Croisière sur le data lake
21
Petite croisière sur le data lake David Morel 1 / 21
-
Upload
david-morel -
Category
Data & Analytics
-
view
394 -
download
1
Transcript of Croisière sur le data lake

Petite croisière sur le data lake
David Morel
1 / 21

L'ère des mega-données (big data)
Tout est données !Croissance exponentielle, possible grâce à un prix du stockage accessibleEnjeux économiques, politiques, sociaux, philosophiques : tout changeComprendre, ou influencer ? Modéliser, ou modeler ?Tout le monde en parle mais peu de gens en font (pour l'instant)Festival permanent de nouveautés, difficile de garder la tête froide
2 / 21

Des données pour quoi faire ?
Mes données ne sont pas votre contenu (ou si peu), mais ce qui l'entoure ; leproduit de l'interaction (ou de son absence) avec l'utilisateurA partir du moment où une chose est mesurable, elle devient "actionable"Utilisations: partout !
marketing et tout ce qui s'en rapproche (audience de site...)prévisions, planifications, améliorations de tous les systèmes et processus,dans tous les domaines
On ne déduit que des corrélations, pas du sens
3 / 21

Tout est nombre
Place centrale des maths, et plus spécialement des statsConnaissances de base (mais solides) nécessairesExemple, les intervalles de confiance : essentiels pour l'audience des sites web, A/Btests etc. http://www.uxmatters.com/mt/archives/2011/11/what-is-a-confidence-interval-and-why-would-you-want-one.php
Le data-centrisme n'a ni imagination ni intelligence, il n'est qu'une méthodeaccompagnée d'outilsL'intervention humaine est toujours nécessaire
4 / 21

Data science
https://fr.wikipedia.org/wiki/Science_des_données
La science des données (en anglais data science) est une nouvellediscipline qui s'appuie sur des outils mathématiques, de statistiques,d'informatique (cette science est principalement une « science des donnéesnumériques » et de visualisation des données).
Décrire (statistiques descriptives, phase exploratoire)Déduire (inférence, déterminer une probabilité)Prévoir et choisir (machine learning etc.) ; différence déduire/prédire souvent flouePrésenter (visualisation, construction de modèles pour classification, etc)
La visualisation intervient toujours aussi dans la phase exploratoireC'est un processus itératif : on creuse...A part ça, c'est un métier :-)
5 / 21

Les algorithmes ne sont pas magiques
Des probabilités, pas des certitudesLa qualité des données est primordiale : garbage in, garbage outExemple douloureux : les botsConnaître ses données, les analyser pour elles-mêmesLes nettoyer sans relâcheC'est un processus d'amélioration permanente
6 / 21

Machine learning
https://en.wikipedia.org/wiki/Machine_learning
Machine learning explores the study and construction of algorithms thatcan learn from and make predictions on data. Such algorithms operate bybuilding a model from example inputs in order to make data-drivenpredictions or decisions, rather than following strictly static programinstructions.
On travaille avec des matrices, les data points sont des vecteurs dans un espacemultidimensionelAlgorithmes supervisés ou non
supervisé nécessite une période d'entraînement avec des données deréférencenon supervisé se base uniquement sur les données disponibles
Différentes familles, des centaines d'algorithmes (régression, classification...)
http://loic.knuchel.org/blog/2013/11/22/le-machine-learning-cest-quoi-exactement/
http://machinelearningmastery.com/a-tour-of-machine-learning-algorithms/
7 / 21

Data science HowTo
La phase d'exploration est laborieuseIl y a 1001 manières de procéder :-(Données généralement extraites sous forme tabulaire du data storeTravail sur un cluster ou local (laptop de l'analyste)R et RStudio + Plugins http://blog.datacamp.com/machine-learning-in-r/ ou Python(+NumPy/SciPy), qui devient le langage standard de la science des donnéesParfois on s'arrête là, parfois on demande à R ou python de produire un modèleutilisable en temps réel:
code qui doit être recodé dans le langage de destinationou utilisation de PMML :https://www.ibm.com/developerworks/opensource/library/ba-ind-PMML1/ou appeler R ou python directement, ou en webservice (huh?)
8 / 21

RStudio
9 / 21

Confession
Trop difficile de retenir toutes ces choses, en particulier RInternet est ma mémoireJe mets des bookmarks dans delicious.com, et je garde des notesLes ours polaires sont nos amis, il faut les aimer aussi
10 / 21

