

Podstawy statystyki dla psychologów - zajęcia 10 - wprowadzenie do wnioskowania statystycznego

2
Program zajęć
Opis i wyjaśnienie sposobu porządkowania i przedstawiania
danych doświadczalnych. Rozkład dla zmiennej losowej
dyskretnej i ciągłej. Zagadnienia próbkowania populacji.
Estymatory wartości środkowej i wariancji. Rozkłady
Gaussa i Studenta. Testowanie hipotezy statystycznej.
Statystyczne opracowanie wyników pomiarów. Inne
rozkłady statystyczne. Metoda najmniejszych kwadratów.
Regresja liniowa. Problemy korelacji. Obliczanie wariancji
wielkości złożonych. Zaokrąglanie liczb.

3
Podstawowe definicje
• Statystyka – badanie zbiorów danych (statystyka
matematyczna i opisowa)
• Przedmiot analizy statystycznej – obserwacja,
zdarzenie w relacji wartość ↔ częstotliwość
(rozkład)
• Populacja – zbiór wszystkich danych
• Próbka n-elementowa – n obserwacji
• Cel analizy statystycznej – ustalenie relacji
między próbką a populacją
4
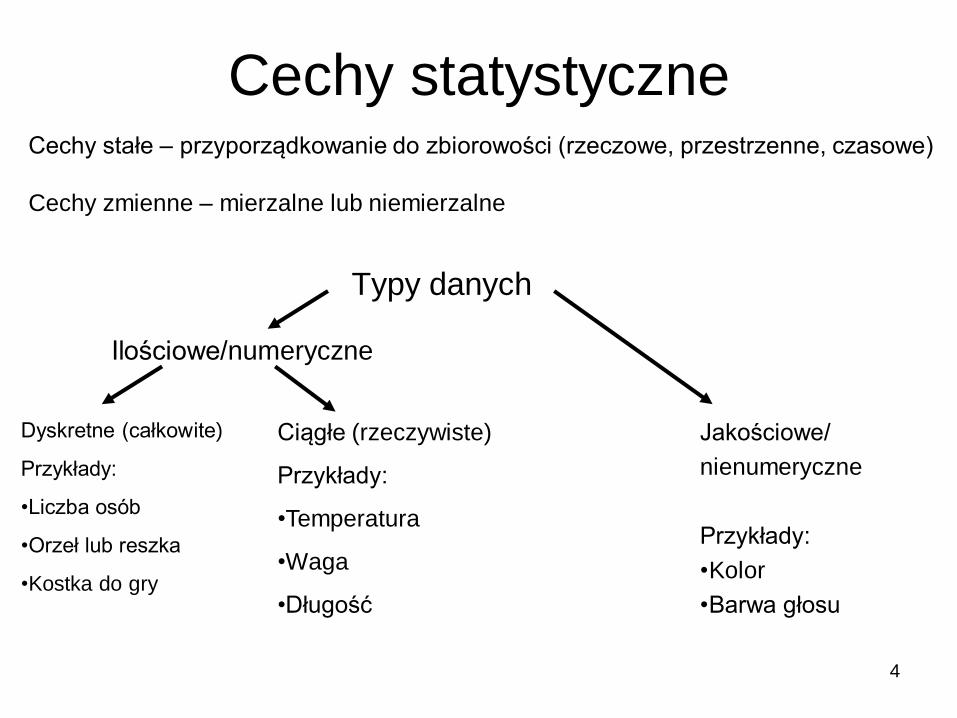
Typy danych
Ilościowe/numeryczne
Jakościowe/
nienumeryczne
Przykłady:
•Kolor
•Barwa głosu
Dyskretne (całkowite)
Przykłady:
•Liczba osób
•Orzeł lub reszka
•Kostka do gry
Ciągłe (rzeczywiste)
Przykłady:
•Temperatura
•Waga
•Długość
Cechy statystyczne Cechy stałe – przyporządkowanie do zbiorowości (rzeczowe, przestrzenne, czasowe)
Cechy zmienne – mierzalne lub niemierzalne

Skale pomiarowe
5
nominalne - relacja: równe ↔ różne; pomiar polega na zastosowaniu liczby jako nazwy,
czyli grupowaniu jednostek w klasy (kategorie), którym przypisuje się nazwy czy liczby,
np. studenci wg rodzaju studiów, szczególny przypadek - skala dychotomiczna
(dwupunktowa)
porządkowe - relacja: większe ↔ mniejsze; pomiar polega na grupowaniu jednostek w
klasy (kategorie), którym przypisuje się nazwy lub liczby i porządkuje się te klasy ze
względu na stopień natężenia, w jakim posiadają one badaną cechę
przedziałowe - relacja: większe o tyle; pomiar występuje wtedy, gdy uporządkowany
zbiór wartości cechy składa się z liczb rzeczywistych, ZERO w tej skali ustalone jest
dowolnie, np. skala Celsjusza i Fahrenheita, skala pozwala stwierdzić tylko o ile jest coś
wyższe
stosunkowe (ilorazowe) - relacja: tyle razy większe; spełnia wszystkie aksjomaty liczb,
pomiary w tej skali charakteryzują się stałymi ilorazami i zerem bezwzględnym, tylko w tej
skali możliwe jest porównywanie jednostek za pomocą względnych charakterystyk: np.
jeden obiekt jest dwa razy cięższy od drugiego

Statystyki opisowe w Excelu
6
•średnia arytmetyczna x
•odchylenie standardowe s
•wariancja s2
•kurtoza K
•skośność q
•mediana wartość środkowa
•wartość maksymalna xmax
•wartość minimalna xmin
•rozstęp R = xmax - xmin
•klasy liczba klas=(liczebność próbki)1/2
Statystyka opisowa zajmuje się wstępnym opracowaniem wyników
pomiarów (próbki) bez posługiwania się rachunkiem prawdopodobieństwa.

