
Eksploracja danych · LUDZKA INTELIGENCJA • Praktyczna: – umiejętność rozwiązywania...
77
Eksploracja danych Adam Pelikant
-
Upload
nguyenkhanh -
Category
Documents
-
view
223 -
download
0
Transcript of Eksploracja danych · LUDZKA INTELIGENCJA • Praktyczna: – umiejętność rozwiązywania...

Eksploracja danych
Adam Pelikant

LUDZKA INTELIGENCJA
• Praktyczna:– umiejętność rozwiązywania konkretnych zagadnień
• Abstrakcyjna:– zdolność operowania symbolami i pojęciami
• Społeczna:– umiejętność zachowania się w grupie
Test Bineta ok. 1904
Iloraz inteligencji (IQ)

SZTUCZNA INTELIGENCJA(ARTIFICIAL INTELLIGENCE)
• Dział informatyki, którego przedmiot to:– badanie reguł rządzących inteligentnymi zachowaniami człowieka
– tworzenie modeli formalnych zachowań człowieka
– tworzenie programów komputerowych symulujących zachowania człowieka
Test Turinga (1950 Alan Turing)
Allen Newell, Herbert Simon (Uniwersytet Carnegie Mellon) John McCarthy (Massachusetts Institute of Technology)
„Konstruowanie maszyn, o których działaniu dałoby się powiedzieć, że są podobne do ludzkich przejawów inteligencji”
ELIZA – program symulujący psychoanalityka, Josepha Weizenbauma 1966 r.
ALICE - nazwa najskuteczniejszego obecnie programu starającego naśladować ludzką konwersację (projekt Open Source - pomysłodawca Richard Wallace)
Nagroda Loebnera - od 1990 dla programu, który skutecznie przejdzie Test Turinga.
Konkurs Loebnera – najlepszy program do konwersacji
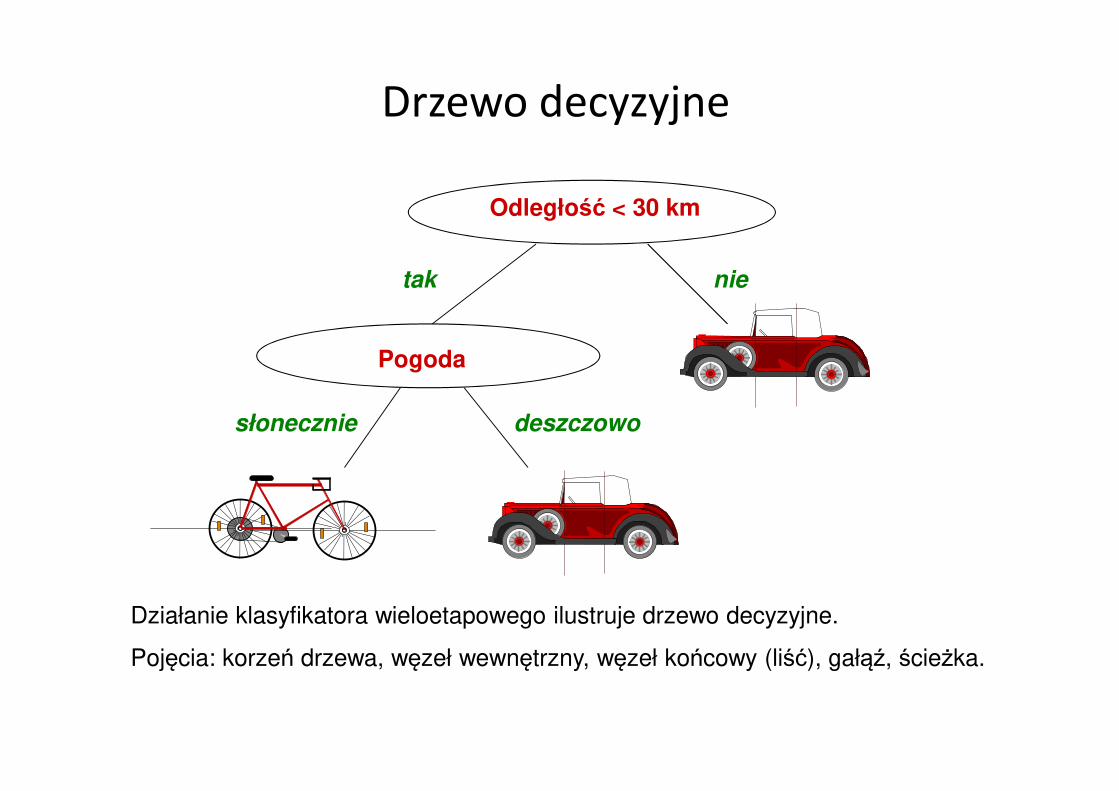
Pogoda
Drzewo decyzyjne
tak nie
Odległość < 30 km
deszczowosłonecznie
Działanie klasyfikatora wieloetapowego ilustruje drzewo decyzyjne.
Pojęcia: korzeń drzewa, węzeł wewnętrzny, węzeł końcowy (liść), gałąź, ścieżka.

Pogoda
Drzewo decyzyjne
tak nie
Odległość < 30 km
deszczowo
Odległość: 8
Pogoda: deszczowo
słonecznie
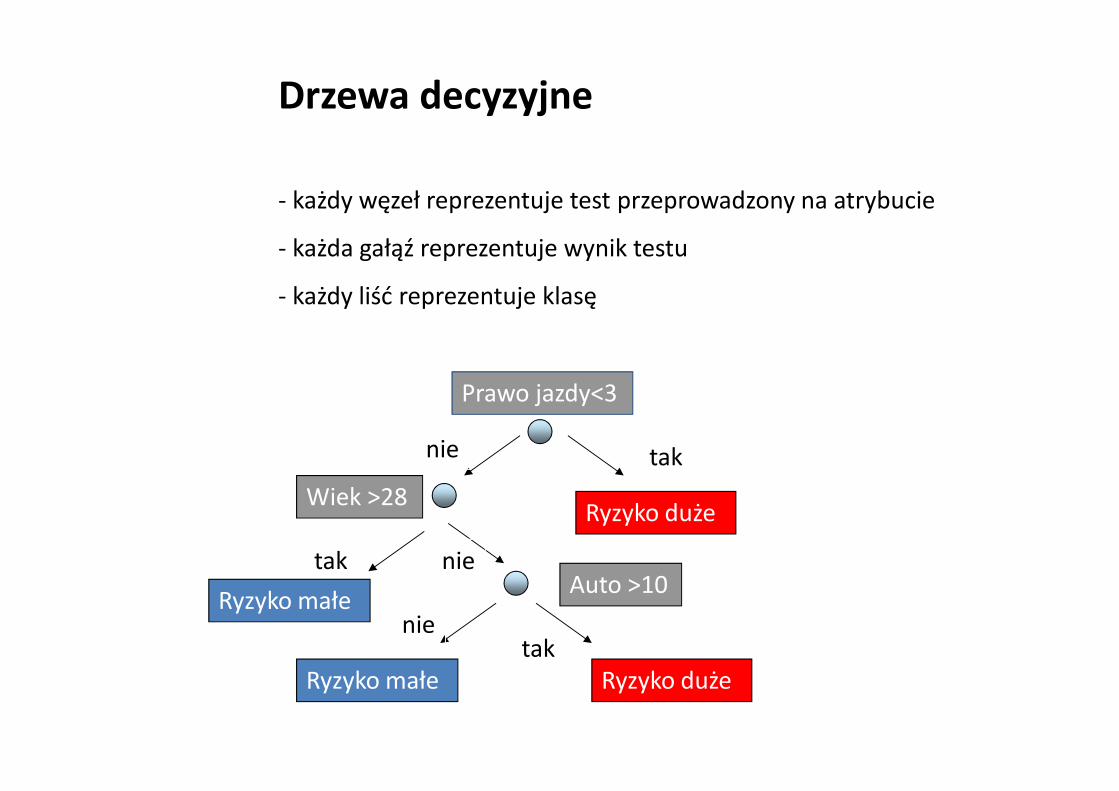
Drzewa decyzyjne
- każdy węzeł reprezentuje test przeprowadzony na atrybucie
- każda gałąź reprezentuje wynik testu
- każdy liść reprezentuje klasę
Prawo jazdy<3
taknie
Wiek >28
Auto >10
Ryzyko duże
tak
takRyzyko duże
nieRyzyko małe
nie
Ryzyko małe

Konstrukcja drzewa decyzyjnego
AA
A
A
B
B
B
BB
B
BB
B
x
y
a2
a1
B
a3
tak nie
y < a1
A
tak nie
x < a2
B
B
B
nietak
x < a1
A
nie
y< a3
tak
AA
A
A
B
B
B
BB
B
BB
B
x
y
a1

Drzewo decyzji: Ogólne => Szczegółowewęzeł - test atrybuturozgałęzienie - wartość atrybutu lub podzbiórliście - przypisane do klas
Testy: podział pojedynczej cechy, lub kombinacjiAttrybut=wartośći lub Attrybut < wartośći
Kryteria: maksymalizacja ilości informacji, maksymalizacja liczby poprawnie podzielonych obiektów, „czystość” węzła
Przycinanie: usuń gałęzie, które zawierają zbyt mało przypadkówprostsze drzewo może lepiej generalizowaćoceń optymalną złożoność na zbiorze walidacyjnym.
Kryterium stopu: osiągnięta dokładność podziałów, zbyt wiele gałęzi.
Drzewa decyzyjne

