![Statystyka opisowa [18 stron]](https://static.fdocuments.pl/doc/165x107/5571f41149795947648ef59a/statystyka-opisowa-18-stron.jpg)
Niniejszy ebook jest własnością...
397
-
Upload
duongthuan -
Category
Documents
-
view
217 -
download
0
Transcript of Niniejszy ebook jest własnością...


Niniejszy ebook jest własnością prywatną.
Niniejsza publikacja, ani żadna jej część, nie może być kopiowana, ani
w jakikolwiek inny sposób reprodukowana, powielana, ani odczytywana
w środkach publicznego przekazu bez pisemnej zgody wydawcy. Zabrania się jej
publicznego udostępniania w Internecie, oraz odsprzedaży zgodnie z regulaminem
Wydawnictwa Złote Myśli.
© Copyright for Polish edition by ZloteMysli.pl
Data: 13.06.2007
Tytuł: Statystyka po ludzku
Autor: Paweł Tatarzycki
Wydanie I
ISBN: 978-83-7521-303-4
Projekt okładki: Marzena Osuchowicz
Korekta: Anna Popis-Witkowska
Skład: Anna Popis-Witkowska
Internetowe Wydawnictwo Złote Myśli
Netina Sp. z o. o.
ul. Daszyńskiego 5
44-100 Gliwice
WWW: www.ZloteMysli.pl
EMAIL: [email protected]
Wszelkie prawa zastrzeżone.
All rights reserved.

SPIS TREŚCI
WSTĘP ............................................................................................................................5
1. CHARAKTERYSTYKA ETAPÓW BADANIA STATYSTYCZNEGO ..............7 1.1. Przygotowanie badania .......................................................................................10
1.1.1. Ustalenie celu badania statystycznego ........................................................10 1.1.2. Określenie przedmiotu badania ...................................................................12 1.1.3. Wybór metody badania statystycznego .......................................................22
1.2. Obserwacja statystyczna .....................................................................................27 1.2.1. Gromadzenie informacji ze źródeł pierwotnych .........................................30 1.2.2. Kontrola zebranych danych .........................................................................49
1.3. Opracowanie i prezentacja materiału statystycznego .........................................52 1.3.1. Grupowanie i zliczanie danych ...................................................................52 1.3.2. Prezentacja materiału statystycznego ..........................................................69
1.4. Analiza statystyczna ..........................................................................................110 1.5. Trening i ewaluacja ...........................................................................................114
2. OPIS STATYSTYCZNY .......................................................................................130 2.1. Opis struktury zbiorowości ...............................................................................131
2.1.1. Miary natężenia i struktury ......................................................................134 2.1.2. Miary położenia ........................................................................................138 2.1.3. Miary dyspersji ..........................................................................................159 2.1.4. Miary asymetrii .........................................................................................172 2.1.5. Miary koncentracji ....................................................................................177 2.1.6. Trening i ewaluacja ...................................................................................183
2.2. Analiza współzależności ...................................................................................191 2.2.1. Miary korelacji ..........................................................................................191 2.2.2. Analiza regresji .........................................................................................215 2.2.3. Trening i ewaluacja ...................................................................................235
2.3. Analiza dynamiki ..............................................................................................249 2.3.1. Wybrane modele tendencji rozwojowej ....................................................252 2.3.2. Analiza sezonowości .................................................................................261 2.3.3. Indeksy indywidualne i agregatowe ..........................................................268 2.3.4. Trening i ewaluacja ...................................................................................285
3. WNIOSKOWANIE STATYSTYCZNE ...............................................................294 3.1. Wybrane zagadnienia z rachunku prawdopodobieństwa ..................................294 3.2. Charakterystyka wybranych rozkładów prawdopodobieństwa .......................303
3.2.1. Rozkład dwumianowy ...............................................................................304 3.2.2. Rozkład Poissona ......................................................................................309 3.2.3. Rozkład hipergeometryczny ......................................................................311 3.2.4. Rozkład jednostajny ..................................................................................312 3.2.5. Rozkład normalny .....................................................................................315 3.2.6. Rozkład t-Studenta ....................................................................................324 3.2.7. Rozkład chi-kwadrat .................................................................................328

3.2.8. Rozkład F ..................................................................................................330 3.2.9. Twierdzenia graniczne ..............................................................................332
3.3. Dobór próby ......................................................................................................334 3.4. Estymacja przedziałowa ....................................................................................344
3.4.1. Przedział ufności dla wartości przeciętnej ................................................346 3.4.2. Przedział ufności dla frakcji ......................................................................351 3.4.3. Przedział ufności dla odchylenia standardowego .....................................354
3.5. Weryfikacja hipotez statystycznych .................................................................356 3.5.1. Wybrane hipotezy parametryczne .............................................................359 3.5.2. Wybrane hipotezy nieparametryczne ........................................................374
3.6. Trening i ewaluacja ...........................................................................................379
TABLICE STATYSTYCZNE....................................................................................385Tablice rozkładu Poissona........................................................................................385Dystrybuanta rozkładu normalnego..........................................................................386Tablice rozkładu t-Studenta......................................................................................387Tablice rozkładu chi-kwadrat...................................................................................388
BIBLIOGRAFIA.........................................................................................................389Literatura...................................................................................................................389Inne źródła................................................................................................................390
SPIS TABEL................................................................................................................392
SPIS RYSUNKÓW......................................................................................................395

STATYSTYKA PO LUDZKU – Paweł Tatarzycki Wstęp
str. 5
WstępWstęp
Celem tej publikacji jest „poukładanie” obszernego materiału ze statystyki, ze wskazaniem na praktyczne zastosowania nabywanej wiedzy w tym za-kresie. W myśl zasady stopniowania trudności – najtrudniejsze, najbardziej złożone zagadnienia omówiono pod koniec tego opracowania. Przykłado-wo, dobór próby – mimo że jest to elementarne pojęcie statystyki – omó-wiono w rozdziale ostatnim, co jest konsekwencją wprowadzonej zasady.
Aby ułatwić przejścia do pokrewnych tematów czy trudnych pojęć staty-stycznych, zastosowano nowatorskie rozwiązanie na wzór hiperłączy inter-netowych. Rozwiązanie to ma szczególne znaczenie przy powtarzaniu ma-teriału na „za pięć dwunasta”, przed kolokwium czy egzaminem. I tak np. odwołanie w kolorze hiperłącza „(zob. Dobór próby)” przyciąga uwagę Czytelnika. W wersji elektronicznej możliwe jest kliknięcie na linku powo-dujące przejście do podrozdziału „Dobór próby”.
W myśl zasady związku teorii z praktyką wprowadzany materiał wyjaśnia-ny jest na przykładach, co ułatwia jego zrozumienie, a dodatkowo czyni na-ukę ciekawszą. Integralną częścią publikacji są przykłady wykonane w ar-kuszu kalkulacyjnym MS Excel. W tekście publikacji znajdują się informa-cje typu (zob. Przykłady…).
Każdy większy dział „wieńczy” zestaw zadań do samodzielnego wykona-nia, poprzedzonych rozbudowanym przykładem, zawartych w podrozdzia-łach „Trening i ewaluacja”. Czytelnik może dokonywać analiz, wykorzy-stując szereg danych praktycznych zebranych w pliku Dane_do_analizy. xls. Obok tradycyjnych zadań – w większości działów sprawdzających za-mieszczono testy wielokrotnego wyboru, które Czytelnik z łatwością
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki Wstęp
str. 6
sprawdzi w specjalnie przygotowanych w tym celu arkuszach MS Excel pt. Ewaluacja.
Animacje, czyli prezentacje PowerPoint ukazujące w sposób dynamiczny wykonywanie złożonych czynności obliczeniowych w arkuszu kalkulacyj-nym Excela, są pomocne przy studiowaniu rozbudowanych przykładów w działach „Trening i ewaluacja”, jak również przy analizie wspomnianych przykładów wykonanych w arkuszu MS Excel.
Do publikacji dołączono ponadto trzy aplikacje wykonane w programie MS Excel:
Bonus 1: „Szeregi statystyczne” – aplikacja do grupowania i prezentacji da-nych.
Bonus 2: „Rozkłady prawdopodobieństwa” – pozwala błyskawicznie obli-czyć prawdopodobieństwo dla zadanej wartości lub odwrotnie – dla wybra-nych rozkładów.
Bonus 3: „Chi-kwadrat” – wspomaga analizę współzależności danych jako-ściowych.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1. Charakterystyka etapów badania statystycznego
str. 7
1.1. Charakterystyka etapówCharakterystyka etapów badaniabadania statystycznegostatystycznego
Badanie statystyczne to złożony proces składający się z kilku etapów. Po-niższa tabela zawiera syntetyczne zestawienie podziału badań statystycz-nych na poszczególne etapy według wybranych autorów.
Tabela 1.1. Etapy badania statystycznego w świetle literatury przedmiotu.
Autorzy Etapy badania statystycznegoA. Bielecka 1. Planowanie i organizacja badania.
2. Zbieranie danych statystycznych.3. Opracowanie zebranego materiału statystycznego.4. Analiza wyników badania.
A. Komosa, J. Musiałkiewicz
1. Przygotowanie badania.2. Zebranie materiału statystycznego (danych statystycznych).3. Przygotowanie materiału statystycznego do opracowania.4. Opracowanie materiału statystycznego.5. Prezentacja materiału statystycznego.6. Analiza statystyczna – podstawa wyciągnięcia wniosków.
T. Michalski 1. Przygotowanie badania.2. Zebranie materiału statystycznego i przygotowanie do opracowania.3. Opracowanie materiału statystycznego.4. Prezentacja danych statystycznych i analiza statystyczna.
J. Pociecha 1. Rozpoznanie i sformułowanie problemu.2. Postawienie hipotezy i ustalenie możliwych rozwiązań.3. Określenie źródeł informacji.4. Przygotowanie do gromadzenia danych pierwotnych.5. Gromadzenie danych.6. Opracowanie danych i ich analiza.7. Przygotowanie sprawozdania.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1. Charakterystyka etapów badania statystycznego
str. 8
B. Pułaska-Turyna 1. Projektowanie badania.2. Obserwacja statystyczna.3. Opracowanie materiału statystycznego.4. Analiza statystyczna.
M. Sobczyk 1. Przygotowanie (programowanie) badania.2. Obserwacja statystyczna.3. Opracowanie i prezentacja materiału statystycznego.4. Opis lub wnioskowanie statystyczne.
W. Starzyńska 1. Przygotowanie lub programowanie badania statystycznego.2. Obserwacja statystyczna.3. Opracowanie surowego materiału statystycznego.4. Analiza opracowanego materiału statystycznego.
Źródło: Opracowanie własne na podstawie: [3, s. 29], [7, s. 22], [10, s. 28], [14, s. 33], [15, s. 19-20], [19, s. 20], [21, s. 22].
W literaturze przedmiotu najczęściej wymienia się cztery podstawowe eta-py badania statystycznego. Mimo pewnych rozbieżności w nazwach, moż-na wymienić następujące podstawowe etapy:
1. Przygotowanie (planowanie, projektowanie, programowanie) badania.2. Obserwacja statystyczna (zbieranie materiału statystycznego).3. Opracowanie i prezentacja materiału statystycznego.4. Analiza statystyczna (opis lub wnioskowanie statystyczne).
Bardziej szczegółową klasyfikację przedstawili A. Komosa i J. Musiałkie-wicz [7, s. 22]. Autorzy ci wyodrębnili dodatkowy etap: „przygotowanie materiału statystycznego do opracowania” (np. T. Michalski włącza je do etapu drugiego) oraz oddzielny etap „prezentacja materiału statystycznego” – na ogół jest ona zaliczany do etapu trzeciego (T. Michalski wyjątkowo zalicza ją do ostatniego etapu, związanego z analizą danych [10, s. 28]).
Nieco odmienną klasyfikację etapów badania statystycznego (marketingo-wego) przedstawia J. Pociecha [14, s. 33]. Po pierwsze etap – szósty stano-wi połączenie dwóch wyodrębnionych wcześniej (opracowanie materiału statystycznego i analiza danych). Po drugie – wyodrębniony przez tego au-tora etap piąty („gromadzenie danych”) stanowi jedną z podstawowych
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1. Charakterystyka etapów badania statystycznego
str. 9
czynności zaliczanych do etapu, jakim jest obserwacja statystyczna. Zatem rozpisany został szczegółowo etap pierwszy, związany z przygotowaniem badania statystycznego (trzy pierwsze wymienione przez tego autora etapy).
W dalszej części tego rozdziału dokładniej scharakteryzowano cztery etapy badań statystycznych według podziału odpowiadającego klasyfikacji M. Sobczyka [19, s. 20]. Autor ten w ramach poszczególnych etapów wy-mienia następujące czynności:
Tabela 1.2. Czynności wchodzące w skład badania statystycznego w przekroju poszcze-gólnych etapów.
Etap badania statystycznego
Wykaz czynności wchodzących w skład danego etapu
IPrzygotowanie badania
1. Ustalenie celu badania statystycznego.2. Określenie przedmiotu badania (zbiorowości i jednostki statystycznej).3. Właściwe określenie jednostki sprawozdawczej (źródeł danych).4. Decyzja co do metody badania (pełne czy częściowe).
IIObserwacja statystyczna
1. Ustalenie wartości cech ilościowych lub odmian cech jakościowych u wszystkich jednostek badanej zbiorowości (generalnej bądź próbnej).2. Kontrola formalna i merytoryczna zebranych danych.
IIIOpracowanie
i prezentacja materiału statystycznego
1. Grupowanie lub klasyfikacja.2. Zliczanie danych.3. Tabelaryczna prezentacja materiału statystycznego.4. Graficzna prezentacja materiału statystycznego.
IVAnaliza statystyczna
1. Opis statystyczny.2. Wnioskowanie statystyczne (badanie częściowe – próba losowa).
Źródło: Opracowanie własne na podstawie: [19, s. 20-30].
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.1. Przygotowanie badania
str. 10
1.1. Przygotowanie badania
Na tym etapie należy sprecyzować cel badania statystycznego, określić zbiorowość i jednostkę statystyczną, jak również dokonać wyboru metody badania. Jest to ważny etap, ponieważ popełnione tu błędy w dużym stop-niu mogą zaważyć na jakości całego badania.
1.1.1. Ustalenie celu badania statystycznego
Na wstępie formułowane są koncepcje dotyczące całości badania staty-stycznego. Podstawową kwestią jest dokładne określenie celów (ogólnych i szczegółowych) oraz hipotez roboczych [10, s. 28]. A. Bielecka [3, s. 29] wyróżnia dwa zasadnicze cele badania statystycznego, tj.:
1. Cel diagnostyczny – określa, co i dlaczego jest przedmiotem badania statystycznego.
2. Cel praktyczny – precyzuje, komu i czemu badanie ma służyć.
Oto przykłady określenia celu diagnostycznego i praktycznego (por. [3, s. 30]):
Przykład 1. Celem diagnostycznym jest określenie skuteczności wybra-nych narzędzi marketingowych stosowanych w sprzedaży jogurtów w pew-nym supermarkecie – badaniu poddano takie narzędzia, jak: promocje ce-nowe, degustacje, zamieszczenie oferty w gazetce reklamowej. Cel prak-tyczny takiego badania to zweryfikowanie hipotezy głoszącej, iż na wzrost popytu znacząco wpływa połączenie promocji cenowej z prezentacją pro-mowanego jogurtu w gazetce reklamowej. Jeśli hipoteza ta okaże się słusz-na, to w przyszłości dział marketingu supermarketu zawsze będzie stoso-wał promocje cenowe dla tej grupy produktów, w połączeniu z wydrukiem oferty promocyjnej w gazetce reklamowej (efekt synergiczny).
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.1. Przygotowanie badania
str. 11
Przykład 2. Firma zajmująca się pośrednictwem finansowym planuje wprowadzenie do oferty pośredniczenia w zawieraniu umów odnośnie zmiany Otwartego Funduszu Emerytalnego. Może jednak podpisać umowę wyłącznie z jednym funduszem. Celem diagnostycznym badania będzie określenie częstotliwości i kierunku zmian poszczególnych OFE przez za-pisane już do nich osoby oraz identyfikacja kluczowych czynników powo-dujących te zmiany. Można postawić hipotezę, iż o zmianie OFE decydują głównie czynniki ekonomiczne, takie jak stopa zwrotu czy prowizja od składki. Gdy hipoteza ta okaże się słuszna, to firma podpisze umowę z fun-duszem o najwyższej stopie zwrotu netto, tj. stopie skorygowanej o koszty prowizji od składek. W przeciwnym razie należy określić czynniki poza-ekonomiczne (np. podpisać umowę z funduszem gwarantującym najwyższą stawkę dla akwizytora od podpisanej umowy – czynnik ten może okazać się skutecznym motywatorem dla osób pozyskujących klientów dla danego OFE).
Przykład 3. Firma edukacyjna zamierza rozszerzyć swoją ofertę o naucza-nie na odległość (tzw. e-learning). Celem diagnostycznym projektowanego badania statystycznego będzie określenie preferencji wśród wybranej grupy studentów odnośnie różnych form nauczania, w tym stosunku do nauczania na odległość. Ponadto celem diagnostycznym jest określenie najbardziej popularnych przedmiotów. Początkowo – z uwagi na znaczne koszty inwe-stycji w platformę e-learningową – planowane jest wprowadzenie tylko dwóch przedmiotów. Celem praktycznym będzie w tym przypadku zwery-fikowanie hipotezy o dużym zainteresowaniu nauczaniem on-line, a w przypadku jej poprawności – optymalne dostosowanie oferty do rynku (wybór najbardziej popularnych przedmiotów).
Jak widać, cel diagnostyczny określa obecny stan rzeczy, natomiast cel praktyczny zmierza do wyciągnięcia wniosków i podjęcia odpowiednich kroków w przyszłości.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.1. Przygotowanie badania
str. 12
1.1.2. Określenie przedmiotu badania
Mając ustalone cele badania statystycznego oraz hipotezy robocze – można przejść do kolejnej czynności, jaką jest określenie zbiorowości i jednostki statystycznej.
Zbiorowość statystyczna – zwana też populacją statystyczną lub generalną – to „ogół osób, rzeczy bądź zjawisk będących przedmiotem badań statystycznych” [3, s. 15]. Oto przegląd klasyfikacji populacji statystycznych według wybranych kryteriów:
Tabela 1.3. Klasyfikacja zbiorowości statystycznych pod kątem wybranych kryteriów.
Kryterium klasyfikacji
Rodzaje zbiorowości statystycznych
IKryterium
jednorodności jednostek zbiorowości
1. Zbiorowość jednorodna – wszystkie jednostki są tego samego typu, rodzaju i gatunku.2. Zbiorowość niejednorodna – jednostki różnią się cechami jakościowymi.
IICharakter jednostek
zbiorowości
1. Zbiorowość statyczna – badanie na określony moment.2. Zbiorowość dynamiczna – badanie w danym przedziale czasowym.
IIIIlość badanych cech
1. Zbiorowość jednowymiarowa – badanie ze względu na jedną cechę.2. Zbiorowość wielowymiarowa – badanie ze względu na wiele cech.
IVLiczba elementów
zbiorowości
1. Zbiorowość skończenie liczna – ograniczona możliwa do określenia liczba jednostek.2. Zbiorowość nieskończenie liczna – nieograniczona pod względem liczebności.
VZasięg (zakres)
1. Zbiorowość całkowita (populacja generalna).2. Zbiorowość próbna (próba).
Źródło: Opracowanie własne na podstawie: [2, s. 22-25].
Jednostka statystyczna – zwana też jednostką badania lub obserwacją – to „najmniejszy element zbiorowości statystycznej” [3, s. 15].
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.1. Przygotowanie badania
str. 13
Wchodzące w skład badanej zbiorowości jednostki statystyczne odznaczają się pewnymi właściwościami, określanymi mianem cech statystycznych [19, s. 12]. Oto szczegółowa klasyfikacja cech statystycznych:
Rysunek 1.1. Klasyfikacja cech statystycznych.
Źródło: Opracowanie własne na podstawie: [2, s. 26-28], [3, s. 18].
Ogólnie rzecz biorąc, cechy statystyczne można podzielić na dwie grupy [21, s. 15]:
1. CECHY STAŁE – własności wspólne wszystkim jednostkom badanej zbiorowości statystycznej.
2. CECHY ZMIENNE – własności, dzięki którym poszczególne jednostki różnią się między sobą, przy czym dokładny stopień zmienności po-szczególnych cech jest możliwy lub niemożliwy do określenia.
Cechy stałe służą do określenia jednostki statystycznej, a tym samym zbio-rowości statystycznej, pod względem rzeczowym, przestrzennym i czaso-wym i nie podlegają badaniu statystycznemu (pełnią rolę „klasyfikatorów”)
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.1. Przygotowanie badania
str. 14
[19, s. 12]. Zatem jednostką statystyczną jest „każdy element wchodzący w skład zbiorowości statystycznej i posiadający – tak jak wszystkie jed-nostki tej zbiorowości – tę samą lub te same cechy stałe” [2, s. 25]. Wyróż-nia się następujące typy cech stałych [2, s. 26-27]:
1. Cechy rzeczowe (przedmiotowe) – właściwości, którymi charakteryzu-je się ściśle określony zbiór osób, rzeczy lub zjawisk. Cecha rzeczowa precyzuje, kto lub co jest przedmiotem badania statystycznego.
2. Cechy przestrzenne – informują o tym, z jakiego miejsca lub obszaru pochodzą jednostki włączone do badania statystycznego.
3. Cechy czasowe – określają, z jakiego okresu lub momentu włączono daną jednostkę w skład zbiorowości statystycznej.
M. Sobczyk podkreśla, iż w tej samej zbiorowości można wyodrębnić róż-ne jednostki statystyczne [19, s. 12]. Wybór właściwej jednostki statystycz-nej zależy głównie od określonego celu badania statystycznego, co ukazują poniższe przykłady:
Przykład 1. Celem badania statystycznego jest określenie struktury liczby uczestników Otwartych Funduszy Inwestycyjnych (FIO), które inwestują powierzone środki na krajowym rynku papierów wartościowych. Raport ma dotyczyć stanu na koniec 2005 roku. Oto jak zostały określone cechy stałe (zob. rys. 1.1):
1. Cecha rzeczowa informuje, iż przedmiotem badania jest struktura liczby osób lokujących środki finansowe w Otwartych Funduszach Inwestycyj-nych (FIO).
2. Cecha przestrzenna zawęża krąg analizy do polskich funduszy inwestu-jących w krajowe papiery wartościowe.
3. Cecha czasowa określa moment w czasie, czyli dane za rok 2005.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.1. Przygotowanie badania
str. 15
Rysunek 1.2. Przykład określenia zbiorowości i jednostek statystycznych według cech stałych.
Źródło: Opracowanie własne.
Z powyższego schematu wynika, iż jednostkami statystycznymi wchodzą-cymi w skład oznaczonej kolorem niebieskim populacji generalnej są po-szczególne Fundusze Inwestycyjne Otwarte, lokujące powierzone środki wyłącznie na rynku krajowym (stąd nie uwzględniono funduszu „Z”) i pro-wadzące działalność w 2005 roku (nie uwzględniamy w analizie funduszy, które powstały w trakcie 2005 roku) – łącznie 18 jednostek statystycznych. W wyniku analizy statystycznej – zgodnie z celem tego badania – otrzyma się rozkład liczby uczestników FIO w zależności od klasy ryzyka funduszu (zob. miary natężenia i struktury).
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.1. Przygotowanie badania
str. 16
Innym celem jest porównanie dynamiki liczby uczestników Funduszu „A” Zrównoważonego z Funduszem „A” Akcji w latach 2000-2005 (zob. anali - za dynamiki). Celem praktycznym jest określenie zmian w preferencjach odnośnie tych dwóch funduszy i odpowiednie przygotowanie oferty pro-mocyjnej. Porównywane będą dwie populacje:
1. Jako cechę rzeczową przyjęto odpowiednio FIO „A” Zrównoważony (pierwsza populacja) i FIO „A” Akcji (druga populacja).
2. W tym przypadku nie ma potrzeby określania cechy przestrzennej, po-nieważ wybrane fundusze działają na określonym rynku.
3. Cecha czasowa jest wspólna dla obu porównywanych populacji – jest nią zakres czasowy określony na lata 2000-2005.
W tej sytuacji jednostką statystyczną (obserwacją) jest konkretny punkt da-nych w przekroju czasowym – liczba obserwacji jest równa liczbie lat obję-tych analizą. Należy zaznaczyć, iż możliwe jest porównywanie funduszy, które działają na rynku w określonym czasie (np. porównanie z FIO „E” Akcji ogranicza analizę do lat 2002-2005).
Przykład 2. Celem badania jest analiza dziennych zmian procentowych in-deksu największych polskich spółek WIG 20 w określonym czasie:
1. Cecha rzeczowa określa przedmiot analizy, czyli procentowe dzienne zmiany indeksu WIG 20 (można dokonać porównań z innymi indeksami giełdowymi, np. WIG-iem).
2. Cecha przestrzenna precyzuje, iż chodzi o GPW w Warszawie.3. Cecha czasowa określa liczbę sesji giełdowych (np. 50 ostatnich sesji).
W tej sytuacji jednostką statystyczną jest sesja giełdowa. Celem analizy może być także ustalenie, jakie spółki w danym dniu wpłynęły pozytywnie na poziom badanego indeksu. Należy wyjaśnić, iż indeks ten jest wypadko-wą zmian kursów akcji 20 największych spółek wchodzących w jego skład. Oto określenie cech stałych:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.1. Przygotowanie badania
str. 17
1. Cecha rzeczowa – procentowe dzienne zmiany kursów akcji spółek WIG 20.
2. Cecha przestrzenna – GPW w Warszawie.3. Cecha czasowa – określenie sesji giełdowej (np. ostatnia sesja).
W tej sytuacji jednostką statystyczną nie będzie już sesja giełdowa, lecz spółka zaliczana do indeksu WIG 20. Nietrudno zauważyć, iż istnieje dwa-dzieścia jednostek statystycznych (w skład WIG 20 wchodzi bowiem dwa-dzieścia spółek).
Przykład 3. Celem badania statystycznego jest analiza wyników egzaminu ze statystyki w semestrze letnim roku akademickiego 2005/2006 na stu-diach dziennych uczelni państwowych. Populację generalną określono pod względem cech stałych następująco:
1. Cecha rzeczowa – studenci studiów dziennych uczelni państwowych, którzy w semestrze letnim przystąpili do egzaminu ze statystyki (możli-we porównanie ze studiami wieczorowymi i zaocznymi).
2. Cecha przestrzenna – osoby studiujące na terytorium RP (wyniki można porównać np. z innymi krajami Unii Europejskiej).
3. Cecha czasowa – semestr letni roku akademickiego 2005/2006 (wyniki analizy można np. porównać z analogicznym okresem roku poprzednie-go).
Jednostki statystyczne w tym przypadku tworzą studenci studiów dzien-nych polskich uczelni państwowych, którzy w semestrze letnim w roku akademickim 2005/2006 przystąpili do egzaminu ze statystyki.
Druga grupa cech statystycznych to cechy zmienne – podlegają one bada-niu statystycznemu [19, s. 12]. Należą do nich trzy kategorie cech, a mia-nowicie (zob. rys. 1.1):
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.1. Przygotowanie badania
str. 18
1. Cecha jakościowa (nominalna) to „niemierzalna właściwość, której konkretny wariant występuje lub nie występuje w danej zbiorowości i nie dając wyrażać się liczbowo, daje się opisać jedynie za pomocą określeń słownych” [2, s. 28]. Wariantów cech nominalnych (zob. skala no minalna ) nie da się uporządkować (por. [20, s. 22]).
2. Cecha quasi-ilościowa (niby-ilościowa, porządkowa) to „właściwość, która określa natężenie badanej cechy u poszczególnych jednostek danej zbiorowości w sposób opisowy” [2, s. 28]. Warianty cech porządko-wych (zob. skala porządkowa) – w przeciwieństwie do wariantów cech nominalnych – można uporządkować (por. [20, s. 22]). Cechy porządkowe – w bardziej ogólnej klasyfikacji – zaliczane są do cech jakościowych. Istotne jest to, iż warianty cech jakościowych wyrażone są za pomocą określeń słownych (werbalnych). Przypisywane niekiedy cechom jakościowym (nominalnym lub porządkowym) liczby nie wyrażają bowiem ich wartości – pełnią jedynie rolę „etykiet” (por. [3, s. 18]). Przyjęta w niniejszej publikacji szczegółowa klasyfikacja cech statystycznych – wyodrębniająca cechy quasi-ilościowe – ma za zadanie ułatwienie doboru skal pomiarowych w zależności od rodzaju cechy statystycznej.
3. Cecha ilościowa to „mierzalna właściwość, występująca z określonym natężeniem u wszystkich jednostek zbiorowości statystycznej” [2, s. 27]. Właściwości cech ilościowych – określanych też mianem cech mie-rzalnych – można mierzyć za pomocą liczb mianowanych typu: metry, kilogramy, sztuki, lata, jednostki pieniężne, czas itp. (por. skala prze - działowa i skala ilorazowa). Do cech ilościowych należą [3, s. 18]: cecha skokowa – warianty tej cechy wyrażone są za pomocą liczb
należących do zbioru przeliczalnego lub skończonego (typową jed-nostką miary są sztuki/liczby naturalne),
cecha quasi-ciągła (niby-ciągła) – cecha ze swej natury skokowa, ale z uwagi na bardzo dużą liczbę przyjmowanych wartości liczbo-wych traktowana jako cecha ciągła. Różnica między kolejnymi war-
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.1. Przygotowanie badania
str. 19
tościami liczbowymi jest niewielka (np. ceny wyrażone z dokład-nością do jednego grosza).
cecha ciągła – cecha, której warianty wyrażone są za pomocą liczb rzeczywistych, gdzie pomiędzy dwiema dowolnymi wartościami liczbowymi danej cechy można teoretycznie zawsze znaleźć wartość pośrednią cechy (typowymi jednostkami miary cech ciągłych są m.in.: czas, metry, kilogramy, wiek).
Należy podkreślić, iż warunkiem zaklasyfikowania danej cechy do cech skokowych nie jest fakt, iż jej warianty występują w postaci liczb całkowi-tych. Przykładem mogą być oceny z egzaminu: 3; 3,5 (3+); 4; 4,5 (4+); 5. Mimo że cecha ta nie przyjmuje wyłącznie liczb całkowitych (np. tak jak miałoby to miejsce w przypadku liczby nieobecności w szkole), to – z uwa-gi na niewielką liczbę możliwych wariantów – jest ona cechą skokową.
Przy charakterystyce cech statystycznych kilkakrotnie pojawiło się pojęcie wariantu cechy. Wariant cechy statystycznej jest „informacją uzyskaną o jednostce statystycznej w trakcie badania statystycznego” [7, s. 10]. Z uwagi na liczbę możliwych wariantów, cechy statystyczne dzieli się na [20, s. 22]:
cechy dychotomiczne (zero-jedynkowe) – cecha może przyjąć tylko dwa warianty.
cechy wielodzielne (politomiczne) – przyjmują więcej niż dwa warianty.
Liczba wariantów danej cechy może być co najwyżej równa liczbie jedno-stek wchodzących w skład określonej zbiorowości statystycznej – jest to możliwe w przypadku cech ciągłych. Zazwyczaj jednak liczba wariantów jest mniejsza od liczby jednostek, ponieważ identyczny wariant cechy mo-że występować u kilku jednostek statystycznych (por. [19, s. 13]). Oto przykłady identyfikacji rodzaju cech statystycznych (zmiennych):
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.1. Przygotowanie badania
str. 20
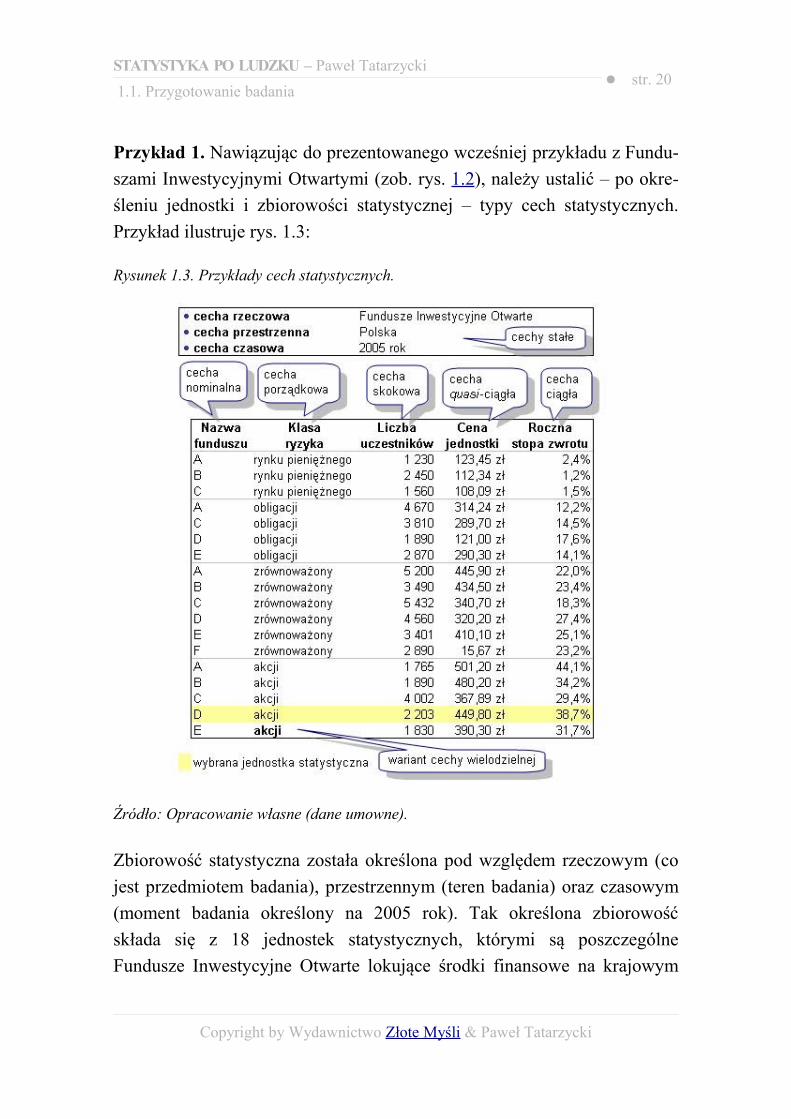
Przykład 1. Nawiązując do prezentowanego wcześniej przykładu z Fundu-szami Inwestycyjnymi Otwartymi (zob. rys. 1.2), należy ustalić – po okre-śleniu jednostki i zbiorowości statystycznej – typy cech statystycznych. Przykład ilustruje rys. 1.3:
Rysunek 1.3. Przykłady cech statystycznych.
Źródło: Opracowanie własne (dane umowne).
Zbiorowość statystyczna została określona pod względem rzeczowym (co jest przedmiotem badania), przestrzennym (teren badania) oraz czasowym (moment badania określony na 2005 rok). Tak określona zbiorowość składa się z 18 jednostek statystycznych, którymi są poszczególne Fundusze Inwestycyjne Otwarte lokujące środki finansowe na krajowym
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.1. Przygotowanie badania
str. 21
rynku w 2005 roku. Wybraną jednostkę statystyczną zaznaczono żółtym kolorem. Każda jednostka posiada szereg właściwości, czyli zmiennych cech statystycznych. Dwie pierwsze, „Nazwa funduszu” i „Klasa ryzyka”, mają jakościowy charakter, ponieważ ich warianty dają się opisać w sposób słowny. Pogrubionym kolorem zaznaczono jeden z wariantów cechy „Klasa ryzyka” – cecha ta jest cechą quasi-ilościową (porządkową), ponieważ jej warianty można uporządkować pod kątem stopnia ryzyka (niemniej jednak w innych analizach, gdzie ryzyko nie ma znaczenia, cecha ta jest cechą nominalną). „Stopa zwrotu” nie jest cechą quasi-ciągłą, ponieważ teoretycznie można ją wyznaczyć z nieskończenie dużą precyzją – jest to iloraz ceny jednostki uczestnictwa z końca do ceny z początku 2005 roku. Natomiast ceny z definicji podaje się z dokładnością do 1 grosza.
Przykład 2. Celem badania statystycznego jest analiza rynku mieszkań w tzw. standardzie deweloperskim w Polsce. Oto zestaw cech statystycz-nych branych pod uwagę:
1. Nazwa województwa – cecha jakościowa nominalna.2. Ilość pokoi – cecha ilościowa skokowa.3. Cena mieszkania (zł/m2) – cecha ilościowa quasi-ciągła.
Przykład 3. Przedmiotem badania statystycznego jest określenie czynni-ków wpływających na wyniki egzaminu ze statystyki. Jako cechę zależną przyjęto liczbę punktów uzyskanych na egzaminie (cecha ilościowa quasi-ciągła – punkty mierzone w skali od zera do 100 z dokładnością do 0,1). Oto zestaw zmiennych objaśniających:
1. Liczba nieobecności na zajęciach – cecha ilościowa skokowa.2. Przeciętna liczba godzin poświęconych nauce statystyki tygodniowo –
jw.3. Preferencje co do przedmiotu statystyka (nudny, ciekawy) – cecha po-
rządkowa.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.1. Przygotowanie badania
str. 22
4. Płeć studenta – cecha jakościowa (nominalna).
Reasumując, zbiorowość statystyczną tworzą poszczególne jednostki staty - styczne, posiadające określone cechy statystyczne. O ile cechy stałe – wspólne wszystkim jednostkom badania statystycznego – służą do określe-nia zbiorowości, o tyle cechy zmienne podlegają badaniu. Należy ustalić, czy będzie ono obejmowało wszystkie jednostki, czy tylko wybrane z nich, a następnie dokonać wyboru adekwatnej metody badania.
1.1.3. Wybór metody badania statystycznego
Kolejną czynnością w fazie wstępnej jest określenie metody badania staty-stycznego. Wybór metody zależy od takich czynników, jak (por. [19, s. 16]):
– cel badania statystycznego,– rodzaj zbiorowości statystycznej,– stopień szczegółowości badania,– ilość dostępnych środków finansowych,– stosowane metody analizy (opis lub wnioskowanie statystyczne).
Badanie statystyczne obejmuje wszystkie jednostki statystyczne lub tylko wybrane z nich, czyli próbę. Próba to pewien podzbiór populacji general-nej, którego elementy zostały dobrane w sposób losowy bądź nielosowy (por. [20, s. 20]). Innymi słowy: próba to „liczebność jednostek badania” [5, s. 19].
Klasyfikacja metod badania statystycznego – ze względu na liczbę jedno-stek objętych badaniem – przedstawia się następująco:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.1. Przygotowanie badania
str. 23
Rysunek 1.4. Klasyfikacja metod badań statystycznych ze względu na liczbę jednostek objętych badaniem.
Źródło: Opracowanie na podstawie: [7, s. 14].
Ogólnie rzecz biorąc, można wyodrębnić trzy grupy metod badania staty-stycznego:
1. BADANIE PEŁNE (całkowite, wyczerpujące) – polega na tym, że in-formacje o badanych cechach statystycznych są gromadzone od wszyst-kich jednostek statystycznych wchodzących w skład zbiorowości staty-stycznej [7, s. 15].
2. BADANIE CZĘŚCIOWE (niepełne, fragmentaryczne) – obejmuje wy-brane jednostki zbiorowości statystycznej [19, s. 16].
3. SZACUNEK STATYSTYCZNY (szacunek wartości) – interpolacyjny lub ekstrapolacyjny szacunek statystyczny zaliczany jest niekiedy w li-teraturze przedmiotu do metod badania częściowego (zob. [3, s. 32]): interpolacja polega na znajdowaniu nieznanych wartości funkcji
w dowolnym punkcie przedziału (x1, xn) na podstawie dostępnych wartości funkcji, należących do tego przedziału (np. ustalanie warto-ści kwartyli).
ekstrapolacja polega na ustaleniu nieznanych wartości funkcji w do-wolnym punkcie leżącym poza przedziałem wartości posiadanych: xn+1, xn+i (np. prognozowanie).
Do metod badania pełnego należą (zob. [7, s. 15-18]):
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.1. Przygotowanie badania
str. 24
1. Spis statystyczny jest to badanie polegające na zbieraniu informacji o wartościach cechy statystycznej bezpośrednio od wszystkich jedno-stek tworzących zbiorowość statystyczną. Informacje te są zbierane przez specjalnie do tego celu przeszkolone osoby (rachmistrzów spiso-wych). Jednocześnie informacje te są utrwalane na formularzach spiso-wych, przygotowanych przez instytucję organizującą spis. Rachmistrze spisowi dokonują zatem bezpośredniej obserwacji statystycznej. Spisy statystyczne dostarczają szczegółowych informacji o badanej zbiorowo-ści. Ze względu na bardzo wysokie koszty omawiana metoda znajduje zastosowanie w badaniach najważniejszych zjawisk społeczno-gospo-darczych (np. Narodowy Spis Powszechny Ludności i Mieszkań z 2002 roku przeprowadzony przez Główny Urząd Statystyczny).
2. Rejestracja statystyczna polega na wpisywaniu zdarzeń i faktów do odpowiednich rejestrów. Rejestracja statystyczna ma węższy zakres te-matyczny aniżeli spis statystyczny. Ponadto różni się ona od niego spo-sobem gromadzenia informacji – przy rejestracji statystycznej nie wy-stępuje bezpośrednia obserwacja statystyczna, lecz informacje będące przedmiotem rejestracji są zgłaszane w punktach rejestracyjnych. Wy-różnia się: doraźną rejestrację statystyczną – polega ona na tym, że w wyzna-
czonym czasie określone osoby zgłaszają się w wyznaczonych miej-scach i udzielają informacji objętej tematyką rejestracji (np. ewiden-cja działalności gospodarczej),
bieżącą rejestrację statystyczną – polega ona na ciągłym, bieżącym, systematycznym notowaniu zdarzeń i faktów określonych przez in-stytucję prowadzącą rejestrację (np. ewidencja ludności).
3. Sprawozdawczość statystyczna to najbardziej powszechny rodzaj peł-nych badań statystycznych – polega na przekazywaniu przez jednostki sprawozdawcze określonych informacji liczbowych i opisowych w po-staci standardowych sprawozdań. Instytucja organizująca badanie staty-styczne powinna opracować odpowiednie formularze statystyczne wraz z instrukcjami ich wypełniania, jak również określić termin ich przeka-
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.1. Przygotowanie badania
str. 25
zywania (jako przykład można podać opracowane dla celów podatko-wych formularze PIT adresowane do osób fizycznych czy też formula-rze ZUS wypełniane przez przedsiębiorców).
Zbiorowości statystycznej nie można poddać badaniu pełnemu w takich sy-tuacjach, jak (por. [2, s. 23], [3, s. 31-32]):
– badany element ulega zniszczeniu (badanie pełne oznaczałoby w tej sy-tuacji zniszczenie wszystkich elementów),
– badanie pełne jest zbyt kosztowne (np. z uwagi na dużą populację gene-ralną),
– badanie pełne jest zbyt czasochłonne (np. duża dynamika zmian badane-go zjawiska wymaga podjęcia szybkich decyzji),
– badana zbiorowość jest nieskończenie duża (w praktyce za taką popula-cję można też uznać bardzo liczne populacje, np. liczbę potencjalnych internautów – w tej sytuacji można mówić wyłącznie o badaniu częścio-wym).
W powyższych sytuacjach odpowiednim badaniem jest badanie częściowe. W literaturze statystycznej wymienia się następujące metody badania czę-ściowego:
1. Metoda monograficzna polega na wszechstronnym opisie i szczegóło-wej analizie pojedynczej jednostki statystycznej lub niewielkiej liczby charakterystycznych (typowych) jednostek badanej zbiorowości. Dzięki niewielkiej grupie jednostek można w badaniu uwzględnić stosunkowo dużą liczbę cech statystycznych (zob. cechy zmienne). Podstawowe znaczenie w tej metodzie ma opis w oparciu o dane liczbowe [10, s. 25]. Przykładem może być opis wybranej placówki wychowawczo-oświato-wej.
2. Metoda ankietowa polega na tym, że podmiot organizujący badanie zwraca się do określonej grupy osób (respondentów) z zaproszeniem do dobrowolnego wypowiedzenia się w określonej sprawie. Zaproszenie to
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.1. Przygotowanie badania
str. 26
może mieć charakter powszechny (ankieta kierowana do szerokiego gro-na osób, np. za pośrednictwem Internetu) lub selektywny (ankieta kiero-wana do wąskiej grupy respondentów, np. za pośrednictwem prasy spe-cjalistycznej). Z uwagi na fakt, iż ankieta wypełniana jest przez respon-denta, powinna być ona zredagowana w taki sposób, aby każdy ankieto-wany jednoznacznie rozumiał stawiane mu pytania i potrafił udzielić na nie odpowiedzi [7, s. 19-20] (zob. Gromadzenie danych ze źródeł pier - wotnych).
3. Metoda reprezentacyjna opiera się na próbie pobranej ze zbiorowości generalnej w sposób losowy. Z teoretycznego i praktycznego punktu wi-dzenia metoda ta jest najbardziej prawidłową formą badania częściowe-go. Zastosowanie rachunku prawdopodobieństwa przy uogólnianiu wy-ników z próby losowej na całą zbiorowość (zob. wnioskowanie staty - styczne) pozwala na określenie wielkości popełnianego błędu. Możli-wości tej nie stwarzają pozostałe metody badania częściowego, tj. meto-da monograficzna i ankietowa [19, s. 17-18].
Przyjmując jako kryterium klasyfikacji częstotliwość przeprowadzania ba-dania statystycznego, można wyróżnić trzy rodzaje badań statystycznych [7, s. 15]:
1. Badania doraźne (sporadyczne, jednorazowe, ad hoc) – są prowadzone wówczas, gdy zapotrzebowanie na określony rodzaj informacji pojawia się bardzo rzadko i jest spowodowane nieprzewidzianymi przyczynami (np. badanie preferencji nabywców danego produktu).
2. Badania okresowe są badaniami powtarzalnymi, które przeprowadza się w określonych momentach (np. publikowany na koniec każdego kwartału ranking Otwartych Funduszy Emerytalnych).
3. Badania ciągłe polegają na tym, że obserwacja i rejestracja określonych zdarzeń i faktów odbywa się w sposób ciągły. Badania ciągłe dotyczą jedynie niektórych, ściśle określonych faktów i zdarzeń (np. analiza pro-cesu produkcyjnego pod względem jakości – konstrukcja tzw. kart kontrolnych).
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.1. Przygotowanie badania
str. 27
W wypadku podjęcia decyzji o wyborze metody badania częściowego poja-wia się kwestia doboru próby. Z uwagi na złożony charakter tego zagad-nienia – metody doboru próby omówiono w ostatnim rozdziale (zob. Dobór próby). W tym miejscu warto podkreślić, iż w przypadku metody reprezen - tacyjnej dobór próby powinien być wyłącznie losowy.
1.2. Obserwacja statystyczna
Po ustaleniu celu badania statystycznego (diagnostycznego i praktycznego), określeniu zbiorowości i jednostki statystycznej (pod względem rzeczowym, przestrzennym i czasowym), jak również dokonaniu wyboru odpowiedniej metody badania (pełnego lub częściowego) – można przystąpić do drugiego etapu, jakim jest obserwacja statystyczna.
Ogólnie rzecz biorąc, metody pozyskiwania danych można podzielić na dwie grupy (por. [19, s. 20], [21, s. 20]):
1. Metody korzystania z publikowanych źródeł informacji (odpłatne lub nieodpłatne pozyskiwanie informacji od jednostek sprawozdawczych).
2. Metody przeprowadzania własnego badania statystycznego (zob. gro - madzenie informacji ze źródeł pierwotnych).
Zebrane w wyniku obserwacji statystycznej dane określa się mianem mate-riału statystycznego [19, s. 20], przy czym – w zależności od przyjętej metody gromadzenia danych – rozróżnia się [10, s. 32]:
1. Materiał statystyczny pierwotny – informacje do prowadzenia danego badania statystycznego uzyskiwane są drogą odrębnego badania. Infor-macje te pochodzą z tzw. źródeł pierwotnych w wyniku pomiaru bezpośredniego (zob. kwestionariusz).
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.2. Obserwacja statystyczna
str. 28
2. Materiał statystyczny wtórny – materiał zaczerpnięty spoza statystycz-nych źródeł, zwanych źródłami wtórnymi, który został wykorzystany w badaniach statystycznych.
Wybrane wtórne źródła danych znajdują się w pliku dane_do_analizy.xls, stanowiącym integralną część niniejszego opracowania. Plik ten zawiera wybrane dane finansowe i dane społeczno-gospodarcze. Poniżej przedsta-wiono przykłady wtórnych źródeł informacji:
Przykład 1. Jednostką sprawozdawczą dostarczającą co kwartał informacji o trzyletnich stopach zwrotu Otwartych Funduszy Emerytalnych jest Komi-sja Nadzoru Ubezpieczeń i Funduszy Emerytalnych (http://www.knuife - .gov.pl/).
Przykład 2. Spółki notowane na Giełdzie Papierów Wartościowych w Warszawie (http://www.gpw.pl) mają obowiązek sporządzania okresowych raportów finansowych.
Przykład 3. Jednostką sprawozdawczą prezentującą m.in. poziom stóp pro-centowych jest Narodowy Bank Polski (http://www.nbp.pl).
Przykład 4. Instytucją prezentującą dane o przestępczości w Polsce jest Komenda Główna Policji (http://www.kgp.gov.pl).
W tym miejscu warto zwrócić uwagę na szereg zniekształceń rzeczywisto-ści, wynikających z błędnej interpretacji oficjalnych informacji pochodzą-cych właśnie ze źródeł wtórnych. Oto następujące sytuacje:
Sytuacja 1. Oficjalny ranking najlepiej sprzedających się płyt CD (np. z oprogramowaniem edukacyjnym) nie musi odzwierciedlać nawet kolej-ności miejsc w rankingu. Dzieje się tak za sprawą „drugiego” – nieoficjal-nego – obrotu nielegalnym oprogramowaniem, w wyniku czego ustalenie najbardziej popularnych programów komputerowych wymaga
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.2. Obserwacja statystyczna
str. 29
przeprowadzenia odrębnych badań wśród wybranej grupy respondentów (anonimowość ankiety sprzyja zakreślaniu odpowiedzi, jaki program ostat-nio kupił ankietowany – nie wnika się przy tym, z jakiego źródła on pocho-dzi).
Sytuacja 2. Ustalenie faktycznej liczby rozwiedzionych rodzin jest prak-tycznie niemożliwe w oparciu o dane ze źródeł wtórnych – wiadomo bo-wiem, iż część rodzin rozwodzi się fikcyjnie („na papierze”) w celu otrzy-mania zasiłku dla matki samotnie wychowującej dziecko. W tym przypad-ku wiarygodnych informacji mogłaby dostarczyć anonimowa ankieta.
Sytuacja 3. Kwestią kłopotliwą jest określenie skali ruchu turystycznego w pewnej nadmorskiej miejscowości w oparciu o wpływy z podatku klima-tycznego (np. 1 zł za dobę). Takie informacje nie uwzględniają osób, które specjalnie przyjeżdżają na jeden dzień do tej miejscowości (np. na organi-zowany koncert), czy też turystów znajdujących zakwaterowanie bez reje-stracji i tym samym niepłacących podatku klimatycznego.
Ponadto należy pamiętać, iż źródła wtórne niekiedy dostarczają tylko po-bieżnych informacji. I tak śledząc dostępne statystyki odwiedzin pewnego portalu internetowego można dowiedzieć się, ile procent odwiedzających to kobiety, jaka jest struktura wiekowa itp. Niestety, takie zbiorcze informacje nie pozwalają na określenie zależności np. pomiędzy wiekiem a płcią osób odwiedzających portal – tu konieczne jest dotarcie do danych niepogrupo-wanych.
Powyższe przykłady pokazują, iż mimo bogactwa informacji pochodzą-cych ze źródeł wtórnych, niekiedy niezbędne jest dotarcie do informacji pochodzących ze źródeł pierwotnych. W kolejnym podrozdziale dokładniej omówiono organizację własnego badania statystycznego (gromadzenie informacji ze źródeł pierwotnych).
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.2. Obserwacja statystyczna
str. 30
1.2.1. Gromadzenie informacji ze źródeł pierwotnych
Gromadzenie informacji ze źródeł pierwotnych jest znacznie droższe, aniżeli pozyskanie informacji ze źródeł wtórnych. Z tego też względu in-formacje te należy gromadzić wówczas, gdy informacje ze źródeł wtórnych nie są wystarczające do osiągnięcia postawionych celów i weryfikacji hipo-tez roboczych (por. [6, s. 73]).
Informacje ze źródeł pierwotnych zbierane są specjalnie dla określonych celów praktycznych i diagnostycznych badania statystycznego (zob. ustale - nie celu badania statystycznego). Badający uczestniczy w procesie groma-dzenia danych pierwotnych (tzw. badanie w terenie), stosując odpowiednie metody, techniki i narzędzia w sposób pośredni lub bezpośredni [3, s. 34].
J. Pociecha wyodrębnia etap poprzedzający gromadzenie danych, a miano-wicie „przygotowanie do gromadzenia danych pierwotnych” (por. tabela 1.1). Zdaniem tego autora na tym etapie należy (zob. [14, s. 33]):
1. Określić metody gromadzenia danych.2. Zaprojektować użyteczne narzędzia badawcze i określić czas trwania
badania.3. Określić sposoby doboru próby. 4. Przeszkolić osoby przeprowadzające badanie.
Do technik pomiaru danych pierwotnych należą m.in.:
– ankieta (zob. metoda ankietowa),– wywiad,– obserwacja,– eksperyment.
Ankieta to technika gromadzenia informacji ze źródeł pierwotnych, pole-gająca na uzyskiwaniu potrzebnych danych przez zadawanie pytań respon-dentom. Cechą charakterystyczną ankiety jest wysoki stopień standaryzacji
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.2. Obserwacja statystyczna
str. 31
badań, tj. ujednolicenie sytuacji badawczej oraz wykonywanych czynności. Należy podkreślić, iż wyraz „ankieta” ma dwojakie znaczenie. Po pierwsze – oznacza on technikę pozyskiwania informacji ze źródeł pierwotnych, a po drugie – określa nazwę narzędzia, jakim jest formularz zawierający pytania do respondenta, na które udziela on samodzielnie pisemnych odpowiedzi (zob. kwestionariusz) [14, s. 49].
Wywiad to kolejna technika pozyskiwania informacji ze źródeł pierwot-nych, polegająca na zbieraniu danych od respondentów w toku bezpośred-niej rozmowy przeprowadzanej przez odpowiednio przeszkolone osoby. Ponieważ wywiad – w odróżnieniu od ankiety, którą charakteryzuje wysoki stopień standaryzacji badań – jest swobodną techniką badawczą, dlatego ja-kość przeprowadzonego wywiadu w znacznym stopniu uzależniona jest od wiedzy i umiejętności osoby go przeprowadzającej. Wyróżnia się następu-jące rodzaje wywiadu [14, s. 51-52]:
– wywiad skategoryzowany/nieskategoryzowany,– wywiad jawny/ukryty,– wywiad indywidualny/zbiorowy.
W wywiadzie skategoryzowanym rozmowa przebiega w określony, zaplanowany sposób – w tym miejscu pomocnym narzędziem jest kwestionariusz. W wywiadzie kwestionariusz jest wypełniany przez osobę prowadzącą wywiad, a nie – jak ma to miejsce w przypadku ankiety – przez respondenta. Wywiad nieskategoryzowany może przyjąć formę „luźnej” rozmowy – w tym przypadku prowadzący nie trzyma się ściśle określonych pytań.
Wywiad jawny to taki wywiad, w którym osoba pytana jest poinformowana o celu badania statystycznego (wie, w jakim celu wywiad jest prowadzony). Niemniej jednak niekiedy pytany świadomie nie jest infor-mowany o faktycznym celu badania np. po to, aby uzyskać wiarygodne od-powiedzi – wówczas można mówić o wywiadzie ukrytym.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.2. Obserwacja statystyczna
str. 32
Wywiad indywidualny to wywiad prowadzony z jednym respondentem w danym momencie – ma to m.in. miejsce w przypadku wywiadu skatego-ryzowanego, gdzie odpowiedzi osoby pytanej są zapisywane w przygoto-wanym wcześniej kwestionariuszu. Jak już wspomniano, wywiad może przyjąć formę rozmowy (dyskusji) – w sytuacji, gdy rozmowa prowadzona jest z więcej niż jednym respondentem, można mówić o wywiadzie grupo-wym. Przykładowo, mieszkańcy pewnego miasta są pytani o warunki so-cjalno-bytowe.
Obserwacja to następna technika zbierania informacji (nie należy jej mylić z omawianym drugim etapem badania statystycznego!). Instrumentem po-miaru są tu najczęściej zmysły wzroku i słuchu obserwatora czy też urzą-dzenia techniczne (magnetofony, kamery, tachometry itp.). Wyróżnia się następujące formy obserwacji [3, s. 35]:
– obserwacja bezpośrednia/pośrednia,– obserwacja jawna/ukryta,– obserwacja uczestnicząca/nieuczestnicząca.
Aby łatwiej rozróżnić poszczególne rodzaje obserwacji, warto posłużyć się przykładem. Załóżmy, że obserwacja dotyczy pewnej jednostki oświatowej – celem obserwacji jest określenie postępów w nauce, jak również zacho-wania się uczniów na terenie szkoły. Jeżeli na lekcji pojawi się wizytator, który obserwuje jej przebieg, to można mówić o obserwacji bezpośredniej i jawnej. Obserwacja pośrednia ma miejsce wówczas, gdy lekcja jest ob-serwowana np. za pośrednictwem kamer. Jeżeli uczniowie wiedzą, że są zainstalowane kamery, to jest to obserwacja jawna. Jeśli natomiast zainstalowano ukrytą kamerę (ukryto magnetofon), to w tej sytuacji ma miejsce obserwacja ukryta. Aby można było dokładniej poznać zwyczaje panujące w danej szkole, konieczna może okazać się obserwacja uczestnicząca – wówczas np. obserwator może być jednym z uczniów (grać rolę ucznia). Jest to w tym przypadku obserwacja ukryta, ponieważ pozostali uczniowie nie są świadomi, że są obserwowani.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.2. Obserwacja statystyczna
str. 33
Eksperyment to następna metoda zbierania danych pierwotnych. Może mieć on charakter laboratoryjny lub terenowy. Eksperyment terenowy dokonywany jest w warunkach naturalnych. Jego zaletą jest możliwość zapewnienia nieskrępowanych zachowań badanych osób. Istnieje jednak ryzyko wystąpienia w eksperymencie nieprzewidzianych czynników i sytuacji. Natomiast w eksperymencie laboratoryjnym ma miejsce sytuacja odwrotna – osoby przeprowadzające badanie w pełni kontrolują wszystkie czynniki, ale istnieje ryzyko nienaturalnego, niecodziennego zachowywania się badanych osób [14, s. 52].
W badaniu statystycznym można stosować jednocześnie kilka technik gro-madzenia danych, w tym danych pierwotnych. Dobrym przykładem jest metoda monograficzna, gdzie badania ilościowe z wykorzystaniem np. an-kiety i wywiadu skategoryzowanego mogą zostać uzupełnione badaniami jakościowymi, opartymi na obserwacji czy wywiadzie z określoną grupą pytanych. Przykładowo, w wybranej jednostce oświatowej można przepro-wadzić wywiad z dyrekcją i nauczycielami odnośnie standardów kształce-nia, a następnie rozdać ankiety rodzicom na temat jakości kształcenia w szkole, do której uczęszczają ich dzieci. Obserwacja może dotyczyć rela-cji uczeń-uczeń i nauczyciel-uczeń. Ponadto wielu istotnych informacji mo-że dostarczyć analiza dokumentów szkoły (źródła wtórne).
Kolejną czynnością związaną z przygotowaniem do gromadzenia danych pierwotnych jest zaprojektowanie użytecznych narzędzi badawczych. W pomiarze pierwotnym powszechnie wykorzystywane są kwestionariu-sze.
Kwestionariusz to lista pytań na jeden lub więcej tematów, uporządkowa-na merytorycznie i graficznie. Aby prawidłowo opracować kwestionariusz ankiety, warto stosować się do pewnych zasad (por. [6, s. 110-111]):
1. Po pierwsze: należy określić, jakie informacje mają charakter jakościo-wy, a jakie ilościowy (zob. cechy zmienne), a także od kogo zostaną one
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.2. Obserwacja statystyczna
str. 34
pobrane – ma to istotny wpływ na treść i formę pytań kwestionariuszo-wych. Pytania te – w zależności od podmiotu badania – mogą mieć bar-dziej lub mniej złożony charakter.
2. Kolejną kwestią jest dostosowanie kwestionariusza do wybranej techni-ki pomiaru. Kwestionariusze wywiadu mogą być bardziej skomplikowa-ne, ponieważ są wypełniane przez osoby przeprowadzające wywiad (an-kieterów). Natomiast kwestionariusze ankiety – z uwagi, że są samo-dzielnie wypełniane przez respondentów – muszą być prostsze, jak rów-nież zawierać takie informacje, jak: cel badania statystycznego, sposób wpisania (zaznaczenia) odpowiedzi, czyli instrukcje, sposób oddania kwestionariusza. W szczególności kwestionariusz powinien zawierać następujące elementy:– informację o instytucji przeprowadzającej badanie,– tytuł (temat) badania,– zwięzłą informację na temat celu badania,– dodatkowe wyjaśnienia (np. zapewnienie o anonimowości badań),– instrukcje kwestionariuszowe (wyjaśniają jak odpowiadać na po-
szczególne pytania),– pytania kwestionariuszowe,– dane dotyczące podmiotu badania (metryczka).
3. Treść pytań kwestionariusza ankiety (wywiadu) powinna być zgodna z określonym celem badania statystycznego. Należy też uwzględnić fakt, czy respondent będzie potrafił udzielić odpowiedzi na dane pytanie i czy będzie skłonny to zrobić.
4. Kolejną czynnością jest określenie sposobu odpowiedzi na poszczegól-ne pytania, a następnie ich liczby i kolejności w kwestionariuszu. W dalszej części tego podrozdziału więcej miejsca poświęcono kwestii budowy pytań kwestionariusza.
Pytania stosowane w kwestionariuszach można podzielić na dwie zasadni-cze grupy (por. [16, s. 46]):
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.2. Obserwacja statystyczna
str. 35
1. Pytania otwarte – zakładają sformułowanie odpowiedzi przez respon-denta w sposób całkowicie dowolny. Pytania otwarte umieszcza się w kwestionariuszu wówczas, gdy trudno jest przewidzieć odpowiedzi czy też wtedy, gdy pytanie wymaga „trudnych” odpowiedzi. Podstawo-wą wadą tego rodzaju pytań jest nieporównywalność zebranych w ten sposób informacji.
2. Pytania zamknięte (skategoryzowane, kafeteryjne) – przewidują wybór odpowiedzi z przygotowanego zestawu wariantów (tzw. kafeterie). Tego typu pytania przeważają w badaniach ilościowych (pytania otwarte pełnią tu rolę pytań uzupełniających).
Bardziej szczegółową klasyfikację pytań wykorzystywanych w kwestiona-riuszach ankiety (wywiadu) przedstawia poniższa tabela:
Tabela 1.4. Klasyfikacja pytań kwestionariusza ankietowego (kwestionariusza wywiadu).
Rodzaj pytania Przykłady pytań wraz z kafeteriami (1, 2, …)
OTWARTE I Z czym kojarzy się Panu/Pani wyraz „statystyka”? …………..
PÓŁOTWARTE – w porównaniu z pytaniem zamkniętym dodatkowo pojawia się tzw. kafeteria półotwarta
II Proszę wskazać maksymalnie trzy praktyczne Pana/Pani zdaniem zastosowania statystyki: 1. Giełda, finanse2. Analiza danych w przedsiębiorstwie3. Analiza rynku4. Inne (jakie?) ……………………….…………
ZAMKNIĘTE
dychotomicznewybór jednego z dwóch wariantów odpowiedzi
III Czy korzysta Pan/Pani z dodatkowych zajęć ze statystyki?1. Tak2. Nie
kafeteria dysjunktywnawybór tylko jednej z wymienionych odpowiedzi
IV Jaki dział statystyki sprawia Panu/Pani najwięcej trudności?(proszę wskazać tylko jedną odpowiedź)1. Wnioskowanie statystyczne2. Analiza szeregów czasowych3. Analiza regresji4. Analiza struktury
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.2. Obserwacja statystyczna
str. 36
kafeteria koniunktywnawybór więcej niż jednego wariantu odpowiedzi (należy pamiętać o poinstruowaniu respondenta, ile opcji odpowiedzi może maksymalnie wskazać)
V Z jakich form dodatkowych zajęć ze statystyki Pan/Pani korzysta?1. Korepetycje2. Kursy tradycyjne3. E-learning (nauczanie na odległość)4. Nie dotyczy
TABELE – pytania tabele umożliwiają zadanie kilku lub kilkunastu prostych pytań, odwołujących się do tej samej skali, lecz odnoszących się do różnych przedmiotów, wartości, cech, poglądów, zjawisk
VI Ile godzin średnio tygodniowo uczy się Pan/Pani statystyki?
do 2 godzin2-45-10ponad 10
sesja
poza sesją
SPECJALNE
Filtrujące celem jest wychwycenie niezgodności w odpowiedziach
Pytaniem filtrującym jest pytanie piąte w stosunku do pytania trzeciego – wybór kafeterii „Nie” w pytaniu trzecim powinien odpowiadać zaznaczonej opcji „nie dotyczy” w pytaniu piątym
Metryczkoweokreślają cechy respondenta (wiek, płeć, stan cywilny itp.)
Płeć:1. Kobieta2. Mężczyzna
Źródło: Opracowanie na podstawie: [6, s. 112-113].
W tym miejscu warto dodać, iż przy konstrukcji coraz bardziej powszech-nych ankiet internetowych wykorzystuje się tzw. formularze, dostępne w różnych programach do tworzenia stron internetowych. Na formularzach umieszcza się pewne elementy graficzne. Przykładowo, w programie MS Word elementy te znajdują na pasku Narzędzia sieci Web. Standardowo nie jest on jednak widoczny, stąd należy zaznaczyć ten pasek, wybierając
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.2. Obserwacja statystyczna
str. 37
w menu Widok funkcję Paski narzędzi i zaznaczyć szukany pasek narzędzi. Po zaznaczeniu opcji tego paska pojawi się on na ekranie…
Do konstrukcji formularza ankiety internetowej wykorzystywane są m.in. następujące elementy:
1. Pole wyboru HTML – służy do konstrukcji pytań zamkniętych o kafete-riach koniunktywnych (możliwy wybór kilku wariantów odpowiedzi).
2. Przycisk opcji HTML – służy do konstrukcji pytań zamkniętych o kafe-teriach dysjunktywnych (możliwe zaznaczenie tylko jednej opcji odpo-wiedzi).
3. Pole tekstowe można wykorzystać jako dodatkową kafeterię półotwartą, co w połączeniu z przyciskami opcji lub wyboru da pytanie półotwarte, jak również do konstrukcji pytań otwartych i części pytań metryczko-wych (np. miasto, w którym mieszka ankietowany).
4. Obszar tekstu HTML doskonale nadaje się do pytań otwartych, wyma-gających dłuższej odpowiedzi respondenta (dostępny jest tu pasek prze-wijania, co pozwala na sprawdzenie przez respondenta i poprawienie ewentualnych błędów w całej wypowiedzi).
Ponadto można stosować pole rozwijane HTML – pełni ono analogiczną rolę do przycisku opcji HTML, przy czym znacznie lepiej nadaje się do pytań o dużej liczbie wariantów odpowiedzi (np. wybór województwa).
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.2. Obserwacja statystyczna
str. 38
Z kolei inny element – pole listy HTML – może pełnić rolę pól wyboru HTML, ponieważ pozwala na jednoczesne wybranie kilku możliwych od-powiedzi (klikanie na wybieranych wariantach odpowiedzi z przytrzyma-nym prawym przyciskiem Shift).
Oprócz rozplanowania omówionych elementów graficznych – konieczne jest ponadto dodanie kodu źródłowego HTML. Niniejsza publikacja ukazu-je jedynie konstrukcję formularza ankiety internetowej pod kątem meryto-rycznym. Oto przykład takiej ankiety:
Rysunek 1.5. Przykład ankiety internetowej.
Źródło: Opracowanie własne.
Kształt pola wyboru sugeruje, iż respondent może zaznaczyć kilka odpo-wiedzi. Niemniej jednak należy – jeśli to konieczne – określić liczbę wska-zań (w powyższym przykładzie wymagane są dokładnie trzy wskazania
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.2. Obserwacja statystyczna
str. 39
praktycznych zastosowań statystyki). Przyciski opcji uniemożliwiają zazna-czenie więcej niż jednej odpowiedzi (doskonale nadają się do pytań typu TAK/NIE, płeć). Przy konstrukcji kwestionariusza ankiety internetowej możliwe jest wskazanie opcji domyślnej, tak jak to uczyniono przy pytaniu trzecim w powyższym przykładzie (ustawienie odpowiedniego parametru na wartość logiczną true). Formularz kończy się poprzez dodanie przycisku Resetuj (ang. Reset), umożliwiającego wyczyszczenie wszystkich zaznaczonych odpowiedzi oraz przycisku Prześlij kwerendę (ang. Submit) – umożliwiającego przesłanie formularza np. na wskazany adres poczty elektronicznej. Aby uniknąć niejasności, należy kolejno określić nazwy poszczególnych elementów. Przykładowo obszar tekstu HTML można nazwać „Pytanie_1”. W nadesłanym kwestionariuszu obok nazwy „Pytanie_1” pojawi się treść tego pytania: „Statystyka (łac. status – państwo) …”.
Jak już zasygnalizowano, na treść i formę pytań kwestionariuszowych istotny wpływ ma to, czy pozyskiwane informacje mają jakościowy czy ilościowy charakter. Innymi słowy, należy określić rodzaj cechy statystycz-nej (np. płeć jest cechą jakościową nominalną – zob. cechy zmienne). Z ro-dzajem cech statystycznych wiąże się z kolei pojęcie skalowania.
Skalowanie to „takie postępowanie, które umożliwia przyporządkowanie pewnym właściwościom obiektów liczb lub innych symboli w celu okre-ślonego uporządkowania badanych stanów rzeczy (postaw, ocen, poglądów itp.) i wyrażenia ich w sposób liczbowy lub wartościowy” ([6, s. 113]).
Nie wszystkie rodzaje pytań ankietowych są pytaniami skalowanymi – do tej grupy pytań nie należą pytania otwarte. Skalowanie dotyczy więc pytań skategoryzowanych, gdzie respondent może wybrać jeden lub kilka możli-wych wariantów odpowiedzi. W tym celu stosuje się określone typy skal pomiarowych. Skala pomiarowa umożliwia transformację informacji po-chodzących ze źródeł pierwotnych – pobieranych za pośrednictwem narzę-
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.2. Obserwacja statystyczna
str. 40
dzia jakim jest kwestionariusz – w symbole, tworzące dane podlegające dalszej obróbce statystycznej. W latach pięćdziesiątych XX w. S.S. Stevens zaproponował czteropoziomową klasyfikację skal pomiarowych, a miano-wicie skale [16, s. 46]:
– nominalne,– porządkowe,– przedziałowe,– ilorazowe.
Przedstawione cztery typy skal pomiarowych są powszechnie wymieniane w literaturze statystycznej. Poniżej kolejno omówiono te skale.
Skala nominalna stanowi najniższy poziom w klasyfikacji skal pomiaro-wych (jest to bowiem skala „najsłabsza”). Zastosowanie tego typu skali po-miaru danych pozwala na podzielenie zebranego materiału statystycznego na pewne rozłączne podzbiory i identyfikacje jednostki statystycznej ze względu na posiadanie lub nieposiadanie danego wariantu cechy (zob. ce - chy nominalne). Poszczególnym wariantom cech jakościowych (nominal-nych) przypisuje się „etykiety” bądź liczby, na których nie można wykony-wać żadnych działań arytmetycznych – liczby pełnią jedynie rolę wariantu cechy jakościowej [3, s. 20]. Skale nominalne można podzielić na dwie grupy (por. [6, s. 114]):
1. Alternatywa – możliwy wybór jednej z dwóch opcji odpowiedzi (skala ta znajduje zastosowanie w przypadku cech dychotomicznych typu płeć, odpowiedź tak/nie).
2. Niealternatywa – możliwy wybór odpowiedzi z listy złożonej z więcej niż dwóch wariantów odpowiedzi, których nie da się uporządkować (zob. cechy wielodzielne).
W przykładowej ankiecie internetowej (zob. rys. 1.5) pytaniami skalowa-nymi za pomocą skali nominalnej są pytania nr: 2, 4 i 5. Pytania te zostały
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.2. Obserwacja statystyczna
str. 41
skonstruowane w celu poznania struktury odpowiedzi. Uzyskany z wyko-rzystaniem tej skali materiał statystyczny można pogrupować (zob. grupo - wanie i zliczanie danych), a następnie obliczyć wskaźniki struktury (por. tabela 1.5).
Skala porządkowa (rangowa) posiada wszystkie właściwości skali nomi-nalnej, a ponadto umożliwia porządkowanie jednostek statystycznych w ra-mach wyróżnionych kategorii pod względem natężenia wybranej cechy sta-tystycznej. O ile w skali nominalnej podstawą zaliczenia obserwacji do da-nej kategorii jest wyłącznie fakt posiadania określonego wariantu cechy, o tyle w skali porządkowej możliwe są stwierdzenia dotyczące nie tylko równości czy różności elementów, ale także określenia pozwalające na po-rządkowanie obserwacji. Porządkowanie jednostek według badanej cechy może być uporządkowaniem słabym lub mocnym. Uporządkowanie słabe to takie, w którym występuje relacja typu „mniejszy lub równy” (≤) albo „większy lub równy” (≥). Oznacza to, że kilka jednostek może być sobie równych. Natomiast uporządkowanie mocne charakteryzuje relacja typu „mniejszy niż” (<) albo „większy niż” (>). W przypadku skali porządkowej liczby pełnią rolę tzw. rang – wyznaczają one kolejność występowania jed-nostek statystycznych, ale nie określają – tak jak ma to miejsce w skali przedziałowej – odległości między nimi [19, s. 14]. Skale porządkowe po-wszechnie stosowane są do pomiaru określonych postaw respondentów (np. marketing, nauki społeczne). Do porządkowych skal pomiaru postaw należą m.in. (por. [16, s. 48-50]):
1. Skala Likerta – często stosowana pięciostopniowa skala pomiaru postaw typu:– zdecydowanie nie,– raczej nie,– raczej tak,– zdecydowanie tak,– trudno powiedzieć.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.2. Obserwacja statystyczna
str. 42
Jest to przykład skali porządkowej zrównoważonej, tj. posiadającej jedna-kową liczbę ocen negatywnych („zdecydowanie nie”, „raczej nie”) i pozy-tywnych („raczej tak”, „zdecydowanie tak”), jak również opcję środkową (neutralną) typu „trudno powiedzieć”.
2. Skala porównań parami – porównuje się tu parami obiekty na zasadzie „każdy z każdym”. Respondent wskazuje, który np. produkt bardziej preferuje – nie określa jednak, o ile bardziej. Stosując tę skalę, po zli-czeniu odpowiedzi i sprawdzeniu przechodniości relacji (jeżeli A < B i B < C, to z tego wynika, że A < C), można uszeregować obiekty w określonej kolejności (np. można wyciągnąć wniosek, iż najlepszym narzędziem dydaktycznym są animacje, gorszym – elementy graficzne, zaś najmniej skutecznym – hiperłącza).
3. Skala rang – respondent może bezpośrednio uszeregować poszczególne elementy, przypisując im kolejno liczby od 1 do n (rangi), gdzie n ozna-cza liczbę tych elementów. Na ogół przyjmuje się, iż obiektowi najlep-szemu przypisuje się rangę o numerze 1. Podobnie jak w przypadku po-równywania parami, rangi nie rozstrzygają, o ile dany element jest lep-szy lub gorszy od pozostałych porównywanych. Można sprawdzić zgodność rang np. ze względu na płeć (zob. współczynnik korelacji rang Spearmana).
Omówione powyżej trzy typy skal pomiaru postaw zilustrowano w przy-kładowej ankiecie adresowanej do Czytelników niniejszej publikacji (zob. rys. 1.6).
Skala przedziałowa (interwałowa, równomierna) określa różnicę pomię-dzy stopniami skali z dokładnością do przyjętej jednostki miary. Skala ta zachowuje właściwości skal słabszych, tj. identyfikacje jednostek staty-stycznych (zob. skala nominalna) oraz relacje umożliwiające porządkowa-nie tych jednostek ze względu na wybraną cechę (zob. skala porządkowa).
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.2. Obserwacja statystyczna
str. 43
Ponadto ten typ skali pomiarowej pozwala określić odległości między ele-mentami, zaś zero jest tu przyjęte w sposób umowny (tzw. zero względne) [3, s. 21]. Istotne jest to, iż punkt zerowy jest tu tylko umowny, a nie – jak ma to miejsce w przypadku skali ilorazowej – bezwzględny (absolutny). Przykładowo, temperatura mierzona na skali Celsjusza posiada taki umow-ny punkt zerowy przy zamarzaniu wody (zero stopni Celsjusza). Wysokość nad poziomem morza jest mierzona w oparciu o umowny punkt zerowy, ja-kim jest poziom morza (0 m n.p.m.). Zmiany temperatur wyrażonych w stopniach Celsjusza czy wysokości w metrach nad poziomem morza na-leży interpretować tylko w wielkościach absolutnych, a nie względnych.
Oto praktyczny przykład: ze schroniska położonego na wysokości 700 m n.p.m. na szczyt góry „A” (800 m n.p.m.) prowadzi niebieski szlak, a na górę „B” (900 m n.p.m.) – zielony. Teoretycznie góry te są prawie równe, ale przy przyjęciu za punkt zerowy położenie schroniska okaże się, iż wy-sokość względna góry „A” to 100 m (800 m n.p.m. – 700 m n.p.m.), zaś góry „B”: 200 m (900 m n.p.m. – 700 m n.p.m.). W rzeczywistości okazało się, że góra „B” jest aż dwa razy wyższa od góry „A”, nie zaś zaledwie o kilkanaście procent.
Wracając do konstrukcji kwestionariusza: należy zaznaczyć, iż w bada-niach marketingowych skale przedziałowe znajdują zastosowanie w przy-padku pomiaru cech, które nie posiadają naturalnej jednostki miary. W tej sytuacji skale porządkowe traktuje się jako skale przedziałowe (zob. rys. 1.7). Zakłada się tu, że różnice pomiędzy sąsiednimi klasami są takie same.
Przejście ze skali słabszej, jaką jest skala porządkowa, na skalę mocniejszą – przedziałową – daje konkretne wartości liczbowe, na których można już wykonywać operacje dodawania i odejmowania [3, s. 21]. W związku z tym można wyznaczyć więcej miar statystycznych (por. tabela 1.5). Do skal przedziałowych, powstałych wskutek przypisania wartości liczbowych skalom porządkowym, należą:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.2. Obserwacja statystyczna
str. 44
1. Skala rangowa stałych sum – w przypadku tej skali respondent ma za zadanie rozdysponować 100 jednostek (procentowych, pieniężnych itp.) zgodnie ze swoim uznaniem na poszczególne elementy [16, s. 49]. Waż-ne jest, aby poszczególne punkty (kwoty) sumowały się do stu. Skala rangowa stałych sum jest zbliżona do skali, na której ankietowany okre-śla w przedziale od zera do stu np. poziom satysfakcji – jednostka miary i punkt zerowy są tu przyjęte w sposób umowny. Innym przykładem jest skala punktów uzyskanych na egzaminie (od zera do stu) i odpowiadają-ca im skala ocen od 2 do 5 (por. [3, s. 21-22]).
2. Skala dyferencjału semantycznego – na dwóch przeciwstawnych biegu-nach tej skali umieszcza się antonimy, tj. wyrazy o przeciwstawnych znaczeniach (np. tani/drogi, standardowy/ekskluzywny, wysoki/niski itp.). Na siedmiopolowej skali respondent zaznacza swoją opinię. Kolej-nym opcjom można przypisać wartości liczbowe od 1 do 7 [16, s. 49]. Środkowe pole można traktować jako wartość przeciętną (np. przeciętna cena).
3. Skala Stapela – skala ta powstaje poprzez zastąpienie antonimów w ska-li dyferencjału semantycznego poprzez wprowadzenie dodatnich i ujem-nych symboli liczbowych, tak aby oprócz intensywności widoczny był również kierunek postaw. Respondent wyraża swoją pozytywną lub ne-gatywną opinię w skali od –5 do +5 [16, s. 50]. Zamiast antonimów „ta-ni/drogi” można tu wprowadzić czynnik „cena”. Zbyt wysoka cena znajdzie odzwierciedlenie w ocenach ujemnych, zaś przystępna – w do-datnich.
Skala ilorazowa to „najmocniejszy” typ skali pomiarowej. W przypadku tej skali znaczenie ma nie tylko odległość między dwoma obserwowanymi obiektami, określona jako różnica między nimi, ale także ilorazy tych odle-głości. Skalę tę można stosować w przypadku pomiaru cech ilościowych posiadających naturalny – a nie umowny, jak ma to miejsce w skalach
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.2. Obserwacja statystyczna
str. 45
przedziałowych – punkt zerowy [1, s. 37]. Oprócz naturalnego punktu zerowego tym, co odróżnia skalę ilorazową od przedziałowej jest naturalna – a nie umowna – jednostka miary.
Przykładem cechy ilościowej skokowej, której pomiaru można dokonać z wykorzystaniem tej skali, jest ilość sprzedaży (szt.), cechy quasi-ciągłej – wielkości wyrażone w jednostkach pieniężnych typu przychody, cechy zaś ciągłej – wielkości wyrażone w jednostkach czasu (por. [16, s. 53]).
Oto przykładowy formularz ankiety – wykorzystujący omówione wyżej skale pomiarowe – mającej na celu poznanie opinii Czytelników odnośnie tej publikacji:
Rysunek 1.6. Przykład formularza ankiety dla Czytelników publikacji „Statystyka po ludzku”.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.2. Obserwacja statystyczna
str. 46
Źródło: Opracowanie własne.
Powyższy formularz ma na celu zapoznanie się z opiniami Czytelników ni-niejszej publikacji. Formularz został tak opracowany, że może być wypeł-niony za pośrednictwem Internetu.
Podsumowując: wybór skali pomiarowej związany jest z rodzajem danej cechy statystycznej – cechy nominalne można mierzyć jedynie na skalach najsłabszych, tj. nominalnych. Natomiast cech quasi -ilościowych (porząd-kowych) nie można mierzyć na skali wyższej niż przedziałowa. Adekwatną skalą dla cech ilościowych, posiadających naturalną jednostkę miary typu:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.2. Obserwacja statystyczna
str. 47
metry, waluta, kg, czas mierzony liczbą lat itp., jest najsilniejsza skala ilo-razowa. Co prawda możliwy jest tu pomiar na skalach słabszych (każda ce-cha mierzona na skali silniejszej może być bowiem mierzona za pomocą skali słabszej), ale wiąże się to z utratą informacji. Z uwagi na fakt, że ko-lejna skala pomiarowa posiada wszystkie właściwości skal od niej słab-szych i dodatkowo nowe własności, nie jest możliwe przejście ze skali słabszej na skalę silniejszą po zebraniu danych (por. [3, s. 22]). Poniższy schemat ukazuje zależność pomiędzy rodzajem cechy statystycznej a ty-pem skali pomiaru danych:
Rysunek 1.7. Typ skali pomiarowej a rodzaj cechy statystycznej.
Źródło: Opracowanie własne.
Zastosowane w badaniu statystycznym skale pomiarowe decydują o możli-wościach analizy danych. W poniższej tabeli przedstawiono zestaw możli-wych do obliczenia miar statystycznych w zależności od typu skali pomia-rowej (zob. opis statystyczny):
Tabela 1.5. Skale pomiarowe a przykłady możliwych do obliczenia miar statystycznych.
RODZAJE MIAR
RODZAJE SKAL POMIARU DANYCHnominalna porządkowa przedziałowa ilorazowa
Miary struktury
wskaźnik struktury
wskaźnik struktury wskaźnik struktury wskaźnik struktury
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.2. Obserwacja statystyczna
str. 48
Miary położenia
dominanta dominanta,mediana, kwartyle
dominanta,mediana, kwartyle,średnia arytmetyczna
dominantamediana, kwartyle,średnia arytmetyczna,średnia geometryczna
Miary dyspersji
rozstęp,odchylenie standardowe,odchylenie ćwiartkowe
rozstęp,odchylenie standardowe,odchylenie ćwiartkowe,współczynniki zmienności
Miary asymetrii
współczynniki asymetrii (klasyczne i pozycyjne)
współczynniki asymetrii (klasyczne i pozycyjne)
Miary zależności
współczynnik V-Cramera
współczynniki korelacji rang
współczynnik korelacji liniowej Pearsona
współczynnik korelacji liniowej Pearsona
Źródło: Opracowanie na podstawie [3, s. 25].
Jak widać, im silniejsza skala pomiarowa, tym więcej miar można obliczyć. Dlatego skalowanie pytań stanowi istotny element konstrukcji kwestiona-riusza ankiety lub wywiadu.
Z opracowywaniem pytań kwestionariusza – oprócz doboru ich treści, for-my i skalowania – związana jest jeszcze kwestia tworzenia tzw. reguł przejścia (por. [16, s. 57]). Np. ankieter przeprowadzający wywiad pytając respondenta, czy korzysta z dodatkowych zajęć ze statystyki (por. rys. 1.5) w przypadku uzyskania negatywnej odpowiedzi przechodzi do kolejnego bloku tematycznego, pomijając tym samym pytania związane z dodatkowy-mi formami kształcenia.
Zanim zostanie przeprowadzone badanie zasadnicze, należy wypróbować opracowane narzędzia, jakimi są kwestionariusze, przeprowadzając tzw. badanie próbne. Badanie próbne (pilotażowe) to na ogół badanie na małą skalę, przeprowadzane przed badaniem głównym w celu uzyskania infor-macji mogących poprawić jego efektywność (zob. [6, s. 116]).
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.2. Obserwacja statystyczna
str. 49
Po opracowaniu ostatecznej wersji kwestionariusza ankiety lub wywiadu można przystąpić do gromadzenia danych zgodnie z przyjętą techniką.
1.2.2. Kontrola zebranych danych
Zebrany materiał statystyczny – bez względu na to, czy pochodzi on ze źró-deł pierwotnych, czy wtórnych – należy poddać kontroli. Oto typologia kontroli według wybranych autorów:
Tabela 1.6. Typologia kontroli materiału statystycznego według wybranych autorów.
Autorzy Rodzaje kontroliA. Bielecka 1. Kontrola o charakterze formalnym (ilościowym)
2. Kontrola o charakterze merytorycznym (jakościowym)A. Komosa, J. Musiałkiewicz
1. Kontrola formalna: kontrola kompletności materiału statystycznego, kontrola zupełności zapisu2. Kontrola merytoryczna: kontrola zgodności rachunkowej, kontrola logicznej poprawności zapisów
T. Michalski 1. Kontrola formalna: kontrola kompletności materiału statystycznego, kontrola zupełności zapisów, kontrola zgodności rachunkowej2. Kontrola merytoryczna – sprowadza się do kontroli logicznej poprawności zapisów
M. Sobczyk 1. Kontrola formalna (ilościowa): sprawdzenie kompletności, pełności i zupełności danego materiału statystycznego2. Kontrola merytoryczna: kontrola logiczna i arytmetyczna (kontrola zgodności rachunkowej)
Źródło: Opracowanie własne na podstawie: [3, s. 38], [7, s. 35-36], [10, s. 37-38], [19, s. 21].
Generalnie w literaturze przedmiotu wyróżnia się dwa główne rodzaje kontroli:
1. Kontrola formalna (ilościowa).2. Kontrola merytoryczna (jakościowa).
Do kontroli formalnej zalicza się kontrolę kompletności materiału staty-stycznego oraz kontrolę zupełności zapisów. Część autorów (np. T. Michal-
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.2. Obserwacja statystyczna
str. 50
ski, [10, s. 37]) do tego rodzaju kontroli zalicza ponadto kontrolę zgodności rachunkowej. M. Sobczyk kontrolę tę określa mianem arytmetycznej i zali-cza – podobnie jak A. Komosa i J. Musiałkiewicz – do kontroli meryto-rycznej (por. [7, s. 35-36], [19, s. 21]). Wszyscy wymienieni autorzy (zob. tabela 1.6) są zgodni co do tego, że kontrolą merytoryczną jest kontrola lo-gicznej poprawności zapisów. Poniżej omówiono poszczególne typy kon-troli materiału statystycznego, tj.:
– kontrolę kompletności materiału statystycznego,– kontrolę zupełności zapisów,– kontrolę zgodności rachunkowej,– kontrolę logicznej poprawności zapisów.
Kontrola kompletności materiału statystycznego polega na porównaniu liczby jednostek objętych badaniem z liczbą np. uzyskanych formularzy ankiety (gromadzenie danych ze źródeł pierwotnych) czy też formularzy od jednostek sprawozdawczych (materiał wtórny). Kontrola ta pozwala usta-lić, czy zebrano wszystkie formularze. Jeżeli – mimo podjętych działań – podmiot organizujący badanie statystyczne w dalszym ciągu nie otrzyma wypełnionych brakujących formularzy, to można oszacować wynik dla tych jednostek, które nie przekazały materiału statystycznego. Przy prezen-tacji wyników badania statystycznego należy zaznaczyć, dla jakich jedno-stek wynik został określony na podstawie szacunku statystycznego. Jeżeli okaże się, że informacje od jednostek, które nie przesłały formularzy staty-stycznych, w istotny sposób mogą zmienić wynik badania, to oszacowane dane mogą znacząco obniżyć jakość całego badania statystycznego [7, s. 36]. Przykładowo, niech celem badania statystycznego będzie określenie struktury wiekowej klientów operatorów telefonii komórkowej. Załóżmy, że w danym kraju działają czterej operatorzy z następującymi udziałami w rynku: Operator „A” – 20 proc., „B” – 15 proc., „C” – 25 proc. oraz „D” – 40 proc. Udostępnienia wymaganych badaniem statystycznych danych odmówił jedynie operator „D” – z uwagi na znaczny udział w rynku błędne
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.2. Obserwacja statystyczna
str. 51
oszacowanie struktury wiekowej klientów tego operatora może przekreślić sens całego badania statystycznego. Przykład ten pokazuje, iż stopień kom-pletności materiału statystycznego nie jest równoważny ze stopniem kom-pletności danych statystycznych (różne udziały w rynku operatorów). Nie-mniej jednak kontrola ta jest bardzo ważna z punktu widzenia rzetelności wyników badań ( por. [10, s. 38]).
Kontrola zupełności zapisu polega na sprawdzeniu, czy udzielono odpo-wiedzi na wszystkie pytania w kwestionariuszu ankiety, wywiadu czy też innych materiałach statystycznych. Sprawdza się tu czy zostały wypełnione wszystkie pozycje. Pozostawienie pozycji niewypełnionej (np. brak zazna-czonej odpowiedzi na pytanie ankietowe) stwarza różne możliwości inter-pretacyjne [10, s. 39]. W celu dokonania kontroli zupełności zapisu należy przejrzeć każdy formularz statystyczny. W przypadku, gdy stwierdzono niezupełność zapisu, należy skontaktować się z osobą sporządzającą (wy-pełniającą) formularz w celu uzupełnienia brakujących informacji [7, s. 36].
Kontrola zgodności rachunkowej jest przeprowadzana wówczas, gdy in-formacje w formularzach statystycznych mają postać liczbową. Jeżeli w materiale statystycznym występują jakieś obliczenia (np. sumowanie), to kontrola zgodności rachunkowej polega głównie na sprawdzeniu popraw-ności obliczeń. Ponadto – w ramach tej kontroli – sprawdza się, czy wszystkie wartości zostały podane we właściwych jednostkach miary oraz czy dokonano odpowiednich zaokrągleń – dzięki temu zapewniona zosta-nie porównywalność materiału statystycznego [7, s. 36-37]. Jeśli nie stwierdzono błędów rachunkowych, to można przypuszczać, iż sprawozda-nie czy kwestionariusz wypełniono poprawnie. Niejednokrotnie w bieżącej kontroli zgodności rachunkowej oraz dla ułatwienia sporządzania sprawoz-dań podaje się w tytułach rubryk/wierszy formularza informacje mówiące, że dane w tej rubryce/wierszu stanowią np. sumę liczb zawartych w wy-mienionych rubrykach/wierszach [10, s. 39]. Przykładem takiego rozwiąza-
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.2. Obserwacja statystyczna
str. 52
nia jest pytanie nr 4 zamieszczone w formularzu ankiety skierowanej do Czytelników niniejszej publikacji, gdzie podano informację, że przypisane treści teoretycznej i praktycznej punkty sumują się do 100 procent (zob. rys. 1.6).
Kontrola logicznej poprawności zapisów wymaga dokładnej znajomości badanego zagadnienia, stąd może być przeprowadzona przez specjalistów z danej dziedziny. Polega ona na sprawdzeniu zapisów formularza staty-stycznego z punktu widzenia ich logicznej poprawności. W wyniku tej kon-troli można stwierdzić, czy w odpowiedziach nie ma błędów wynikających ze złego sformułowania pytań w formularzu lub wyjaśnień w instrukcji sta-tystycznej oraz czy odpowiedzi są zgodne ze stanem faktycznym (wiary-godne) i z obowiązującymi przepisami prawa. Dokonując omawianej kon-troli porównuje się często zgromadzony materiał statystyczny z innymi ma-teriałami zawierającymi informacje na temat tego samego zjawiska – zbyt duże rozbieżności wymagają wyjaśnienia. Ułatwieniem dla przeprowadze-nia kontroli merytorycznej jest np. zamieszczanie w formularzu tzw. pytań fil trujących , polegających na wykryciu niezgodności w odpowiedziach [7, s. 37]. Przykładem takiego pytania jest pytanie nr 5 wobec pytania nr 3 w ankiecie internetowej (zob. rys. 1.5).
1.3. Opracowanie i prezentacja materiału statystycznego
1.3.1. Grupowanie i zliczanie danych
Po sprawdzeniu jakości zebranego materiału statystycznego można przejść do czynności związanych z grupowaniem (porządkowaniem) danych. Gru-powanie jest „ciągiem czynności logicznych polegających na wyodrębnia-niu jednorodnych lub względnie jednorodnych części z większej, zróżnico-wanej całości” [3, s. 39].
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.3. Opracowanie i prezentacja materiału statystycznego
str. 53
W zależności od liczby cech będących podstawą podziału badanej zbioro-wości statystycznej wyróżnia się [10, s. 47]:
1. Grupowanie proste – polega na podziale badanej zbiorowości ze względu na jedną cechę charakterystyczną (zob. cechy zmienne). Stoso-wanie grupowania prostego umożliwia przedstawienie tylko jednego aspektu badanego zjawiska.
2. Grupowanie złożone – polega na tym, że w podziale badanej zbioro-wości uwzględnia się kilka cech charakterystycznych, przy czym po-szczególne części (grupy, klasy) wyodrębnione na podstawie jednej ce-chy dzielone są na dalsze części (podgrupy) ze względu na kolejne ce-chy charakterystyczne itd. Zastosowanie tego typu grupowania sprawia, iż w efekcie otrzymuje się części (grupy, klasy) mniej zróżnicowane ja-kościowo, przez co obraz badanych zjawisk jest głębszy i pełniejszy.
Przykładem grupowania prostego jest podział badanej zbiorowości ze względu na płeć. Natomiast przykładem grupowania złożonego może być podział badanej zbiorowości ze względu na dwie cechy – płeć i wykształce-nie. W ten sposób można uzyskać strukturę wykształcenia populacji, w tym strukturę wykształcenia kobiet i mężczyzn.
W wyniku uporządkowania lub grupowania prostego jednostek statystycz - nych otrzymuje się szereg statystyczny. Szereg statystyczny stanowi „zbiór wyników obserwacji jednostek według pewnej cechy” [19, s. 25].
Sposób przedstawienia danych za pomocą szeregu statystycznego zależy od takich czynników, jak (por. [11, s. 24]):
1. Rodzaj analizy (opis struktury zbiorowości/analiza dynamiki).2. Liczba obserwacji.3. Rodzaj cechy statystycznej.4. Liczba wariantów cechy statystycznej.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.3. Opracowanie i prezentacja materiału statystycznego
str. 54
Schemat porządkowania/grupowania zebranego materiału statystycznego w szeregi statystyczne – z uwzględnieniem powyższych czynników – zilu-strowano na rys. 1.8:
Rysunek 1.8. Schemat wyboru odpowiedniego szeregu statystycznego.
Źródło: Opracowanie własne na podstawie: [3, s. 46], [11, s. 25].
Według kryterium merytorycznego, związanego ze sposobem analizy da-nych, wyróżnić można dwie grupy szeregów statystycznych [2, s. 47]:
1. Szeregi przestrzenne – ukazują strukturę zbiorowości statystycznej (zob. opis struktury zbiorowości) w jednym okresie lub w jednym mo-mencie (zob. rys. 1.2).
2. Szeregi czasowe – ukazują zmiany w czasie wybranego zjawiska (zob. analiza dynamiki).
Oto kilka przykładów rozróżniających dane czasowe od danych struktural-nych:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.3. Opracowanie i prezentacja materiału statystycznego
str. 55
Przykład 1. Przedstawione na rys. 1.3 umowne dane dotyczące funduszy inwestycyjnych można analizować pod kątem struktury. I tak można wy-znaczyć strukturę funduszy ze względu na klasę ryzyka czy też przedstawić rozkład rocznych stóp zwrotu. Dysponując analogicznymi danymi z kilku lat (np. z roku 2003, 2004 i 2005) można np. przedstawić zmiany w czasie rocznych stóp zwrotu.
Przykład 2. Jednostką statystyczną jest dana sesja giełdowa – zbiorowość statystyczną stanowi 50 ostatnich sesji giełdowych. Cechami statystyczny-mi tak określonej jednostki są m.in.: nazwa spółki, cena zamknięcia (zł), dzienna zmiana kursu (proc.). W zależności od przyjętego kryterium mery-torycznego i wyboru cechy statystycznej inwestor może dokonać opisu struktury (np. opis struktury dziennych stóp zwrotu dla 50 dostępnych da-nych), jak również przeprowadzić analizę szeregu czasowego (np. analizę zmian kursu akcji (cena zamknięcia) wybranej spółki w ciągu 20 ostatnich sesji.
Przykład 3. Dysponując danymi odnośnie ocen ze statystyki pewnej grupy studentów z pięciu testów sprawdzających wiedzę z poszczególnych dzia-łów można dokonać analizy pod kątem postępów w nauce (analiza liczby punktów z poszczególnych testów w danym roku akademickim), jak rów-nież pod kątem zróżnicowania wyników (np. analiza struktury otrzyma-nych przez poszczególnych studentów punktów na ostatnim teście). W przypadku analizy szeregów czasowych liczbę obserwacji stanowi ilość przeprowadzonych testów, zaś w przypadku analizy struktury – liczba stu-dentów, którzy wzięli udział w ostatnim teście.
Dane przeznaczone do opisu struktury zbiorowości statystycznej – w zależ-ności od liczby obserwacji – można przedstawić w postaci szeregu szcze-gółowego lub też pogrupować w szereg rozdzielczy (zob. rys. 1.8).
W przypadku gdy liczba obserwacji jest niewielka, materiał statystyczny można przedstawić w postaci szeregu szczegółowego (zob. [11, s. 24]).
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.3. Opracowanie i prezentacja materiału statystycznego
str. 56
Szereg szczegółowy prezentuje materiał statystyczny uporządkowany według wartości badanej cechy w kolejności rosnącej lub malejącej [19, s. 23-24].
Jeśli natomiast liczba obserwacji jest duża, to zastosowanie znajduje grupo-wanie zebranych danych w szereg rozdzielczy. Szereg rozdzielczy stanowi „zbiorowość statystyczną, podzieloną na części (klasy) według określonej cechy jakościowej lub ilościowej, z podaniem liczebności lub częstości każdej z wyodrębnionych klas” [11, s. 25].
Problemem może okazać się określenie „niewielkiej” liczby obserwacji. W przypadku egzaminu ze statystyki na problem ten należy patrzeć pod ką-tem praktycznym, tj. wykonywanych obliczeń arytmetycznych. Przykłado-wo, obliczenie odchylenia standardowego dla kilku obserwacji nie nastrę-cza trudności i nie jest czasochłonne. Jednak wykonanie tego samego obli-czenia np. dla 15 niepogrupowanych w szereg rozdzielczy obserwacji może okazać się bardziej czasochłonne, aniżeli ich pogrupowanie w szereg z czterema przedziałami klasowymi (zob. szereg rozdzielczy z przedziała - mi klasowymi), a następnie obliczenie tej miary z wykorzystaniem odpo-wiedniego wzoru dla danych pogrupowanych. Ponadto należy pamiętać, iż pogrupowanie danych niekiedy wymusza treść zadania. Nie ulega wątpliwości, iż 25-30 lub więcej obserwacji należy pogrupować w odpo-wiedni szereg rozdzielczy. Jako dolną umowną granicę można przyjąć 8-10 obserwacji.
Ze statystycznego punktu widzenia pogrupowanie materiału statystycznego pozwala na jego prezentację graficzną, ukazującą tzw. rozkład empiryczny badanej cechy (zob. prezentacja materiału statystycznego).
Kolejnym czynnikiem wpływającym na wybór szeregu statystycznego jest rodzaj cechy statystycznej (zob. cecha zmienna). Istotny jest tu podział na cechy jakościowe i ilościowe, jak również liczba przyjmowanych przez da-
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.3. Opracowanie i prezentacja materiału statystycznego
str. 57
ną cechę wariantów. Z uwagi na rodzaj cechy, według której grupowane są zebrane dane, statystyczne wyróżnia się [3, s. 39]:
1. Grupowanie typologiczne – dotyczy cech jakościowych lub ilościowych mierzonych na skalach słabszych (zob. skala nominalna i skala porząd - kowa). Jednostki statystyczne grupowane są z punktu widzenia wyróż-nionego wariantu cechy.
2. Grupowanie wariancyjne – dotyczy cech mierzonych na skalach moc-nych, tj. skali przedziałowej i skali ilorazowej. Chodzi tu głównie o ce-chy ilościowe, których warianty różnią się pod względem liczb, a nie opisów słownych. Jednostki statystyczne można tu zliczyć według po-wtarzających się wariantów, jak również zaliczyć do określonych prze-działów wartości.
Punktem wyjścia przy grupowaniu danych w szereg rozdzielczy jest spo-rządzenie tzw. wykazu klasyfikacyjnego. Pod pojęciem tym należy rozu-mieć uporządkowany wykaz wariantów cech [7, s 43]. Wykaz klasyfikacyj-ny powinien odznaczać się następującymi cechami [10, s. 50]:
– wyczerpujący – żaden wariant cechy nie może znaleźć się poza konstru-owanym wykazem,
– grupowanie rozłączne – każdą jednostkę statystyczną można zaszerego-wać wyłącznie do jednej z grup klasyfikacyjnych.
Jeśli chodzi o cechy jakościowe, to według kryterium ilości możliwych wa-riantów ich grupowanie można podzielić na (por. [2, s. 45]):
1. Dychotomiczne – polega na podziale zbiorowości na dwie różne jako-ściowo klasy (podgrupy).
2. Politomiczne – polega na podziale zbiorowości na więcej niż dwie roz-łączne klasy (podgrupy).
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.3. Opracowanie i prezentacja materiału statystycznego
str. 58
Przykładem grupowania dychotomicznego jest podział badanej zbiorowo-ści ze względu na płeć czy też osoby korzystające lub niekorzystające z do-datkowych form kształcenia w zakresie przedmiotu statystyka. Natomiast przykładem grupowania politomicznego jest klasyfikacja funduszy inwe-stycyjnych według następujących klas ryzyka: Fundusze Rynku Pieniężne-go, Fundusze Obligacji, Fundusze Stabilnego Wzrostu, Fundusze Zrówno-ważone i Fundusze Akcji. Ponadto do tej grupy szeregów rozdzielczych na-leży zaliczyć szeregi geograficzne (terytorialne). Szeregi te ukazują roz-mieszczenie pewnych zjawisk w przestrzeni, np. liczba szkół ponadgimna-zjalnych w przekroju poszczególnych województw (por. [11, s. 25]).
Strukturę badanej zbiorowości pod kątem określonej ilościowej cechy sta-tystycznej odzwierciedla tzw. rozkład empiryczny, czyli zestawienie wyni-ków w postaci szeregu rozdzielczego z cechą mierzalną [11, s. 25].
To, w jaki sposób należy grupować dane o charakterze ilościowym, zależy od liczby przyjmowanych przez daną cechę wariantów. I tak: w przypadku cechy ilościowej ze zmiennością skokową (zob. cecha skokowa) o niewiel-kiej liczbie wariantów sporządzenie wspomnianego wykazu klasyfikacyjne-go sprowadza się do wyszczególnienia tych wariantów [7, s. 43]. W tej sy-tuacji dane należy pogrupować w szereg rozdzielczy punktowy. Natomiast gdy liczba wariantów cechy jest duża, to wówczas należy zbudować szereg rozdzielczy z przedziałami klasowymi (por. [11, s. 25]). Z definicji są to cechy ciągłe, w tym cechy quasi -ciągłe . Poniżej dokładniej omówiono budowę szeregów rozdzielczych z przedziałami klasowymi.
Konstrukcja szeregu rozdzielczego z przedziałami klasowymi wymaga na wstępie określenia ilości przedziałów klasowych. Przedział klasowy to pewien przedział liczbowy, w którym mniejsza z liczb określona jest mia-nem dolnej granicy przedziału, zaś większa – górnej granicy. Należy pod-kreślić, iż przy konstrukcji przedziałów klasowych sposób zapisu ich dol-nej i górnej granicy powinien jednoznacznie wskazywać, do którego prze-
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.3. Opracowanie i prezentacja materiału statystycznego
str. 59
działu zaliczyć konkretną obserwację. Jednoznaczność w zaliczaniu po-szczególnych obserwacji do właściwych przedziałów klasowych można uzyskać poprzez zapis wariantów cechy z zastosowaniem znaku lewostron-nego ([ lub <) bądź prawostronnego (] lub >) domknięcia przedziału. In-nym rozwiązaniem jest zapisanie granic przedziałów w ten sposób, że dol-na granica przedziału następnego jest o określoną jednostkę większa od górnej granicy przedziału poprzedniego (por. [7, s. 44-45]). Oto przykłady:
Przykład 1. Znowelizowana Ustawa o swobodzie działalności gospodar-czej zmieniła m.in. definicję małego i średniego przedsiębiorcy, a ponadto wprowadziła zupełnie nową definicję – mikroprzedsiębiorcy. Jednym z kryteriów grupowania przedsiębiorstw jest liczba zatrudnionych pracow-ników. Zgodnie z tym kryterium „mały przedsiębiorca to taki, który w co najmniej jednym z dwóch ostatnich lat obrotowych zatrudniał średniorocz-nie mniej niż 50 pracowników (…). Za średniego przedsiębiorcę uważa się takiego, który w co najmniej jednym z dwóch ostatnich lat obrotowych za-trudniał średniorocznie mniej niż 250 pracowników (…). Natomiast jako mikroprzedsiębiorca określany jest przedsiębiorca, w przypadku którego poziom zatrudnienia, o którym mowa powyżej, wyniósł średniorocznie mniej niż 10 pracowników (…)” [PAIiIZ, http://paiz.gov.pl]. Wykaz klasy-fikacyjny ze względu na liczbę pracowników przedstawia się następująco:
Przedsiębiorstwo Sposób I Sposób IIMikroprzedsiębiorstwo poniżej 10 osób poniżej 10 osób
Małe [10-50) 10-49Średnie [50-250) 50-249Duże 250 i więcej 250 i więcej
Przykład 2. Oto przykład ukazujący grupowanie klientów wybranego sklepu według wartości rachunków płaconych przy kasie:
Sposób I Sposób IIdo 20 zł do 20 zł(20-50] 20,01-50(50-100] 50,01-100
ponad 100 zł 100,01 i więcej
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.3. Opracowanie i prezentacja materiału statystycznego
str. 60
Powyższe przykłady ukazują dwa sposoby określania przedziałów klaso-wych. W przypadku ustalenia wariantów klasyfikacyjnych drugim sposo-bem istotne jest właściwe ustalenie stopnia dokładności jednostki. Jeśli ce-cha według której grupowane są obserwacje statystyczne jest cechą skoko-wą przyjmującą wartości z przedziału liczb naturalnych – tak jak ma to miejsce w pierwszym przykładzie – jako jednostkę można przyjąć liczbę całkowitą. W przypadku cech ciągłych konieczne jest dostosowanie jed-nostki do stopnia dokładności, z jaką zebrany został materiał statystyczny. Jeżeli np. dane mają charakter cechy quasi-ciągłej (waluta), to jednostkę należy ustalić z dokładnością do 0,01 (zob. przykład 2). Przyjęcie jednostki ze zbyt małą dokładnością (np. 0,1) spowodowałoby, że niektóre rachunki nie zostałyby zaliczone do żadnej z wyznaczonych klas – przeczyłoby to bowiem zasadzie głoszącej, iż wykaz klasyfikacyjny powinien być wyczerpujący. Ponadto ważne jest to, czy przedziały są domykane lewostronnie (przykład 1), czy prawostronnie (przykład 2). Wybór sposobu domknięcia przedziałów klasowych ma znaczenie przy zliczaniu danych (np. z wykorzystaniem funkcji częstość w programie Microsoft Excel).
W tym miejscu należy rozróżnić terminy grupowanie i klasyfikacja. Klasy-fikacja to jednolity system grupowania. Klasyfikacja znajduje zastosowa-nie w badaniach ciągłych i okresowych, gdzie istotną rolę odgrywa kwestia porównywalności danych. Natomiast w badaniach doraźnych na ogół ma miejsce grupowanie materiału statystycznego, przeprowadzane w odmien-ny sposób w każdym badaniu statystycznym – zależy to od celu tego bada-nia [19, s. 22]. Przykładem klasyfikacji jest przedstawiony wyżej wykaz klasyfikacyjny przedsiębiorstw według kryterium liczby zatrudnionych. Generalnie przyjmuje się, iż sektor małych i średnich przedsiębiorstw (MSP) stanowią przedsiębiorstwa zatrudniające nie więcej niż 250 pracow-ników. Niemniej jednak badanie własne mające na celu ukazanie dokład-niejszej struktury firm z sektora MSP może zakładać bardziej szczegółową klasyfikację. W tym przypadku można mówić o grupowaniu danych.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.3. Opracowanie i prezentacja materiału statystycznego
str. 61
Poniżej przedstawiono czynności związane z grupowaniem materiału staty-stycznego w szereg rozdzielczy z przedziałami klasowymi. Należą do nich:
1. Określenie liczby przedziałów klasowych.2. Wyznaczenie długości przedziału klasowego.3. Określenie wykazu klasyfikacyjnego.
Pierwszą kwestią jest określenie liczby przedziałów klasowych. Najprost-szym sposobem jest określenie liczby przedziałów klasowych jako pier-wiastka kwadratowego z liczby obserwacji (zaokrąglenie do liczby całko-witej):
Niemniej jednak w literaturze przedmiotu można spotkać się z innymi – bardziej złożonymi – sposobami wyznaczania liczby klas (zob. [19, s. 25]):
W niektórych wzorach liczbę obserwacji oznacza się dużą literą N, w in-nych zaś – małą literą n. Aby jasno rozróżnić te oznaczenia można przyjąć, iż dużą literą N oznaczana jest liczebność całej zbiorowości statystycznej, zaś małą literą n – liczebność zbiorowości próbnej, czyli próby. W niniej-szym opracowaniu wzory są podawane głównie dla liczebności próbnej, stąd oznaczanie liczebności małą literą n (z powodzeniem mogą też być one stosowane w badaniu pełnym). Odwołania do niektórych wzorów poja-wią się w ostatnim rozdziale, jakim jest wnioskowanie statystyczne (przy estymacji przedziałowej i weryfikacji hipotez statystycznych). Zastosowa-nie we wzorze małej litery sugeruje, iż w tym przypadku chodzi o liczeb-ność próby losowej (a nie o liczebność całej N-elementowej populacji).
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.3. Opracowanie i prezentacja materiału statystycznego
str. 62
Po ustaleniu liczby przedziałów klasowych należy określić rozpiętość (dłu-gość, interwał) przedziału klasowego. W przypadku równych przedziałów klasowych ich długość wyznacza się według wzoru:
Rozstęp wyznacza się następująco (zob. także miary dyspersji):
Ważne jest, aby nigdy nie zaokrąglać otrzymanej długości przedziału klasowego w dół – możliwe jest jedynie pewne zaokrąglenie w górę (im większe, tym mniejsza dokładność wyników analizy). W warunkach egzaminu ze statystyki dobrym rozwiązaniem jest wyznaczenie przedziałów klasowych, których granice są liczbami całkowitymi (najlepiej parzystymi). Ułatwi to późniejszą analizę danych (np. obliczanie miar klasycznych).
Mając już ustaloną rozpiętość przedziału klasowego oraz liczbę klas, moż-na przejść do określenia wykazu klasyfikacyjnego, poczynając od wartości minimalnej. Jeżeli rozpiętość przedziału klasowego została zaokrąglona w górę, to jest możliwe wyznaczenie dolnej granicy pierwszego przedziału klasowego od mniejszej wartości aniżeli wartość minimalna (najlepiej dla celów analitycznych przyjąć tu liczbę całkowitą).
Wyznaczanie przedziałów klasowych w celu grupowania danych zilustro-wano na przykładzie firm z sektora MSP. Oto dane umowne z badania an-kietowego dotyczące liczby pracowników wybranych 15 firm (dane w po-staci szeregu szczegółowego):
1, 1, 3, 4, 7, 12, 14, 17, 21, 23, 42, 57, 102, 117, 195
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.3. Opracowanie i prezentacja materiału statystycznego
str. 63
Krok 1: Ustalenie liczby przedziałów klasowych. Ponieważ liczba obserwa-cji wynosi n = 15, to stosując najprostszy wzór (pierwiastek z liczby obser-wacji) należy wyznaczyć k = 4 przedziały klasowe.
Krok 2: Określenie długości przedziału klasowego. W tym celu należy wy-znaczyć rozstęp, czyli różnicę pomiędzy wartością maksymalną a wartością minimalną. Rozstęp wynosi: 195 – 1 = 194. Następnie otrzymany wynik należy podzielić przez liczbę przedziałów klasowych, czyli 4. Po podziele-niu otrzymanego rozstępu przez liczbę przedziałów klasowych okazuje się, że długość przedziału klasowego wynosi h = 48,5. Jak widać, nie jest to „najlepsza” liczba do obliczeń na egzaminie. Zdecydowanie korzystniej-szym rozwiązaniem jest tu przyjęcie długości przedziału klasowego h = 50. Wówczas „nowy” rozstęp wyniesie h × k = 50 × 4 = 200 (nie zaś 194). No-wy przedział jest większy o 6 od rozstępu wyznaczonego na wstępie.
Krok 3. Opracowanie wykazu klasyfikacyjnego. Jak już stwierdzono, dolna granica pierwszego przedziału klasowego może być mniejsza od wartości minimalnej – w tym przypadku nie może to być wartość większa od „zapa-su” wynoszącego 6. Trafnym rozwiązaniem jest przyjęcie tej granicy na poziomie zera. Należy zwiększać kolejno granice przedziałów klasowych o przyjętą ich długość, czyli o 50. Oto wyznaczony wykaz klasyfikacyjny (przedziały domknięte lewostronnie zilustrowane za pomocą dwóch omó-wionych wcześniej sposobów):
Sposób I * Sposób II[0 – 50) 0 – 49
[50 – 100) 50 – 99[100 – 150) 100 – 149[150 – 200) 150 – 200
* W praktyce można pominąć symbole domykania przedziałów.
Jeszcze jedna uwaga praktyczna: przy określaniu przedziałów klasowych typu „mniej niż”/„więcej niż”, „poniżej”/„powyżej” itp. należy pamiętać, iż bez znajomości wartości minimalnej/maksymalnej nie jest m.in. możliwe
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.3. Opracowanie i prezentacja materiału statystycznego
str. 64
obliczenie wartości przeciętnej (średniej arytmetycznej). Taka sytuacja miałaby miejsce w przypadku prezentowanej – przy okazji omawiania dru-giego etapu badań statystycznych – ankiety internetowej. Chodzi tu o pyta-nie nr 6 (zob. rys. 1.5). Respondent zaznaczając opcję „powyżej 10” może mieć na myśli zarówno 11, jak i np. 50 godzin tygodniowo. Gdyby zamiast zaznaczenia jednej z możliwych opcji ankietowany miał podać konkretną liczbę godzin uczenia się statystyki tygodniowo, to wówczas można by przeprowadzić grupowanie analogiczne do grupowania z przykładu doty-czącego przedsiębiorstw z sektora MSP.
Do tej pory przedstawiono sposób grupowania danych ze względu na jedną cechę. W przypadku gdy grupowania danych dokonuje się równocześnie w oparciu o więcej niż jedną cechę statystyczną, to można tu mówić o gru-powaniu złożonym. Należy pamiętać, iż przy dokonywaniu grupowania złożonego nie powinno się jednocześnie uwzględniać zbyt wielu cech, po-nieważ staje się ono wówczas nieczytelne, co z kolei utrudnia analizę [7, s. 47]. W praktyce dane najczęściej grupuje się jednocześnie ze względu na dwie cechy, przy czym mogą być to obie cechy jakościowe, obie ilościowe, jak również jedna ilościowa, a druga jakościowa. O ile jedną cechę można przedstawić w postaci szeregu statystycznego (szczegółowego, czasowego lub rozdzielczego), o tyle dwie cechy można pogrupować w tzw. tablicę korelacyjną (dwudzielną). Tablica korelacyjna jest to tablica konstruowa-na w ten sposób, iż w poszczególnych wierszach występują warianty jednej cechy (np. cechy X), a w kolumnach odmiany drugiej (np. cechy Y) [15, s. 232-233]. Grupowanie danych ze względu na dwie cechy jednocześnie w tablicę korelacyjną znajduje zastosowanie w analizie współzależności.
Czynnością ściśle związaną z grupowaniem danych jest ich zliczanie. Zli-czanie materiału statystycznego polega na ustaleniu liczebności poszcze-gólnych grup (klas). W rezultacie można stwierdzić, ile jednostek staty-stycznych przypada na poszczególne warianty cechy czy też wyznaczone
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.3. Opracowanie i prezentacja materiału statystycznego
str. 65
przedziały klasowe. Istnieje szereg sposobów zliczania materiału staty-stycznego, a mianowicie (por. [7, s. 48-50]):
1. Zliczanie bezpośrednie (ręczne) – polega na zliczaniu i zanotowaniu liczby jednostek statystycznych (obserwacji) posiadających określony wariant cechy. Znajduje zastosowanie w sytuacji, gdy liczba obserwacji jest niewielka, a ich podział na grupy jest prosty.
2. Zliczanie sposobem kreskowym – polega na tym, że w specjalnie skon-struowanej tablicy roboczej pionowymi kreskami zaznacza się wystą-pienie określonego wariantu cechy. W literaturze statystycznej proponu-je się, aby piąta kreska była przekreśleniem czterech pozostałych, tj. sta-nowiła kreskę poziomą (istnieje jednak ryzyko, iż kreska ta nie zostanie w zliczaniu danych potraktowana jako obserwacja, tylko jako zwykłe przekreślenie czterech zliczonych obserwacji). Dobrym rozwiązaniem jest stawianie kresek tak, aby tworzyły one pewne grupy, co ułatwi póź-niejsze zliczanie danych. Warto dodać, iż sposób zliczania danych metodą kreskową doskonale nadaje się do grupowania danych na egzaminie, gdzie nie ma dostępu do komputera. Poniżej zamieszczono przykład grupowania danych metodą kreskową w tablicę korelacyjną. Oto dane umowne dla 14 osób, dotyczące dychotomicznych cech jakościowych płeć oraz cechy korepetycje, określającej. czy dana osoba korzysta z korepetycji:
Lp 1 2 3 4 5 6 7 8 9 10 11 12 13 14płeć K K K K K M M M K M K K M Mkorepetycje T T N N N T N N T N N T T N
Oto dane pogrupowane metodą kreskową:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.3. Opracowanie i prezentacja materiału statystycznego
str. 66
3. Zliczanie sposobem kartkowym – polega na posegregowaniu materiału statystycznego w postaci wypełnionych formularzy na tzw. stosy o jed-nakowych wariantach cechy. Wskutek zliczenia tych formularzy – od-dzielnie dla każdego stosu określa się liczebność danej grupy (klasy). Sposób ten może być stosowany w przypadku zliczania danych ankieto-wych ze względu na wybraną cechę (np. płeć, osoby korzystające lub niekorzystające z dodatkowych form nauczania).
4. Zliczanie sposobem maszynowym – w tym przypadku należy wykonać symbolizację (kodowanie) zebranych danych, polegającą na tym, że po-szczególnym wariantom cechy statystycznej przypisywane są konkretne symbole słowne bądź liczbowe. Następnie zakodowane informacje wprowadzone są do komputera i analizowane za pomocą wybranego programu, np. MS Excel. Ten sposób zliczania materiału statystycznego znajduje zastosowanie w praktycznej analizie danych, gdzie występuje znaczna liczba obserwacji.
Poniżej omówiono dokładniej wybrane narzędzie komputerowej analizy danych, jakim jest arkusz kalkulacyjny Excela. W przypadku grupowania prostego w szereg rozdzielczy z przedziałami klasowymi zastosowanie znajduje funkcja częstość. Generalnie przedziały należy tu traktować jako lewostronnie domknięte (pierwszy przedział klasowy zlicza dane mniejsze bądź równe podanej wartości). Dlatego jest tu istotne przyjęcie jednostki z odpowiednią dokładnością (np. 9 oznacza, że w pierwszej klasie znajdą się firmy zatrudniające poniżej 10 osób, a 19,99 – ceny poniżej 20 zł). Na-stępnie należy podawać kolejne wartości (np. 49, 249). Listę zamyka górna
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.3. Opracowanie i prezentacja materiału statystycznego
str. 67
granica przedostatniego przedziału – do ostatniego przedziału zakwalifiko-wane zostaną liczby powyżej wskazanej (np. większe od 49,99 – ceny 50 zł i więcej). Zastosowanie tej funkcji ilustruje prezentacja PowerPoint pt. Excel_grupowanie_danych.
Kolejnym narzędziem Excela – posiadającym znacznie szersze możliwości – jest Raport tabeli przestawnej. Narzędzie to pozwala w prosty sposób po-grupować dane jakościowe, jak również dane ilościowe o niewielkiej licz-bie powtarzających się wariantów, tj. grupowanych w szereg rozdzielczy punktowy. Ogromną zaletą tego narzędzia jest możliwość grupowania da-nych w tablice korelacyjne. Tego rodzaju grupowaniu złożonemu (ze względu na dwie cechy) poddawane są zwykle dane ankietowe (zebrany materiał pierwotny). Przed pogrupowaniem tych danych za pomocą Rapor-tu tabeli przestawnej objęte badaniem cechy statystyczne należy przedsta-wić w kolumnach. Innymi słowy, każdy wiersz to jedna jednostka staty-styczna (por. rys. 1.3). Tabela przestawna tworzy zestawienia wyników w oparciu o poddane analizie kolumny, tj. cechy statystyczne. W szczegól-ności może istnieć jedna kolumna zawierająca np. nazwy wariantów cechy jakościowej – ma tu więc miejsce grupowanie danych w szereg rozdzielczy dychotomiczny lub politomiczny. Konieczne jest wprowadzenie dodatko-wej kolumny, zawierającej liczebności. Jeżeli chodzi o grupowanie danych w tablicę korelacyjną, to w układzie tabeli przestawnej w wierszu można przyjąć zestaw wariantów pierwszej cechy, zaś w kolumnie – zestaw wa-riantów drugiej. Natomiast w komórce na ich przecięciu należy umieścić dodatkową zmienną ukazującą liczebności elementów posiadających obie cechy (por. [18, s. 23]). Oto fragment arkusza kalkulacyjnego, sporządzony w oparciu o przykładową ankietę internetową (por. rys. 1.5):
Rysunek 1.9. Arkusz do grupowania danych zebranych za pomocą ankiety internetowej.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.3. Opracowanie i prezentacja materiału statystycznego
str. 68
Źródło: Dane umowne.
Techniczny sposób wykorzystania narzędzia Raport tabeli przestawnej ukazuje prezentacja o nazwie Excel_grupowanie_danych. Ponadto do ni-niejszego opracowania dołączono przykłady grupowania danych z wyko-rzystaniem tego narzędzia (zob. Trening i ewaluacja ). W części teoretycz-nej należy zwrócić uwagę na sposób kodowania zebranego pierwotnego materiału statystycznego. Pytania ankietowe z kafeterią koniunktywną (np. w przypadku pytania nr 2 respondent miał wskazać na trzy praktyczne za-stosowania statystyki) wymagały rozpisania, podobnie jak złożone pytanie nr 6 (sesja/poza sesją). W przypadku cech dychotomicznych (dwuwarianto-wych), gdzie możliwy jest tylko wybór jednej opcji, można zastosować na-zwy charakterystyczne dla danej cechy (np. TAK/NIE). W przypadku pytań z kafeterią dysjunktywną (możliwy wybór tylko jednej opcji) nie ma potrzeby rozpisania w oddzielnych kolumnach poszczególnych wariantów. Istotne jest określenie pewnego klucza, według którego kodowane są po-szczególne opcje odpowiedzi. I tak np. w pytaniu nr 6 przyjęto następujący sposób kodowania:
– do 2 godzin: „1”,– 2-4 godziny: „2”,– 5-10 godzin: „3”,
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.3. Opracowanie i prezentacja materiału statystycznego
str. 69
– ponad 10 godzin: „4”.
Ponadto należy zaznaczyć, iż nie wolno przy nazwach kolumn (cech/wa-riantów cech) stosować spacji. Zmienna „ID”, oznaczająca numer formula-rza ankiety, ma tu podwójne znaczenie – jest ona też wykorzystywana do zliczania danych, tj. pełni rolę tzw. Licznika.
1.3.2. Prezentacja materiału statystycznego
Generalnie stosuje się trzy podstawowe metody prezentacji materiału statystycznego, a mianowicie [10, s. 61]:
1. Tablice statystyczne – przedstawienie danych w formie tabelarycznej.2. Wykresy statystyczne – prezentacja danych w formie graficznej.3. Włączenie danych do tekstu – forma opisowa.
Forma tabelaryczna znajduje zastosowanie w prezentacji danych staty-stycznych uporządkowanych według jednego (zob. grupowanie proste) lub kilku kryteriów (zob. grupowanie złożone), gdzie opis słowny okazałby się zbyt obszerny [7, s. 51]. W zależności od tego, ile kryteriów (cech) jest bra-nych pod uwagę, pogrupowany materiał statystyczny można przedstawić w postaci [3, s. 48]:
– tablicy prostej – zawiera informacje dotyczące jednej cechy, przedsta-wione za pomocą jednego szeregu statystycznego,
– tablicy złożonej – zawarte w niej informacje dotyczą więcej niż jednej cechy danej zbiorowości lub jednej cechy w wielu zbiorowościach; składa się ona z minimum dwóch szeregów statystycznych (por. tablica korelacyjna).
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.3. Opracowanie i prezentacja materiału statystycznego
str. 70
Tablice proste można przedstawić w układzie (por. [3, s. 46]):
– pionowym (wertykalnym) – tablica przedstawiająca dany szereg staty-styczny z reguły składa się z dwóch kolumn, przy czym w pierwszej ko-lumnie zawarty jest wykaz klasyfikacyjny, a w drugiej natężenie danego zjawiska (liczba obserwacji posiadających określony wariant cechy),
– poziomym (horyzontalnym) – tablica składa się z dwóch wierszy, gdzie pierwszy z nich pełni rolę nagłówka tabeli, a drugi zawiera informacje odnośnie badanej cechy.
W niniejszej publikacji ukazujące szeregi statystyczne tablice będą najczę-ściej występowały w układzie pionowym. Zasada ta będzie ściśle przestrze-gana w przypadku szeregów rozdzielczych.
W tablicy prostej, ukazującej szereg rozdzielczy, w pierwszej kolumnie przedstawiony jest w sposób uporządkowany wykaz klasyfikacyjny, w dru-giej zaś – liczebności (częstości) odpowiadające poszczególnym wariantom lub klasom danej cechy statystycznej [7, s. 53]. Jak już wspomniano przy okazji omawiania grupowania i zliczania danych, szeregi rozdzielcze moż-na różnicować ze względu na rodzaj cechy statystycznej (zob. rys. 1.8).
W przypadku cech statystycznych jakościowych można mówić o dychoto-micznych i politomicznych (wielodzielnych) szeregach statystycznych. Je-śli chodzi o szereg dychotomiczny, to lepszą od tabelarycznej może okazać się metoda graficzna (zob. wykresy kołowe), dlatego poniżej zamieszczono przykłady tablicy prostej, ukazującej dane jakościowe pogrupowane w sze-reg rozdzielczy wielodzielny:
Przykład 1. Oto przykład tablicy prostej, ukazującej liczbę wskazań prak-tycznych zastosowań statystyki (pytanie nr 2 ankiety internetowej – por. dane na rys. 1.9):
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.3. Opracowanie i prezentacja materiału statystycznego
str. 71
Tabela 1.7. Struktura odpowiedzi na pytanie dotyczące praktycznych zastosowań staty-styki.
Sposoby praktycznych zastosowań
Liczba wskazań
Giełda, finanse 12Analiza danych w przedsiębiorstwie 13
Analiza rynku 11Inne 9
Σ 45
Źródło: Dane umowne.
Z przedstawionych danych wynika, że najwięcej respondentów wskazało na drugi wariant odpowiedzi. Należy zaznaczyć, iż w przypadku pytań z kafeterią koniunktywną liczba wskazań nie sumuje się do liczby obserwa-cji (15 ankiet). Pytanie to wymagało bowiem wskazania dokładnie trzech praktycznych zastosowań statystyki, stąd liczba wszystkich wskazań wy-niosła 3×n, gdzie n oznacza liczbę respondentów (wypełnionych formula-rzy).
Przykład 2. Poniżej zamieszczono przykład tablicy prostej, ukazującej strukturę odpowiedzi na pytanie nr 4 ankiety internetowej (por. dane na rys. 1.9):
Tabela 1.8. Struktura odpowiedzi na pytanie dotyczące działów statystyki sprawiających najwięcej trudności.
Działy statystyki Liczba odpowiedzi
Wnioskowanie statystyczne 8Analiza szeregów czasowych 3
Analiza regresji 4Analiza struktury 0
Σ 15
Źródło: Dane umowne.
W tym przypadku liczba odpowiedzi sumuje się do liczby wypełnionych formularzy ankiet – pytanie nr 4 było bowiem pytaniem z kafeterią dys-junktywną, gdzie możliwy był wybór wyłącznie jednej opcji (zob. rys. 1.5).
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.3. Opracowanie i prezentacja materiału statystycznego
str. 72
W takiej sytuacji uzasadnione jest przedstawienie struktury odpowiedzi na wykresie kołowym.
Do szeregów rozdzielczych z cechą jakościową należy zaliczyć – jak wyżej wspomniano – szeregi geograficzne (zob. [10, s. 67], [11, s. 25]). Tablica prosta, przedstawiająca szereg geograficzny zbudowana jest – w ujęciu wertykalnym – z dwóch kolumn.
W pierwszej z nich wymienione są jednostki podziału terytorialnego. W za-leżności od stopnia szczegółowości badania statystycznego mogą to być kontynenty, państwa, województwa, powiaty itd. Wyodrębnić można też regiony geograficzne z punktu widzenia powiązań gospodarczych (np. pań-stwa Unii Europejskiej) czy też krainy geograficzne (np. nazwy szczytów górskich).
W drugiej kolumnie szeregu geograficznego zawarte są informacje odno-śnie wielkości badanego zjawiska (np. dynamika PKB, wysokość szczytów górskich n.p.m.), odpowiadające wariantom z kolumny pierwszej. Szereg geograficzny umożliwia przedstawienie przestrzennego rozmieszczenia ba-danego zjawiska w określonym czasie [7, s. 56-57].
Przykładem tablicy prostej, ukazującej szereg geograficzny może być tabe-la zawierająca nazwy państw Unii Europejskiej (kraje dawnej „Piętnastki”, tj. sprzed rozszerzenia Unii z dniem 1 maja 2004 r. o dziesięć nowych państw) i odpowiadające im wartości realnego Produktu Krajowego Brutto za 2005 rok.
Tabela 1.9. Realny Produkt Krajowy Brutto państw UE-15 w 2005 r. (proc.).
PKB (proc.)
Austria 2,0Belgia 1,2Dania 3,2
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.3. Opracowanie i prezentacja materiału statystycznego
str. 73
Finlandia 2,9Francja 1,2Grecja 3,7Hiszpania 3,4Holandia 1,1Irlandia 4,7Luksemburg 4,0Niemcy 1,0Portugalia 0,4Szwecja 2,7Wielka Brytania 1,9
Włochy 0,1
Źródło: Opracowanie na podstawie: Eurostat, http://epp.eurostat.ec.europa.eu
W przypadku cech ilościowych można mówić o ich rozkładzie empirycz-nym (por. Charakterystyka wybranych rozkładów prawdopodobieństwa – są to tzw. rozkłady teoretyczne). Określenie empirycznego rozkładu cechy – ogólnie rzecz biorąc – polega na przyporządkowaniu uszeregowanym ro-snąco wartościom przyjmowanym przez tę cechę odpowiednio zdefiniowa-nych liczebności ich występowania [5, s. 22]. Liczebności (częstości abso-lutne) to „liczba rzeczywistych obserwacji odpowiadających danej wartości cechy lub jej przedziałowi klasowemu” [21, s. 32].
Tablica prosta, ukazująca szeregi rozdzielcze cech mierzalnych składa się z dwóch kolumn. Pierwsza z nich to wykaz klasyfikacyjny: warianty cechy (szereg punktowy) albo przedziały klasowe (szereg rozdzielczy klasowy). Niezależnie od tego, czy dane można pogrupować w szereg punktowy, czy klasowy, w drugiej kolumnie tej tabeli zamieszcza się liczebności. Warianty lub przedziały klasowe oznaczane są w niniejszej publikacji jako xi, zaś odpowiadające im liczebności – jako ni, gdzie i oznacza numer wariantu/klasy. Suma poszczególnych liczebności cząstkowych stanowi liczbę obserwacji n. Oto przykłady tablic prezentujących empiryczny rozkład cech ilościowych:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.3. Opracowanie i prezentacja materiału statystycznego
str. 74
Przykład 1. Cechę ilościową skokową, jaką jest liczba kont e-mail wybra-nej grupy internautów, można pogrupować w szereg punktowy. Poniższa tabela prezentuje rozkład liczby kont e-mail:
Tabela 1.10. Rozkład liczby kont e-mail losowo wybranej grupy internautów.
Liczba kont e-mail
xi
Liczba internautów
ni
0 21 142 63 24 1Σ 25
Źródło: Dane umowne.
Przykład 2. W przypadku cech ilościowych skokowych o znacznej liczbie wariantów, jak również cech ciągłych, w pierwszej kolumnie tablicy prostej podaje się przedziały klasowe. Nawiązując do wcześniejszego przykładu wyjaśniającego sposób grupowania przedsiębiorstw sektora MSP w szereg rozdzielczy z przedziałami klasowymi – tablica będzie następująca:
Tabela 1.11. Rozkład liczby zatrudnionych w losowo wybranej grupie przedsiębiorstw sektora MSP.
Wielkość zatrudnienia
xi
Liczba przedsiębiorstw
ni
0 – 49 1150 – 99 1
100 – 149 2150 – 200 1
Σ 15
Źródło: Dane umowne.
Jeżeli prezentacja zebranego materiału statystycznego dotyczy więcej niż jednej cechy statystycznej, to zastosowanie znajdują tablice złożone.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.3. Opracowanie i prezentacja materiału statystycznego
str. 75
W przypadku tablic złożonych z szeregów zespolonych można mówić o po-wiązaniu kilku cech pochodzących z tej samej zbiorowości. Z punktu wi-dzenia analizy współzależności szczególne znaczenie ma budowa tablicy złożonej z dwóch cech, tj. tablicy korelacyjnej. Przykładowo, na podstawie zebranych danych z wykorzystaniem ankiety internetowej (zob. dane na rys. 1.9) można zbudować następującą tablicę korelacyjną:
Tabela 1.12. Przykład tablicy złożonej krzyżowej – cechy dychotomiczne.
Licznik z ID Płeć Suma końcowa
PYT_3 K MNIE 4 4 8TAK 4 3 7Suma końcowa 8 7 15
Źródło: Dane umowne.
Powyższa tablica – określana niekiedy w literaturze przedmiotu mianem ta-blicy krzyżowej (zob. [3, s. 49]) – powstała w wyniku skrzyżowania dwóch cech dychotomicznych: pytania nr 3 odnośnie korzystania z dodatkowych zajęć ze statystyki oraz cechy płeć. Do budowy wykorzystano narzędzie Excela Raport tabeli przestawnej.
Drugą odmianę tablic złożonych stanowią tablice będące zespołem szere-gów statystycznych. Szczególnym przypadkiem tego typu tablic są tablice ukazujące dwie zbiorowości badane pod względem tej samej cechy (por. [21, s. 34]). Przykładem może być cecha opisująca liczbę wskazań na prak-tyczne zastosowania statystyki wśród Polaków (1 populacja) i mieszkań-ców Unii Europejskiej (2 populacja – wyłączając Polskę). Oto zestawienie wyników:
Tabela 1.13. Praktyczne zastosowania statystyki według Polaków i mieszkańców UE.
Sposoby praktycznych zastosowań Liczba wskazańPolska UE
Giełda, finanse 12 19Analiza danych w przedsiębiorstwie 13 11
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.3. Opracowanie i prezentacja materiału statystycznego
str. 76
Analiza rynku 11 12Inne 9 3
Σ 45 45
Źródło: Dane umowne.
Poniżej zamieszczono bardziej rozbudowany przykład tablicy złożonej z 15 szeregów czasowych i 5 szeregów geograficznych:
Tabela 1.14. Realny Produkt Krajowy Brutto w przekroju państw UE-15 w latach 2001-2005.
2001 2002 2003 2004 2005Austria 0,8 0,9 1,1 2,4 2,0Belgia 1,0 1,5 0,9 2,6 1,2Dania 0,7 0,5 0,7 1,9 3,2Finlandia 2,6 1,6 1,8 3,5 2,9Francja 1,9 1,0 1,1 2,3 1,2Grecja 5,1 3,8 4,8 4,7 3,7Hiszpania 3,5 2,7 3,0 3,1 3,4Holandia 1,9 0,1 -0,1 1,7 1,1Irlandia 6,2 6,1 4,4 4,5 4,7Luksemburg 2,5 3,6 2,0 4,2 4,0Niemcy 1,2 0,1 -0,2 1,6 1,0Portugalia 2,0 0,8 -1,1 1,2 0,4Szwecja 1,1 2,0 1,7 3,7 2,7Wielka Brytania
2,4 2,1 2,7 3,3 1,9
Włochy 1,7 0,3 0,1 0,9 0,1
Źródło: Opracowanie na podstawie: Eurostat, http://epp.eurostat.ec.europa.eu
Każda kolumna powyższej tabeli stanowi jeden z szeregów geograficznych (jeden z takich szeregów zamieszczono dla 2005 roku w tabeli 1.8). Nato-miast każdy wiersz stanowi jeden z szeregów czasowych, ukazujących dy-namikę PKB dla poszczególnych państw dawnej „Piętnastki”.
Jeśli chodzi o szeregi czasowe, ukazane za pomocą tablicy prostej, to – zgodnie z przyjętym układem pionowym – w pierwszej kolumnie przedsta-wione są momenty lub okresy czasu. W kolumnie drugiej znajdują się wiel-kości badanego zjawiska, jakie wystąpiły w kolejnych momentach lub
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.3. Opracowanie i prezentacja materiału statystycznego
str. 77
okresach czasu, określonych w pierwszej kolumnie [7, s. 58]. W związku z powyższym, szeregi czasowe można podzielić na dwie grupy [10, s. 69]:
1. Szeregi okresów – ukazują zmiany badanych zjawisk w ciągu pewnego okresu czasu (np. roku, kwartału, miesiąca).
2. Szeregi momentów – określają stan zjawiska w ściśle określonych mo-mentach czasu (np. stan na dzień 31 grudnia 2005 r.).
Wybór szeregu czasowego determinowany jest charakterem badanego zja-wiska. I tak np. składniki bilansu przedsiębiorstwa można przedstawić za pomocą szeregu momentów (np. bilans sporządzony na dzień 31 grudnia 2002, 2003, 2004, 2005 r.). Oto przykład tablicy ukazującej trzy takie sze-regi w układzie horyzontalnym:
Tabela 1.15. Wartość majątku trwałego i obrotowego Grupy Żywiec SA w latach 2002-2005 (mln zł).
2002 2003 2004 2005Aktywa trwałe 1485,3 1492,1 1662,9 1708,6Aktywa obrotowe 408,5 540,4 632,5 671,7RAZEM AKTYWA 1893,8 2032,5 2295,4 2380,3
Źródło: Opracowanie na podstawie: Skonsolidowane raporty roczne Grupy Żywiec SA, http://www.grupazywiec.pl/inwestorzy.php?p=3&inwestorzy_id=3.
Natomiast – w odróżnieniu od stanu majątku – trudno jest np. uchwycić wielkość przychodów ze sprzedaży w danej chwili. Przychody są bowiem tzw. strumieniem ekonomicznym. W tym przypadku dynamikę zmian przy-chodów należy ukazać z wykorzystaniem szeregu okresów. Badając np. se-zonowość przychodów ze sprzedaży (zob. Analiza sezonowości), wygodnie jest określić sumę przychodów w poszczególnych miesiącach czy kwarta-łach. Oto przykład tabeli ukazującej szereg czasowy momentów – tym ra-zem w układzie pionowym:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.3. Opracowanie i prezentacja materiału statystycznego
str. 78
Tabela 1.16. Dynamika przychodów Grupy Żywiec SA w latach 2002-2005 (mln zł).
Kwartały PrzychodyI Q 2002 559,2II Q 2002 880,4III Q 2002 908,2IVQ 2002 608,7I Q 2003 558,9II Q 2003 927,2III Q 2003 991,4IV Q 2003 727,1I Q 2004 626,0II Q 2004 795,1III Q 2004 839,3IV Q 2004 528,1I Q 2005 548,3II Q 2005 801,3III Q 2005 862,0IV Q 2005 656,0
Źródło: Opracowanie na podstawie: Skonsolidowane raporty kwartalne Grupy Żywiec SA, http://www.grupazywiec.pl/inwestorzy.php?p=3&inwestorzy_id=5
Drugą metodą prezentacji danych statystycznych jest metoda graficzna, polegająca na sporządzaniu różnego rodzaju wykresów [10, s. 23]. Wykresy są graficzną formą rejestracji danych oraz narzędziem prezentacji i analizy uogólnionych informacji statystycznych. Najczęściej wykresy sporządza się na podstawie tablic statystycznych [19, s. 29]. Dzięki graficznej prezen-tacji danych zawartych w prostej lub złożonej tablicy statystycznej w wielu przypadkach stają się one bardziej przejrzyste [21, s. 34]. Inną zaletą wy-kresów – obok przejrzystej formy prezentacji danych – jest to, że ułatwiają one prawidłowy wybór miar opisu struktury (zob. Opis struktury zbiorowo - ści) [8, s. 61].
Część wykresów – np. w warunkach egzaminu pisemnego – można łatwo wykonać odręcznie. Niemniej jednak istnieje pewna grupa wykresów (np. wykresy kołowe czy tzw. kartogramy), do wykonania których pożądane jest zastosowanie komputera. Przydatnym narzędziem może okazać się tu arkusz kalkulacyjny MS Excel. W programie MS Excel dostępne są nastę-
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.3. Opracowanie i prezentacja materiału statystycznego
str. 79
pujące standardowe typy wykresów (zaproponowano tu sposoby wykorzy-stania tych wykresów):
1. Kolumnowy – analiza struktury, ukazanie dynamiki danych rocznych.2. Słupkowy – analiza struktury.3. Liniowy – analiza szeregów czasowych.4. Kołowy – analiza struktury (niewielka liczba wariantów).5. XY (Punktowy) – analiza współzależności.6. Warstwowy – analiza zmian struktury w czasie.7. Pierścieniowy – analiza struktury (więcej elementów – por. wykres ko-
łowy).8. Radarowy – analiza porównawcza kilkunastu wymiarów (np. oceny kil-
ku kryteriów dotyczących produktu w skali od zera do 10).9. Powierzchniowy – ukazanie na wykresie trzech wymiarów (wykres 3D).10.Bąbelkowy – analiza regresji (wykres XY wzbogacony o trzeci wymiar,
będący długością promienia kół).11.Giełdowy – stwarza możliwość utworzenia wykresu pudełkowego,
znacznie ułatwiającego analizę porównawczą struktur.12.Walcowy.13.Stożkowy.14.Ostrosłupowy.
Trzy ostatnie z wymienionych wykresów są odmianami wykresu kolumno-wego – ich nazwa związana jest z kształtem słupka. Wśród wykresów nie-standardowych na uwagę zasługują wykresy dwuosiowe, np. pozwalające na ukazanie dynamiki dwóch zjawisk o istotnie różniących się skalach (np. cena w tys. zł i wielkości procentowe). Bardzo interesującym jest również wykres logarytmiczny, pozwalający m.in. ukazać wykładniczy wzrost wielkości (np. wzrost cen z kilku złotych do kilku tysięcy złotych w danym czasie).
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.3. Opracowanie i prezentacja materiału statystycznego
str. 80
W literaturze przedmiotu wyróżnia się następujące podziały wykresów sta-tystycznych (por. [2, s. 51]):
1. Według form graficznych.2. Według kryterium rodzaju szeregu statystycznego.
Klasyfikację wykresów statystycznych z punktu widzenia form graficznych według wybranych autorów przedstawia tabela:
Tabela 1.17. Typologie wykresów statystycznych z punktu widzenia form graficznych.
Autorzy Rodzaje wykresówH. G. Adamkiewicz 1. Liniowe.
2. Powierzchniowe, w tym: – słupkowe, – kołowe.3. Histogram, diagram.
A. Bielecka Pomiar na skalach słabszych:1. Wymiarowe: – liniowe, – kołowe, – słupkowe (pionowe i poziome, rozdzielone, nakładane, 3D).2. Wykresy ilościowe (piktogramy). 3. Wykresy obszaru (kartogramy).
Pomiar na skalach mocniejszych:1. Histogram: – liczebności (absolutnych i względnych), – skumulowany (liczebności skumulowanych).2. Wielobok (diagram): – liczebności (absolutnych i względnych), – liczebności skumulowanych (kumulata), – liczebności względnych skumulowanych (ogiwa).
Z. Kędzior 1. Kołowe.2. Słupkowe.3. Liniowe.4. Piktogramy.5. Mapy graficzne (kartogramy).
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.3. Opracowanie i prezentacja materiału statystycznego
str. 81
M. Sobczyk 1. Liniowe.2. Powierzchniowe.3. Pasmowe.4. Bryłowe.5. Punktowe.6. Mapowe (kartogramy).7. Kombinowane.8. Specjalne.
Źródło: Opracowanie własne na podstawie: [2, s. 51-55], [3, s. 53-54; 84], [6, s. 197-199], [19, s. 29].
W świetle potrzeb tego opracowania istotniejsza jest typologia wykresów statystycznych według drugiego z wymienionych kryteriów, tj. według kry-terium rodzaju szeregu statystycznego. Podział taki z jednej strony pozwoli na graficzną prezentację danych zawartych w omówionych wcześniej tablicach statystycznych, z drugiej zaś stanowi podstawę do dalszej analizy (zob. Opis statystyczny). Według kryterium rodzaju szeregu statystycznego można wyróżnić następujące kategorie wykresów statystycznych (por. [2, s. 51], [19, s. 29]):
1. Wykresy strukturalne – prezentacja graficzna szeregów rozdzielczych, w tym szeregów geograficznych.
2. Wykresy korelacyjne – prezentacja graficzna zależności między cecha-mi.
3. Wykresy dynamiczne – graficzna prezentacja kształtowania się zjawisk w czasie.
Powyższa klasyfikacja wykresów statystycznych odpowiada trzem kolej-nym podrozdziałom następnego rozdziału, gdzie zaprezentowano sposoby obliczania ważniejszych miar wspomagających analizę struktury zbiorowo-
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.3. Opracowanie i prezentacja materiału statystycznego
str. 82
ści, analizę współzależności zjawisk oraz analizę szeregów czasowych (dy-namiki zjawisk). W trakcie obliczania poszczególnych miar pomocne jest sporządzenie odpowiedniego wykresu – stąd będą pojawiać się odwołania do tego podrozdziału. Poniżej omówiono wybrane wykresy zgodnie z przy-jętą klasyfikacją.
W przypadku szeregów rozdzielczych wybór odpowiedniego wykresu strukturalnego uwarunkowany jest rodzajem cechy statystycznej i – co się z tym wiąże – rodzajem skali pomiarowej. Takie rozróżnienie stosuje A. Bielecka (zob. tabela 1.17). I tak w przypadku danych nominalnych (zob. skala nominalna) możliwe jest ich przedstawienie w postaci szeregu rozdzielczego dychotomicznego (dwa warianty cechy) lub politomicznego (więcej wariantów). Jeżeli liczba wariantów cechy jest stosunkowo nie-wielka, np. nie przekracza 7-8 (zob. Z. Kędzior [6, s. 197]), to można sto-sować wykresy kołowe. Wykres kołowy – określany też mianem struktu-ralnego czy „tortowego” – stanowi prosty sposób prezentacji danych sumu-jących się do pewnej całości. Na wykresie przedstawia się procentowe udziały w tej całości [1, s. 38].
Aby odręcznie sporządzić wykres kołowy (np. na tradycyjnym egzaminie, gdzie nie można skorzystać z komputera), po pierwsze należy wyrazić po-szczególne udziały w stopniach według wzoru (por. [7, s. 64]):
Po wyznaczeniu kątów – odpowiadających poszczególnym udziałom (frak-cjom) – należy je nanieść na wykres za pomocą kątomierza (np. poczynając od linii obrazującej na tarczy zegara godzinę 12.00 i poruszając się w kie-runku przeciwnym do ruchu wskazówek zegara). Jednak do precyzyjnego
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
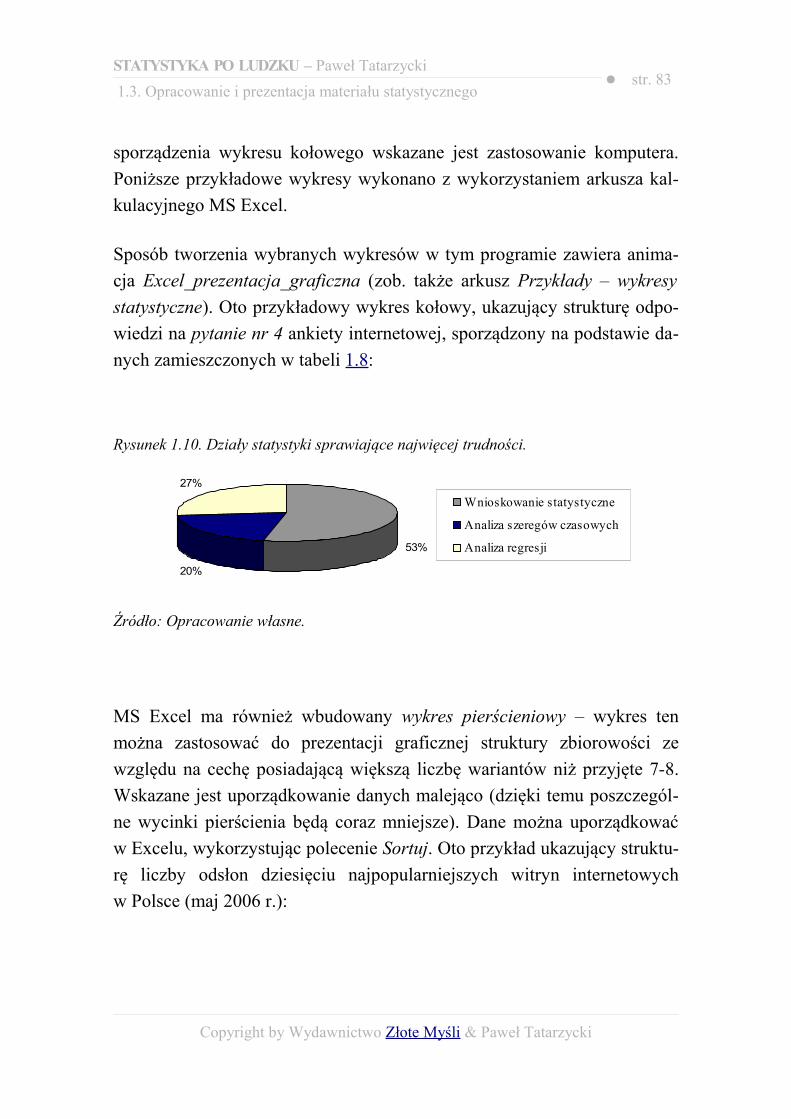
STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.3. Opracowanie i prezentacja materiału statystycznego
str. 83
sporządzenia wykresu kołowego wskazane jest zastosowanie komputera. Poniższe przykładowe wykresy wykonano z wykorzystaniem arkusza kal-kulacyjnego MS Excel.
Sposób tworzenia wybranych wykresów w tym programie zawiera anima-cja Excel_prezentacja_graficzna (zob. także arkusz Przykłady – wykresy statystyczne). Oto przykładowy wykres kołowy, ukazujący strukturę odpo-wiedzi na pytanie nr 4 ankiety internetowej, sporządzony na podstawie da-nych zamieszczonych w tabeli 1.8:
Rysunek 1.10. Działy statystyki sprawiające najwięcej trudności.
Źródło: Opracowanie własne.
MS Excel ma również wbudowany wykres pierścieniowy – wykres ten można zastosować do prezentacji graficznej struktury zbiorowości ze względu na cechę posiadającą większą liczbę wariantów niż przyjęte 7-8. Wskazane jest uporządkowanie danych malejąco (dzięki temu poszczegól-ne wycinki pierścienia będą coraz mniejsze). Dane można uporządkować w Excelu, wykorzystując polecenie Sortuj. Oto przykład ukazujący struktu-rę liczby odsłon dziesięciu najpopularniejszych witryn internetowych w Polsce (maj 2006 r.):
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
20%
27%
53%
Wnioskowanie statystyczne
Analiza szeregów czasowych
Analiza regresji
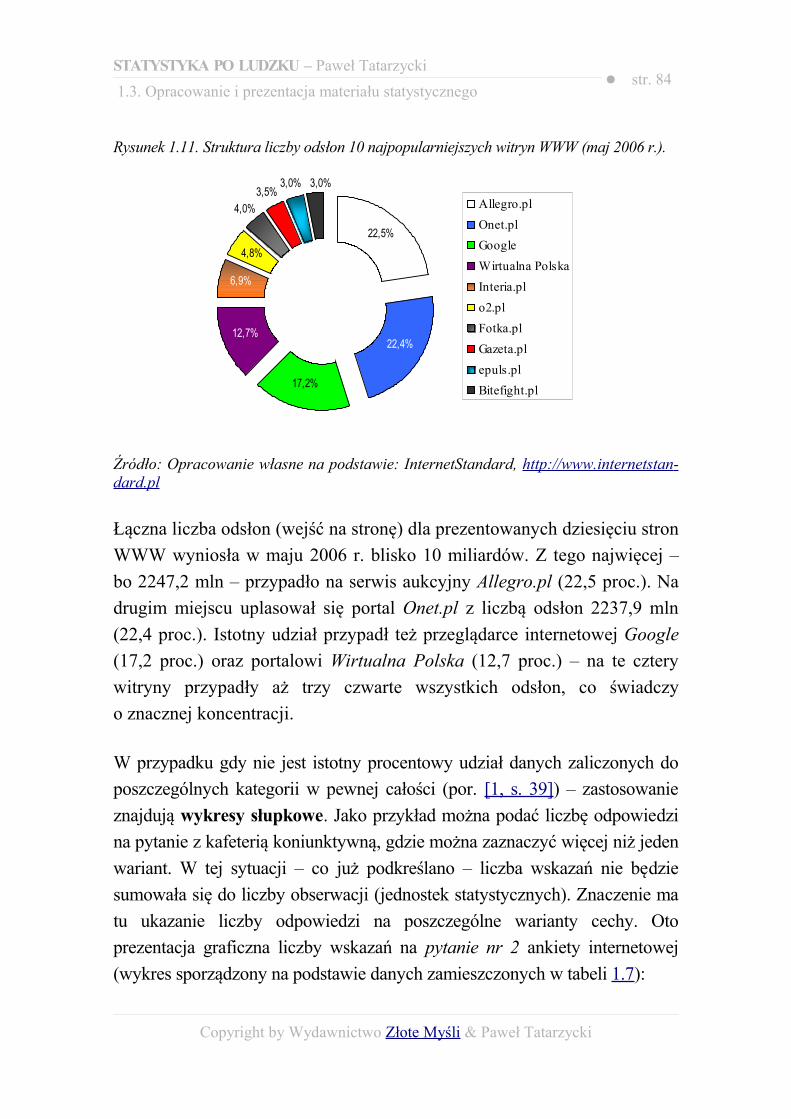
STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.3. Opracowanie i prezentacja materiału statystycznego
str. 84
Rysunek 1.11. Struktura liczby odsłon 10 najpopularniejszych witryn WWW (maj 2006 r.).
Źródło: Opracowanie własne na podstawie: InternetStandard, http://www.internetstan - dard.pl
Łączna liczba odsłon (wejść na stronę) dla prezentowanych dziesięciu stron WWW wyniosła w maju 2006 r. blisko 10 miliardów. Z tego najwięcej – bo 2247,2 mln – przypadło na serwis aukcyjny Allegro.pl (22,5 proc.). Na drugim miejscu uplasował się portal Onet.pl z liczbą odsłon 2237,9 mln (22,4 proc.). Istotny udział przypadł też przeglądarce internetowej Google (17,2 proc.) oraz portalowi Wirtualna Polska (12,7 proc.) – na te cztery witryny przypadły aż trzy czwarte wszystkich odsłon, co świadczy o znacznej koncentracji.
W przypadku gdy nie jest istotny procentowy udział danych zaliczonych do poszczególnych kategorii w pewnej całości (por. [1, s. 39]) – zastosowanie znajdują wykresy słupkowe. Jako przykład można podać liczbę odpowiedzi na pytanie z kafeterią koniunktywną, gdzie można zaznaczyć więcej niż jeden wariant. W tej sytuacji – co już podkreślano – liczba wskazań nie będzie sumowała się do liczby obserwacji (jednostek statystycznych). Znaczenie ma tu ukazanie liczby odpowiedzi na poszczególne warianty cechy. Oto prezentacja graficzna liczby wskazań na pytanie nr 2 ankiety internetowej (wykres sporządzony na podstawie danych zamieszczonych w tabeli 1.7):
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
22,5%
17,2%
4,8%
22,4%12,7%
6,9%
4,0%3,5%
3,0% 3,0%
Allegro.plOnet.plGoogleWirtualna PolskaInteria.plo2.plFotka.plGazeta.plepuls.plBitefight.pl

