
ISSN Nº 1390 - 3802 matemáticablog.espol.edu.ec/revismat/files/2011/03/VOLUMEN-8... ·...
48
1001000101001010010101011000111010 ISSN Nº 1390 - 3802 1010011001000101010100010100100010101001010110100101 0010100100010010010111100101010010010100100100100101 1010010001111001010100100101010010001001001001001010 0100100100100100010010010010010100010100100101001001 0101000100100100100100100101001001001001001010010010 0100100100010010010001001010010010010001001010010010 0010100100100100100101001010010100101001010100100101 1010110101001001001010010101010101010010011001010010 0101010010010100101010010100100100101001001001010010 0100101001010101001001001010101100101010010010010010 1001011001010101100100101010110101010100100110010100 1100100101001010010001010100100100101001001010101010 0110010100110010101010100010010100101010001010010100 1001010011010010100100101001010010100101010010100100 0101000100100100010100100100101010100100100101001011 0100110101101010010010010100101001001001010010011110 1001001001010010010010010010110110010100101010010100 1010010101010101010010101001001100101001010110101011 1100100101010010100101010111010010101001110010101010 0101001010010100101100101001010101001111001010010101 0010101001010010100101010011010101010110100101010100 1010101001001010010111010100101011100101000101010000 1111010101001011001011110101001001101000010010101111 0100111010101010100011010101001011101010110101010110 0101010110100100100111100110110101011101010010010111 1110101001000100100100100100100100100001001001001000 1010100010100111001011101010101011101101101001011100 100111110010100101001100101001001011010100101001101 0010100100101001010010100101010010100100100010100101 0010101011000111010100010100101001100100010101010001 0100100010101001010110100101001010010001001001011110 0101010010010100100100100101101001000111100101010010 0101010010001001001001001010010010010010010001001001 0010010100010100100101001001010100010010010010010010 0101001000101001010010100101010010100100100010100101 0010101011001000101001010010101011000111010100010100 1010011001000101010100010100100010101001010110100101 matemática UNA PUBLICACIÓN DEL ICM - ESPOL Volumen 8 Número 2 Octubre 2010 Escuela Superior Politécnica del Litoral - ESPOL Instituto de Ciencias Matemáticas - ICM Z Y X
Transcript of ISSN Nº 1390 - 3802 matemáticablog.espol.edu.ec/revismat/files/2011/03/VOLUMEN-8... ·...

1001000101001010010101011000111010 ISSN Nº 1390 - 3802 1010011001000101010100010100100010101001010110100101001010010001001001011110010101001001010010010010010110100100011110010101001001010100100010010010010010100100100100100100010010010010010100010100100101001001010100010010010010010010010100100100100100101001001001001001000100100100010010100100100100010010100100100010100100100100100101001010010100101001010100100101101011010100100100101001010101010101001001100101001001010100100101001010100101001001001010010010010100100100101001010101001001001010101100101010010010010010100101100101010110010010101011010101010010011001010011001001010010100100010101001001001010010010101010100110010100110010101010100010010100101010001010010100100101001101001010010010100101001010010101001010010001010001001001000101001001001010101001001001010010110100110101101010010010010100101001001001010010011110100100100101001001001001001011011001010010101001010010100101010101010100101010010011001010010101101010111100100101010010100101010111010010101001110010101010010100101001010010110010100101010100111100101001010100101010010100101001010100110101010101101001010101001010101001001010010111010100101011100101000101010000111101010100101100101111010100100110100001001010111101001110101010101000110101010010111010101101010101100101010110100100100111100110110101011101010010010111111010100100010010010010010010010010000100100100100010101000101001110010111010101010111011011010010111001001111100101001010011001010010010110101000101001101001010010010100101001010010101001010010010001010010100101010110001110101000101001010011001000101010100010100100010101001010110100101001010010001001001011110010101001001010010010010010110100100011110010101001001010100100010010010010010100100100100100100010010010010010100010100100101001001010100010010010010010010010100100010100101001010010101001010010010001010010100101010110010001010010100101010110001110101000101001010011001000101010100010100100010101001010110100101
matemática UNA PUBLICACIÓN DEL ICM - ESPOL
Volumen 8 Número 2 Octubre 2010
Escuela Superior Politécnica del Litoral - ESPOL Instituto de Ciencias Matemáticas - ICM
Z
Y
X

INSTITUTO DE CIENCIAS MATEMÁTICAS El Instituto de Ciencias Matemáticas (ICM) es una unidad académica de la ESPOL. Desde el inicio la función del ICM ha sido la docencia en Matemáticas, Ciencias Gráficas e Informática, para la formación de profesionales en ingeniería, tecnología y ciencias, habiendo tenido a su cargo en los albores de la ESPOL, el dictado de 10 materias. Con el transcurso del tiempo y acorde con la era de la información, el ICM creó en mayo de 1995 la carrera de “Ingeniería en Estadística Informática”, como alternativa en ingeniería en información y servicios. Posteriormente, con el fin de garantizar la eficiencia en el control y gestión empresarial con profesionales capacitados y de excelencia se creó la carrera de “Auditoría y Control de Gestión” en mayo de 2000. También el Instituto ha incursionado en una de las más importantes ramas de la matemática aplicada que tiene grandes aplicaciones en el mundo moderno, esto es la Investigación de Operaciones, la Teoría de Optimización, y particularmente las aplicaciones logísticas, a través del ofrecimiento de programas de pre-grado y post-grado en estas áreas. Así es como desde el año 2005 se viene ofreciendo la maestría en Control de Operaciones y Gestión Logística y desde el año 2006 la carrera de Ingeniería en Logística y Transporte. El ICM también cuenta con el CENTRO DE INVESTIGACIONES ESTADÍSTICAS, a través del cual, se realizan: estudios de predicción, estudios actuariales, estudios de mercado, diseños de experimentos, planificación y dirección de censos, análisis financieros, bases de datos estadísticos, formulación de proyectos, ingeniería de la calidad, etc. Entre otras actividades que desarrolla el ICM anualmente están: las JORNADAS EN ESTADÍSTICA E INFORMÁTICA que actualmente está en su décimoquinta versión, el CONCURSO INTERCOLEGIAL DE MATEMÁTICAS que se viene realizando en forma continúa desde 1988. .
Más información: www.icm.espol.edu.ec o escribirnos al e-mail: [email protected], [email protected], [email protected], 30 ½ vía Perimetral: Edificios 25 – B Planta alta (Área de Institutos) Telfs.: (593-4)
2269525 – 2269526, fax: (593–4) 853138. Guayaquil – Ecuador

matemática UNA PUBLICACIÓN DEL ICM – ESPOL
Volumen 8 Número 2 Octubre 2010
Rector ESPOL: Ph.D. Moisés Tacle Galárraga Vicerrector General ESPOL: M.Sc. Armando Altamirano Chávez
Director ICM: M.Sc. Washington Armas Subdirector ICM: M.Sc. Luis Rodríguez Ojeda Editor de publicaciones del ICM: M.Sc. Eduardo Rivadeneira Consejo Editorial ICM: M.Sc. Efrén Jaramillo Carrión M.Sc. Jorge Fernández Ronquillo M.Sc. Luis Rodríguez Ojeda
Redacción y estilo: M.Sc. Janet Valdiviezo M.Sc. Gaudencio Zurita Herrera Edición: Ing. Eva María Mera Intriago Srta. Carolina Carrasco Salas

matemática es una publicación del Instituto de Ciencias Matemáticas de la Escuela Superior Politécnica del Litoral, y pretende constituirse en un órgano de difusión científico – tecnológico, con el fin de incentivar y motivar el desarrollo y avance de la matemática y sus aplicaciones. matemática publica artículos teóricos y de tipo experimental tales como ensayos, resúmenes de tesis de grado y trabajos de investigación relacionados con la aplicación de la matemática en los diferentes ámbitos de la realidad.

EDITORIAL La Universidad Ecuatoriana se encuentra ante el reto que le ha planteado la nueva ley de Educación Superior. La exigencia de que los académicos posean la más alta calificación y que sus investigaciones sean publicadas más allá de las fronteras de nuestro país, ha dado el golpe inicial para una avalancha de reformas que no siempre son bien acogidas. Nosotros, desde aquí, confiamos en que todos estos requerimientos serán cumplidos y así nuestra universidad irá por camino seguro al nivel de excelencia que todos aspiramos. Los que hacemos Revista Matemática estamos siempre dispuestos a fortalecer este proceso de superación, con nuestro humilde trabajo.

CONTENIDO
EDITORIAL..................................................................................................... 5 PROPUESTA METODOLÓGICA PARA EL CÁLCULO DE LOS NIVELES SOCIOECONÓMICOS EN EL ECUADOR A PARTIR DE LA ENEMDU 2009 Choez Geovanny…………………..........…………….................. 7 APLICACIÓN DEL CÁLCULO DE LA ENTROPÍA PARA EL ESTUDIO DE REGISTROS ELECTROENCEFALOGRÁFICOS González Javier, Granados Carlos, López Hernán, Torres Iván…. 16 ESTIMADORES ROBUSTOS PARA EL VECTOR DE MEDIAS Y LA MATRIZ DE VARIANZAS Y COVARIANZAS DE VECTORES ALEATORIOS MULTIVARIADOS Montaño Néstor, Zurita Gaudencio....………………….................... 22 DYNAMICAL SYSTEMS AND DIFFERENTIAL EQUATIONS Páez Joseph………………………………….…………………… 33 RESOLUCIÓN EXACTA DEL MODELO DEL MÁXIMO PROMEDIO PARA EL PROBLEMA DE LA DISPERSIÓN MÁXIMA Sandoya Fernando....................................................................……….. 41

matemática: Una publicación del ICM – ESPOL 2010, Vol. 8, No. 2
PROPUESTA METODOLÓGICA PARA EL CÁLCULO DE LOS NIVELES SOCIOECONÓMICOS EN EL ECUADOR A PARTIR DE
LA ENEMDU 2009
1Choez Geovanny Resumen. Se realizó este trabajo con el propósito de presentar una metodología preliminar para el cálculo de los niveles socioeconómicos en el Ecuador reflexionando en metodologías implementadas en países europeos y también en Chile. Se identificaron 8 niveles socioeconómicos a partir de la tenencia acumulada de bienes, cada uno de los bienes multiplicado por un factor obtenido a través del análisis de componentes principales categórico. Además se logró clasificar los bienes en primarios, secundarios y extras. Posteriormente se evalúo la relación estadística entre los niveles socioeconómicos obtenidos y variables que conceptualmente están vinculadas a estos. Los resultados son congruentes respecto a las metodologías implementadas en otros países. Palabras Clave: INEC, ENEMDU, Niveles socioeconómicos, componentes principales. Abstract. Introduction: This work presents a new methodology to calculate the social grades or social class in the Ecuador, taking into consideration implemented methodologies in countries in Europe and Chile. Objective: Identify the social level or social class in the Ecuadorian population using multivariate statistical methods. Methods: The statistical technique used is categorical principal components which provide a factor based off the assets of the investigated people. Results: The analysis provides eight social levels where 1 is the lowest level and 8 is the highest level. Conclusions: These social grades obtained with this methodology are congruent between others revised methodologies. Key words. INEC, ENEMDU, Social grades, categorical componentes principales.
Recibido: Agosto, 2010 Aceptado: Septiembre, 2010
1. INTRODUCCIÓN El Instituto Nacional de Estadística y Censos (INEC) considera de suma importancia la estratificación socioeconómica en el país, por esto el área de análisis de la regional del litoral decidió explorar las bases teóricas y métodos estadísticos multivariados utilizados para la clasificación de datos que permita establecer un marco de referencia metodológico como guía en la clasificación de los hogares según los niveles socioeconómicos. Un primer trabajo referente a la temática se realizó utilizando la información de la Encuesta de Empleo, Desempleo y Subempleo (ENEMDU 2008) y su modulo de opinión (auto percepción) en el que se construyó un modelo estadístico para determinar las características o grupo de características que mayor relación tienen con el bienestar del hogar (según la percepción del/la jefe/a del hogar). Consecuentemente se decidió realizar éste trabajo cuyo propósito es proponer una metodología preliminar para la estructuración de los niveles socioeconómicos (NSE) de los hogares ecuatorianos, a través de la aplicación de métodos multivariados con los datos de la ENEMDU 2009. ________________________
1 Choez Geovanny, Ingeniero en Estadística e Informática, Escuela Superior Politécnica del Litoral (ESPOL); Departamento de Análisis Socioeconómico, INEC. (e_mail: [email protected])
Para el desarrollo de la propuesta el primer objetivo es analizar los métodos estadísticos multivariados utilizados para la clasificación de datos. Luego combinar los métodos para la estructuración de los niveles socioeconómicos de los hogares ecuatorianos. Finalmente se quiere comparar los resultados de la metodología obtenida frente a otros métodos de estratificación de estudios similares.
2. MARCO TEÓRICO
NSE ESOMAR 2 En 1997, y en respuesta a las necesidades de la creciente investigación paneuropea en el mercado único, European Society for Opinion and Marketing Research 3 (ESOMAR) propuso un nuevo método de clasificación. Su objetivo era incrementar la convergencia de los criterios socioeconómicos y demográficos utilizados en cada país para tabular los estudios de marketing y de opinión. La clasificación propuesta (Social Grade Matrix) se investigó en los doce países que en 1997 formaban la Unión Europea sobre la base de las cerca de 90.000 entrevistas del Eurobarómetro. Consiste en la utilización de los procedimientos que se aplican alternativamente según que el principal sustentador del hogar sea
2 Transcrito desde “Investigación Comercial 22 casos prácticos y un apéndice teórico”, Pg. 49, 50 3 Sociedad Europea para investigaciones de opinión y marketing.
G. CHOEZ
8
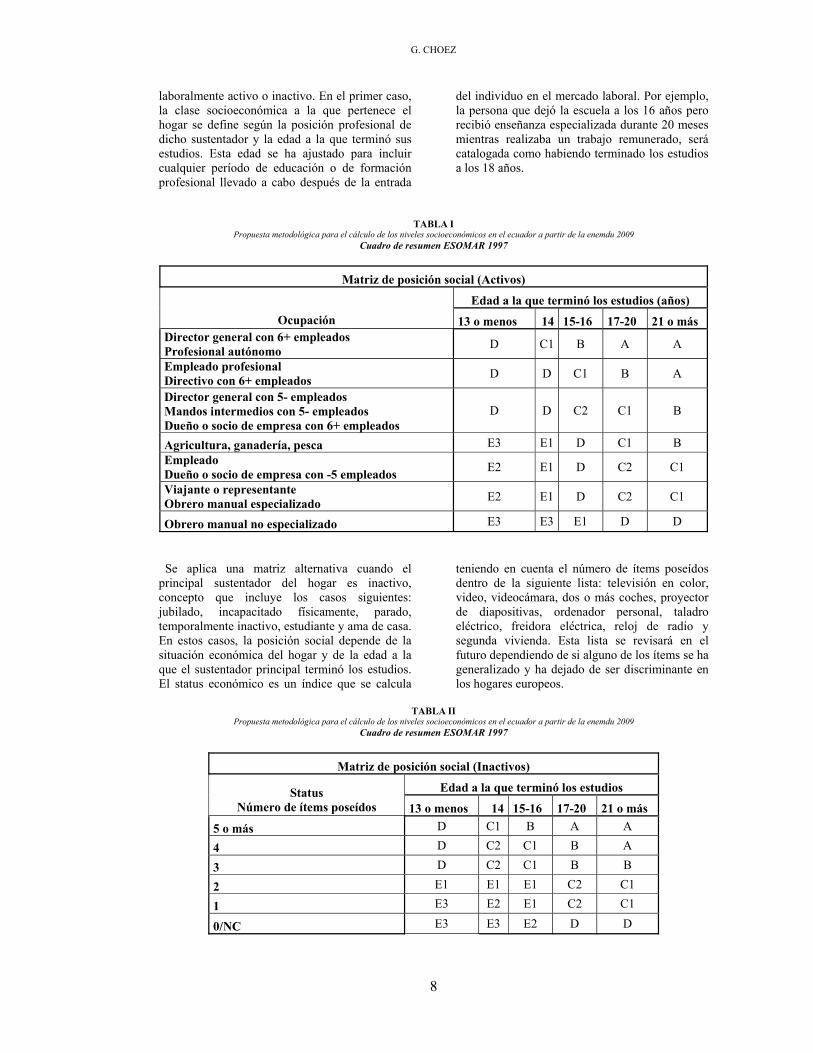
laboralmente activo o inactivo. En el primer caso, la clase socioeconómica a la que pertenece el hogar se define según la posición profesional de dicho sustentador y la edad a la que terminó sus estudios. Esta edad se ha ajustado para incluir cualquier período de educación o de formación profesional llevado a cabo después de la entrada
del individuo en el mercado laboral. Por ejemplo, la persona que dejó la escuela a los 16 años pero recibió enseñanza especializada durante 20 meses mientras realizaba un trabajo remunerado, será catalogada como habiendo terminado los estudios a los 18 años.
TABLA I Propuesta metodológica para el cálculo de los niveles socioeconómicos en el ecuador a partir de la enemdu 2009
Cuadro de resumen ESOMAR 1997
Matriz de posición social (Activos)
Edad a la que terminó los estudios (años) Ocupación 13 o menos 14 15-16 17-20 21 o más
Director general con 6+ empleados Profesional autónomo D C1 B A A
Empleado profesional Directivo con 6+ empleados D D C1 B A
Director general con 5- empleados Mandos intermedios con 5- empleados Dueño o socio de empresa con 6+ empleados
D D C2 C1 B
Agricultura, ganadería, pesca E3 E1 D C1 B Empleado Dueño o socio de empresa con -5 empleados E2 E1 D C2 C1
Viajante o representante Obrero manual especializado E2 E1 D C2 C1
Obrero manual no especializado E3 E3 E1 D D
Se aplica una matriz alternativa cuando el principal sustentador del hogar es inactivo, concepto que incluye los casos siguientes: jubilado, incapacitado físicamente, parado, temporalmente inactivo, estudiante y ama de casa. En estos casos, la posición social depende de la situación económica del hogar y de la edad a la que el sustentador principal terminó los estudios. El status económico es un índice que se calcula
teniendo en cuenta el número de ítems poseídos dentro de la siguiente lista: televisión en color, video, videocámara, dos o más coches, proyector de diapositivas, ordenador personal, taladro eléctrico, freidora eléctrica, reloj de radio y segunda vivienda. Esta lista se revisará en el futuro dependiendo de si alguno de los ítems se ha generalizado y ha dejado de ser discriminante en los hogares europeos.
TABLA II
Propuesta metodológica para el cálculo de los niveles socioeconómicos en el ecuador a partir de la enemdu 2009 Cuadro de resumen ESOMAR 1997
Matriz de posición social (Inactivos)
Edad a la que terminó los estudios Status Número de ítems poseídos 13 o menos 14 15-16 17-20 21 o más
5 o más D C1 B A A
4 D C2 C1 B A
3 D C2 C1 B B
2 E1 E1 E1 C2 C1
1 E3 E2 E1 C2 C1
0/NC E3 E3 E2 D D

