
Slaska Internetowa Biblioteka Zbiorow Zabytkowych - zbiory wybrane do digitalizacji

Zbiory przyblizone w obliczeniachgranularnych
Anna GomolinskaUniwersytet w Białymstoku
Poznan, Instytut Informatyki Politechniki Poznanskiej,2011.11.22
Sem-PP’2011 – p. 1/124

Plan wystapienia• Motywacje.• Obliczenia granularne.• Zbiory przyblizone.• Główne kierunki badan autorki.• Podsumowanie.
Sem-PP’2011 – p. 2/124

Motywacje• Odkrywanie wiedzy o obiektach złozonych jak
systemy inteligentne oraz o procesach iinterakcjach zachodzacych w takich systemach.
• Rozwój podstaw obliczen granularnych.• Dostarczenie nowych i udoskonalenie
istniejacych narzedzi i technik słuzacychrozwiazywaniu problemów metodamigranularnymi.
Sem-PP’2011 – p. 3/124

Obliczenia granularne• Pojecie ‘granula informacyjna’ pochodzi od
L. A. Zadeha.• W ujeciu Zadeha granula informacyjna (w
skrócie infogranula) to skupisko obiektówzebranych ze wzgledu na nierozróznialnosc,podobienstwo lub funkcjonowanie(funkcjonalnosc).
• Aktualnie rozwaza sie takze infogranuleustrukturyzowane (struktury, systemy, procesy).
Sem-PP’2011 – p. 4/124

Obliczenia granularne c.d.• Granulacja przestrzeni badanych obiektów
(uniwersum) jako wynik celowych zabiegów lubjako skutek naturalnych ograniczen w zakresiepercepcji, dokładnosci pomiarów i gromadzeniadanych o obiektach.
• Wykorzystanie tej granulacji do rozwiazywaniaproblemów, w tym obliczeniowych w warunkachniedoskonałej informacji.
• Realizacja idei obliczen granularnych metodamianalizy przedziałowej, analizy skupien, zbiorówprzyblizonych, zbiorów rozmytych i innych.
Sem-PP’2011 – p. 5/124

Zbiory przybli zone• W oryginalnym ujeciu zaproponowanym przez
Z. Pawlaka granulacja przestrzeni generowanaprzez nierozróznialnosc obiektów z uwagi narozwazane atrybuty, modelowana jako pewnarelacja równowaznosci.
• Zbiór definiowalny: suma pewnych infogranulelementarnych, czyli klas abstrakcji relacjinierozróznialnosci.
• Dolne przyblizenie zbioru: najwiekszy zbiórdefiniowalny zawarty w tym zbiorze.
• Górne przyblizenie zbioru: najmniejszy zbiórdefiniowalny zawieraj ˛acy ten zbiór.
Sem-PP’2011 – p. 6/124

Zbiory przybli zone c.d.• Brzeg zbioru: róznica miedzy górnym i dolnym
przyblizeniem zbioru.• Zbiór jest dokładny, jesli jego brzeg jest pusty; w
przeciwnym przypadku zbiór jest przyblizony.• W podejsciu Pawlaka dokładnosc i
definiowalnosc sa równowazne.• Pierwotnie przestrzen przyblizen to para
(zbiór_ obiektów, relacja_równowaznosci).
Sem-PP’2011 – p. 7/124

Wybrane uogólnienia modeluPawlaka• Model A. Skowrona i J. Stepaniuka (dolne i
górne przyblizenia zdefiniowane za pomocafunkcji inkluzji przyblizonej, granulacjagenerowana przez podobienstwo obiektówmodelowane przez relacje zwrotna).
• Model DRSA R. Słowinskiego, S. Greco iB. Matarazzo (uwzglednienie oprócz zwykłychatrybutów takze kryteriów, granulacjagenerowana przez relacje oparta na dominacji lubpodobienstwie obiektów).
Sem-PP’2011 – p. 8/124

Wybrane uogólnienia c.d.• Model S. K. M. Wonga, L. S. Wanga & Y. Y. Yao
(granulacja jak u Pawlaka, dwusortowaprzestrzen obiektów lub inaczej, dwa uniwersaobiektów dwóch róznych rodzajów).
• Modele VPRS W. Ziarko (w podstawowymmodelu granulacja jak u Pawlaka, dolne i górneprzyblizenia zast ˛apione rodzina regionówt-pozytywnych i rodzina regionóws-negatywnych, gdzies, t – stopnie precyzji(0 ≤ s < t ≤ 1), do których zdefiniowania uzytajest standardowa funkcja inkluzji przyblizonej).
Sem-PP’2011 – p. 9/124

Główne kierunki moich badanKI. Model Pawlaka zbiorów przyblizonych i jego
uogólnienia.
KII. Potencjalne czesci „w stopniu” pewnej całosci.
KIII. Przyblizone spełnianie formuł i ich zbiorów.
KIV. Porównywanie infogranul pod wzgledem ichzawierania sie i podobienstwa.
Sem-PP’2011 – p. 10/124

KI: Główne wyniki• Porównanie własnosci operacji przyblizania w
sensie Pawlaka i w sensie Skowrona – Stepaniukaprzy róznych załozeniach o relacji miedzyobiektami.
• Model zmienno-precyzyjny o dwóch uniwersach(kombinacja modelu Wonga, Wanga i Yao zpodstawowym modelem VPRS Ziarki).
• Model, w którym oprócz podobienstwa poduwage brane jest takze niepodobienstwoobiektów.
• Model uogólniaj ˛acy podejscie Skowrona –Stepaniuka, w którym do zdefiniowaniaprzyblizen zbioru uzyte s ˛a funkcje inkluzjisłabsze niz funkcja inkluzji przyblizonej.
Sem-PP’2011 – p. 11/124

KI: Publikacje• Variable-precision compatibility spaces,
Electronical Notices in Theoretical ComputerScience, 82(4):120–131, 2003,http://www.elsevier.nl/locate/entcs/volume82.html
• A comparison of Pawlak’s and Skowron –Stepaniuk’s approximation of concepts,Transactions on Rough Sets VI: journal sublineof LNCS, 4374:64–82, 2007.
Sem-PP’2011 – p. 12/124

KI: Publikacje c.d.• Approximation spaces based on relations of
similarity and dissimilarity of objects,Fundamenta Informaticae, 79(3–4):319–333,2007.
• Rough approximation based on weak q-RIFs,Transactions on Rough Sets X: journal subline ofLNCS, 5656:117–135, 2009.
Sem-PP’2011 – p. 13/124

KII: Wprowadzenie
• Z zagadnieniem potencjalnych czesci „wstopniu” wiaze sie problem stabilnoscikonstruowanych infogranul.
• Formalna teoria pojecia „bycia czescia” jestmereologia Lesniewskiego, natomiast pojecia„bycia czescia w stopniu” – mereologiaprzyblizona (L. Polkowski & A. Skowron).
Sem-PP’2011 – p. 14/124

KII: Główne wyniki• Uogólnienie pojecia „czesci w stopniu” do
pojecia „potencjalnej czesci w stopniu”.• Zbadanie własnosci wprowadzonego pojecia.
Referencje:• Possible rough ingredients of concepts in
approximation spaces,Fundamenta Informaticae,72(1–3):139–154, 2006.
Sem-PP’2011 – p. 15/124

KII: Główne wyniki c.d.
• Czesc potencjalna pewnej całosciX toinfogranula na tyle pasuj ˛aca (bliska, podobna) dopewnej czesciY całosciX, ze mozna nia zast ˛apicY .
• Potencjalna czesc „w stopniu” całosciX toinfogranula na tyle pasuj ˛aca do pewnej czesci „wstopniu”Y całosciX, ze mozna nia zast ˛apic Y .
Sem-PP’2011 – p. 16/124

KIII: Wprowadzenie• Przyblizone spełnianie formuł i zbiorów formuł
badane jest na przykładzie formuł jezykadeskryptorów systemu informacyjnego Pawlaka.
• Dostepna informacja o rozwazanych obiektachjest niedoskonała.
• Celem jest odkrywanie pojecia spełniania formułi ich zbiorów, a nie zbudowanie formalnegosystemu logicznego.
Sem-PP’2011 – p. 17/124

KIII: Wprowadzenie c.d.• U – dany skonczony, niepusty zbiór obiektów
(aktualne uniwersum).• U∞ – potencjalne uniwersum, zawieraU .• Obiekty oznaczamy przezu, z indeksami w razie
potrzeby.
Sem-PP’2011 – p. 18/124

KIII: Wprowadzenie c.d.• A – skonczony, niepusty zbiór rozwazanych cech
(atrybutów).• Atrybuty, oznaczane przeza (z indeksami),
traktujemy jako funkcjea : U∞ 7→ Va ∪ {⊥}.• Va – zbiór rozwazanych wartoscia.• Wartosci atrybutów oznaczamy przezv (z
indeksami).• a(u) =⊥ – „wartosc a nau jest nieznana”.• Para (atrybut, wartosc_atrybutu) – deskryptor.
Sem-PP’2011 – p. 19/124

KIII: Wprowadzenie c.d.• Przykład systemu informacyjnego Pawlaka (w
skrócie infosystemu) to paraIS = (U,A), gdzieU i A sa jak wyzej.
• Infosystemy decyzyjne = infosystemy zwyróznionym atrybutem decyzyjnymd (lubzbiorem atrybutów decyzyjnych).
• Przykład infosystemu decyzyjnego to paraISd = (U,A ∪ {d}), gdzied 6∈ A.
Sem-PP’2011 – p. 20/124

