
Sterowanie adaptacyjne i uczenie maszynowestaff.elka.pw.edu.pl/~pwawrzyn/pub-s/SAUM-skrypt.pdf ·...
166
PROGRAM ROZWOJOWY POLITECHNIKI WARSZAWSKIEJ Paweł Wawrzyński Sterowanie adaptacyjne i uczenie maszynowe preskrypt Grudzień 2012, wersja poprawiona we wrześniu 2016 Projekt wspó³finansowany przez Uniê Europejsk¹ w ramach Europejskiego Funduszu Spo³ecznego
Transcript of Sterowanie adaptacyjne i uczenie maszynowestaff.elka.pw.edu.pl/~pwawrzyn/pub-s/SAUM-skrypt.pdf ·...

PROGRAM ROZWOJOWYPOLITECHNIKI WARSZAWSKIEJ
Paweł Wawrzyński
Sterowanie adaptacyjnei uczenie maszynowe
preskrypt
Grudzień 2012, wersja poprawiona we wrześniu 2016
Projekt wspó³finansowany przez Uniê Europejsk¹ w ramach Europejskiego Funduszu Spo³ecznego

II
Publikacja dystrybuowana jest bezpłatnie

Spis treści
I. Preliminaria
Rozdział 1. Wprowadzenie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.1. Przykłady zagadnień, w których pojawia się potrzeba adaptacji i uczenia się . . . . . . . 41.2. Cel skryptu i poruszane zagadnienia . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51.3. Trzy dziedziny składające się na zawartość skryptu . . . . . . . . . . . . . . . . . . . . . 51.4. Adaptacja i uczenie się jako droga do inteligentnego zachowania się maszyn i programów 81.5. Organizacja skryptu . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
Rozdział 2. Aproksymacja funkcji i podstawowe mechanizmy adaptacji . . . . . . . . . . . . 11
2.1. Aproksymatory i zagadnienie aproksymacji . . . . . . . . . . . . . . . . . . . . . . . . 112.2. Zagadnienie uczenia na zbiorze nieskończonym, on-line . . . . . . . . . . . . . . . . . . 132.3. Perceptron wielowarstwowy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 152.4. Najszybszy spadek i stochastyczny najszybszy spadek . . . . . . . . . . . . . . . . . . . 20
Algorytm gradientu prostego . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21Procedura Robbinsa-Monro . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
2.5. Uczenie się przy użyciu aproksymacji stochastycznej . . . . . . . . . . . . . . . . . . . . 262.6. Zagadnienia praktyczne związane z używaniem sieci neuronowych w systemach
uczących się . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
II. Uczenie się ze wzmocnieniem
Rozdział 3. Podstawy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
3.1. Proces Decyzyjny Markowa . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 333.2. Algorytmy Q-Learning i SARSA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 363.3. Rozszerzenie algorytmów Q-Learning i SARSA do ciągłych przestrzeni stanów i decyzji . 39
Rozdział 4. Optymalizacja stochastycznego wyboru . . . . . . . . . . . . . . . . . . . . . . . 43
4.1. Parametryzowane rozkłady prawdopodobieństwa . . . . . . . . . . . . . . . . . . . . . . 43Rozkład logitowy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45Wielopunktowy rozkład logitowy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45Normalna zmienna losowa . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46Normalny wektor losowy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48Losowanie z rozkładu normalnego . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
4.2. Algorytm REINFORCE punktowy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 494.3. Stacjonarna polityka decyzyjna . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 514.4. Algorytm REINFORCE statyczny . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 534.5. Algorytm REINFORCE epizodyczny . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
Polityka stacjonarna . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
Rozdział 5. Algorytm Aktor-Krytyk . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
5.1. Aktor, Krytyk i idea algorytmu . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 595.2. Klasyczny Aktor-Krytyk . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 605.3. Aktor-Krytyk(λ) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62

IV Spis treści
Rozdział 6. Aktor-Krytyk z kompatybilną aproksymacją . . . . . . . . . . . . . . . . . . . . 67
6.1. Optymalizacja średniej nagrody . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 676.2. Gradient polityki . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 686.3. Aktor-Krytyk z kompatybilną aproksymacją . . . . . . . . . . . . . . . . . . . . . . . . 716.4. Naturalny Aktor-Krytyk . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 736.5. Dyskonto ograniczenie wariancji estymatora gradientu . . . . . . . . . . . . . . . . . 74
Rozdział 7. Wielokrotne przetwarzanie obserwacji . . . . . . . . . . . . . . . . . . . . . . . . 77
7.1. Algorytm Q-Learning z powtarzaniem doświadczenia . . . . . . . . . . . . . . . . . . . 787.2. Próbkowanie ważnościowe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 797.3. Algorytm Aktor-Krytyk z powtarzaniem doświadczenia . . . . . . . . . . . . . . . . . . 81
Inkrementacyjne algorytmy z Aktorem . . . . . . . . . . . . . . . . . . . . . . . . . . . 81Powtarzanie doświadczenia w inkrementacyjnym algorytmie z Aktorem . . . . . . . . . 82Klasyczny Aktor-Krytyk, estymatory φ oraz ψ . . . . . . . . . . . . . . . . . . . . . . . 82Uogólniony Aktor-Krytyk, estymatory φ oraz ψ . . . . . . . . . . . . . . . . . . . . . . 84Aktor-Krytyk z powtarzaniem doświadczenia, implementacja . . . . . . . . . . . . . . . 86
7.4. Optymalizacja estymatora wskaźnika jakości . . . . . . . . . . . . . . . . . . . . . . . . 88
Rozdział 8. Podsumowanie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 89
III. Sterowanie adaptacyjne
Rozdział 9. Obiekty dynamiczne . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 95
9.1. Wstęp . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 95Obiekt dynamiczny . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 95Model referencyjny i sterownik . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 95Zagadnienie adaptacji . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 96
9.2. Liniowe obiekty SISO . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 96Ogólny obiekt SISO i jego opis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 97Reprezentacja systemu SISO w przestrzeni stanów . . . . . . . . . . . . . . . . . . . . . 99Interpretacja i własności systemów SISO . . . . . . . . . . . . . . . . . . . . . . . . . . 99
9.3. Dyskretna aproksymacja obiektów o ciągłej dynamice . . . . . . . . . . . . . . . . . . . 104
Rozdział 10. Stabilność i funkcja Lapunowa . . . . . . . . . . . . . . . . . . . . . . . . . . . 107
10.1. Ogólna postać typowego schematu adaptacji . . . . . . . . . . . . . . . . . . . . . . . . 107System nieautonomiczny . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 108
10.2. Stabilność . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10810.3. Funkcja Lapunowa . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11010.4. Stabilność w kontekście funkcji Lapunowa . . . . . . . . . . . . . . . . . . . . . . . . . 112
Funkcja Lapunowa dla stacjonarnego systemu liniowego . . . . . . . . . . . . . . . . . . 114
Rozdział 11. Sterowanie adaptacyjne z modelem referencyjnym . . . . . . . . . . . . . . . . 117
11.1. Liniowy obiekt SISO pierwszego rzędu . . . . . . . . . . . . . . . . . . . . . . . . . . . 11711.2. Uogólnienie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 121
Dysuksja . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12211.3. Obiekty liniowe wyższych rzędów . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 122
Rozdział 12. Zaawansowane schematy adaptacji . . . . . . . . . . . . . . . . . . . . . . . . . 127
12.1. Obiekty o nieliniowej dynamice . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12712.2. Obiekty z nieobserwowalnymi pochodnymi stanu . . . . . . . . . . . . . . . . . . . . . 129
Obiekty drugiego rzędu . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 130Obiekty dowolnego rzędu . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 133
Rozdział 13. Samostrojące się regulatory . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 135
13.1. Dynamika liniowo parametryzowalna . . . . . . . . . . . . . . . . . . . . . . . . . . . . 135

13.2. Liniowe najmniejsze kwadraty . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 137Własności . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 138
13.3. Najmniejsze kwadraty z wykładniczym zapominaniem . . . . . . . . . . . . . . . . . . . 139Własności . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 140
13.4. Adaptacyjny dobór współczynnika zapominania . . . . . . . . . . . . . . . . . . . . . . 141
IV. Inne podejścia do adaptacji
Rozdział 14. Aproksymowane programowanie dynamiczne . . . . . . . . . . . . . . . . . . . 145
Rozdział 15. Stochastyczne sterowanie adaptacyjne . . . . . . . . . . . . . . . . . . . . . . . 147
Rozdział 16. Sterowanie z iteracyjnym uczeniem się . . . . . . . . . . . . . . . . . . . . . . . 149
Rozdział 17. Filtr Kalmana . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 153
17.1. Model . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15317.2. Algorytm . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15417.3. Wyprowadzenia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15617.4. Rozszerzony Filtr Kalmana . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 157
Bibliografia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 159


Część I
Preliminaria

2
Część pierwsza skryptu wprowadza do jego tematyki a także przedstawia w stopniu wystar-czającym do jego dalszej lektury sieci neuronowe oraz optymalizację stochastczyną, czyli dwapodstawowe narzędzia służące do budowy systemów adaptacyjnych i uczących się.

Rozdział 1
Wprowadzenie
Ogólną tematyką niniejszego skryptu jest projektowanie sterowników dla sztucznych syste-mów takich jak roboty, automaty, agenty programowe czy boty w grach komputerowych. Rozwi-jając cywilizację techniczną człowiek tworzy systemy, które są w znacznym stopniu autonomicz-ne i osiągają swoje cele pozostając w interakcji ze swoim otoczeniem. Projektowanie sterownikatakiego systemu może polegać na dopasowywaniu jego działań do stanu systemu i jego otocze-nia. Taki projekt musi wynikać z pewnej wiedzy o tym, w jaki sposób akcje systemu wpływająna ów stan: w ogólności, aby wiedzieć co robić trzeba wiedzieć jakie konsekwencje mogą miećróżne działania.
W miarę rozwoju cywilizacji technicznej coraz bardziej naturalne jest oczekiwanie, że sys-temy tworzone przez człowieka będą efektywnie działać również w sytuacjach nie przewidywa-nych przez ich projektantów. Oczekiwanie to może wynikać ze złożoności systemu i mnogościsytuacji, z którymi może mieć on do czynienia. Odpowiedzią na to oczekiwanie są sterowniki,które adaptują się do warunków, w których przychodzi im działać. Na początku sterują syste-mem w sposób nieoptymalny, może nawet niezdarny, jednak w miarę zbierania doświadczeniaich sterowanie jest coraz lepsze, aż w końcu zbliża się do optymalnego. Innymi słowy, zamiastprojektować sterownik, który dobrze steruje, projektujemy taki, który uczy się dobrze sterować.
Tematem niniejszego skryptu jest adaptacja, której celem jest poprawa efektywności systemuw trakcie jego działania. Jego początkowy sposób działania może być daleki od doskonałości.Chcemy jednak aby z biegiem czasu uczył się on w oparciu o swoje doświadczenie podejmowaćnajlepsze decyzje w reakcji na stan otaczającego go świata.
Ogólny schemat sytuacji, w której pojawia się problem adaptacji dyskutowany w niniejszymskrypcie przedstawia Rysunek 1.1. Punktem wyjścia jest pewien system dynamiczny: może to byćurządzenie wraz ze środowiskiem, w którym działa lub świat, na który oddziałuje pewien pro-gram komputerowy. Przez decydenta należy rozumieć sterownik urządzenia lub (pod)program
Rysunek 1.1. Okoliczności, w których pojawia się potrzeba adaptacji / uczenia się.

4 Rozdział 1. Wprowadzenie
komputerowy. Na podstawie stanu systemu generuje on decyzje, którymi na ten system oddzia-łuje, np. powoduje podejmowanie przez urządzenie pewnych działań. Problem polega na tym,że nie można z góry zdefiniować dobrych reguł decyzyjnych dla decydenta z następującychpowodów:— dynamika systemu jest nieznana, czyli nie wiadomo w jaki sposób na jego stan wpływają
aplikowane decyzje,— dynamika systemu jest znana w sposób niepełny/niedokładny,— dynamika systemu jest na tyle skomplikowana, że projektowanie decydenta staje się bardzo
kosztowne.Narzucającym się w takiej sytuacji rozwiązaniem jest wyposażenie decydenta w możliwość ad-aptacji lub uczenia się na podstawie interakcji z systemem dynamicznym.
Ostatnim elementem powyższego schematu jest arbiter. Spełnia on dwie funkcje. Po pierw-sze stanowi interfejs między parą decydent – system dynamiczny a człowiekiem, który jestużytkownikiem tej pary. Po drugie, arbiter ocenia skutki działań decydenta. Zwykle zadaniedecydenta polega na tym, aby w sekwencji decyzji osiągnąć pewne cele lub utrzymać pewnąkorzystną sytuację. Arbiter nie musi wiedzieć jakie decyzje prowadzą do tego, ale musi umiećrozpoznawać moment, w którym cel zostaje osiągnięty lub ocenić jak korzystna bieżąca jestsytuacja.
1.1. Przykłady zagadnień, w których pojawia się potrzeba adaptacji i
uczenia się
1. Przeszłość, teraźniejszość, przyszłość: Systemy sterujące mają do czynienia z obiektami,których parametry są nieznane lub zmieniają się w czasie.
Przykład: Dynamika samolotu zmienia się w zależności od wielu czynników: jego prędkości,siły wiatru, temperatury itd. Chcielibyśmy aby sposób reagowania na ruchy sterami był takisam niezależnie od różnych czynników. Recepta: sterowniki adaptujące się do zmieniającychsię parametrów sterowanego obiektu.
Przykład, generalizacja: istota znacznej części współczesnej gospodarki światowej opierasię na tym, że maszyny coś produkują: przedmioty, substancje, czy nawet organizmy. Niekiedymożemy zaprojektować sztywny system sterujący dla maszyny, którego działanie będzie satys-fakcjonujące. W pewnych warunkach efektywniejsze, np. tańsze, może okazać się stworzeniesystemu sterującego, który “w locie” będzie adaptował się do warunków, w których działa ma-szyna.
2. Teraźniejszość, przyszłość: Programy podejmujące decyzje.Przykład 1: Gry komputerowe. Świat przedstawiany przez gry komputerowe powoli robi
się zbyt skomplikowany, aby można było po prostu zaprogramować działające w nim postaci,czyli boty. Podejmują one złożone decyzje na podstawie wielu przesłanek. W tej sytuacji możesię okazać, że najlepszą receptą na to, aby postaci zachowywały się w sposób inteligentny jestzaopatrzenie je we względnie elastyczne sterowniki, które uczą się w interakcji z przeciwnikiem.
Przykład 1, generalizacja: W miarę jak rozwija się współczesna cywilizacja techniczna, lu-dzie poświęcają coraz więcej czasu na rozrywkę, ponieważ nie muszą wiele pracować aby prowa-dzić życie na satysfakcjonującym poziomie. Część tej rozrywki ma charakter udziału w pewnychwirtualnych światach. Niekiedy zamiast programować sterowniki mieszkańców tych światów,bardziej opłaca się wyposażyć ich w elastyczne reguły decyzyjne, które podlegają adaptacji.
Przykład 2: Księgarnia internetowa. Niektóre księgarnie internetowe wyposażane są w mo-duł, który analizuje sekwencje książek nabywanych przez użytkowników i na tej podstawie pro-

1.2. Cel skryptu i poruszane zagadnienia 5
ponuje im kolejne książki do kupienia. Oczywiście propozycje są składane w taki sposób, abybyły łatwe do zignorowania i nie irytowały użytkownika, który nie jest nimi zainteresowany.Dzięki takiemu rozwiązaniu użytkownicy serwisu mają szybki dostęp do tego, co zazwyczajmusieliby pracowicie wyszukiwać.
Przykład 2, generalizacja: Internet odgrywa coraz większą rolę w życiu ludzi. Jednym zesposobów na uczynienie serwisu internetowego bardziej atrakcyjnym jest dostosowanie go doużytkownika i wyeliminowanie sztywnych procedur identycznych dla wszystkich. Serwis, napodstawie interakcji z użytkownikami, uczy się jak oferować im szybki dostęp do treści, doktórej i tak docieraliby ale okrężnymi drogami.
3. Przyszłość: Maszyny w dużym stopniu autonomiczne.Przykład: Zdalna obecność. Wyobraźmy sobie platformę wiertniczą na Antarktydzie. Praca
w temperaturze -70oC jest dla człowieka nieprzyjemna i niebezpieczna dla zdrowia. Dlategokoszty pracy ponoszone przez firmy eksploatujące tam bogactwa naturalne są ogromne. Możnasobie wyobrazić ogromne oszczędności uzyskane dzięki temu, że na takiej platformie pracu-ją zdalnie sterowane roboty humanoidalne. Wtedy wydobycie odbywałoby się na Antarktydziea dokonywaliby go ludzie w biurze w miejscu zamieszkania pracujący w hełmach tworzącychwirtualną rzeczywistość. Zdalnie sterowane roboty musiałyby być do pewnego stopnia autono-miczne (np. sterowanie ich chodzeniem, przynajmniej na niskim poziomie, musiałoby odbywaćsię lokalnie). Im więcej autonomii miałby taki robot, tym trudniej byłoby zaprogramować jegozachowanie i w tym większym stopniu musiałoby ono być rezultatem adaptacji lub uczenia się.
Przykład, generalizacja: Należy się spodziewać, że w niedalekiej przyszłości coraz większąrolę w gospodarce będą odgrywały maszyny w znacznym stopniu autonomiczne, których zacho-wanie będzie trudne do zestandaryzowania ze względu na złożoność okoliczności, w którychbędą działać, mnogość typów ich środowiska oraz zadań, które będą wykonywać. Programowa-nie takich maszyn będzie trudne lub niemożliwe ponieważ procedury, według których będą onedziałać będą trudne do przewidzenia z góry. W takim razie ich działanie będzie opierało się nazasadach, które będą rezultatem uczenia się / adaptacji a nie zwykłego programowania.
1.2. Cel skryptu i poruszane zagadnienia
Generalizując powyższe przykłady można sformułować cel niniejszego wykładu oraz za-gadnienia, które będą w nim poruszane.
We współczesnym świecie coraz bardziej potrzebne są autonomiczne sterowniki (programy)działające w skomplikowanym, trudnym do zamodelowania z góry otoczeniu. Ich projektowaniew taki sposób, aby działały w sposób optymalny natychmiast po uruchomieniu byłoby bardzokosztowne lub niemożliwe. Zamiast tego lepiej jest projektować sterowniki być może działającepoczątkowo w sposób nieoptymalny, jednak wyposażone w mechanizmy adaptacji i umożliwićim uczenie się optymalnego zachowania w trakcie działania. W kolejnych rozdziałach omawianesą techniki adaptacji (uczenia się), które mogą być zastosowane w takich sterownikach.
1.3. Trzy dziedziny składające się na zawartość skryptu
Treść skryptu odwołuje się do trzech dziedzin: sieci neuronowych i uczenia się ze wzmocnie-niem wywodzących się ze sztucznej inteligencji oraz sterowania adaptacyjnego wywodzącegosię z automatyki.
1. Aproksymacja funkcji; sieci neuronowe

6 Rozdział 1. Wprowadzenie
Sztuczna inteligencja jest dziedziną, której zdefiniowanie nastręcza pewne trudności. Kiedyw przeszłości opracowywany był nowy sposób przetwarzania informacji, to tym chętniej zali-czano go do tego obszaru, im bardziej był wzorowany na zjawiskach obserwowanych w naturze.Obecnie sztuczna inteligencja to luźny konglomerat takich dziedzin jak:— Algorytmy ewolucyjne— Logika rozmyta— Sieci neuronowe— Uczenie maszynoweDziedzina sieci neuronowe zajmuje się specyficznymi strukturami złożonymi z połączonychze sobą elementów przetwarzających informację (neuronów), które zmieniają sposób działaniaw jego trakcie – uczą się. Kontekst i cel tego uczenia się może być rozmaity, np. grupowanie lubkompresja sygnałów docierających do sieci z zewnątrz, filtrowanie, detekcja pewnych własno-ści sygnału itd. Z naszego punktu widzenia istotne jest to, że sieć neuronowa uczona pewnymiszczególnymi metodami potrafi nauczyć się zadanej, lub najlepszej w pewnym sensie, zależno-ści funkcyjnej między sygnałami, które stanowią jej wejścia i wyjścia. Szczególną postacią siecipoddającą się tego rodzaju uczeniu jest perceptron wielowarstwowy.
Większość zagadnień uczenia się i adaptacji sprowadza się do znalezienia najlepszej funkcjiprzekształcającej stan w decyzję. Perceptron wielowarstwowy okazuje się jednym z najlepszychnarzędzi znajdujących i reprezentujących taką funkcję. Czyni to z sieci neuronowych i metodich uczenia naturalny przedmiot naszego zainteresowania.
Dziedzina sieci neuronowe została ufundowana w roku 1943, kiedy to Pitts i McCulloughprzeanalizowali sieć wyidealizowanych komórek nerwowych i zaproponowali sposób naucze-nia takiej sieci dokonywania prostych operacji logicznych. Ich dzieło dopiero później zostałonazwane sieciami neuronowymi. W 1951 r. Marvin Lee Minsky przedstawił system SNARC,sieć neuronową, której zadaniem było nauczyć się, przy wykorzystaniu paradygmatu nagrody,przechodzić przez labirynt.
Kilka lat później Hebb zaproponował metodą uczenia się sieci, w której połączenia międzyneuronami są wzmacniane, kiedy ich aktywność jest skorelowana ze sobą i osłabiane w prze-ciwnym wypadku. Autor pokazał jaki jest skutek uczenia się sieci w taki sposób.
W 1962 roku Rosenblatt opublikował książkę prezentującą teorię dynamicznych systemówneuronowych wzorowanych na mózgu, opartą na modelu komórki nerwowej, który nazywał„perceptronem”. Rosenblatt argumentował, że jego sieć może nauczyć się dowolnej klasyfikacjidanych wejściowych.
W 1969 ukazała się książka Minsky’ego i Papert’a „Perceptrons” wskazująca ograniczeniaperceptronu Rosenblatt’a. Stanowiła ona na tyle poważną krytykę tego podejścia, że zahamowałbadania w dziedzinie sztucznych sieci neuronowych na ok. 10 lat.
Gwałtowny rozwój technologii układów o wielkim stopniu scalenia (VLSI) w latach osiem-dziesiątych spowodował znaczący wzrost zainteresowania mechanizmami równoległego prze-twarzania informacji, do których zaliczają się także sieci neuronowe. W ślad za tym zaintere-sowaniem pojawiły się znaczące prace. W 1982 r. Hopfiled przedstawił sposób adaptacji sieciprowadzący do tego, że sieć uczy się klasyfikować sygnały wejściowe wg zadanego klucza. Wtym samym czasie Werbos przedstawił metodę propagacji wstecznej stanowiącą rozwiązanieproblemu obliczania gradientu w sieci wskazywanego przez Minsky’ego i Papert’a jako kluczo-wą przeszkodę w użytecznym stosowaniu sieci neuronowych. Odkrycia te uruchomiły lawinębadań, w rezultacie których sieci neuronowe stały się narzędziami służącymi do rozwiązywaniaróżnorodnych problemów.
2. Sztuczna inteligencja; uczenie maszynowe; uczenie się ze wzmocnieniem.
Uczenie maszynowe, będące także poddziedziną sztucznej inteligencji, koncentruje się na tech-

1.3. Trzy dziedziny składające się na zawartość skryptu 7
nikach automatycznego pozyskiwania wiedzy opisowej oraz proceduralnej. Metody pozyskiwa-nia wiedzy opisowej to grupowanie pojęciowe, klasyfikacja czy data mining, czyli wydobywaniereguł z baz danych. Przez pozyskiwanie wiedzy proceduralnej rozumiemy w istocie uczenie sięsterowania procesami dynamicznymi czyli dokładnie to czym zajmujemy się w ramach niniej-szego skryptu. Trzon technik tego rodzaju stanowi dziedzina uczenie się ze wzmocnieniem.
Uczenie się ze wzmocnieniem zajmuje się problemem agenta, który podejmując i egzekwu-jąc decyzje w pewnym środowisku, zmienia w nim swój stan otrzymując przy tym nagrody. Jegozadanie polega na wypracowaniu takiego mechanizmu podejmowania decyzji, który w każdejchwili zapewniałyby maksymalizację przyszłych nagród. Odpowiada to dokładnie schematowiz Rys. 1.1, w którym rola arbitra polega na nagradzaniu decydenta za osiąganie jego celów.
Sam termin “wzmocnienie” (ang. reinforcement) został zaadaptowany do dziedzin technicz-nych z psychologii przez Minsky’ego w pracy [16]. Ukazanie się tej pracy w 1954 roku byłojednym ze zwiastunów powstania sztucznej inteligencji jako dziedziny dążącej do zbudowaniamaszyn charakteryzujących się inteligencją podobną do ludzkiej. Pionierski rozwój metod adap-tacji systemów decyzyjnych odniósł spektakularny sukces w postaci programu, który nauczył sięgrać w warcaby na poziomie mistrzowskim (uczył się grać sam ze sobą; pokonywali go jednakarcymistrzowie tej gry). Program ten został opisany w pracy [26] z roku 1959.
Lata 60-te i 70-te XX wieku nie obfitowały w odkrycia znaczące dla mechanizmów ucze-nia się w okolicznościach przedstawionych na Rys. 1.1. Na początku lat 80-tych pp. RichardSutton i Andrew Barto wraz ze współpracownikami uruchomili na dużą skalę badania w dzie-dzinie, która wkrótce potem zyskała nazwę uczenie się ze wzmocnieniem (ang. reinforcement
learning). Pionierską pracą z tego okresu jest [4]. Lata 80-te były okresem obfitej twórczościw tym obszarze nieskrępowanej rygorami teoretycznymi. W latach 90-tych część tej twórczościzostała porzucona, a część wzmocniona przez pojawiające się rezultaty teoretyczne. Był to takżeokres, w którym dziedzina ta zyskała znaczną popularność wśród badaczy. W początkach XXIwieku uczenie się ze wzmocnieniem rozwija się w dwóch kierunach: dowodzone są formalniewłasności znanych mechanizmów uczenia się, np. [14, 12], a także algorytmy adaptowane są dozastosowań, przede wszystkim w obszarze robotyki.
3. Automatyka; sterowanie adaptacyjne
Trzon teorii sterowania zajmuje się problemem takiego wyznaczania wejścia systemu dynamicz-nego, aby otrzymać pożądany przebieg stanu lub wyjścia systemu. Niekiedy “pożądany” znaczyoptymalizujący pewien wskaźnik jakości. Na ogół jednak “pożądany” znaczy bliski zadanej tra-jektorii.
Specyficznym zagadnieniem rozważanym w teorii sterowania jest osiąganie celu sterowaniaprzy nieznajomości (ew. niedokładnej znajomości) parametrów sterowanego systemu dynamicz-nego. Zagadnienie takie jest ważne z praktycznego punktu widzenia: na ogół istnieją modele ma-tematyczne obiektów, dla których inżynierowie projektują układy sterowania; dla konkretnychprzypadków nieznane są jednak pewne parametry tych modeli, co może wynikać z niedokład-ności wykonania, zmęczenia materiału, czynników trudnych do precyzyjnego zmierzenia takichjak tarcie itd. W takim razie pożądany jest sterownik, który potrafi dostroić się do nieznanych(niedokładnie znanych) parametrów obiektu.
Badania nad sterowaniem adaptacyjnym rozpoczęły się na poważnie na początku lat 50-tychwraz z intensywnym rozwojem lotnictwa wojskowego. Od samolotów wojskowych wymaga sięniezawodnego działania w zróżnicowanych warunkach (przeciążenie, temperatura, wiatr, itd.)Rozpoczęte zostały poszukiwania sterowników, które potrafią się do tych zmiennych warun-ków przystosować. Zaproponowano wówczas kilka mechanizmów adaptacji, jednak mało by-ło rezultatów teoretycznych gwarantujących ich poprawność (zbieżność). Skala badań została

8 Rozdział 1. Wprowadzenie
ograniczona niemal u ich zarania w związku z brakiem odpowiedniej teorii a przede wszystkimkatastrofą samolotu testowego.
W latach 60-tych pojawił się szereg rezultatów z teorii sterowania, które potem umożliwiłyrozwój sterowania adaptacyjnego. W tym czasie pojawił się formalizm przestrzeni stanów orazteoria stabilności. Richard E. Bellman wprowadził programowanie dynamiczne. Jakow Tsypkinpokazał, że wiele schematów uczenia oraz sterowania adaptacyjnego można opisać przy pomocyrekurencyjnych równań pewnego szczególnego typu. W tym czasie pojawiły się ponadto ważnerezultaty w zakresie identyfikacji systemów.
Lata 70-te były czasem proponowania ad hoc różnorodnych schematów adaptacji dla potrzebsterowników rozmaitej konstrukcji. Pojawiło się wiele udanych wdrożeń, choć uzasadnienie teo-retyczne tych rozwiązań było wciąż ograniczone.
Lata 80-te przyniosły dowody stabilności i zbieżności znacznej części wcześniej opracowa-nych schematów adaptacji. Wtedy pojawiła się spójna teoria sterowania adaptacyjnego oparta nafunkcjach Lapunowa. Jest to okres, w którym także pojawiło się wiele aplikacji w takich dzie-dzinach jak robotyka manipulatorów, sterowanie samolotami i rakietami, inżynieria chemiczna,elektrownie i sterowanie statkami.
W latach 90-tych sterowanie adaptacyjne było obszarem dalszych intensywnych badań na-ukowych. Zaowocowały one m.in. zaproponowaniem i udowodnieniem zbieżności pewnych me-chanizmów adaptacji, które optymalizują sieci neuronowe stosowane do sterowania.
1.4. Adaptacja i uczenie się jako droga do inteligentnego zachowania się
maszyn i programów
Niniejszy wstęp uwieńczymy refleksją na temat jakie funkcje musi mieć maszyna i programkomputerowy, abyśmy nazywali je inteligentnymi i jaką rolę w powstawaniu tych funkcji możepełnić adaptacja. Bezpośrednia odpowiedź na to pytanie byłaby raczej kwestią filozoficzną: corozumiemy przez funkcje inteligentne. A zatem, podejdziemy do zagadnienia z innej strony,a mianowicie rozważymy jakie zdolności intelektualne odróżniają nieinteligentne zwierzęta, np.konia, do bardziej inteligentnych, np. szympansa i najinteligentniejszej znanej istoty biologicz-nej, czyli człowieka.
1. Sterowanie. Ludzie w porównaniu z innymi zwierzętami potrafią bardzo zręcznie manipulo-wać własnym ciałem oraz innymi obiektami (przy pomocy własnego ciała). W tej dziedzinienajbliżej nas są małpy, które wyjątkowo zręcznie sterują własnym ciałem, natomiast dosyć nie-zręcznie manipulują innymi obiektami.
Rola adaptacji w powstawaniu umiejętności ruchowych u człowieka i zwierząt jest zupełnieoczywista. Rodzący się człowiek nie ma praktycznie żadnych predyspozycji w tym zakresie. Cowięcej, kiedy dorosły człowiek po raz pierwszy wykonuje jakąś czynność ruchową (np. gra wtenisa stołowego lub żonglowanie piłeczkami), na ogół wychodzi mu to ślamazarnie chyba, żejest w stanie zdekomponować ją na jakieś prostsze czynności, które potrafi wykonywać dobrze.
2. Planowanie. Badania w dziedzinie neuropsychologii wskazują, że w chwili gdy człowiekpodejmuje jakiekolwiek działania, w jego mózgu odbywa się zakrojony na bardzo szeroką ska-lę proces przeszukiwania przestrzeni scenariuszy dalszego przebiegu zdarzeń. To co człowiekfaktycznie wykonuje jest rezultatem znalezienia możliwie najlepszego elementu tej przestrzeni.
Przestrzeń scenariuszy przyszłych zdarzeń ma charakter drzewa, które zbiega się w teraź-niejszości i rozgałęzia w miarę jak w kolejnych momentach człowiek i jego otoczenie możepodejmować różne działania. Człowiek bardzo zręcznie przeszukuje tą przestrzeń szybko po-rzucając rozpatrywanie scenariuszy, które prowadzą do mało atrakcyjnych rezultatów. Dobrym

1.5. Organizacja skryptu 9
przykładem jest gra w szachy (lub każda inna tego typu): doświadczony gracz rozpatruje pewnescenariusze na niewiele kroków naprzód i porzuca podczas gdy inne, bardziej perspektywiczne,rozważa na bardzo długim horyzoncie. Niewątpliwie adaptacja odgrywa istotną rolę w mecha-nizmach pozwalających człowiekowi efektywnie planować swoje losy bez znacznej straty czasuna analizę planów, które nie mają sensu. W przypadku szachów ta rola adaptacji jest stwierdzonaprzy okazji badań nad wybitnymi szachistami.
3. Funkcjonowanie mózgu w ogóle. Procesy w ludzkim mózgu manifestowane takimi predyspo-zycjami jak percepcja, pamięć, rozwiązywanie problemów czy świadomość, są dla współczesnejnauki wciąż w dużym stopniu zagadkowe. Na poziomie fizjologicznym mózg stanowi sieć ko-mórek strzelających do siebie wyładowaniami elektrycznymi poprzez łączące je synapsy. Mózgprzychodzącego na świat człowieka nie przejawia wszystkich wyżej wymienionych kompetencjii nabywa je w procesie rozwoju, którego fizjologicznym objawem jest zmiana konduktancji połą-czeń synaptycznych między neuronami. Oczywiście mózg człowieka od początku ma potencjał,aby te kompetencje nabyć, ale ostatecznie nabywa je dzięki adaptacji i uczeniu się.
1.5. Organizacja skryptu
Poza niniejszym, wprowadzającym, skrypt zawiera 16 rozdziałów. Rozdział 2 poświęco-ny jest zagadnieniu aproksymacji funkcji i procedurze Robbinsa-Monro jako podstawowemumechanizmowi adaptacji. Rozdziały 38 poświęcone są uczeniu się ze wzmocnieniem, roz-działy 9, 10 zawierają preliminaria z teorii sterowania potrzebne do omówienia sterowania ad-aptacyjnego przedstawionego w rozdziałach 1113. Rozdziały 1417 omawiają podejścia douczenia-się/adaptacji, które nie wpisują się jednoznacznie do żadnego z głównych nurtów. Sąto, odpowiednio, Aproksymowane Programowanie Dynamiczne (ang. Approximate Dynamig
Programming), Stochastyczne Sterowanie Adaptacyjne (ang. Stochastic Adaptive Control), Ste-rowanie z Iteracyjnym Uczeniem się (ang. Iterative Learning Control) oraz Filtr Kalmana.
Skrypt jest przeznaczony dla studentów informatyki, automatyki oraz matematyki, naukow-ców zajmujących się tymi i pokrewnymi dziedzinami, a także praktyków projektujących systemysterujące i moduły decyzyjne w programach komputerowych. Treść skryptu jest skomponowanaw taki sposób, aby czytelnikowi do jej przyswojenia wystarczyła znajomość, na poziomie akade-mickim, analizy matematycznej i probabilistyki. Oznacza to, że poza zagadnieniami adaptacji,na których skrypt się koncentruje, zawiera on także sporo materiału wstępnego, pogłębiającegowiedzę czytelnika w dziedzinach takich jak procesy stochastyczne oraz teoria sterowania.
Wydaje się, że materiał zawarty w skrypcie powinien być prezentowany na wykładzie dwu-semestralnym. Zajęcia jednosemestralne obejmujące cały materiał zostałyby prawdopodobnieuznane przez studentów za radykalnie przeładowane. Jeśli skrypt ma służyć jako podstawa wy-kładu jednosemestralnego dla studentów kierunków innych niż matematyka, proponuję pominąćnastępujące jego części:- z początkowych rozdziałów poświęconych uczeniu się ze wzmocnieniem sekcje 3.3 oraz 4.5,- rozdział 6,- część sekcji 7.3 poświęconą algorytmowi Aktor-Krytyk(λ) z powtarzaniem doświadczenia
i sekcję 7.4,- cały rozdział 12 poświęcony zaawansowanym schematom adaptacji.Ponadto, wykład w ramach wykładu jednosemestralnego ostatnia część skryptu (rozdziały 1417)może być przedstawiona w taki sposób, aby jedynie przybliżyć główne idee opisywanych tammetod.


Rozdział 2
Aproksymacja funkcji i podstawowe mechanizmy
adaptacji
2.1. Aproksymatory i zagadnienie aproksymacji
Niech X będzie pewną przestrzenią wejść z elementami x, Θ = Rnθ będzie pewną prze-
strzenią parametrów z elementami θ, zaś Y = Rny będzie przestrzenią wartości z elementami
y. Aproksymatorem będziemy nazywali przekształcenie postaci
f : X ×Θ 7→ Y ,
które jest ciągłe i różniczkowalne ze względu na swój drugi argument. Wartości tego przekształ-cenia będziemy oznaczali przez f(x; θ).
Aproksymatory spełniają dwie różne role. Z pierwszej z nich wynika nazwa „aproksyma-tor”. Chodzi mianowicie o to, aby dla pewnego ustalonego parametru θ, wartość f(x; θ) byłoprzybliżeniem f(x) dla pewnej funkcji
f : X 7→ Y (2.1)
i wszystkich argumentów x ∈ X . Dla przykładu: f może być pewną istniejącą w przyrodzie za-leżnością; na przykład między stanem robota i przykładanymi do niego siłami a przyspieszeniemjego elementów. Rozważamy sytuację, w której potrzebna jest pewna przybliżona reprezenta-cja, czyli aproksymacja tej zależności. Symbol f określa rodzinę funkcji, z których każda możestanowić tę reprezentację. Parametr θ określa, którą z funkcji z rodziny f posługujemy się doaproksymacji funkcji f . W przyszłości zajmiemy się zagadnieniem wyboru odpowiedniego θ.
Aproksymator f , jako rodzina funkcji postaci (2.1) parametryzowana przez θ ∈ Θ, możemieć ogólniejsze zastosowanie. Może nam zależeć na tym, aby wybrać z tej rodziny funkcję naj-lepszą według pewnego kryterium. Dla przykładu: dla ustalonego θ, funkcja f(· ; θ) przekształcastany decydenta w jego decyzje. Nam zależy na tym, aby decyzje w każdym stanie były jak naj-lepsze i właśnie ze względu na to kryterium powinno być wyznaczone θ. Na ogół wyznaczanieparametru θ właśnie w takim kontekście jest istotą algorytmów uczenia się ze wzmocnieniem,które zostaną omówione w kolejnych rozdziałach.
Przykład 2.1.1. Aproksymacja wielomianowa
Jak wiadomo, każda funkcja ciągła daje się, na skończonym przedziale, aproksymować wielo-mianami. Niech więc X = R, Θ = R
4, Y = R zaś f jest postaci
f(x; θ) = θ1 + θ2x+ θ3x2 + θ4x
3.
Jest to więc nic innego jak wielomian 3-ciego stopnia z parametrami θ.
Przykład 2.1.2. Szereg trygonometryczny
Inna typowa rodzina aproksymatorów odwołuje się do faktu, iż każda funkcja ciągła może być

12 Rozdział 2. Aproksymacja funkcji i podstawowe mechanizmy adaptacji
na przedziale skończonym dowolnie dokładnie aproksymowana przy pomocy szeregu Fouriera.Niech X = [−π, π], Θ = R
2n+1, Y = R zaś f przyjmie postać
f(x; θ) = θ1 +
n∑
k=1
θ2k cos(kx) + θ2k+1 sin(kx).
Ważną klasę stanowią aproksymatory liniowe, które mają postać
f(x; θ) = Φ(x)θ, (2.2)
gdzie Φ(x) jest pewną macierzą ny×nθ. Funkcję Φ można także interpretować jako przekształ-cającą x w macierz cech wejścia x. Łatwo zauważyć, że oba powyżej omówione aproksymatorymają taką właśnie strukturę. Dwa przykłady omówione poniżej również ją mają, natomiast siećneuronowa omówiona w dalszej części nie jest już aproksymatorem liniowym.
Przykład 2.1.3. Aproksymator liniowy z radialnymi funkcjami bazowymi (RBF)
Niech X będzie pewnym ograniczonym zbiorem w Rn (np. kostką), zaś Y = R. Wybierzmyzbiór punktów xk, k = 1, . . . , n względnie równomiernie pokrywających zbiór X ; wartośćf(x; θ) będzie pewną średnią ważoną elementów wektora θ, przy czym waga θk jest tym większa,im mniejsza jest odległość między x a xk. Realizacja tej idei jest następująca. Niech
φ : R+ 7→ R+
będzie pewną ciągłą funkcją malejącą. φ(z) = exp(−z) jest doskonałym przykładem takiejfunkcji. Wybierzmy zbiór Ak, k = 1, . . . , n macierzy dodatnio określonych. Elementy wek-tora Φ(x) definiujemy jako
Φk(x) =φ ((x− xk)TAk(x− xk))∑ni=1 φ ((x− xi)TAi(x− xi))
.
Kształt funkcji φ wraz z macierzamiAk określa w jaki sposób funkcje Φk(x) “pokrywają” prze-strzeń X . Elementy te należy projektować w taki sposób, aby wartości Φk(x) nie zmieniały sięskokowo w żadnym obszarze w X .
Rysunek 2.1 przedstawia przykład aproksymacji przy użyciu sieci z radialnymi funkcjamibazowymi.
We wszystkich powyższych przykładach powołujemy się na twierdzenia mówiące, że funk-cje daje się dowolnie dokładnie aproksymować przy użyciu pewnych nieskończonych szeregów.Tymczasem jako aproksymatora używamy szeregu skończonego. W efekcie nasz aproksymatornie przybliża dowolnie dokładnie wszystkich funkcji. A jednak zwykle możliwy jest taki jegowybór, aby przybliżenia, które oferuje były wystarczające do rozwiązania stojącego przed namiproblemu.
Przed omówieniem kolejnego przykładu aproksymatora liniowego, przyjmijmy następującąwygodną konwencję: niech ϕ będzie pewnym predykatem1, wówczas
[ϕ] =
1 jeśli ϕ jest prawdą,0 w przeciwnym razie.
(2.3)
Np. dla x ∈ R mam prostą definicję modułu x, a mianowicie
|x| = ([x > 0]− [x < 0]) x.
1 Predykatem jest tu formuła posiadająca wartość logiczną.
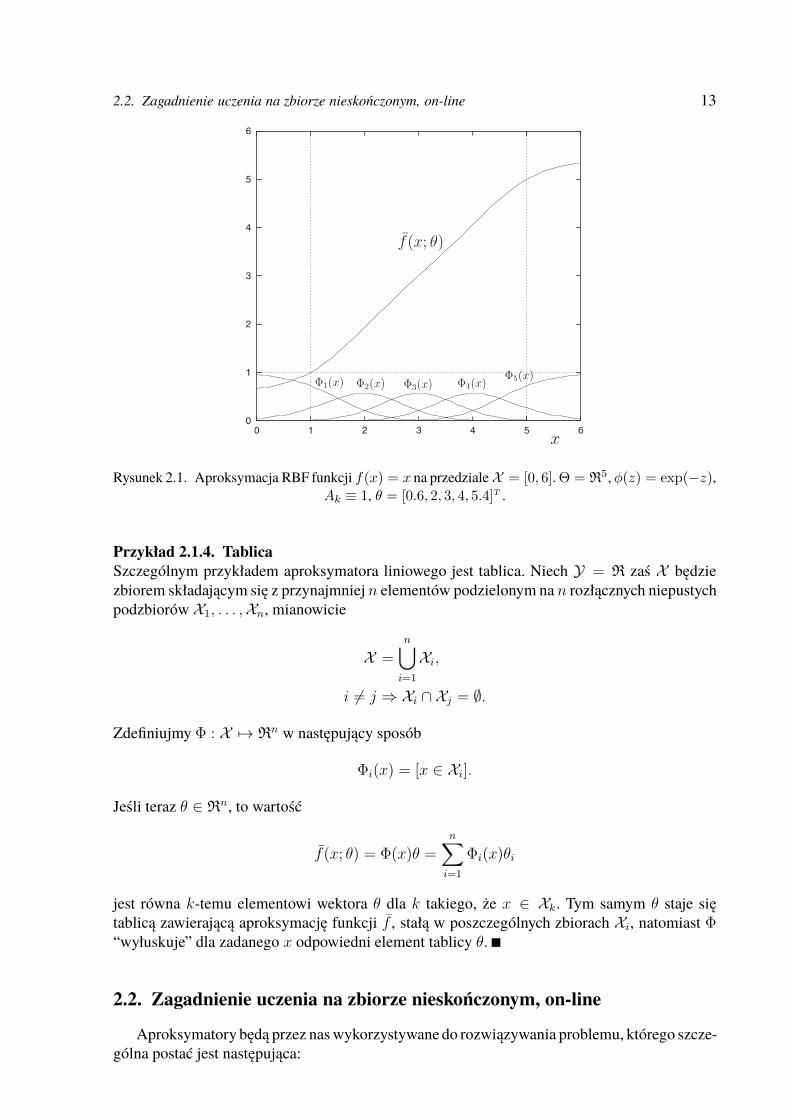
2.2. Zagadnienie uczenia na zbiorze nieskończonym, on-line 13
Rysunek 2.1. Aproksymacja RBF funkcji f(x) = x na przedzialeX = [0, 6].Θ = R5, φ(z) = exp(−z),
Ak ≡ 1, θ = [0.6, 2, 3, 4, 5.4]T .
Przykład 2.1.4. Tablica
Szczególnym przykładem aproksymatora liniowego jest tablica. Niech Y = R zaś X będziezbiorem składającym się z przynajmniej n elementów podzielonym na n rozłącznych niepustychpodzbiorów X1, . . . ,Xn, mianowicie
X =
n⋃
i=1
Xi,
i 6= j ⇒ Xi ∩ Xj = ∅.
Zdefiniujmy Φ : X 7→ Rn w następujący sposób
Φi(x) = [x ∈ Xi].
Jeśli teraz θ ∈ Rn, to wartość
f(x; θ) = Φ(x)θ =n∑
i=1
Φi(x)θi
jest równa k-temu elementowi wektora θ dla k takiego, że x ∈ Xk. Tym samym θ staje siętablicą zawierającą aproksymację funkcji f , stałą w poszczególnych zbiorach Xi, natomiast Φ“wyłuskuje” dla zadanego x odpowiedni element tablicy θ.
2.2. Zagadnienie uczenia na zbiorze nieskończonym, on-line
Aproksymatory będą przez nas wykorzystywane do rozwiązywania problemu, którego szcze-gólna postać jest następująca:

14 Rozdział 2. Aproksymacja funkcji i podstawowe mechanizmy adaptacji
1. W kolejnych chwilach czasowych t = 1, 2, 3, . . . udostępniane są pary
〈xt, ydt 〉gdzie xt ∈ X , ydt ∈ Y . Próbki są losowane niezależnie z tego samego rozkładu P .
2. Na podstawie kolejnej próbki 〈xt, ydt 〉 wyznaczana jest kolejna wartość parametru aproksy-matora, θt.
3. Ciąg parametrów θt, t = 1, 2, . . . powinien zbiegać do wektora minimalizującego funkcję
J(θ) = E 12‖f(x; θ)− yd‖2 = 1
2
∫∫‖y − f(x; θ)‖2P (x, y)dxdy.
Jest to więc wartość oczekiwana połowy kwadratu rozbieżności między f(x; θ) a wartościąyd należącą do tej samej próbki co x.
A zatem oczekujemy, że w ciągu kolejnych próbek nasz aproksymator będzie „uczył się”, abywartość f(x; θ) jak najlepiej przybliżała yd pochodzące z tej samej próbki 〈x, yd〉. Wektor yd
jest „pożądanym” wyjściem aproksymatora dla wejścia x, stąd górny indeks d (ang. desired).Minimalizowana funkcja J jest zdefiniowana jako połowa pewnej wartości oczekiwanej. Równiedobrze mogłaby to być po prostu wartość oczekiwana; ułamek 1/2 występuje w tej definicji zewzględu na tradycję i ponieważ nieznacznie upraszcza to pewne rachunki.
W szczególnym przypadku,ydt = f(x) + ξt
gdzief : X 7→ Y
jest pewną funkcją, którą chcemy aby nasz aproksymator przybliżał, zaś ξt jest to losowy szumo zerowej wartości oczekiwanej. A zatem, funkcja nie jest poznawana bezpośrednio, a mamyjedynie do czynienia z pewnym jej zaszumionym oszacowaniem. Istotna własność, na którejoparte są metody znajdowania optymalnego parametru θ, mówi nam, że możemy ignorowaćszum. Dla każdego θ ∈ Θ zachodzi bowiem
E‖yt − f(xt; θ)‖2= E(f(xt) + ξt − f(x; θ))T (f(xt) + ξt − f(x; θ))= EξT
t ξt + E2ξT
t (f(xt)− f(x; θ)) + E(f(xt)− f(x; θ))T (f(xt)− f(x; θ))= Vξt + 2(Eξt)T (f(xt)− f(x; θ)) + E(f(xt)− f(x; θ))T (f(xt)− f(x; θ))= Vξt + 0 + E‖f(xt)− f(x; θ)‖2.
Ponieważ wariancja szumu, Vξt, jest pewną stałą, to możemy minimalizować średniokwadrato-wą odległość między f(xt; θ) a yt, zamiast między f(xt; θ) a nieznanym f(xt).
Problem ogólny. Będzie nas także interesowało uogólnienie powyższego problemu, polegającena tym, że zamiast żądać, aby wartość f(xt; θ) przybliżała się do pewnej zadanej wartości ydt ,żądamy, aby minimalizowała ona pewien zadany wskaźnik jakości zwany funkcją kosztu i ozna-czany przez qt. Oto problem sformułowany w swojej ogólnej postaci.1. W kolejnych chwilach czasowych t = 1, 2, 3, . . . udostępniane są pary
〈xt, qt〉gdzie
xt ∈ X ,qt : Y 7→ R.
Próbki są losowane niezależnie z tego samego rozkładu prawdopodobieństwa.

