Relacyjne Bazy Danych - podyplomowe studium 'systemy ... rok.kons/bazy_danych_wyklad_Ireneusz... ·...
44
POLITECHNIKA WROCLAWSKA WROCLAWSKIE CENTRUM SIECIOWO-SUPERKOMPUTEROWE Relacyjne Bazy Danych mgr inż. Ireneusz Tarnowski e-mail: [email protected] Ireneusz Tarnowski, Relacyjne Bazy Danych 26.02.2011 1
Transcript of Relacyjne Bazy Danych - podyplomowe studium 'systemy ... rok.kons/bazy_danych_wyklad_Ireneusz... ·...

POLITECHNIKA WROCŁAWSKA
WROCŁAWSKIE CENTRUM SIECIOWO-SUPERKOMPUTEROWE
Relacyjne Bazy Danych
mgr inż. Ireneusz Tarnowski
e-mail: [email protected]
Ireneusz Tarnowski, Relacyjne Bazy Danych 26.02.2011 1

PLAN SEMINARIUM
1. Wprowadzenie (definicje - małe powtórzenie)
2. System Zarządzania Bazą danych
3. Relacyjne bazy danych
4. Dane, struktury, relacje
5. Projektowanie bazy danych
6. MySQL jako SZBD
7. Oracle Database jako SZBD
8. Język SQL
9. Aplikacja bazodanowa
Ireneusz Tarnowski, Relacyjne Bazy Danych 26.02.2011 2
Wprowadzenie (definicje - małe powtórzenie)
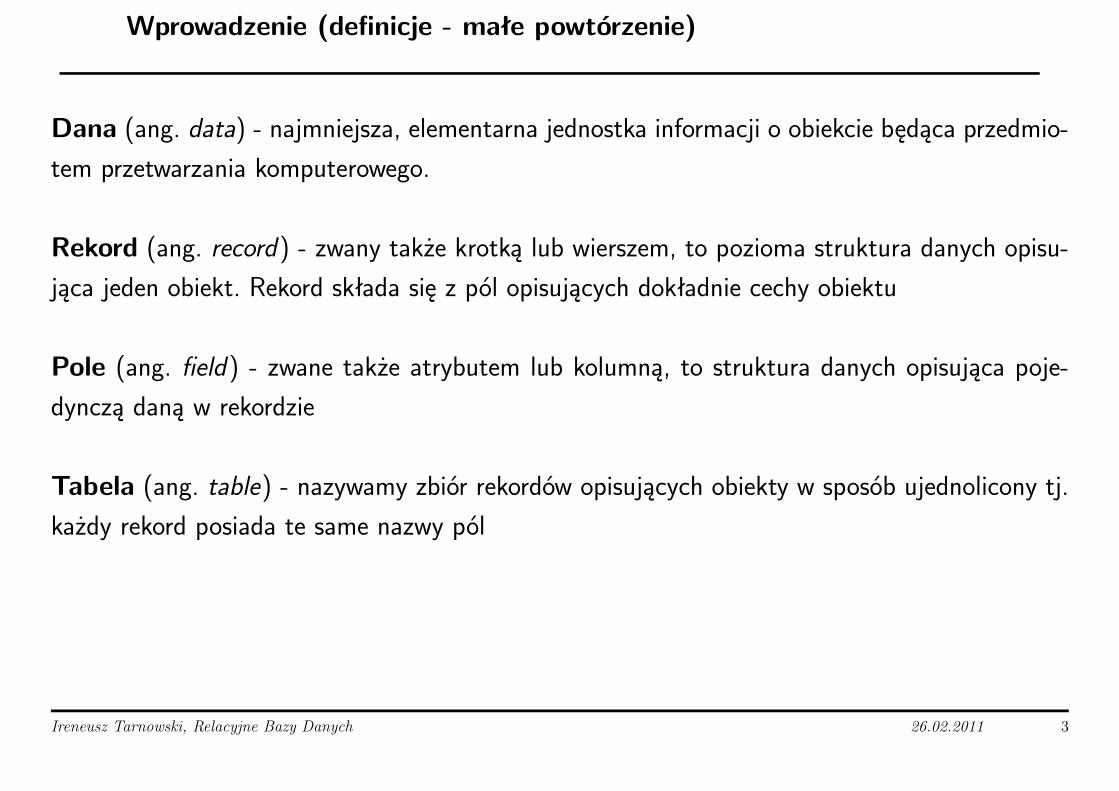
Dana (ang. data) - najmniejsza, elementarna jednostka informacji o obiekcie będąca przedmio-
tem przetwarzania komputerowego.
Rekord (ang. record) - zwany także krotką lub wierszem, to pozioma struktura danych opisu-
jąca jeden obiekt. Rekord składa się z pól opisujących dokładnie cechy obiektu
Pole (ang. field) - zwane także atrybutem lub kolumną, to struktura danych opisująca poje-
dynczą daną w rekordzie
Tabela (ang. table) - nazywamy zbiór rekordów opisujących obiekty w sposób ujednolicony tj.
każdy rekord posiada te same nazwy pól
Ireneusz Tarnowski, Relacyjne Bazy Danych 26.02.2011 3
Wprowadzenie (definicje - małe powtórzenie)
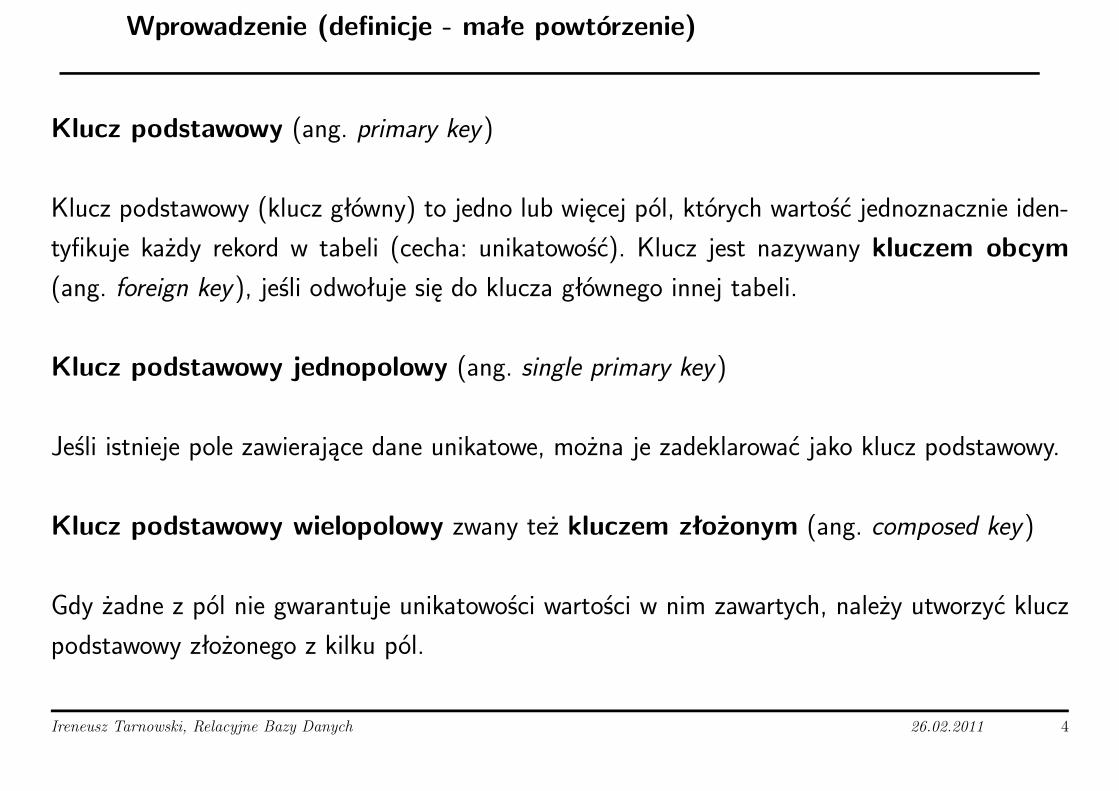
Klucz podstawowy (ang. primary key)
Klucz podstawowy (klucz główny) to jedno lub więcej pól, których wartość jednoznacznie iden-
tyfikuje każdy rekord w tabeli (cecha: unikatowość). Klucz jest nazywany kluczem obcym(ang. foreign key), jeśli odwołuje się do klucza głównego innej tabeli.
Klucz podstawowy jednopolowy (ang. single primary key)
Jeśli istnieje pole zawierające dane unikatowe, można je zadeklarować jako klucz podstawowy.
Klucz podstawowy wielopolowy zwany też kluczem złożonym (ang. composed key)
Gdy żadne z pól nie gwarantuje unikatowości wartości w nim zawartych, należy utworzyć klucz
podstawowy złożonego z kilku pól.
Ireneusz Tarnowski, Relacyjne Bazy Danych 26.02.2011 4

