
Analiza struktury i przeciętnego poziomu cechymath.uni.lodz.pl/~skalskg/MiSwF/09wyklad08.pdf · 35...
55
Analiza struktury i przeciętnego poziomu cechy
Transcript of Analiza struktury i przeciętnego poziomu cechymath.uni.lodz.pl/~skalskg/MiSwF/09wyklad08.pdf · 35...

Analiza struktury i przeciętnego poziomu cechy

Analiza strukturyPod pojęciem analizy struktury rozumiemy badanie budowy (składu) określonej zbiorowości, lub próby, tj. ustalenie, z jakich składa się elementów oraz jaką część stanowią owe elementy w całym zbiorze.

Wskaźniki strukturyWyrażają stosunek części zbiorowości statystycznej (ni) do jej całości (N). Można je wyznaczyć za pomocą formuły
wi =ni
N⋅ 100 % , i = 1,2,…, k .
Wskaźniki struktury są liczbami względnymi (niemianowanymi). Ma to nie tylko duże znaczenie poznawcze, ale również praktyczne. Przykładowo: w przedsiębiorstwie A wykształcenie wyższe ma 10 na 1000 pracowników, natomiast w przedsiębiorstwie B — 5 na 50 pracujących, zatem 1% pracowników w firmie A, a 10% w firmie B ma wykształcenie wyższe.

Wskaźniki strukturyWskaźniki struktury mówią jaką część stanowi wybrana grupa klasyfikacyjna w całej zbiorowości.
Wskaźniki struktury, jako proste i zrozumiałe mierniki, znajdują szerokie zastosowanie w praktyce badań statystycznych. Istotną ich zaletą jest fakt, że mogą być stosowane dla dowolnych cech (mierzalnych i niemierzalnych), gdyż wykorzystują liczebności cząstkowe i łączną liczebność zbiorowości, bez udziału samych wariantów cechy.
wi =ni
N⋅ 100 % , i = 1,2,…, k .

PrzykładW pewnym łódzkim liceum do egzaminu maturalnego w 2009 roku przystąpiło 240 uczniów, z czego 162 osoby stanowiły kobiety.
w1 =162240
⋅ 100 % = 0,675 ⋅ 100 % = 67,5 % .
Aby obliczyć jaki procent zdających maturę stanowiły kobiety (w1) stosujemy wzór:
Z kolei w celu ustalenia, jaki odsetek stanowili mężczyźni (w2) stosujemy wzór:
w2 =240 − 162
240⋅ 100 % = 0,325 ⋅ 100 % = 32,5 % .

Wskaźnik podobieństwa struktur
Czasami badacza interesuje nie tylko, jaka jest struktura danej zbiorowości, ale także to, czy jest ona podobna do innej (np. czy struktura zarobków kobiet i mężczyzn jest do siebie zbliżona). Syntetycznym miernikiem podobieństwa struktur jest wskaźnik podobieństwa struktur dany wzorem:
wp =k
∑i=1
min(w1i, w2i),
gdziew1i - wskaźnik struktury pierwszej zbiorowości,
w2i - wskaźnik struktury drugiej zbiorowości.

Wskaźnik podobieństwa struktur
Warunkiem zastosowania tego wskaźnika jest takie samo grupowanie obu zbiorowości ze względu na badaną cechę mierzalną lub niemierzalną.
Wartości wskaźnika podobieństwa struktur zawierają się w przedziale od 0 do 1 (lub w wyrażeniu procentowym od 0 do 100 procent). Im bliższe jedności (lub 100%) wartości tego wskaźnika, tym większe podobieństwo analizowanych struktur. Wartość wskaźnika równa 1 (100%) oznacza, że struktury są identyczne.

PrzykładPoniższa tablica przedstawia liczbę osób ukaranych przez sąd grodzki w miejscowościach A i B. Zbadamy czy struktura wiekowa ukaranych w tych dwóch miejscowościach jest podobna.
Wiek (w latach)Liczba ukaranych
A B20 — 24 5 1025 — 29 10 6030 — 34 12 9035 — 39 20 10040 — 44 130 9045 — 49 23 50Razem 200 400

PrzykładWiek
(w latach)Liczba ukaranych Wskaźniki struktury
min(w1i, w2i)A B w1i w2i
20 — 24 5 10 0,025 0,025 0,02525 — 29 10 60 0,05 0,15 0,0530 — 34 12 90 0,06 0,225 0,0635 — 39 20 100 0,1 0,25 0,140 — 44 130 90 0,65 0,225 0,22545 — 49 23 50 0,115 0,125 0,115Razem 200 400 1 1 0,575
Wskaźnik podobieństwa struktur wynosi wp = 0,575. Wielkość ta świadczy o umiarkowanym podobieństwie badanych struktur ze względu na wiek osób ukaranych przez sądy grodzkie w porównywanych miejscowościach.

Miary średnieJeżeli cecha, którą analizujemy w zbiorowości jest cechą mierzalną, to zbiorowość możemy scharakteryzować w sposób syntetyczny za pomocą miar wyrażających jej przeciętny poziom.
Miary przeciętne charakteryzują średni lub typowy poziom wartości cechy. Są to więc takie miary, wokół których skupiają się wszystkie pozostałe wartości analizowanej cechy.
Miary przeciętne dzielą się na miary klasyczne i pozycyjne. Pierwsze wyznaczane w oparciu o wszystkie wartości cechy drugie wskazują określoną pozycję jednostek (np. środkową lub dominującą).

Miary średnie
Miary przeciętne
Klasyczne • Średnia arytmetyczna • Średnia harmoniczna • Średnia geometryczna
Pozycyjne • Dominanta • Mediana

Średnia arytmetycznaWyraża ona przeciętny poziom badanej cechy (zmiennej) w populacji, np. przeciętna miesięczna sprzedaż, średnia ocena na świadectwie szkolnym itp. Interpretacja średniej i metoda jej wyznaczania jest zawsze taka sama, jednak techniczny sposób obliczenia średniej zależy od typu szeregu statystycznego, z którym mamy do czynienia. Średnia jest sumą wartości cechy podzieloną przez liczbę jednostek zbiorowości. Średnią arytmetyczną oznaczamy symbolem:
x - dla próby,μ - dla populacji.

