









Języki
Strony
Prawny


Algorytmy Rozproszone
Jacek Dziedzic
FTiMS, PG
2004-2017
v2.14 2017.11.29.

Informacje organizacyjne• Prowadzący: Jacek Dziedzic,
s. 106 GG, [email protected].
• Konsultacje: środa, 13:15-14:00. s. 106 GG.
• Forma zaliczenia: kolokwium zaliczeniowe na ostatnich
zajęciach. Na kolokwium składa się kilka pytań
opisowych i kilkanaście testowych.
• Obecności nie są obowiązkowe, ale będą punktowane
dodatkowo. Każda obecność na wykładzie: +2 pkt.
Zatem samą obecnością można zdobyć ca. 26-28 pkt,
testem zaliczeniowym ca. 94 pkt, razem ca. 130 pkt,
zalicza 65 pkt (na oko).
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 2

Informacje organizacyjne 2• Slajdy z wykładu będą dostępne na stronie przedmiotu:
http://tiny.pl/rq8m (będę uaktualniał co jakiś czas).
• Warto bywać na wykładach!
• Na zaliczeniu specjalnie pytam o niektóre szczegóły,
które były na wykładzie wspomniane, ale o których nie
ma ani słowa na slajdach dodatkowa motywacja!
• Warto robić notatki.
• Nie brać slajdów z zeszłych lat, bo trochę będzie zmian
– przedmiot ewoluuje.
• W następnym semestrze będą poważne laborki z tego
przedmiotu – tym bardziej warto robić dobre notatki.
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 3

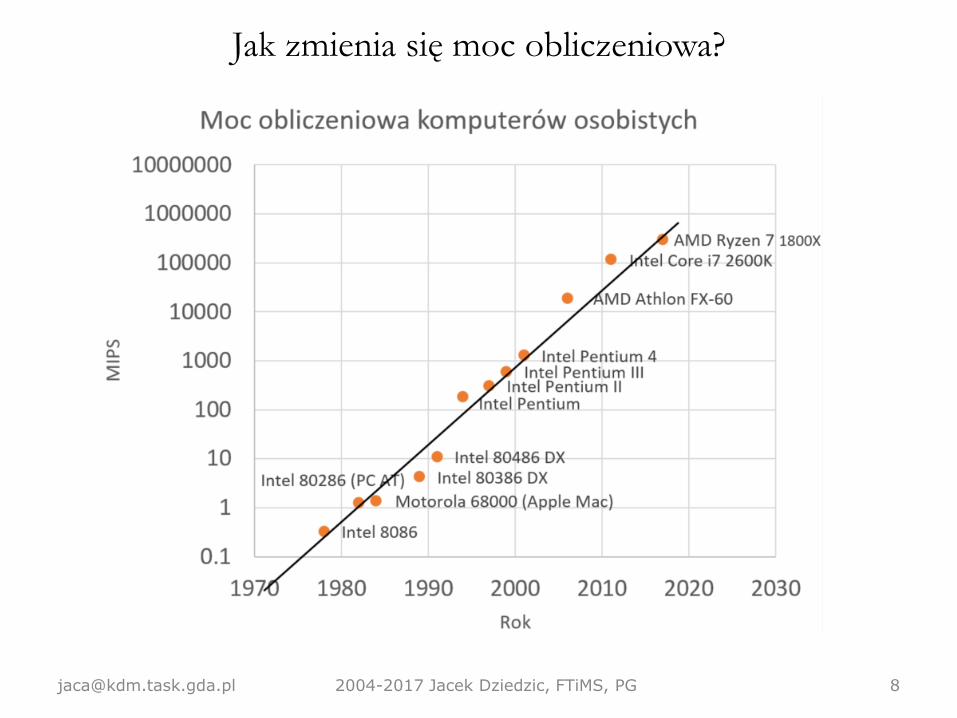
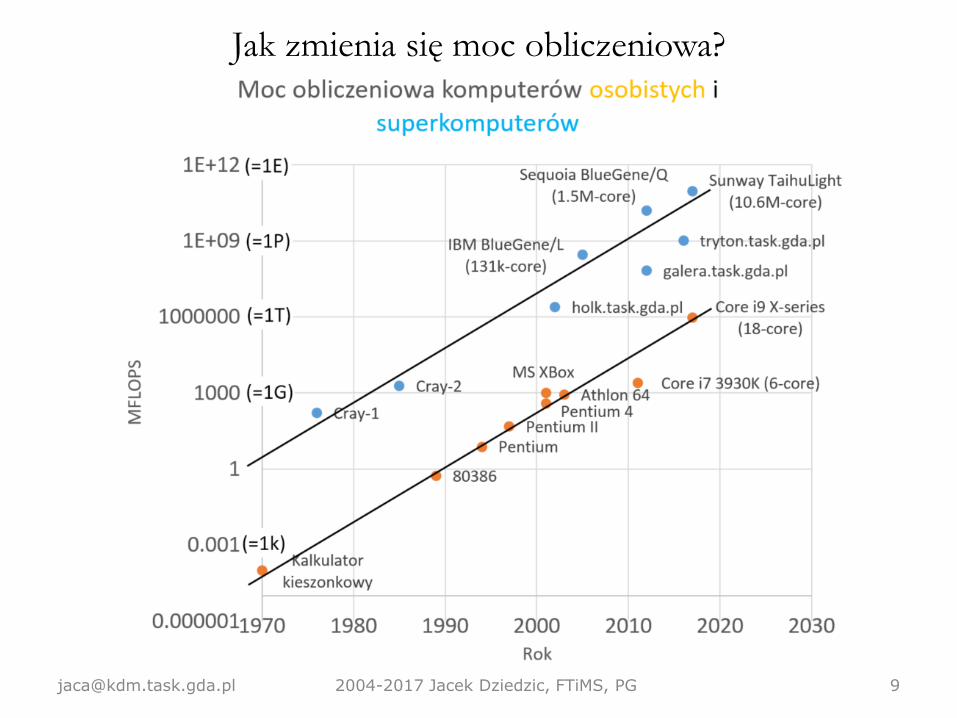
Czym się zajmujemy• Rys historyczny – jak zmienia się wydajność komputerów na
przestrzeni lat, jak ją mierzyć. Dlaczego pojawiły się komputery
wektorowe i na czym polega ich wyjątkowość.
• Na czym polega przetwarzanie równoległe i rozproszone. Podział
komputerów ze względu na sposób przetwarzania.
• Przetwarzanie równoległe, prawo Amdahla, schematy podziału
programu na zadania równoległe (dekompozycja).
• Message Passing Interface (MPI)w szczegółach (40% semestru). Podstawy MPI, komunikacja punktowa,
komunikacja zbiorowa. Efekty synchroniczne, gwarancje. Komunikacja
blokująca (w szczegółach) i nieblokująca (w skrócie). Zakleszczenie.
Pułapki komunikacji zbiorowej.
• Przetwarzanie z pamięcią współdzieloną na przykładzie OpenMP.
• Przetwarzanie GPGPU (karty graficzne) i MIC (koprocesory
Intel Xeon Phi).
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 4

Mierzenie wydajności obliczeniowej: MIPS
• Million Instructions Per Second – milion instrukcji na
sekundę.
• MIPS≠MHz (dlaczego?).
• Nie uwzględnia wydajności innych komponentów
(przede wszystkim pamięci).
• Nieporównywalny pomiędzy różnymi architekturami.
• Producenci (przez marketingowców) na ogół podają
wydajność szczytową (peak) trochę oszustwo.
• W konsekwencji miara ta popadła w niełaskę
(MIPS – Meaningless Indicator of Processor Speed).
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 6
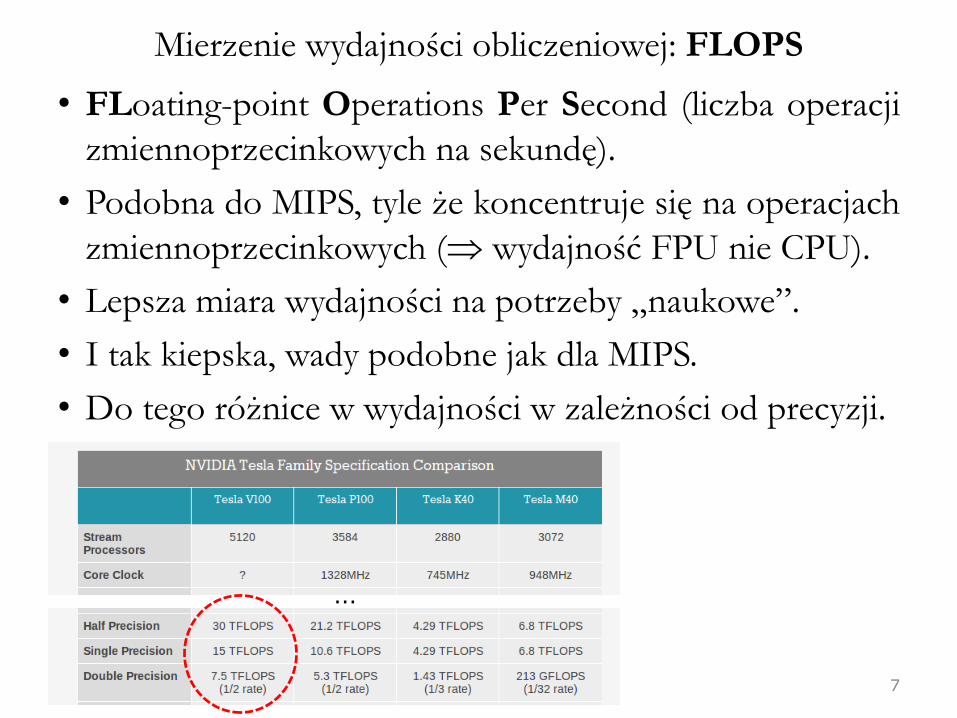
Mierzenie wydajności obliczeniowej: FLOPS
• FLoating-point Operations Per Second (liczba operacji
zmiennoprzecinkowych na sekundę).
• Podobna do MIPS, tyle że koncentruje się na operacjach
zmiennoprzecinkowych ( wydajność FPU nie CPU).
• Lepsza miara wydajności na potrzeby „naukowe”.
• I tak kiepska, wady podobne jak dla MIPS.
• Do tego różnice w wydajności w zależności od precyzji.
...

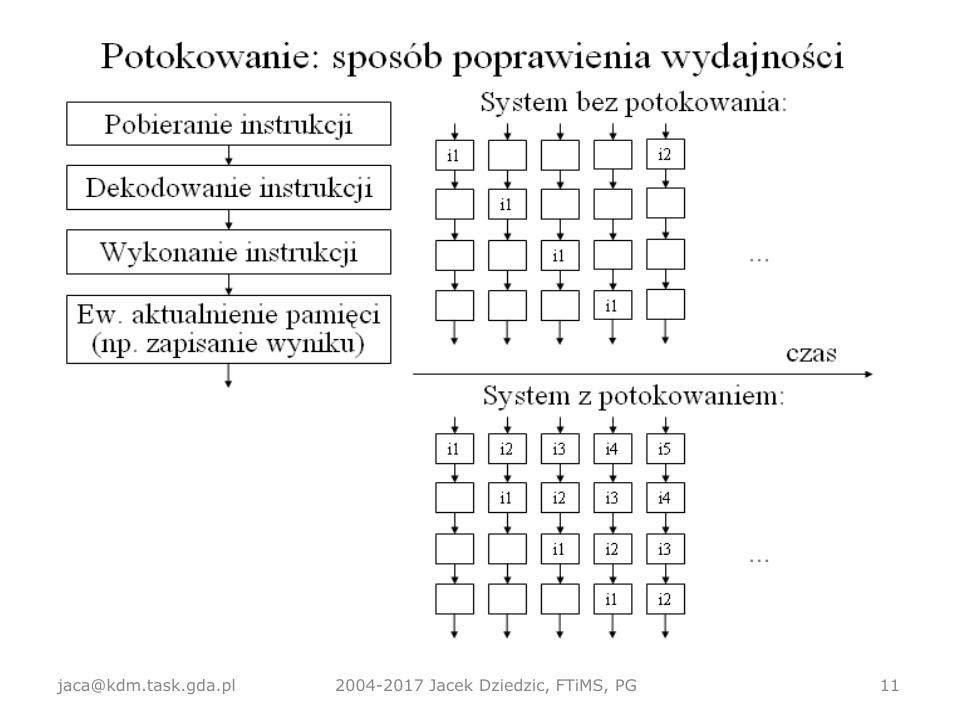
Kroki podejmowane przez procesor
przy wykonywaniu pojedynczej instrukcji
• Pobranie (wczytanie) instrukcji z pamięci (instruction fetch).
• Dekodowanie. Jeśli instrukcja ma argumenty, być może
trzeba je pobrać z pamięci, a wcześniej obliczyć spod jakiego
adresu.
• Wykonanie (i ew. odesłanie wyniku do pamięci).
• Często kroki te (zwłaszcza dekodowanie) można podzielić
na drobniejsze. Pentium-1 przetwarza instrukcje w 5
etapach, a potok instrukcji Pentium-4 ma aż 24 etapy!
Sposób na zwiększenie wydajności:
• Pobierać i dekodować kolejną instrukcję, gdy bieżąca jeszcze
się wykonuje (pipelining, potokowanie).
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 10
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 11

Potokowanie c.d.
• Pozwala znacznie zwiększyć szybkość przetwarzania
instrukcji.
• Stosowane praktycznie we wszystkich nowoczesnych
architekturach (u Intela począwszy od Pentium-1).
• Trudność: gdy instrukcja n zależy od wyników
instrukcji n-1.
• Trudność: gdy instrukcja n jest skokiem warunkowym,
to co będzie instrukcją n+1?
• Koszt: znaczna komplikacja procesora.
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 12

Komputer szeregowy vs. wektorowy
• Dodawanie 1M liczb przez komputer szeregowy:
– i=0.
– Pobierz instrukcję (a[i] = a[i] + b[i]).
– Wczytaj po jednej liczbie z pamięci do rejestrów
(pobierz a[i], b[i]).
– Dodaj je do siebie.
– Zapisz wynik do pamięci, do a[i].
– Zwiększ i.
– Czy i<1000000? Jeśli tak, to zapętl się.
• Nie musi to wyglądać dokładnie tak, bo zależy to od architektury
maszyny, ale ważny jest ogólny [email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 13

Komputer szeregowy vs. wektorowy
• Dodawanie 1M liczb przez komputer wektorowy:
– i=0.
– Pobierz instrukcję (a[i..i+63] = a[i..i+63] + b[i..i+63]).
– Wczytaj 64 kolejne liczby z pamięci do długich
rejestrów (pobierz a[i], b[i] i kolejne).
– Dodaj je do siebie parami.
– Zapisz wynik do pamięci, do a[i] i kolejnych.
– Zwiększ i o 64.
– Czy i<1000000? Jeśli tak, to zapętl.(zadbaj o końcówkę, pozostałą po podzieleniu 1000000 przez 64).
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 14

Powody zwiększonej wydajności
komputerów wektorowych
• W naszym przykładzie pętla kręci się 64-krotnie razy
mniej. Mamy zatem mniej pobrań instrukcji, mniej
dekodowań, mniej razy sprawdzamy warunek "czy to już
koniec pętli", mniej razy skaczemy na początek.
• Jest bardzo prawdopodobne, że operacja "dodaj do
siebie 64 kolejne liczby" będzie pracowała na wszystkich
liczbach jednocześnie, tj. w komputerze będzie
wyspecjalizowana jednostka dodająca w jednej instrukcji
całe bloki (wektory) liczb.
• To jest główna cecha komputerów wektorowych:są one zdolne wykonywać proste operacje na wieludanych jednocześnie.
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 15

Pierwszy komputer wektorowy: ILLIAC IV ('72)
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 16

Pierwszy komputer wektorowy: ILLIAC IV ('72)
• 1 procesor (CPU), ale aż 64 jednostki arytmetyczne
(FPU).
• Ta sama instrukcja arytmetyczna była kierowana do
wszystkich FPU, ale każdy dostawał inną daną do
przetworzenia.
• Dzięki temu długie bloki operacji na ciągach liczb
(wektory, macierze) mogły wykonywać się (prawie)
64 razy [email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 17

Inny znany komputer wektorowy: Cray-1 ('76)
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 18

Inny znany komputer wektorowy: Cray-1 ('76)
• Długie, wektorowe rejestry. Każdy rejestr mógł mieścić
64 liczby 64-bitowe.
• Dzięki temu mógł dodawać, mnożyć, odejmować, etc.
64 (duże) liczby na raz!
• Oddzielne potoki dla różnych instrukcji – np. dodawanie
i odejmowanie realizowane było przez oddzielne układy.
Dzięki temu niektóre instrukcje mogły być wykonywane
współbieżnie – można było jednocześnie dodawać
i odejmować (i to 64 liczby).
• Na tamte czasy – ogromny sukces, był to pierwszy
„udany” komputer wektorowy.
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 19
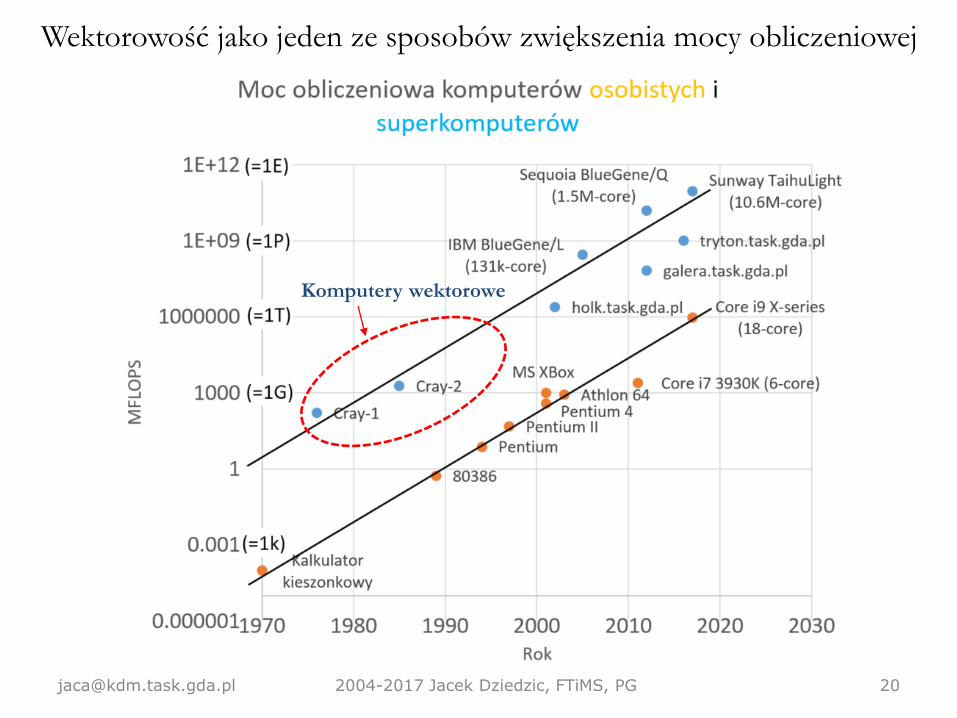
Wektorowość jako jeden ze sposobów zwiększenia mocy obliczeniowej
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 20
Komputery wektorowe
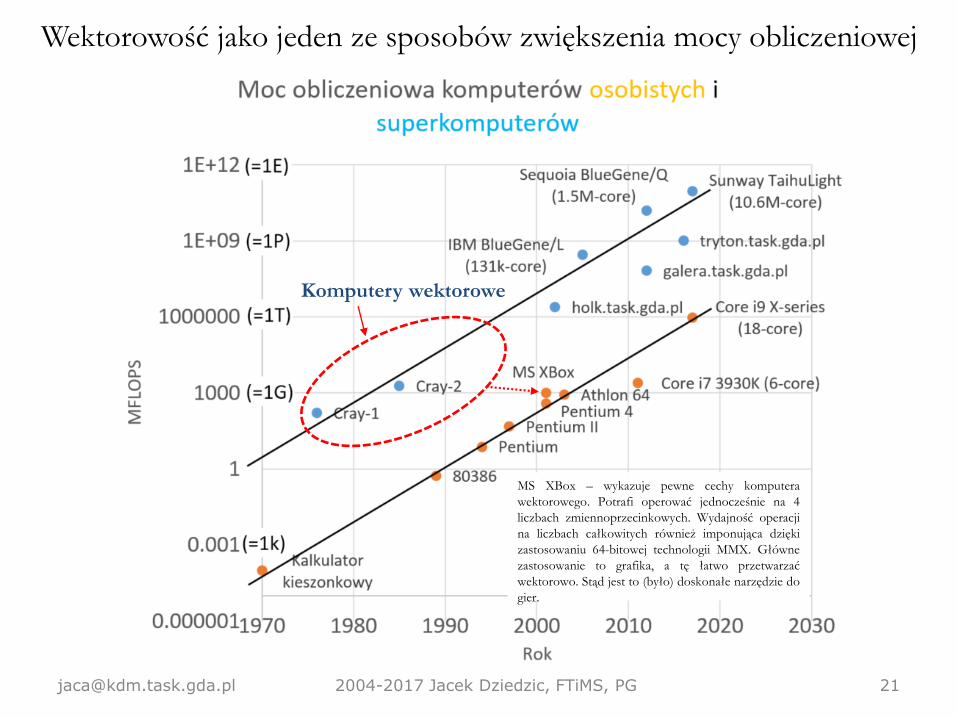
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 21
MS XBox – wykazuje pewne cechy komputera
wektorowego. Potrafi operować jednocześnie na 4
liczbach zmiennoprzecinkowych. Wydajność operacji
na liczbach całkowitych również imponująca dzięki
zastosowaniu 64-bitowej technologii MMX. Główne
zastosowanie to grafika, a tę łatwo przetwarzać
wektorowo. Stąd jest to (było) doskonałe narzędzie do
gier.
Komputery wektorowe
Wektorowość jako jeden ze sposobów zwiększenia mocy obliczeniowej
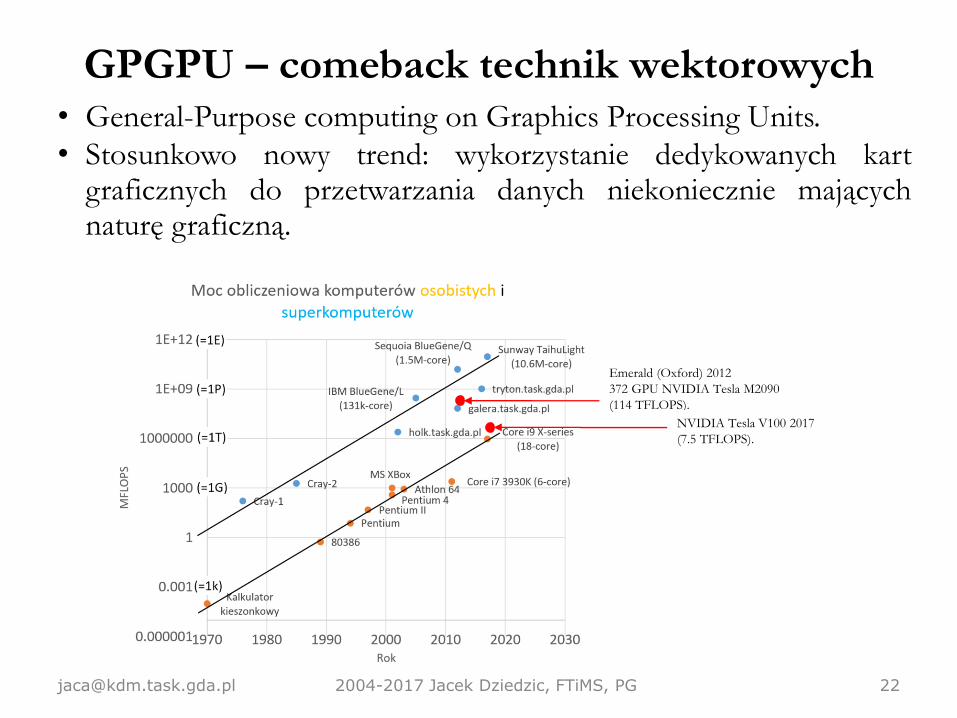
GPGPU – comeback technik wektorowych
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 22
• General-Purpose computing on Graphics Processing Units.
• Stosunkowo nowy trend: wykorzystanie dedykowanych kartgraficznych do przetwarzania danych niekoniecznie mającychnaturę graficzną.
Emerald (Oxford) 2012
372 GPU NVIDIA Tesla M2090
(114 TFLOPS).
NVIDIA Tesla V100 2017
(7.5 TFLOPS).
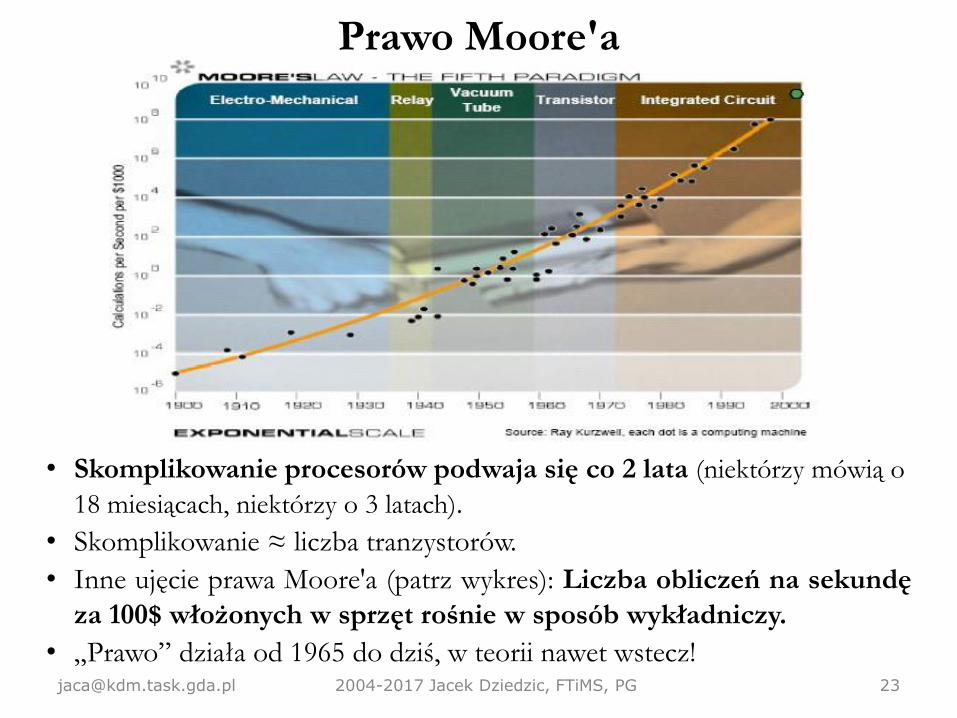
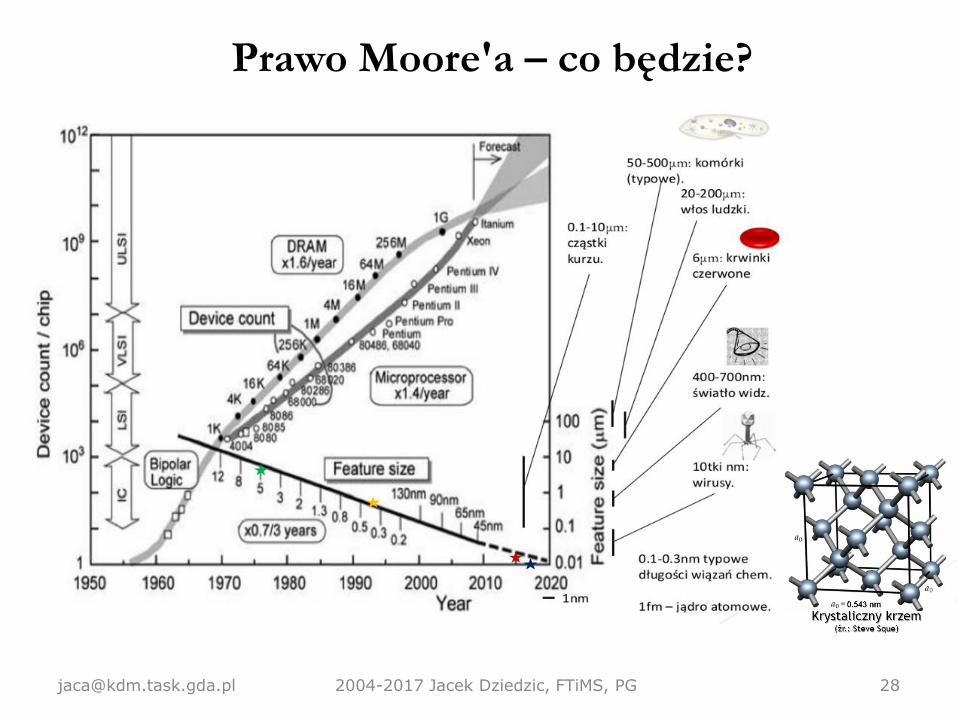
Prawo Moore'a
• Skomplikowanie procesorów podwaja się co 2 lata (niektórzy mówią o
18 miesiącach, niektórzy o 3 latach).
• Skomplikowanie ≈ liczba tranzystorów.
• Inne ujęcie prawa Moore'a (patrz wykres): Liczba obliczeń na sekundę
za 100$ włożonych w sprzęt rośnie w sposób wykładniczy.
• „Prawo” działa od 1965 do dziś, w teorii nawet [email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 23

