







Języki
Strony
Prawny


CPU GPU Architektura CUDA Programowanie GPU Przykłady Na Koniec
Technologia GPGPUna przykładzie środowiska CUDA
Maciej Matyka
Instytut Fizyki TeoretycznejUniwersytet Wrocławski
Maciej Matyka IFT
Technologia GPGPU na przykładzie środowiska CUDA

CPU GPU Architektura CUDA Programowanie GPU Przykłady Na Koniec
Plan prezentacjiCPU
Architektura CPU
GPU
Architektura GPU
Architektura CUDA
Istniejące środowiska programowania GPU
Programowanie GPU
Typy danych i jądro
Krata, bloki, wątki, pamięć
Przykłady
HelloWorld w wersji wielowątkowej
Problem N ciał bez oddziaływania O(N)Problem N oddziałujących ciał O(N2)
Na Koniec
Na Deser
Maciej Matyka IFT
Technologia GPGPU na przykładzie środowiska CUDA

CPU GPU Architektura CUDA Programowanie GPU Przykłady Na Koniec
Plan prezentacjiCPU
Architektura CPU
GPU
Architektura GPU
Architektura CUDA
Istniejące środowiska programowania GPU
Programowanie GPU
Typy danych i jądro
Krata, bloki, wątki, pamięć
Przykłady
HelloWorld w wersji wielowątkowej
Problem N ciał bez oddziaływania O(N)Problem N oddziałujących ciał O(N2)
Na Koniec
Na Deser
Maciej Matyka IFT
Technologia GPGPU na przykładzie środowiska CUDA

CPU GPU Architektura CUDA Programowanie GPU Przykłady Na Koniec
Architektura CPU
Plan prezentacjiCPU
Architektura CPU
GPU
Architektura GPU
Architektura CUDA
Istniejące środowiska programowania GPU
Programowanie GPU
Typy danych i jądro
Krata, bloki, wątki, pamięć
Przykłady
HelloWorld w wersji wielowątkowej
Problem N ciał bez oddziaływania O(N)Problem N oddziałujących ciał O(N2)
Na Koniec
Na Deser
Maciej Matyka IFT
Technologia GPGPU na przykładzie środowiska CUDA

CPU GPU Architektura CUDA Programowanie GPU Przykłady Na Koniec
Architektura CPU
Architektura CPU
CPU = Central Processing Unit
◮ ALU - jednostka arytmetyczno-logiczna◮ Rejestry - integralna pamięć CPU (dane)◮ IR - rejestr instrukcji (rozkazów procesora)◮ PC - licznik programu (miejsce w liścierozkazów procesora)
Maciej Matyka IFT
Technologia GPGPU na przykładzie środowiska CUDA

CPU GPU Architektura CUDA Programowanie GPU Przykłady Na Koniec
Architektura CPU
Schemat działania CPU
CPU był z założenia procesorem sekwencyjnym1:
◮ fetch - pobieranie rozkazu do wykonania (PC)◮ decode - przekładanie rozkazu na operacje elementarne CPU◮ execute - wykonanie operacji (ALU)◮ writeback - zapisanie wyniku (np. do rejestrów)
1http:en.wikipedia.orgwikiCentral processing unit
Maciej Matyka IFT
Technologia GPGPU na przykładzie środowiska CUDA

CPU GPU Architektura CUDA Programowanie GPU Przykłady Na Koniec
Architektura CPU
Obliczenia równoległe, a CPU:
Obliczenia równoległe, a CPU:
◮ poziom instrukcji (instruction pipelining, superscalar pipeline)- wykorzystanie opóźnień w sekwencji podstawowej procesora
◮ poziom wątków (Multiple Instructions-Multiple Data)- od kilku procesorów (1960 r.) do wielordzeniowości (2001 r.)
◮ poziom danych (Single Instruction-Multiple Data) -wektoryzacja CPU, nadaje się do specjalnej klasy problemów
Maciej Matyka IFT
Technologia GPGPU na przykładzie środowiska CUDA
CPU GPU Architektura CUDA Programowanie GPU Przykłady Na Koniec
Plan prezentacjiCPU
Architektura CPU
GPU
Architektura GPU
Architektura CUDA
Istniejące środowiska programowania GPU
Programowanie GPU
Typy danych i jądro
Krata, bloki, wątki, pamięć
Przykłady
HelloWorld w wersji wielowątkowej
Problem N ciał bez oddziaływania O(N)Problem N oddziałujących ciał O(N2)
Na Koniec
Na Deser
Maciej Matyka IFT
Technologia GPGPU na przykładzie środowiska CUDA
CPU GPU Architektura CUDA Programowanie GPU Przykłady Na Koniec
Architektura GPU
Plan prezentacjiCPU
Architektura CPU
GPU
Architektura GPU
Architektura CUDA
Istniejące środowiska programowania GPU
Programowanie GPU
Typy danych i jądro
Krata, bloki, wątki, pamięć
Przykłady
HelloWorld w wersji wielowątkowej
Problem N ciał bez oddziaływania O(N)Problem N oddziałujących ciał O(N2)
Na Koniec
Na Deser
Maciej Matyka IFT
Technologia GPGPU na przykładzie środowiska CUDA
CPU GPU Architektura CUDA Programowanie GPU Przykłady Na Koniec
Architektura GPU
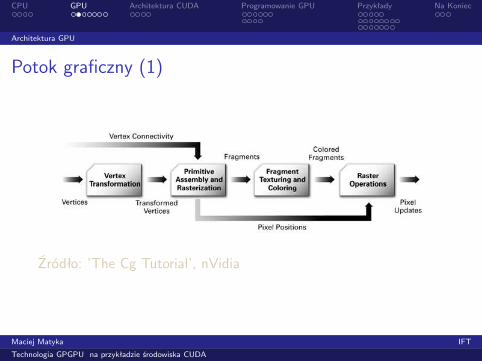
Potok graficzny (1)
Źródło: ’The Cg Tutorial’, nVidia
Maciej Matyka IFT
Technologia GPGPU na przykładzie środowiska CUDA

