
AWS Lambda
36
AWS Lambda Alexander Savchuk Xero @endofcake
-
Upload
alexander-savchuk -
Category
Engineering
-
view
549 -
download
0
Transcript of AWS Lambda

AWS LambdaAlexander Savchuk
Xero@endofcake

Lambda basics

What is Lambda
● A managed compute service that runs your code, written as a single function● Triggered by events
○ AWS events (S3, Kinesis, DynamoDB etc)○ direct sync and async invocations○ calls to API Gateway○ scheduled events

Overview
● languages: JavaScript (Node.js v0.10.36), Java (any JVM language), Python, + BYO
● simple resource allocation○ memory from 128MB to 1.5GB in 64MB increments○ CPU and network allocated proportionately to RAM○ 500MB of scratch space on disk
● max execution time - 300 s, rounded to the nearest 100 ms by AWS● AWS Free Tier includes 1 million free requests and up to 3.2 million seconds
of compute time per month● runs on top of Amazon Linux AMI with pre-installed AWS SDK and
ImageMagick
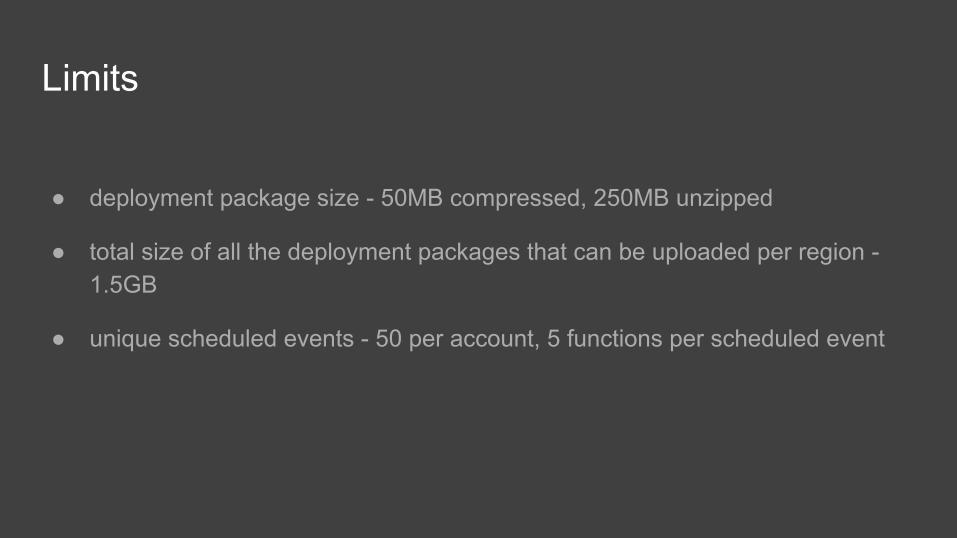
Limits
● deployment package size - 50MB compressed, 250MB unzipped
● total size of all the deployment packages that can be uploaded per region - 1.5GB
● unique scheduled events - 50 per account, 5 functions per scheduled event

Use cases
● event-driven tasks● scheduled events (cron-like)● offloading heavy processing tasks● infrequently used services● API endpoints

Obligatory buzzwords
● “serverless”● “stateless”● “infinitely scaleable”

“Serverless”
● host access is severely restricted○ can’t SSH into the server○ no direct access to system logs○ no control over security patches and OS upgrades○ can’t fine-tune hardware configuration (memory is the only dial you get)
● not suitable for long-running tasks

● it’s still a server under the hood, and you can execute (some) arbitrary shell commands
● can start other process(es) from your lambda● this can be used to write lambdas in other languages (example: Goad.io, a
distributed load testing tool written in Go)

