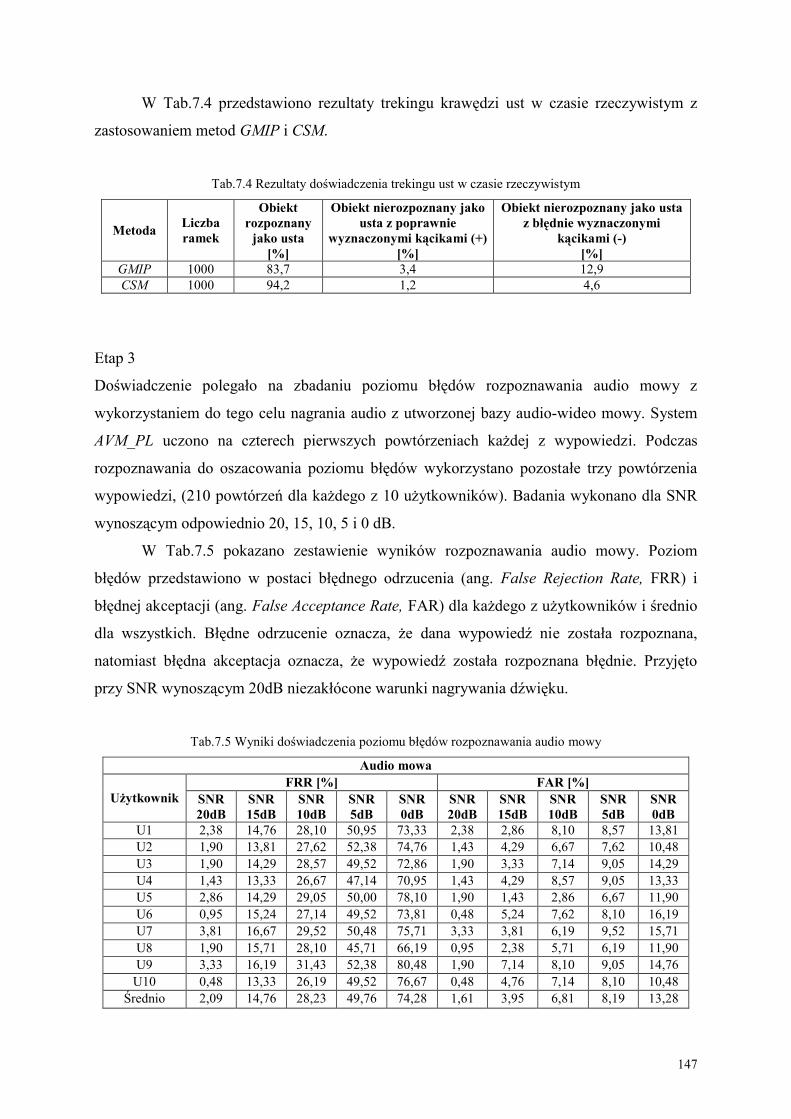
147
W Tab.7.4 przedstawiono rezultaty trekingu krawędzi ust w czasie rzeczywistym z
zastosowaniem metod GMIP i CSM.
Tab.7.4 Rezultaty doświadczenia trekingu ust w czasie rzeczywistym
Metoda Liczba ramek
Obiekt rozpoznany
jako usta [%]
Obiekt nierozpoznany jako usta z poprawnie
wyznaczonymi kącikami (+)[%]
Obiekt nierozpoznany jako usta z błędnie wyznaczonymi
kącikami (-) [%]
GMIP 1000 83,7 3,4 12,9 CSM 1000 94,2 1,2 4,6
Etap 3
Doświadczenie polegało na zbadaniu poziomu błędów rozpoznawania audio mowy z
wykorzystaniem do tego celu nagrania audio z utworzonej bazy audio-wideo mowy. System
AVM_PL uczono na czterech pierwszych powtórzeniach każdej z wypowiedzi. Podczas
rozpoznawania do oszacowania poziomu błędów wykorzystano pozostałe trzy powtórzenia
wypowiedzi, (210 powtórzeń dla każdego z 10 użytkowników). Badania wykonano dla SNR
wynoszącym odpowiednio 20, 15, 10, 5 i 0 dB.
W Tab.7.5 pokazano zestawienie wyników rozpoznawania audio mowy. Poziom
błędów przedstawiono w postaci błędnego odrzucenia (ang. False Rejection Rate, FRR) i
błędnej akceptacji (ang. False Acceptance Rate, FAR) dla każdego z użytkowników i średnio
dla wszystkich. Błędne odrzucenie oznacza, że dana wypowiedź nie została rozpoznana,
natomiast błędna akceptacja oznacza, że wypowiedź została rozpoznana błędnie. Przyjęto
przy SNR wynoszącym 20dB niezakłócone warunki nagrywania dźwięku.
Tab.7.5 Wyniki doświadczenia poziomu błędów rozpoznawania audio mowy
Audio mowa FRR [%] FAR [%]
Użytkownik SNR 20dB
SNR 15dB
SNR 10dB
SNR 5dB
SNR 0dB
SNR 20dB
SNR 15dB
SNR 10dB
SNR 5dB
SNR 0dB
U1 2,38 14,76 28,10 50,95 73,33 2,38 2,86 8,10 8,57 13,81 U2 1,90 13,81 27,62 52,38 74,76 1,43 4,29 6,67 7,62 10,48 U3 1,90 14,29 28,57 49,52 72,86 1,90 3,33 7,14 9,05 14,29 U4 1,43 13,33 26,67 47,14 70,95 1,43 4,29 8,57 9,05 13,33 U5 2,86 14,29 29,05 50,00 78,10 1,90 1,43 2,86 6,67 11,90 U6 0,95 15,24 27,14 49,52 73,81 0,48 5,24 7,62 8,10 16,19 U7 3,81 16,67 29,52 50,48 75,71 3,33 3,81 6,19 9,52 15,71 U8 1,90 15,71 28,10 45,71 66,19 0,95 2,38 5,71 6,19 11,90 U9 3,33 16,19 31,43 52,38 80,48 1,90 7,14 8,10 9,05 14,76
U10 0,48 13,33 26,19 49,52 76,67 0,48 4,76 7,14 8,10 10,48 Średnio 2,09 14,76 28,23 49,76 74,28 1,61 3,95 6,81 8,19 13,28
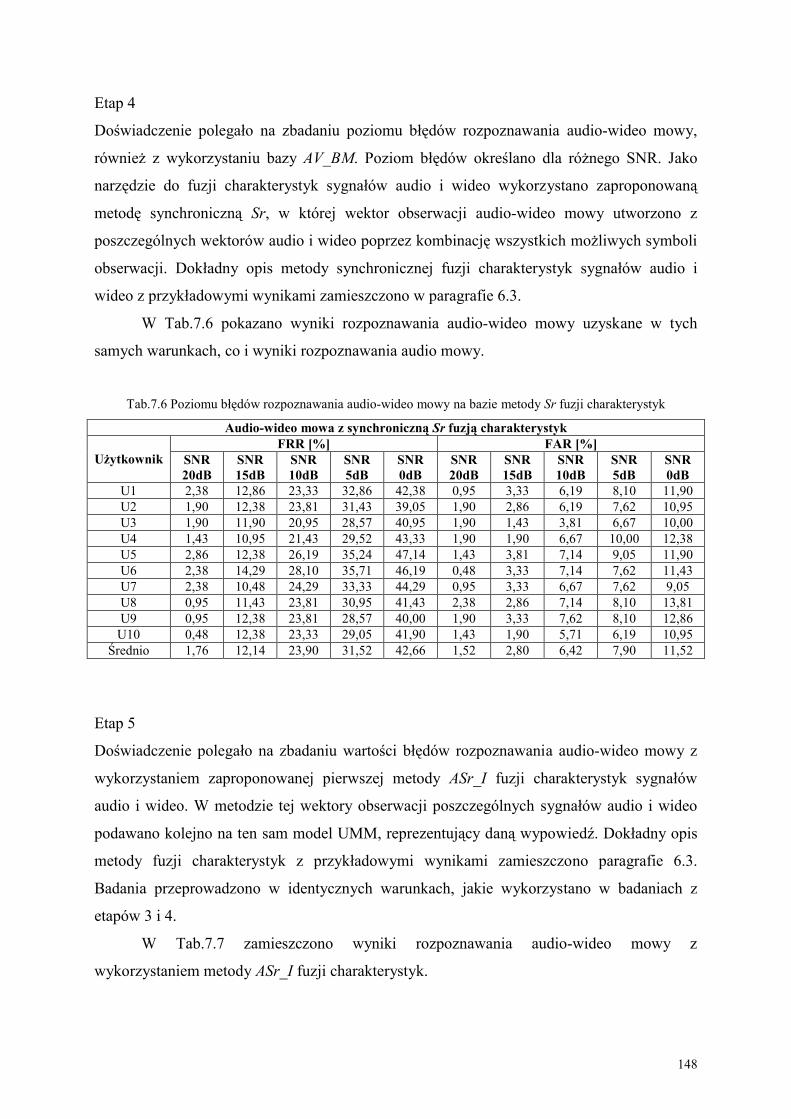
148
Etap 4
Doświadczenie polegało na zbadaniu poziomu błędów rozpoznawania audio-wideo mowy,
również z wykorzystaniu bazy AV_BM. Poziom błędów określano dla różnego SNR. Jako
narzędzie do fuzji charakterystyk sygnałów audio i wideo wykorzystano zaproponowaną
metodę synchroniczną Sr, w której wektor obserwacji audio-wideo mowy utworzono z
poszczególnych wektorów audio i wideo poprzez kombinację wszystkich możliwych symboli
obserwacji. Dokładny opis metody synchronicznej fuzji charakterystyk sygnałów audio i
wideo z przykładowymi wynikami zamieszczono w paragrafie 6.3.
W Tab.7.6 pokazano wyniki rozpoznawania audio-wideo mowy uzyskane w tych
samych warunkach, co i wyniki rozpoznawania audio mowy.
Tab.7.6 Poziomu błędów rozpoznawania audio-wideo mowy na bazie metody Sr fuzji charakterystyk
Audio-wideo mowa z synchroniczną Sr fuzją charakterystyk FRR [%] FAR [%]
Użytkownik SNR 20dB
SNR 15dB
SNR 10dB
SNR 5dB
SNR 0dB
SNR 20dB
SNR 15dB
SNR 10dB
SNR 5dB
SNR 0dB
U1 2,38 12,86 23,33 32,86 42,38 0,95 3,33 6,19 8,10 11,90 U2 1,90 12,38 23,81 31,43 39,05 1,90 2,86 6,19 7,62 10,95 U3 1,90 11,90 20,95 28,57 40,95 1,90 1,43 3,81 6,67 10,00 U4 1,43 10,95 21,43 29,52 43,33 1,90 1,90 6,67 10,00 12,38 U5 2,86 12,38 26,19 35,24 47,14 1,43 3,81 7,14 9,05 11,90 U6 2,38 14,29 28,10 35,71 46,19 0,48 3,33 7,14 7,62 11,43 U7 2,38 10,48 24,29 33,33 44,29 0,95 3,33 6,67 7,62 9,05 U8 0,95 11,43 23,81 30,95 41,43 2,38 2,86 7,14 8,10 13,81 U9 0,95 12,38 23,81 28,57 40,00 1,90 3,33 7,62 8,10 12,86
U10 0,48 12,38 23,33 29,05 41,90 1,43 1,90 5,71 6,19 10,95 Średnio 1,76 12,14 23,90 31,52 42,66 1,52 2,80 6,42 7,90 11,52
Etap 5
Doświadczenie polegało na zbadaniu wartości błędów rozpoznawania audio-wideo mowy z
wykorzystaniem zaproponowanej pierwszej metody ASr_I fuzji charakterystyk sygnałów
audio i wideo. W metodzie tej wektory obserwacji poszczególnych sygnałów audio i wideo
podawano kolejno na ten sam model UMM, reprezentujący daną wypowiedź. Dokładny opis
metody fuzji charakterystyk z przykładowymi wynikami zamieszczono paragrafie 6.3.
Badania przeprowadzono w identycznych warunkach, jakie wykorzystano w badaniach z
etapów 3 i 4.
W Tab.7.7 zamieszczono wyniki rozpoznawania audio-wideo mowy z
wykorzystaniem metody ASr_I fuzji charakterystyk.
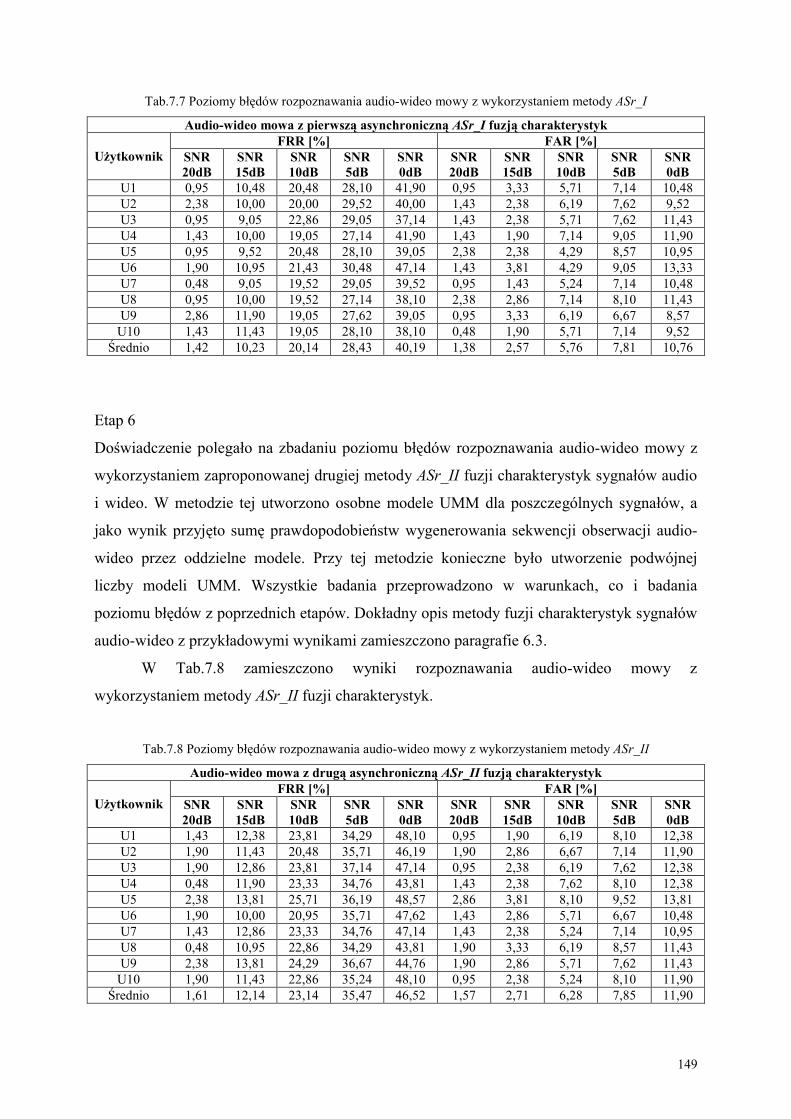
149
Tab.7.7 Poziomy błędów rozpoznawania audio-wideo mowy z wykorzystaniem metody ASr_I
Audio-wideo mowa z pierwszą asynchroniczną ASr_I fuzją charakterystyk FRR [%] FAR [%]
Użytkownik SNR 20dB
SNR 15dB
SNR 10dB
SNR 5dB
SNR 0dB
SNR 20dB
SNR 15dB
SNR 10dB
SNR 5dB
SNR 0dB
U1 0,95 10,48 20,48 28,10 41,90 0,95 3,33 5,71 7,14 10,48 U2 2,38 10,00 20,00 29,52 40,00 1,43 2,38 6,19 7,62 9,52 U3 0,95 9,05 22,86 29,05 37,14 1,43 2,38 5,71 7,62 11,43 U4 1,43 10,00 19,05 27,14 41,90 1,43 1,90 7,14 9,05 11,90 U5 0,95 9,52 20,48 28,10 39,05 2,38 2,38 4,29 8,57 10,95 U6 1,90 10,95 21,43 30,48 47,14 1,43 3,81 4,29 9,05 13,33 U7 0,48 9,05 19,52 29,05 39,52 0,95 1,43 5,24 7,14 10,48 U8 0,95 10,00 19,52 27,14 38,10 2,38 2,86 7,14 8,10 11,43 U9 2,86 11,90 19,05 27,62 39,05 0,95 3,33 6,19 6,67 8,57
U10 1,43 11,43 19,05 28,10 38,10 0,48 1,90 5,71 7,14 9,52 Średnio 1,42 10,23 20,14 28,43 40,19 1,38 2,57 5,76 7,81 10,76
Etap 6
Doświadczenie polegało na zbadaniu poziomu błędów rozpoznawania audio-wideo mowy z
wykorzystaniem zaproponowanej drugiej metody ASr_II fuzji charakterystyk sygnałów audio
i wideo. W metodzie tej utworzono osobne modele UMM dla poszczególnych sygnałów, a
jako wynik przyjęto sumę prawdopodobieństw wygenerowania sekwencji obserwacji audio-
wideo przez oddzielne modele. Przy tej metodzie konieczne było utworzenie podwójnej
liczby modeli UMM. Wszystkie badania przeprowadzono w warunkach, co i badania
poziomu błędów z poprzednich etapów. Dokładny opis metody fuzji charakterystyk sygnałów
audio-wideo z przykładowymi wynikami zamieszczono paragrafie 6.3.
W Tab.7.8 zamieszczono wyniki rozpoznawania audio-wideo mowy z
wykorzystaniem metody ASr_II fuzji charakterystyk.
Tab.7.8 Poziomy błędów rozpoznawania audio-wideo mowy z wykorzystaniem metody ASr_II
Audio-wideo mowa z drugą asynchroniczną ASr_II fuzją charakterystyk FRR [%] FAR [%]
Użytkownik SNR 20dB
SNR 15dB
SNR 10dB
SNR 5dB
SNR 0dB
SNR 20dB
SNR 15dB
SNR 10dB
SNR 5dB
SNR 0dB
U1 1,43 12,38 23,81 34,29 48,10 0,95 1,90 6,19 8,10 12,38 U2 1,90 11,43 20,48 35,71 46,19 1,90 2,86 6,67 7,14 11,90 U3 1,90 12,86 23,81 37,14 47,14 0,95 2,38 6,19 7,62 12,38 U4 0,48 11,90 23,33 34,76 43,81 1,43 2,38 7,62 8,10 12,38 U5 2,38 13,81 25,71 36,19 48,57 2,86 3,81 8,10 9,52 13,81 U6 1,90 10,00 20,95 35,71 47,62 1,43 2,86 5,71 6,67 10,48 U7 1,43 12,86 23,33 34,76 47,14 1,43 2,38 5,24 7,14 10,95 U8 0,48 10,95 22,86 34,29 43,81 1,90 3,33 6,19 8,57 11,43 U9 2,38 13,81 24,29 36,67 44,76 1,90 2,86 5,71 7,62 11,43
U10 1,90 11,43 22,86 35,24 48,10 0,95 2,38 5,24 8,10 11,90 Średnio 1,61 12,14 23,14 35,47 46,52 1,57 2,71 6,28 7,85 11,90
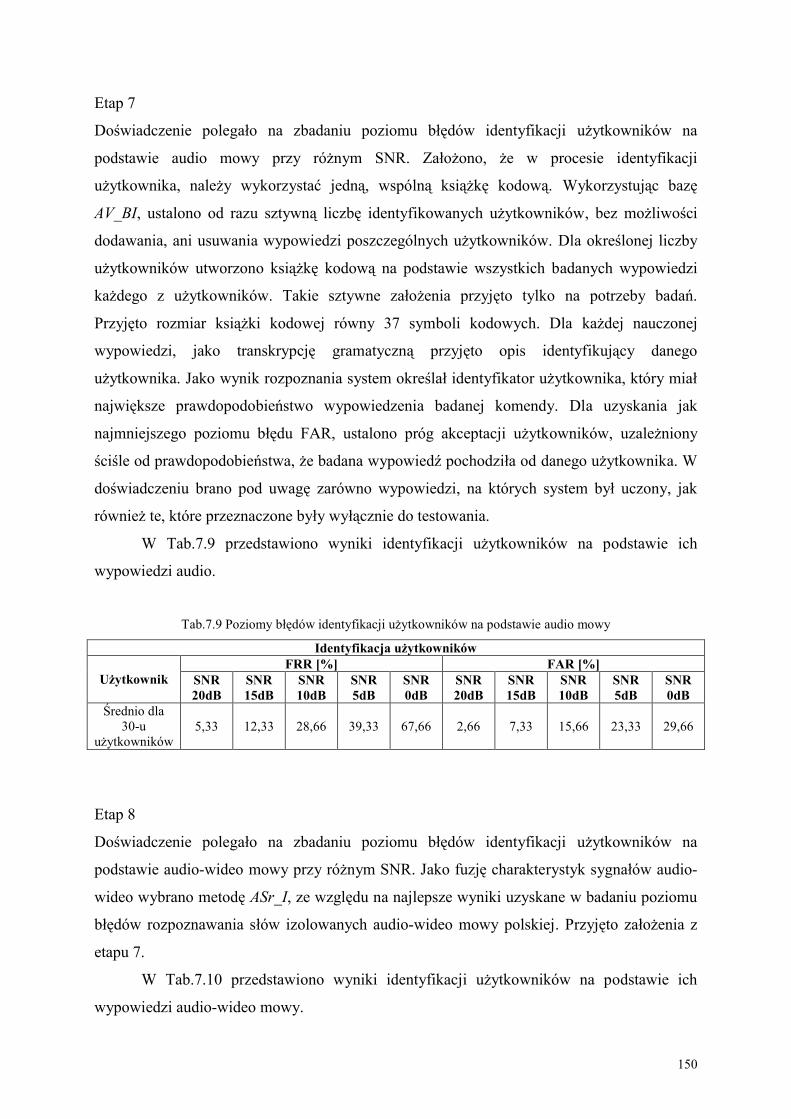
150
Etap 7
Doświadczenie polegało na zbadaniu poziomu błędów identyfikacji użytkowników na
podstawie audio mowy przy różnym SNR. Założono, że w procesie identyfikacji
użytkownika, należy wykorzystać jedną, wspólną książkę kodową. Wykorzystując bazę
AV_BI, ustalono od razu sztywną liczbę identyfikowanych użytkowników, bez możliwości
dodawania, ani usuwania wypowiedzi poszczególnych użytkowników. Dla określonej liczby
użytkowników utworzono książkę kodową na podstawie wszystkich badanych wypowiedzi
każdego z użytkowników. Takie sztywne założenia przyjęto tylko na potrzeby badań.
Przyjęto rozmiar książki kodowej równy 37 symboli kodowych. Dla każdej nauczonej
wypowiedzi, jako transkrypcję gramatyczną przyjęto opis identyfikujący danego
użytkownika. Jako wynik rozpoznania system określał identyfikator użytkownika, który miał
największe prawdopodobieństwo wypowiedzenia badanej komendy. Dla uzyskania jak
najmniejszego poziomu błędu FAR, ustalono próg akceptacji użytkowników, uzależniony
ściśle od prawdopodobieństwa, że badana wypowiedź pochodziła od danego użytkownika. W
doświadczeniu brano pod uwagę zarówno wypowiedzi, na których system był uczony, jak
również te, które przeznaczone były wyłącznie do testowania.
W Tab.7.9 przedstawiono wyniki identyfikacji użytkowników na podstawie ich
wypowiedzi audio.
Tab.7.9 Poziomy błędów identyfikacji użytkowników na podstawie audio mowy
Identyfikacja użytkowników FRR [%] FAR [%]
Użytkownik SNR 20dB
SNR 15dB
SNR 10dB
SNR 5dB
SNR 0dB
SNR 20dB
SNR 15dB
SNR 10dB
SNR 5dB
SNR 0dB
Średnio dla 30-u
użytkowników 5,33 12,33 28,66 39,33 67,66 2,66 7,33 15,66 23,33 29,66
Etap 8
Doświadczenie polegało na zbadaniu poziomu błędów identyfikacji użytkowników na
podstawie audio-wideo mowy przy różnym SNR. Jako fuzję charakterystyk sygnałów audio-
wideo wybrano metodę ASr_I, ze względu na najlepsze wyniki uzyskane w badaniu poziomu
błędów rozpoznawania słów izolowanych audio-wideo mowy polskiej. Przyjęto założenia z
etapu 7.
W Tab.7.10 przedstawiono wyniki identyfikacji użytkowników na podstawie ich
wypowiedzi audio-wideo mowy.
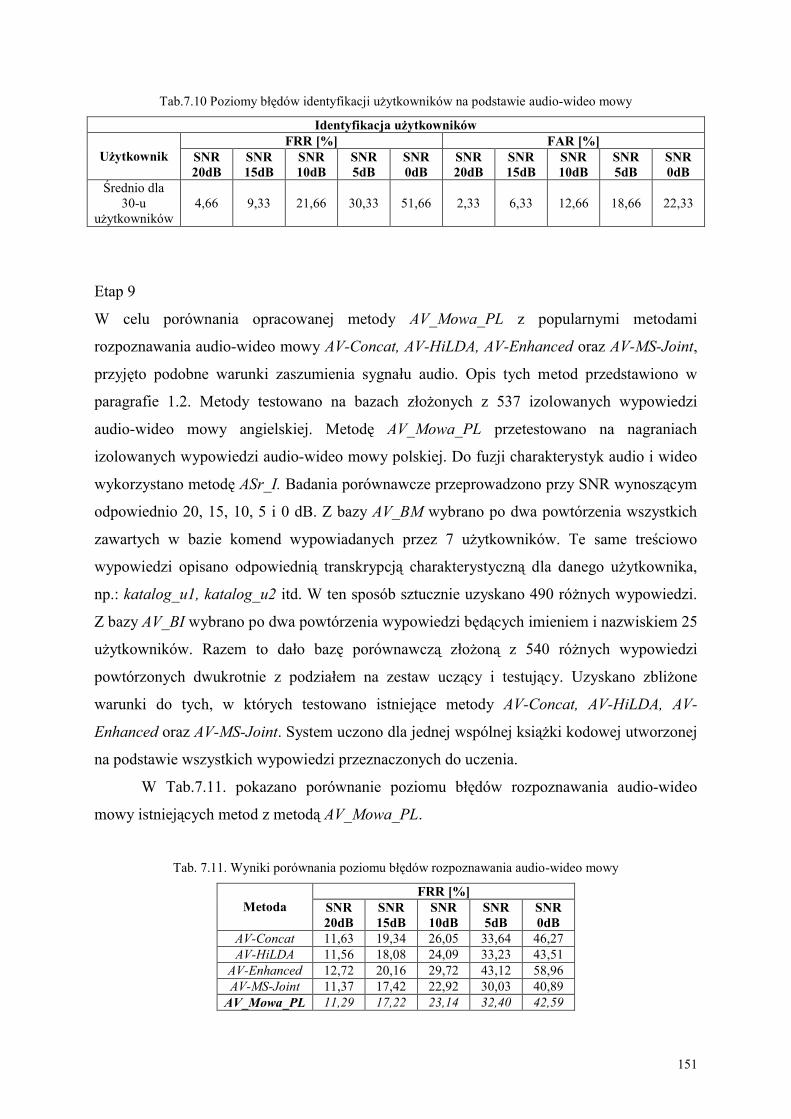
151
Tab.7.10 Poziomy błędów identyfikacji użytkowników na podstawie audio-wideo mowy
Identyfikacja użytkowników FRR [%] FAR [%]
Użytkownik SNR 20dB
SNR 15dB
SNR 10dB
SNR 5dB
SNR 0dB
SNR 20dB
SNR 15dB
SNR 10dB
SNR 5dB
SNR 0dB
Średnio dla 30-u
użytkowników 4,66 9,33 21,66 30,33 51,66 2,33 6,33 12,66 18,66 22,33
Etap 9
W celu porównania opracowanej metody AV_Mowa_PL z popularnymi metodami
rozpoznawania audio-wideo mowy AV-Concat, AV-HiLDA, AV-Enhanced oraz AV-MS-Joint,
przyjęto podobne warunki zaszumienia sygnału audio. Opis tych metod przedstawiono w
paragrafie 1.2. Metody testowano na bazach złożonych z 537 izolowanych wypowiedzi
audio-wideo mowy angielskiej. Metodę AV_Mowa_PL przetestowano na nagraniach
izolowanych wypowiedzi audio-wideo mowy polskiej. Do fuzji charakterystyk audio i wideo
wykorzystano metodę ASr_I. Badania porównawcze przeprowadzono przy SNR wynoszącym
odpowiednio 20, 15, 10, 5 i 0 dB. Z bazy AV_BM wybrano po dwa powtórzenia wszystkich
zawartych w bazie komend wypowiadanych przez 7 użytkowników. Te same treściowo
wypowiedzi opisano odpowiednią transkrypcją charakterystyczną dla danego użytkownika,
np.: katalog_u1, katalog_u2 itd. W ten sposób sztucznie uzyskano 490 różnych wypowiedzi.
Z bazy AV_BI wybrano po dwa powtórzenia wypowiedzi będących imieniem i nazwiskiem 25
użytkowników. Razem to dało bazę porównawczą złożoną z 540 różnych wypowiedzi
powtórzonych dwukrotnie z podziałem na zestaw uczący i testujący. Uzyskano zbliżone
warunki do tych, w których testowano istniejące metody AV-Concat, AV-HiLDA, AV-
Enhanced oraz AV-MS-Joint. System uczono dla jednej wspólnej książki kodowej utworzonej
na podstawie wszystkich wypowiedzi przeznaczonych do uczenia.
W Tab.7.11. pokazano porównanie poziomu błędów rozpoznawania audio-wideo
mowy istniejących metod z metodą AV_Mowa_PL.
Tab. 7.11. Wyniki porównania poziomu błędów rozpoznawania audio-wideo mowy
FRR [%] Metoda SNR
20dB SNR 15dB
SNR 10dB
SNR 5dB
SNR 0dB
AV-Concat 11,63 19,34 26,05 33,64 46,27 AV-HiLDA 11,56 18,08 24,09 33,23 43,51
AV-Enhanced 12,72 20,16 29,72 43,12 58,96 AV-MS-Joint 11,37 17,42 22,92 30,03 40,89
AV_Mowa_PL 11,29 17,22 23,14 32,40 42,59