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.3. Opracowanie i prezentacja materiału statystycznego
str. 85
Rysunek 1.12. Liczba wskazań dotyczących praktycznych zastosowań statystyki.
Źródło: Opracowanie własne.
Powyższy wykres został wykonany w Excelu z wykorzystaniem narzędzia wykres słupkowy. W tym miejscu należy wyjaśnić, iż w programie MS Excel wykres ze słupkami pionowymi określono mianem wykresu kolum-nowego. W literaturze statystycznej ten typ wykresu określa się jako wy-kres słupkowy (ze słupkami pionowymi). Oto przykład takiego wykresu ukazującego realne zmiany PKB wybranych państw Unii Europejskiej w 2005 roku:
Rysunek 1.13. Dynamika realnego Produktu Krajowego Brutto państw UE-15 w 2005 r.
Źródło: Opracowanie własne na podstawie: Eurostat, http://epp.eurostat.ec.europa.eu
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
9
11
12
13
0 2 4 6 8 10 12 14
Inne
Analiza rynku
Giełda, finanse
Analiza danych w przedsiębiorstwie
liczba wskazań
4,7
4,03,7
3,4 3,22,9 2,7
2,0 1,9
1,2 1,2 1,1 1,00,4
0,10
1
2
3
4
5
Irlandia
Luksem
burg
Grecja
Hiszpa
niaDan
ia
Finland
ia
Szwec
ja
Austria
Wielka B
rytani
aBelg
ia
Francja
Holandia
Niemcy
Portugali
a
Włochy
PKB
(pro
c.)

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.3. Opracowanie i prezentacja materiału statystycznego
str. 86
Spośród państw „starej Unii” największą dynamiką wzrostu PKB w 2005 roku odznaczała się Irlandia (4,7 proc.) – najmniejszą zaś Włochy (zaled-wie 0,1 proc.). Wykres ten – po wcześniejszym uporządkowaniu danych – z powodzeniem może być wykorzystywany w różnego rodzaju rankingach.
Interesującą odmianą wykresu słupkowego jest wykres słupkowy nakładany z cechą kategoryzującą (zob. [3, s. 64]). W przypadku danych jakościowych taką cechą może być np. miejsce zamieszkania. Wprowadzenie tego rodzaju wykresu pozwala na porównanie struktur kilku populacji. W tym przypadku można porównać trzy populacje: obszary wiejskie, miasta do 100 tys. mieszkańców oraz miasta powyżej 100 tys. mieszkańców ze względu na odsetek gospodarstw domowych posiadających dostęp do Internetu (zob. plik z danymi do analizy – zakładka Internet):
Rysunek 1.14. Odsetek gospodarstw domowych posiadających dostęp do Internetu (stan na koniec 2005 r.).
Źródło: Opracowanie własne na podstawie: GUS, http://www.stat.gov.pl
Powyższy wykres został sporządzony w Excelu poprzez wybranie narzę-dzia wykres kolumnowy, a następnie 100% skumulowany kolumnowy.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
0%
20%
40%
60%
80%
100%
Obszarywiejskie
Miasta do100 tys.mieszk.
Miastapowyżej 100tys. mieszk.
Dostęp do Internetu Brak

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.3. Opracowanie i prezentacja materiału statystycznego
str. 87
Jeżeli chodzi o szeregi geograficzne, to specyficzną dla tego rodzaju szere-gów statystycznych formą graficznej prezentacji danych są tzw. kartogra-my. Kartogram to „wykres statystyczny sporządzony na mapie lub planie. Sporządzenie tego wykresu polega na naniesieniu wielkości prezentowa-nych zjawisk na mapy za pomocą znaków umownych” [10, s. 82]. Przy sporządzaniu kartogramu szczególnego znaczenia nabiera prawidłowe opracowanie legendy, gdzie w sposób jednoznaczny należy objaśnić stoso-wane oznaczenia [7, s. 78]. Dobór oznaczeń (legendy) związany jest z za-stosowaną metodą sporządzania kartogramu (por. [10, s. 83-87]). I tak:
1. W metodzie symboli na wycinku mapy odpowiadającemu danej jednost-ce terytorialnej umieszczane są symbole obrazujące dane zjawisko, przy czym ich liczba jest proporcjonalna do wielkości zjawiska na danym ob-szarze. Przykładem zastosowania tej metody może być liczba oddziałów regionalnych dużej sieci handlowej w przekroju województw.
2. W metodzie figur geometrycznych przedstawia się na mapie natężenie danego zjawiska za pomocą wielkości figur geometrycznych. Przykła-dowo, wartość sprzedaży pewnego wyrobu można zilustrować za pomo-cą koła, gdzie jego promień uzależniony jest od wartości w złotych (można przyjąć, że 1 cm to 10 tys. zł). Ponadto można ukazać strukturę sprzedaży – w tym przypadku może to być wartościowy udział w rynku w większych miastach Polski.
3. W metodzie powierzchniowej do ukazania zróżnicowania danego zjawi-ska wykorzystuje się intensywność kolorów bądź tekstur. Przykładem zastosowania takiej metody jest prezentacja graficzna zróżnicowania gę-stości zaludnienia w Polsce.
Przedstawione metody sporządzania kartogramów można ze sobą łączyć. Poniżej zaprezentowano przykładowy kartogram, łączący w sobie metodę figur geometrycznych oraz metodę powierzchniową:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.3. Opracowanie i prezentacja materiału statystycznego
str. 88
Rysunek 1.15. Gęstość zaludnienia a wartość sprzedaży w oddziałach regionalnych.
Źródło: Opracowanie własne na podstawie: GUS, http://www.stat.gov.pl
Zaprezentowany kartogram sporządzono w Excelu posługując się wykre-sem bąbelkowym. Promień „bąbelków” oznacza wartość sprzedaży w da-nym regionie (współrzędne X określają długość geograficzną, zaś Y – sze-rokość geograficzną). Jako tło wykresu określono plik graficzny prezentu-jący mapę – sporządzoną przez GUS metodą powierzchniową – ukazującą gęstość zaludnienia w przekroju województw.
W przypadku cech porządkowych istnieje możliwość pomiaru za pomocą skali przedziałowej. Takie skale zastosowano w formularzu ankiety dla Czytelników niniejszej publikacji (zob. rys. 1.6). Wyniki pomiaru postaw (opinii) na skali dyferencjału semantycznego można zilustrować np. za po-mocą mapy dwukryteriowej.
Mapy dwukryteriowe sporządza się poprzez wyznaczenie średnich warto-ści uzyskanych ocen (punktów) każdego z dwóch zamieszczanych na ma-pie kryteriów [16, s. 188]. W pytaniu nr 3 ankiety dla Czytelników, opar-tym na przedziałowej skali dyferencjału semantycznego, poproszono re-
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
10 tys. zł
50 tys. zł
100 tys. zł

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.3. Opracowanie i prezentacja materiału statystycznego
str. 89
spondentów o określenie ich ocen odnośnie treści niniejszej publikacji w trzech wymiarach. Zestawiając parami te wymiary, można sporządzić trzy różne mapy dwukryteriowe.
Na rysunku 1.16 zamieszczono przykład mapy zestawiającej wymiary nud-ne/ciekawe oraz teoretyczne/praktyczne. Do wykonania wykresu wykorzy-stano materiał statystyczny zamieszczony w zakładce Ankiety w pliku Da-ne_do_analizy.xls (należy podkreślić, iż są to tylko dane umowne, więc ich interpretację należy traktować wyłącznie jako przykładową). Poszczególne pola ponumerowano od 1 do 7, gdzie „siedem” oznacza bardzo praktyczne i bardzo przydatne treści. Średnia ocen dla wspomnianych wymiarów sta-nowi współrzędne punktów dla całej grupy ankietowanych, w tym kobiet i mężczyzn.
Rysunek 1.16. Mapa dwukryteriowa oceny treści publikacji „Statystyka po ludzku”.
Źródło: Opracowanie własne.
Mapę dwukryteriową wykonano w arkuszu Excela z użyciem wykresu XY (Punktowego). Z przedstawionej prezentacji graficznej wspomnianych wy-miarów wynika, iż w ocenie kobiet dobrane treści są raczej ciekawe, zaś
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
OgółemKobiety
Mężczyźni
1
4
7
1 4 7
nudne - ciekawe
teor
etyc
zne
- pra
ktyc
zne

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.3. Opracowanie i prezentacja materiału statystycznego
str. 90
według mężczyzn – dość nudne (wymiar pierwszy). Z odpowiedzi respon-dentów wynika, że jest wystarczająca ilość teorii, przy czym ocena męż-czyzn wskazuje, iż mogłoby być więcej przykładów praktycznych (bardziej rozbudowane podrozdziały Trening i ewaluacja).
Mapy dwukryteriowe nie pozwalają na ukazanie na jednym wykresie wię-cej niż dwóch cech (kryteriów). Taką możliwość stwarzają tzw. profile se-mantyczne. Profile semantyczne umożliwiają prezentację graficzną danych uzyskanych zarówno za pomocą dyferencjału semantycznego, jak również skali Stapela [16, s. 192]. Oto przykład profilu semantycznego opracowa-nego dla pytania nr 6 ankiety dla Czytelników (dane umowne):
Rysunek 1.17. Profil semantyczny według trzech kryteriów.
Źródło: Opracowanie własne.
Z przedstawionego profilu semantycznego – wykonanego w Excelu za po-mocą wykresu XY – wynika, iż ankietowani akceptują cenę e-booka, jak również zadowoleni są z jakości prezentowanych treści oraz szaty graficz-nej (każde kryterium otrzymało ocenę dodatnią). Okazuje się, iż kobiety są nie tylko bardziej zadowolone z jakości treści (zob. rys. 1.16), ale także
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
Cena
Treść
Estetyka
-5 -4 -3 -2 -1 0 1 2 3 4 5
KobietyMężczyźni

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.3. Opracowanie i prezentacja materiału statystycznego
str. 91
z ceny. Lepiej także oceniły estetykę. Komentarza wymaga techniczne spo-rządzenie wykresu. Serie osi X stanowią średnie liczby uzyskanych z for-mularza punktów (każdy respondent mógł ocenić dane kryterium w skali od –5 do +5), zaś serie osi Y to numery kryteriów (1 – cena, 2 – treść, 3 – estetyka). Etykiety na osi pionowej otrzymano poprzez dodanie punktów o współrzędnych (0; 1 – Cena), (0; 2 – Treść); (0; 3 – Estetyka). Graficzne automatyczne znaczniki dodanych punktów ustawiono jako „brak”, a po-nadto usunięto nadane im nazwy z legendy. Ostatnią czynnością było wy-świetlenie etykiet nazw.
Pomiar danych na skalach mocniejszych (przedziałowa, ilorazowa) jest po-stulowany dla cech ilościowych (zwracano już bowiem uwagę na niebez-pieczeństwo utraty informacji w przypadku „zejścia” ze skali mocniejszej na skalę słabszą). W zależności od liczby wariantów cechy ilościowe moż-na pogrupować w szereg rozdzielczy punktowy lub w szereg rozdzielczy z przedziałami klasowymi (znaczna liczba wariantów cechy). Do graficznej prezentacji danych w postaci szeregów rozdzielczych powszechnie wyko-rzystuje się dwa następujące typy wykresów (por. [2, s. 52]):
1. Histogram.2. Diagram.
Wymienione typy wykresów sporządza się w prostokątnym układzie współrzędnych, przy czym na osi odciętych (oś OX) wykazuje się uporząd-kowane rosnąco warianty cechy skokowej (niewielka liczba wariantów) al-bo przedziały klasowe (pozostałe cechy ilościowe). Natomiast na osi rzędnych (oś OY) – w zależności od rodzaju wykresu – przedstawia się:
– liczebności (częstości) ni,– częstości względne fi, – liczebności (częstości) skumulowane ni sk,– częstości względne skumulowane fi sk .
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
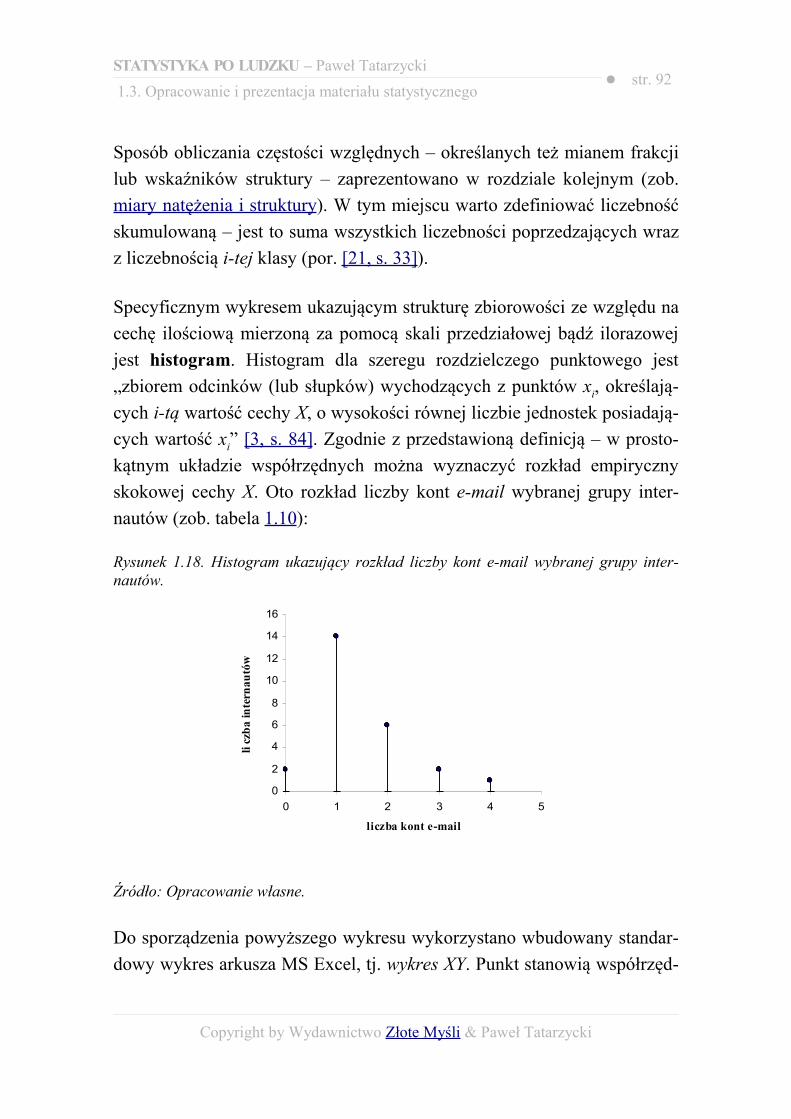
STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.3. Opracowanie i prezentacja materiału statystycznego
str. 92
Sposób obliczania częstości względnych – określanych też mianem frakcji lub wskaźników struktury – zaprezentowano w rozdziale kolejnym (zob. miary natężenia i struktury). W tym miejscu warto zdefiniować liczebność skumulowaną – jest to suma wszystkich liczebności poprzedzających wraz z liczebnością i-tej klasy (por. [21, s. 33]).
Specyficznym wykresem ukazującym strukturę zbiorowości ze względu na cechę ilościową mierzoną za pomocą skali przedziałowej bądź ilorazowej jest histogram. Histogram dla szeregu rozdzielczego punktowego jest „zbiorem odcinków (lub słupków) wychodzących z punktów xi, określają-cych i-tą wartość cechy X, o wysokości równej liczbie jednostek posiadają-cych wartość xi” [3, s. 84]. Zgodnie z przedstawioną definicją – w prosto-kątnym układzie współrzędnych można wyznaczyć rozkład empiryczny skokowej cechy X. Oto rozkład liczby kont e-mail wybranej grupy inter-nautów (zob. tabela 1.10):
Rysunek 1.18. Histogram ukazujący rozkład liczby kont e-mail wybranej grupy inter-nautów.
Źródło: Opracowanie własne.
Do sporządzenia powyższego wykresu wykorzystano wbudowany standar-dowy wykres arkusza MS Excel, tj. wykres XY. Punkt stanowią współrzęd-
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
0
2
4
6
8
10
12
14
16
0 1 2 3 4 5
liczba kont e-mail
li cz
ba in
tern
autó
w
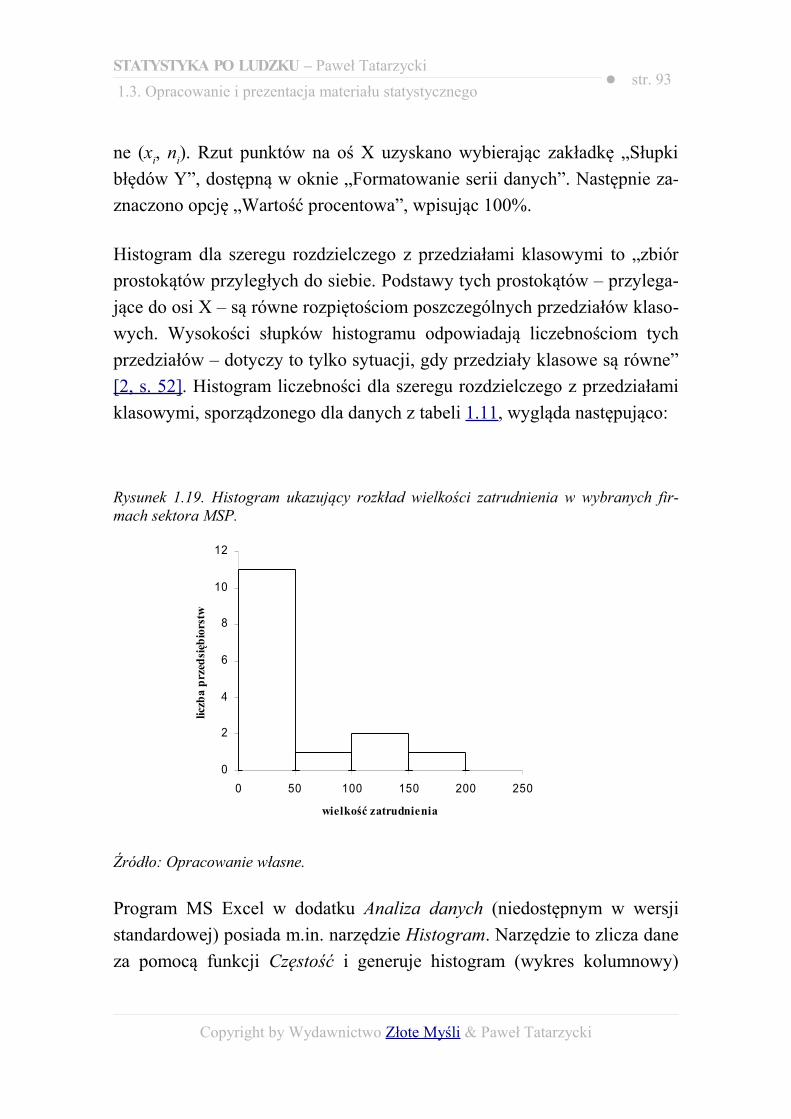
STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.3. Opracowanie i prezentacja materiału statystycznego
str. 93
ne (xi, ni). Rzut punktów na oś X uzyskano wybierając zakładkę „Słupki błędów Y”, dostępną w oknie „Formatowanie serii danych”. Następnie za-znaczono opcję „Wartość procentowa”, wpisując 100%.
Histogram dla szeregu rozdzielczego z przedziałami klasowymi to „zbiór prostokątów przyległych do siebie. Podstawy tych prostokątów – przylega-jące do osi X – są równe rozpiętościom poszczególnych przedziałów klaso-wych. Wysokości słupków histogramu odpowiadają liczebnościom tych przedziałów – dotyczy to tylko sytuacji, gdy przedziały klasowe są równe” [2, s. 52]. Histogram liczebności dla szeregu rozdzielczego z przedziałami klasowymi, sporządzonego dla danych z tabeli 1.11, wygląda następująco:
Rysunek 1.19. Histogram ukazujący rozkład wielkości zatrudnienia w wybranych fir-mach sektora MSP.
Źródło: Opracowanie własne.
Program MS Excel w dodatku Analiza danych (niedostępnym w wersji standardowej) posiada m.in. narzędzie Histogram. Narzędzie to zlicza dane za pomocą funkcji Częstość i generuje histogram (wykres kolumnowy)
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
0
2
4
6
8
10
12
0 50 100 150 200 250
wielkość zatrudnienia
liczb
a pr
zeds
iębi
orst
w

