
Analiza regresji - interpretacja wydruku z programu STATISTICA
5
Przykład 1 Zmienna zależna – czas spędzany przez pracowników w internecie w celach prywatnych podczas godzin pracy Zmienna niezależna – ocena niemoralności tego zjawiska, przykładowe pytanie. „Korzystanie z internetu w pracy w celach prywatnych jest zjawiskiem niemoralnym” Wykres rozrzutu czas względem Moralnosc sumy 30v*432c czas = 3,4422-0,0554*x 0 5 10 15 20 25 30 35 40 Moralnosc 0 1 2 3 4 5 6 7 8 czas Statistica „wypluwa” nam kilka tabel, poniżej ich opisy oraz przykład zastosowania w opisie wyników. Wykres rozrzutu naszych dwóch zmiennych, na osi Y mamy czas. Program automatycznie pokazuje nam jak wyglądać będzie linia regresji dopasowana metodą najmniejszych kwadratów. Wartości w tej tabeli pokazują nam istotność poszczególnych predyktorów w naszym modelu. Póki co mamy oczywiście jeden predyktor czyli moralność. Wyraz wolny póki, co nas również nie interesuje. Na istotność Moralności wskazuje nam test F oraz p.
-
Upload
karol-wolski -
Category
Education
-
view
21.151 -
download
7
description
Transcript of Analiza regresji - interpretacja wydruku z programu STATISTICA

Przykład 1
Zmienna zależna – czas spędzany przez pracowników w internecie w celach prywatnych podczas
godzin pracy
Zmienna niezależna – ocena niemoralności tego zjawiska, przykładowe pytanie. „Korzystanie z
internetu w pracy w celach prywatnych jest zjawiskiem niemoralnym”
Wykres rozrzutu czas względem Moralnosc
sumy 30v*432c
czas = 3,4422-0,0554*x
0 5 10 15 20 25 30 35 40
Moralnosc
0
1
2
3
4
5
6
7
8
czas
Statistica „wypluwa” nam kilka tabel, poniżej ich opisy oraz przykład zastosowania w opisie wyników.
Wykres rozrzutu naszych dwóch
zmiennych, na osi Y mamy czas.
Program automatycznie pokazuje
nam jak wyglądać będzie linia
regresji dopasowana metodą
najmniejszych kwadratów.
Wartości w tej tabeli pokazują nam
istotność poszczególnych
predyktorów w naszym modelu.
Póki co mamy oczywiście jeden
predyktor czyli moralność. Wyraz
wolny póki, co nas również nie
interesuje. Na istotność Moralności
wskazuje nam test F oraz p.

Tabela, w której określone mamy parametry poszczególnych predyktorów w naszym modelu.
Nasze równanie regresji ma więc następującą postać:
Wartości F oraz p mówią nam o
istotności całego modelu regresji.
Warto zwrócić uwagę, że w tej
sytuacji są one równe tym z
poprzedniej tabeli. Będzie się tak
działo zawsze wtedy kiedy mamy
tylko jedną zmienną niezależną.
Kiedy będzie ich więcej statystyka F
w tej tabeli przyjmie inne wartości.
Co ważne odnosi się ona do całego
modelu regresji, który tworzymy.
R^2 to tak zwany współczynnik
wielokrotnej determinacji.
Interpretujemy go w kategoriach %
wyjaśnianej wariancji Y przez
wszystkie zmienne X. W naszym
przypadku oczywiście przez jedną. U
nas wynosi on w zaokrągleniu 4,3%.
Skorygowany R^2 będzie zawsze
niższy. Podajemy przeważnie
„zwykły” R^2, dodatkowo można
podać również skorygowany.
Współczynnik
korelacji
wielokrotnej. W
przypadku kilku
zmiennych X
określa ich związek
z Y (zmienne X są
traktowane
łącznie). Tutaj
można go
oczywiście
interpretować, jako
korelację X i Y.
Waga Beta,
standaryzowany
współczynnik regresji
(patrz slajdy, zajęcia 8.)
Test t wskazujący na
istotność danego
czynnika/predyktora,
przyjmujemy standardowa
p<0,05. Więcej o tym teście
na kolejnych zajęciach
Stała b, czyli
współczynnik
nachylenia linii
regresji.
Interpretujemy
go w następujący
sposób: wraz ze
wzrostem X od
jedną jednostkę Y
wzrasta/spada o
b jednostek (czyli
Stała a, czyli miejsce
przecięcia się linii
regresji z osią Y.
(por. wykres na
samej górze)

