
Wstęp do programowaniaprac.im.pwr.wroc.pl/~szwabin/assets/intro/lectures/6.pdf · Wstęp do...
36
Wstęp do programowania Wykład 6 Złożone typy danych Janusz Szwabiński Plan wykładu: Listy Krotki Słowniki Zbiory Listy Listy to jeden z bardziej użytecznych typów danych w Pythonie. Podobnie jak łańcuch znaków, lista stanowi sekwencję elementów. Różnica polega na tym, że jedna lista może zawierać elementy różnych typów. Najważniejsze własności tego typu: służy do grupowania obiektów może przechowywać obiekty dowolnego typu elementy są indeksowane przypomina typ array w Perlu dynamiczny rozmiar rośnie w miarę dodawania elementów może być przedmiotem operacji wykrawania, sklejania i wielu innych Istnieje kilka sposobów na stworzenie listy. Najprostszy z nich to użycie nawiasów kwadratowych: In [1]: lista = ["a",1.3,204,"Yoda"] In [2]: print(lista) In [3]: type(lista) ['a', 1.3, 204, 'Yoda'] Out[3]: list
Transcript of Wstęp do programowaniaprac.im.pwr.wroc.pl/~szwabin/assets/intro/lectures/6.pdf · Wstęp do...
Wstęp do programowania
Wykład 6 Złożone typy danych
Janusz Szwabiński
Plan wykładu:
ListyKrotkiSłownikiZbiory
ListyListy to jeden z bardziej użytecznych typów danych w Pythonie. Podobnie jak łańcuch znaków, lista stanowisekwencję elementów. Różnica polega na tym, że jedna lista może zawierać elementy różnych typów.Najważniejsze własności tego typu:
służy do grupowania obiektówmoże przechowywać obiekty dowolnego typuelementy są indeksowaneprzypomina typ array w Perludynamiczny rozmiar rośnie w miarę dodawania elementówmoże być przedmiotem operacji wykrawania, sklejania i wielu innych
Istnieje kilka sposobów na stworzenie listy. Najprostszy z nich to użycie nawiasów kwadratowych:
In [1]:
lista = ["a",1.3,204,"Yoda"]
In [2]:
print(lista)
In [3]:
type(lista)
['a', 1.3, 204, 'Yoda']
Out[3]:
list

In [4]:
help(lista)


Help on list object:
class list(object) | list() -> new empty list | list(iterable) -> new list initialized from iterable's items | | Methods defined here: | | __add__(self, value, /) | Return self+value. | | __contains__(self, key, /) | Return key in self. | | __delitem__(self, key, /) | Delete self[key]. | | __eq__(self, value, /) | Return self==value. | | __ge__(self, value, /) | Return self>=value. | | __getattribute__(self, name, /) | Return getattr(self, name). | | __getitem__(...) | x.__getitem__(y) <==> x[y] | | __gt__(self, value, /) | Return self>value. | | __iadd__(self, value, /) | Implement self+=value. | | __imul__(self, value, /) | Implement self*=value. | | __init__(self, /, *args, **kwargs) | Initialize self. See help(type(self)) for accurate signature. | | __iter__(self, /) | Implement iter(self). | | __le__(self, value, /) | Return self<=value. | | __len__(self, /) | Return len(self). | | __lt__(self, value, /) | Return self<value. | | __mul__(self, value, /) | Return self*value.n | | __ne__(self, value, /) | Return self!=value. | | __new__(*args, **kwargs) from builtins.type

| Create and return a new object. See help(type) for accurate signature. | | __repr__(self, /) | Return repr(self). | | __reversed__(...) | L.__reversed__() -- return a reverse iterator over the list | | __rmul__(self, value, /) | Return self*value. | | __setitem__(self, key, value, /) | Set self[key] to value. | | __sizeof__(...) | L.__sizeof__() -- size of L in memory, in bytes | | append(...) | L.append(object) -> None -- append object to end | | clear(...) | L.clear() -> None -- remove all items from L | | copy(...) | L.copy() -> list -- a shallow copy of L | | count(...) | L.count(value) -> integer -- return number of occurrences of value | | extend(...) | L.extend(iterable) -> None -- extend list by appending elements from the iterable | | index(...) | L.index(value, [start, [stop]]) -> integer -- return first index of value. | Raises ValueError if the value is not present. | | insert(...) | L.insert(index, object) -- insert object before index | | pop(...) | L.pop([index]) -> item -- remove and return item at index (default last). | Raises IndexError if list is empty or index is out of range. | | remove(...) | L.remove(value) -> None -- remove first occurrence of value. | Raises ValueError if the value is not present. | | reverse(...) | L.reverse() -- reverse *IN PLACE* | | sort(...) | L.sort(key=None, reverse=False) -> None -- stable sort *IN PLACE* |
Długość i indeksowanie list
Długość listy (tzn. liczbę elementów) sprawdzimy znaną już funkcją len:
In [5]:
len(lista)
Pusta lista ma długość :
In [6]:
pusta_lista = []print(len(pusta_lista))
Elementy w liście są indeksowane od do :
In [7]:
print(lista[0])
In [8]:
print(lista[1])
In [9]:
print(lista[2])
In [10]:
print(lista[3])
0
0 n − 1
| ---------------------------------------------------------------------- | Data and other attributes defined here: | | __hash__ = None
Out[5]:
4
0
a
1.3
204
Yoda
In [11]:
print(lista[4]) #to powinno być wyjście poza zakres
Jeśli chodzi o indeksowanie, obowiązują zasady znane z łańcuchów znaków:
In [12]:
print(lista)
In [13]:
lista[-1] #ostatni element
In [14]:
lista[-2] #przedostatni
In [15]:
lista[:2] #dwa pierwsze
In [16]:
lista[2:] #od trzeciego do końca
In [17]:
lista[1:10] #w przypadku wycinków nie ma wyjścia poza zakres
---------------------------------------------------------------------------IndexError Traceback (most recent call last)<ipython-input-11-667d7b0b636b> in <module>()----> 1 print(lista[4]) #to powinno być wyjście poza zakres
IndexError: list index out of range
['a', 1.3, 204, 'Yoda']
Out[13]:
'Yoda'
Out[14]:
204
Out[15]:
['a', 1.3]
Out[16]:
[204, 'Yoda']
Out[17]:
[1.3, 204, 'Yoda']
Modyfikowanie list
Inaczej niż w przypadku łańcuchów znaków, poszczególne elementy list możemy zmieniać:
In [19]:
print(lista)
In [20]:
lista[3] = 'Chewie'
In [21]:
print(lista)
Możemy przy tym zmieniać całe wycinki:
In [22]:
lista [1:2] = ['Luke', 1024]
In [23]:
print(lista)
Zwróćmy uwagę, że w tym ostatnim przypadku zmienił się rozmiar listy:
In [24]:
len(lista)
Ponadto, gdybyśmy zamiast wycinka, podali indeks zmienianego elementu, otrzymalibyśmy listęzagnieżdżoną:
In [25]:
lista [1] = ['Luke', 1024]
In [26]:
print(lista)
Do elementów tej listy możemy dostać się przez podwójne indeksy:
['a', 1.3, 204, 'Yoda']
['a', 1.3, 204, 'Chewie']
['a', 'Luke', 1024, 204, 'Chewie']
Out[24]:
5
['a', ['Luke', 1024], 1024, 204, 'Chewie']
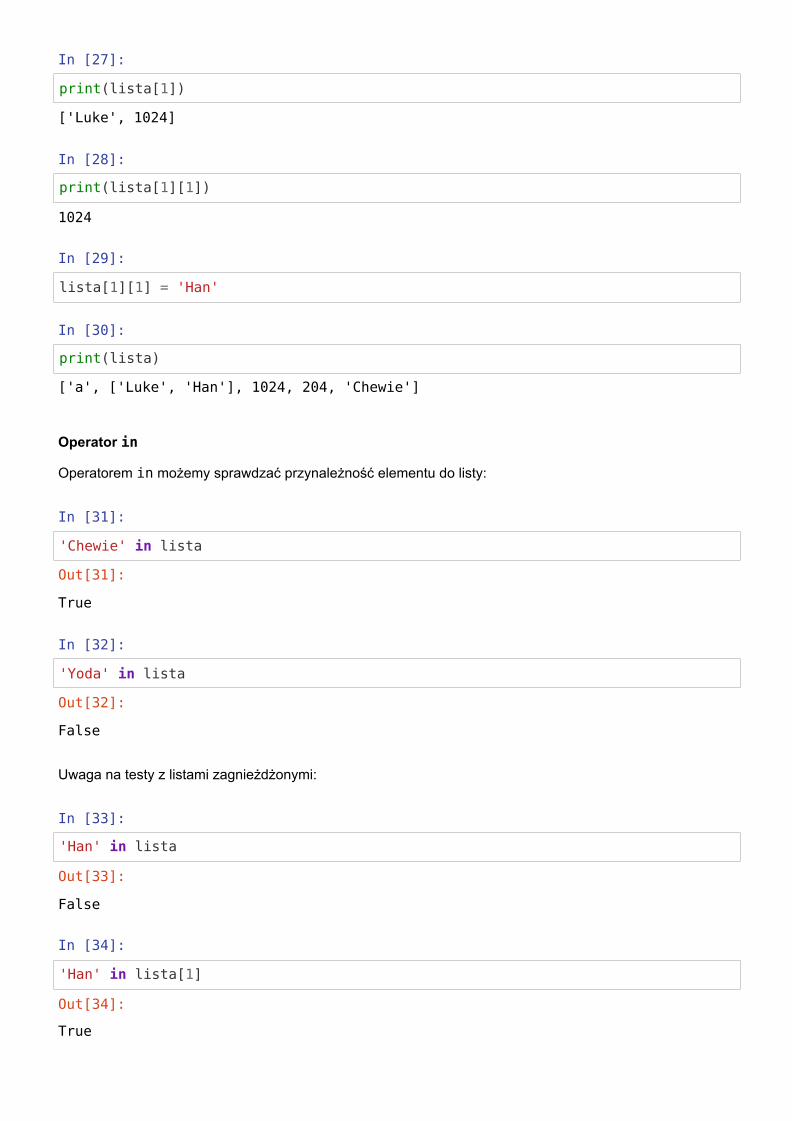
In [27]:
print(lista[1])
In [28]:
print(lista[1][1])
In [29]:
lista[1][1] = 'Han'
In [30]:
print(lista)
Operator in
Operatorem in możemy sprawdzać przynależność elementu do listy:
In [31]:
'Chewie' in lista
In [32]:
'Yoda' in lista
Uwaga na testy z listami zagnieżdżonymi:
In [33]:
'Han' in lista
In [34]:
'Han' in lista[1]
['Luke', 1024]
1024
['a', ['Luke', 'Han'], 1024, 204, 'Chewie']
Out[31]:
True
Out[32]:
False
Out[33]:
False
Out[34]:
True
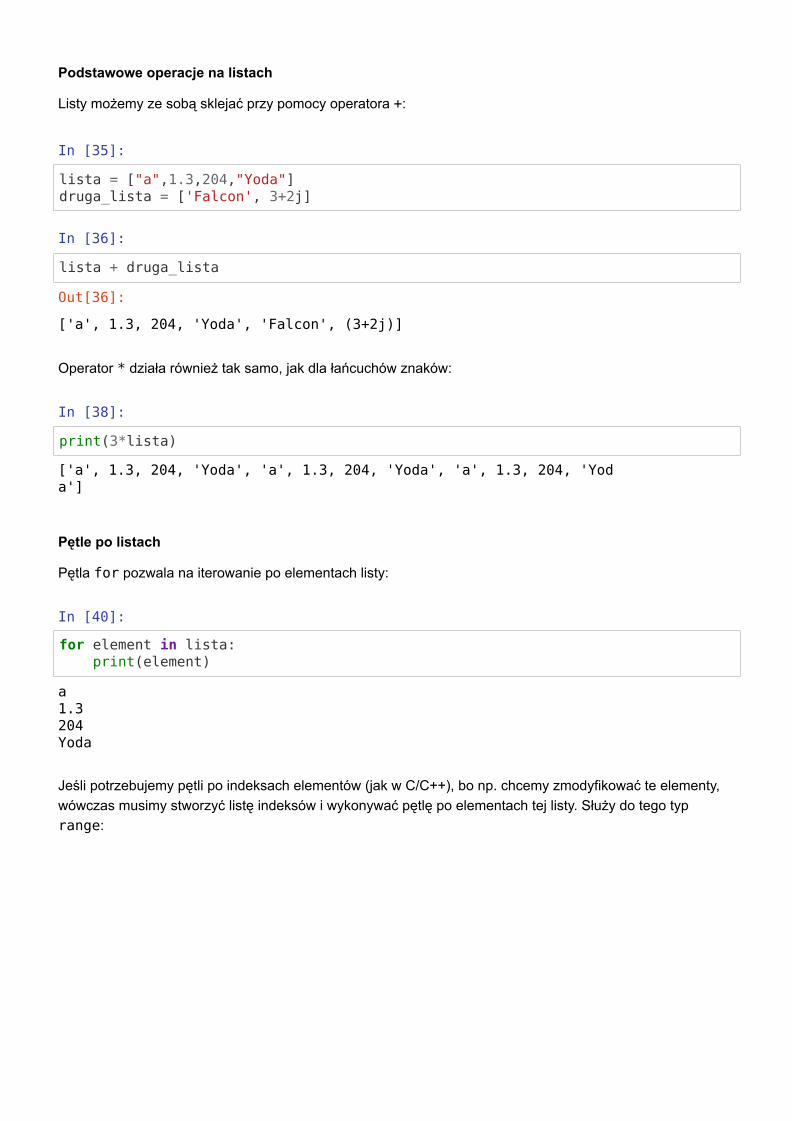
Podstawowe operacje na listach
Listy możemy ze sobą sklejać przy pomocy operatora +:
In [35]:
lista = ["a",1.3,204,"Yoda"]druga_lista = ['Falcon', 3+2j]
In [36]:
lista + druga_lista
Operator * działa również tak samo, jak dla łańcuchów znaków:
In [38]:
print(3*lista)
Pętle po listach
Pętla for pozwala na iterowanie po elementach listy:
In [40]:
for element in lista: print(element)
Jeśli potrzebujemy pętli po indeksach elementów (jak w C/C++), bo np. chcemy zmodyfikować te elementy,wówczas musimy stworzyć listę indeksów i wykonywać pętlę po elementach tej listy. Służy do tego typ range:
Out[36]:
['a', 1.3, 204, 'Yoda', 'Falcon', (3+2j)]
['a', 1.3, 204, 'Yoda', 'a', 1.3, 204, 'Yoda', 'a', 1.3, 204, 'Yoda']
a1.3204Yoda