PROPUESTA METODOLÓGICA PARA EL CÁLCULO DE LOS NIVELES SOCIOECONÓMICOS EN EL ECUADOR A PARTIR DE LA ENEMDU 2009
9
3. MARCO CONCEPTUAL ENEMDU.- Encuesta de Empleo, Desempleo y Subempleo. ESOMAR 43. – European Society for Opinion and Marketing Research Métodos estadísticos multivariados.- Según Daniel Peña (2002) los métodos estadísticos multivariados para el análisis de datos comprende el estudio estadístico de varias variables medidas en elementos de una población con los siguientes objetivos: • Resumir los datos mediante un pequeño
conjunto de nuevas variables. • Encontrar grupos en los datos, si existen. • Clasificar nuevas observaciones en grupos
definidos. • Relacionar dos conjuntos de variables. INEC.- Instituto Nacional de Estadística y Censos. Niveles Socioeconómicos.- Los NSE son un conjunto de estratos a capas en los que se divide una sociedad según el estilo de vida o grupo de características, dichas características son homogéneas dentro de cada capa y heterogéneas entre capas. Las características pueden ser sociales, económicas, demográficas, etc.
4. METODOLOGÍA
ANÁLISIS DE COMPONENTES PRINCIPALES CATEGÓRICO
El análisis estándar de componentes principales asume que todas las variables del análisis se miden a escala numérica, y que las relaciones entre los pares de variables son lineales (Pérez, 2006). Varela (2005) menciona sobre éste análisis que “la primera componente principal es la combinación lineal de las variables originales de varianza máxima”, es decir, que la ecuación de la primera componente (Y1) es:
1 11 1 12 2 1... p pY X X Xα α α= + + +
Donde p es el número de variables originales. La segunda componente principal (Y2) se construye análogamente:
2 2 1 1 2 2 2 2. . . p pY X X Xα α α= + + + El análisis de componentes principales categóricas extiende ésta metodología para permitir la ejecución del análisis de
4 Tomado de “Investigación Comercial 22 casos prácticos y un apéndice teórico”, Pg.37
componentes principales en cualquier mezcla de variables nominales, ordinales y numéricas. El análisis de componentes principales categórico se conoce también por el acrónimo CATPCA, del inglés CATegorical Principal Components Analysis. El objetivo de los análisis de componentes principales es la reducción de un conjunto original de variables en un conjunto más pequeño de componentes no correlacionados que representen la mayor parte de la información encontrada en las variables originales. Para las variables nominales y ordinales del análisis, se calcula puntuaciones óptimas para las categorías (Pérez, 2006).
5. ANÁLISIS DE CORRESPONDENCIAS
Uno de los objetivos del análisis de correspondencias es describir las relaciones existentes entre dos variables nominales, recogidas en una tabla de correspondencias, sobre un espacio de pocas dimensiones, mientras que al mismo tiempo se describen las relaciones entre las categorías de cada variable. Para cada variable, las distancias sobre un gráfico entre los puntos de categorías reflejan las relaciones entre las categorías, con las categorías similares representadas próximas unas a otras. El análisis factorial es una técnica típica para describir las relaciones existentes entre variables en un espacio de pocas dimensiones. Sin embargo, el análisis factorial requiere datos de intervalo y el número de observaciones debe ser cinco veces el número de variables. Por su parte, el análisis de correspondencias asume que las variables son nominales y permite describir las relaciones entre las categorías de cada variable, así como la relación entre las variables. Además, el análisis de correspondencias se puede utilizar para analizar cualquier tabla de medidas de correspondencia que sean positivas.
6. PROPUESTA
Paso 1 El primer paso es establecer un conjunto de variables que permitan encontrar agrupaciones en los datos. Peña Daniel (2002) en su texto considera que el análisis de componentes principales es muy útil como herramienta exploratoria, por esto se utilizó esta técnica para identificar agrupaciones según los bienes que permitan alguna clasificación de los hogares ecuatorianos. El conjunto de bienes considerados para el análisis y que forman parte del equipamiento del hogar son: Refrigerador, televisor, licuadora, computador, equipo de sonido, micro-ondas, cocina con horno, cocina sin

G. CHOEZ
10
horno, radio, lavadora, DVD, bicicleta, moto, auto, línea telefónica e internet. Se omitió algunos bienes poco frecuentes para maximizar la
explicación de los datos y se obtuvo los siguientes grupos:
FIGURA 1
Propuesta metodológica para el cálculo de los niveles socioeconómicos en el ecuador a partir de la enemdu 2009 Componentes Principales - Equipamiento de bienes en el hogar
Dimensión 1
1,0,9,8,7,6,5,4,3,2,10,0
Dim
ensión
2
,6
,4
,2
-,0
-,2
-,4
-,6
Tel.
Auto
Dvd
Lavadora
Cocina H.
Microhondas
Equipo
Pc
Licuadora
TV
Refrigerador
Fuente: ENEMDU 2009 Elaborado por: Autor
Los grupos de bienes con sus respectivos nombres son:
TABLA IV Propuesta metodológica para el cálculo de los niveles socioeconómicos en el ecuador a partir de la enemdu 2009
Clasificación de bienes del hogar
Clasificación de bienes del hogar
Bienes primarios Bienes secundarios Bienes extras Bienes poco frecuentes (omitidos)
Licuadora Equipo de sonido Computador (PC) Internet
Refrigerador DVD Auto Bicicleta
Televisor Cocina con horno Microhondas Moto
Lavadora Radio
Línea telefónica Cocina sin horno Fuente: ENEMDU 2009 Elaborado por: Autor

PROPUESTA METODOLÓGICA PARA EL CÁLCULO DE LOS NIVELES SOCIOECONÓMICOS EN EL ECUADOR A PARTIR DE LA ENEMDU 2009
11
Paso 2 El siguiente paso consiste en asignar una ponderación a la tenencia de cada bien, la tabla de
bienes con los respectivos pesos se presenta a continuación:
TABLA V
Propuesta metodológica para el cálculo de los niveles socioeconómicos en el ecuador a partir de la enemdu 2009 Ponderaciones para bienes del hogar
Ponderaciones para bienes del hogar
Bienes Ponderación Refrigeradora 2 Televisor 1 Licuadora 2 Computador (PC) 10 Equipo de sonido 6 Microhondas 10 Cocina con horno 5 Cocina sin horno 1 Radio 1 Lavadora 10 DVD 5 Bicicleta 1 Moto 1 Auto 9 Línea telefónica 8 Internet 1
Fuente: ENEMDU 2009 Elaborado por: Autor
Las ponderaciones se obtuvieron de los coeficientes de las ecuaciones de las dos primeras componentes principales 54que explican un 52% de la varianza total de los datos. Para obtener la ponderación se sumo el coeficiente de la variable del bien X en la primera componente y el coeficiente en la segunda componente del mismo bien X y se lo multiplicó por factor 10. Así se calculó la ponderación en cada bien excepto los bienes pocos frecuentes que se les dio la ponderación de 1. 5 Revisar teoría de las componentes principales en metodología
Paso 3 Luego se procedió a construir una variable que sume la cantidad de bienes que posee el hogar multiplicado por la ponderación respectiva, es decir, la variable (puntaje total) recopila la tenencia del bien y su respectivo peso. Los niveles socioeconómicos se construyen a partir del puntaje total según la concentración de casos como se muestra a continuación:

G. CHOEZ
12
FIGURA 2 Propuesta metodológica para el cálculo de los niveles socioeconómicos en el ecuador a partir de la enemdu 2009
Construcción de niveles socioeconómicos
Punt
aje
tota
l0123456789
1011121314151617181920212223242526272829303132333435363738394041
Porcentaje
6420
11
1
11
1
111
11
12
21
12
22
22
333
34
44
55
56
77
53
Niv
eles
soc
ioec
onóm
icos
1
2
3
4
5
6
7
8
Porcentaje
403020100
4
5
7
10
20
40
9
Fuente: ENEMDU 2009 Elaborado por: Autor
Los rangos de puntajes para la construcción de los niveles se presentan a continuación:
TABLA VI
Propuesta metodológica para el cálculo de los niveles socioeconómicos en el ecuador a partir de la enemdu 2009 Rangos de puntaje según bienes
Rangos de puntaje según bienes
Puntaje según bienes Nivel socioeconómico % 0 a 1 bien 1 8.7 2 a 8 bines 2 40.3 9 a 14 bienes 3 20.4 15 a 19 bienes 4 10.0 20 a 24 bienes 5 6.8 25 a 29 bienes 6 5.3 30 a 34 bienes 7 4.4 35 o más bienes 8 4.0
Fuente: ENEMDU 2009 Elaborado por: Autor
Paso 4 La validación de los niveles socioeconómicos obtenidos se realizó a través del análisis de correspondencia. La primera validación consiste
en graficar las categorías de las variables (nivel de instrucción y nivel socioeconómico). El gráfico respectivo se presenta a continuación:

PROPUESTA METODOLÓGICA PARA EL CÁLCULO DE LOS NIVELES SOCIOECONÓMICOS EN EL ECUADOR A PARTIR DE LA ENEMDU 2009
13
FIGURA 3 Propuesta metodológica para el cálculo de los niveles socioeconómicos en el ecuador a partir de la enemdu 2009
Nivel de instrcción vs nivel socioeconómico
Dimensión 1
2,52,01,51,0,50,0-,5-1,0-1,5-2,0
Dim
ensi
ón 2
2,0
1,5
1,0
,5
0,0
-,5
-1,0
-1,5
-2,0
Estratos
Nivel de instrucción
8
7
65
43
2
1
superior
ninguno
primaria
secundaria
Fuente: ENEMDU 2009 Elaborado por: Autor
El gráfico de correspondencia indica que existe relación directamente proporcional entre el nivel socioeconómico y el nivel de instrucción, es decir, a mayor nivel de instrucción del jefe de hogar mayor nivel socioeconómico del hogar.
La segunda validación consiste en graficar las categorías de las variables (condición de actividad y nivel socioeconómico) en un gráfico de correspondencias que es presentado a continuación:
FIGURA 4 Propuesta metodológica para el cálculo de los niveles socioeconómicos en el ecuador a partir de la enemdu 2009
Condición de actividad vs nivel socioeconómico
Dimensión 1
1,0,50,0-,5-1,0-1,5
Dim
ensi
ón 2
1,0
,8
,6
,4
,2
,0
-,2
-,4
-,6
-,8
-1,0
Nivel socioeconómico
Condición de
actividad
8
7
6 5
4
3 2
1
Inactivo
Desempleo Oculto
Desempleo Abierto
Otras formas de sube
Subempleo Visible
Ocupados plenos
Fuente: ENEMDU 2009 Elaborado por: Autor

G. CHOEZ
14
En el gráfico de correspondencia se identificaron dos grupos conceptualmente relacionados.
7. CONCLUSIONES
La estructuración de los niveles socioeconómicos a través de los bienes que conforman el equipamiento del hogar conceptualmente es congruente. La metodología implementada para la estructuración de los niveles socioeconómicos a través de los bienes que conforman el equipamiento concuerda con metodologías
similares utilizadas en Chile y en países de Europa.
8. RECOMENDACIONES Revisar ésta primera propuesta y contribuir en la modificación o perfeccionamiento de la misma. Continuar con la revisión de métodos estadísticos multivariados considerando otras variables que conceptualmente estén relacionadas al nivel socioeconómico.

