







Języki
Strony
Prawny


1
Algorytmy genetyczne - plan wykładu
• Wstęp
• Standardowy algorytm genetyczny
• Matematyczne podstawy algorytmów genetycznych
• Techniki poprawiające efektywność algorytmów genetycznych
• Genetyczne systemy uczące się (GBML)
• Programowanie genetyczne
• Genetyczny dobór wag SSN

2
Algorytmy genetyczne - literatura
• John Holland, Adaptation in natural and artificial systems, The University of Michigan Press, 1975
• David E. Goldberg, Algorytmy genetyczne i ich zastosowania, WNT, Warszawa 1995
• Jarosław Arabas, Wykłady z algorytmów ewolucyjnych, WNT, Warszawa 2001
• Robert Schaefer, Podstawy genetycznej optymalizacji globalnej, Wydawnictwo Uniwersytetu Jagiellońskiego, Kraków 2002

3
Definicje
Algorytmy genetyczne – algorytmy poszukiwania oparte na mechanizmach doboru naturalnego oraz łączenia cech rozwiązań
Uczenie się systemu - każda autonomiczna zmiana w
systemie zachodząca na podstawie doświadczeń,
która prowadzi do poprawy jakości jego działania.
Rodzaje uczenia:
• Z nauczycielem
• Z krytykiem
• Samoorganizacja

4
Cele badań nad algorytmami genetycznymi
1. Wyjaśnienie procesów adaptacyjnych występujących w przyrodzie
2. Zastosowanie w zadaniach optymalizacji i uczenia

5
Równoważność algorytmów optymalizacji
Reguła „nie ma nic za darmo” (ang. no free lunch theory):
efektywność różnych typowych algorytmów szukania uśredniona po wszystkich wszystkich możliwych problemach optymalizacyjnych jest taka sama
Typowe algorytmy szukania (optymalizacji):• metoda enumeracyjna (wyliczeniowa)• szukanie gradientowe• symulowane wyżarzanie• strategie ewolucyjne• algorytmy genetyczne• metody wyspecjalizowane (wykorzystujące szczegółową wiedzę o problemie)
6
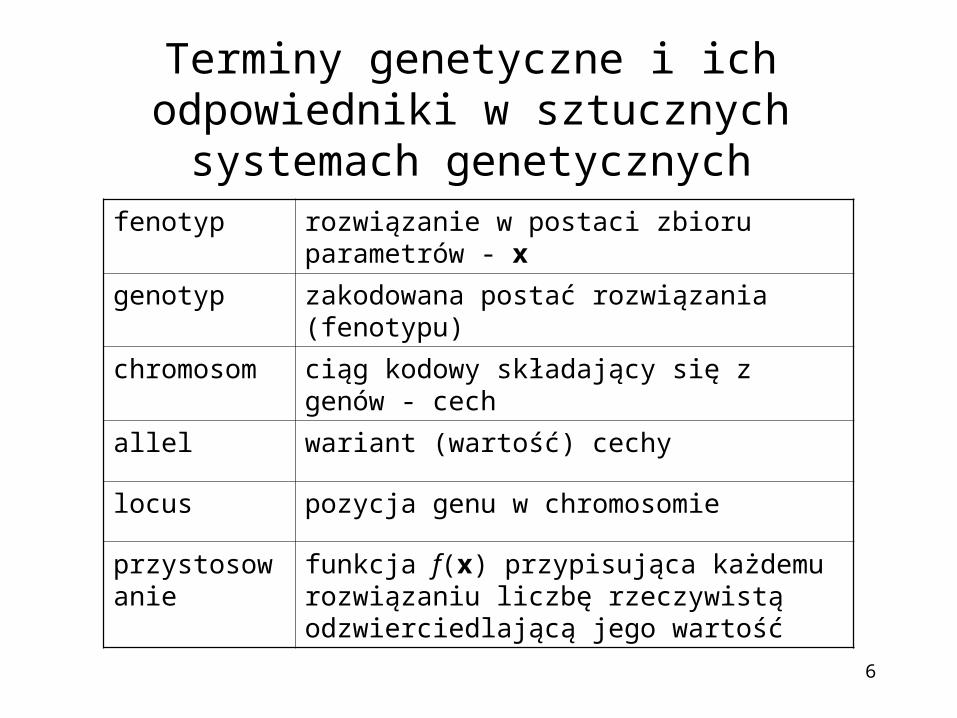
Terminy genetyczne i ich odpowiedniki w sztucznych systemach genetycznych
fenotyp rozwiązanie w postaci zbioru parametrów - x
genotyp zakodowana postać rozwiązania (fenotypu)
chromosom ciąg kodowy składający się z genów - cech
allel wariant (wartość) cechy
locus pozycja genu w chromosomie
przystosowanie funkcja f(x) przypisująca każdemu rozwiązaniu liczbę rzeczywistą odzwierciedlającą jego wartość
7
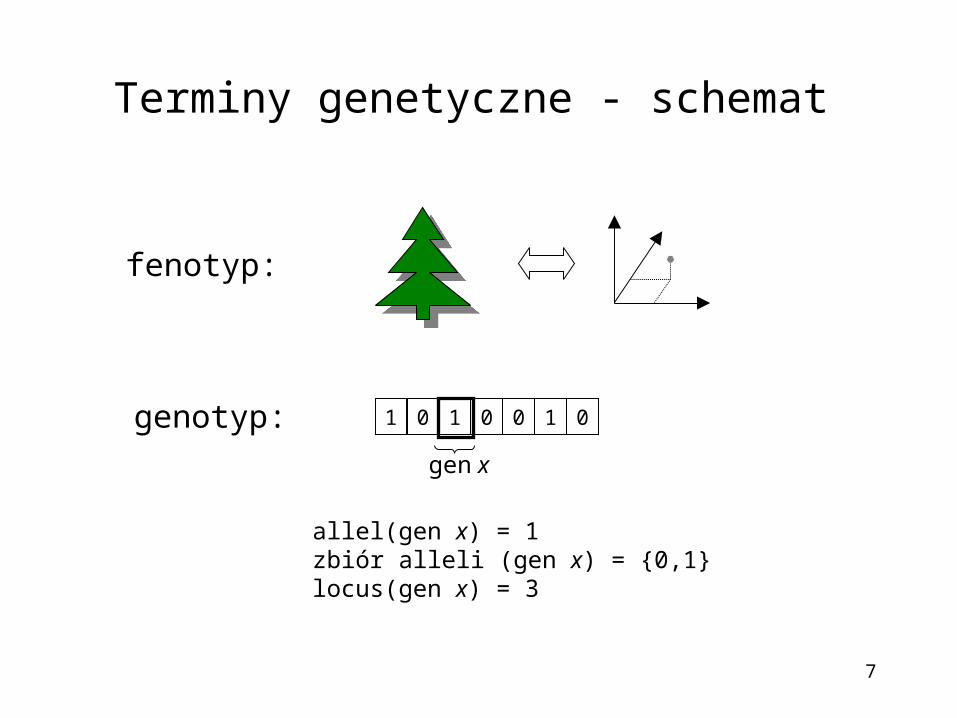
Terminy genetyczne - schemat
1 01 10 00
gen x
allel(gen x) = 1zbiór alleli (gen x) = {0,1}locus(gen x) = 3
fenotyp:
genotyp:
8
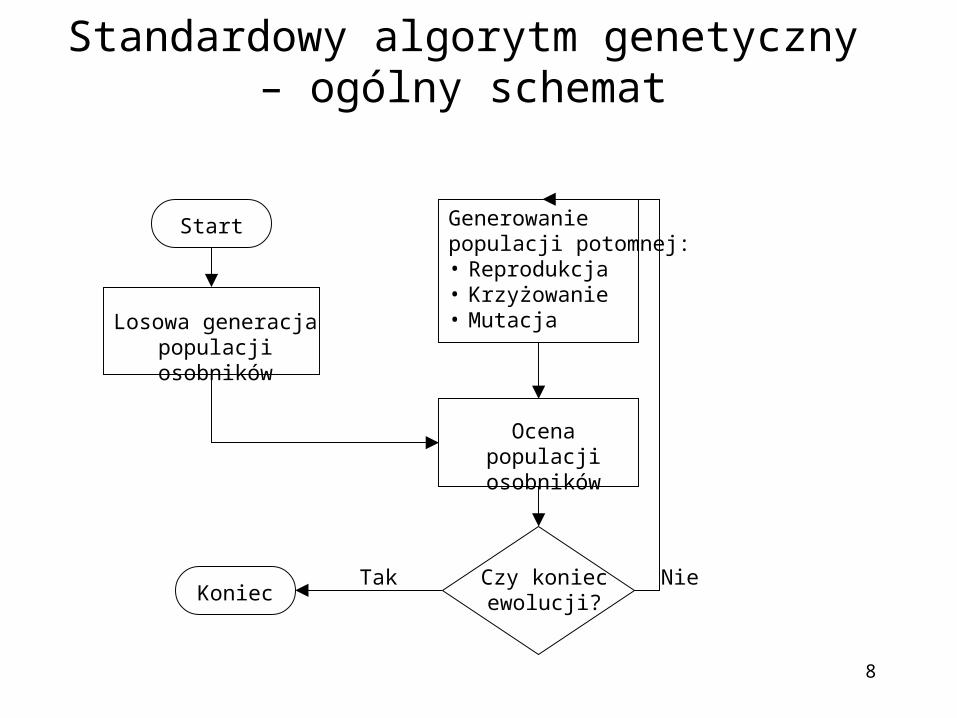
Standardowy algorytm genetyczny – ogólny schemat
Generowanie populacji potomnej:• Reprodukcja• Krzyżowanie• Mutacja
Ocena populacji osobników
Czy koniec ewolucji?
Losowa generacja populacji osobników
Koniec
Start
Tak Nie

