
Data Compression using Antidictionaries
37
Data Compression using Antidictionaries Seminarium: Kompresja danych Marta Cylkowska
-
Upload
sharon-carney -
Category
Documents
-
view
36 -
download
0
description
Data Compression using Antidictionaries. Seminarium: Kompresja danych Marta Cylkowska. Plan seminarium. Przedstawienie metody Dane:tekst T o o długości N Wynik:< M, b 1 b 2 …b n , N > Wyszukiwanie wzorca Dane:wzorzec P o długości m ; wynik kompresji - PowerPoint PPT Presentation
Transcript of Data Compression using Antidictionaries

Data Compression using Antidictionaries
Seminarium: Kompresja danych
Marta Cylkowska

Plan seminarium
Przedstawienie metody Dane: tekst To o długości N
Wynik: <M, b1b2…bn, N>
Wyszukiwanie wzorca Dane: wzorzec P o długości m; wynik kompresji Wynik: wszystkie wystąpienia wzorca P w To

Założenia
Alfabet 2-literowy Σ = {0, 1} Antysłownik – zbiór słów, których nie ma w To
Przykład Antysłownik: {0101, 111, 1100} Zakodowana postać: 1110
1 1 0 1 1 0 1

Antysłownik
DefinicjaSłowo zabronione – nie występuje w To
Minimalne słowo zabronione – nie zawiera zabronionego podsłowa
Antysłownik – zbiór minimalnych słów zabronionych
||M|| - suma długości wszystkich słów z M

Przykłady antysłowników
Tekst To: 11010001M = {0000, 111, 011, 0101, 1100} brak 1001M = {111}
Negatywne przykłady:M = {1110}M = {001, 000}

Kolejny przykład dekodowania
Co jest potrzebne do dekodowania? M = {00, 010, 111} T = 10 (tekst zakodowany)
1 0 1 1 0 1 1 0 1 1 0…
Jaki jest tekst oryginalny??Potrzebna jest długość To

Kodowanie
1. Wyznaczenie antysłownika Czas O(||M||) ||M|| < 2N – 1
2. Budowa automatu skończonego Czas O(||M||)
3. Przejście przez automat Czas O(N)
Wynik: <M, b1b2…bn,N>

1
Automat
M = {0000, 111, 011, 0101, 1100}
0 1
5
3
6
2
9 10 11
0
11
0,1
81
1
0 0
0
0,1
40
010,1
120
0,1
71
0,1
13
1
1 0
0

Budowa automatu (ogólnie)
1. Umieść kolejno słowa z M w automacie2. Ustal funkcję przejścia
δ(u, a) = najdłuższy sufiks ua, który jest prefiksem słowa z M (gdy u nie jest z M) Automat jako drzewo. ~ Przechodząc wszerz ustalamy funkcję przejścia na
podstawie obliczonych już funkcji dla przodków
3. Ustal typ wierzchołków: Q0, Q1, Q2 Czas: O||M|| Rozmiar automatu: O||M||

Przejście przez automat
Niech a będzie kolejną literą tekstu u – aktualny stan automatu
wpp,
gdy ,),( 2
Qua
auoutput
M = {0000, 111, 011, 0101, 1100} Przykład: To = 1 1 0 1 0 0 0 1
1 1 ε ε ε ε 0 ε = 110

Dekodowanie
Korzysta z tego samego automatu Gdy stan Q1 to wykonujemy ε-ruchy Oznaczenia:
Terminal(p) – stan po wykonaniu wszystkich ε-ruchów Sequence(p) – słowo powstałe na ścieżce od p do
Terminal(p) Gdy automat ma pętle:
Terminal(p) = ┴ Sequence(p) nieskończone

Automat bez ε-ruchów
Reprezentacja bez ε-ruchów:δG(u, a) = Terminal(δ(u, a)) (przejście)
λG(u, a) = a∙Sequence(δ(u, a)) (słowo)
0 1 2
9
0/00/01/100
0/01001/100
1/101001/10/0

