
Geo Alp - Science South Tyrol,,NATUR,21,404.pdfGeo Alp - Science South Tyrol

Data ScienceUczenie się pod nadzorem
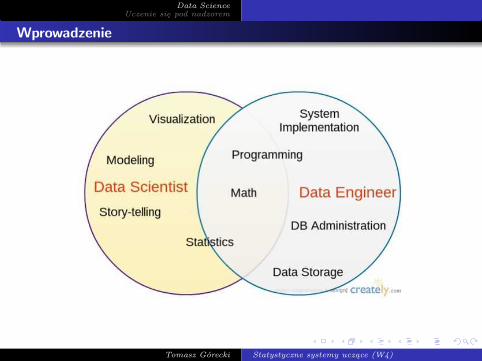
Wprowadzenie
Tomasz Górecki Statystyczne systemy uczące (W4)

Data ScienceUczenie się pod nadzorem
Wprowadzenie
Tomasz Górecki Statystyczne systemy uczące (W4)
Data ScienceUczenie się pod nadzorem
Wprowadzenie
Tomasz Górecki Statystyczne systemy uczące (W4)

Data ScienceUczenie się pod nadzorem
Wprowadzenie
Tomasz Górecki Statystyczne systemy uczące (W4)

Data ScienceUczenie się pod nadzorem
Machine Learning Mind Map
Tomasz Górecki Statystyczne systemy uczące (W4)
Data ScienceUczenie się pod nadzorem
Historia
Tomasz Górecki Statystyczne systemy uczące (W4)

Data ScienceUczenie się pod nadzorem
Wstęp
Uczenie się pod nadzorem lub uczenie się z przykładów jestprocesem budowy, na bazie dostępnych danych wejściowych X i
oraz wyjściowych Yi , i = 1, 2, . . . , n, reguły klasyfikacyjnej zwanejinaczej klasyfikatorem, służącej do predykcji etykiety Y grupy, doktórej należy obserwacja X .
Tomasz Górecki Statystyczne systemy uczące (W4)

Data ScienceUczenie się pod nadzorem
Wstęp
Załóżmy, że dysponujemy K niezależnymi, prostymi próbamilosowymi o liczebnościach, odpowiednio, n1, n2, . . . , nK , pobranymiz K różnych populacji (klas, grup):
X 11,X 12, . . . ,X 1n1 – z populacji 1X 21,X 22, . . . ,X 2n2 – z populacji 2
· · ·XK1,XK2, . . . ,XKnK – z populacji K ,
gdzie X ij = (Xij1,Xij2, . . . ,Xijp)′ jest j-tą obserwacją z i -tejpopulacji zawierającą p obserwowanych cech, i = 1, 2, . . . ,K ,j = 1, 2, . . . , ni .
Tomasz Górecki Statystyczne systemy uczące (W4)

Data ScienceUczenie się pod nadzorem
Wstęp
Powyższe dane można wygodniej zapisać w innej postaci, amianowicie w postaci jednego ciągu n uporządkowanych parlosowych
(X 1,Y1), . . . , (X n,Yn),
gdzie X i = (Xi1,Xi2, . . . ,Xip)′ ∈ X ⊂ Rp jest i -tą obserwacją,natomiast Yi jest etykietą populacji, do której ta obserwacjanależy, przyjmującą wartości w pewnym skończonym zbiorze Y,i = 1, 2, . . . , n, n = n1 + n2 + · · · + nK .Składowe wektora X i = (Xi1,Xi2, . . . ,Xip)′ nazywać będziemycechami, zmiennymi lub atrybutami. PróbęLn = {(X 1,Y1), . . . , (X n,Yn)} nazywać będziemy próbą uczącą.
Tomasz Górecki Statystyczne systemy uczące (W4)

