
PODSTAWY BAZ DANYCHmath.uni.lodz.pl/~cybula/bd/pbd/wyklad_01_04_podstawy_baz_danych... · System...
90
PODSTAWY BAZ DANYCH 2009/2010 1 2009/2010 - Notatki do wykładu "Podstawy baz danych"
Transcript of PODSTAWY BAZ DANYCHmath.uni.lodz.pl/~cybula/bd/pbd/wyklad_01_04_podstawy_baz_danych... · System...

PODSTAWY
BAZ DANYCH
2009/2010
12009/2010 - Notatki do wykładu "Podstawy baz danych"

Literatura
1. Connolly T., Begg C.: Systemy baz danych. Tom 1 i tom 2.
Wydawnictwo RM 2004.
2. R. Elmasri, S. B. Navathe: Wprowadzenie do systemu baz
danych, Wydawnictwo Helion 2005.
3. Garcia-Molina H., Ullman J.D.,:Widom J.: Implementacja
systemów baz danych. WNT 2003.
4. Ullman J.D., Widom J. : Podstawowy wykład z systemów baz
danych. PWN, 1999.
5. Ladanyi H.: SQL. Księga eksperta. Wydawnictwo Helion 2000.
6. Barker R.: Case metod - modelowanie funkcji i procesów 2004.
7. Barker R.: Case metod - modelowanie związków encji. 2004.
22009/2010 - Notatki do wykładu "Podstawy baz danych"

PODSTAWY
BAZ DANYCH
1. Pojęcie Bazy Danych i
Systemu Zarządzania Bazą
Danych
32009/2010 - Notatki do wykładu "Podstawy baz danych"

Proces przechodzenia od świata rzeczywistego do jego
informacyjnej reprezentacji w komputerze nazywać będziemy
modelowaniem,
a pewien dobrze zdefiniowany sposób jego opisu
modelem danych,
przy czym sposób zapisania wyselekcjonowanych informacji jaka
będzie potrzebna użytkownikowi
schematem danych.
Pomiędzy informacjami mogą występować powiązania (też są
informacjami).
Zbiór danych (razem z powiązaniami) nazywać będziemy
bazą danych (BD).
Środki sprzętowe i oprogramowanie umożliwiające współpracę z
bazą danych nazywamy
systemem zarządzania bazą danych, (SZBD).
System zarządzania bazą danych (SZBD)
42009/2010 - Notatki do wykładu "Podstawy baz danych"

• występowanie obiektów (entity – encja) - przedmiotów
materialnych lub abstrakcyjnych reprezentowanych przez
pewne nazwy o których chcemy pamiętać informacje,
np. osoba, zatrudnienie .
• pozostawanie tych obiektów we wzajemnych powiązaniach
(relationship) między sobą wyrażonych przez n-argumentową
funkcję zdaniową (n > 1), której argumentami są nazwy
obiektów,
np. osoba jest zatrudniona
• posiadanie przez obiekty wartości atrybutów (value attribute).
np. pesel, nazwisko, imie, data_ur dla obiektu osoba
Fakty świata rzeczywistego, o których wiedza reprezentowana jest w bazach danych
52009/2010 - Notatki do wykładu "Podstawy baz danych"

• opis danych
- logiczny,
- fizyczny;
• możliwości korzystania z bazy;
• integralność danych;
- określenie pewnych warunków, które muszą być spełnione
w bazie danych, niezależnie od tego, jakie są w niej
aktualnie zapisane wartości;
• poufność danych;
- prawa dostępu poszczególnych użytkowników; ( ustawa o
tajności danych)
• współbieżność dostępu;
- mechanizmy wykrywające sytuacje konfliktowe w
przypadku korzystania jednocześnie z BD przez wielu
użytkowników i ich rozwiązywanie;
• niezawodność.
Funkcje systemu zarządzania bazą danych
62009/2010 - Notatki do wykładu "Podstawy baz danych"

Poziomy opisu baz danych
72009/2010 - Notatki do wykładu "Podstawy baz danych"

Poziomy opisu baz danych
Poziom pojęciowy
w procesie modelowania tworzenie przez projektanta bazy
danych przy pomocy pewnego języka opisu schematu danych
(DDL - Date Description Language ) i ściśle z nim związanego
modelu danych schematu pojęciowego.
Poziom wewnętrzny
schemat fizyczny określający sposoby organizacji danych w
pamięci zewnętrznej.
Poziom zewnętrzny
sposób widzenia danych przez poszczególnych użytkowników.
82009/2010 - Notatki do wykładu "Podstawy baz danych"

W zależności od
• języka opisu schematu danych
( DDL - Data Description Language ),
• języka manipulowania danymi
( DML - Data Manipulation Language )
wyróżnia się następujące modele danych:
Modele danych
• model hierarchiczny i model sieciowy; (historia)
• model relacyjny, (E. F. Cood - 1970); (obecny)
• model zorientowany obiektowo; (przyszłość)
• model relacyjno – obiektowy;
• model semistrukturalny. (przyszłość)
• …
92009/2010 - Notatki do wykładu "Podstawy baz danych"

W zależności od organizacji systemu bazy danych można dokonać
następujących podziałów:
1. ze względu na rozproszenie:
• lokalne bazy danych
- pamiętanie i udostępnianie danych odbywa się w obrębie
jednej instalacji komputerowej;
Organizacja systemu bazy danych
102009/2010 - Notatki do wykładu "Podstawy baz danych"

Organizacja systemu bazy danych
• rozproszone bazy danych
- składają się z wielu lokalnych baz danych znajdujących
się w różnych instalacjach komputerowych;
112009/2010 - Notatki do wykładu "Podstawy baz danych"