Średnia arytmetycznaWzór na średnią arytmetyczną dla szeregu szczegółowego:
x =x1 + x2 + … + xN
N=
N∑i=1
xi
N.
Wzór na średnią arytmetyczną ważoną, gdy wartości cechy występują więcej niż jeden raz (xi występuje ni razy):
x =n1x1 + n2x2 + … + nkxk
N=
k∑i=1
nixi
N.

PrzykładOceny z
matematykixi
Liczba uczniówni
nixi
1 2 22 4 83 10 30
3,5 4 144 4 16
4,5 1 4,55 2 106 1 6
Razem 28 90,5
x =
k∑i=1
nixi
N=
90,528
= 3,23.

Średnia arytmetycznaW szeregach rozdzielczych przedziałowych wartości cechy w każdej klasie nie są jednoznacznie określone, ale mieszczą się w pewnym przedziale. Możemy jednak przyjąć umowę, że wartości cechy wewnątrz każdego przedziału rozłożone są równomiernie, a wówczas środek przedziału jest jednocześnie średnią wartością cechy w danej klasie. Środek i-tego przedziału klasowego oznaczamy przez .∘xi
∘xi =x0i + x1i
2

Średnia arytmetycznaJest to oczywiście pewne przybliżenie wartości cechy.
x =
k∑i=1
ni∘xi
N.
Do obliczenia średniej ważonej dla szeregu rozdzielczego przedziałowego stosujemy:
x0i x1i∘xi
⟨x0i, x1i)

PrzykładW pewnym przedsiębiorstwie zatrudniającym 130 osób przeprowadzono badanie stażu pracy:
Staż pracy(w latach)(x0i — x1i)
Liczba pracowników(ni)
2 — 4 104 — 6 206 — 8 358 — 10 4510 — 12 1512 — 14 5Razem 130
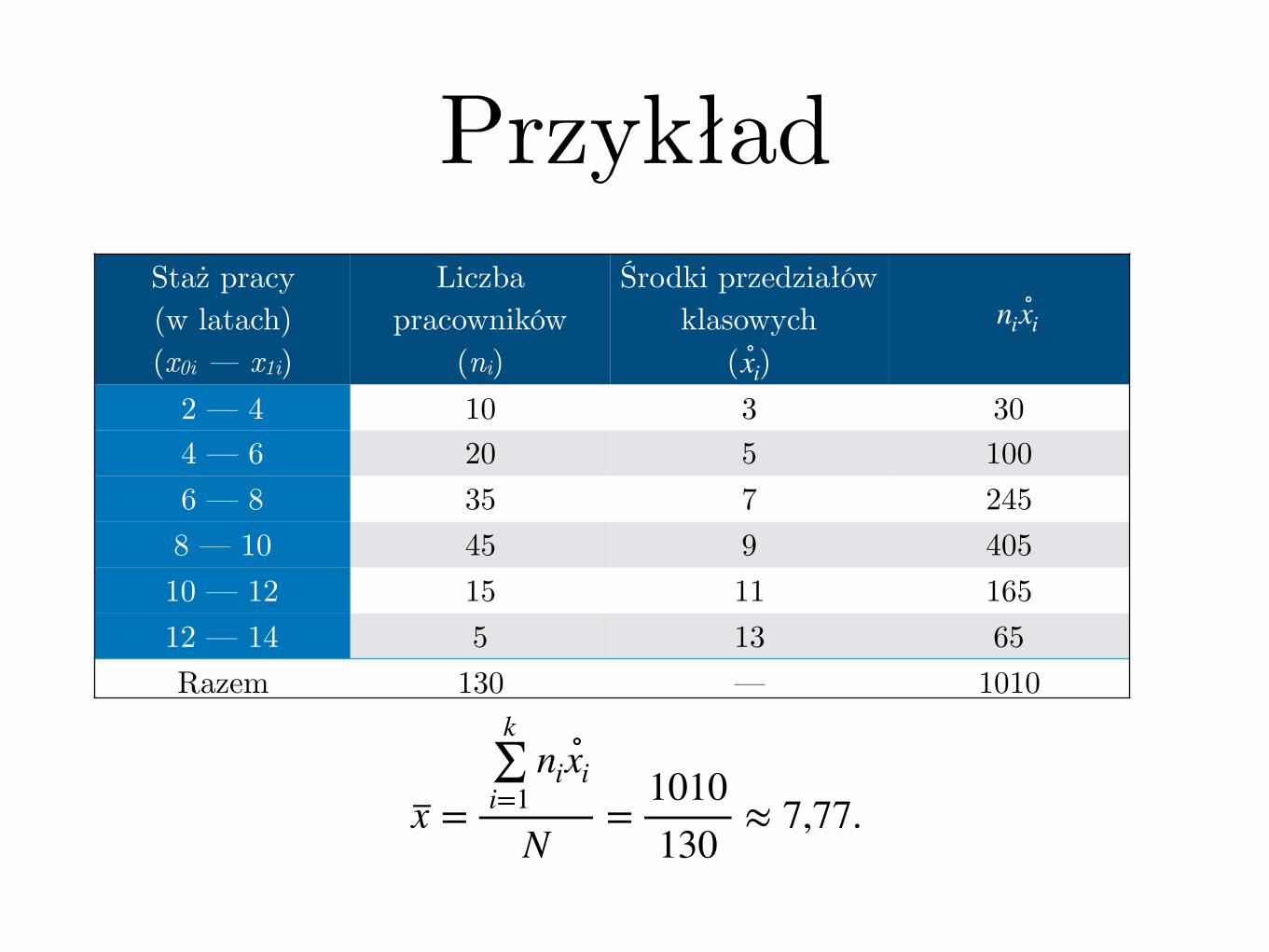
PrzykładStaż pracy(w latach)(x0i — x1i)
Liczba pracowników
(ni)
Środki przedziałów klasowych
( )2 — 4 10 3 304 — 6 20 5 1006 — 8 35 7 2458 — 10 45 9 40510 — 12 15 11 16512 — 14 5 13 65Razem 130 — 1010
ni∘xi
∘xi
x =
k∑i=1
ni∘xi
N=
1010130
≈ 7,77.

