
Praca dyplomowa - magisterskakopel/mgr/2018.06_mgr_Tatina.pdf · progresywne aplikacje webowe...
55
Wydział Informatyki i Zarządzania kierunek studiów: wpisz właściwy specjalność: wpisz właściwą Praca dyplomowa - magisterska Wpływ technologii progresywnych aplikacji webowych na jakość świadczonych usług w sieci Internet Denis Tatina słowa kluczowe: progresywne aplikacje webowe jakość usług w sieci Internet wydajność aplikacji webowych krótkie streszczenie: Celem pracy jest poddanie dokładnej analizie procesu generowania stron przez przeglądarki internetowe, a następnie zbadanie wpływu technologii progresywnych aplikacji webowych na jakość świadczonych usług w sieci Internet. W tym celu przeprowadzony zostanie eksperyment polegający na wykonaniu aplikacji zgodnej z wytycznymi tej techniki, zbadaniu jej wydajności z wykorzystaniem wybranych miar i wydaniu autorskiej oceny podsumowującej. opiekun pracy dyplomowej dr inż. Marek Kopel ....................... ....................... Tytuł/stopień naukowy/imię i nazwisko ocena podpis Ostateczna ocena za pracę dyplomową Przewodniczący Komisji egzaminu dyplomowego .................................................. Tytuł/stopień naukowy/imię i nazwisko ....................... ....................... ocena podpis Do celów archiwalnych pracę dyplomową zakwalifikowano do:* a) kategorii A (akta wieczyste) b) kategorii BE 50 (po 50 latach podlegające ekspertyzie) * niepotrzebne skreślić pieczątka wydziałowa Wrocław 2018
Transcript of Praca dyplomowa - magisterskakopel/mgr/2018.06_mgr_Tatina.pdf · progresywne aplikacje webowe...

Wydział Informatyki i Zarządzania
kierunek studiów: wpisz właściwy
specjalność: wpisz właściwą
Praca dyplomowa - magisterska
Wpływ technologii progresywnych aplikacji webowych na jakość świadczonych usług w sieci Internet
Denis Tatina
słowa kluczowe:
progresywne aplikacje webowe
jakość usług w sieci Internet
wydajność aplikacji webowych
krótkie streszczenie:
Celem pracy jest poddanie dokładnej analizie procesu generowania stron przez
przeglądarki internetowe, a następnie zbadanie wpływu technologii
progresywnych aplikacji webowych na jakość świadczonych usług w sieci
Internet. W tym celu przeprowadzony zostanie eksperyment polegający na
wykonaniu aplikacji zgodnej z wytycznymi tej techniki, zbadaniu jej wydajności
z wykorzystaniem wybranych miar i wydaniu autorskiej oceny podsumowującej.
opiekun pracy
dyplomowej
dr inż. Marek Kopel ....................... .......................
Tytuł/stopień naukowy/imię i nazwisko ocena podpis
Ostateczna ocena za pracę dyplomową
Przewodniczący
Komisji egzaminu
dyplomowego
..................................................
Tytuł/stopień naukowy/imię i nazwisko
....................... .......................
ocena podpis
Do celów archiwalnych pracę dyplomową zakwalifikowano do:* a) kategorii A (akta wieczyste)
b) kategorii BE 50 (po 50 latach podlegające ekspertyzie) * niepotrzebne skreślić
pieczątka wydziałowa
Wrocław 2018

STRESZCZENIE Celem pracy jest zbadanie wpływu technologii progresywnych aplikacji webowych na
jakość świadczonych usług w sieci Internet i wydanie autorskiej oceny tego rozwiązania. W tym celu proces generowania stron przez przeglądarki internetowe zostanie poddany dokładnej analizie, aby określić główne problemy wydajności aplikacji webowych i miejsca ich występowania. Następnie technologia progresywnych aplikacji webowych zostanie zanalizowana w celu poznania głównych zasad działania, wymogów a także jej zalet i wad. Kolejno poruszona zostanie kwestia metodyki prowadzenia badań jakości usług sieciowych z perspektywy użytkownika końcowego i wybrane zostaną adekwatne do tytułowej technologii miary służące do estymowania wydajności stron internetowych. Ostatecznie przeprowadzony zostanie eksperyment polegający na wykonaniu klasycznej aplikacji webowej i poddaniu jej transformacji w zgodną z wytycznymi tej techniki. Dwie wersje strony zostaną zbadane pod kątem różnic w ich wydajności z wykorzystaniem wybranych miar. Praca zakończona zostanie ukazaniem najważniejszych aspektów badanej technologii i wydaniu autorskiej oceny podsumowującej.
SUMMARY
The aim of the thesis is to examine the influence of progressive web applications technology
on quality of services distributed in the Internet and the author's evaluation of this solution. For this purpose, the process of page generation by web browsers will be thoroughly analyzed to determine the main problems of web application performance and where they occur. Then the technology of progressive web applications will be analyzed in order to know fundamental rules, requirements as well as its advantages and disadvantages. Subsequently, the issue of methodology for conducting the quality of network applications from the end-user perspective will be addressed and the measures adequate to estimating the performance of the title technology will be chosen. Finally, an experiment in order to develop web application in classic approach and next transforming it in accordance with the guidelines of title technique will be carried out. Two versions of the webpage will be examined for differences in their performances using selected measures. The thesis will end with the presentation of the most important aspects of this technology and the release of the author's summary evaluation.

Spis treści
1. Wstęp teoretyczny 5 1.1 World Wide Web 7 1.2 Protokół HTTP 8 1.3 Jakość połączenia sieciowego 9 1.4 Buforowanie HTTP 11 1.5 Document Object Model 12 1.6 Krytyczna ścieżka renderowania 13
2. Progresywne aplikacje webowe 15 2.1 SSL 18 2.2 HTTP 2 19 2.3 Web App Manifest 21 2.4 Service worker 22 2.4.1 Cykl życia SW 23 2.4.2 Fetch API 23 2.4.3 Cache API 24 2.4.4 Tryb offline 24 2.5 Powiadomienia push 25 2.6 IndexedDB 25 2.7 Responsywny układ treści 26 2.8 App Shell 26 2.9 Biblioteki wspomagające obsługę SW 27 2.10 Aplikacja natywna 28 2.11 Konkurencyjne rozwiązania 28
3. Miary badania jakości usług sieciowych 30 3.1 Pierwsze oraz ponowne wczytanie witryny 31 3.2 Liczba żądań 31 3.3 Liczba przesłanych danych 32 3.4 Czas wczytania strony internetowej 32 3.5 Obsługa trybu dostępu do sieci online, lie-fi oraz offline 32 3.6 First meaningful paint 33 3.7 Narzędzia oraz audyty - Google Lighthouse, Google Chrome Dev Tools 34 3.8 Perceptual Speed Index 34
4. Przeprowadzony eksperyment 35 4.1 Badana aplikacja 35 4.2 Wizja systemu 35 4.3 Architektura systemu 35 4.4 Zastosowane technologie 36 4.5 Klasyczne rozwiązanie, przegląd wytworzonej aplikacji 36 4.6 PWA 37

4.7 Aspekty pominięte w badaniu 37 4.8 Warunki i środowisko przeprowadzanego badania 37
5. Analiza uzyskanych wyników 38
6. Najważniejsze aspekty PWA 43
7. Podsumowanie 45
8. Przyszły rozwój tej technologii 46
Źródła literaturowe 49
Spis rysunków 51
Spis tabel 52
Spis załączników 52
1. Wstęp teoretyczny
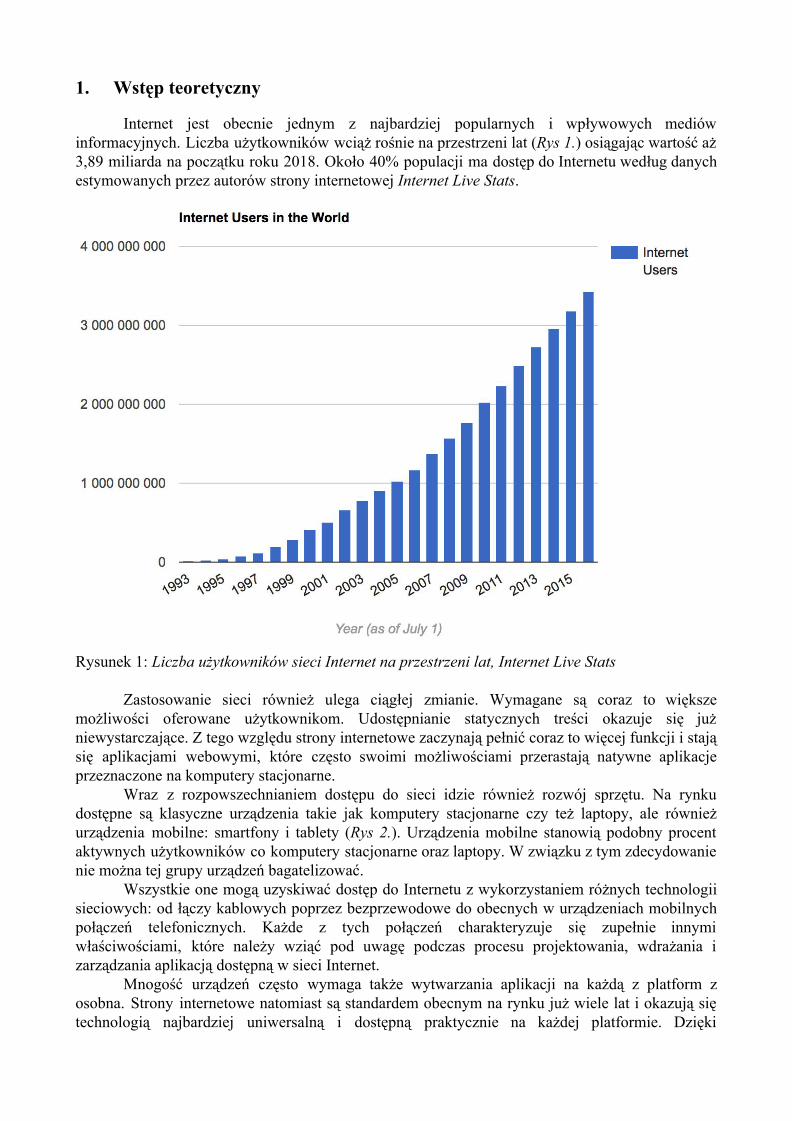
Internet jest obecnie jednym z najbardziej popularnych i wpływowych mediów informacyjnych. Liczba użytkowników wciąż rośnie na przestrzeni lat (Rys 1.) osiągając wartość aż 3,89 miliarda na początku roku 2018. Około 40% populacji ma dostęp do Internetu według danych estymowanych przez autorów strony internetowej Internet Live Stats.
Rysunek 1: Liczba użytkowników sieci Internet na przestrzeni lat, Internet Live Stats
Zastosowanie sieci również ulega ciągłej zmianie. Wymagane są coraz to większe możliwości oferowane użytkownikom. Udostępnianie statycznych treści okazuje się już niewystarczające. Z tego względu strony internetowe zaczynają pełnić coraz to więcej funkcji i stają się aplikacjami webowymi, które często swoimi możliwościami przerastają natywne aplikacje przeznaczone na komputery stacjonarne.
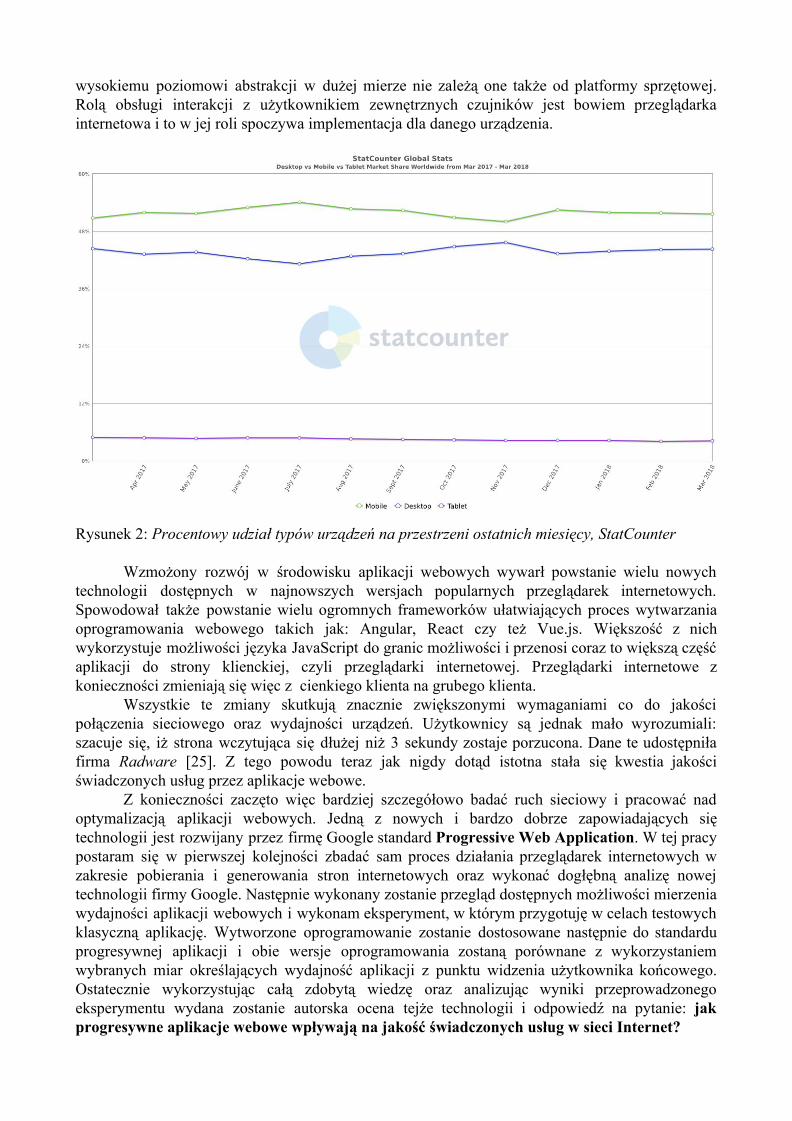
Wraz z rozpowszechnianiem dostępu do sieci idzie również rozwój sprzętu. Na rynku dostępne są klasyczne urządzenia takie jak komputery stacjonarne czy też laptopy, ale również urządzenia mobilne: smartfony i tablety (Rys 2.). Urządzenia mobilne stanowią podobny procent aktywnych użytkowników co komputery stacjonarne oraz laptopy. W związku z tym zdecydowanie nie można tej grupy urządzeń bagatelizować.
Wszystkie one mogą uzyskiwać dostęp do Internetu z wykorzystaniem różnych technologii sieciowych: od łączy kablowych poprzez bezprzewodowe do obecnych w urządzeniach mobilnych połączeń telefonicznych. Każde z tych połączeń charakteryzuje się zupełnie innymi właściwościami, które należy wziąć pod uwagę podczas procesu projektowania, wdrażania i zarządzania aplikacją dostępną w sieci Internet.
Mnogość urządzeń często wymaga także wytwarzania aplikacji na każdą z platform z osobna. Strony internetowe natomiast są standardem obecnym na rynku już wiele lat i okazują się technologią najbardziej uniwersalną i dostępną praktycznie na każdej platformie. Dzięki
wysokiemu poziomowi abstrakcji w dużej mierze nie zależą one także od platformy sprzętowej. Rolą obsługi interakcji z użytkownikiem zewnętrznych czujników jest bowiem przeglądarka internetowa i to w jej roli spoczywa implementacja dla danego urządzenia.
Rysunek 2: Procentowy udział typów urządzeń na przestrzeni ostatnich miesięcy, StatCounter
Wzmożony rozwój w środowisku aplikacji webowych wywarł powstanie wielu nowych technologii dostępnych w najnowszych wersjach popularnych przeglądarek internetowych. Spowodował także powstanie wielu ogromnych frameworków ułatwiających proces wytwarzania oprogramowania webowego takich jak: Angular, React czy też Vue.js. Większość z nich wykorzystuje możliwości języka JavaScript do granic możliwości i przenosi coraz to większą część aplikacji do strony klienckiej, czyli przeglądarki internetowej. Przeglądarki internetowe z konieczności zmieniają się więc z cienkiego klienta na grubego klienta.
Wszystkie te zmiany skutkują znacznie zwiększonymi wymaganiami co do jakości połączenia sieciowego oraz wydajności urządzeń. Użytkownicy są jednak mało wyrozumiali: szacuje się, iż strona wczytująca się dłużej niż 3 sekundy zostaje porzucona. Dane te udostępniła firma Radware [25]. Z tego powodu teraz jak nigdy dotąd istotna stała się kwestia jakości świadczonych usług przez aplikacje webowe.
Z konieczności zaczęto więc bardziej szczegółowo badać ruch sieciowy i pracować nad optymalizacją aplikacji webowych. Jedną z nowych i bardzo dobrze zapowiadających się technologii jest rozwijany przez firmę Google standard Progressive Web Application. W tej pracy postaram się w pierwszej kolejności zbadać sam proces działania przeglądarek internetowych w zakresie pobierania i generowania stron internetowych oraz wykonać dogłębną analizę nowej technologii firmy Google. Następnie wykonany zostanie przegląd dostępnych możliwości mierzenia wydajności aplikacji webowych i wykonam eksperyment, w którym przygotuję w celach testowych klasyczną aplikację. Wytworzone oprogramowanie zostanie dostosowane następnie do standardu progresywnej aplikacji i obie wersje oprogramowania zostaną porównane z wykorzystaniem wybranych miar określających wydajność aplikacji z punktu widzenia użytkownika końcowego. Ostatecznie wykorzystując całą zdobytą wiedzę oraz analizując wyniki przeprowadzonego eksperymentu wydana zostanie autorska ocena tejże technologii i odpowiedź na pytanie: jak progresywne aplikacje webowe wpływają na jakość świadczonych usług w sieci Internet?
1.1. World Wide Web
Skrót WWW, którego pełna nazwa to World Wide Web, z języka angielskiego można przetłumaczyć jako “ogólnoświatowa sieć”. Oparta jest ona na architekturze klient-serwer. Serwer zajmuje się udostępnianiem treści hipertekstowych w sieci, natomiast klient w postaci przeglądarki internetowej przeznaczony jest do wyświetlania tych treści. Standard pisania i przesyłania stron internetowych jest natomiast ustanawiany przez organizację World Wide Web Consortium, w skrócie W3C.
Początkiem hipertekstu w sieci Internet było opracowanie systemu ogólnodostępnych, unikatowych identyfikatorów zasobów sieci: The Universal Document Identifier (UDI) znanych współcześnie jako Uniform Resource Locator (URL) i Uniform Resource Identifier (URI). Kolejnym krokiem było zdefiniowanie języka służącego do projektowania stron – HyperText Markup Language (HTML) oraz protokółu przesyłania dokumentów hipertekstowych Hypertext Transfer Protocol (HTTP). Obecnie sieć WWW jest oczywiście znacznie bardziej rozbudowana: obecne są kaskadowe arkusze stylów (CSS) opisujące wizualny układ treści na stronach czy też skrypty JavaScript dodające do stron dynamiczny aspekt.
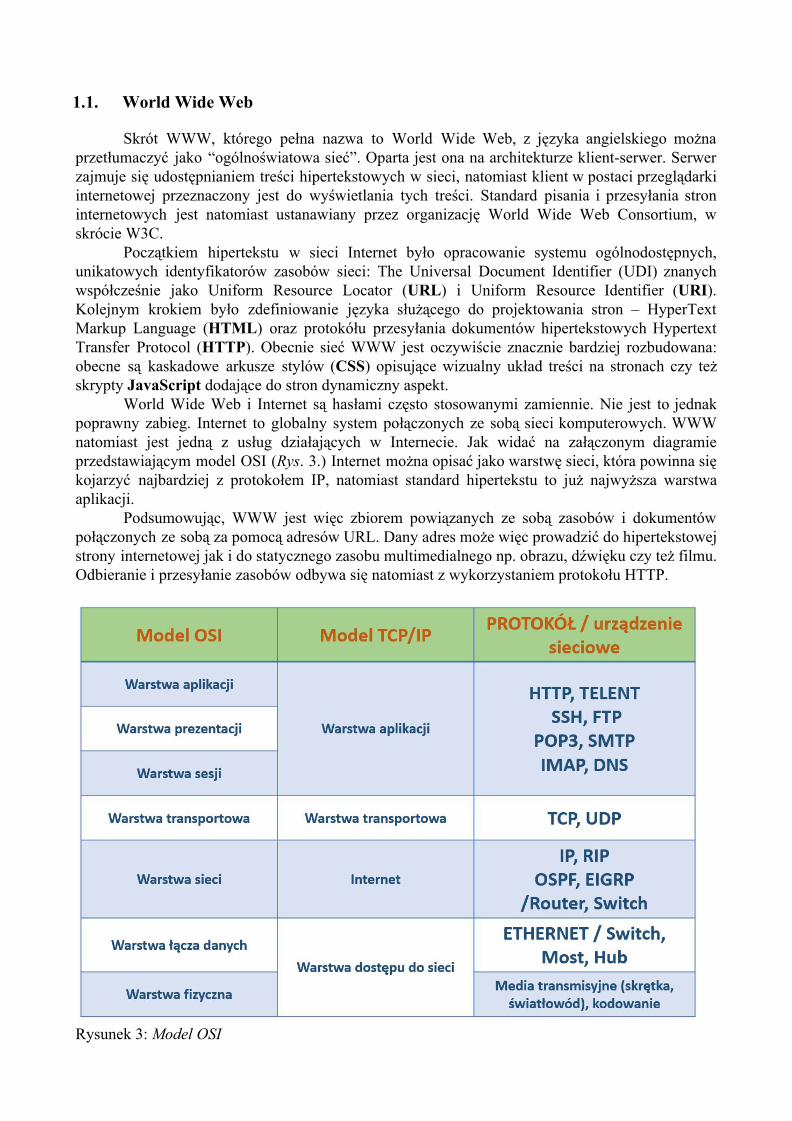
World Wide Web i Internet są hasłami często stosowanymi zamiennie. Nie jest to jednak poprawny zabieg. Internet to globalny system połączonych ze sobą sieci komputerowych. WWW natomiast jest jedną z usług działających w Internecie. Jak widać na załączonym diagramie przedstawiającym model OSI (Rys. 3.) Internet można opisać jako warstwę sieci, która powinna się kojarzyć najbardziej z protokołem IP, natomiast standard hipertekstu to już najwyższa warstwa aplikacji.
Podsumowując, WWW jest więc zbiorem powiązanych ze sobą zasobów i dokumentów połączonych ze sobą za pomocą adresów URL. Dany adres może więc prowadzić do hipertekstowej strony internetowej jak i do statycznego zasobu multimedialnego np. obrazu, dźwięku czy też filmu. Odbieranie i przesyłanie zasobów odbywa się natomiast z wykorzystaniem protokołu HTTP.
Rysunek 3: Model OSI

