
Bazy wiedzy - Instytut Informatyki Politechniki Poznańskiej · • Mikro-teoria musi być wolna od...
61
Bazy wiedzy Agnieszka Ławrynowicz Poznań, rok akademicki 2017
Transcript of Bazy wiedzy - Instytut Informatyki Politechniki Poznańskiej · • Mikro-teoria musi być wolna od...

Bazy wiedzy
Agnieszka Ławrynowicz
Poznań, rok akademicki 2017

Baza wiedzy – pragmatyczna definicja Baza wiedzy – pragmatyczna definicja !
Bazy wiedzy!
Baza wiedzy ≈ kolekcja encji, klas i faktów o postaci „subject-predicate-object” (atrybuty, relacje), istotnych
ogólnie lub w danej dziedzinie, która jest kompleksowa, zorganizowana semantycznie i zdatna
do odczytu maszynowego.

Grafy wiedzy
FacebookEn+tyGraph Microso5BingSatori
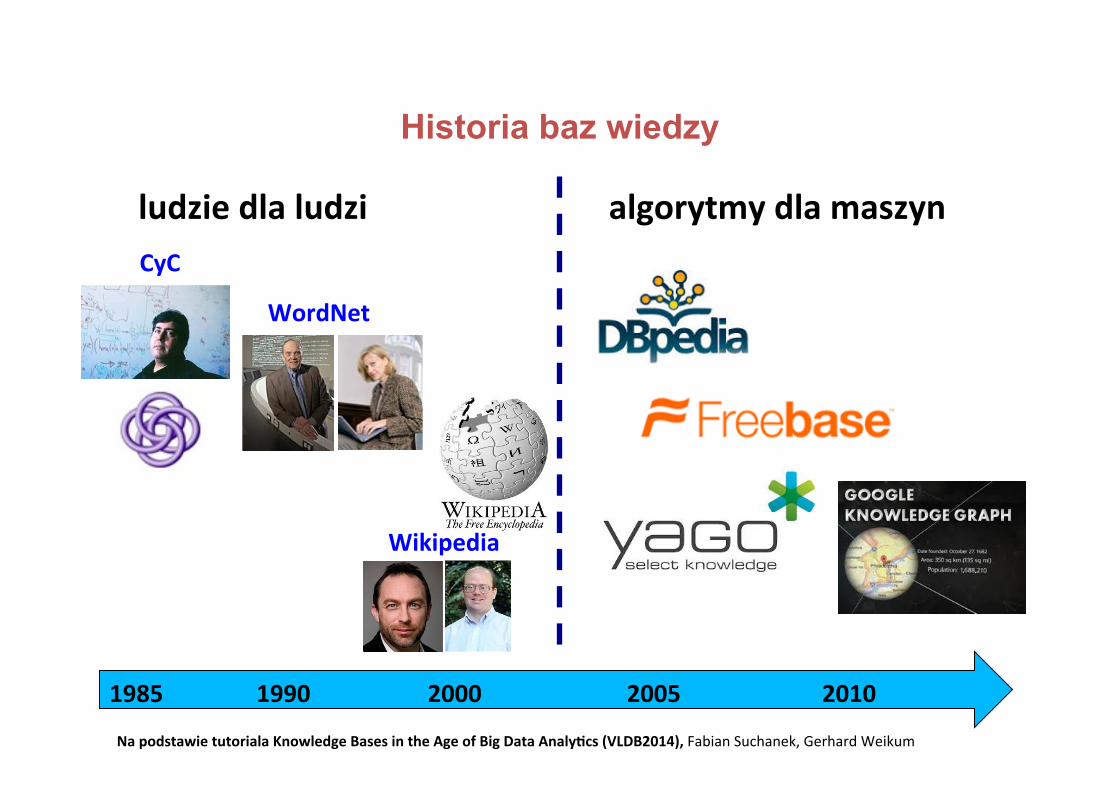
Historia baz wiedzy
ludziedlaludzi algorytmydlamaszyn
NapodstawietutorialaKnowledgeBasesintheAgeofBigDataAnaly+cs(VLDB2014),FabianSuchanek,GerhardWeikum
CyC
WordNet
Wikipedia
History of Digital Knowledge Bases
1985 1990 2000 2005 2010
Cyc
� x: human(x) �(� y: mother(x,y) �� z: father(x,z))
� x,u,w: (mother(x,u) �mother(x,w)
� u=w)
WordNet
guitarist �{player,musician} � artistalgebraist� mathematician� scientist
Wikipedia
4.5 Mio. English articles20 Mio. contributors
from humansfor humans
from algorithmsfor machines
History of Digital Knowledge Bases
1985 1990 2000 2005 2010
Cyc
� x: human(x) �(� y: mother(x,y) �� z: father(x,z))
� x,u,w: (mother(x,u) �mother(x,w)
� u=w)
WordNet
guitarist �{player,musician} � artistalgebraist� mathematician� scientist
Wikipedia
4.5 Mio. English articles20 Mio. contributors
from humansfor humans
from algorithmsfor machines
History of Digital Knowledge Bases
1985 1990 2000 2005 2010
Cyc
� x: human(x) �(� y: mother(x,y) �� z: father(x,z))
� x,u,w: (mother(x,u) �mother(x,w)
� u=w)
WordNet
guitarist �{player,musician} � artistalgebraist� mathematician� scientist
Wikipedia
4.5 Mio. English articles20 Mio. contributors
from humansfor humans
from algorithmsfor machines
1985 1990 2000 2005 2010

Cyc
• Bazawiedzyzawieramikro-teorie–kolekcjepojęćifaktówdotyczącychjakiejśdziedzinyzainteresowania.
• Mikro-teoriamusibyćwolnaodsprzeczności,alecałabazawiedzyniemusi.
• RegułyFOL• CycL(notacjawLisp)
(#$implies(#$and(#$isa?OBJ?SUBSET)(#$genls?SUBSET?SUPERSET))(#$isa?OBJ?SUPERSET))
• DostępnywariantOpenCyc

WordNet
• leksykalnekategorierzeczowników,czasowników,przymiotników,przysłówków
• słowaztejsamejkategorii,zgrubszasynonimy,sąpogrupowanewsynsety(pojęcia)
• hierarchie,zdefiniowanebyhiperonimy(IS-A)• PolskaSłowosieć(rozwijanaod2005rokunaPolitechnice
Wrocławskiej)
Źródło:Wikipedia
dog, domestic dog, Canis familiaris => canine, canid => carnivore => placental, placental mammal, eutherian, eutherian mammal => mammal => vertebrate, craniate => chordate => animal, animate being, beast, brute, creature, fauna => ...

„Powiązane Dane” (ang. Linked Data): definicja
7
„Powiązane Dane” (ang. Linked Data): definicja!
“The Semantic Web isn't just about putting data on the web. It is about making links, so that a person or machine can explore the web of data. With linked data, when you have some of it, you can find other, related, data. “ (Tim Berners-Lee).
46
.Powiązane Dane – wykorzystanie technologii Sieci Semantycznej do publikowania ustrukturalizowanych danych w Sieci i do ustanawiania powiązań między
źródłami danych.
Semantyczna Sieć!