Data ScienceUczenie się pod nadzorem
Wstęp
Interesuje nas problem predykcji etykiety Y na podstawie wektoracech X . Problem ten nazywany jest klasyfikacją, dyskryminacją,uczeniem się pod nadzorem lub rozpoznawaniem wzorców.Reguła klasyfikacyjna, zwana krótko klasyfikatorem, jest funkcjąd : X → Y. Gdy obserwujemy nowy wektor X , to prognoząetykiety Y jest d(X ).
Tomasz Górecki Statystyczne systemy uczące (W4)

Data ScienceUczenie się pod nadzorem
Wstęp
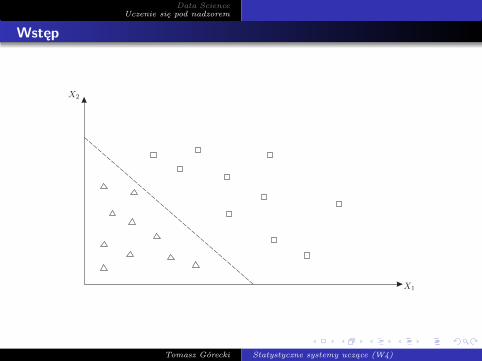
Na poniższym rysunku pokazanych jest 20 punktów. Wektor cechX = (X1,X2)′ jest dwuwymiarowy a etykieta Y ∈ Y = {1, 0}.Wartości cechy X dla Y = 0 reprezentowane są przez trójkąty, adla Y = 1 przez kwadraty. Linia przerywana reprezentuje liniowąregułę klasyfikacyjną postaci
d(x) =
!
1, jeżeli a + b1x1 + b2x2 > 0,0, poza tym.
Każdy punkt leżący poniżej tej linii klasyfikowany jest do grupy oetykiecie 0 oraz każdy punkt leżący powyżej tej linii klasyfikowanyjest do grupy o etykiecie 1.
Tomasz Górecki Statystyczne systemy uczące (W4)
Data ScienceUczenie się pod nadzorem
Wstęp
Tomasz Górecki Statystyczne systemy uczące (W4)

Data ScienceUczenie się pod nadzorem
Rzeczywisty poziom błędu
Klasyczny problem klasyfikacji polega na predykcji nieznanejetykiety Y ∈ Y na podstawie wektora cech X ∈ X ⊆ Rp
klasyfikowanego obiektu. Naszym celem jest znalezienie takiegoklasyfikatora d : X → Y, który daje dokładną predykcję. Miarąjakości klasyfikatora jest jego rzeczywisty poziom błędu.
Definicja
Rzeczywisty poziom błędu klasyfikatora d jest równy
e(d) = P(d(X ) = Y ). (1)
Tomasz Górecki Statystyczne systemy uczące (W4)

Data ScienceUczenie się pod nadzorem
Klasyfikator bayesowski
Weźmy wpierw pod uwagę przypadek dwóch klas, tj. gdyY = {1, 0}. W celu stworzenia modelu klasyfikacji załóżmy, że(X ,Y ) jest parą losową o wartościach w Rp × {1, 0} oraz, że jejrozkład prawdopodobieństwa opisuje para (µ, r), gdzie µ jest miarąprobabilistyczną wektora X oraz r jest regresją Y względem X .Bardziej precyzyjnie, dla zbioru A ⊆ Rp,
µ(A) = P(X ∈ A)
oraz dla każdego x ∈ Rp,
r(x) = E(Y |X = x) = 1 · P(Y = 1|X = x) + 0 · P(Y = 0|X = x)
= P(Y = 1|X = x)
Zatem r(x) jest prawdopodobieństwem warunkowym, że Y = 1,gdy X = x . Rozkład prawdopodobieństwa pary (X ,Y ) wyznaczapara (µ, r). Funkcja r(x) nazywa się prawdopodobieństwem aposteriori.
Tomasz Górecki Statystyczne systemy uczące (W4)