CPU GPU Architektura CUDA Programowanie GPU Przykłady Na Koniec
Architektura GPU
Potok graficzny (2)
Źródło: ’The Cg Tutorial’, nVidiaMaciej Matyka IFT
Technologia GPGPU na przykładzie środowiska CUDA

CPU GPU Architektura CUDA Programowanie GPU Przykłady Na Koniec
Architektura GPU
GPU - Graphics Processor Unit
Procesor GPU został zoptymalizowany pod kątem wykonywaniaelementów potoku graficznego:
◮ te same operacje na ogromnej liczbie elementów◮ architektura SIMD (Single Instruction-Multiple Data)◮ tranzystory używane do wykonywania ogromnej ilości operacjizmiennoprzecinkowych
◮ programowalne jednostki cieniujące (vertex/pixel shaders)◮ języki programowania wysokiego poziomu (CG, HLSL, GLSL)
Maciej Matyka IFT
Technologia GPGPU na przykładzie środowiska CUDA

CPU GPU Architektura CUDA Programowanie GPU Przykłady Na Koniec
Architektura GPU
Porównanie architektury GPU i CPU
Źródło: ’nVidia CUDA, Programming Guide 2.2’, nVidia
Maciej Matyka IFT
Technologia GPGPU na przykładzie środowiska CUDA
CPU GPU Architektura CUDA Programowanie GPU Przykłady Na Koniec
Architektura GPU
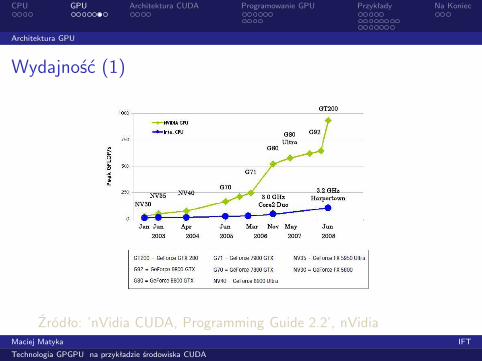
Wydajność (1)
Źródło: ’nVidia CUDA, Programming Guide 2.2’, nVidiaMaciej Matyka IFT
Technologia GPGPU na przykładzie środowiska CUDA

CPU GPU Architektura CUDA Programowanie GPU Przykłady Na Koniec
Architektura GPU
Wydajność (2)
Źródło: ’nVidia CUDA, Programming Guide 2.2’, nVidiaMaciej Matyka IFT
Technologia GPGPU na przykładzie środowiska CUDA

CPU GPU Architektura CUDA Programowanie GPU Przykłady Na Koniec
Plan prezentacjiCPU
Architektura CPU
GPU
Architektura GPU
Architektura CUDA
Istniejące środowiska programowania GPU
Programowanie GPU
Typy danych i jądro
Krata, bloki, wątki, pamięć
Przykłady
HelloWorld w wersji wielowątkowej
Problem N ciał bez oddziaływania O(N)Problem N oddziałujących ciał O(N2)
Na Koniec
Na Deser
Maciej Matyka IFT
Technologia GPGPU na przykładzie środowiska CUDA

CPU GPU Architektura CUDA Programowanie GPU Przykłady Na Koniec
Istniejące środowiska programowania GPU
Plan prezentacjiCPU
Architektura CPU
GPU
Architektura GPU
Architektura CUDA
Istniejące środowiska programowania GPU
Programowanie GPU
Typy danych i jądro
Krata, bloki, wątki, pamięć
Przykłady
HelloWorld w wersji wielowątkowej
Problem N ciał bez oddziaływania O(N)Problem N oddziałujących ciał O(N2)
Na Koniec
Na Deser
Maciej Matyka IFT
Technologia GPGPU na przykładzie środowiska CUDA

CPU GPU Architektura CUDA Programowanie GPU Przykłady Na Koniec
Istniejące środowiska programowania GPU
Środowiska
◮ Początki GPGPU, to obliczenia z użyciem programowalnychjednostek cieniujących
◮ Aktualnie istnieją dwa kompleksowe środowiska doprogramowania procesorów GPU (ATI, nVidia)
◮ Równolegle powstaje OpenCL - otwarty standard doobliczeń równoległych (grupa Khronos)
Maciej Matyka IFT
Technologia GPGPU na przykładzie środowiska CUDA