PROPUESTA METODOLÓGICA PARA EL CÁLCULO DE LOS NIVELES SOCIOECONÓMICOS EN EL ECUADOR A PARTIR DE LA ENEMDU 2009
15
REFERENCIAS BIBLIOGRÁFICAS Y ELECTRÓNICAS
[1]. MEULMAN, J. (2005). SPSS Categories ® 14.0. SPSS Inc. EE.UU.
[2]. NORMAS INTERNACIONALES APA,
“Revista Universitaria Límite”. Facultad de Ciencias Sociales. Departamento de Filosofía y Psicología. Universidad de Tarapacá. Arica – Chile.
[3]. PEÑA, D. (2002). “Análisis de Datos Multivariantes”. McGraw-Hill. España.
[4]. PÉREZ, C. (2006). “Técnicas de Análisis
Multivariante de Datos”. Pearson Educación. España.
[5]. VARELA, L. (2005). “Análisis Multivariante
para las Ciencias Sociales”. Pearson Educación. España.

matemática: Una publicación del ICM – ESPOL 2010, Vol. 8, No. 2
APLICACIÓN DEL CÁLCULO DE LA ENTROPÍA PARA EL ESTUDIO DE REGISTROS ELECTROENCEFALOGRÁFICOS
1González Javier, 2Granados Carlos, 3López Hernán, 4Torres Iván
Resumen Los registros electroencefalográficos (EEG) son señales de tipo electrofisiológicas caracterizadas por su alto grado de aleatoriedad y bajos niveles de amplitud. Por su gran complejidad necesitan ser analizadas mediante la utilización de técnicas no lineales, como es el caso del cálculo de la entropía. La importancia del tratamiento de este tipo de señales, radica en que debido a sus características, son susceptibles a las interferencias producidas por agentes externos como otros equipos alrededor e internos como los movimientos musculares. Esta propuesta de trabajo se enfoca en el uso del cálculo de la entropía aproximada, para caracterizar regularidad de registros EEG. Los algoritmos implementados están basados en el planteamiento matemático realizado por Steven Pincus (Pincus, 1991) referentes a la entropía aproximada, Joshua S. Richman and J. Randall Moorman (Moorman, 2000) referentes a entropía muestral y en los algoritmos desarrollados por George B. Moody (Moody, 2001). Palabras Claves. Señales EEG, entropía, patologías. Abstrat. The electroencephalographic records (EEG) are electrophysiological signal with high randomness properties and low amplitude. The EEG needs nonlinear techniques for its analys because it is a complex time series. In this paper the calculation of the entropy is very important to characterize the EEG. Key words. EEG signals, Entropy, pathologies. Recibido: Junio, 2010 Aceptado: Agosto, 2010
1. INTRODUCCIÓN Dentro del gran grupo de las señales electrofisiológicas, existen los registros electroencefalográficos (EEG), que ha exigido múltiples estrategias matemáticas para extraer información con un alto grado de utilidad e importancia en el campo médico [1]. El EEG es un examen que registra la actividad eléctrica del cerebro y proporciona una aproximación de la actividad de las ondas emitidas por las células nerviosas en la corteza del cerebro. El EEG se compone principalmente de un grupo de ondas clasificadas por su rango en el dominio de la frecuencia, empezando por las ondas tipo Delta que comprenden el rango entre 0 y 4 Hz, seguidamente se tienen las ondas tipo Theta (4 – 8 Hz), las ondas tipo Alpha (8 – 12 Hz), ondas Beta (14 – 30 Hz) y las ondas Gamma (3 – 8 HZ). La adquisición del EEG consta de 4 etapas principales, la primera de ellas es la adquisición de la señal mediante el posicionamiento de electrodos según el estándar internacional 10-20 y se clasifican de acuerdo a la tarea o condiciones experimentales para las que se emplearan, por ejemplo pueden ser __________________________ 1 González Barajas Javier, Docente Facultad de Ing. Electrónica. Universidad Santo Tomás. Cra 9 N° 51-15. Bogotá – Colombia. (e-mail: [email protected]). 2 Granados Guevara Carlos A., Ingeniero Electrónico. Universidad Santo Tomás. Cra 9 N° 51-15. Bogotá. Colombia. (e-mail: [email protected]). 3 Lopez Católico Hernan Camilo. Médico Cirujano. Coordinador Médico Serivico de Neurofisiologia. Liga Central Contra la Epilepsia. (e-mail: [email protected]) 4 Torres Rincón Iván. Ingeniero Electrónico. Universidad Santo Tomás. Cra 9 N° 51-15. Bogotá. Colombia. (e-mail: [email protected]).
electrodos de superficie, de aguja o de profundidad. Por lo general esos registros poseen una amplitud en el rango 10 - 45µv. Para obtener una serie de tiempo de los registros EEG, se realiza un proceso de discretización con frecuencias de muestreo de 200Hz y 250 muestras por segundo. Como estrategia utilizada en los trabajos más actuales sobre el análisis del EEG, se cuenta con los métodos de análisis no lineal de series de tiempo [2]. También se ha citado en la literatura la Trasformada de Fourier, mediante la cual se estudia la distribución de frecuencias en la señal EEG [3]. La Transformada Wavelet, empleada para la clasificación automática de patrones y análisis de energía en las diferentes bandas de frecuencia del EEG [4]. El Filtro Kalman, para la eliminación de señales de artefactos [5]. El análisis de componentes independientes, para la separación de señales estadísticamente independientes y el filtrado de artefactos [6].
Para fines del desarrollo de este trabajo se ha utilizado el cálculo de la entropía aproximada, que refleja la probabilidad de la existencia de patrones no precedidos por otros similares dentro de una serie analizada y asigna valores mayores a secuencias más irregulares [7]. En el caso del EEG se cuantifica la predicción de valores de amplitud sucesivos basándose en el conocimiento de algunos valores de amplitud previos. Por lo tanto una secuencia de datos que contenga gran cantidad de patrones repetitivos, tendrá una entropía aproximada pequeña, mientras que una secuencia de datos más irregular tendrá una entropía aproximada mayor. Pincus la definió como la correlación entera en cada punto dentro de la muestra [8]. El valor de la entropía (ApEn)

J. GONZALEZ, C. GRANADOS, H. LÓPEZ & I. TORRES
17
aproximada depende de tres parámetros la longitud del patrón (observaciones sucesivas) m, el criterio de similitud r y el número de puntos de la serie N. Matemáticamente definida en (1) y (2).
( ) ( ) ( )1, , con 1m mApEn m r N r r r+= Φ −Φ ≥ (1)
∑+−
=+−=
1
1)(log
11)(
mN
i
mi
m rCmN
rφ (2)
Debido a que la entropía aproximada es una medida susceptible a la cantidad de datos que componen la señal analizada y que adicionalmente durante la comparación tiene en cuenta el mismo patrón que se está buscando, se ha optado por trabajar también con la entropía muestral. Ésta es una modificación al planteamiento de Pincus [8] hecha por Richman – Moorman [9]. Matemáticamente definida en (3) y (4).
( ) ( )( )
, , lnm
m
A rSampEn m r N
B r⎛ ⎞
= − ⎜ ⎟⎝ ⎠
(3)
( )1
1 ( )1
N mm m
ii
B r B rN m
−
=
=− − ∑ (4)
( )1
1 ( )N m
m mi
iA r A r
N m
−
=
=− ∑ (5)
Donde mB corresponde a la cantidad de coincidencias por patrón y mA corresponde a la cantidad de patrones coincidentes.
2. MATERIALES Y MÉTODOS Para el desarrollo de este proyecto fueron utilizados registros EEG tomados de la base de datos de la Fundación Liga Central Contra la Epilepsia (LICCE), correspondientes a pacientes con anomalías primarias generalizadas. Registros que fueron analizados de acuerdo a las descargas presentes. Los algoritmos fueron desarrollaron en Matlab. El algoritmo implementado carga en la memoria la señal EEG, que se encuentra en un archivo de cabecera dispuesto como un vector (Sn), el cual se segmenta en series de tiempo de longitud m y se genera la matriz (Pm). Cada serie será un patrón que se desea hallar a lo largo de la señal. A continuación en (6) se muestra la manera como se realiza la segmentación de Sn.
Sn={1,2,3,4,5,…,N}
1 22 3 1
1
mm
N m NPm +
− +
⎡ ⎤⎢ ⎥=⎢ ⎥⎣ ⎦
…
… (6)
Luego cada una de estas series de tiempo es comparada con las demás y si la diferencia entre cada uno de sus respectivos elementos es menor que r se cuenta como una coincidencia, almacenando el total de coincidencias en una variable. Este proceso se repite para m+1, es decir, aumentando el número de elementos de las series de tiempo a m+1. En seguida se promedian la cantidad de coincidencias por patrón para m y m+1 y la cantidad de patrones coincidentes por señal. Finalmente se obtiene el valor de entropía como el logaritmo del cociente entre ambos valores.
3. RESULTADOS Los algoritmos de entropía muestral y aproximada que fueron desarrollados, se implementaron en MATLAB para realizar pruebas con diferentes tipos de señales; esto con el fin de evidenciar las variaciones de los valores de entropía en señales con topologías diferentes. En primer lugar se tomó una función seno a la que se le calculó la entropía aproximada para tener un valor base sobre el cual haríamos las observaciones. En seguida, a esta señal se le sumó una señal de ruido determinístico y luego otra de ruido aleatorio y se les calculó la entropía aproximada. En la figura 1 se presentan las señales utilizadas y en tabla I, se muestran los valores de entropía obtenidos de las tres señales.
FIGURA 1 Aplicación del cálculo de la entropía para el estudio de registros
electroencefalográficos Señales de Prueba

APLICACIÓN DEL CÁLCULO DE LA ENTROPÍA PARA EL ESTUDIO DE REGISTROS ELECTROENCEFALOGRÁFICOS
18
TABLA I Aplicación del cálculo de la entropía para el estudio de registros
electroencefalográficos Valores de entropía para las señales de prueba
Tipo de señal Valor de entropía aproximada
Función seno 0.0428 Función seno con ruido
determinístico 0.0611
Función seno con ruido aleatorio 1.0970
La señal con ruido determinístico, muestra una elevación en su valor de entropía respecto a la señal original debido a que aumenta su complejidad, sin embargo este valor no aumenta considerablemente como en la tercera señal, debido a que mantiene cierta periodicidad en sus valores. El valor de entropía de la señal con ruido aleatorio aumenta ampliamente debido a que se pierde la periodicidad de la señal y por tanto aumenta su complejidad, es decir que tiende a ser una señal caótica. Una de las características de la entropía aproximada, es ser altamente dependiente de la cantidad de datos analizados, por lo que se convierte en una medida poco precisa, haciendo necesario una estimación de la cantidad de datos que se deben tener en cuenta al momento de calcular la entropía. Para mostrar esto, se compara el valor de entropía aproximada obtenido para la función seno formada por una cantidad N de datos y la misma función formada por 2N datos; esto equivale a una misma función muestreada con dos frecuencias diferentes. La figura 2 muestra las funciones utilizadas y la tabla II muestra los valores de entropía obtenidos.
FIGURA 2 Aplicación del cálculo de la entropía para el estudio de registros
electroencefalográficos Función de seno muestreada con dos frecuencias diferentes,
la inferior con el doble de frecuencia que la superior
TABLA II Aplicación del cálculo de la entropía para el estudio de registros
electroencefalográficos Valor de entropía aproximada una señal muestreada con
dos frecuencias diferentes, f1 y 2f1 respectivamente
Número de datos Valor entropía
aproximada 400 0,0207 800 0,0102
Las dos señales tienen la misma forma, pero el número de datos varió en la segunda dos veces más que en la primera. Los valores de entropía variaron igualmente, pero de manera inversa, es decir, con el doble de datos tomados, la entropía disminuye a la mitad. Para evitar el inconveniente de tener dentro de los parámetros de entropía el número de datos, se ha utilizado la entropía muestral; en la que su valor es menos sensible a la longitud de la señal analizada, pues la manera como se hace la comparación de los patrones en el algoritmo cambia al no tener en cuenta dentro de las coincidencias el mismo valor que se está evaluando. Esto a su vez implica que el valor de entropía aumenta respecto al valor obtenido con la entropía aproximada. En la tabla III, se presentan los valores de entropía aproximada y muestral, junto con la variación entre ellos, obtenidos para las señales de la figura 1.
TABLA III Aplicación del cálculo de la entropía para el estudio de registros
electroencefalográficos Valores de entropía muestral y aproximada y variación
entre los dos tipos de entropía
Tipo de señal Valor de entropía
aproximada
Valor de entropía muestral
Variación valor
entropía
Función seno 0.0428 0.0436 0.0008
Función seno con ruido
determinístico 0.6111 0.7086 0.0975
Función seno con ruido aleatorio
1.0970 2.4345 1.3375
El aumento en el valor de entropía de las señales, se debe a que el número de patrones coincidentes en las señales es mucho menor y por tanto se entiende que las señales tienden a ser más caóticas, perdiendo la periodicidad que tenían debido a la señal original (función seno). Luego de mostrar la incidencia que tiene el tipo de señal y su frecuencia de muestreo en el valor de entropía, se calcula el valor de entropía para una señal EEG bipolar. Los EEG utilizados tienen una duración de 30 minutos

J. GONZALEZ, C. GRANADOS, H. LÓPEZ & I. TORRES
19
y 30 segundos y fueron muestreados con una frecuencia de 200Hz, por lo tanto son registros muy largos que deben ser tomados en segmentos más cortos de tiempo llamados ventanas; en este caso cada ventana contiene 5 segundos de señal, lo que equivale a 366 ventanas en total. Cada EEG está conformado por 19 canales, de los cuales se tomaron únicamente dos, seleccionados por la mayor incidencia de las descargas en su comportamiento. A continuación se presentan tres periodos de tiempo de un registro EEG en tres momentos diferentes; La figura 3 muestra un intervalo normal de la señal EEG donde no se evidencian descargas.
FIGURA 3 Aplicación del cálculo de la entropía para el estudio de registros
electroencefalográficos Intervalo de señal normal
la figura 4 muestra una alteración en la actividad cerebral debido a fotoestimulación. En este caso el paciente recibe estimulación provocada por diversas fuentes de luz
FIGURA 4 Aplicación del cálculo de la entropía para el estudio de registros
electroencefalográficos Intervalo de señal con descarga debida o fotoestimulación en
canal
La figura 5 muestra una alteración debida a somnolencia, ya que en muchos casos los registros se toman en periodos de 24 horas consecutivas y se evalúa el comportamiento del paciente durante el ciclo Mañana - noche.
FIGURA 5 Aplicación del cálculo de la entropía para el estudio de registros
electroencefalográficos Intervalo de señal con descarga debida a somnolencia en
canal Fp1-F3
La figura 6 muestra un intervalo normal del registro, la figura 7 muestra la descarga por fotoestimulación y la figura 8 muestra la descarga debido a somnolencia.
FIGURA 6 Aplicación del cálculo de la entropía para el estudio de registros
electroencefalográficos Intervalo de señal normal en canal F3-C3
FIGURA 7 Aplicación del cálculo de la entropía para el estudio de registros
electroencefalográficos Intervalo de señal normal con descarga debida a
fotoestimulación en canal F3-C3

APLICACIÓN DEL CÁLCULO DE LA ENTROPÍA PARA EL ESTUDIO DE REGISTROS ELECTROENCEFALOGRÁFICOS
20
FIGURA 8 Aplicación del cálculo de la entropía para el estudio de registros
electroencefalográficos Intervalo de señal con descarga debida a somnolencia en
canal F3-C3
Se calculó el valor de entropía para las ventanas de tiempo mostradas arriba. La tabla IV contiene los valores de entropía para cada intervalo de señal por canal, la ventana de tiempo que corresponde a la señal analizada y el tipo de activación que produjo la descarga.
TABLA IV Aplicación del cálculo de la entropía para el estudio de registros
electroencefalográficos Valores de entropía aproximada y muestral en dos canales de una señal EEG bipolar de acuerdo a eventos presentes
Activación Entropía Aproximada
Entropía Muestral
Normal 1,0232 1,1290 Fotoestimulación 0,8756 0,9243
Somnolencia 0,9069 0,9684 Normal 1,0985 1,4294
Fotoestimulación 0,7146 0,7340 Somnolencia 0,7124 0,7318
Al revisar los valores de entropía se aprecia que estos disminuyen cuando se presentan anomalías
en la actividad cerebral, esto se debe a que la señal tiende a ordenarse durante este tipo de comportamiento anormal.
4. CONCLUSIONES A través del desarrollo de este trabajo se ha contado en primera instancia con el estudio e implementación de las técnicas para el calculo de la entropía aproximada y la entropía muestral. Por medio de las simulaciones previas realizadas con señales sinusoidales puras se ha podido evidenciar la sensibilidad de esta medida ante el aumento de la complejidad de series de tiempo. Al poder contar con el dominio de los algoritmos se ha tenido la oportunidad de poderlos implementar en una plataforma basada en un procesador digital de señales DSP del fabricante Texas Instrumentes, con lo cual se obtiene el valor agregado de tener una herramienta con capacidad de procesamiento que permite tener gran portabilidad y la posibilidad de realizar análisis no lineales en tiempo real de registros EEG. Los algoritmos implementados en la plataformas para DSP han sido ensayados con registros EEG en diferentes estados: normal, bajo estímulos y con presencia de anomalías y se ha podido evidenciar que la medida de entropía es sensible para los las disminuciones de complejidad que sufre el EEG.
5. AGRADECIMIENTOS Los resultados logrados en este trabajo han sido logrados gracias a la colaboración del cuerpo medico de la Liga Central Contra la Epilepsia de la ciudad de Bogota, DC. Colombia y especialmente a la dedicación del Medico cirujano Hernán Camilo López que coordino el manejo de las bases de datos de EEG.