Prawo Moore'a – uwagi
• "Niedługo komputery będą tak szybkie, że nie trzeba będzie ich już dalej
przyspieszać" – to nieprawda! Apetyt rośnie w miarę jedzenia. Są
zastosowania komputerów (choćby meteorologia, molekularna chemia
białek, wojsko, kryptografia), w których dostępna moc obliczeniowa
zawsze będzie za mała. Zapotrzebowanie na moc rośnie co najmniej tak
szybko jak możliwości…
• Nie tylko procesor trzeba przyspieszać, także I/O i pamięć. Prędkości
pamięci i dysków nie rosną tak szybko (choć pojemności – tak).
• Przyspieszenia nie osiąga się tylko za pomocą szybszego zegara (dwa inne
mechanizmy już poznaliśmy: potokowanie i wektoryzacja). Ciepło
wydzielane w procesorze drastycznie rośnie z częstotliwością taktowania,
więc dużo szybciej taktowanych procesorów nie da się (na razie?)
zbudować.
• Nie samym sprzętem user żyje: jakość oprogramowania zdecydowanie
nie polepsza się wykładniczo. "Software gets slower faster than hardware gets faster".
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 24
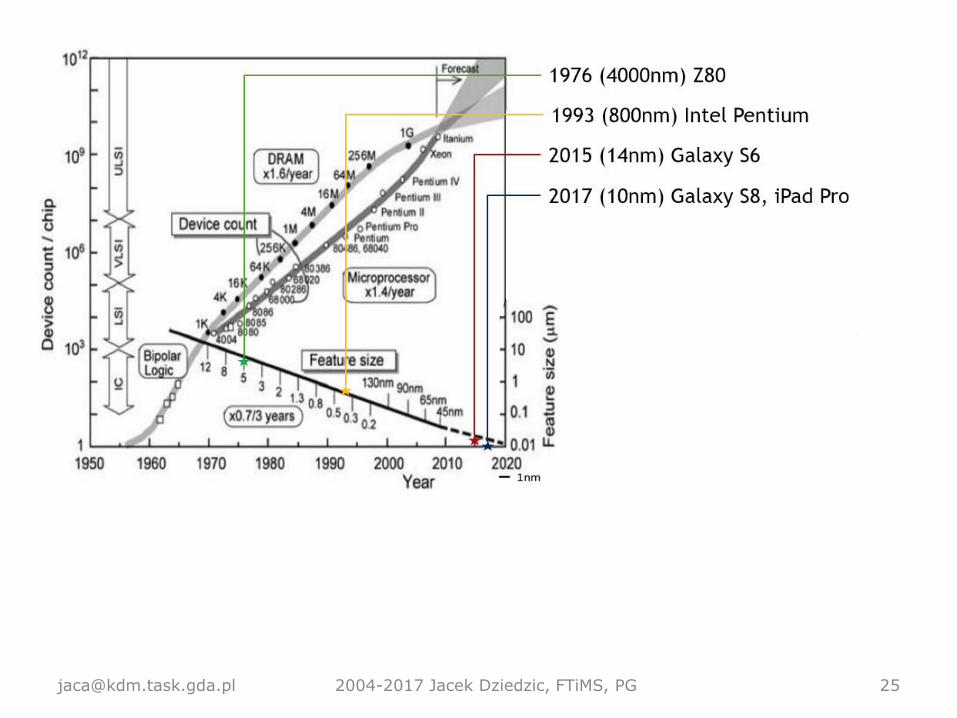
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 25
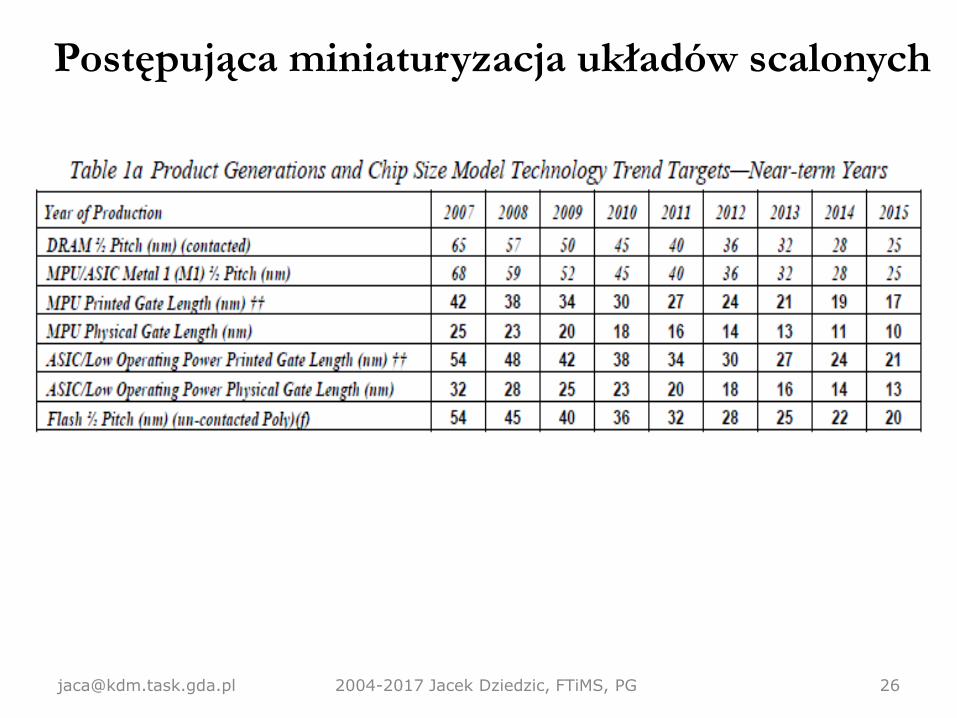
Postępująca miniaturyzacja układów scalonych
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 26
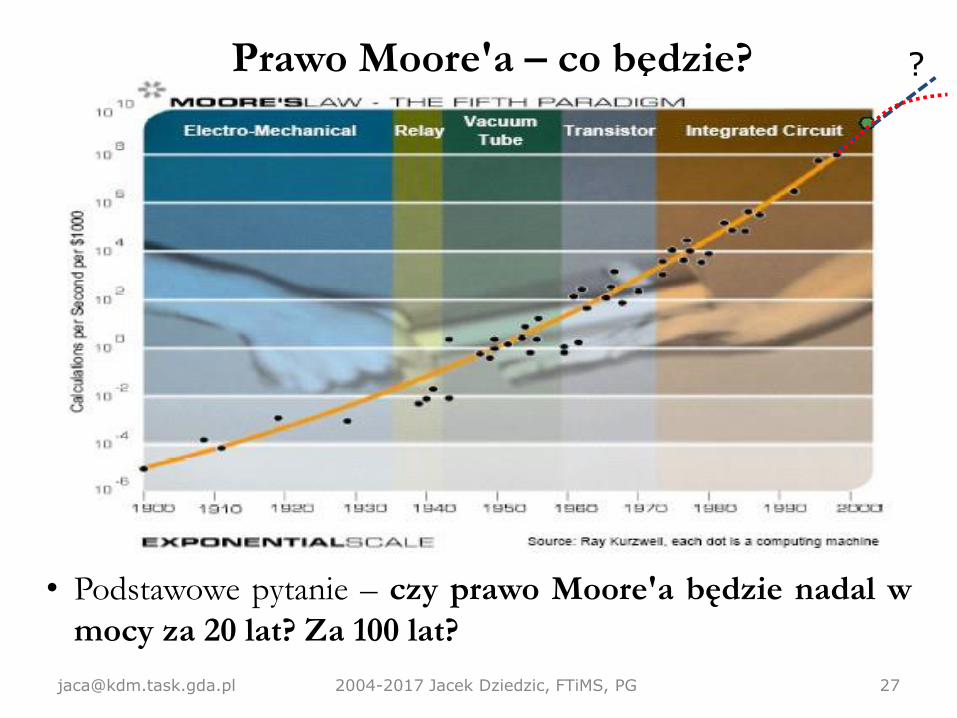
Prawo Moore'a – co będzie?
• Podstawowe pytanie – czy prawo Moore'a będzie nadal w
mocy za 20 lat? Za 100 lat?
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 27
?

Prawo Moore'a – czy będzie nadal w mocy?
• Na NIE: Dochodzimy do granic technologii półprzewodnikowej (teraz jest≈2.3mln tranzystorów na mm2 (Intel Core i7), 2017r: przechodzimy ztechnologii 14 nm na 10 nm). Dalej zmniejszać układy będzie niezwykle trudno(może nawet się da, ale może się to nie opłacać). Technika fotolitograficzna zapomocą której wykonuje się układy jest u granic możliwości. Zmorą stają sięprądy upływu w tak małych tranzystorach, rosną elektryczne pojemnościpasożytnicze oraz wydzielające się ciepło. Efekty kwantowe, ziarnistość materii.
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 29
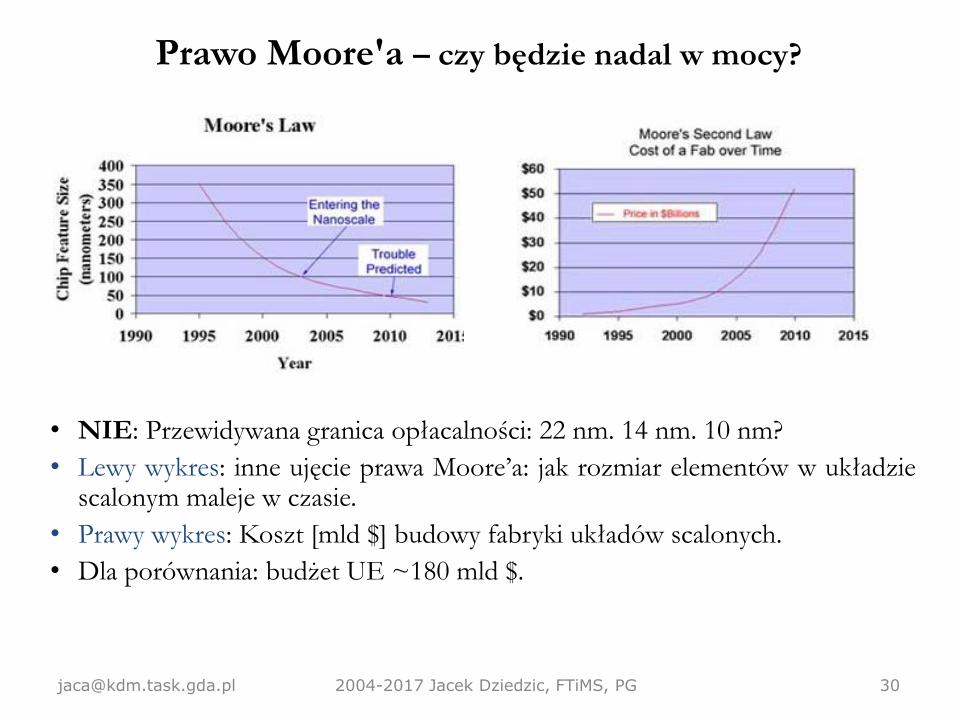
Prawo Moore'a – czy będzie nadal w mocy?
• NIE: Przewidywana granica opłacalności: 22 nm. 14 nm. 10 nm?
• Lewy wykres: inne ujęcie prawa Moore’a: jak rozmiar elementów w układziescalonym maleje w czasie.
• Prawy wykres: Koszt [mld $] budowy fabryki układów scalonych.
• Dla porównania: budżet UE ~180 mld $.
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 30
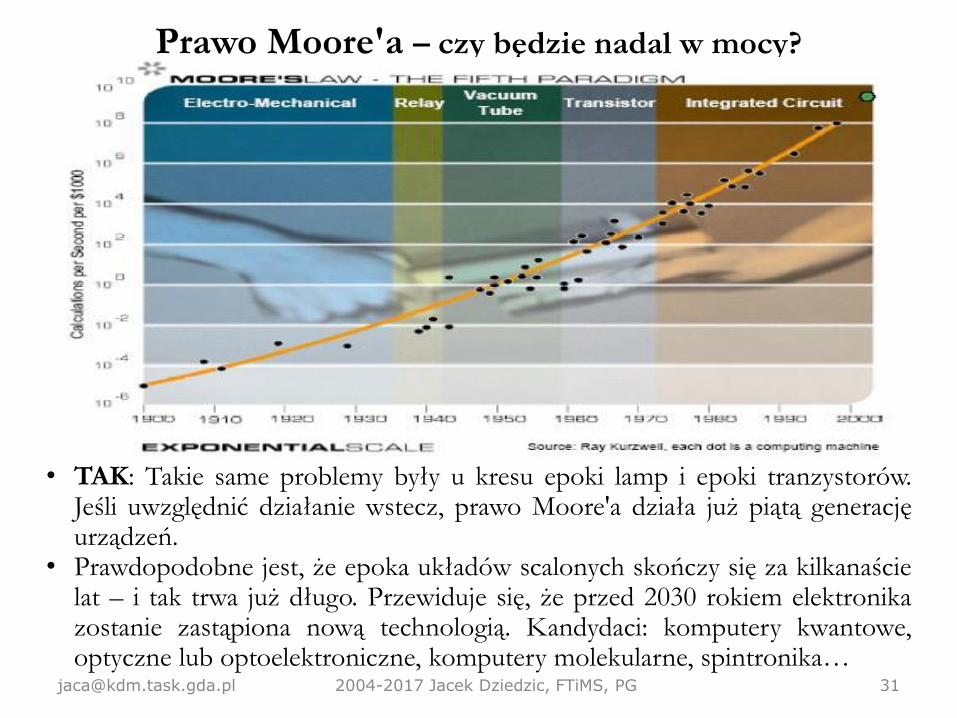
Prawo Moore'a – czy będzie nadal w mocy?
• TAK: Takie same problemy były u kresu epoki lamp i epoki tranzystorów.Jeśli uwzględnić działanie wstecz, prawo Moore'a działa już piątą generacjęurządzeń.
• Prawdopodobne jest, że epoka układów scalonych skończy się za kilkanaścielat – i tak trwa już długo. Przewiduje się, że przed 2030 rokiem elektronikazostanie zastąpiona nową technologią. Kandydaci: komputery kwantowe,optyczne lub optoelektroniczne, komputery molekularne, spintronika…
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 31

Prawo Moore'a – co przez najbliższe 20 lat?
• Wspomniane technologie, które mogłyby zastąpić elektronikę są w
fazie eksperymentalnej, na pewno nie trafią na rynek w ciągu 20 lat.
• Co robić, żeby utrzymać wzrost wydajności? Większość sposobów
na poprawę wydajności już wykorzystaliśmy (potokowanie,
jednoczesne wykonywanie operacji arytmetycznych i I/O, cache,
szybsze taktowanie). Wektoryzacja jest droga.
• Odpowiedzią wydają się komputery równoległe – układy wielu
(na ogół identycznych) jednostek, pracujących wspólnie.
• Łatwiej zrobić sto wolnych komputerów i je połączyć, niźli
jeden sto razy szybszy.
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 32
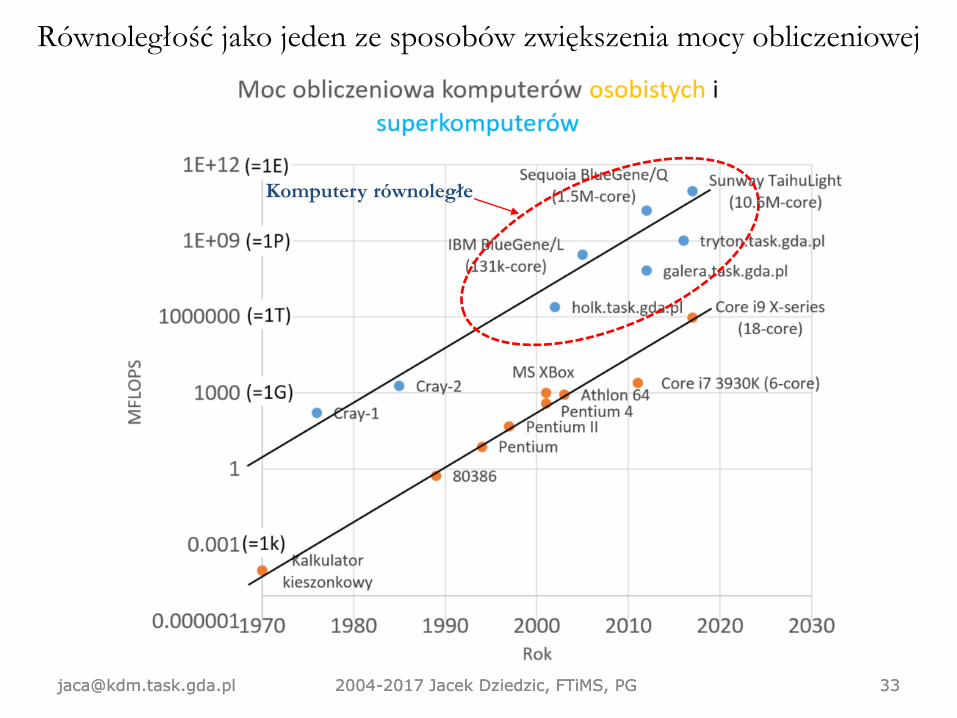
Równoległość jako jeden ze sposobów zwiększenia mocy obliczeniowej
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 33
Komputery równoległe
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 33

Komputer równoległy, system rozproszony
• Równoległy system komputerowy - zbiór co najmniej dwóch
procesorów zdolnych do wspólnego rozwiązywania złożonego
zadania obliczeniowego, na ogół o tej samej architekturze i pod
kontrolą tego samego systemu operacyjnego.
• Rozproszony system komputerowy - zbiór samodzielnych
komputerów połączonych za pomocą sieci, z rozproszonym
oprogramowaniem systemowym, często o różnych
architekturach i systemach operacyjnych.
• Podział nie jest precyzyjny. Typowe systemy równoległe są na
ogół zwarte geograficznie (jeden pokój, budynek) i połączone
bardzo szybkim łączem (np. gigabit ethernet albo i szybszym,
dedykowanym), systemy rozproszone na ogół będą rozległe
geograficznie i połączone wolnym łączem (np. komputery
domowe użytkowników w kilku krajach, połączone
Internetem).
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 34