CPU GPU Architektura CUDA Programowanie GPU Przykłady Na Koniec
Istniejące środowiska programowania GPU
Co to właściwie jest CUDA?
CUDA, Compute Unified Device Architecture:
◮ język wysokiego poziomu oparty na c◮ interfejs programowania aplikacji◮ dedykowany kompilator (nvcc)◮ model pamięci
W przyszłości CUDA będzie obsługiwana z poziomu dowolnegojęzyka (Źródło: ’nVidia CUDA, Programming Guide 2.2’, nVidia).
Maciej Matyka IFT
Technologia GPGPU na przykładzie środowiska CUDA

CPU GPU Architektura CUDA Programowanie GPU Przykłady Na Koniec
Istniejące środowiska programowania GPU
Model pamięci w architekturze CUDA
W CUDA wyróżniamy kilkarodzajów pamięci na którychoperuje GPU:
◮ shared memory (16kb)◮ texture cache◮ constant cache◮ device memory (gb)
Maciej Matyka IFT
Technologia GPGPU na przykładzie środowiska CUDA

CPU GPU Architektura CUDA Programowanie GPU Przykłady Na Koniec
Plan prezentacjiCPU
Architektura CPU
GPU
Architektura GPU
Architektura CUDA
Istniejące środowiska programowania GPU
Programowanie GPU
Typy danych i jądro
Krata, bloki, wątki, pamięć
Przykłady
HelloWorld w wersji wielowątkowej
Problem N ciał bez oddziaływania O(N)Problem N oddziałujących ciał O(N2)
Na Koniec
Na Deser
Maciej Matyka IFT
Technologia GPGPU na przykładzie środowiska CUDA
CPU GPU Architektura CUDA Programowanie GPU Przykłady Na Koniec
Typy danych i jądro
Plan prezentacjiCPU
Architektura CPU
GPU
Architektura GPU
Architektura CUDA
Istniejące środowiska programowania GPU
Programowanie GPU
Typy danych i jądro
Krata, bloki, wątki, pamięć
Przykłady
HelloWorld w wersji wielowątkowej
Problem N ciał bez oddziaływania O(N)Problem N oddziałujących ciał O(N2)
Na Koniec
Na Deser
Maciej Matyka IFT
Technologia GPGPU na przykładzie środowiska CUDA

CPU GPU Architektura CUDA Programowanie GPU Przykłady Na Koniec
Typy danych i jądro
Programowanie w CUDA (1)
◮ nowe typy danych wektorowych:
char1, char2, char3, char4, int1, uint1, int2, uint2, int3, uint3,int4, uint4, float1, float2, float3, float4, double1, double2,dim3 (+ wiele innych)
Maciej Matyka IFT
Technologia GPGPU na przykładzie środowiska CUDA

CPU GPU Architektura CUDA Programowanie GPU Przykłady Na Koniec
Typy danych i jądro
Programowanie w CUDA (2)◮ przykład dla float3:
1 float3 w=make_float3(0.1, 2.2, 4.0);2 float a = w.x + w.z; // a = 4.1
◮ typy wektorowe nie posiadają przeciążonych operatorówarytmetycznych
◮ można próbować tak (prędkość)
1 __devi e__ float3 operator+( onst float3 &a,2 onst float3 &b)3 {4 return make_float3(a.x+b.x, a.y+b.y, a.z+b.z);5 }◮ w praktyce należy bardzo starannie dbać o dostęp do pamięci!
Maciej Matyka IFT
Technologia GPGPU na przykładzie środowiska CUDA