1.2. Protokół HTTP
Komunikacja w sieci WWW odbywa się wykorzystaniem protokołu HTTP [8], którego standard opisywany jest w dokumencie RFC 2616. Pełna nazwa to Hypertext Transfer Protocol. Udostępnia on znormalizowany sposób komunikowania się komputerów w sieci. Definiuje on formę żądań klienta dotyczących danych oraz formę odpowiedzi serwera na te żądania. Żądania klienckie wysyłane są poprzez przeglądarkę internetową. Najważniejszą cechą protokołu HTTP jest jego bezstanowość - nie są przechowywane żadne informacje o poprzedniej wykonanej transakcji klienta. Każde z żądań jest więc traktowane przez serwer jako “nowe”. Pozwala to znacznie odciążyć serwer. Ta cecha w połączeniu z wykorzystanie adresów URL oraz URI jednoznacznie wskazujących na dany zasób pozwala na budowanie wydajnych i zarazem prostych systemów webowych, w których każde z żądań może być obsługiwane oddzielne i niezależnie od siebie. HTTP standardowo korzysta z portu nr 80 i protokołu transportowego TCP zapewniającego niezawodność połączenia.
W żądaniach HTTP możemy wyróżnić dwa elementy: jego nagłówek i ciało. Minimalna zawartość takiego nagłówka to: adres URL, metodą HTTP oraz wersja protokołu HTTP. Określanie metody służy do rozróżniania czynności którą dane żądania ma wykonać na podanym adresie URL. Najbardziej podstawowe z nich to:
● GET - pobieranie zasobu lub jego wyświetlenie ● POST - przesłanie danych zapisanych jako pary klucz-wartość, pliki lub wartość tekstowa
do serwera ● PUT - analogicznie do metody POST, z tą różnicą że to klient decyduje o docelowym
adresie URL przesyłanego zasobu ● PATCH - aktualizacja zasobu o podany adresie URL ● DELETE - usuwanie zasobu na serwerze ● HEAD - pobranie jedynie nagłówków odpowiedzi
W nagłówku mogą się także znaleźć informacje o typie przesyłanego ciała, o kodowaniu, o żądanym typie odpowiedzi oraz znacznie więcej. Poza nagłówkami żądanie takie może zawierać także oddzielone pustą linią przesyłane dane - nazywane ciałem żądania. Rysunek 4. przedstawia przykładowe żądanie HTTP pobierające stronę w formacie HTML przekazujące do serwera dodatkowe parametry.
Rysunek 4: Budowa żądania HTTP
Taka komunikacja wymaga więc zgodnej ze standardem implementacji zarówno w oprogramowaniu serwerowym jak i w oprogramowaniu klienckim, czyli w przeglądarkach internetowych. Najnowsza wersja protokołu HTTP, czyli wersja 2. jest wspierana przez wszystkie popularne przeglądarki internetowe wydane po 2013 roku oraz przez wszystkie znane oprogramowania serwerowe takie jak Apache, Nginx czy też Tomcat.
1.3. Jakość połączenia sieciowego
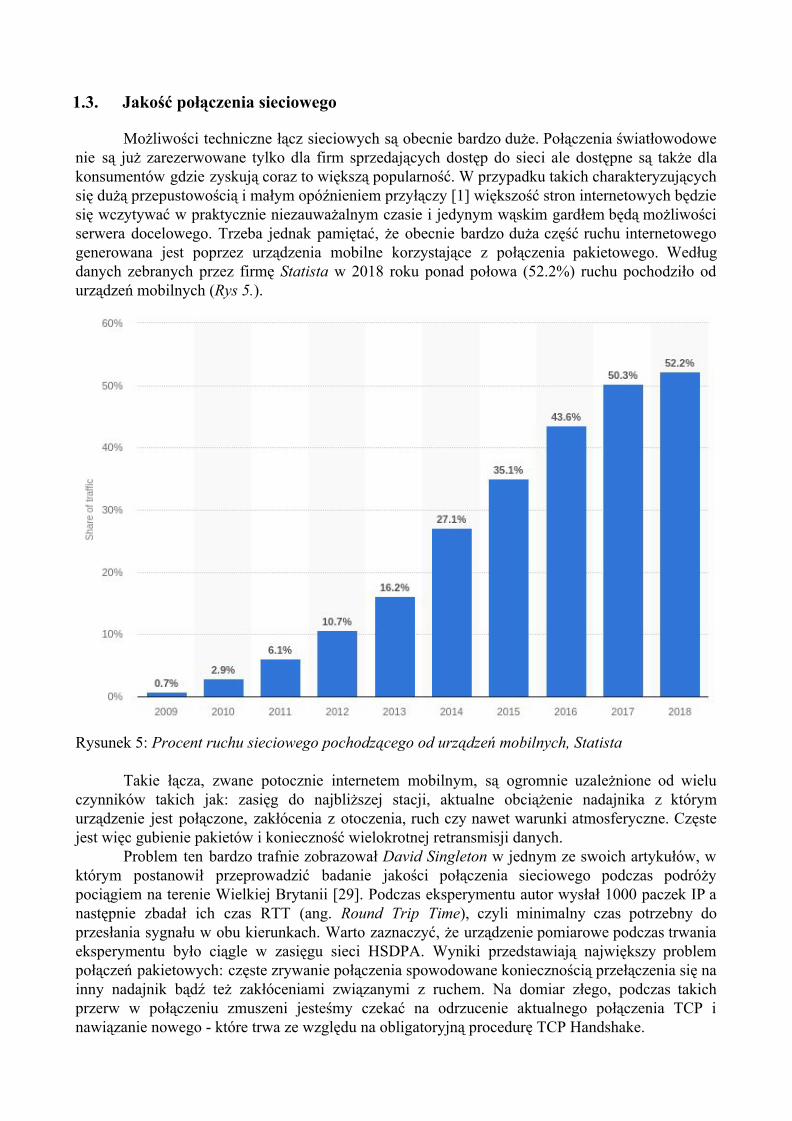
Możliwości techniczne łącz sieciowych są obecnie bardzo duże. Połączenia światłowodowe nie są już zarezerwowane tylko dla firm sprzedających dostęp do sieci ale dostępne są także dla konsumentów gdzie zyskują coraz to większą popularność. W przypadku takich charakteryzujących się dużą przepustowością i małym opóźnieniem przyłączy [1] większość stron internetowych będzie się wczytywać w praktycznie niezauważalnym czasie i jedynym wąskim gardłem będą możliwości serwera docelowego. Trzeba jednak pamiętać, że obecnie bardzo duża część ruchu internetowego generowana jest poprzez urządzenia mobilne korzystające z połączenia pakietowego. Według danych zebranych przez firmę Statista w 2018 roku ponad połowa (52.2%) ruchu pochodziło od urządzeń mobilnych (Rys 5.).
Rysunek 5: Procent ruchu sieciowego pochodzącego od urządzeń mobilnych, Statista
Takie łącza, zwane potocznie internetem mobilnym, są ogromnie uzależnione od wielu czynników takich jak: zasięg do najbliższej stacji, aktualne obciążenie nadajnika z którym urządzenie jest połączone, zakłócenia z otoczenia, ruch czy nawet warunki atmosferyczne. Częste jest więc gubienie pakietów i konieczność wielokrotnej retransmisji danych.
Problem ten bardzo trafnie zobrazował David Singleton w jednym ze swoich artykułów, w którym postanowił przeprowadzić badanie jakości połączenia sieciowego podczas podróży pociągiem na terenie Wielkiej Brytanii [29]. Podczas eksperymentu autor wysłał 1000 paczek IP a następnie zbadał ich czas RTT (ang. Round Trip Time), czyli minimalny czas potrzebny do przesłania sygnału w obu kierunkach. Warto zaznaczyć, że urządzenie pomiarowe podczas trwania eksperymentu było ciągle w zasięgu sieci HSDPA. Wyniki przedstawiają największy problem połączeń pakietowych: częste zrywanie połączenia spowodowane koniecznością przełączenia się na inny nadajnik bądź też zakłóceniami związanymi z ruchem. Na domiar złego, podczas takich przerw w połączeniu zmuszeni jesteśmy czekać na odrzucenie aktualnego połączenia TCP i nawiązanie nowego - które trwa ze względu na obligatoryjną procedurę TCP Handshake.
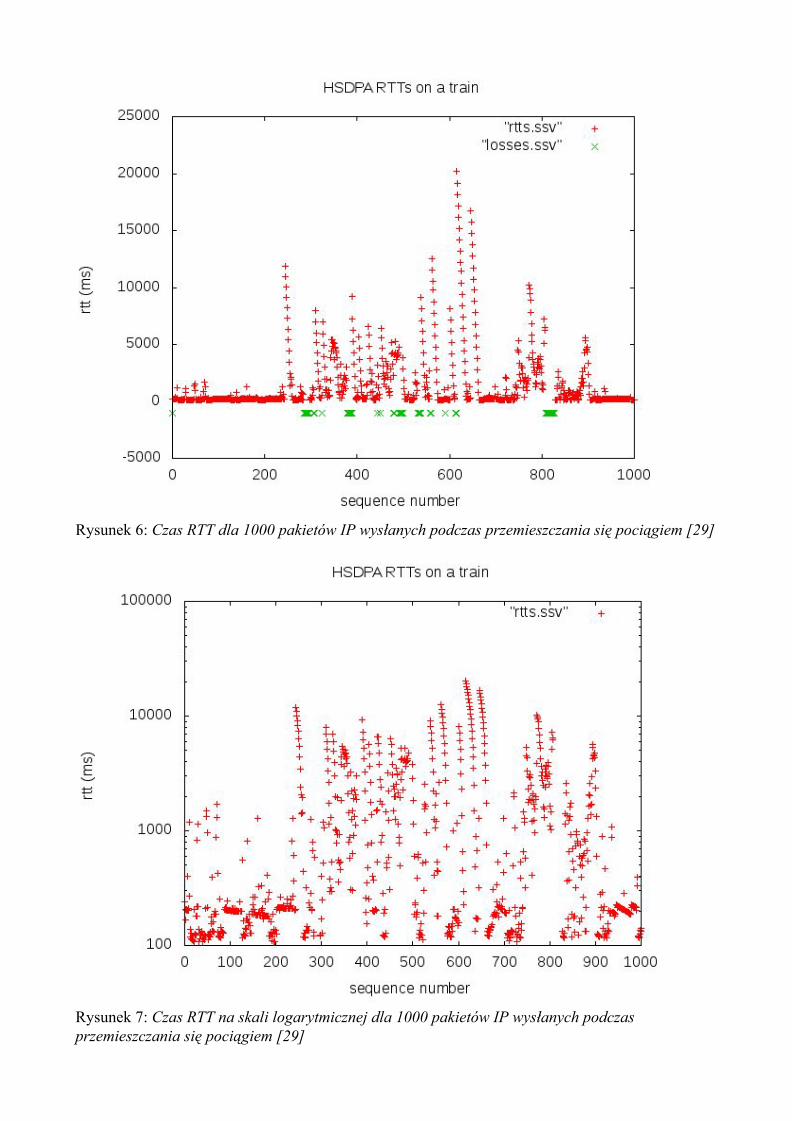
Rysunek 6: Czas RTT dla 1000 pakietów IP wysłanych podczas przemieszczania się pociągiem [29]
Rysunek 7: Czas RTT na skali logarytmicznej dla 1000 pakietów IP wysłanych podczas przemieszczania się pociągiem [29]

1.4. Buforowanie HTTP
Wykonywanie żądań poprzez sieć jest powolne i kosztowne, a do tego wiele z nich jest powtarzanych co odświeżenie strony lub podczas przejścia na kolejną podstronę. Niektóre żądania wymagają wiele cykli wymiany danych pomiędzy serwerem a klientem. Dla użytkownika końcowego oznacza to dłuższy czas oczekiwania na wczytanie strony oraz większe koszty transferu (w przypadku internetu pakietowego). Z tego względu zdolność do ponownego wykorzystywania wcześniej wykonanych żądań jest kluczowa. Każda z przeglądarek internetowych obsługuje technologię zwaną pamięcią podręczną HTTP.
Informacja o tym, czy i na ile zachować odpowiedź na dane żądania w cache znajduje się w nagłówkach odpowiedzi HTTP od serwera. Najbardziej rozpowszechnionym ze standardów jest dyrektywa Expires oraz Cache-Control. Na jej zastosowanie składa się nagłówek zawierający czas wygaśnięcia zasobu. Najbardziej istotna różnica pomiędzy tymi technikami polega na tym, iż starszy nagłówek Expires wymaga podania pełnej daty przeterminowania danej odpowiedzi, natomiast nowsza umożliwia już podanie relatywnego czasu względem wykonanego żądania.
Jest jednak parę bardzo istotnych ograniczeń wykorzystania pamięci podręcznej z wykorzystaniem tych technik: zapisana odpowiedź dotyczy konkretnego adresu URL oraz parametrów żądania HTTP, takich jak dana metoda, typ przesyłanej zawartości itd. Ponadto, zapisanie do pamięci podręcznej odbywa się automatycznie po wykonaniu żądania HTTP. Nie jest możliwym więc stworzenia dynamicznych reguł decydujących co z pamięci cache zwrócić na dane żądanie.
Wszystkie żądania HTTP generowane przez przeglądarkę są najpierw kierowane do pamięci podręcznej przeglądarki, co umożliwia sprawdzenie obecności w pamięci podręcznej ważnej odpowiedzi, której można użyć w odpowiedzi na żądanie HTTP. Wymuszenie pobrania zasobu bezpośrednio z serwera jest więc możliwe tylko poprzez zmianę adresu URL zasobu. To kolejne utrudnienie z którym musi zmagać się twórca aplikacji webowych.
Rysunek 8: Obsługa Cache-Control przez przeglądarki internetowe, diagram opracowany przez Google Web Fundamentals
Poszerzeniem możliwości wykorzystania pamięci podręcznej jest stosunkowo nowa dyrektywa preload, której zastosowanie umożliwia powiadomienie przeglądarek o konieczności pobrania zasobu który w przyszłości będzie potrzebny. Takie żądania mogę się dzięki temu wykonać wcześniej i oczekiwać w pamięci cache na wykorzystanie w odpowiednim czasie. Należy jednak pamiętać, że to bardzo nowa technologia - jest wspierana przez popularne przeglądarki zaledwie od marca 2018 roku. Na domiar złego, pozwala na zapamiętanie jedynie zasobów o

statycznym znanym adresie URL znanym już podczas wysyłania bazowej strony HTML. Wygenerowanie takich powiązań po stronie serwera może się więc okazać dosyć trudne.
1.5. Document Object Model
Model DOM (ang. Document Object Model) jest obiektową reprezentacją hierarchicznej budowy strony internetowej. Do opisania takiej struktury wykorzystana jest wariant grafu nieskierowanego, który jest acykliczny i spójny - czyli drzewo.
Standard opisujący tą strukturę definiowany jest na bieżąco (wciąż się rozwija) przez organizację W3C oraz od 2004 roku także przez WHATWG (ang. Web Hypertext Application Technology Working Group) i implementowany jest przez wszystkie współczesne przeglądarki internetowe. Niestety, zdarzają się niezgodności w tych implementacjach - powoduje to konieczność ciągłego sprawdzania zgodności tworzonego oprogramowania z różnymi przeglądarkami.
Model ten zbudowany jest na bazie dostarczonego kodu HTML - ilustruje to diagram pokazany na Rys. 9. Cały kod jest parsowany i tokenizowany zgodnie ze standardem HTML5 ustalanym przez organizację W3C w celu przedstawienia go w formie drzewa. Ponieważ język HTML pozwala na zagnieżdżone umieszczanie tagów, to drzewo DOM również musi przedstawiać takie zależności. Każdy token ma specjalne znaczenie i opisuje go pewien zestaw reguł. Następnie wyznaczone tokeny są przekształcane w obiekty z określonymi właściwościami i regułami. Część z wierzchołków, takich jak elementy link, meta czy też script mogą kierować do zewnętrznych załączników, takich jak obrazy, filmy, skrypty JavaScript czy też arkusze stylów CSS, które przeglądarka będzie musiała dodatkowo pobrać.
Rysunek 9: Budowa drzewa DOM, diagram opracowany przez Google Web Fundamentals
Tak zbudowany model DOM jest następnie dostępny jako interfejs programowy dla języka JavaScript. Każdy z elementów drzewa posiada swoje właściwości oraz natywne akcje które można wywołać. Umożliwia to wprowadzenie dynamicznych zmian na stronie internetowej po stronie klienckiej. Z jego wykorzystaniem wykonywane jest także renderowanie witryn. Każda zmiana w tej strukturze powoduje w pewnym stopniu konieczność ponownego wygenerowania treści strony.

1.6. Krytyczna ścieżka renderowania
Proces od pobierania zasobów strony do wyświetlenia użytkownikowi pełnej funkcjonalnej strony internetowej jest bardzo złożony. Zaczyna się on od wczytania bajtów znaczników HTML i CSS oraz kodu JavaScript, przez ich przetwarzanie, po przekształcenie na zrenderowane piksele – właśnie z tych etapów składa się krytyczna ścieżka renderowania [3]. Każdy z etapów jest od siebie zależny i kolejność ich wykonania jest stała. Wszystkie one wpływają bezpośrednio na szybkość działania witryny. I to nie tylko pierwszego wyświetlenia, ale także ponownych generowań strony spowodowanych skryptami JavaScript.
Pierwszym etapem jest pobranie kodu HTML strony. Następnie następuje budowanie drzewa DOM omówionego w poprzednim rozdziale. Podczas budowania tej struktury parser przeglądarki może napotkać na zewnętrzne zasoby które również będą wymagały przetwarzania. Takimi zasobami mogą być arkusze stylów CSS, z których również budowane jest drzewo o nazwie CSSOM (ang. CSS Object Model). Arkusze takie zawierają zbiór reguł opisujące głównie aspekt wizualny elementów drzewa DOM. Co bardzo istotne, drzewo CSSOM może zostać zbudowane dopiero w momencie, kiedy wszystkie zewnętrzne arkusze stylów zostaną pobrane.
Kolejnym rodzajem zewnętrznych zasobów są skrypty JavaScript. One również muszą zostać pobrane w całości wszystkie, w celu zbudowania kolejki wykonywania skryptów zgodnej z kolejnością występowania w drzewie DOM. Dopiero kiedy zarówno drzewo CSSOM oraz kolejka skryptów JS jest zbudowana następuje kolejny proces: ewaluacja kolejki skryptów. Ze względu na fakt, iż skrypty mogą wprowadzać zmiany zarówno w drzewie DOM jak i CSSOM, po wykonaniu skryptów należy ponownie przebudować obie struktury.
Następnym etapem jest przetworzenie zależności z drzewa DOM oraz CSSOM i zbudowanie finalnego drzewa zawierającego scalone właściwości o nazwie Render Tree (Rys 10.). W celu jego stworzenia konieczne jest znalezienie dla każdego węzła drzewa DOM pasujących reguł modelu CSSOM i ich zastosowanie. Dopiero ta struktura jest przez przeglądarkę wykorzystana do generowania rzeczywistej strony internetowej widocznej dla użytkownika.
Rysunek 10: Budowa drzewa renderowania strony internetowej, diagram opracowany przez zespół Google Web Fundamentals
Z pomocą przygotowanego Render Tree przeglądarka wykonuje szereg obliczeń
pozwalających na wyznaczenie układu strony, określającego rozmieszczenie elementów na stronie. Wynikiem działania tej procedury jest model ramkowy. Ostatnią czynnością wykonywaną przez