Komputer równoległy – przykład:
tryton w centrum TASK
• 1607 serwerów = 3214 procesorów = 38568 rdzeni (Intel Xeon E5 @2.3GHz).• Pamięć: 128 lub 256 GB na serwer (DDR4).• Pamięć dyskowa: 240 TB i w trakcie rozszerzania.• To wszystko połączone siecią InfiniBand FDR @56 Gb/s.• Wydajność teoretyczna 1.48 PFLOPS.• +48 akceleratorów(Xeon Phi, NVIDIA Tesla).
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 35
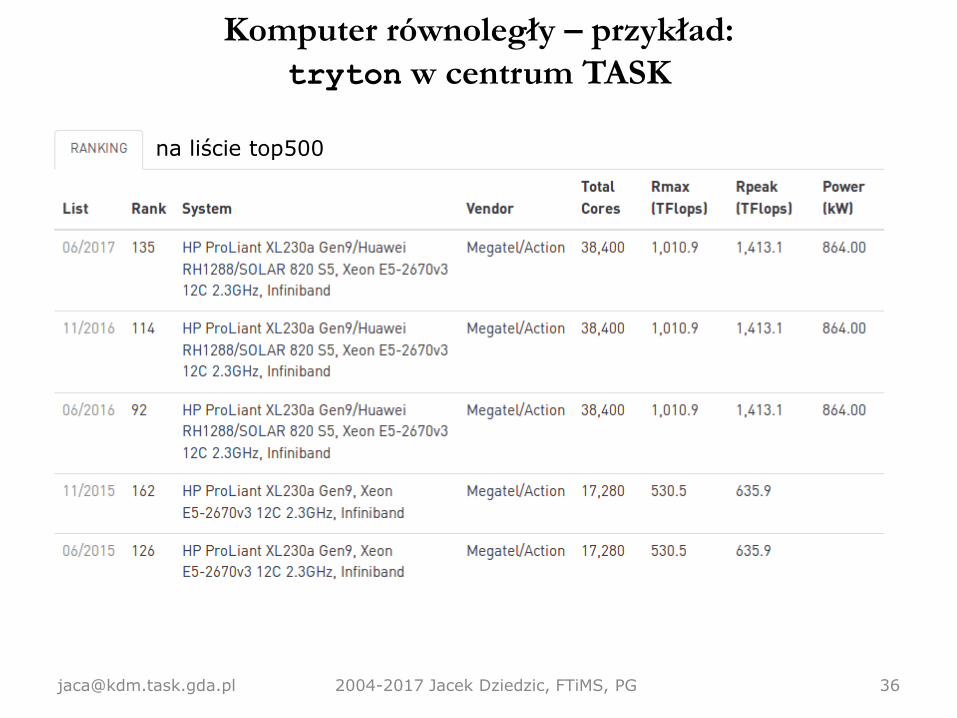
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 36
Komputer równoległy – przykład:
tryton w centrum TASK
na liście top500
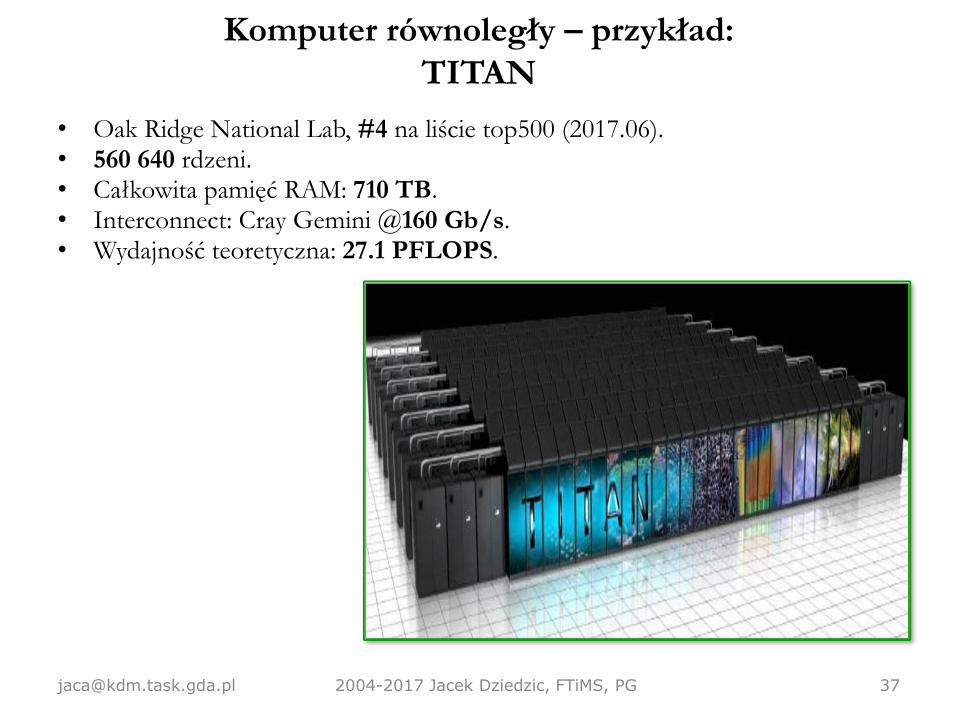
Komputer równoległy – przykład:
TITAN
• Oak Ridge National Lab, #4 na liście top500 (2017.06).• 560 640 rdzeni.• Całkowita pamięć RAM: 710 TB.• Interconnect: Cray Gemini @160 Gb/s.• Wydajność teoretyczna: 27.1 PFLOPS.
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 37
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 38
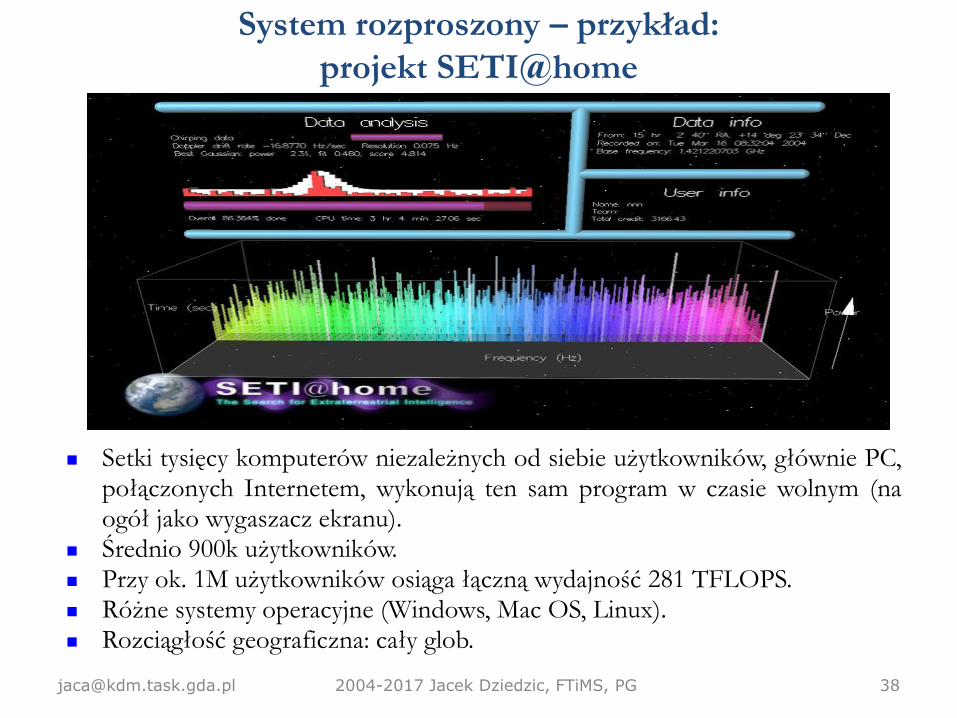
System rozproszony – przykład:
projekt SETI@home
Setki tysięcy komputerów niezależnych od siebie użytkowników, głównie PC,połączonych Internetem, wykonują ten sam program w czasie wolnym (naogół jako wygaszacz ekranu).
Średnio 900k użytkowników. Przy ok. 1M użytkowników osiąga łączną wydajność 281 TFLOPS. Różne systemy operacyjne (Windows, Mac OS, Linux). Rozciągłość geograficzna: cały glob.

Taksonomia Flynna
• Podział komputerów ze względu na sposób przetwarzania
danych.
• Cztery główne sposoby:– SISD (single-instruction, single-data) - w każdym kroku wykonuje jedną
instrukcję na jednej danejtypowy komputer szeregowy,
– SIMD (single-instruction, multiple-data) - w każdym kroku wykonuje jedną
instrukcję, ale na wielu danych jednocześnie typowy komputer
wektorowy,
– MISD (multiple-instruction, single-data) - w każdym kroku wykonuje wiele
instrukcji jednocześnie, ale wszystkie pracują na jednej danej w
praktyce raczej nie spotykane, komputery eksperymentalne,
– MIMD (multiple-instruction, multiple-data) - w każdym kroku wykonuje wiele
instrukcji jednocześnie, na wielu danych typowy komputer
równoległy, ale o tym później.
• Analogia z celnikami.
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 39

Taksonomia Flynna – uwagi• W nowoczesnych komputerach szeregowych można spotkać
rozwiązania podpadające pod SIMD – np. technologia SSE
(streaming SIMD extension) w Pentium-3 i nowszych umożliwia
ograniczone przetwarzanie wektorowe.
• Obecnie tradycyjne komputery SIMD (wektorowe) są na
wymarciu, zastępowane przez komputery równoległe. Spotyka
się natomiast rozwiązania wektorowe na mniejszą skalę, dzięki
temu, że technologia tanieje, np. PowerPC AltiVec bądź moduły
graficzne (znowu XBox). Operacje graficzne doskonale nadają
się do przetwarzania wektorowego (dlaczego?).
• Podobnie: GPGPU, MIC.
• Komputery SIMD przetwarzają dane synchronicznie, wszystkie
procesory w danej chwili wykonują tę samą instrukcję.
• W architekturze MIMD najczęściej wszystkie procesory
wykonują ten sam program, ale ścieżka wykonania jest funkcją
numeru procesora ("każdy jest gdzie indziej w programie").40
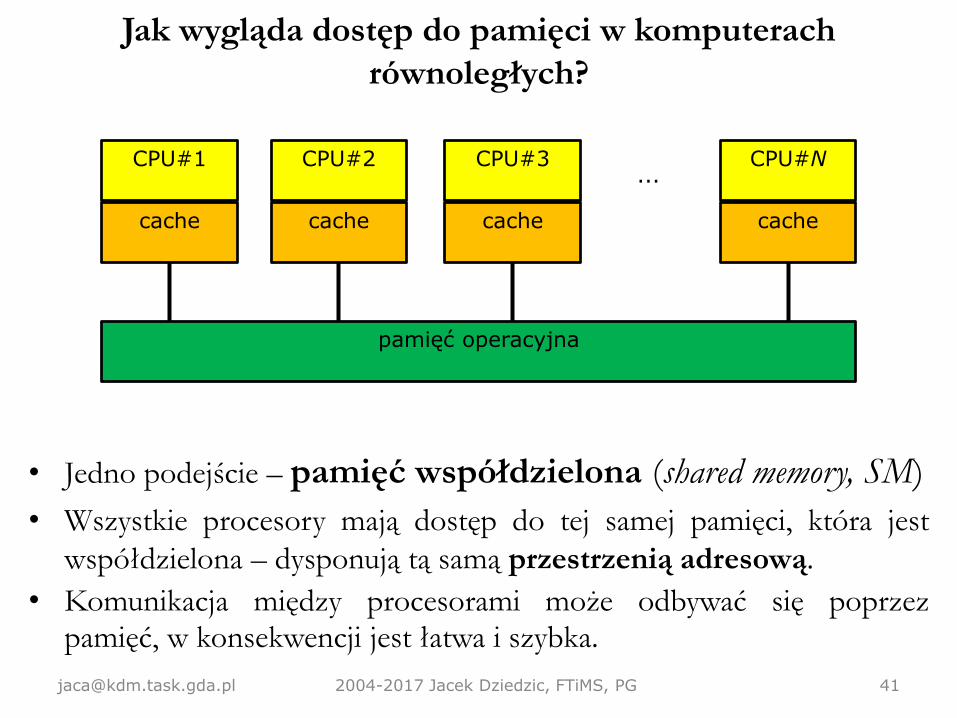
Jak wygląda dostęp do pamięci w komputerach
równoległych?
• Jedno podejście – pamięć współdzielona (shared memory, SM)
• Wszystkie procesory mają dostęp do tej samej pamięci, która jest
współdzielona – dysponują tą samą przestrzenią adresową.
• Komunikacja między procesorami może odbywać się poprzezpamięć, w konsekwencji jest łatwa i szybka.
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 41
CPU#1
cache
pamięć operacyjna
CPU#2
cache
CPU#3
cache
CPU#N
cache
...

Pamięć współdzielona – trudności
• Co jeśli dwa procesory chcą jednocześnie pisać w to samo miejsce pamięci?Co jeśli jeden pisze, a drugi w tej samej chwili czyta? Trudności zsynchronizacją.
• Problemy natury technologicznej – potrzebne specjalne układy (krosownice)pozwalające łączyć jednocześnie wiele procesorów z jedną pamięcią.Trudności te rosną drastycznie dla nproc>8. Dla nproc>20 niewykonalnepraktycznie albo niepraktycznie drogie.
• Przy większej liczbie procesorów pogarsza się też wydajność ze względu nakonieczność synchronizacji. Dostęp do pamięci nie może być prawdziwiejednoczesny, zawsze wszystkie procesory oprócz jednego muszą chwilępoczekać.
• Bardzo wygodne dla programisty, koszmar dla inżyniera projektującegokomputer. Droga.
42
CPU#1
cache
pamięć operacyjna
CPU#2
cache
CPU#3
cache
CPU#N
cache
...
krosownica (crossbar switch)
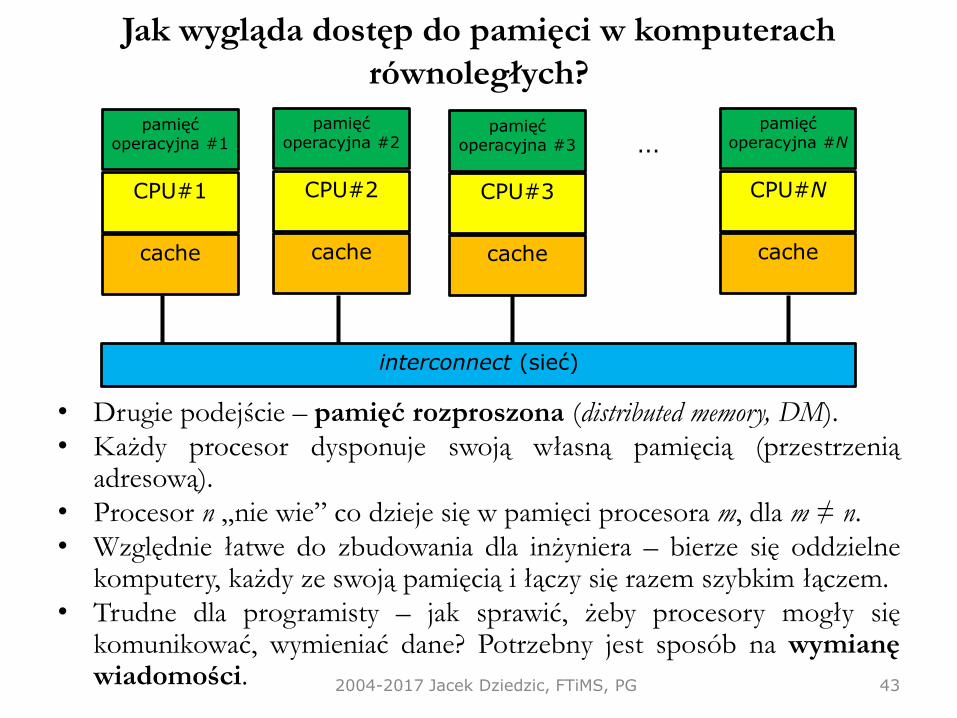
Jak wygląda dostęp do pamięci w komputerach
równoległych?
• Drugie podejście – pamięć rozproszona (distributed memory, DM).
• Każdy procesor dysponuje swoją własną pamięcią (przestrzeniąadresową).
• Procesor n „nie wie” co dzieje się w pamięci procesora m, dla m ≠ n.
• Względnie łatwe do zbudowania dla inżyniera – bierze się oddzielnekomputery, każdy ze swoją pamięcią i łączy się razem szybkim łączem.
• Trudne dla programisty – jak sprawić, żeby procesory mogły siękomunikować, wymieniać dane? Potrzebny jest sposób na wymianęwiadomości. 2004-2017 Jacek Dziedzic, FTiMS, PG 43
CPU#1
cache
pamięć operacyjna #1 ...
interconnect (sieć)
CPU#2
cache
pamięć operacyjna #2
CPU#3
cache
pamięć operacyjna #3
CPU#N
cache
pamięć operacyjna #N
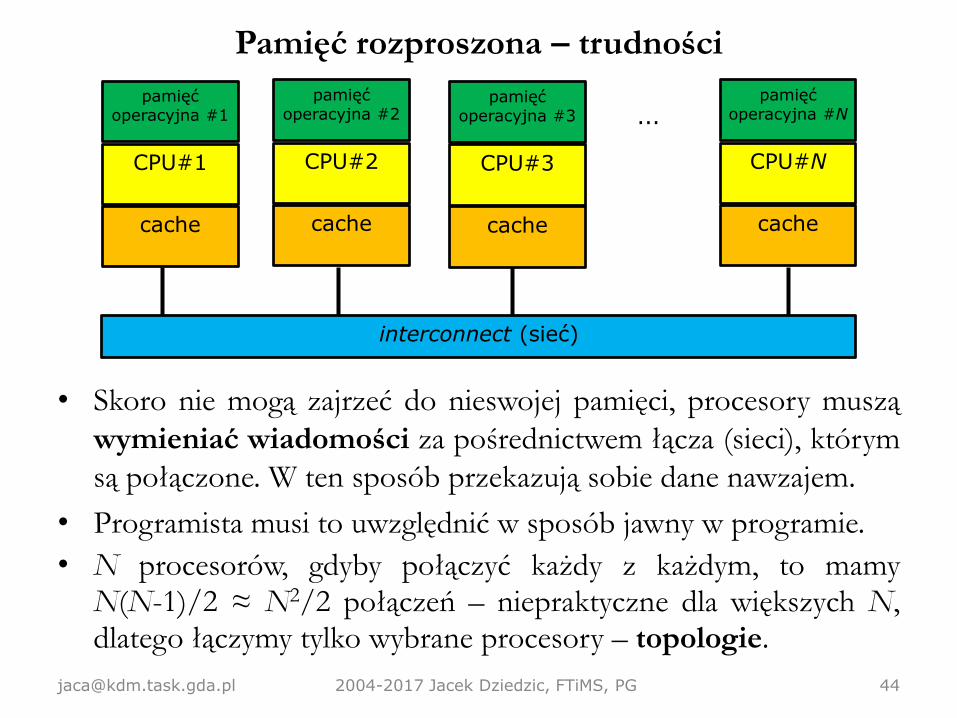
Pamięć rozproszona – trudności
• Skoro nie mogą zajrzeć do nieswojej pamięci, procesory muszą
wymieniać wiadomości za pośrednictwem łącza (sieci), którym
są połączone. W ten sposób przekazują sobie dane nawzajem.
• Programista musi to uwzględnić w sposób jawny w programie.
• N procesorów, gdyby połączyć każdy z każdym, to mamyN(N-1)/2 ≈ N2/2 połączeń – niepraktyczne dla większych N,dlatego łączymy tylko wybrane procesory – topologie.
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 44
CPU#1
cache
pamięć operacyjna #1 ...
interconnect (sieć)
CPU#2
cache
pamięć operacyjna #2
CPU#3
cache
pamięć operacyjna #3
CPU#N
cache
pamięć operacyjna #N
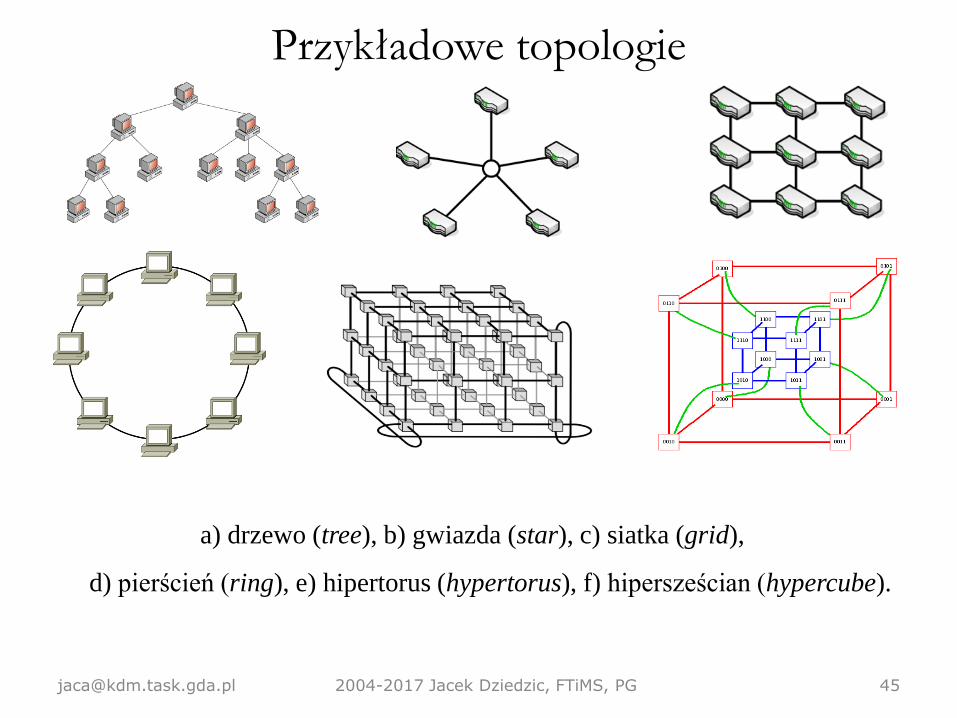
Przykładowe topologie
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 45
a) drzewo (tree), b) gwiazda (star), c) siatka (grid),
d) pierścień (ring), e) hipertorus (hypertorus), f) hipersześcian (hypercube).

Jak wygląda dostęp do pamięci w komputerach
równoległych?
• Podejście pośrednie – rozproszona pamięć współdzielona (distributed shared
memory, DSM).• Próbuje połączyć zalety obydwu modeli pamięci (łatwość budowy DM i łatwość
oprogramowania SM).
• Fizycznie mamy do czynienia z pamięcią rozproszoną, a pamięć współdzieloną emuluje
się, najczęściej na poziomie systemu operacyjnego, jako uogólnienie pamięci wirtualnej.
• Wszystkie procesory widzą jedną logiczną przestrzeń adresową, dostęp do tych jej części,
które są nielokalne ("leżą na innych procesorach") realizowany jest za pomocą sieci, w
sposób niejawny, tj. program nie wie, że transmisja taka ma miejsce.
• Wada: wydajność drastycznie spada, jeśli lokalność jest słaba. Programista musi o tym
pamiętać.
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 46
obrazek © Christian Schaubschläger

Cechy połączeń między węzłami w komputerze równoległym
• Węzły łączymy siecią – jeśli komunikacji między nimi będzie
niemało, to wydajność komputera równoległego będzie zależeć
od parametrów sieci.
• Dwa istotne parametry:
• przepustowość (bandwidth) – prędkość z jaką przesyłane są dane
[MB/s] albo [Mbit/s=Mbps=Mb/s].
• opóźnienie związane z rozpoczęciem komunikacji (latency,
zwłoka) – narzut wymuszony koniecznością przygotowania sieci
do transmisji danych. Najczęściej składa się na niego część stała i
część rosnąca liniowo wraz z rozmiarem danych, czyli
tlat=a∙size + b. Na ogół jest rzędu 1-500 µs. Czy to dużo, czy mało?
Dla człowieka mało: 100µs to 0.001 mgnienia oka, dla maszyny
1GHz 100µs to ≈100000 cykli.
• Oczywiście interesuje nas jak największa przepustowość i jak
najmniejsza zwłoka, ogranicza nas cena.47

Połączenia między węzłami
– szybkie porównanie
• Częściej spotykane są rozwiązania dedykowane (dla komputerów
równoległych), np.
• Avici: 20 Gbps, niezłe latency (≈ 10µs).
• Infiniband: do 300 Gbps, małe latency. (<1 µs).
• Na tryton.task.gda.pl: Infiniband FDR 56 Gbps.
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 48
rozwiązanie maksymalna przepustowość
przeciętna cena 2017r. (2007r.)
modem 0.0003-0.056 Mbps 50 (20) PLN
Ethernet '79-'85 10 Mbps 22 (8) PLN karta
Fast Ethernet '95 100 Mbps 22 (20) PLN karta35-150 (30-250) PLN switch
Gigabit Ethernet '98(latency ~ 50 µs)
1 000 Mbps 40-100 (50-500) PLN karta60-600 (250-150k) PLN switch
10 Gigabit Ethernet '2002 10 000 Mbps 300-1200 PLN karta700-8k PLN (300k-750k) PLN switch
100 Gigabit Ethernet '2015 100 000 Mbps 3k-300k PLN karta

Przetwarzanie równoległe MIMD-DM
• Tym rodzajem przetwarzania będziemy się zajmować przez większość
semestru.
• Najważniejsze do zapamiętania: taki superkomputer to nie monolit,
tylko zespół oddzielnych jednostek połączonych siecią, a każda z nich
ma swoją, odrębną pamięć.
• "Same z siebie" nie są w stanie pracować wspólnie nad jednym
problemem, to programista musi zadbać o rozłożenie zadania
obliczeniowego na poszczególne węzły ( dekompozycja problemu).
• "Jeden robotnik potrzebuje 10 minut na wykopanie otworu pod znak drogowy, więc
600 robotników zrobi to w sekundę" to ta sama pomyłka co "Komputer
szeregowy potrzebuje roku na wykonanie obliczenia, więc komputer równoległy o
365 procesorach wykona je w jeden dzień".
• Program musi być napisany w sposób uwzględniający
równoległość, w ostateczności trzeba przerobić (zrównoleglić) gotowy
program szeregowy.
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 49

Przetwarzanie równoległe MIMD-DM vs MIMD-SM
• Czasami w pisaniu programu równoległego może pomóc
kompilator. Istnieją kompilatory zrównoleglające (np. HPF –
High Performance Fortran, Intel C++ compiler, kompilatory
PGI), które potrafią same zrównoleglić najprostsze konstrukcje
(np. trywialne pętle), a z pomocą człowieka (specjalne dyrektywy
dodawane w kodzie) są w stanie zrównoleglić konstrukcje
średnio-skomplikowane.
#pragma omp parallel for
for (i=0; i < numPixels; i++) {
pGrayScaleBitmap[i] = (unsigned BYTE)
pRGBBitmap[i].red * 0.299 +
pRGBBitmap[i].green * 0.587 +
pRGBBitmap[i].blue * 0.114);
}
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 50
Specjalna dyrektywa kompilatora dodana przed
pętlą instruuje go, aby rozdzielił iteracje pętli
między wiele wątków. Jeśli pętla jest odpo-
wiednio prosta (z góry znana liczba iteracji, brak
zależności obiegu n od obiegu n-1, etc.),
kompilator automatycznie wystartuje dodat-
kowe wątki, rozdzieli im pracę, zbierze wyniki
po czym pouusuwa wątki. Przykład nie ilustruje
programowania równoległego MIMD-DM,
tylko MIMD-SM – taki podział jest ograniczony
do procesorów na jednej maszynie (brak
komunikacji po sieci, a pamięć współdzielona).
OpenMP (MIMD-SM)

Fragment programu korzystającego z kompilatora
zrównoleglającego (HPF)
PROGRAM main
IMPLICIT NONE
INTEGER N
PARAMETER (N=1000)
INTEGER i, procnum(N), procsum(N), sum1, sum2
!HPF$ DISTRIBUTE PROCNUM(BLOCK)
!HPF$ ALIGN PROCSUM(I) WITH PROCNUM(I)
FORALL (i = 1:N) procnum(i) = i
sum1 = SUM(procnum)
PRINT *, 'Sum using global reduction is ', sum1
procsum = 0
DO i = 1, N
procnum = CSHIFT(procnum,1)
procsum = procsum + procnum
END DO
sum2 = procsum(1)
PRINT *, 'Sum using local shifts is ', sum2
FORALL (i = 1:N)
procnum(i) = procsum(i) - procsum(1)
END FORALL
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 51
Dodatkowe dyrektywy i rozszerzenia języka
służą do realizacji równoległości.
To też podejście MIMD-SM.