System Zarządzania Bazą Danych (1)
System Zarządzania Bazą Danych, SZBD (ang. Database Management System, DBMS)
(potocznie: serwer baz danych, system baz danych) to oprogramowanie bądź system informa-
tyczny służący do zarządzania komputerowymi bazami danych. Systemy baz danych mogą być
sieciowymi serwerami baz danych lub udostępniać bazę danych lokalnie.
Większość obecnie spotykanych systemów działa w trybie klient-serwer, gdzie baza danych jest
udostępniana klientom przez SZBD będący serwerem.
Najpopularnijesz dostępne systemy baz danych (Baza danych + System Zarządznaia Bazą Da-
nych):
klient-serwer: Oracle, MySQL, PosgreSQL, DB2, mSQL, dBase, Microsoft SQL Server, Inter-
Base, Informix Dynamic Server, Firebird
lokalne:Microsoft Access, SQLite
Ireneusz Tarnowski, Relacyjne Bazy Danych 26.02.2011 5

System Zarządzania Bazą Danych (2)
ZSBD musi zapewnić:- środki do gromadzenia, utrzymywania i administrowania trwałymi i masowymi zbiorami da-
nych,
- środki zapewniające spójność i bezpieczeństwo danych,
- sprawny dostęp do danych (zwykle poprzez język zapytań, np. SQL),
- środki programistyczne służące do aktualizacji/przetwarzania danych (API dla popularnych
języków programowania),
- jednoczesny dostęp do danych dla wielu użytkowników (z reguły realizowany poprzez trans-
akcje),
- środki pozwalające na regulację dostępu do danych (autoryzację),
- środki pozwalające na odtworzenie zawartości bazy danych po awarii,
- środki do zarządzania katalogami, schematami i innymi metadanymi,
- środki optymalizujące zajętość pamięci oraz czas dostępu (np. indeksy),
- środki do pracy lub współdziałania w środowiskach rozproszonych.
Ireneusz Tarnowski, Relacyjne Bazy Danych 26.02.2011 6

