
Bazy Danych - Strona główna AGHhome.agh.edu.pl/~horzyk/lectures/pi/wdi_13_01_2015_noimg.pdf ·...
28
Wprowadzenie do Informatyki Bazy Danych mgr inż. Michał Grygierzec [email protected] http://home.agh.edu.pl/~horzyk/lectures/pi/ahdydpiwykl10.html
Transcript of Bazy Danych - Strona główna AGHhome.agh.edu.pl/~horzyk/lectures/pi/wdi_13_01_2015_noimg.pdf ·...

Wprowadzenie do Informatyki
Bazy Danychmgr inż. Michał Grygierzec
http://home.agh.edu.pl/~horzyk/lectures/pi/ahdydpiwykl10.html

WDI – Bazy Danych
Agenda:
1) Wstęp
2) Relacyjne bazy danych – teoria
3) Relacyjne bazy danych – praktyka
4) NoSQL
5) Eksploracja danych
6) AAI

Bazy Danych - Zastosowania
● Sektor finansowy● Sektor publiczny● Marketing● Wojsko● Ośrodki badawcze● Telekomunikacja● Social media● ...

Bazy Danych - definicja
BAZA DANYCH:● Kolekcja danych,
istniejących przez długi czas.
● Zarządzana za pomocą systemu DBMS (ang. DataBase Management System)
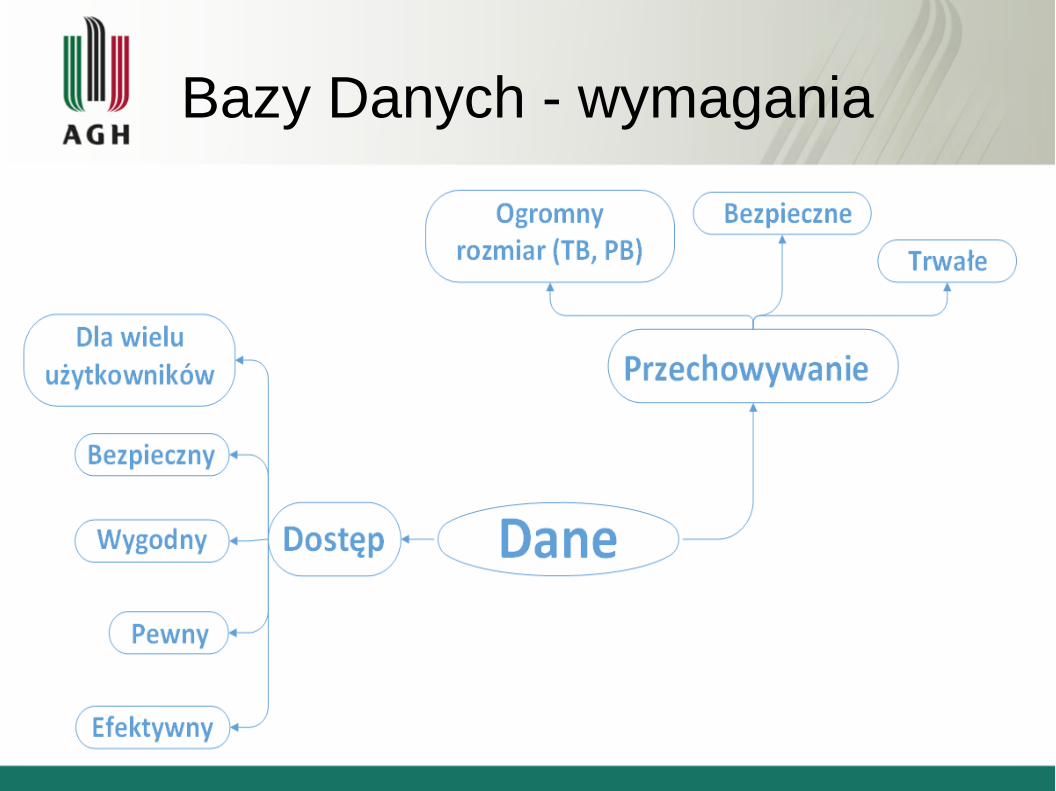
Bazy Danych - wymagania
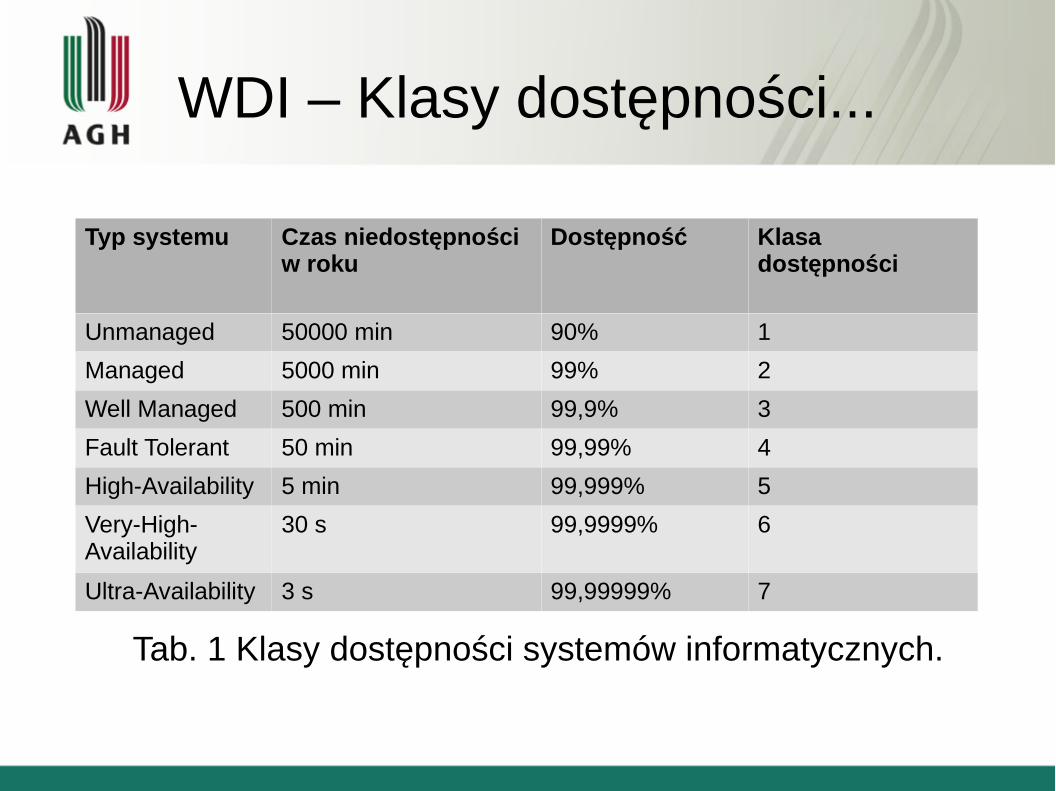
WDI – Klasy dostępności...