J. GONZALEZ, C. GRANADOS, H. LÓPEZ & I. TORRES
21
REFERENCIAS BIBLIOGRÁFICAS Y ELECTRÓNICAS ECTRÓNICAS [1]. THAKOR, N. V.; TONG, S. (2004)
“Advances in quantitative electroencephalogram analysis methods”, Annu. Rev. Biomed. Eng., 6:453-495.
[2]. H. KANTZ AND T. SCHREIBER. (2005).
“Nonlinear Time Series Analysis”, Cambridge: Cambridge.
[3]. BRISMAR T. (2007). “The human EEG -
Physiological and clinical studies”. Physiol Behav, doi: 10.1016/j. physbeh. 2007.05.047.
[4]. O. A. ROSSO ET AL. (2001). “Wavelet
entropy: a new tool for analysis of short duration brain electrical signals”. Journal of Neuroscience Methods (105), pp 65-75.
[5]. JOSÉ L. GUTIERREZ, GUSTAVO F.
NEER Y LAURA R. DE VIÑAS. (2005). “Diagnóstico de Epilepsia a Distancia: una aplicación de la telemedicina”. Buenos Aires: s.n.
[6]. A. DELORME, T. SEJNOWSKI AND S. MAKEIG. (2007). “Enhanced detection of artifacts in EEG data using higher-order statistics and independent component analysis”, Neuroimage 34, pp 1443-1449.
[7]. DANIEL ABÁSOLO BAZ ET AL. (2006).
“Análisis no lineal de la señal electroencefalográfica (EEG) para la ayuda en el diagnóstico de la enfermedad de Alzheimer”, Madrid: s.n.
[8]. S. M. PINCUS AND A. L.
GOLDBERGER. (1994). “Physiological time series analysis: what does regularity quantify?”, Amer. J. Physiol., vol. 66, pp. H1643–Hl656.
[9]. JOSHUA S. RICHMAN AND J.
RANDALL MOORMAN. (2000). “Physiological time-series analysis using approximate entropy and sample entropy, Am J Physiol Heart Circ Physiol”,vol 278, pp H2039–H2049.

matemática: Una publicación del ICM – ESPOL 2010, Vol. 8, No. 2
ESTIMADORES ROBUSTOS PARA EL VECTOR DE MEDIAS Y LA MATRIZ DE VARIANZAS Y COVARIANZAS DE VECTORES
ALEATORIOS MULTIVARIADOS
1Montaño Néstor, 2 Zurita Gaudencio Resumen. La Estimación Robusta nace de la necesidad de estimadores que se comporten “bien” aún cuando existan variaciones en los supuestos iniciales o cuando es posible que la muestra esté “contaminada” por valores aberrantes que producen influencias en los resultados y por lo tanto conducen a estimaciones errónea; siendo este un campo en constante desarrollo se han propuesto diversos métodos de Estimación. Este artículo presenta los resultados de un estudio tipo Monte Carlo realizado para comparar algunos Métodos de Estimación Robusta para el Vector de Medias y Matriz de Varianzas y Covarianzas de un vector aleatorio de seis variables. El propósito es evaluar el comportamiento de los estimadores bajo diversas condiciones como Contaminación total o Contaminación por Variable; además se trata de establecer una “regla empírica” donde se utilice al tamaño de la Muestra, al Sesgo y la Curtosis Muestral como elementos de decisión sobre el estimador a utilizar. Los estimadores M de Huber y Bicuadrático o Biponderado son los que mejor rendimiento presentan, aunque cuando la curtosis es “alta” el Estimador MCD es el mejor. Palabras claves: Estimación Multivariada, Robustez, Monte Carlo Abstract. The Robust Estimation born from the need of estimators to behave "well" even when there are variations in the initial assumptions or when it is possible that the model is "contaminated" by outliers that producing influences the results and thus lead to estimates wrong, because of this is a field in constant development have been proposed various methods of estimation. This article presents the results of a Monte Carlo study realized for to compare some Robust Estimation Methods for Vector averages and Matrix of Variance and Covariance of a random vector of six variables. The purpose is to evaluate the behavior of the estimators under various conditions such as total contamination or contamination for variable, also I seek to establish a “empirical rule" that it use the size of the Sample, the Sample Bias and the Sample Kurtosis as elements of decision on the estimator one to using. The M estimator of Huber and Bisquared are those who present better performance, though when the kurtosis is "high" the Estimator MCD is the best. Key words: Multivariate Estimation, Robustness, Monte Carlo RECIBIDO: Agosto, 2010 Aceptado: Septiembre, 2010 1. INTRODUCCIÓN Para estimar parámetros poblacionales se utiliza información obtenida a partir de los datos que proporciona una Muestra; en la práctica se verifica que un alto porcentaje de las mediciones que se efectúan, por diferentes razones, contienen errores de medición u observaciones atípicas llamadas “valores aberrantes” o “extremos” pues se alejan acentuadamente del comportamiento general de las demás observaciones; bajo este escenario, ¿el estimador seguirá siendo una “buena” aproximación, o se verá afectado por este particular?. Esta situación origina la búsqueda de estimadores robustos, es decir, estimadores “poco” sensibles a errores de medición o a valores aberrantes. ________________________ 1 Montaño Nestor, Ingeniero en Estadística e Informática, Escuela Superior Politécnica del Litoral (ESPOL); (e_mail: [email protected]). 2 Zurita Gaudencio, M.Sc., Profesor de la Escuela Superior Politécnica del Litoral (ESPOL); Director del Centro de Estudios e Investigaciones Estadísticas ICM – ESPOL. (e_mail: [email protected]).
2. ESTIMACIÓN ROBUSTA Para modelar la situación en que la mayoría de las observaciones provienen de una distribución Fθ , pero una pequeña fracción ε de las observaciones son valores atípicos generados por otra distribución H, Tukey en [15] plantea la Familia de Contaminación εF definida por:
( ){ }1 ;F Hε ε ε θθ= − + ∈ΘF (2.1) donde ε representa la proporción de contaminación. Se espera que los Estimadores Robustos cumplan con dos requerimientos: Eficiencia y Estabilidad. Se dice que un estimador es Eficiente si sus estimaciones son “buenas” aunque no exista contaminación, es decir que por ejemplo, el Estimador Robusto debe ser comparable con el Estimador de Máxima Verosimilitud (al que de aquí en adelante llamado Estimador Clásico). Para el caso multivariado este requerimiento implica lo siguiente:
i) Sea ( )∑nnμ , los estimadores de localización y
dispersión para una muestra de tamaño n y sean

ESTIMADORES ROBUSTOS PARA EL VECTOR DE MEDIAS Y LA MATRIZ DE VARIANZAS Y COVARIANZAS DE VECTORES ALEATORIOS MULTIVARIADOS
23
( )∞∞ ∑μ , sus valores asintóticos. Si
( )i p
N∼ ∑,X μ entonces ∞ =μ μ y c∞ =∑ ∑
donde c es una constante; y,
ii) ( )∑nnμ , deben ser asintóticamente normales,
esto es,
( ) ( )pN
Ln ∞− ⎯→ 0, μn Vμ μ
( )( ) ( )qN
Ln vech ∞ ∑− ⎯→ 0,∑ ∑n V
donde ( )1
2
p pq
+= y ( )vech ∑ es el vector que
contiene los q elementos de la triangular inferior de ∑ . Un estimador se lo considera estable si su “buen” comportamiento se preserva incluso ante la presencia de contaminación, esto es cuando F varía sobre εF . Para evaluar la estabilidad se han propuesto varias medidas, como Sesgo Asintótico Máximo y la Varianza asintótica Máxima las cuales miden el “peor” comportamiento del estimador para todo *ε ε< ; también se tiene el Punto de Ruptura Asintótico donde la idea es representar la mayor fracción de contaminación que el estimador puede tolerar. Por otro lado, en varios de los métodos de análisis multivariados se trabaja con transformaciones lineales de las variables, entonces todos los estimadores tratados cumplen la propiedad de equivarianza, esto es: Si y=Ax+b entonces
( ) ( )= +y x bAμ μ
( ) ( ) T=∑ ∑y xA A Se han propuesto diversos Estimadores Robustos, sin embargo para este estudio se ha escogido a considerados “más populares”, a continuación definirá a cada uno de ellos. En lo siguiente, la distancia de Mahalanobis representada por:
( ) ( ) ( )1, ,T
d di i i i i−= − −=x x x∑ ∑μ μ μ
2.1 ESTIMADOR M MULTIVARIADO
Maronna en [9] extiende los estimadores M propuestos por Huber en [5] a espacios p-dimensionales; así, define al estimador M como la solución de
( ) ( )1
1 0n
iiW d i
=− =∑ ⎡ ⎤⎣ ⎦ x μ
( ) ( )( )1
22
1 n
i
TW d i iin =
− − =∑ ⎡ ⎤⎣ ⎦ ∑x xμ μ
donde W1 y W2 no son necesariamente iguales. Nótese que el Estimador M se puede interpretar como un Vector de Medias ponderado y una Matriz de Covarianza ponderada, donde las ponderaciones dependen de la Distancia de Mahalanobis. Se utilizan funciones W1 y W2 de tipo Huber, esto es:
( ) ( ) ( )( )221 2
1 1i
d k W di iW d y W dik d kidi
β
⎧⎪ ≤⎪
= =⎨⎪ >⎪⎩
2.2 ESTIMADOR S BICUADRÁTICO
MULTIVARIADO Se define al Estimador S Bicuadrático o Biponderado multivariado como ˆ pRμ ∈ y ˆ
pS∑ ∈
que minimiza ( )( ) ˆˆ , , 1condiσ ∑ =∑x μ , donde σ̂
es un Estimador M univariado de Escala que satisface
1
1ˆ
n
i
din δσρ
=
⎛ ⎞ =⎜ ⎟⎝ ⎠
∑
siendo ( ) ( ){ }3min 1,1- 1-ttρ = .
Se puede demostrar que, bajo ciertas condiciones, los estimadores S son una particularización de los Estimadores M cuya función de ponderación tiende a cero para distancias “grandes”.
2.3 ESTIMADOR S T-BICUADRÁTICO Mientras mayor sea el número de variables, los estimadores S con función de ponderaciones continua se aproximan al vector de medias muestral y la matriz de varianzas y covarianzas muestral, esto implica una pérdida de robustez; Rocke en [12] considera este problema y propone un tipo de estimador con función dependiente del número de variables, en particular propuso una familia de estimadores cuya función ρ cumple que
( ) ( )lim 1p d I dρ→∞ = > , donde ( )1I d> es la
función “indicador”. El estimador T-Bicuadrático es un estimador que cumple las mismas condiciones del Estimador Bicuadrático con

N. MONTAÑO & G. ZURITA
24
( )
0 0 1
21 1 13 1 14 2
1 1
t
para t
t t para t
para t
γ
ρ γ γγ γ
γ
⎧⎪⎪ ⎡ ⎤⎪⎛ ⎞ ⎛ ⎞⎢ ⎥= ⎨⎜ ⎟ ⎜ ⎟⎝ ⎠ ⎝ ⎠⎢ ⎥⎪ ⎣ ⎦⎪⎪⎩
≤ ≤ −
− −− + − < < +
≥ +
2.4 ESTIMADOR COVARIANZA DE MÍNIMO
DETERMINANTE MCD Zuo en [18] indica que los estimadores MCD propuestos por Rousseeuw escogen h observaciones las cuales minimizan el determinante de la Matriz de Covarianzas Clásica, así, el estimador MCD de localización es el promedio de las h observaciones y el estimador MCD de escala es un múltiplo escalar de la Matriz de Covarianzas correspondiente a las h observaciones. Este estimador es probablemente el más popular debido (en parte) al “rápido” cálculo de los estimadores por parte de varios algoritmos desarrollados.
2.5 ESTIMADOR STAHEL-DONOHO (DS) Maronna en [8] indica que la idea del estimador Stahel-Donoho, propuesto por Stahel (1981) y Donoho (1982) es que un “valor aberrante” multivariado debe serlo también en alguna proyección univariada. Entonces el estimador DS, es un vector de Media y Matriz de Covarianzas ambos ponderados de tal manera que la ponderación de xi es una función de la “lejanía” de xi, denotada por ( )it x . Es decir, siendo W1 y W2 dos funciones de ponderación, se define
111
1
1ni i
n
ii iw x
w= ==∑
∑μ
( ) ( )21
21
1ni i
Tni
ii iw
w= == − −∑
∑ μx μx∑
Con ( )( ) , 1, 2ij j iw w t j= =x
3. DETALLES DE LA SIMULACIÓN Las medidas planteadas para evaluar la Robustez son definidas asintóticamente, quedando sin explicar el comportamiento de dichos Estimadores en muestras finitas, esto es lo que se explora en el presente estudio utilizando Simulación Matemática.
3.1 DISEÑO DEL ESTUDIO En este trabajo se generan muestras aleatorias a partir de distribuciones a las que se les manipula algunos parámetros con el objetivo de simular varias condiciones y así estudiar el comportamiento de los Estimadores Robustos bajo estas condiciones; uno de los estudios seminales en cuanto a comparar Estimadores Robustos fue el realizado por Andrews et al.[1]; en dicho estudio se dio a lugar a la noción de la tres "esquinas" para representar las posibles situaciones que se pueden encontrar en la práctica; se propuso probar los Estimadores Robustos bajo un enfoque muy optimista (Generando una Distribución Normal), muy pesimista (a través de una Cauchy) y la última prueba consistía en 20 datos, 19 de los cuales eran generados a partir de una Normal Estándar y el último generado a partir de una N(0,100). Los dos primeros argumentos son el punto de partida del presente estudio, es decir, se consideraran muestras generadas a partir de la Distribución Normal Multivariada N(0,Σ) y la Distribución Cauchy CAU(0,Σ), considerando la diferencia entre ambas en el “peso” de sus colas. Las muestras generadas son contaminadas, para ello se considera la Familia de Contaminación (2.1) donde 0; 0.05; 0.1ε = y 0.3 de tal manera que se observa el comportamiento de los estimadores analizados bajo condiciones de: • No Contaminación, 0ε = , caso que permitirá compararlos con los Estimadores de Máxima Verosimilitud, • Contaminación Moderada, 0.5ε = y 0.1ε = , que parece ser lo más cercano a la realidad, y • Contaminación Extrema, 0.3ε = , cuyos resultados se pueden utilizar para verificar si el Punto de Ruptura de los Estimadores es mayor a 0.3. Además, para la Distribución H que genera la contaminación en el modelo (2.1) se ha escogido tres Distribuciones: • Distribución Normal Multivariada N (0,9Σ), para seguir con la idea propuesta por Tukey en [15] y que además es la Distribución utilizada con más frecuencia en este tipo de estudios. • Distribución Normal Multivariada
( )60.537 , 9N ∑α , es decir una Contaminación
Asimétrica donde α6 representa el vector propio correspondiente al menor valor propio asociado a la Matriz de Varianzas y Covarianzas; este tipo de contaminación es utilizada por Devlin en [2]; y • Distribución Uniforme Esférica U esf(d), donde d representa la distancia hacia el origen; esta distribución se utiliza bajo el supuesto que una observación errónea puede producirse en cualquier punto con igual probabilidad.