Organizacja systemu bazy danych
2. ze względu na liczbę modeli danych:
• jednomodelowe bazy danych
- przyjmuje się jeden model danych (np. relacyjny);
122009/2010 - Notatki do wykładu "Podstawy baz danych"
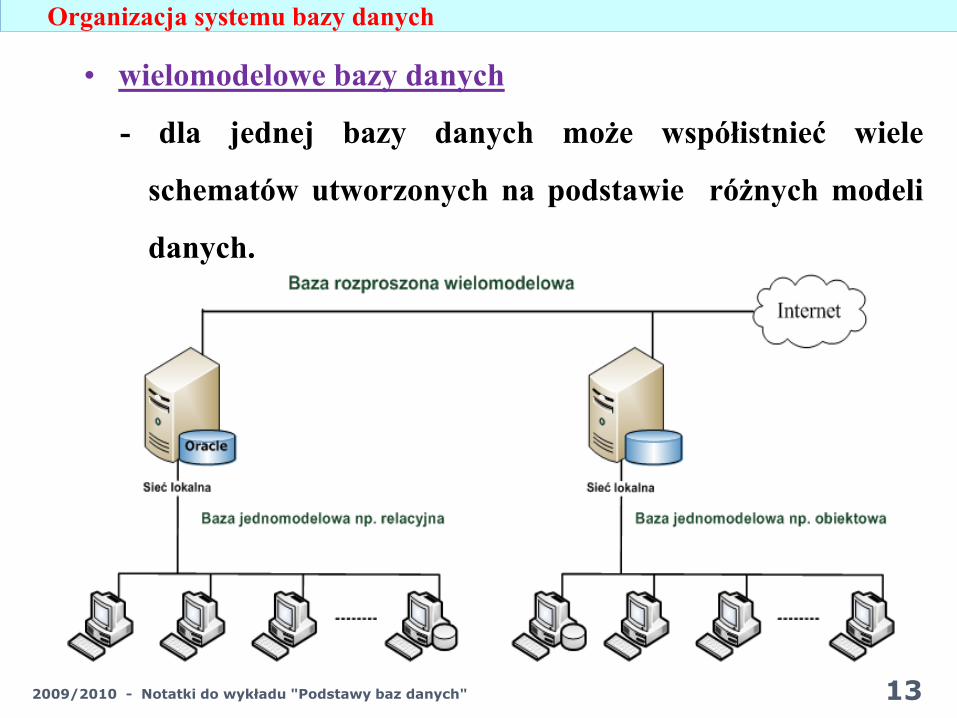
• wielomodelowe bazy danych
- dla jednej bazy danych może współistnieć wiele
schematów utworzonych na podstawie różnych modeli
danych.
Organizacja systemu bazy danych
132009/2010 - Notatki do wykładu "Podstawy baz danych"

Wybór SZBD
Wybór odpowiedniego SZBD
• model danych (relacyjny, obiektowy, …);
• rozmiar bazy;
• koszty oprogramowania;
• wydajność;
• niezawodność;
• bezpieczeństwo;
• ….
• kadra.
142009/2010 - Notatki do wykładu "Podstawy baz danych"

Oprogramowanie systemu zarządzania bazą danych
UNIX Linux Windows As 400
Oracle …, 8, 8i, 9i, 10i, 11 X X X X
DB2 7, 8, 9 X X X X
SQL Server 2000/…/2008 X
Sybase X
Informix X
MySQL 4, 5 (darmowe) ? X X
PostgreSQL (darmowe) X
Access X
…
152009/2010 - Notatki do wykładu "Podstawy baz danych"
Wspomnienia: dBase, FoxPro, Paradox, …

Języki programowania wykorzystywane do baz danych
• SQL – Structured Query Language
• Rozszerzenia np. PL/SQL, …
• Kompilatory
C++, Visual Basic, C# ...
• Java
• PHP
• …
• XML
• inne
162009/2010 - Notatki do wykładu "Podstawy baz danych"

Plan dalszych wykładów
• Modelowanie danych.
• Pojęcie modelu relacyjnego.
• Projektowanie – 2PN, 3PN, ......
• Metody implementacji baz danych.
– indeksy, pamiętanie danych, …
• SQL.
• PL/SQL.
• Optymalizacja zapytań.
• Transakcje.
• Współbieżność.
• Pojęcie modelu obiektowego.
172009/2010 - Notatki do wykładu "Podstawy baz danych"

PODSTAWY
BAZ DANYCH
2. Pojęcie modelu relacyjnego
182009/2010 - Notatki do wykładu "Podstawy baz danych"

Model danych definiuje:
– struktury danych,
– operacje,
– ograniczenia integralnościowe.
Relacyjny model danych:
– relacje,
– selekcja, projekcja, połączenie, operacje na zbiorach,
– klucz podstawowy, klucz obcy, zawężenie dziedziny,
unikalność, wartość pusta/niepusta.
Pojęcie modelu danych
192009/2010 - Notatki do wykładu "Podstawy baz danych"

Definicja. Niech dany będzie skończony zbiór
U := { A1, A2, ..., An },
którego elementy nazywać będziemy atrybutami. Niech każdemu
atrybutowi Ai U przyporządkowany będzie zbiór wartości
DOM(Ai) (może zawierać wartość pustą NULL) zwany dziedziną
atrybutu Ai (domeną).
Niech
Elementy tego zbioru nazywać będziemy krotkami.
Uwaga. Zbiór KROTKA(U) może być zbiorem nieskończonym
(gdy jeden ze zbiorów DOM(Ai) jest zbiorem nieskończonym).
Definicja. Relacją typu U nazywamy dowolny skończony
podzbiór zbioru KROTKA(U).
Zbiór wszystkich relacji typu U oznaczać będziemy przez
REL(U).
)ADOM(X : )UKROTKA(i
1..ni
Pojęcie krotki - definicja
202009/2010 - Notatki do wykładu "Podstawy baz danych"

Pojęcie krotki i relacji - oznaczenia
• Relację typu U oznaczać będziemy przez R(U), S(U), T(U), ..
• Jeżeli z kontekstu wynikać będzie jednoznacznie o jaki zbiór
atrybutów chodzi, pisać będziemy R, S, T, ...
• Krotki typu U oznaczać będziemy r(U), s(U), t(U)....
• Jeżeli z kontekstu wynikać będzie jednoznacznie typ krotki,
pisać będziemy r, s, t, ....
• Podzbiory zbioru atrybutów U oznaczać będziemy dużymi
literami X, Y, Z, ....
• Do oznaczenia sumy dwóch zbiorów X, Y U stosować
będziemy zapis XY zamiast XY.
• Dla zbioru atrybutów { A, B } zamiast pisać R({A, B}),
stosować będziemy zapis R(A,B).
212009/2010 - Notatki do wykładu "Podstawy baz danych"

Przykład. Relacja typu U := { I, N, P, O }
I N P O
10 Nowak a 3
10 Nowak b 4
11 Norek a 3
12 Burek a 3
… … … …
… … … …
Pojęcie krotki i relacji - przykład
U := { nr_Indeksu, Nazwisko_studenta, nr_Przedmiotu, Ocena}
R3
R2R1
krotka
wiersz
rekord
ang. tuple
222009/2010 - Notatki do wykładu "Podstawy baz danych"

Na relacjach definiuje się pewne operacje:
• operacje mnogościowe,
• operacje relacyjne.
Definicja. Sumą, różnicą, przekrojem i dopełnieniem relacji R(U)
nazywamy odpowiednio zbiory
(a) { tKROTKA(U) | tR(U) tS(U) };
(b) { tKROTKA(U) | tR(U) tS(U) };
(c) { tKROTKA(U) | tR(U) tS(U) };
(d) KROTKA(U) - R(U) ,
przy czym zbiór KROTKA(U) musi być zbiorem
skończonym, gdyż w przeciwnym wypadku byłaby
sprzeczność z definicją relacji.
Operacje na relacjach - Operacje mnogościowe
232009/2010 - Notatki do wykładu "Podstawy baz danych"

