
Politechnika Łódzka · Zaproponowane rozwiązanie bazuje na technologii pamięci współdzielonej...
29
Politechnika Łódzka Katedra Mikroelektroniki i Technik Informatycznych Wydajna komunikacja międzyprocesowa dla złożonych systemów akwizycji STRESZCZENIE PRACY DOKTORSKIEJ Rolando Inglés Chávez Promotor: prof. dr hab. Andrzej Napieralski Współpromotor: dr inż. Mariusz Orlikowski Łódź, 2018
Transcript of Politechnika Łódzka · Zaproponowane rozwiązanie bazuje na technologii pamięci współdzielonej...

Politechnika Łódzka
Katedra Mikroelektroniki i Technik Informatycznych
Wydajna komunikacja międzyprocesowa dla
złożonych systemów akwizycji
STRESZCZENIE
PRACY DOKTORSKIEJ
Rolando Inglés Chávez
Promotor:
prof. dr hab. Andrzej Napieralski
Współpromotor:
dr inż. Mariusz Orlikowski
Łódź, 2018

ii
STRESZCZENIE
Celem niniejszej rozprawy było opracowanie biblioteki programistycznej
zawierającej obsługę niskopoziomowych mechanizmów związanych z przydziałem
pamięci dzielonej, wymianą danych oraz synchronizacji między procesami, aby
wesprzeć opracowywanie specjalizowanych aplikacji w systemach ITER-CODAC, w
których niezbędna jest obsługa dużych strumieni danych związanych z systemem
kontrolno-sterującym generatora TOKAMAK.
W pracy zaproponowano rozwiązanie pozwalające na przesyłanie danych pomiędzy
niezależnymi procesami za pomocą pamięci dzielonej. W rozwiązaniu zawarto dwa
główne komponenty. Pierwszy z nich odpowiedzialny jest za synchronizację procesów
przy użyciu mutexów i zmiennych warunkowych umieszczonych w pamięci dzielonej.
Drugi komponent rezerwuje pamięć dzieloną w niezależnych procesach, za pomocą
której następuje wymiana danych.
Zaproponowane rozwiązanie bierze pod uwagę dwa rodzaje procesów. Pierwszy z
nich nazwany producentem (ang. producer) odpowiedzialny jest za zbieranie danych z
czujników i zapamiętywanie ich we wstępnie zaalokowanym bloku pamięci dzielonej.
Drugi, nazwany konsumentem (ang. consumer) odpowiedzialny jest za odbiór
wszystkich dostępnych danych w blokach współdzielonej pamięci. Zaproponowane
rozwiązanie pozwala na opracowywanie wysokowydajnych aplikacji do wymiany
danych pracujących w schemacie producent/konsument, a w szczególności, gdy mamy
do czynienia z aplikacjami z jednym procesem producenta i wieloma procesami
konsumenta przesyłającymi dane, które umieszczane są we wspólnych segmentach
pamięci współdzielonej.
Zaproponowane rozwiązanie bazuje na technologii pamięci współdzielonej POSIX,
która pozwala na opracowywanie wysokowydajnych aplikacji do przesyłania danych
w systemach rodziny UNIX obsługujących tę technologię.
Wkładem niniejszej pracy w dziedzinę informatyki jest zaprojektowanie nowego,
wysokowydajnego i szybkiego mechanizmu komunikacji i synchronizacji pomiędzy
procesami wymaganego przy akwizycji danych na dużą skalę. Możliwe jest to do
osiągnięcia poprzez użycie obiektów synchronizacji (mutex, zmienne warunkowe) w

iii
pamięci współdzielonej. Dzięki temu komunikacja między procesami odbywa się
znacznie efektywniej poprzez wyeliminowanie dodatkowych opóźnień związanych z
kopiowaniem danych między buforami jądra systemu i użytkownika. To podejście
eliminujące kopiowanie danych (ang. zero-copy) jest wykorzystywane do transferu
danych z procesu producenta do procesów konsumentów, a wyspecjalizowany
menedżer pamięci z mechanizmem zero-copy jest częścią zaproponowanego
rozwiązania.

iv
SPIS TREŚCI Rozdział Strona
STRESZCZENIE ........................................................................................................... ii
SPIS TREŚCI ................................................................................................................ iv
Rozdział 1 Wstęp ........................................................................................................... 1
1.1 Projekt ITER ........................................................................................................ 1
1.1.1 TOKAMAK .................................................................................................. 1
1.1.2 CODAC System. ........................................................................................... 2
1.2 Przedstawienie problemu ..................................................................................... 3
1.3 Wkład dysertacji .................................................................................................. 3
1.4 Tezy...................................................................................................................... 4
Rozdział 2. Informacje podstawowe .............................................................................. 5
2.1 System akwizycji danych ..................................................................................... 5
2.2 Procesy i wątki ..................................................................................................... 5
2.2.1 Procesy .......................................................................................................... 5
2.2.2 Wątki ............................................................................................................. 5
2.3 Komunikacja międzyprocesowa .......................................................................... 6
2.4 Problem współbieżności ...................................................................................... 7
2.5.1 Synchronizacja i sekcja krytyczna ................................................................ 7
2.5.2 Sytuacja wyścigów........................................................................................ 7
2.5.3 Impasy ........................................................................................................... 8
Rozdział 3. Opis systemu ............................................................................................... 9
3.1 Wstęp ................................................................................................................... 9
3.2 Projekt logiczny ................................................................................................. 10
3.3 Wymagania ........................................................................................................ 10
3.3.1 Procesy ........................................................................................................ 10

v
3.3.2 IPC .............................................................................................................. 11
3.3.3 Pamięć ......................................................................................................... 11
3.3.4 Obciążenie CPU .......................................................................................... 11
Rozdział 4. Projekt systemu ......................................................................................... 12
4.1 Wstęp ................................................................................................................. 12
4.2 Podejście z pojedynczą wiadomością ................................................................ 12
4.2.1 Projekt fizyczny .......................................................................................... 12
4.3 Podejście z buforem pierścieniowym ................................................................ 13
4.3.1 Projekt fizyczny .......................................................................................... 13
4.4 Podejście z obszarem pamięci ........................................................................... 14
4.4.1 Projekt fizyczny .......................................................................................... 15
4.4.2 Działanie systemu ....................................................................................... 15
Rozdział 5. Test operacyjny ......................................................................................... 17
5.1. Źródło danych ................................................................................................... 17
5.3. Układ doświadczalny ........................................................................................ 18
5.4 Praca systemu..................................................................................................... 18
5.7 Wyniki doświadczalne ....................................................................................... 19
5.7.1 Blokada read-write ..................................................................................... 19
5.7.2 Semafory ..................................................................................................... 20
5.7.3 Mutex .......................................................................................................... 20
5.7.4 Spin-Lock .................................................................................................... 21
5.7.5 Atomic Read-Write Lock ............................................................................ 21
Rozdział 6. Wnioski ..................................................................................................... 23
Rozdział 7. Dodatek ..................................................................................................... 24