2.3. Perceptron wielowarstwowy 15
2. Na podstawie kolejnej próbki 〈xt, qt〉 wyznaczana jest kolejna wartość parametru aproksy-matora, θt.
3. Ciąg parametrów θt, t = 1, 2, . . . powinien zbiegać do wektora minimalizującego funkcję
J(θ) = Eq(f(x; θ)
).
Jest to wartość oczekiwana funkcji kosztu dla argumentu wyznaczanego przez aproksymator.W powyższym wzorze losowe są x oraz q, należące do tej samej próbki. A zatem każdapróbka definiuje wejście dla aproksymatora oraz sposób oceny jego wyjścia.
Rozwiązując powyższy problem chcemy, aby aproksymator nauczył się odpowiadać na zadanewejście w sposób generujący jak najmniejszy koszt. Łatwo zauważyć, że problem ogólniejszysprowadza się do szczególnego jeśli zdefiniujemy funkcję kosztu jako
qt(y) =1
2‖y − ydt ‖2.
W praktyce losowanie funkcji qt wspomniane w punkcie 1. sformułowania problemu polega za-wsze na tym, że wraz z wejściem aproksymatora xt losowany jest pewien wektor (w powyższymprzykładzie ydt ), który definiuje funkcję kosztu.
2.3. Perceptron wielowarstwowy
Najpowszechniej stosowaną klasą aproksymatorów nieliniowych jest szczególna strukturasieci neuronowej, a mianowicie perceptron wielowarstwowy. W niniejszym rozdziale zostanieon przedstawiony wraz z metodami wyznaczania jego parametrów.
Niniejsza sekcja w niewielkim stopniu wyczerpuje temat sieci neuronowych. Są tu one po-traktowane wyłącznie jako prominentny przykład aproksymatorów nieliniowych. Czytelnika za-interesowanego głębszą wiedzą na temat sieci neuronowych odsyłam do bogatej literatury tejdziedziny, np. [10, 17, 18, 7].
Neuron. Perceptron wielowarstwowy jest siecią złożoną z neuronów, które omówimy w pierw-szej kolejności. Niech x ∈ R
n będzie wektorem wejść neuronu, zaś θ ∈ Rn+1 będzie to wektor
jego wag. Ponadto, niechψ : R 7→ R
będzie przekształceniem ciągłym, różniczkowalnym i rosnącym. Neuron przekształca swojewejście na skalarne wyjście wg formuły
y = ψ
(n∑
i=1
θixi + θn+1
). (2.4)
Istnieją dwa popularne typy neuronów:— Neuron nazywamy „liniowym”, jeśli ψ(z) = z,— Neuron nazywamy „sigmoidalnym”, jeśli ψ jest funkcją sigmoidalną (ciągłą, różniczkowal-
ną, rosnącą i ograniczoną), np.:
ψ(z) = arc tg(z), ψ(z) =ez
1 + ez.

16 Rozdział 2. Aproksymacja funkcji i podstawowe mechanizmy adaptacji
Rysunek 2.2. Model neuronu.
W ogólności aproksymującą siecią neuronową jest dowolne acykliczne połączenie neuronów.Wejścia neuronów pochodzą albo z zewnątrz sieci (są wtedy wejściami sieci), albo są to wyjściainnych neuronów. Natomiast wyjścia neuronów trafiają albo do wejść innych neuronów, albo nazewnątrz sieci i stanowią jej wyjścia.
Perceptron dwuwarstwowy. Szczególnie użyteczną strukturę sieci neuronowej stanowi per-ceptron dwuwarstwowy: łączy on prostotę budowy z bardzo silnymi własnościami aproksyma-cyjnymi. Neurony zgrupowane są w dwie warstwy: neurony pierwszej warstwy, zwanej ukrytą,są sigmoidalne. Wejściami każdego z nich są wejścia sieci. Neurony drugiej warstwy są liniowe;ich wejściami są wyjścia neuronów warstwy pierwszej. Wyjścia neuronów drugiej warstwy sąjednocześnie wyjściami całej sieci. Konstrukcja ta jest przedstawiona na Rysunku 2.3 i szcze-gółowo omówiona poniżej.
Niech X = Rnx , Y = R
ny , zaś n będzie pewną liczbą naturalną oznaczającą liczbę neuro-nów w warstwie ukrytej sieci. Niech ponadto wektor parametrów θ będzie poskładany z elemen-tów macierzy θ′ i θ′′, które zawierają wagi neuronów, odpowiednio, pierwszej i drugiej warstwysieci, przy czym wiersze tych macierzy, θ′j oraz θ′′k , zawierają wagi poszczególnych neuronów.Oznaczmy przez
u = [xT , 1]T
wektor wejść sieci rozszerzony o jedynkę. Taka definicja wektora u pozwoli nam zapisać prze-kształcenie (2.4) realizowane przez j-ty neuron warstwy ukrytej jako
ψj(θ′ju).
Niech następnie wyjścia neuronów warstwy ukrytej składają się na wektor z, którego dodat-kowym elementem, ostatnim, jest jedynka. k-ty neuron warstwy wyjściowej realizuje wówczasprzekształcenie
θ′′kz,
które stanowi jednocześnie k-te wyjście sieci. Wymiary macierzy θ′ i θ′′ to, odpowiednio, n ×nx + 1 oraz ny × n + 1.
Uważna analiza prowadzi do wniosku, że perceptron dwuwarstwowy realizuje przekształce-nie, którego k-ta wartość równa jest
fk(x; θ) =
n∑
j=1
θ′′k,jψj
(nx∑
i=1
θ′j,ixi + θ′j,nx+1
)+ θ′′k,n+1 (2.5)
gdzie ψk jest przekształceniem sigmoidalnym, zaś n określa wielkość struktury, czyli także jejmożliwości aproksymacyjne.

2.3. Perceptron wielowarstwowy 17
Rysunek 2.3. Perceptron dwuwarstwowy; napisy θ′j oraz θ′′k oznaczają odpowiednio j-ty wiersz macierzyθ′ oraz k-ty wiersz macierzy θ′′ a jednocześnie wagi j-tego neuronu warstwy ukrytej oraz k-tego neuronu
warstwy wyjściowej.
Możliwości aproksymacyjne perceptronu dwuwarstwowego. Perceptron dwuwarstwowy jestuniwersalnym aproksymatorem. Nieformalnie oznacza to, że dla każdej funkcji można dobraćtaki perceptron dwuwarstwowy, który będzie tę funkcję reprezentował z zadaną dokładnością.Formalnie, niech X ⊂ R
nx będzie zbiorem ograniczonym i domkniętym, a f funkcją ciągłą naX . Dla każdego ǫ > 0 istnieje takie n (wielkość struktury) i taki parametr θ, że
maxx∈X‖f(x)− f(x; θ)‖ ≤ ǫ
czyli odległość supremum między f a jej aproksymacją f(· ; θ) jest mniejsza niż ǫ. Rysunek 2.4ilustruje źródła możliwości aproksymacyjnych perceptronu dwuwarstwowego.
Wsteczna propagacja gradientu. Metody uczenia sieci neuronowej opierają się na rozwiąza-niu następującego problemu: Niech x będzie wektorem wejść sieci, f(x; θ) wektorem jej wyjść,zaś q : R
ny 7→ R pewną funkcją kosztu, oceniającą jak dobre jest wyjście sieci f(x; θ) dlazadanego wejścia x. Dla przykładu trenującego 〈x, y〉 funkcja q może mieć postać
q(f(x; θ)
)=
1
2‖f(x; θ)− y‖2.
Metody uczenia sieci opierają się na znajomości gradientu funkcji kosztu po wagach sieci, czylina wektorze
dq(f(x; θ))
dθT. (2.6)
Wektor ten mówi, w jaki sposób należy manipulować wagami sieci, aby wpływać na koszt tegoco pojawia się na wyjściu sieci.
Wyjście perceptronu dwuwarstwowego można opisać zwartą formułą (2.5). Na jej podstawiemożliwe jest w szczególności wyprowadzenie formuł na gradient (2.6). W ogólnym przypadku,kiedy struktura sieci może być dowolna, obliczanie gradientu (2.6) na podstawie zwartych formułopisujących wyjście sieci jako funkcję wejścia jest nieefektywne i nie jest praktykowane. Zamiasttego, gradient jest obliczany opisaną poniżej metodą propagacji wstecznej.
Idea propagacji wstecznej odwołuje się do struktur ogólniejszych niż sieci neuronowe. Roz-ważmy dowolny, skierowany graf działań obliczający wartość pewnego skalara q. i-ty węzeł tegografu może reprezentować stałą, zi, wówczas nie wchodzą do niego żadne krawędzie. Alterna-tywnie, i-ty węzeł reprezentuje zmienną, zi, obliczaną na podstawie wartości w innych węzłach,co jest oznaczone przez krawędzie wychodzące z tych węzłów i wchodzące do i-tego. W takim
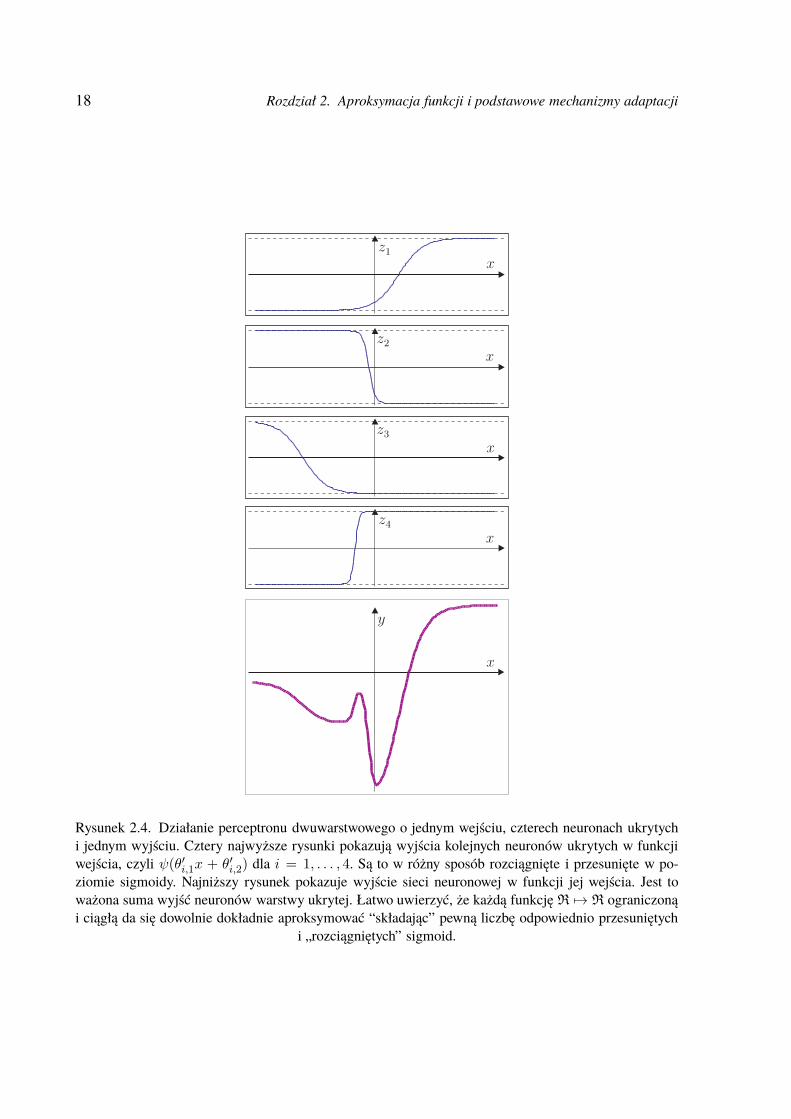
18 Rozdział 2. Aproksymacja funkcji i podstawowe mechanizmy adaptacji
Rysunek 2.4. Działanie perceptronu dwuwarstwowego o jednym wejściu, czterech neuronach ukrytychi jednym wyjściu. Cztery najwyższe rysunki pokazują wyjścia kolejnych neuronów ukrytych w funkcjiwejścia, czyli ψ(θ′i,1x + θ′i,2) dla i = 1, . . . , 4. Są to w różny sposób rozciągnięte i przesunięte w po-ziomie sigmoidy. Najniższy rysunek pokazuje wyjście sieci neuronowej w funkcji jej wejścia. Jest toważona suma wyjść neuronów warstwy ukrytej. Łatwo uwierzyć, że każdą funkcję R 7→ R ograniczonąi ciągłą da się dowolnie dokładnie aproksymować “składając” pewną liczbę odpowiednio przesuniętych
i „rozciągniętych” sigmoid.

2.3. Perceptron wielowarstwowy 19
grafie nie mogą występować cykle, czyli sytuacje polegające na tym, że dla pewnych różnychi, j, wartość zi zależy od zj , natomiast wartość zj zależy od zi. Pozwala to ponumerować węzłygrafu w ten sposób, że wartość zi zależy wyłącznie od wartości zj dla j < i oraz oddziałuje nawartości zk dla k > i. Węzeł o najwyższym indeksie reprezentuje obliczaną przez graf skalarnąwartość q.
Propagacja wsteczna polega na obliczaniu pochodnej dq/dzi w kolejności malejących in-deksów i. Aby zapisać postać tej pochodnej, wyraźmy q jako funkcję zi, posługując się grafemdziałań, na podstawie których wartość q jest obliczana. Otóż można zapisać
q = q(zi, zk1(zi), . . . , zkn(zi)
)(2.7)
przy czym skalary o indeksach k1 . . . kn są obliczane bezpośrednio na podstawie wartości zi(czyli w grafie działań są strzałki między zi a zk1 . . . zkn). Formuła, na której opiera się propa-gacja wsteczna powstaje przez zróżniczkowanie (2.7), a mianowicie
dq
dzi=
∂q
∂zi+∑
k:zi→zk
dq
dzk
∂zk∂zi
. (2.8)
Powyżej “→” oznacza bezpośrednie oddziaływanie. Niektóre zi oddziałują wyłącznie bezpo-średnio na q, i dla tych mamy
dq
dzi=∂q
∂zi,
pozostałe zaś dqdzi
możemy obliczyć przy użyciu (2.8) w kolejności malejących indeksów i.Ideę propagacji wstecznej stosujemy do obliczania gradientu w sieci neuronowej bezpośred-
nio, wprowadzając jedynie nieznaczne urozmaicenie notacyjne. Przez
vi
dla kolejnych i począwszy od 0 oznaczymy: wartość stale równą 1, wejścia sieci, wyjścia kolejnych neuronów tak, że neuron z wyjściem vi ma na wejściu vj tylko dla j < i.
A zatem, cokolwiek jest na wejściu lub wyjściu neuronów w sieci, jest oznaczone przez vi.Wartość v0 = 1 pozwoli nam traktować operację wykonywaną wewnątrz neuronu (2.4) jakojednorodną sumę iloczynów, co uprości dalsze rozważania. Przez
si
oznaczymy sumę obliczaną w neuronie, który na wyjściu ma vi. Mamy więc
vi = ψi(si) (2.9)
oraz∂vi∂si
= ψ′i(si). (2.10)
Wagę połączenia między vj a i-tym neuronem oznaczamy przez θj,i (drugi indeks dotyczy neu-ronu, do którego ta waga należy, zawsze mamy więc j < i). Wyraz wolny przy i-tej sumieoznaczymy przez θ0,i. Mamy zatem
si =∑
j:j→i
vjθj,i oraz∂si∂θj,i
= vj [j → i].

20 Rozdział 2. Aproksymacja funkcji i podstawowe mechanizmy adaptacji
Wyrażenie [·] ma znaczenie opisane w (2.3). Jedynka oddziałuje na każdy neuron, więc dlakażdego i-tego neuronu mamy 0→ i.
Algorytm propagacji wstecznej oblicza dq(f(x; θ))/dθj,i w następujący sposób. Dla neuro-nów wyjściowych mamy vi oddziałujące bezpośrednio na q, si oddziałujące bezpośrednio na vi,a zatem dla tych i mamy
dq
dvi=
∂q
∂vidq
dsi=∂vi∂si
dq
dvi= ψ′
i(si)dq
dvi,
dq
dθj,i=
∂si∂θj,i
dq
dsi= vj
dq
dsi[j → i].
W typowej sytuacji gdy neurony warstwy wyjściowej są liniowe mamyψ′i(si) = 1, co dodatkowo
upraszcza powyższe wzory.Następnie, dla pozostałych neuronów, w odwrotnej kolejności ich indeksów mamy
dq
dvi=∑
k:i→k
∂sk∂vi
dq
dsk=∑
k:i→k
θi,kdq
dsk
dq
dsi=∂vi∂si
dq
dvi= ψ′
i(si)dq
dvidq
dθj,i=
∂si∂θj,i
dq
dsi= vj
dq
dsi[j → i].
Uogólniony wynik wstecznej propagacji. Algorytm wstecznej propagacji na wejściu przyj-muje wektor
∂q(y)
∂y
∣∣∣y=f(x;θ)
i oblicza ddθT
q(f(x; θ)). Wykorzystując wzór na gradient funkcji złożonej można zauważyć, że
dq(f(x; θ))
dθT=∂f (x; θ)
∂θT
∂q(y)
∂y
∣∣∣y=f(x;θ)
.
Ponieważ nie istnieją żadne ograniczenia na wektor ∂q/∂y, to dla dowolnego wektora w o wy-miarze takim jak wyjście sieci możemy obliczyć wartość
∂f(x; θ)
∂θTw
dokonując wstecznej propagacji w przez sieć. Możliwość ta zostanie użyta w kolejnych rozdzia-łach.
2.4. Najszybszy spadek i stochastyczny najszybszy spadek
Skoro już znamy podstawowe zasady posługiwania się siecią neuronową, powróćmy do pro-blemu aproksymacji, do którego chcemy sieć zastosować. A mianowicie, wracamy do problemuzdefiniowanego w Sekcji 2.1, który polega na tym, że dla kolejnych t = 1, 2, 3, . . . , losujemy〈xt, ydt 〉 z rozkładu P i staramy się znaleźć parametr θ aproksymatora minimalizujący
E 12‖f(x; θ)− yd‖2. (2.11)

2.4. Najszybszy spadek i stochastyczny najszybszy spadek 21
W tym celu rozważymy uogólniony problem: niechΘ = Rnθ będzie dziedziną optymalizowanej
funkcji J : Θ 7→ R. Będą nas interesowały procedury, które kierują nieskończonym ciągiemparametrów θt, t = 1, 2, 3, . . . tak, aby zbiegał on do minimum J . Najpierw przedstawimyalgorytm gradientu prostego, który nadaje się do rozwiązania problemów prostszych. Jest onoparty na pewnych ideach, które dodatkowo wzbogacone posłużą do sformułowania proceduryRobbinsa–Monro, nadającej się do rozwiązania problemu właściwego. Zostanie ona przedsta-wiona w dalszej kolejności.
Algorytm gradientu prostego
Niech βt, t = 1, 2, 3, . . . będzie ciągiem parametrów z R+ zaś θt, t = 1, 2, . . . będzieciągiem elementów Θ wyznaczanych w następującej iteracji
θt+1 = θt − βt∇J(θt), t = 1, 2, . . . (2.12)
dla pewnego θ1 ∈ Θ. Powyższa procedura modyfikuje wektory θt przeciwnie do kierunku wzro-stu funkcji J . Łatwo uwierzyć, że kiedy spełnione są pewne warunki regularności, przesuwaniesię w dół wartości funkcji J prowadzi do jej minimalizacji.
Pierwsza grupa warunków na zbieżność (2.12) związana jest z ciągiem parametrów βt.Powinien on mieć następujące własności.A1.
∑t≥1 βt = +∞.
A2. βt jest mniejsze od modułu odwrotności największej wartości własnej jaką osiąga hesjan∇2J(θ).
Dzięki warunkowi A1, cała procedura może pokonać nawet nieskończoną drogę w przestrzeniΘ, aby doprowadzić ciąg θt do minimum J . Warunek A2 ma wykluczyć kroki na tyle długie,że na odcinku θt → θt+1 funkcja J maleje tylko początkowo, po czym rośnie i dla argumentuθt+1 przyjmuje wartość większą niż dla θt.
Druga grupa warunków na zbieżność (2.12) dotyczy regularności funkcji J . Przykładowykomplet warunków wystarczających jest przedstawiony poniżej.A3. Funkcja J jest ciągła i różniczkowalna.A4. Hesjan ∇2J jest ograniczony.A5. Funkcja J osiąga swoje infima.A6. Gradient ∇J zeruje się tylko w minimach J .Warunek A3 jest oczywisty: jeśli funkcja jest nieróżniczkowalna lub nieciągła, wówczas albonie mamy do dyspozycji jej gradientu, albo jest on niedobrym wskaźnikiem kierunku wzrostufunkcji. Warunek A4 eliminuje funkcje, których gradient może być radykalnie różny w bliskichsobie punktach w Θ. W takiej sytuacji iteracja (2.12) może nie być w stanie efektywnie posłu-giwać się gradientem. Warunek A5 mówi, że każda wędrówka w kierunku zmniejszania się Jmusi zakończyć się dojściem do pewnego minimum. Warunek A6 wyklucza utykanie iteracji wpunktach, które nie stanowią minimum funkcji J .
Przykład 2.4.1.
Niech Θ = R2 i oznaczmy θ =
[xy
]. Niech funkcja J ma postać
J(θ) = J(x, y) = x2 + y2 − xy. (2.13)
Charakter tej funkcji stanie się oczywisty gdy zauważymy, że
J(x, y) =1
2
[x2 + y2 + (x− y)2
].

22 Rozdział 2. Aproksymacja funkcji i podstawowe mechanizmy adaptacji
-3
-2
-1
0
1
2
3
-3 -2 -1 0 1 2 3-3
-2
-1
0
1
2
3
-3 -2 -1 0 1 2 3
-3
-2
-1
0
1
2
3
-3 -2 -1 0 1 2 3-3
-2
-1
0
1
2
3
-3 -2 -1 0 1 2 3
Rysunek 2.5. Minimalizacja funkcji (2.13) przy użyciu algorytmu gradientu prostego. Elipsy oznaczająpoziomice funkcji dla jej wartości 1, 2, 3 i 4. Punkt początkowy optymalizacji θ1 = [0 2]T . Lewo/góra:
βt ≡ 0.1, prawo/góra: βt ≡ 0.3, lewo/dół: βt ≡ 0.6, prawo/dół: βt ≡ 0.68.
Widać zatem, że funkcja osiąga swoje minimum w punkcie (0, 0). Jednocześnie mamy gradientfunkcji
∇J(x, y) =[2x− y2y − x
],
który pozwala poszukać minimum J przez poruszanie się po minus gradiencie. Rysunek 2.5pokazują, jak ono przebiega dla różnych βt.
Procedura Robbinsa-Monro
Niekiedy nie jesteśmy w stanie bezpośrednio zastosować iteracji (2.12), ponieważ oblicza-nie gradientu jest czasochłonne lub niemożliwe. Okazuje się, że możemy zastosować iteracjęanalogiczną posługującą się jedynie oszacowaniami gradientu. Rozważmy iterację podobną do

2.4. Najszybszy spadek i stochastyczny najszybszy spadek 23
(2.12) która używa wektora losowego gt będącego nieobciążonym estymatorem ∇J(θt), czylispełniającego warunek2
Egt = ∇J(θt),
albo przynajmniej asymptotycznie nieobciążonym estymatorem∇J(θt), czyli spełniającego ogól-niejszy warunek
limt→∞‖Egt −∇J(θt)‖ = 0.
Iteracja ma postać
θt+1 = θt − βtgt, t = 1, 2, . . . (2.14)
dla pewnego θ1 ∈ Θ. Nosi ona nazwę procedury Robbinsa-Monro od nazwisk jej twórców [23].Modyfikuje ona wektory θt przeciwnie do kierunku, który należy rozumieć jako zaszumionygradient; kierunek ten jest średnio równy gradientowi (albo coraz mu bliższy), choć w konkretnejchwili t równość gt = ∇J(θt) nie musi zachodzić.
Czy procedura Robbinsa-Monro jest zbieżna do minimum J? Okazuje się, że tak [13], jeślitylko wzbogacimy warunki A1-A6 z poprzedniej sekcji. Warunek A2 musimy zastąpić następu-jącym:A2’.
∑t≥1 β
2t < +∞.
Zapewnia on, że kroki wykonywane przez algorytm będą coraz krótsze. W efekcie szum, którymsą obarczone będzie się uśredniał do zera i ostatecznie wypadkowy kierunek zmian θ będzie takijak minus gradient. Warunki A1 i A2’ w postaci
∑t≥1 βt = +∞∑t≥1 β
2t < +∞ (2.15)
dla malejącego ciągu βt występują dosyć powszechnie w różnego rodzaju procedurach zbież-ności stochastycznej.
Aby zapewnić zbieżność (2.14), musimy także dodać pewne warunki dotyczące gt, a miano-wicieA7. Dla każdego t i k ≥ 1 zachodzi P (gt|θt, gt−k) = P (gt|θt).A8. Wariancja gt jest jednostajnie ograniczona.Warunek A7 stanowi, że rozkład prawdopodobieństwa gt jest warunkowany przez θt, natomiastnie jest dodatkowo warunkowany przez przeszłe wartości estymatora gradientu. Innymi słowy,zależność stochastyczna między wektorem losowym gt a wcześniejszymi estymatorami gradien-tu jest w całości przenoszona przez θt. Wektor gt został określony jako zaszumiony gradient∇J(θt). Estymator gt możemy wyrazić jako
gt = ∇J(θt) + ξt,
gdzie ξt reprezentuje szum spełniający warunek
limt→∞Eξt = 0.
2 Wektor losowy X służący do szacowania nielosowej wielkości η jest jej nieobciążonym estymatorem jeślijego wartość oczekiwana jest równa µ, czyli zachodzi EX = µ. Jeśli powyższa równość nie zachodzi, wówczasXjest obciążonym estymatorem µ i jego obciążenie wynosi EX − µ.

24 Rozdział 2. Aproksymacja funkcji i podstawowe mechanizmy adaptacji
Warunek A7 wyklucza np. sytuację polegającą na tym, że ξt są skorelowane dla różnych t.3
Warunek A8 wyklucza nieograniczony wzrost wariancji gt. Niespełnienie warunku A7 lub A8mogłoby uniemożliwić efektywne „wyśrednianie” szumu niesionego przez gt.
Przykład 2.4.2.
Niech Θ = R2, oznaczmy θ =
[xy
]i rozważmy funkcje
J1(x, y) =1
2(x− 1)2 +
1
2(y − 1)2 +
1
2(x− y)2 − 1 (2.16)
J2(x, y) =1
2(x+ 1)2 +
1
2(y + 1)2 +
1
2(x− y)2 − 1. (2.17)
Mamy
J1(x, y) = x2 + y2 − xy − x− y (2.18)
J2(x, y) = x2 + y2 − xy + x+ y. (2.19)
Niech funkcja J będącą średnią J1 i J2,
J(x, y) =1
2(J1(x, y) + J2(x, y)) = x2 + y2 − xy. (2.20)
Okazuje się więc, że jest to funkcja z Przykładu 2.4.1. W tej sytuacji jasne jest, że
∇J(x, y) = 1
2
(∇J1(x, y) +∇J2(x, y)
),
co sugeruje następujący sposób estymacji ∇J(x, y): losujemy indeks i ze zbioru 1, 2 z rów-nym prawdopodobieństwem i szukanym estymatorem jest ∇Ji(x, y). Jest to estymator nieob-ciążony, albowiem
E∇Ji(x, y) =1
2
(∇J1(x, y) +∇J2(x, y)
)= ∇J(x, y).
Mamy
∇J1(x, y) =[2x− y − 1
2y − x− 1
], ∇J2(x, y) =
[2x− y + 1
2y − x+ 1
]
co pozwala nam maksymalizować J posługując się procedurą Robbinsa-Monro i estymatoremgradientu funkcji. Rysunek 2.6 pokazuje jak to wygląda dla różnych βt.
Przykład 2.4.3. Stochastyczne podejście do optymalizacji deterministycznej
Uogólnijmy poprzedni przykład rozważając zagadnienie optymalizacji
minθ∈Θ
J(θ) =1
K
K∑
i=1
Ji(θ)
które, dla ustalenia uwagi, zinterpretujemy w następujący sposób: Ji jest to koszt związany zobsługą i-tego klienta, zaśK to liczba klientów w bazie danych. θ jest parametrem pewnej oferty,którą kierujemy do klientów. Interesuje nas wielkość θ, która minimalizuje średni koszt. Problemten możemy rozwiązać posługując się gradientem
∇J(θ) = 1
K
K∑
i=1
∇Ji(θ)
3 W istocie warunek A7 można znacznie osłabić, nie jest to jednak bardzo istotne z naszego punktu widzenia.
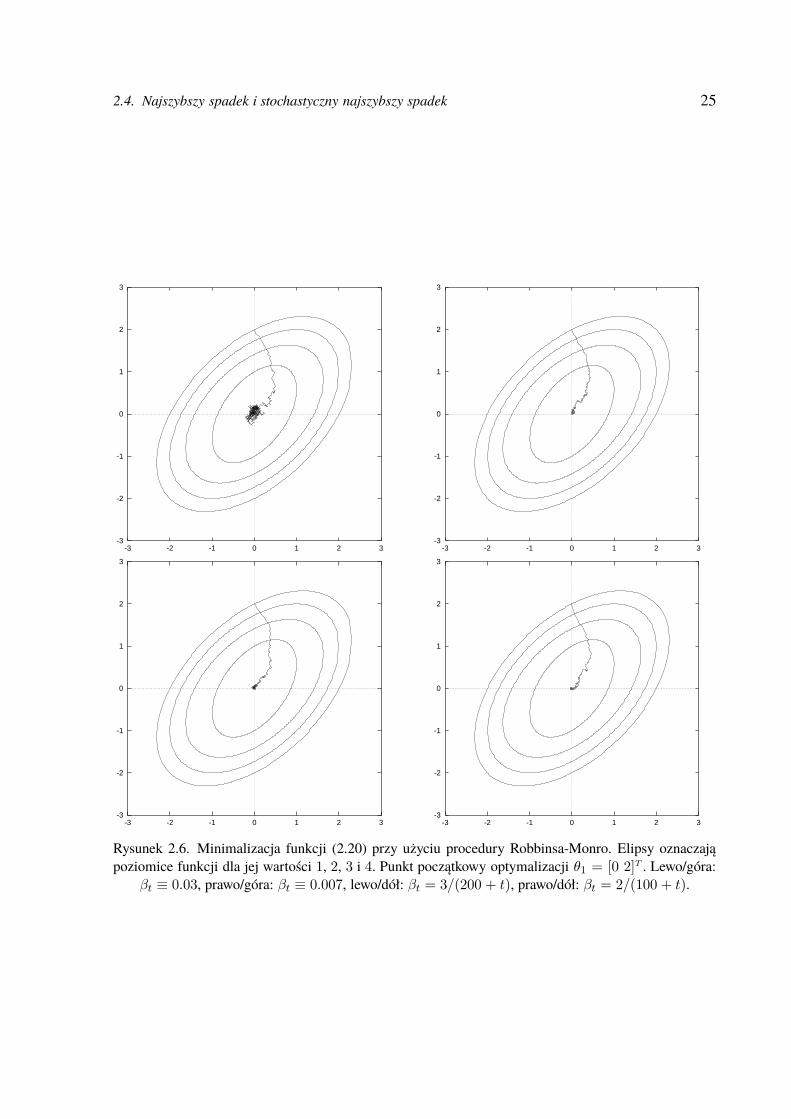
2.4. Najszybszy spadek i stochastyczny najszybszy spadek 25
-3
-2
-1
0
1
2
3
-3 -2 -1 0 1 2 3-3
-2
-1
0
1
2
3
-3 -2 -1 0 1 2 3
-3
-2
-1
0
1
2
3
-3 -2 -1 0 1 2 3-3
-2
-1
0
1
2
3
-3 -2 -1 0 1 2 3
Rysunek 2.6. Minimalizacja funkcji (2.20) przy użyciu procedury Robbinsa-Monro. Elipsy oznaczająpoziomice funkcji dla jej wartości 1, 2, 3 i 4. Punkt początkowy optymalizacji θ1 = [0 2]T . Lewo/góra:
βt ≡ 0.03, prawo/góra: βt ≡ 0.007, lewo/dół: βt = 3/(200 + t), prawo/dół: βt = 2/(100 + t).

26 Rozdział 2. Aproksymacja funkcji i podstawowe mechanizmy adaptacji
oraz iteracją (2.12). Mamy do dyspozycji wartości funkcji i jej gradient; możemy zatem posłużyćsię dowolną inną metodą optymalizacji deterministycznej. Jeśli jednak K jest rzędu milionów(co może mieć miejsce w naszym przykładowym problemie), posługiwanie się dokładną war-tością funkcji i jej gradientu może być bardzo kosztowne obliczeniowo. Alternatywnie, może-my posłużyć się estymatorem gradientu∇J i procedurą Robbinsa-Monro. Estymator gradientufunkcji o postaci średniej możemy wyznaczyć wybierając losowy podzbiór I ⊂ 1, 2, . . . , K iobliczając średnią
gt =1
#I
∑
i∈I
∇Ji(θt). (2.21)
Wartością oczekiwaną gt jest ∇J(θt), co wynika z nieco technicznego wyprowadzenia. Niechmianowicie liczność zbioru I , czyli #I , wynosi k; wówczas podzbiór I możemy wybrać na
(Kk
)
sposobów. Mamy
Egt =1(Kk
)∑
I⊂1,...,K
1
k
∑
i∈I
∇Ji(θt)
=1
k(Kk
)∑
i∈1,...,K
(K − 1
k − 1
)∇Ji(θt)
=1
K
∑
i∈1,...,K
∇Ji(θt) = ∇J(θt).
Obierając liczność zbioru I możemy elastycznie balansować między posługiwaniem się do-kładnym gradientem (#I = K), gradientem nieco zaszumionym (umiarkowane #I) oraz naj-bardziej zaszumionym (#I = 1). Im mniejsza jest losowość estymatora gradientu, tym więcejkosztuje nas jego obliczenie. Jakiekolwiek #I obierzemy, poruszanie się po estymatorze gra-dientu funkcji J zaprowadzi nas w nieskończonym czasie do jej minimum, zaś w skończonymczasie w pobliże tego minimum. W zależności jednak od tego jak dobierzemy #I , w pobliżuminimum J znajdziemy się po krótszym lub dłuższym czasie.
2.5. Uczenie się przy użyciu aproksymacji stochastycznej
W poprzedniej sekcji przedstawiono narzędzia, które teraz posłużą nam do rozwiązania pro-blemów zdefiniowanych w Sekcji 2.2. Rozpocznijmy od problemu szczególnego: dla próbek〈x, y〉 z pewnego stacjonarnego rozkładu szukamy minimum wskaźnika jakości
J(θ) = E 12‖f(x; θ)− y‖2.
Ponieważ mamy4
∇J(θ) = ∂
∂θT
∫∫1
2‖f(x; θ)− y‖2P (x, y)dydx
=
∫∫∂
∂θT
1
2‖f(x; θ)− y‖2P (x, y)dydx
= E(
∂
∂θT
1
2‖f(x; θ)− y‖2
)
4 Uwaga notacyjna: Dla funkcji f : Rn 7→ Rm, zapis ∂
∂θf(θ) oraz ∂f(θ)
∂θoznacza macierz Jakobiego o m
wierszach i n kolumnach. Macierz ta spełnia f(θ+∆) ≈ f(θ)+ ∂∂θf(θ)∆. Transpozycja macierzy ∂
∂θf(θ) będzie
oznaczana przez ∂∂θT f(θ) lub∇θf(θ).

2.5. Uczenie się przy użyciu aproksymacji stochastycznej 27
0. Dane: θ1 – początkowe oszacowanie optymalnego parametru θ, być może losowe.Przypisz t := 1.
1. Wylosuj parę 〈xt, yt〉, gdzie
xt ∼ ϕ,
yt = f(xt) + ξt,
Eξt = 0.
2. Oblicz kolejne przybliżenie θt:
θt+1 := θt − βtd
dθ
1
2‖f(xt; θt)− yt‖2
3. Jeśli spełnione są warunki zakończenia (np. dotyczące t lub osiągniętej jakości aproksy-macji), zakończ. W przeciwnym razie przypisz t := t+ 1 i przejdź do Kroku 1.
Tablica 2.1. Wyznaczanie nieliniowej aproksymacji średniokwadratowej przy użyciu metody stocha-stycznego najszybszego spadku.
To wektor∂
∂θT
1
2‖f(x; θ)− y‖2 = ∂f (x; θ)
∂θT
(f(x; θ)− y
)(2.22)
jest nieobciążonym estymatorem gradientu ∇J(θ) dla każdego 〈x, y〉 wylosowanego wedługrozkładu P . Oznacza to, że możemy posłużyć się estymatorem (2.22) do znajdowania optymal-nej wartości θ przy użyciu procedury Robbinsa-Monro. Algorytm minimalizujący J na podsta-wie kolejnych próbek 〈x, y〉 przedstawia Tablica 2.1.
Przykład 2.5.1. Stała
Niekiedy chcemy jedynie aproksymować wartość oczekiwaną funkcji losowej f(x) przy pomocystałej θ ∈ R. Powyższe rozważania stosują się także do takiego prostego przypadku. Mamywtedy f(x; θ) = θ i estymatorem∇J(θ) obliczanym w t-tej iteracji jest
gt =∂
∂θT
1
2‖f(xt; θt)− yt‖2 =
∂f (xt; θt)
∂θ(f(xt; θt)− yt) = θt − yt
W takim razie kolejne iteracje Kroku 2 Algorytmu z Tablicy 2.1 mają postać
θt+1 := θt + βt(yt − θt) = (1− βt)θt + βtyt,
czyli algorytm działa w ten sposób, że przybliża θ coraz słabiej w stronę kolejnych wartości yt.
Formuła (2.22) ma charakterystyczną postać, którą warto przeanalizować. Rozważmy jakiwektor δ należy dodać do θ aby wartość f(θ) przybliżyć do f(θ) + ∆. Funkcja
J(δ) = 0.5 ‖f(θ + δ)− (f(θ) + ∆)‖2
ma tym mniejszą wartość im bliżej f(θ + δ) jest do f(θ) + ∆. A zatem szukamy wektora rów-noległego do gradientu funkcji J w punkcie δ = 0. Tymczasem widać, że gradient J(δ) mapostać
∇J(δ)|δ=0 =∂
∂θTf(θ)∆.

28 Rozdział 2. Aproksymacja funkcji i podstawowe mechanizmy adaptacji
0. Dane: θ1 – początkowe oszacowanie optymalnego parametru θ, być może losowe.Przypisz t := 1.
1. Wylosuj parę 〈xt, qt〉, gdzie
xt ∼ ϕ,
qt :Y 7→ R.
2. Oblicz kolejne przybliżenie θt:
θt+1 := θt − βtdqt(f(xt; θt))
dθt
3. Jeśli spełnione są warunki zakończenia (np. dotyczące t lub osiągniętej jakości aproksy-macji), zakończ. W przeciwnym razie przypisz t := t + 1 i przejdź do Kroku 1.
Tablica 2.2. Optymalizacja aproksymatora przy użyciu metody stochastycznego najszybszego spadku.
A zatem to, co należy odjąć od θ to krótki wektor równoległy do powyższego. Okazuje się więc,że minus wektor (2.22) to kierunek przybliżający f(x; θ) w stronę f(x).
Rozwiązanie problemu ogólnego sformułowanego w Sekcji 2.2 jest jeszcze łatwiejsze. Dla
J(θ) = Eq(f(x; θ)
)
można bowiem zauważyć, że
∇J(θ) = ∇θEq(f(x; θ)
)
= E∇θq(f(x; θ)
)
a tym samym
∇θq(f(x; θ)) =d
dθTq(f(x; θ)) (2.23)
jest nieobciążonym estymatorem wskaźnika jakości J . Algorytm optymalizujący aproksymatorprzy użyciu stochastycznego najszybszego spadku przedstawia Tablica 2.2.
2.6. Zagadnienia praktyczne związane z używaniem sieci neuronowych w
systemach uczących się
Zastosowanie aproksymatorów nieliniowych, a w szczególności sieci neuronowych, w sys-temie uczącym się wymaga dokonania szeregu rozstrzygnięć, które wywierają istotny wpływ naefektywność systemu. Poniżej zestawiono heurystyki pozwalające dokonywać tych rozstrzygnięćw sposób zwykle przynoszący dobre rezultaty.
Wielkość sieci. Nie ma ogólnej recepty, na podstawie której można byłoby ustalać liczbę neu-ronów w warstwie ukrytej sieci. Dla prostych problemów takich jak sterowanie obiektem zczterema zmiennymi stanu, o dynamice zbliżonej do liniowej, jednak nieliniowej, dobra licz-ba neuronów jest zwykle na poziomie 50. Dla trudniejszych problemów, np. z 30 zmiennymistanu i wyraźnie nieliniową dynamiką, dobrą liczbą okazuje się 200.

2.6. Zagadnienia praktyczne związane z używaniem sieci neuronowych w systemach uczących się 29
Parametry początkowe. Zazwyczaj wagi początkowe warstw ukrytych losuje się z przedziału[−1, 1], natomiast wagi warstwy wyjściowej są inicjalizowane zerem.
Normalizacja wejść. Okolicznością utrudniającą uczenie sieci neuronowych jest zróżnicowa-nie rzędów wielkości pochodnych ∂q/∂θj,i dla różnych wag θj,i. Do takiej sytuacji dochodzi,kiedy wejścia sieci mają bardzo mały lub bardzo duży rząd wielkości. Ze wzorów na propa-gację wsteczną mamy bowiem proporcjonalność
dq
dθj,i∝ vj.
Aby więc ujednolicić rzędy wielkości pochodnych ∂q/∂θj,i, wejścia sieci powinny pokrywaćprzedział [−1, 1], czyli przedział typowo pokrywany przez wyjścia neuronów sigmoidalnych.Oznacza to, wejścia sieci neuronowej powinny być skalowane tak, aby to, co faktycznie trafiado neuronów wejściowych pokrywało przedział [−1, 1].
Normalizacja wyjść. Analizując wzory na propagację wsteczną można zauważyć, że pochod-na ∂q/∂θj,i jest sumą iloczynów, przy czym iloczyny te obejmują wszystkie wagi na drodzesygnału wychodzącego z neuronu i do wyjścia sieci. Aby więc zachować podobny rząd wiel-kości ∂q/∂θj,i, rząd wielkości różnych wag powinien odpowiadać jedności. W szczególnościdotyczy to warstwy wyjściowej. Oznacza to, że sieć powinna uczyć się funkcji znorma-lizowanej. Sposób normalizacji wynika z następującego rozumowania: jeśli potraktujemywejścia liniowego neuronu wyjściowego oraz jego wagi jako niezależne zmienne losoweo wartości oczekiwanej 0 i odchylenie standardowe 1, to wyjście takiego neuronu będziemiało wartość oczekiwaną 0 i odchylenie standardowe równe
√n, gdzie n to liczba wejść
tego neuronu. Z przesłanki tej wynika następująca reguła skalowania funkcji, której uczy sięsieć: jej wartości powinny pokrywać przedział [−√n,√n], gdzie n to liczba wejść neuro-nów wejściowych; w perceptronie dwuwarstwowym n to liczba neuronów warstwy ukrytejpowiększona o 1.
Parametr kroku. Algorytmy oparte na procedurze Robbinsa–Monro, w tym algorytm uczeniasieci neuronowej on-line, wymagają podania ciągu parametrów kroku, oznaczanych powyżejprzez βt. Niestety nie istnieje uniwersalny ciąg, który zapewnia optymalny sposób działaniawszystkich takich algorytmów w każdych warunkach. Zbyt duże parametry kroku dla dane-go problemu uczenia się powodują niestabilność procesu uczenia się, natomiast zbyt małe jego powolność. Istnieją pewne metody strojenia tych parametrów w trakcie procesu uczeniasię [34]. Tutaj niestety ograniczymy się do praktycznej rady, aby eksperymentalnie spraw-dzić kilka wartości stałych parametrów kroku i wyłonić wartość najwłaściwszą dla danegoproblemu uczenia się w oparciu o następujące przesłanki: (i) jeżeli proces uczenia się jestrozbieżny, lub niestabilny, parametr jest zbyt duży, (ii) jeżeli proces uczenia się jest bardzopowolny, ale stabilny parametr jest prawdopodobnie zbyt mały.
Niestety stosowanie się do powyższych rad nie gwarantuje sukcesu polegającego na tym, że siećneuronowa będzie w danym zastosowaniu uczyła się szybko i niezawodnie. W szczególnychprzypadkach może się okazać, że właściwe parametry mają inne wartości. Główny cel sformu-łowania powyższych rad polega na tym, aby przedstawić sposób podejścia do problemów, któremożna napotkać, a mianowicie powolność uczenia się z jednej strony i nadmierna oscylacjaniektórych wag sieci z drugiej strony.


Część II
Uczenie się ze wzmocnieniem

32
Cześć druga skryptu jest poświęcona dziedzinie uczenie się ze wzmocnieniem. Wydaje się,że dosyć rozległy materiał został tu zaprezentowany w sposób bardzo zwarty. Czytelnikom zain-teresowanym intuicyjnym wprowadzeniem do tego materiału, a także jego uzupełnieniem, reko-mendujemy książkę [5], a w szczególności jej Rozdział 13, poświęcony właśnie prezentowanymtu zagadnieniom.

Rozdział 3
Podstawy
Ten i kolejne rozdziały poświęcone są zagadnieniu agenta, który podejmuje decyzje w dyna-micznym środowisku i ponosi ich rozłożone w czasie konsekwencje. Zadanie agenta polega natym, aby nauczył się podejmować takie decyzje, których konsekwencje okażą się w przyszłościpomyślne. Zależności między decyzjami i warunkami, w których są podejmowane a ich konse-kwencjami są na początku nieznane. Rozwiązań tak postawionego problemu dostarcza dziedzinauczenie się ze wzmocnieniem [30], której fundamentem jest model Procesu Decyzyjnego Mar-kowa.
3.1. Proces Decyzyjny Markowa
Rozważamy zagadnienie decydenta, który w dyskretnej chwili czasu t = 1, 2, . . . znajdujesię w pewnym stanie xt i na podstawie tego stanu podejmuje decyzję ut. W rezultacie wykona-nia danej decyzji w danym stanie zostaje przeniesiony do następnego stanu xt+1 i środowiskowypłaca mu nagrodę rt ∈ R, która jest tym wyższa, im bardziej korzystny jest stan decydenta.
Zakładamy, że początkowo decydent nie zna środowiska, czyli relacji między jego decyzja-mi, a tym do jakich stanów trafia i jakie otrzymuje nagrody. W ogólności jego zadanie polegana tym, aby nauczyć się dopasowywać decyzje do stanów w taki sposób, aby w każdej chwilispodziewać się możliwie najwyższych nagród w przyszłości.
Interakcja decydenta ze środowiskiem może być podzielona na niezależne epizody, w któ-rych podejmuje on sekwencję decyzji prowadzącą go do jakiegoś celu. Koniec takiego epizodunastępuje, kiedy decydent trafia do stanu terminalnego, kiedy to cel zostaje osiągnięty lub decy-dent ponosi porażkę. Jest wówczas, bez żadnej decyzji, przeniesiony do stanu wybranego losowoi rozpoczyna się nowy epizod.
Przykład 3.1.1. Sterowanie urządzeniem o nieznanej dynamice
Model Procesu Decyzyjnego Markowa bezpośrednio stosuje się do zagadnień sterowania: decy-dentem jest wówczas sterownik, którego decyzjami są sygnały sterujące. Niech celem sterowaniabędzie stabilizacja wyjścia urządzenia w pewnym, okresowo zmienianym, punkcie. Wówczasstan decydenta składa się ze stanu urządzenia oraz zadanego wyjścia. Nagrodą może być wtym wypadku przeciwieństwo modułu odchyłki między zadanym i faktycznym wyjściem. Wten sposób decydent-sterownik maksymalizujący przyszłe nagrody będzie tak sterował urządze-niem, aby w każdej chwili minimalizować odchyłki między przyszłymi wyjściami urządzenia aich zadanymi wartościami.
Przykład 3.1.2. Sterowanie botem w grze komputerowej
Rozważmy grę komputerową typu FPP (First Person Perspective), w której ludzki gracz ma doczynienia z botami, czyli wirtualnymi postaciami, które są jego przeciwnikami. Rozważmy za-gadnienie zaprogramowania bota. Otóż bot, na podstawie stanu otaczającego go świata oraz jegowłasnej pozycji w tym świecie podejmuje decyzje co robić, które następnie wpływają na stanświata i jego samego. Program sterujący botem może wybierać jego decyzje w sposób określo-

34 Rozdział 3. Podstawy
ny przez projektanta. Alternatywą dla tego podejścia jest program, który w ciągu kolejnych gier„uczy się” podejmować takie decyzje, które przynoszą botowi możliwie najlepsze długofalowekorzyści (co oznacza zwykle zadawanie frustrujących porażek ludzkiemu graczowi). A zatem,bot może zbierać nagrody ilekroć osiąga swoje cele, zaś jego program ma tak nauczyć się nimsterować, aby w każdej chwili mógł spodziewać się jak najwyższych nagród w przyszłości.
Formalny opis problemu w postaci modelu Procesu Decyzyjnego Markowa charakteryzuje sięnastępującymi parametrami— Czas t = 1, 2, . . .— Przestrzeń stanów X , x ∈ X .— Przestrzeń decyzji U , u ∈ U .— Rozkład prawdopodobieństwa przejścia stanów Px(xt+1|xt, ut), czyli xt+1 ∼ Px(·|xt, ut).— Funkcję r określającą nagrodę w momencie t na podstawie decyzji ut i następnego stanu
xt+1, czyli rt = r(ut, xt+1).— Zbiór stanów terminalnych epizodu X ∗ (który jest pusty, jeśli cały proces decyzyjny jest
pojedynczym epizodem).— Rozkład prawdopodobieństwa stanów początkowych epizodu P0.Elementy Px, r, X ∗ i P0 nazywane są środowiskiem. Rozważa się różne założenia dotyczącewstępnej wiedzy decydenta na temat problemu, przed którym stoi. Zazwyczaj przyjmuje się,że ta wiedza jest skromna i ogranicza się do znajomości X i U ; tym samym zakłada się, żeśrodowisko jest nieznane.
Decydent posługuje się pewnym mechanizmem wyboru decyzji, który nazwiemy polityką
decyzyjną lub, w skrócie, polityką. Polityka definiuje dla każdego stanu rozkład prawdopodo-bieństwa decyzji. Różne polityki charakteryzują się różną jakością w tym sensie, że posługiwa-nie się nimi przynosi decydentowi mniejsze lub większe nagrody. Ogólnym celem uczenia sięjest wyłonienie polityki, która jest najlepsza w sensie wysokości nagród. Niekoniecznie jest tak,że polityka przypisuje każdemu stanowi jedną decyzję, którą należy w nim podjąć. Wręcz niepowinno tak być dopóki decydent uczy się, ponieważ aby określić które decyzje są dobre a którezłe trzeba różne decyzje wypróbować.
Cel decydenta może być zdefiniowany na kilka sposobów, przy czym nas będą interesowałyprzede wszystkim dwa.1. Niech funkcja wartości dla polityki π będzie zdefiniowana jako
V π(x) = E(
∞∑
i=0
γirt+i
∣∣∣xt = x; π
)(3.1)
przy czym γ ∈ (0, 1) to dyskonto. V π(x) jest więc wartością oczekiwaną sumy zdyskonto-wanych nagród, których decydent może się spodziewać począwszy od chwili t, jeśli jestwówczas w stanie xt = x i stosuje politykę π. Celem decydenta może być znalezienieπ ∈ Π dającego największe V π(x) dla każdego x. W ten sposób polityka jest optymali-zowana z uwzględnieniem przyszłych nagród, przy czym im bliżej one są w czasie, tymwiększa jest ich waga. “Długowzroczność” tej optymalizacji określana jest przez γ; im bliż-szy jedności jest ten parametr, tym większą wagę ma nagroda zdobyta po każdym ustalonymczasie.
2. Alternatywnie, celem decydenta może być maksymalizacja wartości oczekiwanej średniej
nagrody w przyszłości, czyli wyrażenia
E(
limT→∞
1
T
T−1∑
i=0
rt+i
∣∣∣xt = x; π
).

