Paweł Kucharski: Oswajamy Słonia czyli po co nam Hadoop
85
Paweł Kucharski Oswajamy Słonia czyli po co nam Hadoop
-
Upload
analyticsconf -
Category
Data & Analytics
-
view
445 -
download
0
Transcript of Paweł Kucharski: Oswajamy Słonia czyli po co nam Hadoop
Paweł Kucharski
Oswajamy Słonia
czyli
po co nam Hadoop

• Sotrender
• Hadoop• Czym jest Hadoop?
• Podstawowe elementy
• Ekosystem Hadoop• Hive, Pig
• Spark
• HBase
• Nasze doświaczenia• MySQL vs Hadoop
• R

CO ROBIMY?
Sotrender

SOTRENDER

SOTRENDER
• Sotrender: narzędzie do analiz social media
• Badania i raporty na życzenie
Więcej: 2015.sotrender.pl

SOTRENDER

SOTRENDER

SOTRENDER
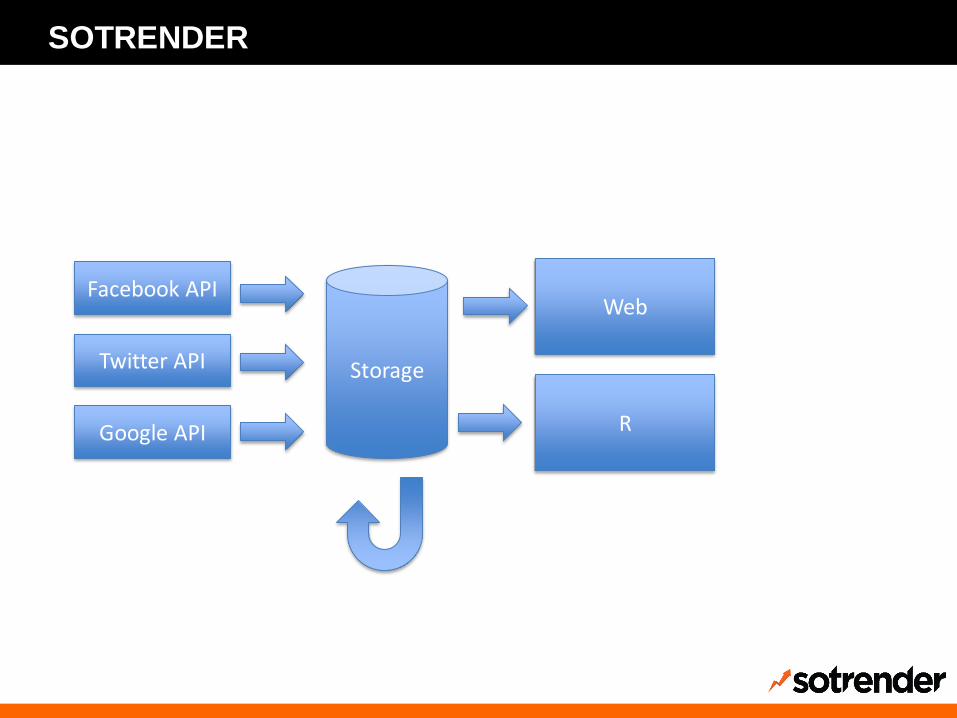
Zbieramy dane:
• Facebook, Twitter, YouTube, Instagram
• 30k profili
• 250k API calls na godzinę
SOTRENDER
Facebook API
Twitter API
Google API
Storage
Web
R

OSWAJAMY SŁONIA
Hadoop

CZYM JEST HADOOP
• Święty gral Big Data
• Rozproszony system przechowywania
przetwarzania danych

CZYM JEST HADOOP

CZYM JEST HADOOP
Otwarta implementacja paradygmatów
Google: GoogleFileSystem i MapReduce
Hadoop umożliwia:
• przetwarzanie dużych ilościach danych
• równolegle
• niezawodnie
• skalowalnie
• zbudowanych z tanich komponentów

CZYM JEST HADOOP
Zalety
• Elastyczny format danych
• Nie wymaga agregacji (surowe dane)
• Nie wymaga próbkowania (wszystkie dane)
• Nie ma potrzeby usuwania danych
• Skalowalny (od kilku do tysięcy węzłów)

CZYM JEST HADOOP
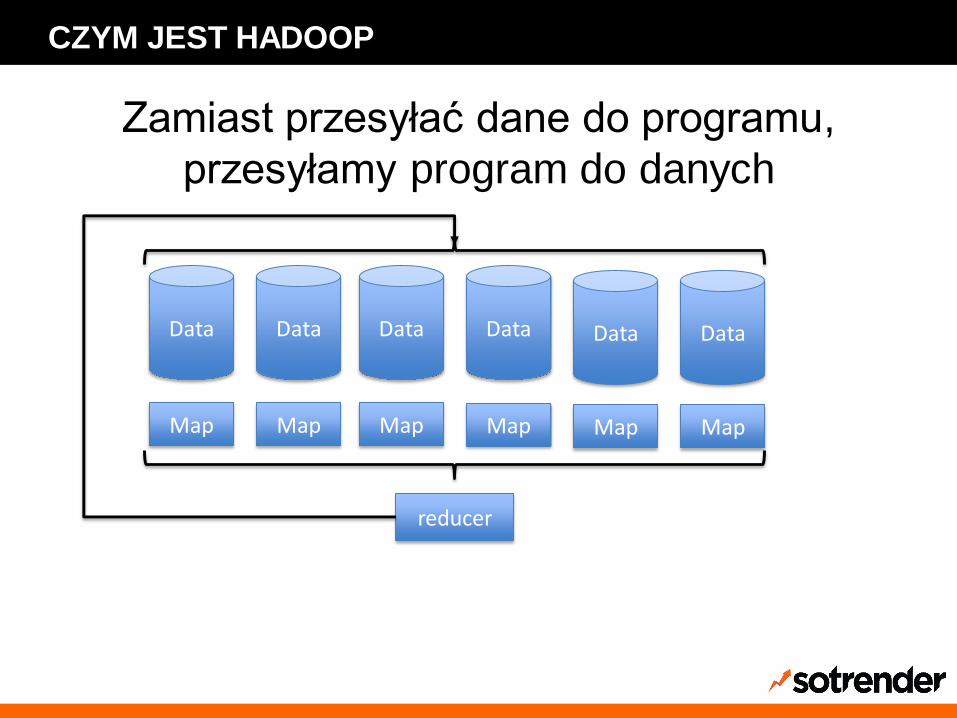
Zamiast przesyłać dane do programu,
przesyłamy program do danych
Data Data Data DataData Data
Map Map Map Map Map Map
reducer
CZYM JEST HADOOP