1
Rozdział 1 Wstęp Niniejsza rozprawa proponuje nowe rozwiązanie, w którym dane do komunikacji między
procesami oraz ich synchronizacji umieszczone są w dzielonej pamięci. Budując użyteczne
klasy oparte na dostępnych systemach współdzielonej pamięci IPC, rozprawa pokazuje, że
wysokowydajny system do szybkiego mechanizmu komunikacji i synchronizacji pomiędzy
procesami występującymi przy akwizycji danych na dużą skalę może być zaprojektowany.
Możliwe jest to do osiągnięcia poprzez użycie obiektów synchronizacji umieszczonych
również w pamięci współdzielonej. Dodatkowo, małe zużycie CPU osiągnięte zostało poprzez
zastosowanie specjalnego algorytmu do kontroli procesów czytania i zapisywania do i z bufora
dzielonej pamięci.
1.1 Projekt ITER
ITER jest najbardziej ambitnym projektem na świecie, którego celem jest zbadanie
ekonomicznych i technicznych możliwości fuzji nuklearnej poprzez magnetyczne ograniczenie
wytwarzanej energii. Jest to pierwszy krok do budowy pokazowego systemu przemysłowego
[1] [2].
Pomimo, że ITER jest w dalszym ciągu na etapie budowy, a pierwsza plazma ma być
wygenerowana w 2019 roku, następnym etapem, który już obecnie jest projektowany jest
budowa elektrowni pokazowej (ang. Demonstration Power Plant (DEMO)). Koncepcja
projektu DEMO planowana jest na rok 2017 a jego celem jest produkcja energii z fuzji
nuklearnej dla sektora przemysłowego. Przewiduje się, że uruchomienie DEMO nastąpi około
2030 roku a produkcja przemysłowa nastąpi około roku 2040 [4] [5].
1.1.1 TOKAMAK
„Tokamak” jest najbardziej obiecującym urządzeniem do produkcji energii elektrycznej
poprzez fuzję nuklearną przy użyciu ograniczenia magnetycznego. Słowo „tokamak” pochodzi
z rosyjskiego skrótu (“тороидальная камера с магнитными катушками”). Rysunek 1.1
pokazuje użycie urządzenia Tokamak w projekcie ITER jako maszyny eksperymentalnej do
fuzji cząstek plazmy produkującej ogromne ilości energii. Energia cieplna jest absorbowana w
ścianach urządzenia [1].

2
Rysunek 1.1 Tokamak [5]
Podobnie do elektrowni konwencjonalnych, Tokamak używa ciepło wytwarzane w czasie
fuzji do produkcji pary, która następnie używana jest do napędzania turbiny.
1.1.2 CODAC System.
CODAC (Control, Data Access and Communication System) jest zbiorem różnych
systemów odpowiedzialnych za monitorowanie urządzenia Tokamak używając lokalnych
systemów pomiarowych i kontrolnych. CODAC, będący centralnym systemem kontrolującym
działanie ITER’a, pokazany jest na Rysunku 1.2.
Rysunek 1.2 Architektura fizyczna systemu pomiarowego i kontrolnego [6]

3
Każdy z podsystemów wchodzących w skład architektury CODAC’a posiada własny system
zbierania danych z własnymi czujnikami i elementami wykonawczymi, sprzętem oraz
oprogramowaniem kontrolującym, alarmującym lub monitorującym wybrany aspekt
sterowania lub obserwowanego zjawiska [14] [15]. Każdy z tych podsystemów generuje
ogromne ilości danych i dlatego CODAC uważany jest za system przetwarzania danych dużej
skali.
1.2 Przedstawienie problemu
Podstawowym zagadnieniem poruszanym w tej rozprawie jest opracowywanie
wysokowydajnych aplikacji do przesyłania danych używając technologii współdzielonej
pamięci POSIX w systemach rodziny UNIX obsługujących tę technologię. Głównym celem tej
aplikacji jest zapewnienie indywidualnym aplikacjom dostępu do współdzielonej pamięci oraz
zapewnienie odpowiednich narzędzi do synchronizacji procesów, gdy „wyścig danych” (ang.
data races) wymaga odpowiedniego zarządzania. W ten sposób, proponowana aplikacja
pozwoli skorzystać w sposób efektywny z wbudowanych mechanizmów oraz z użycia
współdzielonej pamięci.
W szczególności niniejsza rozprawa poświęcona jest systemowi ITER-CODAC, w którym
wszystkie podsystemy generują duże ilości danych przychodzących z urządzeń kontrolujących,
czujników czy kamer. Podstawowy system przedstawiony jest na Rysunku 1.3. W systemie tym
pojedyncze niezależne programy reprezentujące jednego producenta i wielu konsumentów
uruchamiane są na głównym komputerze.
SHAREDMEMORYSEGMENT
PRODUCERRAW DATA
CONSUMER 1
CONSUMER 2
CONSUMER N
MONITORING SUBSYSTEM
ARCHIVING SUBSYSTEM
MONITORING SUBSYSTEM
Rysunek 1.3 Producent i Konsumenci
1.3 Wkład dysertacji
Wkładem tej dysertacji do informatyki jest opracowanie nowego, bardzo wydajnego
mechanizmu komunikacji pomiędzy procesowej we współdzielonej pamięci. Pozwala to na
synchronizację procesów tak szybko, jak to jest niezbędne w dużych systemach akwizycji
danych. Osiągnięte to jest poprzez zastosowanie obiektów synchronizacyjnych (mutexy,
zmienne warunkowe) w oparciu o współdzieloną pamięć. Komunikacja między procesami jest

4
bardziej wydajna, gdy używa się współdzielonej pamięci głównie z powodu wyeliminowania
kopiowania danych pomiędzy jądrem i buforami. To podejście „zero-copy” jest również
używane przy przekazywaniu danych pomiędzy producentem i procesami konsumentów. W
tym celu specjalistyczny manager pamięci z mechanizmem zero-copy włączony jest jako część
zaproponowanego rozwiązania.
1.4 Tezy
Niniejsza dysertacja zamierza podjąć wyzwania związane z przesyłaniem ogromnej ilości
danych poprzez użycie współdzielonej pamięci oraz wspólnych struktur danych.
Zagadnienia omówione w powyższych rozdziałach pozwalają na sformułowanie
następujących tez, dyskutowanych w następnych rozdziałach.
Teza 1
Użycie obiektów synchronizacji w pamięci dzielonej do komunikacji pomiędzy procesami
w systemach akwizycji danych na dużą skalę daje porównywalne wyniki do rozwiązań
używających wielowątkowego modelu programowania.
Teza 2
Możliwe jest wykonanie oprogramowania opartego na pamięci dzielonej do tworzenia
niezależnych wieloprocesowych aplikacji pracujących w modelu producent/konsumer, które
mogą być użyte w systemach akwizycji na dużą skalę z wysoką przepustowością strumieni
danych.

5
Rozdział 2. Informacje podstawowe
2.1 System akwizycji danych
System akwizycji danych (ang. Data Acquisition - DAQ) może być zdefiniowany jako
proces odpowiedzialny za pomiar zjawisk rzeczywistych i przetwarzanie pozyskanych danych
w odpowiednio sformatowane dane przetwarzane komputerowo przez specjalistyczne
oprogramowanie. DAQ uważany jest za system, gdy posiada aspekt kontrolny wobec
pozyskanych danych pozwalając tym samym monitorować i kontrolować cały system [16] [17].
Podstawowe składowe systemu DAQ przedstawione są na Rysunku 2.1 i mogą być opisane
następująco [18]:
Czujnik/miernik/kamera mierzy dane rzeczywiste,
Pomiar zostaje zmieniony na sygnał elektryczny,
Hardware sytemu DAQ zamienia sygnał elektryczny na sygnał cyfrowy,
Oprogramowanie systemu DAQ steruje działanie hardwaru DAQ i przetwarza dane
do transmisji do specjalistycznych aplikacji softwarowych w celu kontroli systemu.
Data Acquisition Software
Data Acquistion Hardware
SENSORS
TRANSDUCERS
ACTUATORS
CAMERAS
REAL WORLD PHENOMENA
Rysunek 0.1: Wykres funkcjonalny systemu akwizycji danych [18] [19]
2.2 Procesy i wątki
2.2.1 Procesy
Działanie programu nazywamy procesem. Zaawansowane metody programowania często
używają wielu współpracujących procesów w jednej aplikacji w celu umożliwienia aplikacji
wykonywania więcej niż jednej czynności jednocześnie, jak również w celu zwiększenia
niezawodności działania lub użycia już istniejących programów [25]. Proces jest jednostką
pracy wykonanej przez system operacyjny. Proces i program niekoniecznie są równoważne.
Procesy są artefaktami systemu operacyjnego, gdy tymczasem programy są artefaktami
programistów [26].
2.2.2 Wątki
Koncepcja wątku pozwala programowi wykonać więcej niż jedno zadanie w danym czasie.
Podobnie jak procesy, wątki mogą być wykonywanie jednocześnie. Są one uruchamiane przez