7
Prawdopodobieństwo = P(A)
A, B są podzbiorami należącymi do zbioru Ω
Własności prawdopodobieństwa
• 0 ≤ P(A) ≤ 1
• P(Ω) = 1
• Jeżeli A i B wykluczają się wzajemnie, wtedy
P(A lub B) = P(A) + P(B)
• Jeżeli A i B nie wykluczają się wzajemnie, wtedy
P(A lub B) = P(A) + P(B) – P(A i B)
Obliczenie prawdopodobieństwa: P(A) = nA/n
gdzie nA – liczba zdarzeń realizujących A
n – ogólna liczba zdarzeń

8
Prosty rozkład
Średnia arytmetyczna:
Wariancja:
Odchylenie standardowe:
n
1kkk xPx
2n
1kkk
2 xxP
2
Rzut kostką do gry:
P1 = P2 = P3 = P4 = P5 = P6 = 1/6
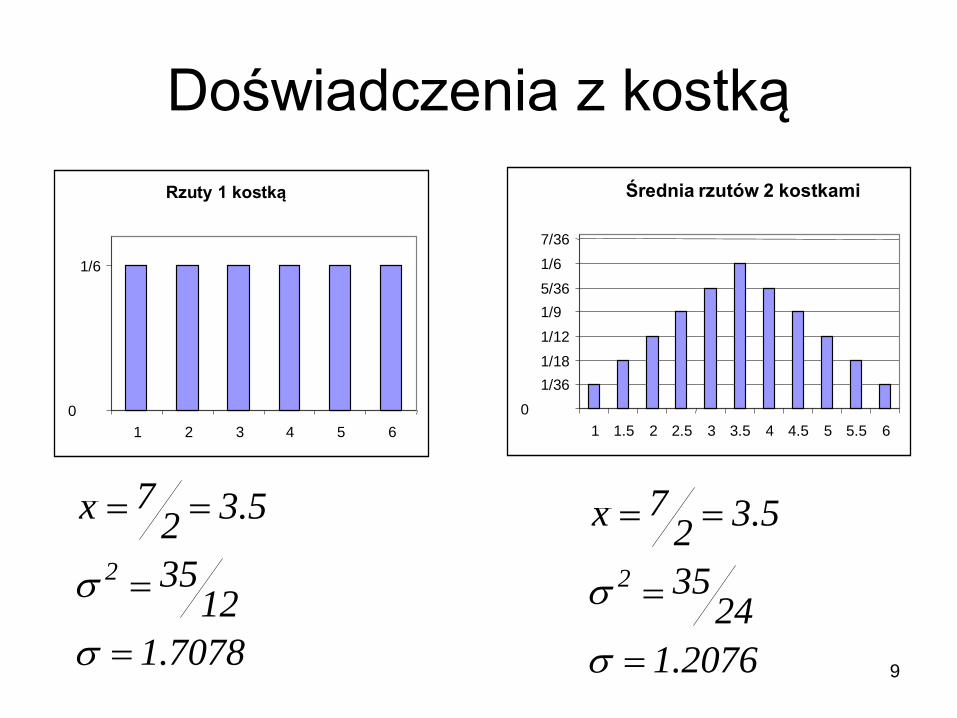
9
Doświadczenia z kostką
7078.1
1235
5.32
7x
2
2076.1
2435
5.32
7x
2
Rzuty 1 kostką
0
1/6
1 2 3 4 5 6
Średnia rzutów 2 kostkami
0
1/36
1/18
1/12
1/9
5/36
1/6
7/36
1 1.5 2 2.5 3 3.5 4 4.5 5 5.5 6

10
Kostka do gry - obliczenia
n
1kkk xPx
2n
1kkk
2 xxP
27
61
61
61
61
61
61 654321x
12352
252
232
212
212
232
25
61
2
27
612
27
612
27
612
27
612
27
612
27
612 654321
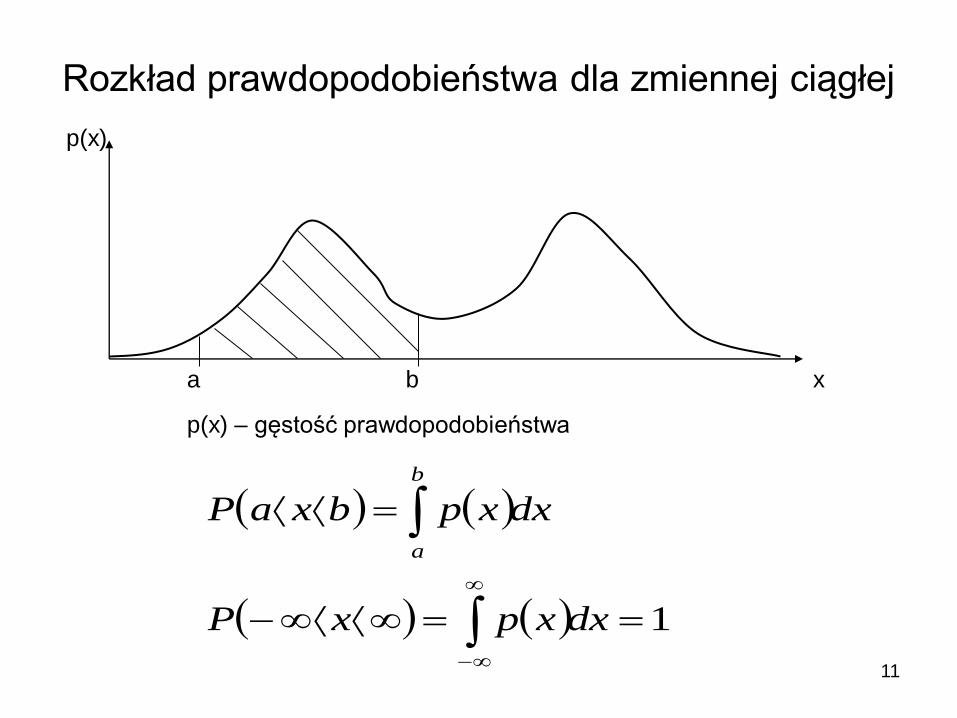
11
Rozkład prawdopodobieństwa dla zmiennej ciągłej
a b
p(x)
x
1
dxxpxP
dxxpbxaP
b
a
p(x) – gęstość prawdopodobieństwa

