
POLITECHNIKA KRAKOWSKA - riad.pk.edu.plriad.pk.edu.pl/~zk/PRIR_W17.pdf · sterowane (co nie jest...
35
Przetwarzanie Równoległe i Rozproszone Wykładowca: dr inż. Zbigniew Kokosiński [email protected] POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI I TECHNOLOGII INFORMACYJNYCH www.pk.edu.pl/~zk/PRIR_HP.html
-
Upload
nguyendieu -
Category
Documents
-
view
218 -
download
0
Transcript of POLITECHNIKA KRAKOWSKA - riad.pk.edu.plriad.pk.edu.pl/~zk/PRIR_W17.pdf · sterowane (co nie jest...

Przetwarzanie Równoległe i Rozproszone
Wykładowca:
dr inż. Zbigniew Kokosiń[email protected]
POLITECHNIKA KRAKOWSKA - WIEiK
KATEDRA AUTOMATYKI I TECHNOLOGII INFORMACYJNYCH
www.pk.edu.pl/~zk/PRIR_HP.html

Wykład 17: Architektury GP-GPUs
i programowanie CUDA/OpenCL
• Rys historyczny
• Opis architektur GPUs (procesor wielościeżkowy SIMD, Nvidia Fermi, NVIDIA Kepler)
• Charakterystyka NVIDIA GPUs
• Wprowadzenie do programowania CUDA
• Synchronizacja i organizacja pamięci dzielonej (SM)
• Przykład mnożenia dwóch wektorów
• Szeregowanie wątków CUDA
• Efektywny dostęp do pamięci
• Wprowadzenie do Open CL

Rys historyczny
• Od akceleracji grafiki w procesorach GPU do obliczeń naukowych i naukowej symulacji w GP-GPU
• Optymalizacja dla dużej liczby danych i wydajnych obliczeń zmienno-przecinkowych wykonywanych przez
bardzo wiele wątków i rdzeni
• Wielordzeniowość w GPU wcześniej i w szerszym zakresie niż w CPU
• Skrajna pracochłonność programowania dla celów pozagraficznych w środowiskach DirectX i Open GL
• Odpowiedź - nowe środowiska programowania :
CUDA (Compute Unified Device Architecture, 2007)
OpenCL (Open Computing Language, 2008, Apple/
Intel/AMD-ATI/NVIDIA) - oba na bazie języka C

Architektury GPUs
• Paralelizm danych GPU odpowiada charakterowi obliczeń numerycznych w naukowej symulacji (np.
algorytmy iteracyjne dla systemów równań liniowych)
• GPU składa się z kilku wielościeżkowych procesorów
SIMD, które są niezależnymi rdzeniami procesorów MIMD, przetwarzającymi niezależne sekwencje
instrukcji.
• Liczba SIMD w jednym GPU zależy od modelu GPU
• Każdy SIMD ma kilka jednostek funkcyjnych FU, które
wykonują tą samą instrukcję na różnych danych
• Każda FU posiada oddzielny zbiór rejestrów danych pobierających dane z pamięci globalnej GPU (off-chip)
• W nowszych GPUs istnieje hierarchia pamięci cache