6
system operacyjny asynchronicznie i są przerywane od czasu do czasu aby dać szansę
wykonania operacji innym [25].
Koncepcyjnie, wątki istnieją w procesie. Kiedy program jest wywołany, system operacyjny
kreuje nowy proces i w tym procesie wytworzony jest pojedynczy wątek, tak więc program
wykonywany jest sekwencyjnie.
2.3 Komunikacja międzyprocesowa
Komunikacja międzyprocesowa (ang. Inter-Process Communication - IPC) opisuje różne
mechanizmy współdzielenia danych (przekazywanie wiadomości) pomiędzy niezależnymi
procesami w jakimś systemie operacyjnym. Z rozwojem technologii współdzielonej pamięci
wbudowanej w nowoczesnych procesorach, IPC nie ogranicza się jedynie do przekazywania
danych pomiędzy procesami. Zawiera on również wyspecjalizowane mechanizmy do
synchronizacji dostępu dwóch lub więcej niezależnych procesów do wyznaczonych obszarów
pamięci [29] [30].
Rysunek 2.2 pokazuje podstawowe nazewnictwo używane przez mechanizmy IPC
pogrupowane zgodnie z ich użyciem. Gniazdo (ang. socket), współdzielona pamięć oraz
technologia kolejności sygnałów uważane są za mechanizmy komunikacji IPC używane do
wymiany pakietów danych (ang. packet of data) pomiędzy procesami [31] [32].
SIGNALING
IPC
SOCKET
SHARED MEMORY
MESSAGE QUEUE
SEMAPHORE
MUTEX
CONDITION VARIABLE
Rysunek 0.2 Nazewnictwo mechanizmu IPC [17]

7
2.4 Problem współbieżności
W terminologii komputerowej, współbieżność oznacza, że jeden system wykonuje wiele
niezależnych zadań równocześnie, a nie jedno po drugim. Wielozadaniowe systemy operacyjne
dają wrażenie, że wykonują wiele aplikacji równocześnie poprzez zamiany zadań [55]. Oznacza
to, że współbieżność może występować bez rzeczywistego wykonywania zadań równolegle.
To ostatnie wymaga wielu procesorów (CPUs). Oznacza to, że współbieżność umożliwia
działanie kilku procesów, ale niekoniecznie jednocześnie. Z wykonaniem równoległym,
zadania są rzeczywiście wykonywane jednocześnie [34].
2.5.1 Synchronizacja i sekcja krytyczna
Programy wieloprocesowe i wielowątkowe są skomplikowane ponieważ wykonywane są
jednocześnie, ale nie wiadomo kiedy system operacyjny uruchomi dany proces lub wątek, a
kiedy inny. System operacyjny może zamienić jeden proces na inny bardzo prędko. Gdy
używany jest system z wieloma procesorami, system operacyjny może wyznaczyć jednoczesne
wykonanie wielu procesów. Pisanie programów współdziałających jest trudne i jeśli w trakcie
wykonywania programu pojawi się problem, trudno jest go powtórzyć. Program może działać
prawidłowo raz, a gdy wywołany jest innym razem może nie działać poprawnie [25].
2.5.2 Sytuacja wyścigów
Gdy dwa lub więcej zadania próbują użyć tego samego zasobu i gdy prowadzi to do błędnego
wykonania zadania w czasie egzekucji programu, mamy do czynienia z sytuacją wyścigu [35].
Wspólny zasób może oznaczać urządzenie sprzętowe, jądro lub też współdzieloną pamięć. Ten
ostatni przypadek występuje najczęściej i nazywa się wyścigiem danych [34].
Wyścig danych zdefiniowany jest przez następujące sytuacje [56]:
Dwie operacje zajmują dokładnie te same obszary pamięci; to znaczy, to samo pole w
tym samym obiekcie i przynajmniej jedna z nich jest operacją pisania (write).
Różne procesy wykonują dwie operacje dostępu.
Wspólny obiekt synchronizujący, jak na przykład blokada, nie kontroluje dwóch
operacji dostępu i nie ma określonego porządku w jaki te dwa dojścia mają być
wykonane.
Część kodu gdzie wywoływana jest współdzielona pamięć nazywa się obszarem krytycznym.
By zapewnić spójność danych, obszary krytyczne muszą zawierać mechanizmy
synchronizujące takie jak: semafory, file-lock, mutex oraz zmienne warunkowe (ang. condition
variables) [38].

8
2.5.3 Impasy
Gdy chcemy aby różne procesy mogły jednocześnie użyć współdzielonych zasobów,
proponowane rozwiązania niosą ze sobą wiele problemów. Procesy te mają być wykonywane
jednocześnie, ale to może prowadzić do sytuacji wyścigów. Jako rozwiązanie wprowadza się
mutexy, ale one powodują inny rodzaj błędu programowania zwany impasem (ang. deadlock)
[34].
Deadlock występuje wtedy, gdy dwa procesy czekają na siebie, aż ten drugi skończy, ale
żaden z nich w rzeczywistości nie kończy. Gdy dotyczy to mutexów, dwa procesy czekają na
mutex, który jest w posiadaniu jednego z nich. Ekstremalny przypadek deadlock występuje
wtedy gdy proces czeka na mutex, który jest mu już przypisany. Debugowanie takich sytuacji
jest bardzo trudne i zdradliwe ponieważ program nie musi się zawiesić. Zamiast tego, program
może zaprzestać produkowania jakichkolwiek rezultatów czekając na coś co nigdy nie nastąpi
[34].

9
Rozdział 3. Opis systemu
3.1 Wstęp
Proponowane rozwiązanie idzie naprzeciw wymaganiom zaproponowanym przez
architekturę systemu ITER-CODAC, w którym systemy kontrolne generują i przetwarzają
ogromne ilości danych w czasie rzeczywistym wykorzystując wydajne CPU lub GPU [77]. To
wymaga wydajnego buforowania danych by je przesyłać pomiędzy systemami kontrolującymi
i synchronizacyjnymi [73]. Rozwiązanie składa się z dwóch składników: alokatora dzielonej
pamięci i współdzielonych obiektów synchronizujących. Alokator pamięci jest odpowiedzialny
za przydział i identyfikację każdego segmentu wspólnej pamięci w celu komunikowania
danych i synchronizacji procesów. Obiekty synchronizujące, które umieszczone są w
wyznaczonych obszarach wspólnej pamięci, używane są do kontroli wyścigu danych w
obszarach krytycznych. Tworzone są one w dwóch rodzajach procesów: producenta i
konsumenta. Z ogólnego punktu widzenia, opracowanie rozwiązania pozwalającego na
kontrolę wszystkich wywołań niskopoziomowych oraz stworzenia struktury
producenta/konsumenta, wymaga spełnienia szeregu wymagań. Podstawowym wymaganiem
jest stworzenie wszystkich niezbędnych narzędzi do obsługi pamięci dzielonej tak, aby były
dostępne i pozwalały na komunikację wszystkich procesów przypisanych do regionu dzielonej
pamięci. Ogólny widok proponowanego rozwiązania przedstawiony jest na Rysunku 3.1.
PROCESSES SYNCHRONIZATION
SHARED-MEMORY MANAGER
Create Shared Buffer for Data
Transfer
Attach Shared Resources
Notify about new data is available
Wait for data
ProducerProcess
ConsumerProcess
Write data into the shared buffer
Create Shared Segments for IPC
Read data from shared buffer
Wait for free space for data
Notify data has been read
Rysunek 3.1 Ogólne spojrzenia na najważniejsze zastosowania