“Infinitely scaleable”
● default safety throttle of 100 concurrent executions per account per region● working with streams (Kinesis or DynamoDB Stream) is special:
○ processing of each shard is done serially. This means that each batch of records must
succeed before Lambda will move on to the next batch, which preserves the ordering guarantee of the shard.
○ within one stream, each shard is treated individually. As long as the account remains under its total concurrency limit, all shards will be processed in parallel
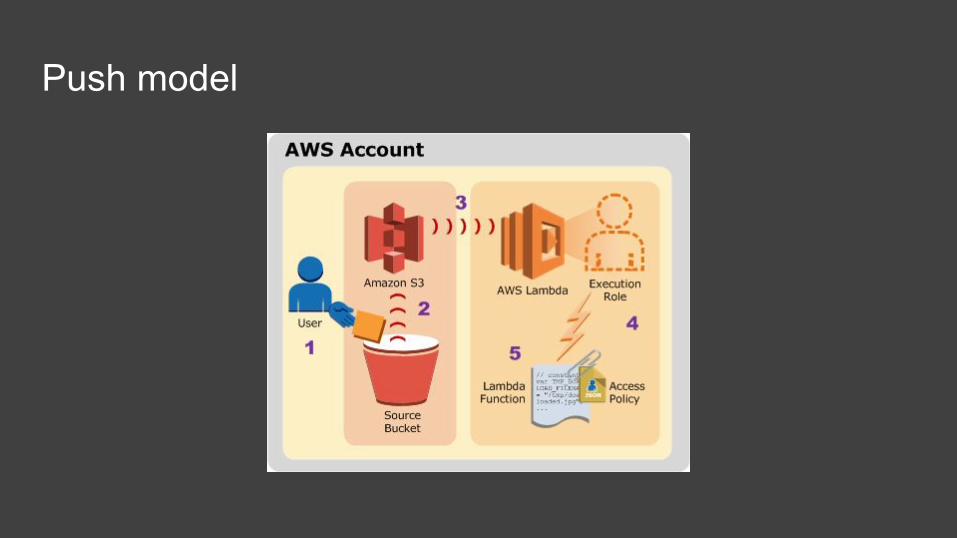
Push model
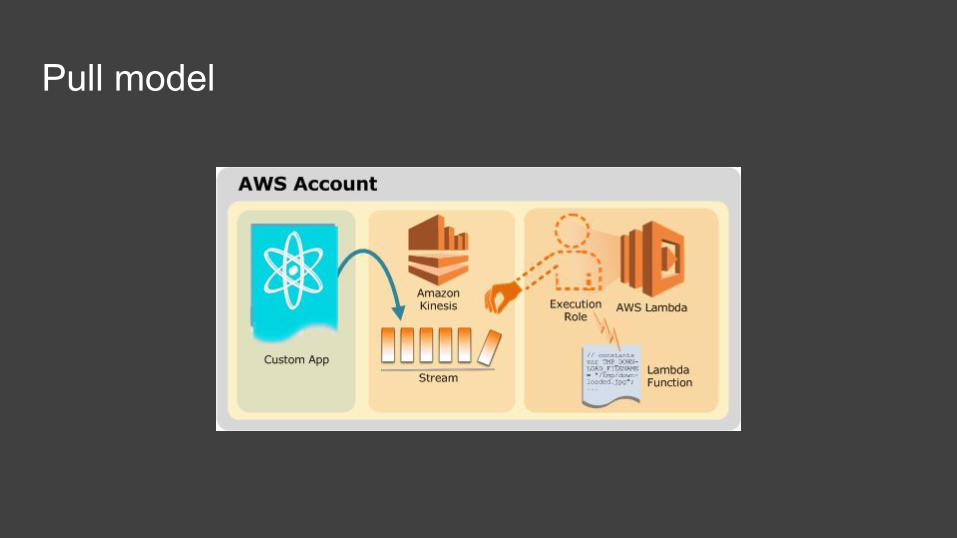
Pull model
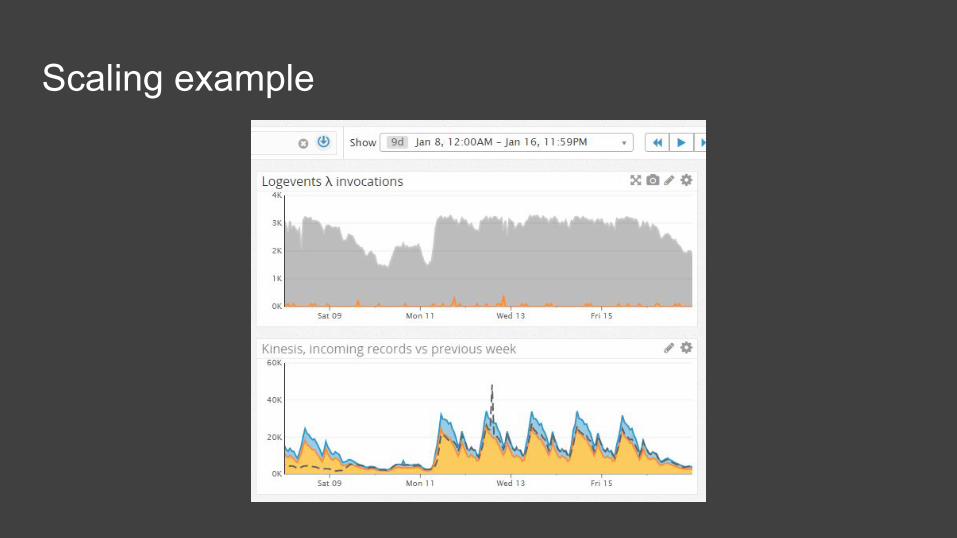
Scaling example

