
Biologiczne bazy i modele danych -...
31
Biologiczne bazy i modele danych
Transcript of Biologiczne bazy i modele danych -...

Biologiczne bazy i modele danych

Przełom XX i XXI wieku to okres dynamicznego rozwoju programów sekwencjonowania genomów:
1995 genom Haemophilus influenzae
1997 genom E. coli
1997 genom drożdży S. cerevisiae
1998 genom nicienia Caenorhabditis elegans
1999 genom Muszki owocowej
2000 genom rzodkiewnika A. thaliana
2001 genom człowieka
2005 genom szympansa
2007 pierwszy indywidualny genom człowieka
i wiele innych…………..

Nadeszła era METAGENOMIKI, która zajmuje się uzyskiwaniem i analizą sekwencji genomowych całych populacji a nie pojedynczych organizmów

Termin "bioinformatyka" po raz pierwszy pojawił się w 1989 roku
Bioinformatyka jest nauką interdyscyplinarną, która integruje: biologię
molekularną, informatykę, matematykę, genetykę, genomikę oraz
biochemię
Bioinformatyka rozwiązuje problemy nagromadzone w wyniku
intensywnego rozwoju nauk przyrodniczych przy użyciu metodologii nauk
informatycznych: używa metod komputerowych w celu uzyskania
odpowiedzi na pytania biologiczne
Oxford English Dictionary definiuje bioinformatykę jako: " Naukę
zbierania i analizowania złożonych biologicznych danych takich jak kod
genetyczny".
Bioinformatyka
(ang. bioinformatics, biocomputing)

Bioinformatyka
Podstawowym zadaniem bioinformatyki jest rozpoznawanie in silico reguł kierujących zarządzaniem informacją genetyczną przez komórkę dzięki wzorom obserwowanym w ogromie danych sekwencyjnych
• przetwarzanie „surowych” danych o sekwencjach, tworzenie baz danych i zarządzanie bazami danych
• poszukiwanie, analiza i interpretacja informacji z biologicznych baz danych (analiza sekwencji DNA i białek)
• tworzenie nowych algorytmów i metod statystycznych do analizy danych biologicznych: struktury, funkcji, ewolucji genów, białek i całych genomów
• symulacje komputerowe w biochemii i biologii molekularnej
• inne techniki informatyczne związane z naukami biologicznymi

Po co tworzyć biologiczne bazy danych?
•Napływ nowego rodzaju danych biologicznych (sekwencji DNA) wymusił rozwój metod ich analiz i klasyfikacji, pozwalających na ich katalogowanie np. pod względem informacji zakodowanych w DNA i charakteryzowanie związków funkcjonalnych między nimi. Dzięki temu możliwe są analizy porównawcze sekwencji – obecnie kluczowe podejście w procesie opisywania nowo poznanych genomów
•Przedstawianie danych sekwencyjnych w szerszym biomedycznym kontekście który z kolei prowadzi do integracji danych z zakresu biologii molekularnej z innymi dziedzinami (bazami): biologią komórki, metabolomiką, medycyną itd.

Podział baz danych przyrodniczych i biomedycznych

Kiedy powstały pierwsze biologiczne (sekwencyjne) bazy danych?
Historycznie bazy danych nukleotydowe są młodsze niż bazy danych sekwencji białkowych
1965 Dayhoff i wsp. Opublikowali Atlas of Protein Sequences and Structures, w którym zawarli wszystkie znane wtedy sekwencje białkowe (pojemność 1 dyskietki)
1980 roku powstała baza danych EMBL, potem pojawił się GenBank (1982) a następnie DDBJ.