Wybór atrybutuKtóry atrybut powinien być najpierw?
Ile informacji zawiera dany podział ? (Entropia)Średnia l. bitów do zakodowania dowolnego wektora z S wynosi:
p+ i p− - proporcje w lewej i prawej gałęzi.Zbiór wektorów S
2 2( ) lg lgI S p p p p+ + − −= − −
( , ) ( ) ( ) ( )S S
G S A I S I S I SS S
+ −+ −= − −
Informacja dla czystych węzłów = 0; jest max dla najbardziej pomieszanych.
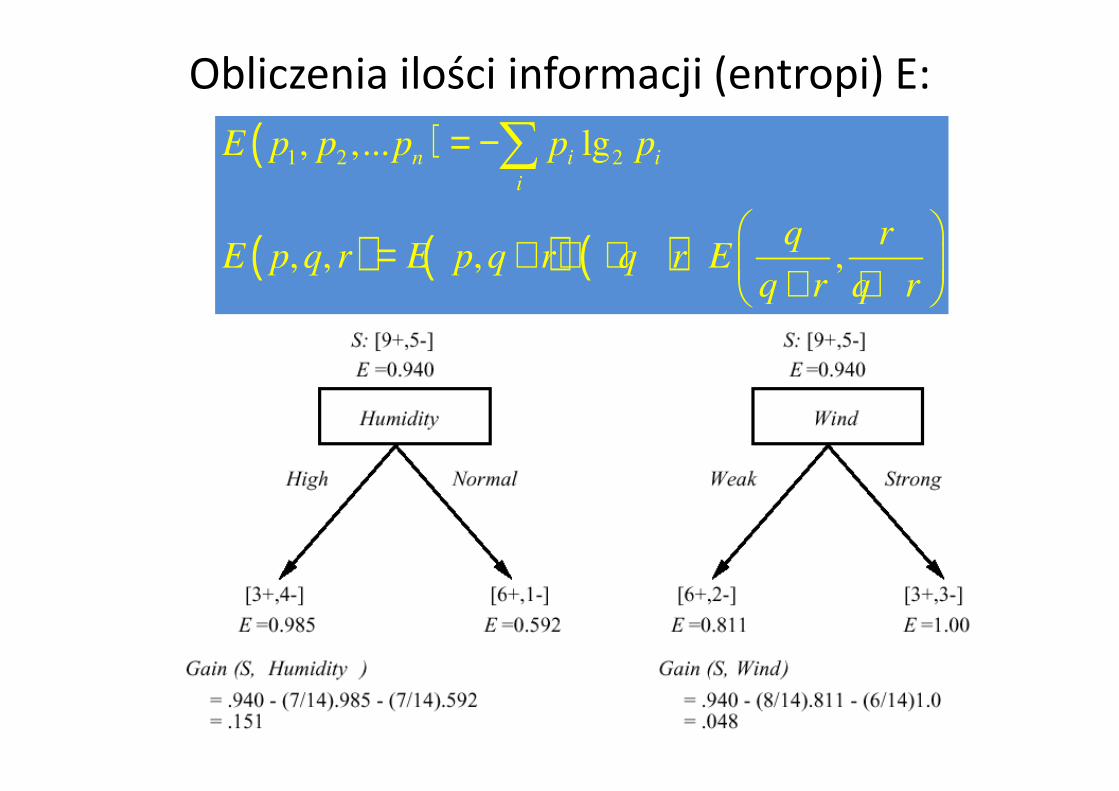
Obliczenia ilości informacji (entropi) E:
( )
( ) ( ) ( )
1 2 2, ,... lg
, , , ,
n i i
i
E p p p p p
q rE p q r E p q r q r E
q r q r
= −
= + + + + +
∑
14 7 7
9 5 3 4 6 10,642857143 0,357143 0,428571429 0,571429 0,857142857 0,142857143
-0,63742992 -1,48543 -1,22239242 -0,80735 -0,22239242 -2,80735492
0,409776378 0,53051 0,523882466 0,461346 0,190622075 0,401050703
0,940286 0,985228 0,591673
0,151835501
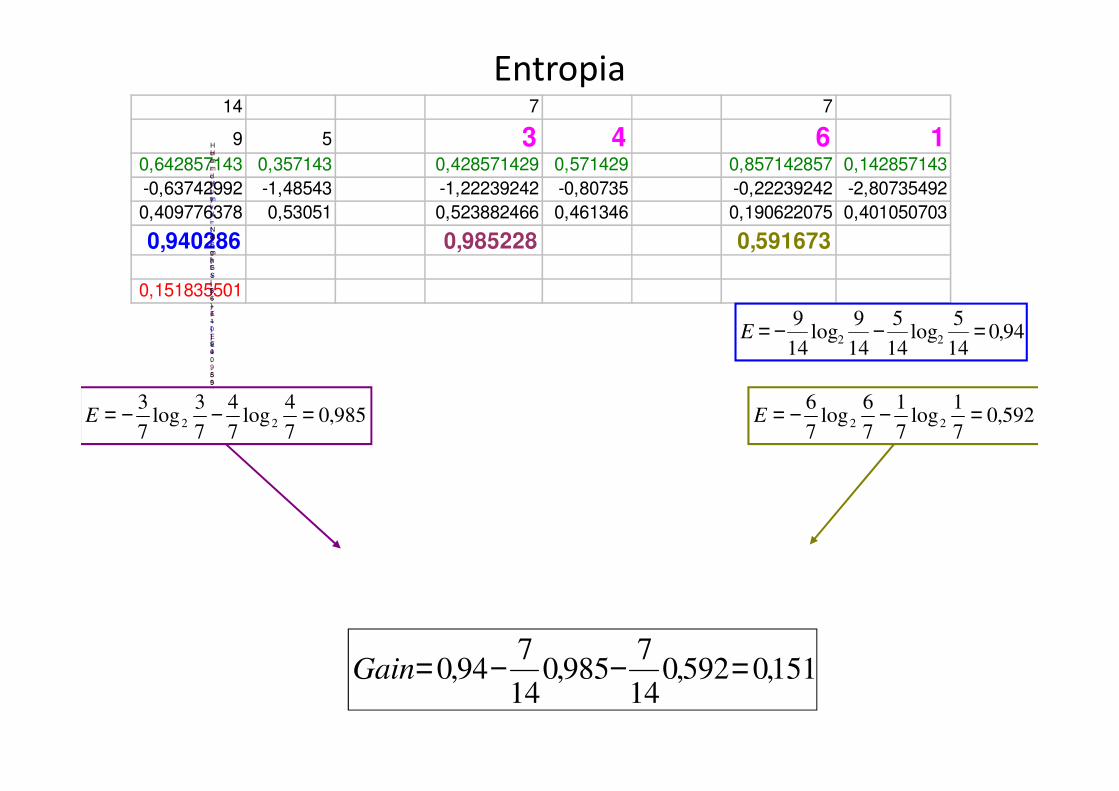
Entropia
HumidityS:[9+,5-]E=0,94
Humidity
=
HighS:[3+,4-]E=0,985
Humidity
=
NormalS:[6+,1-]E=0,592
94,014
5log
14
5
14
9log
14
922 =−−=E
592,07
1log
7
1
7
6log
7
622 =−−=E985,0
7
4log
7
4
7
3log
7
322 =−−=E
151,0592,014
7985,0
14
794,0 =−−=Gain

Tworzenie drzewa
Tworzenie drzewa: szukanie w przestrzeni hipotez.
ID3 - podział w oparciu o zysk informacyjny.
Lepsze mniejsze drzewo.
Dość odporne na szum.
Lokalne minima.

Podział hierarchiczny na hiperprostokąty.
Granice decyzji
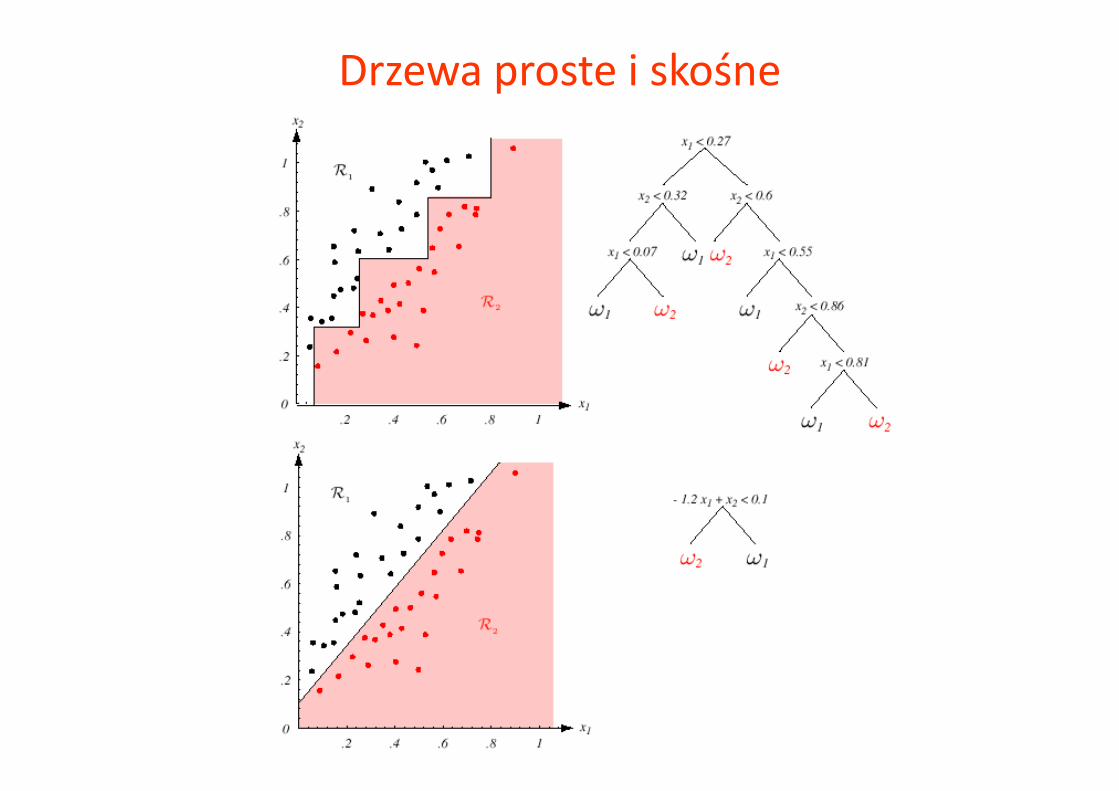
Drzewa proste i skośne
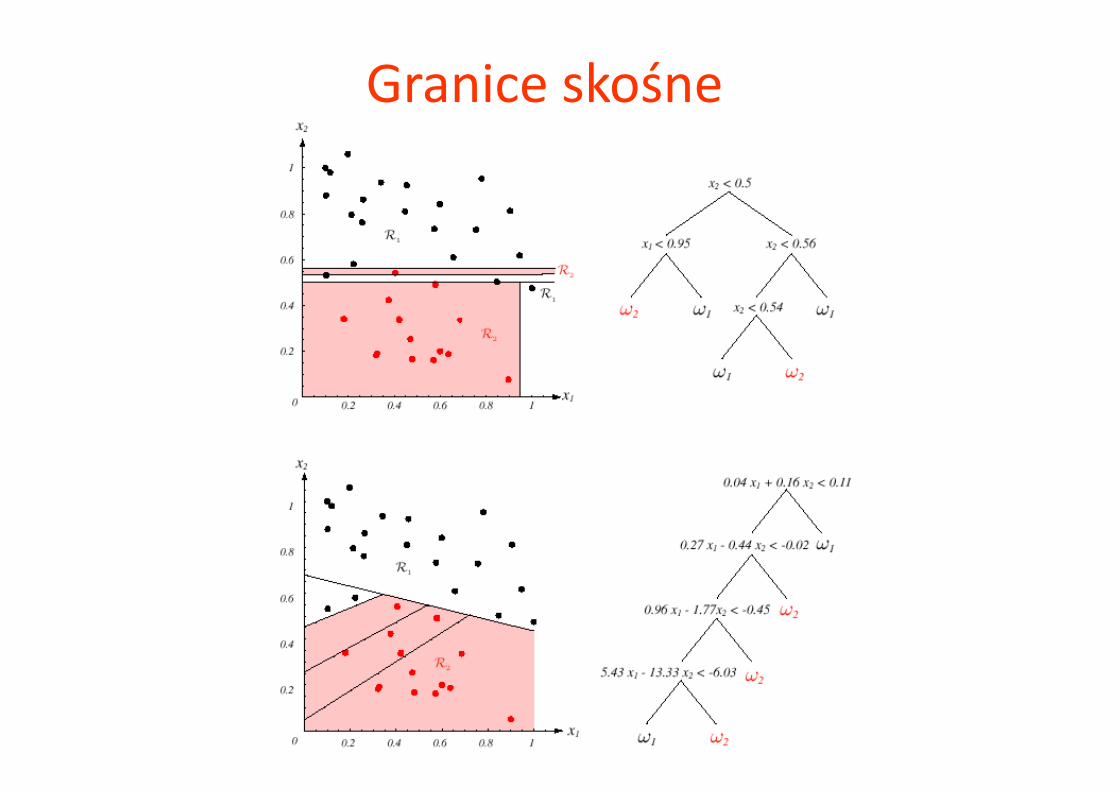
Granice skośne