Visualisation
Sur R: ggplot2Pour des pages web, d3js est la bibliothèque de présentation la plus utiliséeEcrite en JS, données en entrée en JSON, produit du SVG (Scalable Vector Graphics)Binding : lorsque les données changent (ex. AJAX), la présentation réagit d'elle-même et s'adapteDes wrappers qui facilitent la familiarisation avec le framework (dimple, nvd3, etc.)Abondance d'autres solutions en ligne, pas toujours adaptées ; d3 rules!
http://christopheviau.com/d3_tutorial/
http://biovisualize.github.io/d3visualization/
La dataviz a ses pièges UX
http://fr.slideshare.net/idigdata/data-visualization-best-practices-2013
11 / 21

BIG DATA & NoSQL
12 / 21

Size matters
Les SGBDR sont limités à une seule machine, même s'il est possible departitionnerLes architectures NoSQL sont optimisées pour le stockage de données massives, dequelques machines à l'infiniToutes les machines travaillent ensemble en découpant le travailLes algorithmes complexes, demandant beaucoup de ressources, deviennentaccessiblesL'exploration, la répétition du travail avec des paramètres différents devientpossibleOn gagne donc en temps et en puissance, donc aussi en agilité
13 / 21

Pourquoi NoSQL ?
Besoin de stocker des données brutes, ou de formats divers, pas adaptées auformat en colonnes optimisé du SQL (bases orientées document, graphe, etc.)Flexibilité : scalabilité horizontale, liberté de développementVitesse : dans certains cas, optimisation pour des rythmes de requêtes très rapide(Redis)
Pourquoi pas NoSQL ?
Le NoSQL n'est pas un "drop-in replacement" pour le SQL
Performances aléatoires dans certains casTechnologies jeunes et pas aussi éprouvéesComplexité architecturale des clustersLe diable est dans les détails
14 / 21

La menace des
unknown unknowns
15 / 21

Hadoop, le poids lourd du NoSQL
Implémentation du paradigme map-reduce décrit par Google en 2004:http://research.google.com/archive/mapreduce.html
Système de fichiers distribué (HDFS)Exécution du code sur les noeuds du cluster, au plus près des donnéesData agnostique (tout type de contenu, le code décide que faire)Un écosystème complet : Hive (SQL), Pig, Mahout, Sqoop, Flume...Une interface web facilitant la prise en mains : Hue
16 / 21

Hue
17 / 21

Cas pratique
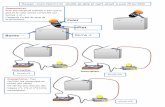
«parmi nos utilisateurs enregistrés, quels sont ceux qui utilisent le formulaire de recherchedepuis la page d’accueil ?»
Import des logs en continu via FlumeApplication mapreduce
1. [MAP] extraction des lignes de log du serveur web2. [MAP] construction d'une clé pour chaque ligne: user id + timestamp3. [MAP] valeur extraite pour chaque ligne : l'URL4. [REDUCE] regroupement de toutes les lignes d'un utilisateur sur 1 reducer, tri
sur chaque reducer par user id5. [REDUCE] tri secondaire par timestamp6. [REDUCE] le code regarde deux lignes consécutives: la succession des 2 pages
attendues produit un 1, toute autre séquence un 07. [REDUCE] on compte les "1" par user id
Résultats écrits sur HDFS ou exportés vers une BDD via Sqoop
18 / 21

Mapreduce inadapté au machine learning
Le ML a besoin de garder ses données en RAM pour les traiter récursivement,mapreduce est prévu pour la lecture séquentielleSpark est prévu pour prendre en charge ce modèleSpark fonctionne sur Hadoop (YARN) ou indépendamment, lit HDFSTrès à la mode :-)Hive fonctionne également sur Spark pour des requêtes interactivesDes workloads différents
19 / 21

Comment survivre à Hadoop et Spark
Complexité opérationnelle, demande des moyens importantsDes offres hébergées existent : Amazon EMR, Google Compute Engine, MicrosoftAzureDes offres SaaS comme AltiscaleUne alternatives hébergée : Google BigQueryDe (trop?) nombreuses alternatives NoSQL existent, certaines dignes d'intérêt:
Couchbase, une BDD distribuée puissante (plutôt que MongoDB)Riak, un store clé/valeur sophistiqué
Les bases SQL et NoSQL ont tendance à converger fonctionnellement (ex. datatypeJSON MySQL 5.7)Allons-y doucement...
20 / 21

21 / 21