152
7.3. Analiza wyników eksperymentu
Przeprowadzenie badań wstępnych miało na celu dobór optymalnych parametrów dla
prawidłowego funkcjonowania systemu AVM_PL, w celu sprawdzenia poprawności metody
AV_Mowa_PL. Najlepsze wyniki rozpoznawania przykładowych słów izolowanych uzyskano
dla książki kodowej złożonej z 37 symboli kodowych oraz dla modeli UMM złożonych z 8
stanów. Mimo, iż badania przeprowadzono na audio mowie, należy przypuszczać, że podobne
taki dobór parametrów również w przypadku audio-wideo mowy da najlepsze rezultaty.
Wyniki badania poprawności definiowania sygnału audio mowy z nagrania
zawierającego zbędną ciszę pokazują, że zastosowanie zaproponowanych metod ES i CZS,
stosowanych osobno, pozwala na poprawne zdefiniowanie sygnału mowy w większości
przypadków. Jednak dla kilku nagrań zdarzyły się błędy. Połączenie obu metod dało 100 %
poprawności definiowania sygnału audio na wszystkich przetestowanych nagraniach z
własnej bazy AV_BM, nagrań wprowadzanych do systemu na bieżąco oraz dla
przykładowych nagrań w języku angielskim z baz IBM ViaVoice LVCSR i DIGITS.
Poprawne działanie algorytmu trekingu ust pozwala na prawidłowe sprawdzenie
funkcjonowania metody AV_Mowa_PL. Uzyskane wyniki pokazują, że zastosowana metoda
CSM lepiej lokalizuje kąciki i krawędzie ust niż metoda GMIP. Obie metody dają podobne
wyniki w przypadku użytkowników bez jakiegokolwiek zarostu na twarzy. W przypadku
użytkowników z zarostem na twarzy, zdecydowanie lepsze wyniki daje metoda CSM,
którą to właśnie zastosowano do przeprowadzenia wszystkich badań związanych z audio-
wideo mową. Również przybliżony dobór wartości progowych T1, T2 i T3, opisanych w
paragrafie 5.3. dla badanych osób okazał się poprawny.
Wyniki badania poprawności rozpoznawania mowy pokazują, iż duży wpływ na
właściwe rozpoznawanie ma wpływ zakłóconego, bądź nie, otoczenia. W przypadku, gdy
badany sygnał audio mowy pozbawiony jest całkowicie szumu, rozpoznawanie audio mowy
oraz audio-wideo mowy daje podobne rezultaty (przy SNR = 20 dB, FRR_audio = 2,09 %,
FRR_audio-wideo = Sr{1,76 %}, ASr_I{1,42 %} i ASr_II{1,61%}). Jednak w miarę
zaszumienia sygnału audio, poprawność rozpoznawania audio mowy znacznie się
pogarsza w porównaniu z rozpoznawaniem audio-wideo mowy (przy SNR = 0 dB,
FRR_audio = 74,28 %, FRR_audio-wideo = Sr{42,66 %}, ASr_I{40,19 %} i ASr_II{46, 52
%}). W badaniach przyjęto, że sygnał audio mowy zostaje zakłócony, natomiast sygnał wideo
mowy pozostaje bez zmian.
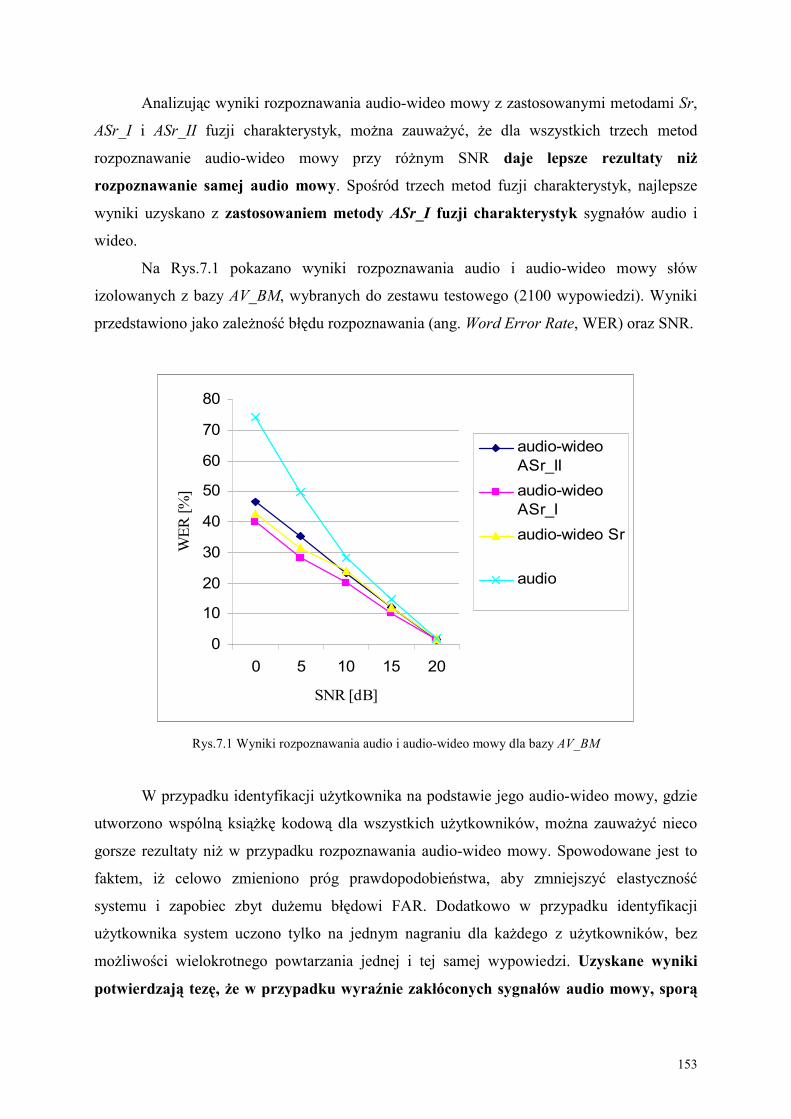
153
Analizując wyniki rozpoznawania audio-wideo mowy z zastosowanymi metodami Sr,
ASr_I i ASr_II fuzji charakterystyk, można zauważyć, że dla wszystkich trzech metod
rozpoznawanie audio-wideo mowy przy różnym SNR daje lepsze rezultaty niż
rozpoznawanie samej audio mowy. Spośród trzech metod fuzji charakterystyk, najlepsze
wyniki uzyskano z zastosowaniem metody ASr_I fuzji charakterystyk sygnałów audio i
wideo.
Na Rys.7.1 pokazano wyniki rozpoznawania audio i audio-wideo mowy słów
izolowanych z bazy AV_BM, wybranych do zestawu testowego (2100 wypowiedzi). Wyniki
przedstawiono jako zależność błędu rozpoznawania (ang. Word Error Rate, WER) oraz SNR.
0
10
20
30
40
50
60
70
80
0 5 10 15 20
SNR [dB]
WER
[%]
audio-wideoASr_IIaudio-wideoASr_Iaudio-wideo Sr
audio
Rys.7.1 Wyniki rozpoznawania audio i audio-wideo mowy dla bazy AV_BM
W przypadku identyfikacji użytkownika na podstawie jego audio-wideo mowy, gdzie
utworzono wspólną książkę kodową dla wszystkich użytkowników, można zauważyć nieco
gorsze rezultaty niż w przypadku rozpoznawania audio-wideo mowy. Spowodowane jest to
faktem, iż celowo zmieniono próg prawdopodobieństwa, aby zmniejszyć elastyczność
systemu i zapobiec zbyt dużemu błędowi FAR. Dodatkowo w przypadku identyfikacji
użytkownika system uczono tylko na jednym nagraniu dla każdego z użytkowników, bez
możliwości wielokrotnego powtarzania jednej i tej samej wypowiedzi. Uzyskane wyniki
potwierdzają tezę, że w przypadku wyraźnie zakłóconych sygnałów audio mowy, sporą
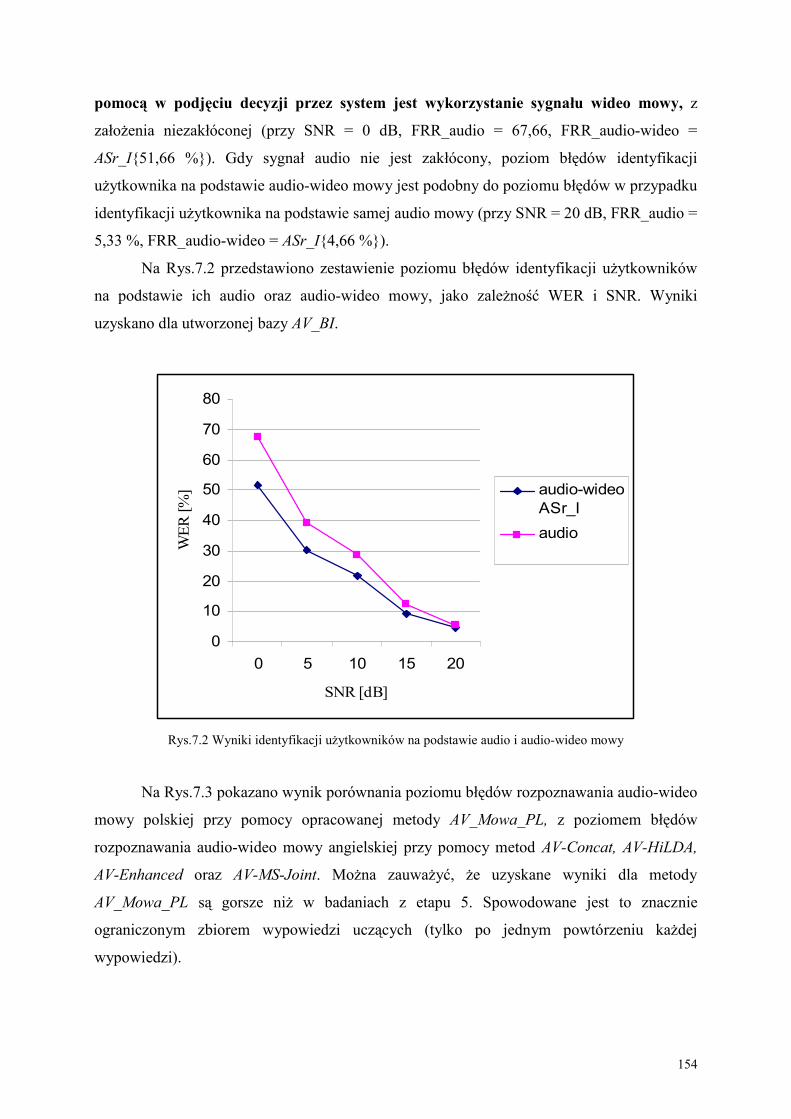
154
pomocą w podjęciu decyzji przez system jest wykorzystanie sygnału wideo mowy, z
założenia niezakłóconej (przy SNR = 0 dB, FRR_audio = 67,66, FRR_audio-wideo =
ASr_I{51,66 %}). Gdy sygnał audio nie jest zakłócony, poziom błędów identyfikacji
użytkownika na podstawie audio-wideo mowy jest podobny do poziomu błędów w przypadku
identyfikacji użytkownika na podstawie samej audio mowy (przy SNR = 20 dB, FRR_audio =
5,33 %, FRR_audio-wideo = ASr_I{4,66 %}).
Na Rys.7.2 przedstawiono zestawienie poziomu błędów identyfikacji użytkowników
na podstawie ich audio oraz audio-wideo mowy, jako zależność WER i SNR. Wyniki
uzyskano dla utworzonej bazy AV_BI.
0
10
20
30
40
50
60
70
80
0 5 10 15 20
SNR [dB]
WER
[%] audio-wideo
ASr_Iaudio
Rys.7.2 Wyniki identyfikacji użytkowników na podstawie audio i audio-wideo mowy
Na Rys.7.3 pokazano wynik porównania poziomu błędów rozpoznawania audio-wideo
mowy polskiej przy pomocy opracowanej metody AV_Mowa_PL, z poziomem błędów
rozpoznawania audio-wideo mowy angielskiej przy pomocy metod AV-Concat, AV-HiLDA,
AV-Enhanced oraz AV-MS-Joint. Można zauważyć, że uzyskane wyniki dla metody
AV_Mowa_PL są gorsze niż w badaniach z etapu 5. Spowodowane jest to znacznie
ograniczonym zbiorem wypowiedzi uczących (tylko po jednym powtórzeniu każdej
wypowiedzi).
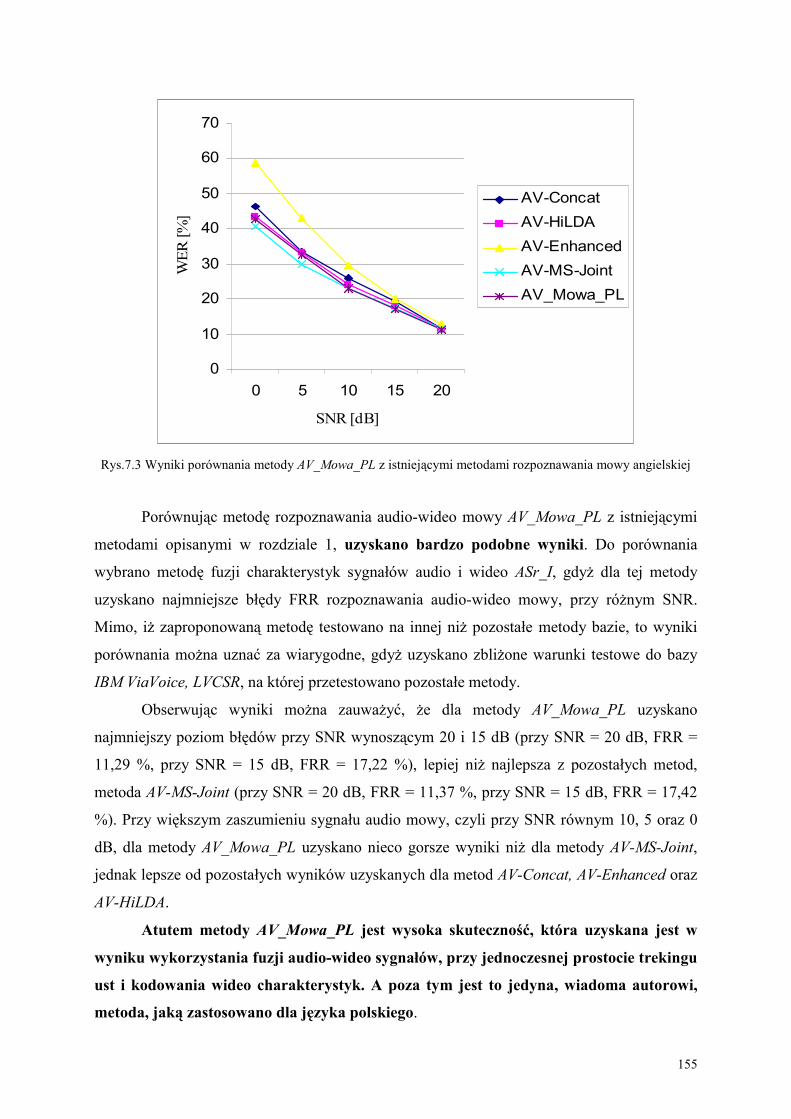
155
0
10
20
30
40
50
60
70
0 5 10 15 20
SNR [dB]
WER
[%]
AV-ConcatAV-HiLDAAV-EnhancedAV-MS-JointAV_Mowa_PL
Rys.7.3 Wyniki porównania metody AV_Mowa_PL z istniejącymi metodami rozpoznawania mowy angielskiej
Porównując metodę rozpoznawania audio-wideo mowy AV_Mowa_PL z istniejącymi
metodami opisanymi w rozdziale 1, uzyskano bardzo podobne wyniki. Do porównania
wybrano metodę fuzji charakterystyk sygnałów audio i wideo ASr_I, gdyż dla tej metody
uzyskano najmniejsze błędy FRR rozpoznawania audio-wideo mowy, przy różnym SNR.
Mimo, iż zaproponowaną metodę testowano na innej niż pozostałe metody bazie, to wyniki
porównania można uznać za wiarygodne, gdyż uzyskano zbliżone warunki testowe do bazy
IBM ViaVoice, LVCSR, na której przetestowano pozostałe metody.
Obserwując wyniki można zauważyć, że dla metody AV_Mowa_PL uzyskano
najmniejszy poziom błędów przy SNR wynoszącym 20 i 15 dB (przy SNR = 20 dB, FRR =
11,29 %, przy SNR = 15 dB, FRR = 17,22 %), lepiej niż najlepsza z pozostałych metod,
metoda AV-MS-Joint (przy SNR = 20 dB, FRR = 11,37 %, przy SNR = 15 dB, FRR = 17,42
%). Przy większym zaszumieniu sygnału audio mowy, czyli przy SNR równym 10, 5 oraz 0
dB, dla metody AV_Mowa_PL uzyskano nieco gorsze wyniki niż dla metody AV-MS-Joint,
jednak lepsze od pozostałych wyników uzyskanych dla metod AV-Concat, AV-Enhanced oraz
AV-HiLDA.
Atutem metody AV_Mowa_PL jest wysoka skuteczność, która uzyskana jest w
wyniku wykorzystania fuzji audio-wideo sygnałów, przy jednoczesnej prostocie trekingu
ust i kodowania wideo charakterystyk. A poza tym jest to jedyna, wiadoma autorowi,
metoda, jaką zastosowano dla języka polskiego.