9
Funkcje podstawowych operatorów genetycznych
Reprodukcja – wybór najlepiej przystosowanych osobników (rozwiązań) do następnego pokolenia
Krzyżowanie – szukanie rozwiązań zawierających cechy wielu dobrych rozwiązań
Mutacja – dostarczanie nowego materiału genetycznego

10
Czynności związane z realizacją algorytmu genetycznego
• Wybór metody kodowania - reprezentacji fenotypu (rozwiązania)
• Wybór operatorów genetycznych w zależności od problemu i przyjętego sposobu kodowania
• Dobór wartości parametrów ewolucji

11
Typy reprodukcji
• Ruletkowa – proporcjonalna do wartości funkcji przystosowania - konieczność skalowania
• Rangowa – zależna od rangi – numeru na liście posortowanej względem przystosowania
• Turniejowa – wielokrotny wybór najlepszego osobnika z losowo wybieranej podpopulacji aż do skompletowania populacji potomnej

12
Reprodukcja ruletkowa
Nr Ciąg kodowy Przystosowanie % całości
1 01101 169 14,4
2 11000 576 49,2
3 01000 64 5,5
4 10011 361 30,9
Łącznie 1170 100,0
Przykład: optymalizacja funkcji 2)( xxf
Koło ruletki:

13
Metody wyznaczania prawdopodobieństwa reprodukcji:
• Liniowa:
• Potęgowa:
gdzie: r(X) – ranga rozwiązania X,rmax – ranga maksymalna,a,b,k – stałe spełniające warunki:
Reprodukcja rangowa
))(
1()(maxr
XrkaXp
bXrrkaXp ))(()( max
)()()()(
,1)(0
,1)(1
YpXpYrXr
Xp
XpN
ii
*

14
Wyznaczanie prawdopodobieństwa reprodukcji metodą liniową dla funkcji przystosowania
Reprodukcja rangowa - przykład
))(
1()(maxr
XrkaXp
2)( xxf
Nr Ciąg kodowy Przystosowanie Ranga r(X)p(X) dla
k=2/3 i a=0
1 01101 169 3 0,25 0,17
2 11000 576 1 0,75 0,50
3 01000 64 4 0 0
4 10011 361 2 0,50 0,33
Łącznie 1170 1,5 1,0
max
)(1
r
Xr
*

15
Typy krzyżowania - 1/2
Ze względu na sposób kojarzenia osobników:
• Kojarzenie losowe - jednakowe prawdopodobieństwo dla wszystkich par
• Kojarzenie krewniacze (endogamia) - wśród osobników pokrewnych
• Kojarzenie według linii - szczególnie wartościowy osobnik jest kojarzony ze wszystkimi członkami populacji
• Kojarzenie selektywne dodatnie - kojarzenie osobników podobnych np. w sensie odległości Hamminga
• Kojarzenie selektywnie ujemne - kojarzenie osobników niepodobnych
*

16
Typy krzyżowania - 2/2
Ze względu na liczbę przecięć:
• Jednopunktowe
• Wielopunktowe
Ze względu na liczbę osobników:
• Dwuosobnicze
• Wieloosobnicze
W przypadku rzeczywistoliczbowej reprezentacji genotypu:
• Przez wymianę wartości genów
• Przez uśrednienie wartości genów
*
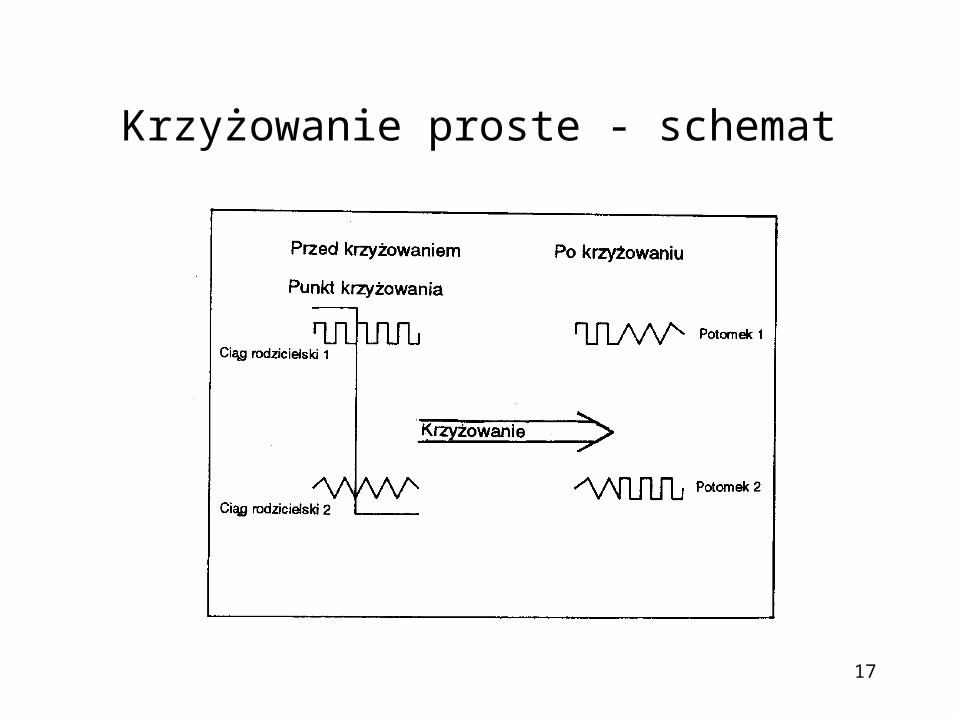
17
Krzyżowanie proste - schemat
18
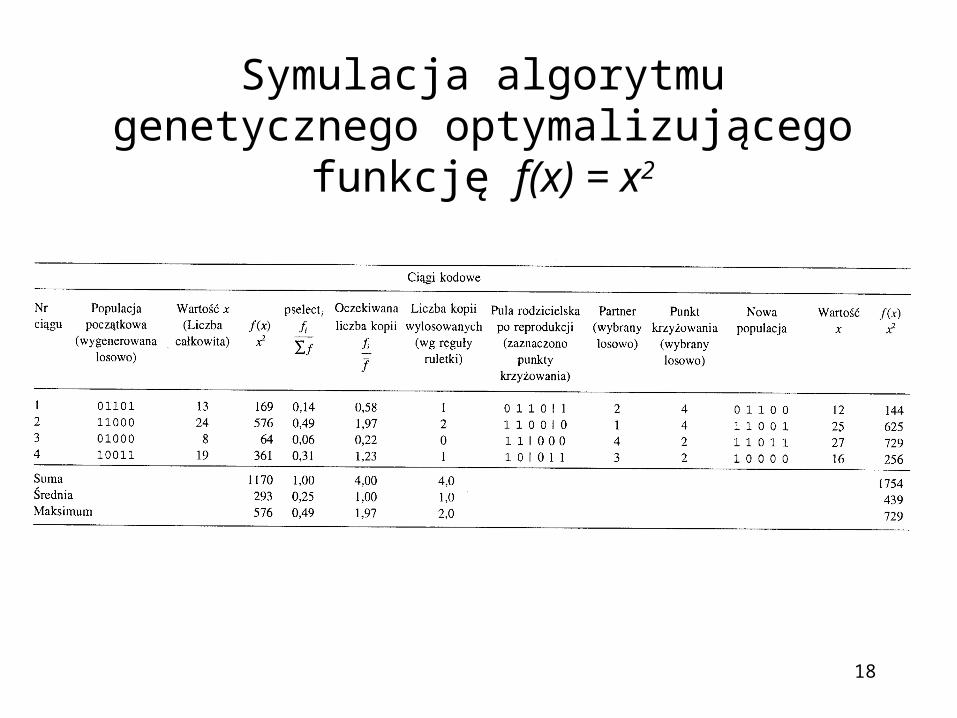
Symulacja algorytmu genetycznego optymalizującego funkcję f(x) = x2

19
Metody kodowania
Ze względu na typ wartości genu - allelu:
• Binarne np. 1000110
• Całkowitoliczbowe
• O wartościach rzeczywistych (fenotypowe)

20
Kodowanie binarne
Kodowanie pozycyjne:
l
i
iiax
1
12
j
i
ji ab
1
gdzie x - parametr rozwiązania,
- element ciągu kodowego ia ),,,( 21 laaa
Kodowanie Graya:
0 0000 00001 0001 00012 0010 00113 0011 00104 0100 01105 0101 01116 0110 01017 0111 01008 1000 11009 1001 110110 1010 111111 1011 111012 1100 101013 1101 101114 1110 100115 1111 1000
liczba kod pozycyjny
kod Graya
*

21
Kodowanie fenotypowe
Wybrane operatory fenotypowe:
),0(' Nxx ii - mutacja fenotypowa normalna:
NixxNxx iiii ,1 ),(),0(' 121 - krzyżowanie fenotypowe:
),,,( 21 Nxxx x - wektor parametrów fenotypu
*

