
5. Podstawowe algorytmy i ich cechy. - ics.p.lodz.plics.p.lodz.pl/~stokfi/aisd/aisd_2.pdf ·...
17
23 5. Podstawowe algorytmy i ich cechy. 5.1. Wyszukiwanie liniowe i binarne 5.1.1. Wyszukiwanie liniowe Wyszukiwanie jest jedną z najczęściej wykonywanych operacji na strukturach danych i dotyczy wszystkich, omawianych w trakcie wykładu, struktur danych. Wyszukując możemy mieć różne cele. Możemy szukać: elementów posiadających określone cechy (w szczególności - elementów najmniejszych, lub największych). Możemy też zadowolić się tylko stwierdzeniem, czy element o określonych cechach występuje w strukturze, czy też nie. Przedstawiony na rys. 12 przykładowy algorytm zwraca indeks tego elementu tablicy, którego wartość po raz pierwszy równa się zadanej wartości x. Wyszukiwanie odbywa się w jednowymiarowej tablicy danych typu całkowitego, zadeklarowanej według (1) [str. 18] . W przypadku nie stwierdzenia wystąpień elementów o wartościach równych zadanej wartości x, algorytm zwraca sygnał o nieistnieniu takich elementów. W celu uproszczenia zapisu algorytmów i skupienia się wyłącznie na ich idei, w odniesieniu do algorytmów operu- jących na tablicach, przyjmiemy, że: - algorytm ma dostęp do istniejącej tablicy, przechowującej dane typu całkowitego, zadeklarowanej według (1) [str. 18] , - t jest nazwą tablicy o rozmiarze N, gdzie N>0.
Transcript of 5. Podstawowe algorytmy i ich cechy. - ics.p.lodz.plics.p.lodz.pl/~stokfi/aisd/aisd_2.pdf ·...

23
5. Podstawowe algorytmy i ich cechy.
5.1. Wyszukiwanie liniowe i binarne
5.1.1. Wyszukiwanie liniowe Wyszukiwanie jest jedną z najczęściej wykonywanych operacji na strukturach danych i dotyczy wszystkich, omawianych w trakcie wykładu, struktur danych. Wyszukując możemy mieć różne cele. Możemy szukać: elementów posiadających określone cechy (w szczególności - elementów najmniejszych, lub największych). Możemy też zadowolić się tylko stwierdzeniem, czy element o określonych cechach występuje w strukturze, czy też nie. Przedstawiony na rys. 12 przykładowy algorytm zwraca indeks tego elementu tablicy, którego wartość po raz pierwszy równa się zadanej wartości x. Wyszukiwanie odbywa się w jednowymiarowej tablicy danych typu całkowitego, zadeklarowanej według (1) [str. 18]. W przypadku nie stwierdzenia wystąpień elementów o wartościach równych zadanej wartości x, algorytm zwraca sygnał o nieistnieniu takich elementów.
W celu uproszczenia zapisu algorytmów i skupienia się wyłącznie na ich idei, w odniesieniu do algorytmów operu-jących na tablicach, przyjmiemy, że: - algorytm ma dostęp do istniejącej tablicy, przechowującej dane typu całkowitego, zadeklarowanej według (1) [str. 18], - t jest nazwą tablicy o rozmiarze N, gdzie N>0.

24
// tablica przechowuje dane nieuporządkowane wprowadź: x; jest = 0; //zakładamy wstępnie ,że wartość x nie występuje i=0; while((jest = = 0) and (i<N)) if( t[i]= =x ) jest =1; else i=i+1; if(jest = = 1) wyprowadź: i; else wyprowadź sygnał „Nie ma takiego elementu”
Rys. 12. Iteracyjny algorytm wyszukiwania elementu o zadanej wartości, zapisany w języku C++ Sygnał, o którym mowa w algorytmie, powinien mieć postać pewnej szczególnej wartości, której wystąpienie w tablicy nie jest możliwe. Algorytm jest przykładem tzw. wyszukiwania liniowego. Jego cechą charakterystyczną jest konieczność przeglądania, w sytuacji nie uporządkowania danych, całej struktury. Jego schemat jest prosty i naturalny:
1. Pobierz pierwszy element rozpatrywanej struktury, 2. Sprawdź, czy analizowany element jest elementem
poszukiwanym ? Jeśli TAK – zakończ działanie algorytmu, Jeśli NIE – pobierz kolejny element i roz- pocznij realizację punktu 2. od początku.