156
WNIOSKI KOŃCOWE
Praca dotyczy opracowania metody AV_Mowa_PL do rozpoznawania słów izolowanych
audio-wideo mowy polskiej, w której do podjęcia decyzji o rozpoznawanej wypowiedzi
wykorzystuje się charakterystyki synchronicznych sygnałów audio i wideo mowy. Założono,
że głównym sygnałem jest sygnał audio, który może zostać zakłócony, natomiast sygnał
wideo, który nie może zostać zakłócony, służy do wspomagania w podjęciu decyzji.
Sformułowano i opracowano nowe dla polskiej mowy zagadnienie rozpoznawania mowy oraz
identyfikacji użytkownika, które może być wykorzystywane w systemach sterowania
systemem operacyjnym, kontroli dostępu. Jako aparat matematyczny do rozpoznawania
wykorzystano ukryte modele Markowa UMM.
W pracy:
1. Stworzono metodę AV_Mowa_PL, a także odpowiedni system programowy AVM_PL do
rozpoznawania słów izolowanych audio-wideo mowy polskiej, bazujące się na fuzji audio
i wideo sygnałów (czytania z ruchu warg); jako matematyczne narzędzie do
rozpoznawania wykorzystano ukryte modele Markowa (UMM).
2. Opracowano pomocnicze metody ES i CZS do definiowania początku i końca słów
izolowanych audio mowy, a także zbadano efekt połączenia tych metod dla skrajnych
przypadków.
3. Zbadano specyfikę tworzenia wektorów obserwacji audio mowy polskiej za pomocą
kodowania współczynników cepstralnych.
4. Opracowano metodę trekingu ust na podstawie metod: detekcji twarzy w oparciu o kolor
skóry; lokalizacji oczu i definiowania obszaru ust; stworzonej metody CSM do
wykrywania kącików i zewnętrznych krawędzi ust.
5. Opracowano metodę EP do ekstrakcji/kodowania wektorów obserwacji wideo mowy.
6. Zdefiniowano i zbadano efektywność metod Sr, ASr_I i ASr_II fuzji charakterystyk
sygnałów audio-wideo mowy.
7. Dobrano struktury i parametry modeli UMM, a także optymalny rozmiar książki kodowej
wypowiedzi polskich mówców.
8. Eksperymentalnie udowodniono większą efektywność identyfikacji użytkownika na
podstawie audio-wideo mowy, od identyfikacji na podstawie tylko audio mowy.
9. Stworzono dla wymagań testowania metody AV_Mowa_PL bazę AV_BM do
rozpoznawania słów izolowanych audio-wideo mowy, zawierającą zbiór komend