Czemu preferować prostsze drzewa?
•Mało prostych hipotez, więc mała szansa, że przypadkiem pasują do danych.
•Proste drzewa nie powinny zbytnio dopasować się do danych.
•Przetrenowanie modelu dla zbyt złożonych drzew, zła generalizacja.
Ale: •Dla małych zbiorów o wielu atrybutach można tworzyć
wiele prostych opisów danych.
Brzytwa Ockhama

Zamień DT na reguły i uprość: łatwo ocenić, które reguły można usunąć i optymalizować pozostałe.
DT => reguły

Ciągłe wartości numeryczne w DTPodziel obszary na interwały i traktuje je jak nominalne.
Dla każdego atrybutu A
porządkuj przypadki zgodnie z wartościami tego atrybutu ustal granice przedziałów dla wartości, przy których zmienia
się klasa mająca większość.
Minimalizuje to liczbę błędów w algorytmie 1R.
Przykład: temperatura i jej korelacja z decyzją gracza:
By uniknąć szumu można wprowadzić minimalną liczbę danych/interwał:

Prymitywne metody dyskretyzacji
A. według równej szerokości
yi
yi
B. według równej częstości
Są to metody globalne, bez nauczyciela.

Dyskretyzacja zstępująca – wybór progu
Im wyraźniejsza dominacja pewnych klas, tym mniejsza wartość Ha,próg.
Obliczamy H dla progów wybranych między każdymi dwiema kolejnymi wartościami
atrybutu a i wybieramy próg, dla którego wartość Ha,próg jest najmniejsza.
próga
próga
próga
próga
próga Hm
mH
m
mH >
>≤
≤ +=,
∑≤
≤
≤
≤≤ −=
i
ii
c próga
cpróga
próga
cpróga
prógam
m
m
mH 2log
Ważona entropia zbioru przykładów ze względu na podział zakresu wartości atrybutu
a za pomocą wartości progowej próg:

Dyskretyzacja zstępująca – wybór progu
a
pA
Ha,pA
Ha,pB
pB
p3
Ha,p3
p5
Ha,p5
p7
Ha,p7
p9
Ha,p9
p11
Ha,p11
p13
Ha,p13
Ha,p4
p4
Ha,p6
p6
Ha,p8
p8
Ha,pA0
p10
Ha,p12
p12
Ha,p14
p14
Wybieramy pi, dla którego wartość Ha,pi jest najmniejsza.
a
Ha,p10
p10
Dla dwóch powstałych przedziałów powtarzamy procedurę szukania progu.
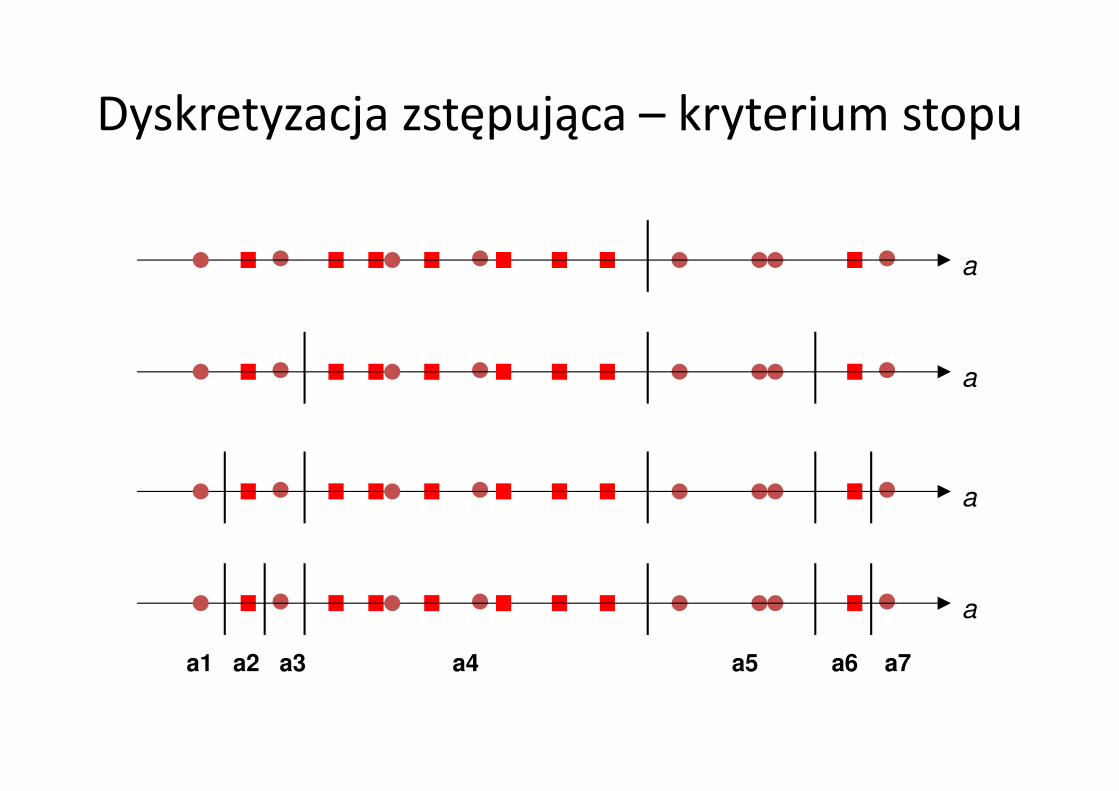
Dyskretyzacja zstępująca – kryterium stopu
a
a
a
a
a1 a2 a3 a4 a5 a6 a7

Dyskretyzacja wstępująca – łączenie przedziałów
∑∑−+−=
i
i
ii
i
i
ii
cc
z
c
z
c
z
cc
z
c
z
c
zzz
e
em
e
em
2
2
22
1
2
112
2,1
)()(χ
21
2111
zz
c
zzz
c
zm
mme
i
i
∪
∪=21
2122
zz
c
zzz
c
zm
mme
i
i
∪
∪=
Statystyka χB określająca różnicę między kandydującymi do połączenia przedziałami
zA i zB ze względu na rozkład klas:
Im bardziej podobny rozkład częstości klas w przedziałach, tym mniejsza wartość χB.
Obliczamy χ2 dla każdej pary sąsiednich przedziałów i łączymy przedziały, dla których wartość χ2 jest najmniejsza.
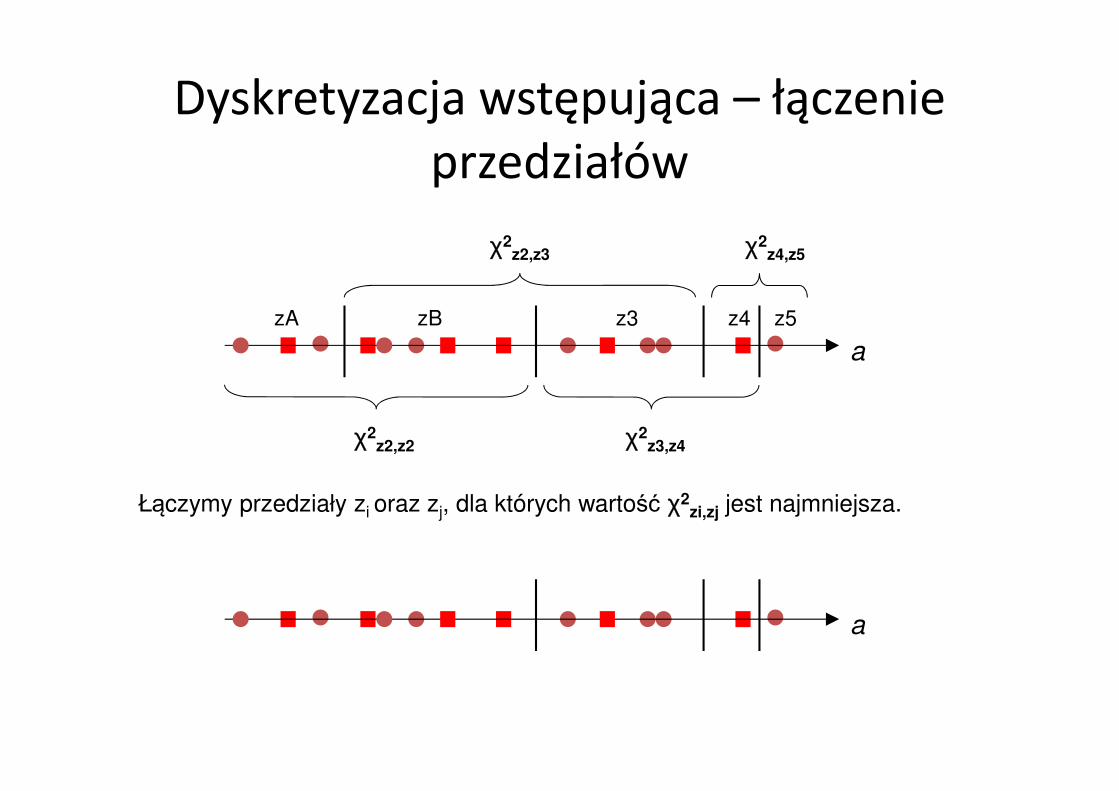
Dyskretyzacja wstępująca – łączenie przedziałów
Łączymy przedziały zi oraz zj, dla których wartość χ2zi,zj jest najmniejsza.
a
zA zB z3 z4 z5
χ2z2,z2
χ2z2,z3
χ2z3,z4
χ2z4,z5
a

CARTClassification and Regression Trees (Breiman 1984).
Kryterium podziału: indeks Gini; w danym węźle pc określa procent wektorów z klasy c; czystość węzła można zmierzyć za pomocą:
Kryterium stopu: MDL, złożoność drzewa + informacja w liściach
2
1
1C C
c d c
c d c
Gini p p p≠ =
= = −∑ ∑
1 max cc
Mi p= −
( ) ( )l leaf
Size Tree I lα∈
+ ∑