Architektury GPUs – procesor SIMD
• 16 function units (rdzeń + rejestry + load-store unit)
• Każda FU posiada jednostkę całkowito-liczbową (INT unit) oraz zmienno-przecinkową (FP unit)
• Kilka niezależnych wątków SIMD (!) z niezależnymi zbiorami rejestrów, szeregowanych przez SIMD thread
scheduler (rekompensuje to opóźnienia przy transferze danych)
• Score board śledzi numery instrukcji w każdym wątku SIMD oraz informacje dot. obecności operandów w rejestrach (rozmiar SB ogranicza ilość wątków SIMD, dla architektury Fermi – 32)
• Jednostka adresowa zapewnia dostęp do pamięci lokalnej i globalnej
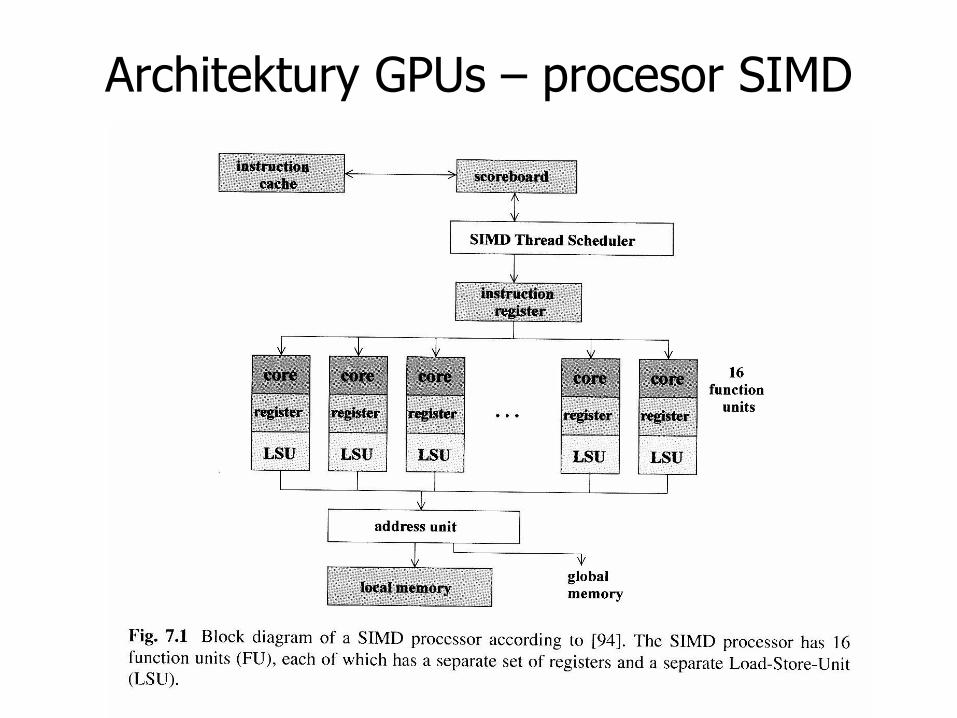
Architektury GPUs – procesor SIMD
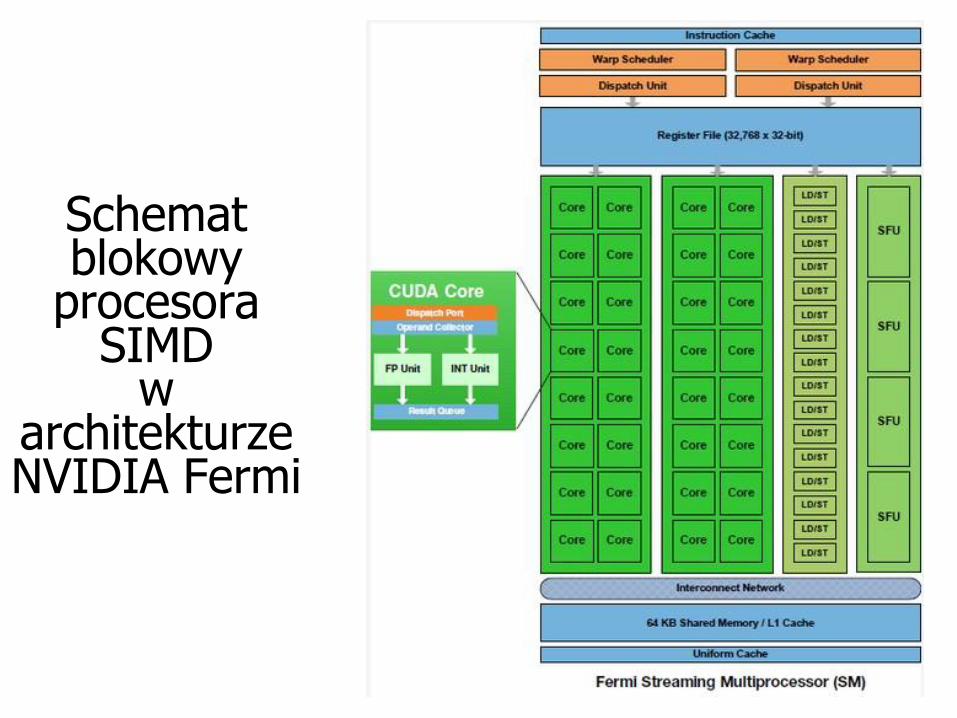
Schemat blokowy
procesoraSIMD
warchitekturzeNVIDIA Fermi
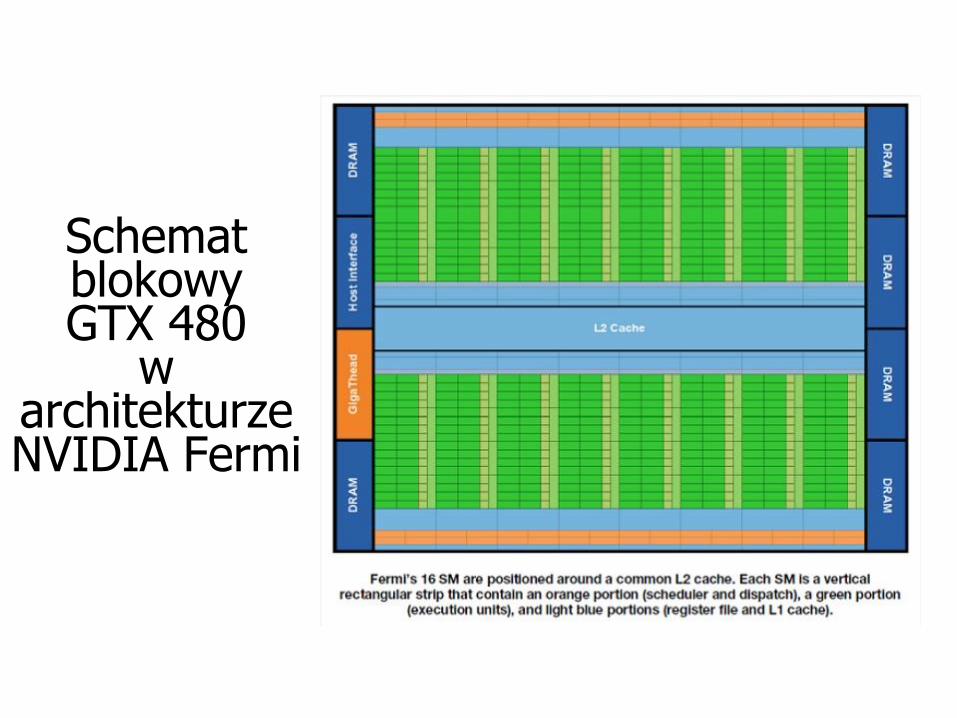
Schemat blokowy GTX 480
warchitekturzeNVIDIA Fermi