Powyższy schemat sugeruje rekurencyjną wersję algorytmu. W odniesieniu jednak do struktur liniowych o nieskomplikowanej budowie, takich jak: tablice, pliki, czy nawet listy liniowe, stosowanie rekurencji nie jest potrzebne. Wystarczy zwykły proces iteracyjny. Jego złożoność obliczeniowa jest liniowa, co zapisujemy O(N). Oznacza to, że

25
w sytuacji najgorszego przypadku ilość wykonywanych operacji rośnie liniowo (tak jak funkcja liniowa f(N)=N) z rozmiarem tablicy. Złożoność obliczeniowa algorytmu, inaczej zwana kosztem algorytmu jest funkcją podającą jak w sytuacji najgorszego przypadku rośnie czas realizacji algorytmu w miarę zwiększania rozmiarów zadania. Rozmiarem zadania, polegającego na wyszukiwaniu elementu w jednowymiarowej tablicy, będzie N, tj. ilość elementów tej tablicy. W następnym podrozdziale przedstawione zostanie wyszukiwanie binarne, które jest znacznie efektywniejsze. Wymaga jednak uporządkowania danych w strukturze. Następny przykładowy algorytm wyszukuje najmniejszy element tablicy jednowymiarowej. Tego typu operacje są wykonywane równie często, jak, przedstawione wyżej, wyszukiwanie elementu o zadanej wartości Zanim jednak przejdziemy do algorytmu rozwiązującego ten problem zauważmy, że aby mógł być on w ogóle rozwiązywalny, na elementach tablicy musi być określona pewna relacja liniowego porządku, która sprowadza się do możliwości wykonywania operatorów relacyjnych ( ) w zbiorze wartości, znajdujących się w tablicy. Jest to możliwe dla typów uporządkowanych, takich jak: boolean, int, char, string.

26
t_min=t[0]; i_min=0; for (int i=1; i<N; i++) if( t[i]<t_min) { t_min=t[i]; i_min=i; }; wyprowadź: t_min, i_min
Rys. 13. Algorytm wyszukiwania najmniejszego elementu w tablicy jednowymiarowej Analizując powyższy algorytm zauważymy, że jego wynik zależy od tego, czy wartości elementów tablicy mogą się powtarzać, czy też nie (co nie zostało zawarte w asercji początkowej !!!). Jeśli mogą, to i_min jest indeksem ostatniego elementu o wartości najmniejszej w tablicy. Jeśli nie mogą – i_min jest indeksem jedynego, najmniejszego elementu.
5.1.2. Wyszukiwanie połówkowe (binarne) Zaprezentowany w podrozdziale 5.1.1. algorytm wyszukiwa-
nia w tablicy miał cechy przeszukiwania liniowego.
Zauważmy, że dla struktur liniowych uporządkowanych, takich jak: tablice, pliki i listy, średni czas wyszukania elementu można skrócić o połowę. Bezcelowym jest bowiem dalsze przeszukiwanie struktury po stwierdzeniu, że jej elementy mają wartości wyższe (dla struktury uporządkowanej rosnąco), niż wartość elementu wyszukiwanego. Złożoność obliczeniowa takiego algorytmu dalej jednak wynosi O(N), bowiem w sytuacji najgorszego przypadku

27
dalej zależność ilości wykonywanych operacji rośnie liniowo z rozmiarem zadania N.
Poznamy teraz algorytm przeszukiwania połówkowego zwany czasem przeszukiwaniem binarnym, który podobnie jak wspomniany wyżej algorytm wykorzystuje uporządko-wanie elementów struktury liniowej, ale w sposób znacznie bardziej efektywny. Na pomyśle tym opiera się idea wielu algorytmów, rozpatrywanych w dalszej części wykładu.