CZYM JEST HADOOP

HISTORIA HADOOP
• Stworzony w 2005 w Yahoo przez Doug
Cutting
• Wersja 0.14.1 w 2007
• Wersja 1.0 – grudzień 2011
• Wersja 2.2 - październik 2013

HADOOP
Główne dystrybucje
• Hortonworks
• HDP
• Cloudera
• CDH
• MapR
• M3

HISTORIA HADOOP
https://wiki.apache.org/hadoop/PoweredBy

HISTORIA HADOOP
Yahoo
• 600PB, 43k nodes
Twitter:
• 300PB 1000
nodes
• 300PB, 600TB
dziennie
Google (maj 2014)
• 2 EB, 600M QPS

HADOOP
26% dużych firm używa Hadoopa, kolejne
18% zamierza to zrobić w ciągu dwóch lat.

HADOOP

HADOOP
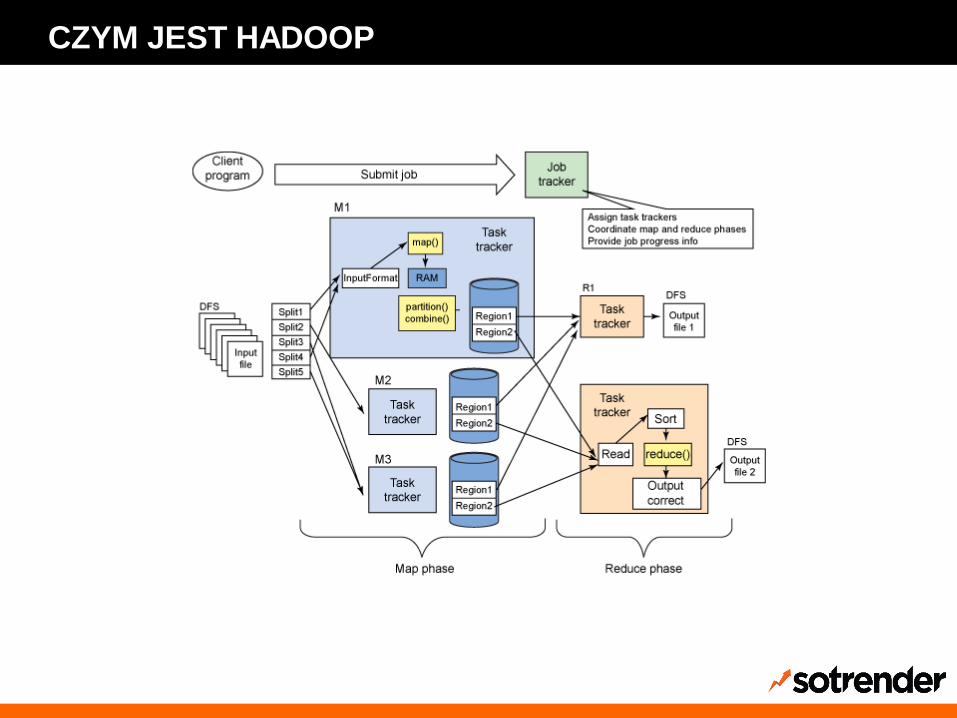
Dwa główne komponenty
HDFS i MapReduce