10
3.2 Projekt logiczny
Rysunek 3.2 przedstawia strukturę logiczną rozwiązania zgodną z funkcjonalnością jego
komponentów. Najpierw obiekty synchronizacyjne zawarte są w zbiorze klas gdzie mutexy oraz
zmienne warunkowe zostały umieszone w dzielonej pamięci. Oznacza to, że elementy zależne
są od menadżera pamięci, który umieszcza je w segmencie dzielonej pamięci. Następnie,
menadżer pamięci kontroluje tworzenie segmentów współdzielonej pamięci. Jest on
odpowiedzialny za identyfikację każdego wspólnego obszaru pracy tak, aby był dostępny dla
wszystkich procesów.
DATA ACQUISITIONHARDWARE
DATA ACQUISITION SOFTWARE
DATA MANAGEMENT
OFF-LINE ANALYSIS
CRITICAL SYSTEM
ADVANCED SYSTEM
DRIVER SHARED MEMORY
Process Synchronization
Synchronization Objects
Memory Allocation
Shared Memory Segments
PRODUCER
CONSUMER1
CONSUMERn
DatabaseDatabase
Rysunek 3.2 Projekt logiczny struktury
3.3 Wymagania
3.3.1 Procesy
Biblioteka powinna pozwolić na stworzenie procesów producenta i konsumenta. Proces
producenta jest odpowiedzialny za wypełnienie bufora pierścieniowego (ang. ring-buffer),
a każdy konsument odpowiada za czytanie danych z tego bufora.
Proces producenta jest odpowiedzialny za pobranie danych z urządzenia sprzętowego
poprzez wywołanie odpowiednich funkcji sterujących. Przed każdym wywołaniem,
producent musi otrzymać wolne miejsce w buforze pierścieniowym prosząc o nie alokatora
pamięci.
Procesy konsumenta powinny pracować w trybie „batch mode” aby otrzymywać ramki z
pamięci pierścieniowej w taki sposób, że gdy istnieje obszar danych pomiędzy obecnie
używanym miejscem i końcowym segmentem pamięci pierścieniowej, wszystkie dane z
tego obszaru muszą być dostępne dla procesów konsumenta, aby dotrzeć do ostatniego
segmentu pamięci pierścieniowej.
Zakończenie procesów producenta i konsumenta powinno odbywać się dwojako. Najpierw,
sygnał EOF wysłany jest do konsumentów, należy odczekać aż sygnał EOF dotrze do

11
każdego z nich w buforze pierścieniowym. Druga metoda polega na wysłaniu sygnału do
konsumentów, aby natychmiast zakończyły przetwarzanie.
3.3.2 IPC
Współdzielona zmienna warunkowa (ang. Shared Condition Variable) powinna być
zastosowana by wskazać procesowi konsumenta, że dostępna jest ramka w buforze
pierścieniowym.
Oczekiwanie przy użyciu zmiennych warunkowych powinno być użyte. Oznacza to, że gdy
tylko jest to możliwe należy unikać nieskończonych cykli.
Najlepiej, aby użyta została metoda reakcji do zakomunikowania procesom konsumenta, że
nowe dane powinny być pobrane.
Jakiś proces monitorowania powinien być zaimplementowany w taki sposób by umożliwić
dwustronną komunikację pomiędzy producentem i procesami konsumenta. To podejście
powinno pomóc w synchronizacji i identyfikacji wolnego miejsca w buforze
pierścieniowym.
3.3.3 Pamięć
W momencie tworzenia procesu producenta, cała pamięć użyta przez bufor pierścieniowy
powinna być alokowana, aby uniknąć późniejszej alokacji pamięci (e.g. malloc, kmalloc,
new) gdy potrzebne jest więcej miejsca.
Efektywne zarządzanie tą pamięcią należy do klasy alokatora pamięci tak, aby zapewnić
jak najmniejszą fragmentaryzację.
Adres pamięci gdzie ramka jest dostępna powinna być obliczona używając bazowego
adresu bufora pierścieniowego, tj. adresu pamięci gdzie przechowywana jest pierwsza
ramka.
Z powodu różnorodności systemów kontrolnych będących składowymi architektury
CODAC’a, różnorakie formaty i rozmiary bloków danych źródłowych muszą być
przechowywane we współdzielonym buforze [82] [83].
3.3.4 Obciążenie CPU
Osiągnięcie wysokiej wydajności jest głównym celem proponowanej struktury, jednakże
należy również pamiętać o obciążeniu CPU. Aby pozostawić część zasobów CPU do
wykonywania dodatkowych zadań, struktura powinna pracować przy małym obciążeniu
CPU tak długo jak to jest możliwe bez obniżania wydajności przepływu danych i działań
synchronizacyjnych.

12
Rozdział 4. Projekt systemu
4.1 Wstęp
W tym rozdziale wyjaśnione jest działanie operacji używanych przez system do
współdzielenia danych pomiędzy niepowiązanymi ze sobą procesami. Szczególna uwaga
poświęcona jest wspomnianym w rozdziale drugim zagadnieniom użycia mechanizmów IPC
dla uniknięcia wyścigów danych i zachowania ich integralności. W trakcie projektowania
systemu mutexy, semafory, futexy, zmienne atomowe i blokady read-write zostały wzięte pod
uwagę do kontroli dostępu do wybranego segmentu pamięci dzielonej. Zarówno procesy
producenta i konsumentów muszą być informowane gdy dane mogą być zapisane lub
odczytane. Osiąga się to poprzez użycie zmiennych warunkowych (ang. condition-variables),
które są tak zaprojektowane aby czekać na zawiadomienie, albo czekając przez krótki ustalony
czas gdy są skonfigurowane w trybie TIMEWAIT.
4.2 Podejście z pojedynczą wiadomością
Pierwszym prototypem zastosowanym do oceny dzielonej pamięci jako najszybszej metody
komunikacji między procesami było zastosowanie jednej komórki do współdzielenia danych,
co oznacza, że w danym momencie czasowym tylko jedna dana może być przesłana od
producenta do konsumenta. Dodatkowo użyto dwóch obiektów synchronizujących. Jeden w
procesie publikacji pozwalający producentowi poinformować, że nowe dane zostały
opublikowane, a drugi dla procesu konsumenta pozwalający konsumentowi powiadomić
producenta, że dane zostały odczytane.
4.2.1 Projekt fizyczny
Diagram klas na Rysunku 4.1 przedstawia elementy struktury i ilustruje jak podejście z
pojedynczą wiadomością zostało zorganizowane. Interfejsy dla aplikacji w opracowanym
rozwiązaniu zostały zrealizowane poprzez klasy producenta i konsumenta. Ponieważ system
został zaprojektowany przy użyciu wzorców, dowolne typy danych mogą być przesyłane
pomiędzy procesami.

13
message data type
producer
base
process mode,message data type
process modeprocess mode
shared data type
process modeshared data type
process mode,synchronization object
process mode,control data type
process mode,message data type
message data type
consumer
<interface>channel
data
<interface>shared resource
process
data channel
progress control channel
synchronization process channel
Rysunek 4.1 Projekt fizyczny podejścia z pojedynczą wiadomością
4.3 Podejście z buforem pierścieniowym
Drugi prototyp oparty jest na strukturze bufora pierścieniowego. Przy tym podejściu,
ustalony obszar wspólnej pamięci jest alokowany i dzielony na komórki. Każda komórka lub
blok pamięci jest logicznie połączony z miejscem w buforze pierścieniowym i jest dostępny
sekwencyjnie.
4.3.1 Projekt fizyczny
Wykres klas na Rysunku 4.2 przedstawia elementy systemu i ilustruje, jak podejście z
buforem pierścieniowym zostało zorganizowane. Interfejsy dla aplikacji w opracowanym
rozwiązaniu zostały zrealizowane poprzez klasy producenta i konsumenta. Ponieważ struktura
została zaprojektowana przy użyciu wzorców, dowolne, dobrze zdefiniowane typy danych
mogą być przesyłane pomiędzy procesami.
Segment z danymi w buforze pierścieniowym został zdefiniowany w wymaganiach
projektu. Dodatkowo do zarządzania buforem opracowano dwie klasy bazujące na klasie bufora
pierścieniowego i odpowiednio dla klas IPC producenta i konsumenta. Bufor pierścieniowy
producenta odpowiedzialny jest za publikowanie danych oraz za zawiadamianie producenta, że
nowe dane zostały opublikowane a drugi dla procesu konsumenta pozwalający na zbieranie
danych przez konsumenta oraz zawiadamianie, gdy dane zostały pobrane.

