
Algebra relacji i SQL
66
Bazy danych
Transcript of Algebra relacji i SQL

Bazy danych

Zagadnienia
• Podstawy relacyjnych baz danych
• SQL
• Języki manipulowania w relacjach
• Aspekty aktywne baz danych
• Aspekty systemowe baz danych
• Projektowanie baz danych
• Zależności funkcyjne i postacie normalne
• Transakcje bazodanowe
• Autoryzacja w bazach danych

Literatura
• J.D. Ullman, J.Widom, Podstawowy wykład z systemów
baz danych, Wydawnictwo Naukowo-Techniczne,
Warszawa, 2000.
• T. Pankowski, Podstawy baz danych, Wydawnictwo
Naukowe PWN, Warszawa, 1992.
• D. Mendrala, M. Szeliga, Praktyczny Kurs SQL
• R. J. Muller, Bazy danych – Język UML w modelowaniu
danych
• Jeffrey D. Ullman - Principles of database systems, 1982

Bazy danych
Informacje podstawowe

Czym jest baza danych?
• Zbiór danych istniejących przez długi czas,
posiadać odpowiednią strukturę (schemat
bazy danych) , można na danych
wykonywać pewne operacje, reprezentuje
pewien fragment rzeczywistości, jest
projektowana, tworzona i utrzymywana z
punktu widzenia pewnych zastosowań.
Zachowane są więzy integralności.

System zarządzania bazą danych
• Zbiór programów umożliwiających
tworzenie i utrzymywanie bazy danych
• Cechy: – Umożliwia dodanie nowej bazy danych i określenia jej schematu
– Umożliwia zadawanie zapytań
– Zapewnia możliwość przechowywania dużej ilości danych
– Jednoczesny dostęp do danych przez wielu użytkowników
– Umożliwia kontrolę dostępu do poszczególnych danych bazy

Architektura systemu
zarządzania bazą danych • Moduł zarządzania pamięcią składa się z modułu
zarządzania plikami i modułu zarządzania buforami: – modułu zarządzania plikami - przechowuje dane o miejscu zapisania plików na
dysku i na polecenie modułu zarządzania buforami przesyła zawartość bloku
danych lub bloków
– moduł zarządzania buforami – przydziela strony pamięci operacyjnej do
odpowiednich bloków
• Moduł zarządzania zapytaniami przetwarza zapytanie
języka SQL na ciąg poleceń żądających dostarczenia
określonych danych . Optymalizacja zapytania…
odpowiedni plan, itd. Indeksy… • Moduł zarządzania transakcjami

Algebra relacji i SQL

Struktury danych
• Relacyjna baza danych jest zbiorem relacji.
• Schemat relacji R(A1, A2, … , An) składa się z
nazwy relacji R oraz listy atrybutów A1, A2, … ,
An.
• Każdy atrybut Ai schematu relacji R posiada
dziedzinę oznaczoną jako dom(Ai).
• Dziedzina definiuje zbiór wartości jakie dany
atrybut może przyjmować. Z atrybutem związany
jest więc typ danych.

Struktury danych (2)
• Relacją r o schemacie R(A1, A2, … , An)
oznaczoną r(R) nazywamy zbiór k krotek
postaci: r = {t1,t2,…, tk}.
• Pojedyncza krotka t jest uporządkowaną
listą n wartości: t=< v1,v2,…, vn > przy
czym vi jest wartością należącą do
dom(Ai) lub wartością pustą (NULL).
• i-ta wartość krotki t odpowiadająca
wartości atrybutu Ai będzie oznaczona
przez t.Ai.

Struktury danych (3)
• Relacja r(R) jest matematyczną relacją
stopnia n zdefiniowaną na zbiorze domen:
dom(A1), dom(A2), … , dom(An) będącą
podzbiorem iloczynu kartezjańskiego
domen definiujących R:
r(R) dom(A1) x dom(A2)x … x dom(An)

Charakterystyka relacji
• Każdy atrybut relacji ma unikalną nazwę
• Porządek atrybutów w relacji nie jest
istotny
• Porządek krotek w relacji nie jest istotny
• Wartości atrybutów są atomowe
(elementarne)
• Relacja nie zawiera rekordów
powtarzających się

Typy atrybutów
Przykładowe typy atrybutów:
• Char(n) – pole tekstowe o stałej długości (jeśli podamy mniej znaków, to pozostałe będą spacjami wypełnione)
• Varchar(n) – pole tekstowe nie dłuższe niż n znaków ( nie ma spacji)
• Int, Integer – liczby całkowite
• Numeric – liczby stałopozycyjne np. Numeric(10,2), 2 miejsca po przecinku
• Float (8 bytes), Real(4 bytes) – liczby zmiennopozycyjne
• BLOB – pola przechowujące liczby binarne

SQL, Algebra relacji
• SQL (Structured Query Language) – język
zapytań dla relacyjnych baz danych;
• Język nieproceduralny – użytkownik
wyszczególnia operacje co ma być zrobione, a
nie w jaki sposób.
• SQL posiada optymalizator, który wybiera
optymalną ścieżkę wykonywania zapytania.
• SQL ma kilka dialektów. Są nieznaczne różnice
pomiędzy różnymi systemami baz danych.