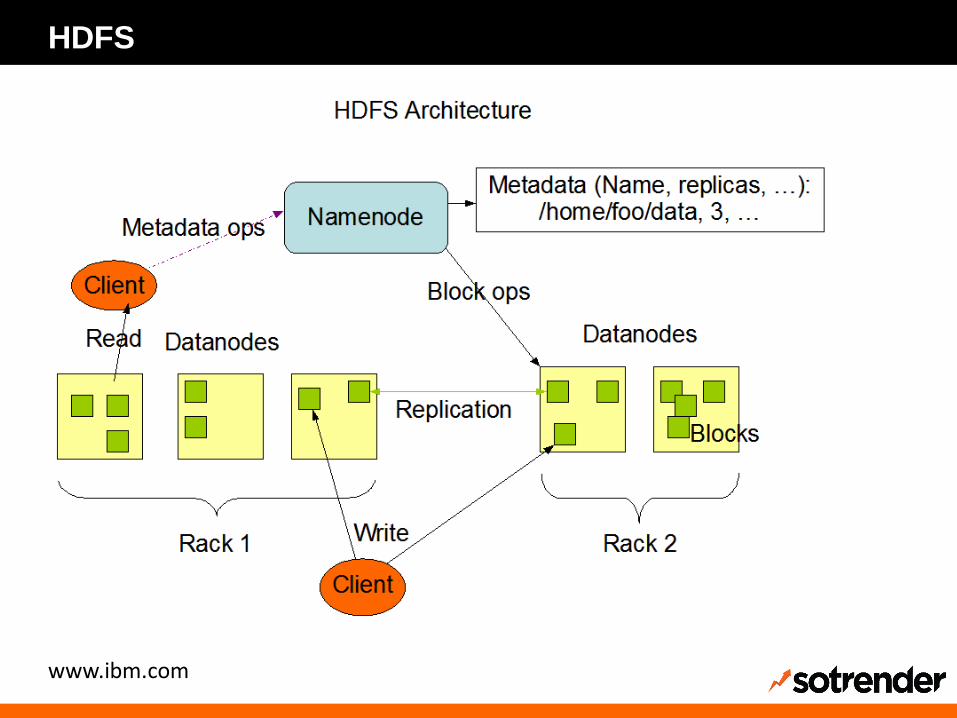
HADOOP DISTRIBUTED FILE SYSTEM
HDFS

HDFS
Rozproszony system plików
• Skalowalny
• Odporny na awarię
• Tani sprzęt
• Duże ilości danych
• Dla dużych klastrów

HDFS
Dwa podstawowe elementy:
• Namenode
• Datanode
Dodatkowo:
• JournalNode
• Zookeeper

HDFS
• Block replication
• Rack awareness
• Self healing
HDFS
www.ibm.com

Konfiguracja węzłów:
- niskiej/średniej klasy sprzęt
- trochę RAMu
- dużo dysków
- szybkie karty sieciowe

MapReduce

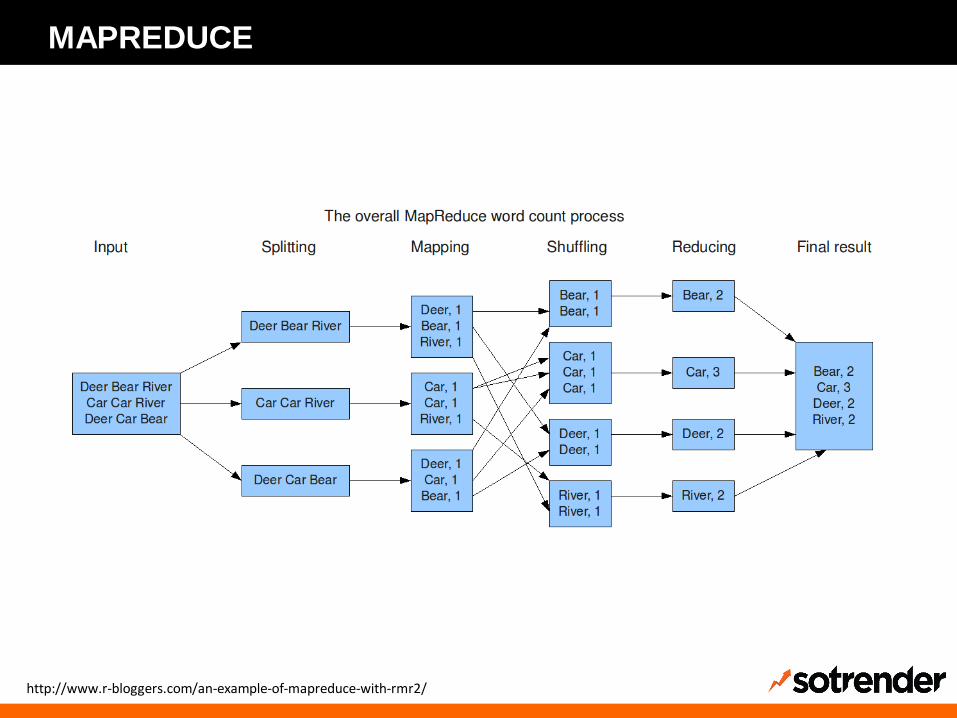
MAPREDUCE
Pochodzenie: MPI, Google
Składa się z trzech kroków
• „Map” – operacje lokalne
• „Shuffle” – redystrybucji wyników
• „Reduce” – grupowanie wyników
MapReduce nie ma być szybki, ale umożliwiać zrównoleglenie obliczeń na dużą skalę.