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.3. Opracowanie i prezentacja materiału statystycznego
str. 94
oraz diagram. Zmiana danych wejściowych pociąga za sobą konieczność ponownego użycia tego narzędzia (por. [17, s. 179]). W dołączonym do tej publikacji programie Szeregi statystyczne po wprowadzeniu danych histo-gramy i diagramy są aktualizowane automatycznie. Ponadto – dzięki wyko-rzystaniu wykresu XY – możliwe jest sporządzenie histogramu dla nierów-nych przedziałów klasowych.
W przypadku histogramu z równymi przedziałami klasowymi pola po-szczególnych słupków powinny dać w sumie liczbę obserwacji n przemno-żoną przez długość klasy h (por. [3, s. 86]). Należy podkreślić, iż w przy-padku nierównych przedziałów klasowych wysokości poszczególnych słupków nie są równe odpowiadającym im liczebnościom. Prawidłowa pre-zentacja graficzna szeregu rozdzielczego z nierównymi przedziałami klaso-wymi ma kluczowe znaczenie przy graficznym wyznaczeniu dominanty i innych pozycyjnych miar położenia (zob. miary położenia). Punktem wyj-ścia jest określenie długości poszczególnych przedziałów klasowych. Przyjmując jako bazę dowolny przedział klasowy (z reguły najszerszy lub najwęższy), należy wyznaczyć tzw. natężenie liczebności według poniższe-go wzoru [15, s. 38]:
Oto sposób obliczeń na przykładzie danych dotyczących rozkładu liczby mieszkań w zależności od wieku budynku mieszkalnego (zob. Dane_do_analizy – zakładka Mieszkania):
Tabela 1.18. Mieszkania zamieszkane według wieku budynku (stan na 2002 r.).
Budynek wybudowany w latach:Liczba mieszkań
(tys.)Rozpiętość
klasyNatężenie liczebn.
xi ni hi li
przed 1918 1 190,3 50 3091918 – 1944 1 538,3 27 7411945 – 1970 3 163,8 26 1 582
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.3. Opracowanie i prezentacja materiału statystycznego
str. 95
1971 – 1978 2 149,5 8 3 4931979 – 1988 2 197,9 10 2 8571989 – 2002 1 361,7 13 1 362
Σ 11 602
Źródło: Opracowanie na podstawie: GUS, http://www.stat.gov.pl/dane_spol-gosp/nsp/mieszkania/tablice.xls
Jako dolną granicę pierwszego przedziału klasowego przyjęto rok 1868, stąd rozpiętość tego przedziału wyniosła 50. Rozpiętość bazową, tj. 13, po-dzielono przez poszczególne rozpiętości pozostałych klas, a następnie prze-mnożono przez odpowiadające im liczebności – w ten sposób otrzymano wskaźniki natężenia liczebności. Z danych zamieszczonych w powyższej tabeli wynika, iż najwięcej mieszkań powstało w latach 1945-1970. Jednak nie będzie to najwyższy słupek histogramu – innymi słowy nie jest to prze-dział, w którym znajduje się wartość najczęstsza (dominanta). Po zastoso-waniu wzoru na natężenie liczebności okazuje się, że dominanta zawiera się w przedziale 1971-1979 (przedziały prawostronnie otwarte):
Rysunek 1.20. Histogram z nierównymi przedziałami klasowymi.
Źródło: Opracowanie na podstawie: GUS, http://www.stat.gov.pl
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
0
500
1 000
1 500
2 000
2 500
3 000
3 500
4 000
1865 1880 1895 1910 1925 1940 1955 1970 1985 2000
lata w których powstał budynek
natę
żeni
e lic
zebn
ości

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.3. Opracowanie i prezentacja materiału statystycznego
str. 96
Powyższy histogram posłuży w następnym rozdziale do graficznego wy-znaczenia dominanty. Powszechnym błędem jest naniesienie na taki wykres liczebności zwykłych ni, zamiast wskaźników natężenia liczebności li (przy prawidłowo określonych szerokościach słupków obrazujących różne rozpiętości przedziałów klasowych).
Kolejnym powszechnie stosowanym do graficznej prezentacji danych ilo-ściowych, opartych na skalach mocnych, wykresem jest diagram (nazy-wany też w literaturze przedmiotu wielobokiem liczebności lub wykresem częstości). Diagram dla szeregu punktowego sporządza się tak jak histo-gram, tj. w prostokątnym układzie współrzędnych, przy czym punkty o współrzędnych (xi, ni) łączy się linią łamaną (por. [21, s. 39]). Oto taki wykres, nawiązujący do przykładu z kontami e-mail (por. rys. 1.18):
Rysunek 1.21. Diagram ukazujący liczbę kont e-mail wybranej grupy internautów.
Źródło: Opracowanie własne.
Diagram dla szeregu rozdzielczego z przedziałami klasowymi sporządza się poprzez połączenie linią łamaną punktów o współrzędnych środków przedziałów klasowych i odpowiadających im liczebności. Ponadto ko-
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
0
2
4
6
8
10
12
14
16
0 1 2 3 4 5
liczba kont e-mail
liczb
a in
tern
autó
w
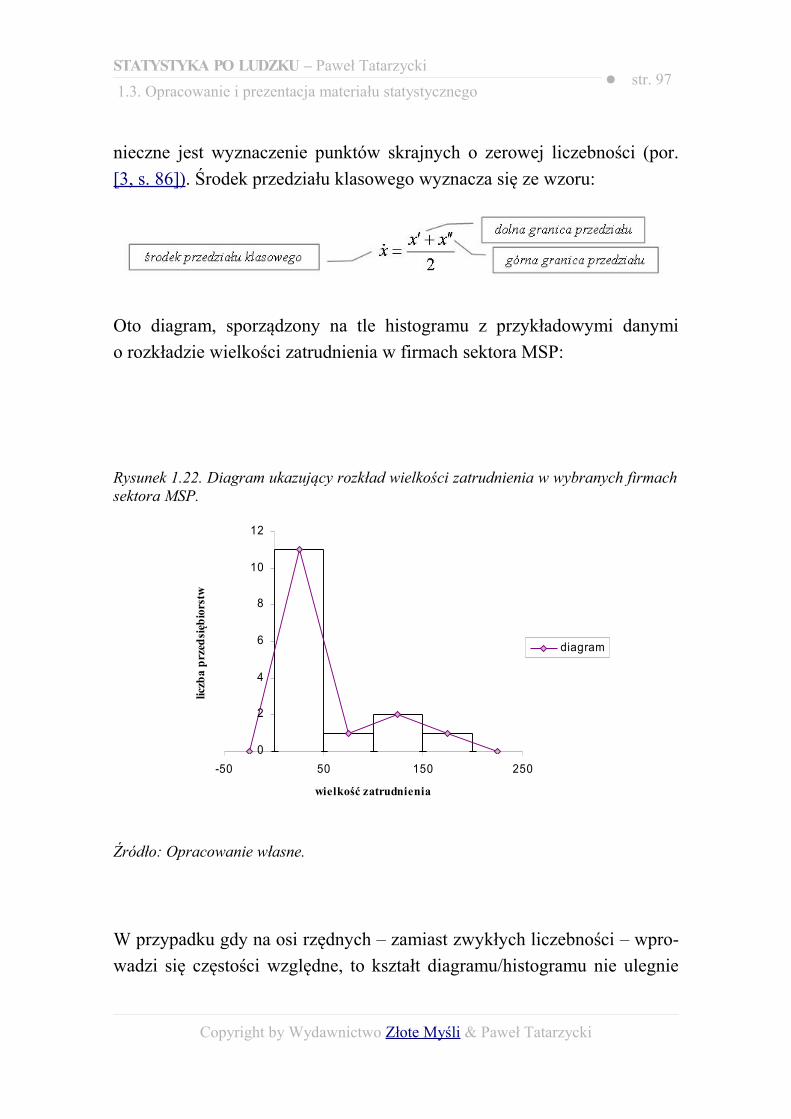
STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.3. Opracowanie i prezentacja materiału statystycznego
str. 97
nieczne jest wyznaczenie punktów skrajnych o zerowej liczebności (por. [3, s. 86]). Środek przedziału klasowego wyznacza się ze wzoru:
Oto diagram, sporządzony na tle histogramu z przykładowymi danymi o rozkładzie wielkości zatrudnienia w firmach sektora MSP:
Rysunek 1.22. Diagram ukazujący rozkład wielkości zatrudnienia w wybranych firmach sektora MSP.
Źródło: Opracowanie własne.
W przypadku gdy na osi rzędnych – zamiast zwykłych liczebności – wpro-wadzi się częstości względne, to kształt diagramu/histogramu nie ulegnie
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
0
2
4
6
8
10
12
-50 50 150 250
wielkość zatrudnienia
liczb
a pr
zeds
iębi
orst
w
diagram
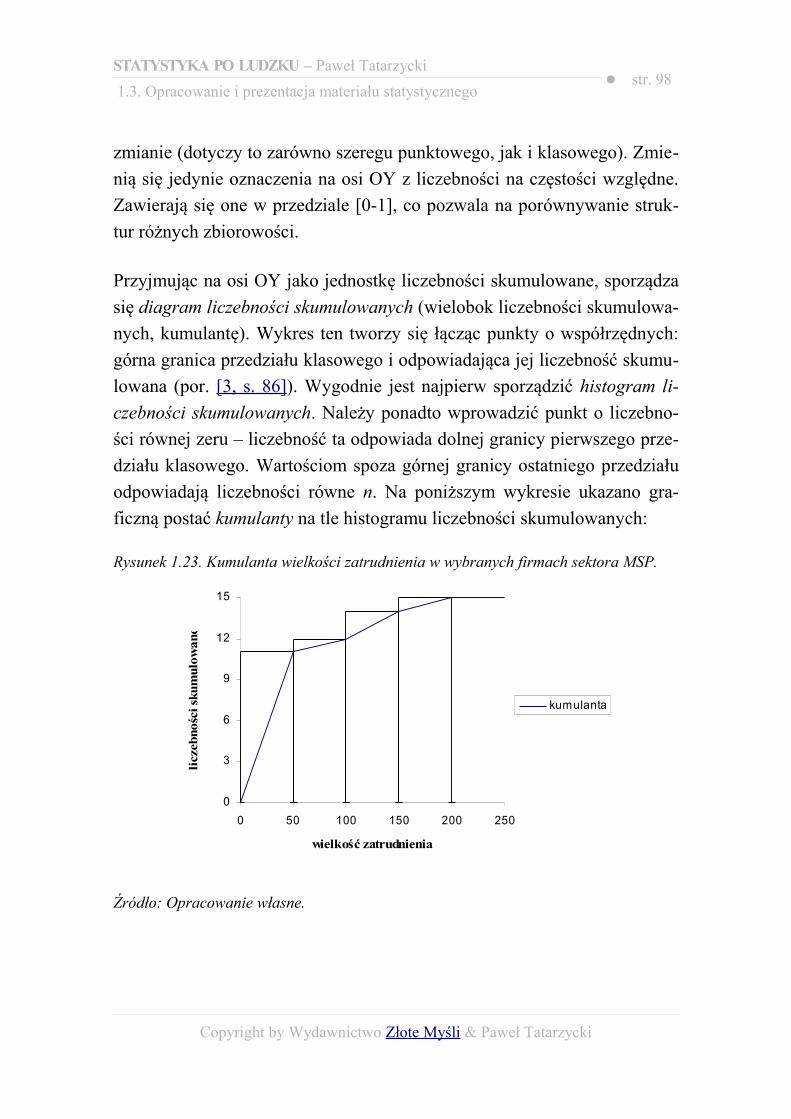
STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.3. Opracowanie i prezentacja materiału statystycznego
str. 98
zmianie (dotyczy to zarówno szeregu punktowego, jak i klasowego). Zmie-nią się jedynie oznaczenia na osi OY z liczebności na częstości względne. Zawierają się one w przedziale [0-1], co pozwala na porównywanie struk-tur różnych zbiorowości.
Przyjmując na osi OY jako jednostkę liczebności skumulowane, sporządza się diagram liczebności skumulowanych (wielobok liczebności skumulowa-nych, kumulantę). Wykres ten tworzy się łącząc punkty o współrzędnych: górna granica przedziału klasowego i odpowiadająca jej liczebność skumu-lowana (por. [3, s. 86]). Wygodnie jest najpierw sporządzić histogram li-czebności skumulowanych. Należy ponadto wprowadzić punkt o liczebno-ści równej zeru – liczebność ta odpowiada dolnej granicy pierwszego prze-działu klasowego. Wartościom spoza górnej granicy ostatniego przedziału odpowiadają liczebności równe n. Na poniższym wykresie ukazano gra-ficzną postać kumulanty na tle histogramu liczebności skumulowanych:
Rysunek 1.23. Kumulanta wielkości zatrudnienia w wybranych firmach sektora MSP.
Źródło: Opracowanie własne.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
0
3
6
9
12
15
0 50 100 150 200 250
wielkość zatrudnienia
licze
bnoś
ci sk
umul
owan
e
kumulanta

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.3. Opracowanie i prezentacja materiału statystycznego
str. 99
Jeżeli na osi rzędnych – zamiast liczebności skumulowanych – pojawią się skumulowane częstości względne, to kształt linii łamanej nie ulegnie zmia-nie. Niemniej jednak przedstawienie rozkładu empirycznego cechy za po-mocą właśnie skumulowanych częstości względnych związane jest z waż-nym w statystyce pojęciem dystrybuanty empirycznej. Dystrybuanta em-piryczna F(x) to funkcja określona na podstawie danych (xi, fi) w następu-jący sposób (por. [5, s. 26]):
Dystrybuantę empiryczną dla szeregu rozdzielczego z przedziałami klaso-wymi wygodnie jest sporządzić w analogiczny sposób jak kumulantę, tj. nanosząc najpierw histogram częstości względnych skumulowanych, a na-stępnie łącząc niejako granice przedziałów (por. rys. 1.23):
Rysunek 1.24. Dystrybuanta empiryczna wielkości zatrudnienia w wybranych firmach sektora MSP.
Źródło: Opracowanie własne.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( )
≥<≤
<= ∑ +
k
iii
i
xxdlaxxxdlaf
xxdlaxF
,1,,0
1
0
0,25
0,5
0,75
1
0 50 100 150 200 250
wielkość zatrudnienia
częs
tośc
i wzg
ledne
sku
mul
owan
e
dys trybuantaempiryczna

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.3. Opracowanie i prezentacja materiału statystycznego
str. 100
W tym miejscu należy zaznaczyć, iż zarówno wykres kumulanty, jak i dys-trybuanty empirycznej w szeregu rozdzielczym klasowym może posłużyć do graficznego wyznaczenia kwartyli, w tym mediany (zob. Miary położe - nia). W warunkach egzaminu pisemnego, gdzie nie można korzystać z pro-gramów komputerowych, w przypadku polecenia odnośnie graficznego wyznaczenia kwartyli – wystarczy sporządzić kumulantę (uniknie się zbęd-nego wyznaczania częstości względnych). Jednak jeżeli polecenie będzie dotyczyło sporządzenia dystrybuanty empirycznej to – z uwagi na jej wła-sności – konieczne jest wyznaczenie linii łamanej, tak jak pokazano to na rys. 1.24. Zgodnie z przedstawioną definicją wartości, dystrybuanty należą do przedziału [0-1].
Ponadto należy wyraźnie rozróżnić wykres dystrybuanty sporządzonej dla szeregu z przedziałami klasowymi od dystrybuanty wyznaczonej dla szere-gu punktowego – w tym przypadku dystrybuanta będzie miała postać schodkową:
Rysunek 1.25. Dystrybuanta empiryczna liczby kont e-mail wybranej grupy internautów.
Źródło: Opracowanie własne.
Cecha X (liczba kont e-mail) przyjmuje wartości od x1 = 0 do x5 = 4. Dla x < x1 dystrybuanta przyjmuje wartość równą zeru (nie ma osób posiadają-
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
0
0,25
0,5
0,75
1
-1 0 1 2 3 4 5
liczba kont e-mail
częs
tośc
i wzg
lędn
e sk
umul
owan
e

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.3. Opracowanie i prezentacja materiału statystycznego
str. 101
cych ujemną liczbę kont e-mail). Z drugiej strony wartość dystrybuanty dla x ≥ x5 wynosi 1 – wszyscy wybrani internauci posiadali co najwyżej 4 kon-ta e-mail. Zamalowane punkty oznaczają, że przedział jest domknięty, zaś puste – otwarty. W punkcie xi dystrybuanta osiąga wartość częstości względnych skumulowanych do i-tej klasy włącznie, czyli:
Powyższe przedziały liczbowe na rys. 1.25 zostały przedstawione w postaci poziomych odcinków lewostronnie domkniętych.
Ostatnim z omawianych wykresów opisujących strukturę zbiorowości jest tzw. wykres pudełkowy (ramkowy). Wykres ten obrazuje położenie miar pozycyjnych, rozproszenie i asymetrię rozkładu cech mierzonych na skali przedziałowej bądź ilorazowej, a także pozwala na wykrycie obserwacji nietypowych (ang. outliers). Do jego sporządzenia niezbędne są następują-ce dane: mediana, kwartyl pierwszy (dolny), kwartyl trzeci (górny) oraz najmniejszy i największy wynik obserwacji. Mediana obrazuje odcinek przecinający pudełko na dwie części, ograniczone kwartylem dolnym i gór-nym. „Wąsy” wyznaczają wartości ekstremalne – minimum i maksimum (por. [1, s. 50-51]). W literaturze statystycznej można spotkać wykresy pu-dełkowe sporządzone w układzie poziomym lub pionowym. Poniżej za-mieszczono wykres pudełkowy w układzie pionowym, gdzie oś pozioma pełni wyłącznie pomocniczą rolę (stąd w opcjach wykresu XY ukryto oś OX):
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( )
≥<≤<≤<≤<≤
<
=
414396,03288,02164,0
|1008,000
xdlaxdlaxdlaxdlaxdla
xdla
xF

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.3. Opracowanie i prezentacja materiału statystycznego
str. 102
Rysunek 1.26. Porównanie tygodniowych stóp zysku akcji spółki Strzelec i Żywiec (dane za I półrocze 2006 r.).
Źródło: Opracowanie na podstawie: Serwis Internetowy Gazety Parkiet, http://www.parkiet.com
Jak już wspomniano, do sporządzenia wykresu pudełkowego w arkuszu Excela można posłużyć się wykresem giełdowym. W tym celu należy wy-brać podtyp „Otwarcie-Maks-Min-Zamknięcie”, wprowadzając kolejno da-ne: wartość dolnego kwartyla, maksimum, minimum, wartość kwartyla górnego (oddzielne serie danych). Wygodniej jest najpierw wpisać niezbędne dane w podanej kolejności do arkusza, następnie zaznaczyć je i wybrać wskazany wykres (por. [3, s. 203]). Jest to prosty sposób wykonania wykresu ramkowego w Excelu, co należy uznać za znaczącą zaletę. Niemniej jednak zastosowanie wykresu giełdowego nie pozwala na ukazanie wartości mediany, co ogranicza interpretację. Dlatego też wykres pudełkowy wykonano w arkuszu Excela za pomocą wykresu XY (zob. Przykłady – wykresy statystyczne). Ponadto w tego rodzaju wykresy wyposażone są programy do statystycznej analizy danych.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
Strzelec Żyw iec-25
-20
-15
-10
-5
0
5
10
15
20
25
30
35
tygo
dnio
we
stop
y zy
sku
(pro
c.)

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.3. Opracowanie i prezentacja materiału statystycznego
str. 103
Jeśli chodzi o interpretację wykresów zamieszczonych na rys. 1.26 – nie wnikając w sposób obliczania miar pozycyjnych – można stwierdzić, że w I półroczu 2006 r. tygodniowe stopy zysku akcji spółki Strzelec były znacznie bardziej zróżnicowane. Świadczy o tym m.in. rozstęp, czyli różnica pomiędzy wartością największą i najmniejszą (zob. Miary dyspersji). Wielkość „pudełek” na tle całego rozstępu obrazuje zmienność wśród 50 proc. obserwacji, określanych mianem typowych – tu także większą dyspersją charakteryzują się stopy zysku akcji spółki Strzelec. Kolejną kwestią jest siła i kierunek asymetrii (zob. Miary asymetrii). Jeżeli mediana dzieli pudełko mniej więcej na pół, to można mówić o symetrii w części centralnej rozkładu. Ponadto należy zwrócić uwagę na odległości pomiędzy dolnym kwartylem a minimum oraz górnym kwartylem a maksimum – przy symetrii postulowane jest, aby odległości te były sobie równe. Nieznaczną asymetrię prawostronną daje się zaobserwować w rozkładzie tygodniowych stóp zysku akcji Strzelec SA Świadczy o tym dłuższy odcinek łączący górny kwartyl z wartością maksymalną od odcinka będącego połączeniem minimum z kwartylem pierwszym, jak również położenie mediany względem kwartyli – w asymetrii prawostronnej mediana znajduje się bliżej dolnego kwartyla (w lewostronnej bliżej górnego). Wreszcie sporządzenie wykresu ramkowego pozwala stwierdzić, czy w badanej zbiorowości występują obserwacje nietypowe. Za takie obserwacje należy uznać te, które są położone w odległości większej niż trzy odchylenia ćwiartkowe (odchylenie jest równe połowie „pudełka”) poniżej pierwszego kwartyla bądź powyżej trzeciego. Zatem obserwacje nietypowe znajdują się w odległości większej niż 1,5 długości „pudełka” (por. [1, s. 53], [3, s. 182-185]).
Kolejną grupą wykresów są wykresy korelacyjne. Powszechnie stosowa-nym wykresem – w przypadku danych niepogrupowanych w tablicę korela - cyjną – jest diagram korelacyjny (zwany także rozrzutem lub chmurą). Diagram korelacyjny służy do graficznej prezentacji danych ilościowych, pogrupowanych w tzw. szereg korelacyjny (zob. np. Dane_do_analizy –
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.3. Opracowanie i prezentacja materiału statystycznego
str. 104
zakładka Akcje). Wykres ten tworzy się w prostokątnym układzie współ-rzędnych poprzez nanoszenie punktów o współrzędnych (x, y), obrazują-cych obserwacje. Diagram korelacyjny pozwala wizualnie ocenić siłę i kie-runek ewentualnej zależności pomiędzy cechami X i Y [15, s. 232-233]. Oto przykład ukazujący zależność wartości księgowej na 1 akcję od ren-towności kapitałów własnych Grupy Żywiec SA:
Rysunek 1.27. Wartość księgowa na 1 akcję a rentowność kapitałów własnych Grupy Żywiec SA
Źródło: Opracowanie na podstawie: Portal Finansowy Money.pl, http://www.money.pl
Mimo niewielkiej liczby obserwacji (dane roczne) – daje się zauważyć ko-relację dodatnią, tzn. wraz ze wzrostem wartości cechy X rosną – ogólnie rzecz biorąc – wartości cechy Y (zob. Miary korelacji).
Jeżeli dane są pogrupowane w tablicę korelacyjną, to można sporządzić efektownie wyglądający wykres w trzech wymiarach: warianty cechy X, warianty cechy Y oraz liczebności (częstości) – pionowa oś Z. Oto przykła-dy:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
90
95
100
105
110
-20% -10% 0% 10% 20% 30%
Rentowność kapitałów własnych (proc.)
War
tość
ksi
ęgow
a na
1 a
kcję
(zł)
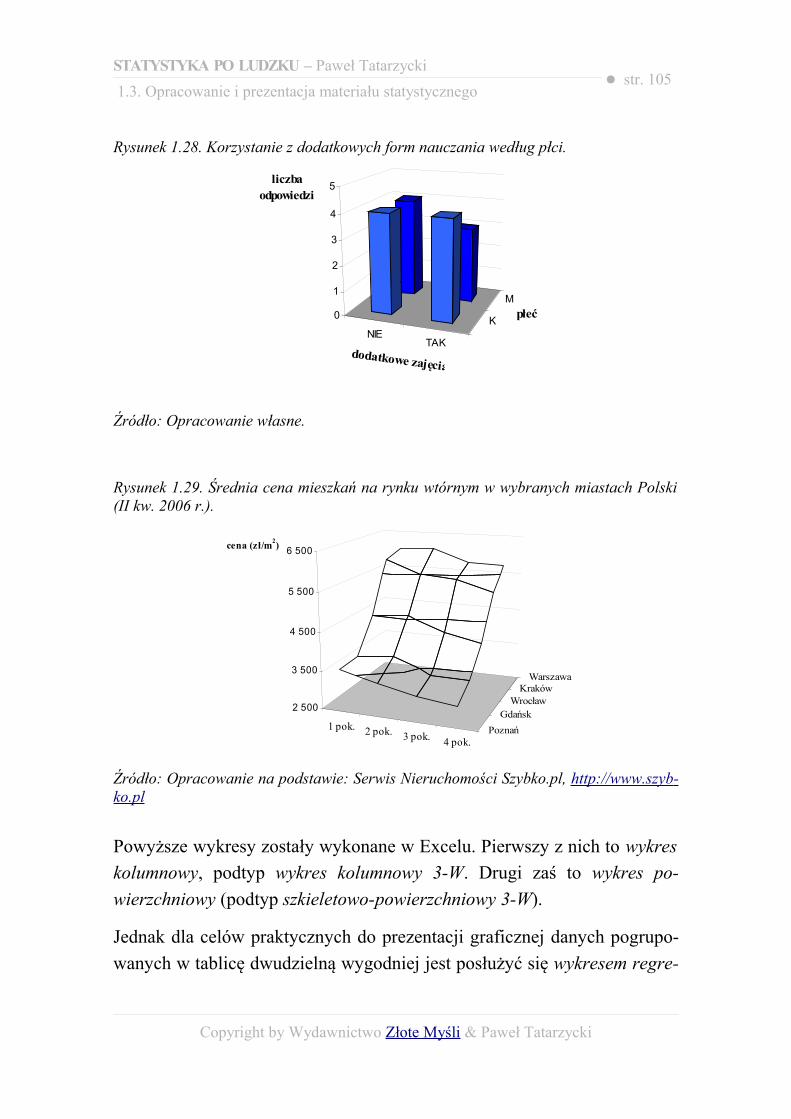
STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.3. Opracowanie i prezentacja materiału statystycznego
str. 105
Rysunek 1.28. Korzystanie z dodatkowych form nauczania według płci.
Źródło: Opracowanie własne.
Rysunek 1.29. Średnia cena mieszkań na rynku wtórnym w wybranych miastach Polski (II kw. 2006 r.).
Źródło: Opracowanie na podstawie: Serwis Nieruchomości Szybko.pl, http://www.szyb - ko.pl
Powyższe wykresy zostały wykonane w Excelu. Pierwszy z nich to wykres kolumnowy, podtyp wykres kolumnowy 3-W. Drugi zaś to wykres po-wierzchniowy (podtyp szkieletowo-powierzchniowy 3-W).
Jednak dla celów praktycznych do prezentacji graficznej danych pogrupo-wanych w tablicę dwudzielną wygodniej jest posłużyć się wykresem regre-
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
NIETAK
K
M0
1
2
3
4
5liczba odpowiedzi
dodatkowe zajęcia
płeć
`
1 pok. 2 pok. 3 pok. 4 pok.Poznań
GdańskWrocław
KrakówWarszawa
2 500
3 500
4 500
5 500
6 500cena (zł/m2)

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.3. Opracowanie i prezentacja materiału statystycznego
str. 106
sji empirycznej. Wykres regresji empirycznej sporządza się poprzez przy-porządkowanie wariantom jednej cechy (w przypadku cechy ciągłej środ-kom przedziałów klasowych) średnich warunkowych drugiej cechy (z reguły jest to cecha ilościowa). Naniesione w układzie współrzędnych punkty łączy się linią ciągłą, w wyniku czego powstaje łamana. Wykres re-gresji empirycznej pozwala przede wszystkim na wizualną ocenę kształtu zależności, jej kierunku (dodatnia lub ujemna), a niekiedy siły zależności porównywanych cech [15, s. 241]. Wykres ten jest bardzo użyteczny w przypadku, gdy jedna z cech ma charakter jakościowy. Odwołując się do cen mieszkań w największych polskich miastach w drugim kwartale 2006 r. (zob. rys. 1.29): cechą jakościową jest nazwa miasta, a ilościową – liczba pokoi. Zmienną zależną jest cena jednego metra kwadratowego (oś Z). W oparciu o te informacje można wyznaczyć średnią cenę jednego metra kwadratowego mieszkania w Polsce w zależności od liczby pokoi:
Rysunek 1.30. Średnia cena mieszkań na rynku wtórnym w Polsce według liczby pokoi (II kw. 2006 r.).
Źródło: Opracowanie na podstawie: Serwis Nieruchomości Szybko.pl, http://www.szyb - ko.pl
Powyższy wykres wykonano w Excelu z wykorzystaniem wykresu liniowe-go (ze znacznikami danych wyświetlanymi przy każdej wartości). Poszcze-gólne cechy to średnie arytmetyczne cen mieszkań w większych miastach Polski według liczby pokoi. Ogólnie rzecz biorąc: w objętych analizą mia-
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
3 800
4 000
4 200
4 400
4 600
4 800
5 000
1 2 3 4
liczba pokoi
śre
dnia
cen
a za
met
r kw
.
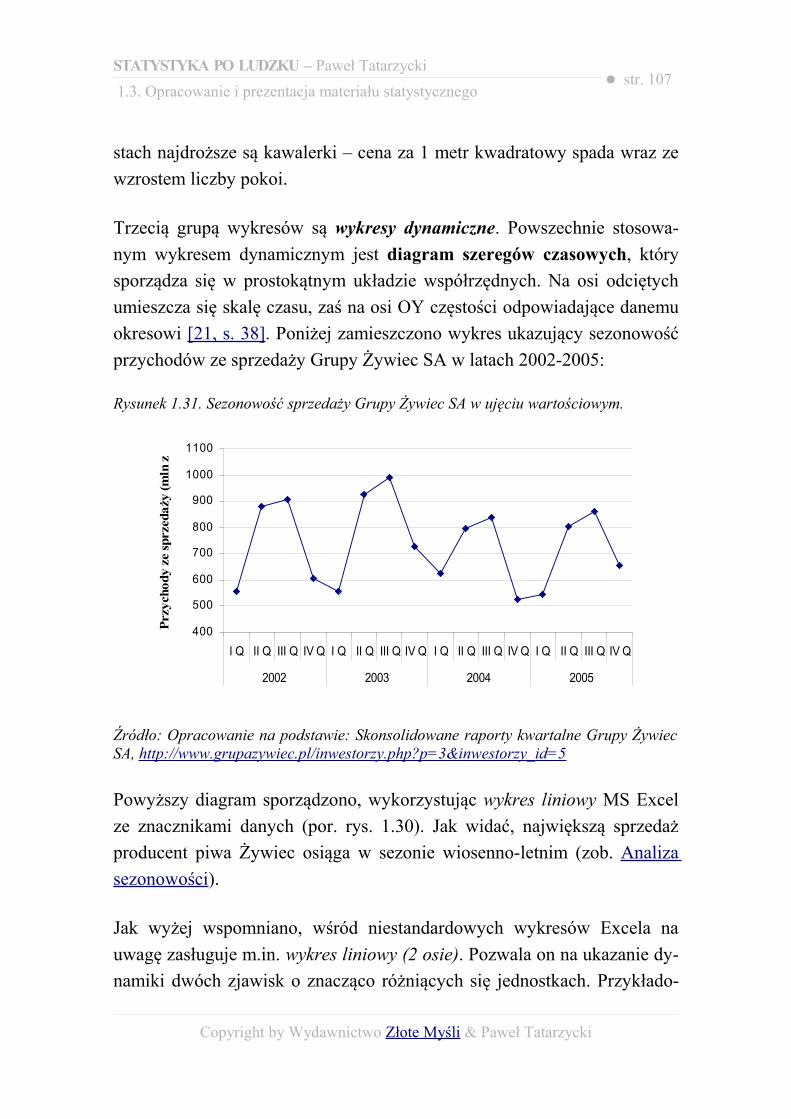
STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.3. Opracowanie i prezentacja materiału statystycznego
str. 107
stach najdroższe są kawalerki – cena za 1 metr kwadratowy spada wraz ze wzrostem liczby pokoi.
Trzecią grupą wykresów są wykresy dynamiczne. Powszechnie stosowa-nym wykresem dynamicznym jest diagram szeregów czasowych, który sporządza się w prostokątnym układzie współrzędnych. Na osi odciętych umieszcza się skalę czasu, zaś na osi OY częstości odpowiadające danemu okresowi [21, s. 38]. Poniżej zamieszczono wykres ukazujący sezonowość przychodów ze sprzedaży Grupy Żywiec SA w latach 2002-2005:
Rysunek 1.31. Sezonowość sprzedaży Grupy Żywiec SA w ujęciu wartościowym.
Źródło: Opracowanie na podstawie: Skonsolidowane raporty kwartalne Grupy Żywiec SA, http://www.grupazywiec.pl/inwestorzy.php?p=3&inwestorzy_id=5
Powyższy diagram sporządzono, wykorzystując wykres liniowy MS Excel ze znacznikami danych (por. rys. 1.30). Jak widać, największą sprzedaż producent piwa Żywiec osiąga w sezonie wiosenno-letnim (zob. Analiza sezonowości).
Jak wyżej wspomniano, wśród niestandardowych wykresów Excela na uwagę zasługuje m.in. wykres liniowy (2 osie). Pozwala on na ukazanie dy-namiki dwóch zjawisk o znacząco różniących się jednostkach. Przykłado-
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
400
500
600
700
800
900
1000
1100
I Q II Q III Q IV Q I Q II Q III Q IV Q I Q II Q III Q IV Q I Q II Q III Q IV Q
2002 2003 2004 2005
Przy
chod
y ze
sprz
edaż
y (m
ln z
ł)

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.3. Opracowanie i prezentacja materiału statystycznego
str. 108
wo, wykres ten można zastosować do ukazania kształtowania się kursów akcji porównywanych już wcześniej spółek (zob. rys. 1.26):
Rysunek 1.32. Kształtowanie się kursów akcji spółek Strzelec i Żywiec w pierwszej połowie 2006 r.
Źródło: Opracowanie na podstawie: Serwis Internetowy Gazety Parkiet, http://www.parkiet.com
Na jednej osi znajdują się ceny akcji spółki Strzelec, a na pomocniczej – spółki Żywiec. Z uwagi na dużą różnicę cen akcji obu spółek porównanie kursów na tradycyjnym wykresie liniowym (jedna oś pionowa) jest bezza-sadne. Podobnie wykres liniowo-kolumnowy (2 osie) może posłużyć do ukazania kursów akcji danej spółki (wykres liniowy) na tle obrotów (wy-kres kolumnowy).
Na zakończenie warto też wspomnieć o wykresach sporządzanych w celu porównywania struktur zbiorowości w czasie. Jako przykład można podać
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
0,60
0,80
1,00
1,20
1,40
1,60
1,80
2006-01
-02
2006-02
-01
2006-03
-02
2006-03
-31
2006-05
-05
2006-06
-05
kurs
akc
ji sp
ółki
Str
zele
c (zł
)
400
450
500
550
600
kurs
akc
ji sp
ółki
Żyw
iec (
zł)
StrzelecŻywiec
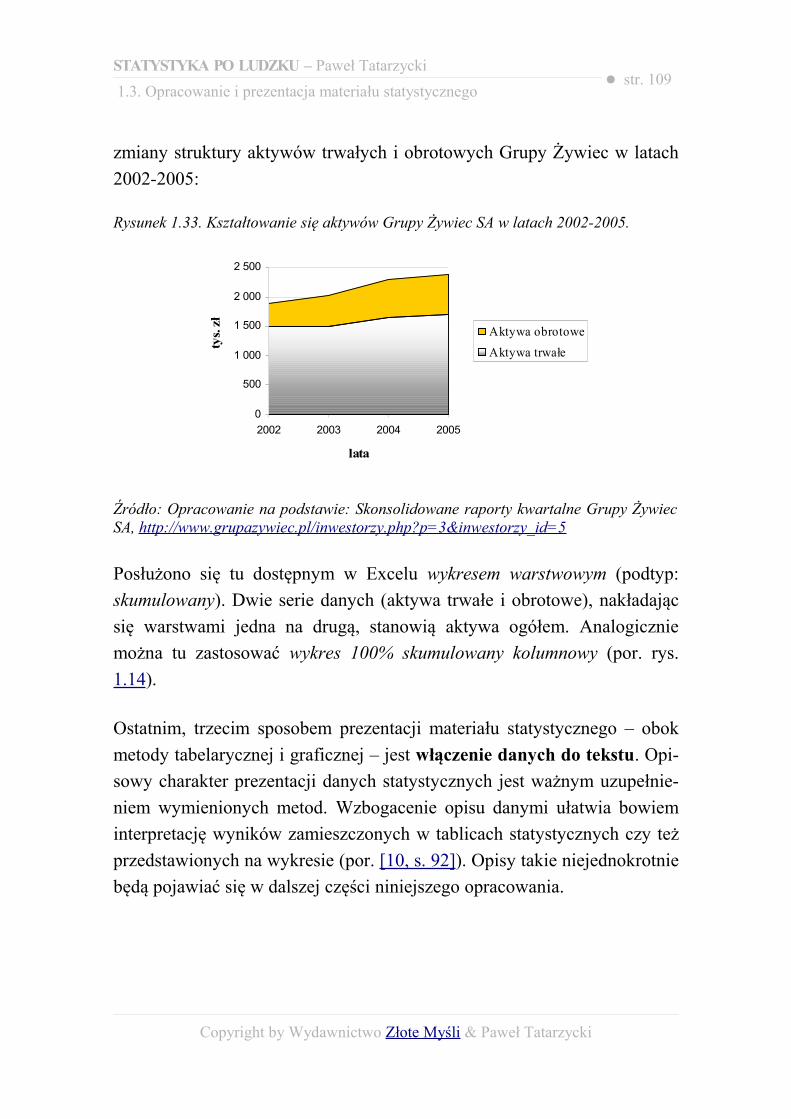
STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.3. Opracowanie i prezentacja materiału statystycznego
str. 109
zmiany struktury aktywów trwałych i obrotowych Grupy Żywiec w latach 2002-2005:
Rysunek 1.33. Kształtowanie się aktywów Grupy Żywiec SA w latach 2002-2005.
Źródło: Opracowanie na podstawie: Skonsolidowane raporty kwartalne Grupy Żywiec SA, http://www.grupazywiec.pl/inwestorzy.php?p=3&inwestorzy_id=5
Posłużono się tu dostępnym w Excelu wykresem warstwowym (podtyp: skumulowany). Dwie serie danych (aktywa trwałe i obrotowe), nakładając się warstwami jedna na drugą, stanowią aktywa ogółem. Analogicznie można tu zastosować wykres 100% skumulowany kolumnowy (por. rys. 1.14).
Ostatnim, trzecim sposobem prezentacji materiału statystycznego – obok metody tabelarycznej i graficznej – jest włączenie danych do tekstu. Opi-sowy charakter prezentacji danych statystycznych jest ważnym uzupełnie-niem wymienionych metod. Wzbogacenie opisu danymi ułatwia bowiem interpretację wyników zamieszczonych w tablicach statystycznych czy też przedstawionych na wykresie (por. [10, s. 92]). Opisy takie niejednokrotnie będą pojawiać się w dalszej części niniejszego opracowania.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
0
500
1 000
1 500
2 000
2 500
2002 2003 2004 2005
lata
tys.
zł
Aktywa obrotoweAktywa trwałe

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.4. Analiza statystyczna
str. 110
1.4. Analiza statystyczna
Analiza statystyczna stanowi ostatni etap badania statystycznego. Ma ona za zadanie „wykrycie prawidłowości i zależności zachodzących w badanej zbiorowości statystycznej” [7, s. 86]. Zakres analizy statystycznej ukazuje poniższy schemat:
Rysunek 1.34. Zakres analizy statystycznej.
Źródło: [9, s. 25].
Ukazany na rys. 1.34 zakres analizy statystycznej wiąże się z klasyfikacją metod statystycznych według następujących kryteriów (por. [9, s. 25], [20, s. 23]):
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.4. Analiza statystyczna
str. 111
1. Kryterium formalnego – metody opisu i wnioskowania statystycznego.2. Kryterium zakresowego – metody analizy struktury, korelacji i dynami-
ki.
Nieostry podział metod analizy statystycznej z punktu widzenia zakresu ich zastosowań staje się bardziej czytelny, jeśli wprowadzi się podział na [9, s. 25]:
1. Deterministyczne metody opisu statystycznego.2. Stochastyczne (oparte na rachunku prawdopodobieństwa) metody wnio-
skowania statystycznego.
Powyższy podział został przyjęty w niniejszym opracowaniu – łączy on w sobie niejako dwa wymienione wyżej kryteria podziału analizy staty-stycznej, tj. kryterium formalne i zakresowe. Oto graficzna prezentacja przyjętego podziału metod analizy statystycznej:
Rysunek 1.35. Klasyfikacja metod analizy statystycznej.
Źródło: Opracowanie na podstawie: [15, s. 25].
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.4. Analiza statystyczna
str. 112
Opis statystyczny obejmuje następujące elementy (por. [15, s. 21-22]):
1. Opis struktury danej zbiorowości – analiza jednowymiarowa (ze wzglę-du na jedną cechę), statyczna (w określonym czasie).
2. Opis współzależności zjawisk – analiza dwuwymiarowa lub wielowy-miarowa (badaniu podlega związek pomiędzy co najmniej trzema ce-chami statystycznymi).Badanie współzależności obejmuje powiązania pomiędzy różnymi ce-chami opisującymi daną zbiorowość statystyczną. Może ono dotyczyć siły, kierunku i rodzaju zależności wybranych cech (np. zależność linio-wa).
3. Opis dynamiki zjawisk stanowi badanie danej zbiorowości w czasie (analiza dynamiki).
Wnioskowanie statystyczne polega na uogólnianiu wyników uzyskanych w próbie na całą populację statystyczną. Weryfikacja pewnych założeń od-noszących się do całej zbiorowości statystycznej (weryfikacja hipotez sta-tystycznych) może dotyczyć struktury zjawisk, ich współzależności, jak również dynamiki (por. [15, s. 22]).
Przyjętej klasyfikacji metod analizy statystycznej odpowiadają dwa duże działy statystyki, a mianowicie (por. [3, s. 14]):
1. Statystyka opisowa – obejmuje metody zbierania danych o całej zbioro-wości statystycznej lub próbnej, ich prezentacji i analizy tej zbiorowości w zakresie: struktury z punktu widzenia wybranych cech statystycz-nych, występowania współzależności między cechami i dynamiki zja-wisk (zagadnieniom z tym związanym poświęcono kolejny rozdział).
2. Statystyka matematyczna – obejmuje metody wnioskowania o właści-wościach danej zbiorowości statystycznej na podstawie próby losowej pobranej z populacji generalnej (np. szacowanie wartości wybranych charakterystyk danej populacji). Uogólnianie wyników badań częścio -
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.4. Analiza statystyczna
str. 113
wych – opartych na próbie losowej – na całą populację określa się mia-nem wnioskowania statystycznego (wybrane zagadnienia statystyki ma-tematycznej opisano w rozdziale trzecim).
Reasumując, można stwierdzić, iż idea statystyki sprowadza się na ogół do wnioskowania o rozkładzie danej cechy w oparciu o pobraną w sposób lo-sowy próbę – zebrany materiał statystyczny, niezależnie od sposobu doboru próby, poddaje się metodom opisu statystycznego. Wyznaczone w oparciu o zbiorowość próbną charakterystyki (miary opisu statystycznego, miary współzależności itp.) różnią się w pewnym stopniu od faktycznych analogicznych miar dla całej populacji. Stąd cennych metod dostarcza wnioskowanie statystyczne, które z określonym prawdopodobieństwem pozwala określić rzeczywistą wartość danej miary statystycznej. Ponadto można postawić pewne hipotezy, dotyczące zarówno wartości parametrów statystycznych, jak również rozkładów cech.
W praktyce niektórzy studenci mają problem z rozróżnieniem miar wyzna-czonych z próby od analogicznych miar dla całej populacji – trudność pole-ga np. na odróżnieniu odchylenia standardowego z próby s od odchylenia, jakie występuje w całej populacji statystycznej σ. W następnym rozdziale wyznaczone miary będą dotyczyć zbiorowości próbnej (przy czym sposób ich obliczania jest taki sam dla całej populacji statystycznej). Natomiast w rozdziale trzecim na podstawie wybranych miar szacowane będą rzeczy-wiste parametry dla całej populacji generalnej (w praktyce poddanie anali-zie wszystkich jednostek statystycznych jest zazwyczaj niemożliwe z uwa-gi na znaczne koszty badań).
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.5. Trening i ewaluacja
str. 114
1.5. Trening i ewaluacja
Aby utrwalić wprowadzone w niniejszym rozdziale wiadomości, warto za-mieścić rozbudowany przykład praktyczny. Poniżej zamieszczono dwa przykłady – pierwszy z nich dotyczy analizy danych zebranych za pomocą kwestionariusza ankietowego (źródła pierwotne), drugi zaś stanowi analizę rozkładu tygodniowych stóp zysku akcji spółki Żywiec na tle WIG (źródła wtórne).
Przykład 1
Celem diagnostycznym jest określenie opinii wybranej grupy Czytelników na temat niniejszej publikacji. Przykładowe dane znajdują się w pliku Da-ne_do_analizy (zakładka Ankiety). Cel praktyczny to dostosowanie treści, metod i narzędzi dydaktycznych do potrzeb respondentów po to, by zwięk-szyć skuteczność uczenia się. Można postawić kilka hipotez roboczych, a mianowicie:
1. Osoby, które są zdania, że e-book ten pomógł im w przygotowaniu się do egzaminu, znacznie lepiej oceniają cenę i jakość treści.
2. Optymalna struktura treści to przewaga praktyki nad teorią.3. Większość respondentów to tzw. „czuciowcy”, którzy – w odróżnieniu
od wzrokowców – bardziej od ilustracji (schematów) preferują w naby-waniu wiedzy animacje i hiperłącza.
4. Najbardziej przydatnym dodatkiem według opinii Czytelników są przy-kłady wykonane w arkuszu kalkulacyjnym.
Mając określony cel badania statystycznego, można przejść do określenia jednostki i zbiorowości statystycznej. Zbiorowość statystyczną tworzą wszyscy potencjalni nabywcy e-booka „Statystyka po ludzku”. Są to najczęściej studenci, dla których nauka statystyki to prawdziwy koszmar… Jednostki statystyczne stanowią poszczególni potencjalni klienci-studenci.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.5. Trening i ewaluacja
str. 115
Z uwagi na znaczną liczebność zbiorowości generalnej – konieczny jest dobór próby. Przykładowe dane dotyczą zaledwie piętnastu ankietowanych (dla celów szkoleniowych przyjęto niewielką liczebność próby). Jest to więc częściowe badanie statystyczne, przeprowadzone metodą ankietową (pominięto tu założenie o losowym doborze próby).
Znając już cel i zakres badania statystycznego, można przejść do etapu dru-giego – obserwacji statystycznej. Z uwagi na specyfikę tematyki badania – ma tu miejsce gromadzenie danych ze źródeł pierwotnych (brak źródeł wtórnych, pozwalających na weryfikację postawionych hipotez roboczych). Posłużono się przy tym metodą ankiety, przeprowadzonej z wykorzystaniem formularza zamieszczonego w Internecie (zob. rys. 1.6). Formularz składa się z siedmiu pytań. I tak: pytanie pierwsze bada przydat-ność publikacji w przygotowaniu się do egzaminu ze statystyki. Zastoso-wano tu pomiar na porządkowej skali Likerta (cecha porządkowa), przyjmując następujący system kodowania kafeterii:
+2: zdecydowanie tak,+1: raczej tak,0: trudno powiedzieć,-1: raczej nie,-2: zdecydowanie nie.
Pytanie drugie – określające preferencje co do przyswajania wiedzy (ele-menty graficzne, hiperłącza i animacje) – określono na porządkowej skali porównywania parami. Zgodnie z postawioną hipotezą nr 3, wprowadzono następujące oznaczenia:
0: najbardziej preferowane są elementy graficzne (wzrokowcy),1: najbardziej preferowane są hiperłącza i animacje (czuciowcy, tj. osoby stroniące od tradycyjnych, statycznych narzędzi dydaktycznych).
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.5. Trening i ewaluacja
str. 116
Pytanie trzecie dotyczy oceny treści zamieszczonych w e-booku według trzech wymiarów:
I Nudne/ciekawe.II Teoretyczne/praktyczne.III Zawiłe/przejrzyste.
Wykorzystano tu pomiar na skali przedziałowej (dyferencjału semantycz-nego).
Jeśli chodzi o pytanie 4, to polegało ono na wpisaniu wartości procento-wych, sumujących się do 100 proc. W arkuszu wyników podano jedynie preferowany przez Czytelnika procentowy udział treści teoretycznych.
Następne pytanie rozpisano na sześć pól, którym nadano analogiczne na-zwy jak w formularzu – od A do E. Są to litery odpowiadające dodatkom do publikacji. Każdej z nich przypisano miejsce od 1 do 6. Jest to przykład cechy porządkowej mierzonej na skali rang.
Pytanie szóste oparto na skali przedziałowej, przy czym wybrano tu skalę Stapela. Respondenci za pomocą liczb od –5 do +5 mieli wyrazić odpo-wiednio dezaprobatę lub aprobatę odnośnie ceny e-booka, jakości treści oraz estetyki.
Ostatnie – tzw. metryczkowe – pytanie dotyczy określenia płci (cecha no-minalna).
Po zebraniu danych pierwotnych i poddaniu ich kontroli formalnej i mery-torycznej następuje przejście do kolejnego etapu badania statystycznego. Grupowanie i zliczanie uzyskanego materiału statystycznego (zob. Przy-kłady – grupowanie danych) jest zgodne z przedstawionymi hipotezami ro-boczymi.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.5. Trening i ewaluacja
str. 117
Aby dokonać weryfikacji pierwszej hipotezy roboczej, należy pogrupować dane w tablicę korelacyjną (dwudzielną), gdzie w wierszach znajdzie się wykaz klasyfikacyjny pytania 1, a w kolumnach średnia uzyskanych punk-tów, dotycząca odpowiednio ceny i treści e-booka. Oto prezentacja tabela-ryczna i graficzna (wykresy regresji empirycznej):
Porównując dwa powyższe wykresy, można stwierdzić, że osoby wyrażają-ce opinię, że e-book ten raczej pomógł (+1) lub zdecydowanie pomógł (+2) im w przygotowaniu się do egzaminu z reguły oceniały cenę i treść publi-kacji na wysokim poziomie, co jest zgodne z wcześniejszym przypuszcze-niem.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
-5-4-3-2-1012345
poziom przydatności e-booka
prze
cięt
na o
cena
cen
y e-
book
a
Serie1 -3,00 0,67 1,75 4,00 4,00
-2 -1 0 1 2
-5-4-3-2-1012345
poziom przydatności e-booka
prze
cięt
na o
cena
treś
ci e
-boo
ka
Serie1 -5,00 -1,67 2,75 3,50 4,33
-2 -1 0 1 2

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.5. Trening i ewaluacja
str. 118
Druga hipoteza dotyczy struktury treści materiału dydaktycznego z podzia-łem na praktyczne i teoretyczne. Wystarczy tu pogrupować dane (udział teorii) w szereg rozdzielczy z przedziałami klasowymi. W oparciu o tak po-grupowane dane można sporządzić wykres dystrybuanty empirycznej:
Wszyscy ankietowani są zgodni, iż powinno być minimum 15 proc. teorii. Aż trzy czwarte ankietowanych wyraziły opinię (wartość dystrybuanty na poziomie 0,75), iż teorii nie powinno być więcej niż 50 proc. Potwierdza się zatem hipoteza, że optymalna struktura treści to przewaga praktyki nad teorią (tylko co czwarty respondent był odmiennego zdania).
Trzecia hipoteza robocza wymaga określenia odsetka odpowiedzi na pyta-nie drugie. Wystarczy jedynie zliczyć odpowiedzi, wykorzystując np. Ra-port tabeli przestawnej Excela:
Okazuje się, iż praktycznie połowa ankietowanych to tzw. czuciowcy. W tej sytuacji nie można mówić o słuszności postawionej hipotezy roboczej.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
0
0,25
0,5
0,75
1
15 25 35 45 55 65
procentowy udział teorii
war
tość
dys
tryb
uant
y em
piry
czne
j
47%
53%
wzrokowcyczuciowcy

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.5. Trening i ewaluacja
str. 119
Ostatnia z postawionych hipotez brzmi: „Najbardziej przydatnym dodat-kiem według opinii Czytelników są przykłady wykonane w arkuszu kalku-lacyjnym”. W tym przypadku wystarczy policzyć średnie miejsce, na któ-rym uplasował się dany dodatek:
Z powyższego wykresu wynika, że najwyższe (bliskie 1) miejsce uzyskał dodatek oznaczony literą „E”, czyli – tak jak przypuszczano – przykłady wykonane w Excelu.
W przedstawionej analizie wykonano pewne obliczenia miar opisu staty-stycznego (średnia arytmetyczna) z wykorzystaniem Raportu tabeli prze-stawnej (zob. Excel_grupowanie_danych). Szczegółowo najważniejsze miary statystyczne omówione zostaną w rozdziale następnym.
Przykład 2
Posiadając dane o cenach akcji spółki Żywiec oraz dane dotyczące pozio-mu Warszawskiego Indeksu Giełdowego WIG, należy określić rozkłady ty-godniowych stóp zwrotu (cel diagnostyczny). Cel praktyczny polega na określeniu atrakcyjności akcji badanej spółki pod względem oczekiwanych stóp zysku.
Można postawić hipotezę, iż – z uwagi na relatywnie niewielkie ryzyko zmian kursu akcji spółki Żywiec – należy oczekiwać średnio mniejszych stóp zysku niż przeciętna zyskowność dla Giełdy Papierów Wartościowych
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
5,73
4,07
4,47
2,53
1,87
0 1 2 3 4 5 6
Średnia z P5_A
Średnia z P5_B
Średnia z P5_C
Średnia z P5_D
Średnia z P5_E

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.5. Trening i ewaluacja
str. 120
mierzona zmianami indeksu WIG. Innymi słowy, rozkład tygodniowych procentowych zmian WIG jest przesunięty „w prawo” w porównaniu z roz-kładem tygodniowych stóp zysku akcji Żywiec.
Zbiorowość statystyczną stanowią sesje giełdowe Giełdy Papierów Warto-ściowych w Warszawie (cecha przestrzenna) z pierwszego półrocza 2006 r. (cecha czasowa). Do obliczeń wybrano sesje w odstępach tygodniowych. Wielkość próby to 25 tygodniowych stóp zysku akcji Żywiec i tygodnio-wych zmian poziomu WIG – cechy ilościowe ciągłe.
Drugi etap w tym przypadku sprowadza się do pozyskania danych ze źró-deł wtórnych (dane pochodzą z Serwisu Internetowego Gazety Parkiet). Konieczne było przeliczenie dziennych stóp zwrotu na tygodniowe.
Etap trzeci stanowi pogrupowanie danych oraz prezentację graficzną. Ce-chy ilościowe ciągłe należy pogrupować w szereg rozdzielczy z przedziała-mi klasowymi. Sposób postępowania jest następujący:
1. Określenie liczby przedziałów klasowych k za pomocą prezentowanych wcześniej wzorów (wybór wzoru zależy z reguły od osoby rozwiązują-cej zadanie):– sposób I: pierwiastek kwadratowy z liczby obserwacji n = 25,– sposób II: 5 log n,– sposób III: 1 + 3,322 log n.
Z obliczeń wynika, że dla 25 sesji giełdowych stopy zwrotu można pogru-pować w 5-7 przedziałów klasowych (zob. Przykłady – grupowanie da-nych).
2. Kolejną kwestią jest obliczenie rozstępu, tj. różnicy pomiędzy wartością maksymalną i minimalną:– rozstęp dla WIG: R = 8,67 – (–7,43) = 16,1 (proc. tygodniowo).
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
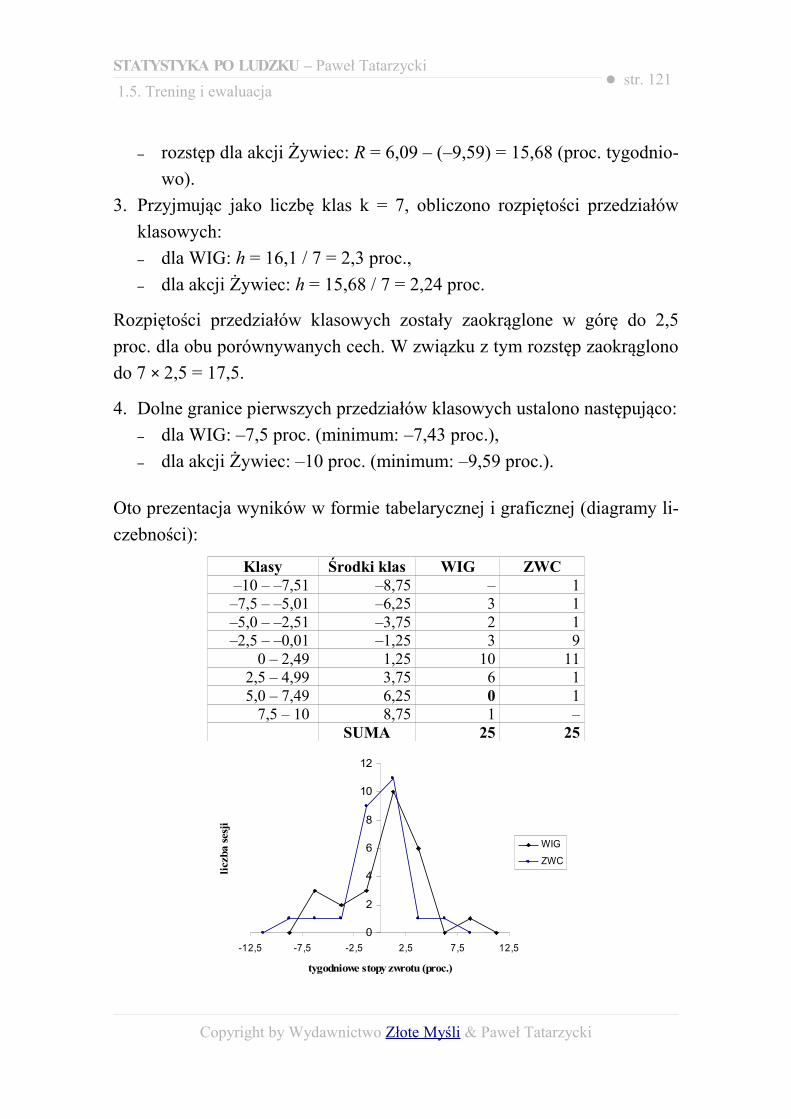
STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.5. Trening i ewaluacja
str. 121
– rozstęp dla akcji Żywiec: R = 6,09 – (–9,59) = 15,68 (proc. tygodnio-wo).
3. Przyjmując jako liczbę klas k = 7, obliczono rozpiętości przedziałów klasowych:– dla WIG: h = 16,1 / 7 = 2,3 proc.,– dla akcji Żywiec: h = 15,68 / 7 = 2,24 proc.
Rozpiętości przedziałów klasowych zostały zaokrąglone w górę do 2,5 proc. dla obu porównywanych cech. W związku z tym rozstęp zaokrąglono do 7 × 2,5 = 17,5.
4. Dolne granice pierwszych przedziałów klasowych ustalono następująco:– dla WIG: –7,5 proc. (minimum: –7,43 proc.),– dla akcji Żywiec: –10 proc. (minimum: –9,59 proc.).
Oto prezentacja wyników w formie tabelarycznej i graficznej (diagramy li-czebności):
Klasy Środki klas WIG ZWC–10 – –7,51 –8,75 – 1–7,5 – –5,01 –6,25 3 1–5,0 – –2,51 –3,75 2 1–2,5 – –0,01 –1,25 3 9
0 – 2,49 1,25 10 112,5 – 4,99 3,75 6 15,0 – 7,49 6,25 0 1
7,5 – 10 8,75 1 –SUMA 25 25
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
0
2
4
6
8
10
12
-12,5 -7,5 -2,5 2,5 7,5 12,5
tygodniowe stopy zwrotu (proc.)
liczb
a se
sji
WIG
ZWC

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.5. Trening i ewaluacja
str. 122
Z porównania obu rozkładów wynika, że postawiona hipoteza jest słuszna (rozkład stóp zwrotu WIG jest przesunięty „w prawo” w porównaniu z roz-kładem dla spółki Żywiec).
EWALUACJA
Test 1
Pytanie 1. Uszereguj kolejno etapy badania statystycznego wpisując liczby od 1 do 4, gdzie „1” oznacza etap pierwszy:
a) obserwacja statystyczna: ___b) przygotowanie badania: ___c) analiza danych: ___d) opracowanie i prezentacja materiału statystycznego: ___
Pytanie 2. Celem badania statystycznego jest określenie struktury klientów wybranego supermarketu pod względem wieku i płci. Mamy tu do czynie-nia ze zbiorowością:
a) nieskończenie licznąb) niejednorodnąc) wielowymiarowąd) jednowymiarową
Pytanie 3. Celem badania statystycznego jest poznanie opinii Czytelników na podstawie przeprowadzonej za pośrednictwem Internetu ankiety. Zasto-sowano tu pomiar:
a) ze źródeł pierwotnych z wykorzystaniem techniki wywiadu skategory-zowanego
b) ze źródeł wtórnych z wykorzystaniem danych internetowych
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.5. Trening i ewaluacja
str. 123
c) ze źródeł pierwotnych z wykorzystaniem techniki ankietyd) ze źródeł pierwotnych posługując się obserwacją jawną
Pytanie 4. Jednostkę statystyczną w zbiorowości dynamicznej stanowi:
a) kwestionariusz ankietyb) data sesji giełdowejc) nazwa spółkid) kwartał
Pytanie 5. Przykładami źródeł wtórnych są:
a) wyniki ankiety zamieszczonej w czasopiśmie branżowymb) dane zamieszczone na stronie WWW Urzędu Statystycznegoc) dane uzyskane w wyniku obserwacji uczestniczącejd) informacje uzyskane z wykorzystaniem wywiadu nieskategoryzowane-
go
Pytanie 6. Do stałych cech statystycznych zalicza się:
a) cechy quasi-ciągłeb) cechy przestrzennec) cechy porządkowed) cechy czasowe
Pytanie 7. Pomiaru cech skokowych (brak własnej jednostki miary) należy dokonać:
a) na skali ilorazowej b) na skali przedziałowejc) na skali porządkowejd) na skali nominalnej
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.5. Trening i ewaluacja
str. 124
Pytanie 8. Przykładami cech mierzonych na skali przedziałowej są:
a) płećb) temperatura w stopniach Celsjuszac) dochody klientów: do 100 zł, 101-500 zł, 501-1000 zł, ponad 1000 złd) preferencje nabywców mierzone za pomocą skali Stapela
Pytanie 9. Przykładami cech ilościowych ciągłych mierzonych na skali ilo-razowej są:
a) wiek respondentab) wysokość nad poziomem morzac) walutad) uzyskane punkty z testu (za zadanie można otrzymać 0; 0,5 lub 1 punkt)
Pytanie 10. Do porządkowych skal pomiaru postaw nie zalicza się:
a) skala Likertab) skala rangowa stałych sumc) skala rangd) skala porównywania parami
Pytanie 11. Pytanie nr 10 to przykład pytania:
a) półotwartegob) zamkniętego z kafeterią dysjunktywnąc) zamkniętego z kafeterią koniunktywnąd) otwartego
Pytanie 12. Cechy jakościowe dychotomiczne można pogrupować: a) w szereg rozdzielczy z dwoma przedziałami klasowymib) szereg rozdzielczy politomiczny
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.5. Trening i ewaluacja
str. 125
c) szereg rozdzielczy dychotomicznyd) szereg czasowy
Pytanie 13. Wykresem ukazującym strukturę cechy z pytania nr 12 jest:
a) diagram czasowyb) wykres pierścieniowyc) wykres kołowyd) histogram
Pytanie 14. Przeciętne oceny z egzaminu ze statystyki studentów wybranej uczelni wyższej w latach 2000-2005 można przedstawić za pomocą:
a) szeregu rozdzielczego z przedziałami klasowymib) szeregu czasowegoc) szeregu rozdzielczego punktowegod) szeregu szczegółowego
Pytanie 15. Dominantę można graficznie wyznaczyć sporządzając:
a) diagram liczebnościb) histogram liczebności skumulowanychc) kumulantęd) histogram natężenia liczebności
Pytanie 16. Miary opisu statystycznego adekwatne dla danych zgromadzo-nych za pomocą skali Likerta to:
a) średnia arytmetycznab) dominantac) wskaźniki struktury (frakcje)d) odchylenie przeciętne
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.5. Trening i ewaluacja
str. 126
Pytanie 17. W przypadku danych zgromadzonych za pomocą skali Stapela nie można stosować następujących miar:
a) średnia arytmetycznab) średnia geometrycznac) kwartyled) współczynnik zmienności
Pytanie 18. Warunki zastosowania metod wnioskowania statystycznego to:
a) badanie pełneb) badanie częściowe – próba pobrana w dowolny sposóbc) badanie częściowe – próba pobrana w sposób losowyd) zastosowanie w badaniach kwestionariusza ankiety
Lista zadań nr 1
Zadanie 1
Na podstawie wyników piętnastu ankiet internetowych (zob. Dane_do_analizy.xls, zakładka: Ankiety) należy pogrupować dane znajdu-jące się w kolumnie P6_Sesja (liczba godzin nauki statystyki tygodniowo w czasie sesji) z uwzględnieniem podziału na osoby korzystające i nieko-rzystające z dodatkowych form nauczania (PYT_4).Zadanie 2
Wykorzystując funkcję Excela Częstość proszę pogrupować roczne stopy realnego wzrostu PKB 25 państw Unii Europejskiej dla 2005 r. (zob. Dane_do_analizy.xls, zakładka: PKB) w odpowiedni szereg statystyczny (proszę nie stosować żadnych zaokrągleń). Dane proszę pogrupować z wy-korzystaniem Raportu tabeli przestawnej.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.5. Trening i ewaluacja
str. 127
Zadanie 3
Proszę sporządzić histogram natężenia liczebności dla danych z zadania 2, przyjmując następujące przedziały klasowe: [0 – 2), [2 – 4), [4 – 6), [6 – 8), [8 – 12].
Zadanie 4
Proszę sporządzić diagram czasowy kształtowania się wartości PKB dla Polski w latach 2001-2005 na tle UE-25 (zob. Dane_do_analizy.xls, za-kładka: PKB).
Zadanie 5
Dla danych z zadania 4 proszę sporządzić diagram korelacyjny z wykorzy-staniem wykresu XY, dostępnego w arkuszu MS Excel.
Zadanie 6
Proszę sporządzić wykres dystrybuanty empirycznej liczby godzin nauki statystyki tygodniowo w czasie sesji dla osób korzystających z dodatko-wych form nauczania (dla danych pogrupowanych w zadaniu 1).
Odpowiedzi do zadań:
Zadanie 1
Licznik z P6_Sesja PYT_3 P6_Sesja NIE TAK Suma końcowa
do 2 godzin 1 12-4 1 1 25-10 2 1 3
ponad 10 5 4 9Suma końcowa 8 7 15
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
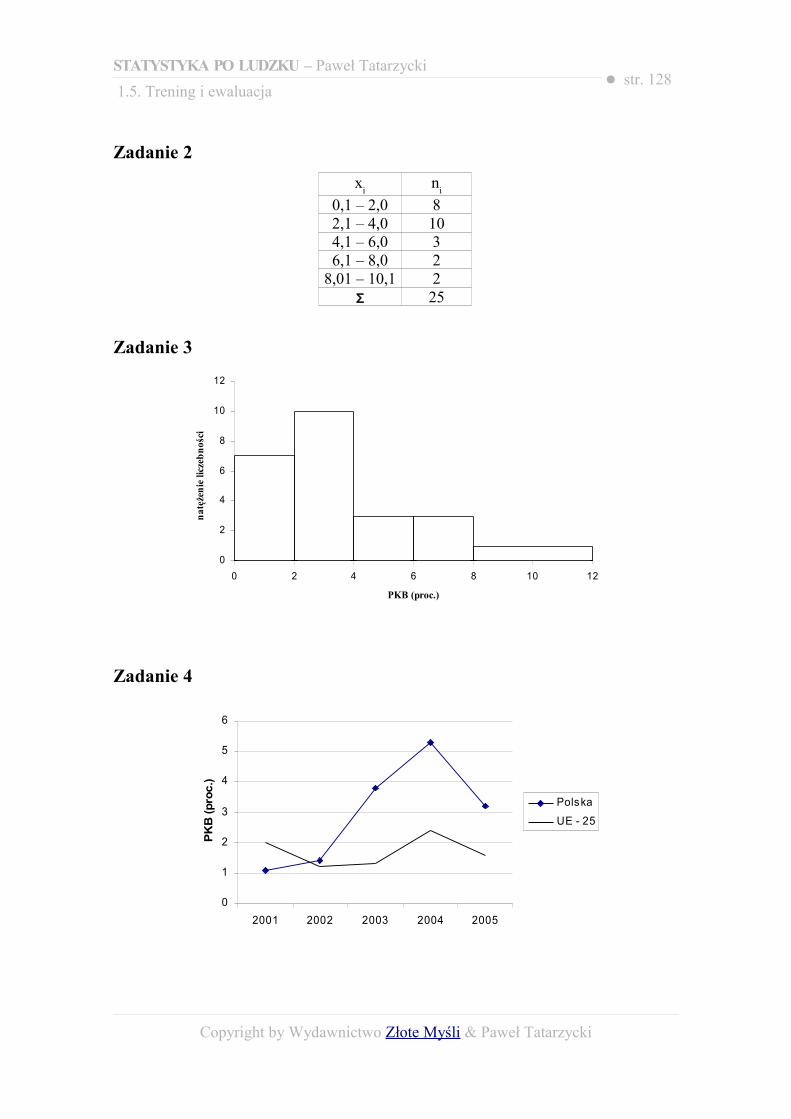
STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.5. Trening i ewaluacja
str. 128
Zadanie 2xi ni
0,1 – 2,0 82,1 – 4,0 104,1 – 6,0 36,1 – 8,0 2
8,01 – 10,1 2Σ 25
Zadanie 3
Zadanie 4
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
0
2
4
6
8
10
12
0 2 4 6 8 10 12
PKB (proc.)
natę
żeni
e licz
ebno
ści
0
1
2
3
4
5
6
2001 2002 2003 2004 2005
PKB
(pro
c.)
Polska
UE - 25
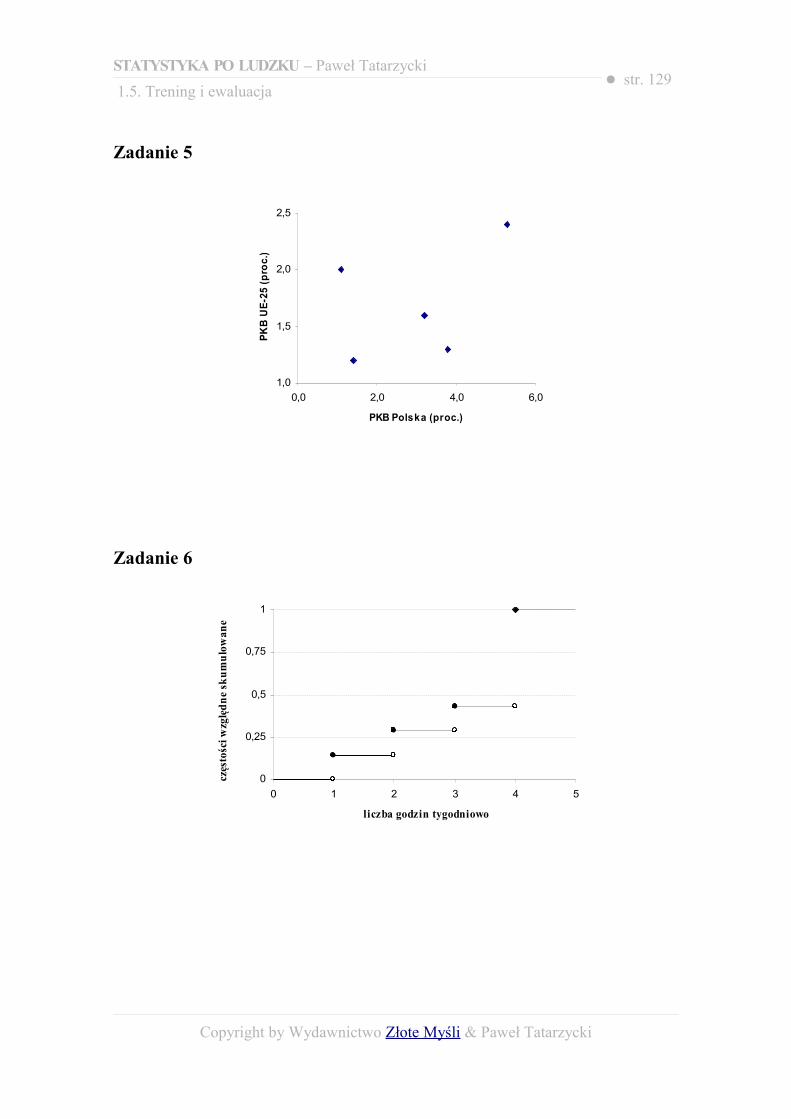
STATYSTYKA PO LUDZKU – Paweł Tatarzycki 1.5. Trening i ewaluacja
str. 129
Zadanie 5
Zadanie 6
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
1,0
1,5
2,0
2,5
0,0 2,0 4,0 6,0
PKB Polska (proc.)
PKB
UE-
25 (p
roc.
)
0
0,25
0,5
0,75
1
0 1 2 3 4 5
liczba godzin tygodniowo
częs
tośc
i wzg
lędn
e sku
mul
owan
e

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2. Opis statystyczny
str. 130
2.2. Opis statystycznyOpis statystyczny
Opis statystyczny ma sumaryczny charakter, co oznacza, że dotyczy on ca-łej zbiorowości generalnej bądź próbnej, a nie poszczególnych jednostek statystycznych. Opisu statystycznego dokonuje się za pomocą odpowied-nich miar [19, s. 30]. W dalszej części tego rozdziału omówiono wybrane miary opisu statystycznego, stosowane w analizie struktury zbiorowości, analizie współzależności oraz analizie dynamiki. Rozdział ten ma zatem analityczny charakter i stanowi wstęp do wnioskowania statystycznego. Dlatego we wszystkich wzorach, gdzie pojawi się liczebność zbiorowości, będzie ona oznaczana literą n jako liczebność zbiorowości próbnej (nie-mniej jednak wzory te znajdują również zastosowanie przy obliczaniu cha-rakterystyk dla całej populacji generalnej).
Tym, na co należy zwrócić uwagę przy studiowaniu niniejszego rozdziału – a o czym niejednokrotnie zdarza się zapominać na egzaminie – jest rodzaj danej cechy statystycznej i związany z nią typ skali pomiarowej. Jak już była mowa, pomiar cech ilościowych na skalach „słabszych” pociąga za so-bą znaczną utratę informacji. Im silniejszy typ skali pomiarowej, tym wię-cej miar statystycznych można obliczyć (zob. tabela 1.5).
Ponadto – w przypadku cech ilościowych – wybór odpowiedniej miary (skorzystanie z prawidłowego wzoru statystycznego) zależy od tego, czy dane są pogrupowane, a jeśli tak, to czy pogrupowano je w szereg rozdziel-czy punktowy, czy też szereg rozdzielczy z przedziałami klasowymi.
W związku z powyższym – przy prezentowaniu miar opisu statystycznego podkreślono, czy dany wzór znajduje zastosowanie dla danych niepogrupo-wanych, czy też pogrupowanych w szereg rozdzielczy (punktowy lub z przedziałami klasowymi). Zwrócono też uwagę na typ skali pomiaru da-nych, umożliwiający zastosowanie określonej miary.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
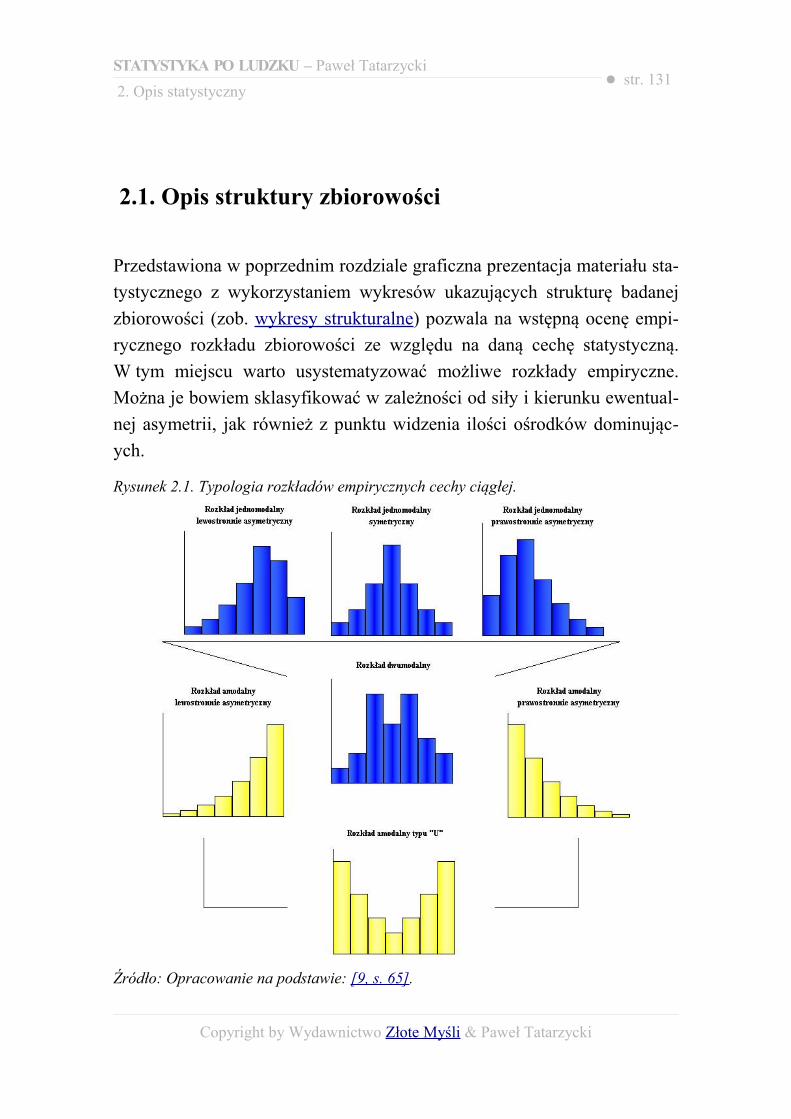
STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2. Opis statystyczny
str. 131
2.1. Opis struktury zbiorowości
Przedstawiona w poprzednim rozdziale graficzna prezentacja materiału sta-tystycznego z wykorzystaniem wykresów ukazujących strukturę badanej zbiorowości (zob. wykresy strukturalne) pozwala na wstępną ocenę empi-rycznego rozkładu zbiorowości ze względu na daną cechę statystyczną. W tym miejscu warto usystematyzować możliwe rozkłady empiryczne. Można je bowiem sklasyfikować w zależności od siły i kierunku ewentual-nej asymetrii, jak również z punktu widzenia ilości ośrodków dominując-ych.
Rysunek 2.1. Typologia rozkładów empirycznych cechy ciągłej.
Źródło: Opracowanie na podstawie: [9, s. 65].
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.1. Opis struktury zbiorowości
str. 132
Szczególne miejsce wśród rozkładów cech zajmuje rozkład normalny, nale-żący do klasy rozkładów jednomodalnych symetrycznych. Jednak w prak-tyce empiryczne rozkłady cech są na ogół bardziej „smukłe” bądź bardziej „spłaszczone” aniżeli teoretyczny rozkład normalny (zob. eksces). Można tu zatem mówić o pewnym stopniu dopasowania danych empirycznych do rozkładu normalnego (zob. Hipotezy nieparametryczne).
Rozkłady cechy są w różnym stopniu lewo- bądź prawostronnie asymet-ryczne. O sile i kierunku asymetrii informują miary asymetrii. Z uwagi na siłę asymetrii rozróżnia się rozkłady umiarkowanie asymetryczne (jeden ośrodek dominujący) bądź rozkłady skrajnie asymetryczne (amodalne). Rozkłady skrajnie asymetryczne to takie, „w których prawie wszystkie jed-nostki mają niskie bądź wysokie wartości cechy” [19, s. 33]. Rozkłady typu „U” – zwane też siodłowymi – stanowią niejako złożenie rozkładu lewo- i prawostronnie asymetrycznego (w tym przypadku zamiast o wartości do-minującej można mówić o tzw. „antymodzie”, tj. wartości będącej przeci-wieństwem dominanty).
Rozkłady dwumodalne (bimodalne) posiadają dwa wyraźnie widoczne ośrodki dominujące, przy czym żaden z nich nie skupia wartości skrajnych (por. rozkład siodłowy). Przykładem takiego rozkładu może być rozkład częstości kursowania autobusów komunikacji miejskiej (ośrodkami domi-nującymi są godziny porannego i popołudniowego szczytu). Analogicznie można wyznaczyć rozkład trimodalny (trzy ośrodki dominujące) oraz – uogólniając – rozkłady wielomodalne (są to raczej teoretyczne przypadki).
Istnieje szereg miar statystycznych, służących do opisu zbiorowości staty-stycznej. Dlatego w literaturze przedmiotu zwykle klasyfikuje się je z punktu widzenia dwóch następujących kryteriów (por. [3, s. 96]):
Pierwszy – podział miar ze względu na zakres danych niezbędnych do ich wyznaczenia:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.1. Opis struktury zbiorowości
str. 133
– miary klasyczne, do wyliczenia których niezbędne są wszystkie jednost-ki objęte badaniem statystycznym,
– miary pozycyjne, dla wyznaczenia których potrzebne są tylko wybrane obserwacje ze względu na zajmowaną pozycję w uporządkowanym zbiorze danych.
Ten podział miar statystycznych ma swoje implikacje w praktyce. Np. w przypadku danych pogrupowanych w szereg rozdzielczy klasowy z otwartym dolnym lub górnym przedziałem klasowym – zastosowanie znajdują miary pozycyjne.
Drugi podział pozwala na klasyfikację miar ze względu na rodzaj informa-cji, jakie one wnoszą o empirycznym rozkładzie cechy statystycznej. I tak wyróżnia się tu (por. [19, s. 35]):
1. Miary położenia (średnie, przeciętne) – służą do określenia wartości ce-chy, wokół której skupiają się wszystkie pozostałe wartości tej cechy.
2. Miary dyspersji (zmienności, rozproszenia) – badają stopień zróżnico-wania wartości cechy, w tym wokół miar średnich.
3. Miary asymetrii (skośności) – służą do badania kierunku i siły ewentu-alnej asymetrii rozkładu zbiorowości ze względu na daną cechę staty-styczną.
4. Miary koncentracji – pozwalają określić stopień koncentracji wokół wartości średniej, jak również ustalić stopień koncentracji jednostek sta-tystycznych ze względu na wartości badanej cechy (np. koncentracja wysokości wynagrodzeń, obrotów ze sprzedaży itp.).
Poniżej przedstawiono typologię miar statystycznych według obu przedsta-wionych klasyfikacji:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
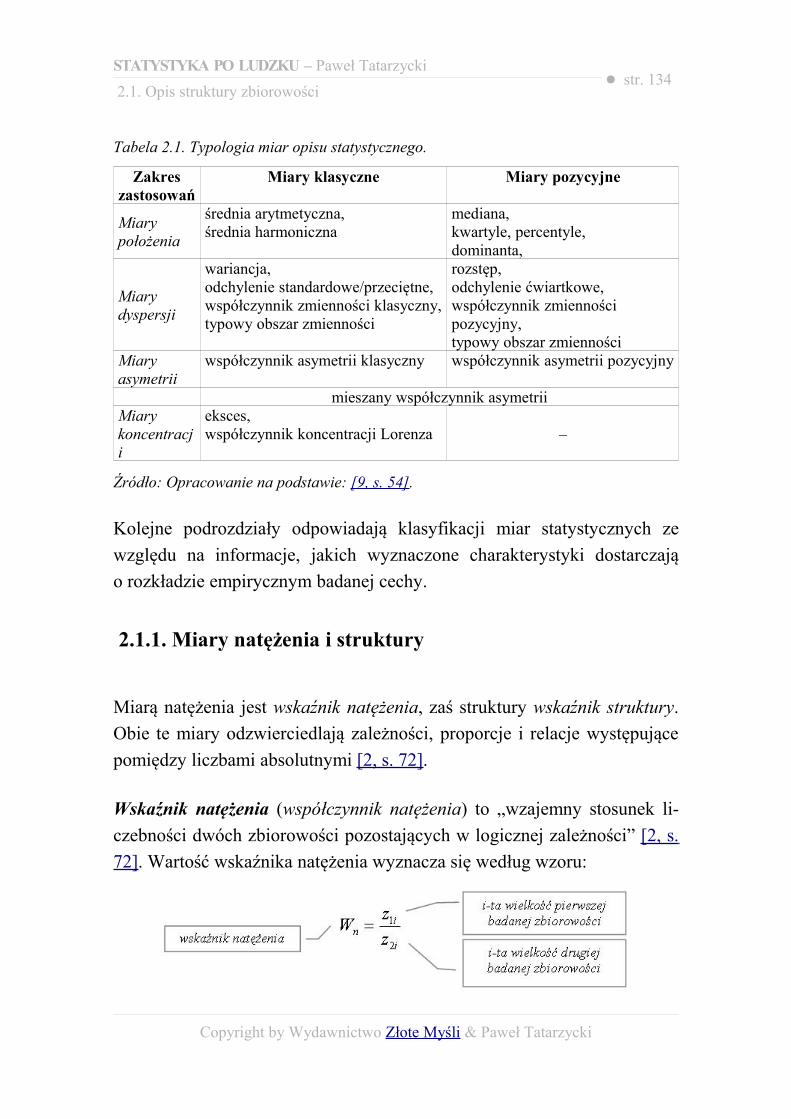
STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.1. Opis struktury zbiorowości
str. 134
Tabela 2.1. Typologia miar opisu statystycznego.
Zakres zastosowań
Miary klasyczne Miary pozycyjne
Miary położenia
średnia arytmetyczna,średnia harmoniczna
mediana,kwartyle, percentyle,dominanta,
Miary dyspersji
wariancja,odchylenie standardowe/przeciętne,współczynnik zmienności klasyczny,typowy obszar zmienności
rozstęp,odchylenie ćwiartkowe,współczynnik zmienności pozycyjny,typowy obszar zmienności
Miary asymetrii
współczynnik asymetrii klasyczny współczynnik asymetrii pozycyjny
mieszany współczynnik asymetriiMiary koncentracji
eksces,współczynnik koncentracji Lorenza –
Źródło: Opracowanie na podstawie: [9, s. 54].
Kolejne podrozdziały odpowiadają klasyfikacji miar statystycznych ze względu na informacje, jakich wyznaczone charakterystyki dostarczają o rozkładzie empirycznym badanej cechy.
2.1.1. Miary natężenia i struktury
Miarą natężenia jest wskaźnik natężenia, zaś struktury wskaźnik struktury. Obie te miary odzwierciedlają zależności, proporcje i relacje występujące pomiędzy liczbami absolutnymi [2, s. 72].
Wskaźnik natężenia (współczynnik natężenia) to „wzajemny stosunek li-czebności dwóch zbiorowości pozostających w logicznej zależności” [2, s. 72]. Wartość wskaźnika natężenia wyznacza się według wzoru:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.1. Opis struktury zbiorowości
str. 135
Współczynnik natężenia jest wielkością mianowaną – określa on liczbę jednostek pierwszej zbiorowości przypadającą na określoną jednostkę dru-giej zbiorowości [7, s. 89].
Wskaźniki natężenia pojawiły się już we wcześniejszej części tego opraco-wania. Klasycznym przykładem jest gęstość zaludnienia (zob. rys. 1.15), czyli liczba mieszkańców przypadająca na 1 km2 powierzchni danego ob-szaru. Inne ekonomiczne przykłady tego typu wskaźników to (por. [7, s. 89]):
– liczba mieszkań oddanych do użytku na 1000 mieszkańców według wo-jewództw,
– cena 1 m2 powierzchni mieszkania w danym województwie,– wskaźnik wydajności pracy, tj. wartość przychodów na 1 zatrudnionego,– wskaźnik rotacji aktywów (wartość przychodów ze sprzedaży na 1 zł
majątku przedsiębiorstwa),– wartość księgowa na 1 akcję,– PKB per capita, tj. Produkt Krajowy Brutto na 1 mieszkańca.
Ponadto w rozdziale pierwszym pojawił się wskaźnik natężenia niezwiąza-ny z ekonomią, a mianowicie wskaźnik natężenia liczebności. Jeśli jako rozpiętość bazowego przedziału klasowego przyjmie się wartość „1”, to wówczas otrzyma się relację liczebności i-tej klasy (ni) do jej rozpiętości (hi). Innym przykładem wskaźnika natężenia – niezwiązanego z dziedziną ekonomii – jest prędkość, czyli relacja drogi do czasu mierzona np. liczbą przebytych kilometrów na godzinę czy też w m/s (np. siła wiatru). Oto przykład obliczania wskaźników natężenia:
Przykład. W tabeli poniżej zawarte są informacje o zatrudnieniu i wielko-ści przychodów ze sprzedaży w trzech oddziałach firmy. Na podstawie tych informacji obliczono wskaźniki wydajności pracy:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.1. Opis struktury zbiorowości
str. 136
Tabela 2.2. Wydajność pracy w poszczególnych oddziałach przedsiębiorstwa.
Oddziały Przychody (zł mies.)
Liczba zatrudnionych
Wydajność pracy (zł/os.)
I 10 000 10 10 000 / 10 = 1 000II 20 000 40 20 000 / 40 = 500III 40 000 20 40 000 / 20 = 2 000Σ 70 000 70 70 000 / 70 = 1 000
Źródło: Obliczenia własne na podstawie danych umownych.
Najwyższą wydajnością pracy odznacza się oddział trzeci (2000 zł mies. przychodu na 1 zatrudnionego). Wyniki te należałoby odnieść do przecięt-nej płacy miesięcznej. Należy zauważyć, iż przeciętna wydajność pracy w firmie na poziomie 1000 zł mies. na 1 zatrudnionego nie jest średnią arytmetyczną wydajności trzech oddziałów – bowiem aby obliczyć średnią wydajność pracy, należy zastosować wzór na średnią harmoniczną.
Wskaźniki struktury – określane również mianem frakcji lub częstości względnych – ukazują udziały poszczególnych części (klas) w danej zbio-rowości [10, s. 100]. Wskaźniki te pojawiły się już przy prezentacji graficz-nej (zob. diagram i histogram). Pojawiło się wtedy pojęcie częstości względnej (frakcji), czyli relacji liczebności danej części (klasy) zbiorowo-ści do ogólnej liczby obserwacji (por. [21, s. 32]):
Powyższy wskaźnik można też wyrazić w postaci procentowej – wystarczy poszczególne frakcje przemnożyć przez 100:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
100⋅=
nnf i
i

