
CROSSDOCKING A OPTYMALIZACJA …keiran.wdfiles.com/local--files/bo-dokumentacja/...Taki kształt...
33
Wydział Elektrotechniki, Automatyki, Informatyki i Elektroniki CROSS-DOCKING A OPTYMALIZACJA SYSTEMÓW KOLEJKOWYCH BADANIA OPERACYJNE – PROJEKT INFORMATYKA II opracowano pod nadzorem: prof. zw. dr hab. inż. Bogusław Filipowicz Kraków, czerwiec 2008
Transcript of CROSSDOCKING A OPTYMALIZACJA …keiran.wdfiles.com/local--files/bo-dokumentacja/...Taki kształt...

Wydział Elektrotechniki, Automatyki, Informatyki i Elektroniki
CROSSDOCKING A OPTYMALIZACJA SYSTEMÓW KOLEJKOWYCH
BADANIA OPERACYJNE – PROJEKTINFORMATYKA II
opracowano pod nadzorem:prof. zw. dr hab. inż. Bogusław Filipowicz
Kraków, czerwiec 2008

Skład grupy projektowej:
Koordynacja:Dawid Ciepliński
Część teoretyczna:Paweł BaraKonrad Delong
Implementacja symulacji:Mariusz BalawajderRobert BoczekRafał CiborBartosz CzerwińskiPiotr DolińskiAdam Kudła
Algorytm genetyczny:Łukasz Wiatrak
GUI:Krzysztof CywickiGrzegorz Baranik

Spis treści
1. Wstęp teoretyczny. 4• pre i postdystrybucja 5• ilość poziomów magazynu 5
2. Sprecyzowanie i formalizacja problemu. 7
3. Implementacja. • symulacja 9• algorytm genetyczny 10• metoda sympleksów 11
4. Funkcjonalność programu. 12
5. Przykładowe testy. • test I 17• test II 20• test III 22• test IV 25• test V 28
6. Zastosowanie i wnioski. 32
7. Bibliografia. 33

1. Wstęp teoretyczny.
Crossdock to typ przeładunku (tzw. przeładunek kompletacyjny) pozwalający na szybką dystrybucję towarów. Idea crossdock'u opiera się na spostrzeżeniu, że skoro przybywający do magazynu towar został wcześniej zamówiony przez klienta, to nie ma konieczności jego przechowywania. Wprost przeciwnie, towar może być bezpośrednio przeładowany na odbierającą ciężarówkę i przetransportowany dalej. Dzięki temu rozmiar magazynu znacząco się zmniejsza i unika się kosztownych opłat za metraż.
W magazynach o dużej pojemności czas obrotu może być mierzony nawet w godzinach. Aby podołać takiemu tempu, magazyn nie może być niczym więcej, jak budynkiem z terminalami do ładowania i rozładowywania przyczep. Przybywający ładunek jest zdejmowany, sortowany i etykietowany (jeśli producent nie zrobił tego wcześniej), po czym ładuję się go na odjeżdżające ciężarówki po drugiej stronie budynku.
Rys. 1. Idea crossdockingu.
Ponieważ czas jaki towar spędza w magazynie jest bardzo krótki, nie przeznacza się (lub przeznacza nieznaczne ilości) miejsca na składowanie paczek. Zamiast tego występuje dużo sprzętu do przewożenia czy przenoszenia towaru, jak np. podnośniki widłowe. Głównym kosztem jest praca związana z załadunkiem i przemieszczaniem towarów do odpowiednich terminali, w związku z czym, zamiast zajmować się rozmieszczeniem towaru w magazynie, rozważa się przede wszystkim zagadnienia dotyczące sposobu przepływu ładunku przez ten magazyn.

Spróbujmy scharakteryzować crossdocking ze względu na dwa typy podziału:
1. Pre i postdystrybucja.
Predystrybucja występuje, gdy producenci etykietują towar nim ten dotrze do magazynu. Robotnicy jedynie sortują palety i przenoszą je do kolejek związanych z odpowiednimi ciężarówkami na wyjściu. Ten rodzaj dystrybucji sprawia więcej trudności sprzedawcom, bowiem wymaga niemalże doskonałej wymiany informacji z producentem. Należy jednak pamiętać, że taki rozkład zadań ułatwia z kolei obsługę ładunku w magazynie oraz wymaga mniej miejsca, bowiem nie ma potrzeby rozkładania towaru na podłodze w celu jego etykietowania.
Przy postdystrybucji miejsce wyjazdu danej paczki ustala się dopiero w magazynie. Przykładowo, po otrzymaniu 40 palet z pewnym towarem, robotnicy mogą wysłać dwie z nich do odbiorcy A, 5 do odbiorcy B, itd., a wszystko to w zależności od aktualnej listy zamówień. Magazyn musi być szerszy niż w przypadku predystrybucji, bo wymagana jest przestrzeń na etykietowanie paczek. Dodatkowo towar spędza więcej czasu w magazynie.
2. Ilość poziomów magazynu.
Magazyn typu singlestage ma jeden poziom kolejek. Kolejki mogą być przyporządkowane wejściom (sortowanie towarów po usunięciu z kolejki) lub wyjściom (sortowanie towarów przed umieszczeniem w kolejce). Jako, że w przypadku postdystrybucji w momencie przybycia towaru, nie jesteśmy w stanie określić dokąd on zostanie wysłany, kolejki wiążemy z terminalami wejściowymi. Przy predystrybucji obowiązuje dowolność wyboru.
Rys. 2. Magazyn typu singlestage.

Typ twostage posiada dwa poziomy kolejek. Na pierwszym z nich składuje się palety z towarem od poszczególnych dostawców. To tu, na wyjściu, etykietuje się towar (jeśli nie zrobił tego producent), a następnie przydziela go do kolejek odpowiadających konkretnym odbiorcom (poziom drugi). Taki typ magazynu umożliwia lepsze upakowanie towaru na paletach, wymaga jednak szerszego magazynu i wydłuża proces przeładunku (przenoszenie paczek między kolejkami).
Rys. 3. Magazyn typu twostage.
Zajmiemy się teraz opisem samych kolejek. Po załadowaniu palety towarem, pracownicy na wejściu przesuwają ją jak najbliżej wyjścia odpowiedniej kolejki. Tam inna grupa pracowników pobiera palety, dostarczając je do odpowiadającego kolejce terminala wyjściowego. Ponieważ linie przeładunkowe są wąskie sprowadza się to do tego, że ludzie z załadunku wyciągają z kolejki pierwszą dostępną paletę, a ludzie z rozładunku wsuwają palety na pierwszą wolną pozycję kolejki. Nie jest to typowy model FIFO, bowiem po usunięciu elementu z linii przeładunkowej, pozostałe paczki w niej występujące nie zostają dosunięte do jej początku.
Rys. 4. Flowrack.
Należy jeszcze nadmienić, że istnieje alternatywa do palet, czyli tzw. flow racks, umożliwiające i automatyzujące proces przepływu towaru na pierwsze wolne miejsce kolejki. Ich zastosowanie wiąże się ze znaczną zmianą sposobu działania linii rozładunkowej i zbliżeniem jej modelu do modelu FIFO.