CPU GPU Architektura CUDA Programowanie GPU Przykłady Na Koniec
Typy danych i jądro
Jądro, deklaracja i wywołanie (1)
◮ w CUDA programy dla GPU to jądra (ang. kernel)◮ kod jąder umieszcza się w plikach .cu◮ Jądro (ang. kernel) deklaruje się podobnie jak funkcje w c◮ dodajemy słowo kluczowe opisującego poziom z jakiegomożna wywołać jądro (z funkcji CPU, z innego jądra itp.)
Maciej Matyka IFT
Technologia GPGPU na przykładzie środowiska CUDA
CPU GPU Architektura CUDA Programowanie GPU Przykłady Na Koniec
Typy danych i jądro
Jądro, deklaracja i wywołanie (2)
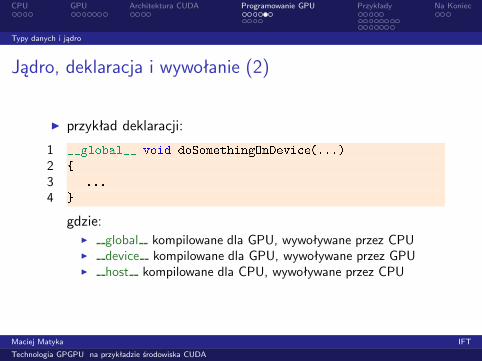
◮ przykład deklaracji:
1 __global__ void doSomethingOnDevi e(...)2 {3 ...4 }gdzie:
◮ global kompilowane dla GPU, wywoływane przez CPU◮ device kompilowane dla GPU, wywoływane przez GPU◮ host kompilowane dla CPU, wywoływane przez CPU
Maciej Matyka IFT
Technologia GPGPU na przykładzie środowiska CUDA
CPU GPU Architektura CUDA Programowanie GPU Przykłady Na Koniec
Typy danych i jądro
Jądro, deklaracja i wywołanie (3)
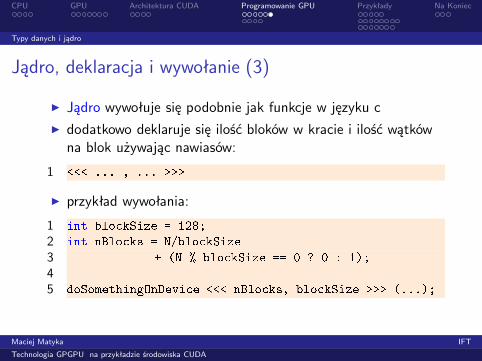
◮ Jądro wywołuje się podobnie jak funkcje w języku c◮ dodatkowo deklaruje się ilość bloków w kracie i ilość wątkówna blok używając nawiasów:
1 <<< ... , ... >>>◮ przykład wywołania:
1 int blo kSize = 128;2 int nBlo ks = N/blo kSize3 + (N % blo kSize == 0 ? 0 : 1);45 doSomethingOnDevi e <<< nBlo ks, blo kSize >>> (...);
Maciej Matyka IFT
Technologia GPGPU na przykładzie środowiska CUDA
CPU GPU Architektura CUDA Programowanie GPU Przykłady Na Koniec
Krata, bloki, wątki, pamięć
Plan prezentacjiCPU
Architektura CPU
GPU
Architektura GPU
Architektura CUDA
Istniejące środowiska programowania GPU
Programowanie GPU
Typy danych i jądro
Krata, bloki, wątki, pamięć
Przykłady
HelloWorld w wersji wielowątkowej
Problem N ciał bez oddziaływania O(N)Problem N oddziałujących ciał O(N2)
Na Koniec
Na Deser
Maciej Matyka IFT
Technologia GPGPU na przykładzie środowiska CUDA

CPU GPU Architektura CUDA Programowanie GPU Przykłady Na Koniec
Krata, bloki, wątki, pamięć
Krata, bloki, wątki...1 doSomethingOnDevi e <<< nBlo ks, blo kSize >>> (...);
◮ tworzy kratę (grid)◮ o nBlocks blokach (blocks)◮ blockSize wątków każdy
Przykład −→◮ nBlocks = dim3(3,2,1);◮ blockSize = dim3(4,3,1);
Źródło: ’nVidia CUDA, Programming Guide 2.2’, nVidiaMaciej Matyka IFT
Technologia GPGPU na przykładzie środowiska CUDA
CPU GPU Architektura CUDA Programowanie GPU Przykłady Na Koniec
Krata, bloki, wątki, pamięć
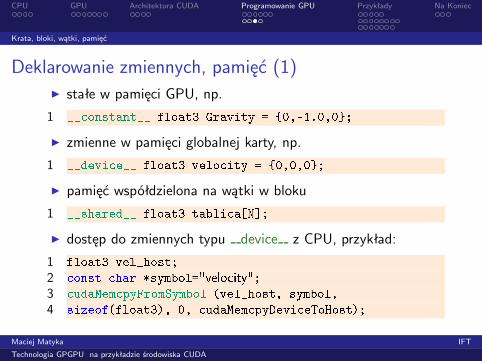
Deklarowanie zmiennych, pamięć (1)◮ stałe w pamięci GPU, np.
1 __ onstant__ float3 Gravity = {0,-1.0,0};◮ zmienne w pamięci globalnej karty, np.
1 __devi e__ float3 velo ity = {0,0,0};◮ pamięć współdzielona na wątki w bloku
1 __shared__ float3 tabli a[N℄;◮ dostęp do zmiennych typu device z CPU, przykład:
1 float3 vel_host;2 onst har *symbol="velo ity";3 udaMem pyFromSymbol (vel_host, symbol,4 sizeof(float3), 0, udaMem pyDevi eToHost);
Maciej Matyka IFT
Technologia GPGPU na przykładzie środowiska CUDA
CPU GPU Architektura CUDA Programowanie GPU Przykłady Na Koniec
Krata, bloki, wątki, pamięć
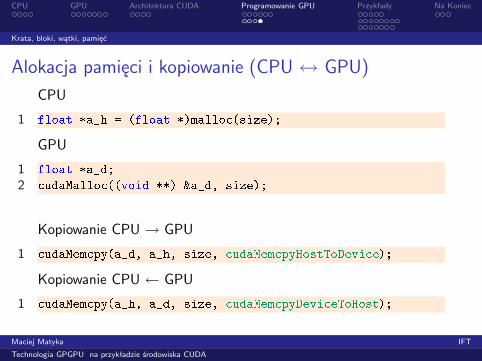
Alokacja pamięci i kopiowanie (CPU ↔ GPU)CPU
1 float *a_h = (float *)mallo (size);GPU
1 float *a_d;2 udaMallo ((void **) &a_d, size);Kopiowanie CPU → GPU
1 udaMem py(a_d, a_h, size, udaMem pyHostToDevi e);Kopiowanie CPU ← GPU
1 udaMem py(a_h, a_d, size, udaMem pyDevi eToHost);Maciej Matyka IFT
Technologia GPGPU na przykładzie środowiska CUDA
CPU GPU Architektura CUDA Programowanie GPU Przykłady Na Koniec
Plan prezentacjiCPU
Architektura CPU
GPU
Architektura GPU
Architektura CUDA
Istniejące środowiska programowania GPU
Programowanie GPU
Typy danych i jądro
Krata, bloki, wątki, pamięć
Przykłady
HelloWorld w wersji wielowątkowej
Problem N ciał bez oddziaływania O(N)Problem N oddziałujących ciał O(N2)
Na Koniec
Na Deser
Maciej Matyka IFT
Technologia GPGPU na przykładzie środowiska CUDA
CPU GPU Architektura CUDA Programowanie GPU Przykłady Na Koniec
HelloWorld w wersji wielowątkowej
Plan prezentacjiCPU
Architektura CPU
GPU
Architektura GPU
Architektura CUDA
Istniejące środowiska programowania GPU
Programowanie GPU
Typy danych i jądro
Krata, bloki, wątki, pamięć
Przykłady
HelloWorld w wersji wielowątkowej
Problem N ciał bez oddziaływania O(N)Problem N oddziałujących ciał O(N2)
Na Koniec
Na Deser
Maciej Matyka IFT
Technologia GPGPU na przykładzie środowiska CUDA
CPU GPU Architektura CUDA Programowanie GPU Przykłady Na Koniec
HelloWorld w wersji wielowątkowej
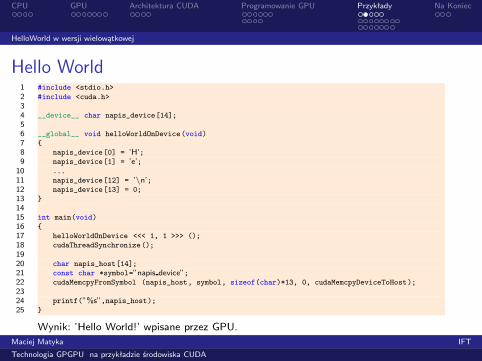
Hello World1 #include <stdio.h>
2 #include <cuda.h>
34 __device__ char napis_device[14];
56 __global__ void helloWorldOnDevice(void)
7 {
8 napis_device[0] = ’H’;9 napis_device[1] = ’e’;10 ...
11 napis_device[12] = ’\n’;12 napis_device[13] = 0;
13 }
1415 int main(void)
16 {
17 helloWorldOnDevice <<< 1, 1 >>> ();
18 cudaThreadSynchronize();
1920 char napis_host[14];
21 const char *symbol=”napis device”;22 cudaMemcpyFromSymbol (napis_host, symbol, sizeof(char)*13, 0, cudaMemcpyDeviceToHost);
2324 printf(”%s”,napis_host);25 }
Wynik: ’Hello World!’ wpisane przez GPU.Maciej Matyka IFT
Technologia GPGPU na przykładzie środowiska CUDA