12
Rzut monetą – orzeł czy reszka? Definicja: P(r)= prawdopodobieństwo r razy reszka (H)
1. Rzut jedną monetą: P(0)=P(1)=½
2. Rzut czterema monetami: P(0)=P(4)=(½)4= TTTT or HHHH
TTTH, TTHT, THTT, HTTT P(1)=P(3)=
TTHH,THHT,HHTT,THTH,HTHT,HTTH P(2)=
161
41
164
83
166
1432101616
161
164
166
164
161 PPPPPrP
r
r= 0 1 2 3 4
16 rzutów
teoria 1 4 6 4 1
doświadczenie 1 4 2 7 2
160 rzutów
teoria 10 40 60 40 10
doświadczenie 13 36 61 40 10
1600 rzutów
teoria 100 400 600 400 100
doświadczenie 96 409 577 403 115

13
Wartości oczekiwane
243210
)(
161
164
166
164
161
rmonetycztery
rrPrliczbaoczekiwanaśredniar
r
rPrff
Prawo wielkich liczb
Gdy liczebność próbki N rośnie, średnia zmierza do wartości
oczekiwanej:
ffN
Oczekiwana wartość funkcji f
14
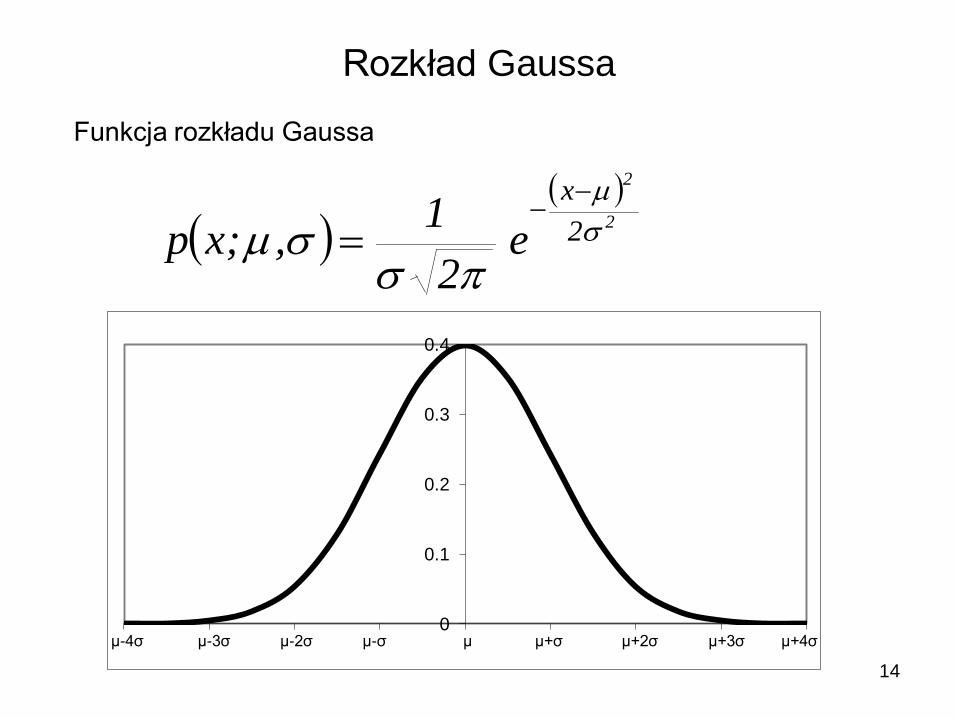
Rozkład Gaussa
Funkcja rozkładu Gaussa
2
2
2
x
e2
1,;xp
0
0.1
0.2
0.3
0.4
μ-4σ μ-3σ μ-2σ μ-σ μ μ+σ μ+2σ μ+3σ μ+4σ

15
Podstawowe własności rozkładu Gaussa
21xPdxxp
1xPdxxp
9973.03x3P
9545.02x2P
6827.0xP
μ-4σ μ-3σ μ-2σ μ-σ μ μ+σ μ+2σ μ+3σ μ+4σ
0.68
Jeżeli potrzebne są okrągłe liczby:
%9.99999.0290.3x290.3P
%9999.0576.2x576.2P
%9595.096.1x96.1P
%9090.0645.1x645.1P

