
Zastosowanie analiz Data Mining w przewidywaniu groźby … · 2016-10-03 · W artykule...
15
MIROSLAWA LASEK MAREK PCZKOWSKI DARIUSZ WIERZBA Uniwersytet Warszawski ZASTOSOWANIE ANALIZ DATA MINING W PRZEWIDYWANIU GROBY UPADLOCI LUB KONIECZNOCI PROWADZENIA POSTPOWANIA UKLADOWEGO PRZEDSIBIORSTWA – BUDOWA MODELI PREDYKCYJNYCH, OCENA ICH JAKOCI I WYBÓR MODELU Streszczenie W artykule przedstawiono przydatno modeli Data Mining do przewidywania groby upadloci lub postpowania ukladowego przedsibiorstwa. Opisano zastoso- wanie modeli predykcyjnych: regresji logistycznej, drzew decyzyjnych oraz sieci neuronowych. Rozwaania zilustrowano poslugujc si danymi okolo szeciu tysicy przedsibiorstw, wród których cz byla zagroona upadloci lub postpowaniem ukladowym. Slowa kluczowe: prognozowanie upadloci lub postpowania ukladowego przedsibiorstwa, modele predykcyjne Data Mining, regresja logistyczna, drzewa decyzyjne, sieci neuronowe 1. Wstp Celem artykulu jest przedstawienie wyników bada przydatnoci analiz Data Mining w wylo- nieniu cech sygnalizujcych grob upadloci przedsibiorstwa lub sklaniajcych do podjcia postpowania ukladowego dla „uratowania” firmy oraz moliwoci pozyskania wiedzy, jak na podstawie znajomoci wartoci tych cech mona przewidzie zagroenie upadloci lub koniecz- noci prowadzenia postpowania ukladowego. Pod pojciem cech rozumie si tu charakterystyki kondycji finansowej i majtkowej firmy, pochodzce ze sprawozda finansowych (bilans, rachunek zysków i strat, rachunek przeplywów pieninych), takie jak majtek trwaly, majtek obrotowy, stan rodków pieninych, przychody ze sprzeday, zobowizania oraz wskaniki charakteryzujce kondycj ekonomiczn, do których nale wskaniki plynnoci, zyskownoci, aktywnoci i zadluenia. Analizy Data Mining s to analizy realizowane za pomoc zaawansowanych metod statystycz- nych oraz metod sztucznej inteligencji, które pozwalaj wykrywa zalenoci midzy obiektami lub cechami opisujcymi obiekty na podstawie nagromadzonych duych zbiorów danych. Metody te pozwalaj na podstawie danych tworzy wiedz – budowa zalenoci, wskazywa wzorce, okrela trendy [4], [8], [10], [11]. 2. Dane wykorzystywane w prowadzeniu analiz Wykorzystywany przez nas zbiór danych obejmowal dane 5828 przedsibiorstw. Sporód tych przedsibiorstw a 4954 to przedsibiorstwa bardzo dobre, tzw. „gazele biznesu” polskiej gospo-
Transcript of Zastosowanie analiz Data Mining w przewidywaniu groźby … · 2016-10-03 · W artykule...

MIROSŁAWA LASEK
MAREK P�CZKOWSKI
DARIUSZ WIERZBA
Uniwersytet Warszawski
ZASTOSOWANIE ANALIZ DATA MINING W PRZEWIDYWANIU GRO�BY UPADŁOCI LUB KONIECZNOCI PROWADZENIA POST�POWANIA
UKŁADOWEGO PRZEDSI�BIORSTWA – BUDOWA MODELI PREDYKCYJNYCH, OCENA ICH JAKOCI I WYBÓR MODELU
Streszczenie
W artykule przedstawiono przydatno�� modeli Data Mining do przewidywania
gro�by upadło�ci lub post�powania układowego przedsi�biorstwa. Opisano zastoso-
wanie modeli predykcyjnych: regresji logistycznej, drzew decyzyjnych oraz sieci
neuronowych. Rozwa�ania zilustrowano posługuj�c si� danymi około sze�ciu tysi�cy
przedsi�biorstw, w�ród których cz��� była zagro�ona upadło�ci� lub post�powaniem
układowym.
Słowa kluczowe: prognozowanie upadłoci lub post�powania układowego przedsi�biorstwa,
modele predykcyjne Data Mining, regresja logistyczna, drzewa decyzyjne, sieci
neuronowe
1. Wst�p
Celem artykułu jest przedstawienie wyników bada� przydatnoci analiz Data Mining w wyło-
nieniu cech sygnalizuj�cych gro�b� upadłoci przedsi�biorstwa lub skłaniaj�cych do podj�cia
post�powania układowego dla „uratowania” firmy oraz mo�liwoci pozyskania wiedzy, jak na
podstawie znajomoci wartoci tych cech mo�na przewidzie� zagro�enie upadłoci� lub koniecz-
noci� prowadzenia post�powania układowego.
Pod poj�ciem cech rozumie si� tu charakterystyki kondycji finansowej i maj�tkowej firmy,
pochodz�ce ze sprawozda� finansowych (bilans, rachunek zysków i strat, rachunek przepływów
pieni��nych), takie jak maj�tek trwały, maj�tek obrotowy, stan rodków pieni��nych, przychody ze
sprzeda�y, zobowi�zania oraz wska�niki charakteryzuj�ce kondycj� ekonomiczn�, do których
nale�� wska�niki płynnoci, zyskownoci, aktywnoci i zadłu�enia.
Analizy Data Mining s� to analizy realizowane za pomoc� zaawansowanych metod statystycz-
nych oraz metod sztucznej inteligencji, które pozwalaj� wykrywa� zale�noci mi�dzy obiektami
lub cechami opisuj�cymi obiekty na podstawie nagromadzonych du�ych zbiorów danych. Metody
te pozwalaj� na podstawie danych tworzy� wiedz� – budowa� zale�noci, wskazywa� wzorce,
okrela� trendy [4], [8], [10], [11].
2. Dane wykorzystywane w prowadzeniu analiz
Wykorzystywany przez nas zbiór danych obejmował dane 5828 przedsi�biorstw. Sporód tych
przedsi�biorstw a� 4954 to przedsi�biorstwa bardzo dobre, tzw. „gazele biznesu” polskiej gospo-

Mirosława Lasek, Marek P�czkowski, Dariusz Wierzba
Zastosowanie analiz Data Mining w przewidywaniu gro�by upadło�ci lub konieczno�ci
prowadzenia post�powania układowego przedsi�biorstwa…
82
darki. S� to dynamicznie rozwijaj�ce si� firmy o czystej reputacji i nie maj�ce problemów finan-
sowych. Pozostałe 874 przedsi�biorstwa to firmy, wobec których s�d ogłosił upadło� oraz firmy,
wobec których s�d ogłosił post�powanie układowe. Przedsi�biorstw, wobec których s�d ogłosił
upadło� – zgodnie z prawem upadłociowym obowi�zuj�cym przed sierpniem 2003 r. lub
upadło� zakładaj�c� likwidacj� firmy zgodnie z prawem upadłociowym i post�powaniem
naprawczym, obowi�zuj�cym po sierpniu 2003 r., było w analizowanym zbiorze 402. Natomiast
przedsi�biorstw, wobec których s�d ogłosił post�powanie układowe było 472. Przyj�to rozumie�post�powanie układowe zgodnie z prawem upadłociowym obowi�zuj�cym przed 08.2003 lub
reorganizacji firmy zgodnie z prawem upadłociowym i post�powaniem naprawczym obowi�zuj�-cym po 08.2003. Post�powanie naprawcze jest form� ochrony przed wierzycielami zgodnie z
prawem upadłociowym i post�powaniem naprawczym, obowi�zuj�cym po 08.2003. Przedsi�bior-
stwa upadłe i z post�powaniem układowym stanowiły 15,7% badanych przedsi�biorstw, a 84,3%
stanowiły „gazele”1. Pomijaj�c „gazele” przedsi�biorstw upadłych było 46%, a przedsi�biorstw z
post�powaniem układowym 54%. Liczba analizowanych cech kondycji firm oraz wska�ników -
dalej nazywamy je tak�e charakterystykami kondycji lub zmiennymi analizy - wynosiła ł�cznie
144. Zostały uwzgl�dnione wielkoci ze sprawozda� finansowych, takie jak maj�tek trwały,
maj�tek obrotowy, rodki pieni��ne, suma aktywów, kapitał (fundusz) własny, zobowi�zania
długoterminowe, zobowi�zania krótkoterminowe i fundusze specjalne, zobowi�zania krótkotermi-
nowe, przychody ze sprzeda�y, amortyzacja, rodki pieni��ne z działalnoci operacyjnej, rodki
pieni��ne z działalnoci inwestycyjnej, rodki pieni��ne z działalnoci finansowej, zmiana stanu
rodków netto, rodki na pocz�tek roku obrotowego, rodki na koniec roku obrotowego oraz
wska�niki, takie jak zysk lub strata (zysk/strata) ze sprzeda�y, zysk/strata na działalnoci operacyj-
nej, zysk/strata brutto na działalnoci operacyjnej, zysk/strata brutto, zysk/strata netto. Uwzgl�d-
niono wska�niki nale��ce do 17 ró�nych grup: płynnoci, rotacji aktywów (maj�tku) trwałych,
rotacji aktywów (maj�tku) w dniach, rotacji kapitału, rotacji kapitałem w dniach, struktury
kapitałowej, struktury maj�tkowej, struktury maj�tkowo-kapitałowej, efektywnoci pracy i wartoci
dodanej, rentownoci, rozwoju, struktury przychodów, struktury kosztów, rynku kapitałowego,
d�wigni finansowej i operacyjnej, wiarygodnoci kredytowej, tendencji.
