
Dobór danych wej ś ciowych sieci neuronowej przy pomocy algorytmów genetycznych
28
Dobór danych wejściowych sieci neuronowej przy pomocy algorytmów genetycznych Mgr inż. Marcin Jaruszewicz Prof. nzw. dr hab. Jacek Mańdziuk - analiza wyników narium Metody Inteligencji Obliczeniowej
description
Dobór danych wej ś ciowych sieci neuronowej przy pomocy algorytmów genetycznych. - a naliza wynik ó w. Mgr inż. Marcin Jaruszewicz Prof. nzw. dr hab. Jacek Mańdziuk. Seminarium Metody Inteligencji Obliczeniowej. Agenda. Kontekst predykcji Algorytm Genetyczny Brute Force Sieć Neuronowa - PowerPoint PPT Presentation
Transcript of Dobór danych wej ś ciowych sieci neuronowej przy pomocy algorytmów genetycznych

Dobór danych wejściowych sieci neuronowej przy pomocy algorytmów genetycznych
Mgr inż. Marcin JaruszewiczProf. nzw. dr hab. Jacek Mańdziuk
- analiza wyników
Seminarium Metody Inteligencji Obliczeniowej

Agenda
Kontekst predykcji Algorytm Genetyczny Brute Force Sieć Neuronowa Eksperyment – parametry Eksperyment - wyniki

Predykcja indeksu giełdowego
Dane wejściowe dla trzech giełd i dwóch kursów walut: wartości indeksu, średnie, oscylatory, formacje
Przestrzeń ponad 300 zmiennych Prognoza zmiany wartości indeksu z zamknięcia
na zamknięcie następnego dnia Problemy: duże sieci neuronowe, zmienność
zależności, różnorodność zmiennych

Metody doboru danych
Macierz autokorelacji – współczynniki określające liniowe zależności między zmiennymi
Nauka sieci neuronowej – wpływ zmiennych na predykcję po procesie nauki ‘maksymalnej’ sieci neuronowej
Algorytm genetyczny – populacja zestawów zmiennych wejściowych

Chromosom
Definicja chromosomu: Zmienne wejściowe z puli dostępnych zmiennych Liczba warstw ukrytych sieci neuronowej
(ustawiona na 1) Zmienny rozmiar chromosomu - kodowanie
liczby zmiennych wejściowych od 4 do 7 (parametr)
Wymuszone zmienne Przystosowanie - chromosomy żywe i martwe, 3
SN

Algorytm genetyczny
Wstępne ograniczenie liczby zmiennych za pomocą metody macierzy autokorelacji (od 10% do 20%), dodatkowo wszystkie zmienne z prognozowanej giełdy – ok. 80 zmiennych
Rekordy w pojedynczym eksperymencie: 140 uczących, 5 walidacyjnych, 5 testowych (niedostępne dla AG, do testowania jego skuteczności)
Dobór danych dla okienka 5 dni, 10 kolejnych przesunięć

Mutacja
Zmianie podlega kodowanie zmiennych wejściowych
Prawdopodobieństwo mutacji: 0.05 (żywe) lub 1 (martwe)
Mutacja żywych po przekroczeniu progu 90% żywych chromosomów w populacji
Parametr określający liczbę zmian w jednym chromosomie w czasie jednej mutacji: 1

Mutacja cd.
Mutacja nie dotyczy najlepszego chromosomu Mutacja nie dotyczy wymuszonych zmiennych Nowa zmienna wybierana jest losowo z
dostępnej puli Prawdopodobieństwo wylosowania nowej
zmiennej zależy od częstości jej występowania w populacji lub najlepszych chromosomach (1 dla najlepszych, 0.75 dla najczęstszych, 0.5 dla pozostałych)

Selekcja
Funkcja przystosowania na podstawie błędu po nauce sieci neuronowej kodowanej przez chromosom
Wybór metodą rankingową Losowanie par chromosomów Wybór rodziców ze zwycięzców z dwóch
sąsiednich par Dzieci zastępują przegranych Stały rozmiar populacji

Krzyżowanie
Prawdopodobieństwo krzyżowania: 1 Prawdopodobieństwo wylosowania nowej
zmiennej zależy od częstości jej występowania w populacji lub najlepszych chromosomach (1 dla najlepszych, 0.75 dla najczęstszych, 0.5 dla pozostałych)
Dzieci zastępują rodziców tylko jeśli mają lepsze przystosowanie
Krzyżowanie na podstawie części wspólnej rodziców