Ile jest baz danych (na koniec 2017):Ok. 1600 + 82 nowych związanych z biologią molekularną

Bazy danych stają się wysoce specjalistyczne:• odziaływania typu białko-białko• niekodujące RNA, microRNA oraz ich docelowe miejsca działania w
komórkach,• geny związane z chorobami

Metabazy: kojarzą ze sobą rekordy z wielu typów baz
The National Center for Biotechnology Information (NCBI)

Zasoby NCBI to nie tylko baza danych GenBank

Czym jest GenBank, co zawiera, jaka jest struktura rekordów zapisanych w tej bazie?
GenBank jest powszechnie dostępną, internetową sekwencyjną bazą
danych, zawierającą sekwencje nukloetydowe, zarządzaną przez
National Center for Biotechnology Information (NCBI) w USA.
Jest częścią przedsięwzięcia jakim jest międzynarodowa współpraca w
tworzeniu bazy danych zawierającej sekwencje nukleotydowe
(International Nucleotide Sequence Database Collaboration - INSDC).
W ramach tej współpracy trzy instytucje: DNA DataBank of Japan (DDBJ),
European Molecular Biology Laboratory (EMBL) oraz GenBank codziennie
wymieniają i uzupełniają własne zasoby zgromadzonych sekwencji
nukleotydowych poszczególnych genów

EBI
GenBank
DDBJ
EMBL
EMBL
Entrez
SRS
getentry
NIG
CIB
NCBI
NIH
•Wprowadzanie•Aktualizacja •Aktualizacja
•Wprowadzanie
•Wprowadzanie•Aktualizacja
•Dane wymieniane codziennie pomiędzy trzema współpracującymi bazami sekwencji nukleotydowch : GenBank, DNA Database of Japan (DDBJ), European Molecular Biology Laboratory Database (EMBL)

Sekwencyjne bazy danych - podział
1. Pierwotne Bazy Danych - Primary Databases
(bezpośrednie wyniki eksperymentów, z nielicznymi interpretacjami – dane pozornie „nieuporządkowane”- dość powierzchowne
Bezpośrednie wprowadzanie pojedynczych rekordów -Oryginalne wprowadzenia - “submissions”(BankIt, Sequin)
Surowe dane sekwencyjne pochodzące z Centrów Genomowych
Obsługa bazy organizuje, ale nie dodaje dodatkowych informacji
2. Pochodne (wtórne) bazy danych - Derivative Databases(uporządkowane zbiory danych) – integracja danych z wielu pierwotnych baz nadaje im dodatkowe ważne informacje
Nadzorowane przez ludzi Składanie, dodawanie i korekta danych z baz pierwotnych Np.: SWISS-PROT, PIR, NCBI RefSeq, mRNA, bazy danych
rodzin białkowych Pochodne komputerowe
Np.: UniGene Łączone
Np.: NCBI Genome Assembly
GenBank jest tzw. pierwotną bazą danych

Struktura rekordów (plików) w bazach danych
•Jest ściśle określona dla poszczególnych baz danych
•Musi być w formacie czytelnym dla człowieka i komputera
•Zawiera absolutnie unikalny element, które precyzyjnie określa dany rekord – kod (numer) dostępu
•Rekordy w bazach danych są tworzone w oparciu o obowiązujący w danej bazie model danych

Model danych NCBI:
•Rekord bazy GenBank jest rekordem „opartym na DNA”
•Pozostałe dane tego modelu tj. translacja regionu kodującego w DNA (o ile występuje) – sekwencja białka, cytowania bibliograficzne, struktury trójwymiarowe białka, powiązania taksonomiczne oraz ewentualne powiązania do map genomów stanowią element dodatkowy, który jak najpełniej stara się opisać sekwencję DNA
Korzyści takiego modelu danych:
•Możliwość integracji programów do przeszukiwania baz danych i samych baz danych
•Możliwość wygodnego śledzenia informacji od sekwencji DNA, jej lokalizacji na mapie chromosomowej do kodowanego białka, jego trójwymiarowego obrazu oraz opublikowanej na dany temat literatur
•Powiązania plików (białko, cytowanie, struktura) z sekwencją DNA wzbogaca model danych i ułatwia potencjalne nowe odkrycia
•Łatwość rozszerzania modelu o kolejne powiązania w miarę ich powstawania bez konieczności nieustannej konwersji formatów