Udostępnienie relacji
Udostępnienie relacji (tabeli) o nazwie R:
Algebra relacji (AR):
R
SQL:
Select * from R
Przykład:
select * from Pracownik

Suma
Definicja:
Operandy R, S – tabele jednakowego typu U, wynik: tabela typu U
Suma mnogościowa (union): R S = { t | t R t S}
Student Pracownik Wynik
Przykład:
select Imie, Nazwisko, NrIndeksu, Rok FROM Student
union
select Imie, Nazwisko, NrPrac, RokPracy FROM Pracownik

Przekrój
Definicja:
Operandy R, S – tabele jednakowego typu U, wynik: tabela typu U
Przekrój (intersect): R S = { t | t R t S}
Student Pracownik Wynik
Przykład:
select Imie, Nazwisko FROM Student
intersect
select Imie, Nazwisko FROM Pracownik

Różnica
Definicja:
Operandy R, S – tabele jednakowego typu U, wynik: tabela typu U
Różnica (except): R - S = { t | t R t S}
Student Pracownik Wynik
Przykład:
select Imie, Nazwisko FROM Student
except
select Imie, Nazwisko FROM Pracownik

Selekcja • Wypisuje tylko takie krotki, które spełniają warunek.
R1 := C (R2) , C – oznacza warunek
Przykład:
Sells Wynik
AR: Tawerna := bar=“Tawerna”(Sells)
SQL: SELECT * FROM Sells WHERE bar = ‘Tawerna’

Selekcja (2)
SQL: SELECT * FROM Sells WHERE bar = ‘Tawerna’
Operatory logiczne: =, <>, >=,<, <=, NOT, LIKE
Działanie operatora LIKE:
AR: T1 := bar like“T%”(Sells)
SQL: SELECT * FROM Sells WHERE bar like ‘T%’

Definicja warunku
Definicja warunku E:
U – zbiór atrybutów, V – zbiór stałych (liczb, tekstów), A, A' U, c V,
{=, !=, <, <=, >, >=, like, ... } – operator porównania,
Warunkiem nad U nazywamy wyrażenie logiczne E :
E ::= A c | A A' | (E ) | not E | E or E | E and E
Krotka r typu U spełnia warunek E,
E (r ) = TRUE,
jeśli wyrażenie powstałe z E przez podstawienie za każde wystąpienie atrybutu A wartości r.A jest prawdziwe.

Projekcja Wypisuje wszystkie krotki, ale ogranicza atrybuty do wyspecyfikowanej
listy.
R1 := L (R2), L – oznacza listę atrybutów należącą do schematu R2.
Przykład:
Sells Wynik
AR: Prices := beer,price(Sells):
SQL: SELECT beer,price FROM Sells

Projekcja - formalnie
Krotka: r = [A:a, B:b, C:c] typu U={A,B,C}
X = {A,C} U
Projekcja r na zbiór X:
X(r) = {A,C}[A:a, B:b, C:c] = [A:a, C:c]
• Definicja:
Niech r będzie krotką typu U i niech X U.
Krotkę t typu X nazywamy projekcją r na X, jeśli t i r
mają jednakowe wartości na wszystkich
atrybutach ze zbioru X, tzn:
t = X(r) A( A X t.A = r.A).
X – operator projekcji, t.A – wartość pola A dla krotki t.

Rozszerzona projekcja • Rozszerzona projekcja umożliwiająca tworzenie nowych atrybutów za
pomocą wyrażeń arytmetycznych oraz duplikowania istniejących. Przykład:
Sells Wynik
AR: Prices := Beer+Bar ->B, Bar, Bar (Sells)
SQL: SELECT Bar + Beer as B, Bar, Bar FROM Sells

Iloczyn kartezjański
• R3 := R1 X R2
Łączy każdą krotkę relacji R1 z każdą krotką R2. Przykład: Sells Bar Wynik
AR: Cartesian := Sells X Bar
SQL: SELECT * FROM Sells, Bar
T- SQL: SELECT * FROM Sells CROSS JOIN Bar

Iloczyn kartezjański - formalnie
Iloczyn kartezjański krotek:
[A:a, B:b]N × M[A:a’, C:c] = [N.A:a, N.B:b, M.A:a’, M.C:c]
Uwaga:
W iloczynie kartezjańskim występują wszystkie kolumny z obydwu operandów. Prefiksowanie nazwami N i M jest potrzebne dla zapewnienia jednoznaczności nazw pól (kolumn). Gdy atrybuty w krotkach są różne, to prefiksowanie nie jest konieczne.

Złączenie warunkowe • R3 := R1 ►◄ C R2
Na iloczyn kartezjański R1 X R2 nakładany jest warunek C. Złączenie jest nazwane Theta Join.
Przykład:
Sells Bar Wynik
AR: ThetaJoin := Sells ►◄ Sells.Bar = Bar.Bar Bar
SQL: SELECT * FROM Sells INNER JOIN Bar ON Bar.Bar = Sells.Bar

Złączenie naturalne • R3 := R1 ►◄ R2
Łączy relacje R1 i R2 po wspólnym atrybucie. Wspólny atrybut wypisuje tylko raz.
Przykład: Sells Bar Wynik
AR: Natural := Sells ►◄ Bar
SQL: SELECT * FROM Sells NATURAL JOIN Bar
SQL: SELECT * FROM Sells, Bar WHERE Sells.Bar = Bar.Bar

Złączenie naturalne - formalnie
Definicja:
Niech r i s będą krotkami typów odpowiednio X i Y.
Krotka t typu X Y jest złączeniem naturalnym r i s,
t = r ►◄ s,
jeśli π X(t) = r i π Y(t) = s.
Krotki naturalnie złączalne:
[A:a, B:b, C:c, D:d] [A:a, B:b, D:d, E:e, F:f]
= [A:a, B:b, C:c, D:d, E:e, F:f]
Krotki niezłączalne:
[A:a, B:b, C:c, D:d], [A:a, B:b’, D:d, E:e, F:f]

Przemianowanie
• R1 := ρ R1(A1,…,An)(R2)
Tworzy relację R1 z przemianowanymi atrybutami relacji R2.
Przykład: Bar Wynik
AR: R:= ρ R(name, addr) (Bar)
SQL: SELECT Bar as Name , Address as addr FROM Bar AS R

Schematy operatorów algebry
relacji
• Suma, różnica, przekrój: schematy
argumentów operacji są takie same jak
schemat wyniku.
• Selekcja: schemat argumentu jest taki
sam jak schemat wyniku.
• Projekcja: lista atrybutów projekcji mówi o
schemacie wynikowym.