Zakończenie AG
Wynikiem jest najlepszy chromosom Najlepszy chromosom musi być żywy dla
każdej równoległej sieci neuronowej Warunek stop według
iteracji bez znalezienia kolejnego najlepszego chromosomu
braku różnorodności populacji po względem przystosowania
Maksymalnej liczby iteracji

Brute Force
Iteracyjna wymiana kolejnych kodowanych zmiennych
Iteracyjne powtarzanie procesu

Nauka sieci neuronowych
Metoda back-propagation z momentem Zatrzymanie nauki na podstawie
rekordów walidacyjnych Małe sieci neuronowe – jedna warstwa
ukryta, rozmiar pierwszej warstwy 4-7

Parametry eksperymentu
Okienko kroku = 150 Krok, liczba testowych i walidacyjnych 5 Stop po iteracjach bez najlepszego = 200 Rozmiar populacji = 400 Liczba iteracji AG = 200 Start liczenia preferencji od 10 iteracji Dodatkowe przeszukanie przestrzeni
powtórzone zgodnie z liczbą kodowanych przez najlepszy chromosom zmiennych

Wyniki
Parametry działania algorytmu genetycznego
Parametry populacji Wyniki prognozy
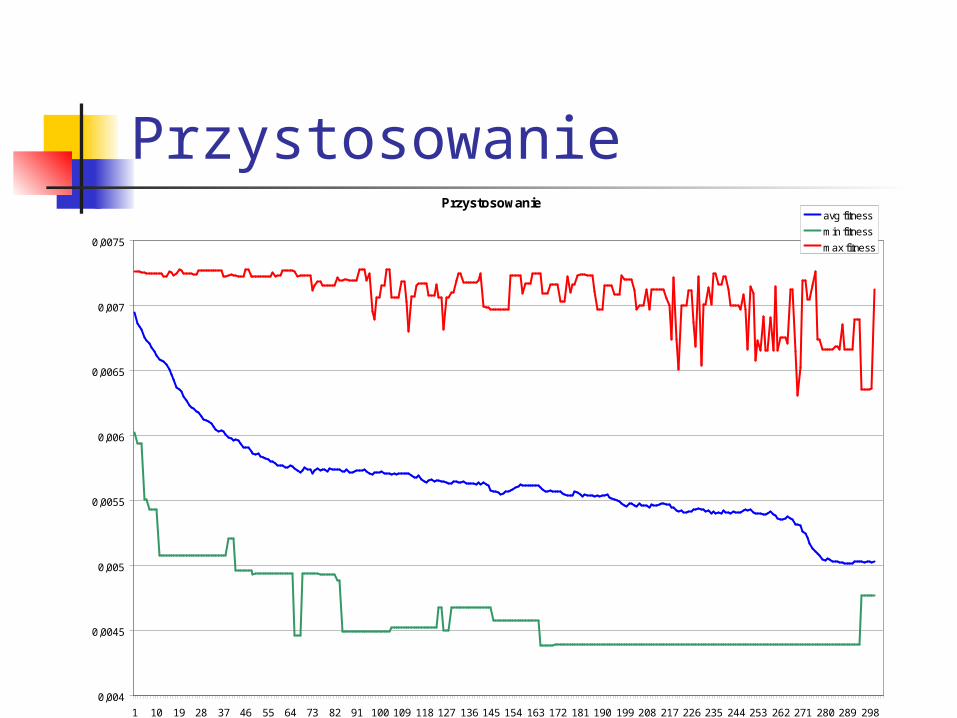
Przystosowanie
0,004
0,0045
0,005
0,0055
0,006
0,0065
0,007
0,0075
1 10 19 28 37 46 55 64 73 82 91 100 109 118 127 136 145 154 163 172 181 190 199 208 217 226 235 244 253 262 271 280 289 298