CPU GPU Architektura CUDA Programowanie GPU Przykłady Na Koniec
HelloWorld w wersji wielowątkowej
Hello World w wersji wielowątkowej
’Hello World!’ w wersji wielowątkowej:
◮ funkcjonalność jądra bez zmian◮ podzielmy zadania na osobne rdzenie◮ niech każda literka zostanie wpisana przez osobny rdzeń!
(Wspólnie z Pawłem Czubińskim)
Maciej Matyka IFT
Technologia GPGPU na przykładzie środowiska CUDA

CPU GPU Architektura CUDA Programowanie GPU Przykłady Na Koniec
HelloWorld w wersji wielowątkowej
Hello World w wersji wielowątkowej
Jądro rozbijamy na 14 bloków po 1 wątku każdy:
1 helloWorldOnDevi e <<< 14, 1 >>> ();Maciej Matyka IFT
Technologia GPGPU na przykładzie środowiska CUDA

CPU GPU Architektura CUDA Programowanie GPU Przykłady Na Koniec
HelloWorld w wersji wielowątkowej
Hello World
12 __device__ char napis_device[14];
3 __constant__ __device__ char hw[] = ”Hello World!\n”;45 __global__ void helloWorldOnDevice(void)
6 {
7 int idx = blockIdx.x;
8 napis_device[idx] = hw[idx];
9 }
1011 int main(void)
12 {
13 helloWorldOnDevice <<< 14, 1 >>> ();
14 cudaThreadSynchronize();
15 ...
16 }
◮ Wynik: ’Hello World!’ wpisane przez GPU wielowątkowo!◮ Każda literka przez inny rdzeń (jeśli zasoby były wolne).
Maciej Matyka IFT
Technologia GPGPU na przykładzie środowiska CUDA
CPU GPU Architektura CUDA Programowanie GPU Przykłady Na Koniec
Problem N ciał bez oddziaływania O(N)
Plan prezentacjiCPU
Architektura CPU
GPU
Architektura GPU
Architektura CUDA
Istniejące środowiska programowania GPU
Programowanie GPU
Typy danych i jądro
Krata, bloki, wątki, pamięć
Przykłady
HelloWorld w wersji wielowątkowej
Problem N ciał bez oddziaływania O(N)Problem N oddziałujących ciał O(N2)
Na Koniec
Na Deser
Maciej Matyka IFT
Technologia GPGPU na przykładzie środowiska CUDA