3. Prowadzone analizy
Przeprowadzono analizy danych, przyjmuj�c ró�ne sposoby podziału przedsi�biorstw na gru-
py i uwzgl�dniania firm z grup o ró�nej kondycji ekonomicznej. W pierwszej z przeprowadzonych
analiz przedsi�biorstwa upadłe i z post�powaniem układowym traktowano ł�cznie i porównywano
z przedsi�biorstwami „gazelami”. W analizie wzi�ły wi�c udział wszystkie badane przedsi�bior-
stwa. W budowanych modelach Data Mining zmienn� objanian� była zmienna binarna, przyjmu-
j�ca warto� 1, je�eli przedsi�biorstwo upadło lub ma post�powanie układowe i 0, gdy jest
„gazel�”. W drugim przypadku staralimy si� zbada�, czy istniej� istotne ró�nice mi�dzy przedsi�-biorstwami upadłymi a przedsi�biorstwami z post�powaniem układowym („gazele” nie były
uwzgl�dniane). Analizowany zbiór przedsi�biorstw liczył 874 przedsi�biorstwa. Jako zmienn�objanian� przyj�to przedsi�biorstwa upadłe, a zatem warto� 1 zmiennej wskazywała przedsi�-biorstwo upadłe, warto� 0 – przedsi�biorstwo z post�powaniem układowym. Trzeci przypadek
1 Zgodnie z zało�eniami analiz Data Mining, w celu przyspieszenia oblicze�, rozkłady cech s� ustalane na podstawie
zbioru metadanych, stanowi�cego losowy zbiór 2000 obserwacji całego zbioru danych.

POLSKIE STOWARZYSZENIE ZARZ�DZANIA WIEDZ�
Seria: Studia i Materiały, nr 22, 2009
83
dotyczył przedsi�biorstw upadłych i „gazel”. Przedsi�biorstwa z post�powaniem układowym nie
były brane pod uwag�. Zbiór analizowanych przedsi�biorstw obejmował 5356 firm (402 upadłych i
4954 „gazel”). Jako zmienn� objanian� przyj�to zmienn� binarn�, okrelaj�c� - firm� upadł�(warto� 1) i „gazel�” (warto� 0). W czwartym przypadku nie wzi�to pod uwag� przedsi�biorstw
upadłych. Analizowane były przedsi�biorstwa z post�powaniem układowym i „gazele”, ł�cznie
5426 przedsi�biorstw. Interesowała nas analiza przedsi�biorstw z post�powaniem układowym i
„gazel”, bez uwzgl�dnienia sytuacji upadłoci. Jako zmienn� objanian� przyj�to zmienn� binarn�okrelaj�c� firm� z post�powaniem układowym (warto� 1 zmiennej) i przeciwny przypadek – nie
ma post�powania układowego, co oznacza „gazel�”.
4. Zastosowane analizy i modele Data Mining
W badaniu wykorzystalimy program Enterprise Miner firmy SAS [5], [7]. Zgodnie z metodo-
logi� modelowania Data Mining wymaga on zbudowania diagramu, wyznaczaj�cego przebieg
przetwarzania. Diagram taki zamieszczono na rysunku 1. Elementami diagramu s� w�zły przetwa-
rzania danych, poł�czone strzałkami wskazuj�cymi kierunek przetwarzania. W celu identyfikacji
w�złów maj� one przypisane nazwy.
Rys. 1. Diagram przebiegu przetwarzania danych
ródło: Opracowanie własne przy wykorzystaniu programu Enterprise Miner.
5. Wprowadzanie danych do analizy i podział zbioru danych na zbiór treningowy, walida-
cyjny i testowy
W�zeł MINER.FIRMY jest w�złem wprowadzania danych wejciowych (rys. 1). Jego nazwa
jest jednoczenie nazw� wejciowego zbioru danych (nazwa ta składa si� z nazwy biblioteki,
w której umieszczony jest zbiór danych oraz nazwy tablicy z danymi). W�zeł Data Partition jest
w�złem podziału zbioru danych na zbiory: treningowy, walidacyjny i testowy (rys. 1). Budowa
modeli eksploracji danych Data Mining wymaga realizacji trzech etapów: trenowania, walidacji
i testowania, i dla wykonania ka�dego z tych etapów musimy utworzy� oddzielne zbiory: trenin-
gowy (Training Set), walidacyjny (Validation Set), testowy (Testing Set). Powstaj� one przez
podział (na ogół losowy) wejciowego zbioru danych na trzy cz�ci. Zbiór treningowy jest zbiorem

Mirosława Lasek, Marek P�czkowski, Dariusz Wierzba
Zastosowanie analiz Data Mining w przewidywaniu gro�by upadło�ci lub konieczno�ci
prowadzenia post�powania układowego przedsi�biorstwa…
84
danych, na podstawie których wykrywamy mo�liwe zale�noci mi�dzy zmiennymi. Zbiór trenin-
gowy jest u�ywany do wst�pnego oszacowania parametrów modelu. Zbiór walidacyjny jest
u�ywany do dostrojenia parametrów modelu, które zostały oszacowane w oparciu o zbiór trenin-
gowy. U�ycie tego zbioru poprawia własnoci predykcyjne modelu, tzn. model pozwala lepiej
przewidywa� wartoci zmiennych objanianych dla nowych obserwacji, niewyst�puj�cych w
dotychczas badanych zbiorach. Zbiór testowy jest zbiorem, który słu�y do zbadania, na ile wykryte
zale�noci s� prawdziwe dla innych zbiorów danych. Domyln� metod� podziału �ródłowego
zbioru danych na zbiór treningowy, walidacyjny i testowy jest losowanie proste (opcja Simple
Random w programie Enterprise Miner). Domylna metoda Simple Random dokonuje podziału
zbioru danych na podzbiory: treningowy, walidacyjny i testowy w sposób losowy, oparty na
losowaniu prostym, gdzie prawdopodobie�stwo wejcia do ka�dego z podzbiorów jest dla ka�dej
obserwacji takie samo. Przy takim post�powaniu struktura ka�dego z tworzonych podzbiorów
powinna by� podobna do struktury całego zbioru i mo�emy przyj��, �e ka�dy z podzbiorów dobrze
reprezentuje cały zbiór. Taki sposób podziału na zbiory treningowy, walidacyjny i testowy
przyj�limy w analizach przedstawianych w tym artykule. Przedstawiony powy�ej sposób tworze-
nia zbiorów: treningowego, walidacyjnego i testowego nie jest odpowiedni w sytuacji, gdy pewne
wartoci zmiennych pojawiaj� si� w całym zbiorze bardzo rzadko (stanowi�c przykładowo 1%,
0,2% wszystkich obiektów). Wówczas próba licz�ca du�o obserwacji (np. 1000) mo�e zawiera�tylko kilka przypadków przyjmuj�cych okrelone wartoci danej zmiennej i nie jest mo�liwe
wierne odzwierciedlenie struktury całego zbioru danych. Przykładem takiego zbioru mo�e by�zbiór przedsi�biorstw zawieraj�cych mał� liczb� bankrutów. W takiej sytuacji zamiast metody
Simple Random proponuje si� inny sposób losowania, np. polegaj�cy na losowaniu osobno z
ka�dego typu obiektów, nazywanych warstwami. Taki sposób losowania nazywa si� losowaniem
warstwowym (Stratified) i mo�e on zapewni� odpowiedni� liczebno� obserwacji posiadaj�cych
rzadk� warto� cechy w zbiorze treningowym, walidacyjnym i testowym w opisywanej sytuacji
nierównomiernego rozkładu wartoci danych. Mo�emy okreli� udział procentowy, jaki b�d�stanowi� dane treningowe, walidacyjne i testowe w zbiorze danych. Przyj�limy w naszej analizie
cz�sto stosowane ustalenie domylne (40% - zbiór treningowy, 30% - zbiór walidacyjny, 30% -
zbiór testowy).