Charakterystyka NVIDIA GTX 480 (Fermi)

Schemat blokowy
procesoraSIMD
warchitekturze
NVIDIA Kepler
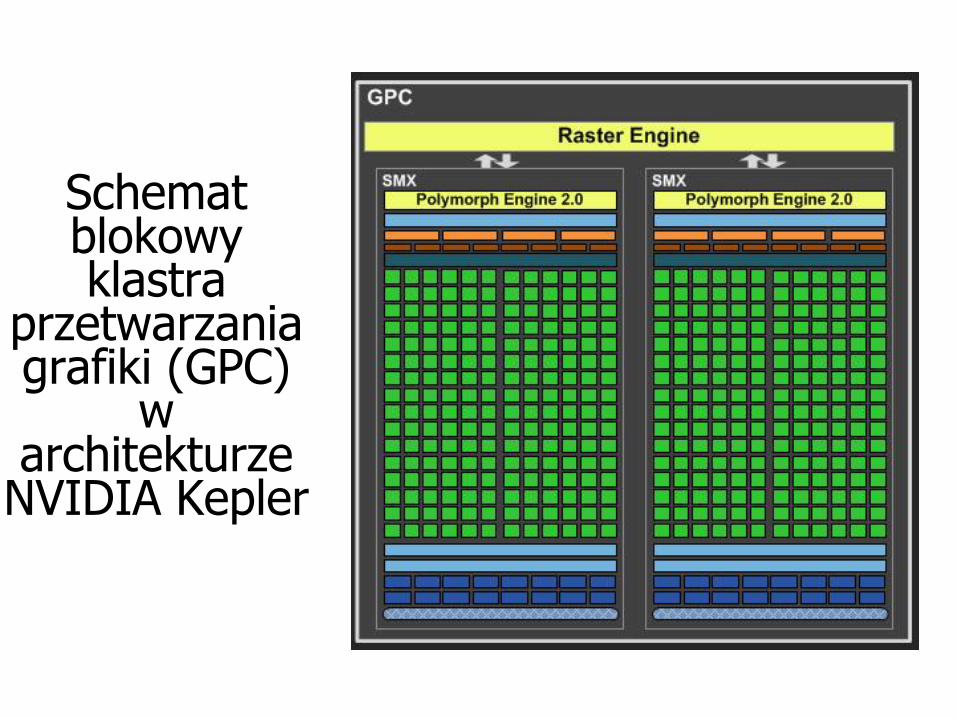
Schemat blokowy klastra
przetwarzaniagrafiki (GPC)
warchitekturze
NVIDIA Kepler
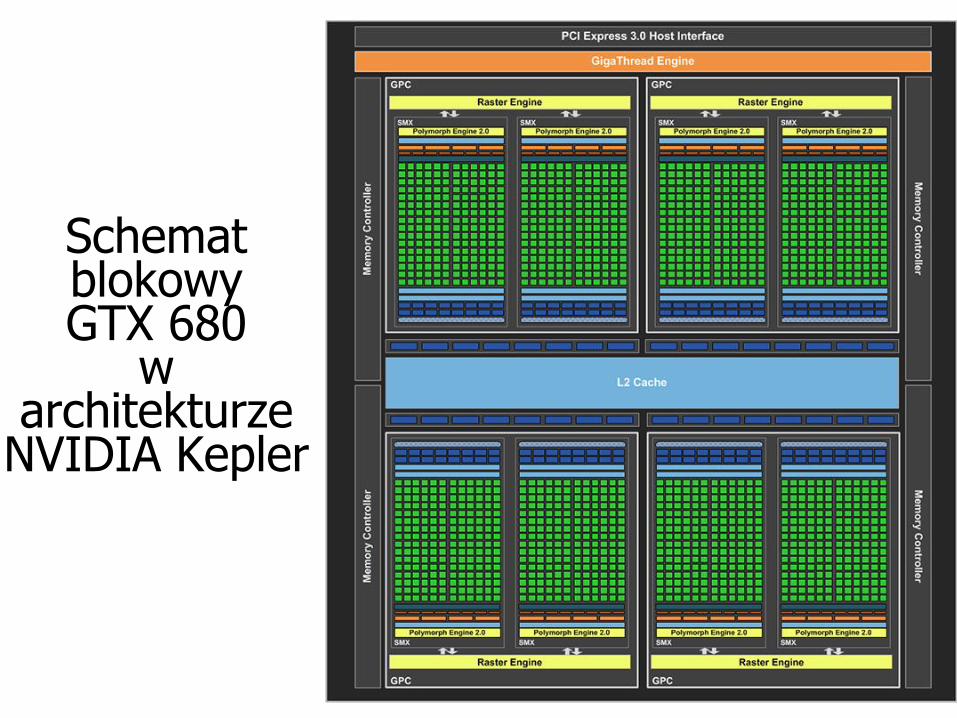
Schemat blokowy GTX 680
w architekturze
NVIDIA Kepler
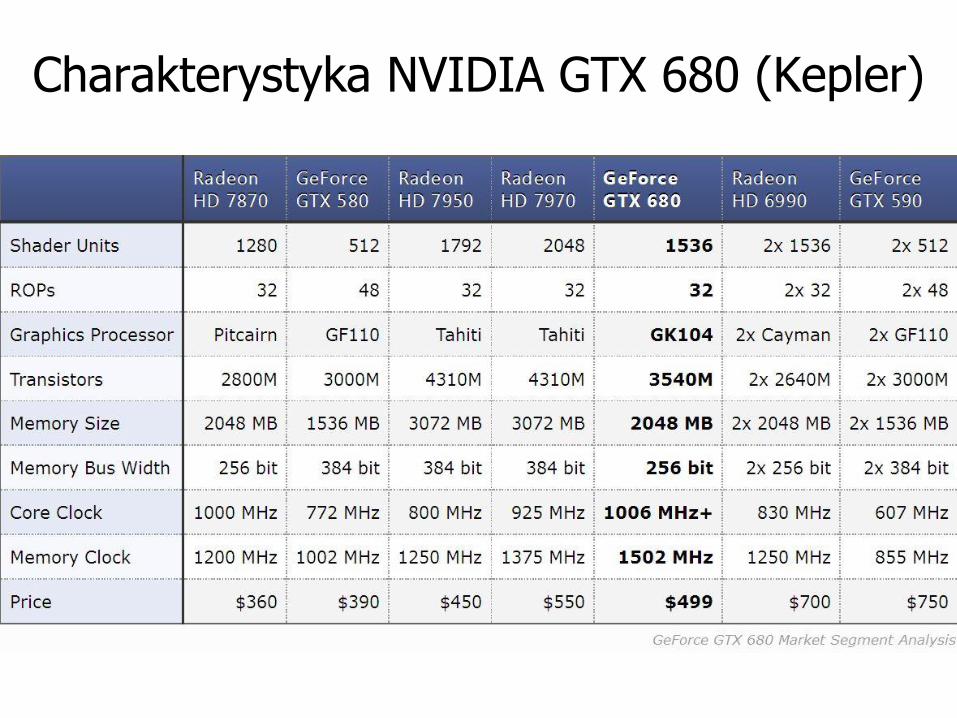
Charakterystyka NVIDIA GTX 680 (Kepler)