Schematy operatorów algebry
relacji (2)
• Iloczyn kartezjański: schemat wynikowy składa się z atrybutów należących do obydwu relacji. Żeby odróżnić atrybuty o tej samej nazwie pochodzące z różnych relacji, należy podać nazwę relacji, np.. R.A
• Złączenie warunkowe: tak samo jak iloczyn kartezjański.
• Złączenie naturalne: suma atrybutów dwóch relacji.
• Przemianowanie: operator określa schemat.

Usuwanie duplikatów
• R1 := δ (R2).
R1 składa się z jednej kopii każdej krotki, która w R2 występuje wiele razy.
Przykład:
AR: BarDist:= δ( Bar (Sells))
SQL: select distinct Bar FROM Sells

Sortowanie • R1 := L (R2)
R1 jest listą krotek z R2 posortowaną najpierw po pierwszym atrybucie z listy L, potem po drugim, itd..
Przykład: Sells Wynik
AR: Ordered : = Price Sells
SQL: select * FROM Sells ORDER BY Price

Agregacje • Operacje agregacji nie są operacjami algebry relacji.
• Na podstawie wszystkich wartości atrybutów obliczają jedną wartość.
Przykład: Sells
SUM(Price) = 12,50
COUNT(Price) = 4
MAX(Price) = 3,50
AVG(Price) = 3,125
SQL: select avg(Price) FROM Sells

Grupowanie
• R1 := L (R2) , L jest listą atrybutów, które są:
• pojedynczymi atrybutami;
• AGG(A), gdzie AGG jest funkcją agregującą na
atrybucie A;
• R1 := L (R2)
– grupuje R2 według wszystkich atrybutów
grupujących w L, czyli formułuje jedną grupę dla
każdej różnej listy wartości tych atrybutów
– dla każdej grupy oblicza wartość funkcji agregującej

Grupowanie (2) Przykład 1:
Sells Wynik
AR: Group := Bar, AVG(Price) -> AvgPrice (Sells)
SQL: select Bar, AVG(Price) As AvgPrice FROM Sells GROUP BY Bar
AR: Group := Bar,Beer, AVG(Price) -> AvgPrice (Sells)
SQL: select Bar,Beer, AVG(Price) As AvgPrice FROM Sells GROUP BY
Bar,Beer
Przykład 2:
Sells Wynik

Grupowanie (3) • Wyniki grupowanie można ograniczyć selekcją
Przykład:
Sells Wynik
AR: Group := AVG(Price)>3 Bar,Beer, AVG(Price) -> AvgPrice (Sells))
SQL: select Bar,Beer, AVG(Price) As AvgPrice FROM Sells GROUP BY
Bar,Beer having AVG(Price)> 3

• obie kolejne instrukcje zwracają wszystkie rekordy X i tylko te rekordy Y, w których <warunek> ma wartość True:
SELECT * FROM X LEFT OUTER JOIN Y
ON <warunek>
SELECT * FROM Y RIGHT OUTER JOIN X
ON <warunek>
Łączenie zewnętrzne

Łączenie zewnętrzne (2)
• Pełne łączenie zewnętrzne zwraca wszystkie
rekordy obu zestawów, łącząc ze sobą tylko te
rekordy, w których warunek jest spełniony (daje
wartość True). SQL Server umożliwia pełne
łączenia zewnętrzne za pomocą warunku FULL
OUTER JOIN:
SELECT * FROM X FULL OUTER JOIN Y ON
<warunek>

Złączenie zewnętrzne Przykład:
SELECT * FROM Sells RIGHT OUTER JOIN Bar ON Bar.Bar = Sells.Bar
SELECT * FROM Bar LEFT OUTER JOIN Sells ON Bar.Bar = Sells.Bar
SELECT * FROM Bar FULL OUTER JOIN Sells ON Bar.Bar = Sells.Bar
Sells Bar Wynik

Operatory mnogościowe (różnica)
select Imie, Nazwisko FROM Student
except
select Imie, Nazwisko FROM Pracownik
select s.Imie, s.Nazwisko from Student as s left
outer join Pracownik as p
on s.imie = p.imie and s.nazwisko = p.nazwisko
where p.imie is null

Operatory mnogościowe (przekrój)
select Imie, Nazwisko FROM Student
intersect
select Imie, Nazwisko FROM Pracownik
select s.Imie, s.Nazwisko from Student as s left outer join Pracownik as p
on s.imie = p.imie and s.nazwisko = p.nazwisko
where p.imie is not null

Instrukcja SELECT
SELECT <ListaPól>
FROM <ListaZestawówRekordów>
<RodzajŁączenia> JOIN <Warunek>
WHERE <KryteriaWyboru>
GROUP BY <ListaPólGrupujących>
HAVING <KryteriaWyboru>
ORDER BY <ListaPólPorządkujących>