6. Wst�pna selekcja zmiennych dla przeprowadzania bada�
Nast�pny z umieszczonych w�złów na diagramie (rys. 1), to w�zeł Variable Selection. Ten
w�zeł umo�liwia wybór zestawu zmiennych, które najsilniej wpływaj� na wartoci zmiennej
objanianej. Jako kryterium wyboru zmiennych, narz�dzie Variable Selection umo�liwia wykorzy-
stanie współczynników determinacji R2.2 W przypadku stosowania R
2 ocena zmiennych dokony-
wana jest na podstawie kryterium dobroci dopasowania (goodness-of-fit). Wykorzystywana jest
technika krokowa wyboru zmiennych. Jest to procedura iteracyjna, która powoduje, �e w kolejnych
krokach poprawiana jest warto� współczynnika determinacji R2. Zako�czenie działania wyboru
nast�puje, gdy poprawa R2 jest mniejsza ni� 0,005. Domylnie, odrzucane s� zmienne, których
wkład w polepszenie wyniku jest mniejszy ni� 0,005. Proces wyboru zmiennych przy przyj�ciu
2 Alternatyw� jest wybór zmiennych w oparciu o kryterium Chi-square, wykorzystuj�ce miar� χ2
.

POLSKIE STOWARZYSZENIE ZARZ�DZANIA WIEDZ�
Seria: Studia i Materiały, nr 22, 2009
85
kryterium R2 składa si� w przypadku binarnej zmiennej objanianej (binary target)3 z trzech
kroków: (1) obliczane s� kwadraty współczynników korelacji ka�dej zmiennej ze zmienn� obja-
nian� i nast�pnie odrzucane s� zmienne, które maj� kwadrat współczynnika korelacji poni�ej
ustalonego poziomu (domylnie 0,005), (2) pozostałe zmienne s� brane pod uwag� w procedurze
regresji krokowej w przód (forward stepwise R2 regression). Zmienne, które powoduj� polepszenie
wyniku w stopniu mniejszym ni� przyj�te kryterium progowe s� odrzucane, (3) dla binarnych
zmiennych objanianych przeprowadzana jest analiza regresji logistycznej z u�yciem wartoci
teoretycznych zmiennej objanianej jako zmiennej niezale�nej. Program podaje przyczyn�odrzucenia zmiennej. W naszym przypadku zostało wybranych 30 zmiennych.4
7. Ocena jako�ci modeli i wybór rodzaju przeprowadzanej analizy za pomoc� modelu
Zastosowalimy trzy modele analizy danych [2], [3]: (1) regresji logistycznej (w�zły RegStep,
RegForw, RegBack), (2) drzew decyzyjnych (w�zeł Tree), (3) sieci neuronowych (w�zeł Neural
Network). Porównanie jakoci tych modeli jest dokonywane w w��le Assessment. Nim szczegóło-
wo rozpatrzymy zastosowane modele, przyjrzyjmy si� wykresom uzyskanym w w��le Assessment.
Wykresy te pozwalaj� porówna� tworzone modele pod wzgl�dem ich jakoci i wybra� najlepszy
model, który mo�e by� zastosowany do wyjanienia zachowania si� zmiennej zale�nej i do
prognozowania. W�zeł Assessment umo�liwia otrzymanie wykresu wzrostu (lift chart) pozwalaj�-cego oceni� wizualnie jako� dopasowania modelu do danych i oceni�, który model jest pod tym
wzgl�dem najlepszy. Wykresy wzrostu pozwalaj� oceni� efektywno� modelu pod wzgl�dem
trafnoci własnoci predykcyjnoci (przewidywania odpowiedzi). Na podstawie oszacowanego
modelu, dla ka�dej obserwacji w zbiorze walidacyjnym jest obliczane przewidywane prawdopodo-
bie�stwo sukcesu. Nast�pnie obserwacje s� ustawiane malej�co według tych prawdopodobie�stw i
zbiór jest dzielony na 10 równych cz�ci. Ka�da cz�� tworzy grup� decylow� w zbiorze walida-
cyjnym.5 Na wykresie zaznaczane s� decyle na osi poziomej (oznaczane jako percentyle: 10,
20,...). Na osi pionowej s� zaznaczane odpowiednie charakterystyki zale�ne od liczby sukcesów w
poszczególnych grupach decylowych. Enterprise Miner umo�liwia wybór jednej z nast�puj�cych
3 Je�eli zmienna obja�niana nie jest binarna, s� wykonywane tylko dwa pierwsze kroki. 4 Wybrane zmienne, to (kolejno�� alfabetyczna): Amortyzacja (AMORTYZACJA), Krótkoterminowe aktywa finansowe
(�rodki pieni��ne) do aktywów ogółem (KAFSPDAO), Kapitał (fundusz) własny (KAPWL), Koszty finansowe do
przychodów ogółem (KFDPO), Kapitał obrotowy netto do aktywów (maj�tku) obrotowych (KONDAO), Korekty o pozycje
(KORPOZ), Kapitał stały do aktywów ogółem (KSDAO), Kapitał własny do aktywów (maj�tku) trwałych (KWDAT),
Nadwy�ka finansowa do aktywów ogółem (NFDAO), Nadwy�ka finansowa do zobowi�za� krótkoterminowych (NFDZK),
Nakłady inwestycyjne do aktywów ogółem (NIDAO), Obci��enia finansowe (OF), Ryzyko likwidacji (RL), Wynik netto do
aktywów ogółem (ROA) skorygowany (ROAS), Rotacja zobowi�za� krótkoterminowych (RZK), Udział aktywów (maj�tku)
obrotowych netto w aktywach (UAMONWA), Udział krótkoterminowych aktywów finansowych (�rodków pieni��nych) w
aktywach (maj�tku) obrotowych (UKAFAO), Udział kosztów działalno�ci operacyjnej w kosztach uzyskania przychodu
(UKDOWKUP), Udział kosztów finansowych w kosztach uzyskania przychodów (UKFWKUP), Udział przychodów
finansowych w przychodach ogółem (UPFWPO), Udział zobowi�za� z tytułu podatków, ceł, ubezpiecze� w zobowi�za-
niach krótkoterminowych (UZPCUZK), Udział zapasów w aktywach (maj�tku) obrotowych (UZWAMO), Wynik na
działalno�ci operacyjnej do aktywów ogółem (WNDODAO), Wska�nik unieruchomienia (WU), Zobowi�zania z tytułu
funduszy specjalnych do sprzeda�y w dniach (ZFSDSD), Zobowi�zania krótkoterminowe (ZOBKR), Zobowi�zania
krótkoterminowe i fundusze specjalne (ZOBKRIFS), Zysk/strata brutto (ZYNSB), Zysk/strata brutto na działalno�ci
operacyjnej (ZYNSBNDO), Zysk/strata ze sprzeda�y (ZYNSZS).5 W programie Enterprise Miner obserwacje s� ustawiane malej�co, a grupy decylowe s� tworzone w odwrotnej
kolejno�ci, ni� zazwyczaj w badaniach statystycznych. Pierwsza grupa decylowa zawiera najwi�ksze warto�ci.