Charakterystyka zbiorcza NVIDIA GPUs

Środowiska programowania GPUs
• środowiska programowania dostarczają model programowania adekwatny dla GPUs
• oba nowe środowiska dzielą dany program na program dla CPU (host program), zawierający operacje we/wy
i/lub interakcję z użytkownikiem, i program dla GPU (device program), zawierający wszystkie obliczenia na
GPU
• Zarządzanie wątkami odbywa się przez ich
pogrupowanie, co ułatwia synchronizację
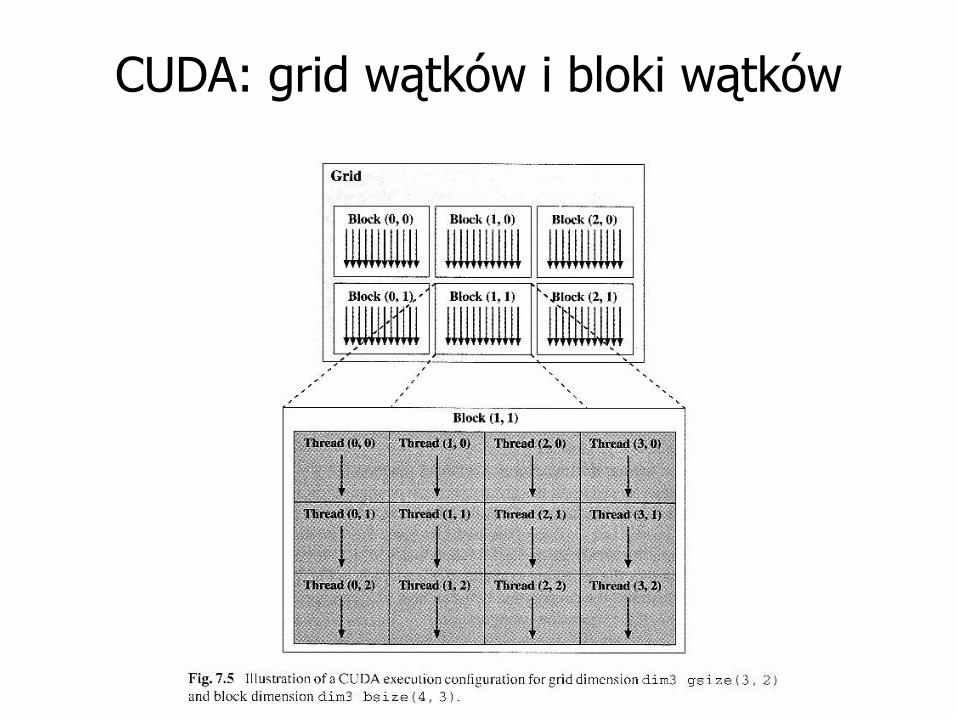
CUDA: grid wątków i bloki wątków

Program CUDA:
dodawanie dwóch
wektorów
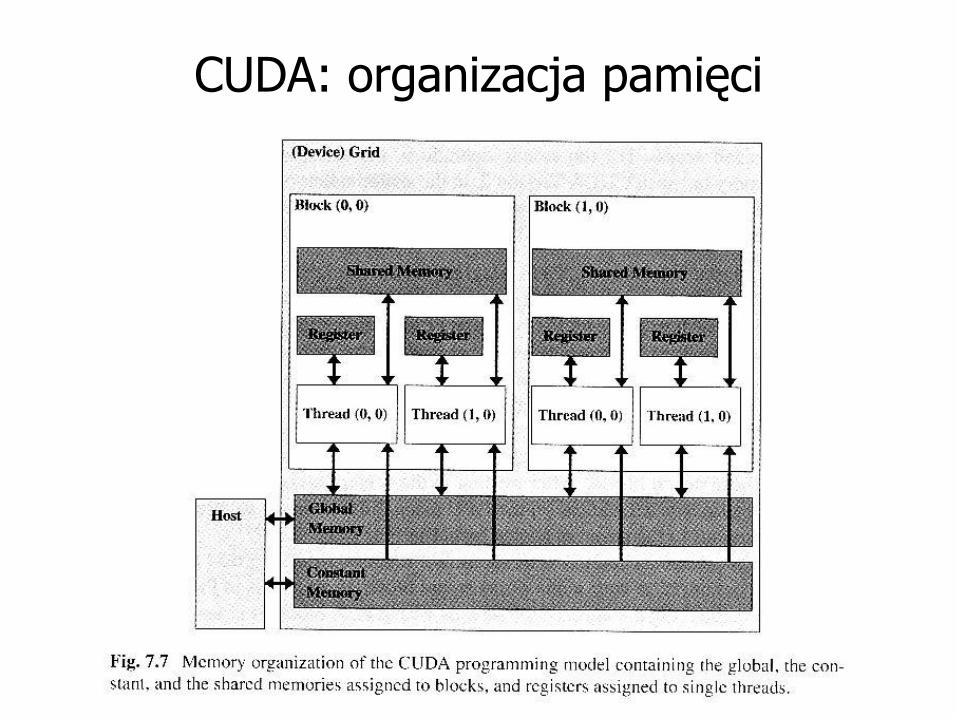
CUDA: organizacja pamięci

