
Ewolucja komputerów o dużej mocy...
40
Superkomputer to maszyna licząca, która w danym okresie jest w czołówce maszyn o największej mocy obliczeniowej. Jednostka szybkości obliczeń to FLOPS (liczba operacji zmiennoprzecinkowych na sekundę) Wikipedia: Ale... maszyna licząca, która spełniała ten warunek 20 lat temu obecnie może być wolniejsza od komputera PC. Superkomputer CDC 6600 z 1964 pracował z imponującą częstotliwością 3 MHz... Ewolucja komputerów o dużej mocy obliczeniowej
Transcript of Ewolucja komputerów o dużej mocy...

Superkomputer to maszyna licząca, która w danym
okresie jest w czołówce maszyn o największej mocy
obliczeniowej. Jednostka szybkości obliczeń to FLOPS
(liczba operacji zmiennoprzecinkowych na sekundę)
Wikipedia:
Ale... maszyna licząca, która spełniała ten warunek 20
lat temu obecnie może być wolniejsza od komputera
PC. Superkomputer CDC 6600 z 1964 pracował z
imponującą częstotliwością 3 MHz...
Ewolucja komputerów o dużej mocy obliczeniowej

Historia
•W 1963/64 pierwszy superkomputer CDC 6600 produkowany przez firmę
Control Data Corporation. Po raz pierwszy zastosowano tranzystory
krzemowe oraz technikę chłodzenia freonem. Częstość taktowania procesora
wynosiła, niespotykane wtedy, 3MHz. Cena jednego egzemplarza wynosiła
ok. 8 mln dolarów. Autorem i nadzorcą projektu był Seymour Cray.
•W latach 70 powstaje firma Cray Research, która do roku 1993 wypuszcza
serię trzech superkomputerów Cray (W '85 – '90 zajmuje ścisłą czołówkę).
•W latach 70-80 większość superkomputerów pracowała na procesorach
wektorowych
•W lata 80-90 następuje powrót do procesorów skalarnych ale wykonujących
obliczenia równoległe. (tysiące procesorów)
•Obecnie większość superkomputerów pracuje jako klastry, składające się z
setek bądź tysięcy połączonych procesorów.

Wspólne cechy superkomputerów
•Obecnie superkomputery najczęściej tworzy się przez połączenie
węzłów (komputerów wchodzących w skład klastra) siecią o
wysokiej przepustowości (InfiniBand, GigaBit Ethernet).
•Większość używa procesorów cztero-rdzeniowych Intel (73%) lub
AMD (12%).
•Wykorzystują system operacyjny Linux.
•Są energożerne.

TOP500.ORG
Strona internetowa zawierająca, aktualizowaną dwa razy
do roku, listę 500 superkomputerów o największej mocy
obliczeniowej. Do mierzenia ich wydajności
wykorzystywany jest benchmark LINPACK (pakiet
procedur z zakresu algebry liniowej).
Rmax - maksymalna wydajność osiągnięta w teście
LINPACK (w TFLOPS-ach),

Zastosowanie
Ogólnie:
• nauki ścisłe, ekonomia, finanse, symulacja pogody, przemysł
lotniczy i samochodowy
• wojsko
Bardziej szczegółowe przykłady:
• aerodynamika - matematyczna symulacja kształtów skrzydła czy
nadwozia i wirtualne testy zderzeniowe,
• biologia - sekwencjonowanie DNA, rozwój komórek rakowych.
• geologia - przewidywanie trzęsień ziemi.
• astrofizyka - symulacje tworzenia się gwiazd, planet oraz ruchu
galaktyk. Procesy te zajmują miliardy lat, więc trudno je
obserwować bezpośrednio.
•monitorowanie arsenałów nuklearnych (starzenie się materiałów
radioaktywnych).