Data ScienceUczenie się pod nadzorem
Klasyfikator bayesowski
Z twierdzenia Bayes’a mamy
r(x) = P(Y = 1|X = x)
=f (x |Y = 1)P(Y = 1)
f (x |Y = 1)P(Y = 1) + f (x |Y = 0)P(Y = 0)
=π1f1(x)
π1f1(x) + π0f0(x),
gdzie
π1 = P(Y = 1), π0 = P(Y = 0), π1 + π0 = 1
są prawdopodobieństwami a priori.
Tomasz Górecki Statystyczne systemy uczące (W4)

Data ScienceUczenie się pod nadzorem
Klasyfikator bayesowski
Definicja
Klasyfikator postaci
dB(x) =
!
1, jeżeli r(x) > 1
2,
0, poza tym.
nazywać będziemy klasyfikatorem bayesowskim
Tomasz Górecki Statystyczne systemy uczące (W4)

Data ScienceUczenie się pod nadzorem
Klasyfikator bayesowski
Klasyfikator bayesowski zapisać można w innych równoważnychpostaciach:
dB(x) =
!
1, jeżeli P(Y = 1|X = x) > P(Y = 0|X = x),0, poza tym.
lub
dB(x) =
!
1, jeżeli π1f1(x) > π0f0(x),0, poza tym.
Tomasz Górecki Statystyczne systemy uczące (W4)

Data ScienceUczenie się pod nadzorem
Klasyfikator bayesowski
Twierdzenie
Klasyfikator bayesowski jest optymalny, tj. jeżeli d jest
jakimkolwiek innym klasyfikatorem, to e(dB ) ≤ e(d), gdzie e(d)jest rzeczywistym poziomem błędu klasyfikatora d .
Tomasz Górecki Statystyczne systemy uczące (W4)

Data ScienceUczenie się pod nadzorem
Aktualny poziom błędu
Niestety, klasyfikator bayesowski zależy od rozkładuprawdopodobieństwa pary (X ,Y ). Najczęściej rozkład ten nie jestznany i stąd również nie jest znany klasyfikator bayesowski dB .Pojawia się zatem problem skonstruowania klasyfikatorad(x) = d(x ;Ln) opartego na próbie uczącejLn = {(X 1,Y1), . . . , (X n,Yn)} zaobserwowanej w przeszłości.Proces konstruowania klasyfikatora d nazywany jest uczeniem się,uczeniem pod nadzorem lub uczeniem się z nauczycielem.Chcemy znaleźć taki klasyfikator d , dla którego e(d) jest bliskiee(dB ). Jednakże e(d) jest zmienną losową, ponieważ zależy odlosowej próby uczącej Ln.
Tomasz Górecki Statystyczne systemy uczące (W4)

Data ScienceUczenie się pod nadzorem
Aktualny poziom błędu
W naszym modelu klasyfikacyjnym zakładamy, że próba uczącaLn = {(X 1,Y1), . . . , (X n,Yn)} jest ciągiem niezależnych parlosowych o identycznym rozkładzie prawdopodobieństwa takim, jakrozkład pary (X ,Y ). Jakość klasyfikatora d mierzona jest zapomocą warunkowego prawdopodobieństwa błędu
e(d) = P(d(X ) = Y |Ln),
gdzie para losowa (X ,Y ) jest niezależna od próby uczącej Ln.Wielkość e(d) nazywamy aktualnym poziomem błęduklasyfikatora. Chcemy znaleźć taki klasyfikator d , dla którego e(d)jest bliskie e(dB). Jednakże e(d) jest zmienną losową, ponieważzależy od losowej próby uczącej Ln.
Tomasz Górecki Statystyczne systemy uczące (W4)

Data ScienceUczenie się pod nadzorem
Estymacja aktualnego poziomu błędu
Niech d(x) = d(x ;Ln) oznacza klasyfikator skonstruowany przypomocy próby uczącej Ln. Niech e ≡ e(d) oznacza ocenęaktualnego poziomu błędu klasyfikatora d . Ocenę tę nazywaćbędziemy błędem klasyfikacji. W sytuacjach, kiedy na populacjenie narzuca się żadnej konkretnej rodziny rozkładów, jedyną drogąoceny prawdopodobieństwa e(d) jest użycie metod estymacjinieparamerycznej.
Tomasz Górecki Statystyczne systemy uczące (W4)

