
BIG DATA praca Mariusza Likszy
58
Politechnika Gdańska Wydzial Fizyki Technicznej i Matematyki Stosowanej Mariusz Liksza Personalizacja reklam internetowych z wykorzystaniem algorytmu locality-sensitive hahsing Opiekun pracy dr hab. Karol Dziedziul 23 marca 2016
Transcript of BIG DATA praca Mariusza Likszy

Politechnika GdańskaWydział Fizyki Technicznej i Matematyki Stosowanej
Mariusz Liksza
Personalizacja reklam internetowych z wykorzystaniemalgorytmu locality-sensitive hahsing
Opiekun pracy
dr hab. Karol Dziedziul
23 marca 2016

Streszczenie
Praca przedstawia proces personalizacji reklamy internetowej. Analizie poddano danehistoryczne (ze stycznia 2015 roku) pochodzące z portalu, zawierającego ogłoszenia do-tyczące nieruchomości. Przetestowano trzy podejścia do tworzenia zmiennych z adresówURL. Do jednego z nich zastosowano algorytm locality-sensitive hashing (LSH), który wwydajny sposób grupuje podobne do siebie ciągi znaków. Pozostałe dwa opierają się naprostych przekształceniach URL-i i nie uwzględniają grupowania.
Przy pomocy odpowiednich skryptów, napisanych w Pythonie, R i Vowpal Wabbit,zbudowano 82 modele (używając metody stochastycznego spadku wzdłuż gradientu). Na-stępnie wykazano, że wyniki otrzymane po redukcji wymiaru przez algorytm LSH są lep-sze. Wnioski zostały oparte o wiele miar oceny jakości klasyfikacji, w tym AUC, F1Scoreoraz macierz pomyłek (TP, TN, FP i FN).
Słowa kluczowe: reklama internetowa, personalizacja, współczynnik klikalności (CTR),locality-sensitive hashing, podobieństwo Jaccarda, redukcja wymiaru, regresja logistyczna,stochastyczny spadek wzdłuż gradientu, miary oceny jakości klasyfikacji, krzywa ROC,wykres przyrostu (Lift)
Dziedzina nauki i techniki (kody wg klasyfikacji OECD): 1.1 Matematyka
1

Abstract
This thesis presents the targeting process of online advertising. It is focused on theanalysis of historical data (January 2015) from a portal containing real estate advertise-ments. Three approaches of creating variables from URLs have been tested. One of themuses locality-sensitive hashing algorithm which efficiently groups similar strings. The othertwo are based on the simple URL transformations and do not include any grouping.
With appropriate scripts written in Python, R and Vowpal Wabbit, 82 models werebuilt (using stochastic gradient descent method). Next, it has been proven that the resultsobtained after dimension reduction by LSH algorithm are better. The conclusions werebased on various measures of quality classification evaluation, including AUC, F1Scoreand confusion matrix (TP, TN, TP and FN).
Keywords: online advertising, targeting, click through rate (CTR), locality-sensitivehashing, Jaccard similarity, dimension reduction, logistic regression, stochastic gradientdescent, classification quality measures, ROC curve, Lift chart
2

Spis treściWprowadzenie 4
Rozdział 1. Spersonalizowana reklama internetowa 61.1 Współczynnik klikalności, a współczynnik konwersji . . . . . . . . . . . . . 61.2 Nierelacyjna baza danych: MongoDB . . . . . . . . . . . . . . . . . . . . . 71.3 Niezbalansowane klasy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
Rozdział 2. Algorytm locality-sensitive hashing: redukcja wymiaru 122.1 Problem wielowymiarowości . . . . . . . . . . . . . . . . . . . . . . . . . . 122.2 Miary odległości . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 132.3 k-Shingles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 162.4 Min-hashing: funkcja hashująca dla podobieństwa Jaccarda . . . . . . . . . 162.5 Locality-sensitive hashing . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
Rozdział 3. Regresja logistyczna i miary dopasowania modelu 283.1 Regresja logistyczna: problem klasyfikacji . . . . . . . . . . . . . . . . . . . 283.2 Metoda gradientu prostego oraz stochastycznego spadku wzdłuż gradientu 303.3 Miary dopasowania modelu . . . . . . . . . . . . . . . . . . . . . . . . . . 333.4 Krzywa ROC . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 353.5 Wykres przyrostu . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
Rozdział 4. Prognozowanie kliknięć w reklamę przy użyciuVowpal Wabbit i algorytmu SGD 454.1 Przygotowanie danych do analizy: Python . . . . . . . . . . . . . . . . . . 454.2 Budowanie modelu: Vowpal Wabbit . . . . . . . . . . . . . . . . . . . . . . 484.3 Ocena modeli i porównanie wyników: R . . . . . . . . . . . . . . . . . . . . 49
Zakończenie 54
Literatura 55
Dodatek A: skrypty Python, R, Vowpal Wabbit 57
3

WprowadzenieZ pewnością każda osoba czytająca tę pracę, spotkała się z niechcianymi reklamami.
Dotyczy to zarówno stron internetowych, jak i wiadomości e-mail. Od wielu lat jest tobardzo istotny problem, z którym zmaga się niejeden użytkownik Internetu. Niestety,nie ma możliwości całkowitej eliminacji tego typu działań, dokonywanych przez wielefirm chcących pozyskać nowych klientów. Do niedawna, jedynym rozwiązaniem (i to zestrony potencjalnych odbiorców) była instalacja rozszerzeń do przeglądarek internetowychtakich jak Adblock. Niemniej jednak, nie było to (ani nie jest obecnie) najlepsze wyjściez tej sytuacji. Po pierwsze, niektóre reklamy są konstruowane w taki sposób, aby omijaćzabezpieczenia ze strony przeglądarki. Z drugiej strony, używanie Adblocka ma swojenegatywne konsekwencje, a największą z nich jest utrata informacji, które mogłyby byćbardzo przydatne, jak np. interesująca oferta prezentu urodzinowego dla koleżanki.
Od pewnego czasu polskie serwisy internetowe takie jak Allegro1, czy Filmweb2, a tak-że zagraniczne, w tym Amazon3 oraz Netflix 4, przy pomocy zaawansowanych systemówrekomendacji składają swoim klientom oferty, które często wzbudzają zainteresowanie iskłaniają do zakupu jakiegoś produktu (sklepy internetowe), obejrzenia, bądź kupna fil-mu (serwisy filmowe). Takie rozwiązania nie byłyby możliwe bez odpowiednich danych, zktórych większość to historia zakupów, odwiedzane strony internetowe, oceny filmów itp.Skoro można przygotować konkretne oferty dla klientów danego portalu, to również niepowinno być wyzwaniem spersonalizowanie reklam internetowych.Od 2014 roku na polskim rynku istnieje start-up5 o nazwie Pin Your Client6, zajmujący siępozyskiwaniem klientów przy użyciu narzędzi uczenia maszynowego7 oraz dużych zbio-rów danych typu Big data8. Jednym z produktów, które oferuje jest właśnie inteligentnypop-up (ang. smart pop-up). W zależności od klienta, który zleca tej firmie podłączenietego typu reklamy na swojej stronie, jest to najczęściej pewna oferta dostosowana do in-dywidualnego użytkownika, która pojawia się w formie wyskakującego okienka.
1Allegro.pl – największa platforma transakcyjna on-line w Polsce. Portal należy do Grupy Allegro,która jest częścią południowoafrykańskiego koncernu mediowego Naspers.
2Filmweb (filmweb.pl) – największy polski serwis internetowy poświęcony filmom i ludziom kina.3Amazon.com – amerykańskie przedsiębiorstwo handlowe, spółka akcyjna założona w 1994 w Seattle;
zajmuje się handlem elektronicznym B2C i prowadzi największy na świecie sklep internetowy.4Netflix – największa wypożyczalnia filmów DVD na świecie, oferująca za stałą opłatą wypożyczanie
filmów poprzez media strumieniowe5Start-up – przedsiębiorstwo lub tymczasowa organizacja stworzona w celu poszukiwania modelu biz-
nesowego, który gwarantowałby jej rozwój. Przedsiębiorstwa te mają zwykle krótką historię, są w fazierozwojowej i aktywnie poszukują nowych rynków.
6http://www.pinyourclient.com, dostęp 11.07.2015.7Uczenie maszynowe (ang. machine learning), to dziedzina nauki zajmująca się tworzeniem algoryt-
mów, które mogą „uczyć” się na podstawie przetwarzanego przez siebie zbioru danych.8Nie ma jednoznacznej definicji pojęcia Big data. Każdy tłumaczy je inaczej, ale w ogólności jest
to termin odnoszący się do dużych, zmiennych i różnorodnych zbiorów danych, których przetwarzanie ianaliza jest trudna ale jednocześnie wartościowa, ponieważ może prowadzić do zdobycia nowej wiedzy.
4

Dane, wykorzystane w tej pracy, zostały dostarczone przez firmę Pin Your Client. Zawie-rają informacje o użytkownikach pewnego serwisu ułatwiającego znalezienie najlepszychofert nieruchomości, w tym domów, mieszkań itp. Z uwagi na ograniczoną infrastruktu-rę sprzętową (obliczenia wykonano na średniej klasy laptopie), analizę oparto o dane zjednego miesiąca, a mianowicie stycznia 2015 roku.
Celem niniejszej pracy jest porównanie trzech podejść do tworzenia zmiennych na pod-stawie adresów URL9 (ang. Uniform Resource Locator) i wykazanie, że grupowanie (przypomocy metody locality-sensitive hashing10) podobnych do siebie adresów skutkujelepszymi wynikami. Wykorzystane w tej pracy algorytmy zostały zaimplementowane wjęzykach programowania R i Python oraz narzędziu Vowpal Wabbit11, które posłużyłodo zbudowania modelu dla danych w czasie rzeczywistym (algorytm stochastic gradientdescent, SGD12).
Rozdział 1 opisuje problem klikalności w reklamy internetowe, zawiera analizę współ-czynnika klikalności oraz konwersji. Ponadto, wprowadza do nierelacyjnych baz danych(na przykładzie MongoDB), w których często są przechowywane dane z Internetu. Wostatniej części znajduje się opis problemu niezbalansowanych klas, który w przypadkureklam jest powszechnym problemem.
W rozdziale 2 został opisany szczegółowo, wspomniany powyżej algorytm locality-sensitive hashing, a także regresja logistyczna w oparciu o metodę stochastycznego spad-ku wzdłuż gradientu (SGD). Zawarto tutaj również najważniejsze miary, które zostaływykorzystane do oceny modelu, w tym pola pod krzywą ROC i wykresem przyrostu.
Rozdział 3 łączy w sobie teorię opisaną w całej pracy. Przy wykorzystaniu przygoto-wanych w Pythonie (przekształcenia na danych, ich przygotowanie oraz zastosowanie nanich metody LSH), Vovpal Wabbit (budowa modelu przy użyciu metody SGD) oraz R(wizualizacje i oceny jakości modelu) skryptów, przedstawia całe badanie oraz wyniki.
9URL - jest to ujednolicony format adresowania zasobów (informacji, danych, usług) stosowany wInternecie i w sieciach lokalnych.
10http://www.mit.edu/∼andoni/LSH/, dostęp 12.07.2015.11https://github.com/JohnLangford/vowpal_wabbit/wiki, dostęp 12.07.2015.12Léon Bottou, NEC Labs America, 2010.
5

Rozdział 1. Spersonalizowana reklama internetowa
1.1 Współczynnik klikalności, a współczynnik konwersji
Analizując ruch na stronie internetowej, wykorzystuje się różne wskaźniki. Pomagająone określić jakich zmiany należy dokonać (np. powiększenie czcionki, modyfikacja baneruitp.), aby pozyskać nowych użytkowników, a także nie dopuścić, aby obecni klienci odeszlido konkurencji (analiza migracji klientów, ang. churn analysis13). Do poprawy jakościstrony internetowej wykorzystuje się testy A/B14. Analogicznie można porównać ze sobąróżne kreacje reklamowe15. Najczęściej do tego celu stosuje się dwa wskaźniki:
1. Współczynnik klikalności (ang. click through rate, CTR) = liczba wyświetleń ÷liczba kliknięć;
2. Współczynnik konwersji (ang. conversion rate, CR) = liczba konwersji ÷ liczba klik-nięć. Konwersja jest tutaj rozumiana wielorako, np. sprzedaż produktu na witrynieinternetowej, rezerwacja wycieczki, kontakt z biurem obsługi klienta itp.
Przykład 1.1. Pewien portal internetowy X, zajmujący się wynajmem mieszkań, posta-nowił zlecić firmie zewnętrznej Y stworzenie reklamy internetowej na swojej stronie. Pozebraniu wszystkich potrzebnych wymagań biznesowych i wspólnym ustaleniu wyglądureklamy, została ona podłączona przez Y pod domenę zleceniodawcy X. Na początku,postanowiono wyświetlać pop-up (wyskakująca na stronie internetowej reklama/oferta)co trzeciemu użytkownikowi po to, aby zebrać potrzebne informacje i zweryfikować aktu-alne potrzeby rynku. Po miesiącu gromadzenia danych sprawdzono wyniki. Odnotowano70 kliknięć, z których tylko 1 osoba skontaktowała się z firmą X. Wszystkich wyświe-tleń reklam było 1600. Zatem CTR = 70
1600 ≈ 4, 4%, a CR = 170 ≈ 1, 4%. Następnie, na
podstawie zebranej historii wybrano kilka cech użytkowników i zbudowano model, którymiał prognozować, kiedy i komu pokazać spersonalizowaną ofertę. Tym razem, po ko-lejnym miesiącu eksperymentu, wyniki były następujące: CTR = 120
1600 ≈ 7, 5%, a CR= 5120 ≈ 4, 2%. Zarówno współczynnik klikalności, jak i konwersji znacznie się zwiększyły,
pomimo że została wyświetlona ta sama liczba reklam.
Powyższy przykład pozwala zrozumieć jak bardzo istotna jest kontrola obu omawianychwspółczynników. Wysoka wartość CTR może przekładać się na zerową konwersję, a więcbezskuteczną reklamę. Należy zatem inwestować pieniądze w dopasowanie oferty do in-dywidualnego odbiorcy, oczywiście w granicach zdrowego rozsądku. Takie podejście jestcoraz częściej stosowane, najczęściej z pozytywnym skutkiem w postaci większych zysków.
13http://www.staspotsoft.pl/Rozwiazania/Zastosowania-biznesowe/Analiza-migracji-klientow-churn,dostęp 13.07.2015.
14Testy A/B – metoda badawcza polegająca na porównaniu dwóch wersji strony internetowej celemwybrania tej wersji, która lepiej spełnia stawiane przed nią zadania.
15Kreacja to inaczej kreatywny pomysł, coś czego do tej pory jeszcze nie było i jest w stanie zaskoczyćużytkowników sieci.
6
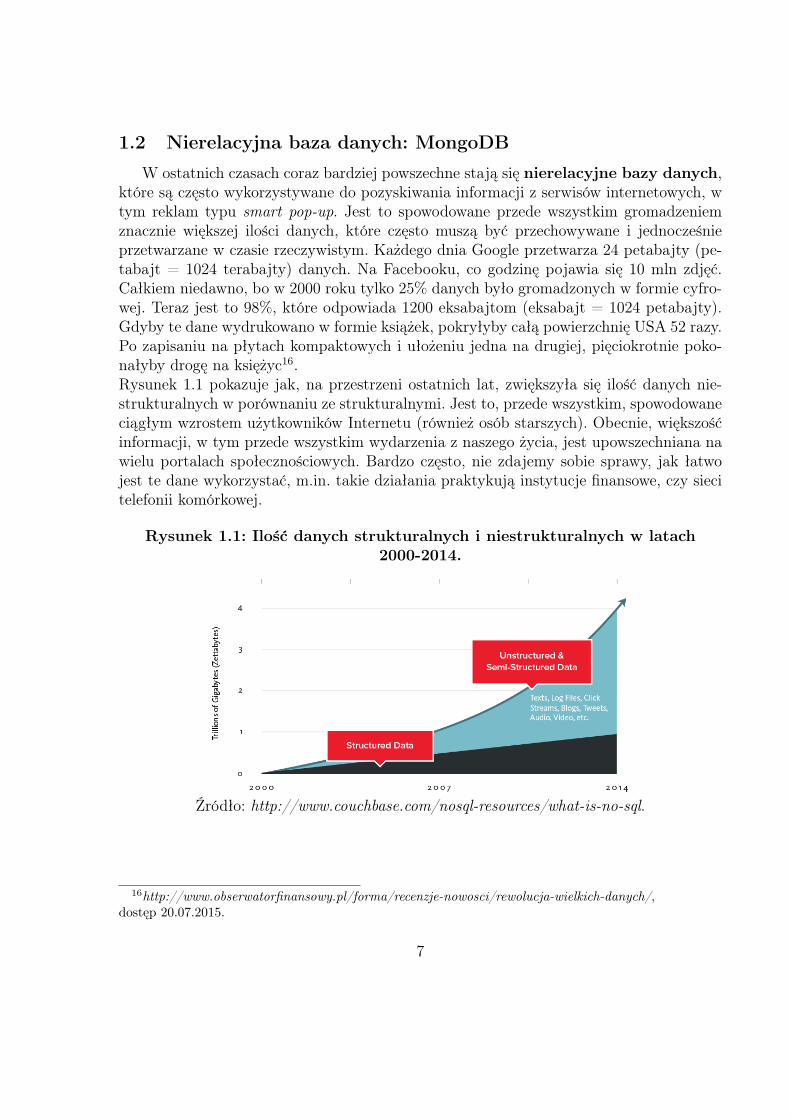
1.2 Nierelacyjna baza danych: MongoDB
W ostatnich czasach coraz bardziej powszechne stają się nierelacyjne bazy danych,które są często wykorzystywane do pozyskiwania informacji z serwisów internetowych, wtym reklam typu smart pop-up. Jest to spowodowane przede wszystkim gromadzeniemznacznie większej ilości danych, które często muszą być przechowywane i jednocześnieprzetwarzane w czasie rzeczywistym. Każdego dnia Google przetwarza 24 petabajty (pe-tabajt = 1024 terabajty) danych. Na Facebooku, co godzinę pojawia się 10 mln zdjęć.Całkiem niedawno, bo w 2000 roku tylko 25% danych było gromadzonych w formie cyfro-wej. Teraz jest to 98%, które odpowiada 1200 eksabajtom (eksabajt = 1024 petabajty).Gdyby te dane wydrukowano w formie książek, pokryłyby całą powierzchnię USA 52 razy.Po zapisaniu na płytach kompaktowych i ułożeniu jedna na drugiej, pięciokrotnie poko-nałyby drogę na księżyc16.Rysunek 1.1 pokazuje jak, na przestrzeni ostatnich lat, zwiększyła się ilość danych nie-strukturalnych w porównaniu ze strukturalnymi. Jest to, przede wszystkim, spowodowaneciągłym wzrostem użytkowników Internetu (również osób starszych). Obecnie, większośćinformacji, w tym przede wszystkim wydarzenia z naszego życia, jest upowszechniana nawielu portalach społecznościowych. Bardzo często, nie zdajemy sobie sprawy, jak łatwojest te dane wykorzystać, m.in. takie działania praktykują instytucje finansowe, czy siecitelefonii komórkowej.
Rysunek 1.1: Ilość danych strukturalnych i niestrukturalnych w latach2000-2014.
Źródło: http://www.couchbase.com/nosql-resources/what-is-no-sql.
16http://www.obserwatorfinansowy.pl/forma/recenzje-nowosci/rewolucja-wielkich-danych/,dostęp 20.07.2015.
7
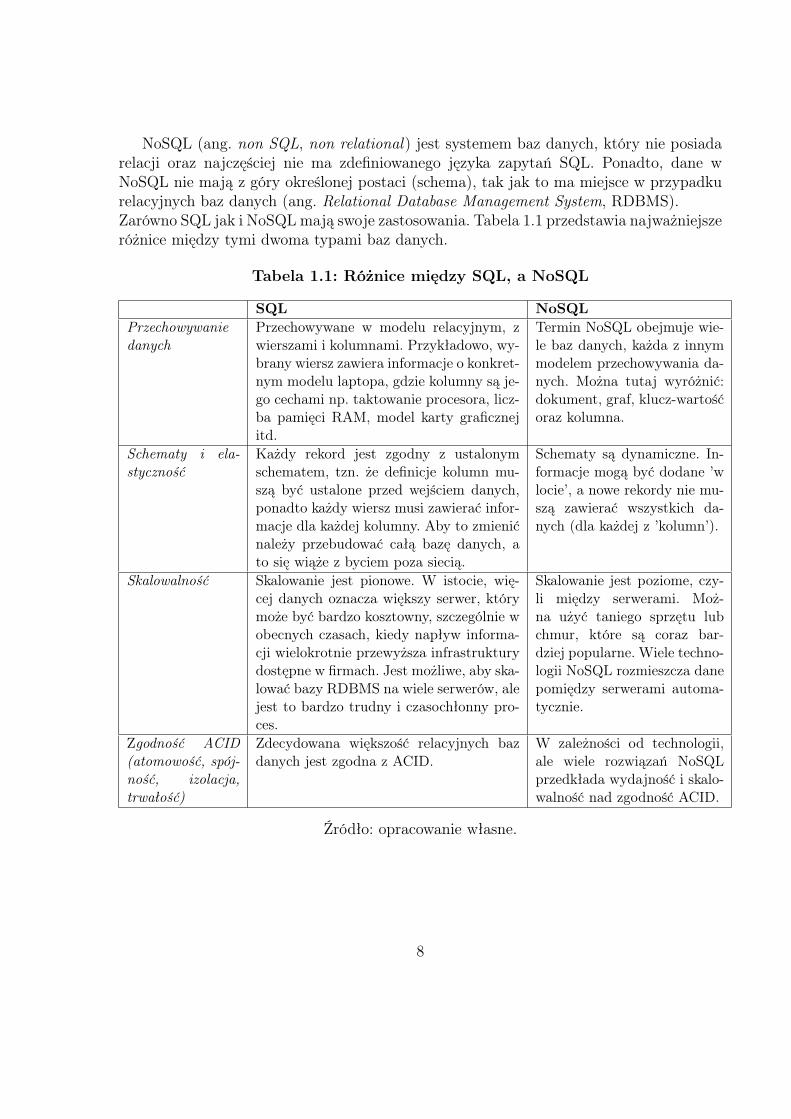
NoSQL (ang. non SQL, non relational) jest systemem baz danych, który nie posiadarelacji oraz najczęściej nie ma zdefiniowanego języka zapytań SQL. Ponadto, dane wNoSQL nie mają z góry określonej postaci (schema), tak jak to ma miejsce w przypadkurelacyjnych baz danych (ang. Relational Database Management System, RDBMS).Zarówno SQL jak i NoSQL mają swoje zastosowania. Tabela 1.1 przedstawia najważniejszeróżnice między tymi dwoma typami baz danych.
Tabela 1.1: Różnice między SQL, a NoSQL
SQL NoSQLPrzechowywaniedanych
Przechowywane w modelu relacyjnym, zwierszami i kolumnami. Przykładowo, wy-brany wiersz zawiera informacje o konkret-nym modelu laptopa, gdzie kolumny są je-go cechami np. taktowanie procesora, licz-ba pamięci RAM, model karty graficznejitd.
Termin NoSQL obejmuje wie-le baz danych, każda z innymmodelem przechowywania da-nych. Można tutaj wyróżnić:dokument, graf, klucz-wartośćoraz kolumna.
Schematy i ela-styczność
Każdy rekord jest zgodny z ustalonymschematem, tzn. że definicje kolumn mu-szą być ustalone przed wejściem danych,ponadto każdy wiersz musi zawierać infor-macje dla każdej kolumny. Aby to zmienićnależy przebudować całą bazę danych, ato się wiąże z byciem poza siecią.
Schematy są dynamiczne. In-formacje mogą być dodane ’wlocie’, a nowe rekordy nie mu-szą zawierać wszystkich da-nych (dla każdej z ’kolumn’).
Skalowalność Skalowanie jest pionowe. W istocie, wię-cej danych oznacza większy serwer, którymoże być bardzo kosztowny, szczególnie wobecnych czasach, kiedy napływ informa-cji wielokrotnie przewyższa infrastrukturydostępne w firmach. Jest możliwe, aby ska-lować bazy RDBMS na wiele serwerów, alejest to bardzo trudny i czasochłonny pro-ces.
Skalowanie jest poziome, czy-li między serwerami. Moż-na użyć taniego sprzętu lubchmur, które są coraz bar-dziej popularne. Wiele techno-logii NoSQL rozmieszcza danepomiędzy serwerami automa-tycznie.
Zgodność ACID(atomowość, spój-ność, izolacja,trwałość)
Zdecydowana większość relacyjnych bazdanych jest zgodna z ACID.
W zależności od technologii,ale wiele rozwiązań NoSQLprzedkłada wydajność i skalo-walność nad zgodność ACID.
Źródło: opracowanie własne.
8