Typ systemu Czas niedostępności w roku
Dostępność Klasa dostępności
Unmanaged 50000 min 90% 1
Managed 5000 min 99% 2
Well Managed 500 min 99,9% 3
Fault Tolerant 50 min 99,99% 4
High-Availability 5 min 99,999% 5
Very-High-Availability
30 s 99,9999% 6
Ultra-Availability 3 s 99,99999% 7
Tab. 1 Klasy dostępności systemów informatycznych.

Bazy Danych – opis
Główne założenia i cechy:
● Złożone są z wielu powiązanych ze sobą tablic (relacji).● Tablice są w postaci dwuwymiarowej (krotki x kolumny).● Wszystkie wartości oparte są na prostych typach danych (int, float, text, datetime,
money, ...).● Schemat relacji: R(A1, …, An)● Rekord (komponent relacji)● Egzemplarz relacji
(zestaw krotek)
Rys. 1 Relacja
● Operacje wykonywane są w oparciu o algebrę relacji.
● Język zapytań baz danych – SQL

Bazy Danych – model relacyjny
Model relacyjny:
1) Struktura danych
2) Operacje na danych (elementy manipulacyjne)
3) Więzy danych (integralność)
place_no place_town place_country
1 Manchester England
2 Edinburgh Scotland
3 Salzburg Austria
Tab. 2 Tabela dwuwymiarowa – zbiór