Średnia arytmetycznaJeśli zamiast liczebnościami (ni) dysponujemy wskaźnikami struktury (wi), to średnią wyznaczamy przy pomocy wzoru:
x =k
∑i=1
wi∘xi
albo wzoru
x =
k∑i=1
wi∘xi
100,
gdy wskaźniki struktury wyrażone są w procentach.

Własności średniej arytmetycznej
∙ xmin < x < xmax,
∙N
∑i=1
(xi − x) = 0, ∙k
∑i=1
ni(xi − x) = 0,
∙ Nx =N
∑i=1
xi, ∙ Nx =k
∑i=1
nixi,
∙ Jeżeli wszystkie wartości cech powiększymy o pewnąstałą, to średnia powiększy się o tą stałą.

DominantaDominanta (wartość modalna, moda) jest to wartość, która w zbiorowości powtarza się najczęściej. Dominantę oznaczamy symbolem
Do
Stosujemy ją wtedy, gdy chcemy za pomocą jednej liczby wyrazić wariant lub wartość cechy najbardziej typowy, najczęściej spotykany.Sposób wyznaczania dominanty zależy od typu szeregu statystycznego, z którym mamy do czynienia. Dla szeregów szczegółowych lub rozdzielczych punktowych dominantę wystarczy wskazać, gdyż jest to wartość o największej liczebności.

PrzykładW roku szkolnym 2017/2018 uczeń otrzymał następujące oceny: 2; 2; 3; 3; 3; 3,5; 3,5; 4; 4; 4,5; 4,5; 4,5; 4,5; 5; 5.
Do = 4,5.
Oznacza to, że uczeń najczęściej otrzymywał ocenę 4,5.

PrzykładWyniki kolokwium ze statystyki w jednej z grup przedstawia poniższa tabela
Do = 3.
Oznacza to, że najwięcej studentów otrzymało ocenę dostateczną 3.
Ocena Liczba uczniów
2 43 10
3,5 44 4
4,5 15 2
Razem 25

DominantaW przypadku danych przedstawionych w postaci szeregu rozdzielczego przedziałowego wiemy, która grupa dominuje na tle całości, ale nie wiemy, która wartość przedziału jest rzeczywistą wartością dominującą. W takich przypadkach obliczamy tylko przybliżoną wartość dominanty:
Do = x0 +(n0 − n−1)h0
(n0 − n−1) + (n0 − n+1),
x0 − dolna granica przedziału dominującego,
n0 − częstość przedziału dominującego,
n−1, n+1 − częstości przedziałów: poprzedzającego i następującego,
h0 − rozpiętość przedziału dominującego.