MAPREDUCE
http://www.r-bloggers.com/an-example-of-mapreduce-with-rmr2/
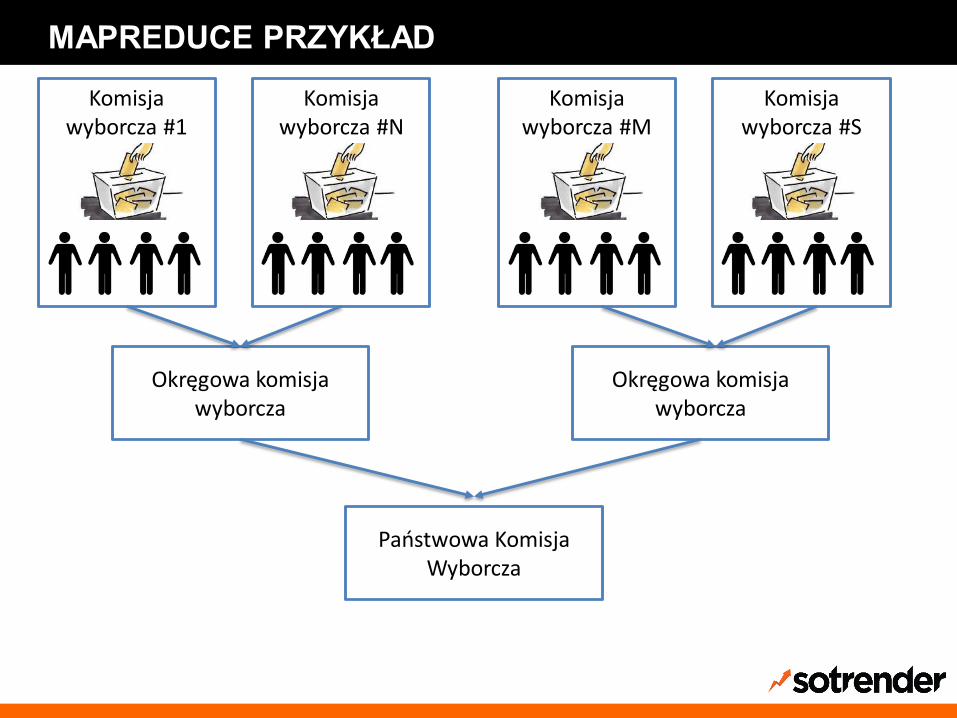
Komisja wyborcza #1
MAPREDUCE PRZYKŁAD
Komisja wyborcza #N
Okręgowa komisja wyborcza
Komisja wyborcza #M
Komisja wyborcza #S
Okręgowa komisja wyborcza
Państwowa Komisja Wyborcza
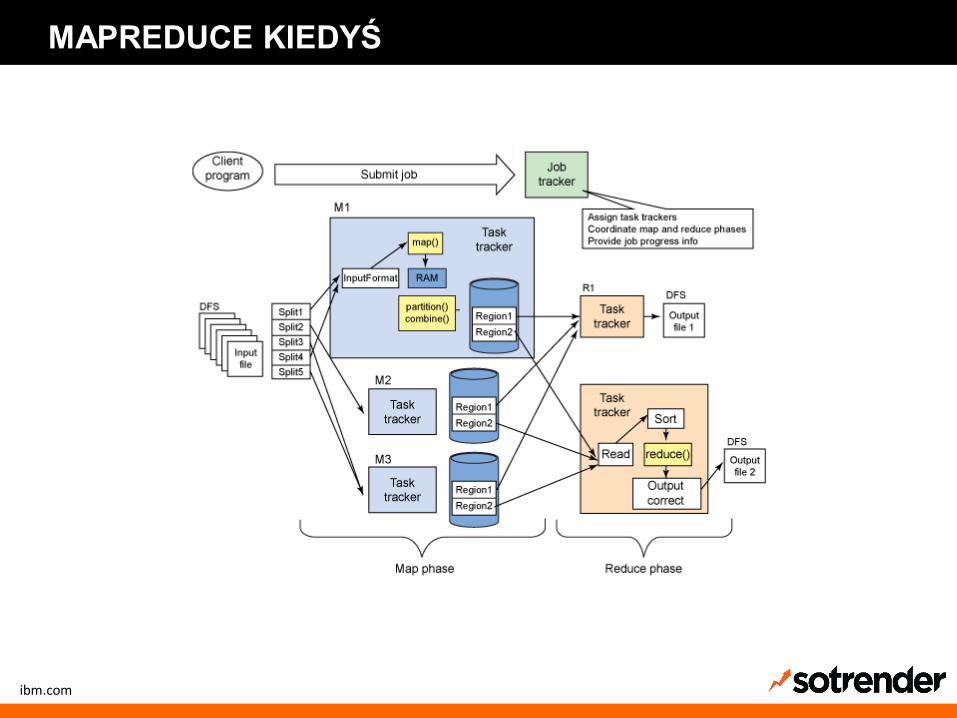
MAPREDUCE KIEDYŚ
ibm.com
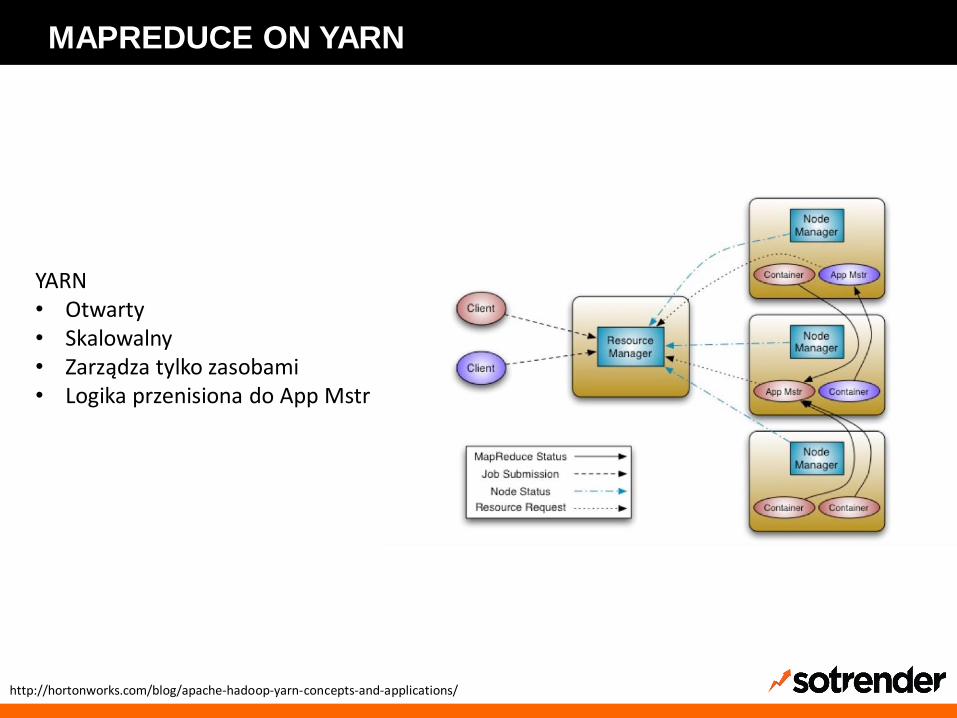
MAPREDUCE ON YARN
YARN• Otwarty • Skalowalny• Zarządza tylko zasobami• Logika przenisiona do App Mstr
http://hortonworks.com/blog/apache-hadoop-yarn-concepts-and-applications/

