
INSTYTUT MASZYN MATEMATYCZNYCH · instytut maszyn matematycznych techniki komputerowe biuletyn...
48
INSTYTUT MASZYN MATEMATYCZNYCH
Transcript of INSTYTUT MASZYN MATEMATYCZNYCH · instytut maszyn matematycznych techniki komputerowe biuletyn...

INSTYTUT MASZYN MATEMATYCZNYCH


INSTYTUT MASZYN MATEMATYCZNYCH
TECHNIKIKOMPUTEROWE
BIULETYN INFORMACYJNY
Warszawa 2011
Rok XLV, Nr 1, 2011

TECHNIKI KOMPUTEROWE, Rok XLVI, Nr 1, 2011
Wydawca: Instytut Maszyn Matematycznych
Projekt okładki: Jerzy KowalskiDTP: Instytut Maszyn Matematycznych
Notka wydawcy:Cała zawartość niniejszego wydania, wraz z rysunkami i zdjęciami jest własnością Instytutu Maszyn Matematycznych oraz Autorów. Kopiowanie lub reprodukowanie niniejszego biuletynu w całości lub cześci jest bez zezwolenia Wydawcy zabronione.
ISSN 0239-8044
Instytut Maszyn Matematycznych02-078 Warszawa, ul. Krzywickiego 34www.imm.org.pl
Biuletyn Informacyjny

Spis treści
Szyfry strumieniowe na przykładzie algorytmów A5/1 i Rabbit,Robert Poznański
Bezpieczne uwierzytelnianie biometryczne na przykładzie rozwiązania AXSionics Internet Passport, Robert Poznański, Karol Szacki
Wybrane zagadnienia zastosowania linii papilarnych w dokumentach identyfikacyjnych , Lech Naumowski
Opory elit społecznych wobec biometrii, Mirosław Owoc
Podpis elektroniczny - zasady działania, Wojciech Nowakowski,Robert Poznański
Algorytm RSA - podstawa podpisu elektronicznego,Wojciech Nowakowski
O protokóle Ekerta w kryptografii kwantowej, Roman CzajkowskiWojciech Nowakowski
Wirtualny konsultant dla Małych i Średnich Przedsiębiorstw,Monika Biskupska, Grzegorz Mazurkiewicz, Piotr Zduńczyk


Robert PoznańskiInstytut Maszyn Matematycznych
Szyfry strumieniowe na przykładzie algorytmów A5/1 i Rabbit
Szyfry strumienioweSzyfry strumieniowe są algorytmami, które przekształcają tekst jawny w
szyfrogram kolejno bit po bicie (rys. 1).
Rys. 1. Szyfr strumieniowy z kluczami
Generator strumienia klucza wytwarza strumień bitów K, który jest dodawany modulo 2 z ciągiem bitów tekstu jawnego P celem wygenerowania strumienia bitów szyfrogramu C = P K.
Bezpieczeństwo systemu całkowicie zależy od wewnętrznych właściwości generatora strumienia klucza. Jeżeli generator strumienia klucza wytwarza nieskończony ciąg zer, to szyfrogram będzie równy tekstowi jawnemu i cała operacja nie będzie miała sensu. Jeżeli generator strumienia klucza wytwarza powtarzający się wzorzec 16-bitowy, to algorytm będzie zwykłym sumatorem modulo 2 z bardzo małym (pomijalnym) stopniem zabezpieczenia. Jeżeli generator strumienia klucza wytwarza nieskończony strumień bitów losowych (nie pseudolosowych), to otrzymujemy klucz jednorazowy i doskonałe zabezpieczenie. W rzeczywistości szyfry strumieniowe to coś pośredniego między prostą sumą modulo 2 i szyfrowaniem z kluczem jednorazowym. Generator strumienia klucza wytwarza ciąg bitów, który wygląda losowo, ale w rzeczywistości jest ciągiem zdeterminowanym, który może być bezbłędnie odtworzony podczas odszyfrowywania. Im bliższy postaci losowej jest ciąg wyjściowy generatora strumienia klucza, tym trudniejsze dla kryptoanalityka będzie jego złamanie. Jak można przypuszczać, zadanie zbudowania generatora strumienia klucza
7

wytwarzającego losowo wyglądający ciąg nie należy do łatwych. Szyfrowanie strumieniowe polega na szyfrowaniu informacji kluczem złożonym ze strumienia danych (bitów lub znaków), nie krótszym od szyfrowanej informacji. Szyfry strumieniowe dzielą tekst M na części lub bity 1, 2,.., m, a następnie każdy element jest szyfrowany kluczem ki należącym do strumienia kluczy.
Szyfr strumieniowy jest okresowy, jeśli strumień klucza powtarza się po T znakach, dla pewnego, ustalonego T . W przeciwnym razie szyfr jest nieokresowy. Do okresowych szyfrów strumieniowych należą np. szyfry generowane przez maszyny rotorowe (Enigma - okres większy niż 26k , gdzie k oznacza liczbę rotorów, oryginalnie k = 3 oraz k = 5 , 265 = 11 881 376). Natomiast szyfr jednokrotny i szyfry z kluczem bieżącym są nieokresowymi szyframi strumieniowymi. Okres jest bardzo istotnym parametrem generatora. Decyduje on jak długo można ten generator stosować bez zmiany parametrów początkowych. Z teorii na temat szyfru z kluczem jednorazowym wiadomo, że niedopuszczalne jest użycie dwa razy tego samego klucza. Oznacza to, że nie można używać generatora dłużej niż wynosi jego okres, gdyż groziłoby to właśnie powtórzeniem tego samego ciągu klucza. Dlatego ważne jest aby kres generatora był jak najdłuższy, co pozwoliłoby długo używać tego samego generatora bez zmiany jego parametrów. Ponieważ konieczna jest zmiana klucza wraz z każdą wiadomością, algorytmy strumieniowe nie są zazwyczaj używane do szyfrowania wydzielonych wiadomości. Bardziej użyteczne są one w szyfrowaniu bardzo długich strumieni informacji. Mogą to być na przykład transmisje sygnałów wideo, audio. Ponieważ generator strumienia klucza musi wytwarzać te same wartości zarówno do szyfrowania, jak i odszyfrowywania, musi być on zdeterminowany. Sekwencje wyjściowe mogą powtarzać się, ponieważ jest on zbudowany z wykorzystaniem maszyny ze skończoną liczbą stanów (tj. komputera). Takie generatory strumieni klucza noszą nazwę okresowych. Z wyjątkiem przypadku wytwarzania kluczy jednorazowych wszystkie generatory strumieni klucza są okresowe. Bardzo ważne jest uzyskanie długiego okresu dla generatora strumienia klucza i to znacznie dłuższego od liczby bitów, które generator wytworzy w czasie pomiędzy zmianami kluczy. Okres generatora strumienia klucza musi być o wiele rzędów wielkości większy niż podana wartość.
Głównym elementem, w oparciu o który można zbudować algorytm strumieniowy jest tzw. LFSR (Linear Feedback Shift Register – Rejestr Przesuwny ze Sprzężeniem Zwrotnym).
Bit wyjściowyBn Bn-1 … … B2 B1 B0
Rys. 2. Rejestr przesuwny ze sprzężeniem zwrotnym
Składa się on z ciągu bitów oraz odczepów, które są wejściem do funkcji XOR generującej bit wchodzący do rejestru na pozycji najbardziej znaczącego bitu. Wyjściem LFSRa jest bit najmniej znaczący (rys. 2.). Aby osiągnąć maksymalny okres LFSRa wielomian charakterystyczny, utworzony z elementów ciągu odczepów musi być wielomianem pierwotnym.
Algorytm A5/1Jednak bezpieczeństwo kryptograficzne algorytmu opartego tylko o LFSR jest
bardzo słabe. Aby je wzmocnić rozbudowuje się algorym o dodatkowe LFSRy
8

oraz dodaje funkcjonalnośćnieliniowego ich taktowania. Jednym z przykładów takiego algorytmu jest A5/1 używany do szyfrowania transmisji GSM. Czas trwania ramki GSM wynosi 4,615 milisekundy i wynosi 114 bitów. Stanem początkowym algorytmu są same zera, natomiast 64 bitowy klucz tajny razem z jawnym 22 bitowym numerem ramki służą do inicjalizacji algorytmu. A5/1 oparty jest na trzech rejestrach przesuwnych ze sprzężeniem zwrotnym R1, R2, R3, o długości 19, 22, 23 bitów. Wielomiany charakterystyczne wynoszą odpowiednio x19+x18+x17+x14+1, x22+x21+1 oraz x23+x22+x21+x8+1, a numery bitów służące do sterowania pracą rejestrów 8, 10, 10 (rys. 3.). Wyjściem algorymu jest suma algebraiczna modulo 2 wyjść wszystkich LFSR.
Rys 3. Schemat budowy A5/1. (źródło wikipedia)
Do taktowania rejestrów wykorzystuje po jednym bicie z każdego rejestru. W każdym cyklu analizowana jest zawartość tych bitów. Jeśli co namniej dwa mają wartość 1 to taktowane są tylko rejestry, w których bity te miały wartość 1. W przeciwnym przypadku taktowane są te rejestry, które miały wartość 0. Jak widać w każdym takcie pracy algorymu taktowane są przynajmniej 2 rejestry, każdy z prawdopodobieństwem 0,75. Schemat ten można zapisać jak w Tabeli 1.
Wartość R1
Wartość R2
Wartość R3 Takt R1 Takt R2 Takt R3
0 0 0 T T T0 0 1 T T N0 1 0 T N T0 1 1 N T T1 0 0 N T T1 0 1 T N T1 1 0 T T N
9

1 1 1 T T TTabela 1. Taktowanie rejestrów
Praca algorytmu zaczyna się od procesu jego inicjalizacji. Najpierw, z pomi-nięciem sterowania taktowaniem rejestrów, wprowadzany jest 64 bitowy klucz, następnie 22 bitowy numer ramki. Obie te operacje trwają odpowiednio 64 i 22 takty. Kolejną operacją jest mieszanie, które trwa 100 cykli zegarowych. W czasie tej operacji sterowanie rejestrami odbywa się już w normalny sposób, natomiast ignorowane są wyjścia z algorymu. Właściwe szyfrowanie trwa 228 rund w czasie których generowanych jest 228 bitów strumienia szyfrującego po 114 bitów na wysłanie i odebranie ramki.
Zaletą algorytmów oparych na LFSR jest wysoka szybkość działania i stosun-kowo łatwa implementacja w rozwiązaniach sprzętowych. Jeden tak pracy zegara może odpowiadać jednemu taktowi pracy rejestru dzięki czemu łatwo jest dostosować pracę takiego algorytmu do pracy innych urządzeń. Jednak algorytmy strumieniowe nie muszą być oparte o rejestr przesuwny ze sprzężeniem zwrotnym.
Algorytm Rabbit
W latach 2004-2008 organizacja ECRYPT przeprowadziła konkurs eSTREAM mający na celu zaprezentowanie nowych technologii w algorytmach strumieniowych. Jednym z algorytmów biorąych udział w konkursie był, zaprezentowany już w 2003 roku na konferencji Fast Software Encryption, algorytm Rabbit. Został on jednym z czterech laureatów konkursu w kategorii algorytmów przeznaczonych do implementacji programowej. Zgłaszany był także w kategorii algorymtów przeznaczonych do implementacji sprzętowej, jednak nie odniósł tam większych sukcesów. Jego budowa jest zdecydowanie bardziej skomplikowana niż A5/1. Parametrami wejściowymi Rabbita są klucz o długości 128 bitów oraz wektor inicjalizujący IV o długości 64 bitów. Wektor IV jest dodatkową wartością służącą do inicjalizacji algorytmów kryptograficznych, użycie jego nie jest obowiązkowe, a przesyłany jest jawnie, dołączony do szyfrogramu. Rabbit generuje strumień klucza w 128 bitowych blokach.
Budowa algorytmu Rabbit nie jest oparta na rejestrze przesuwnym ze sprzężeniem zwrotnym. Jego stan wewnętrzny składa się z 513 bitów podzielonych na dwie grupy po osiem 32 bitowych rejestrów (C0...C7, X0...X7) i jeden bit ‘b’ służący za wskaźnik przeniesienia. Cykl pracy algorytmu podzielić można na poszczególne części takie jak funkcja licznika, funkcja następnego stanu oraz ekstrakcja strumienia. Na główną rundę składa się kolejne przejście przez wszystkie trzech części algorytmu.
Praca algorytmu rozpoczyna się od inicjalizacji, czyli zapełnienia stanu wewnętrznego bitami klucza oraz wektora IV. Klucz dzielony jest na osiem podkluczy Kj dla j=0..7. Następnie wykonywana jest operacja wg schematu, dla parzystych j: Xj = k(j+1 mod 8) ll kj , Cj = k(j+4 mod 8) ll k(j+5 mod 8) dla nieparzystych j: Xj = k(j+5 mod 8) ll k(j+4 mod 8) , Cj = kj ll K(j+1 mod 8) . Operacja ll oznacza konkatenację, czyli złączenie dwóch wartości. Po zapełnieniu wszystkich X oraz C następuje wykonanie czterech iteracji par funkcji licznika i następnego stanu. Ostatnim elementem inicjalizacji klucza jest uaktualnienie stanów Cj = Cj X(j+4 mod 8)
10

Następnie wykonywana jest inicjalizacja wektora IV. Polega ona na dodaniu wartości bitów o numerach IV[63..0] do stanów C:
C0 = C0 IV [31..0] C1 = C1 (IV [63..48] || IV [31..16])C2 = C2 IV [63..32] C3 = C3 (IV [47..32] || IV [15..0])C4 = C4 IV [31..0] C5 = C5 (IV [63..48] || IV [31..16]) C6 = C6 IV [63..32] C7 = C7 (IV [47..32] || IV [15..0])Następnie wykonywana jest czterokrotna iteracja pary funkcji licznika i
następnego stanu.Tak przygotowany algorytm jest już gotowy do działania. Na jego rundę
składają się trzy, kolejno wykonywane po sobie funkcje. Funkcja licznika, funkcja następnego stanu oraz ekstrakcja strumienia. Funkcja licznika służy do uaktualniania stanu C.
C0 = C0 + A0 + b(j-1) modulo 232C1 = C1 + A1 + b0 modulo 232C2 = C2 + A2 + b1 modulo 232C3 = C3 + A3 + b2 modulo 232C4 = C4 + A4 + b3 modulo 232C5 = C5 + A5 + b4 modulo 232C6 = C6 + A6 + b5 modulo 232C7 = C7 + A7 + b6 modulo 232Natomiast bit przeniesienia przyjmuje wartości: bj = 1 jeżeli C0 + A0 + b'7
modulo 232 dla j = 0, 1 jeżeli Cj + Aj + b(j-1) modulo 232 dla j > 0, 0 w przeciwnym przypadku. Operacja + oznacza dodawanie algebraiczne. Stałe mają wartości A0 = 0x4D34D34D, A1 = 0xD34D34D3, A2 = 0x34D34D34, A3 = 0x4D34D34D, A4 = 0xD34D34D3, A5 = 0x34D34D34, A6 = 0x4D34D34D, A7 = 0xD34D34D3.
Głównym elementem algorytmu Rabbit jest funkcja następnego stanu i to przede wszystkim na niej opiera się bezpieczeństwo całego algorytmu. Jej podstawowym działaniem jest funkcja G opisana wzorem: Gj = (Xj + Cj) ((Xj + Cj) << 32) mod 232, gdzie <<i oznacza rotację w lewo o i bitów. Drugim elementem funkcji następnego stanu jest uaktualnienie rejestru X wg opisu:
X0 = G0 + (G7 <<< 16) + (G6 <<< 16)X1 = G1 + (G0 <<< 8) + G7X2 = G2 + (G1 <<< 16) + (G0 <<< 16)X3 = G3 + (G2 <<< 8) + G1X4 = G4 + (G3 <<< 16) + (G2 <<< 16)X5 = G5 + (G4 <<< 8) + G3X6 = G6 + (G5 <<< 16) + (G4 <<< 16)X7 = G7 + (G6 <<< 8) + G5Ostatnią czynnością wykonywaną w każdej rundzie jest ekstrakcja strumienia
szyfrującego. Przebiega ona wg schematu: S[15..0]= X0[15..0]X5[31..16], S[31..16]= X0[31..16] X3[15..0], S[47..32]= X2[15..0]X7[31..16], S[63..48]= X2[31..16]X5[15..0], S[79..64]= X4[15..0]X1[31..16], S[95..80]= X4[31..16]X7[15..0], S[111..96]= X6[15..0]X3[31..16]
11