Rok SuperkomputerSzybkość(Rmax)
Twórca i lokalizacja
1938 Zuse Z1 1 OPS Konrad Zuse, Berlin, Niemcy
1941 Zuse Z3 20 OPS Konrad Zuse, Berlin, Niemcy
1943 Colossus 1 5 kOPS
Post Office Research Station, Bletchley Park, Wielka Brytania1944
Colossus 2 (jednoproserowy)
25 kOPS
1946Colossus 2 (wieloprocesorowy)
50 kOPS
1946 ENIAC 5 kOPS Departament Wojny USA, Maryland, USA
1954 IBM NORC 67 kOPS Departament Obrony Stanów Zjednoczonych, Wirginia, USA
1956 TX-0 83 kOPS MIT, Lexington, Massachusetts, USA
1958 AN/FSQ-7 400 kOPS IBM, 25 lokalizacji w USA i 1 w Kanadzie (52 komputery)
1960 UNIVAC LARC 250 kFLOPSUNIVAC, Atomic Energy CommissionLawrence Livermore National Laboratory, Kalifornia, USA
1961 IBM 7030 Stretch 1,2 MFLOPS Los Alamos National Laboratory, Nowy Meksyk, USA
1964 CDC 6600 3 MFLOPS
CDC, Lawrence Livermore National Laboratory, Kalifornia, USA1969 CDC 7600 36 MFLOPS
1974 CDC STAR-100 100 MFLOPS
Historyczna lista najszybszych komputerów
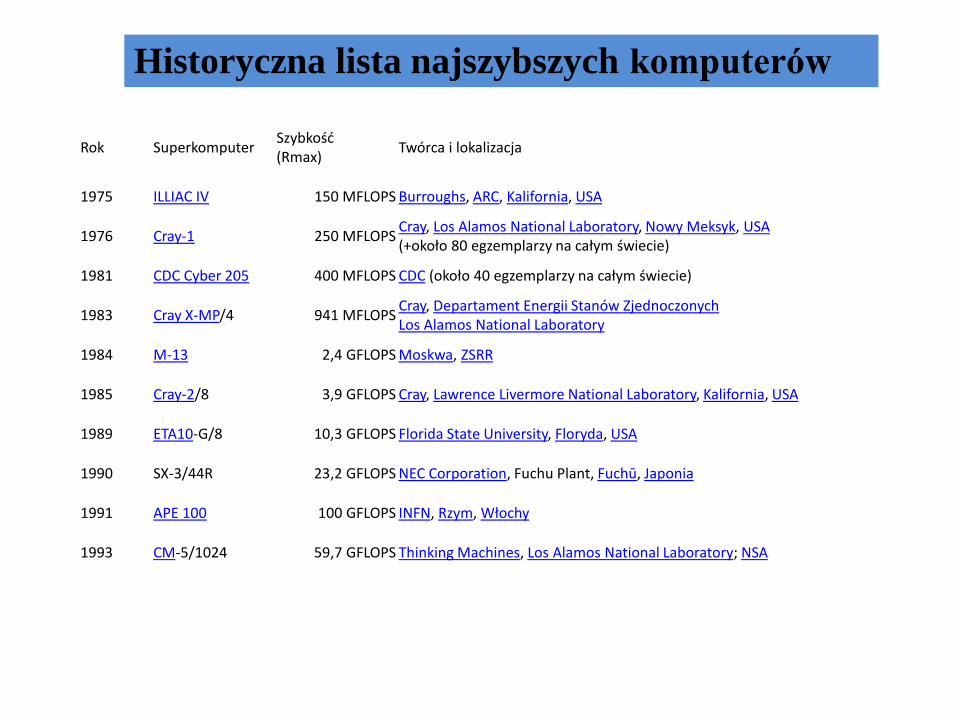
Rok SuperkomputerSzybkość(Rmax)
Twórca i lokalizacja
1975 ILLIAC IV 150 MFLOPS Burroughs, ARC, Kalifornia, USA
1976 Cray-1 250 MFLOPSCray, Los Alamos National Laboratory, Nowy Meksyk, USA(+około 80 egzemplarzy na całym świecie)
1981 CDC Cyber 205 400 MFLOPS CDC (około 40 egzemplarzy na całym świecie)
1983 Cray X-MP/4 941 MFLOPSCray, Departament Energii Stanów ZjednoczonychLos Alamos National Laboratory
1984 M-13 2,4 GFLOPS Moskwa, ZSRR
1985 Cray-2/8 3,9 GFLOPS Cray, Lawrence Livermore National Laboratory, Kalifornia, USA
1989 ETA10-G/8 10,3 GFLOPS Florida State University, Floryda, USA
1990 SX-3/44R 23,2 GFLOPS NEC Corporation, Fuchu Plant, Fuchū, Japonia
1991 APE 100 100 GFLOPS INFN, Rzym, Włochy
1993 CM-5/1024 59,7 GFLOPS Thinking Machines, Los Alamos National Laboratory; NSA
Historyczna lista najszybszych komputerów
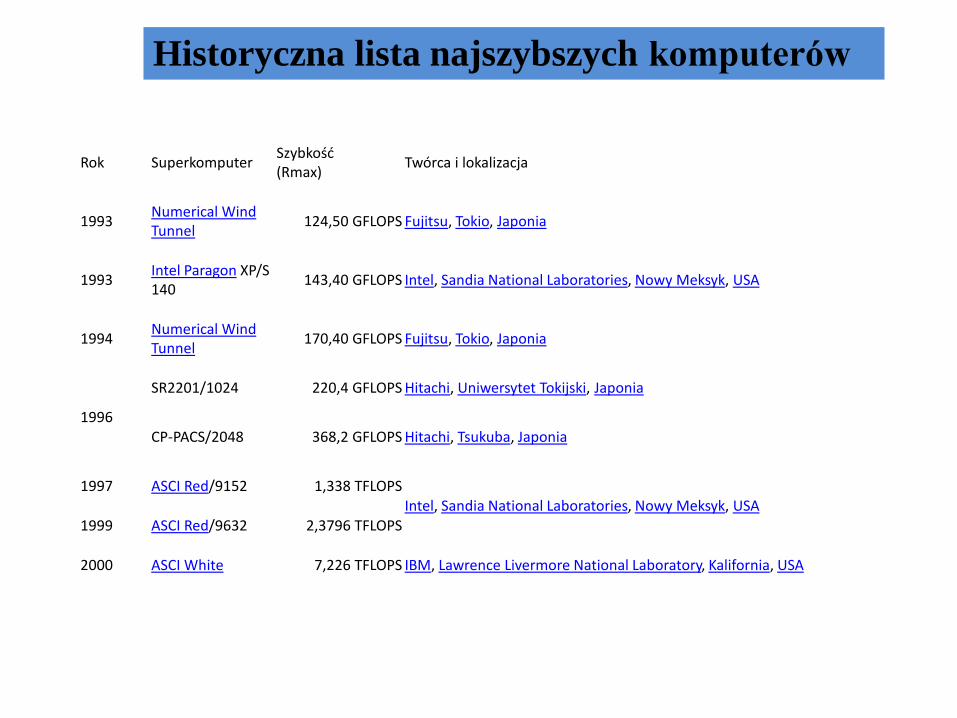
Rok SuperkomputerSzybkość(Rmax)
Twórca i lokalizacja
1993Numerical Wind Tunnel
124,50 GFLOPS Fujitsu, Tokio, Japonia
1993Intel Paragon XP/S 140
143,40 GFLOPS Intel, Sandia National Laboratories, Nowy Meksyk, USA
1994Numerical Wind Tunnel
170,40 GFLOPS Fujitsu, Tokio, Japonia
1996
SR2201/1024 220,4 GFLOPS Hitachi, Uniwersytet Tokijski, Japonia
CP-PACS/2048 368,2 GFLOPS Hitachi, Tsukuba, Japonia
1997 ASCI Red/9152 1,338 TFLOPSIntel, Sandia National Laboratories, Nowy Meksyk, USA
1999 ASCI Red/9632 2,3796 TFLOPS
2000 ASCI White 7,226 TFLOPS IBM, Lawrence Livermore National Laboratory, Kalifornia, USA
Historyczna lista najszybszych komputerów
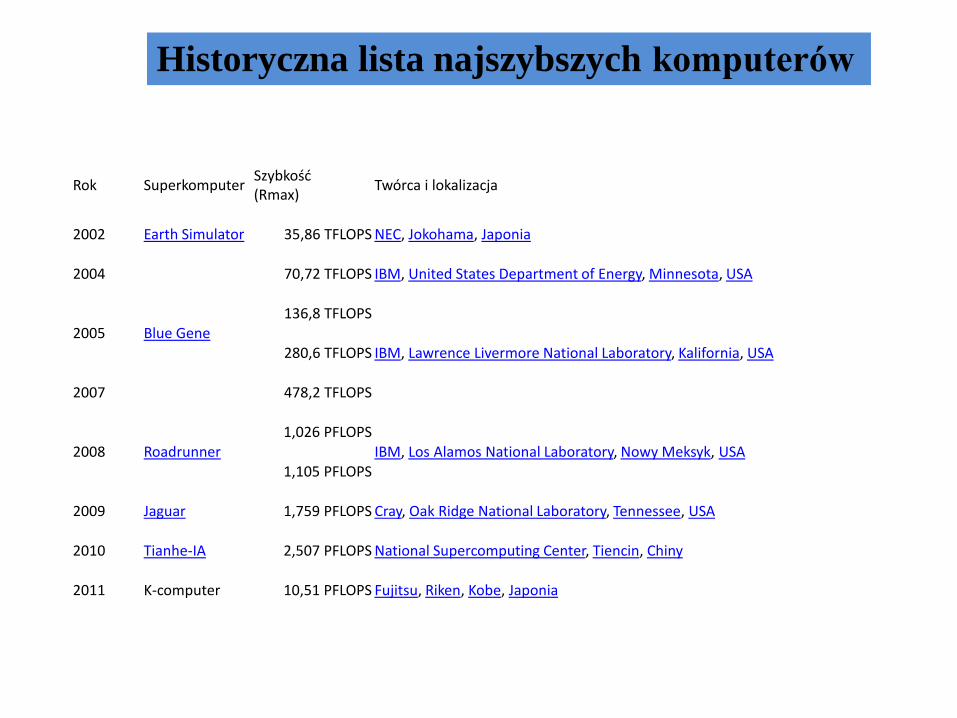
Rok SuperkomputerSzybkość(Rmax)
Twórca i lokalizacja
2002 Earth Simulator 35,86 TFLOPS NEC, Jokohama, Japonia
2004
Blue Gene
70,72 TFLOPS IBM, United States Department of Energy, Minnesota, USA
2005136,8 TFLOPS
IBM, Lawrence Livermore National Laboratory, Kalifornia, USA280,6 TFLOPS
2007 478,2 TFLOPS
2008 Roadrunner1,026 PFLOPS
IBM, Los Alamos National Laboratory, Nowy Meksyk, USA1,105 PFLOPS
2009 Jaguar 1,759 PFLOPS Cray, Oak Ridge National Laboratory, Tennessee, USA
2010 Tianhe-IA 2,507 PFLOPS National Supercomputing Center, Tiencin, Chiny
2011 K-computer 10,51 PFLOPS Fujitsu, Riken, Kobe, Japonia
Historyczna lista najszybszych komputerów