16
Rozkład Gaussa
a μ b
Jak obliczyć?
b
a
?dxxpbxaP
Znormalizowany rozkład Gaussa
z1 0 z2
gdzie:
xz
dzzpzzzP2
1
z
z21
z jest zmienną zredukowaną
17
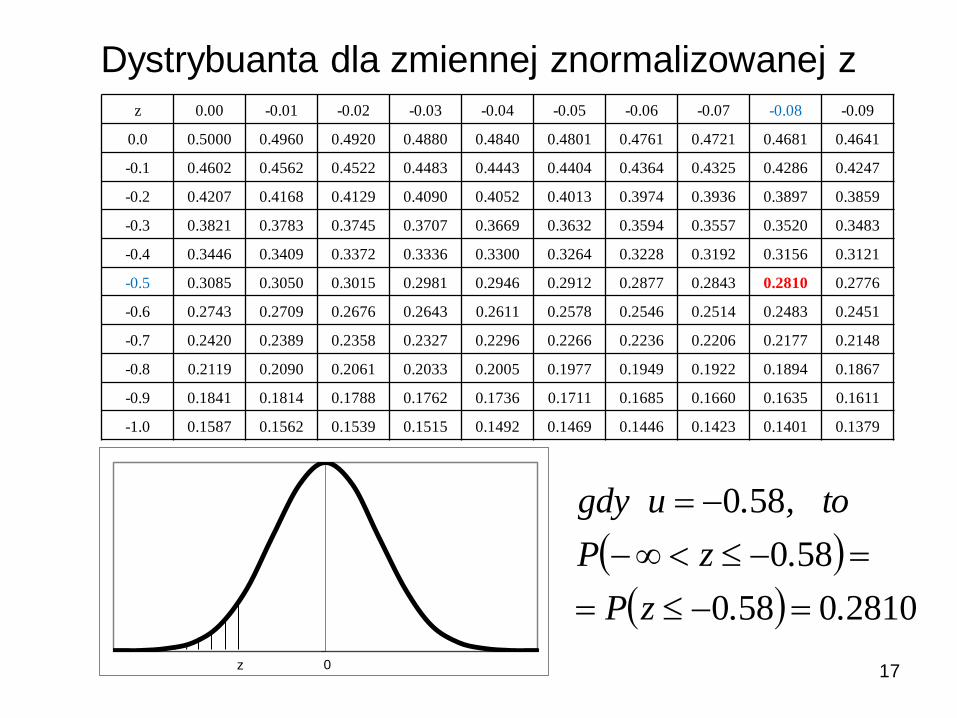
z 0.00 -0.01 -0.02 -0.03 -0.04 -0.05 -0.06 -0.07 -0.08 -0.09
0.0 0.5000 0.4960 0.4920 0.4880 0.4840 0.4801 0.4761 0.4721 0.4681 0.4641
-0.1 0.4602 0.4562 0.4522 0.4483 0.4443 0.4404 0.4364 0.4325 0.4286 0.4247
-0.2 0.4207 0.4168 0.4129 0.4090 0.4052 0.4013 0.3974 0.3936 0.3897 0.3859
-0.3 0.3821 0.3783 0.3745 0.3707 0.3669 0.3632 0.3594 0.3557 0.3520 0.3483
-0.4 0.3446 0.3409 0.3372 0.3336 0.3300 0.3264 0.3228 0.3192 0.3156 0.3121
-0.5 0.3085 0.3050 0.3015 0.2981 0.2946 0.2912 0.2877 0.2843 0.2810 0.2776
-0.6 0.2743 0.2709 0.2676 0.2643 0.2611 0.2578 0.2546 0.2514 0.2483 0.2451
-0.7 0.2420 0.2389 0.2358 0.2327 0.2296 0.2266 0.2236 0.2206 0.2177 0.2148
-0.8 0.2119 0.2090 0.2061 0.2033 0.2005 0.1977 0.1949 0.1922 0.1894 0.1867
-0.9 0.1841 0.1814 0.1788 0.1762 0.1736 0.1711 0.1685 0.1660 0.1635 0.1611
-1.0 0.1587 0.1562 0.1539 0.1515 0.1492 0.1469 0.1446 0.1423 0.1401 0.1379
Dystrybuanta dla zmiennej znormalizowanej z
z 0
28100580
580
580
..zP
.zP
to,.ugdy

18
Przykład
Miesięczne płace w fabryce mają postać rozkładu Gaussa ze średnią
μ=3280 zł i odchyleniem standardowym σ=360 zł. Jakie jest
prawdopodobieństwo, że losowo wybrany pracownik zarabia:
a) Mniej niż 2800 zł
b) Więcej niż 3800 zł
c) pomiędzy 2800 zł a 3800 zł
μ= 3280
σ= 360
z1=(2800-3280)/360= -1.33333 P(z<-1.3333)= 0.0912
z2=(3800-3280)/360= 1.444444 P(z>1.4444)=P(z<-1.4444)= 0.0743
P(2800<x<3800)=P(-1.3333<z<1.4444)=1-P(z<-1.3333)-P(z<-1.4444)=
=1-0.0912-0.0743=0.8345

19
Centralne Twierdzenie Graniczne
Jeżeli jest średnią N niezależnych zmiennych, xi, gdzie i=1,2,3,...,N,
pochodzących z rozkładu o wartości środkowej μ i wariancji σ2, to
rozkład dla
(a) ma wartość oczekiwaną < > = μ,
(b) ma wariancję V( ) = σ2/N
(c) przyjmuje postać rozkładu Gaussa, gdy N →
x
x
x
x
NN
x
x2
2x
N
1ii
Wniosek: Odchylenie standardowe dla średniej jest
mniejsze niż dla rozkładu pojedynczych pomiarów

20
Przedział dla wartości środkowej
W serii n=144 pomiarów średnia wynosi a estymata odchylenia
standardowego . Wyznacz przedział, w którym wartość środkowa
rozkładu znajduje się z prawdopodobieństwem 0.95.
Rozwiązanie:
60x 9sx
75.0144
9
n
ss x
x
Dla P=0.95 zkrytyczna = 1.96
95.05.615.58P
5.1605.160P75.0*96.16075.0*96.160P
95.0s96.1xs96.1xP xx

21
Poziomy ufności i istotności
1-α
α/2 α/2
-Zα/2 Zα/2
Centralny przedział ufności = μ ± Zα/2 * σ
α – współczynnik istotności
(1-α) – współczynnik ufności
Zα/2 – wartość krytyczna

22
Liczebność próbki
Cel: określ centralny przedział ufności dla wartości
środkowej (x ± d), gdzie d jest dane, na poziomie
ufności (1-α):
2
2x
22x
2
x2
x2
d
Zn
nZd
Zd
Zxdx

23
Liczebność próbki - przykład
Załóżmy, że płatki owsiane paczkowane są zgodnie z
rozkładem Gaussa z wartością środkową 350 g i odchyleniem
standardowym 3 g. Ile paczek należy losowo wybrać, aby
określić ich średnią wagę z dokładnością ±2 g na poziomie
ufności (1-α) = 0.99 ?
152
358.2n
58.2Zthen,005.0)ZZ(PIf
005.02/99.012
2
22
22

24
Test statystyczny dla μ – testowanie hipotezy
„Czy wartość środkowa dla populacji wynosi μ0 ?”
Test statystyczny jest oparty o koncepcję dowodu
przez zaprzeczenie i składa się z 5 części:
1.Hipoteza zerowa oznaczona H0.
2.Hipoteza alternatywna oznaczona Ha.
3.Test statystyczny oznaczony T.S.
4.Obszar odrzucenia oznaczony O.O.
5.Wniosek

25
Przykład 1
Test zużycia paliwa dla 100 samochodów:
km100/l80.0skm100/l28.6x x
Czy na poziomie istotności α=0.05 możemy zaakceptować
zużycie paliwa μ0=6,10 l/100km podane przez producenta ?
0a
00
:H
:H
T.S. Rozkład Gaussa
65.1Z 65.1Z
25.210080.0
10.628.6Z
ns
x
s
xZ
x
0
x
0
O.O.
Wniosek: odrzucamy hipotezę zerową