In [41]:
numbers = [1,2,3,4,5,6]print ('before: ', numbers)
for i in range(len(numbers)): # w ten sposób generuję listę indeksów listy numbers numbers[i] = 2*numbers[i] print('after: ', numbers)
Warto wiedzieć, że pętla po pustej liście nie wykona się ani razu:
In [44]:
for i in []: print("Ta instrukcja nie powinna się wykonać")
Dodawanie elementów do istniejącej listy
Omówione wcześniej przypisanie wycinkowi istniejącej listy innej z większą liczbą elementów niż ten wycinekto jeden ze sposobów na dodanie elementów do istniejącej już listy. Python oferuje kilka dodatkowych metod,które upraszczają tę operację:
In [45]:
lista = ['a','Luke',1024,204,'Chewie']
In [46]:
print(lista)
In [47]:
lista.append('Han') #dodajemy element na końcu listyprint(lista)
In [48]:
lista.insert(2,'Darth') #w określonym miejscuprint(lista)
In [49]:
lista.extend(['R2D2','C3P0']) #na końcu raz jeszczeprint(lista)
before: [1, 2, 3, 4, 5, 6]after: [2, 4, 6, 8, 10, 12]
['a', 'Luke', 1024, 204, 'Chewie']
['a', 'Luke', 1024, 204, 'Chewie', 'Han']
['a', 'Luke', 'Darth', 1024, 204, 'Chewie', 'Han']
['a', 'Luke', 'Darth', 1024, 204, 'Chewie', 'Han', 'R2D2', 'C3P0']