ESTIMADORES ROBUSTOS PARA EL VECTOR DE MEDIAS Y LA MATRIZ DE VARIANZAS Y COVARIANZAS DE VECTORES ALEATORIOS MULTIVARIADOS
25
Por otro lado, como se menciona en la segunda sección, el Entorno de Contaminación (2.1) indica que una proporción de vectores no siguen la distribución original, para el caso multivariado esto implica que existen dos escenarios posibles: ó todas las componentes de la observación están contaminadas ó ninguna está contaminada; esto sin embargo no es necesariamente lo que ocurre en la realidad, pues se puede pensar que los errores se dan en una o varias componentes de la observación, difícilmente en todas; en base a esto se considera otro tipo de contaminación, la misma que considera cada variable independientemente, es decir, mientras en el modelo (2.1) una observación tiene probabilidad ε de estar contaminada, el segundo modelo considerado indica que cada componente de la observación tiene probabilidad ε de estar contaminada. Las distribuciones utilizadas para generar la contaminación por variable son: Distribución Normal ( )0, 9 iN σ y la Distribución
Uniforme U ( −5 ,5).
3.2 PARÁMETROS DE LA SIMULACIÓN Además de lo explicado en la sección 3.1, para el presente estudio se trabaja con p=6, donde p representa el número de variables y el tamaño muestral será n=kp donde k=5 ,10 y 20. A continuación se presentan las dos Matrices de Varianzas y Convarianzas utilizadas para generar las muestras aleatorias,
1.950 1.300 .100 1
0 0 0 110 0 0 .499 10 0 0 .499 .499 1
=
−− −
⎛ ⎞⎜ ⎟⎜ ⎟⎜ ⎟⎜ ⎟⎝ ⎠
∑
a la misma que le corresponde los valores propios λ1=2.029, λ2= λ3=1.499, λ4=0.943, λ5=0.028 y λ6=0.002. La segunda matriz considerada es
2
1.08 1.10 .12 1.12 .10 .08 1.10 .08 .08 .10 1.08 .10 .01 .08 .12 1
= − −− −− −
⎛ ⎞⎜ ⎟⎜ ⎟⎜ ⎟⎜ ⎟⎝ ⎠
∑
cuyos valores propios son λ1=1.282, λ2=1.253, λ3=1.120, λ4=1.056, λ5=0.719 y λ6=0.697. La matriz Σ1 fue utilizada por Devlin en [2], la misma tiene correlaciones que varían, es términos absolutos, entre 0 y 0.95, de tal manera que se
prueba la habilidad del estimador para detectar esta variedad de correlaciones, además, λ6 es muy cercano a cero lo que indica que la matriz es “casi” singular, esto permite medir el comportamiento de los estimadores en condiciones de “casi” singularidad, finalmente, al igual que las correlaciones, los valores propios asociados a Σ1 también varían ampliamente. La matriz Σ2 en cambio, presenta correlaciones y valores propios con poca diferencia, así se mide la capacidad del estimador ante matrices con poca variabilidad en sus elementos y los valores propios asociados a la misma. Por otro lado, para la simulación de Monte Carlo cada escenario se repite N=500 veces y el software utilizado para el efecto es R versión 2.8.0 [11]. 3.3 CRITERIOS DE EVALUACIÓN Con el propósito de evaluar la Eficiencia y Estabilidad de los Estimadores estudiados; se define
( ) ( )
1
1N
e e
iN =
= ∑x x
que es el Promedio de las estimaciones correspondientes a “e” para el Vector de Medias, donde e ={Clásico, M Huber, T-Bicuadrático, Bicuadrático, MCD, DS};
( ) ( ){ }e e=max maxx x
que representa a la estimación “más alejada” del verdadero valor del parámetro, en términos de la distancia Euclidiana, de entre los Vectores de Medias correspondientes al estimador e en las N repeticiones. Con estos dos vectores se obtiene el Sesgo Promedio Total y Sesgo Máximo Total, haciendo
( )( ) ( )( ) ( )( )Te eeSesgo Promedio Total = Prom =x x x
( )( ) ( )( ) ( )( )Te e eSesgo Máximo T Max= = max max x x xes decir, calculando Distancia Euclidiana entre el
verdadero valor del Vector de Medias “0” con ( )ex
y con ( )ex respectivamente. Se define también
( )( ) ( )( )6
1total ii
e esd sd=
= ∑x x que es la suma de las Desviaciones Estándar de cada componente del Vector de Medias correspondiente
al estimador e, de tal manera que ( )( )totalesd x
representa la Desviación Total del estimador e.

N. MONTAÑO & G. ZURITA
26
Por último, bajo el supuesto que el mejor estimador es el que presente un mejor balance entre: su comportamiento promedio, su “peor” comportamiento y la dispersión de sus estimaciones, se ha elaborado un índice que es:
( )( ) ( )( ) ( )( )( )3
e e etotalProm Max
Indicesd
=+ +x x x
(3.1) la media aritmética entre el Sesgo Promedio Total, Sesgo Máximo Total y la Desviación Total; de tal manera que el estimador que presente menor índice será el más Eficiente y Estable en cada escenario estudiado, nótese que se da la misma importancia a las tres medidas. Por otro lado, en la práctica no se conoce cuan contaminada está la muestra, ni que Distribución genera la contaminación, etc. solo se tiene la matriz de observaciones y el tamaño muestral, por lo que en el presente estudio también se explora el comportamiento de los estimadores en función del Sesgo y Curtosis Muestral, con el propósito de que dichas medidas junto con el tamaño de la muestra sirvan como criterios para decidir que estimador utilizar. 4. RESUMEN DE RESULTADOS Se simula en total 184 escenarios, el análisis detallado de los mismos es presentado en [10], en esta sección se presenta algunos de los resultados obtenidos dando un breve resumen de los más relevantes. 4.1 ANÁLISIS POR ESCENARIO SIMULADO Las tablas de resultado se encuentran divididas en tres secciones verticales, presentando los resultados para la estimación del vector de medias, los valores propios y la matriz de varianzas y covarianzas, y en tres secciones horizontales, correspondientes a cada tamaño muestral k=5 ,10 y 20 . En cada sección se muestra en la columna denominada “Prom” el Sesgo Promedio Total, el Sesgo Máximo Total es presentado en la columna “Max”, mientras que la Desviación Total se presenta en la columna “Desv” y en la última columna se muestra el Índice (3.1). La Tabla I presenta los resultados obtenidos para el escenario de muestras generadas a partir de una Distribución Normal N(0,Σ), Σ=Σ1 sin contaminar;
se puede ver que los Estimadores Robustos son comparables al Estimadores de Máxima Verosimilitud, pues en todos los casos sus resultados no difieren considerablemente de los resultados del estimador de máxima verosimilitud. En la simulación realizada en [10], para muestras generadas a partir de una Distribución Normal N(0,Σ), Σ=Σ2 se notó un comportamiento parecido, es decir, se verifica que los estimadores Robustos Estudiados son Eficientes. Considerando el Sesgo Promedio Total como medida de la “bondad” del Estimador, en los escenarios simulados, el Estimador Clásico presenta su “peor” rendimiento al tratar de estimar la Matriz de Covarianzas y los Valores Propios asociados a la misma. La Tabla II presenta los resultados obtenidos para muestras generadas a partir de una Distribución Normal N(0,Σ), Σ=Σ1 contaminada con ε =0.10 y H=N(0,9Σ1), se puede ver como el Estimador Clásico estima incorrectamente a los Valores Propios y Matriz de Covarianzas, teniendo un índice más de dos veces mayor al índice alcanzado por el “peor” estimador robusto cuando k =10 y 20. En general, cuando la muestra es generada a partir de una Población Normal N(0,Σ), Σ=Σ1 contaminada con H=N(0,9Σ1), o H = U esf (d=5) los estimadores sobreestiman el primer y segundo valor propio para luego estimar con error “pequeño” los valores propios restantes; en este caso, los Estimadores Clásico y MCD son los que sobreestiman con mayor error el primer valor propio, sin embrago, el Estimador MCD reduce considerablemente su error mientras aumenta el tamaño muestral. Mientras que, cuando Σ=Σ2 los Estimadores sobreestiman el primer y segundo valor propio, sin embargo, al final generalmente subestiman el menor valor propio. De acuerdo a los resultados obtenidos, el tamaño muestral influye en la estimación, pues en todos los estimadores se cumple que al aumentar el mismo, se disminuye el Sesgo Promedio Total y la Desviación Total. El estimador T-Bicuadrático es casi siempre superado por los demás Estimadores Robustos, situación que era previsible pues este estimador fue construido para mejorar el comportamiento de los estimadores S para p “grande” y en el presente estudio se considera p =6. La Tabla III muestra que a pesar de que la mayoría de los Estimadores Robustos considerados han sido construidos bajo el supuesto de contaminación simétrica, al ser sometidos a contaminación asimétrica se comportan de manera similar a cuando la misma es simétrica.

ESTIMADORES ROBUSTOS PARA EL VECTOR DE MEDIAS Y LA MATRIZ DE VARIANZAS Y COVARIANZAS DE VECTORES ALEATORIOS MULTIVARIADOS
27
TABLA I Estimadores robustos para el vector de medias y la matriz de varianzas y covarianzas de vectores aleatorios multivariados
Resultados para Población Normal N (0,Σ), Σ=Σ1 sin Contaminar
TABLA II Estimadores robustos para el vector de medias y la matriz de varianzas y covarianzas de vectores aleatorios multivariados
Resultados para Población Normal N(0,Σ1) Contaminada con ε =0.10 y H=N (0,9 Σ1)

N. MONTAÑO & G. ZURITA
28
TABLA III Estimadores robustos para el vector de medias y la matriz de varianzas y covarianzas de vectores aleatorios multivariados
Resultados para Población Normal N(0,Σ1) Contaminada con ε =0.10 y H=N (0.537α6,9 Σ1)
TABLA IV Estimadores robustos para el vector de medias y la matriz de varianzas y covarianzas de vectores aleatorios multivariados
Resultados para Población Normal N(0,Σ1) Contaminada por variable con ε =0.10 y H=U (-5,5)

ESTIMADORES ROBUSTOS PARA EL VECTOR DE MEDIAS Y LA MATRIZ DE VARIANZAS Y COVARIANZAS DE VECTORES ALEATORIOS MULTIVARIADOS
29
TABLA V Estimadores robustos para el vector de medias y la matriz de varianzas y covarianzas de vectores aleatorios multivariados
Resultados para Población Cauchi CAU(0,Σ), Σ=Σ1 sin Contaminar
Así también, los estimadores han sido construidos siguiendo el entorno de contaminación (2.1), sin embargo, al contaminar por variable, según lo explicado en la sección 3.1, los Estimadores brindan “buenas” estimaciones, véase la Tabla IV; no obstante, en el presente estudio no se analiza las consecuencias que puede tener la contaminación por variable en las Técnicas de Análisis Multivariado. Cuando las Muestras son generadas a partir de la Distribución Cauchy, el Estimador Clásico en todos los casos brinda las estimaciones más distantes de cada parámetro poblacional, la Tabla V presenta el caso cuando se generan muestras a partir de una Cauchy sin contaminar. Además, en estos casos, el algoritmo utilizado para el Estimador M de Huber no siempre converge a una solución. Los valores propios son siempre sobreestimados; en la parte derecha de la Tabla V se muestra los errores absolutos y relativos de la estimación de los valores propios para k=20. A las estimaciones brindadas por el estimador DS en varias ocasiones les corresponde un Sesgo Promedio Total menor al Sesgo presentado por los demás estimadores, sin embargo su “peor” estimación puede incluso encontrarse más alejada que la “peor” estimación utilizando el método Clásico; esto implica que no presente un Balance adecuado y no sea considerado el mejor estimador (de acuerdo al índice planteado) en los escenarios simulados.
4.2 ANÁLISIS POR TAMAÑO MUESTRAL,
SESGO Y CURTOSIS En esta parte del estudio se trata de establecer una “regla empírica” en la cual se utilice el tamaño de la Muestra, el Sesgo y la Curtosis Muestral como elementos de decisión sobre que estimador utilizar en ese caso. A cada muestra generada se le ha calculado Sesgo y Curtosis, además se determinan la distancia Euclidiana entre el verdadero valor del Vector de Medias, la Matriz de Covarianzas y los Valores Propios asociados a la misma con la estimación obtenida por cada Método; a partir de esto se establece el estimador “más cercano” en cada muestra. En las Tablas VI y VII se presenta un resumen de los resultados obtenidos para muestra tamaño 30 y 60 respectivamente; en las mencionadas tablas se puede observar los tres estimadores que con mayor frecuencia presentan la menor distancia entre el valor del parámetro y la estimación; para cada estimador se presenta la distancia Promedio y su Desviación Estándar, además de la Frecuencia Relativa de ser el estimador “más cercano” al valor real. Así, por ejemplo, con tamaño de muestra igual a 30, cuando el Sesgo es menor a 45 y la Curtosis se encuentra en el intervalo [20, 65) el 25,3% de las

N. MONTAÑO & G. ZURITA
30
ocasiones el estimador Clásico es el que presenta la menor distancia para la estimación del Vector de Medias, siendo su distancia Promedio igual a 0.503±0.174. Mientras que para los Valores Propios y la Matriz de Varianzas y Covarianzas el Estimador M de Huber en más del 50% de los casos brinda la estimación “más cercana”. Además, para valores de Sesgo Muestral superiores a 45 pero inferiores a 90, el Estimador DS es con mayor frecuencia el “mejor” estimador, sin embrago su Promedio y Desviación Estándar de la distancia para el caso de los Valores Propios y Matriz de Covarianzas es mayor a la presentada por los otros dos estimadores, por ejemplo, cuando la Curtosis se encuentra en el intervalo [110, 155) la distancia promedio correspondiente al Estimador DS al estimar la Matriz de Varianzas y Covarianzas es 11.075 mientras que para el Estimador Bicuadrático es 8.397, situación que puede ser causada por la alta dispersión observada en el Estimador DS.
De acuerdo a la Tabla VII, cuando el Sesgo Muestral es mayor a 90 y menor a 180 y la Curtosis Muestral se encuentra en el intervalo [130, 220) el estimador MCD alcanza la proporción 0.688 de ser el estimador “más cercano” a los Valores Propios; es seguido por el estimador DS y Bicuadrático. Nótese que el estimador que con mayor frecuencia es el mejor estimador de la Matriz de Covarianzas y los Valores Propios asociados a la misma es, para sesgos mayores a 90, el Estimador MCD. De acuerdo a los resultados obtenidos, para n =120, cuando la Curtosis es menor a 230 el Estimador M de Huber o el Estimador Bicuadrático son los que con mayor frecuencia se constituyen en los “mejores” estimadores, mientras que para Curtosis mayor a 230 el mejor estimador es con mayor frecuencia el MCD.
TABLA VI
Estimadores robustos para el vector de medias y la matriz de varianzas y covarianzas de vectores aleatorios multivariados Resultados en función del Sesgo y la Curtosis para tamaño muestral 30

ESTIMADORES ROBUSTOS PARA EL VECTOR DE MEDIAS Y LA MATRIZ DE VARIANZAS Y COVARIANZAS DE VECTORES ALEATORIOS MULTIVARIADOS
31
TABLA VII Estimadores robustos para el vector de medias y la matriz de varianzas y covarianzas de vectores aleatorios multivariados
Resultados en función del Sesgo y la Curtosis para tamaño muestral 60
5. CONCLUSIONES Se confirma la sensibilidad de los Estimadores de Máxima Verosimilitud para el Vector de Medias y Matriz de Varianzas y Covarianzas ante desviaciones de la Distribución Normal Multivariada. Cuando la muestra es generada a partir de la Distribución Normal Multivariada, para cualquier tamaño muestral los Estimadores M de Huber y Bicuadrático son generalmente los que alcanzan el menor índice al estimar el Vector de Medias, Matriz de Covarianzas y Valores Propios. Cuando se considera muestras generadas a partir de una Distribución Cauchy, el Estimador Bicuadrático
presenta el mejor comportamiento para k =5, mientras que para k =10 y k =20 el Estimador MCD es el que “mejor” estima la Matriz de Covarianzas y los Valores propios, todo ello en base al índice planteado en 3.2. Para ε =0.30 los estimadores Robustos estudiados, se comportan de forma parecida a cuando ε =0.05 y ε =0.10, se concluye entonces que el Punto de Ruptura, para p =6 variables, es mayor a 0.3 Finalmente, se recomienda la realización de próximos estudios que complementen el presente trabajo.