// tablica przechowuje dane uporządkowane rosnąco; N>0 wprowadź: x; jest = 0; //zakładamy wstępnie , że wartość x nie występuje if( ( x >= t[0] ) or ( x <= t[N-1] ) ) // x może być w tablicy { left = 0; right=N-1; do { mid=(left+right) / 2; // dzielenie całkowite if(t[mid] = = x) jest=1; else if( x<t[mid] ) right =mid-1; else left =mid+1; while(not jest and (right>=left)); if(jest) wyprowadź: i; else wyprowadź sygnał „Nie ma takiego elementu”
Rys. 14. Iteracyjny algorytm wyszukiwania binarnego w tablicy zawierającej dane uporządkowane rosnąco Idea tego algorytmu sprowadza się do kolejnego dzielenia całej tablicy na pół i dalszego szukania elementu tylko w tej połówce, w której element ten może potencjalnie wystąpić.
Zastosowano tu tak zwaną metodę dekompozycji problemu, a mówiąc dokładniej znaną w algorytmie metodę ”dziel i zwyciężaj”.

28
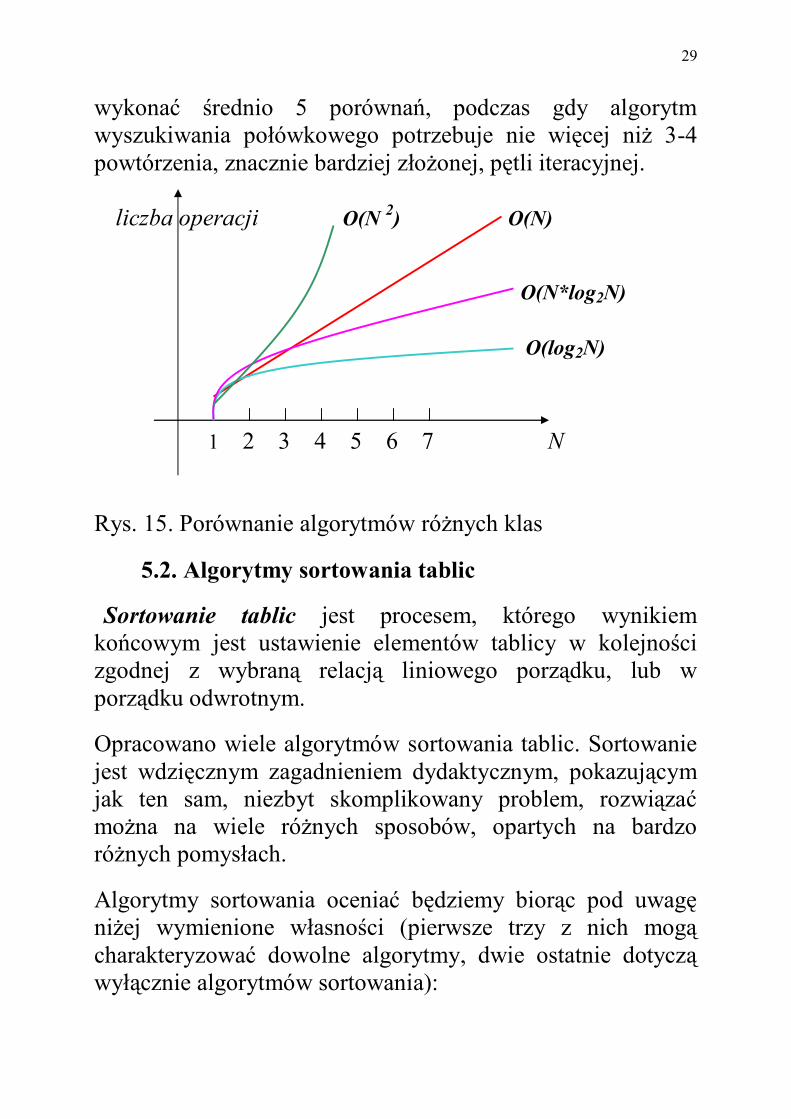
Mówiąc ogólnie metoda ta polega na dzieleniu rozwiązywanego problemu na pewną ilość podproblemów tego samego typu, rozwiązywaniu każdego z nich osobno, a następnie łączeniu otrzymanych wyników cząstkowych w wynik ostateczny. Taka koncepcja rozwiązywania problemu jest bliska idei rekurencji, ale jej wdrożenie niekoniecznie musi być rekurencyjne. Metoda „”dziel i zwyciężaj” pozwala w wielu przypadkach na zmianę klasy algorytmu z liniowej do logarytmicznej. Tak jest również w tym przypadku - złożoność obliczeniowa algo-rytmu wyszukiwania połówkowego wynosi O(log2N) (patrz Rys. 15). Intuicja podpowiada nam, że korzyści, jakie osiągamy stosując algorytm wyszukiwania połówkowego, zamiast wyszukiwania liniowego, powinny być znaczne. Rzeczywistość przerasta jednak nasze wyobrażenia.