KIII: Wprowadzenie c.d.• Niech ⊆ U × U bedzie relacja podobienstwa.• (u, u′) ∈ – „obiektu jest podobny dou′”.• Dwa rodzaje elementarnych infogranul
zwiazanych zu: zbiór obiektów, do którychu jestpodobny, →{u} (= Γ∗u), i zbiór obiektówpodobnych dou, ←{u} (= Γu).
• Zbiory te s ˛a równe dla relacji tolerancji (czylizwrotnej i symetrycznej).
• oraz infogranule elementarne moga byc znaneczesciowo.
Sem-PP’2011 – p. 21/124

KIII: Wprowadzenie c.d.• Rozwazamy pewna przestrzen przyblizenM = (U, , κ) indukowana przez infosystem ISoraz jej potencjalne rozszerzenie doM∞ = (U∞, ∞, κ∞).
• Oprócz przyblizen w stylu Pawlaka i w styluSkowrona – Stepaniuka, interesuja nas regionyt-pozytywne orazs-negatywne zbiorów,podobnie jak w modelu VPRS Ziarki(0 ≤ s < t ≤ 1):
post(X)def= {u ∈ U | κ(Γu,X) ≥ t}
negs(X)def= {u ∈ U | κ(Γu,X) ≤ s}
Sem-PP’2011 – p. 22/124

KIII: J˛ezyk deskryptorówL dlainfosystemu IS• Termy – nazwy elementów zbioruA ∪
⋃
a∈A Va.• ∧,∨,¬ – spójniki zdaniowe.• Formuła = zdanie.• Zdania atomowe – deskryptory.• Zdania oznaczamy przezα, β, γ (z indeksami).• FOR – zbiór wszystkich zdanL.
Sem-PP’2011 – p. 23/124

KIII: J˛ezyk deskryptorów c.d.• Pojecie = podzbiór uniwersum, czyli jakis zbiór
obiektów.• Pojecie definiowalne = suma mnogosciowa
infogranul elementarnych.• Intuicje zwiazane z definiowalnoscia: zbiór
definiowalny = zbiór opisywalny w jezykuL.• Formuła – etykieta pewnego pojecia, mianowicie
ekstensji tej formuły.• Ekstensja formuły = zbiór (infogranula) obiektów
spełniaj ˛acych te formułe.
Sem-PP’2011 – p. 24/124

KIII: Poj˛ecie spełniania|=c
u |=c (a, v)def⇔ a(u) = v
u |=c α ∧ βdef⇔ u |=c α & u |=c β
u |=c α ∨ βdef⇔ u |=c α lub u |=c β
u |=c ¬αdef⇔ u 6|=c α
• Odpowiadajace pojecie ekstensji formuły:
Satc(α)def= {u ∈ U | u |=c α}
Sem-PP’2011 – p. 25/124

KIII: Przybli zone spełnianieformuł i ich zbiorów• Problem jest skomplikowany, gdyz:
• pojecie spełniania jest pojeciem wysokiegopoziomu,
• nie znamy tego pojecia dokładnie: trzeba jeodkryc, np. hierarchicznie,
• w szczególnosci nie znamy w pełni ekstensjiformuł (zbiorów formuł),
• opisy obiektów moga byc niekompletne iniedokładne,
• nie wiadomo, czy wybrany jezyk opisu jestodpowiedni,
• nie wiadomo, czy przyjeta/odkryta relacjapodobienstwa jest własciwa, a st ˛ad nie wiemy,czy granulacja jest prawidłowa.
Sem-PP’2011 – p. 26/124

KIII: Główne wyniki• Modele pojecia spełniania formuł (zbiorów
formuł) w postaci sparametryzowanych rodzinrelacji przyblizonego spełniania formuł (zbiorówformuł).
• Zbadanie własnosci zdefiniowanych relacji.• Propozycja odkrywania pojecia spełniania formuł
i ich zbiorów z dostepnych danych i przykładówdostarczonych przez eksperta.
• Interpretacja wprowadzonych pojecprzyblizonego spełniania formuł oraz pojecstowarzyszonych w terminach teorii zbiorówrozmytych.
Sem-PP’2011 – p. 27/124

KIII: Główne wyniki c.d.• Zastosowanie wprowadzonych pojec
przyblizonego spełniania do zagadnieniaprzyblizonego stosowania reguł.
• Zastosowanie przyblizonych form spełnianiaformuł i zbiorów formuł do zagadnieniakonstrukcji infogranul spełniaj ˛acych danewymagania.
• Badanie kwestii formowania s ˛adów w agentachinteligentnych na temat spełnienia pewnychwymagan, zachodzenia zdarzen itp., gdydostepna informacja jest niedoskonała.
Sem-PP’2011 – p. 28/124

KIII: Publikacje• A graded applicability of rules,Lecture Notes in
Artificial Intelligence, 3066:213–218, 2004.• A graded meaning of formulas in approximation
spaces,Fundamenta Informaticae,60(1–4):159–172, 2004.
• On rough judgment making by socio-cognitiveagents, [in:] A. Skowron et al., editors,Proc.2005 IEEE//WIC//ACM Int. Conf. on IntelligentAgent Technology (IAT’2005), Compiegne,France, September 2005, pages 421–427, IEEEComputer Society Press, Los Alamitos, CA,2005.
Sem-PP’2011 – p. 29/124

KIII: Publikacje c.d.• Satisfiability and meaning of formulas and sets of
formulas in approximation spaces,FundamentaInformaticae, 67(1–3):77–92, 2005.
• Towards rough applicability of rules, [in:]B. Dunin-Keplicz, A. Jankowski, A. Skowron,and M. Szczuka, editors,Monitoring, Security,and Rescue Techniques in Multiagent Systems,pages 203–214, Springer-V., Berlin Heidelberg,2005.
Sem-PP’2011 – p. 30/124

KIII: Publikacje c.d.• Construction of rough information granules, [in:]
W. Pedrycz, A. Skowron, and V. Kreinovich,editors,Handbook of Granular Computing, pages449–470, John Wiley & Sons, Chichester, 2008.
• Rough rule-following by social agents, [in:]H. Flam and M. Carson, editors,Rule SystemsTheory. Applications and Explorations, pages103–118, Peter Lang, Frankfurt am Main, 2008.
• Satisfiability of formulas from the standpoint ofobject classification: The RST approach,Fundamenta Informaticae, 85(1–4):139–153,2008.
Sem-PP’2011 – p. 31/124

KIII: Publikacje c.d.• A fuzzy view on rough satisfiability,Lecture
Notes in Artificial Intelligence, 6086:227–236,2010.
• Satisfiability judgement under incompleteinformation,Transactions on Rough Sets XI:journal subline of LNCS, 5946:66–91, 2010.
Sem-PP’2011 – p. 32/124

KIV: Wprowadzenie• Inkluzja przyblizona – pojecie zaproponowane
przez L. Polkowskiego i A. Skowrona jakokluczowe pojecie mereologii przyblizonej.
• Mereologia przyblizona – formalna teoriauogólniajaca mereologie Lesniewskiego naprzypadek „bycia czescia całosci w pewnymstopniu”.
• Funkcje inkluzji przyblizonej – funkcjedwuargumentowe mierzace stopien zawieraniasie zbioru w zbiorze (takze infogranuli winfogranuli), zgodne z aksjomatami inkluzjiprzyblizonej.
Sem-PP’2011 – p. 33/124

Aksjomaty inkluzji przybli zonej• xεingt(y) – „x jest czesciay w stopniut”.
(PS1) ∃t.xεingt(y)→ xεx ∧ yεy
(PS2) xεing1(y)↔ xεing(y)
(PS3) xεing1(y)→ ∀z.(zεingt(x)→ zεingt(y))
(PS4) x = y ∧ xεingt(z)→ yεingt(z)
(PS5) xεingt(y) ∧ s ≤ t→ xεings(y)
Sem-PP’2011 – p. 34/124

Funkcje inkluzji przybli zonej• Funkcja inkluzji przyblizonej (RIF) nad zbioremU to dowolna funkcjaκ : ℘U × ℘U 7→ [0, 1]spełniaj ˛acarif1 orazrif∗2:
rif1(κ)def⇔ ∀X,Y.(κ(X,Y ) = 1 ⇔ X ⊆ Y )
rif∗2(κ)def⇔ ∀X,Y, Z.(κ(Y, Z) = 1⇒ κ(X,Y ) ≤ κ(X,Z))
Sem-PP’2011 – p. 35/124

RIF-y c.d.• Załozywszy,ze zachodzirif1(κ), warunekrif∗2
mozna zast ˛apic przezrif2:
rif2(κ)def⇔ ∀X,Y, Z.(Y ⊆ Z ⇒ κ(X,Y ) ≤ κ(X,Z))
Sem-PP’2011 – p. 36/124

Przykłady warunków na κ
rif3(κ)def⇔ ∀X 6= ∅.κ(X, ∅) = 0
rif4(κ)def⇔ ∀X,Y.(κ(X,Y ) = 0 ⇒ X ∩ Y = ∅)
rif−14 (κ)def⇔ ∀X 6= ∅.∀Y.(X ∩ Y = ∅ ⇒ κ(X,Y ) = 0)
rif5(κ)def⇔ ∀X 6= ∅.∀Y.(κ(X,Y ) = 0 ⇔ X ∩ Y = ∅)
rif6(κ)def⇔ ∀X 6= ∅.∀Y.κ(X,Y ) + κ(X,Y c) = 1
Sem-PP’2011 – p. 37/124

Przykłady RIF-ów• NiechU – zbiór skonczony.• Najbardziej rozpowszechniona jest standardowa
funkcja inkluzji przyblizonejκ£.• Inny przykład – funkcja inkluzji przyblizonejκ2
(G. Drwal i A. Mrózek, 1998).• Generowanie inkluzji przyblizonej zt-rezydualnej implikacji (L. Polkowski).
Sem-PP’2011 – p. 38/124