14
message data type
producer
base
process mode,message data type
process mode
process mode,shared data type
process mode,shared data type
process mode,synchronization object
process mode,control data type
process mode,message data type
message data type
consumer
<interface>channel
<interface>shared resource
process mode,message data type
process mode,message data type
process mode,message data type
message data type
message data type
ring-buffer producer
ring-buffer consumer
ring-bufferring-buffer
process
shared-memory
processdata progress control channel
data channel
synchronization process channel
Rysunek 4.2 Projekt fizyczny z podejściem z buforem pierścieniowym
4.4 Podejście z obszarem pamięci
Ostatni prototyp zbudowany dla spełnienia zadań postawionych w tej dysertacji oparty jest
na algorytmie bufora pierścieniowego przedstawionego jako prototyp numer dwa z tym, że
sygnalizacja odbywa indywidualnie dla każdego bloku pamięci. Zamiast używać dwóch
globalnych obiektów sygnalizujących pomiędzy producentem i konsumentami, każdy obszar
pamięci posiada własny zestaw obiektów synchronizujących. W takim podejściu nie ma
potrzeby sprawdzania czy nowe dane są dostępne w bieżącym bloku, aż do konsumenta nie
dotrze sygnał związany z tym blokiem.
Trzeba podkreślić, że to podejście wymaga dwóch buforów pierścieniowych: jednego dla
danych, a drugiego dla sygnalizacji. To oczywiście wymaga większej ilości pamięci. Tym
niemniej, to podejście przyczynia się bezpośrednio do zmniejszenia użycia CPU, ponieważ
procesy nie wykonują się aż do czasu gdy odpowiedni sygnał zostaje wysłany dla określonego
obszaru pamięci.
Pomimo, że to podejście zostało zaprojektowane z myślą o zmniejszeniu użycia CPU
generowanego przez globalny obiekt synchronizacyjny oraz zmniejszenia czasu oczekiwania
na sygnały pomiędzy procesami, trzeba pamiętać, że podejście to wymaga zapewnienia
dodatkowego miejsca w buforze pierścieniowym dla obiektów synchronizujących.

15
4.4.1 Projekt fizyczny
By pozwolić na sygnalizację pomiędzy procesami dla każdego obszaru danych, dodatkowy
bufor pierścieniowy został wkomponowany w strukturę opisaną wcześniej. Jak pokazano na
rysunku 4.3 klasy per-slot-producer i per-slot-consumer zostały zaimplementowane,
dziedziczą one klas syn-obj-per-slot-process i zawierającą jako składową per-slot ring-buffer.
message data type
producer
base
process mode,message data type
message data type
consumer
process mode,slab data type
process mode,slot data type
process mode,message data type
message data type
message data type
per-slot producer
per-slot consumer
ring-buffer
shared-memoryprocess mode
process mode
process mode,shared data type
<interface>shared resource
process mode,sync-obj data type
sync-obj per-slotring-buffer
progress control synch-object
progress control data
process
sync-obj per-slotprocess
Rysunek 4.3 Projekt fizyczny podejścia obszarowego
Ponieważ bufor pierścieniowy jest używany do budowy obiektów synchronizujących, taki
bufor jest zaprojektowany z tą samą liczbą elementów jak bufor pierścieniowy z danymi. Jak
podkreślono w poprzednim rozdziale, zużycie współdzielonej pamięci jest większe gdy stosuje
się to podejście, ale w zamian otrzymujemy bardziej efektywny sposób sygnalizacji pomiędzy
procesami.
4.4.2 Działanie systemu
W przeciwieństwie do podejść przedstawionych w poprzednich rozdziałach, gdzie dwa te
same obiekty synchronizujące były używane do komunikacji pomiędzy procesami, niniejsze
podejście używa dwa różne obiekty synchronizujące jak pokazano na Rysunku 4.4. Pomysł
zastosowania dwóch różnych obiektów synchronizujących związany jest określeniem
końcowych bloków, do których możliwy jest zapis i odczyt.

16
01 2
...
nn-1 n-2
n-3
Last slot published and Ready
to be consumed
slot being consumed
Last slot readyto be
published
publishing limit slot
consuming limit slot
producerpublishing
slotsready to be
consumed
(by the slower consumer)
slot being consumed
(by the any consumer)
Rysunek 4.4 Obiekty synchronizujące w podejściu obszarowym bufora pierścieniowego
Można zaobserwować, że pozycja obszaru publishing-limit-slot zależy od prędkości, z którą
wolniejszy konsumer zawiadamia, że ten obszar jest gotowy do ponownego zapisania przez
nowe dane. Dodatkowo, consuming-limit-slot przesuwa się do przodu wraz z nowo
publikowanymi danymi dopóki jest wolny choć jeden obszar pomiędzy blokami
przetwarzanymi przez producenta i konsumentów.
17
Rozdział 5. Test operacyjny
5.1. Źródło danych
Typowe urządzenie stosowane w architekturze ITER-CODAC do monitorowania
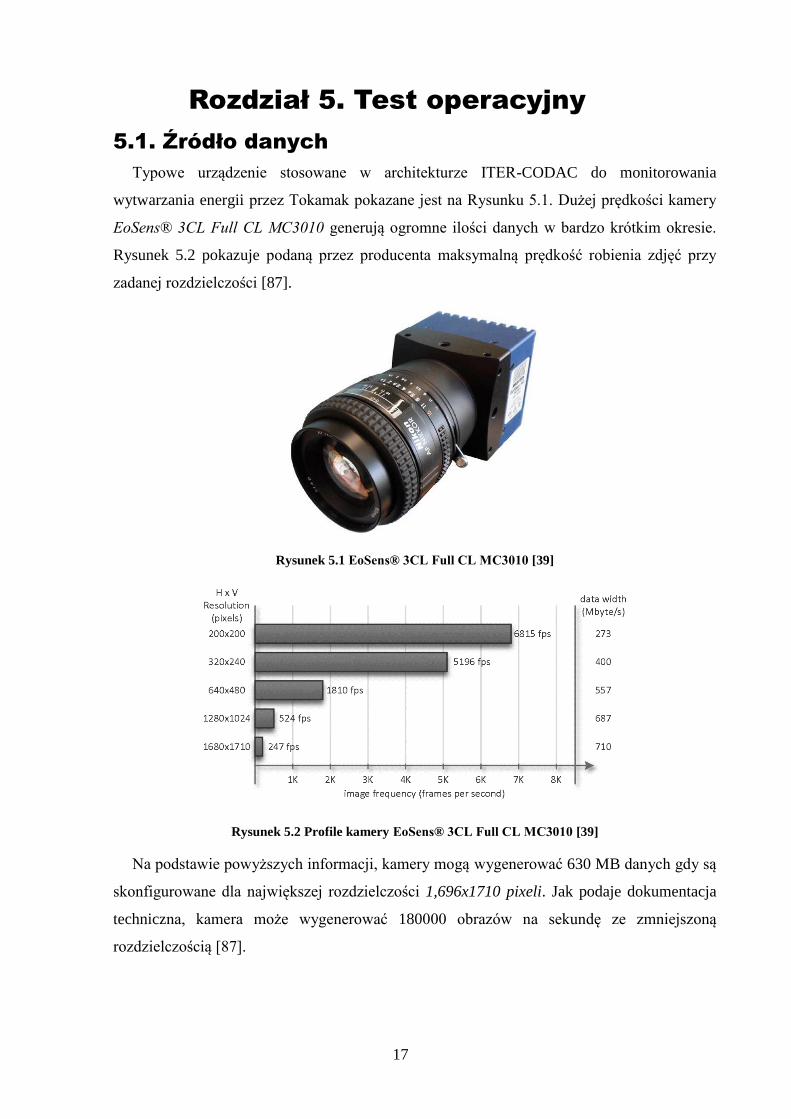
wytwarzania energii przez Tokamak pokazane jest na Rysunku 5.1. Dużej prędkości kamery
EoSens® 3CL Full CL MC3010 generują ogromne ilości danych w bardzo krótkim okresie.
Rysunek 5.2 pokazuje podaną przez producenta maksymalną prędkość robienia zdjęć przy
zadanej rozdzielczości [87].
Rysunek 5.1 EoSens® 3CL Full CL MC3010 [39]
Rysunek 5.2 Profile kamery EoSens® 3CL Full CL MC3010 [39]
Na podstawie powyższych informacji, kamery mogą wygenerować 630 MB danych gdy są
skonfigurowane dla największej rozdzielczości 1,696x1710 pixeli. Jak podaje dokumentacja
techniczna, kamera może wygenerować 180000 obrazów na sekundę ze zmniejszoną
rozdzielczością [87].

