
Maciej Zięba W rocaw University ofTechnology - ii.pwr.edu.plzieba/W6_PMWZI.pdf · Pre-training i...
56
Wroclaw University of Technology Uczenie glębokie Maciej Zięba
Transcript of Maciej Zięba W rocaw University ofTechnology - ii.pwr.edu.plzieba/W6_PMWZI.pdf · Pre-training i...

Wrocław University of Technology
Uczenie głębokie
Maciej Zięba

UCZENIE GŁĘBOKIE (ang. deep learning) =
klasa metod uczenia maszynowego,
gdzie model
ma strukturę hierarchiczną
złożoną z wielu
nieliniowych warstw
2/28

3/28

3/28

3/28

Wpływ uczenia głębokiego
4/28

Obszary zastosowań
Widzenie komputerowe
Wyszukiwanie informacji
Rozpoznawanie mowy
Analiza języka naturalnego
Systemy rekomendacji
Projektowanie leków
5/28
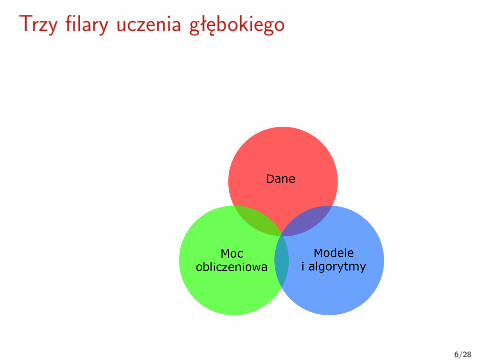
Trzy filary uczenia głębokiego
6/28
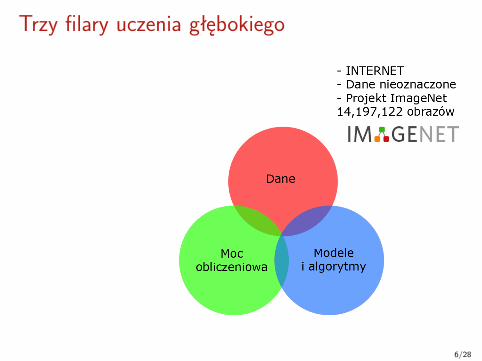
Trzy filary uczenia głębokiego
6/28
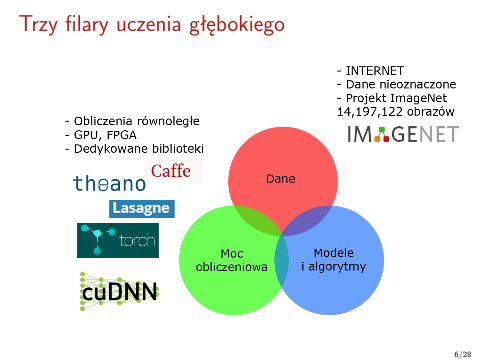
Trzy filary uczenia głębokiego
6/28

Przypomnienie: Regresja logistyczna
Model binarnej regresji logistycznej(ang. logistic regression):
p(y = 1|x,w) = σ(wTφ(x)).
Funkcja sigmoidalna (ang. sigmoidfunction):
σ(a) =1
1 + exp(−a)
Parametry modelu: w ∈ RM .
7/28
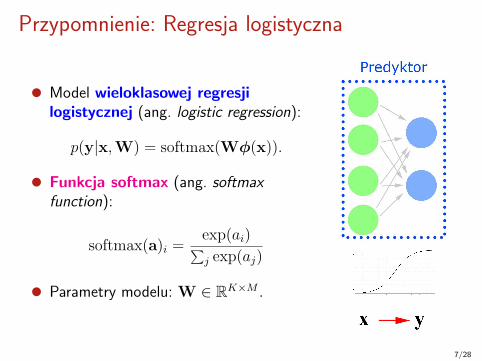
Przypomnienie: Regresja logistyczna
Model wieloklasowej regresjilogistycznej (ang. logistic regression):
p(y|x,W) = softmax(Wφ(x)).
Funkcja softmax (ang. softmaxfunction):
softmax(a)i =exp(ai)∑j exp(aj)
Parametry modelu:W ∈ RK×M .
7/28