Przykłady RIF-ów c.d.
κ£(X,Y )def=
{
#(X∩Y )#X
dlaX 6= ∅1 w przeciwnym przypadku
κ2(X,Y )def=
#(Xc ∪ Y )
#U
Sem-PP’2011 – p. 39/124

Uogólnienia RIF-ów• Sa to, np. funkcjeκκ
s,t orazκπidla i = 1, 2.
• Niechκ bedzie RIF-em nadU oraz0 ≤ s < t ≤ 1.
κκs,t(X,Y )
def=
0 dla κ(X,Y ) ≤ sκ(X,Y )−s
t−s dla s < κ(X,Y ) < t
1 dlaκ(X,Y ) ≥ t
Sem-PP’2011 – p. 40/124

Uogólnienia RIF-ów c.d.• (J. Stepaniuk) NiechU1, U2 – skonczone zbiory
niepuste orazr, r′ ⊆ U1 × U2.
κπ1(r, r′)
def=
{
#(r∩r′)←U2
#r←U2
dla r 6= ∅
1 w przeciwnym przypadku
κπ2(r, r′) =
{
#(r∩r′)→U1
#r→U1
dla r 6= ∅
1 w przeciwnym przypadku
Sem-PP’2011 – p. 41/124

KIV: Główne wyniki• Zaproponowanie funkcji inkluzji przyblizonej
mogacych stanowic alternatywe dla funkcjistandardowej.
• Zbadanie własnosci funkcji standardowej orazfunkcji alternatywnych, w tym wykryciewzajemnych zaleznosci.
• Zbadanie zwiazków miedzy rozwazanymiRIF-ami a pewnymi miarami podobienstwainfogranul uzywanymi w analizie skupien.
Sem-PP’2011 – p. 42/124

KIV: Główne wyniki c.d.• Uogólnienie pojecia RIF-a (zbadanie własnosci,
znalezienie nowych przykładów).• Zastosowanie operacji algebraicznych,
odpowiadajacych pewnym implikacjom3-wartosciowym, do otrzymania nowych funkcjiinkluzji; nastepnie zbadanie własnosci tychfunkcji.
• Zastosowanie rozwazanych funkcji inkluzji, np.do• badania podobienstwa infogranul,• przyblizania zbiorów i w szczególnosci
infogranul,• oceny jakosci reguł.
Sem-PP’2011 – p. 43/124

KIV: Publikacje• Rough validity, confidence, and coverage of rules
in approximation spaces,Transactions on RoughSets III: journal subline of LNCS, 3400:57–81,2005.
• On certain rough inclusion functions,Transactions on Rough Sets IX: journal sublineof LNCS, 5390:35–55, 2008.
• Rough approximation based on weak q-RIFs,Transactions on Rough Sets X: journal subline ofLNCS, 5656:117–135, 2009.
• A logic-algebraic approach to graded inclusion,Fundamenta Informaticae, 109:265–279, 2011.
Sem-PP’2011 – p. 44/124

KIV: RIF-y alternatywne do κ£
• Funkcjaκ1 : ℘U × ℘U 7→ [0, 1] dana ponizej ma„wspólne korzenie” zκ£ i κ2.
κ1(X,Y ) =
{
#Y#(X∪Y ) dlaX ∪ Y 6= ∅
1 w przeciwnym przypadku
Sem-PP’2011 – p. 45/124

KIV: Własno sciκ£, κ1 i κ2
• NiechX ,Y – niepuste rodziny podzbiorówU .
κ£(X,⋃
Y) ≤∑
Y ∈Y
κ£(X,Y )
(„=” je sli X jest niepusty orazY jest rodzina zbiorówparami rozłacznych.)
κ£(⋃
X , Y ) ≤∑
X∈X
κ£(X,Y ) · κ£(⋃
X , X)
(„=” je sli X jest rodzina zbiorów paramirozłacznych.)
Sem-PP’2011 – p. 46/124

KIV: Własno sci c.d.• Niech terazX 6= ∅ orazY – rodzina parami
rozłacznych podzbiorówU bedaca pokryciemU .
∑
Y ∈Y
κ£(X,Y ) = 1
κ£(X,Y ) = 0⇔ X ∩ Y = ∅
κ£(X, ∅) = 0
Sem-PP’2011 – p. 47/124
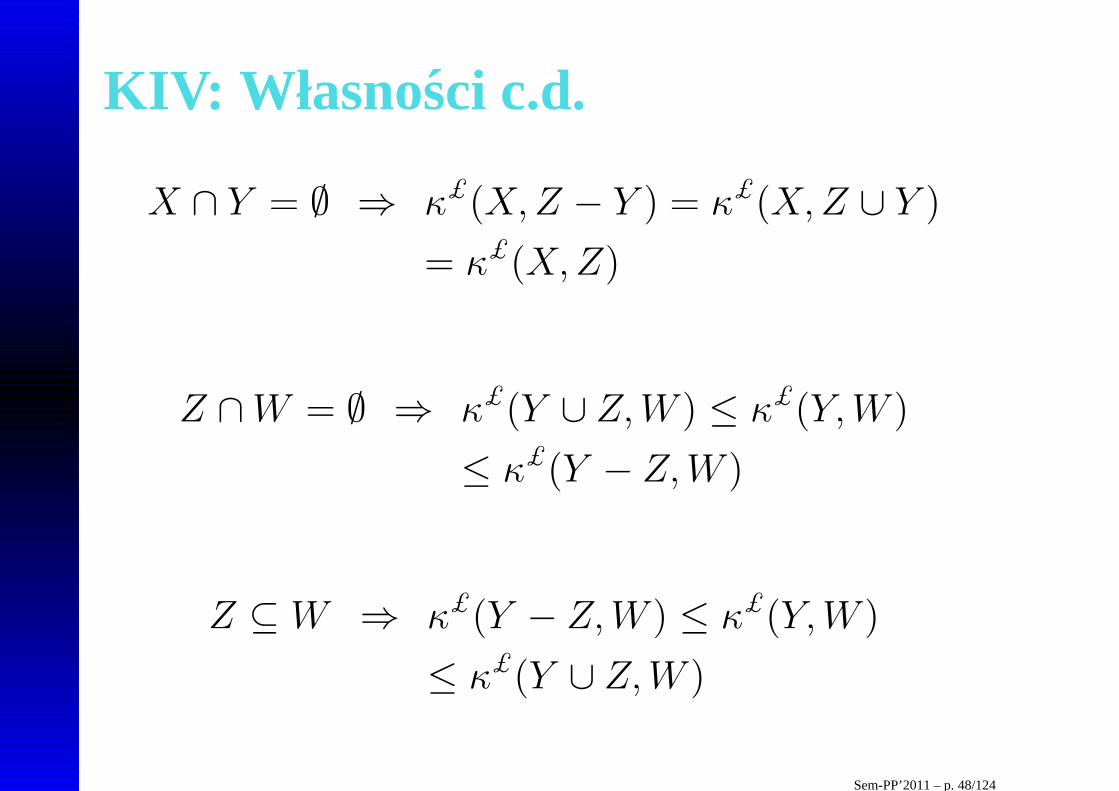
KIV: Własno sci c.d.
X ∩ Y = ∅ ⇒ κ£(X,Z − Y ) = κ£(X,Z ∪ Y )
= κ£(X,Z)
Z ∩W = ∅ ⇒ κ£(Y ∪ Z,W ) ≤ κ£(Y,W )
≤ κ£(Y − Z,W )
Z ⊆ W ⇒ κ£(Y − Z,W ) ≤ κ£(Y,W )
≤ κ£(Y ∪ Z,W )
Sem-PP’2011 – p. 48/124
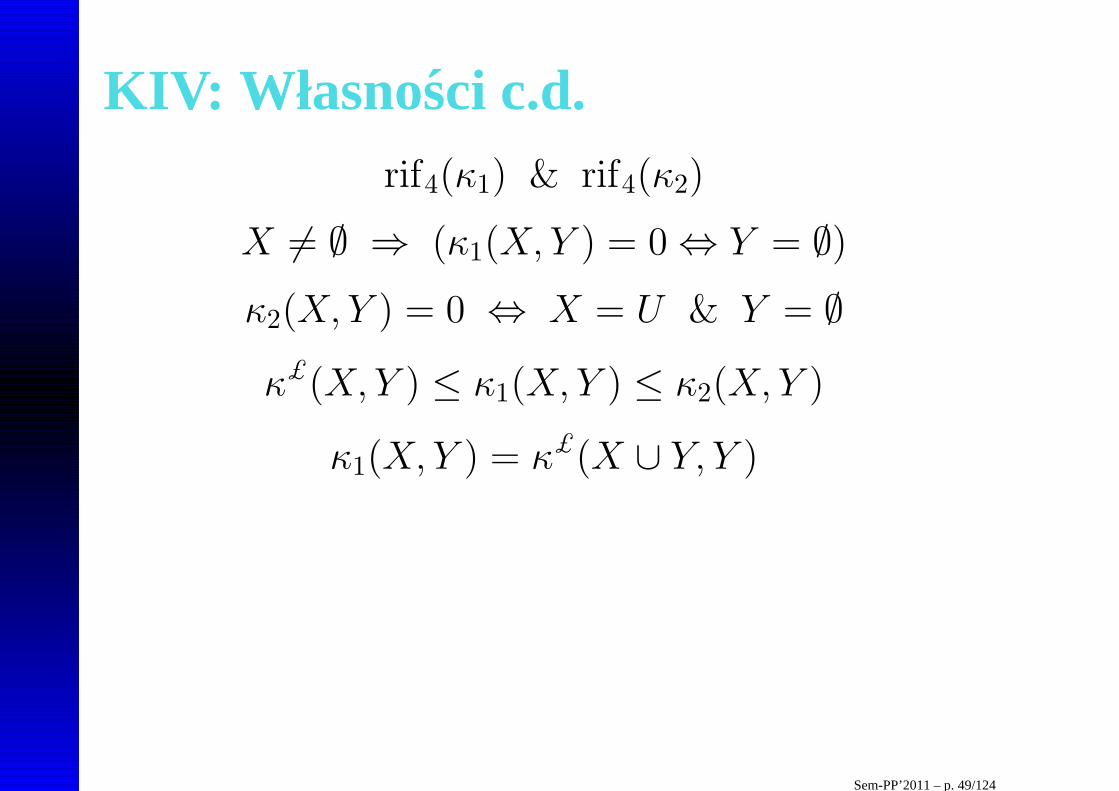
KIV: Własno sci c.d.rif4(κ1) & rif4(κ2)
X 6= ∅ ⇒ (κ1(X,Y ) = 0⇔ Y = ∅)
κ2(X,Y ) = 0 ⇔ X = U & Y = ∅
κ£(X,Y ) ≤ κ1(X,Y ) ≤ κ2(X,Y )
κ1(X,Y ) = κ£(X ∪ Y, Y )
Sem-PP’2011 – p. 49/124
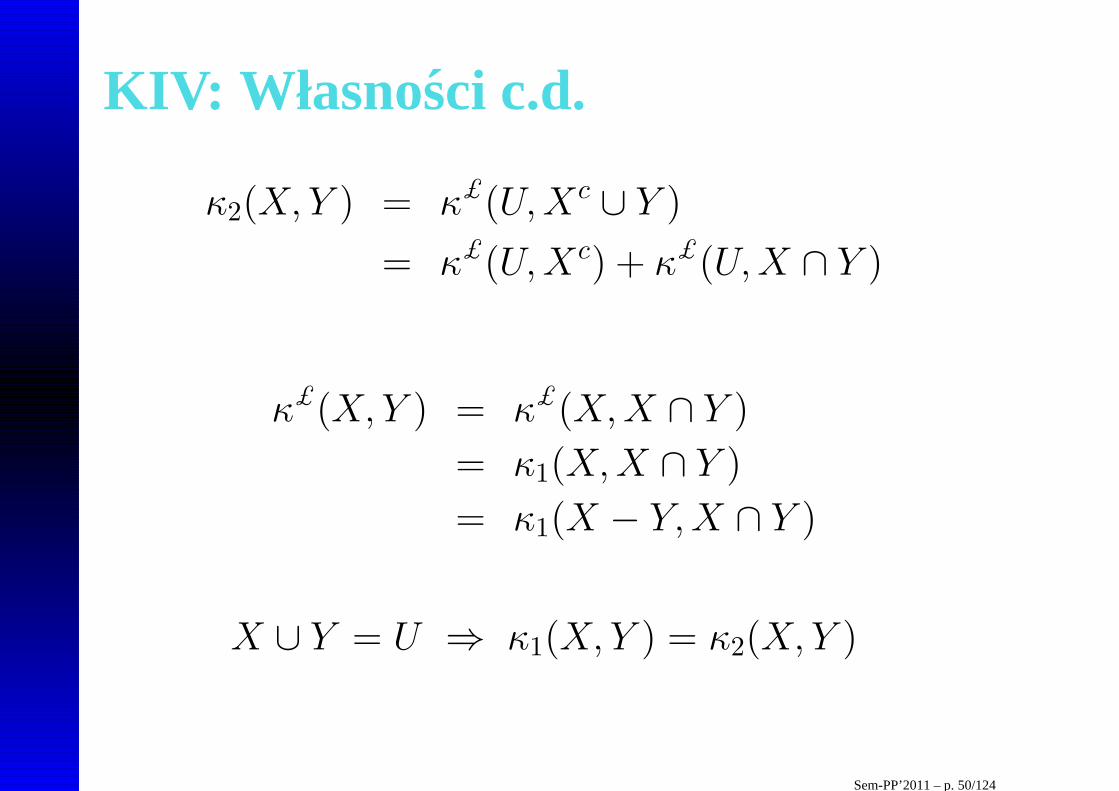
KIV: Własno sci c.d.
κ2(X,Y ) = κ£(U,Xc ∪ Y )
= κ£(U,Xc) + κ£(U,X ∩ Y )
κ£(X,Y ) = κ£(X,X ∩ Y )
= κ1(X,X ∩ Y )
= κ1(X − Y,X ∩ Y )
X ∪ Y = U ⇒ κ1(X,Y ) = κ2(X,Y )
Sem-PP’2011 – p. 50/124