Uwaga! Metody append i extend nie są równoważne:
In [50]:
li = ['a','b','c']li.extend(['d','e','f'])print(li)print(len(li))print(li[-1])
In [51]:
li = ['a','b','c']li.append(['d','e','f'])print(li)print(len(li))print(li[-1])
Usuwanie elementów
In [52]:
print(lista)
In [53]:
lista.remove('Luke') #usuwamy konkretny element (jego pierwsze wystąpienie)print(lista)
In [52]:
lista.remove('Anakin')
['a', 'b', 'c', 'd', 'e', 'f']6f
['a', 'b', 'c', ['d', 'e', 'f']]4['d', 'e', 'f']
['a', 'Luke', 'Darth', 1024, 204, 'Chewie', 'Han', 'R2D2', 'C3P0']
['a', 'Darth', 1024, 204, 'Chewie', 'Han', 'R2D2', 'C3P0']
---------------------------------------------------------------------------ValueError Traceback (most recent call last)<ipython-input-52-dbb5be6900c1> in <module>()----> 1 lista.remove('Anakin')
ValueError: list.remove(x): x not in list
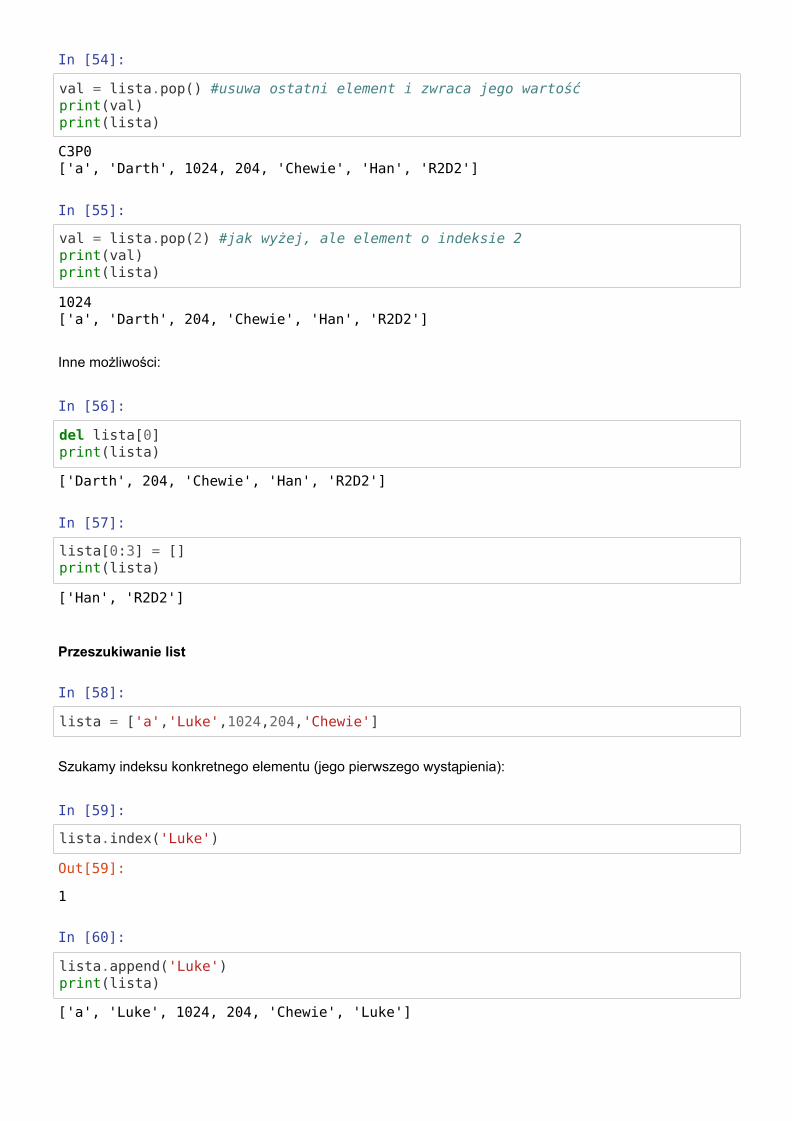
In [54]:
val = lista.pop() #usuwa ostatni element i zwraca jego wartośćprint(val)print(lista)
In [55]:
val = lista.pop(2) #jak wyżej, ale element o indeksie 2print(val)print(lista)
Inne możliwości:
In [56]:
del lista[0]print(lista)
In [57]:
lista[0:3] = []print(lista)
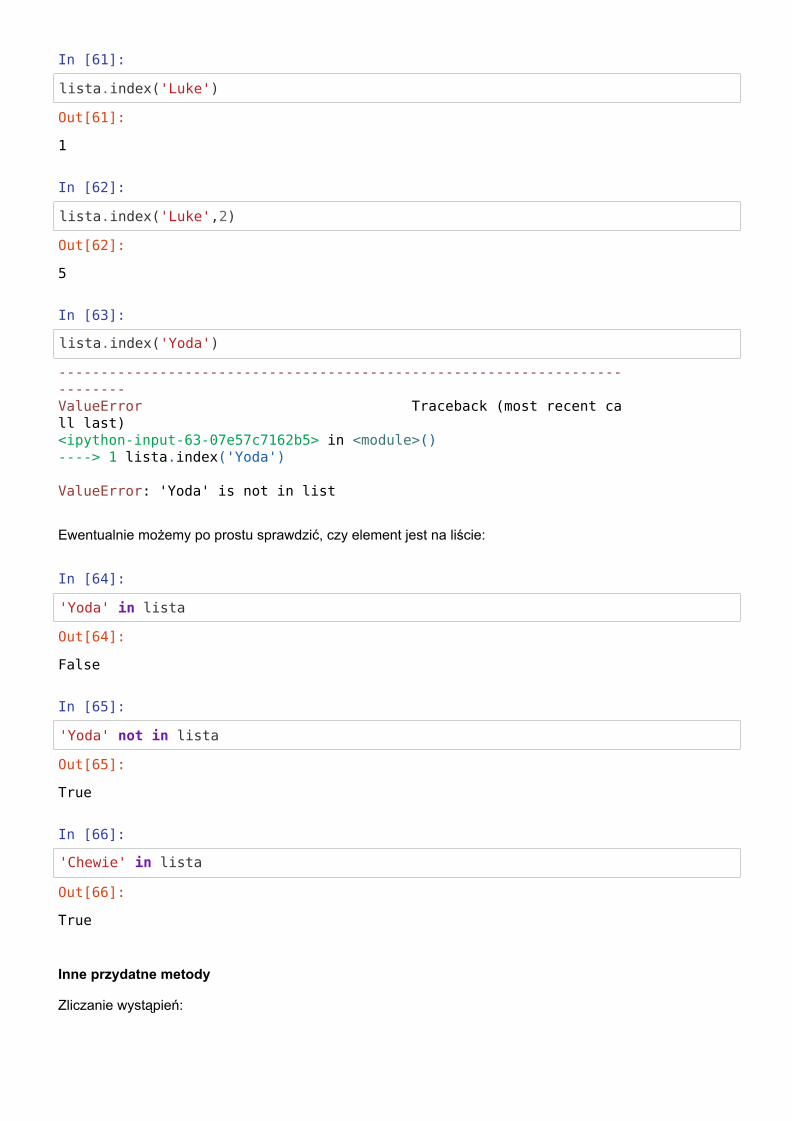
Przeszukiwanie list
In [58]:
lista = ['a','Luke',1024,204,'Chewie']
Szukamy indeksu konkretnego elementu (jego pierwszego wystąpienia):
In [59]:
lista.index('Luke')
In [60]:
lista.append('Luke')print(lista)
C3P0['a', 'Darth', 1024, 204, 'Chewie', 'Han', 'R2D2']
1024['a', 'Darth', 204, 'Chewie', 'Han', 'R2D2']
['Darth', 204, 'Chewie', 'Han', 'R2D2']
['Han', 'R2D2']
Out[59]:
1
['a', 'Luke', 1024, 204, 'Chewie', 'Luke']
In [61]:
lista.index('Luke')
In [62]:
lista.index('Luke',2)
In [63]:
lista.index('Yoda')
Ewentualnie możemy po prostu sprawdzić, czy element jest na liście:
In [64]:
'Yoda' in lista
In [65]:
'Yoda' not in lista
In [66]:
'Chewie' in lista
Inne przydatne metody
Zliczanie wystąpień:
Out[61]:
1
Out[62]:
5
---------------------------------------------------------------------------ValueError Traceback (most recent call last)<ipython-input-63-07e57c7162b5> in <module>()----> 1 lista.index('Yoda')
ValueError: 'Yoda' is not in list
Out[64]:
False
Out[65]:
True
Out[66]:
True

In [67]:
liczby = [10,21,33,11,24,11]liczby.count(11)
Sortowanie (tracimy oryginał!!!):
In [68]:
liczby.sort()print(liczby)
Odwrócenie porządku (również tracimy oryginał!!!):
In [69]:
liczby.reverse()print(liczby)
Wyższy stopień wtajemniczenia map, filter i (ewentualnie) reduce
Większość operacji, jakie można przeprowadzić na listach, daje się sprowadzić do trzech funkcji, któreznajdziemy w Pythonie:
map(funkcja,sekwencja) wywołuje funkcję funkcja dla każdego elementu listy wejściowej izwraca listę wynikówfilter(funkcja,sekwencja) zwraca sekwencję zawierającą te elementy z listy wejściowej,dla których wywołanie funkcja(element) zwróci wartość prawdziwąreduce(funkcja,sekwencja) zwraca pojedynczą wartość, która powstała w wynikuwywołania dwuparametrowej funkcji funkcja dla dwóch pierwszych elementów sekwencji, potemdla wyniku tego działania i następnego elementu sekwencji itd.
Należy przy tym wspomnieć, że w Pythonie 3.X reduce zostało usunięte z listy funkcji wbudowanych. Jest toczęściowo związane z faktem, że Guido van Rossum nigdy nie przepadał za tą funkcją:
"So now reduce(). This is actually the one I've always hated most, because, apart from a fewexamples involving + or *, almost every time I see a reduce() call with a nontrivial functionargument, I need to grab pen and paper to diagram what's actually being fed into thatfunction before I understand what the reduce() is supposed to do. So in my mind, theapplicability of reduce() is pretty much limited to associative operators, and in all other casesit's better to write out the accumulation loop explicitly." (artima.com, 10.03.2005)
Przykład szukamy liczb pierwszych w przedziale przy pomocy filter:⟨4, 25)
Out[67]:
2
[10, 11, 11, 21, 24, 33]
[33, 24, 21, 11, 11, 10]