22
Metody kodowania
Ze względu na sposób reprezentowania cech:
• Klasyczne - każda cecha fenotypu jest kodowana przez wartość odpowiedniego genu niezależnie od jego umiejscowienia
• Permutacyjne - cechy kodowane są przez pozycje genów (locus)
• Mieszane - cechy kodowane zarówno przez pozycje jak i umiejscowienie genów
23
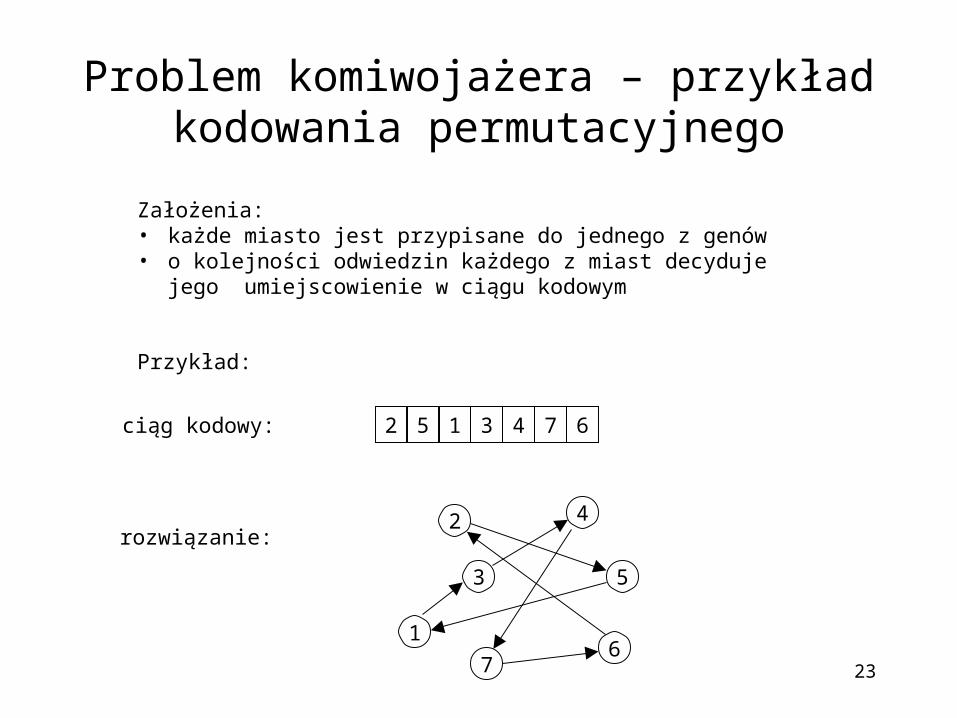
Problem komiwojażera – przykład kodowania permutacyjnego
Założenia:• każde miasto jest przypisane do jednego z genów • o kolejności odwiedzin każdego z miast decyduje jego
umiejscowienie w ciągu kodowym
Przykład:
5 1 3 42 7 6
2 4
7
1
5
6
3
ciąg kodowy:
rozwiązanie:

24
Metody kodowania - cd
Ze względu na strukturę genotypu:
• Za pomocą ciągów
• Za pomocą innych struktur np. drzew, grafów, sieci

25
Dobór wartości parametrów algorytmu genetycznego
Typy doboru:
• arbitralny – stałe wartości
• heurystyczny
• ewolucyjny
Sposoby doboru ewolucyjnego ze względu na metodę reprezentowania parametrów:
• z podziałem na podpopulacje
• z parametrami zakodowanymi we wspólnym genotypie
*
26
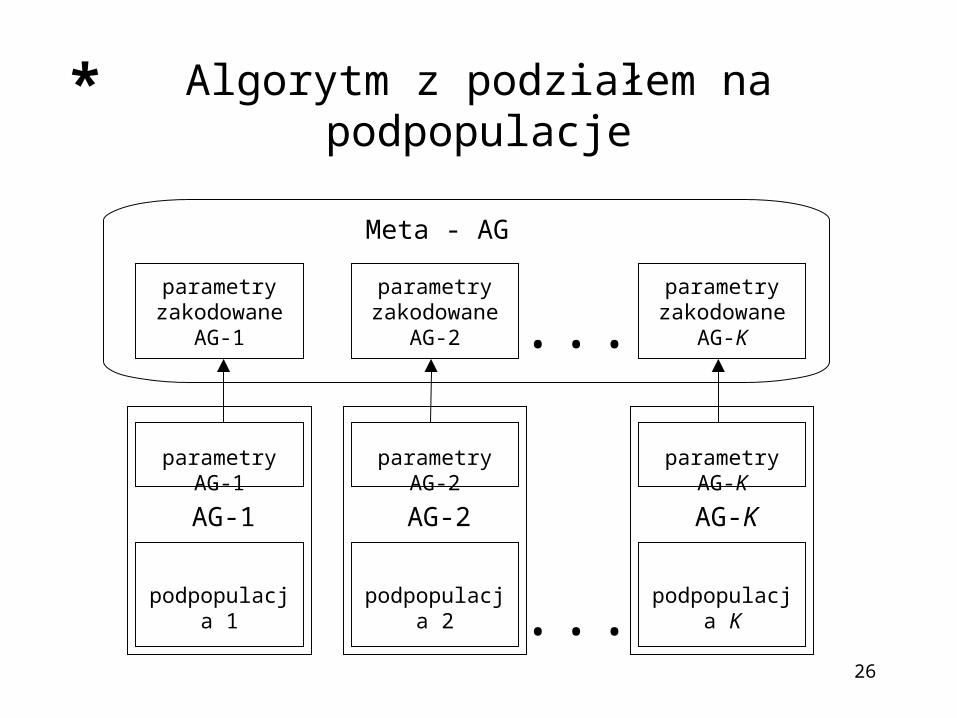
Algorytm z podziałem na podpopulacje
podpopulacja 1
parametry AG-1
AG-1
podpopulacja 2
parametry AG-2
AG-2
podpopulacja K
parametry AG-K
AG-K
...
parametry zakodowane
AG-1
parametry zakodowane
AG-2
parametry zakodowane
AG-K
Meta - AG
...
*

27
Algorytm z podziałem na podpopulacje
Założenia:1. Algorytm działa dwufazowo: najpierw uruchamiane są
algorytmy dla poszczególnych podpopulacji a następnie uruchamiany jest metaalgorytm (z reguły dużo rzadziej), którego osobnikami są zbiory parametrów algorytmów genetycznych
2. Poszczególne podpopulacje mogą być kopiowane lub usuwane w ramach reprodukcji dla metaalgorytmu
*
28
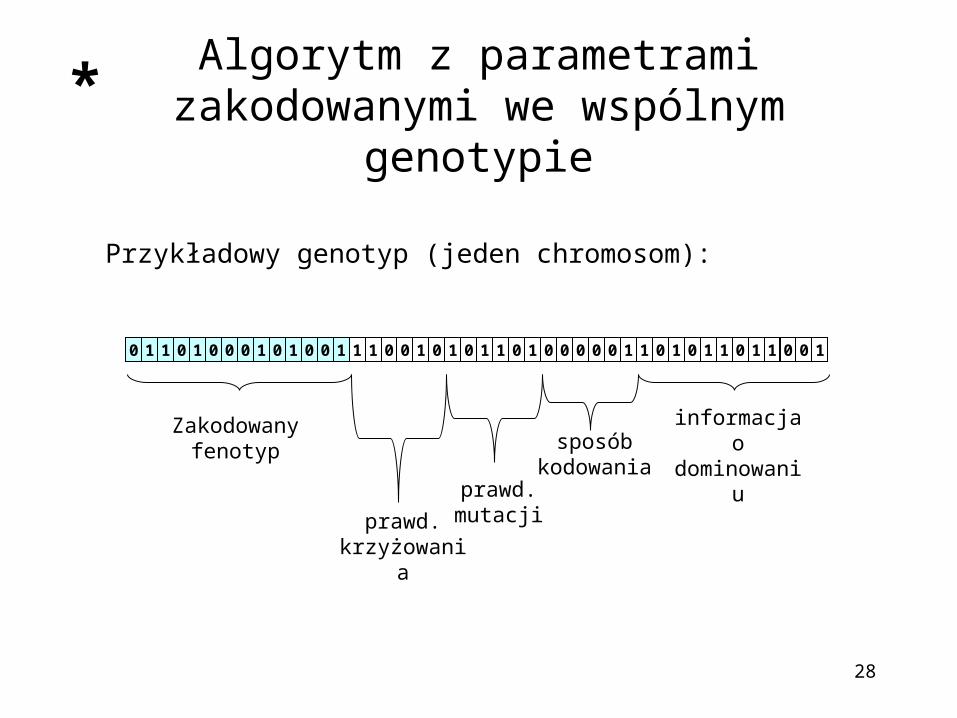
Algorytm z parametrami zakodowanymi we wspólnym genotypie
Przykładowy genotyp (jeden chromosom):
10 1 1 1 1 1110 0 0 0 0 0 0 0 1 11 1 1 10 0 0 0 0 0 0 11 1 1 1 1 10 0 0 0 0 0 0
Zakodowany fenotyp
prawd.krzyżowania
prawd.mutacji
sposób kodowania
informacja odominowaniu
*