Załóżmy przykładowo, że uporządkowana tablica zawiera aż 10 000 elementów. Średnia ilość porównań kluczy kolejnych elementów tablicy z wartością poszukiwaną x wynosi przy wyszukiwaniu liniowym 10000 / 2 = 5 000 porównań, podczas gdy przy wyszukiwaniu połówkowym - nie więcej niż log210 000, to jest około 13 porównań. Wynik jest oszałamiający.
Tak dużą różnice w ilości wykonanych operacji (patrz Rys. 15) uzyskamy jednak wtedy, gdy rozmiary zadania są znaczne. Natomiast dla tablic o małych rozmiarach nie warto używać aż tak złożonego algorytmu, gdyż zysk czasowy będzie niewielki. Na przykład, dla tablicy zawierającej 10 elementów, algorytm wyszukiwania liniowego będzie musiał
29
wykonać średnio 5 porównań, podczas gdy algorytm wyszukiwania połówkowego potrzebuje nie więcej niż 3-4 powtórzenia, znacznie bardziej złożonej, pętli iteracyjnej. liczba operacji O(N 2) O(N)
O(N*log2N) O(log2N)
1 2 3 4 5 6 7 N Rys. 15. Porównanie algorytmów różnych klas
5.2. Algorytmy sortowania tablic
Sortowanie tablic jest procesem, którego wynikiem końcowym jest ustawienie elementów tablicy w kolejności zgodnej z wybraną relacją liniowego porządku, lub w porządku odwrotnym. Opracowano wiele algorytmów sortowania tablic. Sortowanie jest wdzięcznym zagadnieniem dydaktycznym, pokazującym jak ten sam, niezbyt skomplikowany problem, rozwiązać można na wiele różnych sposobów, opartych na bardzo różnych pomysłach. Algorytmy sortowania oceniać będziemy biorąc pod uwagę niżej wymienione własności (pierwsze trzy z nich mogą charakteryzować dowolne algorytmy, dwie ostatnie dotyczą wyłącznie algorytmów sortowania):

30
5.2.1. Cechy algorytmów sortowania:
prostota algorytmu, Ta cecha jest dość istotna. Algorytmy o prostej strukturze, oparte na prostym pomyśle, można łatwo modyfikować i dostosowywać do aktualnych potrzeb
zajętość pamięci, Ta cecha jest bardzo istotna. Na ogół bowiem sięgamy do metod tak zwanego sortowania w miejscu, zwanych inaczej metodami „in situ”(łac.). Ich zapotrzebowanie na dodatkową pamięć ogranicza się na ogół do wielkości zajmowanej przez wartość pojedynczego elementu tablicy.
koszt algorytmu Większość algorytmów sortowania charakteryzuje się kosztem O(N2), gdzie N jest ilością elementów tablicy. Algorytmy te wymagają dwóch pętli iteracyjnych, przy czym jedna z nich jest zanurzona w drugiej.
wrażliwość na uporządkowanie sortowanej tablicy, Z tego punktu widzenia algorytmy sortowania dzielić będziemy na: - całkowicie niewrażliwe na uporządkowanie, - częściowo wrażliwe na uporządkowanie, - całkowicie wrażliwe na uporządkowanie.