Słowa nieskończone
Definicja automatuδG(u, a) = Terminal(p) = ┴ λG(u, a) = a∙Sequence(p) = a∙uvvv…= a∙uv*
Gdy dekoder jest w takim stanie, to…Znaczy, że przeczytał wszystko co miał na
wejściuTeraz doczyta tyle liter z Sequence(p), aby
tekst miał długość N
0 1 2
9
0/00/01/100
0/01001/100
1/101001/10/0
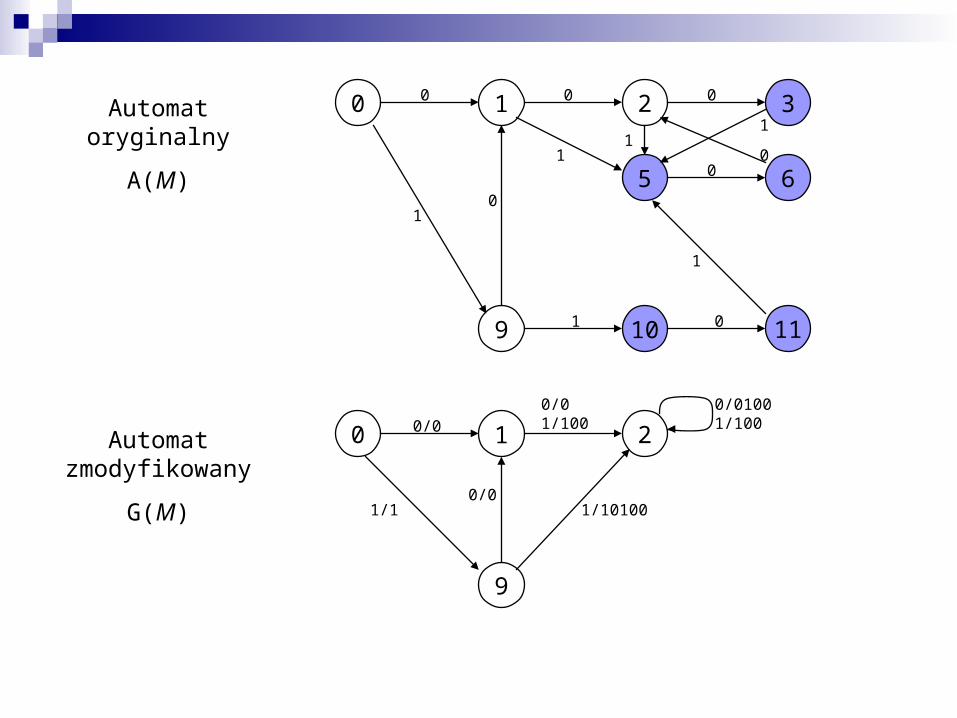
Automat oryginalny
A(M)
Automat zmodyfikowany
G(M)
1
0 1
5
3
6
2
9 10 11
0
11
1
0 0
0
01
1 0
0

Dekodowanie – algorytm
Dane: <M, b1b2…bn, N> Algorytm:
l := 0 długość odkodowanego już tekstu q := ε aktualny stan for i:=1 to n – 1 czytamy do przedostatniej litery!
u := λG(q, bi) odczytanie słowa wypisz u q := δG(u, bi) przejście do kolejnego stanu l := l + |u| aktualizacja długości
u := λG(q, bn) odczytanie słowa dla ostatniej litery wypisz prefiks u o długości N – l

Wyszukiwanie wzorca

Definicja problemu
Dane:<M, b1b2…bn, N> - skompresowana postać To
P – wzorzec nieskompresowany, |P| = m Wynik
Occurences(P, To) – zbiór wystąpień (pozycji końcowych)

Możliwe rozwiązania i złożoność Przypomnienie oznaczeń:
N – długość tekstu przed kompresją C – długość skompresowanego tekstu, całości m – długość wzorca, postać jawna
Odkodować tekst i wyszukać w nim wzorzec Złożoność:
O(N) Algorytm efektywny O(C∙logm+m) Algorytm prawie optymalny O(C+m) Algorytm optymalny

Algorytm wyszukiwania wzorca
Preprocessing: O(||M||+m2) Skanowanie tekstu O(n)
Tekst po kompresji C = ||M||+n+logN Czas algorytmu: O(C+m2)

Pomocniczy automat
Automat KMP dla wzorca PDla słowa u wyznacza najdłuższy jego sufiks
będący prefiksem wzorca PTrochę inny automat, można przerobić do
zwykłego
0 1 2 3 41 0 1 0
Σniedopasowanieniedopasowanie
niedopasowanie
niedopasowanie