Roadrunner @ LANL: 1.1 PF/s
kukawka kalifornijska
• IBM• 12,960 procesorów Cell (8+1) (w kasetach serwerowych typu IBM Blade QS22)• 6,948 dwu-rdzeniowe AMD Opteron (LS21 blade)• 104 TB pamięci operacyjnej• RedHat Linux• Konsumpcja mocy 2.5 MW• 294 raki pogrupowane w 18 jednostek• 540 m2
Jako pierwszy w historii pokonał barierę jednego 1 PF/s.

Jaguar : 1.75 PFLOPS
• W latach 2009-2010 był najszybszym superkomputerem na świecie. Znajduje się w laboratorium w Oak Ridge w stanie Tennessee w USA, służy do badań od podstawowych do wdrożeniowych. Prace zadawane maszynie są recenzowane.
• Ten Cray XT5-HE jest wyposażony w sześciordzeniowe procesory AMD Opteron, w sumie 224256 rdzeni. Każdy węzeł posiada 16 GB DDR2 RAM. Poszczególne węzły łączy rozgwiazda 2+ (SeaStar) router z jednej strony do łączy HT a z drugiej do innych rozgwiazd. System operacyjny tego komputera to Linux.

Tianhe-1: 2.566 PFLOPS
• Tianhe-I lub TH-1 (天河一号) (transkrypcja: Tiānhé yīhào), po polsku"Droga Mleczna 1”- superkomputer o wydajności 2,566 PFLOPS. Znajdujesię w National Supercomputing Center w mieście Tiencin w Chinach i aktualnie (2010 rok) jest najszybszym superkomputerem na świecie.
• W październiku 2010 roku jego najnowsza wersja (Tianhe-1A), prześcigneła wcześniejszego rekordzistę, superkomputer Jaguar.
• Tianhe-1A wykorzystuje 14336 procesorów Xeon X5670 i 7168 procesorówNvidia Tesla M2050. Jest w nim dodatkowo zainstalowanych 2048 chińskich procesorów FT1000, ale nie są one aktualnie uwzględnione w jego mocy obliczeniowej. Jego teoretyczna maksymalna wydajność to 4,701 PFLOPS. Zużywa 4,04 MW mocy. Posiada 262 TB pamięci operacyjnejoraz 5 PB dysku twardego w systemie plików Lustre.

K-computer: 10.51 PFLOPS
• K computer – superkomputer o mocy obliczeniowej 10,51 PFLOPS, wyprodukowany przez Fujitsu w 2011 roku i zainstalowany w Riken w Kobew Japonii. Jego nazwa pochodzi od japońskiego słowa Kei, oznaczającego liczbę 1016.
• Pierwsza wersja K komputera, zaprezentowana w czerwcu 2011, osiągnęła moc obliczeniową 8,162 PFLOPS. Zawierała 68544 ośmiordzeniowe procesory SPARC64 VIIIfx, co dawało w sumie 548352 rdzenie. Do listopada 2011 rozbudowano ją do 88128 procesorów (705024 rdzeni), co pozwoliło zwiększyć moc obliczeniową do 10,51 PFLOPS.
• K komputer zbudowany jest z ośmiordzeniowych procesorów SPARC64 VIIIfx, wykonanych w technologii 45 nanometrów. Węzły superkomputera połączone są siecią tworzącą wirtualny sześciowymiarowy torus, co umożliwia efektywną komunikację między oddalonymi węzłami oraz izolowanie wadliwie pracujących węzłów. Jest chłodzony cieczą, aby zminimalizować zużycie energii i awaryjność. Zużywa 12,6 MW mocy.
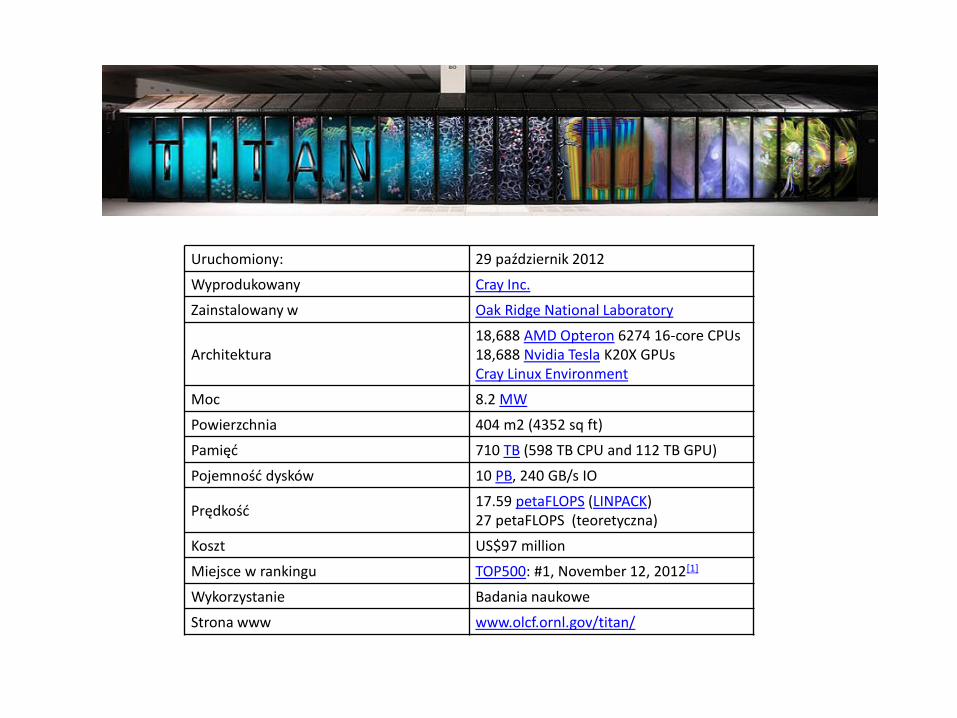
Uruchomiony: 29 październik 2012
Wyprodukowany Cray Inc.
Zainstalowany w Oak Ridge National Laboratory
Architektura18,688 AMD Opteron 6274 16-core CPUs18,688 Nvidia Tesla K20X GPUsCray Linux Environment
Moc 8.2 MW
Powierzchnia 404 m2 (4352 sq ft)
Pamięć 710 TB (598 TB CPU and 112 TB GPU)
Pojemność dysków 10 PB, 240 GB/s IO
Prędkość17.59 petaFLOPS (LINPACK)27 petaFLOPS (teoretyczna)
Koszt US$97 million
Miejsce w rankingu TOP500: #1, November 12, 2012[1]
Wykorzystanie Badania naukowe
Strona www www.olcf.ornl.gov/titan/