“Stateless”● persistent data should be stored outside of the container● it is still possible to reuse config settings and global variables● data on disk is persisted between invocations, as long as the same container
is used● if you spawn long running background threads / processes, they will be frozen
when your handler terminates, and will “thaw” the next time container is reused
https://aws.amazon.com/blogs/compute/container-reuse-in-lambda/

Security● each Lambda assumes an IAM role, which allows it to interact with other AWS
services● if a resource doesn’t support IAM (VPC hosted data stores like Redshift or
RDS), you will still have to manage secrets

A closer look at lambda

Anatomy of a lambdaconsole.log('Loading function');
var AWS = require('aws-sdk'); // runs once at start time
function doStuff(event, cb) {...}
exports.handler = function (event, context) { // runs on every invocation
doStuff(event, function (err, data) {
if (err) {
context.fail('Something went wrong');
}
context.succeed();
});
};

Handler
● the exported method will be called when lambda is invoked● doesn’t have to be called handler● must take 2 arguments: event and context
○ event is an object that contains information about the event that triggered the function○ context contains internal information about the function itself and methods for ending it
■ context.fail()
■ context.succeed()
■ context.functionName
■ context.getRemainingTimeInMillis()

Lambda lifecycle
● after uploading is stored encrypted in S3● on first invocation (cold execution)
○ download from S3 to a container of an appropriate size○ run checksum and unzip / decrypt○ initialise everything outside of event handler○ call event handler
● subsequent invocations - hot execution (only handler is called)● on error - reinitialise on the same container, or initialise on a new one● decommissioned after some time of inactivity (~10-15 minutes)

Cold execution vs hot execution
● cold boot hit: ~600 ms for simple Node functions, several seconds for Java● infrequent calls to lambda functions can make a single invocation orders of
magnitude slower● subsequent invocations seem to be faster for Java, Java also seems to
benefit more from higher memory / CPU● API Gateway enforces a 10-second timeout → 504 Gateway Timeout Error
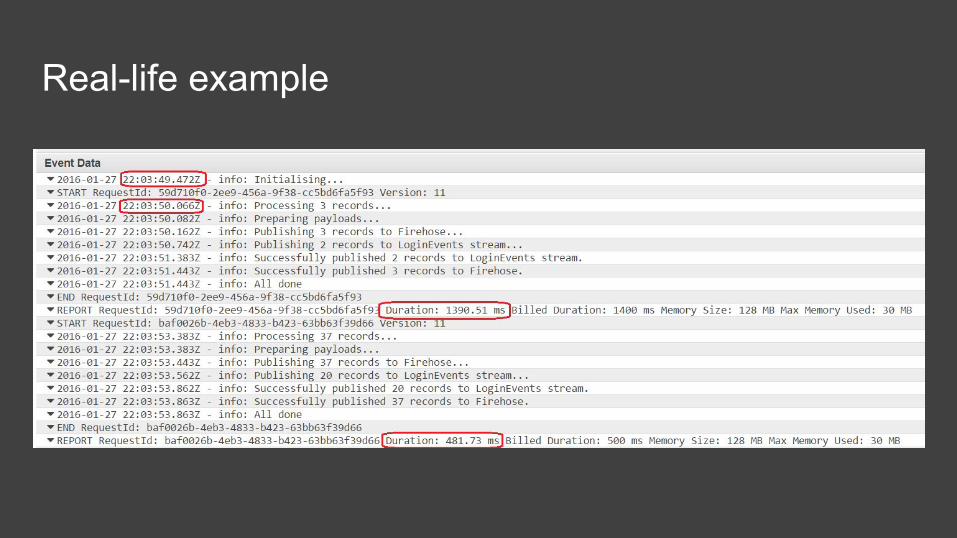
Real-life example