26
Przykład 2 W 49 pokojach zamku średnia temperatura wynosi:
CsprzyCt t
35.080.20 Na czujnikach kontrolnych temperaturę ustawiono na 21ºC.
Czy na poziomie istotności α=0.05 możemy stwierdzić, że
czujniki pracują poprawnie?
0a
00
:H
:H
T.S. Rozkład Gaussa
96.1Z 2 96.1Z
0.44935.0
00.2180.20Z
ns
tZ
t
0
R.R.
Wniosek: odrzucamy hipotezę zerową

27
Podsumowanie
ns
xZ
dwustronnytest)
nyjednostrontest)
):H
)dane(:H
x
a
0
0
0
0
000
3
2
1
O.O. na poziomie istotności α. H0 odrzucona, jeżeli:
2ZZ)3
ZZ)2
ZZ)1

28
Błędy I i II rodzaju
Zasady podejmowania decyzji przy testach statystycznych
Stan rzeczywisty
Decyzja H0 prawdziwa H0 fałszywa
H0 odrzucona Błąd I rodzaju α Poprawnie: P=1-β
H0 nie odrzucona Poprawnie: 1-α Błąd II rodzaju β
α – poziom istotności 1-β – moc testu
β – prawdopodobieństwo nieodrzucenia fałszywej hipotezy H0
Hipoteza zerowa H0 Hipoteza alternatywna Ha
α
PRZYJĘTA ODRZUCONA PRZYJĘTA ODRZUCONA
β

29
5.7 6.7
Błędy I i II rodzaju H0: μ=6.1 Ha: μ=6.3
Odchylenie standardowe średniej = 0.1
Jak można rozróżnić obie hipotezy?
6.1 6.3
α
β
x

30
Jak zwiększyć moc testu?
5.7 6.7
5.7 6.7
6.1 6.3
β
05.0400n
1.0100n
1
x
x
P=1-β

31
Test dla różnicy dwóch środkowych μ1- μ2
1) Obie populacje mają jednakowe wariancje σ2
2) Porównuje się dwie próbki, po jednej z każdej populacji
3) Czy wartości środkowe obu populacji są równe?
2222
2111
snx
snx
H0: μ1- μ2 = 0
Ha: μ1- μ2 0 poziom istotności = α
Zα/2 dla df = n1+n2-2
2121
2
22
2
1121 11
2
11021
21nnnn
snsns
s
xxZ xx
xx

32
Test dla μ1- μ2: przykład
Wyniki badań z dwóch niezależnych laboratoriów:
H0: μ1- μ2 = 0
Ha: μ1- μ2 0 poziom istotności α=0.05
Zα/2=1.96 dla df = n1+n2-2=92+112-2=202
3.7s112n7.87x
8.9s92n3.90x
222
111
16.2198.1
7.873.90Z
198.1112
1
92
1
211292
3.711128.9192s
22
xx 21
Z > Zα/2 H0 odrzucona (wyniki z obu laboratoriów różnią się)

33
Estymata wariancji z próbki
1
1
10
11
21
1
2
2
2
1
22
2
1
22
2
1
2
1
2
1
2
1
22
1
2
1
2
2
n
xx
xxn
nxx
n
xxn
xn
xxn
xxxxxxnn
xxx
n
x
n
i
i
n
i
i
n
i
i
x
n
i
i
n
i
n
i
i
n
i
ii
n
i
in
i
i
Jak wyznaczyć wariancję z małej próbki?
Estymata odchylenia standardowego:
11
2
n
xx
s
n
i
i

34
Rozkład t Studenta
xs
xtor
s
xxt 0
1) Stosowany dla małych próbek – estymata wariancji oszacowana z grubsza
2) Dla duzych próbek rozkład t zbliża się do rozkładu Gaussa
3) Kształ rozkładu zależy od liczby stopni swobody df
4) Zaproponowany przez Williama Gosseta w 1900 roku
Test hipotezy:
H0
Ha
Poziom istotności α
Próbka: x1, x2, …,xn
Estymata odchylenia standardowego s
Zmienna zredukowana:
Wartość krytyczna tα or tα/2
Jeżeli t> tα (test jednostronny)
lub t> tα/2 (test dwustronny), to H0 odrzucona
35
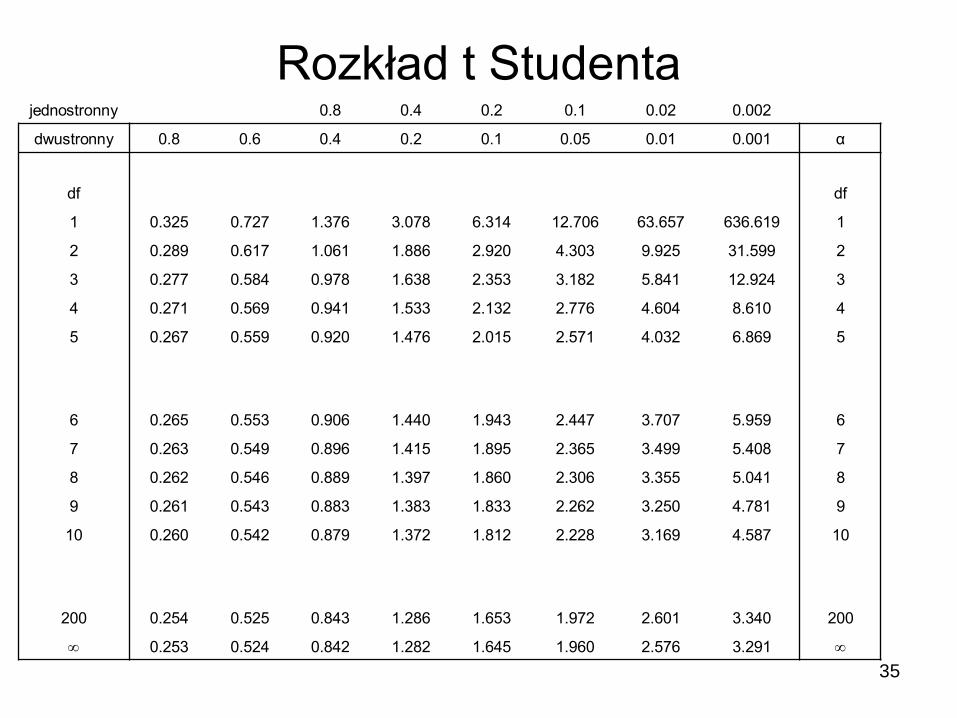
Rozkład t Studenta jednostronny 0.8 0.4 0.2 0.1 0.02 0.002
dwustronny 0.8 0.6 0.4 0.2 0.1 0.05 0.01 0.001 α
df df
1 0.325 0.727 1.376 3.078 6.314 12.706 63.657 636.619 1
2 0.289 0.617 1.061 1.886 2.920 4.303 9.925 31.599 2
3 0.277 0.584 0.978 1.638 2.353 3.182 5.841 12.924 3
4 0.271 0.569 0.941 1.533 2.132 2.776 4.604 8.610 4
5 0.267 0.559 0.920 1.476 2.015 2.571 4.032 6.869 5
6 0.265 0.553 0.906 1.440 1.943 2.447 3.707 5.959 6
7 0.263 0.549 0.896 1.415 1.895 2.365 3.499 5.408 7
8 0.262 0.546 0.889 1.397 1.860 2.306 3.355 5.041 8
9 0.261 0.543 0.883 1.383 1.833 2.262 3.250 4.781 9
10 0.260 0.542 0.879 1.372 1.812 2.228 3.169 4.587 10
200 0.254 0.525 0.843 1.286 1.653 1.972 2.601 3.340 200
0.253 0.524 0.842 1.282 1.645 1.960 2.576 3.291