Instrukcja WHERE
select * FROM Pracownik WHERE Nazwisko < Imie
select * FROM Pracownik WHERE Wydzial IN('PPT', 'IZ')
select * FROM Pracownik WHERE Wydzial NOT IN('PPT', 'IZ')
select * FROM Pracownik WHERE Wydzial IN ('PPT') OR Wydzial IN ('IZ')
select * FROM Pracownik WHERE NrPrac BETWEEN 3300 AND 3600
select * FROM Pracownik WHERE NrPrac IS NULL
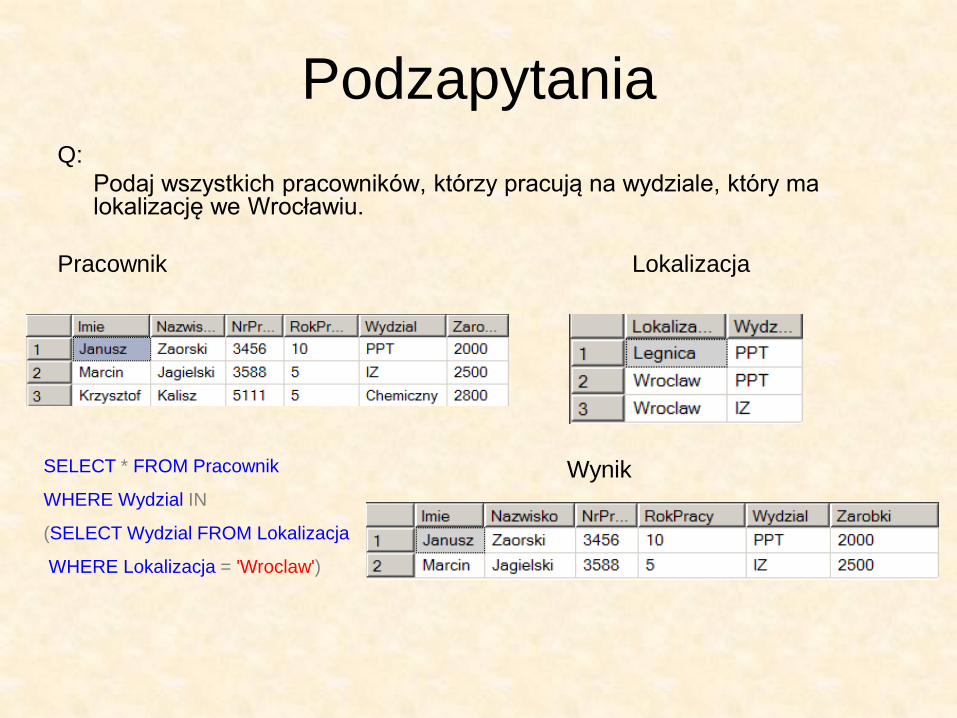
Podzapytania Q:
Podaj wszystkich pracowników, którzy pracują na wydziale, który ma lokalizację we Wrocławiu.
Pracownik Lokalizacja
SELECT * FROM Pracownik
WHERE Wydzial IN
(SELECT Wydzial FROM Lokalizacja
WHERE Lokalizacja = 'Wroclaw')
Wynik
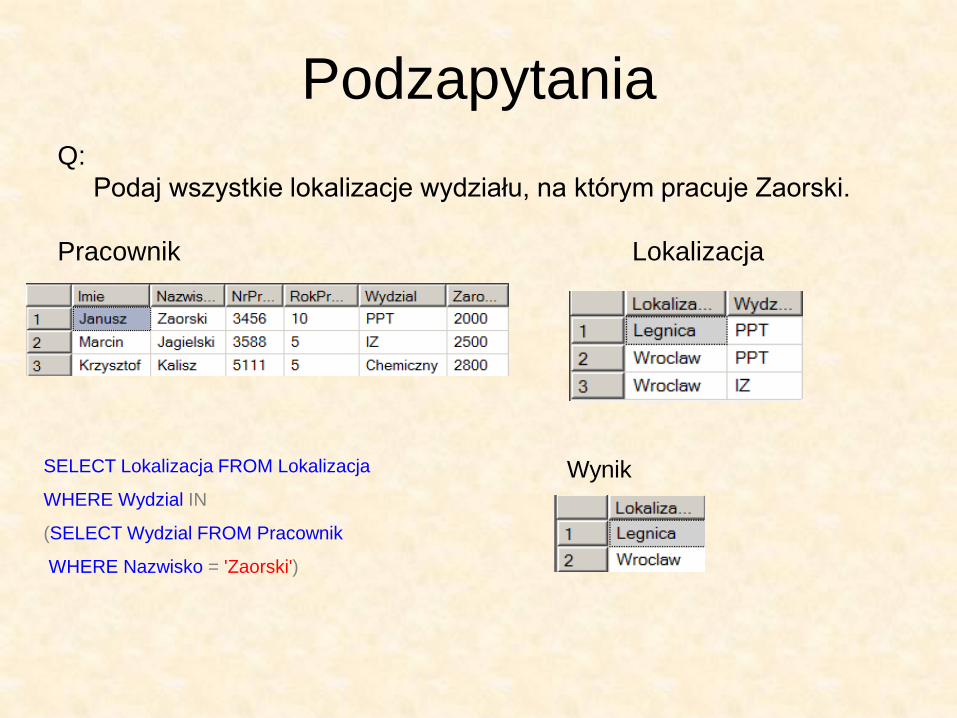
Podzapytania Q:
Podaj wszystkie lokalizacje wydziału, na którym pracuje Zaorski.
Pracownik Lokalizacja
SELECT Lokalizacja FROM Lokalizacja
WHERE Wydzial IN
(SELECT Wydzial FROM Pracownik
WHERE Nazwisko = 'Zaorski')
Wynik
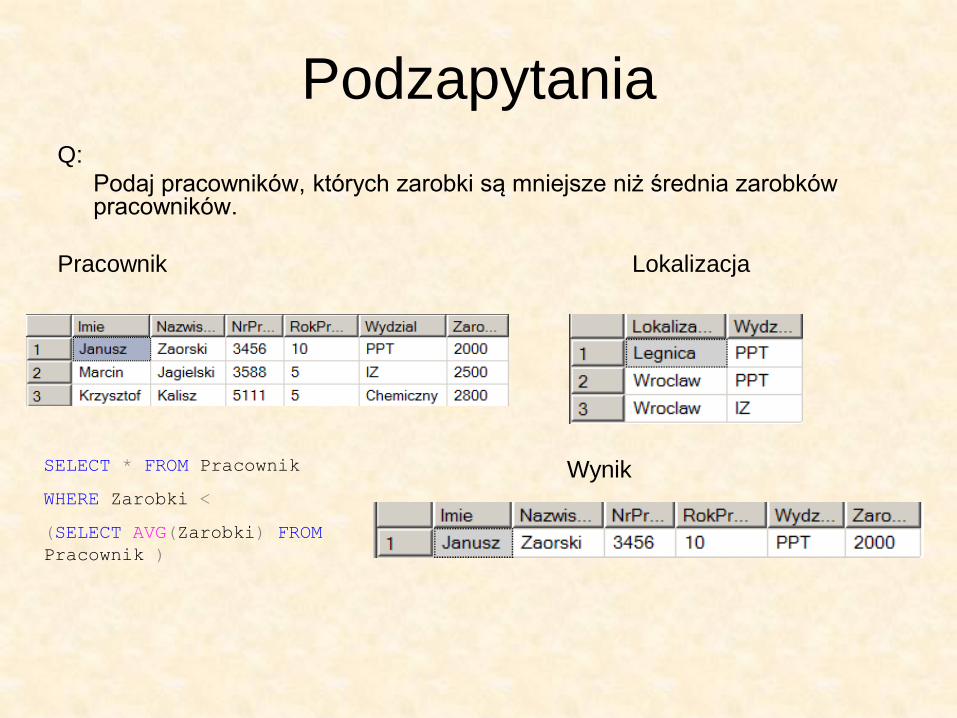
Podzapytania Q:
Podaj pracowników, których zarobki są mniejsze niż średnia zarobków pracowników.
Pracownik Lokalizacja
SELECT * FROM Pracownik
WHERE Zarobki <
(SELECT AVG(Zarobki) FROM
Pracownik )
Wynik