Program CUDA:
mnożenie dwóch
wektorów
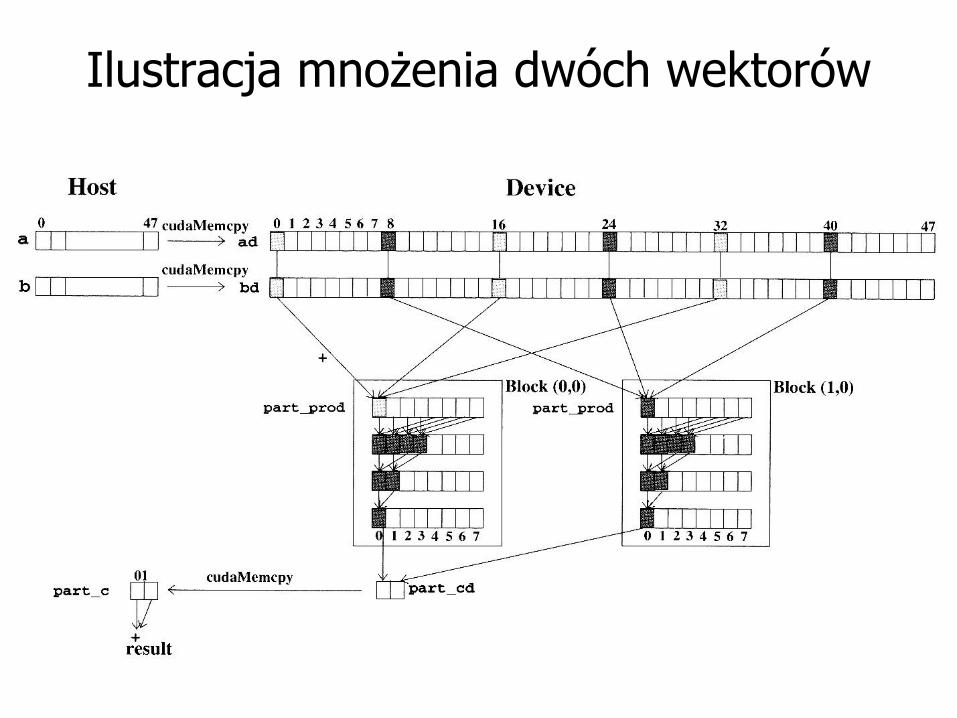
Ilustracja mnożenia dwóch wektorów

Opis mnożenia dwóch wektorów

CUDA: szeregowanie wątków
• Zwykle liczba wątków przekracza liczbę jednostek wykonawczych (function units)
• Przydział niezależnych bloków wątków gridu do jednostek (niezależne wykonanie)
• Duże bloki wątków są dalej dzielone (warps – obecnie 32 wątki) i szeregowane w oparciu o zakresy indeksów wątków (threadIdx) – „puste” wątki wirtualne
• Warps są wykonywane w modelu obliczeń CUDA: SIMT
• Model SIMT jest efektywny, gdy wątki są tak samo sterowane (co nie jest regułą w przypadku konstrukcji warunkowych)
• Różne ścieżki sterowania wątków w warp spowalniają
obliczenia

Efektywny dostęp do pamięci
• Dostęp do globalnej pamięci jest kosztowny
• Niezbędne jest kopiowanie danych do pamięci dzielonej lub rejestrów
• Efektywne kopiowanie „sąsiednich” danych przy jednokrotnym dostępie do pamięci (coalescing)
• Sąsiednie identyfikatory wątków muszą mieć dostęp do sąsiednich komórek pamięci zawierających dane (np. w tablicy jednowymiarowej)
• W tablicy 2-wymiarowej występuje sąsiedztwo w wierszach, ale nie w kolumnach, które znajdują się w odległych miejscach pamięci - stąd konieczność
stosowania specjalnej techniki zwanej kafelkowaniem (tiling)

Program CUDA:
mnożenie macierzy
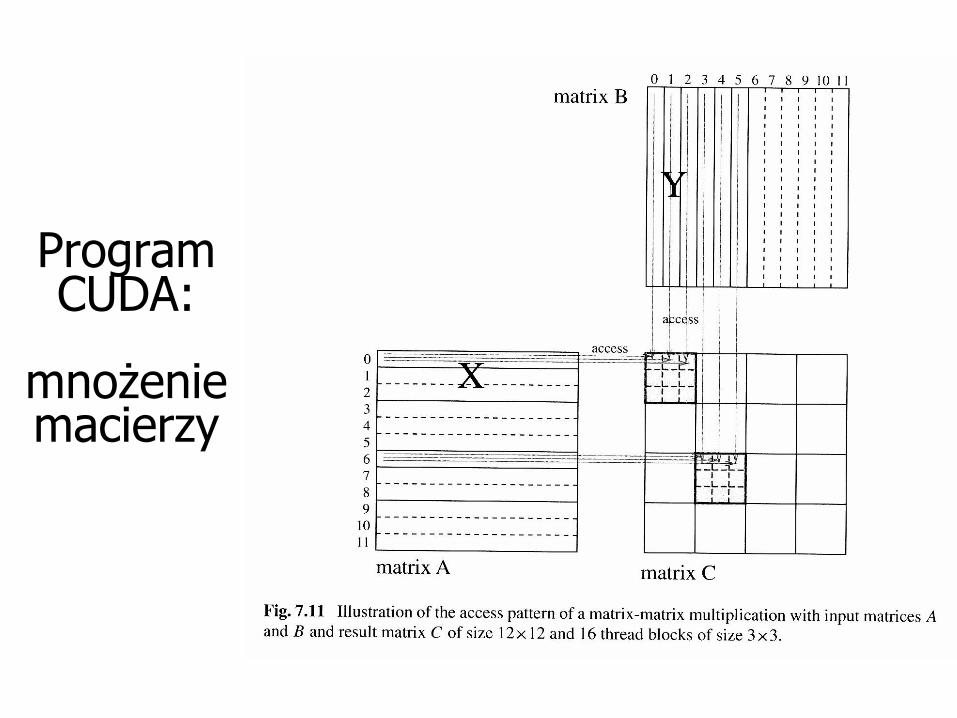
Program CUDA:
mnożenie macierzy