8
Od „Sieci Dokumentów” do „Sieci Danych”
Sieć dokumentów • Podstawowe elementy: 1. Nazwy (URI) 2. Dokumenty (Zasoby) opisane w HTML, XML, itp. 3. Interakcja poprzez HTTP 4. (Hiper)linki pomiędzy dokumentami lub anchors w dokumentach
• Wady: – Nietypowane linki – Wyszukiwarki nie potrafią obsłużyć skomplikowanych zapytań
“Dokumenty”
Hyperlinks
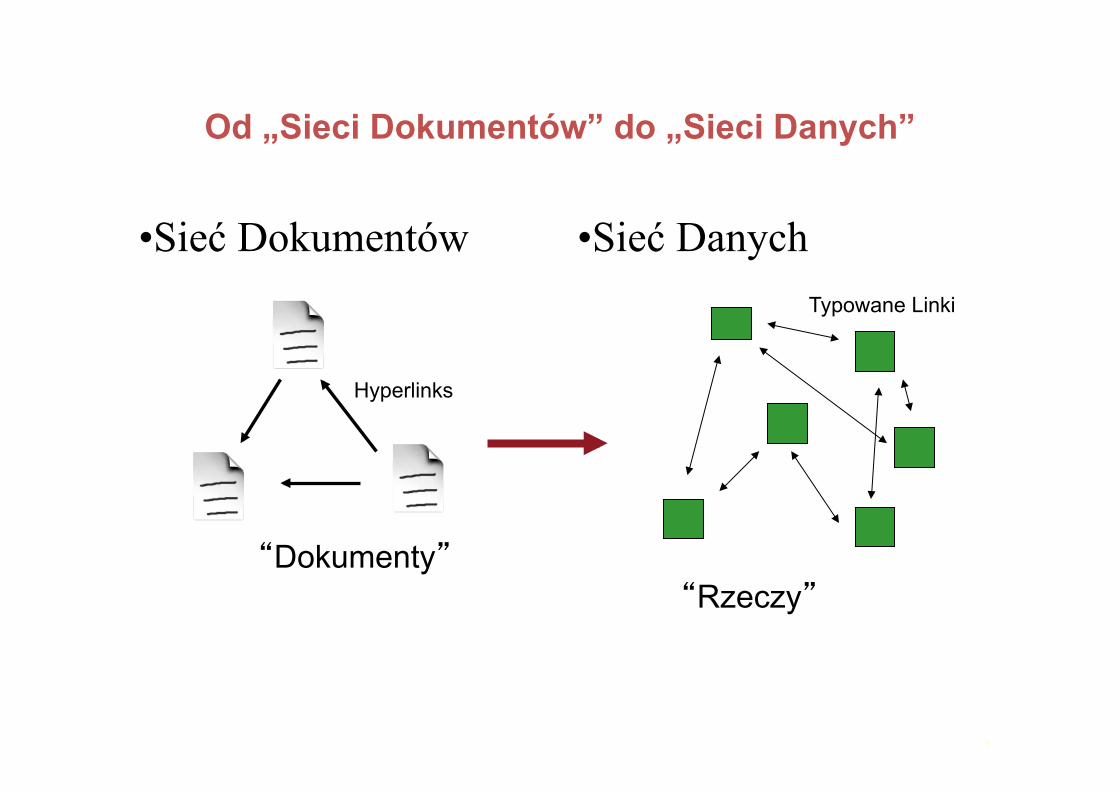
9
Od „Sieci Dokumentów” do „Sieci Danych”
• Sieć Dokumentów • Sieć Danych
“Dokumenty” “Rzeczy”
Hyperlinks
Typowane Linki
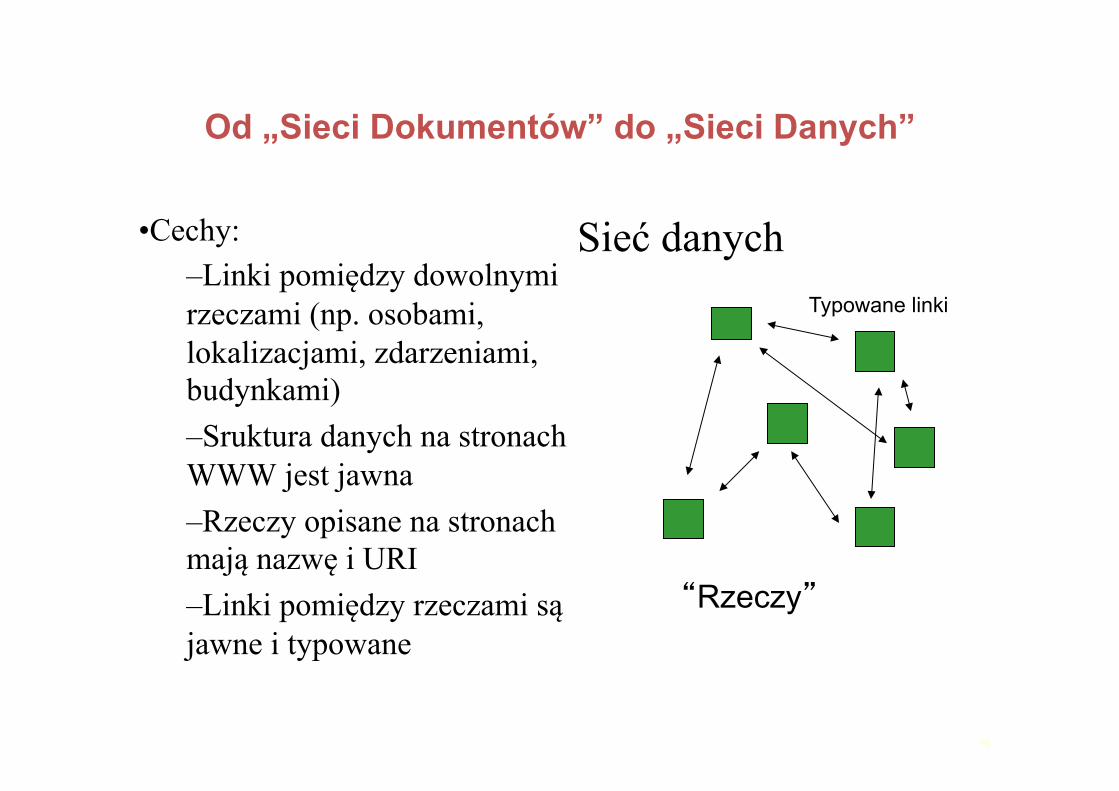
10
Od „Sieci Dokumentów” do „Sieci Danych”
• Cechy: – Linki pomiędzy dowolnymi rzeczami (np. osobami, lokalizacjami, zdarzeniami, budynkami) – Sruktura danych na stronach WWW jest jawna – Rzeczy opisane na stronach mają nazwę i URI – Linki pomiędzy rzeczami są jawne i typowane
Sieć danych
“Rzeczy”
Typowane linki

11
Wizja Sieci Danych 1/2
• Sieć dzisiaj – składasięzodizolowanychsilosówdanych,któresądostępnepoprzezwyspecjalizowanewyszukiwarki– jednastrona(silosdanych)przechowujefilmy,innerecenzje,jeszczeinneinformacjeoaktorach– wielepopularnychrzeczyjestreprezentowanychwwieluróżnychzbiorachdanych– „linkowanie”identyfikatorówłączytezbiorydanych

12
Wizja Sieci Danych 2/2
• SiećDanych-globalnabazadanych– składasięzobiektówiichopisów– obiektysązesobąpowiązanelinkami– zwysokimstopniemustrukturalizowaniaobiektów– zjawnąsemantykąlinkówitreści– zaprojektowanadlaludziimaszyn

13
„Powiązane Dane” - zasady
UżywajURIjakonazwydlarzeczy.UżywajHTTPURItakabyludziemogliwyszukiwać
tychnazw.KiedyużytkownikwyszukujeURI,dostarczużytecznej
informacjiwRDF.ZawrzyjwyrażeniaRDF,któresąpowiązanelinkami
doinnychidentyfikatorówURItakabymogłyonepomócwwykryciupowiązanychrzeczy.

14
Projekt „Linking Open Data” (Otwarte Powiązane Dane)
ProjektspołecznościowyzewsparciemW3C
Cel:PomocwutworzeniuSieciSemantycznejpoprzez
publikowaniezbiorówdanychzwykorzystaniemRDF.Spełniazasady„połączonychdanych”(LinkedDataprinciples)Głównaidea:wziąćistniejące(otwarte)zbiorydanychiuczynićje
dostępnymiwSieciwformacieRDFRazopublikowanewRDF,połączyćjelinkamizinnymizbioramidanych
PrzykładowylinkRDF:hkp://dbpedia.org/resource/Berlin
[IdentyfikatorBerlinawDBPedia]owl:sameAshkp://sws.geonames.org/2950159[IdentyfikatorBerlinawGeonames].
15
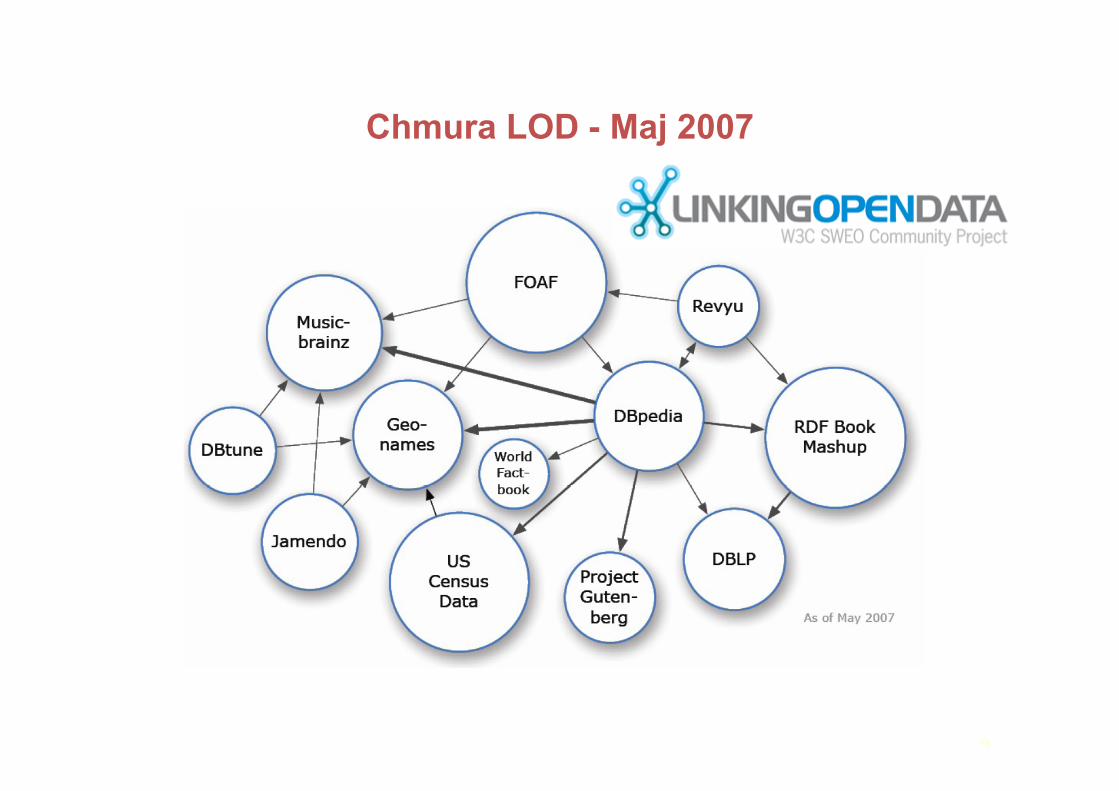
Chmura LOD - Maj 2007