Mirosława Lasek, Marek P�czkowski, Dariusz Wierzba
Zastosowanie analiz Data Mining w przewidywaniu gro�by upadło�ci lub konieczno�ci
prowadzenia post�powania układowego przedsi�biorstwa…
86
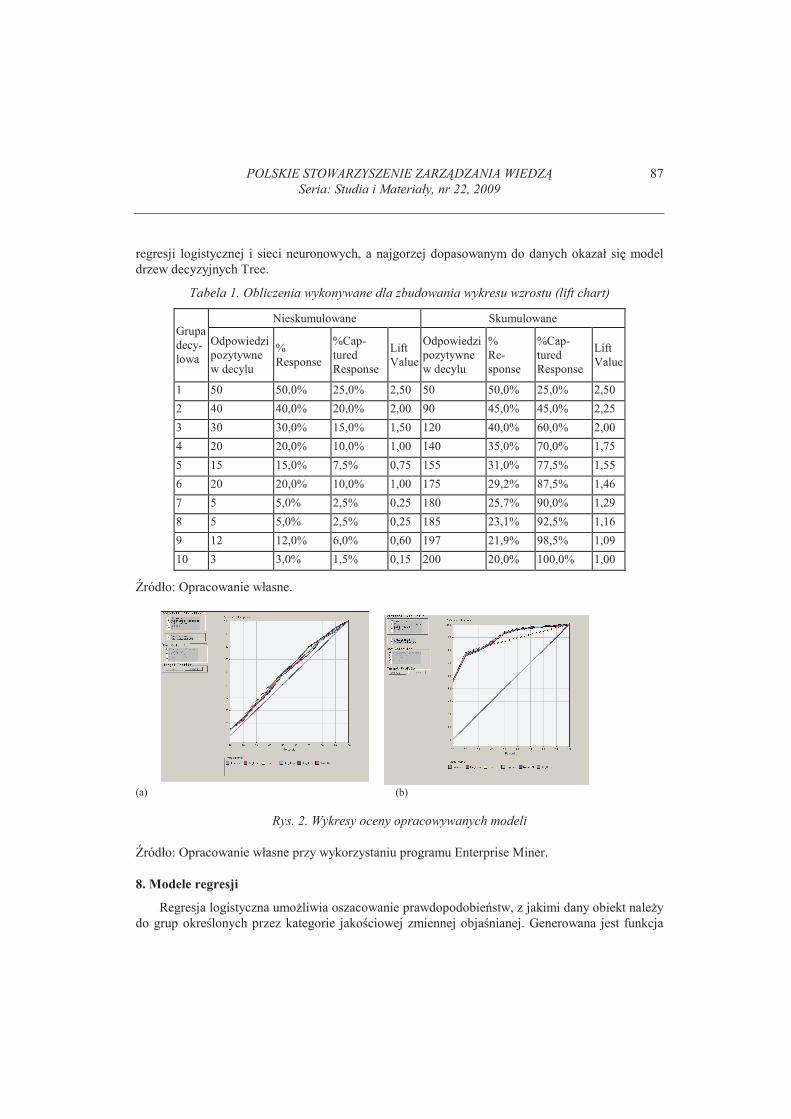
charakterystyk (Vertical Axis Value): % Response, % Captured Response, Lift Value. Ka�dy z
wykresów mo�e przedstawia� wartoci skumulowane (Cumulative) lub nieskumulowane (Non-
Cumulative). Sposób tworzenia wartoci na osi pionowej wyjaniamy na przykładzie – tabela 1.6
Przypu�my, �e zbiór walidacyjny ma 1000 obserwacji, zatem ka�da grupa decylowa ma 100
obserwacji. Załó�my dalej, �e w zbiorze walidacyjnym było 200 sukcesów (tzn. wyst�piło badane
zdarzenie) i rozkładały si� one w nast�puj�cy sposób w grupach decylowych: 50, 40, 30, 20, 15,
20, 5, 5, 12, 3. W dobrze dopasowanym modelu udział pozytywnych odpowiedzi powinien by�najwi�kszy w ostatnich grupach decylowych, a mały w pocz�tkowych grupach decylowych. Aby
ułatwi� interpretacj� wykresu, jest on zaopatrzony w lini� (baseline curve), która przedstawia
wynik dla stałej liczby sukcesów wynikaj�cej z prawdopodobie�stwa sukcesu w zbiorze walidacyj-
nym. Je�eli krzywa jest zbli�ona do prostej Baseline, to oznacza, �e model jest słabo dopasowany
do danych. Na rysunku 2 (a) i 2 (b) przedstawilimy wykresy, wybieraj�c opcj� % Captured
Response i Cumulative. Rysunek 2 (a) ilustruje przypadek analizy dwóch grup przedsi�biorstw:
grupy „gazel” oraz grupy przedsi�biorstw z orzeczon� upadłoci� i prowadzeniem post�powania
układowego. Rysunek 2 (b) przedstawia wyniki, gdy nie uwzgl�dnialimy „gazel” i porównywali-
my przedsi�biorstwa z orzeczon� upadłoci� z przedsi�biorstwami prowadz�cymi post�powanie
układowe. W pierwszym przypadku modele charakteryzuj� si� dobr� jakoci�, tzn. pozwalaj� one
odró�ni� przedsi�biorstwa dobre („gazele”) i złe (upadłe lub z post�powaniem układowym). W
drugim przypadku wida�, �e na podstawie wybranych zmiennych objaniaj�cych nie mo�na
zadowalaj�co prognozowa�, do której grupy (z orzeczon� upadłoci�, czy te� prowadzeniem
post�powania układowego) nale�y przedsi�biorstwo. Grupy te maj� podobne własnoci. Dlatego w
dalszych analizach zajmowalimy si� tylko przypadkiem porównywania własnoci „gazel” i
traktowanych ł�cznie przedsi�biorstw upadłych lub zagro�onych post�powaniem układowym.
Rysunek 2 (a) ukazał te�, �e najlepsze pod wzgl�dem własnoci predykcyjnych okazały si� modele
6 W obliczeniach przyj�to oznaczenia: N - liczba obserwacji w zbiorze walidacyjnym (1000), K - liczba sukcesów w
zbiorze walidacyjnym (200), n - liczba obserwacji w grupie decylowej (N/10=100), k - �rednia liczba sukcesów w grupie
decylowej (K/10=20), m(j) - liczba pozytywnych odpowiedzi w j-tej grupie decylowej. Dla wykresów nieskumulowanych:
% Response jest liczone jako udział (wyra�ony w procentach) odpowiedzi pozytywnych w danej grupie decylowej. Jest to
ułamek, w którym licznik wynosi m(j), mianownik wynosi n (patrz kolumna % Response). Np. 1 decyl - 50/100=50% , 2
decyl - 40/100 =40%. % Captured Response – jest to udział pozytywnych odpowiedzi znajduj�cych si� w danej grupie
decylowej do wszystkich pozytywnych odpowiedzi. Licznik ułamka wynosi m(j), a mianownik wynosi K (patrz kolumna %
Captured Response). Np. 1 decyl - 50/200=25% , 2 decyl - 40/200 =20%. Lift Value - jest to stosunek pozytywnych
odpowiedzi w danej grupie decylowej do �redniej liczby pozytywnych odpowiedzi przypadaj�cej na grup� decylow�.
Licznik ułamka wynosi m(j), a mianownik wynosi k (patrz kolumna Lift Value). Np. 1 decyl - 50/20=2,50 , 2 decyl - 40/20
=2,00. Zatem dla warto�ci nieskumulowanych licznik ułamka wynosi zawsze m(j), a mianownik ułamka jest stały, ale
ró�ny dla ró�nych rodzajów wykresów. Dla wykresów skumulowanych licznik ułamków zawiera skumulowan� liczb�
pozytywnych odpowiedzi: M(1)=m(1), M(j)=M(j-1)+m(j) dla j=2,...,10. % Response jest liczone jako udział (wyra�ony w
procentach) odpowiedzi pozytywnych w danej grupie decylowej i w grupach decylowych wcze�niejszych. Licznik ułamka
wynosi M(j), a mianownik wynosi jn (patrz kolumna % Response). Np. 1 decyl - 50/100=50% , 2 decyl -
(50+40)/(2*100) =90/200=45%. % Captured Response – stosunek pozytywnych odpowiedzi znajduj�cych si� w danej
grupie decylowej i w grupach decylowych poprzednich do wszystkich pozytywnych odpowiedzi. Licznik ułamka wynosi
M(j), a mianownik jest stały i wynosi K (patrz kolumna % Captured Response). Np. 1 decyl - 50/200=25% , 2 decyl -
(50+40)/200 =45%. Lift Value - jest to stosunek pozytywnych odpowiedzi w danej grupie decylowej i w grupach
decylowych poprzednich do przewidywanej liczby pozytywnych odpowiedzi w tych grupach decylowych (gdyby
pozytywne odpowiedzi rozkładały si� po równo w grupach decylowych). Licznik ułamka wynosi M(j), a mianownik
wynosi jn (patrz kolumna Lift Value). Np. 1 decyl - 50/20=2,50, 2 decyl - (50+40)/(2*20) =90/40=2,25. W naszym
przykładzie otrzymali�my lini� bazow� (baseline curve), gdy wszystkie m(j)=k=20.