157
sterowania systemem operacyjnym, i bazę AV_BI do identyfikacji użytkownika na
podstawie audio-wideo mowy.
10. Przeprowadzono szereg badań, na podstawie których dokonano eksperymentalnego
potwierdzenia faktu, że rozpoznawanie audio-wideo mowy jest szczególnie przydatne w
warunkach mocno zakłóconego sygnału audio, dając zdecydowanie mniejszy poziom
błędów niż rozpoznawanie w tych samych warunkach samej audio mowy.
Na podstawie przeprowadzonych badań stwierdzono:
1. Poprawność postawionej tezy badawczej.
2. Dostatecznie wysoki poziom naukowo-techniczny opracowanej metody AV_Mowa_PL,
złożonej z komponentów charakteryzujących się nowatorstwem w realizacji.
Przedstawiona metoda charakteryzuje się nowatorstwem:
1. Opracowanie metod ES i CZS do definiowania początku i końca słów izolowanych audio
mowy, dla których zaproponowano połączone działanie.
2. Opracowanie metody CSM do wykrywania kącików i zewnętrznych krawędzi ust w
procesie trekingu ust oraz metody Sr, ASr_I i ASr_II do łączenia charakterystyk sygnałów
audio i wideo mowy polskiej.
3. Opracowanie metody AV_Mowa_PL do rozpoznawania audio-wideo mowy polskiej oraz
identyfikacji użytkownika.
W porównaniu z istniejącymi metodami rozpoznawania audio-wideo mowy angielskiej,
charakterystyki techniczne metody AV_Mowa_PL są porównywalne. Poziom błędów
uzyskany na podstawie przeprowadzonych badań jest zbliżony do metod rozpoznawania
audio-wideo mowy AV-Concat, AV-HiLDA, AV-Enhanced, AV-MS-Joint, wahając się w
granicach pomiędzy najlepszą a najgorszą z przytoczonych metod.
Atutem metody AV_Mowa_PL jest zadawalająca skuteczność opracowanego trekingu
ust oraz prostota i funkcjonalność zaproponowanych metod Sr, ASr_I i ASr_II fuzji
charakterystyk audio i wideo. Uzyskano zdecydowanie mniejsze poziomy błędów
rozpoznawania audio-wideo mowy w porównaniu z rozpoznawaniem samej audio mowy,
szczególnie w warunkach mocno zakłóconego sygnału audio.
Analizując literaturę pod kątem istniejących metod rozpoznawania audio-wideo mowy
nie napotkano na prace dotyczące rozpoznawania audio-wideo mowy dla języka polskiego.

