
Analiza wariancji -...
41
ANALIZA WARIANCJI - PRZYPOMNIENIE Dr Wioleta Drobik
Transcript of Analiza wariancji -...

ANALIZA WARIANCJI -
PRZYPOMNIENIE Dr Wioleta Drobik

ANALIZA WARIACJI
Podział zaobserwowanej zmienności (wariancji) na zmienność między grupami i w obrębie grup
Pozwala na ocenę istotności różnic wielu średnich, hipoteza zerowa:
H0 : µ1 = µ2 = ... = µt
Założenia: Zmienne objaśniające są niezależne
Cecha ma rozkład normalny dopuszczalne są niewielkie odstępstwa
często badane są wyłącznie reszty (czynnik losowy)
Wariancje są jednorodne (homogeniczność wariancji)

Rodzaje analizy wariancji:
ANOVA - jednowymiarowa analiza wariancji :
Jednoczynnikowa – wpływ jednego czynnika na jedną zmienną zależną
Wieloczynnikowa - wpływ kilku czynników na jedną zmienną zależną
MANOVA - wielowymiarowa analiza wariancji
wpływ kilku czynników na kilka zmiennych zależnych
ANALIZA WARIACJI
Model Znaczenie
Y ~ X Jednoczynnikowa analiza wariancji
Y ~ X1 + X2 Dwuczynnikowa analiza wariancji
Y ~ X1 * X2 Dwuczynnikowa analiza wariancji z interakcją
Y ~ X1 + X2 + X1 : X2 Dwuczynnikowa analiza wariancji z interakcją (inny zapis)