36
Rozkład t Studenta - przykład
Test 9 profesorów daje średnią wartość IQ 128, z odchyleniem
standardowym s 15. Jaki jest 95% przedział ufności dla rzeczywistej
średniego IQ wszystkich profesorów?
59
15s
819df9n
x
Dla rozkładu Gaussa granice wyniosłyby 128 ± 1,96 sx ,
Tzn. <118,2 ; 137,8>
Dla rozkładu Studenta krytyczna wartość tα/2 dla df = 8 wynosi 2,306
Granice są szersze <116,5 ; 139,5>
37
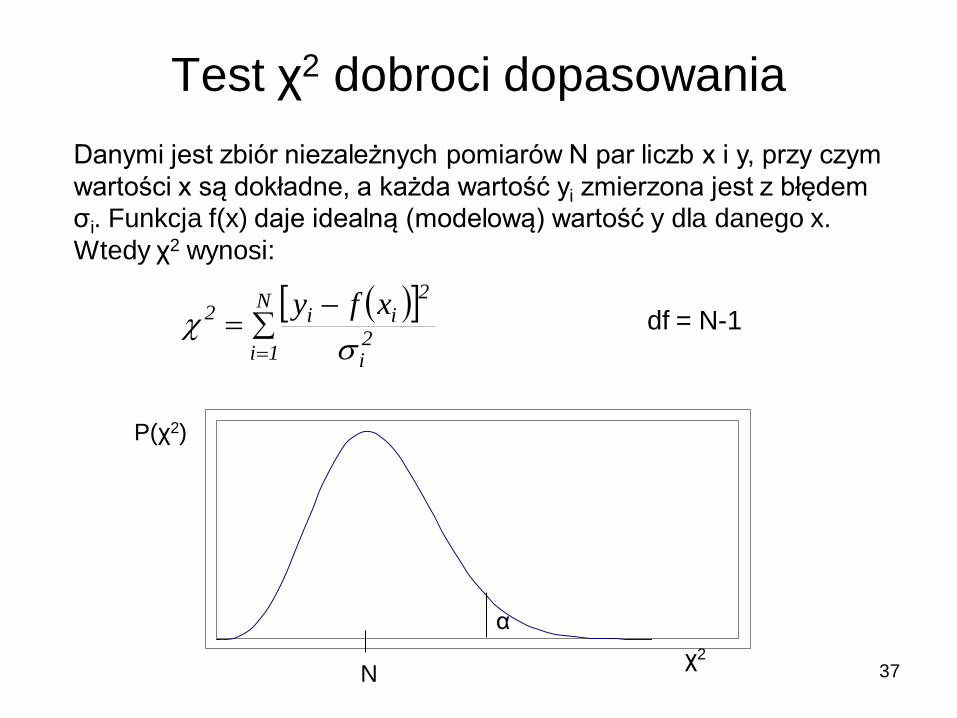
Test χ2 dobroci dopasowania
Danymi jest zbiór niezależnych pomiarów N par liczb x i y, przy czym
wartości x są dokładne, a każda wartość yi zmierzona jest z błędem
σi. Funkcja f(x) daje idealną (modelową) wartość y dla danego x.
Wtedy χ2 wynosi:
N
1i2i
2ii2 xfy
N
P(χ2)
χ2
α
df = N-1

38
Test χ2 dobroci dopasowania
Testujemy liczbę zdarzeń należących do i-tej kategorii. Zdarzenia
podlegają rozkładowi Poissona.
N
1i i
2ii2
E
En
ni – rzeczywista liczba zdarzeń w i-tej kategorii
Ei – teoretyczna liczba zdarzeń w i-tej kategorii
Przykład: test dobroci kostki do gry w 300 próbach na poziomie α=0,1
Wyniki 1 2 3 4 5 6
ni 52 46 59 44 48 51
Ei 50 50 50 50 50 50
χ2=(52-50)2/50 + (46-50)2/50 + … + (51-50)2/50 = 2.84
df=6-1=5 χα2=9.24 χ2 < χα
2 Kostka OK
H0: χ2=0
Ha: χ2 0
df = N - 1