Rekord GenBank

LOCUS AF062069 3808 bp mRNA INV 02-MAR-2000
DEFINITION Limulus polyphemus myosin III mRNA, complete cds.
ACCESSION AF062069
VERSION AF062069.2 GI:7144484
KEYWORDS .
SOURCE Atlantic horseshoe crab.
ORGANISM Limulus polyphemus
Eukaryota; Metazoa; Arthropoda; Chelicerata; Merostomata;
Xiphosura; Limulidae; Limulus.
REFERENCE 1 (bases 1 to 3808)
AUTHORS Battelle,B.-A., Andrews,A.W., Calman,B.G., Sellers,J.R.,
Greenberg,R.M. and Smith,W.C.
TITLE A myosin III from Limulus eyes is a clock-regulated phosphoprotein
JOURNAL J. Neurosci. (1998) In press
REFERENCE 2 (bases 1 to 3808)
AUTHORS Battelle,B.-A., Andrews,A.W., Calman,B.G., Sellers,J.R.,
Greenberg,R.M. and Smith,W.C.
TITLE Direct Submission
JOURNAL Submitted (29-APR-1998) Whitney Laboratory, University of Florida,
9505 Ocean Shore Blvd., St. Augustine, FL 32086, USA
REFERENCE 3 (bases 1 to 3808)
AUTHORS Battelle,B.-A., Andrews,A.W., Calman,B.G., Sellers,J.R.,
Greenberg,R.M. and Smith,W.C.
TITLE Direct Submission
JOURNAL Submitted (02-MAR-2000) Whitney Laboratory, University of Florida,
9505 Ocean Shore Blvd., St. Augustine, FL 32086, USA
REMARK Sequence update by submitter
COMMENT On Mar 2, 2000 this sequence version replaced gi:3132700.
Rekord GenBanku
Podstawową jednostką informacji bazy danych GenBank jest prosty plik tekstowy GBFF
(GenBank Flat File)
GBBF składa się z 3 podstawowych części:
1. Nagłówek

FEATURES Location/Qualifiers
source 1..3808
/organism="Limulus polyphemus"
/db_xref="taxon:6850"
/tissue_type="lateral eye"
CDS 258..3302
/note="N-terminal protein kinase domain; C-terminal myosin
heavy chain head; substrate for PKA"
/codon_start=1
/product="myosin III"
/protein_id="AAC16332.2"
/db_xref="GI:7144485"
/translation="MEYKCISEHLPFETLPDPGDRFEVQELVGTGTYATVYSAIDKQA
NKKVALKIIGHIAENLLDIETEYRIYKAVNGIQFFPEFRGAFFKRGERESDNEVWLGI
EFLEEGTAADLLATHRRFGIHLKEDLIALIIKEVVRAVQYLHENSIIHRDIRAANIMF
SKEGYVKLIDFGLSASVKNTNGKAQSSVGSPYWMAPEVISCDCLQEPYNYTCDVWSIG
ITAIELADTVPSLSDIHALRAMFRINRNPPPSVKRETRWSETLKDFISECLVKNPEYR
PCIQEIPQHPFLAQVEGKEDQLRSELVDILKKNPGEKLRNKPYNVTFKNGHLKTISGQ
BASE COUNT 1201 a 689 c 782 g 1136 t
ORIGIN
1 tcgacatctg tggtcgcttt ttttagtaat aaaaaattgt attatgacgt cctatctgtt
3781 aagatacagt aactagggaa aaaaaaaa
//
Rekord GenBanku, cd.
GBFF jest formą w jakiej wymieniane są dane pomiędzy GenBank, EMBL, DDBJ
2. Tabela cech
3. Sekwencja

LOCUS AF062069 3808 bp mRNA INV 02-MAR-2000
Struktura rekordu w GenBanku
Nazwa Locus
(dawniej oznaczała
faktyczną nazwę locus
którego dotyczył np.
HUMBG)
Długość
sekwencji
Typ cząsteczki
mRNA (= cDNA)
rRNA
snRNA
DNA
GB Division
(dawniej miało znaczenie
taksonomiczne)
Data wprowadzenia
lub modyfikacji
1. Nagłówek: część rekordu charakterystyczna dla bazy danych
Pierwszy wiersz nagłówka we wszystkich GBFF to wiersz LOCUS

VERSION AF062069.2 GI:7144484
ACCESSION AF062069
DEFINITION Limulus polyphemus myosin III mRNA, complete cds.
wiersz definicji - tytuł
podsumowuje informację
biologiczną rekordu
Accession Number (kod dostępu)
Zapisywany jako 1+5 albo 2+6
Numer gi (kolejny numer rekordu
w bazie danych) (znika z rekordów od
09-2016)
Wersja Accession,
Historia aktualizacji
Nagłówek c.d.