W pierwszej grupie znajdą się algorytmy, dla których uporządkowanie tablicy (pierwotne, bądź uporządkowanie powstałe w trakcie sortowania) nie wpływa w sposób zasadniczy na czas realizacji algorytmu. Za algorytmy częściowo wrażliwe na uporządkowanie uznamy te algorytmy sortowania, które w sposób znamienny ograniczają ilość wykonywanych operacji w trakcie procesu

31
sortowania (np. poprzez zawieszenie wykonywania pewnych pętli wewnętrznych). Algorytmy sortowania całkowicie wrażliwe na uporządkowanie potrafią w trakcie realizacji algorytmu, niejako przy okazji, stwierdzić uporządkowanie tablicy (pierwotne, bądź powstałe w dowolnym momencie procesu sortowania), przerywając natychmiast proces sortowania. Niżej przedstawiono ilustracje do czterech, wybranych metod sortowania tablic.
Dokładne omówienie przebiegu procesu sortowania w tych przykładach zostanie podane na wykładzie.
5.2.2. Sortowanie przez proste wstawianie
a) indeksy 0 1 2 3 4 t
b) indeksy 0 1 2 3 4 t i
c) x indeksy 0 1 2 3 4 t
i j
Rys. 16. Algorytm sortowania przez proste wstawianie a) stan wyjściowy, b) stan po zakończeniu pierwszej
7 1 6 4 3
1 7 6 4 3
1 7 6 4 3
3

32
iteracji, c) ilustracja procesu przepisywania elementów
5.2.3. Sortowanie przez prostą zamianę (sortowanie bąbelkowe) 7 1 1 1 1 1 i 7 6 6 6 6 6 i 7 4 4 4 4 4 i 7 3
________ 3 3 3 3 7 i
Rys. 17. Algorytm sortowania bąbelkowego
5.2.4. Algorytm sortowania przez podział (QuickSort). Algorytmy typu ”dziel i zwyciężaj”.
Jest to algorytm oparty na zupełnie innym pomyśle, w porównaniu z algorytmami omawianymi powyżej. Zastosowano tu (omawianą już przy okazji wyszukiwania binarnego) metodę dekompozycji problemu w wersji ”dziel i zwyciężaj”.
Rys. 18. Ilustracja idei algorytmu sortowania szybkiego QuickSort
5 2 7 1 3 4 6 8
7 6 8 2 1 3 4
3 4 1 6 8
7

33
Wersja rekurencyjna tego algorytmu charakteryzuje się (co jest charakterystyczne dla algorytmów rekurencyjnych) niesłychaną prostotą. Nie robi bowiem prawie nic. Na każdym poziomie wywołania rozdziela elementy coraz krótszych tablic na dwie tablice – lewą, zawierającą elementy mniejsze od tzw. elementu osiowego, i prawą zawierającą elementy większe od elementu osiowego. Elementem osiowym może być dowolny element tablicy. Tutaj wybrano element pierwszy. Następnym krokiem algorytmu jest rekurencyjne wywołanie samego siebie. Rekurencja zapewnia automatyczne połączenie tablic cząstkowych z odpowiednimi włączeniami elementów osiowych. Jest wiele odmian tego algorytmu. Ich złożoność obliczeniowa wynosi O(N*log2N) (patrz Rys. 15).
5.2.5. Sortowanie z użyciem dodatkowej tablicy
Elementami tablicy są często rekordy, bądź obiekty klas (na rys. 19 w owalu), z których każdy zawiera szereg pól. Jedno z nich jest zwykle wybierane jako klucz sortowania. Zaprezentowana niżej metoda sortowania sprowadza się do wytworzenia dodatkowej tablicy (zwanej tablicą indeksową), której pierwszy wiersz przechowuje, ustawione w porządku rosnącym, klucze z oryginalnej tablicy a drugi - odpowiadające kluczom indeksy. Metoda ta wymaga użycia dodatkowej tablicy, w zamian – pozwala zachować sortowaną tablicę w stanie pierwotnym, jak również generować wiele tablic indeksowych wg różnych kluczy. Ocenę złożoności czasowej pozostawmy czytelnikowi.