Program CUDA:
mnożenie macierzy
technika „tiling”
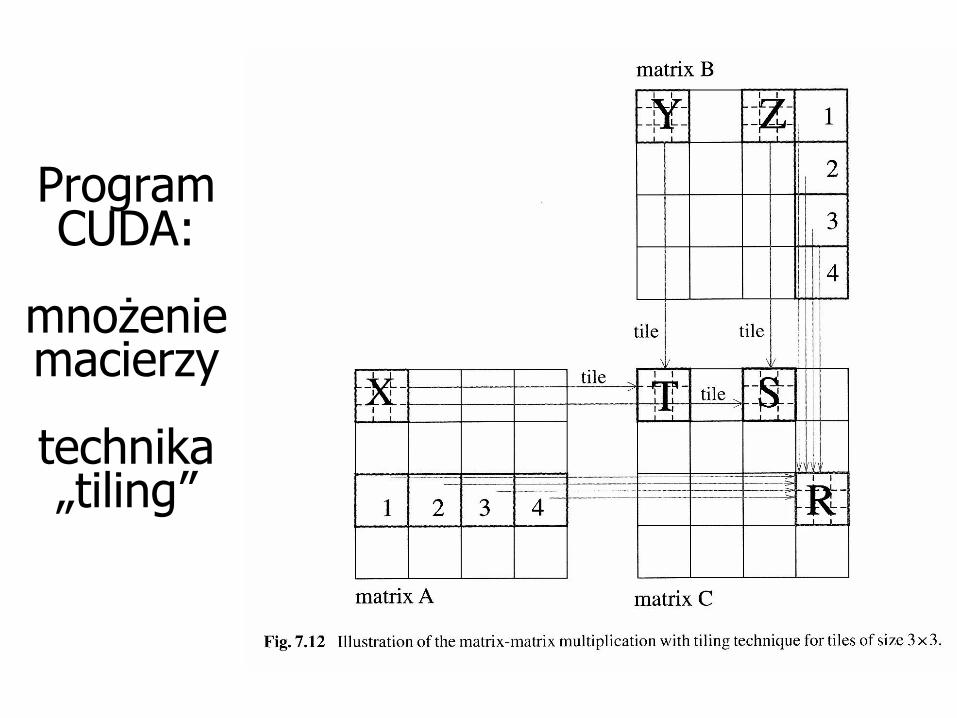
Program CUDA:
mnożenie macierzy
technika „tiling”

Wprowadzenie do OpenCL
• Metody pozwalające przyporządkować zadania do zaadresowanych wprost komponentów heterogenicz-
nych platform sprzętowych (od laptopów do węzłów superkomputera)
• Platforma OpenCL składa się z jednego hosta i co najmniej jednego urządzenia wykonującego obliczenia
• Aplikacja OpenCL składa się z programu hosta i zbioru jąder (kernels) zaimplementowanych w języku
OpenCL-C
• Program host wywołuje jądra do obliczeń na jednym z urządzeń, czemu towarzyszy generacja przez runtime system globalnej przestrzeni indeksowej, nazywanej
NDRanges (N-dimentional index space, N=1, 2, 3)

OpenCL - NDRanges
• Dla każdego punktu przestrzeni indeksowej, nazywanego work item wykonywana jest jedna
instancja jądra
• work items korespondują z wątkami CUDA, różnica
polega na możliwości ich adresowania przez globalne indeksy w NDRanges
• work items można pogrupować w work groups posiadające ten sam rozmiar jako NDRanges
• w każdym rozmiarze (dimension) rozmiary (sizes)
NDRanges muszą być podzielne przez liczbę work groups