Słowa Kluczowe
KEYWORDS .
SOURCE Atlantic horseshoe crab.
ORGANISM Limulus polyphemus
Eukaryota; Metazoa; Arthropoda; Chelicerata; Merostomata;
Xiphosura; Limulidae; Limulus.
Nagłówek c.d.
Nazwa zwyczajowa Nazwa gatunkowa
Powiązania taxonomiczne
według GenBanku

REFERENCE 1 (bases 1 to 3808)
AUTHORS Battelle,B.-A., Andrews,A.W., Calman,B.G., Sellers,J.R.,
Greenberg,R.M. and Smith,W.C.
TITLE A myosin III from Limulus eyes is a clock-regulated phosphoprotein
JOURNAL J. Neurosci. (1998) In press
REFERENCE 2 (bases 1 to 3808)
AUTHORS Battelle,B.-A., Andrews,A.W., Calman,B.G., Sellers,J.R.,
Greenberg,R.M. and Smith,W.C.
TITLE Direct Submission
JOURNAL Submitted (29-APR-1998) Whitney Laboratory, University of Florida,
9505 Ocean Shore Blvd., St. Augustine, FL 32086, USA
REFERENCE 3 (bases 1 to 3808)
AUTHORS Battelle,B.-A., Andrews,A.W., Calman,B.G., Sellers,J.R.,
Greenberg,R.M. and Smith,W.C.
TITLE Direct Submission
JOURNAL Submitted (02-MAR-2000) Whitney Laboratory, University of Florida,
9505 Ocean Shore Blvd., St. Augustine, FL 32086, USA
REMARK Sequence update by submitter
COMMENT On Mar 2, 2000 this sequence version replaced gi:3132700.
Odnośniki literaturoweNagłówek c.d.

FEATURES Location/Qualifiers
source 1..3808
/organism="Limulus polyphemus"
/db_xref="taxon:6850"
/tissue_type="lateral eye"
CDS 258..3302
/note="N-terminal protein kinase domain;
C-terminal myosin heavy chain head; substrate for PKA"
/codon_start=1
/product="myosin III"
/protein_id="AAC16332.2"
/db_xref="GI:7144485"
/translation="MEYKCISEHLPFETLPDPGDRFEVQELVGTGTYATVYSAIDK
NKKVALKIIGHIAENLLDIETEYRIYKAVNGIQFFPEFRGAFFKRGERESDNEVWL
"
2. Tabela Cech – środkowy segment GBFF
Cecha: źródło biologiczne
-pochodzenie materiału
genetycznego,
Cecha: sekwencja
kodująca białko (jeśli DNA koduje
białko)
Jeśli DNA koduje białko pojawiają się dodatkowe
informacje tzw. kwalifikatory
-rodzaj kodu genetycznego
-faza (ramka )odczytu kodonów
odnośniki krzyżowe do bazy
danych sekwencji białkowych