Pomocniczy zbiór
AKMP = Occurences(P, w)
]}:1[]:1[ sufiksemjest |:|1{),( iujPPuiujAKMP
w uP1 j

Skanowanie tekstu1. l := 0 długość skanowanego tekstu gdyby był odkodowany2. q := ε aktualny stan3. state := 0 stan w automacie KMP4. for i:=1 to n – 1 czytamy do przedostatniej litery!
1. u := λG(q, bi) odczytanie słowa2. q := δG(u, bi) przejście do kolejnego stanu3. dla każdego p z AKMP(state, u) jest wystąpienie na pozycji l + p4. q := δKMP(state, u) przejście do kolejnego stanu w automacie KMP5. l := l + |u| aktualizacja długości
5. u := λG(q, bn) odczytanie słowa dla ostatniej litery6. dla każdego p z AKMP(state, u) że l + p < N + 1 jest wystąpienie na pozycji l + p
Skanowanie ma zająć czas O(n + r) Wszystkie funkcje muszą być obliczane w czasie
stałym (preprocessing)

Preprocessing
Czas: O(||M||+m2) λG(q, bi) O(||M||) δG(u, bi) O(||M||) δKMP(state, u) O(||M||+m2) AKMP(state, u) O(||M||+m2)
Suffix TRIE dla P, PR O(m2) Automat KMP dla P, PR O(m) Automat A(M) O(||M||) Graf ścieżek predykcyjnych O(||M||)

Automaty przypomnienie
1
0 1
5
3
6
2
9 10 11
0
11
1
0 0
0
01
1 0
0
0 1 2
9
0/00/01/100
0/01001/100
1/101001/10/0
Automat zmodyfikowany G(M)
Funkcja przejścia: δG(u, b)
Słowa na krawędziach: λG(q, b)
Automat oryginalny A(M)
Funkcja przejścia: δ(u, b)
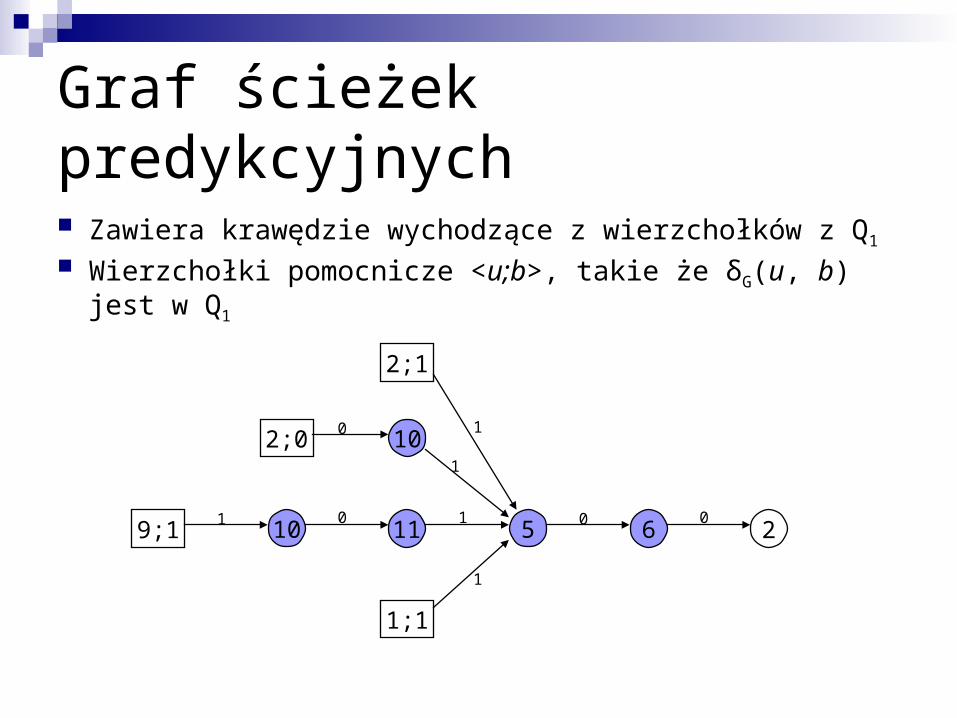
Graf ścieżek predykcyjnych
Zawiera krawędzie wychodzące z wierzchołków z Q1
Wierzchołki pomocnicze <u;b>, takie że δG(u, b) jest w Q1
10 11 65 2
10
1;1
9;1
2;0
2;1
0
0 0 0
1
1
1
1
1