Podzapytania
• Podzapytania mogą być bardziej zagnieżdżone, tzn. w warunku może być następny warunek, itd.
• W podzapytaniu lewa strona predykatu wymaga zgodnego wyniku z podzapytaniem po prawej stronie.
• Przykład: – Liczba > (podzapytanie zwracające pojedynczą
liczbę)
– Napis = (podzapytanie zwracające pojedynczy napis)
• Nie może być: – Liczba > (Lista liczb)

Podzapytania
• Składnia z użyciem IN:
– liczba IN (podzapytanie zwracające listę liczb)
– text IN (podzapytanie zwracające listę testów)
• Nie może być:
– Liczba > (Lista liczb)
• Może być:
– Liczba > ANY (Lista liczb)
– Liczba > ALL (Lista liczb)
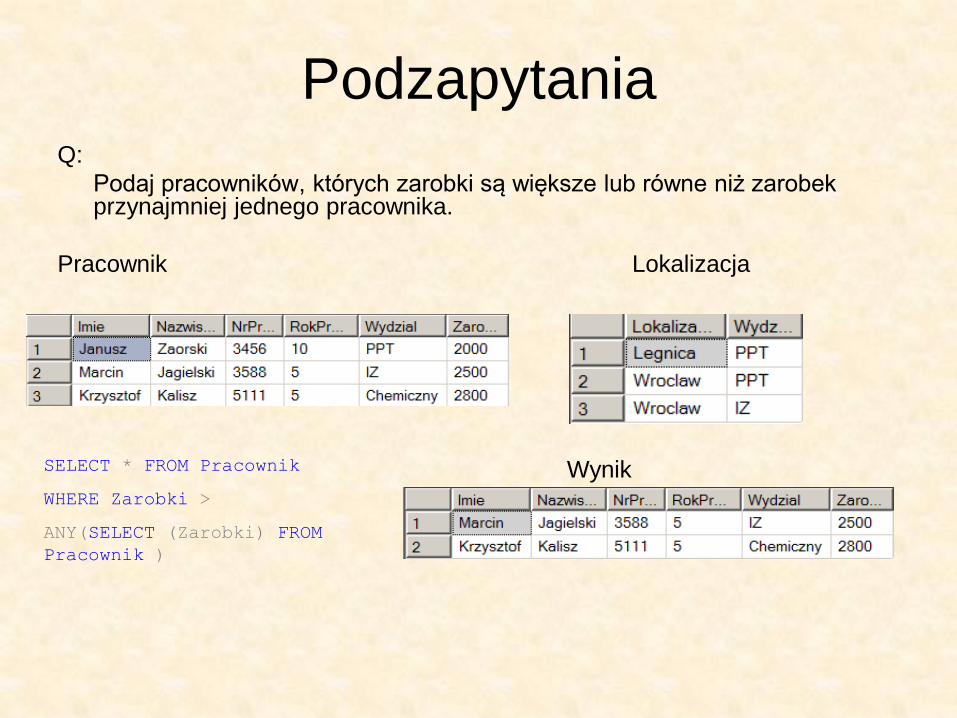
Podzapytania Q:
Podaj pracowników, których zarobki są większe lub równe niż zarobek przynajmniej jednego pracownika.
Pracownik Lokalizacja
SELECT * FROM Pracownik
WHERE Zarobki >
ANY(SELECT (Zarobki) FROM
Pracownik )
Wynik
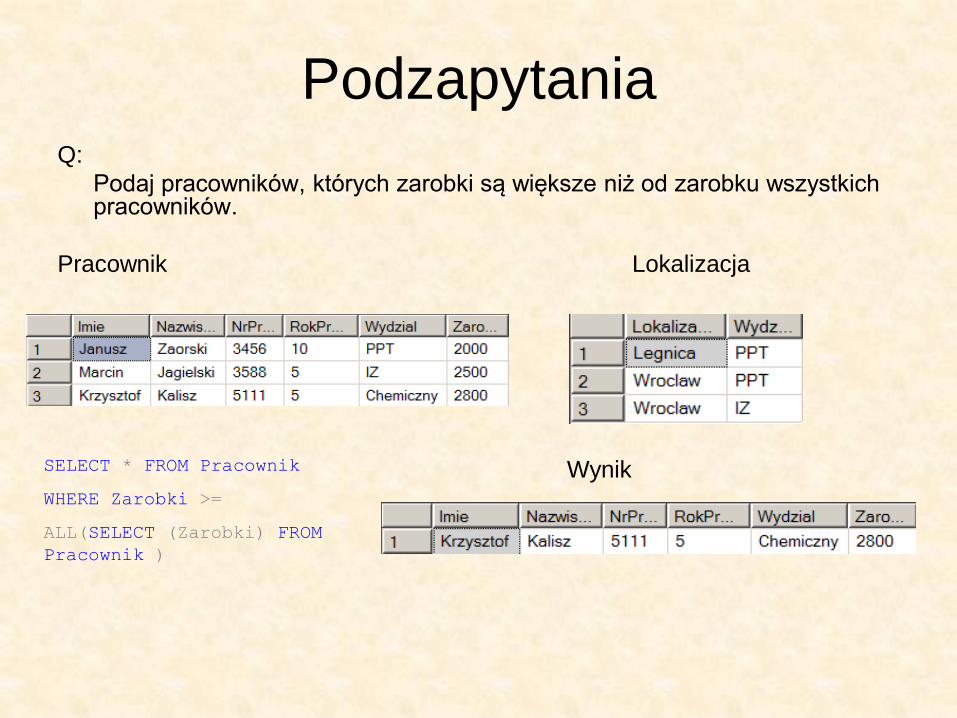
Podzapytania Q:
Podaj pracowników, których zarobki są większe niż od zarobku wszystkich pracowników.
Pracownik Lokalizacja
SELECT * FROM Pracownik
WHERE Zarobki >=
ALL(SELECT (Zarobki) FROM
Pracownik )
Wynik