29
Najlepsze osobniki w populacji przechodzą do następnego pokolenia bez jakichkolwiek zmian.
Model elitarny
zaleta - zachowanie najlepszych znanych rozwiązańwada - nadmierne skupienie populacji w obszarach
wybranych rozwiązań

30
Zalety i wady algorytmów genetycznych
Zalety:
• Odporność - unikanie ekstremów lokalnych, prawdopodobieństwo znalezienia dobrych rozwiązań jest w dużym stopniu niezależne od wyboru punktów początkowych
• Wydajność – duża liczba przetwarzanych schematów - ok. m3, gdzie m - liczba osobników w populacji
• Łatwość zastosowania w niemal każdym zadaniu optymalizacji
Wady:
• Brak gwarancji zbieżności do optymalnego rozwiązania
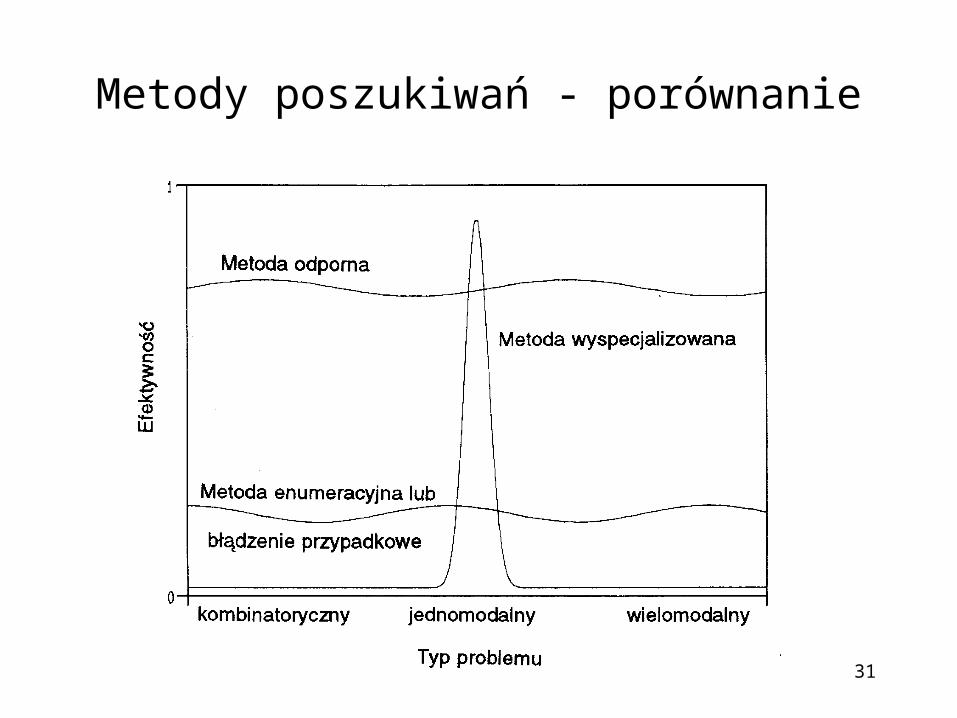
31
Metody poszukiwań - porównanie

32
Różnice pomiędzy algorytmami genetycznymi a tradycyjnymi metodami szukania
• Algorytmy genetyczne przetwarzają zakodowaną postać parametrów zadania (ciąg kodowy) a nie same parametry
• Poszukiwania prowadzone są w obrębie całej populacji rozwiązań (osobników) a nie pojedynczego rozwiązania
• Wykorzystywana jest tylko funkcja celu (uczenie z krytykiem) bez żadnej dodatkowej informacji naprowadzającej np. pochodnej funkcji celu
• Stosowane są probabilistyczne a nie deterministyczne reguły wyboru
*

33
Schematy 1/5
Schemat (H) - ciąg złożony z symboli alfabetu ciągu kodowego i symbolu specjalnego -”*” reprezentującego dowolny symbol alfabetu ciągu kodowego
W przypadku kodowania binarnego schemat składa się z symboli alfabetu V+={0,1, *}
Przykładowo ciąg kodowy 0110100 jest reprezentantem schematu H=*11***0 o długości l=7
Gdy alfabet ciągu kodowego składa się z k symboli, można określić (k+1)l schematów.
Rząd schematu o(H) - liczba pozycji ustalonych (zer i jedynek w przypadku binarnym), np. o(011*1**) = 4
Rozpiętość schematu (H) - odległość pomiędzy dwiema skrajnymi pozycjami ustalonymi, np. (011*1**) = 5-1 = 4
*

34
Schematy 2/5
Przyjmijmy standardowy algorytm genetyczny z kodowaniem binarnym, reprodukcją ruletkową, krzyżowaniem prostym losowym i losową mutacją jednopozycyjną
Niech w chwili t w populacji znajduje się m(H,t) reprezentantów schematu H. Oczekiwana liczba schematów w populacji potomnej wyniesie wówczas:
n
iif
nf
f
HftHmtHm
1
1
,)(
),()1,(
f(H) - średnie przystosowanie wszystkich ciągów reprezentujących schemat H w chwili t
fi - przystosowanie i-tego ciągu w chwili t
*

35
Załóżmy, że pewien schemat H przewyższa średnią o , gdzie c jest stałą. W efekcie otrzymujemy:
Zaczynając natomiast od t=0 otrzymujemy:
co świadczy o wykładniczym tempie rozprzestrzeniania się schematów o lepszym niż przeciętne przystosowaniu za sprawą samej reprodukcji.
Schematy 3/5
)1(),(/))(,()1,( ctHmffcftHmtHm
fc
tcHmtHm )1()0,(),(
*

36
Uwzględniając krzyżowanie i mutację otrzymujemy dolne oszacowanie oczekiwanej liczby schematów w pokoleniu potomnym:
gdzie pc i pm oznaczają odpowiednio prawdopodobieństwa krzyżowania osobnika i mutacji genu
Schematy 4/5
mc pHo
l
Hp
f
HftHmtHm )(
1
)(1
)(),()1,(
*

37
Wnioski:
• Krzyżowanie przyczynia się do niszczenia schematów o dużych rozpiętościach
• Schematy o wysokim przystosowaniu i małej rozpiętości rozprzestrzeniają się w wykładniczym tempie - hipoteza schematów-cegiełek mogących łączyć się w struktury o wysokim przystosowaniu
• Brak dobrych schematów może być przyczyną niestabilności procesu szukania, a w efekcie braku zbieżności do dobrych rozwiązań
Schematy 5/5*

38
Minimalny problem zwodniczy 1/3
Wybierzmy 4 schematy rzędu 2 o następujących średnich przystosowaniach:
***0*****0* f(00)***0*****1* f(01)***1*****0* f(10)***1*****1* f(11)
Załóżmy, że f(11) jest globalnym maksimum. Można wyróżnić dwa typy problemów zwodniczych:
•Typ 1: f(01)>f(00) i f(10)<f(00) lub f(01)<f(00) i f(10)>f(00)•Typ 2: f(01)<f(00) i f(10)<f(00)
Oba wiążą się z pozycyjną epistazą - zmiana w lepszym kierunku może pogorszyć przystosowanie
*

39
Minimalny problem zwodniczy 2/3
Typ 1 Typ 2
*

40
Minimalny problem zwodniczy 2/3
Typ 2
Jeśli w przypadku typu 2
f(00)+f(01) > f(10)+f(11),
to proces szukania w zależności od początkowej liczności schematów może być rozbieżny (problem AG-trudny)
*

41
Wady standardowego algorytmu genetycznego
• Niestabilność, brak zbieżności przy braku dobrych schematów
• Spadek różnorodności małej populacji w końcowej fazie ewolucji związana z tzw. dryfem genetycznym - odchylenia liczby osobników przy podobnych wartościach funkcji przystosowania
• Nieefektywność w przypadku niestacjonarności środowiska
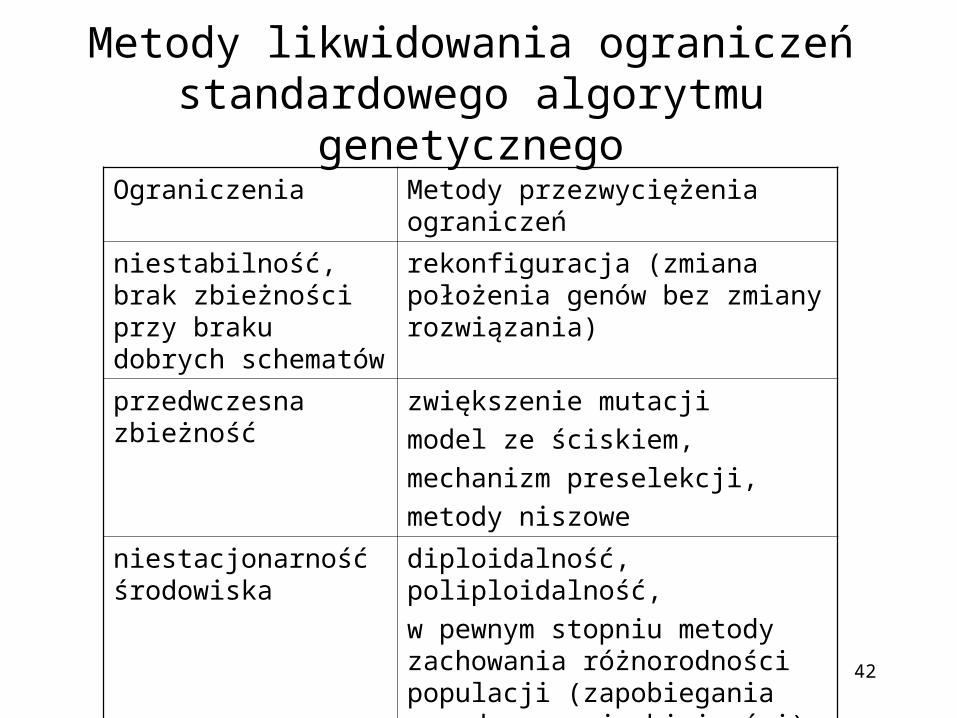
42
Metody likwidowania ograniczeń standardowego algorytmu genetycznego
Ograniczenia Metody przezwyciężenia ograniczeń
niestabilność, brak zbieżności przy braku dobrych schematów
rekonfiguracja (zmiana położenia genów bez zmiany rozwiązania)
przedwczesna zbieżność zwiększenie mutacji
model ze ściskiem,
mechanizm preselekcji,
metody niszowe
niestacjonarność środowiska
diploidalność, poliploidalność,
w pewnym stopniu metody zachowania różnorodności populacji (zapobiegania przedwczesnej zbieżności)