Ogólnie:ChmuraPowiązanychOtwartychDanych(LinkedOpenData)jestzbiorempowiązanychmiędzysobązbiorówdanych,którezostałyopublikowaneipowiązanelinkamizgodniezzasadami„powiązanychdanych”.Fakty:Punkty„ogniskujące”:
DBPedia:wersjaWikipiediiwformacieRDF;wieleprzychodzącychiwychodzącychlinków
ZbiorydanychdotyczącemuzykiDużezbiorydanychzawierają:FOAF,USCensusdataRozmiarwprzybliżeniu1biliontrójek,250klinków
16
Chmura LOD - Maj 2007
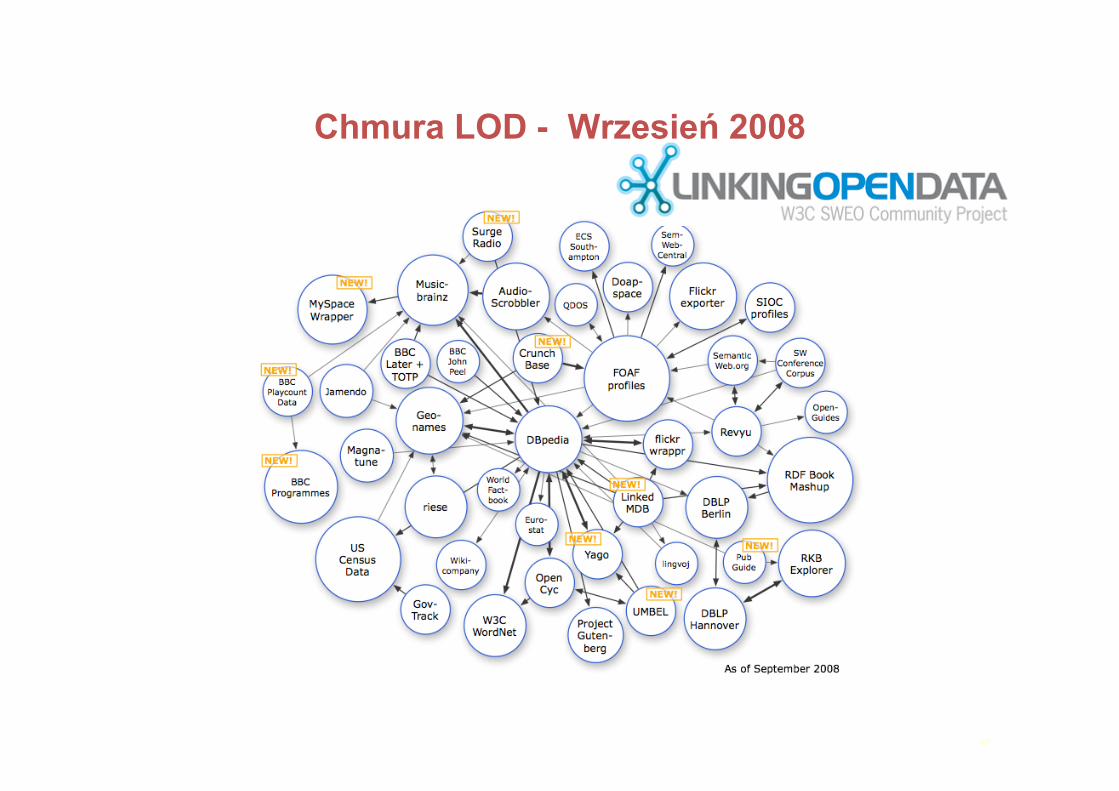
17
Chmura LOD - Wrzesień 2008

18
Chmura LOD - Wrzesień 2008
Fakty:Więcejniż35powiązanychzbiorówdanychGraczekomercyjnidołączylidochmury(np.BBC)Firmyzaczęłypublikowaćiprzechowywaćzbiorydanych(OpenLink,Talis,Garlik)Rozmiarwprzybliżeniu2bilion’ytrójek,3milionylinków
19
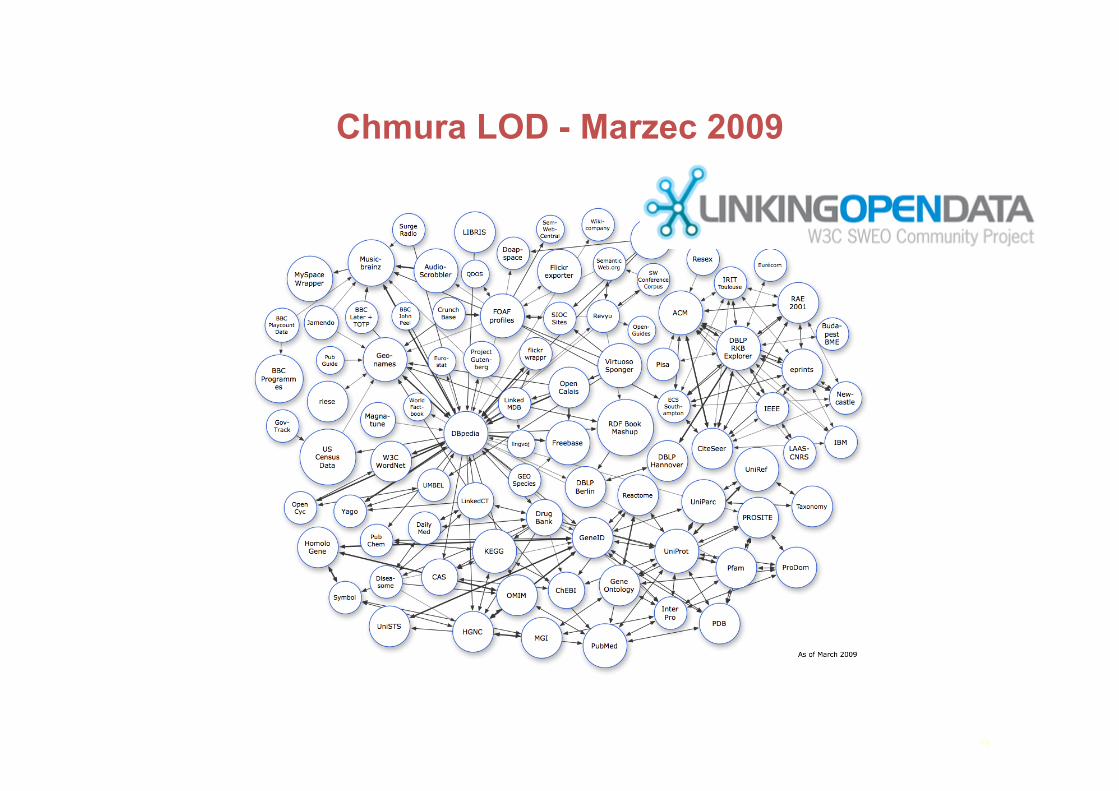
Chmura LOD - Marzec 2009

20
Chmura LOD - Marzec 2009
Fakty:Wielkaczęśćzchmury‘Drug’iprojektuBIO2RDFZnaczącenowezbiorydanych:Freebase,OpenCalais,ACM/IEEERozmiar>10bilionówtrójek