3.1. Proces Decyzyjny Markowa 35
Rysunek 3.1. Sterowanie urządzeniem jako Proces Decyzyjny Markowa.
W praktyce stosuje się zwykle algorytmy maksymalizujące zdyskontowane sumy nagród. Algo-rytmy maksymalizujące średnią nagrodę znajdują wprawdzie lepsze polityki, ale uzyskują je pobardzo długim czasie działania.
W praktyce stosujemy model Procesu Decyzyjnego Markowa przy konstruowaniu sterownikalub modułu decyzyjnego dla pewnego procesu. Na ogół nie zdarza się tak, że kompletnie nic niewiemy o tym procesie i o sterowaniu nim. Co więcej, zwykle jesteśmy w stanie skonstruowaćpewien rozsądnie zachowujący się sterownik (moduł decyzyjny) i zadanie polega nie tyle natym, aby on uczył się sterować procesem od “zera” tylko na tym, aby jego początkowe, ułom-ne działanie poprawiało się z biegiem czasu. A zatem chodzi o stworzenie uczącej się częścisterownika (modułu decyzyjnego). Rozważmy jak to może wyglądać w praktyce.
Rozważmy przykład 3.1.1 ze sterowaniem urządzeniem o nieznanej dynamice. Dysponuje-my pewnym pierwotnym jego sterownikiem, który zapewnia przynajmniej tyle, aby nie uległoono w czasie działania całkowitemu zniszczeniu. Nasz uczący się moduł będzie dodawał swojedecyzje do zmiennych obliczanych przez ten pierwotny sterownik. Na początku dodaje zera,czyli urządzenie jest sterowane przez sterownik pierwotny. Uczy się jednak dodawać wartościtak, aby całkowite sterowanie urządzeniem zbliżało się do optymalnego. Sytuację taką obrazujeRysunek 3.1.
Dla odmiany rozważmy przykład 3.1.2, w którym zadanie polega na zaprogramowaniu botaw grze FPP. Przypuśćmy, że w grze tej bohaterowie strzelają do siebie bezlitośnie. Przypuśćmy,że po wstępnej analizie problemu zaprojektowaliśmy sterownik pierwotny działający na takiejzasadzie, że cyklicznie bada on stan gry i bota, po czym wyznacza bieżącą wytyczną dla dzia-łania bota ze skończonego zbioru obejmującego takie pozycje jak: (i) goń przeciwnika i strzelajdo niego, (ii) uciekaj od przeciwnika do najbliższej kryjówki strzelając do niego, (iii) uciekajod przeciwnika jak najszybciej, itd. Wyznaczanie wytycznej polega na sprawdzeniu pewnegozbioru aspektów stanu gry (ilość amunicji, odległość do kryjówki, itp.) i rozstrzygnięciu za któ-rą wytyczną przemawia dany aspekt. Tak określone przesłanki są agregowane i wynika z nichwytyczna. Zadanie uczącego się modułu może polegać na dostarczaniu kolejnej przesłanki narzecz którejś z wytycznych. Sytuację tą przedstawia Rysunek 3.2.

36 Rozdział 3. Podstawy
Rysunek 3.2. Sterowanie botem jako Proces Decyzyjny Markowa.
3.2. Algorytmy Q-Learning i SARSA
Q-Learning [32] jest najpopularniejszym algorytmem uczenia się ze wzmocnieniem. Jest tojednocześnie jedna z najprostszych i najbardziej intuicyjnych metod tego typu.
Centralnym narzędziem algorytmu jest funkcja wartości-decyzji zdefiniowana jako
Qπ(x, u) = E(
∞∑
i=0
γirt+i
∣∣∣xt = x, ut = u; π
). (3.2)
Jest to więc wartość oczekiwana sumy zdyskontowanych nagród, których decydent może spo-dziewać się w stanie x, jeśli jego decyzją w tym stanie jest u, a kolejne decyzje są dyktowaneprzez politykę π. Łatwo udowodnić, że funkcję wartości-decyzji i funkcję wartości (3.1) są zwią-zane następującymi równościami
Qπ(x, u) = E(rt + γV π(xt+1)
∣∣xt = x, ut = u)
V π(x) = E (Qπ(xt, ut)|xt = x; π) .
NiechQ : X × U 7→ R (3.3)
będzie pewną funkcją. Nieprzypadkowo ma ona taką samą dziedzinę i przeciwdziedzinę jakfunkcja wartości-decyzji. Funkcja Q indukuje politykę π, jeśli tylko decyzje ut są wybierane zezbioru
argmaxu
Q(xt, u).
W szczególności, jeśli powyższy zbiór zawiera tylko jeden element, to decyzja ut staje się wła-śnie tym elementem.
Indukowanie polityki przez funkcjęQma bardzo istotne znaczenie. Wybierzmy pewną poli-tykę π i określmy jej funkcję wartości decyzjiQπ. Okazuje się, że polityka π′ indukowana przezQπ jest nie gorsza niż π w tym sensie, że
(∀x ∈ X )V π′
(x) ≥ V π(x).

3.2. Algorytmy Q-Learning i SARSA 37
0. Określ dowolną politykę początkowa π.1. Wyznacz funkcję Qπ dla polityki π.2. Wyznacz politykę indukowaną przez Qπ i przypisz ją do π.3. Jeśli w ostatnim kroku polityka zmieniła się, wróć do 1.
Tablica 3.1. Algorytm Iteracja Polityki.
0. Dane: sekwencja βt, t = 1, 2, . . . spełniająca (2.15).Zainicjalizuj: t := 1, Q.
1. Wylosuj ut na podstawieQ i xt.2. Wykonaj ut, zarejestruj xt+1 i rt.3. Przypisz
Q(xt, ut) := Q(xt, ut) + βt
(rt + γmax
uQ(xt+1, u)−Q(xt, ut)
).
przy czym Q(xi+1, ·) ≡ 0, jeśli po decyzji ui skończył się epizod.4. Przypisz t := t + 1 i wróć do Punktu 1.
Tablica 3.2. Algorytm Q-Learning.
Ponadto, jeśli tylko π nie jest polityką optymalną, to dla pewnych x zachodzi V π′
(x) > V π(x).Na własności tej oparta jest algorytm iteracji polityki, którego celem jest znalezienie optymal-nej polityki decyzyjnej w oparciu o model środowiska. Algorytm ten został przedstawiony wTablicy 3.1. Zawsze zbiega on do optymalnej polityki czyli takiej, która maksymalizuje V π(x)dla każdego x. Politykę taką, jej funkcję wartości i funkcję wartości-decyzji oznaczamy przez
π∗, V ∗, Q∗,
odpowiednio.Krok algorytmu Iteracji Polityki bazuje na funkcjiQπ wyznaczonej na podstawie zadanej po-
lityki π. Niestety, jeśli środowisko jest nieznane, bezpośrednie wyznaczenieQπ jest niemożliwei potrzebne jest inne podejście, które jedynie ideowo może być wzorowane na Iteracji Polityki.Realizuje to podejście algorytm Q-Learning przedstawiony w Tablicy 3.2. Zakłada on, żeX orazU są zbiorami skończonymi. Podstawowym narzędziem używanym przez algorytm jest funkcja(de facto tablica)Q : X ×U 7→ R, której zadanie polega na przybliżaniu się z biegiem czasu dofunkcji wartości-decyzji optymalnej polityki. Ostatecznie więcQ indukuje optymalną politykę.
Na wyjaśnienie zasługuje Krok 3 algorytmu. Chcemy aby
Q(xt, ut) = E(rt + γmax
uQ(xt+1, u)
∣∣∣xt, ut),
czyli aby Q(xt, ut) było wartością minimalizującą miarę błędu
Jt(q) = E(1
2
(rt + γmax
uQ(xt+1, u)− q
)2 ∣∣∣xt, ut)
ze względu na q. Estymatorem gradientu powyższego wskaźnika po q jest
−(rt + γmax
uQ(xt+1, u)− q
)

38 Rozdział 3. Podstawy
0. Dane: sekwencja βt, t = 1, 2, . . . spełniająca (2.15).Zainicjalizuj: t := 1, Q. Wylosuj u1.
1. Wykonaj ut, zarejestruj xt+1 i rt.2. Wylosuj ut+1 na podstawieQ i xt+1.3. Przypisz
Q(xt, ut) := Q(xt, ut) + βt (rt + γQ(xt+1, ut+1)−Q(xt, ut)) .
4. Przypisz t := t + 1 i wróć do Punktu 1.
Tablica 3.3. Algorytm SARSA.
i przeciwnie do tego właśnie kierunku zmieniane jest Q(xt, ut) = q.Algorytm Q-Learning ma silne gwarancje zbieżności: z prawdopodobieństwem 1 funkcjaQ
zbiega do funkcji wartości-decyzji optymalnej polityki. W rezultacie algorytm znajduje opty-malną politykę; jest ona indukowana przez ostateczną postać Q. Warunkiem tej zbieżności jestjednak, aby poprawka w kroku 3. algorytmu była wykonana nieskończenie wiele razy dla każdejpary stan-decyzja. Spełnienie tego warunku nakłada ograniczenia na sposób wyboru decyzji wkroku 1; żadna nie może być w sposób systematyczny wykluczona. W praktyce osiąga się tostosując ǫ-zachłanną lub Bolzmannowską strategię wyboru decyzji.
Strategia ǫ-zachłanna przewiduje, że z prawdopodobieństwem 1 − ǫ (ǫ jest małą liczbą do-datnią) wybierana jest decyzja indukowana przez bieżącą postać funkcji Q; z prawdopodobień-stwem ǫ wybierana jest decyzja całkowicie losowa. Mamy zatem:
P (ut = u|xt) = ǫ1
#U + (1− ǫ) [u ∈ argmaxuQ(xt, u)]
# argmaxuQ(xt, u)
gdzie argmax to zbiór maksymalizujący wartość funkcji, # oznacza liczność zbioru, a [ϕ] jestrówne 1 jeśli predykat ϕ jest prawdziwy i 0 w przeciwnym razie.
Strategia Bolzmannowska także przewiduje losowy wybór decyzji, przy czym prawdopodo-bieństwa określone są formułą
P (ut = u|xt) =exp(Q(xt, u)/T )∑
u′∈U exp(Q(xt, u′)/T ).
Dodatni parametr T , zwany temperaturą, określa w jakim stopniu wybór decyzji jest zbliżonydo zachłannego: Im mniejsze T , tym częściej wybierana jest decyzja maksymalizującaQ(xt, ·)dla danego xt, czyli tym częściej wybór jest zbieżny z indukowanym przez Q.
Istotną cechą algorytmu Q-Learning jest to, że metoda ta optymalizuje politykę inną niżta, która jest stosowana w procesie nauki. Ma to pewne namacalne konsekwencje: optymalnapolityka nie antycypuje błędów popełnianych w przyszłości, podczas gdy one faktycznie będąpopełniane, ponieważ uczący się decydent faktycznie podejmuje systematycznie losowe decyzjenie indukowane przez funkcję Q. Niewielka modyfikacja zamienia Q-Learning w metodę, któ-ra optymalizuje faktycznie stosowaną politykę. Algorytm ten, znany pod nazwą SARSA [25],przedstawiony jest w Tablicy 3.3.
Krok 3. algorytmu SARSA przeanalizujemy tak samo jak wyżej przeanalizowany był krokalgorytmu Q-Learning. Chcemy aby
Q(xt, ut) = E(rt + γQ(xt+1, ut+1)
∣∣∣xt, ut),

3.3. Rozszerzenie algorytmów Q-Learning i SARSA do ciągłych przestrzeni stanów i decyzji 39
czyli aby Q(xt, ut) było wartością minimalizującą miarę błędu
Jt(q) = E(1
2(rt + γQ(xt+1, ut+1)− q)2
∣∣∣xt, ut)
ze względu na q. Estymatorem gradientu powyższego wskaźnika po q jest
− (rt + γQ(xt+1, ut+1)− q)
i przeciwnie do tego właśnie kierunku zmieniane jest Q(xt, ut) = q.
3.3. Rozszerzenie algorytmów Q-Learning i SARSA do ciągłych przestrzeni
stanów i decyzji
Zastosowanie algorytmów Q-Learning oraz SARSA prowadzi zwykle do pożądanych re-zultatów. W swoich podstawowych wersjach metody te są jednak ograniczone do problemów,w których przestrzenie stanów i decyzji są skończone. Tymczasem szerszą i ciekawszą klasęstanowią zagadnienia z ciągłymi przestrzeniami stanów i decyzji. Większość problemów stero-wania należy do tej właśnie klasy.
Dyskretyzacja. Najprostszymsposobem na to, aby zastosować rozważane algorytmy do proble-mu z ciągłymi przestrzeniami stanów/decyzji jest dyskretyzacja tych przestrzeni. W przypadkuprzestrzeni decyzji polega to na wyborze skończonej podprzestrzeni U+ zawartej w U i ogra-niczenie faktycznie wykonywanych decyzji do U+. Dla przykładu: jeśli U = [−10, 10], jakoskończoną podprzestrzeń U możemy wybrać U+ = −10,−9, . . . , 10. Istotną konsekwencjątakiego kroku jest to, że dla znacznej części stanów optymalna decyzja z U może być znaczącolepsza niż najlepsza decyzja z ograniczonego zbioru U+. Dlatego, dokonując wyboru podzbiorudecyzji trzeba zadbać o to, aby był on „reprezentatywny” dla całego zbioru decyzji U .
Dyskretyzacja nieskończonej przestrzeni stanów zmierza do tego, aby decydent postrzegałzamiast oryginalnego stanu, wartość pewnej jego funkcji, należącą do zbioru skończonego. Nie-uniknione jest w takim razie, aby pewne różne stany, w których faktycznie znajduje się decydentbyły przez niego postrzegane jako jeden (dyskretny) stan. Jeśli jednak te różne lecz tak samo po-strzegane stany będą do siebie podobne, decydent wciąż może nauczyć się podejmować dobredecyzje na podstawie swoich obserwacji. Dyskretyzacja przestrzeni stanów polega na realizacjinastępujących postulatów. Po pierwsze, przestrzeń stanów jest podzielona na rozłączne podzbio-ry:
X =n⋃
i=1
Xi, i 6= j ⇒ Xi ∩ Xj = ∅.
Po drugie, algorytm uczący się nie posługuje się przestrzenią stanówX , tylkoX+ = 1, 2, . . . , n.Po trzecie, jeśli faktyczny stan decydenta to xt ∈ Xi, to stanem postrzeganym przez algorytmuczący się jest i ∈ X+.
Zastosowanie aproksymatora. Innym sposobem adaptacji algorytmów Q-Learning i SARSAdo problemów z ciągłymi przestrzeniami stanów i decyzji jest zastosowanie oryginalnych prze-strzeni oraz aproksymatora określającego funkcję Q. Oznaczmy przez
Q(x, u; υ)

40 Rozdział 3. Podstawy
0. Dane: sekwencja βt, t = 1, 2, . . . spełniająca (2.15).Zainicjalizuj: t := 1, υ.
1. Wylosuj ut ∈ U+ na podstawie Q i xt.2. Wykonaj ut, zarejestruj xt+1 i rt.3. Przypisz
υ := υ + βt∂Q(xt, ut; υ)
∂υT
(rt + γ max
u∈U+Q(xt+1, u; υ)− Q(xt, ut; υ)
).
4. Przypisz t := t + 1 i wróć do Punktu 1.
Tablica 3.4. Algorytm Q-Learning dla ciągłej przestrzeni stanów i zdyskretyzowanej przestrzeni decyzji.
ten właśnie aproksymator; jest on parametryzowany przez υ ∈ Rnυ . Algorytm Q-Learning opar-
ty na aproksymacji wykonuje taki sam zestaw kroków co metoda oryginalna. Różnice polegająna tym, ze zmodyfikowany algorytm nie posługuje się tablicą. Rozważmy Krok 3. tego algoryt-mu: oryginalnie w tym kroku minimalizowana jest rozbieżność między wartością
Q(xt, ut)
a wartością
E(rt + γmax
uQ(xt+1, u)
∣∣xt, ut).
Używając aproksymatora wykonujemy działanie w dokładnie tym samym celu, a mianowicieminimalizujemy rozbieżność między
Q(xt, ut; υ)
a wartością
E(rt + γmax
uQ(xt+1, u; υ)|xt, ut
).
Różnica polega na tym, że robimy to ze względu na parametr υ. Przedmiotem minimalizacji jestteraz
Jt(υ) = E(1
2
(rt + γmax
uQ(xt+1, u; υ
′)− Q(xt, ut; υ))2∣∣∣xt, ut
) ∣∣∣∣υ′=υ=const
Estymatorem gradientu tego wskaźnika jakości jest
−∂Q(xt, ut; υ)∂υT
(rt + γmax
uQ(xt+1, u; υ)− Q(xt, ut; υ)
)(3.4)
i przeciwnie do tego wektora modyfikujemy parametry aproksymatora υ.W podobny sposób do ciągłej przestrzeni stanu dostosowany jest algorytm SARSA. W każdej
iteracji wykonuje on krok przeciwnie do kierunku estymatora gradientu wskaźnika jakości
Jt(υ) = E(1
2
(rt + γQ(xt+1, ut+1; υ
′)− Q(xt, ut; υ))2∣∣∣xt, ut
) ∣∣∣∣υ′=υ=const
.
Estymatorem gradientu tego wskaźnika jakości jest
−∂Q(xt, ut; υ)
∂υT
(rt + γQ(xt+1, ut+1; υ)− Q(xt, ut; υ)
)(3.5)

3.3. Rozszerzenie algorytmów Q-Learning i SARSA do ciągłych przestrzeni stanów i decyzji 41
0. Dane: sekwencja βt, t = 1, 2, . . . spełniająca (2.15).Zainicjalizuj: t := 1, υ. Wylosuj u1 ∈ U+.
1. Wykonaj ut, zarejestruj xt+1 i rt.2. Wylosuj ut+1 ∈ U+ na podstawie Q i xt+1.3. Przypisz
υ := υ + βt∂Q(xt, ut; υ)
∂υT
(rt + γQ(xt+1, ut+1; υ)− Q(xt, ut; υ)
).
4. Przypisz t := t + 1 i wróć do Punktu 1.
Tablica 3.5. Algorytm SARSA dla ciągłej przestrzeni stanów i zdyskretyzowanej przestrzeni decyzji.
i przeciwnie do tego wektora algorytm modyfikuje υ.Zastosowanie algorytmu Q-Learning z aproksymatorem bezpośrednio do problemu z ciągłą
przestrzenią decyzji wiąże się z następującą trudnością: algorytm ten w każdym kroku losujedecyzję wg rozkładu wynikającego z wartości Q(xt, u; υ) dla różnych decyzji u. W najprost-szym podejściu, tzn. kiedy stosowana jest ǫ-zachłanna strategia wyboru decyzji, oznacza tokonieczność znalezienia wartości u ∈ U maksymalizującej funkcję Q(xt, · ; υ). W typowychokolicznościach znalezienie takiej wartości uwymagałoby rozwiązania problemu optymalizacjistatycznej. Jest to wyobrażalne, ale na tyle obciążające obliczeniowo, że w praktyce nie stosu-je się takiego podejścia. Zamiast tego, stosuje się opisaną poniżej kombinację: zastosowanieaproksymatora, oryginalnej przestrzeni stanu i zdyskretyzowanej przestrzeni decyzji.
Aproksymator, ciągły stan i zdyskretyzowana decyzja. Polecana kombinacja powyżej prze-dyskutowanych podejść polega na zastosowaniu oryginalnej przestrzeni stanów, aproksymatorafunkcji Q, oraz zdyskretyzowanej przestrzeni decyzji. Oznaczmy tą ostatnią przez U+; jest toskończony zbiór elementów przestrzeni U . Algorytm Q-Learning dostosowany w ten sposób doproblemów ciągłych jest przedstawiony w Tabeli 3.4. Posługuje się on estymatorem kierunkupoprawy postaci (3.4).
Algorytm SARSA dostosowany w podobny sposób jest przedstawiony w Tabeli 3.5. Posłu-guje się on estymatorem kierunku poprawy postaci (3.5).


Rozdział 4
Optymalizacja stochastycznego wyboru
Niech
φ(u)
będzie gęstością pewnej zmiennej losowej U o wartościach w U ⊂ Rnu . Będziemy rozważali
rozkłady z tej samej rodziny różniące się między sobą pewnymi parametrami. Aby odróżniać odsiebie różne gęstości, parametry będą podawane explicite po argumentach gęstości i średniku,np.
φ(u;µ).
Dla przykładu, powyższy zapis może oznaczać gęstość normalnej zmiennej losowej o pewnejstałej wariancji i wartości oczekiwanej µ.
W niniejszym rozdziale będą nas interesowały problemy o następującej strukturze:— W kroku t = 1, 2, . . . następuje losowanie wartości ut z rozkładu φ(· ;µt).— Odpowiedzią na ut jest nagroda rt ∈ R będąca liczbą losową, której rozkład jest warunko-
wany przez ut.— Problem polega na tym, aby kolejne wartości µt zapewniały możliwie wysokie nagrody.Jeśli φ(u;µ) jest gęstością rozkładu normalnego o wartości oczekiwanej µ, to problem ma nastę-pującą interpretację: poszukujemy wartości µ, która ma taką własność, że kiedy podejmujemydecyzje stanowiące sumęµ i normalnego szumu, dostajemy najwyższe nagrody. Szum dodawanydo wartości µ tworzy następującą sytuację: z jednej strony nie możemy być pewni jaka faktycz-nie decyzja zostanie zrealizowana, z drugiej jednak strony szum powoduje, że ma miejsce ciągłesprawdzanie konsekwencji różnych decyzji; dzięki temu rozkład prawdopodobieństwa decyzjimoże być dostosowany w taki sposób, aby zwiększane było prawdopodobieństwo decyzji przy-noszących wysokie nagrody i zmniejszane prawdopodobieństwo takich, które przynoszą niskienagrody.
Rozważymy trzy warianty powyższego problemu: (i) rt jest deterministyczną funkcją ut, (ii)rt zależy dodatkowo od dwóch elementów losowych, znanego i nieznanego, (iii) rt zależy odwszystkich elementów losowych zarejestrowanych do chwili t.
Praktycznie całość materiału w tym rozdziale jest objęta artykułem [36].
4.1. Parametryzowane rozkłady prawdopodobieństwa
W niniejszej sekcji rozważymy podstawowe narzędzie pojawiające się w sformułowaniu pro-blemu z początku rozdziału. Rozważamy parametryzowane gęstości prawdopodobieństwa
φ(u;µ).
Jeśli pewien parametr gęstości jest stały lub oczywisty, nie będzie specyfikowany explicite. Po-wyższy zapis uwypukla fakt, że gęstość jest w istocie funkcją nie tylko wartości zmiennej loso-

44 Rozdział 4. Optymalizacja stochastycznego wyboru
wej ale także parametrów. Jako taka, może być np. różniczkowana ze względu na parametr przydanym argumencie. Niech np. µ będzie parametrem. Rozważmy wartość
∂∂µT
φ(u;µ)
φ(u;µ)=∇µφ(u;µ)
φ(u;µ)= ∇µ lnφ(u;µ).
Ostatnia równość wynika z ogólnego wzoru na pochodną logarytmu funkcji. Powyższa wielkośćmówi nam w którym kierunku należy zmienić parametr µ, aby gęstość rozkładu prawdopodo-bieństwa dla danego u wzrosła. Oczywiście tą informację daje nam także wektor ∇µφ(u;µ).Okazuje się, że w zagadnieniach adaptacji użyteczniejszy jest wektor ∇µ lnφ(u;µ), który maten sam co ∇µφ(u;µ) kierunek, choć inną długość.
Niekiedy będą nas także interesowały rozkłady prawdopodobieństwa w dyskretnych (byćmoże skończonych) zbiorach U . W takim wypadku
φ(u;µ)
będzie oznaczało po prostu prawdopodobieństwo danej wartości u ∈ U , gdy jest ona losowanaz rozkładu o parametrze µ.
Bez względu na to, czy zbiór U jest dyskretny, czy ciągły, prawdopodobieństwo zbioru A ⊂U będziemy zapisywali przy pomocy całki
Pµ(X ∈ A) =∫
A
φ(u;µ)du.
Przykład 4.1.1.
Niech U = 0, 1, µ ∈ [0, 1], natomiast φ(u;µ) oznacza prawdopodobieństwo według wzoru
φ(u;µ) =
µ dla u = 11− µ dla u = 0.
Jasne jest, że im większa jest wartość µ, tym większe prawdopodobieństwo, że u = 1. Faktycznie
∇µφ(u;µ) =
1 dla u = 1−1 dla u = 0
i wobec tego∇µφ(u;µ)
φ(u;µ)=
1/µ dla u = 1−1/(1− µ) dla u = 0.
(4.1)
A zatem prawdopodobieństwo, że u = i rośnie wraz z µi. Z drugiej strony
lnφ(u;µ) =
lnµ dla u = 1ln(1− µ) dla u = 0
i ponownie dostajemy (4.1)
∇µ lnφ(u;µ) =
1/µ dla u = 1−1/(1− µ) dla u = 0.
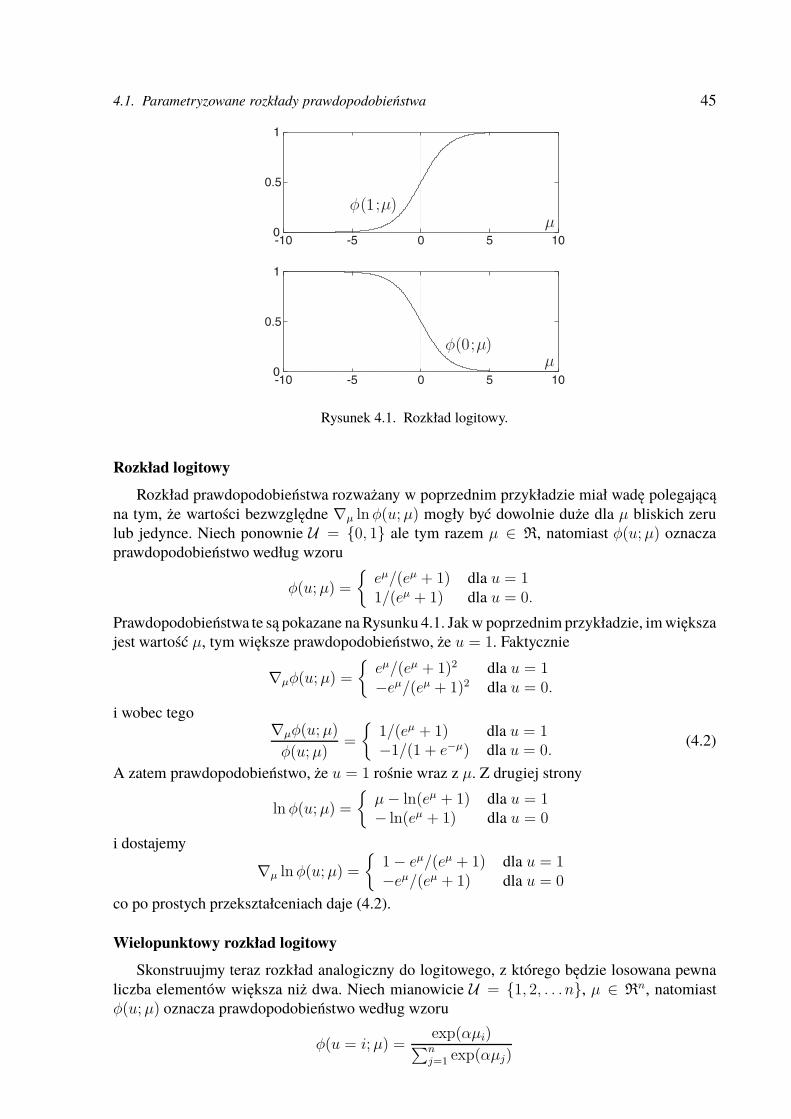
4.1. Parametryzowane rozkłady prawdopodobieństwa 45
Rysunek 4.1. Rozkład logitowy.
Rozkład logitowy
Rozkład prawdopodobieństwa rozważany w poprzednim przykładzie miał wadę polegającąna tym, że wartości bezwzględne ∇µ lnφ(u;µ) mogły być dowolnie duże dla µ bliskich zerulub jedynce. Niech ponownie U = 0, 1 ale tym razem µ ∈ R, natomiast φ(u;µ) oznaczaprawdopodobieństwo według wzoru
φ(u;µ) =
eµ/(eµ + 1) dla u = 11/(eµ + 1) dla u = 0.
Prawdopodobieństwa te są pokazane na Rysunku 4.1. Jak w poprzednim przykładzie, im większajest wartość µ, tym większe prawdopodobieństwo, że u = 1. Faktycznie
∇µφ(u;µ) =
eµ/(eµ + 1)2 dla u = 1−eµ/(eµ + 1)2 dla u = 0.
i wobec tego∇µφ(u;µ)
φ(u;µ)=
1/(eµ + 1) dla u = 1−1/(1 + e−µ) dla u = 0.
(4.2)
A zatem prawdopodobieństwo, że u = 1 rośnie wraz z µ. Z drugiej strony
lnφ(u;µ) =
µ− ln(eµ + 1) dla u = 1− ln(eµ + 1) dla u = 0
i dostajemy
∇µ lnφ(u;µ) =
1− eµ/(eµ + 1) dla u = 1−eµ/(eµ + 1) dla u = 0
co po prostych przekształceniach daje (4.2).
Wielopunktowy rozkład logitowy
Skonstruujmy teraz rozkład analogiczny do logitowego, z którego będzie losowana pewnaliczba elementów większa niż dwa. Niech mianowicie U = 1, 2, . . . n, µ ∈ R
n, natomiastφ(u;µ) oznacza prawdopodobieństwo według wzoru
φ(u = i;µ) =exp(αµi)∑nj=1 exp(αµj)

46 Rozdział 4. Optymalizacja stochastycznego wyboru
dla pewnej stałej α > 0. Aby uprościć dyskusję, oznaczmy
Σ =
n∑
j=1
exp(αµj).
Im większa jest wartość µi, tym większe prawdopodobieństwo, że u = i. Faktycznie
∂φ(u = i;µ)
∂µj=
α exp(αµi)
(Σ− exp(αµi)
)/Σ2 dla i = j
−α exp(αµi) exp(αµj)/Σ2 dla i 6= j.
i wobec tego∂φ(u = i;µ)/∂µj
φ(u = i;µ)=
α(Σ− exp(αµi)
)/Σ dla i = j
−α exp(αµj)/Σ dla i 6= j.(4.3)
A zatem prawdopodobieństwo, że u = 1 rośnie wraz z µ. Z drugiej strony
lnφ(u = i;µ) = αµi − ln Σ
i dostajemy∂ lnφ(u = i;µ)
∂µj=
α− α exp(αµi)/Σ dla i = j−α exp(αµj)/Σ dla i 6= j
co po prostym przekształceniu daje (4.3).Parametr α może pełnić rolę regularyzującą, np. może nam zależeć, aby prawdopodobień-
stwa były rozsądnie zróżnicowane dla parametrów µj mających pewną skalę, np. należących doprzedziału (−m,m). W takim razie należy rozważać α = 1/m.
Normalna zmienna losowa
Zmienna losowaX o wartościachu ∈ Rma rozkład normalnyN(µ, σ2) dlaµ ∈ R, σ ∈ R+,jeśli jej gęstość wyraża się wzorem
φ(u;µ) =1√2Πσ
exp
(− 1
2σ2(u− µ)2
). (4.4)
Kształt tej funkcji przedstawiony jest na Rysunku 4.2. Zwykle będziemy rozważać rozkładynormalne o tym samym parametrze σ, stąd nie będzie on specyfikowany w zapisie gęstości (czylinie będziemy pisać φ(u;µ, σ2)). Wartością oczekiwaną zmiennej losowej X jest
EX = µ
zaś wariancjąVX = σ2.
Ponieważ
lnφ(u;µ) = −12lnΠ− ln σ − 1
2σ2(u− µ)2
to∇µ lnφ(u;µ) = (u− µ)/σ2.
Ważną cechą normalnej zmiennej losowej jest to, że każde jej afiniczne nieosobliwe przekształ-cenie także ma rozkład normalny. W rezultacie normalna zmienna losowa zwiększana o stałąi mnożona przez stałą daje w rezultacie także normalną zmienną losową, choć zwykle o innejwartości oczekiwanej i macierzy kowariancji.
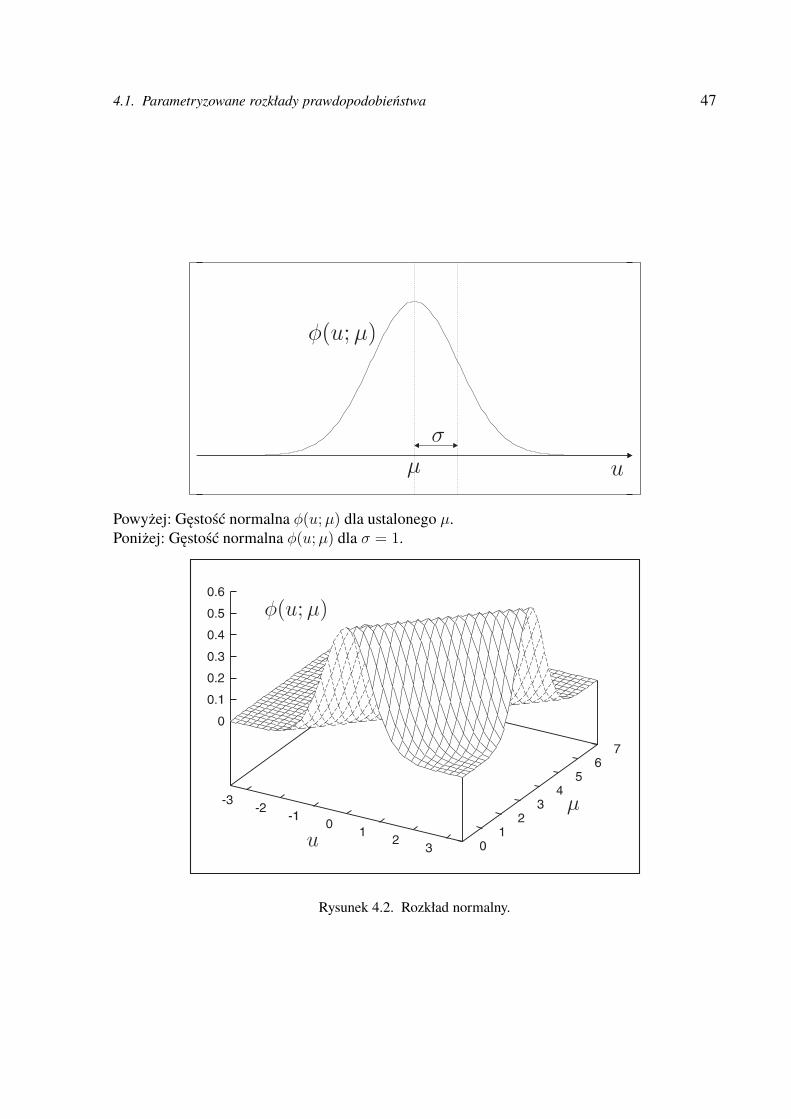
4.1. Parametryzowane rozkłady prawdopodobieństwa 47
Powyżej: Gęstość normalna φ(u;µ) dla ustalonego µ.Poniżej: Gęstość normalna φ(u;µ) dla σ = 1.
Rysunek 4.2. Rozkład normalny.

48 Rozdział 4. Optymalizacja stochastycznego wyboru
Normalny wektor losowy
Wektor losowy X o wartościach u ∈ Rn ma wielowymiarowy rozkład normalny N(µ,Σ),
jeśli jego gęstość wyraża się wzorem
φ(u;µ) =1
(2Π)n/2|Σ|1/2 exp(−12(u− µ)TΣ−1(u− µ)
). (4.5)
Wartością oczekiwaną X jest w tym przypadku
EX = µ
zaś macierz kowariancji jest równa
VX = E(X − EX)(X − EX)T = Σ.
Ponieważ
lnφ(u;µ) = −n2lnΠ− ln |Σ| − 1
2(x− µ)TΣ−1(x− µ)
to∇µ lnφ(u;µ) = Σ−1(u− µ).
Niech teraz X będzie wektorem losowym o wartościach w Rn, którego komponenty są nie-
zależne i mają rozkłady N(0, 1). W takim razie X ma rozkład N(0, I). Poszukujemy sposobugenerowania wektora losowego o rozkładzieN(µ,Σ) dla dowolnego wektora µ ∈ R
n i dowolnejdodatnio półokreślonej macierzy Σ ∈ R
n×n. Niech L będzie macierzą spełniającą
Σ = LLT .
Innymi słowy, L jest efektem faktoryzacji Choleskiego macierzy Σ. Operacji takiej potrafi do-konać większość pakietów do algebry liniowej. Wektor losowy
Y = µ+ LX
ma rozkład N(µ,Σ) co wynika z tego, iż
EY = µ+ LEX = µ,
VY = E(Y − EY )(Y − EY )T = ELX(LX)T = L(VX)LT = Σ.
Losowanie z rozkładu normalnego
Rozważmy techniczny problem losowania z rozkładu normalnego. Większość języków pro-gramowania udostępnia możliwość losowania z rozkładu jednostajnego. Tymczasem funkcje lo-sujące z rozkładu normalnego stanowią rzadkość. Poniższa metoda pozwala generować próbkiz rozkładu normalnego posługując się losowaniami z rozkładu jednostajnego.
Niech X i Y będą niezależnymi zmiennymi losowymi z rozkładu jednostajnego na odcinku[0, 1). Okazuje się, że zmienna losowa
Z =√−2 ln(1−X) cos(2πY )
ma rozkład normalny N(0, 1). Wynika to z rozumowania, którego szkic tu przedstawiamy:— Jeśli [Z,Z ′]T jest wektorem losowym o rozkładzie normalnym N(0, I), rozkład promienia
r =√Z2 + Z ′2 ma gęstość φr(x) ∝ x exp(−x2/2) dla x > 0.

4.2. Algorytm REINFORCE punktowy 49
— W takim razie rozkład połowy kwadratu promienia r′ = r2/2 jest wykładniczy i ma gęstośćφr′(x) = exp(−x), x ≥ 0.
— Rozkład zmiennej losowej − ln(1−X) jest właśnie wykładniczy i ma gęstość φr′ .Afiniczne przekształcenie zmiennej losowej Z o rozkładzie N(0, 1) postaci
Z ′ = µ+ σZ
daje zmienną losową o rozkładzie N(µ, σ2).
4.2. Algorytm REINFORCE punktowy
W niniejszej sekcji poszukamy sposobów optymalizacji polityki decyzyjnej w następującymproblemie. W dyskretnym momencie t decyzja ut ∈ U zostaje wylosowana z rozkładu prawdo-podobieństwa
φ(· ;µt)
parametryzowanego przez µt. Decyzja ut owocuje wypłatą R(ut), przy czym funkcja R : U 7→R jest ograniczona i nieznana z góry. Dla parametru µ, wartość oczekiwana wypłaty równa jest
J(µ) =
∫
U
R(u)φ(u;µ)du.
Problem polega na tym, aby tak modyfikowaćµt w kolejnych krokach, aby ciąg µt, t = 1, 2, 3, . . .dążył do wektora maksymalizującego J . Do rozwiązania problemu możemy posłużyć się pro-cedurą Robbinsa-Monro z Sekcji 2.4, o ile tylko uda nam się znaleźć nieobciążony estymator∇J(µ). Aby zaprojektować ten estymator możemy zauważyć, że zachodzi
∇J(µ) = ∂
∂µT
∫
U
R(u)φ(u;µ)du
=
∫
U
R(u)∂
∂µTφ(u;µ)du
=
∫
U
R(u)
∂∂µT
φ(u;µ)
φ(u;µ)φ(u;µ)du
=
∫
U
[R(u)
∂
∂µTlnφ(u;µ)
]φ(u;µ)du.
Ostatnia równość oznacza, że wartość oczekiwana wektora losowego
R(u)∂
∂µTlnφ(u;µ) (4.6)
jest równa ∇J(µ), czyli, że jest on nieobciążonym estymatorem ∇J(µ). Powyższy estymatorma jednak tą wadę, że może mieć dużą wariancję gdy wypłaty R(u) mają pewien duży stałykomponent. Aby ograniczyć wariancję, wyeliminujemy ten komponent. Zauważmy, że gęstośćprawdopodobieństwa całkuje się do jedynki, a zatem
∫
U
φ(u;µ)du ≡ 1.

50 Rozdział 4. Optymalizacja stochastycznego wyboru
0. Dane: sekwencje βµt , t = 1, 2, . . . i βbt , t = 1, 2, . . . spełniające (2.15).Zainicjalizuj: t := 1, µ1, b1.
1. Wylosuj ut z φ(· ;µt).2. Przypisz µt+1 = µt + βµt (R(ut)− bt) ∂
∂µTlnφ(ut;µt).
3. Przypisz bt+1 = bt + βbt (R(ut)− bt).4. Przypisz t := t + 1 i wróć do Punktu 1.
Tablica 4.1. Algorytm REINFORCE punktowy.
W związku z tym, dla dowolnej stałej b mamy
0 =∂
∂µT
[b
∫
U
φ(u;µ)du
]=
∫
U
b∂
∂µTlnφ(u;µ)φ(u;µ)du
= E(b∂
∂µTlnφ(u;µ)
).
W efekcie wektor losowy podobny do (4.6), w którym od wypłaty odjęta jest stała wartość, czyli
gt = (R(ut)− b)∂
∂µTlnφ(u;µ) (4.7)
jest nieobciążonym estymatorem∇J(µ), ponieważ
Egt = ER(u)∂
∂µTlnφ(u;µ)− 0 = ∇J(µ).
Dobierając odpowiednie b minimalizujemy wariację estymatora (4.7) po prostu zmniejszającliczby, które są przez siebie mnożone przy obliczaniu tego estymatora. Wartość b optymalna ztego punktu widzenia jest trudna do wyznaczenia. Można jednak zauważyć, że wybór bw okoli-cach typowych wartości R(u) zmniejsza E(R(u)− b)2 i tym samym sprzyja temu aby wariancjaestymatora (4.7) była relatywnie mała. Stałą b zwyczajowo nazywa się punktem odniesienia (ang.baseline).
Algorytm REINFORCE punktowy, oparty na Procedurze Robbinsa-Monro z Sekcji 2.4 jestzapisany w Tablicy 4.1. W Punkcie 2 przesuwa parametr µ w kierunku estymatora gradien-tu maksymalizowanej funkcji J . Oryginalnie Procedura Robbinsa-Monro służy minimalizacjifunkcji, podczas gdy tutaj ją maksymalizujemy, stąd tutaj estymator jest dodawany, podczas gdy

4.3. Stacjonarna polityka decyzyjna 51
wówczas był odejmowany. W Punkcie 3. algorytm przybliża bt w stronę wartości minimalizu-jącej E(R(u)− bt)2.Przykład 4.2.1.
Niech U = Rn i niech φ(· ;µ) będzie to rozkład normalny o wartości oczekiwanej µ i macierzy
kowariancji σ2I . Tym samym
φ(u;µ) =1√
2Πnσn
exp
(− 1
2σ2‖u− µ‖2
)
oraz∂
∂µTlnφ(u;µ) =
1
σ2(u− µ).
Poprawka parametru µ dokonywana w Punkcie 1. algorytmu REINFORCE punktowy ma postać
µt+1 = µt + βµt (R(ut)− bt)1
σ2(ut − µt).
Przyrównanie powyższe można zinterpretować w następujący sposób: parametr µ jest przybli-żany do wylosowanegou tym bardziej, im większą wartość miałoR(u). Tym samymµ przesuwasię w stronę, gdzie możliwe jest losowanie wyższych wypłat.
4.3. Stacjonarna polityka decyzyjna
W poprzednich dwóch sekcjach rozważany był uproszczony problem, w którym decyzjabyła losowana stale z tego samego rozkładu. Powracamy teraz do problemu Procesu Decyzyj-nego Markowa, w którym decyzja jest podejmowana na podstawie stanu, w którym znajduje siędecydent. Rozszerzając materiał z poprzednich sekcji rozważamy teraz rozkłady prawdopodo-bieństwa parametryzowane nie tylko przez niezależny parametr θ, ale także przez stan decydentaxt. Taki rozkład będzie oznaczany przez
π(u; x, θ)
i nazywany stacjonarną polityką decyzyjną. Decydent będzie posługiwał się nią w celu losowa-nia swoich decyzji. Przedmiotem uczenia się będzie natomiast parametr polityki θ, który będziemodyfikowany w taki sposób, aby decydent mógł spodziewać się jak najwyższych nagród.
W niniejszej sekcji będą nas interesowały w szczególności dwa zagadnienia: (i) w jaki sposóbprojektować stacjonarne polityki decyzyjne oraz (ii) w jaki sposób, dla danej polityki, obliczaćgradient
∂ lnπ(u; x, θ)
∂θT
mówiący, w którą stronę należy zmieniać parametr θ, aby manipulować prawdopodobieństwemdanej decyzji w danym stanie. Przedmiotem kolejnych sekcji i rozdziałów będą algorytmy po-prawy parametru θ pozwalające na uzyskanie najwyższych nagród.
Rozważmyφ(· ;µ)
jako gęstość w U parametryzowaną przez µ ∈ Rnµ . Gęstości takie były rozważane w Sekcji
4.1. Aby φ mogła służyć jako budulec polityki parametryzowanej przez θ, pewna funkcja musigenerować jej parametr µ na podstawie stanu i właśnie θ. Powiedzmy, że taką funkcją jest
µ : X ×Rnθ 7→ R
nµ .

52 Rozdział 4. Optymalizacja stochastycznego wyboru
Mamy więc dla każdej trójki 〈u, x, θ〉
π(u; x, θ) = φ(u; µ(x; θ)) (4.8)
i wobec tego dobrze określoną politykę. Taki sposób projektowania polityki jest bardzo wygodnyponieważ pozwala posłużyć się dobrze znanymi komponentami: typowymi rodzinami rozkładówprawdopodobieństwa (jako φ) i typowymi aproksymatorami (jako µ). Stosowanie tak skonstru-owanej polityki polega na tym, że dla wskazanego stanu x aproksymator wyznacza parametr µ,na podstawie którego rozkład φ generuje decyzję u.
Do posługiwania się polityką zaprojektowaną wg. (4.8) potrzebny jest nam wektor
∇θ ln π(ut; xt, θ).
Ponieważ π jest w tym przypadku złożoną funkcją θ, to wektor ten jest równy
∇θ ln π(ut; xt, θ) =∂µ(xt; θ)
∂θT× ∂ lnφ(ut; µ(xt; θ))
∂µ(xt; θ)T.
Przykład 4.3.1. Polityka oparta na sieci neuronowej
Rozważmy przestrzeń stanów X = Rnx i decyzji U = R
nu . Niech w stanie x decyzja będziegenerowana z rozkładu normalnego o wartości oczekiwanej µ i macierzy kowariancji σ2I (czyliN(µ, σ2I), (4.5)). Załóżmy, że parametr µ jest wyznaczany przez sieć neuronową (np. (2.5)).A zatem, sieć neuronowa, na podstawie stanu, wskazuje punkt, który po dodaniu szumu staje siędecyzją; szum jest niezbędny do wyznaczania kierunków poprawy. W przypadku rozważanegorozkładu normalnego mamy
∂ lnφ(u;µ)
∂µT= (u− µ)/σ2.
i wobec tego
∇θ lnπ(u; x, θ) =∂µ(x; θ)
∂θT
u− µ(x; θ)σ2
.
Powyższy wektor można obliczyć przy pomocy algorytmu propagacji wstecznej przyjmując, żewektor (
u− µ(x; θ))/σ2
oznacza gradient funkcji kosztu (∂/∂y)q(y) i jest wstecznie propagowany przez sieć.
Przykład 4.3.2. Polityka oparta na aproksymatorze liniowym
Podobnie jak w przykładzie 4.3.1 rozważamy przestrzeń stanów X = Rnx i decyzji U = R
nu .W stanie x decyzja jest generowana z rozkładu normalnego N(µ, σ2I). Źródłem parametru µjest teraz aproksymator liniowy (2.2), czyli
µ(x; θ) = Φ(x)θ.
W tym przypadku mamy∂µ(x; θ)
∂θT= Φ(x)T
i wobec tego∇θ ln π(u; x, θ) = Φ(x)T (u− Φ(x)θ)/σ2.