Bazy Danych – klucze
Klucz:
1) Kandydujący – taki zestaw atrybutów, że dwie krotki w egzemplarzu relacji nie mogą mieć tych samych wartości we wszystkich atrybutach klucza
2) Główny - Jeśli relacja (tabela) posiada jeden klucz kandydujący, to staje się on automatycznie kluczem głównym. W przeciwnym wypadku trzeba dokonać wyboru.
3) Obcy - Klucz obcy jest zbiorem atrybutów jednej relacji (tabeli) i wskazuje wartości klucza kandydującego innej lub tej samej relacji (tabeli).
place_no place_town place_country
1 Manchester England
2 Edinburgh Scotland
3 Salzburg Austria
Tab. 2 Tabela z kluczem głównym place_no.
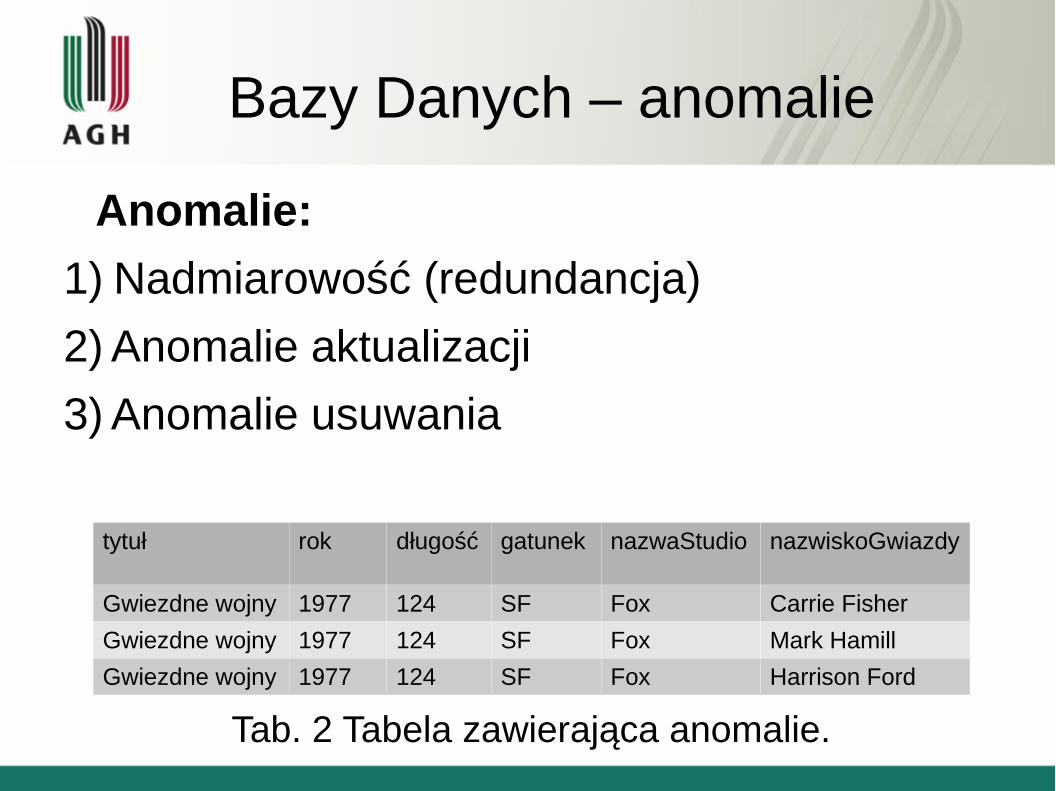
Bazy Danych – anomalie
Anomalie:
1) Nadmiarowość (redundancja)
2) Anomalie aktualizacji
3) Anomalie usuwania
tytuł rok długość gatunek nazwaStudio nazwiskoGwiazdy
Gwiezdne wojny 1977 124 SF Fox Carrie Fisher
Gwiezdne wojny 1977 124 SF Fox Mark Hamill
Gwiezdne wojny 1977 124 SF Fox Harrison Ford
Tab. 2 Tabela zawierająca anomalie.