Model liniowy analizy wariancji:
Gdzie: yij − j-ta obserwacja z i-tej grupy
µ − średnia wartość cechy w populacji
i − efekt i-tej grupy
eij − błąd czyli efekt związany ze zmiennością osobniczą, przypadkową, niewyjaśnioną modelem, może być również błędem pomiaru
ANALIZA WARIACJI
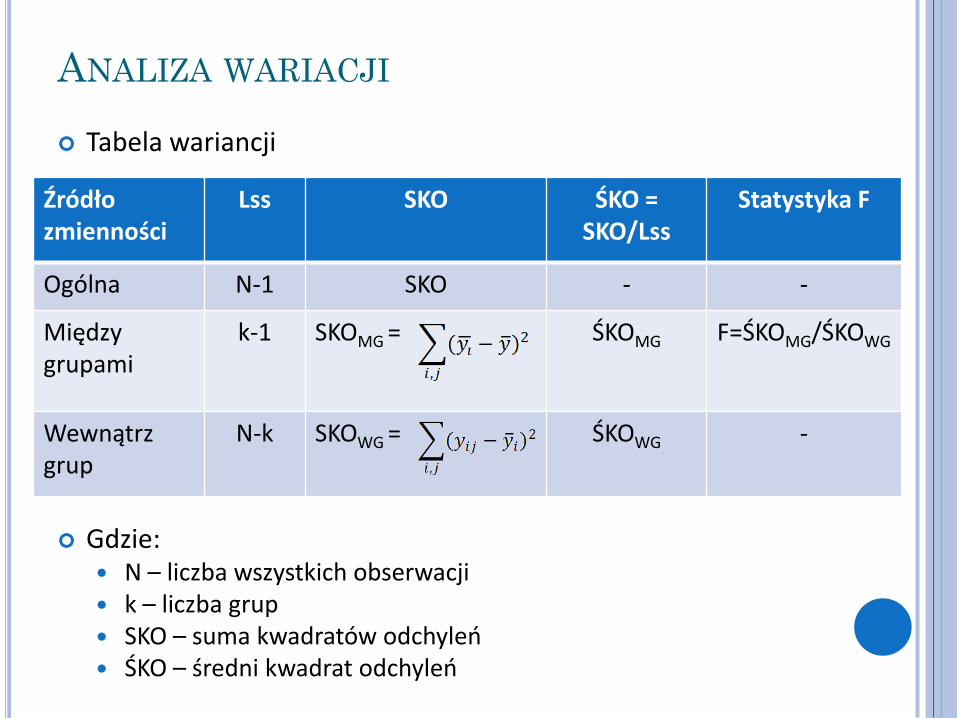
Tabela wariancji
Gdzie:
N – liczba wszystkich obserwacji k – liczba grup SKO – suma kwadratów odchyleń ŚKO – średni kwadrat odchyleń
ANALIZA WARIACJI
Źródło zmienności
Lss SKO ŚKO = SKO/Lss
Statystyka F
Ogólna N-1 SKO - -
Między grupami
k-1 SKOMG =
ŚKOMG F=ŚKOMG/ŚKOWG
Wewnątrz grup
N-k SKOWG = ŚKOWG
-
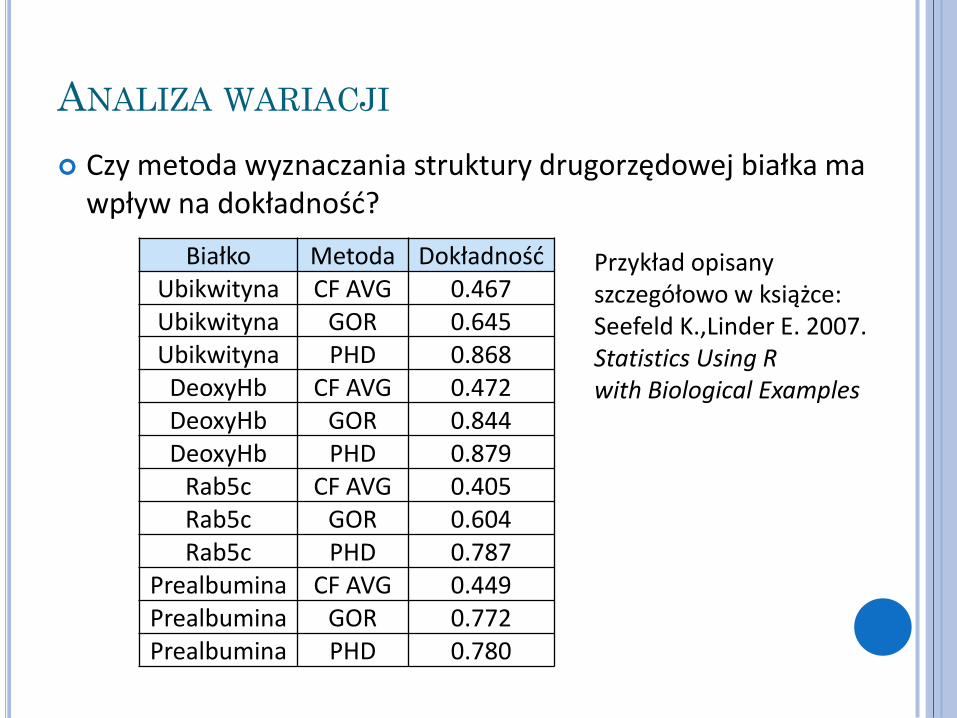
Czy metoda wyznaczania struktury drugorzędowej białka ma wpływ na dokładność?
ANALIZA WARIACJI
Białko Metoda Dokładność Ubikwityna CF AVG 0.467 Ubikwityna GOR 0.645 Ubikwityna PHD 0.868
DeoxyHb CF AVG 0.472 DeoxyHb GOR 0.844 DeoxyHb PHD 0.879
Rab5c CF AVG 0.405 Rab5c GOR 0.604 Rab5c PHD 0.787
Prealbumina CF AVG 0.449 Prealbumina GOR 0.772 Prealbumina PHD 0.780
Przykład opisany szczegółowo w książce: Seefeld K.,Linder E. 2007. Statistics Using R with Biological Examples
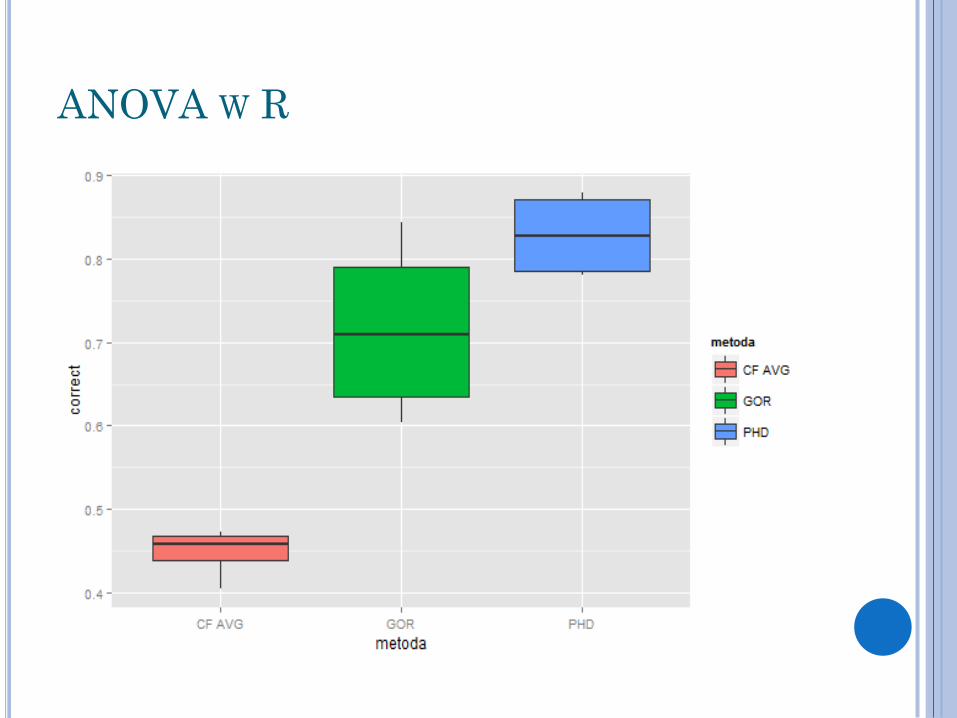
ANOVA W R