Piz Daint - Cray XC50 – 19.59 PFLOPS
• Swiss National Supercomputing Centre (CSCS)
• Liczba procesorów 361 760 Xeon E5-2690v3 12C 2.6GHz
• Pamięć: 340 TB
• System operacyjny: Cray Linux Environment
• Moc: 2.27 MW (Optimized: 1.63 MW)

Tianhe-2: 33,86 PFLOPS
• Tianhe-2 (Droga Mleczna-2) – superkomputer o mocy obliczeniowej 33,86 PFLOPS. W czerwcu 2013 roku znalazł się na pierwszym miejscu listy TOP500 – superkomputerów o największej mocy obliczeniowej na świecie.
• Koszty budowy Tianhe-2 wyniosły 390 milionów dolarów. Składa się ze 125 szaf, w każdej po 64 płyty zawierające po 2 węzły. Daje to w sumie 16 000 węzłów. Każdy węzeł zawiera 2 procesory Xeon Ivy Bridge i 3 koprocesory Xeon Phi oraz 88 GB RAM. Każdy procesor Ivy Bridge zawiera 12 rdzeni obliczeniowych, a każdy koprocesor 57 rdzeni. Daje to w sumie 3 120 000 rdzeni. Procesory są taktowane zegarem 1,1 GHz. Daje to teoretyczną moc obliczeniową 54,9 PFLOPS[3]. W testach LINPACK Tianhe-2 osiągnął moc obliczeniową 33,86 PFLOPS, co oznacza efektywność 61,5%.
• Tianhe-2 posiada 1,34 PB pamięci operacyjnej i 12,4 PB pamięci masowej. Wymaga do zasilania 17,6 MW mocy. Razem z chłodzeniem zużycie mocy wynosi 24 MW.

Sunway TaihuLight: 93.01PFLOPS
Site:NationalSupercomputing Center in Wuxi
Manufacturer: NRCPC
Cores: 10,649,600
Linpack Performance (Rmax)
93,014.6 TFlop/s
Theoretical Peak (Rpeak) 125,436 TFlop/s
Nmax 12,288,000
Power: 15.37 MW
Memory: 1,3 PB
Processor:Sunway SW26010 260C 1.45GHz
Operating System: Sunway RaiseOS 2.0.5

Sunway TaihuLight: 93.01PFLOPS

Sierra 125 PFLOPS
Site:Lawrence Livermore National Laboratory
Manufacturer: IBM/NVIDIA/Mellanox
Cores 1 572 480
Linpack Performance (Rmax)
94 PFlop/s
Theoretical Peak (Rpeak) 125 PFlop/s
Memory per node 256 GB
Power: 7.4 MW
Memory: 1.38 PB
Processor:IBM POWER9 22C 3.1GHz
Operating System: Red Hat Enterprise Linux

Summit 200 PFLOPS
Site:Oak Ridge NationalLaboratory
Manufacturer: IBM
Cores 2 397 824
Linpack Performance (Rmax)
143.5 PFlop/s
Theoretical Peak(Rpeak)
200 PFlop/s
Power: 9.8 MW
Memory: 2.8 PB
Processor: IBM POWER9 22C 3.07GHz
Operating System:
RHEL 7.4
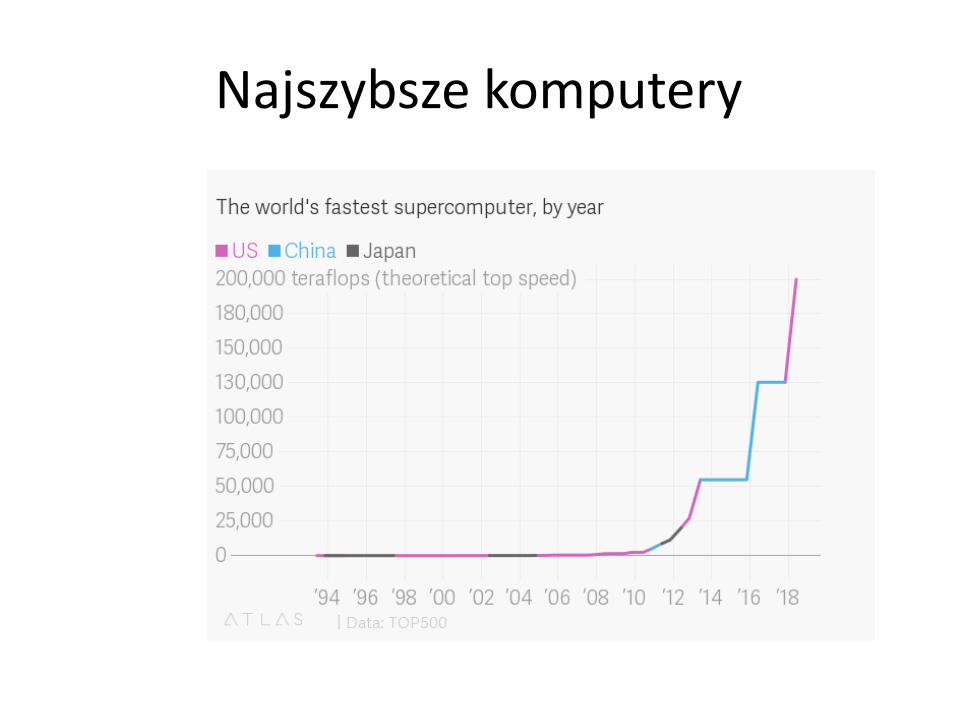
Najszybsze komputery
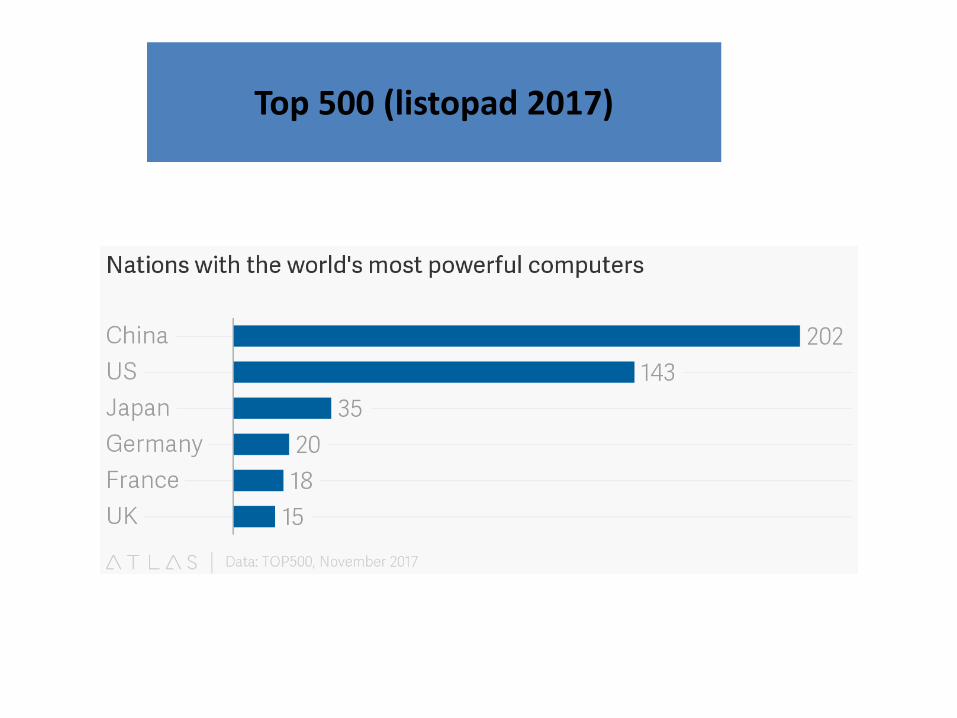
Top 500 (listopad 2017)
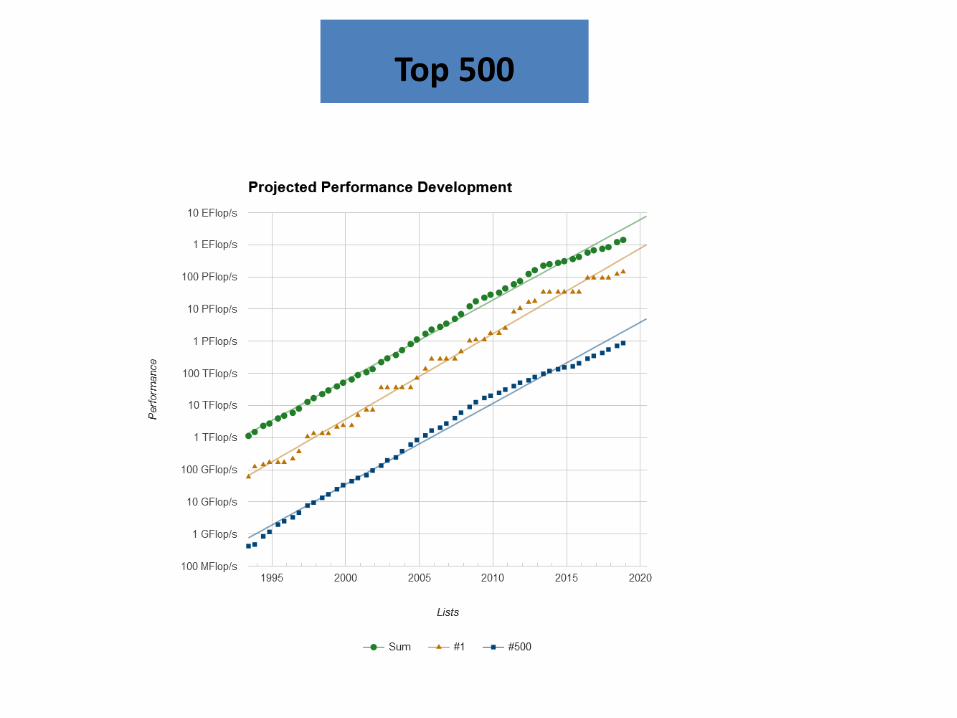
Top 500
N=500