18
5.3. Układ doświadczalny
Symulacje zostały przeprowadzone przy użyciu Red Hat Enterprise Linux Workstation
release 6.5 (Santiago) distribution with the Linux® Kernel 2.6.32-431.20.3.el6.x86_64 oraz
posiadający następujące parametry hardwarowe:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 16
On-line CPU(s) list: 0-15
Thread(s) per core: 2
Core(s) per socket: 4
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU MHz: 2526.976
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 8192K
System został skonfigurowany z 24 GB pamięci RAM. Dystrybutor Linux g++ (GCC) 4.4.7
20120313 (Red Hat 4.4.7-4) kompilator i cały kod źródłowy został skompilowany przy użyciu
flagi –O3 pozwalając użytkować wszystkie cechy optymalizacyjne charakteryzujące ten
kompilator.
5.4 Praca systemu
Zgodnie z wymaganiami ITER-CODAC, dane powinny być odczytane ze sprzętu
zbierającego dane i umieszczone w dzielonym buforze pamięci przez proces nazwany
producentem. Jednocześnie, inne procesy zwane konsumentami, pobierają dane z dzielonej
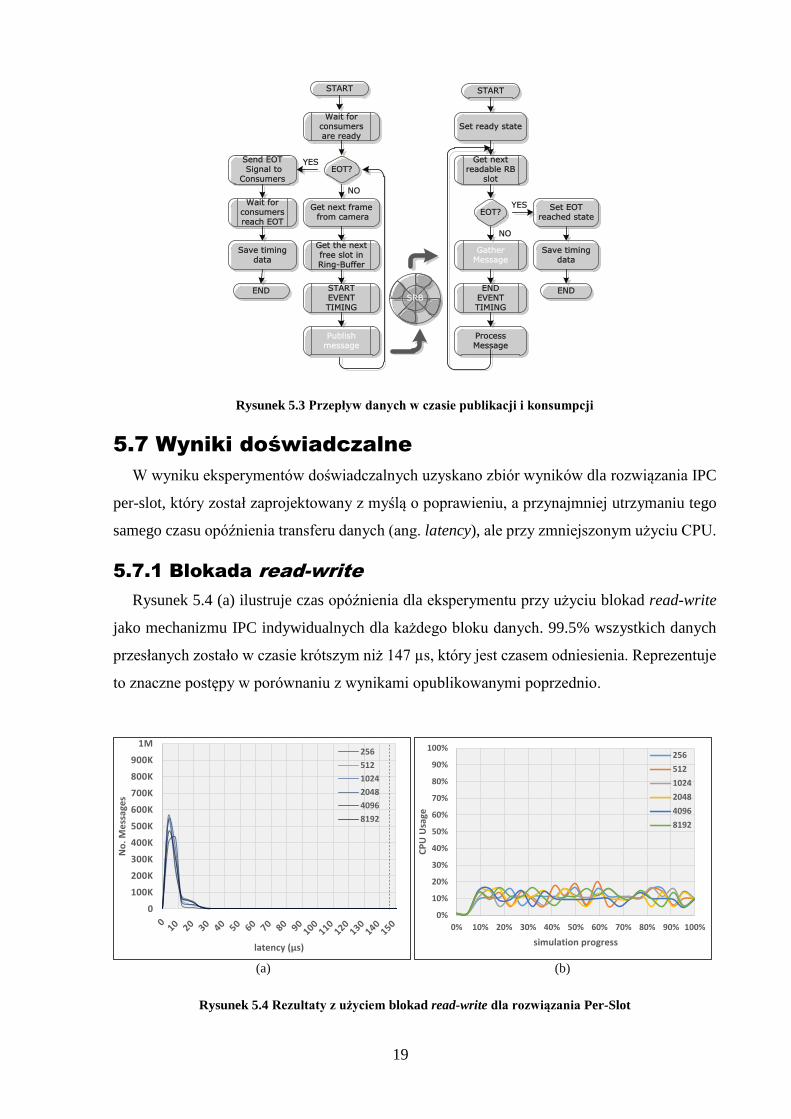
pamięci i są przetwarzane przez inne podsystemy zgodnie ze specyfikacjami. Rysunek 5.3
przedstawia pracę aplikacji użytej w tym eksperymencie.
19
START
EOT?
Get the next free slot in Ring-Buffer
START EVENTTIMING
Publish message
Get next frame from camera
Wait for consumers reach EOT
Save timing data
END
START
Set ready state
ENDEVENTTIMING
Process Message
Save timing data
END
Send EOT Signal to
Consumers
EOT?
Wait for consumers are ready
Get next readable RB
slot
Gather Message
Set EOT reached state
NO
YES
NO
YES
SRB
Rysunek 5.3 Przepływ danych w czasie publikacji i konsumpcji
5.7 Wyniki doświadczalne
W wyniku eksperymentów doświadczalnych uzyskano zbiór wyników dla rozwiązania IPC
per-slot, który został zaprojektowany z myślą o poprawieniu, a przynajmniej utrzymaniu tego
samego czasu opóźnienia transferu danych (ang. latency), ale przy zmniejszonym użyciu CPU.
5.7.1 Blokada read-write
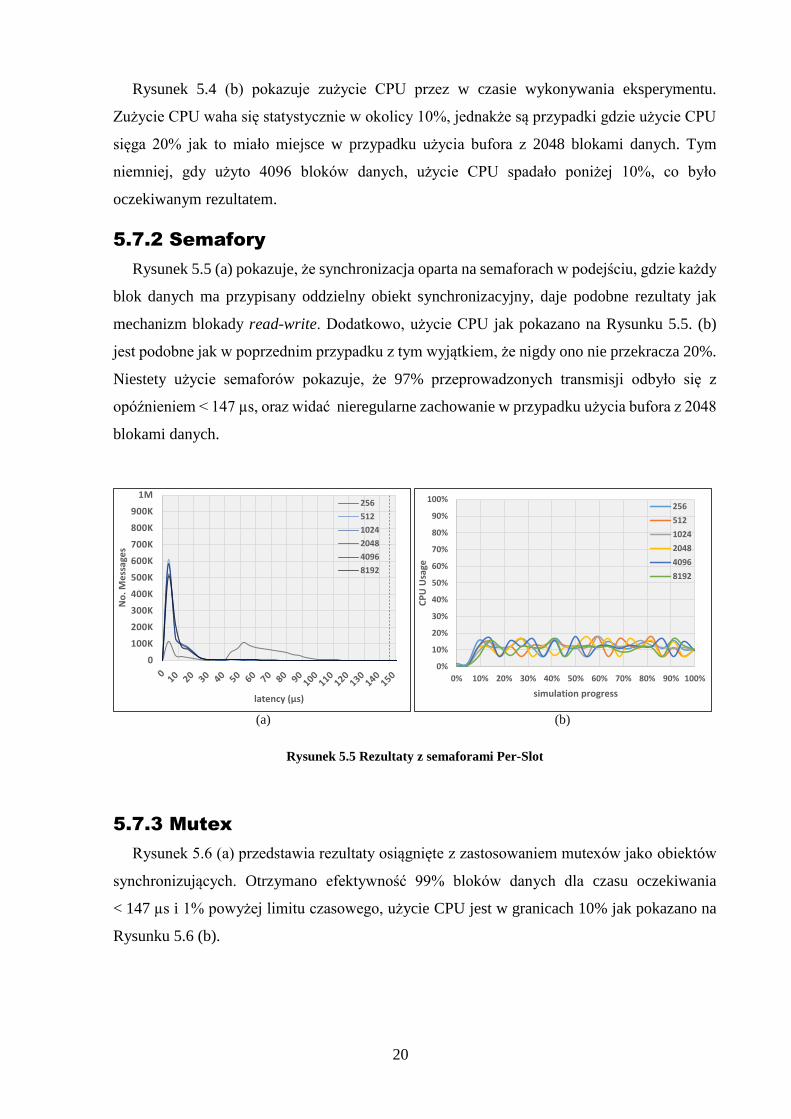
Rysunek 5.4 (a) ilustruje czas opóźnienia dla eksperymentu przy użyciu blokad read-write
jako mechanizmu IPC indywidualnych dla każdego bloku danych. 99.5% wszystkich danych
przesłanych zostało w czasie krótszym niż 147 µs, który jest czasem odniesienia. Reprezentuje
to znaczne postępy w porównaniu z wynikami opublikowanymi poprzednio.
Rysunek 5.4 Rezultaty z użyciem blokad read-write dla rozwiązania Per-Slot
(a) (b)
0
100K
200K
300K
400K
500K
600K
700K
800K
900K
1M
No
. Me
ssag
es
latency (µs)
256
512
1024
2048
4096
8192
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100%
CP
U U
sage
simulation progress
256
512
1024
2048
4096
8192
20
Rysunek 5.4 (b) pokazuje zużycie CPU przez w czasie wykonywania eksperymentu.
Zużycie CPU waha się statystycznie w okolicy 10%, jednakże są przypadki gdzie użycie CPU
sięga 20% jak to miało miejsce w przypadku użycia bufora z 2048 blokami danych. Tym
niemniej, gdy użyto 4096 bloków danych, użycie CPU spadało poniżej 10%, co było
oczekiwanym rezultatem.
5.7.2 Semafory
Rysunek 5.5 (a) pokazuje, że synchronizacja oparta na semaforach w podejściu, gdzie każdy
blok danych ma przypisany oddzielny obiekt synchronizacyjny, daje podobne rezultaty jak
mechanizm blokady read-write. Dodatkowo, użycie CPU jak pokazano na Rysunku 5.5. (b)
jest podobne jak w poprzednim przypadku z tym wyjątkiem, że nigdy ono nie przekracza 20%.
Niestety użycie semaforów pokazuje, że 97% przeprowadzonych transmisji odbyło się z
opóźnieniem < 147 µs, oraz widać nieregularne zachowanie w przypadku użycia bufora z 2048
blokami danych.
Rysunek 5.5 Rezultaty z semaforami Per-Slot
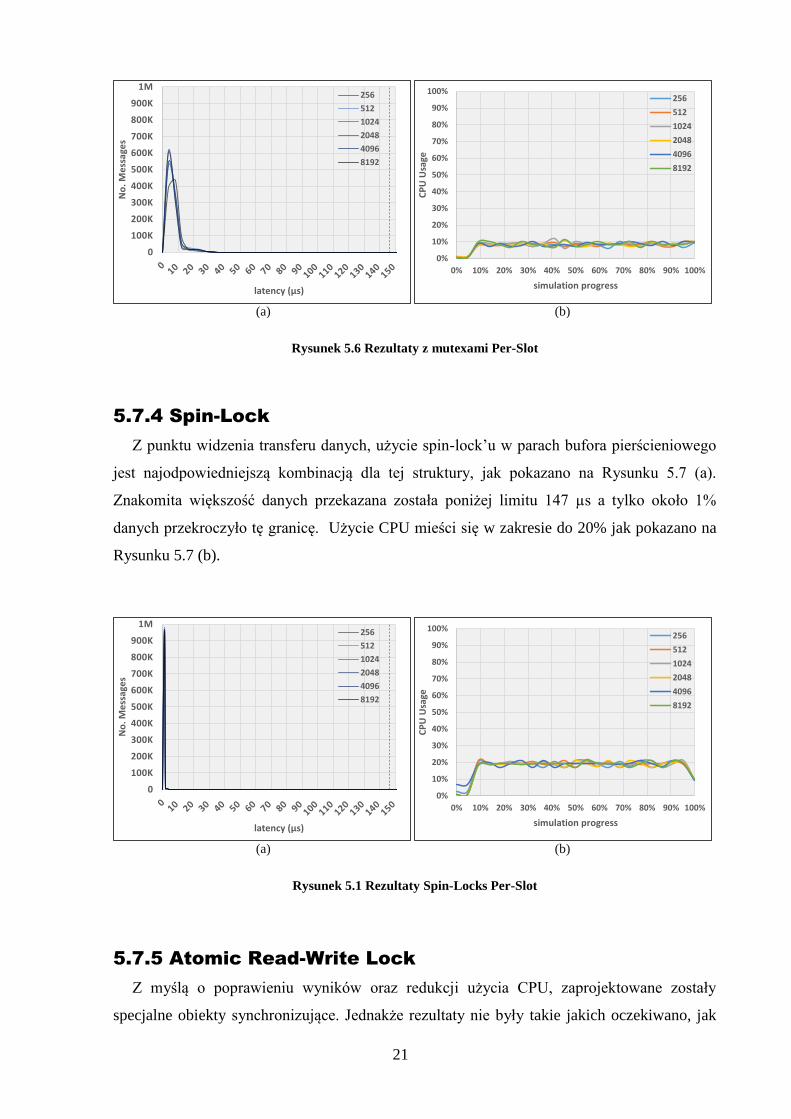
5.7.3 Mutex
Rysunek 5.6 (a) przedstawia rezultaty osiągnięte z zastosowaniem mutexów jako obiektów
synchronizujących. Otrzymano efektywność 99% bloków danych dla czasu oczekiwania
< 147 µs i 1% powyżej limitu czasowego, użycie CPU jest w granicach 10% jak pokazano na
Rysunku 5.6 (b).
(a) (b)
0
100K
200K
300K
400K
500K
600K
700K
800K
900K
1M
No
. Me
ssag
es
latency (µs)
256
512
1024
2048
4096
8192
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100%
CP
U U
sage
simulation progress
256
512
1024
2048
4096
8192
21
Rysunek 5.6 Rezultaty z mutexami Per-Slot
5.7.4 Spin-Lock
Z punktu widzenia transferu danych, użycie spin-lock’u w parach bufora pierścieniowego
jest najodpowiedniejszą kombinacją dla tej struktury, jak pokazano na Rysunku 5.7 (a).
Znakomita większość danych przekazana została poniżej limitu 147 µs a tylko około 1%
danych przekroczyło tę granicę. Użycie CPU mieści się w zakresie do 20% jak pokazano na
Rysunku 5.7 (b).
Rysunek 5.1 Rezultaty Spin-Locks Per-Slot
5.7.5 Atomic Read-Write Lock
Z myślą o poprawieniu wyników oraz redukcji użycia CPU, zaprojektowane zostały
specjalne obiekty synchronizujące. Jednakże rezultaty nie były takie jakich oczekiwano, jak
(a) (b)
0
100K
200K
300K
400K
500K
600K
700K
800K
900K
1M
No
. Me
ssag
es
latency (µs)
256
512
1024
2048
4096
8192
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100%
CP
U U
sage
simulation progress
256
512
1024
2048
4096
8192
(a) (b)
0
100K
200K
300K
400K
500K
600K
700K
800K
900K
1M
No
. Me
ssag
es
latency (µs)
256
512
1024
2048
4096
8192
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100%
CP
U U
sage
simulation progress
256
512
1024
2048
4096
8192
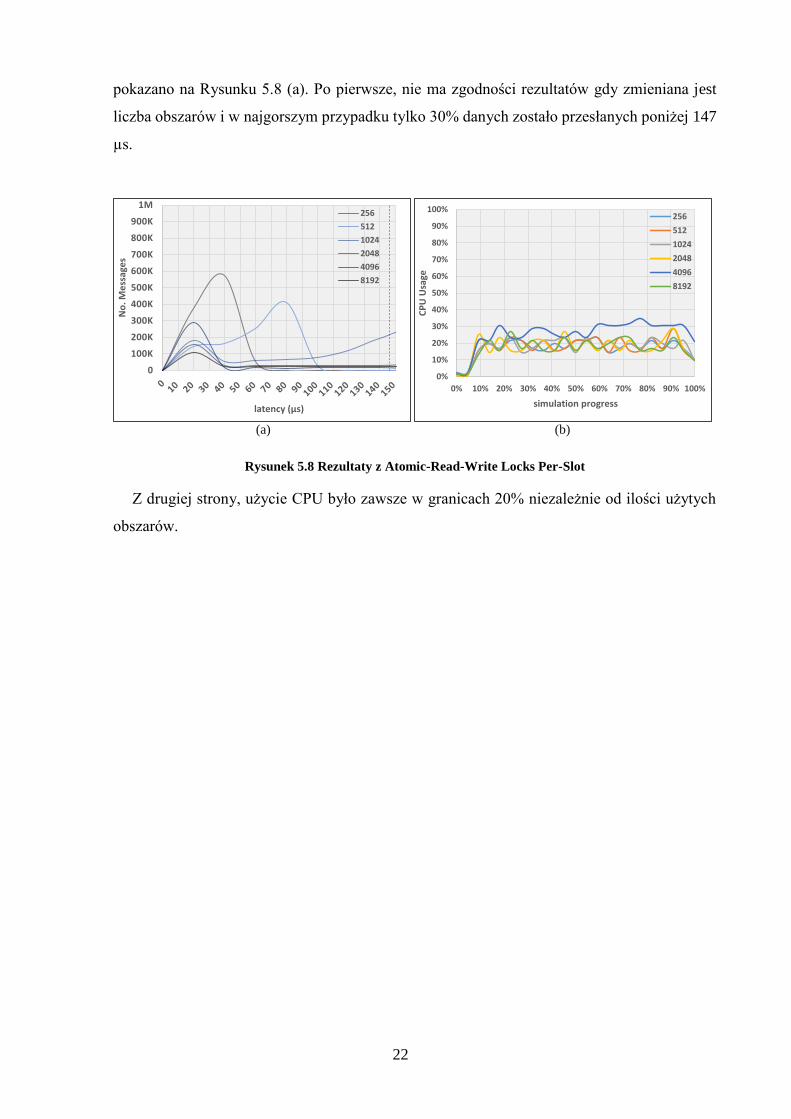
22
pokazano na Rysunku 5.8 (a). Po pierwsze, nie ma zgodności rezultatów gdy zmieniana jest
liczba obszarów i w najgorszym przypadku tylko 30% danych zostało przesłanych poniżej 147
µs.
Rysunek 5.8 Rezultaty z Atomic-Read-Write Locks Per-Slot
Z drugiej strony, użycie CPU było zawsze w granicach 20% niezależnie od ilości użytych
obszarów.
(a) (b)
0
100K
200K
300K
400K
500K
600K
700K
800K
900K
1M
No
. Me
ssag
es
latency (µs)
256
512
1024
2048
4096
8192
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100%
CP
U U
sage
simulation progress
256
512
1024
2048
4096
8192