158
WYKAZ DEFINICJI I SKRÓTÓW
Audio mowa – mowa charakteryzowana wyłącznie przez dźwięk; stanowi sekwencję
fonemów.
Wideo mowa – mowa charakteryzowana wyłącznie przez obraz; stanowi sekwencję
wideo przedstawiającą ruch ust mówcy.
Audio-wideo mowa – mowa charakteryzowana zarówno przez dźwięk, jak i obraz;
stanowi sekwencję fonemów i odpowiadającą im sekwencję wideo ruchu ust mówcy.
Obserwacja – wartości krótkookresowe zakodowanej stacjonarnej ramki
dźwiękowej/wideo, która poddana kwantyzacji wektorowej, jest przedstawiana w formie
symbolu obserwacji.
Wektor obserwacji – wartości długookresowe sekwencji dźwiękowej/wideo; stanowi
zbiór czasowej sekwencji obserwacji.
Książka kodowa –zbiór różnych, pojedynczych symboli kodowych, reprezentujących
poszczególne obszary przestrzeni akustycznej/wideo.
Mowa izolowana – mowa złożona z poszczególnych słów, oddzielonych od siebie
celowo robionymi przerwami w wypowiedzi.
Treking ust – śledzenie na bieżąco ruchu ust, poprzez sekwencyjną lokalizację na
obrazie kącików i krawędzi ust.
Fonem - zbiór alofonów, które mają jednakowe funkcje i nie wywołają znaczeniowych
rozróżnień w obrębie danego języka; fonem to inaczej głoska.
Diafon - jednostka językowa, która zawiera informację przejściową od środka quasi-
stacjonarnych odcinków pary samogłoska-spółgłoska lub spółgłoska-samogłoska.
Trifon – model uwzględniający pojedyncze lewo i prawostronne sąsiedztwo
wymawianej głoski.
AAM aktywny model wyglądu (ang. Active Appearance Model).
ALR automatyczne czytanie z ruchu warg (ang. Automatic Lip-Reading).
ALT ciągłe śledzenie ruchu ust (ang. Automatic Lip-Tracking).
ANN sztuczne sieci neuronowe (ang. Artificial Neural Network).
ASM aktywny model kształtu (ang. Active Shape Model).
ASr_I pierwsza asynchroniczna metoda fuzji charakterystyk sygnałów audio-
wideo.
ASr_II druga metoda fuzji charakterystyk sygnałów audio- wideo.