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.1. Opis struktury zbiorowości
str. 137
Frakcje sumują się do jedności lub – w ujęciu procentowym – do 100 pro-cent. Niekiedy w literaturze podaje się wzór pozwalający na wyrażenie wskaźników struktury w promilach (zob. [7, s. 92], [10, s. 101]).
Należy podkreślić, iż wskaźniki struktury można wyznaczyć dla cech mie-rzonych na każdym rodzaju skali pomiarowej – do ich obliczenia niezbęd-ne są bowiem liczebności obserwacji posiadających dany wariant cechy bądź należących do określonego przedziału klasowego (por. [20, s. 87]). Jest to zatem uniwersalna miara statystyczna. Oto przykład obliczenia wskaźników struktury na podstawie danych umownych, dotyczących an-kiety internetowej odnośnie liczby godzin uczenia się statystyki tygodnio-wo (zob. Dane_do_analizy.xls, zakładka: Ankiety). Poniższa tabela zawiera niezbędne obliczenia:
Tabela 2.3. Wskaźniki struktury liczby godzin nauki statystyki tygodniowo w czasie sesji i poza sesją.
Liczba godzin tygodniowo
xi
Liczebności Wskaźniki strukturysesja
n1i
poza sesjąn2i
sesjaf1i
poza sesjąf2i
do 2 godzin 1 7 1/15 = 0,067 7/15 = 0,4672 – 4 godziny 2 7 2/15 = 0,133 7/15 = 0,4675 – 10 godzin 3 1 3/15 = 0,200 1/15 = 0,067ponad 10 godzin 9 0 9/15 = 0,600 0/15 = 0,000
Σ 15 15 1 1
Źródło: Obliczenia własne na podstawie danych umownych.
Do porównania struktur dwóch zbiorowości można zastosować wskaźnik podobieństwa struktur (por. [20, s. 88-89]):
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.1. Opis struktury zbiorowości
str. 138
Nawiązując do powyższego przykładu: do wyznaczenia wskaźnika podo-bieństwa struktur potrzebne będzie wprowadzenie dodatkowej kolumny (por. tabela 2.3):
Tabela 2.4. Wskaźnik podobieństwa struktur godzin nauki statystyki tygodniowo w cza-sie sesji i poza sesją.
Liczba godzin tygodniowo
xi
liczebności wskaźniki strukturysesja
n1i
poza sesjąn2i
sesjaf1i
poza sesjąf2i
minf1i, f2i
do 2 godzin 1 7 0,067 0,467 0,0672 – 4 godziny 2 7 0,133 0,467 0,0675 – 10 godzin 3 1 0,200 0,067 0,000ponad 10 godzin 9 0 0,600 0,000 0,000
Σ 15 15 1 1 0,133
Źródło: Obliczenia własne na podstawie danych umownych.
Wartość omawianego wskaźnika jest wielkością unormowaną, tzn. zawiera się w przedziale [0,1]. Im większe podobieństwo struktur porównywanych zbiorowości, tym wartość wskaźnika bliższa jedności (dla struktur iden-tycznych wskaźnik osiąga wartość równą 1). Wskaźnik na poziomie 0,133 świadczy o dużym zróżnicowaniu struktur liczby godzin nauki statystyki w sesji i poza sesją.
2.1.2. Miary położenia
Miary położenia (średnie, tendencji centralnej) w syntetyczny sposób cha-rakteryzują badaną zbiorowość statystyczną. Z uwagi na swój syntetyczny charakter nadają się one do porównań zbiorowości w czasie i przestrzeni. Główną zaletą tych miar – w odróżnieniu od wskaźników struktury – jest wyrażanie ich wielkości w liczbach mianowanych, tj. w takich jednostkach miary, w jakich wyrażona jest wartość danej cechy statystycznej [7, s. 116-117].
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.1. Opis struktury zbiorowości
str. 139
Klasyczną miarą położenia jest średnia arytmetyczna. Należy zaznaczyć, iż miara ta jest dostępna tylko dla cech mierzonych za pomocą skali prze - działowej bądź ilorazowej. W statystyce matematycznej (zob. Wnioskowa - nie statystyczne) istotne jest rozróżnienie średniej arytmetycznej dla próby od średniej arytmetycznej dla populacji generalnej m (por. [3, s. 99]).
To, z jakiego wzoru należy obliczyć średnią arytmetyczną, zależy od tego, czy dane zostały pogrupowane w szereg rozdzielczy czy też nie. I tak, dla danych niepogrupowanych średnią arytmetyczną wyznacza się ze wzoru:
Oto przykład obliczania średniej arytmetycznej według powyższego wzoru:
Przykład. W ankiecie dla Czytelników (zob. rys. 1.6) w pytaniu nr 6 po-proszono respondentów m.in. o ocenę jakości treści niniejszego opracowa-nia na pięciostopniowej skali Stapela. Oto oceny uzyskane na podstawie piętnastu ankiet internetowych (dane umowne):
5, 4, 4, 5, 3, 4, 2, 4, 3, 5, -1, -4, 1, -2, -5
W rozbudowanym przykładzie zamieszczonym w rozdziale pierwszym (Trening i ewaluacja) powyższe dane uśredniono za pomocą Raportu tabeli przestawnej (zob. aplikacja MS Excel: Przykłady – grupowanie danych). Ponadto w programie MS Excel wśród funkcji statystycznych (Wstaw…, Funkcja…, a następnie określenie funkcji statystycznych) dostępna jest wbudowana funkcja obliczająca średnią arytmetyczną dla danych niepogrupowanych:
ŚREDNIA(zakres_danych)
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.1. Opis struktury zbiorowości
str. 140
Aby tradycyjnie obliczyć średnią arytmetyczną, należy zsumować uzyska-ne punkty, a następnie podzielić je przez liczbę obserwacji, tj. n = 15 (licz-ba otrzymanych ankiet):
Przeciętna liczba punktów wskazuje na pozytywną ocenę prezentowanych treści.
Dla danych pogrupowanych w szereg rozdzielczy punktowy oblicza się ważoną średnią arytmetyczną według poniższego wzoru:
Przykład. Pewna szkoła prywatna ocenia swoją ofertę edukacyjną według sporządzonej listy kryteriów. W ankiecie przeprowadzonej na reprezenta-tywnej grupie 200 studentów zadano pytanie: Który z wymienionych czyn-ników jest dla Pana/Pani najistotniejszy? (tylko jedna opcja odpowiedzi):
a) cena kursu,b) zróżnicowanie oferty edukacyjnej,c) wiedza i umiejętności kadry dydaktycznej,d) możliwość nauki przez Internet,e) dogodna lokalizacja,f) materiały dydaktyczne wliczone w cenę kursu.
Ocena oferty według każdego z powyższych kryteriów została dokonana przez właściciela szkoły w skali od 0 do 10. Aby obliczyć średnią arytme-tyczną ważoną, konieczne jest wprowadzenie dodatkowej kolumny xi ni. Oto niezbędne obliczenia:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
866,1
1528 ==x

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.1. Opis struktury zbiorowości
str. 141
Tabela 2.5. Średnia ważona ocena atrakcyjności oferty edukacyjnej szkoły prywatnej.
Czynniki i Ocenaxi
Liczba wskazańni
Obliczenia pomocniczexi ni
a) 7 92 7 × 92 = 644b) 4 29 116c) 8 38 304d) 0 17 0e) 4 14 56f) 0 10 0
Σ 200 1120
Źródło: Obliczenia własne na podstawie danych umownych.
Na podstawie sporządzonej tabeli pomocniczej można stosunkowo łatwo obliczyć niezbędne sumy xi ni, a następnie podstawić do wzoru na średnią ważoną:
Z uwagi na dysjunktywny charakter pytania ankiety (wymagane wskazanie tylko jednego czynnika) liczba wskazań jest równa liczbie respondentów (n = 200). Uzyskana ważona ocena punktowa – gdzie wagami ni są liczby wskazań – sugeruje, iż oferta szkoły jest przeciętna. W związku z tym nale-żałoby podjąć pewne działania zmierzające do uczynienia tej oferty bar-dziej atrakcyjną (np. poszerzenie oferty o dodatkowe kursy).
Podstawowym błędem jest niestosowanie odpowiedniego wzoru dla da-nych pogrupowanych, tj. nieuwzględnianie wag, czyli liczebności cząstko-wych ni. W związku z tym – zamiast dzielenia przez liczbę wszystkich ob-serwacji n (w powyższym przykładzie liczbę wskazań), niektórzy studenci dzielą przez liczbę wariantów k (na zasadzie analogii do wzoru na tradycyj-ną średnią). Należy więc pamiętać o uwzględnianiu wag w przypadku da-nych pogrupowanych w szereg punktowy bądź z przedziałami klasowymi.
Dla danych pogrupowanych w szereg rozdzielczy z przedziałami klasowy - mi średnią arytmetyczną ważoną oblicza się w analogiczny sposób jak
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
6,5200
11201 ===∑
=
n
nxx
k
iii

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.1. Opis struktury zbiorowości
str. 142
średnią dla szeregu punktowego, przy czym zamiast wartości xi zastosowa-nie znajdują środki przedziałów klasowych:
Środki przedziałów klasowych były już wyznaczane przy prezentacji mate-riału statystycznego (zob. diagram). Stanowią one średnią arytmetyczną dolnej i górnej granicy przedziału klasowego.
Przykład. Inwestor rozważa zakup akcji spółki Żywiec. W związku z tym interesuje go przeciętna wartość tygodniowych stóp zwrotu tych akcji, uzy-skanych w pierwszym półroczu 2006 r. (zob. Dane_do_analizy.xls, zakład-ka: Akcje). Dane pogrupowaneow szereg rozdzielczy z przedziałami klaso-wymi (zob. Przykłady – grupowanie danych). Na podstawie pogrupowa-nych danych należy wyznaczyć ważoną średnią arytmetyczną tygodnio-wych stóp zwrotu akcji spółki Żywiec. W tabeli poniżej znajdują się nie-zbędne obliczenia:
Tabela 2.6. Oczekiwana stopa zwrotu z inwestycji w akcje spółki Żywiec (proc. tygo-dniowo).
I Stopy zwrotu Liczba tygodni Środki klas Obliczenia pomocnicze
1 –10,00 – –7,51 1 –8,75 1 × (–8,75) = –8,752 –7,50 – –5,01 1 –6,25 –6,253 –5,00 – –2,51 1 –3,75 –3,754 –2,50 – –0,01 9 –1,25 –11,255 0,00 – 2,49 11 1,25 13,756 2,50 – 4,99 1 3,75 3,757 5,00 – 7,50 1 6,25 6,25
Σ 25 –6,25
Źródło: Obliczenia własne na podstawie danych pochodzących z Serwisu Internetowe-go Gazety Parkiet, http://www.parkiet.com/dane/dane_atxt.jsp
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
ix in ix ii nx ⋅

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.1. Opis struktury zbiorowości
str. 143
Należy wyjaśnić, iż wartość górnego przedziału klasowego odpowiada wartości dolnego przedziału następnej klasy (różnice z dokładnością do 0,01 informują, że przedziały są lewostronnie domknięte). Przykładowo, środek pierwszego przedziału klasowego obliczono następująco:
Wartość średnią obliczono w oparciu o wyznaczone sumy w powyższej ta-beli:
Przeciętna tygodniowa stopa zwrotu akcji spółki Żywiec wyniosła –0,25 proc., stąd w pierwszym półroczu 2006 r. inwestycje w te walory nie przy-niosły zysków w dłuższym horyzoncie czasu (niewielka strata).
Wagami we wzorach na średnie ważone – oprócz liczebności ni – mogą też być wskaźniki struktury (frakcje – fi). Wówczas wzory będą miały postać:
a) szereg punktowy:
b) szereg klasowy:
Przykład. Praktycznym przykładem zastosowania pierwszego z zaprezen-towanych powyżej wzorów na średnią ważoną (szereg punktowy) jest okre-ślenie oczekiwanej stopy zwrotu portfela akcji. Wagami są udziały po-szczególnych walorów. Oto sposób obliczeń:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( ) 75,82
5,710 −=−+−=ix
25,025
25,61 −=−==∑
=
n
nxx
k
iii
∑
==
k
iii fxx
1
∑
==
k
iii fxx
1

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.1. Opis struktury zbiorowości
str. 144
Tabela 2.7. Oczekiwana roczna stopa zwrotu portfela akcji.
SpółkiI
Stopa zwrotu (proc.)xi
Struktura portfela
fi
Obliczenia pomocnicze
xi fi
A 33 0,24 33 × 0,24 = 7,92B 40 0,15 6,00C 14 0,05 0,70D 22 0,27 5,94E 18 0,29 5,22
Σ 1,00 25,78
Źródło: Obliczenia własne na podstawie danych umownych.
Średnia stopa zwrotu portfela wyniosła 25,78 proc. rocznie. Jak widać, wartość średniej została odczytana bezpośrednio z tabeli, bez konieczności dodatkowych obliczeń.
Ponieważ miary klasyczne dla danych pogrupowanych w szereg rozdziel-czy punktowy oraz dla danych pogrupowanych w szereg z przedziałami klasowymi wyznacza się w sposób analogiczny, stąd w dalszej części teoretycznej będą pojawiać się przykłady obliczeń tego typu miar dla szeregu z przedziałami klasowymi (kontynuacja przykładu z tygodniowymi stopami zwrotu akcji spółki Żywiec).
Jeżeli dane występują w postaci wskaźników natężenia, to do wyznaczenia ich wartości przeciętnej – jak już zasygnalizowano – stosuje się średnią harmoniczną. Rozróżnia się średnią harmoniczną prostą oraz ważoną (por. [21, s. 54]):
a) średnia harmoniczna prosta:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.1. Opis struktury zbiorowości
str. 145
b) średnia harmoniczna ważona:
Przykład 1. Student postanowił przeznaczyć 300 zł na korepetycje ze sta-tystyki. Wybrał losowo trzech korepetytorów (n = 3), oferujących odpo-wiednio ceny za godzinę korepetycji: 25 zł, 40 zł i 50 zł. U każdego z nich postanowił zakupić lekcje za kwotę 100 zł. Przeznaczone kwoty pozwoliły odpowiednio na zakup 4 godzin u pierwszego korepetytora, 2,5 godziny u drugiego oraz 2 godzin u trzeciego (w sumie 8,5 godziny). Ponieważ po-szczególne kwoty są sobie równe (po 100 zł), stąd przeciętną cenę jednej godziny korepetycji można obliczyć ze wzoru na prostą średnią harmonicz-ną:
Przeciętna cena korepetycji to 35,29 zł/godz. Wartość tę można uzyskać, dzieląc łączne wydatki na korepetycje (300 zł) przez zakupioną liczbę go-dzin ogółem (8,5 godz.). Średnią harmoniczną prostą można wyznaczyć w Excelu, posługując się funkcją:
ŚREDNIA.HARMONICZNA(25; 40; 50)
Możliwe jest oczywiście podanie zakresu komórek, do których wpisano ce-ny korepetycji (w trzech sąsiadujących wierszach lub kolumnach).
Przykład 2. Wracając do przykładu dotyczącego wydajności pracy (war-tość przychodów na 1 zatrudnionego): można stwierdzić, że mamy tu do czynienia ze średnią harmoniczną ważoną. Jako wagi ni cechy będącej rela-cją dwóch wielkości należy przyjąć wartości jej licznika – w tym przykła-
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
29,35
085,03
501
401
251
31
1
==++
==∑
=
n
i i
H
x
nx

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.1. Opis struktury zbiorowości
str. 146
dzie będą to przychody wyrażone w zł (w mianowniku występuje liczba za-trudnionych). Oto sposób obliczenia średniej harmonicznej ważonej:
Tabela 2.8. Przeciętna wydajność pracy w przedsiębiorstwie posiadającym trzy oddzia-ły regionalne.
Oddziały Wydajność pracy (zł/os.)
xi
Przychody (zł)ni
Liczba zatrudnionychni / xi
I 1 000 10 000 10 000 / 1 000 = 10II 500 20 000 20 000 / 500 = 40III 2 000 40 000 40 000 / 2 000 = 20
Σ 70 000 70
Źródło: Obliczenia własne na podstawie danych umownych.
Na podstawie obliczeń pomocniczych zawartych w powyższej tabeli moż-na wyznaczyć w prosty sposób średnią harmoniczną ważoną:
Suma wag stanowi ogólną wartość przychodów przedsiębiorstwa (n = 70 000). Wartość średniej harmonicznej informuje, że przeciętna wydajność pracy w badanym przedsiębiorstwie to 1000 zł na 1 zatrudnionego.
Kolejną grupę – obok klasycznych – stanowią pozycyjne miary średnie. Ich niewątpliwą zaletą jest to, że mogą być one – w przeciwieństwie do śred-niej arytmetycznej – wyznaczone również dla cech mierzonych za pomocą skal słabszych (zob. skala nominalna i skala porządkowa), przy czym do-minantę można określić nawet dla cechy mierzonej na skali nominalnej. In-ną zaletą jest to, że miary te można obliczyć w oparciu o ograniczony zbiór danych (ma to znaczenie, gdy np. skrajne przedziały klasowe nie są do-mknięte).
Dominantą (modalną, modą) w zbiorze danych jakościowych jest występu-jący najczęściej i-ty wariant cechy (por. [3, s. 116-117]):
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
1000
7070000
1
===∑
=
k
i i
iH
xn
nx

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.1. Opis struktury zbiorowości
str. 147
Przykład. Właściciel szkoły prywatnej chce określić najistotniejszy czyn-nik decydujący o atrakcyjności oferty edukacyjnej. W tym celu poproszono grupę losowo wybranych studentów o określenie jednego z sześciu sugerowanych czynników. Po zliczeniu odpowiedzi okazało się, że aż 92 respondentów (wielkość próby to n = 200 studentów) wskazało na cenę (zob. tabela 2.5). Zatem cena okazała się czynnikiem najważniejszym.
W przypadku danych ilościowych dominantę można wyznaczyć przy zało-żeniu, że rozkład cechy jest jedno- lub wielomodalny, nie zaś amodalny (zob. rys. 2.1). Sposób obliczania dominanty zależy od tego czy dane po-grupowano w szereg rozdzielczy punktowy czy też z przedziałami klaso-wymi (dominanty nie można obliczyć dla danych niepogrupowanych). W szeregu rozdzielczym punktowym wartość dominanty można wskazać od razu, tak jak w przypadku danych jakościowych.
Przykład. Rozkład liczby kont e-mail (zob. rys. 1.18) jest rozkładem jed-nomodalnym prawostronnie asymetrycznym (zob. rys. 1.18). Na podstawie sporządzonego histogramu łatwo zauważyć, iż najwięcej ankietowanych internautów posiadało jedno konto e-mail.
W tym miejscu warto podkreślić, iż dominanta to wartość cechy, a nie od-powiadająca jej liczebność. Niejednokrotnie zamiast podania wartości do-minanty (w tym przypadku jedno konto e-mail) zdarza się, że student poda-je liczebność (w tym przykładzie liczba internautów).
W szeregu rozdzielczym z przedziałami klasowymi wyznaczenie wartości dominanty wymaga zastosowania wzoru interpolacyjnego (zob. szacunek statystyczny). Bardzo pomocne jest graficzne wyznaczenie dominanty. W tym celu należy sporządzić histogram (dla równych przedziałów klaso-wych jest to histogram liczebności lub histogram częstości względnych),
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.1. Opis struktury zbiorowości
str. 148
a następnie ustalić punkt przecięcia się linii, tak jak pokazano to na rys. 2.2:
Rysunek 2.2. Rozkład tygodniowych stóp zwrotu akcji spółki Żywiec w I półroczu 2006 r.
Źródło: Opracowanie na podstawie danych pochodzących z Serwisu Internetowego Ga-zety Parkiet, http://www.parkiet.com/dane/dane_atxt.jsp
Po zrzutowaniu argumentów punktu, w którym przecięły się wyznaczone linie, na oś OX otrzymano wartość dominanty (por. [3, s. 119]). Analitycz-nie wielkość tę można wyznaczyć ze wzoru dla danych pogrupowanych w szereg rozdzielczy z równymi przedziałami klasowymi:
Przykład. Na podstawie danych dotyczących tygodniowych stóp zwrotu akcji spółki Żywiec należy obliczyć dominantę, czyli najczęstszą tygodnio-wą stopę zwrotu. W oparciu o sporządzony histogram (zob. rys. 2.2) nie-
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
0
2
4
6
8
10
12
-12,5 -10 -7,5 -5 -2,5 0 2,5 5 7,5 10
tygodniowe stopy zwrotu (proc.)
liczb
a se
sji

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.1. Opis struktury zbiorowości
str. 149
trudno stwierdzić, iż przedziałem dominanty jest przedział: [0-2,5 proc.). Do obliczenia dominanty niezbędne są następujące informacje (zob. tabela 2.6):
a) dolna granica przedziału dominanty: x0 = 0,b) liczebność przedziału dominanty: nd = 11,c) liczebność przedziału sąsiedniego poprzedzającego: nd-1 = 9,d) liczebność przedziału sąsiedniego następnego: nd+1 = 1,e) rozpiętość przedziału klasowego (wszystkie przedziały są sobie równe):
h = 2,5.
Po podstawieniu do wzoru należy pamiętać, że otrzymaną liczbę na końcu dodajemy do dolnej granicy (w tym przykładzie nie ma to znaczenia, bo wartość ta jest równa zeru):
Zatem w pierwszym półroczu 2006 r. najczęstsza tygodniowa stopa zysku z akcji spółki Żywiec była wielkością dodatnią (0,42 proc.), tj. ok. 1,7 proc. miesięcznie.
Szczególną ostrożność przy wyznaczaniu miar pozycyjnych, w tym domi-nanty, należy zachować w przypadku szeregu rozdzielczego z nierównymi przedziałami klasowymi. Zwrócono już na ten fakt uwagę przy omawianiu wykresów statystycznych. Wracając do przykładu z rozkładem wieku bu-dynków mieszkalnych w Polsce (stan na 2002 r.): w tym wypadku można obliczyć dominantę na podstawie rys. 1.20. Jak stwierdzono, dominanta za-wiera się w przedziale 1971-1979 (zob. tabela 1.18). Znajduje tu zastoso-wanie wzór analogiczny do wzoru na dominantę w szeregu rozdzielczym z równymi przedziałami klasowymi, przy czym pojawią się tu wskaźniki natężenia liczebności li:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( ) ( ) ( ) ( ) 417,05,2
12205,2
1119119110
11
10 =×+=×
−+−−+=×
−+−−+=
+−
− hnnnn
nnxDdddd
dd

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.1. Opis struktury zbiorowości
str. 150
Podstawiamy do wzoru następujące wartości:
a) dolna granica przedziału dominanty: x0 = 1971,b) natężenie liczebności przedziału dominanty: ld = 3493,c) natężenie liczebności przedziału sąsiedniego poprzedzającego:
ld-1 = 1582,d) natężenie liczebności przedziału sąsiedniego następnego: ld+1 = 2857,e) rozpiętość przedziału dominanty: hd = 8.
Jak wynika z obliczeń przeprowadzonych na podstawie danych Narodowe-go Spisu Powszechnego z 2002 r. – najwięcej mieszkań w Polsce wybudo-wano w 1977 r. Są to na ogół piętrowe budynki, wznoszone z betonowych płyt.
W szeregach rozdzielczych z nierównymi przedziałami klasowymi wyzna-czenie dominanty niejednokrotnie może okazać się sprawą trudną. Podsta-wowy błąd polega na nieodpowiednim sporządzeniu histogramu (dla li-czebności zwykłych zamiast dla natężenia liczebności) i co się z tym wiąże niestosowaniu wzoru uwzględniającego wskaźniki natężenia liczebności – stąd kluczowe znaczenie ma prawidłowe sporządzenie histogramu.
Dla danych opartych minimum na skali porządkowej można – obok domi-nanty – obliczyć kwantyle. Kwantyle to „wartości cechy badanej w zbioro-
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( ) ( ) 1977619718
2857349315823493158234931971 =+=×
−+−−+=D

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.1. Opis struktury zbiorowości
str. 151
wości, które dzielą ją na określone części pod względem liczby jednostek. Części te mogą być równe lub pozostawać do siebie w określonych propor-cjach” [19, s. 43]. W szczególności wśród kwantyli wyróżnia się percentyle (dzielące zbiorowość na 100 części), decyle (10 części) i kwartyle (4 części).
W przypadku danych indywidualnych (niepogrupowanych) istotne jest to, aby warianty cechy były uporządkowane rosnąco. Ogólnie k-tym percenty-lem w uporządkowanym zbiorze wartości cechy jest taka wartość, poniżej której znajduje się k-ty procent wartości z tego zbioru (por. [13, s. 29]):
Przykładowo, 28 percentyl (k = 0,28) dzieli zbiorowość w ten sposób, że 28 proc. jednostek statystycznych posiada wartości nie większe niż wartość tego kwantyla.
W wielu sytuacjach wartość danego percentyla nie pokrywa się z wartością danego wyrazu w uporządkowanym rosnąco szeregu statystycznym, lecz z wielkością znajdującą się pomiędzy dwoma wyrazami:
W tej sytuacji należy skorzystać z bardziej zaawansowanego wzoru inter-polacyjnego:
Pozycję percentyla ustala się analogicznie jak numer obserwacji w pierw-szym prezentowanym wzorze na k-ty percentyl:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( )1, +∈ iik xxP

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.1. Opis struktury zbiorowości
str. 152
Jedynie w przypadku szczególnym, gdzie pozycja percentyla jest liczbą całkowitą, jej wartość można wyznaczyć od razu: Pk = xi.
Medianę, będącą drugim kwartylem (5 decylem, 50 percentylem), można obliczyć z następujących (uproszczonych) wzorów:
a) liczba obserwacji nieparzysta:
b) liczba obserwacji parzysta:
Wielkość ta dzieli populację na dwie części. Dla parzystej liczby obserwa-cji jest to wyraz środkowy uporządkowanego ciągu (szereg szczegółowy), zaś dla nieparzystej liczby obserwacji – średnia arytmetyczna z dwóch środkowych wartości tego ciągu. Oto przykłady:
Przykład 1. Wyznaczyć medianę i pozostałe kwartyle przeciętnej ceny jed-nego metra kwadratowego mieszkania 1-pokojowego na rynku wtórnym w większych miastach Polski (zob. Dane_do_analizy.xls; zakładka: Miesz-kania).
Punktem wyjścia jest uporządkowanie danych rosnąco:
1. Poznań: 3606 zł/m2.2. Gdańsk: 3630 zł/m2.3. Wrocław: 4500 zł/m2.4. Kraków: 5843 zł/m2.5. Warszawa: 5993 zł/m2.
Z uwagi na nieparzystą liczbę danych (n = 5) – medianę wyznacza się we-dług wzoru:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( )11 −⋅+= nkNkP
( )1
21
+⋅=
nxMe
+⋅=
+ 121
212
1nn
xxMe

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.1. Opis struktury zbiorowości
str. 153
Wartością środkową, czyli medianą, okazała się przeciętna cena 1 metra kw. mieszkania 1-pokojowego we Wrocławiu. W dwóch porównywanych miastach ceny w analogicznym okresie okazały się niższe (Poznań, Gdańsk), a w pozostałych dwóch – wyższe (Kraków, Warszawa).
Pozostałe kwartyle, tj. kwartyl pierwszy (dolny) i trzeci (górny) można wy-znaczyć z ogólnego wzoru na k-ty percentyl:
a) kwartyl pierwszy (25 percentyl):
b) kwartyl trzeci (75 percentyl):
W przypadku jednej czwartej miast objętych analizą cena 1 metra kw. ka-walerki nie przekroczyła 3630 zł (Poznań) – w pozostałych miastach ceny w badanym okresie były wyższe. Analogicznie interpretuje się kwartyl trzeci: ceny 1 metra kw. kawalerki w 75 proc. analizowanej zbiorowości nie przekroczyły 5843 zł – w pozostałych 25 proc. porównywanych miast były one wyższe (Warszawa). Analizę tę można uogólnić na większą liczbę miast.
Przykład 2. W pierwszym pytaniu kwestionariusza ankiety dla Czytelni-ków (wzór kwestionariusza zaprezentowano na rys. 1.6) respondenci mieli określić czy niniejsza publikacja pomogła im w przygotowaniu się do egza-minu. Dane umowne zawiera arkusz Dane_do_analizy.xls (zakładka Ankie-ty). Przyjęto następujący sposób kodowania danych:
–2 – zdecydowanie nie,–1 – raczej nie, 0 – trudno powiedzieć,
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( ) ( )
4500315211
21 ====
+⋅+⋅xxxMe
n
( ) 36302111525,0125,0 ==== +−⋅+ xxxP
( ) 58434311575,0175,0 ==== +−⋅+ xxxP

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.1. Opis struktury zbiorowości
str. 154
+1 – raczej tak,+2 – zdecydowanie tak.
Należy obliczyć medianę i pierwszy kwartyl na podstawie wybranych an-kiet. Tak jak w przykładzie poprzednim, najpierw należy posortować odpo-wiedzi rosnąco:Numer obserwacji i 1 2 3 4 5 6 7 8 9 10 11 12Wartości wyrazów xi -2 -1 -1 0 0 0 1 1 1 1 2 2
Z uwagi na parzystą liczbę objętych analizą formularzy (n = 12) – do obli-czenia mediany znajduje zastosowanie drugi z prezentowanych wyżej wzo-rów:
Zatem połowa respondentów nie miała zdania (0) lub stwierdziła, że e-bo-ok nie był pomocny w przygotowaniu się do egzaminu ze statystyki (−2, −1). Jednocześnie co drugi ankietowany przyznał, że publikacja okazała się przydatna w zdaniu egzaminu (+1, +2).
Jeśli chodzi o kwartyl pierwszy, to w tym przykładzie szukana wartość znajduje się pomiędzy trzecim (i = 3) a czwartym wyrazem uporządkowa-nego rosnąco ciągu liczb:
W tej sytuacji należy posłużyć się wzorem interpolacyjnym.
Zdaniem co czwartego Czytelnika publikacja nie była lub raczej nie była mu pomocna w przygotowaniu się do egzaminu.
Dane w postaci szeregu punktowego należy tak traktować, jak dane w po-staci omówionego szeregu szczegółowego (analogiczny sposób wyznacza-nia percentyli). W programie MS Excel wbudowana jest funkcja, którą
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( ) ( ) 5,010
21
21
21
21
761122112
211
21
21 =+⋅=+⋅=
+⋅=
+⋅=
+⋅⋅+xxxxxxMe
nn
( ) ( ) ( )4,375,311225,01125,0125,0
∈=−⋅+=−⋅+= nNP
( ) ( ) ( ) ( )( ) 25,0175,0110375,313 34325,0 25,0−=×+−=−−×−+−=−×−+= xxNxP P

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.1. Opis struktury zbiorowości
str. 155
można stosować do wyznaczania wartości k-tego percentyla dla danych niepogrupowanych:
PERCENTYL(zakres_danych; k)
Dla danych pogrupowanych w szereg rozdzielczy z przedziałami klasowy-mi – jak już zasygnalizowano – kwartyle można wyznaczyć graficznie po-przez narysowanie wykresu kumulanty (zob. rys. 1.23). Poniżej przedsta-wiono sposób graficznego wyznaczania wartości kwartyli (analogicznie można wyznaczyć dowolny percentyl) dla danych będących kontynuacją przykładu dotyczącego tygodniowych stóp zysku cen akcji spółki Żywiec:
Rysunek 2.3. Wykres kumulanty tygodniowych stóp zwrotu akcji spółki Żywiec w I półroczu 2006 r.
Źródło: Opracowanie na podstawie danych pochodzących z Serwisu Internetowego Ga-zety Parkiet, http://www.parkiet.com/dane/dane_atxt.jsp.
Po zrzutowaniu punktów przecięcia się pozycji kwartyli (poziome linie przerywane) z kumulantą – otrzyma się wartości kwartyli (odczyt z osi OX). Wielkości te można obliczyć, stosując wzór interpolacyjny dla da-
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
0
6,25
12,5
18,75
25
-12,5 -7,5 -2,5 2,5 7,5
tygodniowe stopy zwrotu (proc.)
liczb
a se
sji n
aras
tają
co

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.1. Opis struktury zbiorowości
str. 156
nych pogrupowanych w szereg rozdzielczy z przedziałami klasowymi (uogólnienie interpolacyjnego wzoru dla danych niepogrupowanych):
Pozycję percentyla wyznacza się natomiast ze wzoru:
Przy obliczaniu kwartyli najpierw należy ustalić ich pozycje:
1. Pierwszy kwartyl to wartość cechy, dzieląca daną zbiorowość w ten spo-sób, że 25 proc. jednostek przyjmuje wartości mniejsze lub równe tej wartości, a pozostałe – większe; stąd pozycja tego kwartyla wynosi 0,25⋅n.
2. Drugi kwartyl (mediana) to wartość cechy, dzieląca populację na poło-wę – stąd pozycja 0,5⋅n.
3. Trzeci kwartyl to wartość cechy, dzieląca populację w proporcji: 75 proc. jednostek przyjmuje wartości nie większe od trzeciego kwartylu, a pozostałe 25 proc. wartości większe – dlatego pozycja tego kwartyla to 0,75⋅n.
Następnie należy określić przedziały klasowe, w których znajdują się po-szczególne kwartyle. Pomocne jest tu graficzne wyznaczenie kwartyli (zob. rys. 2.3). Niemniej jednak przedział kwartyla można wyznaczyć bezpośred-nio z tabeli danych (zob. tabela 2.9). Jeśli suma liczebności przekroczy po-
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.1. Opis struktury zbiorowości
str. 157
ziom pozycji kwartyla, to w danym przedziale zawiera się kwartyl, którego szukamy. Oto określenie przedziału mediany (pozycja mediany to 12,5):
Tabela 2.9. Tygodniowe stopy zwrotu z inwestycji w akcje spółki Żywiec (liczba sesji narastająco).
I
Stopy zwrotu Liczba tygodni
Liczba sesji narastająco Komentarz
1 –10,00 – –7,51 1 1 Wartości mniejsze od pozycji mediany: 12 < 12,5
2 –7,50 – –5,01 1 23 –5,00 – –2,51 1 34 –2,50 – –0,01 9 125 0,00 – 2,49 11 23 Pozycja mediany przekroczona: 23 > 12,56 2,50 – 4,99 1 247 5,00 – 7,50 1 25
Σ 25
Źródło: Obliczenia własne na podstawie danych pochodzących z Serwisu Internetowe-go Gazety Parkiet, http://www.parkiet.com/dane/dane_atxt.jsp.
Mając już określone przedziały kwartyli, w kolejnym kroku należy określić dolną granicę, liczebność i rozpiętość przedziału danego kwartyla (zakłada-my tu równe klasy). Potrzebne są także liczebności skumulowane – do przedziału poprzedzającego włącznie. Oto zestawienie danych niezbędnych do obliczenia pierwszego kwartyla:
a) pozycja pierwszego kwartyla: 6,25b) dolna granica przedziału pierwszego kwartyla: –2,5c) liczebność przedziału pierwszego kwartyla: 9d) suma liczebności trzech klas poprzedzających przedział pierwszego
kwartyla: 3 e) rozpiętość przedziału pierwszego kwartyla: 2,5
Podstawiamy do wzoru:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
ix in
( ) ( ) 597,195,2325,65,225,0 101 −=×−+−=×−⋅+= −
i
iski n
hnnxQ

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.1. Opis struktury zbiorowości
str. 158
Jedna czwarta tygodniowych stóp zwrotu to spadki na poziomie minimum 1,6 proc.
A oto analogiczne dane niezbędne do wyznaczenia mediany:
a) pozycja mediany: 12,5b) dolna granica przedziału mediany: 0c) liczebność przedziału mediany: 11d) suma liczebności czterech klas poprzedzających przedział mediany: 12e) rozpiętość przedziału mediany: 2,5
Połowa osiągniętych tygodniowych stóp zysku przekroczyła poziom 1,1 proc.
W przedziale czwartym znajduje się także trzeci kwartyl, stąd w porówna-niu z medianą zmieni się tu tylko pozycja kwartyla:
W przypadku 25 proc. tygodni miały miejsce stopy zysku przekraczające 1,5 proc.
Pomiędzy wyznaczonymi miarami tendencji centralnej mogą zachodzić na-stępujące zależności (por. [7, s. 121]):
a) rozkład symetryczny:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( ) ( ) 114,011
5,2125,1205,0 10 =×−+=×−⋅+= −i
iski n
hnnxMe
( ) ( ) 534,111
5,21275,18075,0 103 =×−+=×−⋅+= −i
iski n
hnnxQ
DMex ==

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.1. Opis struktury zbiorowości
str. 159
b) rozkład lewostronnie asymetryczny:
c) rozkład prawostronnie asymetryczny:
Z powyższego porównania wynika, że miary pozycyjne są znacznie mniej „czułe” na obserwacje nietypowe, stąd jest postulowane ich zastosowanie w przypadku rozkładów cechy o znacznej asymetrii. Ponadto – jak już wspomniano – zastosowanie tych miar nie wymaga zaangażowania do obli-czeń wszystkich obserwacji, co jest ważne w przypadku niedomkniętych skrajnych przedziałów klasowych.
Średnią arytmetyczną można zastosować w przypadku, gdy rozkład cechy nie jest skrajnie asymetryczny czy wielomodalny. Dużym atutem tej miary jest jej stosunkowo proste obliczanie. Poza tym stanowi ona podstawę do wyznaczania innych miar klasycznych.
2.1.3. Miary dyspersji
Miary rozproszenia – tak jak miary położenia – można podzielić na kla-syczne i pozycyjne. Ponadto możliwy jest podział tych miar na (por. [19, s. 48]):
– bezwzględne (absolutne),– względne (relatywne, stosunkowe).
Powyższy podział ma istotne znaczenie z punktu widzenia skal pomiaro-wych. Miary zróżnicowania bezwzględne – z uwagi na konieczność okre-ślenia odchyleń (różnic) – można obliczyć w przypadku, gdy pomiar danych odbywa się co najmniej na skali przedziałowej (jest tu zatem mowa o cechach ilościowych oraz quasi-ilościowych, tj. porządkowych mierzo-nych na tej skali). Natomiast miary rozproszenia względne – ze względu na
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
DMex <<
xMeD <<

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.1. Opis struktury zbiorowości
str. 160
ich relatywny charakter – można wyznaczyć wyłącznie dla cech, których pomiaru dokonano na najsilniejszej skali, tj. skali ilorazowej (stosunkowej). Mamy tu zatem do czynienia wyłącznie z cechami ilościo-wymi, posiadającymi naturalny (a nie umowny) punkt zerowy i własną (a nie umowną) jednostkę miary. Oto klasyfikacja omawianej grupy miar opisu statystycznego według obu wspomnianych kryteriów:
Tabela 2.10. Klasyfikacja miar dyspersji.
MIARY KLASYCZNE MIARY POZYCYJNE
MIARY BEZWZGLĘDNE(skala przedziałowa lub
ilorazowa)
wariancja,odchylenie przeciętne,odchylenie standardowe,typowy obszar zmienności
rozstęp,rozstęp międzykwartylowy,odchylenie ćwiartkowe,typowy obszar zmienności
MIARY WZGLĘDNE(skala ilorazowa)
współczynnik zmienności oparty na odchyleniu przeciętnym,współczynnik zmienności oparty na odchyleniu standardowym
współczynnik zmienności kwartylowy,współczynnik zmienności oparty na odchyleniu ćwiartkowym
Źródło: Opracowanie na podstawie: [3, s. 140].
Wariancja to „przeciętne kwadratowe odchylenie poszczególnych wyni-ków do ich średniej” [1, s. 24]. Interpretacja wariancji jest utrudniona z uwagi na fakt, że jej mianem jest kwadrat jednostki, w jakiej mierzona jest dana cecha – można stwierdzić, że im wyższa jest wariancja, tym więk-sze zróżnicowanie zbiorowości ze względu na badaną cechę (por. [19, s. 52]).
W związku z powyższym – bardziej adekwatną miarą jest odchylenie stan-dardowe, czyli pierwiastek z wariancji. W tej sytuacji interpretacja jest pro-sta, ponieważ odchylenie standardowe nie podnosi jednostek miary danej cechy do kwadratu. Informuje, ile średnio wartości odchylają się +/– od średniej arytmetycznej.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.1. Opis struktury zbiorowości
str. 161
Przy obliczaniu wariancji lub odchylenia standardowego należy zwrócić uwagę, czy dane są pogrupowane, jak również na liczbę obserwacji. W tej publikacji za małą zbiorowość statystyczną – w tym zbiorowość próbną – uznano taką zbiorowość, w której liczba obserwacji nie przekracza 30 (n ≤ 30). W tej sytuacji dla danych niepogrupowanych do obliczenia wariancji znajduje zastosowanie następujący wzór (w mianowniku wzoru zamiast n znajduje się n – 1):
Wariancję dla dużych prób (n > 30) – w zależności od sposobu pogrupowa-nia danych – oblicza się następująco:
a) dane niepogrupowane:
b) szereg rozdzielczy punktowy:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.1. Opis struktury zbiorowości
str. 162
c) szereg rozdzielczy z przedziałami klasowymi:
Odchylenie standardowe oblicza się jako pierwiastek kwadratowy z wa-riancji. Zatem wyznaczenie wariancji można traktować jako etap pośredni do obliczenia odchylenia standardowego. Oto wzory (odpowiednio: mała i duża próba):
Kolejną klasyczną miarą rozrzutu jest odchylenie przeciętne, czyli „średnia arytmetyczna modułów odchyleń wartości cechy o jej średniej arytmetycz-nej” [3, s. 143]. Oto wzory na obliczanie tej miary w zależności od sposobu pogrupowania danych (oznaczenia analogiczne do oznaczeń we wzorach na obliczanie wariancji):
a) dane niepogrupowane:
b) szereg rozdzielczy punktowy:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
2ˆˆ ss =
2ss =
n
xxd
n
ii∑
=
−= 1
2
n
nxxd
i
k
ii ⋅−
=∑
= 1
2

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.1. Opis struktury zbiorowości
str. 163
c) szereg rozdzielczy z przedziałami klasowymi:
Wartość odchylenia przeciętnego jest mniejsza od odchylenia standardowe-go, ponieważ zamiast sumy kwadratów odchyleń od średniej arytmetycznej – stosuje się tu sumę wartości bezwzględnych. Jeżeli rozkład cechy charak-teryzuje niewielka asymetria, to między tymi miarami zachodzi następująca relacja [3, s. 143]:
Oto przykłady obliczenia wybranych klasycznych miar absolutnych:
Przykład 1. Nawiązując do przykładu z przeciętną ceną 1 metra kwadrato-wego kawalerki w większych miastach Polski (xi) należy obliczyć zróżni-cowanie cen w tych miastach. Znajduje tu zastosowanie wzór na wariancję dla danych niepogrupowanych (mała próba). Godnym polecenia rozwiąza-niem jest sporządzenie następującej tabeli pomocniczej:
Tabela 2.11. Zmienność cen kawalerek w wybranych miastach Polski na rynku wtórnym (tys. zł/m2).
i Miasto
1 Gdańsk 3,630 –1,084 1,084 1,1762 Kraków 5,843 1,129 1,129 1,2743 Poznań 3,606 –1,108 1,108 1,2294 Warszawa 5,993 1,279 1,279 1,6355 Wrocław 4,500 –0,214 0,214 0,046
Σ 23,572 4,814 5,359
Źródło: Obliczenia własne na podstawie danych pochodzących z Serwisu Nieruchomo-ści Szybko.pl, http://www.szybko.pl/nav1-raport.html
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
n
nxxd
i
k
ii ⋅−
=∑
= 1
2
ix xxi − xxi − ( ) 2xxi −
sd ⋅≈ 8,0

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.1. Opis struktury zbiorowości
str. 164
Średnia cena metra kwadratowego kawalerki to 4,7 tys. zł. Wartość ta jest niezbędna do obliczenia wariancji. Po dokonaniu obliczeń pomocniczych sumę z ostatniej kolumny tabeli 2.11 podstawiamy do licznika odpowied-niego wzoru na wariancję:
Mając wyznaczoną wariancję, można łatwo obliczyć odchylenie standardo-we:
Ponadto można obliczyć odchylenie przeciętne, stąd w tabeli 2.11 pojawiła się kolumna z wartościami bezwzględnymi:
Jak widać, odchylenie przeciętne jest mniejsze od standardowego. Z po-wyższych obliczeń wynika, że ceny mieszkań w analizowanym okresie od-chylały się od wartości przeciętnej dla porównywanych miast o ok. 1 tys. zł/m2. Warto zaznaczyć, że celowo wprowadzono ceny mieszkań w tys. zł po to, aby uniknąć bardzo dużych liczb (w dalszych obliczeniach liczby będą podnoszone nawet do czwartej potęgi – zob. miary koncentracji).
Przykład 2. W finansach odchylenie standardowe można interpretować ja-ko ryzyko danego instrumentu finansowego, zaś średnią arytmetyczną jako oczekiwaną stopę zysku. Aby obliczyć ryzyko inwestycji w akcje spółki Żywiec, należy wprowadzić dodatkowe kolumny, zawierające obliczenia pomocnicze (por. Tabela 2.6):
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( )34,1
15359,5
1ˆ 1
2
2 =−
=−
−=
∑=
n
xxs
n
ii
157,134,1ˆˆ 2 === ss
963,05814,41
2
==−
=∑
=
n
xxd
n
ii

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.1. Opis struktury zbiorowości
str. 165
Tabela 2.12. Obliczenie ryzyka inwestycji w akcje spółki Żywiec (proc. tygodniowo).
iStopy zwrotu Liczba tygodni
1 –10,00 – –7,51 1 –8,75 –8,75 –8,50 72,25 72,252 –7,50 – –5,01 1 –6,25 –6,25 –6,00 36,00 36,003 –5,00 – –2,51 1 –3,75 –3,75 –3,50 12,25 12,254 –2,50 – –0,01 9 –1,25 –11,25 –1,00 1,00 9,005 0,00 – 2,49 11 1,25 13,75 1,50 2,25 24,756 2,50 – 4,99 1 3,75 3,75 4,00 16,00 16,007 5,00 – 7,50 1 6,25 6,25 6,50 42,25 42,25
Σ 25 –6,25 212,5
Źródło: Obliczenia własne na podstawie danych pochodzących z Serwisu Internetowe-go Gazety Parkiet, http://www.parkiet.com/dane/dane_atxt.jsp
W przypadku danych pogrupowanych należy pamiętać o wprowadzeniu ostatniej kolumny uwzględniającej liczebności ni (por. tabele 2.11 i 2.12). Dla danych niepogrupowanych wagi ni są równe jedności, stąd uproszczo-ny wzór na obliczanie wariancji w przykładzie poprzednim. Mając określo-ną sumę kwadratów odchyleń od średniej arytmetycznej, podstawiamy tę wartość do licznika odpowiedniego wzoru (w tym przykładzie przyjęto wzór dla dużej liczby obserwacji):
Po obliczeniu wariancji wyznaczamy odchylenie standardowe:
Oczekiwana tygodniowa stopa zysku z inwestycji w akcje analizowanej spółki wyniosła –0,25 proc., zaś będące miarą ryzyka odchylenie standar-dowe informuje, iż przeciętnie osiagane stopy zwrotu odchylały się od war-tości średniej plus/minus 2,9 proc.
W oparciu o bezwzględne miary statystyczne trudno jest wnioskować np. które papiery waartościowe są bardziej ryzykowne w porównaniu z oczeki-
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
ix in ix ii nx ⋅ xxi − ( ) 2xxi − ( ) ii nxx ⋅− 2
( )5,8
255,2121
2
2 ==⋅−
=∑
=
n
nxxs
k
iii
915,25,82 === ss

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.1. Opis struktury zbiorowości
str. 166
wanymi stopami zysku. W tej sytuacji zastosowanie znajdują względne miary dyspersji. Do klasycznych miar tego typu należy klasyczny współczynnik zmienności (por. [21, s. 78]):
a) oparty na odchyleniu standardowym (proc.):
b) oparty na odchyleniu przeciętnym (proc.):
Oto prosty przykład, pozwalający ocenić, który fundusz inwestycyjny nale-ży wybrać, tak aby osiągnąć możliwie duże zyski przy umiarkowanym ry-zyku inwestycyjnym:
Przykład. Inwestor rozważa zakup jednostek uczestnictwa funduszu zrów-noważonego „Z” lub zainwestowanie tych samych środków finansowych w jednostki uczestnictwa funduszu akcji „A”. W ciągu ostatnich 2 lat fun-dusz akcji osiągnął średnią miesięczną stopę zwrotu na poziomie 4,4 proc., zaś zrównoważony średnio 2,1 proc. miesięcznie. Jednak ryzyko związane z inwestowaniem w fundusze akcji jest również większe. I tak odchylenie standardowe dla funduszu „A” wyniosło 1,2 proc. miesięcznie, zaś dla zrównoważonego odpowiednio 0,5 proc. Należy obliczyć współczynniki zmienności:
a) fundusz akcji:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
27,27100
4,42,1100 =⋅=⋅=
xsVs

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.1. Opis struktury zbiorowości
str. 167
b) fundusz zrównoważony:
Optymalną decyzją jest tu wybór funduszu zrównoważonego, ponieważ charakteryzuje się on względnie małym ryzykiem w porównaniu z oczeki-wanym zyskiem.
Klasyczne miary dyspersji badają zmienność wartości danej cechy w opar-ciu o wszystkie obserwacje. W przypadku występowania obserwacji niety-powych może dojść do znacznego zwiększenia zmienności, co niekiedy prowadzi do błędnej interpretacji.
W związku z powyższym można zastosować pozycyjne miary dyspersji. Prostą miarą jest rozstęp, czyli różnica pomiędzy wartością największą i najmniejszą (rozstęp był już obliczany do wyznaczenia przedziałów kla-sowych). Jednak rozstęp – podobnie jak miary klasyczne – jest wrażliwy na nietypowe obserwacje. Mniej wrażliwy na wyniki skrajne jest natomiast odstęp międzykwartylowy, czyli różnica pomiędzy górnym (trzecim) a dol-nym (pierwszym) kwartylem (por. [1, s. 24]).
Nawiązując do prezentowanego w poprzednim rozdziale wykresu pudełko-wego (zob. rys. 1.26), można stwierdzić, że rozstęp międzykwartylowy sta-nowi wysokość „pudełka”. Jak można zauważyć, dyspersja mierzona roz-stępem międzykwartylowym jest również większa w przypadku akcji spół-ki Strzelec.
Kolejną miarą określającą zmienność wśród 50 proc. środkowych jedno-stek zbiorowości, tj. zawierających się pomiędzy dolnym a górnym kwarty-lem (obszar „pudełka”), jest odchylenie ćwiartkowe:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
81,23100
1,25,0100 =⋅=⋅=
xsVs

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.1. Opis struktury zbiorowości
str. 168
Jest to zatem połowa długości rozstępu międzykwartylowego. Odchylenie ćwiartkowe informuje, ile – średnio rzecz biorąc – najbardziej typowe jed-nostki różnią się od mediany. Zaletą tej miary opisu statystycznego jest to, że nie wpływają na nią skrajne, nierzadko nietypowe, obserwacje. Unika się tu więc zniekształceń, stąd postulowane jest stosowanie odchylenia ćwiartkowego, a nie standardowego, w przypadku znacznej asymetrii roz-kładu cechy. Ponadto zaletą tej miary jest to, że może być ona wyznaczona nawet wówczas, gdy w szeregu rozdzielczym klasowym jeden bądź dwa skrajne przedziały klasowe nie są domknięte (por. [20, s. 138]).
Z uwagi na fakt, że odchylenie ćwiartkowe pomija 25 proc. skrajnych ob-serwacji poniżej pierwszego i 25 proc. powyżej trzeciego kwartyla, jest ono mniejsze od analogicznej miary klasycznej, jaką jest powszechnie stosowa-ne w analizach statystycznych odchylenie standardowe. Pomiędzy tymi miarami zachodzi relacja (por. [19, s. 54]):
Q < s
Względną miarą pozycyjną, opartą na odchyleniu ćwiartkowym, jest pozy-cyjny współczynnik zmienności, określony wzorem:
Jest to miara analogiczna do klasycznego współczynnika zmienności, opar-tego na odchyleniu standardowym. Pozycyjny współczynnik zmienności mierzy – tak jak odchylenie ćwiartkowe – zmienność wśród typowych jed-
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.1. Opis struktury zbiorowości
str. 169
nostek badania, stąd należy oczekiwać, iż zmienność w tym obszarze bę-dzie mniejsza niż w całym zbiorze danych.
Innym pozycyjnym współczynnikiem zmienności jest współczynnik kwar-tylowy (por. [3, s. 160], [19, s. 56]):
Poniższy przykład obrazuje sposób obliczania względnych pozycyjnych miar zmienności dla danych pogrupowanych w szereg punktowy (analo-giczne postępowanie ma miejsce w przypadku szeregu z przedziałami kla-sowymi – środki klas zamiast wielkości xi).
Przykład. Należy obliczyć absolutne i względne pozycyjne miary dotyczą-ce przeciętnej ceny jednego metra kwadratowego mieszkania 1-pokojowe-go na rynku wtórnym w większych miastach Polski (zob. Dane_do_anali-zy.xls; zakładka: Mieszkania). Z wcześniejszych obliczeń wynika, że:
– kwartyl I (Gdańsk): Q1 = 3,630 tys. zł/m2.– mediana (Wrocław): Me = 4,5 tys. zł/m2.– kwartyl III (Kraków): Q3 = 5,843 tys. zł/m2.
Mając wyznaczone powyższe miary pozycyjne – można obliczyć odchyle-nie ćwiartkowe:
Po odrzuceniu skrajnych cen okazuje się, że zmienność 1 m kw. mieszkania mierzona odchyleniem ćwiartkowym jest nieznacznie mniejsza niż w przypadku wszystkich obserwacji – dla porównania, odchylenie standardowe wyniosło 1,157 tys. zł/m2. W następnym kroku obliczamy pozycyjny współczynnik zmienności:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
107,1
2630,3843,5
213 =−=−= QQQ

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.1. Opis struktury zbiorowości
str. 170
W tym przypadku wartości klasycznego i pozycyjnego współczynnika zmienności są praktycznie takie same.
Bezpośrednio z danych wejściowych (kwartyl I, mediana, kwartyl III) można też wyznaczyć współczynnik kwartylowy:
W ujęciu procentowym wartość powyższego współczynnika wynosi 24,4 proc., więc jest nieznacznie mniejsza od wartości pozycyjnego współczyn-nika zmienności opartego na odchyleniu przeciętnym (24,6 proc.).
Interpretując wartości wyznaczonych klasycznych i pozycyjnych współ-czynników zmienności można przyjąć, że zróżnicowanie danej cechy jest [3, s. 160]:
– słabe, gdy wartość współczynnika zmienności nie przekracza 30 proc.,– zróżnicowanie wyraźne: wartość współczynnika w przedziale 31-60
proc.,– zróżnicowanie silne: poziom współczynnika powyżej 60 proc.
Na ogół wartość współczynnika zmienności waha się w przedziale 15-35 proc. Jeżeli poziom współczynnika zmienności przekracza 60 proc., to można wnioskować o niejednorodności zbiorowości statystycznej z punktu widzenia badanej cechy [2, s. 112]. Na przykład może się zdarzyć, że zmienność rocznych stóp zwrotu Otwartych Funduszy Inwestycyjnych przekracza krytyczną wartość wspomianych 60 proc. Przyczyną tak dużej zmienności może być uwzględnienie w analizie stóp zysku funduszy o róż-nych klasach ryzyka (np. fundusze obligacji, zrównoważone, akcji).
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
6,24
500,4107,1100 ==⋅=
MeQVQ
234,0
630,3843,5630,3843,5
13
1331
=+−=
+−=
QQQQV QQ

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.1. Opis struktury zbiorowości
str. 171
Ostatnią kwestią związaną z omawianymi miarami jest określenie tzw. ty-powego obszaru zmienności. Można tu wyróżnić klasyczny typowy obszar zmienności – obszar ten jest wyznaczany jako przedział liczbowy, którego dolną granicę stanowi wartość średniej arytmetycznej pomniejszona o war-tość odchylenia standardowego, górną zaś – wartość będąca sumą średniej arytmetycznej i odchylenia standardowego:
Jeżeli rozkład empiryczny badanej cechy jest zbliżony do rozkładu normal-nego, to można stwierdzić następujące prawidłowości (por. [3, s. 147]):
– ok. 70 proc. jednostek statystycznych ze względu na daną cechę zawiera się w typowym obszarze zmienności,
– ok. 95 proc. obserwacji znajduje się w obszarze:
– zgodnie z tzw. regułą trzech sigm co najmniej 99 proc. jednostek bada-nej zbiorowości znajduje się w obszarze:
Za nietypowe należy uznać zatem te obserwacje, których wartości wykra-czają poza wyznaczony powyżej przedział trzech sigm.
Ponadto można określić pozycyjny typowy obszar zmienności. Wykrycie ewentualnych obserwacji nietypowych znacznie ułatwi sporządzenie wy - kresu pudełkowego. W tym celu należy określić, czy istnieją obserwacje, których wartości znajdują się poza następującym przedziałem (por. [3, s. 185]):
Za nietypowe należy uznać te obserwacje, które są położone poniżej pierw-szego kwartyla w odległości przekraczającej trzy odchylenia ćwiartkowe,
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
[ ]sxsx +− ;
[ ]sxsx ⋅+⋅− 2;2
[ ]sxsx ⋅+⋅− 3;3
[ ]QQQQ ⋅+⋅− 3;3 31

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.1. Opis struktury zbiorowości
str. 172
jak również obserwacje znajdujące się powyżej trzeciego kwartyla w odle-głości większej niż trzy odchylenia ćwiartkowe.
2.1.4. Miary asymetrii
W statystycznej analizie ilościowej, gdzie warianty cech mają liczbowy charakter (tj. liczby nie są jedynie „etykietami” cech) można stosować mia-ry asymetrii. Ich rolą jest określenie siły i kierunku empirycznego rozkładu cechy mierzonej na skali przedziałowej lub ilorazowej. W literaturze przed-miotu – oprócz podziału tych miar na klasyczne i pozycyjne – stosuje się także rozróżnienie na miary bezwzględne (absolutne), które określają jedy-nie kierunek asymetrii, oraz względne (stosunkowe, relatywne), pozwalają-ce zarówno na ocenę kierunku, jak i siły asymetrii (por. [3, s. 163], [2, s. 128]). Praktyczna przydatność bezwzględnych miar asymetrii jest jednak niewielka, ponieważ ich poziom uzależniony jest w pewnym stopniu od zmienności danej cechy. Ponadto wskaźników tych nie można porównywać w przypadku cech o różnych jednostkach miary (por. [20, s. 144]). W związku z tym w dalszej części tego podrozdziału zaprezentowane zo-staną pozbawione tych wad względne miary asymetrii.
Jak już wspomniano w podrozdziale Miary położenia – podstawowe cha-rakterystyki tendencji centralnej, tj. średnia arytmetyczna, mediana i domi-nanta, pozostają ze sobą w relacji zależnej od kierunku asymetrii rozkładu badanej cechy statystycznej.
W zależności od kierunku asymetrii rozkładu empirycznego jednomodalne-go (wyraźny jeden ośrodek dominujący) średnia arytmetyczna zmienia swoje położenie względem dominanty (mediana jest zawsze wartością po-średnią). W przypadku idealnej symetrii rozkładu średnia, mediana i domi-nanta są sobie równe. W przypadku empirycznych rozkładów cechy taka sytuacja jest praktycznie niemożliwa (por. [9, s. 71]).
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.1. Opis struktury zbiorowości
str. 173
Klasyczną względną miarą asymetrii rozkładu jest klasyczny współczynnik asymetrii, określany też mianem momentu trzeciego centralnego względne-go (por. [2, s. 128]). Ogólnie wskaźnik ten wyznacza się według wzoru (por. [19, s. 59]):
W praktyce łatwiej jest najpierw obliczyć wartość µ3. W zależności od spo-sobu pogrupowania danych, wielkość tę oblicza się według jednego z po-niższych wzorów:
a) dane niepogrupowane:
b) szereg rozdzielczy punktowy:
c) szereg rozdzielczy klasowy:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.1. Opis struktury zbiorowości
str. 174
Poniżej zaprezentowano sposób obliczenia klasycznego współczynnika asymetrii na przykładzie tygodniowych stóp zwrotu akcji spółki Żywiec. Należy wprowadzić dodatkową kolumnę, zawierającą obliczenia pomocni-cze (por. tabela 2.12):
Tabela 2.13. Obliczenie współczynnika asymetrii dla tygodniowych stóp zwrotu akcji spółki Żywiec.
IA B C D = A⋅B E F = E2 G = F⋅B H = E⋅G
1 –10,00 – –7,51 1 –8,75 –8,75 –8,50 72,25 72,25 –614,132 –7,50 – –5,01 1 –6,25 –6,25 –6,00 36,00 36,00 –216,003 –5,00 – –2,51 1 –3,75 –3,75 –3,50 12,25 12,25 –42,884 –2,50 – –0,01 9 –1,25 –11,25 –1,00 1,00 9,00 –9,005 0,00 – 2,49 11 1,25 13,75 1,50 2,25 24,75 37,136 2,50 – 4,99 1 3,75 3,75 4,00 16,00 16,00 64,007 5,00 – 7,50 1 6,25 6,25 6,50 42,25 42,25 274,63
Σ 25 –6,25 212,50 –506,25
Źródło: Obliczenia własne na podstawie danych pochodzących z Serwisu Internetowe-go Gazety Parkiet, http://www.parkiet.com/dane/dane_atxt.jsp
W oparciu o powyższe dane najpierw należy obliczyć trzeci moment cen-tralny:
Warto zauważyć, że wartości w kolumnie „H” łatwo wyznaczyć, mnożąc kolejno wielkości z kolumny „E” i „G”. Dzięki temu czas obliczeń jest znacznie krótszy. Mając już obliczone odchylenie standardowe (zob. Miary dyspersji) – można przejść do obliczenia współczynnika asymetrii:
Znak współczynnika asymetrii – niezależnie od tego, czy jest on klasyczny, czy pozycyjny – informuje o kierunku asymetrii: znak ujemny wskazuje na
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
ix in ix ii nx ⋅ xxi − ( ) 2xxi − ( ) ii nxx ⋅− 2 ( ) ii nxx ⋅− 3
( )25,20
2525,5061
3
3 −=−=⋅−
=∑
=
n
nxxk
iii
µ
( ) 817,0
915,225,20
333 −=−==
sAs
µ

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.1. Opis struktury zbiorowości
str. 175
asymetrię lewostronną, zaś dodatni na asymetrię dodatnią. W niniejszym przykładzie występuje asymetria lewostronna, co oznacza, że w przeszłości miały miejsce istotne spadki kursu akcji analizowanej spółki (w skali tygo-dnia), co zaniża przeciętną stopę zwrotu.
Wartość bezwzględna współczynnika asymetrii informuje natomiast o jej sile. Badania empiryczne dowiodły, że wartość klasycznego współczynnika asymetrii zawiera się w przedziale od –2 do +2. Im wartość bliższa zeru, tym słabsza asymetria (por. [2, s. 129]).
Tabela 2.14. Interpretacja klasycznego współczynnika asymetrii co do wartości bez-względnej.
| As | Asymetria0 – 0,65 słaba
0,65 – 1,3 umiarkowana1,3 – 2,0 silna
więcej niż 2,0 bardzo silnaŹródło: Opracowanie na podstawie: [3, s. 164].
Zatem istnieje nieznaczna asymetria lewostronna rozkładu tygodniowych stóp zwrotu akcji Żywiec SA Na tym etapie możemy stwierdzić, iż jest to rozkład symetryczny. Dla celów praktycznych można bowiem przyjąć, że wartość współczynnika asymetrii bliska zeru wskazuje, iż rozkład cechy jest symetryczny.
Asymetrię w części centralnej rozkładu empirycznego cechy (obszar „pu-dełka” – zob. wykres pudełkowy) mierzy się za pomocą pozycyjnego wskaźnika asymetrii (por. [21, s. 82]):
Inną pozycyjną miarą asymetrii jest współczynnik skośności Pearsona, mierzący asymetrię całego rozkładu względem dominanty [3, s. 164]:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.1. Opis struktury zbiorowości
str. 176
Współczynniki asymetrii pozycyjny, jak również współczynnik skośności Pearsona, na ogół osiągają wartości z przedziału od –1 do +1, przy czym w przypadku bardzo silnej asymetrii miary te mogą osiągnąć wartości spo-za tego przedziału (por. [21, s. 83]). Interpretacja wartości współczynników AQ i AD jest następująca:Tabela 2.15. Interpretacja pozycyjnych współczynników asymetrii co do wartości bez-względnej.
| AQ | lub | AD | Asymetria0 – 0,65 słaba
0,35 – 0,65 umiarkowana0,65 – 1,0 silna
więcej niż 1,0 bardzo silnaŹródło: Opracowanie na podstawie: [3, s. 164].
Przedstawione wzory na obliczanie pozycyjnych miar asymetrii warto po-przeć przykładem. W celu porównania obliczeń z analogicznymi miarami klasycznymi niech będzie to kontynuacja przykładu dotyczącego tygodnio-wych stóp zwrotu akcji spółki Żywiec. Do obliczenia pozycyjnego współ-czynnika asymetrii niezbędne jest wcześniejsze wyznaczenie pozycyjnych miar położenia (zob. Miary położenia) oraz odchylenia ćwiartkowego:
– kwartyl I: –1,597– mediana: 0,114– kwartyl III: 1,534– odchylenie ćwiartkowe: 1,566
Podstawiamy do wzoru na pozycyjny współczynnik asymetrii:
Natomiast w przypadku obliczania współczynnika Pearsona niezbędne jest wcześniejsze wyznaczenie następujących miar:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
093,0
556,12114,02534,1157,1
2231 −=
⋅⋅−+−=
⋅⋅−+=
QMeQQAQ

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.1. Opis struktury zbiorowości
str. 177
– średnia arytmetyczna: –0,25– dominanta: 0,417– odchylenie standardowe: 2,915
Pozycyjne współczynniki asymetrii okazały się miarami mniejszymi co do wartości bezwzględnej od klasycznego współczynnika asymetrii (–0,817), ponieważ badają asymetrię w części centralnej rozkładu cechy. Potwierdzi-ła się więc symetria rozkładu tygodniowych stóp zwrotu.
2.1.5. Miary koncentracji
Miary koncentracji można podzielić na dwie grupy (por. [2, s. 42]):
1. Miary koncentracji (skupienia) wokół średniej arytmetycznej – ocena koncentracji wokół średniej arytmetycznej znajduje zastosowanie w przypadku empirycznych rozkładów badanej cechy o co najwyżej umiarkowanym stopniu asymetrii (zob. Miary asymetrii).
2. Miary koncentracji wokół dowolnej wartości cechy mierzalnej (mierzo-nej na skali przedziałowej lub ilorazowej) – miary te znajdują zastoso-wanie w rozkładach o silnej asymetrii dodatniej.
Do oceny stopnia skupienia wartości cechy wokół średniej arytmetycznej wykorzystuje się moment czwarty centralny µ4. Miara ta posiada analogicz-ne wady jak moment trzeci centralny µ3, tzn. uniemożliwia porównanie rozkładów cech o różnych jednostkach miary (np. zł, zł/m2 itp.). Z tego też względu do praktycznych obliczeń stosuje się moment centralny względny – niekiedy w literaturze przedmiotu pomniejszany o wartość 3 – zwany współczynnikiem ekscesu. Inne nazwy to współczynnik spłaszczenia lub kurtozy (por. [3, s. 167]). Współczynnik ekscesu, określany w niniejszej publikacji mianem ekscesu, wyznacza się według wzoru:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
229,0
915,2417,025,0 −=−−=−=
sDxAD

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.1. Opis struktury zbiorowości
str. 178
Moment czwarty centralny oblicza się według jednego z poniższych wzorów:
a) dane niepogrupowane:
b) szereg rozdzielczy punktowy:
c) szereg rozdzielczy klasowy:
Eksces informuje o tym, czy koncentracja wartości cechy wokół średniej arytmetycznej jest mniejsza, czy też większa niż w zbiorowości o rozkła - dzie normalnym [19, s. 64]. Można tu wyróżnić trzy sytuacje:
1. E = 0: Rozkład empiryczny danej cechy ma kształt rozkładu normalne-go.
2. E < 0: Rozkład empiryczny cechy jest rozkładem spłaszczonym (plato-kurtycznym) w porównaniu z rozkładem normalnym. Innymi słowy
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.1. Opis struktury zbiorowości
str. 179
dyspersja wartości cechy wokół średniej arytmetycznej jest większa niż ma to miejsce w rozkładzie normalnym.
3. E > 0: Rozkład empiryczny danej cechy jest rozkładem bardziej smu-kłym (leptokurtycznym) w porównaniu z rozkładem normalnym. Zatem wartości cechy są bardziej skupione wokół wartości średniej arytme-tycznej aniżeli w rozkładzie normalnym.
Aby stwierdzić, czy rozkład empiryczny badanej cechy jest zbliżony do teoretycznego rozkładu normalnego – nie wystarczy sporządzić histogramu i obliczyć miar asymetrii. Konieczne jest ponadto obliczenie współczynni-ka spłaszczenia (ekscesu) – rozkład normalny jest rozkładem symetrycz-nym, ale nie każdy rozkład symetryczny jest rozkładem normalnym. Od-rębną kwestią jest weryfikacja nieparametrycznej hipotezy statystycznej o normalności rozkładu danej cechy (zob. Wybrane hipotezy nieparame - tryczne).
Poniżej zamieszczono przykład obliczania ekscesu dla danych dotyczących tygodniowych stóp zwrotu z akcji spółki Żywiec SA. Wskazane jest spo-rządzenie tabeli z obliczeniami pomocniczymi (por. tabela 2.13):
Tabela 2.16. Obliczenie ekscesu dla tygodniowych stóp zwrotu akcji spółki Żywiec.
IA B C D =
A×BE F = E2 G = F×B H = E×G I = F×G
1 –10,0 – –7,51 1 –8,75 –8,75 –8,50 72,25 72,25 –614,13 5220,062 –7,50 – –5,01 1 –6,25 –6,25 –6,00 36,00 36,00 –216,00 1296,003 –5,00 – –2,51 1 –3,75 –3,75 –3,50 12,25 12,25 –42,88 150,064 –2,50 – –0,01 9 –1,25 –11,25 –1,00 1,00 9,00 –9,00 9,005 0,00 – 2,49 11 1,25 13,75 1,50 2,25 24,75 37,13 55,696 2,50 – 4,99 1 3,75 3,75 4,00 16,00 16,00 64,00 256,007 5,00 – 7,50 1 6,25 6,25 6,50 42,25 42,25 274,63 1785,06
Σ 25 –6,25 212,50 –506,25 8771,88
Źródło: Obliczenia własne na podstawie danych pochodzących z Serwisu Internetowe-go Gazety Parkiet, http://www.parkiet.com/dane/dane_atxt.jsp.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( ) ii nxx ⋅− 4 ( ) ii nxx ⋅− 3 ( ) ii nxx ⋅− 2 ( ) 2xxi − xxi − ii nx ⋅
ix in ix

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.1. Opis struktury zbiorowości
str. 180
Ostatnią kolumnę obliczeń pomocniczych łatwo wyznaczyć, mnożąc są-siednie kolumny „F” i „G”. Sumę wartości z tej kolumny podstawiamy na-stępnie do wzoru na czwarty moment centralny:
W drugim kroku otrzymaną wielkość µ4 podstawiamy do wzoru na eksces:
Wartość współczynnika ekscesu informuje o znacznej koncentracji tygo-dniowych stóp zysku wokół wartości średniej – zatem ryzyko związane ze zmianą kursu akcji Żywiec SA w pierwszej połowie 2006 r. należy określić jako relatywnie niewielkie.
Jeżeli chodzi o koncentrację wokół dowolnej wartości badanej cechy, to można tu wyróżnić dwie metody (por. [20, s. 148]):
1. Metoda graficzna.2. Metoda numeryczna.
Metoda graficzna polega na wyznaczeniu krzywej Lorenza. Na osi OX zaznacza się wyrażone w procentach liczebności skumulowane, zaś na osi OY skumulowane – także wyrażone w procentach – wartości zmiennej zi:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( )88,350
2588,87711
4
4 ==⋅−
=∑
=
n
nxxk
iii
µ
( ) 856,1
915,288,3503 44
4 ==−=s
E µ

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.1. Opis struktury zbiorowości
str. 181
Rysunek 2.4. Koncentracja liczby odsłon wśród 10 najpopularniejszych witryn interne-towych w Polsce.
Źródło: Opracowanie na podstawie danych pochodzących z serwisu InternetStandard, http://www.internetstandard.pl/news/96475/100.html
Powyższy wykres sporządzono na podstawie danych dotyczących miesięcznej liczby odsłon popularnych witryn internetowych (zob. Dane_do_analizy.xls; zakładka: Internet).
Siłę koncentracji można wyznaczyć obliczając współczynnik koncentracji Lorenza. Współczynnik ten oblicza się ze wzoru (por. [20, s. 149]):
Pole obszaru b, tj. pole pomiędzy krzywą koncentracji a osią OX, można wyznaczyć przybliżoną metodą trapezów (jeden z takich trapezów zazna-czono na rys. 2.4). Pole b jest wyrażone wzorem:
Częstości względne fi wyznacza się ze wzoru na wskaźnik struktury. Współczynnik koncentracji Lorenza jest wielkością unormowaną, tj. przyj-
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
0
20
40
60
80
100
0 10 20 30 40 50 60 70 80 90 100
procentowy udział komunikatorów (f i sk)
skum
ulow
ana
sttr
uktu
ra
użyt
kow
nikó
w (z
i sk )

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.1. Opis struktury zbiorowości
str. 182
muje wartości z przedziału 0-1. Jeżeli wartość tego współczynnika jest równa 0, to koncentracja nie występuje (podział równomierny). Natomiast im wyższy poziom współczynnika, tym większy stopień koncentracji. In-terpretację współczynnika zawiera tabela:
Tabela 2.17. Interpretacja współczynnika koncentracji Lorenza.
Poziom współczynnika Koncentracja0 Podział równomierny
0 – 0,3 Słaba0,3 – 0,6 Znaczna
powyżej 0,6 Silna
Źródło: Opracowanie na podstawie: [3, s. 170].
Poniżej przedstawiono sposób obliczania współczynnika koncentracji Lo-renza na przykładzie miesięcznej liczby użytkowników najpopularniej-szych komunikatorów w Polsce. Pomocne jest skonstruowanie następującej tabeli, zawierającej obliczenia pomocnicze:
Tabela 2.18. Współczynnik koncentracji Lorenza liczby odsłon najpopularniejszych ko-munikatorów w Polsce.
Nazwa komunikatora Użytkownicy
0,00Miranda 8 086 0,09 0,09 0,045 10 10 0,45Xfire 10 891 0,12 0,21 0,149 10 20 1,49Konnekt 21 426 0,24 0,45 0,328 10 30 3,28ICQ 22 401 0,25 0,69 0,569 10 40 5,69Spik 94 550 1,04 1,74 1,214 10 50 12,14AQQ 128 504 1,42 3,15 2,445 10 60 24,45MSN Messenger 130 518 1,44 4,59 3,874 10 70 38,74Tlen.pl 784 280 8,65 13,25 8,920 10 80 89,20Skype 2 426 314 26,77 40,02 26,631 10 90 266,31Gadu-Gadu 5 436 811 59,98 100,00 70,008 10 100 700,08
Σ 9 063 781 100 100 1141,84
Źródło: Obliczenia własne na podstawie danych pochodzących z serwisu: InternetStan-dard, http://www.internetstandard.pl/news/96475/100.html
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
i ix iz skiz
21−+ skiski zz if skif
iskiski f
zz×
+ −
21

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.1. Opis struktury zbiorowości
str. 183
Wartości zmiennej pomocniczej zi obliczono jako relacje liczby użytkowni-ków i-tego komunikatora do liczby użytkowników:
Wskaźniki struktury (frakcje) są sobie równe – określono je jako udziały w liczbie komunikatorów ogółem:
Z ostatniej kolumny tabeli 2.18 odczytujemy pole obszaru b (b = 1141,84). Następnie wartość b podstawiamy do wzoru na współczynnik koncentracji Lorenza:
Wartość współczynnika świadczy o silnej koncentracji liczby użytkowni-ków wśród analizowanych komunikatorów – warto zauważyć, iż najpopu-larniejszy komunikator Gadu-Gadu skupia niemal 60 proc. ogólnej liczby użytkowników.
2.1.6. Trening i ewaluacja
Poniżej przedstawiono rozbudowany przykład ilustrujący sposób wyzna-czania miar klasycznych i pozycyjnych dla danych pogrupowanych w sze - reg rozdzielczy punktowy (rozkład liczby kont e-mail). Wprowadzamy na-stępujące oznaczenia:
xi – liczba kont e-mail, jaką posiada internauta (cecha skokowa),ni – liczba internautów posiadających określoną liczbę kont e-mail.
Z uwagi na fakt, iż cecha xi mierzona jest na najsilniejszej skali pomiaro-wej, tj. skali ilorazowej (absolutny punkt zerowy), można stąd wyznaczyć także miary względne. Niezbędne obliczenia wykonano w programie MS
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
100
1
×=∑
=
n
ii
ii
x
xz
1001 ×=
nfi
772,0
500084,11415000 =−=L

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.1. Opis struktury zbiorowości
str. 184
Excel (zob. Przykłady – analiza struktury; zakładka: Szereg punktowy). Oto tabela zawierająca obliczenia pomocnicze:
A B C = A×B D E = D2 F = E×B G = D×F H = E×F
0 2 0 -1,44 2,07 4,15 -5,97 8,601 14 14 -0,44 0,19 2,71 -1,19 0,522 6 12 0,56 0,31 1,88 1,05 0,593 2 6 1,56 2,43 4,87 7,59 11,844 1 4 2,56 6,55 6,55 16,78 42,95
Σ 25 36 20,16 18,26 64,51
Na podstawie powyższych obliczeń wyznaczono następujące miary kla-syczne:
a) średnia arytmetyczna:
b) odchylenie standardowe:
c) współczynnik zmienności klasyczny:
d) klasyczny współczynnik asymetrii:
e) eksces:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
ix in iinx xxi − ( ) 2xxi − ( ) ii nxx ⋅− 2 ( ) ii nxx ⋅− 3 ( ) ii nxx ⋅− 4
44,125361 ===
∑=
n
nxx
k
iii
( )
898,0806,025
16,201
2
===⋅−
=∑
=
n
nxxs
k
iii
4,62100
44,1898,0100 =⋅=⋅=
xsVs
( )7304,0
2526,181
3
3 ==⋅−
=∑
=
n
nxxk
iii
µ
( ) 009,1
898,07304,0
333 ===
sAs
µ
( )5804,2
2551,641
4
4 ==⋅−
=∑
=
n
nxxk
iii
µ

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.1. Opis struktury zbiorowości
str. 185
Współczynnik zmienności nieznacznie przekroczył 60 proc. Można więc tu mówić o dużej zmienności liczby kont. Przeciętnie losowo wybrany inter-nauta posiadał 1-2 skrzynki mailowe (wartość średnia to 1,44). Niemniej jednak wśród respondentów znalazła się osoba posiadająca aż cztery konta e-mail. Dodatni znak klasycznego współczynnika asymetrii informuje, że rozkład liczby kont e-mail jest rozkładem o asymetrii prawostronnej. War-tość tego współczynnika wskazuje natomiast na umiarkowaną asymetrię (por. tabela 2.14). Interpretacja współczynnika ekscesu przy umiarkowanej asymetrii nie znajduje uzasadnienia – można bowiem stwierdzić, iż rozkład kont e-mail nie jest rozkładem normalnym.
Z uwagi na znaczną asymetrię rozkładu liczby kont e-mail bardziej odpo-wiednimi miarami są miary pozycyjne. W celu wyznaczenia wartości naj-częstszej należało pogrupować dane w szereg rozdzielczy punktowy. Z dia-gramu liczebności (zob. rys. 1.21) łatwo odczytać, iż najwięcej internautów posiada jedną skrzynkę poczty elektronicznej. Kolejną istotną pozycyjną miarą położenia jest mediana. W przypadku szeregu punktowego dane lepiej jest przedstawić w postaci szeregu szczegółowego:
0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 3. 3. 4.
W przypadku nieparzystej liczby obserwacji (w tym przykładzie n = 25 internautów) medianą jest środkowy wyraz w szeregu szczegółowym, co można zapisać za pomocą wzoru:
Z uwagi na fakt, że mamy tu do czynienia z asymetrią prawostronną, bardziej precyzyjnymi miarami położenia są miary pozycyjne – zarówno wartość dominanty, jak i mediany wyniosła 1. Średnia arytmetyczna jest większa z uwagi na nietypową obserwację (cztery konta e-mail).
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( ) 968,03
898,05804,23 44
4 =−=−=s
E µ
( ) ( )
113125211
21 ====
+⋅+⋅xxxMe
n