PRZYKŁAD - WORDCOUNT
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context ) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException,
InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}

PRZYKŁAD - WORDCOUNT
import sys
for line in sys.stdin:
line = line.strip()
words = line.split()
for word in words:
print '%s\t%s' % (word, 1)
from operator import itemgetter
import sys
current_word = None
current_count = 0
word = None
for line in sys.stdin:
line = line.strip()
word, count = line.split('\t', 1)
try:
count = int(count)
except ValueError:
continue
# this IF-switch only works because Hadoop sorts map output
if current_word == word:
current_count += count
else:
if current_word:
print '%s\t%s' % (current_word, current_count)
current_count = count
current_word = word
if current_word == word:
print '%s\t%s' % (current_word, current_count)
http://www.michael-noll.com/tutorials/writing-an-hadoop-mapreduce-program-in-python/

PRZYKŁAD - WORDCOUNT
test@debian:~$ hadoop jar /usr/lib/hadoop-mapreduce/hadoop-streaming.jar \
-file /home/test/mapper.py -mapper /home/test/mapper.py \
-file /home/test/reducer.py -reducer /home/test/reducer.py \
-input /user/test/gutenberg/* -output /user/test/gutenberg-output

Ekosystem Hadoop

EKOSYSTEM HADOOP
Na tych dwóch głównych elementach
zbudowano wiele gotowych rozwiązań
https://hadoopecosystemtable.github.io/
134 różne projekty

Hive

HIVE
• Prosty interfejs do przetwarzania danych w
Hadoopie, wygodniejszy niż pisanie
własnych funkcji
• Wykorzystuje język HiveQL, podobny do
SQL

HIVE
SQL -> MapReduce
SELECT COUNT(*) FROM test_table
WHERE id IN( SELECT id FROM
test_table2) GROUP BY grp_id
zostaje przeszktałocne w serię zadań
MapReduce

HIVE
• Możliwość czytania z wielu źródeł
• External Tables
• Pliki, Hbase, Hypertable, Cassandra, JDBC
• Indeksy
• Własne UDF i funkcje Map/Reduce

HIVE
CREATE TABLE input (line STRING);
LOAD DATA LOCAL INPATH 'input.tsv'
OVERWRITE INTO TABLE input;
SELECT word, COUNT(*) FROM input
LATERAL VIEW explode(split(text, ' '))
ITable as word GROUP BY word;
Przykład: word count

HIVE
Dostęp
• CLI
• JDBC, ODBC
• Thrift

• Zapytania ad-hoc
• Nie wymaga programowania
• Zna informacje o strukturze danych

Pig

PIG
Ten sam cel co HIVE inna droga
Pig Latin
Język skryptowy kompilowanych do zadań
MapReduce

PIG
a = load '/user/test/word_count_text.txt';
b = foreach a generate flatten(TOKENIZE((chararray)$0)) as word;
c = group b by word;
d = foreach c generate COUNT(b), group;
store d into '/user/test/pig_wordcount';
Wordcount example