In [72]:
def f(x): return x%2 != 0 and x%3 != 0 #prawda,jeśli niepodzielne przez 2 i 3
print(list(filter(f,range(4,25)))) #różnica w porównaniu z Pythonem 2.7!!!
To samo przy pomocy pętli:
In [73]:
pierwsze = []for liczba in range(4,25): if f(liczba): pierwsze.append(liczba) print(pierwsze)
Przykład obliczamy listę sześcianów przy pomocy map:
In [76]:
def cube(x): return x**3
list(map(cube,range(1,11)))
Przykład chcemy połączyć dwie listy w listę par przy pomocy map:
In [79]:
def sq(x): return x**2
liczby = range(4)list(map(sq,liczby))
Przykład chcemy obliczyć sumę sekwencji liczb w wykorzystaniem reduce:
[5, 7, 11, 13, 17, 19, 23]
[5, 7, 11, 13, 17, 19, 23]
Out[76]:
[1, 8, 27, 64, 125, 216, 343, 512, 729, 1000]
Out[79]:
[0, 1, 4, 9]
In [80]:
def add(x,y): return x+y
reduce(add,range(1,11))
In [81]:
import functools>>> functools.reduce(add,range(1,11))
Generowanie list (ang. list comprehensions)
Generowanie list to kolejny wygodny sposób na tworzenie nowych list z tych już istniejących:
In [83]:
lista = list(range(1,11))print(lista)
In [84]:
nowa_lista = [x for x in lista if x>5]print(nowa_lista)
In [85]:
[str(round(355/113.0,i)) for i in range(1,6)]
---------------------------------------------------------------------------NameError Traceback (most recent call last)<ipython-input-80-b8c55f93ce00> in <module>() 2 return x+y 3 ----> 4 reduce(add,range(1,11))
NameError: name 'reduce' is not defined
Out[81]:
55
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
[6, 7, 8, 9, 10]
Out[85]:
['3.1', '3.14', '3.142', '3.1416', '3.14159']
In [86]:
l1 = [2,4,6]l2 = [4,3,-9][x*y for x in l1 for y in l2]
Listy i łańcuchy znaków
Aby przekształcić łańcuch znaków na listę znaków, korzystamy z funkcji list:
In [87]:
s = 'spam't = list(s)print(s)print(t)
Metoda split pozwala rozbić napis na listę słów:
In [88]:
s = 'pinning for the fjords't = s.split()print(t)
In [89]:
s = 'spam-spam-spam'delimiter = '-'s.split(delimiter)
Operacją odwrotną do split jest join:
In [90]:
t = ['pinning', 'for', 'the', 'fjords']delimiter = ':' #spacjadelimiter.join(t)
Out[86]:
[8, 6, -18, 16, 12, -36, 24, 18, -54]
spam['s', 'p', 'a', 'm']
['pinning', 'for', 'the', 'fjords']
Out[89]:
['spam', 'spam', 'spam']
Out[90]:
'pinning:for:the:fjords'
In [91]:
';'.join(t)
Ostrożnie z operacją przypisania
In [93]:
a = [1,2,3]b = aprint(b)
In [94]:
b[2] = 30
In [96]:
print(a)
Out[91]:
'pinning;for;the;fjords'
[1, 2, 3]
[1, 2, 30]