CPU GPU Architektura CUDA Programowanie GPU Przykłady Na Koniec
Problem N ciał bez oddziaływania O(N)
N nieoddziałujących ciał, problem O(N)
◮ N nieoddziałujących punktów materialnych◮ grawitacja g = (0, gy , 0)◮ przyciąganie do wybranego punktu◮ pętla obliczeniowa:1. wyliczenie sił 2. całkowanie równań ruchu
◮ mało operacji na odczyt z pamięci!◮ złożoność problemu rośnie liniowo - O(N)
Maciej Matyka IFT
Technologia GPGPU na przykładzie środowiska CUDA

CPU GPU Architektura CUDA Programowanie GPU Przykłady Na Koniec
Problem N ciał bez oddziaływania O(N)
Rozwiązanie 1. CPU12 for(int i=0; i < N; i++)
3 {
45 DIST = sqrt( (_ATR.x - pos[i].x)*(_ATR.x - pos[i].x)
6 + (_ATR.y - pos[i].y)*(_ATR.y - pos[i].y));
78 if(DIST)
9 {
10 ATRF.x = KD * ((_ATR.x - pos[i].x))/DIST;
11 ATRF.y = KD * ((_ATR.y - pos[i].y))/DIST;
12 }
1314 vel[i].x = vel[i].x + (G.x + ATRF.x) * dt;
15 vel[i].y = vel[i].y + (G.y + ATRF.y) * dt;
1617 pos[i].x = pos[i].x + vel[i].x * dt;
18 pos[i].y = pos[i].y + vel[i].y * dt;
1920 if(pos[i].x >1) {pos[i].x = 1; vel[i].x = -vel[i].x;}
21 if(pos[i].y >1) {pos[i].y = 1; vel[i].y = -vel[i].y;}
22 if(pos[i].x <-1) {pos[i].x = -1; vel[i].x = -vel[i].x;}
23 if(pos[i].y <-1) {pos[i].y = -1; vel[i].y = -vel[i].y;}
2425 }
x2dostęp do pamięci!
Maciej Matyka IFT
Technologia GPGPU na przykładzie środowiska CUDA

CPU GPU Architektura CUDA Programowanie GPU Przykłady Na Koniec
Problem N ciał bez oddziaływania O(N)
Rozwiązanie 2. GPU, float31 __global__ void movepartOnDevice
2 (float3* posvbo, float3 *vel, ...)
3 {
4 int idx = blockIdx.x*blockDim.x + threadIdx.x;
56 float3 posidx;
7 float3 velidx;
89 (...)
1011 if (idx < _N)
12 {
13 posidx = posvbo[idx];
14 velidx = vel[idx];
1516 // -------------------------------------
17 // Tu: pętla analogiczna z CPU, z zamianą
18 // pos[i] -> posidx
19 // vel[i] -> velidx
20 // -------------------------------------
2122 posvbo[idx] = posidx;
23 vel[idx] = velidx;
24 }
25 }
◮ x2◮ dostęp do pamięci!
Maciej Matyka IFT
Technologia GPGPU na przykładzie środowiska CUDA
CPU GPU Architektura CUDA Programowanie GPU Przykłady Na Koniec
Problem N ciał bez oddziaływania O(N)
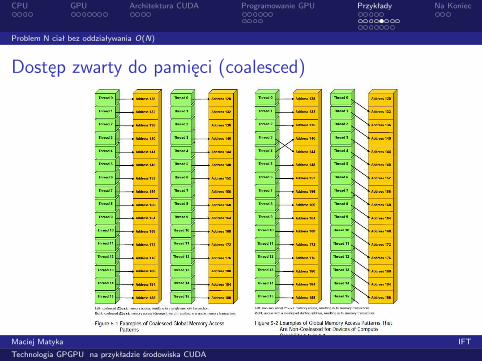
Dostęp zwarty do pamięci (coalesced)
Źródło: ’nVidia CUDA, Programming Guide 2.2’, nVidia
Maciej Matyka IFT
Technologia GPGPU na przykładzie środowiska CUDA

CPU GPU Architektura CUDA Programowanie GPU Przykłady Na Koniec
Problem N ciał bez oddziaływania O(N)
Rozwiązanie 3. GPU, float41 __global__ void movepartOnDevice
2 (float4* posvbo, float4 *vel, ...)
3 {
4 int idx = blockIdx.x*blockDim.x + threadIdx.x;
56 float4 posidx;
7 float4 velidx;
89 (...)
1011 if (idx < _N)
12 {
13 posidx = posvbo[idx];
14 velidx = vel[idx];
1516 // -------------------------------------
17 // Tu: pętla analogiczna z CPU, z zamianą
18 // pos[i] -> posidx
19 // vel[i] -> velidx
20 // -------------------------------------
2122 posvbo[idx] = posidx;
23 vel[idx] = velidx;
24 }
25 }
◮ x10◮ rząd wielkości!
Maciej Matyka IFT
Technologia GPGPU na przykładzie środowiska CUDA