Model Multilayer Perceptron
8/28
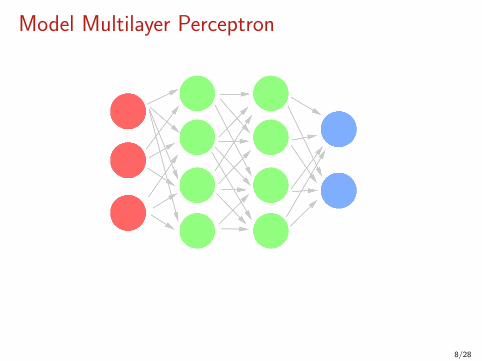
Model Multilayer Perceptron
8/28
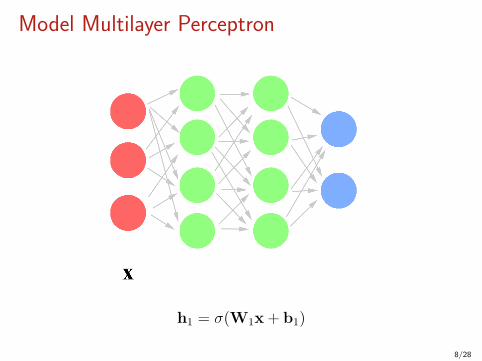
Model Multilayer Perceptron
h1 = σ(W1x+ b1)
8/28

Model Multilayer Perceptron
h2 = σ(W2h1 + b2)
8/28

Model Multilayer Perceptron
y = softmax(W3h2 + b3)
8/28

Model Multilayer Perceptron
h2 traktujemy jako cechy wyekstrahowane z x
8/28

Model Multilayer Perceptron
Predyktor to np. wieloklasowa regresja logistyczna
8/28

Model Multilayer Perceptron
8/28

Typowe funkcje aktywacji neuronów
Funkcja sigmoidalna:
σ(a) =1
1 + exp(−a)
Wartości: σ(a) ∈ (0, 1)Pochodna: σ(a)′ = σ(a)(1− σ(a))
Tangens hiperboliczny:
tgh(a) =exp(a)− exp(−a)exp(a) + exp(−a)
Wartości: tgh(a) ∈ (−1, 1)Pochodna: tgh(a)′ = 1− tgh2(a)
9/28

Automatyczna ekstrakcja cech
Cechy na kolejnych warstwach reprezentującoraz wyższy poziom abstrakcji: krawędzie,części obiektu, grupy części.
Pożądane własności cech:
Informacyjne (np. dyskryminujące)
Odporne (ang. robust)
Niezmiennicze (ang. invariant)
Lee et al. Convolutional Deep Belief Networks for Scalable Unsupervised Learning of Hierarchical Representations.
ICML 200910/28

Automatyczna ekstrakcja cech
Cechy na kolejnych warstwach reprezentującoraz wyższy poziom abstrakcji: krawędzie,części obiektu, grupy części.
Pożądane własności cech:
Informacyjne (np. dyskryminujące)
Odporne (ang. robust)
Niezmiennicze (ang. invariant)
Lee et al. Convolutional Deep Belief Networks for Scalable Unsupervised Learning of Hierarchical Representations.
ICML 200910/28

Czy głębokość ma znaczenie?
Twierdzenie o uniwersalnej aproksymacjiNiech D ⊂ RN ; Niech f : RN → R będzie ciągła i skończonana D. Dodatkowo niech y(x) =
∑i g(wTi x), gdzie g jest
ciągła, ograniczona i monotoniczna. Wówczas dla każdegoε > 0 istnieje taki zbiór {wi}, że dla każdego x ∈ RNzachodzi:
|y(x)− f(x)| < ε
Wystarczy zatem tylko jedna warstwa jednostek ukrytych,aby z dowolną precyzją aproksymować każdą funkcję ciągłą.
Ale. . .11/28

Czy głębokość ma znaczenie?W praktyce modele hierarchiczne potrzebują dużo mniejjednostek ukrytych (a zatem dużo mniej parametrów) douzyskania wysokiej jakości aproksymacji.
Przykładem może być problem parzystości ciągu bitów.Model płaski potrzebuje 2N jednostek ukrytych, model głębokiN(N − 1)/2.
12/28