39
Test dla wariancji populacji
Zmienność populacji jest czasem bardziej istotna niż jej wartość środkowa.
Estymata wariancji próbki:
1n
xx
s
n
1i
2i
2
może być użyta do badania wariancji populacji σ2.
Wielkość (n-1)s2/σ2 zachowuje się zgodnie z rozkładem chi2 dla df=n-1.
Przedział ufności dla σ2 określa nierówność:
2L
22
2U
2 s1ns1n
gdzie …
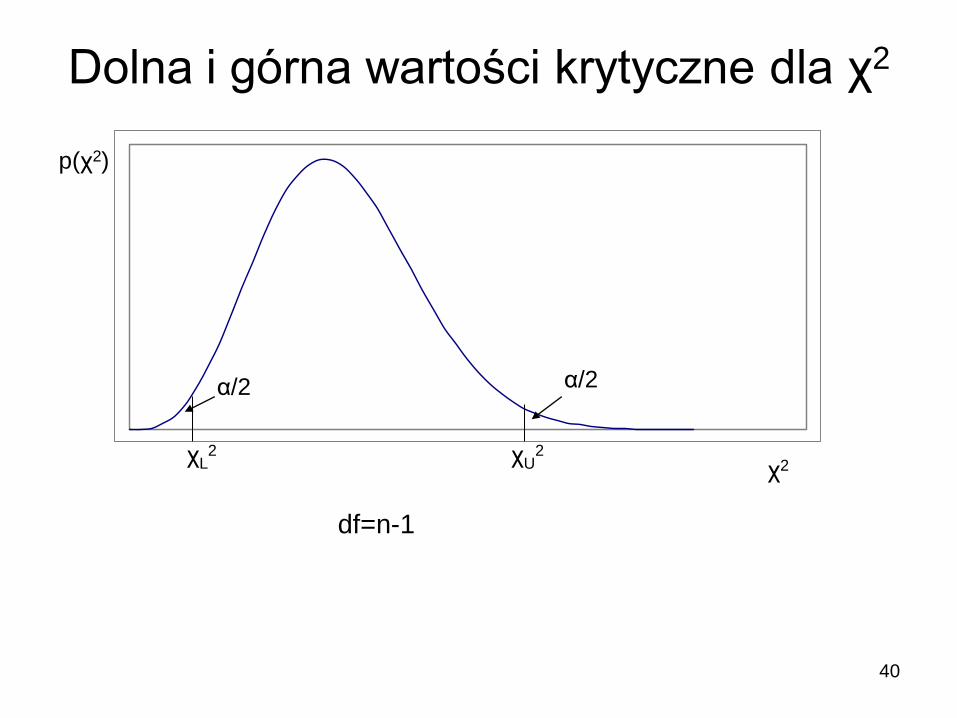
40
Dolna i górna wartości krytyczne dla χ2
χ2
p(χ2)
χL2 χU
2
α/2 α/2
df=n-1

41
Przykład: czas reakcji kierowców
Zmienność czasu reakcji była testowana na grupie 7 kierowców a
wyniki w ms są następujące:
120, 102, 135, 115, 118, 112 124
Określ przedział dla wariancji populacji σ2 dla czasu reakcji na
poziomie ufności 1-α = 0.90
6.191.7
23.385033.50
6354.1
105*6
5916.12
105*6
5916,126354.1105s
05.02
617df118x
2
2
2U
2L
2