Testowanie jednorodności wariancji
Test F – test F-Snedecora dla dwóch prób
Test Barletta – dla wielu prób
Test Leven’a – dla wielu prób
Test Barletta ma wyższa moc niż test Leven’a, jednak nie może być stosowany przy odstępstwach od normalności rozkładu
Przy braku pewności co do normalności rozkładu wyniki testu Leven’a będą bardziej wiarygodne, niż testu Barletta
ANALIZA WARIANCJI - ZAŁOŻENIA
ANALIZA WARIANCJI
– ROZKŁAD ZMIENNEJ ZALEŻNEJ
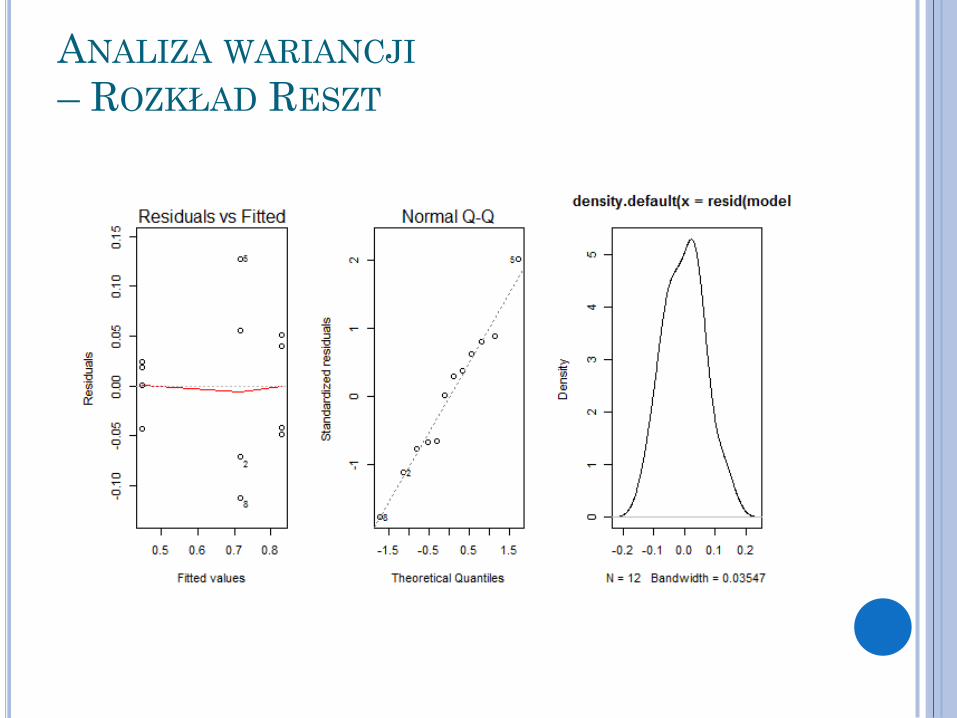
ANALIZA WARIANCJI
– ROZKŁAD RESZT