Bazy Danych – normalizacja
Normalizacja:● Pozwala uniknąć anomalii● Dekomponuje tabelę na pomniejsze relacje
Tab. 2 Tabele po dekompozycji
tytuł rok nazwiskoGwiazdy
Gwiezdne wojny 1977 Carrie Fisher
Gwiezdne wojny 1977 Mark Hamill
Gwiezdne wojny 1977 Harrison Ford
● Może przyczynić się do pogorszenia wydajności dla bardzo złożonych danych
tytuł rok długość gatunek nazwaStudio
Gwiezdne wojny 1977 124 SF Fox

Bazy Danych - SQL
SQL – (ang. Structured Query Language) to deklaratywny, strukturalny język zapytań. Sposób pobierania i przechowywania danych wybierany jest przez DBMS. Podzbiory zapytań:
● SQL DML (ang. Data Manipulation Language – „język manipulacji danymi”),
● SQL DDL (ang. Data Definition Language – „język definicji danych”),
● SQL DCL (ang. Data Control Language – „język kontroli nad danymi”),
● SQL DQL (ang. Data Query Language – „język definiowania zapytań”).

Bazy Danych – SQL - DML
SQL DML – przeznaczony do manipulacji
danymi. Najważniejsze polecenia:
● INSERT – umieszcza dane w tabeli
● UPDATE – zmienia dane w tabeli
● DELETE – usuwa dane z tabeli

Bazy Danych – SQL - DDL
SQL DDL – umożliwia operowanie na strukturach
bazy danych (bazy, tabele, indeksy, kolumny).
Najważniejsze polecenia:
● CREATE – tworzy odpowiednie struktury
● DROP – usuwa odpowiednie struktury
● ALTER – zmienia odpowiednie struktury

Bazy Danych – SQL - DCL
SQL DCL – zarządzanie uprawnieniami w
bazie danych. Najważniejsze polecenia:
● GRANT – nadawanie uprawnień
● REVOKE – odbieranie (usuwanie) uprawnień
● DENY – zabranianie dostępu

Bazy Danych – SQL - DQL
SQL DQL – odpytywanie bazy danych. Najważniejsze słowa
kluczowe:
● SELECT (DISTINCT)
● FROM
● WHERE
● ORDER BY
● GROUP BY
● HAVING
● AVG, MIN, MAX, COUNT, SUM

WDI – NOSQL
NOSQL – (ang. Not Only SQL) bazy nie relacyjne (nie operują na tabelach).
● Alternatywa dla baz relacyjnych● Różne modele danych (key-value, graph, documents,...)● Wykorzystywane w problemach BigData i
nowoczesnych aplikacjach webowych● Popularne ze względu na łatwość projektowania,
użytkowania, skalowalność horyzontalną, lepszą kontrolę nad dostępnością

WDI – Eksploracja Danych
Eksploracja danych (ang. data mining) - to metodologia przeszukiwania danych (zwykle baz danych) w celu wydobycia wiedzy (czyli odpowiednio powiązanych ze sobą informacji) z eksplorowanego zbioru danych.
Wobec tego eksploracja danych jest interdyscyplinarną dziedziną łączącą techniki uczenia maszynowego, rozpoznawania i klasyfikacji wzorców, statystyki, baz danych, sztucznej inteligencji oraz wizualizacji w celu uzyskania informacji z dużych baz danych.

WDI – Eksploracja Danych
● W danych mogą występować tzw. punkty (obserwacje) oddalone (ang. outliers) zwane też czasami artefaktami danych (ang. artefacts) - które są pewnymi skrajnymi wartościami znajdującymi się blisko granic zakresu danych i występują w dużym oddaleniu od pozostałych danych lub są sprzeczne z ogólnym trendem pozostałych danych.