2. Sprecyzowanie i formalizacja problemu.
Towary przyjeżdżają od dostawców do magazynu, gdzie są segregowane, po czym natychmiast odjeżdżają do celu, w dalszą drogę.
Nasz magazyn przepływowy będzie należał do sklepu internetowego. Sklep dostaje zamówienie za pośrednictwem swojej witryny, a następnie sam składa zamówienie u odpowiedniego dostawcy dysponującego potrzebnym towarem. Jeżeli w sąsiadujących odcinkach czasu notujemy wiele zamówień o podobnej treści, nic nie stoi na przeszkodzie by jeden dostawca dostarczył produkty, które potem rozdzielimy między wielu klientów. Zakładamy wersję singlestage (jedna sieć kolejek) oraz predistribution, czyli to nasi dostawcy zajmują się etykietowaniem paczek.
W momencie złożenia zamówienia przez klienta naszego sklepu, do jednego z wyjść magazynu kierowany jest samochód przewozowy, który będzie czekał na przyjazd dostawców. Dostawcy przywożący potrzebny towar podjeżdżają do wolnego wejścia. To tu pracownicy posortują ładunek i za pośrednictwem kolejki przekażą go do odpowiedniego samochodu dostawczego na wyjściu. Po skompletowaniu zamówienia samochód taki odjeżdża zgłoszenie uznajemy za obsłużone.
Problem wygląda następująco: mamy sekcje wejściową i wyjściową magazynu, połączone siecią kolejek. Każdemu wejściu odpowiada dokładnie jedno wyjście i jedna kolejka. Pracownicy, podzieleni na stałe na dwie grupy, zajmują się obiema sekcjami. Ci na wejściu rozładowują transporty dostawców i umieszczają je na podstawie etykiet w kolejkach do odpowiednich wyjść. Jako, że samochód dostawcy może wieźć towary dla wielu osób, zadaniem tej grupy pracowników jest segregacja. Pracownicy na wyjściu pobierają jedynie paczki z kolejki i umieszczają je na samochodzie utożsamianym z naszym zamówieniem. W obu przypadkach nie jest powiedziane, że dany pracownik odpowiada na stałe danej kolejce – pracuje tam, gdzie jest potrzebny. Jako, że opieramy się na tzw. flowrackach, kolejki działają zgodnie ze zwykłym modelem FIFO. Jest ich m, a każda mieści k paczek z towarem.
Mówimy tu o sieci m niezależnych, ale identycznych kolejek. Strumień wejściowy kształtowany jest przez kilka rozkładów zmiennych losowych:a) na wejściu pojawiają się paczki, każda z nich należy do któregoś z aktualnych zamówieńb) w momencie, gdy w systemie pojawia się nowe zgłoszenie, losowana jest ilość paczek dla tego zamówienia (tzn. ilość paczek, które zostaną odebrane ze strumienia wejściowego, nim zgłoszenie zostanie uznane za obsłużone)
Każda paczka zdejmowana z kolejki strumienia wejściowego należy do któregoś z zamówień. Opiszemy teraz sposób wyznaczania tego zamówienia.
Załóżmy, że w momencie t w systemie znajdują się zamówienia Z1
t , Z 2 t , ... , Zn
t . Dla każdego z nich określamy n it , czyli liczbę paczek, które

muszą się jeszcze pojawić na wejściu systemu i zostać obsłużone, aby dane zgłoszenie można było uznać za zrealizowane. Jeżeli n i
t =0 , to
prawdopodobieństwo pojawienia się na wejściu paczki z zamówienia i wynosi pi t=0 . Jeżeli natomiast n i
t !=0 , to prawdopodobieństwo tego, że następna pojawiająca się paczka będzie należeć do zamówienia i wynosi:
pi t=
n i t
∑ n jt
Taki wzór oznacza, że to, jaka paczka pojawi się na wejściu zależy ściśle od tego, jakie paczki pojawiały się na wejściu wcześniej, co oznacza, że strumień wejściowy taśm przeładunkowych nie jest strumieniem prostym, jego natężenie zmienia się bowiem w czasie i zależy od historii zgłoszeń.
Taki kształt strumienia utrudnia analityczne podejście do systemu. To, do której z kolejek przydzielamy paczkę nie zależy tylko od tego która z kolejek jest aktualnie wolna / w której jest najwięcej miejsc, ale również od tego, do którego ze zgłoszeń paczka należy. Z tego powodu zdecydowaliśmy się na symulację.
Cel, jaki sobie postawiliśmy, to minimalizacja powierzchni magazynu i ilości pracowników (a więc de facto kosztów utrzymania magazynu), przy warunku, że firma wciąż musi być w stanie obsłużyć zadaną ilość zamówień w ciągu doby. Wprowadzamy dodatkowo funkcję wagową (bo koszty pracowników mogą być w zależności od kraju większe niż koszty utrzymania magazynu, tudzież odwrotnie) i otrzymujemy poglądowy obiekt minimalizacji:
F=w1∗k∗m w
2∗p
l , gdzie:
k – ilość kolejek, m – ilość miejsc w kolejce,pl – łączna ilość pracowników, w1, w2 wagi
Zarówno symulację, jak i algorytm genetyczny piszemy w C++, aby osiągnąć jak najlepszą efektywność złożonych operacji. W celu sprawdzenia poprawności działania algorytmu genetycznego odwołujemy się do deterministycznej metody sympleksów pochodzącej z darmowej biblioteki numerycznej GSL.

3. Implementacja.
3.1. SymulacjaDziałaniem symulacji steruje moduł zegara, który jest odpowiedzialny za
wywoływanie w odpowiedniej kolejności metod step poszczególnych elementów:
1. Zarządca wejścia (klasa DoorManager). 2. Planista wyjścia (klasa Planner). 3. Moduł statystyk (klasy LocalStat i GlobalStat).
Rys. 5. Schemat symulacji.
3.1.1. Zarządca wejścia.
W każdej iteracji tworzy pewną ilość zamówień o losowej ilości paczek w każdym z nich. Liczba zamówień i paczek są dane rozkładem Poissona o parametrach λZ i λP definiowanych przez użytkownika przed uruchomieniem symulacji. Po wygenerowaniu nowych paczek, jeżeli są dostępni wolni pracownicy, zarządca podejmuje próbę przydzielenia paczek z wejścia do odpowiednich kolejek.

3.1.2. Planista wyjścia.
Jeśli istnieją niepuste kolejki, przydzielani są do nich pracownicy ładujący paczki na odjeżdżające ciężarówki. Przydział do kolejek jest realizowany na podstawie:
• zapełnienia kolejki • ilości nieobsłużonych paczek dla zamówienia aktualnie przypisanego do
kolejki• długości czasu pozostałego do przekroczenia deadline’u
3.1.3. Moduł statystyk.
Moduł statystyk na koniec każdej z iteracji aktualizuje informacje o:
• czasie “życia” paczki równym różnicy czasów: stworzenia paczki i opuszczenia magazynu
• czasie dojazdu paczki do magazynu • czasie pobytu paczki w magazynie
Dodatkowo moduł zbiera informacje o liczbie paczek wygenerowanych, aktualnie obsługiwanych i już obsłużonych.
3.2. Algorytm genetycznyPrzypomnijmy, że funkcja celu dana jest wzorem:
f wm , wn , qs , qn=C 1wmwnC2qnC 3qs , dla t stmax
oraz
f wm , wn , qs , qn=∞ , dla t s≥tmax
Poszczególne parametry wzoru mają następujące znaczenie:
wm – ilość pracowników na wejściuwn – ilość pracowników na wyjściuqs – długość kolejki (taśmy przeładunkowej)qn – ilość kolejekC1 – koszt zatrudnienia pracownikaC2 – koszt utrzymania powierzchni potrzebnej do obsługi kolejkiC3 – koszt utrzymania fragmentu kolejki o rozmiarze mieszczącym jedną paczkęts – średni czas przebywania paczki w systemietmax – maksymalny dopuszczalny czas przebywania paczki w systemie

Funkcja ta niestety nie spełnia warunków narzucanych przez algorytmy genetyczne. Przede wszystkim problem polega na minimalizacji funkcji celu, podczas gdy algorytmy takie funkcje celu maksymalizują. Zamieńmy nasz problem na problem dualny:
gwm ,wn , qs , qn= f max− f wm , wn , qs , qn , dla tstmax
oraz
gwm ,wn , qs , qn=0, dlat s≥tmax
fmax wyznaczamy poprzez podstawienie maksymalnych dopuszczalnych wartości dla wszystkich czterech parametrów.
Teraz krzyżując wyniki poszczególnych symulacji dążymy do uzyskania optymalnej konfiguracji parametrów roboczych magazynu.
3.3. Metoda sympleksówMetoda ta jest to prosta i stabilna, ale powoli zbieżna. Funkcja celu jest wyrażona wzorem:
f x1 , x2 , x3 , x4 =c1∗x1x2c2∗x3c3∗x4∗ stu∗pspt
w , gdzie:
x1 – ilość pracowników na wejściux2 – ilość pracowników na wyjściux3 – ilość taśmx4 – długość taśmy
wartości zależne od symulacji:ps – liczba obsłużonych paczek w pojedynczej iteracjipt – liczba wygenerowanych paczek w symulacjist – średni czas pobytu paczki w systemie
wartości stałe:c1 – koszt utrzymania pracownikac2 – koszt utrzymania taśmyc3 – koszt utrzymania jednostki długości taśmyu – współczynnik określający wagę parametru stw – współczynnik określający wagę stosunku wartości ps do pt

4. Funkcjonalność programu.
Interface głównej części programu pozwala:
– przeprowadzić symulację magazynu dla danych parametrów wejściowych; dane wyjściowe reprezentowane są w postaci pięciu rodzajów wykresów
– dokonać optymalizacji funkcji celu z wykorzystaniem algorytmu genetycznego– dokonać optymalizacji funkcji celu z wykorzystaniem metody simpleks
Całość wygląda następująco:
Rys. 6. GUI.