DominantaAby wyznaczyć dominantę w przypadku szeregu rozdzielczego przedziałowego muszą być spełnione następujące warunki:
• Musi występować jeden przedział klasowy z wyraźnie dominującą liczebnością w stosunku do pozostałych,
• Przedział klasowy, w którym znajduje się dominanta oraz przedziały z nią sąsiadujące muszą mieć jednakowe rozpiętości,
• Szereg nie może być skrajnie asymetryczny z otwartym przedziałem dominującym.
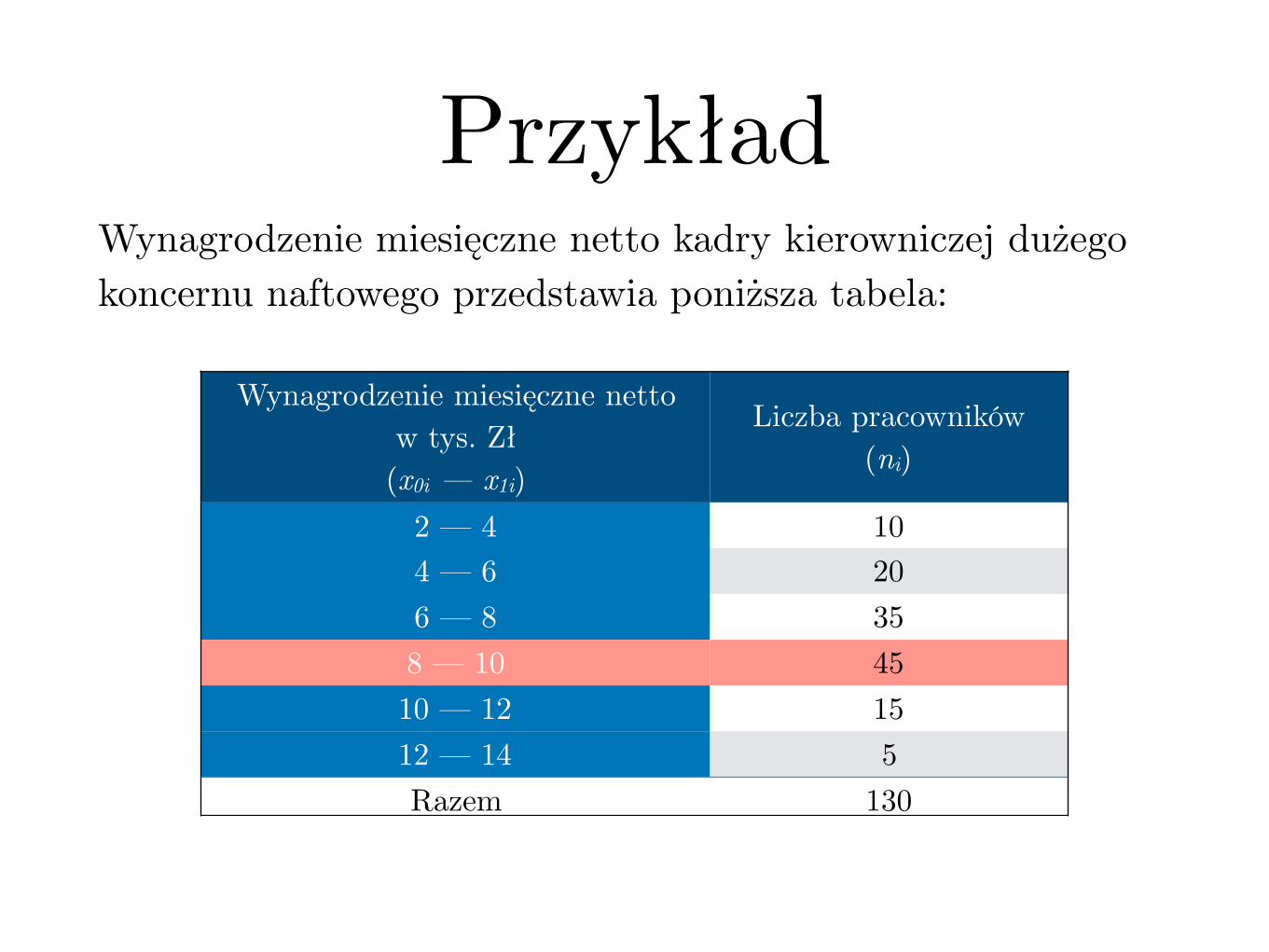
PrzykładWynagrodzenie miesięczne netto kadry kierowniczej dużego koncernu naftowego przedstawia poniższa tabela:
Wynagrodzenie miesięczne nettow tys. Zł(x0i — x1i)
Liczba pracowników(ni)
2 — 4 104 — 6 206 — 8 358 — 10 4510 — 12 1512 — 14 5Razem 130
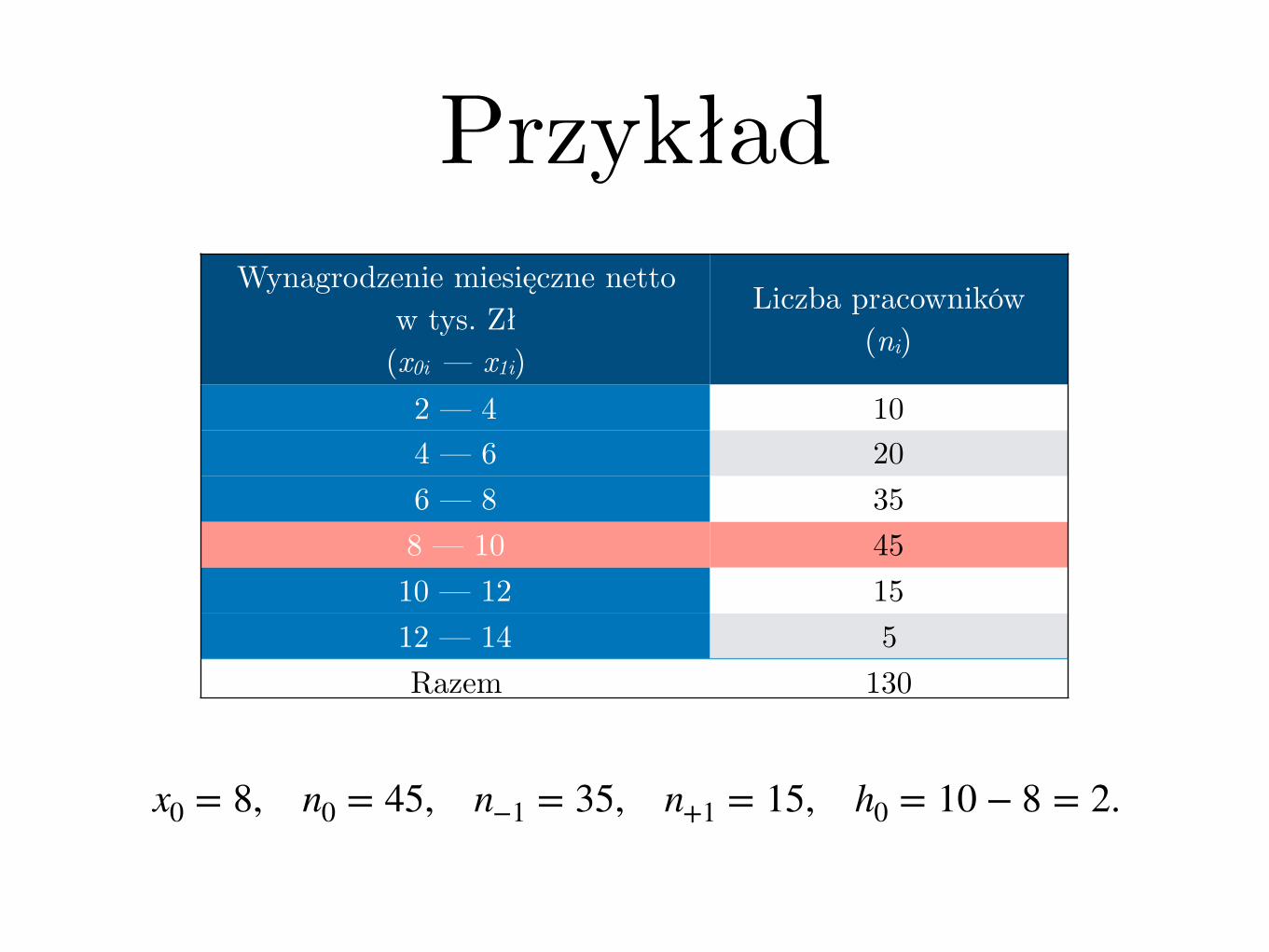
PrzykładWynagrodzenie miesięczne netto
w tys. Zł(x0i — x1i)
Liczba pracowników(ni)
2 — 4 104 — 6 206 — 8 358 — 10 4510 — 12 1512 — 14 5Razem 130
x0 = 8, n0 = 45, n−1 = 35, n+1 = 15, h0 = 10 − 8 = 2.