WDI – Zadania eksploracji danych I
● Opis - znalezienie metod opisu wzorców i trendów, jakie występują w danych, celem ich wyjaśnienia i zwiększenia przejrzystości.
● Klasyfikacja - to proces przyporządkowania obiektów do klas bazując na cechach obiektów obserwacji. W klasyfikacji istnieje pewna jakościowa zmienna celu, która decyduje o przyporządkowaniu obiektu. Zwykle obiekty pewnej klasy mają pewną ilość cech podobnych i to decyduje o sklasyfikowaniu - poprawnym przyporządkowaniu obiektu do klasy. Algorytm klasyfikujący może też uczyć się takiego przyporządkowania na podstawie pewnego zbioru uczącego poprawnych przyporządkowań.
● Grupowanie (klasteryzacja, ang. clustering) - oznacza grupowanie obiektów (rekordów, obserwacji) w klasy podobnych obiektów, które łączy pewna ilość wspólnych lub podobnych cech. Grupowanie od klasyfikacji różni się tym, że w przypadku grupowania nie ma określonej zmiennej celu, nie ma też podanego żadnego zbioru uczącego, wg którego takie grupowanie miałoby się odbywać. W procesie grupowania zasadnicze znaczenie odgrywa relacja podobieństwa stosowana do różnych cech lub ich kombinacji, która zwykle decyduje o sposobie pogrupowania obiektów. W bardziej zaawansowanych procesach grupowania mogą zostać wykorzystane również inne relacje grupujące.

WDI – Zadania eksploracji danych II
● Szacowanie (estymacja) - to zagadnienie podobne do klasyfikacji za wyjątkiem zmiennej celu, która jest numeryczna, a nie jakościowa. Modele są budowane za pomocą "pełnych rekordów" zawierających wartości zarówno zmiennej celu jak i zmiennych estymacji. Następnie dla nowych obserwacji, szacuje się wartość zmiennej celu, opierając się na wartościach opisujących.
● Przewidywanie (predykcja) - to zagadnienie podobne do klasyfikacji i szacowania za wyjątkiem faktu, iż w przewidywaniu wynik dotyczy przyszłości.
● Odkrywanie reguł (ang. association rules) - polega na szukaniu, które atrybuty "są powiązane ze sobą" najczęściej na podstawie analizy podobieństw (ang. affinity analysis). Odkrywanie reguł może też przybierać postać różnych reguł asocjacji danych, które mogą być nie tylko relacjami podobieństwa, ale również antagonizmu, zawierania, dopełnienia, następstwa, sąsiedztwa itp.

Wstępne przetwarzanie danych
Zmienne (dane) mają na ogół bardzo różne zakresy, więc może istnieć pewna trudność w ich porównywaniu czy dokonywaniu obliczeń na nich tak, żeby pewne dane nie zdominowały tego procesu. Dlatego dane bardzo często są najpierw normalizowane lub standaryzowane przed dokonaniem na nich obliczeń:
● Normalizacja min-max (ang. min-max normalization) określa jak bardzo wartość pola jest większa od wartości minimalnej i skalowanej na zakres zmienności danych:
X* = [X - min(X)] / [max(X) - min(X)]
● Standaryzacja (ang. Z-score standardization) polega na obliczeniu różnicy pomiędzy daną wartością pola i średnią wartością pola oraz przeskalowaniu tej różnicy przez odchylenie standardowe wartości pól:
X* = [X - średnie(X)] / odchylenie_standardowe(X)