ANALIZA WARIANCJI - ZAŁOŻENIA
Czy wariancje w grupach są jednorodne?
Prawdopodobieństwo testowe jest wyższe niż 0,05 brak podstaw do odrzucenia hipotezy zerowej wariancje w grupach nie różnią się istotnie
Przeciwny wynik

Wyniki analizy
ANALIZA WARIANCJI
Prawdopodobieństwo testowe jest mniejsze od 0,01, w związku z czym odrzucamy hipotezę zerową wysoko istotnie Dokładność oceny struktury drugorzędowej zależy od stosowanej metody Które metody różnią się dokładnością?

TEST POST - HOC
Testy post-hoc wykonujemy, jeżeli różnice pomiędzy grupami są istotne. Najczęściej stosowane testy:
Test Tukeya (inaczej UIR - test uczciwie istotnych różnic)
Powinien być stosowany jedynie dla zrównoważonego układu doświadczenia – podobna liczba obserwacji we wszystkich grupach
LSD Fishera (inaczej NIR - najmniejsza istotna różnica)
nie zakłada się równoliczności grup
Polega na wykonaniu k(k-1)/2 testów t-studenta i zastosowaniu korekty na liczbę przeprowadzonych testów np. Holm, Bonferroni, fdr

Które metody różnią się dokładnością?
Test post-hoc Tukeya:
ANALIZA WARIANCJI
Zestawienie grup Różnica 95% przedział ufności
Prawdopodobieństwo testowe dla każdego zestawienia

ANOVA DWUCZYNNIKOWA
Model:
Gdzie:
yijk − k-ta obserwacja z i-tej i j-tej grupy
µ − średnia wartość cechy w populacji
i − efekt i-tej grupy
i − efekt j-tej grupy
eijk − błąd czyli efekt związany ze zmiennością osobniczą, jak i błąd pomiaru
(αβ)ij – efekt interakcji pomiędzy czynnikami

Interakcje
Interakcją nazwiemy niejednakową reakcję jednego czynnika na zmianę poziomu drugiego czynnika
Nieaddytywne działanie jednego czynnika z drugim
W modelu zachowujemy jedynie istotne statystycznie interakcje, co zwiększa siłę działania czynników głównych
Jeśli interakcja jest istotna nie ma możliwości porównywania średnich dla czynników głównych konieczne jest indywidualne porównanie poszczególnych podgrup
ANOVA DWUCZYNNIKOWA

ANOVA DWUCZYNNIKOWA
Różnice pomiędzy metodami są istotne, ale pomiędzy białkami już nie
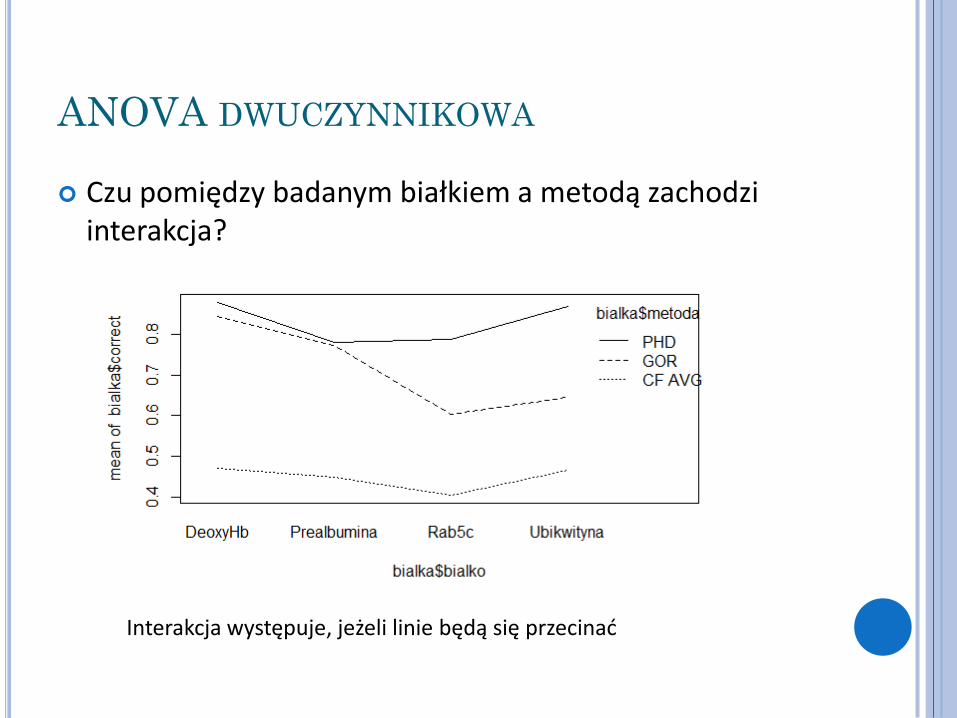
Czu pomiędzy badanym białkiem a metodą zachodzi interakcja?
ANOVA DWUCZYNNIKOWA
Interakcja występuje, jeżeli linie będą się przecinać