34
indeksy 0 1 2 3 4
klucz 7 1 6 4 3 ... ... ... ... ... ... ... ... ... ... ... ... ... ... ...
a) klucz 1 3 4 6 7 indeksy 1 4 3 2 0
b) Rys. 19 Tablica indeksowa b) powstała z posortowania
wejściowej tablicy rekordów a). Owalem zaznaczono pojedynczy rekord.
6. Algorytmy rekurencyjne
6.1. Wprowadzenie
Dokładne omówienie procesów związanych z rekurencją, wraz z pokazem, zostanie przedstawione na wykładzie. n * silnia(n-1) dla n > 0 silnia(n) =
1 dla n = 0 fib(n-1) + fib(n-2) dla n > 1 fib(n) = 1 dla n = 0,1 Rys. 20. Funkcje rekurencyjne – postacie analityczne

35
int silnia( int n ) { // n jest dowolną liczbą naturalną if( n > 0 ) return n*silnia( n-1); else return 1; }
Rys.21 Funkcja rekurencyjna silnia( ) zapisana w języku C\C++
silnia(3) = 3 * silnia(2) 2 * silnia(1) 1 * silnia(0) 1
Rys. 22. Przebieg obliczeń wartości funkcji rekurencyjnej silnia(3) fib(n-1) + fib(n-2) dla n > 1 fib(n) =
1 dla n = 0,1
Rys. 23. Ciąg liczb Fibonacciego
n 0 1 2 3 4 5 6 7 8 ... fib(n) 1 1 2 3 5 8 13 21 34 ...
36
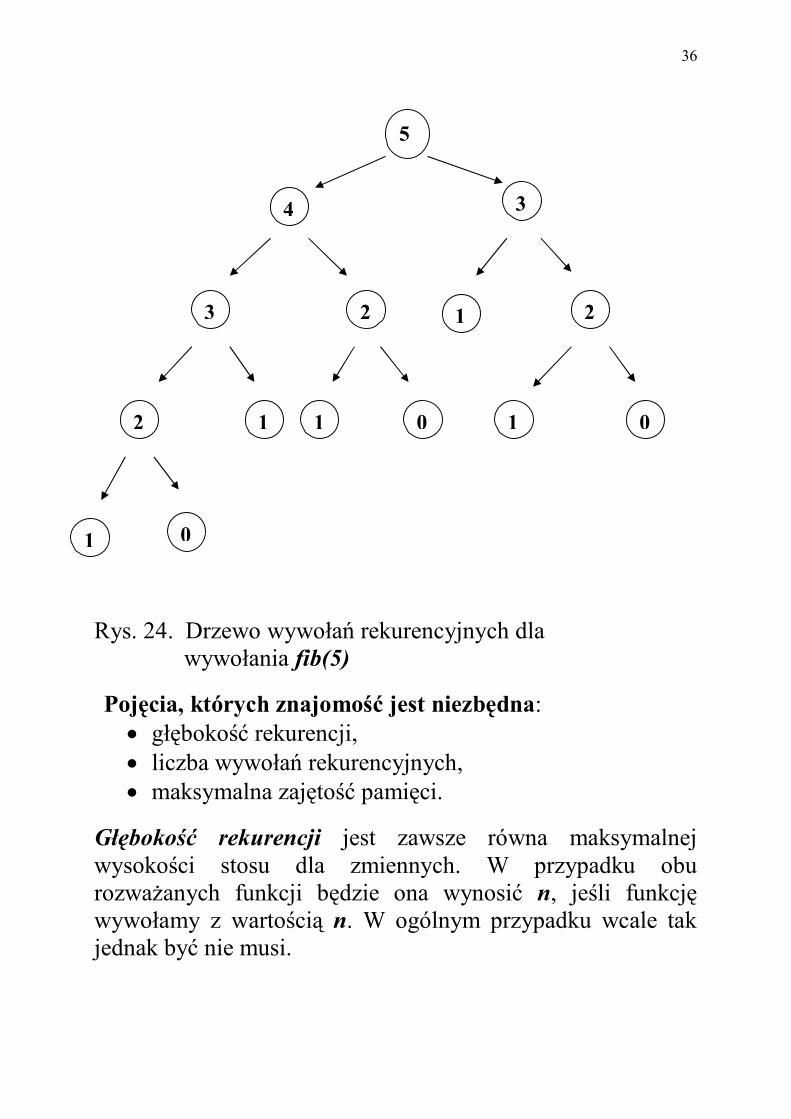
Rys. 24. Drzewo wywołań rekurencyjnych dla wywołania fib(5)
Pojęcia, których znajomość jest niezbędna: głębokość rekurencji, liczba wywołań rekurencyjnych, maksymalna zajętość pamięci.