Podzapytania
• W przypadku zapytania ze zwykłym podzapytaniem, podzapytanie wykonywane jest jako pierwsze, a wyniki tymczasowe są przechowywane w pamięci SZRBD.
• Przykład:
– WHERE Zarob < (SELECT AVG(ZAROB)….)
• Wynik podzapytania jest sprawdzany z każdym wierszem tabeli.

Podzapytania skolerowane Q:
Którzy ludzie zarabiają mniej niż wynosi średnia pensja na tym wydziale, na którym dany pracownik pracuje.
Pracownik Lokalizacja
SELECT * FROM Pracownik AS p
WHERE Zarobki <
(SELECT AVG(Zarobki) FROM
Pracownik AS s
WHERE p.Wydzial = s.Wydzial)
Wynik
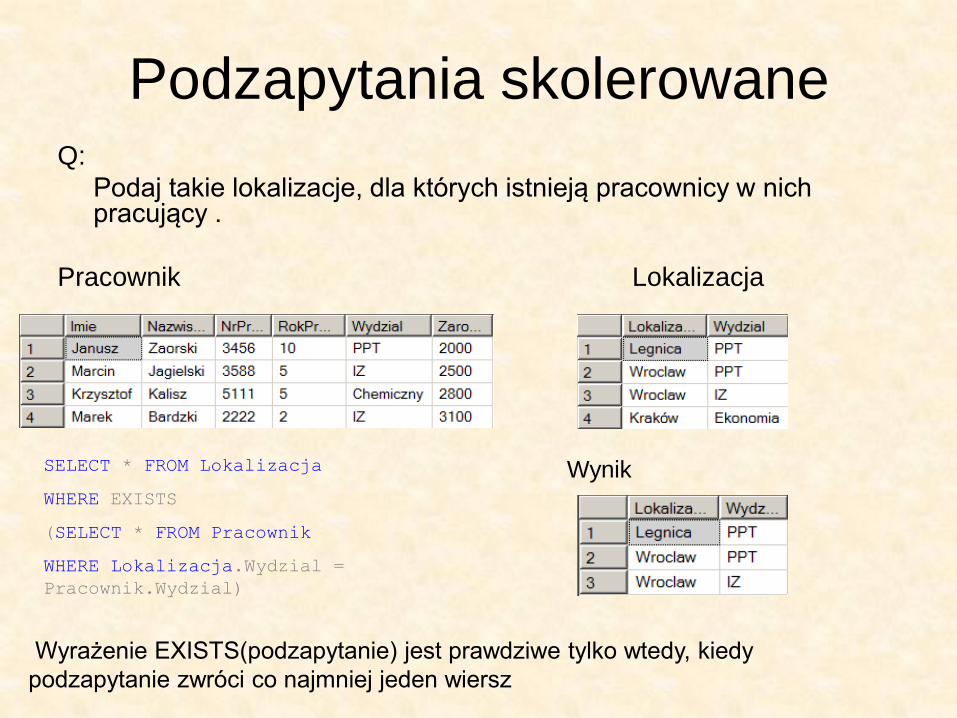
Podzapytania skolerowane Q:
Podaj takie lokalizacje, dla których istnieją pracownicy w nich pracujący .
Pracownik Lokalizacja
SELECT * FROM Lokalizacja
WHERE EXISTS
(SELECT * FROM Pracownik
WHERE Lokalizacja.Wydzial =
Pracownik.Wydzial)
Wynik
Wyrażenie EXISTS(podzapytanie) jest prawdziwe tylko wtedy, kiedy
podzapytanie zwróci co najmniej jeden wiersz

Podzapytania skolerowane Q:
Podaj takie lokalizacje, dla których nie istnieją pracownicy w nich pracujący .
Pracownik Lokalizacja
SELECT * FROM Lokalizacja
WHERE NOT EXISTS
(SELECT * FROM Pracownik
WHERE Lokalizacja.Wydzial =
Pracownik.Wydzial)
Wynik
Wyrażenie NOT EXISTS(podzapytanie) jest prawdziwe tylko wtedy, kiedy
podzapytanie nie zwróci żadnego wiersza.