POLSKIE STOWARZYSZENIE ZARZ�DZANIA WIEDZ�
Seria: Studia i Materiały, nr 22, 2009
87
regresji logistycznej i sieci neuronowych, a najgorzej dopasowanym do danych okazał si� model
drzew decyzyjnych Tree.
Tabela 1. Obliczenia wykonywane dla zbudowania wykresu wzrostu (lift chart)
Nieskumulowane Skumulowane Grupa
decy-
lowa
Odpowiedzi
pozytywne
w decylu
%
Response
%Cap-
tured
Response
Lift
Value
Odpowiedzi
pozytywne
w decylu
%
Re-
sponse
%Cap-
tured
Response
Lift
Value
1 50 50,0% 25,0% 2,50 50 50,0% 25,0% 2,50
2 40 40,0% 20,0% 2,00 90 45,0% 45,0% 2,25
3 30 30,0% 15,0% 1,50 120 40,0% 60,0% 2,00
4 20 20,0% 10,0% 1,00 140 35,0% 70,0% 1,75
5 15 15,0% 7,5% 0,75 155 31,0% 77,5% 1,55
6 20 20,0% 10,0% 1,00 175 29,2% 87,5% 1,46
7 5 5,0% 2,5% 0,25 180 25,7% 90,0% 1,29
8 5 5,0% 2,5% 0,25 185 23,1% 92,5% 1,16
9 12 12,0% 6,0% 0,60 197 21,9% 98,5% 1,09
10 3 3,0% 1,5% 0,15 200 20,0% 100,0% 1,00
ródło: Opracowanie własne.
(a) (b)
Rys. 2. Wykresy oceny opracowywanych modeli
ródło: Opracowanie własne przy wykorzystaniu programu Enterprise Miner.
8. Modele regresji
Regresja logistyczna umo�liwia oszacowanie prawdopodobie�stw, z jakimi dany obiekt nale�y
do grup okrelonych przez kategorie jakociowej zmiennej objanianej. Generowana jest funkcja
Mirosława Lasek, Marek P�czkowski, Dariusz Wierzba
Zastosowanie analiz Data Mining w przewidywaniu gro�by upadło�ci lub konieczno�ci
prowadzenia post�powania układowego przedsi�biorstwa…
88
nieliniowa, której wartoci s� interpretowane jako prawdopodobie�stwa lub warunkowe wartoci
oczekiwane zmiennej zale�nej. Do oszacowania parametrów funkcji logistycznej wykorzystywana
jest Metoda Najwi�kszej Wiarygodnoci. Jest to technika iteracyjna. Je�eli stosujemy dobór
zmiennych objaniaj�cych do modelu, to podczas realizacji procedury badane s� własnoci
statystyczne modelu i sprawdza si�, czy dodanie lub usuni�cie zmiennej istotnie polepszyło model.
Je�eli nie ma istotnej zmiany, to procedura zostaje zako�czona. W programie Enterprise Miner
dost�pne s� nast�puj�ce metody doboru zmiennych objaniaj�cych do modelu: (1) krokowa
(stepwise) – zmienne objaniaj�ce s� kolejno wprowadzane do modelu, zaczynaj�c od modelu
bazowego (bez zmiennych objaniaj�cych); dodawane s� zmienne, które s� znacz�co powi�zane ze
zmienn� objanian�. Wprowadzona do modelu zmienna mo�e zosta� usuni�ta, je�eli polepszy to
warto� przyj�tej miary jakoci modelu. W tej metodzie zmienne wprowadzane we wczeniejszym
etapie mog� zosta� usuni�te pó�niej, je�eli oka�e si�, �e b�d�c wród zmiennych w modelu nie
przyczyniaj� si� do jego polepszenia. (2) w przód (forward) – zmienne objaniaj�ce s� kolejno
wprowadzane do modelu. Najpierw rozpatruje si� model bez zmiennych objaniaj�cych. Potem
dodaje si� zmienn� najsilniej skorelowan� ze zmienn� objanian�. Potem dodaje si� kolejn�zmienn�, która polepsza model a� osi�gnie si� najlepsz� jako� modelu. Zmienne wprowadzone do
modelu nie s� usuwane; (3) w tył (backward) – najpierw jest rozwa�any model ze wszystkimi
zmiennymi objaniaj�cymi, a nast�pnie kolejno s� usuwane zmienne, które nie wywieraj�znacz�cego wpływu na zmienn� objanian�. Post�powanie kontynuuje si� do momentu, gdy
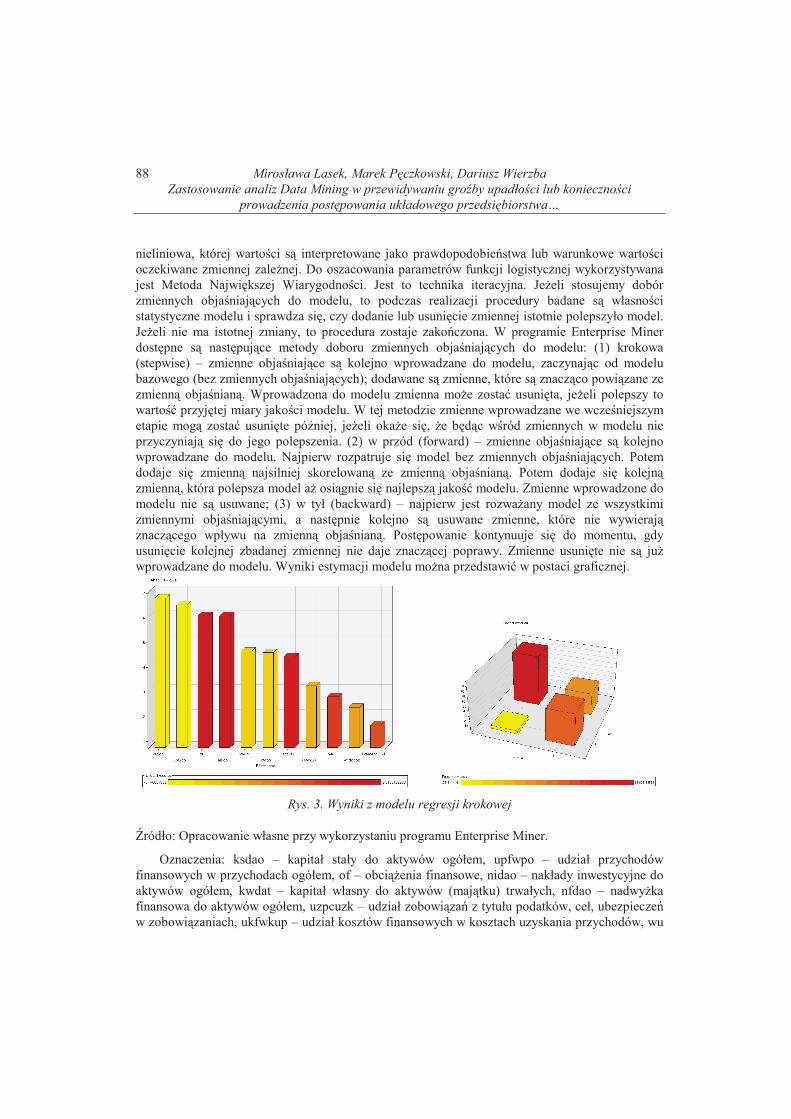
usuni�cie kolejnej zbadanej zmiennej nie daje znacz�cej poprawy. Zmienne usuni�te nie s� ju�wprowadzane do modelu. Wyniki estymacji modelu mo�na przedstawi� w postaci graficznej.
Rys. 3. Wyniki z modelu regresji krokowej
ródło: Opracowanie własne przy wykorzystaniu programu Enterprise Miner.