Aby wyjaśnić powyższy wynik, musimy wiedzieć nieco więcej na temat tego, jak Python traktuje zmienne, iczym to traktowanie różni się od innych języków, jak np. C/C++ czy Java.
Zmienne w C
Rozważmy najpierw następującą deklarację w C:
int a = 1;
W języku C deklaracja zmiennej powoduje stworzenie w pamięci operacyjnej komputera bloku, któryumożliwi przechowanie wartości przypisanej do tej zmiennej. Mówiąc bardziej obrazowo, zmienna w C (iwielu innych językach) to odpowiednio nazwane pudełko, do którego możemy wrzucać wartości oodpowiednim rozmiarze (typie):
a1
Jeżeli wykonamy operację przypisania
a = 2;
do pudełka wrzucona zostanie po prostu nowa wartość:
a2
Przyrównując starą zmienną do nowej,
int b = a
tworzymy nowe pudełko, do którego skopiowana zostanie zawartość pierwszego pudełka. Jednak w pamięcioperacyjnej będą to dwa różne obiekty:
a2
b2
Zmienne w Pythonie
W Pythonie w pamięci alokowana jest wartość. Operacja przypisania wartości do zmiennej
'a = 1'
może być interpretowana, jako przypięcie etykiety do wartości w pamięci komputera:
a1
Zmieniając wartość zmiennej,
a = 2
przenosimy etykietę do nowej wartości:
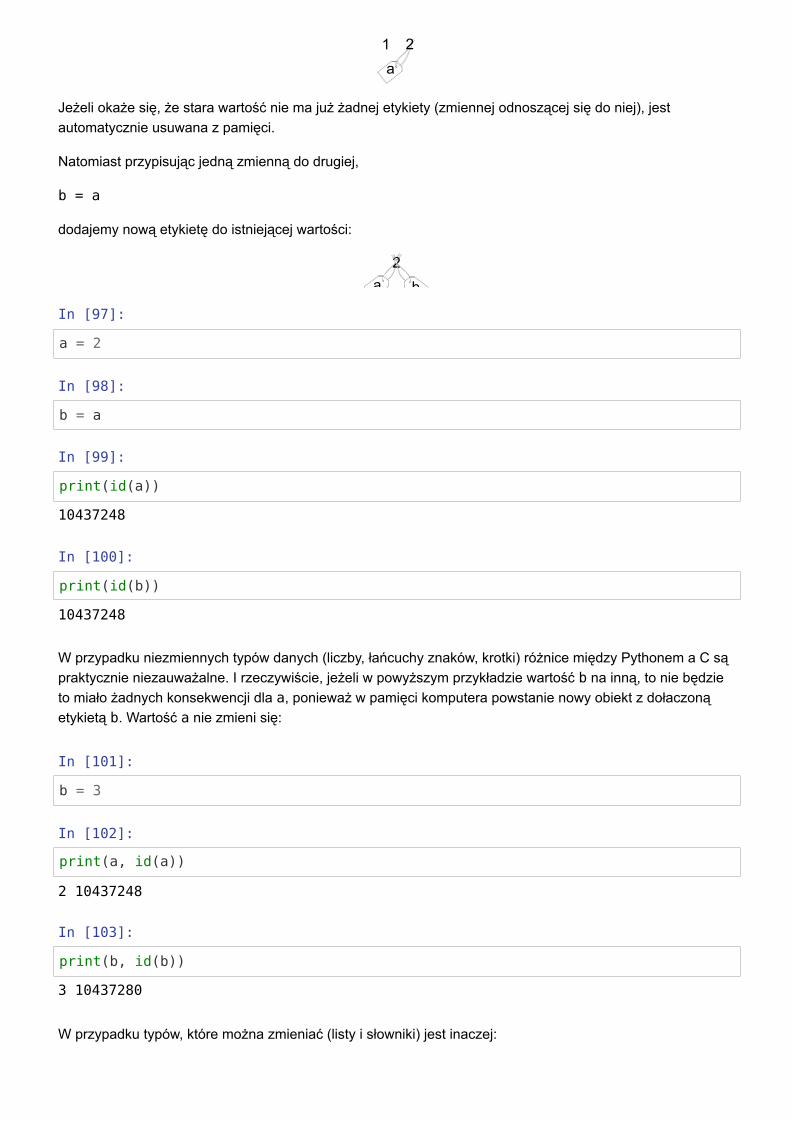
a21
Jeżeli okaże się, że stara wartość nie ma już żadnej etykiety (zmiennej odnoszącej się do niej), jestautomatycznie usuwana z pamięci.
Natomiast przypisując jedną zmienną do drugiej,
b = a
dodajemy nową etykietę do istniejącej wartości:
a2
b
In [97]:
a = 2
In [98]:
b = a
In [99]:
print(id(a))
In [100]:
print(id(b))
W przypadku niezmiennych typów danych (liczby, łańcuchy znaków, krotki) różnice między Pythonem a C sąpraktycznie niezauważalne. I rzeczywiście, jeżeli w powyższym przykładzie wartość b na inną, to nie będzieto miało żadnych konsekwencji dla a, ponieważ w pamięci komputera powstanie nowy obiekt z dołaczonąetykietą b. Wartość a nie zmieni się:
In [101]:
b = 3
In [102]:
print(a, id(a))
In [103]:
print(b, id(b))
W przypadku typów, które można zmieniać (listy i słowniki) jest inaczej:
10437248
10437248
2 10437248
3 10437280
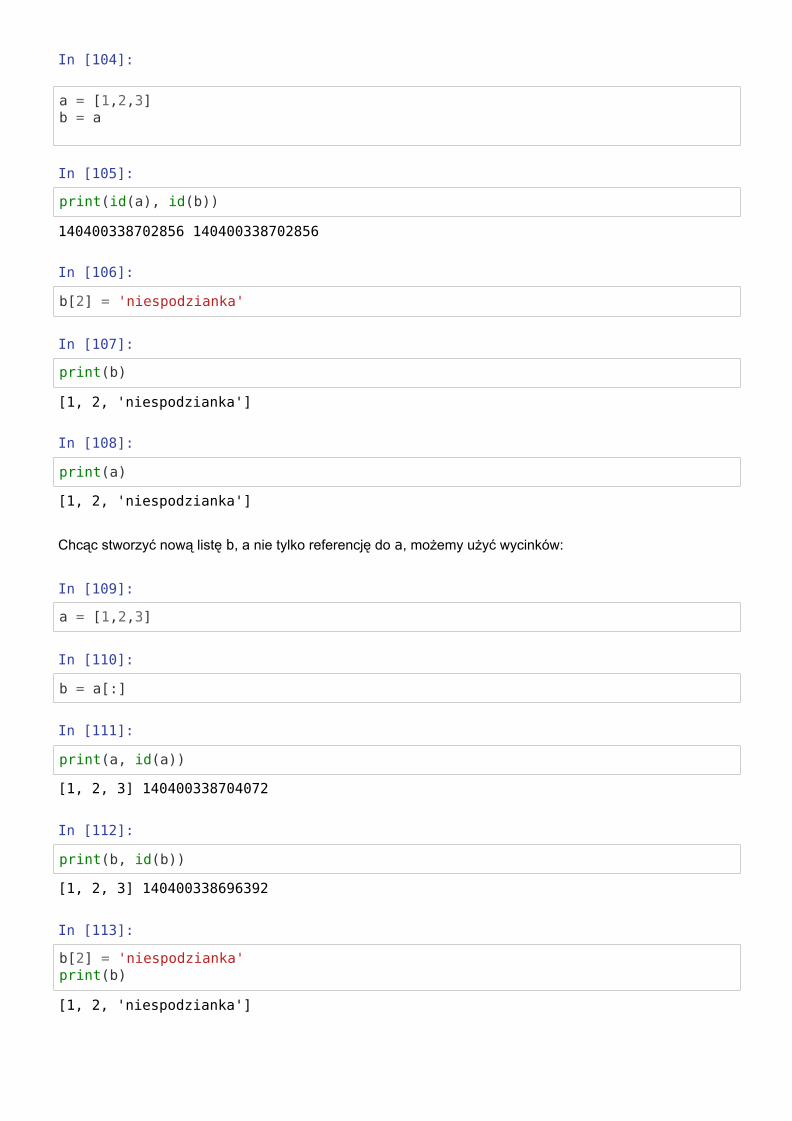
In [104]:
a = [1,2,3]b = a
In [105]:
print(id(a), id(b))
In [106]:
b[2] = 'niespodzianka'
In [107]:
print(b)
In [108]:
print(a)
Chcąc stworzyć nową listę b, a nie tylko referencję do a, możemy użyć wycinków:
In [109]:
a = [1,2,3]
In [110]:
b = a[:]
In [111]:
print(a, id(a))
In [112]:
print(b, id(b))
In [113]:
b[2] = 'niespodzianka'print(b)
140400338702856 140400338702856
[1, 2, 'niespodzianka']
[1, 2, 'niespodzianka']
[1, 2, 3] 140400338704072
[1, 2, 3] 140400338696392
[1, 2, 'niespodzianka']
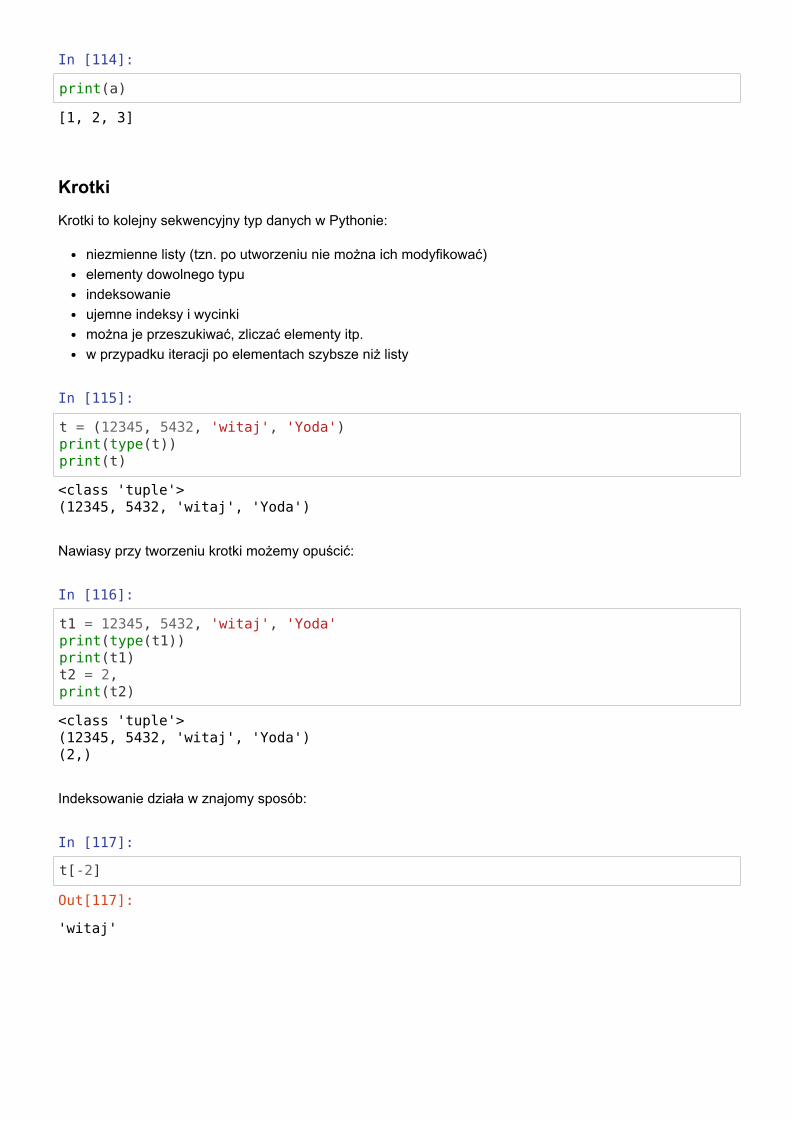
In [114]:
print(a)
KrotkiKrotki to kolejny sekwencyjny typ danych w Pythonie:
niezmienne listy (tzn. po utworzeniu nie można ich modyfikować)elementy dowolnego typuindeksowanieujemne indeksy i wycinkimożna je przeszukiwać, zliczać elementy itp.w przypadku iteracji po elementach szybsze niż listy
In [115]:
t = (12345, 5432, 'witaj', 'Yoda')print(type(t))print(t)
Nawiasy przy tworzeniu krotki możemy opuścić:
In [116]:
t1 = 12345, 5432, 'witaj', 'Yoda'print(type(t1))print(t1)t2 = 2,print(t2)
Indeksowanie działa w znajomy sposób:
In [117]:
t[-2]
[1, 2, 3]
<class 'tuple'>(12345, 5432, 'witaj', 'Yoda')
<class 'tuple'>(12345, 5432, 'witaj', 'Yoda')(2,)
Out[117]:
'witaj'
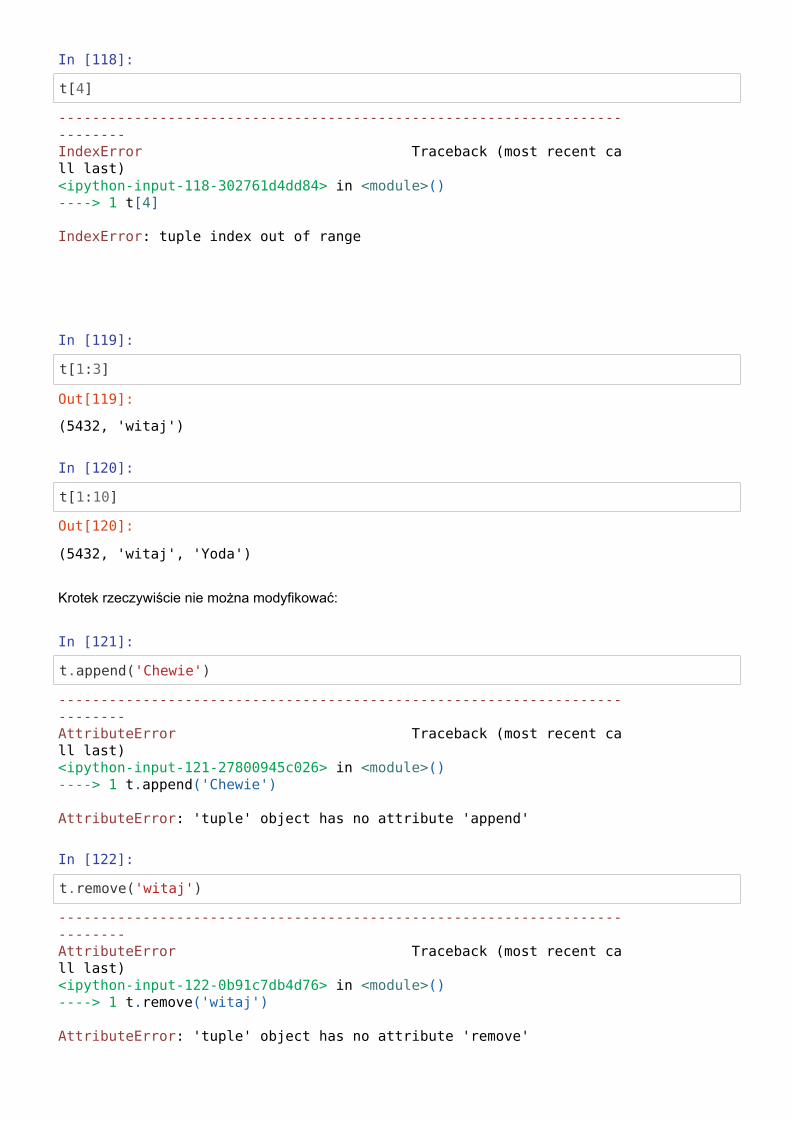
In [118]:
t[4]
In [119]:
t[1:3]
In [120]:
t[1:10]
Krotek rzeczywiście nie można modyfikować:
In [121]:
t.append('Chewie')
In [122]:
t.remove('witaj')
---------------------------------------------------------------------------IndexError Traceback (most recent call last)<ipython-input-118-302761d4dd84> in <module>()----> 1 t[4]
IndexError: tuple index out of range
Out[119]:
(5432, 'witaj')
Out[120]:
(5432, 'witaj', 'Yoda')
---------------------------------------------------------------------------AttributeError Traceback (most recent call last)<ipython-input-121-27800945c026> in <module>()----> 1 t.append('Chewie')
AttributeError: 'tuple' object has no attribute 'append'
---------------------------------------------------------------------------AttributeError Traceback (most recent call last)<ipython-input-122-0b91c7db4d76> in <module>()----> 1 t.remove('witaj')
AttributeError: 'tuple' object has no attribute 'remove'