Chmura LOD - Wrzesień 2011
Liczbazbiorówdanych:295Liczbatrójek:31634213770

Chmura „Linking Open Data”!Semantyczna Sieć!
Chmura LOD - Sierpień 2014

23
Tworzenie powiązań (linków)
• Popularne predykaty: owl:sameAs, foaf:homepage, foaf:topic, foaf:based_near, foaf:maker/foaf:made, foaf:depiction, foaf:page, foaf:primaryTopic, rdfs:seeAlso

Przykładowe zbiory danych
DBpediaBBCMusicOpengovernment(UK),Data.gov(US)FreebaseZbiorydanychbiologicznychimedycznych

DBpedia
Inicjatywaspołeczna:EkstrakcjastrukturalnejinformacjizWikipediiUdostępnienieinformacjiwSiecinaotwartejlicencjiPowiązanielinkamizbiorudanychDBpediizinnymizbioramidanychwSieci
DBpediatojedenznajbardziejcentralnych”hubów”wtworzącejsięSieciDanych

Creating)a)Data)Ecosystem)
1. Gather data � from many places and give it freely to
developers, scientists, and citizens
2. Connect the community � in finding solutions to allow collaboration
through social media, events, and platforms
3. Provide an infrastructure � built on standards and interoperability
4. Encourage technology developers � to create apps, maps, and visualizations of
���������������������� ������
5. Gather more data � and connect more people
7
�A Strategy for American Innovation� published September 2009
Data.gov Creating)a)Data)Ecosystem)
1. Gather data � from many places and give it freely to
developers, scientists, and citizens
2. Connect the community � in finding solutions to allow collaboration
through social media, events, and platforms
3. Provide an infrastructure � built on standards and interoperability
4. Encourage technology developers � to create apps, maps, and visualizations of
���������������������� ������
5. Gather more data � and connect more people
7
�A Strategy for American Innovation� published September 2009
“AStrategyforAmericanInnova2on”wrzesień2009
1.Zgromadźdane–zwielumiejsc,udostępnijjezadarmodeweloperom,naukowcom,obywatelom2.Połączspołeczność–wznajdowaniurozwiązańpozwalającychnawspółpracępoprzezmediaspołecznościowe,wydarzenia,plapormy3.Dostarczinfrastrukturę–woparciuostandardyiinteroperacyjność4.Zachęćtwórcówtechnologii–dotworzeniaaplikacji,map,wizualizacjidanych,którewzmocniąwyborydokonywaneprzezludzi5.Zgromadźwięcejdanych–ipołączwięcejludzi

27
Powiązane Dane – Narzędzia i Aplikacje
NarzędziadoprzenoszeniadanychzinnychformatówizfunkcjonującychwewnętrzniesystemówdoSieciDanych
NarzędziadowykorzystywaniaPowiązanychDanych:przeszukiwanie,przeglądanie,tworzeniemashups,inne

28
Przenoszenia danych z innych formatów do Sieci Danych
• DostarczeniedanychprzechowywanychwrelacyjnychbazachdanychdoSieciDanych:– Triplify:pozwalanaspecyfikacjęzapytańSQLizrenderowanie
wynikówjakoRDF– D2RQ,ontop:odwzorowanierelacyjnychbazdanychdoRDF;
dostarczająkońcówkęSPARQLzdostępemdodanych– VirtuosoRDFViews:oferujedeklaratywnyjęzykdotworzenia
odwzorowańpomiędzydanymiSQLiRDF• EkstrakcjadanychzSieciWWW(np.DBPedia:danezWikipedii)• KonwersjaistniejącychdanychiekstrakcjaznichRDF:zJPEG,
Email,BibTex,Javabytecode,Javadoc,Excel

29
Repozytoria trójek RDF
– OntotextGraphDB:natywne,wykorzystujemechanizmwnioskowaniawprzód(forwardchaining)imaterializację
– AllegroGraph:natywne– JenaTDB:natywne– OpenLinkVirtuoso:hybrydowe,hostujezbiórDBpedia,
Virtuoso7-VirtuosoColumnStore– Blazegraph:natywne
Publikowanie powiązanych - typowe wzorce
12-10-22 21:11Linked Data: Evolving the Web into a Global Data Space
Strona 44 z 112http://linkeddatabook.com/editions/1.0/
5.1 Linked Data Publishing Patterns
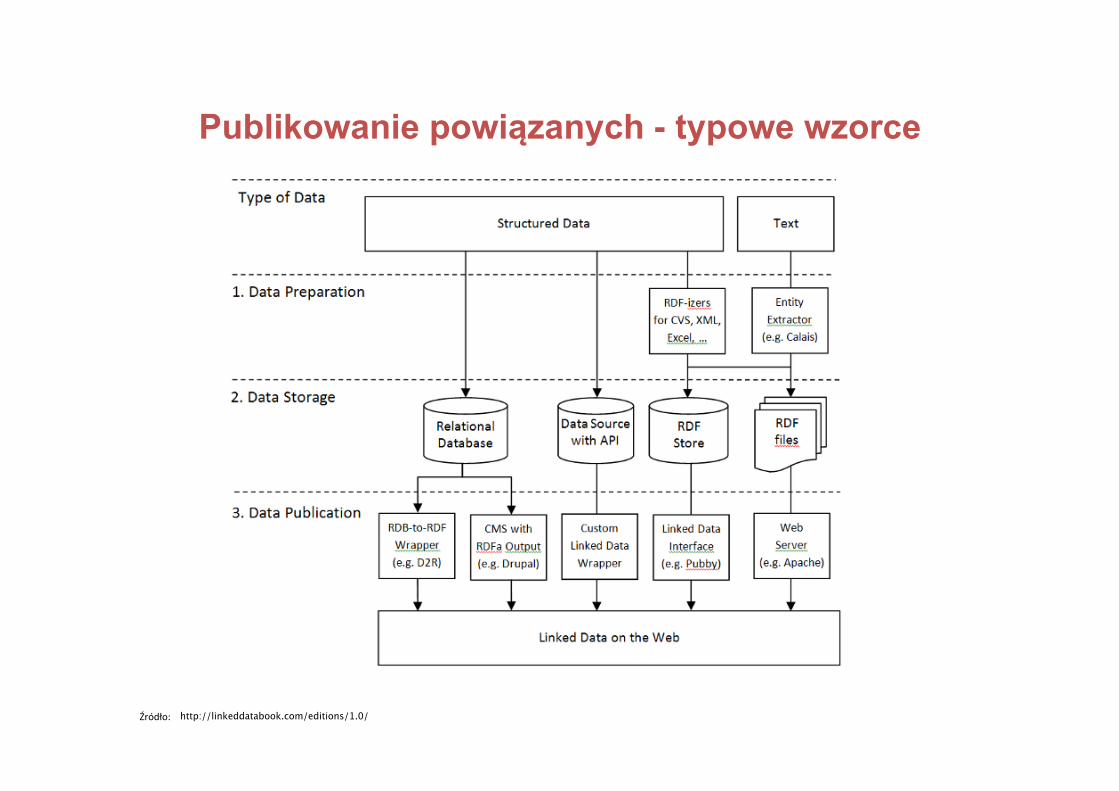
Publishing Linked Data requires adoption of the basic principles outlined in Chapter 2. Compliance with the standards and best practices thatunderpin these principles is what enables Linked Data to streamline data interoperability and reuse over the Web. However, compliance with theLinked Data principles does not entail abandonment of existing data management systems and business applications but simply the addition ofextra technical layer of glue to connect these into the Web of Data. While there is a very large number of technical systems that can be connectedinto the Web of Data, the mechanisms for doing so fall into a small number of Linked Data publishing patterns. In this section, we will give anoverview of these patterns.
Figure 5.1 shows the most common Linked Data publishing patterns in the form of workflows, from structured data or textual content through toLinked Data published on the Web. In the following section, we will briefly address some of the key features of the workflows in 5.1.
Figure 5.1: Linked Data Publishing Options and Workflows.
5.1.1 Patterns in a Nutshell
The primary consideration in selecting a workflow for publishing Linked Data concerns the nature of the input data.
From Queryable Structured Data to Linked Data
Data sets stored in relational databases can be published relatively easily as Linked Data through the use of relational database to RDFwrappers. These tools allow the data publisher to define mappings from relational database structures to RDF graphs that are served up on theWeb according to the Linked Data principles. Section 5.2.4 gives an overview of relational database to RDF wrappers.
Where structured data exists in queryable form behind a custom API (such as the Flickr or Amazon Web APIs, or a local application or operatingsystem API), the situation is a little more complex, as a custom wrapper will likely need to be developed according to the specifics of the API inquestion. However, examples such as the RDF Book Mashup [29] demonstrate that such wrappers can be implemented in relatively trivialamounts of code, much of which can likely be componentised for reuse across wrappers. The wrapper pattern is described in more detail inSection 5.2.6.
From Static Structured Data to Linked Data
12-10-22 21:11Linked Data: Evolving the Web into a Global Data Space
Strona 44 z 112http://linkeddatabook.com/editions/1.0/
5.1 Linked Data Publishing Patterns
Publishing Linked Data requires adoption of the basic principles outlined in Chapter 2. Compliance with the standards and best practices thatunderpin these principles is what enables Linked Data to streamline data interoperability and reuse over the Web. However, compliance with theLinked Data principles does not entail abandonment of existing data management systems and business applications but simply the addition ofextra technical layer of glue to connect these into the Web of Data. While there is a very large number of technical systems that can be connectedinto the Web of Data, the mechanisms for doing so fall into a small number of Linked Data publishing patterns. In this section, we will give anoverview of these patterns.
Figure 5.1 shows the most common Linked Data publishing patterns in the form of workflows, from structured data or textual content through toLinked Data published on the Web. In the following section, we will briefly address some of the key features of the workflows in 5.1.
Figure 5.1: Linked Data Publishing Options and Workflows.
5.1.1 Patterns in a Nutshell
The primary consideration in selecting a workflow for publishing Linked Data concerns the nature of the input data.
From Queryable Structured Data to Linked Data
Data sets stored in relational databases can be published relatively easily as Linked Data through the use of relational database to RDFwrappers. These tools allow the data publisher to define mappings from relational database structures to RDF graphs that are served up on theWeb according to the Linked Data principles. Section 5.2.4 gives an overview of relational database to RDF wrappers.
Where structured data exists in queryable form behind a custom API (such as the Flickr or Amazon Web APIs, or a local application or operatingsystem API), the situation is a little more complex, as a custom wrapper will likely need to be developed according to the specifics of the API inquestion. However, examples such as the RDF Book Mashup [29] demonstrate that such wrappers can be implemented in relatively trivialamounts of code, much of which can likely be componentised for reuse across wrappers. The wrapper pattern is described in more detail inSection 5.2.6.
From Static Structured Data to Linked Data
Źródło:

31
Konsumowanie Powiązanych Danych
• PrzeglądarkiPowiązanychDanych:eksplorowanierzeczyizbiorówdanychinawigacjapomiędzynimi
• Mashup’yPowiązanychDanych:strony,którełączą(„mieszają”)powiązanedane
• Wyszukiwarkipowiązanychdanych

Przykładowy Mashup: Revyu.com 1/2
Revyu.com-stronadoocenianiawszystkiego.PowiązaneDanewykorzystywanedowzbogacaniaocen.Ocenyzawierająlinkidoocenianej“rzeczy” ilinki„seeAlso”
doWikipediiiinnychzbiorówdanych.
32
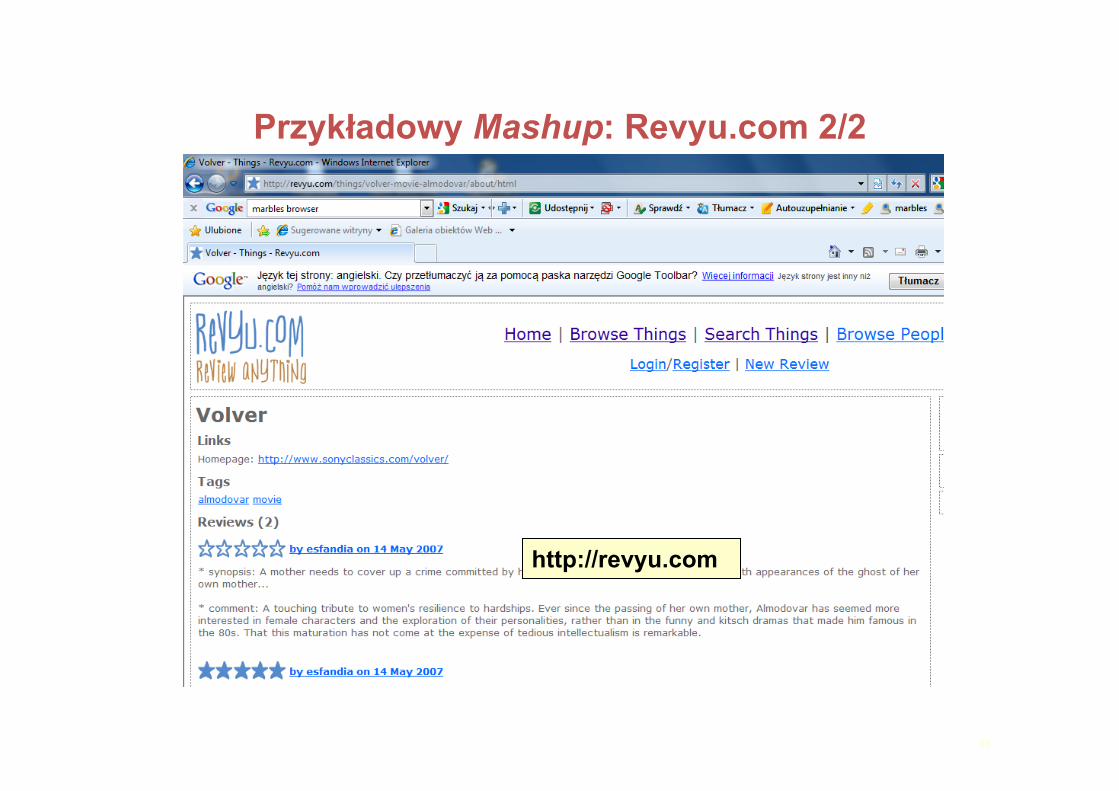
33
Przykładowy Mashup: Revyu.com 2/2
http://revyu.com

Inne inicjatywy Open*
OpenSourceOpenContentOpenScience(OpenNotebookScience)OpenAccessOpenCourseWareOpenSocietyFounda+onsOpenHealth
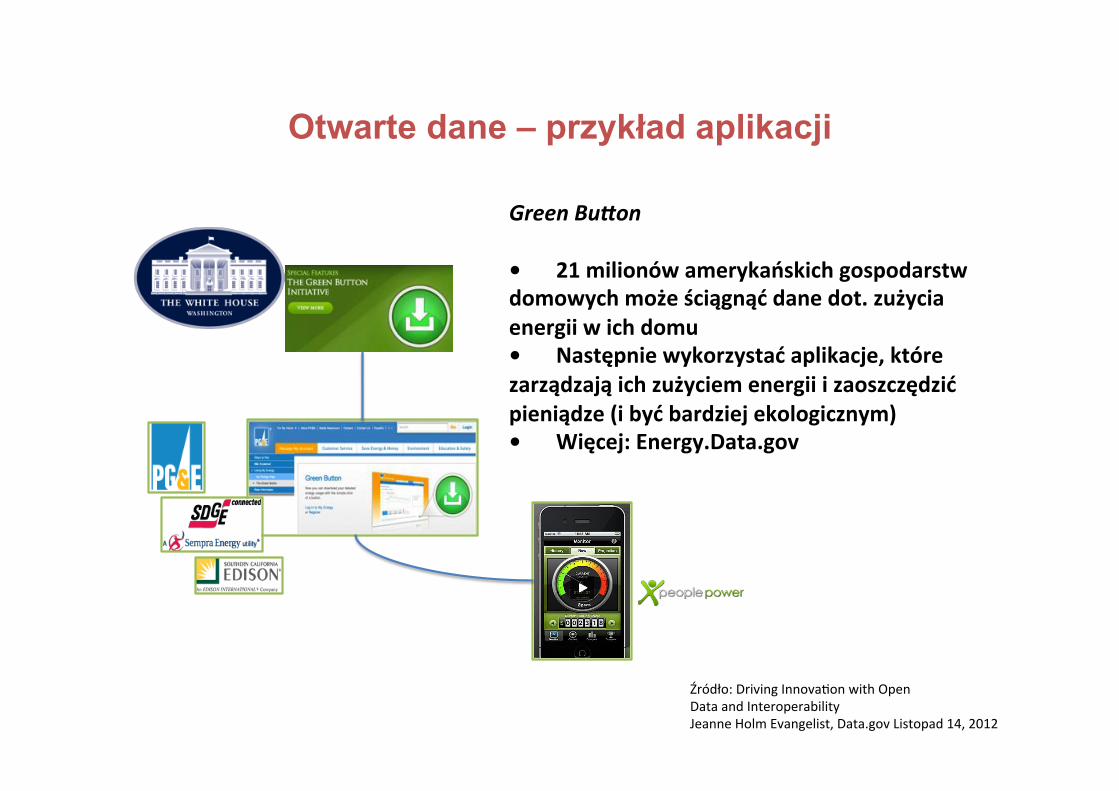
Otwarte dane – przykład aplikacji
Green%Button%� 21 million American households
can now download their home or business energy use data from their local utility
� Then use apps to manage their energy use to save money and go green
� More at Energy.Data.gov
21
GreenBu-on• 21milionówamerykańskichgospodarstwdomowychmożeściągnąćdanedot.zużyciaenergiiwichdomu• Następniewykorzystaćaplikacje,którezarządzająichzużyciemenergiiizaoszczędzićpieniądze(ibyćbardziejekologicznym)• Więcej:Energy.Data.gov
Źródło:DrivingInnovavonwithOpenDataandInteroperabilityJeanneHolmEvangelist,Data.govListopad14,2012