43
Rekonfiguracja - zmiana pozycji genów
Założenia:
• Rekonfiguracja nie zmienia rozwiązania• Konieczne jest dołączenie informacji o pozycjach
poszczególnych genów w trakcie krzyżowania• Jeśli parametry AG są kodowane we wspólnym genotypie
to informację taką można reprezentować za pomocą dodatkowego chromosomu lub dołączyć bezpośrednio do ciągu kodowego kodującego fenotyp
• Jeśli informacja o pozycjach poszczególnych genów jest kodowana permutacyjnie to można ją poddać ewolucji stosując np. operację inwersji oraz krzyżowanie ciągów permutacyjnych metodą PMX, OX lub CX

44
Rekonfiguracja - zmiana pozycji genów
Inwersja liniowa:
Numerujemy geny w ciągu kodowym, wybieramy losowo 2 punkty przecięcia, obracamy środkowy fragment chromosomu. Przykład dla genów o wartościach binarnych:
1 2 3 4 5 6 7 81 0 1 1 1 0 1 1 - przed inwersją ^ ^
1 2 6 5 4 3 7 81 0 0 1 1 1 1 1 - po inwersji
postać genotypu: 1 2 6 5 4 3 7 8 - ciąg porządkowyg1 g2 g6 g5 g4 g3 g7 g8 - ciąg genów (kodowy)

45
Typy inwersji
Ze względu na liczbę punktów przecięcia:• Inwersja liniowa• Inwersja liniowo-boczna: z prawdopodobieństwem 0,75
inwersja liniowa, z prawdopodobieństwem 0,125 inwersja boczna dla każdego z końców (zapobiega faworyzowaniu środkowej części chromosomu)
Ze względu na wymóg homologiczności (zgodności pozycyjnej) chromosomów przy krzyżowaniu:
• Inwersja ciągła - niehomologiczne chromosomy w jednej populacji
• Inwersja masowa - dla każdego uporządkowania genów tworzona jest oddzielna podpopulacja

46
Metody kojarzenia ciągów kodowych przy inwersji
• Kojarzenie ściśle homologiczne (w przypadku wylosowania ciągów niehomologicznych krzyżowanie nie zachodzi)
• Kojarzenie na podstawie żywotności - w przypadku ciągów niehomologicznych do populacji potomnej wchodzą tylko ciągi o odpowiednio dużym zestawie genów
• Kojarzenie według wzorca - jeden z ciągów jest rekonfigurowany względem drugiego
• Kojarzenie według wzorca lepiej przystosowanego osobnika

47
ciąg 1 ciąg 2pozycja: 1 2 3 5 4 2 4 1 3 5wartość: 1 1 1 1 1 1 1 0 0 0
Po wybraniu wzorca ciągu 1, pozycje ciągu 2 muszą zostać dopasowane do ciągu 1:
2 4 1 3 5 1 2 3 5 41 1 0 0 0 0 1 0 0 1
Teraz można dokonać krzyżowania w wybranym losowo punkcie:
1 1 1|1 1 1 1 1 0 10 1 0|0 1 0 1 0 1 1
I przekonfigurować ciąg 2 do pierwotnej postaci:
2 4 1 3 51 1 0 0 1
Kojarzenie według wzorca

48
Metody krzyżowania przy kodowaniu permutacyjnym
• PMX (partially matched crossover) • OX (order crossover)• CX (cycle crossover)
Wszystkie z powyższych operacji pozwalają na zachowanie pełnego zestawu genów przy jednoczesnym krzyżowaniu i inwersji
*

49
Metoda PMX
Zamiana numerów pozycji na podstawie przyporządkowania numerów w środkowym fragmencie ciągu:
A = 9 8 4 | 5 6 7 | 1 3 2 10B = 8 7 1 | 2 3 10 | 9 5 4 6
A’ = 9 8 4 | 2 3 10 | 1 6 5 7B’ = 8 10 1 | 5 6 7 | 9 2 4 3
Zamieniamy miejscami 5 i 2, 6 i 3 oraz 7 i 10 w obu ciągach
*
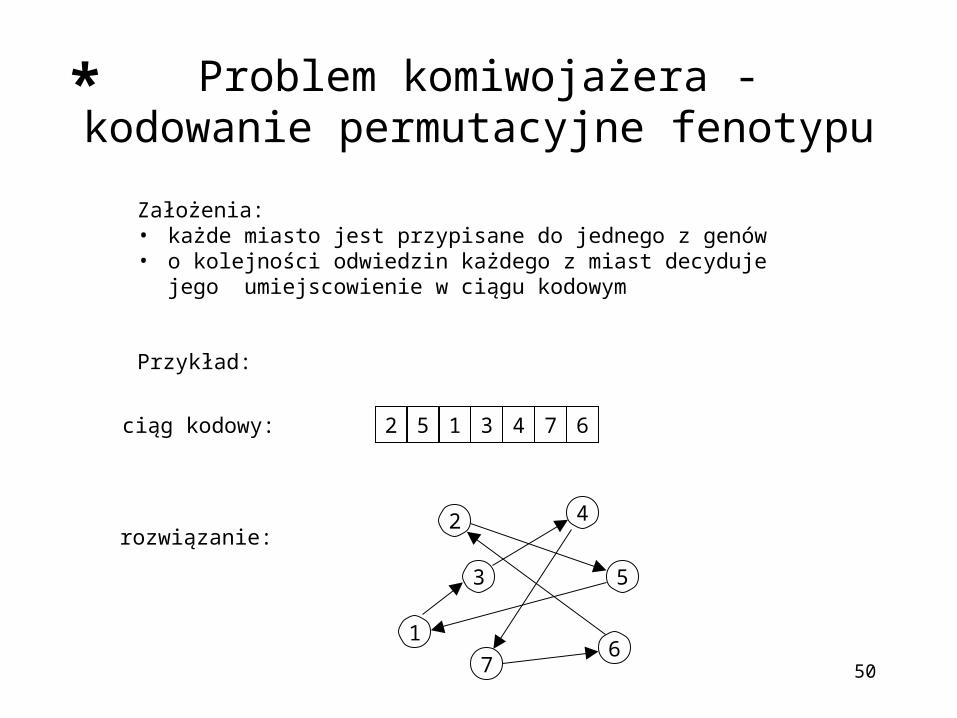
50
Problem komiwojażera - kodowanie permutacyjne fenotypu
Założenia:• każde miasto jest przypisane do jednego z genów • o kolejności odwiedzin każdego z miast decyduje jego
umiejscowienie w ciągu kodowym
Przykład:
5 1 3 42 7 6
2 4
7
1
5
6
3
ciąg kodowy:
rozwiązanie:
*
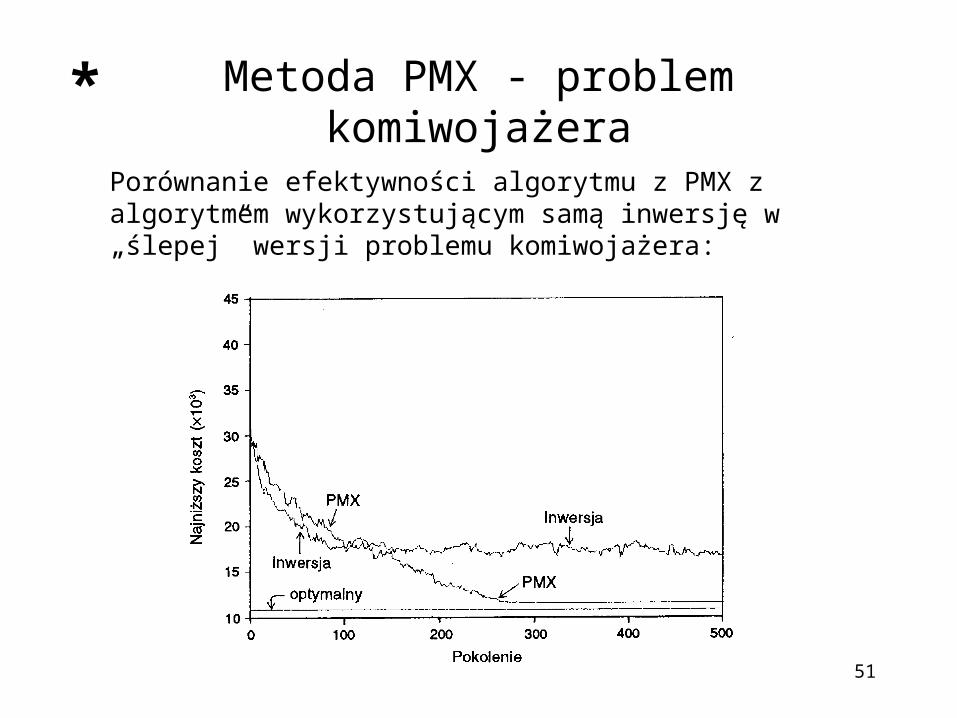
51
Metoda PMX - problem komiwojażera
Porównanie efektywności algorytmu z PMX z algorytmem wykorzystującym samą inwersję w „ślepej” wersji problemu komiwojażera:
*