Operacje na relacjach - Operacje mnogościowe
Zbiory te będziemy oznaczać odpowiednio przez
R(U) S(U), R(U) S(U), R(U) - S(U), - R(U).
Zauważmy, że definicje te dotyczą relacji tego samego typu.
Przykład. Mamy dwie relacje Osoby i Osoby1 postaci:
ID_OS NAZWISKO IMIE
1 Lis Jan
2 Kot Adam
3 Norek Tadeusz
4 Krawczyk Adam
5 Lis Anna
242009/2010 - Notatki do wykładu "Podstawy baz danych"

Operacje na relacjach - Operacje mnogościowe
Przykład. Operacje mnogościowe w SQL.
SELECT id_os, nazwisko, imie FROM osoby
UNION /* suma */
SELECT id_os, nazwisko, imie FROM osoby1;
SELECT id_os, nazwisko, imie FROM osoby
INTERSECT /* część wspólna */
SELECT id_os, nazwisko, imie FROM osoby1;
SELECT id_os, nazwisko, imie FROM osoby
MINUS /* różnica */
SELECT id_os, nazwisko, imie FROM osoby1;
252009/2010 - Notatki do wykładu "Podstawy baz danych"

Operacje na relacjach – Operacja selekcji
Przykład. Przykład operacji selekcji w SQL.
SELECT *
FROM osoby
WHERE nazwisko = ’Lis’ AND imie =’Anna’;
( * oznacza, że wybieramy wszystkie atrybuty )
Operacja selekcji polega na wyborze z relacji podzbioru krotek
spełniających określony warunek selekcji, gdzie warunek selekcji
może np. być postaci:
• <atrybut> <operator relacyjny> <atrybut>
• <atrybut> <operator relacyjny> <wyrażenie>
• …
Te predykaty mogą być łączone operatorami logicznymi AND ,OR.
262009/2010 - Notatki do wykładu "Podstawy baz danych"

Definicja. Niech U będzie zbiorem atrybutów i X, Y U,
r KROTKA(X), s KROTKA(Y), Z := X Y.
Krotkę t KROTKA(Z) nazywamy złączeniem krotki r i s, co
oznaczamy t = r s, gdy t[X] = r i t[Y ] = s,
gdzie t[X] i t[Y ] oznacza obcięcie krotki t do atrybutów X i Y.
Przykład. Niech U := { I, N, P, O } i X := { I, N } i Y := { I, P, O }
oraz Z := X Y = { I, N, P, O }.
Jeżeli r(X) = { 10, Nowak } i s(Y) = { 10, a, 3 } to krotka t typu Z
postaci t(Z) = { 10, Nowak, a, 3 } jest złączeniem krotek r(X) i s(Y),
bo t[X] = { 10, Nowak } i t[Y] = { 10, a, 3 }.
Złączenie krotek - definicja
272009/2010 - Notatki do wykładu "Podstawy baz danych"

Definicja. Dla danej relacji R(U) oraz zbioru X U zbiór
R[X]: ={ t KROTKA(X) | ( r R(U) ( t = r[X] ) }.
nazywamy projekcją R na X.
Stwierdzenie. Jeżeli dana jest relacja R(U) i X U to
R[X]={ tKROTKA(X) | ( sKROTKA(U-X) ) (t s R(U))}.
Projekcja - definicja
Przykład. Mamy relację Student typu U := { I, N, P, O }, gdzie
U :={ nr_Indeksu, Nazwisko_studenta, nr_Przedmiotu, Ocena}
I N P O
10 Nowak a 3
10 Nowak b 4
11 Norek a 3
12 Burek a 3
282009/2010 - Notatki do wykładu "Podstawy baz danych"

Przykład. Przykłady dwóch projekcji:
I N
10 Nowak
11 Norek
12 Burek
Projekcja - przykład
I P O
10 a 3
10 b 4
11 a 3
12 a 3
Student[IN] Student[IPO]
SELECT I,N
FROM Student; SELECT I,P,N
FROM Student;
SELECT DISTINCT I,N
FROM Student;
SELECT DISTINCT I,P,N
FROM Student;
Przyjmijmy, że SELECT … zwraca tylko różne wiersze.
292009/2010 - Notatki do wykładu "Podstawy baz danych"

Definicja. Dla danych relacji R(X) i S(Y) relację
T := { tKROTKA(XY) | ( t[X]R ) ( t[Y]S ) }
typu XY nazywamy złączeniem relacji i oznaczamy przez R S.
Stwierdzenie. Jeżeli dane są relacje R(X) i S(Y) to
R S={ t KROTKA( XY ) | ( r R(X) ) ( s S(Y) )
( t = r s ) }.
Złączenie relacji - definicja
302009/2010 - Notatki do wykładu "Podstawy baz danych"

Przykład. Student(X), X = { I, N } i Oceny(Y), Y = { I, P, O }
U = XY = { I, N, P, O }
I N
10 Nowak
11 Norek
12 Burek
I P O
10 a 3
10 b 4
11 a 3
12 a 3
Złączenie relacji - przykład
Student (X) Oceny (Y)
312009/2010 - Notatki do wykładu "Podstawy baz danych"

I N P O
10 Nowak a 3
10 Nowak b 4
11 Norek a 3
12 Burek a 3
Złączenie relacji - przykład
Relacja Student Oceny typu U := { I, N, P, O } ma postać:
W języku SQL realizuje to polecenie:
SELECT s.I, s.N, o.P, o.O
FROM Student s JOIN Oceny o ON s.I = o.I;
lub równoważne
SELECT s.I, s.N, o.P, o.O
FROM Student s, Oceny o
WHERE s.I = o.I;
322009/2010 - Notatki do wykładu "Podstawy baz danych"

Przykład. Student(X), X = { I, N } i Oceny(Y), Y = { P, O }
U = XY = { I, N, P, O }
I N
10 Nowak
11 Norek
12 Burek
P O
a 3
b 4
Złączenie relacji - przykład
Student(X) Oceny(Y)
W języku SQL realizuje to polecenie:
SELECT s.I, s.N, o.P, o.O
FROM Student s, Oceny o;
lub równoważne
SELECT s.I, s.N, o.P, o.O
FROM Student s CROSS JOIN Oceny o;
332009/2010 - Notatki do wykładu "Podstawy baz danych"

Definicja. Niech U będzie zbiorem atrybutów i X,Y U.
Mówimy, że istnieje zależność funkcyjna między X i Y, co
oznaczamy X Y, gdy w każdej relacji
R(U) KROTKA(U)
istnieje pewna funkcja R[X] R[Y],
( przy różnych relacjach R(U) funkcje te mogą być różne ).
Zależności funkcyjne - definicja
Gdy
X = { A1, A2..., An } i Y = { B1, B2..., Bm },
gdzie Ai, Bi oznaczają pojedyncze atrybuty z U, to będziemy
również używać oznaczenia
A1A2...An B1B2...Bm.
342009/2010 - Notatki do wykładu "Podstawy baz danych"