Brak statystyki F i prawdopodobieństwa testowego wynika z braku podstaw do testowania istotności przy zbyt małej próbie
Zbyt mało danych aby oszacować efekt interakcji
ANOVA DWUCZYNNIKOWA
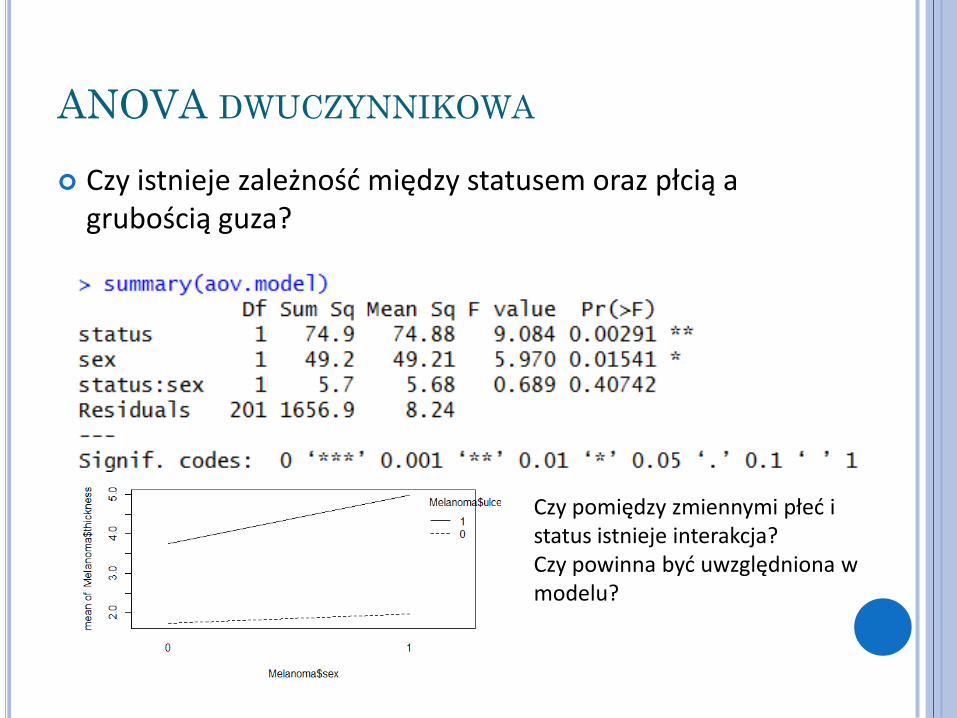
Czy istnieje zależność między statusem oraz płcią a grubością guza?
ANOVA DWUCZYNNIKOWA
Czy pomiędzy zmiennymi płeć i status istnieje interakcja? Czy powinna być uwzględniona w modelu?