Relacyjne bazy danych (1)
Relacyjna baza danych (RDBMS ang. Relational Database Management Systems) oparta jest
ma modelu relacyjnym.
Model relacyjny to model baz danych oparty na postulatach relacyjności. Twórcą teorii rela-
cyjnych baz danych jest nieżyjący już Edgar Frank Codd.
Dane w modelu relacyjnym są reprezentowane jako zbiór krotek, które w znormalizowanych
bazach danych są unikatowe i nie gra roli ich kolejność. Dostęp do nich jest realizowany
za pomocą algebry relacji - czyli dostęp do danych definiujemy poprzez operatory relacyjne
takie jak: rzutowanie, selekcja, złączenie, suma, różnica, produkt kartezjański. Ograniczenie
redundancji danych dokonuje się w procesie przejścia do kolejnych postaci normalnych. Zbiory
danych powiązane są logicznie za pomocą encji. W ten sposób uniezależnia się widziany przez
użytkownika obraz bazy danych od jej postaci fizycznej.
Ireneusz Tarnowski, Relacyjne Bazy Danych 26.02.2011 7

Relacyjne bazy danych (2)
W modelu relacyjnym każda relacja (prezentowana w postaci np. tabeli) posiada nagłówek i za-
wartość. Nagłówek relacji to zbiór atrybutów, gdzie atrybut jest parą nazwa atrybutu:nazwa typu,
zawartość natomiast jest zbiorem krotek (reprezentowanych najczęściej w postaci wiersza lecz
ściślej określane jako zbiór wartości atrybutów).
Sukces relacyjnych baz danych leży w istnieniu formalnej matematycznej struktury zwanej ra-
chunkiem relacyjnym, pozwalającym przeprowadzić automatyczne sprawdzanie pewnych kon-
strukcji. Gwarantuje to wykonalność pewnych operacji i spójność zbiorów danych.
Ireneusz Tarnowski, Relacyjne Bazy Danych 26.02.2011 8

Relacje (1)
Relacja (ang. relation) - informacja na temat sposobu poprawnego łączenia powiązanych da-
nych w logiczną całość.
Typy relacji:
Relacja jeden-do-jednego (1:1)
W relacji 1:1 każdy rekord w tabeli A może mieć tylko jeden dopasowany rekord z tabeli B, i
tak samo każdy rekord w tabeli B może mieć tylko jeden dopasowany rekord z tabeli A. Ten
typ relacji spotyka się rzadko, ponieważ większość informacji powiązanych w ten sposób byłoby
zawartych w jednej tabeli. Relacji 1:1 można używać do podziału tabeli z wieloma polami,
do odizolowania części tabeli ze względów bezpieczeństwa, albo do przechowania informacji
odnoszącej się tylko do podzbioru tabeli głównej.
Ireneusz Tarnowski, Relacyjne Bazy Danych 26.02.2011 9

Relacje (2)
Typy relacji: (c.d.)
Relacja jeden-do-wielu Relacja (1:n)
W relacji jeden-do-wielu rekord w tabeli A może mieć wiele dopasowanych do niego rekordów z
tabeli B, ale rekord w tabeli B ma tylko jeden dopasowany rekord w tabeli A.
Relacja wiele-do-wielu Relacja (m:n)
W relacji m:n, rekord w tabeli A może mieć wiele dopasowanych do niego rekordów z tabeli
B i tak samo rekord w tabeli B może mieć wiele dopasowanych do niego rekordów z tabeli A.
Jest to możliwe tylko przez zdefiniowanie trzeciej tabeli (nazywanej tabelą łącza), której klucz
podstawowy składa się z dwóch pól - kluczy obcych z tabel A i B. Relacja m:n jest w istocie
dwiema relacjami 1:n z trzecią tabelą.
Ireneusz Tarnowski, Relacyjne Bazy Danych 26.02.2011 10

Projektowanie bazy danych (1)
- Przechowywanie wymaganych danych
podstawowa struktura musi być prawidłowa w pierwszej iteracji
- Tworzenie wymaganych relacji
schemat musi pozwolić na utworzenie relacji między tabelami
- Rozwiązywanie problemów
baza musi rozwiązywać problemy - a nie być ich źródłem
- Wymuszenie integralnosci danych
unikać degradacji danych oraz niekompletnych danych
- Efektywny dostęp do danych
tworzyć z zasadami sztuki; na końcu optymalizacja
- Rozszerzalność
nie zablokować rozbudowy bazy danych oraz tabel
Ireneusz Tarnowski, Relacyjne Bazy Danych 26.02.2011 11

Projektowanie bazy danych (2)
- Zbieranie informacji
- Projekt logiczny
- Określanie encji
- Konwersja encji na tabele
- Określanie relacji i liczebności
- Diagram związkow encji
- Konwersja do modelu fizycznego
- Tworzenie kluczy głównych
- Tworzneie kluczy obcych
- Ustalanie typów danych
- Dokończenie definicji tabel
- Sprawdzenie projektu
- Normalizacja (zmiana postaci normalnej 1→2→3)
- Wzorce projektowe (relacja wiele-do-wielu, hierarchia, rekurencja)
Ireneusz Tarnowski, Relacyjne Bazy Danych 26.02.2011 12