Definicja. Dla danej relacji
R(U), X, Y U,
mówimy, że w R(U)
spełniona jest zależność funkcyjna X Y,
gdy
() ( r1, r2R(U) ) [ ( r1[X] = r2[X] ) ( r1[Y] = r2[Y] ) ].
Zależności funkcyjne - definicja
Przykład. Niech dany będzie
U:={nr_Indeksu, Nazwisko_studenta, nr_Przedmiotu, Ocena}
i relacja R(U) będzie określona następująco:
352009/2010 - Notatki do wykładu "Podstawy baz danych"

I N P O
1 A 101 3
1 A 102 4
2 B 101 3
3 C 101 3
Zależności funkcyjne - przykład
W relacji R(U) spełnione są następujące zależności funkcyjne
(nasze założenie): I N , IP O.
Zauważmy, że dla zbiorów { P } i { O } warunek z () jest również
spełniony, ale między tymi zbiorami nie istnieje zależność
funkcyjna.
Istotnie, po dodaniu krotki ( 3, C, 102, 3 ) warunek z () nie będzie
spełniony.
362009/2010 - Notatki do wykładu "Podstawy baz danych"

Przykład. Niech U := { Przedmiot, nr_Indeksu, Ocena,
nr_Egzaminatora, Godzina_egzaminu, Sala }
tzn. U := { P, I, O, E, G, S }.
Aksjomaty Armstronga - przykład
Zamiast zależności funkcyjnej P GS można łatwo wprowadzić
dwie zależności P G i P S. Poza tym np. z zależności P GS
i PGS E wynika zależność P E.
Na tym zbiorze atrybutów można określić np. następujący zbiór
zależności funkcyjnych:
F := { P GS, GS P, PI O, GI PS, PGS E }.
372009/2010 - Notatki do wykładu "Podstawy baz danych"

Przez F+ oznaczmy najmniejszy (ze względu na relację
zawierania) zbiór zależności funkcyjnych, który zawiera zbiór F i
dla dowolnych X, Y, Z U spełnia następujące aksjomaty:
Aksjomaty Armstronga - domknięcie zbioru F
Definicja. Niech U będzie zbiorem atrybutów i niech
F { X Y | ( X U ) ( Y U ) }.
F1. ( Y X ) [ (X Y ) F+ ], (zwrotność);
F2. [ (X Y ) F+ ] [ (XZ YZ ) F+ ], (poszerzalność);
F3. [ (X Y ) F+ (Y Z ) F+] [ (X Z ) F+ ],
(przechodniość).
Zbiór F+ nazywamy najmniejszym domknięciem zbioru F.
382009/2010 - Notatki do wykładu "Podstawy baz danych"

Aksjomaty Armstronga
Uwaga. Armstrong (1974) wykazał, że zbiór F+ można otrzymać
ze zbioru F używając tylko reguł wnioskowania F1, F2 i F3.
Uwaga. Niech U będzie zbiorem atrybutów i niech F będzie
zbiorem zależności funkcyjnych. Wykazano, że zbiór F+ jest
zbiorem wszystkich możliwych zależności funkcyjnych, które
można w sposób logiczny wyprowadzić z zależności ze zbioru F.
Stwierdzenie. (wynikające z aksjomatów Armstronga).
F4. [ (X Y ) F+ (YW Z ) F+] [ (XW Z ) F+ ],
F5. [ (X Y ) F+ (X Z ) F+] [ (X YZ ) F+ ],
F6. [ (X YZ ) F+ ] [ (X Y ) F+ (X Z ) F+ ].
392009/2010 - Notatki do wykładu "Podstawy baz danych"

Definicja. Niech dla danego zbioru atrybutów U zbiór F będzie
zbiorem zależności funkcyjnych określonych na U.
Parę uporządkowaną
RR := ( U, F )
nazywamy schematem relacyjnym o zbiorze atrybutów U i ze
zbiorem zależności F.
Schemat relacyjny i jego związek z relacją - definicja
Definicja. Mówimy, że relacja R jest przypadkiem schematu
relacyjnego RR := ( U, F ), (lub, że jej schematem jest RR ), gdy R
jest relacją typu U i spełniona jest w niej każda zależność
funkcyjna X Y F.
Zbiór wszystkich relacji R o schemacie RR oznaczać będziemy
przez INST(RR).
402009/2010 - Notatki do wykładu "Podstawy baz danych"

Definicja. Dla danego schematu relacyjnego
RR := ( U, F ) i X U
schemat relacyjny ( X, G ) nazywamy projekcją schematu RR na
zbiór X,
co oznaczamy przez RR[X], gdy
G+ = { (Y Z ) F+ | Y Z X }+,
tzn. G jest podzbiorem zbioru tych zależności ze zbioru F+, w
których występują tylko atrybuty ze zbioru X.
Schemat relacyjny - projekcja
412009/2010 - Notatki do wykładu "Podstawy baz danych"

Definicja. Dla schematów relacyjnych
RR := ( X, F ) i SS := ( Y, G )
schemat relacyjny ( Z, H ) nazywamy złączeniem schematów RR i SS,
co oznaczamy przez RR SS, gdy
Z = X Y i H = F G.
Schemat relacyjny - złączenie
422009/2010 - Notatki do wykładu "Podstawy baz danych"

Rozkładalność schematów relacyjnych
Twierdzenie. Schemat relacyjny RR := ( U, F ) jest rozkładalny bez
straty danych na schematy relacyjne
RR[XY] i RR[XZ], X Y Z = U, Y Z =
wtedy i tylko wtedy, gdy
( X Y ) F+ lub ( X Z ) F+
tzn., gdy dla każdej relacji R o schemacie R R := ( U, F ) mamy
( R = R[XY] R[XZ] ) [ (XY)F+ (XZ )F+ ].
X Y Z
Definicja. Mówimy, że schemat relacyjny RR := ( U, F ) jest
rozkładalny bez straty danych na dwa schematy relacyjne
RR[X] i RR[Y],
gdy
a) X Y = U,
b) ( R INST(RR ) ) ( R = R[X] R[Y]).
432009/2010 - Notatki do wykładu "Podstawy baz danych"

Przykład. Relacja EGZ(U), U := { I, N, P, O }, gdzie
I N P O
10 f a 3
10 f b 4
11 g a 3
12 h a 3
jest przypadkiem schematu relacyjnego
EGZEGZ := ( { I, N, P, O }, { I N, IP O } ).
Rozkładalność schematów relacyjnych
W zależności od wyboru zbioru zależności funkcyjnych jako
podstawy rozkładu relację tą można rozłożyć bez straty danych na
dwa sposoby:
442009/2010 - Notatki do wykładu "Podstawy baz danych"