JEDNOCZYNNIKOWA VS WIELOCZYNNIKOWA
ANOVA
Istnieje możliwość przeprowadzenia jednoczynnikowej analizy wariancji oddzielnie dla wszystkich zmiennych objaśniających
Wady takiego postępowania:
Utrata informacji o zależnościach między zmiennymi objaśniającymi
Większa wariancja – trudniej stwierdzić istotność niektórych zmiennych
Zmiennych objaśniających nie powinno być zbyt dużo:
Wraz ze wzrostem liczby zmiennych maleje dokładność oceny efektów modelu
Idealna sytuacja: min 30 obserwacji na każdą kombinację czynników

ANALIZA REGRESJI WIELOKROTNEJ

REGRESJA WIELOKROTNA
Wpływ wielu zmiennych niezależnych (X1, X2, X3,...) na zmienną zależną (Y)
Najczęściej stosowanym modelem jest regresja wielokrotna liniowa
Model:
Gdzie
p jest liczbą zmiennych
Xi – zbiór kolumn opisujących zmienną i
i – wektor współczynników odpowiadających zmiennej i
REGRESJA WIELOKROTNA

Interpretacja współczynników jest jak w przypadku regresji prostej:
Stała regresji jest to szacowana średnia wartość zmiennej objaśniającej Y, gdy wszystkie zmienne niezależne (Xi) są równe 0
Cząstkowe współczynniki regresji - szacowana średnia zmiana wartości zmiennej objaśniającej Y, gdy wartość zmiennej niezależnej (Xi) zwiększy się o jednostkę
REGRESJA WIELOKROTNA

Problemy:
Jak dobrać zmienne?
Jak zinterpretować współczynniki regresji?
Jak poradzić sobie z ewentualną współliniowością zmiennych objaśniających?
Czy zmienne objaśniające są niezależne?
Zbyt mała liczba obserwacji w stosunku do liczby zmiennych objaśniających
REGRESJA WIELOKROTNA

WSPÓŁLINIOWOŚĆ ZMIENNYCH
VIF (ang. variance inflation factor)
o ile wariancje współczynników są zawyżone z powodu zależności liniowych w badanym modelu regresji
Funkcja vif(model) w R wyświetla wektor wartości współczynnika VIF dla każdej zmiennej objaśniającej
Zmienne objaśniające są współliniowe, gdy są mocno skorelowane ze sobą Może to skutkować zawyżonym oszacowaniem współczynników i
dużymi wartościami błędów standardowych
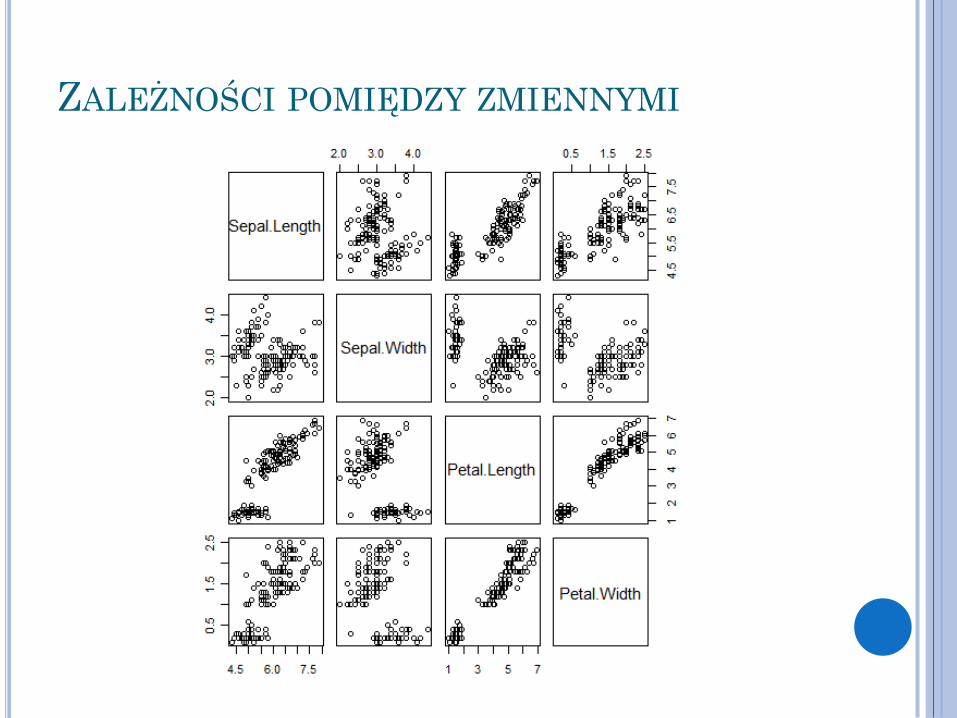
ZALEŻNOŚCI POMIĘDZY ZMIENNYMI