Teraz powinno się pojawić pytanie, no ok., ale, po co mi to wszystko? I co ja mam z tym zrobić?
Zobaczmy, zatem jak będzie wyglądał fragment artykułu/pracy magisterskiej opisujący nasze wyniki.
W celu oszacowaniu wpływu Moralności na czas spędzany przez pracowników w internecie na
czynnościach niezwiązanych bezpośrednio z wykonywanymi obowiązkami zastosowany regresję
liniową. Model regresji okazał się istotny (F1,430=19,41; p<0,001) i wyjaśniał ok. 4% zmiennej
niezależnej (R2=0,043). Do modelu włączono jeden predyktor – ocenę moralności korzystania.
Predytkor ten okazał się istotny dla zmiennej niezależnej (β=-0,21; t=-4,41; p<0,001).
Przykład 2
Zmienna zależna – czas spędzany przez pracowników w internecie w celach prywatnych podczas
godzin pracy
Zmienna niezależna – ocena niemoralności tego zjawiska, przykładowe pytanie. „Korzystanie z
internetu w pracy w celach prywatnych jest zjawiskiem niemoralnym”
Zmienna niezależna 2 – ocena przydatności zjawiska: „Uważam, że korzystanie z sieci w celach
prywatnych pozwala mi lepiej wykonywać moją pracę”
Zmienna niezależna 3 – zadowolenie z finansów, czyli zadowolenie z wynagrodzenia w pracy
Zmienna niezależna 4 – odczuwana nuda w miejscu pracy „Uważam, że moja praca jest nudna”
Przed dokonaniem analizy regresji powinniśmy wykonać serię korelacji poszczególnych
zmiennych. Po pierwsze aby sprawdzić czy nasze predyktory korelują ze zmienną Y, a po
drugie aby sprawdzić czy nie korelują one między sobą. Predyktory powinny korelować ze
zmienną Y ale NIE powinny korelować między sobą. A przynajmniej nie być związane zbyt
mocno. Jedyne zastzenieżenia, może u nas budzić korelacja moralności z przydatnością. Jest
dość wysoka, ale póki co włączamy do modelu obie zmienne. Oczywiście analizujemy tylko
pół tabeli, druga połówka zawiera te same wartości.
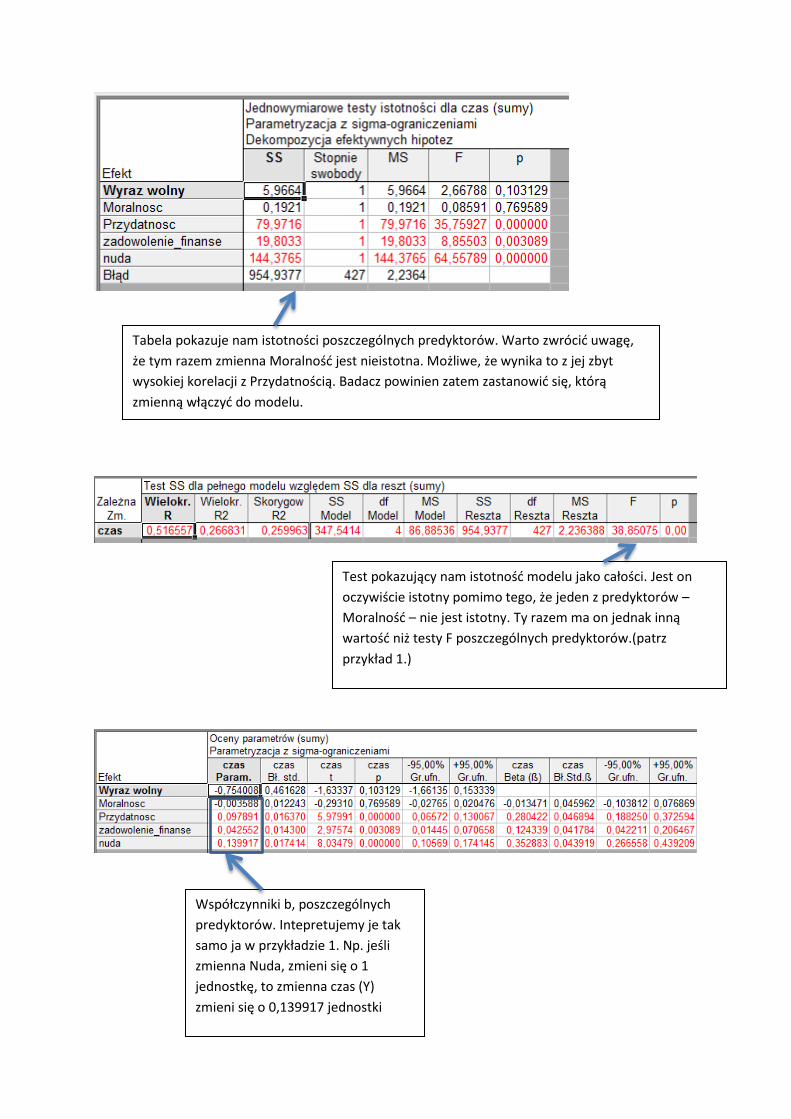
Tabela pokazuje nam istotności poszczególnych predyktorów. Warto zwrócić uwagę,
że tym razem zmienna Moralność jest nieistotna. Możliwe, że wynika to z jej zbyt
wysokiej korelacji z Przydatnością. Badacz powinien zatem zastanowić się, którą
zmienną włączyć do modelu.
Test pokazujący nam istotność modelu jako całości. Jest on
oczywiście istotny pomimo tego, że jeden z predyktorów –
Moralność – nie jest istotny. Ty razem ma on jednak inną
wartość niż testy F poszczególnych predyktorów.(patrz
przykład 1.)
Współczynniki b, poszczególnych
predyktorów. Intepretujemy je tak
samo ja w przykładzie 1. Np. jeśli
zmienna Nuda, zmieni się o 1
jednostkę, to zmienna czas (Y)
zmieni się o 0,139917 jednostki

Nasze równanie regresji będzie więc wyglądać w następujący sposób:
A opis wyników będzie wyglądał w następujący sposób:
W celu oszacowania wpływu poszczególnych zmiennych na czas korzystania przez pracowników z
internetu w celach prywatnych zastosowano analizę regresji. Model okazał się istotny (F4,427=38,85;
p<0,001) a wszystkie predyktory wyjaśniały łącznie 26% zmiennej zależnej (R2=0,27). Istotny wpływ na
czas korzystania miały trzy z czterech uwzględnionych w modelu predyktorów: Przydatność (β=0,28;
t=5,98; p<0,001); Zadowolenie z finansów (β=0,12; t=2,96; p<0,001) oraz Nuda w pracy (β=0,35;
t=8,03; p<0,001).


