Czy głębokość ma znaczenie?W praktyce modele hierarchiczne potrzebują dużo mniejjednostek ukrytych (a zatem dużo mniej parametrów) douzyskania wysokiej jakości aproksymacji.
Przykładem może być problem parzystości ciągu bitów.Model płaski potrzebuje 2N jednostek ukrytych, model głębokiN(N − 1)/2.
12/28

Uczenie sieci neuronowej Niech p(yk = 1|x,θ) k-te oznacza wyjście z sieci, gdzieθ = {W1,b1,W2, . . .}. Wtedy warunkowawiarygodność to:
p(Y|X,θ) =N∏n=1
K∏k=1
p(yk = 1|xn,θ)ynk
Biorąc ujemny logarytmy i dzieląc przez N dostajemykryterium uczenia zwane entropią krzyżową (ang.cross-entropy):
L(θ) = − 1N
N∑n=1
K∑k=1
ynk log p(yk = 1|xn,θ)
Uczyć możemy z użyciem stochastycznego gradientuprostego. Potrzebny gradient po wszystkich parametrach– metoda propagacji wstecznej (ang. backpropagation).
13/28

Uczenie i propagacja wsteczna
14/28

Uczenie i propagacja wsteczna
Np. entropia krzyżowa L(y, t) = −∑k
tk log yk
14/28

Uczenie i propagacja wsteczna
wij3 ← wij3 − η∂L
∂yi∂yi
∂wij3
14/28

Uczenie i propagacja wsteczna
wij2 ← wij2 − η∂L
∂hi2
∂hi2∂wij2
14/28
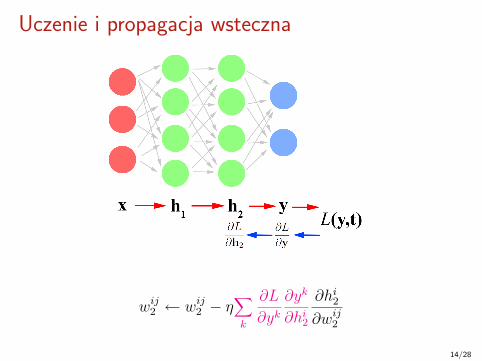
Uczenie i propagacja wsteczna
wij2 ← wij2 − η∑k
∂L
∂yk∂yk
∂hi2
∂hi2∂wij2
14/28

Uczenie i propagacja wsteczna
wij1 ← wij1 − η∂L
∂hi1
∂hi1∂wij1
14/28

Uczenie i propagacja wsteczna
wij1 ← wij1 − η∑l
∑k
∂L
∂yk∂yk
∂hl2
∂hl2∂hi1
∂hi1∂wij1
14/28

Problem zanikającego gradientuDla typowych funkcji aktywacji σ(x) i tgh(x) wartościpochodnych są zawsze w [0, 1].
W konsekwencji wyrażenia typu:
. . .∂hit+1∂hjt
∂hjt∂hkt−1
∂hkt−1∂hlt−2
. . .
często będą bliskie zeru.
Jest to zjawisko zanikającego gradientu (ang. vanishinggradient) i powoduje problem z wyuczeniem cech na niższychwarstwach.
Był to jeden z głównych powodów spowolnienia rozwoju siecineuronowych w latach 90.
15/28

Problem zanikającego gradientuDla typowych funkcji aktywacji σ(x) i tgh(x) wartościpochodnych są zawsze w [0, 1].
W konsekwencji wyrażenia typu:
. . .∂hit+1∂hjt
∂hjt∂hkt−1
∂hkt−1∂hlt−2
. . .
często będą bliskie zeru.
Jest to zjawisko zanikającego gradientu (ang. vanishinggradient) i powoduje problem z wyuczeniem cech na niższychwarstwach.
Był to jeden z głównych powodów spowolnienia rozwoju siecineuronowych w latach 90.
15/28

Problem zanikającego gradientuDla typowych funkcji aktywacji σ(x) i tgh(x) wartościpochodnych są zawsze w [0, 1].
W konsekwencji wyrażenia typu:
. . .∂hit+1∂hjt
∂hjt∂hkt−1
∂hkt−1∂hlt−2
. . .
często będą bliskie zeru.
Jest to zjawisko zanikającego gradientu (ang. vanishinggradient) i powoduje problem z wyuczeniem cech na niższychwarstwach.
Był to jeden z głównych powodów spowolnienia rozwoju siecineuronowych w latach 90.
15/28