silnik przeglądarki jest rasteryzacja drzewa renderowania: przekształcenia każdego węzła w drzewie renderowania na rzeczywiste piksele na ekranie.
Z konieczności zachowania kolejności wykonywania kolejnych etapów wynika pewne niepożądane zachowanie parsera: oczekiwanie na pobranie niektórych zewnętrznych zasobów blokujące wykonanie się strony. Takie zachowanie ma swoją nazwę: blokujący renderowanie kod JavaScript i CSS. Prosty przykład takiego blokowania przedstawiony jest na poniższym diagramie (Rys 11.)
Rysunek 11: Przykład blokującego renderowanie kodu JavaScript i CSS, diagram opracowany przez zespół Google Web Fundamentals
Powyższy rysunek przedstawia bardzo prostą stronę internetową. Należy jednak mieć na uwadze, że istnieje wiele znacznie bardziej złożonych czynności które mogą powodować blokowanie renderowania strony. Jednym z takich przypadków może być np. zagnieżdżone dołączanie arkuszy CSS z wykorzystaniem dyrektywy @import url("kolejny_plik.css"). W takiej sytuacji pobranie jednego zasobu wymusza pobranie kolejnego pliku - a takich zagnieżdżeń może być wiele. Analogicznie skrypty JavaScript mogą programowo tworzyć w drzewie DOM linki do kolejnych zewnętrznych skryptów.
Optymalna ścieżka renderowania jest bardzo istotna podczas pierwszego wczytania aplikacji webowej. Dobra optymalizacja tego procesu zapewnia szybkie wczytanie strony. Bardzo często stosowanym zabiegiem podczas takiej optymalizacji jest przesyłanie w pierwszej kolejności tylko stylów oraz skryptów odpowiedzialnych za górną część witryny widoczną od razu po załadowaniu strony - ta część strony została nazwana Above the fold. Pozostałe zasoby są wczytywane dopiero po tym, jak przeglądarka wyświetli użytkownikowi górną część strony.
Warto jednak pamiętać, że ścieżka renderowania wykonywana jest przy każdej zmianie w drzewie DOM spowodowanej poprzez skrypty JS. Każde takie wykonanie kosztuje moc obliczeniową komputera, a zbyt częste jej wykonywanie powoduje znaczny spadek płynności działania strony oraz nadmierne zużycie prądu.
Podsumowując, krytyczna ścieżka renderowania składa się z następujących etapów: 1. Przetworzenie znaczników HTML i utworzenie drzewa DOM. 2. Przetworzenie znaczników CSS i utworzenie drzewa CSSOM. 3. Połączenie drzew DOM i CSSOM w jedno drzewo renderowania. 4. Wyznaczenie układu strony na podstawie drzewa renderowania i określenie geometrii każdego
węzła. 5. Odmalowanie poszczególnych węzłów na ekranie.
2. Progresywne aplikacje webowe
Stworzona w 2015 roku przez firmę Google, a konkretniej przez jej oddział Web Fundamentals, platforma technologiczna Progressive Web Application definiuje pojęcie progresywnej aplikacji webowej jako strony internetowej wykorzystującej nowe, poszerzone funkcjonalności dostępne w aktualnych wersjach przeglądarek internetowych zbliżające jej możliwości do natywnych aplikacji. Platforma ta sama w sobie nie określa jednak żadnej nowej technologii, a jedynie stawia klasycznym aplikacjom webowym szereg wymagań, których spełnienie pozwala takim witrynom pracować w trybie aplikacji natywnej, również w trakcie braku dostępu do sieci.
Progresywne aplikacje mają więc na celu zacieranie różnic pomiędzy aplikacjami webowymi a natywnymi. Do osiągnięcia tego celu wykorzystane są techniki pozwalające na pracę takiej aplikacji w trybie offline, wyświetlanie natywnych powiadomień systemowych czy też możliwość instalacji na lokalnym dysku urządzenia.
Od 2015 roku platforma ta zyskała już sporą popularność i jest obecnie wykorzystywana przez wiele firm w środowisku produkcyjnym. Nadal jest aktywnie rozwijana a jej możliwości wciąż są poszerzane. Poniższe zestawienie (Tab. 1.) przedstawia popularne aplikacje progresywne obecne na rynku konsumenckim wraz z wnioskami płynącymi z wykorzystania tejże techniki wyciągniętymi przez właścicieli tych witryn. Można zauważyć, że niektóre z obecnych na tejże liście aplikacji to bardzo popularne witryny wykorzystywane przez miliony internautów. Dane te zostały zebrane przez autorów strony PWA Stats. Zbiór ten jest na bieżąco aktualizowany i uzupełniany o nowe witryny. Przedstawione zestawienie korzysta z danych pobranych w kwietniu 2018 roku.
Nazwa aplikacji Wnioski
Twitter Lite
- 65% poprawa współczynnika liczby przeglądanych stron w czasie trwania jednej sesji
- czas wczytania strony zredukowany do 3s - średni czas wczytania strony niezależnie od jakości
połączenia sieciowego został zmniejszony o ponad 30% - 20% mniej odrzuceń wczytania strony
OLX
- zastosowanie notyfikacji poprawiło czas spędzany w aplikacji o 250% oraz zwiększyło przychód z reklam o 146%
- współczynnik odrzuceń strony zmalał o 80% - czas wczytania został zredukowany do 23%
początkowej wartości
Uber
- strona działa wydajnie nawet z wykorzystaniem wolnej sieci 2G
- wczytanie strony trwa 3 sekundy dla połączenia 2G - wielkość aplikacji została zredukowana do 50kb
Trivago
- wzrost o 150% liczby osób dodających stronę do ekranu głównego
- 97% wzrost klikalności w oferty hotelowe - 67% osób korzystających ze strony w trybie offline nie
opuszcza strony aż do powrotu połączenia
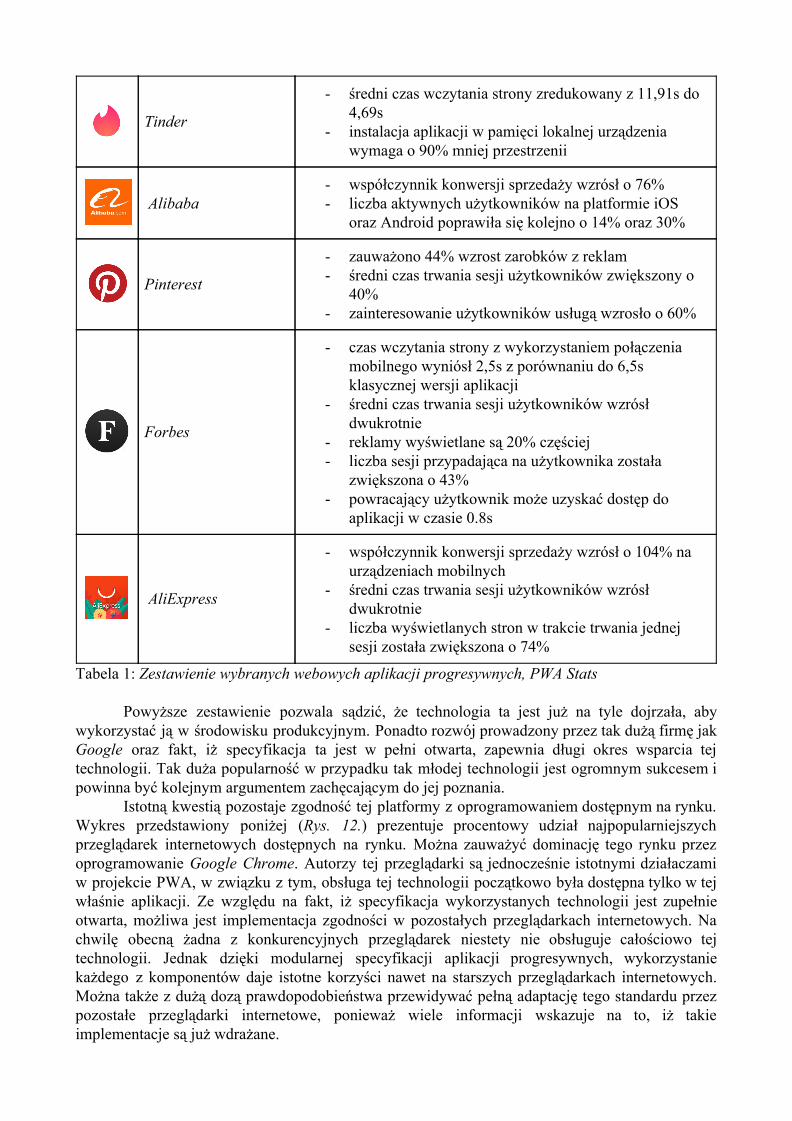
Tinder
- średni czas wczytania strony zredukowany z 11,91s do 4,69s
- instalacja aplikacji w pamięci lokalnej urządzenia wymaga o 90% mniej przestrzenii
Alibaba
- współczynnik konwersji sprzedaży wzrósł o 76% - liczba aktywnych użytkowników na platformie iOS
oraz Android poprawiła się kolejno o 14% oraz 30%
- zauważono 44% wzrost zarobków z reklam - średni czas trwania sesji użytkowników zwiększony o
40% - zainteresowanie użytkowników usługą wzrosło o 60%
Forbes
- czas wczytania strony z wykorzystaniem połączenia mobilnego wyniósł 2,5s z porównaniu do 6,5s klasycznej wersji aplikacji
- średni czas trwania sesji użytkowników wzrósł dwukrotnie
- reklamy wyświetlane są 20% częściej - liczba sesji przypadająca na użytkownika została
zwiększona o 43% - powracający użytkownik może uzyskać dostęp do
aplikacji w czasie 0.8s
AliExpress
- współczynnik konwersji sprzedaży wzrósł o 104% na urządzeniach mobilnych
- średni czas trwania sesji użytkowników wzrósł dwukrotnie
- liczba wyświetlanych stron w trakcie trwania jednej sesji została zwiększona o 74%
Tabela 1: Zestawienie wybranych webowych aplikacji progresywnych, PWA Stats
Powyższe zestawienie pozwala sądzić, że technologia ta jest już na tyle dojrzała, aby wykorzystać ją w środowisku produkcyjnym. Ponadto rozwój prowadzony przez tak dużą firmę jak Google oraz fakt, iż specyfikacja ta jest w pełni otwarta, zapewnia długi okres wsparcia tej technologii. Tak duża popularność w przypadku tak młodej technologii jest ogromnym sukcesem i powinna być kolejnym argumentem zachęcającym do jej poznania.
Istotną kwestią pozostaje zgodność tej platformy z oprogramowaniem dostępnym na rynku. Wykres przedstawiony poniżej (Rys. 12.) prezentuje procentowy udział najpopularniejszych przeglądarek internetowych dostępnych na rynku. Można zauważyć dominację tego rynku przez oprogramowanie Google Chrome. Autorzy tej przeglądarki są jednocześnie istotnymi działaczami w projekcie PWA, w związku z tym, obsługa tej technologii początkowo była dostępna tylko w tej właśnie aplikacji. Ze względu na fakt, iż specyfikacja wykorzystanych technologii jest zupełnie otwarta, możliwa jest implementacja zgodności w pozostałych przeglądarkach internetowych. Na chwilę obecną żadna z konkurencyjnych przeglądarek niestety nie obsługuje całościowo tej technologii. Jednak dzięki modularnej specyfikacji aplikacji progresywnych, wykorzystanie każdego z komponentów daje istotne korzyści nawet na starszych przeglądarkach internetowych. Można także z dużą dozą prawdopodobieństwa przewidywać pełną adaptację tego standardu przez pozostałe przeglądarki internetowe, ponieważ wiele informacji wskazuje na to, iż takie implementacje są już wdrażane.
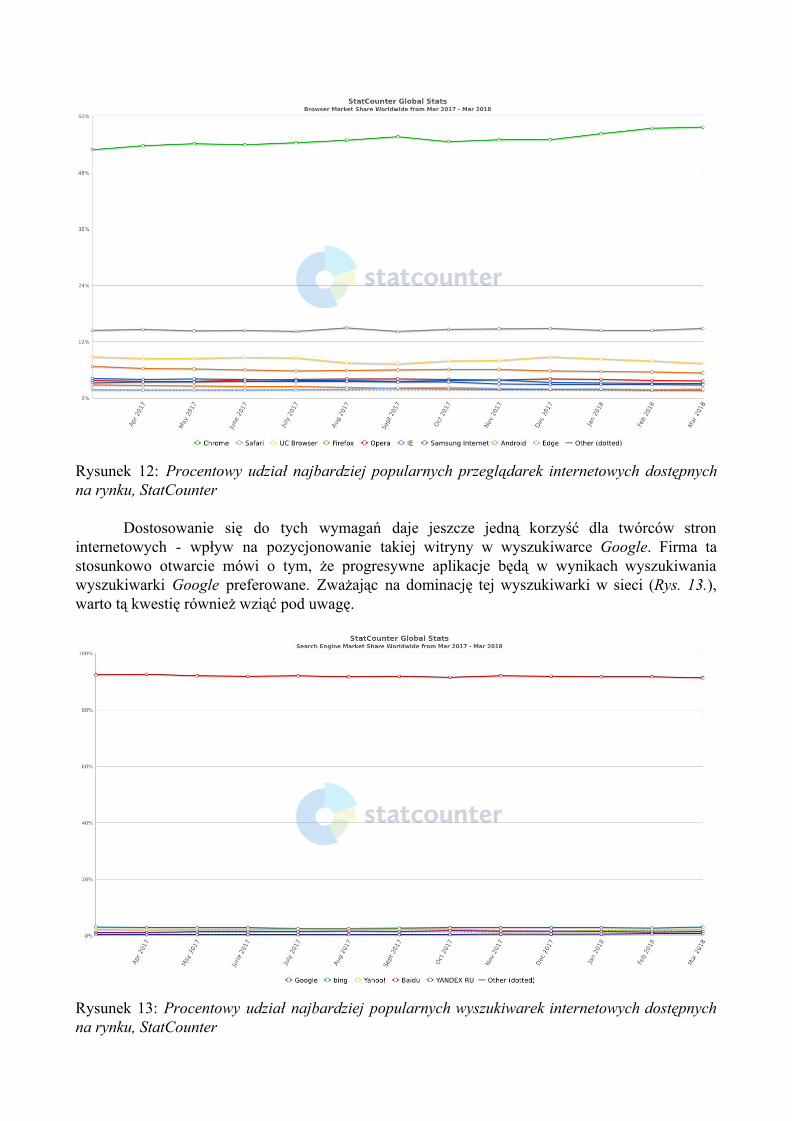
Rysunek 12: Procentowy udział najbardziej popularnych przeglądarek internetowych dostępnych na rynku, StatCounter
Dostosowanie się do tych wymagań daje jeszcze jedną korzyść dla twórców stron internetowych - wpływ na pozycjonowanie takiej witryny w wyszukiwarce Google. Firma ta stosunkowo otwarcie mówi o tym, że progresywne aplikacje będą w wynikach wyszukiwania wyszukiwarki Google preferowane. Zważając na dominację tej wyszukiwarki w sieci (Rys. 13.), warto tą kwestię również wziąć pod uwagę.
Rysunek 13: Procentowy udział najbardziej popularnych wyszukiwarek internetowych dostępnych na rynku, StatCounter
W kolejnych rozdziałach przeprowadzona zostanie analiza definiowanych przez PWA
wymagań, proponowanych technologiach wykorzystywanych do budowy takiej aplikacji oraz oferowanej funkcji aplikacji natywnej.
2.1. SSL
SSL (ang. Secure Socket Layer) [31] jest nazwą protokołu służącego do transmisji zaszyfrowanych danych. Został opracowany w roku 1994 przez firmę Netscape, która w tamtych czasach prężnie działała w obrębie technologii internetowych. Niedługo później organizacja Internet Engineering Task Force opracowała specyfikację opisujacą tą technologię jako standard w sieci Internet i nazwałą ją TLS (ang. Transport Layer Security). Standard ten zapewnia pełną poufność i integralność podczas transmisji danych, a także umożliwia uwierzytelnienie serwera oraz klienta. Opiera się na szyfrowaniu asymetrycznym z wykorzystaniem certyfikatów opisanych w specyfikacji jako X.509 - opierających się na zaufaniu do urzędów certyfikacji. Najnowszym stabilnym wydaniem tego protokołu jest wersja 1.2 opisana przez dokument RFC 5246. Protokół HTTP również umożliwia szyfrowanie zgodne ze specyfikacją TLS - bezpieczna wersja tego protokołu nosi nazwę HTTPS (ang. Hypertext Transfer Protocol Secure).
Z punktu widzenia użytkownika końcowego rozwiązanie to zapewnia więc bezpieczną wymianę wrażliwych danych pomiędzy serwerem a klientem, czyli w tym przypadku przeglądarka internetową. Jednak aby taka transmisja była rzeczywiście zabezpieczona, konieczne jest zastosowanie klucza o odpowiedniej długości.
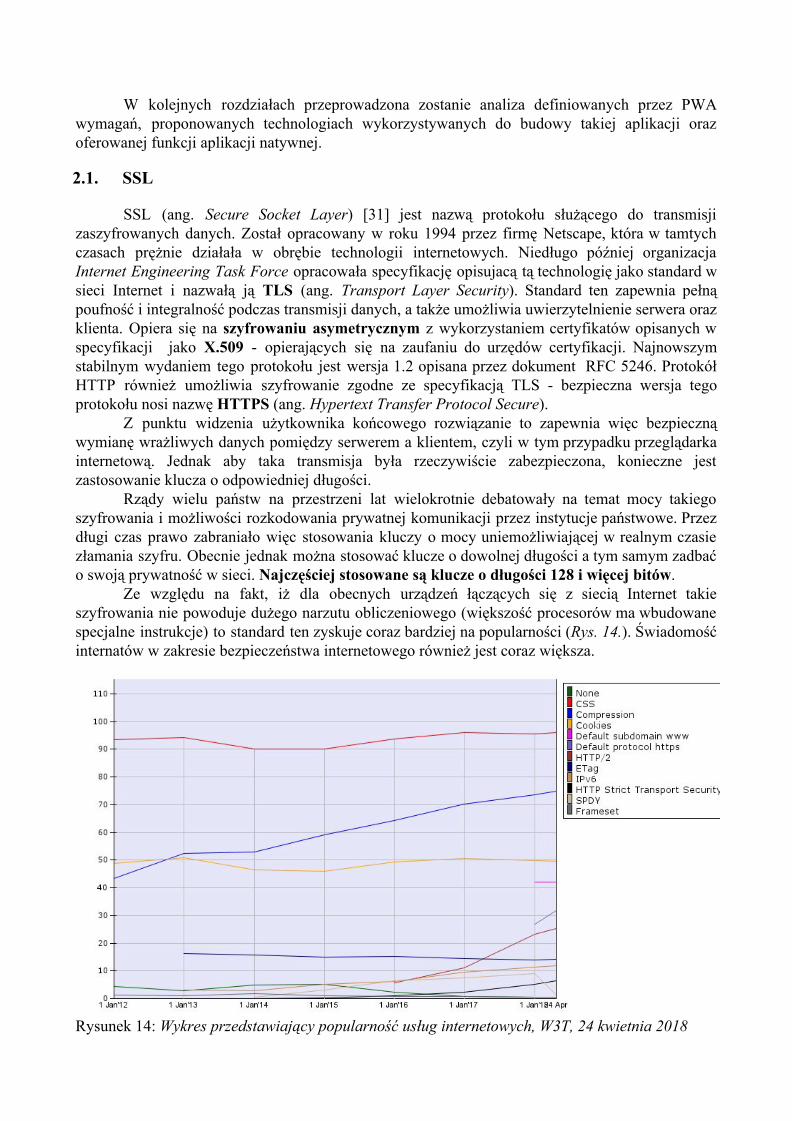
Rządy wielu państw na przestrzeni lat wielokrotnie debatowały na temat mocy takiego szyfrowania i możliwości rozkodowania prywatnej komunikacji przez instytucje państwowe. Przez długi czas prawo zabraniało więc stosowania kluczy o mocy uniemożliwiającej w realnym czasie złamania szyfru. Obecnie jednak można stosować klucze o dowolnej długości a tym samym zadbać o swoją prywatność w sieci. Najczęściej stosowane są klucze o długości 128 i więcej bitów.
Ze względu na fakt, iż dla obecnych urządzeń łączących się z siecią Internet takie szyfrowania nie powoduje dużego narzutu obliczeniowego (większość procesorów ma wbudowane specjalne instrukcje) to standard ten zyskuje coraz bardziej na popularności (Rys. 14.). Świadomość internatów w zakresie bezpieczeństwa internetowego również jest coraz większa.
Rysunek 14: Wykres przedstawiający popularność usług internetowych, W3T, 24 kwietnia 2018
Firma Google od wielu lat promuje ideę “HTTPS Everywhere” - brak zastosowanie tego protokołu przez witrynę skutkuje obniżeniem jej pozycji w wynikach wyszukiwania wyszukiwarki Google. Tym samym wprowadzenie wymogu stosowanie komunikacji HTTPS przez aplikacje progresywne zezwalające na jeszcze mocniejszą integrację z urządzeniami nie powinien wzbudzać zdziwienia. Wymaganie to istotnie wpływa na podnoszenie poziomu bezpieczeństwa w sieci, więc jak najbardziej należy je uważać za słuszne.
2.2. HTTP 2
Najnowszą stabilną wersją opisanego we wcześniejszych rozdziałach protokołu HTTP jest wersja HTTP/2 [7]. Bazuje ona na własnościowym protokole SPDY [30], zapoczątkowanym przez firmę Google. Jest pierwszą wersją od wydanego w 1997 roku HTTP 1.1, który przez ostatnie 20 lat nieco się zestarzał. Od zaprezentowania tego standardu w 2014 roku zatwierdzony został w maju 2015 roku przez instytucję Internet Engineering Task Force. Obecnie jest on wspierany przez stabilne wersje większości oprogramowania serwerowego jak i przez wszystkie znane przeglądarki internetowe.
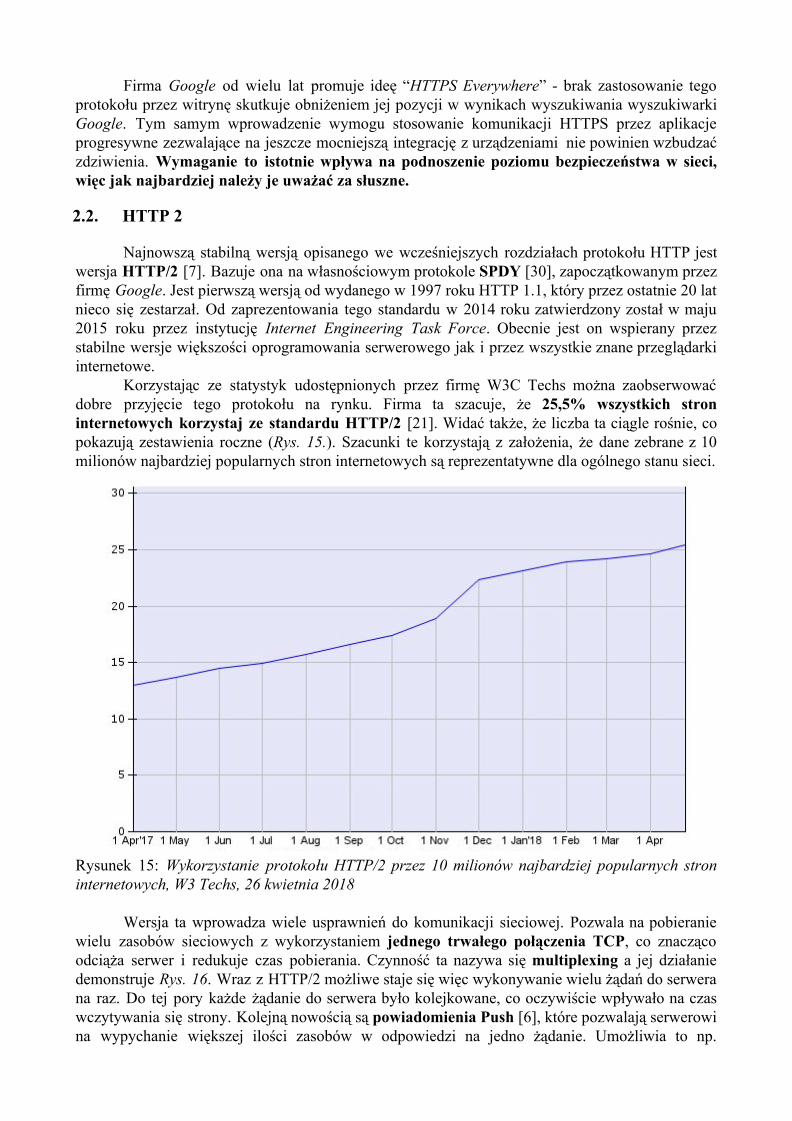
Korzystając ze statystyk udostępnionych przez firmę W3C Techs można zaobserwować dobre przyjęcie tego protokołu na rynku. Firma ta szacuje, że 25,5% wszystkich stron internetowych korzystaj ze standardu HTTP/2 [21]. Widać także, że liczba ta ciągle rośnie, co pokazują zestawienia roczne (Rys. 15.). Szacunki te korzystają z założenia, że dane zebrane z 10 milionów najbardziej popularnych stron internetowych są reprezentatywne dla ogólnego stanu sieci.
Rysunek 15: Wykorzystanie protokołu HTTP/2 przez 10 milionów najbardziej popularnych stron internetowych, W3 Techs, 26 kwietnia 2018
Wersja ta wprowadza wiele usprawnień do komunikacji sieciowej. Pozwala na pobieranie
wielu zasobów sieciowych z wykorzystaniem jednego trwałego połączenia TCP, co znacząco odciąża serwer i redukuje czas pobierania. Czynność ta nazywa się multiplexing a jej działanie demonstruje Rys. 16. Wraz z HTTP/2 możliwe staje się więc wykonywanie wielu żądań do serwera na raz. Do tej pory każde żądanie do serwera było kolejkowane, co oczywiście wpływało na czas wczytywania się strony. Kolejną nowością są powiadomienia Push [6], które pozwalają serwerowi na wypychanie większej ilości zasobów w odpowiedzi na jedno żądanie. Umożliwia to np.

przesłanie przeglądarce internetowej zasobów, które będą potrzebne podczas dalszej pracy z aplikacją webową. Warto także zaznaczyć, że protokół ten pozwala na priorytetyzowanie żądań oraz na przesyłanie danych w formacie binarnym.
Rysunek 16: Pobieranie wielu zasobów z wykorzystaniem protokołu TCP, Blog CloudFlare
Istotny jest także wpływ wszystkich tych zmian w standardzie HTTP na wydajność komunikacji sieciowej pomiędzy serwerem a przeglądarką internetową. W pracy THE INFLUENCE OF HTTP/2 ON USER-PERCEIVED WEB APPLICATION PERFORMANCE wydanej w STUDIA INFORMATICA w 2017 roku przez autorów Jakub PROKOPIUK oraz Ziemowit NOWAK [23] zbadany został wpływ zastosowania protokołu HTTP/2 na wydajność wczytywania strony internetowej z perspektywy użytkownika końcowego. Autorzy wykonali pomiary na statycznej stronie internetowej zawierającej 20 zasobów zewnętrznych o łącznej wadze 617kB. Analizując uzyskane pomiary (Rys. 17.), bez zagłębiania się w szczegóły wybranych przez autorów pracy miar, można zauważyć zredukowanie czasu wczytania witryny o prawie 25%.
Rysunek 17: Wydajność wczytywania badanej strony internetowej w zależności od zastosowanej wersji i konfiguracji protokołu HTTP, THE INFLUENCE OF HTTP/2 ON USER-PERCEIVED

WEB APPLICATION PERFORMANCE, Jakub PROKOPIUK, Ziemowit NOWAK, STUDIA INFORMATICA, 2017 [23]
Dodatkowo znacznie wpływa na bezpieczeństwo w sieci. Co prawda ostatecznie protokół ten nie wymaga zastosowania polityki TLS, jednak we wszystkich dostępnych na rynku przeglądarkach internetowych implementacja bezpośrednio wymaga połączenia szyfrowanego z użyciem TLS w wersji 1.2. Ponadto, technologia ta jest bardzo prosta do wdrożenia i wstecznie kompatybilna.
W związku z wszystkimi usprawnieniami wprowadzonymi przez tą wersję protokołu, istotnym wpływem na wydajność komunikacji sieciowej oraz poprawie bezpieczeństwa internatów wymóg zastosowania najnowszej wersji protokołu HTTP przez aplikacje progresywne jest słusznym posunięciem i zwiększa jakość usług sieciowych.
2.3. Web App Manifest
Kolejnym wymogiem jest obecność w głównym katalogu witryny specjalnego pliku opisującego właściwości strony internetowej którego format zdefiniowany jest przez firmę Google pod nazwą Web App Manifest. Plik musi nosić nazwę manifest.json, a jego struktura być zgodna ze standardem JSON. Dodatkowo w plikach źródłowych HTML konieczne jest dodanie odpowiedniego znacznika informującego o położeniu pliku manifestu, np. <link rel="manifest" href="/manifest.json">. Wymaganymi właściwościami są:
● Pełna oraz skrócona nazwa aplikacji ● Ikona w formacie PNG w określonych wymiarach ● Początkowy adres URL
Ponadto, może się w nim znaleźć wiele dodatkowych, opcjonalnych parametrów, takich jak np. główny akcent kolorystyczny strony, preferencje dotyczącą trybu poziomego lub pionowego w przypadku urządzeń mobilnych czy też opcja widoczności paska adresu URL wraz z głównymi kontrolkami. Tak ustandaryzowany format parametrów stron internetowych umożliwia lepsze dostosowanie się przeglądarki do stron internetowych oraz zapewnia niezbędne do pracy w formie aplikacji natywnej informacje. Wszystko to wpływa na zwiększenie komfortu korzystania z aplikacji webowych i zapewnia warunki do wytwarzania aplikacji wizualnie spójnych z resztą systemu operacyjnego. Przykładem może być dostosowanie wyglądu strony internetowej na urządzeniu mobilnym pracujacycm pod kontrola systemu Android - Rys. 18.
Rysunek 18: Wizualizacja parametrów ustawianych za pomocą pliku manifest.json na platformie mobilnej Android, Google Web Fundamentals

2.4. Service worker
Programiści aplikacji webowych od wielu lat borykają się z jednym problem - obsługą problemów z połączeniem sieciowym. Jeżeli podczas wczytywania zasobów sieciowych użytkownik utraci połączenie, bądź też jakość połączenia drastycznie spadnie, może się okazać, że strona nie zostanie w ogóle wyświetlona, albo zostanie wyświetlona niekompletna. Potrzebny jest więc mechanizm umożliwiający stronom internetowym pewną kontrolę nad takimi zachowaniami. Jednym z najnowszych podejść do rozwiązania tego problemu jest technologia Service Worker, która pozwala na rejestrację pewnego pośrednika pomiędzy skryptami aplikacji webowej, a mechanizmem wykonywania żądań przeglądarki internetowej.
Rozwiązanie to czerpie garściami z obecnej już wcześniej na rynku technologii Web Worker, która umożliwia na uruchomianie w środowisku przeglądarki internetowej skryptów JavaScript w niezależnych, odizolowanych wątkach pracujących w tle. Takie skrypty nie mają w związku z tym dostępu do drzewa DOM aplikacji webowej. W przypadku Service Worker odizolowany kontekst takich skryptów ma jednak dodatkowo dostęp do paru programowych interfejsów dotyczących wykonywania, przechwytywania i zapisywania żądań HTTP (Rys. 19.). Możliwości tej technologii są jednak znacznie większe: w fazie rozwoju są takie funkcjonalności jak np. dostęp do aktualnych danych żyroskopu. Ze względu na fakt, iż takie wątki wykonują się asynchronicznie, komunikacja pomiędzy takimi skryptami a głównym wątkiem przeglądarki odbywa się tylko za pomocą prostej szyny wymiana danych.
Rysunek 19: Diagram przedstawiający architekturę Service Worker, Beginning Progressive Web App Development [27]
Aby taki pośrednik mógł pracować w tle, konieczna jest jego jawna rejestracja z poziomu
skryptu JavaScript znajdującego się w treści witryny. Aktywny może przechwytywać każde wykonane przez stronę internetową żądanie, modyfikować je i wpływać na to, co zostanie zwrócone. Nawet w momencie, kiedy urządzenie nie ma dostępu do sieci. Pozwala to na pracę aplikacji w trybie offline.
Wszystkie te potężne możliwości wiążą się jednak z pewnymi niebezpieczeństwami. Umożliwienie całkowitej kontroli nad ruchem sieciowym danej domeny na urządzeniu końcowym otwiera pewną furtkę dla internetowych hakerów. Przejęcie kontroli nad Service Workerem jest bowiem jednoznaczne z kompromitacją danej witryny na danym urządzeniu. Taki atak ma swoją nazwę: man-in-the-middle. Dlatego instalacja takiego pośrednika wymaga bezpiecznego, szyfrowanego certyfikatem SSL, połączenia sieciowego.
Ten komponent uważany jest za najbardziej istotny aspekt progresywnych aplikacji webowych i z pewnością wywiera istotny wpływ na jakość świadczonych usług w sieci Internet, szczególnie poprzez doskonałą obsługę utrudnień sieciowych.