Oznaczenia: ksdao – kapitał stały do aktywów ogółem, upfwpo – udział przychodów
finansowych w przychodach ogółem, of – obci��enia finansowe, nidao – nakłady inwestycyjne do
aktywów ogółem, kwdat – kapitał własny do aktywów (maj�tku) trwałych, nfdao – nadwy�ka
finansowa do aktywów ogółem, uzpcuzk – udział zobowi�za� z tytułu podatków, ceł, ubezpiecze�w zobowi�zaniach, ukfwkup – udział kosztów finansowych w kosztach uzyskania przychodów, wu

POLSKIE STOWARZYSZENIE ZARZ�DZANIA WIEDZ�
Seria: Studia i Materiały, nr 22, 2009
89
– wska�nik unieruchomienia, wndodao – wynik na działalnoci operacyjnej do aktywów ogółem,
uu – zmienna objaniana: przedsi�biorstwo z orzeczeniem upadłoci lub z post�powaniem
układowym
Przyjrzyjmy si� wynikom uzyskanym w przypadku poszczególnych modeli regresji.
Rozpatrzmy przykładowo wykresy dla regresji krokowej (rys 3). Pierwszy wykres (w lewej cz�ci)
przedstawia zmienne objaniaj�ce wyst�puj�ce w oszacowanym modelu, uporz�dkowane malej�co
według wartoci bezwzgl�dnych współczynników t-Studenta (Effect T-scores). Wartoci ujemne s�zaznaczone słupkami – jasnym kolorem, wartoci dodatnie – ciemnym. Legenda umieszczona
w dolnej cz�ci wykresów pozwala na prawidłow� interpretacj� wartoci wska�nika Effect T-
scores dla ka�dego ze słupków na wykresach. Współczynnik t-Studenta jest ilorazem oszacowania
parametru stoj�cego przy zmiennej modelu i jego bł�du szacunku. Warto� bezwzgl�dna tego
wska�nika informuje o istotnoci zmiennej w oszacowanym modelu. Zmienne na wykresach s�uporz�dkowane malej�co według wartoci bezwzgl�dnej wska�nika. Na rysunku 3 – w prawej
cz�ci, przedstawiono wyniki w postaci wykresu, przedstawiaj�cego zale�no� mi�dzy wartociami
przewidywanymi (into) a obserwowanymi (from) wartociami zmiennej objanianej. Wykres jest
graficzn� ilustracj� tablicy klasyfikacji krzy�owej. Słupki na głównej przek�tnej dotycz�przedsi�biorstw, dla których model poprawnie przewiduje warto� zmiennej objanianej. Je�eli
model jest dobry, to powinna istnie� zgodno� wartoci przewidywanych (oczekiwanych)
z wartociami obserwowanymi: słupki na wykresie na przeci�ciu tych samych wartoci into i from
powinny by� najwy�sze. Tak jest w naszym przypadku, co wskazuje, �e model dobrze nadaje si�do identyfikacji przedsi�biorstw z orzeczon� upadłoci� lub post�powaniem układowym. Zmienne
o najwi�kszej istotnoci w przypadku modelu regresji w przód oraz w tył zamieszczono
w przypisie.7 W przypadku tych modeli, podobnie jak regresji krokowej, tak�e istnieje zgodno�wartoci przewidywanych z wartociami obserwowanymi, co moglimy stwierdzi� analizuj�c
wykres ilustracji tablicy klasyfikacji krzy�owej.
9. Drzewa decyzyjne
Drzewa decyzyjne stanowi� graficzn� reprezentacj� algorytmu rekurencyjnego podziału, który
polega na hierarchicznym podziale wielowymiarowej przestrzeni cech (w której znajduje si� zbiór
obiektów) na rozł�czne podzbiory a� do osi�gni�cia ich jednorodnoci ze wzgl�du na wyró�nion�cech� – zmienn� objanian�. W praktyce proces podziału jest cz�sto zatrzymywany wczeniej, aby
unikn�� tworzenia podzbiorów o bardzo małej liczbie elementów. Warunkiem zatrzymania procesu
podziału, mo�e by� maksymalna warto� okrelaj�ca liczb� poziomów drzewa (oznacza to
7 Zmienne obja�niaj�ce o najwi�kszej istotno�ci w przypadku modelu regresji w przód: nidao – nakłady inwestycyjne do
aktywów ogółem, upfwpo – udział przychodów finansowych w przychodach ogółem, ksdao – kapitał stały do aktywów
ogółem, of – obci��enia finansowe, uzpcuzk – udział zobowi�za� z tytułu podatków, ceł, ubezpiecze� w zobowi�zaniach,
nfdao – nadwy�ka finansowa do aktywów ogółem, kwdat – kapitał własny do aktywów (maj�tku) trwałych, ukfwkup –
udział kosztów finansowych w kosztach uzyskania przychodów, wu – wska�nik unieruchomienia, wndodao – wynik na
działalno�ci operacyjnej do aktywów ogółem, uzwamo – udział zapasów w aktywach (maj�tku) obrotowych.
Zmienne obja�niaj�ce o najwi�kszej istotno�ci w przypadku modelu regresji w tył: nfdao – nadwy�ka finansowa do
aktywów ogółem, upfwpo – udział przychodów finansowych w przychodach ogółem, of – obci��enia finansowe, ksdao –
kapitał stały do aktywów ogółem, nidao – nakłady inwestycyjne do aktywów ogółem, uzpcuzk – udział zobowi�za� z
tytułu podatków, ceł, ubezpiecze� w zobowi�zaniach, kwdat – kapitał własny do aktywów (maj�tku) trwałych, kfdpo –
koszty finansowe do przychodów ogółem, zynszs – zys/strata ze sprzeda�y, amortyzacja, korpoz – korekty o pozycje.

Mirosława Lasek, Marek P�czkowski, Dariusz Wierzba
Zastosowanie analiz Data Mining w przewidywaniu gro�by upadło�ci lub konieczno�ci
prowadzenia post�powania układowego przedsi�biorstwa…
90
osi�gni�cie maksymalnej „gł�bokoci drzewa”) lub osi�gni�cie minimalnej liczebnoci w w�złach
podlegaj�cych podziałowi. Drzewa s� grafami spójnymi, nie zawieraj�cymi cykli. Drzewa decy-
zyjne umo�liwiaj� przedstawianie procesu podziału zbioru obiektów na jednorodne klasy, charak-
teryzowane okrelonymi wartociami atrybutów. Wewn�trzne wierzchołki okrelaj� sposób
dokonywania podziału w oparciu o wartoci cech obiektów. Wierzchołki ko�cowe, z których nie
wychodz� �adne kraw�dzie, nazywane s� li�mi drzewa. Kraw�dzie drzewa wskazuj� wartoci
cech, na podstawie których dokonywany jest podział. Na podstawie drzewa klasyfikacyjnego
mo�emy odczyta� reguły przynale�noci obiektów do poszczególnych klas. Istniej� ró�ne algoryt-
my generowania drzew klasyfikacyjnych: Chaid, Exhaustive Chaid, C&RT, Quest. Algorytmy
ró�ni� si� sposobem wyboru cech, w oparciu o które nast�puje podział zbioru obiektów, kryterium
zako�czenia podziału powstaj�cego podzbioru obiektów, sposobem przydzielania obiektów
znajduj�cych si� w liciu drzewa do okrelonej klasy, postaci� funkcji oceniaj�cej jako� podziału,
sposobem klasyfikacji obiektów o brakuj�cych wartociach cech, charakterem rozpatrywanych
zmiennych (cech obiektów): nominalne, porz�dkowe, ci�głe. Tworzone s� drzewa klasyfikacyjne
lub regresyjne. Algorytmy klasyfikacyjne pozwalaj� na podstawie zbioru ucz�cego znale��charakterystyki podzbiorów obiektów, tak aby w oparciu o uzyskane wyniki podziału mo�na było
dokona� klasyfikacji obiektów, których przynale�no� do klas nie jest znana. W algorytmach
regresyjnych celem jest znalezienie zwi�zku opisuj�cego wpływ jednej lub wybranej liczby cech na
wskazan� cech� ilociow�. Zalety drzew decyzyjnych w stosunku do metod takich jak analiza
dyskryminacyjna, czy analiza regresji s� nast�puj�ce: (i) unika si� koniecznoci weryfikowania
zało�e� dotycz�cych rozkładów zmiennych objaniaj�cych, (ii) w modelu mog� wyst�powa�jednoczenie zmienne jakociowe i ilociowe, (iii) metody s� mało wra�liwe na wyst�powanie
wartoci odstaj�cych (outliers) dla zmiennych objaniaj�cych, (iv) wykazuj� tolerancj� na poja-
wianie si� brakuj�cych wartoci obserwowanych zmiennych, (v) dobór zmiennych objaniaj�cych
jest dokonywany automatycznie podczas działania algorytmu. Problemy czasem stwarza du�a
zło�ono� drzewa, a tak�e mo�liwo� ró�nej interpretacji uzyskanych wyników. Nie ma tak�e
�adnych wskazówek dotycz�cych wyboru optymalnego modelu. Ustalenia takie jak chocia�by
wybór metody generowania drzewa, liczby poziomów drzewa, reguł zatrzymania procedury
generuj�cej drzewo s� podejmowane dosy� arbitralnie. Przydatne jest przeprowadzanie wielu
ró�nych eksperymentów przy zastosowaniu ró�nych modeli i zało�e�. W przypadku jakociowej
zmiennej objanianej ka�dy w�zeł drzewa programu Enterprise Miner zawiera domylnie informa-
cje: w pierwszej kolumnie wartoci zmiennej objanianej (1 lub 0) i nagłówek dla ostatniego
wiersza (Total), w drugiej kolumnie dla danych ze zbioru danych treningowych - w dwóch
pierwszych wierszach udział procentowy liczby obserwacji (firm) dla ka�dej wartoci zmiennej, w
dwóch nast�pnych wierszach: liczby obserwacji (firm) dla ka�dej wartoci zmiennej, w ostatnim
wierszu ł�czn� liczb� obserwacji (firm), w trzeciej kolumnie te same dane co w drugiej, ale dla
danych ze zbioru danych walidacyjnych.