avg fitness
min fitness
max fitness
Przystosowanie
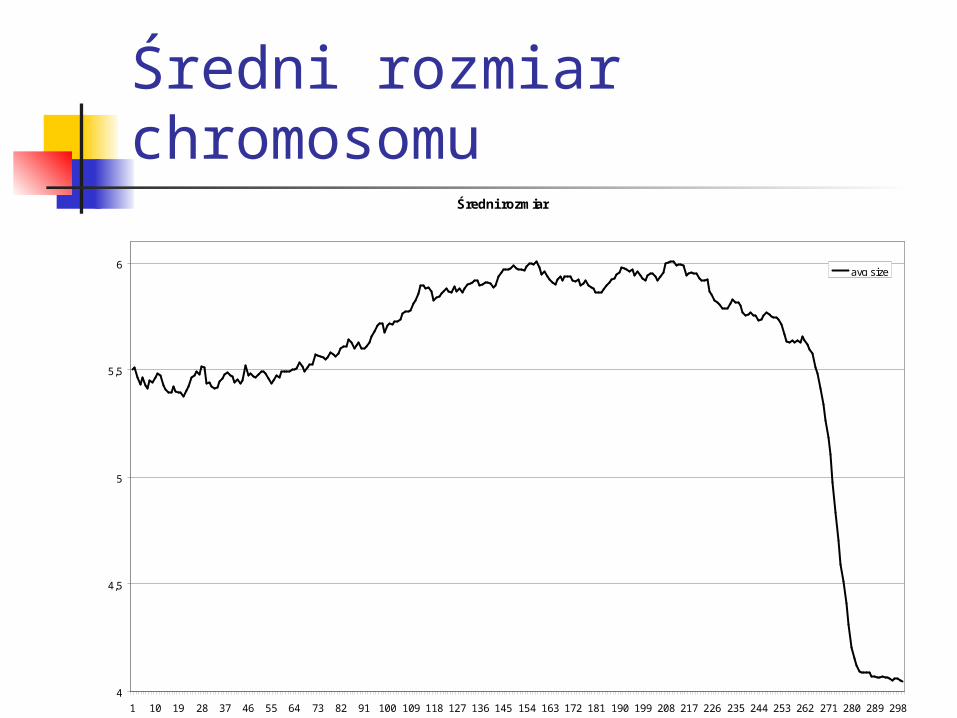
Średni rozmiar chromosomu
Średni rozmiar
4
4,5
5
5,5
6
1 10 19 28 37 46 55 64 73 82 91 100 109 118 127 136 145 154 163 172 181 190 199 208 217 226 235 244 253 262 271 280 289 298
avg size
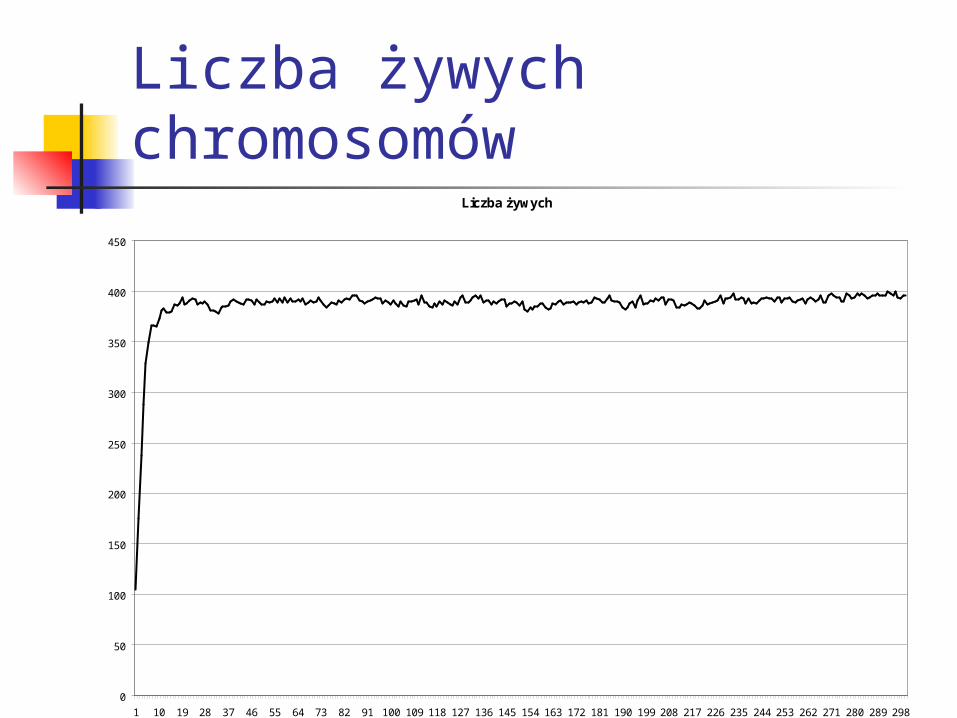
Liczba żywych
0
50
100
150
200
250
300
350
400
450
1 10 19 28 37 46 55 64 73 82 91 100 109 118 127 136 145 154 163 172 181 190 199 208 217 226 235 244 253 262 271 280 289 298
Liczba żywych chromosomów
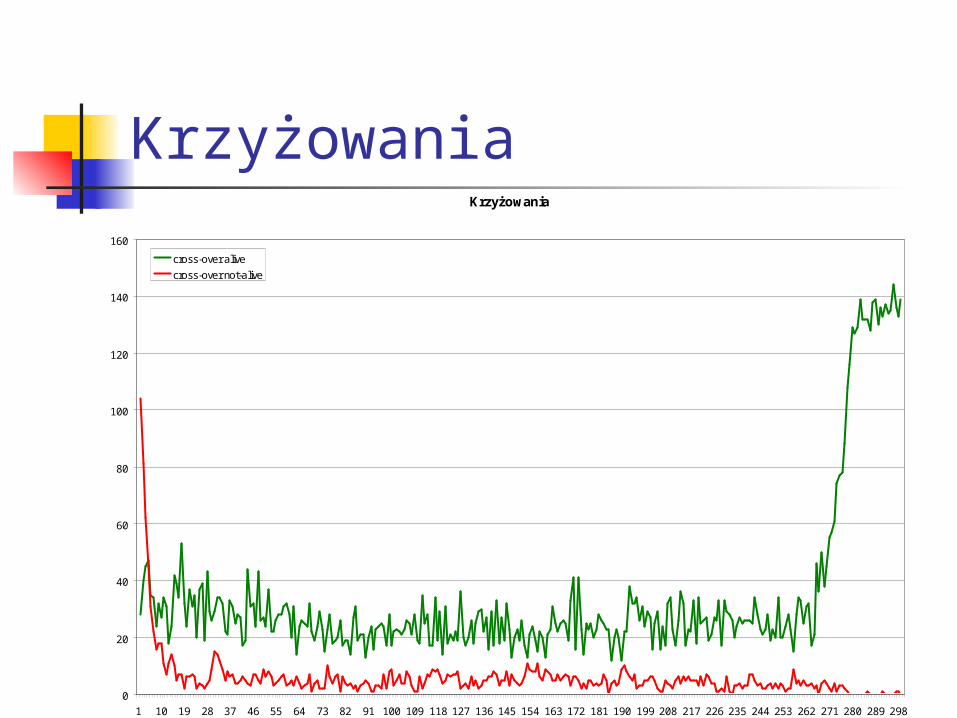