2.4.1. Cykl życia SW
We wcześniejszym rozdziale zostało powiedziane, że aby Service Worker mógł rozpocząć swoja prace, konieczna jest jego jawna rejestracja. Ciekawe jednak jest to, co dzieje się z takim pośrednikiem później, np. po zamknięciu okna przeglądarki?
Technologia ta w celu efektywnego działania wprowadza więc zupełnie inny cykl życia w stosunku do klasycznej strony. Przedstawia się on następująco:
● Rejestracja i pobieranie ● Instalacja ● Oczekiwanie ● Aktywacja ● Aktualizacja
Każde otworzone okno przeglądarki jest automatycznie łączone z odpowiednim Service Workerem odpowiedzialnym za obsługę danej domeny.
2.4.2. Fetch API
Interfejs programowy dotyczący przechwytywania żądań HTTP nosi nazwę Fetch API. Z jego wykorzystaniem możliwe jest podsłuchiwanie ruchu sieciowego i w razie potrzeby manipulowania nim. W klasycznej stronie internetowej wszystkie wykonane żądania są wysyłane bezpośrednio do przeglądarki internetowej, która w pierwszej kolejności sprawdza czy dany zasób jest dostępny w statycznej pamięci podręcznej a następnie wykonuje żądanie z wykorzystaniem połączenia sieciowego. Progresywna aplikacja webowa dodaje więc jedną dodatkową warstwę w procesie komunikacji sieciowej w które dostępne są narzędzia opisane w standardzie Fetch API. Jego działanie ilustruje diagram opracowany przez firmę Mozilla (Rys. 20.).
Rysunek 20: Zastosowanie Fetch API do przechwytywania żądań HTTP, Using Service Workers, MDN web docs

2.4.3. Cache API
Możliwości praktycznego zastosowania interfejsu Fetch API są znacznie poszerzone przez funkcję przechowywania całych żądań oraz odpowiedzi na żądania HTTP w pewnym rodzaju wyspecjalizowanej pamięci podręcznej (Rys. 21.), nazwanej Cache API [26].
Rysunek 21: Diagram przedstawiający wykorzystanie dynamicznej pamięci podręcznej cache API poprzez Service Worker, Beginning Progressive Web App Development [1]
Cała komunikacja z tą pamięcią odbywa się również asynchronicznie. Wydobywanie danych z takiego cache jest równie proste: dostępne jest wyszukiwanie po adresie URL oraz metodzie żądania HTTP jak i uzyskiwanie zapisanej odpowiedzi poprzez podanie całego żądania. W celu zwiększenia wydajności możliwe jest także wprowadzenie indeksów po których następnie wykonywane jest wyszukiwanie.
Zastosowanie tej technologii pozwala na stworzenie dynamicznej pamięci podręcznej, w której dopuszczalne jest zwracanie dla żądań wcześniej zapisanej odpowiedzi na dowolne inne żądanie. Przykładem może być pobieranie zasobów graficznych które na stronie internetowej dostępne są w różnych rozmiarach w zależności od aktualnej wielkości okna przeglądarki internetowej. Klasyczna pamięć podręczna podczas zmiany takiego rozmiaru wymusi pobranie nowego obrazu, dynamiczny cache może jednak sprawdzić, czy zapisany zasób jest dostępny lokalnie w innym rozmiarze i zwrócić go pomimo innego adresu URL żądania.
2.4.4. Tryb offline
Wykorzystanie technologii Service Worker wraz z Fetch API oraz Cache API daje możliwość kompleksowej obsługi każdej zmiany połączenia sieciowego oraz znacznie lepszego zarządzania pamięcią podręczną [17]. Pozwala to zredukować ilość wykonywanych żądań HTTP a tym samym przyspieszyć działanie aplikacji webowej jak i zredukować konieczny przesył danych sieciowych.
Podczas braku dostępu do sieci możliwe jest więc zwrócenie albo już uprzednio pobranych danych albo specjalnie spreparowanych danych. Każde z tych rozwiązań jest zdecydowanie lepsze z punktu widzenia użytkownika końcowego od błędu informującego o braku dostępu do sieci zwróconego przez przeglądarkę internetową. Część istotnych podstron może być dzięki temu dostępna w każdych warunkach sieciowych, a doczytywane przez Internet są tylko nowe, nigdy

wcześniej nie pobrane przez użytkownika zasoby. Znakiem rozpoznawczym dobrze napisanej aplikacji progresywnej jest więc bardzo dobra obsługa trybu offline i sprawne działanie w trudnych warunkach sieciowych.
W wielu materiałach dotyczących wskazówek projektowych tej nowej technologii można znaleźć podejście nazwane offline first. Polega ono na tym, że najbardziej istotne fragmenty aplikacji są zapisywane do pamięci podręcznej i w pierwszej kolejności generowana jest użytkownikowi strona internetowa składająca się jedynie z zasobów dostępnych już na urządzeniu.
2.5. Powiadomienia push
Jedną z najbardziej pożądanych funkcjonalności współczesnych aplikacji webowych są dynamiczne powiadomienia wyświetlane użytkownikom bez wymagania ciągłego utrzymywania aktywności danego okna przeglądarki. Do niedawna potrzeba wyświetlania takich notyfikacji zmuszała do konieczności napisania natywnej aplikacji na daną platformę.
W tym celu opracowano właśnie technologię Push API [13] oraz Notifications API [13]. Zastosowanie ich wymaga wykorzystanie Service Workera, ponieważ przesył danych polega tutaj na założeniu subskrypcji na asynchroniczne powiadomienie w jego kontekście. W ramach takiej subskrypcji przeglądarka zwraca stosowny adres URL kierujący na serwer (zwany Push Service) współpracujący z daną przeglądarką oraz wymagane klucze autoryzacji z pomocą których możliwe jest późniejsze przesłanie danych od serwera. Format komunikacji pomiędzy tymi serwerami opisuje standard HTTP Web Push [13] opracowany w roku 2016 przez organizację Internet Engineering Task Force. Przeglądarka po otrzymaniu danych od Push Service wybudza odpowiedni wątek Service Worker a następnie z jego wykorzystaniem wyświetla natywne powiadomienie systemowe. Cały proces zilustrowany jest na poniższym diagramie (Rys. 22.).
Rysunek 22: Proces wysyłania powiadomienia push od serwera danej witryny internetowej do przeglądarki użytkownika końcowego, Google Web Fundamentals
Promowanie stosowania tej technologii w progresywnych aplikacja pozwala na znaczne poprawienie interakcji użytkownika z witryną i zapewnia dostęp do funkcjonalności obecnych do niedawna tylko dla aplikacji natywnych.
2.6. IndexedDB
Wiele aplikacji webowych operuje na stosunkowo złożonych danych których przechowuje się najlepiej w formie bazy relacyjnej. Aby dobrze wykorzystać dynamiczną pamięć podręczną oraz wytworzyć aplikację zgodną z podejście offline first potrzebny jest więc dostęp do bardziej złożonej pamięci podręcznej, która umożliwii wydajne zapisywanie, przechowywanie oraz wyszukiwanie dużych i złożonych zbiorów danych.
Twórcy przeglądarek internetowych od wielu lat próbowali upowszechnić swoje autorskie rozwiązania, takie jak np. Web SQL. Nie zdobyły one jednak dużej popularności, głównie za sprawą słabej kompatybilności i niedopracowanej dokumentacji. Upowszechnił się jednak znacznie nowszy standard o nazwie IndexedDB [37] którego wsparcie zapewnia według statystyk firmy caniuse.com 94.49% przeglądarek internetowych dostępnych na rynku.

Jest systemem zapewniającym wsparcie dla transakcji oraz przechowywania obiektów bazujących na obiektach JavaScript. Możliwe jest także tworzenie indeksów oraz złożonych żądań. Cechuje się wysoką wydajnością i w pełni asynchroniczną obsługą nie blokującą działania witryny.
Aplikacje progresywne korzystające z takiego rozwiązania są w stanie zapewnić dzięki temu dużą część funkcjonalności nawet w trybie offline. Filtrowanie czy sortowanie danych również może się odbywać po stronie klienckiej bez dodatkowego narzutu komunikacyjnego.
2.7. Responsywny układ treści
Ze względu na nacisk, aby aplikacje progresywne były możliwie jak najbardziej uniwersalne i zgodne z wieloma platformami sprzętowymi, logiczny jest wymóg zastosowania responsywnego układu treści. Wdrożenie takie układu wymaga jedynie specjalnego ułożenia arkuszów styli z wykorzytsaniem znaczników @media pozwalajacych określić, na jakiej wielkości ekranu mają być zastosowane dane bloki styli. Technologia ta nie jest nowa - programistom aplikacji webowych jest doskonale znana i powszechnie stosowana. Nadal jednak dostępnych jest w sieci Internet wiele witryn nie dostosowanych do urządzeń mobilnych takich jak smartfony czy też tablety.
Podczas projektowania takich aplikacji należy także pamiętać o właściwym dostosowaniu interfejsu w taki sposób, aby możliwa była obsługa za pomocą dotyku. Wymaga to poświęcenia sporej uwagi podczas określania takich parametrów jak wielkość elementów udostępniających akcję po dotyku czy też odległość takich przycisków pomiędzy sobą, aby zredukować do minimum wykonywanie omyłkowych akcji. Obecnie możliwe jest także wykorzystanie do interakcji z użytkownikiem wielu gestów wykonywanych na ekranie urządzenia dotykowego za pomocą technologii multitouch.
Firma Google we wszystkich materiałach promocyjnych technologii PWA jak i jej oficjalnej aplikacji nie narzuca co prawda żadnego konkretnego rozwiązanie, niemniej jednak na prezentowanych materiałach wideo, zrzutach ekranów z różnych urządzeń jak i przykładowych aplikacjach można zauważyć zastosowanie układu treści zgodnego ze standardem Material Design [12]. Definiuje on zbiór funkcjonalnych komponentów takich jak gotowe kontrolki, elementy formularzy czy też multimedialne galerie. Sama firma rozwija gotowe biblioteki implementujące te komponenty w wielu popularnych frameworkach.
2.8. App Shell
Strony internetowe coraz częściej są bardzo rozbudowanymi aplikacjami webowymi a nie tylko sformatowanymi dokumentami. Z drugiej strony, znaczna część urządzeń mających obecnie dostęp do sieci to słabe urządzenia mobilne z niepewnym połączeniem sieciowym. Wczytanie na nich takich aplikacji może zajmować sporo czasu.
Progresywne aplikacje webowe mają swój wzorzec projektowy, proponujący strukturalny podział aplikacji (Rys. 23.) w taki sposób, aby możliwie jak najlepiej wykorzystać nowe technologie webowe i optymalnie używać pamięć podręczna. Nosi on nazwę wzorca PRPL [19], oznaczającą:
● Push - przesłanie krytycznych, najbardziej istotnych fragmentów strony ● Render - wyświetlanie wstępnej wersji strony ● Pre-cache - pobranie do pamięci podręcznej zasobów potrzebnych w przyszłości ● Lazy-load - wczytanie dalszych podstron w tle
Kluczowym elementem w strukturze takiej aplikacji jest wyznaczenie szkieletowej aplikacji, zwanej App Shell [18] i umieszczenie jej w pamięci cache. Następnie dla każdej z podstron lub kolejnych widoków aplikacji rozpocząć od wyświetlenia właśnie tej bazowej części.

Rysunek 23: Wzorzec projektowy PRPL/App Shell, Google Web Fundamentals
Zastosowanie takiej struktury zwiększa modularność wytwarzanego oprogramowania, wspomaga wykorzystanie pamięci podręcznej oraz znacząco przyspiesza czas wyświetlenia użytkownikowi końcowemu pierwsze interaktywnej wersji aplikacji. Wzorzec ten jest więc w pełni spójny z technologiami dobranymi do technologii Progressive Web Apps i jest jego integralną częścią pozwalającą na wykorzystanie pełnego potencjału tego rozwiązania.
2.9. Biblioteki wspomagające obsługę SW
Ogromne możliwości które daje zastosowanie technologii Service Worker powoduje, że interfejs jej obsługi nie należy do prostych. Jest bardzo rozbudowany i wymaga od programistów bardzo dobrego poznania tej techniki i zrozumienia zasad jej działania. Ponadto opisane we wcześniejszych rozdziałach metody wykorzystania dynamicznej pamięci podręcznej można zaimplementować na wiele sposobów, w zależności od zapotrzebowania i własności danych zasobów sieciowych. Z tego wynika powtarzalność wytwarzanego kodu reguł służących do obsługi konkretnych typów zasobów.
Google opracowało jednak pewną biblioteką wraz z zestawem narzędzi wspomagających pisanie aplikacji webowych wykorzystujących Service Workery. Nazywa się ona Workbox [4] i obecnie dostępna jest już 3. wersja tego narzędzia. Jej zastosowanie ułatwia i przyspiesza proces wytwarzania aplikacji progresywnych. Zawiera w sobie gotowe zestawy reguł definiujące obsługę popularnych w sieci rozwiązań, takich jak np. Google Fonts czy też Google Analytics. Wprowadza także wiele strategii wykorzystania pamięci cache których użycie w prostych sposób wprowadza do aplikacji webowej obsługą trybu offline.
Ponadto, wiele z popularnych frameworków służących do wytwarzania aplikacji webowych od niedawna oferuje integrację z technologią Service Worker. Dla frameworka Angular jest to np. Angular-CLI. Dla frameworka React są to kolejno PawJS oraz ReactPWA.
Zastosowanie takich bibliotek nie tylko ułatwia pracę podczas wytwarzania takich aplikacji. Warto także pamiętać o tym, że ich użycie w pewien sposób wymusza stosowanie dobrych praktyk i wzorców projektowych. Zapewnienie wielu rozbudowanych strategii wykorzystania pamięci cache również może powodować zredukowanie wprowadzania do sieci złych, nieprzemyślanych implementacji, które mają bezpośredni wpływ na to, co i w jakiej ilości jest zapisywane na dyskach urządzeń internatów.

2.10. Aplikacja natywna
Jedną z kluczowych i przełomowych funkcjonalności oferowanych przez technologię PWA jest możliwość pracowania tych aplikacji w trybie aplikacji natywnej i ich instalację w pamięci lokalnej urządzeń. W tym celu wykorzystane są praktycznie wszystkie opisane w poprzednich rozdziałach technologie, wzorce projektowe i narzędzia. Dzięki temu, aplikacje webowe mogą rozpocząć bezpośrednio konkurować z aplikacjami natywnymi na wszystkich obsługiwanych obecnie platformach. Są to kolejno Android, iOS oraz od kwietnia 2018 roku także Windows od wprowadzonej w tym czasie aktualizacji Spring Creators Update. Z wielu nieoficjalnych wiadomości wiadomo także, że firma Apple pracuje nad wprowadzeniem obsługi tej technologii w swoim systemie Mac OS.
Proces instalacji progresywnej aplikacji webowej odbywa się poprzez otworzenie danej witryny internetowej w wspieranej przeglądarce internetowej. Następnie użytkownikowi możliwe jest wyświetlenie interaktywnego komunikatu (ang. Progressive Web App Install Banner) informującego o możliwości dodania takiej aplikacji do pulpitu (na komputerach stacjonarnych) lub do ekranu głównego (na urządzeniach mobilnych).
Aplikacja progresywna po instalacji zyskuje nowe możliwości prezentacyjne. Dostępne jest ustawienie ekranu wczytywania aplikacji, całkowite ukrycie elementów przeglądarki internetowej czy też ustawienie początkowego adresu URL. Taka instalacja jest niebywale szybka i wymaga niewielkiej przestrzeni pamięciowej. Co ważne, jej aktualizacja jest również automatyczna i działa na dokładnie takiej samej zasadzie jak strona internetowa korzystająca z Service Worker.
Jak podaje sama firma Google w jednym z wpisów na swoim oficjalnym profilu serwisu Medium, konwersja takich banerów jest średnio 5-6 razy bardziej efektywna niż komunikatów proponujących instalację pełnej aplikacji natywnej. Przedstawiona na początku rozdziału 2. lista popularnych aplikacja progresywnych pokazuje jak wiele natywnych aplikacji zostało zastąpionych nowymi PWA oraz jak korzystne takie zmiany okazały się dla właścicieli tych serwisów.
Zdecydowanie jest to jedna z największych nowości w standardzie webowym a co najważniejsze, od samego początku jest otwartym, multiplatformowym standardem. Nie jest powiązana z żadną własnościową platformą sprzedaży oprogramowania i nie wymusza korzystania z infrastruktury żadnej z korporacji.
2.11. Konkurencyjne rozwiązania
Na rynku dostępnych jest wiele alternatywnych technologii skoncentrowanych na możliwości optymalizacji dostarczania stron internetowych. Warto jednak zaznaczyć, że wszystkie te rozwiązania przeznaczone są do mocno wyspecjalizowanego celu. Z tego też powodu wyjątkowo trudne jest porównywanie ich między sobą. Określenie ich więc jako konkurencyjne rozwiązania należy rozumieć jako technologie przeznaczone do podobnego celu a nie jako zamienniki.
Po przeprowadzonej analizie aplikacji progresywnych i wykonanemu eksperymentowi można zdefiniować przeznaczenie tej technologii. O ile możliwe jest jej zastosowanie praktycznie do każdego rodzaju witryny internetowej, to zdecydowanie najlepiej sprawdzi się w przypadku rozbudowanych aplikacji webowych. Wtedy też koszt wdrożenia tejże technologii jest w pełni zrekompensowany poprzez zalety idące z dostosowania się do wymagań PWA.
Firma Google jednocześnie promuje także inne rozwiązanie, będące na rynku już od 2015 roku, o nazwie AMP (ang. Accelerated Mobile Pages) [16]. W wielu artykułach dostępnych w sieci obie te technologie są ze sobą porównywane, a wielokrotnie pada w nich pytanie dlaczego internetowy gigant, firma Google, jednocześnie rozwija dwie technologie pozornie dotyczące tej samej dziedziny. Nic jednak bardziej mylnego - różnią się one swoim docelowym zastosowaniem i posiadają inne zalety i wady (Rys. 24.).

AMP składa się z frameworka wprowadzającego do użycia zmodyfikowaną wersję języka HTML pod nazwą AHTML. Jest to znacznie uproszczona wersja języka HTML w standardzie 5 wzbogacona jednak o wiele dodatkowych komponentów poszerzających bardzo ograniczone możliwości AHTML. Wartym dodania jest także fakt, że wersja AMP danej strony jest zapisywana do Google Cache przez web crawlery. Użytkownicy wczytujący taką stronę pobierają ją więc z serwerów firmy Google. Wszystko to jednak pozwala na osiągnięcie znakomitej wydajności. Ale te osiągnięcia mają swoją cenę - ograniczenia AHTML są na tyle duże, że zawężają zastosowanie AMP w zasadzie jedynie to mało zaawansowanych stron statycznych. W wielu przypadkach okaże się to wystarczające - strony zajmujące się udostępnianiem artykułów najczęściej nie wymagają niczego spoza specyfikacji AHTML. Większe aplikacje webowe obsługujące dynamiczne treści i bogata interakcję z użytkownikiem niestety nie są możliwe do wykonania w tej technologii.
Co ciekawe, te dwie zupełnie różne, można by nawet powiedzieć konkurencyjne, technologie mogą ze sobą całkiem dobrze współpracować. Język AHTML posiada specjalny znacznik o nazwie <amp-install-serviceworker> którego celem jest po bardzo szybkim wczytaniu statycznej treści za pomocą AMP w tle pobrać i przygotować do uruchomienia pełną wersję strony w technologii PWA. Dzięki temu możliwe jest połączenie najważniejszych zalet obu rozwiązań: bardzo szybkie pierwsze wczytanie strony oraz płynne przejście na pełną aplikację progresywną, której najważniejsze aspekty zostały już określone wcześniej.
Rysunek 24: Porównanie zalet technologii PWA oraz AMP
Analogicznie działającą platformą do AMP jest propozycja rozwijana przez firmę Facebook o nazwie Instant Articles. Różnią się oczywiście składnią, ale główne zastosowanie pozostaje takie samo - szybkie dostarczanie statycznych treści, najczęściej artykułów. Istotną różnicą jest natomiast skoncentrowanie się tej usługi na dystrybuowanie treści wewnątrz serwisu Facebook. Specyfikacja jest jednak tak samo jak w przypadku AMP otwarta, więc nie wykluczone jest zastosowanie tej technologii w zupełnie innym celu. Nie spiera także połączenia z aplikacjami progresywnymi tak jak to miało miejsce w przypadku AMP.
Podsumowując, ciężko wymienione rozwiązania nazwać konkurencyjnymi. Każda z nich ma trochę inne możliwości, przeznaczenie, zalety i wady. Czasami możliwe jest połączenie tych technologii w celu dostarczenia jeszcze lepszego doświadczenia wczytywania strony internetowej użytkownikowi końcowemu. Warto także zaznaczyć, że temat optymalizacji aplikacji webowych jest stosunkowo młody, należy się więc spodziewać ciągłego rozwoju tej dziedziny oraz pojawiania się na rynku rozwiązań proponujących zupełnie nowe koncepcje.