Dekompozycja problemu
• Zdolności kompilatora do "auto-zrównoleglania" są
ograniczone, człowiek wciąż potrafi zrobić to lepiej.
• Na ogół, w poważnych zastosowaniach, musimy sami
rozdzielić zadanie obliczeniowe tak, aby nadawało się do
przetwarzania równoległego. Proces ten nazywa się
dekompozycją problemu.
• Poznamy następujące sposoby dekompozycji:– dekompozycja trywialna,
– dekompozycja funkcjonalna,
– dekompozycja danych:• geometryczna,
• rozproszona przestrzenna (ssd),
• farma zadań (task farm).
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 52

Dekompozycja trywialna
• Występuje, gdy da się podzielić dane na niezależne od siebie
części, z których każdą da się potraktować tym samym
algorytmem.
• Inna nazwa: embarassingly parallel problem, czyli "zagadnienie
żenująco proste do zrównoleglenia".
• Każdy procesor dostaje porcję danych do przetworzenia i zajmuje
się nią. Brak zależności → brak komunikacji (co najwyżej
rozesłanie danych na początku i zebranie wyników na końcu).
• Przykład: zwiększanie jasności bitmapy 1000x1000.
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 53
1000
1000procesor #1
procesor #3
procesor #2
procesor #4
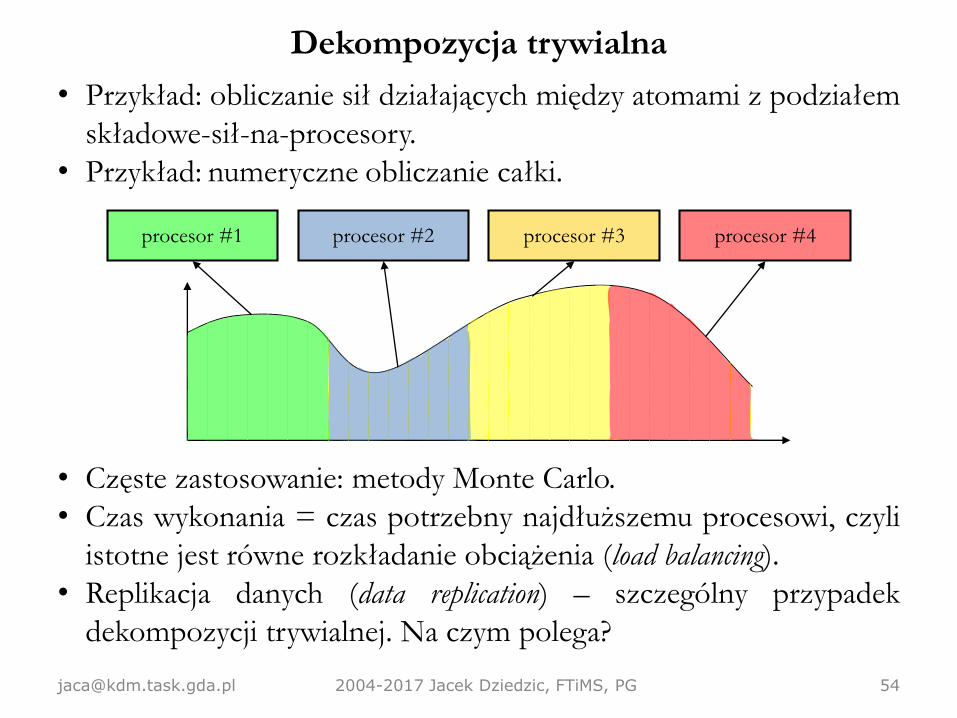
Dekompozycja trywialna
• Przykład: obliczanie sił działających między atomami z podziałem
składowe-sił-na-procesory.
• Przykład: numeryczne obliczanie całki.
• Częste zastosowanie: metody Monte Carlo.
• Czas wykonania = czas potrzebny najdłuższemu procesowi, czyli
istotne jest równe rozkładanie obciążenia (load balancing).
• Replikacja danych (data replication) – szczególny przypadek
dekompozycji trywialnej. Na czym polega?
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 54
procesor #1 procesor #3procesor #2 procesor #4

Dekompozycja funkcjonalna
• Nie dzielimy danych, tylko algorytm.
• Dzielimy zadanie na niezależne sekcje, każdy procesor zajmuje się
jedną sekcją, wyniki z sekcji n idą do sekcji n +1, a sekcja n może
zajmować się kolejnymi danymi.
• Przetwarzanie taśmowe (pipelining), bo dane płyną wzdłuż taśmy –
podejście analogiczne do potokowania (też pipelining), o którym
mówiliśmy już w kontekście jednego procesora.
• Analogia z fabryką samochodów: jedna sekcja montuje silnik i
bebechy, jedna podwozie, jedna karoserię, jedna klamki.
Oczywiście nie da się zamontować klamek przed zamontowaniem
karoserii, ale gdy montujemy klamki w samochodzie k, można
zakładać karoserię w samochodzie k+1, podwozie w
samochodzie k+2, a silnik w samochodzie k+3.
• Przestoje na początku i na końcu (dlaczego?), wobec czego musi
być dużo danych, żeby było to wydajne.
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 55

Dekompozycja funkcjonalna c.d.
• Nie da się bardziej zrównoleglić niż
wynosi liczba sekcji.
• Ale można bardziej pracochłonne
sekcje podzielić na podsekcje albo
przydzielić kilka procesorów do jednej
sekcji (jeśli np. samą sekcję można
zdekomponować trywialnie – w
analogii samochodowej: czterech
pracowników może jednocześnie
zakładać klamki, każdy po jednej).
• Równomierny podział obciążenia
jeszcze istotniejszy – jeśli jedna sekcja
zwleka, wszystkie następne muszą na
nią czekać.
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 56
źródło: pcc.qub.ac.uk

Dekompozycja danych
• Dzielimy dane na procesory, podobnie jak w dekompozycji
trywialnej, ale tym razem mogą występować zależności między
danymi przypisanymi różnym procesorom.
• Zależności potrzeba komunikacji.
• Bardzo często występująca dekompozycja.
• Trzy często spotykane odmiany: dekompozycja danych-
geometryczna, rozproszona dekompozycja przestrzenna
(scattered spatial decomposition, ssd) i farma zadań (task farm).
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 57
#1 #2
#3 #4
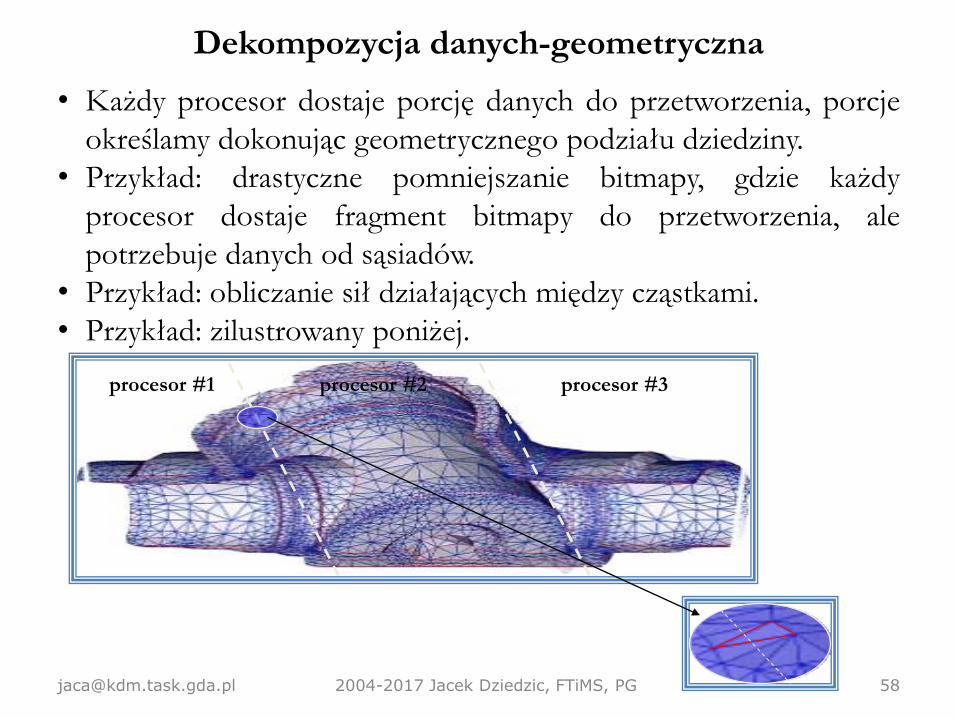
Dekompozycja danych-geometryczna
• Każdy procesor dostaje porcję danych do przetworzenia, porcje
określamy dokonując geometrycznego podziału dziedziny.
• Przykład: drastyczne pomniejszanie bitmapy, gdzie każdy
procesor dostaje fragment bitmapy do przetworzenia, ale
potrzebuje danych od sąsiadów.
• Przykład: obliczanie sił działających między cząstkami.
• Przykład: zilustrowany poniżej.
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 58
procesor #1 procesor #2 procesor #3

Dekompozycja danych-geometryczna
• Mogą występować problemy z bilansowaniem pracy – trzeba
pilnować, żeby żaden procesor nie został bez pracy (np. gdyby
cząstki zebrały się w jednym rogu pudła).
• Pracę można bilansować dynamicznie, np. przesuwając granice
podziału na procesory. Wiąże się to jednak ze skomplikowaniem
algorytmu (np. przenoszenie cząstek z jednego procesora na
drugi, gdy granica się przesuwa) oraz…
• … trzeba pilnować, żeby komunikacja nie zdominowała czasu
przetwarzania – aby wszystko szło sprawnie obliczenia powinny
być prawie-lokalne – przyda się dobra topologia.
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 59
#1 #2
#3 #4
#1 #2
#3 #4
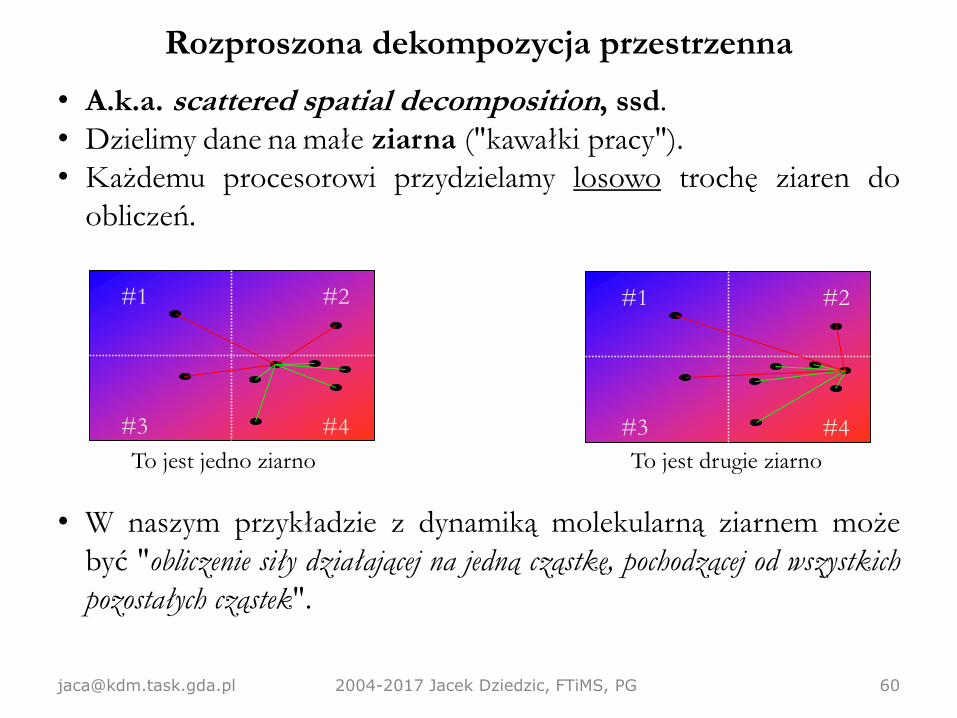
Rozproszona dekompozycja przestrzenna
• A.k.a. scattered spatial decomposition, ssd.
• Dzielimy dane na małe ziarna ("kawałki pracy").
• Każdemu procesorowi przydzielamy losowo trochę ziaren do
obliczeń.
• W naszym przykładzie z dynamiką molekularną ziarnem może
być "obliczenie siły działającej na jedną cząstkę, pochodzącej od wszystkich
pozostałych cząstek".
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 60
#1 #2
#3 #4
#1 #2
#3 #4
To jest jedno ziarno To jest drugie ziarno

Rozproszona dekompozycja przestrzenna
• Istotna sprawa: ziarna muszą być bardzo małe, tak aby każdy
procesor dostał wiele ziaren. Gdy tak jest, Centralne Twierdzenie
Graniczne gwarantuje nam, prawie-doskonały rozkład pracy.
• Niestety, kosztem jest potencjalnie mała lokalność obliczeń
(bo nie przydzielamy procesorom zwartych "stref danych", tylko
wiele drobnych, rozproszonych kawałeczków).
• Przykład: (na granicy dekompozycji trywialnej) rozjaśnianie dużej
bitmapy bloczkami 32x32 px.
• Przykład (poprzedni slajd): obliczanie sił działających na cząstki z
przypisaniem losowe-cząstki-do-procesorów.
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 61
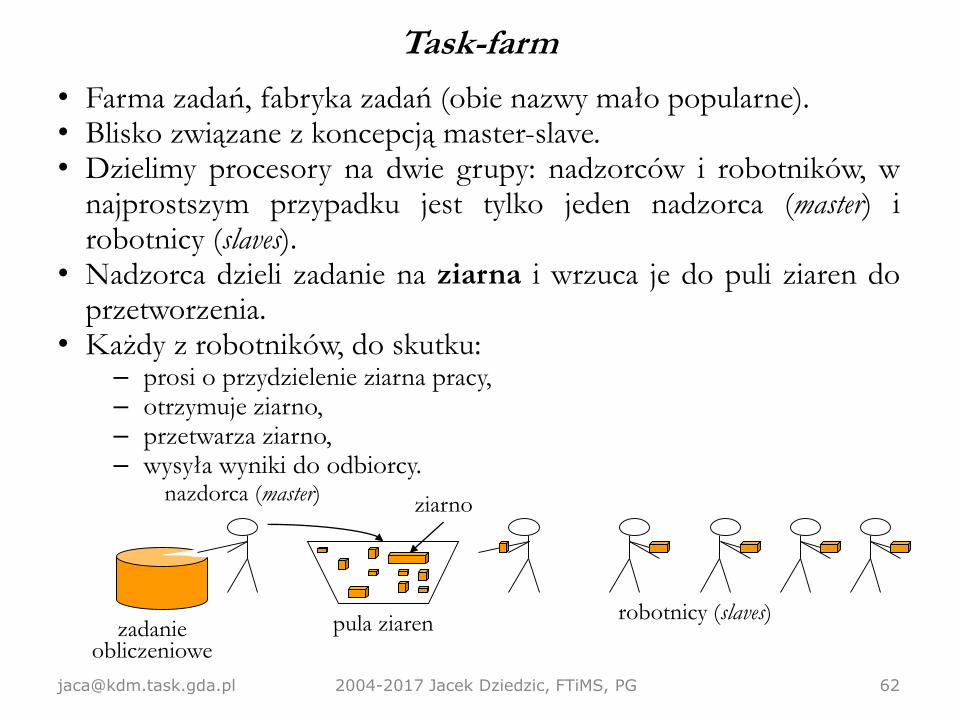
Task-farm
• Farma zadań, fabryka zadań (obie nazwy mało popularne).• Blisko związane z koncepcją master-slave.• Dzielimy procesory na dwie grupy: nadzorców i robotników, w
najprostszym przypadku jest tylko jeden nadzorca (master) irobotnicy (slaves).
• Nadzorca dzieli zadanie na ziarna i wrzuca je do puli ziaren doprzetworzenia.
• Każdy z robotników, do skutku:– prosi o przydzielenie ziarna pracy,– otrzymuje ziarno,– przetwarza ziarno,– wysyła wyniki do odbiorcy.
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 62
zadanie obliczeniowe
pula ziarenrobotnicy (slaves)
nazdorca (master)ziarno

Task-farm c.d.
• Odbiorca składa wyniki w całość. Odbiorcą często jest nadzorca,
żeby nie nudził się tak drastycznie.
• Znowu CTG gwarantuje nam świetny rozkład pracy, jeśli ziarna
są drobne, nawet lepszy niż w ssd, bo obciążenia bilansują się
dynamicznie (kto skończył wcześniej, dostaje nową pracę).
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 63

Task-farm c.d.
• Analogia: hurtowa pracownia lutnicza, gdzie każdy z
pracowników potrafi wykonywać każdą z czynności (przygotować
deskę, założyć struny, założyć klucze, ustawić menzurę, nastroić).
Jeśli jest dużo gitar do przygotowania, to każdy z pracowników
przychodzi do szefa po coś do zrobienia, a jak skończy,
przychodzi po nowe zadanie.
• Przestojów nie ma w ogóle, najwyżej na końcu pracy, gdy brakuje
ziaren.
• Niestety nie może być zależności między ziarnami – wtedy
robotnicy musieliby się komunikować.
• Przykład: rozjaśnianie bitmapy bloczkami 32x32.
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 64

Dekompozycje – podsumowanie
• Najważniejszy morał – na nas, jako programistach, spoczywa
problem takiego postawienia problemu (zdekomponowania
zadania), żeby nadawał się do pracy na komputerze równoległym.
• Jest wiele sposobów na dekompozycję – poznaliśmy najbardziej
podstawowe, często różne dekompozycje łączy się.
W domu:• Przeczytać: http://tiny.pl/qs49, punkty 1-3.
• Przeczytać: http://tiny.pl/qspc.
• Przeczytać pobieżnie: http://tiny.pl/qs4r.
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 65

Przyspieszenie, efektywność
• Przyspieszenie (speed-up), S(N), mówi nam ile razy szybciej program
równoległy działa na N rdzeniach w porównaniu z wersją szeregową.
• Oczywiście przyspieszenie rośnie wraz z N (poza przypadkami
patologicznymi).
• Wgląd w to, jak dobrze zrównoleglony jest program daje efektywność
(efficiency), E(N).
• Zatem efektywność jest "przyspieszeniem odniesionym do liczbyprocesorów, na których to przyspieszenie uzyskano".
• Zobaczmy jak duże przyspieszenie możemy osiągnąć w praktyce. NiechF oznacza procent zrównoleglenia naszego programu (w sensie czasudziałania). Przykładowo, jeśli 95% nakładu programu udało sięzrównoleglić, a 5% pozostało szeregowe, to F=0.95.
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 66

Przyspieszenie, efektywność. Prawo Amdahla
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 67
Zatem nasz przykładowy program nigdy nie osiągnieprzyspieszenia lepszego niż 20-krotne, bez względu na to ilomaprocesorami dysponujemy! Powodem tego jest to 5% programu,które pozostało szeregowe.
Zatem przyspieszenie:
Czas pracy programu po zrównolegleniu:
Gdy mamy dowolnie dużo procesorów (tj. N dąży do
nieskończoności):

Przyspieszenie, efektywność. Prawo Amdahla
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 68
Jeśli można zrównoleglić F-tą część programu, pozostawiając
(1-F)-tą część szeregową, to maksymalne przyspieszenie
wyniesie 1/(1-F) (niezależnie od liczby procesorów).
Prawo Amdahla (Amdahl's Law)

Krytyka prawa Amdahla
• Nie wszyscy wierzą w prawo Amdahla!
• Ważny argument przeciwko temu prawu:
• Prawo Amdahla po cichu zakłada, że ułamek zrównoleglenia, F,
nie zależy od N i jest stały. W rzeczywistości często jest tak, że
im więcej procesorów, tym większą część programu można
zrównoleglić, czyli F rośnie z N.
• Na ogół jest tak, że słabo zrównoleglonych zadań nie
uruchamiamy na dużej liczbie procesorów – na ogromne
maszyny trafiają tylko dobrze zrównoleglone (massively parallel)
programy.
• Podsumowując krytykę: najczęściej ułamek zrównoleglenia, F,
zależy od rozmiaru problemu, x, tj. F rośnie wraz z x ("duże
problemy lepiej się zrównoleglają"). Na wielkich komputerach
rozwiązujemy wielkie problemy, zatem x rośnie z N. Zatem F też
rośnie z N, a nie jest stałe, jak postuluje Amdahl.
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 69

Prawo Gustafsona
• Formalnie ujmuje krytykę prawa Amdahla.• Przyjmijmy czas wykonania programu zrównoleglonego za
jednostkowy i rozłóżmy go na dwie części – szeregową, a,i równoległą, b,:
• Obie wartości: a, b zależą od rozmiaru problemu (x).• Na komputerze szeregowym ten sam program będzie się
wykonywał w ciągu
• A zatem przyspieszenie:
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 70
a bproc. 1proc. 2proc. 3proc. 4
a b b b…

Prawo Gustafsona
• Wiemy, że przyspieszenie dane jest przez:
• Zakładamy, że wraz ze wzrostem rozmiaru problemu, x, część
szeregowa, a(x) maleje – zatem przyspieszenie S dąży do N
– tego właśnie chcemy – żeby program przyspieszał liniowo wraz
z liczbą procesorów!
• Dużo bardziej optymistyczny pogląd w porównaniu z prawem
Amdahla.
• Analogia samochodowa (za wikipedią):
– prawo Amdahla: jeśli przejechałeś połowę drogi z prędkością 40 km/h, to
choćbyś jechał drugą połowę nieskończenie szybko, nie osiągniesz lepszej
średniej prędkości niż 80 km/h.
– prawo Gustafsona: jeśli jechałeś przez godzinę z prędkością 40 km/h, to
możesz osiągnąć nawet i średnią prędkość 100 km/h, jeśli odpowiednio
długo będziesz jechał 120 km/[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 71