KIV: RIF-y a podobie nstwo in-fogranul• Dla dowolnej funkcjif : ℘U × ℘U 7→ [0, 1] orazX,Y ⊆ U , definiujemy jej funkcjekomplementarnaf :
f(X,Y )def= 1− f(X,Y )
Sem-PP’2011 – p. 51/124

KIV: RIF-y a podobie nstwo c.d.• Dostajemy zatem:
κ£(X,Y ) =
{
#(X−Y )#X
dlaX 6= ∅0 w przeciwnym przypadku
κ1(X,Y ) =
{
#(X−Y )#(X∪Y ) dlaX ∪ Y 6= ∅
0 w przeciwnym przypadku
κ2(X,Y ) =#(X − Y )
#U
Sem-PP’2011 – p. 52/124

KIV: RIF-y a podobie nstwo c.d.• Niechκ – dowolny RIF nadU orazi = 1, 2.
κ£(X,Y ) = κ£(X,Y c)
Jesli X 6= ∅, to
κ£(X,Y ) =κ1(X,Y c)
κ1(Y c, X)=
κ2(X,Y c)
κ2(U,X).
κ(X,Y ) = 0 ⇔ X ⊆ Y
Sem-PP’2011 – p. 53/124

KIV: RIF-y a podobie nstwo c.d.
Y ⊆ Z ⇒ κ(X,Z) ⊆ κ(X,Y )
κ2(X,Y ) ≤ κ1(X,Y ) ≤ κ£(X,Y )
κi(X,Y ) + κi(Y, Z) ≥ κi(X,Z)
Sem-PP’2011 – p. 54/124

KIV: RIF-y a podobie nstwo c.d.
0 ≤ κi(X,Y ) + κi(Y,X) ≤ 1
Jesli X = ∅ i Y 6= ∅ (lub odwrotnie), to
κ£(X,Y ) + κ£(Y,X) = κ1(X,Y ) + κ1(Y,X) = 1.
Sem-PP’2011 – p. 55/124

KIV: RIF-y a podobie nstwo c.d.• Funkcje komplementarne doκ£, κ1 i κ2 generuja
funkcje odległosci δ£, δi : ℘U × ℘U 7→ [0, 1](i = 1, 2) nastepuj ˛aco:
δ£(X,Y )def=
1
2
(
κ£(X,Y ) + κ£(Y,X))
δi(X,Y )def= κi(X,Y ) + κi(Y,X)
• Zauwazmy, ze:
δ2(X,Y ) ≤ δ1(X,Y ) ≤ 2δ£(X,Y )
Sem-PP’2011 – p. 56/124

KIV: RIF-y a podobie nstwo c.d.
δ£(X,Y ) =
12
(
#(X−Y )#X
+ #(Y−X)#Y
)
dla X,Y 6= ∅
0 dla X,Y = ∅12 w p.p.
Sem-PP’2011 – p. 57/124

KIV: RIF-y a podobie nstwo c.d.
δ1(X,Y ) =
{
#(X÷Y )#(X∪Y ) dla X ∪ Y 6= ∅
0 w przeciwnym przypadku,
• zatemδ1 jest metryka Marczewskiego –Steinhausa (1958).
δ2(X,Y ) =#(X ÷ Y )
#U
Sem-PP’2011 – p. 58/124

KIV: RIF-y a podobie nstwo c.d.
• W koncu rozwazamy funkcje komplementarne dofunkcji odległosci.
• Dla dowolnychX,Y ⊆ U :
δ£(X,Y ) =1
2
(
κ£(X,Y ) + κ£(Y,X))
=
#(X∩Y )2
(
1#X
+ 1#Y
)
dla X,Y 6= ∅
1 dla X,Y = ∅12 w p.p.
Sem-PP’2011 – p. 59/124

KIV: RIF-y a podobie nstwo c.d.
δ1(X,Y ) = κ1(X,Y ) + κ1(Y,X)− 1
=
{
#(X∩Y )#(X∪Y ) dla X ∪ Y 6= ∅
1 w przeciwnym przypadku
δ2(X,Y ) = κ2(X,Y ) + κ2(Y,X)− 1
=#((X ∪ Y )c ∪ (X ∩ Y ))
#U
Sem-PP’2011 – p. 60/124

KIV: RIF-y a podobie nstwo c.d.
• Funkcje te to miary podobienstwa znane zanalizy skupien:• δ£ – Kulczynski (1927)• δ1 – Jaccard (1908)• δ2 – Sokal and Michener (1958); Rand (1971)
Sem-PP’2011 – p. 61/124

KIV: Uogólnianie poj ecia ‘RIF’• Warunekrif1(κ) jest równowazny koniunkcjirif0(κ) i rif−10 (κ), gdzie
rif0(κ)def⇔ ∀X,Y.(X ⊆ Y ⇒ κ(X,Y ) = 1),
rif−10 (κ)def⇔ ∀X,Y.(κ(X,Y ) = 1 ⇒ X ⊆ Y ).
Sem-PP’2011 – p. 62/124