Z wyjścia S pobierane są 128 bitowe bloki strumieni szyfrującego. Jest to całkiem odmienne podejście niż przy poprzednim algorytmie. W A5/1 w jednym takcie zegara generowany był jeden bit strumienia szyfrującego. Jednak zaznaczyć trzeba, że Rabbit jest algorytmem ogólnego przeznaczenia projektowanym przede wszystkim do zastosowania w implementacjach programowych. A5/1 jest algorytmem projektowanym do konkretnego zastosowania jakim jest szyfrowanie transmisji w sieciach GSM i jest implementowany w sprzęcie.
PodsumowanieNa przykładzie algorytmów A5/1 oraz Rabbit widać wyraźnie jak odmienne
może być podejście do projektowania szyfrów strumieniowych. W pierwszym przypadku zastosowano trzy rejestry liniowe ze sprzężeniem zwrotnym, sterowane w nieregularny sposób, a wyjście z każdego z nich bierze udział w generowaniu strumienia szyfrującego. Takie rozwiązanie stawia przede wszystkim na wydajność i łatwość implementacji. Algorytm Rabbit został zorientowany przede wszystkim na bezpieczeństwo. W celu jego zapewnienia została stworzona funkcja G. Niestety wysokie bezpieczeństwo zostało okupione niższą wydajnością, choć wcale nie niską, gdyż operacja potęgowania jest jedną z najwolniejszych w działaniu.
12

Robert PoznańskiKarol SzackiInstytut Maszyn Matematycznych
Bezpieczne uwierzytelnianie biometrycznena przykładzie rozwiązania AXSionics Internet Passport
SW świecie, w którym kradzież tożsamości jest poważnym zagrożeniem, biometria staje się niezwykle istotną techniką bezpiecznego uwierzytelniania. W odróżnieniu od wszelkiego rodzaju kodów i haseł, cecha biometryczna jest ściśle i nierozerwalnie powiązana z daną osobą.
Wykorzystanie biometrii może stanowić pewne zagrożenie dla prywatności użytkownika. Ujawnienie danych biometrycznych osoby może skutkować różnego rodzaju nadużyciami. Z tego względu informacje te nigdy nie powinny być narażone na nieuprawnione modyfikacje lub kopiowanie. Ze względów bezpieczeństwa nie zaleca się też stosowania centralnych repozytoriów danych biometrycznych, gdyż przełamanie zabezpieczeń jednego systemu będzie miało konsekwencje dla wszystkich osób, których wzorce biometryczne były tam przechowywane.
Na rynku pojawia się wiele nowych systemów uwierzytelniających. Szczególnie interesujące są te z potencjałem powszechnego wykorzystania w sieci Internet i posiadające jednocześnie możliwość uwierzytelniania biometrycznego chroniącego zarazem prywatność osób. Odznaczają się one przechowywaniem informacji wrażliwych oraz wykonywaniem operacji na tych danych bezpośrednio na urządzeniu będącym w posiadaniu użytkownika.
Jednym z takich rozwiązań jest AXSionics Authentication System. Pozwala on na uwierzytelnianie osób przy użyciu systemu zdecentralizowanego. Możliwe jest to dzięki obecności spersonalizowanego tokenu przypisanego do konkretnej osoby (Internet Passport).
Jak to działa
Rys. 1 Urządzenie AXSionisc Internet Passport
13

AXSionics Internet Passport (rys. 1) jest urządzeniem o rozmiarach zbliżonych do wymiarów powszechnie stosowanych kart elektronicznych. Wyposażony jest w monochromatyczny wyświetlacz OLED oraz czytnik linii papilarnych. Posiada także zestaw sześciu sensorów optycznych służących do odczytu danych wejściowych ze specjalnych animacji pokazywanych na ekranie komputera lub innego urządzenia wyposażonego w wyświetlacz graficzny.
Odczyt danych kanałem optycznym następuje poprzez przyłożenie urządzenia na czas kilku sekund do ekranu w obszar, na którym wyświetlona zostaje animacja (rys. 2).
Rys. 2 Wygląd animacji ekranowej wykorzystywanej w systemie AXSionics.
Główną funkcjonalnością paszportu internetowego AXSionics jest generowanie kodów jednorazowych. Mogą one znaleźć zastosowanie np. w bankowości elektronicznej, uwierzytelnianiu transakcji czy dostępie do systemów informatycznych.
Podstawą działania systemu, obok samego urządzenia, jest technologia animacji (rys. 2) wyświetlanych na witrynach internetowych. Użytkownik chcąc zalogować się do danej usługi podaje numer seryjny swojego paszportu internetowego oraz nazwę użytkownika. Na podstawie tych danych tworzona jest animacja, która pojawia się na ekranie komputera. Za generowanie animacji odpowiedzialna jest infrastruktura firmy AXSionics. Następnie, po przyłożeniu urządzenia do ekranu, dane zawarte w animacji zostają wczytane do jego pamięci. Aby rozszyfrować i wyświetlić komunikat użytkownik musi autoryzować się do swojego paszportu internetowego przeciągając palec przez czytnik linii papilarnych. Jeśli weryfikacja jest poprawna, na ekranie pojawia się kod jednorazowy, który należy przepisać jako hasło służące do logowania.
Łatwo zauważyć, że funkcjonalność paszportu internetowego AXSionics zbliżona jest do zastosowania jednorazowych kodów PIN powszechnie używanych w bankowości elektronicznej. Jednak tradycyjne kody jednorazowe przypisane są do jednej usługi. Jeśli posiadamy konta w różnych bankach lub korzystamy z innych usług wymagających bezpiecznego logowania otrzymamy do każdej z tych usług osobne listy kodów lub urządzenia służące do ich generowania tzw. tokeny. Rozwiązanie AXSionics Internet Passport integruje wszystkie te rozwiązania w jedno urządzenie dające dostęp do wielu usług on-line, oferowanych przez różne instytucje.
W przypadku zgubienia lub kradzieży listy kodów PIN jesteśmy narażeni na oszustwo i możliwość wykorzystania tych informacji bez naszej wiedzy. Dzięki wykorzystaniu biometrii nasz paszport internetowy jest zabezpieczony przed użyciem go przez niepowołane osoby.
14

Inną ciekawą możliwością zastosowania AXS Internet Passport jest przesyłanie wiadomości tekstowych. W animacji może być zakodowanych więcej informacji niż tylko kod jednorazowy. Istnieją witryny, które umożliwiają zaszyfrowanie krótkiego tekstu o długości około 160 znaków. Dodatkowym zabezpieczeniem jest przypisanie wiadomości do wybranego numeru seryjnego urządzenia, które będzie mogło ją odkodować. Adresat otrzymuje tylko plik graficzny przedstawiający animację. Po wczytaniu danych do urządzenia i uwierzytelnieniu, informacje zostaną wyświetlone na ekranie.
Połączenie obu funkcjonalności, generowania kodów oraz przesyłania wiadomości, może posłużyć do zabezpieczenia transakcji on-line. W przypadku dokonywania na przykład przelewu lub zakupów, w animacji poza samym kodem jednorazowym może zostać przesłany np. identyfikator transakcji, jej wartość czy inne informacje jednoznacznie ją identyfikujące.
Zabezpieczenie transakcji on-line oznacza, że wszystkie zagrożenia muszą być zminimalizowane do pewnego akceptowalnego poziomu. Jednocześnie powinna być zapewniona obsługa funkcjonalności, takich jak:
1. wzajemne bezpieczne uwierzytelnianie użytkownika i operatora2. ochrona prywatnych danych obu kontaktujących się stron3. zachowanie anonimowości, w najlepszy możliwy sposób w zależności
od charakteru transakcji4. integralność i aktualność danych transakcyjnych5. poufność danych transakcji6. niezaprzeczalność
Do tych wymagań możemy dodać jeszcze wymaganie łatwości obsługi (użyteczności), która oznacza ciągłą dostępność, ergonomię użytkowania i niskie koszty operacyjne. Warto w tym momencie zastanowić się jakie zagrożenia można napotkać w globalnej sieci.
Zagrożenia komunikacji elektronicznejPotencjalnym słabym punktem narażonym na atak jest sama infrastruktura
Internetu. Każda bramka czy inny przekaźnik danych może być wykorzystany do podsłuchania lub posłużyć do ingerencji w przesyłane informacje. Jeżeli komunikacja pomiędzy serwerem a urządzeniem końcowym zabezpieczona jest poprzez połączenie SSL/TLS ryzyko tego rodzaj ataku staje się marginalne. Istnieje jednak niebezpieczeństwo, że atakujący zmieni konfigurację lokalnej infrastruktury sieciowej, tak aby akceptowano fałszywe certyfikaty SSL. Może to skutkować tym, że niczego nieświadomy użytkownik połączy się z serwerem cyberprzestępcy. W takim przypadku atakujący staje się oszustem, który kieruje cały ruch sieciowy przez swoją maszynę i poprzez takie działanie może się podszyć pod osobę, którą zaatakował. Tego typu zachowanie nazywane jest atakiem Man-in-the-Middle (MitM).
Najbardziej narażone na atak jest urządzenie, przy pomocy którego użytkownik łączy się z Internetem. Komputery osobiste są zwykle niedostatecznie zabezpieczone przeciw najnowszemu złośliwemu oprogramowaniu. Dodatkowo ludzie są często podatni na phishing. Atakujący przy pomocy fałszywych wiadomości, podobnych w wyglądzie np. do e-maili wysyłanych przez banki, nakłania użytkownika do instalacji złośliwego oprogramowania. Takie działanie
15

pozwala napastnikowi na monitorowanie komputera użytkownika, a nawet na wprowadzanie modyfikacji w oprogramowaniu bez jego wiedzy. Tego typu ataki są zwykle nazywane atakami Man-in-the-Browser (MitB).
Kradzieże tożsamości oraz ataki polegające na przechwytywaniu sesji połączeniowej (MitM, MitB) to najczęstsze typy ataków na użytkownika i jego komputer. Mogą być stosowane z powodzeniem w przypadku słabego zabez-pieczenia systemu uwierzytelnienia użytkownika do usług oferowanych on-line.
Aby ochronić informacje przesyłane poprzez sieć Internet należy położyć szczególny nacisk na metody autoryzacji i uwierzytelniania. To one są punktem wyjściowym do nawiązania bezpiecznego połączenia pomiędzy dwiema stronami wymieniającymi się danymi. Firma AXSionics zaprezentowała system AXS Authentication System wspomagający te mechanizmy. Daje on możliwość wzajemnego uwierzytelniania oraz weryfikacji autentyczności.
Główną ideą rozwiązania jest zastąpienie wrażliwych na ataki części kanału komunikacyjnego bezpośrednim połączeniem z bezpiecznej strefy do dedykowanego terminala będącego w posiadaniu użytkownika. W systemie AXS-AS takie bezpieczne połączenie jest realizowane przez wykorzystanie stosunkowo prostego urządzenia Internet Passport, które nie jest zintegrowane z lokalnym systemem komputerowym i nie jest narażone na atak.
Bezpieczny dostępu do wielu usługRozwiązanie z użyciem AXS Internet Passport wprowadza możliwość
uwierzytelnienia na trzech poziomach (rys. 3). Pierwszym jest coś co się posiada, czyli właśnie Paszport Internetowy. Na drugim poziomie użytkownik musi zaprezentować coś co może wiedzieć tylko on, np. hasło albo kod PIN, czyli kod jednorazowy odczytany z animacji i wyświetlony na ekranie urządzenia. Trzeci poziom uwierzytelnienia polega na sprawdzeniu unikalnej cechy użytkownika weryfikującej dostęp do kodu jednorazowego czy cechy biometrycznej. Część ta jest realizowana poprzez technologię skanowania linii papilarnych.
Rys. 3 Architektura AXS-AS.Całkowita siła zabezpieczeń jest wypadkową zastosowania powyższych
składowych. W przypadku Internet Passport możliwe jest wykorzystanie
16
3 stopniowe uwierzytelnienie
Bezpieczny kanał typu end-to-end

wszystkich trzech poziomów na raz co daje najwyższy poziom bezpieczeństwa. Nawet w przypadku zgubienia urządzenia, dzięki wykorzystaniu biometrii, osoby trzecie nie będą mogły z niego skorzystać.
Dane biometryczne od początku użytkowania urządzenia są pod wyłączną kontrolą użytkownika. Żadne informacje nie są nigdy przechowywane w centralnej bazie danych tylko bezpośrednio w urządzeniu.
Każdy paszport Internetowy AXSionics może zarządzać wieloma tożsamościami w pełni niezależnymi od siebie. Interfejs zarządzania bezpieczeństwem bazuje na prostym w implementacji modelu realizowanym w technologii WebService. To sprawia, że rozwiązanie oferowane przez AXSionics zapewnia wysoki stopień skalowalności w dwóch kierunkach – zarówno w ilości użytkowników końcowych jak i ilości dostawców usług. Dodatkowo nie jest potrzebna instalacja żadnego dodatkowego oprogramowania lub sprzętu. Klawiatura i monitor są jedynie urządzeniami wejścia/wyjścia, które są obecne wszędzie gdzie odbywa się interakcja użytkownika z komputerem osobistym. Do wyświetlenia animacji może być użyty zarówno monitor komputerowy jak i ekran telefonu komórkowego. Nie ma zatem potrzeby inwestowania w dodatkową infrastrukturę.
Wzrost bezpieczeństwa, ale nie bez wadW związku z coraz większym znaczeniem roli Internetu, a co za tym idzie,
zwiększającą się skalą przestępstw w sieci, społeczność E-biznesu jest zmuszona do znajdowania coraz to nowszychi skuteczniejszych rozwiązań. Niezbędne jest zapewnienie bezpiecznej komunikacji pomiędzy operatorami usług, a użytkownikami. Nadal jednak nie ma jednomyślności co do sposobu, który miałby sprostać temu wyzwaniu. Istnieje natomiast przekonanie, że do bezpiecznej komunikacji potrzebny jest pewien rodzaj dedykowanej infrastruktury.
Jak można zauważyć tendencja prowadzi do unifikacji rozwiązań i integracji ich w jedno urządzenie. Jednak niezależnie od wszystkich technologii, które mogą zaistnieć w przyszłości, efektywne rozwiązania potrzebne są już dzisiaj. Powinno być to rozwiązanie działające w oparciu o obecną infrastrukturę IT, ponadto będące stosunkowo wygodne w użyciu, oraz zapewniające ochronę prywatności a także niewygórowane koszta. Zaprezentowany system AXSionics Internet Passport wydaje się spełniać pokładane w nim nadzieje. Trzeba również zaznaczyć, że paszporty internetowe są dopiero na poziome adoptowania przez społeczności użytkowników Internetu.
Model systemu AXSionics w zdecentralizowany sposób łączy osobę fizyczną z jej cyfrowym odpowiednikiem tożsamości, tokenem, przechowującym informacje takie jak np. dane biometryczne. Paszport internetowy sam w sobie jest potwierdzeniem tożsamość jego posiadacza. Służy przede wszystkim do generowania kodów jednorazowych oraz do przesyłania bezpiecznych wiadomości. Może współpracować z wieloma witrynami i usługami, bez potrzeby rozbudowy infrastruktury i oprogramowania. System AXSionicsa pokazuje, że możliwa jest pełna ochrona prywatności oraz danych biometrycznych, niezależnie od tego z jakiej maszyny podczas uwierzytelniania korzystamy. AXSionics pozwala także w łatwy sposób wykorzystać zalety standardu OpenID. W szybki i łatwy sposób pozwala właścicielowi paszportu internetowego potwierdzić swoją tożsamość 3-stopnowym poziomem uwierzytelnienia na każdym komputerze i dla wszystkich usług, które akceptują OpenID.
17