3. Miary badania jakości usług sieciowych
Pojęcie jakości świadczonych usług w sieci Internet jest pojęciem bardzo rozległym. Można je rozważać zarówno od strony oprogramowania serwerowego jak i internaty. Dotyczyć może aspektów funkcjonalnych, wizualnych, kosztowych czy też wydajnościowych. Wszystkie te aspekty wpływają na ogólne doznania z użytkowania oprogramowania.
W tej pracy pod pojęciem jakości świadczonych usług sieciowych rozumiana będzie wydajność aplikacji webowych z perspektywy użytkownika końcowego [33]. Na taką wydajność co prawda ma w oczywisty sposób wpływ jakość oprogramowania serwerowego, jednak celem tej pracy jest zbadanie wpływu technologii progresywnych aplikacji webowych na jakość świadczonych w sieci Internet usług. W związku z faktem, iż PWA jako specyfikacja dotyczy głównie części klienckiej wytwarzanych aplikacji webowych to miarami wykorzystanymi do aproksymacji tejże jakości będą wartości opisujące wydajność strony internetowej.
Jak więc prawidłowo mierzyć wydajność aplikacji webowych? Posiłkując się materiałami z konferencji Google I/O 2017 postaram się na to pytanie odpowiedzieć w tym rozdziale. Jednym z tematów poruszanych na tejże konferencji była kwestia badania wpływu wydajności stron internetowych na doświadczenia internautów, co idealnie wpasowuje się w problematykę tego rozdziału. Prezentacja ta została przez autorów nazwana “Web Performance: Leveraging the Metrics that Most Affect User Experience” i jest dostępna na oficjalnym kanale konferencji w serwisie YouTube wraz ze spisanym artykułem podsumowujący cm prezentacje.
Prelegenci stwierdzili, że większośc przeprowadzanych audytów wydajności aplikacji webowych wykonywana jest niewłaściwie. Zaznaczają, że czas wczytania witryny jest miarą zależną od bardzo wielu czynników, takich jak np. jakość połączenia sieciowego, urządzenie na którym witryna jest pobierana czy też informacja o tym, czy jest to wizyta powracająca. Stwierdzenie, że dana strona jest dobrze zoptymalizowana, bo wczytuje się jedną sekundę jest więc kompletnie błędne. Należy bowiem przynajmniej sprawdzić taką miarę w różnych warunkach połączenia sieciowego.
Dodatkowo bardzo istotne jest wykorzystanie miar bardziej ukierunkowanych na doświadczenia towarzyszące użytkownikom danego serwisu. Podczas procesu wczytywania aplikacji webowej użytkownik kieruje się najczęściej wzrokiem - ważne jest więc, aby treść została wyświetlona jak najszybciej. Strona której kompletne wczytanie zajmuje 3s, ale która po 0,5s dostarcza internaucie części treści jest poprzez użytkownika końcowego znacznie lepiej odbierana aniżeli strona która przez 2s wyświetla jedynie białe tło. Przykładem takiej miary może być czas pierwszego istotnego wyświetlenia witryny.
Zaznaczono również, że w dobie królowania urządzeń mobilnych zbyt często pomijany jest aspekt oszczędności transferu danych czy też wykorzystania pamięci podręcznej. W związku z tym, każda z badanych miar powinna być zbadana ponownie z użyciem pamięci podręcznej.
Poruszona we wcześniejszych rozdziałach kwestia pracy aplikacji w momencie braku połączenia z siecią również może być uznana za miarę wydajności oprogramowania klienckiego. Warto więc taką sytuację uznać za kolejny przypadek uwarunkowania sieciowego.
Podsumowując, do przeprowadzanego w tej pracy eksperymentu pomiarowego pewnej aplikacji webowej wykorzystana zostanie wiedza z konferencji Google I/O 2017 [35][34]. Wybrane miary pozwalające dobrze odwzorować jakość usługi sieciowej to:
● Liczba żądań ● Ilość przesyłanych danych ● Czas wczytania strony ● First meaningful paint
Dwie ostatnie miary zostaną dodatkowo zbadane w 4 warunkach sieciowych:

● Połączenie bez ograniczeń ● Sieć komórkowa ● Li-fie ● Offline
Każde z badań zostanie wykonane ponownie z zachowaniem instalacji przeglądarki internetowej i jej pamięci podręcznej. Taki zabieg posłuży za symulację pierwszego oraz ponownego wczytania strony. W kolejnych rozdziałach opisane zostaną wybrane miary, ich wpływ na wydajność aplikacji sieciowych oraz narzędzia, które zostaną wykorzystane do pobrania pomiarów.
3.1. Pierwsze oraz ponowne wczytanie witryny
Dlaczego badać ponowne wczytanie aplikacji webowej? Nowoczesne przeglądarki internetowe oferują ogromne możliwości wykorzystywania różnego rodzaju specjalistycznych pamięci podręcznych. Użycie Service Workera, które jest wymagane przez każdą aplikację progresywną, jeszcze bardziej poszerza te możliwości, dodając obsługę dynamicznego cache i przetwarzania całych żądań oraz odpowiedzi HTTP. Jak zostało już wyjaśnione, podczas pierwszego wczytania strony następuje instalacja Service Worker, więc w przypadku takich witryn czas ten będzie wydłużony. W syntetycznych badaniach wynik taki pokazywałby tylko, że zastosowanie tej techniki przynosi spadek wydajności aplikacji. A jak wiemy, nie jest to prawdą - dopiero ponowne wczytania przynoszą wymierne korzysći. Analogicznie wygląda sytuacja z wykorzystaniem tradycyjnej pamięci podręcznej. Z tego też powodu niezwykle istotnym jest, aby podczas przeprowadzania badań wydajności aplikacji webowych brać pod uwagę zastosowanie takich właśnie usprawnień.
W tym celu konieczne jest przeprowadzanie pomiarów w rzeczywistym środowisku danej przeglądarki internetowej oraz ponawianie procesu wczytania danej podstrony bez czyszczenia wszystkich pamięci podręcznych oraz bez zamykania danej instancji przeglądarki. Taki zabieg pozwoli ustalić dwie wartości dla każdej z mierzonych miar: jedną określającą pierwsze wczytanie strony oraz drugą, przedstawiającą wartość danej miary dla ponownego wczytania strony. Różnica pomiędzy tymi wartościami pokaże jak efektywnie wykorzystywane są przez badaną aplikację techniki wykorzystania pamięci cache oraz jak dana strona będzie się zachowywać z perspektywy powracających internatów.
3.2. Liczba żądań
Jedną z bardzo popularnych miar określających wydajność aplikacji webowej jest liczba żądań HTTP wykonywanych podczas wczytania danej podstrony. Wprowadzenie obowiązku użycia protokołu HTTP2 w dużej mierze zmniejsza istotność tej miary, ponieważ protokół ten umożliwia wykonywanie wielu transakcji na bazie jednego połączenia TCP, co znacząco redukuje narzut spowodowany dużą ilością osobnych żądań. Pomimo tego, jest to nadal parametr wart uwagi podczas przeprowadzania kompleksowych badań wydajności aplikacji webowych.
Każde z żądań posiada przecież swój nagłówek i wymaga osobnej obsługi przez przeglądarki internetowe. Korzystając z wyników badań przeprowadzonych w ramach projektu Chromium [30] możemy założyć, że wielkość nagłówka to średnio ~700-800 bajtów. Tak więc każde z wysłanych żądań powoduje dodatkowy narzut przesyłanych danych.
W pewnym stopniu może on służyć także do aproksymacji złożoności danego serwisu internetowego - czym więcej żądań, tym więcej mocy obliczeniowej musi zostać poświęcone na ich obsłużenie, tym bardziej rozłożona jest dystrybucja zasobów danej podstrony i tym bardziej skomplikowany jest proces generowania takiej strony. Liczba żądań może mieć więc znaczący wpływ na krytyczną ścieżkę renderowania i idący za tym opóźnienia w renderowaniu aplikacji.
3.3. Liczba przesłanych danych
Często pomijaną miarą podczas badań dotyczących wydajności apliakcji sieciowych jest liczba przesłanych danych. Określa ona łączny transfer konieczny do wykonania w celu wczytania całej witryny. W dobie coraz to szybszych połączeń sieciowych stała się praktycznie zapomniana. Jednak duża popularność urządzeń mobilnych, a co za tym idzie częste korzystanie z usług sieciowych za pośrednictwem połączenia komórkowego spowodowała ponowne zainteresowanie się tą wartością.
Na jej wartość wpływa bardzo dużo czynników, takich jak: liczba żądań HTTP, kompresja żądań HTTP, waga statycznych zasobów (pliki multimedialne, skrypty JavaScript, arkusze stylów CSS) oraz sama treść strony HTML. O ile powolne pobieranie obrazku skutkować będzie powolnym pojawianiem się fragmentów obrazu na ekranie, o tyle zbyt wolne pobieranie kodu HTML oznaczać będzie dla użytkownika wyświetlanie jedynie pustej, białej strony. Analogicznie, bez arkusza stylów układ treści będzie zupełnie chaotyczny a jego późniejsze odczytanie może spowodować konieczność ponownego generowania całej strony.
3.4. Czas wczytania strony internetowej
Najczęściej stosowaną z miar jest czas kompletnego wczytania strony internetowej. Liczona jest od rozpoczęcia pierwszego żądania, do całkowitego zakończenia ostatniego z nich. Ze względu na fakt, iż część żądań jest od siebie zależna i następuje tzw. blokowanie się żądań, czas ten może się znacząco różnić pomiędzy kolejnymi pomiarami. Ponadto, jest on istotnie zależy także od urządzenia na którym dany pomiar jest wykonywany. W związku z tym, uzyskane pomiary należy bezpośrednio powiązać z parametrami urządzenia.
3.5. Obsługa trybu dostępu do sieci online, lie-fi oraz offline
Wzrostowa tendencja osób przeglądających strony internetowe na urządzeniach mobilnych i korzystających z połączeń komórkowych (Rys. 25.) zmusza nas do rozważania miar określających wydajność aplikacji webowych w kontekście jakości aktualnego połączenia sieciowego.
Rysunek 25: Porównanie użyciu mobilnego internetu w roku 2013 i 2015, Understanding Low Bandwidth and High Latency
Konieczne jest więc zbadanie, jak badana aplikacja zachowuje się z perspektywy użytkownika końcowego na połączeniu o małej przepustowości i dużych opóźnieniach.

Rozważyć należy także połączenie lie-fi. Termin ten wprowadzono w 2008 roku i odnosi się on do połączenia, które “nie jest takie, jakie się wydaje”. Oznacza to mniej więcej tyle, że przeglądarka internetowa dostaje informacje, że połączenie sieciowe jest aktywne, natomiast w rzeczywistości z jakiegoś powodu tak nie jest. W praktyce taki stan może okazać się gorszy niż kompletny brak dostępu do sieci - jedyny sposób na jego wykrycie, to obsługa czasu timeout żądań HTTP.
Aplikacje progresywne wprowadzają dodatkowo obsługę trybu offline. Dzięki temu taka aplikacja webowa może funkcjonować w pewnym ograniczonym stopniu nawet bez aktywnego dostępu do sieci. Warto więc taki stan również zbadać podczas analizowania wydajności stron internetowych.
3.6. First meaningful paint
Badając wydajność z perspektywy użytkownika końcowego nie można pominąć samej responsywności aplikacji. Rozkłada się ona na wiele czynników, takich jak czas pokazania treści, płynność animacji czy też zdolność strony na reagowanie na akcje internaty. Firma Google opracowała ku temu specjalny model o nazwie RAIL [11], czyli kolejno: Response, Animation, Idle i Load. Przedstawia on bardzo nowoczesne podejście do tematyki wydajności stron internetowych. Po pierwsze określa on dziedziny problemów, na których powinniśmy się skupić, aby poprawić doświadczenia użytkowników aplikacji webowych.
Pierwszym zaleceniem jest czas odpowiedzi na reakcję użytkownika. Powinien wynosić poniżej 100ms aby praca strony uznana została za płynną. Druga wskazówka dotyczy animacji. Ludzkie oko uznaje za płynną animację tak, która wyświetla 60 klatek na sekundę. Aplikacja ma więc 10ms na każde wygenerowanie następnej klatki. Kolejna z uwag dotyczy wykorzystania czasu bezczynności, w którym to zaleca się wykonywanie prac odłożonych w czasie. Przykładem może być doczytywanie treści, które potrzebne będę w niedalekiej przyszłości. Ostatnia z wytycznych dotyczy procesu wczytania witryny. Cały czas od rozpoczęcia tego procesu do momentu, w którym aplikacja umożliwia reakcję na akcje użytkownika (czyli jest interaktywna) powinien być mniejszy niż 5s.
Po drugie, wszystkie te zalecenia mają odzwierciedlenie w specjalnie zdefiniowanych w tym celu miarach czasowych (Rys. 26.). Są to kolejno:
1. First Paint (FP) 2. First Contentful Paint (FCP) 3. First Meaningful Paint (FMP) 4. Time To Interact (TTI)
Rysunek 26: Metryki charakteryzujące proces wczytywania strony internetowej, Web Performance: Leveraging the Metrics that Most Affect User Experience (Google I/O '17) [1]

Do niedawna tak dokładne mierzenie wydajności procesu generowania stron internetowych
przez przeglądarki nie było możliwe. Przedstawione powyżej miary bazują na czasach których pobranie wymagałoby bezpośredniego dostępu do silnika przeglądarek odpowiedzialnego za cały ten proces. Firma Google wprowadzając jednak takie miary zadbała także o możliwość ich praktycznego pobrania - w tym celu opracowana została technologia o nazwie Performance API [20], która została zaprezentowana jednocześnie z modelem RAIL na konferencji Google I/O 2017.
Kodowanie dla każdej badanej aplikacji webowej komponentów wyznaczających takie miary byłoby jednak bardzo pracochłonne i kosztowne. Na rynku istnieje więc szereg gotowych rozwiązań, pozwalających ten proces znacznie przyspieszyć i zautomatyzować.
3.7. Narzędzia oraz audyty - Google Lighthouse, Google Chrome Dev Tools
Na rynku dostępnych jest wiele narzędzi wspomagających wykonywanie audytów stron internetowych w zakresie wydajności. Bardzo często oferują wykonywanie pomiarów z serwerów znajdujących się w różnych krajach a także na innych kontynentach. Podstawowe miary, takie jak czas wczytywania strony, liczba żądań czy też analizę transferu, są obsługiwane w większości z nich. Ponadto, często oferują spersonalizowane wskazówki jak taką wydajność poprawić. W większości wypadków ogranicza się to jednak do zalecanych kompresji obrazów czy też plików źródłowych oraz ustawienia nagłówków służących do włączenia statycznej pamięci podręcznej dla konkretnych zasobów. Problem pojawia się wtedy, kiedy chcemy zmierzyć wydajność z wykorzystaniem bardziej wyspecyfikowanych metryk. A w wielu przypadkach, tak jak np. dla aplikacji progresywnych, podstawowe miary nie ukazują wielu aspektów wydajnościowych.
Firma Google wydała jedno z najbardziej rozbudowanych, a jednocześnie najbardziej uniwersalnych, narzędzi do przeprowadzania audytów witryn internetowych. Projekt nazywa się Google Lighthouse [10][32], a od niedawna jest wbudowany w panel narzędzi deweloperski przeglądarki Google Chrome - Chrome DevTools [9]. Audyt ten zawiera (Rys. 27.), poza metrykami dotyczącymi wydajności, także testy oceniające dostępność (w kontekście projektowania) oraz moduł sprawdzający przyjazność dla użytkowników oraz dostosowanie się do standardu aplikacji progresywnych.
Rysunek 27: Wizualizacja wartości zebranych przez narzędzie Google Lighthouse
Poza tym, oprogramowanie to pozwala na symulację różnych warunków sieciowych. Do wykonania nawet bardzo zaawansowanych pomiarów wystarczy więc de facto tylko zainstalowana przeglądarka internetowa Google Chrome wraz z włączonym panelem Chrome DevTools.
Na rynku obecnych jest oczywiście wiele innych konkurencyjnych rozwiązań, którym zapewne warto się przyjrzeć. Opisywane narzędzie spełnia jednak kompleksowo wszystkie wymagania do przeprowadzenia opisywanego w tej pracy badania.
3.8. Perceptual Speed Index
Omawiane powyżej narzędzie Google Lighhouse wprowadza swoją własną miarę, o nazwie Perceptual Speed Index. Definiuje ona szybkość populowania treści widocznych na ekranie niezależnie od urządzenia a także warunków sieciowych. Czym więc mniejsza jest jego wartość, tym strona szybciej jest gotowa do wyświetlenia. Jego szczegółowe składowe nie są jednak znane.

4. Przeprowadzony eksperyment
W celu zobrazowania różnic pomiędzy klasycznym sposobem wytwarzania aplikacji webowych, a proponowanym przez internetowego giganta, firmę Google, innowacyjnym podejściem PWA przedstawiony zostanie proces transformacji przygotowanej na potrzeby tejże pracy aplikacji zgodnie z wymaganiami zaprezentowanymi w rozdziale drugim.
Następnie początkowa i końcowa forma zostaną skonfrontowane z wykorzystaniem miar i narzędzi omówionych w rozdziale trzecim. Zebrane pomiary zostaną zilustrowane a ich wpływ na jakość świadczonych usług w sieci Internet poddany analizie. Finalnie przedstawione zostaną najważniejsze aspekty PWA oraz poruszona zostanie kwestia konkurencyjnych rozwiązań z dziedziny optymalizacji dostarczania stron internetowych.
4.1. Badana aplikacja
W celu umożliwienia ukazania wszelkich zalet koncepcji PWA, w szczególności tych dotyczących komunikacji sieciowej, wytwarzany serwis musi spełniać określone funkcjonalności użytkowe:
● prezentowanie dynamicznej treści pobieranej w czasie rzeczywistym ● znaczna ilość zawartości multimedialnej (np. obrazy) ● prezentowanie zawartości strony poprzez propagowanie treści po stronie klienckiej
posortowanej według dowolnego atrybutu
Ponadto koniecznym aspektem aplikacji umożliwiającym przeprowadzenie wiarygodnego i powtarzalnego badania wydajności jest fakt, iż każde z losowo generowanych dynamicznych treści musi posiadać takie same właściwości i być generowanych w takich samych odstępach czasowych.
4.1.1. Wizja systemu
Wytworzony zostanie prosty serwis internetowy którego zadaniem będzie wyświetlanie w czasie rzeczywistym losowo generowanych wpisów posiadających:
● autora ● treść ● avatar ● datę stworzenia ● obraz
Zgodnie z powyższymi założeniami każdy z generowanych wpisów musi posiadać taki sam rozmiar i wymiary obrazu, taką samą długość tekstu i równe odstępy czasu.
4.1.2. Architektura systemu
Ze względu na fakt, iż będzie to aplikacja webowa, całość musi pracować w architekturze klient-serwer. Klientem będzie oczywiście przeglądarka internetowa a serwerem serwer www.
Część kliencka będzie korzystać z hybrydy dwóch bardzo popularnych architektur dla serwisów internetowych: SPA (ang. Single Page Application) [28] oraz App Shell, omawianą we wcześniejszych rozdziałach. Witryna nie będzie więc posiadać żadnych podstron poza stroną główną wyświetlającą listę postów posortowanych względem daty dodania.

Komunikacja pomiędzy obiema częściami będzie odbywać się z wykorzystaniem dwóch protokołów: HTTP oraz WebSockets [36] w celu zapewniania połączenia w czasie rzeczywistym do przesyłania nowych postów.
4.1.3. Zastosowane technologie
Serwer www obsłużony zostanie z wykorzystaniem oprogramowania Node.js [15] w wersji 9. oraz frameworka Express [2] w wersji 4. umożliwiającego stosunkowo prostą implementację zarówno protokołu HTTP jak i pełną obsługę technologii WebSockets. Wzorcem architektonicznym zastosowanym do organizowania struktury aplikacji jest MVC (ang. Model–view–controller) [14]. Do generowania losowych treści zastosowany zostanie algorytm markov chain zaimplementowany w pakiecie Markov-Generator [22] oraz niewielka baza przykładowych obrazów i avatarów charakteryzujących się stałą wielkością.
Strona wytworzona zostanie całkowicie w oparciu o język HTML, CSS oraz JavaScript i będzie jednym z widoków frameworka Express.
Budowanie aplikacji odbywać się będzie również w środowisku uruchomieniowym Node.js przy użyciu narzędzia deweloperskiego Gulp [5] w wersji 3. Jego zadaniem będzie spakowanie wszystkich wymaganych bibliotek oraz kodu źródłowego do pożądanego formatu, czyli głównego pliku strony HTML wraz z dołączonymi skryptami JS oraz arkuszami stylów CSS.
4.2. Klasyczne rozwiązanie, przegląd wytworzonej aplikacji
Serwis wyświetla przy pierwszym wejściu na stronę 30 ostatnich wpisów. Cała zawartość strony jest generowana po stronie serwera jako statyczny widok HTML. Następnie uruchamiany jest w części klienckiej skrypt nawiązujący połączenie WebSocket pomiędzy przeglądarką internetową a serwerem aplikacji którego zadaniem jest dodawanie nowych postów do treści strony w czasie rzeczywistym.
Interfejs użytkownika (Rys. 28.) korzysta bezpośrednio z wytycznych określonych w standardzie Google Material Design [12] i oferują pełną responsywność wyświetlanego układu na całej gamie urządzeń zdolnych do konsumowania stron internetowych, co również zostało zaprezentowane na poniższej grafice.
Rysunek 28: Podgląd uruchomionej aplikacji eksperymentalnej kolejno na laptopie dysponującym ekranem MDPI oraz smartfonie iPhone 7