MongoDBDane rzeczywiste, które zostały wykorzystane w tej pracy, są przechowywane w niere-lacyjnej bazie danych, a dokładniej w MongoDB. Wybór ten był determinowany przedewszystkim szybkością działania, jako że mamy tutaj do czynienia z danymi niestruktural-nymi (adresy URL, czasy wejść, nazwy przeglądarek internetowych itd.) i ich gromadzeniew relacyjnej bazie danych byłoby co najmniej kłopotliwe, a na pewno czasochłonne.
MongoDB jest to otwarty, nierelacyjny system zarządzania bazą danych napisany wjęzyku C++. Charakteryzuje się dużą skalowalnością, wydajnością oraz brakiem ściślezdefiniowanej struktury obsługiwanych baz danych. Zamiast tego, dane składowane sąjako dokumenty w stylu JSON (ang. JavaScript Object Notation), które złożone są zpar: klucz-wartość, co umożliwia aplikacjom bardziej naturalne ich przetwarzanie, przyzachowaniu możliwości tworzenia hierarchii oraz indeksowaniaPoniżej przedstawiono strukturę nierelacyjnej bazy danych MongoDB.
"wp.pl/pogoda": 23,
"wp.pl/sport": 35
Kluczem jest tutaj adres URL, a wartość to liczba jego wyświetleń, a więc dla przy-kładu, klucz: wp.pl/pogoda; wartość: 23.
1.3 Niezbalansowane klasy
W przypadku reklam internetowych bardzo często zdarza się, że liczba wyświetleń jestzdecydowanie większa od liczby kliknięć. Jest to bardzo ważny problem, z którym zmagająsię firmy chcące przyciągnąć do siebie większą rzeszę klientów. Należy jednak pamiętać, żemodelowanie takiego zjawiska jest trudnym i pracochłonnym procesem, który nie zawszeprowadzi do satysfakcjonujących wyników.W życiu niejednego statystyka zdarzyło się uzyskać model z ponad 90% dokładnością. Nie-stety, w większości przypadków okazało się, że te 90% poprawnych prognoz dotyczy jedneji tej samej klasy. Jest to tzw. paradoks dokładności (ang. accuracy paradox 17). Problemniezbalansowanych klas (ang. class imbalance) jest coraz częściej spotykany, a pojawia sięwtedy kiedy liczba przypadków w jednej klasie jest większa niż w pozostałych. Bardzodużo algorytmów, w tego typu sytuacjach, traktuje główną klasę (ang. majority class) ja-ko ważniejszą, ignorując przy tym, bądź źle klasyfikując przypadki z klas rzadszych (ang.minority classes), na których zwykle nam bardziej zależy. W dalszej części, będziemy ana-lizować problem klasyfikacyjny w oparciu o dwie klasy, ponieważ takie podejście pozwolilepiej zrozumieć to zagadnienie.
17https://en.wikipedia.org/wiki/Accuracy_paradox, dostęp 10.08.2015.
9

Przykład 1.2. Rozważmy następujący problem klasyfikacyjny, który jednocześnie na-wiązuje do tematu tej pracy: w grudniu 2015 roku wyświetlono 100100 reklam na stronieinternetowej pewnego serwisu społecznościowego, jednakże tylko 100 spośród nich za-chęciło użytkowników do kliknięcia. Mamy tutaj do czynienia z typowym zagadnieniemniezbalansowanych klas, mianowicie ich stosunek to 100000 : 100, a więc 1000 : 1.
Powyższy przykład w prosty sposób ilustruje omawiane zjawisko. Należy jednak pa-miętać, że tego typu problemy pojawiają się coraz częściej, nie tylko w przypadku reklaminternetowych, ale również w medycynie, czy biologii. Czasami, różna liczność klas, a na-wet jak najmniejsza liczba przypadków w grupie rzadszej, jest pożądana. Na przykład,wykrywanie fałszywych transakcji, gdzie zależy nam na jak najmniejszej liczbie oszustw.
Poniżej podano kilka podejść w przypadku niezbalansowanych klas, które pomagająuzyskać lepsze wyniki.
1. Zebranie większej ilości danych. Te podejście wydaje się oczywiste, ale nie zawszejest uwzględniane (z różnych powodów, w tym głównie braku czasu). Należy jednako nim pamiętać, w szczególności w przypadku mniejszych zbiorów danych, kiedykolejne obserwacje mogą zmienić rozkład i ułatwić analizę.
2. Skorzystanie z innych miar dopasowania modelu, jak np. precision, recall czyF1Score, które wskażą bardziej wiarygodne wyniki w przypadku klas o różnej licz-ności. Zostały one opisane w dalszej części tej pracy.
3. Próbkowanie (ang. sampling), czyli zmiana zbioru danych w celu wyrównania klas.Wyróżniamy dwa podejścia:
• powiększenie klasy rzadszej poprzez próbkowanie ze zwracaniem, czyli doda-wanie istniejących już przypadków, przez co część obserwacji będzie powielona(ang. over-sampling),
• usunięcie pewnej liczby obserwacji z klasy głównej (and. under-sampling), coskutkuje utratą informacji o danych.
4. Generowanie syntetycznych próbek z klasy rzadszej. Najbardziej popularnym algo-rytmem jest SMOTE (ang. Synthetic Minority Over-sampling Technique), który dlakażdej obserwacji z klasy mniejszościowej znajduje k-najbliższych sąsiadów (używa-jąc wybranej miary odległości), a następnie generuje nowe przypadki wzdłuż liniiłączących analizowaną obserwację z wybranymi sąsiadami18.
18Nitesh V. Chawla, Kevin W. Bowyer i inni, 2002.
10

5. Wypróbowanie wielu algorytmów. W przypadku klas o różnej liczności, dobrymwyborem może okazać się las losowy (ang. random forest19), bądź metoda LASSO(ang. Least Absolute Shrinkage and Selection Operator 20).
6. Zwiększenie wag obserwacji w klasie rzadszej. To podejście zostało zastosowane wtej pracy, ze względu na kompatybilność z wykorzystywanym algorytmem. Przykła-dowo, stosunek liczności klas to 1 : 5, zatem obserwacje w klasie rzadszej otrzymająwagę 5, natomiast te z klasy głównej wagę 1. Takie rozwiązanie spowoduje potrak-towanie (przez algorytm) przypadków mniejszej klasy z 5-krotnie większą ’uwagą’.Efekt jest zbliżony do wymienionego wyżej over-samplingu.
19https://www.stat.berkeley.edu/∼breiman/RandomForests/cc_home.htm, dostęp 22.08.2015.20http://statweb.stanford.edu/∼tibs/lasso.html, dostęp 22.08.2015.
11

Rozdział 2. Algorytm locality-sensitive hashing: reduk-cja wymiaru
2.1 Problem wielowymiarowości
Fundamentalnym problemem eksploracji danych jest analiza danych pod kątem zna-lezienia podobnych do siebie pozycji. Takie podejście jest jak najbardziej zasadne, szcze-gólnie w czasach nadmiarowości informacji. Metody, znane obecnie, nie są do końca przy-szykowane na starcie z danymi typu Big data. Często zdarza się, że liczba zmiennych jestzdecydowanie większa niż liczba obserwacji (p N). Taka sytuacja może spowodowaćzbyt dobre dopasowanie modelu do danych (ang. overfitting) ze zbioru uczącego (ang.train set). W tym miejscu ktoś by mógł zapytać: a co w tym złego? Odpowiedź jest nastę-pująca: jeśli zastosujemy taki model do nowych danych, które nie znalazły się w zbiorzeuczącym, bądź znacznie się różnią, wyniki będą zdecydowanie gorsze.Podsumowując, celem zbudowania dobrego modelu jest uzyskanie jak najlepszych prognozna zbiorze testowym (ang. test set). W tym miejscu, warto również podkreślić, że istnie-je wiele metod statystycznych, które mogą pomóc w uniknięciu problemu nadmiernegodopasowania. Najbardziej znaną jest walidacja krzyżowa (ang. cross validation), która po-lega na podziale próby statystycznej na podzbiory, a następnie przeprowadzeniu wszelkichanaliz na niektórych z nich (zbiór uczący), podczas gdy pozostałe służą do potwierdzeniawiarygodności jej wyników (zbiór testowy, zbiór walidacyjny).
Locality-sensitive hashing: redukcja wymiaruIstnieje wiele metod służących redukcji wymiaru, w tym:
• Analiza głównych składowych (ang. Principal Component Analysis, PCA);
• Analiza czynnikowa (ang. Factor Analysis, FA);
• Rozkład według wartości osobliwych (ang. Singular Value Decomposition, SVD).
Po przeanalizowaniu wielu czynników, do pogrupowania adresów URL wybrano algo-rytm locality-sensitive hashing (LSH). Jest to mniej znana metoda, z pewnością nie takpowszechna jak te wymienione powyżej. Niemniej jednak, zasługuje na szczególną uwagę.W dużym uproszczeniu, algorytm LSH porównuje ze sobą dokumenty (mogą to być ar-tykuły, e-maile, czy omawiane w tej pracy adresy URL), szukając tych najbardziej dosiebie podobnych (wg. określonej miary podobieństwa), a następnie tworząc z nich grupy.Jest to tylko prosty przekaz sensu działania, jednakże jak się okaże w dalszej części tegopodrozdziału, poszczególne elementy (między innymi sposób sprawdzania podobieństwadwóch elementów) nie są już tak proste i oczywiste.
12

Algorytm złożony jest z 3 kroków:
1. Shingling: zamiana adresów URL w zbiór złożony z k-shingelsów 21;
2. Min-hashing: przekształcenie dużych zbiorów danych w krótkie sygnatury, zacho-wując podobieństwo22;
3. Locality-sensitive hashing : koncentracja tylko na parach kandydujących23.
Poniżej ogólny schemat działania LSH.
Rysunek 2.1: Locality-sensitive hashing.
Źródło: opracowanie własne na podstawiehttp://snap.stanford.edu/class/cs246-2012/slides/03-lsh.pdf.
2.2 Miary odległości
W pierwszej kolejności należy wprowadzić podstawowe miary odległości. Są one dośćspecyficzne, ponieważ ich główne zastosowanie to porównywanie tekstów.
1. Odległość JaccardaPodobieństwo Jaccarda między zbiorami skończonymi i niepustymi S i T wynosi:|S∩T ||S∪T | , czyli iloraz iloczynu zbiorów S i T przez ich sumę. Najczęściej, podobieństwoJaccarda pomiędzy S i T oznaczane jest jako SIM(S, T ).Odległość Jaccarda między S i T wynosi: 1− SIM(S, T ).Własności:
21Podrozdział 2.3.22Podrozdział 2.4.23Podrozdział 2.5.
13

• d(S, T ) 0, ponieważ iloczyn dwóch zbiorów nie może być większy niż ichsuma.
• d(S, T ) = 0, jeżeli S = T , ponieważ S∪S = S∩S = S. Jednakże, jeżeli S 6= T ,wtedy S ∩ T jest mniejszy niż S ∪ T , a więc d(S, T ) jest dodatnia.
• d(S, T ) = d(T, S), ponieważ zarówno iloczyn, jak i suma zbiorów są symetrycz-ne, tj. S ∪ T = T ∪ S i S ∩ T = T ∩ S.
• zachodzi nierówność trójkąta: d(S, U) + d(T, U) d(S, T ), poniżej szkic dowo-du.
Szkic dowodu. Należy wyjść od następującej notacji:
d(S, T ) = 1− SIM(S, T ) = 1− |S ∩ T ||S ∪ T |
=|S 4 T ||S ∪ T |
(2.1)
Rozważmy tylko sytuację, kiedy U ⊆ S oraz U ⊆ T , ponieważ każdy elementw U , nie występujący w S lub T powiększałby tylko lewą stronę nierówności.Jeżeli U = S = T , wtedy 0 + 0 0, w przeciwnym razie mamy:
d(S, U) + d(T, U) =|S \ U ||S|
+|T \ U ||T |
(1) |S \ U |+ |T \ U |
|S ∪ T |(2) |S 4 T ||S ∪ T |
= d(S, T )
(2.2)
Nierówność (1) zachodzi, ponieważ |S|, |T | ¬ |S ∪ T |.Nierówność (2) jest spełniona, ponieważ zgodnie z założeniem U ⊆ (S ∩ T ), awięc |S \ U |+ |T \ U | |S 4 T | dla dowolnego zbioru U .24
Do opisania powyższej miary użyto dwóch pojęć: odległość oraz podobieństwo. Wcelu uniknięcia niejasności, poniżej przedstawiono poszczególne ich własności:
Odległość d(S, T):
• jest mała, jeżeli obiekty S i T są blisko (analogicznie, jeżeli są daleko, odległośćjest duża);
• wynosi 0, jeżeli S i T są takie same;
• zawiera się w przedziale [0, 1].24J. Phillips, Distances, 2015.
14