Rozwiązanie Internet Passport nie jest wolne od wad. Oparcie się na biometrii niesie za sobą pewne implikacje. W przypadku urazu dłoni czy samych palców traci się dostęp do usług i urządzenie jest wtedy bezużyteczne. Powszechnie znanym faktem jest także nieczytelność linii papilarnych u pewnego odsetka populacji. Kłopotliwą czynnością może też być przyłożenie paszportu internetowego do ekranu. Trzeba to zrobić w odpowiednim miejscu i przytrzymać nieruchomo na czas potrzebny do odczytania danych z animacji. Wykonanie tych czynności wymaga pewnej wprawy i precyzji co może stanowić kłopot w przypadku starszych użytkowników systemu.
Istotnym zagrożeniem może być także kwestia stabilności działania serwerów firmy AXSionics, które odpowiadają za generowanie animacji. W przypadku awarii bądź ataku na nie operacja logowania do jakiejkolwiek witryny korzystającej z paszportu internetowego stanie się niemożliwe.
Ponieważ liczba usług wykorzystujących AXS Internet Passport będzie stopniowo rosła, wraz z nią zwiększać się będzie potencjał i możliwości zastosowania urządzenia. Jednak nawet już teraz jest to ciekawa propozycja dla instytucji traktująco priorytetowo bezpieczeństwo danych. Dodatkowym atutem jest uniezależnienie działania od dodatkowego oprogramowania czy sprzętu. Powoduje to, że ciekawym obszarem użycia może być dyplomacja, lub dostęp do danych w firmach, których pracownicy często podróżują. Jednak głównym środowiskiem, które może najwięcej skorzystać na takim urządzeniu, jest bankowość elektroniczna i wszelkie inne usługi finansowe zarządzane przez Internet. Są to jedne z najbardziej narażonych na ataki pól, dlatego wprowadzenie dodatkowych mechanizmów uwierzytelniania i ochrony mogłoby przyczynić się do dalszego upowszechnienia tego typu usług.
18

mgr inż. Lech NaumowskiInstytut Maszyn Matematycznych
Wybrane zagadnienia zastosowania linii papilarnychw dokumentach identyfikacyjnych
StreszczenieOd początku XXI wieku następuje burzliwy rozwój zastosowań
elektronicznych, biometrycznych dokumentów identyfikacyjnych w tym paszportów, które zostały wprowadzone w USA, Unii Europejskiej (Rozporządzenia Rady WE nr 2252/2004 z dnia 13.12.2004 r.) w tym w Polsce i w wielu innych krajach. W artykule przedstawiono niektóre zagadnienia dotyczące stosowanych w systemach ewidencji osób czytników linii papilarnych oraz oprogramowania sterującego procesem pobierania, przetwarzaniem i oceną jakości uzyskanych obrazów. Syntetycznie przedstawiono dokonania IMM na tym polu.
1. Dokumenty biometryczneW pierwszej dekadzie XXI wieku nastąpił bardzo szybki rozwój zastosowań
biometrycznych, elektronicznych dokumentów uwierzytelniających takich jak paszporty, dowody osobiste, karty ubezpieczeniowe, prawa jazdy i inne. Zagrożenie zamachami terrorystycznymi spowodowało zintensyfikowanie działań zmierzających do podniesienia poziomu bezpieczeństwa dokumentów podróży, między innymi przez umieszczenie w nich danych biometrycznych. W stanach Zjednoczonych, gdzie po zamachach z 11 września 2001 r. gwałtownie zaczęto poszukiwania rozwiązań dających wysoki poziom bezpieczeństwa wprowadzono biometryczne paszporty dla własnych obywateli, a także sformułowano wymaganie posiadania takich paszportów dla obcokrajowców przyjeżdżających do USA. W pierwszej kolejności dotyczyło to obywateli wszystkich państw posiadających umowy o ruchu bez wizowym, w tym większość państw Unii Europejskiej. Równolegle w Unii Europejskiej były prowadzone działania, które doprowadziły do opracowania i przyjęcia Rozporządzenia Rady Wspólnoty Europejskiej nr 2252/2004 z dnia 13 grudnia 2004 r. w sprawie standardów zabezpieczeń i danych biometrycznych w paszportach oraz dokumentach podróży wydawanych przez Państwa Członkowskie. Zgodnie z tym rozporządzeniem Polska wprowadziła paszporty biometryczne dla swoich obywateli od dnia 28 sierpnia 2006 r. zawierające jako dane biometryczne wizerunek twarzy posiadacza zapisany w formie elektronicznej. Od 22 czerwca 2009 r. wypełniając wcześniej podjęte zobowiązania wprowadzono także zapis odcisków dwóch palców, przez co uzyskano istotne podniesienie poziomu bezpieczeństwa paszportu przez wzmocnienie związku dokumentu z jego posiadaczem oraz radykalne utrudnienie przestępczości związanej z kradzieżą tożsamości i fałszerstwami oraz dostosowano polski paszport do wymagań USA. Obecnie polski paszport jest dokumentem przystosowanym do maszynowego odczytu, biometrycznym
19

i elektronicznym, zawierającym umieszczony w okładce chip mikroprocesorowy z pamięcią i anteną. Elementy elektroniczne paszportu umożliwiają odczyt z małej odległości zgromadzonych w pamięci danych przez uprawnione urządzenia czytające. Chip zbliżeniowy umieszczony w paszporcie jest zgodny ze standardem ISO/IEC 14443 a struktura danych w dokumencie i sposób ich zapisu/odczytu określa norma ICAO Doc. 9303 zapewniająca bardzo wysoki stopień ochrony dostępu do danych. W wielu krajach wprowadzane są również biometryczne, elektroniczne dokumenty tożsamości (dowody osobiste), jednak umieszczanie w pamięci tych dokumentów obrazów linii papilarnych w niektórych krajach napotyka na poważne trudności związane z nie do końca unormowanym problemem ochrony danych osobowych.
2. Czytniki linii papilarnychObrazy odcisków palców od dawna są wykorzystywane do identyfikacji osób.
Linie papilarne znalazły zastosowanie w identyfikacji i weryfikacji osób od pierwszych etapów rozwoju elektronicznych technik biometrycznych. Do chwili obecnej notowany jest w tej dziedzinie stały i szybki postęp polegający na ciągłej poprawie parametrów i obniżce cen. Na rynku biometrycznym techniki rozpoznawania linii papilarnych zajmują stale pierwsze miejsce. Jest to możliwe dzięki niepowtarzalności linii papilarnych u ludzi, łatwości pozyskiwania ich obrazów, postępowi w dziedzinie eliminacji możliwości oszukiwania urządzeń czytających, istnieniu stosunkowo prostych i wydajnych metod porównywania linii papilarnych oraz dzięki opracowaniu i wdrożeniu do produkcji stosunkowo prostych, tanich i szybko działających urządzeń.
Urządzenia odczytujące linie papilarne (czytniki) można podzielić na cztery zasadnicze grupy w pewien sposób powiązane z zastosowaniami.
Do pierwszej grupy można zaliczyć najprostsze, o najmniejszej rozdzielczości (rzędu 250 ppi) i najtańsze sensory linii papilarnych przeznaczone do stosowania w sprzęcie powszechnego użytku takim jak np. palmtopy, telefony komórkowe itp. W tej grupie znajdują się niewielkie i tanie czytniki oraz sensory linii papilarnych wykorzystujące różne techniki odczytu, głównie pojemnościowe z płaską powierzchnią skanującą, a także liniowe (najmniejsze i najtańsze) o niewielkich wymiarach wystarczających do pobrania odcisku 1 palca.
Do drugiej grupy należą względnie proste sensory i czytniki linii papilarnych o średniej rozdzielczości (250 – 300 ppi) z płaską powierzchnią skanującą o niewielkich wymiarach wystarczających do pobrania odcisku 1 palca (np. 15 mm x 15 mm czy 20 mm x 20 mm) W tej klasie znajdują się m. in. sensory takich firm jak Identics czy AuthenTec. Czytniki te, podobnie jak urządzenia z pierwszej grupy, w większości przetwarzają uzyskane obrazy linii papilarnych do postaci tak zwanych wzorców, których wielkość liczona w bajtach (rzędu 300 - 400 bajtów) jest nieduża w porównaniu z wielkościami plików zawierających obrazy odcisków w formie bezstratnych map bitowych czy nawet obrazy skompresowane (np. jpg, png). Przesyłanie i dalsze przetwarzanie wzorców jest szybkie i proste, co umożliwia konstruowanie prostych i tanich mikroprocesorowych urządzeń biometrycznych przeznaczonych do działania w bardzo wielu dziedzinach. Czytniki te znajdują głównie zastosowanie w kontroli dostępu do budynków, pomieszczeń i urządzeń (np. komputerów), rejestracji czasu pracy, w bankowości, handlu, służbie zdrowia itp.
20

Trzecią grupę tworzą czytniki skonstruowane specjalnie na potrzeby policyjnych systemów automatycznej identyfikacji typu AFIS. Wymienić tu należy systemy takie jak FBI IAFIS w USA czy tworzony system informacji o osobach SIS II dla obszaru Schengen. Czytniki z tej grupy cechują się bardzo wysokimi parametrami uzyskiwanych obrazów odcisków palców a ich rozwój rozpoczął się stosunkowo dawno.
Czwartą grupę tworzą czytniki przeznaczone dla potrzeb związanych z dokumentami biometrycznymi takimi jak dokumenty podróży (paszporty, wizy) czy inne dokumenty identyfikacyjne spotykane w obszarze zastosowań cywilnych. W tej dziedzinie mieszczą się urządzenia zdejmujące obrazy linii papilarnych dla potrzeb takich systemów jak VIS w obszarze Schengen, US-VISIT w Stanach Zjednoczonych oraz dla potrzeb innych cywilnych systemów operujących biometrycznymi dokumentami uwierzytelniającymi. Urządzenia z tej grupy mają dużo cech wspólnych z czytnikami stosowanymi w dziedzinie AFIS i są obecnie mocno rozwijane.
W trzeciej i czwartej klasie czytników linii papilarnych znajdują się urządzenia specjalnie projektowane dla uzyskania bardzo wysokiej jakości obrazów odcisków palców, dzięki zastosowaniu wyrafinowanych technik skanowania optycznego oraz specjalnych rodzajów szkła i pokryć okna skanującego. Stosowane są specjalne rozwiązania sprzętowe i technologie oraz rozwiązania programowe w firmware, dzięki którym możliwa jest eliminacja śladów odcisków palców i obrazów podobnych do linii papilarnych, eliminacja wilgotnego hallo wokół palców oraz eliminacja efektów związanych z ślizganiem się palców podczas pobierania obrazu. Rozwiązania te umożliwiają uzyskiwanie wysokiej jakości obrazów linii papilarnych z suchych, wilgotnych i uszkodzonych palców. Czytniki z tych grup umożliwiają pobieranie czarno białych obrazów linii papilarnych w 256 stopniach szarości o rozdzielczości 500 dpi i zapamiętywanie ich w postaci map bitowych (formaty plików raw, bmp, tiff) bez strat informacji oraz w formatach wsq, jp2 i innych. W tej grupie znajdują się urządzenia stacjonarne jak i przenośne, umożliwiające pobieranie obrazu jednego palca (rozmiar okna rzędu 25 mm x 16 mm), dwóch palców (rozmiar okna rzędu 40 mm x 40 mm) i czterech palców (rozmiar okna rzędu 81 mm x 76 mm). Większość czytników jest w stanie przekazywać obrazy na bieżąco (livescan). Urządzenia tego typu są przede wszystkim stosowane w dziedzinach, gdzie zapamiętywane i elektronicznie przetwarzane są rzeczywiste obrazy linii papilarnych. Ze względu na przeznaczenie czytniki z omawianych tu grup posiadają certyfikaty FBI IAFIS Appendix F, CE, WHQL, FCC, EMV, UL, oraz BSI TR-PDÜ i SG (dot. Dermalog). Do obsługi omawianej tu klasy czytników ze względu na duże ilości danych i skomplikowane oprogramowanie sterujące i przetwarzające dane nie wystarczą proste systemy mikroprocesorowe, konieczne są komputery klasy PC. Czytniki z tej grupy wytwarzają firmy od dawna istniejące na rynku i posiadające wiedzę i doświadczenie wymagane przy produkcji urządzeń najwyższej klasy. Są to firmy takie jak Cross Match Technologies wytwarzająca rodziny czytników Guardian (4 palce) i L SCAN (1 palec), L-1 Identity Solutions produkująca rodziny czytników Agile TP, TouchPrint 4100 (4 palce) i DFR (1 i 2 palce), GreenBit z czytnikami DactyScan84 (4 palce) i Dermalog wytwarzający czytnik1 Z1 (1 palec). Jest także rosyjska firma PAPILLON Systems produkująca wysokiej jakości czytniki rodziny Papillon DS dla potrzeb instytucji podległych ministerstwom spraw wewnętrznych krajów tworzących Federację Niepodległych
21