Obrazy zawarte w treści postów oraz avatary autorów dodatkowo zapisane i zwracane są w
różnych rozmiarach w zależności od urządzenia na którym aplikacja zostanie uruchomiona. Np. urządzenie mobilne pobiera obraz o znacznie mniejszej rozdzielczości niż laptop z ekranem HiDPI. Pozwala to zaoszczędzić transfer oraz zmniejszyć obciążenie urządzenia spowodowane wyświetlaniem dużych obrazów.
4.3. PWA
Aplikacja została zmodyfikowana zgodnie z wytycznymi PWA dodając lub modyfikując procedury pobierania i wyświetlania postów.
Pierwsza zmiana polegała na dodaniu procedury instalacji oraz aktualizacji Service Workera po wykryciu nowej wersji aplikacji oraz stworzenia szeregu reguł przechwytywania adresów URL oraz wstępnego ładowania statycznych plików za pomocą Fetch API. Do przechowywania danych po stronie klienckiej wykorzystane zostało Cache API.
Podczas cyklu instalacji SW do cache dodane zostają skrypty JS, arkusze styli CSS, fonty oraz specjalnie przygotowana zgodnie z ideą App Shell podstrona zawierająca szkielet aplikacji. W tym przypadku będzie to więc podstrona zawierająca jedynie menu, główny kontener oraz skrypt dodający do treści strony nowe posty.
Dynamiczne media takie jak obrazy zawarte w treści postów oraz avatary autorów które pobierane w rozdzielczości i rozmiarze adekwatnym od urządzenia również są dodawane do cache. Ciekawym rozwiązaniem okazała się możliwość zapisywania i zwracania tych treści z i do cache niezależnie od aktualnie żądanego rozmiaru obrazu. Przechowywany jest więc zawsze tylko wersja obrazu w największej pobranej rozdzielczości. Rodzaj urządzenia bardzo rzadko ulega zmianom, więc w najgorszym przypadku zostanie zwrócony obraz za duży lub za mały, ale za to pobrany z cache i nie wymagający wykonania kolejnego żądania.
Kolejną konieczną modyfikacją była zmiana procedury wyświetlania pobranych postów. Każdy pobrany post zostaje po wyświetleniu zapisany w lokalnej bazie danych z wykorzystaniem technologii LocalDB. Każdy post identyfikowany jest poprzez ID postu oraz zostaje oznaczony datą dodania wpisu do bazy. Umożliwia to sortowanie wszystkich wpisów od najnowszych do najstarszych. Ze względu na częsty odczyt danych posortowanych po dacie dodania założony został stosowny indeks. Pozwala to znacząco zredukować czas potrzebny na sortowanie odczytywanie postów. Aby treści zapisanych lokalnie nie było zbyt dużo, przechowywane jest tylko 30 ostatnich postów. Dodatkowo, podczas startu aplikacji wyświetlane są wszystkie zgromadzone lokalne posty.
4.4. Aspekty pominięte w badaniu
Badanie serwisu skupione będzie głównie na aspekcie komunikacji sieciowej. Wynika to z faktu, iż celem pracy jest wykazanie wpływu technologii PWA na jakość świadczonych usług w sieci Internet. Kwestia responsywności układu zostanie całkowicie pominięta, ponieważ poza walorami wizualnymi i użytecznościowymi jest wręcz niemożliwym do określenia wpływu jaki wywiera na usługi sieciowe. Analogicznie powiadomienia push czy też wsparcie instalacji jako natywna aplikacja, które są wyjątkowo użytecznym dodatkiem do stron internetowych, nie dają możliwości bezpośredniego zmierzenia wpływu na jakość świadczonych usług.
4.5. Warunki i środowisko przeprowadzanego badania
Działanie aplikacja jak i wszystkie dalsze operacje wykonane zostały na przeglądarce internetowej Google Chrome w wersji 64 oraz serwerze pracującym pod kontrolą systemu operacyjnego Fedora 27 wraz ze środowiskiem uruchomieniowym Node.js w wersji 9. Zarówno serwer jak i przeglądarka internetowa uruchomione zostały na tej samej maszynie, a więc w
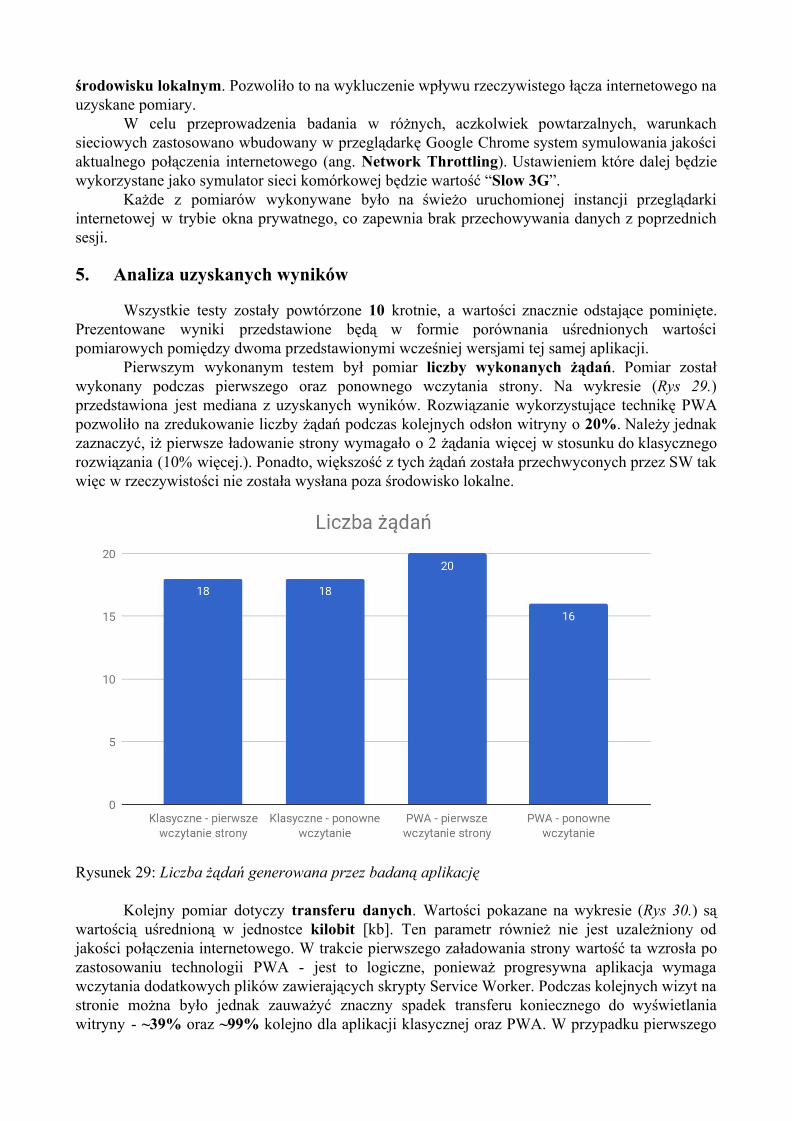
środowisku lokalnym. Pozwoliło to na wykluczenie wpływu rzeczywistego łącza internetowego na uzyskane pomiary.
W celu przeprowadzenia badania w różnych, aczkolwiek powtarzalnych, warunkach sieciowych zastosowano wbudowany w przeglądarkę Google Chrome system symulowania jakości aktualnego połączenia internetowego (ang. Network Throttling). Ustawieniem które dalej będzie wykorzystane jako symulator sieci komórkowej będzie wartość “Slow 3G”.
Każde z pomiarów wykonywane było na świeżo uruchomionej instancji przeglądarki internetowej w trybie okna prywatnego, co zapewnia brak przechowywania danych z poprzednich sesji.
5. Analiza uzyskanych wyników
Wszystkie testy zostały powtórzone 10 krotnie, a wartości znacznie odstające pominięte. Prezentowane wyniki przedstawione będą w formie porównania uśrednionych wartości pomiarowych pomiędzy dwoma przedstawionymi wcześniej wersjami tej samej aplikacji.
Pierwszym wykonanym testem był pomiar liczby wykonanych żądań. Pomiar został wykonany podczas pierwszego oraz ponownego wczytania strony. Na wykresie (Rys 29.) przedstawiona jest mediana z uzyskanych wyników. Rozwiązanie wykorzystujące technikę PWA pozwoliło na zredukowanie liczby żądań podczas kolejnych odsłon witryny o 20%. Należy jednak zaznaczyć, iż pierwsze ładowanie strony wymagało o 2 żądania więcej w stosunku do klasycznego rozwiązania (10% więcej.). Ponadto, większość z tych żądań została przechwyconych przez SW tak więc w rzeczywistości nie została wysłana poza środowisko lokalne.
Rysunek 29: Liczba żądań generowana przez badaną aplikację
Kolejny pomiar dotyczy transferu danych. Wartości pokazane na wykresie (Rys 30.) są wartością uśrednioną w jednostce kilobit [kb]. Ten parametr również nie jest uzależniony od jakości połączenia internetowego. W trakcie pierwszego załadowania strony wartość ta wzrosła po zastosowaniu technologii PWA - jest to logiczne, ponieważ progresywna aplikacja wymaga wczytania dodatkowych plików zawierających skrypty Service Worker. Podczas kolejnych wizyt na stronie można było jednak zauważyć znaczny spadek transferu koniecznego do wyświetlania witryny - ~39% oraz ~99% kolejno dla aplikacji klasycznej oraz PWA. W przypadku pierwszego
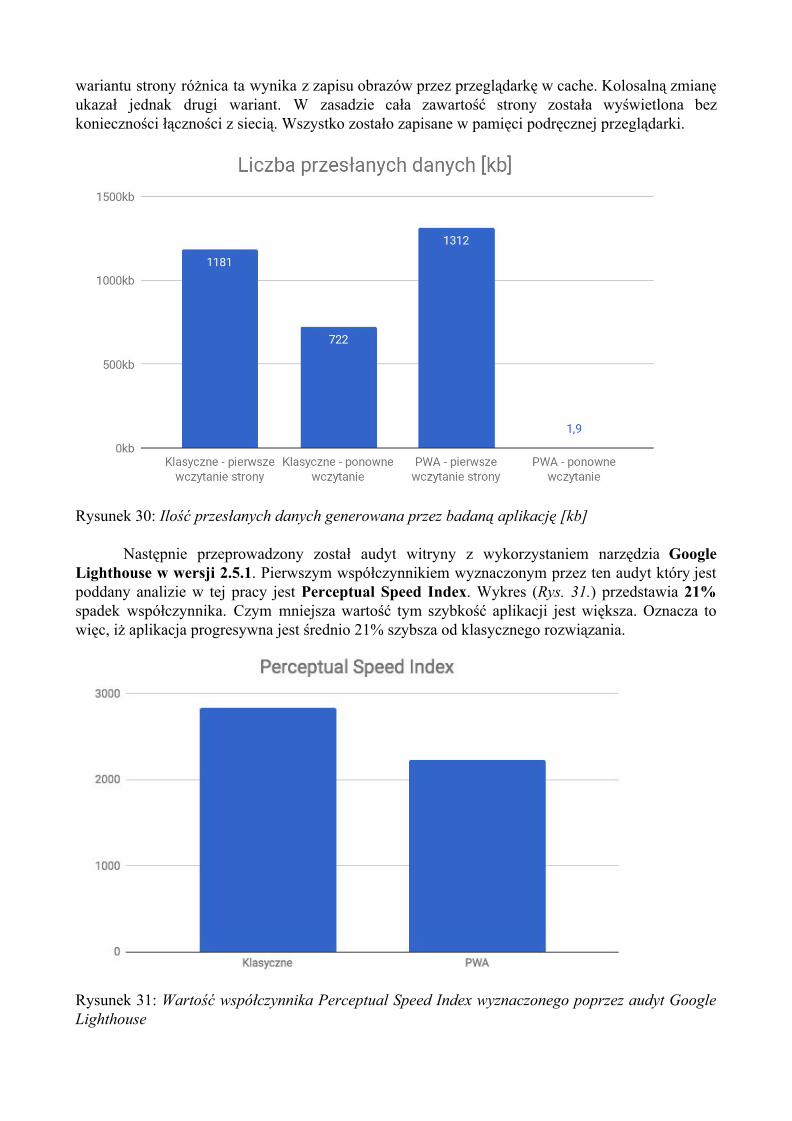
wariantu strony różnica ta wynika z zapisu obrazów przez przeglądarkę w cache. Kolosalną zmianę ukazał jednak drugi wariant. W zasadzie cała zawartość strony została wyświetlona bez konieczności łączności z siecią. Wszystko zostało zapisane w pamięci podręcznej przeglądarki.
Rysunek 30: Ilość przesłanych danych generowana przez badaną aplikację [kb]
Następnie przeprowadzony został audyt witryny z wykorzystaniem narzędzia Google Lighthouse w wersji 2.5.1. Pierwszym współczynnikiem wyznaczonym przez ten audyt który jest poddany analizie w tej pracy jest Perceptual Speed Index. Wykres (Rys. 31.) przedstawia 21% spadek współczynnika. Czym mniejsza wartość tym szybkość aplikacji jest większa. Oznacza to więc, iż aplikacja progresywna jest średnio 21% szybsza od klasycznego rozwiązania.
Rysunek 31: Wartość współczynnika Perceptual Speed Index wyznaczonego poprzez audyt Google Lighthouse
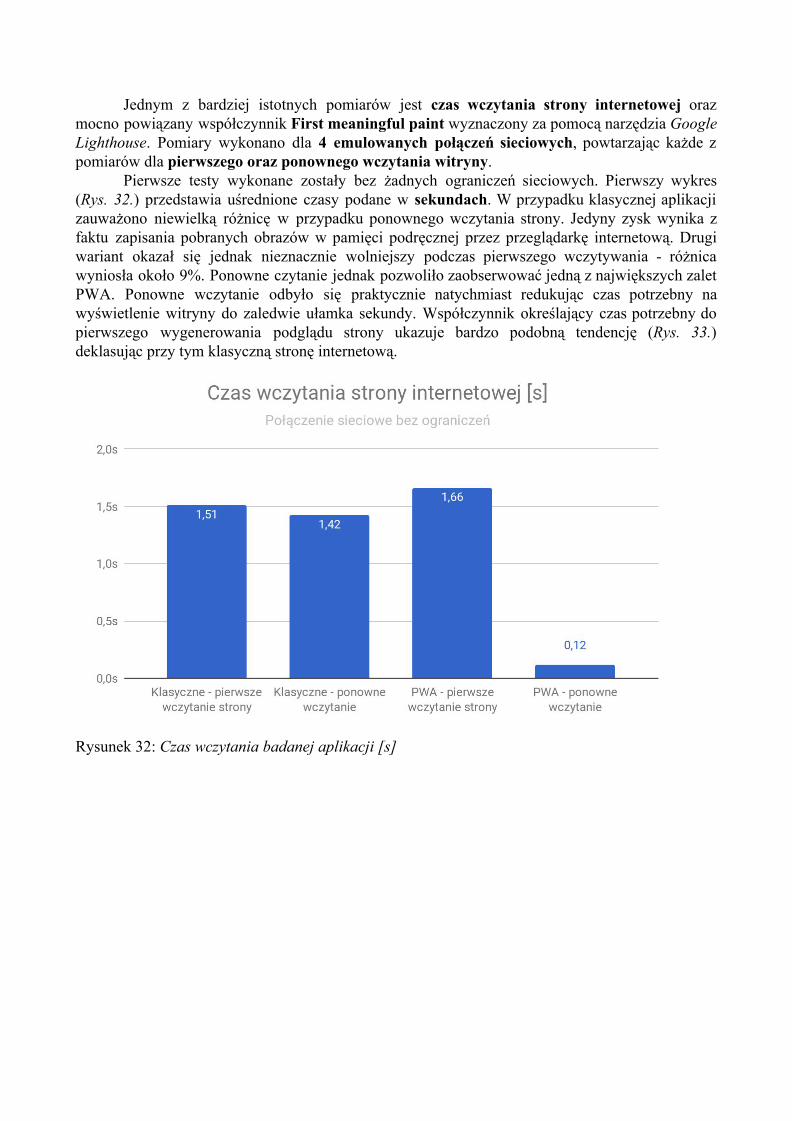
Jednym z bardziej istotnych pomiarów jest czas wczytania strony internetowej oraz
mocno powiązany współczynnik First meaningful paint wyznaczony za pomocą narzędzia Google Lighthouse. Pomiary wykonano dla 4 emulowanych połączeń sieciowych, powtarzając każde z pomiarów dla pierwszego oraz ponownego wczytania witryny.
Pierwsze testy wykonane zostały bez żadnych ograniczeń sieciowych. Pierwszy wykres (Rys. 32.) przedstawia uśrednione czasy podane w sekundach. W przypadku klasycznej aplikacji zauważono niewielką różnicę w przypadku ponownego wczytania strony. Jedyny zysk wynika z faktu zapisania pobranych obrazów w pamięci podręcznej przez przeglądarkę internetową. Drugi wariant okazał się jednak nieznacznie wolniejszy podczas pierwszego wczytywania - różnica wyniosła około 9%. Ponowne czytanie jednak pozwoliło zaobserwować jedną z największych zalet PWA. Ponowne wczytanie odbyło się praktycznie natychmiast redukując czas potrzebny na wyświetlenie witryny do zaledwie ułamka sekundy. Współczynnik określający czas potrzebny do pierwszego wygenerowania podglądu strony ukazuje bardzo podobną tendencję (Rys. 33.) deklasując przy tym klasyczną stronę internetową.
Rysunek 32: Czas wczytania badanej aplikacji [s]
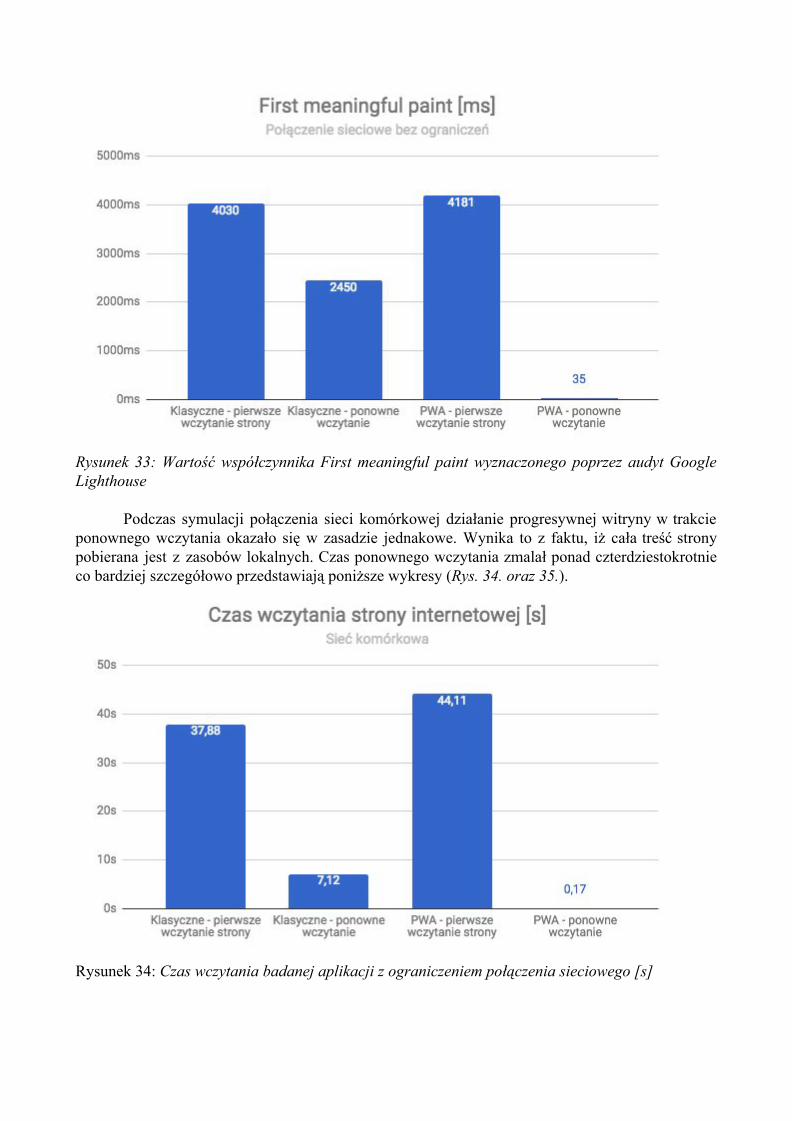
Rysunek 33: Wartość współczynnika First meaningful paint wyznaczonego poprzez audyt Google Lighthouse
Podczas symulacji połączenia sieci komórkowej działanie progresywnej witryny w trakcie ponownego wczytania okazało się w zasadzie jednakowe. Wynika to z faktu, iż cała treść strony pobierana jest z zasobów lokalnych. Czas ponownego wczytania zmalał ponad czterdziestokrotnie co bardziej szczegółowo przedstawiają poniższe wykresy (Rys. 34. oraz 35.).
Rysunek 34: Czas wczytania badanej aplikacji z ograniczeniem połączenia sieciowego [s]
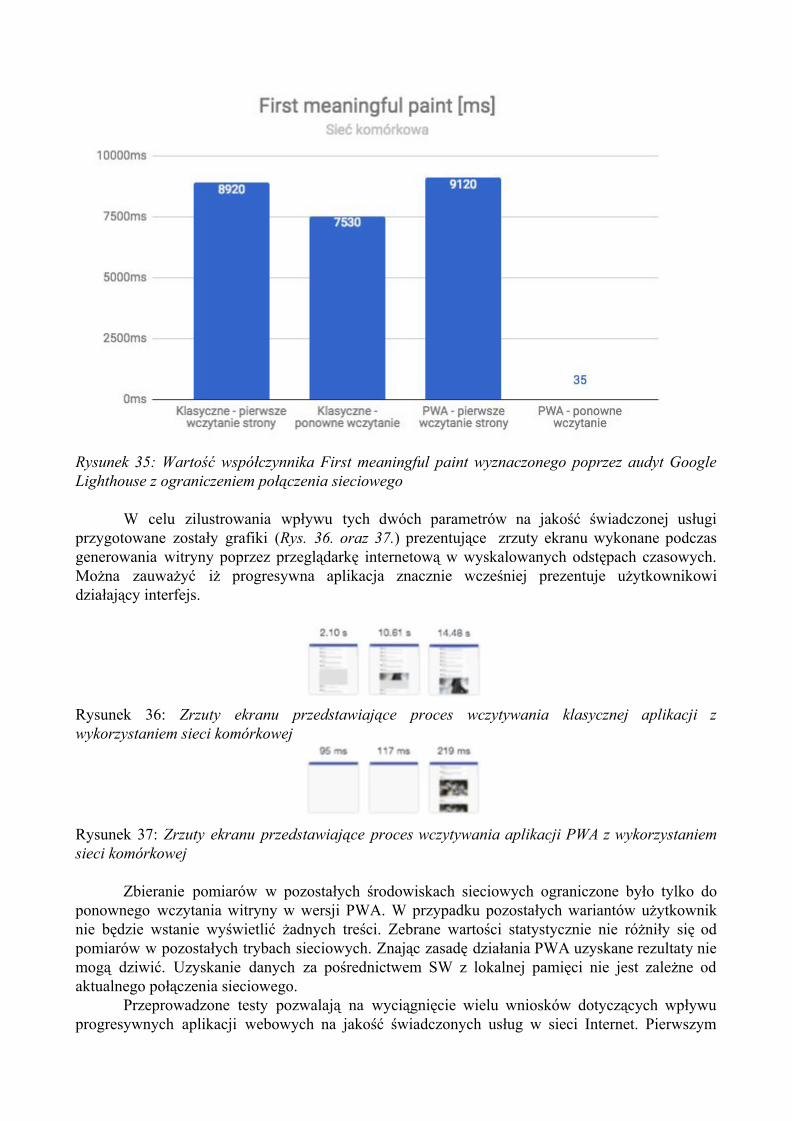
Rysunek 35: Wartość współczynnika First meaningful paint wyznaczonego poprzez audyt Google Lighthouse z ograniczeniem połączenia sieciowego
W celu zilustrowania wpływu tych dwóch parametrów na jakość świadczonej usługi przygotowane zostały grafiki (Rys. 36. oraz 37.) prezentujące zrzuty ekranu wykonane podczas generowania witryny poprzez przeglądarkę internetową w wyskalowanych odstępach czasowych. Można zauważyć iż progresywna aplikacja znacznie wcześniej prezentuje użytkownikowi działający interfejs.
Rysunek 36: Zrzuty ekranu przedstawiające proces wczytywania klasycznej aplikacji z wykorzystaniem sieci komórkowej
Rysunek 37: Zrzuty ekranu przedstawiające proces wczytywania aplikacji PWA z wykorzystaniem sieci komórkowej
Zbieranie pomiarów w pozostałych środowiskach sieciowych ograniczone było tylko do ponownego wczytania witryny w wersji PWA. W przypadku pozostałych wariantów użytkownik nie będzie wstanie wyświetlić żadnych treści. Zebrane wartości statystycznie nie różniły się od pomiarów w pozostałych trybach sieciowych. Znając zasadę działania PWA uzyskane rezultaty nie mogą dziwić. Uzyskanie danych za pośrednictwem SW z lokalnej pamięci nie jest zależne od aktualnego połączenia sieciowego.
Przeprowadzone testy pozwalają na wyciągnięcie wielu wniosków dotyczących wpływu progresywnych aplikacji webowych na jakość świadczonych usług w sieci Internet. Pierwszym