PrometheusCyfronet Kraków
• Typ komputera: klaster
• Konfiguracja: HP Apollo 8000
• Moc obliczeniowa: 2,4 Pflops
• Ilość rdzeni: 53568
• Pamięć: 279 TB
• Pojemność dysków: 10 PB
• System operacyjny: Linux CentOS 7
131 (77) miejsce na liście
TOP500
listopad 2018 (2017)
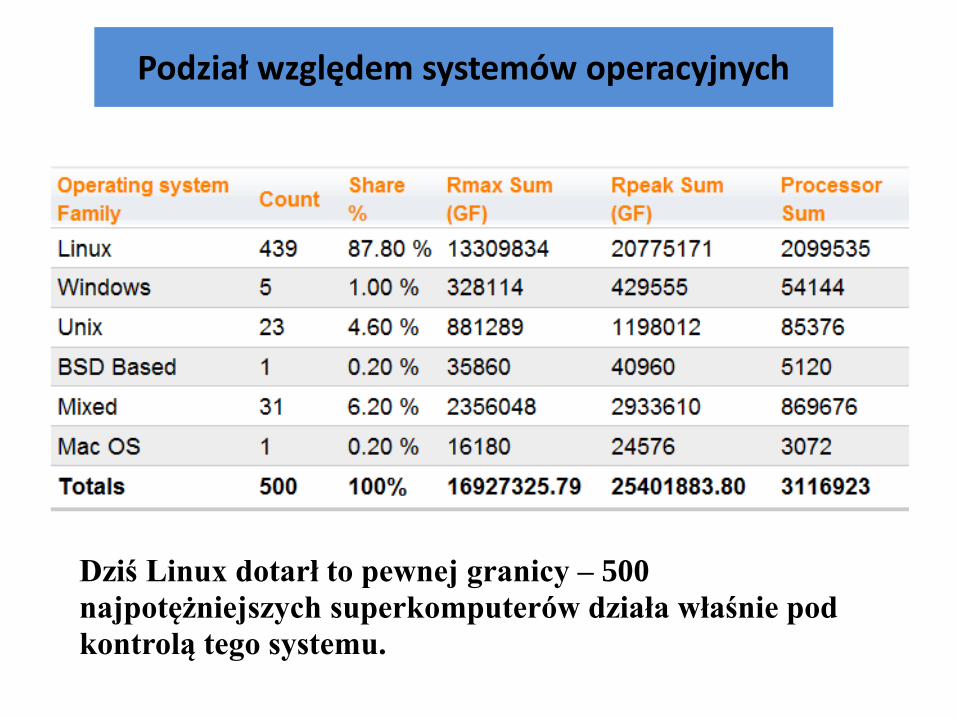
Podział względem systemów operacyjnych
Dziś Linux dotarł to pewnej granicy – 500
najpotężniejszych superkomputerów działa właśnie pod
kontrolą tego systemu.
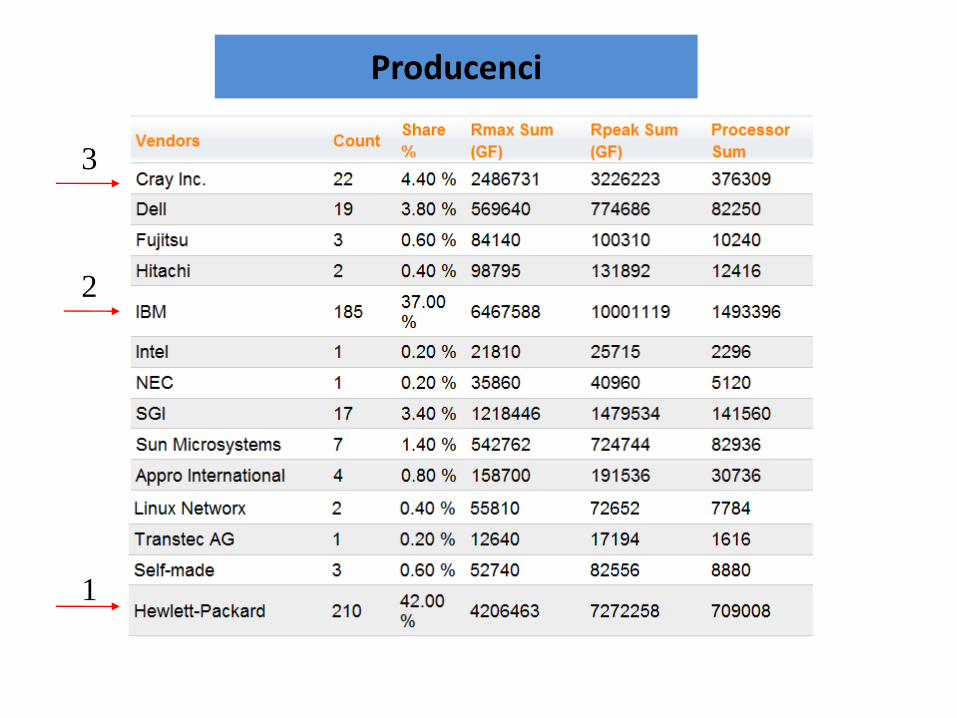
Producenci
2
1
3