W obydwu przypadkach mamy:
EGZ=E1 E2, EGZ=E3 E4.
Rozkładalność schematów relacyjnych
E1: I N E2: I P O
10 f 10 a 3
11 g 10 b 4
12 h 11 a 3
12 a 3
E3: I P O E4: I P N
10 a 3 10 a f
10 b 4 10 b f
11 a 3 11 a g
12 a 3 12 a h
452009/2010 - Notatki do wykładu "Podstawy baz danych"

Definicja. Mówimy, że schemat relacyjny RR := ( U, F ) jest
rozkładalny bez straty zależności na dwa schematy relacyjne
RR1 := ( X, G ), RR2 := ( Y, H ),
gdy
a) X Y = U,
b) F+ = ( G H )+.
Przykład. Oba rozkłady ze slajdu 45 są rozkładami bez straty
zależności.
EE1 := ( { I, N }, { I N } ), EE2 := ( { I, P, O }, { I PO } ),
EE3 := ( { I, P, O }, { I PO } ), EE4 := ( { I, P, N }, { I N } ),
Rozkładalność schematów relacyjnych
462009/2010 - Notatki do wykładu "Podstawy baz danych"

Przykład. Dla schematu relacyjnego RR := ( U, F )
U := { A, B, C, D },
F := { A B, BC D, D B, D C }
rozważmy następujące schematy:
RR1 := ( { A, B }, { A B } ),
RR2 := ( { B, C, D }, { BC D, D B, D C } ),
będące rozkładami schematu RR bez straty zależności.
Rozkład ten nie jest jednak rozkładem bez straty danych.
Rozkładalność schematów relacyjnych
Istotnie, rozważmy relację RINST(R) postaci:
R: A B C D
a b c d
a1 b c1 d1
a2 b c1 d1
472009/2010 - Notatki do wykładu "Podstawy baz danych"

Wówczas relacje:
R1 := R[AB] i R2 := R[BCD]
mają postać:
Rozkładalność schematów relacyjnych
R1: A B R2: B C D
a b b c d
a1 b b c1 d1
a2 b
i RR1 R2 (następny slajd).
Zauważmy, że zależności B A i B CD nie należą do F+, tzn.
nie są spełnione założenia twierdzenia o warunku koniecznym i
dostatecznym rozkładalności bez straty danych.
482009/2010 - Notatki do wykładu "Podstawy baz danych"

R1 R2 A B C D
a b c d
a b c1 d1
a1 b c d
a1 b c1 d1
a2 b c d
a2 b c1 d1
Rozkładalność schematów relacyjnych
R: A B C D
a b c d
a1 b c1 d1
a2 b c1 d1
492009/2010 - Notatki do wykładu "Podstawy baz danych"

Pojęcie klucza
Definicja. Mówimy, że zbiór K U jest kluczem dla schematu
relacyjnego RR := ( U, F ), gdy spełnia warunki:
a) ( K U ) F+,
b) ( X U ) ( [ ( X U ) F+ ] [ ( X K ) ] )
c) wartościami K nie mogą być wartości NULL.
Jeżeli zbiór K spełnia tylko warunek a) i c) to nazywamy go
nadkluczem.
Elementy zbioru K nazywamy atrybutami kluczowymi.
502009/2010 - Notatki do wykładu "Podstawy baz danych"

Przykład. Dla schematu relacyjnego
EE := ( { I, N, P, O }, { I N, IP O } )
warunek a) definicji klucza spełniają zbiory
{ I, P }, { I, N, P }, { I, N, P, O }.
Warunek b) definicji klucza spełnia tylko zbiór
{ I, P }
i ten zbiór jest kluczem schematu EE.
Pojęcie klucza
512009/2010 - Notatki do wykładu "Podstawy baz danych"

Uwaga. Schemat relacyjny może posiadać wiele kluczy (klucze
kandydujące).
Jeden z nich nazywamy kluczem głównym (Primary key).
Atrybuty nie należące do żadnego klucza nazywamy atrybutami
niekluczowymi.
Pojęcie klucza
Atrybuty niekluczowe K2K1
522009/2010 - Notatki do wykładu "Podstawy baz danych"

PODSTAWY
BAZ DANYCH
3. Normalizacja schematów
relacyjnych
532009/2010 - Notatki do wykładu "Podstawy baz danych"

Normalizacja schematów relacyjnych - 1PN
Definicja. Schemat relacyjny
RR := ( U, F )
jest w pierwszej postaci normalnej (1PN), gdy dla każdego atrybutu
AU zbiór DOM(A) składa się z wartości elementarnych (atomic
value).
Przykład. Np. gdybyśmy przyjęli, że mamy atrybut Adres i
wartościami byłyby np. 95-003 Łódź ul. Piotrkowska 5 m.6 to
dziedzina tego atrybutu nie składałaby się z wartości
elementarnych (o ile w jakimś zapytaniu występowałyby tylko np.
miasta) .
542009/2010 - Notatki do wykładu "Podstawy baz danych"

Normalizacja schematów relacyjnych - 2PN
Definicja. Niech X, Y U i X Y = .
Mówimy, że Y jest w pełni funkcyjnie zależny od X, gdy istnieje
zależność funkcyjna X Y i nie istnieje zależność z żadnego
właściwego podzbioru X1 zbioru X w Y.
XY F+
Y
X
X1Y F+
X1
552009/2010 - Notatki do wykładu "Podstawy baz danych"

Definicja. Schemat relacyjny
RR := ( U, F )
jest w drugiej postaci normalnej (2PN), gdy każdy niekluczowy
atrybut A U jest w pełni zależny od każdego klucza tego
schematu.
Oznacza to, że nie ma miejsca przypadek:
Normalizacja schematów relacyjnych - 2PN
K2AK1
K1A F+
K11A F+
562009/2010 - Notatki do wykładu "Podstawy baz danych"

Normalizacja schematów relacyjnych - 2PN
Przykład. Schemat relacyjny EE = ( U, F )
gdzie
U := { Indeks, Nazwisko, Kierunek, Adres, Przedmiot, Ocena },
F := { I NAK, IP O }
z kluczem K := { I, P } nie jest w 2PN, bo np. niekluczowy atrybut
N jest zależny funkcyjnie tylko od { I } K.
Niech E będzie relacją o schemacie EE = ( U, F ) określoną
następująco:
E: I N A K P O
10 f x mat a 3
10 f x mat b 4
11 g y inf a 3
12 h x inf a 3
10 f x mat c 5
572009/2010 - Notatki do wykładu "Podstawy baz danych"