OpenCL - synchronizacja
• work groups posiadają identyfikator grupy, a składowe work items – identyfikator lokalny w swoich grupach
• NDRanges przypominają grid w CUDA, a work groups przypominają bloki w CUDA
• identyfikacja work items za pomocą dwóch
identyfikatorów grupy i lokalnego LUB identyfikatora globalnego w NDRanges (brak w CUDA)
• bariera synchronizacyjna barrier() odnosi się TYLKO do work items w grupie (powód wprowadzenia grup)
• OpenCL stosuje równoległy model SIMD lub SPMD(wszystkie work items wykonują tą samą operację na
różnych danych)

OpenCL: hierarchia pamięci
• W Open CL występuje 5 rodzajów pamięci:
- pamięć hosta dla programu hosta, oraz
- pamięci globalna, stała, lokalna i prywatna w urządzeniu (Computing Device)
• Program host dynamicznie alokuje przestrzeń w pamięci globalnej GPU (dostęp przez programy hosta i urządzenia), co odpowiada global memory w CUDA
• Pamięć stała (constant) : RW dla hosta, R dla
programu CD, w odróżnieniu od CUDA program host może dynamicznie alokować również pamięć constant
• Pamieć lokalna : RW dla work items w jednej grupie, odpowiada SM w CUDA
• Pamięć prywatna : dla pojedynczego work item
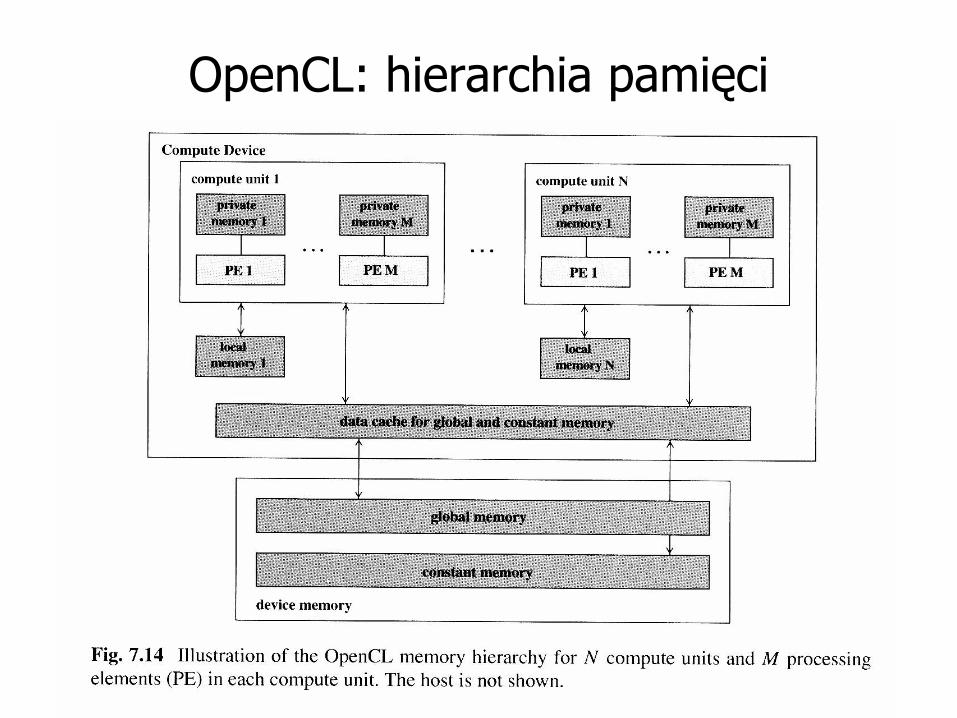
OpenCL: hierarchia pamięci

OpenCL – przykład dodawania 2 wektorów
- deklaracja jądra vectoradd : _kernel zamiast _global w CUDA
(suma wektorów a i b, wynik w c)
- każdy work item ma globalny identyfikator get_global_id(0)
i oblicza dokładnie jeden element wektora wyniku

OpenCL: kolejki rozkazów
• W Open CL przyporządkowanie obliczeń do urządzeń jest określone za pomocą kolejki rozkazów (command
queue)
• W kolejce dla urządzenia występują : wywołania jąder, operacje alokacji pamięci, operacje kopiowania i synchronizacji – są wykonywane kolejno
• Task parallelism – wiele kolejek rozkazów
• Poprawna interakcja pomiędzy kolejkami jest zapewniona w OpenCL poprzez koncepcję zdarzeń
(events) inicjowanych przez rozkazy z kolejki

Literatura
1. Rauber T., Ruenger G.: Parallel programming for multicore and cluster systems, 2nd ed., Springer 2012
2. Schematy procesorów GPU – internet.


