N. MONTAÑO & G. ZURITA
32
REFERENCIAS BIBLIOGRÁFICAS Y ELECTRÓNICAS
[1]. ANDREWS, D. et al. (1972). Robust Estimates of Location: Survey and Advances. Princeton Univ. Press.
[2]. DEVLIN, S., GNANADESIKAN, R., Y
KETTENRING J. (1981). “Robust estimation of dispersion matrices and Principal Components”, Journal of the American Statistical Association; 76, 354-362.
[3]. HAMPEL, F. (1971). “A general
qualitative definition of robustness”, The Annals of Mathematical Statistics; 42, 1887–1896.
[4]. HAMPEL, F. (1974). “The influence curve
and its role in robust estimation”, Journal of the American Statistical Association; 69, 383–393.
[5]. HUBER, P. (1964). “Robust estimation of a
location parameter”, The Annals of Mathematical Statistics; 35, 73–101.
[6]. HUBER, P. (1972). “The 1972 wald lecture.
Robust Statistics: A Review”, The Annals of Mathematical Statistics; 43, 1041–1067.
[7]. HUBER, P. (1979). “Robust Statistical
Procedures”, Society for industrial and Applied Mathematics.
[8]. MARONNA, R., MARTIN, D. Y YOHAI,
V. (2006). “Robust Statistics: Theory and Methods”, John Willey & Sons, New York–USA.
[9]. MARONNA, R. (1976). “Robust M-
Estimators of Multivariate Location and Scatter”, The Annals of Statistics; 4, 51–67.
[10]. MONTAÑO, N. (2009) “Estimadores
Robustos para el Vector de Medias y la Matriz de Varianzas y Covarianzas de Vectores Aleatorios Multivariados”, Tesis de Grado.
[11]. R DEVELOPMENT CORE TEAM (2008). “R: A language and environment for statistical computing. R Foundation for Statistical Computing”, Vienna, Austria.
[12]. ROCKE D. (1996) “Robustness
properties of multivariate location and shape in high dimension”, The Annals of Statistics; 24, 1327–1345.
[13]. RENCHER, A. (1998). “Multivariate
Statistical Inference and Applications”, John Willey & Sons, New York–USA.
[14]. SEBER, G. (1984). “Multivariate
observation”, John Willey & Sons, New York–USA.
[15]. TUKEY, J. (1960). “A survey of
sampling from contaminated distributions”, Contributions to Probability and Statistics: Essays in Honor of Harold Hotelling”, Olkin Ediciones Stanford University Press, Stanford. CA.
[16]. YOHAI, V. (2004). “Notas de
probabilidad y estadística”, [en línea] Universidad de Buenos Aires, Buenos Aires – Argentina.
[17]. ZAMAR, R. (1994) “Estimación
Robusta” , Estadística Española; 36, 327–387.
[18]. ZUO, Y. (2006). “Robust location and
scatter estimators in multivariate análisis” (invited book chapter to honor Peter Bickel on his 65th Birthday), The Frontiers in Statistics, Imperial College Press.

matemática: Una publicación del ICM – ESPOL 2010, Vol. 8, No. 2
DYNAMICAL SYSTEMS AND DIFFERENTIAL EQUATIONS
Páez Chávez Joseph1
Abstract. In this manuscript we introduce some important concepts concerning dynamical systems theory. We devote special attention to studying differential equations from a dynamical systems viewpoint. The introduced concepts are illustrated by examples. Keywords: Dynamical Systems, discrete-time systems, continuous-time systems, differential equations, vector fields. Resumen. En este manuscrito presentamos algunos conceptos importantes concernientes a la teoría de los sistemas dinámicos. Se presta especial atención al estudio de ecuaciones diferenciales desde el punto de vista de sistemas dinámicos. Los conceptos presentados son ilustrados mediante ejemplos. Keywords: Sistemas dinámicos, sistemas de tiempo discreto, sistema de tiempo contínuo, modelaje matemático. RECIBIDO: Agosto, 2010 ACEPTADO: Septiembre, 2010
1. INTRODUCTION Nowadays dynamical systems phenomena appear in almost every area of science, from the oscillating Belousov-Zhabotinsky reaction in chemistry to the chaotic Lorenz system in meteorology, from complicated behavior in celestial mechanics to the bifurcations arising in ecological models. It turns out that many of the phenomena mentioned above can be described by means of differential equations. For this reason, it is an important task to understand the connections between differential equations and dynamical systems. By doing this, we obtain a powerful tool which allows us to study the qualitative behavior of differential equations without having to solve them analytically. This is specially useful when a general solution is not available or the numerical simulations are too expensive. In this article, we continue the study started in [7]. We recall some basic Concepts introduced in that manuscript and bring some new ones. We also present a theorem concerning existence and uniqueness of the solution of initial value problems and show the connection between these problems and dynamical systems. Most of the material presented in this manuscript can be found in the lectures notes of Prof. Beyn, [4, 5]. There is nevertheless plenty of literature on this subject, e.g., see [1, 2, 3, 6, 8]. ______________________________ 1Joseph Páez Chávez, Ph.D, Profesor del Instituto de Ciencias Matemáticas, ESPOL. (e_mail: [email protected])
2. BASIC CONCEPTS AND THEOREMS
To begin with, we recall the definition of dynamical system (cf. [7]): Definition 2.1. A dynamical system is a triple
{ }{ }, ,t
tX ϕ∈T
T , where T is a time set, X is a state
space and tϕ : X → X is a family of operators parametrized by t ∈ T , such that: DS1 ( )0 0: , . ., ,xu X u u i e Idϕ ϕ∀ ∈ = = DS2 , , :u X s t∀ ∈ ∀ ∈ T
( ) ( )( ) , . ., ot s t s t s t su u i eϕ ϕ ϕ ϕ ϕ ϕ+ += = Here, the set X stands for a metric space. The function tϕ is known as evolution operator. This operator can be thought of as a “law” that governs the behavior of the system. Furthermore, the time set T has the following properties: • , : 00 t t t∀ ∈ + =∃ ∈T T , • , :t s s t∀ ∈ + ∈T T , • , :t s s t t s∀ ∈ + = +T . This means that T equipped with the operation + is a commutative semigroup. In [7, Example 2.1], the author explains the fact that a discrete-time system is completely defined by knowing the function
1ϕg := . Hence the evolution operator can be constructed as follows
0x , and o o ... o ,
times
kIdϕ ϕ= = g g g
k
(2.1)
k ∈ . Further, if g is invertible, the system admits negative values of k. For this reason, the function g is said to be the generator of the dynamical system. Now the natural question that arises from this fact is

J. PÁEZ
34
whether continuous-time systems also have, in some sense, generators. Note that in this case we deal with values of time on the real line, so the function
1ϕ does not allow us to construct the evolution operator, at least not on the whole real line. These considerations lead us to the following definition:
Definition 2.2. Let { }{ }, ,t
tX ϕ∈T
T , where
{ }0or += ∪T , be a dynamical system such
that ( )xϕ• is differentiable for all x X∈ . Then the function f: X → X given by
( ) ( )( ) ( ) ( )0
0: lim
0
ht
t
x xdf x xdt hh
h
ϕ ϕϕ
=
−= =
→∈T
is referred to as infinitesimal generator of the dynamical system2.1Of course, the spirit of a generator is that we can in some way construct the evolution operator from the generator. In (2.1) we explained how the evolution operator of a discrete-time system can be obtained from its generator. Now we will show that this is possible for continuous-time systems, too: Theorem 2.3. Let : N Nf → be the infinitesimal generator of a dynamical system
{ }{ },,t
N tϕ∈T
T . Then the function
( )1 , Nu C∈ T defined as ( ) ( )0tu t uϕ= is a
solution of the initial value problem ( ) ( )( ) 0, (0)y t f y t y u= = .
Proof. By DS1 we have that ( ) ( )00 00u u uϕ= = ,
so the initial condition is satisfied. According to the definition of infinitesimal generator we have that
( )( ) ( )( ) ( )
( )( ) ( )
( ) ( )
0
0
: lim0
lim0
2lim
0
h
h t
h t
u t u tt f u t
hhh
u u t
hhh
DS u u t
hhh
ϕ
ϕ ϕ
ϕ +
−∀ ∈ =
→∈
−=
→∈
−=
→∈
T
T
T
T
______________________________ 2 Also called vector field of the dynamical system.
( ) ( )
( )
lim0
u t h u t
hhh
u t
+ −=
→∈
=
T
This theorem asserts that every dynamical system (of the type introduced in Definition 2.2) is completely defined by its infinitesimal generator, or, more precisely, by the initial value problem presented above. Now the natural question is whether every inicial value problem represents a dynamical system. For this issue to be dealt with, we first present a standard result about the existence and uniqueness of the solution of inicial value problems: Theorem 2.4. Let NΩ ⊂ be open and
( )1 , Nf C∈ Ω . Then the initial value problem
( ) ( )( ) 0, (0)y t f y t y u= = (2.2)
has for each 0u ∈Ω exactly one nonextendible
solution ( )0,u t u ∈Ω , where
( ) ( ) ( )( )0 0 0, 0t T u t u t u− +∈ = ∋ . The domain of
the function u ( ) ( ){ }0 0, :D t u t J u= ∈ × Ω ∈
is open and ( )1 , Nu C D∈ . Furthermore, if
( ),k Nf C∈ Ω , then ( ), , 1k Nu C D k∈ ≥ .
FIGURE 1 Dynamical systems and differential equations Domain of definition of the solution of (2.2)
Proof. This is a classical result and its proof can be found in any book on Differential Equations, e.g., see [1, Chapter II]. Besides guaranteeing existence and uniqueness, this theorem also gives valuable information about the domain D of definition of the solution. This domain turns out to be open and furthermore the solution of

DYNAMICAL SYSTEMS AND DIFFERENTIAL EQUATIONS
35
the initial value problem (2.2) does not exist outside D. For this reason, the interval J(u0) is referred to as the maximal interval of existence. Here, it is important to point out that this interval varies with the initial value u0, see Figure 1. With this few remarks we can turn back to the question we outlined before, that is, whether an initial value problem defines a dynamical system. We will see that this is true, but in a local sense: Theorem 2.5. Let the assumptions of Theorem 2.4 hold. Then the operador ( ) : NDϕ →i i , given
by ( ) ( )0 0,t u u t uϕ = , defines a local dynamical system. Proof. Let us first show DS1. By the initial value condition in (2.2), we have that
( ) ( )00 0 0 0: 0,u u u u uϕ∀ ∈Ω = =
Now let us work with DS2. Let 0u ∈Ω and
( )0s J u∈ be arbitrary, but fixed. Then the
function ( ) ( )( ) ( )( )0: ,0t s sv t u t J uϕ ϕ ϕ= ∈ , is
a solution of ( ) ( )( ) ( )0, (0) sy t f y t y uϕ= = (2.3)
Now consider the function ( ) ( )0: t sw t uϕ += . If follows that
( ) ( )( ) ( )( ) ( )( )(2.2)
0 0, ,dw t u t s u f u t s u f w tdt
= + = + =
and ( ) ( ) ( )00 00 s sw u uϕ ϕ+= = .
Therefore, w is another solution of (2.3) and by uniqueness (cf. Theorem 2.4), v w= ,i.e.
( )( ) ( )0 0t s t su uϕ ϕ ϕ += .
FIGURE 2
Dynamical systems and differential equations Forced pendulum
According to this theorem, the initial value problem (2.2) always represents an autonomous dynamical system. Thus, by combining this result with Theorem 2.3, we can realize that the concept of dynamical system is closely related to initial value problems, and, more generally, to differential equations (see [7, Example 3.2]). In many cases, physical phenomena includes the action of an external time-dependent “force”, which leads us to modeling the underlying phenomena by means of non-autonomous differential equations of the form ( ) ( )( ) [ ]0 0 0, , ( ) , , Ey t f t y t y t u t t t= = ∈ (2.4)
Where ( )1 , Nf C∈ ×Ω . Studying in detail non-autonomous dynamical systems is beyond the scope of this article, however, we do want to point out that such systems can be written in an autonomous way as the following example shows. Example 2.6. Consider a pendulum of mass m attached to a string of length L, which is displaced by an angle from the vertical rest position, see Figure 2. Suppose that there exists an external sinusoidal force F(t) acting on the system. The dynamics of the pendulum can then be described by the ODE
( ) ( )( ) ( ) ( )sin sin cos ,g
t t A t B t tL
θ θ β β+ = + ∈
(2.5) where , , , 0A B β β∈ > are fixed and g stands for the gravity constant. The case where there is no external force (i.e. A = B = 0) was studied in [7, Example 2.3]. There, it is proved that the pendulum can be seen as an autonomous dynamical system. Now we will show how to deal with the external force in order to preserve the autonomous carácter of the system. One way to achieve this is adding a nonlinear oscillator to the system. An example of such an oscillator is given by
( ) ( ) ( ) ( ) ( ) ( )( )( ) ( ) ( ) ( ) ( ) ( )( )
2 2
2 2
,
,
x t x t y t x t x t y t
y t y t x t y t x t y t
β
β
= + − +
= − − +
⎧⎪⎨⎪⎩
which has the solution ( ) ( ) ( ) ( )sin , cosx t t y t tβ β= = . Now consider
the functions ( ) ( ) ( ) ( ), ,u t t v t t tθ θ= = ∈ , and define

J. PÁEZ
36
( ) ( )( )( )
2 2
2 2
sin, , , : ,
vg
u Ax ByLG u v x y
x y x x yy x y x y
ββ
− + +=
+ − +
− − +
⎛ ⎞⎜ ⎟⎜ ⎟⎜ ⎟⎜ ⎟⎜ ⎟⎝ ⎠
Where ( ) 4: , , ,z u v x y= ∈ . Thus, it is easy to see that the non-autonomous system (2.5) can be written as
( ) ( )( )z t G z t= , which is an autonomous differential equation of the type of (2.2). This discussion provides us with a way of applying the theory developed for autonomous dynamical systems to the present non-autonomous case. In many cases it may happen that the external force is not periodic, or difficult to model by an autonomous oscillator. If this is so, we can resort to writing system (2.4) in autonomous form as follows:
( ) ( ) ( )( ) [ ]
( )
( )
( )
0
0 0
0 0
, , , ,
1,
,
.
Ey t f h t y t t t t
h t
y t u
h t t
= ∈
=
=
=
⎧⎪⎪⎪⎨⎪⎪⎪⎩
This is an autonomous system of N + 1 ODEs with N + 1 initial conditions.
3. EQUILIBRIA, ORBITS, AND PHASE
DIAGRAMS A common approach for starting the study of dynamical systems consists in introducing geometrical objects that allow us to visualize dynamical properties, thereby making their analysis easier. To achieve this, we will begin with the concept of orbit. Then we will realize that a dynamical system can be qualitatively described by drawing some “typical” orbits. This process leads us to the so-called phase diagram. To begin with, let us first introduce the notion of equilibrium, which is the simplest object of study in dynamical systems. To this end, we consider the Example 2.6 without forcing, see Figure 2. In [7, Example 3.1], the (approximate) evolution operator
( ) ( ) 2 2:ϕ ⋅ × →i is found to be
00 0
0 0 0
( ) sin( ) cos( ) ,( ) cos( ) sin( )
t gt t tt Lt t
θθ θ ω θ ωϕ ωωθθ θ ω θ ω ω
⎛ ⎞⎜ ⎟⎜ ⎟⎜ ⎟⎝ ⎠
′+= = =′′ ′ −
⎛ ⎞ ⎛ ⎞⎜ ⎟⎜ ⎟⎝ ⎠⎝ ⎠
(3.1) where
0θ and
0θ ′ represent the angle and angular
velocity of the pendulum, respectively, at t = 0. Now suppose that we let the pendulum run with the initial conditions
0 00θ θ= ′ = . How does the
system evolve in time? From the formula for the evolution operador presented above, it is easy to see that ( )0 0
, 0tϕ θ θ ′ = , for all t. We can also arrive at
this conclusion from a physical point of view. Initializing the system with
0 00θ θ= =′ amounts
to placing the pendulum at the vertical position with initial angular velocity equal to zero. It is then clear that the pendulum will remain at the vertical position 0θ = forever. This illustrates the simplest behavior that a dynamical system may present. However, this simple behavior can be seen in more complicated/abstract systems, too. Consider for example the PDE
( ) ( )
( ) ( )
( ) ( )1 2 1
, , 0
,, 0
, ,
u ux t x x tt x
u x f x
u C f C
∂ ∂+ =∂ ∂
=
∈ ∈
⎧⎪⎪⎨⎪⎪⎩
with evolution operator
( ) ( )( ) 1 1( ) : C Cϕ ⋅ ⋅ × → given by
( )( )( ) ( )t tf x f xeϕ −= (cf. [7, Example 3.2]).
Choose the initial condition ( )f x K= for all
x∈ being a real constant. Then it follows that
( )( )( ) ( ) ( ) ( ): t t tt f x f xe K f x f fϕ ϕ−∀ ∈ = = = ⇒ =
This means that if we initialize the system at a constant function, the system will remain at that function forever. These two examples illustrate the concept of equilibrium of a dynamical system, which is formally defined as follows:
Definition 3.1. Let { }{ }, ,t
tX ϕ∈T
T be a dynamical
system. A point 0x X∈ is referred to as equilibrium point if
( )0 0: tt x xϕ∀ ∈ =T In other words, we can say that if a dynamical system is placed at an equilibrium point, it will