Normalizacja schematów relacyjnych - 2PN
W relacji tej można zauważyć następujące anomalia:
dołączania - nie można dołączyć
studenta, który nie zdał żadnego
egzaminu;
aktualizacji - zmiana adresu studenta wymaga zmiany w
kilku krotkach;
usuwania - np. przy unieważnieniu egzaminu studenta o
indeksie 11 należy usunąć całą krotkę, co spowoduje utratę
informacji o studencie.
E: I N A K P O
10 f x mat a 3
10 f x mat b 4
11 g y inf a 3
12 h x inf a 3
10 f x mat c 5
582009/2010 - Notatki do wykładu "Podstawy baz danych"

Normalizacja schematów relacyjnych - 2PN
Dla każdej relacji E INST(EE) mamy
E = E[INKA] E[IPO]
tzn. uzyskaliśmy dwa schematy relacyjne
EE1 := ( { I, N, K, A }, { I NAK } )
i
EE2 := ( { I, P, O }, { IP O } )
odpowiednio z kluczami { I } i { I, P }.
Jest to rozkład bez straty danych.
592009/2010 - Notatki do wykładu "Podstawy baz danych"

E1: I N A K E2: I P O
10 f x mat 10 a 3
11 g y inf 10 b 4
12 h x inf 11 a 3
12 a 3
10 c 5
Stwierdzenie. Jeżeli każdy klucz schematu jest zbiorem
jednoelementowym to schemat jest w 2PN.
Relację E można zastąpić dwiema relacjami:
Normalizacja schematów relacyjnych - 2PN
Każdy ze schematów EE1 i EE2 jest w 2PN.
602009/2010 - Notatki do wykładu "Podstawy baz danych"

Normalizacja schematów relacyjnych - 3PN
Definicja. Niech X, Z U. Zbiór atrybutów Z jest tranzytywnie
zależny od zbioru X, gdy
Z
Y
X
(XY )F+ (YX)F+ (YZ)F+
a) X Z = ,
b) ( Y U ) { ( Y X = Y Z = )
[ ( X Y ) F+ ( Y X ) F+ ( Y Z) F+ ] }.
612009/2010 - Notatki do wykładu "Podstawy baz danych"

Definicja. Schemat relacyjny
RR := ( U, F )
jest w trzeciej postaci normalnej ( 3PN ), gdy
• jest w 2PN;
• każdy zbiór niekluczowych atrybutów Z U nie jest
tranzytywnie zależny od każdego zbioru atrybutów K
będącego kluczem tego schematu.
Normalizacja schematów relacyjnych - 3PN
622009/2010 - Notatki do wykładu "Podstawy baz danych"

Przykład. Rozważmy schemat relacyjny EE := ( U, F ) gdzie
U :={ Wykonawca, Adres, Projekt, Data_zakonczenia },
F := { W APD, P D }
z kluczem K := { W } jest w 2PN.
Normalizacja schematów relacyjnych - 3PN
Zakładamy, że
1. wykonawca może realizować tylko jeden projekt,
2. wszyscy wykonawcy dany projekt muszą zakończyć tego
samego dnia.
Niech E będzie relacją o schemacie EE := (U, F) określoną
następująco:E: W A P D
30 x a 01/01/2000
40 y a 01/01/2000
50 y b 01/01/1999
60 z c 01/01/2000
632009/2010 - Notatki do wykładu "Podstawy baz danych"

Normalizacja schematów relacyjnych - 3PN
Ponieważ W P P D to W D tzn. zbiór { D } jest
tranzytywnie zależny od zbioru { W }.
W relacji tej można zauważyć następujące anomalia:
dołączania, aktualizacji i usuwania.
Dla każdej relacji E INST(EE) mamy
E = E[WAP] E[PD]
tzn. uzyskamy dwa schematy relacyjne będące w 3PN
E1 := ( { W, A, P }, { W A, W P } )
i
E2 := ( { P, D }, { P D } ).
Jest to rozkład bez straty danych.
642009/2010 - Notatki do wykładu "Podstawy baz danych"

E1: W A P E2: P D
30 x a a 01/01/2000
40 y a b 01/01/1999
50 y b c 01/01/2000
60 z c
Normalizacja schematów relacyjnych - 3PN
Relację E można zastąpić dwoma relacjami:
Uwaga. W każdym schemacie będącym w 3PN między
atrybutami niekluczowymi nie ma zależności funkcyjnych.
Zadanie. Sprawdzić, czy schemat relacyjny
EE := ( { A, B, C }, { AB C, C A } )
jest w 3PN.
652009/2010 - Notatki do wykładu "Podstawy baz danych"

Normalizacja schematów relacyjnych - 3PN - Przykład
Przykład.
Pesel Nip Nazwisko Imie D_urodzenia Plec
Przyjmijmy założenie, że każda osoba posiada Pesel i Nip.
Wtedy kluczami mogą być np. zbiór { Pesel } lub { Nip }.
Niekluczowymi atrybutami są
{ Nazwisko, Imie, D_urodzenia, Plec }.
Ten schemat relacyjny jest w 3PN (dlaczego?).
662009/2010 - Notatki do wykładu "Podstawy baz danych"

Normalizacja schematów relacyjnych - PNB-C
Definicja. Schemat relacyjny
RR := ( U, F )
jest w postaci normalnej Boyce'a-Codda, (PNB-C),
gdy z faktu
( X Y ) F+, Y U - X,
wynika, że ( X U ) F+.
Przykład. Schemat relacyjny
EE := ( { Student, Przedmiot, Wykładowca }, { W P, SP W } )
z kluczem K := { S, P } nie jest w PNB-C, bo mimo, że W PF+,
to nie istnieje zależność W U.
Uwaga. Każdy schemat w PNB-C jest w 3PN. Jest bardziej
restrykcyjny niż schemat w 3PN.
672009/2010 - Notatki do wykładu "Podstawy baz danych"

Normalizacja schematów relacyjnych - PNB-C
K2AK1
K11A F+
Gdyby nie był w 2PN to z faktu K11A F+
wynikałoby z B-C, że K11 U tzn. K1 nie byłoby kluczem. Z
YK1
(K1Y )F+ (YK1)F+ (YZ)F+
Gdyby nie był w 3PN to istniałyby atrybuty niekluczowe Y, Z
i z B-C Y U F+ tzn. Y albo jego podzbiór byłby kluczem co
jest sprzeczne z tym, że Y jest atrybutem niekluczowym.
682009/2010 - Notatki do wykładu "Podstawy baz danych"

Przykład. Niech E będzie relacją o schemacie RR := ( U, F )
określoną następująco:
Normalizacja schematów relacyjnych - PNB-C
E: S P W
10 a x
11 a x
10 b y
11 b z
W relacji E występują anomalia usuwania i dołączania:
• Nie można dołączyć wykładowcy i przedmiotu jeżeli brak
chociaż jednego studenta uczęszczającego na wykład.
• Nie można również usunąć ostatniego studenta uczęszczającego
na dany przedmiot.
692009/2010 - Notatki do wykładu "Podstawy baz danych"