KIV: Uogólnianie poj ecia ‘RIF’c.d.• κ : ℘U × ℘U 7→ [0, 1] nazywamy
• funkcja quasi-inkluzji przyblizonej nadU ,jesli spełniarif0 i rif∗2,
• słaba funkcja quasi-inkluzji przyblizonej nadU , jesli spełniarif0 i rif2,
• funkcja quasi’-inkluzji przyblizonej nadU ,jesli spełniarif−10 i rif∗2,
• mocna funkcja quasi’-inkluzji przyblizonejnadU , jesli spełniarif−10 i rif2.
Sem-PP’2011 – p. 63/124
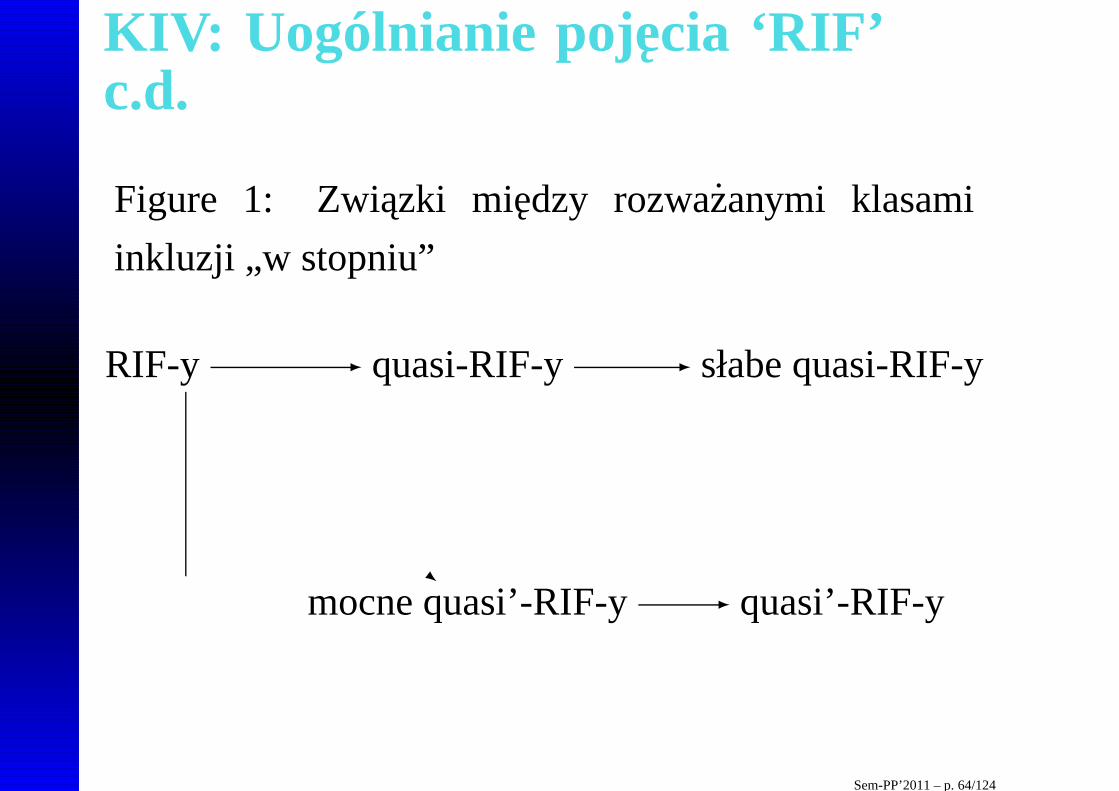
KIV: Uogólnianie poj ecia ‘RIF’c.d.
Figure 1: Zwiazki miedzy rozwazanymi klasami
inkluzji „w stopniu”
RIF-y - quasi-RIF-y - słabe quasi-RIF-y
mocne quasi’-RIF-y -
-
quasi’-RIF-y
Sem-PP’2011 – p. 64/124

KIV: Uogólnianie poj ecia ‘RIF’c.d.
• Niechκ bedzie RIF-em nadU .• Niech·, · : ℘U 7→ ℘U – monotoniczne operacje
„dolnego i górnego przyblizenia”, takieze dladowolnegoX,
X ⊆ X ⊆ X.
Sem-PP’2011 – p. 65/124

KIV: Uogólnianie poj ecia ‘RIF’c.d.• Przykładami funkcji quasi-inkluzji przyblizonej
saκκl i κκ
up dane przez:
κκl (X,Y )
def= κ(X,Y ),
κκup(X,Y )
def= κ(X,Y ).
• Natomiastκκs,t orazκπi
(i = 1, 2) sa słabymifunkcjami quasi-inkluzji przyblizonej.
Sem-PP’2011 – p. 66/124

KIV: Funkcje inkluzji a 3-wart.implikacje• Przebadane zostały nastepuj ˛ace 3-wartosciowe
logiki zdanioweL: logika Fenstada (F), logikaGödla (G), mocna logika Kleene’go (K), słabalogika Kleene’go (Kw), logika Łukasiewicza(Lu), logika McCarthy’ego (MC), logika Posta(P), logika Słupeckiego (S) i logikaSobocinskiego (So).
• Prawda jest symbolizowana przez1, fałsz przez0, trzecia wartosc logiczna przez12 .
Sem-PP’2011 – p. 67/124

KIV: Funkcje inkluzji a 3-wart.implikacje c.d.• Kazda z logikL ma adekwatna matryce logicznaML.
• Operacje matrycowef→L : {0, 12 , 1}2 7→ {0, 12 , 1}
odpowiadaja implikacjom w logikachL.• DL – zbiór wartosci wyróznionychML;DL = {1} dla wszystkichL poza So orazDSo = {
12, 1}.
• Formułaα jest tautologiaML, jesli przydowolnym wartosciowaniu wartosc α jestwyrózniona.
Sem-PP’2011 – p. 68/124

KIV: Funkcje inkluzji a 3-wart.implikacje c.d.• NiechX,Y – zbiory rozmyte o funkcjach
nalezeniaµX , µY : U 7→ [0, 1], odpowiednio.• Inkluzja rozmyta wg Zadeha, ozn.⊑, jest
naturalnym uogólnieniem inkluzji:
X ⊑ Ydef⇔ ∀u ∈ U.µX(u) ≤ µY (u)
Sem-PP’2011 – p. 69/124

KIV: Funkcje inkluzji a 3-wart.implikacje c.d.• Dowolny zbiórX ⊆ U mozna postrzegac jako
zbiór rozmyty z funkcja nalezeniaµX : U 7→ [0, 1], takaze
µX(u)def=
1 dla u ∈ X,
0 dla u ∈ (X)c,12 w pozostałym przypadku.
Sem-PP’2011 – p. 70/124

KIV: Funkcje inkluzji a 3-wart.implikacje c.d.• Z kazda logikaL wiazemy relacje⊆L na℘U ,
która jest pewnego rodzaju uogólnienieminkluzji:
X ⊆L Ydef⇔ ∀u ∈ U.f→L (µX(u), µY (u)) ∈ DL
• Stad dostajemy:
X ⊆Kw Y ⇔ ((X)c ∩ (Y ∪ (Y )c)) ∪
((X ∪ (X)c) ∩ Y ) = U
X ⊆MC Y ⇔ (X)c ∪ ((X ∪ (X)c) ∩ Y ) = U
Sem-PP’2011 – p. 71/124

KIV: Funkcje inkluzji a 3-wart.implikacje c.d.
X ⊆K Y ⇔ (X)c ∪ Y = U
X ⊆G Y ⇔ X ⊆Lu Y
⇔ (X)c ∪ Y ∪ ((X −X) ∩ (Y − Y )) = U
X ⊆So Y ⇔ (X)c ∪ Y = U
X ⊆P Y ⇔ (X −X) ∪ Y = U
X ⊆F Y ⇔ X ⊆S Y ⇔ (X)c ∪ Y = U
Sem-PP’2011 – p. 72/124

KIV: Funkcje inkluzji a 3-wart.implikacje c.d.• Definiujemy funkcje L-inkluzji nad skonczonymU jako funkcjeκL : (℘U)2 7→ [0, 1] dana przez:
κL(X,Y )def=
#{u ∈ U | f→L (µX(u), µY (u)) ∈ DL}
#U.
• κL(X,Y ) czytamy jako „stopien L-inkluzji X wY ”.
Sem-PP’2011 – p. 73/124

KIV: Funkcje inkluzji a 3-wart.implikacje c.d.
κKw(X,Y ) =
=#(((X)c ∩ (Y ∪ (Y )c)) ∪ ((X ∪ (X)c) ∩ Y ))
#U
κMC(X,Y ) =#((X)c ∪ ((X ∪ (X)c) ∩ Y ))
#U
κK(X,Y ) =#((X)c ∪ Y )
#U
Sem-PP’2011 – p. 74/124

KIV: Funkcje inkluzji a 3-wart.implikacje c.d.
κG(X,Y ) = κLu(X,Y )
=#((X)c ∪ Y ∪ ((X −X) ∩ (Y − Y )))
#U
κSo(X,Y ) =#((X)c ∪ Y )
#U
κP(X,Y ) =#((X −X) ∪ Y )
#U
κF(X,Y ) = κS(X,Y ) =#((X)c ∪ Y )
#U
Sem-PP’2011 – p. 75/124