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.1. Opis struktury zbiorowości
str. 186
Interpretacja mediany jest następująca: połowa internautów posiada więcej niż jedno konto poczty elektronicznej. Interesującą interpretację posiada również trzeci kwartyl (75 percentyl). Oblicza się go ze wzoru.
Trzy czwarte objętych badaniem internautów posiada nie więcej niż dwa konta e-mail. Analogicznie można obliczyć kwartyl pierwszy (25 percentyl) – jest to siódmy wyraz uporządkowanego rosnąco ciągu liczb, tj. P0,25 = 1.
Mając już wyznaczony dolny i górny kwartyl, można obliczyć wartość odchylenia ćwiartkowego:
Ponieważ powyższa miara bada zmienność w obszarze 50 proc. najbardziej typowych obserwacji, dlatego jest wartością mniejszą od odchylenia standardowego. Podobnie mniejszy jest pozycyjny współczynnik zmienności w porównaniu ze współczynnikiem klasycznym:
Nawet po odrzuceniu najbardziej nietypowych obserwacji – zmienność badanej cechy jest znaczna. Z analizy typowego obszaru zmienności wynika, iż mało prawdopodobne jest, aby internauta posiadał więcej niż trzy konta poczty elektronicznej. Górną granicę tego przedziału można określić następująco:
Zatem uzasadnionym jest, by liczbę czterech kont mailowych traktować jako nietypową obserwację.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( ) ( ) 21912575,01175,0175,0 ==== −⋅+−⋅+ xxxP n
5,0
212
213 =−=−= QQQ
50100
25,0100 =⋅=⋅=
MeQVQ
5,35,03233 =⋅+=⋅+ QQ

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.1. Opis struktury zbiorowości
str. 187
EWALUACJA
Test 2
Pytanie 1. Proszę określić kolejność obliczania miar klasycznych, tak aby korzystać z miar wcześniej już obliczonych (proszę wpisać liczby od 1 do 4, gdzie „1” oznacza miarę obliczaną w pierwszej kolejności).
a) wariancja: ___b) średnia arytmetyczna: ___c) klasyczny współczynnik zmienności: ___d) odchylenie standardowe: ___Pytanie 2. Klasyczny współczynnik zmienności można obliczyć dla da-nych mierzonych za pomocą:
a) skali nominalnejb) skali porządkowejc) skali ilorazowejd) skali przedziałowej
Pytanie 3. Uczniowie popełnili następującą liczbę błędów ortograficznych na sprawdzianie:
0, 0, 1, 1, 1, 2, 2, 2, 2, 2, 3, 3, 3, 4, 4, 5, 6.
Wartością dominanty dla danych pogrupowanych w szereg punktowy jest:
a) liczba 5b) liczba 2c) liczba 6d) dominanta nie występuje
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.1. Opis struktury zbiorowości
str. 188
Pytanie 4. Stosowania miar klasycznych należy unikać wówczas, gdy:
a) występuje silna asymetria rozkładu cechyb) dolne lub górne granice przedziałów nie są domkniętec) cecha jest mierzona na skalach silniejszych (przedziałowej lub ilorazo-
wej)d) rozkład cechy jest zbliżony do rozkładu normalnego
Pytanie 5. W przypadku danych zebranych za pomocą skali Stapela można obliczyć:
a) medianęb) klasyczny współczynnik asymetriic) wskaźniki strukturyd) współczynnik zmienności
Pytanie 6. Nawiązując do danych z pytania nr 3 – można stwierdzić, że:
a) połowa uczniów popełniła nie więcej niż dwa błędy na sprawdzianieb) co czwarty popełnił mniej niż pięć błędówc) uczniowie popełniali najczęściej po pięć błędówd) trzy czwarte uczniów popełniło ponad trzy błędy
Pytanie 7. Wartość klasycznego współczynnika asymetrii na poziomie 0,5 świadczy o asymetrii rozkładu:
a) słabejb) umiarkowanejc) silnejd) bardzo silnej
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.1. Opis struktury zbiorowości
str. 189
Pytanie 8. O znacznej koncentacji wartości cechy świadczy następujący poziom współczynnika koncentracji Lorenza:
a) 0b) 1c) 0,4d) 0,7
Pytanie 9. Aby rozkład cechy był symetryczny, to spełnione muszą zostać następujące warunki:
a) średnia arytmetyczna jest równa medianieb) współczynnik asymetrii równy zeru
c) współczynnik ekscesu równy zerud) odchylenie standardowe bliskie zeru
Pytanie 10. Wzór na średnią ważoną stosuje się wówczas, gdy:
a) dane są niepogrupowaneb) dane pogrupowano w szereg punktowyc) dane przedstawiono w postaci szeregu czasowegod) dane pogrupowano w szereg rozdzielczy z przedziałami klasowymi
Lista zadań nr 2
Zadanie 1
Dla pogrupowanych rocznych stóp realnego wzrostu PKB 25 państw Unii Europejskiej dla 2005 r. (zob. Dane_do_analizy.xls, zakładka: PKB) należy graficznie i algebraicznie wyznaczyć pozycyjne miary położenia. Wyniki proszę porównać z analogiczną miarą klasyczną.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.1. Opis struktury zbiorowości
str. 190
Zadanie 2
Proszę określić stopień koncentracji transakcji kupna-sprzedaży mieszkań w Polsce dla 2005 r. (zob. Dane_do_analizy.xls, zakładka: Mieszkania).
Zadanie 3
Proszę dokonać analizy porównawczej tygodniowych stóp zwrotu akcji spółek Żywiec SA i Strzelec SA, wykorzystując do tego celu dane licz-bowe znajdujące się w pliku Dane_do_analizy.xls (zakładka: Akcje). Proszę także sporządzić wykresy pudełkowe.
Wskazówki do zadań:
Zadanie 1
Dane należy pogrupować w szereg rozdzielczy z przedziałami klasowymi (można skorzystać z danych pogrupowanych w zadaniu 2 z listy nr 1).
Zadanie 2
Należy obliczyć współczynnik koncentracji Lorenza. Najpierw trzeba upo-rządkować dane dotyczące liczby transakcji-kupna sprzedaży mieszkań ro-snąco.
Zadanie 3
Bardzo pomocne będzie wykorzystanie wyników analizy zamieszczonej w części teoretycznej niniejszego podrozdziału, dotyczącej tygodniowych stóp zwrotu spółki Żywiec.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.2. Analiza współzależności
str. 191
2.2. Analiza współzależności
Zaprezentowane w poprzednim podrozdziale miary opisu statystycznego stanowiły element analizy zbiorowości statystycznej ze względu na jedną wybraną cechę. W niniejszym podrozdziale analiza będzie ukierunkowana nie na jedną, lecz na dwie wybrane cechy danej zbiorowości. Wybór metod analizy współzależności zjawisk uzależniony jest – podobnie jak wybór od-powiednich miar opisu statystycznego – od typu skal pomiarowych, jak również od tego, czy dane zostały pogrupowane w tablicę korelacyjną, czy też występują w formie szeregów korelacyjnych.
2.2.1. Miary korelacji
Przy wyborze odpowiedniej miary współzależności dwóch cech – obok określenia skali pomiarowej dla każdej z nich – należy zwrócić szczególną uwagę na to, która z nich jest zmienną niezależną (objaśniającą), a która zmienną zależną (objaśnianą). Poniższa tabela zawiera wykaz przykłado-wych miar współzależności z uwzględnieniem typu skali pomiarowej ce-chy zależnej i niezależnej:
Tabela 2.19. Wybrane miary analizy współzależności a skale pomiarowe.
CECHA ZALEŻNA CECHA NIEZALEŻNA
skala nominalna skala porządkowa skala przedziałowa/ilorazowa
skala nominalna współczynnik ϕ-Yule’a, V-Cramera, -
skala porządkowaC-Pearsona,T-Czuprowa
współczynnik korelacji rang Spearmana
-
skala przedziałowa/ilorazowa współczynnik eta
współczynnik korelacji liniowej Pearsona
Źródło: Opracowanie na podstawie: [6, s. 142], [16, s. 134].
Należy podkreślić, iż współczynniki korelacji, które mają zastosowanie w przypadku skal słabszych, można również stosować dla cech mierzonych
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.2. Analiza współzależności
str. 192
na skalach mocniejszych (przedziałowa, ilorazowa). Niemniej jednak po-stulowane jest zastosowanie tu bardziej precyzyjnych współczynników. I tak współczynniki korelacji rang oraz współczynnik korelacji liniowej Pe-arsona pozwalają na określenie zarówno kierunku, jak i siły zależności. Na-tomiast współczynniki typowe dla danych jakościowych (ϕ-Yule’a, V-Cra-mera, C-Pearsona, T-Czuprowa) pozwalają jedynie na określenie siły związku badanych cech. Poza tym nie wszystkie z nich są możliwe dla da-nych niepogrupowanych w tablicę korelacyjną, tj. występujących w postaci szeregu korelacyjnego (xi, yi), gdzie i oznacza numer obserwacji.
Aby określić siłę współzależności pomiędzy cechami mierzonymi na ska-lach słabszych (nominalna, porządkowa), konieczne jest ich wcześniejsze pogrupowanie w tablicę korelacyjną (zob. Grupowanie i zliczanie danych). Ogólna postać tablicy (macierzy) korelacyjnej jest następująca:
Szczególnym przypadkiem macierzy korelacyjnej jest tablica o wymiarach 2×2, grupująca obserwacje według wariantów dwóch cech dychotomicz - nych:
Przedstawiony podział ma istotne znaczenie z punktu widzenia możliwości stosowania wzorów uproszczonych na obliczanie miar korelacji. Do anali-
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
nnnnnnnnx
nnnnxnnnnx
yyyYX
jk
iijiir
j
j
rk
•••
•
•
•
∑
∑
↓
→
21
21
2222212
1112111
21\
ndbcadcdcbaba
YX
++++
∑
∑
10
10\

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.2. Analiza współzależności
str. 193
zy współzależności danych o charakterze jakościowym stosuje się m.in. na-stępujące miary korelacji:
1. Współczynnik ϕ-Yule’a.2. Współczynnik V-Cramera.3. Współczynnik kontyngencji C-Pearsona.4. Współczynnik T-Czuprowa.
Współczynnik ϕ-Yule’a dla dowolnego wymiaru tablicy korelacyjnej wy-znacza się według wzoru:
Statystykę χ2 („chi-kwadrat”) wykorzystuje się także do testowania hipotez statystycznych o niezależności cech (zob. Wybrane hipotezy nieparame - tryczne). Statystykę tę oblicza się według wzoru:
Oto wzór pomocniczy służący do wyznaczenia teoretycznej liczby obserwacji:
Przedstawione wzory na obliczanie współczynnika ϕ-Yule’a i statystyki χ2
mają uniwersalny charakter, tzn. znajdują również zastosowanie w przy-padku szczególnym, jakim jest tablica korelacyjna o wymiarach 2×2. Nie-mniej jednak w warunkach egzaminu pisemnego, gdzie ważny jest czas
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.2. Analiza współzależności
str. 194
wykonania zadania, znacznie wygodniejsze jest zastosowanie wzorów uproszczonych. I tak wartość statystyki χ2 można obliczyć ze wzoru:
Współczynnik ϕ-Yule’a otrzymamy, podstawiając wartość powyższej staty-styki do zaprezentowanego ogólnego wzoru lub bezpośrednio z poniższej formuły:
W przypadku tablicy o wymiarach 2×k omawiana miara korelacji jest wiel-kością unormowaną, tzn. przyjmuje wartości z przedziału [0,1]. Generalnie zasada jest następująca – im wyższy poziom współczynnika, tym silniejszy związek korelacyjny pomiędzy analizowanymi cechami.
Współczynnik V-Cramera dla tablicy 2×2 ma identyczną postać jak pre-zentowany powyżej współczynnik ϕ-Yule’a. Jest to jednak miara unormowana dla tablicy korelacyjnej o dowolnym wymiarze. Fakt ten sprawia, że współczynnik ten ma uniwersalny charakter. Oto ogólny wzór na obliczanie współczynnika V-Cramera (por. [19, s. 248]):
Nietrudno zauważyć, że dla tablicy składającej się z dwóch wierszy (r = 2) i dwóch kolumn (k = 2) powyższy wzór sprowadza się do ogólnego wzoru na współczynnik ϕ-Yule’a.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( ) ( ) ( ) ( )dcdbcaba
bcad+⋅+⋅+⋅+
−=ϕ

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.2. Analiza współzależności
str. 195
Kolejna miara – współczynnik kontyngencji C-Pearsona – wyraża się wzorem:
Powyższy współczynnik nie jest wielkością unormowaną, ponieważ nie jest ograniczony od góry (podobnie jak w przypadku pozostałych omawia-nych miar korelacji – wartość bliska zeru świadczy o braku współzależno-ści cech). Im więcej wierszy i kolumn, tym wartość współczynnika C-Pear-sona jest wyższa [19, s. 249]. W związku z tym należy posłużyć się tzw. skorygowanym współczynnikiem C-Pearsona (por. [20, s. 185]):
Skorygowany współczynnik Ckor-Pearsona przyjmuje, tak jak współczynnik V-Cramera, wartości z przedziału [0-1].
W przypadku kwadratowych macierzy korelacji, tj. o wymiarach n×n bądź gdy liczba kolumn jest zbliżona do liczby wierszy, warto posłużyć się współczynikiem T-Czuprowa. Wyznacza się go według wzoru:
Im większa asymetria, tj. większa różnica pomiędzy liczba wierszy i ko-lumn, tym gorsza jakość omawianej miary korelacji.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.2. Analiza współzależności
str. 196
W przypadku gdy liczebności empiryczne pokrywałyby się z liczebnościa-mi teoretycznymi, to statystyka χ2 wyniosłaby zero. Jak widać, występuje ona we wszystkich prezentowanych ogólnych wzorach na miary korelacji. Zatem zerowy poziom omawianych miar oznacza statystyczną niezależ-ność cech. Niemniej jednak w praktyce współczynniki te nie osiągają war-tości równych zeru, a jedynie wielkości bliskie zeru. W tej sytuacji ko-nieczne może okazać się zweryfikowanie hipotezy o niezależności cech.
Przykład 1. Niniejszy przykład ilustruje sposób obliczania wprowadzo-nych miar korelacji dla cech nominalnych dwuwariantowych (dychoto-micznych). Należy określić siłę ewentualnej zależności pomiędzy płcią Czytelnika niniejszej publikacji (cecha niezależna) a preferowanymi ele-mentami ułatwiającymi przyswajanie materiału. Dokonano tu podziału Czytelników na „wzrokowców” (preferujących elementy graficzne typu wykresy, tabele) oraz „czuciowców” (ta grupa Czytelników łatwiej przy-swaja sobie treści dzięki elementom dynamicznym, jak hiperłącza, anima-cje wykonane w programie MS PowerPoint). Punktem wyjścia jest pogru-powanie danych (zob. Dane_do_analizy.xls; zakładka Ankiety) w tablicę dwudzielną. Oto dane pogrupowane z wykorzystaniem Raportu tabeli przestawnej Excela:
Tabela 2.20. Elementy publikacji najbardziej ułatwiające, zdaniem Czytelników, przy-swajanie wiedzy a płeć.
Płeć: Suma końcowaPreferowane elementy: K MElementy graficzne 3 4 7Hiperłącza/animacje 5 3 8Suma końcowa 8 7 15
Źródło: Opracowanie własne na podstawie danych umownych.
W oparciu o pogrupowane dane należy wyznaczyć statystykę χ2. Z uwagi na wymiary tablicy znajduje tu zastosowanie wzór uproszczony (por. Przy-kłady – miary zależności.xls; zakładka: cechy_jakościowe):
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( )( ) ( ) ( ) ( )
( ) 5788,031361815
8778543315 22
2 ==⋅⋅⋅
⋅−⋅⋅=+⋅+⋅+⋅+
−⋅=dcdbcaba
bcadnχ

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.2. Analiza współzależności
str. 197
Następnie otrzymaną wielkość wystarczy podstawić do wzorów ogólnych na omówione miary korelacji:
a) współczynnik ϕ-Yule’a:
Sposób II: Można od razu zastosować wzór uproszczony na współczynnik ϕ-Yule’a:
b) współczynnik V-Cramera:
c) współczynnik C-Pearsona:
Korekta współczynnika C-Pearsona:
d) współczynnik T-Czuprowa:
W przypadku dwóch cech dychotomicznych liczba wierszy i kolumn wy-nosi 2, stąd podstawiając: r = 2 i k = 2 do prezentowanych wzorów (z wy-jątkiem wzorów na obliczanie współczynnika C-Pearsona) – otrzymuje się wzór ogólny na współczynnik ϕ-Yule’a. Zatem dla tablicy korelacyjnej o wymiarach 2×2 wartości współczynników ϕ, V i T są sobie równe.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
196,0
155788,02
===n
χϕ
( ) ( ) ( ) ( ) 196,0
5611
87785433 −=−=⋅⋅⋅
⋅−⋅=+⋅+⋅+⋅+
−=dcdbcaba
bcadϕ
( ) ( ) ( ) ( ) 196,0112;12min1;1min
222
=⋅
=−−⋅
=−−⋅
=nnkrn
V χχχ
193,0
5788,0155788,0
2
2
=+
=+
=χ
χn
C
273,02193,0
12,5min2,5min193,0
1,min,min =⋅=
−⋅=
−⋅=
krkrCCkor
( ) ( ) ( ) ( ) 196,01121211
222
=⋅
=−⋅−⋅
=−⋅−⋅
=nnkrn
T χχχ

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.2. Analiza współzależności
str. 198
Istnieje ponadto możliwość zastosowania wzoru uproszczonego z pominię-ciem obliczenia statystyki χ2 (w praktyce jest ona – jak już sygnalizowano – wykorzystywana do zweryfikowania hipotezy o niezależności cech). W tej sytuacji otrzymano identyczny poziom współczynnika co do wartości bezwzględnej. Interpretacja znaku w przypadku cech nominalnych nie znajduje uzasadnienia (generalnie ujemny poziom współczynnika interpre-towany jest jako korelacja ujemna). Wartość obliczonych współczynników wskazuje na niewielką zależność pomiędzy preferowanymi elementami w przyswajaniu wiedzy a płcią – postulowane jest uprzednie przeprowa-dzenie testu statystycznego o niezależności obu tych cech (zob. test nieza - leżności „chi-kwadrat”).
Przykład 2. Należy określić siłę związku pomiędzy płcią Czytelnika (ce-cha niezależna) a preferencjami co do przydatości niniejszej publikacji (ce-cha porządkowa – pomiar danych z wykorzystaniem skali Likerta). Z uwa-gi, że jest to tablica o wymiarach r = 5 wierszy i k = 2 kolumny – koniecz-ne jest zastosowanie wzorów uogólnionych.
Tabela 2.21. Ocena przydatności publikacji „Statystyka po ludzku” a płeć Czytelnika.
PYT_1: Czy niniejsza publikacja pomogła Panu/Pani w przygotowaniu się do egzaminu ze statystyki?
Płeć:K M
Suma końcowa
zdecydowanie nie 0 1 1raczej nie 1 2 3trudno powiedzieć 2 2 4raczej tak 2 2 4zdecydowanie tak 3 0 3Suma końcowa 8 7 15
Źródło: Opracowanie własne na podstawie danych umownych.
Najpierw należy obliczyć statystykę χ2. W tym celu dogodnym rozwiąza-niem jest wprowadzenie tabel pomocniczych. Pierwsza z nich zawiera war-tości teoretyczne, będące efektem przemnożenia sum poszczególnych wier-szy i kolumn na zasadzie „każda z każdą” i podzieleniu otrzymanego wyni-ku przez liczbę obserwacji. Oto sposób obliczenia liczebności teoretycznej dla pierwszego wiersza i pierwszej kolumny:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.2. Analiza współzależności
str. 199
Wszystkie liczebności teoretyczne zawiera tabela:
Tabela 2.22. Wyznaczanie liczebności teoretycznych – obliczenia pomocnicze.
PYT_1: Płeć:K M ←
zdecydowanie nie 8⋅1/15 = 0,53 0,47 1raczej nie 1,60 1,40 3trudno powiedzieć 2,13 1,87 4raczej tak 2,13 1,87 4zdecydowanie tak 1,60 1,40 3
8 7 15
Źródło: Opracowanie własne na podstawie danych zawartych w tabeli 2.21.
Druga tabela bazuje na wyznaczonych powyżej wartościach teoretycznych oraz odpowiadających im liczebnościach empirycznych, zawartych w tabe-li 2.21. Oto sposób wyznaczenia wielkości znajdującej się w pierwszym wierszu i pierwszej kolumnie:
Pozostałe wielkości wyznaczono w analogiczny sposób. Wyniki z dokład-nością do trzech miejsc po przecinku zawiera poniższa tabela:
Tabela 2.23. Wyznaczanie statystyki „chi-kwadrat” – obliczenia pomocnicze.
PYT_1: Płeć:K M Σ
zdecydowanie nie 0,533 0,610 1,143raczej nie 0,225 0,257 0,482trudno powiedzieć 0,008 0,010 0,018raczej tak 0,008 0,010 0,018zdecydowanie tak 1,225 1,400 2,625
Σ 2,000 2,286 4,286
Źródło: Opracowanie własne na podstawie danych zawartych w tabeli 2.21 i 2.22.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
53,0
1518ˆ 11
11 =⋅=×= ••
nnnn
( ) ( ) 53,053,0
53,00ˆ
ˆ 2
11
21111 =−=−
nnn

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.2. Analiza współzależności
str. 200
Szukana statystyka stanowi sumę po wierszach bądź kolumnach:
W kolejnym kroku należy obliczyć współczynniki korelacji, podstawiając otrzymaną wartość statystyki do wzorów ogólnych:
a) współczynnik ϕ-Yule’a:
b) współczynnik V-Cramera:
c) współczynnik C-Pearsona:
Korekta współczynnika C-Pearsona:
d) współczynnik T-Czuprowa:
Wartości obliczonych miar korelacji wskazują na istotną współzależność pomiędzy oceną przydatności publikacji a płcią respondentów – generalnie kobiety wyżej oceniały użyteczność e-booka w kontekście przygotowywa-nia się do egzaminu ze statystyki.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( )286,4
ˆˆ
1 1
22 =
−= ∑ ∑
= =
r
i
k
j ij
ijij
nnn
χ
535,0
15286,42
===n
χϕ
( ) ( ) ( ) ( ) 535,0115
286,412;15min15
286,41;1min
2
=⋅
=−−⋅
=−−⋅
=krn
V χ
471,0
286,415286,4
2
2
=+
=+
=χ
χn
C
667,02471,0
12,5min2,5min471,0
1,min,min =⋅=
−⋅=
−⋅=
krkrCCkor
( ) ( ) ( ) ( ) 378,030286,4
415286,4
121515286,4
11
2
==⋅
=−⋅−⋅
=−⋅−⋅
=krn
T χ

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.2. Analiza współzależności
str. 201
W sytuacji gdy cecha niezależna mierzona jest za pomocą skali nominalnej lub porządkowej, natomiast zmienną zależną jest cecha ilościowa (pomiar na skali mocniejszej), można obliczyć współczynnik eta (por. [16, s. 141-142]):
Warto podkreślić, iż nie jest tu wymagane pogrupowanie danych w tablicę korelacyjną. Poniżej zamieszczono przykład, ukazujący sposób obliczania współczynnika eta właśnie dla danych niepogrupowanych.
Przykład. Na podstawie ankiety skierowanej do Czytelników „Vademe-cum Studenta” określono preferowany przez respondentów udział teorii w tej publikacji (zob. Dane_do_analizy.xls; zakładka: Ankiety). Należy okre-ślić siłę związku pomiędzy preferowanym udziałem treści teoretycznych a płcią Czytelników. Oto niezbędne dane:
Tabela 2.24. Preferowany przez respondentów udział teorii w publikacji „Statystyka po ludzku” według płci.
Płeć Procentowy udział teorii (zmienna zależna) Σ
K 25 40 50 25 33 15 35 55 278M 50 50 33 60 20 45 30 - 288Σ 566
Źródło: Opracowanie własne na podstawie danych umownych.
Nietrudno zauważyć, iż nie mamy w tym przypadku do czynienia – jak już wspomniano – z tablicą korelacyjną. W powyższej tabeli zaprezentowano bowiem dwie próbki o różnych liczebnościach – odpowiedzi udzieliło osiem kobiet (n1 = 8) i siedmiu mężczyzn (n2 = 7). Taka prezentacja ułatwia
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.2. Analiza współzależności
str. 202
obliczenia wykonywane w arkuszu kalkulacyjnym MS Excel (zob. Przy-kłady – miary zależności; zakładka: cechy_jakościowa_i_ilościowa).
Punktem wyjścia jest obliczenie wartości średniej cechy zależnej. W tym celu należy podzielić sumę ogólną przez liczbę respondentów ogółem (n = n1 + n2 = 15):
Analogicznie wyznaczamy wartości średnie cechy zależnej dla pierwszego (K) i drugiego (M) wariantu cechy niezależnej, jaką jest w tym przypadku płeć Czytelnika:
a) przeciętny preferowany udział teorii wśród kobiet:
b) przeciętny preferowany udział teorii wśród mężczyzn:
Teraz można przejść do wyznaczenia licznika wzoru na współczynnik eta. W tym celu dobrym rozwiązaniem jest konstrukcja następującej tabeli po-mocniczej:
Tabela 2.25. Wyznaczanie wartości licznika wzoru na współczynnik eta – obliczenia po-mocnicze.
A B C D E = D2 F = E⋅B
Płeć
K 8 34,75 34,75 – 37,73 = -2,98 8,90 71,20M 7 41,14 41,14 – 37,73 = 3,41 11,62 81,37Σ 15 152,58
Źródło: Opracowanie własne na podstawie danych umownych.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
73,37155661 1 ===
∑ ∑= =
n
xx
r
i
k
jij
75,348
278
1
11
1 ===∑
=
n
xx
k
jj
14,417
288
2
12
2 ===∑
=
n
xx
k
jj
jn jx xx j − ( )2xx j − ( ) jj nxx ⋅− 2

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.2. Analiza współzależności
str. 203
Druga tabela pomocnicza służy do obliczenia mianownika wzoru:
Tabela 2.26. Wyznaczanie wartości mianownika wzoru na współczynnik eta – obliczenia pomocnicze.
Płeć Σ
K (25 – 37,73)2 = = 162,14 5,14 150,47 162,14 22,40 516,80 7,47 298,14 1324,7
0
M 150,47 150,47 22,40 495,80 314,47 52,80 59,80 1423,80 2670,04
Σ 3994,74
Źródło: Opracowanie własne na podstawie danych zawartych w tabeli 2.24.
Wartości zawarte w powyższej tabeli otrzymano odejmując od poszczegól-nych liczb xij z tabeli 2.24 średnią arytmetyczną cechy zależnej. Obliczony mianownik i licznik (wartości pogrubione w tabelach 2.25 i 2.26) podsta-wiamy do wzoru na współczynnik eta:
Poziom bliski zeru wskazuje na brak zależności oczekiwanego poziomu teorii w publikacji od płci Czytelnika.
W przypadku cech porządkowych, którym przypisano rangi, można posłu-żyć się współczynnikami korelacji rang. Powszechnie stosowaną miarą te-go typu jest współczynnik korelacji rang Spearmana. Oblicza się go we-dług poniższego wzoru:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( )2xxij −
( )
( )038,0
74,399458,152
1 1
2
2
1 ==−
⋅−=
∑ ∑
∑
= =
=r
i
k
jij
j
k
jj
xx
nxxη

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.2. Analiza współzależności
str. 204
Komentarza wymaga sposób określania rang. Mogą tu zaistnieć dwie na-stępujące sytuacje:
1. Poszczególnym obserwacjom przypisywane są rangi od 1 do n, gdzie 1 oznacza wartość najlepszą (pierwsze miejsce w rankingu). Nie ma tu miejsca sytuacja, w której przynajmniej dwa obiekty są jednakowo ważne.
2. Przy rangowaniu dopuszcza się sytuację, że przynajmniej dwa porówny-wane obiekty są jednakowo ważne. Może się np. zdarzyć, że konsument jednakowo preferuje produkty. W takiej sytuacji należy zastosować średnią arytmetyczną rang (np. 1 i 2) i dalej przypisywać rangi od 3 do n.
Oto przykład, wyjaśniający sposób przypisywania rang w sytuacji, gdy co najmniej dwa porównywane obiekty są jednakowo ważne:
Przykład. Konsument najbardziej preferuje dwie marki produktu: „A” oraz „B”. Na kolejnym miejscu uplasował produkt „D”. Następnie wskazał po-zostałe marki („C”, „E” i „F”) jako nieporównywalne (relacja równoważ-ności). Przykład ten pokazuje, jak poradzić sobie z przypisaniem rang obiektom w sytuacji, gdy są one jednakowo ważne:
Tabela 2.27. Sposób przypisywania rang w sytuacji, gdy przynajmniej dwa obiekty są jednakowo ważne.
Marka Sposób wyznaczania rangi Rangi Komentarz
A (1 + 2) / 2 = 1,5 1,5A jest tak samo ważne jak B – można przypisać rangi: A = 1, B = 2 lub odwrotnie, stąd obliczamy średnią
B (1 + 2) / 2 = 1,5 1,5C (4 + 5 + 6) / 3 = 5 5 Produkt C jest tak samo preferowany jak E i F
D Przypisanie kolejnej liczby 3
Jest to kolejny obiekt po A i B, stąd przypisujemy 3
E(4 + 5 + 6) / 3 = 5 5
Markom C, E i F trzeba przypisać rangi większe od 3 (np. C = 4, E = 5, F = 6) – obliczamy średnią tych rang
F (4 + 5 + 6) / 3 = 5 5
Źródło: Opracowanie własne.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.2. Analiza współzależności
str. 205
O ile przypisanie rang od 1 do 6 nie stanowi większego problemu, o tyle określenie rang dla obiektów jednakowo ważnych (równie preferowanych) może przysporzyć trudności. Należy pamiętać, że rangi są przypisywane niejako każdej obserwacji (stąd np. dla „D” przypisano rangę 3, a nie 2).
W przypadku dwóch cech ilościowych (pomiar danych na skalach mocniej-szych) zastosowanie znajduje bardziej zaawansowany współczynnik kore-lacji liniowej Pearsona. Stanowi on relację:
Sposób obliczania kowariancji i odchyleń standardowych zależy od tego, czy dane występują w postaci szeregu korelacyjnego, czy też w postaci ta-blicy korelacyjnej. Jeśli chodzi o odchylenia standardowe, to:
a) w przypadku szeregu korelacyjnego znajduje zastosowanie wzór dla da-nych niepogrupowanych (oznaczenia analogiczne jak w podrozdziale Miary dyspersji):
b) w sytuacji gdy obserwacje zliczano w tablicę korelacyjną stosuje się wzory adekwatne dla danych pogrupowanych w szereg punktowy lub z przedziałami klasowymi (zob. Miary dyspersji). Nawiązując do ozna-czeń w prezentowanej na wstępie niniejszego rozdziału ogólnej postaci macierzy korelacyjnej można wyprowadzić analogiczne wzory:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( )
n
xxs
n
ii
x
∑=
−= 1
2
( )
n
yys
n
ii
y
∑=
−= 1
2

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.2. Analiza współzależności
str. 206
Natomiast kowariancję, czyli nienormowaną miarę korelacji, wylicza się z następujących wzorów (por. [19, s. 237-238]):
a) dane indywidualne (szereg korelacyjny):
lub:
b) dane pogrupowane (tablica korelacyjna):
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( )
n
nxxs
i
r
ii
x
•=
⋅−=
∑1
2
nnxx ii •⋅=
( )n
nyys
j
k
ij
y
•=
⋅−=
∑1
2
nny
y jj •⋅=
( ) yxn
yxyx
n
iii
⋅−⋅
=∑
= 1,cov

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.2. Analiza współzależności
str. 207
lub:
W praktyce współczynnik korelacji liniowej Pearsona (dane niepogrupowa-ne) łatwiej wyznaczyć ze wzoru uproszczonego (por. [10, s. 176]):
Współczynnik korelacji rang Spearmana jest szczególnym przypadkiem współczynnika korelacji liniowej Pearsona, stąd interpretacja obu tych miar jest analogiczna (por. [19, s. 244]). Współczynniki te przyjmują wartości z przedziału [–1, +1]. Znak współczynnika informuje o kierunku zależności (por. [6, s. 148]):
1. Znak ujemny informuje o korelacji ujemnej – wraz ze wzrostem warto-ści jednej cechy rosną wartości drugiej cechy (np. wraz ze wzrostem produkcji rosną koszty).
2. Znak dodatni oznacza korelację dodatnią – wzrostowi wartości jednej cechy towarzyszy spadek wartości drugiej (np. wzrostowi cen towarzyszy – przy założeniu, że inne czynniki nie ulegną zmianie – spadek popytu).
W przypadku współczynnika korelacji rang na szczególną uwagę zasługują następujące wartości tej miary korelacji:
Tabela 2.28. Interpretacja współczynnika korelacji rang Spearmana. sr Interpretacja –1 maksymalna niezgodność rang 0 rangi w obu ciągach są niezależne+1 idealna zgodność rang
Źródło: Opracowanie własne na podstawie [13, s. 97].
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( ) yxn
nyxyx
r
i
k
jijji
⋅−−⋅⋅
=∑ ∑
= =1 1,cov

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.2. Analiza współzależności
str. 208
Poziom współczynnika korelacji liniowej Pearsona – co do wartości bez-względnej – interpretuje się jako siłę związku pomiędzy badanymi cecha-mi:
Tabela 2.29. Interpretacja współczynnika korelacji liniowej Pearsona.
Interpretacja
0 brak korelacjido 0,3 korelacja słaba
[0,3 – 0,5) korelacja umiarkowana[0,5 – 0,7) korelacja znaczna[0,7-0,9) korelacja silna[0,9-1,0) korelacja bardzo silna
1,0 liniowa zależność funkcyjna
Źródło: Opracowanie własne na podstawie [10, s. 177].
Należy zaznaczyć, że współczynnik korelacji liniowej Pearsona jest miarą wyłącznie zależności liniowej, co nie wyklucza innego kształtu zależności. Różnicę tę dobrze ilustrują poniższe przykładowe rozrzuty korelacyjne:
Rysunek 2.5. Przykładowy diagram korelacyjny ukazujący brak jakiejkolwiek zależno-ści.
Źródło: Opracowanie własne.
Przedstawiony rozrzut punktów sugeruje brak jakiejkolwiek zależności po-między analizowanymi zmiennymi. W praktyce potwierdza to wartość współczynnika korelacji liniowej Pearsona bliska – a nie równa – zeru.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
xyr
0
0,2
0,4
0,6
0,8
1
0 0,2 0,4 0,6 0,8 1

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.2. Analiza współzależności
str. 209
Rysunek 2.6. Przykładowy diagram korelacyjny ukazujący brak zależności liniowej.
Źródło: Opracowanie własne.
W drugim przypadku wartość współczynnika korelacji liniowej jest rów-nież bliska zeru. Jednak nie można tu mówić o braku jakiejkolwiek zależ-ności – występuje bowiem zależność sinusoidalna: y = sin(x).
Poniższe przykłady ukazują sposób obliczania współczynników korelacji: rang Spearmana (przykład 1) oraz korelacji liniowej Pearsona (przykład 2 i 3).
Przykład 1. W oparciu o wyniki ankiety dla Czytelników (zob. Dane_do_analizy.xls; zakładka: Ankiety) należy dokonać oceny podobień-stwa preferencji dwóch respondentów:
a) X – „praktyk” (najmniejszy preferowany udział treści teoretycznych, tj. 15 proc.),
b) Y – „teoretyk” (największy udział treści teoretycznych w publikacji, tj. 60 proc.).
Wymienieni respondenci przypisali rangi poszczególnym rodzajom dodat-ków do publikacji w następujący sposób:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
-1,5
-1
-0,5
0
0,5
1
1,5
0 5 10 15

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.2. Analiza współzależności
str. 210
Tabela 2.30. Analiza korelacji rang przypisanych dodatkom do e-booka „Statystyka po ludzku”.
A B C D = B – C E = D2
Rodzaj dodatku do e-booka Rangi X Rangi Y id 2id
A Bonus Chi-Kwadrat 5 6 –1 1B Bonus Szeregi statystyczne 4 2 2 4C Bonus Rozkłady prawdop. 6 3 3 9D Plik z danymi do analiz 2 5 –3 9E Przykłady w Excelu 1 1 0 0F Animacje PowerPoint 3 4 –1 1
Σ 24
Źródło: Obliczenia własne na podstawie danych umownych.
Obliczoną różnicę korelacji rang podstawiamy do wzoru na współczynnik:
Zgodność preferencji wybranych respondentów jest niewielka. Obaj naj-bardziej cenią sobie przykłady w Excelu. Wysoce ceniony przez „praktyka” plik z danymi do analiz nie stanowił większej wartości dla „teoretyka”. Podobne rozbieżności miały miejsce w ocenie przydatności bonusu Rozkłady prawdopodobieństwa – dodatek ten „praktyk” uplasował dopiero na ostatnim miejscu.
Przykład 2. Inwestor giełdowy w celu zmniejszenia ryzyka portfela poszu-kuje akcji, których stopy zwrotu są ze sobą słabo skorelowane. Interesuje go poziom współczynnika korelacji liniowej Pearsona (skale ilorazowe) pomiędzy tygodniowymi stopami zwrotu spółek branży piwnej: Żywiec SA i Strzelec SA (zob. Dane_do_analizy.xls; zakładka: Akcje). Przyjęto oznaczenia:
X – tygodniowe stopy zwrotu akcji spółki Żywiec SA,Y – tygodniowe stopy zwrotu akcji spółki Strzelec SA
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( ) ( ) 314,02101441
1662461
1
61 22
1
2
=−=−⋅
⋅−=−⋅
⋅−=
∑=
nn
dr
n
ii
s

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.2. Analiza współzależności
str. 211
Dane występują w postaci szeregu korelacyjnego, stąd można zastosować wzór uproszczony na obliczanie współczynnika korelacji liniowej Pearsona:
Najpierw konstruujemy tabelę z obliczeniami pomocniczymi (por. Przykła-dy – miary zależności; zakładka: skale_mocniejsze):Tabela 2.31. Analiza korelacji tygodniowych stóp zwrotu akcji Żywiec SA i Strzelec SA (I kw. 2006 r.).
IA B C D E = C2 F = D2 G = C⋅D
1 –0,82 17,07 –0,70 14,89 0,48 221,81 –10,362 –0,83 4,17 –0,70 1,99 0,49 3,95 –1,403 1,68 10,00 1,81 7,82 3,26 61,15 14,124 –1,75 31,82 –1,62 29,64 2,64 878,43 –48,125 1,47 –16,55 1,60 –18,73 2,55 350,87 –29,936 –0,72 4,96 –0,59 2,78 0,35 7,72 –1,657 –3,23 –0,79 –3,10 –2,97 9,61 8,80 9,208 2,05 7,94 2,17 5,76 4,73 33,14 12,529 –0,42 –2,94 –0,29 –5,12 0,09 26,22 1,5010 4,45 –12,88 4,58 –15,06 20,96 226,76 –68,9411 1,42 4,35 1,55 2,17 2,40 4,70 3,3612 1,00 2,50 1,13 0,32 1,27 0,10 0,3613 0,79 13,01 0,92 10,83 0,85 117,25 9,9714 6,09 7,19 6,22 5,01 38,68 25,14 31,1915 0,37 –2,68 0,50 –4,86 0,25 23,66 –2,4316 –9,59 –6,21 –9,47 –8,39 89,59 70,34 79,3817 –2,04 3,68 –1,91 1,50 3,66 2,24 –2,8618 2,08 –1,42 2,21 –3,60 4,89 12,95 –7,9619 –1,22 18,71 –1,10 16,53 1,20 273,08 –18,1020 –5,99 –19,39 –5,86 –21,57 34,37 465,43 126,4821 2,20 –2,26 2,33 –4,44 5,41 19,67 –10,3222 –1,08 –3,85 –0,95 –6,03 0,90 36,31 5,7023 0,00 –16,00 0,13 –18,18 0,02 330,51 –2,3524 –1,09 12,38 –0,96 10,20 0,92 104,06 –9,7725 1,98 1,69 2,11 –0,48 4,44 0,24 –1,02Σ –3,22 54,50 234,01 3304,56 78,56
Źródło: Obliczenia własne na podstawie danych pochodzących z Serwisu Internetowe-go Gazety Parkiet, http://www.parkiet.com/dane/dane_atxt.jsp.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( ) ( )
( ) ( )∑
∑
=
=
−⋅−
−⋅−=
n
iii
n
iii
xy
yyxx
yyxxr
1
1
ix iy xxi − yyi − ( ) 2xxi − ( ) 2yyi − ( ) ( )yyxx ii −⋅−

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.2. Analiza współzależności
str. 212
Na podstawie sum z kolumn A i B obliczamy średnią arytmetyczną cechy X i Y:
Uzupełniamy tabelę i sumujemy trzy ostatnie kolumny. Sumy te podstawiamy do wzoru na współczynnik korelacji:
Wartość współczynnika świadczy o braku korelacji. Jest to sytuacja ko-rzystna dla inwestora z punktu widzenia minimalizacji ryzyka inwestycyj-nego (w przypadku silnej korelacji dodatniej spadkowi cen akcji jednej spółki towarzyszy też znaczny spadek kursów drugiej, co zwiększa skalę poniesienia ewentualnej straty).
Przykład 3. Należy obliczyć współczynnik korelacji pomiędzy oceną treści publikacji „Statystyka po ludzku” (cecha X) a oceną wysokości ceny e-bo-oka (cecha Y). Pomiaru dokonano za pomocą porządkowej skali Stapela (zob. rys. 1.6). Zebrane dane pogrupowano w tablicę korelacyjną (por. Przykłady – miary zależności; zakładka: skale_mocniejsze):
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
129,02522,31 −===
∑=
n
xx
n
ii
18,225
50,541 ===∑
=
n
yy
n
ii
( ) ( )
( ) ( )089,0
56,330401,23456,78
1
1 =⋅
=−⋅−
−⋅−=
∑
∑
=
=n
iii
n
iii
xy
yyxx
yyxxr

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.2. Analiza współzależności
str. 213
Tabela 2.32. Ocena treści a ocena wysokości ceny publikacji „Statystyka po ludzku”.
–3 –1 1 2 3 4 5–5 1 1 –5 47,15 47,15–4 1 1 –4 34,42 34,42–2 1 1 –2 14,95 14,95–1 1 1 –1 8,22 8,221 1 1 1 0,75 0,752 1 1 2 0,02 0,023 2 2 6 1,28 2,574 1 2 1 4 16 4,55 18,205 1 2 3 15 9,82 29,45
1 2 2 1 4 2 3 15 28 155,73
–3 –2 2 2 12 8 15 34
27,74 10,67 1,60 0,07 0,54 3,00 7,47
27,74 21,34 3,21 0,07 2,15 6,0122,4
182,9
3Źródło: Obliczenia własne na podstawie danych umownych.
Obliczenia pomocnicze do wyznaczenia kowariancji:
Tabela 2.33. Ocena treści a ocena wysokości ceny publikacji „Statystyka po ludzku” – tabela pomocnicza.
Σ
–3 –1 1 2 3 4 5
–5 –5⋅(–3)⋅1 = 15 15–4 –8 –8–2 2 2–1 –1 -11 1 12 6 63 18 184 12 32 20 645 1 50 51
Σ 15 3 0 –8 36 32 70 148
Źródło: Obliczenia własne na podstawie danych zawartych w tabeli 2.32.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
ijji nyx ⋅⋅ jy
ix
ix jy •in •⋅ ii nx ( ) 2xxi − ( ) •⋅− ii nxx 2
jn•
jj ny •⋅
( )2yy j −
( ) jj nyy •⋅− 2

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.2. Analiza współzależności
str. 214
Korzystając z sum w tabeli 2.32 – obliczamy średnie arytmetyczne cech X i Y:
Uzupełniamy do końca tabelę i wyznaczamy odchylenia standardowe:
Sumę ogólną (po wierszach i kolumnach) z tabeli 2.33, jak również wyzna-czone wyżej wartości średnie, podstawiamy do wzoru na kowariancję:
W ostatnim kroku obliczamy współczynnik korelacji liniowej Pearsona ze wzoru:
Wysoki poziom współczynnika wskazuje na silną korelację pomiędzy oce-ną jakości prezentowanych treści a wysokością ceny publikacji „Vademe-cum Studenta”. Wartość współczynnika większa od zera informuje o kore-lacji dodatniej – osoby, które nisko oceniły prezentowane w publikacji tre-
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
867,115281 ==
⋅=
∑=
•
n
nxx
r
iii
267,215341 ==
⋅=
∑=
•
n
nyy
k
jjj
( )
222,3382,1015
73,1551
2
===⋅−
=•
=∑
n
nxxs
i
r
ii
x
( )351,2529,5
1593,821
2
===⋅−
=•
=∑
n
nyys
j
k
ij
y
( ) 636,5267,2867,115148,cov 1 1 =⋅−=⋅−
⋅⋅=
∑ ∑= = yx
n
nyxyx
r
i
k
jijji
( ) 744,0351,2222,3
636,5,cov =⋅
=⋅
=yx
xy ssyxr

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.2. Analiza współzależności
str. 215
ści także – ogólnie rzecz biorąc – wyraziły pogląd, iż cena publikacji jest wygórowana.
Obliczenie miar korelacji jest punktem wyjścia do dokładniejszego badania współzależności występujących pomiędzy analizowanymi cechami staty-stycznymi. I tak współczynnik korelacji liniowej Pearsona dostarcza infor-macji, czy pomiędzy badanymi cechami występuje zależność liniowa. Silna korelacja (zob. tab. 2.29) pozwala przypuszczać, iż do opisu kształtowania się wartości danej cechy uzasadnione jest wyznaczenie prostej regresji. W przeciwnym razie (niski poziom współczynnika Pearsona) należy poszu-kiwać innych – nieliniowych – funkcji lepiej opisujących współzależności występujące pomiędzy badanymi zjawiskami (regresja nieliniowa). Kolej-ny podrozdział poświęcono właśnie analizie regresji.
2.2.2. Analiza regresji
Na wstępie tego podrozdziału warto wyjaśnić, na czym polega różnica po-między zależnością funkcyjną a zależnością korelacyjną (por. [21, s. 288]):
1. Zależność funkcyjna (dokładna) – jest to relacja pomiędzy zmienną za-leżną Y i niezależną X, pozwalająca na wyznaczenie jednej dokładnej wartości zmiennej zależnej dla każdej wartości zmiennej niezależnej:
Innymi słowy – zgodnie z definicją funkcji – danemu argumentowi xi
można przypisać tylko jedną wartość yi.
2. Zależność korelacyjna (stochastyczna, statystyczna) – jest relacją po-między zmienną zależną Y i zmienną niezależną X, wyznaczającą dla wybranej wartości zmiennej niezależnej (objaśniającej) pewien prze-dział wartości zmiennej zależnej (objaśnianej). Znajomość poziomu
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( )xfy =

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.2. Analiza współzależności
str. 216
zmiennej niezależnej xi – z uwagi na oddziaływanie czynnika losowego ε – nie wystarcza na jednoznaczne określenie poziomu cechy zależnej yi:
W przypadku zależności korelacyjnej można oszacować jedynie wartość przybliżoną (teoretyczną) zmiennej objaśnianej, co zawsze związane jest z pewnym ryzykiem błędu.
Wybór metody analizy współzależności zjawisk zależy od rodzaju cechy zależnej (objaśnianej) i cechy niezależnej (objaśniającej) oraz związanego z tym typu skali pomiarowej.
W pierwszej kolejności omówiona zostanie regresja empiryczna, określa-na w literaturze przedmiotu także mianem regresji I rodzaju. Niewątpliwą zaletą tej metody jest możliwość badania współzależności cech jakościo-wych, przy czym zmienna objaśniana (Y) musi być minimum cechą po - rządkową, określoną na skali przedziałowej (np. za pomocą skali Stapela). Wynika to z faktu konieczności obliczania warunkowych średnich arytme-tycznych dla cechy Y. Średniej arytmetycznej nie można – jak wiadomo – obliczyć, gdy pomiaru dokonano na skalach słabszych, tj. nominalnej bądź porządkowej (zob. tabela 1.5).
Metoda ta sprowadza się do sporządzenia wykresu regresji empirycznej (zob. rys. 1.30), określanego też krzywą regresji I rodzaju zmiennej zależ-nej Y względem zmiennej niezależnej X – wariantom zmiennej objaśniającej xi przyporządkowuje się średnie arytmetyczne (warunkowe wartości ocze-kiwane) zmiennej zależnej. Wartości średnie wyznacza się według poniż-szego wzoru (por. [21, s. 317]):
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( )ε,xfy =

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.2. Analiza współzależności
str. 217
Po połączeniu punktów odpowiadających kolejnym warunkowym warto-ściom oczekiwanym otrzymamy łamaną, tj. krzywą regresji I rodzaju. Wzrost średnich warunkowych (grupowych) wskazuje na korelację dodat-nią, zaś spadek – na korelację ujemną.
Ponadto w przypadku, gdy zmienną objaśniającą X jest cecha porządkowa, o sile korelacji informuje wartość współczynnika eta , zaś gdy zmienna X została określona na skali mocniejszej – poziom współczynnika korelacji liniowej Pearsona (wzór dla danych pogrupowanych).
Warto dodać, iż krzywą regresji korzystnie jest wyznaczyć, gdy zmienną niezależną X jest ilościowa cecha skokowa. Wówczas krzywą regresji em-pirycznej wyznacza się tak, jak ukazuje to poniższy przykład (jest to konty-nuacja przykładu na obliczanie współczynnika korelacji liniowej Pearsona dla danych pogrupowanych w tablicę korelacyjną):
Przykład. W oparciu o dane z tabeli 2.32 należy sporządzić wykres regre-sji empirycznej (krzywą regresji I rodzaju) ocen wartości publikacji „Vade-mecum Studenta” (zmienna objaśniana Y) względem postrzeganej jakości prezentowanych treści (zmienna X).
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.2. Analiza współzależności
str. 218
Tabela 2.34. Zależność postrzeganej wartości publikacji „Statystyka po ludzku” od oceny jakości treści.
–3 –1 1 2 3 4 5–5 (–3)×1 = –3 –3 1 (–3) / 1 = –3–4 2 2 1 2–2 (–1)×1 = –1 –1 1 –1–1 1 1 1 11 1 1 1 12 3 3 1 33 6 6 2 34 3 8 5 16 4 45 (–1)×1 = –1 10 9 3 3
Źródło: Obliczenia własne na podstawie danych zawartych w tabeli 2.32.
Dla określonego wariantu cechy X obliczamy średnią ważoną ocen dla ce-chy Y – w tym celu przemnażamy kolejno liczebności nij z tabeli 2.32 przez odpowiadające im warianty cechy zależnej yj. Następnie sumujemy po wierszach i stosujemy wzór (por. Przykłady – analiza regresji; zakładka: regresja_empiryczna). Oto przykład obliczenia średniej warunkowej dla wartości x1 = –5:
Oto wykres regresji empirycznej cechy Y względem cechy X:Rysunek 2.7. Krzywa regresji oceny wartości publikacji „Statystyka po ludzku” wzglę-dem oceny jakości treści.
Źródło: Opracowanie własne na podstawie danych zawartych w tabeli 2.34.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
-5
-4
-3
-2
-1
0
1
2
3
4
5
-5 -4 -3 -2 -1 0 1 2 3 4 5
ocena jakości prezentowanych treści (xi)
prze
cięt
na o
cena
war
tośc
i pub
likac
ji
ijj ny ⋅ jy
ix
∑=
⋅k
jijj ny
1
in ( )ixy
( ) 313
1
11
1 −=−=⋅
=∑
=
n
nyxy
k
jjj

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.2. Analiza współzależności
str. 219
Jak widać, wraz ze wzrostem oceny jakości prezentowanych treści w pię-ciostopniowej skali Stapela rosły także – średnio rzecz biorąc – noty co do korzystnej ceny e-booka. Zatem cena jest tu pojęciem względnym – wygó-rowana wydaje się osobom, którym publikacja wydaje się mało interesują-ca. Warto dodać, iż średnie warunkowe można błyskawicznie uzyskać, sto-sując Raport tabeli przestawnej (zob. Przykłady – grupowanie danych).
Regresja II rodzaju znajduje zastosowanie w sytuacji, gdy analiza współ-zależności dotyczy cech ilościowych, występujących w postaci szeregu ko-relacyjnego (xi, yi). Wyróżnia się regresję prostą (jedna zmienna objaśniająca) i regresję wieloraką (minimum dwie zmienne objaśniające). W niniejszej publikacji dalsze rozważania ograniczone zostały do regresji prostej. Przyjęto następujące założenia:
1. Na osi OX znajdują się wartości cechy (zmiennej) niezależnej (objaśnia-jącej).
2. Na osi OY znajdują się wartości cechy zależnej (objaśnianej).
Ocenę zależności Y względem X – i co się z tym: wiąże wybór właściwej funkcji regresji – niewątpliwie ułatwi sporządzenie diagramu korelacyjne - go. Jak już wspomniano, na wykresie sporządzonym w prostokątnym ukła-dzie współrzędnych (w Excelu: wykres XY) zaznaczamy kolejno punkty da-nych o współrzędnych (xi, yi), gdzie i oznacza i-tą obserwację.
Szczególnym przypadkiem omawianej regresji II rodzaju jest regresja li-niowa, w której zależności opisuje linia prosta [21, s. 288]. Jak już wspo-mniano, wartość współczynnika korelacji liniowej Pearsona pozwala okre-ślić siłę zależności liniowej pomiędzy dwoma cechami mierzonymi na ska-lach „mocniejszych” (por. tabela 2.19). Jeżeli wartość tego współczynnika nie wskazuje na silną zależność liniową, to wówczas pomocne jest sporzą-dzenie diagramu korelacyjnego celem ustalenia zależności nieliniowej. Równanie liniowej funkcji regresji zmiennej zależnej Y względem zmien-nej niezależnej (objaśnianej) X ma postać:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.2. Analiza współzależności
str. 220
Parametry a i b prezentowanego modelu liniowego standardowo można oszacować, posługując się klasyczną metodą najmniejszych kwadratów (KMNK). Idea tej metody polega na oszacowaniu parametrów modelu (w przypadku modelu liniowego są to: parametr kierunkowy prostej regre-sji i wyraz wolny) tak, aby suma kwadratów reszt modelu była jak naj-mniejsza (por. [20, s. 168]). Reszty modelu wyznacza się według wzoru:
Reszty stanowią zatem różnicę pomiędzy wartościami empirycznymi (punktami danych odpowiadającymi wartościom zmiennej objaśnianej Y) a wartościami wynikającymi z równania funkcji regresji. W ujęciu graficz-nym reszty modelu można przedstawić jako pionowe odcinki, łączące po-szczególne punkty danych z funkcją regresji:
Rysunek 2.8. Idea klasycznej metody najmniejszych kwadratów na przykładzie regresji liniowej.
Źródło: Opracowanie własne.
Na powyższym wykresie linię poprowadzono w ten sposób, aby zminimali-zować sumę kwadratów reszt. W literaturze statystycznej – zamiast skom-
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
0
2
4
6
8
10
12
14
0 1 2 3 4 5 6
zmienna objasniająca (X)
zmie
nna
obja
snia
na (Y
)

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.2. Analiza współzależności
str. 221
plikowanego zapisu macierzowego – najczęściej podaje się gotowe wzory na oszacowanie parametrów a i b:
a) parametr kierunkowy:
b) wyraz wolny:
Parametr kierunkowy w warunkach egzaminu łatwiej wyznaczyć – podob-nie jak współczynnik korelacji liniowej Pearsona – ze wzoru uproszczone-go:
Analogicznie można wyznaczyć parametry prostej regresji cechy X wzglę-dem Y. Wzory na ich obliczenie zestawiono w poniższej tabeli:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.2. Analiza współzależności
str. 222
Tabela 2.35. Wzory na wyznaczanie prostych regresji Y względem X oraz X względem Y.
Regresja Y względem X Regresja X względem YRównanie prostej regresji:
Parametr kierunkowy:lub lub
Wyraz wolny:
Źródło: Opracowanie własne na podstawie [19, s. 258].
Parametr kierunkowy w liniowej funkcji regresji Y względem X posiada następującą interpretację (por. [20, s. 169]):
1. Ujemna wartość współczynnika (b < 0): wzrost zmiennej niezależnej X o jednostkę wywoła przeciętnie spadek zmiennej zależnej Y o b jedno-stek (korelacja ujemna).
2. Dodatnia wartość współczynnika (b > 0): wzrost zmiennej niezależnej X o jednostkę wywoła przeciętnie przyrost zmiennej zależnej Y o b jed-nostek (korelacja dodatnia).
Natomiast wyraz wolny a informuje, jaki będzie poziom zmiennej objaśnia-nej Y przy zerowym poziomie cechy objaśniającej X.
Sposób wyznaczania linii regresji prezentuje poniższy przykład:
Przykład. Należy wyznaczyć prostą regresji tygodniowych procentowych zmian kursu akcji spółki Strzelec SA (zmienna zależna Y) względem pro-
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
ybax ′+′=ˆ bxay +=ˆ
( )2,cov
xsyxb =
( ) ( )
( )∑
∑
=
=
−
−⋅−=′ n
ii
n
iii
yy
yyxxb
1
2
1
( )2,cov
ysyxb =′
( ) ( )
( )∑
∑
=
=
−
−⋅−= n
ii
n
iii
xx
yyxxb
1
2
1
xbya ⋅−= ybxa ⋅′−=′
bbrxy ′⋅±=
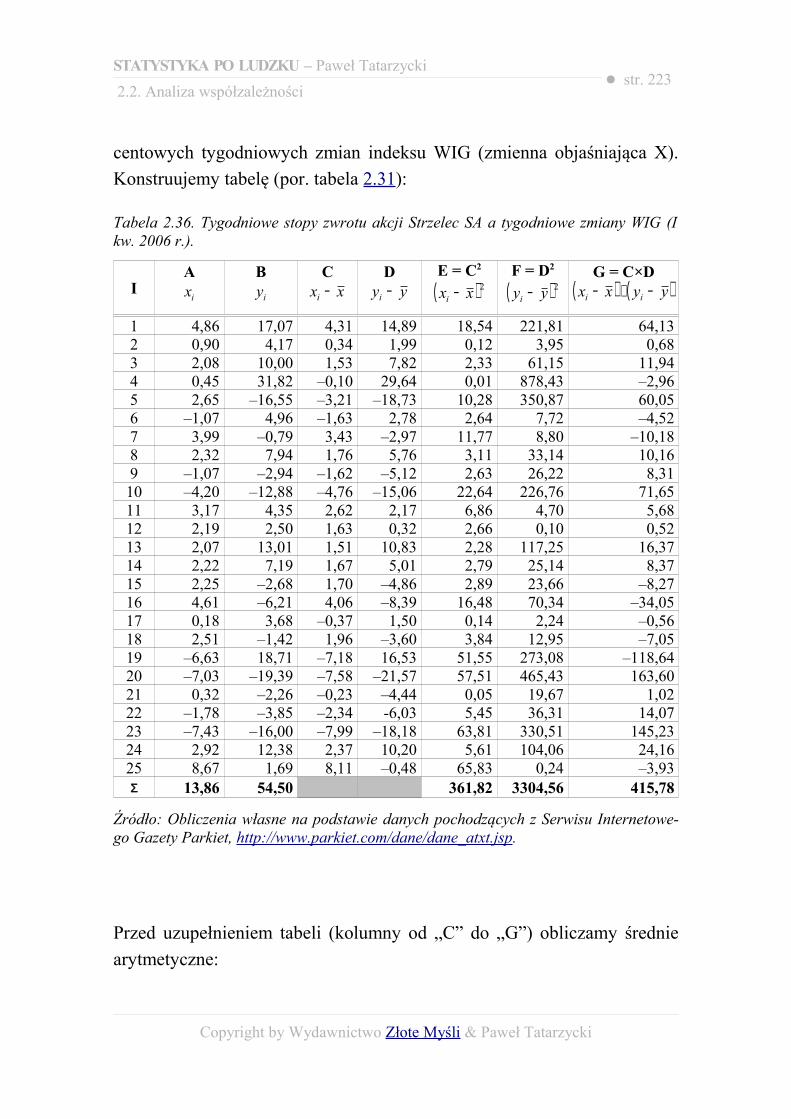
STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.2. Analiza współzależności
str. 223
centowych tygodniowych zmian indeksu WIG (zmienna objaśniająca X). Konstruujemy tabelę (por. tabela 2.31):
Tabela 2.36. Tygodniowe stopy zwrotu akcji Strzelec SA a tygodniowe zmiany WIG (I kw. 2006 r.).
IA B C D E = C2 F = D2 G = C×D
1 4,86 17,07 4,31 14,89 18,54 221,81 64,132 0,90 4,17 0,34 1,99 0,12 3,95 0,683 2,08 10,00 1,53 7,82 2,33 61,15 11,944 0,45 31,82 –0,10 29,64 0,01 878,43 –2,965 2,65 –16,55 –3,21 –18,73 10,28 350,87 60,056 –1,07 4,96 –1,63 2,78 2,64 7,72 –4,527 3,99 –0,79 3,43 –2,97 11,77 8,80 –10,188 2,32 7,94 1,76 5,76 3,11 33,14 10,169 –1,07 –2,94 –1,62 –5,12 2,63 26,22 8,3110 –4,20 –12,88 –4,76 –15,06 22,64 226,76 71,6511 3,17 4,35 2,62 2,17 6,86 4,70 5,6812 2,19 2,50 1,63 0,32 2,66 0,10 0,5213 2,07 13,01 1,51 10,83 2,28 117,25 16,3714 2,22 7,19 1,67 5,01 2,79 25,14 8,3715 2,25 –2,68 1,70 –4,86 2,89 23,66 –8,2716 4,61 –6,21 4,06 –8,39 16,48 70,34 –34,0517 0,18 3,68 –0,37 1,50 0,14 2,24 –0,5618 2,51 –1,42 1,96 –3,60 3,84 12,95 –7,0519 –6,63 18,71 –7,18 16,53 51,55 273,08 –118,6420 –7,03 –19,39 –7,58 –21,57 57,51 465,43 163,6021 0,32 –2,26 –0,23 –4,44 0,05 19,67 1,0222 –1,78 –3,85 –2,34 -6,03 5,45 36,31 14,0723 –7,43 –16,00 –7,99 –18,18 63,81 330,51 145,2324 2,92 12,38 2,37 10,20 5,61 104,06 24,1625 8,67 1,69 8,11 –0,48 65,83 0,24 –3,93Σ 13,86 54,50 361,82 3304,56 415,78
Źródło: Obliczenia własne na podstawie danych pochodzących z Serwisu Internetowe-go Gazety Parkiet, http://www.parkiet.com/dane/dane_atxt.jsp.
Przed uzupełnieniem tabeli (kolumny od „C” do „G”) obliczamy średnie arytmetyczne:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
ix iy xxi − yyi − ( ) 2xxi − ( ) 2yyi − ( ) ( )yyxx ii −⋅−

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.2. Analiza współzależności
str. 224
Uzupełniamy tabelę, sumujemy kolumny i ze wzoru uproszczonego obli-czamy parametr kierunkowy b prostej regresji Y względem X (por. Przy-kłady – analiza regresji; zakładka: regresja_liniowa):
Następnie, korzystając z obliczonych wyżej miar, wyznaczamy wyraz wol-ny a:
Oszacowane parametry podstawiamy do wzoru na prostą regresji Y wzglę-dem X:
W analogiczny sposób możemy wyznaczyć prostą regresji X względem Y:
Niemniej jednak w praktyce niektóre zmienne z góry należy przyjąć jako niezależne – trudno sobie wyobrazić sytuację, w której indeks WIG („baro-
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
554,025
86,131 ===∑
=
n
xx
n
ii
( ) ( )
( )149,1
82,36178,415
1
2
1 ==−
−⋅−=
∑
∑
=
=n
ii
n
iii
xx
yyxxb
xy 149,1154,1ˆ +=
543,1554,0149,118,2 =⋅−=⋅−= xbya
( ) ( )
( )126,0
56,330478,415
1
2
1 ==−
−⋅−=′
∑
∑
=
=n
ii
n
iii
yy
yyxxb
28,018,2126,0554,0 =⋅−=⋅′−=′ ybxa
yx 126,028,0ˆ +=
18,225
50,541 ===∑
=
n
yy
n
ii

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.2. Analiza współzależności
str. 225
metr” gospodarki) zależy np. od zmian kursu wybranej spółki giełdowej. Mamy tu bowiem do czynienia z ogólną tendencją na rynku papierów war-tościowych – na poziom WIG wpływają kursy wszystkich spółek.
Warto dodać, iż w arkuszu kalkulacyjnym MS Excel wbudowano narzędzie Dodaj linię trendu. Narzędzie to pozwala m.in. na dodanie liniowej funkcji regresji do danych przedstawionych na wykresie XY. Opcjonalnie na wy-kresie można wyświetlić równanie wybranej funkcji regresji – należy wy-brać zakładkę Opcje, a następnie zaznaczyć Wyświetl równanie na wykresie (zob. Prezentacja PowerPoint pt. Excel_dodawanie_linii_trendu).
Rysunek 2.9. Regresja liniowa zmian stóp zwrotu akcji Strzelec SA względem zmian WIG (I kw. 2006 r.).
Źródło: Opracowanie własne.
Na powyższym wykresie XY linią przerywaną zaznaczono również regresję X względem Y (linia niemal pokrywająca się z osią OX). W równaniu re-gresji tygodniowych procentowych stóp zwrotu spółki Strzelec SA wzglę-dem procentowych zmian WIG (linia ciągła) interesująca jest interpretacja parametru kierunkowego. Informuje on, o ile punktów procentowych zmieni się kurs analizowanej spółki przy zmianie WIG o 1 proc. Ma tu
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
y = 1,1491x + 1,5428R2 = 0,1446-25
-20
-15
-10
-5
0
5
10
15
20
25
30
35
-10 -5 0 5 10
tygodniowe zmiany WIG (proc.) tygo
dnio
we
stop
y zw
rotu
akc
ji St
rzel
ec S
.A.
(pro
c.)

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.2. Analiza współzależności
str. 226
miejsce korelacja dodatnia, przy czym kurs spółki ulega relatywnie większym zmianom niż WIG – wzrost głównego indeksu giełdowego o 1 proc. spowoduje średnio rzecz biorąc wzrost kursu akcji Strzelec o 1,15 proc. Parametr kierunkowy wyznaczonej funkcji regresji w finansach określa się mianem współczynnika beta (β). Poziom tej miary większy od jedności świadczy o tym, że dany walor jest akcją agresywną – można dużo zarobić, ale ryzyko poniesienia strat jest większe. W sytuacji gdy współczynnik β co do wartości bezwzględnej jest mniejszy od jedności mówimy, że akcja jest defensywna (bezpieczna). Jest to szczególnie dobra inwestycja w sytuacji spowolnienia gospodarczego, kiedy to większość akcji tanieje, co znajduje swoje odzwierciedlenie w spadającym poziomie głównego indeksu giełdowego.
Do opisu niektórych zjawisk – zamiast regresji liniowej – niejednokrotnie korzystniej jest posłużyć się regresją nieliniową (krzywoliniową). Istnieje szereg postaci nieliniowych funkcji regresji, opisujących współzależności pomiędzy wybranymi cechami. Oto niektóre z nich (por. [3, s. 300-301]):
a) funkcja potęgowa:
b) wielomian stopnia trzeciego:
c) funkcja logarytmiczna:
Wybór właściwej postaci analitycznej modelu regresji niekiedy zależy od specyfiki danego zjawiska. I tak np. całkowite koszty produkcji względem wielkości produkcji można opisać za pomocą wielomianu stopnia trzecie-go, co jest uzasadnione z ekonomicznego punktu widzenia. Wpływ rekla-my na wielkość obrotów – z uwagi na fakt, że odbiorcy „uodparniają” się
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
10
axay ⋅=
33
2210 xaxaxaay +++=
( )xaay ln10 +=

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.2. Analiza współzależności
str. 227
na przekazy reklamowe – trafnie opisze np. funkcja logarytmiczna (coraz mniejsze przyrosty obrotów przy jednakowych przyrostach wydatków na reklamę). Wreszcie analizę współzależności pomiędzy ceną (zmienna obja-śniana Y) a wielkością popytu (zmienna objaśniająca X) warto opisać z wykorzystaniem funkcji potęgowej – wykładnik potęgi jest tu interpreto-wany jako cenowa elastyczność popytu.
Z uwagi na złożoną stronę analityczną szacowania parametrów ai funkcji nieliniowych (konieczność sprowadzenia modelu do postaci liniowej) w poniższym przykładzie do wyznaczenia funkcji regresji posłużono się narzędziem Excela Dodaj linię trendu.
Przykład. W podrozdziale Prezentacja materiału statystycznego przedsta-wiono sposób sporządzania diagramu korelacyjnego, ukazującego zależ-ność wartości księgowej na 1 akcję od rentowności kapitałów własnych Grupy Żywiec SA Do danych przedstawionych na wykresie XY (zob. rys. 1.27) dodano funkcję regresji – wielomian stopnia drugiego – wybierając typ Wielomianowy (opcjonalnie jest to wielomian stopnia drugiego). Część funkcji była niedostępna, ponieważ występowały liczby ujemne.
Rysunek 2.10. Zależność wartości księgowej na 1 akcję od rentowności kapitałów wła-snych Grupy Żywiec SA
Źródło: Opracowanie własne na podstawie danych pochodzących z Portalu Finansowe-go Money.pl, http://www.money.pl
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
y = 43,93x2 + 20,84x + 94,95R2 = 0,8183
90
92
94
96
98
100
102
104
106
-15% -10% -5% 0% 5% 10% 15% 20% 25% 30%
rentowność kapitałów własnych
war
tość
ksi
ęgow
a na
1 a
kcję

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.2. Analiza współzależności
str. 228
Wyznaczenie funkcji regresji pozwala na oszacowanie wartości zmiennej zależnej Y poprzez podstawienie żądanej wartości za zmienną X. W pre-zentowanym przykładzie można oszacować wartość księgową przypadają-cą na jedną akcję, podstawiając za x przyjęty poziom rentowności kapita-łów własnych (ROE) do poniższego równania:
Przykładowo, można oszacować wartość księgową przypadającą na jedną akcję spółki Strzelec przy rentowności kapitałów własnych równej 40 proc. (x = 40% = 40/100 = 0,4):
Przy prognozowanym poziomie ROE = 40 proc. na podstawie wyznaczonej funkcji regresji wartość księgową na 1 akcję oszacowano na poziomie 120,86 zł.
Po wyznaczeniu funkcji regresji należy sprawdzić, w jakim stopniu jest ona dopasowana do danych empirycznych. Wybór analitycznej postaci funkcji regresji należy uznać za poprawny, jeżeli wartości reszt (różnice pomiędzy wartościami zaobserwowanymi a wartościami teoretycznymi wynikającymi z funkcji regresji) są stosunkowo niewielkie i mają charakter przypadkowy [20, s. 172].
Istnieje szereg miar służących do oceny jakości modelu regresji. W niniej-szej publikacji zostaną omówione wybrane z nich. Miarą dobroci dopaso-wania funkcji regresji, w tym linii regresji, do danych jest współczynnik zbieżności ϕ2 (nie należy mylić go z omówionym wcześniej współczynni-kiem ϕ -Yule’a ):
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
293,4384,2095,94ˆ xxy ++=
( ) 24,093,434,084,2095,94ˆ ⋅+⋅+=y
86,120ˆ =y

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.2. Analiza współzależności
str. 229
Powyższy współczynnik jest wielkością unormowaną, tj. przyjmuje warto-ści z przedziału [0,1]. Wartości bliskie zeru świadczą o dobrym dopasowaniu funkcji regresji do danych empirycznych [3, s. 274]. Jeżeli po sporządzeniu diagramu korelacyjnego okaże się, że wybrana postać anali-tyczna funkcji regresji (np. postać liniowa) jest uzasadniona, to współczyn-nik zbieżności określa wpływ czynnika losowego na zmiany cechy zależnej (objaśnianej).
Inną miarą dobroci dopasowania funkcji regresji do danych jest współczyn-nik determinacji R2. Generalnie wyznacza się go ze wzoru:
Współczynnik R2, tak jak ϕ2, jest miarą unormowaną, przyjmującą wartości z przedziału [0-1]. Współczynnik ten informuje, w jakim stopniu zmienna objaśniająca X wyjaśnia zmienność cechy objaśnianej Y. Gdy wartość tego współczynnika wynosi 1, to wówczas zmienność cechy X w stu procentach wyjaśnia zmienność cechy Y. Z uwagi na brak oddziaływania czynnika lo-sowego można tu mówić o zależności funkcyjnej (przypadek szczególny) [1, s. 492]. Innymi słowy, współczynnik determinacji określa, ile procent zmienności Y zostało wyjaśnione przy pomocy oszacowanej funkcji regre-sji, tj. ile procent tej zmienności wynika z czynników uwzględnionych w równaniu regresji, a ile z pozostałych czynników, w tym czynnika loso-wego (por. [20, s. 172]). Jak już wspomniano, w tej publikacji ograniczono
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.2. Analiza współzależności
str. 230
się do regresji prostej, uwzględniającej jedną zmienną objaśniającą, stąd niekiedy poziom omawianej miary może być niesatysfakcjonujący. W praktyce należałoby wziąć pod uwagę więcej zmiennych objaśniających (regresja wieloraka – tj. uwzględniająca więcej niż dwie zmienne objaśniające – jest domeną ekonometrii).
Pomiędzy omówionymi miarami jakości modelu regresji zachodzi następu-jąca zależność:
W przypadku regresji liniowej współczynnik determinacji R2 jest równy kwadratowi współczynnika korelacji liniowej Pearsona (por. [20, s. 173]):
Przykład. Należy obliczyć współczynnik determinacji R2 i współczynnik zbieżności ϕ2 pomiędzy analizowanym we wcześniejszym przykładzie wpływem procentowych zmian WIG (zmienna niezależna X) a procento-wymi zmianami kursu akcji spółki Strzelec SA (zmienna zależna Y), wie-dząc, że:
Ponieważ oszacowano zarówno parametr kierunkowy prostej regresji Y względem X, jak również X względem Y, to można obliczyć współczyn-nik korelacji liniowej Pearsona z następującego wzoru:
W przypadku regresji liniowej prawdziwa jest zależność:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
22 1 ϕ−=R
22xyrR =
xy 149,1154,1ˆ +=
yx 126,028,0ˆ +=
22xyrR =

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.2. Analiza współzależności
str. 231
Zatem wartość współczynnika determinacji R2 to:
Na rys. 2.9 dodano wartość współczynnika R2, wybierając zakładkę Opcje w oknie dialogowym Dodaj linię trendu, a następnie zaznaczając Wyświetl wartość R-kwadrat na wykresie (w analogiczny sposób dodano linię regre-sji). Współczynnik ten informuje, że jedynie w 14,5 proc. na zmiany stóp zwrotu akcji spółki Strzelec wpłynęły zmiany indeksu WIG, tj. zmiany ryn-kowe – resztę zmian wyjaśniają inne czynniki. Mamy tu do czynienia z tzw. ryzykiem systematycznym, związanym ze zmianami na rynku kapita-łowym (ogólnej poprawie na rynku towarzyszy na ogół wzrost cen więk-szości akcji – i odwrotnie).
Wpływ pozostałych czynników, w tym czynnika losowego, określa wartość współczynnika zbieżności ϕ2:
W tej sytuacji mówimy o tzw. ryzyku specyficznym, związanym z daną ak-cją. Oprócz zmian „czysto” losowych mają tu miejsce m.in. zmiany zwią-zane z sytuacją finansową danej spółki (poprawie sytuacji finansowej po-winno towarzyszyć większe zainteresowanie ze strony inwestorów). Czyn-niki specyficzne aż w 85,5 proc. wyjaśniają zmiany zyskowności akcji ana-lizowanej spółki. Niewątpliwie dużą rolę odgrywa tu czynnik losowy (zob. rys. 2.9).
Interpretacja współczynników R2 i ϕ2 jest analogiczna dla różnych postaci analitycznych funkcji regresji, co czyni te miary uniwersalnymi. Należy podkreślić, iż relatywnie niska wartość współczynnika R2 (wysoka ϕ2) mo-że wynikać nie tylko ze znacznego oddziaływania czynnika losowego i in-nych – nieuwzględnionych w modelu – czynników, ale również z nieodpo-wiedniego doboru postaci analitycznej funkcji regresji. W związku z tym przed dokonaniem ostatecznego doboru postaci analitycznej funkcji warto
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( ) 145,0126,0149,1222 =⋅=′⋅=′⋅±== bbbbrR xy
855,0145,011 22 =−=−= Rϕ

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.2. Analiza współzależności
str. 232
obliczyć współczynniki determinacji dla kilku potencjalnych modeli i wy-brać ten, dla którego wartość współczynnika R2 jest największa. Oto przy-kład obliczenia współczynnika determinacji dla nieliniowej funkcji regre-sji:
Przykład. Należy obliczyć współczynnik determinacji R2 dla danych z przykładu prezentującego analizę regresji nieliniowej wartości księgowej przypadającej na 1 akcję (zmienna zależna Y) względem poziomu wskaźni-ka rentowności kapitałów własnych (zmienna niezależna X). Wartości teo-retyczne zmiennej objaśnianej wyznaczamy podstawiając kolejno wartości xi do uprzednio oszacowanej funkcji regresji:
Następnie obliczamy wartość średnią zmiennej zależnej Y i uzupełniamy tabelę:
Tabela 2.37. Wpływ wskaźnika ROE na wartość księgową na 1 akcję spółki Strzelec SA
LataA B C D E F = D2 G = E2
2001 –10,0% 92,8 93,304 –6,611 –6,077 43,708 36,9342002 7,0% 99,0 96,626 –0,412 –2,756 0,170 7,5942003 18,6% 97,6 100,364 –1,824 0,983 3,328 0,9662004 24,0% 101,8 102,483 2,372 3,102 5,625 9,6222005 27,7% 105,9 104,116 6,476 4,735 41,936 22,417
Σ 496,9 94,767 77,533
Źródło: Obliczenia własne na podstawie danych pochodzących z Portalu Finansowego Money.pl, http://www.money.pl/gielda/profile/ZYWIEC,ZWC,raporty,finansowe.html
Sumy z kolumny F i G podstawiamy do wzoru na współczynnik determina-cji:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
293,4384,2095,94ˆ xxy ++=
ix iy iy yyi − yyi −ˆ ( ) 2yyi − ( ) 2ˆ yyi −
( )
( )818,0
767,94533,77
ˆ
1
2
1
2
2 ==−
−=
∑
∑
=
=n
ii
n
ii
yy
yyR

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.2. Analiza współzależności
str. 233
Wysoki poziom współczynnika świadczy o dobrym dopasowaniu funkcji kwadratowej do danych (zob. rys. 2.10). Zmienność wartości księgowej na jedną akcję w niemal 82 proc. została wyjaśniona zmiennością wskaźnika rentowności kapitałów własnych – wskaźnik ten w syntetyczny sposób ukazuje bowiem sytuację finansową przedsiębiorstwa. Zgodnie z modelem Du Ponta – można go przedstawić w postaci iloczynu innych wskaźników finansowych (zob. Indeksy indywidualne i agregatowe).
Klasyczna metoda najmniejszych kwadratów znajduje zastosowanie nie tylko do szacowania parametrów funkcji regresji, gdzie zmiennymi obja-śniającymi są cechy ilościowe. Do modelu regresji – nie tylko liniowej – można włączyć także zmienną jakościową jako zmienną niezależną. W tym celu należy wprowadzić tzw. zmienną wskaźnikową, zwaną też sztuczną, binarną czy zero-jedynkową. Zmienna ta przyjmuje dwie wartości (por. [1, s. 558]):
1 – gdy dany wariant występuje,0 – pozostałe warianty cechy.
Jeżeli cecha jest dychotomiczna, to powyższe kodowanie jest wystarczają-ce. Jednak w przypadku jakościowych cech przyjmujących więcej niż dwa warianty konieczne jest wprowadzenie kilku zmiennych sztucznych. W ni-niejszym opracowaniu ograniczono się do cechy dychotomicznej (regresja prosta z jedną zmienną sztuczną z). Oto przykład:
Przykład. Należy oszacować parametry funkcji regresji ukazującej wpływ płci respondenta na wizualną ocenę publikacji „Statystyka po ludzku”. Postać liniowej funkcji regresji jest następująca:
Wprowadzona zmienna sztuczna przyjmuje wartość równą 1, jeżeli respon-dentem jest kobieta – w przeciwnym razie wartość tej zmiennej jest równa
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
zaay ⋅+= 10ˆ

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.2. Analiza współzależności
str. 234
zeru. Dane przedstawione w postaci szeregu korelacyjnego wraz z oblicze-niami pomocniczymi są następujące:
Tabela 2.38. Zależność oceny wyglądu publikacji „Statystyka po ludzku” od płci respondenta.
iA B C D E = C2 F = D2 G = C×D
1 1 3 0,47 0,20 0,22 0,04 0,092 1 5 0,47 2,20 0,22 4,84 1,033 1 5 0,47 2,20 0,22 4,84 1,034 1 4 0,47 1,20 0,22 1,44 0,565 1 4 0,47 1,20 0,22 1,44 0,566 0 3 –0,53 0,20 0,28 0,04 –0,117 0 5 –0,53 2,20 0,28 4,84 –1,178 0 4 –0,53 1,20 0,28 1,44 –0,649 1 3 0,47 0,20 0,22 0,04 0,0910 0 2 –0,53 –0,80 0,28 0,64 0,4311 1 3 0,47 0,20 0,22 0,04 0,0912 1 1 0,47 –1,80 0,22 3,24 –0,8413 0 –1 –0,53 –3,80 0,28 14,44 2,0314 0 2 –0,53 –0,80 0,28 0,64 0,4315 0 –1 –0,53 –3,80 0,28 14,44 2,03Σ 8 42 3,73 52,40 5,60
Źródło: Obliczenia własne na podstawie danych umownych.
Parametry funkcji regresji szacowane są klasyczną metodą najmniejszych kwadratów (zob. regresja liniowa):
Mężczyźni ocenili wygląd publikacji w skali Stapela (od –5 do +5) na po-ziomie 2 (za zmienną z podstawiamy wartość 0), natomiast kobiety – śred-nio rzecz biorąc – wyżej oceniały szatę graficzną e-booka – do równania za zmienną z podstawiamy wartość 1:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
iz iy zzi − yyi − ( ) 2zzi − ( ) 2yyi − ( ) ( )yyzz ii −⋅−
zy ⋅+= 5,12ˆ
5,315,12ˆ =⋅+=y

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.2. Analiza współzależności
str. 235
Wartości 2 oraz 3,5 to średnie warunkowe cechy zależnej obliczone odpo-wiednio dla wariantów „mężczyzna” i „kobieta” (por. regresja empirycz - na). Niemniej jednak prezentowana metoda pozwala na wprowadzenie ze-społu zmiennych, w tym właśnie jakościowych, dzięki czemu dane zjawi-sko będzie lepiej opisane. Poruszone zagadnienia związane z analizą współzależności stanowią podbudowę do dalszego studiowania w ramach ekonometrii.
2.2.3. Trening i ewaluacja
Podsumowaniem podrozdziału Analiza współzależności jest przedstawiona poniżej analiza. Ma ona na celu budowę modelu regresji z jedną zmienną niezależną X, najlepiej wyjaśniającą zmienność przeciętnych cen mieszkań w Polsce w II kw. 2006 r. w przeliczeniu na metr kwadratowy powierzchni lokalu. Analizę przeprowadzono na podstawie danych o rynku mieszkanio-wym w największych miastach Polski (zob. Dane_do_analizy.xls; zakład-ka: Mieszkania). Potencjalne zmienne objaśniające to: lokalizacja oraz licz-ba pokoi. Niezbędne obliczenia wykonano w arkuszu kalkulacyjnym MS Excel (zob. Przykłady – analiza współzależności). W tym miejscu zostanie przedstawiony raport z analizy. Postawiono dwie hipotezy robocze:
1. Na przeciętną cenę mieszkania (zł/m2) wpływa lokalizacja, niezależnie od wielkości mieszkania mierzonej liczbą pokoi. Im większe miasto, tym wyższe ceny mieszkań.
2. Podstawowym czynnikiem wpływającym na cenę mieszkania (zł/m2) jest liczba pokoi. Generalnie droższe są małe mieszkania, zwłaszcza ka-walerki (lokalizacja jest tu bez znaczenia).
Aby zweryfikować pierwszą hipotezę, należy określić siłę korelacji pomię-dzy przeciętną ceną mieszkania a rodzajem miasta (cecha nominalna). Naj-pierw dane pogrupowano w tablicę korelacyjną:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.2. Analiza współzależności
str. 236
Ceny mieszkań(zł/m2)
LokalizacjaGdańsk Kraków Poznań Warszawa Wrocław Σ
3000 do 3759 3 4 73760 do 4519 1 3 44520 do 5279 1 1 25280 do 6040 3 4 7
Σ 4 4 4 4 4 20
Dla każdego z analizowanych miast podano średnie ceny metra kwadrato-wego mieszkania jedno-, dwu-, trzy- i czteropokojowego, stąd sumy dla poszczególnych wariantów zmiennej lokalizacja wyniosły 4. Warto zauwa-żyć, iż w przypadku Warszawy wszystkie ceny mieszkań zaklasyfikowano w ostatnim przedziale klasowym – w Poznaniu sytuacja przedstawiała się natomiast odwrotnie.
Korzystając z danych zawartych w tablicy korelacyjnej, wyznaczono li-czebności teoretyczne (por. Przykłady – analiza współzależności; zakładka: Lokalizacja). W kolejnym kroku wykonano obliczenia pomocnicze zmie-rzające do wyznaczenia statystyki chi-kwadrat:
χ2 = 33,214
Następnie obliczono wybrane miary korelacji (r = 5 wierszy, k = 4 kolum-ny):
a) współczynnik V-Cramera:
b) współczynnik T-Czuprowa:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( ) ( ) ( ) ( ) 744,0320
214,3314;15min20
214,331;1min
2
=⋅
=−−⋅
=−−⋅
=krn
V χ
( ) ( ) ( ) ( ) 692,01220
214,33141520
214,3311
2
=⋅
=−⋅−⋅
=−⋅−⋅
=krn
T χ