Państw, jednak dotarcie do głębszej wiedzy na temat tych czytników czy uzyskanie wsparcia technicznego odbywa się na zupełnie innych zasadach niż dla firm z obszaru USA, Wspólnoty Europejskiej czy Azji południowo wschodniej. Firmy zachodnie z reguły udostępniają pełną dokumentację, oprogramowanie SDK i pomoc techniczną.
Oprogramowanie SDK (Software Development Kit) dostarczane przez producentów czytników zawiera zastawy procedur umożliwiających sterowanie czytnikiem i przetwarzanie uzyskanych obrazów. Dzięki SDK możliwe jest tworzenie oprogramowania działającego na komputerach klasy PC pod systemami operacyjnymi Windows lub Linux dla potrzeb dowolnych systemów wykorzystujących biometrię, w tym systemów AFIS, ewidencji, paszportowych, wizowych i innych z zastosowaniem dokumentów biometrycznych. Zestawy SDK zawierają dokumentację, narzędzia i biblioteki funkcji niezbędnych do sterowania czytnikiem, przetwarzania obrazów i tworzenia aplikacji. Najważniejsze i standardowo obecne w SDK funkcje są następujące:
wspomaganie funkcji pobierania odcisków zgodnie z wymaganiami zastosowań policyjnych i cywilnych,
wspomaganie funkcji automatycznego pobierania sekwencji obrazów odcisków (np. 4 palce lewej dłoni, 4 palce prawej dłoni, 2 kciuki),
wspomaganie funkcji pobierania odcisków rolowanych,sprawdzanie właściwego położenia palców,funkcja przekazywania na bieżąco obrazów odcisków palców (livescan),automatyczne wybierania najlepszego obrazu odcisków palców (auto capture),segmentacja obrazów odcisków palców (czytniki dla 2 i 4 palców),ocena jakości obrazów odcisków palców (ocena liniowa oraz z
wykorzystaniem standardów NFIQ),zapamiętywanie obrazów linii papilarnych w różnych formatach: mapy bitowe
raw, bmp, tiff, skompresowane wsq, jpeg, jpeg2000, gif (wg wymagań ANSI/NIST-ITL-1-2007).
Czytniki z omawianych tu grup wraz z tworzonym dla nich na bazie dostarczanych przez producentów SDK oprogramowaniem umożliwiają masowe i szybkie pobieranie obrazów odcisków palców możliwie najwyższej jakości. Szczególnie szybkie pobieranie skanów można uzyskać za pomocą czytników dla 4 palców takich jak np. Lscan Guardian, TP 4100 czy DactyScan84. Funkcja przekazywania na bieżąco obrazów odcisków palców w połączeniu z procedurą oceny jakości skanów zaimplementowaną w aplikacjach obsługujących czytniki umożliwia natychmiastowe wyłapanie błędów przykładania palców do okna skanującego i ich skorygowanie. Dzięki funkcji oceny jakości obrazów możliwe jest też wyselekcjonowanie palców, które mają najlepszej jakości linie papilarne dla danej osoby. Daje to możliwość zapamiętania w dokumentach biometrycznych, w których wymagana jest obecność np. dwóch skanów, tylko najlepszych z punktu widzenia daktyloskopii obrazów odcisków palców posiadacza dokumentu.
3. Miejsce IMM w obszarze biometriiIMM w dziedzinie zastosowań czytników linii papilarnych należących do
omawianych powyżej klas ma duże doświadczenie będąc niejednokrotnie pionierem w opracowywaniu i wdrażaniu urządzeń i systemów zwłaszcza w dzie-
22

dzinie kontroli dostępu i rejestracji czasu pracy z wykorzystaniem biometrii, w tym linii papilarnych. W IMM były i są prowadzone studialne i projektowe prace dotyczące oprogramowania i sprzętu z wykorzystaniem optycznych czytników linii papilarnych służących do pobierania wysokiej jakości obrazów odcisków palców dla potrzeb dokumentów elektronicznych. IMM był jednym z projektantów Systemu Produkcji Dokumentów Elektronicznych – PERSON spełniającego wymagania projektowanych polskich systemów wydawania dokumentów biometrycznych, w tym dowodów osobistych i paszportów. Prowadzono też prace z dziedziny przetwarzania (m. in. segmentacja obrazów i przetwarzanie formatów plików) i oceny jakości obrazów odcisków palców pochodzących z czytników różnych typów z wykorzystaniem składników SDK producentów czytników. W oprogramowaniu tworzonym w IMM do oceny porównawczej obrazów linii papilarnych uzyskanych z różnych czytników wykorzystywano też „Biometric Matching System - BMSSC1-CD30 – BMS-VIS User Software Kit” firmy Sagem Sécurité. To oprogramowanie BMS zawiera składniki umożliwiające ocenę pobranych obrazów odcisków palców dla potrzeb systemów wizowych, paszportowych i ewidencji ludności oraz spełnia wymagania międzynarodowe odnośnie oceny jakości skanów linii papilarnych i jest zaakceptowane przez właściwe organa Komisji Europejskiej. W skład zestawu oprogramowania BMS wchodzą składniki umożliwiające: segmentację skanów dłoni, kontrolę unikalności skanów, ocenę jakości skanów oraz ocenę jakości i unikalności kompletów skanów 10 palców.
Doświadczenie IMM w dziedzinie sprzętu i oprogramowania może być wykorzystane do budowy systemów akwizycji cech biometrycznych osób dla potrzeb dokumentów biometrycznych. IMM jest także gotowy do przeprowadzenia porównawczych badań jakości obrazów odcisków palców uzyskiwanych od reprezentatywnej grupy osób pobieranych za pomocą czytników różnych typów i producentów oraz do badań statystycznych jakości skanów linii papilarnych dla różnych grup osób w zależności np. od wieku, płci, zawodu, stanu zdrowia, cech charakterystycznych, uszkodzeń i zmian chorobowych dłoni oraz w zależności innych parametrów ważnych w obszarach działalności związanych z biometrycznymi dokumentami uwierzytelniającymi.
1. Dokumenty biometryczneW pierwszej dekadzie XXI wieku nastąpił bardzo szybki rozwój zastosowań
biometrycznych, elektronicznych dokumentów uwierzytelniających takich jak paszporty, dowody osobiste, karty ubezpieczeniowe, prawa jazdy i inne. Zagrożenie zamachami terrorystycznymi spowodowało zintensyfikowanie działań zmierzających do podniesienia poziomu bezpieczeństwa dokumentów podróży, między innymi przez umieszczenie w nich danych biometrycznych. W stanach Zjednoczonych, gdzie po zamachach z 11 września 2001 r. gwałtownie zaczęto poszukiwania rozwiązań dających wysoki poziom bezpieczeństwa wprowadzono biometryczne paszporty dla własnych obywateli, a także sformułowano wymaganie posiadania takich paszportów dla obcokrajowców przyjeżdżających do USA. W pierwszej kolejności dotyczyło to obywateli wszystkich państw posiadających umowy o ruchu bez wizowym, w tym większość państw Unii Europejskiej. Równolegle w Unii Europejskiej były prowadzone działania, które doprowadziły do opracowania i przyjęcia Rozporządzenia Rady Wspólnoty Europejskiej nr 2252/2004 z dnia 13 grudnia 2004 r. w sprawie standardów
23

zabezpieczeń i danych biometrycznych w paszportach oraz dokumentach podróży wydawanych przez Państwa Członkowskie. Zgodnie z tym rozporządzeniem Polska wprowadziła paszporty biometryczne dla swoich obywateli od dnia 28 sierpnia 2006 r. zawierające jako dane biometryczne wizerunek twarzy posiadacza zapisany w formie elektronicznej. Od 22 czerwca 2009 r. wypełniając wcześniej podjęte zobowiązania wprowadzono także zapis odcisków dwóch palców, przez co uzyskano istotne podniesienie poziomu bezpieczeństwa paszportu przez wzmocnienie związku dokumentu z jego posiadaczem oraz radykalne utrudnienie przestępczości związanej z kradzieżą tożsamości i fałszerstwami oraz dostosowano polski paszport do wymagań USA. Obecnie polski paszport jest dokumentem przystosowanym do maszynowego odczytu, biometrycznym i elektronicznym, zawierającym umieszczony w okładce chip mikroprocesorowy z pamięcią i anteną. Elementy elektroniczne paszportu umożliwiają odczyt z małej odległości zgromadzonych w pamięci danych przez uprawnione urządzenia czytające. Chip zbliżeniowy umieszczony w paszporcie jest zgodny ze standardem ISO/IEC 14443 a struktura danych w dokumencie i sposób ich zapisu/odczytu określa norma ICAO Doc. 9303 zapewniająca bardzo wysoki stopień ochrony dostępu do danych. W wielu krajach wprowadzane są również biometryczne, elektroniczne dokumenty tożsamości (dowody osobiste), jednak umieszczanie w pamięci tych dokumentów obrazów linii papilarnych w niektórych krajach napotyka na poważne trudności związane z nie do końca unormowanym problemem ochrony danych osobowych.
2. Czytniki linii papilarnychObrazy odcisków palców od dawna są wykorzystywane do identyfikacji osób.
Linie papilarne znalazły zastosowanie w identyfikacji i weryfikacji osób od pierwszych etapów rozwoju elektronicznych technik biometrycznych. Do chwili obecnej notowany jest w tej dziedzinie stały i szybki postęp polegający na ciągłej poprawie parametrów i obniżce cen. Na rynku biometrycznym techniki rozpoznawania linii papilarnych zajmują stale pierwsze miejsce. Jest to możliwe dzięki niepowtarzalności linii papilarnych u ludzi, łatwości pozyskiwania ich obrazów, postępowi w dziedzinie eliminacji możliwości oszukiwania urządzeń czytających, istnieniu stosunkowo prostych i wydajnych metod porównywania linii papilarnych oraz dzięki opracowaniu i wdrożeniu do produkcji stosunkowo prostych, tanich i szybko działających urządzeń.
Urządzenia odczytujące linie papilarne (czytniki) można podzielić na cztery zasadnicze grupy w pewien sposób powiązane z zastosowaniami.
Do pierwszej grupy można zaliczyć najprostsze, o najmniejszej rozdzielczości (rzędu 250 ppi) i najtańsze sensory linii papilarnych przeznaczone do stosowania w sprzęcie powszechnego użytku takim jak np. palmtopy, telefony komórkowe itp. W tej grupie znajdują się niewielkie i tanie czytniki oraz sensory linii papilarnych wykorzystujące różne techniki odczytu, głównie pojemnościowe z płaską powierzchnią skanującą, a także liniowe (najmniejsze i najtańsze) o niewielkich wymiarach wystarczających do pobrania odcisku 1 palca.
Do drugiej grupy należą względnie proste sensory i czytniki linii papilarnych o średniej rozdzielczości (250 – 300 ppi) z płaską powierzchnią skanującą o niewielkich wymiarach wystarczających do pobrania odcisku 1 palca (np. 15 mm x 15 mm czy 20 mm x 20 mm) W tej klasie znajdują się m. in. sensory takich
24

firm jak Identics czy AuthenTec. Czytniki te, podobnie jak urządzenia z pierwszej grupy, w większości przetwarzają uzyskane obrazy linii papilarnych do postaci tak zwanych wzorców, których wielkość liczona w bajtach (rzędu 300 - 400 bajtów) jest nieduża w porównaniu z wielkościami plików zawierających obrazy odcisków w formie bezstratnych map bitowych czy nawet obrazy skompresowane (np. jpg, png). Przesyłanie i dalsze przetwarzanie wzorców jest szybkie i proste, co umożliwia konstruowanie prostych i tanich mikroprocesorowych urządzeń biometrycznych przeznaczonych do działania w bardzo wielu dziedzinach. Czytniki te znajdują głównie zastosowanie w kontroli dostępu do budynków, pomieszczeń i urządzeń (np. komputerów), rejestracji czasu pracy, w bankowości, handlu, służbie zdrowia itp.
Trzecią grupę tworzą czytniki skonstruowane specjalnie na potrzeby policyjnych systemów automatycznej identyfikacji typu AFIS. Wymienić tu należy systemy takie jak FBI IAFIS w USA czy tworzony system informacji o osobach SIS II dla obszaru Schengen. Czytniki z tej grupy cechują się bardzo wysokimi parametrami uzyskiwanych obrazów odcisków palców a ich rozwój rozpoczął się stosunkowo dawno.
Czwartą grupę tworzą czytniki przeznaczone dla potrzeb związanych z dokumentami biometrycznymi takimi jak dokumenty podróży (paszporty, wizy) czy inne dokumenty identyfikacyjne spotykane w obszarze zastosowań cywilnych. W tej dziedzinie mieszczą się urządzenia zdejmujące obrazy linii papilarnych dla potrzeb takich systemów jak VIS w obszarze Schengen, US-VISIT w Stanach Zjednoczonych oraz dla potrzeb innych cywilnych systemów operujących biometrycznymi dokumentami uwierzytelniającymi. Urządzenia z tej grupy mają dużo cech wspólnych z czytnikami stosowanymi w dziedzinie AFIS i są obecnie mocno rozwijane.
W trzeciej i czwartej klasie czytników linii papilarnych znajdują się urządzenia specjalnie projektowane dla uzyskania bardzo wysokiej jakości obrazów odcisków palców, dzięki zastosowaniu wyrafinowanych technik skanowania optycznego oraz specjalnych rodzajów szkła i pokryć okna skanującego. Stosowane są specjalne rozwiązania sprzętowe i technologie oraz rozwiązania programowe w firmware, dzięki którym możliwa jest eliminacja śladów odcisków palców i obrazów podobnych do linii papilarnych, eliminacja wilgotnego hallo wokół palców oraz eliminacja efektów związanych z ślizganiem się palców podczas pobierania obrazu. Rozwiązania te umożliwiają uzyskiwanie wysokiej jakości obrazów linii papilarnych z suchych, wilgotnych i uszkodzonych palców. Czytniki z tych grup umożliwiają pobieranie czarno białych obrazów linii papilarnych w 256 stopniach szarości o rozdzielczości 500 dpi i zapamiętywanie ich w postaci map bitowych (formaty plików raw, bmp, tiff) bez strat informacji oraz w formatach wsq, jp2 i innych. W tej grupie znajdują się urządzenia stacjonarne jak i przenośne, umożliwiające pobieranie obrazu jednego palca (rozmiar okna rzędu 25 mm x 16 mm), dwóch palców (rozmiar okna rzędu 40 mm x 40 mm) i czterech palców (rozmiar okna rzędu 81 mm x 76 mm). Większość czytników jest w stanie przekazywać obrazy na bieżąco (livescan). Urządzenia tego typu są przede wszystkim stosowane w dziedzinach, gdzie zapamiętywane i elektronicznie przetwarzane są rzeczywiste obrazy linii papilarnych. Ze względu na przeznaczenie czytniki z omawianych tu grup posiadają certyfikaty FBI IAFIS Appendix F, CE, WHQL, FCC, EMV, UL, oraz BSI TR-PDÜ i SG (dot. Dermalog). Do obsługi omawianej tu klasy czytników ze względu na duże ilości
25