52
Zapobieganie przedwczesnej zbieżności Sposoby zapobiegania:
• Zwiększanie prawdopodobieństwa mutacji• Mechanizm preselekcji• Model ze ściskiem• Metody niszowe
Duża częstość mutacji często nie gwarantuje opuszczenia ekstremum lokalnego w przypadku ujednoliconej populacji
Mechanizm preselekcji: w ramach reprodukcji osobniki potomne zastępują swoich rodziców (o ile są lepiej przystosowane)
Model ze ściskiem: w ramach reprodukcji nowy osobnik zastępuje osobnika podobnego i słabo przystosowanego.

53
Model ze ściskiem
Wersja Goldberga:
Tworzymy populację mieszaną o współczynniku wymiany G:0<G1. Wybieramy m·G nowych osobników np. metodą ruletki. Dla każdego nowego osobnika:
1. Losujemy CF (crowding factor) podpopulacji k-elementowych
2. Z każdej wylosowanej podpopulacji wybieramy po jednym osobniku najgorzej przystosowanym i tworzymy listę (o liczności CF)
3. Z listy wybieramy osobnika najbliższego w stosunku do nowego (np. w sensie odległości Hamminga w przestrzeni ciągów kodowych)
4. Zastępujemy wybranego osobnika nowym.
54
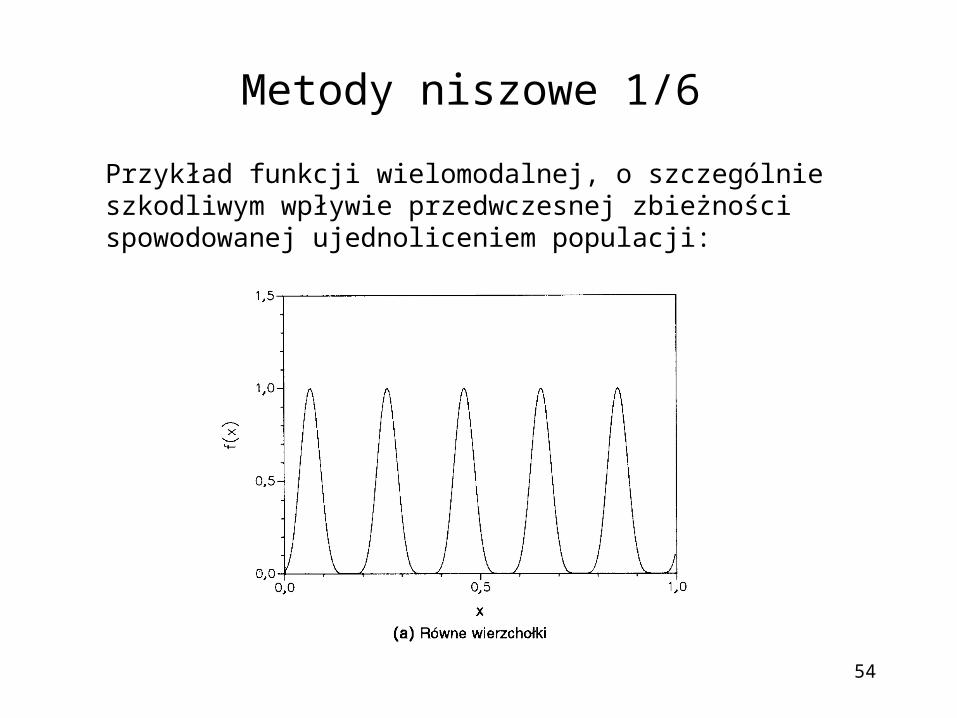
Metody niszowe 1/6
Przykład funkcji wielomodalnej, o szczególnie szkodliwym wpływie przedwczesnej zbieżności spowodowanej ujednoliceniem populacji:
55
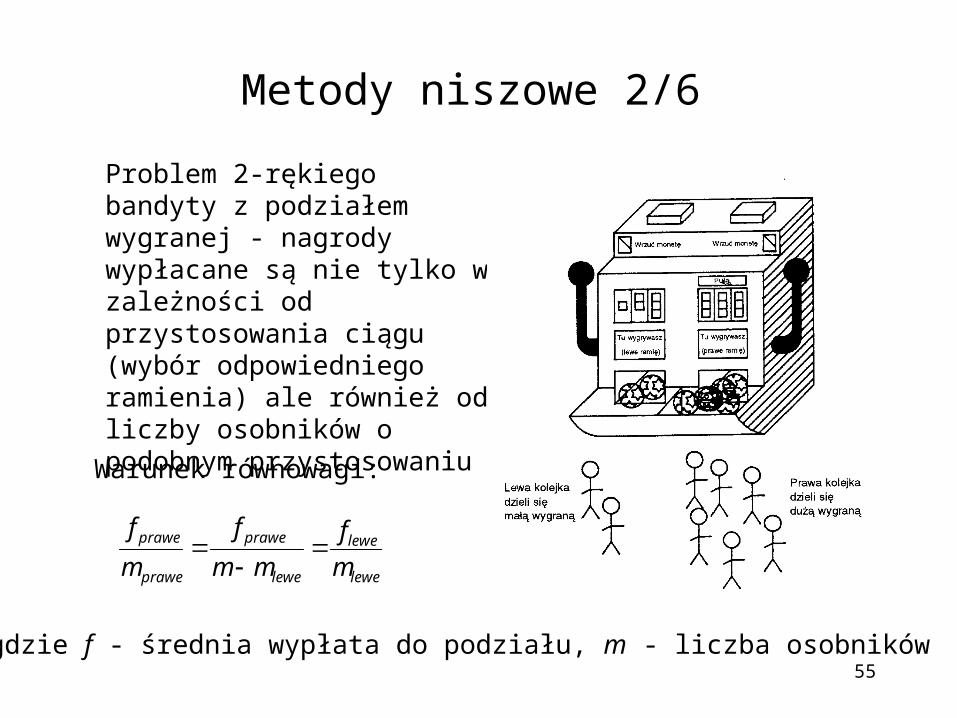
Metody niszowe 2/6
Problem 2-rękiego bandyty z podziałem wygranej - nagrody wypłacane są nie tylko w zależności od przystosowania ciągu (wybór odpowiedniego ramienia) ale również od liczby osobników o podobnym przystosowaniu
Warunek równowagi:
lewe
lewe
lewe
prawe
prawe
prawe
m
f
mm
f
m
f
gdzie f - średnia wypłata do podziału, m - liczba osobników

56
Metody niszowe 3/6
Metody kreowania nisz i gatunków (specjacja):
• Ograniczenie migracji w sensie „geograficznym” np. model wyspowy lub komórkowy
• Zastosowanie funkcji współudziału (s) obniżającej wartość funkcji przystosowania gdy osobnik znajduje się blisko innych osobników z populacji:
m
jji
iis
xxds
xfxf
1
)),((
)()(
gdzie odległość d może być obliczana na poziomie genotypów (np. odległość Hamminga) lub fenotypów (rozwiązań), funkcja s() powinna maleć wraz z d, przy czym s(0) = 1
57
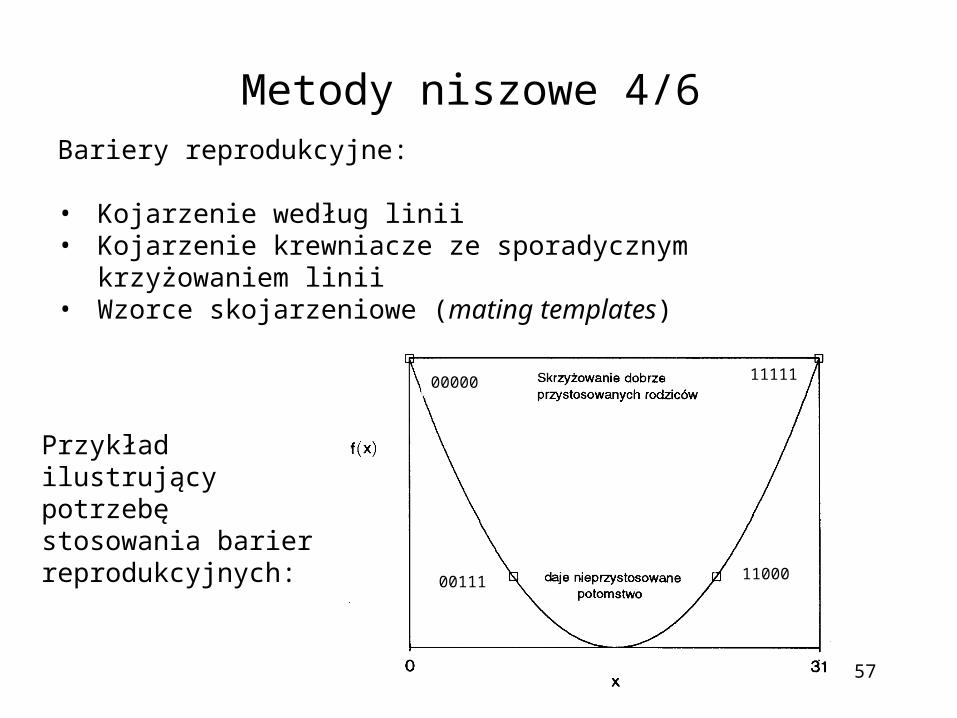
Metody niszowe 4/6
Przykład ilustrujący potrzebę stosowania barier reprodukcyjnych:
00000 11111
00111 11000
Bariery reprodukcyjne:
• Kojarzenie według linii• Kojarzenie krewniacze ze sporadycznym krzyżowaniem linii• Wzorce skojarzeniowe (mating templates)