KrzyżowaniaKrzyżowania
0
20
40
60
80
100
120
140
160
1 10 19 28 37 46 55 64 73 82 91 100 109 118 127 136 145 154 163 172 181 190 199 208 217 226 235 244 253 262 271 280 289 298
cross-over alive
cross-over not-alive
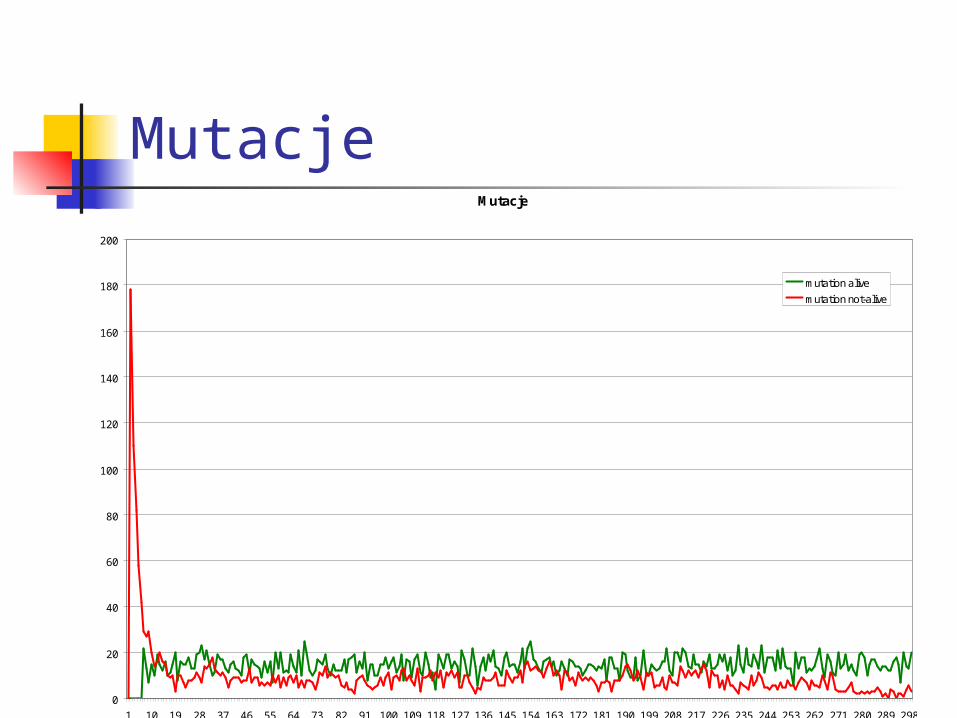
MutacjeMutacje
0
20
40
60
80
100
120
140
160
180
200
1 10 19 28 37 46 55 64 73 82 91 100 109 118 127 136 145 154 163 172 181 190 199 208 217 226 235 244 253 262 271 280 289 298
mutation alive
mutation not-alive
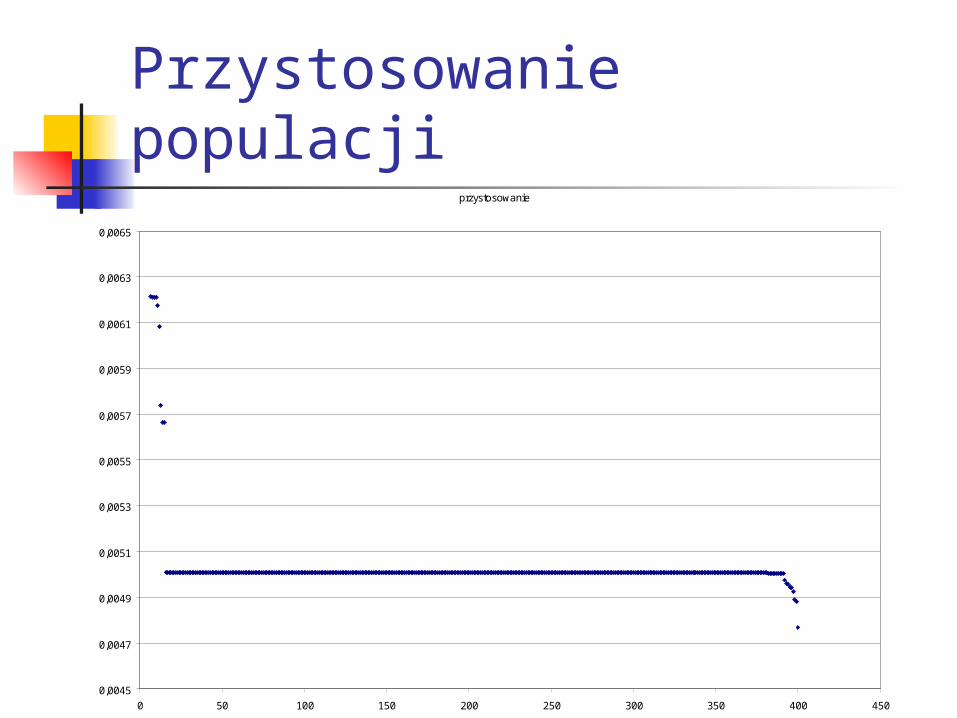
Przystosowanie populacjiprzystosowanie
0,0045
0,0047
0,0049
0,0051
0,0053
0,0055