Przykładx0 = 8, n0 = 45, n−1 = 35, n+1 = 15, h0 = 10 − 8 = 2.
Do = x0 +(n0 − n−1)h0
(n0 − n−1) + (n0 − n+1)=
= 8 +(45 − 35) ⋅ 2
(45 − 35) + (45 − 15)=
= 8 +2040
= 8,5 tys. zł.

Mediana i pozostałe kwantyleMediana jest to wartość, która jest umieszczona dokładnie w środku, pod warunkiem, że mamy do czynienia z uporządkowaną (z punktu widzenia badanej cechy) zbiorowością według wielkości jej elementów, tzn. od ich wartości najmniejszej do największej.
Mediana dzieli zbiorowość na dwie równe części w ten sposób, że połowa jednostek ma wartość cechy niższe lub równe medianie, a połowa ma wartości cechy większe lub równe od mediany.
Mediana zwykle jest oznaczana przez Me.

Mediana i pozostałe kwantyle
Sposób wyznaczania mediany zależy od rodzaju szeregu statystycznego, z którym mamy do czynienia.
Jeżeli informacje o wartościach cechy są przedstawione w postaci danych indywidualnych (niepogrupowane), to w celu wyznaczenia mediany należy uporządkować informacje rosnąco i ustalić, która z nich zajmuje miejsce środkowe. Wartość tej cechy będzie wartością mediany.
50%
xmin xmax
50%
Me

Mediana i pozostałe kwantyleW tym przypadku sposób wyznaczenia mediany zależy też od tego, czy liczba obserwacji jest parzysta czy nieparzysta.
• N jest nieparzysta,
Me = x(N+1)/2
• N jest parzysta,
Me =xN/2 + xN/2+1
2

PrzykładZapytano o wiek dwie grupy osób i otrzymano odpowiedzi:
• Dla pierwszej grupy: 25, 32, 18, 22, 37 lat,
Me = x(N+1)/2 = x3 = 25
• Dla drugiej grupy: 43, 24, 26, 29, 32, 41 lat.
Me =xN/2 + xN/2+1
2=
x3 + x4
2
1 2 3 4 518 22 25 32 37
1 2 3 4 5 624 26 29 32 41 43
N = 5 N = 6
=29 + 32
2= 30,5

Mediana i pozostałe kwantyleW sytuacji, gdy informacje o wartościach cechy przedstawione są w postaci szeregu rozdzielczego punktowego medianę wyznaczamy na podstawie częstości (liczebności) skumulowanych nisk w następujący sposób:
• Wyznaczamy częstości skumulowane nisk,
• Obliczamy numer mediany ze wzoru
NrMe = {N/2, gdy N jest parzyste,(N + 1)/2, gdy N jest nieparzyste,

Mediana i pozostałe kwantyle• Wyznaczamy klasę, w której znajduje się mediana, tzn.
odszukujemy wartość numeru mediany NrMe wśród częstości skumulowanych nisk. Jest to klasa o pierwszym numerze i, dla którego
• Odczytujemy wartość mediany.
NrMe ⩽ nisk .
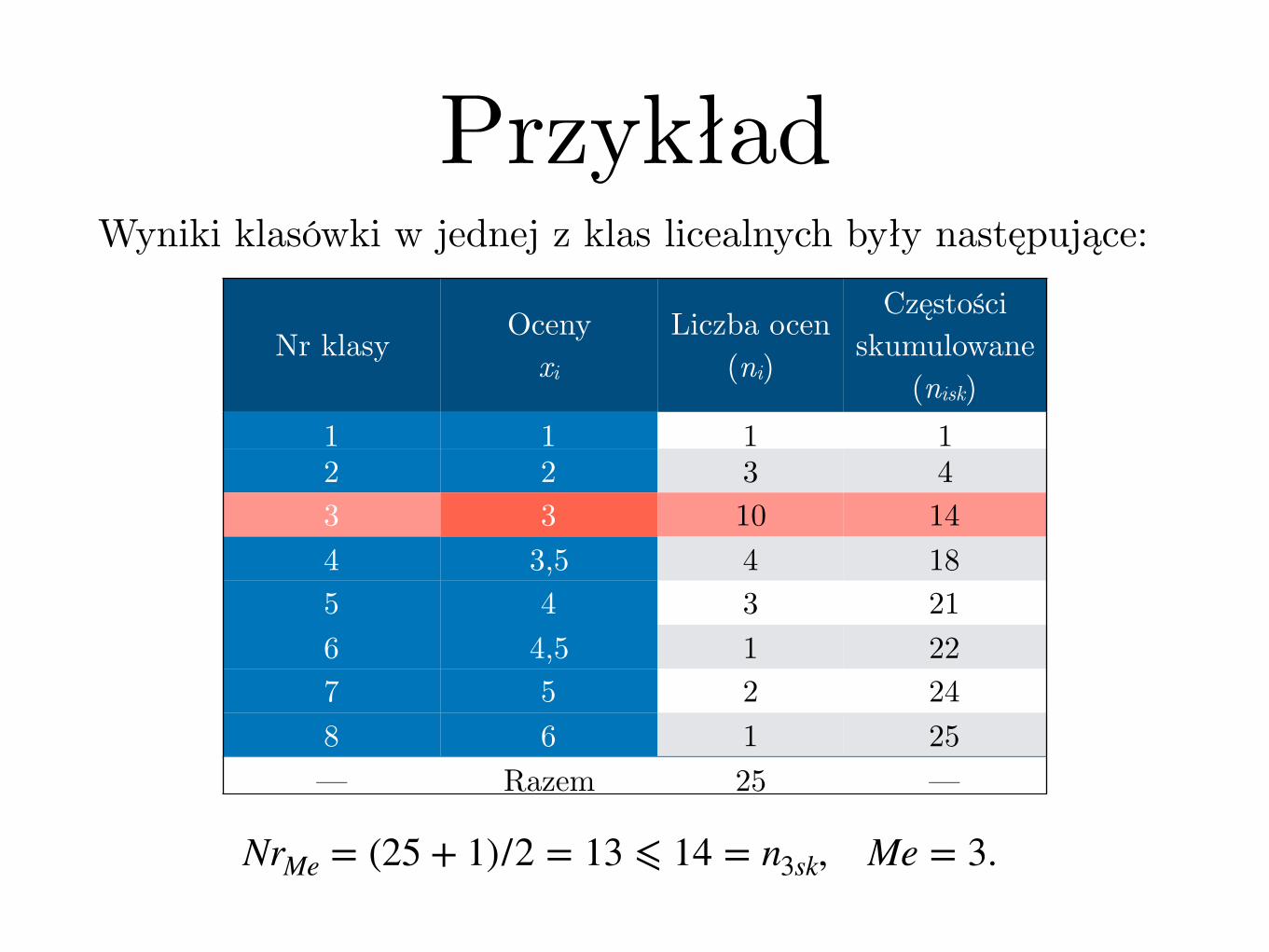
PrzykładWyniki klasówki w jednej z klas licealnych były następujące:
NrMe = (25 + 1)/2 = 13 ⩽ 14 = n3sk, Me = 3.
Nr klasy Ocenyxi
Liczba ocen(ni)
Częstości skumulowane
(nisk)1 1 1 12 2 3 43 3 10 144 3,5 4 185 4 3 216 4,5 1 227 5 2 248 6 1 25— Razem 25 —