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.2. Analiza współzależności
str. 237
Oba współczynniki wskazują na istotny wpływ lokalizacji na cenę metra kwadratowego mieszkania.
Z uwagi na fakt, że zmienna objaśniająca jest cechą ilościową, można obli-czyć współczynnik eta . Nawiązując do oznaczeń w prezentowanym wcze-śniej wzorze przyjęto:
xij – i-ta cena mieszkania (tys. zł/m2) w j-tym mieście
Dane xij zestawiono w tabeli:
Lokalizacja Cena mieszkania (tys. zł/m2) ΣGdańsk 3,630 3,766 3,376 3,351 14,123Kraków 5,843 5,504 5,435 5,136 21,918Poznań 3,606 3,360 3,150 3,037 13,153Warszawa 5,993 6,037 5,704 5,688 23,422Wrocław 4,500 4,588 4,205 4,017 17,310
Σ 89,926
Cenę mieszkania celowo przedstawiono w tysiącach złotych – dzięki temu uniknięto bardzo dużych liczb przy podnoszeniu do kwadratu. Średnia cena mieszkania w Polsce to:
Średnie ceny mieszkań dla poszczególnych wariantów cechy niezależnej, tj. miast, obliczono dzieląc kolejno sumy z powyższej tabeli przez liczbę obserwacji dla danego wariantu. Np. dla Gdańska i Krakowa średnie wa-runkowe obliczono następująco:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
496,4
02926,89 ==x
531,3
4123,14 ==ix
480,5
4918,21
2 ==x

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.2. Analiza współzależności
str. 238
Analogicznie wyznaczono średnie dla pozostałych miast. Wielkości te są następnie wykorzystywane w dalszych obliczeniach pomocniczych, któ-rych celem jest wyznaczenie wartości licznika wzoru na współczynnik eta (por. Przykłady – analiza współzależności; zakładka: Lokalizacja):
A B C D E = D2 F = E×B
Lokalizacja
Gdańsk 4 3,531 – 0,966 0,932 3,73Kraków 4 5,480 0,983 0,967 3,87Poznań 4 3,288 –1,208 1,459 5,84Warszawa 4 5,856 1,359 1,847 7,39Wrocław 4 4,328 –0,169 0,028 0,11
Σ 20 20,94
Obliczenia pomocnicze do wyznaczenia mianownika wzoru:
Lokalizacja Σ
Gdańsk 0,750 0,533 1,255 1,312 3,85Kraków 1,814 1,015 0,881 0,409 4,12Poznań 0,793 1,291 1,813 2,130 6,03
Warszawa 2,240 2,374 1,459 1,420 7,49Wrocław 0,000 0,008 0,085 0,230 0,32
Σ 21,81
Obliczamy współczynnik eta:
Bardzo wysoka wartość współczynnika świadczy o silnej zależności ceny metra kwadratowego mieszkania od lokalizacji. Oto ranking przeciętnych cen mieszkań:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
jn jx xx j − ( )2xx j − ( ) jj nxx ⋅− 2
( )2xxij −
( )
( )96,0
81,2194,20
1 1
2
2
1 ==−
⋅−=
∑ ∑
∑
= =
=r
i
k
jij
j
k
jj
xx
nxxη

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.2. Analiza współzależności
str. 239
Jak widać, zróżnicowanie cen w porównywanych miastach jest znaczne – najdroższe mieszkania są w stolicy, najtańsze zaś w Poznaniu.
W celu sprawdzenia siły zależności pomiędzy ceną metra kwadratowego mieszkania (zmienna zależna Y) a liczbą pokoi (zmienna objaśniająca X) obliczono współczynnik korelacji liniowej Pearsona dla danych pogrupo-wanych w tablicę korelacyjną (por. Przykłady – analiza współzależności; zakładka: liczba_pokoi):
(liczba pokoi) cena mieszkania (tys. zł/m2) – środki klas
3,38 4,14 4,90 5,661 2 1 0 2 5 5 2,25 11,252 1 1 1 2 5 10 0,25 1,253 2 1 0 2 5 15 0,25 1,254 2 1 1 1 5 20 2,25 11,25
7 4 2 7 20 50 25,00
23,66 16,56 9,8 39,62 89,64
1,21 0,12 0,17 1,39
8,50 0,47 0,35 9,71 19,03
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
0
1
2
3
4
5
6
śred
nia
cena
mie
szka
nia
(tys.
zł/m
2 )
Poznań Gdańsk Wrocław Kraków Warszawa
ix jy •in •⋅ ii nx ( ) 2xxi − ( ) •⋅− ii nxx 2
jn•
jj ny •⋅
( )2yy j −
( ) jj nyy •⋅− 2

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.2. Analiza współzależności
str. 240
Wartości średnie dla obu zmiennych wynoszą:
Odchylenia standardowe wynoszą odpowiednio:
Obliczenia pomocnicze do wyznaczenia kowariancji:
(liczba pokoi) cena mieszkania (tys. zł/m2) – środki klas3,38 4,14 4,90 5,66
Σ
1 6,76 4,14 0,00 11,32 22,2202 6,76 8,28 9,80 22,64 47,4803 20,28 12,42 0,00 33,96 66,6604 27,04 16,56 19,60 22,64 85,840Σ 60,84 41,40 29,40 90,56 222,20
Sumę po wierszach i kolumnach z powyższej kolumny oraz obliczone wcześniej wartości średnie podstawiamy do wzoru na kowariancję:
Obliczoną powyżej wartość kowariancji, jak również odchylenia standar-dowe, podstawiamy do wzoru ogólnego na współczynnik korelacji liniowej Pearsona:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
5,2
2050 ==x
482,4
2064,89 ==y
118,1
2025 ==xs
975,0
2003,19 ==ys
( ) 095,0482,45,220
220,cov 1 1 −=⋅−=⋅−−⋅⋅
=∑ ∑
= = yxn
nyxyx
r
i
k
jijji
( ) 087,0975,0118,1
095,0,cov −=⋅
−=⋅
=yx
xy ssyxr
ijji nyx ⋅⋅ jy

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.2. Analiza współzależności
str. 241
Otrzymana wartość współczynnika świadczy o braku korelacji pomiędzy analizowanymi cechami.
Z uwagi na fakt, że zmienną objaśniającą jest cecha skokowa – a nie ciągła – zamiast diagramu korelacyjnego postulowane jest sporządzenie krzywej regresji I rodzaju przeciętnych cen mieszkań względem liczby pokoi (zob. regresja empiryczna):
Z powyższego wykresu średnich warunkowych cen mieszkań wynika, że w Polsce – bez względu na lokalizację – najdroższe okazały się mieszkania dwupokojowe, co przeczy postawionej na wstępie hipotezie roboczej. Nie sprawdziło się przypuszczenie, że od lokalizacji ważniejszą zmienną obja-śniającą może okazać się liczba pokoi – różnice pomiędzy przeciętnymi ce-nami mieszkań jedno-, dwu-, trzy- i czteropokojowych okazały się relatyw-nie niewielkie.
Zatem zmienną trafnie opisującą zróżnicowanie cen mieszkań w Polsce okazała się lokalizacja. Do modelu regresji włączono więc cechę jakościo-wą wprowadzając zmienną sztuczną Z:
gdzie:Y – przeciętna cena mieszkania (tys. zł/m2)Z – zmienna sztuczna.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
3
4
5
6
0 1 2 3 4
liczba pokoi
cena
mies
zkan
ia
(tys
. zł/m
2 )
ZaaY ⋅+= 10

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.2. Analiza współzależności
str. 242
Zmienna sztuczna przyjmuje następujące wartości:
0 – gdy mieszkanie wybudowano w Warszawie bądź Krakowie,1 – pozostałe lokalizacje (Gdańsk, Poznań, Wrocław).
Parametry funkcji regresji oszacowano klasyczną metodą najmniejszych kwadratów. Obliczenia pomocnicze (dane w postaci szeregu korelacyjne-go) prezentuje tabela:
iA B C D E = C2 F = D2 G = C×D
1 0 3,630 –0,400 –0,866 0,160 0,750 0,3472 1 5,843 0,600 1,347 0,360 1,814 0,8083 0 3,606 –0,400 –0,890 0,160 0,793 0,3564 1 5,993 0,600 1,497 0,360 2,240 0,8985 0 4,500 –0,400 0,004 0,160 0,000 –0,0016 0 3,766 –0,400 –0,730 0,160 0,533 0,2927 1 5,504 0,600 1,008 0,360 1,015 0,6058 0 3,360 –0,400 –1,136 0,160 1,291 0,4559 1 6,037 0,600 1,541 0,360 2,374 0,92410 0 4,588 –0,400 0,092 0,160 0,008 –0,03711 0 3,376 –0,400 –1,120 0,160 1,255 0,44812 1 5,435 0,600 0,939 0,360 0,881 0,56313 0 3,150 –0,400 –1,346 0,160 1,813 0,53914 1 5,704 0,600 1,208 0,360 1,459 0,72515 0 4,205 –0,400 –0,291 0,160 0,085 0,11716 0 3,351 –0,400 –1,145 0,160 1,312 0,45817 1 5,136 0,600 0,640 0,360 0,409 0,38418 0 3,037 –0,400 –1,459 0,160 2,130 0,58419 1 5,688 0,600 1,192 0,360 1,420 0,71520 0 4,017 –0,400 –0,479 0,160 0,230 0,192Σ 8 89,926 4,800 21,811 9,370
Sumy z kolumn A i B posłużyły kolejno do obliczenia wartości średnich:
Parametr kierunkowy obliczamy dzieląc sumę z kolumny G przez sumę z kolumny E:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
iz iy zzi − yyi − ( ) 2zzi − ( ) 2yyi − ( ) ( )yyzz ii −⋅−
4,0
208 ==z
496,4
20926,89 ==y

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.2. Analiza współzależności
str. 243
Wartości średnie i obliczony poziom parametru kierunkowego podstawia-my do wzoru na wyraz wolny:
Oszacowana funkcja regresji ma postać:
Podstawiając za zmienną Z wartość 1 – otrzymamy przeciętną cenę miesz-kania w Warszawie i Krakowie (5,668 tys. zł/m2). Podstawiając za zmienną wartość zero – otrzymamy wartość wyrazu wolnego, ktorą interpretujemy tu jako przeciętną cenę mieszkania w pozostałych miastach (Gdańsk, Po-znań, Wrocław).
Kolejną kwestią jest ocena jakości modelu. W tym celu posłużono się współczynnikiem determinacji R 2 . Punktem wyjścia jest określenie warto-ści teoretycznych (podstawiamy za zmienną Z odpowiednio wartości 0 lub 1). Oto obliczenia pomocnicze:
iA B C D = C2
1 3,630 3,716 –0,781 0,6102 5,843 5,668 1,171 1,3723 3,606 3,716 –0,781 0,6104 5,993 5,668 1,171 1,3725 4,500 3,716 –0,781 0,6106 3,766 3,716 –0,781 0,6107 5,504 5,668 1,171 1,3728 3,360 3,716 –0,781 0,6109 6,037 5,668 1,171 1,37210 4,588 3,716 –0,781 0,61011 3,376 3,716 –0,781 0,61012 5,435 5,668 1,171 1,37213 3,150 3,716 –0,781 0,61014 5,704 5,668 1,171 1,37215 4,205 3,716 –0,781 0,610
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( ) ( )
( )952,1
8,437,9
1
2
1 ==−
−⋅−=
∑
∑
=
=n
ii
n
iii
zz
yyzzb
716,34,0952,1496,4 =⋅−=⋅−= xbya
ZY ⋅+= 952,1716,3
iy iy yyi −ˆ ( ) 2ˆ yyi −

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.2. Analiza współzależności
str. 244
16 3,351 3,716 –0,781 0,61017 5,136 5,668 1,171 1,37218 3,037 3,716 –0,781 0,61019 5,688 5,668 1,171 1,37220 4,017 3,716 –0,781 0,610
Σ 18,289
Współczynnik determinacji obliczamy dzieląc sumę z ostatniej kolumny powyższej tabeli przez sumę z kolumny F wcześniejszej tabeli, zawierają-cej obliczenia pomocnicze do wyznaczenia parametrów funkcji regresji:
Wartość współczynnika świadczy o wysokiej jakości modelu. Wysokość ceny mieszkania niemal w 84 proc. zależy od lokalizacji – resztę stanowią pozostałe czynniki, w tym czynnik losowy. Niewykluczone, że dodatkowe wprowadzenie drugiej branej pod uwagę zmiennej – liczby pokoi – jeszcze bardziej zwiększyłoby poziom współczynnika R2.
EWALUACJA
Test 3
Pytanie 1. Biorąc pod uwagę typ skali pomiarowej oraz fakt czy dana mia-ra jest unormowana, wymienionym współczynnikom korelacji proszę przy-pisać rangi od 1 do 4, gdzie „1” oznacza miarę „najdokładniejszą”:
a) współczynnik korelacji rang: ___b) współczynnik C-Pearsona: ___c) współczynnik V-Cramera: ___d) współczynnik korelacji liniowej Pearsona: ___
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( )
( )839,0
811,21289,18
ˆ
1
2
1
2
2 ==−
−=
∑
∑
=
=n
ii
n
ii
yy
yyR

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.2. Analiza współzależności
str. 245
Pytanie 2. Współczynnik eta można obliczyć, gdy:
a) obie cechy mierzone są na skali nominalnejb) pomiaru zmiennej zależnej dokonano na skali porządkowejc) obie cechy mierzone są na skali porządkowejd) pomiaru zmiennej zależnej dokonano na skali przedziałowej/ilorazowej
Pytanie 3. Wartość współczynnika korelacji Pearsona równa –0,75 świad-czy o:
a) znacznej korelacji ujemnej b) znacznej korelacji dodatniejc) silnej korelacji ujemnejd) silnej korelacji dodatniej
Pytanie 4. Parametr kierunkowy prostej regresji informuje o:
a) poziomie cechy zależnej, gdy wartość cechy objaśniającej jest równa zeru
b) stopniu dopasowania linii regresji do danych empirycznychc) zmianie cechy zależnej, gdy wartość cechy niezależnej zmieni się o jed-
nostkęd) sile zależności liniowej
Pytanie 5. Prosta regresji typu y = a0 + a1⋅x2 dotyczy:
a) regresji prostejb) regresji wielorakiejc) regresji liniowejd) regresji nieliniowej
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.2. Analiza współzależności
str. 246
Pytanie 6. Na podstawie 120 obserwacji należy dokonać analizy współza-leżności pomiędzy ceną 1 m2 losowo wybranego mieszkania a wojewódz-twem. Wówczas:
a) odpowiednią miarą korelacji będzie współczynnik korelacji rangb) odpowiednią miarą korelacji będzie współczynnik etac) odpowiedni jest model regresji prostej ze zmienną sztucznąd) odpowiedni jest model regresji wielorakiej ze zmienną sztuczną
Pytanie 7. Dana jest funkcja kosztów:
y = a0 + a1 ⋅ x
gdzie:
y – poziom kosztów całkowitych,x – wielkość produkcji.
Wówczas wyraz wolny interpretowany jest jako:
a) jednostkowy koszt zmiennyb) koszt stałyc) przeciętny koszt całkowityd) przeciętny koszt stały
Pytanie 8. Model regresji nieliniowej należy stosować w następujących sy-tuacjach:
a) wartość współczynnika korelacji liniowej Pearsona wyniosła 0,8 b) wartość współczynnika korelacji liniowej Pearsona wyniosła 0,3c) diagram korelacyjny ma postać:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.2. Analiza współzależności
str. 247
d) przyrost zmiennej niezależnej o jednostkę wywoła proporcjonalny wzrost zmiennej zależnej
Pytanie 9. Współczynnik beta jest:
a) parametrem kierunkowym prostej regresji zmian kursu akcji wybranej spółki giełdowej względem zmian WIG (proc.)
b) wyrazem wolnym w wyżej wymienionej funkcji c) miarą ryzyka systematycznegod) miarą ryzyka specyficznego
Lista zadań nr 3
Zadanie 1
Dla tygodniowych stóp zwrotu akcji spółki Żywiec (zob. Dane_do_anali-zy.xls; zakładka: Akcje) należy obliczyć i zinterpretować współczynnik be-ta. Miarę tę proszę porównać z obliczonym już współczynnikiem dla spółki Strzelec w celu stwierdzenia, która z porównywanych spółek jest bezpiecz-niejszą.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
0
0,2
0,4
0,6
0,8
1
0 0,2 0,4 0,6 0,8 1

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.2. Analiza współzależności
str. 248
Zadanie 2
Proszę określić siłę i kierunek korelacji pomiędzy stopami realnego PKB Polski na tle średniej krajów UE-15 dla lat 2001-2005 (Dane_do_analizy-.xls; zakładka: PKB).
Zadanie 3
Korzystając z wyników ankiety dla Czytelników (Dane_do_analizy.xls; za-kładka: Ankiety) należy wyznaczyć krzywą regresji I rodzaju Y względem X, gdzie:
Y – wymiar: sama teoria/niezwykle praktyczne (P3_II).X – wymiar: bardzo zawiłe/bardzo przejrzyste (P3_III).Powyższe wymiary dotyczą ocen treści na skali dyferencjału semantyczne-go. W oparciu o wykres regresji empirycznej należy stwierdzić czy istnieje zależność pomiędzy danymi wymiarami.
Zadanie 4
Korzystając z wyników ankiety dla Czytelników należy określić wpływ płci respondenta na ocenę przejrzystości treści (P3_III) – w tym celu należy obliczyć współczynnik eta.
Zadanie 5
W oparciu o dane z poprzedniego zadania proszę zbudować model regresji poprzez wprowadzenie zmiennej jakościowej płeć do modelu i ocenić ja-kość tego modelu – w jakim stopniu płeć Czytelnika wpłynęła na ocenę przejrzystości treści publikacji?
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.3. Analiza dynamiki
str. 249
2.3. Analiza dynamiki
Prezentowane do tej pory metody opisu statystycznego nie uwzględniały czynnika czasu. Jeżeli nawet niektóre zbiory danych przedstawiały kolejno wartości w określonych jednostkach czasu, to były one traktowane jako szeregi korelacyjne.
W niniejszym podrozdziale przedstawione zostaną wybrane metody analizy danych w czasie. Podstawą analizy dynamiki zjawisk jest szereg czasowy (wartości szeregu czasowego oznaczane będą jako yi). Analiza szeregów czasowych obejmuje (por. [3, s. 224]):
1. Zmienność badanego zjawiska – ustalenie tendencji rozwojowej, wahań okresowych i przypadkowych, w tym prognozowanie.
2. Metody indeksowe – badanie dynamiki zjawisk z wykorzystaniem me-tod indeksowych (indeksy indywidualne i agregatowe).
Analiza empirycznych szeregów czasowych powinna więc prowadzić do odpowiedzi na dwa zasadnicze pytania (por. [9, s. 283-284]):
Pytanie 1: Jakie są zmiany w poziomach obserwowanych zjawisk w dwóch okresach czasu? – zastosowanie znajdują tu wyłącznie metody rachunku indeksowego.
Pytanie 2: Jakie czynniki wywołują dynamiczną zmienność obserwowa-nych zjawisk i jaka jest siła i kierunek oddziaływania tych czynników? – za-stosowanie znajdują metody delimitacji, tj. eliminacji wahań w czasie (licz-ba obserwacji wyraźnie większa od 2).
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.3. Analiza dynamiki
str. 250
W celu wyodrębnienia poszczególnych składowych danego szeregu czaso-wego należy dokonać tzw. jego dekompozycji. Przy ocenie poszczegól-nych składowych szeregu czasowego pomocna jest wizualna ocena sporzą-dzonego wykresu (por. rys. 1.31 rys. 1.32). Elementami (składowymi) sze-regu czasowego mogą być (por. [4, s. 62]):
1. Trend (T) – długookresowa skłonność do jednokierunkowych zmian wartości badanej zmiennej. Występowanie trendu jest związane z od-działywaniem stałego zestawu czynników. Zgodnie z przyjętą definicją wyróżnia się:
a) trend malejący,b) trend rosnący.
W literaturze poruszającej tematykę gry na giełdzie papierów wartościo-wych wymienia się ponadto trend boczny – określany też mianem horyzon-talnego. Wartości zmiennej zależnej (ceny akcji, poziom indeksu giełdowe-go) oscylują wokół pewnego stałego poziomu.
2. Wahania cykliczne (C) – powtarzające się rytmicznie wahania wartości cechy w przedziałach czasu dłuższych niż 1 rok (np. cykl koniunktural-ny).
3. Wahania sezonowe (S) – wahania wartości obserwowanego zjawiska wokół trendu, powtarzające się w przedziałach krótszych niż 1 rok (np. sezonowość ruchu turystycznego).
4. Składnik losowy (ξ) – są to wahania przypadkowe, występujące – w mniejszym czy większym stopniu – praktycznie w każdym szeregu czasowym.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.3. Analiza dynamiki
str. 251
Poniższy schemat ukazuje wpływ poszczególnych składowych (T, C, S) na kształtowanie się danego zjawiska w czasie:
Rysunek 2.11. Klasyfikacja szeregów czasowych.
Źródło: Opracowanie własne na podstawie [4, s. 63].
Wyróżnia się dwa podstawowe modele szeregów czasowych (por. [1, s. 632]):
1. Model addytywny – szereg czasowy ukazany jest jako superpozycja czterech składowych, które po „zsumowaniu” dają w rezultacie obser-wowane poziomy wartości szeregu. Takie podejście jest niezbędne przy
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.3. Analiza dynamiki
str. 252
wprowadzeniu zmiennych zero-jedynkowych w analizie regresji, gdzie zmienną objaśniającą jest zmienna określająca sezonowość.
2. Model multiplikatywny (powszechnie stosowany) – szereg czasowy ukazany jest jako iloczyn czterech elementów składowych. Iloczyn tych składowych stanowi kolejne zaobserwowane wartości:
W dalszej części publikacji omówiono wybrane metody analizy szeregów czasowych. Powyższe założenia co do rodzaju modelu szeregu czasowego są ważne w przypadku analizy sezonowości.
2.3.1. Wybrane modele tendencji rozwojowej
W celu wyodrębnienia tendencji rozwojowej wykorzystuje się metody sta-tystyczne, które podzielić można na dwie grupy [2, s. 181]:
1. Mechaniczne metody wyznaczania trendu (np. metoda średnich rucho-mych).
2. Analityczne metody wyznaczania trendu (metoda najmniejszych kwa-dratów).
Przykładem mechanicznej metody wyznaczania trendu jest metoda śred-nich ruchomych. Idea wygładzania szeregu czasowego za pomocą śred-nich ruchomych polega na zastąpieniu pierwotnych wartości zmiennej ob-jaśniającej Y średnimi arytmetycznymi, obliczanymi sekwencyjnie dla
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.3. Analiza dynamiki
str. 253
wybranej liczby obserwacji (por. [4, s. 67]). Średnie ruchome dla przyjętej stałej wygładzania k oblicza się ze wzoru:
W przypadku gdy stała wygładzania k jest liczbą nieparzystą – wyznaczone wartości średnie przypisuje się na ogół środkowym obserwacjom, w opar-ciu o które wyznaczono średnie ruchome. W tej sytuacji wzór na średnią ruchomą przyjmuje postać (oznaczenia analogiczne jak w prezentowanym powyżej wzorze):
Oto dwa przykłady ukazujące sposób zastosowania przedstawionych wzo-rów na obliczanie średnich ruchomych:
Przykład 1. Na podstawie kursów zamknięcia akcji spółki Żywiec SA za pierwsze półrocze 2006 r. (zob. Dane_do_analizy.xls; zakładka: Akcje) na-leży wyznaczyć 12-dniowe oraz 26-dniowe średnie ruchome.
Wykresy średnich ruchomych dodano z wykorzystaniem narzędzia MS Excel Dodaj linię trendu. Jako stałą wygładzania przyjęto odpowiednio k = 12 i k = 26 sesji giełdowych (wartości te wpisano kolejno w polu Okres okna dialogowego Dodaj linię trendu).
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( )
( )
∑−⋅+
−⋅−=
=15,0
15,0
1 kt
ktiit y
ky

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.3. Analiza dynamiki
str. 254
Rysunek 2.12. Średnie ruchome z 12 i 26 sesji giełdowych kursów zamknięcia akcji Żywiec SA
Źródło: Opracowanie własne na podstawie danych pochodzących z Serwisu Interneto-wego Gazety Parkiet, http://www.parkiet.com/dane/dane_atxt.jsp
Ponadto przedstawione na powyższym wykresie średnie ruchome obliczo-no z wykorzystaniem arkusza MS Excel (zob. Przykłady – średnia rucho-ma), stosując następujące wzory:
a) średnia ruchoma 12-dniowa:
b) średnia ruchoma 26-dniowa:
Przykładowo, pierwszą wartość 12-dniowej średniej ruchomej, przypisaną dla t = 13 sesji giełdowych, obliczono jako średnią arytmetyczną kursów zamknięcia akcji z pierwszych 12 sesji:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
425
450
475
500
525
550
1 13 25 37 49 61 73 85 97 109 121
sesje
kurs
zam
knię
cia
(zł)
12 okr. śr. ruchoma
26 okr. śr. ruchoma
∑
−
−=
=1
12121 t
tiit yy
∑
−
−=
=1
26261 t
tiit yy

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.3. Analiza dynamiki
str. 255
Podstawiamy kolejno ceny zamknięcia akcji Żywiec SA do wzoru:
Analogicznie wyznacza się kolejne wartości średnie.
Przykład 2. Należy wyznaczyć średnią ruchomą o stałej wygładzania k = 9 z różnicy średnich, wyznaczonych w poprzednim przykładzie: średniej 12-dniowej i 26-dniowej.
Zastosowano tu wzór dla nieparzystej stałej wygładzania k, gdzie wyzna-czone wartości średnie przypisuje się środkowym obserwacjom. Oto wzór dla k = 9:
Z uwagi na utratę danych – związaną z obliczeniem 26-dniowej średniej ru-chomej – najmniejsza wartość szeregu czasowego to t = 27. Poniższa tabela przedstawia dziesięć pierwszych wyrazów szeregu czasowego, na podsta-wie których dokonano obliczeń 9-dniowej średniej ruchomej:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
1212
1121 121110987654321
12
1
113
121313
yyyyyyyyyyyyyyyi
ii
i+++++++++++=== ∑∑
=
−
−=
5,481
124794774774824855,4804814854814855,480485
13 =+++++++++++=y
( )
( )
∑∑+
−=
−⋅+
−⋅−=
==4
4
195,0
195,0 91
91 t
tii
t
tiit yyy

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.3. Analiza dynamiki
str. 256
Tabela 2.39. Średnia ruchoma (k = 9) z różnicy średnich kroczących cen akcji Żywiec SA (k = 12 i k = 26).
A B C D E = C – D F
TKurs zamknięcia
(zł)Średnia
ruchoma (k = 12)
Średnia ruchoma (k = 26)
Różnica średnich
Średnia ruchoma
(k = 9)27 476,00 478,17 480,12 –1,9528 484,00 477,42 479,77 –2,3529 480,00 478,17 479,90 –1,7430 480,00 477,67 479,71 –2,0431 460,00 477,17 479,67 –2,51 –2,4932 465,00 475,92 478,71 –2,79 –2,5933 469,00 474,96 478,10 –3,14 –2,6134 478,50 474,46 477,65 –3,20 –2,7535 464,50 474,75 477,40 –2,65 –2,8036 476,00 473,88 476,73 –2,86 –2,76
Źródło: Obliczenia własne na podstawie danych pochodzących z Serwisu Internetowe-go Gazety Parkiet, http://www.parkiet.com/dane/dane_atxt.jsp
Pierwszą wartość średnią obliczono dla obserwacji od t = 27 do t = 35, przy czym wartość tę przypisano środkowemu wyrazowi, tj. t = 31:
W ten sam sposób obliczono pozostałe średnie ruchome.
Dotychczas ukazano sposób obliczania tzw. prostych średnich ruchomych. W praktyce lepszym rozwiązaniem może okazać się jednak obliczenie wa-żonych średnich ruchomych. Większą wagę przypisuje się tu nowszym da-nym – im starsze dane, tym mniejsze ich znaczenie. Praktyczny przykład zastosowania ważonych średnich ruchomych przedstawiono w podrozdzia-le Trening i ewaluacja.
Wśród metod analitycznych na szczególną uwagę zasługuje klasyczna me - toda najmniejszych kwadratów. Metoda ta jest powszechnie stosowana do wyznaczania trendu liniowego – linię trendu wyznacza się w analogiczny
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
49,2
991
91 353433323130292827
35
27
431
43131 −=++++++++=== ∑∑
=
+
−==
yyyyyyyyyyyyi
ii
it

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.3. Analiza dynamiki
str. 257
sposób jak prostą regresji (por. regresja liniowa). Postać analityczna linii trendu jest następująca:
Parametry powyższej funkcji można wyznaczyć z analogicznych wzorów jak na regresję liniową lub stosując nieco uproszczone:
a) parametr kierunkowy:
b) wyraz wolny:
Linię trendu można, tak jak linię regresji, dodać do danych przedstawio-nych w postaci wykresu XY za pomocą narzędzia Excela Dodaj linię tren-du (zob. Prezentacja PowerPoint pt. Excel_dodawanie_linii_trendu). Poniżej zaprezentowano sposób wyznaczania linii trendu z wykorzysta-niem prezentowanych wyżej wzorów na parametr kierunkowy i wyraz wol-ny.
Przykład. Na podstawie danych odnośnie wysokości wyniku finansowego netto Grupy Żywiec SA (lata 2001-2005) należy wyznaczyć linię trendu i dokonać prognozy na 2007 rok.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.3. Analiza dynamiki
str. 258
Wprowadzamy następujące oznaczenia:
yt – wynik finansowy netto Grupy Żywiec SA (mln zł)t – lata (t = 1, …, 5)
Teraz konstruujemy tabelę z obliczeniami pomocniczymi:
Tabela 2.40. Wynik finansowy netto Grupy Żywiec SA w latach 2001-2005 (mln zł).
LataA B C D = C2 E = B × C
2001 1 –107,7 –2 4 215,42002 2 102,6 –1 1 –102,62003 3 257,5 0 0 0,02004 4 329,4 1 1 329,42005 5 416,8 2 4 833,6
Σ 998,6 10 1 275,8
Źródło: Obliczenia własne na podstawie danych pochodzących z Serwisu Money.pl, http://www.money.pl/gielda/profile/ZYWIEC,ZWC,raporty,finansowe.html.
W celu wypełnienia tabeli (kolumny C, D i E) konieczne jest obliczenie średniej wartości zmiennej czasowej t. Skorzystamy tu z uproszczonego wzoru:
Korzystając z wyznaczonych w powyższej tabeli sum, wyznaczamy para-metr kierunkowy linii trendu:
Aby obliczyć wartość wyrazu wolnego, konieczne jest uprzednie wyzna-czenie średniej arytmetycznej zmiennej objaśniającej:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
3
251
21 =+=+= nt
( )
( )58,127
108,1275
1
2
11 ==
−
⋅−=
∑
∑
=
=n
ii
n
iii
tt
ytta
t ty tt − ( ) 2tt − ( ) tytt ⋅−

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.3. Analiza dynamiki
str. 259
Średnie arytmetyczne oraz wartość parametru kierunkowego podstawiamy do wzoru na wyraz wolny:
Równanie linii trendu jest następujące:
Na podstawie oszacowanej liniowej funkcji trendu można wyznaczyć pro-gnozowaną wartość wyniku finansowego na 2007 r., tj. na t = 7 okres. W tym celu do funkcji trendu za t podstawiamy wartość 7:
Prognozowany na podstawie wyznaczonej linii trendu wynik finansowy netto na 2007 rok to 710 mln zł.
Oczywiście liniowa funkcja trendu nie zawsze dostatecznie dobrze opisuje kształtowanie się danego zjawiska w czasie. Poniżej zaprezentowano przy-kłady innych funkcji trendu (por. [4, s. 75-77]):
a) funkcja wykładnicza – odznacza się stałymi stopami wzrostu a1:
Ponadto można wyznaczyć wykładniczą funkcję trendu, gdzie stałe stopy wzrostu to ln a1, o następującej postaci analitycznej:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
72,1995
6,9981 ===∑
=
n
yy
n
ii
01,183358,12772,19910 −=⋅−=⋅−= taya
01,18358,127ˆ −⋅= tyt
05,71001,18306,89301,183758,127ˆ7 =−=−⋅=y
0,ˆ 110 >⋅= aaay tt
0,ˆ 110 >= ⋅⋅ aey taa
t
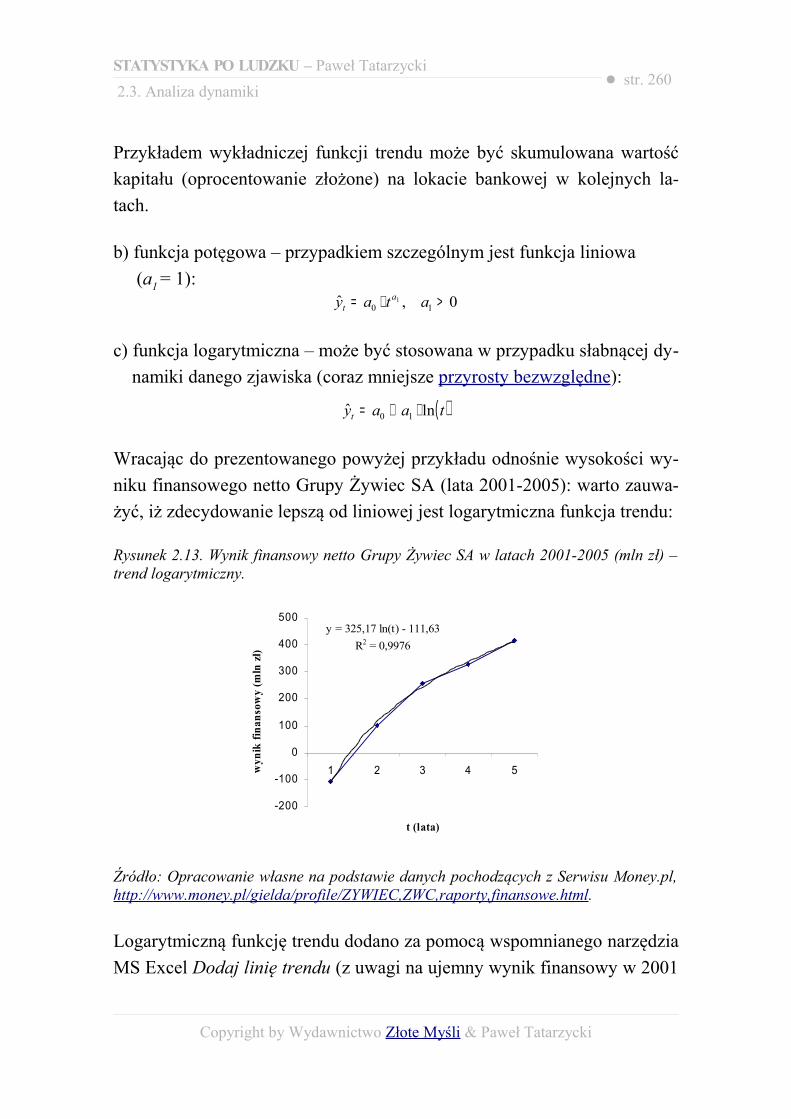
STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.3. Analiza dynamiki
str. 260
Przykładem wykładniczej funkcji trendu może być skumulowana wartość kapitału (oprocentowanie złożone) na lokacie bankowej w kolejnych la-tach.
b) funkcja potęgowa – przypadkiem szczególnym jest funkcja liniowa (a1 = 1):
c) funkcja logarytmiczna – może być stosowana w przypadku słabnącej dy- namiki danego zjawiska (coraz mniejsze przyrosty bezwzględne):
Wracając do prezentowanego powyżej przykładu odnośnie wysokości wy-niku finansowego netto Grupy Żywiec SA (lata 2001-2005): warto zauwa-żyć, iż zdecydowanie lepszą od liniowej jest logarytmiczna funkcja trendu:
Rysunek 2.13. Wynik finansowy netto Grupy Żywiec SA w latach 2001-2005 (mln zł) – trend logarytmiczny.
Źródło: Opracowanie własne na podstawie danych pochodzących z Serwisu Money.pl, http://www.money.pl/gielda/profile/ZYWIEC,ZWC,raporty,finansowe.html.
Logarytmiczną funkcję trendu dodano za pomocą wspomnianego narzędzia MS Excel Dodaj linię trendu (z uwagi na ujemny wynik finansowy w 2001
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
0,ˆ 101 >⋅= atay a
t
( )taayt lnˆ 10 ⋅+=
y = 325,17 ln(t) - 111,63R2 = 0,9976
-200
-100
0
100
200
300
400
500
1 2 3 4 5
t (lata)
wyn
ik fi
nans
owy
(mln
zł)

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.3. Analiza dynamiki
str. 261
roku nie były dostępne modele: potęgowy i wykładniczy). Bliska jedności wartość współczynnika determinacji R 2 świadczy o bardzo dobrym dopaso-waniu wybranego modelu do danych empirycznych.
2.3.2. Analiza sezonowości
W analizie wahań sezonowych powszechnie stosowana jest metoda wskaźników. Metoda ta polega na wyznaczeniu tzw. wskaźników sezono-wości dla poszczególnych faz cyklu wahań. Cykl – zwany też okresem wa-hań – to okres, w którym występują wszystkie fazy wahań. Można wyróż-nić tu dwie następujące sytuacje [4, s. 83-84]:
1. Wahania bezwzględnie stałe – amplitudy wahań, tj. różnice pomiędzy wartościami empirycznymi a teoretycznymi, wynikającymi z funkcji trendu w analogicznych fazach cyklu są mniej więcej takie same. W tej sytuacji zastosować można model addytywny.
2. Wahania względnie stałe – amplitudy wahań w analogicznych fazach cyklu zmieniają się mniej więcej w tym samym stopniu. Jest to częstszy przypadek, w którym zastosowanie znajduje model multiplikatywny.
W analizie wahań sezonowych można wyodrębnić cztery etapy (por. [4, s. 84-85]):
Krok 1. Wyznaczenie funkcji trendu, a następnie wartości teoretycznych dla okresów od t = 1 do n. W niniejszym opracowaniu przyjęto postać li-niową:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
taayt ⋅+= 10ˆ

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.3. Analiza dynamiki
str. 262
Krok 2. Eliminacja trendu z szeregu czasowego:
a) model addytywny – obliczenie różnic pomiędzy wartościami empirycz-nymi zmiennej objaśniającej yt a wartościami teoretycznymi wyznaczo-nymi z funkcji trendu:
b) model multiplikatywny – podzielenie wartości empirycznych przez od-powiadające im wartości teoretyczne:
Krok 3. Eliminacja wahań przypadkowych poprzez obliczenie tzw. suro-wych wskaźników sezonowości jako średnich arytmetycznych wielkości zt
dotyczących danej fazy cyklu wahań:
Krok 4. Obliczenie średniej arytmetycznej z surowych wskaźników sezo-nowości:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.3. Analiza dynamiki
str. 263
Krok 5. Wyznaczenie czystych wskaźników sezonowości:
a) model addytywny:
b) model multiplikatywny:
Suma „oczyszczonych” wskaźników sezonowości w przypadku modelu ad-dytywnego powinna być równa zeru:
Jeśli natomiast przyjęto model multiplikatywny, to czyste wskaźniki sezo-nowości powinny sumować się do liczby faz cyklu wahań (np. w przypad-ku analizy sezonowości sprzedaży w ujęciu kwartalnym suma oczyszczo-nych wskaźników sezonowości powinna być równa 4):
Wskaźniki sezonowości informują, o ile wartości dla danej fazy cyklu od-chylają się średnio – w ujęciu bezwzględnym lub względnym – od funkcji trendu. Odchylenia te należy uwzględnić przy prognozie na okres t [4, s. 85]:
a) model addytywny:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
∑ =k
kc 0
∑ =k
k Nc

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.3. Analiza dynamiki
str. 264
b) model multiplikatywny:
Poniższy przykład ukazuje sposób wyznaczania wskaźników sezonowości w przypadku modelu multiplikatywnego (sposób postepowania dla modelu addytywnego zestawiono w podrozdziale Trening i ewaluacja, podsumo-wującym ten dział).
Przykład. Biuro turystyczne w ramach biznes planu powinno m.in. doko-nać prognozy sprzedaży map turystycznych na okres najbliższych dwóch lat. Firma dysponuje danymi kwartalnymi odnośnie ilości sprzedanych map z czterech ostatnich lat (16 obserwacji):
Tabela 2.41. Sprzedaż map turystycznych (szt.).
t (kwartały) sprzedaż map (szt.) 1 102 253 704 145 126 307 838 179 14
10 3611 10012 2113 1914 4515 12516 32
Źródło: Dane umowne.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.3. Analiza dynamiki
str. 265
Wprowadzamy oznaczenia:
yt – ilość sprzedanych map w danym kwartale (szt.)t – czas w kwartałach
Szacujemy parametry liniowej funkcji trendu (zob. trend liniowy):
Na podstawie wyznaczonej linii trendu wyznaczamy wartości teoretyczne. W tym celu za t podstawiamy kolejno liczby od 1 do 16. W następnym kro-ku obliczamy relacje zt. Oto tabela prezentująca obliczenia pomocnicze nie-zbędne do wyznaczenia wskaźników sezonowości:
Tabela 2.42. Sprzedaż map turystycznych (szt.) – obliczenia pomocnicze.
A B C D = B / C
1 10 19,95 + 2,454 × 1 = 22,4 10 / 22,4 = 0,4462 25 24,9 1,0063 70 27,3 2,5634 14 29,8 0,4705 12 32,2 0,3726 30 34,7 0,8657 83 37,1 2,2368 17 39,6 0,4299 14 42,0 0,33310 36 44,5 0,80911 100 46,9 2,13012 21 49,4 0,42513 19 51,9 0,36614 45 54,3 0,82915 125 56,8 2,20216 32 59,2 0,540Σ 653
Źródło: Obliczenia własne na podstawie danych umownych.
Surowe wskaźniki sezonowości obliczamy jako średnie zt jednoimiennych okresów (por. Przykłady – analiza sezonowości_model multiplikatywny):
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
tyt ⋅+= 454,295,19ˆ
t ty ty tz

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.3. Analiza dynamiki
str. 266
a) k = 1 (I kw.):
b) k = 2 (II kw.):
c) k = 3 (III kw.):
d) k = 4 (IV kw.):
Nietrudno sprawdzić, iż otrzymane wskaźniki sezonowości nie sumują się do liczby 4. Zatem konieczne jest ich „oczyszczenie”. W tym celu najpierw obliczamy średnią arytmetyczną surowych wskaźników sezonowości:
Następnie poszczególne surowe wskaźniki sezonowości dzielimy przez otrzymaną wielkość średnią:
a) k = 1 (I kw.):
b) k = 2 (II kw.):
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
3796,0
441 13951
11 =+++==′ ∑ zzzzzc t
8772,0
441 141062
22 =+++==′ ∑ zzzzzc t
2827,2
441 151173
33 =+++==′ ∑ zzzzzc t
4663,0
441 161284
44 =+++==′ ∑ zzzzzc t
00145,1
40058,4
441 4321 ==
′+′+′+′=′= ∑
kk
cccccq
3790,0
0014,13796,01
1 ==′
=qcc
8759,0
0014,18772,02
2 ==′
=qcc

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.3. Analiza dynamiki
str. 267
c) k = 3 (III kw.):
d) k = 4 (IV kw.):
Wartość wskaźnika sezonowości większa od jedności oznacza, iż sprzedaż w danym kwartale jest wyższa od przeciętnej, wynikającej z trendu. I tak najwięcej map biuro sprzedaje w sezonie letnim (III kw.). Wówczas obroty ponad dwukrotnie przekraczają przeciętny poziom sprzedaży. Najgorszy jest pod tym względem pierwszy kwartał, kiedy to sprzedaż – ogólnie rzecz biorąc – jest mniejsza o (0,379 – 1) ⋅ 100 = 62,1 proc. Nieznacznie lepiej jest w ostatnim kwartale – przychody stanowią (0,4657 – 1) ⋅ 100 = 53,43 proc. przeciętnego poziomu.
Po wyznaczeniu funkcji trendu oraz wskaźników sezonowości można przejść do przeprowadzenia prognozy na najbliższe dwa lata, tj. okresy od t = 17 do 24. Oto prognoza na okres t = 17:
a) wyznaczenie wartości teoretycznej wynikającej z funkcji trendu:
b) korekta o wskaźnik sezonowości (w tym przypadku jest to I kw.):
Zatem prognoza sprzedaży map turystycznych na okres t = 17 wynosi 23 szt. Analogicznie wyznaczono pozostałe prognozowane wartości, które na poniższym wykresie zaznaczono linią przerywaną.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
2794,2
0014,12827,23
3 ==′
=qcc
4657,0
0014,14663,04
4 ==′
=qcc
67,617454,295,19ˆ*17 =⋅+=y
1
*17
*17 ˆ cyy ⋅=
37,23379,067,61*17 =⋅=y

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.3. Analiza dynamiki
str. 268
Rysunek 2.14. Prognoza sprzedaży map turystycznych na okres dwóch najbliższych lat.
Źródło: Opracowanie własne na podstawie danych umownych.
Daje się zauważyć wyraźną sezonowość sprzedaży. Jak już wspomniano, najwięcej map sprzedaje się w sezonie letnim (lipiec, sierpień), kiedy to ruch turystyczny jest największy (wakacje, urlopy wypoczynkowe).
2.3.3. Indeksy indywidualne i agregatowe
Drugą grupą metod analizy szeregów czasowych – obok ustalenia tendencji rozwojowej czy też wahań okresowych – są metody indeksowe. Zanim przejdziemy do omawiania metod indeksowych, warto usystematyzować sposób obliczania przyrostów względnych i bezwzględnych (por. [3, s. 225]):
1. Przyrosty bezwzględne:a) jednopodstawowe:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
0
20
40
60
80
100
120
140
160
180
0 4 8 12 16 20 24t (kwartały)
sprz
edaż
map
(szt
.)
wartości teoretyczne prognoza

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.3. Analiza dynamiki
str. 269
b) łańcuchowe:
2. Przyrosty względne:a) jednopodstawowe:
b) łańcuchowe:
Indywidualne indeksy dynamiki możemy obliczyć według poniższych wzorów, jak również zwiększając przyrosty względne – jednopodstawowe lub łańcuchowe – o 1 (tj. 100 proc.):
a) indywidualne indeksy jednopodstawowe:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
ptpt dI // 1 +=

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.3. Analiza dynamiki
str. 270
b) indywidualne indeksy łańcuchowe:
Indywidualne indeksy dynamiki, tak jak przyrosty względne, można wyra-zić w wielkościach procentowych (mnożąc je przez 100). Niemniej jednak wielkości wyznaczone z prezentowanych wyżej wzorów stosuje się do wy-znaczenia średniej geometrycznej:
Sposób II:
Średnia geometryczna służy do określenia średniookresowego tempa zmian danego zjawiska w określonym czasie:
Sposób obliczania przyrostów bezwzględnych i względnych, indywidual-nych indeksów dynamiki oraz średniookresowego tempa zmian ukazuje przykład:
Przykład. Należy dokonać analizy dynamiki przychodów ze sprzedaży Grupy Żywiec SA na przestrzeni lat 2001-2005. Dane – wraz z niezbęd-nymi obliczeniami – prezentuje tabela (por. Przykłady – indeksy dynamiki; zakładka: indeksy_indywidualne):
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
1/1/ 1 −− += tttt dI
( ) %1001 ⋅−Gx

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.3. Analiza dynamiki
str. 271
Tabela 2.43. Analiza dynamiki przychodów ze sprzedaży Grupy Żywiec SA w latach 2001-2005.
2001 2002 2003 2004 2005
Przychody netto ze sprzedaży (mln zł) 2 630,0 2 956,5 3 204,6 3 629,1 2 867,6
1. Przyrosty bezwzględne (mln zł):a) jednopodstawowe (rok bazowy: 2001.) 326,5 574,6 999,1 237,6b) łańcuchowe 326,5 248,1 424,4 –761,5
2. Przyrosty względne (proc.):a) jednopodstawowe (rok bazowy: 2001.) 12,4% 21,8% 38,0% 9,0%b) łańcuchowe 12,4% 8,4% 13,2% –21,0%
3. Indeksy dynamiki:a) jednopodstawowe (rok bazowy: 2001.) 1 1,124 1,218 1,380 1,090b) łańcuchowe 1,124 1,084 1,132 0,790
Źródło: Obliczenia własne na podstawie danych pochodzących z Serwisu Money.pl, http://www.money.pl/gielda/profile/ZYWIEC,ZWC,raporty,finansowe.html.
Przyrosty bezwzględne jednopodstawowe obliczono jako różnicę pomiędzy poszczególnymi wartościami przychodów ze sprzedaży w latach 2002-2005 a przychodami z okresu bazowego, tj. 2001 r. (jako bazę można także przyjąć inny rok):
a) rok 2002:
b) rok 2003:
c) rok 2004:
d) rok 2005:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
5,32626305,2956200120022001/2002 =−=−=∆ yy
6,57426306,3204200120032001/2003 =−=−=∆ yy
1,99926301,3629200120042001/2004 =−=−=∆ yy
6,23726306,2867200120052001/2005 =−=−=∆ yy

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.3. Analiza dynamiki
str. 272
Przyrosty bezwzględne łańcuchowe to różnice pomiędzy sąsiednimi warto-ściami przychodów ze sprzedaży:
a) rok 2002:
b) rok 2003:
c) rok 2004:
d) rok 2005:
Przyrosty względne jednopodstawowe obliczamy, dzieląc przyrosty bez - względne jednopodstawowe przez wartość zmiennej objaśnianej y z okresu bazowego (aby przyrosty względne wyrazić w wielkościach procentowych wynik dzielenia mnożymy przez 100). Sposób obliczenia jednopodstawo-wego przyrostu względnego dla 2002 i 2005 roku – przy założeniu, że 2001 rok to rok bazowy – jest następujący:
a) rok 2002:
b) rok 2005:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
5,32626305,2956200120022001/2002 =−=−=∆ yy
1,2485,29566,3204200220032002/2003 =−=−=∆ yy
4,4246,32041,3629200220032003/2004 =−=−=∆ yy
5,7611,36296,2867200420052004/2005 −=−=−=∆ yy
%4,12124,0
26305,326
2001
2001/20022001/2002 ===∆=
yd
%909,0
26306,237
2001
2001/20052001/2005 ===∆=
yd

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.3. Analiza dynamiki
str. 273
Przyrosty względne łańcuchowe obliczamy, dzieląc przyrosty bezwzględne łańcuchowe przez wartość zmiennej objaśnianej z okresu bezpośrednio po-przedzającego. Dla porównania obliczono łańcuchowy przyrost względny dla 2005 roku:
Jeśli chodzi o indywidualne indeksy jednopodstawowe, to obliczamy je, dzieląc poszczególne wartości zmiennej objaśnianej przez wartość bazową. Indeks jednopodstawowy dla okresu bazowego wynosi 1. Indeksy zawarte w tabeli 2.43 obliczono następująco:
a) rok 2002:
b) rok 2003:
c) rok 2004:
d) rok 2005:
Natomiast indywidualne indeksy łańcuchowe otrzymamy, dzieląc wartość zmiennej objaśnianej z okresu t przez wartość z okresu t – 1. W rozpatry-wanym przykładzie mamy n = 5 okresów (lat), stąd liczba indeksów łańcu-chowych wynosi n – 1 = 4:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
%2121,0
1,36295,761
2004
2004/20052004/2005 −=−=−=∆=
yd
124,1
26305,2956
2001
20022001/2002 ===
yyI
218,1
26306,3204
2001
20032001/2003 ===
yyI
38,1
26301,3629
2001
20042001/2004 ===
yyI
09,1
26306,2867
2001
20052001/2005 ===
yyI

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.3. Analiza dynamiki
str. 274
a) rok 2002:
b) rok 2003:
c) rok 2004:
d) rok 2005:
W oparciu o wyznaczone indywidualne indeksy łańcuchowe możemy obli-czyć średnioroczne tempo zmian przychodów ze sprzedaży. W tym celu najpierw obliczamy średnią geometryczną z wyznaczonych indeksów (n = 5 lat):
Tę samą wartość możemy uzyskać, wykorzystując wartość indeksu jedno-podstawowego z 2005 roku:
Reasumując, w analizowanym okresie przychody ze sprzedaży Grupy Ży-wiec SA rosły średnio o 2,2 proc.:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
124,1
26305,2956
2001
20022001/2002 ===
yyI
084,1
5,29566,3204
2002
20032002/2003 ===
yyI
132,1
6,32041,3629
2003
20042003/2004 ===
yyI
79,0
1,36296,2867
2004
20052004/2005 ===
yyI
152004/20052003/20042002/20032001/2002
− ⋅⋅⋅= IIIIxG
022,109,179,0132,1084,1124,1 44 ==⋅⋅⋅=Gx
022,109,1412001/2005 === −n
G Ix
( ) ( ) %2,2%1001022,1%1001 =⋅−=⋅−Gx
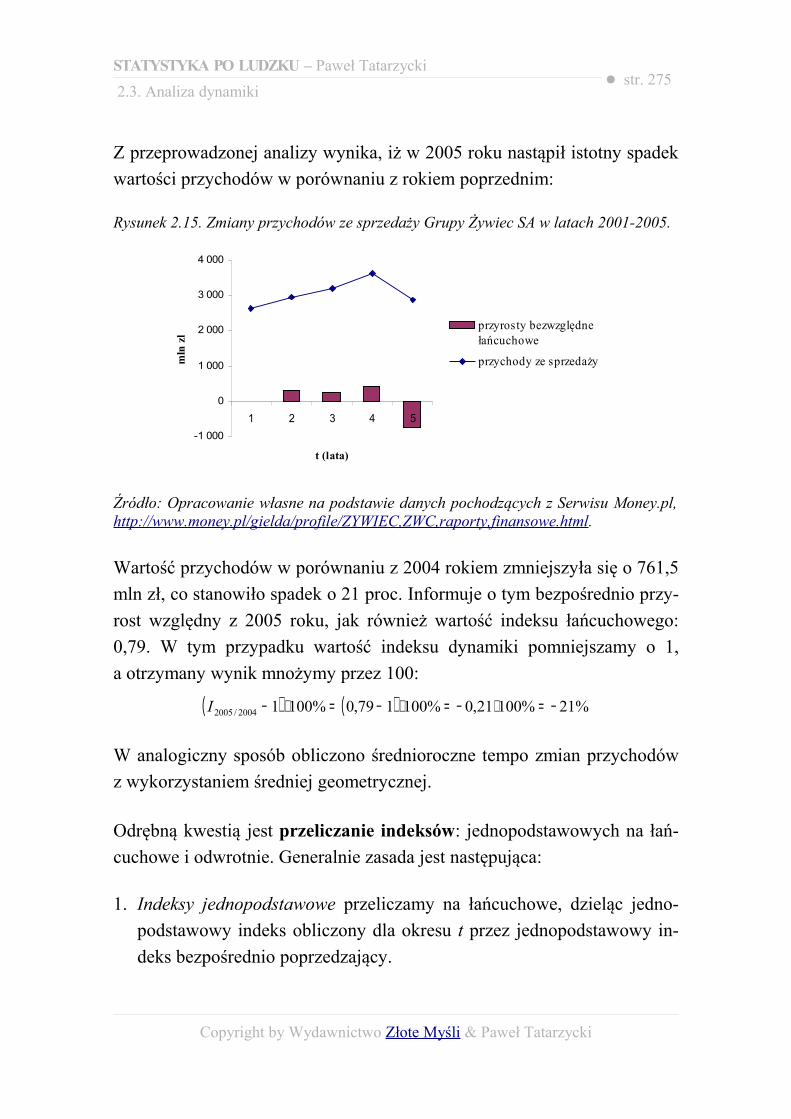
STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.3. Analiza dynamiki
str. 275
Z przeprowadzonej analizy wynika, iż w 2005 roku nastąpił istotny spadek wartości przychodów w porównaniu z rokiem poprzednim:
Rysunek 2.15. Zmiany przychodów ze sprzedaży Grupy Żywiec SA w latach 2001-2005.
Źródło: Opracowanie własne na podstawie danych pochodzących z Serwisu Money.pl, http://www.money.pl/gielda/profile/ZYWIEC,ZWC,raporty,finansowe.html.
Wartość przychodów w porównaniu z 2004 rokiem zmniejszyła się o 761,5 mln zł, co stanowiło spadek o 21 proc. Informuje o tym bezpośrednio przy-rost względny z 2005 roku, jak również wartość indeksu łańcuchowego: 0,79. W tym przypadku wartość indeksu dynamiki pomniejszamy o 1, a otrzymany wynik mnożymy przez 100:
W analogiczny sposób obliczono średnioroczne tempo zmian przychodów z wykorzystaniem średniej geometrycznej.
Odrębną kwestią jest przeliczanie indeksów: jednopodstawowych na łań-cuchowe i odwrotnie. Generalnie zasada jest następująca:
1. Indeksy jednopodstawowe przeliczamy na łańcuchowe, dzieląc jedno-podstawowy indeks obliczony dla okresu t przez jednopodstawowy in-deks bezpośrednio poprzedzający.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
-1 000
0
1 000
2 000
3 000
4 000
1 2 3 4 5
t (lata)
mln
zl
przyrosty bezwzględnełańcuchowe
przychody ze sprzedaży
( ) ( ) %21%10021,0%100179,0%10012004/2005 −=⋅−=⋅−=⋅−I

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.3. Analiza dynamiki
str. 276
2. Indeksy łańcuchowe przeliczamy na jednopodstawowe, mnożąc je kolej-no przez siebie (por. sposób obliczania średniej geometrycznej).
Sposób przeliczania indeksów wyjaśniono na przykładzie liczbowym:
Tabela 2.44. Indeksy dynamiki przychodów ze sprzedaży Grupy Żywiec SA w latach 2001-2005.
2001 2002 2003 2004 20051. Indeksy jedno- podstawowe: 1 1,124 1,218 1,380 1,090
Przeliczanie na łańcuchowe:
1,124 / 1 = = 1,124
1,218 / 1,124 = =1,084
1,380 / 1,218 = = 1,132
1,090 / 1,380 = = 0,790
2. Indeksy łańcuchowe: – 1,124 1,084 1,132 0,790
Przeliczanie na jedno-podstawowe:
1 1 × 1,124 = =1,124
1,124 × 1,084 = = 1,218
1,218 × 1,132 = = 1,380
1.380 × 0,790 = = 1,090
Źródło: Obliczenia własne na podstawie danych pochodzących z Serwisu Money.pl, http://www.money.pl/gielda/profile/ZYWIEC,ZWC,raporty,finansowe.html.
Ważne jest, aby przed przystąpieniem do przeliczania indeksów najpierw wyrazić je w wielkościach absolutnych – tak jak uczyniono to w powyższej tabeli – a nie w wielkościach procentowych.
W praktyce – obok przedstawionych indeksów indywidualnych – zastoso-wanie znajdują także indeksy zespołowe (agregatowe), a mianowicie (por. [2, s. 169-173]):
1. Zespołowe indeksy cen i ilości:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.3. Analiza dynamiki
str. 277
2. Zespołowe indeksy wielkości stosunkowych:
Zespołowe indeksy cen i ilości pozwalają wyjaśnić, w jakim stopniu dany czynnik decyduje o zmianie wartości – możemy tu odpowiednio mówić o efekcie cenowym bądź efekcie ilościowym. Jeśli np. przedsiębiorstwo sprzedaje wyłącznie jeden produkt, to określenie zmian wartości przycho-dów ze sprzedaży sprowadza się do obliczenia indeksu indywidualnego (wartość z okresu bieżącego podzielona przez wartość z okresu bazowego). Sytuacja komplikuje się, gdy w ofercie znajduje się więcej niż jeden asor-tyment. Wówczas należy obliczyć tzw. zespołowy indeks wartości według wzoru:
Kolejną kwestią jest określenie wpływu zmian cen i ilości na zmianę indek-su wartości. Zespołowe indeksy cen i ilości możemy wyznaczyć według formuły Laspeyresa lub Paaschego. Uśredniając za pomocą średniej geo - metrycznej otrzymane wyniki – odpowiednio dla cen i ilości – otrzymamy indeksy typu Fishera. Wzory zestawiono w tabeli:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.3. Analiza dynamiki
str. 278
Tabela 2.45. Zespołowe indeksy cen i ilości.
Indeks cen Indeks ilości
Formuła Laspeyresa
Formuła Paaschego
Indeks typu Fishera
Źródło: Opracowanie własne.
Aby sprawdzić poprawność obliczeń, warto skorzystać z poniższej równo-ści indeksowej:
Wprowadzone zagadnienia odnośnie zespołowych indeksów cen, ilości i wartości poparto prostym przykładem liczbowym:
Przykład. Firma edukacyjna organizuje kurs przygotowujący do matury z języka polskiego i matematyki. W pierwszym roku działalności łączna liczba przeuczonych godzin w ramach kursu przygotowującego do matury z języka polskiego wyniosła 3 tys., zaś do matury z matematyki 2 tys. W roku kolejnym przeuczono w sumie po 2 tys. godzin matematyki i języ-ka polskiego. Jeśli chodzi o ceny, to w roku bazowym koszt jednej godziny lekcyjnej matematyki wynosił 4 zł. Z uwagi na mniejsze zainteresowanie językiem polskim cena godziny lekcyjnej tego przedmiotu była niższa o złotówkę. W roku następnym nastąpił wzrost zainteresowania oferowany-mi przez firmę kursami, przy utrzymującym się niedoborze nauczycieli. W związku z tym dyrekcja podjęła decyzję o podwyższeniu cen kursów
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
∑
∑
=
=
⋅
⋅= n
iii
n
iii
Lp
qp
qpI
100
101
)(
∑
∑
=
=
⋅
⋅= n
iii
n
iii
Lq
qp
qpI
100
110
)(
∑
∑
=
=
⋅
⋅= n
iii
n
iii
Pp
qp
qpI
110
111
)(
∑
∑
=
=
⋅
⋅= n
iii
n
iii
Pq
qp
qpI
101
111
)(
)()()( PpLpFp III ×=
)()()( PqLqFq III ×=
)()()()( PpLqPqLpw IIIII ×=×=

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.3. Analiza dynamiki
str. 279
z każdego przedmiotu o złotówkę – nowa cena godziny lekcyjnej matema-tyki to 5 zł, a języka polskiego to 4 zł. Działanie to pozwoliło na zniwelo-wanie nadwyżki popytu nad podażą godzin, wynikającą z wielkości zatrud-nienia. Należy obliczyć:
a) zespołowy indeks wartości,b) określić który efekt – cenowy czy ilościowy – miał decydujący wpływ
na zmianę przychodów ze sprzedaży analizowanej firmy,c) dokonać poprawności obliczeń indeksów zespołowych za pomocą rów-
ności indeksowej.
Wprowadzamy następujące oznaczenia:
pi0 – cena godziny lekcyjnej i-tego przedmiotu w pierwszym roku działal- ności,qi0 – ilość przeuczonych godzin i-tego przedmiotu w pierwszym roku dzia- łalności,pi1 – cena godziny lekcyjnej i-tego przedmiotu w kolejnym roku działalno- ści,qi1 – ilość przeuczonych godzin i-tego przedmiotu w kolejnym roku działal- ności.
Tworzymy tabelę z danymi i obliczeniami pomocniczymi:
Tabela 2.46. Analiza przyczyn zmian wartości przychodów ze sprzedaży firmy edukacyj-nej.
IA B C = A × B D E F = D × E G = A ×
E H = D × B
1. Matematyka 4 2 8 5 2 10 8 102. Język polski 3 3 9 4 2 8 6 12
Σ 5 17 4 18 14 22
Źródło: Obliczenia własne na podstawie danych umownych.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
0ip 0iq 00 ii qp ⋅ 1ip 1iq 11 ii qp ⋅ 10 ii qp ⋅ 01 ii qp ⋅

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.3. Analiza dynamiki
str. 280
Obliczamy zespołowy indeks wartości, dzieląc sumę wartości z kolumny „F” przez sumę wartości z kolumny „C” (dla ułatwienia wprowadzono do-datkowo oznaczenia kolumn):
W porównaniiu z pierwszym rokiem działalności nastąpił wzrost przycho-dów ze sprzedaży o (1,059 – 1) ⋅ 100 = 5,9 proc.
Aby odpowiedzieć na pytanie, jaki efekt – cenowy czy ilościowy – zdecy-dował o wzroście wpływów ze sprzedaży, należy wyznaczyć indeksy cen i ilości, zgodnie z przedstawionymi w tabeli 2.45 wzorami:
Tabela 2.47. Wyznaczenie zespołowych indeksów cen i ilości godzin przeprowadzonych kursów.
Indeks cen Indeks ilości
Formuła Laspeyresa
Formuła Paaschego
Indeks typu
Fishera
Źródło: Obliczenia własne.
Zespołowy indeks wartości możemy także obliczyć, korzystając z równo-ści indeksowej (ponadto sprawdzimy, czy poprawnie wyznaczyliśmy war-tości indeksów zespołowych):
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
059,11718
100
111
===⋅
⋅=
∑∑
∑
∑
=
=
CF
qp
qpI n
iii
n
iii
w
294,11722
100
101
)( ===⋅
⋅=
∑∑
∑
∑
=
=
CH
qp
qpI n
iii
n
iii
Lp
824,01714
100
110
)( ===⋅
⋅=
∑∑
∑
∑
=
=
CG
qp
qpI n
iii
n
iii
Lq
286,11418
110
111
)( ===⋅
⋅=
∑∑
∑
∑
=
=
GF
qp
qpI n
iii
n
iii
Pp
818,02218
101
111
)( ===⋅
⋅=
∑∑
∑
∑
=
=
HF
qp
qpI n
iii
n
iii
Pq
29,1286,1294,1)( =⋅=FpI 821,0818,0824,0)( =⋅=FpI
)()()()( PpLqPqLpw IIIII ×=×=

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.3. Analiza dynamiki
str. 281
Lewa strona równania:
Prawa strona równania:
Różnice w obliczeniach wynikają z zaokrągleń. Lewa strona równości in-deksowej jest równa prawej, jeśli zamiast liczb dziesiętnych podstawimy wyznaczone wielkości ułamkowe.
Reasumując, o wzroście przychodów ze sprzedaży zdecydował efekt ceno-wy – podwyższenie cen pozwoliło ograniczyć popyt do możliwości kadro-wych szkoły. Negatywny efekt ilościowy (indeks mniejszy od jedności oznacza bowiem spadek wartości) jest skutkiem zmniejszenia liczby prze-prowadzonych godzin kursu z języka polskiego. Należy podkreślić, iż nie musi to oznaczać spadku popytu, lecz może być przyczyną mniejszej liczby polonistów – w tej sytuacji wzrost ceny za kurs z języka polskiego mógł być większy niż wprowadzony.
Drugą grupę indeksów zespołowych stanowią zespołowe indeksy wielko-ści stosunkowych. Indeksy te znajdują zastosowanie w sytuacji, gdy daną wielkość możemy wyrazić w postaci ilorazu dwóch czynników, a nie ilo-czynu, jak miało to miejsce w przypadku zespołowego indeksu cen i ilości. W praktyce można wskazać szereg wielkości tego typu. Przykładem jest wskaźnik wydajności pracy, będący relacją przychodów ze sprzedaży do wielkości zatrudnienia (zob. Miary natężenia i struktury). W przypadku ze-społowych indeksów wielkości stosunkowych miarą analogiczną do zespo - łowego indeksu wartości jest zespołowy indeks wszechstronny wyznaczany według wzoru:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
058,1818,0294,1)()( =⋅=×= PqLpw III
06,1286,1824,0)()( =⋅=×= PpLqw III

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.3. Analiza dynamiki
str. 282
Aby określić wpływ zmian czynników x i z na poziom wielkości y = x / z, należy skorzystać ze wzorów zamieszczonych w tabeli 2.48:
Tabela 2.48. Indeksy o stałej strukturze oraz indeksy wpływu zmian strukturalnych.
Indeksy o stałej strukturze Indeksy wpływu zmian strukturalnych
Formuła Laspeyres
a
Formuła Paaschego
Źródło: Opracowanie własne.
W przypadku wielkości stosunkowych również możemy wyznaczyć rów-ność indeksową, pozwalającą sprawdzić poprawność obliczeń, jak również wyznaczyć zespołowy indeks wszechstronny:
Przykład. Należy dokonać analizy zmian ogólnej wydajności pracy w przedsiębiorstwie, przyjmując jako okres bazowy dane z tabeli 2.2 oraz wiedząc, że:
1. Wielkość zatrudnienia w porównaniu z okresem bazowym:– w oddziale I nie zmieniła się,– w oddziale II zmniejszyła się o 25 proc.,– w oddziale III wzrosła o 25 proc.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
∑
∑
=
=
⋅
⋅= n
iii
n
iii
Ls
zy
zyI
100
101
)(
∑
∑
∑
∑
=
=
=
=
⋅÷
⋅= n
ii
n
iii
n
ii
n
iii
Lwzs
z
zy
z
zyI
10
100
11
110
)(
∑
∑
=
=
⋅
⋅= n
iii
n
iii
Ps
zy
zyI
110
111
)(
∑
∑
∑
∑
=
=
=
=⋅
÷⋅
= n
ii
n
iii
n
ii
n
iii
Pwzs
z
zy
z
zyI
10
101
11
111
)(
)()()()( LwzsPsPwzsLsy IIIII ×=×=

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.3. Analiza dynamiki
str. 283
2. Wydajność pracy w pierwszym i trzecim oddziale wzrosła o 10 proc., zaś w drugim odnotowano 20-procentowy wzrost wydajności.
W tym miejscu warto przypomnieć, iż przeciętna wydajność pracy nie jest średnią arytmetyczną poszczególnych wydajności, w tym przypadku trzech oddziałów, lecz ich średnią harmoniczną. Stąd zastosowanie znajduje wzór na zespołowy indeks wszechstronny.
Najpierw wprowadzamy oznaczenia:
yi0 – wydajność pracy i-tego oddziału w okresie bazowym,z i0 – wielkość zatrudnienia w i-tym oddziale w okresie bazowym,yi0 – wydajność pracy i-tego oddziału w okresie bieżącym,z i0 – wielkość zatrudnienia w i-tym oddziale w okresie bieżącym.
Następnie tworzymy tablicę z danymi i obliczeniami pomocniczymi:
Tabela 2.49. Analiza przyczyn zmian wydajności pracy przedsiębiorstwa.
IA B C = A × B D E F = D × E G = A × E H = D × B
Oddział I 1 000 10 10 000 1 100 10 11 000 10 000 11 000Oddział II 500 40 20 000 600 30 18 000 15 000 24 000Oddział III 2 000 20 40 000 2 200 25 55 000 50 000 44 000
Σ 70 70 000 65 84 000 75 000 79 000
Źródło: Obliczenia własne na podstawie danych umownych.
Zespołowy indeks wszechstronny stanowi w niniejszym przykładzie relację przeciętnej wydajności pracy w okresie bieżącym do przeciętnej wydajno-ści pracy w okresie bazowym (por. Miary natężenia i struktury):
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
292,11000
32,129270
7000065
84000
10
100
11
111
==÷=÷=⋅
÷⋅
=∑∑
∑∑
∑
∑
∑
∑
=
=
=
=
BC
EF
z
zy
z
zyI n
ii
n
iii
n
ii
n
iii
y
0iy 0iz 00 ii zy ⋅ 1iy 1iz 11 ii zy ⋅ 10 ii zy ⋅ 01 ii zy ⋅

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.3. Analiza dynamiki
str. 284
W kolejnym kroku – zgodnie ze wzorami zamieszczonymi w tabeli 2.49 – obliczamy indeksy o stałej strukturze oraz indeksy wpływu zmian struktu-ralnych (ze względu na złożoność wzorów przyjęto bardziej komunikatyw-ne oznaczenia sum kolumn):
Tabela 2.50. Wyznaczenie indeksów o stałej strukturze oraz indeksów wpływu zmian strukturalnych.
Indeksy o stałej strukturze Indeksy wpływu zmian strukturalnych
Formuła Laspeyresa
Formuła Paaschego
Źródło: Obliczenia własne.
Aby sprawdzić poprawność obliczeń, można skorzystać z równości indek-sowej:
Lewa strona równania:
Prawa strona równania:
Nieznaczna różnica wynika, tak jak to było w przypadku indeksów cen i ilości, z zaokrągleń. Na poprawę wydajności pracy w niemal równym stopniu wpłynęły zmiany w strukturze zatrudnienia, jak również ogólna po-prawa sytuacji przedsiębiorstwa, przejawiająca się we wzroście przycho-dów ze sprzedaży.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
129,1
7000079000
)( ===∑∑
CH
I Ls
154,1
7070000
6575000
)( =÷=÷=∑∑
∑∑
BC
EG
I Lwzs
120,1
7500084000
)( ===∑∑
GF
I Ps
145,1
7079000
6584000
)( =÷=÷=∑∑
∑∑
BH
EF
I Pwzs
)()()()( LwzsPsPwzsLsy IIIII ×=×=
293,1145,1129,1)()( =⋅=×= PwzsLsy III
292,1154,112,1)()( =⋅=×= LwzsPsy III

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.3. Analiza dynamiki
str. 285
2.3.4. Trening i ewaluacja
Poniżej przedstawiono praktyczne przykłady analizy szeregów czasowych. Z uwagi na stopień złożoności obliczeń – niezbędne staje się wykorzysta-nie komputera. Obliczenia wykonano z wykorzystaniem arkusza kalkula-cyjnego MS Excel i dołączono je do niniejszej publikacji w formie przykła-dów. Przykłady te powinny pomóc Czytelnikowi w utrwaleniu wiadomości z zakresu analizy szeregów czasowych.
Przykład 1. Na podstawie kursów akcji spółki Żywiec SA za I półrocze 2006 roku (zob. Dane_do_analizy.xls; zakładka: Akcje) należy określić sy-gnały kupna i sprzedaży akcji, płynące z analizy wskaźnika analizy tech-nicznej MACD.
Przykład ten ukazuje praktyczne wykorzystanie średniej ruchomej. Intere-sującym wskaźnikiem, wykorzystywanym na giełdzie papierów wartościo-wych, opartym na tzw. średnich ruchomych wykładniczych, jest wskaźnik MACD (zob. Przykłady – średnia ruchoma; zakładka: MACD).
Prezentowana w tym rozdziale średnia ruchoma prosta różni się tym od średniej ruchomej wykładniczej, że traktuje ona wszystkie obserwacje jako jednakowo ważne. Natomiast w przypadku średniej wykładniczej „naj-świeższym” danym przypisuje się relatywnie większe wagi. Sposób obli-czania tej miary jest następujący (http://bossa.pl):
gdzie:
EMA (Exponential Moving Average) – średnia ruchoma wykładnicza,a – wagi przypisane kolejnym obserwacjom,Ci – cena akcji w i-tym okresie,
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
12
11
22
10
1 −+−
−−−
++++⋅++⋅+⋅+= N
NN
aaaCaCaCaCEMA

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.3. Analiza dynamiki
str. 286
N – liczba obserwacji, na podstawie których obliczono średnią (stała wy- gładzania).
Sposób przypisywania wag a określono następująco:
Dla pierwszej ceny przypisano wagę równą 1, dla drugiej a, dla trzeciej a2
itd.
Wskaźnik MACD składa się z dwóch linii (por. http://inwestycje.elfin.pl):
1. Linii MACD (linia ciągła).2. Linii sygnału (linia przerywana).
Linię MACD wyznacza się jako różnicę pomiędzy wykładniczą średnią ru-chomą „krótszą”, tj. obliczaną dla niewielkiej liczby sesji giełdowych, a analogiczną średnią dla większej liczby sesji. W obliczeniach przyjęto odpowiednio następujące wielkości wygładzania: k = 12 i k = 26.
Linia sygnału to średnia ruchoma wykładnicza linii MACD, przy czym sta-ła wygładzania jest mniejsza niż przyjęte wielkości, służące do wyznacze-nia linii MACD (k = 12 i k = 26). Do obliczenia linii sygnału przyjęto stałą wygładzania k = 9 sesji giełdowych.
Interpretacja wskaźnika jest następująca:
1. Sygnał kupna – przecięcie linii sygnału przez linię MACD od dołu.2. Sygnał sprzedaży – przecięcie linii sygnału przez linię MACD od góry.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
k
a 21 −=

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.3. Analiza dynamiki
str. 287
Oto wskaźnik MACD dla kursów akcji spółki Żywiec:
Jak widać, w historii notowań spółki istniał szereg sygnałów kupna, które zaznaczono za pomocą trójkątow. Linia MACD przecięła też przerywaną linię sygnału od góry (punkt przecięcia oznaczono kwadratem), co stanowi-ło poważny sygnał sprzedaży akcji Żywiec SA
Przykład 2. Proszę dokonać analizy sezonowości sprzedaży Grupy Żywiec SA wraz z prognozą na kolejny rok (zob. Dane_do_analizy.xls; zakładka: Żywiec SA).
Sposób postępowania obejmuje wyznaczenie linii trendu, obliczenia wskaźników sezonowości (model addytywny), a następnie dokonanie pro-gnozy. Ma tu miejsce wyraźna sezonowość sprzedaży (zob. rys. 1.31). Ob-liczenia zostały przeprowadzone w arkuszu kalkulacyjnym MS Excel (zob. Przykłady – analiza sezonowości_model addytywny).
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
1 13 25 37 49 61 73 85 97 109 121MA
CD

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.3. Analiza dynamiki
str. 288
Do danych empirycznych dodajemy linię trendu:
Następnie wyznaczamy wartości teoretyczne oraz wielkości zmiennej po-mocniczej zt:
A B C D = B – C
1 559,2 759,0 –199,82 880,4 756,3 124,13 908,2 753,6 154,64 608,7 750,8 –142,15 558,9 748,1 –189,26 927,2 745,4 181,87 991,4 742,7 248,78 727,1 740,0 –12,99 626,0 737,2 –111,210 795,1 734,5 60,611 839,3 731,8 107,512 528,1 729,1 –201,013 548,3 726,4 –178,114 801,3 723,6 77,715 862,0 720,9 141,116 656,0 718,2 –62,2
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
y = -2,72 t + 761,72R2 = 0,007
400
500
600
700
800
900
1000
1100
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
kwartały
przy
chod
y ze
spr
zeda
ży (m
ln z
ł)
t ty ty tz

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.3. Analiza dynamiki
str. 289
Obliczamy surowe wskaźniki sezonowości:
I kw.
II kw.
III kw.
IV kw.
Σ –0,10
W modelu addytywnym wskaźniki sezonowości powinny dać w sumie ze-ro. Dlatego konieczne jest oczyszczenie surowych wskaźników sezonowo-ści poprzez podzielenie poszczególnych wskaźników przez ich średnią arytmetyczną:
Oto oczyszczone wskaźniki sezonowości:
kw. ck
I –169,56II 111,07III 163,01IV –104,52Σ 0,00
Ostatnim etapem jest wyznaczenie prognozy. Najpierw prognozę wyzna-czamy na podstawie linii trendu, a następnie korygujemy ją o wpływ wskaźnika sezonowości (należy podkreślić, iż w modelu addytywnym wskaźniki sezonowości dodajemy, a nie mnożymy przez wartości prognozy wynikające z linii trendu). Prognoza na 2006 rok przedstawia się następują-co:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
58,169
413951
1 −=+++=′ zzzzc
04,111
4141062
2 =+++=′ zzzzc
99,162
4151173
3 =+++=′ zzzzc
55,104
4161284
4 −=+++=′ zzzzc
025,0
41,01 −=−=′= ∑
kkc
Nq

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.3. Analiza dynamiki
str. 290
A B C D E = C + D
16 656,0 718,217 715,5 –169,56 545,9318 712,8 111,07 823,8319 710,0 163,01 873,0520 707,3 –104,52 602,80
W ujęciu graficznym wielkość prognozy na ogół zaznacza się linią przery-waną:
Sezonowość sprzedaży jest ściśle związana z porami roku – najwięcej piwa sprzedaje się w okresie letnim, czemu z jednej strony sprzyja pogoda, z drugiej zaś sezon wypoczynkowy.
Przykład 3. Sposób przeliczania indeksów dynamiki znajduje praktyczne zastosowanie np. przy przeliczaniu inflacji. W pliku Dane_do_analizy.xls (zakładka: Inflacja) ukazano kwartalne indeksy cen (tj. potoczną inflację) w postaci indeksów łańcuchowych. Należy przeliczyć te indeksy na indek-sy jednopodstaawowe, tak aby okresem bazowym był IV kw. 2005 r. Po-zwoli to na wyrażenie przychodów Grupy Żywiec w cenach bieżących,
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
t ty ty kc *ty
500
600
700
800
900
1000
0 4 8 12 16 20kwartały
przy
chod
y ze
spr
zeda
ży (m
ln z
ł)
wartości empiryczne wartości teoretyczne prognoza

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.3. Analiza dynamiki
str. 291
czyli wyeliminowanie wpływu inflacji na poziom przychodów ze sprzeda-ży.
Najpierw przeliczamy indeksy łańcuchowe na jednopodstawowe, a następ-nie zmieniamy bazę (zob. Przykłady – indeksy dynamiki; zakładka: przeli-czanie_indeksów):
KWARTAŁY t INDEKSYI t/t-1 I t/p
Zmiana bazy (t = 24)
0 1,000 I Q 2000 1 1,037 1,000 × 1,037 = 1,037 1,037 /1,226 = 0,846
II Q 2000 2 1,020 1,037 × 1,020 = 1,058 1,058 / 1,226 = 0,863III Q 2000 3 1,016 1,075 0,876IVQ 2000 4 1,017 1,093 0,891I Q 2001 5 1,014 1,108 0,904
II Q 2001 6 1,018 1,128 0,920III Q 2001 7 0,999 1,127 0,919IV Q 2001 8 1,006 1,134 0,925
I Q 2002 9 1,011 1,146 0,935II Q 2002 10 1,004 1,151 0,938
III Q 2002 11 0,991 1,141 0,930IVQ 2002 12 1,004 1,145 0,934I Q 2003 13 1,006 1,152 0,939
II Q 2003 14 1,004 1,157 0,943III Q 2003 15 0,994 1,150 0,937IV Q 2003 16 1,011 1,162 0,948
I Q 2004 17 1,008 1,172 0,955II Q 2004 18 1,020 1,195 0,974
III Q 2004 19 1,006 1,202 0,980IV Q 2004 20 1,009 1,213 0,989
I Q 2005 21 1,003 1,217 0,992II Q 2005 22 1,006 1,224 0,998
III Q 2005 23 0,998 1,221 0,996IV Q 2005 24 1,004 1,226 1,226 / 1,226 = 1,000
Początkowo okresem bazowym był IV kw. 1999 roku. Zmiana bazy na IV kw. 2005 r. nastąpiła w wyniku podzielenia indeksów jednopodstawowych przez indeks 1,226.
Kolejną kwestią jest skorygowanie wartości przychodów ze sprzedaży Gru-py Żywiec o inflację (począwszy od I kw. 2002 r.). W tym celu
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.3. Analiza dynamiki
str. 292
poszczególne wartości przychodów ze sprzedaży dzielimy przez otrzymane indeksy jednopodstawowe. W szczególności wartość przychodów dla ostatniego kwartału 2005 r. nie zmieni się, ponieważ zostanie podzielona przez indeks 1.
EWALUACJA
Lista zadań nr 4
Zadanie 1
Proszę wyznaczyć linię trendu, opisującą dynamikę zmian PKB 25 państw członkowskich Unii Europejskiej (UE-25) w latach 2001-2005 (zob. Dane_do_analizy.xls; zakładka: PKB).
Zadanie 2
Na podstawie danych z zadania pierwszego proszę wyznaczyć średniorocz-ne tempo zmian PKB w latach 2003-2005.
Zadanie 3
Korzystając z narzędzia MS Excel Dodaj linię trendu dla I półrocza 2006 r. – proszę przedstawić wygładzony szereg czasowy indeksu WIG (zob. Da-ne_do_analizy.xls; zakładka: Akcje). Jako stałą wygładzania proszę przyjąć k = 26 sesji giełdowych. Czy w analizowanym okresie inwestorzy – ogólnie rzecz biorąc – przeważnie realizowali zyski?
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 2.3. Analiza dynamiki
str. 293
Zadanie 4
Inwestor w dniu 2 stycznia 2006 r. kupił 2000 szt. akcji spółki Strzelec po 82 gr/szt. oraz 10 szt. akcji Żywiec SA po 485 zł. W dniu 30 czerwca in-westor posiadał o połowę więcej walorów Strzelec i 8 akcji spółki Żywiec. Ceny akcji tych spółek kształtowały się odpowiednio: 1,20 zł i 464 zł. Pro-szę obliczyć zespołowy indeks wartości portfela oraz określić wpływ czyn-nika ilościowego i cenowego na zmianę wartości tego portfela akcji.
Wskazówka: zob. Przykłady – indeksy dynamiki; zakładka: indeksy_zespo-łowe.
Zadanie 5
Na podstawie dowolnych danych kwartalnych wykazujących sezonowość (n – 12 kwartałów) proszę obliczyć wskaźniki sezonowości oraz dokonać prognozy na najbliższy kwartał.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3. Wnioskowanie statystyczne
str. 294
3.3. Wnioskowanie statystyczneWnioskowanie statystyczne
Wnioskowanie statystyczne opiera się na rachunku prawdopodobieństwa, a reguły tego wnioskowania określają metody wchodzące w skład statysty-ki matematycznej, w tym metody estymacji (szacowania) nieznanych para-metrów strukturalnych oraz metody weryfikacji (sprawdzania) hipotez sta-tystycznych [8, s. 10]. Estymację przedziałową oraz weryfikację hipotez statystycznych poprzedzono krótkim wprowadzeniem do rachunku praw-dopodobieństwa, jak również omówiono wybrane skokowe i ciągłe rozkła-dy prawdopodobieństwa. Rozkłady te w większości przypadków znajdują bowiem zastosowanie w metodach wnioskowania statystycznego.
3.1. Wybrane zagadnienia z rachunku prawdopodobieństwa
Na wstępie należałoby zdefiniować pojęcie prawdopodobieństwa. Prawdo-podobieństwo to „numeryczne wyrażenie szansy wystąpienia jakiegoś zda-rzenia” [21, s. 166]. Jest to miara unormowana, tj. należąca do przedziału [0-1]. Jeżeli prawdopodobieństwo jest równe zeru, to wówczas dane zda-rzenie nie wystąpi, gdy jest równe 1 – to zdarzenie jest pewne. Natomiast zdarzenia, dla których wartości prawdopodobieństwa należą do zbioru (0,1) nie są ani pewne, ani niemożliwe – przypisane im ułamki są prawdopodo-bieństwem zajścia danego zdarzenia.
Zgodnie z klasyczną definicją prawdopodobieństwa: prawdopodobieństwo zdarzenia losowego A – przy założeniu, że wszystkie zdarzenia elementar-ne są jednakowo możliwe – jest ilorazem liczby zdarzeń elementarnych sprzyjających temu zdarzeniu i liczby wszystkich zdarzeń elementarnych
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.1. Wybrane zagadnienia z rachunku prawdopodobieństwa
str. 295
[19, s. 78]. Klasyczną definicję prawdopodobieństwa zdarzenia A można wyrazić wzorem:
Oto dwa proste przykłady ilustrujące sposób obliczania prawdopodobień-stwa zgodnie z klasyczną definicją:
Przykład 1. Gra „szczęśliwy numerek” polega na wylosowaniu jednej licz-by spośród 49. W tej sytuacji liczba zdarzeń elementarnych wynosi n = 49 (może zostać wylosowana liczba od 1 do 49). Tylko jedna z nich okaże się wygrywającą, stąd k = 1. Prawdopodobieństwo wygranej to:
Przykład 2. Wśród 200 złożonych w pewnej miejscowości wniosków o dotacje unijne 25 okazało się źle wypełnionych. Należy obliczyć prawdo-podobieństwo błędnego wypełnienia wniosku. Dane:
n = 200 wniosków,k = 25 wniosków źle wypełnionych.
Prawdopodobieństwo zdarzenia A, polegającego na wylosowaniu wniosku posiadającego wady, wynosi:
Rozwinięciem klasycznej definicji prawdopodobieństwa jest definicja graficzna:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( )491==
nkAP
( ) %5,12125,020025 ====
nkAP