danych i skomplikowane oprogramowanie sterujące i przetwarzające dane nie wystarczą proste systemy mikroprocesorowe, konieczne są komputery klasy PC. Czytniki z tej grupy wytwarzają firmy od dawna istniejące na rynku i posiadające wiedzę i doświadczenie wymagane przy produkcji urządzeń najwyższej klasy. Są to firmy takie jak Cross Match Technologies wytwarzająca rodziny czytników Guardian (4 palce) i L SCAN (1 palec), L-1 Identity Solutions produkująca rodziny czytników Agile TP, TouchPrint 4100 (4 palce) i DFR (1 i 2 palce), GreenBit z czytnikami DactyScan84 (4 palce) i Dermalog wytwarzający czytnik1 Z1 (1 palec). Jest także rosyjska firma PAPILLON Systems produkująca wysokiej jakości czytniki rodziny Papillon DS dla potrzeb instytucji podległych ministerstwom spraw wewnętrznych krajów tworzących Federację Niepodległych Państw, jednak dotarcie do głębszej wiedzy na temat tych czytników czy uzyskanie wsparcia technicznego odbywa się na zupełnie innych zasadach niż dla firm z obszaru USA, Wspólnoty Europejskiej czy Azji południowo wschodniej. Firmy zachodnie z reguły udostępniają pełną dokumentację, oprogramowanie SDK i pomoc techniczną.
Oprogramowanie SDK (Software Development Kit) dostarczane przez producentów czytników zawiera zastawy procedur umożliwiających sterowanie czytnikiem i przetwarzanie uzyskanych obrazów. Dzięki SDK możliwe jest tworzenie oprogramowania działającego na komputerach klasy PC pod systemami operacyjnymi Windows lub Linux dla potrzeb dowolnych systemów wykorzystujących biometrię, w tym systemów AFIS, ewidencji, paszportowych, wizowych i innych z zastosowaniem dokumentów biometrycznych. Zestawy SDK zawierają dokumentację, narzędzia i biblioteki funkcji niezbędnych do sterowania czytnikiem, przetwarzania obrazów i tworzenia aplikacji. Najważniejsze i standardowo obecne w SDK funkcje są następujące:
• wspomaganie funkcji pobierania odcisków zgodnie z wymaganiami zastosowań policyjnych i cywilnych,
• wspomaganie funkcji automatycznego pobierania sekwencji obrazów odcisków (np. 4 palce lewej dłoni, 4 palce prawej dłoni, 2 kciuki),
• wspomaganie funkcji pobierania odcisków rolowanych,• sprawdzanie właściwego położenia palców,• funkcja przekazywania na bieżąco obrazów odcisków palców (livescan),• automatyczne wybierania najlepszego obrazu odcisków palców (auto
capture),• segmentacja obrazów odcisków palców (czytniki dla 2 i 4 palców),• ocena jakości obrazów odcisków palców (ocena liniowa oraz z
wykorzystaniem standardów NFIQ),• zapamiętywanie obrazów linii papilarnych w różnych formatach: mapy
bitowe raw, bmp, tiff, skompresowane wsq, jpeg, jpeg2000, gif (wg wymagań ANSI/NIST-ITL-1-2007).
Czytniki z omawianych tu grup wraz z tworzonym dla nich na bazie dostarczanych przez producentów SDK oprogramowaniem umożliwiają masowe i szybkie pobieranie obrazów odcisków palców możliwie najwyższej jakości. Szczególnie szybkie pobieranie skanów można uzyskać za pomocą czytników dla 4 palców takich jak np. Lscan Guardian, TP 4100 czy DactyScan84. Funkcja przekazywania na bieżąco obrazów odcisków palców w połączeniu z procedurą oceny jakości skanów zaimplementowaną w aplikacjach obsługujących czytniki
26

umożliwia natychmiastowe wyłapanie błędów przykładania palców do okna skanującego i ich skorygowanie. Dzięki funkcji oceny jakości obrazów możliwe jest też wyselekcjonowanie palców, które mają najlepszej jakości linie papilarne dla danej osoby. Daje to możliwość zapamiętania w dokumentach biometrycznych, w których wymagana jest obecność np. dwóch skanów, tylko najlepszych z punktu widzenia daktyloskopii obrazów odcisków palców posiadacza dokumentu.
3. Miejsce IMM w obszarze biometriiIMM w dziedzinie zastosowań czytników linii papilarnych należących do
omawianych powyżej klas ma duże doświadczenie będąc niejednokrotnie pionierem w opracowywaniu i wdrażaniu urządzeń i systemów zwłaszcza w dziedzinie kontroli dostępu i rejestracji czasu pracy z wykorzystaniem biometrii,
w tym linii papilarnych. W IMM były i są prowadzone studialne i projektowe prace dotyczące oprogramowania i sprzętu z wykorzystaniem optycznych czytników linii papilarnych służących do pobierania wysokiej jakości obrazów odcisków palców dla potrzeb dokumentów elektronicznych. IMM był jednym z projektantów Systemu Produkcji Dokumentów Elektronicznych – PERSON spełniającego wymagania projektowanych polskich systemów wydawania dokumentów biometrycznych, w tym dowodów osobistych i paszportów. Prowadzono też prace z dziedziny przetwarzania (m. in. segmentacja obrazów i przetwarzanie formatów plików) i oceny jakości obrazów odcisków palców pochodzących z czytników różnych typów z wykorzystaniem składników SDK producentów czytników. W oprogramowaniu tworzonym w IMM do oceny porównawczej obrazów linii papilarnych uzyskanych z różnych czytników wykorzystywano też „Biometric Matching System - BMSSC1-CD30 – BMS-VIS User Software Kit” firmy Sagem Sécurité. To oprogramowanie BMS zawiera składniki umożliwiające ocenę pobranych obrazów odcisków palców dla potrzeb systemów wizowych, paszportowych i ewidencji ludności oraz spełnia wymagania międzynarodowe odnośnie oceny jakości skanów linii papilarnych i jest zaakceptowane przez właściwe organa Komisji Europejskiej. W skład zestawu oprogramowania BMS wchodzą składniki umożliwiające: segmentację skanów dłoni, kontrolę unikalności skanów, ocenę jakości skanów oraz ocenę jakości i unikalności kompletów skanów 10 palców.
Doświadczenie IMM w dziedzinie sprzętu i oprogramowania może być wykorzystane do budowy systemów akwizycji cech biometrycznych osób dla potrzeb dokumentów biometrycznych. IMM jest także gotowy do przeprowadzenia porównawczych badań jakości obrazów odcisków palców uzyskiwanych od reprezentatywnej grupy osób pobieranych za pomocą czytników różnych typów i producentów oraz do badań statystycznych jakości skanów linii papilarnych dla różnych grup osób w zależności np. od wieku, płci, zawodu, stanu zdrowia, cech charakterystycznych, uszkodzeń i zmian chorobowych dłoni oraz w zależności innych parametrów ważnych w obszarach działalności związanych z biometrycznymi dokumentami uwierzytelniającymi.
Literatura[1] Rozporządzenia Rady Wspólnoty Europejskiej nr 2252/2004 z dnia 13
grudnia 2004 r. w sprawie standardów zabezpieczeń i danych
27

biometrycznych w paszportach oraz dokumentach podróży wydawanych przez Państwa Członkowskie.
[2] Ustawa z dnia 13 lipca 2006 r. o dokumentach paszportowych wraz z Rozporządzeniem Ministra Spraw Wewnętrznych i Administracji z dnia 24 sierpnia 2006 r. w sprawie dokumentów paszportowych i Rozporządzeniem Ministra Spraw Wewnętrznych i Administracji z dnia 15 lutego 2010 r. w sprawie ewidencji paszportowych i centralnej ewidencji.
[3] Standard ISO/IEC 14443 Identification cards - Contactless integrated circuit(s) cards - Proximity cards.
[4] ICAO Document 9303 Machine Readable Travel Documents (http://www.icao.org).
[5] Rudd M. Bolle, Jonathan H. Connel, Sharath Pankanti, Nalini K. Ratha, Andrew W. Senior tłum. Mirosław Korzeniowski Biometria WNT 2008.
[6] Mirosława Plucińska, Jan Ryżko „Nowe technologie i zastosowania w biometrii” Techniki komputerowe Biuletyn IMM 2005.
[7] Materiały firm: Cross Match Technologies (http://www.crossmatch.com), L-1 Identity Solutions (http://www.l1id.com), GreenBit (http://www.greenbit.com), Dermalog (http://www.dermalog.de/english/1/Home.html), Papillon Systems (http://www.papillon.ru/eng/).
[8] Dokumentacja: Cross Match Technologies live scanner devices L SCAN Essentials Software Development Kit (SDK), L SCAN Essentials API Documentation.
[9] Dokumentacja L1 Identity Solutions TouchPrint Live Scan Multi-Use Software Development Kit Programmer’s Manual.
[10] Dokumentacja Dermalog ZF1 SDK 2.2.0 User Guide.[11] Dokumentacja Sagem Sécurité Biometric Matching System - BMSSC1-
CD30_BMS-VIS User Software Kits User Guide_v01 00 00.
28

Wojciech NowakowskiRobert PoznańskiInstytut Maszyn Matematycznych
Podpis elektroniczny - zasady działania
WprowadzeniePrzez bardzo długi czas techniki kryptograficzne wykorzystywane były do
szyfrowania i utajniania wiadomości i informacji. Praktyki takie stosowano już za czasów Cesarstwa Rzymskiego za pomocą prostego algorytmu podstawieniowego (tzw. szyfr cezara). Każda litera szyfrogramu była zastępowana inną, odległą o kilka pozycji w alfabecie (a -> d, b-> e itd.). W tym przypadku kluczem do odszyfrowania była wiedza w jaki sposób przestawione są litery alfabetu. Szczytowym osiągnięciem kryptografii sprzed ery komputerów i maszyn liczących była niemiecka maszyna szyfrująca Enigma.
Miała ona budowę mechaniczno – elektryczną. Najważniejszymi elementami były 26 znakowa klawiatura oraz zespół kilku, najczęściej 3-5 rotorów, oraz jednego nieruchomego rotoru odwracającego. Każdy z nich posiadał 26 styków odpowiadających kolejnym literom alfabetu. Często między klawiaturą a zespołem wirników znajdowała się też centralka pozwalająca na ręczną zmianę znaków przy pomocy kabelków łączących poszczególne litery. Po naciśnięciu klawisza obwód elektryczny zamykał się, a prąd przepływa przez elementy składowe maszyny ostatecznie powodując zapalenie się jednej z wielu lampek podświetlających literę wyjściową. Ciągłe obroty wirników zmieniały drogę jaką przebywał sygnał. Enigma szyfrowała tzw. szyfrem poliaflabetycznym.
Jednym z pierwszych zaawansowanych algorytmów szyfrujących jest zatwierdzony przez NIST w 1976 roku Data Encryption Standard, znany szerzej jako DES. W ten algorytmie, jak i wszystkich poprzednich do szyfrowania i deszyfrowania używano tego samego klucza. Były to tzw. algorytmy symetryczne. W tym samym 1976 roku Martin Hellman i Whitfield Diffi opublikowali nowy pomysł, który polegał na zastosowaniu dwóch powiązanych ze sobą matematycznie kluczy – publicznego oraz prywatnego, z których jeden służy do szyfrowania a drugi do deszyfrowania wiadomości.Tak powstała kryptografia asymetryczna, która stała się podstawą podpisu elektronicznego.
Podpis cyfrowy a elektronicznyPojęcie „podpisu cyfrowego” (digital signature) zostało zdefiniowane przez
normę ISO 7498-2:1989 jako „dane dołączone do danych lub ich przekształcenie kryptograficzne, które pozwala odbiorcy danych udowodnić pochodzenie danych i zabezpieczyć je przed fałszerstwem”. Podpis cyfrowy jest pojęciem szerszym niż podpis elektroniczny. Podpis cyfrowy nie musi być generowany przez człowieka – do tej kategorii zalicza się np. zastosowania matematycznej operacji „podpisywania cyfrowego” wykorzystywane np. w protokołach kryptogra-ficznych, które „podpisują” np. tymczasowe liczby losowe w celu potwierdzenia
29

posiadania klucza prywatnego. Pojęcie „podpis elektroniczny” (electronic signature) jest natomiast wprowadzone przez unijną Dyrektywę 1999/93/EC i jednoznacznie określa, że jest to operacja podpisywania konkretnych danych (dokumentu) przez osobę fizyczną. Podpis elektroniczny to w istocie dodatkowa informacja dołączona do wiadomości służąca do weryfikacji jej źródła. Norma PN-I-02000 podaje definicję: podpis cyfrowy „to przekształcenie kryptograficzne danych umożliwiające odbiorcy danych sprawdzenie autentyczności i integralności danych oraz zapewniające nadawcy ochronę przed sfałszowaniem danych przez odbiorcę”. Cztery główne warunki jakie muszą być spełnione przez to przekształcenie to:
- uniemożliwienie podszywania się innych pod daną osobę (uwierzytelnienie osoby, autentyfikacja),
- zapewnienie wykrywalności wszelkiej zmiany w danych transakcji (integralność transakcji),
- zapewnienie niemożliwości wyparcia się podpisu przez autora,- umożliwienie weryfikacji podpisu przez osobę niezależną.
RSAPodstawową cechą uniemożliwiającą zastosowanie w procedurze podpisu
elektronicznego szyfrowania symetrycznego (z jednym kluczem) jest to, że klucz musi być przekazany odbiorcy przez nadawcę informacji. Po co szyfrować wiadomość jeżeli klucz do jej odszyfrowania może być przejęty przez osoby trzecie? Dlatego do szyfrowania wykorzystuje się algorytmy symetryczne, z dwoma kluczami: publicznym, jawnym i zależnym od niego kluczem prywatnym. Pierwszy z nich służy do szyfrowania wiadomości przeznaczonych dla właściciela kluczy. Klucz prywatny jest tajny i tylko przy jego pomocy można odszyfrować to, co zostało zakodowane kluczem publicznym. Najszerzej stosowanym algorytmem szyfrowania asymetrycznego jest RSA (Rivest, Shamir, Adleman), przedstawiony bardziej szczegółowo w [1].
System kryptograficzny z kluczem publicznym i prywatnym może być wykorzystywany do podpisywania dokumentów cyfrowych. Jednak w tym przypadku rola kluczy zostaje odwrócona. Ponieważ klucz prywatny przechowywany jest wyłącznie u podpisującego, służy on do szyfrowania danych. Klucz publiczny, ogólnie dostępny, służy do deszyfrowania i upewnienia się, czy tylko właściciel skorzystał z klucza prywatnego. Nadawca szyfruje dokument używając swojego klucza prywatnego. Odbiorca deszyfruje dokument używając klucza publicznego nadawcy weryfikując w ten sposób jego podpis. Podpis ten jest prawdziwy, gdyż został zweryfikowany prze użycie klucza publicznego nadawcy; podpis nie może być sfałszowany gdyż tylko nadawca zna swój klucz prywatny. Podpisany dokument nie może być zmieniony, gdyż zmieniony dokument nie da się rozszyfrować kluczem publicznym nadawcy.
Wadą takiego sposobu podpisywania dokumentów jest to, że podpis jest co-najmniej tak długi jak sam dokument, co uniemożliwia praktyczne zastosowanie tej, jednak wymagającej dużych mocy obliczeniowych, procedury. Dlatego stosuje się procedurę z wykorzystaniem jednokierunkowej funkcji skrótu, tzw. funkcji hash.
Funkcja skrótu (haszująca)
30