Inny czynnik, który daje nadzieję,
mimo prawa Amdahla
• Załóżmy, że stosujemy dekompozycję danych. Wówczas, wraz ze
wzrostem liczby procesorów maleje ilość danych przypadających
na procesor. Często zdarza się, że dla pewnej odpowiednio dużej
liczby procesorów N, całe dane zaczynają mieścić się w pamięci
cache procesora, co skutkuje dramatycznym wzrostem
wydajności.
• Zjawisko to może skutkować przyspieszeniem superliniowym
i, w konsekwencji, efektywnością E(N)>1, która jest –
teoretycznie – niemożliwa do osiągnięcia.
podział danych
przy 1 procesorzepodział danych
przy 4 procesorachpodział danych
przy 16 procesorach
rozmiar
cache L2
nagły skok
wydajności
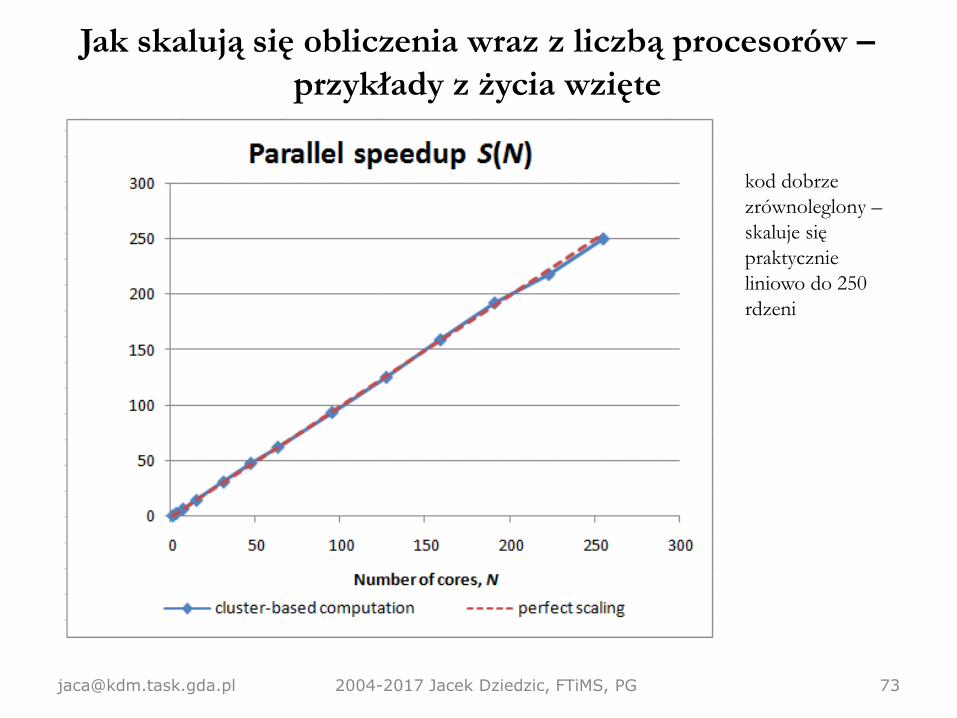
Jak skalują się obliczenia wraz z liczbą procesorów –
przykłady z życia wzięte
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 73
kod dobrze
zrównoleglony –
skaluje się
praktycznie
liniowo do 250
rdzeni
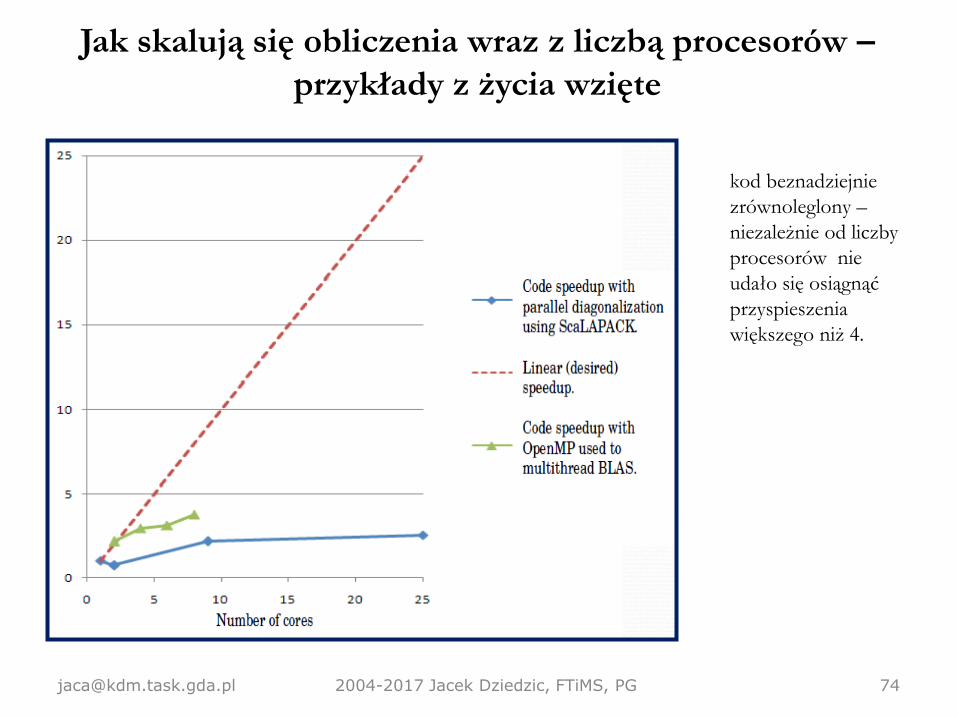
Jak skalują się obliczenia wraz z liczbą procesorów –
przykłady z życia wzięte
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 74
kod beznadziejnie
zrównoleglony –
niezależnie od liczby
procesorów nie
udało się osiągnąć
przyspieszenia
większego niż 4.
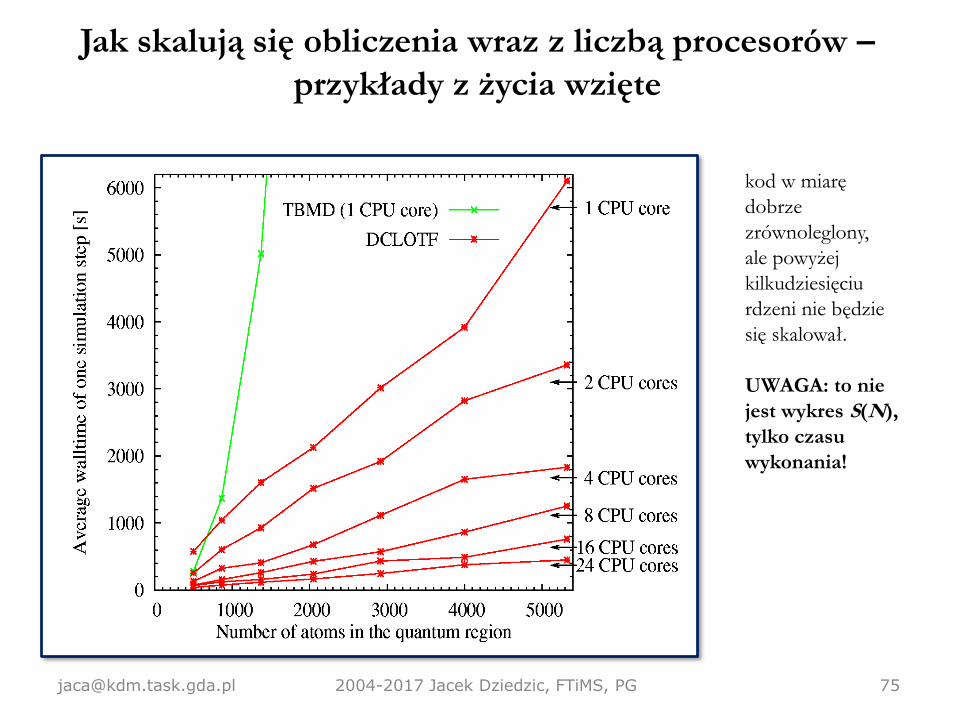
Jak skalują się obliczenia wraz z liczbą procesorów –
przykłady z życia wzięte
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 75
kod w miarę
dobrze
zrównoleglony,
ale powyżej
kilkudziesięciu
rdzeni nie będzie
się skalował.
UWAGA: to nie
jest wykres S(N),
tylko czasu
wykonania!
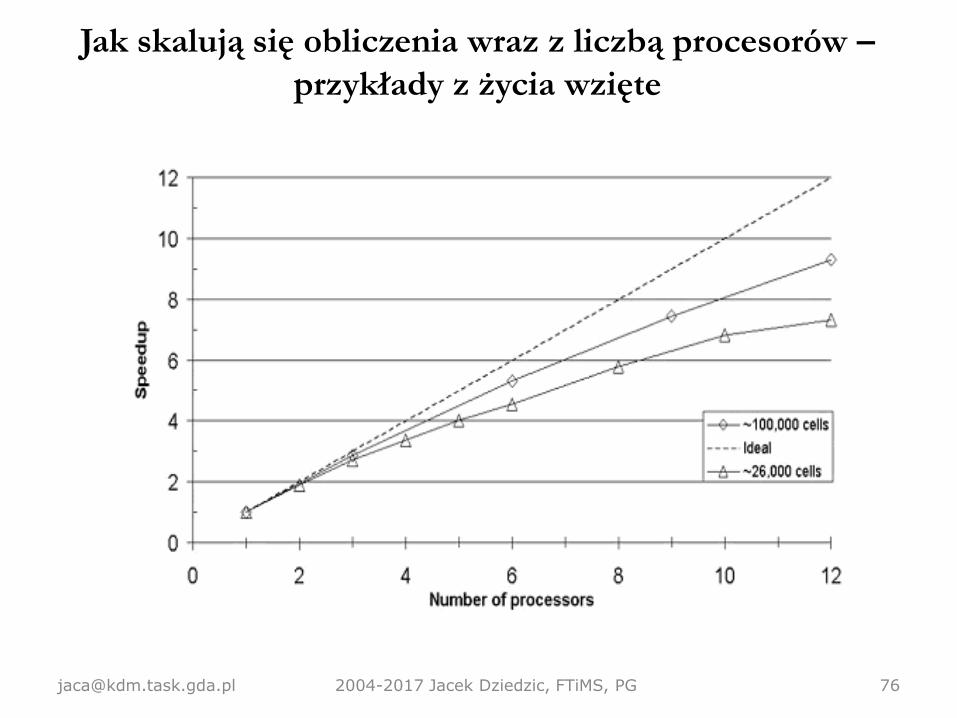
Jak skalują się obliczenia wraz z liczbą procesorów –
przykłady z życia wzięte
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 76
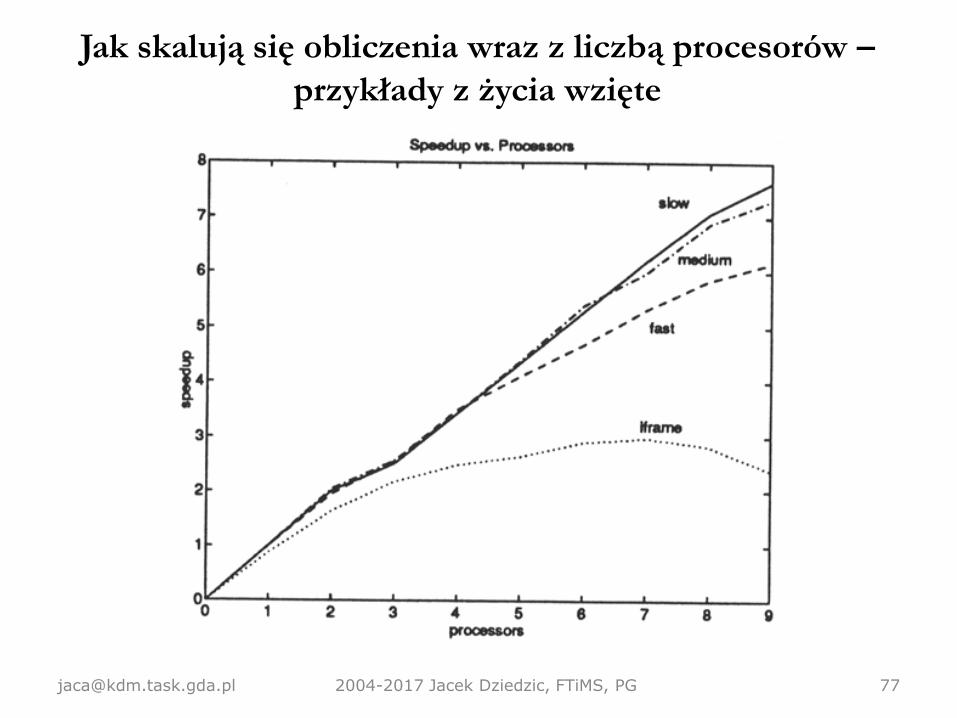
Jak skalują się obliczenia wraz z liczbą procesorów –
przykłady z życia wzięte
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 77
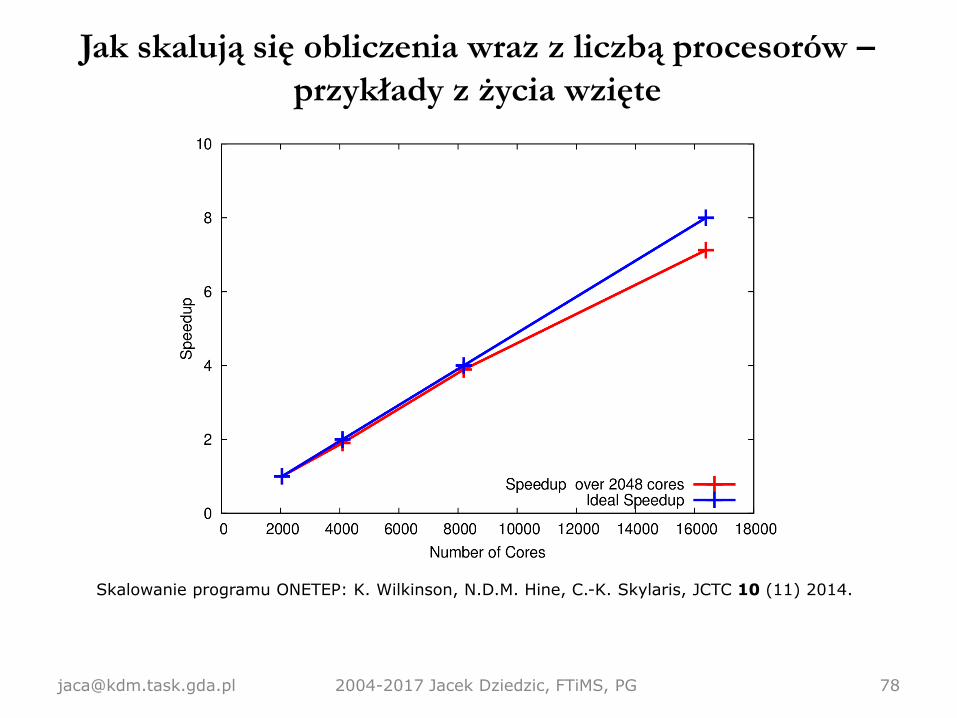
Jak skalują się obliczenia wraz z liczbą procesorów –
przykłady z życia wzięte
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 78
Skalowanie programu ONETEP: K. Wilkinson, N.D.M. Hine, C.-K. Skylaris, JCTC 10 (11) 2014.
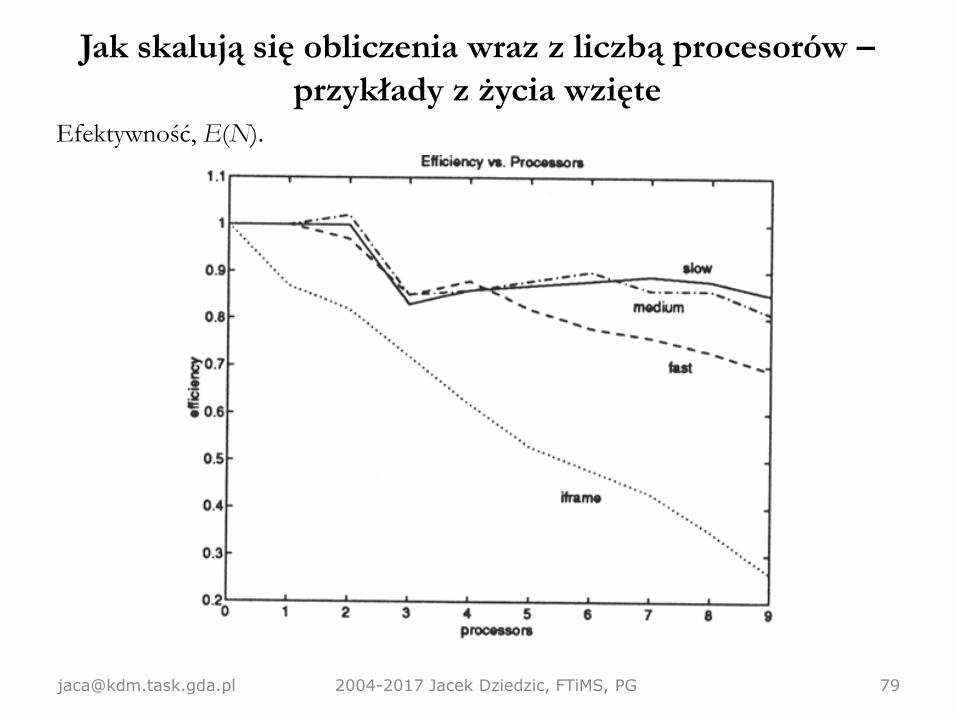
Jak skalują się obliczenia wraz z liczbą procesorów –
przykłady z życia wzięteEfektywność, E(N).
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 79

Metryka Karpa-Flatta
• Inna miara zrównoleglenia.
• Opisuje "eksperymentalnie wyznaczony ułamek szeregowy", czyli jest
sposobem na empiryczne wyznaczenie (1-F).
• Dana jest wzorem:
dla N>1.
• Oczywiście im mniejsze e(N), tym lepiej. Empiryczność metody
polega na tym, że stojące we wzorze przyspieszenie mierzymy,
nie obliczamy.
• Pozwala zdiagnozować wąskie gardło zrównoleglenia na podsta-wie zachowania e(N) wraz ze wzrostem N:– gdy e(N) rośnie: mamy do czynienia z narzutami równoległości
(komunikacja, źle zbilansowana praca).– gdy e(N) pozostaje stałe: spora część programu pozostaje szeregowa, tj. nie
została zrównoleglona.– gdy e(N) maleje: mamy przyspieszenie superliniowe (na ogół: efekty cache).
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 80

MPI – the Message Passing Interface
• Na początku lat '90 popularność komputerów równoległych szybko
rosła. Każdy z producentów proponował swoje rozwiązania
umożliwiające programowanie równoległe.
• Chaos, brak standardu.
• 1993: IBM, Intel, Express, p4 i inni tworzą szkic standardu.• http://www.netlib.org/utk/papers/mpi-book/mpi-book.ps
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 81

MPI – charakterystyka• Kod jest napisany w „zwyczajnym” języku programowania (Fortran 77,
Fortran 90, C, C++); przesyłanie wiadomości jest realizowane poprzezwywołanie odpowiednich procedur lub funkcji.
• Wszystkie zmienne są lokalne dla danego procesora; inny procesor madostęp do ich wartości tylko poprzez wymianę wiadomości.
• Najczęstsze podejście: każdy procesor realizuje ten sam programwykonywalny, jednak występuje podział na procesor (procesory)nadzorujące (master) oraz „robotników” (workers) lub „niewolników”(slaves); realizują one inne fragmenty kodu, niż master.
• if(i_am_master) {
// do what a master does
}
else {
// do what a slave does
}
• Każdy procesor ma własny identyfikator (0, 1, ..., NPROC-1).
• Zatem niby wszystkie procesory ten sam program realizują, ale ścieżkawykonywania jest funkcją numeru procesora.
fragmenty© Adam Liwo
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 82

MPI – jak skonstruowane są wiadomości
• Wiadomość: pakiet danych przemieszczających się między procesorami.
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 83
• Podobnie jak list czy faks, oprócz właściwych przesyłanych danych musiona być opakowana w „kopertę” (zawierać nagłówek) umożliwiający jejdostarczenie do właściwego odbiorcy.
• „Koperta” musi zawierać następujące informacje dla systemu przesyłaniawiadomości:
• Nadawca (procesor wysyłający),
• Typ przesyłanych danych,
• Długość przesyłanych danych (liczba elementów),
• Odbiorca (procesor(y) odbierające),
• Identyfikator („tag”), który pozwala odróżnić wiadomość od innych.
fragmenty© Adam Liwo

MPI – c.d.• Procesory możemy podzielić na grupy, tzw. komunikatory.
• Wiadomości są przesyłane zawsze w obrębie jednego komunikatora – pozwala touniknąć wysyłania wiadomości zbiorczych ("list otwarty" – do wszystkich) doprocesorów, które nie mają ich odczytać.
• Pozwala to na izolację "grup zadaniowych" od innych.
• W prostych przypadkach mamy tylko jeden komunikator zwanyMPI::COMM_WORLD, który grupuje wszystkie dostępne procesory.
Dwa sposoby wysyłania wiadomości:
• Wstrzymujące (blocking send) - nadawca wstrzymuje dalszą akcję do czasupotwierdzenia dotarcia wiadomości (można to porównać do wysyłania faksu lubrozmową telefoniczną). Łatwiejsza do wykonania, ale mniej wydajna.
• Niewstrzymujące (nonblocking send) - nadawca po wysłaniu wiadomości możewykonywać coś innego (obliczenia, I/O), po czym w innym momencie sprawdza,czy wiadomość dotarła (można to porównać do wysłania e-maila). Trudniejsza dowykonania, ale lepsza wydajność.
fragmenty © Adam Liwo
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 84

MPI – jak wygląda wysłanie wiadomości?
• Skoncentrujemy się na C++ – amatorzy Fortrana mogą rzucić okiem do
"MPI Complete Reference".
• Symbole (funkcje, stałe, typy) wprowadzane przez MPI umieszczone są w
przestrzeni nazw MPI.
• Do komunikacji punktowej (wysyła jeden procesor i odbiera jeden procesor)
korzystamy z klasy Comm (reprezentującej komunikator), która daje metody
realizujące komunikację.
• Metoda wysyłająca wiadomość nazywa się Send i ma następujący prototyp:
void MPI::Comm::Send(const void* buf, int count,
const Datatype& datatype,
int dest, int tag);
• Zatem metodę Send wołamy na rzecz konkretnego komunikatora, np:
MPI::COMM_WORLD.Send(...);
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 85

MPI – jak wygląda wysłanie wiadomości?
void MPI::Comm::Send(const void* buf, int count,
const Datatype& datatype, int dest, int tag);
Kolejne parametry reprezentują:buf – wskaźnik do bufora nadawcy (adres w pamięci danych, które
chcemy wysłać),count – liczba elementów, która jest w buforze (na ogół przesyłamy
tablice, nie pojedyncze elementy – trzeba więc powiedzieć ile elementówmamy w tej tablicy),
datatype – stała symboliczna określająca typ danych, które przesyłamy.MPI definiuje kilka stałych, które odpowiadają podstawowym typomdanych, np. MPI::CHAR, MPI::INTEGER, MPI::DOUBLE, etc.
dest – numer procesora-odbiorcy,tag – znacznik wiadomości. Jest to liczba całkowita, za pomocą której
nadawca może dowolnie oznaczyć wiadomość. Pozwala ona naidentyfikację wiadomości po stronie odbiorcy. "Kod kreskowy".
W odróżnieniu od wersji fotranowskiej i od wersji C, wersja C++ nie zwracakodu błędu, w razie niepowodzenia zgłasza wyjątek MPI::Exception.
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 86

MPI – jak wygląda odebranie wiadomości?
void MPI::Comm::Recv(void* buf, int count,
const Datatype& datatype, int source, int tag,
Status& status);
Podobnie, jak przy wysyłaniu wiadomości:buf – wskaźnik bufora odbiorcy, tu trafiają odebrane dane. Odbiorca musi
sam zadbać o przydzielenie bufora i o to, by pomieściły się w nimodebrane dane,
count – maksymalna liczba elementów, jaką jesteśmy gotowi przyjąć(rozmiar bufora w elementach),
datatype – stała symboliczna określająca typ danych, które odbieramy.Powinna zgadzać się z typem określonym po stronie nadawcy,
source – numer procesora-nadawcy. Gdy podamy konkretny, zaznaczamy,że interesuje nas wiadomość tylko od tego procesora. PodającANY_SOURCE godzimy się na przyjęcie wiadomości od dowolnegonadawcy.
tag – znacznik wiadomości, podobnie jak przy wysyłaniu. Jeśli podamykonkretny, zaznaczamy że interesuje nas wiadomość o tym konkretnymznaczniku. Podając ANY_TAG, godzimy się na przyjęcie wiadomości zdowolnym znacznikiem. 87

MPI – jak wygląda odebranie wiadomości?
void MPI::Comm::Recv(void* buf, int count,
const Datatype& datatype, int source, int tag,
Status& status);
status – zawiera dodatkowe informacje o odebranej wiadomości.Przy odbiorze przekazujemy tu obiekt klasy MPI::Status, którymetoda Recv wypełnia. Korzystając z wypełnionego obiektu będziemożna sprawdzić– ile faktycznie elementów otrzymaliśmy:
MPI::Status::Get_count(const Datatype&);
– od kogo przyszła wiadomość (jeśli godziliśmy się na wiadomości oddowolnego nadawcy):MPI::Status::Get_source();
– jaki był znacznik wiadomości (jeśli godziliśmy się na odbiór wiadomości zdowolnym znacznikiem).MPI::Status::Get_tag();
• Jeśli nie interesuje nas status wiadomości, MPI daje nam dodyspozycji przeciążoną wersję MPI::Comm::Recv pozbawionąostatniego z parametrów.
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 88

MPI – kiedy kończy się Send()?
• Send() jest przykładem komunikacji blokującej, a zatem kończy się
dopiero po przesłaniu wiadomości.
• Ale co dokładnie to oznacza?
– czy po tym jak została pomyślnie wysłana?
– czy po tym jak dotarła siecią na drugą stronę?
– czy po tym jak odbiorca pomyślnie odebrał ją za pomocą Recv()?
• Żadna z powyższych!
• Send() kończy się, gdy nadawca może bezpiecznie zamazać
bufor nadawczy.
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 89
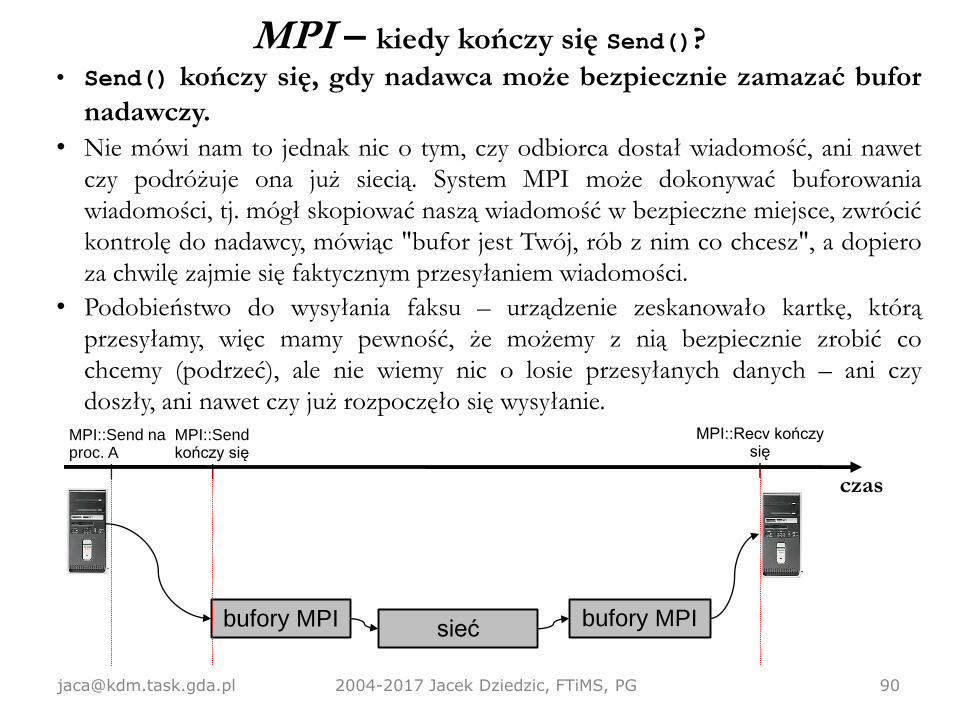
MPI – kiedy kończy się Send()?
• Send() kończy się, gdy nadawca może bezpiecznie zamazać bufor
nadawczy.
• Nie mówi nam to jednak nic o tym, czy odbiorca dostał wiadomość, ani nawet
czy podróżuje ona już siecią. System MPI może dokonywać buforowania
wiadomości, tj. mógł skopiować naszą wiadomość w bezpieczne miejsce, zwrócić
kontrolę do nadawcy, mówiąc "bufor jest Twój, rób z nim co chcesz", a dopiero
za chwilę zajmie się faktycznym przesyłaniem wiadomości.
• Podobieństwo do wysyłania faksu – urządzenie zeskanowało kartkę, którą
przesyłamy, więc mamy pewność, że możemy z nią bezpiecznie zrobić co
chcemy (podrzeć), ale nie wiemy nic o losie przesyłanych danych – ani czy
doszły, ani nawet czy już rozpoczęło się wysyłanie.
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 90
czas
MPI::Send na proc. A
|
MPI::Send kończy się
|
bufory MPI
MPI::Recv kończy się|
sieć bufory MPI