0,0057
0,0059
0,0061
0,0063
0,0065
0 50 100 150 200 250 300 350 400 450
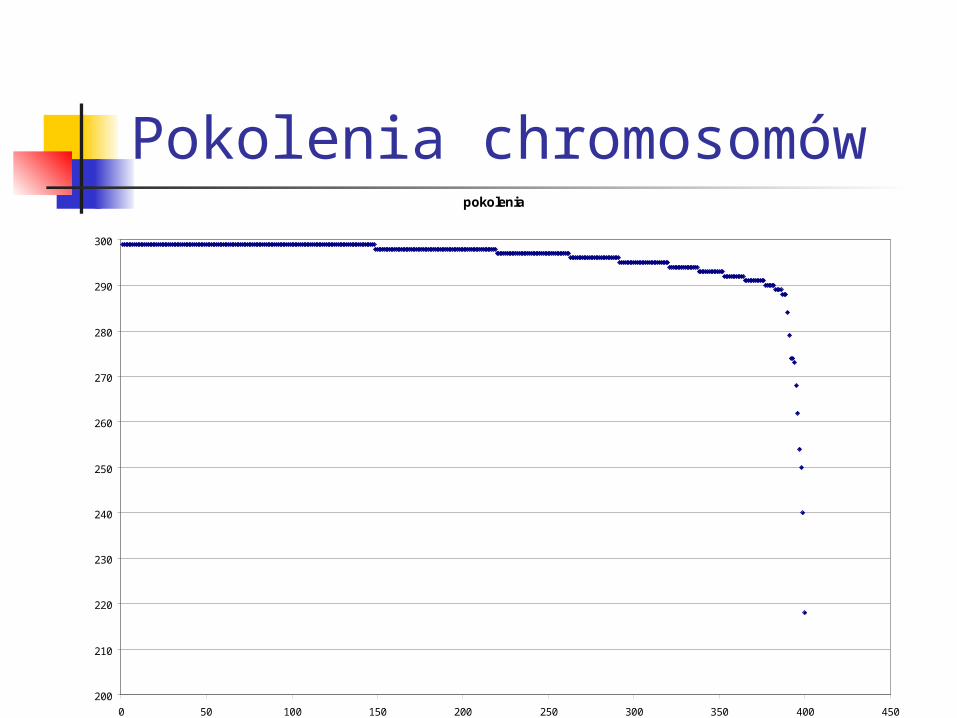
Pokolenia chromosomówpokolenia
200
210
220
230
240
250
260
270
280
290
300
0 50 100 150 200 250 300 350 400 450
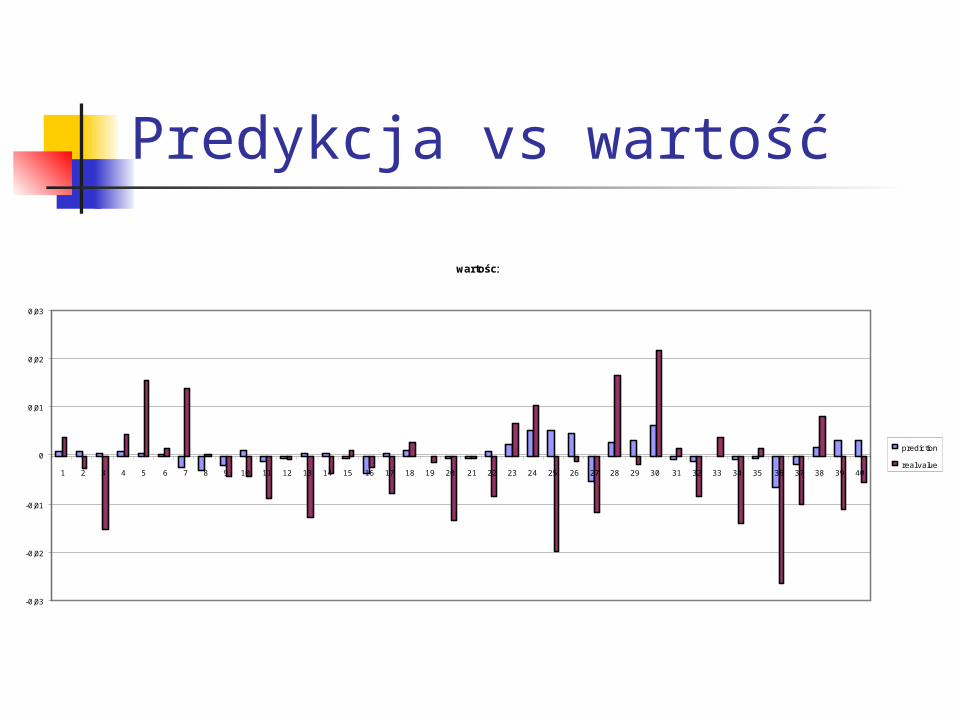
Predykcja vs wartość
wartości
-0,03
-0,02
-0,01
0
0,01
0,02
0,03
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40
prediction
real value
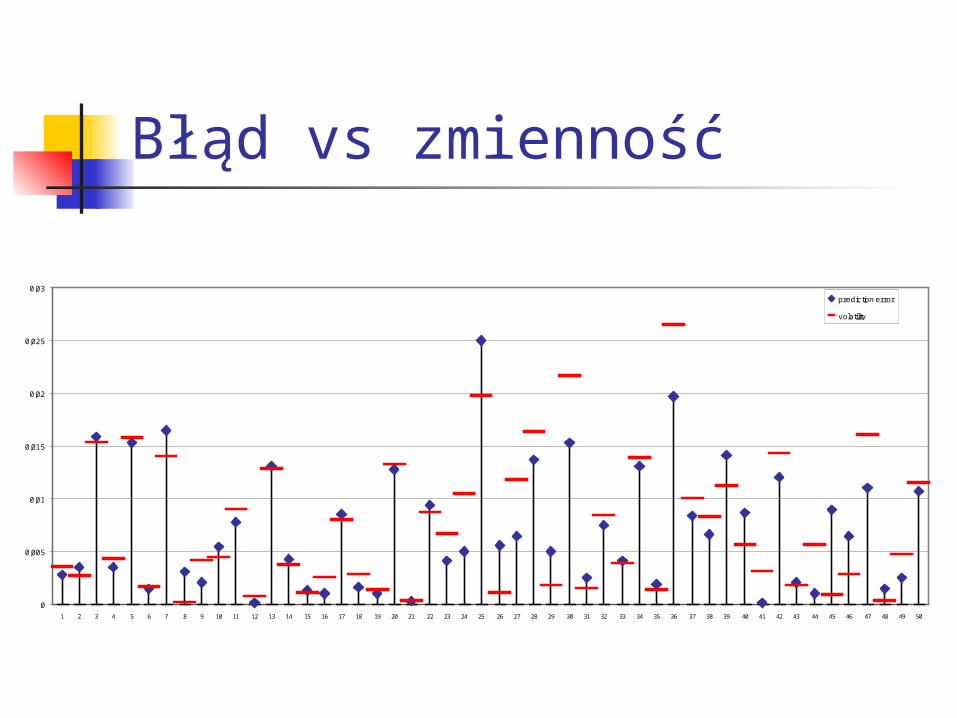
Błąd vs zmienność
0
0,005
0,01
0,015
0,02
0,025
0,03
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50
prediction error
volatility