MySQL jako SZBD
MySQL jest szybkim, wielowątkowym serwerem relacyjnych baz danych obsługującym język
zapytań baz danych - SQL. Pracuje z wieloma użytkownikami jednocześnie, jest szybki, wydajny,
ma wbudowane wydajne i bezpieczne mechanizmy transakcji i widoków.
Działa na niemal wszystkich systemach operacyjnych, tj. Microsoft Windows, Oracle (Sun)
Solaris, FreeBSD, IBM i5/OS, IBM AIX, Mac OS X HP-UX, Red Hat Enterprise Linux, SuSE
Linux Enterprise Server, Linux - Generic (Ubuntu, Fedora, Debian, CentOS, ...).
Mechanizmy HA: replikacja, klaster
Ireneusz Tarnowski, Relacyjne Bazy Danych 26.02.2011 13
MySQL - licencjonowanie, ograniczenia
Dwa modele licencyjne
1. GNU General Public License (Community Edition)
2. komercyjne (Enterprise Edition)
Ograniczenia związane są z możliwością przetworzenia rekordów oraz wielkościami plików bazy
danych (ograniczenie wynikające z systemu plików OS).
Otwarte źródła (Open Source)
Uznaje się, że:
→ doskonale pracuje do 1 000 0000 rekordów,
→ producent zaleca nie więcej niż 50 000 0000 rekordów,
→ pracujące sa instalacje z 60 000 tabel i 5 000 000 000 rekordów.
Ireneusz Tarnowski, Relacyjne Bazy Danych 26.02.2011 14

MySQL w praktyce (1)
> mysql -u root -p
Enter password: *******
Welcome to the MySQL monitor. Commands end with ; or g.
Your MySQL connection id is 456 to server version 5.1.2
Type ’help’ for help.
mysql>
use - polecenie służące do wyboru interesującej nas bazy danych (nie podaliśmy nazwy bazy
danych w sposób jawny lub chcemy zmienić bazę danych, z którą do tej pory interaktywnie
pracowaliśmy).
show databases; - wyświetla nazwy baz danych na serwerze (do których mamy dostęp).
show tables; - wyświetla listę wszystkich tabel wybranej bazy danych.
Ireneusz Tarnowski, Relacyjne Bazy Danych 26.02.2011 15

MySQL w praktyce (2)
describe nazwa tabeli; - wyświetla informacje o strukturze tabeli (nazwy kolumn wybranej
tabeli, typy danych kolumn, domyślne wartościach pól danych, które znajdą się w rekordach).
source - polecenia SQL w zebrane pliku tekstowym, który jako parametr polecenia source
(wykonamy polecenia zebrane w pliku).
pager - polecenie pager nazwa programu możemy uruchomić odpowiedni program nazwa programu
aby włączyć odpowiedni mechanizm przeglądania wyników przez formatowanie ich na ekranie
zewnętrznym programem. Takim programem może być albo program less albo more. Kiedy
chcemy wyłączyć mechanizm stronicowania można wydać polecenie nopager.
tee - polecenie używane do zapisu sesji pracy z bazą danych (podając jednocześnie nazwę
pliku jako parametr wywołania). Od momentu wydania tego polecenia wszystkie polecenia będą
zapisywane do pliku. Aby zakończy zapisywanie do pliku wystarczy wydać polecenie notee.
Ireneusz Tarnowski, Relacyjne Bazy Danych 26.02.2011 16

Oracle Database
Oracle Enterprise Edition,
Oracle Standard Edition,
Oracle Standard Edition One– bazy komercyjne o różnej funkcjonalności, najnowszy wydanie Oracle Database 11g,
Oracle Database Express Edition (Oracle Database XE )
– wersja darmowa, ograniczona (m.in. jeden procesor, obsługa maksymalnie 4 GB danych użyt-
kownika, etc.), udostępniona od wersji 10g.
Ireneusz Tarnowski, Relacyjne Bazy Danych 26.02.2011 17
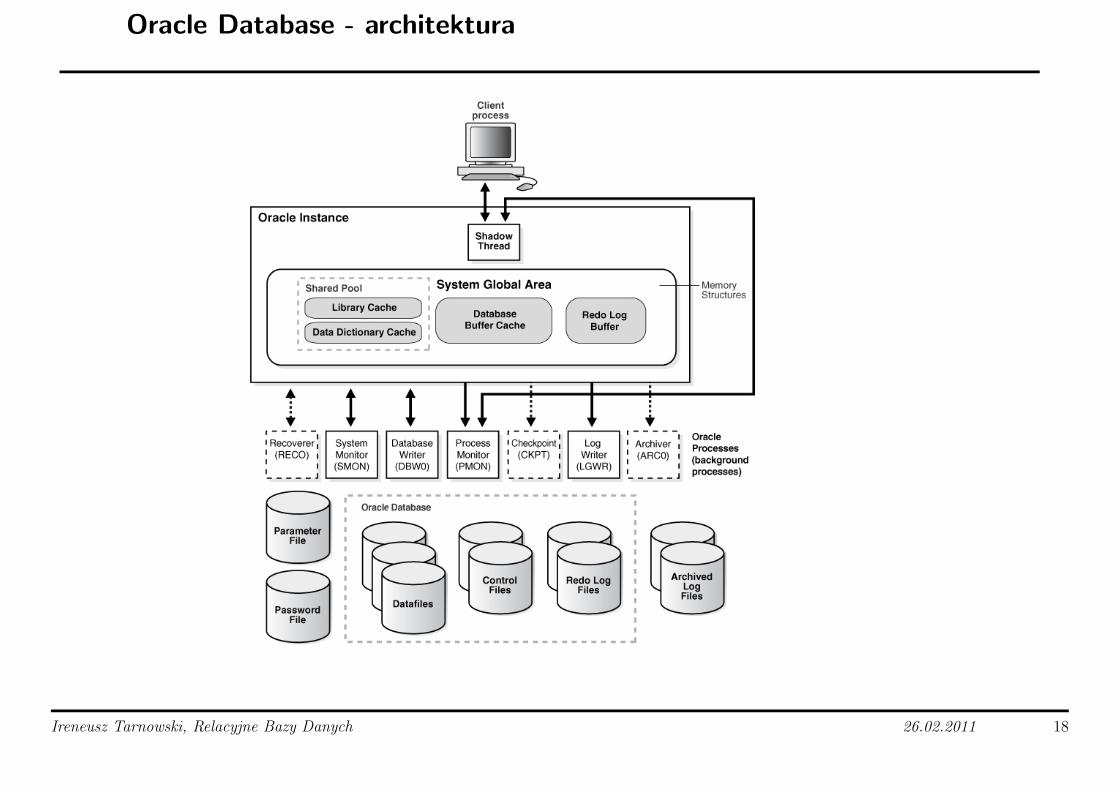
Oracle Database - architektura
Ireneusz Tarnowski, Relacyjne Bazy Danych 26.02.2011 18