4.4. Algorytm REINFORCE statyczny 53
4.4. Algorytm REINFORCE statyczny
W niniejszej sekcji stacjonarna polityka decyzyjna stanie się punktem wyjścia do sformu-łowania i rozwiązania uproszczonego Problemu Decyzyjnego Markowa, w którym po każdymkroku stan jest ponownie losowany z tego samego rozkładu P0. Oto dokładne sformułowanietego problemu— W kolejnym kroku t = 1, 2, . . . stan xt jest losowany z rozkładu P0.— Z rozkładu π(· ; xt, θ) zostaje wylosowana decyzja ut.— Decydent otrzymuje nagrodę rt ∈ R, której rozkład ϕr jest warunkowany przez xt oraz ut.— Celem jest dokonywanie takich poprawek parametru θ, aby zmaksymalizować wartość ocze-
kiwaną nagrody w pojedynczym kroku.Oznaczmy przez R(x, u) wartość oczekiwaną nagrody zdobywanej w stanie x, kiedy podjętajest decyzja u. Mamy
rt = R(xt, ut) + ξt, przy czym Eξt ≡ 0.
Dodatkowo oznaczmy gęstość szumu ξ przez ϕξ(· ; x, u).Wskaźnikiem jakości, który chcemy tutaj maksymalizować jest wartość oczekiwana nagrody
warunkowana przez parametr polityki decyzyjnej θ. Jest to średnia otrzymywanych nagród postanach, w których podejmowana jest decyzja i wszystkich decyzjach, które polityka z parame-trem θ może wygenerować, czyli
J(θ) = E (rt|θ)
=
∫
X
∫
U
∫
R
rϕr(r|x, u)drπ(u; x, θ)duP0(x)dx
=
∫
X
∫
U
∫
R
(R(x, u) + ξ)ϕξ(ξ|x, u)dξπ(u; x, θ)duP0(x)dx
=
∫
X
∫
U
R(x, u)π(u; x, θ)duP0(x)dx.
Ostatnia równość wynika z tego, że wartość oczekiwana szumu ξ jest zerowa.Rozwiązanie, które tutaj omawiamy opiera się na procedurze Robbinsa-Monro: każda trójka
(xt, ut, rt) służy do obliczenia estymatora gradientu wskaźnika jakości J(θ). Parametr θt jestmodyfikowany w kierunku zgodnym z tym estymatorem.
W celu poprawy jakości estymatora gradientu, zastosowany zostanie aproksymator V (x; υ),przybliżający funkcję
E (r|x; θ) .
Jest to więc funkcja mapująca stan na wartość oczekiwaną zdobywanej nagrody przy bieżącymsposobie losowania nagrody, charakteryzowanym przez wartość parametru polityki θ.
Do estymacji gradientu wskaźnika jakości J(θ) zastosujemy funkcję losową wzorowaną na(4.7), a mianowicie
gt =(rt − V (xt; υ)
) ∂
∂θTln π(ut; xt, θ). (4.9)

54 Rozdział 4. Optymalizacja stochastycznego wyboru
0. Dane: sekwencje βθt , t = 1, 2, . . . i βυt , t = 1, 2, . . . spełniające (2.15).Zainicjalizuj: t := 1, θ1, υ1.
1. Zarejestruj stan xt wylosowany z rozkładu P0.2. Wylosuj ut z rozkładu π(· ; xt, θt).3. Przypisz θt+1 = θt + βθt
(rt − V (xt; υt)
) ∂ lnπ(ut;xt,θt)∂θT
.
4. Przypisz υt+1 = υt + βυt(rt − V (xt; υt)
) ∂V (xt;υt)∂υT
.5. Przypisz t := t + 1 i wróć do Punktu 1.
Tablica 4.2. Algorytm REINFORCE statyczny.
Zobaczmy jaka jest wartość oczekiwana gt.
Egt =∫
X
∫
U
∫
R
(R(x, u)+ξ−V (x; υ)
)∂ ln π(u; x, θ)∂θT
ϕξ(ξ|x, u)dξπ(u; x, θ)duP0(x)dx
=
∫
X
∫
U
(R(x, u)− V (x; υ)
) ∂ ln π(u; x, θ)∂θT
π(u; x, θ)duP0(x)dx
=
∫
X
∫
U
(R(x, u)− V (x; υ)
) ∂π(u; x, θ)∂θT
P0(x)dx
=∂
∂θT
∫
X
∫
U
(R(x, u)− V (x; υ)
)π(u; x, θ)P0(x)dx
=∂
∂θT
(J(θ)−
∫
X
V (x; υ)P0(x)dx
)
= ∇J(θ).
Aproksymator V (xt; υ) uczy się na podstawie kolejnych przykładów trenujących na dokładnietakiej samej zasadzie jak aproksymatory rozważane w Rozdziale 2.5. Celem uczenia aproksy-matora V jest minimalizacja miary błędu
Jθ(υ) = Eθ(1
2‖rt − V (xt; υ)‖2
).
Powyższa wartość oczekiwana jest zdefiniowana przy założeniu, że nagrody rt są zdobywanedzięki decyzjom generowanym przez politykę z parametrem θ. Estymatorem gradientu powyż-szego wskaźnika jakości jest
gυt = −∂V (xt; υ)
∂υT
(rt − V (xt; υ)
).
Przeciwnie do tego kierunku jest zatem modyfikowany wektor parametrów υ.Algorytm REINFORCE statyczny, realizujący cel nakreślony we wstępie do niniejszej sekcji,
został przedstawiony w Tablicy 4.2.
4.5. Algorytm REINFORCE epizodyczny
W niniejszej sekcji rozważymy klasyczny problemem uczenia się ze wzmocnieniem z do-datkowym założeniem, iż interakcja decydenta z jego środowiskiem jest podzielona na epizody.

4.5. Algorytm REINFORCE epizodyczny 55
Odpowiada to takiej sytuacji, w której proces decyzyjny zmierza do pewnego celu i kończysię porażką lub sukcesem. Wyklucza natomiast takie zagadnienia, w których proces decyzyjnypolega na reagowaniu na zdarzenia na nieskończonym horyzoncie czasu. Idee przedstawionew niniejszej sekcji pochodzą z artykułów [36, 15].
Niech zatem w chwili tj rozpoczyna się j-ty epizod trwający lj chwil; ciąg tj, j = 1, 2, . . . wyznacza nam chwile początków epizodów. Przyjmijmy, że w momencie tj + lj decydent znaj-duje się w terminalnym stanie epizodu, w którym już nie podejmuje decyzji. W chwili tj+ lj+1znajduje się w początkowym stanie nowego epizodu, który nie zależy w żaden sposób od wcze-śniejszych wydarzeń. Oznaczmy przez Xj wektor poskładany z lj kolejnych stanów począwszyod xtj , natomiast przez X ′
j , trajektorię stanów o jedną chwilę późniejszych. A zatem
Xj = [xT
tj, . . . , xT
tj+lj−1]T
X ′j = [xT
tj+1, . . . , xT
tj+lj]T .
(4.10)
Decydent rozpoczyna bieżący epizod w stanie xtj , po czym przechodzi przez trajektorię stanówX ′j . Analogicznie, niech Uj oznacza wektor poskładany ze wszystkich decyzji wykonanych w
j-tym epizodzie. ZatemUj = [uT
tj, . . . , uT
tj+lj−1]T .
Oznaczmy przestrzeń, do której należą pary 〈Uj, X ′j〉 przez
T =⋃
i≥1
(U × X )i.
W każdej chwili decydent otrzymuje nagrodę rt, która jest funkcją decyzji ut i kolejnegostanu xt+1. W ciągu epizodu zbiera sumę nagród
Rj =
tj+lj−1∑
t=tj
rt.
Do wyznaczania decyzji, decydent posługuje się pewną polityką parametryzowaną przez θ. Ce-lem uczenia się jest maksymalizacja wartości oczekiwanej sumy nagród gromadzonych w ciąguepizodu:
maxθJ(θ) = ERj.
W największym skrócie, algorytm REINFORCE epizodyczny działa tak jak jego statycznyodpowiednik opisany w poprzedniej sekcji. Wtedy przedmiotem wyboru dokonywanego przezdecydenta była decyzja ut. Algorytm manipulował prawdopodobieństwem dokonanego wyborustosownie do zebranej zań wypłaty. Tutaj dla każdego stanu początkowego xtj losowana jest para〈Uj, X ′
j〉 ∈ T . Jeśli oznaczymy przez PUX rozkład prawdopodobieństwa takich par, mamy
〈Uj, X ′j〉 ∼ PUX(· |xtj ; θ).
Rozkład ten warunkowany jest przez początkowy stan epizodu i parametryzowany przez wektorwag polityki, którą posługuje się decydent. Algorytm REINFORCE epizodyczny, stosownie dozebranej wypłaty Rj manipuluje parametrem θ, aby zmienić prawdopodobieństwo pojawieniasię pary 〈Uj , X ′
j〉 w przyszłości w odpowiedzi na stan xtj . Aby robić to efektywnie, potrzebujeodpowiednika stałej b lub bk z poprzedniego rozdziału. Tym razem stała ta będzie uzależnionaod początkowego stanu epizodu. Niech aproksymator V (x; υ) parametryzowany przez wektor

56 Rozdział 4. Optymalizacja stochastycznego wyboru
υ przybliża oczekiwaną wartość wypłaty spodziewanej przez decydenta od znalezienia się wstanie x do końca epizodu, czyli
V (x; υ) ∼= E(Rj
∣∣xtj = x; θ).
W tym momencie jesteśmy już w stanie zapisać estymator gradientu∇J(θ). Może on być postaci
(Rj − V (xtj ; υ)
) ∂
∂θTlnPUX(Uj , Xj|xtj ; θ).
Algorytm poprawy polityki będzie po każdym epizodzie poprawiał θ w kierunku wskazywanymprzez powyższy estymator. Powstaje pytanie, w jaki sposób będzie adaptowany aproksymator V .Po każdym epizodzie, algorytm przybliża υ w stronę minimum wskaźnika błędu
JV (υ) = E(1
2
(Rj − V (xtj ; υ)
)2; π
)
Estymatorem gradientu powyższej funkcji jest
−(Rj − V (xtj ; υ)
) ∂
∂υTV (xtj ; υ).
Staje się on kierunkiem poprawy υ.Z powyższych estymatorów wynikają kroki wykonywane przez algorytm REINFORCE epi-
zodyczny:1. Wykonuj decyzje w kolejnym, j-tym epizodzie (początkowy stan epizodu, xtj jest losowy).2. Poprawka polityki
θ := θ + βθj(Rj − V (xtj ; υ)
) ∂
∂θTlnPUX(Uj, X
′j |xtj ; θ).
3. Poprawka aproksymacji V :
υ := υ + βυj(Rj − V (xtj ; υ)
) ∂
∂υTV (xtj ; υ).
4. Przypisz j := j + 1 i wróć do Punktu 1.Powyższy algorytm posługuje się gradientem ∂
∂θTlnPUX . Jednakże rozkład PUX zależy od
własności środowiska, których nie znamy. Poniżej przekonamy się jednak, że wartości ∂∂θT
lnPUXmogą być wyznaczona jedynie na podstawie własności polityki. Rozkład PUX zdefiniowany jestprzez to, jak losowane są kolejne stany
xtj+i+1 ∼ Px(· |xtj+i, utj+i)
i kolejne decyzje. Rozkład kolejnych decyzji, czyli polityka decyzyjna, zależy w ogólności odstanów i decyzji odwiedzanych dotychczas w ciągu bieżącego epizodu. Jest on dodatkowo para-metryzowany przez wektor θ, który jest przedmiotem optymalizacji w trakcie uczenia ze wzmoc-nieniem. Mamy zatem
utj+i ∼ π(· ;H ij, θ), 0 ≤ i < lj ,
gdzie H ij to (2i+ 1)-elementowa historia zdarzeń do i-tej chwili epizodu, czyli
H ij = 〈xtj , utj , . . . , utj+i−1, xtj+i〉.

4.5. Algorytm REINFORCE epizodyczny 57
Kolejne komponenty ciągu
〈Uj , X ′j〉 = 〈utj , xtj+1, . . . , utj+lj−1, xtj+lj〉
pojawiają się jako rezultaty losowania dokonywanego przez decydenta (kolejne decyzje) i śro-dowisko (kolejne stany). Mamy
PUX(Uj , X′j|xtj ; θ) = PUX(utj , xtj+1, . . . , utj+lj−1, xtj+lj |xtj ; θ)
=
lj−1∏
i=0
π(utj+i;Hij, θ)Px(xtj+i+1|xtj+i, utj+i).
Oznaczmy przez
πU(Uj ;Xj, θ) =
lj−1∏
i=0
π(utj+i;Hij, θ).
Jest to rozkład prawdopodobieństwa decyzji generowanych przez politykę przy ustalonej trajek-torii stanów. Rozkład ten zależy jedynie od definicji polityki; natomiast nie zależy od rozkładówrządzących środowiskiem. Z drugiej strony, ponieważ rozkłady rządzące środowiskiem nie za-leżą od polityki, mamy
∂
∂θTlnPUX(Uj , X
′j|xtj ; θ)
=∂
∂θTln
lj−1∏
i=0
π(utj+i;Hij, θ)Px(xtj+i+1|xtj+i, utj+i)
=∂
∂θTln πU(Uj ;Xj, θ).
Daje to wzór na estymator gradientu∇J(θ) postaci
(Rj − V (xtj ; υ)
) ∂
∂θTln πU(Uj ;Xj, θ) (4.11)
i wyjaśnia w jaki sposób należy implementować Punkt 2. algorytmu REINFORCE epizodyczny.Bazowa wersja algorytmu jest sformułowana w Tablicy 4.3.
Algorytm REINFORCE epizodyczny jest zbieżny do lokalnego optimum polityki, o ile tyl-ko rodzina polityk π spełnia pewne oczywiste warunki regularności. Co ciekawe, jego zbież-ność zachodzi przy warunkach znacznie słabszych niż te które zakładaliśmy. Oto najistotniejszeuogólnienia:1. Algorytm niekoniecznie musi posługiwać się stanami x ∈ X . Dla jego zbieżności wystar-
czy, że będą to pewne obserwacje pozostające w stacjonarnej zależności stochastycznej zestanami. Np. mogą to być pewne funkcje stanów przekazujące o nich jedynie cząstkowąinformację.
2. Zakładaliśmy, że przedmiotem optymalizacji jest suma nagród zebranych przez decydentaw ciągu epizodu. W istocie może to być dowolna funkcjaR : T 7→ R oceniająca epizod, np.średnia nagroda w epizodzie, czy długość epizodu.
Polityka stacjonarna
Załóżmy, że decydent dokonuje wyboru decyzji jedynie na podstawie swojego bieżącegostanu, niezależnie od poprzednich wydarzeń w ciągu epizodu. Oznacza to, że
(∀i, u)π(u;H ij, θ) = π(u; xtj+i, θ).

58 Rozdział 4. Optymalizacja stochastycznego wyboru
0. Dane: sekwencje βθj , j = 1, 2, . . . i βυj , j = 1, 2, . . . spełniające (2.15).Zainicjalizuj: j := 1, θ, υ.
1. W j-tym epizodzie, dla i = 0, . . . , lj − 1, losuj decyzje z π(· ;H ij, θ).
2. Przypisz
θ := θ + βθt(Rj − V (xtj ; υ)
) ∂
∂θTln πU (Uj;Xj , θ)
3. Przypisz
υ := υ + βυj(Rj − V (xtj ; υ)
) ∂
∂υTV (xtj ; υ)
4. Przypisz j := j + 1 i wróć do Punktu 1.
Tablica 4.3. Algorytm REINFORCE epizodyczny, wersja podstawowa.
W takim wypadku mamy
πU(Uj ;Xj, θ) =
tj+lj−1∏
t=tj
π(ut; xt, θ) (4.12)
oraz
∇θ ln πU(Uj ;Xj, θ) =
tj+lj−1∑
t=tj
∇θ ln π(ut; xt, θ).
Daje to wzór na estymator gradientu∇J(θ) postaci
(Rj − V (xtj ; υ)
) tj+lj−1∑
t=tj
∂
∂θTln πU(ut; xt, θ).

Rozdział 5
Algorytm Aktor-Krytyk
W niniejszym rozdziale omówione zostaną dwa algorytmy typu Aktor-Krytyk. W ogólnościmetody Aktor-Krytyk służą do optymalizacji polityki dla Procesu Decyzyjnego Markowa (Sek-cja 3.1). Zaproponowanie pierwszego algorytmu tego typu w pracy [4] na początku lat 80-tychXX wieku zainicjowało dziedzinę uczenie się ze wzmocnieniem. Struktura Aktor-Krytyk byłaprzedmiotem intensywnych badań, które zaowocowały szeregiem efektywnych metod. W niniej-szym rozdziale przedstawimy dwa algorytmy zaprezentowane w pracy [11]. Charakteryzują sięone prostotą i w praktyce działają bardzo dobrze, choć nie doczekały się dowodu zbieżności.Bardziej skomplikowane algorytmy, które posiadają dowody zbieżności omówimy w kolejnymrozdziale.
5.1. Aktor, Krytyk i idea algorytmu
Algorytm Aktor-Krytyk posługuje się dwoma strukturami danych: Aktorem, który repre-zentuje parametryczną politykę decyzyjną i Krytykiem, który jest parametryczną aproksymacjąfunkcji wartości (3.1). A zatem Aktor reprezentuje gęstość prawdopodobieństwa
π(· ; x, θ) (5.1)
elementów w U parametryzowaną przez stan, x ∈ X , i wektor θ ∈ Rnθ . W każdej chwili t
decyzja ut jest losowana z rozkładu (5.1).Krytyk,
V (x; υ)
jest to aproksymator (vide Sekcja 2.1) parametryzowany przez υ ∈ Rnυ o wartościach w R.
Chcielibyśmy, aby w każdej chwili, dla każdego stanu x ∈ X zachodziła przybliżona równość
V (x; υ) ∼= V πθ(x) = E(∑
i≥0
γirt+i∣∣xt = x; polityka = πθ
)
gdzie wyraz πθ oznacza politykę (5.1) z bieżącą wartością parametru Aktora, θ, stała γ ∈ (0, 1)to dyskonto, a rt+i to nagrody zdobywane począwszy od chwili t.
Algorytm Aktor-Krytyk po każdej wykonanej decyzji rejestruje otrzymaną nagrodę orazkolejny stan. Na tej podstawie dokonuje poprawki parametrów Aktora oraz Krytyka. Celem jegodziałania jest wyznaczenie optymalnej wartości parametru θ.
Po wykonaniu decyzji ut w stanie xt, zarejestrowaniu nagrody rt i następnego stanu xt+1,algorytm wyznacza oszacowanie wartości
Qπθ(xt, ut)
gdzie πθ to właśnie używana polityka decyzyjna. Oznaczmy to oszacowanie przez Rt i nazwij-my je wypłatą za decyzję w chwili t. Celem poprawki parametru Aktora jest taka modyfikacja

60 Rozdział 5. Algorytm Aktor-Krytyk
bieżącej polityki, aby zwiększyć prawdopodobieństwo decyzji ut jeśli przyniosła ona relatywniewysoką wypłatę i zmniejszyć je, jeśli przyniosła relatywnie niską wypłatę.
Do wyznaczenia powyżej wspomnianej wypłaty potrzebny jest Krytyk, który powinien byćaktualizowany w miarę jak optymalizowana jest polityka. Jest to dokonywane w taki sposób, żewartość V (xt; υ) jest przybliżana do wypłaty Rt.
5.2. Klasyczny Aktor-Krytyk
Poprawka θ, czyli uczenia Aktora, ma na celu taką zmianę rozkładu decyzji w bieżącymstanie, aby zwiększyć wartość oczekiwaną sumy przyszłych nagród,
EθQπ(xt, u) =
∫
U
Qπ(xt, u)π(u; xt, θ)du. (5.2)
W wartości oczekiwanej po lewej stronie powyższego wyrażenia zmienną losową jest u, przyczym jej rozkład jest parametryzowany przez θ, stąd zapis Eθ. Niestety wartości Qπ(x, u) (3.2)są nieznane. Wersja algorytmu Aktor-Krytyk, którą będziemy tu nazywać klasyczną, opiera sięna tożsamości
Qπ(x, u) = E (rt + γV π(xt+1)|xt = x, ut = u)
prawdziwej dla każdej polityki decyzyjnej π i posługuje się wynikającym z niej przybliżeniemQπθ(xt, ut) postaci
R1t = rt + γV (xt+1; υ). (5.3)
Kierunek poprawki θ wynika z powyższej zdefiniowanej wypłaty za decyzję ut. A mianowicie,w chwili t dokonywana jest poprawka θ wzdłuż estymatora gradientu wskaźnika jakości
Jπt (θ) = E(rt + γV (xt+1; υ)
∣∣∣xt; θ, υ).
Zmiennymi losowymi w powyższej wartości oczekiwanej jest decyzja ut, będące jej konsekwen-cją nagroda rt i następny stan xt+1. Zgodnie z dyskusją o sposobach optymalizacji stochastycz-nego wyboru w Rozdziale 4, nieobciążonym estymatorem gradientu Jπt jest
(rt + γV (xt+1; υ)− bt
) ∂
∂θTlnπ(ut; xt, θ),
gdzie bt to dowolny nielosowy punkt odniesienia. Odpowiednim punktem odniesienia jest w tymprzypadku V (xt; υ).
Poprawka parametru υ, czyli uczenie Krytyka, ma na celu przybliżenie wartości V (xt; υ) doV π(xt). Ponieważ jednak ta ostatnia wielkość jest nieznana, algorytm opiera się na tożsamości
V π(x) = E (rt + γV π(xt+1)|xt = x; π)
i przybliża V (xt; υ) w stronęR1t = rt + γV (xt+1; υ)
WielkośćR1t opiera się na faktycznie zebranej nagrodzie oraz na oszacowaniu wartościV π(xt+1),
które być może jest błędne, ale błąd ten jest stłumiony przez γ < 1.Po wykonaniu każdej decyzji, algorytm przybliża υ w stronę minimum wskaźnika błędu
J Vt (υ) = E(1
2
(rt + γV (xt+1; υ
′)− V (xt; υ))2 ∣∣∣xt; θ, υ
)

5.2. Klasyczny Aktor-Krytyk 61
0. Dane: sekwencje βθt , t = 1, 2, . . . i βυt , t = 1, 2, . . . spełniające (2.15).Zainicjalizuj θ i υ; przypisz t := 1.
1. W chwili t wykonaj decyzję ut ∼ π(· ; xt, θ).2. Oblicz różnicę czasową: Jeśli t jest ostatnią chwilą epizodu oblicz
dt = rt − V (xt; υ)
w przeciwny raziedt = rt + γV (xt+1; υ)− V (xt; υ).
3. Poprawka Aktora (polityki):
θ := θ + βθt dt∂
∂θTlnπ(ut; xt, θ).
4. Poprawka Krytyka (aproksymatora V ):
υ := υ + βυt dt∂
∂υTV (xt; υ).
5. Przypisz t := t + 1 i przejdź do Punktu 1.
Tablica 5.1. Algorytm Klasyczny Aktor-Krytyk.
dla υ′ ustalonego na moment na wartości υ; xt jest ustalone natomiast xt+1 oraz rt są losowe.Estymatorem gradientu J Vt jest
−(rt + γV (xt+1; υ)− V (xt; υ)
) ∂V (xt; υ)
∂υT.
Jego przeciwieństwo staje się kierunkiem poprawy υ.Z powyższych rozważań wynika postać algorytmu Aktor-Krytyk przedstawiona w Tablicy
5.1. Poprawka polityki dokonywana w Punkcie 3. algorytmu może być interpretowana w nastę-pujący sposób. W momencie t wykonywana jest decyzja ut. Jest ona oceniana przez
rt + γV (xt+1; υ).
Wielkość ta jest porównywana z jej prognozą sprzed wykonania decyzji, V (xt; υ) przez obli-czenie tzw. różnicy czasowej (ang. temporal difference, TD),
dt = rt + γV (xt+1; υ)− V (xt; υ). (5.4)
Jeśli dt > 0 to znaczy, że decyzja przyniosła nagrody wyższe niż spodziewane, więc zwiększamyprawdopodobieństwo decyzji u = ut w stanie x = xt w przyszłości. W przeciwnym raziezmniejszamy je.
Przykład 5.2.1. π i V reprezentowane w tablicy
W przypadku gdy przestrzeń stanów X jest dyskretna (lub zdyskretyzowana), π i V mogą byćreprezentowane w tablicach.
W przypadku Krytyka, taką tablicą może być wektor υ indeksowany przez dyskretny stan.Mamy wówczas
V (x; υ) = Φ(x)υ = υx

62 Rozdział 5. Algorytm Aktor-Krytyk
przy czym Φ(x) jest funkcją “wyłuskującą” odpowiednią wartość z tablicy υ (vide Przykład2.1.4), zaś υx jest elementem wektora υ odpowiadającym stanowi x. Poprawka Krytyka w chwilit dotyczy wyłącznie elementu υxt tablicy υ i ma postać
υxt := υxt + βυt dt.
Powiedzmy, że polityka ma postać taką jak w Sekcji 4.3, czyli
π(u; x, θ) = φ(u; µ(x; θ))
gdzie φ jest pewną gęstością parametryzowaną przez µ ∈ M. Niech µ będzie reprezentowanew tablicy w następujący sposób: tablicą tą jest θ, jej elementami są wartości z M i jest onaindeksowana przez stan, czyli µ(x; θ) = θx, gdzie θx jest elementem tablicy θ odpowiadającymstanowi x. Podobnie jak w przypadku Krytyka, mamy
µ(x; θ) = Ψ(x)θ = θx,
przy czym tutaj Ψ(x) jest funkcją “wyłuskującą” odpowiedni element tablicy θ, którym jest θx.Poprawka Aktora w chwili t dotyczy wyłącznie elementu θxt tablicy θ i ma postać
θxt := θxt + βθt dt∂
∂θxtlnφ(ut; θxt).
A zatem, dla dt > 0 mamy efekt wykonania decyzji ut lepszy niż oczekiwany w stanie xt iprawdopodobieństwo wylosowania takiej decyzji w stanie xt jest odpowiednio zwiększane. Dladt < 0 zachodzi odwrotna sytuacja i to prawdopodobieństwo jest zmniejszane.
5.3. Aktor-Krytyk(λ)
Klasyczny Aktor-Krytyk opiera się na pewnych heurystykach, które w praktyce działają le-piej lub gorzej. Do uczenia Aktora, algorytm estymuje wielkość
V π(x) = E(rt + γrt+1 + γ2rt+2 + . . . |xt = x; π
)
natomiast do uczenia Krytyka, estymuje
Qπ(x, u) = E(rt + γrt+1 + γ2rt+2 + . . . |xt = x, ut = u; π
).
W obu przypadkach estymator ma postać
R1t = rt + γV (xt+1; υ)
i jego jakość jest związana bezpośrednio z jakością aproksymacji V . Powstaje pytanie, czy całegomechanizmu nie da się, przynajmniej w pewnym stopniu, uniezależnić od jakości aproksymacjiV . Okazuje się, że tak, a sposobem na to jest zastąpienie estymatora R1
t takim, który w więk-szym stopniu będzie oparty na faktycznie zdobywanych nagrodach, a w mniejszym stopniu naaproksymacji V . Rozważmy sumę
Rnt = rt + γrt+1 + · · ·+ γn−1rt+n−1 + γnV (xt+n; υ).

5.3. Aktor-Krytyk(λ) 63
Ponieważ zarówno V π(xt) jak i Qπ(xt, ut) są definiowane jako wartości oczekiwana R∞t , to
można się spodziewać, że R∞t jest nieobciążonym estymatorem1 tych wielkości.2 Co więcej,
obciążenie Rnt wynika z zastosowania do jego obliczania aproksymacji V . Wraz z rosnącym n
aproksymacja odgrywa coraz mniejszą rolę w Rnt i zmniejsza się obciążenie, które powoduje.
Niech λ ∈ [0, 1] i zdefiniujmy λ-estymator przyszłych nagród, R(λ)t , jako średnią z Rn
t wa-żoną przez λn, mianowicie
R(λ)t = lim
N→∞
∑Nn=0 λ
nRn+1t∑N
n=0 λn
. (5.5)
Dla λ < 1 mamy zatem
R(λ)t = (1− λ)
∞∑
n=0
λnRn+1t (5.6)
natomiast dla λ = 1,R
(λ)t = R∞
t .
Im większe λ, w tym większym stopniu R(λ)t zależy od faktycznych nagród i w mniejszym od
aproksymacji V . Zmodyfikowany Aktor-Krytyk posługuje się estymatorem R(λ)t zamiast, jak
Klasyczny Aktor-Krytyk, estymatorem R1n. Po każdym kroku t algorytm wykonuje sekwencję
operacji modyfikującą parametr Aktora θ w kierunku estymatora gradientu wskaźnika jakości
Jπt (θ) = Eθ(R
(λ)t |xt
).
Estymatorem gradientu powyższego wskaźnika jakości może być
(R
(λ)t − V (xt; υ)
) ∂
∂θTln π(ut; xt, θ). (5.7)
Jednocześnie, wykonywane są operacje modyfikujące parametr Krytyka υ w kierunku przeciw-nym do estymatora gradientu wskaźnika jakości
J Vt (υ) = Eθ(0.5(R
(λ)t − V (xt; υ)
)2∣∣xt).
Estymatorem jego gradientu może być
−(R
(λ)t − V (xt; υ)
) ∂
∂υTV (xt; υ). (5.8)
PonieważR(λ)t jest nieskończoną sumą, posłużenie się estymatorami gradientów Jπt oraz J Vt bez-
pośrednio jest niemożliwe i musi być wykonane przy użyciu pewnej sztuczki. Sztuczka polegana tym, że w każdej chwili t inicjowana jest nieskończona sekwencja poprawek składającychsię w sumie na poprawkę wzdłuż estymatorów wspomnianych gradientów. Oparty na nich algo-rytm Aktor-Krytyk(λ) został przedstawiony jest w Tablicy 5.2, natomiast wspomnianą sztuczkęwyjaśnimy poniżej w podziale na trzy etapy:1. Wyrażenie R(λ)
t − V (xt; υ) jako sumę części, które można obliczyć w kolejnych chwilachczasowych począwszy od t.
2. Wyrażenie aktualizacji parametru Aktora, którą należy dokonać w chwili t, jako sumy częścipoprawek wynikających ze zdarzeń w chwili t, t− 1, t− 2 itd.
3. Wyrażenie aktualizacji Krytyka, którą należy dokonać w chwili t, jako sumy poprawek wy-nikających ze zdarzeń w chwili t, t− 1, t− 2 itd.

64 Rozdział 5. Algorytm Aktor-Krytyk
0. Dane: sekwencje βθt , t = 1, 2, . . . i βυt , t = 1, 2, . . . spełniające (2.15).Zainicjalizuj θ i υ; przypisz t := 1, z = 0, y = 0.
1. W chwili t wykonaj decyzje ut ∼ π(· ; xt, θ).2. Obliczenie różnicy czasowej: Jeśli t jest ostatnią chwilą epizodu oblicz
dt = rt − V (xt; υ)
w przeciwny raziedt = rt + γV (xt+1; υ)− V (xt; υ).
3. Poprawka polityki (uczenie Aktora)
z := λγz +∂
∂θTln π(ut; xt, θ),
θ := θ + βθt dtz.
4. Poprawka aproksymatora V (uczenie Krytyka)
y := λγy +∂
∂υTV (xt; υ),
υ := υ + βυt dty.
5. Jeśli t jest ostatnią chwilą epizodu, wyzeruj z i y.6. Przypisz t := t + 1 i przejdź do Punktu 1.
Tablica 5.2. Algorytm Aktor-Krytyk(λ).

5.3. Aktor-Krytyk(λ) 65
Pierwszy etap polega na wyrażeniu różnicy R(λ)t − V (xt; υ) jako ważonej sumy różnic cza-
sowych (5.4). A mianowicie zachodzi tożsamość
R(λ)t − V (xt; υ) =
∞∑
n=0
(λγ)ndt+n, (5.9)
którą wyprowadzimy dla λ < 1. Z (5.6) mamy
R(λ)t = (1− λ)
∞∑
n=0
λn( n∑
j=0
γjrt+j + γn+1V (xt+n+1; υ))
= (1− λ)∞∑
j=0
γjrt+j
∞∑
n=j
λn + (1− λ)∞∑
n=0
λnγn+1V (xt+n+1; υ)
=
∞∑
n=0
rt+nγnλn + γ
∞∑
n=0
(λγ)nV (xt+n+1; υ)−∞∑
n=0
(λγ)n+1V (xt+n+1; υ)
= V (xt; υ) +
∞∑
n=0
(λγ)n(rt+n + γV (xt+n+1; υ)− V (xt+n; υ)
),
co po prostym przekształceniu daje (5.9).W etapie drugim wykorzystamy tożsamość (5.9) do zaprojektowania poszukiwanej sekwen-
cji poprawek parametru Aktora. Chcemy, aby w sekwencji kroków następującej po chwili t doparametru θ została dodana poprawka będąca iloczynem parametru kroku i estymatora (5.7),czyli
∆θt = βθt
(R
(λ)t − V (xt; υ)
) ∂
∂θTln π(ut; xt, θ)
= βθt∂
∂θTln π(ut; xt, θ)
∞∑
n=0
(λγ)ndt+n
=∞∑
n=0
βθt∂
∂θTln π(ut; xt, θ)(λγ)
ndt+n (5.10)
A zatem ∆θt jest sumą zanikających elementów możliwych do obliczenia w chwilach t, t +1, t + 2, . . . . Aby uzyskać algorytm dodający do θ kolejne wektory ∆θt, potrzebujemy, aby wkażdym kroku t do wektora θ była dodawane części wektorów ∆θt,∆θt−1, . . . ,∆θ1 możliwe doobliczenia w chwili t. Jest to suma n-tych elementów (5.10) dla t, t− 1, . . . , 1; jest ona równa
t−1∑
n=0
βθt−n∂
∂θTln π(ut−n; xt−n, θ)(λγ)
ndt
= βθt dt
t−1∑
n=0
βθt−nβθt
(λγ)n∂
∂θTln π(ut−n; xt−n, θ) (5.11)
Algorytm Aktork-Krytyk(λ), w swoim Punkcie 3. modyfikuje wektor θ o wyrażenie podobnedo (5.11), w którym jednak nie ma ilorazu βθt−n/β
θt . Zbiega on jednak do 1 dla t zbiegającego
1 Pojęcie obciążenia estymatorów jest omówione w przypisie na stronie 23.2 Właściwie byłby to nieobciążonyestymator, gdyby polityka nie zmieniała się w czasie obliczaniaR∞
t . Ponie-waż jednak jej zmiany są coraz mniejsze (malejące parametry kroku), to faktycznie jest to estymator asymptotycznienieobciążony. Vide początek Sekcji 2.4.

66 Rozdział 5. Algorytm Aktor-Krytyk
do nieskończoności. Suma widoczna w wyrażeniu (5.11) jest naliczana w pomocniczym wek-torze z.
W etapie trzecim wykorzystamy tożsamość (5.9) do zaprojektowania poszukiwanej sekwen-cji poprawek parametru Krytyka. W tym celu powtórzymy kroki wykonane przy projektowaniuanalogicznej sekwencji poprawek dla Aktora. Chcemy, aby w sekwencji kroków następującej pochwili t do parametru θ został dodany wektor będący iloczynem parametru kroku i estymatora(5.8), czyli
∆υt = βυt
(R
(λ)t − V (xt; υ)
) ∂
∂υTV (xt; υ)
= βυt∂
∂υTV (xt; υ)
∞∑
n=0
(λγ)ndt+n
=∞∑
n=0
βθt∂
∂υTV (xt; υ)(λγ)
ndt+n (5.12)
A zatem ∆υt jest sumą zanikających elementów możliwych do obliczenia w chwilach t, t +1, t + 2, . . . . Aby uzyskać algorytm dodający do υ kolejne wektory ∆υt potrzebujemy, aby wkażdym kroku t do wektora υ była dodawane części wektorów ∆υt,∆υt−1, . . . ,∆υ1 możliwedo obliczenia w chwili t. Jest to suma n-tych elementów (5.12) dla t, t−1, . . . , 1; jest ona równa
t−1∑
n=0
βυt−n∂
∂υTV (xt−n; υ)(λγ)
ndt
= βυt dt
t−1∑
n=0
βθt−nβθt
(λγ)n∂
∂υTV (xt−n; υ) (5.13)
Algorytm Aktork-Krytyk(λ) w swoim Punkcie 4. zwiększa wektor υ o wyrażenie podobne do(5.13), w którym jednak nie ma ilorazu βθt−n/β
θt . Suma widoczna w wyrażeniu (5.13) jest nali-
czana w pomocniczym wektorze y.

Rozdział 6
Aktor-Krytyk z kompatybilną aproksymacją
Badania nad strukturami uczącymi się typu Aktor-Krytyk przyniosły algorytmy, dla którychistnieją gwarancje zbieżności. Metody takie są przedmiotem niniejszego rozdziału. Jest opartyw największej mierze na artykułach [31, 21, 12].
6.1. Optymalizacja średniej nagrody
Najbardziej oczywistym wymogiem wobec polityki decyzyjnej jest, aby przynosiła możliwienajwyższą nagrodę średnią, a mianowicie aby maksymalizowała wskaźnik jakości
J(θ) = limt→∞
1
t
t∑
i=1
ri,
którego argumentem jest wektor parametrów polityki. Powstaje pytanie jakie są warunki na po-prawność powyższej definicji; występująca tam średnia może przecież nie mieć granicy lub jejgranicą może być zmienna losowa. Okazuje się, że warunkiem wystarczającym na to, aby po-wyższa definicja była poprawna jest istnienie rozkładu stacjonarnego stanów.
Definicja 6.1.1. Niech η(· ; θ) będzie miarą probabilistyczną w przestrzeni stanów X . Jeśli dla
każdego t ∈ 1, 2, . . . i X ⊂ X zachodzi
limk→∞
P (xt+k ∈ X|xt) = η(X ; θ) (6.1)
wówczas η(· ; θ) jest rozkładem stacjonarnym stanów dla polityki z parametrem θ.
Miara η ma intuicyjną interpretację. Stosownie do polityki, decydent pojawia się w różnychstanach częściej lub rzadziej. Niekiedy środkiem do tego, aby polityka była dobra jest unika-nie pewnych stanów i dążenie do innych. Miara η wyraża więc to, jak często decydent “bywa”w poszczególnych częściach przestrzeni stanów.
Rozważmy okoliczności, w których stacjonarny rozkład stanów może nie istnieć. Może tomieć miejsce, jeśli w X znajdują się (przynajmniej) 2 takie rozłączne zbiory X ′ i X ′′, że jeślidecydent znajdzie się w którymś z nich, wówczas już na pewno w nim pozostanie. Mówimywówczas, że proces decyzyjny Markowa (PDM) dla polityki z parametrem θ jest redukowal-
ny. Jeśli takich podzbiorów X nie da się wyróżnić, wówczas mówimy, że PDM dla polityki zparametrem θ jest nieredukowalny. Redukowalność objawia się w ten sposób, że granica
limk→∞
P (xt+k ∈ X|xt)
jest różna dla różnych xt i granica w (6.1) nie istnieje.Kolejna okoliczność, która wyklucza istnienie stacjonarnego rozkładu stanów to istnienie
takiego podzbioru X ⊂ X , że dla pewnego t,
P (xt ∈ X) > 0

68 Rozdział 6. Aktor-Krytyk z kompatybilną aproksymacją
oraz wielkośćP (xt+k ∈ X|xt)
jest dodatnia jedynie dla k podzielnego przez pewne n > 1. W takiej sytuacji w wędrówcedecydenta po przestrzeni stanów można wskazać cykle. Mówimy wówczas, że PDM dla politykiz parametrem θ jest periodyczny. Jeśli rozważanego podzbioruX nie da się wyróżnić, wówczasmówimy, że PDM dla polityki z parametrem θ jest aperiodyczny. Periodyczność objawia się wten sposób, że granica
limk→∞
P (xt+k ∈ X|xt)
nie istnieje.Dla polityki z parametrem θ, dla której istnieje stacjonarny rozkład stanów, średnią nagrodą
jest oczekiwana nagroda z danego stanu uśredniona przez stacjonarny rozkład stanów, miano-wicie
J(θ) =
∫
X
E(rt|xt = x; θ)η(dx; θ).
Istnienie rozkładu stacjonarnego zapewnia, że startując z dowolnego stanu x decydent pojakimś czasie zacznie wizytować stany z częstością określaną przez η. Rozważmy sumę nagródwykraczającą ponad J(θ), którą decydent zbierze startując ze stanu x, a mianowicie
∑
i≥0
(rt+i − J(θ)
).
Z istnienia stacjonarnego rozkładu stanów wynika (choć nie jest to trywialne), że powyższa war-tość jest zmienną losową o wartościach skończonych i dobrze określonej wartości oczekiwanej.Oznaczmy ją przez
V θ(x) = E(∑
i≥0
(rt+i − J(θ)
)∣∣∣xt = x; θ
).
Jest to analog funkcji wartości definiowanej dla zdyskontowanej sumy nagród. Zdefiniujmy takżefunkcję analogiczną do funkcji wartości-decyzji, mianowicie
Qθ(x, u) = E(∑
i≥0
(rt+i − J(θ)
)∣∣∣xt = x, ut = u; θ
).
Obie powyższe funkcje będą przydatne w definiowaniu metod optymalizacji średniej nagrody.
6.2. Gradient polityki
Zasadnicze znaczenie dla konstrukcji algorytmów uczenia się ze wzmocnieniem o gwaran-towanej zbieżności ma następujące twierdzenie.
Twierdzenie 6.2.1. Dla każdej funkcji b : X 7→ R zachodzi
∇J(θ) =∫
X
(∫
U
∇θπ(u; x, θ)(Qθ(x, u)− b(x)
)du
)η(dx; θ), (6.2)
jeśli tylko obie strony powyższej równości istnieją.

6.2. Gradient polityki 69
Dowód powyższego twierdzenia znajduje się w artykule [31]. Wprawdzie na jego podstawie nieda się obliczać gradientu polityki∇J(θ), ale można go estymować. Skorzystajmy z równości
∇θ ln π(u; x, θ) =∇θπ(u; x, θ)
π(u; x, θ)(6.3)
i zapiszmy równanie (6.2) w postaci
∇J(θ) =∫
X
∫
U
(∇θ ln π(u; x, θ)
(Qθ(x, u)− b(x)
))π(u; x, θ)du η(dx; θ). (6.4)
Widać teraz, że wartość∇J(θ) jest równa wektorowi
∇θ lnπ(u; x, θ)(Qθ(x, u)− b(x)
)(6.5)
uśrednionemu przez rozkład decyzji (wewnętrzna całka w (6.4)) i stacjonarny rozkład stanów(zewnętrzna całka w (6.4)). Jeśli teraz uznamy kolejny wizytowany stan x za wylosowany zη(· ; θ), co jest nieodległe od prawdy, a decyzję u za wylosowaną z π(· ; x, θ), co dokładnie od-powiada prawdzie, możemy potraktować obliczony na ich podstawie wektor (6.5) za estymatorkierunku poprawy parametru polityki.
Łatwo zauważyć, że szereg algorytmów dokonuje poprawki polityki w analogiczny sposób.Np. klasyczny Aktor-Krytyk estymuje odpowiednik Qθ(x, u) przez rt + γV (xt+1; υ) zaś jakob(x) używa V (xt; υ).
Bezpośrednie zastosowanie Twierdzenia 6.2.1 jest niemożliwe ponieważ funkcja Qθ jest wogólności nieznana. Okazuje się jednak, że znajomość Qθ nie jest konieczna; wystarczy pewnaaproksymacja tej funkcji skonstruowana na podstawie polityki.
Definicja 6.2.1. Aproksymator Q(x, u; υ) jest kompatybilny z polityką π z parametrem θ, jeśli
spełnia następujące warunki:
1. Jest liniowy1 ze względu na υ.
2. Ustalone współrzędne wektora υ tworzą wektor υ′ ∈ Rnθ taki, że2
∂
∂υ′Q(x, u; υ) =
∂
∂θln π(u; x, θ).
3. Pozostałe współrzędne wektora υ tworzą wektor υ′′ ∈ Rnυ−nθ taki, że żadna ze współrzęd-
nych wektora ∂∂υ′′
Q(x, u; υ) nie jest kombinacją liniową elementów wektora ∂∂υ′Q(x, u; υ).
A zatem kompatybilna z polityką π aproksymacja funkcji Qθ jest postaci
Q(x, u; υ) = Φ′(x, u)υ′ + Φ′′(x, u)υ′′ (6.6)
przy czym υ′ ∈ Rnθ , υ′′ ∈ R
nυ−nθ i υ′ wraz z υ′′ składają się na υ. Ponadto
Φ′(x, u) =∂
∂υ′Q(x, u; υ) =
∂
∂θlnπ(u; x, θ)
Φ′′(x, u) =∂
∂υ′′Q(x, u; υ).
Funkcja Φ′′(x, u) musi być skonstruowana w ten sposób, aby nie naruszyć warunku 3. W prak-tyce Φ′ wynika bezpośrednio z definicji polityki natomiast Φ′′ jest dobierane w ten sposób, abyuzyskać dobre własności aproksymacyjne Q. W efekcie naruszenie Warunku 3 mogłoby byćjedynie wynikiem bardzo nieszczęśliwego zbiegu okoliczności.
Z następnego twierdzenia wynika użyteczność kompatybilnej aproksymacji Qθ.
1 Vide Sekcja 2.1.2 Należy pamiętać, że tu i w kolejnym akapicie po definicji rozważane są wektory wierszowe.

70 Rozdział 6. Aktor-Krytyk z kompatybilną aproksymacją
Twierdzenie 6.2.2. Niech dany będzie parametr θ polityki π. Jeśli
1. Q jest kompatybilną aproksymacją funkcji Qθ dla polityki π,
2. υ jest parametrem optymalizującym aproksymację Q w sensie najmniejszych kwadratów,
wówczas dla każdej funkcji b : X 7→ R zachodzi
∇J(θ) =∫
X
(∫
U
∇θπ(u; x, θ)(Q(x, u; υ)− b(x)
)du
)η(dx; θ). (6.7)
Dowód znajduje się w [31].Porównanie równań (6.2) i (6.7) pokazuje sens Twierdzenia 6.2.2: do znalezienia gradien-
tu polityki nie jest nam potrzebna znajomość funkcji Qθ, co jest zwykle nierealne. Wystarczykompatybilna aproksymacja tej funkcji.
Wyjaśnijmy znaczenie warunku 2 powyższego twierdzenia. Chodzi mianowicie o to, żefunkcja Q(·, · ; υ) jest najlepszą aproksymacją Qθ w sensie najmniejszych kwadratów, czyli υminimalizuje błąd średniokwadratowy postaci
ǫ(υ, θ) =
∫
X
∫
U
1
2
(Q(x, u; υ)−Qθ(x, u)
)2π(u; x, θ)du η(dx; θ).
Kolejne istotne dla nas własności uzyskamy dodatkowo ograniczając kompatybilną aproksy-mację funkcji Qθ. Niech mianowicie gradient ∂Q(x,u;υ)
∂υ′′nie zależy od u.
Definicja 6.2.2. Aproksymator Q(x, u; υ) jest ściśle kompatybilny z polityką π z parametremθ, jeśli spełnia następujące warunki:
1. Jest kompatybilny z polityką π z parametrem θ.2. Ma postać
Q(x, u; υ) = Φ′(x, u)υ′ + Φ′′(x)υ′′
Φ′(x, u) = ∂∂θ
ln π(u; x, θ)(6.8)
W analizie własności tak zdefiniowanej aproksymacji Q przyda nam się macierz informacji Fi-
shera
G(θ) =
∫
X
∫
U
∂ ln π(u; x, θ)
∂θT
∂ ln π(u; x, θ)
∂θπ(u; x, θ)du η(dx; θ). (6.9)
Ma ona postać wartości oczekiwanej macierzy losowych postaciXXT , łatwo więc uwierzyć, żepoza przypadkami zdegenerowanymi jest ona dodatnio określona. Taki zdegenerowany przypa-dek mógłby polegać na tym, że niektóre komponenty wektora∇θ ln π(u; x, θ) są kombinacjamiliniowymi innych. Ale to by oznaczało, że polityka jest de facto definiowana przez jedynie częśćwspółrzędnych wektora θ. Taką zaś sytuację możemy łatwo wykluczyć projektując politykę π.
Z postaci (6.8) funkcji Q wynikają dwie ważne konsekwencje.
Twierdzenie 6.2.3. Jeśli
1. Q jest postaci (6.8),2. υ jest parametrem optymalizującym aproksymację Q w sensie najmniejszych kwadratów,
3. θ wyznacza lokalne ekstremum średniej nagrody J ,
4. Informacja Fishera polityki π jest dodatnio określona,
wówczas υ′ = 0.
Dowód tego twierdzenia znajduje się w artykule [31].Następne twierdzenie pokazuje, że pod pewnymi warunkami poszukując aproksymacji Qθ
dostajemy także aproksymację V θ.

6.3. Aktor-Krytyk z kompatybilną aproksymacją 71
Twierdzenie 6.2.4. Jeśli spełnione są założenia Twierdzenia 6.2.3, wówczas υ′′ ma wartość
optymalizującą
Φ′′(x)υ′′
jako średniokwadratową aproksymacją funkcji V θ.
Dowód powyższego twierdzenia znajduje się w artykule [31]. Ze względu na własność, którąstwierdza, będziemy od tej pory traktować Φ′′(x)υ jako aproksymację funkcji V θ i oznaczać
V (x; υ′′) = Φ′′(x)υ′′.
6.3. Aktor-Krytyk z kompatybilną aproksymacją
W niniejszym rozdziale wyprowadzimy algorytm Aktor-Krytyk z kompatybilną aproksyma-cją [12]. Wykorzystuje on wszystkie omawiane w tym rozdziale własności. Algorytm będzie sięposługiwał ściśle kompatybilną aproksymacją funkcji Qθ, czyli aproksymatorem postaci
Q(x, u; υ) = Φ′(x, u)υ′ + Φ′′(x)υ′′
gdzie
Φ′(x, u) =∂
∂θln π(u; x, θ).
Może to oznaczać, że Φ′ jest explicite zależne od θ, co dla uproszczenia zostało pominięte w no-tacji.
Po każdej decyzji algorytm będzie dokonywał pojedynczej poprawki parametrów θ i υ. Pew-nym novum jest to, że algorytm będzie także w każdym kroku poprawiał estymator J średniejnagrody J(θ). Ta poprawka jest najbardziej oczywista i ma postać
J := J + βJ(rt − J),
gdzie βJ to parametr kroku.Poprawka θ (uczenie Aktora) będzie oparta bezpośrednio na Twierdzeniu 6.2.2. Wynika z
niego, że∇J(θ) jest wartością oczekiwaną3 wektora(Q(xt, ut; υ)− b(x)
)∇θ ln π(ut; xt, θ).
Sugeruje to poprawkę postaci
θ := θ + βθ(Q(xt, ut; υ)− b(x)
)∇θ ln π(ut; xt, θ)
Okazuje się jednak, że aby zagwarantować zbieżność algorytmu, musimy skracać długość po-wyższego wektora dla dużego ‖υ′‖. Niech Γ będzie funkcją spełniającą
c11 + ‖υ′‖ ≤ Γ(υ′) ≤ c2
1 + ‖υ′‖dla pewnych dodatnich c1 ≤ c2. Dyskutowany algorytm posługuje się poprawką θ postaci
θ := θ + βθΓ(υ′)(Q(xt, ut; υ)− V (xt; υ′′)
)∇θ ln π(ut; xt, θ)
= θ + βθΓ(υ′)∇θ ln π(ut; xt, θ)Φ′(xt, ut)υ
′
= θ + βθΓ(υ′)Φ′(xt, ut)TΦ′(xt, ut)υ
′.
3 Vide dyskusja po sformułowaniu Twierdzenia 6.2.