KIV: Funkcje inkluzji a 3-wart.implikacje c.d.• Zauwazmy, ze
κF(X,Y ) = κ2(X,Y ) & κSo(X,Y ) = κ2(X,Y ).
• GdyX,Y sa dokładne, tzn.X = X orazY = Y ,to κL(X,Y ) = κ2(X,Y ) dlaL 6= P.
Sem-PP’2011 – p. 76/124

KIV: Funkcje inkluzji a 3-wart.implikacje c.d.• W celu porównaniaκL dla róznychL,
definiujemy
κL � κL′def⇔ ∀X,Y.κL(X,Y ) ≤ κL′(X,Y ),
κL∼= κL′
def⇔ κL � κL′ & κL′ � κL.
Sem-PP’2011 – p. 77/124

KIV: Funkcje inkluzji a 3-wart.implikacje c.d.• Okazuje sie,ze:
(a) κKw � κMC � κK � κLu∼= κG � κF
∼= κS
& κG � κSo & κP � κF
(b) κL(X,Y ) = 1 ⇔ X ⊆L Y
(c) X ⊑ Y ⇒ κL(X,Y ) = 1 dlaL = F,G,Lu, S, So
Sem-PP’2011 – p. 78/124

KIV: Funkcje inkluzji a 3-wart.implikacje c.d.
(d) κL(X,Y ) = 1 ⇒ X ⊑ Y dlaL = G,K,Kw,Lu,MC
(e) κL(Y, Z) = 1 ⇒ κL(X,Y ) ≤ κL(X,Z)
(f) Y ⊑ Z ⇒ κL(X,Y ) ≤ κL(X,Z) dlaL 6= Kw
(g) Z ⊑ Y ⊑ X ⇒ κL(X,Z) ≤ κL(Y, Z) dlaL 6= P
Sem-PP’2011 – p. 79/124

KIV: Funkcje inkluzji a 3-wart.implikacje c.d.• Warunki „rif” dostosowane do 3-wartosciowej
interpretacji zbioru:
rifg0(κ)def⇔ ∀X,Y ⊆ U.(X ⊑ Y ⇒ κ(X,Y ) = 1)
rif−1g0 (κ)def⇔ ∀X,Y ⊆ U.(κ(X,Y ) = 1 ⇒ X ⊑ Y )
rifg1(κ)def⇔ ∀X,Y ⊆ U.(κ(X,Y ) = 1 ⇔ X ⊑ Y )
rifg2(κ)def⇔ ∀X,Y, Z ⊆ U.(Y ⊑ Z
⇒ κ(X,Y ) ≤ κ(X,Z))
Sem-PP’2011 – p. 80/124

KIV: Funkcje inkluzji a 3-wart.implikacje c.d.• Okazuje sie,zeκL jest
• RIF-em dlaL = G,Lu,• quasi-RIF-em dlaL = F,G,Lu, S, So,• mocnym quasi’-RIF-em dlaL = G,K,Lu,MC,
• quasi’-RIF-em dlaL = G,K,Kw,Lu,MC.
Sem-PP’2011 – p. 81/124

KIV: Zastosowanie funkcjiinkluzji• Badanie podobienstwa infogranul.• Przyblizanie zbiorów i w szczególnosci
infogranul.• Ocena jakosci reguł (decyzyjnych,
asocjacyjnych).
Sem-PP’2011 – p. 82/124

Podsumowanie• W referacie ujete zostały główne kierunki moich
badan (lata 2003-2010) z zakresu obliczengranularnych realizowanych metodami zbiorówprzyblizonych.
• Uzyskane rezultaty maj ˛a znaczenie nie tylko dlarozwoju teorii zbiorów przyblizonych i podstawobliczen granularnych.
• Proponowane rozwiazania mozna zastosowac,np.:• do modelowania zachowan grupowych w
systemach wieloagentowych,• w odkrywaniu wiedzy z danych,• do tworzenia przyblizonych ontologii pojec.
Sem-PP’2011 – p. 83/124

Dziekuje za uwag˛e!
Sem-PP’2011 – p. 84/124

DI: Porównanie modeli Pawlakai Skowrona – Stepaniuka
• A. Gomolinska: A comparison of Pawlak’s andSkowron – Stepaniuk’s approximation ofconcepts,Transactions on Rough Sets VI: journalsubline of LNCS, 4374:64–82, 2007.
Sem-PP’2011 – p. 85/124

• Przestrzen przyblizen: M = (U, , κ), gdzie• U – niepusty zbiór obiektów,• – niepusta relacja binarna naU ,• κ – funkcja inkluzji przyblizonej nadU .
Γudef= ←{u} & Γ∗u
def= →{u}
Sem-PP’2011 – p. 86/124

• Funkcja inkluzji przyblizonej nad zbioremU todowolna funkcjaκ : ℘U × ℘U 7→ [0, 1]spełniaj ˛acarif1 orazrif∗2:
rif1(κ)def⇔ ∀X,Y.(κ(X,Y ) = 1 ⇔ X ⊆ Y )
rif∗2(κ)def⇔ ∀X,Y, Z.(κ(Y, Z) = 1⇒ κ(X,Y ) ≤ κ(X,Z))
Sem-PP’2011 – p. 87/124

• Dolne i górne przyblizenia zbioru w sensiePawlaka:
lowXdef= {u | Γu ⊆ X}
uppXdef= {u | Γu ∩X 6= ∅}
Sem-PP’2011 – p. 88/124

• Γ-definiowalne dolne i górne przyblizenia zbioruw sensie Pawlaka:
low∪Xdef=
⋃
{Γu | Γu ⊆ X}
upp∪Xdef=
⋃
{Γu | Γu ∩X 6= ∅}
Sem-PP’2011 – p. 89/124

• Dolne i górne przyblizenia zbioru w sensieSkowrona – Stepaniuka:
lowSXdef= {u | κ(Γu,X) = 1}
uppSXdef= {u | κ(Γu,X) > 0}
Sem-PP’2011 – p. 90/124

• Γ-definiowalne dolne i górne przyblizenia zbioruw sensie Skowrona – Stepaniuka:
lowS∪Xdef=
⋃
{Γu | κ(Γu,X) = 1}
uppS∪Xdef=
⋃
{Γu | κ(Γu,X) > 0}
Sem-PP’2011 – p. 91/124

• Postepuj ˛ac podobnie dla infogranul postaciΓ∗udostajemy operacje dolnego przyblizenialow∗,low∪∗, lowS∗, lowS∪∗ oraz górnego przyblizeniaupp∗, upp∪∗, uppS∗, uppS∪∗.
• Dla f ∈ {low, upp, lowS, uppS} zachodzi:
f∪ = upp∗ ◦ f
Sem-PP’2011 – p. 92/124

• Zbadane zostały własnosci i porównane zostałyoperacje przyblizania w obu modelach przyróznych dodatkowych warunkach nałozonych na i/lub −1 (serialnosc, zwrotnosc,symetrycznosc, przechodniosc i ich kombinacje)oraz przy róznych dodatkowych warunkachnałozonych naκ.
Sem-PP’2011 – p. 93/124

DI: Model zmienno-precyzyjnyo dwóch uniwersach
• A. Gomolinska: Variable-precision compatibilityspaces,Electronical Notices in TheoreticalComputer Science, 82(4):120–131, 2003,http://www.elsevier.nl/locate/entcs/volume82.html
Sem-PP’2011 – p. 94/124

• Rozwazamy niepuste zbioryU1, U2 oraz funkcjegranulujaca∆ : U1 7→ ℘U2, takaze∆→U1
stanowi pokrycie zbioruU2 niepustymiinfogranulami postaci∆u.
• Definiujemy funkcje∆∗ : U2 7→ ℘U1
stowarzyszona z∆:
∆∗udef= {v ∈ U1 | u ∈ ∆v}
Sem-PP’2011 – p. 95/124

• WWY-dolne i WWY-górne przyblizenia zbioruX ⊆ U2:
lowWWYXdef= {u ∈ U1 | ∆u ⊆ X}
uppWWYXdef= {u ∈ U1 | ∆u ∩X 6= ∅}
Sem-PP’2011 – p. 96/124

• ∆-definiowalne WWY-dolne i WWY-górneprzyblizenia zbioruX:
lowWWY∪Xdef=
⋃
{∆u | u ∈ U1 ∧∆u ⊆ X}
uppWWY∪Xdef=
⋃
{∆u | u ∈ U1 ∧∆u ∩X 6= ∅}
Sem-PP’2011 – p. 97/124