Otwarte dane to ekosystem

Wspólna wizja
1. Wizja:Cobędziełączyćspołeczność,jakwspółpracabędziewyglądaćwprzyszłości?
2. Liderzy:Ktobędzieprzewodzićspołeczności?3. Uczestnicy:Ktobędzieuczestniczyć?4. Wyniki:Jakiesąoczekiwanewyniki,miaryichosiągnięcia?5. Funckcjonalność:Jakietypyaktywnościbędąfunkcjonować
(fora,blogi,wiki,rankingikonkursy,aplikacje)?6. Treść:Jakatreśćbędziepokazywana?7. Interakcyjność:Jakspołecznośćbędziekomunikowaćsięz
lideramiizzewnętrznymiosobami,jednostkami?

Google: Graf Wiedzy
semantycznewyszukiwaniemaj2012:bazawiedzywykorzystywanaprzezGoogledo
rozszerzeniawynikówwyszukiwaniawieleźródełwiedzy:CIAWorldFactbook,Freebase,Wikipedia
siećsemantycznazawieraponad570mlnobiektówiponad18mldfaktów
maj2013:polskawersjajęzykowa;zadawaniepytańraczejniżwyszukiwanie,informacjeipowiązaniamiędzynimiraczejniżzestawlinkówsystemposzukującyniefrazkluczowych,lecz"bytów”stojącychzawpisanymiwwyszukiwarkęsłowami

Dwa główne sposoby działania Grafu Wiedzy
dopasowywanieodpowiedzidokontekstu;wprzypadkudwuznacznychhasełprezentacjaróżnychwersjiodpowiedzi
podsumowanianajbardziejistotnychinformacji:-biogramy,wyróżnionenajważniejszeelementy,powiązaniamiędzykluczowymihasłami,odnośnikidokolejnychinformacji
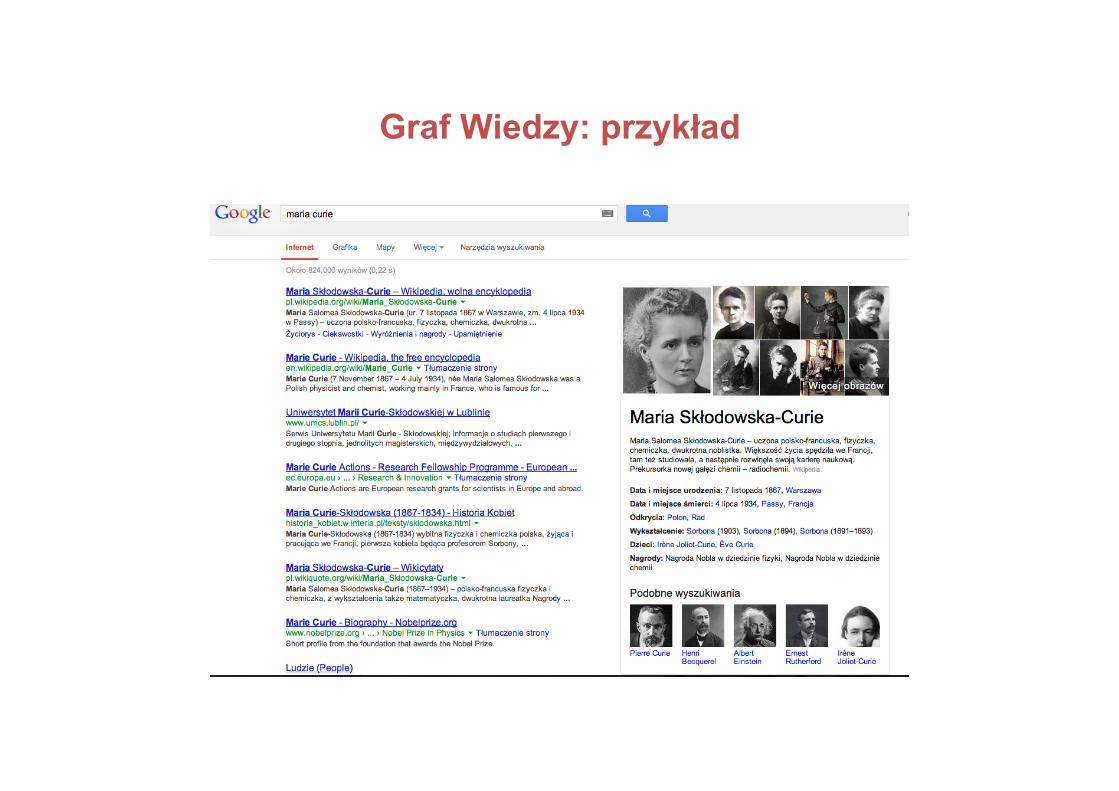
Graf Wiedzy: przykład
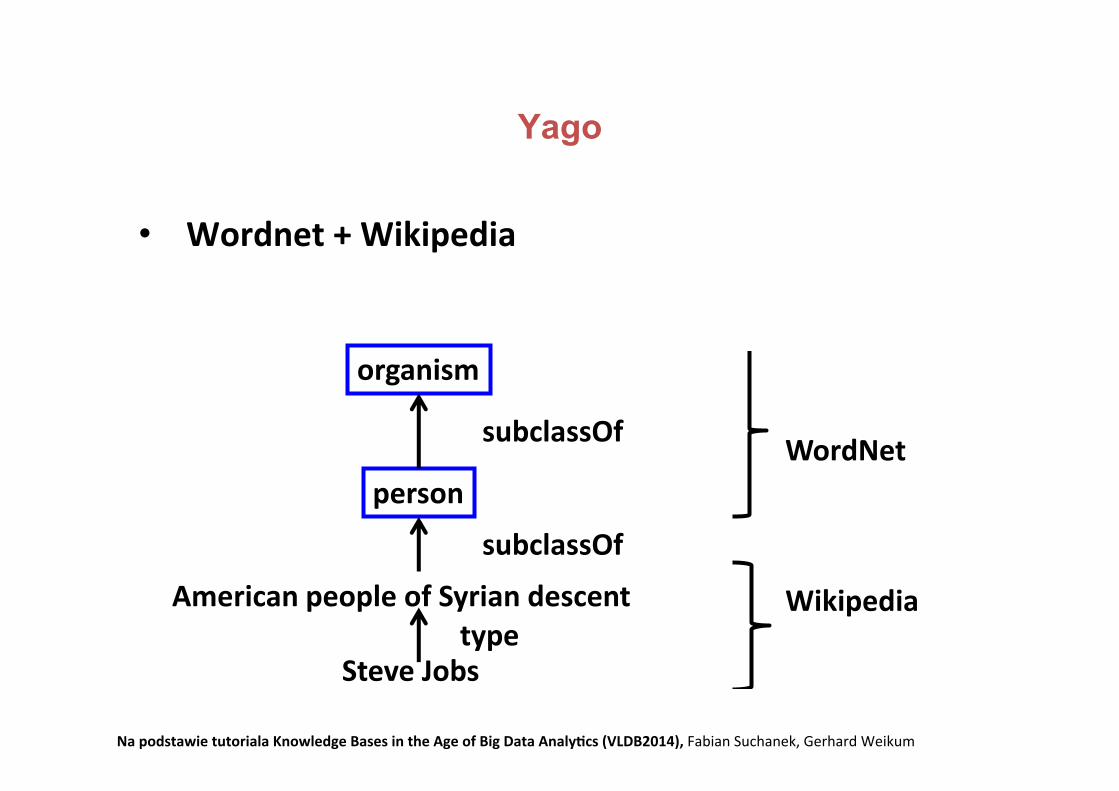
Yago
• Wordnet+Wikipedia
YAGO = WordNet+Wikipedia
American people of Syrian descent
WordNetperson
Wikipedia
organism
subclassOf
subclassOf
Related project:
WikiTaxonomy105,000 subclassOf links88% accuracy[Ponzetto & Strube: AAAI‘07]200,000 classes
460,000 subclassOf3 Mio. instances96% accuracy[Suchanek: WWW‘07]
Steve Jobstype
33
NapodstawietutorialaKnowledgeBasesintheAgeofBigDataAnaly+cs(VLDB2014),FabianSuchanek,GerhardWeikum