Spark

SPARK
Apache Spark™ is a fast and general
engine for large-scale data processing.
• Łatwy w użyciu
• Możliwość pisania w:
• Java, Scala, Python, R
• Ponad 80 operacji wysokiego poziomu
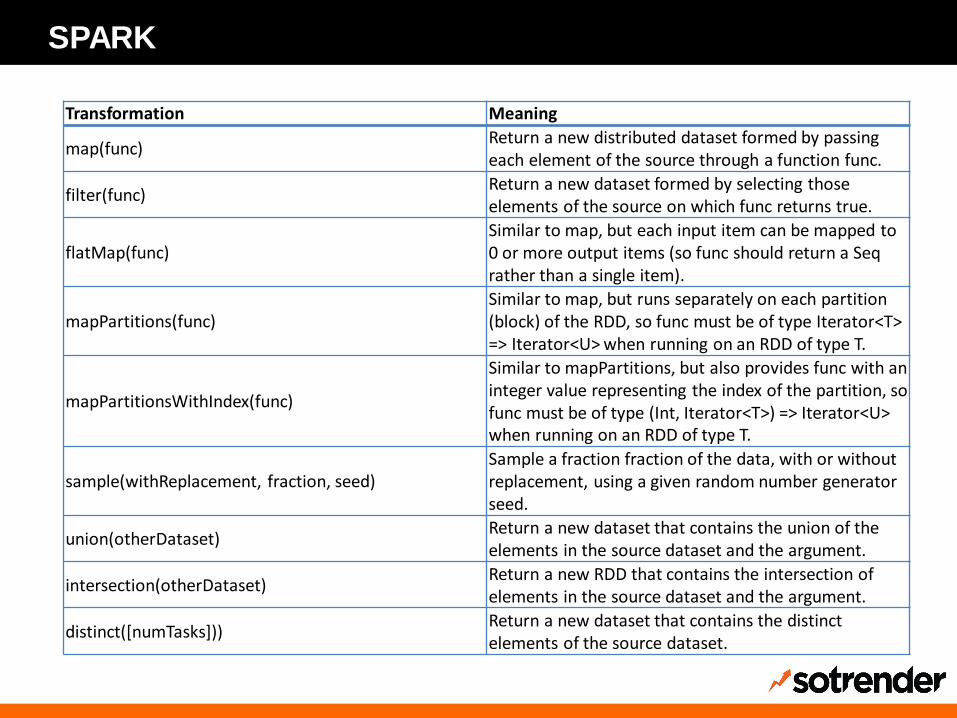
SPARK
Transformation Meaning
map(func) Return a new distributed dataset formed by passing each element of the source through a function func.
filter(func) Return a new dataset formed by selecting those elements of the source on which func returns true.
flatMap(func) Similar to map, but each input item can be mapped to 0 or more output items (so func should return a Seq rather than a single item).
mapPartitions(func) Similar to map, but runs separately on each partition (block) of the RDD, so func must be of type Iterator<T> => Iterator<U> when running on an RDD of type T.
mapPartitionsWithIndex(func)
Similar to mapPartitions, but also provides func with an integer value representing the index of the partition, so func must be of type (Int, Iterator<T>) => Iterator<U> when running on an RDD of type T.
sample(withReplacement, fraction, seed) Sample a fraction fraction of the data, with or without replacement, using a given random number generator seed.
union(otherDataset) Return a new dataset that contains the union of the elements in the source dataset and the argument.
intersection(otherDataset) Return a new RDD that contains the intersection of elements in the source dataset and the argument.
distinct([numTasks])) Return a new dataset that contains the distinct elements of the source dataset.
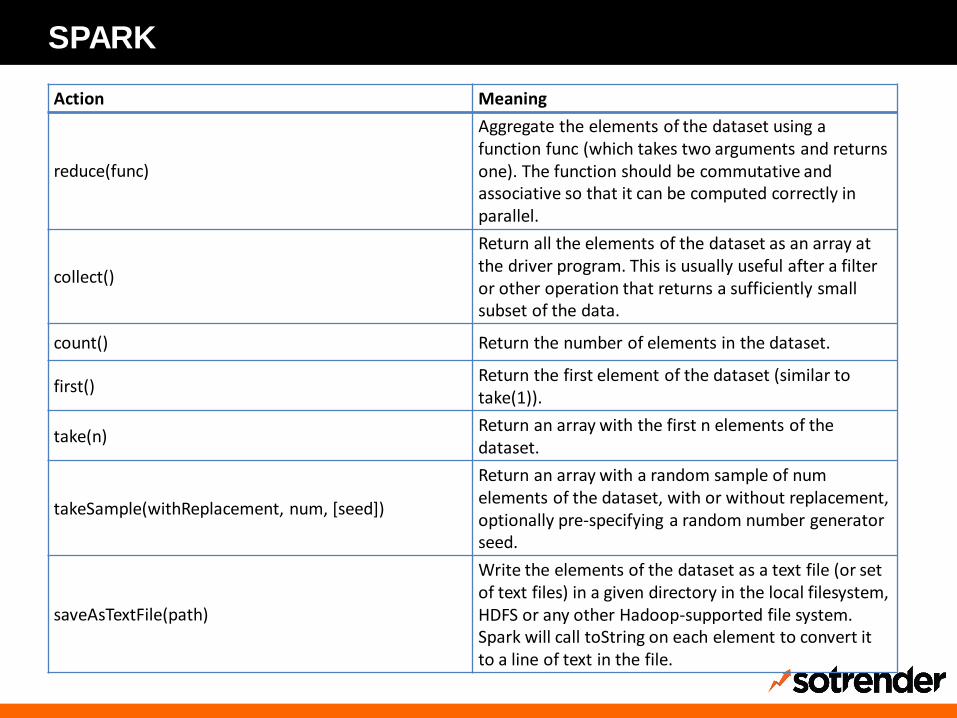
SPARK
Action Meaning
reduce(func)
Aggregate the elements of the dataset using a function func (which takes two arguments and returns one). The function should be commutative and associative so that it can be computed correctly in parallel.
collect()
Return all the elements of the dataset as an array at the driver program. This is usually useful after a filter or other operation that returns a sufficiently small subset of the data.
count() Return the number of elements in the dataset.
first() Return the first element of the dataset (similar to take(1)).
take(n) Return an array with the first n elements of the dataset.
takeSample(withReplacement, num, [seed])
Return an array with a random sample of numelements of the dataset, with or without replacement, optionally pre-specifying a random number generator seed.
saveAsTextFile(path)
Write the elements of the dataset as a text file (or set of text files) in a given directory in the local filesystem, HDFS or any other Hadoop-supported file system. Spark will call toString on each element to convert it to a line of text in the file.