Technologia grid
Grid ma pozwolić na
rozwiązywanie
problemów dużej
skali, w zakresie
znacznie większym
niż pozwalają na to
superkomputery.
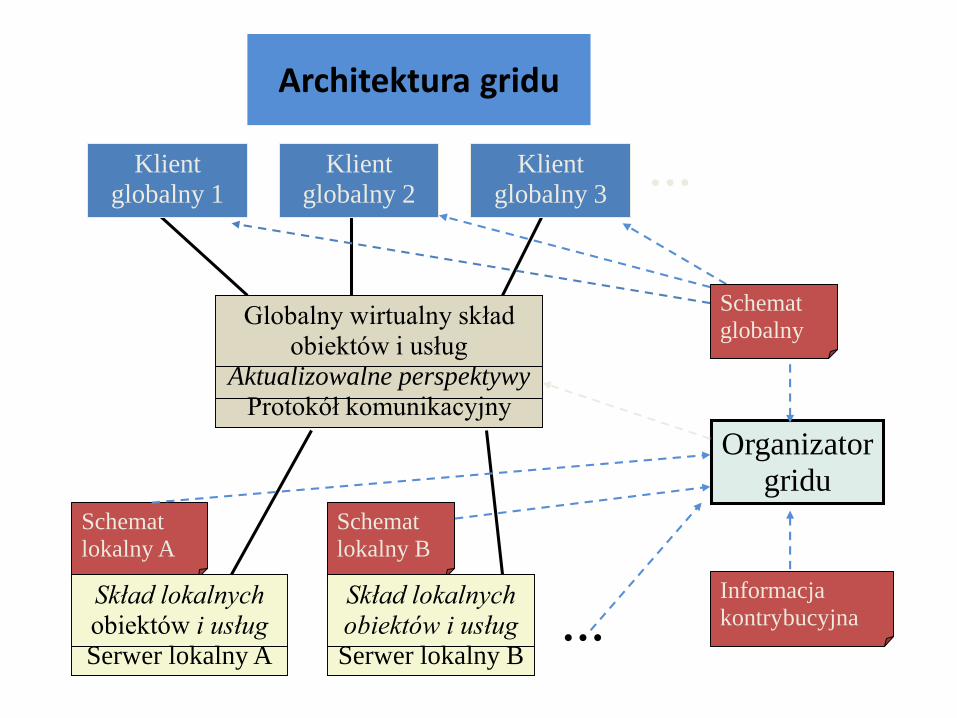
Schemat
lokalny A
Schemat
lokalny B
Architektura gridu
...Klient
globalny 1
Klient
globalny 2
Klient
globalny 3
...Skład lokalnych
obiektów i usług
Serwer lokalny A
Skład lokalnych
obiektów i usług
Serwer lokalny B
Globalny wirtualny skład
obiektów i usług
Aktualizowalne perspektywy
Protokół komunikacyjny
Organizator
gridu
Informacja
kontrybucyjna
Schemat
globalny

Objaśnienie architektury (1)
• Linie ciągłe grube: związki między oprogramowaniem w run-time
(zapytania, zlecenia, odpowiedzi).
• Linie i strzałki przerywane: związki definicyjne (podczas tworzenia
oprogramowania).
• Klient globalny: program aplikacyjny wykorzystujący globalny
wirtualny skład.
• Globalny wirtualny skład obiektów i usług: skład, do którego
adresowane są zapytania i zlecenia ze strony klienta globalnego; w
rzeczywistości nie istnieje.
• Schemat globalny: definicje obiektów i usług wirtualnych
wykorzystywane (głównie) przez programistów podczas tworzenia
klientów globalnych.

Objaśnienie architektury (2)
• Aktualizowalne perspektywy: oprogramowanie, którego celem jest
wytworzenie globalnego wirtualnego składu.
• Protokół komunikacyjny: zestaw funkcji działających na odległych
serwerach używanych do definicji perspektyw.
• Organizator gridu: osoba, zespół osób lub program definiujący
perspektywy na podstawie schematów lokalnych, schematu
globalnego i informacji kontrybucyjnej.
• Schemat lokalny: informacja katalogowa o obiektach i usługach
udostępnianych przez serwer lokalny (IDL, WSDL, ODL, ...)
• Serwer lokalny: jednostka sprzętowa/programowa identyfikowana
przez system rozproszony.

Informacja kontrybucyjna
• Określa w jaki sposób poszczególne serwery kontrybuują do
globalnego wirtualnego składu obiektów.
• Określa redundancje w danych trzymanych na poszczególnych
serwerach.
• Określa replikacje.
• Określa sposoby aktualizacji danych.
• Określa zależności pomiędzy poszczególnymi serwerami.
• Jest podstawą definicji odpowiednich perspektyw.

Cztery najważniejsze problemy
• Przezroczystość (transparency): traktowanie rozproszonych zasobów i
usług tak, jak gdyby były one wewnątrz przestrzeni adresowej jednego
komputera.
• Bezpieczeństwo: przeciwdziałanie losowym awariom oraz
możliwościom ataku z zewnętrz.
• Interoperacyjność (interoperability): umożliwienie współpracy
heterogenicznych platform, aplikacji, logik biznesowych i organizacji
danych.
• Efektywność: uzyskanie czasów przetwarzania akceptowalnych dla
szerokiego kręgu użytkowników rozproszonych aplikacji.