Data ScienceUczenie się pod nadzorem
Estymacja aktualnego poziomu błędu
W najlepszej sytuacji jesteśmy wtedy, gdy dysponujemym-elementową próbą testową Tm niezależną od próby uczącej Ln.Niech zatem Tm = {(X t
1,Yt1 ), . . . , (X
tm,Y
tm)}. Wtedy za
estymator aktualnego poziomu błędu klasyfikatora d przyjmujemy:
eT =1
m
m"
j=1
I (d(X tj ;Ln) = Y t
j ).
W przypadku gdy nie dysponujemy niezależną próbą testową, doestymacji używamy jedynie próby uczącej.
Tomasz Górecki Statystyczne systemy uczące (W4)

Data ScienceUczenie się pod nadzorem
Estymacja aktualnego poziomu błędu
Naturalną oceną aktualnego poziomu błędu jest wtedy wartośćestymatora ponownego podstawienia (resubstytucji)
eR =1
n
n"
j=1
I (d(X j ;Ln) = Yj).
Wartość tego estymatora uzyskuje się poprzez klasyfikację regułą dtych samych obserwacji, które służyły do jej konstrukcji. Oznaczato, iż próba ucząca jest zarazem próbą testową. Estymator ten jestwięc obciążonym estymatorem wielkości e(d) i zaniża jejrzeczywistą wartość. Uwidacznia się to szczególnie w przypadkuzłożonych klasyfikatorów opartych na relatywnie małych próbachuczących. Redukcję obciążenia można uzyskać stosując poniższemetody estymacji.
Tomasz Górecki Statystyczne systemy uczące (W4)

Data ScienceUczenie się pod nadzorem
Estymacja aktualnego poziomu błędu
Jednym ze sposobów redukcji obciążenia estymatora eR jesttzw. metoda podziału próby na dwa podzbiory: próbę uczącąi próbę testową. Wówczas klasyfikator konstruuje się za pomocąpierwszego z nich, drugi natomiast służy do konstrukcjiestymatora. Wykorzystanie tylko części informacji w celu uzyskaniareguły klasyfikacyjnej prowadzi jednak często do zawyżeniawartości estymatora błędu. Rozwiązaniem tego problemu jestmetoda sprawdzania krzyżowego.
Oznaczmy przez L(−j)n próbę uczącą Ln z której usunięto
obserwację Z j = (X j ,Yj). Klasyfikator konstruuje się
wykorzystując próbę L(−j)n , a następnie testuje się go na
pojedynczej obserwacji Z j . Czynność tę powtarza się n razy, dlakażdej obserwacji Z j z osobna. Odpowiedni estymator ma postać:
eCV =1
n
n"
j=1
I (d(X j ;L(−j)n ) = Yj).
Tomasz Górecki Statystyczne systemy uczące (W4)

Data ScienceUczenie się pod nadzorem
Estymacja aktualnego poziomu błędu
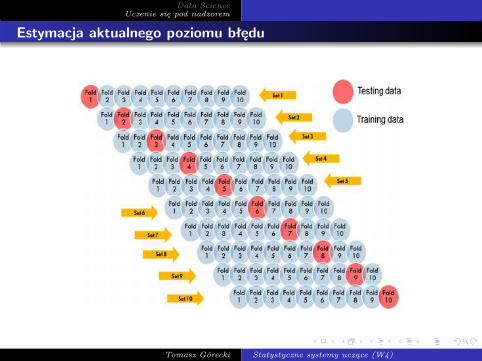
Procedura ta w każdym z n etapów jest w rzeczywistości metodąpodziału próby dla przypadku jednoelementowego zbiorutestowego. Każda obserwacja próby jest użyta do konstrukcjiklasyfikatora d . Każda z nich jest też (dokładnie jeden raz)elementem testowym.Estymator ten, choć granicznie nieobciążony, ma większąwariancję. Ponadto wymaga on konstrukcji n klasyfikatorów, co dladużych n oznacza znaczący wzrost obliczeń. Rozwiązaniempośrednim jest metoda rotacyjna, zwana często v-krokową metodąsprawdzania krzyżowego. Polega ona na losowym podziale próbyna v podzbiorów, przy czym v − 1 z nich tworzy próbę uczącą,natomiast pozostały — próbę testową. Procedurę tę powtarza sięv razy, dla każdego podzbioru rozpatrywanego kolejno jako zbiórtestowy.
Tomasz Górecki Statystyczne systemy uczące (W4)
Data ScienceUczenie się pod nadzorem
Estymacja aktualnego poziomu błędu
Tomasz Górecki Statystyczne systemy uczące (W4)