Dealing with cold boot
● keep your functions lean: require only modules that are absolutely necessary, don’t include any unnecessary files (READMEs, tests, utility functions)
○ don’t include AWS SDK, put it into ‘devDependencies’
● increase memory size (affects CPU and network proportionally). Containers with higher memory assignment may have a longer lifetime
● combine your code with config at deploy time to avoid having to hit S3, DynamoDB or KMS
● invoke your function periodically using a scheduled lambda

Initialisation
● “global” code (outside of request handler) is initialised once per container● good place to do any static configuration, set global variables or make any
external calls to DynamoDB / S3 / KMS to retrieve dynamic config

Static configuration● pre-baked
- need to redeploy to update config, + after a redeployment you’re guaranteed that lambda will pick up the latest
config ● config.js(on)
○
● .env (‘dotenv’ npm module) + environment variables when run locally○ system-level env vars trump .env○ set env vars at the process level (in the test harness)○ load .env on lambda init
○ add .env to .gitignore, commit .sample-env to source control, initialise using a custom npm script (npm run setup)
var config = require('./config.json');

Dynamic configuration
● DynamoDB or S3, + KMS for secrets● lambda is aware of its name, so you can run multiple stacks in one account,
add an appropriate postfix to each lambda, and then look for this key in a shared table / bucket
● still need to recycle lambda to ensure that it picks up the latest config, or hit an external resource on each request

Error handling
● for S3 bucket notifications and custom events Lambda will retry three times● for ordered event sources (DynamoDB or Kinesis streams), Lambda will retry
until the data expires (maximum of 7 days for Kinesis)○ that’s how long a shard can be completely blocked with a bad record
● rule of thumb for Kinesis:○ context.fail() for transient errors (network timeouts etc). Lambda will retry automatically○ context.succeed() for “hard” (irrecoverable) errors, isolate the borked event and carry on○ JSON.parse() is the worst offender

Authoring your first lambda

Get samples of the event object
exports.handler = function(event, context) {
console.log("event: ", JSON.stringify(event, null, 1));
context.succeed();
}

Ways to test
● unit tests: modularise your code and test it outside lambda using conventional tools
● integration: invoke lambda locally and validate that it has no compilation errors, can successfully run the provided event.json and call AWS services
● full stack: deploy to AWS and run there (helps to find missing libs, permission issues)

A simple test harnessvar lambda = require('./lambda.js');
describe('Some integration tests', function () {
// Set Mocha timeout to 5 seconds, as the whole suite can take a while to run
this.timeout(5000);
this.slow(3000);
it('should more or less work', function (done) {
var event; // set up event object
var context = getFakeContext(done);
lambda.handler(event, context);
});
});

Mock context object
function getFakeContext(done) {
return {
succeed: function () {
assert.ok(true);
done();
},
fail: function (err) {
assert.fail(err);
done();
}
};
}