SSVKryterium separowalności par danych z różnych klas.
Oddziel maksymalnie dużo par z różnych klas.Jeśli różne podziały dają to samo minimalizuj l. podziałów wewnątrz klasy
Kryterium:
( )
( ) ( )
: ( ) , ciągłe, ,
: ( ) , dyskretne
, , , ,
x D f x s fLS s f D
x D f x s f
RS s f D D LS s f D
∈ <= ∈ ∉
= −
Proste kryterium, różne metody obcinania drzewa, dobre wyniki.
( ) ( ) ( )
( ) ( )( )( ) 2 , , , ,
min , , , , ,
c c
c C
c c
c C
SSV s LS s f D D RS s f D D D
LS s f D D RS s f D D
∈
∈
= ⋅ −
−
∑
∑
I I
I I

Do mechanizmów używanych w systemach OLAP i DSS zaliczająsię:
Reguły asocjacyjne
Np.:
75% reklamowanych w 2002 dysków twardychzawierających „bad sektory” i okresowo zawieszajacychkomputer miało ślady uszkodzeń mechanicznych. Takiedyski stanowiły 0,6% produkcji
Bad sektory ^ wieszanie systemu → uszkodzeniemechaniczne s=0,6 c=75
Mechanizmy wspomagania decyzji

Grupowanie (klasteryzacja)
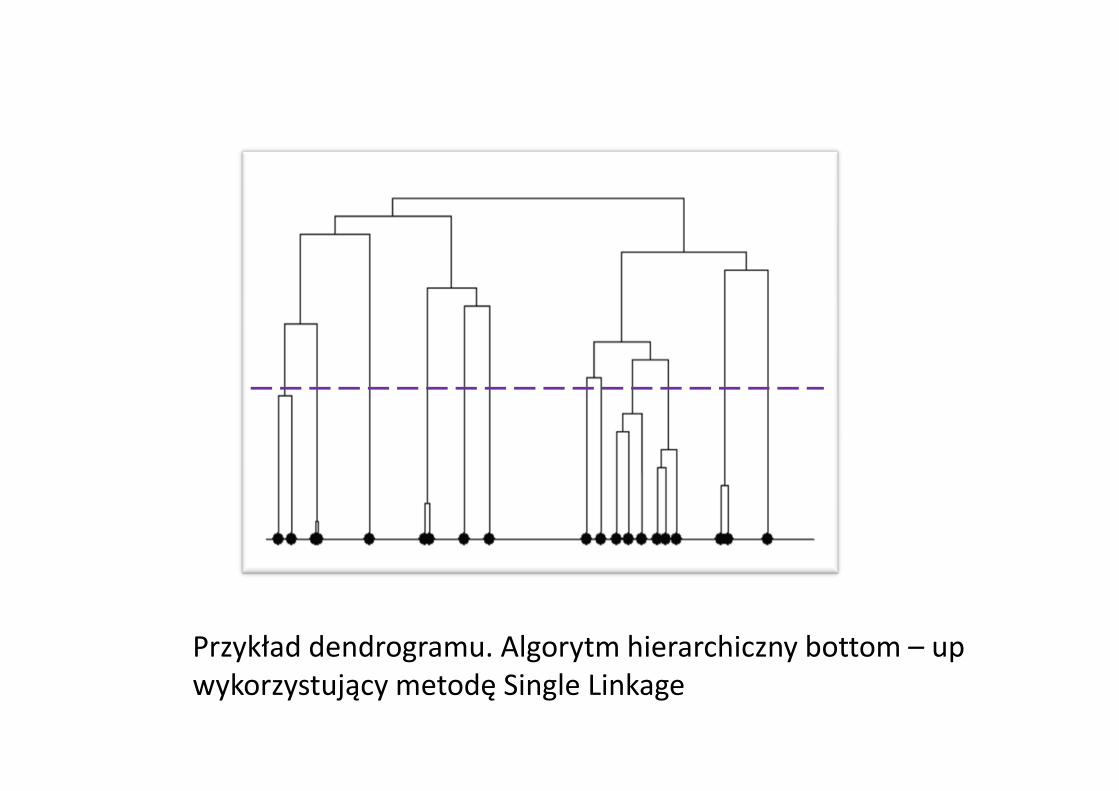
Przykład dendrogramu. Algorytm hierarchiczny bottom – upwykorzystujący metodę Single Linkage

Metody gęstościowe - DBSCAN
Bezpośrednia osiągalność
gęstości
Osiągalność gęstościowa
punkt p jest bezpośrednio osiągalny gęstościowo z punktu q, gdy q jest punktem rdzeniowym oraz p znajduję się w sąsiedztwie punktu q (sąsiedztwo punktu q zawiera co najmniej minPts a p∈ Ns(q)
punkt p jest osiągalny gęstościowo z punktu q, gdy istnieje zbiór punktów p1,...,pn, gdzie p1=p a pn=q. Zbiór taki musi spełniać warunek bezpośredniej osiągalności gęstościowej pomiędzy każdą parą sąsiadujących punktów zbioru

Metody gęstościowe - DBSCAN
Połączenie gęstościowe Przykład realizacji
punkt p jest połączony gęstościowo z punktem q wtedy i tylko wtedy gdy istnieje taki punkt O , że punkty p i q są osiągalne gęstościowo z punktem O.

Algorytmm Fuzzy K-means
Algorytmm Fuzzy K-means należy do grupy nie-hierarchicznych algorytmów grupowania. Jego istotą jest początkowy losowy wybór położenia środków grup. W kolejnych krokach iteracji po obliczeniu funkcji przynależności poszczególnych punktów od środków grup są one każdorazowo przeliczane. Takie postępowanie powoduje, że środki grup "wędrują" do swoich prawidłowych położeń.
gdzie
jest prawdopodobieństwem warunkowym przynależności j-go elementu do i-tej grupy,b - parametr, którego wartość musi być różna od 1, najczęściej jest przyjmowana jako 2.Funkcja przynależności jest normalizowana według:
( )
( )∑
∑
=
==n
j
b
ji
n
j
j
b
ji
j
xp
xxp
1
1
ω
ωµ
( )ji xp ω
( )∑=
=c
j
ji xp1
1ωgdzie j=1,2…n

kmeans clustering
• Przykład klasteryzacji algorytmem kmeans
m1
m2
m1
m2
m1
m2
m1
m2
m1
m2
m1
m2
m1
m2
K=2
m1
m2
m3
m1
m2
m3
m1m2
m3
m1m2
m3
m1m2
m3
m1m2
m3
m1
m2
m3
K=3

Algorytmm Fuzzy K-means
Przynależność elementu do każdej z grup
obliczane jest według:
gdzie
jest odległością punktu xj od środka grupy µi, natomiast b jest parametrem, którego wartość musi być różna od 1, najczęściej jest przyjmowana jako 2.
( )ji xp ω
( )∑
=
−
−
=c
r
b
rj
b
ij
ji
d
dxp
1
1
1
1
1
1
1
ω
22
jjij xd µ−=

Algorytmm Fuzzy K-means
Schemat działania algorytmu K-means można przedstawić w kilku punktach:
1. Losowe wyznaczenie środków poszukiwanych grup,
2. Obliczenie odległości punktów od środków grup,
3. Obliczenie wartości funkcji przynależności wszystkich elementów ,
4. Obliczenie środków grup µi
Jeżeli:
brak zmian w µi oraz - zwróć
w przeciwnym wypadku skok do p.2.
( )ji xp ω
( )ji xp ωc
µµµ ,,,21K

Algorytm Fuzzy C-means
Algorytm Fuzzy C-means należy do grupy nie-hierarchicznych algorytmówgrupowania. Jego istotą jest początkowe usytuowanie położenia środków grupw środkowej części rozpatrywanej przestrzeni.
W kolejnych krokach iteracji po obliczeniu funkcji przynależności poszczególnychpunktów od środków grup są one każdorazowo przeliczane. Takie postępowaniepowoduje, że środki grup "wędrują" do swoich prawidłowych położeń.
Mając do obliczeń skończony zbiór elementów X=x1,...,xN) oraz liczbę C środkówgrup, wyznaczamy N elementów dla C grup i przedstawiamy w postaci macierzyprzynależności U=[uik]. Z k=1,...,N , i=1,...,C oraz uik wyraża rozmytąprzynależność elementu vk do środka grupy vi.

Algorytm Fuzzy C-means
Środki zgrupowań oraz przynależność elementów wyznaczamy z zależności:
gdzie 1 ≤ i ≤ C
m - parametr fuzyfikacji,
dik - miara odległości pomiędzy środkiem vi oraz elementem xk, która w tymwypadku jest odległością Euklidesową.
∑=
−
=c
j
m
jk
ik
ik
d
d
u
1
1
2
1
( )
( )∑
∑
=
==n
k
k
m
ik
n
k
m
ik
i
xu
u
1
1ν

Algorytm Fuzzy C-means
Schemat działania algorytmu K-means można przedstawić w kilku punktach:
1. Ustalanie liczby C środków grup. Inicjalizacja macierzy przynależności,
2. Obliczenie C środków grup vi zgodnie z aktualna macierzą przynależności,
3. Przeliczenie do zgodnie z aktualnymi środkami grup vi,
Jeżeli:
- zwróć macierz przynależności
w przeciwnym wypadku skok do p.2.
( )0U
( )lU
( )0U( )1+lU
( ) ( ) ε<− +1ll UU

Metoda górskaPierwszy etap metody górskiej polega na stworzeniu dyskretnej przestrzeni Xx Y przez podział X i Y za pomocą odpowiednio r1 i r2 równomiernieoddalonych od siebie linii. Przecięcia tych linii siatkowych, zwane węzłami,tworzą nasz zbiór potencjalnych środków grupowania. Oznaczamy element Nprzez Nij, (Xi,Yj).
( )∑
=
−=q
k
ONd
ijkijeNM
1
),()(
α
dla każdego punktu Nij, (Xi,Yj) w zbiorze N funkcję górską określa
zależność
przy czym Ok jest k-tym punktem danych (xk,yk), α jest stałą dodatnią i d(Nij,Ok)
jest miarą odległości miedzy Nij i Ok. Najczęściej, ale nie koniecznie tą miarą
jest miara Euklidesowa
( ) ( ) ( )22, kjkikij yYxXONd −+−=

Metoda górskaTrzeci etap metody górskiej polega na wykorzystaniu funkcji górskiej dotworzenia środków grupowania. Niech węzeł N1* będzie punktem siatki omaksymalnej sumie całkowitej, szczytem funkcji górskiej. Jego wygranąbędziemy oznaczali M1*=Max[M(Nij)]. Jeżeli jest więcej niż jedno maksimum, towybieramy losowo jeden z nich. Wyróżniamy ten węzeł jako pierwszy środekgrupowania i oznaczamy jego współrzędne N1*=(x1*,y1*). Aby otrzymaćnastępny środek grupowania, musimy wyeliminować wpływ dopiero cozidentyfikowanego środka, ponieważ zazwyczaj ten szczyt jest otoczony przezpewną liczbę punktów siatki, które również mają wysokie wygrane. W tym celumusimy usunąć wpływ szczytu będącego ostatnio zidentyfikowanym środkiemgrupowania i skorygować funkcję górską. Dokładniej mówiąc, tworzymyskorygowaną funkcję górską M2, określoną na N, taką że
( )),(*
112
*1)()( ijNNd
ijij eMNMNMβ−−=
przy czym M1 jest pierwotną funkcją górską M, β jest stałą dodatnią, N1* i
M1* są to położenie i wygrana środka grupowania ostatnio
zidentyfikowanego i d=(N1*,Nij) jest miarą odległości.