MPI – "paradoksy" przesyłania wiadomości
• Ponieważ oba procesory (nadawca i odbiorca) pracują niezależnie, to mamy do
czynienia z pewnymi komplikacjami, które powodują że niektóre zachowania
wydają się nieintuicyjne:
• MPI::Recv() po stronie odbiorcy może zakończyć się zanim MPI::Send()
zakończy się po stronie nadawcy.
• Nie oznacza to, że "wiadomość została odebrana przed nadaniem" tylko że
"wiadomość została odebrana, zanim stwierdzono zakończenie nadania". Proces
nadawcy mógł na przykład zostać przyblokowany czymś (np. wywłaszczony przez
SO na rzecz innego procesu) w momencie między nadaniem wiadomości a
powrotem z funkcji MPI::Send().
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 91
czas
początekMPI::Send na proc. A
|
MPI::Send prawie się zakończyło, ale proces został wywłaszczony
|
bufory MPI
MPI::Recv kończy się
|
sieć bufory MPI
|||||||
kontrola wraca do procesu na A,
MPI::Send kończy się
← proces na A jest nieaktywny aż dotąąąąąąąąąąąąąąąąąąąąąąąąąąąąąąd →
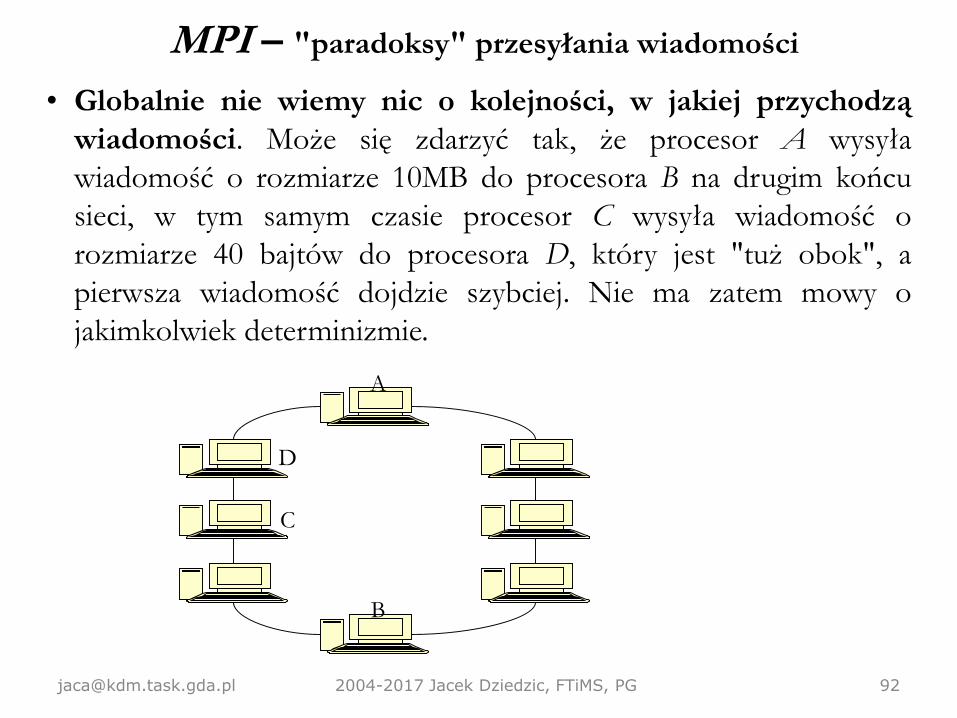
MPI – "paradoksy" przesyłania wiadomości
• Globalnie nie wiemy nic o kolejności, w jakiej przychodzą
wiadomości. Może się zdarzyć tak, że procesor A wysyła
wiadomość o rozmiarze 10MB do procesora B na drugim końcu
sieci, w tym samym czasie procesor C wysyła wiadomość o
rozmiarze 40 bajtów do procesora D, który jest "tuż obok", a
pierwsza wiadomość dojdzie szybciej. Nie ma zatem mowy o
jakimkolwiek determinizmie.
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 92
A
B
C
D

MPI – gwarancja kolejności
• Gwarancję "kolejności" mamy tylko dla dwóch konkretnych
procesorów, tj. jeśli procesor A wyśle do B wiadomości w1, w2, w3,
…, wn, to do B dojdą one w tej samej kolejności. Normalnie
wybieramy wiadomości u odbiorcy dzięki możliwości zadania
źródła i znacznika wiadomości, której odebranie nas interesuje, ale
gdy korzystamy z ANY_SOURCE i ANY_TAG, to dostajemy wiadomości
"jak leci", więc dobrze jest wiedzieć że są w tej samej kolejności, w
której wysłał je nadawca. Jeśli wysyła dwóch lub więcej nadawców
– nie mamy żadnych gwarancji co do tego, jak wiadomości od nich
będą się przeplatać.
• Krótko mówiąc, wiadomości nie wyprzedzają się, ale tylko
wiadomości konkretnego nadawcy skierowane do
konkretnego odbiorcy.
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 93

MPI – inicjalizacja i deinicjalizacja
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 94
Zanim skorzystamy z jakiejkolwiek funkcji MPI (z wyjątkiem jednej),
musimy zainicjować środowisko MPI.
Inicjalizacji dokonujemy za pomocą MPI::Init().
void MPI::Init(int& argc, char**& argv);
Przekazujemy do MPI::Init te same parametry, które otrzymuje
main(). Przesyłane są one przez referencję, dzięki czemu
MPI::Init może je zmodyfikować, jeśli to konieczne.
Nie oszukujemy! Przekazujemy dokładnie te same parametry, które
otrzymuje main() – w przeciwnym wypadku mamy zachowanie
niezdefiniowane.

• Przed wywołaniem MPI::Init() nie wolno wykonywać żadnych
operacji we/wy (czytanie i pisanie do plików, wypisywanie komunikatówna konsolę, czytanie znaków z klawiatury, etc.). Nie próbuj tego robić –może udawać, że działa a stać się powodem trudnych do znalezieniabłędów.
• W C sprawa jest prosta – wystarczy wywołać MPI::Init() na samympoczątku funkcji main().
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 95
MPI – inicjalizacja i deinicjalizacja [2]

• W C++ sprawa jest trochę trudniejsza – trzeba pamiętać, że obiektyglobalne będą, a statyczne mogą być zainicjowane przed main().
Musimy mieć pewność, że konstruktory tych obiektów nie próbująwykonywać operacji we/wy, nawet tak trywialnych jak wypisywaniewiadomości diagnostycznych na konsolę.
// prosimy się o kłopoty
class kłopot {
public:
kłopot() {
cerr << "To ja, konstruktor\n";
}
};
kłopot tutaj; // konstruktor przed MPI::Init
int main(int argc, char** argv) {
MPI::Init(argc,argv);
}
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 96
MPI – inicjalizacja i deinicjalizacja [2]

MPI – inicjalizacja i deinicjalizacja [3]• Aby posprzątać po środowisku MPI gdy program zakończył się,
należy wywołać MPI::Finalize().
• Po MPI::Finalize() nie wolno wołać żadnych funkcji MPI, nawetMPI::Init().
• Należy wywołać MPI::Finalize() na każdym procesorze (tzw.operacja kolektywna (zbiorowa, grupowa)) – to niezwykle istotne!
• Po wejściu do funkcji MPI::Finalize(), każdy procesor czeka napozostałe, opuszczając tę funkcję dopiero gdy wszystkie procesorydotrą do tego miejsca programu. Zachowanie takie nazywa siębarierą (więcej o barierze przy operacjach kolektywnych).
• Musimy zagwarantować, że w chwili wywołania MPI::Finalize()
wszystkie wysłane uprzednio wiadomości zostały odebrane.
• Z powyższych powodów funkcja ta nie nadaje się do awaryjnegokończenia programu. W razie wystąpienia błędu krytycznego możebyć trudno zapewnić odebranie wszystkich wiadomości, a tymbardziej wywołać MPI::Finalize() na wszystkich procesorach.
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 97

MPI – awaryjne kończenie programu (abort)
• W przypadkach nagłych możemy zakończyć program korzystając zMPI::Comm::Abort().
MPI::Comm::Abort(int error);
• Funkcję tę wołamy na rzecz komunikatora, którego procesychcemy zakończyć. Obecnie MPI gwarantuje poprawne działanietylko dla komunikatora MPI::COMM_WORLD.
• error – kod błędu, który chcemy zwrócić do systemu op..
• Zatem np. MPI::COMM_WORLD.Abort(42);
• Funkcja ta natychmiast zamyka środowisko MPI, po czym kończy procesy komunikatora za pomocą abort().
• Nie dostajemy szansy na jakiekolwiek posprzątanie po programie.Nie zostaną wywołane destruktory, zasoby nie zostaną zwolnione,pliki nie zostaną zamknięte, etc... Musimy liczyć na to, że posprzątaSO. Ekran zostanie zalany serią komunikatów o błędach.
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 98

MPI – uwagi nt. we/wy
• Niedozwolone przed MPI::Init().
• Standard MPI nie precyzuje powiązań strumieni standardowych
(stdout, stdin, stderr) – nie wiadomo dokąd prowadzą. W praktyce
stdout i stderr są na ogół przekierowane do plików wyspecyfiko-
wanych przy uruchamianiu programu.
• W praktyce nie ma dostępu do klawiatury (większość węzłów
obliczeniowych nawet nią nie dysponuje). Dane wejściowe
będziemy pobierać z plików. Nie będzie interakcji z użytkownikiem
w rodzaju zapytań "czy na pewno T/N?".
• Nie ma gwarancji, że każdy węzeł może wykonywać operacje
we/wy. Może się zdarzyć, że tylko niektóre węzły (albo jeden, albo
żaden) dysponują we/wy. Można wybadać sytuację sprawdzając
atrybut MPI::IO. Na laboratorium będziemy zakładać, że wszystkie
procesory mają dostęp do we/wy.
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 99

MPI – uwagi nt. we/wy [2]
• Nie można oczekiwać jakiegokolwiek uporządkowania wiadomości
wysyłanych na wyjście standardowe. Komunikaty wypisywane przez
procesory będą się przeplatać. Co więcej tekst wypisany przez jeden
procesor w czasie t2 może dotrzeć na wyjście przed tekstem
wypisanym przez inny procesor w czasie t1, nawet gdy t2>t1.
Buforowanie wyjścia przez SO pogarsza jeszcze sprawę.
• Próba pisania do tego samego pliku z więcej niż jednego procesora
nie powiedzie się (uda się to wykonać, ale nie ma gwarancji co do
tego, co znajdzie się w pliku). Należy albo pisać do oddzielnych
plików, pisać tylko na jednym procesorze albo (najlepiej) użyć
równoległego we/wy, którym dysponuje MPI-2.
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 100

MPI – jak sprawdzić ile jest procesorów
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 101
Zdobycie tej informacji jest na ogół pierwszą czynnością
wykonywaną po MPI::Init(). Służy do tego funkcja
MPI::Comm::Get_size().
int MPI::Comm::Get_size();
Funkcja zwraca liczbę procesorów w komunikatorze. Jeśli wywołamy
ją na rzecz MPI::COMM_WORLD dostaniemy całkowitą liczbę
procesorów, na których pracuje program.
Analogicznie, przy użyciu MPI::Comm::Get_rank() możemy
sprawdzić numer bieżącego procesora.
int MPI::Comm::Get_rank();
Zwrócony numer należy do przedziału <0, N-1>, gdzie N jest liczbą
procesorów zwróconą przez MPI::Comm::Get_size().

MPI – kompletny program przykładowy
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 102
// czyta 10 liczb z pliku wejscie.txt na procesorze 0, przesyla liczby do
// procesora 1, zapisuje do pliku wyjscie.txt na procesorze 1.
#include <mpi.h>
#include <iostream>
#include <fstream>
using namespace std;
int main(int argc, char** argv) {
MPI::Init(argc, argv);
cout << "Po inicjalizacji!" << endl;
int size=MPI::COMM_WORLD.Get_size();
int rank=MPI::COMM_WORLD.Get_rank();
cout << "Start na processorze " << rank << " z " << size << endl;
int tab[10];
if(rank==0) {
ifstream we("wejscie.txt");
for(int i=0; i<10; ++i) we >> tab[i];
cout << "Procesor 0 – wysyłam" << endl;
MPI::COMM_WORLD.Send(tab,10,MPI::INTEGER,1,0);
}
if(rank==1) {
cout << "Procesor 1 – odbieram" << endl;
MPI::Status status;
MPI::COMM_WORLD.Recv(tab,10,MPI::INTEGER,0,0,status);
ofstream wy("wyjscie.txt");
for(int i=0; i<10; ++i) wy << tab[i];
}
if(rank>1) cout << "Procesor " << rank << " – nudzę się" << endl;
cout << "Kończę pracę na procesorze " << rank << endl;
MPI::Finalize();
}

MPI – przykładowe wyjście programu
przykładowego
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 103
LAM 7.1.1/MPI 2 C++/ROMIO – Indiana University
uruchamiam na: h98, h110, h125, h126.
Po inicjalizacji.
Po inicjalizacji.
Start na procesorze 1 z 4
Po inicjalizacji
Start na proStart na procesorze 0 z 4
cesorze 2 z 4
Procesor 1 - odbieram
Procesor 0 – wysylam
Po inicjalizacji
Start na procesorze 3 z 4
Procesor 3 – nuProcesor 2 – nudze się
Kończę pracę na procesorze 2
dze sięKończę pracę na procesorze 3
Kończę pracę na procesorze 1
Kończę pracę na procesorze 0
Widać, że wyjście może się przeplatać
Ten sam kod wykonuje się na każdym z 4 procesorów – jeśli czegoś
nie otoczymy warunkiem typu if(mój_numer_to…), to wykona się to
na każdym z procesorów.

MPI – kompilacja i wiązanie
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 104
#include <mpi.h>
Przy kompilacji trzeba podać ścieżkę do plików nagłówkowych, żeby kompilator
wiedział gdzie znaleźć "mpi.h". Przykładowo
g++ -I/apl/mpi/lam/ia64/include –c test.cpp
Przy linkowaniu trzeba podać ścieżkę, gdzie kompilator może znaleźć plik
biblioteki mpi (libmpi.a) oraz włączyć bibliotekę mpi (czasem też inne, np. pthread).
Przykładowo
g++ -L/apl/mpi/lam/ia64/lib test.o \
–lmpi –lpthread –llam –o test
Czasem środowisko daje nam skrypty albo programy, które dodają wszystko za nas.
Kompilujemy i linkujemy wtedy posługując się nazwą skryptu/programu zamiast
nazwy kompilatora. Przykładowo (skrypt nazywa się mpic++)
mpic++ test.cpp -o test

MPI – uruchamianie
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 105
Trzeba uruchomić kopię programu na każdym z procesorów, ponadto każdy musi
wiedzieć z kim ma się komunikować (numery/nazwy pozostałych węzłów).
Robi to za nas "skrypt do uruchamiania" dostarczany przez środowisko, często
nazywa się on mpirun.
Przykładowa składnia (uruchamia program test na sześciu procesorach,
przekierowując standardowe wyjście do pliku "stdout.txt" a standardowe wyjście
błędów do "stderr.txt"):
mpirun –np 6 –o stdout.txt –e stderr.txt ./test

MPI – próbujemy wymiany wiadomości// Spróbujmy wymienić zawartość dwóch tablic między dwoma procesorami. Zakładamy,
// że tablice są już przydzielone, wypełnione, mój_numer zawiera numer procesora (0 lub 1),
// a do przesłania jest n elementów typu int.
int jego_numer=1-mój_numer;
if(mój_numer==0) {
// wyślij
MPI::COMM_WORLD.Send(moje_dane, n, MPI::INTEGER, jego_numer, 1234);
// odbierz
MPI::Status status;
MPI::COMM_WORLD.Recv(jego_dane, n, MPI::INTEGER, jego_numer, 1234, status);
// tu możemy sprawdzić status
}
if(mój_numer==1) {
// wyślij
MPI::COMM_WORLD.Send(moje_dane, n, MPI::INTEGER,
jego_numer, 1234);
// odbierz
MPI::Status status;
MPI::COMM_WORLD.Recv(jego_dane, n, MPI::INTEGER,
jego_numer, 1234, status);
// tu możemy sprawdzić status
}
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 106
NIE zadziała tak, jak byśmy tego oczekiwali, z uwagi na buforowanie!

Dlaczego nie zadziała? Analogia.
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 107
Rozważmy dwa oddziały firmy kurierskiej, które wymieniająprzesyłki korzystając z magazynu. Kurierzy z każdego oddziałówoznaczają przesyłki numerem odbiorcy i nadawcy, po czymzostawiają je w magazynie, aby odebrali je kurierzy z drugiegooddziału. Następnie zabierają przesyłki pozostawione dla nich.
Oba oddziały pracują zgodnie z dwiema wytycznymi:
Wytyczna #1 dla pracowników
Jeśli magazyn jest pełny, należy czekać. Bez wątpienia pracownicydrugiego oddziału pojawią się za moment, zabiorą trochę paczeki zrobi się miejsce.
Wytyczna #2 dla pracowników
Jeśli nie widać przesyłek, które możnaby zabrać, należy czekać.Bez wątpienia pracownicy drugiego oddziału pojawią się zamoment i przywiozą paczki.