GIC (ang. Generalized Information Criterion) – oparte na funkcji wiarygodności i karze za liczbę elementów w modelu
h – pewien współczynnik, k - liczba parametrów w modelu M, logL(M|y,X) – funkcja wiarygodności dla modelu
Specjalne przypadki: AIC (h=2), BIC (h=log(n))
KRYTERIA OCENY MODELU
Idealny model w jak najlepszy sposób wyjaśnia zmienność zbioru danych wykorzystując przy tym jak najmniej parametrów (k)

R2 – współczynnik determinacji (omówiony na wykładzie o regresji liniowej)
można stosować do porównywania modeli tylko wtedy, gdy nie różnią się one liczbą zmiennych objaśniających
Poprawiony R2
uwzględnia dodatkowo liczbę zmiennych w modelu
im wyższa wartość tym lepszy model
KRYTERIA OCENY MODELU

Kryterium Akaike (AIC – ang. Akaike information criterion) Interpretacja:
Im mniejsza wartość tym lepiej
Nie unormowany – tylko do porównań między modelami
Wzór:
Gdzie:
k – liczba parametrów modelu (złożoność modelu)
L – maksimum funkcji największej wiarygodności (precyzja modelu)
KRYTERIA OCENY MODELU

Kryterium Schwartza (ang. BIC – Bayesian information criterion)
Interpretacja jak w przypadku AIC – im mniejsza wartość tym lepiej
Większa kara za złożoność modelu niż AIC
Gdzie:
k – liczba parametrów modelu
L – maksimum funkcji największej wiarygodności
n – liczba obserwacji
KRYTERIA OCENY MODELU

MODEL Z KILKOMA ZMIENNYMI OBJAŚNIAJĄCYMI
Doboru odpowiednich zmiennych możemy dokonać wykorzystując funkcję step step(nazwa_modelu, direction = c("both", "backward", "forward"),
steps = 1000)
Funkcja ta znajduje najlepiej dopasowany model do naszych danych metodą krokową
Domyślnie kryterium wyboru jest AIC wybierając k=log(n) zmieniamy kryterium na kryterium Schwartza
(BIC)

WYBÓR ZMIENNYCH OBJAŚNIAJĄCYCH
Metoda budowy modelu jest określona w zależności od wyboru parametru „direction”: Backward (wtecz) - z modelu zawierającego wszystkie zmienne
objaśniające usuwane są najmniej istotne zmienne, dopóki wszystkie zmienne w modelu będą istotne
Forward (wprzód) - określa metodę dodawania najbardziej istotnych zmiennych do modelu zawierającego tylko wyraz wolny
Both - oznacza metodę, którą do modelu dodajemy zmienną istotną posiadającą najmniejszą p-value, a następnie usuwamy zmienną nieistotną z największą p-value. Kroki te są powtarzane aż model przestaje ulegać zmianie