PL/SQL - co to jest?
— Proceduralne rozszerzenie programistyczne języka SQL, stworzone, udostępnione przez Orac-
le i przeznaczone do obsługi narzędzi tej firmy,
— Wywodzi się z języka ADA, wiele pomysłów jest zapożyczonych z tego języka, PL w nazwie
to skrót od procedural language (z ang.), czyli języka proceduralnego,
— Jest chroniony prawami autorskimi,
— Jest językiem trzeciej generacji 3GL,
— Początkowo jedynie proceduralny, obecnie możemy go traktować jako obiektowy,
— Powstał jako odpowiedź na zapotrzebowanie samych pracowników firmy Oracle oraz ze-
wnętrznych użytkowników jej produktów.
Ireneusz Tarnowski, Relacyjne Bazy Danych 26.02.2011 19

PL/SQL zalety
— Łączy SQL z konstrukcjami proceduralnymi – SQL jest prosty, ale ma ograniczone możliwości,
— Poprawia wydajność – pozwala przetwarzać bloki instrukcji, a nie pojedyncze zapytania SQL,
— Modularyzacja – pozwala na tworzenie bloków, które mogą skupiać logicznie powiązane
wyrażenia, zagnieżdżać bloki, dzielić program na mniejsze logiczne jednostki, to pozwala na
łatwiejsze utrzymywanie i debugowanie kodu,
— Jest zintegrowany z innymi narzędziami Oracle (Reprots, Forms), dzięki temu kod przetwa-
rzany jest przez lokalny silnik a do bazy danych przesyłane są tylko zapytania SQL,
— Jest przenośny – działa tak samo na różnych platformach i w różnych systemach operacyj-
nych,
— Posiada obsługę wyjątków
Ireneusz Tarnowski, Relacyjne Bazy Danych 26.02.2011 20

Oracle SQL*Plus
— Podstawowy interfejs bazy danych niezależnie od wersji,
— Dołączany do wszystkich wersji serwera bazodanowego,
— Dostępny z poziomu serwera i klienta,
— Wykorzystywane poprzez wiersz poleceń, graficzny interfejs bądź przeglądarkę,
— Jest zawsze dostępny i niezmienny.
Ireneusz Tarnowski, Relacyjne Bazy Danych 26.02.2011 21

Oracle SQL Developer
— Darmowe, graficzne narzędzie dla programistów Oracle,
— Wspomaga i ułatwia pracę z bazą danych,
— Ułatwia przeglądanie obiektów bazy i zarządzanie nimi, wykonywanie zapytań i skryptów,
edycję i debugowanie poleceń PL/SQL, kreowanie raportów,
— Posiada udogodnienia typu: podpowiedzi, kolorowanie kodu, etc.
Ireneusz Tarnowski, Relacyjne Bazy Danych 26.02.2011 22

Oracle JDeveloper
— Wymaga licencji w przypadku zastosowań komercyjnych, darmowy w przypadku gdy używany
w celach niekomercyjnych,
— Od wersji 9i umożliwia tworzenie, pielęgnację i diagnozowanie kodu PL/SQL,
— JDeveloper 10g pozwala na: wyświetlanie wszystkich obiektów bazodanowych, edycję kodu
PL/SQL oraz dostarcza szablony kodu, porady w sprawie optymalizacji SQL i mechanizmy
diagnostyczne.
Ireneusz Tarnowski, Relacyjne Bazy Danych 26.02.2011 23

Język SQL
SQL (ang. Structured Query Language) – strukturalny język zapytań używany do tworzenia,
modyfikowania baz danych oraz do umieszczania i pobierania danych z baz danych.
SQL - standard w komunikacji z serwerami relacyjnych baz danych; W 1986 roku SQL stał się
oficjalnym standardem, wspieranym przez Międzynarodową Organizację Normalizacyjną (ISO)
oraz Amerykański Narodowy Instytut Normalizacji (ANSI).
Język SQL pozwala wprowadzać zmiany w strukturze bazy danych, jak również zmiany danych
w bazie i wybieranie informacji z bazy danych. Język ten opiera się na silniku bazy danych,
który pozwala zadawać w języku SQL pewnego rodzaju pytania (kwerendy) i wyświetlać dane,
które spełniają warunki zapytania. Zapytania SQL mogą także wykonywać operacje wstawiania
danych, usuwania danych i ich aktualizacji. Język SQL zapewnia również zarządzanie bazą
danych. Informacja o samej bazie przechowywana jest w postaci relacji (tabel) wewnątrz bazy
danych.
Ireneusz Tarnowski, Relacyjne Bazy Danych 26.02.2011 24