W procedurze podpisu elektronicznego pierwszym krokiem jest wygenerowaniu z pliku zawierającego dane, tzw. skrótu (hash) Jest to jednokierunkowe przekształcenie matematyczne zamieniające ciąg bitów dowolnej długości w inny ciąg bitów o zadanej długości (np. 128 czy 192 bity). Bezpieczna kryptograficznie funkcja skrótu powinna spełniać trzy podstawowe założenia:
- brak możliwości wygenerowania dwóch wiadomości o takim samym skrócie (z czysto matematycznego punktu widzenia jest to niewykonalne. Jeśli wyjście funkcji ma 128 bitów oznacza to, że biorąc 2128+1 różnych stanów wejściowych jakiś wynik na pewno się powtórzy)
- brak możliwości wygenerowania dwóch wiadomości o takim samym skrócie, czyli brak tzw. kolizji
- brak możliwości odtworzenia danych wejściowych na podstawie skrótu.Podkreślmy, że uznanie funkcji za bezpieczną do zastosowań kryptograficz-
nych opiera się wyłącznie na domniemaniu odporności na znane ataki kryptoanalityczne, nie zaś na matematycznych dowodach gwarantujących niemożność złamania [2]. Istnienie jednokierunkowych funkcji nie zostało dotychczas dowiedzione. Poważne słabości znaleziono w wielu funkcjach skrótu, które historycznie uchodziły za bezpieczne, nawet w jeszcze używanych (m.in. w SHA, MD5).
Funkcje haszujące używane obecnie w kryptografii to MD5, SHA-1, SHA-2, RIPEMD-160. Jedną z najbardziej popularnych rodzin funkcji skrótu jest rodzina MD (Message Digest) Ronalda Rivesta (współtwórcy RSA). MD5 (Message-Digest algorithm 5), piata wersja funkcji został opracowana w 1991 roku, która z dowolnego ciągu danych generuje 128-bitowy skrót. W 2004 znaleziono sposób na generowanie kolizji w MD5, co spowodowało, że nie jest już ona polecana do zastosowań wymagających wysokiego poziomu bezpieczeństwa [3]. Jest jednak w dalszym ciągu powszechnie stosowana w internecie jako suma kontrolna przesyłanych plików.
SHA (Secure Hash Algorithm) to rodzina kryptograficznych funkcji skrótu zaprojektowanych przez NSA (National Security Agency) i publikowanych przez NIST (National Institute of Standards and Technology) [4]. Pierwsza z tych funkcji, opublikowana w 1993 roku, została wycofana ze względu na oficjalnie nieujawnione wady. Została onazastąpiona w 1995 roku przez algorytm SHA-1. Algorytm ten generuje 160-bitowy skrót z wiadomości o maksymalnym rozmiarze 264 bitów. W budowie jest podobna do MD5.
Podobnie jak MD5, algorytm ten nie jest już zalecany do nowych aplikacji [5]. W 2001 roku powstały cztery następne warianty określane jako SHA-2 (SHA-224, SHA-256, SHA-384, SHA-512). Obecnie NIST prowadzi publiczny konkurs na następcę dotychczasowych funkcji skrótu. Na razie wiadomo tylko, że nowa funkcja zostanie nazwana SHA-3 [6].
RIPEMD to funkcja skrótu opracowana w ramach projektu Unii Europejskiej o nazwie RIPE (RACE Integrity Primitives Evaluation) realizowanego w latach 1988-1992. W 1996 roku powstała wersja generująca skrót 160-bitowy nazwana RIPEMD-160. W 2004 roku Xiaoyun Wang, Dengguo Feng, Xuejia Lai oraz Hongbo Yu opublikowali dokument w którym dwie pary wiadomości produkujących te same skróty [7]. Algorytm RIPEMD-160 jest stosunkowo mało popularny i słabo zbadany z punktu bezpieczeństwa stosowania.
Zastosowanie funkcji skrótu umożliwia więc następującą procedurę (rys. 1): nadawca najpierw tworzy skrót a następnie podpisuje ten skrót szyfrując go
31

kluczem prywatnym i przesyła wraz z dokumentem odbiorcy. Odbiorca używa tej samej funkcji hashującej do otrzymania skrótu dokumentu, a następnie deszyfruje podpisany skrót używając klucza publicznego nadawcy. Jeżeli zdeszyfrowany skrót zgadza się z przesłanym, to podpis jest prawdziwy. Zalety tej procedury są oczywiste: podpis jest znacznie krótszy od dokumentu, a jego wiarygodność można sprawdzić bez oglądania samego dokumentu. W praktyce sam przesyłany dokument jest również szyfrowany, ale już jakimkolwiek szybkim algorytmem symetrycznym, np. DES.
.
.Rys 1. Schemat weryfikacji integralności przesyłki przy użyciu funkcji skrótu
wiadomości [8]
Procedura złożenia i weryfikacji podpisu elektronicznegoPraktyczna procedura złożenia podpisu pod przygotowanym wcześniej
dokumentem elektronicznym jest następująca. W pierwszym kroku obliczany jest skrót dokumentu, np. za pomocą funkcji SHA-1 i przesyłany do karty kryptograficznej. Tam wykonywane jest szyfrowanie tego skrótu, np. według algorytmu RSA za pomocą klucza prywatnego zapisanego na tej karcie. Warunkiem wykonania tej operacji jest jej uwierzytelnienie kodem PIN. Wygenerowane dane odsyłane są do komputera i dołączane do oryginalnego dokumentu. Dodatkowo do dokumentu oraz zaszyfrowanego skrótu dołączany zostaje certyfikat zawierający dane osoby składającej podpis oraz jej klucz publiczny. Tak przygotowane dane można nazwać podpisem elektronicznym dołączonym do dokumentu i z nim powiązanym (rys.2).
32
Nadawca, np. klient Odbiorca, np. bank

Rys. 2. Konstrukcja przesyłki podpisanej elektronicznie przez nadawcę
Weryfikacja dokumentu z podpisem polega ponownym obliczeniu skrótu z do-kumentu. W następnym kroku, przy pomocy klucza publicznego rozszyfrowywany jest skrót dołączony do dokumentu. Jeśli rozszyfrowany skrót jest równy obliczo-nemu skrótowi, wtedy weryfikacja jest pozytywna.
Zastosowanie technik kryptograficznych w procedurze podpisu elektronicz-nego nie wystarcza dla pewności, że przesłany dokument jest właściwy. Zaszyf-rowanie lub elektroniczne podpisanie dokumentu nie daje bowiem gwarancji, że osoba, która użyła klucza prywatnego jest tą, za którą się podaje. Gwarancję taką daje dopiero system certyfikacji kluczy.
Certyfikat cyfrowy to elektroniczne zaświadczenie, że dane służące do weryfikacji podpisu elektronicznego są przyporządkowane określonej osobie i potwierdzają jej tożsamość. Certyfikacji dokonuje odpowiedni organ, poświadczający autentyczność danego klucza publicznego. Jest to tzw. Zaufana Trzecia Strona (Trusted Third Party). Zadaniem urzędu certyfikacji jest wydawanie i zarządzanie certyfikatami.
Certyfikat cyfrowy posiada następujące informacje: unikalny numer seryjny, tożsamość urzędu certyfikacji wydającego certyfikat, okres ważności certyfikatu, identyfikator właściciela certyfikatu (imię, nazwisko, pseudonim, e-mail itp.), klucz publiczny właściciela certyfikatu i podpis cyfrowy urzędu certyfikacji potwierdzający autentyczność certyfikatu.
Dodatkowymi aspektami, o których warto w tym momencie wspomnieć są ważność certyfikatu oraz możliwość jego zawieszenia lub unieważnienia. W ustawie o podpisie elektronicznym określona jest maksymalna ważność certyfikatu kwalifikowanego, która wynosi 2 lata. Po tym czasie certyfikat staje się nieważny i podpisy złożone po upłynięciu terminu ważności stają się automatycznie weryfikowane negatywnie. Możliwe jest także unieważnienie lub zawieszenie certyfikatu, następuje ono na wyraźną prośbę użytkownika np. w przypadku poznania przez osoby niepowołane kodu PIN. Fakt ten zostaje odnotowany i opublikowany na tzw. liście CRL (certificate revocation list). Listę taką publikuje i uaktualnia codziennie na swoich stronach każdy kwalifikowany urząd certyfikacji.
Na polskim rynku działa sześć firm oferujących zestawy do składania bezpiecznego podpisu elektronicznego. Są to Krajowa Izba Rozliczeniowa, Unizeto, Polska Wytwórnia Papierów Wartościowych, Mobicert, Enigma oraz Safe Technologies (CenCert). W skład typowego zestawu wchodzą: czytnik kart
33

kryptograficznych, karta kryptograficzna oraz zapisany na karcie certyfikat, który zawiera parę kluczy RSA, a także informacje o osobie na którą jest wystawiony. Ponieważ bezpieczny podpis elektroniczny weryfikowany jest tzw. certyfikatem kwalifikowanym, ma moc prawną odpowiadającą podpisowi odręcznemu i przy jego wystawianiu i wydawaniu weryfikowana jest tożsamość osoby. Niezbędne jest także odpowiednie oprogramowanie służące do składania oraz weryfikacji podpisów elektronicznych.
Warto w tym momencie zaznaczyć, że taka konstrukcja systemu powoduje iż dane służące do składania bezpiecznego podpisu faktycznie znajdują się pod wyłączną kontrolą podpisującego. Certyfikat z parą kluczy znajdują się na karcie kryptograficznej i dostęp do nich chroniony jest kodem PIN. Niemożliwe jest także skopiowanie lub usunięcie kluczy z karty. Po kilkukrotnym błędnym wpisaniu kodów PIN oraz PUK dostęp do certyfikatu oraz kluczy zostaje zablokowany.
Bezpieczeństwo podpisu elektronicznegoAlgorytm RSA jest dobrze znany a jego wady są bardzo dokładnie opisane.
Oparty jest na złożoności faktoryzacji dużych liczb, dlatego jedynym zabezpieczeniem przed złamaniem klucza prywatnego jest czasochłonność obliczeniowa. Na dziś największym kluczem, jaki praktycznie udało się rozłożyć na czynniki pierwsze jest klucz 768 bitowy. W Polsce stosowane są klucze 1024 bitowe, co, jakkolwiek wydaje się niewiele więcej, to zapewnia wystarczający margines bezpieczeństwa. Prawdopodobnie następną minimalną stosowaną długością klucza będzie 2048 bitów.
Aktualnie stosowana funkcja SHA-1 także jest uznawana za bezpieczną w istniejących aplikacjach. Znane są co prawda próby ataku, jednak na razie są zbyt mało obliczeniowo skuteczne, by można było mówić o realnym zagrożeniu dla bezpieczeństwa podpisu elektronicznego. Ponadto coraz bardziej powszechne stosowana rodzina funkcji SHA-2 stwarza możliwość zastąpienia SHA-1 bezpieczniejszym algorytmem.
Użycie kombinacji algorymtów RSA oraz SHA-1 zabezpiecza więc skutecznie przed ingerencją w podpisany dokument. Każda jego modyfikacja powoduje zmianę skrótu, co doprowadza do negatywnej weryfikacji podpisu. Żeby skutecznie podrobić podpis należałoby wygenerować drugi identyczny skrót, co jest na dzień dzisiejszy praktycznie niewykonalne. Poza tym, nie wystarczy przełamanie tylko jednego zabezpieczenia. Istotne jest na przykład, aby drugi „podrobiony” dokument niewiele różnił się od oryginału. W końcu, jeśli nawet będą istnieć dwa dokumenty o takim samym skrócie, muszą być te skróty podpisane - a do tego niezbędna jest znajomość klucza prywatnego, którego odtworzenie wymaga ogromnej złożności obliczeniowej. Poznanie tego klucza z karty kryptograficznej również nie jest proste, gdyż karty, na których przechowywane są klucze oraz certyfikaty kwalifikowane są specjalnie zabezpieczane przed dostępem do pamięci osób trzecich.
ZakończeniePodpis elektroniczny stanowi ukoronowanie osiągnięć kryptografii naszych
czasów wykorzystującej zarówno szyfrowanie asymetryczne, jak i jedno-kierunkową funkcję skrótu. Jednak każdy system kryptograficzny jest tak słaby jak jego najsłabsze ogniwo. Tym najsłabszym ogniwem jest człowiek. Często każdy
34

użytkownik różnych kart bankowych, kredytowych i in. musi pamietać wiele kodów PIN. Niektóre osoby przechowują więc numery PIN zapisane na kartce przylepionej do monitora lub leżącej na biurku. Równie często zestawy do składania podpisu są na stale podłączone do komputera użytkownika i łatwo dostępne. Taka kombinacja niedopatrzeń pozwala składać podpisy osobie postronnej. Każdy kto używa podpisu elektronicznego powinien o tym pamietać.
Literatura[1] Nowakowski, W.: Algorytm RSA - podstawa podpisu elektronicznego. Elektronika 6/2010, Warszawa 2010.[2] Sklarov, D. V.: Łamanie zabezpieczeń programów. RM, Warszawa 2004.[3] http://blog.securitystandard.pl/news/342130.html[4] http://csrc.nist.gov/groups/ST/toolkit/index.html[5] http://tools.ietf.org/html/rfc3174[6] http://ipsec.pl/kryptografia/2008/trzydziestu-kandydatow-do-sha-3.html[7] http://eprint.iacr.org/2004/199.pdf[8] http://krystian.jedrzejczak.webpark.pl/podpis.htm#podpis
Literatura uzupełniająca:[9] Tanaś R.: http://zon8.physd.amu.edu.pl/~tanas/[10] http://www.ebanki.pl/technika/podpis_cyfrowy.html[11] RSA Laboratories. RSA Laboratories' Frequently Asked Questions About Today's Cryptography, Version 4.1. RSA Security Inc. 2002.[12] Ustawa z dnia 22 sierpnia 2001 roku o podpisie elektronicznym (Dz.U. 2001 nr 130 poz. 1450, tekst ujednolicony)
35

Wojciech NowakowskiInstytut Maszyn Matematycznych
Algorytm RSA - podstawa podpisu elektronicznego
WprowadzenieKlasyczne metody szyfrowania danych cyfrowych stosowane od lat, od
początku istnienia kryptografii opierały się na podstawieniach i permutacji. W szy-frowaniu konwencjonalnym informacja zostaje przekształcona na postać zaszyfro-waną za pomocą algorytmu szyfrujący oraz klucza. Różne klucze generują różne dane wyjściowe, czyli inną postać informacji zaszyfrowanej. Odbiorca może tę informację odszyfrować, ale tylko wtedy, gdy dysponuje identycznym kluczem, jaki został użyty do szyfrowania.
Wystąpił więc podstawowy problem dystrybucji kluczy. Korzystanie z szyfrowania było uwarunkowane posiadaniem przez obie strony transmisji tego samego klucza, w jakiś sposób dostarczonego, lub tworzenia central dystrybucji kluczy, co niewątpliwe utrudnia lub w ogóle uniemożliwia zachowanie tajności kluczy.
Rozwiązanie tego problemu przyniósł rozwój kryptografii klucza jawnego. Algorytmy z kluczem jawnym wykorzystują funkcje matematyczne. Jest to szyfrowanie asymetryczne, za pomocą dwóch kluczy, jednego publicznego, jawnego i drugiego prywatnego, niejawnego i chronionego, ale nie przekazywanego.
Jednym z pierwszych, a obecnie najbardziej popularnym asymetrycznym algorytmem kryptograficznym jest algorytm RSA [1]. Został opracowany w 1977 r. przez Rona Rivesta, Adi Shamira oraz Leonarda Adlemana. Jest to jednocześnie pierwszy algorytm, który można stosować zarówno do szyfrowania jak i do podpisów cyfrowych.
Klucz publiczny umożliwia jedynie zaszyfrowanie danych i w żaden sposób nie ułatwia ich odczytania, nie musi więc być chroniony. Drugi klucz, prywatny, przechowywany pod nadzorem, służy do odczytywania informacji zakodowanych za pomocą klucza publicznego. Możliwe jest także zaszyfrowanie wiadomości za pomocą klucza tajnego prywatnego, a następnie jej odszyfrowanie za pomocą klucza publicznego. To właśnie ta własność sprawia, że RSA może zostać wykorzystany do cyfrowego podpisywania dokumentów.
System RSA umożliwia bezpieczne przesyłanie danych w środowisku, w którym może dochodzić do różnych nadużyć. Bezpieczeństwo szyfrowania opiera się w tym algorytmie na bardzo czasochłonnej obliczeniowo faktoryzacji (znajdowaniu czynników pierwszych) dużych liczb złożonych. Najszybszym komputerom może zajmować to obecnie wiele dziesiątków lat. Sytuacja może ulec zmianie po wprowadzeniu tzw. komputerów kwantowych [2], które będą pracowały miliony razy szybciej od współczesnych, ale to dopiero przyszłość.
Opis algorytmu [3]:System RSA to szyfr blokowy, w którym tekst jawny i zaszyfrowany są
liczbami całkowitymi od 0 do n-1 dla pewnego n. Korzysta on z wyrażenia
36