Normalizacja schematów relacyjnych - PNB-C
Schemat E można rozłożyć na dwa schematy relacyjne
E1 := ( { W, P }, { W P } ) i E2 := ( { W, S }, ),
z których każdy jest w PNB-C.
Wtedy relację E można przedstawić w postaci:
E1: W P E2: W S
x a x 10
y b x 11
z b y 10
z 11
Ponieważ E = E1 E2 , więc rozkład ten jest rozkładem bez
straty danych, ale nie jest rozkładem bez straty zależności,
bowiem
{ W P, SP W }+ { { W P } }+.
702009/2010 - Notatki do wykładu "Podstawy baz danych"

Zależność wielowartościowa
Definicja. Niech X, Y U, Z := U - XY.
Mówimy, że istnieje
zależność wielowartościowa między zbiorami X i Y,
co oznaczamy przez X ─>>Y, gdy dla każdego zbioru
KROTKA(U) istnieje pewna funkcja
: KROTKA(X) (KROTKA(YZ)),
gdzie (KROTKA(YZ)) oznacza zbiór wszystkich podzbiorów
zbioru KROTKA(YZ), taka, że jeżeli do zbioru (x) należą krotki
(y, z) i (y, z), to należą również krotki ( y, z ) i (y, z ).
X Y Z
712009/2010 - Notatki do wykładu "Podstawy baz danych"

Definicja. Niech dana będzie relacja R(U), X, Y U i Z:=U-XY.
Mówimy, że w R spełniona jest zależność wielowartościowa
X─>>Y, gdy spełniony jest jeden z równoważnych warunków:
a)
b)
x R X y y R Y z z R Z, ,
}
{
RzyxRzyx
RzyxRzyx
.XZRXYRR
Zależność wielowartościowa
X Y Z
722009/2010 - Notatki do wykładu "Podstawy baz danych"

Uwaga. Każda zależność funkcyjna X Y F+ jest zależnością
wielowartościową tzn. mamy X ─>> Y . Spełniony jest warunek
konieczny rozkładu bez straty danych (punkt b).
Uwaga. Zależności X ─>> U i X ─>> spełnione są w każdej
relacji R(U). Istotnie
Nazywamy je trywialnymi zależnościami wielowartościowymi.
Zależność wielowartościowa
.XZRXYRR
.XZRXYRR
, Z = , Y = U
, Z = U-X, Y =
732009/2010 - Notatki do wykładu "Podstawy baz danych"

E: P D Z R
a x 1000 1983 D ─>> P
a y 1000 1983 P ─>> ZR
a x 1500 1984
a y 1500 1984
b z 1200 1983
b z 1600 1984
Przykład. U := { Pracownik, Imię_Dziecka, Zarobki, Rok }
Zależność wielowartościowa
E1: P D E2: P Z R
a x a 1000 1983
a y a 1500 1984
b z b 1200 1983
b 1600 1984
( D ─> P ) PR ─> Z
742009/2010 - Notatki do wykładu "Podstawy baz danych"

Zależność wielowartościowa
Definicja. Niech U będzie zbiorem atrybutów i
M { X ─>> Y | X U Y U }.
Przez M + oznaczmy najmniejszy (ze względu na relację ) zbiór
zależności wielowartościowych takich, że M M + i dla
( X, Y, Z U ) ( X Y = X Z = Z Y = )
spełnione są następujące aksjomaty:
752009/2010 - Notatki do wykładu "Podstawy baz danych"

M0. (zwrotność),
M1. (dopełnialność),
M2. (poszerzalność),
M3. (przechodniość),
M4.
(pseudo-przechodniość),
M5.
(addytywność),
M6.
(dekompozycja).
Zależność wielowartościowa
, MYXXY
, MXYUXMYX
, MYZXZMYX
, MZXMZYMYX
, MWXZMWYZMYX
, MYZXMZXMYX
, MZYXMZXMYX
762009/2010 - Notatki do wykładu "Podstawy baz danych"

Uwaga. Między zależnościami funkcyjnymi i wielowartościowymi
zachodzą następujące związki:
FM1.
FM2.
Zależność wielowartościowa
, MYXFYX
.
FVX
ZYZVMVYMZX
X Y Z
V
772009/2010 - Notatki do wykładu "Podstawy baz danych"

Definicja. Dla zbioru atrybutów U i zbiorów F i M, (zakładamy, że
zbiór M nie zawiera zależności funkcyjnych), parę
RR := ( U, F M )
nazywamy schematem relacyjnym i mówimy, że relacja R jest
przypadkiem schematu relacyjnego RR jeśli jest relacją typu U oraz
każda zależność funkcyjna i wielowartościowa jest spełniona w R.
Schemat relacyjny
782009/2010 - Notatki do wykładu "Podstawy baz danych"

Zależność wielowartościowa - 4PN
Definicja. Mówimy, że schemat relacyjny
RR := ( U, F M )
jest w czwartej postaci normalnej (4PN) gdy jest w 3PN i
. FUXXUYMYX
Przykład. Dla schematu relacyjnego
RR := ( { P, D, Z, R }, { D P, PR Z, P > D, P > ZR } )
który nie jest w 4PN i relacji E z przykładu ze slajdu 74 rozważmy
dwa schematy
RR1 := ( { P, D }, {D P }),
RR2 := ( { P, Z, R }, { PR Z }).
Wtedy schematy RR1 i RR2 są w 4PN.
-
E P D Z R
a x 1000 1983 D ─>> P
a y 1000 1983 P ─>> ZR
a x 1500 1984
a y 1500 1984
b z 1200 1983
b z 1600 1984
792009/2010 - Notatki do wykładu "Podstawy baz danych"
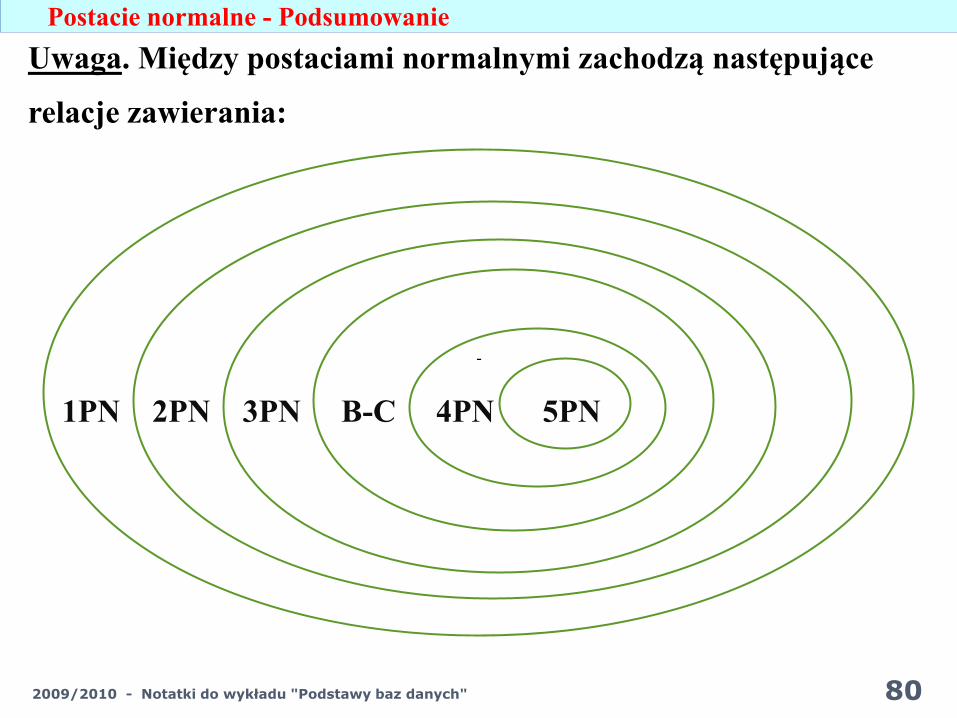
Postacie normalne - Podsumowanie
-
Uwaga. Między postaciami normalnymi zachodzą następujące
relacje zawierania:
1PN 2PN 3PN B-C 4PN 5PN
802009/2010 - Notatki do wykładu "Podstawy baz danych"