• Zmienno-precyzyjna przestrzen zgodnosci:(U1, U2,∆, κ1, κ2), gdzie
• U1, U2,∆ sa jak wyzej,• κi : ℘Ui × ℘Ui 7→ [0, 1] – funkcja inkluzji
przyblizonej nadUi (i = 1, 2) spełniaj ˛acarif6:
rif6(κi)def⇔ ∀X 6= ∅.∀Y.κi(X,Y )+κi(X,Ui−Y ) = 1
Sem-PP’2011 – p. 98/124
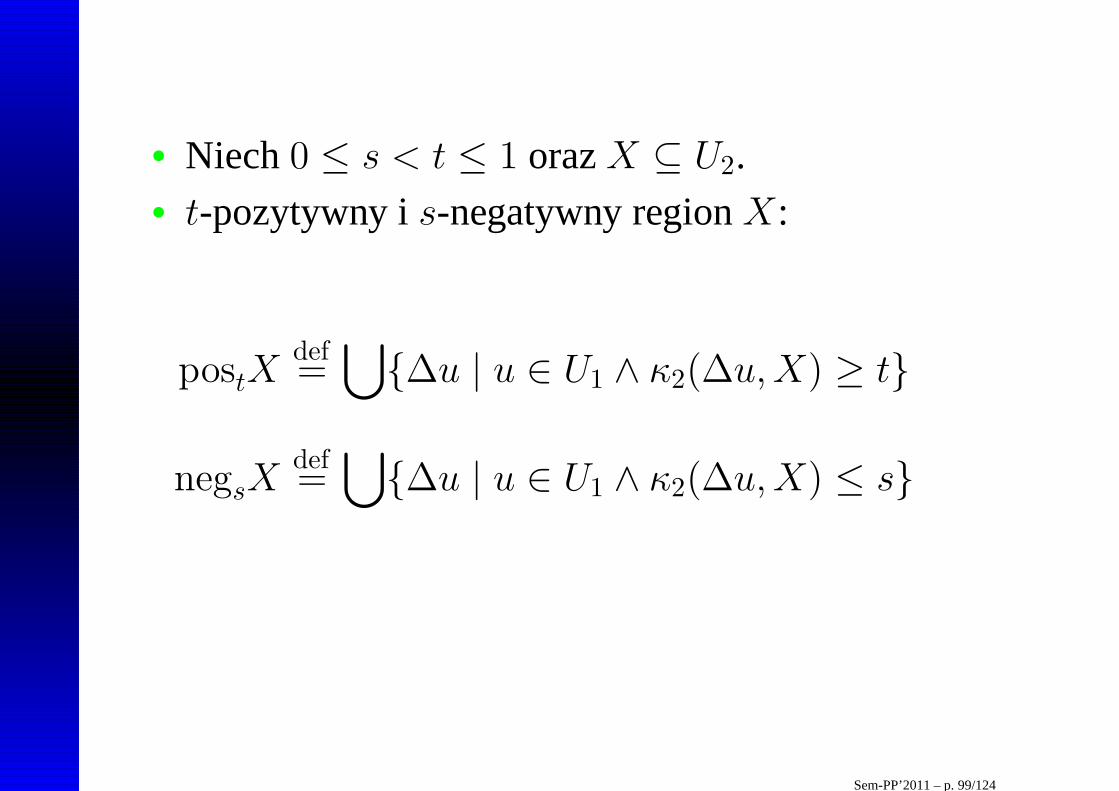
• Niech0 ≤ s < t ≤ 1 orazX ⊆ U2.• t-pozytywny is-negatywny regionX:
postXdef=
⋃
{∆u | u ∈ U1 ∧ κ2(∆u,X) ≥ t}
negsXdef=
⋃
{∆u | u ∈ U1 ∧ κ2(∆u,X) ≤ s}
Sem-PP’2011 – p. 99/124

• Podobniet∗-pozytywny is∗-negatywny regionX:
pos∗tXdef=
⋃
{∆∗u | u ∈ U2 ∧ κ1(∆∗u,X) ≥ t}
neg∗sXdef=
⋃
{∆∗u | u ∈ U2 ∧ κ1(∆∗u,X) ≤ s}
Sem-PP’2011 – p. 100/124

DI: Model uwzgl edniajacypodobienstwo i niepodobienstwo
• A. Gomolinska: Approximation spaces based onrelations of similarity and dissimilarity of objects,Fundamenta Informaticae, 79(3–4):319–333,2007.
Sem-PP’2011 – p. 101/124

• A. Tversky postuluje rozwazanie argumentów„za” i „przeciw” przy ustalaniu podobienstwamiedzy obiektami.
• W modelu proponowanym przez autorkeargumenty „za” uwzglednione s ˛a przez pewnarelacje zwrotna zwana relacja podobienstwa, aargumenty „przeciw” przez pewna relacjeprzeciwzwrotna zwana relacja niepodobienstwa(jest ona zawarta w dopełnieniu relacjipodobienstwa).
• Mamy dwa rodzaje infogranul elementarnych:generowane przez relacje podobienstwa orazgenerowane przez relacje niepodobienstwa.
Sem-PP’2011 – p. 102/124

• Przestrzen przyblizen: (U, r, , κ), gdzie• U – niepusty zbiór obiektów,• r – relacja podobienstwa naU ,• – relacja niepodobienstwa naU ,• κ – funkcja inkluzji przyblizonej nadU .
Γudef= r←{u} & Θu
def= ←{u}
Sem-PP’2011 – p. 103/124

• Rózne operacje przyblizania zbioru (t ∈ [0, 1]):• int – operacja wnetrza (dolnego przyblizenia),• ext – operacja zewnetrza,• ppos – operacja regionu „byc moze”
pozytywnego (górnego przyblizenia),• pneg – operacja regionu „byc moze”
negatywnego,• ign – operacja regionu niewiedzy,• intt – operacja regionut-wewnetrznego
(regionut-pozytywnego),• extt – operacja regionut-zewnetrznego.
Sem-PP’2011 – p. 104/124
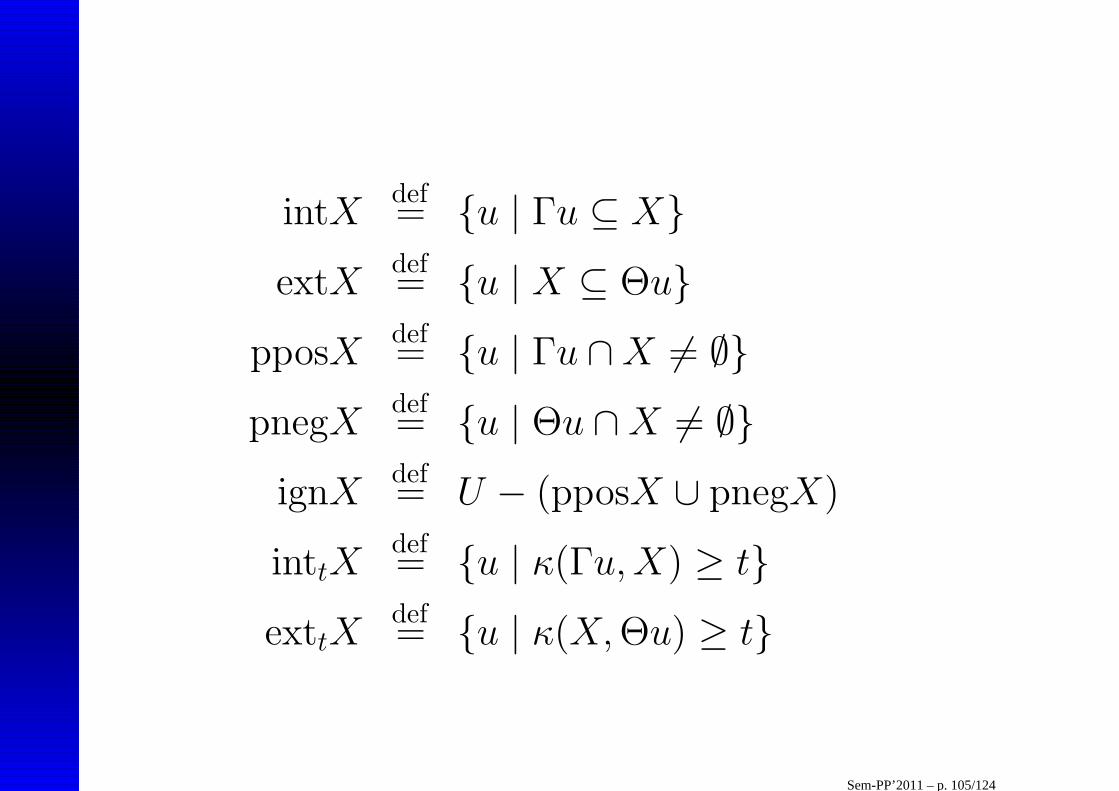
intXdef= {u | Γu ⊆ X}
extXdef= {u | X ⊆ Θu}
pposXdef= {u | Γu ∩X 6= ∅}
pnegXdef= {u | Θu ∩X 6= ∅}
ignXdef= U − (pposX ∪ pnegX)
inttXdef= {u | κ(Γu,X) ≥ t}
exttXdef= {u | κ(X,Θu) ≥ t}
Sem-PP’2011 – p. 105/124

Niech
rif3(κ)def⇔ ∀X 6= ∅.κ(X, ∅) = 0.
• Własnosci operacji przyblizania:
int1 = int & ext1 = ext
u ∈ ignX ⇔ X ∩ (Γu ∪Θu) = ∅
int0X = ext0X = inttU = extt∅ = pposU = U
pnegU = {u | Θu 6= ∅}
int∅ = extU = ppos∅ = pneg∅ = ∅
rif3(κ) & t > 0⇒ intt∅ = ∅
Sem-PP’2011 – p. 106/124