In [123]:
t[1] = 'Luke'
Działają tylko niektóre metody znane z list:
In [124]:
t = 1,2,3,4,5,6
In [125]:
t.index(6)
In [126]:
t.count(3)
In [127]:
t.sort()
---------------------------------------------------------------------------TypeError Traceback (most recent call last)<ipython-input-123-d8d86ca30d95> in <module>()----> 1 t[1] = 'Luke'
TypeError: 'tuple' object does not support item assignment
Out[125]:
5
Out[126]:
1
---------------------------------------------------------------------------AttributeError Traceback (most recent call last)<ipython-input-127-0708f4171c7e> in <module>()----> 1 t.sort()
AttributeError: 'tuple' object has no attribute 'sort'
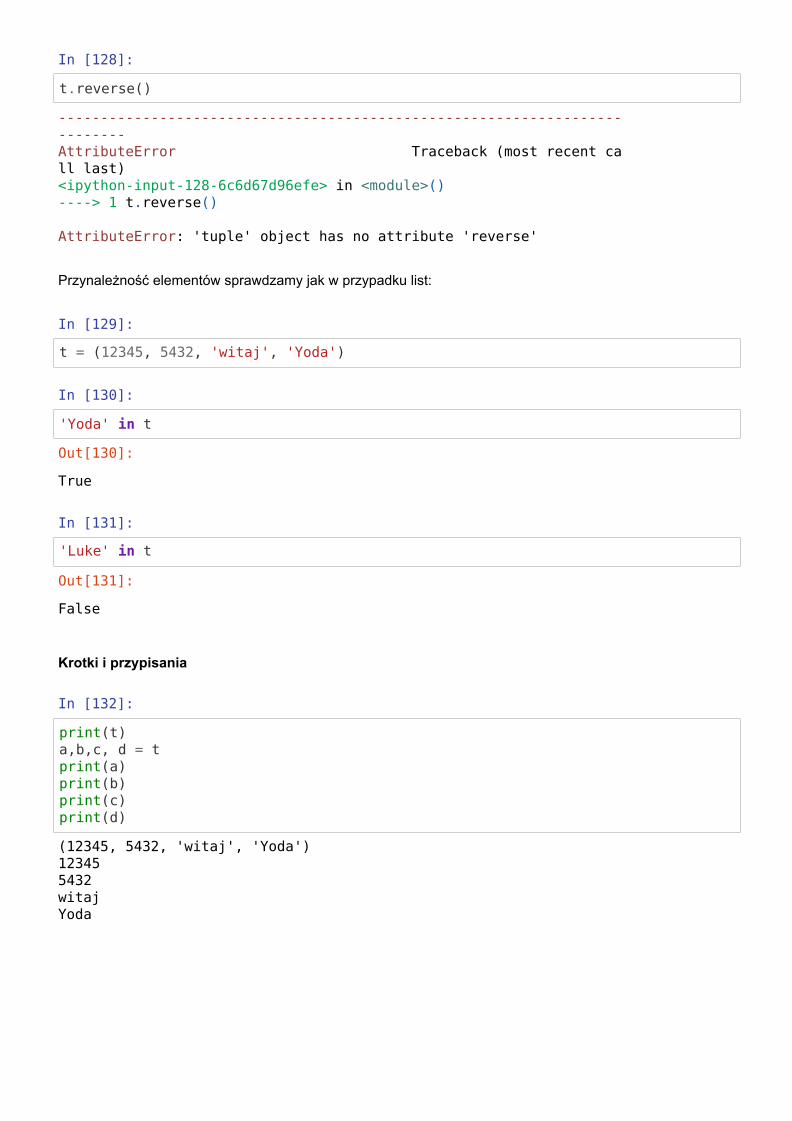
In [128]:
t.reverse()
Przynależność elementów sprawdzamy jak w przypadku list:
In [129]:
t = (12345, 5432, 'witaj', 'Yoda')
In [130]:
'Yoda' in t
In [131]:
'Luke' in t
Krotki i przypisania
In [132]:
print(t)a,b,c, d = tprint(a)print(b)print(c)print(d)
---------------------------------------------------------------------------AttributeError Traceback (most recent call last)<ipython-input-128-6c6d67d96efe> in <module>()----> 1 t.reverse()
AttributeError: 'tuple' object has no attribute 'reverse'
Out[130]:
True
Out[131]:
False
(12345, 5432, 'witaj', 'Yoda')123455432witajYoda
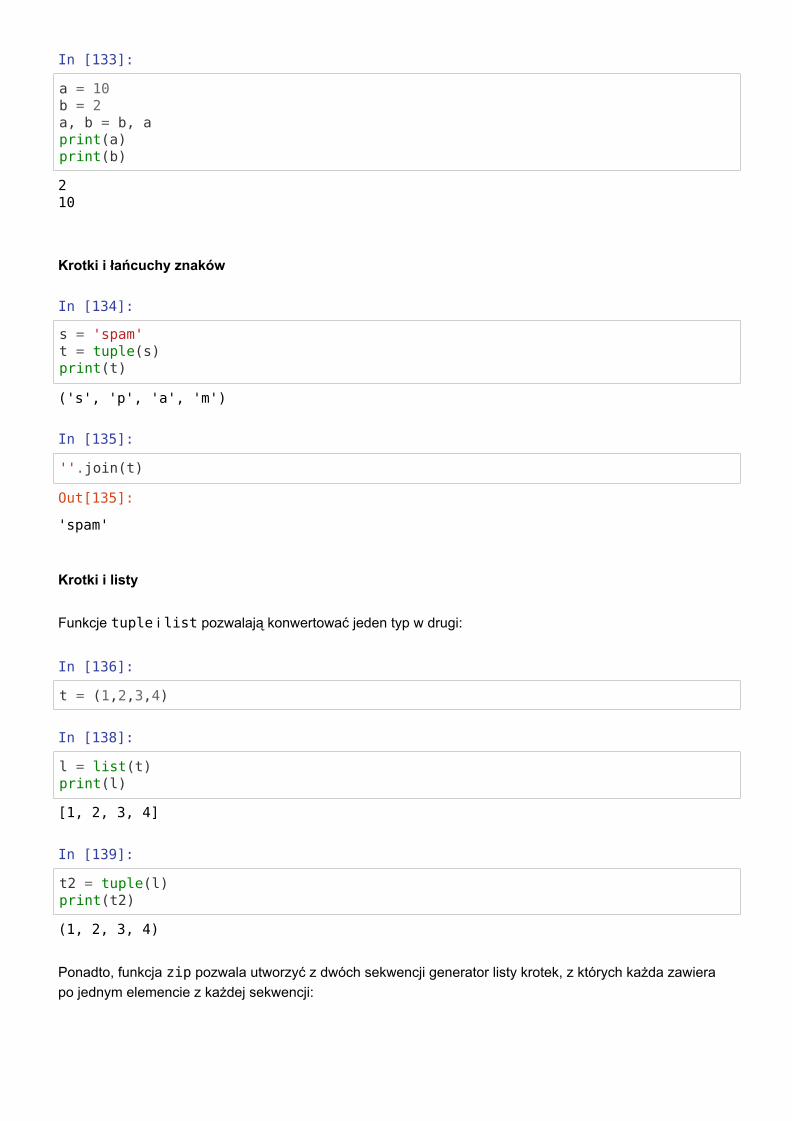
In [133]:
a = 10b = 2a, b = b, aprint(a)print(b)
Krotki i łańcuchy znaków
In [134]:
s = 'spam't = tuple(s)print(t)
In [135]:
''.join(t)
Krotki i listy
Funkcje tuple i list pozwalają konwertować jeden typ w drugi:
In [136]:
t = (1,2,3,4)
In [138]:
l = list(t)print(l)
In [139]:
t2 = tuple(l)print(t2)
Ponadto, funkcja zip pozwala utworzyć z dwóch sekwencji generator listy krotek, z których każda zawierapo jednym elemencie z każdej sekwencji:
210
('s', 'p', 'a', 'm')
Out[135]:
'spam'
[1, 2, 3, 4]
(1, 2, 3, 4)

In [142]:
s = 'abcd't = 1,2,3,4zip(s,t)
In [143]:
list(zip(s,t))
Przy tym, jeśli sekwencje są różnych długości, wynikowa lista będzie miała długość krótszej z nich:
In [144]:
s1 = 'abc's2 = 'ABCD'list(zip(s1,s2))
Krotki i pętle
Funkcji zip oraz rozpakowywania krotek używa się często w pętlach for, aby iterować po elementachdwóch sekwencji jednocześnie:
In [146]:
s = 'abcd't = 1,2,3,4for litera, cyfra in zip(s,t): print(litera, cyfra)
Równie przydatna jest funkcja enumerate, która zwraca (na żądanie) pary (indeks,element) danejsekwencji (nie tylko krotki):
In [149]:
enumerate(s)
Out[142]:
<zip at 0x7fb1805118c8>
Out[143]:
[('a', 1), ('b', 2), ('c', 3), ('d', 4)]
Out[144]:
[('a', 'A'), ('b', 'B'), ('c', 'C')]
a 1b 2c 3d 4
Out[149]:
<enumerate at 0x7fb1804e96c0>