Metoda górska• Teraz użyjemy skorygowanej funkcji górskiej M2 do znalezienia następnego
środka grupowania, określając jego położenie N2* i wygraną M2* owartości maksymalnej. N2* staje się nowym drugim środkiem grupowania.Następnie korygujemy naszą funkcję, aby otrzymać M3
• Mówiąc ogólnie, startując od skorygowanej funkcji górskiej Mk, którą otrzymujemy w rezultacie znalezienia (k-1)-szego środka grupowania, postępujemy następująco:
1. Znajdź Mk*=Max[(Mk(Nij)]
2. Oznacz k-ty środek grupowania w Nk* - położenia maksymalnego węzła, znalezionego w punkcie 1.
3. Utwórz skorygowaną funkcje górską Mk+1 jako
4. Jeżeli:- M*m+1d - zakończ proces- w przeciwnym wypadku skok do punktu 2.
( )),(*
1
*
)()( ijk NNd
kijkijk eMNMNMβ−
+ −=

Metoda górska
• Ważną cechą metody funkcji górskiej jest brak wymagania założenia liczbyśrodków grupowania. Metoda ta wyznacza m pierwszych środków, którespełniają kryterium zakończenia obliczeń, począwszy od najważniejszych, któremają maksymalne wartości funkcji górskiej w węzłach N1*,N2*,...,Nm*.
• m - parametr fuzyfikacji,
• dik - miara odległości pomiędzy środkiem vi oraz elementem xk, która w tymwypadku jest odległością Euklidesową.
∑=
−
=c
j
m
jk
ik
ik
d
d
u
1
1
2
1

Odległości między grupami
Pojedyncze wiązanie (Single Linkage) Pełne wiązanie (Complete Linkage)
Średnie wiązanie (Avarage Linkage)

Miary odległościOdległość Minkowskiego
Odległość Miejska (Manhattan) (n=1)
Odległość Euklidesowa (n=2)
Odległość Czebyszewa (n→∞)
Odległość Canberra
Odległość kątowa (kosinusowa)
( ) nd
k
n
kjkijin xxxxd
1
1
,,),(
−= ∑=
∑=
−=d
k
kjkiji xxxxd1
,,1 ),(
( ) 2
1
1
2
,,2 ),(
−= ∑=
d
k
kjkiji xxxxd
nd
k
n
kjkim
ji xxxxd
1
1
,,lim),(
−= ∑=∞→∞
dodatniesąxorazxxx
xxxxd kjki
d
k kjki
kjki
ji ,,
1 ,,
,,
1 ,),( ∑= +
−=
2
1
1
2
,
1
2
,
1
,,
1 ),(
=
∑∑
∑
==
=
d
k
kj
d
k
ki
d
k
kjki
ji
xx
xx
xxd

Kryteria oceny jakości grupowania
• Graficzna ocena postaci wyników procesu grupowania (2d, 3d)
• Na podstawie ilorazu średniej odległości elementów w grupie i średniej odległości grup
)),((
)),((1
11
qp
L
k
ji
vvdmean
vvdmeann
e∑
==

Kryteria oceny jakości grupowania
• Na podstawie funkcji oceny grupowania wykorzystującej funkcję oceny klastra.
Zwykle jako funkcji oceny proponowanego grupowania używa się sumy miar odległości przykładów od klastrów, do których te przykłady zostały zaklasyfikowane

Kryteria oceny jakości grupowania
• Gdzie f(x,c) jest wybraną funkcją odległości
• u(x,c) określa stopień przynależności przykładu x do klastra c.
• Dla klastrów twardych
• Dla klastrów rozmytych
∑∑∈ ∈
⋅=Cc Xx
cxucxfCe ),(),()(
1,0),( ∈cxu
]1,0[),( ∈cxu

Kryteria oceny jakości grupowania
• C1,C2 proponowane grupowania zbioru danych.
• Bayesowskie Kryterium Informacji (Bayesian
Information Criterion, BIC)
)()( 21 CeCe <21 CC >
∑∑∈ ∈
⋅=Cc Xx
cxucxfCe ),(),()(

Bayesowskie Kryterium Informacji
v(C) - liczba parametrów modelu C,
N - wielkość zbioru danych.
Funkcja porównuje zysk, jaki uzyskujemy zezwiększonej liczby klastrów, z wiążącym się z tymwzrostem skomplikowania opisu modelu.
NCvCeCBIC log)()(2)( ⋅+⋅−=

Co jest dobrą granicą decyzji?
• Rozważmy problem klasyfikacji dla dwóch separowanych liniowo klas
• Możemy znaleźć wiele możliwych podziałów!– Różne algorytmy dają
różne podziały Czy wszystkie granice decyzji są równie dobre?
klasa 1
klasa 2

Przykłady złych granic decyzji
klasa 1
klasa 2
klasa 1
klasa 2
Kodujemy klasy dwoma wartościami 1 oraz -1
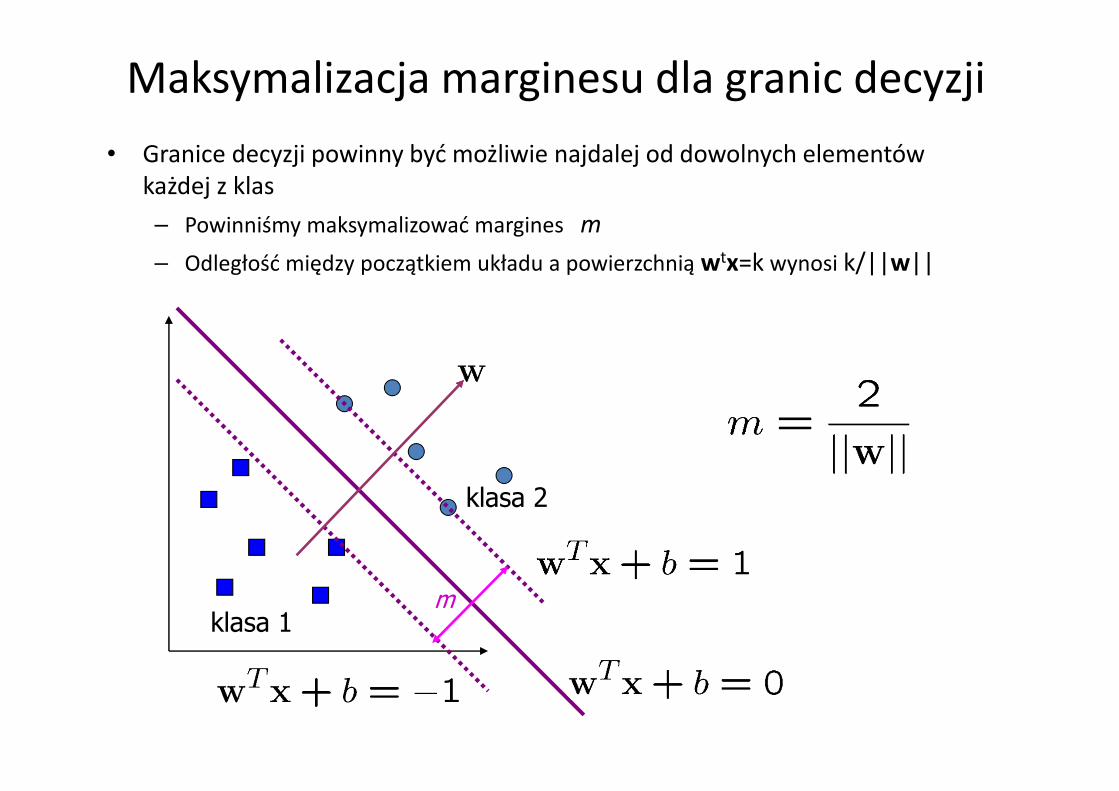
Maksymalizacja marginesu dla granic decyzji
• Granice decyzji powinny być możliwie najdalej od dowolnych elementów każdej z klas
– Powinniśmy maksymalizować margines m
– Odległość między początkiem układu a powierzchnią wtx=k wynosi k/||w||
klasa 1
klasa 2
m
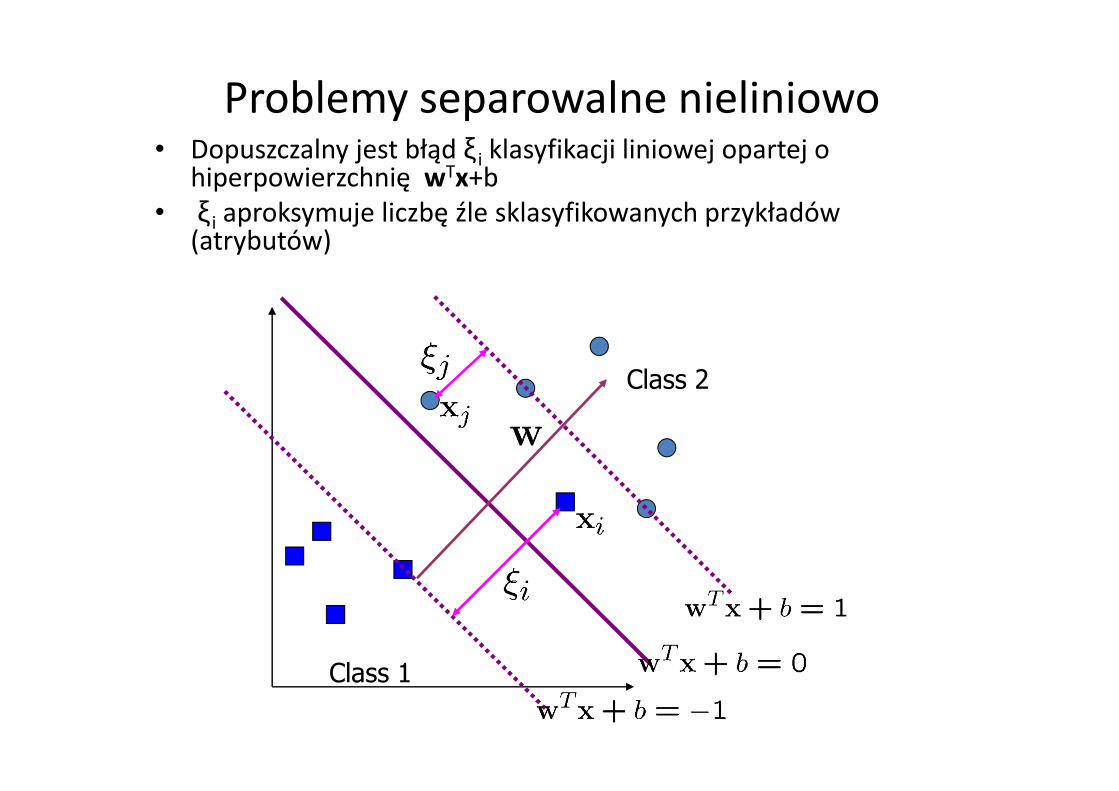
Problemy separowalne nieliniowo• Dopuszczalny jest błąd ξi klasyfikacji liniowej opartej o
hiperpowierzchnię wTx+b• ξi aproksymuje liczbę źle sklasyfikowanych przykładów
(atrybutów)
Class 1
Class 2