CPU GPU Architektura CUDA Programowanie GPU Przykłady Na Koniec
Problem N ciał bez oddziaływania O(N)
Problem O(N), wizualizacja w OpenGL, GPU vs CPU
[run]
◮ 0.5 miliona punktów◮ wizualizacja w czasierzeczywistym
◮ OpenGL◮ GL Utility Toolkit (GLUT)◮ Vertex Buffer Object (VBO)
Maciej Matyka IFT
Technologia GPGPU na przykładzie środowiska CUDA

CPU GPU Architektura CUDA Programowanie GPU Przykłady Na Koniec
Problem N ciał bez oddziaływania O(N)
Problem O(N) w działaniu, porównanie
0.001
0.01
0.1
1
105 106 107
t[ms]
N
CPUGPU3GPU4
◮ złożoność liniowa◮ GPU→pamięć karty >CPU→pamięć na płycie.
◮ dostęp zwarty → x10!
Maciej Matyka IFT
Technologia GPGPU na przykładzie środowiska CUDA

CPU GPU Architektura CUDA Programowanie GPU Przykłady Na Koniec
Problem N oddziałujących ciał O(N2)
Plan prezentacjiCPU
Architektura CPU
GPU
Architektura GPU
Architektura CUDA
Istniejące środowiska programowania GPU
Programowanie GPU
Typy danych i jądro
Krata, bloki, wątki, pamięć
Przykłady
HelloWorld w wersji wielowątkowej
Problem N ciał bez oddziaływania O(N)Problem N oddziałujących ciał O(N2)
Na Koniec
Na Deser
Maciej Matyka IFT
Technologia GPGPU na przykładzie środowiska CUDA

CPU GPU Architektura CUDA Programowanie GPU Przykłady Na Koniec
Problem N oddziałujących ciał O(N2)
N oddziałujących ciał, problem O(N2)
◮ N mas oddziałujących grawitacyjnie◮ oddziaływanie każdy z każdym◮ pętla obliczeniowa:
1. wyliczenie sił (podwójna)
2. całkowanie równań ruchu
Maciej Matyka IFT
Technologia GPGPU na przykładzie środowiska CUDA

CPU GPU Architektura CUDA Programowanie GPU Przykłady Na Koniec
Problem N oddziałujących ciał O(N2)
Rozwiązanie 1. CPU, N=32000
12 (...)
34 for(int i=0; i < N; i++)
5 for(int j=0; j < N; j++)
6 {
7 n.x = pos[j].x - pos[i].x;
8 n.y = pos[j].y - pos[i].y;
910 DIST = sqrt(n.x * n.x + n.y * n.y + EPS2);
1112 // fg = n*G*m1m2/r**3
1314 forc[i].x += (n.x * BIGG / DIST*DIST*DIST);
15 forc[i].y += (n.y * BIGG / DIST*DIST*DIST);
1617 }
1819 (...)
Maciej Matyka IFT
Technologia GPGPU na przykładzie środowiska CUDA
CPU GPU Architektura CUDA Programowanie GPU Przykłady Na Koniec
Problem N oddziałujących ciał O(N2)
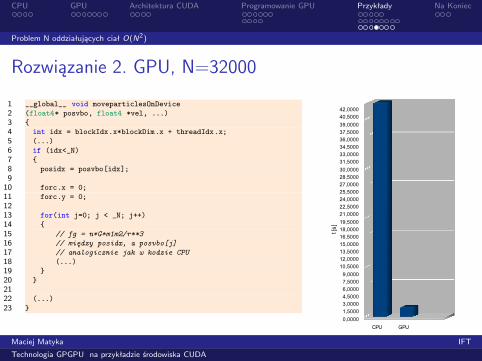
Rozwiązanie 2. GPU, N=32000
1 __global__ void moveparticlesOnDevice
2 (float4* posvbo, float4 *vel, ...)
3 {
4 int idx = blockIdx.x*blockDim.x + threadIdx.x;
5 (...)
6 if (idx<_N)
7 {
8 posidx = posvbo[idx];
910 forc.x = 0;
11 forc.y = 0;
1213 for(int j=0; j < _N; j++)
14 {
15 // fg = n*G*m1m2/r**3
16 // między posidx, a posvbo[j]
17 // analogicznie jak w kodzie CPU
18 (...)
19 }
20 }
2122 (...)
23 }
Maciej Matyka IFT
Technologia GPGPU na przykładzie środowiska CUDA

CPU GPU Architektura CUDA Programowanie GPU Przykłady Na Koniec
Problem N oddziałujących ciał O(N2)
Algorytm n ciał z pamięcią sharedEfektywny algorytm N ciał dla CUDA:
◮ Lars Nyland, Mark Harris, Jan PrinsFast N-Body Simulation with CUDAGPU Gems 3
◮ algorytm n ciał z wykorzystaniem pamięci współdzielonej◮ w każdym wątku wyznaczanych jest N sił◮ p - ilość wątków w bloku◮ każdy wątek wykonuje p razy pętlę liczącą N/p oddziaływań◮ te N/p oddziaływań obliczanych jest w pamięci shared◮ mapowanie wątek/blok -¿ miejsce w pamięci
Maciej Matyka IFT
Technologia GPGPU na przykładzie środowiska CUDA
CPU GPU Architektura CUDA Programowanie GPU Przykłady Na Koniec
Problem N oddziałujących ciał O(N2)
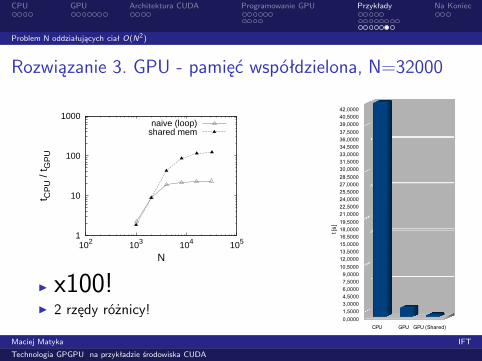
Rozwiązanie 3. GPU - pamięć współdzielona, N=32000
1
10
100
1000
102 103 104 105
t CP
U /
t GP
U
N
naive (loop)shared mem
◮ x100!◮ 2 rzędy różnicy!
Maciej Matyka IFT
Technologia GPGPU na przykładzie środowiska CUDA