159
AV_BI baza danych do identyfikacji użytkownika na podstawie słów izolowanych
audio-wideo mowy polskiej.
AV_BM baza izolowanych komend sterowania systemem operacyjnym, zawierająca
nagrania audio-wideo mowy polskiej.
AV_Mowa_PL metoda rozpoznawania słów izolowanych audio-wideo mowy polskiej.
AVM_PL system do rozpoznawania słów izolowanych audio wideo mowy polskiej.
AVSR rozpoznawanie audio-wideo mowy (ang. Audio-Visual Speech Recognition).
CSM metoda wyznaczania kącików ust, bazująca na specyficznym kolorze i
kształcie ust (ang. Color and Shape of Mouths)
CZS algorytm bazowany na charakterystykach częstości zmian sygnału.
DCT dyskretna transformata kosinusowa (ang. Discrete Cosine Transform).
DFFS dystans pomiędzy wektorami w przestrzeni (ang. Distance From Face
Space).
DTW dynamiczna zmienność w czasie (ang. Dynamic Time Warping).
DWT dyskretna transformata falkowa (ang. Discrete Wavelet Transform).
EP metoda ekstrakcji i kodowania parametrów z ruchomego obrazu ust,
ES algorytm bazowany na charakterystykach energii sygnału.
FAR współczynnik błędnej akceptacji (ang. False Acceptance Rate).
FFT, IFFT prosta i odwrotna szybka transformacja Fouriera (ang. Fast Fourier
Transform).
FL lokalizacja twarzy (ang. Face Localization).
FRR współczynnik błędnego odrzucenia (ang. False Rejection Rate).
FT treking twarzy (ang. Face Tracking).
GMIP metoda obliczania gradientów jasności pikseli wzdłuż kolumn i wierszy
obrazu wejściowego, a następnie integralnej projekcji poziomej i pionowej
(ang. Gradient Method and Integral Projection).
LDA liniowa analiza dyskryminacyjna (ang. Linear Discriminant Analysis)
LKU algorytm lokalizacji krawędzi ust.
LPC liniowe kodowanie predykcyjne (ang. Linear Prediction Coding).
LT algorytm lokalizacji twarzy.
LU algorytm lokalizacji ust.
MFCC współczynniki cepstralnej w częstotliwościowej skali mel (ang. Mel
Frequency Cepstral Coefficients).

160
MLLT maksymalne prawdopodobieństwo transformacji liniowej (ang. Maximum
Likelihood Linear Transform).
PCA analiza głównych komponentów (ang. Principal Components Analysis).
PDF funkcją gęstości prawdopodobieństwa (ang. Probability Density Function).
SCD metoda wyodrębniania twarzy z obrazu kolorowego, bazująca na
specyficznym kolorze (ang. Skin Color Detection).
SNR stosunek sygnału do szumu (ang. Signal to Nosie Ratio).
SOI filtr o skończonej odpowiedzi impulsowej.
SR czytanie mowy (ang. Speech Reading).
Sr Synchroniczna metoda fuzji charakterystyk sygnałów audio-wideo.
UMM Ukryte Modele Markowa (ang. Hidden Markov Model).
WER współczynnik błędu rozpoznawania słów (ang. Word Error Rate).

161
SUMMARY
THE METHOD OF AUDIO-VISUAL POLISH SPEECH RECOGNITION BASED ON
HIDDEN MARKOV MODELS
The problem of speech recognition is one of the main questions of many research centers at
present. The recognition of speech is used in many areas. Interest of this discipline is a result
of potential possibilities of practical applications in real world, where the audio signal is very
intensely disturbed and changed.
In the work, the method was proposed to limitation of negative influence of external
factors on audio speech. The method, called as AV_Mowa_PL and based on hidden Markov
models, was worked up to recognition of audio-visual Polish speech. Novel peculiarity of the
method is using vector of data, in which the audio and visual signals were joined. The method
AV_Mowa_PL was proposed also to speaker identification.
To extraction of the audio feature of person’s speech, the mechanism of cepstral
speech analysis was applied. The mechanism uses a bank of amplitude-frequency filters with
characteristics similar to human hearing. Own methods was created to determine the
beginning and end of isolated words in audio speech.
To extracting of the visual feature, automatic methods of detection of face, eyes and
region of mouth was used. The visual features are the corners and outside edges of the lips.
The method CSM (Color and Shape of Mouth) worked up to detect the corners and outside
edges of the lips, needed to obtain a precise level of function for lip-tracking procedures.
Three methods of fuse the audio and visual signals were proposed. In first method, vector of
observation of audio-visual speech is resultant from separate observation of both signals. In
second, separate vectors of observation of both signals are passed in succession for this
individual model. In third, separate models were applied for vectors of observation of both
signals.
An advantage of the method AV_Mowa_PL is the satisfactory effectiveness created by
the lip-tracking procedures, and the simplicity and functionality by the proposed methods,
which fuse together the audio and visual signals. A decisively lower level of mistakes was
obtained in audio-visual speech recognition, and speaker identification, in comparison to only
audio speech, particularly in facilities, where the audio signal is strongly disrupted. The
method obtains similar results to other existing audio-visual speech recognition methods,
published in scientific literature.

162
LITERATURA
1. Adjoudani A., et al.: „A multimedia platform for audio-visual speech processing”. Proc.
European Conference on Speech Communication and Technology, Rhodes, 1997,
Grecee, 1671–1674
2. Adjoudani, A., Benoit, C.: „On the integration of auditory and visual parameters in an
HMM-based ASR”. In Stork, D. G., Hennecke M. E., (Eds.): „Speechreading by
Humans and Machines”. Berlin, 1996, Germany: Springer, 461–471
3. Alissali, M., Del´eglise, P., Rogozan, A.: „Asynchronous integration of Visual
information in an automatic speech recognition system”. Proc. International Conference
on Spoken Language Processing, Philadelphia, 1996, PA, 34–37
4. Andr´e-Obrecht, R., Jacob, B., Parlangeau, N.: „Audio visual speech recognition and
segmental master slave HMM”. Proc. European Tutorial Workshop on Audio-Visual
Speech Processing, Rhodes, 1997, Greece, 49–52
5. Baldi, P., et al.: „Hidden Markov-Models of Biological Primary Sequence Information”.
Proc. National Academy of Science of the United States, 91(3): 1059-1063, 1994
6. Basu, S., Oliver, N., Pentland, A.: „3D modeling and tracking of human lip motions”.
Proc. International Conference on Computer Vision, Mumbai, 1998, India, 337-343
7. Basztura, C.: „Rozmawiać z komputerem”. Wydawnictwo Prac Naukowych FORMAT,
Wrocław, 1992
8. Baum, L. E., Patrie, T.: „Statistical interface for probabilistic functions of finite state
Markov chains”. Ann. Math. Statist. 37, 1966
9. Bogert, B. P., Healy, M. J. R., Tukey, J. W.: „The Frequency Analisys of Time-Series
for Echoes”. Proc. Symp. Time Series Analisys, 1963, Chap, 209-243
19. Bregler, C., et al.: „Improving connected letter recognition by lipreading”. Proc.
International Conference on Acoustics, Speech and Signal Processing, Minneapolis,
1993, MN, 557-560
11. Bregler, C., Konig, Y.: „Eigenlips for robust speech recognition”. Proc. International
Conference on Acoustics, Speech and Signal Processing, Adelaide, 1994, Australia,
557–560
12. Bub, U., Hunke, M., Waibel, A.: „Knowing who to listen to in speech recognition:
Visually guided beamforming”. Proc. International Conference on Acoustics, Speech
and Signal Processing, Detroit, 1995, MI, 848-851