23
Rozdział 6. Wnioski Zaproponowane w tej rozprawie rozwiązanie potwierdza tezy przedstawione w rozdziale
pierwszym i spełnia wymagania opisane w rozdziale trzecim. Pokazano jak można
skonstruować wysoko wydajną strukturę używając struktur do komunikacji między procesami
w dzielonej pamięci. Zamykając wszystkie wywołania systemowe związane z dzieloną
pamięcią w klasie, struktura ma charakter przyjazny dla użytkownika i pozwala deweloperom
na skoncentrowanie się na pobieraniu danych z systemów sprzętowych i przekazywaniu ich do
dzielonej pamięci dla procesów producenta i pobieranie tych danych przez procesy
konsumenta.
Pokazano, że proponowane rozwiązanie jest dostatecznie rozwinięte pozwalając na
zaprojektowanie w pełni funkcjonalnej aplikacji monitorującej potrzebnej dla systemu ITER-
CODAC. Potwierdzono 100% niezawodność w przesyłaniu danych z zadawalającym użyciem
CPU, zostawiając dostatecznie dużo zasobów CPU dla wykonania dodatkowych zadań.
Używając tego samego sposobu projektowania przy użyciu klas, jedna aplikacja producenta
może porozumiewać się z wieloma różnorodnymi aplikacjami konsumentów poprzez
zastosowanie tego samego mechanizmu umieszczonego we współdzielonej pamięci a to
potwierdza pierwszą tezę.
Generowanie dużej ilości danych przez systemy wchodzące w skład ITER-CODAC’a
zostało zasymulowane poprzez aplikację zaproponowaną w tej dysertacji i osiągnięto bardzo
dobrą wydajność, co potwierdza drugą tezę. Wynika to z tego, że użyty proces alokacji pamięci
oraz operacja na buforach metodą batch zmniejsza opóźnienia czasowe pomiędzy publikacją i
odczytywaniem danych.
Niniejsza praca sugeruje również dalsze kierunki badań. Pierwszy to zbudowanie
odpowiedniego ogólnego alokatora pamięci dla kontenerów C++ STL tak, aby mogła być
dzielona pomiędzy różne niezależne procesy. Po drugie, struktura mogłaby być wykonywana
w trybie usługi Linux’a przez co możliwe jest zarządzanie określonym obszarem pamięci
fizycznej unikając zarządzania pamięcią przez system operacyjny. Jako ostatni punkt, struktura
mogłaby być rozszerzona tak aby uczynić ją strukturą rozproszoną dla pamięci współdzielonej.