Użytkownik może z poziomu GUI sterować wszystkimi parametrami aplikacji. Są to:
• pracownicy:– ilość pracowników zatrudnionych na wejściu\wyjściu– wydajność pracy pracowników („czas przenoszenia”) wyrażona w ilości iteracji
koniecznych do obsłużenia paczki
• magazyn:– ilość kolejek– długość każdej z kolejek
• parametry rozkładu:– średnia ilość paczek na zamówienie– średnia ilość zamówień na iterację– maksymalny czas oczekiwania ciężarówki w jednostkach czasu (0 oznacza brak
deadline'u)
• algorytm genetyczny:– maksymalny numer pokolenia– wielkość populacji– prawdopodobieństwo krzyżowania– prawdopodobieństwo mutacji– maksymalny czas przebywania paczki w systemie– koszt utrzymania pracownika– koszt utrzymania taśmy długości 0– koszt utrzymania fragmentu taśmy
• wybór wykresów
• ilość iteracji w każdej symulacji
Program jako całość ma za zadanie znaleźć taki rozkład oraz ilość pracowników, a także kształt magazynu, żeby budynek był jak najtańszy w utrzymaniu i jednocześnie spełniał wymagania sklepu co do przepustowości.
Parametry rozkładu oraz ilość pracowników to współczynniki znane użytkownikowi aplikacji z analizy pracy jego aktualnego magazynu. Sterują one rozkładem oraz tempem pracy podczas symulacji.
Koszty utrzymania magazynu są również znane użytkownikowi. Wszystkie trzy odgrywają ważną rolę w naszej funkcji celu. Dzięki nim jesteśmy w stanie określić, który wyjściowy parametr jest najbardziej opłacalny pod względem optymalizacji.
Kosztom utrzymania budynku należy się osobne wyjaśnienie. Koszt utrzymania taśmy długości 0 charakteryzuje cenę jaką płacimy za utrzymanie
powierzchni poza kolejką, tzn. tej, którą zajmują robotnicy. Koszt utrzymania fragmentu taśmy z kolei jest opłatą za metraż równy powierzchni jednej paczki.
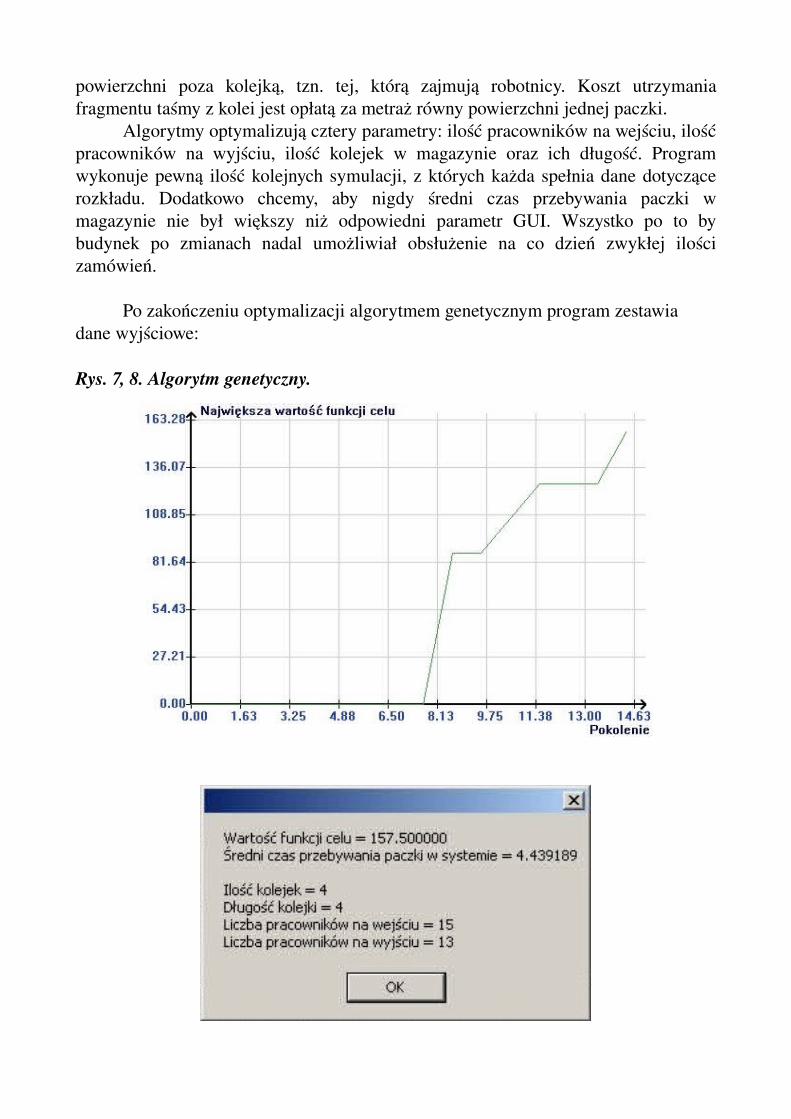
Algorytmy optymalizują cztery parametry: ilość pracowników na wejściu, ilość pracowników na wyjściu, ilość kolejek w magazynie oraz ich długość. Program wykonuje pewną ilość kolejnych symulacji, z których każda spełnia dane dotyczące rozkładu. Dodatkowo chcemy, aby nigdy średni czas przebywania paczki w magazynie nie był większy niż odpowiedni parametr GUI. Wszystko po to by budynek po zmianach nadal umożliwiał obsłużenie na co dzień zwykłej ilości zamówień.
Po zakończeniu optymalizacji algorytmem genetycznym program zestawia dane wyjściowe:
Rys. 7, 8. Algorytm genetyczny.
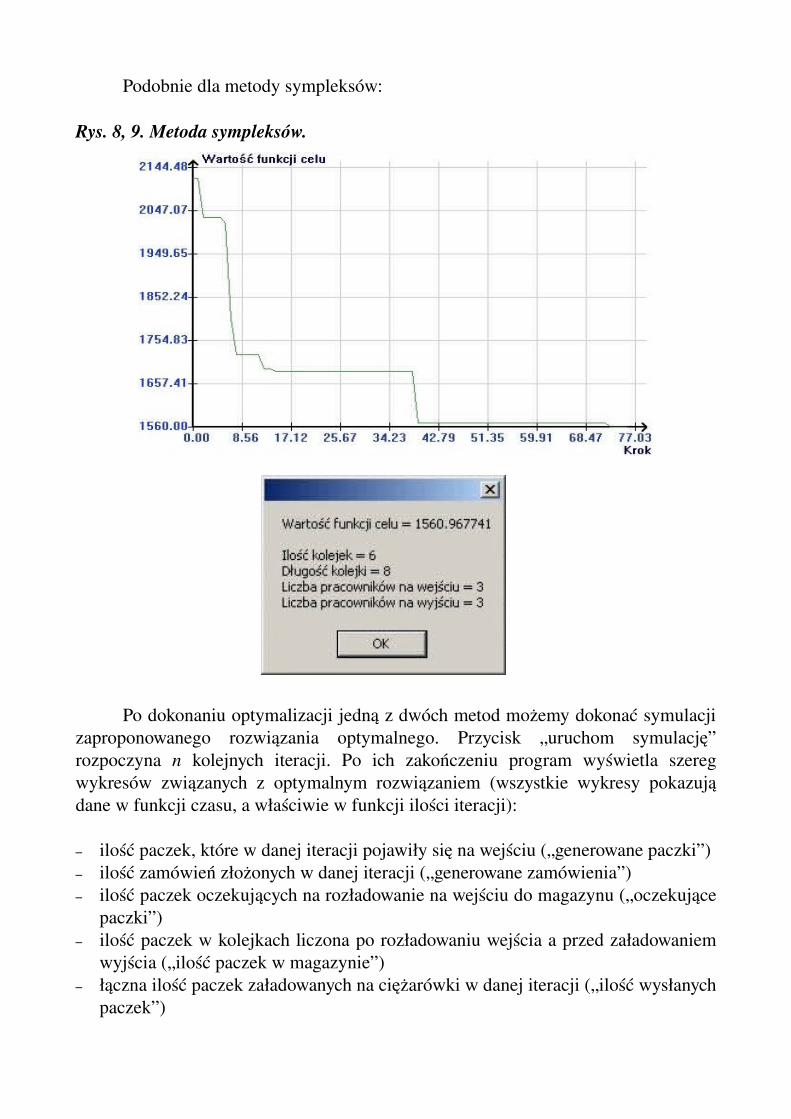
Podobnie dla metody sympleksów:
Rys. 8, 9. Metoda sympleksów.
Po dokonaniu optymalizacji jedną z dwóch metod możemy dokonać symulacji zaproponowanego rozwiązania optymalnego. Przycisk „uruchom symulację” rozpoczyna n kolejnych iteracji. Po ich zakończeniu program wyświetla szereg wykresów związanych z optymalnym rozwiązaniem (wszystkie wykresy pokazują dane w funkcji czasu, a właściwie w funkcji ilości iteracji):
– ilość paczek, które w danej iteracji pojawiły się na wejściu („generowane paczki”)– ilość zamówień złożonych w danej iteracji („generowane zamówienia”)– ilość paczek oczekujących na rozładowanie na wejściu do magazynu („oczekujące
paczki”)– ilość paczek w kolejkach liczona po rozładowaniu wejścia a przed załadowaniem
wyjścia („ilość paczek w magazynie”)– łączna ilość paczek załadowanych na ciężarówki w danej iteracji („ilość wysłanych
paczek”)