Podzapytania skolerowane
• W przypadku zapytania ze zwykłym podzapytaniem, podzapytanie wykonywane jest jako pierwsze, a wyniki tymczasowe są przechowywane w pamięci SZRBD.
• W przypadku zapytań skolerowanych wartość z głównego zapytania jest przekazywana do podzapytania, aby mogło być ono wykonane.
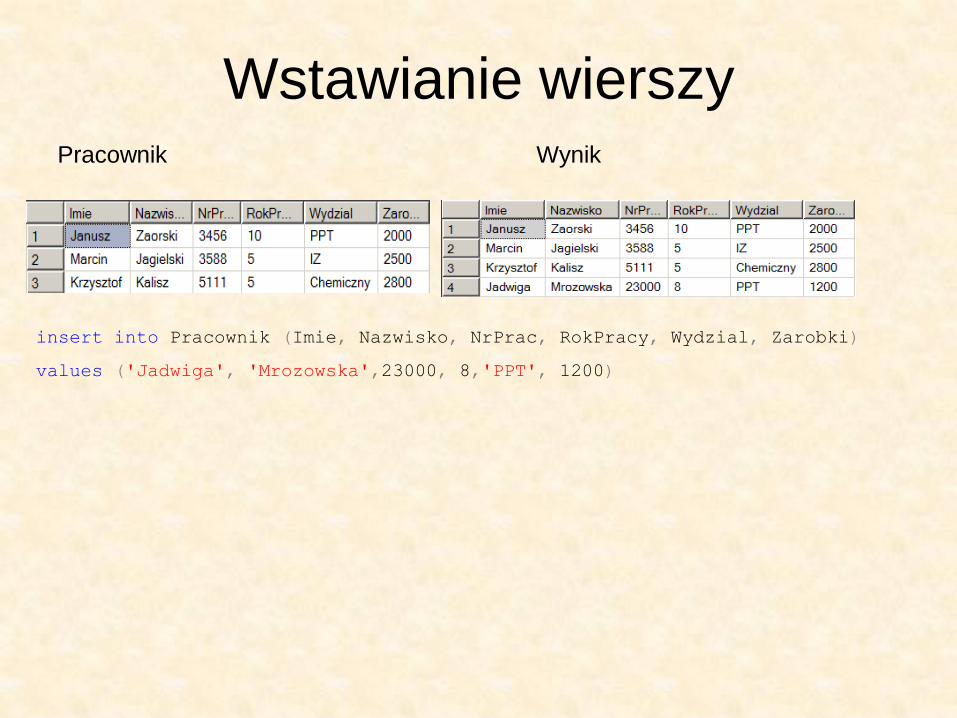
Wstawianie wierszy Pracownik Wynik
insert into Pracownik (Imie, Nazwisko, NrPrac, RokPracy, Wydzial, Zarobki)
values ('Jadwiga', 'Mrozowska',23000, 8,'PPT', 1200)

Wstawianie wierszy
Pracownik Wynik
insert into Pracownik (Imie, Nazwisko, NrPrac, RokPracy)
values ('Jadwiga', 'Hajnicz',23000,4)
Można opuścić jakiś atrybut: np. RokPracy, Wydział. Jeśli dla tego atrybutu jest zdefiniowana wartość domyślna, wówczas wpisywana jest wartość domyślna. Jeśli nie ma domyślnej wartości to wstawiany jest NULL o ile dla atrybutu można wstawić NULL .
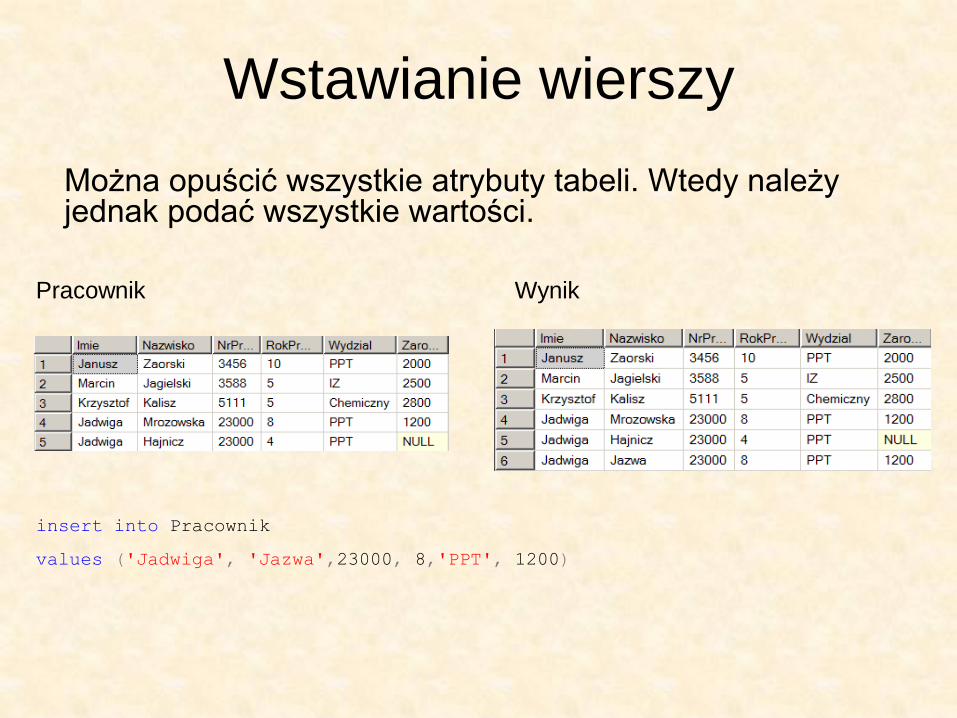
Wstawianie wierszy
Pracownik Wynik
insert into Pracownik
values ('Jadwiga', 'Jazwa',23000, 8,'PPT', 1200)
Można opuścić wszystkie atrybuty tabeli. Wtedy należy jednak podać wszystkie wartości.