wnioskiem z pewnością powinien być istotny wpływ na komunikację podczas kolejnych wizyt witryny. PWA pozwala na znaczną redukcję przesyłu danych oraz liczby wymaganych żądań, a tym samym na przyspieszenie wczytywania strony. Najwięcej korzyści zdecydowanie można było zauważyć podczas wykorzystania słabej jakości połączenia sieciowego. Trzeba jednak zaznaczyć, że niestety korzyści te zauważyć mogą tylko i wyłącznie powracający użytkownicy danego serwisu. Technologia ta nie ma więc wpływu na pierwsze pobranie strony internetowej, a nawet może je nieznacznie wydłużyć. Wartym uwagi jest również wsparcie pozostałych trybów sieciowych: lie-fi oraz offline. Użytkownik zyskuje tym samym możliwość skorzystania z serwisu bazując na pobranych już wcześniej zasobach. Podczas pobierania nowych, aktualnych danych do dyspozycji ma wszystkie treści pobrane podczas poprzedniej sesji. Z punktu widzenia użyteczności aplikacji jest to znaczny krok do przodu przybliżający zachowaniem strony internetowe do pełnoprawnych aplikacji natywnych.
6. Najważniejsze aspekty PWA
Bazując na wykonanym w tej pracy przeglądzie procesu działania współczesnych przeglądarek internetowych w zakresie pobierania i wyświetlania stron internetowych, dogłębnej analizie technologii PWA oraz przeprowadzonemu eksperymentowi konwersji klasycznej aplikacji webowej wraz z badaniem wydajności z punktu widzenia użytkownika końcowego z pewnością można scharakteryzować najważniejsze aspekty technologii progresywnych aplikacji webowych.
Zaczynając od wymaganego zastosowania protokołu HTTP 2 i obowiązkowej szyfrowanej komunikacji za pomocą certyfikatu SSL można zdecydowanie stwierdzić, iż w dłuższej perspektywie czasu przyniesie to znaczące korzyści dla ogólnej kondycji sieci Internet. Upowszechnianie użycia SSL jest bardzo ważne dla przeciętnego użytkownika końcowego ponieważ znacząco wpływa to na zwiększenie bezpieczeństwa w sieci oraz pozwala zadbać o poufność przesyłanych danych. Protokół HTTP 2 pozwala natomiast zwiększyć wydajność przesyłanych w sieci danych. Samo zastosowanie tego protokołu w przypadku eksperymentu przeprowadzonego w pracy “THE INFLUENCE OF HTTP/2 ON USER-PERCEIVED WEB APPLICATION PERFORMANCE” [23] zmniejszyło czas wczytania strony o prawie 30%. Prawidłowe wykorzystanie techniki Server push z HTTP 2 znacząco redukuje czas wczytanie strony poprzez wypychanie zasobów potrzebnych podczas dalszego działania serwisu. W przypadku dużych aplikacji progresywnych takich zasobów może być bardzo dużo, więc wzrost jest jak najbardziej zauważalny.
Ważnym aspektem jest też nacisk na zgodność aplikacji webowych z urządzeniami mobilnymi głównie za sprawą popularyzowania responsywnego układu treści oraz obowiązkowego pliku manifestu wskazującego takie parametry strony internetowej jak główna ikona w odpowiednich rozdzielczościach, przewodni kolor motywu strony, preferowana pozycja urządzenia (horyzontalna lub wertykalna) czy też startowy adres URL.
Wykorzystanie wzorca projektowego App shell wraz z zastosowaniem Service Worker, Fetch API, Cache API oraz IndexedDB pozwala na wytwarzanie aplikacji pozwalających na znacznie większą kontrolę cyklu życia strony oraz komunikacji sieciowej od strony programistycznej. Możliwości wykorzystania cache przeglądarki internetowej są dzięki temu większe i bardziej precyzyjne. Nawet bardzo specyficzne dynamiczne żądania mogą zostać obsłużone przez autora aplikacji używając Fetch API, a przechowane mogą być w wydajnej bazie danych IndexedDB. Wszystko to wpływa na istotny spadek transferu zużywanego przez daną aplikację, szybsze reagowanie na komendy użytkownika oraz wsparcie trudnych warunków sieciowych - w tym nawet obsługę trybu offline. W wielu przypadkach to właśnie tryb offline staje się kluczową, bardzo pożądaną funkcjonalnością - likwiduje bowiem jedną z najstarszych bolączek aplikacji webowych: działanie tylko podczas aktywnego połączenia sieciowego.
Warto także zaznaczyć jedną z najbardziej promowanych przez firmę Google funkcjonalności - działania aplikacji progresywnych w trybie natywnych aplikacji systemowych.
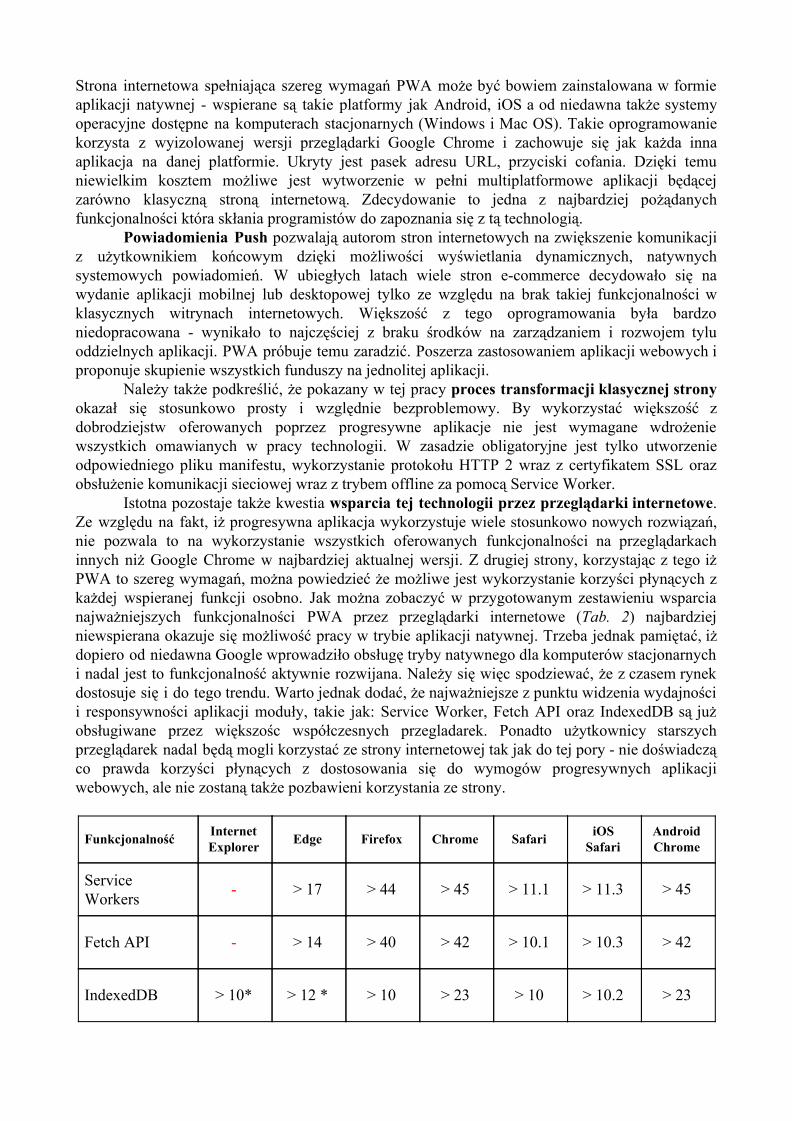
Strona internetowa spełniająca szereg wymagań PWA może być bowiem zainstalowana w formie aplikacji natywnej - wspierane są takie platformy jak Android, iOS a od niedawna także systemy operacyjne dostępne na komputerach stacjonarnych (Windows i Mac OS). Takie oprogramowanie korzysta z wyizolowanej wersji przeglądarki Google Chrome i zachowuje się jak każda inna aplikacja na danej platformie. Ukryty jest pasek adresu URL, przyciski cofania. Dzięki temu niewielkim kosztem możliwe jest wytworzenie w pełni multiplatformowe aplikacji będącej zarówno klasyczną stroną internetową. Zdecydowanie to jedna z najbardziej pożądanych funkcjonalności która skłania programistów do zapoznania się z tą technologią.
Powiadomienia Push pozwalają autorom stron internetowych na zwiększenie komunikacji z użytkownikiem końcowym dzięki możliwości wyświetlania dynamicznych, natywnych systemowych powiadomień. W ubiegłych latach wiele stron e-commerce decydowało się na wydanie aplikacji mobilnej lub desktopowej tylko ze względu na brak takiej funkcjonalności w klasycznych witrynach internetowych. Większość z tego oprogramowania była bardzo niedopracowana - wynikało to najczęściej z braku środków na zarządzaniem i rozwojem tylu oddzielnych aplikacji. PWA próbuje temu zaradzić. Poszerza zastosowaniem aplikacji webowych i proponuje skupienie wszystkich funduszy na jednolitej aplikacji.
Należy także podkreślić, że pokazany w tej pracy proces transformacji klasycznej strony okazał się stosunkowo prosty i względnie bezproblemowy. By wykorzystać większość z dobrodziejstw oferowanych poprzez progresywne aplikacje nie jest wymagane wdrożenie wszystkich omawianych w pracy technologii. W zasadzie obligatoryjne jest tylko utworzenie odpowiedniego pliku manifestu, wykorzystanie protokołu HTTP 2 wraz z certyfikatem SSL oraz obsłużenie komunikacji sieciowej wraz z trybem offline za pomocą Service Worker.
Istotna pozostaje także kwestia wsparcia tej technologii przez przeglądarki internetowe. Ze względu na fakt, iż progresywna aplikacja wykorzystuje wiele stosunkowo nowych rozwiązań, nie pozwala to na wykorzystanie wszystkich oferowanych funkcjonalności na przeglądarkach innych niż Google Chrome w najbardziej aktualnej wersji. Z drugiej strony, korzystając z tego iż PWA to szereg wymagań, można powiedzieć że możliwe jest wykorzystanie korzyści płynących z każdej wspieranej funkcji osobno. Jak można zobaczyć w przygotowanym zestawieniu wsparcia najważniejszych funkcjonalności PWA przez przeglądarki internetowe (Tab. 2) najbardziej niewspierana okazuje się możliwość pracy w trybie aplikacji natywnej. Trzeba jednak pamiętać, iż dopiero od niedawna Google wprowadziło obsługę tryby natywnego dla komputerów stacjonarnych i nadal jest to funkcjonalność aktywnie rozwijana. Należy się więc spodziewać, że z czasem rynek dostosuje się i do tego trendu. Warto jednak dodać, że najważniejsze z punktu widzenia wydajności i responsywności aplikacji moduły, takie jak: Service Worker, Fetch API oraz IndexedDB są już obsługiwane przez większośc współczesnych przegladarek. Ponadto użytkownicy starszych przeglądarek nadal będą mogli korzystać ze strony internetowej tak jak do tej pory - nie doświadczą co prawda korzyści płynących z dostosowania się do wymogów progresywnych aplikacji webowych, ale nie zostaną także pozbawieni korzystania ze strony.
Funkcjonalność Internet Explorer Edge Firefox Chrome Safari iOS
Safari Android Chrome
Service Workers - > 17 > 44 > 45 > 11.1 > 11.3 > 45
Fetch API - > 14 > 40 > 42 > 10.1 > 10.3 > 42
IndexedDB > 10* > 12 * > 10 > 23 > 10 > 10.2 > 23
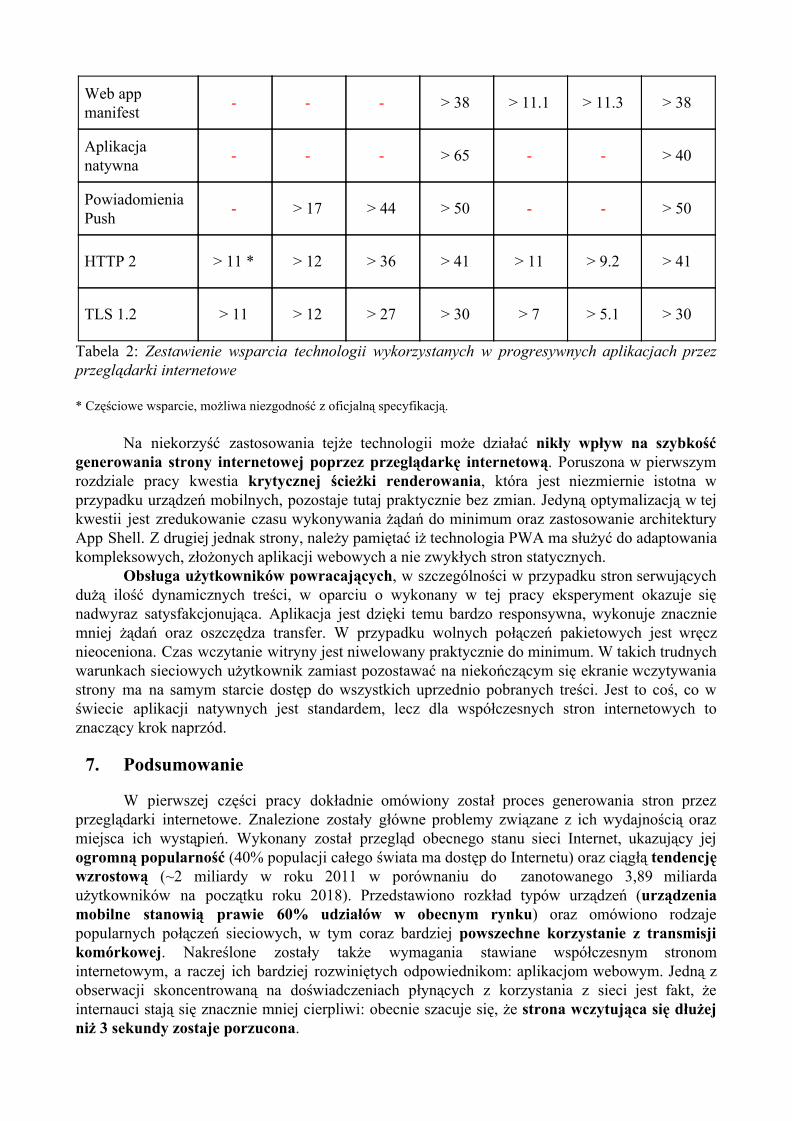
Web app manifest - - - > 38 > 11.1 > 11.3 > 38
Aplikacja natywna - - - > 65 - - > 40
Powiadomienia Push - > 17 > 44 > 50 - - > 50
HTTP 2 > 11 * > 12 > 36 > 41 > 11 > 9.2 > 41
TLS 1.2 > 11 > 12 > 27 > 30 > 7 > 5.1 > 30
Tabela 2: Zestawienie wsparcia technologii wykorzystanych w progresywnych aplikacjach przez przeglądarki internetowe * Częściowe wsparcie, możliwa niezgodność z oficjalną specyfikacją.
Na niekorzyść zastosowania tejże technologii może działać nikły wpływ na szybkość generowania strony internetowej poprzez przeglądarkę internetową. Poruszona w pierwszym rozdziale pracy kwestia krytycznej ścieżki renderowania, która jest niezmiernie istotna w przypadku urządzeń mobilnych, pozostaje tutaj praktycznie bez zmian. Jedyną optymalizacją w tej kwestii jest zredukowanie czasu wykonywania żądań do minimum oraz zastosowanie architektury App Shell. Z drugiej jednak strony, należy pamiętać iż technologia PWA ma służyć do adaptowania kompleksowych, złożonych aplikacji webowych a nie zwykłych stron statycznych.
Obsługa użytkowników powracających, w szczególności w przypadku stron serwujących dużą ilość dynamicznych treści, w oparciu o wykonany w tej pracy eksperyment okazuje się nadwyraz satysfakcjonująca. Aplikacja jest dzięki temu bardzo responsywna, wykonuje znacznie mniej żądań oraz oszczędza transfer. W przypadku wolnych połączeń pakietowych jest wręcz nieoceniona. Czas wczytanie witryny jest niwelowany praktycznie do minimum. W takich trudnych warunkach sieciowych użytkownik zamiast pozostawać na niekończącym się ekranie wczytywania strony ma na samym starcie dostęp do wszystkich uprzednio pobranych treści. Jest to coś, co w świecie aplikacji natywnych jest standardem, lecz dla współczesnych stron internetowych to znaczący krok naprzód.
7. Podsumowanie
W pierwszej części pracy dokładnie omówiony został proces generowania stron przez przeglądarki internetowe. Znalezione zostały główne problemy związane z ich wydajnością oraz miejsca ich wystąpień. Wykonany został przegląd obecnego stanu sieci Internet, ukazujący jej ogromną popularność (40% populacji całego świata ma dostęp do Internetu) oraz ciągłą tendencję wzrostową (~2 miliardy w roku 2011 w porównaniu do zanotowanego 3,89 miliarda użytkowników na początku roku 2018). Przedstawiono rozkład typów urządzeń (urządzenia mobilne stanowią prawie 60% udziałów w obecnym rynku) oraz omówiono rodzaje popularnych połączeń sieciowych, w tym coraz bardziej powszechne korzystanie z transmisji komórkowej. Nakreślone zostały także wymagania stawiane współczesnym stronom internetowym, a raczej ich bardziej rozwiniętych odpowiednikom: aplikacjom webowym. Jedną z obserwacji skoncentrowaną na doświadczeniach płynących z korzystania z sieci jest fakt, że internauci stają się znacznie mniej cierpliwi: obecnie szacuje się, że strona wczytująca się dłużej niż 3 sekundy zostaje porzucona.

Omówienie pojęcia Word Wide Web (WWW) i związanych z nim podstawowymi zasadami działania dzisiejszej sieci pozwoliło na wyznaczenie dwóch głównych problemów wydajnościowych występujących podczas przeglądanie sieci. Bardzo istotny okazał się tutaj wpływ jakości połączenia sieciowego, a szczególnie problemy związane z częstym przerywaniem połączeń TCP oraz zbyt długimi czasami odpowiedzi towarzyszące głównie transmisji komórkowej. Nie bez znaczenia okazał się także problem związany z kolejnością pobierania zasobów podczas generowania strony internetowej, zwana krytyczną ścieżką renderowania.
Przegląd tytułowej technologii progresywnych aplikacji webowych przedstawił aktualny stan rozwoju tego rozwiązania stworzonego w 2015 roku, rozwijanego i promowanego przez firmę Google i zademonstrował wybrane aplikacje webowe które już korzystają z tego standardu. Zestawienie to, któremu towarzyszyły komentarze twórców tych stron, wykazało, że technologia ta jest już na tyle dojrzała, aby wykorzystać ją w środowisku produkcyjnym. Przedstawiona została także kwestia stawianych przez nią wymagań w stosunku do klasycznych stron internetowych oraz zgodności tych rozwiązań z popularnymi na rynku przeglądarkami internetowymi. Zdecydowana większość z tych wymagań po dokładnej analizie okazała się mieć bardzo dobry wpływ na podnoszenie jakości świadczenia usług w sieci Internet, więc można je uznać za bardzo dobry kierunek rozwoju formy aplikacji webowych.
W dalszej części pracy poruszona została kwestia metodyki przeprowadzania badań jakości usług sieciowych z perspektywy użytkownika końcowego, ukierunkowana na wydajność aplikacji webowych. Okazało się, że większośc przeprowadzanych audytów wydajności aplikacji webowych wykonywana jest niewłaściwie. Rozróżnione zostało pierwsze oraz ponowne wczytanie witryny. Wprowadzone zostały wybrane miary służące do estymowania wydajności stron internetowych, takie jak: liczba żądań, liczba przesłanych danych, czas wczytania strony internetowej czy też obsługa połączenia sieciowego zwanego lie-fi oraz trybu offline. Wykorzystano także model RAIL i powiązany z nim parametr first meaningful paint. Opisane zostały także sposoby pobierania takich parametrów i narzędzia do tego służące.
Znając już dziedzinę problemu, sposoby wykonywania pomiarów wydajnościowych oraz główne zasady działania technologii PWA możliwe było wykonanie eksperymentu właściwego. W tym celu została wykonana klasyczna aplikacja webowa, oferująca takie funkcjonalności, które pozwoliły na pełne zademonstrowanie zalet badanej techniki. Koniecznym wymaganiem była także powtarzalność jej działania, aby badania mogły być wiarygodne. Następnie aplikacja ta została poddana transformacji mającej na celu dostosowanie jej do spełnienia wymogów progresywnych aplikacji webowych. Pobrano pomiary wybranych miar z obu wersji wytworzonej strony, a następnie ich różnice zostały skonfrontowane, przedstawione na wykresach i przeanalizowane.
Zbierając wszystkie wnioski z poprzednich dwóch rozdziałów oraz wiedzę przedstawioną w pozostałej części pracy, badana technologia ma istotny wpływ na jakość świadczonych usług w sieci Internet. Przedstawiony przegląd najważniejszych aspektów PWA jasno pokazuje, że nie jest to technologia bez wad. Ale należy tutaj zaznaczyć, że pomimo tego, iż nie rozwiązuje wszystkich obecnych problemów z dziedziny wydajności, to znacznie podnosi komfort korzystania ze stron internetowych w trudnych warunkach sieciowych, szczególnie na urządzeniach mobilnych korzystających z transmisji komórkowej. Potwierdzają to uzyskane w przeprowadzonym na potrzeby tej pracy eksperymencie wyniki, jak i zbiór opinii właścicieli popularnych serwisów już korzystających z tej technologii. Ponadto, wymagania stawiane stronom internetowym przez badana technologię wpływają pozytywnie na bezpieczeństwo w sieci oraz znacznie poszerzają możliwości wytwarzania aplikacji webowych.
8. Przyszły rozwój tej technologii
Na odbywającej się niedawno, bo zaledwie 8 maja bieżącego roku, konferencji Google I/O 2018 [24] przedstawionych zostało mnóstwo kluczowych informacji dotyczących technologii PWA. To pierwsza z serii tych konferencji, na której aż tak dużą uwagę poświęcono rozwojowi aplikacji
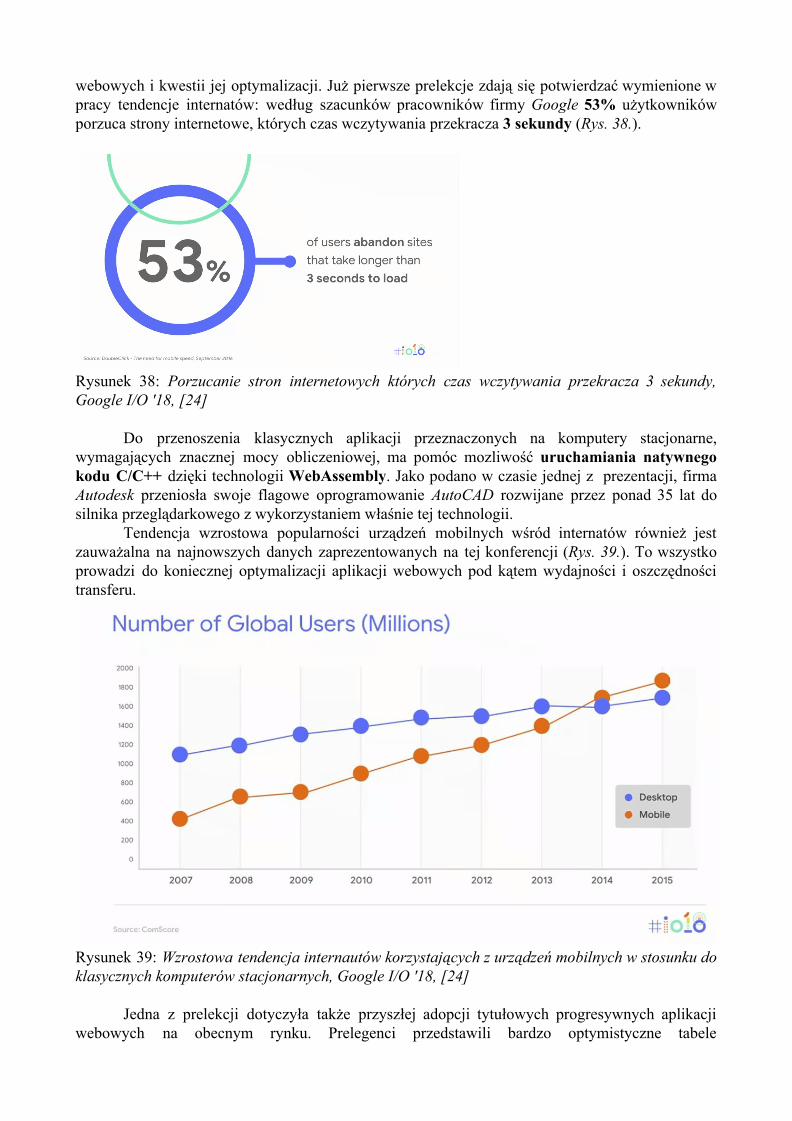
webowych i kwestii jej optymalizacji. Już pierwsze prelekcje zdają się potwierdzać wymienione w pracy tendencje internatów: według szacunków pracowników firmy Google 53% użytkowników porzuca strony internetowe, których czas wczytywania przekracza 3 sekundy (Rys. 38.).
Rysunek 38: Porzucanie stron internetowych których czas wczytywania przekracza 3 sekundy, Google I/O '18, [24]
Do przenoszenia klasycznych aplikacji przeznaczonych na komputery stacjonarne, wymagających znacznej mocy obliczeniowej, ma pomóc mozliwość uruchamiania natywnego kodu C/C++ dzięki technologii WebAssembly. Jako podano w czasie jednej z prezentacji, firma Autodesk przeniosła swoje flagowe oprogramowanie AutoCAD rozwijane przez ponad 35 lat do silnika przeglądarkowego z wykorzystaniem właśnie tej technologii.
Tendencja wzrostowa popularności urządzeń mobilnych wśród internatów również jest zauważalna na najnowszych danych zaprezentowanych na tej konferencji (Rys. 39.). To wszystko prowadzi do koniecznej optymalizacji aplikacji webowych pod kątem wydajności i oszczędności transferu.
Rysunek 39: Wzrostowa tendencja internautów korzystających z urządzeń mobilnych w stosunku do klasycznych komputerów stacjonarnych, Google I/O '18, [24]
Jedna z prelekcji dotyczyła także przyszłej adopcji tytułowych progresywnych aplikacji webowych na obecnym rynku. Prelegenci przedstawili bardzo optymistyczne tabele
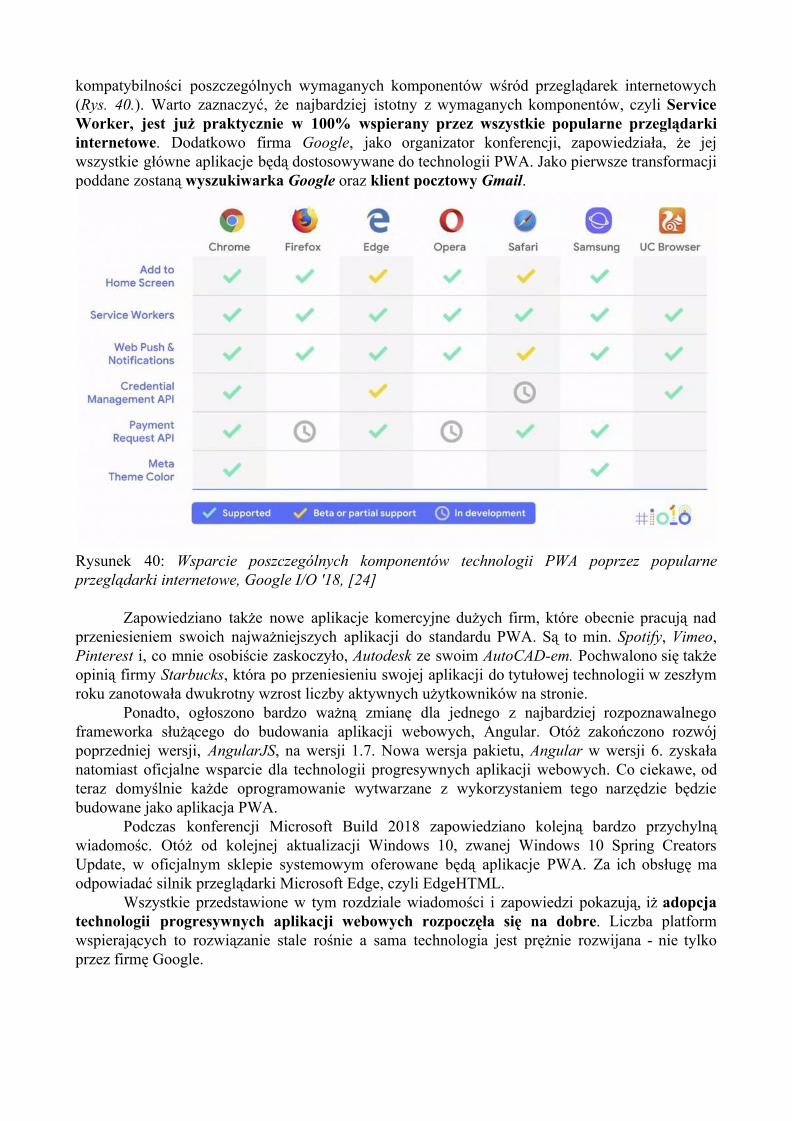
kompatybilności poszczególnych wymaganych komponentów wśród przeglądarek internetowych (Rys. 40.). Warto zaznaczyć, że najbardziej istotny z wymaganych komponentów, czyli Service Worker, jest już praktycznie w 100% wspierany przez wszystkie popularne przeglądarki internetowe. Dodatkowo firma Google, jako organizator konferencji, zapowiedziała, że jej wszystkie główne aplikacje będą dostosowywane do technologii PWA. Jako pierwsze transformacji poddane zostaną wyszukiwarka Google oraz klient pocztowy Gmail.
Rysunek 40: Wsparcie poszczególnych komponentów technologii PWA poprzez popularne przeglądarki internetowe, Google I/O '18, [24]
Zapowiedziano także nowe aplikacje komercyjne dużych firm, które obecnie pracują nad przeniesieniem swoich najważniejszych aplikacji do standardu PWA. Są to min. Spotify, Vimeo, Pinterest i, co mnie osobiście zaskoczyło, Autodesk ze swoim AutoCAD-em. Pochwalono się także opinią firmy Starbucks, która po przeniesieniu swojej aplikacji do tytułowej technologii w zeszłym roku zanotowała dwukrotny wzrost liczby aktywnych użytkowników na stronie.
Ponadto, ogłoszono bardzo ważną zmianę dla jednego z najbardziej rozpoznawalnego frameworka służącego do budowania aplikacji webowych, Angular. Otóż zakończono rozwój poprzedniej wersji, AngularJS, na wersji 1.7. Nowa wersja pakietu, Angular w wersji 6. zyskała natomiast oficjalne wsparcie dla technologii progresywnych aplikacji webowych. Co ciekawe, od teraz domyślnie każde oprogramowanie wytwarzane z wykorzystaniem tego narzędzie będzie budowane jako aplikacja PWA.
Podczas konferencji Microsoft Build 2018 zapowiedziano kolejną bardzo przychylną wiadomośc. Otóż od kolejnej aktualizacji Windows 10, zwanej Windows 10 Spring Creators Update, w oficjalnym sklepie systemowym oferowane będą aplikacje PWA. Za ich obsługę ma odpowiadać silnik przeglądarki Microsoft Edge, czyli EdgeHTML.
Wszystkie przedstawione w tym rozdziale wiadomości i zapowiedzi pokazują, iż adopcja technologii progresywnych aplikacji webowych rozpoczęła się na dobre. Liczba platform wspierających to rozwiązanie stale rośnie a sama technologia jest prężnie rozwijana - nie tylko przez firmę Google.