72 Rozdział 6. Aktor-Krytyk z kompatybilną aproksymacją
0. Przypisz t := 1, J := 0, υ := 0, y := 0.Zainicjuj θ i wylosuj u1 ∼ π(· ; x1, θ).
1. Wykonaj decyzję ut, zarejestruj nagrodę rt i następny stan xt+1.2. Popraw Aktora:
θ := θ + βθt Γ(υ′)Φ′(xt, ut)
TΦ′(xt, ut)υ′.
3. Wylosuj decyzję ut+1 ∼ π(· ; xt+1, θ).4. Popraw Krytyka:
y := λy +∂
∂υTQ(xt, ut; υ)
υ := υ + βυt
(rt − J + Q(xt+1, ut+1; υ)− Q(xt, ut; υ)
)y.
5. Popraw J :J := J + βJt (rt − J).
6. Przypisz t := t + 1 i wróć do Punktu 1.
Tablica 6.1. Algorytm Aktor-Krytyk z kompatybilną aproksymacją.
Do poprawki parametru υ (uczenia Krytyka) użyjemy standardowej metody TD(λ) (Sekcja5.3). A mianowicie, chcemy aby po każdej chwili t, wartość Q(xt, ut; υ) została zmodyfikowanaw kierunku
Q(xt, ut; υ) +∑
i≥0
λi(rt+i − J(θ) + Q(xt+i+1, ut+i+1; υ)− Q(xt+i, ut+i; υ)
)
dla pewnego λ ∈ [0, 1]. Odbywa się to w ten sposób, że w każdym kroku aktualizowany jestpomocniczy wektor y według formuły
y := λy +∂Q(xt, ut; υ)
∂υT
natomiast υ jest poprawiane według wzoru
υ := υ + βυ(rt − J + Q(xt+1, ut+1; υ)− Q(xt, ut; υ)
)y,
czyli w oparciu o zasadę stosowaną w klasycznym Aktorze-Krytyku posługującym sięλ-estyma-torami przyszłych nagród.
Algorytm Aktor-Krytyk z kompatybilną aproksymacją jest sformułowany w Tablicy 6.1.Przy spełnieniu odpowiednich warunków regularności sprawia on zbieganie θ z prawdopodo-bieństwem 1 do lokalnego maksimum J(θ). Jednym z tych warunków jest relacja między współ-czynnikami kroku, a mianowicie
βθtβυt≤ 1
td
dla pewnego d ∈ (0, 1). W warunku tym chodzi o to, aby parametr kroku Krytyka, βυt , zbiegałdo zera wolniej i dzięki temu aby dostosowania Krytyka były coraz szybsze w porównaniu zdostosowaniami Aktora.

6.4. Naturalny Aktor-Krytyk 73
6.4. Naturalny Aktor-Krytyk
Optymalizacja wskaźnika jakości polityki w oparciu o estymatory jego gradientów ma godnąuwagi alternatywę. Okazuje się bowiem, że wektorem lepiej niż gradient wskazującym drogę doekstremum tej funkcji jest tzw. naturalny gradient polityki [1]. Algorytmem opartym na natural-nym gradiencie polityki jest Naturalny Aktor-Krytyk [21], którego pewną wersję przedstawiamyponiżej.
Powróćmy do problemu rozważanego w Rozdziale 4 i rozwiązywanego tam przy użyciualgorytmu REINFORCE, a mianowicie do maksymalizacji funkcji postaci
J(θ) =
∫
U
R(u)φ(u; θ)du.
Niech θt będzie pewnym, opartym na t próbkach, nieobciążonym estymatorem argumentu θmaxmaksymalizującego J , czyli
θmax = argmaxθJ(θ).
Okazuje się, że wariancja tego estymatora nie może być mniejsza niż pewna graniczna wartość.Mianowicie zachodzi
V θt ≥1
tG(θmax),
gdzie
G(θ) =
∫
U
∂ lnφ(u; θ)
∂θT
∂ lnφ(u; θ)
∂θφ(u; θ)du
to Informacja Fishera rodziny rozkładów φ. Nieobciążony estymator, który realizuje to dol-ne ograniczenie na wariancję, nazywa się Fisher-efektywnym. Powstaje pytanie, czy elementyciągu θt, t = 1, 2, . . . generowane przez algorytm REINFORCE statyczny są estymatoramiFisher-efektywnymi. Okazuje się, że nie ale można zaproponować taki sposób poprawiania θt,który będzie dawał estymatory “niemal” Fisher-efektywne. A mianowicie, jeśli zamiast popra-wek
θt+1 = θt + βt(R(ut)− bt)∇θ lnφ(ut; θt)
zastosujemy
θt+1 = θt +1
tG(θt)
−1(R(ut)− bt)∇θ lnφ(ut; θt), (6.10)
to θt, t = 1, 2, . . . będzie ciągiem asymptotycznie Fisher-efektywnych estymatorów θ. Oka-zuje się, że macierz informacji Fishera G(θ) jest w optymalizacji stochastycznej mniej więcejtym, czym jest hesjan w zwykłej optymalizacji. Opłaca się mnożyć estymatory gradientu przezG(θ)−1. Oczekiwany kierunek poprawki (6.10), czyli
∫
U
G(θ)−1(R(ut)− bt)∇θ lnφ(u; θ)φ(u; θ)du = G(θ)−1∇J(θ)
nosi nazwę naturalnego gradientu funkcji J [1].Przyjrzyjmy się poprawce Aktora w algorytmie Aktor-Krytyk z kompatybilną aproksymacją.
Jej uśredniony kierunek to∫
X
∫
U
Γ(υ′)Φ′(xt, ut)TΦ′(xt, ut)υ
′π(u; x, θ)du η(dx; θ)
=
∫
X
∫
U
Γ(υ′)∂ lnπ(u; x, θ)
∂θT
∂ ln π(u; x, θ)
∂θυ′π(u; x, θ)du η(dx; θ)
= Γ(υ′)G(θ)υ′.

74 Rozdział 6. Aktor-Krytyk z kompatybilną aproksymacją
0. Przypisz t := 1, J := 0, υ := 0, y := 0.Zainicjuj θ i wylosuj u1 ∼ π(· ; x1, θ).
1. Wykonaj decyzję ut, zarejestruj nagrodę rt i następny stan xt+1.2. Popraw Aktora:
θ := θ + βθt Γ(υ′)υ′.
3. Wylosuj decyzję ut+1 ∼ π(· ; xt+1, θ).4. Popraw Krytyka:
y := λγy +∂Q(xt, ut; υ)
∂υT
υ := υ + βυt(rt + γQ(xt+1, ut+1; υ)− Q(xt, ut; υ)
)y.
5. Przypisz t := t + 1 i wróć do Punktu 1.
Tablica 6.2. Naturalny Aktor-Krytyk z kompatybilną aproksymacją i dyskontem.
Nasza wiedza o zaletach naturalnego gradientu polityki sugeruje, iż lepiej działałaby poprawka,której zagregowanym kierunkiem byłoby
G(θ)−1Γ(υ′)G(θ)υ′ = Γ(υ′)υ′.
Mogłaby ona mieć prostą postaćθ := θ + βθt Γ(υ
′)υ′.
Faktycznie, działa ona lepiej.
6.5. Dyskonto ograniczenie wariancji estymatora gradientu
Nic nie stoi na przeszkodzie, aby opisywana w tym rozdziale metodologia służyła to mak-symalizacji zdyskontowanej sumy nagród. Takie podejście, jakkolwiek nie gwarantuje optymal-ności rozwiązania, zazwyczaj daje dobre rozwiązanie w krótszym czasie [20].
Algorytm maksymalizujący zdyskontowaną sumę nagród posługuje się aproksymacją Q oidentycznej strukturze jak pozostałe metody omawiane w tym rozdziale. Q jest w tym przypadkuaproksymacją klasycznej, zdyskontowanej funkcji Qπ. Poprawka Krytyka ma teraz klasycznąpostać
y := λγy +∂Q(xt, ut; υ)
∂υT
υ := υ + βυt(rt + γQ(xt+1, ut+1; υ)− Q(xt, ut; υ)
)y.
Poprawianie estymatora J nie jest potrzebne. Poprawka Aktora nie ulega zmianie. Może onamieć klasyczną postać taką jak w algorytmie z Tablicy 6.1 lub opartą na naturalnym gradienciepolityki. Ten drugi wariant algorytmu jest przestawiony w Tablicy 6.2.
Algorytmy przedstawione w Sekcjach 6.3 i 6.4 służą do optymalizacji średniej nagrody wprocesach decyzyjnych Markowa, które nie są podzielone na epizody. Algorytmy te można ła-two zaadaptować do problemów epizodycznych; wystarczy, że będą one zerować y na początkukażdego epizodu. Wówczas jednak optymalizują one sumę nagród w epizodzie zamiast średnią

6.5. Dyskonto ograniczenie wariancji estymatora gradientu 75
nagrodę i w rezultacie starają się przedłużać epizod dopóki nagrody są dodatnie. W niektórychzastosowaniach ma to sens, w innych nie. Zdyskontowana wersja algorytmu przestawiona po-wyżej może być z powodzeniem zastosowana zarówno do problemów epizodycznych jak i nie-epizodycznych.


Rozdział 7
Wielokrotne przetwarzanie obserwacji
Dotychczas omawiane algorytmy uczenia się ze wzmocnieniem działały na następującej za-sadzie: wykorzystywały kolejne wydarzenia składające się na interakcję decydenta z jego środo-wiskiem (decyzje lub epizody) do wyznaczania pewnych poprawek parametrów polityki oraz,być może, parametrów jakiejś dodatkowej struktury danych jak aproksymator funkcji wartości.Rozważmy ogólny algorytm uczenia się jako procedurę, która przetwarza historię procesu de-cyzyjnego, np. zgromadzoną w bazie danych, na parametry polityki. Możemy sobie wyobrazić,że sięga ona po dostępne jej dane w dowolnej kolejności i z wielokrotnymi powtórzeniami. Do-tychczas omawiane algorytmy uczenia się ze wzmocnieniem są tego rodzaju procedurami ogra-niczonymi w ten sposób, że przetwarzają dostępne dane jednokrotnie, zgodnie z kolejnością ichnapływania. Narzuca się pytanie, czy na takim ograniczeniu cierpi wydajność uczenia się i czyw taki sposób nie jest tracona część informacji zawartej w doświadczeniu. Wiele wskazuje nato, że odpowiedź na oba te pytania jest twierdząca.
W niniejszym rozdziale będziemy omawiać algorytmy oparte na dwóch równolegle działa-jących wątkach:A. Proces decyzyjny: Wykonuj decyzje i zapisuj zachodzące zdarzenia w bazie danych.B. Optymalizacja polityki: Poprawiaj politykę używaną w wątku A w oparciu o całe doświad-
czenie decydenta zgromadzone w bazie danych.O ile wątek A należy sobie wyobrażać jako interakcję decydenta z jego środowiskiem to wątek Bjest raczej działającą w nieskończonej pętli procedurą obliczeniową, która przetwarza dane. Al-gorytmy skonstruowane według powyższego schematu, nie ograniczone koniecznością sekwen-cyjnego przetwarzania napływających danych będą nastawione na wydobycie całej informacjidostępnej w doświadczeniu. Stąd będą nazywane intensywnymi.
Można wyróżnić trzy podstawowe zasady konstruowania procedur obliczeniowych optyma-lizujących politykę decyzyjną na podstawie danych historycznych:1. Programowanie dynamiczne.
Optymalizacja polityki może polegać na (i) budowie modelu środowiska na podstawie do-świadczenia oraz (ii) wyznaczaniu optymalnej polityki na podstawie modelu. Istnieje szero-ka gama technik służących do optymalizacji polityk decyzyjnych w oparciu o model. Wy-wodzą się one z programowania dynamicznego i ich przykładem jest wspomniana w Sekcji3.2 Iteracja Polityki. Efektywność tego podejścia zależy od odpowiedniego doboru technikmodelowania i optymalizacji polityki w oparciu o model.
2. Powtarzanie doświadczenia.
Omawiane dotychczas algorytmy, w większości działały na takiej zasadzie, że znalezienie siędecydenta w kolejnym stanie indukowało ciąg zmian parametru polityki w takim kierunku,aby poprawić sumę nagród oczekiwaną w tym właśnie stanie. Powtarzanie doświadczenia,zastosowane do tego typu algorytmu, jest rodzajem symulatora jego pracy opartego na da-nych z przebiegu procesu decyzyjnego. Polega ono na iteracyjnym losowaniu stanu spośródpoprzednio odwiedzonych i dokonywaniu poprawki wynikającej z decyzji, stanów i nagród,

78 Rozdział 7. Wielokrotne przetwarzanie obserwacji
0. Dane: sekwencja βt, t = 1, 2, . . . spełniająca (2.15).Zainicjalizuj: Q, t := 1, x1 ∼ P0.
1. Wylosuj ut na podstawieQ i xt; wykonaj ut.2. Wykonaj ν(t) razy2a. Wylosuj i-tą próbkę z bazy danych.2b. Przypisz
Q(xi, ui) := Q(xi, ui) + βt
(ri + γmax
uQ(x′i, u)−Q(xi, ui)
),
przy czym Q(x′i, ·) ≡ 0, jeśli po decyzji ui skończył się epizod.3. Zarejestruj rt i następny stan x′t.4. Zapisz 〈xt, ut, rt, x′t〉 jako t-tą próbkę w bazie danych; usuń z bazy danych próbki sprzedponad M jednostek czasu.
5. Przypisz t := t + 1 i wróć do Punktu 1.
Tablica 7.1. Algorytm Q-Learning z powtarzaniem doświadczenia.
które nastąpiły potem. Poprawka taka jest analogiczna do tej, której dokonuje oryginalnyalgorytm, ale uwzględnia fakt, że polityka decyzyjna zmieniła się.
3. Optymalizacja estymatora wskaźnika jakości.
Na ogół chcemy, aby polityka decydenta była najlepsza w sensie pewnego kryterium jako-ści. Niech dla ustalonego parametru polityki θ, wartość tego kryterium wynosi J(θ). Celemadaptacji decydenta jest maksymalizacja funkcji J ze względu na jej argument. Powiedzmy,że na podstawie danych zgromadzonych do chwili t potrafimy estymować J(θ). Oznaczmytaki estymator przez Jt(θ). Optymalizacja polityki może więc polegać na maksymalizacjiJt(θ) ze względu na θ.W kolejnych sekcjach nie omówimy pierwszego z powyższych podejść, odsyłając zaintereso-
wanego czytelnika do bogatej literatury poświęconej programowaniu dynamicznemu. Powodembraku naszego zainteresowania tą kategorią metod jest jej sprzeczność z założeniem, na którymoparte są algorytmy uczenia się ze wzmocnieniem, a które stanowi, że metody te są stosowanew warunkach braku wiedzy na temat środowiska, w którym działa system uczący się skoro nico nim nie wiemy, to nie wiemy też jak je modelować. Szczególną uwagę poświęcimy natomiastidei powtarzania doświadczenia. Algorytmy optymalizujące estymator wskaźnik jakości zostanątylko zasygnalizowane. Zainteresowanego czytelnika odsyłamy do publikacji np. [28, 27, 9].
7.1. Algorytm Q-Learning z powtarzaniem doświadczenia
Idea powtarzania doświadczenia (ang. experience replay) może być bezpośrednio zastoso-wana do algorytmu Q-Learning. Zostało to zaprezentowane w Tablicy 7.1.
Punkt 1. algorytmu polega na wylosowaniu i realizacji decyzji ut wynikającej z bieżącegostanu xt i postaci funkcji Q. Odbywa się to w dokładnie taki sposób, jak robi to oryginalnametoda Q-Learning.
W czasie kiedy realizowana jest decyzja ut, algorytm przetwarza dotychczas zebrane danena temat przebiegu interakcji decydenta i jego środowiska. Polega to na kilkukrotnym losowaniujednej z zarejestrowanych wcześniej czwórek 〈xi, ui, ri, xi+1〉, i dokonaniu na niej dokładnie ta-

7.2. Próbkowanie ważnościowe 79
kiego samego przypisania, jakie wykonuje oryginalna metoda Q-Learning przy użyciu czwórki〈xt, ut, rt, xt+1〉. W kroku t wykonywanych jest ν(t) takich przypisań.
W Punkcie 3. zostaje zarejestrowana nagroda rt i kolejny stan xt+1. W kolejnym punkcieczwórka 〈xt, ut, rt, xt+1〉 zostaje zapisana do bazy danych. Jednocześnie, zawartość bazy danychzostaje ograniczona do M ostatnich czwórek. Punkt 5. zamyka pętlę algorytmu.
Dlaczego Q-Learning z powtarzaniem doświadczenia miałby działać szybciej (w sensie ilo-ści interakcji decydenta ze środowiskiem), niż oryginalna metoda? W ogólności, działanie al-gorytmu uczenia się ze wzmocnieniem musi przynosić efekt polegający na tym, że informacja omożliwych do zdobycia nagrodach jest propagowana do wartościQ(x, u) dla stanów x i decyzjiu daleko poprzedzających te nagrody. Oryginalny algorytm w pojedynczym kroku propagujeinformację o nagrodach o jedną chwilę czasową wstecz. Tymczasem metoda z powtarzaniemdoświadczenia w ciągu jednego kroku propaguje taką informację o jedną chwilę czasową wsteczdla różnych punktów w przestrzeni X × U . Tym samym, globalnie porcje informacji na tematnagród są propagowane wstecz intensywniej.
Funkcja ν stosowana w Punkcie 2. algorytmu musi być ograniczona przez moc obliczeniowąkomputera, który dokonuje przeliczeń. Dodatkowo funkcja ta może być ograniczona dla małychwartości t, kiedy to wielokrotne przeliczanie niewielkich ilości danych prowadzi do efektu okre-ślanego jako „przeuczenie”, który polega na tym, że system wykształca politykę decyzyjną napodstawie ograniczonego doświadczenia. Postacią tej funkcji sprawdzającą się w praktyce jest
ν(t) = mincνδ t, cν0. (7.1)
Dla niewielkich t rośnie ona liniowo. Przynosi to efekt polegający na ograniczeniu tempa po-prawiania parametrów we wczesnej fazie procesu uczenia. Okazuje się, że wartość cνδ = 0.3 jestzazwyczaj odpowiednio mała, aby uniknąć przeuczenia i jednocześnie dość duża aby nadmiernienie opóźniać optymalizacji polityki. Dla dostatecznie dużego argumentu t, wartość funkcji jeststale równa cν0 , co odzwierciedla fakt, że dostępna moc obliczeniowa jest ograniczona i międzydwoma decyzjami można wykonać ograniczoną liczbę poprawek funkcji Q.
W Punkcie 4. algorytmu użyty jest parametrM określający rozmiar bazy danych stosowanejdo gromadzenia informacji o interakcji decydenta ze środowiskiem. Wielkość tego parametrupowinna być uzależniona od górnego ograniczenia funkcji ν. W ogólności, M powinno być oprzynajmniej rząd wielkości większe od ograniczenia ν. W szczególnym przypadku, kiedy mocobliczeniowa komputera stosowanego do obliczeń jest praktycznie nieograniczona, po każdymwykonaniu Punktu 2. algorytmu, zostaje wyznaczona postać funkcji Q optymalna w świetledotychczas zgromadzonego doświadczenia. W takiej sytuacji w bazie danych powinny być gro-madzone informacje o całej dotychczasowej interakcji.
7.2. Próbkowanie ważnościowe
Powtarzanie doświadczenia w algorytmach typu Aktor-Krytyk sprowadza się do wnioskowa-nia o jakości pewnych rozkładów prawdopodobieństwa (decyzji) na podstawie wcześniejszychlosowań z innych rozkładów (decyzji). W tej sekcji zajmiemy się wyizolowanym problememtego typu. Źródłami dla niniejszego rozdziału jest książka [24] oraz artykuły [19, 28, 27, 35].
Niech φ(· ;µ) będzie gęstością elementu losowego o wartościach w U parametryzowanąprzez µ ∈ M ⊂ R
nµ . Powiedzmy, że u0 zostało wylosowane z φ(· ;µ0) dla danego parame-tru µ0. Przynosi ona “zwrot”, czyli pewien wektor d(u0) gdzie d : U 7→ R
n. Interesuje nasestymacja wartości oczekiwanej d(u) dla u losowanego z użyciem zadanego parametru µ, czyli
Eµd(u) =∫
U
d(α)φ(α;µ) dα = D(µ). (7.2)

80 Rozdział 7. Wielokrotne przetwarzanie obserwacji
W celu skonstruowania estymatora wielkościD(µ), możemy posłużyć się techniką estymacjizwaną próbkowaniem ważnościowym (ang. importance sampling, [24]). Mianowicie, dla danychµ0 oraz µ, statystyka
d(u0)φ(u0;µ)
φ(u0;µ0)(7.3)
jest nieobciążonym estymatorem wielkości D(µ). Rzeczywiście,
Eµ0(d(u0)
φ(u0;µ)
φ(u0;µ0)
)=
∫d(α)
φ(α;µ)
φ(α;µ0)φ(α;µ0) dα (7.4)
=
∫d(α)φ(α;µ) dα
= D(µ).
Wadą estymatora (7.3) jest jego potencjalnie nieograniczona wariancja gdy rozkłady φ(· ;µ0)oraz φ(· ;µ) są od siebie odległe. Wariancja tego estymatora jest tym większa, im częściej zda-rza się, że iloraz gęstości występujący w (7.3) jest duży. Prostą receptą na ograniczenie wariancjiestymatora jest więc obcięcie ilorazu gęstości. Zmodyfikowany w ten sposób estymator ma po-stać
d(u0)min
φ(u0;µ)
φ(u0;µ0), b
(7.5)
gdzie b jest pewnym parametrem większym od 1. Estymator (7.5) będziemy nazywali obciętym
IS estymatorem.Aby uzasadnić konieczność posługiwania się obciętym IS estymatorem, przeanalizujemy
problem wariancji oryginalnego estymatora (7.3). W tym celu posłuży nam oczekiwany kwadrat
ilorazu gęstości postaci
κ(µ, µ0) = Eµ0(φ(u0;µ)φ(u0;µ0)
−1)2. (7.6)
Zachodzi
κ(µ, µ0) ≥(Eµ0φ(u0;µ)φ(u0;µ0)
−1)2
= 1.
Jeśli założymy, że d jest ograniczone w U , wtedy wariancja (7.3) może być ograniczona przez
Vµ0(d(u0)
φ(u0;µ)
φ(u0;µ0)
)≤ Eµ0
(d(u0)
φ(u0;µ)
φ(u0;µ0)
)2
= c2κ(µ, µ0), (7.7)
gdzie c = supu∈U ‖d(u)‖. Można skonstruować przykład demonstrujący, że powyższe ograni-czenie wariancji jest ścisłe [35]. Aby docenić wagę problemu wariancji estymatora (7.3), roz-ważmy φ(· ;µ) jako gęstość rozkładu normalnego ze średnią µ i nieosobliwą macierzą kowa-riancji C (4.5). W tym przypadku
φ(u;µ) =1√
(2Π)nµ|C|exp
(−0.5 (u− µ)TC−1(u− µ)
)
i mamy
κ(µ, µ0) = exp((µ− µ0)
TC−1(µ− µ0)).
Wartość ta, podobnie jak ograniczenie wariancji (7.7), rośnie bardzo szybko wraz z ‖µ− µ0‖.

7.3. Algorytm Aktor-Krytyk z powtarzaniem doświadczenia 81
7.3. Algorytm Aktor-Krytyk z powtarzaniem doświadczenia
W niniejszej sekcji przeanalizujemy w jaki sposób powtarzanie doświadczenia można za-stosować do szerokiej klasy algorytmów obejmującej metody Aktor-Krytyk. Klasę tą nazwiemyinkrementacyjnymi algorytmami z Aktorem i zdefiniujemy poniżej. Materiał z niniejszej sekcjioparty jest na artykule [33].
Inkrementacyjne algorytmy z Aktorem
Inkrementacyjny algorytm z Aktorem charakteryzuje się następującymi cechami:1. Optymalizuje parametr θ ∈ R
nθ stacjonarnej polityki decyzyjnej.2. Być może korzysta z pewnego pomocniczego parametru υ ∈ R
nυ , np. parametru aproksy-macji funkcji wartości. Także on jest przedmiotem optymalizacji.
3. W chwili t rozpoczęty zostaje ciąg modyfikacji parametru polityki, w efekcie czego do wek-tora parametrów Aktora θ, dodany jest wektor
βθt φt.
Celem tej modyfikacji θ jest zwiększenie oczekiwanej sumy nagród w stanie xt. βθt , t =1, 2, . . . jest malejącym ciągiem parametrów kroku.
4. W chwili t rozpoczęty zostaje ciąg modyfikacji pomocniczego parametru, υ, w rezultaciektórego zostaje do niego dodany wektor
βυt ψt.
Celem tej modyfikacji υ jest poprawienie jakości estymatorów φt (które w jakiś sposóbopierają się na υ) jako wskazujących kierunek poprawy polityki. βυt , t = 1, 2, . . . jestmalejącym ciągiem parametrów kroku.
Przykład 7.3.1. Klasyczny Aktor-Krytyk
W przypadku klasycznego Aktora-Krytyka mamy
φt = (rt + γV (xt+1; υ)− V (xt; υ))∂
∂θTlnπ(ut; xt, θ)
ψt = (rt + γV (xt+1; υ)− V (xt; υ))∂
∂υTV (xt; υ).
W tym przypadku φt oraz ψt są obliczane w chwili t+1. Tym samym “ciągi modyfikacji” θ orazυ są jednoelementowe. W przypadku innych algorytmów mogą one być nawet nieskończone.
Przykład 7.3.2. Aktor-Krytyk(λ)
Oznaczmy przezdt(υ) = rt + γV (xt+1; υ)− V (xt; υ)
różnicę czasową; tym razem będzie to funkcja pomocniczego wektora υ.W przypadku Aktora-Krytyka(λ) mamy
φt ∼=∂
∂θTln π(ut; xt, θ)
∑
i≥0
(λγ)idt+i(υ) =(R
(λ)t − V (xt; υ)
) ∂
∂θTlnπ(ut; xt, θ)
ψt ∼=∂
∂υTV (xt; υ)
∑
i≥0
(λγ)idt+i(υ) =(R
(λ)t − V (xt; υ)
) ∂
∂υTV (xt; υ)
Obie powyższe przybliżone równości stają się ścisłe gdy parametry kroku βθt oraz βυt zbiegajądo zera (vide Sekcja 5.3).

82 Rozdział 7. Wielokrotne przetwarzanie obserwacji
Zdefiniujmy dwie funkcje stanowiące wartości oczekiwane φt oraz ψt. Mianowicie
φ(x, θ, υ) = Eθ,υ,β(φt∣∣xt = x
), (7.8)
ψ(x, θ, υ) = Eθ,υ,β(ψt∣∣xt = x
). (7.9)
Funkcje te są określone przy założeniu, że w trakcie obliczania φt oraz ψt, nie następują zmia-ny θ, υ oraz parametrów kroku. Z biegiem czasu, gdy parametry kroku stają się bardzo małe,założenia te są coraz bardziej zbliżone do rzeczywistości.
Jak zatem działają inkrementacyjne algorytmy z Aktorem? Dla każdego stanu xt, w któ-rym znajdzie się decydent, losują estymator kierunku φ(xt, θ, υ) i wzdłuż niego modyfikują θ.Podobnie, losują estymator kierunku ψ(xt, θ, υ) i w tą stronę poprawiają υ. Średnio, θ oraz υpodążają za kierunkami, które są wypadkową φ i ψ dla stanów, które odwiedza decydent. Jeślioznaczmy przez η(· ; θ) stacjonarny rozkład stanów dla parametru polityki θ, to średni kierunekzmian θ będzie określony przez
Φ(θ, υ) =
∫
X
φ(x, θ, υ)η(dx; θ) (7.10)
zaś średni kierunek ruchu υ to
Ψ(θ, υ) =
∫
X
ψ(x, θ, υ)η(dx; θ). (7.11)
Powtarzanie doświadczenia w inkrementacyjnym algorytmie z Aktorem
Powtarzanie doświadczenia może posłużyć do przyspieszenia algorytmu uczenia się ze wzmoc-nieniem. W przypadku inkrementacyjnego algorytmu z Aktorem będzie to polegało na wyko-nywaniu w pętli następującej sekwencji:1. Wylosuj jeden z poprzednio odwiedzonych stanów, xi.2. Zmodyfikuj θ wzdłuż pewnego estymatora φ(xi, θ, υ) opierającego się na danych opisują-
cych decyzję i-tą i kolejne.3. Zmodyfikuj υ wzdłuż pewnego estymatora ψ(xi, θ, υ) opierającego się na tych samych da-
nych co estymator φ(xi, θ, υ).Przypomnijmy, inkrementacyjny algorytm z Aktorem robił powyższe czynności, tyle, że dlakolejnych stanów xt, t = 1, 2, . . . Jeśli jednak wydarzenia, które następują po chwili t niosąjakieś informacje, które mogłyby być użyte do modyfikacji przyszłych wartości θ i υ, są onetracone. Powtarzanie doświadczenia opiera się na założeniu, że takie informacje istnieją, więcpróbuje je wydobyć powracając do wcześniej odwiedzonych stanów.
Klasyczny Aktor-Krytyk, estymatory φ oraz ψ
W przypadku klasycznego Aktora-Krytyka mamy
φ(x, θ, υ) = Eθ((rt + γV (xt+1; υ)− V (xt; υ)
) ∂
∂θTln π(ut; xt, θ)
∣∣∣xt = x
).
Poszukujemy estymatora wartości φ(xi, θ, υ) dla pewnego i. Zauważmy, że
(ri + γV (xi+1; υ)− V (xi; υ)
) ∂
∂θTlnπ(ui; xi, θ) (7.12)

7.3. Algorytm Aktor-Krytyk z powtarzaniem doświadczenia 83
jest funkcją pary (ui, xi+1), która została wylosowana z rozkładu
π(· ; xi, θi)Px(· |xi, ui),
gdzie θi to parametr polityki używany w i-tej chwili, zaś Px to rozkład przejścia stanów. Chcie-libyśmy estymować wartość oczekiwaną funkcji (7.12) dla rozkładu pary argumentów (ui, xi+1)określonego przez dany parametr θ. Gęstość tego rozkładu to
π(· ; xi; θ)Px(· |xi, ui).
Zagadnieniem konstrukcji tego typu estymatorów zajęliśmy się w Sekcji 7.2. Możemy posłużyćsię zaproponowanym tam estymatorem (7.3), który w tym wypadku przyjmie postać
φi(θ, υ) = di(υ)
[∂
∂θTln π(ui; xi, θ)
]π(ui; xi, θ)
π(ui; xi, θi).
dladi(υ) = ri + γV (xi+1; υ)− V (xi; υ).
Jak wiemy z Sekcji 7.2, taki estymator może mieć dowolnie dużą wariancję. Lepszym pomysłemjest więc posłużenie się estymatorem obciętym (7.5)
φbi(θ, υ) = di(υ)
[∂
∂θTln π(ui; xi, θ)
]min
π(ui; xi, θ)
π(ui; xi, θi), b
dla pewnego stałego b > 1.Analogicznie postępujemy konstruując estymator wartości ψ(xi, θ, υ). Mamy
ψ(x, θ, υ) = Eθ((rt + γV (xt+1; υ)− V (xt; υ)
) ∂
∂υTV (xt; υ)
∣∣∣xt = x
).
Zauważmy, że wartość
(ri + γV (xi+1; υ)− V (xi; υ)
) ∂
∂υTV (xi; υ) (7.13)
jest funkcją pary (ui, xi+1), która została wylosowana z rozkładu
π(· ; xi, θi)Px(· |xi, ui).
Tymczasem chcielibyśmy estymować wartość oczekiwaną funkcji (7.13) dla rozkładu pary jejargumentów (ui, xi+1) określonego przez dany parametr θ. Gęstość tego rozkładu to
π(· ; xi; θ)Px(· |xi, ui).
Możemy się więc posłużyć zaproponowanym w Sekcji 7.2 estymatorem (7.3), który w tym przy-padku przyjmie postać
ψi(θ, υ) = di(υ)
[∂
∂υTV (xi; υ)
]π(ui; xi, θ)
π(ui; xi, θi).
Jak wiemy, taki estymator może mieć dowolnie dużą wariancję. Lepszym pomysłem jest więcposłużenie się estymatorem obciętym
ψbi (θ, υ) = di(υ)
[∂
∂υTV (xi; υ)
]min
π(ui; xi, θ)
π(ui; xi, θi), b

84 Rozdział 7. Wielokrotne przetwarzanie obserwacji
dla b tej samej wartości co w przypadku estymatora φbi .Chodzi nam o to, aby algorytm z powtarzaniem doświadczenia działał tak, jak algorytm ory-
ginalny, tylko szybciej. A zatem, chcemy aby średnia wektorów φi(θ, υ) i ψi(θ, υ) była zbieżna,odpowiednio, do Φ(θ, υ) (7.10) i Ψ(θ, υ) (7.11). W osiągnięciu tego celu przeszkadzają dwieokoliczności.
Po pierwsze, aby ograniczyć wariancję stosowanych estymatorów, posługujemy się obcina-niem. Niestety obcinanie sprawia, że używane estymatory są obciążone. Aby obciążenie genero-wane przez obcinanie było asymptotycznie eliminowane, należy zadbać, aby jego rola była corazmniejsza w miarę działania algorytmu. Okazuje się, że potrzebne jest do tego spełnienie przezrodzinę π pewnych warunków regularności, które na szczęście są spełnione przez większośćwyobrażalnych polityk decyzyjnych [33].
Druga okoliczność przeszkadzająca w tym, aby średnie wartości φbi(θ, υ) i ψbi (θ, υ) zbiegałydo Φ(θ, υ) i Ψ(θ, υ) polega na tym, że estymatory φi i ψi związane są z wcześniej odwiedzony-mi stanami a zatem z takimi, które na pewno nie pochodzą z bieżącego rozkładu stacjonarnegoη(· ; θ). Biorąc jednak pod uwagę, że polityka nie zmienia się szybko, a z biegiem czasu zmieniasię coraz wolniej, można zakładać, że im mniejsza jest różnica t− i, tym bardziej stan xi jest re-prezentatywny dla bieżącego rozkładu stacjonarnego. Ponieważ jednak baza danych zawierającapróbki ma skończoną pojemność, znajdują się znajdują się w niej dane z czasów nieodległych,kiedy polityka nie różniła się zasadniczo od bieżącej. W związku z tym można je traktować jakoodzwierciedlające w pewnym stopniu bieżący rozkład stacjonarny.
Klasyczny Aktor-Krytyk rozbudowany o powtarzanie doświadczenia został przedstawionyw Tablicy 7.2.
Uogólniony Aktor-Krytyk, estymatory φ oraz ψ
W tej części rozważymy uogólniony algorytm Aktor-Krytyk, w którym φt oraz ψt są postaci
Gt(θ, υ)∑
k≥0
(αρ)kzt,k(θ, υ) (7.14)
gdzie Gt jest pewnym wektorem zależnym od xt i ut, α ∈ [0, 1) oraz ρ ∈ [0, 1), natomiastzt,k ∈ R jest określone przez xt+k, ut+k, rt+k, xt+k+1 i być może ut+k+1.
Przykład 7.3.3. Aktor-Krytyk(λ)
Dla przykładu, w wypadku Aktora-Krytyka(λ) mamy φt oraz ψt postaci (7.14) z γλ = αρ oraz
Gt(θ, υ) =∂
∂θTln π(ut; xt, θ)
zt(θ, υ) = dt(υ)
dla Aktora oraz
Gt(θ, υ) =∂
∂υTV (xt; υ)
zt(θ, υ) = dt(υ)
dla Krytyka.
Powtarzanie doświadczenia w uogólnionym algorytmie Aktor-Krytyk przebiega na dokład-nie takiej samej zasadzie, jak w klasycznym Aktorze-Krytyku. Sposób estymacji φ oraz ψ jest

7.3. Algorytm Aktor-Krytyk z powtarzaniem doświadczenia 85
0. Zainicjuj losowe θ i υ. Przypisz t := 1.1. Wylosuj i wykonaj decyzję ut:
ut ∼ π(· ; xt; θ)
rejestrując πt = π(ut; xt, θ).2. (Pętla wewnętrzna) Powtórz ν(t) razy:a. Wylosuj i-tą próbkę z bazy danych.b. Oblicz różnicę czasową
di(υ) :=
ri + γV (x′i; υ)− V (xi; υ) jeśli x′i /∈ X ∗
ri − V (x′i; υ) w innym razie.
c. Oblicz estymatory kierunków poprawy
φbi(θ, υ) = di(υ)∂ ln π(ui; xi, θ)
∂θTmin
π(ui; xi, θ)
πi, b
ψbi (θ, υ) = di(υ)∂V (xi; υ)
∂υTmin
π(ui; xi, θ)
πi, b
d. Popraw politykę i aproksymator funkcji wartości:
θ := θ + βθt φbi(θ, υ)
υ := υ + βυt ψbi (θ, υ)
3. Zarejestruj nagrodę rt i następny stan x′t.4. Zapisz 〈xt, ut, rt, x′t, πt〉 jako t-tą próbkę w bazie danych; usuń z bazy próbki poza Mostatnimi.
5. Przypisz t := t + 1 i wróć do Punktu 1.
Tablica 7.2. Klasyczny Aktor-Krytyk z powtarzaniem doświadczenia.

86 Rozdział 7. Wielokrotne przetwarzanie obserwacji
dostosowany do postaci (7.14) wartości oczekiwanych wektorów losowych φt oraz ψt. Kon-struujemy poszukiwane estymatory w następujący sposób: Niech K będzie liczbą całkowitąwylosowaną niezależnie z rozkładu geometrycznego o parametrze ρ; oznacza to, że
P (K = m) = (1− ρ)ρm dla m = 0, 1, 2, . . .
zapisujemy to jakoK ∼ Geom(ρ).
Okazuje się, że nieobciążonym estymatorem φ(xi, θ, υ) i ψ(xi, θ, υ) jest
Gi(θ, υ)
K∑
k=0
αkzi+k(θ, υ)
k∏
j=0
π(ui+j; xi+j, θ)
π(ui+j; xi+j , θi+j). (7.15)
Jak widać, powyższy estymator przypomina wektory losowe φt oraz ψt, którymi posługuje sięoryginalny uogólniony algorytm Aktor-Krytyk. Dodatkowe elementy, które w nim występują toprzede wszystkim losowe ograniczenie sumy. Jest to zabieg, dzięki któremu możemy efektywnieestymować wartość oczekiwaną sumy, która ma nieskończenie wiele elementów. Drugi dodat-kowy element to iloczyn ilorazów gęstości. Kompensuje on fakt, że obecny parametr polityki θma inną wartość niż ten, który służył do losowania faktycznie wykonanych decyzji θi+k.
Estymator (7.15) jest praktycznie nieprzydatny ze względu na swoją potencjalnie nieogra-niczoną wariancję. Możemy ją jednak ograniczyć przez obcięcie ilorazu gęstości. Obcięty esty-mator ma postać
Gi(θ, υ)K∑
k=0
αkzi+k(θ, υ)min
k∏
j=0
π(ui+j; xi+j , θ)
π(ui+j; xi+j , θi+j), b
. (7.16)
Uogólniony algorytm Aktor-Krytyk z powtarzaniem doświadczenia został zapisany w Tablicy7.3.
Aktor-Krytyk z powtarzaniem doświadczenia, implementacja
Implementując algorytmy Aktora-Krytyka z powtarzaniem doświadczenia, należy zwrócićuwagę na dwa elementy: sposób losowania stanów oraz intensywność obliczeń.
Uczenie aproksymatorów nieliniowych, takich jak sieć neuronowa, na małych zbiorach da-nych niesie za sobą niebezpieczeństwo utykania parametrów tych aproksymatorów w ekstre-mach lokalnych. W związku z tym należy ograniczać tempo powtarzania doświadczenia sto-sownie do wielkości (czy raczej małości) zbioru odwiedzonych już stanów. Przyjmijmy, że pododaniu do bazy danych t-tego opisu wydarzenia z procesu decyzyjnego, dokonywanych jestν(t) poprawek (czyli tyle losowań przeszłych stanów). Okazuje się, że postacią funkcji ν, któradobrze sprawdza się w praktyce jest
ν(t) = mincνδ t, cν0.
a więc ta sama, (7.1), która została zaproponowana dla algorytmu Q-Learning. Dla niewielkichargumentów rośnie ona liniowo. Przynosi to efekt polegający na ograniczeniu tempa poprawia-nia parametrów we wczesnej fazie procesu uczenia. Okazuje się, że wartość cνδ = 0.3 jest za-zwyczaj odpowiednio mała, aby uniknąć utykania aproksymatorów w ekstremach lokalnych ijednocześnie dość duża, aby nadmiernie nie opóźniać optymalizacji polityki. Dla dostateczniedużego argumentu, funkcja ν „nasyca się” i pozostaje stała.

7.3. Algorytm Aktor-Krytyk z powtarzaniem doświadczenia 87
0. Zainicjuj losowe θ i υ. Przypisz t := 1.1. Wylosuj i wykonaj decyzję ut:
ut ∼ π(· ; xt; θ)
rejestrując πt = π(ut; xt, θ).2. (Pętla wewnętrzna) Powtórz ν(t) razy:a. Wylosuj i oraz K ∼ Geom(ρ); ewentualnie zmniejsz K tak aby chwile i . . . i+K były
w tym samym epizodzie.b. Oblicz estymatory kierunków poprawy
Di(θ, υ) =K∑
k=0
αkzi+k(θ, υ)min
k∏
j=0
π(ui+j; xi+j, θ)
πi+j, b
,
φbi(θ, υ) = Gφi (θ, υ)Di(θ, υ),
ψbi (θ, υ) = Gψi (θ, υ)Di(θ, υ).
c. Popraw politykę i aproksymację funkcji wartości:
θ := θ + βθt φbi(θ, υ)
υ := υ + βυt ψbi (θ, υ).
3. Zarejestruj nagrodę rt i następny stan x′t.4. Zapisz 〈xt, ut, rt, x′t, πt〉 jako t-tą próbkę w bezie danych; usuń z bazy próbki poza Mostatnimi.
5. Przypisz t := t + 1 i wróć do Punktu 1.
Tablica 7.3. Uogólniony Aktor-Krytyk z powtarzaniem doświadczenia.

88 Rozdział 7. Wielokrotne przetwarzanie obserwacji
7.4. Optymalizacja estymatora wskaźnika jakości
W rozdziale 4 omówiony został problem optymalizacji sposobu wybierania decyzji, abyzmaksymalizować oczekiwane wypłaty: Losowanie decyzji ut z rozkładu φ(· ;µt) owocowałowypłatą R(ut). Zastosowana tam metoda poprawiała w kolejnych krokach parametr µ po esty-matorze gradientu wskaźnika jakości J postaci
J(µ) =
∫
U
R(u)φ(u;µ)du.
Teraz zastosujemy zupełnie inne podejście. Mianowicie, kolejny parametr µt+1 będzie wyzna-czany jako rezultat optymalizacji funkcji
Jt(·),
która dla argumentu µ ∈ M jest estymatorem wielkości J(µ) skonstruowanym na podstawiehistorii losowań do chwili t.
W konstrukcji estymatorów J(µ) korzystamy z faktu, że jest to funkcja zdefiniowana analo-gicznie jak D(µ) z Sekcji 7.2. Wiemy więc, że nieobciążonym estymatorem J(µ) jest
R(ui)φ(ui;µ)
φ(ui;µi)(7.17)
dla dowolnego i ∈ 1, . . . , t oraz parametru µi zastosowanego do wylosowania decyzji ui.Wydaje się sensowne zastosowanie zagregowanego estymatora będącego średnią ważoną (7.17)w postaci
Jt(µ) =
∑ti=1R(ui)
φ(ui;µ)φ(ui;µi)
q(µ, µi)∑t
i=1 q(µ, µi),
gdzie q : M2 7→ R+ jest funkcją wyznaczającą wagi próbek. Okazuje się, że korzystając zfunkcji κ można tak zaprojektować funkcję ważącą q w konstrukcji Jt(µ), aby zminimalizować
E(Jt(µ)− J(µ)
)2
czyli pewną miarę jakości estymatora Jt(µ). A mianowicie, miara ta jest zoptymalizowana dla
q(µ, µi) ∝ 1/κ(µ, µi). (7.18)
Estymator Jt(µ) dla powyższego q ma prostą interpretację: κ(µ, µi) definiuje pewną miarę roz-bieżności rozkładów φ(· ;µi) oraz φ(· ;µ). Im większa miara, tym mniej “wiarygodna” staje sięi-ta próbka i tym mniejsza jest jej waga w Dt(µ).
Powyższą metodologię można zastosować także od algorytmu Epizodyczny REINFORCE.Zgodnie z dyskusją z Rozdziału 4.5, metoda ta sprowadza się do swojej statycznej wersji, jeślipotraktujemy całą sekwencję stanów i decyzji w epizodzie jako pojedynczą makro-decyzję [28,27].

Rozdział 8
Podsumowanie
Najważniejsze podejścia do uczenia się ze wzmocnieniem polegają na takiej optymalizacjiprawdopodobieństwa wyboru decyzji, aby “dobre” decyzje były podejmowane z dużym prawdo-podobieństwem a “złe” z małym. W celu osiągnięcia takiego zróżnicowania prawdopodobień-stwa decyzji, algorytmy opierają się na sformułowaniu pewnego wskaźnika jakości w postaciwartości oczekiwanej (ważonej sumy) przyszłych nagród. Ów wskaźnik jakości jest maksyma-lizowany w kolejnych krokach w oparciu o estymator jego gradientu.
Postarajmy się teraz sprowadzić omówione w niniejszym skrypcie metody uczenia się zewzmocnieniem do jednego schematu opartego na przyrostowej optymalizacji prawdopodobień-stwa wyboru decyzji. Do tej podstawowej idei dodawane są kolejne elementy.
— REINFORCE punktowy. Ideę optymalizacji prawdopodobieństwa decyzji w czystej formierealizuje algorytm REINFORCE punktowy. W każdym kroku estymuje on gradient wskaź-nika jakości, którym jest wartość oczekiwana wypłaty. Estymator ma postać
(R(ut)− bt)∇θ lnφ(ut; θt).
— REINFORCE statyczny. Algorytm REINFORCE statyczny wyznacza politykę decyzyjną dlaagenta, który w każdym kroku znajduje się w pewnym stanie wylosowanym niezależniez rozkładu stanów. Zadaniem algorytmu jest optymalizacja parametru stacjonarnej polity-ki decyzyjnej, której drugim parametrem jest stan. Estymator użyty w tym algorytmie mapostać
(rt − V (xt; υ))∇θ ln π(ut; xt, θ).
— Aktor-Krytyk. Okazuje się, że uczenie się może posłużyć nie tylko do optymalizacji na-tychmiast otrzymywanych nagród, ale także do otrzymywania nagród odległych w czasie.Potrzebna jest jednak do tego pewna miara jakości każdej decyzji możliwa do obliczenia na-tychmiast po jej wykonaniu. Skonstruowanie takiej miary jest o tyle kłopotliwe, że przecieżdecyzja może mieć dalekosiężne konsekwencje. Taką miarę oferuje Krytyk, który jest nośni-kiem aproksymacji zdyskontowanej sumy nagród dla danego stanu. Algorytm posługującysię Krytykiem wyznacza estymator gradientu wskaźnika jakości postaci
(rt + γV (xt+1; υ)− V (xt; υ))∇θ ln π(ut; xt, θ)
lub pewną jego modyfikacją.— Aktor-Krytyk(λ). Wadą klasycznego algorytmu Aktor-Krytyk jest jego uzależnienie od jako-
ści aproksymacji jaką oferuje Krytyk. Sposobem na ograniczenie tej zależności jest zastoso-wanieλ-estymatorów przyszłych nagród, w postaci pewnych nieskończonych sum. Posługujesię nimi algorytm Aktor-Krytyk(λ).
— Aktor-Krytyk z kompatybilną aproksymacją. Algorytmy klasyczny Aktor-Krytyk i Aktor-Kry-tyk(λ) działają efektywnie, ale nie doczekały się dowodów zbieżności. Tymczasem opraco-wany został algorytm, którego zbieżność z prawdopodobieństwem 1 została dowiedziona.Jest on oparty na Krytyku w specyficzny sposób kompatybilnym z Aktorem.
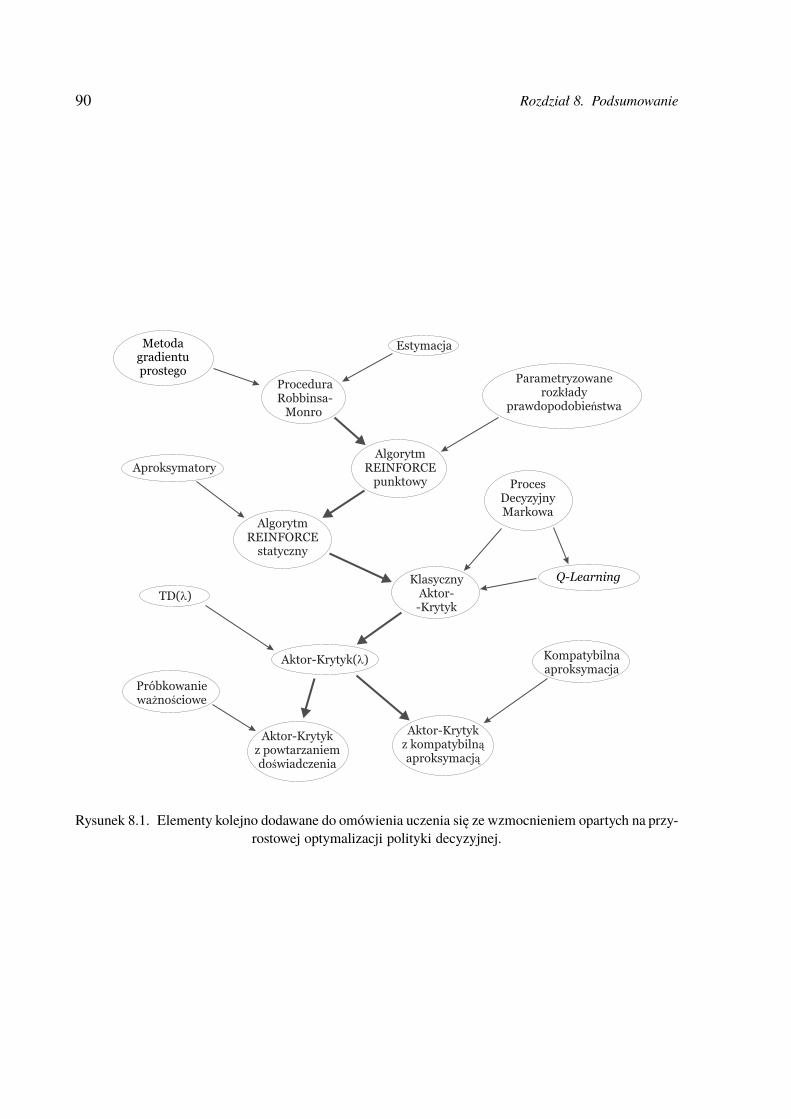
90 Rozdział 8. Podsumowanie
Metodagradientuprostego
Q-Learning
Rysunek 8.1. Elementy kolejno dodawane do omówienia uczenia się ze wzmocnieniem opartych na przy-rostowej optymalizacji polityki decyzyjnej.