Logging
● all console.log() statements are accessible in CloudWatch within a couple minutes
● each lambda function creates a separate log group● within the group, each instance creates a new log stream● logs contain lots of (not always useful) information and are difficult to visually
parse and search● no clear differentiation between various log levels
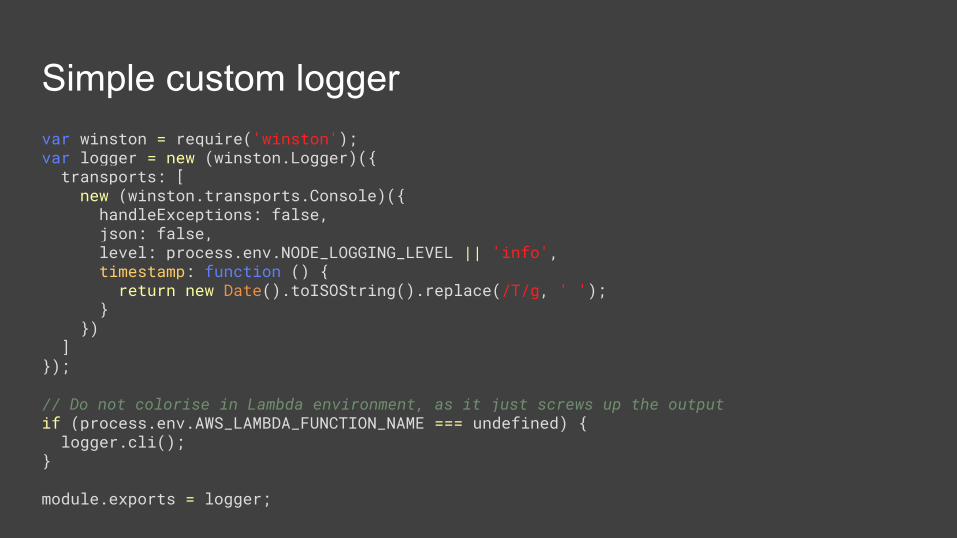
Simple custom loggervar winston = require('winston');var logger = new (winston.Logger)({ transports: [ new (winston.transports.Console)({ handleExceptions: false, json: false, level: process.env.NODE_LOGGING_LEVEL || 'info', timestamp: function () { return new Date().toISOString().replace(/T/g, ' '); } }) ]});
// Do not colorise in Lambda environment, as it just screws up the outputif (process.env.AWS_LAMBDA_FUNCTION_NAME === undefined) { logger.cli();}
module.exports = logger;
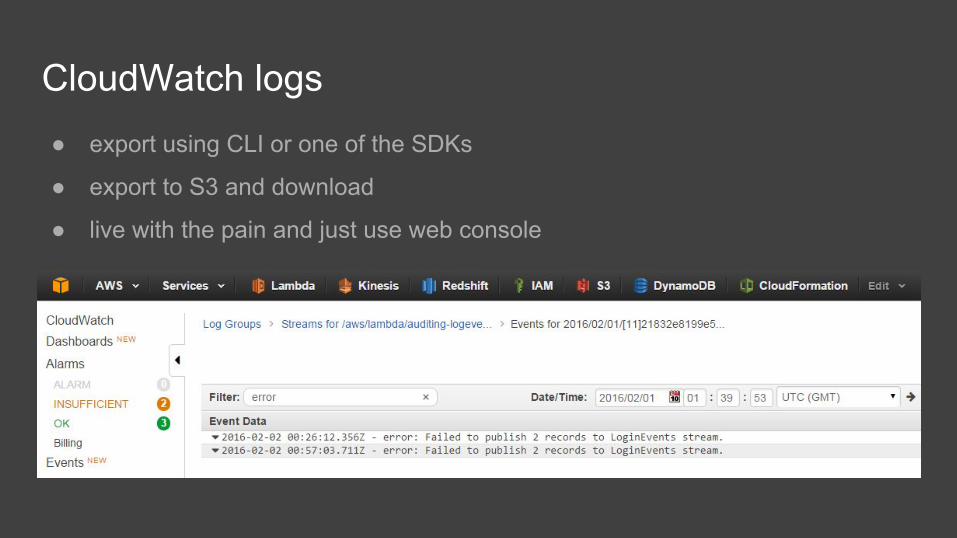
CloudWatch logs● export using CLI or one of the SDKs
● export to S3 and download
● live with the pain and just use web console

DeploymentCustom deployment script
● npm install --production● zip contents of the folder, not the folder itself● mutable code vs immutable (published) versions + aliases● every version counts towards 1.5 GB limit for total size of all deployed
packages● package.json to keep lambda metadata (name, description, files and the
main entry point / handler)
Or use a wrapper like claudia.js

Thanks!


