potęgowego. Tekst jawny jest szyfrowany blokami, z których każdy ma wartość binarną mniejsza od pewnej liczby n. Szyfrowanie dla bloku tekstu jawnego m i zaszyfrowanego c ma następująca postać:
Wartość n musi być znana nadawcy i odbiorcy. Nadawca zna wartość e, a odbiorca d. Klucz publiczny to {e, n} ,a prywatnym {d, n}.
Generowanie kluczy:
Wybieramy dwie duże liczby pierwsze:{p, q}Obliczamy ich iloczyn:
oraz funkcję Eulera
Wybieramy losowo liczbę e < n , względnie pierwszą z liczbą = (p - 1)(q - 1). Liczba e będzie kluczem szyfrującym. Znajdujemy liczbę (korzystając z rozsze-rzonego algorytmu Euklidesa) d taką, że
lub
Liczby d i n są także względnie pierwsze
Jak wspomniano liczby {e,n} stanowią klucz publiczny, który ujawniamy, zaś liczby {d,n} stanowią klucz prywatny, który powinien być ściśle chroniony (liczba d)
Przy korzystaniu z algorytmu RSA bardzo ważna jest kwestia złożoności obliczeń. Pierwszy problem to znalezienie dwóch liczb pierwszych p i q. Muszą być one wybierane z dużego zbioru, aby niełatwe było ich znalezienie z iloczynu n metodą kolejnych prób. Metoda poszukiwania liczb pierwszych musi być więc dostatecznie efektywna. Obecnie nie istnieją szybkie metody poszukiwania dużych liczb pierwszych, dlatego stosuje się metodę pośrednią, polegającą na wylosowaniu liczby nieparzystej żądanego rzędu wielkości, a następnie sprawdzaniu, np. testem Millera-Rabina, czy jest to liczba pierwsza.
Procedura ta jest uciążliwa, jednak wykonuje się ją tylko w celu stworzenia nowej pary kluczy. Natomiast przy szyfrowaniu i deszyfrowaniu oblicza się jedynie potęgi liczb całkowitych mod n. Przy tym pewne trudności powodują
37

ogromne wartości pośrednie. Można jednak je ominąć korzystać z własności arytmetyki modulo:
dzięki czemu możliwe jest zredukowanie wyników pośrednich modulo n.
Przykład liczbowy
Oto prosty przykład liczbowy algorytmu RSA (w praktyce użyte liczby są znacznie większe):
Niech dwie liczby pierwsze p i q to 7, 19n = pq = 133(n) = (p-1)(q-1) = 108
Wybieramy e = 5 takie, że e jest liczbą względnie pierwszą z (n) i e < (n) Na tej podstawie obliczamy d = 65 takie, żede = 1 mod (n) i d < (n) 5 * x = 1 mod 108 = 65 Klucz publiczny to = {5, 133}, zaś klucz prywatny to {65, 133}Niech tekst jawny to m = 54 Szyfrujemy c = 545 mod 133 = 80Deszyfrujemy m = 8065 mod 133 = 54
Do obliczeń modulo tak w powyższym przykładzie jak i innych obliczeniach można użyć bardzo wygodnego kalkulatora modulo opublikowanego w [4].
Technologia szyfrowania asymetrycznego z kluczami publicznymi i prywatnymi, umożliwia wprowadzenie podpisu elektronicznego. Pozwala on na jednoznaczne i nie budzące wątpliwości podpisywanie waznych dokumentów, plików, programów, itp. Klucz prywatny wraz z funkcją „haszującą” (wykonania zaszyfrowanego tzw. skrótu dokumentu - np. algorytmy SHA-1 i MD5) tworzą podpis elektroniczny dokumentu - pliku, natomiast klucz publiczny weryfikuje taki podpis, sprawdzając jego prawdziwość. Podpis elektroniczny i narzędzia do jego weryfikacji, stają się zatem ważnymi elementami strategii uwierzytelniania zasobów danych.
Jak dotąd nie są znane przypadki odszyfrowania informacji zakodowanych współczesnymi (1024-bitowymi i dłuższymi) kluczami asymetrycznymi bez znajomości odpowiednich kluczy prywatnych. Świadczy to o skuteczności algorytmu RSA w zabezpieczaniu poufnych informacji cyfrowych.
Literatura[1] RSA Cryptography Standard, PKCS, RSA Laboratories, June 14, 2002[2] Nowakowski W., O kryptografii kwantowej. Elektronika 2/2010,
Warszawa[3] Prasał B. J., http://www.prasal.com/kryptografia/index.php[4] Świątkowski Ł., Kalkulator modulo, Wydział Informatyki i Zarządzania
PWr, http://www.im.pwr.wroc.pl/~tjurlew/sa.htm
38

Literatura uzupełniająca:[5] Wiera R., Rdest M.: Szyfrowanie RSA.
http://stud.wsi.edu.pl/~siwierar/szyfrowanie/index.php[6] Tanaś R.: http://zon8.physd.amu.edu.pl/~tanas/[7] Denning D.E.: Kryptografia i ochrona danych. WNT, Warszawa 1992.[8] http://www.ebanki.pl/technika/podpis_cyfrowy.html[9] http://www.rsasecurity.com/rsalabs/faq/3-6-4.html[10] Koblitz N.: Wykład z teorii liczb i kryptografii. WNT, Warszawa 1995.[11] Krawczyk P.: Leksykon kryptograficzny. http://echelon.pl/leksykon/.[12] RSA Laboratories. RSA Laboratories' Frequently Asked Questions About
Today's Cryptography, Version 4.1. RSA Security Inc. 2002.[13] Tipton H., Krause M. (Consulting Editors). Handbook of Information
Security Management. CRC Press 1998.[14] Ustawa z dnia 22 sierpnia 2001 roku o podpisie elektronicznym (Dz.U.
2001 nr 130 poz. 1450, tekst ujednolicony)[15] Wobst R.: Kryptologia: budowa i łamanie zabezpieczeń. Wydawnictwo
RM, Warszawa 2002.
39

Roman CzajkowskiWojciech NowakowskiInstytut Maszyn Matematycznych
O protokóle Ekerta w kryptografii kwantowej
WprowadzenieW [1] przedstawiono podstawowe pojęcia i informacje dotyczące informatyki
kwantowej i jej zastosowania do kryptografii. Przedstawiono też pojęcia i zasady kryptografii kwantowej i działania całkowicie bezpiecznego kanału dystrybucji klucza, co w kryptografii jest zagadnieniem zasadniczym, na przykładzie protokołu BB84 (Charles H. Bennett i Gilles Brassard, 1984). Nieco później, polski fizyk, absolwent Uniwersytetu Jagiellońskiego, obecnie profesor fizyki kwantowej na Uniwersytecie w Cambridge, w swojej rozprawie doktorskiej (Oxford, 1991) pokazał jak można wykorzystać zjawisko splątania fotonów do kwantowej dystrybucji klucza z zapewnieniem pełnego bezpieczeństwa transmisji.Splątanie
Mechanika kwantowa zakłada, że przed pomiarem wielkości kwantowej mierzona zmienna nie ma ustalonej wartości, dopiero pomiar ją ustala, a wcześniej można mówić tylko o rozkładach prawdopodobieństwa. Istnieją jednak pewne tzw. stany splątane par obiektów kwantowych, które mają taką właściwość, że gdy dokonujemy pomiaru pewnej wartości obiektu, otrzymujemy zawsze przeciwne wyniki (pełna anty-korelacja). Tego rodzaju obiektem mogą być m. in. kubity w postaci spolaryzowanych fotonów.
Stan splątany polaryzacji dwóch fotonów ma taką właściwość, że jeżeli będziemy mierzyć polaryzacje obu fotonów, używając dwóch identycznie ustawionych, ale odległych od siebie polaryzatorów, to zawsze otrzymamy dwie przeciwne polaryzacje. Natomiast zmierzone polaryzacje każdego z fotonów z osobna są zupełnie przypadkowe. Zatem para fotonów splątanych ma precyzyjnie określoną własność wspólną (polaryzacje mierzone tak samo ustawionymi polaryzatorami są zawsze przeciwne), natomiast stan podukładu, czyli pojedynczego fotonu, jest całkowicie nieokreślony — wynik pomiaru polaryzacji pojedynczego fotonu jest zupełnie przypadkowy. Splątanie nie zanika wraz z odległością – tak przewiduje teoria kwantów (w latach 90. XX wieku eksperymentalnie udowodniono istnienie splątania pomiędzy fotonami odległymi od siebie o kilkanaście kilometrów (grupa Gisin'a, Genewa), potem zaobser-wowano to zjawisko na odległości 144km - na wyspach La Palma i Teneryfa (Anton Zeilinger i współpracownicy).
Pojęcie splątania zostało wprowadzone przez Erwina Schroedingera w 1935 roku. Leży ono u podstaw paradoksu EPR (Einsteina, Podolskiego i Rosena), że istnieje oddziaływanie rozchodzące się natychmiastowo na dowolną odległość, a szczególna teoria względności zabrania przekazywania informacji i oddziaływań z prędkością większą od prędkości światła. Rozumując dalej wywnioskowali, że zmienne kwantowe muszą mieć ustaloną wartość przed pomiarem, co z kolei musiało prowadzić do wniosku, że mechanika kwantowa jest teorią niepełną, bo nie określa tych ustalonych wartości, a jedynie ich prawdopodobieństwa.
40

Wszystko to doprowadziło do twierdzenia Bella o niemożliwości pogodzenia opi-su kwantowego mikroświata z opisem o charakterze klasycznym zgodnym z teorią względności. Stany splątane jednak istnieją i mają szerokie zastosowanie w in-formatyce kwantowej (zwłaszcza w kryptografii i teleportacji kwantowej).
Rozróżnia [1] się dwa główne typy kryptosystemów kwantowych: - kryptosystemy z kodowaniem opartym na pomiarze jednej z dwóch
możliwych wielkości reprezentowanych przez niekomutujące (nieprzemienne) operatory hermitowskie, tzw. protokół BB84 (Charles H. Bennett i Gilles Brassard, 1984 [2]), który można pokrótce przedstawić następująco (N - nadawca, O - odbiorca):1. N losuje klucz i przesyła go O przy losowo ustawionych bazach polaryzatorów: prostej 0/90 lub ukośnej +45/–45 stopni.2. O za pomoca losowo ustawionych baz swoich polaryzatorów i detektorów odbiera transmisję.3. O jawnym kanałem przekazuje w jaki sposób ustawił swoje detektory.4. N informuje O kanałem jawnym, w których przypadkach się pomylił.5. N i O odrzucają niezgodne części klucza.6. N i O jawnym kanałem porównują kilka bitów z uzyskanego klucza. Jeżeli sprawdzane fragmenty są zgodne odrzucają je i rozpoczynają transmisję z użyciem pozostałej części klucza.
- kryptosystemy z kodowaniem opartym na zjawisku stanów splątanych , tzw. protokół EPR. Protokół ten został zaproponowany w 1991 roku przez Ekerta [3] opiera się na zjawisku EPR (Einstein-Podolsky-Rosen). Najogólniej mówiąc polega on na tym, że w generowanej sekwencji par splątanych (czyli związanych nierównością Bella par EPR) N i O badają polaryzację tych par:1. Splątane fotony są wytwarzane przez źródło niezależne od N i O.2. N i O otrzymują po jednym fotonie ze splątanej pary.3. N poprzez pomiar polaryzacji swojego fotonu wpływa na stan kwantowyfotonu O.4. O dokonuje pomiaru stanu kwantowego swojego fotonu. 5. Po zakończeniu procedury przesyłania fotonów, O posiada pierwotny kod (raw key) zawierający około 25% błędów i kontaktuje się z N w celu porównania bramek użytych do polaryzacji fotonów i jej pomiaru.6. Klucz przesiany (shifted key) składa się z ciągu bitów, dla których bramki wybrane przez N i O były zgodne (około 50%)
Wyżej opisany algorytm można zilustrować następującymi schematami:
Rys 1. Zasada transmisji według protokołu Ekerta
41
Filtr polaryzujący Źródło światła Filtr detekcyjny

Rys 2. Uzyskany kod
Bezpieczeństwo kryptosystemu kwantowego Ekerta polega przede wsszystkim na tym, że informacja definiująca klucz pojawia się nie podczas procesu przesyłania, lecz dopiero po pomiarach dokonanych przez nadawcę i odbiorcę. każdy pomiar jest natomiast integralną częścią badanego układu.
Literatura:[1] Nowakowski W.: O kryptografii kwantowej. Elektronika, nr 2, Warszawa
2010[2] Bennett C. H., Brassard G.: Quantum Cryptography: Public key distribution
and coin tossing. Proceedings of the IEEE International Conference on Computers, Systems, and Signal Processing, Bangalore 1984
[3] Ekert A.K.: Quantum cryptography based on Bell's theorem. Phys. Rev. Lett., 1991
[4] Borkowska A.(UMCS Lublin): Kryptografia kwantowa, czyli praktyczne zastosowanie nieintuicyjnych cech realnego świata. Referat wygłoszony na V OSKNF, Wrocław 17-19.09.2006.
[5] Tanaś R.: http://zon8.physd.amu.edu.pl/~tanas/
42