Problem zanikającego gradientuDla typowych funkcji aktywacji σ(x) i tgh(x) wartościpochodnych są zawsze w [0, 1].
W konsekwencji wyrażenia typu:
. . .∂hit+1∂hjt
∂hjt∂hkt−1
∂hkt−1∂hlt−2
. . .
często będą bliskie zeru.
Jest to zjawisko zanikającego gradientu (ang. vanishinggradient) i powoduje problem z wyuczeniem cech na niższychwarstwach.
Był to jeden z głównych powodów spowolnienia rozwoju siecineuronowych w latach 90.
15/28

Pre-training i fine-tuning
Problem zanikającego gradientu możnarozwiązać stosując tzw. pre-training, czyliuczenie wstępne.
Polega to na nauczeniu warstwa powarstwie modelu nienadzorowanegozłożonego z warstw sieci, np. głębokiegoautokodera.
Wyczuone parametry traktujemy jakopunkt startowy dla algorytmubackpropagation. Jest to tzw. fine-tuning.
Hinton, Salakhutdinov. Reducing the Dimensionality of Data with Neural Networks. Science 2006
16/28

Pre-training i fine-tuning
Problem zanikającego gradientu możnarozwiązać stosując tzw. pre-training, czyliuczenie wstępne.
Polega to na nauczeniu warstwa powarstwie modelu nienadzorowanegozłożonego z warstw sieci, np. głębokiegoautokodera.
Wyczuone parametry traktujemy jakopunkt startowy dla algorytmubackpropagation. Jest to tzw. fine-tuning.
Hinton, Salakhutdinov. Reducing the Dimensionality of Data with Neural Networks. Science 2006
16/28
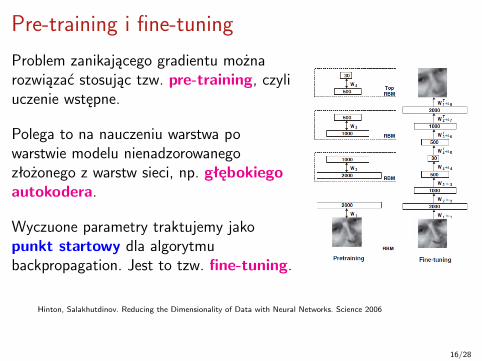
Pre-training i fine-tuning
Problem zanikającego gradientu możnarozwiązać stosując tzw. pre-training, czyliuczenie wstępne.
Polega to na nauczeniu warstwa powarstwie modelu nienadzorowanegozłożonego z warstw sieci, np. głębokiegoautokodera.
Wyczuone parametry traktujemy jakopunkt startowy dla algorytmubackpropagation. Jest to tzw. fine-tuning.
Hinton, Salakhutdinov. Reducing the Dimensionality of Data with Neural Networks. Science 2006
16/28

Jednostki ReLUJednostki ReLU (ang. Rectified LinearUnit) są to funkcje aktywacji o postaci:
f(x) = max(0, x)
Dzięki nim:
Nie ma zanikającego gradientu i niepotrzeba uczenia wstępnego
Uczymy się bardziej odpornych cechdzięki rzadkiej (ang. sparse) aktywacjijednostek
Uczenie trwa dużo szybciej
Nair, Hinton. Rectified Linear Units Improve Restricted Boltzmann Machines. ICML 2010
17/28

Jednostki ReLUJednostki ReLU (ang. Rectified LinearUnit) są to funkcje aktywacji o postaci:
f(x) = max(0, x)
Dzięki nim:
Nie ma zanikającego gradientu i niepotrzeba uczenia wstępnego
Uczymy się bardziej odpornych cechdzięki rzadkiej (ang. sparse) aktywacjijednostek
Uczenie trwa dużo szybciej
Nair, Hinton. Rectified Linear Units Improve Restricted Boltzmann Machines. ICML 2010
17/28