Źródła literaturowe
[1] Dutton S., Understanding Low Bandwidth and High Latency, Web Fundamentals, https://developers.google.com/web/fundamentals/performance/poor-connectivity
[2] Express JS framework 4.x Documentation, Node.js Foundation, https://expressjs.com/en/4x/api.html
[3] Grigorik I., Krytyczna ścieżka renderowania, Web Fundamentals, https://developers.google.com/web/fundamentals/performance/critical-rendering-path/
[4] Guide to Workbox JavaScript libraries, Google Developers, https://developers.google.com/web/tools/workbox/
[5] Gulp.js Documentation, https://gulpjs.com/ [6] Han B., Hao S., Qian F., MetaPush: Cellular-Friendly Server Push For HTTP/2,
5th Workshop on All Things Cellular: Operations, Applications and Challenges, ACM SIGCOMM, 2015, 57-62
[7] HTTP/2 Frequently Asked Questions, https://http2.github.io/faq/ [8] Hypertext Transfer Protocol (HTTP), MDN web docs, Mozilla,
https://developer.mozilla.org/en-US/docs/Web/HTTP [9] Introduction to Chrome DevTools, Tools for Web Developers,
https://developers.google.com/web/tools/chrome-devtools/ [10] Introduction to Lighthouse, Tools for Web Developers,
https://developers.google.com/web/tools/lighthouse/ [11] Kearney M., Osmani A., Basques K., Measure Performance with the RAIL Model,
Web Fundamentals, https://developers.google.com/web/fundamentals/performance/rail [12] Material Design Guidelines, Google, https://material.io/design/ [13] Medley J., Web Push Notifications: Timely, Relevant, and Precise, Web Fundamentals,
https://developers.google.com/web/fundamentals/push-notifications/ [14] Model–view–controller architecture, https://en.wikipedia.org/wiki/Model-view-controller [15] Node.js v8 Documentation, Node.js Foundation,
https://nodejs.org/docs/latest-v8.x/api/documentation.html [16] O'Donoghue R., AMP: Building Accelerated Mobile Pages: Create lightning-fast mobile
pages by leveraging AMP technology, Packt Publishing Ltd, 2017, 43-49 [17] Osmani A., Cohen M., Offline Storage for Progressive Web Apps, Web Fundamentals,
https://developers.google.com/web/fundamentals/instant-and-offline/web-storage/offline-for-pwa
[18] Osmani A., The App Shell Model, Web Fundamentals, https://developers.google.com/web/fundamentals/architecture/app-shell
[19] Osmani A., The PRPL Pattern, Web Fundamentals, https://developers.google.com/web/fundamentals/performance/prpl-pattern/
[20] Performance API, MDN web docs, Mozilla, https://developer.mozilla.org/en-US/docs/Web/API/Performance
[21] Porter Felt A. - Google, Barnes R. - Cisco; King A. - Mozilla; Palmer C., Bentzel C., Tabriz P. - Google, Measuring HTTPS Adoption on the Web, 26th USENIX Security Symposium, 2017, Vancouver, BC, Canada, https://www.usenix.org/system/files/conference/usenixsecurity17/sec17-felt.pdf
[22] Powell V., Markov Chains Explained Visually, http://setosa.io/ev/markov-chains/ [23] Prokopiuk J., Nowak Z., THE INFLUENCE OF HTTP/2 ON USER-PERCEIVED WEB
APPLICATION PERFORMANCE, STUDIA INFORMATICA, 2017 [24] PWAs: building bridges to mobile, desktop, and native, Google I/O '18, California, 2018,
https://www.youtube.com/watch?v=NITk4kXMQDw

[25] Radware Ltd., Ecommerce Page Speed & Web Performance, State of the Union, 2015, https://www.slideshare.net/Radware/2015-spring-state-of-the-union-ecommerce-page-speed-web-performance-infographic, https://www.radware.com/spring-sotu2015-lpc-6442455858/
[26] Scales M., Using the Cache API, Web Fundamentals, https://developers.google.com/web/fundamentals/instant-and-offline/web-storage/cache-api
[27] Sheppard D., Beginning Progressive Web App Development, Creating a Native App Experience on the Web, ISBN 978-1-4842-3090-9, Apress, 2017, https://www.apress.com/la/book/9781484230893
[28] Single-page application, https://en.wikipedia.org/wiki/Single-page_application [29] Singleton D., Why mobile apps suck when you're mobile,
http://blog.davidsingleton.org/mobiletcp/ [30] SPDY: An Experimental Protocol for a Faster Web, The Chromium Projects,
http://dev.chromium.org/spdy/spdy-whitepaper/ [31] SSL Glossary, MDN web docs, Mozilla,
https://developer.mozilla.org/en-US/docs/Glossary/SSL_Glossary [32] Staying off the Rocks: Using Lighthouse to Build Seaworthy Progressive Web Apps,
Google I/O '17, California, 2017, https://www.youtube.com/watch?v=NoRYn6gOtVo [33] Stępniak W., Nowak Z., Performance Analysis of SPA Web Systems, 37th International
Conference on Information Systems Architecture and Technology, Springer, 2017, 235-247 [34] Walton P., User-centric Performance Metrics, Web Fundamentals,
https://developers.google.com/web/fundamentals/performance/user-centric-performance-metrics
[35] Web Performance: Leveraging the Metrics that Most Affect User Experience, Google I/O '17, California, 2017, https://www.youtube.com/watch?v=6Ljq-Jn-EgU
[36] WebSockets, MDN web docs, Mozilla, https://developer.mozilla.org/pl/docs/WebSockets [37] Working with IndexedDB, Google Developers,
https://developers.google.com/web/ilt/pwa/working-with-indexeddb

Spis rysunków
Rysunek 1: Liczba użytkowników sieci Internet na przestrzeni lat, Internet Live Stats Rysunek 2: Procentowy udział typów urządzeń na przestrzeni ostatnich miesięcy, StatCounter Rysunek 3: Model OSI Rysunek 4: Budowa żądania HTTP Rysunek 5: Procent ruchu sieciowego pochodzącego od urządzeń mobilnych, Statista Rysunek 6: Czas RTT dla 1000 pakietów IP wysłanych podczas przemieszczania się pociągiem [29] Rysunek 7: Czas RTT na skali logarytmicznej dla 1000 pakietów IP wysłanych podczas przemieszczania się pociągiem [29] Rysunek 8: Obsługa Cache-Control przez przeglądarki internetowe, diagram opracowany przez Google Web Fundamentals Rysunek 9: Budowa drzewa DOM, diagram opracowany przez Google Web Fundamentals Rysunek 10: Budowa drzewa renderowania strony internetowej, diagram opracowany przez zespół Google Web Fundamentals Rysunek 11: Przykład blokującego renderowanie kodu JavaScript i CSS, diagram opracowany przez zespół Google Web Fundamentals Rysunek 12: Procentowy udział najbardziej popularnych przeglądarek internetowych dostępnych na rynku, StatCounter Rysunek 13: Procentowy udział najbardziej popularnych wyszukiwarek internetowych dostępnych na rynku, StatCounter Rysunek 14: Wykres przedstawiający popularność usług internetowych, W3T, 24 kwietnia 2018 Rysunek 15: Wykorzystanie protokołu HTTP/2 przez 10 milionów najbardziej popularnych stron internetowych, W3 Techs, 26 kwietnia 2018 Rysunek 16: Pobieranie wielu zasobów z wykorzystaniem protokołu TCP, Blog CloudFlare Rysunek 17: Wydajność wczytywania badanej strony internetowej w zależności od zastosowanej wersji i konfiguracji protokołu HTTP, THE INFLUENCE OF HTTP/2 ON USER-PERCEIVED WEB APPLICATION PERFORMANCE, Jakub PROKOPIUK, Ziemowit NOWAK, STUDIA INFORMATICA, 2017 [23] Rysunek 18: Wizualizacja parametrów ustawianych za pomocą pliku manifest.json na platformie mobilnej Android, Google Web Fundamentals Rysunek 19: Diagram przedstawiający architekturę Service Worker, Beginning Progressive Web App Development [27] Rysunek 20: Zastosowanie Fetch API do przechwytywania żądań HTTP, Using Service Workers, MDN web docs Rysunek 21: Diagram przedstawiający wykorzystanie dynamicznej pamięci podręcznej cache API poprzez Service Worker, Beginning Progressive Web App Development [1] Rysunek 22: Proces wysyłania powiadomienia push od serwera danej witryny internetowej do przeglądarki użytkownika końcowego, Google Web Fundamentals Rysunek 23: Wzorzec projektowy PRPL/App Shell, Google Web Fundamentals Rysunek 24: Porównanie zalet technologii PWA oraz AMP Rysunek 25: Porównanie użyciu mobilnego internetu w roku 2013 i 2015, Understanding Low Bandwidth and High Latency Rysunek 26: Metryki charakteryzujące proces wczytywania strony internetowej, Web Performance: Leveraging the Metrics that Most Affect User Experience (Google I/O '17) [1] Rysunek 27: Wizualizacja wartości zebranych przez narzędzie Google Lighthouse Rysunek 28: Podgląd uruchomionej aplikacji eksperymentalnej kolejno na laptopie dysponującym ekranem MDPI oraz smartfonie iPhone 7 Rysunek 29: Liczba żądań generowana przez badaną aplikację Rysunek 30: Ilość przesłanych danych generowana przez badaną aplikację [kb]

Rysunek 31: Wartość współczynnika Perceptual Speed Index wyznaczonego poprzez audyt Google Lighthouse Rysunek 32: Czas wczytania badanej aplikacji [s] Rysunek 33: Wartość współczynnika First meaningful paint wyznaczonego poprzez audyt Google Lighthouse Rysunek 34: Czas wczytania badanej aplikacji z ograniczeniem połączenia sieciowego [s] Rysunek 35: Wartość współczynnika First meaningful paint wyznaczonego poprzez audyt Google Lighthouse z ograniczeniem połączenia sieciowego Rysunek 36: Zrzuty ekranu przedstawiające proces wczytywania klasycznej aplikacji z wykorzystaniem sieci komórkowej Rysunek 37: Zrzuty ekranu przedstawiające proces wczytywania aplikacji PWA z wykorzystaniem sieci komórkowej Rysunek 38: Porzucanie stron internetowych których czas wczytywania przekracza 3 sekundy, Google I/O '18, [24] Rysunek 39: Wzrostowa tendencja internautów korzystających z urządzeń mobilnych w stosunku do klasycznych komputerów stacjonarnych, Google I/O '18, [24] Rysunek 40: Wsparcie poszczególnych komponentów technologii PWA poprzez popularne przeglądarki internetowe, Google I/O '18, [24]
Spis tabel
Tabela 1: Zestawienie wybranych webowych aplikacji progresywnych, PWA Stats Tabela 2: Zestawienie wsparcia technologii wykorzystanych w progresywnych aplikacjach przez przeglądarki internetowe
Spis załączników
Załącznik 1: Słownik techniczny Załącznik 2: Uzyskane wyniki przeprowadzonego eksperymentu przedstawione w formie tabeli Załącznik 3: Instrukcja uruchomienia aplikacji przygotowanej do przeprowadzonego w pracy eksperymentu w środowisku Linux Załącznik 4: Płyta CD zawierająca kod źródłowy aplikacji przygotowanej do przeprowadzonego w pracy eksperymentu

Załącznik 1. - Użyte skróty PWA - Progressive web application, progresywna aplikacja webowa SW - Service Worker RAIL - Response, Animation, Idle, Load SPA - Single Page Application JS - Java Script HTML - HyperText Markup Language CSS - Cascading Style Sheets WWW - World Wide Web HTTP - Hypertext Transfer Protocol SSL - Secure Socket Layer
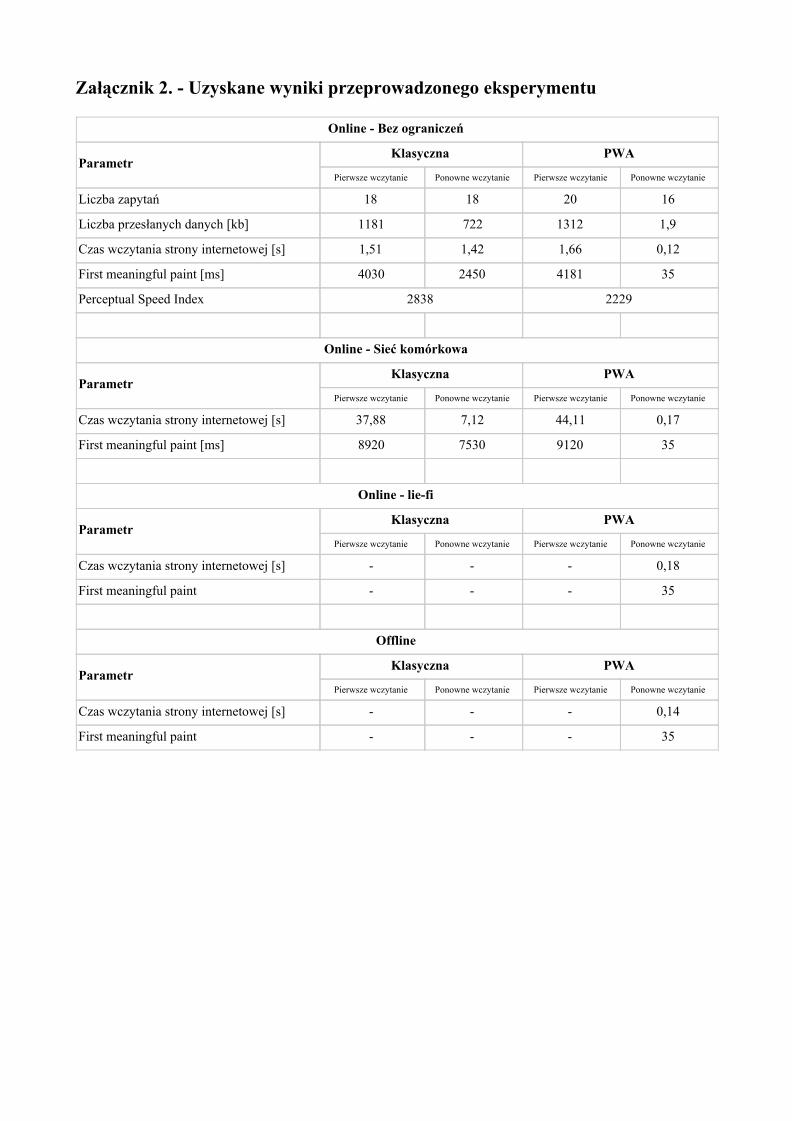
Załącznik 2. - Uzyskane wyniki przeprowadzonego eksperymentu
Online - Bez ograniczeń
Parametr Klasyczna PWA
Pierwsze wczytanie Ponowne wczytanie Pierwsze wczytanie Ponowne wczytanie
Liczba zapytań 18 18 20 16
Liczba przesłanych danych [kb] 1181 722 1312 1,9
Czas wczytania strony internetowej [s] 1,51 1,42 1,66 0,12
First meaningful paint [ms] 4030 2450 4181 35
Perceptual Speed Index 2838 2229
Online - Sieć komórkowa
Parametr Klasyczna PWA
Pierwsze wczytanie Ponowne wczytanie Pierwsze wczytanie Ponowne wczytanie
Czas wczytania strony internetowej [s] 37,88 7,12 44,11 0,17
First meaningful paint [ms] 8920 7530 9120 35
Online - lie-fi
Parametr Klasyczna PWA
Pierwsze wczytanie Ponowne wczytanie Pierwsze wczytanie Ponowne wczytanie
Czas wczytania strony internetowej [s] - - - 0,18
First meaningful paint - - - 35
Offline
Parametr Klasyczna PWA
Pierwsze wczytanie Ponowne wczytanie Pierwsze wczytanie Ponowne wczytanie
Czas wczytania strony internetowej [s] - - - 0,14
First meaningful paint - - - 35

Załącznik 3. - Instrukcja uruchomienia aplikacji przygotowanej do przeprowadzonego w pracy eksperymentu w środowisku Linux Wymagania:
● Środowisko uruchomieniowe Linux (testowane na systemie operacyjnym Fedora 28) ● Pakiet Node.js w wersji 8.x LTS (https://nodejs.org/en/download/)
Płyta CD zawiera dwa spakowane programem ZIP archiwa o nazwach “classic.zip” oraz “pwa.zip” zawierająco dwie wersje aplikacji opisanej w pracy. Należy je rozpakować na dysku komputera. Następnie w powstałych katalogach wykonać kolejno polecenia w wierszu poleceń:
● npm install ● npm run serve
Po prawidłowym zakończeniu wykonanych poleceń aplikacja dostępna jest pod adresem:
● classic: localhost:8111 ● pwa: localhost:8112
Zamknięcie aplikacji odbywa się poprzez kombinację klawiszy CTRL+C wykonanej w oknie konsoli. Powoduje to zamknięcie procesu głównego aplikacji. Uwagi:
● Pakiet Node.js musi być dostępny jako globalny plik wykonywujący. W innym przypadku, przedstawione tutaj polecenia powinny zawierać pełną ścieżkę do pliku wykonywalnego.
● Obie aplikacje mogą działać jednocześnie. ● Uwagi o możliwych aktualizacjach pakietów NPM należy pominąć.


