Podobieństwo SIM(S, T):
• jest duże, jeżeli S i T są blisko (analogicznie, jeżeli są daleko, podobieństwojest małe);
• wynosi 1, jeżeli S i T są takie same;• zawiera się w przedziale [0, 1].
Przykład 2.1. Rysunek 2.2 przedstawia dwa zbiory S i T . Cyfry pojawiające się nadiagramie Venna odpowiadają liczbie elementów danego zbioru. Część wspólna to 3pozycje, a całkowita liczba elementów, które wystąpiły w obydwu zbiorach wynosi15. Zatem SIM(S, T ) = 3/15.
Rysunek 2.2: Podobieństwo Jaccarda.
Źródło: opracowanie własne.
2. Odległość Levenshteina (edycyjna)Odległość między dwoma ciągami znaków x = x1x2...xn i y = y1y2...ym to naj-mniejsza liczba wstawień i usunięć pojedynczych znaków, taka że x zamieni się wy.
Przykład 2.2. Odległość Levenshteina pomiędzy napisami x = qwerty i y = wetrywynosi 3, mianowicie żeby zamienić x na y należy:
• usunąć q
15

• usunąć r
• wstawić r po t
3. Odległość HammingaOdległość Hamminga jest stosowana tylko i wyłącznie do ciągów o tej samej długości,wyraża ona liczbę miejsc (pozycji), na których się one różnią. Tak jak w odległościLevenshteina jest to najmniejsza liczba zmian, jakie pozwalają zamienić jeden ciągna drugi.
Przykład 2.3. Odległość Hamminga między dwoma ciągami znaków małpa orazmarka wynosi 2. Teksty te różnią się na 3 i 4 miejscu.
2.3 k-Shingles
Najbardziej wydajnym sposobem reprezentacji dokumentów/tekstów (w celu ich po-równywania) jest konstrukcja zbiorów złożonych z krótkich ciągów znaków, które się wnich pojawiły. Dokumenty, które mają wiele takich wspólnych ciągów, są do siebie po-dobne (nawet jeżeli tekst pojawia się w innej kolejności).Na potrzeby tej pracy jako dokument przyjęto adres URL. Zatem k− shingle dla danegoadresu URL będzie dowolnym podciągiem o długości k, który pojawił się w tym URL-u.
Przykład 2.4. Niech A oznacza następujący adres URL: http://wp.pl/portal/nowosci,a k wynosi 5. Po oczyszczeniu (usunięcie znaków specjalnych oraz protokołu przesyłaniadokumentów hipertekstowych, czyli http) adres URL wygląda następująco: wpplportalno-wosci.Teraz należy utworzyć shingelsy o długości = 5: wpplp, pplpo, plpor, lport, porta, ortal,rtaln, talno, alnow, lnowo, nowos, owosc, wosci.
Wartość parametru k zależy od tego jak długie są teksty, które mają być analizowane.Należy wybrać k tak duże, aby prawdopodobieństwo pojawienia się jakiegokolwiek shinglew jakimkolwiek dokumencie było małe25.Zwykle przyjmuje się k = 5 dla krótkich ciągów znaków, jak np. adresy URL, czy e-maile. Natomiast dla długich tekstów (artykuły, dokumenty itd.) k = 10. Są to wartościorientacyjne - należy je dopasować samemu w zależności od rodzaju analizy.
2.4 Min-hashing: funkcja hashująca dla podobieństwa Jaccarda
Po konstrukcji shingelsów dla wszystkich URL-i można utworzyć następującą macierzcharakterystyczną (ang. characteristic matrix ): kolumny odpowiadają zbiorom shingel-sów dla poszczególnych adresów URL, a wiersze to wszystkie shingelsy, które się w nich
25Jure Leskovec, Anand Rajaraman, Jeffrey D. Ullman, podrozdział 3.2.2, 2010.
16

pojawiły. Jeżeli shingle i zawiera się w URL-u j to element ij macierzy wynosi 1, w prze-ciwnym wypadku 0. Taka macierz będzie rzadka (ang. sparse matrix ) dla dużej liczbyURL-i, tj. wypełniona prawie samymi zerami. Sprawia to wiele problemów, związanychgłównie ze złożonością obliczeń, jednakże część z nich można rozwiązać poprzez utworze-nie macierzy sygnatur, która reprezentuje wejściową macierz.
Przykład 2.5. Rozważmy trzy adresy URL: onet.pl/pogoda/gdansk, wp.pl/gry/mario,google.pl/szyszka i oznaczmy je jako URL1, URL2, URL3. Zgodnie z podrozdziałem 2.3,wybierając tym razem k = 4, tworzymy zbiór 4 − shingles, które pojawiły się w tychURL-ach. Wygląda on następująco: onet, netp, etpl, tplp, plpo, lpog, pogo, ogod, goda,odag, dagd, agda, gdan, dans, ansk, wppl, pplg, plgr, lgry, grym, ryma, ymar, mari, ario,goog, oogl, ogle, glep, lepl, epls, plsz, lszy, szys, zysz, yszk, szka, gdzie URL1 = onet,netp, ..., ansk, URL2 = wppl, pplg, ..., ario, a URL3 = goog, oogl, ..., szka. Tabela2.1 przedstawia tylko częściowo wypełnioną macierz charakterystyczną dla powyższychdanych, ponieważ wszystkich shingelsów o długości 4, które pojawiły się w analizowanychadresach URL jest aż 36.
Tabela 2.1: Fragment macierzy charakterystycznej dla danych z przykładu2.5.
Shingle URL1 URL2 URL3onet 1 0 0netp 1 0 0etpl 1 0 0... ... ... ...
wppl 0 1 0pplg 0 1 0plgr 0 1 0... ... ... ...
goog 0 0 1oogl 0 0 1ogle 0 0 1... ... ... ...
Żródło: opracowanie własne.
Jak widać, uzyskano macierz, w której dominują zera, pomimo, że do jej budowy użytotylko trzech adresów URL. W tym przypadku nie miały one żadnego wspólnego shingelsa,jednakże bardzo często zdarza się, że ten sam człon występuje w kilku adresach URL.Należy wtedy pamiętać, że macierz charakterystyczna zawiera tylko unikalne shingelsy.Ten przykład pozwala zrozumieć, jak ważna jest konstrukcja macierzy sygnatur.
17

Funkcje hashująceDalsza analiza algorytmu LSH będzie wymagała znajomości pojęcia funkcji hashującej.Jest to funkcja h ∈ H, która odwzorowuje zbiór o pewnym rozmiarze (niekoniecznieskończonym) w zbiór o określonej wielkości (stałej).Przykład 2.6. Hashing multiplikatywny: ha(x) = bm ∗ frac(x ∗ a)c, gdzie a jestliczbą rzeczywistą, frac(·) wybiera część dziesiętną liczby (np. frac(21.624) = 0.624), ab·c część całkowitą, przy zaokrągleniu w dół (np. b21.624 = 21c). W celu zwiększeniawydajności, funkcję tę często implementuje się jako (xa2q )modm, gdzie q zastępuje frac(·)i określa jaka ma być precyzja bitowa (np. 12-bitowa precyzja).
Min-hashingNależy wykonać n losowych i niezależnych od siebie permutacji m wierszy macierzy cha-rakterystycznej (n oznacza liczbę sygnatur, jaka ma zostać utworzona). Wartość minhashdla kolumny S to numer pierwszego wiersza (według kolejności z permutacji), dla któregota kolumna ma wartość 1. Macierz sygnatur ma taką samą liczbę kolumn, co macierz cha-rakterystyczna, jednakże tylko n wierszy (zwykle 100 lub więcej, przy czym, dla dużychzbiorów danych zachodzi n m).Przykład 2.7. Załóżmy tym razem (dla uproszczenia), że nasza macierz charakterystycz-na zawiera zbiory złożone z kilku pojedynczych znaków: S1 = a, b, c, S2 = b, d, e,S3 = a, b, e, f i S4 = a, f. Cały proces powstawania takiej macierzy jest analogicznyjak w przykładzie 2.5. Następnie, dokonajmy losowej permutacji wierszy, zdefiniowanejprzez funkcję minihash h, w wyniku której naturalna kolejność 1, 2, 3, 4, 5, 6 zostanie za-mieniona na 3, 5, 1, 4, 2, 6. Tabela 2.2 zawiera macierze przed i po permutacji wierszy.
Tabela 2.2: Macierz charakterystyczna z ’normalną’ (po lewej) oraz zezmienioną (po prawej) kolejnością wierszy.
Nr wiersza Element S1 S2 S3 S41 a 1 0 1 12 b 1 1 1 03 c 1 0 0 04 d 0 1 0 05 e 0 1 1 06 f 0 0 1 1
Nr wiersza Element S1 S2 S3 S43 c 1 0 0 05 e 0 1 1 01 a 1 0 1 14 d 0 1 0 02 b 1 1 1 06 f 0 0 1 1
Żródło: opracowanie własne.
Na podstawie tabeli ze zmienioną kolejnością wierszy, obliczmy wartość minihash dlazbioru S1 używając funkcji h. Wartość 1 pojawia się już w pierwszym wierszu (kieruje-my się z góry do dołu) dla elementu c, a więc h(S1) = 3. Analogicznie postępujemy wprzypadku pozostałych zbiorów, a więc h(S2) = 5, h(S3) = 5 oraz h(S4) = 1.
18

Minhashing, a podobieństwo Jaccarda
Twierdzenie 2.1. Prawdopodobieństwo tego, że funkcja minhash (dla losowej permutacjiwierszy) da te same wartości dla dwóch zbiorów, jest równe podobieństwu Jaccarda dlatych zbiorów, tj. P [h(S1) = h(S2)] = E(SIM(S1, S2)) = SIM(S1, S2), gdzie
SIM(S1, S2) =
1, jeżeli h(S1) = h(S2)0, w przeciwnym wypadku
(2.3)
oznacza estymator podobieństwa Jaccarda, skonstruowany w oparciu o macierz sygnatur.
Dowód. Istnieją trzy typy wierszy:Typ X: x wierszy z 1 dla obu kolumn;Typ Y : y wierszy z 1 w jednej z dwóch kolumn;Typ Z: z wierszy z 0 w obu kolumnach.Całkowita liczba wierszy to: x+y+z. Podobieństwo Jaccarda wynosi dokładnie SIM(S1, S2) =xx+y (zwykle z x, y, a więc przypadki typu z można pominąć).Niech wiersz r = minh(S1), h(S2). Zgodnie z wcześniejszymi założeniami r może być al-bo typu X albo typu Y . Co więcej, zdarzenia typu X występują z prawdopodobieństwemdokładnie x
x+y , jako że permutacje są losowe. Jest to zatem jedyny przypadek, dla któregoh(S1) = h(S2), w przeciwnym razie S1 albo S2 jest równe 1, ale nigdy jednocześnie.
Takie podejście daje w wyniku tylko dwie wartości 0 lub 1. Aby otrzymać lepszą es-tymację, należy powtórzyć działanie k razy.Niech H1,H2, ... ciąg niezależnych zmiennych losowych o jednakowym rozkładzie, gdzieΩHj−→ h1, h2, ..., hn!. Następnie wybierzmy n losowych permutacji h1, h2, ..., hn, które two-
rzą ciąg n zmiennych losowych X1, X2, ..., Xn. Wtedy:
Xl =
1, jeżeli hl(S1) = hl(S2)0, w przeciwnym wypadku
(2.4)
Teraz można estymować SIM(S1, S2) jako SIMn(S1, S2) = 1n
∑nl=1Xl (średnia z n
losowych estymacji).
W tym miejscu pojawia się bardzo ważne pytanie, mianowicie jakie n należy wybrać,aby otrzymać precyzyjną miarę? W celu znalezienia takiej wartości, wykorzystamy twier-dzenie oparte o nierówność Chernoff’a Hoefdding’a.
Twierdzenie 2.2. Nierówność Chernoff’a-Hoeffding’a26 (specyficzna forma)Rozważmy zbiór r niezależnych zmiennych losowych X1, X2, ..., Xr. Jeżeli wiemy, że
26J. Phillips, Chernoff-Hoeffding Inequality tw. 3.1.1, 2015.
19

ai ¬ Xi ¬ bi, to 4i = bi − ai oraz M =∑ri=1Xi. Wtedy dla każdego α ∈ (0, 1/2):
P[|M − E[M ]| α
]¬ 2 exp
( −2α2∑ri=142i
)(2.5)
Jako, że minhashing jest losowym algorytmem, należy wprowadzić pojęcie tolerancjibłędu, zdefiniowane jako ε ∈ (0, 1) (tj. chcemy, aby |SIM(S1, S2) − SIMn(S1, S2)| ¬ ε)oraz prawdopodobieństwo porażki, które wynosi δ (tj. prawdopodobieństwo, że błąd jestwiększy niż ε). Następnie, korzystając z twierdzenia 2.2 opartego o nierówność Chernoff’a-Hoeffding’a podstawiamy M =
∑nl=1Xl, a więc E[M ] = n ∗ SIM(S1, S2) (na podstawie
twierdzenia 2.1) . Ponieważ 0 ¬ Xi ¬ 1, 4i = 1. Ostatecznie, dla pewnej wartości αmożna zapisać:
P[|SIMn(S1, S2)− SIM(S1, S2)|
α
n
]= P
[|n ∗ SIMn(S1, S2)− n ∗ SIM(S1, S2)| α
]= P
[|M − E[M ]| α
]¬ 2 exp
(−2α2∑ni=142i
)= 2 exp
(−2α2
n
)(2.6)
Podstawiając α = εn oraz n = 12ε2 ln(2
δ) otrzymujemy:
P[|SIMn(S1, S2)− SIM(S1, S2)| ε
]¬ 2exp
(−2(ε2n2)n
)= 2exp
(− 2ε2
12ε2
ln(2δ
))
= δ
(2.7)
Innymi słowy, jeżeli wybierzemy n = 12ε2 ln(2
δ), to prawdopodobieństwo tego, że na-
sza estymacja SIMn(S1, S2) podobieństwa Jaccarda SIM(S1, S2) mieści się w granicachbłędu ε, wynosi co najmniej 1− δ.
Przykład 2.8. Chcemy, aby błąd był co najwyżej ε = 0.08, natomiast δ = 0.01 (praw-dopodobieństwo porażki), wtedy n = 1
2∗0.082 ln( 20.01) = 78.125 ∗ ln(200) ≈ 414.
Min-hashing a Big DataPermutacje wierszy, w przypadku dużych zbiorów danych, wymagają ogromnej mocy ob-liczeniowej, dlatego powyższe podejście nie jest implementowalne. Jednakże istnieje moż-liwość zasymulowania efektów losowych permutacji, używając losowych funkcji haszują-cych, które odwzorowują numery wierszy na taką liczbę koszyków (ang. buckets) ile jestwierszy (zwykle część par znajdzie się w tych samych koszykach, przez co pozostałe zosta-ną puste). Załóżmy w tym miejscu, że nasza funkcja hashująca h zamienia numer wiersza
20

r na pozycję h(r).Tak więc, zamiast wybierać n losowych permutacji wierszy, należy wskazać n losowychfunkcji hashujących h1, h2, ..., hn dla tych wierszy. Niech SIG(i, S) oznacza element ma-cierzy sygnatur dla i-tej funkcji hashującej i kolumny S. Początkowo wszystkie elementymacierzy sygnatur mają wartość ∞.
Algorytm 2.1:
1. Oblicz h1(r), h2(r), ..., hn(r).
2. Dla każdej kolumny S wykonaj:
• Jeżeli kolumna S ma wartość 0 w wierszu r - nie rób nic.
• Jeżeli kolumna S ma wartość 1 w wierszu r, wtedy dla każdego i = 1, 2, ..., nustaw SIG(i, S) na mniejszą spośród obecnej wartości SIG(i, S) oraz hi(r).
Tabela 2.3: Min-hashing - inne podejście, x oznacza numer wiersza.
Wiersz S1 S2 S3 S4 (x+ 1)mod5 (3x+ 1)mod50 1 0 0 1 1 11 0 0 1 0 2 42 0 1 0 1 3 23 1 0 1 1 4 04 0 0 1 0 0 3
Źródło: opracowanie własne.
Przykład 2.9. Tabela 2.3 przedstawia porównanie 4 zbiorów (S1, ..., S4). Wybrano dwiefunkcje hashujące: h1(x) = (x+1)mod5 oraz h2(x) = (3x+1)mod5, dla których argumen-tem jest numer wiersza. Otrzymane wartości znajdują się w dwóch ostatnich kolumnach.Są one unikalne, ponieważ liczba wierszy równa 5 jest liczbą pierwszą. W przypadku więk-szych zbiorów danych mogą zdarzyć się tzw. kolizje (ang. collisions), kiedy dwa wierszeotrzymają taką samą wartość hashującą. Jednakże, bardzo istotne jest, aby dobrać funkcjehashujące w taki sposób, aby liczba kolizji była jak najmniejsza.Poniżej symulacja algorytmu 2.1 w wyniku, której obliczana jest macierz sygnatur. Po-czątkowo, zgodnie z tym co napisano wyżej, wszystkie wartości ustawione są na ∞. Dlaprzykładu zostanie opisany 1. krok, a więc wiersz z indeksem 0. Jak widać w tabeli 2.3h1(0) oraz h2(0) wynoszą 1. Zgodnie z algorytmem 2.1 należy rozważyć tylko i wyłączniekolumny niezerowe, tj. S1 oraz S4. Jako, że wartość 1 jest mniejsza niż ∞, w obu ko-lumnach i wierszach dokonywana jest zamiana: ∞ → 1. W pozostałych krokach należy
21

postąpić w analogiczny sposób. Na rysunku 2.3 przedstawiono cały proces powstawaniamacierzy sygnatur.
Rysunek 2.3: Symulacja algorytmu 2.1: powstawanie macierzy sygnatur.
Źródło: opracowanie własne.
2.5 Locality-sensitive hashing
Obliczenie podobieństwa każdej pary adresów URL zajęłoby bardzo dużo czasu, na-wet jeżeli wykorzystano by w badaniu obliczenia równoległe27 (ang. parallel computing).Jednakże, często cel jest zupełnie inny, a mianowicie znalezienie podobnych do siebie par(na ustalonym poziomie podobieństwa), a następnie pogrupowanie ich w odpowiedni spo-sób. Jednym z rozwiązań takiego problemu jest omawiany w tym podrozdziale algorytmlocality-sensitive hashing. W tej pracy wykorzystano specyficzną formę LSH, odpowiedniądla badanego zagadnienia, tj. adresów URL, reprezentowanych przez zbiory shingelsów,a następnie przekształcanych na krótkie sygnatury za pomocą opisanej wyżej metodyminhashingu. Ogólna teoria locality-sensitive hashing oraz szereg zastosowań tej metodyznajduje się w książce Mining of Massive Datasets28.
27Obliczenia równoległe – forma wykonywania obliczeń, w której wiele instrukcji jest wykonywanychjednocześnie.
28Jure Leskovec, Anand Rajaraman, Jeffrey D. Ullman, podrozdział 3.6, 2010.
22