Dlaczego nie zadziała? Analogia.
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 108
Dokładnie takie samo zachowanie mamy w naszym
(niedziałającym) programie. Oddziały są reprezentowane przez
procesory, przesyłki to dane, a magazyn to wewnętrzne bufory
MPI.if(mój_numer==0) {
Send(…);
Recv(…);
}
if(mój_numer==1) {
Send(…);
Recv(…);
}
Algorytm pracowników firmy wygląda tak:if(jestem z oddziału A) {
zostaw przesyłki dla B
zabierz przesyłki adresowane do nas
}
if(jestem z oddziału B) {
zostaw przesyłki dla A
zabierz przesyłki adresowane do nas
}
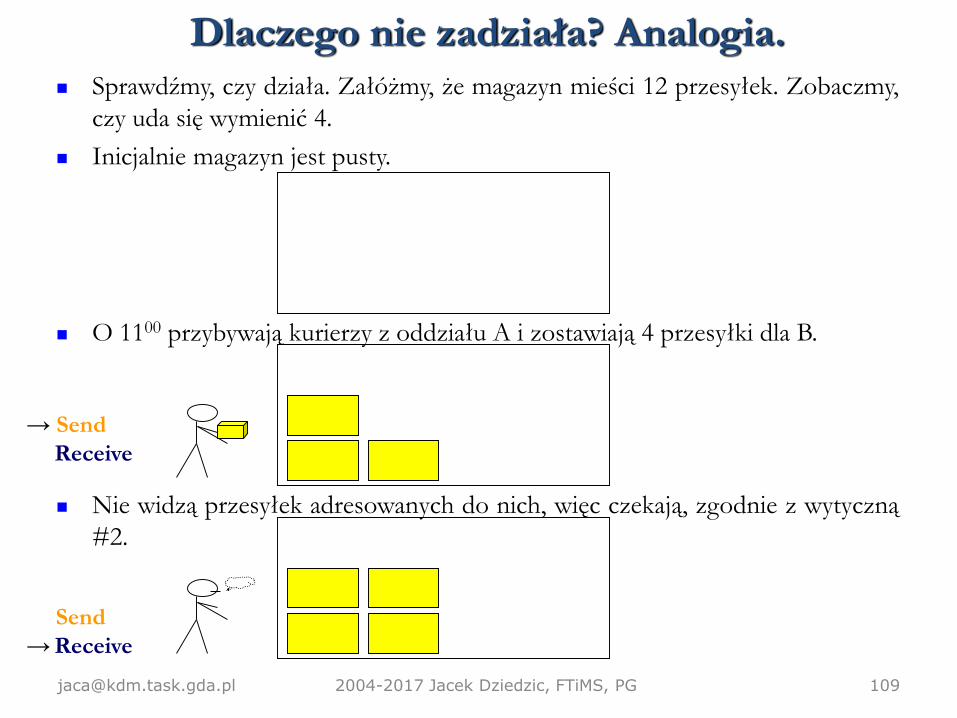
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 109
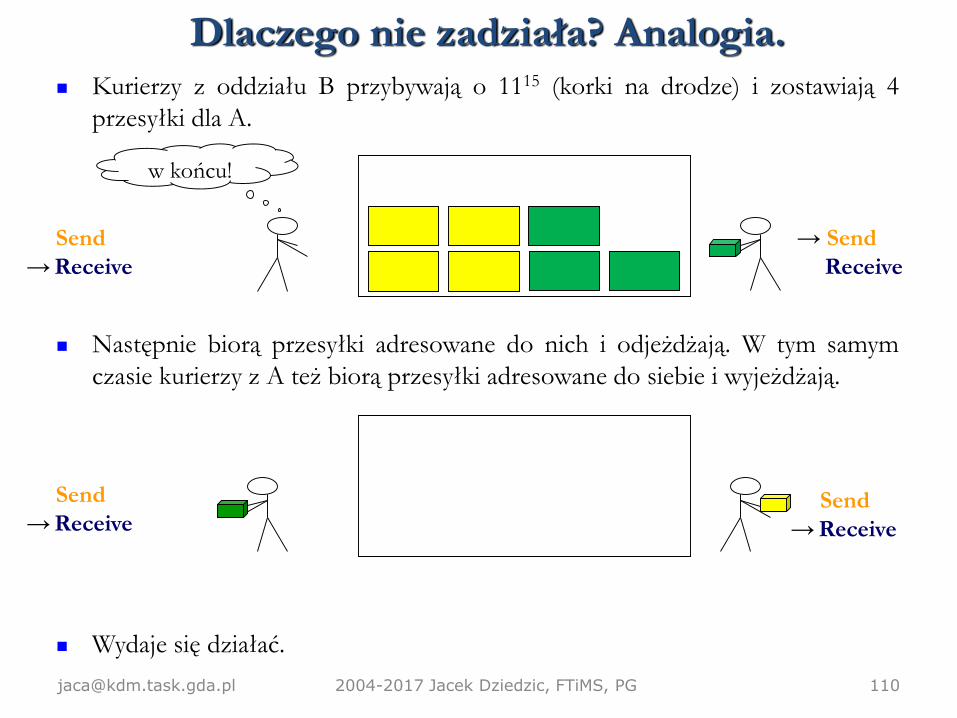
Sprawdźmy, czy działa. Załóżmy, że magazyn mieści 12 przesyłek. Zobaczmy,
czy uda się wymienić 4.
Inicjalnie magazyn jest pusty.
O 1100 przybywają kurierzy z oddziału A i zostawiają 4 przesyłki dla B.
Nie widzą przesyłek adresowanych do nich, więc czekają, zgodnie z wytyczną
#2.
Send
→ Receive
→ Send
Receive
Dlaczego nie zadziała? Analogia.
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 110
Kurierzy z oddziału B przybywają o 1115 (korki na drodze) i zostawiają 4
przesyłki dla A.
Następnie biorą przesyłki adresowane do nich i odjeżdżają. W tym samym
czasie kurierzy z A też biorą przesyłki adresowane do siebie i wyjeżdżają.
Wydaje się działać.
w końcu!
→ Send
Receive
Send
→ Receive
Send
→ ReceiveSend
→ Receive
Dlaczego nie zadziała? Analogia.
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 111
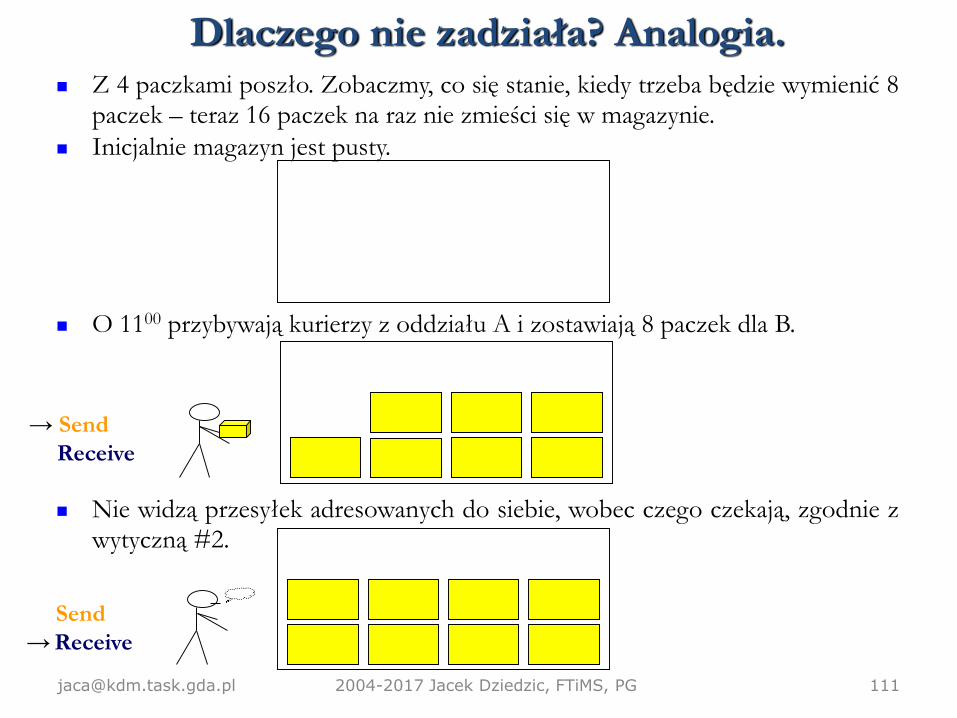
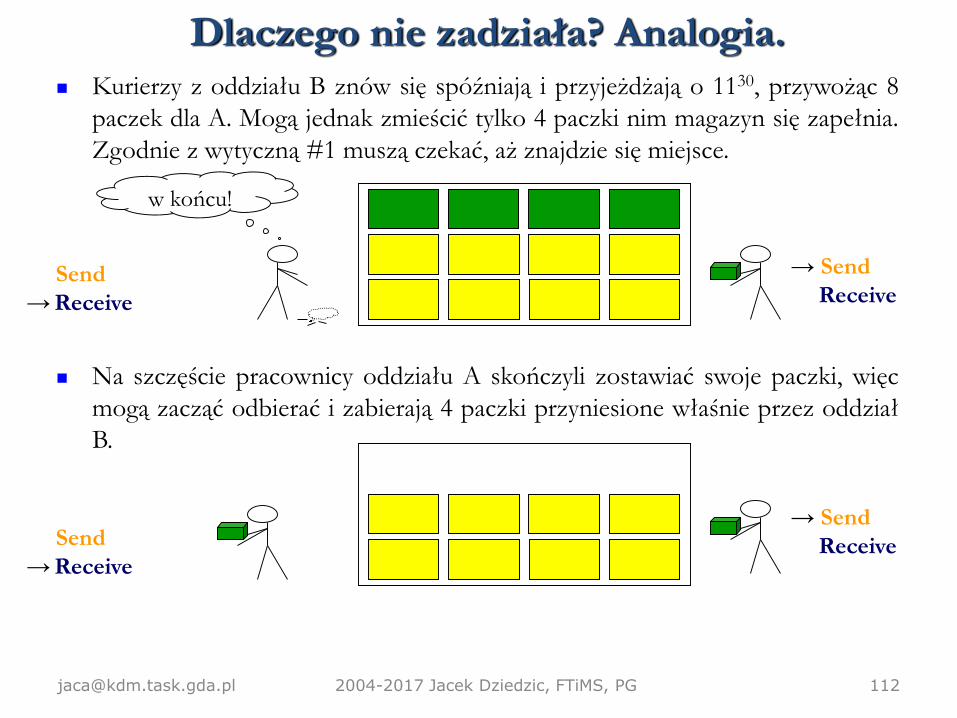
Z 4 paczkami poszło. Zobaczmy, co się stanie, kiedy trzeba będzie wymienić 8paczek – teraz 16 paczek na raz nie zmieści się w magazynie.
Inicjalnie magazyn jest pusty.
O 1100 przybywają kurierzy z oddziału A i zostawiają 8 paczek dla B.
Nie widzą przesyłek adresowanych do siebie, wobec czego czekają, zgodnie zwytyczną #2.
→ Send
Receive
Send
→ Receive
Dlaczego nie zadziała? Analogia.
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 112
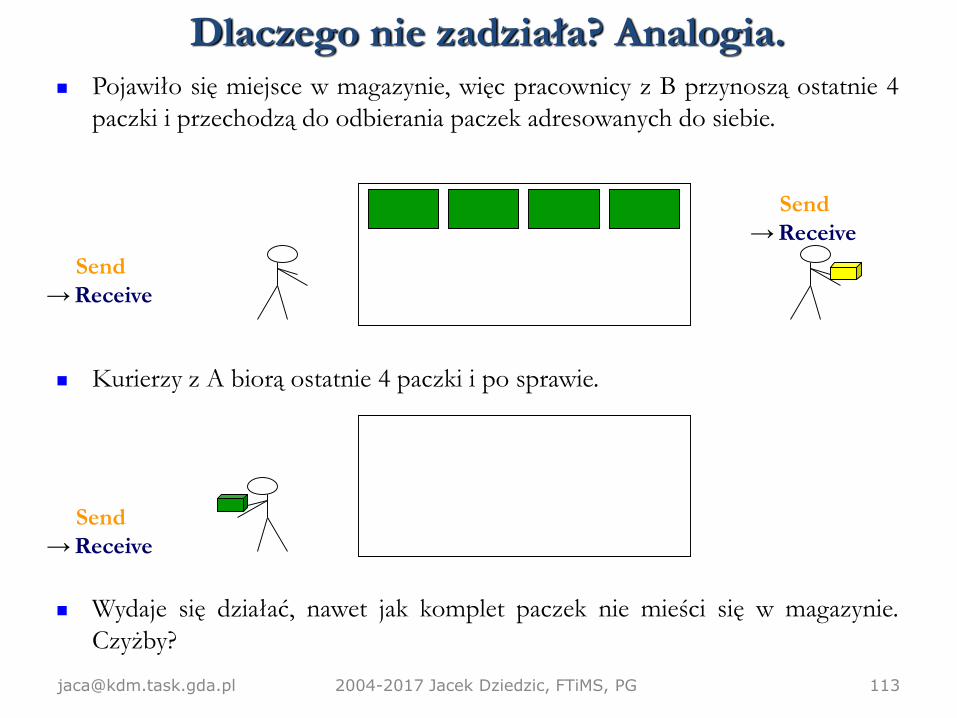
Kurierzy z oddziału B znów się spóźniają i przyjeżdżają o 1130, przywożąc 8
paczek dla A. Mogą jednak zmieścić tylko 4 paczki nim magazyn się zapełnia.
Zgodnie z wytyczną #1 muszą czekać, aż znajdzie się miejsce.
Na szczęście pracownicy oddziału A skończyli zostawiać swoje paczki, więc
mogą zacząć odbierać i zabierają 4 paczki przyniesione właśnie przez oddział
B.
w końcu!
Send
→ Receive
→ Send
Receive
→ Send
ReceiveSend
→ Receive
Dlaczego nie zadziała? Analogia.
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 113
Pojawiło się miejsce w magazynie, więc pracownicy z B przynoszą ostatnie 4
paczki i przechodzą do odbierania paczek adresowanych do siebie.
Kurierzy z A biorą ostatnie 4 paczki i po sprawie.
Wydaje się działać, nawet jak komplet paczek nie mieści się w magazynie.
Czyżby?
Send
→ Receive
Send
→ Receive
Send
→ Receive
Dlaczego nie zadziała? Analogia.
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 114
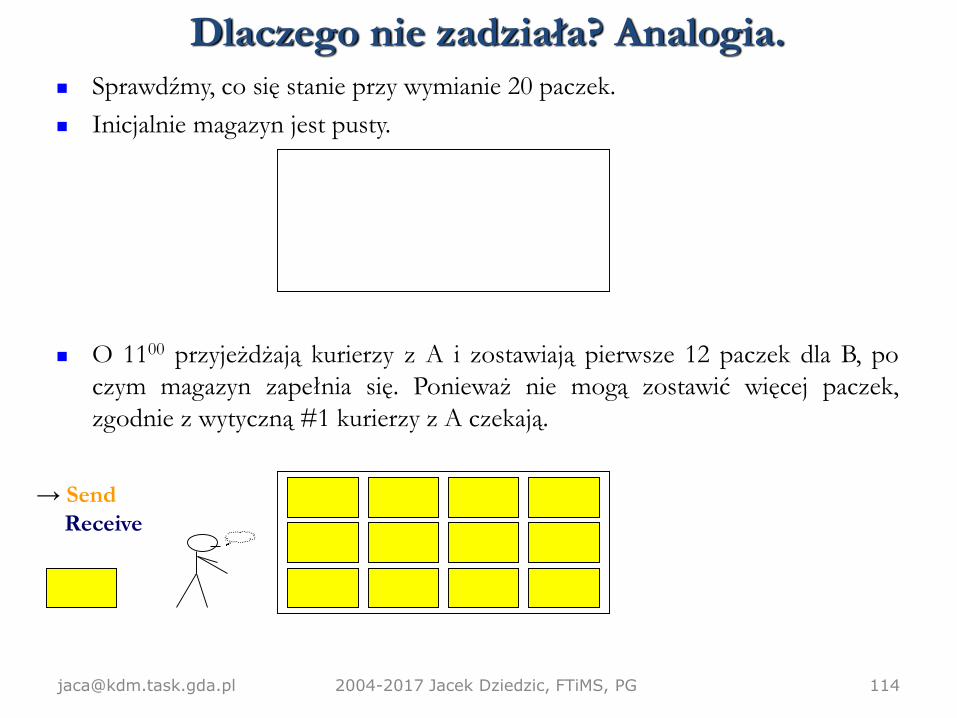
Sprawdźmy, co się stanie przy wymianie 20 paczek.
Inicjalnie magazyn jest pusty.
O 1100 przyjeżdżają kurierzy z A i zostawiają pierwsze 12 paczek dla B, po
czym magazyn zapełnia się. Ponieważ nie mogą zostawić więcej paczek,
zgodnie z wytyczną #1 kurierzy z A czekają.
→ Send
Receive
Dlaczego nie zadziała? Analogia.
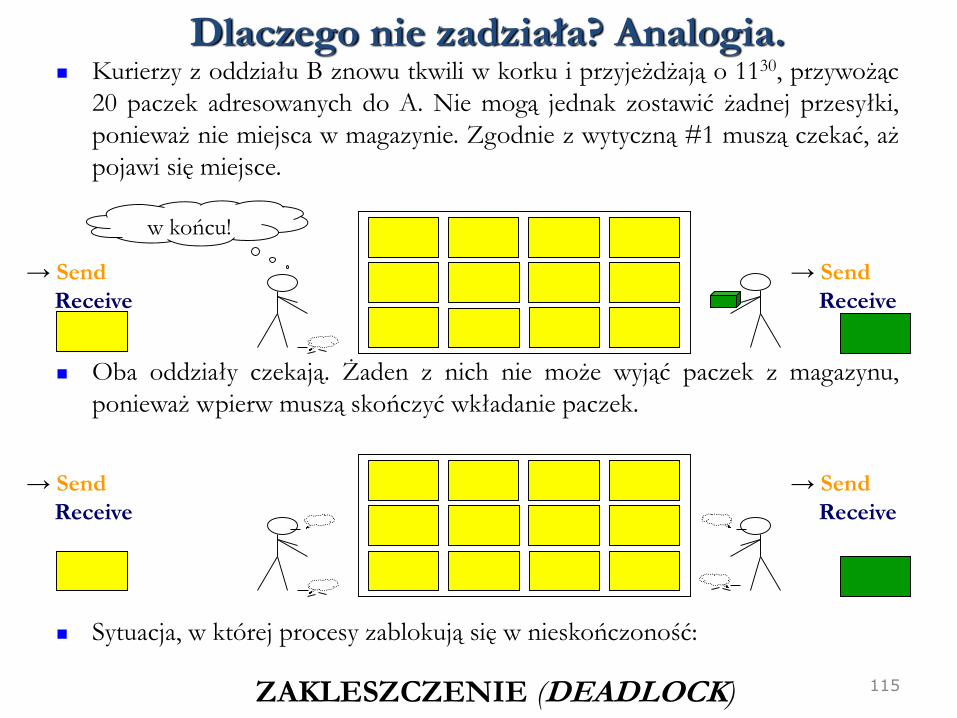
115
Kurierzy z oddziału B znowu tkwili w korku i przyjeżdżają o 1130, przywożąc
20 paczek adresowanych do A. Nie mogą jednak zostawić żadnej przesyłki,
ponieważ nie miejsca w magazynie. Zgodnie z wytyczną #1 muszą czekać, aż
pojawi się miejsce.
Oba oddziały czekają. Żaden z nich nie może wyjąć paczek z magazynu,
ponieważ wpierw muszą skończyć wkładanie paczek.
Sytuacja, w której procesy zablokują się w nieskończoność:
ZAKLESZCZENIE (DEADLOCK)
w końcu!
→ Send
Receive
→ Send
Receive
→ Send
Receive
→ Send
Receive
Dlaczego nie zadziała? Analogia.

Czyli ten program zakleszcza się...• Zatem nasz program będzie się zakleszczał, gdy tylko rozmiar przesyłanej
wiadomości będzie większy od rozmiaru wewnętrznych buforów MPI (a te nie
wiemy jak duże są).
• Przyczyną zakleszczenia jest fakt, że Send() nie może się zakończyć zanim nie
zostanie przetworzona cała wiadomość. Pełna wiadomość nie mieści się w
buforze i obydwa procesory blokują się na Send() zanim mogą zainicjować
odbiór.
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 116
if(mój_numer==0) {
// wyślij
MPI::COMM_WORLD.Send(moje_dane, n, MPI::INTEGER,
jego_numer, 1234); // * blokuje
// odbierz
MPI::COMM_WORLD.Recv(jego_dane, n, MPI::INTEGER, jego_numer, 1234, status);
}
if(mój_numer==1) {
// wyślij
MPI::COMM_WORLD.Send(moje_dane, n, MPI::INTEGER,
jego_numer, 1234); // * blokuje
// odbierz
MPI::COMM_WORLD.Recv(jego_dane, n, MPI::INTEGER, jego_numer, 1234, status);
}

Ten program też się zakleszcza• Może należy najpierw odbierać, potem wysyłać?
if(mój_numer==0) {
Recv(…);
Send(…);
}
if(mój_numer==1) {
Recv(…);
Send(…);
}
• To też się zakleszcza i to niezależnie od rozmiaru buforów MPI, bo oba
procesory próbują odbierać wiadomości, podczas gdy żaden nic nie nadał.
Pamiętamy, że operacjia odbioru nie może się zakończyć zanim nie zostanie
odebrana cała wiadomość.
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 117
→ Receive
Send→ Receive
Send

Rozwiązanie:
ten program NIE zakleszcza się
• Problem można rozwiązać wykonując najpierw nadanie, a potem
odbiór na pierwszym proce-sorze, a najpierw odbiór, a potem
nadanie na drugim procesorze:
if(mój_numer==0) {
Send(…);
Recv(…);
}
if(mój_numer==1) {
Recv(…);
Send(…);
}
• Przy więcej niż dwóch procesorach można robić odbiór-nadanie na
nieparzystych, a nadanie-odbiór na parzystych.
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 118
Dlaczego teraz działa: analogia
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 119
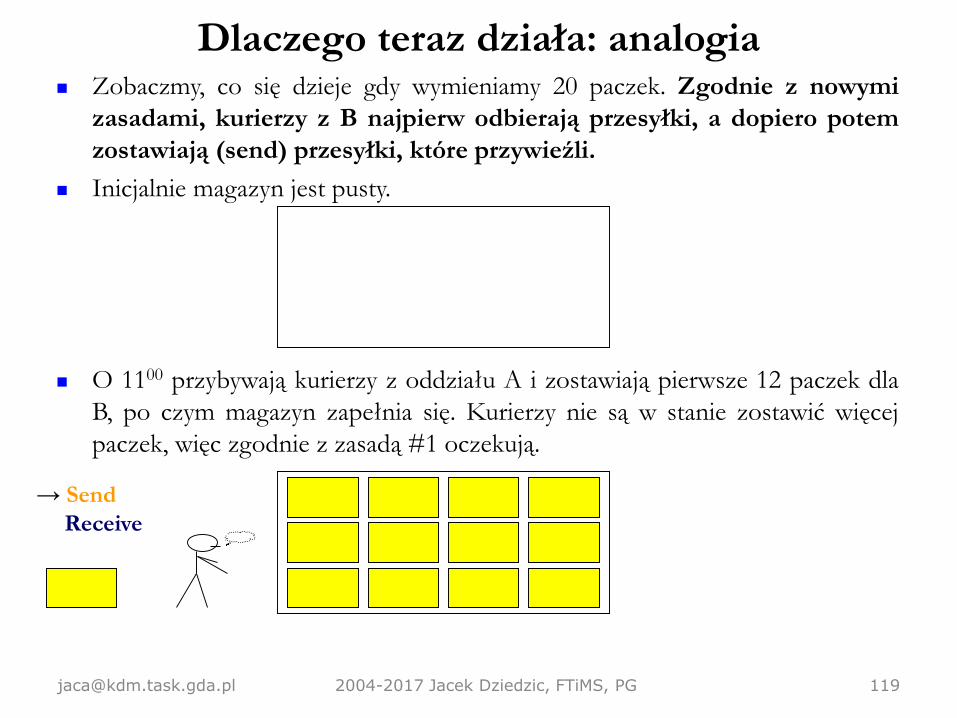
Zobaczmy, co się dzieje gdy wymieniamy 20 paczek. Zgodnie z nowymi
zasadami, kurierzy z B najpierw odbierają przesyłki, a dopiero potem
zostawiają (send) przesyłki, które przywieźli.
Inicjalnie magazyn jest pusty.
O 1100 przybywają kurierzy z oddziału A i zostawiają pierwsze 12 paczek dla
B, po czym magazyn zapełnia się. Kurierzy nie są w stanie zostawić więcej
paczek, więc zgodnie z zasadą #1 oczekują.
→ Send
Receive
Dlaczego teraz działa: analogia
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 120
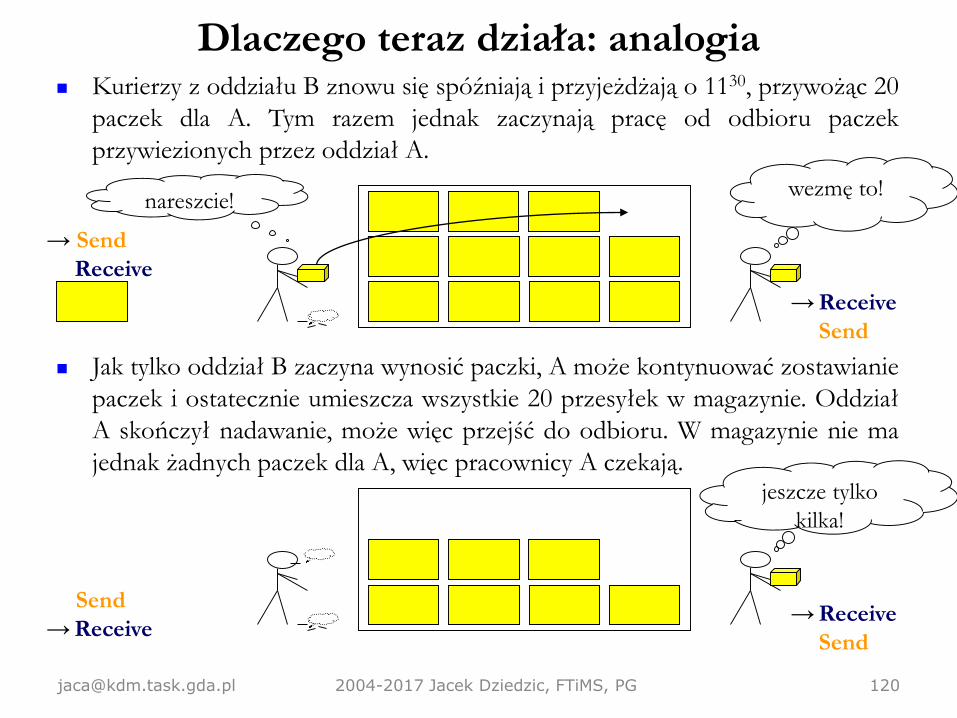
Kurierzy z oddziału B znowu się spóźniają i przyjeżdżają o 1130, przywożąc 20
paczek dla A. Tym razem jednak zaczynają pracę od odbioru paczek
przywiezionych przez oddział A.
Jak tylko oddział B zaczyna wynosić paczki, A może kontynuować zostawianie
paczek i ostatecznie umieszcza wszystkie 20 przesyłek w magazynie. Oddział
A skończył nadawanie, może więc przejść do odbioru. W magazynie nie ma
jednak żadnych paczek dla A, więc pracownicy A czekają.
nareszcie!wezmę to!
jeszcze tylko
kilka!
→ Send
Receive
→ Receive
Send
→ Receive
Send
Send
→ Receive
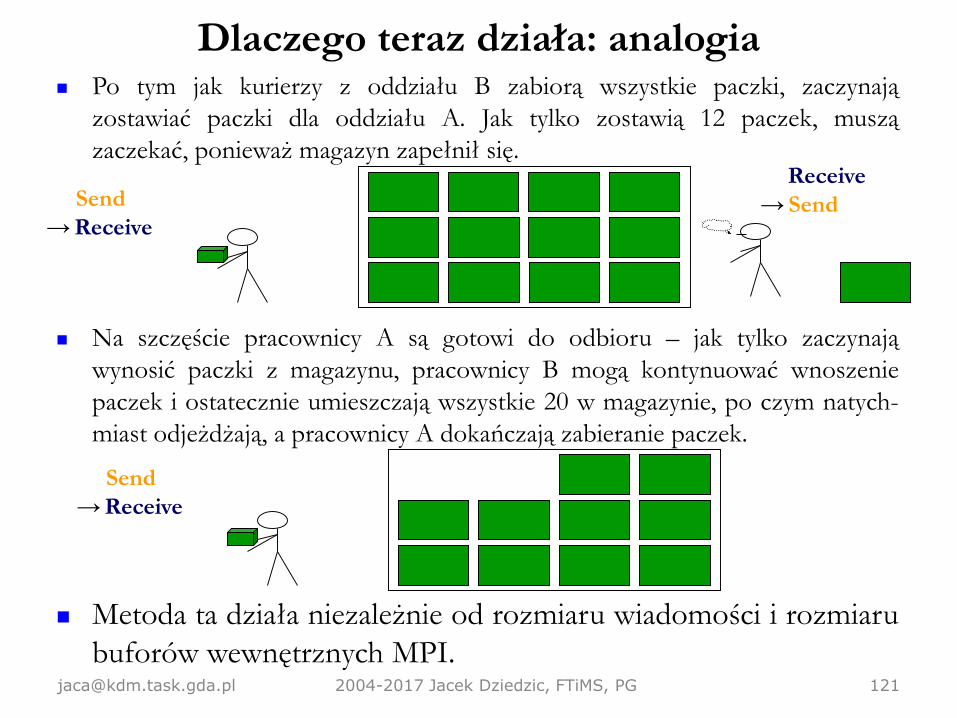
Dlaczego teraz działa: analogia
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 121
Po tym jak kurierzy z oddziału B zabiorą wszystkie paczki, zaczynają
zostawiać paczki dla oddziału A. Jak tylko zostawią 12 paczek, muszą
zaczekać, ponieważ magazyn zapełnił się.
Na szczęście pracownicy A są gotowi do odbioru – jak tylko zaczynają
wynosić paczki z magazynu, pracownicy B mogą kontynuować wnoszenie
paczek i ostatecznie umieszczają wszystkie 20 w magazynie, po czym natych-
miast odjeżdżają, a pracownicy A dokańczają zabieranie paczek.
Metoda ta działa niezależnie od rozmiaru wiadomości i rozmiaru
buforów wewnętrznych MPI.
Send
→ Receive
Receive
→ Send
Send
→ Receive

Po co unikać zakleszczenia?
• Nie wiemy jak pojemne są bufory wewnętrzne MPI (magazyn),
dlatego bezwzględnie musimy dbać o to, żeby zakleszczenie nigdy
nie było możliwe!
• Program, który się zakleszcza wydaje się działać dobrze, dopóki
rozmiar danych jest mały albo bufor duży.
• Ale bufor może być dowolnie mały…
• Czyli dla takiego programu zawsze można znaleźć taki system, na
którym zakleszczenie jednak nastąpi!
Program, w którym możliwe
jest zakleszczenie jest więc
programem niepoprawnym!… i na nic tłumaczenie "przecież widać że działa".
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 122

Procedura odbiór-i-nadanie to inny sposób zapobieżenia zakleszczeniu
void MPI::Comm::Sendrecv(const void *sendbuf,
int sendcount, const Datatype& sendtype, int dest
int sendtag, void *recvbuf, int recvcount,
const Datatype& recvtype, int source, int recvtag,
Status& *status)
• Pozwala na odebranie i odbiór za pomocą jednej operacji.
• Automagicznie zapewnia, że nie wystąpi zakleszczenie!
• Bufory: nadawczy i odbiorczy nie mogą się nakładać.
• Można wysyłać dane jednego typu, a odbierać innego (jeśli się
wie co się robi), byleby długość wiadomości się zgadzała.
if(mój_numer==0 || mój_numer==1) {
Sendrecv(…);
}
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 123

MPI – dygresja: proces pusty
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 124
• Czasami żeby nie gmatwać kodu przydaje się możliwość
wysłania wiadomości do nieistniejącego odbiorcy
(dlaczego?). Możemy wtedy skorzystać z identyfikatora
MPI::PROC_NULL, posługując się nim jako numerem
procesu odbiorcy. Wiadomość taka "wyśle się
błyskawicznie" i zostanie zignorowana.
• Podobnie możemy odebrać wiadomość od
nieistniejącego procesu – odbiór od MPI::PROC_NULL
zakończy się błyskawicznie, pomyślnie, nie modyfikując
bufora. Status będzie wówczas zawierał
source == MPI::PROC_NULL, count == 0,
tag == MPI::ANY_TAG.