BASE COUNT 1201 a 689 c 782 g 1136 t
ORIGIN
1 tcgacatctg tggtcgcttt ttttagtaat aaaaaattgt attatgacgt cctatctgtt
<opuszczona sekwencja>
3721 accaatgtta taatatgaaa tgaaataaag cagtcatggt agcagtggct gtttgaaata
3781 aagatacagt aactagggaa aaaaaaaa
//
3. Sekwencja
Początek podawania
sekwencji
Znak: koniec rekordu
Statystyka składu
sekwencji nt
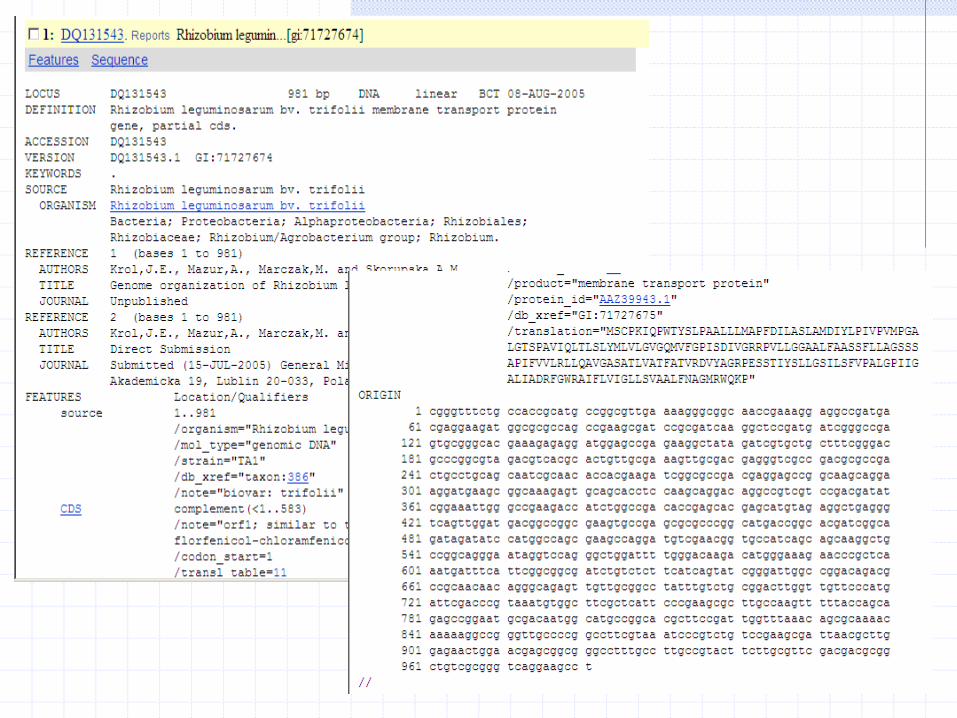

Format EMBL
Numer dostępu
OPIS

Odnośniki literaturowe
Tabela cech:
Nazwa organizmu, taksonomia, ramka odczytu itp.
Odsyłacze (odnośniki krzyżowe) do rekordów innych baz powiązanych z tą sekwencją


>gi|205364858|gb|DQ836933.2| Rhizobium leguminosarum
bv. trifolii strain TA1 lipid A oxidase (lpxQ) gene, complete
cds
AAAAGCCATATGCCGTCGAGGGCAAGGTCAGCTGCGGCACCAAATAGCGCCGCAGCCGAAATTTACTCTT
ACCAGTGGAACGATACGCCGACGTTGACGGCATTCGTGAAGATGTTGGTCTTCAGGTCCACGCCGCTATC
GATCGGAACGTCGATGCGCGAATAGGTGCCCTTGTATTCGACGAAGGTCGACCAGCGCTCGGTCACCTTG
AAGTCGACGCCGGCCTGGGCCTGCAGCGTCACGCCGCCGAATTCATAAGCCCAGGTCTTGCCCTCAGGGC
GAATCACTTCGACATGCGGAATGTTCACGCCGATGCCGGCGCCGAGATAGGGCGTCCAGCGGCGGGTCGG
ATCCTGGAAGCGATAGAGACCGTTCACCGTGATGAGGTTCAGGCCGTCGGTGAATTCGAAATGCGACCAG
CCGGTCTTGGCCAGCGTATCGTCGTCGGCATAGACCTTGTCATGGGTATAATCGAGCGAGATACCCCAGT
TCGGTTTGTTGAAGTTCTCGAGCCACCAGGTGACGCGGCCGCCGTAATAAGGCGGGCTGCCGAAGGACTT
GCCTTCCCAGCCGGCGGTGAAATGCGTGCCGTCGGAGAGATCGACGCCGCTGTGTGGTGCGGTCTGATAG
CCGCCGTAGACGGAGAATTGCAGATCTTCCGCCGAGGCGGAAGCTGCCGAACAGATGGTGAAAAACGCGA
TGCCCGCAAGCAGTGAAGCGGAGGAACGCAGCGCATATGTCATTGAATAGCCCCGATATTGCAAATGTGT
CGACTCTTAGGCAGGTTTGCCAGCTTTTGGCCGCAAAGTCTAAGCAAAACAAAAGGCGCGTCAAATGCGC
Numer w bazieIdentyfikator bazy
danych: gb oznacza
GenBankKod dostępu
Opis rekordu i nazwa genu
Format Fasta – maksymalnie uproszczona wersja rekordu


