W oczekiwaniu na wynik symulacji można przyjrzeć się pracy magazynu:
Rys. 10. Animacja magazynu.
Wizualizację wyświetla się przyciskiem „pokaż magazyn”. Obraz prezentuje pracowników na wejściu\wyjściu, walczących z zapełniającymi się kolejkami magazynu przepływowego. Wszystko to dla danych zgodnych z tymi podanymi przez użytkownika pod kątem symulacji (ilość pracowników, ilość kolejek, długość kolejek).
5. Przykładowe testy.
Przedstawimy teraz wyniki pięciu testów przeprowadzonych dla różnych parametrów wejściowych.
5.1. Test I.
pracowników na wejściu = 10pracowników na wyjściu = 10czasy przenoszenia = 1średnia ilość paczek na zamówienie = 2.2średnia ilość zamówień na iterację = 2max czas oczekiwania ciężarówki = 0ilość kolejek = 10długość kolejki = 10
Rys. 11. Test I – Wykres 1.
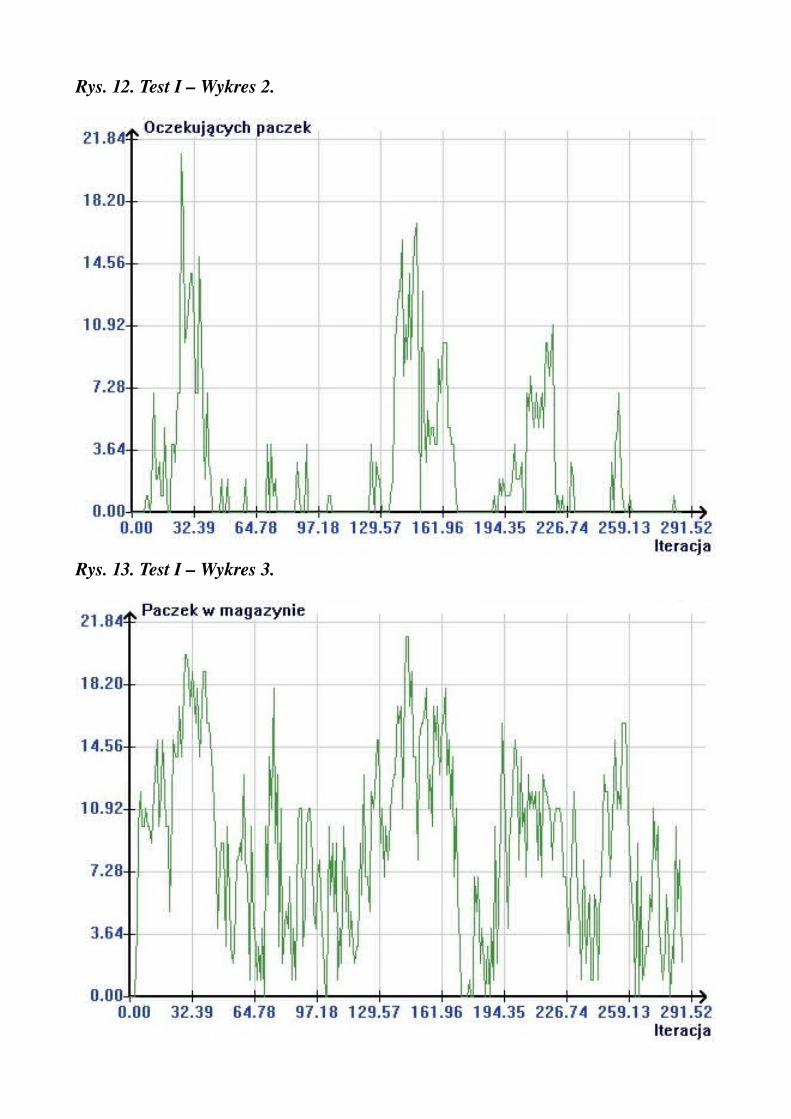
Rys. 12. Test I – Wykres 2.
Rys. 13. Test I – Wykres 3.
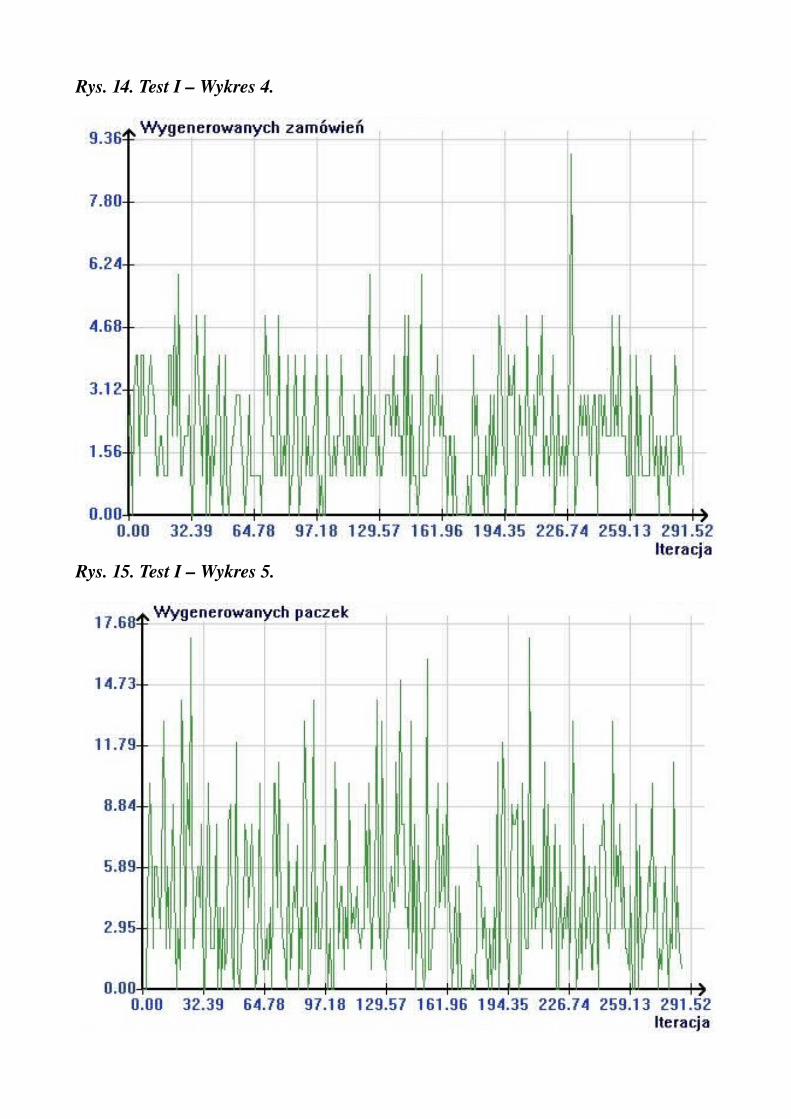
Rys. 14. Test I – Wykres 4.
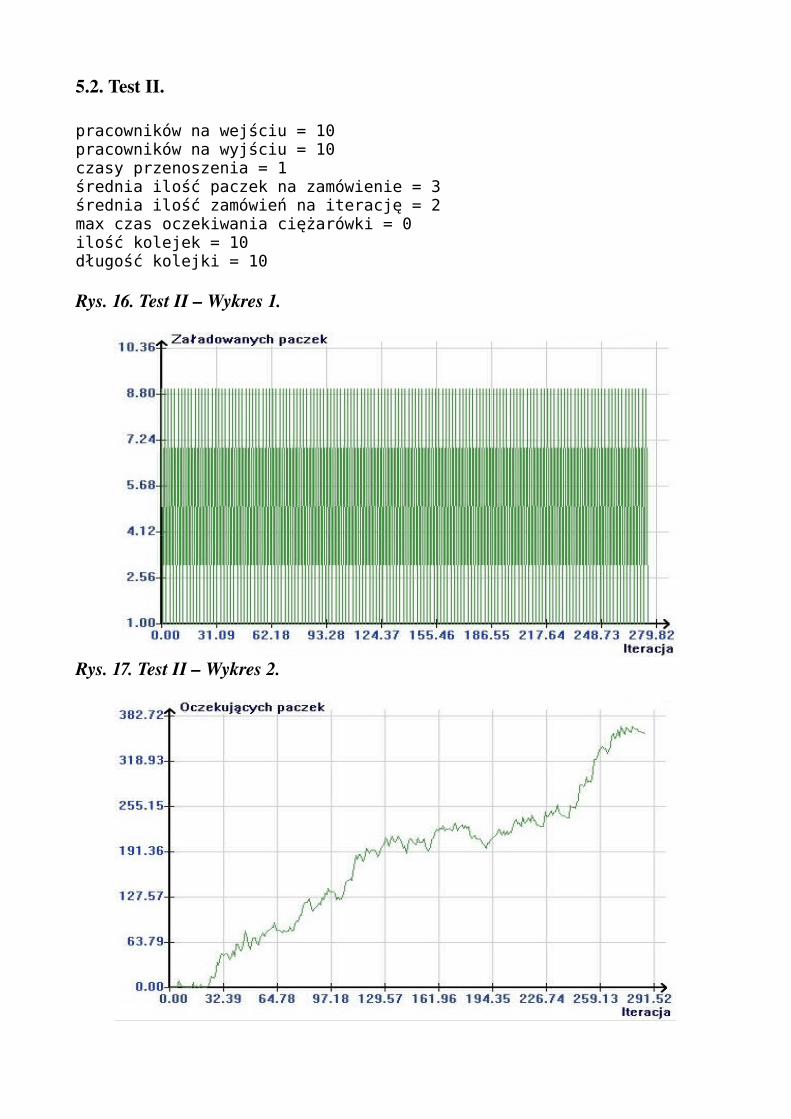
Rys. 15. Test I – Wykres 5.
5.2. Test II.