Głębokość rekurencji jest zawsze równa maksymalnej wysokości stosu dla zmiennych. W przypadku obu rozważanych funkcji będzie ona wynosić n, jeśli funkcję wywołamy z wartością n. W ogólnym przypadku wcale tak jednak być nie musi.
4 3
2
2
2 3
1 1 0
1
1 0
1 0
5

37
Liczba wywołań rekurencyjnych jest równa liczbie wszyst-kich wewnętrznych wywołań rekurencyjnych. Dla funkcji rekurencyjnej silnia( ) zmienia się liniowo, jak funkcja n, natomiast dla fib( ) liczba wywołań rekurencyjnych zmienia się wykładniczo ze wzrostem n, tak jak funkcja 2 n, co widać na Rys. 24. Maksymalna zajętość pamięci jest zawsze proporcjonalna do maksymalnej wysokości stosu (patrz Rys. 25). Ocena tych trzech parametrów dla rozważanego algorytmu rekurencyjnego jest ważna, pozwala bowiem wstępnie ocenić jego złożoność, to jest zapotrzebowanie na pamięć i na czas obliczeń.
6.2. Derekursywacja Derekursywacja jest procesem polegającym na przekształce-niu algorytmu rekurencyjnego na postać iteracyjną. Często bywa to bardzo trudne, lub wręcz niemożliwe. Tam gdzie jest możliwe należy jednak tego dokonywać, gdyż algorytmy ite-racyjne dla dużych rozmiarów zadania, zawsze mają mniejsze zapotrzebowanie na pamięć, i najczęściej są znacznie efektywniejsze czasowo. Natomiast wielką zaletą algorytmów iteracyjnych jest ich prostota. W przypadku struktur dynamicznych (listy, drzewa), które z natury są definiowane w sposób rekurencyjny, stosowanie algorytmów rekurencyjnych jest naturalne i proste, a często – jedynie możliwe.