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.1. Wybrane zagadnienia z rachunku prawdopodobieństwa
str. 296
Obszar całkowity to przestrzeń zdarzeń elementarnych o określonej jedno-stce miary (długość, pole, objętość). Obszar A spełnia warunki określone zdarzeniem A. Przedstawiona definicja znajduje zastosowanie np. w roz - kładach ciągłych, gdzie pole pod tzw. funkcją gęstości wynosi 1. W przy-padku cech ciągłych skorzystanie z klasycznej definicji prawdopodobień-stwa jest bezzasadne, ponieważ w tej sytuacji prawdopodobieństwo przyję-cia określonej wartości przez zmienną losową jest równe zeru.
Trzecia, statystyczna definicja prawdopodobieństwa – zwana też często-ściową lub frekwencyjną – mówi, że prawdopodobieństwo zdarzenia A jest granicą częstości tego zdarzenia, gdy liczba doświadczeń n rośnie nieogra-niczenie [19, s. 81]. Można to zapisać następująco:
Statystyczna definicja prawdopodobieństwa pozwala przypuszczać, że wraz ze wzrostem próby losowej frakcja (zob. wskaźnik struktury) wyzna-czona na jej podstawie jest coraz bliższa wartości prawdopodobieństwa określonej według definicji częstościowej. Można tu posłużyć się prostym przykładem:
Przykład. Funkcja los() programu MS Excel generuje liczby z przedziału [0,1]. Jako nA można określić wartości mniejsze bądź równe 0,5. Im więcej prób, tym wartości empiryczne (frakcje) będą bliższe teoretycznej wartości 0,5 (zob. Przykłady – zbieżność prawdopodobieństwa).
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.1. Wybrane zagadnienia z rachunku prawdopodobieństwa
str. 297
Rysunek 3.1. Zbieżność prawdopodobieństwa do teoretycznej wartości 0,5.
Źródło: Opracowanie własne.
Symulację przeprowadzono dla 10, 50 i 100 prób. Im więcej prób, tym różnice pomiędzy frakcjami a wartością teoretyczną 50 proc. są coraz mniejsze. Jest to zgodne z przedstawioną statystyczną definicją prawdopo-dobieństwa.
Mając już zdefiniowane prawdopodobieństwo, możemy sprecyzować, czym jest zdarzenie losowe A – jest to podzbiór przestrzeni zdarzeń ele-mentarnych (Ω), zawierający wyróżnione ze względu na daną cechę zda-rzenia elementarne, czyli wyniki doświadczenia losowego (por. [21, s. 167]). Nawiązując do powyższego przykładu: interesującymi nas zdarze-niami elementarnymi były wygenerowane za pomocą funkcji los() liczby nieprzekraczające 0,5.
Kolejną kwestią jest algebra zdarzeń. Na szczególną uwagę zasługuje tu prawdopodobieństwo dopełnienia zdarzenia A (zwanego też zdarzeniem przeciwnym do A). Prawdopodobieństwo dopełnienia można zapisać nastę-pująco [1, s. 79]:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
0%
25%
50%
75%
100%
0 20 40 60 80 100 120
liczba dośw iadczeń (n)
frak
cje

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.1. Wybrane zagadnienia z rachunku prawdopodobieństwa
str. 298
Powyższa reguła będzie stosowana przy omawianiu rozkładów prawdopo-dobieństwa (zob. Charakterystyka wybranych rozkładów prawdopodobień - stwa).
Przykład. Należy obliczyć prawdopodobieństwo tego, że losowo wybrany wniosek o dotację UE został prawidłowo wypełniony, wiedząc, że co ósmy zawiera błędy. Oznaczamy:
P(A) – prawdopodobieństwo tego, że wniosek został źle wypełniony.
Podstawiamy do wzoru:
Zatem prawdopodobieństwo prawidłowego wypełnienia wniosku wynosi 7/8.
Następną ważną regułą w algebrze zdarzeń jest tzw. reguła sumowania. Prawdopodobieństwo sumy dwóch zdarzeń można przedstawić następująco [1, s. 79]:
Warto tu wskazać na przypadek szczególny, jakim są zdarzenia wyklucza-jące się wzajemnie. W tej sytuacji brak jest części wspólnej:
stąd:
W rachunku prawdopodobieństwa istotny jest podział zdarzeń losowych na:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( ) ( )87
8111 =−=−= APAP
( ) 0=∩ BAP
( ) ( ) ( )BPAPBAP +=∪

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.1. Wybrane zagadnienia z rachunku prawdopodobieństwa
str. 299
1. Zdarzenia niezależne – zajście jednego z tych zdarzeń nie ma wpływu na prawdopodobieństwo zajścia drugiego z nich. Oto warunek niezależ-ności zdarzeń:
2. Zdarzenia zależne – prawdopodobieństwo zajścia zdarzenia A zależy od zajścia zdarzenia B. Można tu mówić o tzw. prawdopodobieństwie warunkowym zdarzenia A przy założeniu, że zaszło zdarzenie B:
Z powyższego równania można wyprowadzić wzór na iloczyn zdarzeń A i B:
W przypadku gdy zdarzenia są zależne – warto posłużyć się tzw. drzewem stochastycznym:
Rysunek 3.2. Drzewo stochastyczne.
Źródło: Opracowanie własne.
Zdarzenia na poszczególnych „gałęziach” drzewa są parami przeciwstaw-ne, stąd np.:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( ) ( ) ( )BPBAPBAP ⋅=∩ |

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.1. Wybrane zagadnienia z rachunku prawdopodobieństwa
str. 300
P(B1) + P(B2) + … + P(Bn) = 1
Na podstawie powyższego schematu można wyprowadzić ogólny wzór na prawdopodobieństwo całkowite:
Mając obliczone prawdopodobieństwo zajścia zdarzenia X – można sko-rzystać z tzw. wzoru Bayesa:
Wzór ten pozwala na wyznaczenie prawdopodobieństw zdarzeń Bi, gdy wiemy, że zaszło zdarzenie X.
Przykład. Prawdopodobieństwo zdania egzaminu ze statystyki w pierw-szym terminie uzależnione jest od tego, czy student korzysta z dodatko-wych form nauczania. Z badań przeprowadzonych wśród wybranej grupy studentów wynika, iż czterech na dziesięciu studentów skorzystało z dodat-kowych form nauczania. Wśród tej grupy osób aż 70 proc. zdało egzamin w pierwszym terminie. Natomiast egzamin w pierwszym terminie zdał tyl-ko co drugi student niekorzystający z dodatkowych form nauczania. Należy obliczyć:
a) prawdopodobieństwo zdania egzaminu ze statystyki w pierwszym ter-minie,
b) prawdopodobieństwo, że losowo wybrany student, który zdał egzamin w pierwszym terminie korzystał z dodatkowych form nauczania.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.1. Wybrane zagadnienia z rachunku prawdopodobieństwa
str. 301
Wprowadzamy następujące oznaczenia:
P(X) – prawdopodobieństwo zdania egzaminu ze statystyki w pierwszym terminie,P(B1) – prawdopodobieństwo, że student korzystał z dodatkowych form nauczania,P(B2) – prawdopodobieństwo, że student nie korzystał z dodatkowych form nauczania.
Dane przedstawiono na drzewie stochastycznym:
Rysunek 3.3. Drzewo stochastyczne – przykład liczbowy.
Źródło: Dane umowne.
a) obliczamy prawdopodobieństwo całkowite:
b) korzystamy ze wzoru Bayesa:
Prawdopodobieństwo zdania egzaminu w pierwszym terminie wynosi 58 proc. Prawdopodobieństwo, że losowo wybrany student, który zdał egza-min w pierwszym terminie, korzystał z dodatkowych form nauczania wy-nosi 48,3 proc.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( ) ( ) ( ) ( ) ( ) 58,03,028,05,06,07,04,0|| 2211 =+=⋅+⋅=⋅+⋅= BXPBPBXPBPXP
( ) ( ) ( )( ) 483,0
5828
58,07,04,0|| 11
1 ==⋅=⋅=XP
BXPBPXBP

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.1. Wybrane zagadnienia z rachunku prawdopodobieństwa
str. 302
To, czy zdarzenia są od siebie zależne, czy też nie, będzie miało wpływ na wybór rozkładu prawdopodobieństwa, a także na dobór niektórych testów statystycznych.
Opis struktury zbiorowości dotyczył empirycznych rozkładów cech jako-ściowych i ilościowych. W przypadku teoretycznych rozkładów prawdopo-dobieństwa można mówić o tzw. zmiennej losowej. Mianem zmiennej lo-sowej określa się „każdą jednoznacznie określoną funkcję rzeczywistą wy-znaczoną na zbiorze zdarzeń elementarnych” [9, s. 88]. Zmienne losowe dzielą się na (por. [8, s. 30]):
1. Skokowe (por. cecha skokowa) – w przypadku zmiennych losowych skokowych (dyskretnych) można mówić o rozkładzie masy prawdopo-dobieństwa:
2. Ciągłe (por. cecha ciągła i quasi -ciągła ) – w przypadku zmiennych loso-wych ciągłych mówimy o tzw. rozkładzie gęstości prawdopodobień-stwa:
Teoretyczne rozkłady prawdopodobieństwa posiadają syntetyczne charak-terystyki (por. [8, s. 35]):
– wartość oczekiwana (por. średnia arytmetyczna),– wariancja bądź odchylenie standardowe (pierwiastek kwadratowy z wa-
riancji).
Sposób obliczania wymienionych charakterystyk zawiera tabela:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( ) ii pxXP ==
( ) ( )∫ ==<<
b
aipdxxfbXaP

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.1. Wybrane zagadnienia z rachunku prawdopodobieństwa
str. 303
Tabela 3.1. Podstawowe charakterystyki rozkładów zmiennych losowych.
Zmienne losowe skokowe Zmienne losowe ciągłe
Wartość oczekiwana
Wariancja
Źródło: Opracowanie własne na podstawie: [8, s. 35].
W kolejnym podrozdziale omówiono wybrane rozkłady skokowe i ciągłe. Należy zaznaczyć, iż charakterystyki są obliczane nie ze wzorów prezento-wanych w tabeli 3.1, lecz ze wzorów uproszczonych.
3.2. Charakterystyka wybranych rozkładów prawdopodobieństwa
W niniejszym podrozdziale omówiono wybrane rozkłady prawdopodobień-stwa. Obliczeń można dokonać w załączonym dodatku Rozkłady prawdo-podobieństwa. W tym podrozdziale położono nacisk na odpowiedni wybór rozkładu, a także na umiejętność odczytu żądanych wartości z tablic staty-stycznych. Oto klasyfikacja omówionych w dalszej części rozkładów praw-dopodobieństwa:
Tabela 3.2. Klasyfikacja rozkładów prawdopodobieństwa.
Rozkłady skokowe Rozkłady ciągłe
Zmienne niezależne
1. Rozkład dwumianowy.2. Rozkład dwupunktowy.3. Rozkład geometryczny.4. Rozkład Poissona.
1. Rozkład jednostajny.2. Rozkład normalny.3. Rozkład T-Studenta.4. Rozkład Chi-kwadrat.5. Rozkład F.
Zmienne zależne 1. Rozkład hipergeometryczny
Źródło: Opracowanie własne.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( ) ∑=
==k
iii pxmXE
1
( ) ( )∫
+ ∞
∞−
⋅== dxxfxmXE
( ) ( )∑=
⋅−==k
iii pmxXD
1
222 σ
( ) ( ) ( )∫+ ∞
∞−
⋅−== dxxfmxXD 222 σ

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.2. Charakterystyka wybranych rozkładów prawdopodobieństwa
str. 304
3.2.1. Rozkład dwumianowy
Rozkład dwumianowy (Bernoulliego) zmiennej losowej X znajduje zasto-sowanie wówczas, gdy (por. [21, s. 195]):
1. Przeprowadza się n jednakowych doświadczeń.2. Dla każdego doświadczenia możliwe są dwa wyniki: sukces lub poraż-
ka.3. Prawdopodobieństwo sukcesu p w kolejnych doświadczeniach nie zmie-
nia się (doświadczenia niezależne).4. Liczba doświadczeń n jest niewielka (zał. n < 30).
Funkcja prawdopodobieństwa rozkładu dwumianowego jest następująca:
Dwumian Newtona oblicza się według wzoru:
Oto podstawowe charakterystyki rozkładu:
a) wartość oczekiwana:
b) odchylenie standardowe:
Dystrybuantą zmiennej losowej X o rozkładzie dwumianowym jest funkcja postaci (por. [9, s. 95]):
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( ) !!
!knk
nkn
−=
npm =
( )pnp −= 1σ

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.2. Charakterystyka wybranych rozkładów prawdopodobieństwa
str. 305
Analogicznie można określić dystrybuantę dla pozostałych rozkładów sko-kowych.
Przykład. Student na „chybił-trafił” rozwiązuje test wielokrotnego wyboru ze statystyki, gdzie tylko jedna spośród czterech opcji odpowiedzi jest pra-widłowa. Test liczy 10 pytań. Proszę obliczyć prawdopodobieństwo tego, że ponad 40 proc. odpowiedzi będzie prawidłowych. Wypisujemy dane:
a) liczba sukcesów polegających na właściwym zaznaczeniu odpowiedzi: P(X > 4),
b) liczba niezależnych prób (pytań w teście): n = 10, c) prawdopodobieństwo sukcesu: p = 0,25.
Możemy skorzystać ze wzoru na prawdopodobieństwo dopełnienia zda-rzeń:
Następnie obliczamy prawdopodobieństwa cząstkowe ze wzoru na funkcję prawdopodobieństwa rozkładu dwumianowego. Oto sposób obliczeń dla k = 0:
Wracamy do wzoru:
Analogicznie obliczamy prawdopodobieństwa dla k = 1, k = 2, k = 3 i k = 4. Suma prawdopodobieństw cząstkowych to:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( ) ( )kXPkF ≤=
( ) ( ) ( ) ( ) ( ) ( ) ( )[ ]432101414 =+=+=+=+=−=≤−=> XPXPXPXPXPXPXP
( ) ( ) ( ) 0100 25,0125,00
100 −−⋅⋅
==XP
( ) 1!101
!10!010!0
!100
10=
⋅=
−=
( ) ( ) ( ) 0563,075,025,01110 1010 ==−⋅⋅==XP
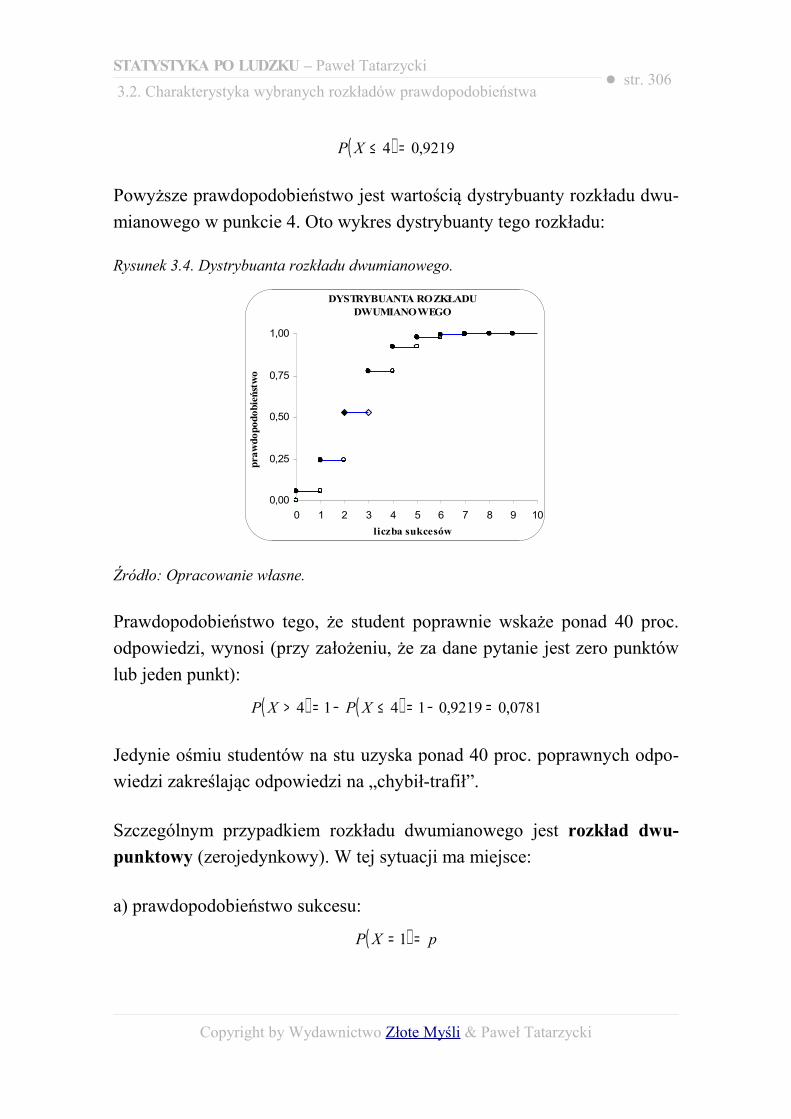
STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.2. Charakterystyka wybranych rozkładów prawdopodobieństwa
str. 306
Powyższe prawdopodobieństwo jest wartością dystrybuanty rozkładu dwu-mianowego w punkcie 4. Oto wykres dystrybuanty tego rozkładu:
Rysunek 3.4. Dystrybuanta rozkładu dwumianowego.
Źródło: Opracowanie własne.
Prawdopodobieństwo tego, że student poprawnie wskaże ponad 40 proc. odpowiedzi, wynosi (przy założeniu, że za dane pytanie jest zero punktów lub jeden punkt):
Jedynie ośmiu studentów na stu uzyska ponad 40 proc. poprawnych odpo-wiedzi zakreślając odpowiedzi na „chybił-trafił”.
Szczególnym przypadkiem rozkładu dwumianowego jest rozkład dwu-punktowy (zerojedynkowy). W tej sytuacji ma miejsce:
a) prawdopodobieństwo sukcesu:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( ) 9219,04 =≤XP
DYSTRYBUANTA ROZKŁADU DWUMIANOWEGO
0,00
0,25
0,50
0,75
1,00
0 1 2 3 4 5 6 7 8 9 10liczba sukcesów
praw
dopo
dobi
eńst
wo
( ) ( ) 0781,09219,01414 =−=≤−=> XPXP
( ) pXP == 1

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.2. Charakterystyka wybranych rozkładów prawdopodobieństwa
str. 307
b) prawdopodobieństwo porażki:
Charakterystyki tego rozkładu są następujące:
a) wartość oczekiwana:
b) odchylenie standardowe:
Nawiązując do powyższego przykładu: możemy stwierdzić, że prawdopo-dobieństwo sukcesu, jakim jest losowy wybór prawidłowej opcji odpowie-dzi wynosi 0,25. Jednocześnie prawdopodobieństwo porażki, tj. zaznacze-nia nieprawidłowej odpowiedzi, wynosi 0,75.
O ile rozkład dwumianowy określa liczbę k sukcesów wśród n powtórzeń doświadczenia (np. n rzutów monetą), o tyle rozkład geometryczny wy-znacza prawdopodobieństwo pojawienia się pierwszego sukcesu:
Charakterystyki:
a) wartość oczekiwana:
b) odchylenie standardowe:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( ) qpXP =−== 10
pm =
( )pp −⋅= 1σ
p
m 1=
2
1p
p−=σ

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.2. Charakterystyka wybranych rozkładów prawdopodobieństwa
str. 308
Przykład. Średnio rzecz biorąc, co piąty internauta odwiedzający pewien sklep internetowy robi w nim zakupy. Należy obliczyć prawdopodobień-stwo tego, że pierwsza transakcja pojawi się przy trzecim wejściu na stro-nę. Ile powinno być wejść na stronę, aby została dokonana transakcja kup-na-sprzedaży?:
Wypisujemy dane:
p = 0,2 (co piąty internauta)k = 3
Podstawiamy do wzoru na funkcję prawdopodobieństwa rozkładu geome-trycznego:
Prawdopodobieństwo tego, że pierwsza transakcja zostanie zawarta po trze-cim wejściu na stronę, wynosi 12,8 proc.
Aby odpowiedzieć na pytanie, ile powinno być średnio wejść na stronę, by została dokonana transakcja kupna-sprzedaży, obliczamy wartość oczeki-waną:
Należy oczekiwać, iż średnio przy pięciu wejściach na stronę zostanie za-kupiony jakiś produkt ze sklepu internetowego. Oczywiście pierwszy inter-nauta może od razu nabyć pewien produkt, ale też może zdarzyć się sytu-acja, w której nawet pięć wejść nie gwarantuje zbytu produktów. Warto więc obliczyć jeszcze odchylenie standardowe:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( ) ( ) ( ) 128,08,02,02,012,03 213 =⋅=−⋅== −XP
( ) 55,0
11 ===p
XE
( ) 47,42,0
2,01122 =−=−=
ppσ

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.2. Charakterystyka wybranych rozkładów prawdopodobieństwa
str. 309
Górną granicę typowego obszaru zmienności uzyskamy, dodając do warto-ści oczekiwanej obliczone powyżej odchylenie standardowe. Zatem o nie-typowej sytuacji możemy mówić w przypadku, gdy na stronę wejdzie wię-cej niż dziewięciu internautów i nie zostanie zawarta transakcja kupna-sprzedaży.
3.2.2. Rozkład Poissona
Rozkład dwumianowy można przybliżyć rozkładem Poissona wówczas, gdy spełnione są następujące warunki (por. [9, s. 96]):
1. Liczba doświadczeń powinna być dostatecznie duża (zał. n > 30).2. Stałe prawdopodobieństwo sukcesu powinno być bliskie zeru (zał. p < 0,1).
Powyższe założenia należy traktować jako umowne. Rozkład Poissona jest rozkładem asymetrycznym – im silniejsza asymetria (mniejsze p), tym le-piej. Innymi słowy: jeśli p jest dość duże, to próba powinna być dostatecz-nie duża (ważne jest, by p nie było bliskie 0,5, co wskazywałoby na syme-trię rozkładu). Funkcja prawdopodobieństwa rozkładu Poissona jest dana wzorem:
Parametr λ jest wartością oczekiwaną, którą w tym przypadku obliczamy następująco:
Wartość oczekiwana jest równa wariancji, stąd odchylenie standardowe wynosi:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
npm ==λ
np=σ

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.2. Charakterystyka wybranych rozkładów prawdopodobieństwa
str. 310
Rozkład Poissona został stablicowany (zob. Tablice rozkładu Poissona), stąd nie ma potrzeby korzystania ze skomplikowanego wzoru na funkcję prawdopodobieństwa. Oto przykład wyjaśniający odczyt z tablic tego roz-kładu:
Przykład. Prawdopodobieństwo wygrania „trójki” w Dużego Lotka wyno-si 1,8 proc. Gracz wysłał sto kuponów. Jakie jest prawdopodobieństwo te-go, że:
a) co najwyżej jeden los jest wygrywający („trójka”),b) przynajmniej trzy zakłady zawierają trzy trafne skreślenia,c) wśród wysłanych kuponów stwierdzono tylko jedną „trójkę”,d) stwierdzono minimum jedną „trójkę”, ale nie więcej niż cztery.
Wypisujemy dane:
n = 100p = 0,018
Obliczamy wartość oczekiwaną:
a) szukaną wartość od razu możemy odczytać z tablic rozkładu Poissona:
b) korzystamy ze wzoru na dopełnienie prawdopodobieństwa i odczytuje-my wartość z tablic rozkładu Poissona:
c) w przypadku tablic załączonych do tej publikacji musimy obliczyć róż-nicę pomiędzy odczytanymi wartościami skumulowanymi prawdopodo-bieństwa:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
8,1018,0100 =⋅== npλ
( ) 4628,01 =≤XP
( ) ( ) ( ) 2694,07306,0121313 =−=≤−=<−=≥ XPXPXP
( ) ( ) ( ) 1607,07306,08913,0233 =−=≤−≤== XPXPXP

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.2. Charakterystyka wybranych rozkładów prawdopodobieństwa
str. 311
d) odczytujemy prawdopodobieństwo wartości skumulowanych do 4 włącznie, po czym odejmujemy prawdopodobieństwo P(X < 1), tj. P(X = 0):
W przypadku wartości prawdopodobieństw, których nie ma w załączonych tablicach warto posłużyć się dodatkiem „Rozkłady prawdopodobieństwa”.
3.2.3. Rozkład hipergeometryczny
Rozkład hipergeometryczny znajduje zastosowanie wówczas, gdy [1, s. 141]:
1. Pobierana jest próba w sposób zależny (zmienia się prawdopodobień-stwo sukcesu),
2. Populacja generalna N jest relatywnie niewielka w porównaniu z próbą n.
Funkcja prawdopodobieństwa rozkładu hipergeometrycznego jest następu-jąca:
Wartość oczekiwana jest obliczana następująco (z uwagi na złożoność obli-czeń pominięto wzór na odchylenie standardowe):
Przykład. Należy obliczyć prawdopodobieństwo trafienia „trójki” w Duże-go Lotka (gracz wybiera 6 liczb spośród 49).
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( ) ( ) ( ) 7983,01653,09636,00441 =−==−≤=≤≤ XPXPXP
NSnm ⋅=

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.2. Charakterystyka wybranych rozkładów prawdopodobieństwa
str. 312
Najpierw określamy dane:
N = 49 liczb,n = 6 liczb spośród 49,S = 6 liczb wylosowanych, wśród których znajdują się trzy wytypowane przez gracza,k = 3 sukcesy polegające na wytypowaniu trafnych liczb.
Podstawiamy do wzoru:
Dwumiany Newtona obliczamy oddzielnie, po czym wracamy do wzoru wyjściowego (w tym przykładzie obliczeń dokonano z wykorzystaniem do-datku „Rozkłady prawdopodobieństwa”).
Prawdopodobieństwo trafienia „trójki” w Dużego Lotka wynosi 1,77 proc. (w obliczeniach dot. rozkładu Poissona wartość tę zaokrąglono do 1,8 proc.). Wartość oczekiwana w tej grze wynosi 0,73 trafień (praktycznie jedna liczba).
3.2.4. Rozkład jednostajny
Dotychczas omówione rozkłady były rozkładami zmiennej losowej skoko - wej. W tym miejscu zostaną kolejno omówione rozkłady ciągłe. Zmienna losowa X ma rozkład jednostajny (prostokątny, równomierny) wówczas, gdy funkcja gęstości tego rozkładu jest określona następująco (por. [21, s. 203]):
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( ) 0177,0
649
343
36
649
36649
36
=
⋅
=
−−
⋅
=
−−
⋅
==
nN
knSN
kS
kXP

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.2. Charakterystyka wybranych rozkładów prawdopodobieństwa
str. 313
Dystrybuantą rozkładu jednostajnego – tak jak innych rozkładów ciągłych – jest funkcja pierwotna do funkcji gęstości:
W praktyce korzysta się już z wyprowadzonych wzorów bądź stablicowa-nych wartości funkcji dystrybuanty (por. rozkład normalny).
Charakterystyki rozkładu:
a) wartość oczekiwana:
b) odchylenie standardowe:
Przykład 1. Program MS Excel posiada wbudowaną funkcję los(), generu-jącą liczby pseudolosowe z przedziału [0, 1]. Zakładając, że są to wartości dystrybuanty rozkładu jednostajnego, można opracować model generujący liczby z przedziału [a, b]. Należy dokonać odpowiedniego przekształcenia, tak aby program generował liczby losowe z przedziału [1, 6].
Parametry wejściowe to a i b. Zatem dokonujemy przekształcenia dystry-buanty do następującej postaci:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( )abaxxF
−−=
2
bam +=
12
ab −=σ
( ) ( )ababaxxF −×
−−=

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.2. Charakterystyka wybranych rozkładów prawdopodobieństwa
str. 314
W miejsce wartości dystrybuanty F(x) podstawiamy funkcję los():
Wprowadzamy wartości określające przedział liczbowy [1, 6]:
a = 1,b = 6.
Teraz możemy wygenerować n wartości x według formuły (zob. Przykłady – generowanie liczb pseudolosowych; zakładka: Rozkład jednostajny):
Wartość oczekiwana wygenerowanych za pomocą funkcji los() liczb wyno-si:
Odchylenie standardowe to:
W praktyce – im więcej wygenerowanych liczb, tym obliczane na ich pod-stawie charakterystyki są bliższe wyznaczonym wartościom teoretycznym 3,5 i 1,443.
Przykład 2. Należy obliczyć prawdopodobieństwo tego, że losowo wyge-nerowana liczba z przedziału [1, 6] jest większa od 2.
Dane są następujące:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( ) ( ) axabxF −=−⋅
( ) ( ) xaabxF =+−⋅
( ) aablosx +−⋅= ()
1()5 +⋅= losx
5,3
261
2=+=+= bam
443,1
1216
12=−=−= abσ

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.2. Charakterystyka wybranych rozkładów prawdopodobieństwa
str. 315
a = 1,b = 6.
Korzystamy ze wzoru na dopełnienie prawdopodobieństwa:
Obliczamy wartość dystrybuanty w punkcie 2:
Obliczoną wartość dystrybuanty w punkcie 2 podstawiamy do wzoru wyj-ściowego:
Prawdopodobieństwo tego, że losowo wygenerowana liczba będzie więk-sza niż 2, wynosi 0,8.
3.2.5. Rozkład normalny
W praktyce wiele cech statystycznych ciągłych lub quasi-ciągłych posiada rozkłady empiryczne zbliżone do rozkładu normalnego, co sprawia, że roz-kład ten jest jednym z najważniejszych w statystyce. Rozkład normalny jest szeroko stosowany w estymacji przedziałowej, jak również w testowaniu hipotez statystycznych (duża próba losowa).
Zmienna losowa ciągła X posiada rozkład normalny – zwany też rozkła-dem Gaussa-Laplace’a – jeżeli funkcja gęstości tego rozkładu jest określo-na wzorem (por. [19, s. 112], [21, s. 204]):
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( ) ( ) ( )21212 FXPXP −=≤−=>
( )5
1161 −=
−−=
−−= xx
abaxxF
( ) 2,05
122 =−=F
( ) ( ) ( ) 8,02,0121212 =−=−=≤−=> FXPXP

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.2. Charakterystyka wybranych rozkładów prawdopodobieństwa
str. 316
Powyższe równanie zawiera dwa bardzo ważne parametry, a mianowicie:
a) średnią (wartość oczekiwaną),b) odchylenie standardowe.
Rozkład normalny jest całkowicie określony przez dwa powyższe parame-try. Zmienna losowa X ma rozkład normalny o średniej m i odchyleniu standardowym σ, co w sposób symboliczny zapisujemy następująco (por. [9, s. 98]):
Istnieje nieskończenie wiele rozkładów normalnych zmiennej losowej cią-głej, różniących się właśnie pod względem tych parametrów. Kształt funk-cji gęstości rozkładu normalnego przybiera formę „kapelusza” (por. [1, s. 187]). Oto przykładowe rozkłady:
Rysunek 3.5. Kształt funkcji gęstości rozkładu normalnego w zależności od parametrów m i σ.
Źródło: Opracowanie własne.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( )σ,~ mNX
0
0,1
0,2
0,3
0,4
0,5
-7 -6 -5 -4 -3 -2 -1 0 1 2 3 4 5 6 7
Rozkład "A": X ~ N(0,1)
Rozkład "B": X ~ N(0,2)
Rozklad "C": X ~ N(3,1)

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.2. Charakterystyka wybranych rozkładów prawdopodobieństwa
str. 317
Jak widać, średnia odpowiada za przesunięcie rozkładu równolegle do osi OX (por. rozkłady A i C). Natomiast odchylenie standardowe sprawia, że rozkład jest bardziej lub mniej smukły – niska wartość odchylenia standar-dowego świadczy o dużym skupieniu wartości wokół średniej (rozkład A).
Dystrybuanta rozkładu normalnego, czyli scałkowana funkcja gęstości, jest dana wzorem (por. [19, s. 113]):
Rozkład normalny jest stablicowany (zob. Dystrybuanta rozkładu normal - nego), stąd nie ma konieczności obliczania dystrybuanty tego rozkładu z przedstawionego powyżej wzoru. Należy jednak pamiętać, że odczyt szu-kanej wartości prawdopodobieństwa z tablic dystrybuanty rozkładu nor-malnego musi zostać poprzedzony standaryzacją zmiennej losowej X we-dług wzoru:
Standaryzowana zmienna Z ma rozkład normalny o średniej równej zeru i odchyleniu standardowym równym 1 (por. [19, s. 113]):
Funkcja gęstości standaryzowanego rozkładu normalnego jest następująca:
Interpretacją graficzną szukanego prawdopodobieństwa jest pole pod funk-cją gęstości:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( )
( )dxexF
x mx
∫∞−
−−
⋅= 2
2
2
21 σ
πσ
( )1,0~ NZ
( ) 2
2
21 z
ezf−
⋅=π

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.2. Charakterystyka wybranych rozkładów prawdopodobieństwa
str. 318
Rysunek 3.6. Funkcja gęstości standaryzowanego rozkładu normalnego.
Źródło: Opracowanie własne.
Zaznaczone pole wyznaczymy obliczając całkę z funkcji gęstości, tj. dys-trybuantę standaryzowanego rozkładu normalnego w punkcie z:
W praktyce wartość dystrybuanty odczytujemy bezpośrednio z tablic:
Rozkład normalny jest rozkładem symetrycznym względem osi OY. Z wła-sności tej korzysta się przy odczytywaniu wartości dystrybuanty z tablic statystycznych:
Oto kilka sytuacji ukazujących sposób posługiwania się tablicami dystry-buanty rozkładu normalnego:
Przykład 1. Klienci pewnego hipermarketu nabywają w ciągu tygodnia produkty spożywcze. Rozkład wydatków jest rozkładem normalnym o pa-rametrach m = 150 i σ = 50:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
-3 -2 -1 0 1 2 3
( ) ∫
∞−
−
⋅=z z
dzezF 2
2
21
π
( ) 5,00 =F
( ) ( )zFzF −=− 1
( )50,150~ NX

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.2. Charakterystyka wybranych rozkładów prawdopodobieństwa
str. 319
Należy obliczyć prawdopodobieństwo tego, że tygodniowe wydatki losowo wybranego klienta:
a) nie przekraczają 50 zł,b) są większe niż 200 zł,c) należą do przedziału 200-300 zł,d) są większe niż 100 zł, ale nie przekraczają 250 zł.
Przed odczytem z tablic najpierw należy dokonać standaryzacji:
a)
W zamieszczonych na końcu niniejszej publikacji tablicach (zob. Dystry - buanta rozkładu normalnego) możliwy jest odczyt nieujemnych wartości z. Korzystamy z zależności:
Prawdopodobieństwo tego, że losowo wybrany klient w ciągu tygodnia wydał na żywność nie więcej niż 50 zł, wynosi 2,3 proc.
b)
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( ) ( ) ( )2250
1505050 −=−≤=
−≤=≤ FZPZPXP
( ) ( )zFzF −=− 1
( ) ( ) 0228,09772,01212 =−=−=− FF
( ) ( )150
150200200 >=
−>=> ZPZPXP
-3 -2 -1 0 1 2 3

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.2. Charakterystyka wybranych rozkładów prawdopodobieństwa
str. 320
Z tablic statystycznych nie możemy odczytać wartości prawdopodobień-stwa dla z > 1, stąd konieczne jest skorzystanie ze wzoru na dopełnienie prawdopodobieństwa:
Z niemal 16-procentowym prawdopodobieństwem możemy stwierdzić, iż losowo wybrany klient hipermarketu wydaje na żywność ponad 200 zł ty-godniowo.
c)
W tej sytuacji odczytujemy wartości dystrybuanty w punkcie 3 i 1 (zob. podpunkt b), a następnie obliczamy różnice pól:
Zgodnie z regułą „trzech sigm” - prawdopodobieństwo tego, że wartość z > 3, jest bliskie zeru (średnia plus trzy odchylenia standardowe). Dlatego otrzymane prawdopodobieństwo jest zbliżone do wyniku z poprzedniego podpunktu.
d)
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( ) ( ) 1587,08413,01111 =−=−=> FZP
( ) ( )3150
15030050
150200300200 <<=
−<<−=<< ZPZPXP
-3 -2 -1 0 1 2 3
( ) ( ) ( ) 1574,08413,09987,01331 =−=−=<< FFZP
( ) ( )2150
15025050
150100250100 ≤<−=
−≤<−=≤< ZPZPXP

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.2. Charakterystyka wybranych rozkładów prawdopodobieństwa
str. 321
W tym przypadku pole obszaru pod funkcją gęstości rozkładu normalnego obejmuje zarówno wartości ujemne, jak i dodatnie:
Zaznaczone pole obliczono – podobnie jak w poprzednim podpunkcie – ja-ko różnicę pól: wartość dystrybuanty rozkładu normalnego w punkcie 2 (większy obszar) pomniejszono o wartość dystrybuanty w punkcie –1 (pole obszaru mniejszego od –∞ do –1):
Wartości dystrybuant obliczono z wykorzystaniem dodatku Rozkłady praw-dopodobieństwa. Odczyt z tablic wartości dystrybuanty w punkcie –1 jest możliwy po prezentowanym już wyżej przejściu:
Z prawdopodobieństwem bliskim 82 proc. możemy stwierdzić, iż losowo wybrany klient wydaje w danym hipermarkecie na żywność od 100 do 250 zł tygodniowo.
Przykład 2. Na podstawie danych z przykładu pierwszego należy obliczyć medianę oraz pierwszy i trzeci kwartyl tygodniowych wydatków na żyw-ność (w tym przypadku dystrybuantą teoretyczną jest dystrybuanta rozkła-du normalnego).
Jest to sytuacja odwrotna do prezentowanej w przykładzie poprzednim – najpierw odczytujemy wartości zmiennej z odpowiednio przy następują-cych prawdopodobieństwach:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
-3 -2 -1 0 1 2 3
( ) ( ) ( ) 8185,01587,09772,01221 =−=−−=≤<− FFZP
( ) ( ) 1587,08413,01111 =−=−=− FF
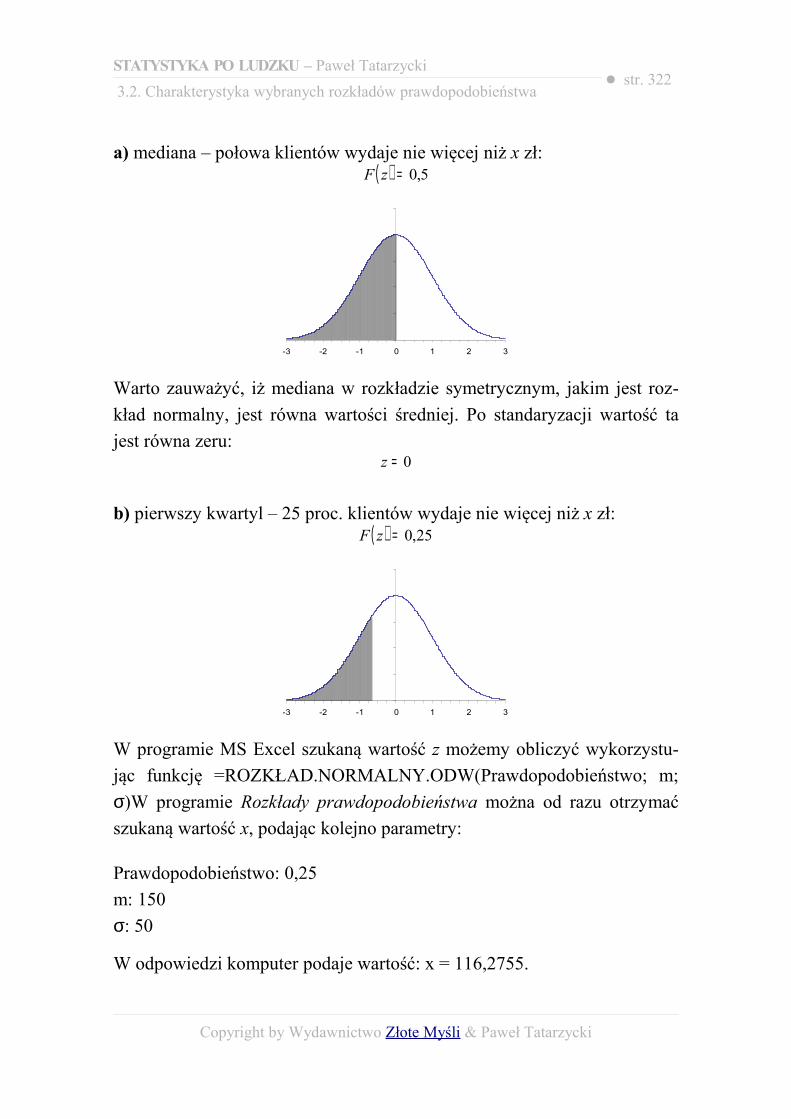
STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.2. Charakterystyka wybranych rozkładów prawdopodobieństwa
str. 322
a) mediana – połowa klientów wydaje nie więcej niż x zł:
Warto zauważyć, iż mediana w rozkładzie symetrycznym, jakim jest roz-kład normalny, jest równa wartości średniej. Po standaryzacji wartość ta jest równa zeru:
b) pierwszy kwartyl – 25 proc. klientów wydaje nie więcej niż x zł:
W programie MS Excel szukaną wartość z możemy obliczyć wykorzystu-jąc funkcję =ROZKŁAD.NORMALNY.ODW(Prawdopodobieństwo; m; σ)W programie Rozkłady prawdopodobieństwa można od razu otrzymać szukaną wartość x, podając kolejno parametry:
Prawdopodobieństwo: 0,25m: 150σ: 50
W odpowiedzi komputer podaje wartość: x = 116,2755.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( ) 5,0=zF
-3 -2 -1 0 1 2 3
0=z
( ) 25,0=zF
-3 -2 -1 0 1 2 3

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.2. Charakterystyka wybranych rozkładów prawdopodobieństwa
str. 323
W przypadku odczytu z „tradycyjnych” tablic dystrybuanty rozkładu nor-malnego (np. na egzaminie pisemnym ze statystyki) nie jest możliwy od-czyt wartości –z, lecz wartości do niej przeciwnej z. W tym celu korzysta-my z symetrii rozkładu normalnego:
W tablicach szukamy wartości najbliższej prawdopodobieństwu 0,75. Oto ich fragment:
Z ,_0 ,_1 ,_2 ,_3 ,_4 ,_5 ,_6 ,_7 ,_8 ,_90,0 0,5000 0,5040 0,5080 0,5120 0,5160 0,5199 0,5239 0,5279 0,5319 0,53590,1 0,5398 0,5438 0,5478 0,5517 0,5557 0,5596 0,5636 0,5675 0,5714 0,57530,2 0,5793 0,5832 0,5871 0,5910 0,5948 0,5987 0,6026 0,6064 0,6103 0,61410,3 0,6179 0,6217 0,6255 0,6293 0,6331 0,6368 0,6406 0,6443 0,6480 0,65170,4 0,6554 0,6591 0,6628 0,6664 0,6700 0,6736 0,6772 0,6808 0,6844 0,68790,5 0,6915 0,6950 0,6985 0,7019 0,7054 0,7088 0,7123 0,7157 0,7190 0,72240,6 0,7257 0,7291 0,7324 0,7357 0,7389 0,7422 0,7454 0,7486 0,7517 0,75490,7 0,7580 0,7611 0,7642 0,7673 0,7704 0,7734 0,7764 0,7794 0,7823 0,78520,8 0,7881 0,7910 0,7939 0,7967 0,7995 0,8023 0,8051 0,8078 0,8106 0,81330,9 0,8159 0,8186 0,8212 0,8238 0,8264 0,8289 0,8315 0,8340 0,8365 0,83891,0 0,8413 0,8438 0,8461 0,8485 0,8508 0,8531 0,8554 0,8577 0,8599 0,8621
Odczytujemy wartość z (wiersz oznacza dokładność do jednego miejsca po przecinku, zaś kolumna precyzuje dokładność do dwóch miejsc po przecin-ku):
Zatem szukana wartość -z wynosi w przybliżeniu -0,67.
Kolejną kwestią jest zamiana zestandaryzowanej wartości z na szukaną wartość x. Korzystamy ze wzoru na standaryzację:
Wyznaczamy x:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( ) ( )zFzF −−= 1
( ) 75,025,01 =−=zF
67,0≈z
σ
mxz ii
−=
mzx ii +⋅= σ

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.2. Charakterystyka wybranych rozkładów prawdopodobieństwa
str. 324
Podstawiamy do wzoru:
Co czwarty klient „zostawia” tygodniowo w hipermarkecie do 116,5 zł.
c) trzeci kwartyl – 75 proc. klientów wydaje nie więcej niż x zł:
Wartość z odczytano już w poprzednim podpunkcie:
W kroku drugim z przekształconego wzoru na standaryzację obliczamy wartość x:
W analizowanym hipermarkecie trzy czwarte klientów wydaje tygodniowo na żywność nie więcej niż 183,5 zł.
3.2.6. Rozkład t-Studenta
Zmienna losowa t ma rozkład t-Studenta, określony przez v = n – 1 stopni swobody, gdzie n oznacza liczbę obserwacji. Rozkład ten jest zbliżony do standaryzowanego rozkładu normalnego (dla niewielkich prób jest on nieco
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
5,1161505,331505067,0 =+−=+⋅−=Ix
( ) 75,0=zF
-3 -2 -1 0 1 2 3
67,0≈z
mzx ii +⋅= σ
5,1831505,331505067,0 =+=+⋅=IIIx

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.2. Charakterystyka wybranych rozkładów prawdopodobieństwa
str. 325
bardziej „płaski” od rozkładu normalnego). Wartości podstawowych para-metrów rozkładu t-Studenta są następujące (por. [9, s. 107]):
a) wartość oczekiwana:
b) odchylenie standardowe:
Wraz ze wzrostem wielkości próby n wartość odchylenia standardowego dąży do 1.
Na poniższym wykresie porównano funkcję gęstości rozkładu t-Studenta z funkcją gęstości standaryzowanego rozkładu normalnego.
Rysunek 3.7. Kształt funkcji gęstości rozkładu t-Studenta na tle funkcji gęstości rozkładu normalnego.
Źródło: Opracowanie własne.
Jak widać, dla dużych prób (zał. n > 30) kształt funkcji gęstości rozkładu t-Studenta niemal pokrywa się z kształtem funkcji gęstości standaryzowane-go rozkładu normalnego.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
0=m
31
−−=
nnσ
0
0,1
0,2
0,3
0,4
0,5
-7 -6 -5 -4 -3 -2 -1 0 1 2 3 4 5 6 7
Rozkład normalny
Rozkład t-Studenta (n = 5)
Rozkład t-Studenta (n = 10)

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.2. Charakterystyka wybranych rozkładów prawdopodobieństwa
str. 326
Rozkład t-Studenta jest stablicowany (zob. Tablice rozkładu t-Studenta). W niniejszej publikacji przyjęto wariant „dwustronny” – dla danego pozio-mu istotności α i n – 1 stopni swobody następuje odczyt wartości tα co do wartości bezwzględnej (por. [9, s. 107-108]):
Rysunek 3.8. Sposób odczytywania wartości krytycznej dla dwustronnego rozkładu t-Studenta.
Źródło: Opracowanie własne.
Wartość prawdopodobieństwa interpretowana jest tu jako łączna po-wierzchnia pól pod funkcją gęstości rozkładu t-Studenta:
Oto dwa przykłady ukazujące sposób posługiwania się tablicami rozkładu t-Studenta:
Przykład 1. Dla n = 8 obserwacji należy znaleźć taką wartość graniczną tα, przy której pole obszaru pod funkcją gęstości rozkładu t-Studenta w prze-dziale (–tα, tα) wynosi 0,9.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
ααα =+
22

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.2. Charakterystyka wybranych rozkładów prawdopodobieństwa
str. 327
Pole obszaru w przedziale (-tα, tα) oznaczamy jako 1 – α:
Stąd wyznaczamy poziom istotności α:
Dla v = 8 – 1 = 7 stopni swobody i obliczonego poziomu istotności α = 0,1 z tablic rozkładu t-Studenta odczytujemy wartość graniczną (krytyczną). Oto fragment tych tablic:
0,005 0,01 0,02 0,05 0,1 0,2 0,9 0,95 0,99 0,9951 127,32 63,655931,821012,7062 6,3137 3,0777 0,1584 0,0787 0,0157 0,00792 14,0892 9,9250 6,9645 4,3027 2,9200 1,8856 0,1421 0,0708 0,0141 0,00713 7,4532 5,8408 4,5407 3,1824 2,3534 1,6377 0,1366 0,0681 0,0136 0,00684 5,5975 4,6041 3,7469 2,7765 2,1318 1,5332 0,1338 0,0667 0,0133 0,00675 4,7733 4,0321 3,3649 2,5706 2,0150 1,4759 0,1322 0,0659 0,0132 0,00666 4,3168 3,7074 3,1427 2,4469 1,9432 1,4398 0,1311 0,0654 0,0131 0,00657 4,0294 3,4995 2,9979 2,3646 1,8946 1,4149 0,1303 0,0650 0,0130 0,0065
tα = 1,8946
Szukany przedział wartości to (–1,8946; 1,8946).
Przykład 2. W oparciu o dane z powyższego przykładu należy wyznaczyć wartość prawdopodobieństwa dla wartości tα > 2,36.
Najpierw z dwustronnego rozkładu t-Studenta odczytujemy wartość α:
Następnie otrzymane prawdopodobieństwo dzielimy przez 2 – interesuje nas jedynie połowa odczytanego łącznego pola (zob. rys. 3.8):
Prawdopodobieństwo tego, że zmienna t > 2,36, wynosi 0,025.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
9,01 =− α
1,09,01 =−=α
( ) 1,0|| =≥ αttP
α
v
( ) α=≥ 36,2|| tP
05,0=α
( ) 025,0205,0
236,2 ===> αtP

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.2. Charakterystyka wybranych rozkładów prawdopodobieństwa
str. 328
3.2.7. Rozkład chi-kwadrat
Rozkład chi-kwadrat (χ2) jest rozkładem prawdopodobieństwa sumy kwa-dratów niezależnych zmiennych losowych o standaryzowanym rozkładzie normalnym (por. [1, s. 244]):
Zmienna losowa χ2 ma rozkład całkowicie zależny od liczby stopni swobo-dy v = n, gdzie n oznacza liczebność próby. Dla niewielkiej liczby stopni swobody jest to rozkład silnie asymetryczny. Jednak przy wzrastającej li-czebności próby ciąg dystrybuant tego rozkładu jest szybko zbieżny do cią-gu dystrybuant rozkładu normalnego. Wartość oczekiwana i odchylenie standardowe rozkładu chi-kwadrat wynoszą odpowiednio [8, s. 70-71]:
Rozkład chi-kwadrat – podobnie jak rozkład normalny i rozkład t-Studenta – jest stablicowany. Wartość krytyczną odczytuje się dla określonej liczby stopni swobody v oraz ustalonego poziomu istotności α z tablic rozkładu chi-kwadrat:
Sposób odczytywania wartości krytycznej z tablic rozkładu chi-kwadrat w ujęciu graficznym przedstawia się następująco:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
∑
==
n
inX
1
22χ
( )1,0~ NX n
nm =
n2=σ
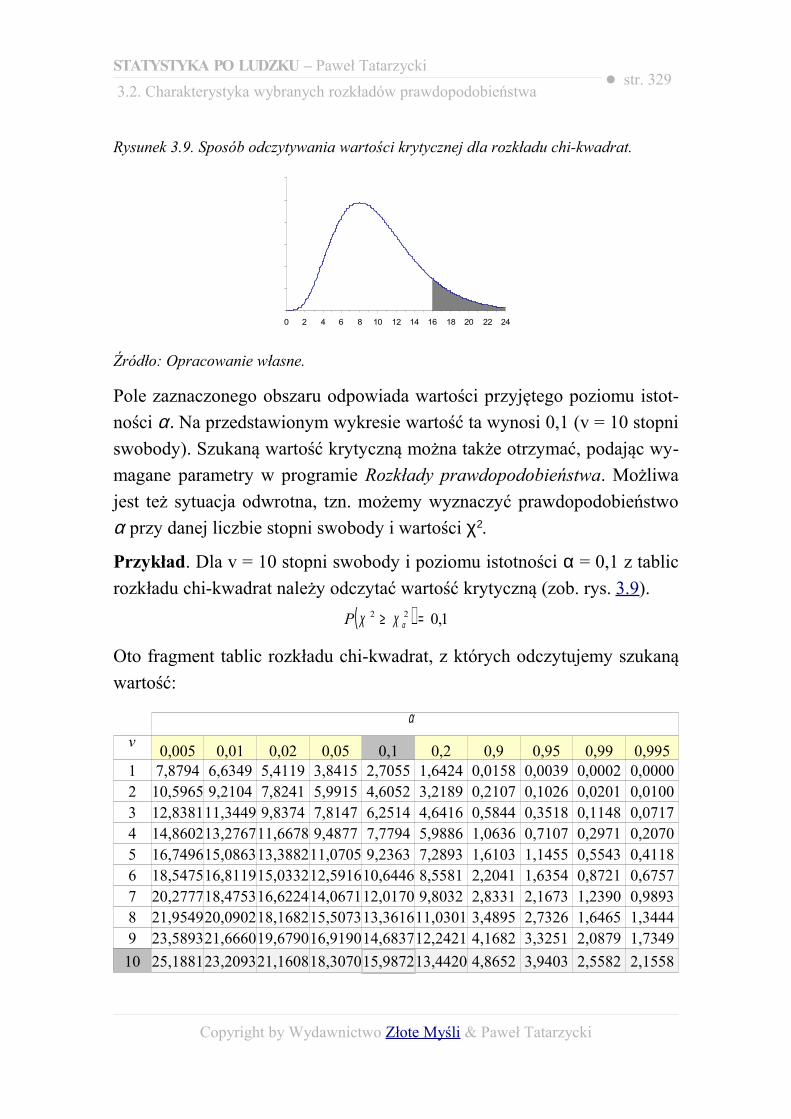
STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.2. Charakterystyka wybranych rozkładów prawdopodobieństwa
str. 329
Rysunek 3.9. Sposób odczytywania wartości krytycznej dla rozkładu chi-kwadrat.
Źródło: Opracowanie własne.
Pole zaznaczonego obszaru odpowiada wartości przyjętego poziomu istot-ności α. Na przedstawionym wykresie wartość ta wynosi 0,1 (v = 10 stopni swobody). Szukaną wartość krytyczną można także otrzymać, podając wy-magane parametry w programie Rozkłady prawdopodobieństwa. Możliwa jest też sytuacja odwrotna, tzn. możemy wyznaczyć prawdopodobieństwo α przy danej liczbie stopni swobody i wartości χ2.
Przykład. Dla v = 10 stopni swobody i poziomu istotności α = 0,1 z tablic rozkładu chi-kwadrat należy odczytać wartość krytyczną (zob. rys. 3.9).
Oto fragment tablic rozkładu chi-kwadrat, z których odczytujemy szukaną wartość:
0,005 0,01 0,02 0,05 0,1 0,2 0,9 0,95 0,99 0,9951 7,8794 6,6349 5,4119 3,8415 2,7055 1,6424 0,0158 0,0039 0,0002 0,00002 10,5965 9,2104 7,8241 5,9915 4,6052 3,2189 0,2107 0,1026 0,0201 0,01003 12,838111,3449 9,8374 7,8147 6,2514 4,6416 0,5844 0,3518 0,1148 0,07174 14,860213,276711,6678 9,4877 7,7794 5,9886 1,0636 0,7107 0,2971 0,20705 16,749615,086313,388211,0705 9,2363 7,2893 1,6103 1,1455 0,5543 0,41186 18,547516,811915,033212,591610,6446 8,5581 2,2041 1,6354 0,8721 0,67577 20,277718,475316,622414,067112,0170 9,8032 2,8331 2,1673 1,2390 0,98938 21,954920,090218,168215,507313,361611,0301 3,4895 2,7326 1,6465 1,34449 23,589321,666019,679016,919014,683712,2421 4,1682 3,3251 2,0879 1,734910 25,188123,209321,160818,307015,987213,4420 4,8652 3,9403 2,5582 2,1558
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
0 2 4 6 8 10 12 14 16 18 20 22 24
( ) 1,022 =≥ αχχP
α
v

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.2. Charakterystyka wybranych rozkładów prawdopodobieństwa
str. 330
Dla przyjętego poziomu istotności szukana wartość wynosi w przybliżeniu 16.
3.2.8. Rozkład F
Rozkład F jest rozkładem ilorazu dwóch niezależnych zmiennych loso-wych χ2, podzielonych przez odpowiadającą im liczbę stopni swobody (por. [1, s. 375]):
Rozkład F znajduje zastosowanie np. w testowaniu hipotezy statystycznej o równości wariancji. Jest on stablicowany. Odczyt wartości krytycznej z tablic rozkładu F (w tej publikacji wartość tę znajduje program Rozkłady prawdopodobieństwa) jest analogiczny, jak w przypadku rozkładu chi-kwa drat :
Rysunek 3.10. Sposób odczytywania wartości krytycznej dla rozkładu F.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
9872,152 =αχ
STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.2. Charakterystyka wybranych rozkładów prawdopodobieństwa
str. 331
Źródło: Opracowanie własne.
Różnica polega na tym, że – obok poziomu istotności – należy podać stop-nie swobody dla dwóch prób o liczebnościach n1 i n2. Stopnie swobody wy-znaczamy następująco:
Przykład. Na podstawie ankiet przeprowadzonych wśród n1 = 6 kobiet oraz n2 = 13 mężczyzn określono miesięczne wydatki celem porównania zmienności tych wydatków. Na tym etapie należy wyznaczyć wartość kry-tyczną Fα na poziomie istotności α = 0,05.
Najpierw obliczamy stopnie swobody:
Posługując się programem Rozkłady prawdopodobieństwa z łatwością mo-żemy wyznaczyć wartość krytyczną (zob. rys. 3.10 – ilustracja graficzna te-go przykładu). Wprowadzamy dane (Rozkład F odwrotny): v1 = 5, v2 = 12 oraz α = 0,05. Oto wynik:
Fα = 3,1059
Szukana wartość krytyczna to 3,1.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
0 1 2 3 4
111 −= nv
122 −= nv
516111 =−=−= nv
12113122 =−=−= nv

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.2. Charakterystyka wybranych rozkładów prawdopodobieństwa
str. 332
3.2.9. Twierdzenia graniczne
Jak wyżej wspomniano, dla dużych prób rozkład t-Studenta jest niemal identyczny jak standaryzowany rozkład normalny. Również asymetryczny rozkład chi-kwadrat, w miarę wzrostu liczebności próby, zmierza do roz-kładu normalnego. Z rozkładem normalnym związane są ponadto dwa waż-ne twierdzenia graniczne, a mianowicie:
1. Integralne twierdzenie Moivre’a-Laplace’a.2. Centralne twierdzenie graniczne Lindberga-Levy’ego.
Na mocy integralnego twierdzenia granicznego Moivre’a-Laplace’a dla znacznej liczby prób (zał. n > 30) rozkład dwumianowy zmiennej losowej X można przybliżyć rozkładem normalnym. Wówczas:
Centralne twierdzenie graniczne Lindberga-Levy’ego mówi o zbieżności sumy niezależnych zmiennych losowych o tym samym rozkładzie (nie mu-szą to być rozkłady znane) do rozkładu normalnego.
Poniższe przykłady ukazują praktyczne zastosowanie wprowadzonych twierdzeń granicznych:
Przykład 1. Test wielokrotnego wyboru liczy 48 pytań. Spośród czterech możliwych opcji tylko jedna odpowiedź jest prawidłowa (sprawdzający przyznają jeden punkt za dobrze zaznaczoną odpowiedź lub nie przyznają żadnego, gdy odpowiedź jest zła). Należy obliczyć prawdopodobieństwo tego, że student, zaznaczający odpowiedzi na „chybił-trafił”, udzieli mniej niż 40 proc. poprawnych odpowiedzi.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( )( )pnpnpNX n −⋅ 1,~
∑
==
n
inn XY
1
( )nnmNYn σ,~

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.2. Charakterystyka wybranych rozkładów prawdopodobieństwa
str. 333
Ponieważ liczba pytań testu jest duża (n > 30), to rozkład dwumianowy możemy przybliżyć rozkładem normalnym. Wypisujemy dane (por. Roz - kład dwumianowy):
n = 48 obserwacji,p = 0,25 (prawdopodobieństwo sukcesu),k < 0,4 × 48 = 19,2 (maksymalna liczba sukcesów to 19 poprawnych odpo-wiedzi).
Zmienna losowa X ma rozkład normalny o parametrach:
Obliczamy prawdopodobieństwo tego, że student wskaże nie więcej niż 19 poprawnych odpowiedzi (mniej niż 40 proc.):
Po dokonaniu standaryzacji zmiennej X, z tablic dystrybuanty rozkładu normalnego odczytujemy szukane prawdopodobieństwo:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( )( )pnpnpNX n −⋅ 1,~
( )( )25,0125,048,25,048~48 −⋅⋅⋅NX
( )3,12~ NX n
( ) ( )33,23
121919 ≤=
−≤=≤ ZPZPXP
-3 -2 -1 0 1 2 3
( ) ( ) 9901,033,233,2 ==≤ FZP

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.2. Charakterystyka wybranych rozkładów prawdopodobieństwa
str. 334
Prawdopodobieństwo tego, że student losowo wskaże mniej niż 40 proc. poprawnych odpowiedzi, wynosi 99 proc.
Przykład 2. Firma ogrodnicza zajmuje się sprzedażą arbuzów, które skła-dowane są w skrzyniach o przeciętnej wadze 50 kg. Waga skrzyni (kg) ma rozkład normalny o parametrach:
Jakie jest prawdopodobieństwo tego, że łączna waga stu losowo wybranych skrzyń przekroczy 5050 kg?
Zmienna losowa Y, będąca sumą stu niezależnych zmiennych losowych X, ma rozkład:
Dokonujemy standaryzacji, korzystamy ze wzoru na dopełnienie prawdo-podobieństw i odczytujemy wartość dystrybuanty rozkładu normalnego w punkcie 1,66:
Prawdopodobieństwo tego, że waga łączna stu losowo wybranych skrzyń przekroczy 5050 kg, wynosi ok. 5 proc.
3.3. Dobór próby
Elementarnym zagadnieniem statystyki jest pojęcie próby. Próba to pod-zbiór elementów populacji generalnej podlegających badaniu. Innymi sło-wy, jest to liczebność jednostek badania [5, s. 19]. Kwestię określania
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( )3,50~ NX
( )1003,50100~100 ⋅⋅NY
( )30,5000~100 NY
( ) ( ) ( ) 05,09515,0166,1166,130
500050505050100 ≈−=−=>=
−>=> FZPZPYP

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.3. Dobór próby
str. 335
minimalnej liczebności próby przedstawiono w podrozdziale Estymacja przedziałowa. W tym miejscu dokonano omówienia wybranych metod do-boru próby. Podział metod doboru próby prezentuje schemat:
Rysunek 3.11. Klasyfikacja metod doboru jednostek statystycznych do próby.
Źródło: Opracowanie na podstawie [20, s. 30].
Istnieją dwa zasadnicze sposoby doboru jednostek statystycznych do pró-by:
1. Dobór losowy.2. Dobór celowy.
Wnioskowanie statystyczne ma zastosowanie jedynie w przypadku losowe-go doboru próby (zob. metoda reprezentacyjna). Poniżej dokonano ogólnej charakterystyki wybranych metod losowego doboru próby. Losowy dobór próby to taki sposób wyboru, przy którym są spełnione dwa następujące warunki [5, s. 20]:
1. Każda jednostka populacji generalnej ma dodatnie znane prawdopodo-bieństwo znalezienia się w próbie.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.3. Dobór próby
str. 336
2. Istnieje możliwość ustalenia prawdopodobieństwa znalezienia się w próbie dla każdego zespołu elementów populacji.
W wyniku doboru losowego otrzymujemy próbę losową. Aby otrzymać próbę losową, należy określić tzw. operat losowania, czyli wykaz wszyst-kich elementów populacji. Wykaz ten pozwala wybierać elementy z popu-lacji poprzez losowe generowanie numerów elementów, które znajdą się w próbie (por. [1, s. 192]).
Rozróżnia się dwa zasadnicze schematy losowego doboru próby [8, s. 47-48]:
1. Schemat losowania niezależnego – każde pojedyncze losowanie odbywa się z takiej samej zbiorowości statystycznej, stąd dana jednostka staty-styczna może się znaleźć w próbie więcej niż jeden raz (stałe prawdopo-dobieństwo wylosowania danej obserwacji).
2. Schemat losowania zależnego – w każdym kolejnym losowaniu nie bie-rze się pod uwagę jednostki uprzednio wylosowanej – jest ona „wyklu-czana”. Wynika z tego, że w próbie dana jednostka statystyczna może znaleźć się tylko raz (prawdopodobieństwo wylosowania danej jednost-ki zmienia się podczas losowania).
Powyższy podział ma istotne znaczenie z punktu stosowanych metod wnio-skowania statystycznego (niejednokrotnie jest poczynione założenie o loso-waniu niezależnym).
Wśród metod losowego doboru próby wyróżnia się (zob. rys. 3.11):
– metodę warstwową,– metodę wielostopniową,– dobór losowy prosty.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.3. Dobór próby
str. 337
Metoda warstwowa znajduje zastosowane w przypadku niejednorodnych populacji statystycznych (zob. tabela 1.3), gdzie możliwy jest podział na rozłączne podpopulacje, określane w tej metodzie warstwami. Istotne jest to, że n-elementowa próba uzyskana w wyniku zastosowania omawianej metody powinna uwzględniać strukturę liczebności (wagi) warstw popula-cji. Wagę dla i–tej warstwy oblicza się według wzoru (por. [1, s. 920]):
Liczbę jednostek statystycznych pobranych z i-tej warstwy obliczamy na-stępująco:
Dobór jednostek statystycznych do próby w ramach poszczególnych warstw jest losowy (zob. dobór losowy prosty).
Przykład 1. W ramach egzaminu ze statystyki studenci mają rozwiązać 10 zadań z czterech działów tematycznych: statystyka opisowa, analiza regre-sji, analiza szeregów czasowych oraz wnioskowanie statystyczne. Egzami-natorzy przygotowali 200 zadań, w tym:
a) statystyka opisowa: N1 = 80 zadań,b) analiza regresji: N2 = 40 zadań,c) analiza szeregów czasowych: N3 = 20 zadań,d) wnioskowanie statystyczne: N4 = 60 zadań.
Dysponując liczebnościami poszczególnych warstw, możemy określić na-stępujące wagi (zob. Przykłady – losowy dobór próby; zakładka: losowanie warstwowe):
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.3. Dobór próby
str. 338
Następnie wagi przemnażamy przez ogólną liczebność próby (n = 10 za-dań), określając w ten sposób liczebności zadań, które losowo zostaną wy-brane w ramach poszczególnych działów tematycznych (warstw):
Zadania podzielono proporcjonalnie do liczby zadań przygotowanych w ra-mach poszczególnych działów – na egzaminie pojawi się najwięcej zadań ze statystyki opisowej.
Przykład 2. Firma kosmetyczna zamierza przeprowadzić badanie staty-styczne wśród Polaków w wieku 18-25 lat w celu porównania kryteriów, jakimi kierują się przy wyborze kosmetyków kobiety i mężczyźni. Z uwagi na ograniczone nakłady na badania marketingowe, zarząd zamierza prze-prowadzić 500 ankiet. Należy określić sposób doboru próby.
W tym przypadku objęta badaniem statystycznym zbiorowość nie jest jed-norodna ze względu na płeć – możemy wyróżnić dwie podpopulacje (war-stwy): kobiet i mężczyzn. Należy zauważyć, iż nie jest możliwe w oparciu o dostarczone dane określenie wag dla poszczególnych warstw, jak miało
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
4,0
200801
1 ===NNw
2,0
200402
2 ===NNw
1,0
200203
3 ===NNw
3,0
200604
4 ===NNw
4104,011 =⋅=⋅= nwn
2102,022 =⋅=⋅= nwn
1101,033 =⋅=⋅= nwn
3103,044 =⋅=⋅= nwn

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.3. Dobór próby
str. 339
to miejsce w przykładzie pierwszym. Ponieważ w przybliżeniu połowę populacji stanowią kobiety, stąd przyjmujemy wagi na poziomie 0,5.
Zatem należy przeprowadzić połowę ankiet wśród kobiet i połowę wśród mężczyzn. W kroku drugim wybieramy losowo po 250 respondentów z jednej i drugiej warstwy.
Dobór losowy prosty stanowi grupę metod, które można zastosować przy wyborze jednostek z populacji niejednorodnej w ramach poszczególnych warstw (zob. losowanie warstwowe), jak również w przypadku pozostałych zbiorowości statystycznych, gdzie określono operat losowania. Podstawo-wym schematem losowania w ramach doboru prostego jest losowanie pro-ste (zob. rys. 3.11), w wyniku którego otrzymuje się tzw. próbę prostą (jest to ważne pojęcie niejednokrotnie pojawiające się w statystyce matematycz-nej). W losowaniu prostym każdy z N elementów populacji posiada jedna-kowe stałe prawdopodobieństwo znalezienia się w próbie (por. [5, s. 20]):
Fakt, że wszystkie jednostki statystyczne z jednakowym prawdopodobień-stwem mogą znaleźć się w próbie, to szczególny przypadek, który można opisać za pomocą rozkładu jednostajnego (zob. Przykłady – generowanie liczb pseudolosowych). Funkcja gęstości tego rozkładu ma postać:
Graniczne wartości przedziału [a, b] określamy następująco:
a = 0,b = N (liczebność elementów operatu losowania).
Wówczas dystrybuanta rozkładu jednostajnego będzie miała postać:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
N
p 1=
( )Nab
xf 11 =−
=
( )Nx
abaxxF =
−−=

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.3. Dobór próby
str. 340
I tak: pierwszy element z ponumerowanej listy zostanie wybrany wówczas, gdy wartość dystrybuanty będzie mniejsza bądź równa 1/N, drugi element: dla wartości z przedziału (1/N; 2/N], trzeci: (2/N; 3/N] itd. Zakładając, że wartości funkcji LOS() są dystrybuantą rozkładu jednostajnego, wyprowa-dzono wzór:
W praktyce otrzymaną wartość x należy zaokrąglić w górę do najbliższej liczby całkowitej, będącej numerem obserwacji wybranej z listy od 1 do N.
Przykład. Egzaminator spośród przygotowanych 20 zadań z analizy szere-gów czasowych musi losowo wybrać jedno na egzamin (zob. losowanie warstwowe – przykład 1). W tym celu chce posłużyć się schematem loso-wania prostego.
Prawdopodobieństwo znalezienia się każdego zadania w próbie wynosi:
Krok 1. Określamy operat losowania – w tym przypadku jest to lista zadań ponumerowanych od 1 do 20 (zob. Przykłady – losowy dobór próby; za-kładka: losowanie proste).
Krok 2. Generujemy losowo liczbę z przedziału od 0 do 1. W tym celu posłużymy się funkcją LOS(). Załóżmy, że otrzymana wartość wynosi 0,514.
Krok 3. Stosujemy przekształcenie według wyprowadzonego wyżej wzoru:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( ) aablosx +−⋅= ()
Nlosx ⋅= ()
05,0
2011 ===
np
Nlosx ⋅= ()
1128,1020514,0 ≈=⋅=x

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.3. Dobór próby
str. 341
Otrzymany wynik po zaokrągleniu w górę to numer zadania, które należy wybrać z przygotowanej listy potencjalnych zadań egzaminacyjnych.
Dobór losowy prosty za pomocą liczb losowych pozwala na wybór jedno-stek do próby według dowolnego – a nie tylko przedstawionego powyżej, jednostajnego – rozkładu prawdopodobieństwa. Zaawansowanym narzę-dziem Excela – domyślnie niedostępnym – jest aplikacja Generowanie liczb pseudolosowych, posiadająca szereg wbudowanych rozkładów praw-dopodobieństwa i pozwalająca określić dowolny rozkładu prawdopodo-bieństwa dla cechy skokowej (zob. animacja Excel_generowanie_liczb_ pseudolosowych). Przykładowo, zadaniom z listy można nadać wagi w za-leżności od ich stopnia trudności. Dzięki temu prawdopodobieństwo poja-wienia się zadań trudniejszych, bardziej złożonych jest większe (zob. Przy-kłady – generowanie liczb pseudolosowych).
W przypadku uporządkowanej zbiorowości (np. ranking funduszy inwesty-cyjnych) zastosowanie znajduje dobór losowy systematyczny. Metoda ta polega na tym, że losuje się tylko jedną jednostkę statystyczną, a pozostałe dobiera się w taki sposób, aby między jednostką wylosowaną a następną znajdował się stały odstęp (por. [20, s. 31]). Odstęp k pomiędzy losowany-mi obserwacjami można określić za pomocą wzoru (por. [1, s. 937]):
W tej sytuacji N-elementową populację podzielimy na n mniejszych grup (podpopulacji) – pierwszą obserwację będziemy losować z pierwszej pod-populacji, a następnie do próby wybierzemy co k-tą jednostkę statystyczną. W praktyce jako wartość k należy przyjąć najbliższą liczbę całkowitą wyniku dzielenia N/n (por. [1, s. 937]).
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
knn ii +=+ 1

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.3. Dobór próby
str. 342
Przykład. Spośród 40 zadań z analizy regresji wykładowca ma wybrać lo-sowo na egzamin dwa. Ponieważ zadania są ułożone od najłatwiejszych do najtrudniejszych, stąd zamierza posłużyć się losowaniem systematycznym. Przyjęty schemat losowania pozwoli na wybór zadania łatwiejszego i bar-dziej złożonego.
Dobór jednostek do próby (n = 2 zadania) przebiega w następujących kro-kach (zob. Przykłady – losowy dobór próby; zakładka: losowanie systema-tyczne):
Krok 1. Określenie listy ponumerowanych zadań od 1 do 40.
Krok 2. Obliczenie wartości odstępu k i podział zbiorowości na dwie pod-populacje:
Podział obejmuje dwie grupy zadań – zadania od 1 do 20 oraz od 21 do 40 włącznie.
Krok 3. Wylosowanie pierwszego zadania z grupy zadań od 1 do 20 metodą losowania prostego. Załóżmy, że wylosowano zadanie nr 11.
Krok 4. Wybór drugiego zadania z grupy zadań od 21 do 40:
Zgodnie ze schematem losowania systematycznego – na egzamin wybrane zostanie jedno zadanie łatwiejsze (nr 11) oraz zadanie o relatywnie wyż-szym stopniu trudności (nr 31).
Kolejnym schematem losowego doboru próby jest dobór losowy wielo-stopniowy, określany też losowaniem zespołowym. Metoda ta znajduje za-stosowanie, gdy daną populację można podzielić kolejno na mniejsze gru-
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
20
240 ===
nNk
31201112 =+=+= knn

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.3. Dobór próby
str. 343
py (stopnie losowania). W ten sposób tworzy się kolejne „warstwy w war-stwach” i losuje jednostki statystyczne proporcjonalnie do liczebności po-szczególnych warstw [20, s. 32]. W tym miejscu warto podkreślić różnice pomiędzy losowaniem wielostopniowym a losowaniem warstwowym:
Tabela . Losowanie wielostopniowe a losowanie warstwowe.
Losowanie warstwowe Losowanie wielostopniowe1. Losowanie elementów każdej warstwy
– jednostki statystyczne z każdej warstwy są w pełni reprezentowane w próbie losowej.
Losowanie elementów tylko z wybranych zespołów (mogą to być zespoły jednorodne w postaci warstw) – nie wszystkie warstwy są reprezentowane w próbie.
2. Podział populacji na podgrupy (warstwy) prowadzi na ogół do mniejszej wariancji estymatorów (zob. estymacja przedziałowa), tj. zwiększa precyzję wnioskowania statystycznego.
Podstawowym celem podział populacji generalnej na podgrupy jest ułatwienie doboru próby i zmniejszenie kosztów z tym związanych – wyniki estymacji nie są bardziej precyzyjne.
Źródło: Opracowanie własne na podstawie: [1, s. 934].
Metoda doboru losowego wielostopniowego jest szczególnie użyteczna w przypadku dużych populacji. Np. w badaniach marketingowych najpierw losowane jest województwo, zaś w następnym etapie można dokonać loso-wego wyboru respondentów według poszczególnych miast wojewódzkich (wagi powinny odpowiadać liczbie ludności).
Drugą grupę metod doboru próby stanowią metody doboru celowego. Na-leżą do nich m.in. (por. [20, s. 33]):
– metoda doboru jednostek typowych,– metoda eliminacji,– metoda doboru proporcjonalnego (kwotowego).
Metoda doboru jednostek typowych polega na wyborze do próby jedno-stek uważanych za charakterystyczne dla danej zbiorowości, tj. jednostki przeciętne (np. w badaniu jakości kształcenia należałoby w tym przypadku
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.3. Dobór próby
str. 344
„wykluczyć” prymusa). Metoda ta dostarcza ogólnych informacji o popula-cji generalnej. Interpretacja wyników analizy jest możliwa jedynie w przy-padku niektórych aspektów kształtowania się cech. Stąd metoda doboru jednostek typowych znajduje zastosowanie w przypadku badań wstępnych.
Metoda eliminacji uwzględnia w doborze jednostek statystycznych do próby zjawisko koncentracji. Najwięcej jednostek statystycznych pochodzi z grup, w których koncentruje się największa liczba obserwacji o interesu-jących cechach – eliminuje się zatem jednostki nieistotne z punktu widze-nia celu badania statystycznego.
Metoda doboru proporcjonalnego – w metodzie tej na wstępie dokonuje się podziału zbiorowości statystycznej na określone grupy. Jednak – w przeciwieństwie do metody warstwowej – doboru jednostek statystycz-nych wewnątrz wydzielonych grup dokonuje się subiektywnie, a nie w spo-sób losowy.
W następnym podrozdziale – na gruncie teorii estymacji – poruszono kwe-stię minimalnej liczebności próby.
3.4. Estymacja przedziałowa
Na wstępie należy rozróżnić pojęcie parametru zbiorowości generalnej, którego wartość jest z reguły nieznana, od estymatora tego parametru. Es-tymator (statystyka) to „miara opisowa pochodząca z n-elementowej pró - by losowej” [21, s. 28]. W tej sytuacji możemy mówić o tzw. estymacji punktowej, której celem jest oszacowanie wartości parametrów z populacji generalnej na podstawie pobranej próby losowej. W poniższej tabeli zesta-wiono punktowe estymatory następujących parametrów:
– średniej arytmetycznej,– odchylenia standardowego,
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.4. Estymacja przedziałowa
str. 345
– wskaźnika struktury w populacji (frakcji). Tabela 3.4. Estymatory punktowe wybranych parametrów w populacji generalnej.
Parametr populacji generalnej Estymatory
Średnia arytmetyczna (wartość oczekiwana)
Odchylenie standardowe
mała próba (n < 30):
duża próba:
Wskaźnik struktury (frakcja)
Źródło: Opracowanie własne.
W tym podrozdziale przedstawiony zostanie drugi sposób estymacji, a mia-nowicie estymacja przedziałowa. Estymacja przedziałowa polega na sza-cowaniu wartości parametru populacji generalnej z wykorzystaniem tzw. przedziału ufności. Przedział ten pokrywa nieznaną wartość szacowanego parametru z określonym z góry prawdopodobieństwem 1 – α, zwanym po-ziomem istotności bądź współczynnikiem ufności (por. [11, s. 260]).
Ważną własnością estymatorów wartości wymienionych w tabeli 3.4. jest zbieżność do rozkładu normalnego przy wzrastającej liczebności próby – dla dużych prób rozkład estymatora w próbie jest zbliżony do rozkładu nor-malnego (por. [21, s. 230]). Opierając się na tej zależności w dalszej części tego rozdziału wyznaczono przedziały ufności dla wartości przeciętnej m, wskaźnika struktury p oraz odchylenia standardowego σ. W tej publikacji wyznaczono jedynie przedziały ufności przy założeniu dużej próby losowej (zał. n ≥ 30).
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( )
1ˆ 1
2
−
−=
∑=
n
xxs
n
ii
( )
n
xxs
n
ii∑
=
−= 1
2
nkp =ˆ
n
xx
n
ii∑
== 1
σ
m
p

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.4. Estymacja przedziałowa
str. 346
3.4.1. Przedział ufności dla wartości przeciętnej
Na mocy centralnego twierdzenia granicznego Lindberga-Levy’ego rozkład wartości średniej z próby jest zbieżny do rozkładu normalnego o następujących parametrach:
Z powyższego wynika, że wartość oczekiwana średniej z próby jest równa wartości oczekiwanej badanej cechy w populacji (m). Natomiast odchyle-nie standardowe średniej arytmetycznej z próby maleje do zera wraz ze wzrostem liczebności próby (por. [19, s. 133]).
Punktem wyjścia do wyprowadzenia przedziału ufności dla średniej aryt-metycznej w populacji (duża próba) jest standaryzacja średniej z próby (por. [8, s. 57]):
Z powyższego równania wyznaczamy dolną i górną granicę przedziału uf-ności:
1. Dolna granica przedziału ufności:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
nmNx σ,~
ασ −=
<−<− 1z
n
mxzP
n
z
n
mx σσ ×<−
n
zmx σ⋅<−
m
nzx <⋅− σ

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.4. Estymacja przedziałowa
str. 347
2. Górna granica przedziału ufności:
W rezultacie dwustronny przedział ufności dla wartości średniej m – przy założeniu, że mamy do czynienia z dużą próbą losową – jest następujący (por. [11, s. 262]):
a) znane odchylenie standardowe w populacji σ:
b) nieznane odchylenie standardowe w populacji (σ ≈ s):
Wartość krytyczną z należy odczytać z tablic dystrybuanty rozkładu nor - malnego (lub skorzystać np. z dodatku Rozkłady prawdopodobieństwa), przy czym wartość dystrybuanty w punkcie z jest określona następująco:
Oto prezentacja graficzna przedziału ufności dla poziomu ufności 1 – α: :
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
n
n
mxz σσ ×−<−
mx
nz −<⋅− σ
n
zxm σ⋅+<
( )2
1 α−=zF

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.4. Estymacja przedziałowa
str. 348
Rysunek 3.12. Prezentacja graficzna dwustronnego przedziału ufności (duża próba).
Źródło: Opracowanie własne.
Połowę długości przedziału ufności stanowi tzw. maksymalny błąd sza-cunku, który w przypadku wartości średniej – dla dużej próby – wyraża się wzorem (por. [11, s. 263]):
Podstawiając do wzoru na przedział ufności dla wartości przeciętnej, otrzy-mamy przejrzystą postać tego przedziału:
Im mniejszy maksymalny błąd szacunku, tym większa dokładność oszaco-wania (zmniejsza się bowiem długość przedziału ufności 1 – α pokrywają-cego nieznany parametr). Dokładność ta zależy od trzech parametrów:
1. Przyjęty poziom ufności – im wyższy, tym mniejsza dokładność (przy danym poziomie pozostałych czynników).
2. Liczba obserwacji – dokładność oszacowania jest tym większa, im licz-niejsza próba (na poziomie istotności 1 – α).
3. Zmienność wartości cechy mierzona odchyleniem standardowym – po-ziom tego parametru w pewnym stopniu można zmniejszyć, dobierając
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( ) α−=+<<− 1xx dxmdxP

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.4. Estymacja przedziałowa
str. 349
odpowiedni schemat losowania jednostek statystycznych do próby (zob. Dobór próby).
Kolejną kwestią jest zagadnienie minimalnej wielkości próby. Minimalną liczebność próby niezbędną do oszacowania wartości przeciętnej m nie-trudno wyznaczyć ze wzoru na maksymalny błąd szacunku:
Po przekształceniach otrzymujemy wzór na obliczanie minimalnej wielko-ści próby:
W praktyce wartość n obliczona według powyższego wzoru nie jest liczbą całkowitą, stąd należy pamiętać o zaokrągleniu w górę do najbliższej liczby całkowitej. Minimalna liczebność próby zależy od przyjętego poziomu uf-ności 1 – α i z góry określonej wartości dopuszczalnego błędu szacunku.
Przykład 1. Na poziomie ufności 1 – α = 0,9 należy wyznaczyć przedział ufności na wartość wydatków przypadających na jednego klienta pewnego sklepu internetowego. Właściciel sklepu przeanalizował w tym celu 50 lo-sowo wybranych transakcji, z których wynika, że średnio internauci zaku-pili produkty na kwotę 140 zł +/– 20 zł.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
n
nszdx ×⋅=
xx dsznd ⋅=
2
xdszn ⋅=
2
⋅=xdszn

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.4. Estymacja przedziałowa
str. 350
Krok 1. Wypisujemy dane:
a) wielkość próby:
b) poziom ufności:
c) średnia arytmetyczna z próby:
d) odchylenie standardowe z próby:
Krok 2. Z tablic dystrybuanty rozkładu normalnego odczyt wartości z (α = 0,1):
Krok 3. Obliczamy maksymalny błąd szacunku:
Krok 4. Wyznaczamy przedział ufności dla wartości przeciętnej:
Z prawdopodobieństwem równym 90 proc. można stwierdzić, iż średnie wydatki – w przeliczeniu na jednego klienta – w analizowanym sklepie in-ternetowym mieszczą się w przedziale od 135,33 do 144,67 zł. Jednak istnieje prawdopodobieństwo (α = 10 proc.), iż rzeczywiste przeciętne wy-datki wszystkich internautów, którzy dokonali zakupu w tym sklepie, znaj-dują się poza wyznaczonym przedziałem.
Przykład 2. Na podstawie danych z przykładu pierwszego należy wyzna-czyć minimalną liczebność próby, tak aby oszacować średnie wydatki
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( )2
1 α−=zF
( ) 95,005,0121,01 =−=−=zF
65,1≈z
67,4
502065,1 ≈⋅=⋅=
nszdx
( ) α−=+<<− 1xx dxmdxP
( ) 9,067,414067,4140 =+<<− mP
50=n
9,01 =− α
140=x
20=s

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.4. Estymacja przedziałowa
str. 351
w sklepie internetowym z dokładnością do 3 zł (maksymalny błąd szacunku).
Krok 1. Dane:
a) maksymalny błąd szacunku:
b) poziom ufności:
c) odchylenie standardowe z próby:
Krok 2. Z tablic dystrybuanty rozkładu normalnego odczyt wartości z (z ≈ 1,65).
Krok 3. Wyznaczamy minimalną wielkość próby ze wzoru:
Minimalna wielkość próby, pozwalająca oszacować na poziomie ufności 90 proc. przeciętne wydatki w sklepie internetowym z dokładnością do 3 zł, wynosi n = 74.
3.4.2. Przedział ufności dla frakcji
Gdy liczebność próby wzrasta, to na mocy centralnego twierdzenia gra - nicznego Lindberga-Levy’ego rozkład frakcji z próby (zob. wskaźnik struktury) jest zbieżny do rozkładu normalnego (por. [1, s. 203]):
Im większa liczebność próby, tym oszacowana na jej podstawie frakcja jest bliższa oczekiwanej wartości p, zaś odchylenie standardowe jest coraz mniejsze (zob. rys. 3.1). Na gruncie dotychczasowych rozważań (zob. Przedział ufności dla wartości przeciętnej) można wyprowadzić dla dużych
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( ) ( ) 33,739
6603
2065,12
22
2
22
==⋅=⋅≈x
dszn
( )
−n
pppNp 1,~ˆ
3=xd
9,01 =− α
20=s

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.4. Estymacja przedziałowa
str. 352
prób (w literaturze przedmiotu zakłada się niekiedy nawet n>100) przedział ufności dla frakcji p:
Wygodniejszy jest zapis:
Nietrudno zauważyć, iż maksymalny błąd szacunku oblicza się ze wzoru:
Z powyższego wzoru – analogicznie jak w przypadku wartości średniej – można wyznaczyć minimalną liczebność próby, niezbędną do oszacowania frakcji w populacji p, przy czym możliwe jest oszacowanie frakcji z próby:
W sytuacji, gdy nie jest możliwe oszacowanie frakcji na podstawie próby losowej – należy przyjąć „najbardziej pesymistyczny” wariant, tj. frakcję na poziomie 0,5. Po podstawieniu tej wartości do powyższego wzoru – otrzymamy wzór uproszczony (por. [11, s. 272]):
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( )2
1 α−=zF
( ) α−=+<<− 1ˆˆ ˆˆ pp dppdpP