58
Metody niszowe 5/6Wzorce skojarzeniowe – kojarzenie zachodzi tylko wtedy, gdy
wzorzec pierwszego osobnika pasuje do części funkcjonalnej drugiego osobnika i/lub na odwrót
przykład:
<Wzorzec>:<Część funkcjonalna> #10#:1010 #01#:1100 #00#:0000
wersja z wydzielonym identyfikatorem linii (do którego dopasowywany jest wzorzec):
<Wzorzec>:<Id>:<Część funkcjonalna> #10#:1010:10001000101110101011 #01#:1100:00101010000111110000 #00#:0000:11100001111000001110
*

59
Metody niszowe 6/6Porównanie rozmieszczeń rozwiązań dla modów o równej i różnej wysokości:

60
Środowisko - typy
Ze względu na element losowości (niezerowej wariancji) w funkcji oceny lub metody selekcji:
• Deterministyczne• Niedeterministyczne
Ze względu na zmienność oceny w funkcji czasu:
• Stacjonarne• Niestacjonarne

61
Metody adaptacji do zmieniającego się środowiska
1. Utrzymanie różnorodności populacji - model ze ściskiem, niszowanie
2. Adoptowalna (lub bardziej elastyczna postać fenotypowa rozwiązań)
3. Wykorzystanie dodatkowych zmiennych lub struktur:• Na poziomie populacji - zapisywanie najlepszych
osobników w populacji lub całych populacji • Na poziomie osobnika - diploidalność i dominowanie

62
Diploidalność i dominowanie 1/12
Diploidalność, poliploidalność - zdwojenie lub zwielokrotnienie (poliploidalność) liczby homologicznych chromosomów, reprezentujących fenotyp (rozwiązanie)
Dominowanie - faworyzowanie wariantu dominującego w stosunku do wariantu recesywnego cechy podczas ekspresji
Ekspresja - wybór wariantu cechy, który decyduje o postaci fenotypu

63
Przyjmijmy, że podczas ekspresji 2 warianty recesywne dają wariant recesywny (mała litera), a w pozostałych przypadkach otrzymujemy wariant dominujący (duża litera):
aa a, aA A, Aa A,AA A,
wówczas operacja ekspresji homologicznych chromosomów wygląda następująco:
AbCDeABCDe
aBCde
Diploidalność i dominowanie 2/12

64
Diploidalność i dominowanie 3/12
Mechanizm dominowania:• Stały (np. model diploidalny prosty)• Adaptacyjny - podlegający ewolucji
Metody reprezentowania informacji o dominowaniu:• Trzeci chromosom – wzorzec dominacji • Dodatkowy pole genu (obok allelu)• Informacja wbudowana w strukturę chromosomu np.
poprzez rozszerzenie alfabetu np. model trialleliczny
65
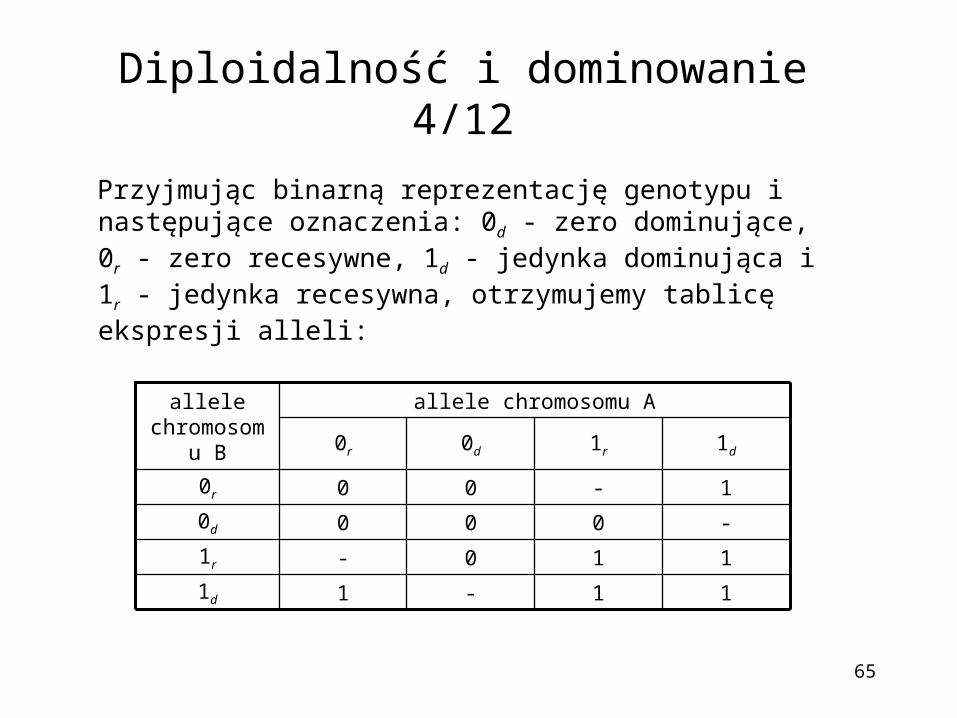
Diploidalność i dominowanie 4/12
Przyjmując binarną reprezentację genotypu i następujące oznaczenia: 0d - zero dominujące, 0r - zero recesywne, 1d - jedynka dominująca i 1r - jedynka recesywna, otrzymujemy tablicę ekspresji alleli:
11-11d
110-1r
-0000d
1-000r
1d1r0d0r
allele chromosomu Aallele chromosomu
B

66
Diploidalność i dominowanie 5/12Metody rozwiązywania konfliktów:• Losowanie wariantu genu• Wybór według następnego genu• Wybór arbitralny np. w modelu triallelicznym Hollstiena -
Hollanda: 0 oznacza zero dominujące, 1 - jedynka recesywna, 2 - jedynka dominująca
allele chromosomu
B
allele chromosomu A
0 1 2
0 0 0 1
1 0 1 1
2 1 1 1
Przykład ekspresji: A: 12022110
B: 2100212111011110