91
— Aktor-Krytyk z powtarzaniem doświadczenia. Oryginalny algorytm Aktor-Krytyk jest wy-dajnym narzędziem do wyznaczania polityki decyzyjnej przy minimalnym nakładzie obli-czeniowym. Jeśli jednak istotne jest skrócenie do minimum interakcji między decydentem ajego środowiskiem, potrzebny jest mechanizm, który pozwoli na wydajniejsze wykorzystanieinformacji płynącej z tej interakcji, być może za cenę dodatkowego nakładu obliczeniowego.Takim mechanizmem jest powtarzanie doświadczenia.
Rysunek 8.1 przedstawia schemat naszego omówienia algorytmów opartych na przyrostowejoptymalizacji zrandomizowanej polityki (zrandomizowanej czyli opartej na losowaniu decyzji).Jest to rdzeń naszej dyskusji o uczeniu się ze wzmocnieniem, natomiast nie opisuje jej całości.Poza tym rdzeniem znajdują się jeszcze tak ważne elementy jak Q-Learning i SARSA.


Część III
Sterowanie adaptacyjne

94
Część trzecia skryptu jest poświęcona, jak na to zwięźle wskazuje tytuł, sterowaniu adapta-cyjnemu. Mając na uwadze samowystarczalność skryptu, wykład z tej dziedziny rozpoczynamyod zaawansowanych podstaw teorii sterowania: formalizmu służącego do opisywania obiektówdynamicznych (Rozdział 9) i teorii stabilności (Rozdział 10). Kolejne dwa rozdziały poświęconesą koncepcji systemów adaptacyjnych z modelem referencyjnym (ang. model reference adaptive
systems, MRAS). Rozdział 13 jest poświęcony koncepcji samostrojących się regulatorów (ang.self-tuning regulators, STR). Większość materiału prezentowanego w tej części jest także po-kryta przez książki [3, 29].

Rozdział 9
Obiekty dynamiczne
9.1. Wstęp
Obiekt dynamiczny
W tej części skryptu interesuje nas sterowanie obiektami dynamicznymi działającymi w cza-sie ciągłym. Stan x(t) takiego obiekt w chwili t ∈ R jest elementem przestrzeni X = R
nx . Nawejście obiektu podawane jest sterowanie u(t) ∈ U = R
nu . Dynamika obiektu jest opisywanarównaniem postaci
d
dtx(t) = f (x(t), u(t);µ) , (9.1)
w którym µ jest pewnym wektorem parametrów, µ ∈ M = Rnµ . Równanie (9.1) będziemy
także zapisywać w skrótowej postaci
x = f(x, u;µ). (9.2)
Warto zwrócić uwagę na następujące cechy obiektu opisywanego równaniem (9.1).— Determinizm. Na obiekt nie działają zakłócenia losowe.— Stacjonarność. Dynamika obiektu nie zmienia się w czasie.
Model referencyjny i sterownik
Obiekt dynamiczny służy pewnym celom. Na ogół ten cel jest zdefiniowany w następującysposób. Trajektoria z : R 7→ R
nz to sygnał referencyjny: pewna zewnętrzna wartość, np. zada-wana joystickiem przez człowieka. Chcemy, aby stan obiektu zmieniał się stosownie do z(t) wsposób zadany przez model referencyjny postaci
d
dtx(t) = fr (x(t), z(t))
lubx = fr(x, z). (9.3)
W pierwszym podejściu można sobie wyobrażać model referencyjny jako sposób dochodzeniastanu obiektu do pozycji z(t) zadawanej przez człowieka. Na ogół to dochodzenie powinno byćpewnym rozłożonym w czasie procesem, opisywanym właśnie przez równanie (9.3). Jeśli np.z(t) oznacza docelową pozycję windy, zaś x jej obecną pozycję to docieranie x do z powin-no zająć windzie trochę czasu (próba dotarcia tam natychmiast dałaby sporo zajęcia dla ekipyremontowej oraz personelu medycznego).
Aby obiekt realizował swoje cele, jest sterowany sygnałem
u(t) = g(x(t), z(t); θ(t)) (9.4)

96 Rozdział 9. Obiekty dynamiczne
Rysunek 9.1. Kluczowe elementy problemu sterowania
gdzie θ(t) ∈ Θ = Rnθ to pewien parametr sterownika. W ogólności parametr θ zmienia się
w czasie, np. tak, aby działanie sterownika było coraz lepsze.Rysunek 9.1 przedstawia wszystkie wymienione elementy.
Zagadnienie adaptacji
Klasyczna teoria sterowania zajmuje się problemami związanymi z projektowaniem sterow-nika, czyli funkcji g, na podstawie funkcji f (z ustalonym µ) oraz fr. W niniejszym skrypciezakładamy dodatkowe utrudnienie. Mianowicie, parametr µ określający dynamikę obiektu jestnieznany. W tej sytuacji zadanie polega na tym, aby zaprojektować odpowiednią strukturę ste-rownika, czyli funkcję g, oraz mechanizm optymalizacji parametru θ sterownika, który dostosujego do nieznanego parametru µ.
9.2. Liniowe obiekty SISO
Najlepiej zbadaną klasą obiektów dynamicznych są liniowe obiekty SISO (ang. signle-input-
-single-output). Oto przykład takiego obiektu.
Przykład 9.2.1. Kulka i sprężyna
Rozważmy kulkę połączoną ze stałym punktem poprzez sprężynę (Rysunek 9.2). W chwili tznajduje się w odległości x(t) od punktu równowagi sprężyny. Na kulkę oddziałują następującesiły:
— Siła sprężystości −a0x.— Siła tarcia kulki o ośrodek, w którym się porusza. Załóżmy, że siła ta jest proporcjonal-na do prędkości kulki1 i skierowana przeciwnie. Wynosi zatem −a1x, gdzie a1 to dodatniwspółczynnik tarcia.
1 Jest to jeden z wielu rodzajów tarcia.

9.2. Liniowe obiekty SISO 97
Rysunek 9.2. System sprężyna–ciężarek
— Zewnętrzna siła u, którą przykładamy do kulki. Jest to sterowanie, które ma służyć namdo osiągania naszych celów związanych z położeniem kulki.
Przyspieszenie kulki jest proporcjonalne do sumy sił, które oddziałują na nią i odwrotnie pro-porcjonalna do jej masy m. Mamy
x =1
m(−a0x− a1x+ u),
a zatem jej ruch jest definiowany przez liniowe równanie różniczkowe postaci
x+a1mx+
a0mx =
1
mu. (9.5)
Ogólny obiekt SISO i jego opis
W ogólności, obiekt SISO wiąże swoje skalarne wejście u ze skalarnym wyjściem x linio-wym równaniem różniczkowym postaci
n∑
i=0
aidi
dtix =
m∑
j=0
bjdj
dtju, (9.6)
w którym a0, . . . , an oraz b0, . . . , bm są skalarnymi stałymi oraz an = 1, bm 6= 0.Powstaje pytanie, czy obiekt opisany równaniem (9.6) można sprowadzić do postaci kano-
nicznej (9.2). Można zrobić to np. definiując stan ~x i sterowanie ~u jako wektory składające się zkolejnych pochodnych x i u, odpowiednio. Mamy wówczas
~u =
uddtu...
dm
dtmu
~x =
xddtx...
dn−1
dtn−1x
f(~x, ~u;µ) =
~x1...
~xn−1∑mj=0 bj~uj −
∑n−1i=0 ai~xi
.
Dla przejrzystości w powyższym zapisie elementy wektorów ~u i ~x indeksowane są począwszyod 0 (a nie od 1 jak się to zwykle robi). Ponadto, spotykamy się tu z typową sytuacją polegającąna tym, że skalarne sygnały, x oraz u tworzą, wraz ze swoimi pochodnymi po czasie, wartościwektorowe ~x oraz ~u, odpowiednio. Jedne i drugie będziemy oznaczać tymi samymi literami;kiedy znajdą się w tych samych formułach, wektorom będą towarzyszyć strzałki. W przeciwnymrazie strzałki będą pomijane.

98 Rozdział 9. Obiekty dynamiczne
Użytecznym narzędziem służącym do analizy równań postaci (9.6) jest transformata Lapla-ce’a
Lf(t) =∫ ∞
0
f(t) exp(−pt)dt. (9.7)
Przekształca ona funkcję R+ 7→ R na funkcję o dziedzinie i wartościach zespolonych. Ototransformaty kilku funkcji, które będą nas szczególnie interesować w przyszłości
Le−λt = 1
p+ λ(9.8)
Le−λt sinωt = ω
(p+ λ)2 + ω2. (9.9)
Poniżej przedstawiono własności transformaty Laplace’a najistotniejsze z naszego punktu wi-dzenia. Oznaczmy Lf(t) = F (p).1. Liniowość:
L
n∑
i=1
aifi(t)
=
n∑
i=1
aiFi(p). (9.10)
2. Transformata całki:
L
∫ t
0
f(τ)dτ
=F (p)
p. (9.11)
3. Transformata pochodnej:
L
dn
dtnf(t)
= pnF (p)−
n−1∑
i=0
pn−i−1 limtց0
f(t). (9.12)
Dla zerowych warunków początkowych (czyli f (i)(0) ≡ 0) mamy
L
dn
dtnf(t)
= pnF (p). (9.13)
4. Transformata splotu:Lf1(t) ∗ f2(t) = F1(p)F2(p) (9.14)
gdzie
f1(t) ∗ f2(t) =∫ t
0
f1(τ)f2(t− τ)dτ =
∫ t
0
f2(τ)f1(t− τ)dτ.
Transformata Laplace’a jest podstawowym narzędziem analizy równań postaci (9.6). Przyzałożeniu zerowych warunków początkowych i przy wykorzystaniu (9.13) i (9.10) równanie(9.6) transformuje się do
A(p)X(p) = B(p)U(p) (9.15)
gdzie
A(p) =
n∑
i=0
aipi, B(p) =
m∑
i=0
bipi.
Obiekt definiowany przez (9.6) przetwarza wejście o transformacie U(p) na wyjście o transfor-macie X(p) w ten sposób, że
X(p) = K(p)U(p)
gdzie (z (9.15))
K(p) =B(p)
A(p)(9.16)
to transmitancja obiektu.

9.2. Liniowe obiekty SISO 99
Reprezentacja systemu SISO w przestrzeni stanów
Demonstrując użycie transformaty Laplace’a jako narzędzia analitycznego przedstawmy sys-tem (9.6) w postaci kanonicznej (9.2) w taki sposób, aby wejściem tego systemu była jedynieskalarna wartość u (bez odpowiednich pochodnych). Załóżmy dodatkowo, żem ≤ n. Rozważmysygnał
x0(p) =1∑n
i=0 aipiu(p)
czyli
x(n)0 (t) = u(t)−
n−1∑
i=0
aix(i)0 (t) (9.17)
ponieważ an = 1. Jeśli teraz określimy ~x0 jako
~x0 = [x0, x0, . . . , x(n−1)0 ]T
to możemy zapisać~x0 = A~x0 + bu (9.18)
dlaA ∈ Rn×n i b ∈ R
n. Równanie (9.18) jest w istocie zapisem n równań skalarnych. Pierwszen−1 spośród nich mówi tylko tyle, że kolejne elementy ~x0 są pochodnymi po czasie elementówpoprzedzających. A zatem, indeksując elementy od zera, mamy dla i = 0, . . . , n− 2
Ai,i+1 = 1, Ai,j = 0 dla j 6= i+ 1, bi = 0.
Natomiast ostatni wiersz (9.18) przedstawia równanie (9.17), a zatem
An−1 = [−a0,−a1, . . . ,−an−1], bn−1 = 1.
Sygnał x możemy odtworzyć z x0 przez statyczne przekształcenie. Mamy bowiem
x(p) =
∑mj=0 bjp
j
∑ni=0 aip
iu(p) =
(m∑
j=0
bjpj
)x0(p)
lub inaczej
x(t) =
m∑
j=0
bjx(j)0 (t)
x = cTx0, c = [b0, . . . , bm, 0, . . . , 0]T (9.19)
Równania (9.18) i (9.19) stanowią kanoniczną postać dynamiki systemu liniowego.
Interpretacja i własności systemów SISO
Definiowanie systemów liniowych przy użyciu transmitancji pozwala na łatwą analizę sys-temów “poskładanych” z innych. Niech wyjście obiektu (9.15) będzie wejściem x1 obiektu
A1(p)X1(p) = B1(p)X(p).
W jaki zatem sposób sygnał u jest przetwarzany na x1? Otóż
X1(p) = K∗(p)U(p)

100 Rozdział 9. Obiekty dynamiczne
Rysunek 9.3. Składanie transmitancji
gdzie
K∗(p) =B1(p)
A1(p)K(p).
W ogólności szeregowe połączenie n systemów o transmitancjach Ki(p), i = 1, . . . , n tworzyobiekt o transmitancji będącej iloczynem Ki(p), czyli
K∗(p) =n∏
i=1
Ki(p).
Sytuację tą przedstawia Rysunek 9.3.Pokusimy się o interpretację transmitancji złożenia systemów postaci (9.6). W ogólności,
transmitancja taka jest funkcją wymierną zmiennej p, a zatem może być sprowadzona do postaciiloczynu elementów następujących typów:
n∑
i≥0
bipi, 1/p,
λ
p + λ,
λ2 + ω2
(p+ λ)2 + ω2.
Tym samym każdy obiekt postaci (9.6) może być uważany jako szeregowe złożenie elementówo powyższych transmitancjach. Przeanalizujemy je po kolei.
T1 Element postacin∑
i≥0
bipi
tworzy wyjście będące kombinacją liniową pochodnych wejścia po czasie (z (9.10)).T2 Element całkujący postaci
1/p
tworzy wyjście będące całką wejścia (z (9.11)).T3 Filtr dolnoprzepustowy. Dla λ 6= 0 element postaci
λ
p+ λ(9.20)
tworzy wyjście x będące (przeskalowanym) splotem (9.14) wejścia u i funkcji e−λt (9.8). Azatem mamy
x(t) =
∫ t
0
u(t− τ)λe−λτdτ.
Dla λ > 0 wartość x(t) jest średnią ważoną wejścia systemu z chwil t − τ dla τ > 0;sama funkcja λe−λτ całkuje się do jedynki. Waga wejścia z chwil poprzedzających zanikawykładniczo wraz τ . Dla λ < 0, waga wejść z chwil poprzedzających rośnie wraz z τ , choćpowyższy splot traci interpretację średniej ważonej.

9.2. Liniowe obiekty SISO 101
T4 Filtr oscylacyjny. Element postaci
λ2 + ω2
(p+ λ)2 + ω2(9.21)
działa w sposób analogiczny do rozważanego powyżej, choć nieco bardziej skomplikowa-ny. Wyjście x powstaje w tym przypadku jako (przeskalowany) splot wejścia u i funkcjie−λt sinωt (9.9). A zatem
x(t) =
∫ t
0
u(t− τ)λ2 + ω2
ωe−λτ sinωτ dτ.
Wartość x(t) jest ponownie pewnego rodzaju średnią ważoną wejścia systemu z chwil t− τpoprzedzających t. Sposób tego ważenia jest dosyć wyrafinowany: np. dla λ > 0 skokowazmiana na wejściu systemu powoduje zanikające oscylacje na jego wyjściu.
Rozważmy wpływ wejścia systemu w kwancie czasu [t−δ, t) na jego wyjście w chwili t+∆. Jakwidać z powyższej interpretacji, jeśli w dekompozycji systemu znajdują się jedynie elementyT1 oraz T3, T4 dla λ > 0, wówczas wpływ ten zanika wykładniczo wraz ze wzrostem ∆.W tej sytuacji, jeśli sygnał wejściowy i jego pochodne są ograniczone, wówczas także sygnałwyjściowy musi być ograniczony.
Jeśli jednak w dekompozycji systemu znajdują się elementy T2 oraz T3 lub T4 dla λ ≤ 0,wówczas wpływ wejścia w kwancie [t−δ, t) na x(t+∆) nie zanika ze wzrostem∆. W przypadkuT3 i T4 dla λ < 0, wpływ ten wręcz rośnie i bardzo łatwo uzyskać nieograniczony wzrostx(t+∆), wystarczy stałe niezerowe wejście.
Powyższe rozróżnienie sformalizujemy w następującej definicji.
Definicja 9.2.1. Transmitancja
K(p) =B(p)
A(p),
w której A i B są względnie pierwszymi wielomianami jest ściśle stabilna, jeśli wszystkie zespo-
lone pierwiastki równania
A(p) = 0
leżą w lewej półpłaszczyźnie zespolonej.
Części rzeczywiste rozważanych wyżej pierwiastków odpowiadają dokładnie przeciwieństwomwspółczynników λ w elementarnych składnikach transmitancji dyskutowanych wyżej. A zatem,transmitancja ściśle stabilna to taka, która przetwarza sygnał o skończonych wartościach i po-chodnych na sygnał o również ograniczonych wartościach i pochodnych.
Z punktu widzenia systemów adaptacyjnych szczególnie dużą rolę odgrywają obiekty otransmitancjach, które są regularne w sposób jeszcze dalej idący. Zdefiniujemy je poniżej, poczym nadamy tej definicji bardziej intuicyjną interpretację.
Definicja 9.2.2. Transmitancji K(p) jest ściśle dodatnio rzeczywista (SDR), jeśli istnieje stała
ǫ > 0 taka, że
Re[p ] > −ǫ⇒ Re[K(p)] > 0.
A zatem ściśle dodatnio rzeczywista jest transmitancja, która transformuje prawą półpłaszczyznęwraz z osią urojoną w prawą półpłaszczyznę bez osi urojonej. Dla przykładu rozważmy obiekt
K(p) =1
p+ λ

102 Rozdział 9. Obiekty dynamiczne
0.5
1
1.5
2
0 2 4 6 8 10t
x(t)
Rysunek 9.4. Zachowanie się kulki według modelu referencyjnego: W chwili 0 kulka znajduje się wpunkcje x(0) = 1.5 i ma pewną dodatnią prędkość. W tym momencie z(t) zmienia wartość na 1. Kulka
jest wyhamowywana i cofana do położenia określanego przez z(t).
dla λ > 0. Niech p = q + jr. Wtedy
K(p) =1
(q + λ) + jr=
(q + λ)− jr(q + λ)2 + r2
.
Wystarczy zatem aby q > −λ/2 aby Re[K(p)] > 0. Oznacza to, że mamy do czynienia ztransmitancją ściśle dodatnio rzeczywistą.
W praktyce weryfikacja tego czy transmitancja jest SDR w oparciu o samą tylko definicjęjest kłopotliwa. Poniższe twierdzenie, wraz z wnioskami z niego wynikającymi w znacznymstopniu ułatwia taką weryfikację.
Twierdzenie 9.2.1. Transmitancja K(p) jest ściśle dodatnio rzeczywista (SDR) wtedy i tylko
wtedy gdy
— K(p) jest transmitancją ściśle stabilną,
— Część rzeczywista K(p) jest dodatnia wzdłuż osi urojonej, czyli
∀r ≥ 0 Re[K(jr)] > 0.
Dowód powyższego twierdzenia można znaleźć w [29]. Jak widać, aby zweryfikować czy trans-mitancjaK(p) jest SDR, wystarczy sprawdzić zera jej mianownika i czy krzywaK(jr) znajdujesię w całości w prawej półpłaszczyźnie liczb zespolonych.
Okazuje się, że spełnienie następujących warunków jest konieczne, aby transmitancja K(p)była SDR.— Względny stopień K(p) wynosi 0 lub 1: liczby n,m w równaniu (9.6) spełniają n − m ∈0, 1.
— Zera licznika K(p) znajdują się w lewej półpłaszczyźnie liczb zespolonych. Innymi słowytransmitancjaK(p) jest minimalnofazowa.
Poszukując intuicyjnej interpretacji transmitancji SDR zapiszmy ją jako iloraz wielomianów(9.16). Zera licznika muszą być wówczas w lewej półpłaszczyźnie zespolonej, czyli licznik moż-na sprowadzić do postaci
B(p) = bm
m∏
i=1
(p+ b′j)
gdzie części rzeczywiste współczynników b′j są dodatnie. Oznacza to, że dodatnie wartości nawejściu obiektu o transmitancji SDR i pochodnych tego sygnału przekładają się dodatnio nasygnał na wyjściu nie ma rozbieżności między kierunkiem działania na sygnał wyjściowywartości i różnych pochodnych po czasie sygnału wejściowego.
Przykład 9.2.2. Kulka i sprężyna, model referencyjny i sterowanie
Po zreferowaniu podstawowych własności liniowych obiektów dynamicznych jesteśmy w do-godnej pozycji do zaproponowania systemu sterowania dla dyskutowanego w Przykładzie 9.2.1

9.2. Liniowe obiekty SISO 103
problemu kulki na sprężynie. Niech sygnał referencyjny z wyznacza docelową pozycję kulki iniech dążenie do tej pozycji będzie przebiegało według modelu referencyjnego postaci
x+ 2x+ x = z. (9.22)
Aby wyjaśnić przyczyny takiego właśnie wyboru powiedzmy, że w chwili t0 sygnał z ustala sięna pewnym poziomie z(t0) i oznaczmy
e(t) = x(t)− z(t0).Chcemy aby e(t) zbiegało do zera niezależnie od warunków początkowych. Sygnał e(t) spełniarównanie różniczkowe
e+ 2e+ e = 0.
Można pokazać, że jedyną funkcją e, która je spełnia jest
e(t) = (a + bt)e−(t−t0), t ≥ t0
gdzie a i b to stałe wynikające z warunków początkowych, w tym przypadku z pozycji i prędkościkulki w chwili t0. Funkcja e oczywiście zbiega do zera. Zachowanie się kulki zgodne z modelemreferencyjnym (9.22) demonstruje Rysunek 9.4.
Zwróćmy uwagę, że sterowanie oddziałuje na stan kulki poprzez jej przyspieszenie; nie mo-że bezpośrednio zmienić ani położenia ani prędkości kulki. A zatem model referencyjny takżepowinien zakładać oddziaływanie z na x poprzez drugą pochodną położenia kulki. W ogólnościjeśli model obiektu jest rzędu n (występuje w nim n-ta pochodna jego stanu) to model referen-cyjny powinien być co najmniej rzędu n.
Transformata Laplace’a równania (9.22) ujawnia transmitancję, którą ma realizować naszsystem sterowania, mianowicie
p2X(p) + 2pX(p) +X(p) = Z(p)
czyli
X(p) =1
(p+ 1)2Z(p).
Transmitancję tą interpretujemy jako złożenie dwóch elementów T3, czyli dokonujących wa-żone uśrednianie poprzednich wartości sygnału wejściowego z(t) przypisujące większą wagęwartościom późniejszym.
Zaprojektujmy sterownik postaci
u = g(x, x, z) = cx+ dz + hx.
gdzie c, d oraz h to skalary, których teraz poszukamy. Włączając powyższe równanie do (9.5)dostajemy
x+a1mx+
a0mx =
1
m(cx+ dz + hx)
x+1
m(a1 − h)x+
1
m(a0 − c)x =
1
mdz
Jeśli więc c, d oraz h będą spełniały równania
1
m(a1 − h) = 2,
1
m(a0 − c) = 1,
1
md = 1
to relacja między x a z będzie dokładnie taka, jak tego żądaliśmy specyfikując model referen-cyjny (9.22). Ostatecznie sterownik, którego szukamy ma postać
u = g(x, x, z) = (a0 −m)x+mz + (a1 − 2m)x.

104 Rozdział 9. Obiekty dynamiczne
9.3. Dyskretna aproksymacja obiektów o ciągłej dynamice
Przez obiekty dynamiczne rozumiemy pewne istniejące w przyrodzie systemy. Mamy na-dzieję, że jesteśmy w stanie wiernie oddać zmiany ich stanu przy użyciu modeli typu (9.2).Zanim jednak sterownik zostanie zaimplementowany w fizycznej rzeczywistości, zwykle chce-my przetestować jego działanie w symulacji komputerowej zachodzącej w czasie dyskretnym.Zajmiemy się teraz metodami implementowania takiej symulacji.
Podstawowy algorytm symulacji dynamiki obiektów dynamicznych wyznacza przybliżenia
xk, k = 0, 1, 2, . . .
wartości x(t0 + kδ) na podstawie sterowań
uk, k = 0, 1, 2, . . .
przybliżających u(t0+ kδ) i obliczanych zwykle na podstawie xk. Podstawą do wyznaczania xkjest równanie
x(t + δ) = x(t) +
∫ t+δ
t
f(x(τ), u(τ);µ)dτ
wynikające z (9.2). Symulację prowadzi się przy założeniu, że gdy δ jest małe to funkcja podcałką jest “niemal stała” dla τ ∈ [t, t+ δ]. A zatem zachodzi
x(t+ δ) ∼= x(t) + δf(x(t), u(t);µ). (9.23)
Posługując się przybliżonym równaniem (9.23) obliczamy xk+1 jako
xk+1 = xk + δf(xk, uk;µ) (9.24)
dla k = 0, 1, 2, . . . Dla odpowiednio małych wartości parametru δ, algorytm przybliża przebiegstanu obiektu z satysfakcjonującą dokładnością.2
W przypadku gdy obiekt dynamiczny opisywany jest równaniem (9.6), które tu przytoczymy
n∑
i=0
aidi
dtix =
m∑
j=0
bjdj
dtju,
możemy symulować jego dynamikę z większą dokładnością zakładając, że w ciągu kwantu czasuo długości δ wartość
dn
dtnx(t)
pozostaje stała. Algorytm zakłada pewne oszacowania
ujk
j-tej pochodnej czasowej wejścia w chwili t0 + kδ, czyli
u(j)(t0 + kδ) dla j = 0, 1, . . . , m
2 W istocie mamy tu do czynienia z problemem numerycznego rozwiązywania równań różniczkowych, któryma bogatą literaturę (patrz np. [8]). Bardziej zaawansowane jego rozwiązania stosują szereg usprawnień eliminu-jących konieczność zgadywania odpowiedniej wartości parametru δ. Co więcej, wartość δ jest dobierana z krokuna krok tak aby zapewnić odpowiednią dokładność rozwiązania.

9.3. Dyskretna aproksymacja obiektów o ciągłej dynamice 105
Rysunek 9.5. Pojedyncze wahadło na wózku.
z
zz
ω
oraz oszacowaniaxik
wartościx(i)(t0 + kδ) dla i = 0, 1, . . . , n− 1.
Pozwalają one obliczyć oszacowanie xnk wartości x(n)(t0 + kδ) bezpośrednio z równania dyna-miki obiektu, mianowicie
xnk =
m∑
j=0
bj ujk −
n−1∑
i=0
aixik.
Pamiętamy, że an = 1. Zakładamy, że w przedziale czasu [t, t+ δ), x jest wielomianem stopnian czasu. Wiemy, że gdyby x faktycznie było wielomianem stopnia n, prawdziwe byłoby rozwi-nięcie w skończony szereg Taylora
x(t+ δ) = x(t) +n∑
l=1
δl
l!x(l)(t).
Co więcej, analogiczne rozwinięcie byłoby prawdziwe dla wszystkich pochodnych x. Założe-niem, iż x jest wielomianem posługujemy się obliczając przybliżenia kolejnych pochodnych xpod koniec kwantu czasu, mianowicie
xik+1 = xik +
n∑
l=i+1
δl−i
(l − i)! xlk, dla i = 0, 1, . . . , n− 1. (9.25)
Powtarzając obliczenia dla kolejnych kwantów czasu, otrzymujemy trajektorię x0k, k = 0, 1, 2, . . .przybliżającą właściwą trajektorię x(t0 + kδ), k = 0, 1, 2, . . . .
Przykład 9.3.1. Odwrócone wahadło
Rozważamy wózek poruszający się po odcinku z przyczepionym do niego luźno wahadłem.Obiekt jest sterowany siłą przykładaną do wózka. Istnieją dwa warianty celu sterowania. Wa-riant pierwszy (inverted pendulum [4]) polega na stabilizacji wahadła w górze. Drugi (Cart-Pole
Swing-Up [6]) polega na tym, aby wahadło rozbujać, ustawić pionowo w górze i dopiero wtedystabilizować.
Mamy cztery zmienne stanu: pozycja wózka z, kąt ω między wahadłem a pionem oraz ichpochodne po czasie z, ω. Zmienną sterującą jest siłaF przykładana do wózka. Dynamika obiektujest opisywana dwoma równaniami różniczkowymi
ω =Ω(z, z, ω, ω, F )
z =Z(z, z, ω, ω, F ).

106 Rozdział 9. Obiekty dynamiczne
Postaci funkcji Ω oraz Z nie są istotne z punktu widzenia naszej dyskusji, więc ich nie przyta-czamy. Symulację dynamiki obiektu możemy prowadzić określając stałą kwantyzacji czasu, np.na poziomie δ = 0.001 i szacując wartości kolejnych zmiennych stanu w oparciu o wzory:
z(t0 + kδ) ∼= z0k+1 = z0k + δz1k +1
2δ2Z(z0k, ω
0k, z
1k, ω
1k, Fk)
ω(t0 + dδ) ∼= ω0k+1 = ω0
k + δω1k +
1
2δ2Ω(z0k, ω
0k, z
1k, ω
1k, Fk)
z(t0 + kδ) ∼= z1k+1 = z1k + δZ(z0k, ω0k, z
1k, ω
1k, Fk)
ω(t0 + kδ) ∼= ω1k+1 = ω1
k + δΩ(z0k, ω0k, z
1k, ω
1k, Fk).

Rozdział 10
Stabilność i funkcja Lapunowa
Formalizm funkcji Lapunowa posłużył do uzasadnienia wielu rezultatów teorii sterowania.Służy także do uzasadniania poprawności schematów adaptacji i dlatego zostanie tu przytoczo-ny. Czytelnikom zainteresowanym jeszcze szerszym wprowadzeniem do tej tematyki polecamypodręcznik [29].
10.1. Ogólna postać typowego schematu adaptacji
W poprzednim rozdziale zostało opisane zagadnienie obiektu dynamicznego i sterownika,którego parametr powinien dostosować się do nieznanego parametru obiektu. Aby to dostosowa-nie mogło zachodzić, zazwyczaj niezbędne jest zaprojektowanie ogólnej struktury sterownika gtak, aby realizowała ona następujące wymaganie.Wymaganie wstępne. Sterownik g jest zaprojektowany w taki sposób, że dla każdego paramet-
ru obiektu µ istnieje (przynajmniej jeden) taki parametr θµ, że sterownik g(· , · ; θµ) realizujedokładnie model referencyjny dla dowolnego sygnału referencyjnego.
Równolegle do procesu sterowania działa mechanizm adaptacji. Jest on skonstruowany w takisposób, aby realizował dwa postulaty.Postulat 1. Faktyczna trajektoria stanu powinna zbiegać do trajektorii wynikającej z sygnału i
modelu referencyjnego.Postulat 2. Parametr sterownika θ(t) powinien zbiegać do wartości θµ wskazanej w wymaganiu
wstępnym.Zdefiniujmy xm(t) jako trajektorię stanu odpowiadającą danemu sygnałowi referencyjnemu.Spełnia ona oczywiście
d
dtxm(t) = fr(xm(t), z(t)).
Adaptacja będzie miała formę przyrostowej zmiany parametru sterownika na podstawie tego, cosię w danej chwili dzieje. W ogólności, zmiany te będą postaci
d
dtθ(t) = fθ
(θ(t), x(t), xm(t), u(t), z(t)
).
Projektowanie adaptującego się sterownika będziemy więc rozumieli jako projektowanie funkcjig oraz fθ.
Oby określić cel adaptacji, oznaczmy
y1(t) = x(t)− xm(t)y2(t) = θ(t)− θµ.
Rezultatem adaptacji powinna być zbieżność y1(t) oraz y2(t) do zera. Analiza mechanizmówadaptacji ma na celu sprawdzenie, czy faktycznie do takiej zbieżności dochodzi niezależnie odkonkretnego przebiegu sygnału referencyjnego z(t). Dla ustalonego sterownika g i schematu

108 Rozdział 10. Stabilność i funkcja Lapunowa
adaptacji fθ możemy zapisać, w jaki sposób będzie się zmieniał y1 i y2. Będzie się to odbywałowedług formuły postaci
d
dty(t) = h(y(t), t) (10.1)
gdzie y =[y1y2
]. Funkcja h jest explicite zależna od czasu, ponieważ zmiany y zależą od sygna-
łu referencyjnego z, a ten zależy od czasu. W dalszej części rozdziału zajmiemy się ogólnymzagadnieniem zbieżności do zera funkcji postaci (10.1).
System nieautonomiczny
Będą nas interesowały przede wszystkim systemy dynamiczne należące do pierwszej z klaswymienionych w następującej definicji.
Definicja 10.1.1. Niech x ∈ Rnx będzie stanem systemu dynamicznego. System jest nazywany
nieautonomicznym, jeśli jego stan zmienia się według formuły
x = h(x, t). (10.2)
Jeśli funkcja h faktycznie nie zależy od czasu, wówczas system nazywamy autonomicznym.
Stan systemu dynamicznego będziemy także nazywali punktem. Przez zdefiniowany powyżejsystem należy rozumieć obiekt wraz z oddziałującym na niego sterownikiem adaptującym siędo dynamiki obiektu. Tym samym równanie (10.2) należy rozumieć jako analogiczne do (10.1),a nie do równania obiektu, np. (9.2).
Tradycyjne rozróżnienie na systemy autonomiczne i nieautonomiczne należy interpretowaćw następujący sposób. Przyszły stan systemu autonomicznego jest konsekwencją wyłącznie sta-nu bieżącego; autonomia oznacza tu niezależność od świata zewnętrznego. Tymczasem przyszłystan systemu nieautonomicznego jest zależny od pewnego zewnętrznego czynnika zależnego odczasu. Będą nas interesować systemy nieautonomiczne ze względu na sygnał referencyjny z.Oddziałuje on na system nie będąc jego częścią; to co dzieje się w systemie nie wpływa na z.
10.2. Stabilność
Analiza systemów nieautonomicznych postaci (10.2) ma nam posłużyć do ustalenia, czy ichstan x(t) jest zbieżny do jakiejś granicy. Oczywiście jeśli już w niej jest, chcielibyśmy aby tampozostawał. Granicę taką nazywa następująca definicja.
Definicja 10.2.1. Punkt x∗ nazywamy stanem równowagi jeśli system, kiedy się w nim znajdzie,
pozostanie w nim na zawsze.
Z powyższej definicji wynika, że
∀t ≥ t0 h(x∗, t) = 0
gdzie t0 określa pierwszą chwilę życia systemu.
Przykład 10.2.1. Wahadło
Rozważmy wyidealizowane wahadło w postaci sztywnego pręta zaczepionego w punkcie. Nawolny koniec wahadła działa siła u(t), której kierunek jest zawsze pionowy. Bez względu nakonkretny przebieg siły u(t), wahadło ma dwa stany równowagi: kiedy jest skierowane pionowow dół lub pionowo w górę; przy czym w obu przypadkach jego prędkość kątowa jest zerowa. Poznalezieniu się w tych dokładnie punktach, pozostanie w nich już zawsze.

10.2. Stabilność 109
Przykład 10.2.2.
Liniowy nieautonomiczny systemx = A(t)x
ma stan równowagi w zerze. Jeśli przynajmniej jedna z macierzy A(t) jest nieosobliwa, to zerojest jedynym stanem równowagi systemu.
Poza tym aby system pozostawał w punkcie równowagi kiedy się w nim znajdzie, interesujenas także, aby nie oddalał się zanadto od tego punktu, kiedy już raz znajdzie się w jego pobliżu.
Definicja 10.2.2. Stan równowagi x∗ jest stabilny jeśli
∀R > 0 ∃r > 0
(‖x(t0)− x∗‖ < r ⇒ ∀t ≥ t0 ‖x(t)− x∗‖ < R
).
W przeciwnym razie, punkt x∗ nazywamy niestabilnym. 1
A zatem, punkt jest stabilny jeśli dla każdej odległości R stanu x(t) od punktu równowagi x∗
możemy sprawić, aby stan nie oddalał się od tego punktu na więcej niż R i możemy to zrobićjedynie wybierając dla stanu w chwili t0 odpowiednio bliskie otoczenie stanu równowagi.
Warto zwrócić uwagę, że sam fakt, że stan systemu utrzymuje się w pewnej odległości odx∗ nie wystarczy do powiedzenia, że system jest stabilny. Chodzi o to, aby przez odpowiedniwybór kuli dla stanu początkowego możliwe było utrzymanie systemu dowolnie blisko stanurównowagi przez cały czas.
Kolejna ważna własność systemu nieautonomicznego jest związana ze zbieganiem jego stanudo stanu równowagi.
Definicja 10.2.3. Stan równowagi x∗ jest asymptotycznie stabilny jeśli
— jest stabilny,
— istnieje wartość r > 0, dla której
‖x(t0)‖ < r ⇒ limt→∞
x(t) = x∗.
Przykład 10.2.3.
Rozważmy system
x = − x
1 + sin2 t.
Powiedzmy, że x(t0) > 0; mamy
x
x=
d
dtln x(t) =
−11 + sin2 t
.
Zatem
ln x(t)− ln x(t0) =
∫ t
t0
−11 + sin2 τ
dτ ≤∫ t
t0
−12dτ = −1
2(t− t0)
a więc0 < x(t) ≤ x(t0) exp(−0.5(t− t0)).
Dla x(t0) < 0 analiza jest symetryczna do powyższej zaś dla x(t0) = 0 mamy x(t) ≡ 0.We wszystkich przypadkach stan systemu zbiega do zera, a zatem stan x∗ = 0 okazuje sięasymptotycznie stabilny.
1 Ponieważ r nie zależy tu od t0, tak zdefiniowana stabilność odpowiada temu, co niekiedy nazywa się stabil-
nością jednostajną.

110 Rozdział 10. Stabilność i funkcja Lapunowa
Definicja asymptotycznej stabilności przewiduje zbieżność obwarowaną pewnym istotnymwarunkiem. Punkt początkowy x(t0) musi się znajdować w odpowiednio małej kuli o środkuw x∗. W przeciwnym razie zbieżność może nie zachodzić mimo, iż system jest asymptotyczniestabilny. Kolejny rodzaj stabilności wyklucza taką możliwość.
Definicja 10.2.4. Stan równowagi x∗ jest globalnie asymptotycznie stabilny jeśli
— jest stabilny,
— zachodzi
limt→∞
x(t) = x∗.
Jeśli system jest asymptotycznie stabilny (AS), ale nie globalnie AS, wówczas nazywamy go lo-kalnie asymptotycznie stabilnym.
A zatem, system jest globalnie AS jeśli spełnia definicję asymptotycznej stabilności dla nieskoń-czonej wartości r.
Przykład 10.2.4.
System
x = − x
1 + sin2 t
analizowany w Przykładzie 10.2.3 jest de facto globalnie asymptotycznie stabilny (AS). Tym-czasem system
x = −x(1 − x2)
1 + sin2 t
jest już tylko lokalnie AS. Dla 0 < x(t0) <√0.5 mamy
ln x(t)− ln x(t0) =
∫ t
t0
−(1− x(τ)2)1 + sin2 τ
dτ ≤∫ t
t0
−14dτ = −1
4(t− t0)
a więc0 < x(t) ≤ x(t0) exp(−0.25(t− t0)).
Podobnie rozumując można stwierdzić zbieżność dla−√0.5 < x(t0) < 0. Jednak dla x(t0) > 1
mamyx > 0
co oczywiście wyklucza zbieganie x(t) do zera.
10.3. Funkcja Lapunowa
Wygodnym narzędziem do analizy stabilności systemów dynamicznych jest funkcja Lapu-nowa. Przypisuje ona stanowi x nieujemną wartość L(x), która jest interpretowana jako energiasystemu w tym stanie. Jest naturalne, aby taka funkcja przypisywała najmniejszą ilość energiistanowi, który można interpretować jako bezruch. Jeśli o systemie wiadomo, że systematycznietraci energię na rzecz otoczenia, to można się spodziewać, że będzie sukcesywnie zmierzał dobezruchu. Oznacza to, że stan oznaczający bezruch jest stanem stabilnym sytemu, a być możetakże asymptotycznie stabilnym. Formalizm funkcji Lapunowa dostarcza narzędzi do prowa-dzenia ścisłych rozumowań tego typu. W istocie funkcja Lapunowa nie musi wcale oznaczaćfizycznej energii, musi jedynie definiować coś, czego system systematycznie się pozbywa i czymnie dysponuje kiedy pozostaje w stanie asymptotycznie stabilnym.

10.3. Funkcja Lapunowa 111
Przykład 10.3.1. Kulka na sprężynie
Rozważmy uogólniony system z Rysunku 9.2. Niech jego dynamikę opisuje równanie
mx+ f1(x) + f0(x) = 0. (10.3)
Funkcja f1 : R 7→ R oznacza uogólnioną siłę oporu zaś funkcja f0 : R 7→ R jest to uogólnionasiła sprężystości. Znaki wartości tych funkcji są takie, jak znaki ich argumentów. Zdefiniujmyfunkcję L systemu jako sumę jego energii kinetycznej i energii potencjalnej sprężystości
L(x, x) =1
2mx2 +
∫ x
0
f0(y)dy (10.4)
i zbadajmy jak zmienia się jej wartość w czasie
L =d
dtL(x, x) = mxx+ f0(x)x.
Połączenie powyższego z równaniem (10.3) daje
L = x(−f1(x)− f0(x)) + f0(x)x = −xf1(x).A zatem, system nie traci energii (zdefiniowanej jako (10.4)) tylko w sytuacji, kiedy kulka sięnie porusza. Jeśli jednak nie porusza się i jednocześnie znajduje w innym miejscu niż punktrównowagi sprężyny x = 0, ulega przyspieszeniu, które natychmiast zmienia jego prędkość naniezerową i system ponownie zaczyna tracić energię.
Zanim funkcja stanie się funkcją Lapunowa danego systemu potrzebne jej są pewne własno-ści, których zestaw teraz zdefiniujemy.
Definicja 10.3.1. Niech funkcja L : Rnx 7→ R będzie ciągła i spełnia L(0) = 0. Funkcja taka
jest nazywana
— globalnie dodatnio określoną, jeśli ∀x 6= 0 L(x) > 0,
— globalnie dodatnio pół-określoną, jeśli ∀x L(x) ≥ 0,
— globalnie ujemnie pół-określoną, jeśli ∀x L(x) ≤ 0,
— globalnie ujemnie określoną, jeśli ∀x 6= 0 L(x) < 0.
Na ogół trudno jest udowodnić globalne własności systemu. Do zdefiniowania własności lokal-nych posłużymy się następującym oznaczeniem.
BR = x : ‖x‖ < R.A zatem BR jest to otwarta kula o środku w zerze układu współrzędnych i promieniu R.
Definicja 10.3.2. Niech funkcja L : Rnx 7→ R będzie ciągła i spełnia L(0) = 0. Funkcja taka
jest nazywana
— lokalnie dodatnio określoną jeśli ∃R > 0 ∀x ∈ BR − 0 L(x) > 0,
— lokalnie dodatnio pół-określoną jeśli ∃R > 0 ∀x ∈ BR L(x) ≥ 0,
— lokalnie ujemnie pół-określoną jeśli ∃R > 0 ∀x ∈ BR L(x) ≤ 0,
— lokalnie ujemnie określoną jeśli ∃R > 0 ∀x ∈ BR − 0 L(x) < 0.
Jesteśmy gotowi do zdefiniowania funkcji Lapunowa systemu.
Definicja 10.3.3. Dany jest system
x = h(x, t).
Niech dla pewnego R > 0 w kuli BR funkcja L jest dodatnio określona, ma ciągły gradient, zaś
jej pochodne po czasie wzdłuż dowolnej trajektorii systemu są niedodatnie (a więc L(x(t)) ≤ 0).
Wówczas L jest funkcją Lapunowa tego systemu. 2
2 Zazwyczaj funkcję Lapunowa systemów nieautonomicznych definiuje się jako explicite zależną od czasu.Ponieważ taka zależność nie jest potrzebna w dalszej dyskusji, pomijamy ją.

112 Rozdział 10. Stabilność i funkcja Lapunowa
Jak widać funkcja jest definiowana jako funkcja Lapunowa poprzez własności jej samej orazjej związki z danym systemem dynamicznym.
10.4. Stabilność w kontekście funkcji Lapunowa
Uzasadnieniem formalizmu funkcji Lapunowa był zanik ruchu w systemach, które tracą ener-gię. Bezruch jest stanem stabilnym dla takich systemów. Formalną postacią tej intuicji jest na-stępujące twierdzenie.
Twierdzenie 10.4.1. Niech L będzie funkcją Lapunowa systemu
x = h(x, t).
1. Stan x∗ = 0 jest stabilny.
2. Jeśli dodatkowo istnieje dodatnio określona funkcja l taka, że
L(x(t)) < −l(x(t)),
wówczas stan x∗ = 0 jest asymptotycznie stabilny.
3. Jeśli dodatkowo funkcja L jest radialnie nieograniczona, czyli L(x) → +∞ dla ‖x‖ →+∞, wówczas stan x∗ = 0 jest globalnie asymptotycznie stabilny.
Dowód powyższego twierdzenia można znaleźć w [29].Pierwsza część twierdzenia odpowiada intuicyjnemu rozumieniu stanu x∗ = 0, a mianowicie
jest to stan odpowiadający brakowi energii, którego system nie opuszcza, od kiedy się w nimznajdzie.
Druga część twierdzenia dotyczy stabilności asymptotycznej. Warunkiem wystarczającymdla niej jest istnienie dodatnio określonej funkcji l, dla której
L(x(t)) ≤ −l(x(t)).
Ponieważ lewa strona powyższej nierówności zależy od x(t), to jest funkcją nie tylko stanu wchwili t ale także, implicite, czasu. Tymczasem prawa strona zależy tylko od stanu. Następującyprzykład pokazuje znaczenie tego rozróżnienia.
Przykład 10.4.1.
Rozważmy systemx = −xe−t.
Jego stan zmienia się w stronę zera z coraz mniejszą prędkością. Przyjmijmy t0 = 0, x(t0) > 0.Mamy wówczas
x
x=
d
dtln x(t) = −e−t,
a zatem
ln x(t)− ln x(0) =
∫ t
0
− exp(−τ)dτ = e−t − 1
i stądx(t) = x(0) exp(e−t − 1).
Dla rosnącego t, x(t) nie zbiega do 0 tylko do wartości x(0)/e. Identyczny rezultat zostałbyuzyskany dla x(0) < 0. Dla x(0) = 0 stan systemu pozostałby zerowy. Mamy więc do czynieniaze stabilnością punktu 0, ale nie stabilnością asymptotyczną.
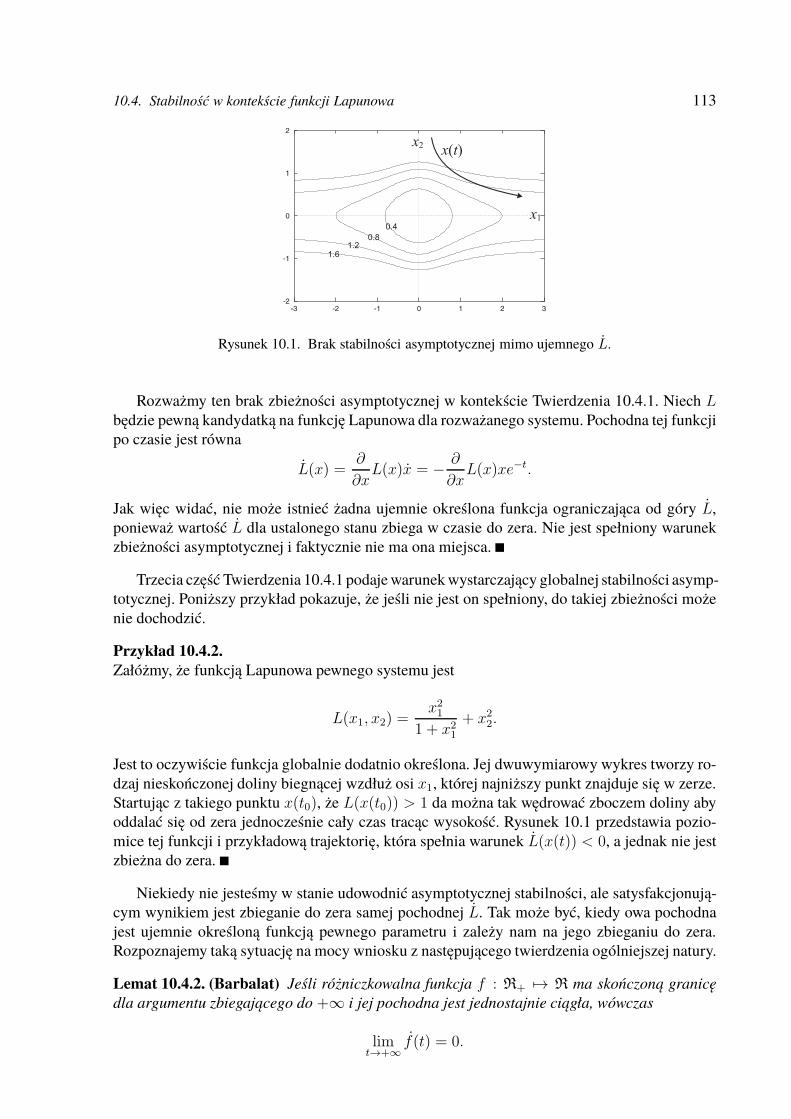
10.4. Stabilność w kontekście funkcji Lapunowa 113
Rysunek 10.1. Brak stabilności asymptotycznej mimo ujemnego L.
Rozważmy ten brak zbieżności asymptotycznej w kontekście Twierdzenia 10.4.1. Niech Lbędzie pewną kandydatką na funkcję Lapunowa dla rozważanego systemu. Pochodna tej funkcjipo czasie jest równa
L(x) =∂
∂xL(x)x = − ∂
∂xL(x)xe−t.
Jak więc widać, nie może istnieć żadna ujemnie określona funkcja ograniczająca od góry L,ponieważ wartość L dla ustalonego stanu zbiega w czasie do zera. Nie jest spełniony warunekzbieżności asymptotycznej i faktycznie nie ma ona miejsca.
Trzecia część Twierdzenia 10.4.1 podaje warunek wystarczający globalnej stabilności asymp-totycznej. Poniższy przykład pokazuje, że jeśli nie jest on spełniony, do takiej zbieżności możenie dochodzić.
Przykład 10.4.2.
Załóżmy, że funkcją Lapunowa pewnego systemu jest
L(x1, x2) =x21
1 + x21+ x22.
Jest to oczywiście funkcja globalnie dodatnio określona. Jej dwuwymiarowy wykres tworzy ro-dzaj nieskończonej doliny biegnącej wzdłuż osi x1, której najniższy punkt znajduje się w zerze.Startując z takiego punktu x(t0), że L(x(t0)) > 1 da można tak wędrować zboczem doliny abyoddalać się od zera jednocześnie cały czas tracąc wysokość. Rysunek 10.1 przedstawia pozio-mice tej funkcji i przykładową trajektorię, która spełnia warunek L(x(t)) < 0, a jednak nie jestzbieżna do zera.
Niekiedy nie jesteśmy w stanie udowodnić asymptotycznej stabilności, ale satysfakcjonują-cym wynikiem jest zbieganie do zera samej pochodnej L. Tak może być, kiedy owa pochodnajest ujemnie określoną funkcją pewnego parametru i zależy nam na jego zbieganiu do zera.Rozpoznajemy taką sytuację na mocy wniosku z następującego twierdzenia ogólniejszej natury.
Lemat 10.4.2. (Barbalat) Jeśli różniczkowalna funkcja f : R+ 7→ R ma skończoną granicę
dla argumentu zbiegającego do +∞ i jej pochodna jest jednostajnie ciągła, wówczas
limt→+∞
f(t) = 0.