Drzewo uzyskane w wyniku badania zbioru danych grupy „gazel” oraz grupy przedsi�biorstw
z orzeczeniem upadłoci lub post�powaniem układowym przedstawiono na rysunku 4. Wyniki
przedstawiono w postaci tradycyjnej drzewa decyzyjnego, cho� Enterprise Miner pozwala prze-
prowadzi� znacznie bogatsz� analiz� wyników i ró�ne postacie wykresów ilustruj�cych drzewa
decyzyjne, np. w postaci piercienia. Rysunek drzewa wskazuje, �e o podziale na firmy upadłe i z
post�powaniem układowym oraz „gazele” najsilniejszy wpływ ma zmienna zysk/strata brutto na
działalnoci operacyjnej. Pozostałe zmienne decyduj�ce o podziale, to wynik netto do aktywów

POLSKIE STOWARZYSZENIE ZARZ�DZANIA WIEDZ�
Seria: Studia i Materiały, nr 22, 2009
91
ogółem (ROA) skorygowany, kapitał (fundusz) własny, udział zobowi�za� z tytułu podatków, ceł,
ubezpiecze� w zobowi�zaniach, rotacja zobowi�za� krótkoterminowych.
Rys. 4. Drzewo decyzyjne analizy przedsi�biorstw
ródło: Opracowanie własne przy wykorzystaniu programu Enterprise Miner.
Oznaczenia: zynsbndo – zysk/strata brutto na działalnoci operacyjnej, roas – wynik netto do
aktywów ogółem (ROA) skorygowany, kapwl – kapitał (fundusz) własny, uzpcuzk – udział
zobowi�za� z tytułu podatków, ceł, ubezpiecze� w zobowi�zaniach, rzk – rotacja zobowi�za�krótkoterminowych
10. Sieci neuronowe
Algorytm w�zła Neural Network umo�liwia trenowanie, walidacj� i testowanie wielowar-
stwowych sieci neuronowych z zastosowaniem algorytmu propagacji wstecznej (multilayer
feedforward neural networks). Domylnie Neural Network tworzy sie�, która ma jedn� warstw�ukryt�. W modelach wielowarstwowych sieci neuronowych ka�dy neuron warstwy wejciowej
odpowiadaj�cy jednej zmiennej objaniaj�cej jest powi�zany z ka�dym neuronem warstwy ukrytej,
ka�dy neuron warstwy ukrytej jest powi�zany z ka�dym neuronem kolejnej warstwy, a ka�dy
neuron ostatniej warstwy ukrytej jest powi�zany z ka�dym neuronem warstwy wyjciowej sieci.
Neurony z warstw, które nie s� s�siednie, nie s� powi�zane. Nie s� te� powi�zane neurony tej
samej warstwy. Taka struktura sieci nosi nazw� perceptronu wielowarstwowego (Multilayer
Perceptron) [9] (por te� [1], s. 162). Algorytm umo�liwia utworzenie sieci wielowarstwowej o

Mirosława Lasek, Marek P�czkowski, Dariusz Wierzba
Zastosowanie analiz Data Mining w przewidywaniu gro�by upadło�ci lub konieczno�ci
prowadzenia post�powania układowego przedsi�biorstwa…
92
ró�nej liczbie warstw i ró�nej liczbie neuronów w warstwach.8 Przebieg uczenia sieci neuronowej
mo�emy obserwowa� na monitorze podczas działania procedury. Mo�emy otrzyma� wykresy
wartoci funkcji bł�dów i statystyk dla kolejnych iteracji trenowania i walidacji sieci. Na rysunku 5
przedstawiono wykres przeci�tnego bł�du trenowania i walidacji w kolejnych iteracjach tworzenia
sieci.
Rys. 5. Wielko�ci przeci�tnego bł�du w kolejnych iteracjach trenowania i walidacji sieci neurono-
wej analizy „gazel” oraz przedsi�biorstw z orzeczeniem upadło�ci lub post�powaniem układowym
ródło: Opracowanie własne przy wykorzystaniu programu Enterprise Miner.
8 Działanie sztucznej sieci w uproszczeniu odpowiada działaniu „biologicznych struktur nerwowych”, zło�onych z
neuronów [9], (por te� [1], s. 158). Najwa�niejsza ró�nica polega na tym, �e neurony sztucznej sieci uporz�dkowane
s� w warstwy: warstw� wej�ciow�, warstw� wyj�ciow� i warstwy ukryte, a poł�czenia istniej� tylko pomi�dzy neuro-
nami s�siednich warstw [9], (por. te� [1], s. 162). Sygnały przekazywane s� w jednym kierunku: od warstwy wej�cio-
wej, poprzez kolejne warstwy ukryte do warstwy wyj�ciowej. Do neuronów docieraj� sygnały wej�ciowe, które w
sztucznej sieci neuronowej mno�one s� przez odpowiednie współczynniki zwane wagami poł�cze�, odpowiadaj�ce sile
poł�cze� synaptycznych mi�dzy biologicznymi neuronami. Wagi sztucznej sieci neuronowej s� modyfikowane na
podstawie przedstawianych sieci danych wzorcowych w trakcie procesu zwanego uczeniem lub trenowaniem sieci. W
przypadku neuronów warstwy wej�ciowej sygnałami wej�ciowymi s� warto�ci danych, podawanych do sieci z ze-
wn�trz, a w przypadku neuronów pozostałych warstw warto�ci po�rednie, pochodz�ce z wyj�� neuronów poprzednich
warstw. W ka�dym neuronie obliczana jest suma warto�ci wej�ciowych pomno�onych przez wagi, która okre�la sił�
reakcji neuronu [6], (por te� [1], s. 159). Uaktywnienie neuronu zachodzi, je�eli zostanie przekroczona pewna warto��
zwana warto�ci� progow� zadziałania (pobudzenia) neuronu. Wielko�� wyliczonego pobudzenia neuronu jest prze-
kształcana przez tzw. funkcj� aktywacji, daj�c w wyniku sygnał wyj�ciowy (warto�� wyj�ciow�) neuronu. Warto�ci
wyj�ciowe neuronów warstwy wyj�ciowej stanowi� wynik działania sieci. Uczenie sieci neuronowej, zwane tak�e
trenowaniem sieci polega na modyfikacji warto�ci wag poł�cze� pomi�dzy neuronami w sieci. Wagi te modyfikowane
s� tak, aby sie� przyj�ła zało�one warto�ci wyj�ciowe dla okre�lonych warto�ci wej�ciowych. Podczas modyfikacji wag
ulega tak�e zmianie struktura sieci. Je�eli podczas modyfikacji waga poł�czenia mi�dzy neuronami w sieci przyjmie
warto�� zero, to poł�czenie zostanie usuni�te, poniewa� warto�� zerowa wagi jest równowa�na brakowi poł�czenia.