Niechf oznacza ppos lub pneg.
intX ⊆ X ⊆ pposX
extX ⊆ int(Xc) = (pposX)c
r ∪ = U × U ⇒ extX = int(Xc)
X 6= ∅ ⇒ extX ⊆ pnegX
s ≤ t⇒ inttX ⊆ intsX & exttX ⊆ extsX
X ⊆ Y ⇒ inttX ⊆ inttY & extY ⊆ extX
& fX ⊆ fY
Sem-PP’2011 – p. 107/124
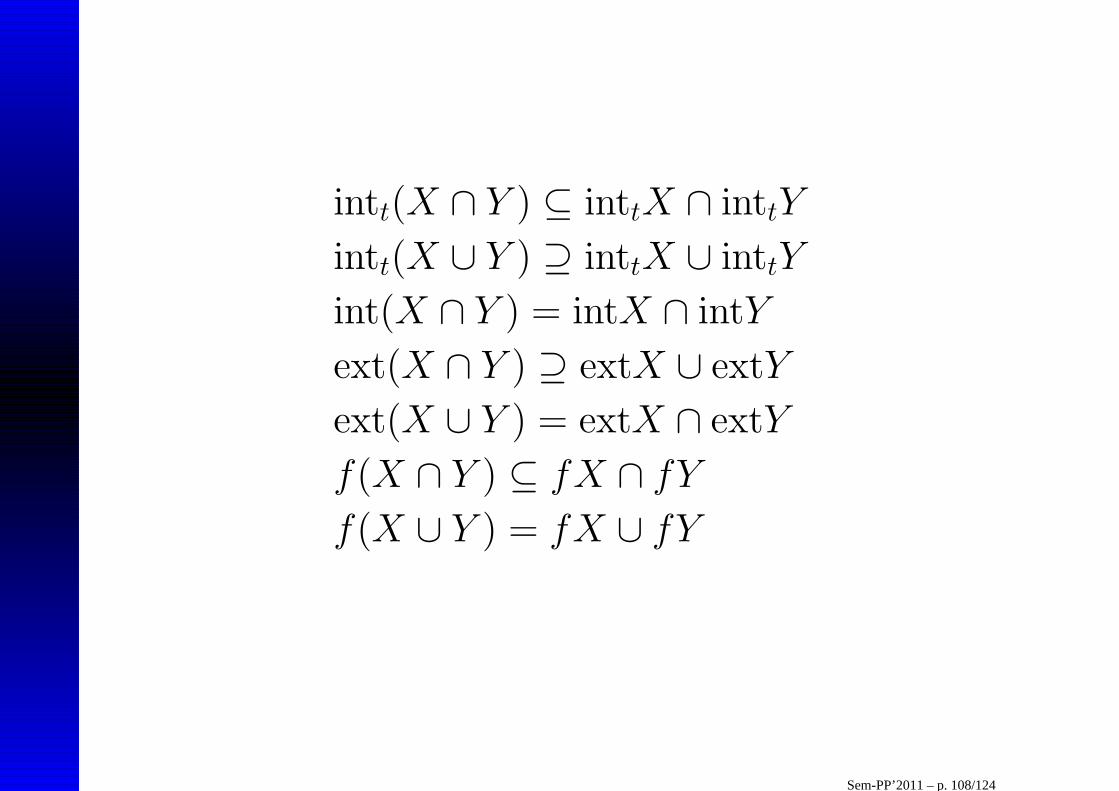
intt(X ∩ Y ) ⊆ inttX ∩ inttY
intt(X ∪ Y ) ⊇ inttX ∪ inttY
int(X ∩ Y ) = intX ∩ intY
ext(X ∩ Y ) ⊇ extX ∪ extY
ext(X ∪ Y ) = extX ∩ extY
f(X ∩ Y ) ⊆ fX ∩ fY
f(X ∪ Y ) = fX ∪ fY
Sem-PP’2011 – p. 108/124

DI: Model oparty na słabszychfunkcjach inkluzji
(„słabszych” w stosunku do inkluzjiprzyblizonej)
• A. Gomolinska: Rough approximation based onweak q-RIFs,Transactions on Rough Sets X:journal subline of LNCS, 5656:117–135, 2009.
Sem-PP’2011 – p. 109/124

DIII: Przybli zone spełnianie for-muł i ich zbiorów• Zagadnienie to jest badane na przykładzie formuł
jezyka deskryptorów systemu informacyjnegoPawlaka.
• Informacja dostepna o rozwazanych obiektachjest niedoskonała.
• Celem jest odkrywanie pojecia spełniania formułi ich zbiorów, a nie zbudowanie formalnegosystemu logicznego.
Sem-PP’2011 – p. 110/124

DIII: Relacje przybli zonegospełnianiaReferencje:• A graded meaning of formulas in approximation
spaces,Fundamenta Informaticae,60(1–4):159–172, 2004.
• Satisfiability and meaning of formulas and sets offormulas in approximation spaces,FundamentaInformaticae, 67(1–3):77–92, 2005.
• Satisfiability judgement under incompleteinformation,Transactions on Rough Sets XI:journal subline of LNCS, 5946:66–91, 2010.
Sem-PP’2011 – p. 111/124

• W tym podejsciu pojecie spełniania formuł zFOR przez obiekty zU modelowane jest jakosparametryzowana rodzina relacji, czylipodzbiorówU × FOR.
• Celem jest odkrycie relacji najlepiej pasuj ˛acej dobadanego przypadku, np. przez optymalizacjewartosci parametrów.
Sem-PP’2011 – p. 112/124

Przykłady• Przykład I:{|=t}t∈[0,1], gdzie
u |=t αdef⇔ κ(Γu, Satc(α)) ≥ t.
• Zauwazmy, ze jesli t > 0, to
Satt(α)def= {u ∈ U | u |=t α}
= post(Satc(α)).
Sem-PP’2011 – p. 113/124

• Przykład II:{|=+t }t∈[0,1], gdzie
|=+t
def= |=t ∩ |=c .
• Zauwazmy, ze jesli t > 0, to
Sat+t (α) = post(Satc(α)) ∩ Satc(α).
Sem-PP’2011 – p. 114/124

• Niech� bedzie porzadkiem „po współrzednych”na [0, 1]2.
• ([0, 1]2,�) – krata z(0, 0) jako zerem i(1, 1) jakojedynka.
• Przykład III:{|=npt }t∈T , gdzie
T = {(t1, t2) | 0 ≤ t1 < t2 ≤ 1} oraz
u |=npt α
def⇔ κ(Γu, Satc(¬α)) ≤ π1(t)
& κ(Γu, Satc(α)) ≥ π2(t).
Sem-PP’2011 – p. 115/124

• Zauwazmy, ze
Satnpt (α) = negπ1(t)(Satc(α)) ∩ posπ2(t)(Satc(α)).
Sem-PP’2011 – p. 116/124

• Przykład IV:|=P , gdzie
u |=P αdef⇔ Γu ∩ Satc(α) 6= ∅.
• Zauwazmy, ze
SatP (α) = upp(Satc(α)).
• To pojecie spełniania koresponduje z pojeciemprawdy przyblizonej wprowadzonym przezZ. Pawlaka i badanym przez M. Banerjee.
Sem-PP’2011 – p. 117/124

• Przykład V:|=S, gdzie
u |=S αdef⇔ κ(Γu, Satc(α)) > 0.
• Zauwazmy, ze
SatS(α) = uppS(Satc(α)).
Sem-PP’2011 – p. 118/124

• Przykład VI:{|=gWt }t∈T , gdzieT = (0, 1] × [0, 1]
oraz
u |=gWt α
def⇔ κ(posπ1(t)(Γu), Satc(α)) ≥ π2(t).
• Relacje spełniania otrzymane dlaπ2(t) = 1 sainspirowane semantyk ˛a „mozliwych swiatów”dla logik modalnych.
Sem-PP’2011 – p. 119/124

DIII: Odkrywanie poj˛ecia speł-niania formuł
A dokładniej – odkrywanie pojecia spełniania formułz dostepnych danych i przykładów (np. przykładówna „tak” i na „nie”) dostarczonych przez eksperta.
Referencje:• Satisfiability of formulas from the standpoint of
object classification: The RST approach,Fundamenta Informaticae, 85(1–4):139–153,2008.
Sem-PP’2011 – p. 120/124

DIII: Przybli zone spełnianie for-muł a zbiory rozmyte• Mianowicie, wprowadzone pojecia przyblizonego
spełniania formuł oraz pojecia pokrewneinterpretowane sa w terminach teorii zbiorówrozmytych jak rdzen czy alfa-ciecie.
Referencje:• A fuzzy view on rough satisfiability,Lecture
Notes in Artificial Intelligence, 6086:227–236,2010.
Sem-PP’2011 – p. 121/124

DIII: Przybli zone stosowanieregułReferencje:• A graded applicability of rules,Lecture Notes in
Artificial Intelligence, 3066:213–218, 2004.• Towards rough applicability of rules, [in:]
B. Dunin-Keplicz, A. Jankowski, A. Skowron,and M. Szczuka, editors,Monitoring, Security,and Rescue Techniques in Multiagent Systems,pages 203–214, Springer-V., Berlin Heidelberg,2005.
• Rough rule-following by social agents, [in:]H. Flam and M. Carson, editors,Rule SystemsTheory. Applications and Explorations, pages103–118, Peter Lang, Frankfurt am Main, 2008.
Sem-PP’2011 – p. 122/124

DIII: Konstrukcja infogranulspełniajacych dane wymagania
Referencje:• Construction of rough information granules, [in:]
W. Pedrycz, A. Skowron, and V. Kreinovich,editors,Handbook of Granular Computing, pages449–470, John Wiley & Sons, Chichester, 2008.
Sem-PP’2011 – p. 123/124

DIII: Formowanie s adów wagentach inteligentnych
Referencje:• On rough judgment making by socio-cognitive
agents, [in:] A. Skowron et al., editors,Proc.2005 IEEE//WIC//ACM Int. Conf. on IntelligentAgent Technology (IAT’2005), Compiegne,France, September 2005, pages 421–427. IEEEComputer Society Press, Los Alamitos, CA,2005.
• Satisfiability judgement under incompleteinformation,Transactions on Rough Sets XI:journal subline of LNCS, 5946:66–91, 2010.
Sem-PP’2011 – p. 124/124



![Minimalne zbiory generatorów grup klas odwzorowańtrojkat/files/Doktorat.pdf · 2009-09-25 · 10]. Znane są również małe zbiory generatorów oraz małe zbiory generatorów składające](https://static.fdocuments.pl/doc/165x107/5f0ddef07e708231d43c7e89/minimalne-zbiory-generatorw-grup-klas-odwzorowa-trojkatfiles-2009-09-25.jpg)