CPU GPU Architektura CUDA Programowanie GPU Przykłady Na Koniec
Problem N oddziałujących ciał O(N2)
Problem O(N2), wizualizacja w OpenGL, GPU vs CPU
[run-CPU] [run-GPU][(GPU+CPU)]
◮ 5835 punktów◮ wizualizacja w czasierzeczywistym
◮ OpenGL◮ GL Utility Toolkit (GLUT)◮ Vertex Buffer Object (VBO)
Maciej Matyka IFT
Technologia GPGPU na przykładzie środowiska CUDA

CPU GPU Architektura CUDA Programowanie GPU Przykłady Na Koniec
Plan prezentacjiCPU
Architektura CPU
GPU
Architektura GPU
Architektura CUDA
Istniejące środowiska programowania GPU
Programowanie GPU
Typy danych i jądro
Krata, bloki, wątki, pamięć
Przykłady
HelloWorld w wersji wielowątkowej
Problem N ciał bez oddziaływania O(N)Problem N oddziałujących ciał O(N2)
Na Koniec
Na Deser
Maciej Matyka IFT
Technologia GPGPU na przykładzie środowiska CUDA

CPU GPU Architektura CUDA Programowanie GPU Przykłady Na Koniec
Na zakończenie
Krótkie podsumowanie:
◮ optymalizacja dostępu do pamięci - kluczowa◮ potrzebna gruntowna rekonstrukcja algorytmów◮ pamięć typu shared - 16kb rejestrów (!)◮ narzut pracy ogromny, ale.. zysk również◮ Przyszłość? GTX300 - ponoć czeka nas zmiana architektury(!)
Uwaga: W trakcie seminarium nie powiedzieliśmy nic o compute capabilities, operacjach atomowych, synchronizacjiwątków, buforach wierzchołków i pikseli, teksturach, rozplątywaniu pętli, konfliktach dostępu do pamięci, zwojach(warpach) wątków itd..
Źródło: ’nVidia CUDA, Programming Guide 2.2’, nVidia
Maciej Matyka IFT
Technologia GPGPU na przykładzie środowiska CUDA
CPU GPU Architektura CUDA Programowanie GPU Przykłady Na Koniec
Żródła
◮
http://4.bp.blogspot.com/ hqgVFA7RYE4/SkAI1b2QGlI/AAAAAAAABd4/Q5mhupfFHCA/s400/Hun+Sen+shaking+han
◮ http://www.ipipan.gda.pl/ wiesiek/pjwstk/08-09/ark/wyklad-03.pdf
◮ http://http.developer.nvidia.com/CgTutorial/cg tutorial chapter01.html
◮ http://arstechnica.com/hardware/reviews/2008/06/nvidia-geforce-gx2-review.ars
◮ ’nVidia CUDA, Programming Guide 2.2’, nVidia
◮ Wikipedia
◮ Zbigniew Koza, ’CUDA na Twoim biurku, czyli słów kilka na temat Compute Unified Device Architecture’,Wykład
Maciej Matyka IFT
Technologia GPGPU na przykładzie środowiska CUDA
CPU GPU Architektura CUDA Programowanie GPU Przykłady Na Koniec
Na Deser
Plan prezentacjiCPU
Architektura CPU
GPU
Architektura GPU
Architektura CUDA
Istniejące środowiska programowania GPU
Programowanie GPU
Typy danych i jądro
Krata, bloki, wątki, pamięć
Przykłady
HelloWorld w wersji wielowątkowej
Problem N ciał bez oddziaływania O(N)Problem N oddziałujących ciał O(N2)
Na Koniec
Na Deser
Maciej Matyka IFT
Technologia GPGPU na przykładzie środowiska CUDA

CPU GPU Architektura CUDA Programowanie GPU Przykłady Na Koniec
Na Deser
Na deser
◮ prosty model materii granulowanej:N. Bell, Y. Yu and P. J. Mucha,Particle-Based Simulation of Granular Materials,Eurographics/ACM SIGGRAPH (2005)
◮ oddziaływania sprężyste między masami◮ CUDA, 4096 ziaren, [run]
Maciej Matyka IFT
Technologia GPGPU na przykładzie środowiska CUDA

CPU GPU Architektura CUDA Programowanie GPU Przykłady Na Koniec
Na Deser
Koniec
Dziękuję za uwagę
Maciej Matyka IFT
Technologia GPGPU na przykładzie środowiska CUDA
Top Related