67
Analiza matematyczna
Dolne oszacowanie liczby schematów w pokoleniu potomnym:
gdzie He - schemat ujawniony. Średni wskaźnik przystosowania dla schematu całkowicie dominującego:
Oczekiwany średni wskaźnik dla schematu zdominowanego:
Stąd wniosek, że dzięki przysłanianiu, liczność schematu H w następnym pokoleniu jest z reguły wyższa, niż by to wynikało z jego rzeczywistego przystosowania
Diploidalność i dominowanie 6/12
mc
e pHol
Hp
f
HftHmtHm )(
1
)(1
)(),()1,(
)()( eHfHf
)()( eHfHf
*
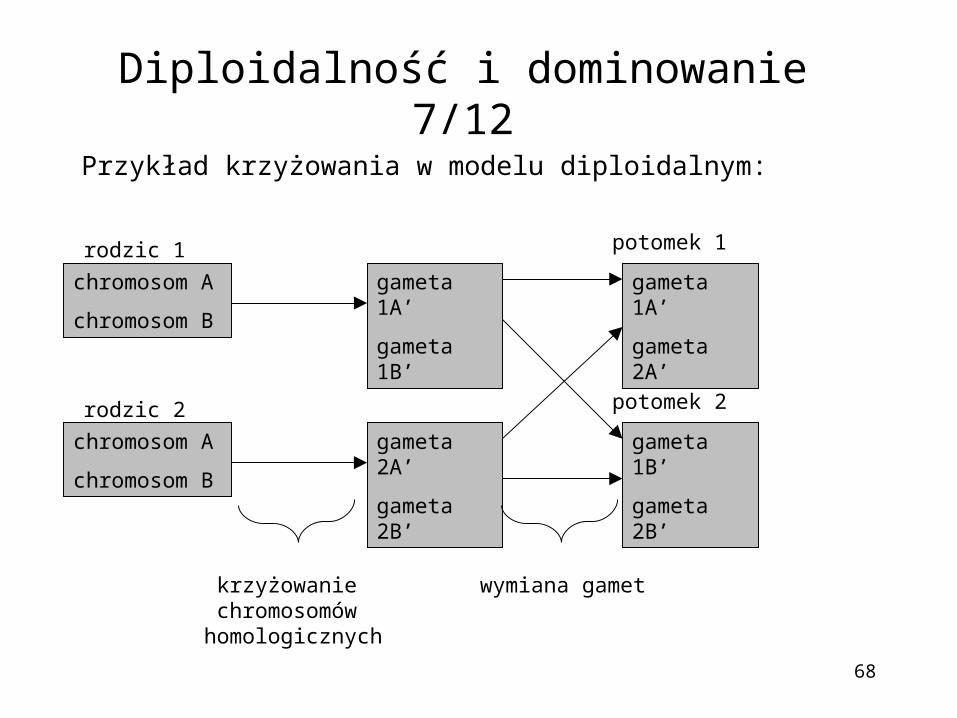
68
Przykład krzyżowania w modelu diploidalnym:
Diploidalność i dominowanie 7/12
chromosom A
chromosom B
chromosom A
chromosom B
gameta 1A’
gameta 1B’
gameta 2A’
gameta 2B’
gameta 1A’
gameta 2A’
gameta 1B’
gameta 2B’
rodzic 1
rodzic 2
potomek 1
potomek 2
krzyżowanie chromosomów homologicznych
wymiana gamet
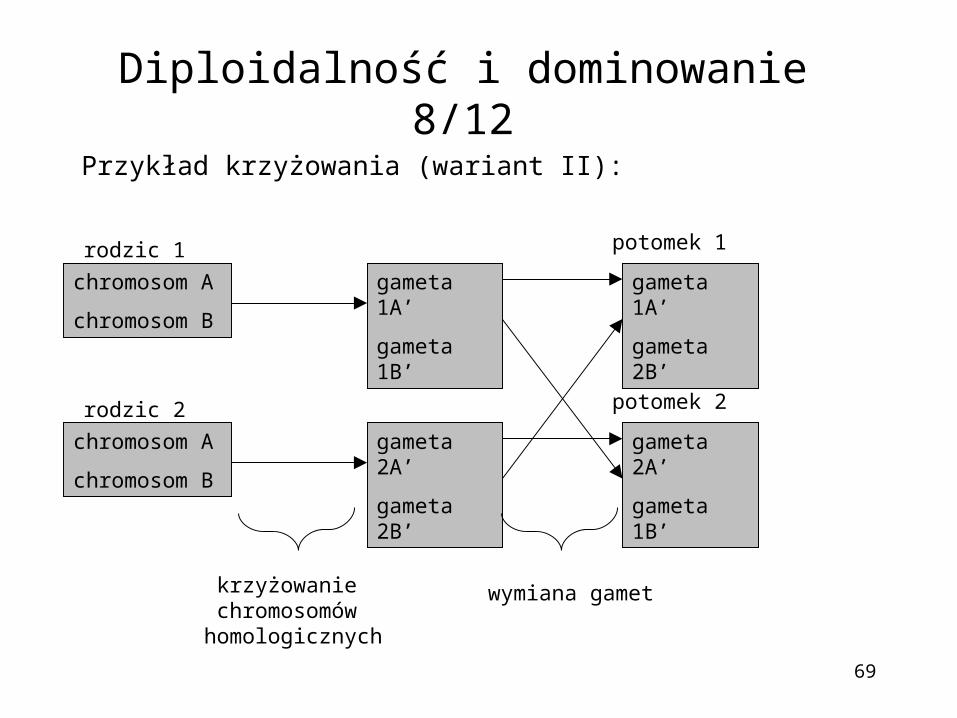
69
Przykład krzyżowania (wariant II):
Diploidalność i dominowanie 8/12
chromosom A
chromosom B
chromosom A
chromosom B
gameta 1A’
gameta 1B’
gameta 2A’
gameta 2B’
gameta 1A’
gameta 2B’
gameta 2A’
gameta 1B’
rodzic 1
rodzic 2
potomek 1
potomek 2
krzyżowanie chromosomów homologicznych
wymiana gamet

70
Symulacja - niestacjonarna wersja zagadnienia plecakowego (Godberg i Smith, 1987):
, gdzie
pod warunkiem, że
Warunek więzów zmienia się skokowo co pewien okres czasu, a następnie powraca do postaci pierwotnej.
Diploidalność i dominowanie 9/12
i
ii xvmax }1,0{x
i
ii Wxw
*
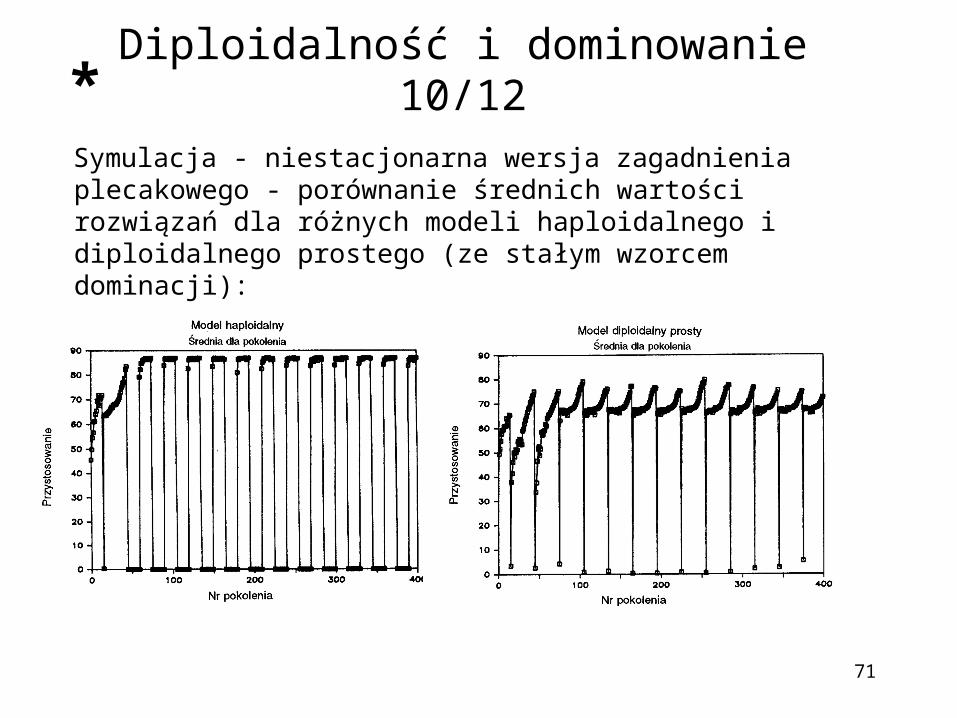
71
Symulacja - niestacjonarna wersja zagadnienia plecakowego - porównanie średnich wartości rozwiązań dla różnych modeli haploidalnego i diploidalnego prostego (ze stałym wzorcem dominacji):
Diploidalność i dominowanie 10/12*

72
Symulacja - niestacjonarna wersja zagadnienia plecakowego - porównanie średnich wartości rozwiązań dla modeli diploidalnego prostego i triallelicznego:
Diploidalność i dominowanie 11/12*
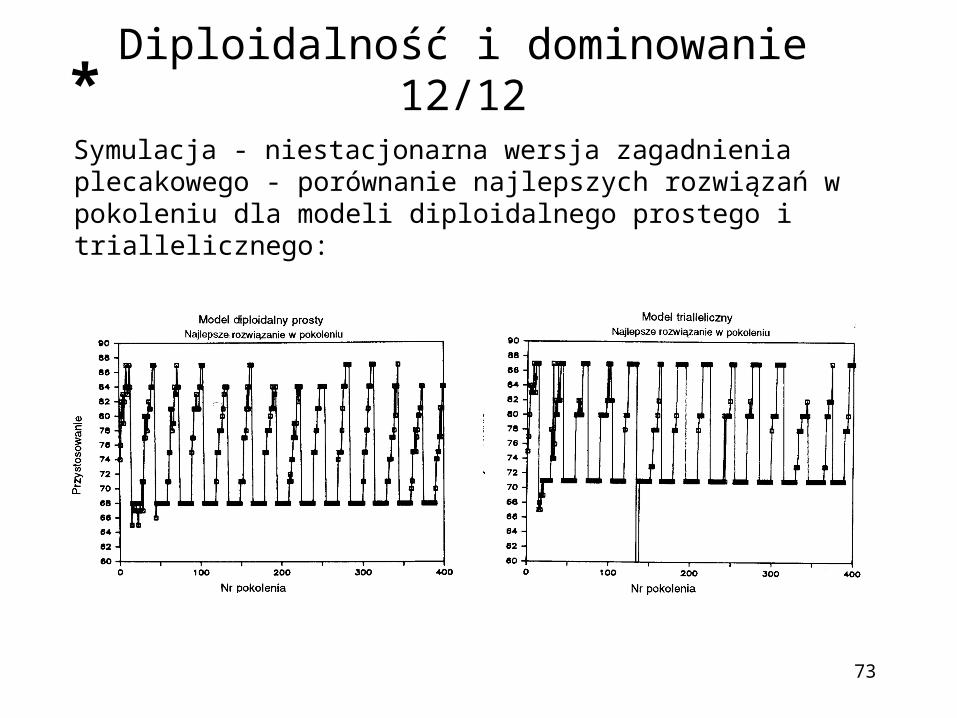
73
Symulacja - niestacjonarna wersja zagadnienia plecakowego - porównanie najlepszych rozwiązań w pokoleniu dla modeli diploidalnego prostego i triallelicznego:
Diploidalność i dominowanie 12/12*
Top Related