Je�eli neuron b�dzie miał wej�ciowe i wyj�ciowe wagi poł�cze� równe zero, to jako zb�dny mo�e zosta� usuni�ty, co
powoduje zmian� w strukturze sieci.

POLSKIE STOWARZYSZENIE ZARZ�DZANIA WIEDZ�
Seria: Studia i Materiały, nr 22, 2009
93
11. Zako�czenie
Analizy Data Mining s� przydatne w poszukiwaniach charakterystyk kondycji finansowej
i maj�tkowej przedsi�biorstw. Poszukiwane s� takie charakterystyki, których wartoci pozwalaj�odró�ni� przedsi�biorstwa „słabe” (z zagro�eniem upadłoci lub post�powaniem układowym) od
przedsi�biorstw „dobrych” (np. zaliczanych do „gazel biznesu” gospodarki). Przeprowadzone
przez nas badania z wykorzystaniem licznego zbioru danych: przedsi�biorstw z orzeczeniem
upadłoci, post�powaniem układowym i „gazel biznesu” pozwoliły nam za pomoc� metod Data
Mining najpierw wst�pnie wyznaczy� istotne charakterystyki – za pomoc� algorytmu selekcji
zmiennych (w�zeł Variable Selection), a nast�pnie budowa� modele umo�liwiaj�ce przewidywa-
nie, którym przedsi�biorstwom grozi upadło� lub post�powanie układowe. Przetestowalimy
modele regresji logistycznej, drzew decyzyjnych i sieci neuronowych. Pokazalimy, �e w zale�no-
ci od posiadanych zbiorów danych (wielkoci finansowych i maj�tkowych) mo�emy otrzymywa�modele o ró�nej jakoci dopasowania do danych i z tego powodu nale�y zbudowa� ró�ne modele,
porówna� ich jako� (w�zeł Assessment), a w ko�cu wybra� model, który umo�liwi nam uzyskanie
jak najlepszych wyników w zakresie przewidywania kondycji przedsi�biorstw. Przeprowadzona
przez nas analiza wskazała na modele regresji logistycznej (krokowej, w przód, w tył) i sieci
neuronowych jako modele najlepiej nadaj�ce si� do przewidywania gro�by upadłoci lub prowa-
dzenia post�powania układowego przedsi�biorstwa. Odznaczaj� si� one przy tym bardzo podob-
nym poziomem dopasowania do danych i zdolnoci prognostycznych. Sporód zbudowanych
modeli najgorszym pod wzgl�dem dopasowania do danych i zdolnoci prognostycznych okazał si�model drzew decyzyjnych. Sporód wzi�tych pocz�tkowo pod uwag� 144 cech, wst�pna selekcja
przeprowadzona z wykorzystaniem współczynnika determinacji R2
wskazała na 30 cech o znacze-
niu diagnostycznym (przewidywania gro�by upadłoci lub podj�cia post�powania układowego). W
przypadku modeli regresji i modelu drzew decyzyjnych moglimy zidentyfikowa� cechy, które w
najwi�kszym stopniu rozstrzygały o tym, czy przedsi�biorstwo powinnimy zaliczy� do przedsi�-biorstw, którym grozi upadło� lub konieczno� prowadzenia post�powania układowego. Sie�neuronowa jest modelem „czarnej skrzynki” – nie ukazuje nam cech uj�tych w modelu i nie daje
nam takich mo�liwoci. Dla modeli regresji logistycznej i drzew decyzyjnych cechy te zostały
wymienione w artykule. W przypadku modeli regresji krokowej, w przód i w tył, wiele cech
powtarza si� w ka�dym z tych modeli. W modelu drzew decyzyjnych znacznie ró�ni� si� od
uwzgl�dnionych w modelach regresji, co mogło zadecydowa� o stwierdzonym zró�nicowaniu pod
wzgl�dem zdolnoci prognostycznych. Interpretacja merytoryczna (w naszym przypadku ekono-
miczne uzasadnienie) obecnoci poszczególnych cech w modelach wykracza poza zakres analiz
Data Mining, a niespodziewane pojawienie si� pewnej cechy w modelu jako prognostycznej mo�e
stanowi� „twórczy” wkład metod Data Mining w dziedzin� problemu (w naszym przypadku
przewidywania upadłoci lub potrzeby prowadzenia post�powania układowego).

Mirosława Lasek, Marek P�czkowski, Dariusz Wierzba
Zastosowanie analiz Data Mining w przewidywaniu gro�by upadło�ci lub konieczno�ci
prowadzenia post�powania układowego przedsi�biorstwa…
94
Bibliografia
1. Lasek M.: Data Mining. Zastosowania w analizach i ocenach klientów bankowych.
Oficyna Wydawnicza „Zarz�dzanie i Finanse”. Biblioteka Mened�era i Bankowca,
Warszawa 2002.
2. Lasek M.:, Od danych do wiedzy. Metody i techniki „Data Mining”. Optimum, nr 2,
2004, s. 17-37.
3. Lasek M.: Metody Data Mining w analizowaniu i prognozowaniu kondycji ekonomicznej
przedsi�biorstw. Zastosowania SAS Enterprise Miner. Centrum Doradztwa i Informacji
Difin, Warszawa 2007.
4. Maimon O., Rokach L. (eds.): The Data Mining and Knowledge Discovery Handbook.
Springer Science+Business Media, Inc., New York 2005.
5. Matignon R.: Data Mining Using SAS Enterprise Miner. John Wiley & Sons, Inc., New
Jersey 2007.
6. P�czkowski M.: Program ORKA 4.0. Sieci neuronowe. „Materiały na zaj�cia
laboratoryjne dla studentów szkół wy�szych”, Wydział Nauk Ekonomicznych
Uniwersytetu Warszawskiego, Warszawa 2007.
7. SAS Institute Inc.: Enterprise Miner Reference Help, SAS Institute Inc 2005.
8. Shmueli G., Patel N.R., Bruce P.C.: Data Mining for Business Intelligence. John Wiley
& Sons, Inc., New Jersey 2007.
9. Tadeusiewicz R.: Wprowadzenie do praktyki stosowania sieci neuronowych,
http://www.statsoft.pl , 2001.9
10. Triantaphyllou E., Felici G.: Data Mining and Knowledge Discovery Approaches Based
on Rule Induction Techniques. Springer Science+Business Media, Inc., New York 2007.
11. Ye N. (ed.): The Handbook of Data Mining. Lawrence Erlbaum Associates, Inc., New
Jersey 2003.
9 Artykuł był nadal dost�pny pod wskazanym adresem 9 stycznia 2009 r.

POLSKIE STOWARZYSZENIE ZARZ�DZANIA WIEDZ�
Seria: Studia i Materiały, nr 22, 2009
95
APPLICATION OF DATA MINING IN THE ENTERPRISE BANKRUPTCY PREDICTION – CONSTRUCTION OF MODELS, THEIR EVALUATION
AND SELECTION
Summary
In the article usefulness of Data Mining models for bankruptcy prediction are
discussed. Application of Data Mining prediction models such as logistic regression
model, decision tree model and neural network model are described. Considerations
are illustrated with the data from about six thousand enterprises, a proportion of
which was in bankruptcy situation.
Keywords: enterprise bankruptcy prediction, Data Mining prediction models, logistic regression,
decision trees, artificial neural networks
Mirosława Lasek
Marek P�czkowski
Dariusz Wierzba
Katedra Informatyki Gospodarczej i Analiz Ekonomicznych
Wydział Nauk Ekonomicznych
Uniwersytet Warszawski
00-241 Warszawa, ul. Długa 44/50
e-mail: [email protected]

















![Data Mining - mif.pg.gda.plM6] DM/[Czw... · Data mining jest to proces analityczny, służący do odkrywania nietrywialnych, dotychczas nieznanych zależności, trendów w dużych](https://static.fdocuments.pl/doc/165x107/5c6db0d909d3f20e3e8bf979/data-mining-mifpggdapl-m6-dmczw-data-mining-jest-to-proces-analityczny.jpg)