SPARK
text_file = spark.textFile("hdfs://...")
counts = text_file.flatMap(lambda line:
line.split(" ")) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda a, b: a + b)
counts.saveAsTextFile("hdfs://...")
Przykład: word count

SPARK

Spark sorts 100 TB in 23 minutes on 206
machines (6592 virtual cores), which
translates into 4.27 TB/min or 20.7
GB/min/node.
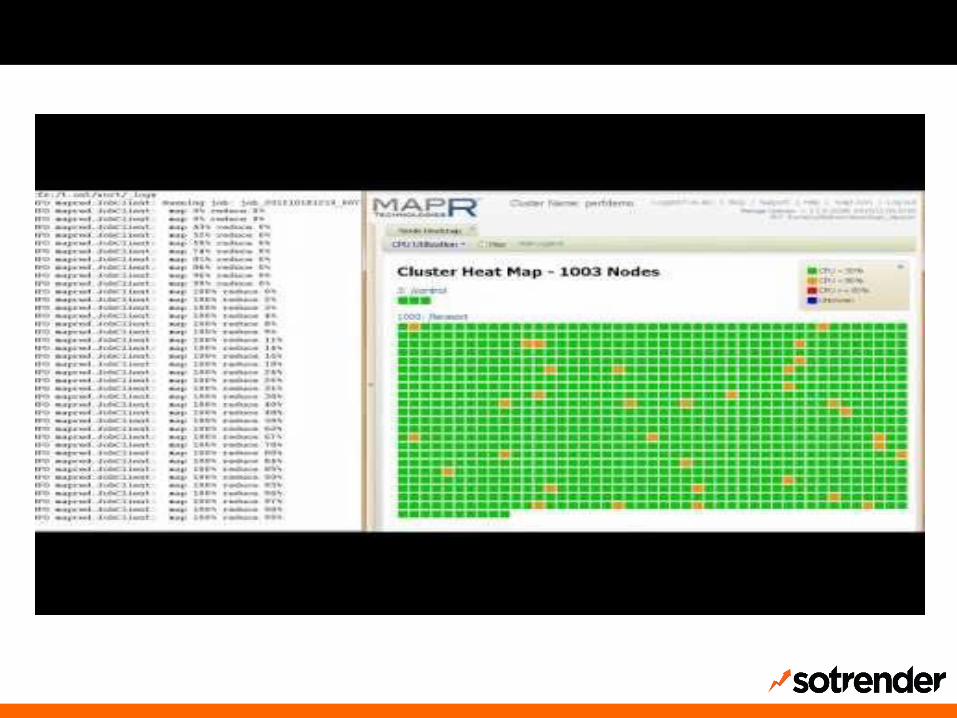

HBase

HBASE
Hbase
• Opraty na Google BigTable
• Baza danych
• Obsługuje szybkie (w czasie rzeczywistym)
operacje CRUD
• Zapewnia spójność oczytu i zapisu
• NoSQL – klucz-wartość
• Jedynie proste operacje
• Zbudowany na bazie HDFS

HBASE
• Rozproszona
• Działa na wielu maszynach
• Skalowalna
• Automatyczny sharding
• Dla dużych danych
• Miliardy wierszy
• Współpracuje z innymi elementami
Hadoop

HBASE
Wady:
• Tylko podstawowy zestaw operacji
• Brak transakcji
• Brak operacji na wielu tabelach
• Wymaga dużych ilości danych
• Inaczej nie ma sensu
• Wymaga dużo IO, CPU i RAM

HBASE
• Dane są zapisywane w tabeli
• Tabela składa się z wierszy
• Każdy wiersz ma przypisany klucz
• Tabela może mieć wiele rodzin kolumn
• W każdej rodzinie kolumn może być wiele
kolumn
Row Stats Text
20151111 Total = 1 Count = 10 Msg = blabla
20151112 Total = 2 Posts = 10 Msg = hehe Tags = funny

HBASE
• Tabele dzielone są na regiony – zakresy
kluczy
• Regiony z jednej tabeli mogą być
obsługiwane przez różne węzły
(RegionServer)

Dostęp:
• Natywne API (Java)
• REST
• Thrift
• Binarny protokół
• Szybki
• Obsługuje wiele języków

Hadoop w Sotrender

POCZĄTKI
MySQL
• Zaczynaliśmy od 1 serwera
• Dodawaliśmy kolejne serwery co kilka
miesięcy
• Zmienialiśmy serwery na co raz
mocniejsze
• Doszliśmy do 6 maszyn

MySQL
• Problem z migracją danych między
serwerami
• Brak skalowalności
• Problem z modyfikacją struktury
• Długi czas odzyskiwania po awarii
• Trudna konfiguracja

MYSQL
TokuDB
• Drzewa fraktalne
• Kompresja (do 25x)
• Tworzenie indeksów bez blokowania
• Modyfikacja struktury bez blokowania
• Działa efektywnie „out of box”
• Replikacja „read free”

HADOOP SOTRENDER
Hadoop
• Hbase
• Zbieranie danych
• Serwowanie danych w narzędziu
• Hive
• Niestandardowe analizy
• Pig
• Wyznaczanie trendów, dzienne obliczenia

HADOOP SOTRENDER
MySQL
• 3 TB danych (skompresowanych)
• 56 mld wierszy
Hadoop:
• 6 wezłów
• 28 TB danych
• HBase, Hive, Spark

HADOOP SOTRENDER
Testujemy:
• Spark
• Solr

HADOOP SOTRENDER
Plusy
• Skalowalność
• Faktycznie działa
• Wydajność
• Jednolity interfejs dostępu do danych
• Integracja z R
• Szybki rozwój

HADOOP SOTRENDER
Minusy
• Braki w dokumentacji
• Problemy ze stabilnością
• Java
• Błędy
• Konfiguracja
• Braki w kontroli dostępu
• Szybki rozwój

Hadoop w R

R I HADOOP
• Do czego wykorzystujemy?
• Delegowanie szczególnie „kosztownych”
operacji na danych (np. tabele frekwencyjne,
agregowanie rekordów
dziennych/godzinnych),
• Łatwy i relatywnie szybki dostęp do
ogromnych tabel,