114 Rozdział 10. Stabilność i funkcja Lapunowa
Dowód lematu można znaleźć w [29]. Przypomnijmy, że jednostajna ciągłość funkcji g oznaczaspełnienie następującego warunku
∀R > 0 ∃r > 0 ∀t1, t2 |t1 − t2| < r ⇒ |g(t1)− g(t2)| < R.
Przykładem funkcji, która nie spełnia tego warunku jest sin(t2). Łatwo sprawdzić, że wartościtej funkcji zmieniają się oR = 2 dla coraz mniejszych przyrostów argumentów. Z drugiej stronydo jednostajnej ciągłości funkcji g wystarczy, aby jej pochodna była ograniczona. Jeśli zatem fjest zbieżna, a f ograniczona, to f spełnia warunki Lematu Barbalata.
Lemat 10.4.2 odzwierciedla intuicję, wedle której jeśli funkcja jest zbieżna, to także corazmniejsze (a więc zbieżne do zera) muszą być jej przyrosty. Okazuje się, że intuicja ta jest trafna,o ile tylko funkcja jest w pewien sposób regularna. Odpowiednią formą regularności jest właśniejednostajna ciągłość pochodnej.
Interesującym nas wnioskiem z Lematu Barbalata jest następujące twierdzenie.
Twierdzenie 10.4.3. Niech L będzie funkcją Lapunowa pewnego systemu (10.2). Jeśli L jest
jednostajnie ciągła, wówczas
limt→∞
L(x(t)) = 0.
Funkcja f(t) = L(x(t)) jako nierosnąca i ograniczona od dołu jest zbieżna. Ponieważ f jestfunkcją jednostajnie ciągłą, teza twierdzenia wynika z Lematu Barbalata.
Funkcja Lapunowa dla stacjonarnego systemu liniowego
Przyjmijmy x ∈ R i rozważmy skalarny system liniowy
x = ax.
Jest oczywiste, że jeśli tylko a < 0, to x∗ = 0 jest stanem globalnie asymptotycznie stabilnymdla tego systemu. Jeśli jednak a > 0, stan x∗ = 0 (czyli jedyny stan równowagi), nie jeststabilny. Jeśli a = 0, system staje się mało ciekawy; dla porządku należy jednak powiedzieć,że wówczas każdy stan x wyznacza równowagę systemu, jest więc stabilny, ale nie jest stabilnyasymptotycznie.
Uogólnieniem skalarnego systemu liniowego jest system
x = Ax
dla x ∈ Rnx i A ∈ R
nx×nx . Jak zweryfikować, czy zero jest stanem asymptotycznie stabilnymtakiego systemu korzystając z formalizmu funkcji Lapunowa? Rozważmy dwa narzucające siępodejścia.1. Wybieramy kandydatkę na funkcję Lapunowa w postaci
L(x) = xTPx (10.5)
gdzie P jest pewną macierzą dodatnio określoną3. Następnie badamy L, a mianowicie
L(x) = xTPx+ xTP x = xT (ATP + PA)x. (10.6)
Jeśli macierzQ = −(ATP + PA)
okazuje się dodatnio określona, wówczas na podstawie trzeciej części Twierdzenia 10.4.1wnioskujemy globalną asymptotyczną stabilność stanu x∗ = 0.
3 Macierz P jest dodatnio określona gdy ∀x 6= 0 xTPx > 0.

10.4. Stabilność w kontekście funkcji Lapunowa 115
2. Możemy także postąpić odwrotnie. Wybieramy dodatnio określoną macierz Q i poszukuje-my takiej kandydatki L na funkcję Lapunowa systemu, która spełni
L = −xTQx.
Z (10.6) wiemy, że jeśli macierz P , która spełnia równanie
ATP + PA = −Q
jest dodatnio określona, to daje nam ona prawidłową funkcję Lapunowa postaci (10.5).Okazuje się, że pierwsze spośród powyższych podejść jest zawodne: ze stabilności danego
systemu i dodatnio określonej macierzy P może wcale nie wynikać dodatnio określona macierzQ. Tymczasem podejście drugie jest niezawodne, o czym mówi następujące twierdzenie.
Twierdzenie 10.4.4. System x = Ax ma globalnie asymptotycznie stabilny stan x∗ = 0 wtedy i
tylko wtedy, gdy dla dowolnej dodatnio określonej macierzy Q, rozwiązanie P równania
ATP + PA = −Q
jest macierzą dodatnio określoną.
Dowód tego twierdzenia można znaleźć w [29].


Rozdział 11
Sterowanie adaptacyjne z modelem referencyjnym
Podejście do sterowania adaptacyjnego omówione w tym rozdziale występuje pod angielskąnazwą Model Reference Adaptive Control (MRAS) i jako pierwsze doczekało się formalnychdowodów poprawności.
11.1. Liniowy obiekt SISO pierwszego rzędu
Dynamika obiektu SISO pierwszego rzędu opisana jest równaniem
x+ µxx = µuu. (11.1)
Przykładem zjawiska, które można opisać powyższym równaniem jest obiekt poruszający sięz prędkością x, na który działa siła oporu −µxx proporcjonalna do prędkości oraz zewnętrznasiła u. Zgodnie z tą interpretacją, będziemy dalej zakładać, że µx > 0.
Model referencyjny dla powyższego obiektu niech będzie postaci
x+ ax = bz (11.2)
dla a > 0. Z Rozdziału 9 wiemy, że model taki będzie realizował transmitancję
b
a
a
p+ a.
Działa ona w ten sposób, że po skokowej zmianie sygnału referencyjnego i ustaleniu się gona poziomie z0, sygnał wyjściowy obiektu x zbiega wykładniczo do (b/a)z0. Stałą czasową tejzbieżności jest 1/a.
Sterownik, który zastosujemy do powyższego problemu będzie postaci
u = θxx+ θzz. (11.3)
Przekonajmy się, że dla pewnych wartości θx oraz θz powyższe sterownie faktycznie daje modelreferencyjny. Włączając (11.3) do (11.1) dostajemy
x+ µxx = µu(θxx+ θzz)
x+ (µx − µuθx)x = µuθzz.
A zatem dla θu oraz θz spełniających
a = µx − µuθx, b = µuθz

118 Rozdział 11. Sterowanie adaptacyjne z modelem referencyjnym
czyli
θx = θ∗x =µx − aµu
, θz = θ∗z =b
µu, (11.4)
mamy sterowanie dokładnie realizujące model (11.2). Problem polega jednak na tym, że nieznamy z góry µu ani µx.
Schemat adaptacji. Oznaczmy przez xm sygnał, który wynika z dokładnej realizacji modelureferencyjnego (11.2). Stan obiektu różni się od xm o błąd
e = x− xm.
Ponadto, w każdej chwili do wyznaczania sterowania używany jest parametr θ, niekoniecznerówny θ∗. Oznaczmy
θ =
[θx
θz
]=
[θx − θ∗xθz − θ∗z
].
Zbadajmy teraz jak zmienia się błąd w czasie. W tym celu wykorzystamy kolejno: model obiektu(11.1), model referencyjny (11.2), sterownik (11.3) i postaci optymalnych parametrów sterow-nika (11.4).
e = x− xm=(µu(θxx+ θzz)− µxx
)− (bz − axm)
= (µuθx − µx)x+ axm + (µuθz − b)z= (µuθ
∗x − µx)x+ µu(θx − θ∗x)x− axm + (µuθz − µuθ∗z)z
= −ae + µu(θx − θ∗x)x+ µu(θz − θ∗z)z= −ae + µu(θxx+ θzz).
(11.5)
Pokuśmy się o heurystyczną analizę powyższego wyniku. Po pierwsze okazuje się, że jeśli ste-rownik ma optymalne parametry θ∗x i θ∗z , to θx = θz = 0 i rozbieżność między faktycznymstanem obiektu, x, a stanem wynikającym z modelu, xm, zanika wykładniczo. Jest to rezultatpożądany.
Rozważmy teraz co się dzieje, jeśli θx > θ∗x, czyli gdy θx > 0. Wtedy błąd e rośnie (więcpewnie jest dodatni) dla x > 0 i maleje (więc pewnie jest ujemny) dla x < 0. Dla θx < 0jest odwrotnie: błąd e maleje (pewnie jest ujemny) dla x > 0 i rośnie (pewnie jest dodatni) dlax < 0. Powyższa analiza uzasadnia sensowność następującego przypuszczenia: θx powinien byćzmieniany w kierunku przeciwnym do iloczynu ex.
Rozumowanie analogiczne do powyższego ujawnia, że θz powinien być zmieniany w kie-runku przeciwnym do iloczynu ez. Sugeruje to następujący schemat adaptacji
θx = −βexθz = −βez
(11.6)
gdzie β jest pewnym dodatnim parametrem.
Poprawność. Korzystając z formalizmu funkcji Lapunowa pokażemy poprawność schematu ad-aptacji (11.6). Niech mianowicie funkcja Lapunowa ma postać
L(e, θ) =1
2e2 +
1
2βµu(θ
2x + θ2z).

11.1. Liniowy obiekt SISO pierwszego rzędu 119
Mamy wówczas
L = ee+µuβ(θxθx + θz θz)
= ee− µue(θxx+ θzz)
= ee− e(e+ ae)
= −ae2.Okazuje się zatem, że wartość funkcji Lapunowa jest nierosnąca w czasie. Biorąc pod uwagękształt funkcji Lapunowa, oznacza to, że wartości e oraz θ są ograniczone (stosownie do swoichwartości początkowych). Co więcej, ponieważ mamy
L = −2aee,to, biorąc pod uwagę (11.5), L jest ograniczone. Tym samym L jest funkcją jednostajnie cią-głą. A zatem, korzystając z Lematu Barbalata wnioskujemy, że błąd e zbiega do zera. A zatemosiągamy pożądany efekt: trajektoria stanów zbiega do tej wynikającej z modelu i sygnału re-ferencyjnego. Niestety nie musi to prowadzić do zbiegania parametrów sterownika θ do swoichwartości docelowych. Demonstruje to poniższy przykład.
Przykład 11.1.1.
Rozważmy obiekt o dynamicex+ x = 3u,
dla którego modelem referencyjnym jest
xm + 4xm = 4z.
Sterownikiem, który realizuje taki model jest
u =4
3z − x.
Sprawdźmy jak schemat adaptacji (11.6) sprawdza się w tym przypadku. Przyjmiemy następu-jące parametry:
x(0) = θx(0) = θz(0) = 0, β = 2.
Na Rysunku 11.1 przedstawiono przebieg symulacji dla z(t) ≡ 4, natomiast na Rysunku 11.2,dla z(t) = 4 sin(3t). Jak widać, o ile w obu przypadkach błąd e zbiega do zera, to jednak tylkow drugim przypadku znikają także błędy parametrów.
Z powyższego przykładu wynika, że jakkolwiek schemat adaptacji (11.6) może prowadzićdo znikania błędu e = x − xm, wcale nie musi to oznaczać zbieżności parametrów sterownikado ich optymalnych wartości. Porównanie (11.6) z finalnym równaniem (11.5) sugeruje w ja-kich okolicznościach parametry sterownika mogą pozostawać nieoptymalne. Po pierwsze, tempozmiany tych parametrów jest proporcjonalne do błędu e. Jeśli z jakichś względów błąd zbiegaszybciej niż parametry, mogą one w ogóle nie dotrzeć do swoich optymalnych wartości.
Rozważmy co się dzieje dla stałego z. Schemat adaptacji (11.6) stara się (co widać z (11.5))zbliżyć wartość θxx + θzz do zera. Tymczasem dla stałego z oznacza to przybliżenie punktu(θx, θz) do prostej
(θx − θ∗x)x = −(θz − θ∗z)z.Dla stałego z ta prosta nie stoi w miejscu, ponieważ x zmienia się zgodnie z (11.5). Tym nie-mniej, zmiany orientacji tej prostej są coraz mniejsze, dąży ona do pewnego swojego położeniaasymptotycznego. Jednocześnie punkt (θx, θz) dąży do pewnego położenia na tej asymptocie.
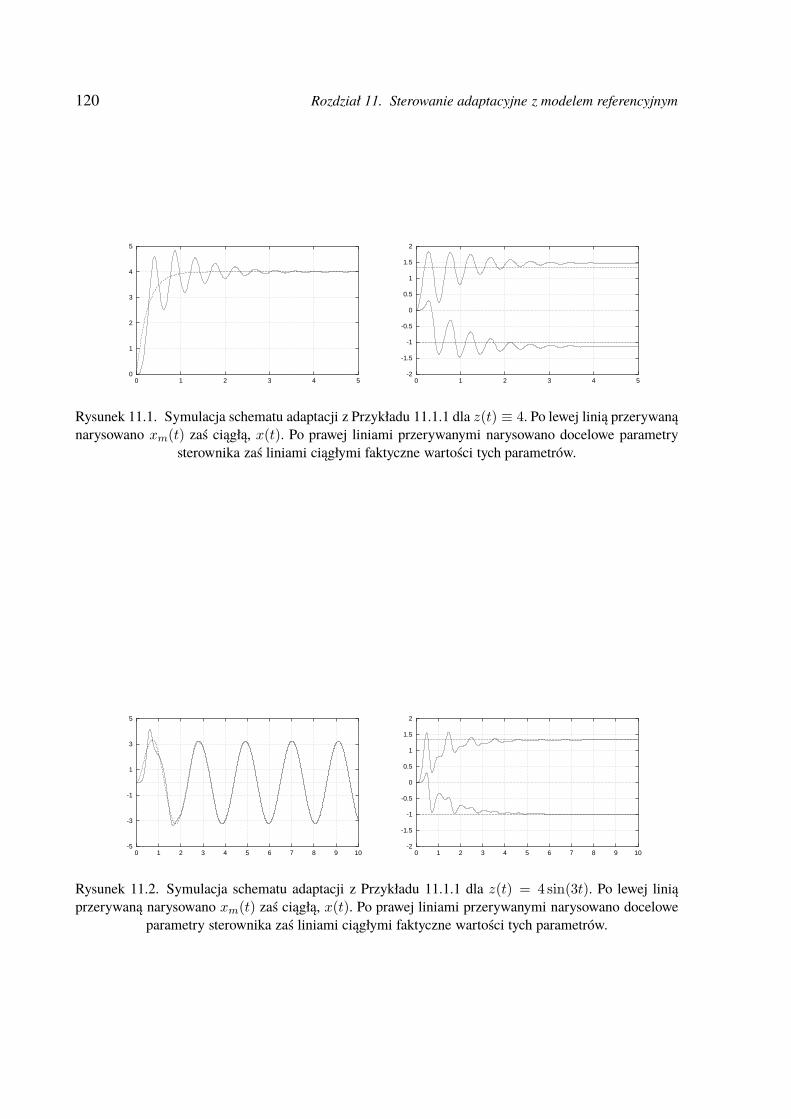
120 Rozdział 11. Sterowanie adaptacyjne z modelem referencyjnym
0
1
2
3
4
5
0 1 2 3 4 5-2
-1.5
-1
-0.5
0
0.5
1
1.5
2
0 1 2 3 4 5
Rysunek 11.1. Symulacja schematu adaptacji z Przykładu 11.1.1 dla z(t) ≡ 4. Po lewej linią przerywanąnarysowano xm(t) zaś ciągłą, x(t). Po prawej liniami przerywanymi narysowano docelowe parametry
sterownika zaś liniami ciągłymi faktyczne wartości tych parametrów.
-5
-3
-1
1
3
5
0 1 2 3 4 5 6 7 8 9 10-2
-1.5
-1
-0.5
0
0.5
1
1.5
2
0 1 2 3 4 5 6 7 8 9 10
Rysunek 11.2. Symulacja schematu adaptacji z Przykładu 11.1.1 dla z(t) = 4 sin(3t). Po lewej liniąprzerywaną narysowano xm(t) zaś ciągłą, x(t). Po prawej liniami przerywanymi narysowano docelowe
parametry sterownika zaś liniami ciągłymi faktyczne wartości tych parametrów.

11.2. Uogólnienie 121
11.2. Uogólnienie
Pomocą dla konstruowania wzorców adaptacji takich jak w poprzedniej sekcji jest następu-jące twierdzenie.
Twierdzenie 11.2.1. Załóżmy, że
— v i φ są wektorowymi funkcjami czasu o tym samym wymiarze wartości,
— k jest pewnym nieznanym skalarem o znanym znaku,
— H(p) jest transmitancją ściśle dodatnio rzeczywistą,
— sygnał e powstaje jako
e = H(p)[kφTv],
— β jest dodatnią stałą,
— φ zmienia się według formuły
φ(t) = −β sign(k)e(t)v(t).
Wtedy e i φ są globalnie ograniczone.
Jeśli dodatkowo v jest ograniczone, wtedy e(t)→ 0 dla t→∞.
Powyższe twierdzenie jest uogólnieniem rozważań z Sekcji 11.1 jeśli pojawiające się w nimsymbole zostaną zinterpretowane w następujący sposób:
φ = θ
v = [x, z]T
k = µu
H(p) =1
p+ a.
Warto prześledzić szkic dowodu Twierdzenia 11.2.1, ponieważ demonstruje bardzo dobrzesposób konstrukcji i uzasadnienia szeregu schematów adaptacji podobnych do opisywanegow Sekcji 11.1. Punktem wyjścia do dowodu jest poniższy techniczny lemat.
Lemat 11.2.2. (Kallman-Jakubowicz) Niech dynamika obiektu liniowego o transmitancjiH(p)ma postać kanoniczną (vide (9.18) i (9.19))
~x0 = A~x0 + bu
x = cT~x0.
TransmitancjaH(p) jest ściśle dodatnio rzeczywista wtedy i tylko wtedy, gdy dla każdej dodatnio
określonej macierzy Q istnieje dodatnio określona macierz P taka, że
ATP + PA = −QPb = c.
(11.7)
Dowód powyższego lematu można znaleźć np. w [29].A zatem, dowodząc Twierdzenie 11.2.1 przedstawiamy dynamikę sygnału e w postaci
~x0 = A~x0 + b[kφTv]
e = cTx0.

122 Rozdział 11. Sterowanie adaptacyjne z modelem referencyjnym
Dla macierzy A, wektorów b, c i dowolnej dodatnio określonej macierzy Q istnieje równieżdodatnio określona macierz P spełniająca (11.7). Określmy kandydatkę na funkcję Lapunowaw postaci
L(~x0, φ) = ~xT
0P~x0 +|k|βφTφ. (11.8)
Mamy wówczas
L = ~xT
0P~x0 + ~xT
0P~x0 +|k|β(φTφ+ φT φ)
= ~xT
0 (PA+ ATP )~x0 + 2xT
0Pb(kφTv)− 2φT (kev)
= −~xT
0Q~x0 ≤ 0.
A zatem wartość funkcji L nie rośnie w czasie, czyli jest to faktycznie funkcja Lapunowa. Stądwynika pierwsza część tezy Twierdzenia 11.2.1: ograniczone są składnikiL, a zatem ograniczo-ne są φ oraz ~x0 (czyli także e).
Pozostała część tezy twierdzenia wynika z Lematu Barbalata 10.4.2. A mianowicie drugapochodna
L = −2~xT
0Qx0
jest ograniczona z racji tego, że ograniczone są ~x0 i, w konsekwencji, także~x0. A zatem, funkcjaL = −~xT
0Q~x0 jest jednostajnie ciągła. Ponieważ L musi zbiegać, Lemat Barbalata stanowi, żeL musi zbiegać do zera, ale w takim razie zbiega tam także e(t).
Dysuksja
Pewne elementy powyższego dowodu Twierdzenia 11.2.1 są typowe dla konstrukcji i uza-sadniania poprawności szerokiej klasy schematów adaptacji:1. Punktem wyjścia jest równanie różniczkowe błędu śledzenia (rozbieżności między faktycz-
nym stanem faktycznym i wynikającym z modelu i sygnału referencyjnego).2. W równaniu tym pojawiają się błędy parametrów (odpowiadające wektorowi φ).3. Konstruowana jest funkcja Lapunowa, która jest sumą dwóch form kwadratowych, pierwsza
z nich jest związana z błędem śledzenia, natomiast druga z błędem parametrów.4. Pochodna funkcji Lapunowa po czasie okazuje się jednostajnie ciągła, co implikuje zbież-
ność błędu śledzenia do zera.Twierdzenia 11.2.1 będzie szeroko wykorzystywane w Rozdziale 12. Tymczasem, realizującpowyższe wytyczne, skonstruujemy schemat adaptacji dla szerokiej klasy sterowników.
11.3. Obiekty liniowe wyższych rzędów
Obiekt. Rozważmy obiekt liniowy rzędu n, którego dynamika opisywana jest równaniem
µnx(n) + µn−1x
(n−1) + · · ·+ µ0x = u.
czylin∑
i=0
µix(i) = u.
Zakładamy, że wektor współczynników µ = [µ0, . . . , µn]T jest nieznany, wiadomo jedynie, że
µn > 0. Przyjmujemy ponadto założenie istotne z punktu widzenia sterownika: obserwowalnesą wartości x(i) dla i = 0, . . . , n− 1, zaś wartość x(n) pozostaje nieobserwowalna.

11.3. Obiekty liniowe wyższych rzędów 123
Przykładem obiektu tego typu jest kulka na sprężynie o liniowej dynamice postaci
mx+ cx+ kx = u.
Model referencyjny. Niech dla parametrów α0, α1, . . . , αn transmitancja
1∑ni=0 αip
i(11.9)
będzie ściśle stabilna. Model referencyjny definiujemy jako
n∑
i=0
αix(i)m = z.
Powyższe wymaganie, aby transmitancja (11.9) była ściśle stabilna staje się oczywiste, jeślioznaczymy przez Xm transmitancję sygnału xm, zaś Z będzie transmitancją sygnału referen-cyjnego z. Mamy wówczas
Xm(p) =1∑n
i=0 αipiZ(p).
Wymóg stabilności transmitancji przekłada się ona żądanie aby ograniczonym wartościom zodpowiadały ograniczone wartości xm.
W tym przypadku, poza modelem referencyjnym wyspecyfikujemy także sposób zanikaniabłędu przy optymalnym sterowaniu. Niech mianowicie dla parametrów β0, β1, . . . , βn−1, trans-mitancja
1
pn +∑n−1
i=0 βipi
(11.10)
będzie ściśle stabilna. Oznaczmy standardowo
e = x− xm.Wymagamy, aby przy idealnym sterowaniu dynamika błędu e była opisywana równaniem róż-niczkowym
e(n) +
n−1∑
i=0
βie(i) = 0. (11.11)
Ścisła stabilność transmitancji (11.10) oznacza zanikanie błędu w czasie, jeśli taki się pojawi.Postulat ten wynika stąd, że błąd jest niezerowy przynajmniej na początku procesu sterowania.
Sterownik. Zdefiniujmy parametry sterownika θ0, . . . , θn. Będą one odpowiadały parametromobiektu µ0, . . . , µn. Celem adaptacji będzie zrównanie parametrów, θi ≡ µi. Wartości sterowa-nia obliczane są jako
u = θnx(n)m +
n−1∑
i=0
θix(i) − θn
n−1∑
i=0
βie(i).
Powyższy sterownik jest w istocie skonstruowany w taki sposób, aby zastępował dynamikęobiektu dynamiką modelu referencyjnego. Zobaczmy, co się dzieje dla µi ≡ θi:
n∑
i=0
µix(i) = µnx
(n)m +
n−1∑
i=0
µix(i) − µn
n−1∑
i=0
βie(i)
µn(x(n) − x(n)m ) + µn
n−1∑
i=0
βie(i) = 0,

124 Rozdział 11. Sterowanie adaptacyjne z modelem referencyjnym
co po podzieleniu przez µn (które jest niezerowe), daje dokładnie (11.11).
Schemat adaptacji. Konstrukcję schematu adaptacji dla analizowanego sterownika rozpoczy-namy tak jak w Sekcji 11.1, czyli od wyprowadzenia dynamiki błędu e jako funkcji błędu para-metrów sterownika. Mamy
n∑
i=0
µix(i) = θnx
(n)m +
n−1∑
i=0
θix(i) − θn
n−1∑
i=0
βie(i)
µnx(n) + µn
n−1∑
i=0
βie(i) = θnx
(n)m +
n−1∑
i=0
(θi − µi)x(i) + (θn − µn)(−1)n−1∑
i=0
βie(i)
µn
(e(n) +
n−1∑
i=0
βie(i)
)=
n−1∑
i=0
(θi − µi)x(i) + (θn − µn)(x(n)m −
n−1∑
i=0
βie(i)
)
czyli
µn
(e(n) +
n−1∑
i=0
βie(i)
)= θT~v (11.12)
dla
θ =
θ0 − µ0
...θn − µn
~v =
x...
x(n−1)
x(n)m −
∑n−1i=0 βie
(i)
.
W zasadzie więc dynamika błędu daje się wyrazić w postaci
e = H(p)[kφTv],
co sugeruje zastosowanie Twierdzenia 11.2.1. Niestety transmitancjaH(p)ma w tym przypadkupostać (11.10), czyli w ogólności nie jest ściśle rzeczywisto dodatnia. Musimy więc posłużyćsię innymi środkami.
Konstruując schemat adaptacji postarajmy się najpierw odgadnąć funkcję Lapunowa dla tegoproblemu. Równanie (11.12) możemy także zapisać w postaci
~e(t) = A~e(t) + (1/µn)bθ(t)T~v(t) (11.13)
dla
~e =
e...
e(n−1)
A =
0 1 0 · · · 00 0 1 · · · 0...
......
. . ....
0 0 0 · · · 1−β0 −β1 −β2 · · · −βn−1
b =
00...01
W Rozdziale 10 udało nam się skonstruować funkcję Lapunowa z dwóch niezależnych składni-ków: odpowiadającego błędowi śledzenia e i odpowiadającego błędowi parametrów. Spróbujmypowtórzyć tę sztukę tutaj. Niech mianowicie kandydatka na funkcję Lapunowa ma postać
L(~e, θ) = ~e TP~e+ (1/µn)θTΓθ

11.3. Obiekty liniowe wyższych rzędów 125
dla pewnych symetrycznych dodatnio określonych macierzy P oraz Γ. Różniczkując powyższerównanie i wykorzystując (11.13) dostajemy
L = ~e TP~e+ ~eT
P~e+ (1/µn)θTΓθ + (1/µn)θ
TΓθ
= ~e T (PA+ ATP )~e+ (2/µn)~eTPbθT~v + (2/µn)θ
TΓθ
Mamy powyżej L złożone z trzech elementów. Dobierając odpowiednieP sprawimy, aby pierw-szy z nich był nieujemny, natomiast suma pozostałych była równa zeru. Pierwszy cel osiągamyposługując się Twierdzeniem 10.4.4. Mówi ono, że w tym przypadku dla każdej dodatnio okre-ślonej macierzy Q rozwiązanie P równania
PA+ ATP = −Q
jest macierzą dodatnio określoną. Wybieramy więc P zadając najpierw dowolne dodatnio okre-ślone Q. Cel drugi osiągamy zadając
θ = −Γ−1~v~e TPb.
Mamy bowiem
~e TPbθT~v + θTΓθ
= ~e TPbθT~v − θTΓΓ−1~v~e TPb
= (θT~v)~e TPb− (θT~v)~e TPb
= 0.
Ostatecznie więc dostajemyL = −~e TQ~e,
co czyni z L funkcję Lapunowa i sprawia, że e dąży do zera.


Rozdział 12
Zaawansowane schematy adaptacji
W niniejszym rozdziale kontynuujemy omówienie metod sterowania z modelem refencyj-nym, tym razem jednak zarówno dynamika sterowanych obiektów, jak i metody adaptacji będąbardziej wyrafinowane.
12.1. Obiekty o nieliniowej dynamice
Obiekt. W tej sekcji przeanalizujemy zagadnienie adaptacyjnego sterowania obiektem o dyna-mice opisanej równaniem
µnx(n) +
n−1∑
i=0
µifi(~x) = u (12.1)
gdzie n > 0, wektor ~x = [x, x, · · · , x(n−1)]T jest znany w każdej chwili t. O parametrach µiwiadomo tylko tyle, że µn 6= 0 i znamy znak µn. Znane są także postaci funkcji fi, które sąciągłe, choć niekoniecznie liniowe. A zatem, zajmujemy się obiektami nieliniowymi, ale liniowoparametryzowalnymi.
Przykładem takiego obiektu może być kulka na sprężynie o nieliniowej charakterystyce
mx+ cf1(x) + kf0(x) = u,
gdzie kf0 to siła sprężystości nieliniowo zależna od położenia kulki x, natomiast cf1 to siła oporunieliniowo zależna od prędkości.
Cel sterowania. W dotychczas analizowanych zagadnieniach celem sterowania było skłonieniestanu obiektu do podążania za sygnałem xm wynikającym z modelu referencyjnego oraz sygnałureferencyjnego. Obecnie pominiemy zarówno sygnał, jak i model referencyjny i przyjmiemy, żesygnał xm jest w chwili t dany wraz z n − 1 pierwszymi pochodnymi. Celem sterowania jestpodążanie stanu obiektu x za sygnałem xm.
W chwili kiedy pojawia się niezerowa rozbieżność e = x − xm między stanem obiektu asygnałem xm, chcemy aby zbiegała ona do zera. Cel ten wyspecyfikujemy w następujący sposób.Niech mianowicie dla parametrów α0, . . . , αn−2 transmitancja
1
pn−1 +∑n−2
i=0 αipi
(12.2)
będzie ściśle stabilna. Chcemy, aby wartość zagregowanego błędu
d = e(n−1) +
n−2∑
i=0
αie(i)

128 Rozdział 12. Zaawansowane schematy adaptacji
zbiegała do zera wykładniczo, jeśli w pewnym momencie t będzie ona niezerowa. Ścisła stabil-ność transmitancji (12.2) gwarantuje, że znikanie d będzie pociągało za sobą znikanie e(i) dlai = 0, . . . , n− 1.
Sterowanie. Sterownik dla naszego obiektu oparty jest na n + 1 adaptowalnych parametrachθ0, . . . , θn. Będą one adaptowane w taki sposób, aby zbiegały do odpowiednich parametrówobiektu µ0, . . . , µn, czyli chcemy, aby θi ≡ µi. Sterowanie ma postać
u = θn(x(n) − d)− kd+
n−1∑
i=0
θifi(~x) (12.3)
dla pewnego k o takim znaku jak µn. Zobaczmy, czy równoważność θi ≡ µi faktycznie gwaran-tuje osiągnięcie celu sterowania. Z równości
µnx(n) +
n−1∑
i=0
µifi(~x) = u = µn(x(n) − d)− kd+
n−1∑
i=0
µifi(~x)
mamyµnd+ kd = 0
a to oznacza właśnie wykładniczy zanik zagregowanego błędu d.Ze sterownikiem (12.3) związany jest pewien problem implementacyjny. Sterowanie zależy
od wartości x(n) oraz d, których nie znamy. Zwróćmy jednak uwagę, że
x(n) − d =(x(n)m + e(n)
)−(e(n) +
n−2∑
i=0
αie(i+1)
)= x(n)m −
n−2∑
i=0
αie(i+1).
A zatem sterowanie (12.3) jest możliwe do obliczenia na podstawie znanych wartości.
Adaptacja. Poszukując schematu adaptacji dla dyskutowanego problemu przeanalizujemy za-leżność między dynamiką zagregowanego błędu d, a błędami parametrów sterownika. Oznacza-jąc θi = θi − µi dostajemy z (12.2) i (12.3)
µnx(n) +
n−1∑
i=0
µifi(~x) = u = θn(x(n) − d)− kd+
n−1∑
i=0
θifi(~x)
µnx(n) = θn(x
(n) − d)− kd+n−1∑
i=0
θifi(~x)
µn(x(n) − d) + µnd = θn(x
(n) − d)− kd+n−1∑
i=0
θifi(~x),
co ostatecznie prowadzi do wyniku
µnd+ kd = θn(x(n) − d) +
n−1∑
i=0
θifi(~x). (12.4)
Powyższe równanie można także zapisać jako
d = H(p)1
k
[θn(x
(n) − d) +n−1∑
i=0
θifi(~x)
](12.5)

12.2. Obiekty z nieobserwowalnymi pochodnymi stanu 129
gdzie
H(p) =k/µn
p+ k/µn.
Ponieważ powyższa transmitancja H(p) jest ściśle dodatnio rzeczywista, możemy skorzystaćz Twierdzenia 11.2.1. Wynika z niego bezpośrednio schemat adaptacji dla naszego problemu,a mianowicie
θi = −β sign(µn)dfi(~x), i = 0, . . . , n− 1
θn = −β sign(µn)d(x(n) − d)(12.6)
dla pewnej dodatniej wartości β.Przeanalizujemy teraz poprawność schematu adaptacji (12.6). W tym celu rozważymy kan-
dydatkę na funkcję Lapunowa postaci
L(d, θ) = |µn|d2 +1
β
n∑
i=0
θ2i .
Znajdując pochodną tej funkcji po czasie, odwołamy się do (12.6) a następnie do (12.4)
L = 2|µn|dd+1
β
n∑
i=0
θiθi
= 2|µn|dd− 2 sign(µn)d
(n−1∑
i=0
θifi(~x) + θn
(x(n) − d
))
= 2|µn|dd− 2 sign(µn)d(µnd+ kd
)
= −2|k|d2.A zatem, nasza kandydatka na funkcję Lapunowa nie zwiększa swojej wartości w czasie, conatychmiast prowadzi do wniosku, że d2 oraz θ2i są ograniczone. Sprawdźmy jeszcze drugą po-chodną funkcji L po czasie. Ponownie posłużymy się wynikiem (12.4)
L = −4|k|dd
= −4|k|d 1
θn
(−kd+ θn +
n−1∑
i=0
θifi(~x)
).
Poprzestaniemy na pokazaniu lokalnej stabilność asymptotycznej schematu adaptacji (12.6).Niech mianowicie d(0) i θ(0) będą dobrane w taki sposób, że
L(d(0), θ(0)) < µ2n/β.
W takim razie istnieje taka wartość ǫ > 0, że zawsze zachodzi |θn| < |µn| − ǫ i wobec tego|θn| > ǫ. Dlatego L jest funkcją ograniczoną i, zgodnie z Lematem Barbalata, L zbiega do zera.To zaś oznacza, że d zbiega do zera.
12.2. Obiekty z nieobserwowalnymi pochodnymi stanu
W niniejszej sekcji przeanalizujemy obiekty o dynamice, którą charakteryzuje równanie
x(n) +
n−1∑
i=0
aix(i) = bmu
(m) + bm
m−1∑
j=0
bju(j).

130 Rozdział 12. Zaawansowane schematy adaptacji
Jest to ekwiwalent równania ogólnego obiektu SISO (9.6), w którym parametry bi zostały, dlai = 0, . . . , m − 1, zastąpione przez bi/bm. Przyjmiemy jednak założenie, iż z wektora ~x =[x, x, · · · , x(n−1)]T obserwowalna jest jedynie wartość x. Oczywiście kapitalnie utrudnia to ste-rowanie takim obiektem. Dla równowagi ograniczymy się jedynie do obiektów, których względ-ny rząd wynosi 1 czyli m = n − 1. Konstruowanie sterowników dla obiektów o wyższym rzę-dzie względnym jest także możliwe, jednak zagadnienie to wykracza ono poza ramy niniejszegoskryptu.
Celem sterowania jest naśladowanie modelu referencyjnego dokładnie tego rzędu i rzęduwzględnego co sam obiekt, a mianowicie
x(n)m +n−1∑
i=0
cix(i)m = dmz
(m) + dm
m−1∑
j=0
djz(j).
Na powyższy model referencyjny nakłada się następujące wymaganie, otóż transmitancja
Hm(p) = dmpm +
∑m−1j=0 djp
j
pn +∑n−1
i=0 cipi
musi być ściśle dodatnio rzeczywista.
Obiekty drugiego rzędu
Obiekt. Rozważamy obiekty o dynamice
x+ a1x+ a0 = b1(u+ b0u).
Realizuje on transmitancję
Ho(p) = b1p+ b0
p2 + a1p+ a0.
Model referencyjny jest w tym przypadku postaci
xm + c1xm + c0 = d1(z + d0z),
czyli realizuje transmitancję
Hm(p) = d1p+ d0
p2 + c1p+ c0.
Sterownik. Ponieważ sterowanie dla naszego obiektu musi realizować model referencyjny po-sługując się jedynie x, może być cokolwiek nietrywialne. Rozważmy sterownik postaci
u =θu
p+ d0u+
θx1p+ θx0p+ d0
x+ θzz. (12.7)
Jest on, wraz z obiektem, przedstawiony na Rysunku 12.1. Zostawiając na później dyskusjęo realizacji takiego sterownika, wyznaczmy parametry θu, θu1, θu0, θz, dla których realizuje onmodel referencyjny.
Dla oznaczeń z Rysunku 12.1 rozważmy w jaki sposób sygnał u4 zamieniany jest na x. Trans-mitancja tego przekształcenia jest równa
Hu4x(p) =p+ b0
p+ d0 − θuHo(p) =
p+ d0p+ d0 − θu
b1(p+ b0)
p2 + a1p + a0.

12.2. Obiekty z nieobserwowalnymi pochodnymi stanu 131
Rysunek 12.1. Obiekt drugiego rzędu z nieobserwowalnymi pochodnymi stanu i jego sterownik.
A zatem, dla θu równegoθu = θ∗u = d0 − b0,
otrzymujemy
Hu4x(p) =b1(p + b0)
p2 + a1p+ a0,
co oznacza, że zera licznika transmitancji Ho są zastępowane przez zera licznika transmitancjiHm. Przyjmując θu = θ∗u rozważmy w jaki sposób sygnał u3 zamieniany jest na x. A mianowicie
Hu3x(p) =Hu4x(p)
1− θx1p+θx0p+d0
Hu4x(p)=
b1(p+ d0)
p2 + (a1 − b1θx1)p+ (a0 − b1θx0).
Oznacza to, że dla θx1 i θx0 spełniających
c1 = a1 − b1θx1, c0 = a0 − b1θx0zera mianownika transmitancji obiektu zostają podmienione na zera mianownika transmitancjimodelu referencyjnego. Oznaczmy θx1 i θx0 spełniające powyższe równania przez odpowiednioθ∗x1 i θ∗x0, czyli
θ∗x1 =a1 − c1b1
, θ∗x0 =a0 − c0b1
.
Ostatecznie, zbadajmy w jaki sposób sygnał referencyjny jest transformowany na stan obiek-tu. Przyjmując θx1 = θ∗x1 i θx0 = θ∗x0 otrzymujemy
Hzx(p) = θzHu3x(p) =θzb1(p+ d0)
p2 + c1p+ c0.
A zatem, dla θz równegoθ∗z = c1/b1
dostajemy ostatecznieHzx(p) = Hm(p).
W jaki sposób realizować sterowanie (12.7)? Na pierwszy rzut oka odwołuje się ono dowartości x, która jest przecież niemierzalna. Można jednak zauważyć, że
u = u1 + u′2 + u′′2 + u3

132 Rozdział 12. Zaawansowane schematy adaptacji
Rysunek 12.2. Dwie postaci systemu równoważnego systemowi z Rysunku 12.1.
dla
u1 =θu
p+ d0u, u′2 = θx1x, u′′2 =
θx0 − θx1d0p+ d0
x, u3 = θzz.
Wartości sygnałów u′2 i u3 są oczywiste, natomiast u1 i u′′2 można śledzić na podstawie równań
d
dtu1(t) = θuu(t)− d0u1(t),
d
dtu′′2(t) = (θx0 − θx1d0)x(t)− d0u′′2(t).
Schemat adaptacji. Jak zwykle, zmierzając do schematu adaptacji będziemy chcieli znaleźćdynamikę błędu śledzenia modelu referencyjnego jako funkcję błędów parametrów. Oznaczmy
θ =
θuθx1θx0θz
, θ∗ =
θ∗uθ∗x1θ∗x0θ∗z
, θ = θ − θ∗, v =
vuvx1vx0vz
=
u/(p+ d0)xp/(p+ d0)x/(p+ d0)
z
.
Przy takich oznaczeniach możemy zapisać sterowanie (12.7) jako
u = θTv = (θ∗)Tv + θTv.
Tym samym, system z Rysunku 12.1 możemy narysować jako system z idealnymi parametramiθ∗, do którego w odpowiednie miejsca dodawane są elementy sumy θTv. Elementy te możnaprzeskalować i wpisać na wejście systemu. System z Rysunku 12.1 staje się równoważny syste-mom z Rysunku 12.2. Okazuje się zatem, że aby uzyskać sygnał x, możemy poddać zmodyfiko-wany sygnał referencyjny z+ θTv/θ∗z działaniu systemu z idealnymi parametrami θ∗. Ale systemz idealnymi parametrami równoważny jest modelowi referencyjnemu. A zatem
x = Hm(p)(z + θTv/θ∗z),
ale przecieżxm = Hm(p)z.

12.2. Obiekty z nieobserwowalnymi pochodnymi stanu 133
Rysunek 12.3. Obiekt n-tego rzędu z nieobserwowalnymi pochodnymi stanu i jego sterownik.
Tym samym równanie
e = x− xm = Hm(p)1
θ∗zθTv
realizuje wszystkie postulaty Twierdzenia 11.2.1. Otrzymujemy stąd schemat adaptacji postaci
θ = −β sign(θ∗z)ev,
w którym β to pewna dodatnia stała.
Obiekty dowolnego rzędu
Przedstawiony powyżej mechanizm można uogólnić do obiektów rzędu n jak przedstawionona Rysunku 12.3. Niech ω1 ∈ R
n−1 zmienia się w czasie według formuły
ω1 = Λω1 + hu,
w której Λ jest macierzą (n−1)× (n−1), zaś h jest wektorem (n−1)-elementowym. Zmiennau1 jest obliczana jako θT
uω1, stąd θu ∈ Rn−1. Zadaniem podsystemu (θu,Λ, h) jest zastąpić zera
licznika transmitancji obiektu przez zera licznika transmitancji modelu referencyjnego. Aby tobyło możliwe, podsystem (Λ, h) musi być sterowalny oraz Λ musi spełniać
det[pI − Λ] = pm +m−1∑
i=0
djpj .
Wektor ω2 ∈ Rn−1 zmienia się w czasie podobnie jak ω1, tylko zmiany te są stymulowane przez
inne wejście, a mianowicieω2 = Λω2 + hx.
Zadaniem podsystemów (θx1,Λ, h) oraz (θx0) jest zastąpienie zer mianownika transmitancjiobiektu przez zera mianownika transmitancji modelu referencyjnego. Stała θz zapewnia odpo-wiednie skalowanie sygnału referencyjnego.
Przyjmijmy oznaczenia
θ =
θuθx1θx0θz
, θ∗ =
θ∗uθ∗x1θ∗x0θ∗z
, φ = θ − θ∗, ω =
ω1
ω2
xz
,

134 Rozdział 12. Zaawansowane schematy adaptacji
w których θ∗ jest takim kompletem parametrów sterownika, dla którego realizuje on dokładnieswoje powołanie. Dalsze rozumowanie przebiega identycznie jak poprzednio: mamy
u = θTv = (θ∗)Tv + θTv.
Aby uzyskać sygnał x, możemy poddać zmodyfikowany sygnał referencyjny z+φTv/θ∗z działa-niu systemu z idealnymi parametrami θ∗. Ale system z idealnymi parametrami równoważny jestmodelowi referencyjnemu. A zatem
x = Hm(p)(z + θTv/θ∗z),
ale przecieżxm = Hm(p)z.
Tym samym równanie
e = x− xm = Hm(p)1
θ∗zφTω
realizuje wszystkie postulaty Twierdzenia 11.2.1. Otrzymujemy zatem schemat adaptacji
θ = −β sign(θ∗z)eω,
w którym β to pewna dodatnia stała.

Rozdział 13
Samostrojące się regulatory
Konstrukcję i sposób działania samostrojących się regulatorów można streścić w następują-cych punktach.1. Dany jest system o dynamice danej równaniami stochastycznymi, przy czym nieznane są
pewne stałe w tych równaniach.2. Konstruujemy sterownik parametryzowany przez stałe z równań dynamiki obiektu.3. W trakcie działania systemu stałe te są estymowane.4. Akcje sterujące są obliczane przez sterownik, przy czym jego parametry przyjmują wartości
estymat stałych parametrów równań dynamiki.Warto zwrócić uwagę, że istotnym założeniem dla wszystkich dotychczas rozważanych schema-tów adaptacji było istnienie idealnego sterownika dla ustalonych parametrów obiektu. Wymaga-nie wstępne postawione na początku Rozdziału 10 głosi, że istnieje taki sterownik parametryzo-wany przez θ, że dla każdego parametru obiektu µ istnieje parametr sterownika θµ powodującyoptymalne jego działanie. W dyskutowanym teraz podejściu to wymaganie jest zachowane. Me-chanizm adaptacji jest tu ideowo bardzo prosty: dynamika obiektu jest obserwowana w trakciesterowania, na podstawie obserwacji wyznaczana jest estymata µ parametru obiektu, zaś sterow-nik posługuje się parametrem θµ.
Takie podejście do adaptacji, zwane w literaturze samostrojeniem się regulatorów (ang.Self-Tuning Regulators, STR), zostało sformułowane przed wszystkimi dotychczas omawiany-mi schematami adaptacji. Nic dziwnego, jest ono intuicyjnie niemal oczywiste: skoro potrafimykonstruować sterowniki na podstawie znanego modelu obiektu, to możemy estymować model “wlocie” i posługiwać się sterownikiem, który przyjmuje estymatę modelu jako właściwy model.
Mimo prostoty schematów adaptacji opartych na samostrojącej się regulacji, dowodzenie ichpoprawności jest znacznie trudniejsze niż w przypadku sterowania adaptacyjnego z modelem re-ferencyjnym, omówionego w dwóch poprzednich rozdziałach. Niedoskonałość procesu sterowa-nia wynika tu bowiem z niedobrej znajomości parametrów obiektu. Wartości tych parametrówwynikają z estymacji, która może być prowadzona rozmaitymi metodami. Co więcej, jakośćtej estymacji zależy od sterowania, które (tu pętla się zamyka) zależy od estymat parametrówobiektu. Dlatego poniżej nie będziemy zajmowali się dowodzeniem poprawności schematówadaptacji, natomiast skoncentrujemy się na wydajnych metodach estymacji.
13.1. Dynamika liniowo parametryzowalna
Założymy, że pewne obserwowalne w obiekcie wartości, “wyjścia” y ∈ Rny są związane z
“wejściami” w ∈ Rny×nw , równaniem1
y(t) = w(t)µ, (13.1)
1 Jest to zależność liniowa względem parametrów, a zatem jej postać jest dokładnie taka jak stosowana dodefiniowania aproksymatorów liniowych (2.2).