38
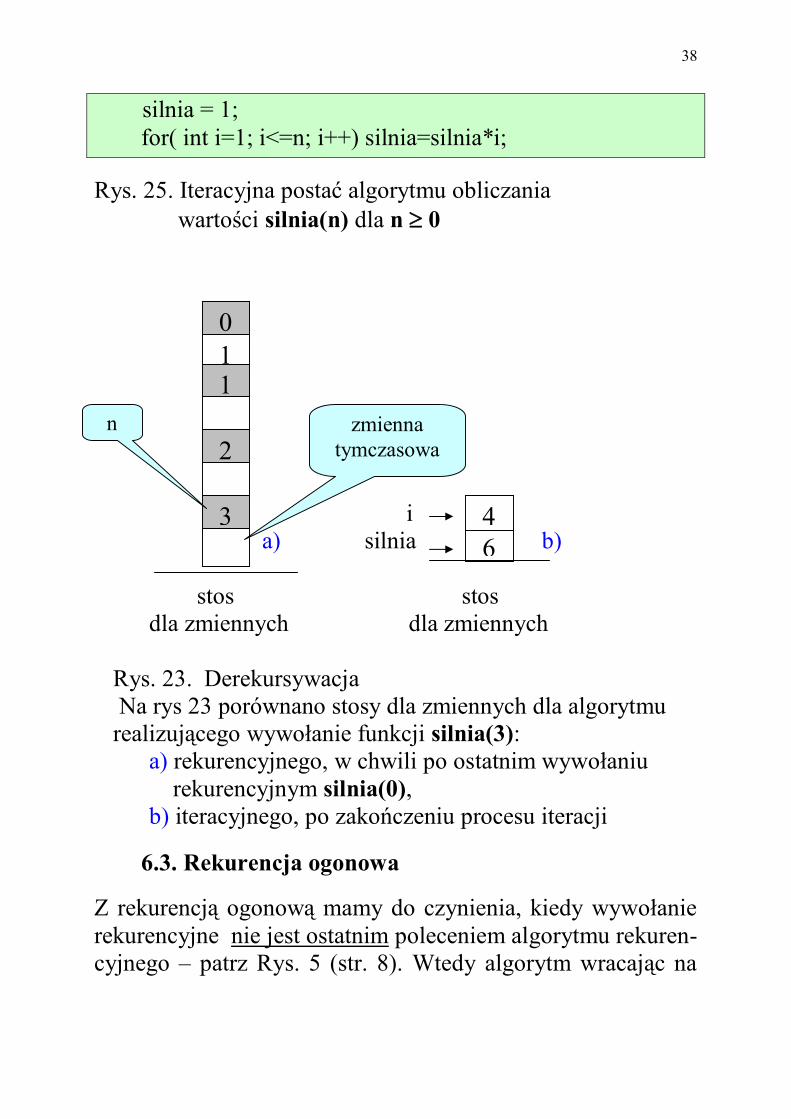
silnia = 1; for( int i=1; i<=n; i++) silnia=silnia*i;
Rys. 25. Iteracyjna postać algorytmu obliczania wartości silnia(n) dla n 0
i
a) silnia b)
stos stos dla zmiennych dla zmiennych Rys. 23. Derekursywacja Na rys 23 porównano stosy dla zmiennych dla algorytmu realizującego wywołanie funkcji silnia(3): a) rekurencyjnego, w chwili po ostatnim wywołaniu rekurencyjnym silnia(0), b) iteracyjnego, po zakończeniu procesu iteracji
6.3. Rekurencja ogonowa
Z rekurencją ogonową mamy do czynienia, kiedy wywołanie rekurencyjne nie jest ostatnim poleceniem algorytmu rekuren-cyjnego – patrz Rys. 5 (str. 8). Wtedy algorytm wracając na
0 1 1
2
3 6
4
zmienna tymczasowa
n

39
dany poziom, wykonuje dalsze czynności kończące algorytm na tym poziomie (”ogonek”). Natomiast, jeśli wywołanie rekurencyjne jest ostatnim wywołaniem, rekurencja symuluje pętlę iteracyjną.
6.4. Rekurencja zagnieżdżona Przykładem funkcji z rekurencją zagnieżdżoną jest podana w 1928 przez W. Ackermanna funkcja m+1 jeśli n = 0 A(n,m) = A(n-1,1) jeśli n>0, m=0
A(n-1, A(n,m-1)) w pozostałych przyp.
Zagnieżdżenie rekurencji, dotyczące parametru m, powoduje nieprawdopodobnie gwałtowne zapotrzebowanie na czas obliczeń ze wzrostem m. Obliczono, że
3232)4,1( 65536216
A co jest liczbą nieporównanie większą od liczby wszystkich atomów we wszechświecie (obecnie szacuje się, że liczba atomów jest rzędu 1080). Definicję funkcji Ackermana bardzo łatwo jest zapisać w postaci funkcji rekurencyjnej, natomiast zapisanie jej w formie innej, niż rekurencyjna, jest bardzo kłopotliwe.
Koniec części 2


