Data ScienceUczenie się pod nadzorem
Estymacja aktualnego poziomu błędu
Odpowiedni estymator jest postaci:
evCV =1
n
v"
i=1
n"
j=1
I (Z j ∈ L(i)n )I (d(X j ; L
(−i)n ) = Yj),
gdzie L(1)n , L(2)
n , . . . , L(v)n jest losowym v -podziałem próby Ln na
równoliczne podzbiory, a L(−i)n = Ln\L
(i)n , i = 1, 2, . . . , v .
Tomasz Górecki Statystyczne systemy uczące (W4)

Data ScienceUczenie się pod nadzorem
Estymacja aktualnego poziomu błędu
Metoda ta daje mniejsze obciążenie błędu niż metoda podziałupróby i wymaga mniejszej liczby obliczeń w porównaniuze sprawdzaniem krzyżowym (jeśli tylko v < n). W zagadnieniuestymacji aktualnego poziomu błędu zalecane jest obranie wartościv = 10. Metoda sprawdzania krzyżowego jest powszechniewykorzystywana w zagadnieniu wyboru modelu. Z rodzinyklasyfikatorów opisanej parametrycznie wybieramy wtedyklasyfikator, dla którego błąd klasyfikacji ma wartość najmniejszą.
Tomasz Górecki Statystyczne systemy uczące (W4)

Data ScienceUczenie się pod nadzorem
Estymacja aktualnego poziomu błędu
Definicja
Próbą bootstrapową nazywamy próbę n-elementową pobranąz n-elementowej próby uczącej w procesie n-krotnego losowaniapojedynczych obserwacji ze zwracaniem.
Niech L∗1n ,L∗2
n , . . . ,L∗Bn będzie ciągiem kolejno pobranych B prób
bootstrapowych. Bootstrapowa ocena aktualnego poziomu błęduma postać
eB =1
B
B"
b=1
n#
j=1I (Z j ∈ L∗b
n )I (d(X j ;L∗bn ) = Yj)
n#
j=1I (Z j ∈ L∗b
n ).
Widać, że powyższa ocena aktualnego poziomu błędu jestuzyskana metodą sprawdzania krzyżowego zastosowaną do próbbootstrapowych.
Tomasz Górecki Statystyczne systemy uczące (W4)

Data ScienceUczenie się pod nadzorem
Estymacja aktualnego poziomu błędu
W celu dalszej redukcji obciążenia tego estymatora zaproponowanoestymator postaci:
e.632 = 0,368 eR + 0,632 eB .
Waga 0,368 jest przybliżoną wartością wielkoście−1 = limn→∞(1− 1/n)n, i jest graniczną wartościąprawdopodobieństwa nie wylosowania obserwacji z próby uczącejdo próby bootstrapowej.
Tomasz Górecki Statystyczne systemy uczące (W4)