136 Rozdział 13. Samostrojące się regulatory
w którym µ ∈ Rnw jest wektorem parametrów dynamiki obiektu, który jest początkowo niezna-
ny i który chcemy poznać. Tak określonych wejść i wyjść obiektu nie należy utożsamiać z jegosterowaniem i stanem; nie zawsze tak musi być, co pokazuje następujący przykład.
Przykład 13.1.1.
Rozważmy obiekt liniowy pierwszego rzędu
x = ax+ bu.
Jeśli x nie jest wielkością obserwowalną, to powyższe równanie nie może być w oczywistysposób przekształcone do (13.1). Poddajmy jednak obie jego strony działaniu filtru dolnoprze-pustowego, λ/(p+ λ). Mamy wówczas
λpx
p+ λ=
λax
p+ λ+
λbu
p+ λ
λ(p+ λ)x
p+ λ= (a+ λ)
λ
p+ λx+ b
λ
p+ λu.
Dostajemy więc równanieλx = (a+ λ)xλ + buλ,
w którymuλ i xλ to przefiltrowane, odpowiednio,u i x. Powyższe równanie jest już postaci (13.1)dla wejścia [xλ, uλ], wyjścia [λx], oraz parametru µ = [a+λ, b]T . Jest jasne, że po wyznaczeniuµ, łatwo określić a oraz b.
Istnieją bardzo efektywne techniki estymacji parametrów równań postaci (13.1). Niektó-re z nich omówimy poniżej. Niestety, nie każde równanie opisujące dynamikę obiektu da sięsprowadzić do takiej właśnie, liniowo parametryzowalnej postaci. Na szczęście jest to możliwew przypadku liniowych obiektów SISO będących uogólnieniem Przykładu 13.1.1. Rozważmyrównanie postaci
xA(p) = uB(p) (13.2)
gdzie
A(p) = pn +
n−1∑
i=0
aipi,
B(p) =n−1∑
i=0
bipi.
Poszukujemy możliwości wyestymowania nieznanych parametrów ai, bi, i = 0, . . . , n − 1. Wtym celu określmy
A0(p) = pn +
n−1∑
i=0
αipi,
w taki sposób, aby transmitancjaA0(p)−1 była stabilna. PonieważA0(p)
−1 jest iloczynem czyn-ników postaci (9.20) i (9.21) z Sekcji 9.2, sygnały
u0 = u/A0(p)
x0 = x/A0(p)

13.2. Liniowe najmniejsze kwadraty 137
są możliwe do śledzenia wraz z ich pochodnymi czasowymi do rzędu n−1, nawet jeśli pochodneczasowe u oraz x są niemierzalne. Obie strony równania (13.2) można podzielić przezA0, dodaćdo nich x, i przekształcić do
x = x(A0(p)−A(p))/A0(p) + uB(p)/A0(p)
= x0(A0(p)− A(p)) + u0B(p)
i ostatecznie do postaci (13.1) dla
y(t) = x(t)
w(t) = [x0, x0, . . . , x(n−1)0 , u0, u0, . . . , u
(n−1)0 ],
µ = [α0 − a0, α1 − a1, . . . , αn−1 − an−1, b0, b1, . . . , bn−1]T .
13.2. Liniowe najmniejsze kwadraty
Celem przedstawionej poniżej metody jest znalezienie przybliżonej wartości wektora µ speł-niającego równanie
y(r) = w(r)µ, r ∈ [0, t] (13.3)
czyli dla przebiegów y(r) oraz w(r) zarejestrowanych do pewnej chwili t > 0. Z uwagi nafakt, że modele na ogół nie odpowiadają w sposób doskonały rzeczywistości, a pomiary nie sąnieskończenie dokładne, to znalezienie µ spełniającego (13.3) dla każdego r ∈ [0, t] nie jestmożliwe. Możliwe jest jednak znalezienie takiego oszacowania µ parametru µ, które w przybli-żeniu spełnia równanie (13.3) dla wszystkich interesujących r. Zdefiniujmy to oszacowanie jakotakie, które minimalizuje wskaźnik błędu postaci
ǫt(µ) =
∫ t
0
‖y(r)− w(r)µ‖2dr.
Rozpisanie kwadratu pod całką ujawnia, że ǫt jest formą kwadratową µ, a mianowicie
ǫt(µ) =
∫ t
0
(y(r)Ty(r)− 2y(r)Tw(r)µ+ µTw(r)Tw(r)µ
)dr
=
∫ t
0
y(r)Ty(r)dr − 2
(∫ t
0
y(r)Tw(r)dr
)µ+ µT
(∫ t
0
w(r)Tw(r)dr
)µ.
A zatem funkcja ta osiąga minimum tam, gdzie jej gradient zeruje się, czyli gdy
0 =∂
∂µTǫt = −2
∫ t
0
w(r)Ty(r)dr + 2
(∫ t
0
w(r)Tw(r)dr
)µ.
Oznaczmy
S(t) = S(0) +
∫ t
0
w(r)Ty(r)dr (13.4)
P (t) =
(P (0)−1 +
∫ t
0
w(r)Tw(r)dr
)−1
(13.5)
i przyjmijmy na początek, że wektor S(0) i macierz P (0)−1 są zerowe. Wówczas wektor µ(t)spełniający
P (t)−1µ(t) = S(t) (13.6)

138 Rozdział 13. Samostrojące się regulatory
minimalizuje ǫt. Będziemy stosowali powyższą definicję także dla ogólnych wartości S(0) iP (0). Wyznaczanie P (t) bezpośrednio z definicji byłoby kłopotliwe ze względu na koniecznośćciągłego odwracania macierzy P−1. Poszukajmy formuł pozwalających aktualizować µ(t) orazP (t)−1 na podstawie danych z chwili t. Oznaczmy w tym celu przez e(t) bieżący błąd, czyli
e(t) = w(t)µ(t)− y(t).
Przez zróżniczkowanie S oraz P ze względu na czas, bezpośrednio z definicji tych wielkościdostajemy
S = wTy,
d
dt[P−1] = wTw.
Różniczkując (13.6) po czasie dostajemy więc
d
dt[P−1]µ+ P−1 ˙µ = S = wTy,
P−1 ˙µ = wTy − wTwµ = wT (y − wµ) = −wTe
˙µ = −PwTe.
Pochodną P znajdziemy dzięki następującej sztuczce
0 =d
dt[PP−1] = PP−1 + P
d
dt[P−1] = PP−1 + PwTw,
z której wynika, żePP−1 = −PwTw.
Mamy zatem
P = −PwTwP
˙µ = −PwTe(13.7)
Aby posługiwać się powyższą rekurencją od początku procesu sterowania (od chwili t = 0), na-leży przyjąć pewne wartości µ(0) oraz P (0). Prostym i skutecznym rozwiązaniem jest przyjęcieµ(0) jako pewnego wstępnego oszacowania właściwego parametru µ oraz
P (0) = (τW )−1
gdzie W jest dodatnio określoną macierzą wyrażającą średnią, domniemaną przez projektan-ta wartością wTw, zaś τ > 0 to stała czasowa. Tak ustalone µ(0) oraz P (0) imituje sytuacjępolegającą na tym, że przez czas o długości τ zbierane są przebiegiw, y, z których wynika osza-cowanie µ(0) oraz macierz P . Wartość τ powinna być tym większa, im większe jest zaufanieprojektanta do wstępnego oszacowania µ(0). Im większa jest bowiem ta wartość tym następniewolniej będzie oszacowanie µ(t) dopasowywało się do napływających danych.
Własności
Wprost z definicji P oraz wyrażenia na ˙µ wynika, że pod nieobecność szumu, czyli kiedyy(t) = w(t)µ, ∀t ≥ 0, mamy
d
dt[P (t)−1(µ(t)− µ)] = d
dt[P (t)−1](µ(t)− µ) + P (t)−1 ˙µ(t) = 0

13.3. Najmniejsze kwadraty z wykładniczym zapominaniem 139
czyli wartość P (t)−1(µ(t)− µ) jest stała w czasie. W efekcie
µ(t)− µ = P (t)P (0)−1(µ(0)− µ).Wynika stąd konieczny warunek na zbieżność µ do właściwej wartości: Wszystkie wartości wła-sne macierzy P (t) muszą zbiegać do zera lub, równoważnie, wszystkie wartości własne macie-rzy P (t)−1 muszą rozbiegać się do +∞. Powstaje pytanie w jakich warunkach taka sytuacjamogłaby nie zachodzić. Otóż tak się dzieje, kiedy przebieg w(r) dla r ∈ [0,+∞) jest „małourozmaicony,” co polega na tym, że wszystkie wektory w(r) należą do pewnej hiperpłaszczyznyw R
nw przechodzącej przez wektor zerowy i mającej wymiar mniejszy niż nw. Tak się zdarzaprzede wszystkim wtedy gdy w(t) powstaje jako liniowe przekształcenie pewnego przebieguv(t) o wymiarze mniejszym niż wymiar w.
13.3. Najmniejsze kwadraty z wykładniczym zapominaniem
Na ogół interesuje nas, aby stosowana technika estymacji była odporna na powolne zmia-ny estymowanego parametru w czasie. Taki postulat realizuje estymacja metodą najmniejszychkwadratów z wykładniczym zapominaniem. Polega ona na tym, aby estymator parametru był wkażdej chwili obliczany jako wektor µ minimalizujący wskaźnik błędu
ǫt(µ) =
∫ t
0
Λ(r, t)‖y(r)− w(r)µ‖2dr (13.8)
gdzie
Λ(r, t) = exp
(−∫ t
r
λ(r′)dr′)
i λ(r′) ≥ 0. Idea wskaźnika błędu (13.8) jest taka, aby przypisywał on tym większą wagę dodanych im są one świeższe. Rozważmy szczególne przypadki wskaźnika (13.8). Dla λ ≡ 0mamy
Λ(r, t) ≡ 1, ǫt(µ) =
∫ t
0
‖y(r)− w(r)µ‖2dr.
Dla λ ≡ λ0 > 0 mamy natomiast
Λ(r, t) = exp(−λ0(t− r)), ǫt(µ) =
∫ t
0
e−λ0(t−r)‖y(r)− w(r)µ‖2dr.
W ogólności λ(r) określa tempo zmniejszania się wagi przebiegu próbek sprzed chwili r wewskaźniku (13.8). Istotną własnością Λ jest to, że dla ustalonej wartości drugiego argumentujest to rosnąca funkcja argumentu pierwszego.
Analogicznie do dyskusji zwykłych najmniejszych kwadratów, definiujemy
S(t) = S(0)Λ(0, t) +
∫ t
0
Λ(r, t)w(r)Ty(r)dr,
P (t) =
(P (0)−1Λ(0, t) +
∫ t
0
Λ(r, t)w(r)Tw(r)dr
)−1
.
Dla zerowych S(0) i P (0)−1 mamy
∂
∂µTǫt = −2
∫ t
0
Λ(r, t)w(r)Ty(r)dr + 2
(∫ t
0
Λ(r, t)w(r)Tw(r)dr
)µ
= −2S(t) + 2P (t)−1µ.

140 Rozdział 13. Samostrojące się regulatory
Funkcja dokonująca ważenia, Λ, robi wrażenie bardzo wyrafinowanej, ale w istocie została onadobrana właśnie tak, aby upraszczać aktualizację S, P−1 i µ indukowaną przez napływającedane. Mamy bowiem
d
dtΛ(r, t) = Λ(r, t)(−λ(t))
i w efekcie
S =d
dt
∫ t
0
Λ(r, t)w(r)Ty(r)dr
= w(t)Ty(t) +
∫ t
0
d
dtΛ(r, t)w(r)Ty(r)dr = w(t)Ty(t)− λ(t)S(t)
oraz
d
dt[P (t)−1] =
d
dt
∫ t
0
Λ(r, t)w(r)Tw(r)dr
= w(t)Tw(t) +
∫ t
0
d
dtΛ(r, t)w(r)Ty(r)dr = w(t)Tw(t)− λ(t)P (t)−1
Wektor µ minimalizujący (13.8) dla zerowych S(0), P (0)−1 spełnia
P (t)−1µ(t) = S(t),
które różniczkujemy, aby wyprowadzić wzór na ˙µ, a mianowicie
d
dt[P−1]µ+ P−1 ˙µ = S = −λS + wTy
(−λP−1 + wTw)µ+ P−1 ˙µ = −λS + wTy
P−1 ˙µ = −λP−1µ+ λP−1µ+ wTy − wTwµ
˙µ = −Pwe
dlae(t) = w(t)µ(t)− y(t).
Wyprowadzenie P ma teraz postać
0 =d
dt[PP−1] = PP−1 + P
d
dt[P−1] = PP−1 + PwTw − PλP−1,
skąd mamyP = λP − PwTwP.
Własności
Posługując się definicją P−1, oraz wzorem na ˙µ można pokazać, że
d
dt[P−1(µ− µ)] = −λ(t)P−1(µ− µ).
Potraktujmy powyższe równanie wektorowe jako zbiór równań skalarnych. i-te spośród nichmożna przekształcić do
d
dtln[P−1(µ− µ)]i = −λ(t).

13.4. Adaptacyjny dobór współczynnika zapominania 141
Całkując obie strony powyższej równości dochodzimy do następującej równości
µ(t)− µ = Λ(0, t)P (t)P (0)−1(µ(0)− µ)lub
µ(t)− µ =
[P (0)−1 +
∫ t
0
Λ(0, r)−1w(r)Tw(r)dr
]−1
P (0)−1(µ(0)− µ).
Ponieważ Λ(0, r)−1 ≥ 1, to dla każdego t > 0 powyższa rozbieżność jest mniejsza niż ana-logiczna rozbieżność dla estymatora klasycznego. Oznacza to, że estymator z wykładniczymzapominaniem szybciej „zapomina” pierwotne oszacowanie µ(0) i dopasowuje się do napły-wających danych niż estymator klasyczny. Nie oznacza to jednak, że jest on preferowany wewszystkich zastosowaniach. Niekiedy opieranie estymatora w większym stopniu o dane „śwież-sze” aniżeli dane wcześniejsze, jak postępuje metoda z wykładniczym zapominaniem, nie jestniczym uzasadnione i jedynie zmniejsza reprezentatywność danych, o które opiera się estymator.
13.4. Adaptacyjny dobór współczynnika zapominania
Problem związany z estymatorem najmniejszych kwadratów pojawia się wówczas, gdy pa-rametr będący przedmiotem estymacji zmienia się oraz w danych ustaje pobudzanie. Ta ostatniaokoliczność zachodzi, gdy P−1 zbiega do macierzy osobliwej, np. gdy pewne elementy w(t)są stałe w czasie (vide także dyskusja kończąca sekcję 13.2). Symptomem takiej sytuacji jestnieograniczone wzrost wartości własnych macierzy P , czyli także ‖P‖. Z kolei sposobem najej zapobieżenie jest ograniczenie zapominania, przez co wartości własne macierzy P−1 zostająograniczone od dołu i sama ta macierz nie zbiega do osobliwej. “Ograniczenie zapominania” wmetodzie z wykładniczym zapominaniem polega na ograniczeniu od góry wartości λ(t) w przy-padku stwierdzenie dużych wartości własnych P . W istocie dla λ(t) ≡ 0 estymator “przestajezapominać” przeszłe dane. Rozważmy sposób wyznaczania λ postaci
λ(t) = λ0 (1− ‖P‖/k0) ,w której λ0 oznacza maksymalny współczynnik zapominania natomiast k0 oznacza maksymal-ną normę macierzy P (należy zatem wybrać P (0) tak, aby ‖P (0)‖ ≤ k0I). Okazuje się, żekonsekwencją takiego sposobu określania λ jest ograniczenie macierzy P−1 od dołu
P (t)−1 ≥ 1
k0I
oraz macierzy P od góryP (t) ≤ k0I.
Co ciekawe, jeżeli przebieg w(t) jest odpowiednio “urozmaicony”, wówczas λ(t) jest ograni-czone od dołu przez pewną wartość większą od zera, a to oznacza, że zapominanie nigdy niejest całkowicie wyłączone. Niech mianowicie sygnał w(t) spełnia następujący warunek:— istnieje T > 0 oraz α > 0, dla których
∫ t+T
t
w(r)Tw(r)dr ≥ αI, ∀t ≥ 0.
Oznacza to, że każdy przyczynek o długości T do macierzy P−1, (13.5), ma dodatnie wartościwłasne. Otóż jeśli tak jest, to wówczas istnieje λ1 > 0 takie, że
λ(t) ≥ λ1, ∀t ≥ 0.
A zatem, jeśli przebieg w(t) jest odpowiednio “urozmaicony”, to zapominanie postępuje ciąglei estymator stale dopasowuje się głównie do ostatnich danych.


Część IV
Inne podejścia do adaptacji

144
Poprzednie dwie części skryptu stanowią zwięzłe wprowadzenie do kluczowych dziedzin,w których należy poszukiwać metod do konstruowania uczących się (adaptacyjnych) systemówsterujących i podejmujących decyzje. Pierwszą z tych dziedzina jest uczenie się ze wzmocnie-niem, a drugą sterowanie adaptacyjne. Ta część skryptu ma na celu zreferowanie podejścia, któremogą stanowić dla tych dziedzin alternatywę.

Rozdział 14
Aproksymowane programowanie dynamiczne
Punktem wyjścia do aproksymowanego programowania dynamicznego (ang. Approximate
Dynamic Programming [22]) jest Proces Decyzyjny Markowa, ten sam, który był dyskutowanyprzy okazji uczenia się ze wzmocnieniem. Ma on tutaj pewne szczególne własności:— Przestrzeń stanów oraz przestrzeń decyzji to wielowymiarowe przestrzenie ciągłe, czyliX =
Rnx oraz U = R
nu .— Kolejny stan i nagroda wynikają deterministycznie z poprzedniego stanu i decyzji (nie ma
zależności stochastycznych).— Rozważa się tylko problem z dyskontem.Przedmiotem optymalizacji jest parametr θ ∈ R
nθ aproksymatora A(x; θ), który przekształcastany w decyzje. Celem optymalizacji jest, jak zwykle przy okazji Procesu Decyzyjnego Marko-wa, maksymalizacja sumy zdyskontowanych nagród, których można się spodziewać w każdymstanie.
Przykładem algorytmu, który stara się optymalizować parametr θ aproksymatoraA jest Heu-rystyczne Programowanie Dynamiczne, (ang. Heuristic Dynamic Programming, HDP). Posłu-guje się on następującymi narzędziami:— Krytyk: Parametryczna aproksymacja sumy nagród, których można się spodziewać przy bie-
żącej polityce.
V (x; υ) ∼=∑
i≥0
γirt+i
∣∣∣∣xt=x,polityka z θ
.
— Model nagrody:
R(x, u) ∼= rt∣∣xt=x,ut=u
.
— Model następnego stanu:
N(x, u) ∼= xt+1
∣∣xt=x,ut=u
.
Ze względu na zakładany determinizm systemu, na który oddziałują decyzje, kolejne stany oraznagrody są po prostu funkcją poprzedzających stanów i decyzji. Stąd w powyższych definicjachnie występuje operator wartości oczekiwanej.
Ogólna postać algorytmu HDP jest przedstawiona w Tablicy 14.1. Jak widać, jest to algo-rytm wielokrotnie przetwarzający obserwacje. W pętli sterowania gromadzi on dane o przebieguprocesu decyzyjnego, które wykorzystuje w wykonywanej równolegle pętli optymalizacji dozbudowania polityki decyzyjnej w procesie podobnym do iteracji polityki.
Realizacja pętli optymalizacji polityki może być zorganizowana rozmaicie. Może polegaćna losowaniu próbek opisujących zdarzenia z bazy danych i dokonywaniu poprawek θ oraz υ napodstawie tych próbek. Poprawki mają wtedy postać
υ ← υ + βυ∂V (xi; υ)
∂υT
(R(xi; A(xi; θ)) + γV (N(xi; A(xi; θ)); υ)− V (xi; υ)
)
θ ← θ + βθ∂A(xi; θ)
∂θT
(∂R(xi, A(xi; θ))
∂A(xi; θ)T+ γ
∂N(xi, A(xi; θ))
∂A(xi; θ)T∂V (N(xi; A(xi; θ)); υ)
∂N(xi; A(xi; θ))T
),

146 Rozdział 14. Aproksymowane programowanie dynamiczne
Pętla sterowania:Wykonuje decyzje na podstawie pewnej (sensownej) polityki. Notujkolejne stany, decyzje i nagrody w bazie danych.
Pętla optymalizacji polityki:Powtarzaj aż do zbieżności θ:Dla wszystkich i ∈ 1, 2, . . . , t, być może nie kolejnych, wykonuj1. (opcjonalnie) Popraw model nagrody używając xi, ui, ri.2. (opcjonalnie) Popraw model następnego stanu używając xi, ui, xi+1.3. Popraw υ przybliżając V (xi; υ) w stronę
R(xi, A(xi; θ)) + γV (N(xi, A(xi; θ)); υ′)
dla stałego υ′ równego bieżącej wartości υ.4. Popraw politykę zmieniając θ w stronę maksimum
R(xi, A(xi; θ)) + γV (N(xi, A(xi; θ)); υ).
Tablica 14.1. Algorytm Heurystyczne Programowanie Dynamiczne, HDP.
gdzie βθ i βυ to parametry kroku. Powyższa poprawka θ polega na potraktowaniu wartości
R(xi, A(xi; θ)) + γV (N(xi, A(xi; θ)); υ) (14.1)
jako złożonej funkcji θ i zmiany tego parametru wzdłuż gradientu tej funkcji. Poprawka υ polegana przybliżeniu V (xi; υ) do wartości (14.1).
W algorytmie zapisanym w Tablicy 14.1 pojawiają się opcjonalne poprawki modelu A orazN . Zakładana jest możliwość polegająca na tym, że początkowo te modele są niedokładne i sąpoprawiane na podstawie danych zbieranych w procesie sterowania. Zatem polityka jest opty-malizowana na podstawie aktualizowanych modeli. Jest to nic innego, jak realizacja koncepcjisamostrojących się regulatorów. Trzeba jednak pamiętać o ograniczeniu tej koncepcji. A miano-wicie, jeśli model ma być budowany na podstawie danych z procesu decyzyjnego, to stosowanatam polityka decyzyjna musi produkować różne decyzje w tym samym stanie. W przeciwnymrazie model nie będzie miał żadnych szans, aby reprezentować kluczową wiedzę o konsekwen-cjach tych różnych decyzji. Z tego względu polityka wyznaczana w pętli optymalizacji politykinie może być bezpośrednio stosowana w pętli sterowania. Także i tutaj potrzebne jest nieustanne
pobudzanie.

Rozdział 15
Stochastyczne sterowanie adaptacyjne
Omówione w Części III algorytmy sterowania adaptacyjnego są oparte na założeniu, że dy-namika sterowanego obiektu jest deterministyczna, a celem sterowania jest śledzenie. Metodystochastycznego sterowania adaptacyjnego [3] stanowią alternatywę opartą na zestawie założeńbardziej zbliżonym do modelu Procesu Decyzyjnego Markowa, a mianowicie— czas jest dyskretny,— obiekt nie przechodzi do kolejnych stanów w sposób deterministyczny,— znany jest model dynamiki obiektu, choć nieznany jest jego parametr,— parametr modelu zmienia się w czasie,— celem sterowania jest optymalizacja pewnego wskaźnika jakości.Jak więc widać, jest to kombinacja założeń stosowanych w sterowaniu adaptacyjnym i stosowa-nych w uczeniu się ze wzmocnieniem. Poniżej referujemy to podejście bardziej szczegółowo.
W dyskretnych chwilach czasu t = 1, 2, . . . obiekt ze stanem xt ∈ Rnx ma na wejściu
sterowanie ut ∈ Rnu . Stan zmienia się według formuły
xt+1 ∼ Px(· |xt, ut;µt)
gdzie Px jest pewnym znanym rozkładem prawdopodobieństwa parametryzowanym przez µt ∈Rnµ . Wartość parametru µt jest nieznana, natomiast wiadomo, że zmienia się według znanego
rozkładu
µt+1 ∼ Pµ(· |µt).
Oznaczmy przez Ht historię, czyli stany i sterowania, które miały miejsce do chwili pojawieniasię obiektu w stanie xt, a mianowicie
Ht = (x1, u1, . . . , xt−1, ut−1, xt).
Zadanie polega na tym, aby w każdej chwili wyznaczyć na podstawie Ht sterowanie ut, abyzminimalizować pewien wskaźnik jakości oceniający wydarzenia od chwili t:
E(Jt(ut, xt+1, ut+1, . . . )
∣∣Ht
).
Zasadnicza pojawiająca się tu trudność polega na tym, że nie wiadomo jaka jest obecna wartośćparametru µt. Jeśli problem daje się rozwiązać dla każdego danego µt, to do rozwiązania go wogólnej postaci potrzeba jedynie rozkładu µt przy warunku Ht. Rozkład taki nazywa się hiper-
stanem; oznaczmy go przez µt. W tej sytuacji problem sprowadza się do znalezienia sterowaniaut maksymalizującego
E(Jt(ut, xt+1, ut+1, . . . )
∣∣xt, µt).
Warto podkreślić, że na ogół µt ma postać znacznie bardziej skomplikowaną niż gdyby to byłjedynie estymator parametru µt.

148 Rozdział 15. Stochastyczne sterowanie adaptacyjne
Powyższy problem jest stosunkowo dobrze zbadany dla następującej postaci. Mamy wyjścieobiektu yt ∈ R i sterowanie ut ∈ R. Wyjście zmienia się według formuły
yt+1 =
n∑
i=0
µt,2iyt−i +
n∑
i=0
µt,2i+1ut−i + et, et ∼ N(0, σ2),
natomiast parametr według formuły
µt+1 = Aµt + ξt, ξt ∼ N(0, C),
gdzie A i C są pewnymi znanymi macierzami. Wskaźnik jakości ma postać
Jt =1
m
m∑
i=1
(xt+i − xdt+i)2.
dla wartości xdt+i, które stanowią zadaną trajektorię stanu. Aby pokazać ten problem jako szcze-gólną postać rozważanego wcześniej, należy jeszcze zdefiniować stan jako
xt = [yt, yt−1, . . . , yt−n, ut−1, . . . , ut−n]T .
Okazuje się, że rozkład µt|Ht jest w tym przypadku normalny, przy czym istnieją metody reku-rencyjnego (z kroku na krok) obliczania jego wartości oczekiwanej i wariancji.
Rozwiązanie analityczne powyższego problemu znane jest jedynie dlam = 1. Dla większychm problem można rozwiązać numerycznie, przy czym rozwiązanie to ma bardzo godne uwagiwłasności. Okazuje się mianowicie, że istotnym celem dobrego sterowania jest gromadzeniedanych pozwalających zawęzić rozkład parametru µt. W ogólności sterowanie, które służy m.in.gromadzeniu wiedzy o dynamiczne obiektu to tzw. sterowanie dualne.

Rozdział 16
Sterowanie z iteracyjnym uczeniem się
W wielu zastosowaniach przedmiotem sterowania jest obiekt, którego działanie daje się zde-komponować na pewne dobrze określone czynności. Wykonanie każdej z czynności polega natym, że pewna funkcja stanu obiektu pokonuje zadaną trajektorię referencyjną. Tą funkcją, czyliwyjściem obiektu może być w szczególności cały stan lub wybrane jego współrzędne. Przykła-dem takich obiektów są urządzenia produkcyjne, których praca składa się z zestawu połączonychw cykl czynności. Sterownik takiego urządzenia musi dla każdej czynności zadawać trajektorięsterowań, które sprawią, że zostanie zrealizowana zadana trajektoria wyjścia obiektu. Jeśli obiektjest deterministyczny i każda czynność rozpoczyna się w takich samych warunkach, to także takasama powinna być trajektoria sterowań.
Koncepcja sterowania z iteracyjnym uczeniem się (ang. Iterative Learning Control [2]) zmie-rza do ustalenia optymalnej trajektorii sterowania dla systemu dynamicznego o częściowo znanejdynamice i zadanej trajektorii referencyjnej. Optymalizacja dokonuje się w sekwencji wykonańtrajektorii, na podstawie których modyfikowana jest trajektoria sterowań. Ogólna zasada tychmodyfikacja jest taka, aby dla każdej chwili przebiegu sterowania poprzez odpowiednią po-prawkę sterowania skompensować wzrost rozbieżności między faktycznym wyjściem obiektu, atrajektorią referencyjną.
Model obejmuje następujące elementy:1. Obiekt charakteryzuje się dynamiką
x = f(t, x) +Bu,y = Cx,
(16.1)
dla t ∈ [0, T ], x ∈ Rn, u, y ∈ R
r, C ∈ Rr×n, B ∈ R
n×r.2. Funkcja f jest dla każdej wartości swojego pierwszego argumentu jednostajnie ciągła ze
względu na swój drugi argument, a zatem istnieje taka ciągła funkcja α : [0, T ] 7→ R, że
‖f(t, x1)− f(t, x2)‖ ≤ α(t)‖x1 − x2‖. (16.2)
3. Celem sterowania jest przybliżenie y na przedziale [0, T ] do trajektorii referencyjnej ym, przyczym
ym : [0, T ] 7→ Rr jest ciągła i różniczkowalna (16.3)
ym(0) = Cx(0). (16.4)
Powyższe sformułowanie jest bardzo ogólne i obejmuje szereg typowych sytuacji. Między in-nymi obejmuje sytuację, w której w systemie (16.1) działa już jakiś sterownik, a także pewiensygnał zakłócający. Mamy wówczas
x(t) = f1(x(t), f2(x(t)) + z(t)) +Bu(t)

150 Rozdział 16. Sterowanie z iteracyjnym uczeniem się
gdzie f1 definiuje dynamikę samego obiektu (odpowiada funkcji f w (9.2)), f2 definiuje pewienpoczątkowy sterownik, natomiast z : [0, T ] 7→ R
r definiuje sygnał zakłócający. Chodzi zatemo znalezienie takiego dodatkowego przebiegu sterującego u : [0, T ] 7→ R
r, który dopasujewyjście obiektu y do trajektorii referencyjnej ym mimo:— niedokładnej znajomości dynamiki obiektu, f1,— niedoskonałości działania początkowego sterownika, f2,— oraz istnienia przebiegu zakłócającego, z.
Proces adaptacji polega na sekwencji przebiegów indeksowanych przez k = 1, 2, 3, . . . , poktórych dostosowywana jest trajektoria sterująca. Początkowa trajektoria sterująca
u1 : [0, T ] 7→ Rr (16.5)
jest ciągła i różniczkowalna. Kolejne trajektorie sterowania są wyznaczane w sposób następujący
xk(t) = x(0) +
∫ t
0
[f(τ, xk(τ)
)+Buk(τ)
]dτ, (16.6)
yk(t) = Cxk(t), (16.7)
ek(t) = yk(t)− ym(t), (16.8)
uk+1(t) = uk(t)− Γek(t). (16.9)
Macierz Γ ∈ Rr×r powinna być dobrana w taki sposób, aby iloczyn CBΓ był w przybliżeniu
równy macierzy jednostkowej. Ścisłe sformułowanie tego warunku przedstawimy poniżej, nato-miast teraz skoncentrujmy się na intuicyjnym sensie tej formy adaptacji. Przebieg ek : [0, T ] 7→Rr reprezentuje rozbieżność między wyjściem obiektu yk, a trajektorią referencyjną ym. Dla
t = 0 ta rozbieżność jest zerowa, ponieważ
ym(0) = yk(0) = Cx(0).
Dla t > 0 niezerowa pochodna ek oznacza, że rozbieżność staje się różna od zera. Celem jestzatem przybliżenie ek+1 do zera. W tym celu:— sterowanie u jest modyfikowane w kierunku −Γek, czyli tak,— aby pochodna x zmieniała się w kierunku −BΓek, czyli tak,— aby powodowane tym zmiany y w kierunku −CBΓek lepiej nadążały za zmianami ym.Konkretna postać warunku, który ma spełniać macierz Γ jest następująca. Zdefiniujmy w tymcelu normę ‖ · ‖∞ macierzy A ∈ R
n×r jako
‖A‖∞ = maxi=1...n
r∑
j=1
|Ai,j|. (16.10)
Otóż aby osiągnąć zbieżność powyżej opisanego mechanizmu adaptacji, macierz Γ powinnaspełniać warunek
‖I − BCΓ‖∞ < 1. (16.11)
Własności. Do ich precyzyjnego określenia zdefiniujmy dla λ ∈ (0, 1) normę ‖ · ‖λ funkcjif : [0, T ] 7→ R
r. Jest to mianowicie
‖f‖λ = supt∈[0,T ],i=1...r
e−λt|fi(t)|
= sup
t∈[0,T ]
e−λt‖f(t)‖∞
. (16.12)
Interesujące nas własności schematu adaptacji zdefiniowanego przez równania (16.6)–(16.9) sąujęte przez następujące twierdzenie.

151
Twierdzenie 16.0.1. Jeśli spełnione są warunki sformułowane w ciągu niniejszego rozdziału,
wówczas
1. Istnieje λ ≥ 0 oraz ρ0 ∈ [0, 1) takie, że dla każdego k ≥ 1 zachodzi
‖ek+1‖λ ≤ ρ0‖ek‖λ.
2. Wraz z rosnącym k, yk zbiega do ym jednostajnie na [0, T ].3. Wraz z rosnącym k, yk zbiega do ym jednostajnie na [0, T ].
Dowód powyższego twierdzenia można znaleźć w artykule [2]. Dosyć dokładnie referuje onomechanizm zdefiniowany przez równania (16.6)–(16.9). A mianowicie, w kolejnych iteracjachmodyfikujemy sterowanie, aby wpłynąć na kierunek zmian wyjścia obiektu. Tego rodzaju inge-rencja w u(t) ma za zadanie poprawić y(t) i tym samym przybliżać yk(t + δ) do ym(t + δ) dlaniewielkiego δ > 0, jednak może oddalać yk(t+ δ) od ym(t+ δ) dla większego δ. Dlatego wrazze wzrostem indeksu iteracji k, przesuwa się umowna granica T0 taka, że dla t ∈ [0, T0] wartościyk(t) są już całkiem nieźle dopasowane do ym(t), natomiast dla t ∈ (T0, T ] już niekoniecznie.Ostatecznie jednak dla rosnącego k przebieg ek zbiega jednostajnie do zera, a to oznacza, że tak-że ek zbiega jednostajnie do zera, a tym samym yk zbiega jednostajnie do trajektorii referencyjnejym.


Rozdział 17
Filtr Kalmana
Ostatni rozdział w tym skrypcie zostanie poświęcony Filtrowi Kalmana, czyli metodzie, któ-rej zadaniem nie jest rozwiązywanie problemu uczącego się lub adaptującego decydenta, zaryso-wanego w Rozdziale 1. Zadaniem Filtru Kalmana jest estymacja stanu systemu dynamicznego woparciu o model tego systemu oraz pochodzące z niego obserwacje. Istnieją jednak dwa bardzopoważne powody uzasadniające zwieńczenie niniejszego skryptu przedstawieniem tego właśnienarzędzia. Po pierwsze, wszystkie dyskutowane tu mechanizmy sterowania (decyzyjne) działająw oparciu o stan systemu, na który oddziałują. W praktyce technicznej oraz ekonomicznej stwier-dzenie w jakim stanie znajduje się sterowany system prawie nigdy nie bywa oczywiste. Jest todokonywane przy użyciu pewnych obserwacji i mechanizmu analitycznego przekształcającegoobserwacje w estymatę stanu. Druga przyczyna uzasadniająca omówienie Filtru Kalmana leżyw sposobie jego działania, który polega na pewnego rodzaju adaptowaniu wyznaczanej przezniego estymaty stanu do obserwacji. Ponadto Filtr Kalmana jest narzędziem, którego znaczeniepraktyczne jest trudne do przecenienia, a liczne grono jego użytkowników jednoznacznie kojarzyje z adaptacją.
17.1. Model
Zakładamy, że w czasie dyskretnym t = 1, 2, . . . działa system, na którego stan xt ∈ Rnx
wpływają wejścia ut ∈ Rnu . Ewolucja stanu systemu przebiega wg formuły
xt = Ftxt−1 +Btut + ξt, (17.1)
gdzie ξt to szum z rozkładu normalnego
ξt ∼ N(0, Qt).
W niektórych chwilach t dostępne są obserwacje yt ∈ Rny z systemu
yt = Htxt + ζt (17.2)
zanieczyszczone przez szum z rozkładu normalnego
ζt ∼ N(0, Rt).
Macierze Ft, Bt, Qt, Ht oraz Rt są znane.Zadanie Filtru Kalmana polega na śledzeniu stanu systemu, poprzez połączenie informa-
cji o jego dynamice (17.1) z jego obserwacjami (17.2). Oba te źródła informacji są obarczonelosowym zakłóceniem, co filtr musi uwzględnić. Formalnie, zadanie filtru polega na oblicze-niu nieobciążonych estymat stanu systemu na podstawie informacji do chwili t, najpierw bezuwzględnienia obserwacji, a potem po uwzględnieniu obserwacji, a także macierzy kowariancjiobu tych estymat.

154 Rozdział 17. Filtr Kalmana
Przykład 17.1.1. Jednowymiarowy AHRS
AHRS (ang. Attitude and heading reference system) jest urządzeniem stosowanym w nawigacjilotniczej do wyznaczania kierunku statku względem północy magnetycznej. Opiera się ono namagnetometrze, który mierzy pole magnetyczne ziemi stanowiące stały punktu odniesienia, orazżyroskopie, służącym do pomiaru prędkości kątowej.1
Rozważmy prosty AHRS przymocowany do pewnego zwrotnego pojazdu kołowego. Ma ondziałać w pozycji równoległej do powierzchni ziemi i wskazywać kąt względem północy ma-gnetycznej. Składa się on z żyroskopu, który co δ = 10−2 sekundy wskazuje prędkość kątowąz szumem o wariancji σ2. Ponadto, do dyspozycji mamy magnetometr, który co 10δ daje odczytkąta względem północy magnetycznej z szumem o wariancji 20σ2.
Co δ = 10−2 mierzymy zatem stan xt ∈ R, który jest kątem względem północy magnetycz-nej. Zmienia się on wg formuły
xt = xt−1 + δut + ξt
gdzie ut to odczyt z żyroskopu, zaś
ξt ∼ N(0, δ2σ2).
Ponadto, co ok. 10 pomiarów z żyroskopu mamy do dyspozycji pomiar z magnetometru
yt = xt + ζt,
gdzieζt ∼ N(0, 20σ2).
Sytuacja zatem odpowiada dokładnie modelowi, do którego stosuje się Filtr Kalmana, dla Ft ≡Ht ≡ I , Bt ≡ δ, Qt ≡ δ2σ2, oraz Rt ≡ 20σ2.
Intuicyjnie sytuację należy rozumieć tak: Jeśli w pewnym momencie wiemy, z pewną do-kładnością, gdzie jest północ i obracamy się, to żyroskop wskazuje jak kierunek północy obracasię względem nas. Z drugiej strony, północ jest bezpośrednio wskazywana przez magnetometr,ale z dużym błędem i rzadko. Zadanie filtru polega więc na tym, aby w każdej chwili wskazywaćpółnoc z jak największą dokładnością na podstawie obu tych źródeł informacji.
17.2. Algorytm
W t-tym kroku swojego działania Filtr Kalmana wyznacza estymatę stanu nie uwzględnia-jącą obserwacji, czyli prognozę, wg wzorów
x0t = Ftxt−1 +Btut (17.3)
P 0t = FtPt−1F
T
t +Qt (17.4)
gdzie x0t to estymata stanu bez uwzględnienia obserwacji, zaś P 0t to macierz kowariancji tej
estymaty.Następnie, dokonuje poprawki wg wzorów
yt = yt −Htx0t (17.5)
St = HtP0t H
T
t +Rt (17.6)
Kt = P 0t H
T
t S−1t (17.7)
xt = x0t +Ktyt (17.8)
Pt = (I −KtHt)P0t (17.9)
1 W praktyce do konstrukcji AHRS-ów stosuje się także akcelerometr, który jednak wyłączymy z naszej dys-kusji tutaj.

17.2. Algorytm 155
gdzie xt to estymata stanu uwzględniająca obserwację, a Pt to jej macierz kowariancji. Wyrazyt zwany jest innowacją lub reziduum pomiaru, zaś St jest to macierz kowariancji tego wektoralosowego. Macierz Kt zwana jest wzmocnieniem Kalmana.
Jeśli z jakiegoś względu w chwili t pomiar yt nie jest dostępny, wówczas przyjmuje się
xt = x0tPt = P 0
t .
Przykład 17.2.1. Jednowymiarowy AHRS, c.d.
Kontynuujemy przykład 17.1.1. Przypomnijmy:
Ft ≡ Ht ≡ I, Bt ≡ δ, Qt ≡ δ2σ2, Rt ≡ 20σ2.
Możemy przyjąć, że mechanizm estymacji stanu zaczyna działać wraz z pierwszym odczytemz megnetometru, czyli
x0 = y0, P0 = 20σ2.
Prognoza ma postać
x0t = xt−1 + δut,
P 0t = Pt−1 + δ2σ2.
A zatem, przed uwzględnieniem obserwacji bierzemy za dobrą monetę odczyt z żyroskopu izakładamy, że obracamy się względem północy magnetycznej tak, jak on wskazuje. Ponieważjego wskazania są obarczone błędem, to wariancja naszego estymatora stanu zwiększa się oodpowiednio przeskalowaną wariancję szumu pomiarowego.
Co pewien czas mierzymy gdzie jest północ przy użyciu magnetometru. Pozwala nam todokonać poprawki estymaty stanu:
yt = yt − x0tSt = P 0
t + 20σ2
Kt = P 0t /St
xt = x0t +Ktyt = ytP 0t
P 0t + 20σ2
+ x0t20σ2
P 0t + 20σ2
Pt =20σ2
P 0t + 20σ2
P 0t
Estymata stanu, czyli wskazanie północy w naszym prostym przykładzie, ma postać średniejważonej prognozy opartej na wcześniejszych pomiarach i obserwacji. Waga każdego elementujest tym większa, im mniejsza jest jego wariancja, a dokładnie jest ona proporcjonalna do wa-riancji tego drugiego elementu. W rezultacie zastosowania poprawki, wariancja estymaty stanuzmniejsza się, dzięki obserwacji wiemy więcej, zatem dokładność oszacowania stanu jest więk-sza.
Powyższy prosty przykład ilustruje typowe warunki stosowania filtru Kalmana:— Pierwsza grupa pomiarów mówi jak ewoluuje stan systemu. Pomiary te są obarczone szu-
mem. Dlatego estymata stanu oparta tylko na nich charakteryzowałaby się narastającą (ko)wa-riancją.
— Inne pomiary są funkcją stanu i także one są obarczone szumem.Kontrola wariancji i kowariancji estymat i pomiarów pozwala połączyć informacje ze wszyst-kich źródeł i uzyskać estymatę stanu o minimalnej wariancji. Poniżej demonstrujemy dowód tejwłasności filtru Kalmana.

156 Rozdział 17. Filtr Kalmana
17.3. Wyprowadzenia
Wzór (17.3) Przy założeniu, że E(xt−1 − xt−1) = 0 dostajemy
E(x0t − xt) = E (Ftxt−1 +Btut − xt)= E (Ftxt−1 +Btut − Ftxt−1 −Btut − ξt)= E (Ft(xt−1 − xt−1)− ξt)= 0,
co potwierdza, że x0t jest nieobciążonym estymatorem xt.Wzór (17.4) Przy założeniu, że E(xt−1 − xt−1) = 0 oraz cov xt−1 = Pt−1 mamy
cov x0t = E(x0t − xt
) (x0t − xt
)T
= E (Ftxt−1 +Btut − Ftxt−1 − Btut − ξt)×× (Ftxt−1 +Btut − Ftxt−1 − Btut − ξt)T
= E (Ft(xt−1 − xt−1)− ξt) (Ft(xt−1 − xt−1)− ξt)T
= FtPt−1FT
t +Qt
= P 0t
Wzór (17.5) W kolejnym punkcie istotna okaże się wartość oczekiwana yt, a mianowicie przyzałożeniu, że E(x0t − xt) = 0 mamy
E yt = E(Htxt + ζt −Htx
0t
)
= HtE(xt − x0t
)+ Eζt
= 0
Wzór (17.6) Przy założeniu, że E yt = 0 oraz cov x0t = P 0t mamy
cov yt = E yt(yt)T= E(yt −Htx
0t )(yt −Htx
0t )
T
= E(Htxt + ζt −Htx0t )(Htxt + ζt −Htx
0t )
T
= HtP0t H
T
t +Rt
= St.
Wzór (17.8) Mimo, że upodobanie do porządku nakazywałoby nam teraz wyprowadzić wzór(17.7), zostawimy to na koniec. Tymczasem zauważmy, że Kt jest pewną stałą wyznaczonąna podstawie innych stałych. Uwzględniając także, że E yt = 0, zbadajmy wartość oczekiwa-ną xt, a mianowicie
E(xt − xt) = E(x0t +Ktyt − xt)= E(x0t − xt) +KtE yt= 0.

17.4. Rozszerzony Filtr Kalmana 157
Wzór (17.9) Rozwijając yt, uwzględniając, że ζt nie jest skorelowana z (xt−x0t ), uwzględniającwzór na St (17.6) i dokonując prostych przekształceń otrzymujemy
cov(xt − xt) = cov(xt − (x0t +Ktyt))
= cov(xt − (x0t +Kt(Htxt + ζt −Htx0t )))
= cov((I −KtHt)(xt − x0t )−Ktζt)
= cov((I −KtHt)(xt − x0t )) + cov(Ktζt)
= (I −KtHt) cov(xt − x0t )(I −KtHt)T +Kt cov(ζt)K
T
t
= (I −KtHt)P0t (I −KtHt)
T +KtRtKT
t
= (I −KtHt)P0t −KtHtP
0t +KtHtP
0t H
T
t KT
t +KtRtKT
t
= (I −KtHt)P0t −KtHtP
0t +Kt(HtP
0t H
T
t +Rt)KT
t
= (I −KtHt)P0t −KtHtP
0t +KtStK
T
t .
Uwzględniając dodatkowo postać Kt wyrażoną w (17.7) możemy stwierdzić, ostatnie dwaelementy powyższej sumy znoszą się nawzajem. Mnożąc obie strony definicji (17.7) przezStK
T
t dostajemy bowiemKtStK
T
t = P 0t H
T
t KT
t ,
co ostatecznie prowadzi nas do wzoru na Pt (17.9).Wzór (17.7) Wybierając postaćKt chcemy zminimalizować wartość E‖xt−xt‖2. Aby to zrobić
minimalizujemy ślad macierzy Pt jako funkcjiKt. W tym celu wracamy do Pt dla ogólnegoKt, różniczkujemy go przez Kt i pochodną przyrównujemy do zera. Prowadzi to do nastę-pującego wyniku
∂Pt∂Kt
= −2(HtP0t )
T + 2KtSt = 0
KtSt = (HtP0t )
T = P 0t H
T
t
Kt = P 0t H
T
t S−1t .
17.4. Rozszerzony Filtr Kalmana
Rozszerzony Filtr Kalmana radzi sobie z systemami nieliniowymi przez ich linearyzacjęwokół estymaty stanu. Model ma następującą postać
xt = f(xt−1, ut) + ξt
yt = h(xt) + ζt
Oznaczając
Ft =∂f(x, u)
∂x
∣∣∣∣x=xt−1,u=ut
Ht =∂h(x)
∂x
∣∣∣∣x=xt
i zakładając, że funkcje f i h są afiniczne, dostajemy następujące wzory na Rozszerzony FiltrKalmana. Prognoza ma postać
x0t = f(xt−1, ut)
P 0t = FtPt−1F
T
t +Qt

158 Rozdział 17. Filtr Kalmana
Następnie, dokonuje poprawki wg wzorów
yt = yt − h(x0t )St = HtP
0t H
T
t +Rt
Kt = P 0t H
T
t S−1t
xt = x0t +Ktyt
Pt = (I −KtHt)P0t .

Bibliografia
[1] S. Amari. Natural gradient works efficiently in learning. Neural Computation, 10(22):251–276,1998.
[2] S. Arimoto, S. Kawamura, & F. Miyazaki. Bettering operation od dynamic systems by learning: Anew control theory for servomechanism or mechatronics systems. W Proceedings of 23rd Confe-
rence on Decision and Control, ss. 1064–1069, 1984.[3] K. J. Astrom & B. Wittenmark. Adaptive Control. Addison-Wesley Publishin Company, 1989.[4] A. G. Barto, R. S. Sutton, & C. W. Anderson. Neuronlike adaptive elements that can learn difficult
learning control problems. IEEE Transactions on Systems, Man, and Cybernetics B, 13:834–846,Sept.-Oct. 1983.
[5] P. Cichosz. Systemy Uczące Się. WNT, 2000.[6] K. Doya. Reinforcement learning in continuous time and space. Neural Computation, 12:243–269,
2000.[7] W. Duch, J. Korbicz, L. Rutkowski, & R. Tadeusiewicz. Sieci neuronowe. Exit, 2000.[8] Z. Fortuna, B. Macukow, & J. Wąsowski. Metody Numeryczne. WNT, 1995.[9] H. Hachiya, J. Peters, & M. Sugiyama. Reward-weighted regression with sample reuse for direct
policy search in reinforcement learning. Neural Computation, 23(11):2798–2832, 2011.[10] S. Haykin. Neural Networks, A Comprehensive Foundation. Macmillan College Publishing Com-
pany, 1994.[11] H. Kimura & S. Kobayashi. An analysis of actor/critic algorithm using eligibility traces: reinforce-
ment learning with imperfect value functions. W Proceedings of the 15th International Conference
on Machine Learning, 1998.[12] V. R. Konda & J. N. Tsitsiklis. Actor-critic algorithms. SIAM Journal on Control and Optimization,
42(4):1143–1166, 2003.[13] H. J. Kushner & G. G. Yin. Stochastic Approximation Algorithms and Applications. Springer, 1997.[14] P. Marbach & J. N. Tsitsiklis. Silumation-based optimization of markov reward processes. IEEE
Transactions on Automatic Control, 46(2):191–209, 2001.[15] N. Meuleau, L. Peshkin, & K.-E. Kim. Exploration in gradient-based reinforcement learning. Tech-
nical Report AI Memo 2001-003, MIT, 2001.[16] M. L. Minsky. Theory of Neural-Analog Reinforcement Systems and Its Application to the
Brain-Model Problem. PhD thesis, Princeton University, 1954.[17] S. Osowski. Sieci neuronowe w ujęciu algorytmicznym. WNT, 1996.[18] S. Osowski. Sieci neuronowe do przetwarzania informacji. Oficyna Wydawnicza Politechniki
Warszawskiej, 2000.[19] L. Peshkin & Ch. R. Shelton. Learning from scarce experience. W Proceedings of the 19th Inter-
national Conference on Machine Learning, ss. 498–505, 2002.[20] J. Peters & S. Schaal. Natural actor-critic. Neurocomputing, 71(7–9):1180–1190, 2008.[21] J. Peters, S. Vijayakumar, & S. Schaal. Reinforcement learning for humanoid robotics. W Huma-
noids2003, 3rd IEEE-RAS International Conference on Humanoid Robots, Sept.29-30, 2003.[22] D. Prokhorov & D. Wunsch. Adaptive critic designs. IEEE Transactions on Neural Networks,
8(5):997–1007, September 1997.[23] H. Robbins & S. Monro. A stochastic approximation method. Annals of Mathematical Statistics,
22:400–407, September 1951.

160 Bibliografia
[24] R. Rubinstein. Simulation and The Monte Carlo Method. Wiley, 1981.[25] G. Rummery & M. Niranjan. On-line q-learning using connectionist systems. Technical Report
CUED/F-INFENG/TR 166, Cambridge University, Engineering Department, 1994.[26] A. L. Samuel. Some studies in machine learning using the game of checkers. IBM Journal on
Research and Development, 3:211–229, 1959. Przedruk w: E. A. Feingenbaum & J. Feldman (Eds):Computers and Thought, McGraw-Hill, ss. 71–105, 1963.
[27] C. R. Shelton. Importance Sampling for Reinforcement Learning with Multiple Objectives. PhDthesis, MIT, August 2001.
[28] Ch. R. Shelton. Policy improvement for pomdps using normalized importance sampling. W Proce-
edings of the 17th International Conference on Uncertainty in Artificial Intelligence, ss. 496–503,2001.
[29] J.-J.E. Slotine & W. Li. Applied Nonlinear Control. Prentice Hall, 1991.[30] R. S. Sutton & A. G. Barto. Reinforcement Learning: An Introduction. MIT Press, 1998.[31] R. S. Sutton, D. McAllester, S. Singh, & Y. Mansour. Policy gradient methods for reinforcement
learning with function approximation. W Advances in Information Processing Systems, volume 12,ss. 1057–1063, 2000.
[32] C. Watkins & P. Dayan. Q-learning. Machine Learning, 8:279–292, 1992.[33] P. Wawrzyński. Real time reinforcement learning by sequential actor–critics with experience replay.
Neural Networks, 22:1484–1497, 2009.[34] P. Wawrzyński & B. Papis. Fixed point method for autonomous on-line neural network training.
Neurocomputing, 74:2893–2905, 2011.[35] P. Wawrzyński & A. Pacut. Balanced importance sampling estimation. W Proceedings of the
11th International Conference on Information Processing and Management of Uncertainty in
Knowledge-based Systems, ss. 66–73, 2006.[36] R. Williams. Simple statistical gradient following algorithms for connectionist reinforcement lear-
ning. Machine Learning, 8:299–256, 1992.


