Język SQL - typy danych
Typ danej - rodzaj danej, czyli forma zapisu informacji:
- znakowy (ang.character) - dana może przybierać tylko wartości znaków pisarskich,
- liczbowy (ang.number) - dana może przechowywać tylko liczby,
- logiczny (ang.logical) - dana może przybierać tylko dwie wartości: prawda, fałsz (tak, nie),
- data (ang.date) - dana może przyjmować postać daty i czasu np. rok.miesiąc.dzień godz:min:sek,
- alfanumeryczny (ang.alphanumeric) - dana może przybierać wartości znaków ASCII oraz cyfry,
- numeryczny (ang.numeric) - wartościami danej mogą być tylko cyfry i znaki: + (plus), -
(minus),
- walutowy (ang.currency) - dana może przyjmować wartości liczbowe razem z symbolem waluty,
- notatnikowy (ang.memo) - dana może być oddzielnym zbiorem tekstowym służącym do prze-
chowywania dowolnych opisów,
- binarny (ang.binary) - dana może być np. plikiem dźwiękowym lub filmowym,
- graficzny (ang.graphic) - dana przechowuje grafikę np. rysunki,
- obiektowy (ang.OLE) - dana przechowuje obiekty.
Ireneusz Tarnowski, Relacyjne Bazy Danych 26.02.2011 25

Język SQL - tworzenie bazy danych
CREATE {DATABASE | SCHEMA} [IF NOT EXISTS] db_name
[create_specification ...]
create_specification:
[DEFAULT] CHARACTER SET [=] charset_name
| [DEFAULT] COLLATE [=] collation_name
Ireneusz Tarnowski, Relacyjne Bazy Danych 26.02.2011 26

Język SQL - tworzenie tabel
CREATE [TEMPORARY] TABLE [IF NOT EXISTS] tbl_name
(create_definition,...)
[table_option] ...
create_definition:
col_name column_definition
| [CONSTRAINT [symbol]] PRIMARY KEY [index_type] (index_col_name,...)
| {INDEX|KEY} [index_name] [index_type] (index_col_name,...)
column_definition:
data_type [NOT NULL | NULL] [DEFAULT default_value]
[AUTO_INCREMENT] [UNIQUE [KEY] | [PRIMARY] KEY]
[COMMENT ’string’] [reference_definition]
Ireneusz Tarnowski, Relacyjne Bazy Danych 26.02.2011 27

Język SQL - tworzenie tabel
data_type:
BIT[(length)]
| TINYINT[(length)] [UNSIGNED] [ZEROFILL]
| SMALLINT[(length)] [UNSIGNED] [ZEROFILL]
| MEDIUMINT[(length)] [UNSIGNED] [ZEROFILL]
| INT[(length)] [UNSIGNED] [ZEROFILL]
| INTEGER[(length)] [UNSIGNED] [ZEROFILL]
| BIGINT[(length)] [UNSIGNED] [ZEROFILL]
| REAL[(length,decimals)] [UNSIGNED] [ZEROFILL]
| DOUBLE[(length,decimals)] [UNSIGNED] [ZEROFILL]
| FLOAT[(length,decimals)] [UNSIGNED] [ZEROFILL]
| DECIMAL[(length[,decimals])] [UNSIGNED] [ZEROFILL]
| NUMERIC[(length[,decimals])] [UNSIGNED] [ZEROFILL]
| DATE | TIME | TIMESTAMP | DATETIME | YEAR
| CHAR[(length)][CHARACTER SET charset_name] [COLLATE collation_name]
| VARCHAR(length) [CHARACTER SET charset_name] [COLLATE collation_name]
| BINARY[(length)]
| VARBINARY(length)
| TINYBLOB | MEDIUMBLOB | LONGBLOB
| TINYTEXT [BINARY][CHARACTER SET charset_name] [COLLATE collation_name]
| TEXT [BINARY][CHARACTER SET charset_name] [COLLATE collation_name]
| MEDIUMTEXT [BINARY][CHARACTER SET charset_name] [COLLATE collation_name]
| LONGTEXT [BINARY][CHARACTER SET charset_name] [COLLATE collation_name]
| ENUM(value1,value2,value3,...)
[CHARACTER SET charset_name] [COLLATE collation_name]
| SET(value1,value2,value3,...)
[CHARACTER SET charset_name] [COLLATE collation_name]
Ireneusz Tarnowski, Relacyjne Bazy Danych 26.02.2011 28

Język SQL - zmiana struktury tabeli
ALTER TABLE tbl_name alter_specification [, alter_specification] ...alter_specification:
| ADD [COLUMN] col_name column_definition [FIRST | AFTER col_name ]
| ADD [COLUMN] (col_name column_definition,...)
| ADD {INDEX|KEY} [index_name] [index_type] (index_col_name,...) [index_type]
| ADD [CONSTRAINT [symbol]] PRIMARY KEY [index_type] (index_col_name,...) [index_type]
| ADD [CONSTRAINT [symbol]] UNIQUE [INDEX|KEY] [index_name]
[index_type] (index_col_name,...) [index_type]
| ADD [FULLTEXT|SPATIAL] [INDEX|KEY] [index_name]
(index_col_name,...) [index_type]
| ADD [CONSTRAINT [symbol]] FOREIGN KEY [index_name] (index_col_name,...)
| ALTER [COLUMN] col_name {SET DEFAULT literal | DROP DEFAULT}
| CHANGE [COLUMN] old_col_name new_col_name column_definition [FIRST|AFTER col_name]
| MODIFY [COLUMN] col_name column_definition [FIRST | AFTER col_name]
| DROP [COLUMN] col_name
| DROP PRIMARY KEY
| DROP {INDEX|KEY} index_name
| DROP FOREIGN KEY fk_symbol
| RENAME [TO] new_tbl_name
| ORDER BY col_name [, col_name] ...
| CONVERT TO CHARACTER SET charset_name [COLLATE collation_name]
| [DEFAULT] CHARACTER SET [=] charset_name [COLLATE [=] collation_name]
Ireneusz Tarnowski, Relacyjne Bazy Danych 26.02.2011 29