In [150]:
for index, element in enumerate(s): print(index, element)
Porównywanie krotek
Krotki, podobnie jak inne sekwencje, można ze sobą porównywać. Python porównuje ze sobą pierwszeelementy krotek, jeżeli są one równe, to drugie i tak aż do znalezienia różnicy. Po jej znalezieniuporównywanie zostaje przerwane:
In [151]:
(0,1,2) < (0,0,4)
In [152]:
(0,1,2) < (0,2,0)
SłownikiSłowniki to w pewnym sensie uogólnienia list. W listach indeksami są liczby całkowite, w przypadkusłowników mogą to być również inne typy. Najważniejsze własności tego typu danych:
definiują relację do między zbiorem kluczy a zbiorem wartościtablice asocjacyjne, odpowiadają typowi hash w Perlu lub instancji klasy Hashtable w Javiewartości mogą być dowolnego typukluczami mogą być łańcuchy znaków, liczby oraz krotki, o ile tylko nie zawierają elementów, któremogą być modyfikowalneklucze muszą być unikalneparę (klucz,wartość) można dodać lub usunąć w dowolnej chwilipary (klucz,wartość) w słowniku nie są uporządkowane
Deklaracja i dostęp do zawartości
In [154]:
tel = {'Yoda' : 1234, 'Chewie' : 5678, 'Luke' : 9002}print(tel)
1 1
0 a1 b2 c3 d
Out[151]:
False
Out[152]:
True
{'Chewie': 5678, 'Luke': 9002, 'Yoda': 1234}

In [155]:
tel2 = dict(Han=1111, R2D2=2222, C3P0=3333)print(tel2)
Do wartości odnosimy się przez klucz:
In [156]:
tel['Yoda']
Jednak przez wartość nie możemy odnieść się do klucza:
In [157]:
tel[1234]
Błąd ten oznacza, że podaliśmy klucz, który nie istnieje. Czasami sytuacja taka może pojawić się wprogramie. Wówczas mamy trzy możliwości:
pojawi się wyjątek (o tym już niedługo) i interpreter przerwie działanie programu, jak powyżejpojawi się wyjątek, ale program wyłapie ten wyjątek, odpowiednio zareaguje i będzie kontynuowałpracę (o tym też już wkrótce)program będzie po prostu działał, ponieważ odczytaliśmy wartość ze słownika w bezpieczny sposób
In [158]:
tel.get('Yoda','not found')
In [159]:
tel.get('Darth','not found')
Wartości w słowniku można zmieniać:
{'Han': 1111, 'C3P0': 3333, 'R2D2': 2222}
Out[156]:
1234
---------------------------------------------------------------------------KeyError Traceback (most recent call last)<ipython-input-157-399835b518f5> in <module>()----> 1 tel[1234]
KeyError: 1234
Out[158]:
1234
Out[159]:
'not found'
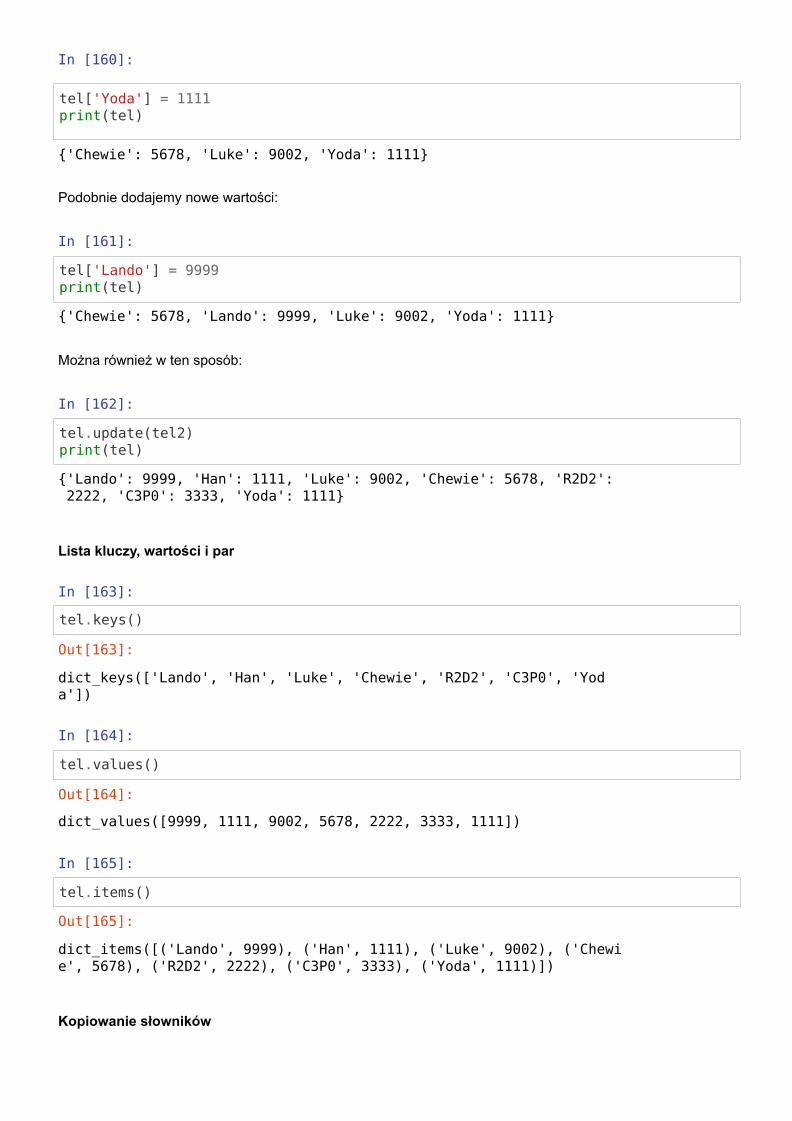
In [160]:
tel['Yoda'] = 1111print(tel)
Podobnie dodajemy nowe wartości:
In [161]:
tel['Lando'] = 9999print(tel)
Można również w ten sposób:
In [162]:
tel.update(tel2)print(tel)
Lista kluczy, wartości i par
In [163]:
tel.keys()
In [164]:
tel.values()
In [165]:
tel.items()
Kopiowanie słowników
{'Chewie': 5678, 'Luke': 9002, 'Yoda': 1111}
{'Chewie': 5678, 'Lando': 9999, 'Luke': 9002, 'Yoda': 1111}
{'Lando': 9999, 'Han': 1111, 'Luke': 9002, 'Chewie': 5678, 'R2D2': 2222, 'C3P0': 3333, 'Yoda': 1111}
Out[163]:
dict_keys(['Lando', 'Han', 'Luke', 'Chewie', 'R2D2', 'C3P0', 'Yoda'])
Out[164]:
dict_values([9999, 1111, 9002, 5678, 2222, 3333, 1111])
Out[165]:
dict_items([('Lando', 9999), ('Han', 1111), ('Luke', 9002), ('Chewie', 5678), ('R2D2', 2222), ('C3P0', 3333), ('Yoda', 1111)])
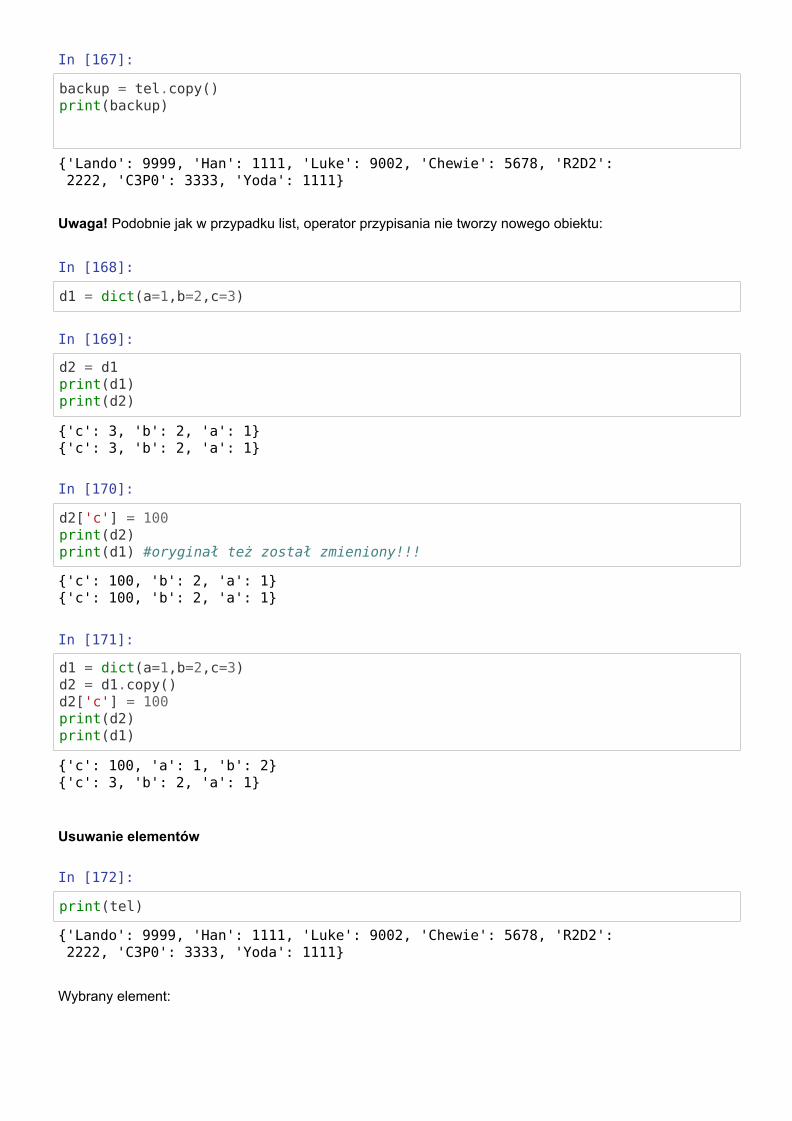
In [167]:
backup = tel.copy()print(backup)
Uwaga! Podobnie jak w przypadku list, operator przypisania nie tworzy nowego obiektu:
In [168]:
d1 = dict(a=1,b=2,c=3)
In [169]:
d2 = d1print(d1)print(d2)
In [170]:
d2['c'] = 100print(d2)print(d1) #oryginał też został zmieniony!!!
In [171]:
d1 = dict(a=1,b=2,c=3)d2 = d1.copy()d2['c'] = 100print(d2)print(d1)
Usuwanie elementów
In [172]:
print(tel)
Wybrany element:
{'Lando': 9999, 'Han': 1111, 'Luke': 9002, 'Chewie': 5678, 'R2D2': 2222, 'C3P0': 3333, 'Yoda': 1111}
{'c': 3, 'b': 2, 'a': 1}{'c': 3, 'b': 2, 'a': 1}
{'c': 100, 'b': 2, 'a': 1}{'c': 100, 'b': 2, 'a': 1}
{'c': 100, 'a': 1, 'b': 2}{'c': 3, 'b': 2, 'a': 1}
{'Lando': 9999, 'Han': 1111, 'Luke': 9002, 'Chewie': 5678, 'R2D2': 2222, 'C3P0': 3333, 'Yoda': 1111}
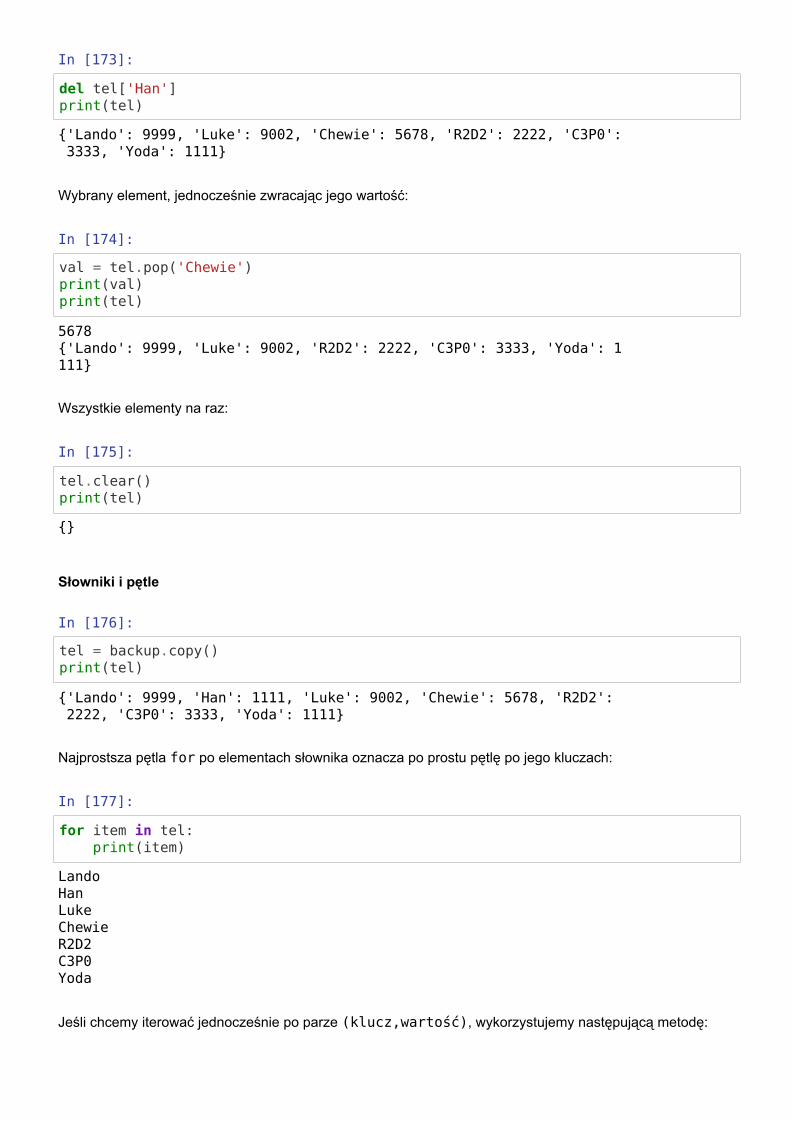
In [173]:
del tel['Han']print(tel)
Wybrany element, jednocześnie zwracając jego wartość:
In [174]:
val = tel.pop('Chewie')print(val)print(tel)
Wszystkie elementy na raz:
In [175]:
tel.clear()print(tel)
Słowniki i pętle
In [176]:
tel = backup.copy()print(tel)
Najprostsza pętla for po elementach słownika oznacza po prostu pętlę po jego kluczach:
In [177]:
for item in tel: print(item)
Jeśli chcemy iterować jednocześnie po parze (klucz,wartość), wykorzystujemy następującą metodę:
{'Lando': 9999, 'Luke': 9002, 'Chewie': 5678, 'R2D2': 2222, 'C3P0': 3333, 'Yoda': 1111}
5678{'Lando': 9999, 'Luke': 9002, 'R2D2': 2222, 'C3P0': 3333, 'Yoda': 1111}
{}
{'Lando': 9999, 'Han': 1111, 'Luke': 9002, 'Chewie': 5678, 'R2D2': 2222, 'C3P0': 3333, 'Yoda': 1111}
LandoHanLukeChewieR2D2C3P0Yoda