pracowników na wejściu = 10pracowników na wyjściu = 10czasy przenoszenia = 1średnia ilość paczek na zamówienie = 3średnia ilość zamówień na iterację = 2max czas oczekiwania ciężarówki = 0ilość kolejek = 10długość kolejki = 10
Rys. 16. Test II – Wykres 1.
Rys. 17. Test II – Wykres 2.
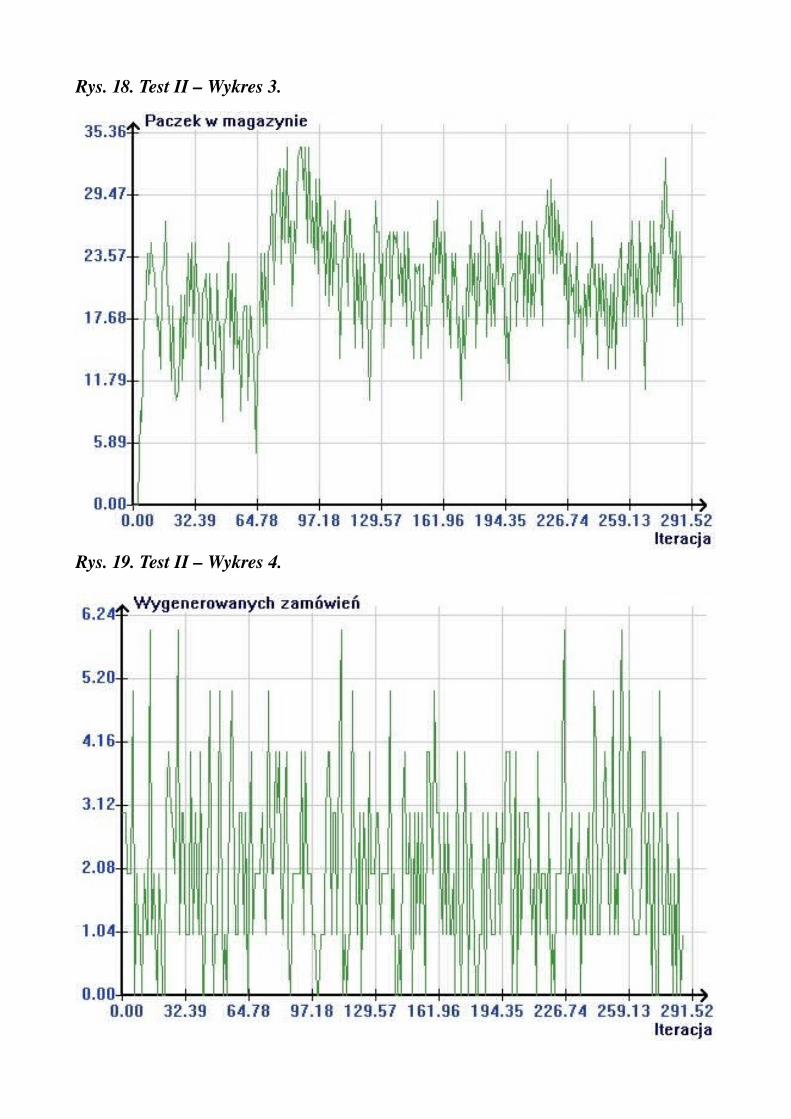
Rys. 18. Test II – Wykres 3.
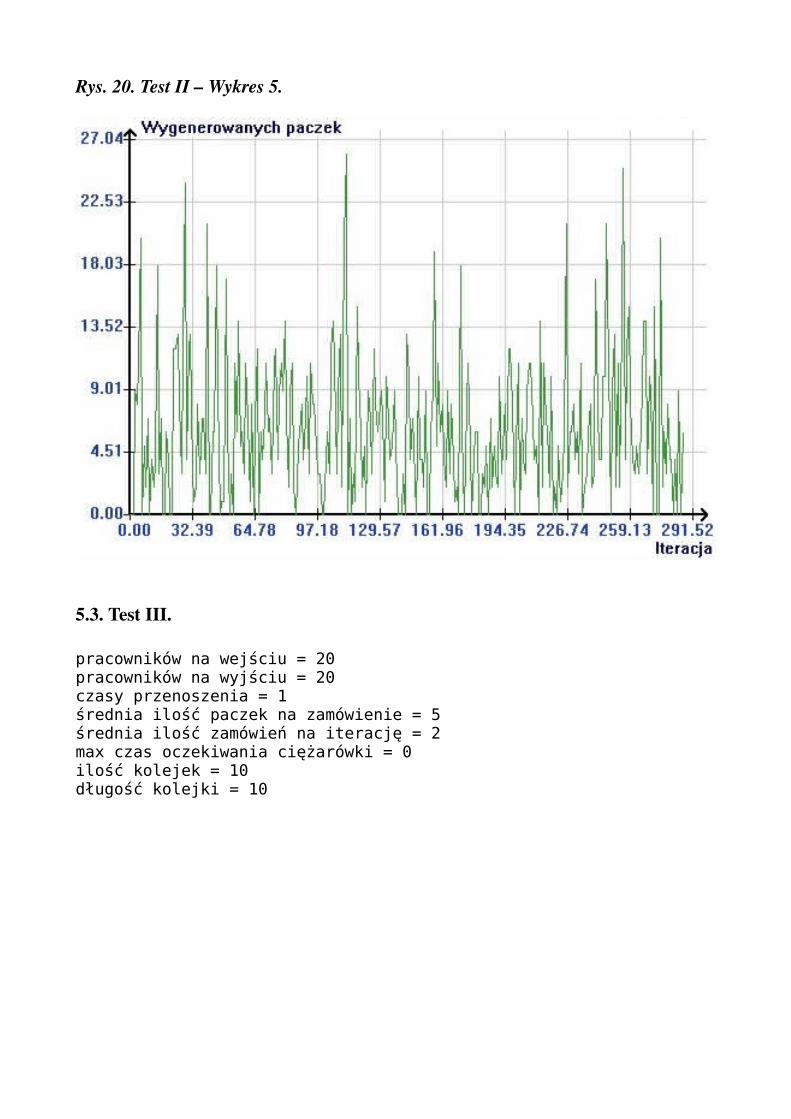
Rys. 19. Test II – Wykres 4.
Rys. 20. Test II – Wykres 5.
5.3. Test III.
pracowników na wejściu = 20pracowników na wyjściu = 20czasy przenoszenia = 1średnia ilość paczek na zamówienie = 5średnia ilość zamówień na iterację = 2max czas oczekiwania ciężarówki = 0ilość kolejek = 10długość kolejki = 10
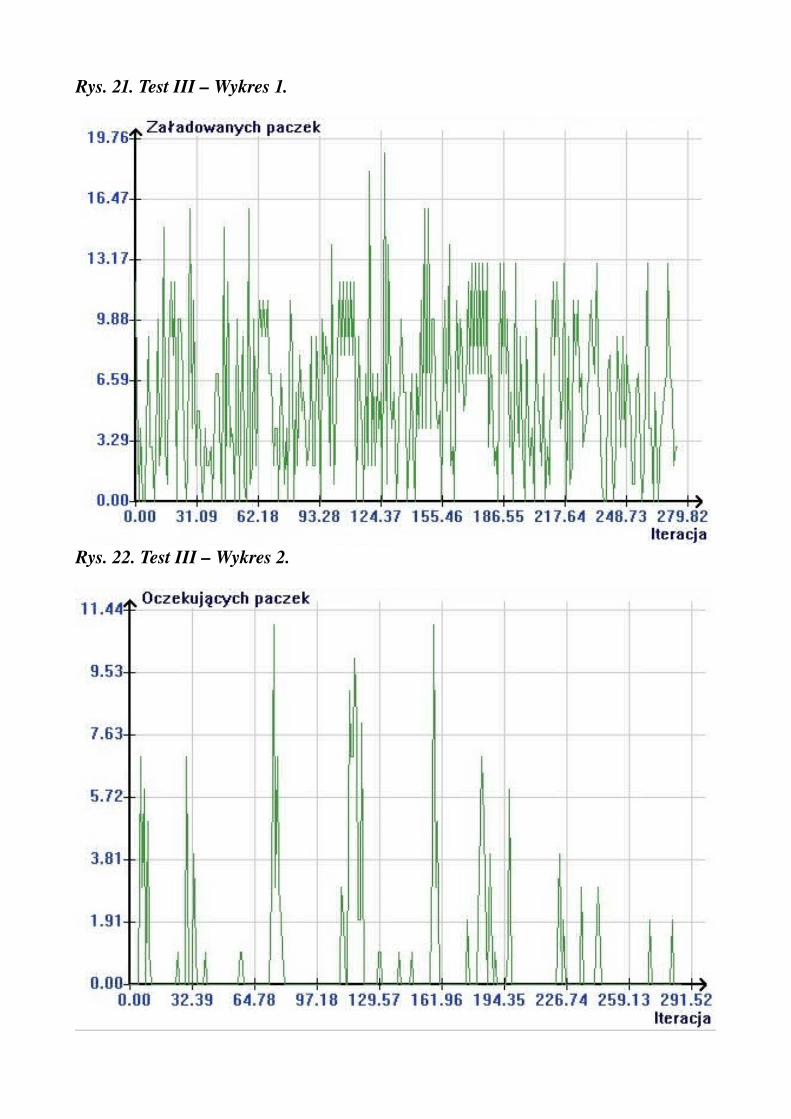
Rys. 21. Test III – Wykres 1.
Rys. 22. Test III – Wykres 2.
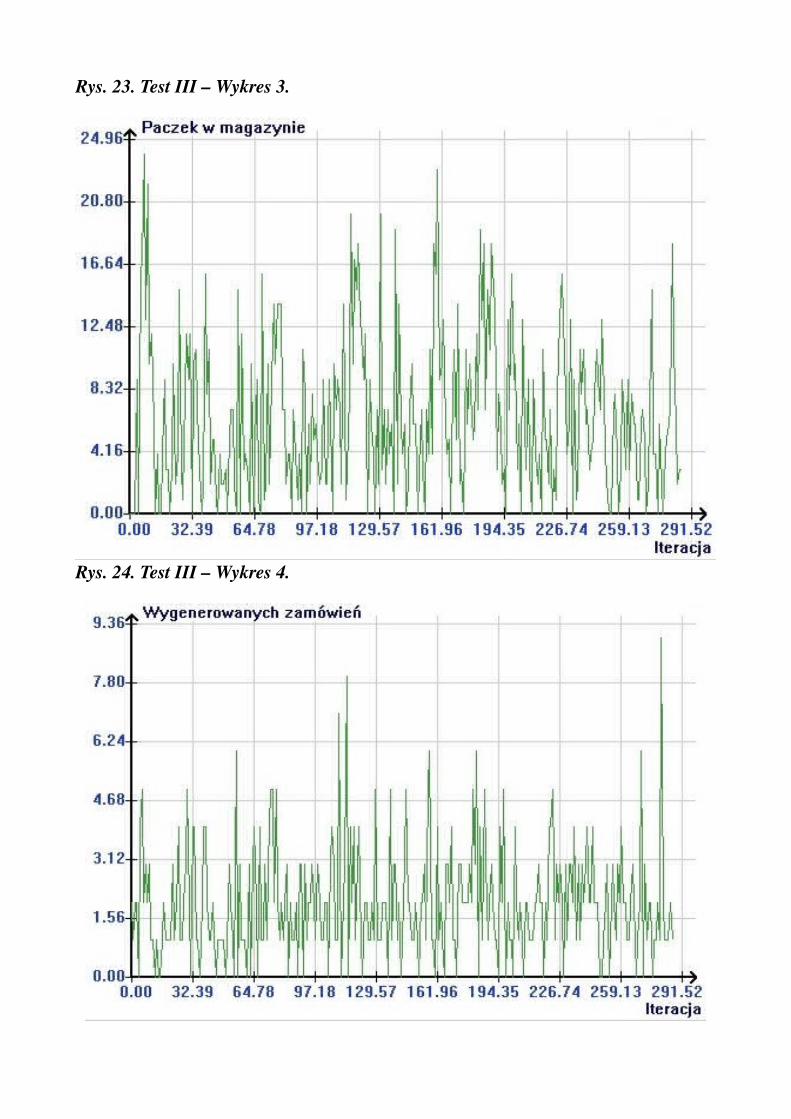
Rys. 23. Test III – Wykres 3.
Rys. 24. Test III – Wykres 4.
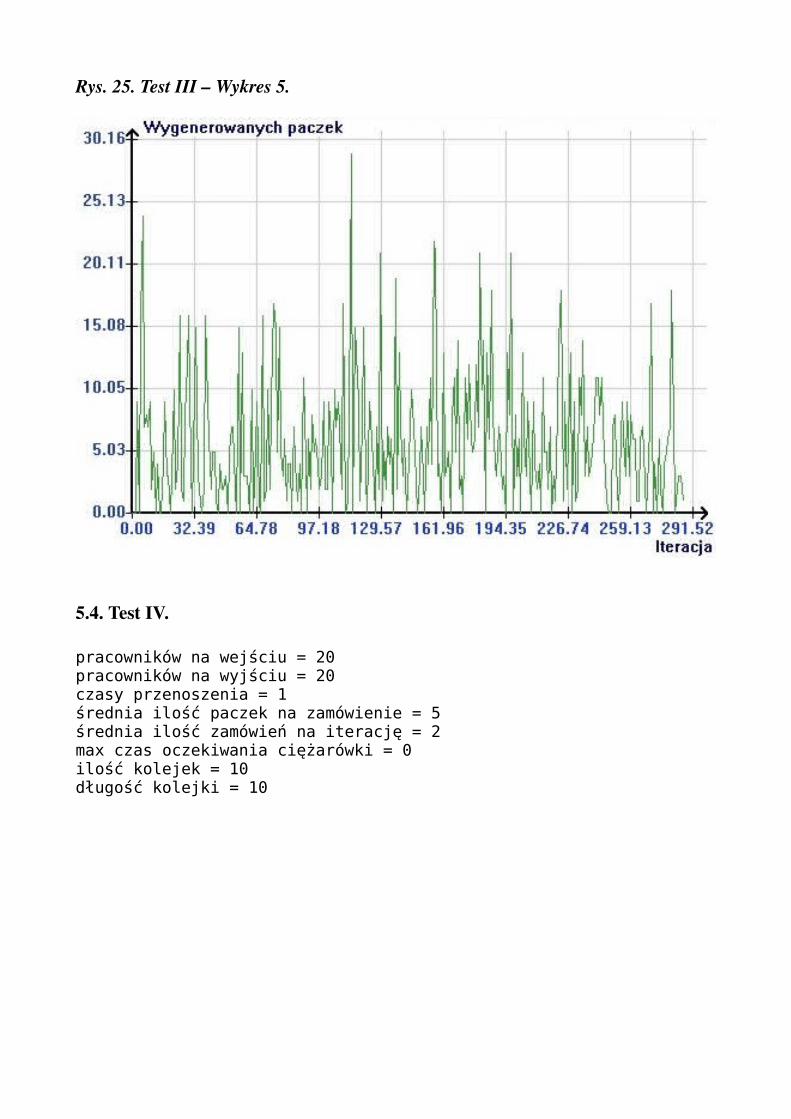
Rys. 25. Test III – Wykres 5.
5.4. Test IV.
pracowników na wejściu = 20pracowników na wyjściu = 20czasy przenoszenia = 1średnia ilość paczek na zamówienie = 5średnia ilość zamówień na iterację = 2max czas oczekiwania ciężarówki = 0ilość kolejek = 10długość kolejki = 10