DYNAMICAL SYSTEMS AND DIFFERENTIAL EQUATIONS
37
remain there forever. This fact was already seen in the examples above. In the literature, equilibrium points are also called “steady states”, “equilibrium solutions”, “stationary points”, “rest points”, and “fixed points”, among others. Some authors reserve the name “equilibrium” for continuous-time systems, while the term “fixed point” is used when dealing with discrete-time systems. However, the reader should have in mind that both terms stand for the same dynamical object. Now that we have introduced our first (and the simplest) dynamical object of study, our next task will be to investigate how to detect such objects, provided the (infinitesimal) generator of the system is known. This task is accomplished in the following: Theorem 3.2. Let ( )1, ,N Nf g C∈ . Consider the Systems
( ) ( )( ) ( ), 0x t f x t x ξ= = , (3.2)
( )1 0, ,n nx g x x nξ−= = ∈ (3.3) Then 0
Nz ∈ is an equilibrium (resp. fixed point)
of (3.2) (resp. (3.3)), if and only if ( )0 0f z = (resp. g(z0) = z0). Proof. Let us first work with system (3.2). Assume that z0 is an equilibrium of (3.2). This means that
( )0 0t z zϕ = for all t. Thus, according to
Definition 2.2, we have that
( ) ( )( ) ( )0 000 0
0t
t t
d df z z zdt dt
ϕ= =
= = =
Now suppose that ( )0 0f z = . Define the constant
function ( ) 0 ,x t z t= ∈ . It is then easy to check that x is a solution of (3.2), and by uniqueness (cf. Theorem 2.4), we can conclude that ( )0 0
t z zϕ =
for all t ∈ . Hence 0z is an equilibrium of (3.2). Now let us turn to the discrete-time case. Assume z0 to be a fixed point of (3.3), i.e., ( )0 0
n z zϕ = for all
{ }0n ∈ ∪ . By (2.1), it is readily seen that
( ) ( )10 0 0g z z zϕ= = . Now suppose that
( )0 0g z z= , and that ( )0 0n z zϕ = for some fixed
n∈ holds. It follows by induction that
( ) ( )( ) ( )1 10 0 0
0
2n n n
DSz z z z
z
ϕ ϕ ϕ ϕ+ = = =
=0
Hence ( )0 0n z zϕ = for all { }0n ∈ ∪ , i.e., z0 is
a fixed point of (3.3). The principal significance of the theorem is that it provides us with a way of finding and characterizing equilibrium points of dynamical systems. In other words, if we are interested in equilibrium points (resp. fixed points) of system (2.2) (resp. (3.3)), we should look for the solutions of the equation ( ) 0f x = (resp. ( )g x x= . Now that we have understood the meaning of equilibrium point, we can proceed with the concept of a somewhat more elaborated dynamical object, the so-called orbit.
Definition 3.3. Let { }{ }, ,t
tX ϕ∈T
T be a
dynamical system and 0x X∈ . The set
( ) ( ){ }0 0: ,rtO x x X x x tϕ= ∈ = ∈ T
is referred to as orbit of x0. Before showing some examples, it is worth presenting a few remarks: • ( )0 0: rx X O x X∀ ∈ ⊂ ,
• If 0x is an equilibrium point, then
( ) { }0 0rO x x= , i.e., an equilibrium point is the simplest orbit,
• in continuous-time dynamical systems, the orbits are curves parametrized by the time t,
• in discrete-time dynamical systems, the orbits are sequences in X, i.e., ( )0O x XΓ ∈ T for all
0x X∈ . Let us illustrate the concept of orbit by some examples.
FIGURE 3 Dynamical systems and differential equations
Orbit of the pendulum system

J. PÁEZ
38
Example 3.4. Consider again the pendulum system of Example 2.6, without external forcing. The evolution operator can be written as (cf. (3.1))
00 0
00 0
sin
COS
t
RR t
R t
ω φϕ ωφ
ω φ
⎛ ⎞⎜ ⎟⎝ ⎠⎛ ⎞⎜ ⎟⎝ ⎠
=+
+
⎛ ⎞⎛ ⎞ ⎜ ⎟⎜ ⎟ ⎜ ⎟⎝ ⎠ ⎜ ⎟
⎝ ⎠
, where
( ) ( )2 2
0 00R θ θ ω′= + and ( ) 0
00
sinRωθ
φ =
Here, we must choose 0Rω
small (why?). Thus, an
orbit of the pendulum system is described by the parametric curve
( )0
00
0
0 0
, sin :rCOS
Rt
R tO tω φθ θ ω
ω φ
⎛ ⎞⎜ ⎟⎝ ⎠⎛ ⎞⎜ ⎟⎝ ⎠
+′+
⎧ ⎫⎛ ⎞⎪ ⎪⎜ ⎟= ∈⎨ ⎬⎜ ⎟⎪ ⎪⎝ ⎠⎩ ⎭
.
A typical example of an orbit of this system is depicted in Figure 3. Note that, in this case, the orbits are always closed curves, which reveals the periodic nature of the system (in the absence of friction!). In the figure, the arrow stands for the direction of the evolution as the time increases. How does the orbit ( )0,0rO look like? Example 3.5. Let :g → be defined by
( ) 2g x x= . Consider the system
( )1 ,n nx g x n−= ∈ .
Choose 0 2x = as initial point. Then we have that
( ) ( ){ } { }{ }02
0
2 : 2 , 0,1,... 2,4,16,...
2
rn
n
n
O x x nϕ∞
=
=
⎛ ⎞⎜ ⎟⎝ ⎠
∈ = = =
= ∈ ∪ .
Clearly, 1x = and 0x = are fixed points of the system, and so it follows that ( ) { }1 1rO = and
( ) { }0 0rO = . In the examples above we have illustrated the concept of orbit for both continuous and discrete-time dynamical systems. As we pointed out before, an orbit is a subset of the state space, and so we can ask ourselves whether the state space could be, in some sense, decomposed into a collection of orbits of a dynamical system. To this end, the following theorem gives us important information:
Theorem 3.6. Let { }{ }, , tt
X ϕ∈T
T be an invertible
(cf. [7, Section 3]) dynamical system.
Let 0 0,u v X∈ . Then ( ) ( )0 0r rO u O v φ=∩ or
( ) ( )0 0r rO u O v∩ .
Proof. Suppose that ( ) ( )0 0r rO u O v φ≠∩ . This means that
( ) ( )( ) ( )
0 0
0 0
: ,:
r rt s
y X y O u y O v s ty u vϕ ϕ
∃ ∈ ∈ ∧ ∈ ⇔ ∃ ∈= =
T
Therefore, we have that
( ) ( )( )( )
( )( ) ( ) ( )2 2
0 0 0 0
0
: 0t t s t st
DS DS
s
u u v v O v
v
ϕ ϕ ϕ ϕ ϕ ϕ
ϕ
Γ Γ− Γ− Γ− +Γ∀Γ∈ = = = ∈
=
This implies that ( ) ( )0 0r rO u O v⊆ . We can prove
analogously that ( ) ( )0 0r rO v O u⊆ and hence
( ) ( )0 0r rO u O v= . From this Theorem, we can conclude the following: • Two orbits satisfying the conditions of the theorem above are either disjoint or identical, • through every point in the state space passes only one orbit. Consequently, it follows that
( )0
0
.r
x X
X O x∈
= ∪
This means that the state space can be represented as the disjoint union of orbits of underlying dynamical system. This motivates the definition of phase diagram (see below).
Definition 3.7. Let { }{ }, , tt
X ϕ∈T
T be a dynamical
system. The partitioning of the state space into orbits is referred to as phase diagram2 of the dynamical system. Let us restrict our attention to initial value problems (cf. (2.2)). In this case, the phase diagram consists of a family of solution curves of the system (2.2) obtained by varying the initial condition 0u . It is clear that if x is any point
in ( )0O uΓ , then ( )f x represents tangent vector of the solution curve at x. For this reason, the ODE (2.2) is also referred to as vector field. Let us consider again the pendulum system of Example 3.4. How does its phase diagram look like? We have seen that any orbit of that system is given by
( )0
00
0
0 0
, sin :rCOS
Rt
R tO tω φθ θ ω
ω φ
⎛ ⎞⎜ ⎟⎝ ⎠⎛ ⎞⎜ ⎟⎝ ⎠
+′+
⎧ ⎫⎛ ⎞⎪ ⎪⎜ ⎟= ∈⎨ ⎬⎜ ⎟⎪ ⎪⎝ ⎠⎩ ⎭
.

DYNAMICAL SYSTEMS AND DIFFERENTIAL EQUATIONS
39
FIGURE 4 Dynamical systems and differential equations
Phase diagram of the pendulum system
If we vary the initial conditions 00
,θ θ ′ , we will then obtain several closed curves centered at the origin, see Figure 4. The phase diagram provides us with an easy way of visualizing the behavior of a dynamical system. Useful information can be obtained from the phase plot, even if we do not know the evolution operator. For instance, suppose that a pendulum system presents the phase plot as shown in Figure 5. From this picture, we can see that the orbits are no longer periodic, but they spiral into the origin, which is an equilibrium point. Hence this point is called a spiral sink. What does this mean from a physical point of view? Note that the phase diagram tells us that any initial point will, after a long time, end at the equilibrium point. This fact reveals the presence of friction, which prevents the system from oscillating forever as it happens in the pendulum system described in Figure 4.
4. CONCLUSIONS In this manuscript we have seen that dynamical systems and autonomous differential equations are intimately related objects. In particular, Theorems 2.3 and 2.5 reflect this fact. We have also learned how to deal with non-autonomous differential equations, which appear when an external forcing is present. More importantly, we have introduced several geometrical objects such as equilibrium points, orbits and phase diagrams. With these concepts, our goal was to provide the reader with tools for facilitating the study of the qualitative behavior of dynamical systems. In forthcoming articles we will explain in more detail how the objects mentioned above can be used for the analysis of dynamical systems.
FIGURE 5 Dynamical systems and differential equations
Phase diagram of a damped pendulum system

J. PÁEZ
40
REFERENCES AND ELECTRONIC [1]. AMANN, H. (1995). “Gewöhnliche
Differentialgleichungen”, second ed. Walter de Gruyter, Berlin.
[2]. ARROWSMITH, D., AND PLACE, C. M.
(1990). “An Introduction to Dynamical Systems”. Cambridge University Press.
[3]. ARROWSMITH, D., AND PLACE, C. M.
“Dynamical Systems: Differential Equations, Maps, and Chaotic Behaviour”. Chapman & Hall, 1992.
[4]. BEYN, W.-J. (1991). “Dynamische Systeme.
Vorlesungsskriptum”, Bielefeld University. [5]. BEYN, W.-J. (2009). “Numerik dynamischer
Systeme”. Vorlesungsskriptum, Bielefeld University.
[6]. GUCKENHEIMER, J., AND HOLMES, P.
(1993). “Nonlinear Oscillations, Dynamical Systems, and Bifurcations of Vector Fields”, vol. 42 of Applied Mathematical Sciences. Springer-Verlag, New York. Fourth printing.
[7]. PÁEZ CHÁVEZ, J. (2010). “A short
Introduction to Dynamical Systems”. Matemática: Una Publicación del ICM - ESPOL 8, 1, 28–33.
[8]. WIGGINS, S. (2003). “Introduction to
Applied Nonlinear Dynamical Systems and Chaos”, second ed., vol. 2 of Texts in Applied Mathematics. Springer-Verlag, New York.

matemática: Una publicación del ICM – ESPOL 2010, Vol. 8, No. 2
RESOLUCIÓN EXACTA DEL MODELO DEL MÁXIMO PROMEDIO
PARA EL PROBLEMA DE LA DISPERSIÓN MÁXIMA
1Sandoya Fernando Resumen. El problema de la dispersión equitativa, o de la dispersión máxima consiste en que dado un conjunto de nodos y una función de “distancias” entre estos nodos, se trata de escoger un subconjunto de ellos de tal manera que este sea lo más “diverso” posible, en términos de alguna métrica considerada, aquí se resuelve un problema denominado del MAXIMO PROMEDIO en el cual el número de elementos a seleccionarse también es una variable de decisión. Otros modelos han sido extensamente estudiados por otros autores Martí y Duarte [1], Glover [2], Prokopyev [3] y Resende y Martí [4]. En este artículo se estudia el modelo del MAXIMO PROMEDIO (MAXMEAN), que en general es un problema difícil de optimización combinatorio, del tipo Strongly NP-hard. También se estudia la utilización del modelo MAXSUM para la resolución del MAXMEAN, y se determina un procedimiento exacto más eficiente para resolverlo. Para comprobar los modelos se desarrollaron instancias de prueba aleatorias para diferentes tamaños del problema. Todos los problemas en su formulación como modelo de programación matemática MIP o MIQCP fueron implementados en GAMS y resueltos con CPLEX 12.0 y con CONOPT3. Palabras Claves. Diversidad máxima, Optimización combinatoria, Programación cuadrática. Abstrat. The equitable dispersion problem, or the maximum dispersion problem is that given a set of nodes and a function of "distance" between these nodes, it comes to choosing a subset of them so this is as "different" possible in terms of some metric considered. Here we solve a problem called the maximum average in which the number of elements to be selected is also a decision variable. Other models have been extensively studied by other authors: Marti and Duarte [1], Glover [2], Prokopyev [3] and Resende and Marti [4]. In this paper we study the model MAXIMUM AVERAGE (MAXMEAN), which in general is a difficult combinatorial optimization, type Strongly NP-hard. To test the models developed random test instances for different sizes of the problem. All the problems in its formulation as a mathematical programming model or MIQCP MIP were implemented in GAMS and solved with CPLEX 12.0 and CONOPT3. Key words. Combinatorial Optimization, Maximum Diversity, Quadratic Programming. Recibido: Agosto, 2010 Aceptado: Septiembre, 2010
1. INTRODUCCIÓN El problema de la dispersión equitativa, o de la dispersión máxima consiste en que dado un conjunto N = {1,2,…,n} de nodos y una función de “distancias” dij entre estos nodos, se trata de escoger un subconjunto M de cardinalidad m (m ≤ n) de tal manera que M sea lo más “diverso” posible, donde el término “diverso” se explica en términos de una métrica considerada; es decir, la dispersión debe relacionarse con algún tipo de medida, en la literatura se han planteado 3 modelos distintos, denotados como: MAXMIN, MAXSUM, y MAXMINSUM, últimamente Prokopyev [3] ha planteado dos problemas adicionales: denominados del MAXIMO PROMEDIO y MINDIFF, de los cuales en uno de ellos, el del MAXIMO PROMEDIO, el número de elementos a seleccionarse también es una variable de decisión, y en los restantes cuatro modelos este es un valor predeterminado, estos autores enuncian los problemas pero no plantean sus soluciones. Los modelos MAXMIN y MAXSUM han sido extensamente estudiados por Martí y Duarte [1], ________________________ 1 Sandoya Fernando, M.Sc., Profesor de la Escuela Superior Politécnica del Litoral (ESPOL); Coordinador de la carrera Ingeniería en Logística y Transporte ICM – ESPOL. (e_mail: [email protected])
Glover [2], Prokopyev [3] y Resende y Martí [4]. En este artículo se estudia el modelo del MAXIMO PROMEDIO (MAXMEAN), que en general es un problema difícil de optimización combinatorio, del tipo Strongly NP-hard. También se estudia la utilización del modelo MAXSUM para la resolución del MAXMEAN, y se determina un procedimiento exacto más eficiente para resolverlo. Para comprobar los modelos se desarrollaron instancias de prueba para diferentes valores de n y m, en estos problemas de prueba se generaron los valores de dij, usando primero una distribución uniforme (0,20). En vista de las soluciones que se observaron en el modelo MAXMEAN para estos valores de dij, se consideró luego instancias en las cuales los valores de dij son positivos y negativos, generándolos por medio de una distribución uniforme (-10,10) Todos los problemas en su formulación como modelo de programación matemática MIP (Mixed integer Programming) con variables binarias fueron implementados en GAMS y resueltos con CPLEX 12.0, y además se trató el problema MAXSUM en su formulación de programación matemática MIQCP (Mixed Integer Quadratically Constrained Programming) con variables binarias usando el solver en período de prueba CONOPT3.