LSH - minhashowanie sygnaturGeneralnie zadaniem LSH jest wielokrotne hashowanie badanych elementów, w taki spo-sób, że podobne do siebie pozycje trafią do tego samego koszyka z większym prawdopo-dobieństwem niż te niepodobne. Wtedy, każda para, która została skierowana do tegosamego koszyka, chociaż przez jedno hashowanie, uznawana jest za parę kandydującą, dlaktórej można (choć nie trzeba) policzyć dokładne podobieństwo. Jednym z głównych celówtej metody jest zminimalizowane (a najlepiej wykluczenie) umieszczania w tym samymkoszyku niepodobnych do siebie elementów, które noszą nazwę fałszywie dodatnich (ang.false positives). Równorzędnym celem jest to, aby jak najwięcej faktycznie podobnych dosiebie elementów zostało skierowanych do tego samego koszyka przez przynajmniej jednąfunkcję hashującą. Analogicznie, te które się tam nie znajdą, a powinny, nazywamy fał-szywie ujemnymi (ang. false negatives).Jednym z bardziej wydajnych sposobów, na umiejscowienie podobnych par w tych samychkoszykach, jest podział macierzy sygnatur na b bandów (części), z których każdy składasię z r wierszy. Dla każdego bandu istnieje funkcja, która hashuje poszczególne wektory odługości r, porównuje ze sobą w celu znalezienia identycznych i umieszcza je w koszykach.Następnie, sprawdzana jest cała przestrzeń koszyków (wymiar równy liczbie bandów), tepary zahashowanych wektorów, które znalazły się w tym samym koszyku co najmniej raz(pary kandydujące) trafiają do tej samej grupy.
Powyższy szczegółowy opis metody można zapisać w 3 krokach:
1 Podziel macierz M (macierz sygnatur) na b bandów, każdy po r wierszy.
2 Dla każdego bandu sprawdź czy występują pary kolumn, które mają te same warto-ści, jeśli choć w jednym bandzie znajdzie się taka para to uznaj ją jako kandydującą,a następnie wrzuć do koszyka.
3 Parametry b i r dobierz tak, aby znaleźć jak najwięcej podobnych par, a jak najmniejniepodobnych (kontrola fałszywie dodatnich i fałszywie ujemnych).
Rysunek 2.4 obrazuje sposób działania algorytmu LSH.
23
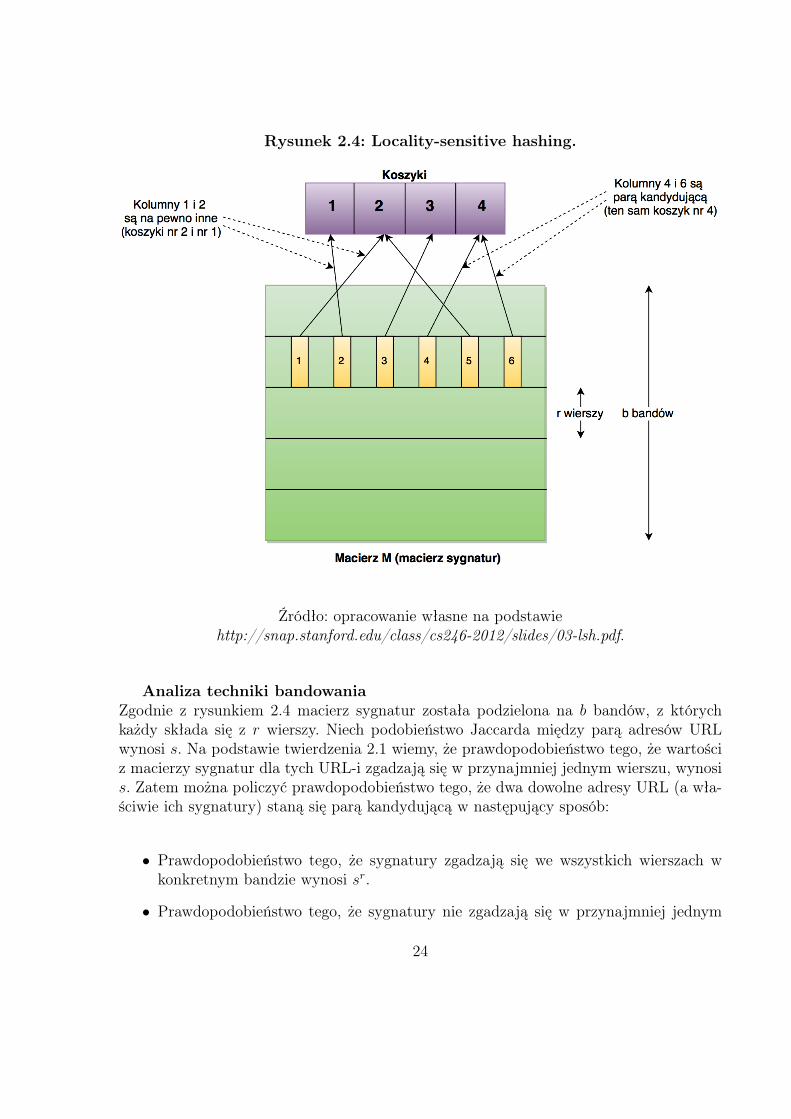
Rysunek 2.4: Locality-sensitive hashing.
Źródło: opracowanie własne na podstawiehttp://snap.stanford.edu/class/cs246-2012/slides/03-lsh.pdf.
Analiza techniki bandowaniaZgodnie z rysunkiem 2.4 macierz sygnatur została podzielona na b bandów, z którychkażdy składa się z r wierszy. Niech podobieństwo Jaccarda między parą adresów URLwynosi s. Na podstawie twierdzenia 2.1 wiemy, że prawdopodobieństwo tego, że wartościz macierzy sygnatur dla tych URL-i zgadzają się w przynajmniej jednym wierszu, wynosis. Zatem można policzyć prawdopodobieństwo tego, że dwa dowolne adresy URL (a wła-ściwie ich sygnatury) staną się parą kandydującą w następujący sposób:
• Prawdopodobieństwo tego, że sygnatury zgadzają się we wszystkich wierszach wkonkretnym bandzie wynosi sr.
• Prawdopodobieństwo tego, że sygnatury nie zgadzają się w przynajmniej jednym
24

wierszu w konkretnym bandzie wynosi 1− sr.
• Prawdopodobieństwo tego, że sygnatury nie zgadzają się w przynajmniej jednymwierszu we wszystkich bandach wynosi (1− sr)b.
• Prawdopodobieństwo tego, że sygnatury zgadzają we wszystkich wierszach w conajmniej jednym bandzie, a więc staną się parą kandydującą wynosi 1− (1− sr)b.
Zależność między miarą podobieństwa s, a prawdopodobieństwem stania się parą kan-dydującą można przedstawić za pomocą krzywej S (ang. S-curve), bez względu na to,jakie wartości parametrów b i r zostaną wybrane. Natomiast próg odcięcia, tj. wartośćpodobieństwa s, dla której prawdopodobieństwo stania się parą kandydującą wynosi 1/2,jest funkcją zależną od b i r i wynosi w przybliżeniu t ≈ (1/b)1/r. Próg znajduje się mniejwięcej tam, gdzie krzywa S jest najbardziej stroma. Dla dużych wartości b i r okazujesię, że prawdopodobieństwo tego, że pary z podobieństwem powyżej t staną się parą kan-dydującą jest bardzo wysokie, w przeciwieństwie do tych par, których podobieństwo jestponiżej progu odcięcia, a więc dokładnie tak jak chcemy.
Przykład 2.10. Niech b = 25, r = 6, wtedy liczba sygnatur wynosi 150 (25 ∗ 6), a prógodcięcia t ≈ 0.58, a więc mniej więcej tam, gdzie wartości krzywej S rosną najszybciej(patrz rysunek 2.5). Tabela 2.4 przedstawia kilka wartości krzywej S. Warto zwrócić uwagęna duże skoki, szczególnie dla s między 0.4, a 0.6 (wzrost o prawie 0.6).
Tabela 2.4: Wartości krzywej S.
s 1− (1− s6)250.2 0.001600.3 0.018070.4 0.097520.5 0.325450.6 0.697140.7 0.956240.8 0.99950
Żródło: opracowanie własne.
Przykładowo, wybierając s = 0.7, prawdopodobieństwo tego, że dwa adresy URL będądo siebie podobne w danym bandzie (te same wartości we wszystkich 6 wierszach) wynosiok. 0.12 (0.76). Jednakże, wszystkich bandów jest 25, a więc prawdopodobieństwo, że dwaURLe z podobieństwem 70% staną się parą kandydującą wynosi 1−(1−0.76)25 = 0.95624.
25
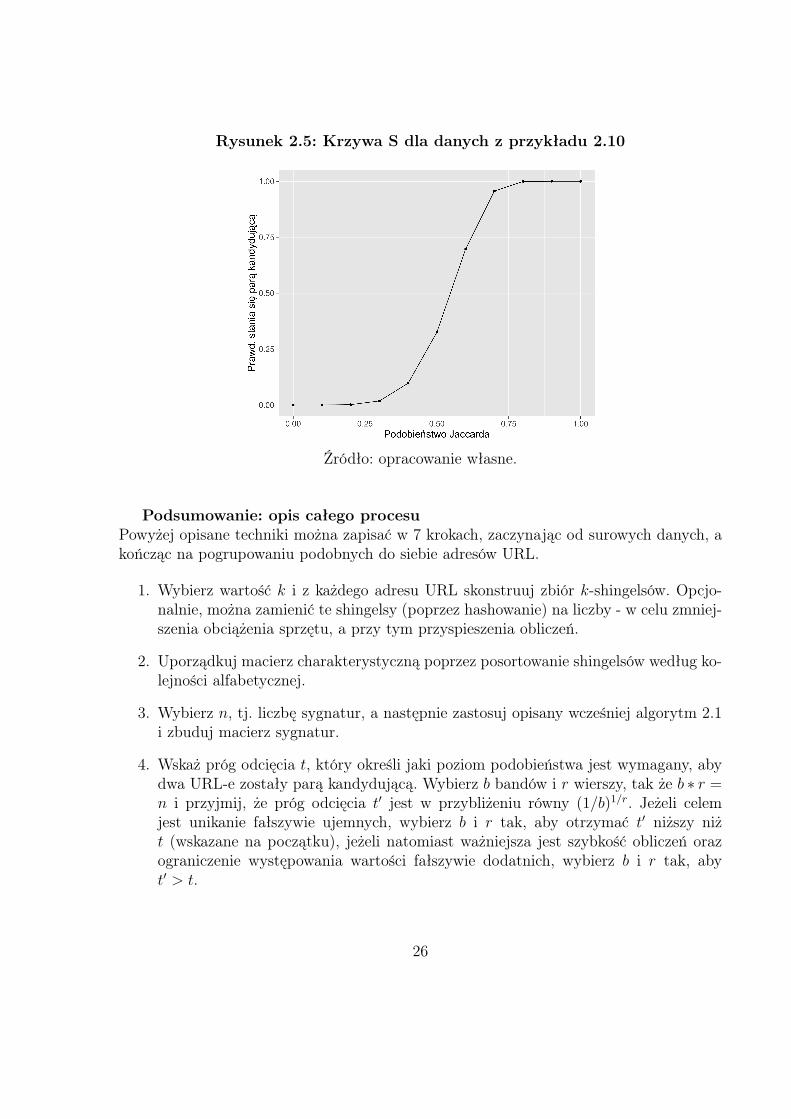
Rysunek 2.5: Krzywa S dla danych z przykładu 2.10
Źródło: opracowanie własne.
Podsumowanie: opis całego procesuPowyżej opisane techniki można zapisać w 7 krokach, zaczynając od surowych danych, akończąc na pogrupowaniu podobnych do siebie adresów URL.
1. Wybierz wartość k i z każdego adresu URL skonstruuj zbiór k-shingelsów. Opcjo-nalnie, można zamienić te shingelsy (poprzez hashowanie) na liczby - w celu zmniej-szenia obciążenia sprzętu, a przy tym przyspieszenia obliczeń.
2. Uporządkuj macierz charakterystyczną poprzez posortowanie shingelsów według ko-lejności alfabetycznej.
3. Wybierz n, tj. liczbę sygnatur, a następnie zastosuj opisany wcześniej algorytm 2.1i zbuduj macierz sygnatur.
4. Wskaż próg odcięcia t, który określi jaki poziom podobieństwa jest wymagany, abydwa URL-e zostały parą kandydującą. Wybierz b bandów i r wierszy, tak że b ∗ r =n i przyjmij, że próg odcięcia t′ jest w przybliżeniu równy (1/b)1/r. Jeżeli celemjest unikanie fałszywie ujemnych, wybierz b i r tak, aby otrzymać t′ niższy niżt (wskazane na początku), jeżeli natomiast ważniejsza jest szybkość obliczeń orazograniczenie występowania wartości fałszywie dodatnich, wybierz b i r tak, abyt′ > t.
26

5. Znajdź pary kandydujące poprzez zastosowanie algorytmu locality-sensitive hashing ;innymi słowy, pogrupuj adresy URL, umieszczając podobne do siebie w tym samymklastrze.
6. Sprawdź sygnatury każdej pary kandydującej i zweryfikuj, czy zgodność elementówwynosi co najmniej t.
7. Opcjonalnie, jeżeli sygnatury są wystarczająco do siebie podobne; czyli jest spełnio-ny krok 6; sprawdź faktyczne podobieństwo między adresami URL w ich oryginalnejpostaci.
27

Rozdział 3. Regresja logistyczna i miary dopasowaniamodelu
3.1 Regresja logistyczna: problem klasyfikacji
Klasyfikacja w odróżnieniu od regresji29 ma na celu prognozowanie zbioru wartościdyskretnych (dwóch lub więcej). Najbardziej popularna jest klasyfikacja binarna (ang.binary classification), gdzie y przyjmuje tylko dwie wartości: 0 lub 1. Przykładowo, jeżelibudowany jest klasyfikator spamu30 dla e-maili, wtedy x(i) są pewnymi cechami opisujący-mi wiadomości elektroniczne, a y może prognozować czy dane e-mail jest spamem (y = 1,klasa pozytywna), czy też nie (y = 0, klasa negatywna).
Regresja logistyczna ma na celu modelowanie prawdopodobieństwa przynależności do jed-nej z grup. W tej pracy wykorzystano przypadek, dla którego zmienna zależna y ma dwiewartości (kliknął/ nie kliknął). Dla większej liczby klas używana jest wielomianowa re-gresja logistyczna (ang. multinomial logistic regression31) albo uporządkowana regresjalogistyczna (ang. ordinal logistic regression32), jeżeli dodatkowo wartości zmiennej zależ-nej można uporządkować (np. słaby/przeciętny/dobry/bardzo dobry/wyśmienity).
Model regresji logistycznej
hθ(x) = g(θTx) =1
1 + exp(−θTx), (3.1)
gdzie
g(z) =1
1 + exp(−z)(3.2)
nazywana jest funkcją logistyczną (ang. logistic function) lub funkcja sigmoidalną (ang.sigmoid function). hθ(x) często nazywana jest hipotezą (również w przypadku regresjiliniowej). θ oraz x są wektorami o długości n, odpowiednio parametrów (w uczeniu ma-szynowym zwykle określanych wagami) i zmiennych, wtedy θTx = θ0 +
∑nj=1 θjxj.
Rysunek 3.1 przedstawia wykres regresji logistycznej na przykładzie zbioru mtcars33, po-równującego dwa rodzaje silników. Ciągły predyktor mpg (ang. miles per gallon) oznacza
29Regresja - metoda statystyczna pozwalająca na badanie związku pomiędzy wielkościami danych iprzewidywanie na tej podstawie nieznanych wartości jednych wielkości na podstawie znanych wartościinnych.
30Spam – niechciane lub niepotrzebne wiadomości elektroniczne.31https://en.wikipedia.org/wiki/Multinomial_logistic_regression, dostęp 12.12.2015.32https://en.wikipedia.org/wiki/Ordered_logit, dostęp 12.12.2015.33https://stat.ethz.ch/R-manual/R-devel/library/datasets/html/mtcars.html, dostęp 12.12.2015.
28
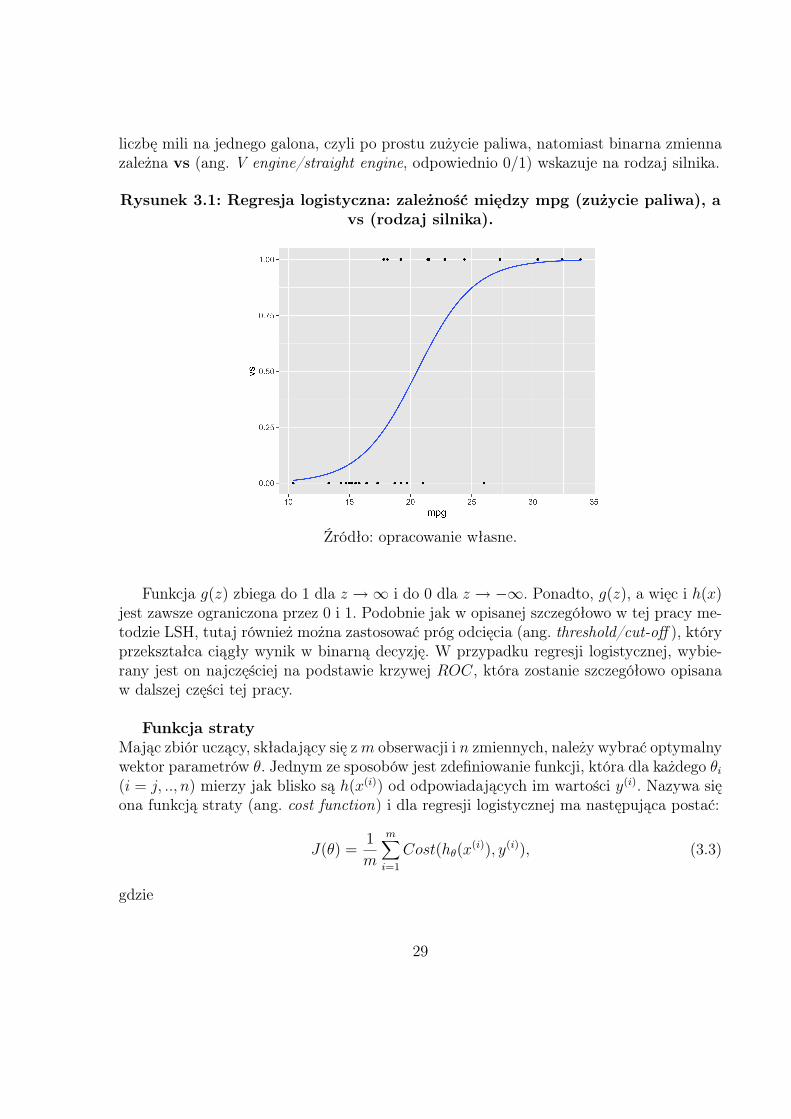
liczbę mili na jednego galona, czyli po prostu zużycie paliwa, natomiast binarna zmiennazależna vs (ang. V engine/straight engine, odpowiednio 0/1) wskazuje na rodzaj silnika.
Rysunek 3.1: Regresja logistyczna: zależność między mpg (zużycie paliwa), avs (rodzaj silnika).
Źródło: opracowanie własne.
Funkcja g(z) zbiega do 1 dla z →∞ i do 0 dla z → −∞. Ponadto, g(z), a więc i h(x)jest zawsze ograniczona przez 0 i 1. Podobnie jak w opisanej szczegółowo w tej pracy me-todzie LSH, tutaj również można zastosować próg odcięcia (ang. threshold/cut-off ), któryprzekształca ciągły wynik w binarną decyzję. W przypadku regresji logistycznej, wybie-rany jest on najczęściej na podstawie krzywej ROC, która zostanie szczegółowo opisanaw dalszej części tej pracy.
Funkcja stratyMając zbiór uczący, składający się zm obserwacji i n zmiennych, należy wybrać optymalnywektor parametrów θ. Jednym ze sposobów jest zdefiniowanie funkcji, która dla każdego θi(i = j, .., n) mierzy jak blisko są h(x(i)) od odpowiadających im wartości y(i). Nazywa sięona funkcją straty (ang. cost function) i dla regresji logistycznej ma następująca postać:
J(θ) =1m
m∑i=1
Cost(hθ(x(i)), y(i)), (3.3)
gdzie
29