163
13. Chan, M. T., Zhang, Y., Huang, T. S.: „Real-time liptracking and bimodal continuous
speech recognition”. Proc. Workshop on Multimedia Signal Processing, Redondo Beach,
1998, CA, 65–70
14. Chan, M. T.: „HMM based audio-visual speech recognition integrating geometric- and
appearance-based visual features”. Proc. Workshop on Multimedia Signal Processing,
Cannes, 2001, France, 9-14
15. Chandramohan, D., Silsbee, P. L.: „A multiple deformable template approach for Visual
speech recognition”. Proc. International Conference on Spoken Language Processing,
Philadelphia, 1996, PA, 50-53
16. Chandramohan, D.: „Realistic articulated character positioning and balance control in
interactive environments”. Proc. Computer Animation, 1999, 160-168
17. Chartfield, C., Collins, A. J.: „Introduction to Multivariate Analysis”. London, 1991,
UK: Chapman and Hall
18. Chen, T., Graf, H. P., Wang, K.: „Lip synchronization using speech-assisted video
processing”. IEEE Signal Processing Letters, 1995, 2(4): 57-59
19. Chibelushi, C. C., Deravi, F., Mason, J. S. D.: „A review of speech-based bimodal
recognition”. IEEE Transactions on Multimedia, 2002, 4(1): 23–37
20. Chibelushi, C. C., Deravi, F., Mason, J. S. D.: „Survey of Audio Visual Speech
Databases”. Technical Report, Swansea, 1996, U. K.: Dep. Electrical and Electronic
Engineering, University of Wales
21. Chiou, G., et al.: „Lipreading from color video”. IEEE Transactions on Image
Processing, 1997, 6(8): 1192-1195
22. Chu, S., Huang, T.: „Bimodal speech recognition Using coupled hidden Markov
models”. Proc. International Conference on Spoken Language Processing, Beijing, 2000,
China, vol. II, 747–750
23. Churchill, G. A.: „Hidden Markov chains and the analysis of genome structure”.
Computers Chem. 16 (1982)
24. Cohen, M. M., Massaro, D. W.: „What can Visual speech synthesis tell visual speech
recognition?”. Proc. Asilomar Conference on Signals, Systems, and Computers, Pacific
Gove, 1994, CA
25. Cootes, T. F., Edwards, G. J., Taylor, C. J.: „Active appearance models”. Proc. European
Conference on Computer Vision, Freiburg, 1998, Germany, 484-498

164
26. Cootes, T. F., Edwards, G. J., „Real-time Lip-tracking For Virtual Lip Implementation in
Virtual Environments and Computer Games”. Proc. International Fuzzy Systems
Conference, 2001
27. Cootes, T. F., et al.: „Active shape models – their training and application”. Computer
Vision and Image Understanding, 1995, 61(1): 38-59
28. Cosatto, E., Potamianos, G., Graf, H. P.: „Audio-visual unit selection for the synthesis of
photo-realistic talking-heads”. Proc. International Conference on Multimedia and Expo,
New York, 2000, NY, 1097-1100
29. Czap, L.: „Lip representation by image ellipse”. Proc. International Conference on
Spoken Language Processing, Beijing, 2000, China, vol. IV, 93–96
30. Dalton, B., Kucic, R., Blade, A.: „Automatic speechreading using dynamic contours”. In
Stork, D. G., Hennecke, M. E., (Eds.): „Speechreading by humans and Machines”.
Berlin, 1996, Germany: Spinger, 373-382
31. De Cuetos, P., Neti, C., Senior, A.: „Audio-visual intent to speak detection for human
computer interaction”. Proc. International Conference on Acoustics, Speech and Signal
Processing, Istanbul, 2000, Turkey, 1325-1328
32. Deller, J. R., Proakis, J. G., Hansen, J. H. L.: „Discrete-Time Processing of Speech
Signal”. Englewood Clifs, 1993, NJ: Macmillan Publishing Company
33. Do, M. N.: „An Automatic Speaker Recognition System”. DSP Mini-project,
Switzerland, 1996
34. Dougherty, E. R., Giardina, C. R.: „Image Processing – Continuous to Discrete, Vol. 1.
Geometric, Transform, and Statistical Methods”. Englewood Cliffs, 1987, NJ: Prentice
Hall
35. Dryden, I. L., Mardia, K. V.: „Statistical Shape Analysis”. London, 1998, United
Kingdom: John Wiley and Sons
36. Duchnowski, P., Meier, U., Waibel, A.: „See me, hear me: Integrating automatic speech
recognition and lipreading”. Proc. International Conference on Spoken Language
Processing, Yokohama, 1994, Japan, 547-550
37. Dupont, S., Luettin, J.: „Audio-visual speech modeling for continuous speech
recognition”. IEEE Transactions on Multimedia, 2000, 2(3): 141–151
38. Elliot, R. J., Aggoun, L., Moore, J. B.: „Hidden Markov Models Estimation and
Control”. New York, Springer, 1995
39. Ferguson, J. D.: „Hidden Markov Analysis: An Introduction in Hidden Markov Models
for Speech”. Institute for Defense Analyses, Princeton, New Jersey, 1980

165
40. Froba, B., et al.: „Multi-sensor biometric person recognition in an access control
system”. Proc. International Conference on Audio and Video-based Biometric Person
Authentication, Washington, 1999, DC, 55-59
41. Furui, S.: „Digital Speech Processing, Synthesis, and Recognition”. New York: Marcel
Dekker Inc., 1989
42. Girin, L., Feng, G., Schwartz, J. L.: „Noisy speech enhancement with filters estimated
from the speaker’s lips”. Proc. European Conference on Speech Communication and
Technology, Madrid, 1995, Spain, 1559-1562
43. Girin, L., Schwartz, J. L., Feng, G.: „Audio-visual enhancement of speech in noise”.
Journal of the Acoustical Society of America, 2001, 109(6): 3007-3020
44. Goldschen, A. J., Garcia, O. N., Petajan, E. D.: „Rationale for phoneme-viseme mapping
and feature selection in visual speech recognition”. In Stork, D. G., Hennecke, M. E.,
(Eds.): „Speechreading by Humans and Machines”. Berlin, 1996, Germany: Springer,
505–515
45. Golub, G. H., Van Loan, C. F.: „Matrix Computations”. Baltimore, 1983, MD, The
Johns Hopkins University Press
46. Gonzales, A. J., Garcia, O. N., Petajan, E. D.: „Rationale for phoneme-viseme mapping
and feature selection In Visual speech recognition”. In Stork, D. G., Hennecke, M. E.,
(Eds.), „Speechreading by Humans and Machines”. Berlin, 1996, Germany: Springer,
505-515
47. Gopinath, R. A.: „Maximum likelihood modeling width Gaussian distributions for
classification”. Proc. International Conference on Acoustics, Speech and Signal
Processing, Seattle, 1998, WA, 661-664
48. Graf, H. P., Cosatto, E., Potamianos, G.: „Robust recognition of faces and facial features
with a multi-modal system”. Proc. International Conference on Systems, Man, and
Cybernetics, Orlando, 1997, FL, 2034-2039
49. Gurbuz, S., et al.: „Application of affine-invariant Fourier descriptors to lipreading for
audio-visual speech recognition”. Proc. International Conference on Acoustics, Speech
and Signal Processing, Salt Lake City, 2001, UT, 177–180
50 Heckmann, M., Berthommier, F., Kroschel, K.: „A hybrid ANN/HMM audio-visual
speech recognition system”. Proc. International Conference on Auditory-Visual Speech
Processing, Aalborg 2001, Denmark, 190–195

166
51. Hennecke, M. E., Stork, D. G., Prasad, K. V.: „Visionary speech: Looping ahead to
practical speechreading systems”. In Stork, D. G., Hennecke, M. E., (Eds.):
„Speechreading by Humans and Machines”. Berlin, 1996, Germany: Springer, 331–349
52. http://sjikp.us.edu.pl/ps/ps_29_10.html
53. Huang, F. J., Chen, T.: „Consideration of Lombard effect for speechreading”. Proc.
Workshop on Multimedia Signal Processing, Cannes, 2001, France, 613–618
54. Iyengar, G., et al.: „Robust detection of Visual ROI for automatic speechreading”. Proc.
Workshop on Multimedia Signal Processing, Cannes, 2001, France, 79-84
55. Iyengar, G., Neti, C.: „Detection on faces under shadows and lighting variations”. Proc.
Workshop on Multimedia Signal Processing, Cannes, 2001, France, 15-20
56. Izworski, A., Tadeusiewicz, R.: „Metody komputerowej ekstrakcji parametrów
dystynktywnych z ciągłego sygnału mowy polskiej”. Archiwum Akustyki, 1983, vol. 18,
nr 3, 253-274
57. Jain, A., Bolle, R., Pankanti, S.: „Introduction to Biometrics”. In Jain, A., Bolle, R.,
Pankanti, S., (Eds.): „Biometrics. Personal Identification in Networked Society”. Orwell,
1999, MA, Kluwer Academic Publisher, 1-41
58. Jourlin, P., et al.: „Acoustic-labial speaker verification”. Pattern Recognition Letters,
1997, 18(9): 853-858
59. Kanugo, T.: „Hidden Markov Models”. www.cfar.umd.edu/~kanugo, April, 1998
60. Kass, M., Witkin, A., Terzopoluos, D.: „Snakes: Active contour models”. International
Journal of Computer Vision, 1988, 1(4): 321-331
61. Kompanec, L., Kubanek, M., Rydzek, Sz.: “Czestochowa’s Precise Model of a Face
Based on the Facial Asymmetry, Ophthalmogeometry, and Brain Asymmetry
Phenomena: the Idea and Algorithm Sketch”. 10th International Multi-Conference on
Advanced Computer Systens ACS, October 22-24, Międazyzdroje
62. Kompanec, L., Kubanek, M.: „Specyfika wykorzystania ukrytych modeli Markowa
przy rozpoznawaniu mowy polskiej”. Informatyka Teoretyczna i Stosowana,
Wydawnictwo Politechniki Częstochowskiej, Częstochowa 2002, nr 3, 45-56
63. Kompanec, L., Wyrzykowski, R., Kubanek, M.: „Zintegrowana metoda
identyfikacji/autentyfikacji użytkownika na bazie sygnałów mowy polskiej i ruchu
warg”. Proc. Intern. Conference IT.FORUM SECURE 2002, Holiday Inn, Warszawa, 6-
7 November 2002, Wydawnictwo NASK i firma MULTICOPY, vol.1, 96-110
64. Kompanets, L., Kubanek, M., Rydzek, Sz.: “Czestochowa Precise Model of a Face
Based on the Facial Asymmetry, Opthalmogeometry, and Brian Asymmetry Phenomena:

167
the Idea and Algorithm Sketch”. Enhanced Methods in Computer Security, Biometric
and Artificial Intelligence Systems, Edited by Jerzy Pejaś, Andrzej Piegat, Kluwer
Academic Publishers, 2005 Springer Science + Business Media, Inc., 239-251
65. Kompanets, L., Kubanek, M., Rydzek, Sz.: “Czestochowa-Faces and Biometrics of
Asymmetrical Face”. Proc. 7th Intern. Conference of Artificial Intelligence and Soft
Computing, ICAISC 2004 - Springer-Verlag Berlin Heildelberg, 2004, LNAI 3070, 742-
747
66. Kompanets, L., Valchuk, T., Wyrzykowski, R., Kubanek, M., Rydzek, Sz., Makowski,
B.: “Based on Pseudo-Information Evaluation, Face Asymmetry and
Ophthalmogeometry Techniques for Human-Computer Interaction, Person Psyche Type
Identification, and Other Applications”. The 7th World Multiconferenceon Systemics,
Cybernetics and Informatics, Orlando, Florida, USA 27-30 July 2003
67. Krone, G., et al.: „Neural architectures for sensorfusion in speech recognition”. Proc.
European Tutorial Workshop on Audio-Visual Speech Processing, Rhodes, 1997,
Greece, 57–60
68. Kubanek, M.: „ Technique of extraction video features for audio - video speech
recognition system”. CMIT, 2005
69. Kubanek, M.: „Metoda krawędziowania "EDGE" do ekstrakcji cech obrazu ust w
technice zintegrowanego rozpoznawania audio/video mowy”. Informatyka Teoretyczna i
Stosowana, Wydawnictwo Politechniki Częstochowskiej, Częstochowa 2003, nr 4, 115-
125
70. Kukharev, G., Kuźmiński, A.: „Techniki biometryczne. Część 1: Metody Rozpoznawania
Twarzy”. Wydział Informatyki, Politechnika Szczecińska, 2003
71. Levison, S. E., Labiner, L. R., Sondhi, M. N.: An introduction to the application of the
theory of probabilistic functions of Markov process to automatic speech recognition.
Bell System Tech., J., 62 (1983)
72. Luettin, J., Thacker, N. A.: „Speechreading using probabilistic models”. Computer
Vision and Image Understanding, 1997, 65(2): 163-178
73. Luettin, J., Tracker, N. A., Beet, S. W.: „Speechreading using shape and intensity
information”. Proc. International Conference on Spoken Language Processing,
Philadelphia, 1996, PA, 58-61
74. Lyons, R. G.: „Wprowadzenie do cyfrowego przetwarzania sygnałów”. WKiŁ,
Warszawa, 1999

168
75. Maison, B., Neti, C., Senior, A.: „Audio-visual speaker recognition for broadcast news:
some fusion techniques”. Proc. Workshop on Multimedia Signal Processing,
Copenhagen, 1999, Denmark, 161-167
76. Makinen, V.: „Front-end Feature Extraction with Mel-scaled Cepstral Coefficients”.
Helsinki University of Technology, 2000
77. Mase, K., Pentland, A.: „Automatic lipreading by optical flow analysis”. Systems and
Computers in Japan, 22(6): 67-76, 1991
78. Massaro, D. W., Stork, D. G.: „Speech recognition and sensory integration”. American
Scientist, 86(3): 236-244, 1998
79. Mattews, I., et al.: „A comparison of model and transform-based visual features for
audio-visual LVCSR”. Proc. International Conference on Multimedia and Expo, Tokyo,
2001, Japan
80. Mattews, I., Bangham, M. E., Cox, S.: „Audio-visual speech recognition using
multiscale nonlinear image de composition”. Proc. International Conference on Spoken
Language Processing, Philadelphia, 1996, PA, 38–41
81. Movellan, J. R., Chadderdon, G.: „Chanel separability in the audio visual integration of
speech: A Bayesian approach”. In Stork, D. G., Hennecke M. E., (Eds.): „Speechreading
by Humans and Machines”. Berlin, 1996, Germany: Springer, 473–487
82. Nakamura, S., Ito, H., Shikano, K.: „Stream wright optimization of speech and lip image
sequence for audio-visual speech recognition”. Proc. International Conference on
Spoken Language Processing, Beijing, 2000, China, vol. III, 20–23
83. Nefian, A. V., et al.: „Dynamic Bayesian networks for audio-visual speech recognition”.
In Press: EURASIP Journal on Applied Signal Processing, 2002
84. Neti, C., et al.: „Audio Visual Speech-Recognition”. Workshop 2000 Final Report,
October 12, 2000
85. Oppenheim, A. V., Schafer, R. W.: „Discrete-Time Signal Processing”. Prentice-Hall,
1989, 447-448
86. Petajan, E. D.: „Automatic lipreading to enhance speech recognition”. Proc. Global
Telecommunications Conference, Atlanta, 1984, GA, 265–272
87. Potamianos, G., et al.: „A cascade visual front end for speaker independent automatic
speechreading”. International Journal of Speech Technology, 2001, 4(3-4): 193-208
88. Potamianos, G., Graf, H. P., Cosatto, E.: „An image transform approach for HMM based
automatic lipreading”. Proc. International Conference on Image Processing, Chicago,
1998, IL, vol. I, 173–177

169
89. Potamianos, G., Graf, H. P.: „Discriminative training of HMM stream exponents for
audio-visual speech recognition”. Proc. International Conference on Acoustics, Speech
and Signal Processing, Seattle, 1998, WA, 3733– 3736
90. Potamianos, G., Neti, C.: „Improved ROI and within frame discriminant features for
lipreading”. Proc. International Conference on Image Processing, Thessaloniki, 2001,
Grece, vol. III, 250-253
91. Press, W. H., et al.: „Numerical Recipes in C”. The Art. Of Scientific Computing,
Cambridge, 1995, UK: Cambridge University Press
92. Rabiner, L., Juang, B. H.: „Fundamentals of Speech Recognition”. Englewood Cliffs, NJ
1993, Prentice Hall
93. Rao, C. R.: „Linear Statistical Interference and Its Applications”. New York, 1965, NY:
John Wiley and Sons
94. Reddy, D.: „Speech recognition by machine: a review”. Proc. IEEE, April 1976, vol. 64,
No 4
95. Rowley, H. A., Baluja, S., Kanade, T.: „Neural network-based face detection”. IEEE
Transactions on Pattern Analysis and Machine Intelligence, 1998, 20(1): 23-38
96. Sayood, K.: „Kompresja danych – wprowadzenie”. Wydawnictwo RM, Warszawa, 2002
97. Senior, A. W.: „Face and feature finding for a face recognition system”. Proc.
International Conference on Audio and Video-based Biometric Person Authentication,
Washington, 1999, DC, 154-159
98. Senior, A. W.: „Visual Speech: A Physiological or Behavioural Biometrics“. Audio- and
Video-Based Biometric Person Authentication, 1998, LNCS 2091, 157-168
99. Silsbee, P. L., Bovik, A. C.: „Computer lipreading for improved accuaracy in automatic
speech recognition”. IEE Transactions on Speech and Audio Processing, 1996, 4(5):
337-351
100. Silsbee, P. M.: „Motion in deformable templates”. Proc. International Conference on
Image Processing, Austin, 1994, TX, vol. 1, 323-327
101. Stiefelhagen, R., Meier, U., Yang, J.: „Real-Time Lip-Tracking for Lipreading”.
Interactive Systems Laboratories, USA-Germany
102. Su, Q., Silsbee, P. L.: „Robust audiovisual integration using semicontinuous hidden
Markov models”. Proc. International Conference on Spoken Language Processing,
Philadelphia, 1996, PA, pp.42–45
103. Sung, K., Loggio, T.: „Example-based learning for view-based human face detection”.
IEEE Transactions on Pattern Analysis and Machine Intelligence, 1998, 20(1): 39-51

170
104. Swets, D. L., Weng, J.: „Using discriminant eigenfaces for image retrieval”. IEEE
Transactions on Pattern Analysis and Machine Intelligence, 1996, 18(8): 831-836
105. Tadeusiewicz, R.: „Sygnał mowy”. WKiŁ, Warszawa, 1988
106. Teissier, P., Robert-Ribes, J., Schwartz, J. L.: „Comparing models for audiovisual fusion
in a noisy-vowel recognition task”. IEEE Transactions on Speech and Audio Processing,
1999, 7(6): 629–642
107. Wahab, A., See Ng, G., Dickiyanto, R.:”Speaker Verification System Based on Human
Auditory and Fuzzy Neural Network System”. Neurocomputing Manuscript Draft,
Singapore
108. Wai, C. C.: „Speech Coding Algorithms”. Foundation and Evolution of Standardized
Coders. John Wiley & Sons, Inc., Hoboken, New Jersey, 2003
109. Wang, C., Brandstein, M. S.: „Multi-source face tracking with audio and Visual data”.
Proc. Workshop on Multimedia Signal Processing, Copenhagen, 1999, Denmark,
pp.475-481
110. Wark, T., Sridharan, S., „A syntactic approach to automatic lip feature extraction for
speaker identification”. Proc. International Conference on Acoustics, Speech and Signal
Processing, Seattle, 1998, WA, 3693-3696
111. Wiśniewski, A. M.: „Automatyczne rozpoznawanie mowy bazujące na ukrytych
modelach Markowa – problemy i metody”. Biuletyn IAiR WAT, nr 12, 2000
112. Wiśniewski, A. M.: „Niejawne modele Markowa w rozpoznawaniu mowy”. Biuletyn
IAiR WAT, nr 7, 1997
113. Yang, J., Waibel, A.: „A Real-time face tracking”. In Proc. WACV, 142-147, 1996
114. Young, S., et al.: „The HTK Book”. Cambridge, 1999, United Kingdom: Entropic Ltd
115. Yuille, A. L., Hallinan, P. W., Cohen, D. S.: „Feature extraction from faces using
deformable templates”. International Journal of Computer Vision, 1992, 8(2): 99-111
116. Zhang, X., et al.: „Automatic speechreading with applications to human-computer
interfaces”. In Press: EURAISP Journal on Applied Signal Processing
117. Zhang, Y., Levinson, S., Huang, T.: „Speaker independent audio-visual speech
recognition”. Proc. International Conference on Multimedia and Expo, New York, 2000,
NY, 1073–1076
118. Zotkin, D. N., Duraiswami, R., Davis, L. S.: „Joint audio-visual tracking using particle
filters”. In Press: EURAISP Journal on Applied Signal Processing









![[Polish] Praca zdalna, praca asynchroniczna](https://static.fdocuments.pl/doc/165x107/55a1e44f1a28ab78508b4656/polish-praca-zdalna-praca-asynchroniczna.jpg)