Mediana i pozostałe kwantyleMedianę w szeregu rozdzielczym przedziałowym wyznaczamy graficznie lub analitycznie, korzystając ze wzoru:
Me = x0 +h0
n0(NrMe − nisk−1),
gdziex0 - dolna granica przedziału zawierającego medianę,h0 - rozpiętość przedziału mediany,n0 - częstość przedziału mediany,nisk−1 - częstość skumulowana przedziału poprzedzającego
przedział mediany,
NrMe - numer mediany.
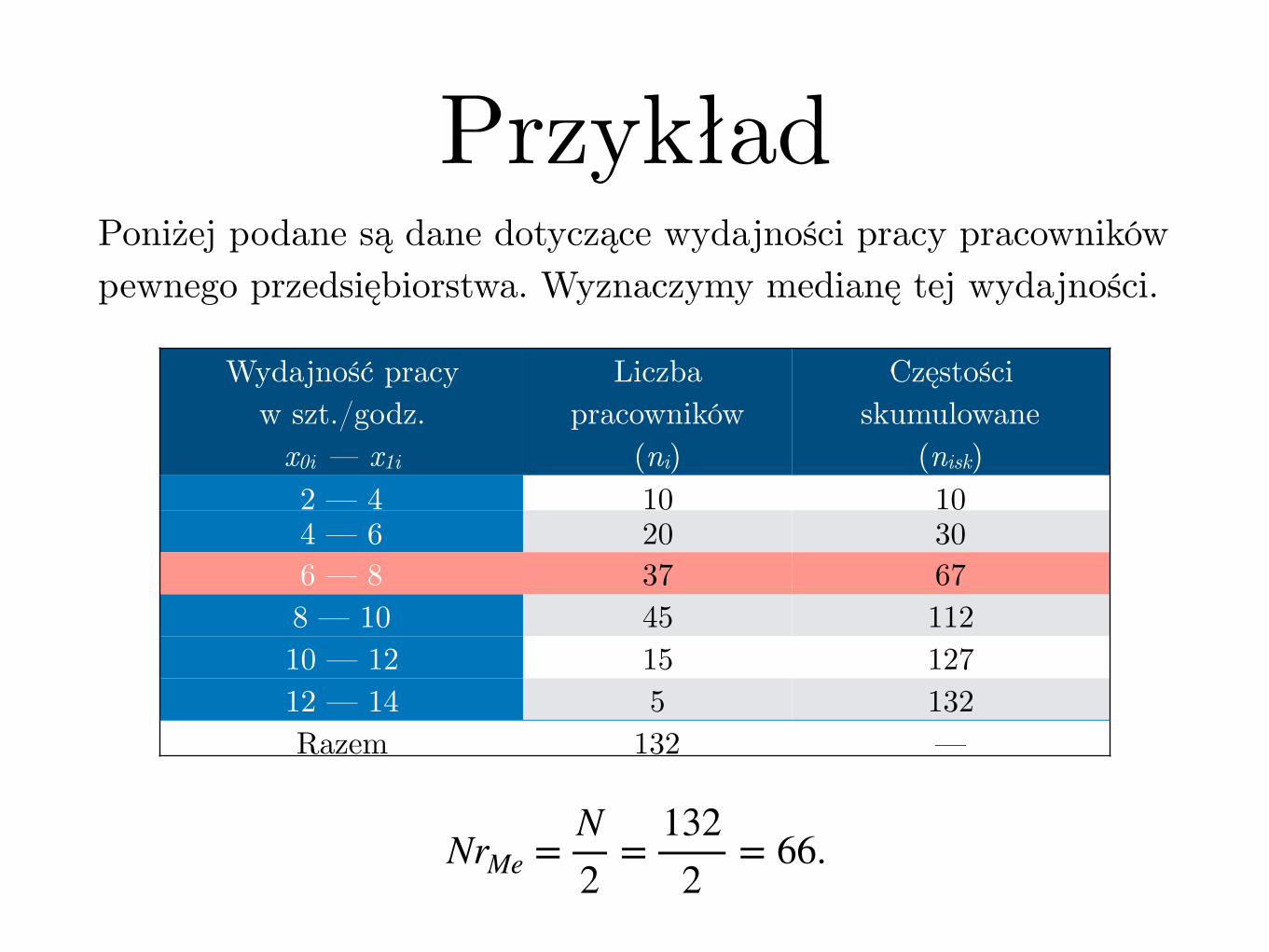
PrzykładPoniżej podane są dane dotyczące wydajności pracy pracowników pewnego przedsiębiorstwa. Wyznaczymy medianę tej wydajności.
Wydajność pracyw szt./godz.
x0i — x1i
Liczba pracowników
(ni)
Częstości skumulowane
(nisk)2 — 4 10 104 — 6 20 306 — 8 37 678 — 10 45 11210 — 12 15 12712 — 14 5 132Razem 132 —
NrMe =N2
=1322
= 66.