Cost(hθ(x), y) =
− log(hθ(x)), jeżeli y = 1− log(1− hθ(x)), jeżeli y = 0
(3.4)
Równanie 3.4 można zapisać w jednym wierszu:
Cost(hθ(x), y) = −y log(hθ(x))− ((1− y) log(1− hθ(x)) (3.5)
Ostatecznie:
J(θ) = − 1m
[m∑i=1
y(i) log(hθ(x(i))) + ((1− y(i)) log(1− hθ(x(i)))]
(3.6)
Należy wybrać θ tak, aby zminimalizować J(θ). Zauważmy, że minimalizacja funk-cji straty w przypadku uczenia maszynowego jest analogiczna do maksymalizacji funkcjiwiarygodności, znanej ze statystyki34.
3.2 Metoda gradientu prostego oraz stochastycznego spadku wzdłużgradientu
W tym podrozdziale omówiono dwa algorytmy (podobne do siebie), które są częstowykorzystywane do minimalizacji J(θ).Pierwszy z nich na samym początku wybiera startowe θ, a następnie wielokrotnie zmieniate wartości w taki sposób, aby J(θ) była coraz mniejsza. Proces ten jest powtarzalny ikończy się w momencie zbieżności, tj. osiągnięcia minimum przez funkcję straty.
Algorytm gradientu prostego, (ang. gradient descent, GD):
θj := θj − αδ
δθjJ(θ) (3.7)
(równocześnie douczając wszystkie parametry θj, j = 0, 1, ..., n).
Parametr α nazywany jest wskaźnikiem uczenia (ang. learning rate). Istotne jest, abywybrać odpowiednią wartość tego parametru (korzystając np. z wykresu funkcji straty).Jeżeli α będzie za duże, optymalne rozwiązanie może zostać pominięte (algorytm zatrzy-ma się w minimum lokalnym, zamiast globalnym), natomiast jeżeli α będzie zbyt małe,uzyskanie najlepszego rozwiązania zajmie za dużo czasu (liczba iteracji zdecydowanieprzewyższy wskazane optimum).
34https://quantivity.wordpress.com/2011/05/23/why-minimize-negative-log-likelihood/,dostęp 14.12.2015.
30

Aby zaimplementować powyższy algorytm, należy obliczyć pochodną z funkcji straty, któ-ra znajduje się po prawej stronie równości.
δ
δθjJ(θ) = − 1
m
[δ
δθj
m∑i=1
y(i) log(hθ(x(i))) + ((1− y(i)) log(1− hθ(x(i)))]
=
− 1m
[m∑i=1
y(i)1
hθ(x(i))δ
δθjhθ(x(i)) + (1− y(i)) 1
1− hθ(x(i))
(− δ
δθjhθ(x(i))
)](∗)=
(3.8)
(∗) g′(z) =d
dz
11 + e−z
=1
(1 + e−z)2e−z =
1 + e−z − 1(1 + e−z)2
=
11 + e−z
− 1(1 + e−z)2
=1
1 + e−z(1− 1
1 + e−z) = g(z)(1− g(z))
(3.9)
(∗)= − 1
m
m∑i=1
y(i)x(i)j
hθ(x(i))hθ(x(i))(1− hθ(x(i)))− (1− y(i))
x(i)j
1− hθ(x(i))hθ(x)(1− hθ(x(i)))
=
− 1m
[m∑i=1
y(i)x(i)j (1− hθ(x(i)))− (1− y(i))x(i)j hθ(x(i)))
]=
1m
[m∑i=1
y(i)x(i)j − x
(i)j hθ(x
(i)))]
(3.10)
Zatem ostatecznie:δ
δθjJ(θ) =
1m
m∑i=1
(hθ(x(i))− y(i))x(i)j (3.11)
Końcowa wersja algorytmu gradientu prostego wygląda następująco:
θj := θj − α1m
m∑i=1
(hθ(x(i))− y(i))x(i)j (3.12)
(równocześnie douczając wszystkie parametry θj, j = 0, 1, ..., n).
Na koniec warto dodać, że nazwa batch, która w bezpośrednim tłumaczeniu z języka an-gielskiego oznacza wsad (często używana w przypadku opisanego wyżej algorytmu) mabezpośredni związek z funkcjonowaniem metody gradientu prostego. Otóż, każda iteracjaopiera się na przeliczaniu różnic między wartością prawdziwą a hipotetyczną na całymzbiorze danych.
Metoda stochastycznego spadku wzdłuż gradientu, (ang. stochastic gra-dient descent, SGD)Powyżej opisana metoda GD ma wiele zalet, jednakże w przypadku dużych zbiorów da-nych (typu Big Data) zaczynają się problemy z szybkośćią działania. Z pomocą przychodzą
31
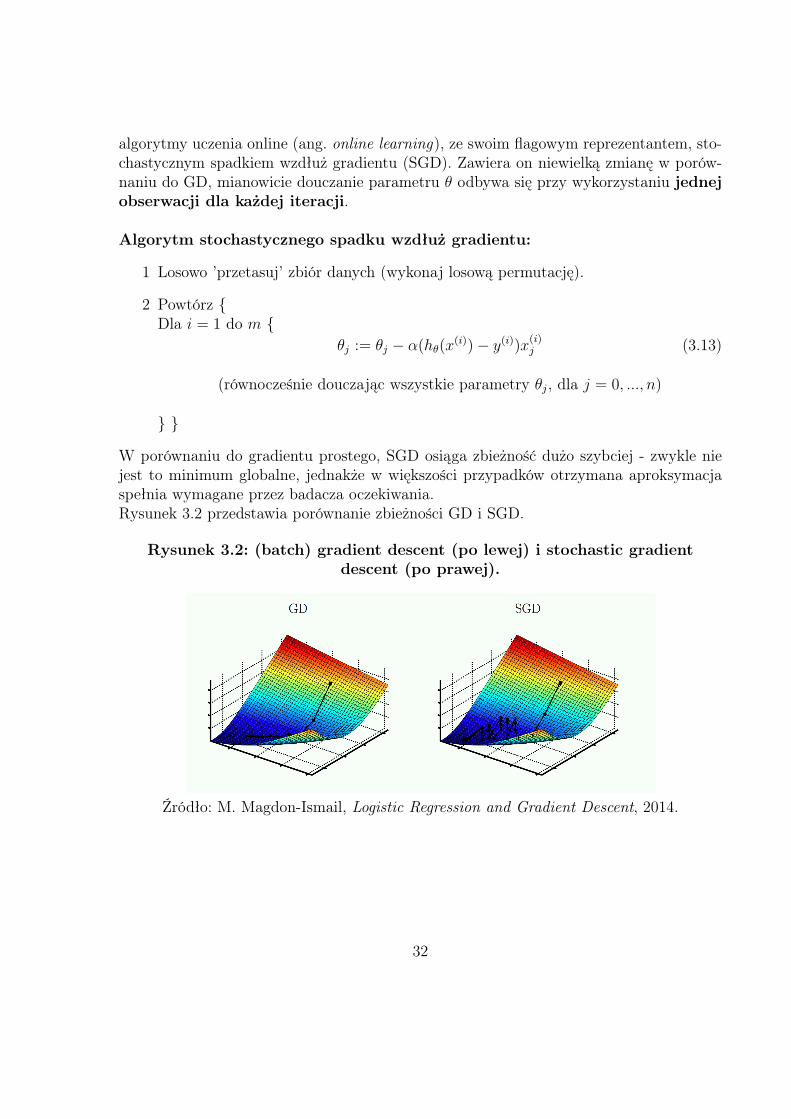
algorytmy uczenia online (ang. online learning), ze swoim flagowym reprezentantem, sto-chastycznym spadkiem wzdłuż gradientu (SGD). Zawiera on niewielką zmianę w porów-naniu do GD, mianowicie douczanie parametru θ odbywa się przy wykorzystaniu jednejobserwacji dla każdej iteracji.
Algorytm stochastycznego spadku wzdłuż gradientu:
1 Losowo ’przetasuj’ zbiór danych (wykonaj losową permutację).
2 Powtórz Dla i = 1 do m
θj := θj − α(hθ(x(i))− y(i))x(i)j (3.13)
(równocześnie douczając wszystkie parametry θj, dla j = 0, ..., n)
W porównaniu do gradientu prostego, SGD osiąga zbieżność dużo szybciej - zwykle niejest to minimum globalne, jednakże w większości przypadków otrzymana aproksymacjaspełnia wymagane przez badacza oczekiwania.Rysunek 3.2 przedstawia porównanie zbieżności GD i SGD.
Rysunek 3.2: (batch) gradient descent (po lewej) i stochastic gradientdescent (po prawej).
Źródło: M. Magdon-Ismail, Logistic Regression and Gradient Descent, 2014.
32

3.3 Miary dopasowania modelu
Końcowym etapem budowania modelu jest sprawdzenie jego jakości, a dokładniej traf-ności predykcji. Istnieje wiele technik, które pomagają badaczowi wybrać odpowiednialgorytm oraz towarzyszące mu parametry. W przypadku regresji logistycznej oraz oma-wianego w tej pracy problemu klikalności w reklamy, do analizy dopasowania modelu dodanych najczęściej wykorzystuje się krzywą ROC oraz wykres lift. Niemniej jednak, tedobrze znane techniki graficzne często nie wystarczają do poprawnej oceny modelu, dla-tego też są one wspierane przez różne miary dopasowania, które również zostały opisanew tym podrozdziale. W sekcji dotyczącej regresji logistycznej opisano dwa możliwe do wy-boru klasyfikatory: decyzja binarna oraz prawdopodobieństwo. To, który z nich zostaniewybrany zależy od zdefiniowanego problemu badawczego.
Klasyfikatory binarneW przypadku problemu klasyfikacyjnego z dwoma klasami do wyboru można oznaczyćjedną z nich jako klasę pozytywną, a drugą negatywną. Zbiór testowy składa się z P pozy-tywnych oraz N negatywnych obserwacji. Zadaniem klasyfikatora jest przyporządkowaniekażdej z obserwacji odpowiedniej klasy, jednakże część tych wyborów jest niepoprawna. Wcelu oceny wyników klasyfikacji, należy policzyć liczbę prawdziwie dodatnich (ang. truepositives, TP), prawdziwie ujemnych (ang. true negatives, TN), a także wspomnianychjuż w tej pracy fałszywie dodatnich (ang. false positives, FP) i fałszywie ujemnych (ang.false negatives, FN)35.Zależności te można zapisać następująco:
TP + FN = P (3.14)
orazTN + FP = N (3.15)
Rysunek 3.3 przedstawia opisane powyżej wskaźniki.35Dla przypomnienia, FP: obserwacje, które zostały umieszczone w klasie dodatniej, a powinny znaleźć
się w ujemnej; FN: sklasyfikowane jako ujemne, a w rzeczywistości są dodatnie.
33

Rysunek 3.3: Wskaźniki: TP, TN, FP oraz FN.
Źródło: opracowanie własne na podstawiehttps://en.wikipedia.org/wiki/Precision_and_recall
Następnie można zdefiniować najczęściej używane miary jakości dopasowania modelu:
FPrate =FP
N, TPrate =
TP
P= Recall,
Precision =TP
TP + FP, Accuracy =
TP + TN
P +N
(3.16)
Na podstawie powyższych miar powstał F1Score (wzór poniżej), który łączy w sobieprecision i recall. Miary te, są bardzo często stosowane w przypadku różnych wielkościanalizowanych klas (problem niezbalansowanych klas został omówiony w rozdziale 1).Jeżeli zależy nam, na jak najlepszych prognozach klasy rzadszej, należy uzyskać jak naj-wyższy Recall, przy możliwie najmniejszej stracie na Precission. F1Score zapewnia balanspomiędzy powyższymi miarami, w związku z tym, może być używany do oceny modelu,szczególnie w przypadku klas o różnej wielkości. Należy jednak pamiętać, że wykorzystaniekilku miar (zamiast jednej) skutkuje najczęściej lepszymi wynikami.
34

F1Score = 2 ∗ Pecision ∗RecallPrecision+Recall
(3.17)
Klasyfikatory probabilistyczneIch celem jest przyporządkowanie punktacji (ang. score) lub prawdopodobieństwa dlakażdej obserwacji. Klasyfikator probabilistyczny to funkcja f : X → [0, 1], która odwzoro-wuje elementy x przestrzeni X w wartości rzeczywiste f(x). Zwykle, wybierany jest punktodcięcia t, dla którego obserwacje spełniające f(x) t są rozważane jako pozytywne, a wprzeciwnym wypadku negatywne. Takie rozumowanie sprowadza każdą parę klasyfikatoraprobabilistycznego do decyzji binarnej. W związku z tym, mają zastosowanie wszystkiemiary opisane powyżej, jednakże są one zawsze funkcją zależną od punktu odcięciat.Warto zwrócić uwagę, że TP (t) oraz FP (t) maleją monotonicznie, a dla zbiorów skończo-nych są funkcjami krokowymi (ang. step function)36, nie ciągłymi.
3.4 Krzywa ROC
Krzywa ROC (ang. receiver operating characteristic curve) jest zdefiniowana poprzeznastępujące parametry:
x = FPrate(t), y = TPrate(t) (3.18)
Oznacza to, że każdy klasyfikator binarny jest reprezentowany przez punkt (FPrate, TPrate)znajdujący się na grafie. Zmiana punktu odcięcia klasyfikatora probabilistycznego, im-plikuje uzyskanie klasyfikatorów binarnych, reprezentowanych przez zbiór punktów nawykresie. Krzywa ROC jest niezależna od stosunku P : N , co oznacza możliwość po-równywania klasyfikatorów ze zróżnicowanym stosunkiem odpowiedzi pozytywnych donegatywnych.
Przykład 3.1. Tabela 3.1 prezentuje wyniki klasyfikatora probabilistycznego dla wy-branego zbioru testowego, natomiast rysunek 3.4 przedstawia krzywą ROC dla tego kla-syfikatora wraz z otrzymanymi prawdopodobieństwami (kolor czerwony - obserwacja wrzeczywistości przynależy do klasy n, czyli negatywnej; kolor zielony - do klasy p, tj.pozytywnej).
36https://en.wikipedia.org/wiki/Step_function, dostęp 20.12.2015.
35