MPI – komunikacja zbiorowa• Czasem (często) będziemy potrzebować czegoś więcej niż możliwości wysłania
wiadomości z procesora A do B. MPI daje nam do dyspozycji komunikacjęzbiorową (grupową, collective communication).
• Najważniejsze operacje zbiorowe:
– bariera (barrier) – synchronizuje procesy,
– rozesłanie (broadcast) – jeden procesor rozsyła jedną daną do wszystkich,
– zebranie (gather) – jeden procesor odbiera dane od wszystkich
– rozproszenie (scatter) – jeden procesor rozsyła dane do wszystkich
– redukcja (reduce) – jeden procesor odbiera przetworzone dane odwszystkich.
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 125
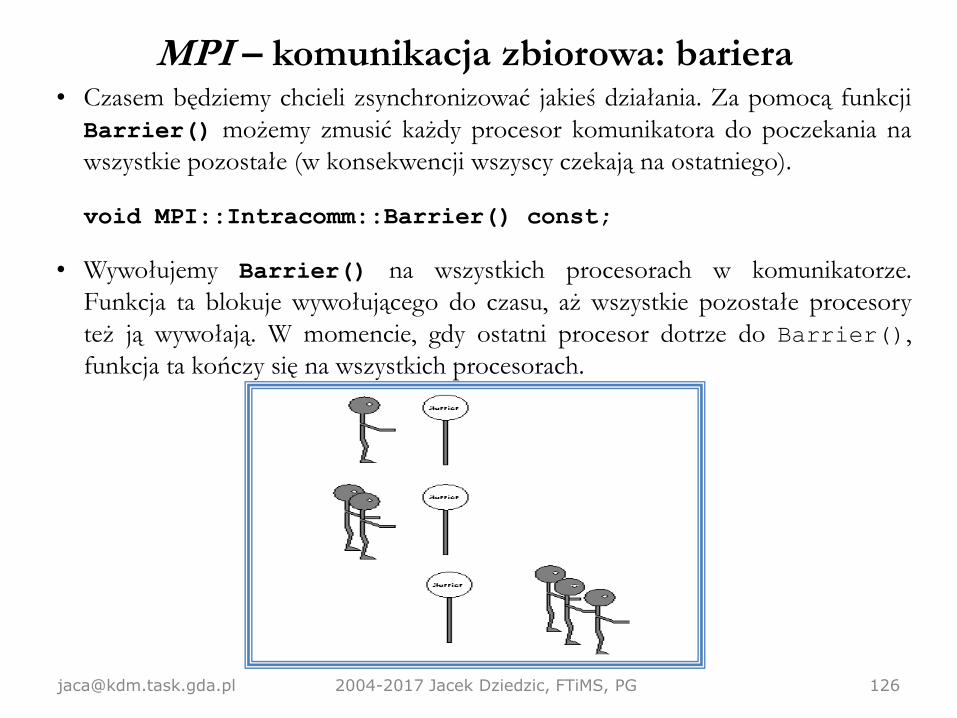
MPI – komunikacja zbiorowa: bariera
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 126
• Czasem będziemy chcieli zsynchronizować jakieś działania. Za pomocą funkcji
Barrier() możemy zmusić każdy procesor komunikatora do poczekania na
wszystkie pozostałe (w konsekwencji wszyscy czekają na ostatniego).
void MPI::Intracomm::Barrier() const;
• Wywołujemy Barrier() na wszystkich procesorach w komunikatorze.
Funkcja ta blokuje wywołującego do czasu, aż wszystkie pozostałe procesory
też ją wywołają. W momencie, gdy ostatni procesor dotrze do Barrier(),
funkcja ta kończy się na wszystkich procesorach.
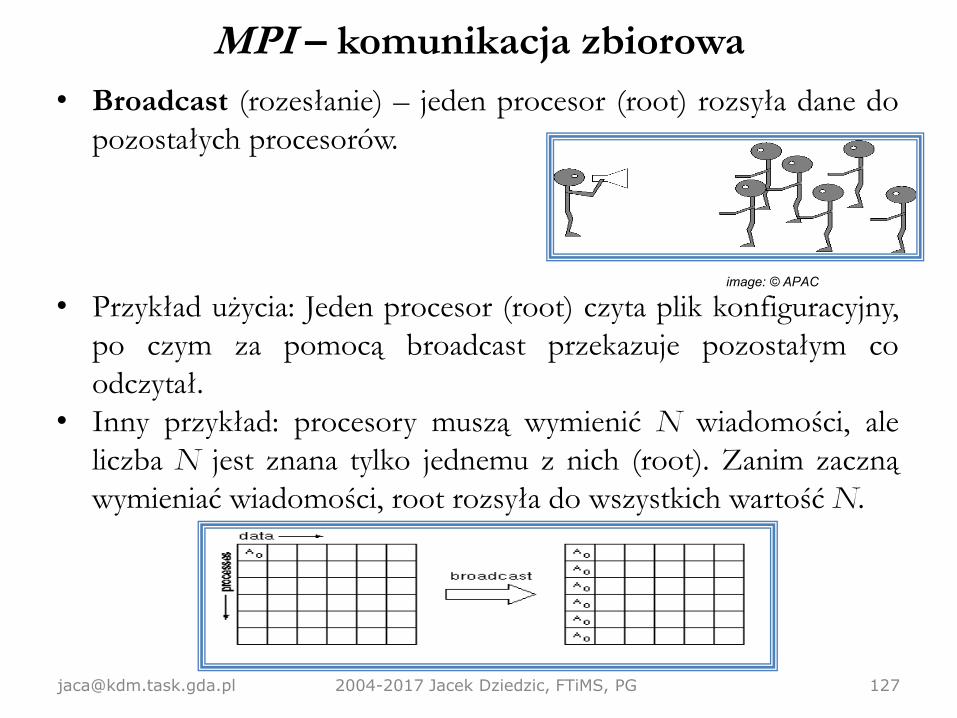
MPI – komunikacja zbiorowa
• Broadcast (rozesłanie) – jeden procesor (root) rozsyła dane do
pozostałych procesorów.
• Przykład użycia: Jeden procesor (root) czyta plik konfiguracyjny,
po czym za pomocą broadcast przekazuje pozostałym co
odczytał.
• Inny przykład: procesory muszą wymienić N wiadomości, ale
liczba N jest znana tylko jednemu z nich (root). Zanim zaczną
wymieniać wiadomości, root rozsyła do wszystkich wartość N.
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 127
image: © APAC

MPI – komunikacja zbiorowa:
broadcast• Jeden procesor (root) rozsyła daną do wszystkich, łącznie ze sobą.
• Podobieństwo składniowe do zwykłego wysłania wiadomości, ale nie ma tag.
Druga różnica: tym razem liczba odebranych elementów musi być taka sama,
jak liczba wysłanych (nie można odebrać "z zapasem" jak w komunikacji
punktowej).
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 128
void MPI::Intracomm::Bcast(void* buffer, int count,
const Datatype& datatype, int root) const;
buffer – bufor danych. Na procesorze root z niego pochodzą dane, na
pozostałych procesorach tu trafiają dane,
count – liczba rozsyłanych/odbieranych elementów,
datatype – stała symboliczna reprezentująca typ danych,
root – numer procesora root,

MPI – komunikacja zbiorowa:
broadcast• Bcast() trzeba wywołać na wszystkich procesorach, które mają
partycypować w komunikacji. Łatwo o tym zapomnieć i próbowaćnp. wywołać to tylko na procesorze root, dlatego że to on rozsyła.
• U wszystkich root musi mieć tę samą wartość.
• Typ danych i liczba elementów też muszą się zgadzać.(nie do końca prawda – musi się zgadzać tylko długość wiadomości)
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 129

MPI – komunikacja zbiorowa:
broadcast• Nie można odbierać wiadomości rozsyłanych za pomocą broadcast
przez punktowe receive (Recv()) – wszyscy, którzy chcąuczestniczyć w operacji rozesłania danych, muszą wykonaćbroadcast.
• Kiedy kończy się funkcja Bcast()? – kiedy dany procesorzakończył swój udział w operacji rozesłania (nadawca – możezniszczyć bufor, odbiorca – może bezpiecznie wyjąć odebranedane z bufora). Zakończenie się Bcast() nie daje żadnejinformacji o tym, co dzieje się na innych procesorach (np. może sięskończyć wcześniej u odbiorcy niż u nadawcy).
• Uwaga: Operacja rozesłania nie gwarantuje synchronizacji
między procesorami. Proces może być wstrzymany do momentu,
aż wszystkie wykonają operację broadcast, ale nie musi. Trzebazagwarantować poprawne działanie w obydwu sytuacjach.
• Operacje komunikacji zbiorowej mogą się wyprzedzać!
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 130

MPI – komunikacja zbiorowa:
pułapki// ten program zakleszczy się na niektórych systemach
if(mój_numer==0) {
Broadcast(nadawca==0);
Send();
}
if(mój_numer==1) {
Recv();
Broadcast(nadawca==0);
}
• Taki program będzie działał poprawnie albo nie, zależnie od tego
czy MPI na tym systemie synchronizuje operacje broadcast (a nie
mamy gwarancji ani synchronizowania, ani niesynchronizowania).
• W razie synchronizowania procesor 0 zatrzyma się na operacji
broadcast przez co nie dotrze do send. Drugi nigdy nie dotrze do
broadcast, bo recv nigdy się nie zakończy (bo send się nie wykonało).
Program zakleszczy się. Jeśli MPI nie synchronizuje operacji
broadcast, program będzie wydawał się działać poprawnie.
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 131

MPI – komunikacja zbiorowa:
pułapki// ten program nie zakleszcza się, ale jest niedeterministyczny
if(mój_numer==0) {
Broadcast(nadawca==0);
Send(odbiorca==1);
}
if(mój_numer==1) {
Recv(nadawca==any);
Broadcast(nadawca==0);
Recv(nadawca==any);
}
if(mój_numer==2) {
Send(odbiorca==1);
Broadcast(nadawca==0);
}
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 132
Wyścigi (race condition/hazard). Sytuacja, w której
program staje się niedeterministyczny przez to,
że nie wiadomo który odbiór zostanie
sparowany z którym nadaniem. Wysłane
wiadomości (send-0 i send-2) "ścigają się" do
odbiorcy.
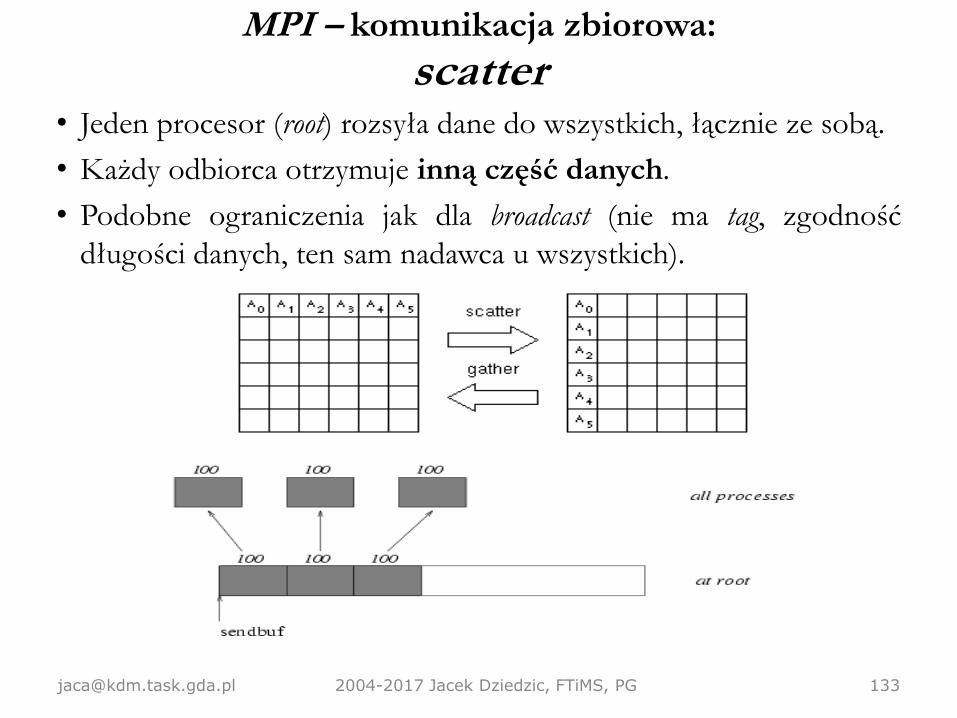
MPI – komunikacja zbiorowa:
scatter• Jeden procesor (root) rozsyła dane do wszystkich, łącznie ze sobą.
• Każdy odbiorca otrzymuje inną część danych.
• Podobne ograniczenia jak dla broadcast (nie ma tag, zgodność
długości danych, ten sam nadawca u wszystkich).
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 133

MPI – komunikacja zbiorowa:
scatter
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 134
void MPI::Intracomm::Scatter(
const void* sendbuf, int sendcount, const Datatype& sendtype,
void* recvbuf, int recvcount, const Datatype& recvtype,
int root);
sendbuf, sendcount, sendtype – bufor danych, liczba elementów i typ
danych – wszystko po stronie nadawcy. Na pozostałych procesorach –
ignorowane.
recvbuf, recvcount, recvtype – bufor danych, liczba elementów i typ
danych – u procesorów odbierających. Uwaga – root (nadawca) też odbiera.
root – numer procesora root, ten sam u wszystkich.
Typy danych i liczba elementów mogą się różnić między nadawcą i odbiorcą, ale
tak, żeby długość wiadomości była taka sama. Można np. nadać 200 liczb
MPI::LONG a odebrać 400 liczb MPI::INTEGER, jeśli na naszym systemiesizeof(long int) = 2*sizeof(int).
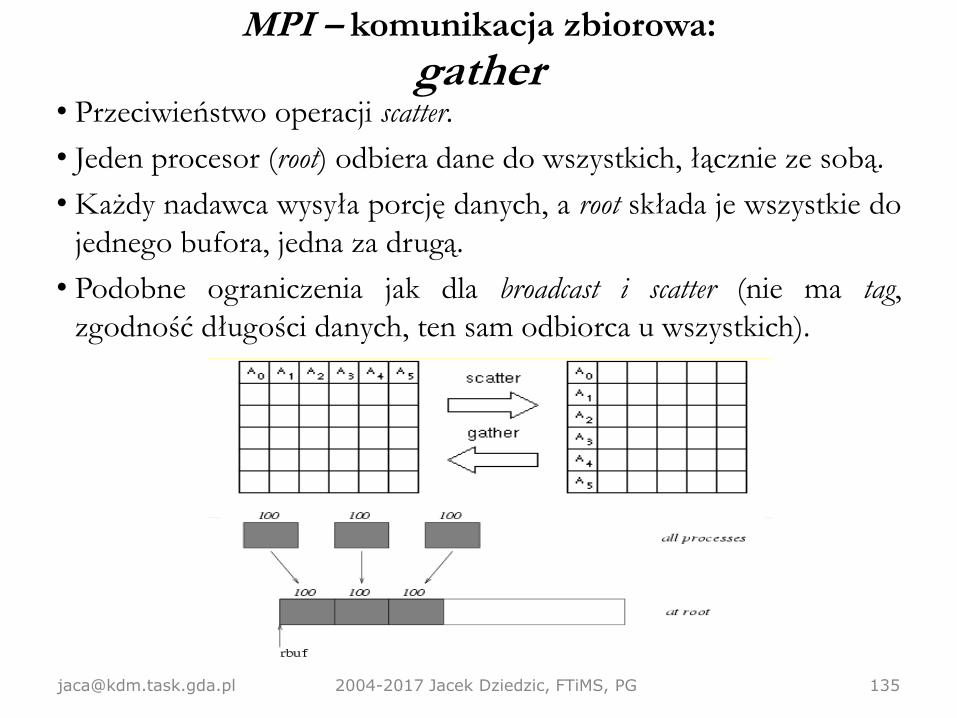
MPI – komunikacja zbiorowa:
gather• Przeciwieństwo operacji scatter.
• Jeden procesor (root) odbiera dane do wszystkich, łącznie ze sobą.
• Każdy nadawca wysyła porcję danych, a root składa je wszystkie do
jednego bufora, jedna za drugą.
• Podobne ograniczenia jak dla broadcast i scatter (nie ma tag,
zgodność długości danych, ten sam odbiorca u wszystkich).
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 135

MPI – komunikacja zbiorowa:
gather
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 136
void MPI::Intracomm::Gather(
const void* sendbuf, int sendcount, const Datatype& sendtype,
void* recvbuf, int recvcount, const Datatype& recvtype,
int root);
sendbuf, sendcount, sendtype – bufor danych, liczba elementów i typ
danych – wszystko po stronie nadawców. Uwaga – root (odbiorca) też nadaje.
recvbuf, recvcount, recvtype – bufor danych, liczba elementów (w
jednej porcji, np. na rysunku poniżej 100, nie 300) i typ danych – u procesora
odbierającego. Na procesorach wysyłających – ignorowane.
root – numer procesora root, ten sam u wszystkich.
Typy danych i liczba elementów spełniają te same założenia, co przy scatter.
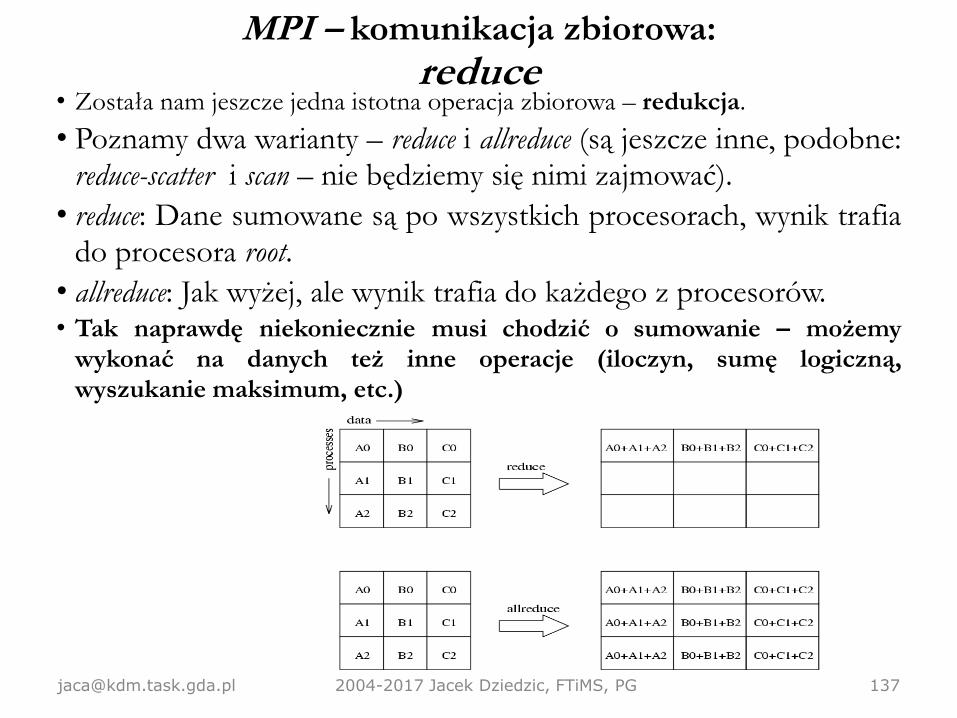
MPI – komunikacja zbiorowa:
reduce• Została nam jeszcze jedna istotna operacja zbiorowa – redukcja.
• Poznamy dwa warianty – reduce i allreduce (są jeszcze inne, podobne:reduce-scatter i scan – nie będziemy się nimi zajmować).
• reduce: Dane sumowane są po wszystkich procesorach, wynik trafiado procesora root.
• allreduce: Jak wyżej, ale wynik trafia do każdego z procesorów.• Tak naprawdę niekoniecznie musi chodzić o sumowanie – możemy
wykonać na danych też inne operacje (iloczyn, sumę logiczną,wyszukanie maksimum, etc.)
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 137
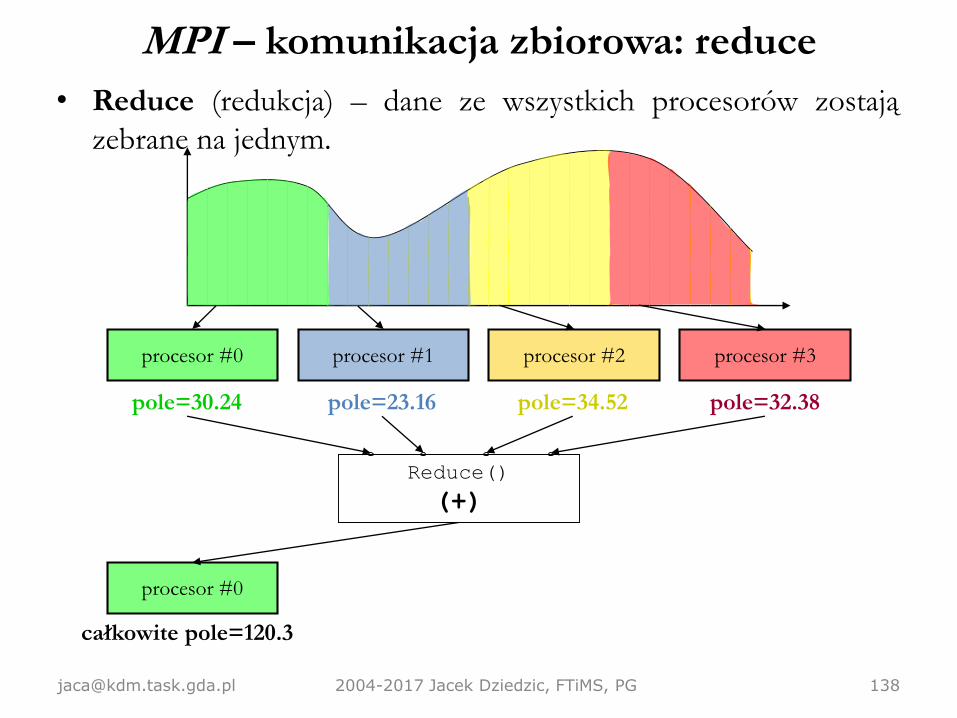
MPI – komunikacja zbiorowa: reduce
• Reduce (redukcja) – dane ze wszystkich procesorów zostają
zebrane na jednym.
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 138
procesor #0 procesor #2procesor #1 procesor #3
pole=30.24 pole=23.16 pole=34.52 pole=32.38
Reduce()
(+)
procesor #0
całkowite pole=120.3

MPI – komunikacja zbiorowa:
reduce• Przykłady (z jedną daną):
– Obliczamy całkę oznaczoną, każdy procesor dostał do obliczeń jeden
podprzedział. Na końcu chcemy wysumować cząstkowe odpowiedzi
każdego procesora, żeby dostać wynik. (op: +)
– Obliczamy prawdopodobieństwo jednoczesnego wystąpienia N zdarzeń
niezależnych. Każdy z procesorów zajmuje się n zdarzeniami z N. Na
końcu chcemy poznać całkowite prawdopodobieństwo, które jest
iloczynem prawdopodobieństw cząstkowych (op: *)
– Poszukujemy największej pośród N wartości. Każdy z k procesorów
przegląda (N/k) wartości z N i znajduje największą z nich. Na końcu
mamy k kandydatów do największej, spośród których trzeba wybrać
"naprawdę największą". (op: max)
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 139

MPI – komunikacja zbiorowa:
reduce
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 140
void MPI::Intracomm::Reduce(const void* sendbuf, void* recvbuf,
int count, const Datatype& datatype, const Op& op, int root)
sendbuf – bufor nadawczy danych, na każdym z procesorów biorących udziałw operacji.
recvbuf – bufor odbiorczy danych – istotny tylko na procesorze odbiorczym(root), na pozostałych ignorowany.
count – liczba rozsyłanych/odbieranych elementów. datatype – typ danych MPI. op – operacja, którą wykonujemy na danych. Dostępne są następujące operacje,
oraz operacje zdefiniowane przez użytkownika (wyższa szkoła jazdy)MPI::SUM suma +
MPI::PROD iloczyn *
MPI::MIN minimum std::min
MPI::MAX maksimum std::max
MPI::LOR suma logiczna ||
MPI::LAND il. logiczny &&
MPI::LXOR albo logiczne nie ma
MPI::BOR suma bitowa |
MPI::BAND iloczyn bitowy &
MPI::BXOR albo bitowe ^
MPI::MINLOC minimum wraz z
położeniem
nie ma
MPI::MAXLOC maksimum wraz z
położeniem
nie ma

MPI – komunikacja zbiorowa:
reduce
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 141
Przykład – sumowanie jednej zmiennej double po procesorach:
// uruchamiamy na 5 procesorach, zakładamy że
// mój_numer jest numerem procesora (0..4)
double send = 10*mój_numer;
double recv;
MPI::COMM_WORLD.Reduce(&send,&recv,1,MPI::DOUBLE,MPI::SUM,0);
cout << "Na procesorze " << mój_numer
<< " recv wynosi " << recv << endl;
Wyprodukuje coś w rodzajuNa procesorze 2 recv wynosi -3.1857e+66
Na procesorze 3 recv wynosi 2.4913e-293
Na procesorze 0 recv wynosi 100
Na procesorze 1 recv wynosi 1.3179e+11
Na procesorze 4 recv wynosi +inf
Na procesorze root w buforze odbiorczym recv dostaliśmy sumę zawartości
buforów send wszystkich procesorów (0+10+20+30+40=100).
Na pozostałych procesorach zawartość bufora odbiorczego jest niezdefiniowana
(bo nic nie odbierają), dostaliśmy więc śmieci.

MPI – komunikacja zbiorowa:
reduce – uwagi
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 142
Podobnie jak przy poprzednich operacjach komunikacji zbiorowej
w komunikacji muszą wziąć udział wszystkie procesory
komunikatora, tj. funkcję Reduce() trzeba wywołać na każdym z
procesorów w komunikatorze, inaczej zakleszczymy program.
Operacja redukcji czyni założenie, że operator #, którym
działamy na dane jest łączny, tj.
A # (B # C) == (A # B) # C
Na ogół jest to prawda, ale:
• przy operacjach definiowanych przez użytkownika –
niekoniecznie, wtedy będą kłopoty.
Dodawanie i mnożenie zmiennoprzecinkowe
nie są łączne.

Jak to dodawanie nie jest łączne?
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 143
Dodawanie jest łączne, to dodawanie liczb zmiennoprzecin-
kowych nie jest. #include <iostream>
#include <iomanip>
using namespace std;
int main() {
float a=4,b=4;
float c=100000000;
cout << setprecision(20) << (a+b)+c << endl
<< a+(b+c) << endl;
}
// wyprodukuje
// 100000008
// 100000000
Innymi słowy – wynik dodawania liczb zmiennoprzecinkowych zależy od
kolejności, w której są dodawane. a Reduce() może dowolnie wybrać kolejność
dodawania żeby mieć pole do optymalizacji. Problem pojawia się tylko, gdy liczby
mocno różnią się rzędami wielkości.
Przyczyna: skończona precyzja. Przy pracy z liczbami rzędu 100000000
najdrobniejszy wkład, który możemy dodać jest większy od 4 i mniejszy od 8.
W konsekwencji dodanie 4 nie skutkuje dodaniem czegokolwiek. Dodanie 8
działa. Próba dodania 9 również skończyłaby się wynikiem 100000008. Taki już
urok liczb zmiennoprzecinkowych.

MPI – komunikacja zbiorowa [2]:
allreduce
• Allreduce() realizuję operację analogiczną do Reduce(), z tą różnicą, że
wynik redukcji trafia do każdego z procesorów, nie tylko do root.
• W konsekwencji na każdym procesorze dostajemy ten sam wynik operacji (przy
założeniu łączności).
• Składnia – taka sama jak dla Reduce(), tylko parametr root nie jest już potrzebny,
bo wszyscy odbierają.
void MPI::Intracomm::Allreduce(const void* sendbuf, void* recvbuf,
int count, const Datatype& datatype, Op& op);
• Obowiązują te same założenia, co dla MPI_Reduce().
[email protected] 2004-2017 Jacek Dziedzic, FTiMS, PG 144
Top Related