Data ScienceUczenie się pod nadzorem
Macierz pomyłek
Sam błąd klasyfikacji nie wystarczy aby stwierdzić, czy klasyfikatordziała dobrze. Po zakonczeniu procedury oceny błędu klasyfikacjinaszego modelu zostajemy z lista obserwacji testowych, gdzie dlakazdej z nich znamy klasę obserwowaną oraz klasę przewidywanąprzez nasz model. Zliczając liczbe przypadkow dla kazdej zkombinacji tych dwóch klas (obserwowanej i przewidywanej)możemy stworzyć tzw. macierz pomyłek (ang. confusion matrix).Możemy na jej podstawie ocenić błąd modelu: musimy zsumowaćwartości na głównej przekątnej (obserwacje poprawnie rozpoznane)i podzielić je przez liczbę wszystkich obserwacji testowych.
Tomasz Górecki Statystyczne systemy uczące (W4)
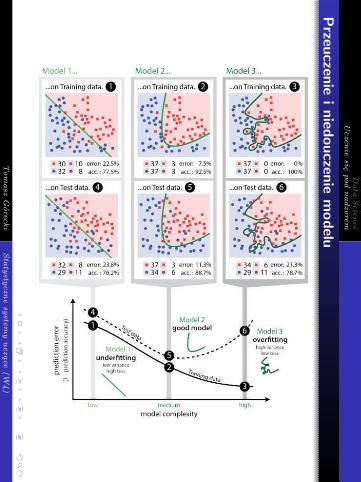
DataScience
Uczeniesiępodnadzorem
Przeuczenieiniedouczeniemodelu
TomaszGórecki
Statystycznesystemyuczące(W4)

Data ScienceUczenie się pod nadzorem
ZeroR – najprostszy klasyfikator
Algorytm ZeroR (Zero Rule) ignoruje wszystkie cechy, opróczetykiet. Na ich podstawie, sprawdza najczęściej występującą klasę itworzy klasyfikator który zawsze będzie ją zwracać. Zatemalgorytm ZeroR zawsze przypisuje nowe obserwacje do tej samejklasy (klasy większościowej), niezależnie od wartości cech.
Tomasz Górecki Statystyczne systemy uczące (W4)

Data ScienceUczenie się pod nadzorem
OneR
Algorytm OneR (One Rule) jest tylko nieco bardziej wyrafinowanyniz ZeroR. Podczas gdy ZeroR ignoruje wszystkie cechy, OneRwybiera tylko jedną i ignoruje pozostałe. Wybierając najlepszącechę sprawdza on błąd na danych uczących dla klasyfikatorowzbudowanych na kazdej z cech osobno i wybiera tą z nich, któraminimalizuje błąd. Dla każdej cechy dzieli on dane uczące napodzbiory ze względu na wartość tej cechy. Następnie, na każdymz nich używa algorytmu ZeroR. Pokazano, że pomimo prostoty jestto metoda jedynie nieznacznie ustępująca najlepszymklasyfikatorom.
R.C. Holte. (1993). Very simple classification rules performwell on most commonly used datasets. Machine Learning11(1):63–90.
Tomasz Górecki Statystyczne systemy uczące (W4)

Data ScienceUczenie się pod nadzorem
OneR
Day Outlook Temperature Humidity PlayTennisD1 sunny hot high NOD2 sunny hot high NOD3 overcast hot high YESD4 overcast hot normal YESD5 rain mild high NO
Skonstruujmy klasyfikatory dla różnych atrybutów:
Outlook YES NO trafnośćsunny 0 2 5/5 = 100%overcast 2 0rain 0 1
Temperature YES NO trafnośćhot 2 2 3/5 = 60%mild 0 1
Humidity YES NO trafnośćhigh 1 3 4/5 = 80%normal 1 0
Jak widzimy, najwyższą trafność osiągamy korzystając z atrybutu Outlook. Algorytmstworzy więc następujący klasyfikator:
IF Outlook = sunny THEN PlayTennis = NOIF Outlook = overcast THEN PlayTennis = Y ESIF Outook = rain THEN PlayTennis = NO
Tomasz Górecki Statystyczne systemy uczące (W4)


