Definicja. Schematem relacyjnej bazy danych nazywamy zbiór
:= { Ri := ( Ui , Fi ) | i = 1,2,..,n }.
wszystkich schematów relacyjnych występujących w danej bazie
danych
Schemat relacyjnej bazy danych
812009/2010 - Notatki do wykładu "Podstawy baz danych"

PODSTAWY
BAZ DANYCH
4. Projektowanie Schematu Bazy
Danych
822009/2010 - Notatki do wykładu "Podstawy baz danych"

1. Określamy jeden schemat relacyjnej bazy danych
{ RR := ( U, F ) },
gdzie U jest zbiorem wszystkich atrybutów występujących w
bazie danych, przy czym zbiór U dobieramy w taki sposób aby
można było na zbiorze U określić zależności funkcyjne.
2. Rozkładając schemat relacyjny RR na schematy
RRii := ( Ui , Fi ), i = 1,2,..,n
spełniające wybrane przez nas warunki normalizacji
otrzymamy schemat bazy danych
:= { RRii := ( Ui , Fi ) | i = 1,2,..,n }.
Algorytm tworzenia schematu relacyjnej bazy danych
832009/2010 - Notatki do wykładu "Podstawy baz danych"

Równoważność schematów
Niech dane będą następujące schematy baz danych:
1 := { RR := ( U, F ) },
2 := { RRi := ( Ui , Fi ) | i = 1,2,..,n }, (n 2).
Wprowadzimy definicję równoważności schematów.
n
i
iUU1
,
.1
i
n
i
URR
Definicja. Mówimy, że dane schematy 1 i 2 są
EQ1-równoważne, gdy dla każdej relacji RINST(1)
Definicja. Mówimy, że dane schematy 1 i 2 są
EQ2-równoważne, gdy
F Fii
n
1
U
842009/2010 - Notatki do wykładu "Podstawy baz danych"

Równoważność schematów
Definicja. Mówimy, że dane schematy 1 i 2 są
EQ3-równoważne, gdy są EQ1 i EQ2-równoważne.
Uwaga. Rozkład 2 EQ1-równoważny rozkładowi 1 jest
rozkładem bez straty danych.
Uwaga. Rozkład 2 EQ2-równoważny rozkładowi 1 jest
rozkładem bez straty zależności.
Uwaga. Przy rozkładach schematów baz danych wymaga się
zazwyczaj aby każdy z wynikowych schematów był w 3PN i aby
liczba ich była jak najmniejsza.
Uwaga. Rozkłady nie muszą być jednoznaczne.
852009/2010 - Notatki do wykładu "Podstawy baz danych"

Algorytmy pomocnicze
Przy rozkładach schematów baz danych wykorzystywane są
algorytmy rozwiązywania następujących zagadnień:
A1. Sprowadzenie schematu relacyjnego do 2PN.
A2. Sprowadzenie schematu relacyjnego do 3PN.
A3. Rozstrzygnięcie, czy dla zadanych X, YU, zachodzi XYF +.
A4. Usunięcie z lewej strony każdej zależności XYF + zbędnych
atrybutów, tzn. takich atrybutów AX , dla których (X-A)YF +.
A5. Znalezienie minimalnego generatora zbioru F tzn. takiego zbioru
G, że F + = G + i żaden jego podzbiór tej własności nie posiada.
A6. Sprawdzenie, czy dla zadanych dwóch zbiorów zależności F1 i F2
zachodzi równość F 1+ = F2
+.
A7. Określenie wszystkich kluczy w schemacie R:= ( U, F ) .
862009/2010 - Notatki do wykładu "Podstawy baz danych"

Algorytmy pomocnicze
Wyznaczenie wszystkich kluczy w schemacie
RR :=( U, F ),
( algorytm A7 ), jest bardziej złożone. Jednym ze sposobów
mogłoby być wyznaczenie, korzystając z aksjomatów Armstronga,
całego zbioru F + i wybranie z niego wszystkich zależności
spełniających warunki występujące w definicji klucza.
Uwaga. Wszystkie algorytmy A3 - A7 można sprowadzić do
problemu wyznaczenia zbioru F +.
872009/2010 - Notatki do wykładu "Podstawy baz danych"

Algorytmy pomocnicze - sprowadzanie do 2PN
882009/2010 - Notatki do wykładu "Podstawy baz danych"

Algorytmy pomocnicze - sprowadzanie do 3PN
892009/2010 - Notatki do wykładu "Podstawy baz danych"

Algorytm dekompozycji
Dla danego schematu bazy danych := { RR := ( U, F ) } należy wykonać
następujące czynności:
1. Wyznaczyć wszystkie klucze w schemacie R.
2. Wykrywanie niepełnych zależności funkcyjnych i rozkład schematu
relacyjnego na zbiór 1
:= {RRii
:= (Ui, F
i) | i = 1,2,..,m } schematów
relacyjnych z których każdy jest w 2PN.
3. Wyznaczyć zbiory atrybutów kluczowych i niekluczowych w każdym
schemacie relacyjnym RRi
1.
4. Wykrywanie tranzytywnych zależności funkcyjnych w schematach
relacyjnych Ri, i=1,2,..,m i sprowadzenie ich do 3PN.
Otrzymany w ten sposób schemat 1 := { RRii := ( Ui , Fi ) | i = 1,2,..,n }
jest EQ1-równoważny schematowi := { RR := ( U, F ) } tzn. zachowuje
dane i nie musi zachowywać zależności funkcyjnych.
902009/2010 - Notatki do wykładu "Podstawy baz danych"


