Wyniki krok 1 średni błąd 0,00820; średnia zmienność 0,00828; źródło: GA [target dax [t]; close change (%); krok 1,3,4,6,7,8,9,10] [target dax [t]; value o; podobne krok 2, podobne krok 9] [eur/usd [t]; impet 20; x] [target dax [t-5]; roc 5; podobne krok 2] [eur/usd [t]; value l; x] [eur/usd [t]; close change (%); x]
krok 2 średni błąd 0,00574, średnia zmienność 0,00483; źródło: BF [eur/usd [t]; so; x] [target dax [t-5]; close change (%); x] [djia [t]; rsi 5; krok 9] [target dax [t]; so; krok 5, podobne krok 6, krok 10] [target dax [t-1]; roc 5; podobne krok 1, podobne krok 7] [djia [t]; close change (%); krok 4, krok 8, krok 9] [target dax [t]; value h; podobne krok 1, podobne krok 9]

Wyniki cd. krok 3 średni błąd 0,00532, średnia zmienność 0,00541; źródło: GA [target dax [t]; close change (%); krok 1,3,4,6,7,8,9,10] [target dax [t]; impet 5; krok 5, podobne krok 10] [djia [t]; 5 days change (%); krok 4] [target dax [t-1]; close change (%); x] [target dax [t]; 2 avg's buy/sell signal; krok 7] [usd/jpy [t]; 20 days change (%); x]
krok 4 średni błąd 0,00501, średnia zmienność 0,00555; źródło: GA [target dax [t]; close change (%); krok 1,3,4,6,7,8,9,10] [target dax [t-1]; 20 days change (%); krok 5, podobne krok 10] [djia [t]; close change (%); krok 2, krok 8, krok 9] [usd/jpy [t]; williams; x] [djia [t]; 5 days change (%); krok 3] [target dax [t]; change o(%); x]

Wybierane zmienne
Zmienne z KOSPI występują dwa razy w dwóch krokach.
Oscylator stochastyczny lub FSO: dla DAX - kroki: 2, 5, 6, 8, 10
Zmiana wartości zamknięcia (%) dla DJIA - kroki: 2, 4, 8, 9

Dziękuję za uwagę
Uwagi i pytania…


