Przekształcenie danych do przestrzeni o większej liczbie wymiarów – funkcje jądra (kernel)
• Obliczenia w przestrzeni przekształconej są bardziej kosztowne ponieważ ma więcej wymiarów
• Stosowanie funkcji jądra (kernel) jest wielokrotnie jedynym rozwiązaniem
φ( )
φ( )
φ( )φ( )φ( )
φ( )
φ( )φ( )
φ(.)φ( )
φ( )
φ( )
φ( )φ( )
φ( )
φ( )
φ( )φ( )
φ( )
Przestrzeń przekształcona
Ma z reguły większą ilości wymiarów
Przestrzeń wyjściowa
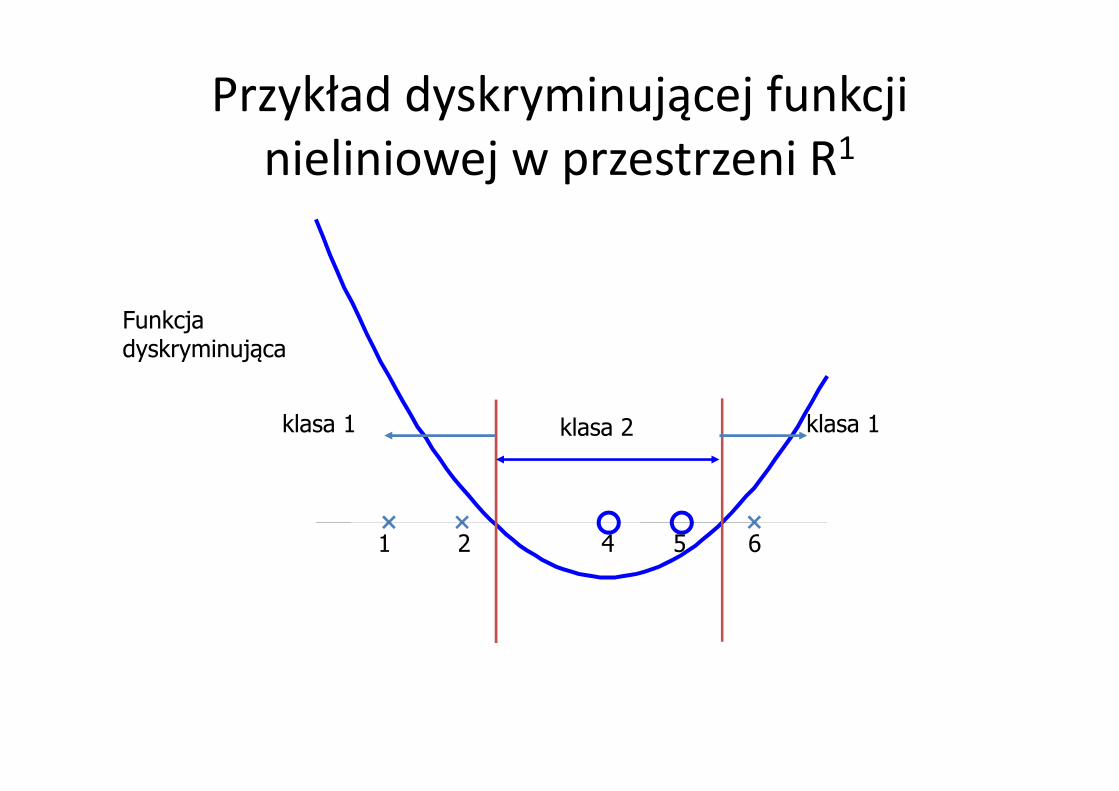
Przykład dyskryminującej funkcji nieliniowej w przestrzeni R1
Funkcja dyskryminująca
1 2 4 5 6
klasa 2 klasa 1klasa 1

Twierdzenie Thomasa Bayesa (1702-1761)
Klasyfikator Bayesa
Niech: Ω – przestrzeń zdarzeń elementarnych, d i h – zdarzenia ztej przestrzeni:
Ω⊆∀ hd , .0)(,0)( >> hPdP
Wtedy prawdopodobieństwo warunkowe zajścia zdarzenia h,pod warunkiem występowania zdarzenia d wynosi:
)(
)()|()|(
dP
hPhdPdhP
⋅=
d – objaw
h – hipoteza

Twój współlokator, który jest trochę próżny, stara się Cię przekonać, że za pieniądze nie można kupić szczęścia, powołując się na badania wykonane na Harvardzie, które pokazują, że tylko 10% osób szczęśliwych stanowią bogacze.Po przemyśleniu sprawy, okazuje się że ta informacja
statystyczna nie jest istotna. To, co naprawdę chcesz wiedzieć to, jaki procent bogatych ludzi jest szczęśliwy. To dałoby lepszy obraz tego, czy stanie się bogatym może uczynić cię szczęśliwym.Twierdzenie Bayesa mówi jak obliczać, odwrócone statystyki za pomocą dwóch dodatkowych informacji:• Procent ogólnej populacji ludzi, którzy są szczęśliwi• Procent populacji ogólnej ludzi, którzy są bogaci
Paradoks ????

Podstawową ideą twierdzenia Bayesa jest odwrócenie statystyki za pomocą współczynników. Mówi ono, że część ludzi bogatych, którzy są szczęśliwi stanowi część ludzi szczęśliwych ludzi, którzy są bogaci, razy ułamek którego licznikiem jest procent ludzi szczęśliwych, a mianownik procent ludzi bogatych. Dlatego, jeżeli• 40% ludzi jest szczęśliwych i• 5% ludzi jest bogatych,A badania z Harvard są poprawne, to procent ludzi bogatych, którzy są szczęśliwi wynosi:
10% ∙%
%= 80%
Dlatego przeważająca większość ludzi bogatych jest szczęśliwychZ drugiej strony liczba ludzi nie będących bogatymi, którzy są szczęśliwi wynosi
10% ∙%
%≈ 4,2%
I to wydaje się zgodne z naszym doświadczeniem
Paradoks ????

Klasyfikator Bayesa
Diagnozowanie w tym modelu polega na znalezieniu zbioru hipotez h ⊆ Hzwanych diagnozą, który najbardziej odpowiada zbiorowi zaobserwowanychsymptomów d ⊆ D. Jeżeli zaobserwowany został zbiór symptomów d ⊆ D,można policzyć prawdopodobieństwo warunkowe P(h|d) dla każdej diagnozy(podzbioru h ⊆ H) i wskazać tę diagnozę, dla której P(h|d) jest największe.Prawdopodobieństwo P(h|d) liczy się zgodnie z twierdzeniem Bayes’a:
,)()|()()|(
)()|()|(
hPhdPhPhdP
hPhdPdhP
¬⋅¬+⋅⋅=
gdzie: P(d) zostało zastąpione wzorem na prawdopodobieństwo całkowite
Model 1 – ogólny bez dodatkowych założeń do hipotez
∑=
=n
i
ii hdPhPdP1
)|()()(
)()|()()|()( hPhdPhPhdPdP ¬⋅¬+⋅=dla i=2

Klasyfikator Bayesa
Przy danych Ω i P dla 1,,1, ≥=Ω⊆ nnihi L
takich, że 0)( >∀ ii hPh
- hi są wzajemnie wykluczające się,- hi są wspólnie wyczerpujące,
oraz
0)( >Ω⊆ dPd
, zachodzi:
∑=
⋅
⋅=n
j
jj
iii
hPhdP
hPhdPdhP
1
)()|(
)()|()|(
njij, ih h ji ≤≤≠=∩ ,1,0
Un
i
ih1=
Ω=
Model 2 – dodatkowe założenia co do hipotez