PL-Grid
• Projekt finansowany w ramach Programu Operacyjnego Innowacyjna Gospodarka
• Cele:
Utworzyć otwartą ogólnopolska infrastrukturę komputerową wspierająca uprawianie nauki w sposób umożliwiający integrację danych doświadczalnych i wyników zaawansowanych symulacji komputerowych
Dostarczyć polskiej społeczności naukowej usług informatycznych opartych na infrastrukturze komputerowej służących e-nauce w różnych dziedzinach
Umożliwić dołączanie lokalnych zasobów komputerowych uczelni, instytutów badawczych, centrów komputerowych czy platform technologicznych do wspólnej infrastruktury gridowej Europy i świata
Wskaźniki:
Ilość naukowców korzystających z usług PL-Grid (700)
Ilość nowych dziedzin (grup naukowców) wspieranych przez PL-Grid (7)
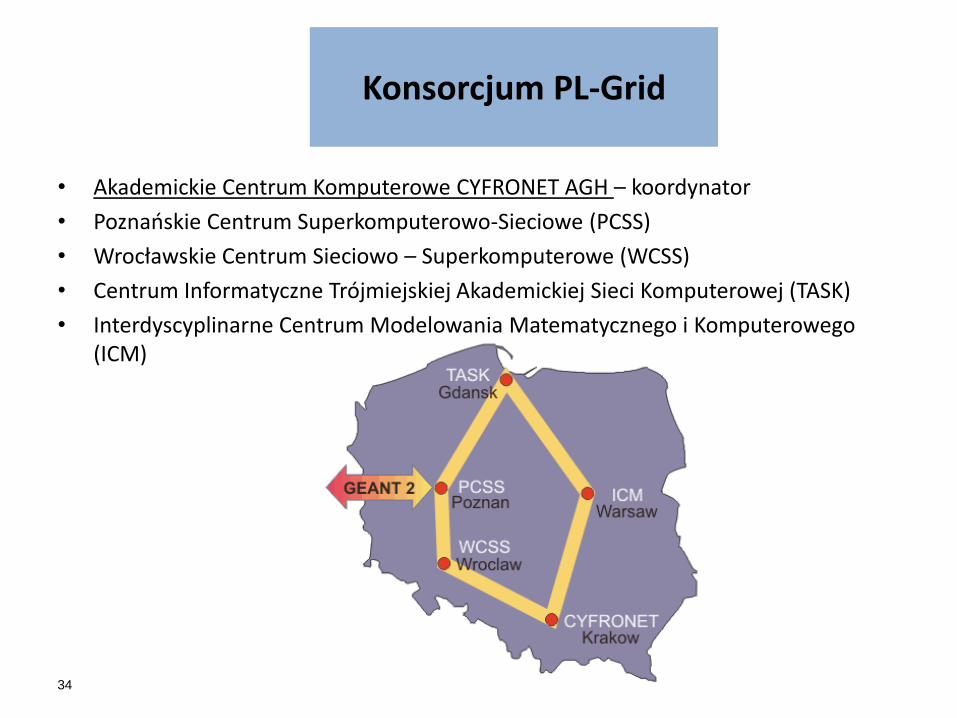
Konsorcjum PL-Grid
• Akademickie Centrum Komputerowe CYFRONET AGH – koordynator
• Poznańskie Centrum Superkomputerowo-Sieciowe (PCSS)
• Wrocławskie Centrum Sieciowo – Superkomputerowe (WCSS)
• Centrum Informatyczne Trójmiejskiej Akademickiej Sieci Komputerowej (TASK)
• Interdyscyplinarne Centrum Modelowania Matematycznego i Komputerowego (ICM)
34

Oferta PL-Grid
• Moc obliczeniowa 5 Pflops
• Liczba rdzeni 130 000
• Pamięć dyskowa 60 PB
• Zestaw zaawansowanych narzędzi do organizacji programów obliczeniowych, który pomożemy dostosować do indywidualnych potrzeb
• Pomoc w zrozumieniu zagadnień związanych z uruchamianiem aplikacji naukowych na rozległych zasobach obliczeniowych
• Wsparcie technologiczne i informatyczne przy projektowaniu własnych aplikacji naukowych i ich wdrażaniu na infrastrukturze PL-Grid
35
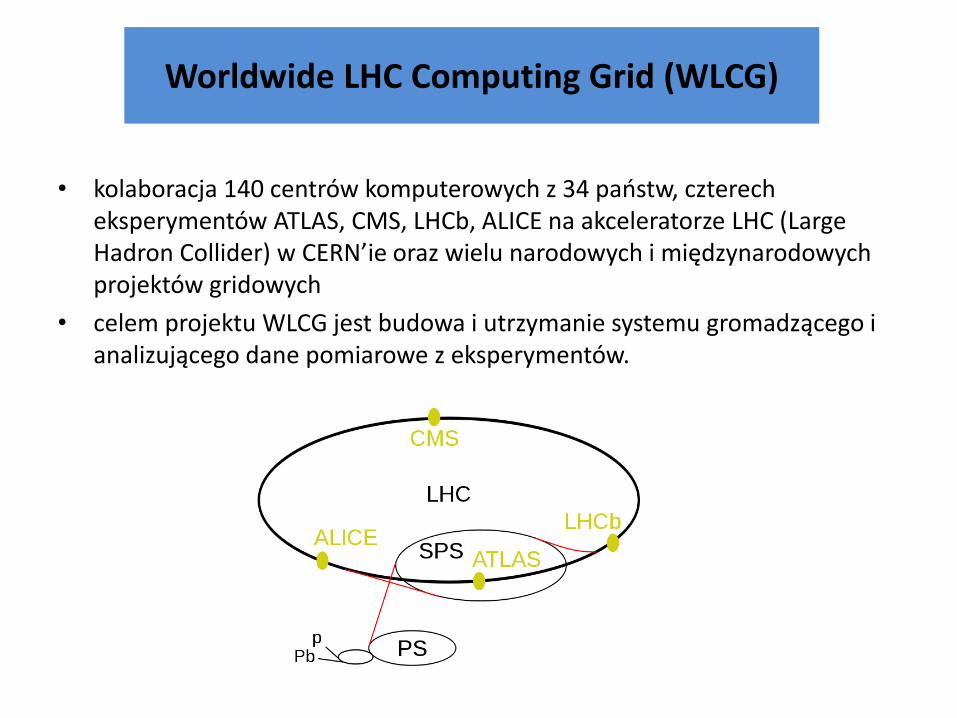
Worldwide LHC Computing Grid (WLCG)
• kolaboracja 140 centrów komputerowych z 34 państw, czterech eksperymentów ATLAS, CMS, LHCb, ALICE na akceleratorze LHC (Large Hadron Collider) w CERN’ie oraz wielu narodowych i międzynarodowych projektów gridowych
• celem projektu WLCG jest budowa i utrzymanie systemu gromadzącego i analizującego dane pomiarowe z eksperymentów.
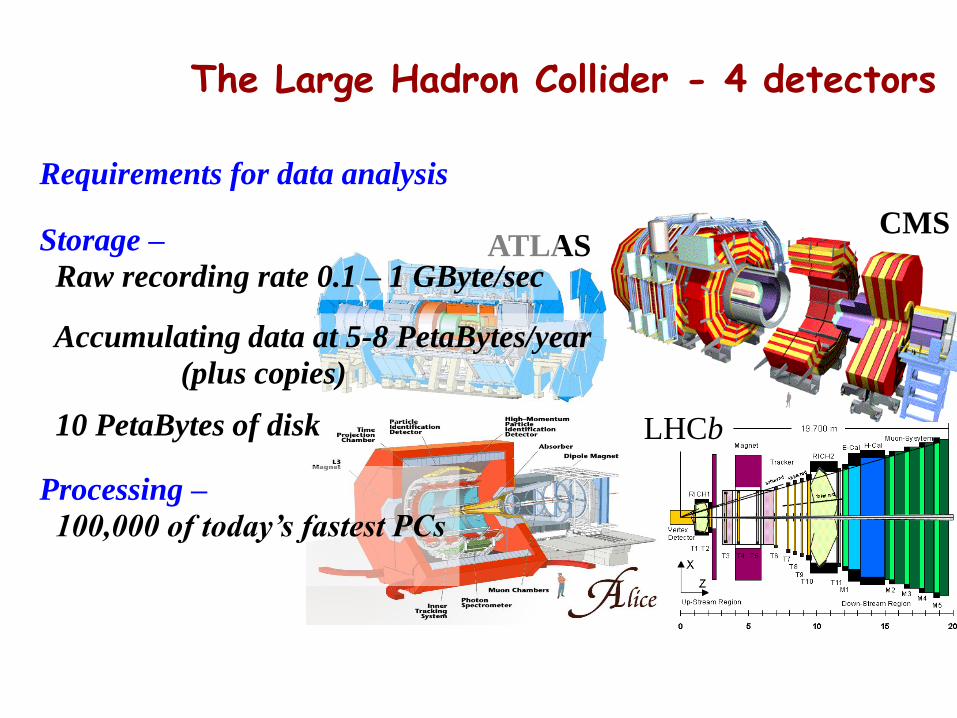
The Large Hadron Collider - 4 detectors
CMSATLAS
LHCb
Requirements for data analysis
Storage –
Raw recording rate 0.1 – 1 GByte/sec
Accumulating data at 5-8 PetaBytes/year
(plus copies)
10 PetaBytes of disk
Processing –
100,000 of today’s fastest PCs
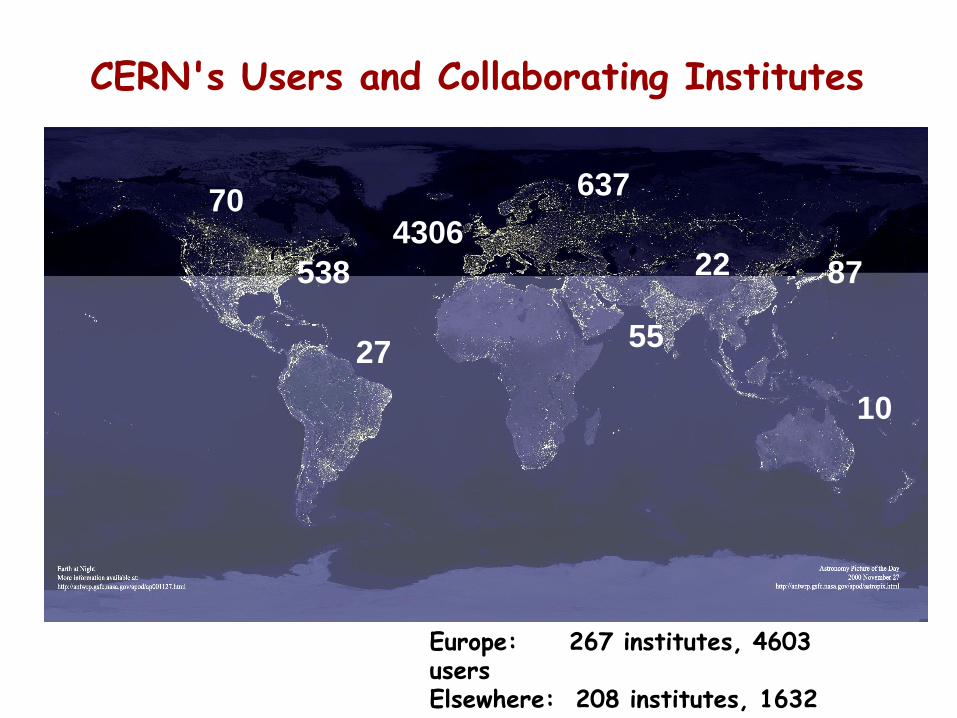
CERN's Users and Collaborating Institutes
Europe: 267 institutes, 4603 usersElsewhere: 208 institutes, 1632 users
70
538
27
10
8722
637
55
4306