AAI
AAI – (ang. Associative Artifficial Intelligence)
● AGDS - (ang. Associative Graph Data Structures) asocjacyjne grafowe struktury danych
● Ciekawa alternatywa dla relacyjnych baz danych
● Efektywna eksploracja danych
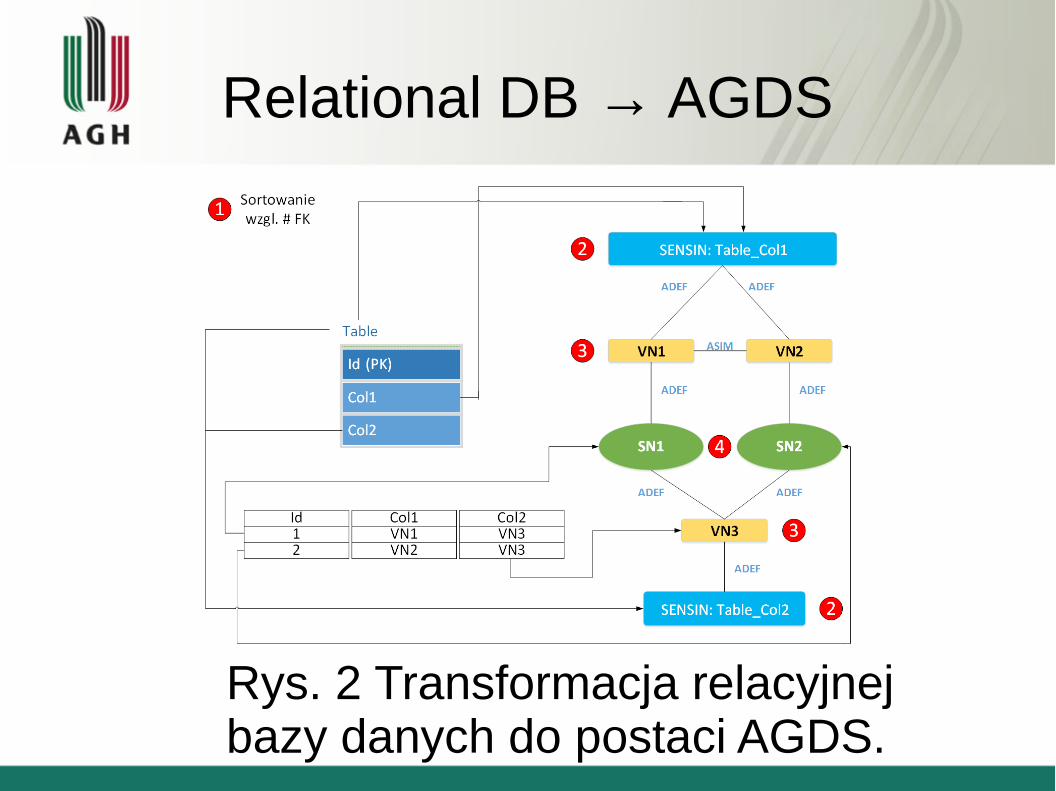
Relational DB → AGDS
Rys. 2 Transformacja relacyjnej bazy danych do postaci AGDS.

Bibliografia - literatura
● Jeffrey D. Ullman, Jennifer Widom: Podstawowy kurs systemów baz danych, Helion, Gliwice, 2011
● Thomas Connolly, Carolyn Begg: Systemy baz danych, tom 1 i 2, Wydawnictwo RM, Warszawa, 2004
● Hector Garcia-Molina, Jeffrey D. Ullman, Jennifer Widom: Systemy baz danych. Pełny wykład, WNT, Warszawa, 2006
● Chris J. Date: Relacyjne bazy danych dla praktyków, Wydawnictwo Helion, Gliwice, 2006● Joe Celko: SQL zaawansowane techniki programowania, Wydawnictwo Naukowe PWN,
Warszawa, 2008● D. T. Larose, Odkrywanie wiedzy z danych. Wprowadzenie do eksploracji danych, PWN,
2006● Data Mining● K. J. Cios, W. Pedrycz, R. W. Swiniarski, L. A. Kurgan, A Knowledge Discovery Approach,
Springer, 2007● Wikipedia - internetowa wolna encyklopedia

Bibliografia - odnośniki
● Wikipedia - internetowa wolna encyklopedia● https://class.stanford.edu/courses/DB/2014/SelfPaced/about - solidne
podstawy, ciekawe zadania● http://sqlzoo.net - tutoriale, zadania● http://db-engines.com/en/ - przegląd systemów baz danych (nie tylko
SQL!): Oracle, SQL Server, PostgreSQL, MongoDB, CouchDB, ArangoDB, Cassandra, Riak, Titan, …
● http://msdn.microsoft.com/en-us/library/ms143432.aspx - ograniczenia
(rozmiar bazy, liczba kolumn, itp.)● https://www.coursera.org/● https://www.edx.org/● http://ocw.mit.edu/index.htm● https://www.codeschool.com/ - technologie webowe

Dziękuję za uwagę[email protected]

Źródła zewnętrzne:
● Tab. 1: ● https://pl.wikipedia.org/wiki/Dost%C4%99pno
%C5%9B%C4%87_%28niezawodno%C5%9B%C4%87%29
● Rys. 1: https://pl.wikipedia.org/wiki/Model_relacyjny#mediaviewer/File:Relational_model_concepts_PL.png


