Rys. 26. Test IV – Wykres 1.
Rys. 27. Test IV – Wykres 2.
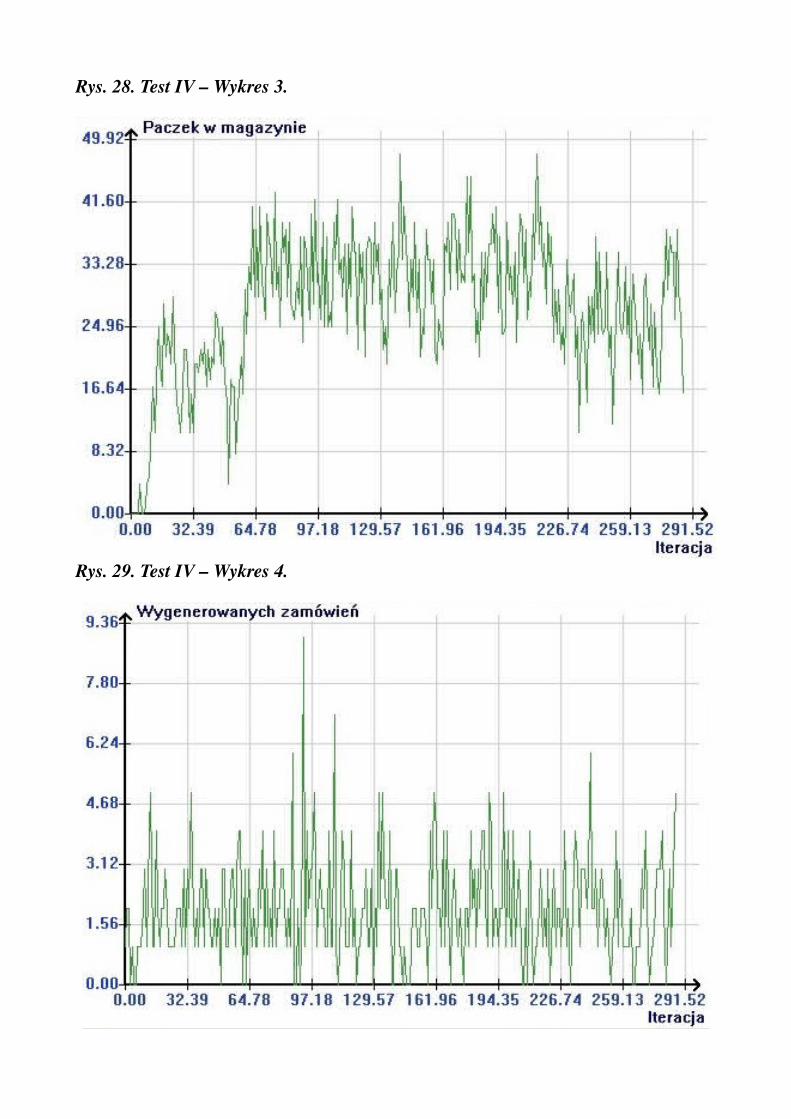
Rys. 28. Test IV – Wykres 3.
Rys. 29. Test IV – Wykres 4.
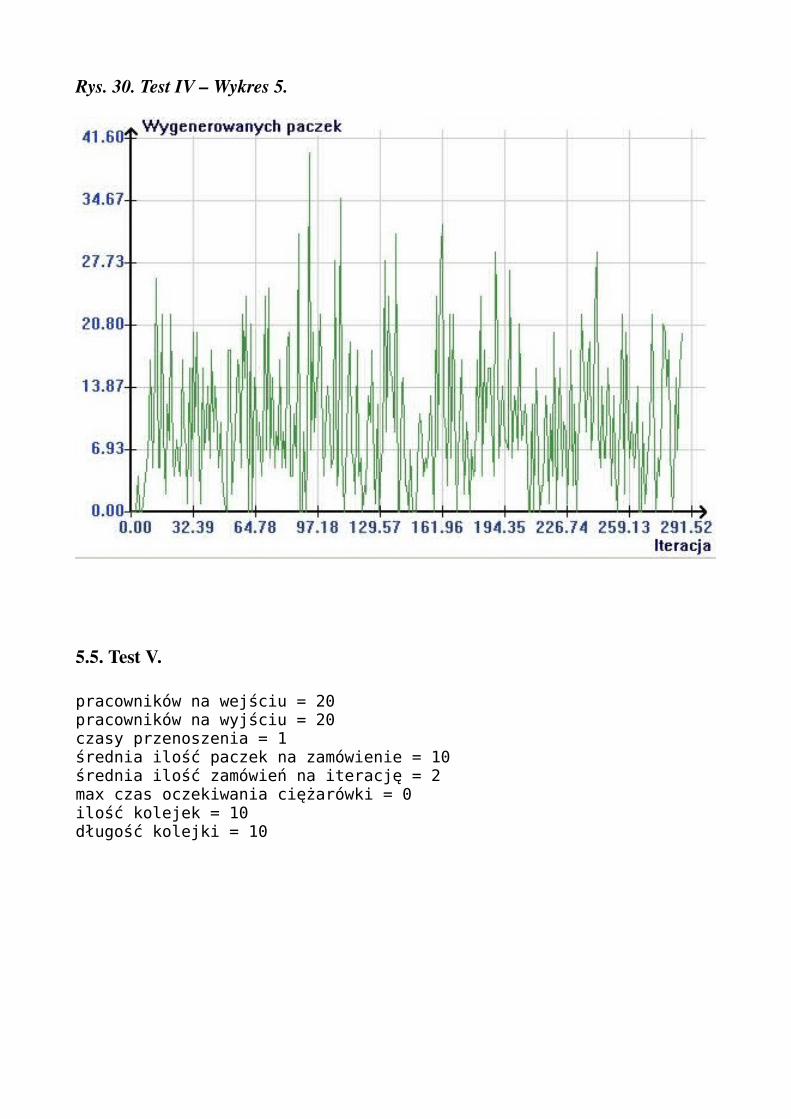
Rys. 30. Test IV – Wykres 5.
5.5. Test V.
pracowników na wejściu = 20pracowników na wyjściu = 20czasy przenoszenia = 1średnia ilość paczek na zamówienie = 10średnia ilość zamówień na iterację = 2max czas oczekiwania ciężarówki = 0ilość kolejek = 10długość kolejki = 10
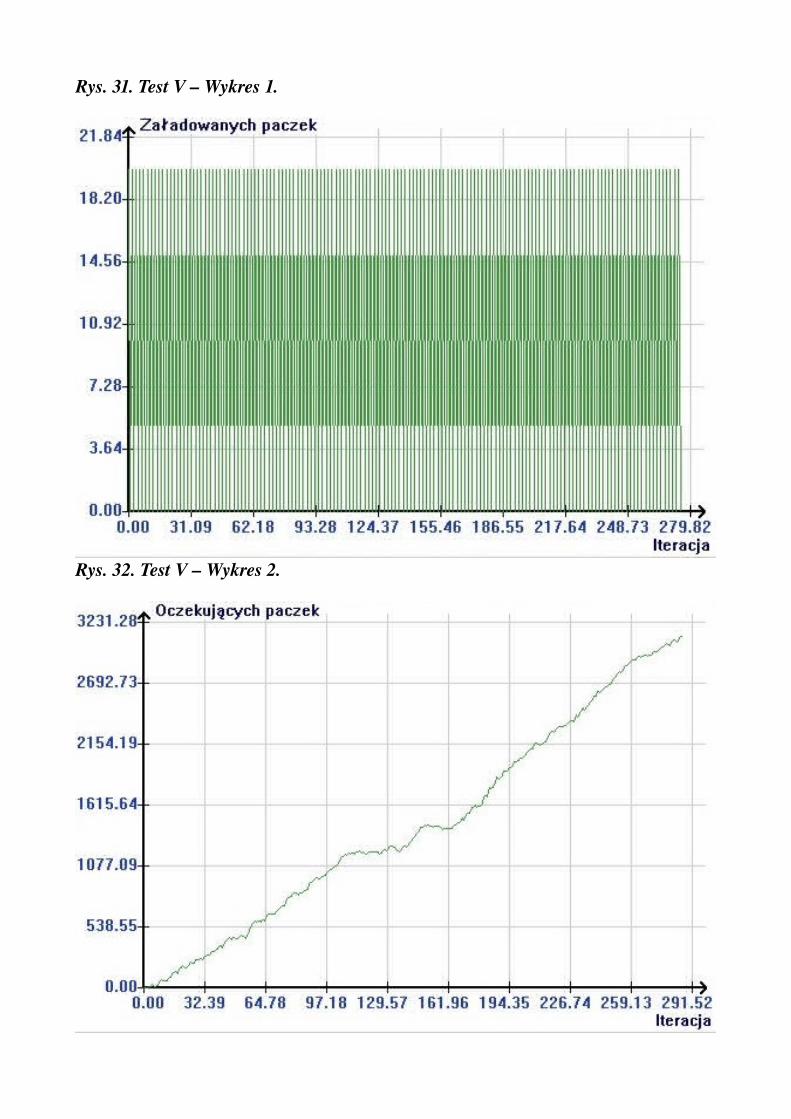
Rys. 31. Test V – Wykres 1.
Rys. 32. Test V – Wykres 2.