Język SQL - wstawianie danych
INSERT [LOW_PRIORITY | DELAYED | HIGH_PRIORITY] [IGNORE]
[INTO] tbl_name [(col_name,...)]
VALUES ({expr | DEFAULT},...),(...),...
Ireneusz Tarnowski, Relacyjne Bazy Danych 26.02.2011 30

Język SQL - modyfikacja danych
UPDATE [LOW_PRIORITY] [IGNORE] tbl_name
SET col_name1=expr1 [, col_name2=expr2 ...]
[WHERE where_condition]
[ORDER BY ...]
[LIMIT row_count]
Ireneusz Tarnowski, Relacyjne Bazy Danych 26.02.2011 31

Język SQL - usuwanie danych
DELETE [LOW_PRIORITY] [QUICK] [IGNORE] FROM tbl_name
[WHERE where_condition]
[ORDER BY ...]
[LIMIT row_count]
DELETE [LOW_PRIORITY] [QUICK] [IGNORE]
tbl_name[.*] [, tbl_name[.*]] ...
FROM table_references
[WHERE where_condition]
Ireneusz Tarnowski, Relacyjne Bazy Danych 26.02.2011 32

Język SQL - usuwanie tabeli i bazy danych
DROP [TEMPORARY] TABLE [IF EXISTS]
tbl_name [, tbl_name] ...
[RESTRICT | CASCADE]
DROP {DATABASE | SCHEMA} [IF EXISTS] db_name
Ireneusz Tarnowski, Relacyjne Bazy Danych 26.02.2011 33

Język SQL - wydobywanie danych
SELECT
[ALL | DISTINCT | DISTINCTROW ]
[HIGH_PRIORITY]
[STRAIGHT_JOIN]
[SQL_SMALL_RESULT] [SQL_BIG_RESULT] [SQL_BUFFER_RESULT]
[SQL_CACHE | SQL_NO_CACHE] [SQL_CALC_FOUND_ROWS]
select_expr, ...
[FROM table_references
[WHERE where_condition]
[GROUP BY {col_name | expr | position}
[ASC | DESC], ... [WITH ROLLUP]]
[HAVING where_condition]
[ORDER BY {col_name | expr | position}
[ASC | DESC], ...]
[LIMIT {[offset,] row_count | row_count OFFSET offset}]
[PROCEDURE procedure_name(argument_list)]
[INTO OUTFILE ’file_name’ export_options
| INTO DUMPFILE ’file_name’
| INTO var_name [, var_name]]
[FOR UPDATE | LOCK IN SHARE MODE]]
Ireneusz Tarnowski, Relacyjne Bazy Danych 26.02.2011 34

Język SQL - uprawneinia
GRANT priv_type [(column_list)] ON [object_type]
{ * | *.* | db_name.* | db_name.tbl_name
| tbl_name | db_name.routine_name }
TO user [IDENTIFIED BY [PASSWORD] ’password’]
[WITH with_option [with_option] ...]
object_type =
TABLE | FUNCTION | PROCEDURE
with_option =
GRANT OPTION | MAX_QUERIES_PER_HOUR count
| MAX_UPDATES_PER_HOUR count | MAX_CONNECTIONS_PER_HOUR count
| MAX_USER_CONNECTIONS count
Ireneusz Tarnowski, Relacyjne Bazy Danych 26.02.2011 35

Język SQL - uprawneinia
REVOKE
priv_type [(column_list)] ON [object_type]
{ * | *.* | db_name.* | db_name.tbl_name
| tbl_name | db_name.routine_name }
FROM user [, user] ...
REVOKE ALL PRIVILEGES, GRANT OPTION FROM user [, user] ...
CREATE USER
DROP USER
SET PASSWORD
RENAME USER
Ireneusz Tarnowski, Relacyjne Bazy Danych 26.02.2011 36

Język SQL - złączenia tabel
Model relacyjny zakłada, że dane, zawarte w bazie danych, podzielone są na tabele. W pewnych
sytuacjach konieczne będzie połączenie danych, zawartych w kilku tabelach, w celu uzyskania
tabeli wynikowej. Proces taki nazywamy złączeniem (ang. join), ze względu na sposób łączenia
dzieli się operacje złączeń na trzy grupy:
- złączenia wewnętrzne
- złączenia zewnętrzne
- samozłączenia
SELECT * FROM tabela1, tabela2
SELECT * FROM tabela1, tabela2 WHERE tabela1.klucz_główny = tabela2.klucz_obcy
SELECT * FROM tabela1 JOIN tabela2 ON warunek_złączenia_tabel
SELECT * FROM tabela1 LEFT OUTER JOIN tabela2...
SELECT * FROM tabela1 RIGHT OUTER JOIN tabela2...
SELECT * FROM tabela1 FULL OUTER JOIN tabela2...
Ireneusz Tarnowski, Relacyjne Bazy Danych 26.02.2011 37