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.4. Estymacja przedziałowa
str. 353
Oto przykłady liczbowe:
Przykład 1. W dniu wyborów parlamentarnych przeprowadzono badanie sondażowe na reprezentatywnej próbie Polaków n = 1040 osób (dane umowne). Ankietowanych pytano m.in. o to, czy głosowali lub zamierzają w tym dniu głosować. Na poziomie istotności 0,99 należało opracować wstępną frekwencję, wiedząc, że 450 pytanych odpowiedziało twierdząco.
Krok 1. Najpierw określamy dane:
a) wielkość próby:
b) poziom ufności:
c) frakcja z próby:
Krok 2. Z tablic dystrybuanty rozkładu normalnego odczytujemy wartość krytyczną z:
Krok 3. Obliczamy maksymalny błąd szacunku:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
1040=n
99,01 =− α
433,0
1040450ˆ ≈==
nkp
( )2
1 α−=zF
( ) 995,0201,01 =−=zF
58,2≈z
( ) %4039,00153,058,21040
567,0433,058,2ˆ1ˆ
ˆ ≈=⋅=⋅⋅=−⋅=n
ppzd p

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.4. Estymacja przedziałowa
str. 354
Krok 4. Wyznaczamy przedział ufności dla frakcji:
Na 99 proc. można stwierdzić, iż frekwencja wyniesie 39,4-47,2 proc. Prawdopodobieństwo, że będzie ona po podliczeniu wszystkich głosów niższa bądź wyższa, wynosi zaledwie 1 proc. (α = 0,01).
Przykład 2. Na podstawie danych z przykładu pierwszego należy wyzna-czyć minimalną liczebność próby, tak aby maksymalny błąd szacunku wy-nosił 3 proc. (tj. 0,03).
Ponieważ oszacowano frakcję na podstawie próby, stąd minimalną wiel-kość próby należy obliczyć ze wzoru:
Minimalna wielkość próby, pozwalająca oszacować frekwencję z dokład-nością do 3 punktów procentowych na przyjętym poziomie ufności, to 1816 respondentów. Gdyby nie oszacowano frekwencji, wówczas należało-by przyjąć poziom 0,5. W rezultacie minimalna wielkość próby wzrosłaby do 1849 ankietowanych.
3.4.3. Przedział ufności dla odchylenia standardowego
W przypadku wystarczająco licznej zbiorowości próbnej (minimum 30 ob-serwacji) rozkład wartości odchylenia standardowego w próbie – podobnie jak średniej i frakcji – jest zbieżny do rozkładu normalnego. W tym przy-padku wartością oczekiwaną jest odchylenie standardowe w populacji σ (por. [8, s. 75]):
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( ) α−=+<<− 1ˆˆ ˆˆ pp dppdpP
( ) 99,0039,0433,0039,0433,0 =+<<− mP
( ) 99,0472,0394,0 =<< mP
( ) ( ) ( )( ) 8,1815
0009,02455,0656,6
03,0567,0433,058,2ˆ1ˆ
2
2
2ˆ
2
=⋅=⋅⋅=−⋅≈pd
ppzn

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.4. Estymacja przedziałowa
str. 355
W rezultacie dwustronny przedział ufności dla odchylenia standardowego σ jest następujący (duża próba):
Dla dużych prób wartość krytyczną z odczytać należy z tablic dystrybuanty rozkładu normalnego (warto więc skorzystać z już wcześniej odczytanych wartości).
Przykład. Inwestor na podstawie losowo wybranych w ciągu roku 50 sesji giełdowych obliczył odchylenie standardowe jako miarę ryzyka portfela akcji: s – 20 proc. Na poziomie ufności 0,9 inwestor ten chce poznać rze-czywiste ryzyko portfela akcji (dla wszystkich sesji giełdowych, na których były te akcje notowane).
Wartość krytyczna z była już odczytana dla poziomu ufności 0,9 i wyniosła 1,65. Pozostałe niezbędne dane to odchylenie standardowe obliczone z pró-by (s = 20) oraz liczebność tej próby: n – 50 sesji giełdowych. Podstawia-my do wzoru:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
nNs
2,~ σσ
5022065,120
5022065,120
⋅⋅+<<
⋅⋅− σ
2,0655,1202,065,120 ⋅+<<⋅− σ
74,02074,020 +<<− σ
74,2026,19 << σ

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.4. Estymacja przedziałowa
str. 356
Z 90-procentowym prawdopodobieństwem ryzyko portfela wynosi co naj-mniej 19,26 proc., ale nie więcej niż 20,74 proc. Jeśli podniesie się poziom ufności (np. do 0,99) przy tej samej liczbie wylosowanych sesji – zostanie zwiększony przedział ufności.
Kolejnym działem statystyki matematycznej – obok estymacji – jest wery-fikacja hipotez statystycznych – ideę testowania hipotez ma wyjaśnić ostat-ni podrozdział tej książki.
3.5. Weryfikacja hipotez statystycznych
Hipoteza statystyczna to „założenie dotyczące wartości parametru lub ro-dzaju rozkładu zmiennej w zbiorowości generalnej” [21, s. 247]. Zgodnie z przytoczoną definicją – można wyodrębnić dwie główne grupy hipotez:
1. Hipotezy parametryczne – wnioskujemy o pewnej wartości parametru w populacji.
2. Hipotezy nieparametryczne – wnioskujemy np. o niezależności cech ja-kościowych.
Zgodnie z przedstawioną klasyfikacją hipotez statystycznych dokonano po-działu tego podrozdziału – najpierw omówione zostały niektóre hipotezy parametryczne (duża próba) oraz wybrane hipotezy nieparametryczne.
Wyróżnia się następujące etapy weryfikacji hipotez statystycznych (por. [8, s. 125]):
I Postawienie hipotezy zerowej H0 i odpowiadającej jej hipotezy alterna-tywnej H1.
II Obliczenie odpowiedniej statystyki testowej (zob. estymator) w celu we-ryfikacji hipotezy zerowej.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.5. Weryfikacja hipotez statystycznych
str. 357
III Wyznaczenie na przyjętym poziomie istotności α zbioru (obszaru) kry-tycznego.
IV Podjęcie decyzji o przyjęciu hipotezy zerowej (jeśli wartość statystyki testowej nie należy do zbioru krytycznego) bądź jej odrzuceniu – gdy war-tość statystyki testowej należy do obszaru krytycznego.
Hipotezę zerową dla wartości Θ0 parametru Θ określamy następująco:
Odpowiednio hipoteza alternatywna może być jedno- bądź dwustronna. Od tego, jaką postawiono hipotezę alternatywną, zależy sposób odczytu warto-ści krytycznej z tablic statystycznych, a tym samym – sposób konstrukcji zbioru krytycznego. Jest to odpowiednio:
a) zbiór krytyczny lewostronny:
b) zbiór krytyczny dwustronny:
c) zbiór krytyczny prawostronny:
W przypadku hipotez nieparametrycznych z definicji mamy do czynienia z obszarami krytycznymi dwustronnymi (np. cechy niezależne/zależne, cecha posiada rozkład normalny lub ma rozkład różny od rozkładu normalnego).
Poziom istotności α jest prawdopodobieństwem popełnienia tzw. błędu I rodzaju. Błąd ten polega na odrzuceniu hipotezy zerowej, mimo że jest ona prawdziwa. Prawdopodobieństwo popełnienia tego błędu jest niewiel-
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
00 : Θ=ΘH
01 : Θ<ΘH
01 : Θ≠ΘH
01 : Θ>ΘH

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.5. Weryfikacja hipotez statystycznych
str. 358
kie, ponieważ jako poziom istotności przyjmuje się zazwyczaj wartości z przedziału 0,01 – 0,10 (por. [8, s. 121], [21, s. 248]).
Jak wyżej wspomniano, hipotezę zerową należy odrzucić, gdy obliczona statystyka testowa należy do wyznaczonego zbioru krytycznego (prawdo-podobieństwo błędnej decyzji wynosi tylko α). Oto prezentacja graficzna tej sytuacji dla dwustronnego zbioru krytycznego:
Rysunek 3.13. Prezentacja graficzna sytuacji, w której należy odrzucić hipotezę zerową.
Źródło: Opracowanie własne.
Jeżeli natomiast wartość statystyki znajduje się poza obszarem krytycznym, to nie ma podstaw do odrzucenia hipotezy zerowej. Oto przykładowa sytu-acja w ujęciu graficznym:
Rysunek 3.14. Prezentacja graficzna sytuacji, w której nie ma podstaw do odrzucenia hipotezy zerowej.
Źródło: Opracowanie własne.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.5. Weryfikacja hipotez statystycznych
str. 359
Oczywiście i w tej sytuacji możemy popełnić błąd, jeśli okaże się, że nie odrzuciliśmy fałszywej hipotezy zerowej, tj. nie przyjęliśmy słusznej alter-natywnej (tzw. błąd II rodzaju).
Odrębną kwestią jest określenie tzw. obserwowalnego poziomu istotności p – jest to minimalna wartość, przy której następuje odrzucenie hipotezy zerowej. Aby przyjąć tę hipotezę, poziom istotności należy ustalić poniżej wartości p (por. [21, s. 249]). W ujęciu graficznym pole obszaru krytyczne-go jest w sumie równe p, zaś wartość statystyki testowej znajduje się na granicy tego przedziału (por. rys. 3.13 i 3.14). Algebraicznie poziom istot-ności p wyznacza się, przyrównując wartość krytyczną do wartości staty-styki testowej (odczyt z tablic statystycznych prawdopodobieństwa dla tak określonej wartości krytycznej).
3.5.1. Wybrane hipotezy parametryczne
Poniżej przedstawiono sposób weryfikacji hipotez statystycznych odnośnie wartości średniej (m0) i frakcji (p0) w populacji dla dużej liczebności próby (zał. n > 30).
Etap I. Stawiamy odpowiednio następujące hipotezy zerowe:
Standardowo hipotezy alternatywne przyjmują postać (zbiór krytyczny dwustronny):
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
00 : mmH =
00 : ppH =
00 : mmH ≠
00 : ppH ≠

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.5. Weryfikacja hipotez statystycznych
str. 360
Etap II. Wyznaczamy statystyki testowe dla dużej próby. Jak już o tym by-ła mowa – wraz ze wzrostem liczby obserwacji rozkłady testowanych para-metrów są zbieżne do rozkładu normalnego:
a) rozkład średniej z próby:
b) rozkład frakcji z próby:
I tak wartość statystyki dla średniej m wyprowadzamy przez standaryzację średniej z próby (por. Przedział ufności dla wartości przeciętnej):
O ile celem estymacji przedziałowej było określenie przedziału, w którym znajduje się nieznana wartość parametru, o tyle testowanie hipotez staty-stycznych polega na sprawdzeniu słuszności hipotezy zerowej, tj. w tym przypadku sprawdzeniu, czy wartość średniej z populacji jest równa m0. Zastępując parametr m wartością m0, w rezultacie określimy statystykę te-stową dla wartości średniej (duża próba):
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
nmNx σ,~
( )
−n
pppNp 1,~ˆ
ns
mx −
( ) ( ) n
smx
snmx
nsmx
ns
mx ⋅−=⋅−=÷−=−

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.5. Weryfikacja hipotez statystycznych
str. 361
Analogicznie wyznaczamy statystykę testową dla frakcji:
Etap III. Na przyjętym poziomie istotności α określamy zbiór krytyczny. W przypadku dużej próby wartość krytyczną odczytujemy z tablic dystry - buanty rozkładu normalnego, przy czym należy zwrócić szczególną uwagę na to, w jaki sposób została sformułowana hipoteza alternatywna. Jak już zasygnalizowano, istnieją trzy możliwości:
a) zbiór krytyczny lewostronny:
Uwaga! Z tablic statystycznych odczytujemy wartość z, ale na wykresie za-znaczamy wartość do niej przeciwną (ujemną): - z.
b) zbiór krytyczny dwustronny (standardowo):
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
01 : Θ<ΘH
( ) α−= 1zF
01 : Θ≠ΘH

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.5. Weryfikacja hipotez statystycznych
str. 362
Odczytujemy wartość z, zaś na wykresie zaznaczamy dwie wartości kry-tyczne: -z i +z.
c) zbiór krytyczny prawostronny:
Wyznaczoną wartość krytyczną z zaznaczamy na wykresie. Sposób odczy-tywania wartości krytycznej z tablic dystrybuanty standaryzowanego roz-kładu normalnego przy danym poziomie istotności α dokładniej omówiono w podrozdziale Rozkład normalny.
Etap IV. Sprawdzamy, czy wyznaczona statystyka testowa (etap II) należy do określonego w trzecim etapie obszaru krytycznego i podejmujemy decy-zję o odrzuceniu hipotezy zerowej (zob. rys. 3.13) bądź braku podstaw do jej odrzucenia (rys. 3.14).
Oto dwa przykłady ukazujące ideę testowania parametrycznych hipotez statystycznych (zob. Przykłady – weryfikacja hipotez statystycznych; za-kładka: wartości_parametrów).
Przykład 1. Właściciel pewnego sklepu internetowego na podstawie 50 lo-sowo wybranych transakcji przeanalizował wydatki przypadające na jedne-go klienta, uzyskując następujące charakterystyki z próby:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( )2
1 α−=zF
01 : Θ>ΘH
( ) α−= 1zF

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.5. Weryfikacja hipotez statystycznych
str. 363
a) średnia arytmetyczna:
b) odchylenie standardowe:
Na poziomie istotności α = 0,1 należy zweryfikować hipotezę, iż przecięt-nie rzecz biorąc, wartość jednej transakcji wyniosła w badanym okresie m0
= 150 zł.
Krok 1. Formułujemy hipotezy statystyczne:
Krok 2. W związku z tym, że mamy do czynienia z dużą próbą (n = 50), obliczamy statystykę testową z prezentowanego wyżej wzoru dla dużej próby:
Krok 3. Z tablic dystrybuanty rozkładu normalnego odczytujemy wartość z (α = 0,1):
Hipotezę alternatywną określono standardowo, stąd zbiór krytyczny jest dwustronny:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
140=x
20=s
150:0 =mH
150:1 ≠mH
536,350
201501400 −≈⋅−=⋅−= n
smxte
( )2
1 α−=zF
( ) 95,005,0121,01 =−=−=zF
65,1≈z

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.5. Weryfikacja hipotez statystycznych
str. 364
Krok 4. Sprawdzamy, czy wartość statystyki testowej należy do wyznaczo-nego dwustronnego obszaru krytycznego. Jak widać, wartość ta należy do zbioru krytycznego, stąd hipotezę zerową należy odrzucić. Na przyjętym poziomie istotności nie możemy zatem twierdzić, iż wydatki przeciętnego internauty wynoszą 150 zł.
Przykład 2. Właściciel sklepu internetowego, chcąc zwiększyć swoje do-chody, zamierza wprowadzić karty stałego klienta, uprawniające do rabatu w wysokości 5 proc. Warunkiem otrzymania karty jest dokonanie w ciągu najbliższego miesiąca zakupów o wartości powyżej 200 zł. Czy na pozio-mie istotności α = 0,05 uzasadniona jest hipoteza, że karty otrzyma ponad połowa klientów sklepu, jeśli w ankiecie internetowej wypełnionej przez 125 internautów 60 z nich wyraziło chęć otrzymania takiej karty?
Posiadamy następujące informacje:
a) liczebność próby: n = 125,b) liczba internautów zainteresowanych posiadaniem karty: k = 60,c) wartość testowanego parametru (frakcji): p0 = 0,5.
Na podstawie posiadanych informacji możemy oszacować frakcję z próby:
Krok 1. Formułujemy hipotezy statystyczne:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
-3 -2 -1 0 1 2 3
48,0
12560ˆ ===
nkp
5,0:0 =pH

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.5. Weryfikacja hipotez statystycznych
str. 365
Uwaga! Należy podkreślić, iż pytamy o słuszność hipotezy alternatywnej (czy ponad połowa klientów wyrazi chęć posiadania karty stałego klienta).
Krok 2. Obliczamy statystykę testową dla frakcji (duża próba) ze wzoru:
Krok 3. Z tablic dystrybuanty rozkładu normalnego odczytujemy wartość krytyczną z na poziomie istotności α = 0,05. Z uwagi na sposób postawie-nia hipotezy alternatywnej jest to zbiór krytyczny prawostronny. Stosujemy więc przekształcenie:
Krok 4. Wartość statystyki testowej jest ujemna, więc – nawet z pominię-ciem powyższego kroku – możemy stwierdzić, iż wartość ta nie należy do prawostronnego zbioru krytycznego. Nie ma więc podstaw do odrzucenia hipotezy zerowej – innymi słowy: musimy odrzucić hipotezę alternatywną. Odpowiadając więc na postawione na wstępie pytanie, z dużym prawdopo-dobieństwem stwierdzimy, że kartą będzie zainteresowanych mniej niż połowa klientów rozpatrywanego sklepu internetowego. Dla sprzedawcy
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
5,0:1 >pH
( ) 447,0
0477,002,0
1255,05,05,048,0
1ˆ
00
0 −=−=⋅
−=−
−=
npp
ppte
( ) α−= 1zF
( ) 95,005,01 =−=zF
65,1≈z
-3 -2 -1 0 1 2 3

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.5. Weryfikacja hipotez statystycznych
str. 366
jest to sygnał, iż warunki, na jakich ma zostać przyznawana karta, są wygórowane (np. należałoby obniżyć kwotę wydatków poniżej 200 zł).
Kolejną kwestią jest weryfikacja hipotez statystycznych o równości wy-branych parametrów w dwóch populacjach. Poniżej scharakteryzowano hipotezy statystyczne:
– o równości wartości oczekiwanych w dwóch populacjach,– o równości frakcji w dwóch populacjach,– o równości wariancji w dwóch populacjach.
Hipoteza o równości wartości oczekiwanych w dwóch populacjach. Sta-wiamy hipotezę zerową głoszącą, iż dwie niezależne próby losowe (por. schemat losowania niezależnego) o liczebnościach n1 i n2 pochodzą z popu-lacji generalnych, w których wartości oczekiwane analizowanej cechy są sobie równe (por. [8, s. 126]):
Dla dużych prób obliczamy statystykę testową według wzoru:
Obszar krytyczny wyznaczamy w sposób analogiczny jak przy testowaniu wartości parametrów strukturalnych m0 i p0.
Przykład. Spośród notowań akcji spółki Żywiec SA obejmujących pierw-sze półrocze 2006 r. (zob. Dane_do_analizy.xls; zakładka: Akcje) wybrano w sposób losowy – zgodnie ze schematem losowania systematycznego –
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
210 : mmH =

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.5. Weryfikacja hipotez statystycznych
str. 367
próbę wielkości n = 42 sesje giełdowe. Dane dotyczą dziennych procento-wych zmian kursu akcji na tle indeksu WIG. Na ich podstawie oszacowano następujące parametry (zob. Przykłady – weryfikacja hipotez statystycz-nych; zakładka: porównywanie_parametrów):
Tabela 3.5. Wybrane charakterystyki dotyczące dziennych zmian akcji Żywiec SA i WIG (I kw. 2006 r.).
Indeks WIG Żywiec SALiczebności niezależnych prób: n1 = 42 n2 = 42Średnie arytmetyczne z prób (proc.): 0,34 –0,08Odchylenia standardowe z prób (proc.): 1,488 1,536Wariancja 2,215 2,361Liczba wzrostów kursów 24 20
Źródło: Obliczenia własne na podstawie danych pochodzących z Serwisu Internetowe-go Gazety Parkiet, http://www.parkiet.com/dane/dane_atxt.jsp.
Na poziomie istotności α = 0,05 należy zweryfikować hipotezę, że prze-ciętna dzienna procentowa zmiana indeksu WIG okazała się w pierwszym półroczu 2006 roku istotnie większa od procentowej zmiany kursu akcji spółki Żywiec.
Krok 1. Stawiamy hipotezę zerową o równości oczekiwanych stóp zwrotu wobec będącej przedmiotem zainteresowania hipotezy alternatywnej: „oczekiwana dzienna zmiana WIG jest większa od oczekiwanej stopy zwrotu akcji Żywiec SA”:
Krok 2. Warunek o niezależności prób, jak również o dużej ich liczebności, został spełniony, więc statystykę testową obliczamy według wzoru:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
210 : mmH =
210 : mmH >
( ) 28,133,042,0
109,042,0
42361,2
42215,2
08,034,0
2
22
1
21
21 ≈==+
−−=+
−=
ns
ns
xxte

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.5. Weryfikacja hipotez statystycznych
str. 368
Warto zauważyć, iż w powyższym wzorze występują odchylenia standar-dowe podniesione do kwadratu, czyli wariancje (zob. Miary dyspersji). Za-tem w praktyce łatwiej jest wcześniej obliczyć wariancje (zob. tabela 3.5), a następnie podstawić je do wzoru.
Krok 3. Konstruujemy prawostronny zbiór krytyczny. W tym celu z tablic dystrybuanty rozkładu normalnego odczytujemy wartość z, korzystając z przekształcenia:
Odczytana wartość to z = 1,65. Zatem obszar krytyczny pod funkcją gęsto-ści rozkładu normalnego należy do przedziału <1,65; +∞):
Z drugiej strony – możemy wyznaczyć obserwowalny poziom istotności p. W tym celu określamy poziom prawdopodobieństwa przy wartości krytycznej równej statystyce testowej:
Dla dwustronnego zbioru krytycznego wartość p – odpowiadającą pozio-mowi istotności α –wyznaczymy z przekształcenia:
Zatem p = 1 – 0,9 = 0,1.
Krok 4. Sprawdzamy, czy statystyka testowa na przyjętym poziomie istot-ności należy do obszaru krytycznego. Odpowiedź brzmi „nie” – nie ma
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( ) 95,005,011 =−=−= αzF
-3 -2 -1 0 1 2 3
c
( ) 9,08997,028,1 ≈=F
( ) )(11 zFzF −=⇒−= αα

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.5. Weryfikacja hipotez statystycznych
str. 369
więc podstaw do odrzucenia hipotezy zerowej, a tym samym do przyjęcia hipotezy alternatywnej, zakładającej, że w pierwszym półroczu 2006 r. dzienne procentowe zmiany WIG były istotnie wyższe od zmian kursu ak-cji spółki Żywiec. Hipotezę tę moglibyśmy przyjąć na poziomie istotności p = 0,1. Jednak wówczas ryzyko błędu I rodzaju, polegającego na odrzuce-niu prawdziwej hipotezy zerowej, wzrosłoby z 5 do 10 proc.
Hipoteza o równości frakcji w dwóch populacjach. Hipotezę zerową, za-kładającą, że wskaźniki struktury (frakcje) obliczone na podstawie nieza-leżnych dwóch prób losowych są równe dla populacji, z których te próby pochodzą, zapisujemy następująco:
Testem istotności weryfikującym słuszność powyższej hipotezy jest staty-styka:
Zbiór krytyczny wyznaczamy analogicznie jak w przypadku weryfikowa-nych dotychczas hipotez parametrycznych.
Przykład. Korzystając z danych zawartych w tabeli 3.5 należy zweryfiko-wać hipotezę (α = 0,05), że frakcja liczby sesji, na których nastąpił wzrost głównego indeksu giełdowego, jest istotnie większa od frakcji sesji, na któ-rych nastąpił wzrost kursu akcji Żywiec SA
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
210 : ppH =
210 : ppH =
210 : ppH >

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.5. Weryfikacja hipotez statystycznych
str. 370
Najpierw obliczamy frakcje (zob. Przykłady – weryfikacja hipotez staty-stycznych; zakładka: porównywanie_parametrów – Przykład 2):
a) frakcja dziennych wzrostów WIG:
b) frakcja dziennych zwyżek kursu Żywiec SA:
Obliczamy średnią frakcję dla obu prób:
Powyższą wartość podstawiamy do wzoru na statystykę testową (pamięta-my o założeniu dostatecznie dużej liczebności prób):
Obszar krytyczny – z uwagi na identyczny poziom istotności i znak hipote-zy alternatywnej – jest taki sam, jak w powyższym przykładzie:
<1,65; +∞)p = 0,191
Wartość statystyki testowej okazała się mniejsza od wartości krytycznej (z = 1,65), stąd nie ma podstaw do odrzucenia hipotezy zerowej głoszącej, że frakcje dziennych wzrostów zmian WIG i kursu Żywiec SA w badanym okresie były statystycznie nieistotne. Hipotezę tę możemy odrzucić dopiero na poziomie istotności przekraczającym 19 proc. I tak np. na poziomie istotności α = 0,2 możemy przyjąć, że dodatnich dziennych zmian indeksu WIG było istotnie więcej aniżeli dziennych wzrostów kursu analizowanej spółki giełdowej.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
571,0
4224ˆ
1
11 ===
nkp
476,0
4220ˆ
2
22 ===
nkp
524,0
8444
42422024
21
21 ==++=
++=
nnkkp
( )874,0
048,0249,0095,0
42424242476,0524,0
476,0571,0
1
ˆˆ
21
21
21 =⋅
=
⋅+⋅⋅
−=
⋅+⋅−
−=
nnnnpp
ppte

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.5. Weryfikacja hipotez statystycznych
str. 371
Hipoteza o równości wariancji w dwóch populacjach. Założenie to jest ważne m.in. z punktu hipotezy o równości wartości oczekiwanych w dwóch populacjach dla niewielkiej liczby prób. Formułujemy hipotezę zerową:
Sposób postępowania przy weryfikacji powyższej hipotezy zależy od po-stawionej hipotezy alternatywnej (por. [1, s. 377-379]):
Tabela 3.6. Weryfikacja hipotez o równości wariancji w dwóch populacjach.
1. Statystyka testowa:
2. Zbiór krytyczny:Lewostronny Dwustronny Prawostronny
Stopnie swobody:
Wartość krytyczna:
q
Stopnie swobody:
Dolna wartość krytyczna:
Górna wartość krytyczna:
Stopnie swobody:
Wartość krytyczna:
Źródło: Opracowanie własne.
Postulowane jest takie ponumerowanie populacji, aby wariancja obliczona na podstawie próby pochodzącej z pierwszej populacji była większa od wa-riancji oszacowanej na podstawie próby pobranej z drugiej populacji (ta
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( ) αα −=≥ 111 , FFP vv
22
210 : σσ =H
22
211 : σσ <H 2
2211 : σσ >H
2
221
22
21
,max,min1
ssss
FF ==′
22
21 ss >
( )211 ,
αα =≥ FFP vv
( ) αα =≥ FFP vv 11 ,
111 −= nv 111 −= nv 121 −= nv
112 −= nv 122 −= nv 122 −= nv
( )2
111 ,
αα −=≥ FFP vv
22
211 : σσ ≠H

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.5. Weryfikacja hipotez statystycznych
str. 372
sama zasada dotyczy zbioru dwustronnego). Dzięki temu odczyt wartości z tablic rozkładu F jest uproszczony (zob. Rozkład F).
Sposób weryfikacji hipotezy o równości wariancji ilustruje przykład (zob. Przykłady – weryfikacja hipotez statystycznych; zakładka: porównywanie_ parametrów – Przykład 3):
Przykład. W oparciu o informacje zawarte w tabeli 3.5 należy zweryfiko-wać hipotezę (α = 0,05), że ryzyko rynkowe mierzone wariancją zmian WIG było w I poł. 2006 r. istotnie mniejsze od ryzyka związanego ze zmianami kursu akcji Żywiec SA
Wobec hipotezy zerowej o równości wariancji stawiamy hipotezę alterna-tywną „zmienność WIG istotnie mniejsza od zmienności Żywiec SA”:
Należy zauważyć, że wariancja zmian WIG (I populacja) jest mniejsza od wariancji w drugiej populacji. Statystykę F zawsze obliczamy, dzieląc większą wariancję przez wariancję mniejszą. Z uwagi na to, że obszar kry-tyczny jest lewostronny, musimy dokonać modyfikacji statystyki F, tak aby otrzymać liczbę mniejszą od jedności (iloraz wariancji mniejszej przez wa-riancję większą):
Po obliczeniu statystyki testowej możemy przejść do wyznaczenia lewo-stronnego zbioru krytycznego. Odczyt wartości krytycznej z tablic rozkładu F następuje dla następujących parametrów:
– prawdopodobieństwo (po modyfikacji dla zbioru krytycznego lewo-stronnego):
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
22
210 : σσ =H
22
211 : σσ <H
938,0
361,2215,2
,max,min1
22
21
22
21 ====′
ssss
FF

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.5. Weryfikacja hipotez statystycznych
str. 373
– stopnie swobody:
Szukaną wartość krytyczną otrzymamy, wpisując powyższe parametry w załączonym programie Rozkłady prawdopodobieństwa. Statystyka F wy-nosi:
Zbiór krytyczny ma postać:
Wartość statystyki testowej (0,938) na danym poziomie istotności nie nale-ży do zbioru krytycznego, stąd nie ma podstaw do odrzucenia zerowej hi-potezy o równości wariancji – należy zatem odrzucić hipotezę głoszącą, że ryzyko rynkowe (zmienność WIG) było w analizowanym czasie istotnie mniejsze od ryzyka dla akcji spółki Żywiec SA
Powyższe przykłady pokazują, jak na język praktyczny można przełożyć terminologię związaną z testowaniem parametrycznych hipotez statystycz-nych. Podrozdział ten nie wyczerpuje obszernego tematu, jakim jest bez wątpienia testowanie hipotez. Niemniej jednak ukazano tu ideę weryfikacji hipotez statystycznych na wybranych przykładach. Szereg innych testów parametrów, takich jak np. współczynniki korelacji czy istotność parame-
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( ) 95,005,01111 , =−=−=≥ ααFFP vv
41142121 =−=−= nv
41142112 =−=−= nv
595,041,41 =F
0 1 2 3

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.5. Weryfikacja hipotez statystycznych
str. 374
trów modelu regresji (zob. Analiza regresji) przeprowadza się według ana-logicznego schematu.
1. Postawienie hipotezy zerowej i alternatywnej.2. Obliczenie statystyki testowej.3. Określenie obszaru krytycznego.4. Sprawdzenie czy wartość statystyki testowej należy do obszaru krytycz- nego:
– TAK: odrzucenie hipotezy zerowej,– NIE: brak podstaw do odrzucenia hipotezy zerowej.
W kolejnym podpunkcie ukazano ideę weryfikacji hipotez nieparametrycz-nych na wybranych przykładach. Z uwagi na wielość testów jest to przed-miot dalszego studiowania statystyki matematycznej.
3.5.2. Wybrane hipotezy nieparametryczne
Jednym z ważniejszych testów nieparametrycznych jest test niezależności chi-kwadrat. Pozwala on określić na ustalonym poziomie istotności α, czy dwie cechy jakościowe pogrupowane w tablicę korelacyjną są zależne, czy też nie. W tym celu stawiamy hipotezę zerową o niezależności cech wobec hipotezy alternatywnej o ich zależności:
H0: cechy niezależne,H1: cechy zależne.
W drugim kroku wyznaczamy wartość statystyki testowej chi-kwadrat, któ-rej sposób obliczania ukazano w podrozdziale Miary korelacji – jest ona równa „kwadratowi różnicy między zaobserwowaną i oczekiwaną liczeb-nością w każdej klasie, podzielonemu przez liczebność oczekiwaną i zsu-mowanemu po wszystkich klasach” [1, s. 747]:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
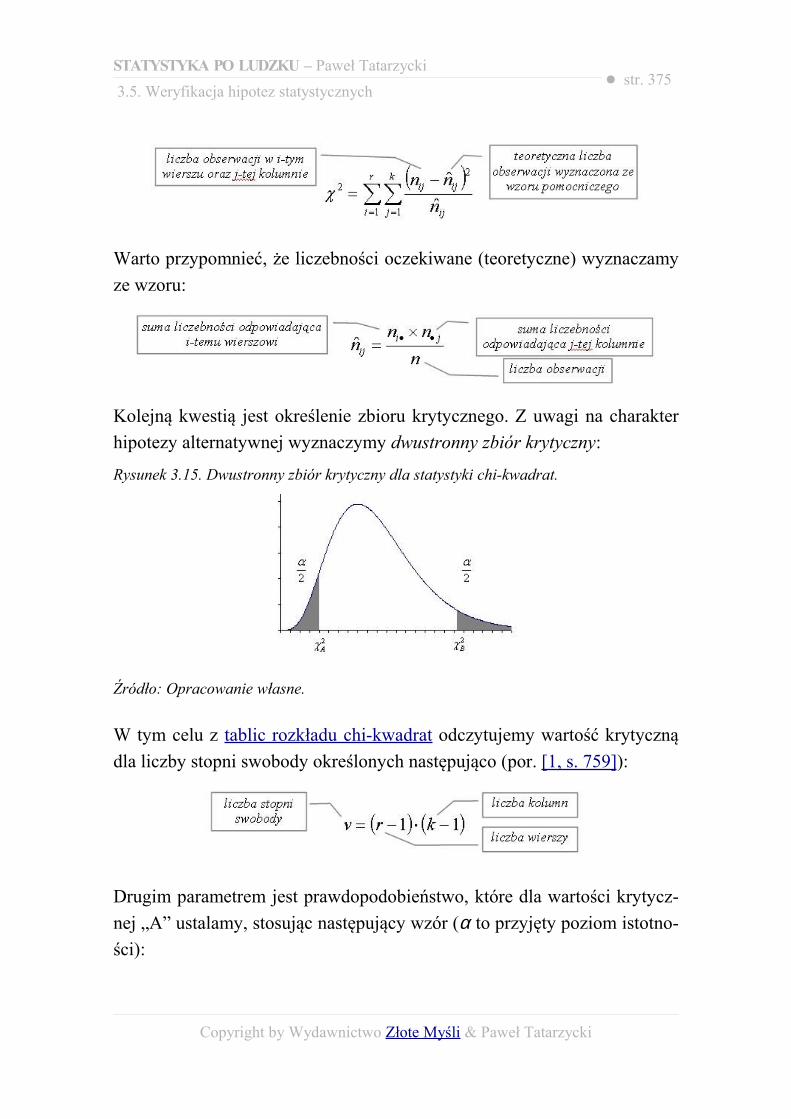
STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.5. Weryfikacja hipotez statystycznych
str. 375
Warto przypomnieć, że liczebności oczekiwane (teoretyczne) wyznaczamy ze wzoru:
Kolejną kwestią jest określenie zbioru krytycznego. Z uwagi na charakter hipotezy alternatywnej wyznaczymy dwustronny zbiór krytyczny:
Rysunek 3.15. Dwustronny zbiór krytyczny dla statystyki chi-kwadrat.
Źródło: Opracowanie własne.
W tym celu z tablic rozkładu chi-kwadrat odczytujemy wartość krytyczną dla liczby stopni swobody określonych następująco (por. [1, s. 759]):
Drugim parametrem jest prawdopodobieństwo, które dla wartości krytycz-nej „A” ustalamy, stosując następujący wzór (α to przyjęty poziom istotno-ści):
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.5. Weryfikacja hipotez statystycznych
str. 376
Prawdopodobieństwo dla wartości krytycznej „B” (por. Rozkład chi-kwa - drat):
Zbiór krytyczny stanowi więc sumę dwóch zbiorów: <0, „A”> ∪ <„B”, +∞).
Na zakończenie – sprawdzamy, czy statystyka testowa należy do zbioru krytycznego i podejmujemy decyzję odnośnie:
a) przyjęcia hipotezy zerowej o niezależności cech (wartość statystyki te-stowej należy do zbioru krytycznego),
b) braku podstaw do odrzucenia hipotezy zerowej o niezależności cech (wartość statystyki testowej nie należy do zbioru krytycznego).
Przykład. W podrozdziale Miary korelacji (w przykładzie nr 2) określono siłę związku pomiędzy płcią Czytelnika a preferencjami co do przydatności niniejszej publikacji. Na podstawie pogrupowanych danych w tablicę kore - lacyjną o wymiarach r = 5 wierszy i k = 2 kolumny (zob. tabela 2.21) obli-czono m.in. wartość statystyki „chi-kwadrat” (zob. Przykłady – miary za-leżności; zakładka: cechy_jakościowe). Wartość ta wynosi:
Na poziomie istotności α = 0,1 należy zweryfikować hipotezę o niezależ-ności oceny co do przydatności publikacji od płci Czytelnika (zob. Przy-kłady – wnioskowanie statystyczne; zakładka: hipotezy nieparametryczne – Przykład 1).
H0: ocena publikacji nie zależy od płci,H1: ocena publikacji zależy od płci.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( )2
122 αχχ α −=≥AP
( )2
22 αχχ α =≥BP
( )286,4
ˆˆ
1 1
22 =
−= ∑ ∑
= =
r
i
k
j ij
ijij
nnn
χ

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.5. Weryfikacja hipotez statystycznych
str. 377
Konstruujemy zbiór krytyczny dwustronny. Zatem określamy liczbę stopni swobody:
Następnie określamy prawdopodobieństwa, dla których odczytamy z tablic rozkładu chi-kwadrat wartości krytyczne przy 4 stopniach swobody:
a) wartość krytyczna „A”:
b) wartość krytyczna „B”:
Zbiorem krytycznym jest przedział wartości: <0; 0,711> ∪ <9,488; +∞).
Nietrudno zauważyć, że wartość statystyki testowej chi-kwadrat (4,286) nie należy do obszaru krytycznego, stąd nie ma podstaw do odrzucenia hipote-zy o niezależności badanych cech. W tym miejscu warto postawić pytanie: „Jaki powinien być minimalny poziom istotności, aby przyjąć hipotezę, że ocena przydatności publikacji zależy od płci?”. Należy określić prawdopodobieństwo przy zadanym poziomie równym wartości statystyki testowej „chi-kwadrat” – jest to połowa obserwowalnego poziomu istotno - ści. Wartość tę mnożymy przez 2, stąd p = 0,737. Odrzucenie hipotezy ze-rowej na tak dużym poziomie istotności wiąże się z bardzo dużym ryzy-kiem popełnienia błędu.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( ) ( ) ( ) ( ) 4121511 =−⋅−=−⋅−= krv
( ) 95,01,0121,01
2122 =−=−=−=≥ αχχ αAP
711,02 =Aχ
( ) 05,021,022 ==≥ αχχ BP
488,92 =Bχ

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.5. Weryfikacja hipotez statystycznych
str. 378
Następnym przykładem nieparametrycznej hipotezy – również opartej na statystyce „chi-kwadrat” – jest test zgodności chi-kwadrat. Test ten po-zwala na weryfkację hipotezy o zgodności rozkładu empirycznego cechy statystycznej (zob. Opis struktury zbiorowości) z teoretycznym rozkładem prawdopodobieństwa. Poniżej przedstawiono procedurę postępowania przy weryfkacji hipotezy o zgodności empirycznego rozkładu cechy z rozkła - dem normalnym (por. [8, s. 136-138]):
Krok 1. Stawiamy hipotezę zerową o zgodności cechy z rozkładem normal-nym
H0: Cecha posiada rozkład normalnyH1: Cecha nie posiada rozkładu normalnego
Krok 2. Obliczamy statystykę „chi-kwadrat” (dla danych pogrupowanych w szereg rozdzielczy z przedziałami klasowymi):
Wartości F(zi) odczytujemy z tablic dystrybuanty rozkładu normalnego dla zmiennej standaryzowanej z. Standaryzacji dokonujemy według wzoru:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.5. Weryfikacja hipotez statystycznych
str. 379
Krok 3. Określamy zbiór krytyczny w sposób analogiczny jak w teście nie - zależności chi-kwadrat, przy czym stopnie swobody obliczamy następują-co:
Krok 4. Podejmujemy decyzję o przyjęciu bądź odrzuceniu hipotezy zero-wej.
W podrozdziale Trening i ewaluacja zamieszczono rozbudowany przykład ukazujący sposób przeprowadzenia testu zgodności rozkładu cechy z roz-kładem normalnym (zob. Przykłady – wnioskowanie statystyczne; zakład-ka: hipotezy nieparametryczne – Przykład 2). Przykład ten stanowi jedno-cześnie podsumowanie wiadomości.
3.6. Trening i ewaluacja
Wprowadzone w tej publikacji wiadomości warto poprzeć rozbudowanym, przekrojowym przykładem. Dotychczas prezentowane przykłady stanowiły podsumowanie pewnego etapu wprowadzonego materiału.
Przykład. Na podstawie danych dotyczących kursów akcji spółki Żywiec SA z pierwszego półrocza 2006 r. (zob. Dane_do_analizy.xls; zakładka: Akcje) należy określić rozkład tygodniowych stóp zwrotu.
1. Na podstawie notowań dziennych obliczamy tygodniowe stopy zwrotu. W tym celu możemy posłużyć się losowaniem systematycznym, wybie-rając np. co piątą sesję giełdową (por. Przykłady – dobór próby; zakład-ka: losowanie systematyczne).
2. Po wybraniu co piątej sesji obliczamy tygodniowe stopy zwrotu, stosu-jąc wzór na przyrosty względne. Otrzymaliśmy n = 25 obserwacji:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.6. Trening i ewaluacja
str. 380
–0,82; –0,83; 1,68; –1,75; 1,47; –0,72; –3,23; 2,05; –0,42; 4,45; 1,42; 1,00; 0,79; 6,09; 0,37; –9,59; –2,04; 2,08; –1,22; –5,99; 2,20; –1,08; 0,00; –1,09; 1,98.
3. Grupujemy powyższe dane indywidualne w szereg rozdzielczy z prze - działami klasowymi (zob. Przykłady – grupowanie danych): Krok 1. Określamy liczbę przedziałów klasowych k jako pierwiastek
kwadratowy z liczby obserwacji n. Zatem k = 5 klas. Krok 2. Obliczamy rozstęp: R = 6,09 - (-9,59) = 15,68 (proc. tygo-
dniowo). Krok 3. Z uwagi na klasyfikacje WIG przyjęto 7 klas k = 7, stąd roz-
piętość przedziałów klasowych to: h = 15,68 / 7 = 2,24 proc. (za-okrąglono do 2,5 proc.).
Oto szereg rozdzielczy klasowy tygodniowych stóp zwrotu akcji Żywiec:
Klasy Środki klas ni
–10 – –7,51 –8,75 1–7,5 – –5,01 –6,25 1–5,0 – –2,51 –3,75 1–2,5 – –0,01 –1,25 9
0 – 2,49 1,25 112,5 – 4,99 3,75 15,0 – 7,49 6,25 1
SUMA 25
4. W celu określenia empirycznego rozkładu tygodniowych stóp zwrotu analizowanej spółki sporządzono diagram liczebności:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
0
2
4
6
8
10
12
-12,5 -7,5 -2,5 2,5 7,5 12,5
tygodniowe stopy zwrotu (proc.)
liczb
a se
sji
ZWC

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.6. Trening i ewaluacja
str. 381
5. Z wizualnej oceny wynika, iż uzasadnione jest przypuszczenie o nor-malności rozkładu tygodniowych stóp zwrotu akcji Żywiec. Fakt ten po-twierdza także analiza miar struktury – wartość średniej arytmetycznej jest bliska medianie i dominancie (zob. Przykłady – analiza struktury; zakładka: Szereg klasowy).
6. Sprawdzamy hipotezę o normalności rozkładu tygodniowych stóp zysku akcji badanej spółki (jako poziom istotności przyjęto α = 0,1). Sformu-łujemy więc hipotezy:
H0: Cecha posiada rozkład normalnyH1: Cecha nie posiada rozkładu normalnego
Przy obliczaniu statystyki testowej chi-kwadrat bardzo pomocne jest spo-rządzenie tabeli z obliczeniami pomocniczymi (zob. Przykłady – weryfika-cja hipotez statystycznych; zakładka: hipotezy nieparametryczne – Przykład 2):
Klasy Środki klas
ni ni zi F(zi) ni teoret chi-kwadrat
–10 – –7,51 –8,75 1 1 –2,49 0,006 0,16 4,432–7,5 – –5,01 –6,25 1 2 –1,63 0,051 1,28 0,404–5,0 – –2,51 –3,75 1 3 –0,78 0,219 5,48 1,120–2,5 – –0,01 –1,25 9 12 0,08 0,533 13,32 0,131
0 – 2,49 1,25 11 23 0,94 0,826 20,66 0,2652,5 – 4,99 3,75 1 24 1,80 0,964 24,10 0,0005,0 – 7,49 6,25 1 25 2,66 0,996 24,90 0,000
SUMA 25 6,353
Na podstawie pogrupowanych wcześniej danych obliczamy liczebności skumulowane. Są one niezbędne do sporządzenia wykresu kumulanty (zob. Przykłady – analiza struktury; zakładka: Szereg klasowy):
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.6. Trening i ewaluacja
str. 382
W tym miejscu należy postawić pytanie, czy skumulowane liczebności teo-retyczne są zbliżone do liczebności teoretycznych (przedostatnia kolumna). Punktem wyjścia jest standaryzacja górnych wartości przedziałów klaso-wych, której dokonujemy ze wzoru:
Konieczne jest zatem obliczenie następujących charakterystyk z próby (zob. Przykłady – analiza struktury; zakładka: Szereg klasowy):
a) średnia arytmetyczna: –0,25b) odchylenie standardowe: 2,915.
Oto przykład standaryzacji pierwszej wartości z powyższej tabeli:
Wartości dystrybuanty rozkładu normalnego F(zi) łatwo wyznaczyć, posłu-gując się dodatkiem Rozkłady Prawdopodobieństwa, podając kolejno war-tości standaryzowane. Oto wartość dystrybuanty w punkcie z1:
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
0
6,25
12,5
18,75
25
-12,5 -7,5 -2,5 2,5 7,5
tygodniowe stopy zwrotu (proc.)
liczb
a se
sji n
aras
tają
co
s
xxz ii
−′′=
( ) 49,291,2
25,05,71 −=−−−=z
( ) 006,049,2 =−F

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.6. Trening i ewaluacja
str. 383
Wreszcie możemy wyznaczyć pierwszą liczebność teoretyczną:
Pierwszą wartość z ostatniej kolumny wyznaczono według wzoru:
Analogicznie wyznaczamy wartości w pozostałych wierszach kolumny. Suma wartości z ostatniej kolumny stanowi statystykę testową:
Wyznaczamy obszar krytyczny dwustronny (zob. rys. 3.15). Wartości kry-tyczne odczytujemy z tablic rozkładu chi-kwadrat dla następującej liczby stopni swobody (7 przedziałów klasowych):
Odczytujemy wartości krytyczne przy prawdopodobieństwach:
a) wartość krytyczna „A”:
b) wartość krytyczna „B”:
Oto zbiór krytyczny: <0; 0,711> ∪ <9,488; +∞).
Statystyka testowa (6,353) nie należy do zbioru krytycznego – zatem nie ma podstaw do odrzucenia hipotezy zerowej o normalności rozkładu tygo-dniowych stóp zwrotu akcji spółki Żywiec. Obserwowalny poziom istotno-
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( ) 16,025006,0ˆ 11 =⋅=⋅= nzFn sk
( ) ( ) ( ) 432,416,016,01
ˆˆ
ˆˆ 2
1
211
2
=−=−
=−
sk
sksk
ski
skiski
nnn
nnn
( )353,6
ˆˆ
1
22 =
−= ∑
=
r
i ski
skiskie n
nnχ
4373 =−=−= kv
( ) 95,01,0121,01
2122 =−=−=−=≥ αχχ αAP
( ) 05,021,022 ==≥ αχχ BP

STATYSTYKA PO LUDZKU – Paweł Tatarzycki 3.6. Trening i ewaluacja
str. 384
ści to p = 0,349 (wysoka wartość p potwierdza słuszność przyjęcia hipotezy zerowej).
EWALUACJA
Lista zadań nr 5
Zadanie 1.
Proszę przeprowadzić analogiczną analizę dla spółki Strzelec SA
Zadanie 2.
Proszę skonstruować przedział ufności w 95 proc. pokrywający przeciętną nieznaną tygodniową stopę zwrotu akcji Żywiec SA (zał. duża próba).
Zadanie 3.
Na poziomie istotności α = 0,05 proszę zweryfikować hipotezę, że średnia cena kupna-sprzedaży mieszkań w 2004 roku była istotnie niższa w porów-naniu z rokiem 2005 (Dane_do_analizy.xls; zakładka: Mieszkania).
Zadanie 4.
Proszę zweryfikować hipotezę (α = 0,05), że fakt korzystania z dodatko-wych form nauczania zależy od płci (Dane_do_analizy.xls; zakładka: An-kiety).
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł TatarzyckiTablice statystyczne
str. 385
Tablice statystyczneTablice statystyczne
Tablice rozkładu Poissona S
0 1 2 3 4 5 6 7 8 9 100,2 0,8187 0,9825 0,9989 0,99990,4 0,6703 0,9384 0,9921 0,9992 0,99990,6 0,5488 0,8781 0,9769 0,9966 0,99960,8 0,4493 0,8088 0,9526 0,9909 0,9986 0,99981 0,3679 0,7358 0,9197 0,9810 0,9963 0,9994 0,99991,2 0,3012 0,6626 0,8795 0,9662 0,9923 0,9985 0,99971,4 0,2466 0,5918 0,8335 0,9463 0,9857 0,9968 0,9994 0,99991,6 0,2019 0,5249 0,7834 0,9212 0,9763 0,9940 0,9987 0,99971,8 0,1653 0,4628 0,7306 0,8913 0,9636 0,9896 0,9974 0,9994 0,99992 0,1353 0,4060 0,6767 0,8571 0,9473 0,9834 0,9955 0,9989 0,99982,2 0,1108 0,3546 0,6227 0,8194 0,9275 0,9751 0,9925 0,9980 0,9995 0,99992,4 0,0907 0,3084 0,5697 0,7787 0,9041 0,9643 0,9884 0,9967 0,9991 0,99982,6 0,0743 0,2674 0,5184 0,7360 0,8774 0,9510 0,9828 0,9947 0,9985 0,9996 0,99992,8 0,0608 0,2311 0,4695 0,6919 0,8477 0,9349 0,9756 0,9919 0,9976 0,9993 0,99983 0,0498 0,1991 0,4232 0,6472 0,8153 0,9161 0,9665 0,9881 0,9962 0,9989 0,99973,2 0,0408 0,1712 0,3799 0,6025 0,7806 0,8946 0,9554 0,9832 0,9943 0,9982 0,99953,4 0,0334 0,1468 0,3397 0,5584 0,7442 0,8705 0,9421 0,9769 0,9917 0,9973 0,99923,6 0,0273 0,1257 0,3027 0,5152 0,7064 0,8441 0,9267 0,9692 0,9883 0,9960 0,99873,8 0,0224 0,1074 0,2689 0,4735 0,6678 0,8156 0,9091 0,9599 0,9840 0,9942 0,99814 0,0183 0,0916 0,2381 0,4335 0,6288 0,7851 0,8893 0,9489 0,9786 0,9919 0,99724,2 0,0150 0,0780 0,2102 0,3954 0,5898 0,7531 0,8675 0,9361 0,9721 0,9889 0,99594,4 0,0123 0,0663 0,1851 0,3594 0,5512 0,7199 0,8436 0,9214 0,9642 0,9851 0,99434,6 0,0101 0,0563 0,1626 0,3257 0,5132 0,6858 0,8180 0,9049 0,9549 0,9805 0,99224,8 0,0082 0,0477 0,1425 0,2942 0,4763 0,6510 0,7908 0,8867 0,9442 0,9749 0,98965 0,0067 0,0404 0,1247 0,2650 0,4405 0,6160 0,7622 0,8666 0,9319 0,9682 0,98635,2 0,0055 0,0342 0,1088 0,2381 0,4061 0,5809 0,7324 0,8449 0,9181 0,9603 0,98235,4 0,0045 0,0289 0,0948 0,2133 0,3733 0,5461 0,7017 0,8217 0,9027 0,9512 0,97755,6 0,0037 0,0244 0,0824 0,1906 0,3422 0,5119 0,6703 0,7970 0,8857 0,9409 0,97185,8 0,0030 0,0206 0,0715 0,1700 0,3127 0,4783 0,6384 0,7710 0,8672 0,9292 0,96516 0,0025 0,0174 0,0620 0,1512 0,2851 0,4457 0,6063 0,7440 0,8472 0,9161 0,9574
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
( )kXP ≤pn ⋅
0,00
0,05
0,10
0,15
0,20
0,25
1 2 3 4 5 6 7 8 9 10 11k
P
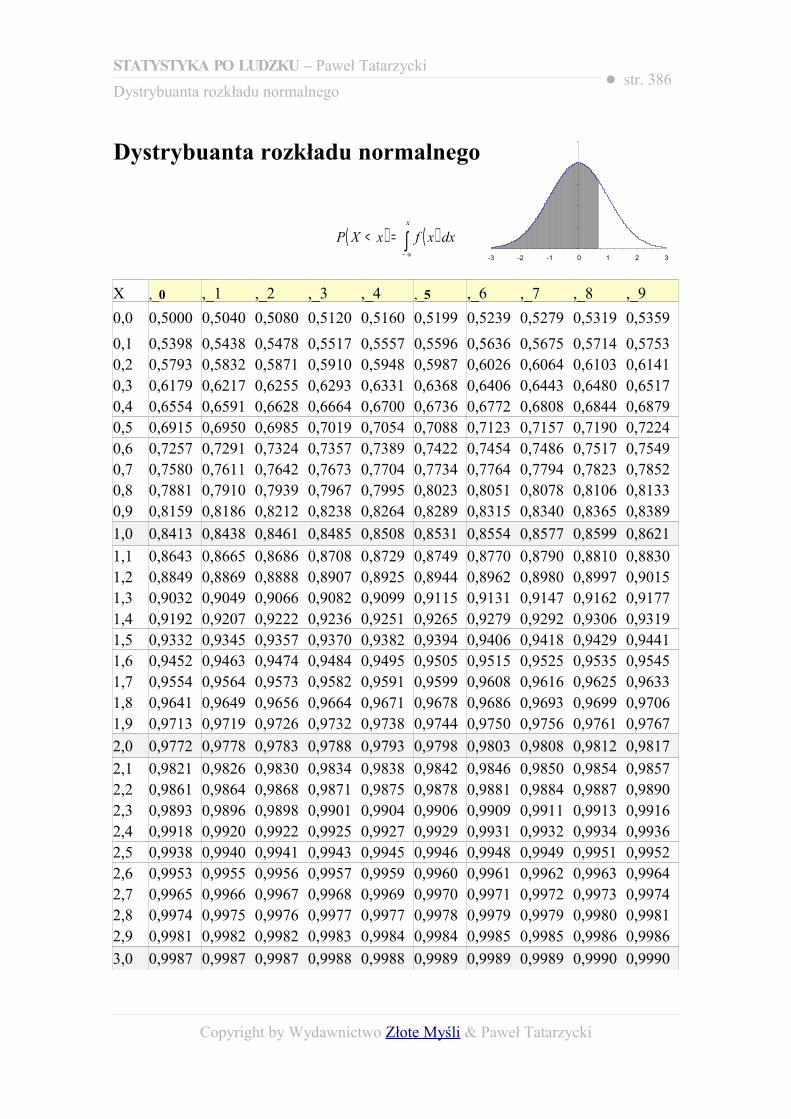
STATYSTYKA PO LUDZKU – Paweł TatarzyckiDystrybuanta rozkładu normalnego
str. 386
Dystrybuanta rozkładu normalnego
X ,_0 ,_1 ,_2 ,_3 ,_4 ,_5 ,_6 ,_7 ,_8 ,_90,0 0,5000 0,5040 0,5080 0,5120 0,5160 0,5199 0,5239 0,5279 0,5319 0,53590,1 0,5398 0,5438 0,5478 0,5517 0,5557 0,5596 0,5636 0,5675 0,5714 0,57530,2 0,5793 0,5832 0,5871 0,5910 0,5948 0,5987 0,6026 0,6064 0,6103 0,61410,3 0,6179 0,6217 0,6255 0,6293 0,6331 0,6368 0,6406 0,6443 0,6480 0,65170,4 0,6554 0,6591 0,6628 0,6664 0,6700 0,6736 0,6772 0,6808 0,6844 0,68790,5 0,6915 0,6950 0,6985 0,7019 0,7054 0,7088 0,7123 0,7157 0,7190 0,72240,6 0,7257 0,7291 0,7324 0,7357 0,7389 0,7422 0,7454 0,7486 0,7517 0,75490,7 0,7580 0,7611 0,7642 0,7673 0,7704 0,7734 0,7764 0,7794 0,7823 0,78520,8 0,7881 0,7910 0,7939 0,7967 0,7995 0,8023 0,8051 0,8078 0,8106 0,81330,9 0,8159 0,8186 0,8212 0,8238 0,8264 0,8289 0,8315 0,8340 0,8365 0,83891,0 0,8413 0,8438 0,8461 0,8485 0,8508 0,8531 0,8554 0,8577 0,8599 0,86211,1 0,8643 0,8665 0,8686 0,8708 0,8729 0,8749 0,8770 0,8790 0,8810 0,88301,2 0,8849 0,8869 0,8888 0,8907 0,8925 0,8944 0,8962 0,8980 0,8997 0,90151,3 0,9032 0,9049 0,9066 0,9082 0,9099 0,9115 0,9131 0,9147 0,9162 0,91771,4 0,9192 0,9207 0,9222 0,9236 0,9251 0,9265 0,9279 0,9292 0,9306 0,93191,5 0,9332 0,9345 0,9357 0,9370 0,9382 0,9394 0,9406 0,9418 0,9429 0,94411,6 0,9452 0,9463 0,9474 0,9484 0,9495 0,9505 0,9515 0,9525 0,9535 0,95451,7 0,9554 0,9564 0,9573 0,9582 0,9591 0,9599 0,9608 0,9616 0,9625 0,96331,8 0,9641 0,9649 0,9656 0,9664 0,9671 0,9678 0,9686 0,9693 0,9699 0,97061,9 0,9713 0,9719 0,9726 0,9732 0,9738 0,9744 0,9750 0,9756 0,9761 0,97672,0 0,9772 0,9778 0,9783 0,9788 0,9793 0,9798 0,9803 0,9808 0,9812 0,98172,1 0,9821 0,9826 0,9830 0,9834 0,9838 0,9842 0,9846 0,9850 0,9854 0,98572,2 0,9861 0,9864 0,9868 0,9871 0,9875 0,9878 0,9881 0,9884 0,9887 0,98902,3 0,9893 0,9896 0,9898 0,9901 0,9904 0,9906 0,9909 0,9911 0,9913 0,99162,4 0,9918 0,9920 0,9922 0,9925 0,9927 0,9929 0,9931 0,9932 0,9934 0,99362,5 0,9938 0,9940 0,9941 0,9943 0,9945 0,9946 0,9948 0,9949 0,9951 0,99522,6 0,9953 0,9955 0,9956 0,9957 0,9959 0,9960 0,9961 0,9962 0,9963 0,99642,7 0,9965 0,9966 0,9967 0,9968 0,9969 0,9970 0,9971 0,9972 0,9973 0,99742,8 0,9974 0,9975 0,9976 0,9977 0,9977 0,9978 0,9979 0,9979 0,9980 0,99812,9 0,9981 0,9982 0,9982 0,9983 0,9984 0,9984 0,9985 0,9985 0,9986 0,99863,0 0,9987 0,9987 0,9987 0,9988 0,9988 0,9989 0,9989 0,9989 0,9990 0,9990
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
-3 -2 -1 0 1 2 3
( ) ( )∫
∞−
=<x
dxxfxXP

STATYSTYKA PO LUDZKU – Paweł TatarzyckiTablice rozkładu t-Studenta
str. 387
Tablice rozkładu t-Studenta
0,005 0,01 0,02 0,05 0,1 0,2 0,9 0,95 0,99 0,9951 127,32 63,655931,821012,70626,3137 3,0777 0,1584 0,0787 0,0157 0,00792 14,08929,9250 6,9645 4,3027 2,9200 1,8856 0,1421 0,0708 0,0141 0,00713 7,4532 5,8408 4,5407 3,1824 2,3534 1,6377 0,1366 0,0681 0,0136 0,00684 5,5975 4,6041 3,7469 2,7765 2,1318 1,5332 0,1338 0,0667 0,0133 0,00675 4,7733 4,0321 3,3649 2,5706 2,0150 1,4759 0,1322 0,0659 0,0132 0,00666 4,3168 3,7074 3,1427 2,4469 1,9432 1,4398 0,1311 0,0654 0,0131 0,00657 4,0294 3,4995 2,9979 2,3646 1,8946 1,4149 0,1303 0,0650 0,0130 0,00658 3,8325 3,3554 2,8965 2,3060 1,8595 1,3968 0,1297 0,0647 0,0129 0,00659 3,6896 3,2498 2,8214 2,2622 1,8331 1,3830 0,1293 0,0645 0,0129 0,006410 3,5814 3,1693 2,7638 2,2281 1,8125 1,3722 0,1289 0,0643 0,0129 0,006411 3,4966 3,1058 2,7181 2,2010 1,7959 1,3634 0,1286 0,0642 0,0128 0,006412 3,4284 3,0545 2,6810 2,1788 1,7823 1,3562 0,1283 0,0640 0,0128 0,006413 3,3725 3,0123 2,6503 2,1604 1,7709 1,3502 0,1281 0,0639 0,0128 0,006414 3,3257 2,9768 2,6245 2,1448 1,7613 1,3450 0,1280 0,0638 0,0128 0,006415 3,2860 2,9467 2,6025 2,1315 1,7531 1,3406 0,1278 0,0638 0,0127 0,006416 3,2520 2,9208 2,5835 2,1199 1,7459 1,3368 0,1277 0,0637 0,0127 0,006417 3,2224 2,8982 2,5669 2,1098 1,7396 1,3334 0,1276 0,0636 0,0127 0,006418 3,1966 2,8784 2,5524 2,1009 1,7341 1,3304 0,1274 0,0636 0,0127 0,006419 3,1737 2,8609 2,5395 2,0930 1,7291 1,3277 0,1274 0,0635 0,0127 0,006320 3,1534 2,8453 2,5280 2,0860 1,7247 1,3253 0,1273 0,0635 0,0127 0,006321 3,1352 2,8314 2,5176 2,0796 1,7207 1,3232 0,1272 0,0635 0,0127 0,006322 3,1188 2,8188 2,5083 2,0739 1,7171 1,3212 0,1271 0,0634 0,0127 0,006323 3,1040 2,8073 2,4999 2,0687 1,7139 1,3195 0,1271 0,0634 0,0127 0,006324 3,0905 2,7970 2,4922 2,0639 1,7109 1,3178 0,1270 0,0634 0,0127 0,006325 3,0782 2,7874 2,4851 2,0595 1,7081 1,3163 0,1269 0,0633 0,0127 0,006326 3,0669 2,7787 2,4786 2,0555 1,7056 1,3150 0,1269 0,0633 0,0127 0,006327 3,0565 2,7707 2,4727 2,0518 1,7033 1,3137 0,1268 0,0633 0,0126 0,006328 3,0470 2,7633 2,4671 2,0484 1,7011 1,3125 0,1268 0,0633 0,0126 0,006329 3,0380 2,7564 2,4620 2,0452 1,6991 1,3114 0,1268 0,0633 0,0126 0,006330 3,0298 2,7500 2,4573 2,0423 1,6973 1,3104 0,1267 0,0632 0,0126 0,0063
v – liczba stopni swobody
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
-3 -2 -1 0 1 2 3
( ) αα =≥ ttP ||
α
v

STATYSTYKA PO LUDZKU – Paweł TatarzyckiTablice rozkładu chi-kwadrat
str. 388
Tablice rozkładu chi-kwadrat
0,005 0,01 0,02 0,05 0,1 0,2 0,9 0,95 0,99 0,9951 7,8794 6,6349 5,4119 3,8415 2,7055 1,6424 0,0158 0,0039 0,0002 0,00002 10,59659,2104 7,8241 5,9915 4,6052 3,2189 0,2107 0,1026 0,0201 0,01003 12,838111,34499,8374 7,8147 6,2514 4,6416 0,5844 0,3518 0,1148 0,07174 14,860213,276711,66789,4877 7,7794 5,9886 1,0636 0,7107 0,2971 0,20705 16,749615,086313,388211,07059,2363 7,2893 1,6103 1,1455 0,5543 0,41186 18,547516,811915,033212,591610,64468,5581 2,2041 1,6354 0,8721 0,67577 20,277718,475316,622414,067112,01709,8032 2,8331 2,1673 1,2390 0,98938 21,954920,090218,168215,507313,361611,03013,4895 2,7326 1,6465 1,34449 23,589321,666019,679016,919014,683712,24214,1682 3,3251 2,0879 1,734910 25,188123,209321,160818,307015,987213,44204,8652 3,9403 2,5582 2,155811 26,756924,725022,617919,675217,275014,63145,5778 4,5748 3,0535 2,603212 28,299726,217024,053921,026118,549315,81206,3038 5,2260 3,5706 3,073813 29,819327,688225,471522,362019,811916,98487,0415 5,8919 4,1069 3,565014 31,319429,141226,872723,684821,064118,15087,7895 6,5706 4,6604 4,074715 32,801530,578028,259524,995822,307119,31078,5468 7,2609 5,2294 4,600916 34,267131,999929,633226,296223,541820,46519,3122 7,9616 5,8122 5,142217 35,718433,408730,995027,587124,769021,614610,08528,6718 6,4077 5,697318 37,156434,805232,346228,869325,989422,759510,86499,3904 7,0149 6,264819 38,582136,190833,687430,143527,203623,900411,650910,11707,6327 6,843920 39,996937,566335,019631,410428,412025,037512,442610,85088,2604 7,433821 41,400938,932236,343432,670629,615126,171113,239611,59138,8972 8,033622 42,795740,289437,659533,924530,813327,301514,041512,33809,5425 8,642723 44,181441,638338,968335,172532,006928,428814,848013,090510,19579,260424 45,558442,979840,270336,415033,196229,553315,658713,848410,85639,886225 46,928044,314041,566037,652534,381630,675216,473414,611411,524010,519626 48,289845,641642,855838,885135,563231,794617,291915,379212,198211,160227 49,645046,962844,139940,113336,741232,911718,113916,151412,878511,807728 50,993648,278245,418841,337237,915934,026618,939216,927913,564712,461329 52,335549,587846,692642,556939,087535,139419,767717,708414,256413,121130 53,671950,892247,961843,773040,256036,250220,599218,492714,953513,7867
v – liczba stopni swobody
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki
0 2 4 6 8 10 12 14 16 18 20 22 24
( ) αχχ α =≥ 22P
α
v

STATYSTYKA PO LUDZKU – Paweł TatarzyckiBibliografia
str. 389
BibliografiaBibliografia
Literatura
[1] Aczel A. D., Statystyka w zarządzaniu, Wydawnictwo Naukowe PWN, Warszawa 2000.
[2] Adamkiewicz H. G., Statystyka. Zastosowania w ekonomii, Ośrodek Doradztwa i Doskonalenia Kadr, Gdańsk 1996.
[3] Bielecka A., Statystyka w biznesie i ekonomii. Teoria i praktyka, Wydawnictwo Wyższej Szkoły Przedsiębiorczości i Zarządzania im. Leona Koźmińskiego, Warszawa 2005.
[4] Cieślak M. (red.), Prognozowanie gospodarcze. Metody i zastoso-wania, Wydawnictwo Naukowe PWN, Warszawa 2002.
[5] Jóźwiak J., Podgórski J., Statystyka od podstaw, Polskie Wydawnic-two Ekonomiczne, Warszawa 2000.
[6] Kędzior Z. (red.), Badania rynku. Metody, zastosowania, Polskie Wydawnictwo Ekonomiczne, Warszawa 2005.
[7] Komosa A., Musiałkiewicz J., Statystyka, Wydawnictwo EKONO-MIK, Warszawa 1999.
[8] Luszniewicz A., Statystyka nie jest trudna. Metody wnioskowania statystycznego, Polskie Wydawnictwo Ekonomiczne, Warszawa 1997.
[9] Luszniewicz A., Słaby T., Statystyka stosowana, Polskie Wydawnic-two Ekonomiczne, Warszawa 1996.
[10] Michalski T., Statystyka, Wydawnictwa Szkolne i Pedagogiczne, Warszawa 1994.
[11] Ostasiewicz S., Rusnak Z., Siedlecka U., Statystyka. Elementy teo-rii i zastosowania. Wydawnictwo Akademii Ekonomicznej we Wrocła-wiu, Wrocław 2006.
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł TatarzyckiLiteratura
str. 390
[12] Paradysz J. (red.), Statystyka, Wydawnictwo Akademii Ekonomicz-nej w Poznaniu, Poznań 2005.
[13] Piłatowska M., Repetytorium ze statystyki, Wydawnictwo Naukowe PWN, Warszawa 2006.
[14] Pociecha J., Metody statystyczne w badaniach marketingowych, Wydawnictwo Naukowe PWN, Warszawa 1996.
[15] Pułaska-Turyna B., Statystyka dla ekonomistów, Wydawnictwo Di-fin, Warszawa 2005.
[16] Rószkiewicz M., Metody ilościowe w badaniach marketingowych, Wydawnictwo Naukowe PWN, Warszawa 2002.
[17] Sej-Kolasa M., Zielińska A., Excel w statystyce. Materiały do ćwi-czeń, Wydawnictwo Akademii Ekonomicznej we Wrocławiu, Wrocław 2004.
[18] Snarska A., Statystyka, Ekonometria, Prognozowanie. Ćwiczenia z Excelem, Wydawnictwo Placet, Warszawa 2005.
[19] Sobczyk M., Statystyka, Wydawnictwo Naukowe PWN, Warszawa 2002.
[20] Starzyńska W. (red.), Podstawy statystyki, Wydawnictwo Difin, Warszawa 2004.
[21] Starzyńska W., Statystyka praktyczna, Wydawnictwo Naukowe PWN, Warszawa 2005.
Inne źródła
Eurostat, http://epp.eurostat.ec.europa.eu Giełda Papierów Wartościowych w Warszawie, http://www.gpw.com.pl Główny Urząd Statystyczny, http://www.stat.gov.pl InternetStandard, http://www.internetstandard.pl Komenda Główna Policji, www.kgp.gov.pl
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł TatarzyckiInne źródła
str. 391
Komisja Nadzoru Ubezpieczeń i Funduszy Emerytalnych, http://wwww.knuife.gov.pl
Narodowy Bank Polski, http://www.nbp.pl Polska Agencja Informacji i Inwestycji Zagranicznych,
http://paiz.gov.pl Portal Finansowy Money.pl, http://www.money.pl Serwis Internetowy Gazety Parkiet, http://www.parkiet.com Serwis Nieruchomości Szybko.pl, http://www.szybko.pl Skonsolidowane raporty kwartalne Grupy Żywiec SA, http://www.gru -
pazywiec.pl Skonsolidowane raporty roczne Grupy Żywiec SA, http://www.grupa -
zywiec.pl
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł TatarzyckiSpis tabel
str. 392
Spis tabelSpis tabel
Tabela 1.1. Etapy badania statystycznego w świetle literatury przedmiotu......................7Tabela 1.2. Czynności wchodzące w skład badania statystycznego w przekroju poszczególnych etapów.....................................................................................................9Tabela 1.3. Klasyfikacja zbiorowości statystycznych pod kątem wybranych kryteriów 12Tabela 1.4. Klasyfikacja pytań kwestionariusza ankietowego (kwestionariusza wywiadu).........................................................................................................................35Tabela 1.5. Typ skali pomiarowej a rodzaj cechy statystycznej......................................48Tabela 1.6. Typologia kontroli materiału statystycznego według wybranych autorów. .49Tabela 1.7. Struktura odpowiedzi na pytanie dotyczące praktycznych zastosowań statystyki..........................................................................................................................71Tabela 1.8. Struktura odpowiedzi na pytanie dotyczące działów statystyki sprawiających najwięcej trudności..................................................................................71Tabela 1.9. Realny Produkt Krajowy Brutto państw UE-15 w 2005 r. (proc.)...............73Tabela 1.10. Rozkład liczby kont e-mail losowo wybranej grupy internautów..............74Tabela 1.11. Rozkład liczby zatrudnionych w losowo wybranej grupie przedsiębiorstw sektora MSP.....................................................................................................................74Tabela 1.12. Przykład tablicy złożonej krzyżowej – cechy dychotomiczne...................75Tabela 1.13. Praktyczne zastosowania statystyki według Polaków i mieszkańców UE.76Tabela 1.14. Realny Produkt Krajowy Brutto w przekroju państw UE-15 w latach 2001-2005........................................................................................................................76Tabela 1.15. Wartość majątku trwałego i obrotowego Grupy Żywiec SA w latach 2002-2005 (mln zł)..........................................................................................................77Tabela 1.16. Dynamika przychodów Grupy Żywiec SA w latach 2002-2005 (mln zł). .78Tabela 1.17. Typologie wykresów statystycznych z punktu widzenia form graficznych.........................................................................................................................................80Tabela 1.18. Mieszkania zamieszkane według wieku budynku (stan na 2002 r.)...........94Tabela 2.1. Typologia miar opisu statystycznego.........................................................134Tabela 2.2. Wydajność pracy w poszczególnych oddziałach przedsiębiorstwa............136Tabela 2.3. Wskaźniki struktury liczby godzin nauki statystyki tygodniowo w czasie sesji i poza sesją.............................................................................................................137Tabela 2.4. Wskaźnik podobieństwa struktur godzin nauki statystyki tygodniowo w czasie sesji i poza sesją..................................................................................................138Tabela 2.5. Średnia ważona ocena atrakcyjności oferty edukacyjnej szkoły prywatnej.......................................................................................................................141Tabela 2.6. Oczekiwana stopa zwrotu z inwestycji w akcje spółki Żywiec (proc. tygodniowo)...................................................................................................................142
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł TatarzyckiSpis tabel
str. 393
Tabela 2.7. Oczekiwana roczna stopa zwrotu portfela akcji.........................................144Tabela 2.8. Przeciętna wydajność pracy w przedsiębiorstwie posiadającym trzy oddziały regionalne......................................................................................................................146Tabela 2.9. Tygodniowe stopy zwrotu z inwestycji w akcje spółki Żywiec (liczba sesji narastająco)....................................................................................................................157Tabela 2.10. Klasyfikacja miar dyspersji......................................................................160Tabela 2.11. Zmienność cen kawalerek w wybranych miastach Polski na rynku wtórnym (tys. zł/ m2)....................................................................................................163Tabela 2.12. Obliczenie ryzyka inwestycji w akcje spółki Żywiec (proc. tygodniowo)........................................................................................................165Tabela 2.13. Obliczenie współczynnika asymetrii dla tygodniowych stóp zwrotu akcji spółki Żywiec................................................................................................................174Tabela 2.14. Interpretacja klasycznego współczynnika asymetrii co do wartości bezwzględnej.................................................................................................................175Tabela 2.15. Interpretacja pozycyjnych współczynników asymetrii co do wartości bezwzględnej.................................................................................................................176Tabela 2.16. Obliczenie ekscesu dla tygodniowych stóp zwrotu akcji spółki Żywiec..179Tabela 2.17. Interpretacja współczynnika koncentracji Lorenza..................................181Tabela 2.18. Współczynnik koncentracji Lorenza liczby odsłon najpopularniejszych komunikatorów w Polsce...............................................................................................182Tabela 2.19. Wybrane miary analizy współzależności a skale pomiarowe...................191Tabela 2.20. Elementy publikacji najbardziej ułatwiające zdaniem czytelników przyswajanie wiedzy a płeć...........................................................................................196Tabela 2.21. Ocena przydatności publikacji „Statystyka po ludzku” a płeć czytelnika............................................................................................................198Tabela 2.22. Wyznaczanie liczebności teoretycznych – obliczenia pomocnicze..........198Tabela 2.23. Wyznaczanie statystyki „chi-kwadrat” – obliczenia pomocnicze............199Tabela 2.24. Preferowany przez respondentów udział teorii w publikacji „Statystyka po ludzku” według płci.......................................................................................................201Tabela 2.25. Wyznaczanie wartości licznika wzoru na współczynnik eta – obliczenia pomocnicze....................................................................................................................202Tabela 2.26. Wyznaczanie wartości mianownika wzoru na współczynnik eta – obliczenia pomocnicze..................................................................................................202Tabela 2.27. Sposób przypisywania rang w sytuacji, gdy przynajmniej dwa obiekty są jednakowo ważne..........................................................................................................204Tabela 2.28. Interpretacja współczynnika korelacji rang Spearmana...........................207Tabela 2.29. Interpretacja współczynnika korelacji liniowej Pearsona.........................208Tabela 2.30. Analiza korelacji rang przypisanych dodatkom do e-booka „Statystyka po ludzku”...........................................................................................................................210Tabela 2.31. Analiza korelacji tygodniowych stóp zwrotu akcji Żywiec SA i Strzelec SA (I kw. 2006 r.)..........................................................................................................211
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł TatarzyckiSpis tabel
str. 394
Tabela 2.32. Ocena treści a ocena wysokości ceny publikacji „Statystyka po ludzku”..................................................................................................213Tabela 2.33. Ocena treści a ocena wysokości ceny publikacji „Statystyka po ludzku” – tabela pomocnicza.........................................................................................................213Tabela 2.34. Zależność postrzeganej wartości publikacji „Statystyka po ludzku” od oceny jakości treści........................................................................................................218Tabela 2.35. Wzoryn a wyznaczanie prostych regresji Y względem X oraz X względem Y.......................................................................................................222Tabela 2.36. Tygodniowe stopy zwrotu akcji Strzelec SA a tygodniowe zmiany WIG (I kw. 2006 r.)................................................................................................................223Tabela 2.37. Wpływ wskaźnika ROE na wartość księgową na 1 akcję spółki Strzelec SA.........................................................................................................232Tabela 2.38. Zależność oceny wyglądu publikacji „Statystyka po ludzku” od płci respondenta....................................................................................................................234Tabela 2.39. Średnia ruchoma (k=9) z różnicy średnich kroczących cen akcji Żywiec SA (k=12 i k=26)...........................................................................................................255Tabela 2.40. Wynik finansowy netto Grupy Żywiec SA w latach 2001-2005 (mln zł)257Tabela 2.41. Sprzedaż map turystycznych (szt.)...........................................................263Tabela 2.42. Sprzedaż map turystycznych (szt.) – obliczenia pomocnicze...................264Tabela 2.43. Analiza dynamiki przychodów ze sprzedaży Grupy Żywiec SA w latach 2001-2005......................................................................................................................270Tabela 2.44. Indeksy dynamiki przychodów ze sprzedaży Grupy Żywiec SA w latach 2001-2005......................................................................................................................275Tabela 2.45. Zespołowe indeksy cen i ilości.................................................................277Tabela 2.46. Analiza przyczyn zmian wartości przychodów ze sprzedaży firmy edukacyjnej....................................................................................................................278Tabela 2.47. Wyznaczenie zespołowych indeksów cen i ilości godzin przeprowadzonych kursów............................................................................................279Tabela 2.48. Indeksy o stałej strukturze oraz indeksy wpływu zmian strukturalnych. .281Tabela 2.49. Analiza przyczyn zmian wydajności pracy przedsiębiorstwa..................282Tabela 2.50. Wyznaczenie indeksów o stałej strukturze oraz indeksów wpływu zmian strukturalnych................................................................................................................283Tabela 3.1. Podstawowe charakterystyki rozkładów zmiennych losowych..................302Tabela 3.2. Klasyfikacja rozkładów prawdopodobieństwa...........................................302Tabela 3.3. Losowanie wielostopniowe a losowanie warstwowe.................................342Tabela 3.4. Estymatory punktowe wybranych parametrów w populacji generalnej.....344Tabela 3.5. Wybrane charakterystyki dotyczące dziennych zmian akcji Żywiec SA i WIG (I kw. 2006 r.).......................................................................................................366Tabela 3.6. Weryfikacja hipotez o równości wariancji w dwóch populacjach.............370
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł TatarzyckiSpis rysunków
str. 395
Spis rysunkówSpis rysunków
Rysunek 1.1. Klasyfikacja cech statystycznych..............................................................13Rysunek 1.2. Przykład określenia zbiorowości i jednostek statystycznych według cech stałych..............................................................................................................................15Rysunek 1.3. Przykłady cech statystycznych..................................................................20Rysunek 1.4. Klasyfikacja metod badań statystycznych ze względu na liczbę jednostek objętych badaniem...........................................................................................................23Rysunek 1.5. Przykład ankiety internetowej...................................................................38Rysunek 1.6. Przykład formularza ankiety dla Czytelników publikacji „Statystyka po ludzku”.............................................................................................................................46Rysunek 1.7. Typ skali pomiarowej a rodzaj cechy statystycznej..................................47Rysunek 1.8. Schemat wyboru odpowiedniego szeregu statystycznego.........................54Rysunek 1.9. Arkusz do grupowania danych zebranych za pomocą ankiety internetowej........................................................................................................68Rysunek 1.10. Działy statystyki sprawiające najwięcej trudności..................................83Rysunek 1.11. Struktura liczby odsłon 10 najpopularniejszych witryn WWW (maj 2006 r.)....................................................................................................................83Rysunek 1.12. Liczba wskazań dotyczących praktycznych zastosowań statystyki........84Rysunek 1.13. Dynamika realnego Produktu Krajowego Brutto państw UE-15 w 2005 r...........................................................................................................................85Rysunek 1.14. Odsetek gospodarstw domowych posiadających dostęp do Internetu (stan na koniec 2005 r.)............................................................................................................86Rysunek 1.15. Gęstość zaludnienia a wartość sprzedaży w oddziałach regionalnych....87Rysunek 1.16. Mapa dwukryteriowa oceny treści publikacji „ Statystyka po ludzku” ....89Rysunek 1.17. Profil semantyczny według trzech kryteriów..........................................90Rysunek 1.18. Histogram ukazujący rozkład liczby kont e-mail wybranej grupy internautów......................................................................................................................92Rysunek 1.19. Histogram ukazujący rozkład wielkości zatrudnienia w wybranych firmach sektora MSP.......................................................................................................93Rysunek 1.20. Histogram z nierównymi przedziałami klasowymi.................................95Rysunek 1.21. Diagram ukazujący liczbę kont e-mail wybranej grupy internautów......96Rysunek 1.22. Diagram ukazujący rozkład wielkości zatrudnienia w wybranych firmach sektora MSP.....................................................................................................................97Rysunek 1.23. Kumulanta wielkości zatrudnienia w wybranych firmach sektora MSP.98Rysunek 1.24. Dystrybuanta empiryczna wielkości zatrudnienia w wybranych firmach sektora MSP.....................................................................................................................99
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł TatarzyckiSpis rysunków
str. 396
Rysunek 1.25. Dystrybuanta empiryczna liczby kont e-mail wybranej grupy internautów....................................................................................................................100Rysunek 1.26. Porównanie tygodniowych stóp zysku akcji spółki Strzelec i Żywiec (dane za I półrocze 2006 r.)...........................................................................................101Rysunek 1.27. Wartość księgowa na 1 akcję a rentowność kapitałów własnych Grupy Żywiec S.A....................................................................................................................103Rysunek 1.28. Korzystanie z dodatkowych form nauczania według płci.....................104Rysunek 1.29. Średnia cena mieszkań na rynku wtórnym w wybranych miastach Polski (II kw. 2006 r.)...............................................................................................................104Rysunek 1.30. Średnia cena mieszkań na rynku wtórnym w Polsce według liczby pokoi (II kw. 2006 r.)...............................................................................................................105Rysunek 1.31. Sezonowość sprzedaży Grupy Żywiec S.A. w ujęciu wartościowym...106Rysunek 1.32. Kształtowanie się kursów akcji spółek Strzelec i Żywiec w pierwszej połowie 2006 r...............................................................................................................107Rysunek 1.33. Kształtowanie się aktywów Grupy Żywiec S.A. w latach 2002-2005.. 108Rysunek 1.34. Zakres analizy statystycznej..................................................................109Rysunek 1.35. Klasyfikacja metod analizy statystycznej..............................................110Rysunek 2.1. Typologia rozkładów empirycznych cechy ciągłej.................................131Rysunek 2.2. Rozkład tygodniowych stóp zwrotu akcji spółki Żywiec w I półroczu 2006 r........................................................................................................148Rysunek 2.3. Wykres kumulanty tygodniowych stóp zwrotu akcji spółki Żywiec w I półroczu 2006 r..............................................................................................................155Rysunek 2.4. Koncentracja liczby odsłon wśród 10 najpopularniejszych witryn internetowych w Polsce.................................................................................................180Rysunek 2.5. Przykładowy diagram korelacyjny ukazujący brak jakiejkolwiek zależności.......................................................................................................................208Rysunek 2.6. Przykładowy diagram korelacyjny ukazujący brak zależności liniowej. 209Rysunek 2.7. Krzywa regresji oceny wartości publikacji „Statystyka po ludzku” względem oceny jakości treści......................................................................................218Rysunek 2.8. Idea klasycznej metody najmniejszych kwadratów na przykładzie regresji liniowej..........................................................................................................................220Rysunek 2.9. Regresja liniowa zmian stóp zwrotu akcji Strzelec S.A. względem zmian WIG (I kw. 2006 r.).......................................................................................................225Rysunek 2.10. Zależność wartości księgowej na 1 akcję od rentowności kapitałów własnych Grupy Żywiec S.A.........................................................................................227Rysunek 2.11. Klasyfikacja szeregów czasowych........................................................250Rysunek 2.12. Średnie ruchome z 12 i 26 sesji giełdowych kursów zamknięcia akcji Żywiec S.A....................................................................................................................253Rysunek 2.13. Wynik finansowy netto Grupy Żywiec S.A. w latach 2001-2005 (mln zł) – trend logarytmiczny....................................................................................................259Rysunek 2.14. Prognoza sprzedaży map turystycznych
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki

STATYSTYKA PO LUDZKU – Paweł TatarzyckiSpis rysunków
str. 397
na okres dwóch najbliższych lat....................................................................................267Rysunek 2.15. Zmiany przychodów ze sprzedaży Grupy Żywiec SA w latach 2001-2005......................................................................................................................274Rysunek 3.1. Zbieżność prawdopodobieństwa do teoretycznej wartości 0,5................296Rysunek 3.2. Drzewo stochastyczne.............................................................................298Rysunek 3.3. Drzewo stochastyczne – przykład liczbowy............................................300Rysunek 3.4. Dystrybuanta rozkładu dwumianowego..................................................305Rysunek 3.5. Kształt funkcji gęstości rozkładu normalnego w zależności od parametrów m i σ ...............................................................................................................................315Rysunek 3.6. Funkcja gęstości standaryzowanego rozkładu normalnego.....................317Rysunek 3.7. Kształt funkcji gęstości rozkładu t-Studenta na tle funkcji gęstości rozkładu normalnego.....................................................................................................324Rysunek 3.8. Sposób odczytywania wartości krytycznej dla dwustronnego rozkładu t-Studenta.......................................................................................................................325Rysunek 3.9. Sposób odczytywania wartości krytycznej dla rozkładu chi-kwadrat.....328Rysunek 3.10. Sposób odczytywania wartości krytycznej dla rozkładu F....................330Rysunek 3.11. Klasyfikacja metod doboru jednostek statystycznych do próby...........334Rysunek 3.12. Prezentacja graficzna dwustronnego przedziału ufności (duża próba)..347Rysunek 3.13. Prezentacja graficzna sytuacji, w której należy odrzucić hipotezę zerową.............................................................................................................357Rysunek 3.14. Prezentacja graficzna sytuacji, w której nie ma podstaw do odrzucenia hipotezy zerowej............................................................................................................357Rysunek 3.15. Dwustronny zbiór krytyczny dla statystyki chi-kwadrat.......................374
Copyright by Wydawnictwo Złote Myśli & Paweł Tatarzycki


![Statystyka opisowa_zestaw1[1]](https://static.fdocuments.pl/doc/165x107/5571f8b049795991698de41e/statystyka-opisowazestaw11.jpg)