Ekstrakcja wiedzy (fakty)
• danesemi-strukturalneWikipedia:infoboksyikategorietabelkiilistyHTML
• tekstwzorceHearst„płytkie”NLP
• tabeleWeb

Wzorce Hearst
• Cel:znajdźinstancjeklas• Hearstzdefiniowałaleksykalno-syntaktycznewzorce:
X such as Y; X like Y; X and other Y; X including Y; X, especially Y;
• Znajdywanietakichwzorcówwtekście:companiessuchasAppleGoogle,Microso}andothercompaniesInternetcompanieslikeAmazonandFacebook
• Wywiedzenietypu(Y,X)type(Apple,company),type(Google,company),...
NapodstawietutorialaKnowledgeBasesintheAgeofBigDataAnaly+cs(VLDB2014),FabianSuchanek,GerhardWeikum

Ekstrakcja z Infoboksów
• językznaczników

Ekstrakcja z Infoboksów
• ekstrakcjazapomocąwyrażeńregularnychPrzykład–ekstrakcjadatyurodzin:\{\{birthdate\|(\d+)\|(\d+)\|(\d+)\}\}|birth_date={{birthdate|1948|6|21}}
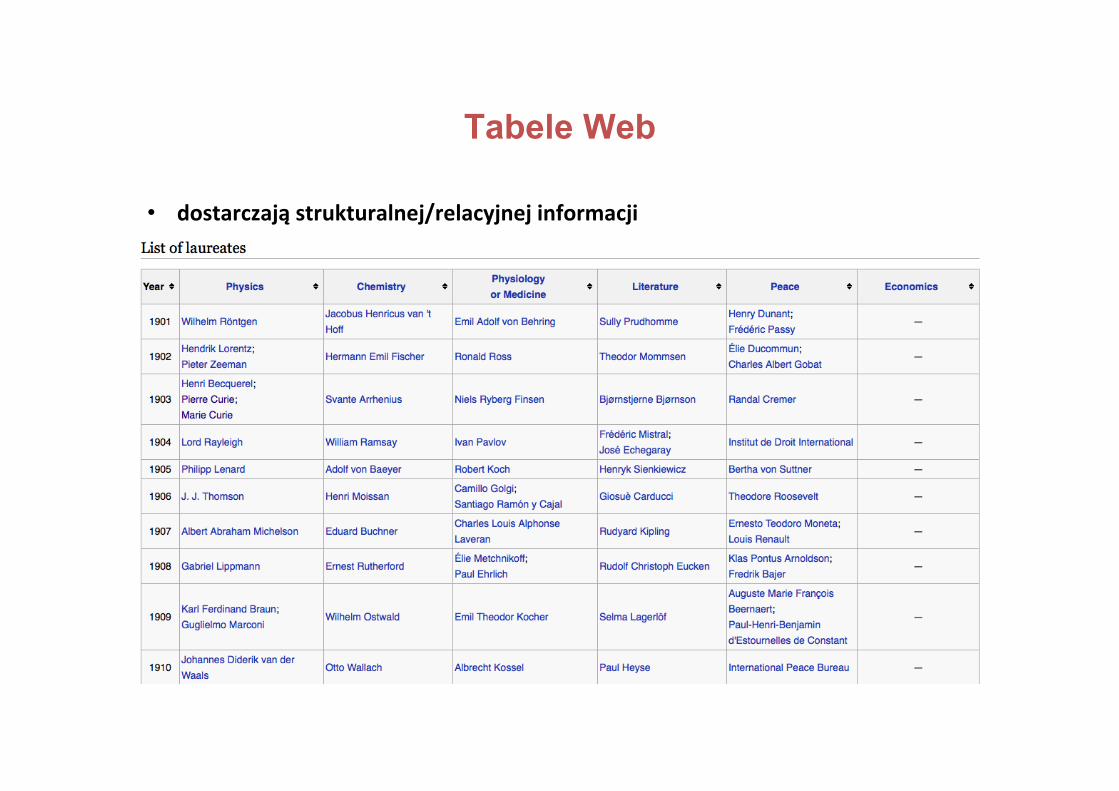
Tabele Web
• dostarczająstrukturalnej/relacyjnejinformacji

Pozyskiwanie wiedzy poprzez CrowdSourcing
• wiedzapowszechna(nie-ekspercka)• gryzcelem• pla�ormyAmazonMechanicalTurk,CrowdFlower

Gry z celem
Procesobliczeniowywykonywanyjestpoprzezzlecanieniektórych
czynnościludziomdowykonaniawzabawny,zajmującysposóbGWAPwykorzystujeróżnicewumiejętnościachikosztachpracyludzi
imetodinformatycznychwceluosiągnięciasymbiotycznejinterakcjiczłowiek-komputer

Gry z celem
LuisVonAhn(2006)Głównamotywacja:nieleżywrozwiązaniuinstancji
problemuobliczeniowego,jesttoludzkiepragnieniezabawy
WGWAPludziewykonująpożyteczneobliczeniajako
efektubocznyprzyjemnejrozrywkiMiarąużytecznościGWAPjestkombinacja
wygenerowanychwynikówiprzyjemnościrozgrywki
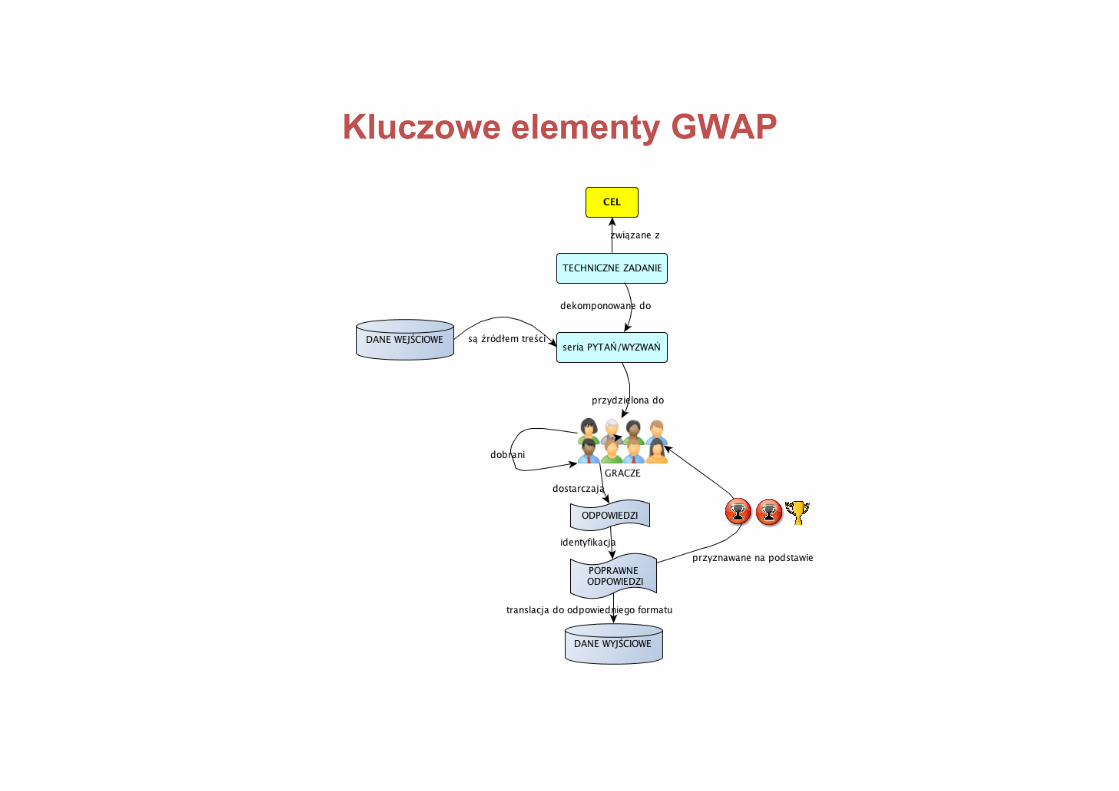
Kluczowe elementy GWAP

Gry z celem tworzenia treści, wiedzy
Adnotacjatekstu/audio/obrazów/videoKonstrukcjaontologiiMapowanieontologiiTworzenielinkówmiędzyzasobami