Język SQL - podzapytania
Podzapytanie, to instrukcja SELECT zagnieżdżona w innej instrukcji SQL, która dostarcza
dla tej drugiej danych wejściowych. Podzapytanie jest zapytaniem zagnieżdżonym. Język SQL
nie wprowadza ograniczeń na ilość zagnieżdżeń, w związku z czym zapytanie otaczające też
może być podzapytaniem.
SELECT * FROM t1 WHERE column1 = (SELECT column1 FROM t2);
Ireneusz Tarnowski, Relacyjne Bazy Danych 26.02.2011 38

Język SQL - transakcje
Transakcja wykonuje się albo w całości, albo wcale. Jeżeli w trakcie wykonywania
transakcji wystąpi jakiś błąd, całą sekwencję operacji można odwołać, przywracając bazę do
stanu sprzed rozpoczęcia tej sekwencji.
START TRANSACTION [WITH CONSISTENT SNAPSHOT] | BEGIN [WORK]
COMMIT [WORK] [AND [NO] CHAIN] [[NO] RELEASE]
ROLLBACK [WORK] [AND [NO] CHAIN] [[NO] RELEASE]
SET AUTOCOMMIT = {0 | 1}
START TRANSACTION;
SELECT @A:=SUM(salary) FROM table1 WHERE type=1;
UPDATE table2 SET summary=@A WHERE type=1;
COMMIT;
Ireneusz Tarnowski, Relacyjne Bazy Danych 26.02.2011 39

Język SQL - wyzwalacze (ang. triggers)
Trigger jest obiektem związanym z tablicą, który aktywuje się gdy do tablicy następuje odpo-
wiednie zapytanie.
Dzięki triggerom można:
- sprawdzać i zapobiegać dostawaniu się do bazy danych „nieodpowiednich danych”.
- zmieniać polecenia INSERT, UPDATE i DELETE lub w ogóle ich zaniechać w zależności od
tego, jakie informacje dostarczy nam trigger.
- monitorować aktywność działań na danych w bazie danych w czasie sesji z bazą danych.CREATE
[DEFINER = { user | CURRENT_USER }]
TRIGGER trigger_name trigger_time trigger_event
ON tbl_name FOR EACH ROW trigger_stmt
CREATE TABLE konto (numer INT, ile DECIMAL(10,2));
CREATE TRIGGER konto_bi BEFORE INSERT ON konto
FOR EACH ROW SET @sum = @sum + NEW.ile;
Ireneusz Tarnowski, Relacyjne Bazy Danych 26.02.2011 40

Język SQL - funckje i operatory
Duża grupa wewnętrznych funkcji:
SUM, RAND, CONCAT, AVG, COUNT, MAX, MIN, SQRT ROUND, DATE, DATE_FORMAT, TIME_FORMAT,
TIME, SUBDATE, FLOOR, EXP, MOD, PI, SIN, RADIANS, UPPER, LOWER, ASCII, ORD, QUOTE
operatory:
BINARY, COLLATE
!
- (unary minus), ~ (unary bit inversion)
^
*, /, DIV, %, MOD
-, +, <<, >>
&, |, =, <=>, >=, >, <=, <, <>, !=, IS, LIKE, REGEXP, IN
BETWEEN, CASE, WHEN, THEN, ELSE
NOT, &&, AND, XOR, ||, OR, :=
Ireneusz Tarnowski, Relacyjne Bazy Danych 26.02.2011 41

Aplikacja bazodanowa
Program komputerowy pośredniczący w wymianie danych między użytkownikiem a bazą danych
(za pośrednictwem SZBD).
1. Aplikacja stanowi ”najwyższy” element systemu bazodanowego.
2. Nie należy do SZBD ani do samej bazy danych.
3. Apliakcja musi się składać z interfejsu komunikacji z użytkownikiem (GUI lub CLI), w którego
skład wchodzą: formularze, raportów, mechanizm kwerend.
Ireneusz Tarnowski, Relacyjne Bazy Danych 26.02.2011 42

Więcej na temat ...
[ 1 ] Ramez Elmasri, Shamkant B. Navathe, Wprowadzenie do systemów baz danych, Helion, 2005
[ 2 ] Richard Stones, Neil Matthew, Bazy danych i MySQL. Od podstaw, Helion, 2003
[ 3 ] Mark Whitehorn, Bill Marklyn, Relacyjne bazy danych, Helion, 2003
[ 4 ] Luke Welling, Laura Thomson, MySQL. Podstawy, oficjalny podręcznik, Helion, 2004
[ 5 ] Michael Abbey, Michael Corey, Ian Abramson, Oracle9i. Przewodnik dla początkujących, Helion, 2003
[ 6 ] Scott Urman, Oracle9i. Programowanie w języku PL/SQL, Helion, 2003
[ 7 ] www.mysql.com, MySQL, podręcznik użytkownika, dokumentacja producenta oprogramowania
[ 8 ] www.oracle.com, Oracle 11g, podręcznik użytkownika, dokumentacja producenta oprogramowania
Ireneusz Tarnowski, Relacyjne Bazy Danych 26.02.2011 43

POLITECHNIKA WROCŁAWSKA
WROCŁAWSKIE CENTRUM SIECIOWO-SUPERKOMPUTEROWE
Relacyjne Bazy Danych
mgr inż. Ireneusz Tarnowski
e-mail: [email protected]
Ireneusz Tarnowski, Relacyjne Bazy Danych 26.02.2011 44