Rys. 33. Test V – Wykres 3.
Rys. 34. Test V – Wykres 4.
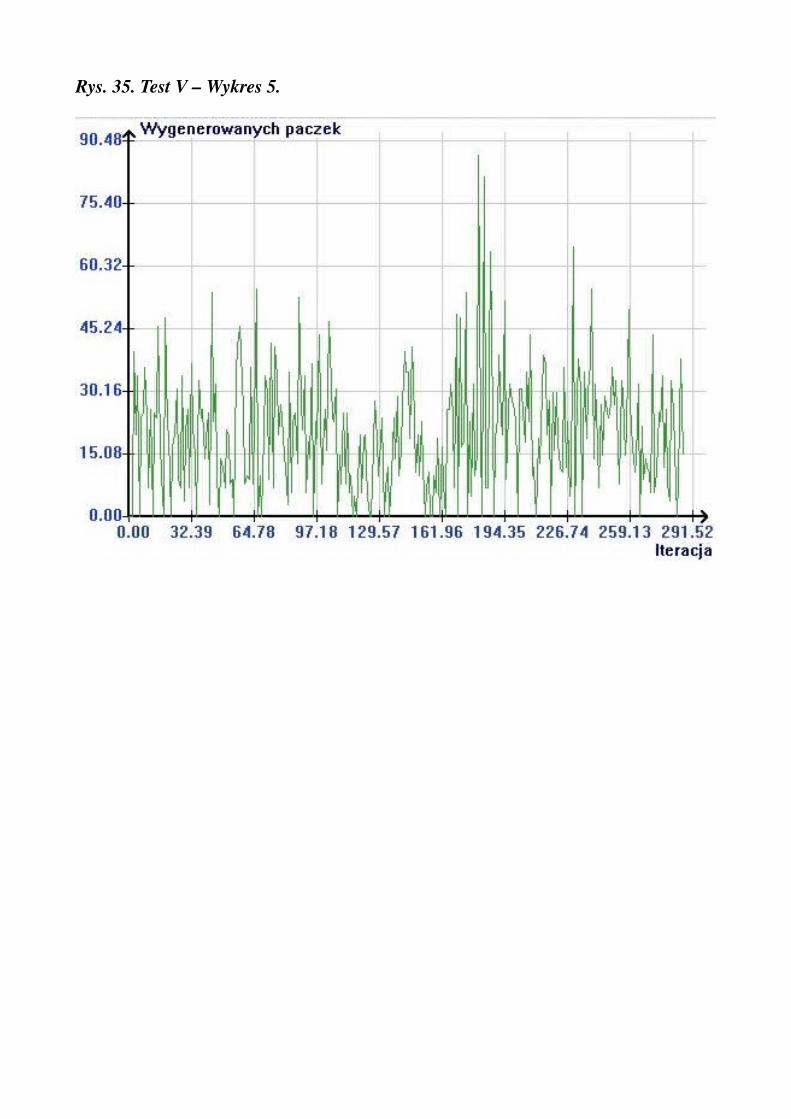
Rys. 35. Test V – Wykres 5.