Tabela 3.1: Przyporządkowane prawdopodobieństwa oraz rzeczywiste klasydla wybranego zbioru testowego.
Obs. Klasa Prawd. Obs. Klasa Prawd.1 p 0.90 11 p 0.402 p 0.82 12 n 0.383 n 0.75 13 p 0.354 p 0.63 14 n 0.325 p 0.57 15 n 0.306 p 0.55 16 n 0.287 n 0.53 17 p 0.258 n 0.50 18 n 0.229 p 0.48 19 p 0.2010 n 0.46 20 n 0.10
Źródło: opracowanie własne.
Sam proces rysowania krzywej ROC odbywa się zgodnie z następującymi krokami:
1. Uporządkuj wszystkie obserwacje ze zbioru danych według prawdopodobieństwa(malejąco);
2. Zacznij od punktu (0, 0);
3. Dla każdej obserwacji x:
• jeżeli x jest w klasie pozytywnej, idź w górę o 1/p,
• jeżeli x jest w klasie negatywnej, idź w prawo o 1/n,
gdzie p i n oznaczają odpowiednio liczbę obserwacji klasy pozytywnej i negatywnej.
36
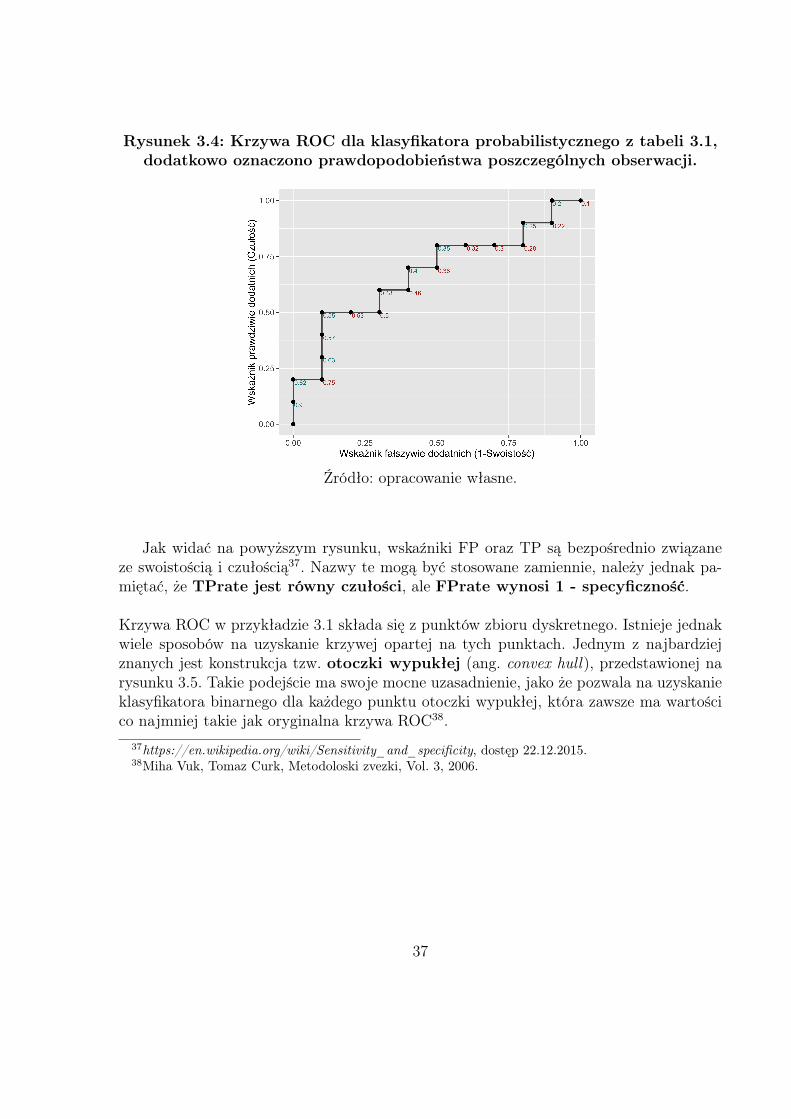
Rysunek 3.4: Krzywa ROC dla klasyfikatora probabilistycznego z tabeli 3.1,dodatkowo oznaczono prawdopodobieństwa poszczególnych obserwacji.
Źródło: opracowanie własne.
Jak widać na powyższym rysunku, wskaźniki FP oraz TP są bezpośrednio związaneze swoistością i czułością37. Nazwy te mogą być stosowane zamiennie, należy jednak pa-miętać, że TPrate jest równy czułości, ale FPrate wynosi 1 - specyficzność.
Krzywa ROC w przykładzie 3.1 składa się z punktów zbioru dyskretnego. Istnieje jednakwiele sposobów na uzyskanie krzywej opartej na tych punktach. Jednym z najbardziejznanych jest konstrukcja tzw. otoczki wypukłej (ang. convex hull), przedstawionej narysunku 3.5. Takie podejście ma swoje mocne uzasadnienie, jako że pozwala na uzyskanieklasyfikatora binarnego dla każdego punktu otoczki wypukłej, która zawsze ma wartościco najmniej takie jak oryginalna krzywa ROC38.
37https://en.wikipedia.org/wiki/Sensitivity_and_specificity, dostęp 22.12.2015.38Miha Vuk, Tomaz Curk, Metodoloski zvezki, Vol. 3, 2006.
37
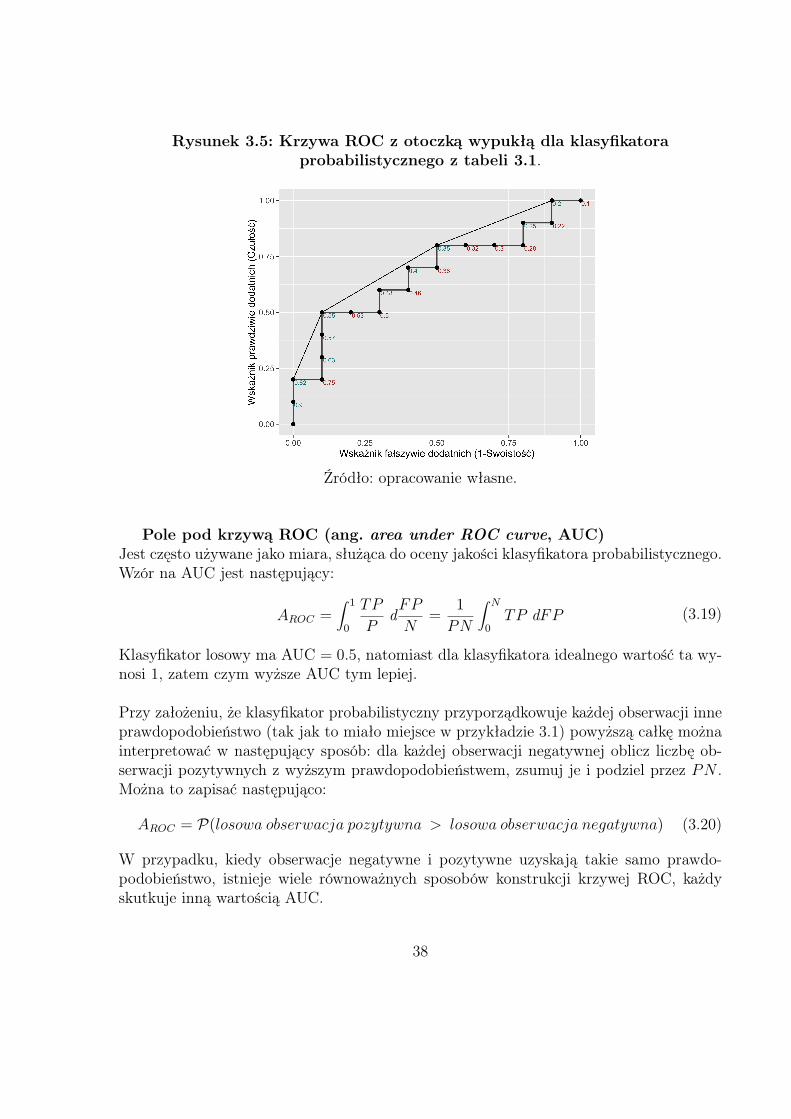
Rysunek 3.5: Krzywa ROC z otoczką wypukłą dla klasyfikatoraprobabilistycznego z tabeli 3.1.
Źródło: opracowanie własne.
Pole pod krzywą ROC (ang. area under ROC curve, AUC)Jest często używane jako miara, służąca do oceny jakości klasyfikatora probabilistycznego.Wzór na AUC jest następujący:
AROC =∫ 10
TP
PdFP
N=
1PN
∫ N
0TP dFP (3.19)
Klasyfikator losowy ma AUC = 0.5, natomiast dla klasyfikatora idealnego wartość ta wy-nosi 1, zatem czym wyższe AUC tym lepiej.
Przy założeniu, że klasyfikator probabilistyczny przyporządkowuje każdej obserwacji inneprawdopodobieństwo (tak jak to miało miejsce w przykładzie 3.1) powyższą całkę możnainterpretować w następujący sposób: dla każdej obserwacji negatywnej oblicz liczbę ob-serwacji pozytywnych z wyższym prawdopodobieństwem, zsumuj je i podziel przez PN .Można to zapisać następująco:
AROC = P(losowa obserwacja pozytywna > losowa obserwacja negatywna) (3.20)
W przypadku, kiedy obserwacje negatywne i pozytywne uzyskają takie samo prawdo-podobieństwo, istnieje wiele równoważnych sposobów konstrukcji krzywej ROC, każdyskutkuje inną wartością AUC.
38

Powyższe równanie nadal ma sens, jednakże bardziej naturalnym podejściem jest połą-czenie takich punktów liniami prostymi.W pierwszej kolejności należy zdefiniować statystykę W dla testu Wilcoxona39.
S(xp, xn) =
1, dla xp > xn12 , dla xp = xn
0, dla xp < xn
(3.21)
W =1PN
∑xp∈poz.
∑xn∈neg.
S(xp, xn) (3.22)
Wtedy:
AROC2 = W = P(losowa obs. pozytywna > losowa obs. negatywna) +12P(losowa obs. pozytywna = losowa obs. negatywna)
(3.23)
Tabela 3.2 zawiera dane, na podstawie których porównano AROC i AROC2 (rysunek3.6).Jeżeli proporcja miedzy przypadkami z tym samym prawdopodobieństwem, a wszystkimiobserwacjami jest niewielka, różnica między AROC , a AROC2 staje się znikoma.
Tabela 3.2: Te same prawdopodobieństwa dla dwóch różnych klas.
Obs. Klasa Prawd.1 p 0.852 p 0.673 n 0.304 p 0.305 n 0.20
Źródło: opracowanie własne.
39Hanley, McNeil, 1982.
39
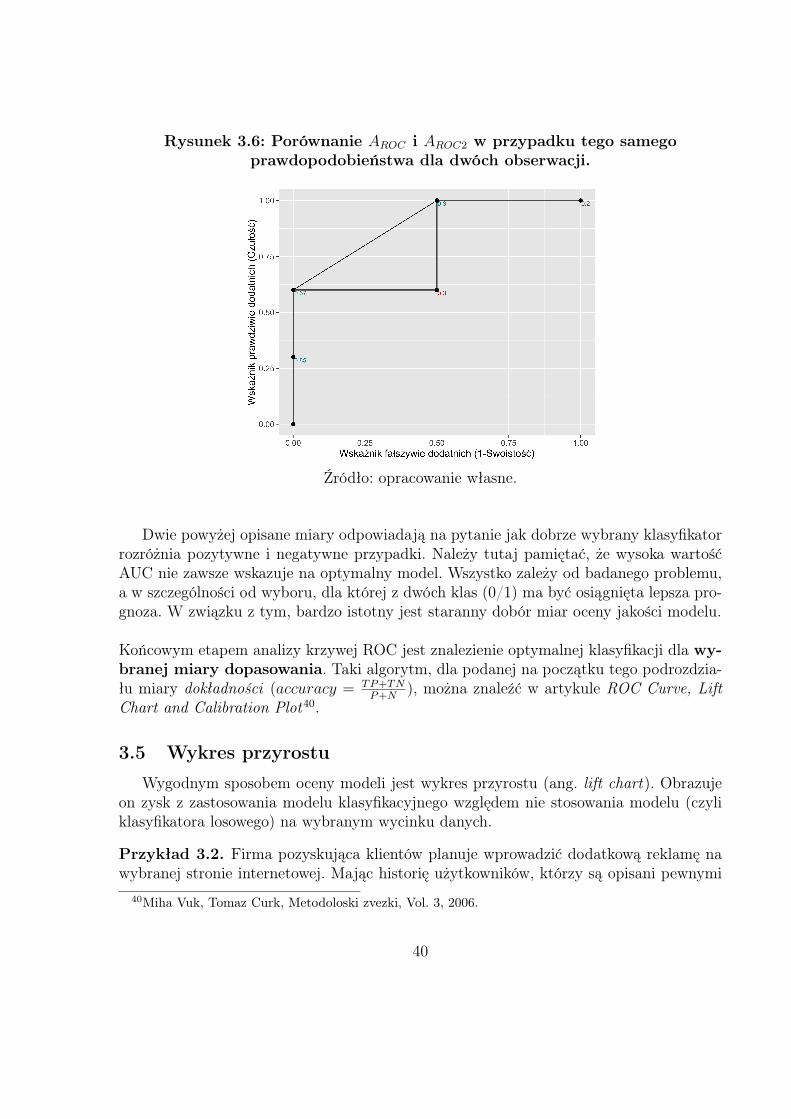
Rysunek 3.6: Porównanie AROC i AROC2 w przypadku tego samegoprawdopodobieństwa dla dwóch obserwacji.
Źródło: opracowanie własne.
Dwie powyżej opisane miary odpowiadają na pytanie jak dobrze wybrany klasyfikatorrozróżnia pozytywne i negatywne przypadki. Należy tutaj pamiętać, że wysoka wartośćAUC nie zawsze wskazuje na optymalny model. Wszystko zależy od badanego problemu,a w szczególności od wyboru, dla której z dwóch klas (0/1) ma być osiągnięta lepsza pro-gnoza. W związku z tym, bardzo istotny jest staranny dobór miar oceny jakości modelu.
Końcowym etapem analizy krzywej ROC jest znalezienie optymalnej klasyfikacji dla wy-branej miary dopasowania. Taki algorytm, dla podanej na początku tego podrozdzia-łu miary dokładności (accuracy = TP+TN
P+N ), można znaleźć w artykule ROC Curve, LiftChart and Calibration Plot40.
3.5 Wykres przyrostu
Wygodnym sposobem oceny modeli jest wykres przyrostu (ang. lift chart). Obrazujeon zysk z zastosowania modelu klasyfikacyjnego względem nie stosowania modelu (czyliklasyfikatora losowego) na wybranym wycinku danych.
Przykład 3.2. Firma pozyskująca klientów planuje wprowadzić dodatkową reklamę nawybranej stronie internetowej. Mając historię użytkowników, którzy są opisani pewnymi
40Miha Vuk, Tomaz Curk, Metodoloski zvezki, Vol. 3, 2006.
40

cechami, celem podstawowym takiej kampanii jest osiągnięcie jak najwyższych zyskówprzy możliwie najniższej stracie. Każde wyświetlenie reklamy na stronie kosztuje, jed-nakże kliknięcia bardzo często powodują zwiększenie zaangażowania danego użytkownika,a następnie np. kupno produktu. Z tego względu firma chce zminimalizować liczbę wy-świetlanych reklam, przy jednoczesnej maksymalizacji sprzedaży. Takie działanie możnaosiągnąć poprzez dotarcie do tych klientów, którzy faktycznie są zainteresowani danymproduktem.
Liczba wszystkich potencjalnych klientów P jest często nieznana, zatem nie ma moż-liwości obliczenia wskaźnika TP i zastosowania krzywej ROC.Do powyższego problemu można użyć wykresu przyrostu, który przedstawi zależność mię-dzy kosztami, a oczekiwanym zyskiem. Z uwagi na duże podobieństwo do szczegółowoomówionej krzywej ROC, podrozdział ten zawiera przede wszystkim różnice między nimi.Wykres przyrostu jest zdefiniowany przez następujące parametry:
x = Y rate(t) =TP (t) + FP (t)
P +N, y = TP (t) (3.24)
Podobnie jak w przypadku krzywej ROC, każdy punkt w przestrzeni parametrycznej od-powiada klasyfikatorowi binarnemu, natomiast zmiana punktu odcięcia klasyfikatora pro-babilistycznego, tworzy zbiór klasyfikatorów binarnych. Krzywa, która powstaje poprzezdorysowanie otoczki wypukłej dla tych punktów nazywana jest wykresem przyrostu. Po-nadto, analogicznie jak wcześniej, należy w pierwszej kolejności uporządkować obserwacje(w tym przypadku użytkowników odwiedzającej analizowaną stronę internetową) wedługprawdopodobieństw otrzymanych z modelu.
Na rysunku 3.7 został przedstawiony wykres przyrostu dla powyższego przykładu. Po-kazując 10% całego potencjału reklam, 4000 użytkowników kliknie w reklamę, natomiastjeżeli zostanie wyświetlone aż 40%, liczba użytkowników zachęconych tymi reklamamiwzrośnie 2-krotnie. W takiej sytuacji należy przeanalizować jaki będzie rzeczywisty zyskkażdej z potencjalnych strategii. W tym przykładzie, wysoce prawdopodobne jest, że zmia-na poziomu wyświetlonych reklam z 10% do 40 − 60% spowoduje zwiększenie wpływówze sprzedaży.
41
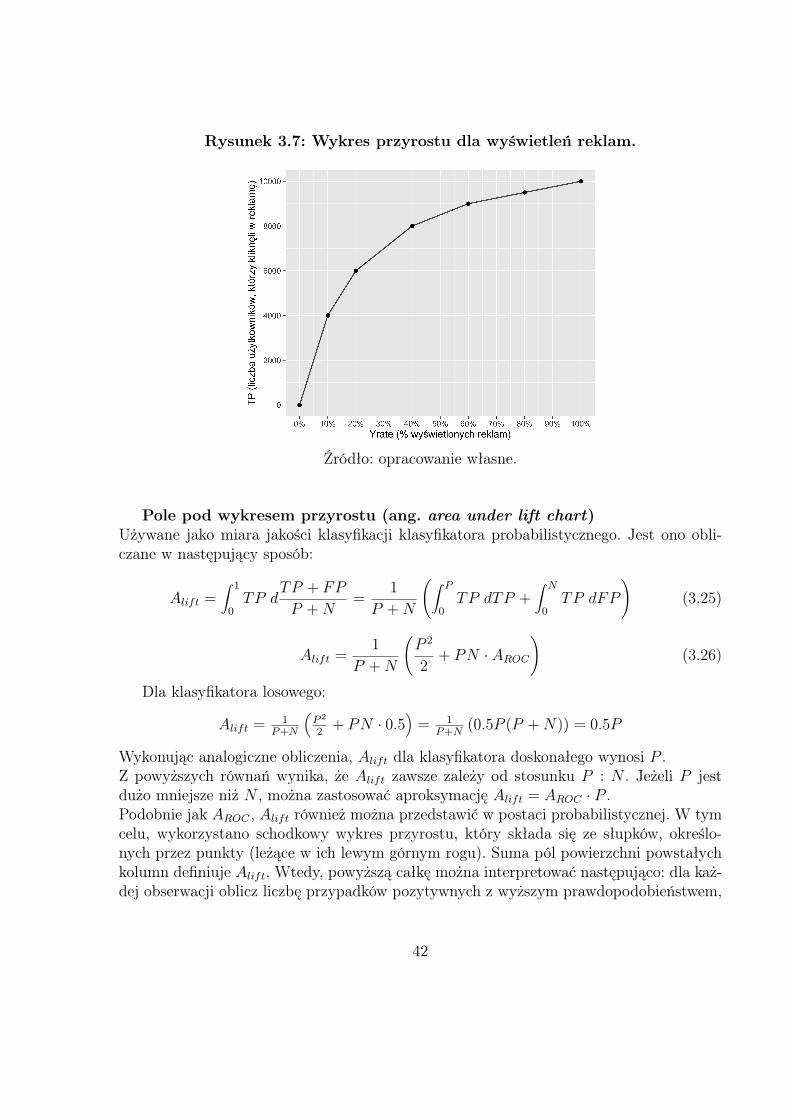
Rysunek 3.7: Wykres przyrostu dla wyświetleń reklam.
Źródło: opracowanie własne.
Pole pod wykresem przyrostu (ang. area under lift chart)Używane jako miara jakości klasyfikacji klasyfikatora probabilistycznego. Jest ono obli-czane w następujący sposób:
Alift =∫ 10TP d
TP + FP
P +N=
1P +N
(∫ P
0TP dTP +
∫ N
0TP dFP
)(3.25)
Alift =1
P +N
(P 2
2+ PN · AROC
)(3.26)
Dla klasyfikatora losowego:
Alift = 1P+N
(P 2
2 + PN · 0.5)
= 1P+N (0.5P (P +N)) = 0.5P
Wykonując analogiczne obliczenia, Alift dla klasyfikatora doskonałego wynosi P .Z powyższych równań wynika, że Alift zawsze zależy od stosunku P : N . Jeżeli P jestdużo mniejsze niż N , można zastosować aproksymację Alift = AROC · P .Podobnie jak AROC , Alift również można przedstawić w postaci probabilistycznej. W tymcelu, wykorzystano schodkowy wykres przyrostu, który składa się ze słupków, określo-nych przez punkty (leżące w ich lewym górnym rogu). Suma pól powierzchni powstałychkolumn definiuje Alift. Wtedy, powyższą całkę można interpretować następująco: dla każ-dej obserwacji oblicz liczbę przypadków pozytywnych z wyższym prawdopodobieństwem,
42