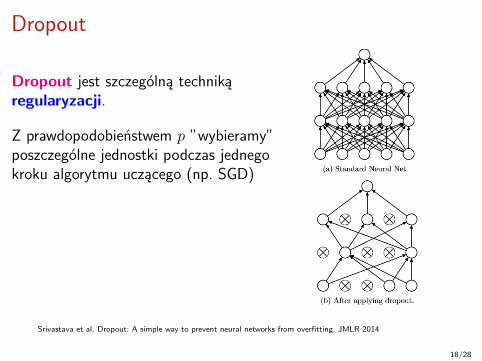
Dropout
Dropout jest szczególną technikąregularyzacji.
Z prawdopodobieństwem p ”wybieramy”poszczególne jednostki podczas jednegokroku algorytmu uczącego (np. SGD)
Wyuczone cechy są bardziej odporne naniewielkie perturbacje w danych, dziękiczemu uzyskujemy wyższą jakośćkońcowego klasyfikatora.
Srivastava et al. Dropout: A simple way to prevent neural networks from overfitting. JMLR 2014
18/28
Dropout
Dropout jest szczególną technikąregularyzacji.
Z prawdopodobieństwem p ”wybieramy”poszczególne jednostki podczas jednegokroku algorytmu uczącego (np. SGD)
Wyuczone cechy są bardziej odporne naniewielkie perturbacje w danych, dziękiczemu uzyskujemy wyższą jakośćkońcowego klasyfikatora.
Srivastava et al. Dropout: A simple way to prevent neural networks from overfitting. JMLR 2014
18/28

Dropout
Dropout jest szczególną technikąregularyzacji.
Z prawdopodobieństwem p ”wybieramy”poszczególne jednostki podczas jednegokroku algorytmu uczącego (np. SGD)
Wyuczone cechy są bardziej odporne naniewielkie perturbacje w danych, dziękiczemu uzyskujemy wyższą jakośćkońcowego klasyfikatora.
Srivastava et al. Dropout: A simple way to prevent neural networks from overfitting. JMLR 2014
18/28

Sieci konwolucyjne CNN (ang. convolutional nets)
Liczba parametrów w warstwie:
l. kanałów× szerokość filtra× wysokość filtra× l. filtrów
Liczba jednostek ukrytych w warstwie:
szerokość obrazu× wysokość obrazu× l. filtrów
Sieci uczą się cech niezmienniczych na translacje.
LeCun et al. Gradient-Based Learning Applied to Document Recognition. Proc. of IEEE 1998
19/28

Warstwa konwolucyjna
Filtry są nakładane na zasadzie okna przesuwnego. Ideawspółdzielenia parametrów (ang. parameter sharing).
Warstwy konwolucyjne ekstrahują cechy z lokalnychfragmentów.
Używa się standardowych funkcji aktywacji: ReLU,sigmoida, tanh.
Images from S. Lazebnik presentation
20/28

Pooling
Pooling służy do lokalnego skompresowania informacji.
Zmniejsza liczbę parametrów, uodparnia sieć na drobnelokalne zaburzenia na obrazie i zbiera informację zszerszego obszaru.
Używa się funkcji max albo sum na lokalnym fragmencie.
Images from S. Lazebnik presentation
21/28

Normalizacja map cech
Normalizacja może być wewnątrz pojedynczej mapycech z lokalnego otoczenia dla każdego piksela albopoprzez przekrój kilku map cech dla każdego pikselaosobno.
Normalizacja ma na celu wyrównanie znaczeniaaktywacji o różnej sile.
Images from S. Lazebnik presentation
22/28

Sieć ImageNet
Model, który zwyciężył w konkursie ImageNet w 2012. 5 warstw konwolucyjnych + 2 warstwy pełne Jednostki ReLU i Dropout w najwyższej warstwie 60 milionów parametrów. 1.2 mln obrazów treningowych. Klasyfikacja do 1000 klas. Uczenie na dwóch GPU przez tydzień. Błąd 16.4%, drugie miejsce – 26.2%.
Krizhevsky et al. ImageNet Classification with Deep Convolutional Neural Networks. NIPS 2012
23/28

Sieć ImageNet – filtry konwolucyjne
Filtry wyuczone na pierwszej warstwie konwolucyjnej
24/28

Sieć ImageNet – filtry konwolucyjne
Zeiler, Fergus. Visualizing and Understanding Convolutional Networks. ECCV 2014
25/28

Sieć ImageNet – filtry konwolucyjne
26/28

Sieć ImageNet – filtry konwolucyjne
27/28

Sieć ImageNet – wyniki
28/28


