Wstawianie wielu wierszy
Pracownik Wynik
insert into Pracownik2 (Imie, Nazwisko, NrPrac, Wydzial)
select Imie, Nazwisko, NrPrac, Wydzial from Pracownik
Można wstawić wiele wierszy do tabeli na podstawie danych z innej tabeli.
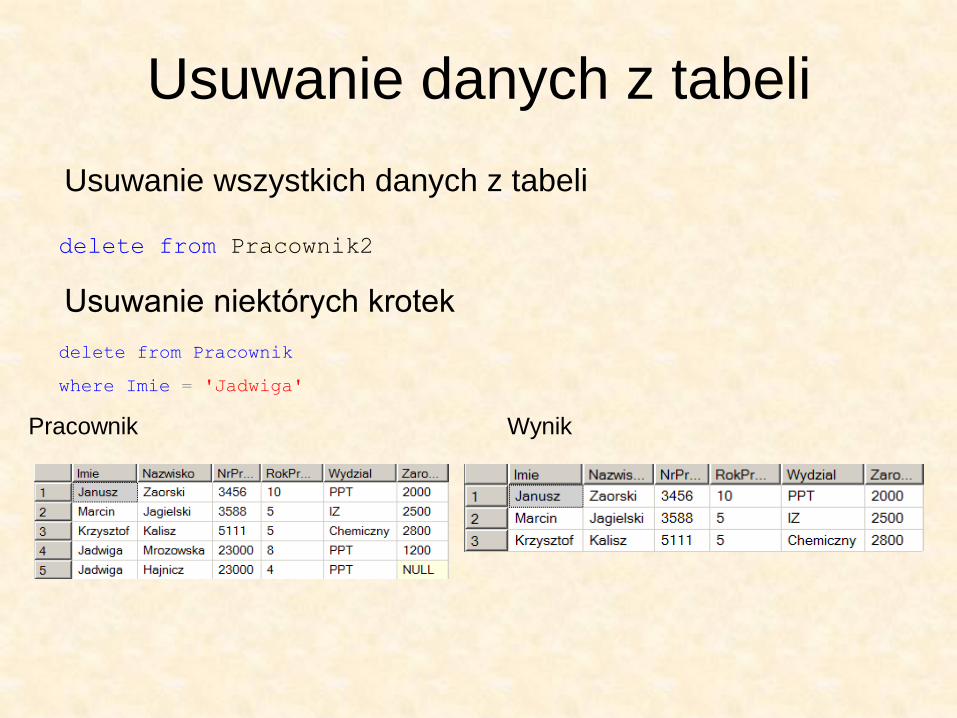
Usuwanie danych z tabeli
Pracownik Wynik
delete from Pracownik
where Imie = 'Jadwiga'
Usuwanie wszystkich danych z tabeli
delete from Pracownik2
Usuwanie niektórych krotek

Usuwanie danych z tabeli
Pracownik2 Wynik
delete FROM Pracownik2
WHERE Wydzial IN
(SELECT Wydzial FROM Lokalizacja
WHERE Lokalizacja = 'Wroclaw')
Przy usuwaniu można korzystać z podzapytań.
Q: Usuń wszystkich pracowników, którzy pracują na wydziale, który ma
lokalizację we Wrocławiu

Modyfikowanie wierszy Pracownik Wynik
update Pracownik
set Wydzial = 'IZ', NrPrac = 22000
WHERE Nazwisko = 'Zaorski'
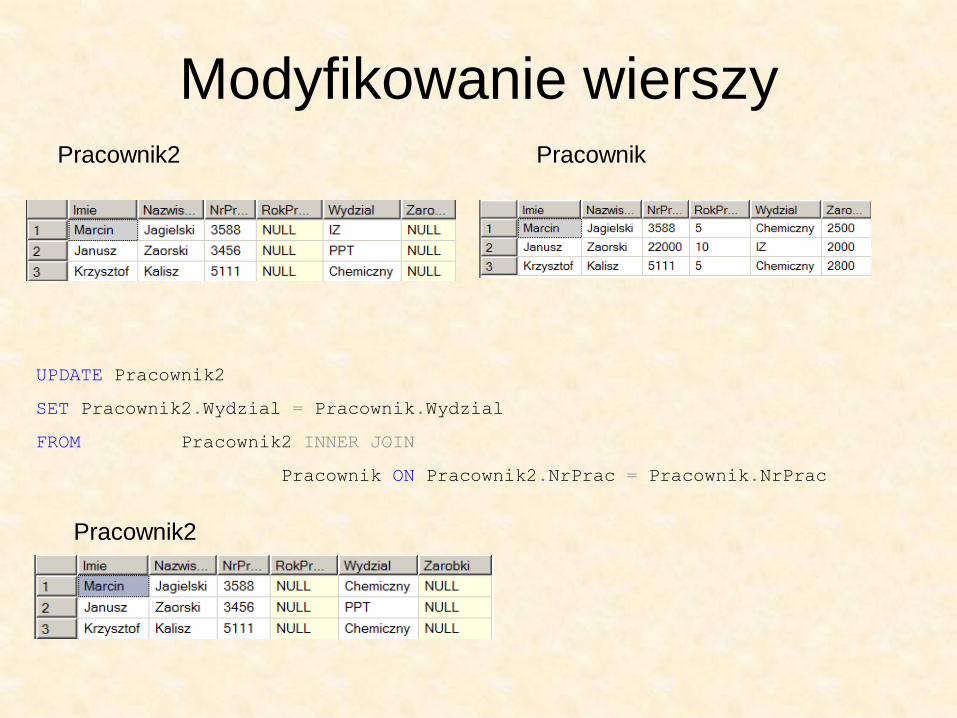
Modyfikowanie wierszy Pracownik2 Pracownik
UPDATE Pracownik2
SET Pracownik2.Wydzial = Pracownik.Wydzial
FROM Pracownik2 INNER JOIN
Pracownik ON Pracownik2.NrPrac = Pracownik.NrPrac
Pracownik2

To tyle….


