5. Zastosowanie i wnioski.
W dobie rozwoju internetu i zakupów online problem crossdockingu nabiera ogromnego znaczenia. Typowy internetowy sklep dysponuje tak szerokim asortymentem towarów i dociera do tak szerokiego grona odbiorców, że nie sposób przechowywać wszystkiego w magazynie. Kluczowe jest tu spostrzeżenie, że towar jest nam potrzebny dopiero wtedy i tylko wtedy, gdy klient złoży na niego zamówienie.
Koszt utrzymania magazynu może być dla takiego przedsiębiorstwa największym problemem, w związku z czym każda, nawet najdrobniejsza, minimalizacja jest opłacalna. Tymczasem proces crossdockingu zmniejsza rozmiar budynku kilkakrotnie, bowiem zanika potrzeba przechowywania czegokolwiek w jego wnętrzu. Choć taki przeładunek wymaga więcej zaangażowanych pracowników i lepszego kontaktu z dostawcami, to dodatkowy wysiłek się opłaca. Konieczność posiadania obszernego magazynu w klasycznych sklepach znacznie ogranicza ich ofertę. Tutaj ogranicza nas jedynie ilość dostawców w danym regionie.
Nie tylko sklepy mogą skorzystać z przejścia na nowy model. Nie zapominajmy o takich przedsiębiorstwach jak poczta. Gdyby pojawiły się pieniądze oraz odpowiednio szczegółowy nadzór nad wdrożeniem, firma mogłaby odnotować znaczne zyski, a jej klienci odnotowaliby zapewne zmniejszenie czasu oczekiwania na przesyłkę (oraz zmniejszenie ilości kradzieży ze starych, niezabezpieczonych magazynów).
Ewentualną opłacalność przejścia na crossdocking dla konkretnego przedsiębiorstwa pozwala sprawdzić nasza aplikacja. Następnie umożliwia ona ocenę uzyskanego rozwiązania za pośrednictwem dokładnej symulacji. Jest to na pewno krok naprzód w kierunku podjęcia trudnej decyzji o kosztownej restrukturyzacji.

6. Bibliografia.
[1] B. Filipowicz, Modelowanie i optymalizacja systemów kolejkowych, cz. I, systemy markowskie, s. 205216, Kraków 1995
[2] J. J. Bartholdi, K. R. Gue, K. Kang, Staging Freigth In A Crossdock, IEPM 2001
[3] en.wikipedia.org/wiki/Crossdocking
[4] projects.bus.lsu.edu/independent_study/vdhing1/othertopics/crossdocking.htm
[5] www2.isye.gatech.edu/~jjb/wh/book/editions/history.html
[6] www2.isye.gatech.edu/~jjb/wh/book/editions/whsci0.87.pdf, tam: special topics, crossdocking
c


