zsumuj je i podziel przez P +N .
Alift = P · P(losowa obserwacja pozytywna > losowa obserwacja) (3.27)
Innymi słowy, Alift pokazuje jak dobrze dany klasyfikator rozróżnia przypadki pozytywneod wszystkich obserwacji.W praktyce, używa się krzywej wygładzonej zamiast schodkowego wykresu przyrostu,gdzie sąsiadujące ze sobą punkty są połączone liniami prostymi. Pole pod tak zdefiniowanąkrzywą opisuje poniższy wzór:
Alift2 =∫ 10
(TP +dTP
2) dTP + FP
P +N
=1
P +N
(∫ P
0(TP +
dTP
2) dTP +
∫ N
0(TP +
dTP
2) dFP
) (3.28)
Tabela 3.3 zawiera dane, na podstawie których porównano Alift i Alift2 (rysunek 3.8).Należy tutaj zauważyć, że oba sposoby wyliczenia pola pod wykresem przyrostu zacho-wują swoją poprawność również wtedy, kiedy obserwacje z różnych klas mają te sameprawdopodobieństwo.
Tabela 3.3: Te same prawdopodobieństwa dla dwóch różnych klas.
Obs. Klasa Prawd.1 p 0.852 p 0.673 n 0.524 n 0.305 p 0.306 n 0.20
Źródło: opracowanie własne.
43
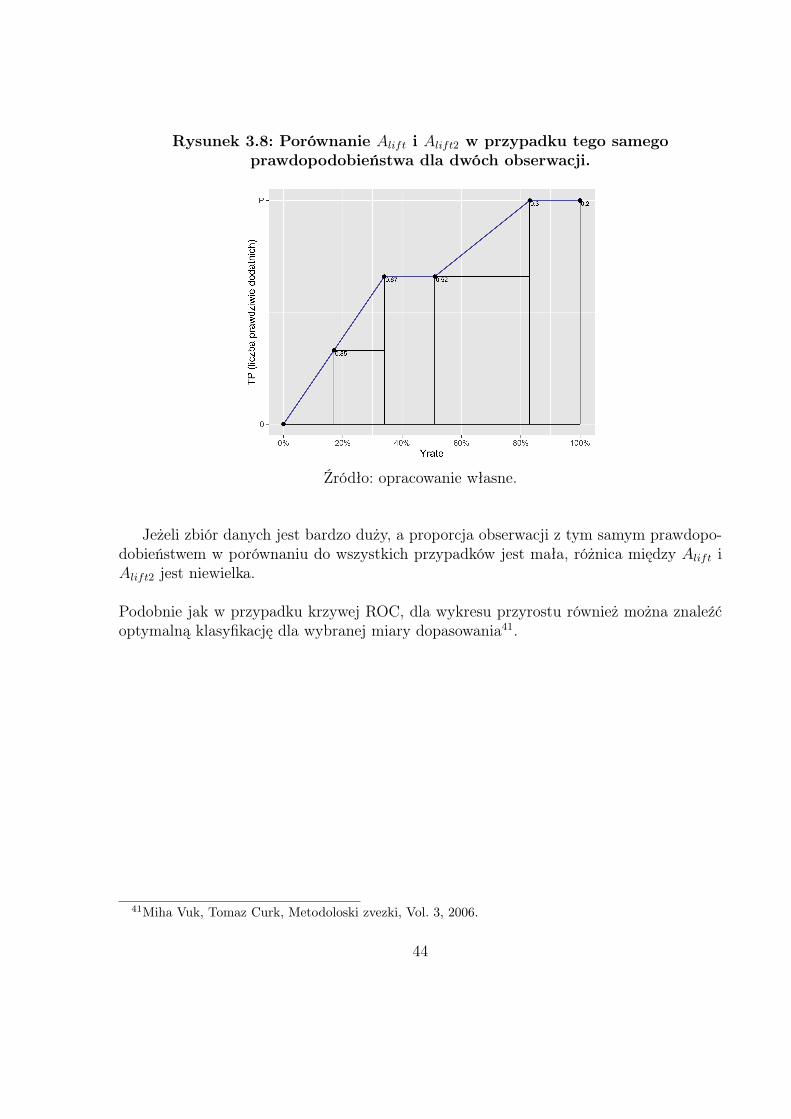
Rysunek 3.8: Porównanie Alift i Alift2 w przypadku tego samegoprawdopodobieństwa dla dwóch obserwacji.
Źródło: opracowanie własne.
Jeżeli zbiór danych jest bardzo duży, a proporcja obserwacji z tym samym prawdopo-dobieństwem w porównaniu do wszystkich przypadków jest mała, różnica między Alift iAlift2 jest niewielka.
Podobnie jak w przypadku krzywej ROC, dla wykresu przyrostu również można znaleźćoptymalną klasyfikację dla wybranej miary dopasowania41.
41Miha Vuk, Tomaz Curk, Metodoloski zvezki, Vol. 3, 2006.
44

Rozdział 4. Prognozowanie kliknięć w reklamę przyużyciu Vowpal Wabbit i algorytmu SGD
4.1 Przygotowanie danych do analizy: Python
Przed rozpoczęciem budowy modelu należy w odpowiedni sposób przygotować dane.Zgodnie z informacjami w rozdziale 1. są one przechowywane w nierelacyjnej bazie da-nych MongoDB. W tej pracy wykorzystano dane z jednego miesiąca, a mianowicie stycznia2015 roku (eksport z bazy znajduje się w pliku export_27012015.json). Zawierają one wie-le informacji o użytkownikach, którzy w styczniu ubiegłego roku odwiedzili chociaż razanalizowany serwis. Są to m. in.: identyfikator użytkownika, przeglądarka, liczba odsłonwszystkich stron, IP oraz adresy URL, które odwiedził dany użytkownik wraz z datą iczasem wejścia. Tylko część z nich została wykorzystana w tej pracy, głównie adresy URL(jako zmienne niezależne w budowanych modelach) wraz z liczbą wyświetleń odpowiada-jącą danemu użytkownikowi.Większość obliczeń została przeprowadzona przy pomocy języka programowania Python,a dokładniej w zintegrowanym środowisku programistycznym PyCharm firmy JetBrains.Ten rozdział nie ma na celu szczegółowego opisu kodu, zamiast tego przedstawiono tutajnajważniejsze aspekty analizy (kody znajdujące się na płycie posiadają wiele komentarzy,które powinny pomóc zrozumieć poszczególne elementy).Całość obliczeń oparta jest na 5 skryptach: MainScript.py - główny skrypt odpowiedzial-ny za cały proces - z jego poziomu można przeprowadzić całą analizę, LSH.py- zawierazaimplementowany algorytm LSH, TestCluster.py - wywołuje LSH.py i zapisuje wynikido plików, UnionFind.py - używany przez LSH.py (szczegóły w komentarzach) oraz Cre-ateVarFromGroups.py - zawiera funkcję, która tworzy słownik z uzyskanych przez LSHgrup.Budowa skryptu MainScript.py jest następująca:
• na początku ładowane są potrzebne do dalszych obliczeń biblioteki oraz moduły,
• po ich wczytaniu, należy zaimportować wszystkie funkcje znajdujące się w powyż-szym skrypcie,
• następnie wczytujemy dane (import_data) oraz wywołujemy jedną z dwóch funkcji:whole_process, bądź whole_process_lsh (przed tą druga należy wcześniej uruchomićmake_lsh_documentation) w celu wykonania całego procesu,
• końcowym etapem jest budowa modelu przy pomocy funkcji build_model, którazawiera komendy systemu uczącego Vowpal Wabbit.
Przygotowanie danychW pierwszej kolejności (po załadowaniu odpowiednich bibliotek) należy wczytać do Py-thona dane z wspomnianego wcześniej pliku export_27012015.json. Kolejnym etapem jest
45

wybranie informacji, które zostaną wykorzystane w modelu, a następnie przypisanie ichdo zmiennych. Ten moment jest kluczowy i zazwyczaj wymaga poświęcenia największejilości czasu. Ze zbioru danych usunięto boty, czyli programy wykonujące pewne czynnościza człowieka, oraz 27 użytkowników, którzy w styczniu 2015 roku wyświetlili co najmniej350 stron (maksymalna liczba odsłon to 3703). Wykres 4.1 przedstawia częstotliwość wy-świetleń dla pozostałych osób.
Rysunek 4.1: Częstotliwość wyświetleń stron przez prawie wszystkichużytkowników.
Źródło: opracowanie własne.
Jak widać na powyższym histogramie zdecydowana większość użytkowników wyświe-tlała strony maksymalnie 100− 150 razy. Zatem ograniczmy się do mniejszego zakresu, wcelu znalezienia optymalnej wartości wyświetleń i wyeliminowania wartości odstających,które mogłyby zaburzyć jakość wyników.
46

Rysunek 4.2: Częstotliwość wyświetleń stron - maksymalnie 150 przezjednego użytkownika.
Źródło: opracowanie własne.
Na podstawie wykresu 4.2 jako punkt odcięcia wybrano 50 wyświetleń, tj. analiziepoddano ostatecznie 51885 użytkowników, którzy w ciągu miesiąca mieli w sumie mniejniż 50 odsłon stron.Następnie w odpowiedni sposób przygotowano adresy URL, w tym przede wszystkim usu-nięto znaki interpunkcyjne. Warto w tymmiejscu zaznaczyć, że w funkcji write_data_to_var(plikMainScript.py) znajduje się parametrmethod, który umożliwia wybór pomiędzy ana-lizą całych adresów URL, a domenami z pierwszym katalogiem. Oba podejścia zostanąw dalszej części zestawione z wynikami uzyskanymi po grupowaniu podobnych do siebieadresów przez algorytm LSH.Kolejnym etapem jest zapisanie oczyszczonych adresów URL do pliku, m. in. w celu ichpóźniejszego wykorzystania w metodzie locality-sensitive hashing.Następne trzy funkcje uruchamiane są tylko w przypadku LSH. Służą one do pogru-powania podobnych do siebie adresów URL, a następnie utworzenia nowych zmiennychz powstałych klastrów. Dla porównania, wcześniej zmiennymi były adresy URL, a ichwartościami liczby wyświetleń. Teraz są to grupy adresów (numery), a ich wartości tozsumowane wyświetlenia wszystkich URL-i w danym klastrze.
47

4.2 Budowanie modelu: Vowpal Wabbit
Istnieje wiele narzędzi służących do budowania modeli, jednakże w tej pracy posta-nowiono wykorzystać poza rdzeniowy (ang. out-of-core lub external memory algorithms)system uczący o nazwie Vowpal Wabbit (VW). Tego typu algorytmy są zaprojektowane,aby przetwarzać duże wolumeny danych, które nie mieszczą się w pamięci komputera42.VW jest projektem, który początkowo był rozwijany przez Yahoo! Research43, natomiastaktualnie głównym sponsorem jest Microsoft Research44.Nawiązując do treści znajdującej się na stronie domowej VW45 istnieją dwa podejściabudowy szybkich algorytmów:
• zacząć od wolnego algorytmu, a następnie go rozwijać i przyspieszać;
• zbudować algorytm, którego cechą dominującą od samego początku będzie szybkośćuczenia.
Vowpal Wabbit dotyczy drugiego podejścia i jest często używany w przypadku danych ty-pu Big data. W tej pracy wykorzystano tylko jeden z wielu zawartych w nim modułów, amianowicie opisany wcześniej algorytm stochastycznego spadku wzdłuż gradientu (SGD).Wszelkie szczegóły dotyczące VW, jak np. opis funkcjonalności, które zostały wykorzysta-ne do budowy modelu można znaleźć w repozytorium hostingowego serwisu internetowegoGitHub: https://github.com/JohnLangford/vowpal_wabbit/.Wiedząc do czego służy VW, można przeanalizować kolejne etapy skryptu MainScript.py.W celu poprawnego rozpoznania danych przez Vowpal Wabbit należy dokonać odpowied-nich przekształceń danych, w tym przede wszystkim zamiany wartości klasy negatywnej,oznaczanej zwykle przez 0, na −1 (domyślnie wyniki końcowe to wartości funkcji straty,aby w wyniku uzyskać prognozy w postaci prawdopodobieństw użyto dodatkowej opcjilink=logistic). Forma zapisu danych w VW jest bardzo specyficzna i wymaga zapoznaniasię z tutorialem dostępnym tutaj:https://github.com/JohnLangford/vowpal_wabbit/wiki/Tutorial.Przedostatnim etapem jest podział przygotowanego zbioru na uczący i testowy (przyjętostosunek 0.7 do 0.3) Należy tutaj pamiętać, że musi być on zawsze taki sam, jeżeli chcemyporównywać wyniki dla różnych zestawów parametrów. Warto w tym miejscu dodać, że zewzględu na testowanie wielu kombinacji, w przypadku algorytmu LSH, została dodana wkodzie funkcja make_lsh_documentation, która pomaga zachować porządek w skrypcie,a ponadto tworzy za każdym razem plik ze szczegółową dokumentacją.Finalnym elementem tego podrozdziału jest budowa modelu przy użyciu stochastycznego
42https://en.wikipedia.org/wiki/Out-of-core_algorithm, dostęp 10.02.2016.43https://yahooresearch.tumblr.com, dostęp 10.02.2016.44http://research.microsoft.com/en-us/, dostęp 10.02.2016.45https://github.com/JohnLangford/vowpal_wabbit/wiki, 10.02.2016.
48