Klasyfikator Bayesa
Przy danych Ω i P dla 1,,1, ≥=Ω⊆ nnihi L
takich, że 0)( >∀ ii hPh
- hi są wzajemnie wykluczające się,- hi są wspólnie wyczerpujące,
oraz
njij, ih h ji ≤≤≠=∩ ,1,0
Un
i
ih1=
Ω=
Model 3 ≡ naiwny klasyfikator Bayesa – dodatkowe założenia co do diagnoz
Ω⊆kjj dd ,...,
1, gdzie 1 ,1,,...,1,...,1 ≥≤≤⊆ mmkmjj k
kjj dd ,...,1
są niezależne warunkowo względem każdej hipotezy hi, zachodzi:
∑=
⋅⋅⋅
⋅⋅⋅=∩∩
n
l
lljlj
iijij
jji
hPhdPhdP
hPhdPhdPddhP
k
k
k
1
)()|(...)|(
)()|(...)|()...|(
1
1
1
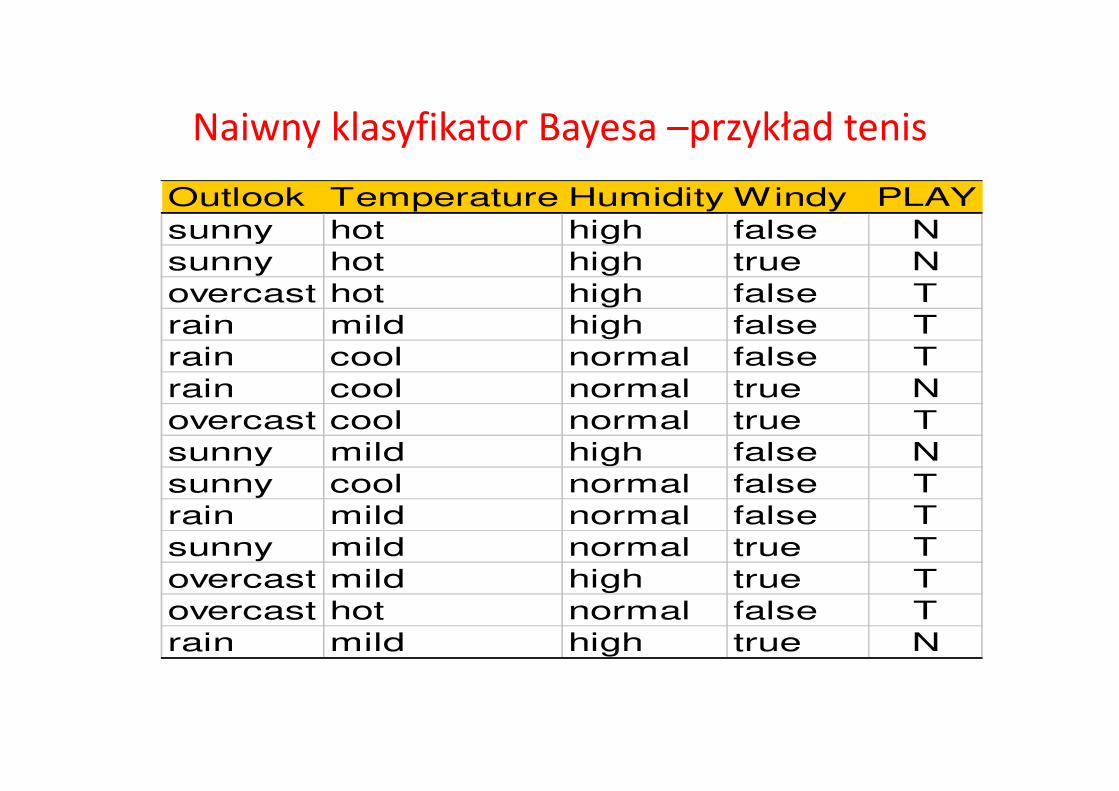
Naiwny klasyfikator Bayesa –przykład tenis
Outlook Temperature Humidity Windy PLAY
sunny hot high false N
sunny hot high true N
overcast hot high false T
rain mild high false T
rain cool normal false T
rain cool normal true N
overcast cool normal true T
sunny mild high false N
sunny cool normal false T
rain mild normal false T
sunny mild normal true T
overcast mild high true T
overcast hot normal false T
rain mild high true N
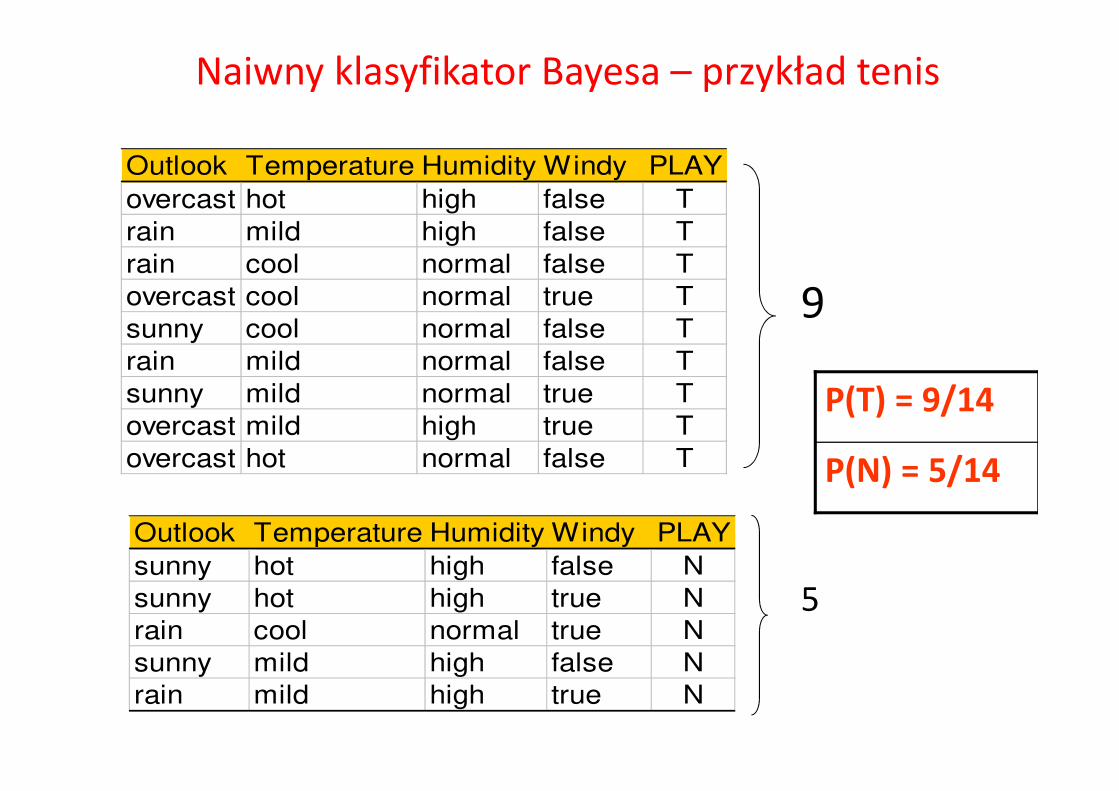
Naiwny klasyfikator Bayesa – przykład tenis
Outlook Temperature Humidity Windy PLAY
sunny hot high false N
sunny hot high true N
rain cool normal true N
sunny mild high false N
rain mild high true N
Outlook Temperature Humidity Windy PLAY
overcast hot high false T
rain mild high false T
rain cool normal false T
overcast cool normal true T
sunny cool normal false T
rain mild normal false T
sunny mild normal true T
overcast mild high true T
overcast hot normal false T
9
5
P(N) = 5/14
P(T) = 9/14

Przykład - tenis : estymacja prawdopodobieństwa warunkowego P(xi|Cj)
Outlook Temperature Humidity Windy PLAY
sunny hot high false N
sunny hot high true N
overcast hot high false T
rain mild high false T
rain cool normal false T
rain cool normal true N
overcast cool normal true T
sunny mild high false N
sunny cool normal false T
rain mild normal false T
sunny mild normal true T
overcast mild high true T
overcast hot normal false T
rain mild high true N
P(true|N) = 3/5P(true|T) = 3/9
P(false|N) = 2/5P(false|T) = 6/9
P(high|N) = 4/5P(high|T) = 3/9
P(normal|N) = 2/5P(normal|T) = 6/9
P(hot|N) = 2/5P(hot|T) = 2/9
P(mild|N) = 2/5P(mild|T) = 4/9
P(cool|N) = 1/5P(cool|T) = 3/9
P(rain|N) = 2/5P(rain|T) = 3/9
P(overcast|N) = 0P(overcast|T) = 4/9
P(sunny|N) = 3/5P(sunny|T) = 2/9
WINDY
HUMIDITY
TEMPERATURE
OUTLOOK
P(N) = 5/14
P(T) = 9/14

Naiwny klasyfikator Bayesa – przykład tenis
Mając dany zbiór treningowy możemy wyznaczyć prawdopodobieństwa warunkowe
Outlook T N Humidity T N
sunny 2/9 3/5 high 3/9 4/5
overcast 4/9 0 normal 6/9 1/5
rain 3/9 2/5
Tempreature Windy
hot 2/9 2/5 true 3/9 3/5
mild 4/9 2/5 false 6/9 2/5
cool 3/9 1/5
P(N) = 5/14
P(T) = 9/14

Naiwny klasyfikator Bayesa – przykład tenis
Problem klasyfikacji jest sformułowany jako prawdopodobieńsktwo a-posteriori :
P(C|X) = prawdopodobieństwo, że testowa krotkaX=<x1,…,xk> jest klasy C.
To znaczy P(class=N | outlook=sunny, windy=true,…)
Przypisz X do klasy C wtedy gdy P(C|X) jest maksymalne
Założenie naiwnego klasyfikatora: niezależność atrybutów
P(x1,…,xk|C) ~ P(x1|C)·…·P(xk|C)

Naiwny klasyfikator Bayesa – przykład tenis
• Aby zaklasyfikować nową krotkę X o atrybutach :– outlook = sunny
– temperature = cool
– humidity = high
– windy = false
P (T|X) =
P (T) ·P(sunny|T) ·P (cool|T) · P (high|T) ·P (false|T) = 9/14· 2/9 · 3/9 · 3/9 · 6/9 = 0.01
P (N|X) =
P (N) ·P (sunny|N) ·Pr(cool|N) · P (high|N) ·P (false|N) = 5/14 · 3/5 · 1/5 · 4/5 · 2/5 = 0.013
Tak więc krotka X należy do klasy N

Inna krotkaX (outlook, temperature, humidity, windy) = <rain, hot, high, false>
P(X|T)·P(T) = P(rain|T)·P(hot|T)·P(high|T)·P(false|T)·P(T) = 3/9·2/9·3/9·6/9·9/14 ≅ 0.011
P(X|N)·P(N) = P(rain|N)·P(hot|N)·P(high|N)·P(false|N)·P(N) = 2/5·2/5·4/5·2/5·5/14 ≅ 0.018
Krotka X jest zakwalifikowana do klasy N
Naiwny klasyfikator Bayesa – przykład tenis