F. SANDOYA
42
2. FORMULACIONES Los modelos considerados son: MAXSUM IQCP, MAXSUM IP, MAX-MEAN, MAX-MIN SUM y MIN-DIFF. La formulación de estos modelos es la siguiente: 2.1 MAXSUM IQCP El problema de la máxima diversidad originalmente fue planteado en términos de seleccionar el conjunto de elementos que maximice la suma de las distancias entre los nodos seleccionados, esta puede ser la forma más “obvia” de plantear el problema, esta línea de pensamiento dio origen al modelo de la Máxima Suma o MAXSUM, que se formula como un problema de programación cuadrática binaria de la siguiente manera: Para 1, 2, ..., ,i n= la variable ix toma el valor 1 si el elemento i-ésimo es seleccionado y 0 sino; el modelo MAXSUM IQCP es entonces formulado como un problema de programación cuadrática binaria:
( )1
1 1MaxSum IQCP Max
n n
ij i ji j i
d x x=
= = +∑ ∑ (1)
1
. .n
ii
s t x m=
=∑ (2)
0,1 1, 2, ...,ix i n= = (3)
2.2 MAXSUM IP El modelo MAXSUM IQCP puede ser fácilmente linealizado introduciendo nuevas variables variables zij de la siguiente manera:
( )1
1 1MaxSum IP Max ij ij
n n
i j id z
=
= = +∑ ∑ (4)
s.t. (2), (3) y:
1, , , 1 ;ij i j ij i ij jz x x z x z x i j n≥ + − ≤ ≤ ≤ ≤ ≤ (5)
{ }0,1 , 1ij i j nz ∈ ≤ ≤ ≤ (6)
2.3 MAX MIN Seleccionar un subconjunto de dispersión máxima de cardinalidad m también puede ser entendido como la selección de los m elementos
para los cuales se maximiza la menor de las distancias dij entre los elementos seleccionados:
( ) { }i,j MM: MMaxMin max min ij i jm
d x x∈=
(7)
{ }0,1 ; 1ix i n∈ ≤ ≤ (8)
El modelo MAXMIN puede ser linealizado y planteado como un problema de programación entera con variables binarias, como se demuestra en [8]. 2.4 MIN DIFF Para formular el problema Min-Diff introducimos el concepto del diferencial
( )d i como:
,( ) dij
j M j id i ∑
∈ ≠= (9)
Así el problema MIN DIFF puede ser formulado como: ( ) ( ) ( ){ }max minMinDiff Min d i d ii M i M−∈ ∈ (10)
1. .
n
ii
s t x m=
=∑ (11)
0,1 1, 2, ...,ix i n= = (12)
Y que puede ser reformulado como un problema MIP con variables binarias de la siguiente manera:
, , ,mint r s x t (13)
. . , 1,..., ;s t t r s i n≥ − = (14)
( ) ( ) ( )1 1 , 1, ..., ;i ii M
r d i U x M x i ni∈−≥ − − + − =∑
(15) ( ) ( ) ( )1 1 , 1, ..., ;i i ii M
s d i L x M x i n+
∈≤ − − + − =∑
(16)
{ }1
0,1 1, ..., ;,n
i
ni ix m x i n
=
= ∈ =∑ (17)
Donde iU y iL cotas superior e inferior
convenientemente escogidas para ( )d i , y

RESOLUCIÒN EXACTA DEL MODELO DEL MÁXIMO PROMEDIO PARA EL PROBLEMA DE LA DISPERSIÒN MÁXIMA
43
,M M− + son constantes grandes, estos valores pueden ser determinados y ajustados adecuadamente, como se observa en [5].
2.5 MAXMEAN El modelo MAXMEAN, o del máximo promedio, implica seleccionar cierto número de elementos del conjunto original, de tal manera que este represente la máxima diferencia promedio. De esta manera también es variable de decisión la cantidad de elementos a seleccionarse. El modelo puede representarse como:
( )1
11 1
MaxMean Max ni i
n n d x xij i ji j i
x=
== = +∑ ∑
∑ (18)
1
. . 2n
ii
s t x=
≥∑ (19)
0,1 1, 2, ...,ix i n= = (20) Tal como se lo presenta este es un problema de optimización binaria fraccional, pero puede ser linealizado utilizando ciertas transformaciones, así en su formulación linealizada el problema MAXMEAN se presenta como:
1
1 1Max ij ij
n n
i j id z
−
= = +∑ ∑ (21)
1 , , ,
0, 1, ...,
. . y z x z y z xi i i i i
z i ni
s t − ≤ − ≤ ≤
≥ = (22)
2 , , ,
0,1
y z x x z y z xij i j ij ij i
z i j nij
−− ≤ − ≤ ≤
≥ ≤ < ≤ (23)
{ }1 1
1 1 0,1,n n
i i
ni i ix z x
= =
≥ = ∈∑ ∑ (24)
3. RESOLUCION EXACTA DEL PROBLEMA MAXMEAN
La siguiente propiedad indica que si d es una distancia, la solución al problema MAXMEAN es que todos los puntos deben ser seleccionados, con lo cual la solución del problema en este caso se vuelve trivial. PROPIEDAD: En el problema MAXMEAN si dij satisfacen la desigualdad triangular, son simétricas y no negativas, es decir d es una distancia, entonces m = n. Demostración:
Se demostrará que 11 1
n n diji j i
n
−= = +∑ ∑
es una
estrictamente creciente en función de n (1) Como ejemplo observemos el caso n = 3
Por demostrar:
12 13 23 12
3 2d d d d+ +
>
Como: 12 12 13 2312
d d d d< ≤ +
12 12 13 2323 d d d d< + +
12 13 23 12
3 2d d d d+ +
>
Lo mismo para 12 13 23 12
3 2d d d d+ +
> y
12 13 23 23
3 2d d d d+ +
> (2) Para n = k+1
Por demostrar:
11 11 1
1
k kk kd dij iji ij i j i
k k
−= == + = +∑ ∑∑ ∑
>+
Es decir por demostrar:
1 , 1
1 11 11 1
1
ki i k
k kk kd dij iji ij i j idk k
= +− −= == + = +∑ ∑ ∑∑ ∑+
>+

F. SANDOYA
44
Es decir:
1 1 1
, 11 1 1 1 1 1 1
1k k k k k k k
ij i k ij iji j i i i j i i j ik
d d d d− − −
+= = + = = = + = = +
+ > +∑ ∑ ∑ ∑ ∑ ∑ ∑
Luego hay que demostrar:
1
, 11 1 1
1k k k
i k iji i j ik
d d−
+= = = +
>∑ ∑ ∑
Como: 12 1, 1 2, 1k kd d d+ +≤ + 13 1, 1 3, 1k kd d d+ +≤ +
1 1, 1 , 1k k k kd d d+ +≤ +
1, 1, 1 , 1k k k k k kd d d− − + +≤ +
1
, 11 1 1
( 1)k k k
ij i ki j i i
d k d−
+= = + =
< −∑ ∑ ∑
, 11
11 1
1k
i ki
k k diji j i dk +
=
−= = +∑ ∑
<− ∑
Como: 1 11 11 1
1
k kk kd dij iji ij i j i
k k
− −= == + = +∑ ∑∑ ∑
<−
ya
está!! OBSERVACION: La propiedad anterior no es cierta si dij son positivas y simétricas pero no satisfacen la desigualdad triangular, es decir se pueden encontrar contrajemplos en los cuales para los cuales dij ≥0 y simétrica y sin embargo m < n. Aunque estos ejemplos serían la excepción, pues al desarrollar simulaciones con los dij generados aleatoriamente en todas las simulaciones m resultó ser igual a n, tal como se observa en la tabla 2, en la cual se presentan los resultados para valores de n = 10, 15, 20, 25 y 30, para cada uno de los cuales se generaron 10 instancias aleatoriamente. Ejemplo: Sea n = 4 y las distancias dij dadas en la tabla 1:
TABLA I
Resolución exacta del modelo del máximo promedio para el problema de la dispersión máxima
Ejemplo con dij ≥ 0 y simétricas con el cual la solución del MAXMEAN es m < n
1 2 3 4
1 2 3 4
0 20 18 1 20 0 20 2 18 20 0 1 1 2 1 0
En este caso m = 3, y se seleccionan los puntos 1, 2 y 3 El mejor promedio es 19.33, considerando X1 = X2 = X3 = 1, X4 = 0. En cambio seleccionando todos los puntos; es decir, X1 = X2 = X3 = X4 = 1 el promedio es 15.5.
TABLA II Resolución exacta del modelo del máximo promedio para el problema
de la dispersión máxima Resultados del modelo MAXMEAN con dij seleccionados
aleatoriamente U[0,20]
n m Mínimo 10 10 Máximo 10 Mínimo 15 15 Máximo 15 Mínimo 20 20 Máximo 20 Mínimo 25 25 Máximo 25 Mínimo 30 30 Máximo 30
SOLUCION DEL PROBLEMA MAXMEAN EN EL CASO NO TRIVIAL Se considera ahora la generación de instancias con dij seleccionadas aleatoriamente con una distribución U[-10,10], y se resuelve el modelo MAXMEAN según la formulación (21) – (24), usando C-PLEX 12 con los parámetros por defecto. Los experimentos fueron desarrollados en una Laptop Intel Core Solo 1.40 GHz, 3 Gb RAM. Los resultados son mostrados en la tabla 3.

RESOLUCIÒN EXACTA DEL MODELO DEL MÁXIMO PROMEDIO PARA EL PROBLEMA DE LA DISPERSIÒN MÁXIMA
45
TABLA III
Resolución exacta del modelo del máximo promedio para el problema de la dispersión máxima Soluciones exactas para el modelo MaxMean para tamaños variando entre n = 10 a n = 30 nodos
TIEMPO CPU (SEGUNDOS) VALOR OBJETIVO M
PARAMETRO MAXIMUM MEDIAN MINIMUM MAXIMU
M MEDIAN MINIMUM
MAXIMUM
MEDIAN
MINIMUM
n = 10 0.330 0.264 0.172 11.75 7.206 6.258 6 4 3 n = 15 3.002 1.5715 0.905 14.63 11.942 7.707 9 7 3
n = 20 72.009 49.1605 25.532 18.505 14.0915 11.034 11 7.5 5
n = 25 2087.09 1191.711 658.721 19.215 16.923 14.503 15 9 5 TA
MA
ÑO
n = 30 > 5 hours
> 5 hours
> 5 hours - - - - - -
4. RELACION ENTRE EL PROBLEMA
MAXSUM Y EL PROBLEMA MAXMEAN
Nótese que se podría resolver alternativamente el problema MAXMEAN a través de la resolución del problema MAXSUM de la siguiente manera: Si resolvemos óptimamente el problema MAXSUM para todos los valores de m posibles; es decir, para m = 2, 3, …, n, y dividimos estos valores óptimos para su respectivo valor de m, tendríamos todos los valores de los mejores promedios, de ahí al seleccionar el máximo valor de ellos se tendrá el óptimo del problema MAXMEAN. Curiosamente en los resultados computacionales, esta estrategia de resolver m problemas MAXSUM resultó más eficiente que resolver el problema MAXMEAN formulado en (21)-(24), tal como se observa en la tabla 4. SOLUCION DEL PROBLEMA MAXMEAN
UTILIZANDO EL MODELO MAXSUM Se considera ahora la generación de instancias con dij seleccionadas aleatoriamente con una distribución U[-10,10], y se resuelve el modelo MAXMEAN siguiendo la estrategia de resolver m problemas MAXSUM en su formulación MAXSUM IQCP (1) –(3) usando el solver de prueba CONOPT3 y MAXSUM IP (4) – (6) usando C-PLEX 12 con los parámetros por defecto. Los experimentos fueron desarrollados en una Laptop Intel Core Solo 1.40 GHz, 3 Gb RAM.
En los experimentos computacionales, al resolver los m problemas MAXSUM, y dividiendo su óptimo para m, se observó en todas las instancias generadas que estos problemas tienen sólo un óptimo local, tal como se observa en las figuras 1, 2 y 3. Tomando en cuenta la forma que toma el máximo promedio para distintos valores de m, con un solo máximo local, se puede explotar esta característica para generar una estrategia de resolver los problemas MAXSUM para valores crecientes de m, dividir su valor para m y parar el momento en que para el siguiente valor de m este valor del promedio decrece, con lo cual se reduciría aún más el tiempo de ejecución utilizando este procedimiento. En cambio en la tabla 4 se observan los tiempos en los cuales se obtuvieron los resultados, cuando se utilizó este procedimiento resolviendo los problemas MAXSUM con la formulación MIP y utilizando C-PLEX12, y resolviendo los problemas MAXSUM con su formulación IQCP utilizando CONOPT3. También se reporta el GAP para el cual el solver CONOPT3 dio el resultado como óptimo, nótese que en este caso también se resolvieron m problemas pero del tipo MAXSUM. Hay que destacar el hecho de que a pesar que con CONOPT3 no se garantiza que se obtenga la solución óptima exacta, en el 40% de los experimentos si se alcanzó el óptimo.

F. SANDOYA
46
FIGURA 1 Resolución exacta del modelo del máximo promedio para el problema
de la dispersión máxima Valores óptimos del problema MAXSUM divididos para m
para una instancia con n=30
FIGURA 2 Resolución exacta del modelo del máximo promedio para el problema
de la dispersión máxima Valores óptimos del problema MAXSUM divididos para m
para una instancia con n=40
FIGURA 3 Resolución exacta del modelo del máximo promedio para el problema
de la dispersión máxima Valores óptimos del problema MAXSUM divididos para m
para una instancia con n=50
TABLA IV Resolución exacta del modelo del máximo promedio para el problema
de la dispersión máxima Tiempos para el problema MAXMEAN al resolverlo con
los tres métodos planteados
n método tiempo CPU m GAP MAXMEAN 17.74 7 - MAXSUM IP 8.506 7 - 20 MAXSUM
IQCP 0.675 8 1.19%
MAXMEAN 788.448 7 - MAXSUM IP 41.884 7 - 25 MAXSUM
IQCP 0.783 7 1.93%
MAXMEAN 57723.918 7 - MAXSUM IP 99.408 7 - 30 MAXSUM
IQCP 0.757 7 5.72%
MAXMEAN ∞ 12 - MAXSUM IP 745.025 12 - 40 MAXSUM
IQCP 1.611 10 0.95%
MAXMEAN ∞ 14 - MAXSUM IP 122576.938 14 - 50 MAXSUM
IQCP 3.66 13 1.86%
5. CONCLUSIONES Y
RECOMENDACIONES En esta investigación se pudo determinar que el problema MAXMEAN sólo tiene sentido estudiarlo para distancias inter elemento dij negativas y positivas, pues si las dij son todas negativas las solución es siempre m =1, mientras que si todas las dij son positivas es casi seguro que m = n. Por otro lado resulta curioso el hecho que el modelo MIP planteado requiere un tiempo excesivo de ejecución incluso para tamaños del problema pequeños, y sólo puede ser resuelto en un tiempo prudencial para valores de n inferiores a 25. Sin embargo se puede resolver de manera exacta el mismo problema resolviendo m problemas del tipo MAXSUM en un tiempo mucho menor. Incluso, tomando en cuenta la forma que toma el máximo promedio para distintos valores de m, con un solo máximo local, podría utilizarse la estrategia de parar el momento en que para un m mayor el valor del promedio decrece, con lo cual se reduciría aún más el tiempo de ejecución utilizando este procedimiento.

RESOLUCIÒN EXACTA DEL MODELO DEL MÁXIMO PROMEDIO PARA EL PROBLEMA DE LA DISPERSIÒN MÁXIMA
47
La utilización de otro tipo de solvers que están en etapa de prueba, tales como CONOPT3 que utiliza procedimientos de optimización numérica no lineal, reduce drásticamente los tiempos de ejecución, en base a los tiempos alcanzados para el tamaño máximo considerado en la versión demo disponible, n = 50. Se especula que se
podrían resolver con la versión profesional problemas de tamaño muy grande, la desventaja es que no está garantizado que este solver alcance la solución óptima, a pesar que el programa reporta GAP cero, sin embargo si lo hizo el 40% de las veces en los experimentos computacionales.

F. SANDOYA
48
REFERENCIAS BIBLIOGRÁFICAS Y ELECTRÓNICAS
[1]. DUARTE A, MARTÍ R. (2007). “Tabu Search and GRASP for the Maximum Diversity Problem”, European Journal of Operational Research; 178, 71-84.
[2]. GLOVER F, KUO CC, DHIR KS. (1998),
“Heuristic Algorithms for the Maximum Diversity Problem”, Journal of Information and Optimization Sciences 1998; vol. 19, no. 1, 109-132.
[3]. PROKOPYEV OA, KONG N,
MARTINEZ-TORRES DL. (2009).
“The equitable dispersion problem”. European Journal of Operational Research; 197: 59-67.
[4]. RESENDE MGC, MARTÍ R, GALLEGO
M, DUARTE A. (2010). GRASP with path relinking for the max-min diversity problema. Computers and Operations Research; 37: 498-508.
[5]. C-PLEX 12.0 User’s Manual (2009), GAMS
documents.


![o nV~# [îmwWße°0 Nº]å ZyS@ y Ô D Wu riSÊ Z ^ ¤}Êv S...od Tá ukT z1 : o nV]ñb e>Nº]å ZyNKsþlÁ ¿gå uk}è _ : 79 ²^ú -3.2- o -20(3-2E) nhvnMd bM l-dX ...](https://static.fdocuments.pl/doc/165x107/60e37aa65171205b512cc544/o-nv-mwwe0-n-zys-y-d-wu-ris-z-v-s-od-t-ukt-z1-.jpg)