PrzykładWydajność pracy
w szt./godz. x0i — x1i
Liczba pracowników
(ni)
Częstości skumulowane
(nisk)2 — 4 10 104 — 6 20 306 — 8 37 678 — 10 45 11210 — 12 15 12712 — 14 5 132Razem 132 —
NrMe =N2
=1322
= 66, h0 = 2, n0 = 37, nisk−1 = 30,
Me = x0 +h0
n0(NrMe − nisk−1) = 6 +
237
(66 − 30) = 7,95.

PrzykładDiagram częstości skumulowanych
Licz
ba p
raco
wni
ków
0
20
40
60
80
100
120
140
Wydajność pracy
2 4 6 Me 10 12 14
Nr mediany

UwagaJeśli mamy dostęp tylko do danych o liczebnościach względnych wi, to w poniżym wzorze
Me = x0 +h0
n0(NrMe − nisk−1),
przyjmujemy:x0 - dolna granica przedziału zawierającego medianę,h0 - rozpiętość przedziału mediany,n0 = w0 - częstość względna przedziału mediany,nisk−1 = wisk−1 - częstość skumulowana względna przedziału
poprzedzającego przedział mediany,
NrMe = 50 - numer mediany.

Własności mediany• Może być ona wyznaczana w szeregach o otwartych przedziałach
klasowych,
• Można ją wyznaczać do opisania zbiorowości, których nie można określić liczbowo (do wyznaczenia mediany nie jest konieczna znajomość wszystkich wartości cechy mierzalnej),
• Jest jedyną średnią, którą można wyznaczyć dla rozkładów skrajnie asymetrycznych,
• Nie jest wrażliwa na wartości skrajne (w przeciwieństwie do średniej arytmetycznej),
• Może być wyznaczana w szeregach o nierównych rozpiętościach przedziałów klasowych, tj. w sytuacji, kiedy niemożliwe jest wyznaczenie dominanty.
KwantyleJeżeli konieczna jest bardziej szczegółowa analiza właściwości strukturalnych, oprócz mediany, która jest kwartylem drugim, znajdują zastosowanie kwartyl pierwszy i trzeci. Kwartyle należą do miar statystycznych zwanych kwantylami, które dzielą zbiorowość statystyczną w określonej proporcji.
Kwantyle
KwartyleQ
DecyleD
Centyle(percentyle)
C

Pierwszy kwartyl Q1
Dzieli zbiorowość na dwie części w ten sposób, że 25% jednostek zbiorowości (czyli 1/4) ma wartości cechy niższe bądź równe wartości Q1, a 75% (czyli 3/4) — równe lub wyższe od wartości tego kwartyla.
xmin xmax
75%
Q1
25%

Trzeci kwartyl Q3
Dzieli zbiorowość na dwie części w ten sposób, że 75% jednostek zbiorowości (czyli 3/4) ma wartości cechy niższe bądź równe wartości Q3, a 25% (czyli 1/4) — równe lub wyższe od wartości tego kwartyla.
xmin xmax
75%
Q3
25%

KwartyleKwartyle wyznaczamy w sposób analogiczny jak w przypadku mediany, z tym że należy uwzględnić konkretny numer kwantyla.
W przypadku danych uporządkowanych rosnąco i przedstawionych w postaci szeregu szczegółowego wartości kwartyla pierwszego i trzeciego możemy wyznaczyć przez podzielenie zbiorowości na dwie części: pierwszą, złożoną z jednostek nie większych od mediany i drugą, złożoną z jednostek nie mniejszych od mediany. Mediana każdej z tych części jest odpowiednio kwartylem pierwszym i trzecim.

Przykład I
1 2 3 4 5 6 7 8 9 10 11 125 7 8 8 8 9 10 10 12 14 15 16
Me = 9,5
1 2 3 4 5 65 7 8 8 8 9
1 2 3 4 5 610 10 12 14 15 16
Q1 =8 + 8
2= 8 Q3 =
12 + 142
= 13
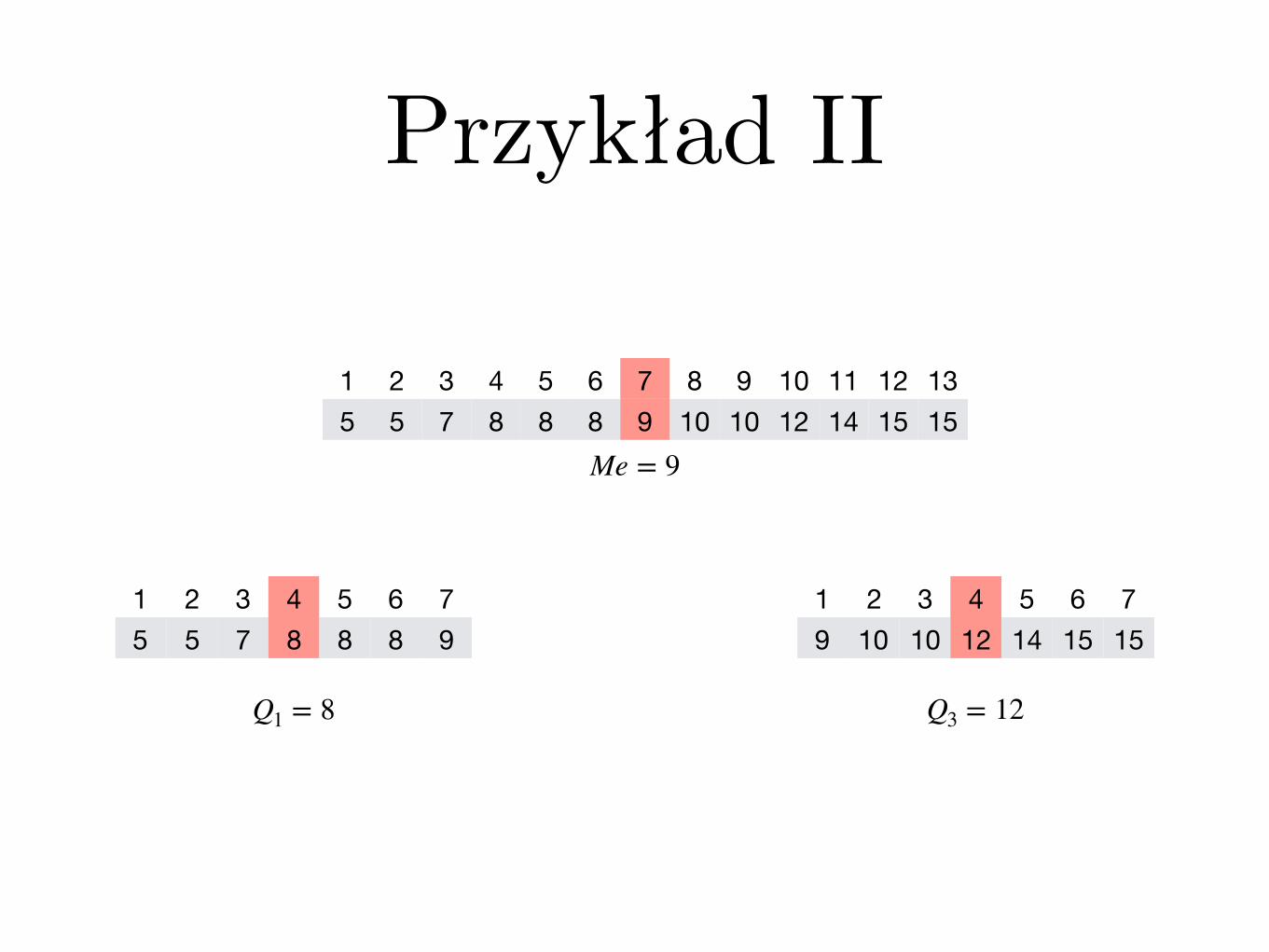
Przykład II
1 2 3 4 5 6 7 8 9 10 11 12 135 5 7 8 8 8 9 10 10 12 14 15 15
Me = 9
1 2 3 4 5 6 75 5 7 8 8 8 9
1 2 3 4 5 6 79 10 10 12 14 15 15
Q1 = 8 Q3 = 12