Wyznaczanie automatu G(M)
Obliczenie fukcji δG(u,b) na podstawie δ(u,b)δG(u,b) = δ(u,b), gdy dla pozostałych wierzchołków (pomocnicze tylko)
obliczymy przechodząc drzewowierzchołek q – korzeńδG(u,b) =q
Co gdy nie ma korzenia?
12 ),(, QbuQu

Wyznaczanie δKMP(j, u)
N1(j, u) – maksymalne k, że P[j – k + 1 … j]∙u jest prefiksem P
N1(j, u) = null gdy nie istnieje takie k
P
uP1 j
k
1 n
wpp.),,0(
),(gdy |,|),(),( 11
u
nullujNuujNuj
KMPKMP

Wyznaczanie δKMP(0, u)
Gdy |u| = 1 to nie ma problemu Wpp należy przejść graf ścieżek predykcyjnych
od końca δKMP(0, u)=max sufiks u, będący prefiksem P
δKMP(0, u)=max prefiks uR, będący sufiksem P
Przejść drzewo sufiksowe wg słowa uR

Wyznaczanie λG(q, b) = u
Wynik – wierzchołek TRIE dla P Warunek: λG(q, b) jest podsłowem P Jak poprzednio przejść graf otrzymując uR
W TRIE dla PR sprawdzić czy uR jest podsłowem PR (u jest podsłowem P)
Znaleźć odpowiedniość między TRIE dla P a PR
Wystarczy naiwnie w czasie O(m2)

Wyznaczanie N1(j, u)
Ma sens gdy u jest podsłowem P Gdy u jest dane jako wierzchołek w TRIE,
to można wyznaczyć N1(j, u) w czasie O(||M||+m2)
Wyznaczane na podstawie poprzedniej funkcji

Co osiągnęliśmy już?
Umiemy obliczać δKMP(j, u)
λG(q, b)
δG(u, b)
Brakuje tylko preprocessingu dla zbioru
wpp.),,0(
),(gdy |,|),(),( 11
u
nullujNuujNuj
KMPKMP
]}:1[]:1[ sufiksemjest |:|1{),( iujPPuiujAKMP

Wyznaczanie zbioru AKMP(j, u)
Zawiera nowe wystąpienia wzorca po przeczytaniu nowego słowa u
Podzielmy wystąpienia na 2 rozłączne zbiory:X(u) – wystąpienia zawarte w u (|P|..|
u|)Y(j, u) – wystąpienia nie zawarte w u (1..|
P-1|)

Wyznaczanie zbioru X(u)
Przechodzimy graf ścieżek predykcyjnych Automat KMP dla PR wyznaczy wystąpienia PR w uR
Wystąpienia jako pozycje początkowe w u Zaznacz wierzchołki na ścieżce predykcji, gdzie były
wystąpienia Dla każdego zaznaczonego wierzchołka utwórz
wskaźnik do najbliższego zaznaczonego poprzednika Czas preprocessingu: O(||M|| + m) Czas wyznaczenia zbioru X(u) dla danego u – O(|X(u)|)
0 0000 0

Wyznaczanie zbioru Y(j, u)
Y(j, u) = Y(j, u*) u* - najdłuższy prefiks u, bedący właściwym
sufiksem P Y(j, u*) = wystąpienia P w słowie
P[1 … j] ∙ P[m–|u*|+1 … m]
Y(j, k) można wyznaczyć w czasie O(||M||+m2) Y(j, k) można reprezentować w stałej pamięci

Wyznaczanie u*
u* - największy prefiks u, bedący właściwym sufiksem P
u* - największy sufiks uR, bedący właściwym prefiksem PR
Automat KMP dla PR
Jeszcze przypadek nieskończonego słowa(xv*)R ≈ (vR)*xPrzeczytać k razy, k min, że k∙|v| > P

Algorytm
1. Preprocessing2. l := 0; q := ε; state := 03. for i:=1 to n – 1
1. u := λG(q, bi)
2. q := δG(u, bi)
3. dla każdego p z AKMP(state, u) jest wystąpienie na pozycji l + p
4. q := δKMP(state, u)5. l := l + |u|
4. u := λG(q, bn)
5. foreach p z AKMP(state, u) takiego że l + p < N + 1 jest wystąpienie na pozycji l + p

Koniec


