LCG: The LHC Computing Grid Project
• a geographically distributed computing facility
• for a very large user population of independently-mindedscientists
• with independent ownership/management of the different nodes
• each with different access and usage policies
• and serving multiple user communities
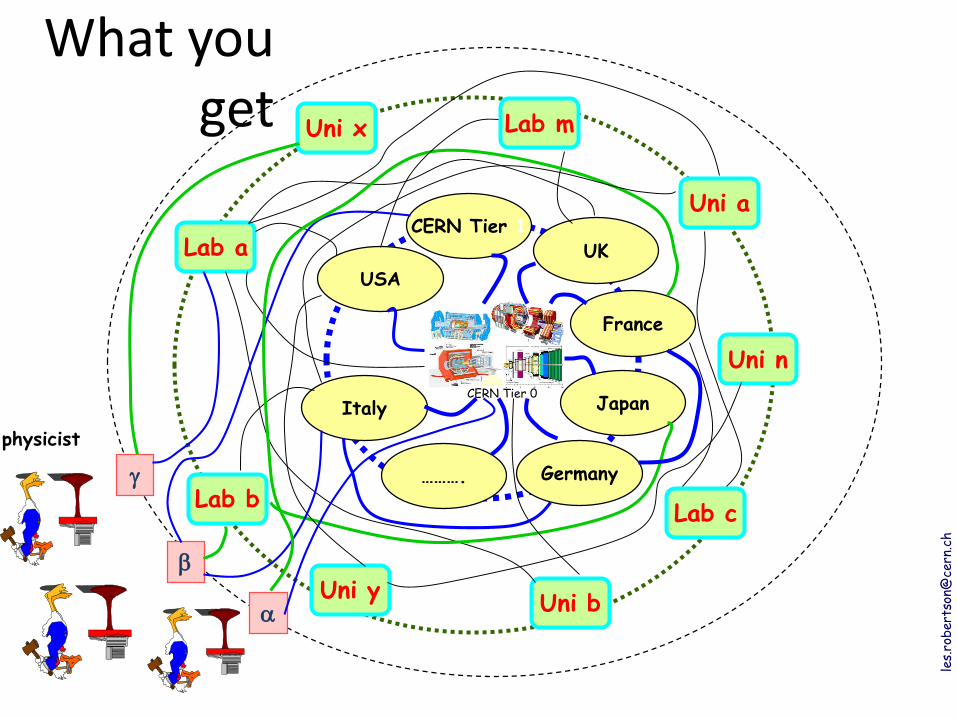
What you get
les.
robert
son@
cern
.ch
physicist
Lab a
Uni a
Lab c
Uni n
Lab m
Lab b
Uni bUni y
Uni x
Germany
USA
UK
France
Italy
……….
CERN Tier 1
JapanCERN Tier 0







![Memy Dawkinsa a memy internetowe - od podstaw [4 miliardy lat w kilku slajdach]](https://static.fdocuments.pl/doc/165x107/54b235b04a7959425d8b45c0/memy-dawkinsa-a-memy-internetowe-od-podstaw-4-miliardy-lat-w-kilku-slajdach.jpg)