R I HADOOP - DOSTĘP
• Szereg pakietów w R do operacji na
klastrze hadoopowym:
• rmr – umożliwiający pisanie programów
MapReduce w R,
• rhdfs – dostęp do plików w HDFS,
• rhbase – funkcje umożliwiające dostęp do
tabel w Hbase
• Możliwość nawiązania połączenia z Hive
przez JDBC (pakiet RJDBC w R)

R I HADOOP – DOSTĘP DO HIVE
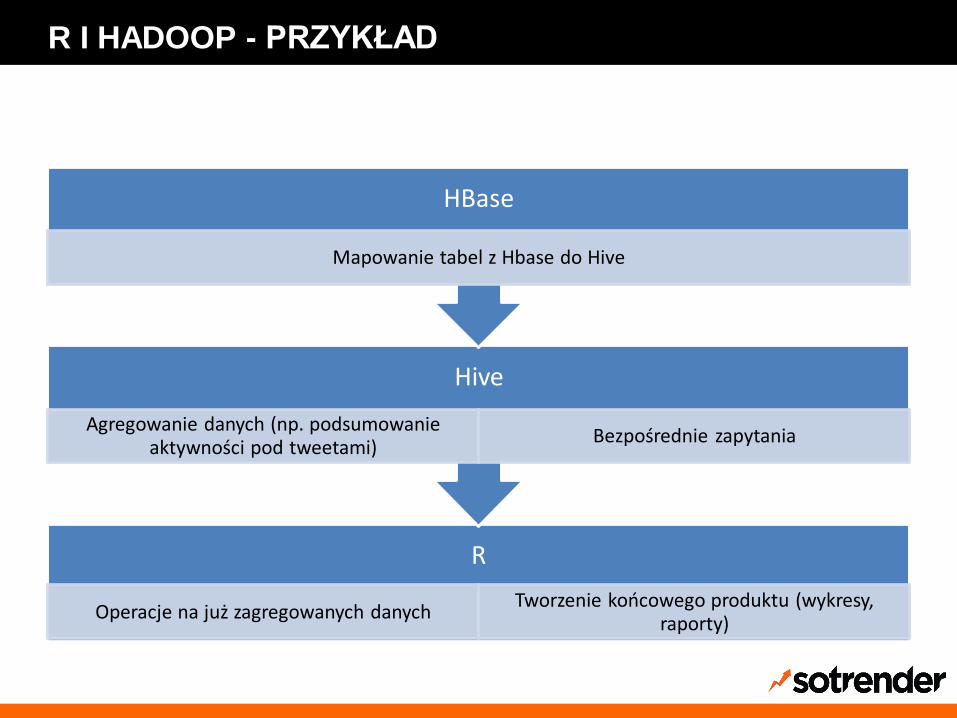
R I HADOOP - PRZYKŁAD
R
Operacje na już zagregowanych danychTworzenie końcowego produktu (wykresy,
raporty)
Hive
Agregowanie danych (np. podsumowanie aktywności pod tweetami)
Bezpośrednie zapytania
HBase
Mapowanie tabel z Hbase do Hive
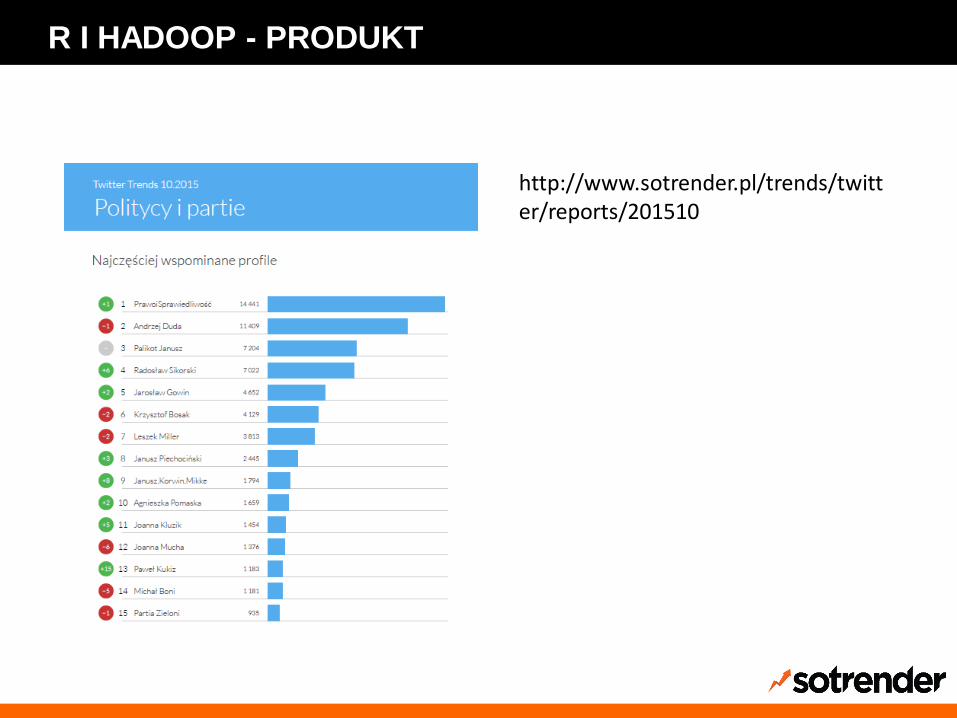
R I HADOOP - PRODUKT
http://www.sotrender.pl/trends/twitter/reports/201510