KwartyleWyznaczenie kwartyla w przypadku danych przedstawionych w postaci szeregu rozdzielczego punktowego sprowadza się do odszukania numeru kwartyla w liczebnościach skumulowa-nych.
NrQ1= {N/4, gdy N jest parzyste,
(N + 1)/4, gdy N jest nieparzyste,
NrQ3= {3N/4, gdy N jest parzyste,
3(N + 1)/4, gdy N jest nieparzyste,

PrzykładNr klasy Oceny
xi
Liczba ocen(ni)
Częstości skumulowane
(nisk)1 1 1 12 2 3 43 3 10 144 3,5 4 185 4 3 216 4,5 1 227 5 2 248 6 1 25— Razem 25 —
NrQ1=
N + 14
=25 + 1
4= 6,5, 6,5 ⩽ 14 = n3sk, Q1 = 3.

PrzykładNr klasy Oceny
xi
Liczba ocen(ni)
Częstości skumulowane
(nisk)1 1 1 12 2 3 43 3 10 144 3,5 4 185 4 3 216 4,5 1 227 5 2 248 6 1 25— Razem 25 —
NrQ3=
3(N + 1)4
=3(25 + 1)
4= 19,5, 19,5 ⩽ 21 = n5sk, Q3 = 4.

KwartyleW przypadku materiału statystycznego przedstawionego w postaci przedziałowych szeregów rozdzielczych Q1 i Q3 wyznaczamy na podstawie wzorów:
Q1 = xQ1+
hQ1
nQ1(NrQ1
− nisk−1), Q3 = xQ3+
hQ3
nQ3(NrQ3
− nisk−1),
xQ - dolna granica przedziału klasowego zawierającego Q,hQ - rozpiętość przedziału kwartyla,nQ - częstość przedziału kwartyla,nisk−1 - częstość przedziału poprzedzającego przedział kwartyla,NrQ - numer kwartyla.

PrzykładWydajność pracy
w szt./godz. x0i — x1i
Liczba pracowników
(ni)
Częstości skumulowane
(nisk)2 — 4 10 104 — 6 20 306 — 8 37 678 — 10 45 11210 — 12 15 12712 — 14 5 132Razem 132 —
NrQ1=
N4
=1324
= 33, xQ1= 6, hQ1
= 2, nQ1= 37, nisk−1 = 30.
Q1 = xQ1+
hQ1
nQ1(NrQ1
− nisk−1) = 6 +237
(33 − 30) = 6,16.

PrzykładWydajność pracy
w szt./godz. x0i — x1i
Liczba pracowników
(ni)
Częstości skumulowane
(nisk)2 — 4 10 104 — 6 20 306 — 8 37 678 — 10 45 11210 — 12 15 12712 — 14 5 132Razem 132 —
NrQ3=
3N4
=3 ⋅ 132
4= 99, xQ3
= 8, hQ3= 2, nQ3
= 45, nisk−1 = 67.
Q3 = xQ3+
hQ3
nQ3(NrQ3
− nisk−1) = 8 +245
(99 − 67) = 9,42.

Własności kwartyliNależy zauważyć, że znajomość wartości Q1 i Q3 w uporządkowanym szeregu pozwala nam na stwierdzenie, że połowa (50%) środkowych jednostek danej zbiorowości statystycznej przyjmuje wartość od Q1 do Q3.
25%
xmin xmaxMe
25% 25% 25%
Q1 Q3
50%

KwantyleJeżeli zbiorowość jest bardzo liczna, może się okazać, że podział zbiorowości na ćwiartki jest niewystarczający. Stosujemy wówczas decyle (dzielące zbiorowość na subpopulacje dziesięcioprocentowe) lub percentyle (dzielące zbiorowość na subpopulacje jednoprocentowe).
10%
xmin xmax
90%
D1
95%
xmin xmax
5%
C95


