spadku wzdłuż gradientu46, który został zaimplementowany w Vowpal Wabbit. Przetesto-wano 80 kombinacji parametrów algorytmu LSH i otrzymane wyniki porównano z tymi,które uzyskano budując modele dla całych adresów URL oraz domen z 1. katalogiem. Jakoże celem tej pracy nie było osiągnięcie możliwie najlepszych wyników, zakończono analizęna zastosowaniu podstawowych opcji VW47.
4.3 Ocena modeli i porównanie wyników: R
Końcowym etapem tej pracy jest ocena oraz porównanie otrzymanych modeli przypomocy wybranych z rozdziału 3 miar dopasowania oraz wykresów.Wszystkie obliczenia oraz wizualizacje zostały wykonane w RStudio (zintegrowane śro-dowisko programistyczne dla języka R).Tabela 4.1 przedstawia wyniki dla dwóch modeli (bez stosowania LSH). W pierwszymz nich zmienne niezależne to całe adresy URL (odpowiednio oczyszczone), a w drugimdomeny z pierwszym katalogiem. We wszystkich modelach zastosowano ten sam punktodcięcia t = 0.5. AUC w poniższej tabeli oznacza obszar pod krzywą ROC.
Tabela 4.1: Wyniki dla całych adresów URL oraz domen z 1. katalogiem.
Postać zm. Liczba zm. AUC F1Score TP TN FP FNcałe URL-e 23121 0.579 0.117 203 10451 4693 231
domeny + 1. kat. 143 0.656 0.093 242 9482 5662 192
Źródło: opracowanie własne.
Analizując powyższe wyniki można stwierdzić, że model oparty na całych URL-achlepiej przewiduje klasę negatywną. Należy jednak pamiętać, że w przypadku reklam inter-netowych chcemy przede wszystkim zminimalizować liczbę wyników fałszywie ujemnych(FN). Wyświetlenie reklamy osobie niezainteresowanej może prowadzić co najwyżej doirytacji, jednakże pominięcie użytkownika wyrażającego chęć jakiejkolwiek konwersji (np.rejestracji na portalu) skutkuje utratą potencjalnego klienta. Z tego względu prawdopo-dobnie firma zajmująca się pozyskiwaniem klientów wybrałaby drugi model, który niedu-żym kosztem (dodatkowe ok. 21% niepotrzebnie wyświetlonych reklam) zwiększa liczbępozytywnie dodatnich o 39 osób (ok. 19% więcej w stosunku do 1. modelu). Spójrzmyjeszcze na koniec na pozostałe dwie miary, które są bardzo często stosowane do oceny mo-deli (szczególnie AUC). Jak widać, wyższe AUC ma model 2., w tym przypadku uznanyjako lepszy, natomiast F1Score jest na korzyść 1. modelu. Jest to spowodowane tym, że ta
46Szczegóły dotyczące tej metody można znaleźć w podrozdziale 3.2.47Vowpal Wabbit jest projektem, który cały czas się rozwija. Posiada on wiele opcji, które z pewnością
warto przetestować.
49
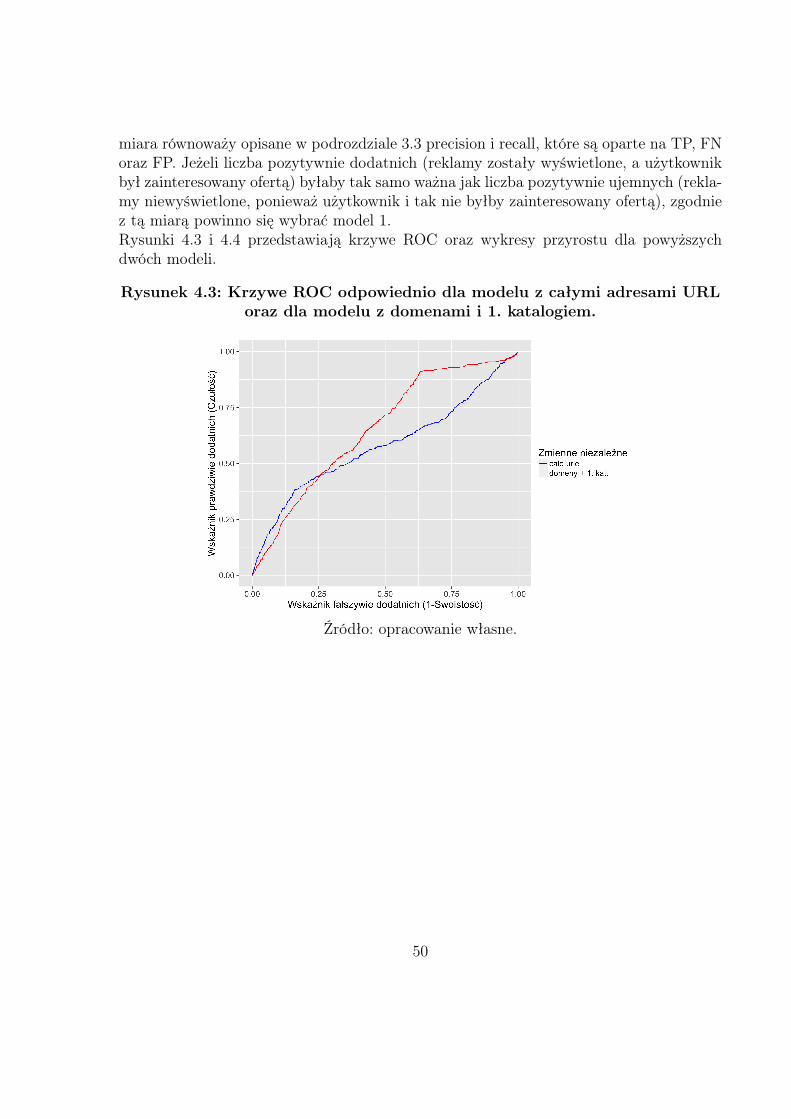
miara równoważy opisane w podrozdziale 3.3 precision i recall, które są oparte na TP, FNoraz FP. Jeżeli liczba pozytywnie dodatnich (reklamy zostały wyświetlone, a użytkownikbył zainteresowany ofertą) byłaby tak samo ważna jak liczba pozytywnie ujemnych (rekla-my niewyświetlone, ponieważ użytkownik i tak nie byłby zainteresowany ofertą), zgodniez tą miarą powinno się wybrać model 1.Rysunki 4.3 i 4.4 przedstawiają krzywe ROC oraz wykresy przyrostu dla powyższychdwóch modeli.
Rysunek 4.3: Krzywe ROC odpowiednio dla modelu z całymi adresami URLoraz dla modelu z domenami i 1. katalogiem.
Źródło: opracowanie własne.
50
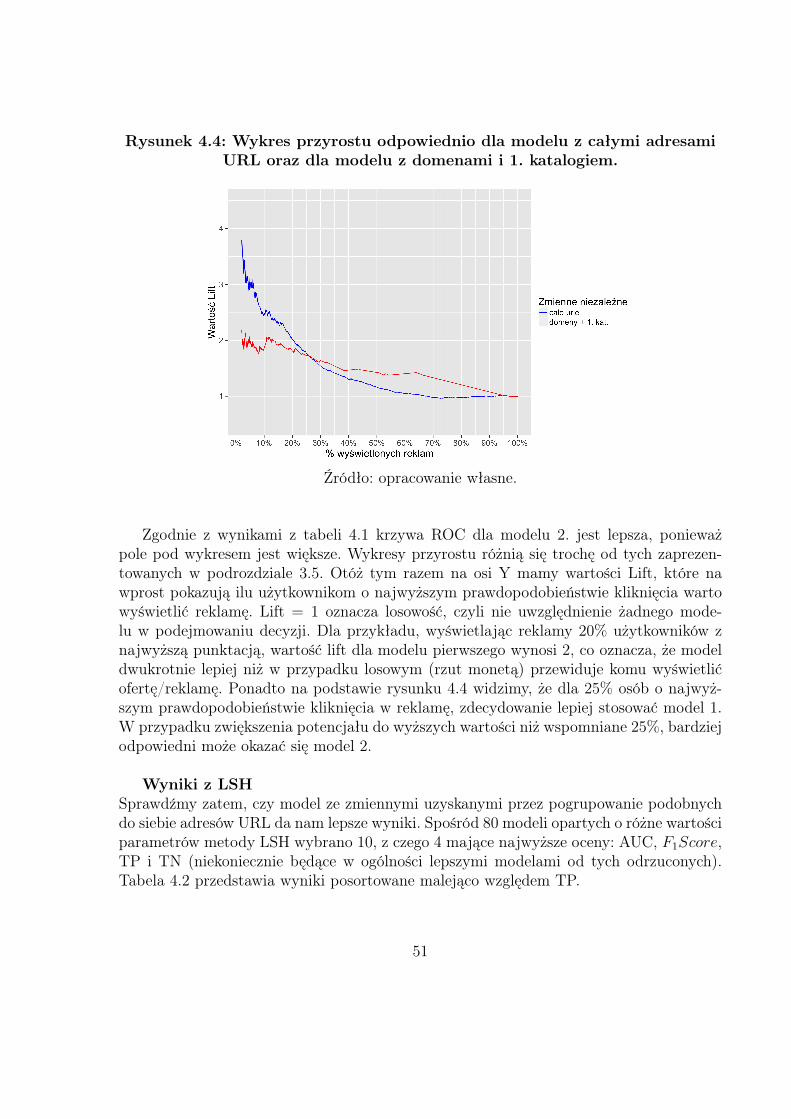
Rysunek 4.4: Wykres przyrostu odpowiednio dla modelu z całymi adresamiURL oraz dla modelu z domenami i 1. katalogiem.
Źródło: opracowanie własne.
Zgodnie z wynikami z tabeli 4.1 krzywa ROC dla modelu 2. jest lepsza, ponieważpole pod wykresem jest większe. Wykresy przyrostu różnią się trochę od tych zaprezen-towanych w podrozdziale 3.5. Otóż tym razem na osi Y mamy wartości Lift, które nawprost pokazują ilu użytkownikom o najwyższym prawdopodobieństwie kliknięcia wartowyświetlić reklamę. Lift = 1 oznacza losowość, czyli nie uwzględnienie żadnego mode-lu w podejmowaniu decyzji. Dla przykładu, wyświetlając reklamy 20% użytkowników znajwyższą punktacją, wartość lift dla modelu pierwszego wynosi 2, co oznacza, że modeldwukrotnie lepiej niż w przypadku losowym (rzut monetą) przewiduje komu wyświetlićofertę/reklamę. Ponadto na podstawie rysunku 4.4 widzimy, że dla 25% osób o najwyż-szym prawdopodobieństwie kliknięcia w reklamę, zdecydowanie lepiej stosować model 1.W przypadku zwiększenia potencjału do wyższych wartości niż wspomniane 25%, bardziejodpowiedni może okazać się model 2.
Wyniki z LSHSprawdźmy zatem, czy model ze zmiennymi uzyskanymi przez pogrupowanie podobnychdo siebie adresów URL da nam lepsze wyniki. Spośród 80 modeli opartych o różne wartościparametrów metody LSH wybrano 10, z czego 4 mające najwyższe oceny: AUC, F1Score,TP i TN (niekoniecznie będące w ogólności lepszymi modelami od tych odrzuconych).Tabela 4.2 przedstawia wyniki posortowane malejąco względem TP.
51
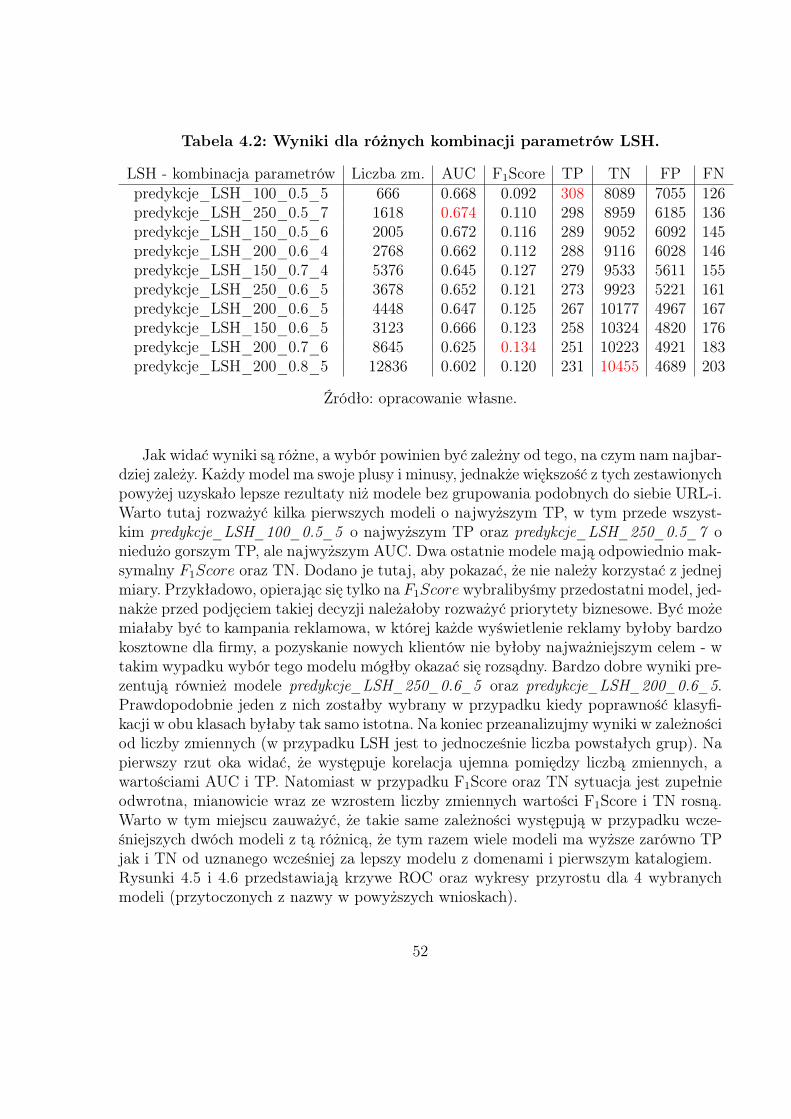
Tabela 4.2: Wyniki dla różnych kombinacji parametrów LSH.
LSH - kombinacja parametrów Liczba zm. AUC F1Score TP TN FP FNpredykcje_LSH_100_0.5_5 666 0.668 0.092 308 8089 7055 126predykcje_LSH_250_0.5_7 1618 0.674 0.110 298 8959 6185 136predykcje_LSH_150_0.5_6 2005 0.672 0.116 289 9052 6092 145predykcje_LSH_200_0.6_4 2768 0.662 0.112 288 9116 6028 146predykcje_LSH_150_0.7_4 5376 0.645 0.127 279 9533 5611 155predykcje_LSH_250_0.6_5 3678 0.652 0.121 273 9923 5221 161predykcje_LSH_200_0.6_5 4448 0.647 0.125 267 10177 4967 167predykcje_LSH_150_0.6_5 3123 0.666 0.123 258 10324 4820 176predykcje_LSH_200_0.7_6 8645 0.625 0.134 251 10223 4921 183predykcje_LSH_200_0.8_5 12836 0.602 0.120 231 10455 4689 203
Źródło: opracowanie własne.
Jak widać wyniki są różne, a wybór powinien być zależny od tego, na czym nam najbar-dziej zależy. Każdy model ma swoje plusy i minusy, jednakże większość z tych zestawionychpowyżej uzyskało lepsze rezultaty niż modele bez grupowania podobnych do siebie URL-i.Warto tutaj rozważyć kilka pierwszych modeli o najwyższym TP, w tym przede wszyst-kim predykcje_LSH_100_0.5_5 o najwyższym TP oraz predykcje_LSH_250_0.5_7 oniedużo gorszym TP, ale najwyższym AUC. Dwa ostatnie modele mają odpowiednio mak-symalny F1Score oraz TN. Dodano je tutaj, aby pokazać, że nie należy korzystać z jednejmiary. Przykładowo, opierając się tylko na F1Score wybralibyśmy przedostatni model, jed-nakże przed podjęciem takiej decyzji należałoby rozważyć priorytety biznesowe. Być możemiałaby być to kampania reklamowa, w której każde wyświetlenie reklamy byłoby bardzokosztowne dla firmy, a pozyskanie nowych klientów nie byłoby najważniejszym celem - wtakim wypadku wybór tego modelu mógłby okazać się rozsądny. Bardzo dobre wyniki pre-zentują również modele predykcje_LSH_250_0.6_5 oraz predykcje_LSH_200_0.6_5.Prawdopodobnie jeden z nich zostałby wybrany w przypadku kiedy poprawność klasyfi-kacji w obu klasach byłaby tak samo istotna. Na koniec przeanalizujmy wyniki w zależnościod liczby zmiennych (w przypadku LSH jest to jednocześnie liczba powstałych grup). Napierwszy rzut oka widać, że występuje korelacja ujemna pomiędzy liczbą zmiennych, awartościami AUC i TP. Natomiast w przypadku F1Score oraz TN sytuacja jest zupełnieodwrotna, mianowicie wraz ze wzrostem liczby zmiennych wartości F1Score i TN rosną.Warto w tym miejscu zauważyć, że takie same zależności występują w przypadku wcze-śniejszych dwóch modeli z tą różnicą, że tym razem wiele modeli ma wyższe zarówno TPjak i TN od uznanego wcześniej za lepszy modelu z domenami i pierwszym katalogiem.Rysunki 4.5 i 4.6 przedstawiają krzywe ROC oraz wykresy przyrostu dla 4 wybranychmodeli (przytoczonych z nazwy w powyższych wnioskach).
52
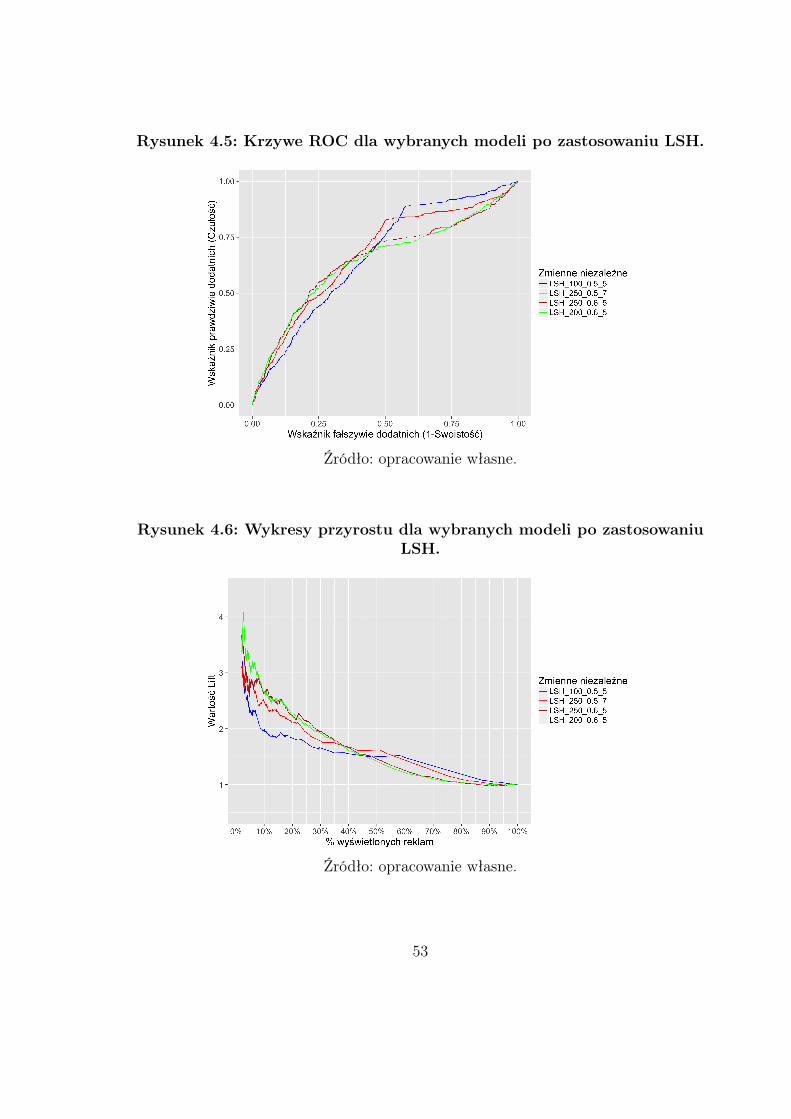
Rysunek 4.5: Krzywe ROC dla wybranych modeli po zastosowaniu LSH.
Źródło: opracowanie własne.
Rysunek 4.6: Wykresy przyrostu dla wybranych modeli po zastosowaniuLSH.
Źródło: opracowanie własne.
53

ZakończenieCelem niniejszej pracy było wykazanie, że grupowanie podobnych do siebie adresów
URL przy pomocy algorytmu locality-sensitive hashing skutkuje lepszymi wynikami. Po-równano trzy podejścia tworzenia zmiennych niezależnych. Pierwsze dwa oparte były naniewielkich modyfikacjach adresów URL, natomiast trzecie opierało się na zastosowaniuwspomnianego wyżej algorytmu LSH. Badanie zostało przeprowadzone na podstawie da-nych historycznych o użytkownikach portalu związanego z nieruchomościami. Używającstochastycznego spadku wzdłuż gradientu, zbudowano modele regresji logistycznej, któremiały jak najlepiej klasyfikować czy dany użytkownik kliknie w wyświetloną reklamę/o-fertę. Spośród wielu wyników otrzymanych z LSH (przetestowano 80 kombinacji wartości3 parametrów) wybrano 10 i porównano je z pozostałymi dwoma metodami. Następniewykorzystując kilka miar oceny jakości klasyfikacji, w tym AUC, F1Score oraz macierzpomyłek wykazano, że wyniki uzyskane po grupowaniu podobnych do siebie URL-i sąlepsze.
Reasumując, badanie wykazało, że w przypadku dużej liczby zmiennych (w tej pra-cy typu tekstowego) warto rozważyć zastosowanie metod redukujących wymiar. Istniejewiele innych algorytmów, które służą grupowaniu podobnych do siebie ciągów znaków.Z pewnością część z nich wymaga szczegółowej analizy oraz wielu testów. Należy pamię-tać, że problem wielowymiarowości jest coraz bardziej powszechny. Era danych typu Bigdata niesie za sobą nie tylko potężne pokłady danych, ale również coraz większą liczbęcech, które warto przeanalizować. Wykorzystując najnowsze technologie, jak Hadoop48
czy Spark49, oraz łącząc potencjał danych z wyborem odpowiednich zmiennych możnadokonać wielu przełomowych odkryć w różnych dziedzinach nauki.
48http://hadoop.apache.org, dostęp 3.03.2016.49http://spark.apache.org, dostęp 3.03.2016.
54

Literatura[1] Jure Leskovec, Anand Rajaraman, Jeffrey D. Ullman, Mining of Massive Datasets,
Cambridge University Press 2010, rozdział 3.
[2] Jeff M. Phillips, http://www.cs.utah.edu/∼jeffp/teaching/cs5140.html, dostęp2015/2016, tematy: Statistics Principles, Chernoff Bounds, Jaccard + k-Grams, MinHashing, LSH, Distances.
[3] http://www.mit.edu/∼andoni/LSH/, dostęp listopad 2015.
[4] T. Hastie, R. Tibsirani, J. Friedman, The Elements of Statistical Learning, Springer2009, podrozdział 4.4.
[5] Andrew Ng, CS229 Lecture notes 1, 2012.
[6] Miha Vuk, Tomaz Curk, ROC Curve, Lift Chart and Calibration Plot, Metodoloskizvezki, Vol. 3, 2006.
[7] Jesse Davis, Mark Goadrich, The Relationship Between Precision-Recall and ROCCurves, University of Wisconsin-Madison, 2006.
[8] Nitesh V. Chawla, Kevin W. Bowyer, Lawrence O. Hall, W. Philip Kegelmeyer, SMO-TE: Synthetic Minority Over-sampling Technique, Journal of Artificial IntelligenceResearch 16, 2002.
[9] W. Dong, Z. Wang, W. Josephson, M. Charikar, K. Li, Modeling LSH for Performan-ce Tuning, Department of Computer Science, Princeton University 35 Olden Street,2008.
[10] Max Kuhn, Kjell Johnson, Applied Predictive Modeling, Springer 2013.
[11] Léon Bottou, Large-Scale Machine Learning with Stochastic Gradient Descent, NECLabs America, Princeton NJ 08542, USA, 2010.
[12] G.Kondakindi, S.Rana, A.Rajkumar, S.K.Ponnekanti, V.Parakh, A Logistic Regres-sion Approach to Ad Click Prediction, Machine Learning - Class Project, 2014.
[13] Mr.Rushi Longadge, Ms. Snehlata S. Dongre, Dr. Latesh Malik, Class ImbalanceProblem in Data Mining: Review, 2013.
[14] Eileen McNulty, http://dataconomy.com/sql-vs-nosql-need-know/, dostęp wrzesień2015.
[15] Jason Brownlee, http://machinelearningmastery.com/tactics-to-combat-imbalanced-classes-in-your-machine-learning-dataset/, dostęp listopad 2015. .
55

[16] J. Brownlee, 8 Tactics to Combat Imbalanced Classes in Your Machine LearningDataset, 2015.
[17] John Langford, https://github.com/JohnLangford/vowpal_wabbit, dostęp 2015/2016.
[18] https://www.r-project.org, dostęp 2015/2016.
[19] https://www.python.org, dostęp 2015/2016.
56

Dodatek A: skrypty Python, R, Vowpal WabbitW przypadku chęci skorzystania ze skryptów, których użyto w tej pracy, proszę o
kontakt pod adresem e-mail: [email protected]ótce będą one dostępne na serwisie hostingowym GitHub w moim repozytorium onazwie masterthesis: https://github.com/mliksza/masterthesis.
57





![[WebMuses] Big data dla zdezorientowanych](https://static.fdocuments.pl/doc/165x107/5481cfea5906b500058b45c7/webmuses-big-data-dla-zdezorientowanych.jpg)