1% kobiet w wieku lat czterdziestu, które uczestniczą w rutynowych badań przesiewowych ma raka piersi. Dla 80% kobiet z rakiem piersi mammografia dała wynik pozytywny, a dla 9.6% kobiet bez raka piersi mammografia dała również wynik pozytywny. Kobieta w tym wieku miał pozytywną mammografię w rutynowych badaniach przesiewowych. Jakie jest prawdopodobieństwo, że ma raka piersi?
Pozytywna mammografia - T Rak - C
P(C|T)=P(T|C)*P(C)/P(T)
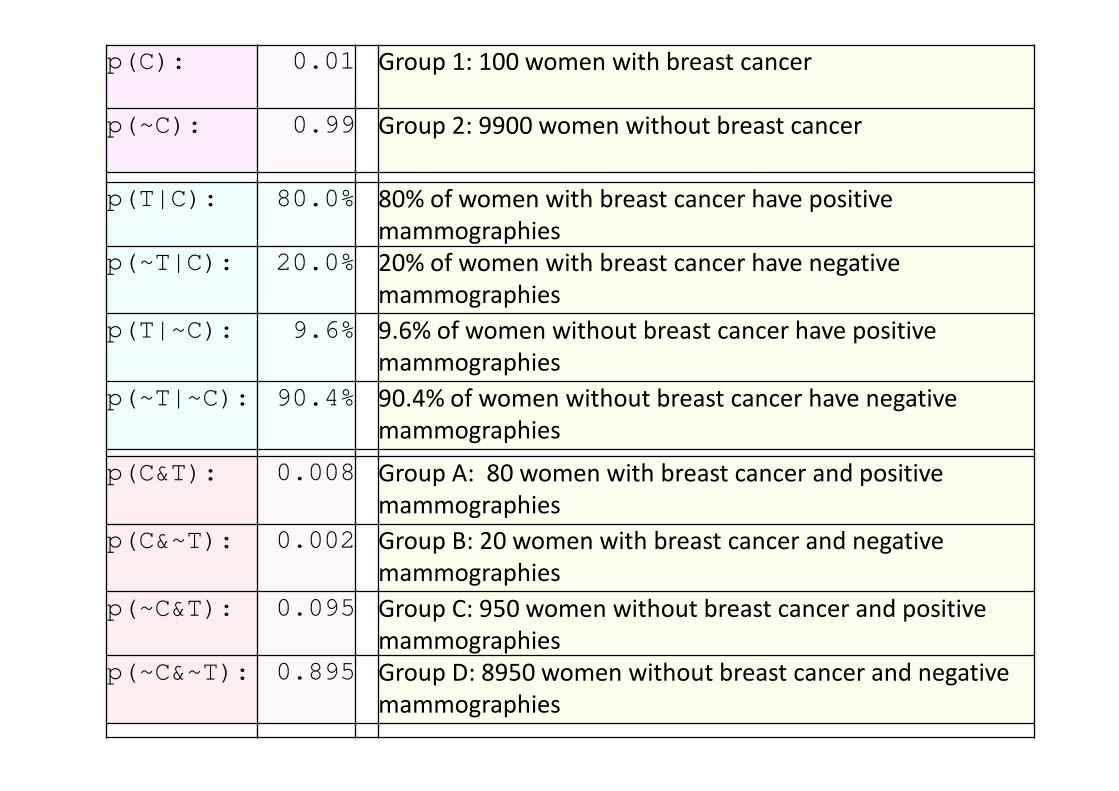
p(C): 0.01 Group 1: 100 women with breast cancer
p(~C): 0.99 Group 2: 9900 women without breast cancer
p(T|C): 80.0% 80% of women with breast cancer have positive mammographies
p(~T|C): 20.0% 20% of women with breast cancer have negative mammographies
p(T|~C): 9.6% 9.6% of women without breast cancer have positive mammographies
p(~T|~C): 90.4% 90.4% of women without breast cancer have negative mammographies
p(C&T): 0.008 Group A: 80 women with breast cancer and positive mammographies
p(C&~T): 0.002 Group B: 20 women with breast cancer and negative mammographies
p(~C&T): 0.095 Group C: 950 women without breast cancer and positive mammographies
p(~C&~T): 0.895 Group D: 8950 women without breast cancer and negative mammographies
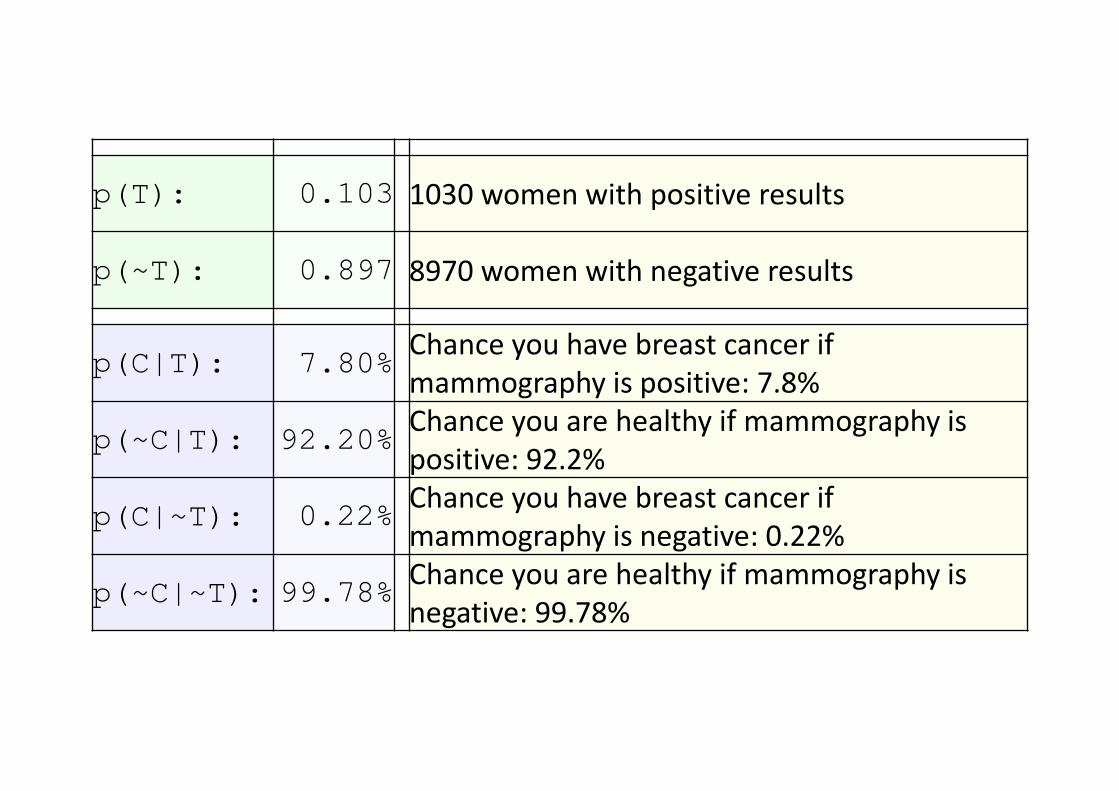
p(T): 0.103 1030 women with positive results
p(~T): 0.897 8970 women with negative results
p(C|T): 7.80%Chance you have breast cancer if mammography is positive: 7.8%
p(~C|T): 92.20%Chance you are healthy if mammography is positive: 92.2%
p(C|~T): 0.22%Chance you have breast cancer if mammography is negative: 0.22%
p(~C|~T): 99.78%Chance you are healthy if mammography is negative: 99.78%

Ocena klasyfikacjiStan Opis
True Positive (TP) Poprawnie zaklasyfikowany
True Negiative (TN) Poprawnie pominięty
False Positive (FP) Zaklasyfikowany mimo iż powinien być pominięty
False Negative (FN) Pominięty mimo, iż powinien być zaklasyfikowany
FNTP
TPCzulosc
+=
FPTN
TNoscSpecyficzn
+=
FNFPTNTP
TNTPACC
++++=Wiarygodność (accuracy)

Wówczas estymator współczynnika korelacji liniowej definiuje się następująco:
Ogólnie współczynnik korelacji liniowej dwóch zmiennych jest ilorazem kowariancji i iloczynu odchyleń standardowych tych zmiennych:
W szczególności dla zmiennych losowych o dyskretnych rozkładach ma on postać
Współczynnik korelacji PearsonaNiech x i y będą zmiennymi losowymi o ciągłych rozkładach. xi, yi
oznaczają wartości prób losowych tych zmiennych (i=1,2, … ,n ), natomiast, - wartości średnie z tych prób, tj. .

Wartość współczynnika korelacji mieści się w przedziale domkniętym [-1, 1]. Im większa jego wartość bezwzględna, tym silniejsza jest zależność liniowa
między zmiennymi.
oznacza brak liniowej zależności między cechami,
oznacza dokładną dodatnią liniową zależność między cechami,
oznacza dokładną ujemną liniową zależność między cechami, tzn. jeżeli zmienna x rośnie, to y maleje i na odwrót.
Współczynnik korelacji liniowej można traktować jako znormalizowaną kowariancję. Korelacja przyjmuje zawsze wartości w zakresie [-1, 1], co pozwala uniezależnić analizę od dziedziny badanych zmiennych.
Współczynnik korelacji Pearsona
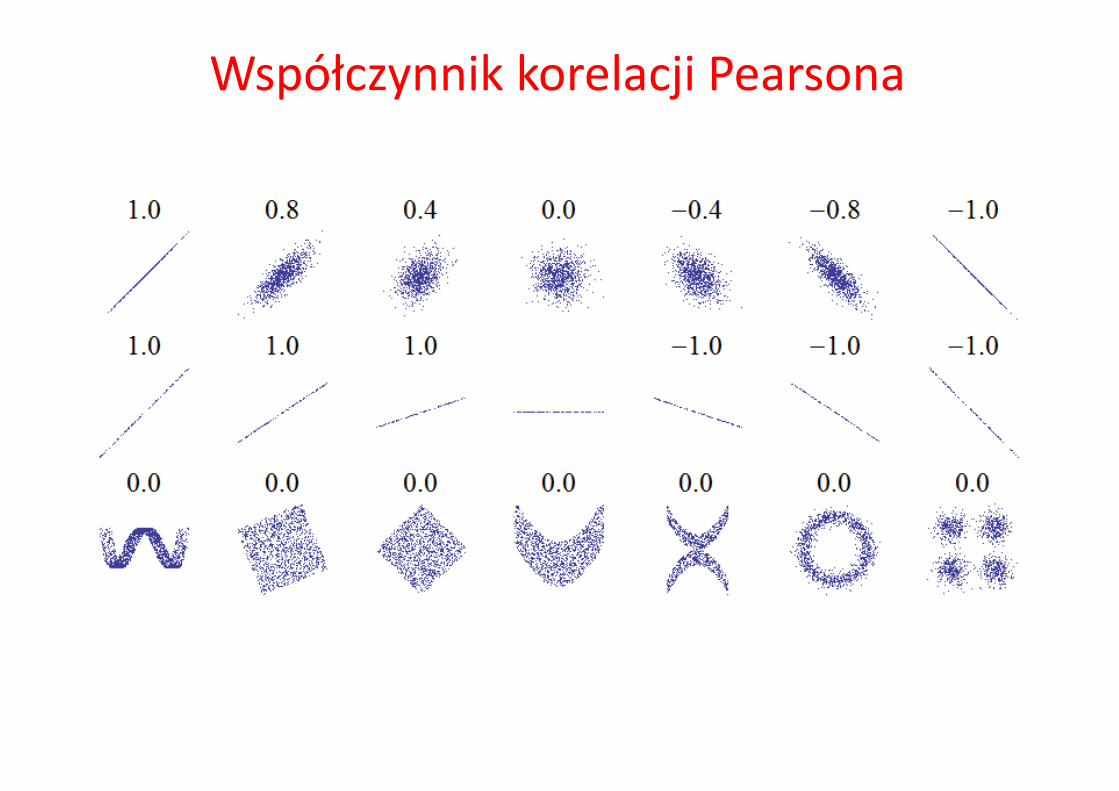
Współczynnik korelacji Pearsona

Twierdzenie Thomasa Bayesa (1702-1761)
Pr(h|d) = Pr(d|h)·Pr(h) ·ΣiPr(d|hi) ·Pr(hi)-1
Optymalny klasyfikator Bayesa
arg max Pr(c(x)=d|t)= ΣhPr (c(x)=d|h) ·Pr(h|t)
Naiwny klasyfikator Bayesa
arg max Pr(c(x)=d|a1(x)=a1(x0), ..., an(x)=an(x0)), czyli
arg max Pr(c(x)=d)*Pr(a1(x)=a1(x0), ..., an(x)=an(x0)|c(x)=d)
Załozenie o warunkowej niezależności atrybutów:
Pr(a1(x)=v1, ..., an(x)=vn|c(x)=d)=∏iPr(ai(x)=vi|c(x)=d)
Klasyfikator Bayesa

Klastrowanie algorytmem górskim
• Przykład:
K=3
m1
m2
m3 m4m3
m2
m1
m4
m1
m2
m3





![KONSYTENCJA FRYTEK ZIEMNIACZANYCH W ZALEŻNOŚCI OD ...journal.pttz.org/wp-content/uploads/2018/01/07_Tajner.pdf · likatna tekstura [33]. W literaturze często spotykamy się z pojęciami:](https://static.fdocuments.pl/doc/165x107/60b8abe4449be72db3777f07/konsytencja-frytek-ziemniaczanych-w-zalenoci-od-likatna-tekstura-33-w.jpg)