Baza alkohol: cirrhosis – marskość wątroby
oop – ludność zamieszkująca w miastach
liquor – Spożycie wysokoprocentowego alkoholu na mieszkańca
wine – spożycie wina na mieszkańca
lb – liczba urodzeń przez kobiety w wieku 45-49
REGRESJA WIELOKROTNA – PRZYKŁAD W R
Źródło danych i tutorial: http://scg.sdsu.edu/mlr-r/
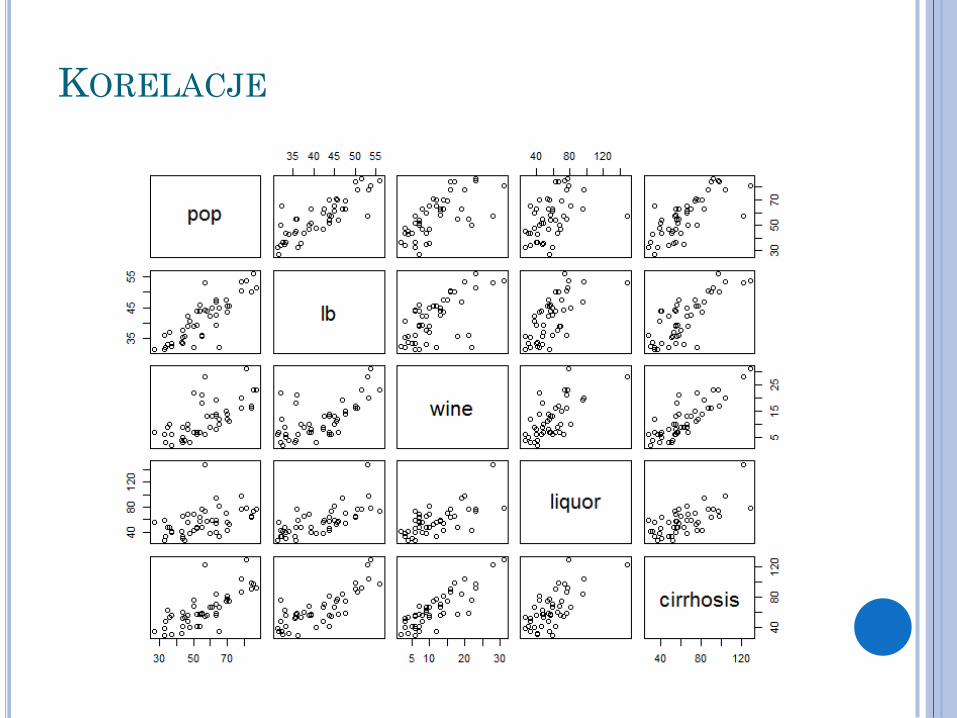
KORELACJE

MODEL

REGRESJA KROKOWA
Metoda: wstecz – z modelu zawierającego wszystkie zmienne usuwamy po jednej sprawdzamy wartość AIC

MODEL
Model po usunięciu zmiennej liquor
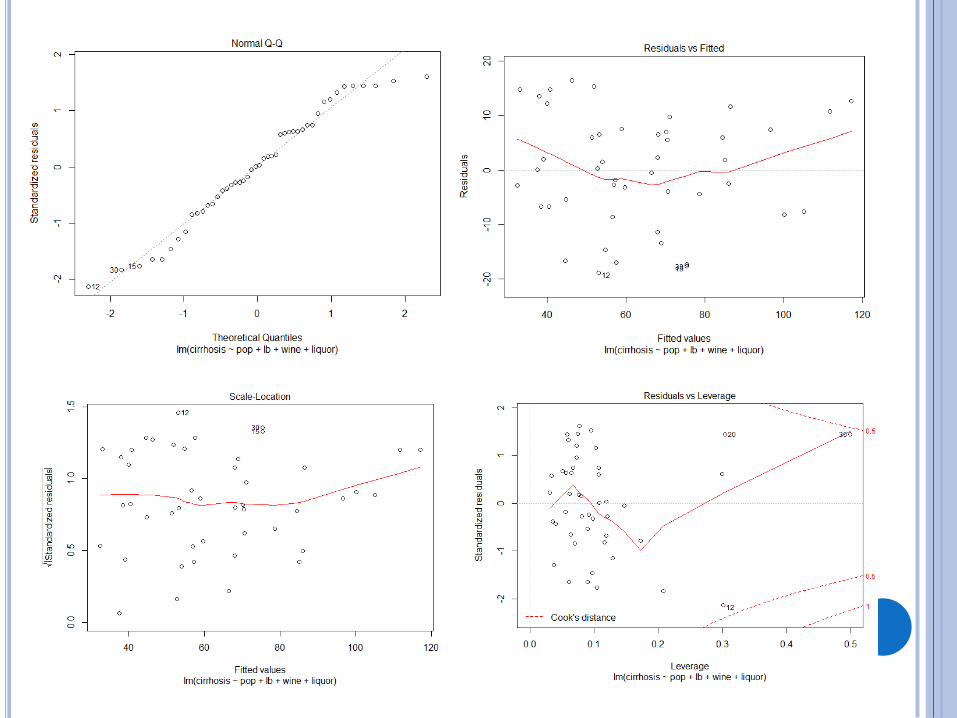

ŹRÓDŁA
Biecek P. 2013. Analiza danych z programem R. Wydawnictwo naukowe PWN. Warszawa
Olech W., Wieczorek M. 2010. Zastosowanie metod statystyki w doświadczalnictwie zootechnicznym. Wydawnictwo SGGW.


