Konstrukcja ontologii: OntoPronto (Ontogame)
DwuosobowagraquizowaCel:budowaontologiidziedzinowejbędącejrozszerzeniemontologiiProton
Zasady:GraczeczytająstreszczenielosowowybranegoartykułuzWikipediiiodpowiadająnazapytaniaorelacjitegoartykułuwstosunkudoontologiiProton.
Danewyjściowe:OntologiadziedzinowaufundowananaontologiiProton
Walidacja:konsensus,większość

OntoPronto (Ontogame)

Mapowanie ontologii: SpotTheLink
DwuosobowagraquizowaCel:uzgadnianieontologii,np.DBpediaiProtonZasady:Graczomprezentowanejestpojęciezjednejontologii.Pierwszykrok:zgadzająsięcodoodpowiadającegomupojęciawdrugiejontologii.Krokdrugi:zgadzająsięcodorelacjiwiążącejtedwapojęcia.
Danewyjściowe:Odwzorowanie(wjęzykuSKOS)pomiędzypojęciamiwontologiach
Walidacja:konsensus,większość

SpotTheLink

Tworzenie linków między zasobami: VeriLinks
Cel:walidacjalinkówwarbitralnymzbiorzedanychZasady:Zgodagraczycodopoprawnościlinkujestnagradzanamonetami,któresąnastępniewykorzystywanedozwalczanianajeźdźcówwgrzepolegającejnaobroniewieży.
Danewyjściowe:zwalidowanelinki
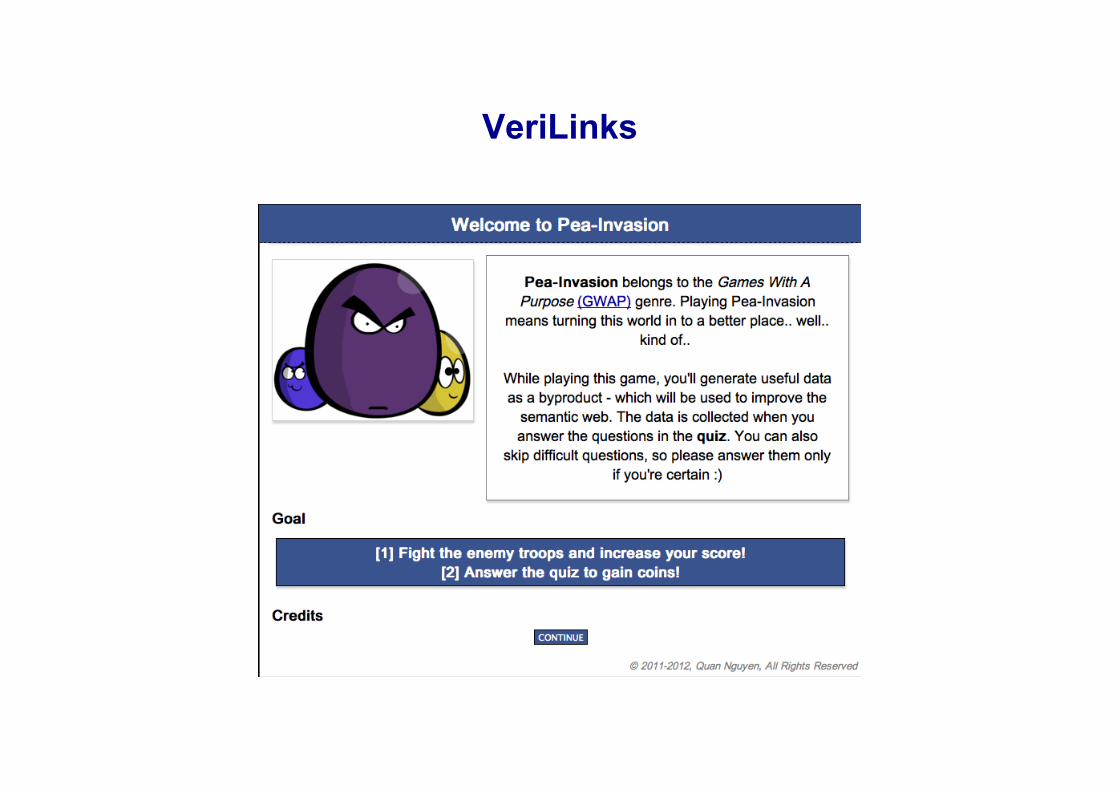
VeriLinks
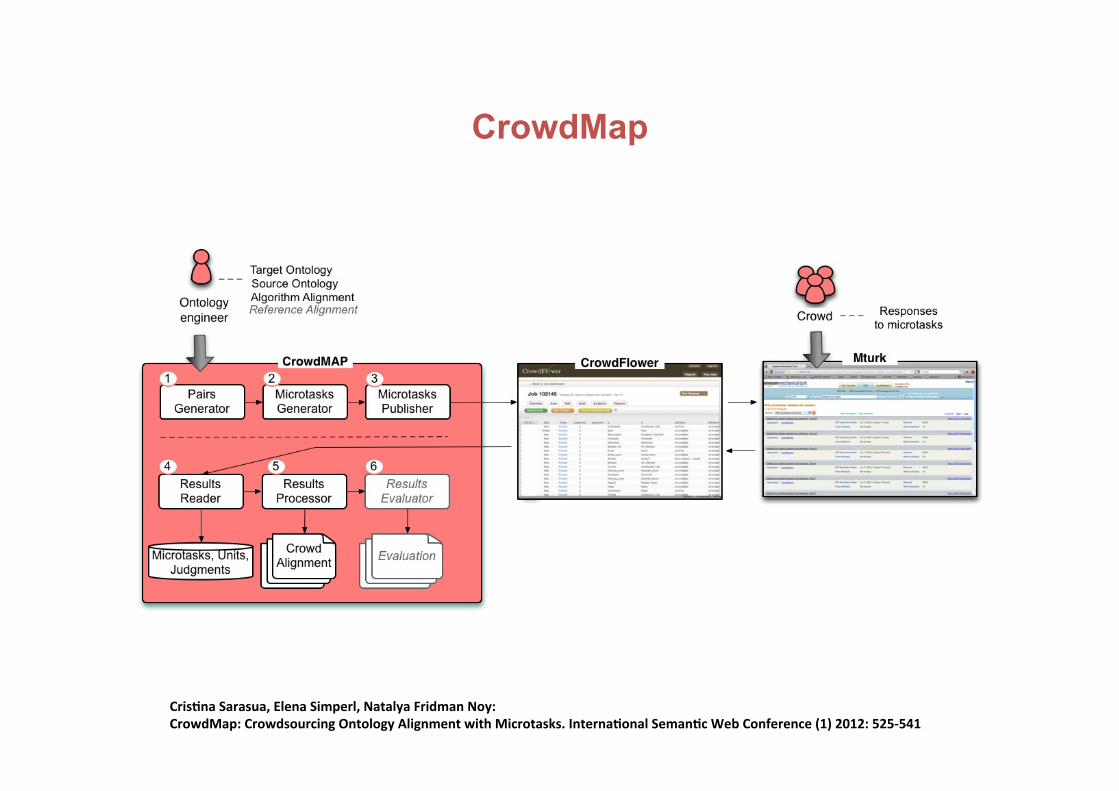
CrowdMap
Cris+naSarasua,ElenaSimperl,NatalyaFridmanNoy:CrowdMap:CrowdsourcingOntologyAlignmentwithMicrotasks.Interna+onalSeman+cWebConference(1)2012:525-541

Dalsze uwagi
NiekażdezadaniedasięłatwoprzerobićnaGWAP(wymógdekompozycjinamikro-zadania)
Tworzenieniektórychontologiiwymagabardzospecjalistycznejwiedzy
TocopowstajewwynikuGWAPjestraczej„płytkim”modelem
GWAPwymagastrategiizapobieganiaoszustwom

Scenariusze użycia baz wiedzy
• Semantycznewyszukiwanie• encjeaniesłowa
• Odpowiadanienapytania• np.IBMWaston,nawigatorywiedzy
• Analitykatekstów,ekstrakcjawiedzy• np.tekstymedyczne
• IntegracjadanychwceluanalitykiBigData• np.analizaefektówubocznychkombinacjileków,analiza
danychpochodzącychzróżnychoddziałówmiędzynarodowychkorporacji

61
Bibliografia
[1]C.Bizer,T.Heath,andT.Berners-lee“LinkedData–TheStorySoFar”InternavonalJournalonSemanvcWebandInformavonSystems(IJSWIS)(2009)
[2]T.Heath,andC.Bizer(2011)LinkedData:EvolvingtheWebintoaGlobalDataSpace(1stedivon).SynthesisLecturesontheSemanvcWeb:TheoryandTechnology,1:1,1-136.Morgan&Claypool.
[3]RDFaPrimer,h�p://www.w3.org/TR/xhtml-rdfa-primer/(lastaccessedon18.03.2009)


