42
Test dla wariancji dwóch populacji
Czy wariancje σ12 i σ2
2 dla dwóch populacji są równe?
Wiedza o wariancjach pochodzi z dwóch niezależnych próbek,
z których oblicza się estymatory wariancji s12 and s2
2 .
22
21
22
22
21
21
s
sF
s
s
F
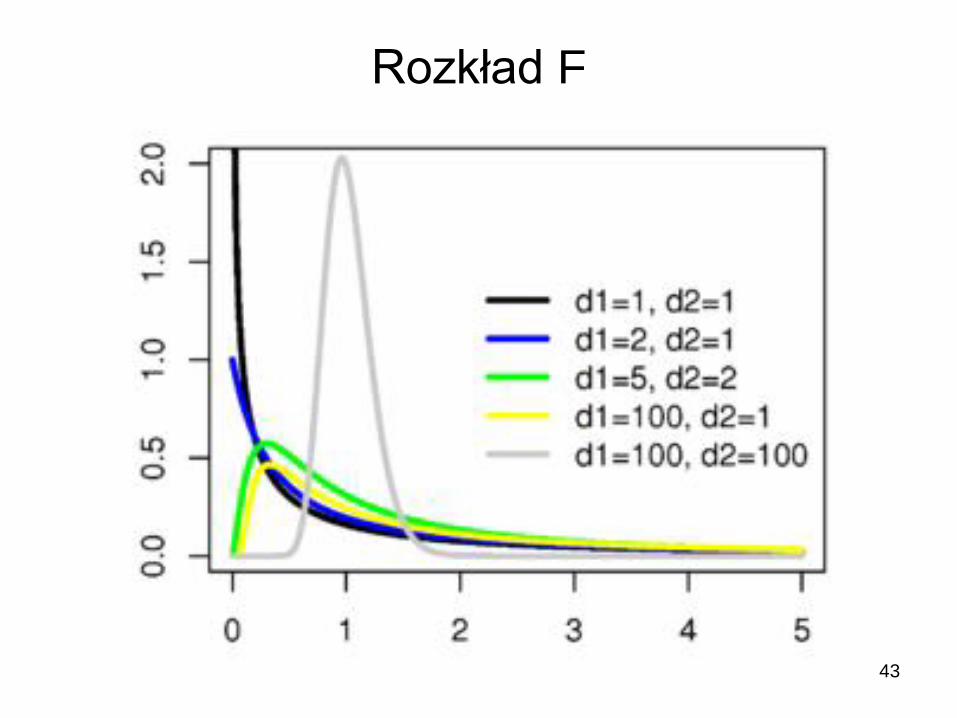
Właściwości rozkładu F :
1. F przyjmuje tylko wartości dodatnie
2. F jest niesymetryczny
3. Jest wiele rozkładów F związanych
z liczbą stopni swobody, df1 i df2,
odpowiednio dla s12 i s2
2.
4. Dla hipotezy zerowej σ12=σ2
2, rozkład F
przyjmuje postać:
5. Tabele rozkładu zbudowane są przy
założeniu, że s12>s2
2
44
df2/df1 1 2 3 4 5 6 7 8 9 10
1 161.4476 199.5 215.7073 224.5832 230.1619 233.986 236.7684 238.8827 240.5433 241.8817
2 18.51282 19 19.16429 19.24679 19.29641 19.32953 19.35322 19.37099 19.38483 19.3959
3 10.12796 9.552094 9.276628 9.117182 9.013455 8.940645 8.886743 8.845238 8.8123 8.785525
4 7.708647 6.944272 6.591382 6.388233 6.256057 6.163132 6.094211 6.041044 5.998779 5.964371
5 6.607891 5.786135 5.409451 5.192168 5.050329 4.950288 4.875872 4.81832 4.772466 4.735063
6 5.987378 5.143253 4.757063 4.533677 4.387374 4.283866 4.206658 4.146804 4.099016 4.059963
7 5.591448 4.737414 4.346831 4.120312 3.971523 3.865969 3.787044 3.725725 3.676675 3.636523
8 5.317655 4.45897 4.066181 3.837853 3.687499 3.58058 3.500464 3.438101 3.38813 3.347163
9 5.117355 4.256495 3.862548 3.633089 3.481659 3.373754 3.292746 3.229583 3.178893 3.13728
10 4.964603 4.102821 3.708265 3.47805 3.325835 3.217175 3.135465 3.071658 3.020383 2.978237
11 4.844336 3.982298 3.587434 3.35669 3.203874 3.094613 3.01233 2.94799 2.896223 2.853625
12 4.747225 3.885294 3.490295 3.259167 3.105875 2.99612 2.913358 2.848565 2.796375 2.753387
13 4.667193 3.805565 3.410534 3.179117 3.025438 2.915269 2.832098 2.766913 2.714356 2.671024
14 4.60011 3.738892 3.343889 3.11225 2.958249 2.847726 2.764199 2.698672 2.645791 2.602155
15 4.543077 3.68232 3.287382 3.055568 2.901295 2.790465 2.706627 2.640797 2.587626 2.543719
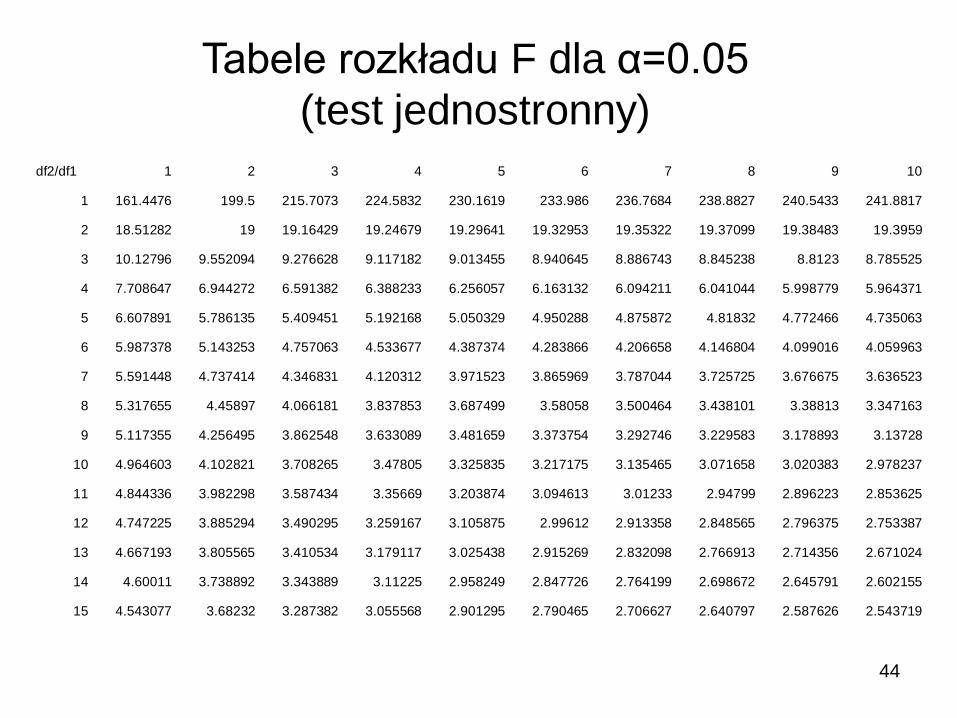
Tabele rozkładu F dla α=0.05
(test jednostronny)

45
Przykład: test trwałości lekarstwa
Badano skuteczność lekarstwa po roku. Porównano próbkę wziętą z
linii produkcyjnej z inną po rocznym przechowywaniu (α=0.01).
105.083.910
058.037.1010
2
222
2
111
sxn
sxnPróbka 1:
Próbka 2:
35.5F01.0for.R.R
81.1058.0
105.0F:.S.T
:H
:H
9,9,01.0
22
21a
22
210
Hipotezy zerowej H0 nie można odrzucić (F<Fcritical)

Test na normalność rozkładu
46
Test Q-Dixona
Test Grubbsa
Test Kołmogorowa - Smirnowa z poprawką Lilleforsa, która jest
obliczana, gdy nie znamy średniej lub odchylenia standardowego
całej populacji.
Test Shapiro - Wilka - najbardziej polecany, ale może dawać błędne
wyniki dla próbek większych niż 2 tys.

Błąd gruby – test Deana Dixona
47
Liczba wyników Poziom ufności 1-α
0.90 0.95 0.98 0.99
3 0.886 0.941 0.972 0.988
4 0.679 0.765 0.846 0.889
5 0.557 0.642 0.729 0.760
6 0.482 0.560 0.644 0.698
7 0.434 0.507 0.586 0.637
8 0.399 0.468 0.543 0.590
9 0.370 0.437 0.510 0.555
10 0.349 0.412 0.483 0.527
Obliczamy parametr Q według wzoru: R
yyQ
12
gdzie y1 - wynik wątpliwy, y2 - wynik mu najbliższy, R - rozrzut wyników.
Wartości krytyczne parametru Q testu Deana Dixona
Wynik wątpliwy należy odrzucić, jeżeli obliczony parametr Q jest większy od odczytanej z tablicy krytycznej wartości dla wybranego poziomu istotności.


