Monika BiskupskaGrzegorz MazurkiewiczPiotr ZduńczykInstytut Maszyn Matematycznych
Wirtualny konsultantdla Małych i Średnich Przedsiębiorstw
StreszczenieW artykule przedstawiono propozycję stworzenia systemu internetowego
przeznaczonego dla małych i średnich przedsiębiorstw, pomagającego użytkownikom w znalezieniu najbliższego ich potrzebom źródła dofinansowania. Podstawą planowanej usługi będzie system ekspercki, który na podstawie informacji dostarczonych przez użytkownika językiem naturalnym lub przez serię formularzy, dokona automatycznego doboru optymalnego dla danego użytkownika źródła finansowania.
WstępWraz z wstąpieniem Polski do Unii Europejskiej pojawiło się wiele możliwości uzyskania pomocy finansowej przy realizacji projektów, przede wszystkim w ramach funduszy strukturalnych oraz innych funduszy pomocowych. Pomimo wielu przedsięwzięć o charakterze informacyjnym i szkoleniowym, prowadzonych przez upoważnione do tego organizacje, stopień poinformowania społeczeństwa, a przede wszystkim zainteresowanych podmiotów gospodarczych, w tej dziedzinie nie jest wysoki. Informacji o funduszach pomocowych jest co prawda wiele, jednak są one bardzo rozproszone, co powoduje ogromne problemy związane z odnalezieniem informacji przydatnych dla konkretnej organizacji, w określonym czasie i dla wymaganego typu przedsięwzięcia. Dotyczy to zwłaszcza małych i średnich przedsiębiorstw (MSP), które nie są w stanie zorganizować specjalizowanych komórek zajmujących się poszukiwaniem źródeł wsparcia dla planowanych przedsięwzięć. Taki stan rzeczy skutkuje utratą potencjalnych szans i niepełnym spożytkowaniem funduszy, które mogłyby i powinny zostać wykorzystane w jak największym stopniu zgodnie z zaplanowaną w danym programie alokacją.
W odpowiedzi na tego typu problemy w Instytucie Maszyn Matematycznych powstała inicjatywa stworzenia systemu wspomagającego dostępność zasobów informacyjnych dotyczących funduszy pomocowych dla małych i średnich przedsiębiorstw, który funkcjonować będzie na zasadzie portalu wiedzy o potencjalnych źródłach finansowania z funduszy pomocowych. Aby zmaksymalizować efektywność dostarczanych informacji proponuje się, by usługa świadczona on-line działała w oparciu o ontologię bazy wiedzy, na której pracować będzie system ekspercki, elementy bazy wiedzy systemu eksperckiego (instancje klas ontologii) oraz scenariusze proponowane przez system ekspercki. Wachlarz usług powinien zostać również uzupełniony o zestaw szkoleń e-learningowych i publikacji elektronicznych związanych z tematyką funduszy
43

pomocowych, bibliotekę oprogramowania wspomagającego oraz tradycyjne usługi portalowe (aktualności, forum dyskusyjne).
Proponowany system udostępniania wiedzy o źródłach wsparcia przedsiębiorstw może zostać zbudowany jako otwarty portal internetowy, zawierającym następujące komponenty (usługi):
1) inteligentny system ekspercki, który na podstawie zgromadzonych informacji dokona automatycznego doboru optymalnego dla danego użytkownika źródła finansowania;
2) zestaw szkoleń e-learningowych, które służyć będą podniesieniu kwalifikacji zainteresowanych w dziedzinie finansowania projektów z funduszy pomocowych i efektywnego ich wykorzystania;
3) biblioteka publikacji elektronicznych związanych z tematyką portalu;4) system wyszukiwawczy dla materiałów przechowywanych
w systemie;5) biblioteka oprogramowania wspomagającego wypełnianie wniosków;6) forum dyskusyjne umożliwiające wymianę doświadczeń oraz
uzyskiwanie odpowiedzi na pytania od ekspertów;7) publikacja nowości związanych z ogłoszeniami nowych konkursów
na projekty, zmianami w przepisach czy pojawianiem się na portalu nowych, ważnych materiałów.
Schemat podstawowych komponentów (usług) oraz ich powiązania między sobą w proponowanym systemie eksperckim przedstawia rysunek 1.
44
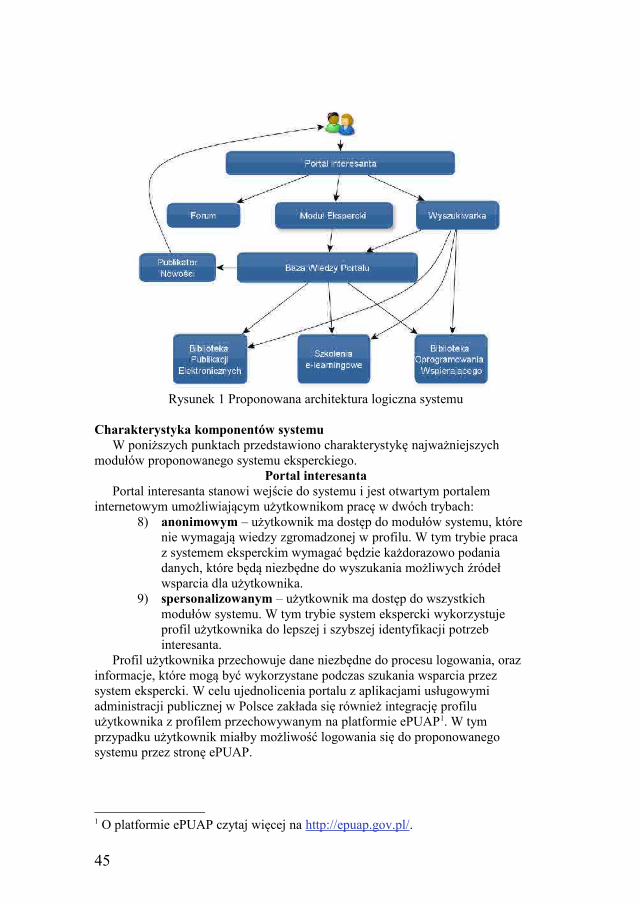
Rysunek 1 Proponowana architektura logiczna systemu Charakterystyka komponentów systemu
W poniższych punktach przedstawiono charakterystykę najważniejszych modułów proponowanego systemu eksperckiego.
Portal interesantaPortal interesanta stanowi wejście do systemu i jest otwartym portalem
internetowym umożliwiającym użytkownikom pracę w dwóch trybach:8) anonimowym – użytkownik ma dostęp do modułów systemu, które
nie wymagają wiedzy zgromadzonej w profilu. W tym trybie praca z systemem eksperckim wymagać będzie każdorazowo podania danych, które będą niezbędne do wyszukania możliwych źródeł wsparcia dla użytkownika.
9) spersonalizowanym – użytkownik ma dostęp do wszystkich modułów systemu. W tym trybie system ekspercki wykorzystuje profil użytkownika do lepszej i szybszej identyfikacji potrzeb interesanta.
Profil użytkownika przechowuje dane niezbędne do procesu logowania, oraz informacje, które mogą być wykorzystane podczas szukania wsparcia przez system ekspercki. W celu ujednolicenia portalu z aplikacjami usługowymi administracji publicznej w Polsce zakłada się również integrację profilu użytkownika z profilem przechowywanym na platformie ePUAP1. W tym przypadku użytkownik miałby możliwość logowania się do proponowanego systemu przez stronę ePUAP.
1 O platformie ePUAP czytaj więcej na http://epuap.gov.pl/.
45

System ekspercki: Moduł Ekspercki i Baza Wiedzy PortaluSystem ekspercki jest najważniejszym elementem portalu, którego zadaniem
jest wyszukanie optymalnego źródła finansowania dla interesanta. Komunikacja systemu eksperckiego z użytkownikiem opiera się na dwóch koncepcjach:
10) interaktywnych kreatorach;11) module rozpoznawania języka naturalnego.
W pierwszym przypadku system wykorzystuje mechanizm przepływów pracy (ang. Workflow). Użytkownik w kolejnych etapach wypełnia proste formularze ekranowe, które sterują przebiegiem pozyskiwania danych od użytkownika, niezbędnych do wyszukania optymalnej propozycji wsparcia. Druga koncepcja systemu eksperckiego opiera się na module rozpoznawania języka naturalnego. Użytkownik nie musi już wypełniać formularzy precyzujących jego problem – stara się opisać go własnymi słowami, w języku polskim. System, wykorzystując bazę wiedzy, inteligentnie go klasyfikuje, a następnie wyświetla listę znalezionych problemów, które najlepiej odpowiadają potrzebom użytkownika. W dalszych krokach problem zostaje uszczegółowiony na podstawie dialogu użytkownika z systemem.Rozwiązanie dla systemu eksperckiego wykorzystujące obie koncepcje pozwala uniknąć wad obydwu wariantów przy zachowaniu ich zalet.Model interaktywnych kreatorów („wizard”), prezentujący użytkownikowi serię pytań dobieranych zależnie od udzielanych przez niego odpowiedzi, jest łatwy w wykorzystaniu i zrozumiały w użytkowaniu. Niestety, w niektórych przypadkach może okazać się nazbyt czasochłonny.Model analizy zapytań języka naturalnego pozwala w najszybszy sposób otrzymać wynik. Jednak bazowanie tylko na tym rozwiązaniu łatwo może wprowadzić w konfuzję początkujących użytkowników, niezorientowanych w tym, o co i jak mogą zapytać. W przypadku systemu podpowiadającego możliwości dofinansowania, niedoświadczony użytkownik najprawdopodobniej wpisze „chcę otrzymać dofinansowanie”. Dla takiego klienta wygodniejszy będzie model kolejnych przybliżeń, realizowany w postaci „wizarda”.Zastosowanie sieci semantycznej jako narzędzia do klasyfikowania i katalogowania danych zawartych w Bazie Wiedzy Portalu pozwoli wykorzystać nie tylko mechanizmy zwykłego wyszukiwania danych, lecz również wykorzystać wnioskowanie podczas wyszukiwania. Dodatkowo będzie możliwe wyszukanie danych, które są skojarzone z danym pojęciem. Kluczową rolę w sieci semantycznej odgrywa ontologia – definicja klas obiektów na podstawie ich właściwości, która dodatkowo posiada zapis logicznych charakterystyk relacji zachodzących pomiędzy klasami2. Dane, jakie przechowuje sieć semantyczna, mogą być zachowane zgodnie ze standardami określonymi przez W3C - RDF, OWL3, czyli w postaci plików XML. W celu zapewnienia odpowiedniej wydajności systemów opartych o sieć semantyczną, zawierających dużą ilość danych, wykorzystywane są środowiska, które umożliwiają przechowywanie i użycie danych zapisanych w relacyjnych bazach danych, bądź indeksowanych bazach plikowych. Nieodłącznym elementem sieci semantycznej jest mechanizm
2 Zeigler B. P., Hammond P. E., Modeling & Simulation-Based Data Engineering: Introducing Pragmatics Into Ontologies for Net-Centric Information Exchange, 2007, ACADEMIC PR INC.3 Więcej o tych standardach można znaleźć na http://www.w3.org/2001/sw/.
46

umożliwiający przeszukiwanie na podstawie ontologii i zapisanych danych. Baza Wiedzy Portalu będzie składała się z dwóch zasadniczych elementów:
12) sieci semantycznej („semantic web”) zapewniającej klasyfikację danych oraz metod inteligentnego wyszukiwania wiedzy powiązanej4;
13) relacyjnej bazy treści, która będzie zawierała dane opisane przez sieć semantyczną.
W procesie przeszukiwania Bazy Wiedzy Portalu wg pojęć zawartych w ontologii moduł odpowiedzialny za wyszukiwanie będzie wykorzystywał siecią semantyczną. Wyniki wyszukiwania zwrócone przez sieć semantyczną przekazane zostaną do bazy treści, która z kolei będzie mogła dostarczyć żądane treści użytkownikowi.
Biblioteki: publikacje elektroniczne, oprogramowanie wspomagające, szkolenia e-learningowe
Informacje prezentowane przez system będą uzupełnione o rozszerzające wiedzę dokumenty zgromadzone w trzech modułach: w bibliotece publikacji elektronicznych, bibliotece oprogramowania wspomagającego oraz w module szkoleń e-learningowych.Biblioteka publikacji elektronicznych będzie zawierać w formie elektronicznej różnego rodzaju dokumenty związane z tematyką projektu i problematyką portalu, takie jak instrukcje, podręczniki, artykuły, teksty aktów prawnych, wzory formularzy do pobrania, prezentacje multimedialne oraz linki do stron z dodatkowymi materiałami, których ze względów prawnych lub z uwagi na częste aktualizacje nie można umieścić na portalu.Częścią biblioteki dokumentów będzie katalog tematyczny, a wszystkie dokumenty będą połączone z systemem wyszukiwania pełnotekstowego zasobów całego portalu. Dodatkowo, dokumenty będą posiadać umieszczony w bazie wiedzy dodatkowy opis semantyczny, wskazujący przeznaczenie dokumentu, co pozwoli wykorzystać je podczas działania systemu eksperckiego oraz usprawni wyszukiwanie.Biblioteka oprogramowania wspomagającego będzie udostępniać programy oraz dokumenty przydatne dla użytkownika podczas wypełniania formularzy wniosków, sporządzania kosztorysów, przeprowadzania analiz, itp. Przykładem takiego oprogramowania są generatory wniosków dla poszczególnych działań i konkursów.W ramach modułu szkoleń e-learningowych udostępniane będą szkolenia elektroniczne związane z tematyką portalu. Szkolenia te służyć będą podniesieniu kwalifikacji zainteresowanych w dziedzinie finansowania projektów z funduszy pomocowych i efektywnego ich wykorzystania. Przewiduje się szkolenia dotyczące m.in. tworzenia budżetu projektów, prowadzenia projektów, zasad tworzenia wniosków, sprawozdawczości, specyfiki konkretnych programów pomocowych.
WyszukiwarkaModuł wyszukiwarki korzystać będzie z zasobów Biblioteki Publikacji Elektronicznych, Biblioteki Oprogramowania Wspierającego oraz Szkoleń e-learningowych. Moduł ten będzie oparty na wnioskowaniu na podstawie bazy wiedzy portalu i oznaczeniu semantycznym dokumentów. Pozwoli to na
4 Czytaj więcej na http://semanticweb.org/.
47

wyszukiwanie dokumentów zawierających nie tylko podane przez użytkownika słowa, lecz również tych, których zawartość jest zbliżona do tego co podał użytkownik. Zastosowanie sieci semantycznej pozwoli przeszukiwać użytkownikowi bazę portalu bez posługiwania się żargonem urzędniczym.
Usługi portalowe: moduł publikacji nowości, forum dyskusyjnePrócz zaawansowanego systemu eksperckiego, proponowany system będzie również udostępniał znane z innych portali internetowych elementy, takie jak subskrypcję aktualności i forum dyskusyjne.Moduł publikacji nowości będzie udostępniał zarejestrowanym użytkownikom spersonalizowane, wyselekcjonowane przy pomocy systemu eksperckiego na podstawie posiadanych przez portal danych o użytkowniku informacje na temat nowych naborów wniosków, zmian w przepisach, itp. Wiadomości będą dostarczane użytkownikom za pomocą kanałów RSS lub ATOM oraz drogą elektroniczną (e-mail).Forum dyskusyjne będzie modułem umożliwiającym użytkownikom wymianę doświadczeń, zgłaszanie problemów, wątpliwości oraz pytań do ekspertów współpracujących z systemem.
PodsumowanieStworzenie systemu w proponowanej formie pozwoliłoby wypełnić lukę w dziedzinie informowania małych i średnich przedsiębiorców o możliwościach uzyskania finansowania ich działalności. Obecność takiego narzędzia przyniosłaby szereg korzyści, nie tylko MSP, ale również administracji publicznej, która zajmuje się rozpatrywaniem wniosków o przydział środków z funduszy pomocowych. Mogłaby ona zostać odciążona od znacznej części działań informacyjnych, konsultacyjnych i weryfikacyjnych, co miałoby wpływ na wzrost jej efektywności i obniżenie kosztów działalności.System ekspercki zwiększyłby efektywność dostarczania właściwej informacji do właściwego odbiorcy. Dzięki spersonalizowanej formie dostarczania kompleksowych informacji o źródłach finansowania, procedurze występowania o środki, warunkach ich uzyskania oraz sposobie prowadzenia i rozliczania projektu, można przewidywać zwiększenie aktywności i efektywności przedsiębiorców korzystających z funduszy europejskich.Łatwa, intuicyjna obsługa systemu przy wykorzystaniu zaawansowanych technologii przeszukiwania zapewniłaby mu liczne grono użytkowników. Realizacja projektu tego typu mogłaby się przyczynić do wzrostu wykorzystania środków dostępnych dla Polski w ramach europejskiej polityki spójności 2007-2013, poprzez rozszerzenie dostępu do wiedzy na temat funduszy.
Literatura http://epuap.gov.pl/ ; http://semanticweb.org/ ; http://www.w3.org/2001/sw/ ; Zeigler B. P., Hammond P. E., Modeling & Simulation-Based Data
Engineering: Introducing Pragmatics Into Ontologies for Net-Centric Information Exchange, 2007, ACADEMIC PR INC.
48


