24
Rozdział 7. Dodatek Odnośniki
[1] SAGE, "ITER IMAS," [Online]. Available: http://www.sagestorage.eu/research/applications/ITER_IMAS.
[Accessed 12 April 2016].
[2] F. Di Mario, "CODAC Core System," 28 January 2016. [Online]. Available:
http://static.iter.org/codac/cs/CODAC_Core_System_Overview_34SDZ5_v5_2.pdf. [Accessed 09 April
2016].
[3] J. Park and S. Mackay, Practical Data Acquisition for Instrumetnation and Control Systems, Newnes, 2003,
pp. 1-2.
[4] M. Alam and M. Azad, "Development of biomedical data acquisition system in Hard Real-Time Linux
environment," in Biomedical Engineering (ICoBE), Penang, 2012.
[5] M. Di Paolo, Data Acquisition Systems, New York: Springer, 2013.
[6] C. Loureiro, M. V. Martins, F. Clemencio and C. Correira, "A fundamental data acquisition saving block,"
in IEEE Nuclear Science Symposium Conference Record, Fajardo, 2005.
[7] R. Stevens, UNIX Network Programming Volume 2, Second Edition, Interprocess Communications,
Prentice Hall, 1999.
[8] H. Marzi, L. Hughes and Y. Lin, "Optimizing interprocess communication for best performance in real-time
systems," in 24th Canadian Conference on Electrical and Computer Engineering (CCECE), Niagara, 2011.
[9] M. Kerrisk, The Linux Programming Interface, William Pollock, 2010.
[10] P. Xiao, Y. Li and D. Wu, "A Model of Distributed Interprocess Communication System," in Second
International Workshop on Knowledge Discovery and Data Mining, 2009, Moscow, 2009.
[11] J.-D. Choi, K. Lee, A. Loginov, R. O'Callahan, V. Sarkar i M. Sridharan, Efficient and Precise Datarace
Detection for Multithreaded Object-Oriented Programs, Berlin, Germany: ACM, 2002.
[12] J. S. Gray, Interprocess Communications in Linux, Prentice Hall PTR, 2003.
[13] Mikrotron, EoSens® 3CL Camera Manual, Rev. 1.01, Copyright © 2010 Mikrotron GmbH, 2010.


