In [179]:
for key, val in iter(tel.items()): print(key, val)
W Pythonie 2.7 podobną funkcjonalność miała metoda iteritems.
Sortowanie słowników
Ogólnie słownik jest sekwencją nieuporządkowaną, co oznacza, że klucze i odpowiadające im wartościpojawiają się w pętli w przypadkowym porządku. Zawsze możemy jednak iterować po posortowanej liściekluczy:
In [180]:
for key in sorted(tel.keys()): print(key,tel[key])
Należy jednak pamiętać, że w ten sposób nie posortowaliśmy samego słownika, a raczej stworzyliśmy jegoreprezentację, która jest posortowana po kluczach.
Skoro już jesteśmy przy funkcji sorted, to oferuje ona również możliwość sortowania po wartościach:
In [181]:
for k in sorted(tel, key=tel.get, reverse=True): print(k, tel[k])
Lando 9999Han 1111Luke 9002Chewie 5678R2D2 2222C3P0 3333Yoda 1111
C3P0 3333Chewie 5678Han 1111Lando 9999Luke 9002R2D2 2222Yoda 1111
Lando 9999Luke 9002Chewie 5678C3P0 3333R2D2 2222Han 1111Yoda 1111

In [182]:
for k in sorted(tel, key=tel.get): print(k, tel[k])
Zbiory
Zbiór to nieuporządkowana kolekcja unikalnych elementów.
Deklaracja
In [183]:
z1 = set('abracadabra')print(z1)z2 = set('alacazam')print(z2)
Zwróćmy uwagę, że w wynikowych zbiorach nie ma powtórzeń. Dlatego ich podstawowe zastosowanie tousuwanie powtórzeń z innych sekwencji:
In [184]:
liczby = [1,2,3,4,5,4,3,3,6,5,1]zbior = set(liczby)print(zbior)unikalne_liczby = list(zbior)print(unikalne_liczby)
Operacje na zbiorach
Różnica zbiorów to elementy, które należą do jednego zbioru, i nie należą do drugiego:
Han 1111Yoda 1111R2D2 2222C3P0 3333Chewie 5678Luke 9002Lando 9999
{'d', 'c', 'r', 'a', 'b'}{'m', 'c', 'z', 'a', 'l'}
{1, 2, 3, 4, 5, 6}[1, 2, 3, 4, 5, 6]

In [185]:
print(z1)print(z2)z1 - z2
Suma zbiorów to wszystkie elementy, które należą albo do jednego albo do drugiego zbioru:
In [186]:
z1 | z2
Iloczyn zbiorów to ich część wspólna:
In [187]:
z1 & z2
Python posiada również operator sumy poprzecznej elementy, które należą do z1 lub z2, ale nie należą doich części wspólnej:
In [188]:
z1 ̂ z2
In [189]:
(z1 | z2) - (z1 & z2)
{'d', 'c', 'r', 'a', 'b'}{'m', 'c', 'z', 'a', 'l'}
Out[185]:
{'b', 'd', 'r'}
Out[186]:
{'a', 'b', 'c', 'd', 'l', 'm', 'r', 'z'}
Out[187]:
{'a', 'c'}
Out[188]:
{'b', 'd', 'l', 'm', 'r', 'z'}
Out[189]:
{'b', 'd', 'l', 'm', 'r', 'z'}












![Sieci komputerowe/Bezpiecze«stwo Janusz Szwabi«skitip.ift.uni.wroc.pl/la/w6.pdf · Kopiowanie plików pierwsze logowanie [ szwabin@voyager ~]$ ssh szwabin@panoramix . i f t . uni](https://static.fdocuments.pl/doc/165x107/5c76bd8809d3f2ff328c3375/sieci-komputerowebezpieczestwo-janusz-szwabi-kopiowanie-plikow-pierwsze.jpg)




